Datenplattformen entwickeln sich seit über drei Jahrzehnten weiter. Zunächst wurde die Branche von lokalen, zentralisierten und strukturierten (meist relationalen) Betriebs-/OLTP-Datenbanken dominiert. Diese wurde auf Data Warehouses-OLAP-/Big Data-Plattformen erweitert, die hauptsächlich für die analytische Verarbeitung verwendet wurden und relational und zentralisiert blieben. Cloud-Speicher steuerte verteilte Architekturen wie Data Warehouses, Lakehouses und disaggregierten Speicher. Vorgangsplattformen und Analyseplattformen blieben jedoch getrennt. Cloud Computing und die AI-Revolution verändern heute die Architektur der Datenplattform grundlegend.
Unternehmen investieren bereits in ausgereifte Big Data-Plattformen wie Snowflake, Databricks, BigQuery und Redshift. Diese Plattformen dienen jedoch als Datensilos. Kunden leiten aus ihren Daten keinen Geschäftswert ab, da die Daten nicht direkt in den Geschäfts-Flows und -Anwendungen bearbeitet werden können. Diesen Lösungen fehlt die Verarbeitung generativer Agentischer AI und sie können den Datenzugriff nicht in Echtzeit bereitstellen. Daher können sie keine AI-gestützte Personalisierung zum Zeitpunkt des Kundenengagements und anderer branchenführender Funktionen bereitstellen.
Die Zukunft von Datenplattformen ist durch eine einheitliche, flexible, zugängliche und offene Dateninfrastruktur gekennzeichnet. Diese neue Architektur basiert auf modernen Rechen- und Speichertrends – GPUs, großer Speicher, NVMe-SSDs und Cloud-Speicher –, die in Cloud Computing und AI integriert werden können. Sie können Echtzeitstatistiken bereitstellen, autonome Entscheidungen treffen und Echtzeitanwendungen vorantreiben. Dies umfasst die Zunahme von Agenten-AI, Prognose-AI, Analysen, Echtzeit-OLTP-Datenbanken, Data Lakes und Lakehouses. Diese modernen Datenplattformen sind auf Einfachheit, Skalierbarkeit, Agilität, Leistung, Sicherheit, Verfügbarkeit und Kosteneffizienz ausgelegt.
Die folgenden Datentrends steuern die Datenplattformarchitektur der nächsten Generation.
- KI, maschinelles Lernen und Analytics im Mittelpunkt: Der Aufstieg der Agenten-AI wird die Entwicklung, Bereitstellung und Nutzung/Zugriff auf die Datenplattform grundlegend verändern. Agentische AI versteht den Unterhaltungs-/Abfrage-Intent, plant, generiert Workflows und automatisiert die Entscheidungsfindung. Der Speicher für Agenten (kurz- und langfristig) wird anhand des Unterhaltungsverlaufs für die Personalisierung der Agentenplanung und -entscheidungen, die Echtzeit-Unterhaltungsmodellierung und die Personalisierungsunterstützung erstellt, die auf Datenplattformen wichtig sind. Agenten unterstützen Sie bei der Automatisierung betrieblicher "Funktionen" wie Datenverwaltung (z. B. Sicherheit, Compliance, Trust), Leistung (z. B. automatische Skalierung für Gleichzeitigkeit, Durchsatz und Latenz), Failover und Verfügbarkeit sowie Beobachtbarkeit und Wartung. AI-gestützte Analysen, Prognosen, die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) für Fragen/Antworten in Analysen und Analysen unstrukturierter Daten (Text wie PDFs, Bilder, Audio, Video) werden Standard sein, sodass Unternehmen tiefere Statistiken aus verschiedenen Datenquellen ableiten können.
- Dezentralisierung von Daten, aber einheitlicher Datenzugriff: Agenten benötigen Unternehmensdaten, um Statistiken abzuleiten und Entscheidungen zu treffen und Geschäftsaktivitäten zu automatisieren. Daten sind in Unternehmen, in unterschiedlichen Anwendungen und Datenplattformen von Natur aus dezentralisiert. Es ist jedoch nicht einfach, die Silos zwischen verschiedenen Geschäftseinheiten innerhalb des Unternehmens und mit Partnern außerhalb des Unternehmens nahtlos zu vereinheitlichen. Die Vereinheitlichung von Daten umfasst die gemeinsame Nutzung von Daten entweder über die Aufnahme aus Quellen oder die Verknüpfung mit Datenquellen, Rohdaten aus der Datenvorbereitung, Harmonisierung und Modellierung für die Analyse und AI-Verarbeitung, die Speicherung und Verwaltung von Daten im richtigen Maßstab für effizienten Zugriff mit niedrigem CTS und den Datenzugriff über verschiedene Abfrage- und Analysemechanismen und -tools, die tief in die zugrunde liegenden Speicher- und Datenzugriffsplattformen integriert sind.
- Cloudbasierte offene Lakehouses: Cloud-basierte Big Data-Plattformen (OLAP) arbeiten daran, offene Dateiformate (Parquet) und Tabellenformate (Iceberg) zu übernehmen, um die Datenzusammenführung (data in) und die Freigabe (data out) zu ermöglichen.
- Unstrukturierte Datenverarbeitung: Mit dem Aufkommen, der Weiterentwicklung und der Einführung der generativen AI beginnen Unternehmen, wertvolle Statistiken und Geschäftswerte aus dem Datenbestand des Unternehmens abzuleiten, der große Mengen an Textdokumenten, Audioabschriften, Videoaufzeichnungen und anderen Medien umfasst. Unstrukturierte Datenverarbeitung, einschließlich Blockierung, Vektorisierung, semantische Suche und Knowledge Diagramme, ermöglichen diese Statistiken. Techniken wie RAG (Retrieval Augmented Generation) und CAG (Cache Augmented Generation) werden zu Haupttreibern der schnellen und agentenbasierten Suche im gesamten Datenkorpus.
- Knowledge Management: Knowledge geht über den Rohinhalt selbst hinaus (Dokumente, Artikel, Videos). Sie stellt eine Erweiterung dieses Inhalts dar, indem Bedeutung abgeleitet, Metadaten zusammengestellt und in einen Kontext gesetzt werden, um ein gemeinsames Verständnis von Inhalten in einer Organisation oder einem Unternehmen zu entwickeln. Knowledge selbst ist in der Regel strukturiert. Knowledge Management umfasst Inhaltsverwaltung, Knowledge Extrahierung, Darstellung durch Modelle wie Diagramme und Navigation.
- Reichweitendatenzugriff: Rich-Data-Zugriff bedeutet, dass Daten, Analysen und AI-Tools für eine Vielzahl von Personas zugänglich sein müssen, einschließlich Endbenutzern, Geschäftsbenutzern, Administratoren und Analysten. Der barrierefreie Zugriff erfolgt über Mechanismen wie Ensembleabfrage (mit relationaler, Stichwort- und semantischer Abfrage), Abfrage natürlicher Sprache in SQL (NL2SQL), Echtzeitzugriff usw.
- Echtzeitverarbeitung: Agentische Anwendungen treffen Echtzeitentscheidungen auf der Grundlage des aktuellen Zustands und auf der Grundlage neuer Ereignisse, wodurch Antworten und Aktionen personalisiert werden, was den Zugriff auf, die Verarbeitung und das Reagieren auf Echtzeitdaten erfordert. Die Echtzeitverarbeitung erfordert aktuelle Daten (Datenlatenz) und interaktiven Zugriff (Zugriffslatenz). Für solche Daten und Zugriffslatenz muss die zugrunde liegende Datenplattform den aktuellen Datenzugriff aus operativen und analytischen Shops, die Verarbeitung des Zugriffs mit geringer Latenz (Punktsuche und Abfrage), die hohe Datenskalierung und den hohen Durchsatz unterstützen.
- Datensicherheit, Unternehmensführung und -residenz: Agenten- und Unterhaltungs-AI vereinfacht die Benutzeroberfläche der Anwendung und ermöglicht es jedem – von Verbrauchern über Mitarbeiter bis hin zu anderen AI-Agenten –, mit Anwendungen in natürlicher Sprache zu interagieren. Die wertvollen Kunden- und persönlichen Daten, die für Agentenanwendungen gespeichert und modelliert werden müssen, müssen durch klar definierte Zugriffs- und Freigaberichtlinien geschützt und verwaltet werden. Viele Kunden müssen sich zunehmend an Vorschriften halten, die eine Datenresidenz in ihrem eigenen Land oder ihrer Region vorschreiben, insbesondere an Behörden oder Behörden.
Salesforce Data 360 ist für die Zukunft konzipiert, um diesen Datentrends gerecht zu werden. Data 360 ist eine Cloud-native, metadatengestützte Datenplattform, die isolierte Daten im gesamten Unternehmen vereinheitlicht und es Organisationen ermöglicht, ihre Daten zu speichern, zu modellieren und zu verarbeiten, um Analysen, AI, maschinelles Lernen und Agentenanwendungen zu ermöglichen.
Dieses Dokument ist ein wichtiger Leitfaden für Unternehmensarchitekten und CTOs. Darin werden die Architektur, Funktionen, Designprinzipien und Anwendungsfälle von Data 360 beschrieben. Sie stellt die Grundlagen der Data 360-Architektur als Vorbereitung vor, gefolgt von einer Reihe tiefer Einblicke in ihre wichtigsten Unterschiede, wie die Interoperabilität mit vorhandenen Datenplattformen, einschließlich Strategie für mehrere Organisationen, Sicherheit, Governance und Datenschutz, Echtzeitaktivierung und Datenreinräume.
Salesforce Data 360 basiert auf einer Reihe von Kernprinzipien, die Unternehmensdaten einsatzbereit, vertrauenswürdig und in Echtzeit bereitstellen.
- Offenheit und Interoperabilität: Für Multi-Cloud-Ökosysteme entwickelt. Verbindet sich ohne Duplikate mit Datenplattformen wie Snowflake, Databricks, BigQuery und Redshift und erweitert Customer 360 unter Beibehaltung vorhandener Investitionen.
- Speicher-Berechnungstrennung: Skaliert die Speicherung und Verarbeitung (Batch, Streaming und interaktiv) unabhängig voneinander. Bietet Elastizität und Effizienz für hohe Arbeitslasten mit hohem Volumen.
- Speichern und Verarbeiten von mehreren Modellen: Unterstützt strukturierte und verschiedene unstrukturierte Datentypen wie Text, Bildaudio und Video. Bietet effizienten Speicher, Echtzeit- und Batchverarbeitung, erweiterbare Indizierung, vereinheitlichte Suche, Abfrage und Analyse.
- Metadatengesteuertes Design: Anwendungen werden durch Metadaten und nicht durch Code definiert. Metadaten werden als erstklassiger Vermögenswert behandelt und ermöglichen eine einheitliche Verwaltung, Flexibilität und eine umfassende Integration in Salesforce Platform.
- Hybridverarbeitung in Echtzeit: Unterstützt Abfragen mit geringer Latenz und sofortige Entscheidungsfindung sowie Batchverarbeitung und analytische Arbeitslasten.
- Intelligente und aktive Daten: Erfasst, analysiert und überträgt Statistiken kontinuierlich direkt in Geschäfts-Workflows. Unterstützt die Automatisierung ohne Code, Low-Code, Pro-Code und AI mit dem neuesten Kontext.
- Governance und Datenschutz nach Design: Abstammung, Zugriffssteuerung, Residenz, Datenverschlüsselung und Compliance sind integriert. Trust und regulatorisches Vertrauen werden auf jeder Ebene gestärkt.
- Mandantenverhältnis 1:1: Eine zentralisierte Data 360-Organisation fungiert als einzige Quelle der Wahrheit für Customer 360 und unterstützt nahtlos Salesforce-Umgebungen mit mehreren Organisationen, die von Salesforce-Kunden häufig verwendet werden.
Diese Grundsätze stellen sicher, dass Daten in Echtzeit offen, intelligent und handlungsrelevant sind.
Salesforce Data 360 ist eine moderne Datenplattform, die auf Designprinzipien basiert, die aktuelle Datentrends berücksichtigen. Seine Architekturfunktionen stellen sicher, dass Unternehmensdaten in Echtzeit vertrauenswürdig, vereinheitlicht und handlungsrelevant sind und mit seinen Leitprinzipien übereinstimmen.
- Cloud-native Foundation: Wird in Hyperforce ausgeführt, das in Hyperscalern (wie AWS) mit unveränderlicher Microservices-basierter Infrastruktur bereitgestellt wird. Bietet elastische Skalierung, Zero Trust Security, kontinuierliche Bereitstellung und globale Compliance.
- Salesforce (Core)-Metadatengesteuert: Metadaten werden als Salesforce-Metadaten konzipiert, modelliert und gespeichert, sodass sie sofort von ALLEN Salesforce-Anwendungen verwendet werden können. Solche Metadaten werden in einem vollständig ACID-konformen RDBMS gespeichert. Gewährleistet Governance, Lebenszykluskonsistenz und eine umfassende Integration in Salesforce Lightning Platform.
- Lakehouse-Speicher: Basiert auf Apache Iceberg und Parquet, kombiniert Data-Lake-Skalierung mit Lagerhaus-Governance, die Schemaentwicklung, Zeitreisen und Aktualisierungen mit hohem Volumen unterstützt. Data 360 speichert, modelliert und verarbeitet strukturierte und unstrukturierte Daten mit extrem großem Speicher mit modernen offenen Standards und umfangreichen Transformations- und Datenverarbeitungsfunktionen für Batch- und ereignisgesteuerte Arbeitslasten.
- Durchgängige Datenpipeline mit flexibler Aufnahme: Deckt den gesamten Lebenszyklus ab – Aufnahme, Vorbereitung, Modellierung, Vereinheitlichung, Analyse und Aktivierung – und reduziert die Abhängigkeit von fragmentierten Punktlösungen. Unterstützt Batch, nahezu in Echtzeit und Streaming mit mehr als 270 Konnektoren und MuleSoft. Der ELT-first-Ansatz ermöglicht eine schnelle Datenverfügbarkeit mit Flexibilität bei der nachgelagerten Transformation.
- Interoperabilität von Unternehmensdaten mit offenen Frameworks und Verbund: Vereinheitlicht silo'd-Daten im gesamten Unternehmen durch die bidirektionale Zero Copy-Verbundorganisation mit Snowflake, Databricks, BigQuery und Redshift, wodurch Datenmigration oder -duplizierung vermieden werden.
- Datenklassifizierung, Modellierung und Organisation: Data 360 organisiert Daten als Rohdaten, bereinigte und gespeicherte Daten und Datenmodelle, die dem allgemeinen Informationsschema SSOT (Single Source of Truth) entsprechen. Solche SSOT-Objekte bilden die Grundlage für die Definition von semantischen Datenmodellen (SDM) und anderen zusammengestellten und anwendungsspezifischen Modellen.
- Integrierte semantische Datenmodellierung für erweiterbare Analysen mit offenen semantischen Abfrage-APIs, die Tableau Next vorantreiben und anwendungsspezifische Analysen aktivieren.
- Das High Performance SQL-Abfragemodul unterstützt eine vereinheitlichte Data 360 SQL-Abfrage für strukturierte, unstrukturierte und Diagrammdaten.
- Datenspeicher mit geringer Latenz: Schlüsselwertspeicher für heiße Daten mit Millisekunden-Antwortzeiten. Ermöglicht die Personalisierung und ereignisgesteuerte Szenarien in Echtzeit. Erfasst und verarbeitet Kundenengagementdaten in Echtzeit. Vereinheitlicht Identitäten, Interaktionen und Unterhaltungen in einem einzigen, vertrauenswürdigen Diagramm "Customer 360 Profile and Context" (Kunden 360-Profil und -Kontext).
- Unstrukturierte Datenverarbeitungspipelines zur flexiblen und erweiterbaren Unterstützung für unstrukturierte Datenspeicherung, Chunking, Generierung von Einbettungen (Vektorisierung), Metadatenextraktion (Vergrößerung), Zusammenfassung, Indizierung, Knowledge Extraktion, intelligente Dokumentverarbeitung, Erstellung von Kurz- und Langzeitspeichern (Unterhaltung) usw.
- Native Keyword, Vector und Hybrid Indexing für genauen und effizienten unstrukturierten Datenzugriff wie Fast and Agentic Search, RAG, Knowledge Extraction, Agentic Memory Derivation usw.
- Profil-, Personalisierungs-, Kontextservices zum Aktivieren von AI/ML- und Agentenanwendungen.
- Integrierte Governance und Sicherheit auf jeder Ebene für die Verfolgung von Abstammungen, die Maskierung von Daten, die Datenresidenz und die Sicherheit von Zero Trust gewährleisten Compliance und Trust.
- Elastisches Rechengewebe: Kubernetes natives, mandantenfähiges Rechengewebe. Führt Spark für die verteilte Verarbeitung und Hyper für SQL-Arbeitslasten aus. Skaliert elastisch über verschiedene Aufträge hinweg und unterstützt die Isolation beim Ausführen von nicht vertrauenswürdigem Code.
All dies wird in Hyperforce ausgeführt, der Cloud-Grundlage von Salesforce. Hyperforce bietet Folgendes:
- Null Trust Sicherheit mit Verschlüsselungs-, Isolations- und Richtlinien mit den geringsten Berechtigungen.
- Resilienz durch Bereitstellungen in mehreren Regionen. Salesforce Data 360 profitiert zwar von der Widerstandsfähigkeit von Hyperforce in mehreren Regionen und der Fehlertoleranz auf Plattformebene, aber die echte Notfallwiederherstellung auf Unternehmensebene erfordert eine breitere Architektur, die jeder Datenplattform mit wichtigen Funktionen ähnelt: wiedergebbare Aufnahmepipelines, Abgleich und metadatengesteuerte Rehydrierung in allen abhängigen Ökosystemen.
- Beobachtbarkeit mit integrierter Überwachung, Kennzahlen und Verfolgung.
- Automatisierte Skalierung und FinOps-Bewusstsein für Effizienz ohne Kostenüberlauf.
Data 360 ersetzt keine vorhandenen Unternehmensinvestitionen. Stattdessen macht Data 360 die Daten, denen Sie bereits vertraut sind, reguliert und handlungsrelevant und bietet AI-gestütztes Engagement in Echtzeit, wo es am wichtigsten ist. Kurz gesagt, Salesforce wandelt alle Unternehmensdaten, einschließlich externer Daten, in (Salesforce-) metadatengesteuerte Objekte um und aktiviert Agentenanwendungen für die Erkennung, Entscheidungsfindung und zum Ergreifen von Aktionen.
Die folgende Abbildung veranschaulicht die Data 360-Referenzarchitektur:
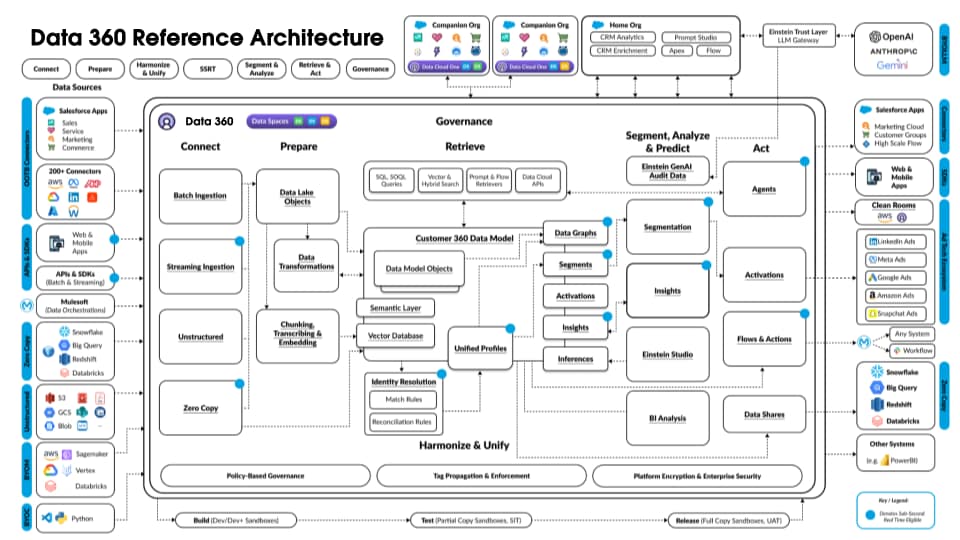
Im Folgenden wird ein hypothetischer Agentforce Loan Agent beschrieben, der in Data 360 überlagert ist. Angenommen, der Darlehensagent ist ein kundenorientierter Agent, bei dem Kunden (Verbraucher) Darlehen beantragen und sofortige Darlehensgenehmigungen erhalten.
Data 360 führt diese Schritte wie geplant aus und bereitet Daten für die Verwendung durch den Darlehensagenten vor.
- Data 360 erfasst strukturierte Kundenaccount-Daten aus CRM und speichert sie im Data Lake.
- Data 360 verarbeitet unstrukturierte Daten zu Unternehmensdarlehen und Finanzpolicen.
- Data 360 führt personenbezogene Daten aus einer externen Datenquelle wie Snowflake zusammen.
- Data 360 transformiert und modelliert aufgenommene und verbundene Daten.
- Data 360 erstellt und verwaltet das Profildatendiagramm.
Jedes Mal, wenn ein Kunde ein Darlehen beantragt, werden diese Aktionen ausgeführt.
- Ein Kunde meldet sich beim Darlehensagenten an, wodurch eine Kundensitzung auf der Echtzeitebene beginnt. Das zusammengeführte Profil des Kunden wird in die Echtzeitebene abgerufen.
