Moderne Salesforce-Integrationen müssen weit mehr unterstützen als den einfachen Datenaustausch. Es wird erwartet, dass sie Kundenerfahrungen in Echtzeit unterstützen, Aktionen über mehrere Systeme hinweg koordinieren und zuverlässig im Unternehmensmaßstab arbeiten – und dies alles unter Einhaltung strenger Sicherheits- und Compliance-Anforderungen. Die Wahl des richtigen Integrationsansatzes ist daher eine wichtige architektonische Entscheidung und kein Implementierungsdetail. Stellen Sie sich ein allgemeines Unternehmensszenario vor. Ein Kunde schließt einen Kauf in einer mobilen Anwendung ab und löst eine Echtzeit-Anspruchsprüfung für ein personalisiertes Angebot aus. Gleichzeitig müssen Transaktionsdaten in einem ERP-System aufgezeichnet, Kundenattribute in Salesforce aktualisiert und Analysen an einen Data Lake übertragen werden, ohne Latenz, Datenduplizierung oder Compliance-Risiko einzuführen. Szenarien wie diese sind nun typisch in modernen Salesforce-Umgebungen, in denen Salesforce selten isoliert arbeitet und sich nahtlos in ein breiteres Ökosystem von Anwendungen und Datenplattformen integrieren muss. Dieser Leitfaden soll Architekten und Entwicklern helfen, diese Integrationen klar und sicher zu entwerfen. Statt sich auf Punkt-zu-Punkt-Implementierungen zu konzentrieren, werden bewährte Integrationsmuster vorgestellt, die sich auf wiederkehrende Unternehmensszenarien wie die Prozessorchestrierung, die Datensynchronisierung und den Echtzeit-Datenzugriff beziehen. Jedes Muster legt den Schwerpunkt auf architektonische Absichten, Kompromisse und Ausführungsmodelle, sodass Teams fundierte Designentscheidungen treffen können, die skaliert und dauerhaft sind. In diesem Dokument finden Sie Folgendes:
- Integrationsmuster, die allgemeine Unternehmens-„Archetypen“ in Prozess-, Daten- und virtuellen Zugriffsszenarien darstellen
- Ein Musterauswahl-Framework, das hilft, den richtigen Ansatz basierend auf Integrationsabsicht und Ausführungszeit zu identifizieren
- Praktische Anleitung zu Skalierbarkeit, Resilienz, Governance und Sicherheitsaspekten
- Bewährte Vorgehensweisen aus realen Salesforce- und Data 360-Implementierungen Das Ziel dieses Dokuments besteht darin, eine gemeinsame Architektursprache für die Integration bereitzustellen und Teams dabei zu unterstützen, Lösungen zu entwickeln, die Leistung, Flexibilität und Trust in Einklang mit Unternehmensdaten und Governance-Strategien bringen.
Dieses Dokument richtet sich an Designer und Architekten, die Daten aus anderen Anwendungen in ihrem Unternehmen in Salesforce Data 360 (ehemals Data Cloud) integrieren müssen. Dieser Inhalt ist eine Zusammenfassung vieler erfolgreicher Implementierungen von Salesforce-Architekten und -Partnern. Wenn Sie sich mit den Integrationsfunktionen und -optionen vertraut machen möchten, die für die umfassende Einführung von Data 360 verfügbar sind, lesen Sie die Abschnitte "Musterübersicht" und "Musterauswahlanleitung" weiter unten. Architekten und Entwickler sollten diese Musterdetails und bewährten Vorgehensweisen während der Entwurfs- und Implementierungsphase von Dateninteraktionsprojekten in Data 360 berücksichtigen. Wenn diese Muster ordnungsgemäß implementiert werden, können Sie so schnell wie möglich zur Produktion gelangen und über die stabilsten, skalierbarsten und wartungsfreien Anwendungen verfügen. Die eigenen beratenden Architekten von Salesforce verwenden diese Muster als Referenzpunkte bei Architekturüberprüfungen und pflegen und verbessern sie aktiv. Wie bei allen Mustern deckt dieser Inhalt die meisten Integrationsszenarien ab, jedoch nicht alle. Salesforce ermöglicht zwar beispielsweise die Integration von Mashups auf der Benutzeroberfläche (UI), diese Integration fällt jedoch nicht in den Geltungsbereich dieses Dokuments.
Jedes Integrationsmuster folgt einer konsistenten Struktur. Dies sorgt für Konsistenz bei den in den einzelnen Mustern bereitgestellten Informationen und erleichtert zudem den Vergleich von Mustern.
- Name: Der Musterkennzeichner, der auch den im Muster enthaltenen Integrationstyp angibt.
- Context: Das allgemeine Integrationsszenario, auf das sich das Muster bezieht. Kontext enthält Informationen darüber, was Benutzer erreichen möchten und wie sich die Anwendung verhält, um die Anforderungen zu erfüllen.
- Problem: Als Frage ausgedrückt, ist dies das Szenario, das das Muster lösen soll. Lesen Sie diesen Abschnitt, um nachzuvollziehen, ob das Muster für Ihr Integrationsszenario geeignet ist.
- Kräfte: Die Einschränkungen und Umstände, die die Lösung des angegebenen Szenarios erschweren.
- Lösung: Die empfohlene Lösung für das Integrationsszenario.
- Skizze: Ein UML-Sequenzdiagramm, das Ihnen zeigt, wie die Lösung das Szenario angeht.
- Ergebnisse: Erläutert, wie die Lösung auf Ihr Integrationsszenario angewendet wird und wie die mit diesem Szenario verbundenen Kräfte aufgelöst werden. Dieser Abschnitt enthält auch neue Herausforderungen, die durch die Anwendung des Musters auftreten können.
- Randleisten: Zusätzliche Abschnitte zum Muster, die wichtige technische Probleme, Variationen des Musters, musterspezifische Bedenken usw. enthalten.
- Beispiel: Ein reales Szenario, das beschreibt, wie das Designmuster in einem realen Salesforce-Szenario verwendet wird. Im Beispiel werden die Integrationsziele erläutert und erläutert, wie das Muster implementiert wird, um diese Ziele zu erreichen.
Verwenden Sie diese Tabelle als Inhaltsverzeichnis für die in diesem Dokument enthaltenen Integrationsmuster.
