Questo testo è stato tradotto utilizzando il sistema di traduzione automatica di Salesforce. Partecipa al nostro sondaggio per fornire un feedback su questo contenuto e dirci cosa vorresti vedere dopo.
Note
Panoramica
Questo documento descrive le opzioni correnti per la distribuzione delle applicazioni in CloudHub 2.0 per soddisfare i requisiti di disponibilità elevata e ripristino di emergenza. Utilizza la regione degli Stati Uniti come esempio e può essere applicato ad altre regioni.
CloudHub 2.0 è una piattaforma di integrazione nativa del cloud completamente gestita che elimina il sovraccarico dell'infrastruttura automatizzando la distribuzione, la scalabilità e la gestione delle API e delle integrazioni MuleSoft nel cloud. È la moderna piattaforma di distribuzione cloud di MuleSoft, eseguita sull'infrastruttura AWS Amazon.
Requisiti per il ripristino di emergenza
Nella maggior parte dei casi, l'Alta disponibilità (HA) e il Ripristino di emergenza (DR) predefiniti forniti da CloudHub 2.0 sono sufficienti. CloudHub 2.0 fornisce HA e DR a livello regionale (per ulteriori dettagli, vedere CloudHub 2.0 Outage Scenarys). La sezione Considerazioni chiave fornisce ulteriori dettagli su HA e DR supportati da CloudHub-2.0.
Le condizioni che impongono una progettazione oltre la disponibilità predefinita di CloudHub 2.0 includono:
Un'applicazione deve garantire l'assenza di perdite di dati in uno scenario di emergenza (ad esempio, una regione dell'Amazzonia che cade).
Un'applicazione dipende dall'Object Store e deve garantire la continuità in caso di guasto della regione di distribuzione.
Ipotesi
I sistemi di backend sono configurati per una disponibilità equivalente. CloudHub 2.0 può talvolta fornire affidabilità tramite aree di attesa o meccanismi simili, ma sia che l'integrazione sia in tempo reale o asincrona, i sistemi di backend devono supportare un livello comparabile di HA e DR.
Quando un guasto a livello di regione AWS influisce sui sistemi di backend, si presume che il ripristino venga eseguito in parallelo al ripristino CloudHub 2.0.
L'impostazione dello spazio privato è completa in più regioni.
Fuori dall'ambito
Le opzioni di progettazione di questa guida si concentrano sulle soluzioni per la disponibilità delle applicazioni in CloudHub 2.0 quando un'intera zona o area geografica di disponibilità AWS non è disponibile.
Questa guida non affronta questi scenari di ripristino, anche se prende nota delle implicazioni laddove pertinenti:
Ripristino di sistemi di backend, applicazioni, database, componenti di rete e data center gestiti e forniti all'esterno di Anypoint CloudHub, in locale o nel cloud.
Ripristino dei link VPN tra CloudHub 2.0 e il data center privato del cliente (ad esempio, tunnel IPsec e gateway VPN). Alcune opzioni di DR in questa guida possono risolvere parzialmente questi scenari.
Modifiche agli IP di uscita MuleSoft durante il ripristino di emergenza quando l'elenco IP consentiti viene utilizzato per le integrazioni. Alcune opzioni di DR in questa guida possono risolvere parzialmente questi scenari.
Sistemi di messaggistica esterni utilizzati nelle soluzioni per i clienti, forniti da MuleSoft (ad esempio Anypoint MQ) o da altri fornitori (ad esempio AWS MSK o Heroku Kafka).
Considerazioni chiave su CloudHub 2.0
Quando si valuta CloudHub 2.0 per i requisiti di ripristino, tenere presenti le seguenti considerazioni chiave.
Dipendenza CloudHub 2.0 dalla disponibilità regionale AWS
CloudHub 2.0 viene eseguito su AWS; la sua disponibilità è legata alle regioni AWS.
Le distribuzioni e la disponibilità delle applicazioni sono organizzate per regione. Queste regioni corrispondono alle regioni AWS.
Se un'intera regione AWS non riesce, le applicazioni in quella regione non sono disponibili e non vengono replicate automaticamente altrove.
Alta disponibilità delle applicazioni e gestione delle repliche
CloudHub 2.0 ridistribuisce automaticamente le applicazioni all'interno della stessa regione in caso di guasto hardware, ma un'applicazione con una singola replica può riscontrare tempi di inattività.
Le applicazioni con più repliche vengono distribuite in zone di disponibilità separate per impostazione predefinita, fornendo HA in tutte le zone.
Se la zona di disponibilità di un'applicazione a replica singola non riesce, l'applicazione viene automaticamente visualizzata in un'altra zona di disponibilità all'interno della stessa regione.
Impatto specifico sulla regione orientale degli Stati Uniti
In caso di guasto della regione US East:
L'interfaccia utente di gestione CloudHub 2.0 e i servizi REST di distribuzione non sono disponibili e non è possibile distribuire nuove applicazioni.
Le applicazioni in altre regioni non sono interessate nella maggior parte degli scenari di errore. Queste applicazioni continuano a funzionare normalmente; tuttavia, le funzionalità di monitoraggio e gestione tramite il piano di controllo non saranno disponibili durante il guasto.
I moduli Core CloudHub 2.0 (ad esempio le impostazioni delle applicazioni) vengono mantenuti negli Stati Uniti orientali, quindi le impostazioni non possono essere modificate durante il guasto.
Monitoraggio e avvisi
Configurare gli avvisi per gli errori a livello di zona di disponibilità o di regione tramite status.mulesoft.com.