- Der Kunde füllt einen Darlehensantrag unter Angabe der erforderlichen Informationen aus.
- Der Kunde lädt Finanzdokumente (wie Steuererklärungen, Investitionen, Kontoauszüge) zur unstrukturierten Datenverarbeitung in Data 360 hoch.
- Hochgeladene Daten werden in Gruppen unterteilt und vektorisiert (Generierung von Einbettungen) und Indizes (Stichwort und Vektor) werden erstellt.
- Als Nächstes füllt der Kunde das Darlehensantragsdokument aus und lädt es hoch. Data 360 extrahiert den Darlehensbetrag und die Laufzeit in Echtzeit.
- Der Darlehensagent ruft relevante Finanzdaten mithilfe der Data 360-Abfrage und der hybriden Suche über das Profil und andere vordefinierte Indizes ab.
- Der Darlehensagent aktiviert einen Genehmigungsagenten mit Darlehensdaten und anderen Finanzprofildaten, um die Darlehensgenehmigungsentscheidung zu treffen.
- Der Darlehensagent antwortet dem Kunden mit einer Entscheidung.
- Diese gesamte Interaktion zwischen dem Kunden und dem Darlehensagenten wird ebenfalls in Data 360 erfasst und gespeichert.
Das obige Beispiel bietet eine Übersicht über Data 360-Architekturkomponenten, die zum Erstellen einer Agentenanwendung wie eines Darlehensagenten verwendet werden. Im nächsten Abschnitt werden die Data 360-Architekturebenen und -Komponenten beschrieben.
In diesem Abschnitt werden die grundlegenden Bausteine von Salesforce Data 360 erläutert, beginnend mit dem robusten Speichermodell und anschließend mit den Mechanismen für die Verbindung, Aufnahme und Vorbereitung von Daten. Anschließend wird untersucht, wie strukturierte und unstrukturierte Daten gespeichert, modelliert und verarbeitet werden, was zu einem besseren Verständnis ihrer Harmonisierung, Vereinheitlichung, Abrufbarkeit und intelligenten Aktivierungsfunktionen führt.
Salesforce Data 360 basiert auf einem mehrstufigen, aber integrierten Speichermodell, das die Stärken eines Lakehouse mit Echtzeitspeicher kombiniert. Die Lakehouse-Ebene bietet skalierbaren, kosteneffizienten Speicher für große Mengen an historischen Daten und Batch-Daten und ermöglicht erweiterte Analysen und Anwendungsfälle für maschinelles Lernen. Die Echtzeitspeicherung hingegen ist für Zugriffe mit geringer Latenz und Aktualisierungen mit hoher Häufigkeit optimiert, um sicherzustellen, dass Kundeninteraktionen, Profile und Interaktionssignale immer aktuell sind. Zusammen funktionieren diese Stufen nahtlos, sodass Daten flüssig zwischen historischen Kontexten und Echtzeitkontexten wechseln können und eine einheitliche Datengrundlage für Personalisierung, AI und Aktivierung bieten.
Data 360 verfügt über eine native Lakehouse-Architektur, die auf Iceberg/Parquet basiert und für die Verwaltung und Verarbeitung umfangreicher Daten für Batch-, Streaming- und Echtzeitszenarien konzipiert wurde, die strukturierte und unstrukturierte Daten unterstützen, was für AI- und Analyseanwendungen entscheidend ist.
In Cloud-basierten Data Lakes wie Azure, AWS oder GCP ist die grundlegende Speichereinheit eine Datei, die in der Regel in Ordnern und Hierarchien organisiert ist. Lakehouse erweitert diese Struktur, indem strukturelle und semantische Abstraktionen auf übergeordneter Ebene eingeführt werden, um Vorgänge wie Abfragen und die AI/ML-Verarbeitung zu vereinfachen. Bei der primären Abstraktion handelt es sich um eine Tabelle mit Metadaten, die ihre Struktur und Semantik definiert und Elemente aus Open-Source-Projekten wie Iceberg oder Delta Lake mit zusätzlichen semantischen Ebenen enthält, die durch Data 360 hinzugefügt wurden.
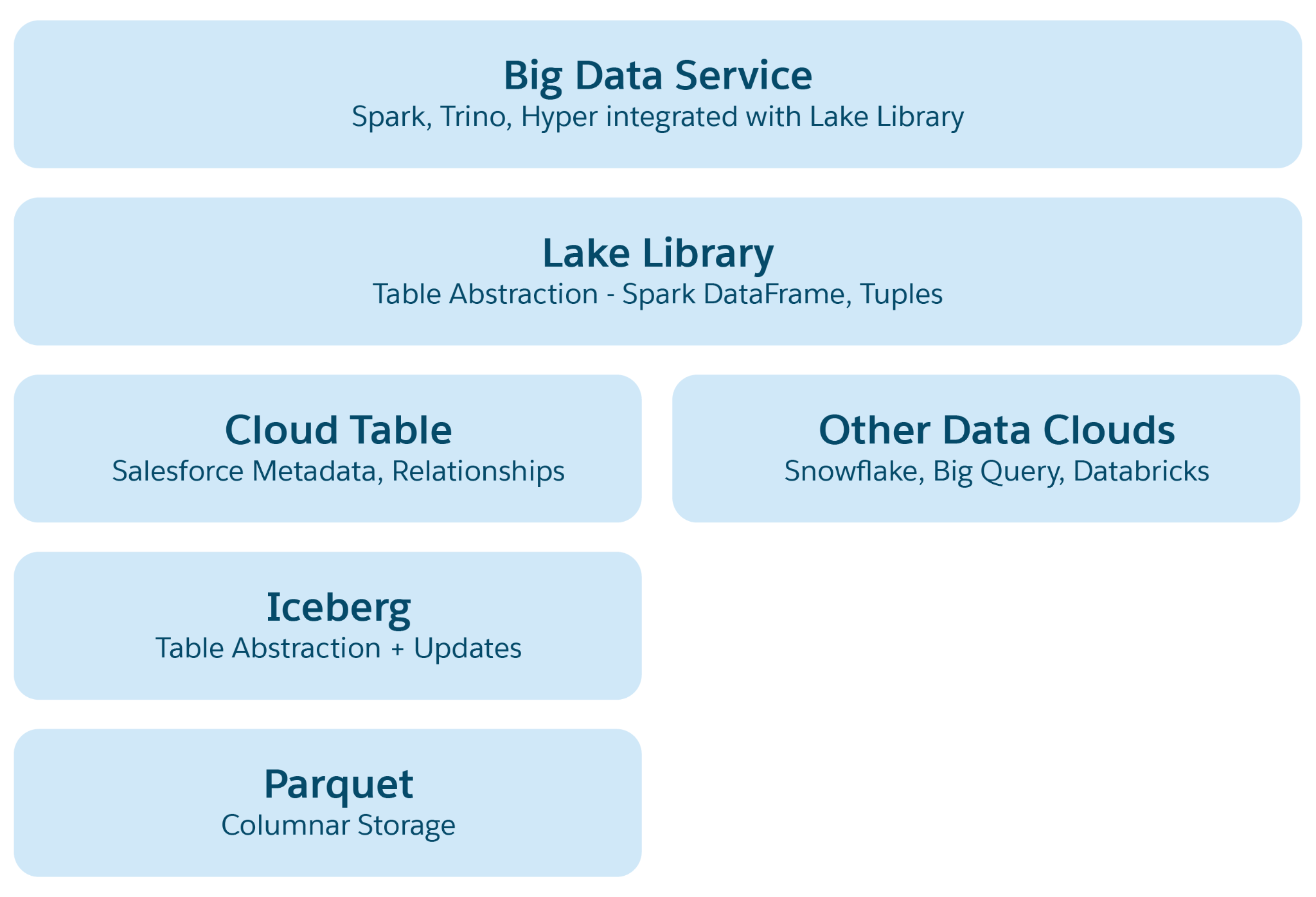
Abstraktionsebenen in Lakehouse:
- Parquet File Abstract (Parquet-Dateiabstraktion): Auf der Basis besteht der Speicher aus Data-Lake-Dateien (z. B. S3 in AWS oder Blob in Azure) im Parquet-Format. Daten für eine Quelltabelle werden in mehreren Partitionen als Parquet-Dateien gespeichert, wobei jede Tabelle eine Sammlung dieser Dateien ist.
- Iceberg-Tabellenabstraktion: Tabellen sind als Ordner organisiert, wobei Datenpartitionen in diesen Ordnern als Parquet-Dateien gespeichert sind. Änderungen an einer Partition führen zu neuen Parquet-Dateien als Snapshots. Iceberg verwaltet eine Metadatendatei für jede Tabelle mit detaillierten Schemas, Partitionsspezifikationen und Snapshots.
- Salesforce Cloud-Tabellenabstraktion: Aufbauend auf Iceberg fügt diese Ebene semantische Metadaten wie Spaltennamen und Beziehungen sowie Konfigurationen wie die Zieldateigröße und die Komprimierung hinzu. Sie abstrahiert Tabellen auf verschiedenen Plattformen wie Snowflake und Databricks und schützt Data 360-Anwendungen vor den zugrunde liegenden Besonderheiten der Speicherplattform.
- Bibliothek für Seezugriff: Diese Bibliothek bietet Zugriff auf die Salesforce Cloud-Tabelle, verarbeitet Daten und Metadaten und abstrahiert die zugrunde liegenden Speichermechanismen für Anwendungsentwickler.
- Big Data-Service-Abstraktion: Dies umfasst Verarbeitungs-Frameworks wie Hyper für Abfragen und Spark für die Verarbeitung auf jeder Cloud-Tabellenplattform.
Data 360 erweitert den Big Data-Speicher von Lakehouse um den Low Latency Store, um Echtzeitanalysen und agentische Anwendungen zu unterstützen. Data 360-Echtzeitebene verarbeitet Echtzeitsignale und Interaktionsdaten im Arbeitsspeicher. Da die speicherbasierte Speicherkapazität jedoch begrenzt ist, können nicht alle Daten passen und die Verarbeitung kann nicht in Echtzeit erfolgen. Data 360 fügt einen Store mit geringer Latenz hinzu, um solche Einschränkungen zu beseitigen und so eine skalierbare Echtzeitverarbeitung zu ermöglichen.
Bei dem Speicher mit niedriger Latenz handelt es sich um eine NVMe-Speicherschicht (SSD) im Petabyte-Format im Lakehouse. Nicht alle Daten müssen im Speicher mit niedriger Latenz aufbewahrt werden. Es ist ein dauerhafter Cache. Die meisten Daten gelangen schließlich zur langfristigen Aufbewahrung ins Lakehouse. Sitzungsdaten in der Echtzeitebene können in den Speicher mit niedriger Latenz gefiltert werden, um anschließend schnell darauf zugreifen zu können. In einer Agentenunterhaltung können beispielsweise aktuelle Nachrichten im Arbeitsspeicher verarbeitet werden. Ältere Nachrichten können in den Speicher mit niedriger Latenz geleert werden. Wenn eine vorherige Unterhaltung erforderlich ist, kann innerhalb weniger Millisekunden über den Speicher mit niedriger Latenz darauf zugegriffen werden. Mit NVMe-basiertem Speicher können große Datenmengen gespeichert und mit Latenzen von Millisekunden aufgerufen werden. Die Daten gelangen möglicherweise in den Lakehouse Cloud-Speicher, um sie langfristig zu speichern. Darüber hinaus werden Daten aus Lakehouse abgerufen und im Speicher mit niedriger Latenz aufbewahrt, die für die Echtzeitverarbeitung oder zur Verbesserung der Echtzeiterfahrungen erforderlich sind. Beispielsweise wird der Kundenprofilkontext vorab abgerufen oder aus dem Lakehouse abgerufen und im Shop mit niedriger Latenz zwischengespeichert. Außerdem können alle Lakehouse-Objekte und anderen Objekte, die für die Echtzeitverarbeitung während der Verarbeitung in der Sitzung erforderlich sind, auch im Speicher mit niedriger Latenz zwischengespeichert werden.
Data 360-Speicher mit niedriger Latenz ermöglicht die Echtzeit-Ebene in einer echten Speicherhierarchie mit Speicherschichten (SSD) in Lakehouse, wobei Daten nahtlos zwischen diesen Schichten migriert werden. Die Data 360-Echtzeitebene wird später in diesem Dokument erläutert.
Salesforce Data 360 wurde entwickelt, um alle Kundendaten – strukturierte und unstrukturierte – nach einem strengen Lebenszyklus zu standardisieren, zu harmonisieren und zu aktivieren, der Rohdaten in ein vereinheitlichtes aktuelles Datenmodell umwandelt.
Der Lebenszyklus konzentriert sich darauf, verschiedene externe Dateneingaben zu übernehmen und sie in persistente, modellierte Objekte zu strukturieren. Modellierte Daten können zu vereinheitlichten Customer 360 Profilen harmonisiert werden.
Rohdaten und anfängliche Transformationen
Der Prozess beginnt mit Rohdaten, die im Ist-Zustand aus Quellsystemen (CRM, Marketing, Dateien usw.) aufgenommen werden. Dies umfasst vollständige Datenladevorgänge und kontinuierliche Änderungsereignisse (deltas), die verwaltet und mit persistenten Daten zusammengeführt werden, um einen aktuellen Status aufrechtzuerhalten.
Inline-Transformationen (z. B. Trimmen, Normalisieren, Verketten) werden sofort während der Aufnahme angewendet, um die vorläufige Datenqualität und Sauberkeit zu gewährleisten.
Data-Lake-Objekte (DLOs): Die persistente Ebene
DLOs (Data-Lake-Objekte) bilden die zentrale persistente Speicherebene in Data 360. Sie speichern die bereinigten umgewandelten Daten und dienen als organisiertes langfristiges Repository für alle Kundeninformationen.
Erweiterte Datentransformationen (z. B. Verknüpfungen, Aggregationen, berechnete Statistiken) werden auf Quell-DLOs angewendet, um neue, hochgradig zusammengestellte abgeleitete DLOs zu erstellen.
Daten, die über die Zero Copy Data Federation zur Verfügung gestellt werden, werden direkt als DLOs dargestellt.
Organisation unstrukturierter Daten und Metadaten
Bei unstrukturierten Inhalten (wie Text, Medien, Dokumenten) integriert Data 360 die Daten, indem die strukturierten Metadaten in bestimmten DLOs, sogenannten Unstructured Data Lake Objects (UDLOs), extrahiert und beibehalten werden.
Diese spezialisierten DLOs fungieren als Verzeichnistabellen und bieten eine Zuordnung zum physischen Standort und Kontext der unstrukturierten Vermögenswerte. Dadurch können Architekten die Metadaten unstrukturierter Daten nahtlos mit den restlichen strukturierten Kundendaten verknüpfen und so eine einheitliche Abfrage und Harmonisierung ermöglichen.
Datenmodellobjekte (DMOs): Die harmonisierte Ebene
DMOs (Datenmodellobjekte) stellen die endgültige, harmonisierte und strukturierte Datenebene dar.
Sie werden erstellt, indem DLO-Felder (aus Quell-, abgeleiteten und unstrukturierten Metadaten-DLOs) dem Customer 360-Standarddatenmodell zugeordnet werden.
Die DMO-Ebene fungiert als zentrale Informationsquelle für alle Kundendaten und ermöglicht die Erstellung, Segmentierung und Aktivierung von vereinheitlichten Profilen im gesamten Ökosystem.
Ein Datenbereich ist der grundlegende logische Container für die Organisation aller Daten und Metadaten in Data 360, einschließlich aller DLOs (strukturiert und unstrukturiert) und DMOs. Datenbereiche bieten eine sichere, isolierte Umgebung für die Datenverarbeitung und -modellierung.
Datenbereiche fungieren als logische und Governance-Grenzen und ermöglichen die interne Multimanenz, indem Daten für unterschiedliche Einheiten wie Geschäftseinheiten, Regionen oder Marken getrennt werden. Gleichzeitig werden die unternehmensweite Transparenz, Herkunft und Compliance gewahrt, was als Grundlage für die Definition der groben Zugriffssteuerung dient.
Die Isolierung in Datenbereichen wird auf mehreren Ebenen der Plattform erzwungen:
- Isolation auf Datenebene: Jedes DLO/DMO gehört zu einem einzelnen Datenbereich. Dadurch wird sichergestellt, dass Abfragen, Transformationen und Objektzuordnungen die Grenzen des Datenbereichs nur überschreiten können, wenn sie explizit autorisiert sind.
- Zugriffssteuerungsintegration: Berechtigungssätze sind nativ an Datenbereiche gebunden und ermöglichen die Kontrolle über Lese-, Schreib- und Verwaltungsvorgänge. Dadurch wird sichergestellt, dass nur autorisierte Benutzer und Services auf Objekte, Statistiken und Aktivierungen in einem Datenbereich zugreifen können.
- Governance und Audit: Alle Vorgänge innerhalb eines Datenbereichs werden mit unternehmensspezifischen Prüfprotokollen protokolliert, wodurch die Rückverfolgbarkeit für Compliance, Stewardship und behördliche Berichte ermöglicht wird.
Der Zugriff und die Berechtigungen werden über Berechtigungssätze verwaltet, wodurch eine genaue Sichtbarkeit, kontrollierte Aktualisierungen und die Vermeidung von domänenübergreifenden Datenlecks gewährleistet werden. Durch die Integration von Datenbereichsgrenzen in die Sicherheits- und Governance-Architektur von Data 360 können Architekten sowohl zentralisierte als auch dezentrale Governance-Strategien sicher implementieren und gleichzeitig die Konsistenz über mehrere Clouds und Geschäftsdomänen hinweg aufrechterhalten.
Die Data 360-Rechenstruktur bietet eine einheitliche Ebene zum Verwalten und Ausführen aller Big Data-Arbeitslasten und vereinfacht so die zugrunde liegenden Infrastrukturkomplexe. Kernkomponente ist das Datenverarbeitungssteuerfeld (DPC).
DPC ist ein umfassender Orchestrierungsservice für die Datenverarbeitung mit mehreren Arbeitslasten, der JaaS-Funktionen (Job-as-a-Service) in verschiedenen Cloud-Rechenumgebungen bereitstellt. Sie abstrahiert die Infrastrukturkomplexität und vereinheitlicht die Auftragsausführung für Frameworks wie Spark (EMR in EC2 und EMR in EKS) und Kubernetes Resource Controller (KRC). Durch die Verwendung als zentrales Gateway für Steuerungsebenen orchestriert, plant und überwacht DPC Aufträge über mehrere Datenebenen hinweg und gewährleistet so Zuverlässigkeit, Skalierbarkeit, Kosteneffizienz und eine konsistente Entwicklererfahrung.
Der Bedarf an DPC ergibt sich aus den Einschränkungen der direkten Interaktion mit nativen Cluster-Verwaltungssystemen wie EMR.
Infrastruktur und Cloud-Abstraktion
EMR bietet zwar APIs für Cluster, Aufgaben und Schritte, belastet Kundenteams jedoch weiterhin mit wichtigen Infrastrukturverwaltungsaufgaben wie Bereitstellung, Skalierung, Leistungsoptimierung und Kostenoptimierung. DPC behebt dies, indem es eine vereinfachte API auf Plattformebene für die Einreichung von Aufträgen bereitstellt. Sie unterstützt die automatische Fehlerbehandlung, Wiederholungen und dynamische Lastenverteilung. Bietet Kosteneffizienz durch Binpacking-, Spot- und Gravitationsknoten. Bietet starke Sicherheit mit TLS, PKI, IAM-Isolation und automatisiertem Patching. Verwaltet Upgrades der Spark- und EMR-Laufzeitversion, um Leistungsverbesserungen, Sicherheitspatches und Funktionsverbesserungen bereitzustellen.
Darüber hinaus bietet DPC eine einheitliche, Cloud-agnostische Oberfläche zum Senden und Verwalten von Datenaufträgen und abstrakte die Komplexitäten und proprietären APIs des zugrunde liegenden Cloud-Substrats (AWS, zukünftige Anbieter). Dadurch wird sichergestellt, dass Kundenteams ausschließlich mit einer gemeinsamen Data 360-API-basierten Auftragseinreichungsoberfläche interagieren, die die Komplexität zugrunde liegender Ressourcenmanager wie Kubernetes und YARN abstrahiert. Dadurch können Clientteams Spark-Aufträge über eine einfache, einheitliche API senden, ohne Pods, Knotenpools oder Spark-Clusterkonfigurationen direkt verwalten zu müssen.
Das manuelle Abstimmen von Spark-Parametern erfordert spezielle Fertigkeiten und falsche Konfigurationen können zu einer langsamen Auftragsausführung führen. Das DPC-Team zentralisiert diese Expertise und bietet optimierte Konfigurationen, um allgemeine Leistungsprobleme zu vermeiden. Dieses spezialisierte Team integriert kontinuierlich Knowledge aus der Open-Source-Community, um eine optimale Leistung für alle vom Controller verwalteten Arbeitslasten zu gewährleisten.
DPC ist nicht auf Spark beschränkt, sondern unterstützt eine Vielzahl von Arbeitslasten. Dazu zählen:
- Echtzeitverarbeitungsarbeitslasten
- Ereigniszustellung für die Funktion "Datenaktionen"
- Verwaltung von Milvus (der Vektordatenbank für die unstrukturierte Datenindizierung)
- Speicherinfrastruktur mit geringer Latenz
DPC nutzt auch das Framework Kubernetes Resource Controller (KRC), das Arbeitslasten wie Trino für Abfragen, Ereigniszustellungen für Datenaktionen, Datenextraktionsaufträge für Konnektoren und Echtzeitverarbeitung unterstützt. Für alle KRC-Arbeitslasten bietet DPC zentrale Job-as-a-Service-Funktionen, die die Bereitstellung, Bereitstellung und Verwaltung von Rechenaufgaben auf einer allgemeinen Auftragsabstraktion übernehmen.
