Este documento descreve as opções atuais para implantar aplicativos no CloudHub 2.0 para atender aos requisitos de alta disponibilidade e recuperação de desastres. Ela usa a região dos EUA como exemplo e pode ser aplicada a outras regiões.
O CloudHub 2.0 é uma plataforma de integração nativa de nuvem totalmente gerenciada que elimina a sobrecarga de infraestrutura automatizando a implantação, a escala e o gerenciamento de APIs e integrações do MuleSoft na nuvem. É a moderna plataforma de implementação de nuvem da MuleSoft, executada na infraestrutura da Amazon AWS.
Na maioria dos casos, a Alta disponibilidade (HA) e a Recuperação de desastres (DR) padrão fornecidas pelo CloudHub 2.0 são suficientes. O CloudHub 2.0 fornece HA e DR a nível regional (para mais detalhes, consulte Cenários de fora do CloudHub 2.0). A seção Considerações-chave do CloudHub 2.0 fornece mais detalhes sobre HA e DR compatíveis com o CloudHub 2.0.
As condições que exigem um design além da disponibilidade padrão do CloudHub 2.0 incluem:
- Um aplicativo precisa garantir que não ocorra perda de dados em um cenário de desastre (por exemplo, uma região da Amazon em queda).
- Um aplicativo depende da Loja de objetos e precisa garantir a continuidade se a região de implementação ficar inativa.
- Os sistemas de back-end são configurados para disponibilidade equivalente. O CloudHub 2.0 às vezes pode fornecer confiabilidade por meio de filas ou mecanismos semelhantes, mas, independentemente de a integração ser em tempo real ou assíncrona, os sistemas de back-end devem dar suporte a um nível comparável de HA e DR.
- Quando uma interrupção no nível da região da AWS afeta sistemas de back-end, a recuperação é presumida ser executada em paralelo com a recuperação do CloudHub 2.0.
- A configuração de espaço privado está concluída em várias regiões.
As opções de design neste guia focam soluções para disponibilidade de aplicativo no CloudHub 2.0 quando uma zona ou região de disponibilidade da AWS ficar indisponível.
Este guia não aborda estes cenários de recuperação, embora observe implicações quando relevante:
- Recuperação de sistemas de back-end, aplicativos, bancos de dados, componentes de rede e data centers gerenciados e provisionados fora do Anypoint CloudHub, seja no local ou na nuvem.
- Recuperação de links de VPN entre o CloudHub 2.0 e o data center privado do cliente (por exemplo, túneis IPsec e gateways de VPN). Algumas opções de DR neste guia podem lidar parcialmente com esses cenários.
- Alterações no MuleSoft enviam IPs durante a recuperação de desastres quando a lista de permissões de IP é usada para integrações. Algumas opções de DR neste guia podem lidar parcialmente com esses cenários.
- Sistemas de mensagens externos usados em soluções do cliente, seja fornecidos pela MuleSoft (como Anypoint MQ) ou outros fornecedores (como AWS MSK ou Heroku Kafka).
Ao avaliar o CloudHub 2.0 para os requisitos de recuperação de desastres, pense nestas considerações importantes.
Dependência do CloudHub 2.0 da disponibilidade regional da AWS
- O CloudHub 2.0 é executado na AWS; sua disponibilidade está vinculada a regiões da AWS.
- As implantações e a disponibilidade do aplicativo são organizadas por região. Essas regiões correspondem às regiões da AWS.
Se toda uma região da AWS falhar, os aplicativos nessa região ficarão indisponíveis e não serão replicados automaticamente em outro lugar.
Aplicativo de alta disponibilidade (HA) e gerenciamento de réplica
- O CloudHub 2.0 reimplanta automaticamente os aplicativos na mesma região quando o hardware falha, mas um aplicativo com uma só réplica pode passar por tempo de inatividade.
- Aplicativos com várias réplicas são implementados em zonas de disponibilidade separadas por padrão, fornecendo HA entre as zonas.
- Se a zona de disponibilidade para um aplicativo de réplica única falhar, o aplicativo será automaticamente gerado em outra zona de disponibilidade dentro da mesma região.
Impacto específico da região leste dos EUA
- No caso de uma falha na região leste dos EUA:
- A IU de gerenciamento do CloudHub 2.0 e os serviços REST de implementação estão indisponíveis e não é possível implementar novos aplicativos.
- Aplicativos em outras regiões não são afetados na maioria dos cenários de falha. Esses aplicativos continuam operando normalmente; no entanto, os recursos de monitoramento e gerenciamento por meio do plano de controle estarão indisponíveis durante a interrupção.
- Os módulos do Core CloudHub 2.0 (como as configurações do aplicativo) são mantidos no Leste dos EUA, portanto, as configurações não podem ser editadas durante a interrupção.
Monitoramento e alerta
- Configure o alerta para falhas no nível da região ou da zona de disponibilidade em status.mulesoft.com.
- Use um mecanismo de verificação de integridade e alerta separado fora do CloudHub 2.0 para que as equipes sejam notificadas se as réplicas falharem ou se os aplicativos pararem de responder.
Persistência de dados (Armazenamento de objetos V2)
- A Loja de objetos V2 está vinculada à região em que o aplicativo é implementado primeiro.
- Se você mover o aplicativo para outra região, a Loja de objetos V2 permanecerá na região original para evitar a perda de dados.
