Die Enterprise-Datenarchitektur befindet sich an einem Wendepunkt. Organisationen müssen gleichzeitig Echtzeit-KI-Systeme unterstützen, immer strengere Datenschutzbestimmungen einhalten und mit externen Partnern zusammenarbeiten, die keine Rohdaten freigeben können. Diese Anforderungen verändern die Gestaltung von Datenplattformen grundlegend.
Traditionelle Architekturen, die auf ETL-Pipelines und zentralisierten Data Warehouses basieren, haben Schwierigkeiten, diese Anforderungen zu erfüllen. Die systemübergreifende Replikation von Daten erhöht Latenz, Kosten und Governance-Komplexität. Jede Kopie wird zu einer neuen Compliance-Verpflichtung, was die Einwilligungsverwaltung, Löschanforderungen und die Durchsetzung von Richtlinien in verteilten Umgebungen erschwert.
Um diese Herausforderungen zu bewältigen, schwenkt die Branche auf Zero-Copy-Modelle für die richtliniengestützte Zusammenarbeit um. Datenreinräume haben sich als wichtige architektonische Funktion herausgestellt, sodass mehrere Organisationen gemeinsam genutzte Signale analysieren können, ohne Rohdaten offenzulegen oder zu übertragen. Anstatt Daten in zentralisierte Umgebungen zu verschieben, wird die Berechnung in der von jedem Teilnehmer verwalteten Domäne ausgeführt und es werden nur Ergebnisse zurückgegeben, die den Datenschutz gewährleisten.
Dieser architektonische Wandel wird zunehmend branchenübergreifend sichtbar. Beispielsweise spiegelt die Übernahme von InfoSum durch WPP, das größte Unternehmen im Marketing und in der Werbung, die wachsende Bedeutung von Reinräumen als Infrastruktur für die datenschutzgerechte Zusammenarbeit wider. Finanzinstitute verwenden sie, um Betrug institutsübergreifend zu erkennen, Einzelhändler, um Sonderangebote mit Verbrauchermarken zu koordinieren, und Gesundheitsorganisationen, um anbieterübergreifende Patientengruppen zu analysieren, ohne sensible zugrunde liegende Datensätze freizugeben.
Salesforce Data 360 operationalisiert dieses Modell über eine auf Hyperforce basierende Zero-Copy-Architektur. Die Daten verbleiben in ihren Quellsystemen, während Verbundabfragen zur Laufzeit Datenschutz-, Einwilligungs- und Aufenthaltsrichtlinien erzwingen. Dieser Ansatz ermöglicht Echtzeitstatistiken, cloudübergreifende Zusammenarbeit und AI-gestützte Entscheidungen, ohne die durch den Datenabgleich entstehende Risikooberfläche zu erweitern.
In diesem Dokument wird untersucht, wie Datenreinräume als grundlegendes Architekturmuster für moderne Unternehmen funktionieren und gleichzeitig und im richtigen Maßstab KI-Innovationen, die Einhaltung gesetzlicher Vorschriften und eine sichere domänenübergreifende Zusammenarbeit unterstützen.
Um zu verstehen, warum Datenreinräume erforderlich sind, müssen Unternehmensarchitekten zunächst mit dem strukturellen Versagen veralteter Integrationsmodelle konfrontiert werden. Die Branche befindet sich in einem entscheidenden Übergang von monolithischen, zentralisierten Daten-Repositorys zu dezentralen Verbund-Ökosystemen. Hier wird vor Ort auf Daten zugegriffen, sie gesteuert und berechnet, statt sie physisch zu verschieben. Diese Schicht ist nicht inkrementell. Es ist eine direkte Reaktion auf den systemischen Druck in Bezug auf Skalierung, Datenschutz und Agilität, den herkömmliche Architekturen nicht mehr aufnehmen können.
Jahrelang setzten Unternehmen auf ETL-gesteuerte Architekturen, die Daten aus CRM, ERP und digitalen Systemen für Berichte und Analysen in zentralisierte Lagerhäuser kopierten. Dieser Ansatz erwies sich als effektiv für historische Analysen, wurde jedoch für eine langsamere, batchorientierte Welt konzipiert.
Als digitale Interaktionen beschleunigt wurden und AI-gestützte Systeme entstanden, wurden die Einschränkungen dieses Modells deutlicher. ETL-Pipelines sind von Natur aus asynchron, d. h., Statistiken werden oft Stunden oder Tage nach Ereignissen angezeigt. Eine solche Latenz ist zunehmend inkompatibel mit modernen Anwendungsfällen wie Echtzeitpersonalisierung, adaptiver Entscheidungsfindung und AI-Systemen, die sofortige Kontextdaten erfordern.
Die Replikation führt auch zu einer wachsenden Governance- und Sicherheitskomplexität. Jede neue Kopie der Daten erfordert zusätzliche Richtlinien, Überwachung und Compliance-Kontrollen. In regulierten Umgebungen müssen Organisationen aufgrund von Frameworks wie der Datenschutz-Grundverordnung (DSGVO) Lösch-, Einwilligungs- und Nutzungseinschränkungen überall dort verwalten, wo Daten vorhanden sind. Dies ist eine betriebliche Herausforderung, wenn Datensets über mehrere Systeme hinweg dupliziert werden.
In großem Umfang werden durch diese Duplizierung die Kosten und der operative Overhead miteinander kombiniert. Organisationen zahlen wiederholt für die Aufnahme, Speicherung, Sicherheit und Verarbeitung auf mehreren Plattformen, während der Grenzwert zusätzlicher Kopien abnimmt.
Infolgedessen wechseln moderne Datenarchitekturen zu Modellen, die die Datenbewegung minimieren und die Governance direkt an der Quelle erzwingen. Die Zero-Copy-Integration und der Verbunddatenzugriff ermöglichen es Organisationen, Statistiken zu generieren, ohne sensible Datensets zu replizieren, was einen skalierbareren, sichereren und richtlinienorientierteren Ansatz für die Zusammenarbeit mit Unternehmensdaten bietet.
Als Reaktion auf diesen Druck hat die Branche zwei sich ergänzende architektonische Paradigmen zusammengeführt: Datenmasche und Datengewebe. Zusammen stellen sie eine Abkehr von der zentralisierten Steuerung hin zu Verbunddatenarchitekturen mit Domänenbewusstsein dar.
Data Mesh dezentralisiert die Dateninhaberschaft für domänenorientierte Teams wie Vertrieb, Marketing oder Lieferkette. Jede Domäne behandelt ihre Daten wie ein Produkt mit klar definierten Verträgen, Qualitätsstandards und Service Level-Zielen. Dieses Modell verbessert die Rechenschaftspflicht und die Geschäftsausrichtung, bringt jedoch im Unternehmensmaßstab neue Herausforderungen in Bezug auf Koordination, Interoperabilität und konsistente domänenübergreifende Unternehmensführung mit sich.
Data Fabric meistert diese Herausforderungen, indem es die Verbindungsebene bereitstellt, die dezentrale Domänen zu einem kohärenten System verbindet. Sie stellt freigegebene Metadaten, gemeinsame Semantik, automatisierte Richtlinienerzwingung, Abstammung und Governance bereit, sodass Daten konsistent erkannt, aufgerufen und verwaltet werden können, ohne die physische Konsolidierung in einem einzelnen Repository zu erzwingen.
Zusammen bilden Datennetz und Datengewebe die Grundlage für den Verbunddatenzugriff. Sie müssen jedoch noch lange nicht ein wichtiges Problem der nächsten Ordnung lösen: die sichere, kontrollierte Zusammenarbeit über Domänen- und Organisationsgrenzen hinweg, bei der Daten gemeinsam analysiert werden müssen, ohne kopiert oder offengelegt zu werden.
Da Unternehmensdaten immer weiter verteilt werden und die Datenschutzbestimmungen strenger werden, stehen Organisationen vor einer zentralen architektonischen Herausforderung. Wie können sie team-, partner- und plattformübergreifend zusammenarbeiten, ohne Rohdaten freizugeben? Herkömmliche Datenintegrationsansätze wurden nicht für diese Verteilungsebene oder behördliche Überprüfung konzipiert, was zu Spannungen zwischen Zusammenarbeit und Compliance führte.
Diese Herausforderung hat zu einer Verschiebung hin zu Datenreinräumen als grundlegender architektonischer Fähigkeit geführt. Reinräume verschieben die Zusammenarbeit weg von der Datenübertragung hin zur gesteuerten Berechnung. Statt Datensets zu kopieren oder auszutauschen, werden Analytics- und AI-Arbeitslasten dort ausgeführt, wo sich die Daten bereits befinden, indem die Metadaten freigegeben werden. Abfragen werden in Echtzeit anhand von Datenschutz-, Einwilligungs- und Nutzungsregeln ausgewertet und nur genehmigte, aggregierte Ergebnisse werden zurückgegeben.