Vorteile und Architektur von JaaS
Das von DPC bereitgestellte Job-as-a-Service-Modell gewährleistet eine kostengünstige und belastbare Auftragsverarbeitungs-Pipeline.
Benutzer stellen einfache Cluster-Spezifikationen bereit, die sich auf die erforderliche CPU, den Speicher, den Speicher, die Instanzanzahl und die Anzahl der Min/Max-Cluster und Tags für den Clusterabgleich konzentrieren. Anschließend verwaltet DPC automatisch abstrakte Infrastrukturdetails, einschließlich der Auswahl optimaler VM-SKUs, der Verwaltung von Instanzflotten und der Bestimmung des Verhältnisses von Core zu Core. Aufgabenknoten und Verwalten von On-Demand vs. Erkennen Sie Instanzen anhand von Eingaben. Außerdem werden EMR- und Komponentenversionsverwaltung sowie Upgrades ohne Ausfallzeiten verarbeitet.
Entscheidend ist, dass DPC von Natur aus die Multitenance unterstützt, die entwickelt wurde, um die Data 360-Mandantengrenzen und die Ressourcentrennung zu verstehen und durchzusetzen. Darüber hinaus gewährleistet sie Sicherheit und Compliance, indem sie Salesforce-zertifizierte Maschinenbilder erzwingt, servicespezifische IAM-Rollen verwaltet und die Verschlüsselung sowohl bei der Übertragung als auch im Leerlauf gewährleistet. Bei der Weiterleitung und Kapazitätssteuerung wird der Abgleich zwischen Aufträgen mithilfe von Cluster-Tags verwaltet und bei der kapazitätsbasierten Weiterleitung wird eine maximale Einstellung für die Auftragsgleichzeitigkeit verwendet, um die Ressourcenauslastung effektiv zu steuern.
Die Cloud Agnostic Client Experience ist ein zentraler Vorteil, da die Komplexität der zugrunde liegenden Cloud-Umgebungen für Kundenservices ausgeblendet ist und sie sich ausschließlich auf Geschäftslogik konzentrieren können. Dadurch wird das Ziel der Cloud-Anbieterabstraktion erreicht. Schließlich ermöglicht DPC eine einfache Nutzung und Kostenverfolgung, wodurch die Clusterauslastung und die Kosten nach Service segmentiert werden können, um eine genaue Buchhaltung zu ermöglichen. Insgesamt folgt DPC einer steckbaren Architektur, die es ermöglicht, neue Ausführungsmodule (z. B. Flink, Ray) und Cloud-Substrate (GKE/Dataproc) nahtlos zu integrieren, ohne Benutzern die zugrunde liegenden Infrastrukturdetails zur Verfügung zu stellen. Durch dieses Design wird die Steuerebene von der Ausführungsebene entkoppelt, wodurch eine konsistente API und Betriebserfahrung unabhängig vom Backend gewährleistet wird.
Data 360 optimiert und erweitert Rohdaten und schließt die Lücke zwischen Rohinformationen und dem handlungsrelevanten Geschäftsverbrauch. Es ergänzt den Lebenszyklus von Datenobjekten, indem es komplexe Daten für eine komplexe Aktivierung und Analyse vorbereitet. Data 360 unterstützt verschiedene Verarbeitungstypen, darunter Batch- und Streaming-Datentransformationen, berechnete Statistiken zum Batch und Streaming, unstrukturierte Datenverarbeitung und Identitätsbestimmung. Um diese vielfältigen Vorgänge effizient zu ermöglichen, insbesondere in nahezu Echtzeit und über massive Datensets hinweg, ist ein komplexer Mechanismus erforderlich, um Datenänderungen effektiv zu verarbeiten.
Data 360 benötigte einen Durchbruch, um eine effiziente Datenverarbeitung nahezu in Echtzeit zu erreichen, insbesondere mit Tabellen in Terabyte-Größe und Millionen potenzieller Aktualisierungen. Sie erforderte eine Möglichkeit, Systeme genau zu benachrichtigen, wenn sich Daten ändern, und dann effizient zu identifizieren, welche Daten geändert wurden, sodass nur relevante Aktualisierungen verarbeitet werden und nur, wenn sie aktualisiert werden. Diese Herausforderung führte zu zwei sich ergänzenden Innovationen: Speichern von nativen Änderungsereignissen (SNCE) zum Benachrichtigen, wenn etwas geändert wird, und Ändern des Datenfeeds (CDF) zum Identifizieren, was geändert wurde.
Native Speicheränderungsereignisse (SNCE)
SNCE hat Data 360 grundlegend in eine reaktive und inkrementelle Datenplattform umgewandelt. Diese Umstellung beinhaltet den Übergang von der aktiven Abfrage des Data Lakes zur passiven Überwachung auf Atom-Commit-Ereignisse mithilfe eines standardisierten Ereignisformats und eines Nachrichtenzustellungssystems mit hohem Durchsatz.
Jeder erfolgreiche Schreibvorgang (EINFÜGEN, AKTUALISIEREN, LÖSCHEN) in eine Iceberg-Tabelle gipfelt in einem Atomtausch des aktuellen Metadatendateizeigers der Tabelle im Katalog. Die zugrunde liegende Objektspeicherebene (beispielsweise S3) ist so konfiguriert, dass ein natives Benachrichtigungsereignis (beispielsweise ein S3-Ereignis) ausgegeben wird, sobald ein neuer Metadaten-Snapshot in das Verzeichnis der Tabelle geschrieben wird.
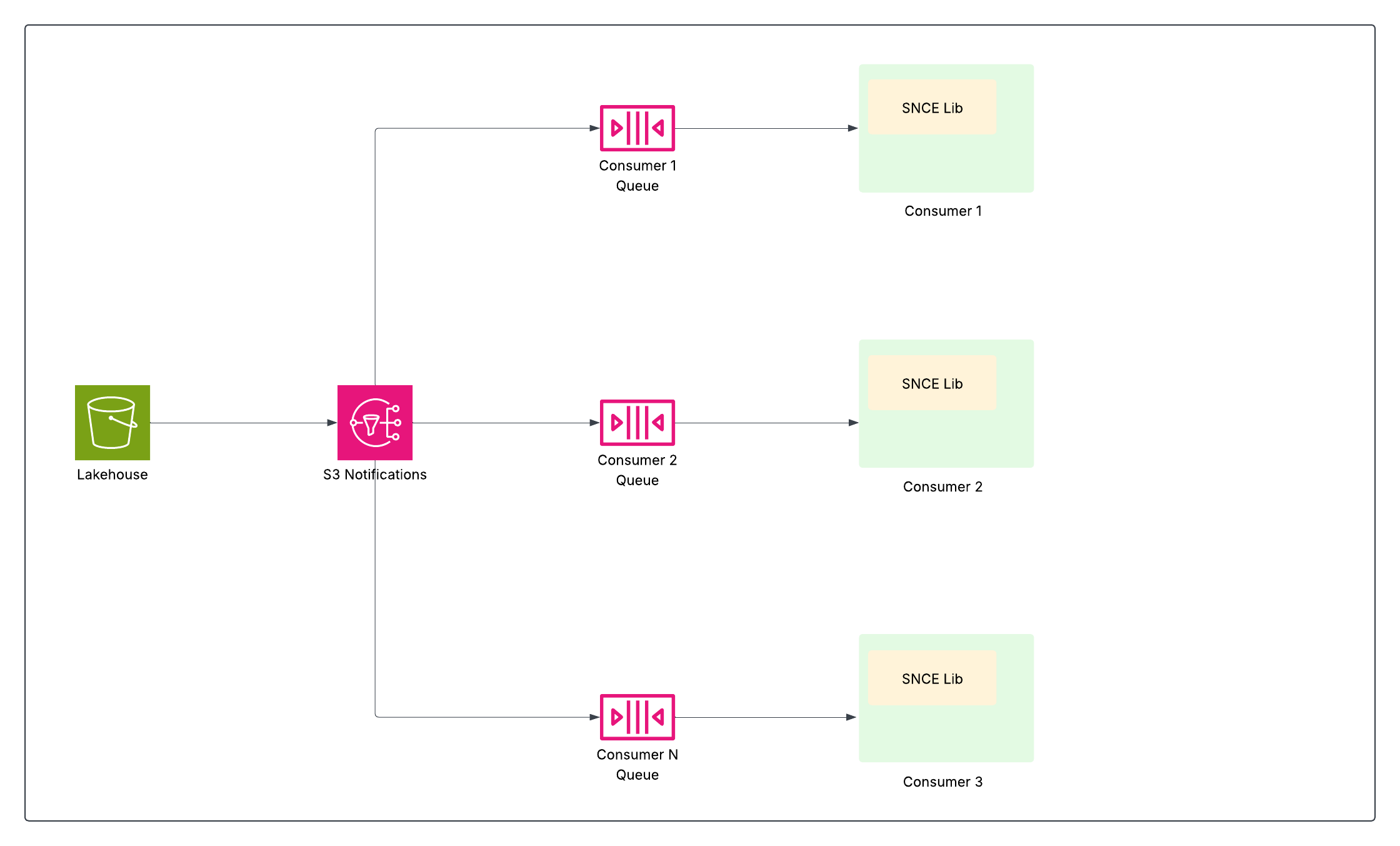
Die SNCE-Bibliothek bietet eine standardisierte Methode zum Verwenden dieser Ereignisse und kann sie auf Anfrage auch mit Snapshot-Metadaten anreichern.
Dadurch können nachgelagerte Datenpipelines wie Streaming berechneter Statistiken, Identitätsbestimmung und Segmentierung nur dann abonniert werden und reagieren, wenn sich Daten geändert haben. Dies erhöht die Effizienz erheblich, da kostspielige Scans mit vollständiger Tabelle vermieden werden.
Datenfeed ändern (CDF)
Aufbauend auf SNCE bietet der Change Data Feed (CDF) einen optimierten Mechanismus zum Verbrauchen und inkrementellen Verarbeiten der Änderungen.
CDF nutzt Iceberg-Snapshots, um den Stream der Änderungen effizient zu generieren. Entscheidend ist, dass der optimierte Iceberg-Schreiber von Data 360 die Änderungen als Teil des Schreibvorgangs selbst berechnet und beibehält, wodurch die CDF-Generierung hocheffizient ist und der zusätzliche Overhead minimiert wird. Dadurch können Verarbeitungsaufträge (wie Streaming-Transformationen oder berechnete Streaming-Statistiken) selektiv nur die geänderten Datensätze verarbeiten, wodurch die aufwendige Snapshot-Diff-Berechnung vermieden wird.
Diese inkrementelle Strategie bietet mehrere Vorteile für große Datensets, einschließlich Kosteneinsparungen, reduzierter Latenz und verbesserter Effizienz. Sie ermöglicht Funktionen wie Streaming-Transformationen und die inkrementelle Identitätsbestimmung, die wiederum zu schnelleren Statistiken, vorhersehbareren Systemlasten, höherer Leistung und niedrigeren Betriebskosten führen.
Data 360 bietet zuverlässige Aufnahmefunktionen mit nativer Unterstützung für Salesforce-Produkte und gewährleistet so einen nahtlosen Datenfluss. Für externe Quellen bietet sie umfangreiche Konnektivität über mehr als 270 Konnektoren, APIs, SDKs und MuleSoft. Darüber hinaus bietet Data 360 eine Zero-Copy-Verbundfunktion, die BI und Analysen ohne Datenduplizierung ermöglicht.
Das Data 360-Konnektor-Framework (DCF) ist die Grundlage für die meisten Data 360-Konnektivitäten. Sie ermöglicht die Aufnahme, den Verbund und die Beendigung über eine einheitliche Architektur. DCF definiert die Standards für das Erstellen und Verwalten von Konnektoren – von der Benutzeroberfläche für Setup und Verwaltung bis hin zur Metadatenpersistenz, Datenextraktion und Bereitstellung in Lakehouse oder über Live-Abfragen für externe Quellen. Sie unterstützt auch private Konnektivitätsoptionen (z. B. private Links, VPNs und sichere Tunnel), um die Datensicherheit und Compliance bei der Verbindung mit Kunden- oder Partnerumgebungen auf Unternehmensebene zu gewährleisten. Durch die Bereitstellung eines konsistenten Ansatzes für alle Konnektoren ermöglicht DCF Data 360 eine nahtlose Verbindung mit dem größeren Ökosystem, indem Erweiterbarkeit, Zuverlässigkeit und sichere Integration gewährleistet werden.
Data 360 bietet zuverlässige Verbindungen zu einem umfangreichen Ökosystem von Datenquellen und unterstützt native Salesforce-Produkte sowie zahlreiche externe Systeme. Diese umfangreiche Konnektivität ist entscheidend für die Vereinheitlichung isolierter Unternehmensdaten und die Aktivierung von AI/ML- und Agentenanwendungen.
Data 360 bietet mehr als 270 Konnektoren nativ oder über MuleSoft, APIs und SDKs, um seine durchgängigen Datenpipeline-Funktionen mit Batch-, Streaming- oder Echtzeitaufnahme zu unterstützen. Diese Konnektoren können grob nach dem Typ des Quellsystems kategorisiert werden, das sie integrieren.
Native Salesforce-Konnektoren
Diese Konnektoren gewährleisten einen nahtlosen und nativen Datenfluss aus Salesforce-Produkten.
Beispiele sind Konnektoren für Salesforce CRM, Data Cloud One , Marketing Cloud Engagement, Marketing Cloud Account Engagement und B2C Commerce.
Externe Anwendungen und SaaS
Konnektoren für verschiedene Geschäftsanwendungen und Cloud-Services ermöglichen die Datenaufnahme von externen Softwareplattformen.
Beispiele sind Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp und Airtable.
Datenbanken und Data Warehouses
Data 360 stellt eine Verbindung zu einer Vielzahl von relationalen und Cloud-basierten Datenspeicherplattformen her.
Beispiele sind Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery und Microsoft SQL Server.
Cloud-Objektspeicher und Dateisysteme
Diese Konnektoren können in Hyperscaler-Speicherlösungen für strukturierte und unstrukturierte Daten integriert werden.
Beispiele sind Amazon S3, Google Cloud Storage (GCS) und Azure Blob Storage.
Streaming- und Messaging-Services
Konnektoren, die kontinuierliche Echtzeit-Datenströme verarbeiten, sind für ereignisgesteuerte Szenarien und die Echtzeitverarbeitung entscheidend.
Ein Beispiel ist der Amazon Kinesis-Konnektor.
Integrationsplattformen
Der MuleSoft Anypoint-Konnektor erweitert die Reichweite von Data 360, indem er über Anypoint Exchange in eine breitere Palette von Anwendungen und Datenbanken integriert wird.
Konnektoren für nicht strukturierte Daten und Cloud-Objektspeicher
Diese Konnektoren sind wichtig für die Aufnahme und Referenzierung unstrukturierter Daten (Daten, für die kein vordefiniertes Modell vorhanden ist), um die Funktionen der generativen AI zu unterstützen.
Alle diese Konnektoren basieren auf dem Data 360-Konnektor-Framework und bieten eine konsistente Erfahrung.
Die Datentransformation ist eine grundlegende Architekturkomponente in Data 360, die entwickelt wurde, um die erfassten Rohdaten zu bereinigen, anzureichern und in normalisierte, handlungsrelevante Datenbestände umzuwandeln, die mit dem Customer 360 Datenmodell übereinstimmen. Dieser Prozess ist wichtig für die Harmonisierung, Qualitätsverbesserung und die Sicherstellung, dass Daten für nachgelagerte Anwendungsfälle wie die Profilvereinheitlichung, Segmentierung und Aktivierung bereit sind. Transformationen verwenden sowohl Data-Lake-Quellobjekte (DLOs) als auch Datenmodellobjekte (DMOs) als Eingabe und generieren die Ergebnisse in neue DLOs bzw. DMOs.
Data 360 bietet zwei primäre Transformationsparadigmen, um unterschiedliche Anforderungen an die Datengeschwindigkeit zu erfüllen: Batch-Datentransformationen und Streaming-Datentransformationen.
Batch-Datentransformationen
Batch-Datentransformationen sind für die Verarbeitung großer Volumen auf der Grundlage eines definierten Zeitplans oder On-Demand-Auslösers konzipiert. Dieses Modul ist für komplexe, ressourcenintensive Umstrukturierungen optimiert.
Der Batch-Transformationsprozess wird mithilfe eines visuellen Low-Code-Pipeline-Zeichenbereichs konfiguriert, mit dem Benutzer mehrstufige Transformationslogik definieren können. Dieses Modul unterstützt auf einzigartige Weise komplexe Umstrukturierungsvorgänge, die für die Ausrichtung kanonischer Datenmodelle wichtig sind: Datenstrukturierung und -normalisierung. Dies beinhaltet das Pivoten (Aufschlüsseln denormalisierter Datensätze in mehrere normalisierte Datensätze) und das Vereinfachen (Umstrukturieren hierarchischer Daten wie JSON in strukturierte Tabellen). Der Ausführungsmodus des Systems unterstützt sowohl die vollständige Synchronisierung (Verarbeitung aller Datensätze) als auch einen hocheffizienten inkrementellen Verarbeitungsmodus. Der inkrementelle Modus reduziert die Verarbeitungszeit und den Ressourcenverbrauch erheblich, da nur Datensätze verarbeitet werden, die sich seit der letzten erfolgreichen Ausführung geändert haben. Batch-Transformationen eignen sich ideal für Aufgaben, bei denen Echtzeitaktualisierungen nicht erforderlich sind, beispielsweise regelmäßige Aggregationen und komplexe Datenumstrukturierungen.
Streaming-Datentransformationen
Streaming-Datentransformationen verarbeiten Daten kontinuierlich und inkrementell nahezu in Echtzeit, während sie in das System fließen, was sie für Anwendungsfälle mit geringer Latenz unerlässlich macht.
Die primäre Schnittstelle ist ein SQL-first-Ansatz, bei dem Transformationen als SQL SELECT-Abfrage definiert sind, die kontinuierlich für den eingehenden Datensatzänderungsstrom ausgeführt wird. Dieses Modul unterstützt zentrale Transformationsfunktionen, einschließlich Datenbereinigung und Standardisierung (z. B. Validierung personenbezogener Daten und Standardisierung von Datenformaten) und Datenanreicherung und -zusammenführung (mit Verknüpfungen und Unionen). Von entscheidender Bedeutung ist, dass Streaming-Nachschlageverknüpfungen unterstützt werden, um die Echtzeit-Datenanreicherung und Nachschlagevorgänge für statische oder sich langsam ändernde Referenzdaten zu ermöglichen und sofortige Profilaktualisierungen zu gewährleisten. Zur Optimierung der Kosten für die Bereitstellung verwendet die Architektur ein Auftragsdesign mit hoher Dichte (HD), das mehrere Streaming-Transformationsdefinitionen für einen einzelnen Mandanten in einen einzelnen zugrunde liegenden Rechenauftrag bündelt und so die Ressourcenauslastung maximiert. Streaming-Transformationen sind für Anwendungsfälle wie die Ereignisüberwachung, sofortige Personalisierung und Echtzeit-Profilaktualisierungen unerlässlich.
Data 360 revolutioniert die Datenverwaltung durch die Unterstützung der Zero Copy-Verbund- und -Datenfreigabe, wodurch keine Daten verschoben oder dupliziert werden müssen. Durch diese Funktion können Benutzer nahtlos und direkt auf Daten aus verschiedenen externen Quellen zugreifen und Daten für externe Umgebungen freigeben, wodurch die Komplexität erheblich reduziert, die Speicherkosten gesenkt und sichergestellt wird, dass alle Entscheidungen auf den neuesten und zuverlässigsten Informationen basieren.
