In diesem Dokument werden die aktuellen Optionen für die Bereitstellung von Anwendungen in CloudHub 2.0 beschrieben, um die Anforderungen an die Hochverfügbarkeit und Notfallwiederherstellung zu erfüllen. Sie verwendet die Region "USA" als Beispiel und kann auf andere Regionen angewendet werden.
CloudHub 2.0 ist eine vollständig verwaltete, Cloud-native Integrationsplattform, die den Infrastrukturaufwand eliminiert, indem die Bereitstellung, Skalierung und Verwaltung von MuleSoft-APIs und -Integrationen in der Cloud automatisiert wird. Es ist die moderne Cloud-Bereitstellungsplattform von MuleSoft, die auf der Amazon AWS-Infrastruktur ausgeführt wird.
In den meisten Fällen ist die standardmäßige Hochverfügbarkeit (HA) und Notfallwiederherstellung (DR) von CloudHub 2.0 ausreichend. CloudHub 2.0 stellt HA und DR auf regionaler Ebene bereit (weitere Details finden Sie unter CloudHub 2.0-Ausfallszenarien). Im Abschnitt "CloudHub 2.0 Key Considerations" (Wichtige Überlegungen zu CloudHub 2.0) finden Sie weitere Details zu den von CloudHub 2.0 unterstützten HAs und DRs.
Zu den Bedingungen, die ein Design vorschreiben, das über die Standardverfügbarkeit von CloudHub 2.0 hinausgeht, zählen:
- Eine Anwendung muss sicherstellen, dass in einem Katastrophenszenario (z. B. wenn eine Amazonasregion untergeht) keine Daten verloren gehen.
- Eine Anwendung hängt vom Objektspeicher ab und muss die Kontinuität sicherstellen, wenn die Bereitstellungsregion ausfällt.
- Backend-Systeme sind für eine gleichwertige Verfügbarkeit konfiguriert. CloudHub 2.0 kann manchmal über Warteschlangen oder ähnliche Mechanismen Zuverlässigkeit bieten. Unabhängig davon, ob die Integration in Echtzeit oder asynchron erfolgt, müssen Backend-Systeme jedoch ein vergleichbares Maß an HA und DR unterstützen.
- Wenn sich ein Ausfall auf AWS-Regionsebene auf Backend-Systeme auswirkt, wird angenommen, dass ihre Wiederherstellung parallel zur CloudHub 2.0-Wiederherstellung ausgeführt wird.
- Die Einrichtung des privaten Bereichs ist in mehreren Regionen abgeschlossen.
Die Designoptionen in diesem Handbuch konzentrieren sich auf Lösungen für die Anwendungsverfügbarkeit in CloudHub 2.0, wenn eine gesamte AWS Availability Zone oder Region nicht mehr verfügbar ist.
In diesem Leitfaden werden die folgenden Wiederherstellungsszenarien nicht behandelt, es werden jedoch ggf. Auswirkungen darauf erwähnt:
- Wiederherstellung von Backend-Systemen, Anwendungen, Datenbanken, Netzwerkkomponenten und Rechenzentren, die außerhalb von Anypoint CloudHub verwaltet und bereitgestellt werden, unabhängig davon, ob sie lokal oder in der Cloud sind.
- Wiederherstellung von VPN-Verbindungen zwischen CloudHub 2.0 und dem privaten Rechenzentrum des Kunden (z. B. IPsec-Tunnel und VPN-Gateways). Einige DR-Optionen in diesem Handbuch können diese Szenarien teilweise berücksichtigen.
- Änderungen an MuleSoft-Ausgangs-IPs während der Notfallwiederherstellung, wenn die IP-Zulassungsliste für Integrationen verwendet wird. Einige DR-Optionen in diesem Handbuch können diese Szenarien teilweise berücksichtigen.
- Externe Messaging-Systeme, die in Kundenlösungen verwendet werden, unabhängig davon, ob sie von MuleSoft (wie Anypoint MQ) oder anderen Anbietern (wie AWS MSK oder Heroku Kafka) bereitgestellt werden.
Beachten Sie beim Auswerten von CloudHub 2.0 für Anforderungen an die Notfallwiederherstellung die folgenden wichtigen Überlegungen.
CloudHub 2.0-Abhängigkeit von der regionalen AWS-Verfügbarkeit
- CloudHub 2.0 wird auf AWS ausgeführt. Die Verfügbarkeit ist an AWS-Regionen gebunden.
- Bereitstellungen und Anwendungsverfügbarkeit sind nach Region organisiert. Diese Regionen entsprechen AWS-Regionen.
Wenn eine gesamte AWS-Region fehlschlägt, sind Anwendungen in dieser Region nicht verfügbar und werden nicht automatisch an anderer Stelle repliziert.
Anwendungshochverfügbarkeit und Replikatsverwaltung
- CloudHub 2.0 stellt Anwendungen in derselben Region automatisch neu bereit, wenn Hardware fehlschlägt. Bei Anwendungen mit einem einzelnen Abgleich kann es jedoch zu Ausfallzeiten kommen.
- Anwendungen mit mehreren Replikaten werden standardmäßig in separaten Verfügbarkeitszonen bereitgestellt und bieten zonenübergreifende HA.
- Wenn die Verfügbarkeitszone für eine Einzelreplikatanwendung fehlschlägt, wird die Anwendung automatisch in einer anderen Verfügbarkeitszone innerhalb derselben Region angezeigt.
Spezifische Auswirkungen der Region 'USA Ost'
- Im Falle eines Ausfalls der Region "US East" (Osten der USA):
- Die CloudHub 2.0-Verwaltungsoberfläche und die Bereitstellungs-REST-Services sind nicht verfügbar und neue Anwendungen können nicht bereitgestellt werden.
- Anwendungen in anderen Regionen bleiben in den meisten Fehlerszenarien unberührt. Diese Anwendungen werden weiterhin normal ausgeführt. Die Überwachungs- und Verwaltungsfunktionen über die Steuerebene sind jedoch während des Ausfalls nicht verfügbar.
- Core CloudHub 2.0-Module (z. B. Anwendungseinstellungen) werden im Osten der USA beibehalten, sodass die Einstellungen während des Ausfalls nicht bearbeitet werden können.
Überwachung und Warnung
- Konfigurieren Sie die Benachrichtigung bei Fehlern auf Verfügbarkeitszone oder Regionsebene über status.mulesoft.com.