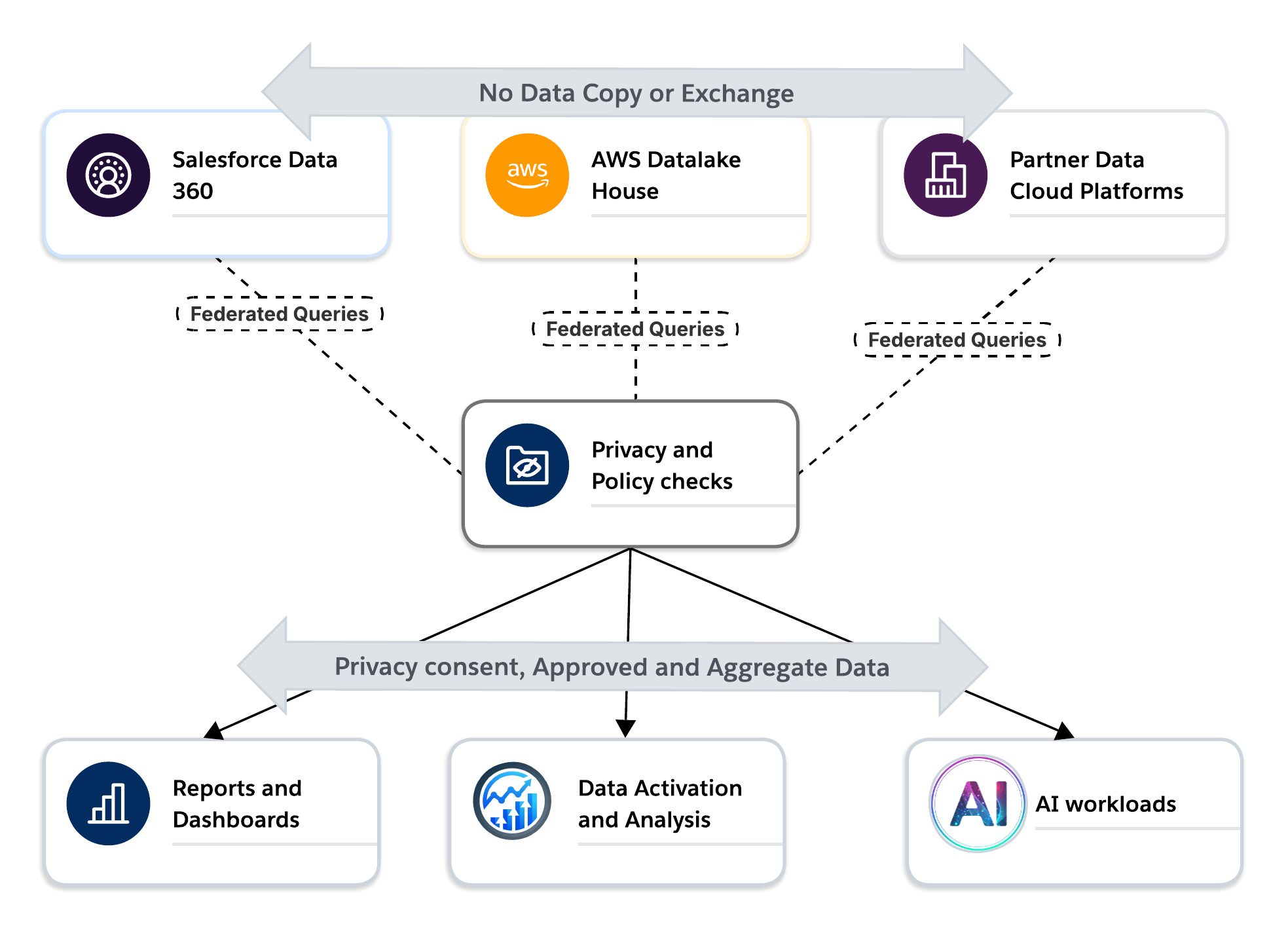
In diesem Modell fungieren Datenreinräume als Trust Grenze moderner Datenarchitekturen. Sie ermöglichen es Organisationen, mit Partnern und Tochtergesellschaften zusammenzuarbeiten, ohne die Kontrolle über ihre Daten zu verlieren, Datenschutz und Einwilligung durch Systemsteuerungen statt durch Richtlinien allein zu erzwingen und Cloud-übergreifend zu arbeiten, während die Obergrenzen für die Datenresidenz und den Vertrag eingehalten werden.
Für Aktivierungs-, Analyse- und AI-Anwendungsfälle bieten Reinräume eine sichere Möglichkeit, Statistiken aus externen Daten zu generieren, ohne sensible Informationen offenzulegen. Sie ermöglichen den Wechsel von der Datenfreigabe zur vertrauenswürdigen Zusammenarbeit. Für Aktivierungsanwendungsfälle bieten Reinräume eine sichere Möglichkeit, Zielgruppen zu generieren, die direkt an einem zulässigen Ziel aktiviert werden können. All dies wird erreicht, ohne dass eine der Parteien personenbezogene Daten offenlegt.Dies markiert einen Wendepunkt in der Unternehmensdatenarchitektur. Data Clean Rooms sind keine Nischentools mehr. Sie entwickeln sich zu einer zentralen Infrastruktur für Verbunddatenplattformen, die die Privatsphäre wahren und AI-fähig sind.
Eine erfolgreiche Datenreinraumarchitektur ist ein System mit mehreren Schnittstellen, das entwickelt wurde, um den konkurrierenden Druck hinsichtlich Datendienstleistung, Sicherheit und Geschwindigkeit zu lösen. Es gibt drei primäre Personas, deren unterschiedliche Reibungspunkte durch das zugrunde liegende technische Design behoben werden müssen.
Datenschutz- und Compliance-Beauftragte verwenden den Datenreinraum als Governance-Tool. Ihr Hauptanliegen ist die Abweichung von der Compliance, also das Risiko, dass externe Zusammenarbeitsumgebungen nicht dieselben strengen Standards wie interne Systeme durchsetzen können.
- Reibungspunkte: Regulatorische Offenlegung (DSGVO, CCPA, DMA) und "Phishing"-Angriffe, bei denen ein Partner versucht, die Identität eines Benutzers durch wiederholte detaillierte Abfragen zu triangulieren.
Datenwissenschaftler betrachten den Datenreinraum als sicheren Zufluchtsort für die erweiterte Modellierung. Ihr Hauptanliegen ist die Beibehaltung des Versorgungsunternehmens, um sicherzustellen, dass Datenschutzmaßnahmen die Daten nicht statistisch unbrauchbar machen.
- Reibungspunkte: Hohe Latenz und eingeschränkter Zugriff auf granulare Attribute, die für maschinelles Lernen (ML), Ähnlichkeitsmodellierung und Abwanderungsprognose erforderlich sind.
Diese Persona konzentriert sich ausschließlich auf Time to Value (TTV). Ihre Sorge ist, dass Datenreinraumprojekte oft zu technischen Engpässen werden, die wochenlange Unterstützung bei der Datentechnik erfordern.
- Reibungspunkte: Komplexe Setup-Prozesse, manuelle Datenbereinigung und das Problem "Leerseite", Code schreiben zu müssen, um einfache Überschneidungsergebnisse zu erhalten.
Während sich traditionelle Architekturen darauf konzentrieren, die Datenebene vor der Benutzerebene zu erstellen, wird dieses Modell durch unseren strategischen Ansatz, der auf der "Business First"-Methodik basiert, umgekehrt. Wir priorisieren einen Ansatz ohne Code bis hin zu wenigen Klicks, mit dem Geschäftsbenutzer Statistiken generieren und sofortige Maßnahmen ergreifen können.
Workflow 'Statistiken zum Handeln': Die Architektur ist als aktive Arbeitsumgebung und nicht als passives Repository konzipiert. Durch die Bereitstellung von Anwendungsfallvorlagen (z. B. Segmentüberschneidung, Aktivierung und Kampagnenleistung) können Geschäftsbenutzer Self-Service-Statistiken bereitstellen. Dadurch wird sichergestellt, dass Statistiken, beispielsweise ein optimiertes Ähnlichkeitssegment, sofort für die Aktivierung im gesamten Marketing-Ökosystem verfügbar sind, ohne dass ein Dateningenieur Dateien manuell verschieben muss.
