Ce texte a été traduit en utilisant le système de traduction automatisé de Salesforce. Répondez à notre sondage pour nous faire part de vos commentaires sur ce contenu et nous dire ce que vous aimeriez voir ensuite.
Note
Vue d'ensemble
Ce document présente les options actuelles de déploiement d'applications vers CloudHub 2.0 pour répondre aux exigences de haute disponibilité et de reprise après sinistre. Il utilise la région des États-Unis comme exemple et peut être appliqué à d'autres régions.
CloudHub 2.0 est une plate-forme d'intégration native entièrement gérée dans le cloud qui élimine les surcoûts d'infrastructure en automatisant le déploiement, la mise à l'échelle et la gestion des API et des intégrations MuleSoft dans le cloud. C'est la plate-forme de déploiement cloud moderne de MuleSoft, exécutée sur l'infrastructure Amazon AWS.
Exigences de reprise après sinistre
Dans la plupart des cas, les paramètres par défaut Haute disponibilité (HA) et Reprise après sinistre (DR) fournis par CloudHub 2.0 sont suffisants. CloudHub 2.0 fournit l'AP et la DR au niveau régional (pour plus de détails, consultez Scénarios de panne CloudHub 2.0). La section Considérations clés relatives à CloudHub 2.0 fournit plus de détails sur les HA et DR pris en charge par CloudHub-2.0.
Les conditions qui imposent une conception au-delà de la disponibilité par défaut de CloudHub 2.0 comprennent :
Une application ne doit garantir aucune perte de données dans un scénario catastrophe (par exemple, une région d'Amazonie en déclin).
Une application dépend de la boutique d'objets et doit assurer la continuité si la zone de déploiement est en panne.
Hypothèses
Les systèmes back-end sont configurés pour une disponibilité équivalente. CloudHub 2.0 peut parfois fournir de la fiabilité via des files d'attente ou des mécanismes similaires, mais que l'intégration soit en temps réel ou asynchrone, les systèmes back-end doivent prendre en charge un niveau comparable de HA et DR.
Lorsqu'une panne au niveau de la région AWS affecte des systèmes back-end, leur reprise est supposée être exécutée parallèlement à la reprise CloudHub 2.0.
La configuration de l'espace privé est terminée dans plusieurs régions.
Hors champ
Les options de conception de ce guide se concentrent sur les solutions de disponibilité des applications dans CloudHub 2.0 lorsqu'une zone ou une région AWS Availability complète n'est plus disponible.
Le présent guide n'aborde pas les scénarios de rétablissement ci-dessous, bien qu'il en fasse état, le cas échéant :
Récupération de systèmes back-end, d'applications, de bases de données, de composants réseau et de centres de données gérés et provisionnés hors d'Anypoint CloudHub, sur site ou dans le cloud.
Récupération des liens VPN entre CloudHub 2.0 et le centre de données privé du client (par exemple, tunnels IPsec et passerelles VPN). Certaines options de RD de ce guide peuvent répondre partiellement à ces scénarios.
Les modifications apportées à MuleSoft entraînent la sortie des adresses IP pendant la reprise après sinistre lorsque la liste d'autorisations IP est utilisée pour des intégrations. Certaines options de RD de ce guide peuvent répondre partiellement à ces scénarios.
Systèmes de messagerie externes utilisés dans les solutions clients, qu'ils soient fournis par MuleSoft (tel que Anypoint MQ) ou d'autres fournisseurs (tels que AWS MSK ou Heroku Kafka).
Considérations clés relatives à CloudHub 2.0
Lors de l'évaluation des exigences de reprise après sinistre de CloudHub 2.0, tenez compte des considérations ci-dessous.
Dépendance de CloudHub 2.0 par rapport à la disponibilité régionale AWS
CloudHub 2.0 fonctionne sur AWS. Sa disponibilité est liée aux régions AWS.
Les déploiements et la disponibilité des applications sont organisés par région. Ces régions correspondent aux régions AWS.
Si une région AWS entière échoue, les applications de cette région ne sont pas disponibles et ne sont pas automatiquement répliquées ailleurs.
Haute disponibilité des applications (HA) et gestion des répliques
CloudHub 2.0 redéploie automatiquement les applications dans la même région en cas de défaillance matérielle, mais une application avec une seule réplique peut rencontrer des temps d'arrêt.
Les applications qui contiennent plusieurs répliques sont déployées par défaut dans des zones de disponibilité séparées, ce qui fournit une AP entre les zones.
Si la zone de disponibilité d'une application à réplique unique échoue, l'application est automatiquement affichée dans une autre zone de disponibilité dans la même région.
Impact spécifique à la région Est des États-Unis
En cas de panne dans la région Est des États-Unis :
L'interface utilisateur de gestion CloudHub 2.0 et les services REST de déploiement ne sont pas disponibles, et les nouvelles applications ne peuvent pas être déployées.
Dans la plupart des cas, les demandes dans d'autres régions ne sont pas affectées. Ces applications continuent de fonctionner normalement; cependant, les capacités de surveillance et de gestion via le plan de contrôle ne seront pas disponibles pendant la panne.
Les modules Core CloudHub 2.0 (tels que les paramètres d'application) sont conservés dans l'est des États-Unis. Par conséquent, les paramètres ne peuvent pas être modifiés pendant la panne.
Surveillance et alerte
Configurez des alertes en cas de défaillance de la zone de disponibilité ou de la région via status.mulesoft.com.