- Verwenden Sie einen separaten Mechanismus zur Integritätsprüfung und Warnung außerhalb von CloudHub 2.0, damit Teams benachrichtigt werden, wenn Replikate fehlschlagen oder Anwendungen nicht mehr antworten.
Datenpersistenz (Objektspeicher V2)
- Objektspeicher V2 ist an die Region gebunden, in der die Anwendung erstmals bereitgestellt wird.
- Wenn Sie die Anwendung in eine andere Region verschieben, verbleibt Objektspeicher V2 in der ursprünglichen Region, um Datenverlust zu vermeiden.
- Wenn in der Region, in der Objektspeicher V2 bereitgestellt wird, ein Fehler auftritt, ist der Objektspeicher nicht verfügbar.
Eingangssteuerungen und private Bereiche
- Die Eingabesteuerfelder von CloudHub 2.0 sind auf Regionsebene hoch verfügbar.
- Wenn in einem freigegebenen Bereich eine Region fehlschlägt, bleibt ein Eingabesteuerfeld in einer anderen Region verfügbar, kann jedoch nur in dieser Region bereitgestellte Anwendungen bereitstellen.
- Wenn eine Region in einem privaten Bereich fehlschlägt, sind Eingabesteuerfelder in anderen Regionen nicht verfügbar, es sei denn, sie wurden zuvor dort eingerichtet.
- Die Einrichtung des privaten Bereichs erfolgt regional. Wenn eine Region fehlschlägt, ist der private Bereich nicht verfügbar, es sei denn, eine andere Region wurde eingerichtet.
| Komponentenstatus | Salesforce-Verantwortung |
|---|---|
| Nachbau unten | Aktion: CloudHub 2.0 startet den Abgleich automatisch in einer anderen Verfügbarkeitszone neu, wenn mit der aktuellen Verfügbarkeitszone etwas nicht stimmt. Die Anwendung ist jedoch offline, bis der neue Abgleich vollständig gestartet ist. Bedingung: Standardkonfiguration. Zeitaufwand: Je nach Anwendungskomplexität und Abgleichsgröße ca. 2-15 Minuten. |
| Verfügbarkeitszone unten | Aktion: Genauso wie die Kopie unten. Bedingung: Standardkonfiguration. Zeitaufwand: Genauso wie die Kopie unten. Benachrichtigung: Genauso wie die Kopie unten. |
| Region nach unten | Aktion: Keine automatische Wiederherstellung. Es muss ein Failover-Design vorhanden sein. |
| Komponentenstatus | Kundenverantwortung |
|---|---|
| Nachbau unten | Benachrichtigung: Führen Sie regelmäßige Integritätsprüfungen mithilfe eines in die APIs integrierten Herzschlagmechanismus aus. Minderung: Stellen Sie die Anwendung für mehrere Abgleiche in derselben Region bereit. Test / Simulation: Erstellen Sie ein Ticket mit MuleSoft-Support und sie unterstützen einen Failover-Test, um zu überprüfen, ob ein neuer Abgleich in einer anderen AZ in 1 bis 15 Minuten ausgeführt wird. |
| Verfügbarkeitszone unten | Benachrichtigung: Genauso wie die Kopie unten. Minderung: Stellen Sie die Anwendung für mehrere Abgleiche in derselben Region oder in verschiedenen Regionen bereit. Test / Simulation: Das Szenario "AZ Down" ist schwer zu simulieren. Es erfordert die Einbeziehung von MuleSoft Engineering, um mögliche Testszenarien zu unterstützen. |
| Region nach unten | Benachrichtigung: Genauso wie die Kopie unten. Überprüfen Sie auch die Statusaktualisierungen unter https://status.aws.amazon.com. Minderung: Genau wie AZ Down. Notfallplan für die Notfallwiederherstellung: 2 private Bereiche mit derselben Konfiguration in verschiedenen Regionen. Test / Simulation: Genau wie AZ Down. |
| Komponentenstatus | Salesforce-Verantwortung |
|---|---|
| VPN-Gateway ausgefallen | Replikatstatus: Wird ausgeführt, kann jedoch keine Verbindung zu Ressourcen herstellen, die vor Ort gehostet werden und über den VPN-Tunnel erreichbar sind. Aktion: Keine automatische Wiederherstellung. Es muss ein Failover-Design vorhanden sein. |
| Eingangskontroller (freigegebener Bereich) | Replikatstatus: Das Eingabesteuerfeld ist ein Cluster-Setup mit mehreren Instanzen, ähnlich wie bei Anwendungsreplikaten. Wenn ein Anwendungsreplikat fehlschlägt, wird automatisch ein neues erstellt und gestartet. Wenn eine Instanz des Eingabesteuerfelds fehlschlägt, bleiben Anwendungen über die andere Instanz verfügbar. Wenn das gesamte Eingabesteuerfeld ausgefallen ist, wird die Region als ausgefallen betrachtet. |
| Eingangskontroller (Privatbereich) | Replikatstatus: Entspricht dem Eingabesteuerfeld im freigegebenen Bereich unten. |
| Komponentenstatus | Kundenverantwortung |
|---|---|
| VPN-Gateway ausgefallen | Benachrichtigung: Führen Sie regelmäßige Integritätsprüfungen mithilfe eines in die APIs integrierten Herzschlagmechanismus aus. Minderung: CloudHub 2.0-VPN-Gateways unterstützen die Hochverfügbarkeit durch eine Dual-Tunnel-Architektur mit automatischem Failover zwischen Tunneln. Ein Kunde muss dieses Muster konfigurieren. Test / Simulation: Das Szenario "VPN Gateway Down" ist schwierig zu simulieren. Erfordert die Beteiligung von MuleSoft Engineering zur Unterstützung möglicher Testszenarien. |
| Eingabesteuerung (freigegebener Bereich) nach unten | Benachrichtigung: Entspricht VPN Gateway Down. Minderung: Entspricht Region Down. Migrieren Sie Anwendungen zu einem Standby- oder aktiven Bereich in einer anderen Region. Test / Simulation: Entspricht VPN Gateway Down. |
| Eingabesteuerung (Privatbereich) nach unten | Benachrichtigung: Entspricht VPN Gateway Down. Minderung: Entspricht Region Down. Migrieren Sie Anwendungen in Abstimmung mit der AWS Route 53-Konfiguration (oder einer entsprechenden Konfiguration) zu einem privaten Standby- oder aktiven Bereich in einer anderen Region. Test / Simulation: Entspricht VPN Gateway Down. |