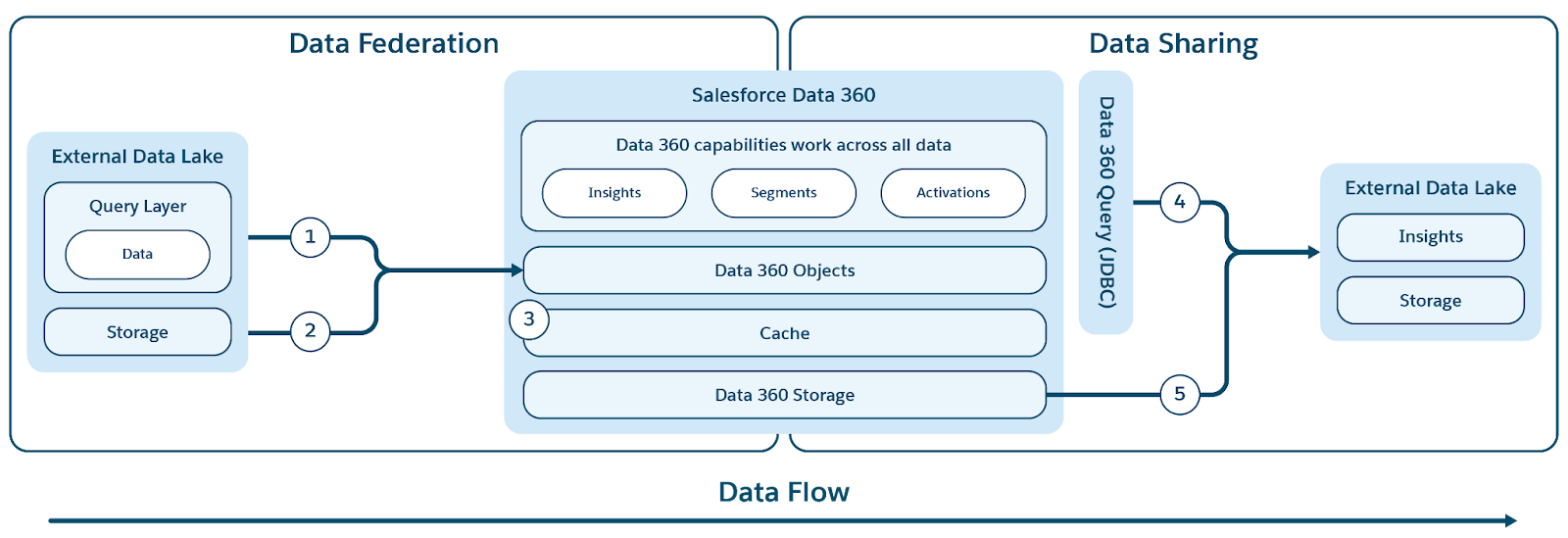
Data 360 unterstützt Zero-Copy-Verbunde mit externen Data Warehouses (Snowflake, Redshift), Lakehouses (Google BigQuery, Databricks, Azure Fabric), SQL-Datenbanken und vielen anderen Quellen. Seine Abstraktionsebenen ermöglichen die direkte Abfrage externer Daten ohne Duplikate, wodurch die Aufnahmezeit, die Speicherkosten und die Gewährleistung aktueller Informationen reduziert werden.
Data 360 vereinfacht den Zugriff auf externe und Verbunddaten, indem eine einheitliche Metadatenebene bereitgestellt wird, die Salesforce und externe Objekte abstrahiert. Dadurch können die gesamte Salesforce Platform und ihre Anwendungen diese Daten nahtlos verwenden.
Data 360 unterstützt die datei- und abfragebasierte Zuordnung mit Live-Abfrage und Zugriffsbeschleunigung, wie in der Abbildung gezeigt.
Die Bezeichnungen (1) und (2) veranschaulichen die Abfrage von Data 360 (einschließlich Pushdowns für Live-Abfragen) und die dateibasierte Zuordnung für den Zugriff auf Daten aus externen Data Lakes/Warehouses/Datenquellen. Die Bezeichnung (3) hebt die Beschleunigung des Verbundzugriffs aus externen Data Lakes/Datenquellen hervor.
Abfrageverbund
Der Kern der Verbundfunktion von Data 360 liegt in der Abfrageverbundebene, die den komplexen Prozess des Zugriffs auf externe Daten und der Durchführung intelligenter Abfrage-Pushdowns (veranschaulicht durch Bezeichnung 1) verwaltet. Data 360 stellt mithilfe des JDBC-Protokolls eine Verbindung zu und ruft Daten aus Quellen ab. Zusätzliche Logik sorgt für mehr Effizienz. Die Abfrageverbundebene ist dafür verantwortlich, verschiedene SQL-Dialekte zu verstehen und zu übersetzen, den optimalen Teil der Abfrage zu ermitteln, der für eine effiziente Verarbeitung an externe Systeme übertragen werden soll, die Ergebnisse abzurufen und alle erforderlichen weiteren Verarbeitungen durchzuführen, um endgültige Statistiken abzuleiten.
Zwischenspeicherung (Abfragebeschleunigung)
Data 360 bietet für erweiterte Dienstprogramme eine optionale Beschleunigungsfunktion für seine Verbundfunktionen.
Wenn die Beschleunigung aktiviert ist, speichert Data 360 die Verbunddaten zwischen, um einen schnelleren Zugriff und niedrigere Kosten zu erzielen, da wiederholter direkter Zugriff auf externe Quellen vermieden wird. Dieser Cache wird als Beschleunigungsebene behandelt und schrittweise aktualisiert, um Änderungen an den externen Quelldaten schnell zu berücksichtigen und sicherzustellen, dass die beschleunigte Ansicht nahezu in Echtzeit erhalten bleibt.
Dateiverbund
Data 360 unterstützt die dateibasierte Zuordnung (dargestellt durch Bezeichnung 2) für den Zugriff auf Daten aus externen Data Lakes und Quellen. Die technische Grundlage für diese Zero-Copy-Funktion basiert auf der Standardisierung: Die zugrunde liegenden Daten müssen im Apache Parquet-Dateiformat vorliegen und das tabellarische Apache Iceberg-Format verwenden. Data 360 kann in eine beliebige Quelle integriert werden, die einen Iceberg-REST-Katalog (IRC) für den Metadaten- und Speicherzugriff bereitstellt, um einen nahtlosen, geregelten Zugriff auf Dateien außerhalb der Plattform zu gewährleisten.
Mit der dateibasierten Zuordnung verarbeitet Data 360 die gesamte Datenverarbeitung, da sie direkt auf den zugrunde liegenden Speicher zugreifen. Dadurch müssen keine Abfrage-Pushdown-Vorgänge mehr ausgeführt und verschiedene SQL-Dialekte verwaltet werden, die bei der abfragebasierten Zuordnung häufig erforderlich sind.
Darüber hinaus erstreckt sich die Zero Copy-Funktion auch auf unstrukturierte Datenquellen wie Hyperscaler-Speicherlösungen (S3/GCS/Azure-Speicher), Slack und Google Drive, auf die über die unstrukturierten Verarbeitungspipelines von Data 360 zugegriffen werden kann.
Data 360 ermöglicht die abfragebasierte und dateibasierte Freigabe der von Data 360 verwalteten Daten für externe Data Lakes und Lagerhäuser (im ursprünglichen Abbildungskontext durch die Bezeichnungen 4 und 5 veranschaulicht).
Abfragebasierte Freigabe
Für die abfragebasierte Datenfreigabe stellt Data 360 einen JDBC-Treiber bereit, mit dem externe Engines und Anwendungen sicheren Zugriff auf die Daten erhalten können. Durch diesen Mechanismus können externe Systeme Live-Abfragen direkt mit den Daten in Data 360 verbinden, authentifizieren und ausführen.
Dateibasierte Freigabe (Datenfreigabe und DaaS)
Der primäre Mechanismus für die dateibasierte Freigabe umfasst zwei Konzepte: die Datenfreigabe und das Datenfreigabeziel, die die DaaS-API (Data as a Service) nutzen.
- Granular Control (Granulare Kontrolle): Das Datenfreigabekonzept ermöglicht es Kunden, genau zu definieren, welche Objekte (DLOs, DMOs, CIOs usw.) extern freigegeben werden, um eine unbeabsichtigte Datenoffenlegung zu verhindern.
- Sicheres Targeting: Sie steuert auch das Datenfreigabeziel und stellt sicher, dass Daten nur explizit autorisierten externen Umgebungen, Accounts oder Partnerorganisationen zur Verfügung gestellt werden (z. B. Freigabe für eine bestimmte Redshift- oder Databricks-Instanz).
Die DaaS-API bietet eine sichere und geregelte Schnittstelle für externe Engines zum Verbrauchen von Daten. Er gewährt Zugriff auf die wesentlichen Metadaten und den zugrunde liegenden Tabellenspeicher, wobei die gesamte Data 360-Semantik erhalten bleibt. Dadurch wird sichergestellt, dass externe Engines auf sichere Weise in einem konsistenten und aussagekräftigen Kontext auf die Daten zugreifen.
Viele sicherheitskritische Kunden, insbesondere große Unternehmen, regulierte Branchen und Organisationen des öffentlichen Sektors, schränken den gesamten Internetzugang auf ihre Data Lakes als Teil ihres Sicherheitsstatus ein. Diese Richtlinie ist für die Einhaltung der Vorschriften und die Risikominderung wichtig, verhindert jedoch auch, dass Salesforce Data 360 und Agentforce über das öffentliche Internet eine Verbindung zu diesen Umgebungen herstellen.
Die meisten dieser Data Lakes werden in Hyperscaler-Umgebungen wie AWS, Azure oder Google Cloud bereitgestellt. Da Data 360 selbst auf AWS ausgeführt wird, ist für den Zugriff auf Kunden-Data-Lakes, die auf einem anderen Cloud-Anbieter gehostet werden, eine cloudübergreifende Netzwerkverbindung erforderlich. Ohne eine sichere, private Konnektivitätsoption, die das öffentliche Internet umgeht, können oder wollen Kunden Data 360 oder Agentforce für Anwendungsfälle, die auf diesen Data Lakes basieren, oft nicht übernehmen.
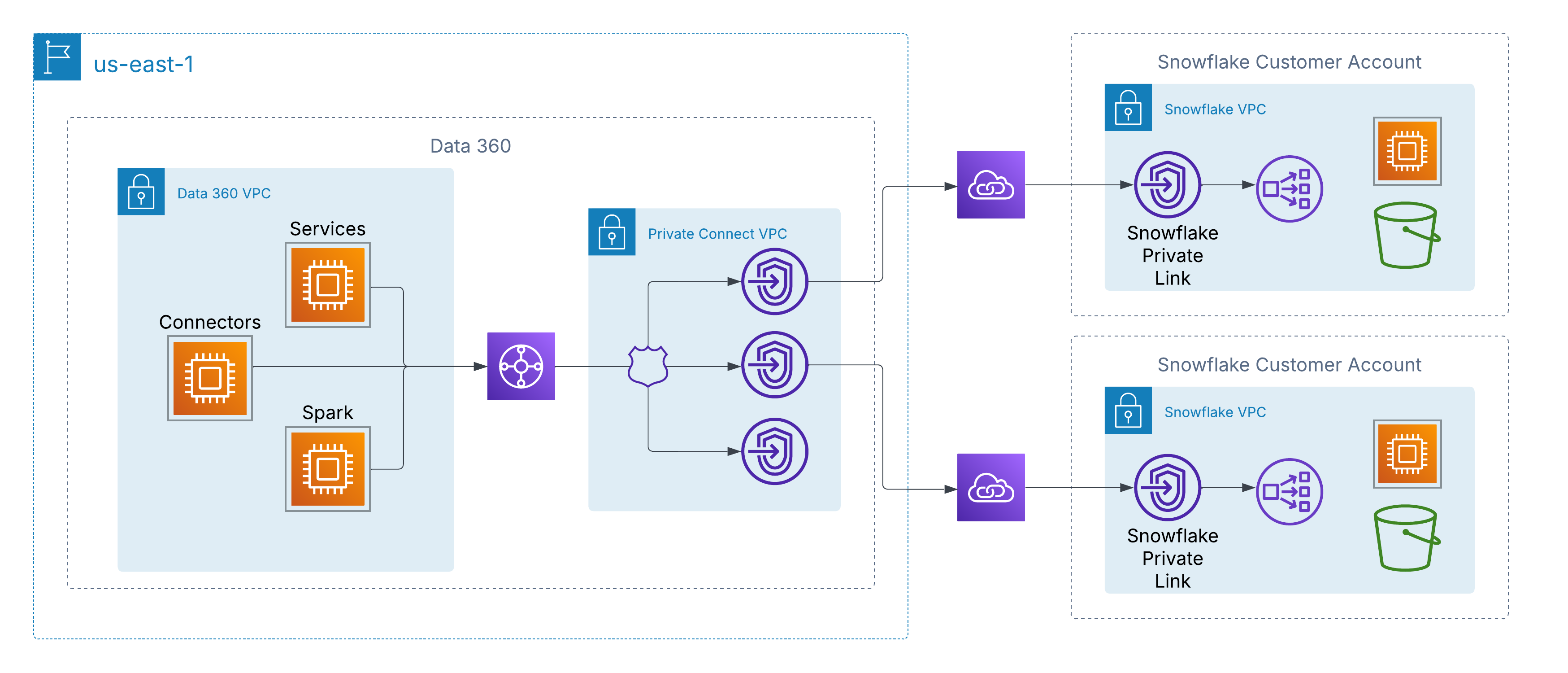
Data 360 unterstützt private Verbindungen auf Netzwerkebene mit vom Kunden verwalteten Datenquellen in verschiedenen Clouds. In AWS wird dies über AWS PrivateLink aktiviert, mit dem Data 360 direkt mit vom Kunden bereitgestellten Endpunkten verbunden werden kann, entweder in ihren eigenen Accounts oder in Data-Lake-Umgebungen von Drittanbietern (z. B. Snowflake), ohne das öffentliche Internet zu durchlaufen.
Diese Architektur stellt sicher, dass der gesamte Datenverkehr vollständig auf dem AWS-Backbone verbleibt, indem private IP-Adressierung und nicht weiterleitbare Netzwerkpfade verwendet werden. Dadurch werden strenge Sicherheits- und Compliance-Anforderungen erfüllt und gleichzeitig ein nahtloser Zugriff auf Kundendaten ermöglicht.
Für Kunden mit Multi-Cloud-Architekturen erweitert Data 360 die private Konnektivität über AWS hinaus durch Unterstützung der cloudübergreifenden Verbindung. Dadurch werden sichere, reine Backbone-Netzwerkpfade von Data 360 zu Data Lakes und Services ermöglicht, die in Azure oder Google Cloud gehostet werden, wobei dieselben Prinzipien wie bei AWS PrivateLink beibehalten werden: private IP-Adressierung, nicht öffentliche Weiterleitung und keine Internetverbindung.
Kunden können zwischen zwei Bereitstellungsmodellen wählen:
-
Vom Kunden verwaltete Verbindungsleitung: Integrieren Sie vorhandene private Schaltungen wie Azure ExpressRoute, Google Cloud Interconnect oder Equinix Fabric direkt in die VPCs von Data 360.
-
Salesforce-Managed Interconnect: Verwenden Sie eine vollständig verwaltete, schlüsselfertige Verbindung, bei der Salesforce den cloudübergreifenden Link bereitstellt und betreibt, wodurch private Endpunkte in der Ziel-Cloud verfügbar gemacht werden.
In beiden Modellen ist die Erfahrung konsistent: Data 360-Services stellen über Hyperskalierer hinweg eine Verbindung mit externen Datenquellen her, als ob sie lokal wären, und ermöglichen eine sichere Aufnahme, Aktivierung und Abfrage, ohne das öffentliche Internet zu durchlaufen.
Für Unternehmensarchitekten ist die zuverlässige Datenverwaltung nicht nur ein Kontrollkästchen für die Einhaltung von Vorschriften, sondern eine grundlegende Säule für den Aufbau vertrauenswürdiger, skalierbarer und handlungsrelevanter Kundenintelligenzen. Salesforce Data 360 wurde mit einem umfassenden Governance-Framework entwickelt, das Datenqualität, Sicherheit und die Einhaltung gesetzlicher Vorschriften über den gesamten Datenlebenszyklus hinweg gewährleistet.
Data 360 fungiert als zentralisiertes Governance-Zentrum und stellt sicher, dass alle Daten – von der Roherfassung bis hin zu aktivierten Statistiken – integritätssicher und kontrolliert verwaltet werden.
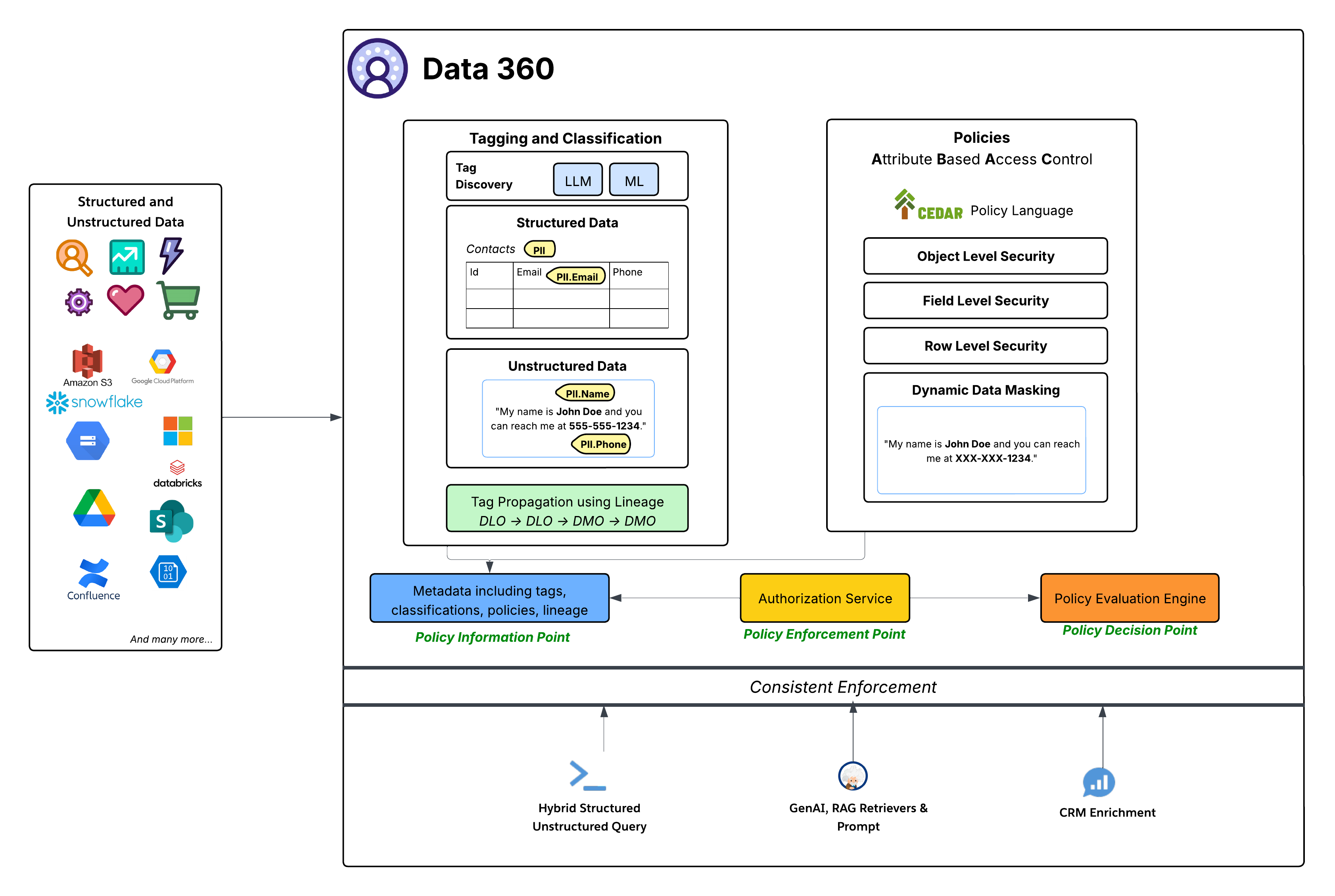
Während der Datenbereich eine grob skalierte Zugriffssteuerung bietet, um den Zugriff auf alle Objekte in einem Datenbereich zu bestimmen, bieten ABAC-basierte Richtlinien eine fein skalierte Zugriffssteuerung für einzelne Objekte, Felder und Zeilen in einem Datenbereich. Data 360 hat die attributbasierte Zugriffssteuerung (ATtribut-Based Access Control, ABAC) als zentrales Autorisierungsmodell für die genaue Zugriffssteuerung übernommen. Diese strategische Entscheidung bietet eine überlegene Flexibilität und Skalierbarkeit im Vergleich zur herkömmlichen rollenbasierten Zugriffssteuerung (RBAC). Dies ist besonders wichtig für dynamische, komplexe Unternehmensumgebungen mit riesigen Datenmengen und unterschiedlichen Zugriffsanforderungen. Mit ABAC können Zugriffsentscheidungen auf Attributen des Benutzers (z. B. Abteilung, Rolle, Standort), der Daten (z. B. personenbezogene Daten, Sensibilität, Datenbereich) und der Umgebung (z. B. Uhrzeit) basieren und nicht nur auf vordefinierten Rollen. Dadurch werden sehr detaillierte und kontextbezogene Zugriffsrichtlinien ermöglicht, die an sich ändernde Daten und Benutzerattribute angepasst werden.
- CEDAR Policy Language (Sprache der Cedar-Richtlinie): Das Herzstück der ABAC-Implementierung von Data 360 ist die Verwendung der CEDAR-Richtliniensprache. Diese speziell entwickelte, formale Richtliniensprache bietet eine präzise und überprüfbare Möglichkeit, komplexe Autorisierungsregeln zu definieren, wodurch sichergestellt wird, dass Richtlinien eindeutig sind und einheitlich im richtigen Maßstab ausgewertet werden können.
Das Governance-System in Data 360 basiert auf einer standardmäßigen, robusten ABAC-Architektur:
- Tagging, Klassifizierung und Richtlinienerstellung (Policy Information Point, PIP):
- Data 360 bietet automatisierte Tagging- und Klassifizierungsmechanismen, die LLM (Large Language Model) und ML (Machine Learning) verwenden, um sensible Datenkategorien (z. B. PII.Email, PII.Phone, PII.Name) und andere zweckgebundene Taxonomien (PHI, FinancialData) in strukturierten Daten (z. B. Tabelle "Kontakte") und unstrukturierten Daten (z. B. aus Google Drive) zu identifizieren.