Utilizzare un meccanismo separato di controllo dello stato e di avviso all'esterno di CloudHub 2.0 in modo che i team ricevano una notifica se le repliche non riescono o se le applicazioni non rispondono più.
Persistenza dei dati (Object Store V2)
Object Store V2 è legato alla regione in cui l'applicazione viene distribuita per la prima volta.
Se si sposta l'applicazione in un'altra regione, Object Store V2 rimane nella regione originale per evitare perdite di dati.
Se la regione in cui è distribuito Object Store V2 non riesce, l'Object Store non è disponibile.
Controller di ingresso e spazi privati
I controller di ingresso di CloudHub 2.0 sono altamente disponibili a livello regionale.
In uno spazio condiviso, se una regione non riesce, un controller di ingresso in un'altra regione rimane disponibile ma può servire solo le applicazioni distribuite in quella regione.
In uno spazio privato, se una regione non riesce, i controller di ingresso in altre regioni non sono disponibili a meno che non siano stati impostati in precedenza.
L'impostazione dello spazio privato è regionale; se una regione non riesce, lo spazio privato non è disponibile a meno che non sia stata impostata un'altra regione.
Scenari di interruzione di CloudHub 2.0
Replica / Disponibilità Zona / Regione Disservizi
Responsabilità Salesforce
Stato componente
Responsabilità Salesforce
Replica giù
Azione: CloudHub 2.0 riavvia automaticamente la replica in una zona di disponibilità diversa se si verifica un errore nella zona di disponibilità corrente. Tuttavia, l'applicazione sarà offline fino a quando la nuova replica non sarà completamente avviata. Condizione: Configurazione predefinita. Tempo impiegato: Circa 2-15 minuti a seconda della complessità dell'applicazione e delle dimensioni della replica.
Zona disponibilità ridotta
Azione: Come la replica giù. Condizione: Configurazione predefinita. Tempo impiegato: Come la replica giù. Notifica: Come la replica giù.
Regione giù
Azione: Nessun ripristino automatico. Deve essere disponibile un progetto di failover.
Responsabilità del cliente
Stato componente
Responsabilità del cliente
Replica giù
Notifica: Eseguire controlli periodici dello stato utilizzando un meccanismo Heartbeat integrato nelle API. Mitigazione: Distribuire l'applicazione a più repliche nella stessa regione. Test / simulazione: Alza un ticket con il supporto MuleSoft e supporterà un test di failover per verificare se una nuova replica viene eseguita in un'AZ diversa in 1-15 minuti.
Zona disponibilità ridotta
Notifica: Come la replica giù. Mitigazione: Distribuire l'applicazione a più repliche nella stessa regione o in regioni diverse. Test / simulazione: Lo scenario AZ Down è difficile da simulare. Richiede il coinvolgimento di MuleSoft Engineering per supportare possibili scenari di test.
Regione giù
Notifica: Come la replica giù. Controllare anche gli aggiornamenti di stato all'indirizzo https://status.aws.amazon.com. Mitigazione: Come AZ Down. Piano di emergenza di ripristino: 2 spazi privati con la stessa configurazione in regioni diverse. Test / simulazione: Come AZ Down.
Gateway VPN e interruzioni del controller di ingresso
Responsabilità Salesforce
Stato componente
Responsabilità Salesforce
Gateway VPN disattivato
Stato replica: In esecuzione ma non in grado di connettersi ad alcuna risorsa ospitata in loco e raggiungibile attraverso il tunnel VPN. Azione: Nessun ripristino automatico. Deve essere disponibile un progetto di failover.
Controllo degli ingressi (spazio condiviso) disattivato
Stato replica: Il controller Ingress è un'impostazione in cluster con più istanze, simile alle repliche delle applicazioni. Se una replica dell'applicazione non riesce, viene creata e avviata automaticamente una nuova replica. Se un'istanza del controller di immissione non riesce, le applicazioni rimangono disponibili tramite l'altra istanza. Se l'intero controller Ingress non è attivo, la regione viene considerata negativa.
Controllo dell'ingresso (spazio privato)
Stato replica: Come il controller di ingresso nello spazio condiviso verso il basso.
Responsabilità del cliente
Stato componente
Responsabilità del cliente
Gateway VPN disattivato
Notifica: Eseguire controlli periodici dello stato utilizzando un meccanismo Heartbeat integrato nelle API. Mitigazione: I gateway VPN CloudHub 2.0 supportano l'alta disponibilità tramite un'architettura a due tunnel con failover automatico tra i tunnel; questo schema deve essere configurato dal cliente. Test / simulazione: Lo scenario Gateway Down VPN è difficile da simulare. Richiede il coinvolgimento di MuleSoft Engineering per supportare possibili scenari di test.
Controller di ingresso (spazio condiviso) giù
Notifica: Come Gateway VPN giù. Mitigazione: Come Regione giù. Eseguire la migrazione delle applicazioni in uno spazio standby o attivo in un'altra regione. Test / simulazione: Come Gateway VPN giù.
Controller di ingresso (spazio privato) giù
Notifica: Come Gateway VPN giù. Mitigazione: Come Regione giù. Eseguire la migrazione delle applicazioni in uno spazio privato in standby o attivo in un'altra regione, in coordinamento con la configurazione AWS Route 53 (o equivalente). Test / simulazione: Come Gateway VPN giù.
Punti vendita oggetti e aree di attesa persistenti
Panoramica Servizi piattaforma Down Scenario – Object Store
Negozio di oggetti in memoria
Negozio di oggetti persistenti v2
Posizione dei dati
Solo locale per l'applicazione.