Zero-Copy-Verbund als strategischer Vermögenswert: Zum Maximieren von TTV verwendet die Architektur eine Nullkopielogik. Anstelle des herkömmlichen ETL-Prozesses, der Latenz- und Sicherheitsrisiken mit sich bringt, führt unsere Architektur Abfragen direkt an den Speicherort der Daten (z. B. Snowflake, BigQuery oder Amazon S3) weiter. Dadurch wird die vorhandene Dateninvestition der Organisation zu einem strategischen Vermögenswert, wodurch Geschäftsbenutzer in Echtzeit auf die neuesten Daten reagieren können, während sie eine strenge Verwaltung aufrechterhalten und die Kosten für die Datenredundanz vermeiden.
Datenreinräume entstanden in der Werbung als Reaktion auf die Cookie-Verschlechterung und die Datenschutzregulierung, haben sich jedoch branchenübergreifend zu Kundenanalysen, Zielgruppensegmentierung und Aktivierungsanwendungsfällen entwickelt. Laut dem State of Retail Media Report 2025 nutzen 66 % der Unternehmen Reinräume in einer gewissen Kapazität, was auf die Notwendigkeit einer datenschutzgerechten Zusammenarbeit zurückzuführen ist, die zu messbaren Geschäftsergebnissen führt. Das Muster ist sektorübergreifend konsistent: Die Daten verbleiben beim Inhaber, die Berechnung wird gesteuert und es werden nur datenschutzsichere Statistiken freigegeben.
Die Herausforderung: Marketingexperten müssen die Kampagneneffektivität messen, doppelte Anzeigenaufrufe vermeiden und die Reichweite/Häufigkeit optimieren – können sich jedoch nicht mehr auf Cookies oder Gerätekennzeichner von Drittanbietern verlassen.
Die Reinraumlösung:
- Werbetreibende tragen gehashte Kunden- oder Kampagnen-Expositionsdaten bei
- Publisher steuern Impressions- und Engagementsignale bei
- Reinraumberechnungen für Reichweite, Häufigkeit, Attribution und Lift
- Die Aktivierung erfolgt über genehmigte Plattformen ohne Rohdatenexporte
Geschäftsergebnis: Reinräume bieten Attribution im geschlossenen Kreislauf, die Anzeigenimpressionen mit tatsächlichen Transaktionen verknüpft, Inkrementalitätsanalysen isoliert die wahre Kampagnensteigerung und einheitliche Messwerte über alle Kanäle hinweg – Funktionen, die herkömmliche digitale Werbung nicht bieten kann.
Branchennachweise: Die Messung ist heute der etablierteste Anwendungsfall für Reinräume. Große Mediennetzwerke wie Pinterest, Disney und Paramount erstellen ihre eigenen Reinräume.
Die Herausforderung: CPG-Marken geben viel für Einzelhandelsmedien aus, haben jedoch keinen Einblick in die Kaufergebnisse. Einzelhändler sind Inhaber umfangreicher Point-of-Sale-Daten, können sie jedoch nicht offenlegen, ohne gegen Datenschutzverpflichtungen zu verstoßen.
Die Reinraumlösung:
- Einzelhändler und CPG-Unternehmen kombinieren Point-of-Sale-Daten von Einzelhandelsstandorten mit Marketingdaten, um Werbeaktivitäten zu optimieren
- Marken tragen gehashte CRM- oder Treuekennzeichner bei
- Reinraum-Links zur Anzeige von Einkäufen im Geschäft/Online
- Aktivierung bleibt im Medienökosystem des Einzelhändlers
Geschäftsergebnis:
- Einzelhändler monetarisieren Erstanbieterdaten, ohne Rohkundeninformationen zu verkaufen
- Marken erhalten geschlossene Attribution, die anzeigt, welche Kampagnen Käufe ankurbelten
- Skalieren von Retail Media Networks ohne Datenschutzrisiko Branchennachweise: Retail Media Networks wie Walmart's Luminate und Kroger Precision Marketing bieten Reinräume, mit denen CPG-Marken das Kundenverhalten analysieren und Marketingstrategien mithilfe von Händlerdaten optimieren können.
Die Herausforderung: Betrugsnetzwerke funktionieren institutsübergreifend. Banken können jedoch aufgrund von Vorschriften wie GLBA und neuen Datenschutzgesetzen keine Kunden- oder Transaktionsdaten offen freigeben.
Die Reinraumlösung:
- Mehrere Banken bündeln anonymisierte Daten, um Muster zu identifizieren, die auf Betrug hinweisen, beispielsweise ungewöhnliche bankübergreifende Aktivitäten
- Verbundanalysen oder -modelle werden über freigegebene Betrugssignale hinweg ausgeführt
- Kein Institut sieht die Daten auf Kundenebene eines anderen
Geschäftsergebnis:
- Früheres Erkennen von institutsübergreifenden Betrugsmustern
- Weniger falsch positive Signale durch umfangreichere Signalsätze
- Einhaltung gesetzlicher Vorschriften ohne Zentralisierung sensibler Daten
Branchennachweise: Finanzdienstleistungslösungen von Experian und TransUnion bieten Reinraumtechnologien, mit denen Banken und Versicherer bei der Betrugserkennung und Risikobewertung zusammenarbeiten und gleichzeitig strenge Datenschutzkontrollen einhalten können.
Die Herausforderung: Pharmaunternehmen benötigen reale Patientenergebnisse für die Arzneimittelentwicklung, die Daten befinden sich jedoch in Krankenhaus-EHR-Systemen, die durch HIPAA und ähnliche Vorschriften geschützt sind.
Die Reinraumlösung:
- Ärzte und Pharmaforscher geben Daten innerhalb eines Reinraums frei, um zu erfahren, wie Patienten auf Behandlungen reagieren.
- Patientendaten verbleiben in Anbieterumgebungen.
- Forscher führen genehmigte statistische Analysen über einen Reinraum aus.
- Unterschiedlicher Datenschutz verhindert die erneute Identifizierung.
Geschäftsergebnis:
- Statistisch valide reale Daten im Maßstab
- Optimierte Patientenrekrutierung für klinische Studien durch Abgleichen anonymisierter Patientendaten mit Testkriterien, Auffinden geeigneter Kandidaten ohne Verstoß gegen die Datenschutzgesetze im Gesundheitswesen
- Reduzierte Abhängigkeit von begrenzten Populationen klinischer Studien
Branchennachweise: Gesundheitsorientierte Reinräume wie Datavant bieten HIPAA-konforme Umgebungen für Forscher und Gesundheitsorganisationen, um Patientendaten für klinische Studien und die Arzneimittelentwicklung sicher zu analysieren.
Über diese primären Anwendungsfälle hinaus ermöglichen Reinräume Folgendes:
- Versorgungskettenoptimierung: Hersteller und Lieferanten arbeiten zusammen, um Inventardetails, Produktionspläne und Bedarfsprognosen freizugeben, was eine bessere Koordinierung ermöglicht und gleichzeitig geschützte Informationen schützt.
- M&A Due Diligence: Wenn ein Unternehmen ein anderes erwirbt, müssen bei der Due Diligence Finanzprognosen und Kundendatenbanken untersucht werden, ohne sensible Informationen direkt freizugeben. Reinräume bieten Statistiken wie die Ausrichtung des Kundensegments und Compliance-Risiken.
- Medien und Unterhaltung: Publisher beweisen Werbetreibenden den Zielgruppenwert und schützen gleichzeitig die Abonnentenidentität, indem sie Premium-CPMs aktivieren, die durch eine vertrauenswürdige Messung statt durch probabilistisches Targeting unterstützt werden Data Clean Rooms sind in AdTech, Einzelhandel, Finanzdienstleistungen, Gesundheitswesen und Medien zu einer grundlegenden Trust Infrastruktur geworden. Sie ermöglichen eine hochwertige Zusammenarbeit, die zuvor durch Datenschutz-, behördliche oder Wettbewerbsbeschränkungen blockiert wurde. Reinräume sind zentrale architektonische Komponenten, die eine sichere, gesteuerte Zusammenarbeit ermöglichen und Einblicke und Monetarisierung ermöglichen, ohne die Datenkontrolle oder Compliance aufzugeben.