- Se a região em que a Loja de objetos V2 está implantada falhar, a loja de objetos estará indisponível.
Controladores de entrada e espaços privados
- Os controladores de entrada do CloudHub 2.0 estão altamente disponíveis no nível da região.
- Em um espaço compartilhado, se uma região falhar, um controlador de entrada em outra região permanecerá disponível, mas poderá atender apenas aplicativos implantados nessa região.
- Em um espaço privado, se uma região falhar, os controladores de entrada em outras regiões estarão indisponíveis, a menos que tenham sido configurados lá com antecedência.
- A configuração de espaço privado é regional; se uma região falhar, o espaço privado ficará indisponível, a menos que outra região tenha sido configurada.
| Status do componente | Responsabilidade do Salesforce |
|---|---|
| Replica para baixo | Ação: O CloudHub 2.0 reinicia automaticamente a réplica em uma zona de disponibilidade diferente se houver algum problema com a zona de disponibilidade atual. Porém, o aplicativo estará offline até que a nova réplica seja totalmente iniciada. Condição: Configuração padrão. Tempo necessário: Aproximadamente 2 a 15 minutos, dependendo da complexidade do aplicativo e do tamanho da réplica. |
| Zona de disponibilidade para baixo | Ação: Igual à réplica abaixo. Condição: Configuração padrão. Tempo necessário: Igual à réplica abaixo. Notificação: Igual à réplica abaixo. |
| Região abaixo | Ação: Nenhuma recuperação automática. Um design de failover deve estar em vigor. |
| Status do componente | Responsabilidade do cliente |
|---|---|
| Replica para baixo | Notificação: Realize verificações periódicas de integridade usando um mecanismo de pulso integrado às APIs. Migração: Implemente o aplicativo em várias réplicas na mesma região. Teste / Simulação: Gere um pedido com o suporte da MuleSoft e eles oferecerão suporte a um teste de fallover para verificar se uma nova réplica é ativada em um AZ diferente em 1 a 15 minutos. |
| Zona de disponibilidade para baixo | Notificação: Igual à réplica abaixo. Migração: Implemente o aplicativo para várias réplicas na mesma região ou em diferentes regiões. Teste / Simulação: O cenário AZ Down é difícil de simular. Ele exige o envolvimento da Engenharia do MuleSoft para dar suporte a possíveis cenários de teste. |
| Região abaixo | Notificação: Igual à réplica abaixo. Verifique também as atualizações de status em https://status.aws.amazon.com. Migração: Igual a AZ Down. Plano de emergência de recuperação de desastres: Dois espaços privados com a mesma configuração em diferentes regiões. Teste / Simulação: Igual a AZ Down. |
| Status do componente | Responsabilidade do Salesforce |
|---|---|
| VPN Gateway seta para baixo | Status da réplica: Em execução, mas sem poder se conectar a nenhum recurso hospedado no local e acessível por meio do túnel de VPN. Ação: Nenhuma recuperação automática. Um design de failover deve estar em vigor. |
| Controlador de entrada (espaço compartilhado) para baixo | Status da réplica: O controlador de entrada é uma configuração agrupada com várias instâncias, semelhante a réplicas de aplicativo. Se uma réplica de aplicativo falhar, uma nova será criada e iniciada automaticamente. Se uma instância do controlador de entrada falhar, os aplicativos permanecerão disponíveis por meio da outra instância. Se todo o controlador de entrada estiver inativo, a região será considerada inativa. |
| Controlador de entrada (espaço privado) para baixo | Status da réplica: Igual ao Controlador de entrada no espaço compartilhado abaixo. |
| Status do componente | Responsabilidade do cliente |
|---|---|
| Gateway de VPN seta para baixo | Notificação: Realize verificações periódicas de integridade usando um mecanismo de pulso integrado às APIs. Migração: Os gateways de VPN do CloudHub 2.0 oferecem suporte à alta disponibilidade por meio de uma arquitetura de duplo túnel com failover automático entre túneis; um cliente deve configurar esse padrão. Teste / Simulação: O cenário de Gateway de VPN seta para baixo é difícil de simular. Requer o envolvimento da Engenharia do MuleSoft para dar suporte a possíveis cenários de teste. |
| Controlador de entrada (espaço compartilhado) seta para baixo | Notificação: Igual ao Gateway de VPN seta para baixo. Migração: Igual a Região abaixo. Migre solicitações para um espaço de espera ou ativo em outra região. Teste / Simulação: Igual ao Gateway de VPN seta para baixo. |
| Controlador de entrada (espaço privado) seta para baixo | Notificação: Igual ao Gateway de VPN seta para baixo. Migração: Igual a Região abaixo. Migre aplicativos para um espaço reservado ou privado ativo em outra região, em coordenação com a configuração da Rota 53 da AWS (ou equivalente). Teste / Simulação: Igual ao Gateway de VPN seta para baixo. |
Scenário de desvio de serviços de plataforma – Loja de objetos
| Loja de objetos na memória | Armazenamento de objetos persistentes v2 | |
|---|---|---|
| Localização dos dados | Local apenas para o aplicativo. | Na mesma região em que o aplicativo MuleSoft foi implementado inicialmente. |
| Compartilhado entre réplicas? | Não | Sim |
| Recuperação de armazenamento de objetos em aplicativos | Os dados são perdidos; todos os dados na memória são perdidos ao reiniciar o aplicativo, uma nova implantação ou falha de réplica. | Os dados não são perdidos, a menos que o aplicativo seja excluído. |
| Recuperação de armazenamento de objetos dentro da região | Os dados são perdidos (igual que acima). | Os dados não são perdidos (igual que acima). |
| Recuperação regional | Igual ao acima. | Os dados estão indisponíveis. Mesmo com uma configuração de DR ativa, a Loja de objetos está disponível apenas na região de implementação original. |
| Migração | Externalize dados para recuperação regional. | Os dados permanecem disponíveis enquanto a região de implementação original está disponível. Para HA ou DR entre regiões, externalize dados fora do repositório de objetos. |
Alta disponibilidade (HA) é a medida da capacidade de um sistema permanecer acessível em caso de falha de um componente do sistema. Geralmente, a HA é implementada criando em vários níveis de tolerância a falhas e/ou recursos de balanceamento de carga em um sistema. Geralmente é uma configuração Ativo-Ativo e resulta em impacto limitado ou nenhum para os Serviços de negócios.