Nella stessa regione in cui l'applicazione MuleSoft è stata distribuita per la prima volta.
Condiviso tra repliche?
No
Sì
Ripristino del punto vendita di oggetti nelle applicazioni
I dati vengono persi; tutti i dati in memoria vengono persi al riavvio dell'app, alla nuova distribuzione o all'errore della replica.
I dati non vanno persi, a meno che l'app non venga eliminata.
Object Store Recovery within Region (Ripristino del punto vendita di oggetti all'interno della regione)
I dati vengono persi (come sopra).
I dati non vengono persi (come sopra).
Ripresa regionale
Come sopra.
I dati non sono disponibili. Anche con una configurazione DR attiva, Object Store è disponibile solo nella regione di distribuzione originale.
Mitigazione
Esternalizzare i dati per il ripristino regionale.
I dati rimangono disponibili finché è disponibile la regione di distribuzione originale. Per HA o DR tra regioni, esternalizzare i dati all'esterno dell'archivio oggetti.
Disponibilità elevata rispetto a Ripristino di emergenza
High Availability (HA) è la misura della capacità di un sistema di rimanere accessibile in caso di guasto del componente di sistema. In generale, l'HA viene implementato creando più livelli di tolleranza dei guasti e/o capacità di bilanciamento del carico in un sistema. Si tratta in genere di una configurazione Attivo-Attivo e ha un impatto limitato o nullo su Servizi aziendali.
Il ripristino di emergenza (DR) è il processo con cui un sistema viene ripristinato a uno stato accettabile precedente dopo uno scenario di emergenza, sia naturale (come inondazioni, tornado, terremoti o incendi) che artificiale (come interruzioni di corrente, guasti del server o configurazioni errate). DR è in genere una configurazione Attivo-Passivo e si traduce in un certo impatto sui Servizi aziendali.
Disponibilità regionale in CloudHub 2.0
Se si desidera ridurre l'impatto aziendale in caso di guasto regionale AWS, tenere presenti i seguenti punti quando si progetta la soluzione in MuleSoft CloudHub 2.0:
Le repliche CloudHub 2.0 e le funzionalità correlate (spazi privati, controller di ingresso e destinazioni Anypoint MQ) sono specifiche della regione.
Se un'intera regione AWS non riesce, tutte le repliche e i servizi associati in quella regione diventano non disponibili.
Quando una regione viene ripristinata, le configurazioni vengono ripristinate; è necessario riavviare le applicazioni.
Se la regione degli Stati Uniti orientali non riesce, anche i servizi Anypoint Platform (ad esempio Gestione accessi e Runtime Manager) non sono disponibili.
MuleSoft fornisce un contratto sul livello di servizio del 99,95% per i servizi piattaforma, incluse le repliche CloudHub 2.0 in una configurazione attiva all'interno di una regione; fare riferimento all'ultimo contratto sul livello di servizio di MuleSoft Cloud che offre i servizi per i dettagli aggiornati.
CloudHub 2.0 non supporta HA o DR multiregione pronti all'uso; la disponibilità è fornita solo all'interno di una singola regione.
Linee guida comuni per la progettazione
Queste linee guida di progettazione si applicano indipendentemente dalla configurazione scelta.
Impostazione degli spazi privati multiregionali
Tutte le opzioni descritte nelle sezioni seguenti richiedono la distribuzione delle applicazioni in aree separate. Questo è possibile solo se la configurazione dello spazio privato viene completata in anticipo, prima di un disastro. Poiché l’impostazione dello spazio privato è regionale, una strategia di DR richiede almeno due spazi privati, uno per regione, e un meccanismo per trasferire il traffico all’endpoint VPN appropriato.
Impostazione dello spazio privato altamente disponibile in una regione
CloudHub 2.0 non fornisce il failover automatico quando uno spazio privato all'interno di una regione non riesce. Una soluzione è un'impostazione attivo-passiva in più ambienti, che richiede:
Configurazione di più gateway VPN nello spazio privato.
Creazione di ambienti separati nella regione CloudHub 2.0, ciascuno con il proprio spazio privato.
Designazione di uno di questi ambienti come passivo (in cui le applicazioni non vengono distribuite inizialmente ma vengono visualizzate se lo spazio privato principale non riesce).
Se un'impostazione ad alta disponibilità senza gateway VPN è un requisito difficile, la distribuzione in due regioni è l'opzione migliore. Un errore del gateway VPN in questo scenario potrebbe essere risolto eseguendo il failover della regione interessata nella regione alternativa in cui lo spazio privato è già configurato.
Zero perdite messaggi
Per ottenere una perdita di messaggi pari a zero quando un'intera regione non riesce, un'applicazione deve prevenire la perdita di dati e gestire i seguenti punti:
Utilizzare la messaggistica esterna per ottenere l'affidabilità dei messaggi.
Assicurarsi che Object Store non venga utilizzato per i dati transazionali in volo di natura transazionale. Se la regione di distribuzione in cui l'applicazione MuleSoft è stata distribuita per la prima volta non è disponibile, l'Object Store non sarà disponibile.
Racchiudere tutto l'accesso all'Object Store in un flusso o sezione separata che continua a funzionare, sia per la gestione delle eccezioni che per il comportamento, quando le operazioni di lettura o scrittura dell'Object Store non riescono.
Nota. Nella maggior parte dei casi, i requisiti di DR non devono garantire una perdita di messaggi pari a zero in caso di disastro e devono garantire che la perdita di dati sia inferiore a quella di un determinato periodo (ad esempio, 1 ora).