| Musterebene1 | Musterebene2 | Muster | Szenario |
|---|---|---|---|
| Datenaufnahmemuster – Eingehende Daten | Batch-Aufnahmemuster | Massendatenaufnahme aus Cloud-Speicher | Daten werden aus einer Enterprise Cloud-Speicherquelle wie Amazon S3, Azure Blob oder Google Cloud Storage in Data 360 in Form großer Batches mit Rohdaten (z. B. Transaktionen oder Produktprotokollen) aufgenommen. |
| Massendatenaufnahme aus Salesforce Clouds | Data 360 empfängt CRM-Daten per Massenvorgang aus mehreren Salesforce-Organisationen (z. B. Sales Cloud, Service Cloud), um zusammengeführte Kundenprofile zu erstellen. | ||
| Streaming und Echtzeit-Aufnahmemuster | Ereignisgesteuerte Aufnahme über die Aufnahme-API – Streaming | Data 360 abonniert Streaming-Aufnahmeendpunkte, die kontinuierliche Ereignisnutzlasten (z. B. Kaufereignisse, IoT-Telemetrie) von Unternehmenssystemen empfangen, um Profilaktualisierungen in Echtzeit vorzunehmen. | |
| Aufnahme von Web- und mobilem Verhalten in Echtzeit | Data 360 erfasst und verarbeitet Verhaltensdaten von Websites und mobilen Anwendungen in Echtzeit über SDKs, um Interaktionskennzahlen und Personalisierungsmodelle anzureichern. | ||
| CRM-Synchronisierung nahezu in Echtzeit über Streaming | Data 360 empfängt CRM-Datenaktualisierungen (z. B. Kontakt-, Kundenvorgangs- oder Opportunity-Änderungen) nahezu in Echtzeit über Ereignisströme, um eine kontinuierlich synchronisierte Customer 360 Ansicht aufrechtzuerhalten. | ||
| Ereignisstromaufnahme aus Cloud-Messaging-Plattformen – Kinesis und MSK | Data 360 verwendet Streaming-Daten direkt von Cloud-Ereignisplattformen wie AWS Kinesis oder Kafka (MSK), um hochfrequente betriebliche oder IoT-Ereignisse zu verarbeiten. | ||
| Null Kopiermuster – Eingehend und ausgehend | Eingehende Nullkopie – externe Plattformen für Data 360 | Data 360 fragt externe Datensets (z. B. Snowflake, BigQuery) bei Bedarf über die Aufnahme von Nullkopien ab, ohne Daten physisch in Salesforce zu verschieben. | |
| Ausgehende Nullkopie – Data 360 für externe Plattformen | Externe Systeme wie Databricks oder Tableau greifen über ausgehende Zero Copy-Verbindungen ohne Datenreplikation auf angereicherte Segmente und Statistiken in Data 360 zu. | ||
| Zusammengeführte Datenplattform für mehrere Organisationen mit Data Cloud One | Data Cloud One vereinheitlicht mehrere Salesforce-Organisationen und externe Datenquellen unter einem gemeinsamen Metadaten- und semantischen Modell und bietet so eine konsistente Customer 360 ohne Datenduplizierung. | ||
| Datenaktivierungsmuster – Ausgehende Daten | Batch-Aktivierungsmuster | Segmentaktivierung für Marketing- und Werbeplattformen | Data 360 aktiviert verwaltete Kundensegmente direkt in Marketing Cloud, Meta, Google Ads oder anderen Anzeigenplattformen für die Bereitstellung personalisierter Kampagnen |
| Datenexport in Cloud-Speicher | Data 360 exportiert zusammengeführte oder gefilterte Datensets (z. B. Datensätze vom Typ "Zustimmung zu Kunden") als CSV- oder Parquet-Dateien in den Enterprise Cloud-Speicher für Analysen oder die Compliance-Archivierung. | ||
| API-basierte On-Demand-Aktivierung | Benutzerdefinierte Anwendungsintegration über die Connect-API | Externe Anwendungen rufen die Data 360 Connect-API in Echtzeit auf, um personalisierte Aktionen (z. B. Treuebilanzprüfung oder Generierung von AI-Angeboten) basierend auf aktuellen Kundendaten abzurufen oder auszulösen.Benutzerdefinierte Web- oder mobile Anwendungen rufen harmonisierte Data 360-Statistiken sicher über die Connect-REST-API ab, um sie auf der Benutzeroberfläche von Unternehmen oder Partnern anzuzeigen. | |
| Abschließen des Kundenprofilabrufs über die Datendiagramm-API | Ein System ruft das vereinheitlichte Profil eines Kunden mithilfe der Datendiagramm-API ab und gibt eine vorverknüpfte JSON-Darstellung in Echtzeit der vollständigen 360°-Ansicht zur Entscheidungsfindung oder Personalisierung zurück. | ||
| Echtzeit-Datenaktionen | Echtzeit-Datenaktion zum Umwandeln von Kundensignalen in sofortige Aktionen | Data 360 erkennt und verarbeitet ein Live-Ereignis (z. B. Einwilligungsaktualisierung, Kaufauslöser) und ruft sofort ein verbundenes System oder einen Salesforce-Flow für nachgelagerte Aktionen auf.Ein Kundenaktivitätssignal (z. B. erkanntes Abwanderungsrisiko) in Data 360 löst eine sofortige Echtzeitaktion aus, beispielsweise das Aktualisieren von CRM, das Aufrufen von Einstein-Bewertungen oder das Starten einer Aufbewahrungs-Journey. |
Die Integrationsmuster in diesem Dokument werden in drei Kategorien unterteilt: Daten-, Prozess- und visuelle Integrationen.
Datenintegrationsmuster in Data 360 zielen auf die Bewegung und Synchronisierung von Daten zwischen Systemen ab, um sicherzustellen, dass Data 360 und externe Plattformen konsistente, aktuelle und vertrauenswürdige Informationen enthalten. Diese Muster verarbeiten in der Regel große Datenflüsse mit hohem Volumen und basieren auf geregelten Pipelines, die Schemakonsistenz, Abstammungsverfolgung und Mastering-Regeln erzwingen.
- Batch-Aufnahmemuster stellen die grundlegende Ebene der Einarbeitung von Unternehmensdaten dar. Die Massendatenaufnahme aus Cloud-Speicherservices wie AWS S3, Azure Blob oder Google Cloud Storage ermöglicht es, große historische Datensets regelmäßig in Data 360 zu laden, um die Identität aufzulösen, zu segmentieren und zu analysieren. Ähnlich verhält es sich bei der Massenaufnahme aus Salesforce Clouds, beispielsweise Sales, Service oder Marketing Cloud, mit nativen Konnektoren und Datenströmen, um CRM-Daten in die vereinheitlichte Datenebene zu integrieren und so Harmonisierung und Kontinuität zwischen den Engagementsystemen zu gewährleisten.
- Streaming und Echtzeit-Aufnahmemuster erweitern dies durch die Erfassung von Ereignisdaten mit hoher Geschwindigkeit. Durch die ereignisgesteuerte Aufnahme über die Aufnahme-API können externe Systeme Kundenaktivitäten kontinuierlich in Data 360 streamen. Die Echtzeit-Aufnahme von Web- und mobilen Verhaltensweisen erfasst Clickstream- und Interaktionsdaten direkt von digitalen Kontaktpunkten, um die sofortige Personalisierung zu fördern. Die CRM-Synchronisierung nahezu in Echtzeit über Streaming-APIs stellt sicher, dass Kundenattribute und Einwilligungsaktualisierungen schnell systemübergreifend berücksichtigt werden. Die Aufnahme von Ereignisströmen aus Messaging-Plattformen wie Amazon Kinesis oder Confluent MSK unterstützt kontinuierliche Pipelines mit hohem Durchsatz, wodurch Data 360 an die Ereignisarchitekturen von Unternehmen angepasst wird.
- Die einheitliche Multi-Org Data Platform mit Data Cloud One veranschaulicht die Datenintegration weiter und bietet eine konsolidierte Umgebung, um Daten aus mehreren Salesforce-Organisationen und externen Quellen unter einer gemeinsamen Governance- und semantischen Ebene zu vereinheitlichen. Dadurch können Organisationen unternehmensweite Datenkonsistenz, freigegebene Datenmodelle und skalierbare Analysen erreichen.