- Entscheidend ist, dass die Tag-Übernahme entlang der Datenherkunft (DLO -> DLO -> DMO) erfolgt. Dadurch wird sichergestellt, dass Klassifizierungen automatisch Datentransformationen und -ableitungen folgen, von den aufgenommenen Rohdaten bis zur harmonisierten DMO-Ebene und über abgeleitete Daten, die aus Prozessdefinitionen erstellt wurden.
- Schließlich bietet der Richtlinienerstellungsbereich eine einfache Erfahrung zum Definieren dynamischer Zugriffsregeln für eine Organisation.
- Diese angereicherten Metadaten (einschließlich Tags, Klassifizierungen, Richtlinien und Abstammung) werden in den Policeninformationspunkt (Police Information Point, PIP) übernommen.
- Autorisierungsservice (Policy Enforcement Point, PEP):
- Der Autorisierungsservice fungiert als Policy Enforcement Point (PEP). Sie fängt alle Datenzugriffsanforderungen aus verschiedenen Verbrauchsebenen ab (Hybridstrukturierte/Unstrukturierte Abfrage, GenAI RAG Retrievers & Prompt, CRM-Anreicherung) und konsultiert den Richtlinienentscheidungspunkt, um festzustellen, ob der Zugriff zulässig ist.
- Policy Evaluation Engine (Policy Decision Point, PDP) (Policy-Bewertungsmodul für Policen (Policy Decision Point, PDP)):
- Dieses Modul fungiert als "Policy Decision Point" (PDP). Es verwendet den Zugriffsanforderungskontext aus dem PEP zusammen mit Richtliniendefinitionen (in CEDAR) und Attributen aus dem PIP, um eine autorisierende Zugriffsentscheidung zu treffen.
- Granulare Sicherheitsrichtlinien: Die in CEDAR definierten Richtlinien erzwingen verschiedene Sicherheitsebenen, darunter:
- Objektebenensicherheit: Steuern des Zugriffs auf gesamte DLOs oder DMOs anhand von Tags, die diesen Objekten zugeordnet sind.
- Feldebenensicherheit: Einschränken des Zugriffs auf bestimmte sensible Felder in einem Objekt anhand von Tags.
- Sicherheit auf Zeilenebene: Filtern von Daten für bestimmte Objekte, um nur relevante Zeilen basierend auf Benutzerattributen anzuzeigen.
- Dynamische Datenmaskierung: Maskieren Sie bestimmte Daten (basierend auf Tags) am Zugriffspunkt dynamisch, ohne die zugrunde liegenden Daten zu ändern. Dadurch wird sichergestellt, dass vertrauliche Informationen geschützt sind und dennoch ein breites Dienstprogramm ermöglicht wird. Dies gilt für Maskierungsfelder in strukturierten Daten sowie für Inhalte in unstrukturierten Daten.
- Konsistente Durchsetzung: Das gesamte ABAC-Framework gewährleistet die konsistente Durchsetzung von Richtlinien in allen Data 360-Verbrauchsmustern, unabhängig davon, ob es sich um Direktdatenabfragen, Abrufe für Anwendungen der generativen AI (RAG) oder die Anreicherung von Salesforce CRM-Erfahrungen über beispielsweise Themenlisten handelt.
- Tiefe Integration in Salesforce Platform: Die Governance-Funktionen von Data 360 werden direkt in der Salesforce Core Platform definiert und verwaltet. Diese Integration ermöglicht es Administratoren, Zugriffsrichtlinien, Benutzeridentitäten und die Attributverwaltung mit vertrauten Salesforce-Tools zu verwalten und so eine einheitliche und konsistente Governance-Ebene im gesamten Salesforce-Ökosystem zu gewährleisten.
Durch die Entwicklung dieses komplexen ABAC-Frameworks mit CEDAR-Richtlinien bietet Data 360 Architekten ein unvergleichliches Maß an Kontrolle und Flexibilität und stellt sicher, dass Kundendaten nicht nur handlungsrelevant, sondern auch unternehmensweit sicher, konform und vertrauenswürdig sind.
Branchenübergreifend legen Organisationen verstärkt Wert auf durchgängige Datensicherheit, um den Schutz vor Datenlecks, unbefugtem Zugriff, Manipulationen oder Zerstörung zu gewährleisten. Die meisten Datenplattformen, einschließlich Data 360, bieten Verschlüsselung im Leerlauf mit einem vom Anbieter verwalteten Verschlüsselungsschlüssel. Unternehmen (insbesondere Unternehmen in regulierten Sektoren) verlangen jedoch zunehmend von Kunden verwaltete Verschlüsselungsfunktionen für Daten im Leerlauf und bei der Übertragung.
Mit diesem Modell können Unternehmen ihre eigenen Verschlüsselungsschlüssel steuern und so sicherstellen, dass die Daten auch im höchst unwahrscheinlichen Fall eines Verstoßes auf Plattformebene oder unbefugten Zugriffs kryptographisch geschützt bleiben. Ohne den proprietären Schlüssel des Kunden kann keine Einheit (einschließlich des Plattformanbieters) die Daten entschlüsseln oder rekonstruieren, wodurch die vollständige Vertraulichkeit und Kontrolle gewahrt bleibt.
Data 360 unterstützt die Speicherung und Verwaltung von strukturierten (Tabellen), halbstrukturierten (JSON) und unstrukturierten Daten nahtlos über die Mechanismen der Datenaufnahme, -verarbeitung, -indizierung und -abfrage hinweg. Data 360 unterstützt verschiedene unstrukturierte Datentypen über Text hinaus, einschließlich Audio, Video und Bildern, was den Umfang der Datenverarbeitung und -analyse erweitert. Die folgende Abbildung veranschaulicht die beiden Seiten der Erdung (Aufnahme und Abruf).
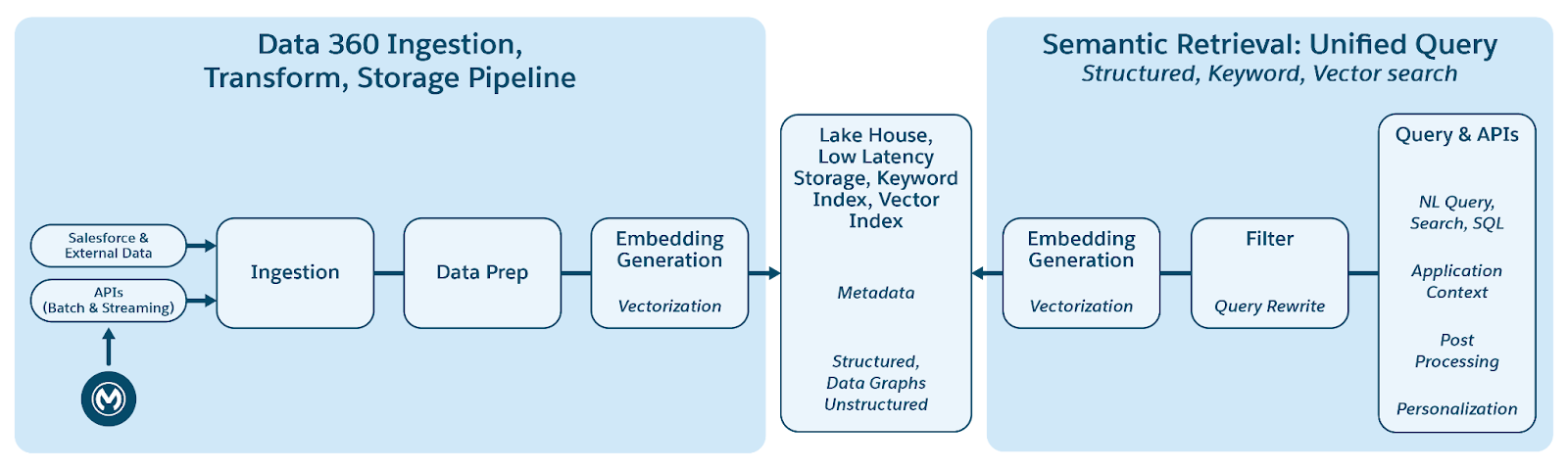
Data 360 verwaltet unstrukturierte Daten, indem es sie in Spalten als Text oder in Dateien für größere Datensets speichert. Sie unterstützt die Datenzuordnung für unstrukturierte Inhalte, wodurch Daten aus mehreren Quellen integriert und verwaltet werden können.
Anschließend werden die Daten vorbereitet und in Gruppen unterteilt, Einbettungen generiert und für die Stichwortindizierung und Vektorindizierung verarbeitet. Data 360 hostet mehrere vorkonfigurierte und steckbare Modelle für die Chunking- und Einbettungsgenerierung. Data 360 unterstützt die automatisierte und konfigurierbare Abschrift von Audio- und Videoinhalten für die nachfolgende Verarbeitung und Indizierung. Der Suchservice wird für die Stichwortindizierung verwendet. Bei der Vektorindizierung unterstützt Data 360 sowohl die native Indizierung (mit Hyper) als auch Vektordatenbanken wie Open-Source-Milvus. Data 360 kann auch in die Salesforce Search-Plattform integriert werden, um die Stichwortindizierung für unstrukturierte Daten zu unterstützen. Diese integrierte multimodale Indizierung in Data 360 ermöglicht die Suche nach unstrukturierten Daten, wie im Abschnitt "Agentische Unternehmenssuche" weiter unten im Dokument erläutert.
Zum Abrufen stellt Data 360 APIs für die Suche bereit. Unsere hyperbasierte zusammengeführte Abfrage erleichtert Ensembleabfragen über strukturierte, Stichwortindex- und Vektorindizes hinweg und behält strenge Sichtbarkeit und Berechtigungen bei, wodurch RAG und Suche verbessert werden.
Die unstrukturierte Datenindizierungs-Pipeline von Data 360 ist als modulare, erweiterbare Architektur mit fünf Kernphasen konzipiert:
- Analysieren
- Vorverarbeitung
- Chunking
- Nachbearbeitung
- Einbetten
Alle Phasen unterstützen auch die LLM-basierte Verarbeitung, wodurch Kunden benutzerdefinierte Eingabeaufforderungen erstellen können. Sowohl die Vor- als auch die Nachbearbeitungsphase können mehrere sequenzielle Schritte umfassen, sodass komplexe Transformationen flexibel zusammengestellt werden können. Jede Phase ist vollständig metadatengesteuert und ermöglicht eine nahtlose Konfiguration und Erweiterung ohne Codeänderungen.
Beispiele für die Vorverarbeitung sind Vorgänge wie Rauschentfernung, Sprachnormalisierung und Bildverständnis (optische Zeichenerkennung und Bildunterschrift), während Phasen nach der Verarbeitung Metadatenanreicherung, semantische Gruppierung oder erweiterte Techniken wie Raptor-Blockierung umfassen können.
Die Data 360 Code Extension wird von der Pipeline vollständig unterstützt, sodass Kunden und interne Teams in jeder Phase benutzerdefinierte Logik einbinden können. Bei den Codeerweiterungskomponenten handelt es sich um leichte Python-Funktionen, deren Lebenszyklus – Ausführung, Skalierung und Fehlerverarbeitung – vollständig von Data 360 verwaltet wird. Durch diesen Ansatz wird sichergestellt, dass Innovationen und domänenspezifische Verarbeitungen schnell eingeführt werden können, während gleichzeitig die betriebliche Konsistenz und Governance auf der gesamten Plattform gewahrt bleibt.
Kontextindizierung
Für die Einrichtung von RAG mit unstrukturierter Verarbeitung sind zwei wichtige Faktoren entscheidend:
- Schnelle Iteration: Die Möglichkeit, schnell mit Beispieltestabfragen zu validieren.
- Personenspezifische Inhalte: Die Fähigkeit, Inhalte zu konfigurieren, die auf die verbrauchende Persona zugeschnitten sind.
Bei der Kontextindizierung handelt es sich um ein benutzerfreundliches Tool, das beide Aspekte berücksichtigen soll. Diese interaktive Benutzeroberfläche wird von einer Echtzeit-Pipeline unterstützt, die alle fünf zuvor beschriebenen Phasen ausführt. Die Pipeline verwendet bei Bedarf GPUs für Aufgaben wie die Generierung von Einbettungen und die optische Zeichenerkennung. Darüber hinaus können Kunden die RAG-Pipeline schnell mit einem Agenten testen, bevor sie die Konfiguration für die umfassende Inhaltsverarbeitung bereitstellen.
Dokument-AI
Mit der Data 360-Dokumenten-AI können unstrukturierte oder halbstrukturierte Daten aus Dokumenten wie Rechnungen, Lebensläufen, Laborberichten und Bestellungen gelesen und importiert werden. Diese Funktion unterstützt die interaktive Ad-hoc-Verarbeitung sowie die Verarbeitung per Massenvorgang. Dies ist eine Schlüsselfunktion, die die Automatisierung von Geschäftsprozessen für unsere Kunden ermöglicht. Dies wird durch künstliche Intelligenz unterstützt, einschließlich LLMs und ML-Modellen.
Unternehmen verfügen über umfangreiche Knowledge-Mengen, die über verschiedene Systeme wie Wikis, Dateifreigaben, Inhaltsverwaltungssysteme, interne Datenbanken und mehr verteilt sind. Diese Fragmentierung erschwert es Mitarbeitern (insbesondere Serviceagenten und Vertriebsmitarbeitern) und Kunden, relevante Informationen schnell und effizient zu finden. Zu den wichtigsten Problemen zählen: Fehlende einheitliche Sucherfahrung in allen Knowledge Quellen, inkonsistente Darstellung und Darstellung von Inhalten aus unterschiedlichen Quellen, mangelnde Zugriffssteuerung auf sensible Informationen, die über mehrere Systeme verstreut sind, und Schwierigkeiten bei der Nutzung der Quelle "Autoritative Knowledge" in zentralen Geschäfts-Workflows (z. B. beim Anhängen relevanter Artikel an einen Kundenvorgang).
Enterprise Knowledge stellt Inhalte dar, die manuell oder automatisch aus dem größeren Pool an Unternehmensdaten zusammengestellt wurden. Bei der manuellen Pflege handelt es sich um gezielte Aktionen wie das Erstellen von Salesforce Knowledge-Artikeln oder das Entwickeln von Knowledge in externen Systemen, die dann aufgenommen werden. Es wird eine automatisierte Kuratierung ins Auge gefasst, die Prozesse wie Salesforce-Agenten und -Transformationen verwendet, die über aufgenommene Daten ausgeführt werden, um raffinierte, zusammengestellte Ebenen zu generieren, die möglicherweise strukturierte und unstrukturierte Inhalte mischen. Unabhängig davon, ob sie manuell oder automatisch, intern in Salesforce oder extern vor der Aufnahme erstellt werden, ergibt sich ein Mehrwertinhalt, der sich von Rohdaten unterscheidet.
Die Enterprise Knowledge Hub-Lösung nutzt Data 360-Funktionen für Folgendes:
- Aufnahme und Speicherung: Der CRM-Konnektor erfasst Salesforce Knowledge-Artikel und nicht strukturierte Konnektoren des Datenkonnektor-Frameworks (DCF) Rohinhalte und Metadaten aus externen Quellen. Der Inhalt wird in quellspezifische unstrukturierte Data-Lake-Objekte (UDLOs) aufgenommen, die dem Inhalt auf SFDrive zugeordnet sind (oder im Falle einer Nullkopie in die Quelle).
- Harmonisierung und Strukturierung: Die Harmonisierung verarbeitet UDLO- und Dateidaten, führt Bereinigungen, Normalisierungen, Anreicherungen (NLP usw.), Maskierungen und Transformationen der personenbezogenen Daten in das harmonisierte Zwischenformat durch, das in SF Drive gespeichert ist, und ein harmonisiertes UDLO (HUDLO), das ihm zugeordnet ist.
- Indizierung: Unstrukturierte Pipeline (UDS) wird über den harmonisierten Inhalt ausgelöst und Suchindizes werden für jedes HUDMO konfiguriert.
- Verbrauch: Verbrauchende Anwendungen umfassen Suchen, Abrufen, Rendern und Verknüpfen mit Geschäftsobjekten wie "Kundenvorgang". Interaktion durch Nutzung von Anwendungen wird gesammelt, um Nutzungsanalysen (wie Klicks, Bewertungen usw.) bereitzustellen.
Mit berechneten Statistiken in Data 360 können Kunden aggregierte Kennzahlen aus ihren Daten definieren und generieren. Diese Kennzahlen werden dann für eine zeitnahe Kundeninteraktion, Analyse, Segmentierung und Aktivierung verwendet. Die von CIs berechneten aggregierten Daten werden in Lakehouse geschrieben und als Objekt für berechnete Statistiken (CIO) dargestellt.
Es gibt zwei Haupttypen berechneter Statistiken:
- Batch-Berechnete Statistiken: Konzipiert für die komplexe Datenaggregation mit hohem Volumen, bei der Kennzahlen regelmäßig (z. B. täglich oder wöchentlich) berechnet werden können.
- Streaming-Statistiken: Bieten Sie die Möglichkeit, Kennzahlen und Aktionen anhand von Echtzeit-Ereignisdaten zu generieren und so ein sofortiges Kundenengagement mit geringer Latenz zu ermöglichen.
Berechnete Statistiken werden für Datenmodellobjekte (DMOs) definiert und können auch für andere Objekte der berechneten Statistik definiert werden. Der Service für berechnete Statistiken verwaltet die Orchestrierung von Batch- und Streamingaufträgen.
Berechnungen für Batch- und Streaming-Statistiken verwenden Spark. Der Hauptunterschied besteht darin, dass Streaming-Statistiken Spark Structured Streaming verwenden, während Batch-CIs mit regelmäßigen geplanten Spark-Batchaufträgen ausgeführt werden. Aus Kostengründen gruppiert der Service für berechnete Statistiken CIs, die zusammen im selben Batch-CI-Auftrag oder Streaming-CI-Auftrag berechnet werden sollen, basierend auf Faktoren wie Abhängigkeiten und Überschneidungen von Quelldatenobjekten.
SNCE und CDF spielen bei der Berechnung von Streaming-Statistiken eine wichtige Rolle.
Die Identitätsbestimmung ist für die Umwandlung unterschiedlicher Daten aus mehreren Quellen in ein einzelnes, umfassendes zusammengeführtes Profil verantwortlich.
Es ist wichtig zu verstehen, dass ein zusammengeführtes Profil kein "goldener Datensatz" ist und dass die Identitätsbestimmung beim Zusammenführen von Profilen keine Gewinnerwerte auswählt oder vorhandene Daten außer Kraft setzt. Vereinheitlichte Profile dienen als Schlüsselsatz, der Ihre Quelldaten entsperrt, indem alle übereinstimmenden Datensätze identifiziert werden, die sich auf dieselbe Einheit beziehen, in einer Datenquelle oder in vielen Quellen. Mit diesen Informationen können Sie die richtigen Quellsystemdaten für einen bestimmten Geschäftsanwendungsfall auswählen.
Die Identitätsbestimmung kann eine Vielzahl von Datensatztypen konsolidieren, darunter Einzelpersonen, Accounts und Haushalte. Sie kann auch verwendet werden, um Leads vorhandenen Accounts zuzuordnen. Der Vereinheitlichungsprozess ist wichtig, um eine vollständige Customer 360-Ansicht zu erhalten und das personalisierte Engagement in Echtzeit in B2C- und B2B-Szenarien zu fördern.
Die Identitätsbestimmungs-Pipeline basiert auf einem hochgradig skalierbaren, Cloud-nativen Framework, das für die kontinuierliche Verarbeitung großer Datenmengen konzipiert ist. Der Abgleichsprozess besteht aus drei wichtigen Phasen und basiert auf einem leistungsstarken Suchindex:
- Abgleich (Kandidatenauswahl): Das Ziel des Abgleichsprozesses besteht darin, nach Datensätzen zu suchen, die möglicherweise zur selben Einheit gehören. Datensätze werden anhand eines anpassbaren Satzes von Regeln analysiert, von denen jede eine Reihe von Kriterien enthält, die definieren, welche Daten mit welcher Strengestufe abgeglichen werden sollen. Um potenzielle Übereinstimmungen effizient aus dem Datenspeicher abzurufen, generiert das System Indizes, um wahrscheinlich übereinstimmende Datensätze mithilfe von zwei Techniken zu finden:
- Blockieren von Schlüsseln: Ein Sperrschlüssel ist ein Wert, der aus den Daten eines Datensatzes generiert wird und Regeln (wie die ersten Buchstaben eines Namens, eine normalisierte Telefonnummer usw.) abgleicht, um potenziell ähnliche Datensätze zu gruppieren. Jeder Datensatz verfügt über mehrere Sperrschlüssel, die indiziert und als invertierter Index gespeichert werden. Dadurch wird sichergestellt, dass das System nur detaillierte Vergleiche für kleine Gruppen von Datensätzen durchführt und nicht für das gesamte Datenset.
- Locality Sensitive Hashing (LSH): Bei Abgleichsregeln mit Fuzzyübereinstimmungen werden Hashes anhand von Einbettungen aus trainierten Modellen generiert.
- Deep Matching: Nachdem der Schritt der Kandidatenauswahl kleinere Gruppen potenzieller Übereinstimmungen erstellt hat, beginnt das System mit einem detaillierteren Vergleich. In dieser Phase analysieren AI-Modelle und erweiterte Algorithmen jedes Datensatzpaar, um eine probabilistische Übereinstimmungsbewertung zu berechnen. Diese Bewertung quantifiziert die Wahrscheinlichkeit, dass sich zwei Datensätze auf dieselbe Einheit beziehen, indem Felder, die häufig Schreibfehler, Variationen oder Formatierungsunterschiede enthalten, intelligent verglichen werden.