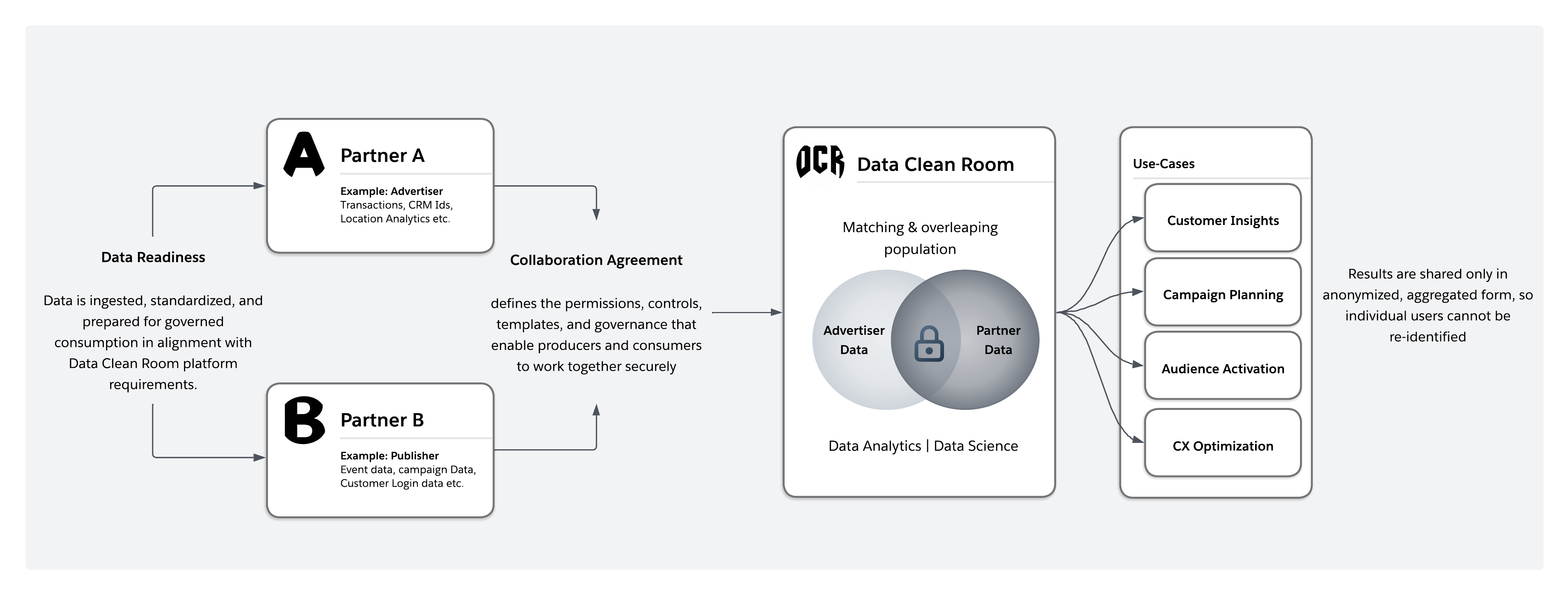
Bei einem Datenreinraum handelt es sich um eine sichere, kontrollierte Umgebung, in der mehrere Beteiligte gemeinsame Statistiken generieren können, ohne Rohdaten offenzulegen oder auszutauschen. Statt Datensets zu replizieren, werden genehmigte Analyse-, AI- und Aktivierungsarbeitslasten ausgeführt und nur richtlinienkonforme Ausgaben zurückgegeben. Wenn für die Aktivierung Datensätze auf Einzelpersonenebene erforderlich sind, werden die Daten direkt an das vorgesehene Ziel gesendet, ohne dass sie für beteiligte Personen zugänglich sind.
Architektonisch verlagern Reinräume die Zusammenarbeit von der Datenfreigabe zur kontrollierten Berechnung. Jeder Teilnehmer behält die Aufbewahrung seiner Daten bei, während die Erzwingung der Laufzeit das Abfrageverhalten, die Ausgabeeinschränkungen, die Einwilligung und die Nutzungsrichtlinien regelt.
Die Zusammenarbeit wird weiter durch Mechanismen zur Kennzeichnerausrichtung ermöglicht, die die Privatsphäre wahren und es ermöglichen, Datensets verschiedener Parteien zu korrelieren, ohne die zugrunde liegenden Kennzeichner offenzulegen. Diese Funktion wird später in diesem Dokument näher erläutert. Daher dienen Datenreinräume als grundlegende Infrastruktur für datenschutzregulierte Unternehmen mit mehreren Clouds und AI, die auf Zero-Copy-Strategien für Verbunddaten basieren.
Frühdaten-Reinigungsräume folgten einem zentralisierten Bunkermodell. Alle Teilnehmer mussten Daten zur Analyse in eine neutrale Drittanbieterumgebung kopieren. Dieser Ansatz war zwar konzeptionell einfach, führte jedoch zu erheblichen Reibungen. Die Datenbewegung erhöhte die Latenz und die Kosten, komplizierte Rechts- und Compliance-Vereinbarungen und zwang Organisationen, die direkte Kontrolle über sensible Daten aufzugeben. In regulierten Branchen machten diese Kompromisse die Zusammenarbeit oft unpraktisch.
Moderne Datenbereinigungsräume haben sich zu einem verteilten Verbundmodell entwickelt. Die Daten verbleiben in der Umgebung des Inhabers und Analysen werden über Verbundabfragen ausgeführt. Der Reinraum selbst fungiert als Governance-Ebene, die jede Abfrage abfängt, Datenschutz- und Richtlinienkontrollen zur Ausführungszeit erzwingt und nur genehmigte, aggregierte Ausgaben zurückgibt.
| Dimension | Traditioneller Reinraum ("Bunker"-Modell) | Moderner Reinraum (verteiltes/verbundenes Modell) |
|---|---|---|
| Datenstandort | Daten werden in eine zentralisierte Drittanbieterumgebung kopiert | Daten verbleiben in der Umgebung des Inhabers |
| Datenbewegung | Erfordert physische Übertragung und Duplizierung von Datensets | Keine Rohdatenbewegung, Abfragen werden ausgeführt |
| Steuerung und Aufbewahrung | Aufbewahrung teilweise an Drittanbieterplattform abgegeben | Inhaberschaft und Aufbewahrung von Rohdaten durch die einzelnen Parteien |
| Architekturmodell | Zentralisierte Aggregation | Verteilte Verbundberechnung |
| Governance-Erzwingung | Nach dem Verschieben von Daten angewendete Richtlinien | Richtlinien, die zum Zeitpunkt der Abfrageausführung erzwungen werden |
| Datenschutzmodell | Stark von vertraglichen und verfahrenstechnischen Kontrollen abhängig | Technisch erzwungen durch Laufzeitsteuerungen und Aggregationsschwellenwerte |
| Latenz | Höhere Latenz durch Aufnahme und Synchronisierung | Geringere Latenz, nahezu Echtzeit-Verbundabfragen |
| Kostenstruktur | Höhere Speicher-, Übertragungs- und Duplizierungskosten | Reduzierte Duplikate, ascompute tritt dort auf, wo sich Daten befinden |
| Compliance-Komplexität | Komplexe rechtliche Vereinbarungen durch grenzüberschreitende Datenverschiebung | Vereinfachte Compliance, da Daten die Quellgrenze nicht verlassen |
| Skalierbarkeit | Skalierung erfordert mehr Speicherplatz und Datenreplikation | Skalieren durch verteilte Berechnungen ohne Duplizieren von Daten |
| Geregelte Branchenanpassung | Oft unpraktisch aufgrund von Sorge- und Aufenthaltsproblemen | Besser auf Souveränität, Einwilligung und behördliche Einschränkungen abgestimmt |
Salesforce Data 360 veranschaulicht dieses Verbundmodell. Publisher und Werbetreibende können plattformübergreifend zusammenarbeiten und Analysen durchführen, ohne dass Rohdaten jemals die Sicherheitsgrenze der Plattform verlassen. Die Datenaufbewahrung bleibt erhalten, das Risiko wird reduziert und die Zusammenarbeit wird schneller und einfacher skalierbar.
Diese Umstellung von freigegebenen Daten auf freigegebene Berechnungen definiert Trust in der Unternehmenszusammenarbeit neu. Reinräume sind keine Ziele mehr, an denen Daten gespeichert werden, sondern Systeme, die bestimmen, wie Statistiken sicher erstellt werden.
Damit ein Datenreinraum für Unternehmen als zentrale Architekturfunktion verwendet werden kann, muss er eine Reihe nicht verhandelbarer Anforderungen erfüllen.
Die grundlegendste Voraussetzung für Datenreinräume ist die Zero-Copy-Architektur. Die traditionelle Datenzusammenarbeit basiert auf ETL-Pipelines, die Daten in freigegebene Umgebungen kopieren. Dies erhöht die Latenz, die Kosten, das Sicherheitsrisiko und das behördliche Risiko und erstellt mehrere nicht verwaltete Kopien vertraulicher Daten.