- In der Aktivierungsphase folgen Batch-Aktivierungsmuster demselben Datenintegrationsprinzip. In Data 360 zusammengestellte Segmente werden in geplanten Aufträgen auf nachgelagerte Marketing- und Werbeplattformen wie Marketing Cloud, Meta Ads oder Google Ads exportiert und lösen dort die Kampagnenausführung aus. Ebenso können Datensets in Cloud-Speicherziele exportiert werden, um externe Analysen und Data Science-Pipelines voranzutreiben. In all diesen Anwendungsfällen fungiert Data 360 als Quelle der Wahrheit für synchronisierte und zusammengestellte Kundendaten.
Prozessintegrationsmuster in Data 360 beinhalten das Auslösen oder Orchestrieren von Geschäftsprozessen über mehrere Systeme hinweg in nahezu Echtzeit. Anhand dieser Muster kann Data 360 aktiv an Unternehmens-Workflows teilnehmen und so kontextbezogene Antworten und dynamische Datenaktivierung ermöglichen.
- Die API-basierte On-Demand-Aktivierung ermöglicht Engagementszenarien in Echtzeit. Über die Connect-API können benutzerdefinierte Anwendungen Kundenprofile direkt in Data 360 im Rahmen von betrieblichen Prozessen abfragen oder aktivieren, beispielsweise eine Agentenkonsole, die während einer Kundeninteraktion zusammengeführte Profilstatistiken abruft. Die Complete Customer Profile Retrieval via Data Graph API unterstützt zusammengesetzte Anwendungen und Microservices, die auf API-gesteuerten Zugriff auf das vollständige Einheitendiagramm eines Kunden angewiesen sind, was dynamische Erfahrungen ohne vordefinierte Segmente ermöglicht.
- Mit Echtzeit-Datenaktionen wird dieser Integrationsansatz weiter vorangetrieben, indem sofortige Reaktionsfähigkeit ermöglicht wird. Wenn ein Kundensignal erkannt wird, beispielsweise ein Kauf, eine Formularsendung oder ein Schwellenwertereignis, kann Data 360 Aktionen wie das Aktualisieren eines CRM-Datensatzes, das Aufrufen eines externen Webhooks oder das Starten eines personalisierten Angebots-Workflows auslösen. Diese Muster verkörpern eine echte Prozessorchestrierung, die Kundenintelligenz in Echtzeit mit automatisierter operativer Ausführung verbindet.
Virtuelle Integrationsmuster in Data 360 ermöglichen den Live-Zugriff auf externe oder Verbunddatenquellen, ohne Daten physisch kopieren oder duplizieren zu müssen. Diese sind wichtig für Unternehmen, die geregelte, aktuelle Informationen zur Abfragezeit benötigen und gleichzeitig die Datenbewegung minimieren.
- Inbound Zero Copy Data Federation(External Platforms-to-Data 360) ermöglicht externen Systemen wie Data Warehouses oder Data Lakes die Freigabe von Datensets für Data 360 über sichere, geregelte Verbindungen (z. B. Snowflake Secure Data Sharing). Dadurch wird sichergestellt, dass Data 360 virtuell auf externe Daten zugreifen und sie bearbeiten kann, wodurch die Aktualität gewahrt bleibt und unnötige Abgleiche vermieden werden.
- Mit der ausgehenden Zero Copy-Datenfreigabe (Data 360-zu-externen Plattformen) kann Data 360 zusammengestellte Datensets für den externen Verbrauch wie AI-Modellierung, Business Intelligence oder erweiterte Analysen über sichere Datenverbund- und Live-Abfragemechanismen bereitstellen. Die Auswahl der besten Integrationsstrategie für Ihr System ist nicht trivial. Es gibt viele Aspekte zu berücksichtigen und viele Tools, die verwendet werden können, wobei einige Tools für bestimmte Aufgaben besser geeignet sind als andere. Jedes Muster richtet sich an bestimmte kritische Bereiche, einschließlich der Funktionen der einzelnen Systeme, des Datenvolumens, der Fehlerverarbeitung und der Transaktionalität.
Beantworten Sie bei der Auswahl eines Integrationsmusters zunächst zwei grundlegende Fragen, die das Gesamtdesign und -verhalten der Integration beeinflussen. Was integrieren Sie? – Prozess-, Daten- oder virtueller Zugriff Diese Dimension definiert den primären Zweck der Integration.
- Prozessintegrationen konzentrieren sich auf die Orchestrierung von Geschäfts-Workflows und die systemübergreifende Koordinierung von Aktionen.
- Bei Datenintegrationen liegt der Fokus auf der Synchronisierung, Anreicherung oder Übertragung von Daten zwischen Systemen.
- Virtuelle Integrationen konzentrieren sich darauf, in Echtzeit auf externe Daten zuzugreifen, ohne sie in Salesforce oder Data 360 kopieren oder beibehalten zu müssen. Wenn Sie diesen Intent verstehen, können Sie die erforderliche Orchestrierung, Datenverschiebung und Kopplung zwischen Systemen bestimmen.
- Wie muss sie ausgeführt werden? – Die Methode Synchron oder Asynchron definiert das Ausführungsmodell der Integration.
- Synchrone Integrationen erfolgen in Echtzeit und blockieren, wobei der Anrufer eine sofortige Antwort erwartet – häufig verwendet für benutzergesteuerte oder Validierungsszenarien.
- Asynchrone Integrationen sind nicht blockierbar und entkoppelt und wurden für Skalierung, langfristige Prozesse, Wiederholungen und hohe Datenvolumen entwickelt. Zusammen bieten diese beiden Dimensionen – Intent und Ausführungszeitpunkt – einen klaren, konsistenten Rahmen für die Auswahl des richtigen Integrationsmusters, während Benutzererfahrung, Skalierbarkeit und betriebliche Widerstandsfähigkeit in Einklang gebracht werden. Hinweis: Für eine Integration kann eine externe Middleware oder Integrationslösung (z. B. Enterprise Service Bus) erforderlich sein, je nachdem, welche Aspekte auf Ihr Integrationsszenario zutreffen.
In dieser Tabelle sind die Muster und ihre wichtigsten Aspekte aufgeführt, damit Sie bestimmen können, welches Muster Ihren Anforderungen am besten entspricht, wenn Ihre Integration von Salesforce in ein anderes System erfolgt.
| Typ | Zeitpunkt | Überlegungen zu "Ausgehend" |
|---|---|---|
| Datenintegration | Asynchron | Segmentaktivierung für Marketing- und Werbeplattformen |
| Prozess-/Datenintegration | Synchronous | Benutzerdefinierte Anwendungsintegration über die Connect-API Abschließen des Kundenprofilabrufs über die Datendiagramm-API |
| Datenintegration | Synchronous | Echtzeit-Datenaktion zum Umwandeln von Kundensignalen in sofortige Aktionen |
| Virtuelle Integration (mit Zero Copy) | Asynchron | Ausgehende Nullkopie – Data 360 für externe Plattformen |
| Virtuelle Integration | Asynchron | Zusammengeführte Datenplattform für mehrere Organisationen mit Data Cloud One |
In dieser Tabelle sind die Muster und ihre wichtigsten Aspekte aufgeführt, damit Sie das Muster ermitteln können, das Ihren Anforderungen am besten entspricht, wenn Ihre Integration von einem anderen System in Salesforce erfolgt.