A recuperação de desastres (DR) é o processo pelo qual um sistema é restaurado a um estado aceitável anterior após um cenário de desastre, seja natural (como inundações, tornados, terremotos ou incêndios) ou causado pelo homem (como falhas de energia, falhas de servidor ou configurações incorretas). DR geralmente é uma configuração Ativo-Passivo e resulta em algum impacto para os Serviços de negócios.
Se a Alta disponibilidade regional ou a Recuperação de desastres regionais forem desejadas para reduzir os impactos de negócios em caso de falha regional da AWS, considere estes pontos ao projetar sua solução no MuleSoft CloudHub 2.0:
- As réplicas do CloudHub 2.0 e os recursos relacionados (espaços privados, controladores de entrada e destinos do Anypoint MQ) são específicos da região.
- Se toda uma região da AWS falhar, todas as réplicas e serviços associados nessa região ficarão indisponíveis.
- Quando uma região é recuperada, as configurações são restauradas; você deve reiniciar os aplicativos.
- Se a região leste dos EUA falhar, os serviços da Anypoint Platform (por exemplo, Gerenciamento de acesso e Gerenciador de tempo de execução) também estarão indisponíveis.
- O MuleSoft fornece um SLA de 99,95% de disponibilidade para Serviços de plataforma, incluindo réplicas do CloudHub 2.0 em uma configuração ativa-ativa em uma região; consulte a nuvem MuleSoft mais recente que oferece o SLA para obter detalhes atuais.
- O CloudHub 2.0 não oferece suporte para HA ou DR de várias regiões prontos para uso; a disponibilidade é fornecida apenas em uma só região.
Essas diretrizes de design se aplicam independentemente da configuração escolhida.
Configuração de espaços privados de várias regiões
Todas as opções descritas nas seções a seguir exigem que os aplicativos sejam implementados em regiões separadas. Isso só é possível se a configuração de espaço privado for concluída com antecedência, antes de um desastre. Como a configuração de espaço privado é regional, uma estratégia de DR exige pelo menos dois espaços privados, um por região, e um mecanismo para migrar o tráfego para o ponto final de VPN adequado.
Configuração de espaço privado altamente disponível dentro de uma região
O CloudHub 2.0 não fornece failover automático quando um espaço privado em uma região falha. Uma solução alternativa é uma configuração ativa-pasiva em vários ambientes, que requer:
- Configurar vários gateways de VPN no espaço privado.
- Estabelecer ambientes separados na região do CloudHub 2.0, cada um com seu próprio espaço privado.
- Designe um desses ambientes como passivo (em que os aplicativos não são implementados inicialmente, mas são buscados se o espaço privado principal falhar).
Se uma configuração de alta disponibilidade sem o Gateway de VPN ser um único ponto de falha for um requisito rígido, implantar em duas regiões é a melhor opção. Uma falha do Gateway de VPN nesse cenário poderia ser resolvida transferindo a região afetada para a região alternativa em que o espaço privado já está configurado.
Perdida de mensagem zero
Para obter zero perda de mensagem quando uma região inteira falha, um aplicativo deve evitar a perda de dados e lidar com estes pontos:
- Use mensagens externas para obter a confiabilidade da mensagem.
- Certifique-se de que a Loja de objetos não seja usada para dados transacionais em andamento que sejam transacionais por natureza. Se a região de implantação em que o aplicativo MuleSoft foi implementado inicialmente estiver inativo, a Loja de objetos estará indisponível.
- Encerre todo o acesso à loja de objetos em um fluxo ou seção separado que continue funcionando, tanto para tratamento de exceção quanto para comportamento, quando as operações de leitura ou gravação da loja de objetos falharem.
Nota. Na maioria dos casos, os requisitos de DR não precisam garantir nenhuma perda de mensagem em caso de desastre e precisam garantir que a perda de dados seja inferior ao valor de dados de um determinado período (por exemplo, 1 hora).
Manter a integração sem Estado
Como um princípio de design geral, é sempre importante garantir que as integrações sejam de natureza sem estado. Isso significa que nenhuma informação transacional é compartilhada entre várias invocações ou execuções de clientes (no caso de serviços agendados). Se alguns dados precisarem ser mantidos pelo middleware devido a uma limitação do sistema, eles deverão ser mantidos em um repositório externo, como um banco de dados ou uma fila de mensagens, e não na infraestrutura ou na memória do MuleSoft. É essencial observar que, à medida que dimensionamos, especialmente na nuvem, o estado e os recursos usados por cada réplica devem ser independentes de outras réplicas. Esse modelo garante melhor desempenho, escalabilidade e confiabilidade.