Utilisez un mécanisme de contrôle d'intégrité et d'alerte séparé hors de CloudHub 2.0 afin de notifier les équipes en cas d'échec des répliques ou d'arrêt de la réponse des applications.
Persistance des données (Boutique d'objets V2)
La boutique d'objets V2 est liée à la région où l'application a été déployée pour la première fois.
Si vous déplacez l'application vers une autre région, Object Store V2 reste dans la région d'origine pour éviter la perte de données.
Si la région dans laquelle le magasin d'objets V2 est déployé échoue, le magasin d'objets n'est pas disponible.
Contrôleurs d'entrée et espaces privés
Les contrôleurs d'entrée de CloudHub 2.0 sont hautement disponibles au niveau régional.
Dans un espace partagé, si une région échoue, un contrôleur d'entrée dans une autre région reste disponible, mais peut servir uniquement les applications déployées dans cette région.
Dans un espace privé, en cas de défaillance d'une région, les contrôleurs d'entrée d'autres régions ne sont pas disponibles, sauf s'ils y ont été configurés à l'avance.
La configuration de l'espace privé est régionale. Si une région échoue, l'espace privé n'est pas disponible, sauf si une autre région a été configurée.
Scénarios de panne CloudHub 2.0
Réplique / Zone de disponibilité / Région Pannes
Responsabilité de Salesforce
Statut du composant
Responsabilité de Salesforce
Replica Down
Action: CloudHub 2.0 redémarre automatiquement la réplique dans une autre zone de disponibilité en cas de problème avec la zone de disponibilité actuelle. Cependant, l'application sera hors ligne jusqu'au démarrage complet de la nouvelle réplique. Condition: Configuration par défaut. Durée: Environ 2-15 minutes selon la complexité de l'application et la taille de la réplique.
Zone de disponibilité vers le bas
Action: Comme la réplique vers le bas. Condition: Configuration par défaut. Durée: Comme la réplique vers le bas. Notification: Comme la réplique vers le bas.
Region Down
Action: Aucune récupération automatique. Une conception de basculement doit être en place.
Responsabilité du client
Statut du composant
Responsabilité du client
Replica Down
Notification: Effectuez des contrôles d'intégrité périodiques en utilisant un mécanisme de battements cardiaques intégré aux API. Mitigation: Déployez l'application dans plusieurs répliques dans la même région. Test / Simulation : Levez un ticket avec le support MuleSoft et ils prendront en charge un test de basculement pour vérifier si une nouvelle réplique tourne dans une autre zone AZ en 1 à 15 minutes.
Zone de disponibilité vers le bas
Notification: Comme la réplique vers le bas. Mitigation: Déployez l'application dans plusieurs répliques dans la même région ou dans différentes régions. Test / Simulation : Le scénario AZ Down est difficile à simuler. Il nécessite l'implication de MuleSoft Engineering pour prendre en charge les scénarios de test possibles.
Region Down
Notification: Comme la réplique vers le bas. Consultez également les mises à jour de statut sur https://status.aws.amazon.com. Atténuation: Comme AZ Down. Plan d'urgence de reprise après sinistre : 2 espaces privés avec la même configuration dans différentes régions. Test / Simulation : Comme AZ Down.
Pannes de la passerelle VPN et du contrôleur de pénétration
Responsabilité de Salesforce
Statut du composant
Responsabilité de Salesforce
VPN Gateway Down
Statut de réplique: En cours d’exécution, mais pas en mesure de se connecter à des ressources hébergées dans des locaux et accessibles via le tunnel VPN. Action: Aucune récupération automatique. Une conception de basculement doit être en place.
Contrôleur d'entrée (espace partagé) vers le bas
Statut de réplique: Le contrôleur Ingress est une configuration en cluster avec plusieurs instances, similaire aux répliques d'application. Si une réplique d'application échoue, une autre est automatiquement créée et démarrée. Si une instance de contrôleur d'entrée échoue, les applications restent disponibles via l'autre instance. Si le contrôleur Entrée est en panne, la région est considérée comme en panne.
Contrôleur d'entrée (espace privé) vers le bas
Statut de réplique : Identique à Contrôleur de pénétration dans l'espace partagé vers le bas.
Responsabilité du client
Statut du composant
Responsabilité du client
Passerelle VPN en panne
Notification: Effectuez des contrôles d'intégrité périodiques en utilisant un mécanisme de battements cardiaques intégré aux API. Mitigation: Les passerelles VPN CloudHub 2.0 prennent en charge la haute disponibilité via une architecture double tunnel avec basculement automatique entre les tunnels. Un client doit configurer ce schéma. Test / Simulation : Le scénario VPN Gateway Down est difficile à simuler. Nécessite l'implication de MuleSoft Engineering pour prendre en charge les scénarios de test possibles.
Contrôleur d'entrée (espace partagé) vers le bas
Notification: Identique à VPN Gateway Down. Mitigation: Identique à Region Down. Migrez des applications vers un espace en attente ou actif dans une autre région. Test / Simulation : Identique à VPN Gateway Down.
Contrôleur d'entrée (espace privé) vers le bas
Notification: Identique à VPN Gateway Down. Mitigation: Identique à Region Down. Migrez des applications vers un espace privé en attente ou actif dans une autre région, en coordination avec la configuration AWS Route 53 (ou équivalente). Test / Simulation : Identique à VPN Gateway Down.
Magasins d'objets et files d'attente permanentes
Vue d'ensemble Scénario descendant des services de plate-forme - Magasin d'objets
Boutique d'objets en mémoire
Magasin d'objets persistants v2
Emplacement des données
Local uniquement dans l'application.