| Typ | Zeitpunkt | Eingehende Überlegungen |
|---|---|---|
| Datenintegration | Asynchron | Massendatenaufnahme aus Cloud-Speicher Massendatenaufnahme aus Salesforce Clouds |
| Datenintegration | Asynchron | Ereignisstromaufnahme aus Cloud-Messaging-Plattformen – Kinesis und MSK CRM-Synchronisierung nahezu in Echtzeit über Streaming |
| Prozessintegration | Synchronous | Ereignisgesteuerte Aufnahme über die Aufnahme-API – Streaming Aufnahme von Web- und mobilem Verhalten in Echtzeit |
| Virtuelle Integration | Asynchron | Eingehende Nullkopie – externe Plattformen für Data 360 |
In dieser Tabelle sind einige wichtige Begriffe in Bezug auf Middleware und ihre Definitionen in Bezug auf diese Muster aufgeführt.
| Term | Definition |
|---|---|
| Ereignisverarbeitung | Die Ereignisverarbeitung bezieht sich auf das Empfangen, Weiterleiten und Reagieren auf identifizierbare Vorkommnisse aus einem Quellsystem oder einer Anwendung. Die Middleware verarbeitet Ereignisse, indem sie den Zielendpunkt identifiziert, das Ereignis weiterleitet und die erforderliche Geschäftsaktion auslöst (z. B. Protokollierung, Wiederholungen oder Aktivierung nachgelagerter Services). In Data 360-Architekturen ist die Ereignisverarbeitung wichtig für die Echtzeit-Datenaufnahme, Aktivierungsauslöser und Veröffentlichungs-/Abonnementmuster. Ereignisse können von externen Systemen (Kafka, AWS Kinesis) oder Salesforce Platform-Ereignissen stammen und von Middleware oder dem Data 360-Ereignis-Bus zur sofortigen Verarbeitung weitergeleitet werden. |
| Protokollkonvertierung | Die Protokollkonvertierung ermöglicht die Kommunikation zwischen Systemen, die unterschiedliche Datentransportstandards verwenden. Middleware übersetzt proprietäre oder ältere Protokolle (wie AMQP, MQTT, FTP) in unterstützte Data 360-Protokolle (REST, gRPC oder HTTPS). Dadurch wird die Interoperabilität über heterogene Systeme hinweg gewährleistet. Da Data 360 die Protokollkonvertierung nicht nativ verarbeitet, stellt Middleware die Anpassungsebene bereit, um Nachrichten in ein Format zu kapseln oder umzuwandeln, das Data 360-APIs und -Konnektoren interpretieren können. |
| Übersetzung und Transformation | Die Übersetzung und Transformation gewährleisten die Interoperabilität, indem sie ein Datenformat oder Schema einem anderen zuordnen. Middleware führt diese Transformationen aus, um verschiedene Datennutzlasten (CSV, XML, JSON) an Data 360-Datenmodellobjekten (DMOs) und Objekten der einheitlichen Datenebene (Unified Data Layer Objects, UDLOs) auszurichten. Dies umfasst die Bereinigung, Anreicherung und Anwendung der semantischen oder ontologiebasierten Zuordnung vor der Aufnahme. Salesforce bietet Transformationstools wie Rezepte für die Datenvorbereitung. Komplexe Transformationen (insbesondere für die semantische Harmonisierung) lassen sich jedoch am besten in Middleware verarbeiten. |
| Warteschlange und Pufferung | Warteschlange und Pufferung basieren auf der asynchronen Nachrichtenweitergabe, um eine belastbare, entkoppelte Kommunikation zu gewährleisten. Middleware-Plattformen (z. B. MuleSoft, Kafka oder Azure Event Hub) stellen persistente Warteschlangen bereit, in denen Daten temporär gespeichert werden, wenn Data 360 oder nachgelagerte Systeme ausgelastet oder nicht erreichbar sind. Dadurch wird Datenverlust verhindert und die Aufnahme oder Aktivierung nahezu in Echtzeit unterstützt. Data 360 unterstützt die Streaming-Aufnahme und das Flow-basierte ausgehende Messaging. Die dauerhafte Warteschlange und die garantierte Zustellung werden jedoch in der Regel von Middleware verarbeitet. |
| Synchrone Transportprotokolle | Synchrone Transportprotokolle beinhalten Blockierungs-/Antwortvorgänge in Echtzeit. Der Absender wartet auf eine Antwort, bevor er fortfährt. In Data 360 werden sie für API-basierte On-Demand-Aktivierungen, Echtzeitanreicherungen oder Profilnachschlagevorgänge verwendet, bei denen Antworten sofort erforderlich sind. Middleware gewährleistet die Verbindungszuverlässigkeit und verwaltet Wiederholungen oder Ausweichvorgänge für synchrone Data 360-API-Aufrufe. |
| Asynchrone Transportprotokolle | Asynchrone Transportprotokolle unterstützen die nicht blockierende, entkoppelte Kommunikation, bei der der Absender die Verarbeitung fortsetzt, ohne auf eine Antwort zu warten. Middleware verarbeitet asynchrone Flows für Batch-Aktivierungen, die Streaming-Aufnahme und die ereignisgesteuerte Aktivierung. Dies ermöglicht einen hohen Durchsatz und Widerstandsfähigkeit – entscheidend für das Streaming von Ereignissen und die nahezu Echtzeit-Datenaufnahme in Data 360. |
| Vermittlungsweiterleitung | Die Vermittlungsweiterleitung definiert einen komplexen Nachrichtenfluss zwischen Systemen und stellt sicher, dass die richtigen Daten oder Ereignisse den richtigen Verbraucher erreichen. Middleware fungiert als Vermittler und verarbeitet Weiterleitungslogik basierend auf Regeln, Kopfzeilen, Inhalten oder Ereignistypen. In Data 360-Integrationen stellt die Mediation sicher, dass Ereignisse und Profilaktualisierungen aus mehreren Systemen ordnungsgemäß an Datenaufnahme-APIs, Aktivierungsendpunkte oder externe Verbraucher weitergeleitet werden. Dies vereinfacht die Orchestrierung und unterstützt die Datensynchronisierung mit mehreren Systemen. |
| Prozesschoreografie und Serviceorchestrierung | Prozesschoreografie und Orchestrierung koordinieren Prozesse mit mehreren Systemen. Die Choreografie unterstützt autonome, asynchrone ereignisgesteuerte Flows, bei denen Systeme auf der Grundlage gemeinsamer Regeln ohne zentrale Steuerung agieren. Die Orchestrierung ist ein zentral verwalteter Flow, der die Serviceausführung steuert. In Data 360-Architekturen verwaltet Middleware die Orchestrierung für die systemübergreifende Aufnahme und Aktivierung, während Salesforce-Workflows oder -Flows leichte Choreografien innerhalb der Plattform verarbeiten. Auf Middleware-Ebene wird eine komplexe Orchestrierung empfohlen, die eine Transaktionskoordination oder eine Verwaltung des Status erfordert. |