- Clustering und Zusammenführung: Sobald übereinstimmende Datensätze anhand der Kandidaten identifiziert wurden, werden sie in einem Cluster gruppiert. Dieser Prozess beinhaltet die Lösung transitiver Übereinstimmungen. Wenn beispielsweise Datensatz A mit Datensatz B übereinstimmt und Datensatz B mit Datensatz C übereinstimmt, werden alle drei mit demselben Cluster verknüpft, selbst wenn A und C nie direkt verglichen wurden. Diese vollständigen Cluster bilden die grundlegende Struktur des zusammengeführten Profils. Durch diesen Clustering-Prozess wird sichergestellt, dass alle zugehörigen Quelldatensätze unter einem einzigen persistenten Kennzeichner richtig verknüpft sind.
- Abstimmung: Datenwerte aus allen geclusterten Quelldatensätzen werden mithilfe definierter Schlichtungsregeln (z. B. Häufigste, Aktuellste oder Quellpriorität) ausgewertet, sodass das resultierende zusammengeführte Profil mit einem Auszug der Profildaten ausgefüllt wird. Bei der Schlichtung werden keine vorhandenen Daten überschrieben, da alle Quelldaten mithilfe der mit dem zusammengeführten Profil verknüpften Schlüssel verfügbar sind.
Die Architektur unterstützt die Auflösung mehrerer Einheitentypen, um eine Vielzahl von Anwendungsfällen zu erfüllen.
- Individueller Abgleich: Konzentriert sich auf die Erstellung der Profile "Zusammengeführte Einzelperson", die alle bekannten persönlichen Kennzeichner (E-Mails, Telefonnummern, Treue-IDs, Cookies) mit einer einzelnen Person verknüpfen.
- Accountabgleich: Konzentriert sich auf die Erstellung der Profile für zusammengeführte Accounts, die Daten zu Accounts verknüpfen. Beim Abgleich von Unternehmensnamen verwendet das Modul beim Fuzzyabgleich ein genau abgestimmtes Modell.
- Haushaltsabgleich: Erweitert die Abgleichslogik, um Datensätze vom Typ "Zusammengeführte Einzelperson" zu Gruppen verwandter Einzelpersonen zu aggregieren.
- Einheitenübergreifender Abgleich: Abgesehen von der Vereinheitlichung erstellt die Identitätsbestimmung auch Links zwischen Profilobjekten mithilfe derselben Abgleichsregeln. Beispielsweise kann ein Lead mithilfe des Fuzzyabgleichs für "Accountname" mit einem Account verknüpft werden.
Damit das zusammengeführte Profil immer aktuell ist, arbeitet das Identitätsbestimmungsmodul mit einer Architektur nahezu in Echtzeit. Diese Cloud-optimierte Architektur wurde für die kontinuierliche Verarbeitung entwickelt, um schnelle Verarbeitungszeiten zu erzielen. Die Verarbeitungsgeschwindigkeit variiert je nachdem, wie Quelldaten empfangen werden. Kleine Batches von Änderungen können jedoch bis zu 15 Minuten lang durch Identitätsbestimmung verarbeitet werden.
Das System verwaltet Identitätslinkobjekte, die jede Quelldatensatz-ID der entsprechenden ID des zusammengeführten Profils zuordnen. Diese grundlegende Datenstruktur ermöglicht es dem Modul, Beziehungen effizient zu verfolgen und Änderungen und Aktualisierungen am zusammengeführten Profil schnell zu übernehmen. So wird sichergestellt, dass Kundenerfahrungen wie die Website-Personalisierung, Next-Best-Action-Empfehlungen und die Segmentierung immer die neuesten verfügbaren Kundendaten nutzen.
Die Segmentierung ist der Kernprozess der Umwandlung von zusammengeführten Kundenprofilen in handlungsrelevante Zielgruppen. Diese Funktion ist entscheidend für die Unterstützung personalisierter Erfahrungen in Marketing-, Commerce- und Servicekanälen. Die Salesforce Data 360-Segmentierungsplattform ist für umfangreiche Vorgänge konzipiert. Sie verwaltet komplexe Metadaten und arbeitet mit einem Datenmodell, das Tausende von Objekten und Beziehungen umfasst. Die Plattform unterstützt komplexe Regeln, aggregationsbasierte Filter und fensterbasierte Rangfolge und gewährleistet gleichzeitig eine schnelle und zuverlässige Berechnung im Petabyte-Bereich.
Data 360 unterstützt verschiedene Segmenttypen, um unterschiedliche Geschäftsanforderungen an Geschwindigkeit, Komplexität und Hierarchie zu erfüllen:
- Standardsegment: Der primäre, im Batch verarbeitete Segmenttyp. Die Veröffentlichung erfolgt nach einem anpassbaren Zeitplan mit einem Standardveröffentlichungsrhythmus von mindestens 12 Stunden bis zu 24 Stunden oder einem schnelleren Schnellveröffentlichungsrhythmus von 1 bis 4 Stunden, der für aktuelle Engagementdaten optimiert ist.
- Echtzeitsegment: Dieses Segment wird basierend auf aktuellen Ereignissen und Profildaten nach Bedarf in Millisekunden für sofortige Maßnahmen abgeschlossen. Sie ist hochgradig für die sofortige Personalisierung optimiert, kann jedoch keine Ausschlusskriterien oder verschachtelten Segmente verwenden.
- Wasserfallsegment: Eine hierarchische Struktur von Untersegmenten, die verwendet wird, um einen Kunden in ein einzelnes, wertvollstes Segment zu priorisieren, wenn er mehrere Kriterien erfüllt.
- Geschachteltes Segment: Dies ermöglicht die Wiederverwendung eines vorhandenen Segments als Filter für ein neues, spezifischeres Segment (eine Verfeinerung eines Basissegments), wobei der Zeitplan des übergeordneten Segments übernommen wird.
Das Segmentierungsmodul arbeitet auf einer robusten, Cloud-nativen Architektur, die Geschwindigkeit, Skalierbarkeit und Widerstandsfähigkeit gewährleistet.
Der Kernprozess wird durch einen Service zur Auftragsorchestrierung verwaltet, der den Lebenszyklus des Segments steuert, die erforderliche Auftragskonfiguration generiert und die Ausführung auslöst. Diese Orchestrierungsebene bewahrt Status- und Metadaten in einer freigegebenen Datenbank auf, um die Skalierbarkeit zu gewährleisten.
Obwohl die Data 360-Abfrage Segmentierungsanzahlberechnungen verarbeitet, ist die Spark-Berechnungsebene für die Berechnung der tatsächlichen Segmentmitgliedschaft verantwortlich. Die Spark-Anwendung führt Spark SQL-Abfragen für umfangreiche Kundendaten aus. Diese Daten können sich im Data 360-Lakehouse, in externen Systemen über die Zero Copy-Datenverbundorganisation oder in einer Kombination aus beidem befinden.
Das System wurde durch die intelligente Abfragegenerierung, die die zugrunde liegende Spark SQL-Abfrage optimiert, stark optimiert. Dazu zählen Techniken wie der intelligente Partitionsschnitt, um das Scannen von Daten zu minimieren und redundante Teilausdrücke zu vermeiden. Zum Sicherstellen der Servicezuverlässigkeit verfügt die Architektur über eine adaptive Ressourcenverwaltung, die Rechenressourcen dynamisch an die Arbeitslastgröße und -komplexität anpasst. Darüber hinaus wird die SLO-Einhaltung proaktiv mit adaptiven Dauern und Wiederholungslogik verwaltet. Für eine schnelle Benutzererfahrung verwenden beschleunigte Segmentzählungen einen Stichproben-basierten Ansatz, um während der Segmenterstellung schnelle Größenschätzungen bereitzustellen und so eine vollständige Abfrageausführung zu vermeiden.
Schließlich wird der Fokus auf die Beobachtbarkeit und die Ursachenzuordnung durch umfassende Spark-Ausführungskennzahlen und die automatisierte Klassifizierung von Fehlern (z. B. kundenseitige und Systemprobleme) aufrechterhalten, wodurch die Diagnosezeit erheblich reduziert und eine hochgradig widerstandsfähige Datenplattform gewährleistet wird.
Die Aktivierung ist der entscheidende letzte Schritt im Data 360-Lebenszyklus. Ihre Kernfunktion besteht darin, statische, segmentierte, zusammengeführte Kundenprofile in handlungsrelevante und angereicherte Daten umzuwandeln und diese Daten an interne und externe Endpunkte (z. B. Marketing Cloud, Commerce Cloud und Adtech-Plattformen) bereitzustellen. Dieser Prozess soll personalisierte Kunden-Journeys und Interaktionen nahezu in Echtzeit auslösen. Sie unterstützt erweiterte Funktionen wie zugehörige Attribute, Filterung der Aktivierungsmitgliedschaft, Einwilligungsfilterung, Begrenzung und Rangfolge.
Die Aktivierung bietet drei unterschiedliche Methoden für die externe Zustellung und die Kanal-Compliance:
- Batch-Aktivierung: Konzipiert für geplante Vorgänge mit hohem Volumen, beispielsweise große E-Mail-Kampagnen und Werbezielgruppenaktualisierungen. Die Daten werden durch Staging in Secure Internal Buckets (Cloud Object Storage) oder über die sichere Dateiübertragung bereitgestellt, gefolgt von einem API-Aufnahmeprozess, der vom Zielsystem initiiert wurde. Bei Batch-Aktivierungen kann ein spezieller Aktualisierungsmodus – inkrementell – verwendet werden, um die an Salesforce-Partner gesendeten und von ihnen verarbeiteten Mengen zu reduzieren.
- Streaming-Aktivierung: Optimiert für Anwendungsfälle nahezu in Echtzeit, die eine ereignisgesteuerte Automatisierung erfordern. Die Zustellung erfolgt über direkte API-Aufrufe, die an den Zielendpunkt gesendet werden.
- Durch Aktivierung ausgelöste Flows: Dieser hochgradig plattformbasierte Kanal bietet einen No-Code/Low-Code-Ansatz für die Integration von Zielgruppendaten in Hunderte von API-fähigen Engagementplattformen für Kunden. Nach Abschluss der Aktivierung füllt Data 360 ein Zielgruppen-DMO aus, das dann einen Flow mit hohem Umfang auslöst. Das Flow-Modul verwendet anschließend die Zielgruppendaten und Plattformfunktionen wie externe Services und Mule Outbound-Ziele, um Aufrufe an das endgültige API-basierte Ziel zu senden. Durch diese Methode wird die für die Einarbeitung neuer Aktivierungsziele benötigte Zeit erheblich reduziert.
Die Aktivierung verwendet dieselben Muster wie die Segmentierung für die Auftragsverwaltung, die verteilte Ausführung und die Überwachung. Dies beinhaltet die Prinzipien des Auftragsorchestrierungsservice für die Lebenszyklusverwaltung und die Rechenebene (Spark) für die Verarbeitung und basiert auf der Auftragstelemetrie für die Beobachtbarkeit der Leistung und die Einhaltung von Service Level Objective (SLO).
Zusätzlich dazu verfügt die Aktivierung über:
Die Aktivierungszielverwaltung überwacht die sicheren Verbindungen, Anmeldeinformationen und Konfigurationen für alle Zielendpunkte. Sie garantiert, dass Datenformate und Sicherheitsprotokolle standardisiert sind, um eine zuverlässige ausgehende Zustellung an verschiedene Plattformen, einschließlich Marketing Cloud, Adtech-Partnern und anderen externen Anwendungen, zu gewährleisten.
Die Aktivierung passt die Nutzlast für bestimmte Ziele an. Für Salesforce Marketing Cloud umfasst dies die bewusste Filterung der Geschäftseinheit (Business Unit, BU), die Unterstützung mehrerer IDs und Steuerelemente für die Kreuzbestäubung.
Die Kommunikationsverwaltung fungiert als Gatekeeper und stellt sicher, dass die Datennutzung und -kommunikation den Kundenpräferenzen und gesetzlichen Anforderungen entspricht. Das zentralisierte Einwilligungsmodell vereinheitlicht alle Kundenpräferenzen – von der globalen Abmeldung bis hin zur kanal- und zweckspezifischen Einwilligung – und wird im Profil der zusammengeführten Einzelperson gespeichert. Während der Ausführung erzwingt die Plattform diese Richtlinien streng, indem sie Ausschlussfilter verwendet, um nicht zustimmende Einzelpersonen automatisch aus der endgültigen Nutzlast zu entfernen. Darüber hinaus wendet das System Kontaktpunkt-Auswahlregeln an, um sicherzustellen, dass der einzelne, konformeste und bevorzugte Kontaktpunkt für den vorgesehenen Kanal verwendet wird, bevor Daten übertragen werden. Dieser Erzwingungsmechanismus wird durch das zugrunde liegende Governance-Framework geschützt, das Schutzmaßnahmen wie dynamische Datenmaskierung und Zugriffssteuerungen verwendet, um sensible Datenfelder während des Aktivierungsprozesses zu schützen.
Der wahre Wert einer vereinheitlichten Datenplattform liegt in ihrer Fähigkeit, mühelosen, konsistenten Zugriff auf alle ihre Datenbestände zu bieten, unabhängig von ihrer Herkunft oder Struktur. Die Funktion "Zusammengeführte Abfrage" von Salesforce Data 360 wurde genau dafür entwickelt, die zugrunde liegenden Komplexitäten verschiedener Datenspeicher zu abstrahieren und so eine einzige leistungsstarke Abfrageoberfläche bereitzustellen.
Die Ebene "Zusammengeführte Abfrage" bietet einen komplexen Zugriff auf verschiedene Verbrauchsmuster:
- Hybridstrukturierte und unstrukturierte Abfrage: Sie bietet umfassende SQL-Unterstützung, um strukturierte Daten und die strukturierten Metadaten unstrukturierter Daten nahtlos abzufragen. Dies wird durch die Erweiterbarkeit des Operators über Tabellenfunktionen verbessert, wodurch eine spezielle Suche über Text-, Bild- und räumliche Typen hinweg ermöglicht wird.
- Beschleunigte Leistung mit Hyper: Data 360 nutzt Hyper, ein leistungsstarkes Modul im Arbeitsspeicher, um komplexe analytische Abfragen und interaktive Dashboards zu beschleunigen und nahezu sofortige Antworten auf massive Datensets bereitzustellen.
- Einheitlicher Ansatz für AI und Personalisierung: Dieser vereinheitlichte Zugriff ist entscheidend für die Generierung zielgerichteter und personalisierter Ergebnisse, wodurch präzisere LLM-Antworten mithilfe der erweiterten Abrufgenerierung (Retrieval Augmented Generation, RAG) direkt ermöglicht werden, indem AI-Modelle auf umfangreichen Unternehmensdaten basieren.
- Integration in nachgelagerten Verbrauch: Sie dient als grundlegende Datenzugriffsebene für benutzeroberflächengesteuerte Erfahrungen, robuste APIs, Workflows mit generativer AI und CRM-Anreicherung und verbindet Daten nahtlos mit der Aktivierung.
Durch die Bereitstellung einer einzigen, intelligenten und hochleistungsfähigen Abfrageoberfläche können Architekten mit der einheitlichen Abfrage von Data 360 agile, datengestützte Anwendungen erstellen, die ihr gesamtes Spektrum an Kundeninformationen vollständig nutzen.
Data 360 ist eine aktive Plattform, die die Aktivierung von Pipelines als Reaktion auf Datenereignisse unterstützt. Beispielsweise kann ein wichtiges Ereignis, beispielsweise ein Rückgang des Accountsaldos eines Kunden, einen Salesforce-Flow auslösen, um eine entsprechende Aktion zu orchestrieren. Ebenso können Aktualisierungen an wichtigen Kennzahlen wie Lebenszeitausgaben automatisch in relevante Anwendungen übernommen werden.
Datenaktionen überwachen kontinuierlich inkrementelle Daten auf Änderungen mithilfe von nativen Speicheränderungsereignissen (SNCE) und Änderungsdatenfeeds (CDF). Diese Daten werden anhand von vom Kunden konfigurierten Aktionsregeln wie Schwellenwertüberwachung oder Statusänderungen ausgewertet. Wenn diese Regeln erfüllt sind, wird ein Datenaktionsereignis generiert. Dieses Ereignis wird mit zusätzlichen Informationen (z. B. Kundentreuestatus) angereichert und sofort an sein konfiguriertes Ziel gesendet, beispielsweise Salesforce-Flow oder eine externe Anwendung, um Geschäftsorchestrierungen auszulösen.
Data 360 unterstützt native CDP-Funktionen (Customer Data Platform), einschließlich erweiterter Identitätsbestimmungsfunktionen und der Erstellung von Kennzeichnern und Profilen für zusammengeführte Einzelpersonen sowie umfassender Interaktionsverläufe. Diese Plattform ist in der Handhabung von Business-to-Business-Frameworks (B2B) und Business-to-Consumer-Frameworks (B2C) durch die Unterstützung von Identitätsbestimmungs- und Identitätsdiagrammen, die sowohl exakte als auch Fuzzy-Abgleichsregeln verwenden, wie oben beschrieben, versiert. Diese Identitätsdiagramme werden mit Interaktionsdaten aus verschiedenen Kanälen angereichert, wodurch detaillierte Profildiagramme mit wertvollen analytischen Statistiken und Segmenten erstellt werden können.
Ein wichtiges Konzept, das das Kundenprofil unterstützt, ist das Datendiagramm. Data 360 bietet ein Unternehmensdatendiagramm im JSON-Format, bei dem es sich um ein denormalisiertes Objekt handelt, das aus verschiedenen Lakehouse-Tabellen und ihren Beziehungen abgeleitet wurde. Dies beinhaltet ein von CDP erstelltes "Profil"-Datendiagramm, das den Kauf- und Browserverlauf einer Person, den Kundenvorgangsverlauf, die Produktnutzung und andere berechnete Statistiken umfasst und von Kunden und Partnern erweitert werden kann. Diese Datendiagramme sind auf bestimmte Anwendungen zugeschnitten und verbessern die Genauigkeit der Eingabeaufforderungen mit generativer AI, indem sie relevanten Kunden- oder Benutzerkontext bereitstellen. Die Echtzeitebene von Data 360 verwendet das Profildiagramm für die Echtzeitpersonalisierung und -segmentierung. Die Modellierung von Agentforce Context umfasst Unterhaltungen, Sitzungen und Agentenspeicher als Datendiagramme.
Darüber hinaus ermöglicht das CDP eine effektive Segmentierung und Aktivierung auf verschiedenen Plattformen wie Marketing Cloud, Facebook und Google. Es verarbeitet Kundenprofile in Batch-, nahezu Echtzeit- und Echtzeit, was eine sofortige Entscheidungsfindung und Personalisierung ermöglicht. Diese Funktion verbessert die Interaktionen in B2C- und B2B-Szenarien und stellt sicher, dass Unternehmen schnell und genau auf Kundenanforderungen und -verhalten reagieren können.
Die Echtzeitebene von Data 360 wird durch das Data 360 CDP unterstützt und erweitert seine Konzepte für Echtzeitanwendungsfälle. Die Echtzeitebene von Data 360 wurde entwickelt, um Ereignisse wie Web- und mobile Clickstreams, Besuche, Einkaufswagendaten und Checkouts mit Latenzen von Millisekunden zu verarbeiten und so die Personalisierung der Kundenerfahrung zu verbessern. Sie überwacht kontinuierlich das Kundenengagement und aktualisiert das Kundenprofil aus Customer 360 mit Echtzeit-Interaktionsdaten, -Segmenten und -Berechnungen, um es sofort zu personalisieren.
Wenn ein Verbraucher beispielsweise einen Artikel auf einer Einkaufswebsite kauft, erkennt und erfasst die Echtzeitebene dieses Ereignis schnell, identifiziert den Verbraucher und reichert sein Profil mit aktualisierten Informationen zu Lebenszeitausgaben an. Dies ermöglicht die Personalisierung ihrer Erfahrung auf der Site in Sekundenschnelle. Darüber hinaus enthält diese Ebene Funktionen für Echtzeitauslöser und -antworten, die sofortige Aktionen basierend auf Kundeninteraktionen ermöglichen.
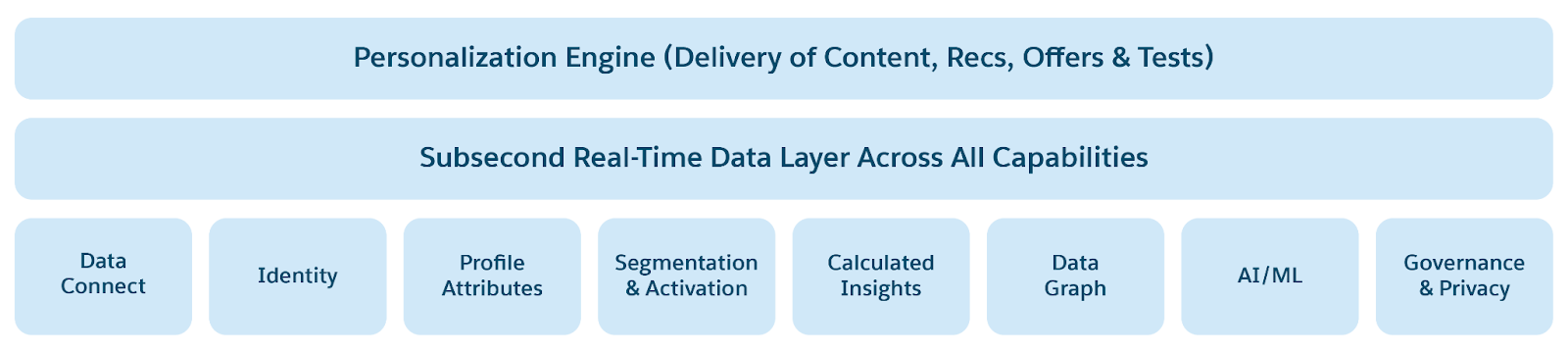
Die Sub-Second Real-Time Platform unterstützt diese Transformation durch mehrere wichtige Funktionen:
- Echtzeit-Datendiagramme: Ein Customer 360 Profil wird mithilfe eines denormalisierten Diagramms erstellt, das wichtige Objekte und Felder enthält, die für Marken am relevantesten sind. Diese Datendiagramme ermöglichen die Echtzeit-Datenverarbeitung und liefern handlungsrelevante Inhalte und Statistiken innerhalb von Millisekunden.