Dans la région où l'application MuleSoft a été déployée pour la première fois.
Partagé entre les répliques ?
Non
Oui
Récupération de magasin d'objets dans les applications
Les données sont perdues. Toutes les données en mémoire sont perdues au redémarrage de l'application, lors d'un nouveau déploiement ou lors d'un échec de réplique.
Les données ne sont pas perdues, sauf si l'application est supprimée.
Récupération de magasin d'objets dans la région
Les données sont perdues (identique à ci-dessus).
Les données ne sont pas perdues (identique à ci-dessus).
Relèvement régional
Comme ci-dessus.
Les données ne sont pas disponibles. Même avec une configuration DR actif-actif, Object Store est disponible uniquement dans la région de déploiement d'origine.
Mitigation
Externalisez les données pour la récupération régionale.
Les données restent disponibles tant que la zone de déploiement d'origine est disponible. Pour une HA ou DR inter-régions, externalisez les données hors du magasin d'objets.
Haute disponibilité par rapport à Reprise après sinistre
Haute disponibilité (HA) est la mesure de la capacité d'un système à rester accessible en cas de défaillance d'un composant système. Généralement, l'AP est implémentée en intégrant plusieurs niveaux de tolérance aux pannes et/ou de capacités d'équilibrage de charge dans un système. Il s'agit généralement d'une configuration Actif-Actif et n'entraîne qu'un impact limité ou nul pour les Services commerciaux.
La reprise après sinistre (DR) est le processus par lequel un système est restauré dans un état acceptable antérieur après un scénario de catastrophe, soit naturel (comme des inondations, des tornades, des tremblements de terre ou des incendies), soit d'origine humaine (comme des pannes de courant, des pannes de serveur ou des configurations incorrectes). DR est généralement une configuration Actif-Passif et entraîne un certain impact pour les Services aux entreprises.
Disponibilité régionale dans CloudHub 2.0
Si la Haute disponibilité régionale ou la Reprise après sinistre régionale est souhaitée pour réduire les impacts métiers en cas d'échec régional AWS, tenez compte des points suivants lors de la conception de votre solution dans MuleSoft CloudHub 2.0 :
Les répliques CloudHub 2.0 et les capacités associées (espaces privés, contrôleurs d'entrée et destinations Anypoint MQ) sont spécifiques à la région.
Si une région AWS entière échoue, toutes les répliques et tous les services associés dans cette région ne sont plus disponibles.
Lorsqu'une région se rétablit, les configurations sont restaurées. Vous devez redémarrer les applications.
Si la région Est des États-Unis échoue, les services Anypoint Platform (par exemple, Gestion de l'accès et Gestionnaire d'exécution) ne sont pas disponibles.
MuleSoft fournit un accord de niveau de service de 99,95 % pour la disponibilité des services de plate-forme, y compris les répliques CloudHub 2.0 dans une configuration active-active dans une région. Pour plus d'informations, consultez le dernier accord de niveau de service d'offre Cloud MuleSoft.
CloudHub 2.0 ne prend pas en charge les zones multiples HA ou DR prêtes à l'emploi. La disponibilité est fournie uniquement dans une seule région.
Consignes de conception communes
Ces consignes de conception s'appliquent quelle que soit la configuration choisie.
Configuration d'espaces privés multirégions
Toutes les options décrites dans les sections suivantes nécessitent que les applications soient déployées dans des régions séparées. Cela est possible uniquement si la configuration de l'espace privé est terminée à l'avance, avant une catastrophe. La configuration des espaces privés est régionale. Par conséquent, une stratégie DR nécessite au moins deux espaces privés (un par région) et un mécanisme pour basculer le trafic vers le point de terminaison VPN approprié.
Configuration de l'espace privé hautement disponible dans une région
CloudHub 2.0 n'offre pas le basculement automatique lorsqu'un espace privé dans une région échoue. Une solution de contournement est une configuration active-passive dans plusieurs environnements, qui nécessite :
Configuration de plusieurs passerelles VPN dans l’espace privé.
Établir des environnements séparés dans la région CloudHub 2.0, chacun avec son propre espace privé.
Désignant l'un de ces environnements comme passif (où les applications ne sont pas initialement déployées, mais affichées si l'espace privé principal échoue).
Si une configuration à haute disponibilité sans passerelle VPN est un point de défaillance unique est une exigence difficile, le déploiement dans deux régions est la meilleure option. Dans ce scénario, un échec de la passerelle VPN peut être résolu en basculant la région affectée vers la région alternative où l’espace privé est déjà configuré.
Zéro perte de message
Pour éviter toute perte de messages lorsqu'une région entière échoue, une application doit empêcher la perte de données et traiter les points suivants :
Utilisez la messagerie externe pour garantir la fiabilité des messages.
Assurez-vous que Object Store n'est pas utilisé pour des données transactionnelles en vol de nature transactionnelle. Si la région de déploiement dans laquelle l'application MuleSoft a été déployée pour la première fois est en panne, la boutique d'objets n'est pas disponible.
Encapsulez tous les accès Magasin d'objets dans un flux ou une section séparé qui continue de fonctionner (pour le traitement des exceptions et le comportement) lorsque les opérations de lecture ou d'écriture de Magasin d'objets échouent.
Note. Dans la plupart des cas, les exigences DR n'ont pas besoin d'assurer une perte de message nulle en cas de catastrophe et doivent s'assurer que la perte de données est inférieure à la valeur de données d'une période donnée (par exemple, 1 heure).