Mantenere l'integrazione apolide
Come principio generale di progettazione, è sempre importante assicurarsi che le integrazioni siano di natura apolide. Ciò significa che non vengono condivise informazioni sulle transazioni tra varie chiamate o esecuzioni client (in caso di servizi pianificati). Se alcuni dati devono essere mantenuti dal middleware a causa di una limitazione del sistema, devono essere mantenuti in un punto vendita esterno, ad esempio un database o un'area di attesa di messaggistica e non nell'infrastruttura o nella memoria MuleSoft. È fondamentale notare che man mano che si scala, soprattutto nel cloud, lo stato e le risorse utilizzate da ogni replica dovrebbero essere indipendenti dalle altre repliche. Questo modello garantisce migliori prestazioni, scalabilità e affidabilità.
Considerazioni aggiuntive su DR per la distribuzione multiregione
Reti e gestione del traffico
I domini di vanità sono necessari per la disponibilità regionale; fungono da DNS globale per tutti i controller di ingresso nelle varie regioni.
Un bilanciatore di carico instrada il traffico tra gli spazi privati della regione principale e della regione DR. I clienti forniscono questo componente; utilizzare AWS Route 53 o una CDN globale con policy di instradamento per instradare il traffico tra le regioni.
Configurare i controller Ingress sia nelle regioni principali che in quelle di DR con un dominio di vanità personalizzato.
Pianificare e gestire le regole del firewall e il tunneling VPN in modo che le applicazioni locali siano raggiungibili sia dagli spazi privati principali che da quelli della regione RD.
La manutenzione del certificato TLS deve coprire gli spazi privati sia nelle regioni principali che in quelle di DR per un ripristino senza interruzioni.
Distribuzione e configurazione delle applicazioni
I nomi delle applicazioni devono essere univoci nelle varie regioni. Ad esempio, una pipeline CI/CD può aggiungere il nome della regione (o un codice regione) ai nomi delle applicazioni prima della distribuzione per mantenere l'univocità tra le regioni principali e DR.
Configurare la pipeline CI/CD per distribuire le applicazioni sia alle regioni principali che a quelle della Repubblica Democratica del Congo in modo che tutte le applicazioni siano disponibili in entrambe le regioni.
Infrastruttura e capacità
Le prestazioni sono migliori quando tutti gli aspetti dell'infrastruttura hanno la stessa capacità principale e regionale di DR. Le prestazioni peggiorano quando questi aspetti dell'infrastruttura non sono identici.
Persistenza e archiviazione dei dati
La memorizzazione della persistenza deve essere sincronizzata periodicamente tra le due regioni. I clienti sono responsabili della replica dell'archiviazione; MuleSoft non la fornisce. È possibile un singolo punto vendita condiviso tra VPC nelle regioni principali e DR, ma lo storage condiviso deve essere altamente disponibile o diventare un singolo punto di errore per entrambe le regioni.
Object Store V2 è regionale ed è disponibile solo nella regione in cui l'applicazione Mule è stata distribuita per la prima volta. Se l'applicazione viene spostata in un'altra regione, Object Store V2 rimane nella regione originale per evitare perdite di dati. Utilizzare altra memoria persistente per le strategie di RS multiregione.
Test e procedure operative
Adottare una strategia di test di DR formale ed eseguire esercitazioni periodiche di DR. Per DR attivo-attivo, utilizzare una strategia di distribuzione canarino per convalidare entrambe le regioni.
Contratti sulle prestazioni e sui livelli di servizio (SLA)
Può verificarsi un certo deterioramento delle prestazioni perché la regione DR può essere più lontana dagli utenti finali o dai sistemi di backend rispetto alla regione principale. Definire e comunicare un SLA di DR agli stakeholder.
Comportamento della modalità di ripristino (nota contestuale)
In modalità attivo-attivo, il failover dalla regione principale allo spazio privato della regione DR è rapido: il bilanciamento del carico globale rileva che la regione principale non è sana e instrada il traffico alla regione sana (DR). In modalità attivo-passivo, è necessario distribuire l'applicazione nello spazio privato della regione DR quando si verifica un disastro.
Opzioni di disponibilità regionale
Esistono 3 opzioni per ottenere una disponibilità di livello DR superiore:
Un'impostazione attivo-attivo si basa su lavoratori attivi distribuiti tra le regioni, che utilizzano un bilanciamento del carico esterno per instradare il traffico tra le due istanze.
Configurazione standby di riscaldamento
Una configurazione attivo-passivo sarebbe basata su un lavoratore attivo in una regione e su un lavoratore passivo in un'altra regione. La regione passiva verrebbe avviata quando necessario.
Alcuni elementi della regione passiva devono rimanere attivi per il failover o essere impostati in precedenza, inclusi spazi privati, VPN e allegati gateway di transito.
Come indicato sopra, le repliche e i controller Ingress vengono forniti in una seconda regione tramite un processo DevOps completamente automatico al failover. Alcuni elementi della regione passiva devono rimanere attivi per il failover, inclusi spazi privati, VPN e allegati gateway di transito.