| Transaktionalität (Verschlüsselung, Signieren, zuverlässige Zustellung, Transaktionsverwaltung) | Die Transaktionalität gewährleistet systemübergreifend atomare, konsistente, isolierte und langlebige Vorgänge (ACID). Salesforce und Data 360 sind Transaktionen innerhalb ihrer Grenzen, unterstützen jedoch keine verteilten Transaktionen über externe Systeme hinweg. Middleware übernimmt die globale Transaktionssteuerung, einschließlich Verschlüsselung, Nachrichtensignatur, Rollback, Vergütung und zuverlässiger Zustellung. Bei geschäftskritischen Datenflüssen (z. B. Finanz- oder Einwilligungsaktualisierungen) gewährleistet Middleware die durchgängige Integrität und Wiederherstellung von Data 360 und externen Systemen. |
| Weiterleitung | Die Weiterleitung gibt den gesteuerten Fluss von Nachrichten oder Daten zwischen Komponenten an. Sie kann auf Kopfzeilen, Inhaltstypen, Prioritäten oder Regeln basieren. Middleware verarbeitet die Weiterleitungslogik für Ereignisse und Aktivierungen, die Data 360 betreffen, beispielsweise die Weiterleitung von Segmenten für angereicherte Zielgruppen an verschiedene nachgelagerte Systeme (Anzeigenplattformen, Lagerhäuser, CRM-Anwendungen). Obwohl die Weiterleitung in Salesforce (Apex, Flows) implementiert werden kann, wird die Middleware-Weiterleitung aus Gründen der Skalierbarkeit, Flexibilität und Governance bevorzugt. |
| Extrahieren, Umwandeln und Laden | Bei der ETL werden Daten aus Quellsystemen extrahiert, in ein konsistentes Schema umgewandelt und in ein Ziel (wie Data 360) geladen. Middleware- oder ETL-Tools verarbeiten diese Vorgänge vor der Datenaufnahme. Data 360 kann ETL-Ausgaben über APIs, Konnektoren oder Massenaufnahmepipelines empfangen und unterstützt zudem die Datenerfassung (CDC) für die Synchronisierung nahezu in Echtzeit. Middleware-ETL-Prozesse sind wichtig für die Integration veralteter Systeme und die Sicherstellung der Datenqualität vor der Vereinheitlichung in Data 360. |
| Lange Abstimmung | Long Polling (Comet-Programmierung) ist eine Methode zur Aufrechterhaltung einer offenen Kommunikation zwischen Systemen für Echtzeitaktualisierungen. Der Client sendet eine Anforderung und der Server hält sie so lange, bis ein Ereignis auftritt. Anschließend antwortet er und öffnet erneut eine Verbindung. Salesforce verwendet dies in den Streaming-API- und CometD/Bayeux-Protokollen für die ereignisgesteuerte Datensynchronisierung. Middleware kann diese Ereignisse abonnieren und sie an Data 360 weiterleiten, um Echtzeit-Aufnahme- oder Aktivierungsauslöser zu erhalten und so eine minimale Latenz zwischen Unternehmenssystemen zu gewährleisten. |
Die Datenaufnahme ist der erste und wichtigste Schritt im Datenlebenszyklus von Salesforce Data 360. Auf diese Weise gelangen Rohinformationen aus mehreren externen Systemen (CRM, ERP, Web, Mobile oder Drittanbieter-APIs) auf die Plattform und werden Teil einer einheitlichen Kundenansicht. Das richtige Aufnahmemuster hängt davon ab, was das Unternehmen benötigt:
- Datenvolumen: Wie viele Daten gleichzeitig verschoben werden
- Latenz: Wie aktuell müssen die Daten sein
- Quellsystemfunktionen – Art und Weise, wie das System Daten verbinden und bereitstellen kann Data 360 unterstützt mehrere Aufnahmemodi, um diese Anforderungen zu erfüllen: Batch für Ladevorgänge mit hohem Volumen, Streaming für Aktualisierungen nahezu in Echtzeit, ereignisbasierte Aufnahme für die Transaktionsunmittelbarkeit und Aufnahme ohne Kopieren für sofortigen Zugriff auf externe Daten, ohne sie physisch zu verschieben. Zusammen stellen diese Muster sicher, dass jedes Kundensignal – sei es ein Kaufereignis, ein Clickstream-Protokoll oder eine Treueaktualisierung – effizient, sicher und im richtigen Zeitrahmen in Data 360 einfließt, um vertrauenswürdige Analysen und AI-gestützte Erfahrungen zu ermöglichen.
Batch-Aufnahmemuster sind das Rückgrat der umfangreichen Dateneinarbeitung in Data 360. Sie sind für Szenarien optimiert, in denen Daten per Massenvorgang verarbeitet werden – in der Regel planmäßig oder regelmäßig – und nicht kontinuierlich. Diese Muster eignen sich am besten für:
- Historische Daten werden geladen, um die Plattform mit vorhandenen Unternehmensdatensätzen zu initialisieren
- Regelmäßige Synchronisierung mit Datensatzsystemen wie ERPs, Data Warehouses oder proprietären Datenbanken
- Anwendungsfälle, in denen die Echtzeitaktualisierung nicht entscheidend ist, Konsistenz, Vollständigkeit und Überprüfbarkeit jedoch Die Batch-Aufnahme bietet eine vorhersehbare Leistung und eine einfache Bedienung, was sie zu einer vertrauenswürdigen Wahl für Unternehmen macht, die Terabyte strukturierter oder halbstrukturierter Daten verwalten. Data 360 bietet eine Reihe allgemein verfügbarer Konnektoren für die Produktion, die die Batch-Aufnahme nativ unterstützen. Diese Konnektoren optimieren das Integrations-Setup, reduzieren die benutzerdefinierte ETL-Entwicklung und gewährleisten Datenqualität und Sicherheit bei jedem Import. In der folgenden Tabelle sind die gängigsten Konnektoren für die Batchaufnahme im Unternehmensmaßstab hervorgehoben.
Context
Dieses Muster wurde für Unternehmensszenarien entwickelt, bei denen große Mengen an strukturierten Daten wie CSV- oder Parquet-Dateien und unstrukturierte Datenbestände aus zentralisierten Data Lakes oder geplanten Dateiablagen aufgenommen werden. Zu den Datenquellen zählen in der Regel Cloud-Speicherplattformen wie Amazon S3, Google Cloud Storage (GCS) und Microsoft Azure Blob Storage, bei denen Dateien regelmäßig als Teil vorgelagerter Datenpipelines oder Batch-Exporte bereitgestellt werden.
Problem
Wie kann eine Organisation einen zuverlässigen, sicheren und durchsatzstarken Prozess einrichten, um massive, dateibasierte Datensets aus ihrer primären Cloud-Speicherplattform nach einem vorhersehbaren, wiederkehrenden Zeitplan in Data 360 aufzunehmen, ohne dabei die Governance, Skalierbarkeit oder Leistung zu beeinträchtigen?
Kräfte
Die Aufnahme massiver, dateibasierter Datensets in Data 360 ist keine einfache Datenübertragung, sondern eine architektonische Herausforderung, die von Skalierung, Governance und Plattformeinschränkungen geprägt ist.