Garder l'intégration apatride
En tant que principe général de conception, il est toujours important de garantir que les intégrations sont de nature apatride. Cela signifie qu'aucune information transactionnelle n'est partagée entre diverses invocations ou exécutions de clients (en cas de services planifiés). Si certaines données doivent être gérées par le middleware en raison d'une limitation système, elles doivent être conservées dans un magasin externe, par exemple une base de données ou une file d'attente de messagerie, pas dans l'infrastructure ou la mémoire MuleSoft. Il est important de noter qu'à mesure que nous évoluons, en particulier dans le cloud, l'état et les ressources utilisés par chaque réplique doivent être indépendants des autres répliques. Ce modèle garantit de meilleures performances, évolutivité et fiabilité.
Considérations supplémentaires relatives à DR pour le déploiement multi-régions
Réseautage et gestion du trafic
Les domaines de vanité sont requis pour la disponibilité régionale. Ils agissent comme un DNS global pour tous les contrôleurs d'entrée dans les régions.
Un équilibreur de charge global achemine le trafic entre les espaces privés de la région principale et de la région DR. Les clients fournissent ce composant. Utilisez AWS Route 53 ou un CDN global avec des stratégies d'acheminement pour acheminer le trafic à travers les régions.
Configurez des contrôleurs de pénétration dans les régions principales et DR avec un domaine de vanité personnalisé.
Planifiez et gérez les règles de pare-feu et le tunnel VPN de sorte que les applications sur site soient accessibles à partir des espaces privés de la région principale et de la région DR.
La maintenance des certificats TLS doit couvrir les espaces privés dans les régions principales et DR pour une récupération transparente.
Déploiement et configuration d'applications
Les noms de demande doivent être uniques entre les régions. Par exemple, un pipeline CI/CD peut ajouter le nom de la région (ou un code de région) aux noms d'application avant le déploiement afin de préserver l'unicité entre les régions principales et DR.
Configurez le pipeline CI/CD pour déployer des applications dans les régions principale et DR afin que toutes les applications soient disponibles dans les deux régions.
Infrastructure et capacité
Les performances sont meilleures lorsque tous les aspects de l'infrastructure ont une capacité primaire et une capacité de zone DR identiques. Les performances se dégradent lorsque ces aspects de l'infrastructure ne sont pas identiques.
Persistance et stockage des données
Le stockage permanent doit être synchronisé périodiquement entre les deux régions. Les clients sont responsables de la réplication du stockage. MuleSoft ne la fournit pas. Un magasin partagé unique entre les VPC dans les régions principale et DR est possible, mais le stockage partagé doit être hautement disponible ou il devient un point de défaillance unique pour les deux régions.
Object Store V2 est régional et disponible uniquement dans la région où l'application Mule a été initialement déployée. Si l'application est déplacée vers une autre région, Object Store V2 reste dans la région d'origine pour éviter la perte de données. Utilisez un autre stockage permanent pour des stratégies de RD multi-régions.
Procédures d'essai et procédures opérationnelles
Adoptez une stratégie de test DR formelle et exécutez des exercices DR périodiques. Pour DR actif-actif, utilisez une stratégie de déploiement de canari pour valider les deux régions.
Accords de performance et de niveau de service (SLA)
Une dégradation des performances peut se produire, car la région DR peut être plus éloignée des utilisateurs finaux ou des systèmes back-end que la région principale. Définissez et communiquez un accord de niveau de service DR aux parties prenantes.
Comportement du mode de récupération (Note contextuelle)
En mode actif-actif, le basculement depuis la région principale vers l'espace privé de la région DR est rapide : l'équilibreur de charge global détecte que le primaire est insalubre et achemine le trafic vers la région saine (DR). En mode actif-passif, vous devez déployer l'application dans l'espace privé de la région DR en cas de sinistre.
Options de disponibilité régionale
Il existe 3 options pour augmenter la disponibilité du niveau DR :
Une configuration active-active est basée sur des travailleurs actifs répartis entre les régions, en utilisant un équilibreur de charge externe pour acheminer le trafic entre les deux instances.
Configuration En attente
Une configuration active-passive serait basée sur un travailleur actif dans une région et un travailleur passif dans une autre région. La région passive serait mise en route en cas de besoin.
Certains éléments de la zone passive doivent rester actifs pour le basculement ou être configurés au préalable, notamment les espaces privés, les VPN et les pièces jointes de la passerelle de transit.
Comme précédemment, les répliques et les contrôleurs Ingress sont provisionnés dans une deuxième région via un processus DevOps entièrement automatisé lors du basculement. Certains éléments de la région passive doivent rester actifs pour le basculement, notamment les espaces privés, les VPN et les pièces jointes de la passerelle de transit.