Abwärtsszenario für Plattformservices im Überblick – Object Store
| Objektspeicher im Speicher | Persistenter Objektspeicher v2 | |
|---|---|---|
| Speicherort der Daten | Nur lokal für die Anwendung. | In derselben Region, in der die MuleSoft-Anwendung erstmals bereitgestellt wurde. |
| Abgleichsübergreifend freigegeben? | Nein | Ja |
| Objektspeicherwiederherstellung in Anwendungen | Daten gehen verloren. Alle Daten im Arbeitsspeicher gehen beim Neustart der Anwendung, bei einer neuen Bereitstellung oder bei einem Replikatfehler verloren. | Daten gehen nicht verloren, es sei denn, die Anwendung wird gelöscht. |
| Objektspeicherwiederherstellung innerhalb der Region | Daten gehen verloren (wie oben). | Daten gehen nicht verloren (wie oben). |
| Regionale Erholung | Wie oben. | Daten sind nicht verfügbar. Selbst bei einer aktiv aktiven DR-Konfiguration ist der Objektspeicher nur in der ursprünglichen Bereitstellungsregion verfügbar. |
| Eindämmung | Externalisieren Sie Daten für die regionale Wiederherstellung. | Die Daten bleiben verfügbar, solange die ursprüngliche Bereitstellungsregion verfügbar ist. Externisieren Sie für regionsübergreifende HAs oder DRs Daten außerhalb des Objektspeichers. |
Hochverfügbarkeit ist die Maßeinheit für die Fähigkeit eines Systems, im Falle eines Systemkomponentenausfalls weiterhin darauf zuzugreifen. Im Allgemeinen wird HA implementiert, indem mehrere Ebenen der Fehlertoleranz und/oder Lastausgleichsfunktionen in ein System integriert werden. Es handelt sich in der Regel um eine Konfiguration vom Typ "Aktiv" und sie hat nur begrenzte oder keine Auswirkungen auf Business Services.
Bei der Katastrophenwiederherstellung handelt es sich um den Prozess, durch den ein System nach einem Katastrophenszenario in einen vorherigen akzeptablen Zustand zurückversetzt wird, entweder durch natürliche (wie Überschwemmungen, Tornados, Erdbeben oder Brände) oder durch Menschen verursachte (wie Stromausfälle, Serverausfälle oder Fehlkonfigurationen). DR ist in der Regel eine Active-Passive-Konfiguration und führt zu einigen Auswirkungen auf Business Services.
Wenn regionale Hochverfügbarkeit oder regionale Notfallwiederherstellung gewünscht wird, um die Auswirkungen auf das Geschäft im Falle eines regionalen AWS-Fehlers zu reduzieren, sollten Sie beim Entwerfen Ihrer Lösung in MuleSoft CloudHub 2.0 folgende Punkte berücksichtigen:
- CloudHub 2.0-Replikate und zugehörige Funktionen – private Bereiche, Eingabesteuerfelder und Anypoint MQ-Ziele – sind regionsspezifisch.
- Wenn eine gesamte AWS-Region fehlschlägt, sind alle Abgleiche und zugehörigen Services in dieser Region nicht mehr verfügbar.
- Wenn eine Region wiederhergestellt ist, werden die Konfigurationen wiederhergestellt. Sie müssen die Anwendungen neu starten.
- Wenn in der Region "US East" ein Fehler auftritt, sind Anypoint Platform-Services (z. B. Zugriffsverwaltung und Laufzeit-Manager) ebenfalls nicht verfügbar.
- MuleSoft bietet ein SLA von 99,95 % für Plattformservices, einschließlich CloudHub 2.0-Replikaten in einer aktiv aktiven Konfiguration innerhalb einer Region. Aktuelle Details finden Sie im aktuellen MuleSoft Cloud-Angebot für SLA.
- CloudHub 2.0 unterstützt standardmäßig weder HA noch DR für mehrere Regionen. Die Verfügbarkeit ist nur in einer einzelnen Region verfügbar.
Diese Designrichtlinien gelten unabhängig von Ihrem ausgewählten Setup.
Setup für private Bereiche mit mehreren Regionen
Für alle in den folgenden Abschnitten beschriebenen Optionen müssen Anwendungen in separaten Regionen bereitgestellt werden. Dies ist nur möglich, wenn die Einrichtung des privaten Bereichs vor einer Katastrophe im Voraus abgeschlossen wurde. Da die Einrichtung des privaten Bereichs regional ist, sind für eine Strategie für die Verwaltung des öffentlichen Raums mindestens zwei private Bereiche (einer pro Region) und ein Mechanismus zum Umschalten des Datenverkehrs auf den entsprechenden VPN-Endpunkt erforderlich.
Hochverfügbare Einrichtung des privaten Bereichs in einer Region
CloudHub 2.0 bietet kein automatisches Failover, wenn ein privater Bereich in einer Region fehlschlägt. Eine Übergangslösung ist eine aktiv-passive Einrichtung in mehreren Umgebungen, die Folgendes erfordert:
- Konfigurieren mehrerer VPN-Gateways im privaten Bereich.
- Einrichten separater Umgebungen in der CloudHub 2.0-Region mit jeweils eigenem privaten Bereich.
- Definieren einer dieser Umgebungen als passiv (dort, wo Anwendungen anfangs nicht bereitgestellt werden, aber angezeigt werden, wenn der primäre private Bereich fehlschlägt).
Wenn ein Hochverfügbarkeits-Setup ohne VPN-Gateway als einzelner Fehlerpunkt eine schwierige Anforderung ist, ist die Bereitstellung in zwei Regionen die beste Option. Ein VPN-Gateway-Fehler in diesem Szenario könnte behoben werden, indem die betroffene Region in die alternative Region verschoben wird, in der der private Bereich bereits konfiguriert ist.
Zero Message Loss
Damit bei einem Fehler in einer gesamten Region keine Nachrichten verloren gehen, muss eine Anwendung Datenverlust verhindern und die folgenden Punkte berücksichtigen:
- Verwenden Sie externe Nachrichten, um die Nachrichtenzuverlässigkeit zu erreichen.