Vanity Domains per la massima disponibilità
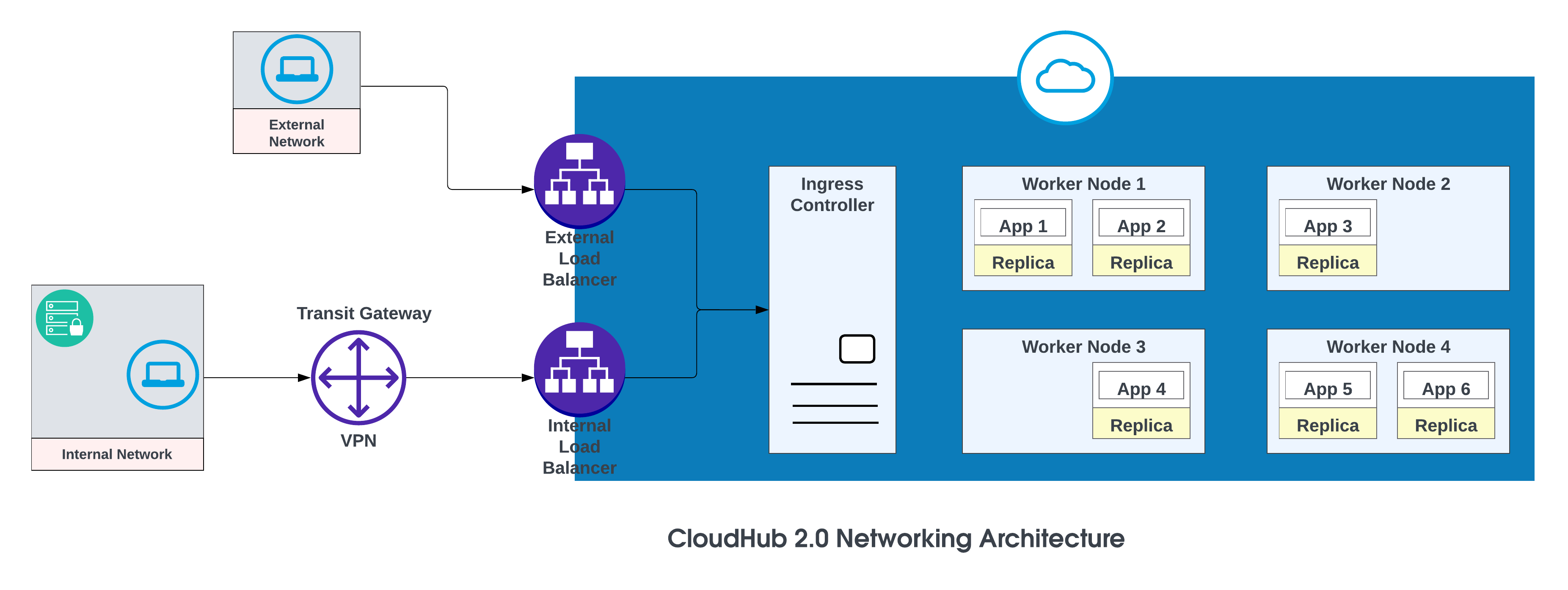
I componenti di base dell'architettura di rete CloudHub 2.0 sono:
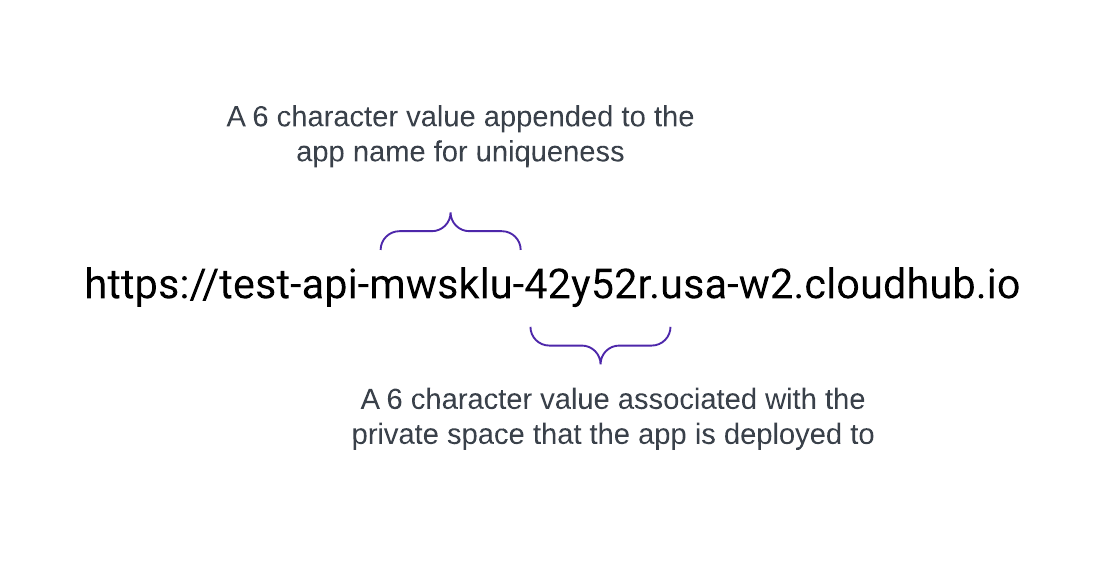
Quando viene creato, uno spazio privato riceve un nome di destinazione DNS nel formato: <space-id>.<region>.cloudhub.io . Alla distribuzione di un'app denominata test-api in quello spazio privato, il relativo endpoint seguirà questo formato:
CloudHub 2.0 supporta anche i domini personalizzati, o vanity, configurandoli all'interno di uno spazio privato utilizzando contesti TLS e record DNS. Per creare un contesto TLS in Runtime Manager per uno spazio privato, caricare il certificato pubblico e la chiave privata, quindi aggiungere un endpoint personalizzato nelle impostazioni dell'applicazione per utilizzare quel dominio. Creare un record DNS (ad esempio un CNAME) che punti il dominio Vanity al nome host predefinito dello spazio privato.