Domaines de vanité pour la haute disponibilité
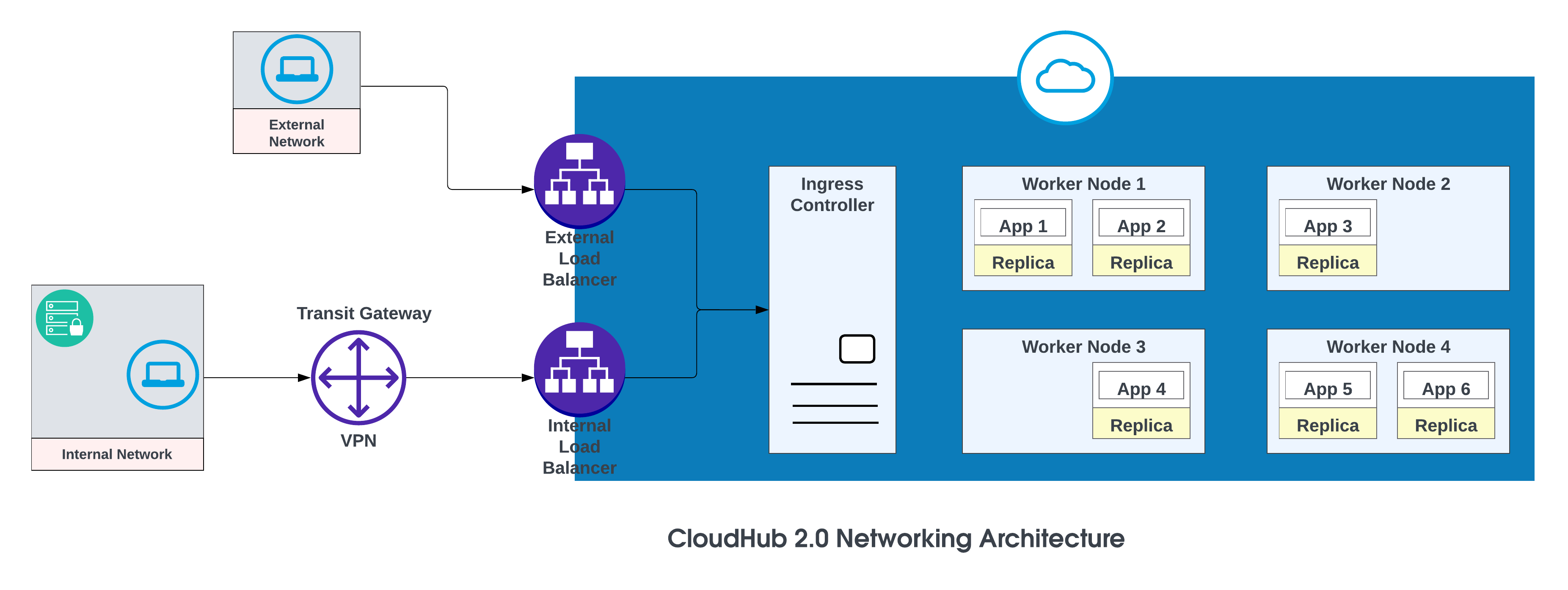
Les composants de base de l'architecture réseau CloudHub 2.0 sont les suivants :
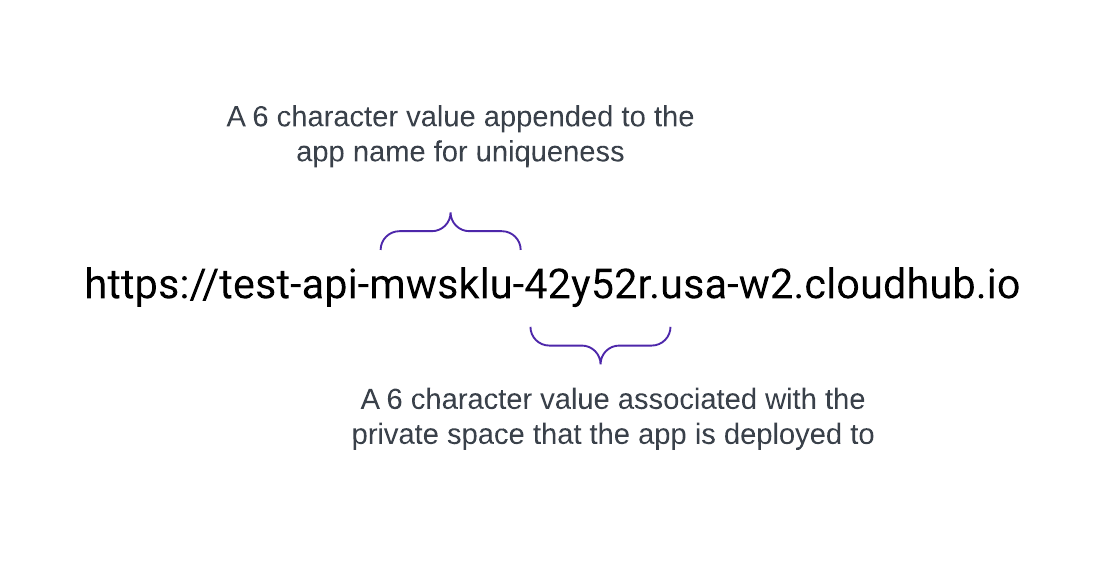
Lorsqu'un espace privé est créé, il reçoit un nom de cible DNS sous le format: <space-id>.<region>.cloudhub.io . Lors du déploiement d'une application nommée test-api dans cet espace privé, son point de terminaison suit le format suivant :
CloudHub 2.0 prend également en charge les domaines personnalisés ou vanités en les configurant dans un espace privé en utilisant des contextes TLS et des enregistrements DNS. Pour créer un contexte TLS dans le Gestionnaire d'exécution pour un espace privé, chargez le certificat public et la clé privée, puis ajoutez un point de terminaison personnalisé dans les paramètres de votre application pour utiliser ce domaine. Créez un enregistrement DNS (tel qu'un CNAME) qui pointe votre domaine de vanité vers le nom d'hôte par défaut de votre espace privé.
Par exemple, une application nommée test-api déployée dans us-west-2 avec le DNS par défaut 42y52r.usa-w2.cloudhub.io a un point de terminaison d'API de :
Cette URL n'utilise pas de domaine vanity ou personnalisé. Pour utiliser acme.com afin d'afficher les URL d'API sous le format https://test-api.acme.com, procédez comme suit.