Ein moderner Datenreinraum beseitigt dieses Problem. Die Daten verbleiben im ursprünglichen Datensatzsystem, unabhängig davon, ob es sich um ein Cloud Data Warehouse, eine betriebliche Plattform oder eine SaaS-Anwendung handelt. Der Reinraum verwendet Verbundabfragen über diese verteilten Quellen hinweg und gibt nur genehmigte, datenschutzsichere Ergebnisse zurück.
Durch die Vermeidung physischer Datenbewegungen reduzieren Zero-Copy-Reinräume die Angriffsfläche, behalten die Datenresidenz und -inhaberschaft bei und stimmen auf natürliche Weise mit den Prinzipien der Datenstruktur und Verbunddatenarchitektur überein.
Die moderne Datenstrategie hängt von der Möglichkeit ab, zusammenzuarbeiten, ohne Daten verschieben zu müssen. Salesforce Data 360 bietet ein flexibles Framework, das Ihr Unternehmen über zwei primäre Modelle mit dem globalen Datenökosystem verbindet:
Native Salesforce-zu-Salesforce-Konnektivität: In diesem Modell erfolgt die Zusammenarbeit direkt zwischen zwei Salesforce-Kunden. Über eine freigegebene Metadatenebene können Anbieter und Verbraucher durch einfache Konfiguration sofort eine Verbindung herstellen. Auf diese Weise können Teams gemeinsame Statistiken generieren, ohne dass es zu Verzögerungen oder dem Risiko des Abgleichens von Daten kommt. So wird sichergestellt, dass die Informationen an ihrem ursprünglichen Speicherort sicher bleiben.
Externe Salesforce-zu-Cloud-Integration (AWS und Snowflake): In diesem Modell erfolgt die Zusammenarbeit zwischen Salesforce und externen Cloud-Umgebungen. Mit einem Zero-Copy-Verbund können Organisationen verschiedene Infrastrukturen ohne Kosten oder Risiko einer Datenverschiebung überbrücken. Auf diese Weise können Teams die Identitätsfragmentierung beheben und die Reichweite erhöhen, während sie Daten in ihrer lokalen Cloud speichern, die zentrale Verwaltung beibehalten und die Ausgangsgebühren eliminieren.
Zero-Copy-Architekturen und Verbundarchitekturen verhindern, dass Rohdaten verschoben oder dupliziert werden. Sie allein garantieren jedoch nicht die Privatsphäre. In diesen Modellen wird das primäre Risiko vom Datenspeicher zur Datenberechnung verschoben.
Sensible Informationen können weiterhin durch Analyseausgaben verloren gehen, selbst wenn nur aggregierte Ergebnisse zurückgegeben werden. Zu den gängigen Angriffsvektoren zählen wiederholte oder sich überschneidende Abfragen (unterschiedliche Angriffe), die Analyse sehr kleiner Populationen und Rückschlüsse mithilfe von externem Knowledge. Daher werden Datenschutzbelange über die Zugriffssteuerung hinaus zu einer dynamischen Anforderung für die Abfrageausführung.
Reinräume für Unternehmensdaten müssen Datenschutztechnologien als obligatorische Kontrollen auf Systemebene behandeln, nicht als optionale Analysefunktionen oder Richtlinienempfehlungen. Aus architektonischer Sicht bedeutet dies:
- Datenschutz wird von der Plattform erzwungen, nicht von Analysten
- Steuerelemente sind über Benutzer, Partner und Arbeitslasten hinweg konsistent
- Datenschutzgarantien sind deterministisch, wiederholbar und überprüfbar
- Das System definiert, welche Berechnungen zulässig sind, wie die Ergebnisse geformt werden und wann Abfragen blockiert werden müssen.
Kernfunktionen für PET
Unterschiedliche Datenschutzbestimmungen: Differential Privacy (DP) bietet eine mathematische Garantie dafür, dass sich die Anwesenheit oder Abwesenheit einer Einzelperson nicht wesentlich auf die Abfrageergebnisse auswirkt. In der Praxis bedeutet dies, dass der Reinraum automatisch kalibrierte statistische Störungen in die Ausgaben einschleust und ein definiertes Datenschutzbudget für jedes Datenset verfolgt. Jede Abfrage verbraucht einen Teil dieses Budgets und sobald sie erschöpft ist, werden weitere Abfragen blockiert. Für Architekten liegt der Wert von DP in der Nachweisbarkeit. Das Datenschutzrisiko ist quantitativ begrenzt, was eine vertretbare Compliance ermöglicht und die Abhängigkeit von subjektiver Richtlinieninterpretation reduziert.
Sichere Kennzeichnerausrichtung: Viele Szenarien für die Zusammenarbeit erfordern die Identifizierung von Überschneidungen zwischen Datensets, beispielsweise freigegebenen Kunden oder Accounts. Die Offenlegung von Rohkennzeichnern würde gegen die Grundsätze der Datenminimierung verstoßen. Eine Architektur mit Reinraumqualität basiert stattdessen auf deterministischem Hashing oder Tokenisierung, die innerhalb der Reinraumgrenze durchgeführt wird. Vergleiche werden durchgeführt, ohne dass rohe Kennzeichner für Dritte offengelegt werden, was ein verknüpfungsähnliches Verhalten ohne Datenoffenlegung ermöglicht.
Aggregationsschwellenwerte und Ergebnisunterdrückung: Selbst vollständig anonymisierte Ausgaben können kompromittiert werden, wenn Ergebnisse aus sehr kleinen Populationen abgeleitet werden. Um dies zu verhindern, muss ein Unternehmensdaten-Reinraum Mindestaggregationsschwellenwerte erzwingen und automatisch Ergebnisse unterdrücken, die darunter fallen. Diese Schwellenwerte müssen nicht überschreibbar sein und einen einheitlichen Schutz gegen Leckagen kleiner Segmente gewährleisten.
Ohne die auf der Ausführungsebene erzwungenen datenschutzerweiternden Technologien (Privacy-Enhancing Technologies, PETs) laufen Datenreinräume Gefahr, zu Trust Umgebungen zu werden, die auf menschlichem Ermessen und vertraglichen Vereinbarungen basieren. Durch die direkte Integration von PETs in die Plattform wird Datenschutz zu einer strukturellen Eigenschaft und nicht zu einer prozeduralen Eigenschaft. Auf diese Weise kann die Zusammenarbeit zwischen Teams und Partnern skaliert werden, ohne Trust neu auszuhandeln, während Regulierungsbehörden und Risikoteams Garantien mithilfe objektiver mathematischer Maßeinheiten statt subjektiver Richtlinien bewerten können.
Für Unternehmensarchitekten sind PETs der entscheidende Mechanismus, der einen Datenreinraum von einer sicheren Sandbox zu einer vertrauenswürdigen Zusammenarbeitsstruktur macht, die regulierte Analysen und AI-Arbeitslasten mehrerer Parteien im Unternehmensmaßstab unterstützt.
Bei der Zusammenarbeit mehrerer Parteien wird Trust durch Sichtbarkeit gewahrt. Ein Datenreinraum auf Unternehmensebene muss eine "Papierspur" für jede Interaktion zwischen den Teilnehmern und den Daten bereitstellen.
Abfrageprotokolle: Jede SQL-Ausführung wird protokolliert und erfasst die Identität des Anforderers, den Zeitstempel und die spezifische verwendete Abfragelogik.
Policy Enforcement Logs (Policy-Erzwingungsprotokolle): Das System muss nicht nur aufzeichnen, was abgefragt wurde, sondern auch, welche Datenschutzrichtlinien (z. B. Aggregationsschwellenwerte oder "Differenzieller Datenschutz") auf die Ergebnisse angewendet wurden.
Zero-Manipulation Records (Zero-Tamper-Datensätze): Mithilfe eines unveränderlichen Überprüfungsprotokolls (dediziertes Datenmodellobjekt) stellt der Datenreinigungsraum sicher, dass Protokolle von keinem Teilnehmer geändert oder gelöscht werden können, und bietet den Regulierungsbehörden eine einzige Version der Wahrheit.
Salesforce ermöglicht moderne Datenreinigungsräume, indem Organisationen Daten analysieren und gemeinsam bearbeiten können, ohne jemals Rohdatensets freizugeben. Salesforce Data 360 basiert auf einer kopierfreien Verbundarchitektur mit Datenschutz, Einwilligung und Governance, die bei der Ausführung erzwungen wird, und stellt sicher, dass Statistiken sicher, konform und vollständig handlungsrelevant sind. Durch die direkte Integration von Reinräumen in den Unternehmensdatenlebenszyklus verwandelt Salesforce Data 360 sie von Nischenanalysetools in eine skalierbare, vertrauenswürdige Infrastruktur für die AI-gestützte Zusammenarbeit und die Zusammenarbeit mehrerer Parteien.