Datenvolumen und Skalierung: Die Data 360-Aufnahmekonnektoren sind für Zuverlässigkeit und Governance optimiert, nicht für den willkürlichen Massendurchsatz. Beispielsweise unterstützt der Amazon S3-Konnektor bis zu 100 Millionen Zeilen oder 50 GB pro Objekt, je nachdem, welche Obergrenze zuerst erreicht wird. Für Unternehmen mit historischen Datensets, die Milliarden von Datensätzen aufweisen, wird diese Grenze zu einer wichtigen Designeinschränkung. Ein Single-File-Lift-and-Shift-Ansatz wird schnell undurchführbar, was intelligente Datenpartitionierungs-, Blockierungs- und Orchestrierungsstrategien erfordert, um eine Skalierung zu erreichen, ohne die Konnektorobergrenzen zu erreichen.
Schemadefinition und -wartung: Data 360 erfordert explizite Schemadefinitionen für jede Aufnahme-Pipeline, um die semantische und strukturelle Integrität sicherzustellen. Bei der S3-Aufnahme muss eine CSV-Datei Spaltenüberschriften und eine einzelne repräsentative Datenzeile definieren. Diese Datei fungiert als kanonischer Vertrag zwischen dem Quellsystem, d. h. dem Cloud-Speicher und Data 360. Fehlausrichtungen – in Feldnamen, Datentypen oder Codierungen – können zu Aufnahmefehlern oder stillen Datenbeschädigungen führen. Das Verwalten dieser Schemadatei in der Versionskontrolle und das Erzwingen der Validierung über CI/CD- oder Data Governance-Workflows wird zu einer bewährten Vorgehensweise für Produktionsumgebungen.
Konventionen für strenge Benennungen: Data 360 erzwingt strenge Objekt- und Feldbenennungsregeln, um die Konsistenz im Metadatendiagramm aufrechtzuerhalten.
- Objektnamen müssen mit einem Buchstaben beginnen und dürfen nur Buchstaben, Ziffern oder Unterstriche enthalten.
- Feldnamen müssen denselben Mustern folgen. Dateien, die gegen diese Konventionen verstoßen, beispielsweise Felder mit Leerzeichen, Sonderzeichen oder nicht unterstützten Symbolen, schlagen bei der Schemavalidierung während der Aufnahme fehl. Unternehmen müssen Datenhygieneprozesse vor der Aufnahme implementieren, um eingehende Dateistrukturen zu bereinigen und zu normalisieren.
Authentifizierung und Sicherheitsstatus: Jede Verbindung mit externem Speicher muss den Sicherheits- und Compliance-Standards auf Unternehmensebene entsprechen.
- Die Authentifizierung wird in der Regel über AWS Access/Secret Keys oder die Authentifizierung mit Verbundidentitätsanbieter (IdP) abgewickelt.
- IAM-Rollen müssen begrenzt sein, um die geringsten Berechtigungen zu erzwingen und nur Lesezugriff auf die angegebenen Speicherpfade zuzulassen.
- Für den sicheren Zugriff müssen ausgehende IP-Adressen direkt zur Zulassungsliste des Quellsystems hinzugefügt werden. Diese mehrschichtigen Steuerelemente stellen sicher, dass jede Dateiübertragung in einem überprüfbaren Null-Trust-Bereich ausgeführt wird, wodurch die Unternehmenskonformität mit der für die Aufnahme in großem Umfang erforderlichen Flexibilität abgewogen wird.
Lösung
Diese Tabelle enthält Lösungen für dieses Integrationsproblem.
| Lösung | Fit | Kommentare |
|---|---|---|
| Verwenden von nativen Cloud-Speicher-Konnektoren (Amazon S3, Google Cloud Storage, Azure Blob Storage) | Best | Dies ist das empfohlene und zuverlässigste Muster für die umfangreiche, wiederkehrende dateibasierte Aufnahme in Data 360\. Native Konnektoren bieten verwaltete Authentifizierung, Schemazuordnung und sichere Datenverschiebung direkt in Data Lake Objects (DLOs) von Data 360. Ideal für geplante Batch-Ladungen, bei denen die Latenz nicht kritisch ist (z. B. stündliche oder tägliche Planung). |
| Umgang mit großen Datensets (über Konnektorobergrenzen hinaus) | Am besten mit Vorverarbeitung | Jeder Konnektor erzwingt Aufnahmeobergrenzen (z. B. S3: 100 Millionen Zeilen oder 50 GB pro Objekt). Implementieren Sie bei größeren Datensets einen ETL-Vorverarbeitungsschritt, um Daten in kleinere Dateien/Ordner zu partitionieren, die unter diese Schwellenwerte fallen. Konfigurieren Sie dann mehrere Datenströme, um jede Partition parallel aufzunehmen, und verwenden Sie den Knoten append in einer Batch-Datentransformation) in Data 360, um die Partitionen erneut zu einem vereinheitlichten Datenset zu kombinieren. |
| Sicherheit und Governance | Best | Alle Konnektoren unterstützen die sichere Authentifizierung über Cloud-native Methoden (IAM-Rollen, Serviceaccounts oder Zugriffsschlüssel). Schränken Sie den Zugriff auf Data 360-IP-Bereiche über die Zulassungsliste des Cloud-Anbieters ein, um mehr Kontrolle zu erhalten. Die Datenübertragung erfolgt über verschlüsselte Kanäle, wobei die Dateien während der Aufnahme in einer temporären sicheren Staging-Ebene gespeichert werden. |
| Wann nicht verwenden | Suboptimal | Dieses Muster ist nicht optimal für:
|
Skizze
In diesem Diagramm wird die Abfolge der Schritte zum Aufnehmen der Daten aus dem Cloud-Speicher in Data 360 veranschaulicht.