Créez un contexte TLS dans Runtime Manager avec des clés publiques et privées.
Ajoutez un domaine vanity dans les paramètres de l'application pour utiliser ce domaine.
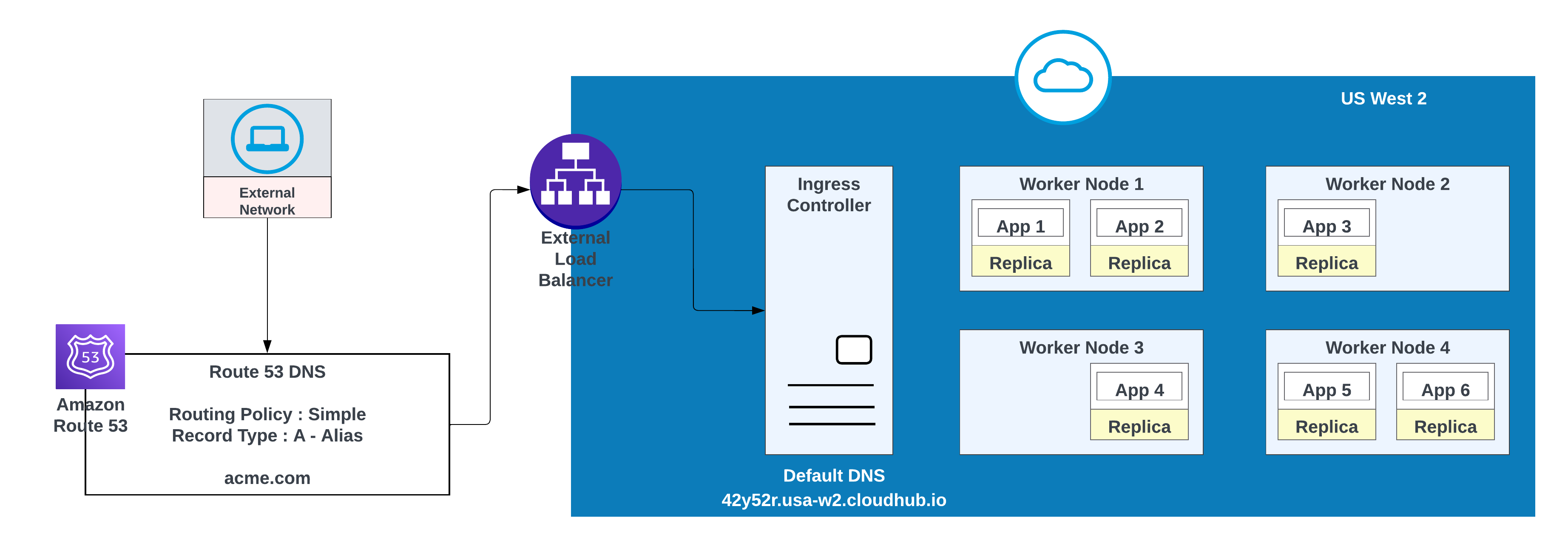
Créez un enregistrement DNS dans AWS Route 53, puis configurez une simple stratégie d'acheminement (par exemple, CNAME) afin de définir le domaine vanity sur le nom d'hôte par défaut de l'espace privé.
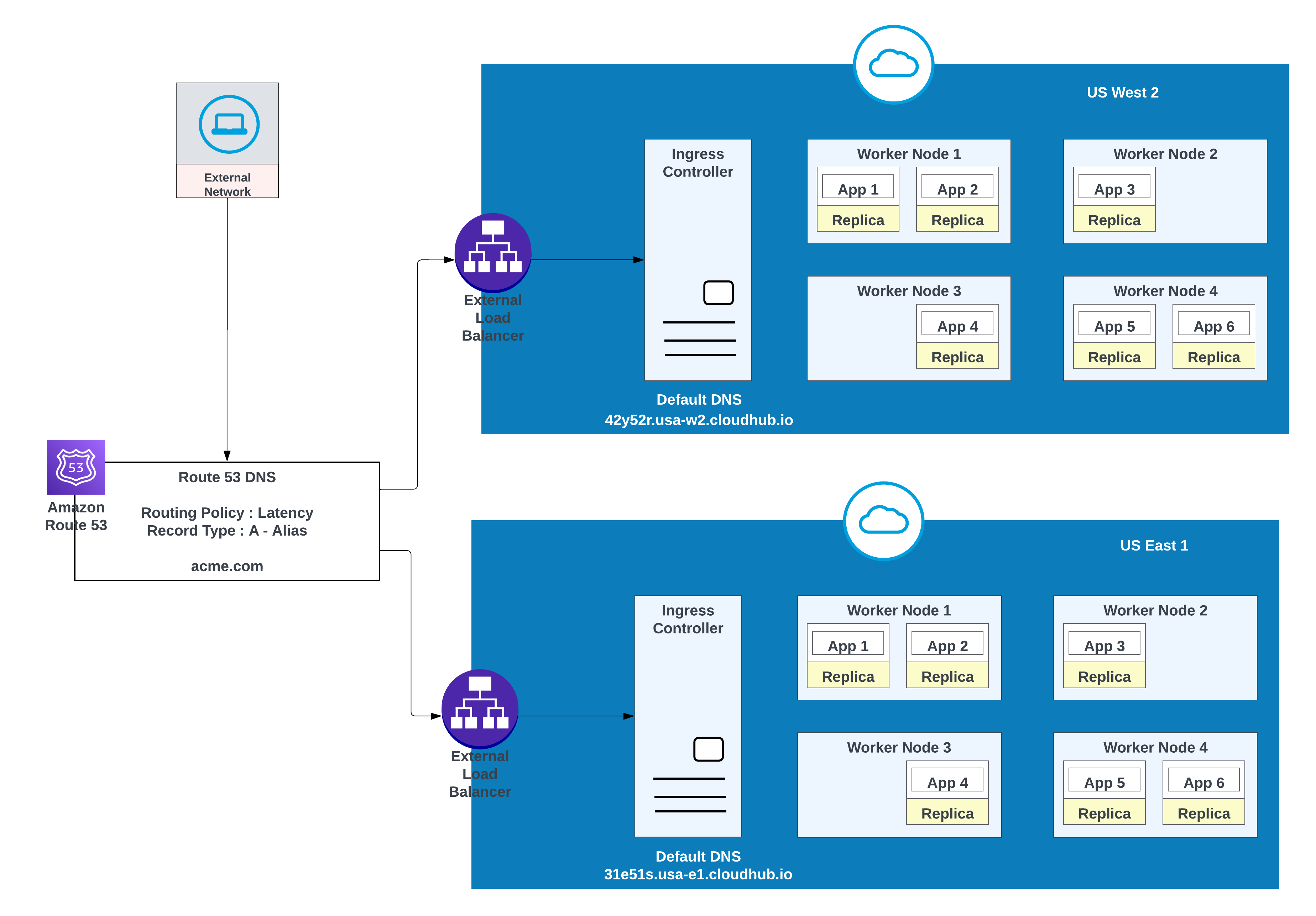
Pour des domaines personnalisés, vous pouvez utiliser AWS Route 53 ou tout autre service CDN global avec des