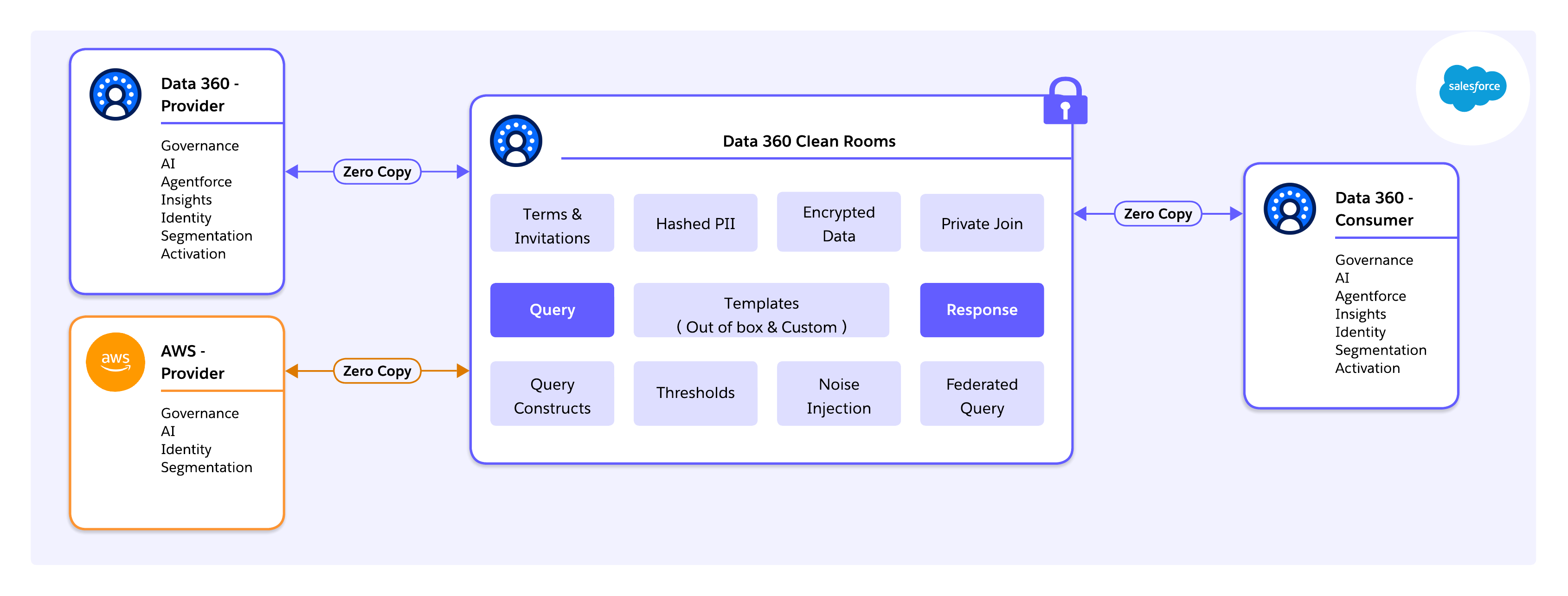
Auf Infrastrukturebene wird Salesforce Data 360 mit Hyperforce ausgeführt, der cloudnativen Laufzeit von Salesforce, die Hyperscaler-Ressourcen (AWS, Azure, GCP) hinter einer einheitlichen Steuerungsebene abstrahiert. Diese Architektur ermöglicht es, dass Daten in der Region verbleiben, um die Anforderungen an die Souveränität und die Residenz zu erfüllen, und ermöglicht gleichzeitig einen geregelten Reinraumbetrieb weltweit.
Entscheidend ist, dass diese Grundlage die cloudübergreifende Reinraumzusammenarbeit ermöglicht, einschließlich der nativen Interoperabilität mit AWS Clean Rooms. Mit Data 360 als Orchestrierungs- und Governance-Ebene können Unternehmen mit Partnern zusammenarbeiten, die direkt in AWS arbeiten, ohne die Datenmigration in den von Salesforce verwalteten Speicher zu erzwingen. Abfragen werden an die Quelle übertragen, Datenschutzregeln werden einheitlich erzwungen und nur konforme, aggregierte Ergebnisse werden plattformübergreifend ausgetauscht.
Compliance und Trust werden an der Infrastruktur- und Ausführungsgrenze erzwungen und nicht auf Anwendungsebene nachgerüstet. Dies bietet eine dauerhafte Grundlage für die Zusammenarbeit mit mehreren Beteiligten in mehreren Clouds.
Data 360 implementiert eine rückverfolgbare, durchgängige Datenpipeline und stellt sicher, dass Reinraumvorgänge über harmonisierte, geregelte und identitätsbewusste Daten statt über Rohextrakte ausgeführt werden. Wichtige Phasen sind:
- Verbinden: Datenaufnahme und Virtualisierung über vorkonfigurierte Konnektoren, APIs, SDKs, MuleSoft oder Zero-Copy-Konnektoren
- Beharren: Speichern von Rohdaten in nativen Formaten (Parquet / Iceberg)
- Harmonisieren: Zuordnung zu kanonischen Datenmodellobjekten (DMOs) für konsistente Verknüpfungen
- Zusammenführen: Identitätsbestimmung erstellt Goldene Datensätze
- Ableiten von Statistiken: Berechnete Statistiken berechnen aggregierte Kennzahlen innerhalb der festgelegten Grenze
- Act: Gesteuerte Ausgaben fließen in Salesforce-Organisationen, Marketingplattformen, Anzeigennetzwerke, externe Datenplattformen oder andere Reinräume und schließen die Statistik-to-Action-Schleife
Durch diese Pipeline wird sichergestellt, dass Reinräume mit Daten auf Unternehmensebene arbeiten und nicht mit Ad-hoc-Extrakten.
Anders als eigenständige Datenreinraumplattformen, die eine separate Bereitstellung und SQL-Entwicklung erfordern, sind Salesforce-Reinräume nativ in Data 360 eingebettet. Dadurch wird die Wiederverwendung von DMOs, Identitätsregeln, Einwilligungsmodellen und Governance-Richtlinien ermöglicht, wodurch doppelte Sicherheitsebenen vermieden werden. Das vorlagengesteuerte Reinraummodell von Salesforce ist ein wichtiger Beschleuniger und verwendet Folgendes:
- Vorkonfigurierte Vorlagen zur Unterstützung allgemeiner Zusammenarbeitsmuster wie Zielgruppenüberschneidung, Unterdrückung, Reichweite und Lift-Messung.
- Benutzerdefinierte Vorlagen, mit denen Architekten und fortgeschrittene Benutzer wiederverwendbare Analyselogik definieren können, die auf branchenspezifische oder partnerspezifische Anforderungen zugeschnitten ist, ohne Rohdaten oder Richtlinienkomplexität offenzulegen. Dieser Ansatz standardisiert die Zusammenarbeit und ermöglicht gleichzeitig Flexibilität, sodass Reinräume als wiederholbare Unternehmensfunktion und nicht als einmaliges Analyseprojekt skaliert werden können.
Data 360 behebt einen gängigen Fehlermodus herkömmlicher Reinräume: die Aktivierungslücke. Das Framework "Goldener Pfad" stellt sicher, dass innerhalb eines Reinraums generierte Statistiken sofort verarbeitet werden können, ohne Rohdaten exportieren zu müssen.
- Setup und Discovery: Partner geben Schema-Metadaten frei und nutzen Vorlagen, um die Durchführbarkeit zu bewerten, bevor Verträge abgeschlossen werden.
- Analyse: Vorgefertigte und benutzerdefinierte Vorlagen steuern die Überschneidungsanalyse, Unterdrückung, Ähnlichkeitsmodellierung und Lift-Messung, die alle innerhalb der festgelegten Grenze ausgeführt werden.
- Aktivierung: Genehmigte Segmente werden direkt in Marketing Cloud, Anzeigenplattformen oder Partnersysteme übertragen, wobei nur aggregierte, konforme Ergebnisse freigegeben werden.
Vorlagen werden zu Ausführungspfaden mit Meinungen, wodurch sichergestellt wird, dass die Zusammenarbeit vorhersehbar von der Analyse zur Aktivierung übergeht.
Die Bereitstellung eines Salesforce Data 360-Reinraums ist nicht nur eine Konfigurationsaufgabe, sondern ein disziplinierter architektonischer Workflow, der Datenbereitschaft, Governance-Design, sichere Konnektivität und Betriebsüberwachung umfasst.