Ad esempio, un'applicazione denominata test-api distribuita in us-west-2 con DNS predefinito 42y52r.usa-w2.cloudhub.io ha un endpoint API di:
Questo URL non utilizza un dominio vanity o personalizzato. Per utilizzare acme.com in modo che gli URL API compaiano come https://test-api.acme.com, seguire questa procedura.
Creare il contesto TLS in Runtime Manager con chiavi pubbliche e private.
Aggiungere un dominio di vanità nelle impostazioni dell'applicazione per utilizzare quel dominio.
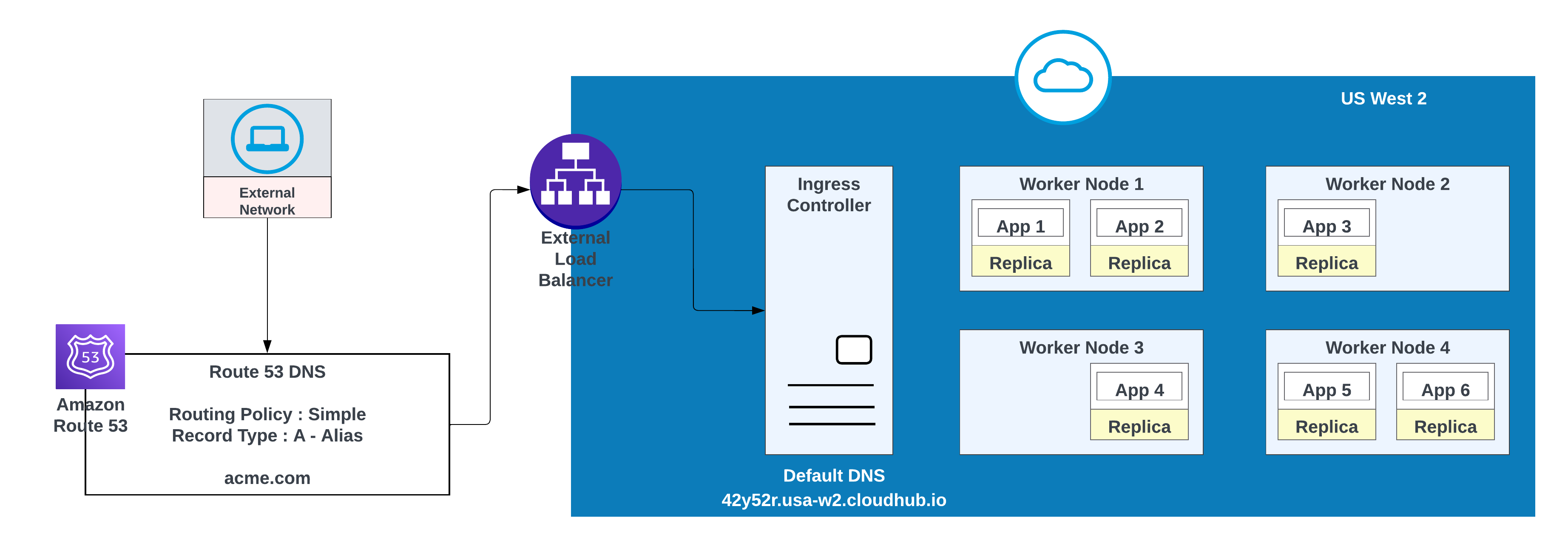
Creare un record DNS in AWS Route 53 e configurare una policy di instradamento semplice (ad esempio, CNAME) in modo che il vanity domain venga risolto nel nome host predefinito dello spazio privato.