stratégies d'acheminement. Dans le diagramme ci-dessous, AWS Route 53 est utilisé avec une stratégie d'acheminement « simple ». Lorsqu'un consommateur d'un réseau public (externe) demande acme.com, AWS Route 53 achemine la demande vers le contrôleur d'entrée de l'espace privé MuleSoft.
Stratégie de basculement
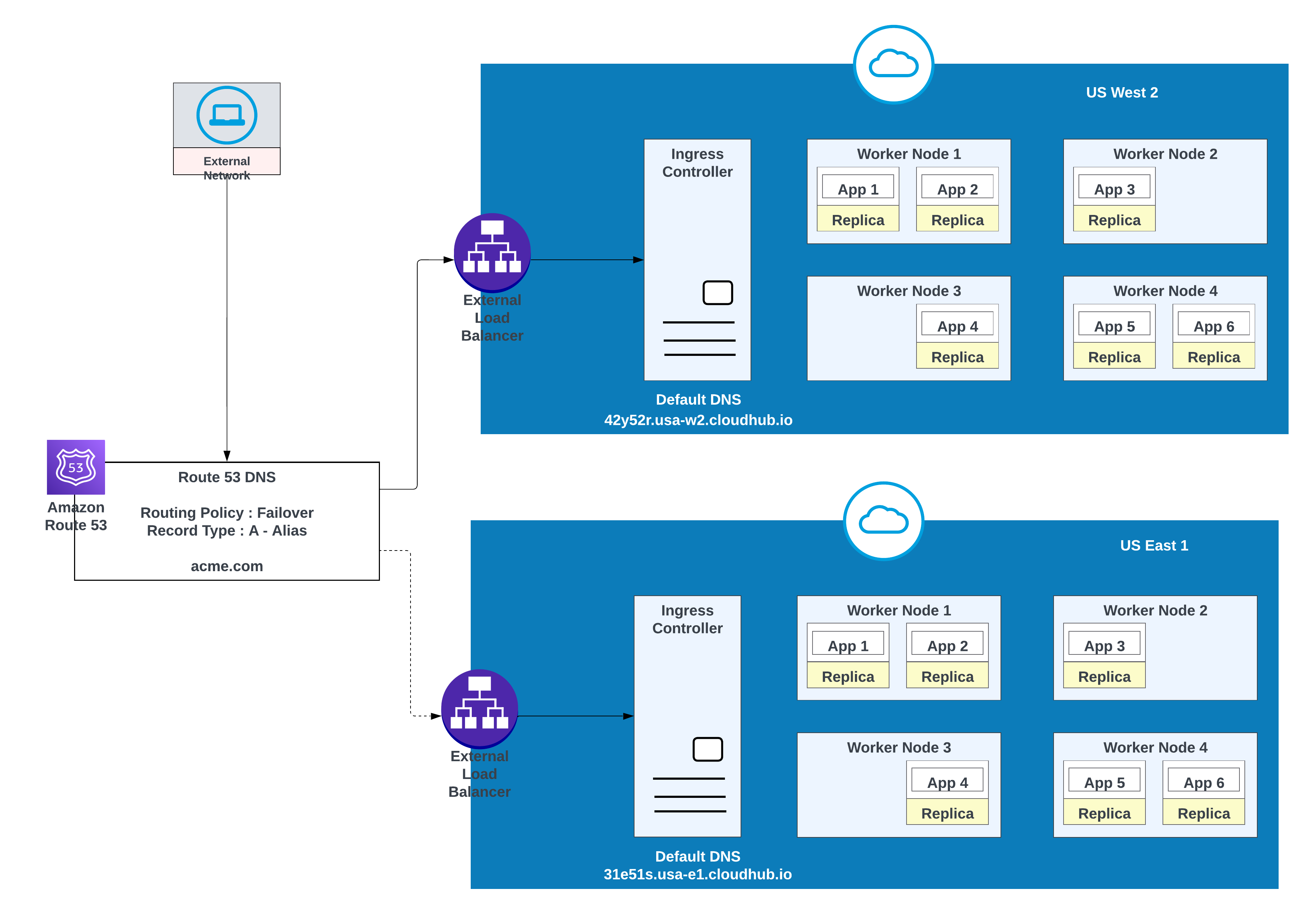
Utilisez cette option lorsque des applications nécessitent un basculement : déployez une instance dans la région principale (par exemple, us-west-2) et une autre dans une région secondaire (par exemple, us-east-1).