Gerenciamento de rede e tráfego
- Domínios intuitivos são necessários para a disponibilidade regional; eles atuam como um DNS global para todos os controladores de entrada entre regiões.
- Um balanceador global de carga encaminha o tráfego entre os espaços primários e privados da região DR. Os clientes fornecem esse componente; use a Rota 53 da AWS ou uma CDN global com políticas de roteamento para rotear o tráfego entre regiões.
- Configure os controladores de entrada nas regiões primária e DR com um domínio intuitivo personalizado.
- Planeje e mantenha as regras de firewall e o túnel de VPN para que os aplicativos locais sejam acessíveis dos espaços privados da região DR e principal.
- A manutenção do certificado TLS deve cobrir espaços privados nas regiões primária e DR para uma recuperação contínua.
Implantação e configuração de aplicativo
- Os nomes de solicitação devem ser exclusivos entre regiões. Por exemplo, um pipeline CI/CD pode anexar o nome da região (ou um código de região) a nomes de aplicativo antes da implantação para manter a exclusividade entre regiões primárias e DR.
- Configure o pipeline CI/CD para implementar aplicativos nas regiões principal e DR para que todos os aplicativos estejam disponíveis em ambas as regiões.
Infra-estrutura e capacidade
O desempenho é melhor quando todos os aspectos da infraestrutura têm a mesma capacidade de região primária e DR. O desempenho diminui quando esses aspectos de infraestrutura não são idênticos.
Persistência e armazenamento de dados
- O armazenamento de persistência deve ser sincronizado periodicamente entre as duas regiões. Os clientes são responsáveis pela replicação de armazenamento; a MuleSoft não a fornece. Um único armazenamento compartilhado entre VPCs nas regiões principal e DR é possível, mas o armazenamento compartilhado deve estar altamente disponível ou se tornar um único ponto de falha para ambas as regiões.
- O Object Store V2 é regional e está disponível apenas na região em que o aplicativo Mule foi implementado pela primeira vez. Se o aplicativo for movido para outra região, a Loja de objetos V2 permanecerá na região original para evitar a perda de dados. Use outro armazenamento persistente para estratégias de DR de várias regiões.
Procedimentos de ensaio e operacionais
Adote uma estratégia de teste de DR formal e execute exercícios de DR periódicos. Para DR ativo, use uma estratégia de implementação canária para validar ambas as regiões.
Acordos de nível de desempenho e serviço (SLAs)
Alguma degradação de desempenho pode ocorrer porque a região DR pode estar mais longe dos usuários finais ou dos sistemas de back-end do que a região primária. Defina e comunique um SLA de DR às partes interessadas.
Comportamento do modo de recuperação (Nota contextual)
No modo ativo-ativo, a transição de falha da região primária para o espaço privado da região de DR é rápida: o balanceador de carga global detecta que a região primária não está saudável e encaminha o tráfego para a região saudável (DR). No modo ativo-pasivo, você deve implementar o aplicativo no espaço privado da região de DR quando ocorrer um desastre.
Há três opções para obter uma maior disponibilidade de nível de DR:
Uma configuração ativa-ativa é baseada em trabalhadores ativos distribuídos entre regiões, usando um Balançador de carga externo para rotear o tráfego entre as duas instâncias.
Configuração de espera quente
Uma configuração ativa-pasiva seria baseada em um trabalhador ativo em uma região e um trabalhador passivo em outra. A região passiva seria iniciada quando necessário.
Alguns elementos da região passiva devem permanecer ativos para failover ou ser configurados previamente, incluindo espaços privados, VPNs e anexos de gateway de trânsito.
Como ocorre acima, as réplicas e os controladores de entrada são provisionados em uma segunda região por meio de um processo DevOps totalmente automatizado após a alteração. Alguns elementos da região passiva precisam permanecer ativos para failover, incluindo espaços privados, VPNs e anexos de gateway de trânsito.