- Stellen Sie sicher, dass "Objektspeicher" nicht für Transaktionsdaten während des Betriebs verwendet wird, die transaktionaler Natur sind. Wenn die Bereitstellungsregion, in der die MuleSoft-Anwendung erstmals bereitgestellt wurde, ausfällt, ist der Objektspeicher nicht mehr verfügbar.
- Wickeln Sie den gesamten Objekt-Shop-Zugriff in einen separaten Flow oder Abschnitt ein, der sowohl für die Verarbeitung von Ausnahmen als auch für das Verhalten weiterhin funktioniert, wenn Lese- oder Schreibvorgänge im Objekt-Shop fehlschlagen.
Notiz. In den meisten Fällen müssen die DR-Anforderungen im Katastrophenfall keinen Nachrichtenverlust von null sicherstellen und sicherstellen, dass der Datenverlust geringer ist als der Wert der Daten für einen bestimmten Zeitraum (beispielsweise 1 Stunde).
Bleiben der Integration ohne Status
Als allgemeines Designprinzip ist es immer wichtig, dass die Integrationen zustandslos sind. Das bedeutet, dass keine Transaktionsinformationen zwischen verschiedenen Clientaufrufen oder -ausführungen (im Falle geplanter Services) freigegeben werden. Wenn einige Daten aufgrund einer Systemeinschränkung von der Middleware verwaltet werden müssen, sollten sie in einem externen Speicher, beispielsweise einer Datenbank oder einer Messaging-Warteschlange, und nicht in der MuleSoft-Infrastruktur oder im MuleSoft-Speicher beibehalten werden. Es ist wichtig zu beachten, dass bei der Skalierung, insbesondere in der Cloud, der Status und die Ressourcen, die von jedem Abgleich verwendet werden, unabhängig von anderen Abgleichen sein sollten. Dieses Modell sorgt für mehr Leistung, Skalierbarkeit und Zuverlässigkeit.
Netzwerk- und Datenverkehrsverwaltung
- Vanity-Domänen sind für die regionale Verfügbarkeit erforderlich. Sie fungieren als globales DNS für alle Eingabesteuerfelder über Regionen hinweg.
- Ein globaler Lastenausgleich leitet den Datenverkehr zwischen den privaten Bereichen der primären und der DR-Region weiter. Kunden stellen diese Komponente bereit. Verwenden Sie AWS Route 53 oder ein globales CDN mit Weiterleitungsrichtlinien, um den Datenverkehr regionsübergreifend weiterzuleiten.
- Konfigurieren Sie die Eingabesteuerfelder in primären und DR-Regionen mit einer benutzerdefinierten Vanity-Domäne.
- Planen und verwalten Sie Firewall-Regeln und VPN-Tunnel, damit lokale Anwendungen sowohl im privaten Bereich der primären als auch der DR-Region erreicht werden können.
- Die TLS-Zertifikatpflege muss private Bereiche in der primären und DR-Region abdecken, um eine nahtlose Wiederherstellung zu ermöglichen.
Anwendungsbereitstellung und -konfiguration
- Anwendungsnamen müssen regionsübergreifend eindeutig sein. Beispielsweise kann eine CI/CD-Pipeline den Regionsnamen (oder einen Regionscode) vor der Bereitstellung an Anwendungsnamen anhängen, um die Eindeutigkeit in primären und DR-Regionen beizubehalten.
- Konfigurieren Sie die CI/CD-Pipeline so, dass Anwendungen in der primären und DR-Region bereitgestellt werden, sodass alle Anwendungen in beiden Regionen verfügbar sind.
Infrastruktur und Kapazität
Die Leistung ist am besten, wenn alle Infrastrukturaspekte identische primäre und DR-Regionskapazität aufweisen. Die Leistung verschlechtert sich, wenn diese Infrastrukturaspekte nicht identisch sind.
Datenpersistenz und -speicherung
- Der Persistenzspeicher muss regelmäßig zwischen den beiden Bereichen synchronisiert werden. Kunden sind für den Speicherabgleich verantwortlich. MuleSoft stellt ihn nicht bereit. Ein einzelner freigegebener Speicher zwischen VPCs in der primären und DR-Region ist möglich. Der freigegebene Speicher muss jedoch hoch verfügbar sein, da er sonst für beide Regionen zu einem einzigen Fehlerpunkt wird.
- Objektspeicher V2 ist regional und nur in der Region verfügbar, in der die Mule-Anwendung erstmals bereitgestellt wurde. Wenn die Anwendung in eine andere Region verschoben wird, verbleibt Objektspeicher V2 in der ursprünglichen Region, um Datenverlust zu vermeiden. Verwenden Sie anderen persistenten Speicher für DR-Strategien mit mehreren Regionen.
Test- und Betriebsverfahren
Nehmen Sie eine formelle DR-Teststrategie an und führen Sie regelmäßig DR-Bohrungen aus. Verwenden Sie bei aktiver DR eine Kanarienvogel-Bereitstellungsstrategie, um beide Regionen zu validieren.
Leistungs- und Service Level Agreements (SLAs)
Es kann zu Leistungseinbußen kommen, da die DR-Region möglicherweise weiter von Endbenutzern oder Backend-Systemen entfernt ist als die primäre Region. Definieren und kommunizieren Sie ein DR-SLA an Beteiligte.
Verhalten im Wiederherstellungsmodus (Kontextnotiz)
Im aktiven Modus erfolgt der Failover von der primären Region in den privaten Bereich der DR-Region schnell: Der globale Lastenausgleich erkennt, dass die primäre Region ungesund ist, und leitet den Datenverkehr an die gesunde Region weiter. Im aktiv-passiven Modus müssen Sie die Anwendung im Notfall im privaten Bereich der DR-Region bereitstellen.
Es gibt 3 Optionen, um eine höhere Verfügbarkeit auf DR-Ebene zu erreichen:
Ein aktiv-aktives Setup basiert auf aktiven Mitarbeitern, die über mehrere Regionen verteilt sind, und verwendet einen externen Lastenausgleich, um den Datenverkehr zwischen den beiden Instanzen weiterzuleiten.
Warme Standby-Konfiguration
Eine aktiv-passive Einrichtung würde auf einem aktiven Mitarbeiter in einer Region und einem passiven Mitarbeiter in einer anderen Region basieren. Die passive Region würde bei Bedarf gestartet.