Vor dem Berühren von Daten oder Konfigurationen müssen Architekten Folgendes klar definieren:
- Welche Frage versuchen wir zu beantworten?
- Welches Ergebnis wird erwartet? (z.B. Überschneidungsanalyse, Lift-Messung, Unterdrückung, Betrugserkennung)
- Welche Aggregationsebene ist erforderlich?
- Welche regulatorischen oder vertraglichen Einschränkungen gelten?
- Welcher Aktivierungspfad verwendet die Ergebnisse?
Wenn Sie die Zielsetzung des Mitarbeiters verstehen, ist dies alles, was folgt: Verknüpfungsschlüssel, Identitätsregeln, Governance-Schwellenwerte und Kostenmodellierung. Reinräume sind zweckgerichtete Umgebungen. Sie sollten auf ein definiertes Analyseziel ausgerichtet sein und nicht auf eine allgemeine Datenoffenlegung.
Bevor die Zusammenarbeit beginnen kann, müssen Unternehmensdaten strukturell und semantisch vorbereitet werden. Reinräume verstärken Stärken und Schwächen der zugrunde liegenden Daten. Müll rein, Müll raus ist hier umso wahrer.
Aufnahme: Verbinden Sie Quellsysteme wie Salesforce CRM, Marketing Cloud, AWS S3 und Google Cloud Storage mit Data 360. Verwenden Sie nach Möglichkeit Zero-Copy-Konnektoren (z. B. Snowflake), um unnötige Verschiebungen oder Duplikate von Daten zu vermeiden.
Semantische Zuordnung: Ordnen Sie dem Customer 360 Datenmodell Datenströme zu. Standardisieren Sie wichtige Felder wie Telefonnummern (E.164-Format), Länder-/Bundeslandcodes (ISO-Standards) und E-Mail-Adressen. Fehlausrichtungen (beispielsweise eine Seite, die "CA" und eine andere "California" verwendet) können bei Verknüpfungen stillschweigend fehlschlagen und die Übereinstimmungsraten reduzieren.
Identitätsbestimmung: Konfigurieren Sie deterministische (genaue Übereinstimmung) und probabilistische (Fuzzyübereinstimmung) Regeln, um eine zusammengeführte Einzelperson (Goldener Datensatz) zu erstellen. Diese zusammengeführte Einheit ist die Oberfläche für den Reinraumabgleich. Die Qualität der Identitätsbestimmung wirkt sich direkt auf den Wert der Zusammenarbeit aus. Eine höhere Übereinstimmungsgenauigkeit erhöht die Überschneidungsraten, die analytische Konfidenz und reduziert falsch negative Werte.
Sobald die Daten harmonisiert sind, muss der Reinraum selbst bereitgestellt werden, um Grenzen für die Zusammenarbeit zu definieren.
Lizenzvalidierung: Stellen Sie sicher, dass alle teilnehmenden Organisationen über die erforderlichen Data 360- und Reinraumansprüche verfügen.
Umfang des Datenbereichs: Reinraumobjekte müssen auf einen bestimmten Datenbereich begrenzt sein. Nur diesem Datenbereich zugeordnete Objekte sind für den Reinraum sichtbar. Dadurch wird die Zusammenarbeit logisch isoliert, ohne dass ein neuer Datenbereich ausschließlich für Reinräume erstellt werden muss.
Leitungsregeln definieren: Richten Sie Richtlinien deklarativ ein, bevor Abfragen ausgeführt werden:
- Aggregationsschwellenwerte: beispielsweise mindestens 100 Datensätze pro Ausgabe
- Join Keys: for example, Email_Hash_SHA256
- Zulässige Vorgänge: Nur aggregierte Funktionen wie COUNT, SUM, AVG
- Explizite Einschränkungen: Blockieren von Exporten auf Zeilenebene (SELECT *)
Governance-Regeln werden zur Ausführungszeit erzwungen, wodurch Eigenschaften auf Datenschutz- und Compliance-Systemebene anstelle von Verfahrensanleitungen verwendet werden.
Reinräume erstrecken sich oft über Organisations- und Plattformgrenzen. Die Konnektivität muss explizit und streng kontrolliert sein.
Accountverknüpfung:
- Salesforce-to-Salesforce: Verwenden Sie Data Cloud One oder genehmigte organisationsübergreifende Freigabemechanismen.
- Szenarien mit mehreren Clouds: Validieren Sie die Regionsausrichtung und die Residenz, bevor Abfragen aktiviert werden.
Authentifizierung und Autorisierung: Konfigurieren Sie den OAuth-basierten Zugriff für dedizierte Integrationsbenutzer mit dem Prinzip der geringsten Berechtigung – beschränken Sie den Zugriff strikt auf die erforderlichen Datenbereiche und vermeiden Sie administrative Berechtigungen. Sicherheitsfehler sind häufig auf überberechtigte Integrationsbenutzer zurückzuführen und nicht auf Schwächen in der Kryptografie oder bei Plattformsteuerungen.
Sobald Sie live sind, konzentrieren Sie sich auf die operative Aufsicht, die Abfragequalität und das Kostenmanagement.
Abfrageausführung: Analysten oder Workflows führen Überschneidungsanalysen und -aggregationen über berechnete Statistiken oder genehmigte SQL-Schnittstellen aus. Alle Abfragen erzwingen automatisch Aggregationsschwellenwerte und Datenschutzkontrollen.
Aktivierung und Rückverfolgbarkeit: Salesforce Data 360-Reinräume bieten Audit Trails in Form eines Audit-Datenmodellobjekts (DMO). Dadurch werden Metadaten über die Abfrageaktivität erfasst, einschließlich der Benutzer, die die Abfrage ausgeführt haben, wann sie ausgeführt wurde und welche Richtlinien angewendet wurden. Das Datenmodellobjekt für Prüfungen ermöglicht Compliance-Berichte, Governance-Validierung und forensische Rückverfolgbarkeit und stellt sicher, dass die Zusammenarbeit sowohl datenschutzgerecht als auch überprüfbar ist.
Verbrauchsüberwachung: Data Cloud verwendet ein verbrauchsbasiertes Kreditmodell. Zu den wichtigsten Faktoren zählen:
- Verarbeitete Zeilen (z. B. 1 Million Zeilen = Basisgutschriftseinheit)
- Abfragekomplexität
- Vorgänge zur Identitätsbestimmung (höherer Multiplikator)
- Batchaufnahme (niedriger Multiplikator)
Digital Wallet und Warnmeldungen: Verwenden Sie Digital Wallet, um den Echtzeitverbrauch zu verfolgen und Benachrichtigungen mit Schwellenwerten von 50 %, 75 % und 90 % zu konfigurieren. Korrelieren Sie Spitzen mit bestimmten Arbeitslasten, um unerwartete Kosten zu vermeiden. Beachten Sie, dass die Berechnungskosten durch Nullkopie nicht beseitigt werden. Während physische Duplikate entfernt werden, erfolgt die Ausführung im Quellsystem. Architekten müssen Abfragemuster, Verknüpfungsselektivität und Ausführungshäufigkeit verwalten, um Kosten und Leistung zu steuern.
In modernen Unternehmen ist Trust nicht an einen Datenreinigungsraum gebunden. Es ist ein architektonisches Ergebnis. Salesforce Data 360 erzwingt kontinuierlich und automatisch Governance, Sicherheit und Compliance und verlagert Reinräume von richtliniengesteuerten Umgebungen zu plattformgesteuerten Systemen. Kontrollen der Ausführungszeit (gesperrte Identitäten, Prüfungsprotokolle und differenzieller Datenschutz) werden einheitlich angewendet, unabhängig davon, ob die Zusammenarbeit innerhalb von Salesforce, partnerübergreifend oder cloudübergreifend erfolgt.
Die wichtigste Veränderung für Architekten besteht darin, dass Trust während der Ausführung erzwungen und nicht im Voraus vorausgesetzt wird. Salesforce Data 360 erreicht dies durch eine Reihe zentraler Plattformsteuerungen:
- Gesperrte Identität: Der Partnerzugriff ist kryptografisch mit überprüften Salesforce-Organisationsidentitäten verknüpft, wodurch Spoofing oder nicht autorisierte Teilnahme verhindert werden.
- Audit Trails: Jede Abfrage, Verknüpfung, Segmentüberschneidung und Aktivierung wird protokolliert, um die vollständige Überprüfbarkeit und Einhaltung gesetzlicher Vorschriften zu gewährleisten.