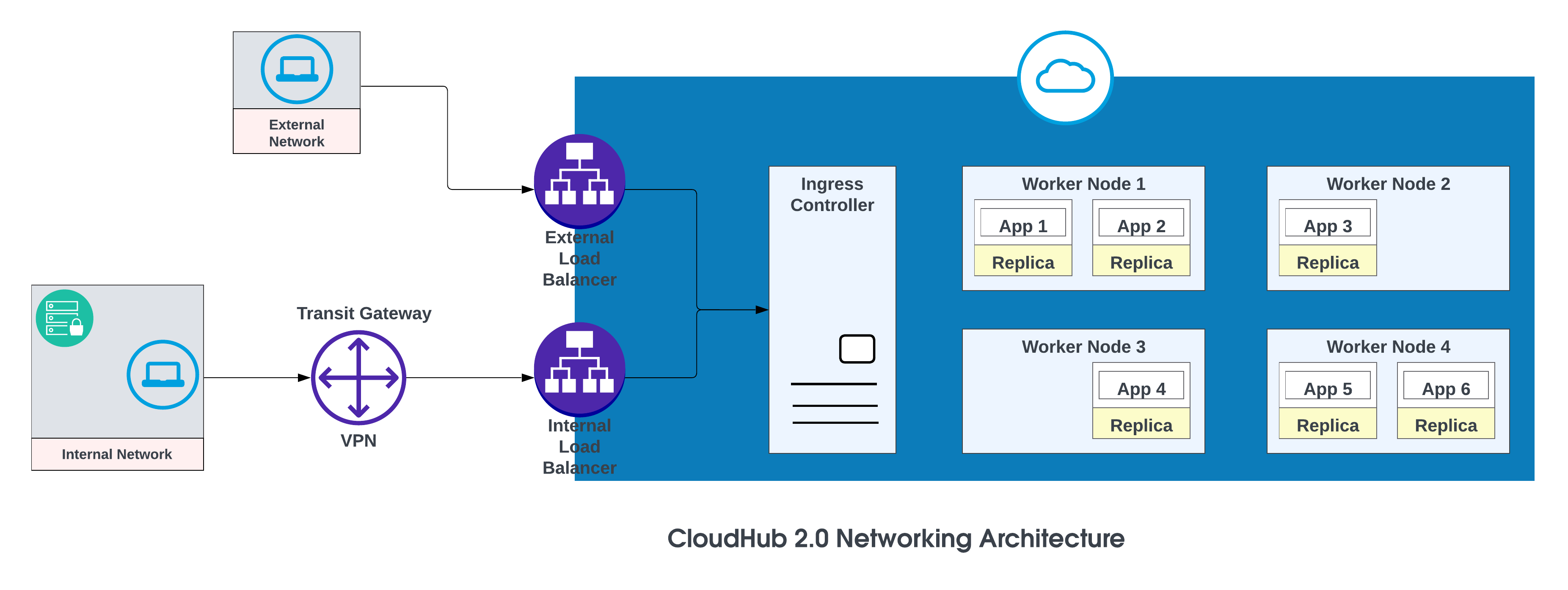
Os componentes básicos da arquitetura de rede do CloudHub 2.0 são:
- Um balanceador de carga HTTP
- Mule registros de DNS de réplica
- Espaços privados
- Serviços regionais
Para obter mais detalhes, consulte Arquitetura de rede do CloudHub 2.0.
Domínios vanity
Quando um Espaço privado é criado, ele recebe um nome de destino DNS no formato: <space-id>.<region>.cloudhub.io . Na implantação de um aplicativo chamado test-api nesse Espaço privado, seu ponto de extremidade seguirá este formato:
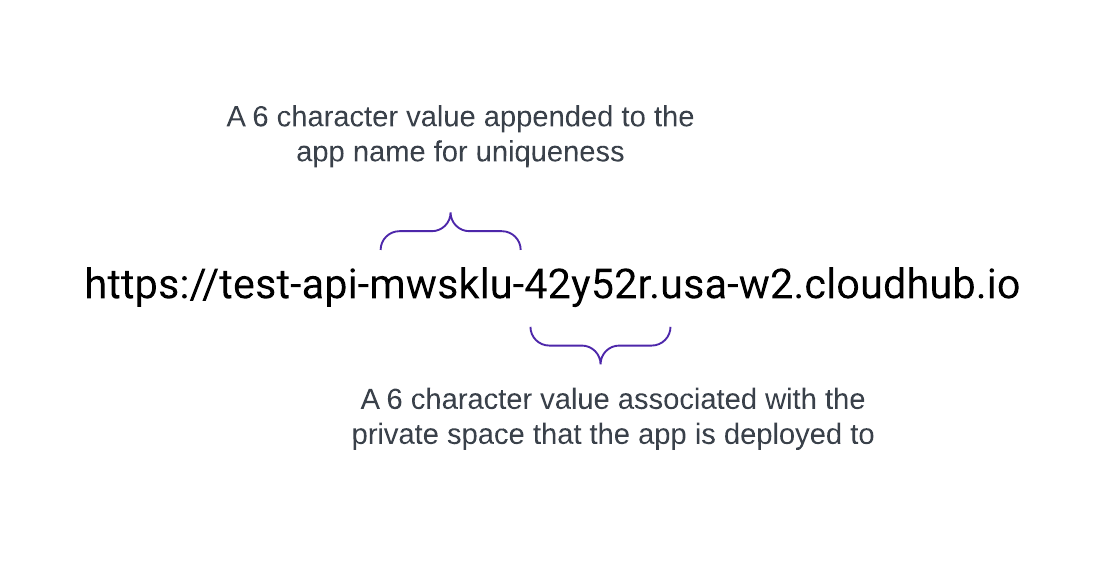
O CloudHub 2.0 também oferece suporte a domínios personalizados ou intuitivos configurando-os em um Espaço privado usando contextos TLS e registros DNS. Para criar um contexto de TLS no Gerenciador de tempo de execução para um espaço privado, carregue o certificado público e a chave privada e adicione um ponto de extremidade personalizado nas configurações do seu aplicativo para usar esse domínio. Crie um registro de DNS (como CNAME) que aponte seu domínio intuitivo para o nome de host padrão do espaço privado.
Por exemplo, um aplicativo chamado test-api implantado em us-west-2 com o DNS padrão 42y52r.usa-w2.cloudhub.io tem um ponto de extremidade de API de:
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
Esse URL não usa um domínio intuitivo ou personalizado. Para usar acme.com para que os URLs da API apareçam como https://test-api.acme.com, siga estas etapas.