Einige Elemente der passiven Region müssen für ein Failover aktiv bleiben oder zuvor eingerichtet werden, einschließlich privater Bereiche, VPNs und Transit-Gateway-Anhänge.
Wie oben werden Abgleiche und Eingabesteuerfelder beim Failover in einem zweiten Bereich über einen vollautomatischen DevOps-Prozess bereitgestellt. Einige Elemente der passiven Region müssen für ein Failover aktiv bleiben, darunter private Bereiche, VPNs und Transit Gateway Attachments.
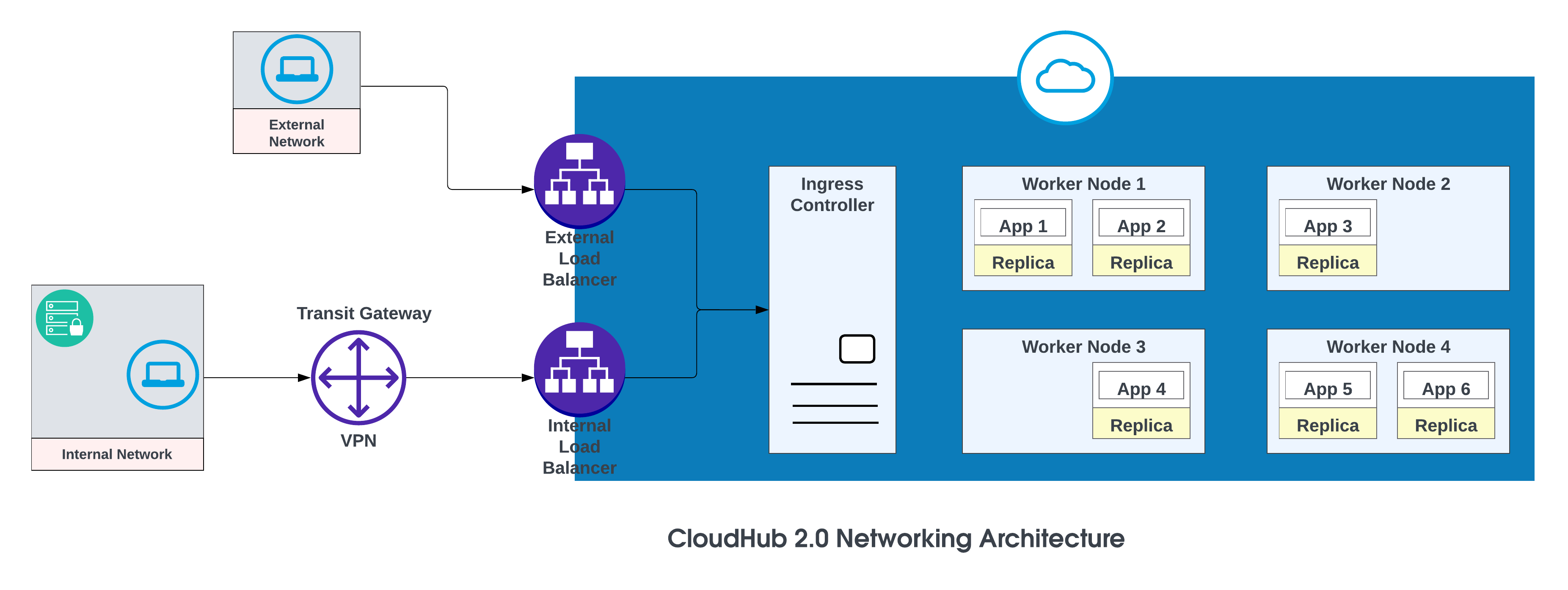
Die grundlegenden Komponenten der CloudHub 2.0-Netzwerkarchitektur sind:
- Ein HTTP-Lastausgleich
- Mule-Replikat-DNS-Datensätze
- Private Bereiche
- Regionale Dienstleistungen
Weitere Details finden Sie unter CloudHub 2.0-Netzwerkarchitektur.
Vanity-Domänen
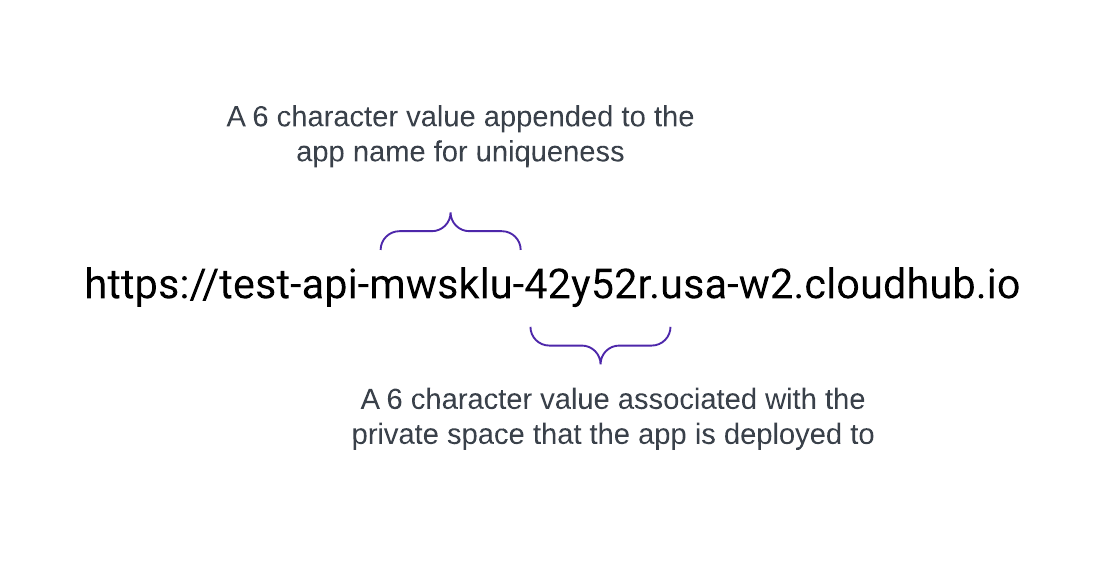
Wenn ein privater Bereich erstellt wird, erhält er einen DNS-Zielnamen im Format: <space-id>.<region>.cloudhub.io . Bei der Bereitstellung einer Anwendung mit dem Namen test-api in diesem privaten Bereich weist der Endpunkt das folgende Format auf:
CloudHub 2.0 unterstützt auch benutzerdefinierte Domänen oder Vanity-Domänen, indem es sie in einem privaten Bereich mithilfe von TLS-Kontexten und DNS-Datensätzen konfiguriert. Laden Sie zum Erstellen eines TLS-Kontexts im Laufzeit-Manager für einen privaten Bereich das öffentliche Zertifikat und den privaten Schlüssel hoch und fügen Sie dann einen benutzerdefinierten Endpunkt in den Einstellungen Ihrer Anwendung hinzu, um diese Domäne zu verwenden. Erstellen Sie einen DNS-Datensatz (z. B. einen CNAME), der Ihre Vanity-Domäne auf den standardmäßigen Hostnamen Ihres privaten Bereichs verweist.