- Echtzeitaufnahme und -transformation: Erfassen Sie Benutzerereignisse und -profile in Millisekunden aus Web- und mobilen Quellen.
- Echtzeit-Identitätsbestimmung: Führen Sie Kundenprofile geräteübergreifend zusammen und vereinheitlichen Sie unbekannte und bekannte Benutzer sofort.
- Berechnete Statistiken in Echtzeit: Berechnen Sie Kennzahlen wie den Lebenszeitwert oder den Benutzerbesuchsverlauf in Millisekunden, um die Personalisierung oder Angebote für Web, ChatBot oder Serviceagenten zu aktivieren.
- Echtzeitsegmentierung: Segmentieren Sie Zielgruppen direkt und personalisieren Sie Nachrichten und Interaktionen in Echtzeit.
- Echtzeitaktionen: Geben Sie Marken die Möglichkeit, jedes Benutzerengagement auszuwerten und über den Salesforce-Flow oder andere relevante Kommunikationskanäle Maßnahmen zu ergreifen.
In Data 360 wurde eine neue Echtzeitplattform mit Echtzeit-Pipeline, Speicher mit geringer Latenz und einer Datenverarbeitungsebene im Sekundenbereich entwickelt. Da schnelle interaktive Daten aus Web- und mobilen Kanälen aufgenommen werden, durchlaufen sie eine Reihe schneller Prozesse.
Unsere Web- und Mobile-SDKs und Echtzeit-APIs erfassen Daten aus Web-/Mobilanwendungen (in künftigen Agenteninteraktionen) und senden sie an unseren Beacon-Server. Diese Daten werden dann zur Verarbeitung in Millisekunden an die Echtzeitebene und zur Integration in Batch-/Streaming-Daten an die Lakehouse-Ebene weitergeleitet. Die Echtzeitebene verarbeitet die eingehenden Echtzeitdaten im Kontext eines Benutzerprofils (anonym oder angemeldet), beispielsweise zur Aktualisierung der Gesamtausgaben oder des Lebenszeitwerts des Benutzers usw. für die Echtzeitpersonalisierung in der Sitzung. Die Echtzeitebene wird durch Arbeitsspeicher und NVme-Speicher (SSD) zum Speichern von Echtzeitdaten und Kundenprofilen unterstützt. Sobald sich die Daten in der Echtzeitebene befinden, durchlaufen sie die folgenden Prozesse, bevor sie in das Echtzeit-Datendiagramm aktualisiert werden:
- Einfache Aufnahme und Transformationen: Die Daten werden aufgenommen und zur weiteren Verarbeitung umgewandelt.
- Identitätsbestimmung: Genaue Abgleichsregeln werden angewendet, um Profile mit allen vorhandenen Abgleichsregelsätzen zu vereinheitlichen, sodass Spezialisten mit Datenbewusstsein keine neuen Regelsätze für die Identitätsbestimmung speziell für Echtzeit erstellen müssen.
- Berechnete Statistiken: Jedes Engagement wird ausgewertet, einfache Berechnungen wie Summe und Anzahl in Millisekunden werden ausgeführt und die Daten werden im Echtzeit-Datendiagramm aktualisiert.
- Echtzeitsegmente: Alle Interaktionsdaten werden ausgewertet, um festzustellen, ob sie die Kriterien für definierte Echtzeitsegmente erfüllen, und Benutzer werden in Millisekunden zu qualifizierenden Segmenten hinzugefügt.
- Echtzeitaktionen und -auslöser: Jedes Engagement wird anhand definierter Regeln ausgewertet, um Aktionen für eine Reihe von Zielen in Echtzeit auszulösen, wenn Regeln in Millisekunden erfüllt sind.
- Echtzeit-Datendiagramm und API: Mit dem Echtzeit-Datendiagramm, das auch eine Echtzeit-API enthält, können Marken aktualisierte Daten im JSON-Format für jeden Benutzer abrufen und so sicherstellen, dass alle Kundeninteraktionen durch die neuesten Daten informiert werden.
Bei der Personalisierung geht es darum, zu wissen, wer wann und wo relevante Inhalte und Empfehlungen bereitstellen soll, was zu sagen ist und wie häufig. Die Personalization Services Platform ist der Orchestrierer der Entscheidungen, die getroffen werden, um die Zielerreichung durch personalisierte Erfahrungen zu optimieren.
Die Personalisierungsservices bieten die folgenden Funktionen:
- Konsistenter Satz an Modellen und Möglichkeiten zur Interpretation von Profil-, Aktivitäts- und Vermögenswertdaten in Data 360
- Plattformintegrierte Experimente (A/B/n, Multi-Arm Bandit)
- Integration von Zielen zur Entwurfszeit (Konfiguration), zur ML-Trainingszeit und zur Laufzeit (ML-Rückschluss)
- Unterstützung von Echtzeit- und Batchinteraktionen im B2C-Bereich (anonyme Benutzer, Echtzeit mit hohem Volumen/interaktiver externer Batch mit hohem Volumen)
- Analytics wird durch Data 360 gesteuert
- Muster zur Integration von AI-Modell und Service von anderen Beteiligten (intern und extern)
- Integration in das zentrale Metadaten-Ökosystem (PLATE-Eigenschaften)
- OOTB-Implementierungen hochwertiger AI-gestützter Anwendungsfälle (Empfehlungen/Entscheidungen mit verschiedenen ML-Algorithmen einschließlich Kontextbanditen für Sonderangebote/Inhaltsauswahl, Produktempfehlungen, Preisentscheidungen usw.)
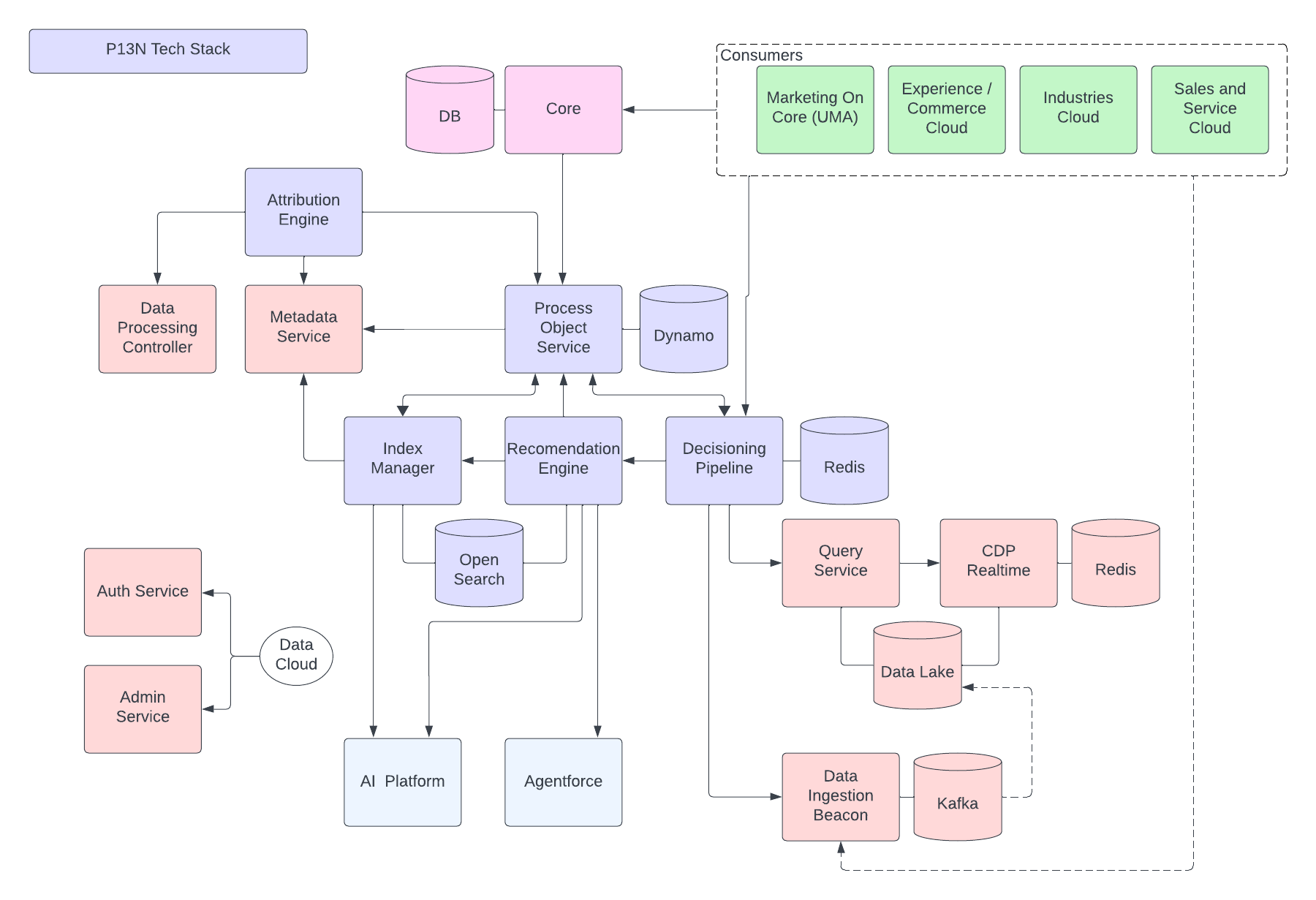
- Entscheidende Pipeline
- Erledigen externer Anforderungen für Personalisierungsentscheidungen, einschließlich Profilvergrößerung, Experimentieren und Empfehlungen.
- Empfehlungsmodul
- Laufzeitservice für regel- oder ML-basierte Empfehlungen.
- Index Manager
- Verwaltet/Orchestriert Workflow für asynchrone Prozesse, einschließlich ML-Schulungen für Empfehlungsmodelle
- Prozessobjektservice
- Verantwortlich für die Synchronisierung von Personalisierungsmetadaten zwischen Core und Off-Core
- Attributionsmodul und Experimente
- Analytics-Attribution und Experimentieren von Personalisierungsempfehlungen
Data 360 ist eine robuste und umfassende Plattform, die speziell für die Unterstützung der neuen Agentenerfahrungen entwickelt wurde. Diese Funktionen werden durch verschiedene vorhandene Data 360-Services und durch eine umfassende Integration in Agentforce erreicht.
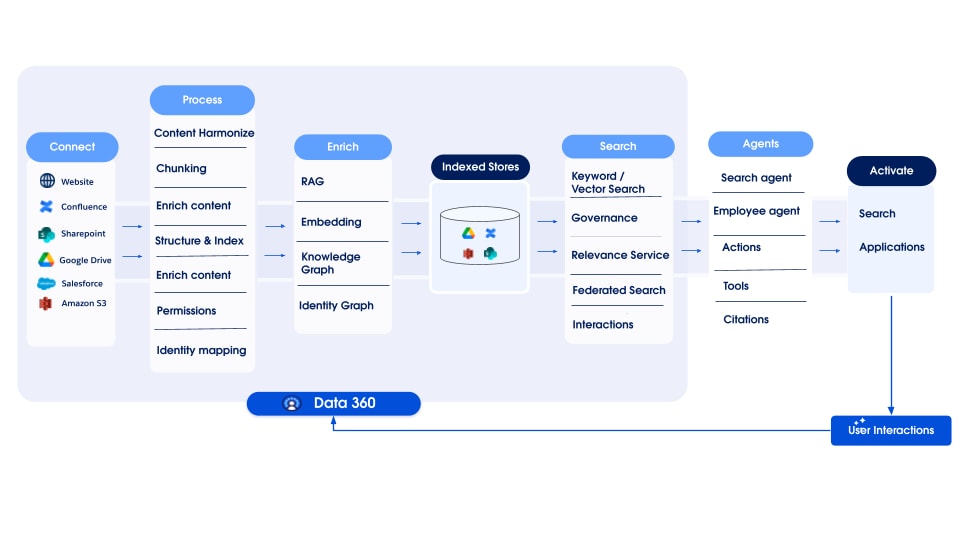
Unser Ansatz für die Agentenunternehmenssuche basiert auf den folgenden Prinzipien:
- Unternehmensdaten werden in isolierten Services oder Geschäften aufbewahrt, wobei sichere Berechtigungen für den Zugriff erforderlich sind. Die Möglichkeit, auf diese Daten zuzugreifen und sie zu verarbeiten, während gleichzeitig die Quellberechtigungen beibehalten werden, ist entscheidend, um Trust sicherzustellen.
- Die übergreifende Zuordnung und Relevanz über den gesamten Datenbestand hinweg ermöglichen bessere Ergebnisse, was wiederum einen besseren Kontext für Agentenerfahrungen bieten kann.
Zum Bereitstellen dieser Erfahrungen basiert die Agentenunternehmenssuche auf den folgenden wichtigen Architekturkomponenten:
- Konnektoren: Mit den in Data 360 verfügbaren Konnektoren können Sie auf Daten aus einer Vielzahl von Quellen zugreifen und sie aufnehmen.
- Unstrukturierte Datenverarbeitung: Dies ist die Grundlage für die Verarbeitung nicht tabellarischer Inhalte, sodass das System Bedeutung und Kontext aus verschiedenen Daten ableiten kann.
- Governance: Gewährleistung der Sicherheit, Compliance und Zugriffssteuerung für alle Daten, die von der Suche verbraucht werden. Die Unterstützung von Quellsichtbarkeitsberechtigungen stellt sicher, dass nur autorisierte Benutzer auf die Daten zugreifen können, sowohl für die einfache Suche als auch für Agentenerfahrungen. Damit ein schneller Abruf gewährleistet ist, werden Sicherheitsberechtigungen von den Such-Backends in der frühesten Phase des Datenzugriffs nativ ausgewertet und erzwungen.
- Zusammengeführte Abrufebene: Die Konnektoren werden in eine umfassende Ebene für den einheitlichen Abruf integriert, um die Herausforderung isolierter Daten zu bewältigen. Diese Ebene bietet einen einzigen Zugriffspunkt auf alle Daten, unabhängig davon, ob sie in externen Systemen verbleiben, auf die über die Verbundsuche zugegriffen wird, oder nativ über erweiterte Indizes für Nullkopie- und aufgenommene Daten verwaltet werden.
- Intelligentes Abfrageverständnis: Vor dem Abruf verwendet das System AI-gestützte Mechanismen zum Interpretieren des Benutzer-Intents. Zusätzlich zum Einbetten von Darstellungen der Abfrage für den semantischen Vektorabgleich können stichwortbasierte Suchen umgeschrieben und erweitert werden, um die Genauigkeit zu erhöhen.
- Hybridsuche und erweiterte Abfrage: Um die relevantesten Informationen zu finden, verwendet die Plattform mehrere Strategien parallel. Die Hybridsuche bietet einen präzisen Stichwortabgleich mit der semantischen Vektorsuche für optimierte Datenblöcke, während die Suche mit vollständigen Datensätzen gleichzeitig ganze Dokumente abruft. Beides wird kombiniert, um sowohl die semantische Relevanz als auch die vollständige Inhaltsabdeckung zu gewährleisten.
- Hierarchischer Rang: Nachdem Daten abgerufen wurden, bewertet, führt eine mehrstufige hierarchische Rangarchitektur die Ergebnisse aus jeder Quelle und Methode zusammen und ordnet sie neu an. Bei diesem Vorgang wird eine einzige, einheitliche Liste erstellt, die die relevantesten Informationen für den Benutzer oder Agenten anzeigt.
Die generative AI verschiebt den primären Verbraucher der Unternehmenssuche von menschlichen Benutzern zu großen Sprachmodellen (LLMs). Data 360 Search wurde von Grund auf für beides entwickelt. Sie ist optimiert, um die längeren, komplexeren Abfragen von Agenten zu verarbeiten und die umfangreichen kontextbezogenen Ergebnisse zurückzugeben, die für die programmgesteuerte Nutzung und Argumentationsschleifen erforderlich sind. Gleichzeitig kann das System die kürzeren, oft mehrdeutigen Abfragen verarbeiten, die für menschliche Benutzer typisch sind, und bietet Funktionen wie Auszüge und Hervorhebungen für eine schnelle Bewertung auf einer Benutzeroberfläche.
Die ultimative Bereitstellung von Agentensucherfahrungen kombiniert beide Ansätze:
- Ergebnisse der direkten Suche: Die Anwendung kann mithilfe einer metadatengesteuerten API, die auf der Grundlage der vereinheitlichten Data 360-Suche basiert, eine traditionelle Liste der Ergebnisse mit Rang anzeigen.
- Agentische Unterhaltungsantworten mit mehreren Umdrehungen: Agentenantworten werden durch native Integration in Agentforce implementiert. Diese Unterhaltungserfahrung wird von einem primären Agenten gesteuert, der Aktionen und Abfragen orchestriert und alle Informationen an einen spezialisierten internen Suchagenten delegiert.
Dieser spezialisierte Suchagent ist für den Abruf von Unternehmensinformationen optimiert. Sie verwendet eine Argumentationsschleife, um parallele Suchvorgänge zu formulieren und auszuführen, um verschiedene Bereiche der Anforderung eines Benutzers zu erkunden. Es verwendet eine Reihe leistungsstarker Tools, einschließlich der einheitlichen Data 360-Suche für alle Datentypen und strukturierter Abfragesprachen, um genaue Daten aus Tabellen und Einheiten abzurufen.
Durch diese architektonische Synthese ermöglicht Data 360 die Erstellung hochintelligenter, kontextbezogener und handlungsrelevanter Agentensucherfahrungen für Unternehmen.
Die Erweiterbarkeit ist eine wichtige Funktion in Salesforce Platform. Die Code-Erweiterung bietet Erweiterbarkeit in Data 360 und ermöglicht es Pro-Code-Benutzern, benutzerdefinierte Python-Logik direkt in der Data 360-Umgebung auszuführen, was die umfangreichen deklarativen und Low-Code-Funktionen ergänzt. Mithilfe der Codeerweiterung können Benutzer Data 360-Kernfunktionen wie Transformationen und unstrukturierte Datenpipelines (benutzerdefiniertes Chunking) sicher erweitern.
Unser Design für die Code-Erweiterung setzt auf Flexibilität, Sicherheit, Effizienz und eine optimierte Entwicklererfahrung. Es unterstützt zwei primäre Ausführungsmodelle, die jeweils auf bestimmte architektonische Anforderungen zugeschnitten sind:
- Skriptmodell:
- Zweck: Für umfassende benutzerdefinierte Logik, die eine direkte Interaktion mit Data 360 Lakehouse erfordert.
- Funktionalität: Kunden schreiben vollständige Python-Skripts mithilfe des Code Extension SDK, wodurch Lese- und Schreibzugriff auf Lakehouse über SDK-APIs ermöglicht wird. Ideal für die benutzerdefinierte/komplexe Datenvorbereitung oder für maßgeschneiderte Datenmanipulationen.
- Isolation und Sicherheit: Während Skripts auf das Lakehouse zugreifen, ist ihre Ausführung auf eine sichere, isolierte Umgebung innerhalb der Data 360-Laufzeit beschränkt, was Störungen anderer Prozesse oder nicht autorisierten Systemzugriff verhindert.
- Funktionsmodell:
- Zweck: Analog zu einer serverlosen Funktion für modulare Berechnungen ohne Status, die aus vorhandenen Data 360-Pipelines aufgerufen werden (z. B. benutzerdefiniertes Blockieren in einer unstrukturierten Pipeline).
- Funktionalität: Vom Kunden bereitgestellte Funktionen übernehmen Eingabe-, Berechnungs- und Rückgabeausgaben.
- Isolation und Sicherheit: Diese Funktionen sind für eine strikte Isolation ausgelegt. Sie verfügen nicht über direkten Lakehouse-Zugriff. Ihre Ausführung erfolgt in Sandbox-Instanzen, zustandslos und ressourcenbeschränkt. Dadurch eignen sie sich für fokussierte Verarbeitungsschritte ohne Zustand, gewährleisten Sicherheit, prognostizierte Ausführung und minimieren den Explosionsradius.