- Crie um contexto de TLS no Gerenciador de tempo de execução com chaves públicas e privadas.
- Adicione um domínio intuitivo nas configurações do aplicativo para usar esse domínio.
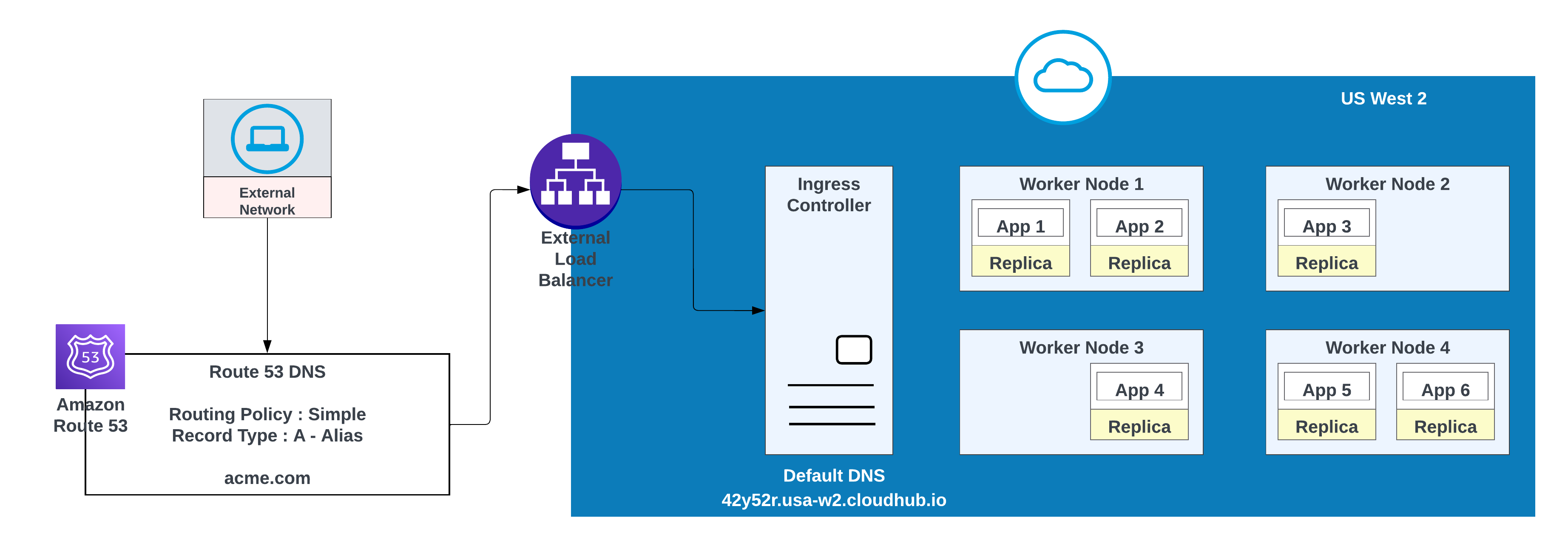
- Crie um registro de DNS na Rota 53 da AWS e configure uma política de roteamento simples (por exemplo, CNAME) para que o domínio intuitivo seja resolvido para o nome de host padrão do espaço privado.
Para domínios personalizados, você pode usar a AWS Route 53 ou qualquer outro serviço de CDN global com políticas de roteamento. No diagrama abaixo, a Rota 53 do AWS é usada com uma política de roteamento "simples". Quando um consumidor de uma rede pública (externa) solicita acme.com, a Rota 53 da AWS encaminha a solicitação para o controlador de entrada de espaço privado do MuleSoft.
Use essa opção quando os aplicativos exigirem a alteração de falha: implemente uma instância na região primária (por exemplo, us-west-2) e outra em uma região secundária (por exemplo, us-east-1).
Use um ambiente existente na região secundária quando possível; criar um novo ambiente requer esforço adicional.