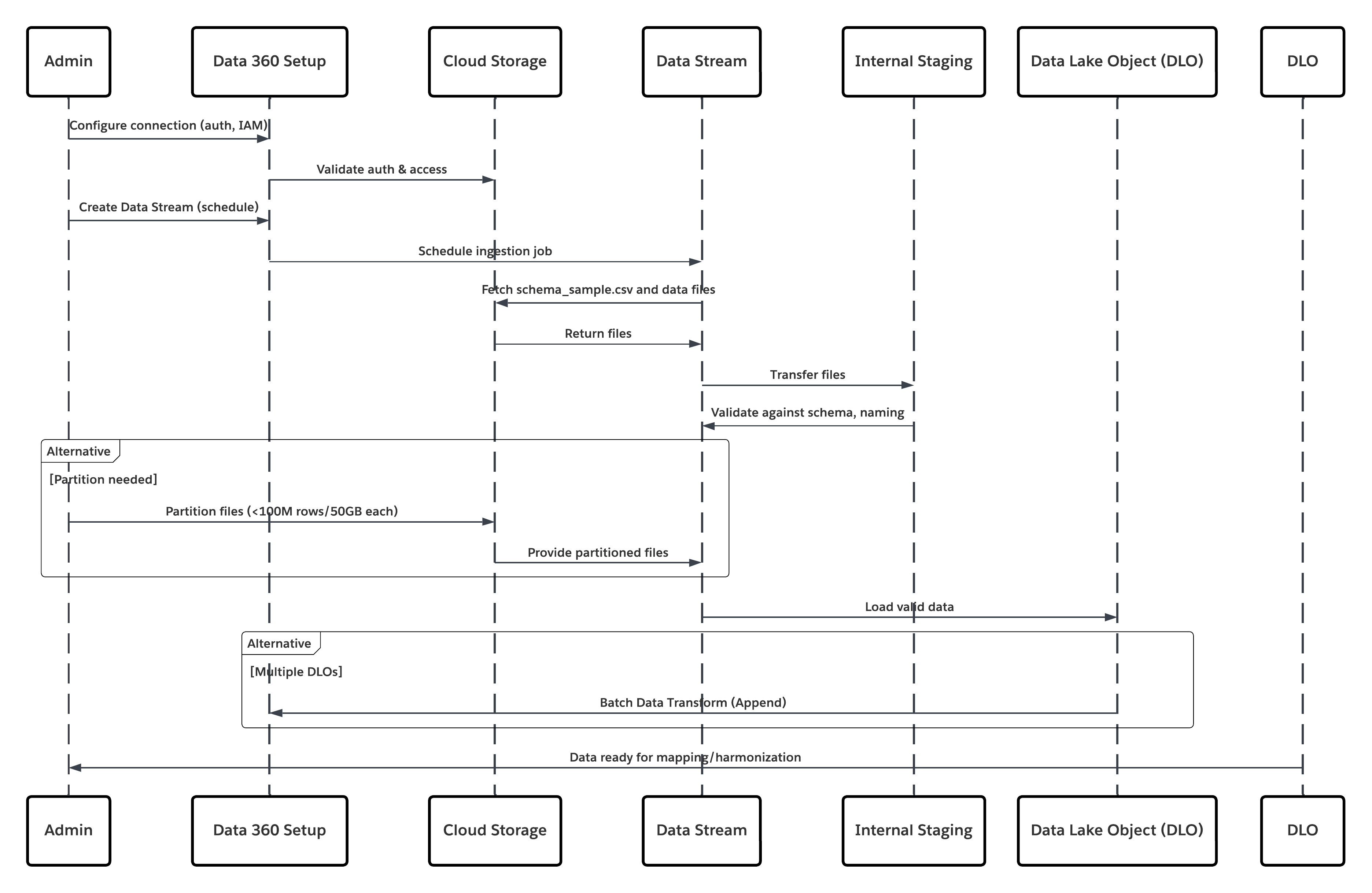
In diesem Szenario:
- Der Administrator konfiguriert eine Verbindung mit dem Cloud-Speicher über die Setup-Schnittstelle für Data 360 (mit Angabe der Authentifizierung, der Bucket-Details, der IAM-Rollen und der Positivliste).
- Die Data Cloud-Setup-Schnittstelle authentifiziert sich bei der Cloud-Speicherplattform und überprüft Anmeldeinformationen und Zugriff.
- Der Administrator erstellt einen Datenstrom in Data 360, verknüpft den Datenstrom mit dem Objekt/Ordner im Cloud-Speicher und definiert den Aufnahmeplan.
- Beim Planauslöser fordert der Datenstrom Quelldateien (z. B. CSV, Parquet) von der Cloud Storage Platform an.
- Die Cloud Storage Platform stellt Dateien bereit, einschließlich der erforderlichen gültigen Datei schema_sample.csv und anderer Datendateien, die mit Benennungskonventionen konform sind.
- Der Datenstrom überträgt Dateien an die interne Staging-Umgebung in Data 360.
- Data 360 Pipeline verarbeitet die Dateien: Verwendet die Schemadefinition aus schema_sample.csv Validiert Struktur, Feldnamen und dividiert die Last, wenn sie über den Aufnahmeschwellenwerten (100 Millionen Zeilen/50 GB pro Datei) liegt. Wenn große Dateien erkannt werden, wird ein Partitionierungsschritt vor der Verarbeitung (dem Administrator für die nächste Ausführung mitgeteilt) extern ausgeführt.
- Datensätze werden aus der Staging-Instanz in ein Data-Lake-Objekt (DLO) importiert.
- Verwenden Sie bei Bedarf den Knoten append in einer Batch-Datentransformation, um mehrere DLOs zu kombinieren.
- Data 360 protokolliert Erfolg/Fehler, aktualisiert den Status für die Überwachung und signalisiert, dass Daten für die Zuordnung, Harmonisierung und Vereinheitlichung bereit sind.
Ergebnisse
Die Anwendung dieses Musters ermöglicht die sichere, geplante und umfangreiche Aufnahme strukturierter oder unstrukturierter Dateien aus Enterprise Cloud-Speicherplattformen in Data 360. Der Prozess ist automatisiert, skalierbar und widerstandsfähig. Er stellt Rohdaten in Data-Lake-Objekten (DLOs) bereit, die als Grundlage für die Harmonisierung und Zuordnung zum Customer 360-Datenmodell dienen.
Aufnahmemechanismen
Der Aufnahmemechanismus hängt vom Konnektor und der in Data 360 definierten Planungsstrategie ab.
| Aufnahmemechanismus | Beschreibung |
|---|---|
| Native Cloud Storage Connector (Amazon S3, GCS, Azure) | Empfohlen für die direkte Aufnahme von Dateien im CSV- oder Parquet-Format aus dem Cloud-Data-Lake des Unternehmens. Diese Konnektoren unterstützen inkrementelle und vollständige Aktualisierungspläne. Beispielsweise kann eine Bank eine tägliche Synchronisierung von Kundentransaktionsdateien aus einem S3-Bucket in ein DLO konfigurieren. |
| Partitionierte Dateistrategie | Bei sehr großen Datensets (über 100 Millionen Zeilen oder 50 GB pro Objekt) werden die Daten in kleinere logische Sätze partitioniert (z. B. nach Monat oder Region). Jede Partition wird als separater Datenstrom verwaltet und später mithilfe einer Batch-Datentransformation mit einem Knoten vom Typ "Anhängen" neu kombiniert. |
| Automatisierte geplante Synchronisierung | Data 360 bietet eine deklarative Planung (Stunden-, Tages- oder benutzerdefinierter Rhythmus), die Aufnahmeaufträge automatisch auslöst und so die Aktualisierung der Daten ohne manuelle Eingriffe sicherstellt. |
Fehlerbehandlung und -behebung
Die Fehlerbehandlung und -behebung sind wichtig, um die Zuverlässigkeit bei der Aufnahme von Daten mit hohem Volumen zu gewährleisten.
- Fehlererkennung: Bei jeder Ausführung des Datenstroms werden Aufnahmefehler (z. B. Schemaabweichungen, Dateibeschädigungen oder Namensverstöße) in der Data 360-Überwachung protokolliert. Administratoren können fehlgeschlagene Batches überprüfen und erneut verarbeiten.
- Wiederherstellungsmechanismus: Data 360 führt die Überprüfung durch, um sicherzustellen, dass fehlgeschlagene Batches vorherige Aufnahmen nicht beschädigen. Wiederholungen können konfiguriert werden, nachdem Quellprobleme (z. B. falsch formatierte CSVs) behoben wurden.
- Schemavalidierung: Die Datei schema_sample.csv definiert Datentypen und Struktur. Alle Änderungen lösen eine Validierung aus, um eine stille Schemaabweichung zwischen Ausführungen zu vermeiden.
Überlegungen zum idempotenten Design
Die Aufnahme ist idempotent. Die erneute Verarbeitung derselben Datei führt nicht zu doppelten Datensätzen. Zu den wichtigsten Strategien zählen:
- Datei-Fingerabdruck: Data 360 berechnet Prüfsummen, um zuvor verarbeitete Dateien zu identifizieren und zu überspringen.