Beispielsweise weist eine in us-west-2 bereitgestellte Anwendung mit dem Namen test-api mit dem Standard-DNS 42y52r.usa-w2.cloudhub.io den folgenden API-Endpunkt auf:
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
Dieser URL verwendet keine Eitelkeit oder benutzerdefinierte Domäne. Führen Sie die folgenden Schritte aus, um acme.com zu verwenden, damit API-URLs als https://test-api.acme.com angezeigt werden.
- Erstellen Sie TLS-Kontext im Laufzeit-Manager mit öffentlichen und privaten Schlüsseln.
- Fügen Sie in den Einstellungen der Anwendung eine Vanity-Domäne hinzu, um diese Domäne zu verwenden.
- Erstellen Sie einen DNS-Datensatz in AWS Route 53 und konfigurieren Sie eine einfache Weiterleitungsrichtlinie (z. B. CNAME), damit die Vanity-Domäne zum Standard-Hostnamen des privaten Bereichs aufgelöst wird.
Bei benutzerdefinierten Domänen können Sie AWS Route 53 oder andere globale CDN-Services mit Weiterleitungsrichtlinien verwenden. Im folgenden Diagramm wird AWS Route 53 mit der Richtlinie für die "einfache" Weiterleitung verwendet. Wenn ein Verbraucher aus einem öffentlichen (externen) Netzwerk acme.com anfordert, leitet AWS Route 53 die Anforderung an das MuleSoft-Steuerfeld für den Eingang des privaten Bereichs weiter.
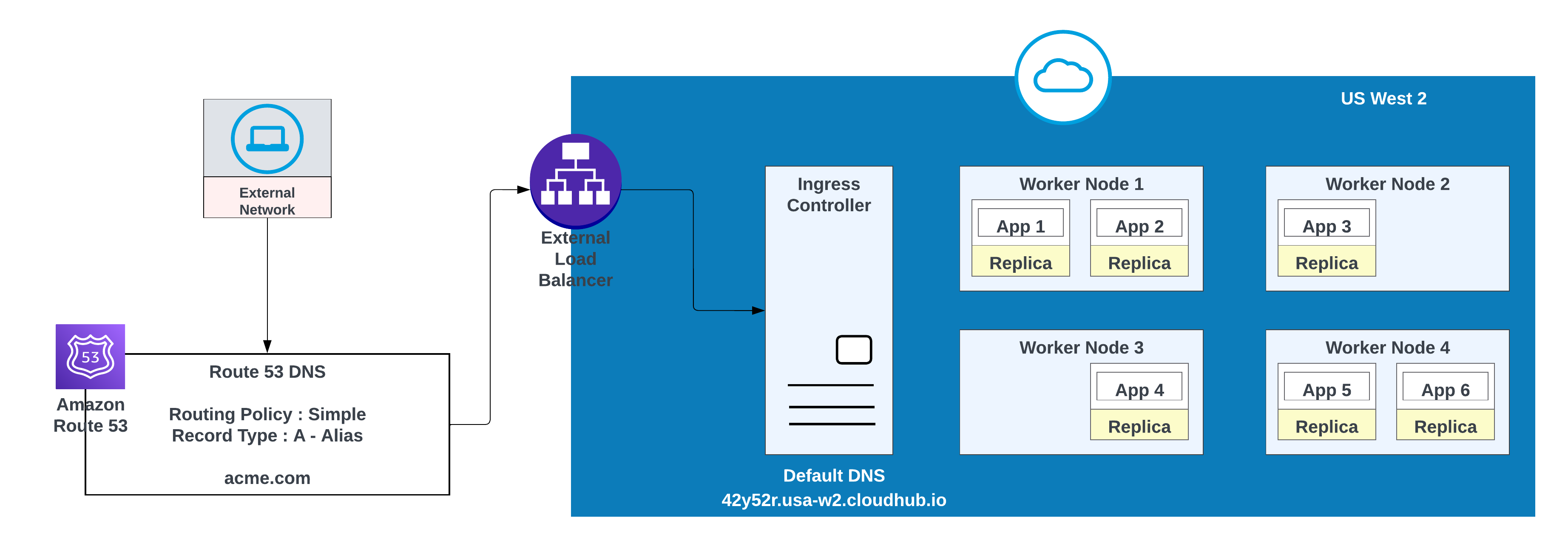
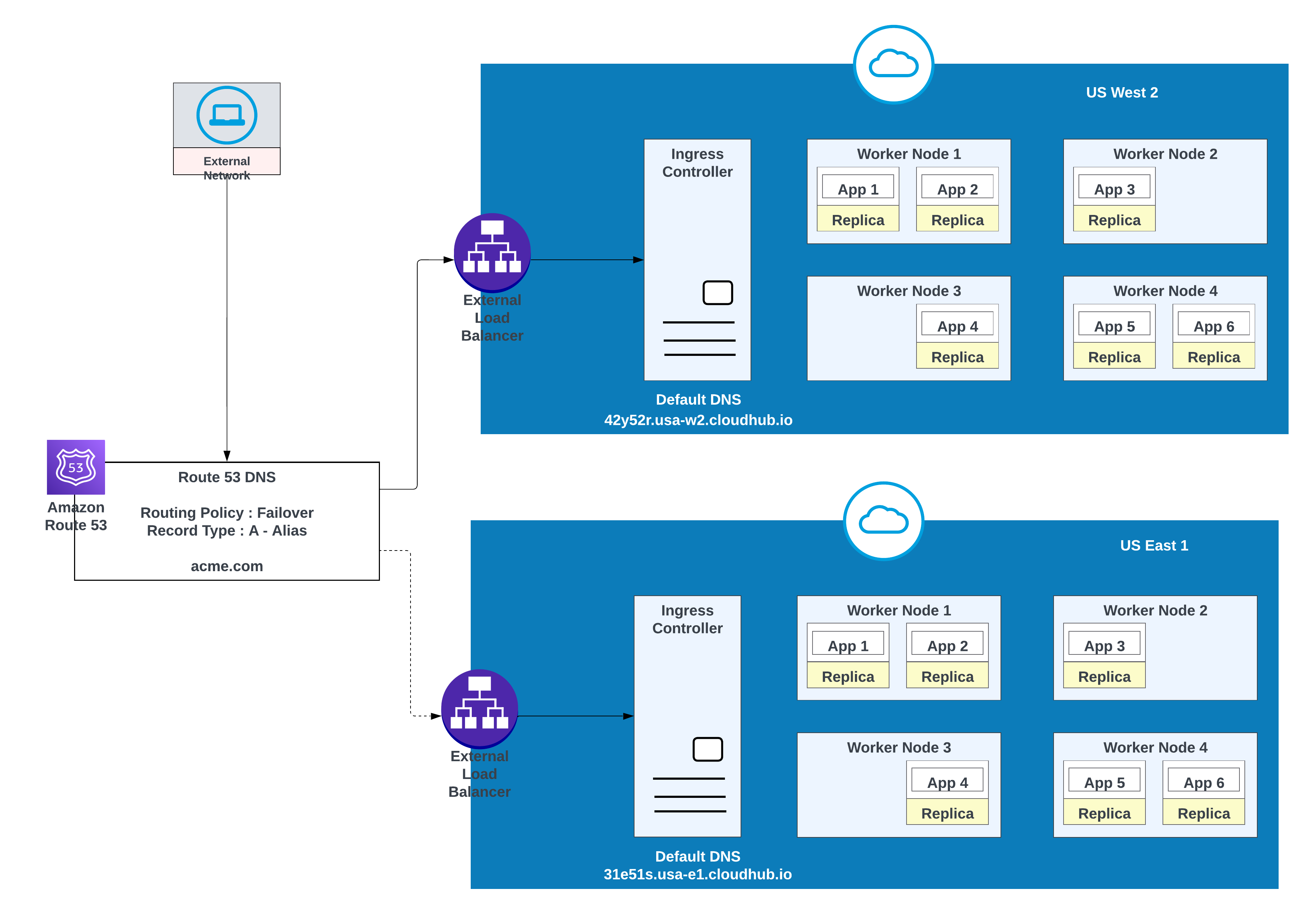
Verwenden Sie diese Option, wenn Anwendungen ein Failover erfordern: Stellen Sie eine Instanz in der primären Region (z. B. us-west-2) und eine andere in einer sekundären Region (z. B. us-east-1) bereit.