Exemplo de aplicativos implantados em uma região (Oeste dos EUA 2) com uma migração de falha para outra região (Leste dos EUA 1)
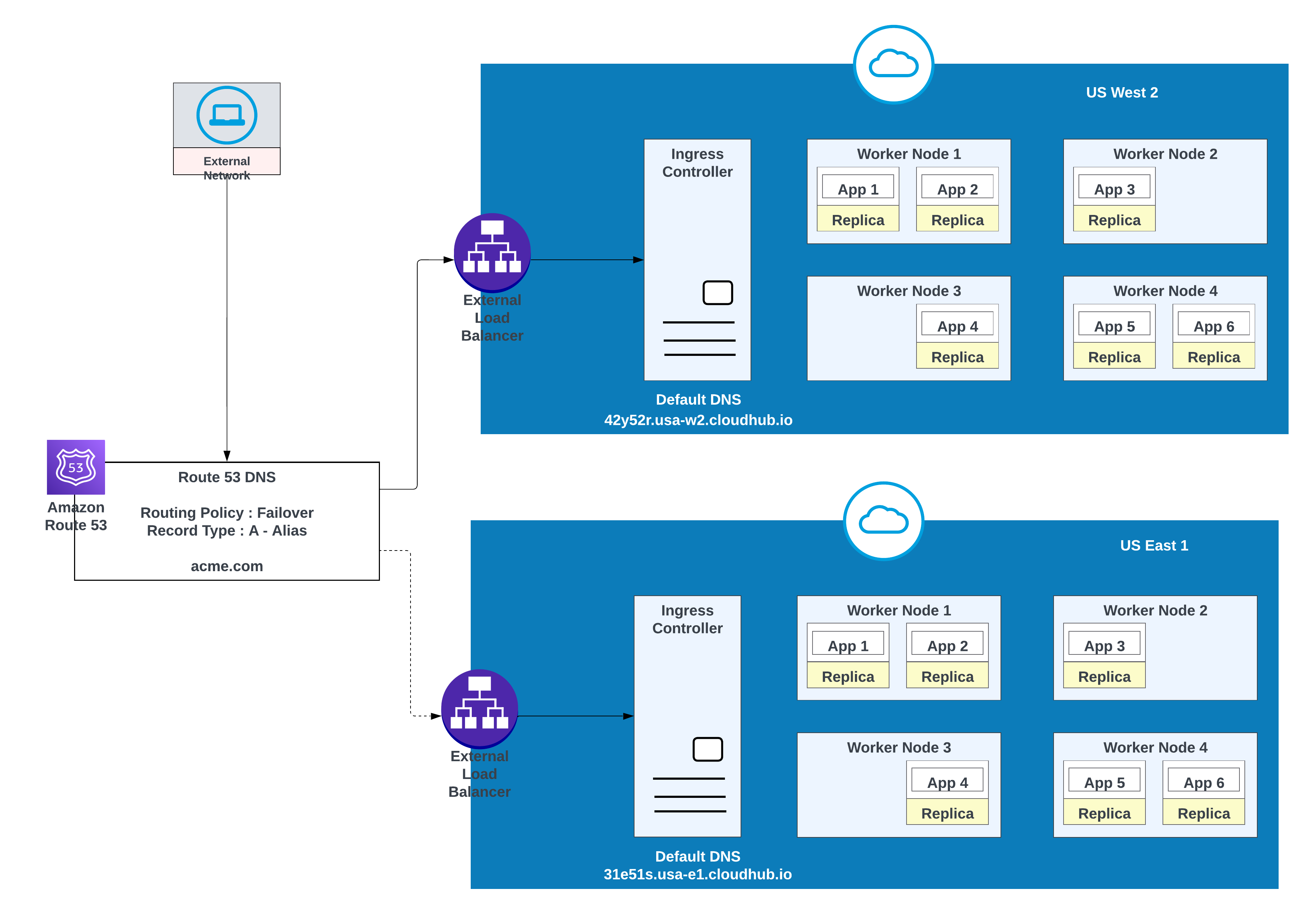
| Nome do registro | Valor/Tráfego de rota para | Política de roteamento | ID da verificação de integridade |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Failover | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Failover | 43e131s131sq |
Nessa configuração, a Rota 53 da AWS encaminha o tráfego para os controladores de entrada para os espaços privados no oeste dos EUA 2 e no leste dos EUA 1. Uma política de roteamento de fallover é configurada com uma verificação de integridade.
Para menor latência e alta disponibilidade, use a estratégia de implantação descrita no diagrama. Com essa estratégia, os aplicativos podem ser implementados em duas regiões (neste exemplo, us-west-2 e us-east-1).
Use a política de roteamento de latência na Rota 53 da AWS para rotear solicitações para a região que oferece a menor latência enquanto mantém a alta disponibilidade. Política de roteamento de "latência" na Rota 53 da AWS para rotear a solicitação para menor latência ainda tendo alta disponibilidade.
Aplicativos implantados nas duas regiões (Oeste dos EUA 2 e Leste dos EUA 1) para menor latência e alta disponibilidade
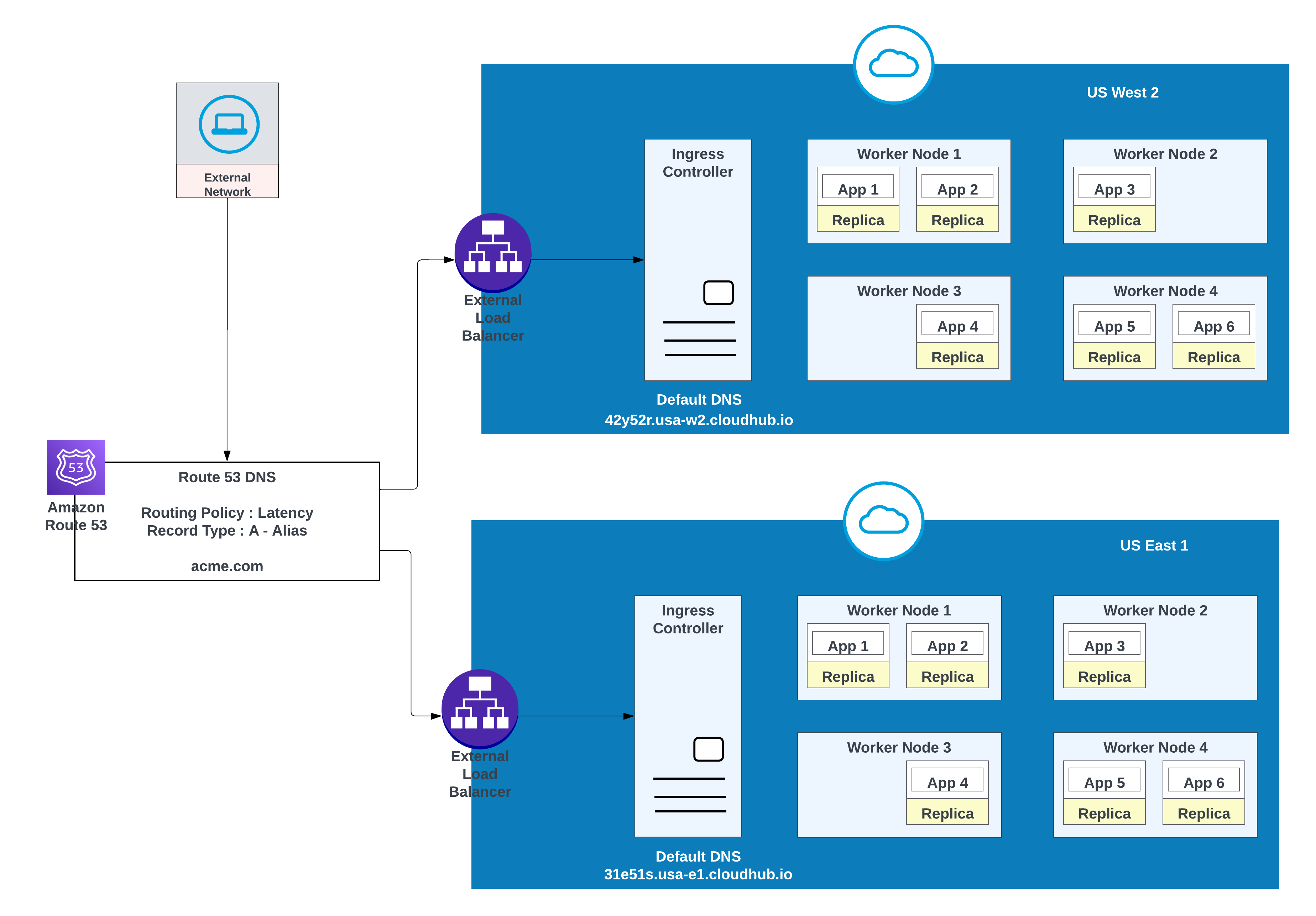
| Nome do registro | Valor/Rotear tráfego para | Política de roteamento | ID da verificação de integridade |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Latência | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Latência | 43e131s131sq |
O MuleSoft CloudHub 2.0 fornece uma base robusta para a resiliência intra-regional, aproveitando principalmente a redundância de réplica automatizada e o balanceamento de carga inteligente. Em uma única região de nuvem, implantar aplicativos com várias réplicas garante que, se uma instância falhar, outras possam assumir imediatamente a carga de trabalho. O balanceador de carga integrado distribui de modo eficiente o tráfego recebido entre essas réplicas saudáveis, minimizando o tempo de inatividade e garantindo a disponibilidade contínua de serviço sob condições de operação normais.