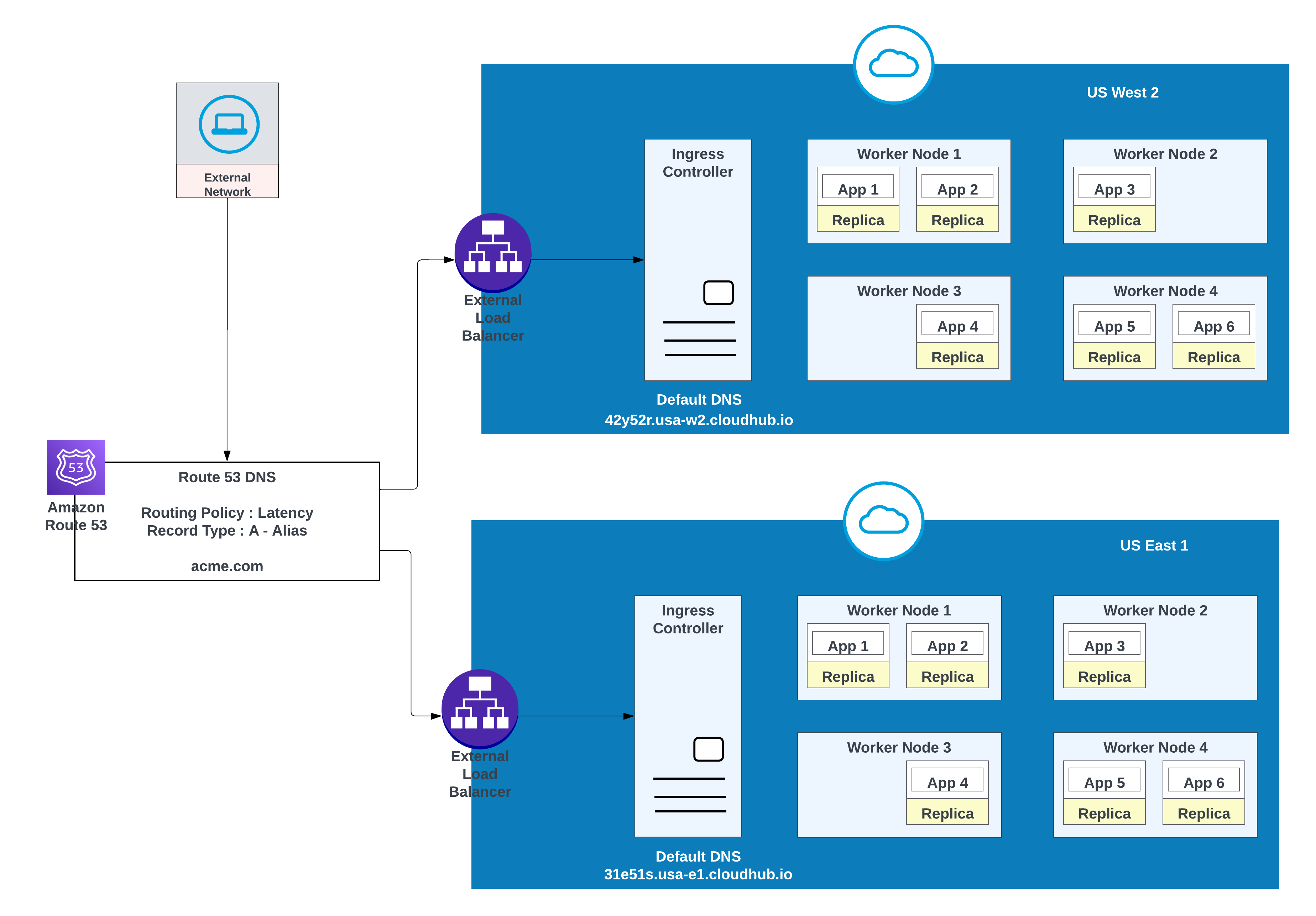
Per i domini personalizzati, è possibile utilizzare AWS Route 53 o qualsiasi altro servizio CDN globale con policy di instradamento. Nel diagramma seguente, AWS Route 53 viene utilizzato con una policy di instradamento "semplice". Quando un consumatore da una rete pubblica (esterna) richiede acme.com, AWS Route 53 instrada la richiesta al controller di ingresso spazio privato MuleSoft.
Strategia di failover
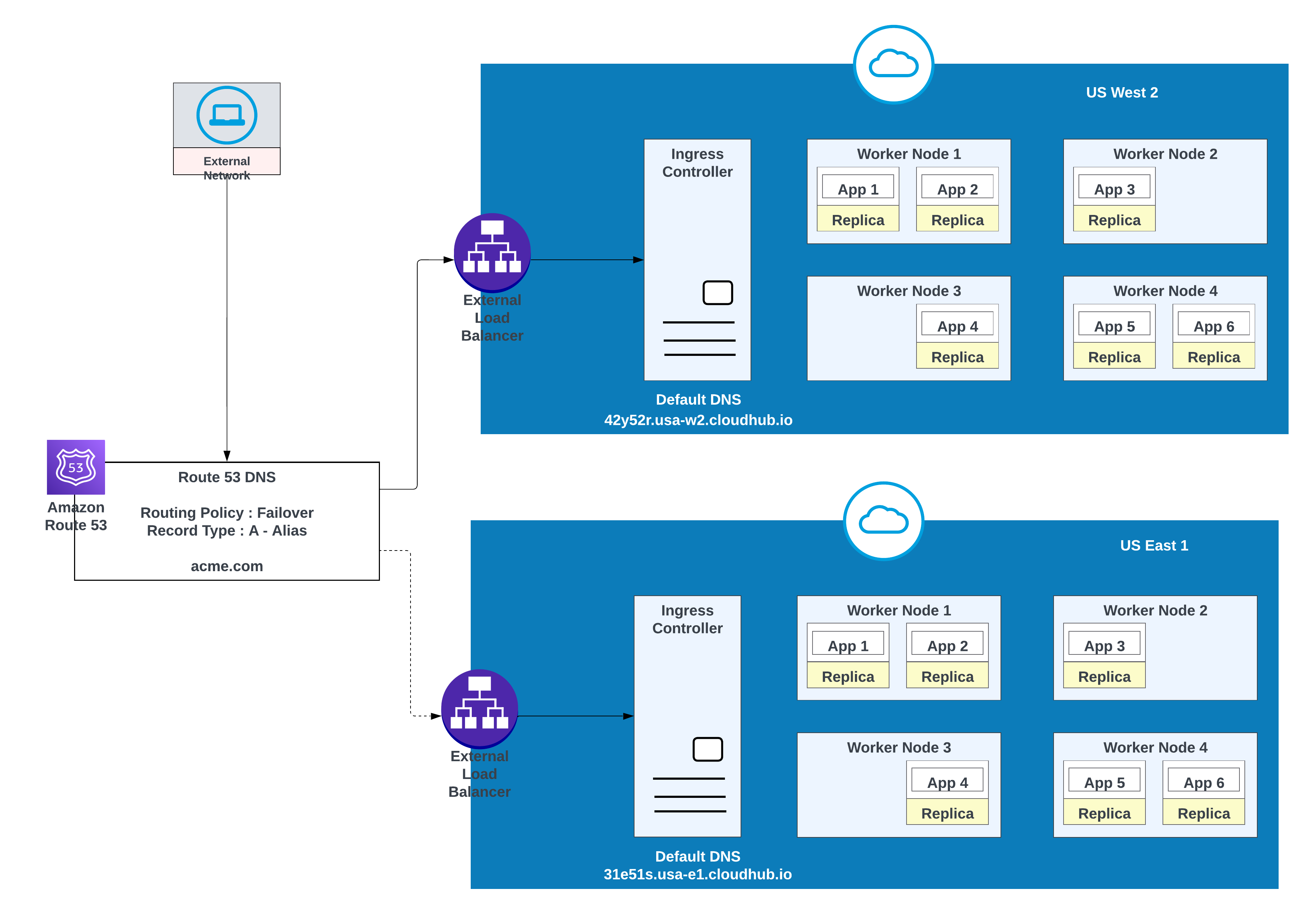
Utilizzare questa opzione quando le applicazioni richiedono il failover: distribuire un'istanza nella regione principale (ad esempio, us-west-2) e un'altra in una regione secondaria (ad esempio, us-east-1).