Verwenden Sie nach Möglichkeit eine vorhandene Umgebung in der sekundären Region. Das Erstellen einer neuen Umgebung erfordert zusätzlichen Aufwand.
Beispiel für Anwendungen, die in einer Region (USA-West 2) mit einem Failover in eine andere Region (USA-Ost 1) bereitgestellt wurden
| Datensatzname | Wert/Weiterleiten des Datenverkehrs an | Weiterleitungsrichtlinie | Integritätsprüfungs-ID |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Failover | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Failover | 43e131s131sq |
In dieser Konfiguration leitet AWS Route 53 den Datenverkehr an die Eingabesteuerfelder für die privaten Bereiche in US West 2 und US East 1 weiter. Eine Failover-Weiterleitungsrichtlinie wird mit einer Integritätsprüfung konfiguriert.
Verwenden Sie für eine geringere Latenz bei gleichzeitig hoher Verfügbarkeit die im Diagramm beschriebene Bereitstellungsstrategie. Mit dieser Strategie können Anwendungen in zwei Regionen bereitgestellt werden (in diesem Beispiel us-west-2 und us-east-1).
Verwenden Sie die Latenzweiterleitungsrichtlinie in AWS Route 53, um Anforderungen an die Region weiterzuleiten, die die niedrigste Latenz bei gleichzeitig hoher Verfügbarkeit bietet. Weiterleitungsrichtlinie 'Latenz' in AWS Route 53, um die Anforderung für eine niedrigere Latenz bei weiterhin hoher Verfügbarkeit weiterzuleiten.