- Unterschiedliche Datenschutzbestimmungen: Eine Inspektion auf Zeilenebene ist strukturell nicht möglich. Ausgaben werden aggregiert und statistisch begrenzt. Mitarbeitern werden nur datenschutzsichere Ergebnisse wie Reichweitenkennzahlen oder Lift-Prozentsätze angezeigt, niemals einzelne Transaktionen oder Identitäten. Diese Steuerelemente ersetzen vertraglichen Trust durch mathematische Garantien und die Durchsetzung auf Plattformebene, was das betriebliche und rechtliche Risiko reduziert.
Da AI-Agenten zunehmend mit Reinraumdaten interagieren, führt Salesforce die Einstein Trust Layer ein. Sie fungiert als architektonische Schleuse zwischen sensiblen Unternehmensdaten und externen LLMs. Auf diese Weise wird sichergestellt, dass Reinraumstatistiken KI-gestützte Entscheidungen sicher vorantreiben können, ohne zugrunde liegende Daten offenzulegen.
Wichtige Funktionen:
- Datenaufbewahrung null: Die an LLMs gesendeten Daten sind vorübergehend. Modellanbieter können keine Aufforderungen oder Antworten für Schulungen speichern.
- Toxische Spracherkennung und Maskierung personenbezogener Daten: Eingaben und Ausgaben werden automatisch gescannt und personenbezogene Daten werden entsprechend den in Data 360 konfigurierten Datenmaskierungsrichtlinien maskiert.
Datenbereiche stellen eine logische Isolation innerhalb einer Organisation dar und sollten mit regulatorischen, geografischen und Partnerschaftsgrenzen in Einklang stehen, beispielsweise:
- EU-Datenbereich
- Nordamerika-Datenbereich
Nur Datensets, die einem Datenbereich zugewiesen sind, sind in seinen Reinräumen sichtbar, wodurch eine versehentliche grenzüberschreitende Offenlegung verhindert wird. Berechtigungssätze bieten eine genaue Kontrolle darüber, wer Reinräume erstellen oder verwalten, Abfragen ausführen oder Segmente aktivieren kann. Berechtigungen mit Datenbewusstsein erzwingen Einschränkungen auf Feldebene in Datenmodellobjekten. Beispielsweise können Marketingexperten Segmentnamen und Zielgruppengröße anzeigen, nicht jedoch Einkommens- oder Gesundheitsindikatoren. Die Sicherheit wird auf semantischer Ebene erzwungen, was Geschäftsbenutzern einen sicheren Self-Service ohne ständige IT-Aufsicht ermöglicht.
Einwilligungssignale werden automatisch über Data 360 in die Reinraumausführung übernommen. Benutzer, die die Einwilligung widerrufen, werden standardmäßig von der Analyse und Aktivierung ausgeschlossen. So wird sichergestellt, dass die Einhaltung vom System erzwungen und nicht manuell überwacht wird.
Salesforce Data 360 behandelt Governance, Sicherheit und Compliance als erstklassige architektonische Primitiven und nicht als optionale Add-Ons. Durch die Kombination von Überprüfbarkeit zur Ausführungszeit, gesperrten Identitäten, unterschiedlicher Privatsphäre, Datenbereichen, der Identitätsbestimmung mit Einwilligungsbewusstsein und der Einstein Trust Layer können Unternehmen die Zusammenarbeit im Reinraum zwischen Partnern, Multi-Cloud-Systemen und AI-gestützten Arbeitslasten skalieren, ohne Trust, Datenschutz oder die Einhaltung gesetzlicher Vorschriften zu beeinträchtigen.
Um den vollen Wert von Datenreinräumen zu erfassen, müssen Architekten sie als zentrale architektonische Infrastruktur und nicht als isolierte Analysetools behandeln. Die folgenden Prioritäten definieren einen pragmatischen und skalierbaren Weg nach vorn: Machen Sie Zusammenarbeit zu einem erstklassigen architektonischen Anliegen: Die Zusammenarbeit mit externen Daten sollte mit der gleichen Strenge wie die interne Integration konzipiert werden. Reinräume sollten neben Datenplattformen, Integrationsebenen und AI-Systemen in Unternehmensreferenzarchitekturen eingebettet sein und nicht als Ad-hoc-Erweiterungen bereitgestellt werden. Mit zunehmender Interoperabilität (z. B. Data 360-Reinraumintegration in AWS-Reinräume und künftige Reinraum-übergreifende Kompatibilität) müssen Architekten Zusammenarbeitsmuster entwerfen, die plattformübergreifende Ökosysteme anstelle von Silos mit einem einzelnen Anbieter antizipieren.
Standardmäßiges Entwerfen für Datenschutz an der Quelle
Design für Datenfluidität: Anstatt standardmäßig auf eine umfangreiche ETL und einen zentralen Abgleich zu setzen, sollten Architekten zunächst Verbund- und Zero-Copy-Zugriff in Betracht ziehen. Durch das Verschieben der Berechnung auf Daten (sofern angemessen) werden unnötige Duplikate reduziert, Kosten gesenkt und die Integrität der Quelle der Wahrheit gewahrt. "Verbinden vs. kopieren" sollte eine bewusste architektonische Entscheidung sein und keine übernommene Gewohnheit.
Schließen der Handlungslücke für Statistiken: Reinräume, die bei der Analyse stehen bleiben, bieten keinen Geschäftswert. Architekturen müssen Reinraumausgaben nativ mit Aktivierungssystemen und AI-Workflows verbinden. Feedbackschleifen, die Leistungsmessung und die nachgelagerte Ausführung müssen von Anfang an konzipiert sein.
Vorbereiten auf das Agentic Enterprise: Da AI-Agenten zunehmend Unternehmensdaten verwenden, dienen Reinräume als kontrollierte Ausführungsumgebungen, in denen Agenten arbeiten können, ohne Rohdaten offenzulegen. Architekten, die die Reinraumstrategie auf AI Governance und Trust Frameworks abstimmen, sind für diese nächste Phase am besten aufgestellt.
Moderne Datenreinräume stellen eine grundlegende Veränderung in der Unternehmensdatenarchitektur dar. Sie lösen die langjährige Spannung zwischen Datendienstprogramm und Datenschutz, indem sie die Zusammenarbeit ohne Offenlegung von Daten ermöglichen.
Architekturen wie Salesforce Data 360 zeigen, dass dieser Kompromiss keine Überlegung vom Typ "Entweder oder" ist. Durch die Entkopplung des Datenspeichers von der Aktivierung durch Zero-Copy-Muster und die direkte Integration von Technologien zur Verbesserung des Datenschutzes in die Ausführung können Unternehmen an hochwertigen Analysen zusammenarbeiten, ohne die Kontrolle über ihre Daten aufzugeben. Datenschutz wird von der vertraglichen Verpflichtung zur architektonischen Garantie.
Am wichtigsten ist, dass Reinräume Daten aus einem statischen, isolierten Vermögenswert in eine verwaltete, handlungsrelevante Ressource umwandeln. Wenn Statistiken nativ mit Aktivierungs- und AI-Ebenen verbunden sind, werden sie in Dashboards nicht mehr verzögert. Sie fließen direkt in Entscheidungen, Kampagnen und autonome Systeme ein und schließen so den Kreis zwischen Daten, Aktionen und Ergebnissen im Unternehmensmaßstab.
Yugandhar Bora ist Software-Engineering-Architekt bei Salesforce und spezialisiert sich auf die Datenarchitektur innerhalb der Plattform für Daten- und Intelligenzanwendungen. Er leitet Initiativen des Enterprise Architecture Review Board (EARB), die sich auf die Datenverwaltung und vereinheitlichte Datenmodelle konzentrieren, und trägt gleichzeitig zu automatisierten Plattformbereitstellungslösungen bei.
Birendra Kumar Singh ist Principal Member of Technical Staff und spezialisiert sich auf Plattform- und Datenarchitektur in Data 360 bei Salesforce. Er ist ein zentrales Mitglied der Aktivierungsplattform und leitet die Initiative "Reinraum", die sich auf die Bereitstellung der Datenreinraum-Infrastruktur für Data 360-Kunden konzentriert.
Priyanka Kshirsagar ist Senior Product Manager bei Salesforce und leitet Data 360-Reinräume. Sie hat diese Funktion von Grund auf neu entwickelt, um Unternehmenskunden die Zusammenarbeit an Erstanbieterdaten in einer Umgebung zu ermöglichen, in der die Privatsphäre gewahrt bleibt. Sie treibt die Vision für agentenbasierte AI und ML-gestützte Anwendungsfälle voran, einschließlich Ähnlichkeitsmodellierung und Identitätsanreicherung in Reinräumen, und hat das Produkt über die allgemeine Verfügbarkeit und eine Einführung von Tier-1-Dreamforce eingeführt.