No entanto, contar exclusivamente com essa arquitetura de região única, mesmo com alta redundância, apresenta um risco significativo de uma falha regional generalizada e catastrófica. A história mostrou que até mesmo os provedores de nuvem mais confiáveis e tecnologicamente avançados são suscetíveis a incidentes de interrupção que podem afetar toda uma região geográfica. Esses pontos únicos de falha, embora raros, podem surgir de vários eventos, incluindo:
- Incidentes de infraestrutura em grande escala
- Principais falhas de energia
- Interrupções de rede amplas
Portanto, para alcançar a alta disponibilidade (HA) e a recuperação de desastres (DR), uma arquitetura deve ser projetada para superar as limitações de um modelo de região única. A estratégia recomendada é a implantação em várias regiões geograficamente distintas. Essa resiliência inter-região garante que, se uma região inteira da nuvem ficar indisponível devido a um desastre inesperado, o tráfego possa ser transferido sem problemas para uma instância de aplicativo em execução em uma região separada e não afetada, garantindo interrupções mínimas de serviço e atingindo metas de tempo de atividade máximo.
Arquitetura de rede CloudHub 2.0
Configurando a alteração de falha entre regiões para filas padrão
Regiões de implementação da Loja de objetos V2
Sua região de implementação da loja de objetos
Gulal Kumar é um arquiteto de engenharia de software na Salesforce, com foco em arquitetura de integração e dados. Com mais de 20 anos de experiência em integração e APIs, programas de modernização, segurança e iniciativas AIML, ele traz uma grande quantidade de conhecimento. O Gulal está empenhado em promover iniciativas de transformação de negócios, aprimorar a segurança e a resiliência, promover a excelência de arquitetura e liderar iniciativas de AIML em vários domínios.
Ajay Nagaraju é um arquiteto corporativo e diretor sênior na MuleSoft com mais de 28 anos de experiência em arquitetura corporativa, integração de sistemas e transformação digital em grande escala. Ele liderou a arquitetura e a entrega de programas complexos de vários milhões de dólares em organizações Fortune 100 e Fortune 500, com profundo conhecimento em conectividade conduzida por API, SOA, tecnologias de nuvem e padrões de integração corporativa. Ajay tem uma parceria estreita com a liderança executiva para modernizar processos de negócios, plataformas de dados e ecossistemas de integração e é apaixonada por criar arquiteturas dimensionáveis, equipes de mentoria e impulsionar resultados de negócios mensuráveis por meio da tecnologia.