In beiden Regionen (USA West 2 und USA East 1) bereitgestellte Anwendungen für geringere Latenz und hohe Verfügbarkeit
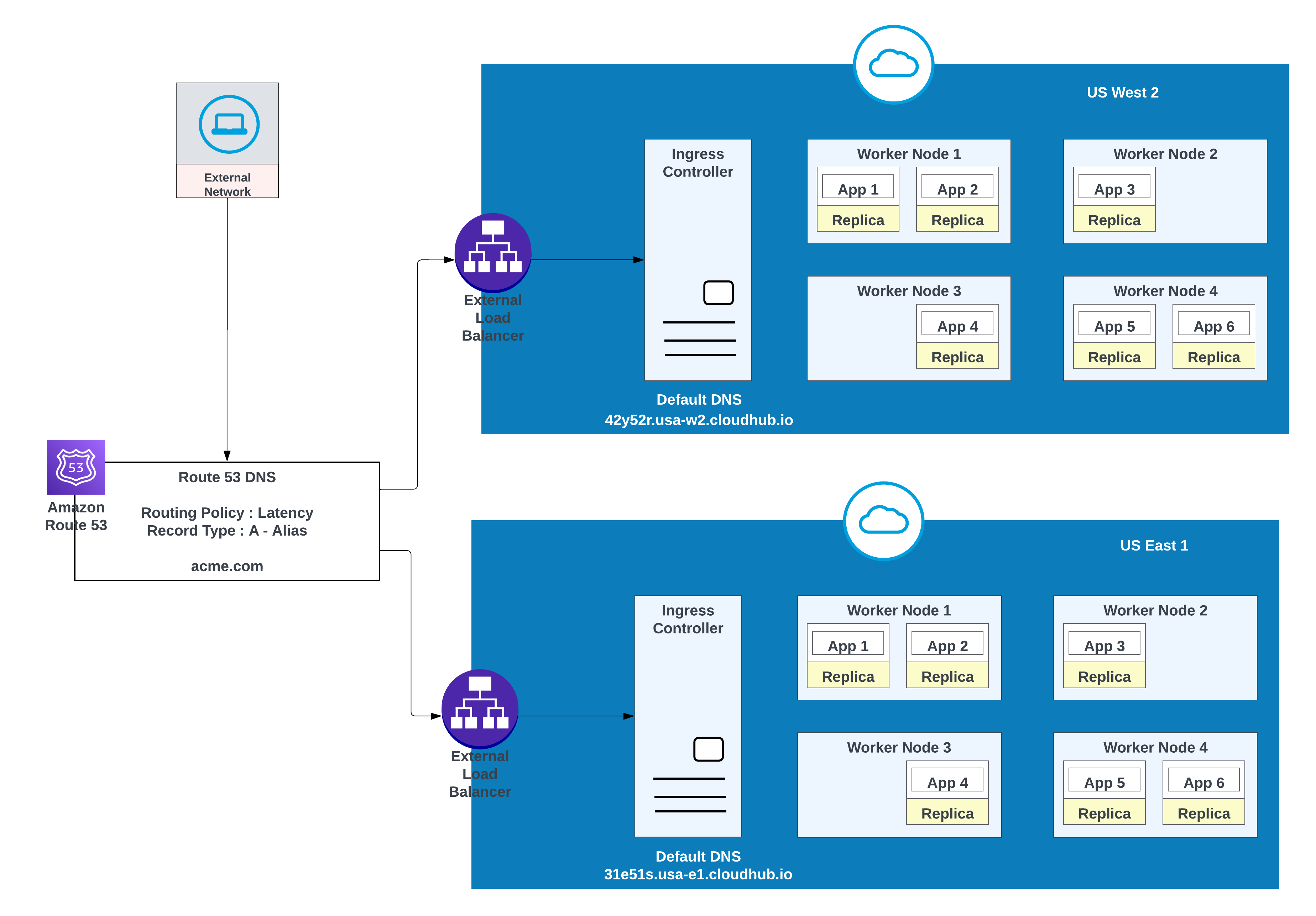
| Datensatzname | Wert/Weiterleiten des Datenverkehrs an | Weiterleitungsrichtlinie | Integritätsprüfungs-ID |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Latenz | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Latenz | 43e131s131sq |
MuleSoft CloudHub 2.0 bietet eine robuste Grundlage für die Resilienz innerhalb der Region und nutzt in erster Linie die automatisierte Abgleichsredundanz und den intelligenten Lastausgleich. In einer einzelnen Cloud-Region wird durch die Bereitstellung von Anwendungen mit mehreren Replikaten sichergestellt, dass bei einem Fehler einer Instanz sofort andere die Arbeitslast übernehmen können. Der integrierte Lastenausgleich verteilt eingehenden Datenverkehr effizient auf diese gesunden Abgleiche, minimiert Ausfallzeiten und gewährleistet eine kontinuierliche Serviceverfügbarkeit unter normalen Betriebsbedingungen.
Wenn Sie sich jedoch ausschließlich auf diese einzelne Regionsarchitektur verlassen, auch auf eine Architektur mit hoher Redundanz, besteht ein erhebliches Risiko eines weitreichenden, katastrophalen regionalen Ausfalls. Die Geschichte hat gezeigt, dass selbst die zuverlässigsten und technologisch fortschrittlichsten Cloud-Anbieter anfällig für störende Vorfälle sind, die sich auf eine gesamte geografische Region auswirken können. Diese einzelnen Fehlerpunkte sind zwar selten, können jedoch durch verschiedene Ereignisse verursacht werden, darunter:
- Groß angelegte Infrastrukturvorfälle
- Schwere Stromausfälle
- Weit verbreitete Netzwerkunterbrechungen
Um eine echte Hochverfügbarkeit (HA) und Notfallwiederherstellung (DR) zu erreichen, muss eine Architektur daher so konzipiert sein, dass sie die Einschränkungen eines Einzelregionsmodells überschreitet. Die empfohlene Strategie ist die Bereitstellung in mehreren geografisch unterschiedlichen Regionen. Durch diese regionsübergreifende Resilienz wird sichergestellt, dass der Datenverkehr nahtlos auf eine Anwendungsinstanz umgeschaltet werden kann, die in einer separaten, nicht betroffenen Region ausgeführt wird, wenn eine gesamte Cloud-Region aufgrund einer unerwarteten Katastrophe nicht verfügbar ist. Dies garantiert minimale Serviceunterbrechungen und das Erreichen maximaler Betriebszeitziele.
CloudHub 2.0-Netzwerkarchitektur
Konfigurieren von regionsübergreifendem Failover für Standardwarteschlangen
Bereitstellungsregionen für Objektspeicher V2
Ihre Objektspeicher-Bereitstellungsregion
Gulal Kumar ist Software-Engineering-Architekt bei Salesforce mit Schwerpunkt auf Daten- und Integrationsarchitektur. Mit über 20 Jahren Erfahrung in Integration und APIs, Modernisierungsprogrammen, Sicherheit und AIML-Initiativen bringt er eine Fülle von Expertise mit. Gulal hat sich verpflichtet, Initiativen zur Geschäftstransformation voranzutreiben, Sicherheit und Widerstandsfähigkeit zu erhöhen, Architekturexzellenz zu fördern und AIML-Initiativen in verschiedenen Bereichen voranzutreiben.
Ajay Nagaraju ist Enterprise Architect und Senior Director bei MuleSoft mit über 28 Jahren Erfahrung in der Unternehmensarchitektur, Systemintegration und der groß angelegten digitalen Transformation. Er hat die Architektur und Bereitstellung komplexer Programme im Wert von mehreren Millionen Dollar in Fortune 100- und Fortune 500-Organisationen geleitet und verfügt über umfassende Expertise in API-gestützter Konnektivität, SOA, Cloud-Technologien und Unternehmensintegrationsmustern. Ajay hat eng mit Führungskräften zusammengearbeitet, um Geschäftsprozesse, Datenplattformen und Integrationsökosysteme zu modernisieren, und ist leidenschaftlich daran interessiert, skalierbare Architekturen zu entwickeln, Teams zu betreuen und messbare Geschäftsergebnisse durch Technologie voranzutreiben.