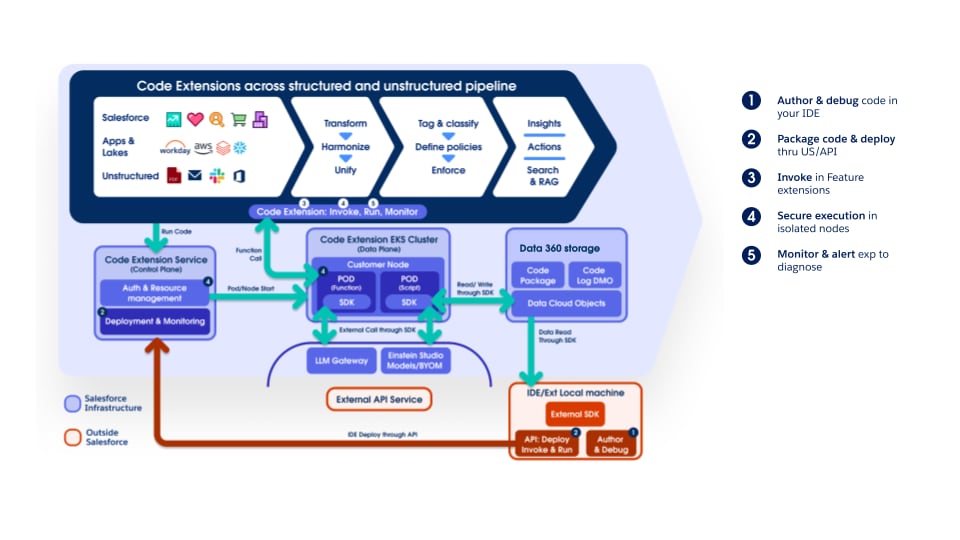
Sowohl das Skript- als auch das Funktionsmodell zielen darauf ab, Kundencode sicher auszuführen und so zu verhindern, dass sich der Code eines Mandanten auf andere auswirkt oder unbefugten Zugriff auf die Daten anderer Mandanten, Salesforce-Ressourcen oder externe Ressourcen erhält. Diese Sicherheit wird durch eine mehrschichtige (verteidigende) Architektur erreicht. Diese Architektur bietet eine isolierte Ausführungsumgebung für den benutzerdefinierten Code jedes Mandanten, die verschiedene Leitplanken enthält. Dazu zählen die logische Isolation auf Kubernetes-Ebene (K8s), die Netzwerkisolation, die Laufzeit-Sandbox-Instanz und Berechtigungen mit den geringsten Berechtigungen, ergänzt durch die Betriebsüberwachung und die Bereitschaft zur Reaktion auf Vorfälle zur Erkennung und Reaktion.
Code Extension bietet Folgendes, um einen robusten Entwicklungslebenszyklus zu unterstützen:
- Externes Erstellen und Debuggen: Entwickler können Python-Code mithilfe des SDK in vertrauten Umgebungen wie VSCode erstellen und debuggen.
- Flexible Bereitstellung: Benutzerdefinierter Code kann mithilfe von SDK-Dienstprogrammen, der Data 360-Benutzeroberfläche oder der API in Pakete aufgenommen und bereitgestellt werden, was die Integration in CI/CD ermöglicht.
Betriebsprotokolle: Der Zugriff auf detaillierte Ausführungsprotokolle bietet Transparenz und erleichtert die Fehlerbehebung in der Produktion.
Data 360 bietet diese sicheren und flexiblen Codeerweiterungsfunktionen und ermöglicht es Architekten, die Plattform an ihre individuellen und komplexesten Datenverarbeitungsanforderungen anzupassen und so ihre Rolle als erweiterbare Unternehmensdatenstruktur zu festigen.
Während Unternehmen die AI-Akzeptanz beschleunigen, pflegen die meisten heterogene ML-Ökosysteme – einschließlich Amazon SageMaker, Google Vertex AI und benutzerdefinierter Python-basierter Umgebungen –, die Modelle hosten, die geschäftskritische Prognosen vorantreiben, beispielsweise Kreditrisikobewertung, Abwanderungsneigung, Produktempfehlungen und Next-Best-Action-Entscheidungen.
Für die Integration dieser externen Modelle in Salesforce waren in der Regel maßgeschneiderte API-Schichten, ETL-Pipelines oder Middleware-Orchestrierungen erforderlich. Außerdem wurden Datenduplizierung, Verwaltungsaufwand, Latenz und betriebliche Komplexität eingeführt – Herausforderungen, die mit einer einheitlichen, konformen und echtzeitfähigen Customer Data Platform-Vision (CDP) in Konflikt stehen.
Bring Your Own Model (BYOM): Über Einstein Studio in Data 360 bereitgestellt, werden diese Herausforderungen angegangen, indem der direkte Aufruf extern trainierter Modelle in Salesforce-Workflows, Apex-Logik und Automatisierungstools ermöglicht wird, ohne Daten verschieben oder replizieren zu müssen. Durch die Zero-Copy-Verbundorganisation fungiert Data 360 als die gesteuerte einzige Datenquelle und stellt harmonisierte Customer 360-Daten für Rückschlüsse an externen Endpunkten bereit. Prognoseausgaben fließen in Echtzeit zurück und unterstützen Geschäftsprozesse mit skalierbarer Intelligenz.
BYOM schließt effektiv die Lücke zwischen Data Science und der operativen Ausführung, indem die Modellentwicklung, die regulierten Daten und die Verbrauchsebenen voneinander getrennt werden. Sie behält die Plattformunabhängigkeit bei, reduziert die Integrationskomplexität, beschleunigt die AI-Bereitstellung und verwaltet sensible Daten.
Die Architektur funktioniert wie folgt: Data 360 bietet eine einheitliche Customer 360-Datengrundlage, während Einstein Studio Verbindungen zu externen ML-Plattformen (SageMaker, Vertex AI oder benutzerdefinierte Endpunkte) orchestriert. Externe Modelle führen Rückschlüsse im Echtzeit-, Batch- oder Streaming-Modus aus. Salesforce-Ebenen – Flow-, Apex- und Abfrage-APIs – verwenden Ausgaben, um personalisierte, automatisierte und analytische Statistiken für Sales, Service, Marketing und Industry Cloud bereitzustellen.
Aus Unternehmenssicht bietet BYOM Folgendes:
- Datenintegrität und -verwaltung: Eliminiert unkontrollierte Datenkopien und erzwingt die Einhaltung von Richtlinien.
- AI-Demokratisierung: Macht komplexe Modelle für nicht technische Benutzer über Salesforce-Tools zugänglich.
- Beschleunigung der Zeit bis zum Wert: Externe Modelle werden sofort in Salesforce-Prozessen aktiviert.
- Unterstützung von Skalierbarkeit und Hybridarchitektur: Ermöglicht die Bereitstellung von AI-Arbeitslasten in mehreren Clouds.
- Zukunftsfähige AI-Architektur: Unterstützt zusammengesetzte AI-Strategien, das Entkoppeln von Daten, Modellen und Verbrauchsebenen für die betriebliche Agilität.
Bring Your Own LLM (BYO-LLM): Bietet denselben Erweiterbarkeitsmechanismus, jedoch für generative Modelle. Durch das Aktivieren des direkten Aufrufs externer Sprachmodelle können Kunden sie auf der Agentforce Platform anstelle der von Salesforce bereitgestellten Modelle verwenden. Für Unternehmen erlaubt BYO-LLM Folgendes:
- Zugriff auf optimierte Modelle
- Integration von Modellen, die derzeit nicht von Salesforce bereitgestellt werden
- Verwendung von Modellen in vom Kunden bereitgestellten Accounts
Moderne Unternehmen arbeiten in einer komplexen Datenlandschaft, die durch zwei große architektonische Herausforderungen gekennzeichnet ist:
- Unternehmensinterne Fragmentierung: Große Organisationen verwenden häufig mehrere Salesforce-Organisationen (oft segmentiert nach Region, Geschäftseinheit oder historischer Erfassung) und zahlreiche andere Datensysteme. Durch diese Fragmentierung werden interne Datensilos erstellt, sodass es nicht möglich ist, eine einzelne, vertrauenswürdige und einheitliche Ansicht des Kunden für die Echtzeitinteraktion im gesamten Unternehmen zu erstellen. Die Herausforderung besteht darin, diese Daten zu vereinheitlichen, ohne sie physisch in allen Systemen zu konsolidieren oder zu duplizieren, um sicherzustellen, dass die Verwaltung intakt bleibt.
- Unternehmensübergreifende Zusammenarbeit: Unternehmen müssen oft Daten für gemeinsames Marketing, Messung und Business Intelligence mit Partnern und Lieferanten teilen. Die Herausforderung besteht darin, diese Zusammenarbeit zu ermöglichen und gleichzeitig sensible, proprietäre Daten zu schützen und Datenschutzbestimmungen wie DSGVO und CCPA sowie Wettbewerbsbarrieren einzuhalten.
Salesforce Data 360 meistert diese Herausforderungen mit einem Zero-Copy-Framework für Trust-by-Design, das auf dem Prinzip der Freigabe von Zugriff und Statistiken basiert, statt Daten zu verschieben oder zu duplizieren.
Salesforce Data 360 bewältigt Herausforderungen bei der Datenfragmentierung und Zusammenarbeit mit Data Cloud One, der Datenfreigabe zwischen Data 360s und den Datenreinigungsräumen vom Typ "Privacy First". Diese Lösungen vereinheitlichen Kundendaten, ermöglichen einen sicheren Datenaustausch und bieten Statistiken zum Schutz der Privatsphäre. Mit einem Zero-Copy-Ansatz vom Typ Trust by Design können Organisationen Datenpotenziale für Echtzeitinteraktionen, erweiterte Partnerschaften und intelligente Entscheidungsfindung erschließen. Jede dieser Optionen für die Datenzusammenarbeit dient unterschiedlichen Zwecken.
Interne Unternehmensaktivierung mit Data Cloud One
Data Cloud One ist die grundlegende Architekturlösung für Unternehmen, die mehrere Salesforce-Organisationen betreiben. Ihr Zweck geht über die einfache Datenfreigabe hinaus. Sie wurde entwickelt, um eine einzelne, vertrauenswürdige Kundenansicht zu erstellen und vollständige Data 360-Plattformfunktionen in der gesamten Organisation zu ermöglichen.
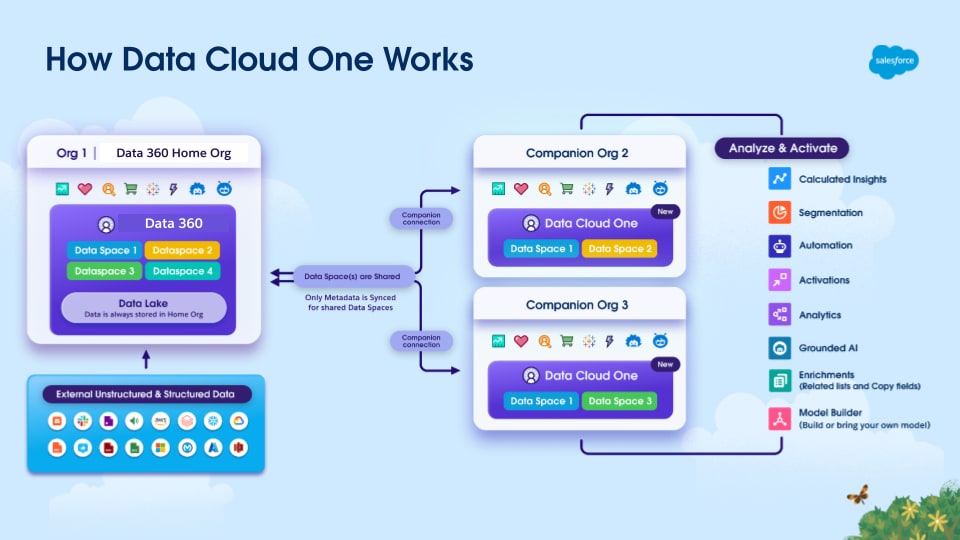
Dieser Mechanismus konzentriert sich auf eine angegebene Instanz vom Typ "Home Org Data 360", die als zentrale Instanz für die Datenverwaltung und die Erstellung des zusammengeführten Kundenprofils fungiert. Die Startseitenorganisation ist die Organisation, in der Data 360 bereitgestellt wird. Es wird eine Data Cloud One-Verbindung zwischen Data 360 und anderen Salesforce-Organisationen hergestellt, die als Begleitorganisationen bezeichnet werden. Als Teil der Data Cloud One-Verbindung gibt Data 360 einen oder mehrere seiner Datenbereiche für jede Begleitorganisation frei und bietet so Zugriff auf Daten und Metadaten in jedem freigegebenen Datenbereich. Dies wird durch ein Verbundmodell ohne Kopierzugriff und eine organisationsübergreifende Metadatensynchronisierung erreicht.
Data Cloud One ermöglicht es Begleitorganisationen auch, die Data 360-Instanz der Heimorganisation für ihre eigenen Aktivierungs-, Personalisierungs- und Intelligenzanforderungen zu nutzen. Diese Strategie ist wichtig, um die interne Datenfragmentierung zu beseitigen und sicherzustellen, dass alle Geschäftseinheiten auf der Grundlage desselben verwalteten und vereinheitlichten Kundenprofils aktiviert werden, wodurch der ROI der zentralen Data 360-Implementierung maximiert wird.
Datenfreigabe zwischen Data 360-Organisationen
Bei verteilten internen Umgebungen (in denen eine vollständige Zentralisierung nicht möglich ist) und bei der Zusammenarbeit mit vertrauenswürdigen externen Partnern verbindet die Data 360-zu-Data 360-Datenfreigabe unabhängige Data 360-Instanzen.
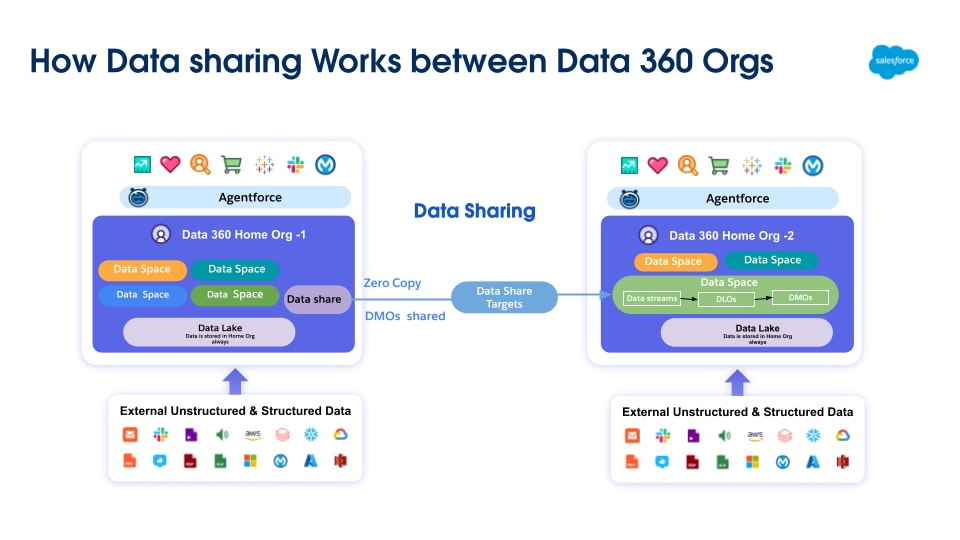
Dieses Zero-Copy-Freigabemodell stellt eine Verbindung zwischen separaten Data 360-Mandanten her, die in verschiedenen Salesforce-Organisationen bereitgestellt werden, um Datenobjekte (DLOs, DMOs und CIOs) sicher auszutauschen. Nach der Verbindung wird im Empfänger Data 360 auf das gesamte Datenobjekt zugegriffen. Der Administrator von Data 360 kann dann Governance-Regeln festlegen, um den Benutzerzugriff auf diese Daten zu verwalten.
Zusammenarbeit an erster Stelle bei Datenschutz mit Data 360-Reinraumzusammenarbeit
Wenn für die Zusammenarbeit ein Höchstmaß an Datenschutz und Compliance erforderlich ist oder Wettbewerbsbedenken die Freigabe von Rohdaten verhindern, werden Data 360-Reinräume architektonisch vorgeschrieben.
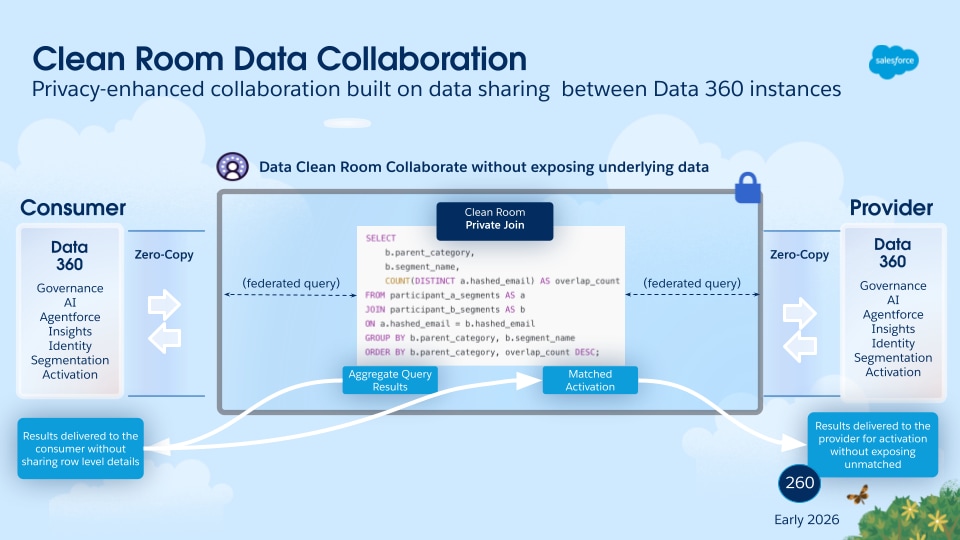
Architektonisch basiert die Data 360-Reinraumzusammenarbeit auf dem Zero-Copy-Freigabe-Framework, das von der Data 360-zu-Data 360-Datenfreigabe verwendet wird, wobei jedoch zusätzliche Verwaltungsebenen und Recheneinschränkungen gelten. Der Data 360-Reinraum bietet eine sichere, kontrollierte Rechenumgebung, in der Beteiligte ihre Datensets anhand anonymisierter Schlüssel verknüpfen können. Ihr Kernzweck besteht darin, eine gemeinsame Analyse und Statistikgenerierung zu ermöglichen, ohne die zugrunde liegenden proprietären Daten offenzulegen. Die Umgebung erzwingt strenge, programmierbare Regeln wie Mindestaggregationsschwellenwerte und nicht exportierbare Kennzeichner. Diese Regeln stellen sicher, dass nur genehmigte, datenschutzoptimierte und aggregierte Statistiken abgeleitet und freigegeben werden. Dadurch sind Reinräume für Anwendungsfälle wie die plattformübergreifende Kampagnenmessung und die Analyse sensibler Zielgruppenüberschneidungen unerlässlich.
Data 360 wurde als intelligente, erweiterbare und vertrauenswürdige Datenstruktur entwickelt, die für die AI der nächsten Generation erforderlich ist. Das Architekturdesign zielt auf das Problem der fragmentierten Daten ab und ermöglicht Organisationen die Vereinheitlichung, Verarbeitung und Aktivierung sämtlicher Kundendaten im richtigen Maßstab.
Die zuverlässige Datenorganisation erstellt eine harmonisierte Ansicht von DLOs (einschließlich unstrukturierter Daten) zu DMOs, die alle in partitionierten Datenbereichen geschützt sind. Die vielseitigen Datenverarbeitungsfunktionen von Data 360 – einschließlich Batch- und Streaming-Transformationen, berechneter Statistiken, unstrukturierter Datenverarbeitung und Identitätsbestimmung – werden durch die inkrementelle SNCE- und CDF-Architektur unterstützt, was eine effiziente Verarbeitung nahezu in Echtzeit und erhebliche Kosteneinsparungen gewährleistet.
Die Erweiterbarkeit wird durch die Code Extension-Architektur bereitgestellt, die benutzerdefinierte Python-Logik über Skripts oder isolierte Funktionen für individuelle Anforderungen sicher aktiviert. Darüber hinaus garantiert ein umfassendes Framework für die Datenverwaltung, das auf der attributbasierten Zugriffssteuerung (ABAC) mit CEDAR-Richtlinien basiert, detaillierte Sicherheit, dynamische Datenmaskierung und konsistente Durchsetzung des gesamten Datenverbrauchs. Dies gipfelt in komplexen Segmentierungs- und Aktivierungsfunktionen, die zusammengeführte Kundenprofile in dynamische Multi-Channel-Engagementstrategien mit Reaktionsfähigkeit in Echtzeit übersetzen.
Die Fähigkeit von Data 360, umfangreiche, vielfältige Daten zu vereinheitlichen, Echtzeitkontext über seine vereinheitlichte Abfrage bereitzustellen (einschließlich strukturierter/unstrukturierter Hybridsuche und Hyperbeschleunigung) und strenge Governance-Vorgaben durchzusetzen, ist von entscheidender Bedeutung für die Unterstützung intelligenter AI-Agenten. Sie stellt die erforderlichen vertrauenswürdigen, aktuellen und relevanten Daten bereit, um Workflows mit generativer AI (Generative AI Workflows, RAG) zu unterstützen und die handlungsorientierten Funktionen von Agentforce Agenten zu erweitern und sicherzustellen, dass sie mit Präzision und Genauigkeit arbeiten.
Data 360 bietet eine zukunftssichere Plattform, auf der Quelldaten in handlungsrelevante Statistiken umgewandelt werden, und ist eine unverzichtbare architektonische Grundlage für Organisationen, die Agentic-Kundenerfahrungen erstellen. Es ist das wichtige Rückgrat, das Kundendaten in die komplexen, personalisierten Kundenerfahrungen verwandelt, die den Erfolg moderner Organisationen steigern.