Utilisez un environnement existant dans la région secondaire lorsque cela est possible; la création d'un nouvel environnement nécessite des efforts supplémentaires.
Exemple d'applications déployées dans une région (Ouest des États-Unis 2) avec un basculement vers une autre région (Est des États-Unis 1)
Nom de l'enregistrement
Valeur/Acheminement du trafic vers
Stratégie d'acheminement
ID de contrôle d'intégrité
acme.com
42y52r.usa-w2.cloudhub.io
Basculement
31s3wseq121
acme.com
31e51s.usa-e1.cloudhub.io
Basculement
43e131s131sq
Dans cette configuration, AWS Route 53 achemine le trafic vers les contrôleurs d'entrée pour les espaces privés dans US West 2 et US East 1. Une stratégie d'acheminement de basculement est configurée avec un contrôle d'intégrité.
Haute disponibilité et faible latence
Pour une latence plus faible et une disponibilité élevée, utilisez la stratégie de déploiement décrite dans le diagramme. Avec cette stratégie, les applications peuvent être déployées dans deux régions (us-west-2 et us-east-1 dans cet exemple).
Utilisez la stratégie d'acheminement de latence dans AWS Route 53 pour acheminer les requêtes vers la région qui offre la latence la plus faible tout en conservant une disponibilité élevée. Stratégie d'acheminement de « latence » dans AWS Route 53 pour acheminer la requête pour une latence plus faible avec une disponibilité élevée.
Applications déployées dans les deux régions (US West 2 et US East 1) pour une latence plus faible et une disponibilité élevée
Nom de l'enregistrement
Valeur/ Acheminer le trafic vers
Stratégie d'acheminement
ID de contrôle d'intégrité
acme.com
42y52r.usa-w2.cloudhub.io
Latence
31s3wseq121
acme.com
31e51s.usa-e1.cloudhub.io
Latence
43e131s131sq
Conclusion
MuleSoft CloudHub 2.0 fournit une base solide pour la résilience intra-région, principalement en exploitant la redondance automatisée des répliques et l'équilibrage de charge intelligent. Dans une seule région cloud, le déploiement d'applications avec plusieurs répliques garantit que si une instance échoue, d'autres peuvent immédiatement prendre en charge la charge de travail. L'équilibreur de charge intégré distribue efficacement le trafic entrant entre ces répliques saines, ce qui réduit les temps d'arrêt et garantit une disponibilité continue du service dans des conditions d'exploitation normales.
Cependant, s'appuyer exclusivement sur cette architecture monorégion, même fortement redondante, présente un risque important de panne régionale généralisée et catastrophique. L'histoire a montré que même les fournisseurs de cloud les plus fiables et les plus avancés technologiquement sont susceptibles d'incidents perturbateurs qui peuvent affecter toute une région géographique. Ces points d'échec uniques, bien que rares, peuvent découler de divers événements, notamment :
Incidents d'infrastructure à grande échelle
Pannes de courant majeures
Interruptions réseau généralisées
Par conséquent, pour atteindre la véritable haute disponibilité (HA) et la reprise après sinistre (DR), une architecture doit être conçue pour transcender les limitations d'un modèle à zone unique. La stratégie recommandée est le déploiement dans plusieurs régions géographiquement distinctes. Cette résilience inter-régions garantit que si une région cloud entière n'est pas disponible en raison d'un sinistre inattendu, le trafic peut échouer de façon transparente vers une instance d'application exécutée dans une région séparée et non affectée, ce qui garantit une interruption minimale du service et atteint les objectifs de temps de fonctionnement maximum.
Gulal Kumar est architecte en génie logiciel chez Salesforce, spécialisé dans l'architecture de données et d'intégration. Avec plus de 20 ans d'expérience dans l'intégration et les API, les programmes de modernisation, la sécurité et les initiatives AIML, il apporte une riche expertise. Gulal s’est engagé à faire progresser les initiatives de transformation métier, à renforcer la sécurité et la résilience, à promouvoir l’excellence en architecture et à piloter des initiatives AIML dans divers domaines.
Ajay Nagaraju est architecte d'entreprise et directeur principal chez MuleSoft avec plus de 28 ans d'expérience dans l'architecture d'entreprise, l'intégration de systèmes et la transformation numérique à grande échelle. Il a dirigé l'architecture et la livraison de programmes complexes de plusieurs millions de dollars dans les organisations Fortune 100 et Fortune 500, avec une expertise approfondie dans la connectivité pilotée par l'API, la SOA, les technologies cloud et les modèles d'intégration d'entreprise. Ajay a travaillé en étroite collaboration avec la direction exécutive pour moderniser les processus métiers, les plates-formes de données et les écosystèmes d'intégration, et est passionné par l'élaboration d'architectures évolutives, le mentorat d'équipes et la génération de résultats commerciaux mesurables grâce à la technologie.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.