Ove possibile, utilizzare un ambiente esistente nella regione secondaria; la creazione di un nuovo ambiente richiede ulteriori sforzi.
Esempio di app distribuite in una regione (Stati Uniti Ovest 2) con failover in un'altra regione ( Stati Uniti Est 1)
Nome record
Valore/Instrada traffico a
Policy di instradamento
ID controllo dello stato
acme.com
42y52r.usa-w2.cloudhub.io
Failover
31s3wseq121
acme.com
31e51s.usa-e1.cloudhub.io
Failover
43e131s131sq
In questa configurazione, AWS Route 53 instrada il traffico ai controller di ingresso per gli spazi privati in US West 2 e US East 1. Viene configurata una policy di instradamento di failover con un controllo dello stato.
Alta disponibilità e bassa latenza
Per una latenza inferiore e una disponibilità elevata, utilizzare la strategia di distribuzione descritta nello schema. Con questa strategia, le app possono essere distribuite in due regioni (US-west-2 e US-east-1 in questo esempio).
Utilizzare la policy di instradamento della latenza in AWS Route 53 per instradare le richieste alla regione che offre la latenza più bassa mantenendo l'alta disponibilità. Policy di instradamento della "latenza" in AWS Route 53 per instradare la richiesta di latenza più bassa che ha ancora un'alta disponibilità.
App distribuite in entrambe le regioni (Stati Uniti Ovest 2 e Stati Uniti Est 1) per una latenza inferiore e un'elevata disponibilità
Nome record
Valore/Instrada traffico a
Policy di instradamento
ID controllo dello stato
acme.com
42y52r.usa-w2.cloudhub.io
Latenza
31s3wseq121
acme.com
31e51s.usa-e1.cloudhub.io
Latenza
43e131s131sq
Conclusione
MuleSoft CloudHub 2.0 offre una solida base per la resilienza all'interno dell'area geografica, sfruttando principalmente la ridondanza automatica delle repliche e il bilanciamento intelligente del carico. All'interno di una singola area cloud, la distribuzione di applicazioni con più repliche garantisce che, se un'istanza non riesce, gli altri possano immediatamente assumere il carico di lavoro. Il bilanciamento del carico integrato distribuisce in modo efficiente il traffico in entrata in queste repliche sane, riducendo al minimo i tempi di inattività e garantendo una disponibilità di servizio continua in condizioni operative normali.
Tuttavia, affidarsi esclusivamente a questa architettura a una sola regione, anche con elevata ridondanza, presenta un rischio significativo di un guasto regionale generalizzato e catastrofico. La storia ha dimostrato che anche i provider di cloud più affidabili e tecnologicamente avanzati sono suscettibili di incidenti dirompenti che possono interessare un'intera area geografica. Questi singoli punti di errore, sebbene rari, possono derivare da vari eventi, tra cui:
Incidenti infrastrutturali su larga scala
Gravi interruzioni di corrente
Interruzioni diffuse della rete
Pertanto, per ottenere una vera disponibilità elevata (HA) e un ripristino di emergenza (DR), è necessario progettare un'architettura che superi le limitazioni di un modello a regione singola. La strategia consigliata è la distribuzione in più regioni geograficamente distinte. Questa resilienza interregionale garantisce che se un'intera area cloud non è disponibile a causa di un disastro imprevisto, il traffico può essere trasferito senza problemi a un'istanza dell'applicazione in esecuzione in una regione separata e non interessata, garantendo interruzioni minime del servizio e raggiungendo gli obiettivi di tempo di attività massimo.
Gulal Kumar è un architetto di ingegneria del software presso Salesforce, con particolare attenzione all'architettura dei dati e dell'integrazione. Con oltre 20 anni di esperienza in integrazione e API, programmi di modernizzazione, sicurezza e iniziative AIML, offre una vasta gamma di competenze. Gulal si è impegnata a promuovere iniziative di trasformazione aziendale, migliorare la sicurezza e la resilienza, promuovere l'eccellenza dell'architettura e guidare iniziative AIML in vari domini.
Ajay Nagaraju è Enterprise Architect e Senior Director presso MuleSoft con oltre 28 anni di esperienza nell'architettura aziendale, nell'integrazione di sistemi e nella trasformazione digitale su larga scala. Ha diretto l'architettura e la consegna di programmi complessi multimilionari nelle organizzazioni Fortune 100 e Fortune 500, con una profonda esperienza nella connettività basata su API, SOA, tecnologie cloud e schemi di integrazione aziendale. Ajay ha collaborato strettamente con la dirigenza per modernizzare i processi aziendali, le piattaforme dati e gli ecosistemi di integrazione ed è appassionata di creare architetture scalabili, di guidare i team e di favorire risultati aziendali misurabili attraverso la tecnologia.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.