- Transaktionsaufnahme: Die Daten werden in eine Phase aufgenommen und erst nach erfolgreicher Verarbeitung aller Datensätze in das DLO übernommen.
- Anhängen vs. Ersetzen: Abhängig von der Geschäftslogik können Streams an das Ziel-DLO angehängt werden oder es vollständig ersetzen. Dadurch werden deterministische Ergebnisse sichergestellt und teilweise Datenüberschneidungen vermieden.
Sicherheitsüberlegungen
Sicherheit ist in der gesamten Aufnahme-Pipeline von entscheidender Bedeutung, von der Authentifizierung über die Verschlüsselung bis hin zur Zugriffskontrolle.
- Authentifizierung und Autorisierung: Konnektoren verwenden das sichere Integrations-Framework von Salesforce und nutzen Anmeldeinformationen mit Namen und externe Anmeldeinformationen für die Authentifizierung, ohne Geheimnisse preiszugeben.
- Verschlüsselung: Die Daten werden während der Übertragung (TLS 1.2+) und im Leerlauf (AES-256) verschlüsselt.
- Netzwerksteuerungen: Quellspeichersysteme (z. B. S3-Buckets) müssen Data 360-IPs auf die Zulassungsliste setzen.
- Compliance-Ausrichtung: Unterstützt Enterprise-Datenschutz-Frameworks wie die DSGVO, HIPAA und FFIEC-Richtlinien in Kombination mit Customer-Managed Keys (CMK).
- Überprüfbarkeit: Jeder Aufnahmeauftrag und jeder Zugriff auf Anmeldeinformationen wird für die Rückverfolgbarkeit und Compliance-Berichte protokolliert.
Randleisten
Aktualität
Die Aktualität hängt vom Aufnahmeplan und dem Datenvolumen ab.
- Für große Unternehmens-Datensets (100 Millionen Zeilen) muss möglicherweise eine Partitionierung vorgenommen werden, damit sie parallel aufgenommen werden können.
- Die typische Aufnahmelatenz liegt je nach Dateigröße und Transformationskomplexität zwischen Minuten und einigen Stunden.
- Bei der Aufnahme nahezu in Echtzeit können Data 360 Streaming- oder API-basierte Konnektoren das dateibasierte Modell ergänzen.
Datenvolumen
- Bestens geeignet für die regelmäßige Aufnahme von Batches mit hohem Volumen.
- Jedes über den S3-Konnektor verarbeitete Objekt unterstützt bis zu 100 Millionen Zeilen oder 50 GB pro Datei.
- Verwenden Sie für Systeme auf Petabyte-Skala die Datenpartitionierung und die Orchestrierung mehrerer Streams.
Unterstützung von Endpunktfunktionen und Standards
Die Funktionen und die Standardunterstützung für den Endpunkt hängen von der von Ihnen ausgewählten Lösung ab.
| Konnektortyp | Endpunktanforderungen |
|---|---|
| Amazon S3 Connector | S3-Bucket mit entsprechender IAM-Richtlinie und schema\_sample.csv-Datei, die das Schema definiert. |
| Google Cloud Storage Connector | Serviceaccount-Anmeldeinformationen und Bucket-Zugriff mit einheitlichen Benennungskonventionen. |
| Azurblauer Speicher-Konnektor | Greifen Sie auf die Schlüssel- oder SAS-Token-basierte Authentifizierung zu. Blob- oder Ordnerstrukturen müssen den Data 360-Konventionen entsprechen. |
Bundesstaatsverwaltung
Der Status wird über Datenströme und ihren letzten erfolgreichen Ausführungszeitstempel verfolgt.
- Data 360 behält automatisch Synchronisierungsstatus und Verschiebungen bei, wodurch sichergestellt wird, dass nur neue oder geänderte Dateien bei nachfolgenden Ausführungen verarbeitet werden.
- Bei der Integration mit externen ETL-Tools werden eindeutige Dateikennzeichner (z. B. UUIDs oder Zeitstempel) empfohlen, um Duplikate zu vermeiden.
Komplexe Integrationsszenarien
In erweiterten Unternehmensarchitekturen kann dieses Muster integriert werden in:
- ETL-Pipelines für Middleware (z. B. Informatica, MuleSoft): Orchestrieren der Vorverarbeitung, Validierung und Dateipartitionierung vor der Übergabe an Data 360.
- AI/ML-Workflows: Verarbeitete DLO-Daten können über das DMO veröffentlicht werden, um Trainingsumgebungen oder RAG-Indizes über Data 360-Aktivierungsziele zu modellieren.
- Transaktionale Systeme: Harmonisierte DMOs können über Datenaktionen oder Plattformereignisse nachgelagerte Aktualisierungen in Salesforce CRM oder externen Systemen auslösen.
Beispiel
Ein globales Finanzinstitut speichert Kunden- und Transaktionsdaten in einem AWS S3-Data-Lake, in dem partitionierte Parquet-Dateien nachts nach Region (z. B. USA, EU und APAC) generiert werden. Das Datenarchitekturteam konfiguriert mehrere Datenströme in Data 360, die jeweils mit einem regionalen Ordner verbunden sind, wobei eine freigegebene schema_sample.csv konsistente Kopfzeilen und Datentypen über alle Partitionen hinweg gewährleistet. Nächtliche Aufnahmepläne laden die Daten automatisch in DLOs. Anschließend hängen Batch-Datentransformationen alle regionalen Partitionen an ein vereinheitlichtes Customer_Transactions_DLO an. Dieses harmonisierte Datenset wird dann dem Customer 360-Datenmodell zugeordnet, wodurch nachgelagerte Analysen und AI-Aktivierungen ermöglicht werden. Der Ansatz bietet eine automatisierte und zuverlässige Aufnahme aus dem vorhandenen Data Lake, erzwingt eine starke Authentifizierung und Verschlüsselung in Übereinstimmung mit den IT-Richtlinien des Unternehmens und bietet eine skalierbare, modulare Grundlage, die zukünftige Erweiterungen und Schemaentwicklungen unterstützt.
Context
Ein primärer und wichtiger Anwendungsfall für Data 360 ist die Vereinheitlichung von Kundendaten im gesamten Salesforce-Ökosystem. Dieses Muster deckt nativ Daten aus Salesforce-Kernplattformen ab – Sales Cloud und Service Cloud (zusammen Salesforce CRM) und Marketing Cloud Engagement. Zu den Quellen gehören standardmäßige und benutzerdefinierte CRM-Objekte (z. B. Account, Kontakt, Kundenvorgang, Opportunity) und Marketing Cloud Engagement-Data Extensions, die Engagementereignisse, E-Mail-Sendungen und Verfolgungsdaten enthalten.
Problem
Wie kann eine Organisation standardmäßige und benutzerdefinierte CRM-Objekte und Marketing Cloud Engagement-Data Extensions effizient und zuverlässig in Data 360 aufnehmen, damit die Daten zum Erstellen von vereinheitlichten Kundenprofilen (Identitätsbestimmung, Customer 360) verwendet werden können, während gleichzeitig Leistung, Governance und minimale Unterbrechungen der Quellsysteme gewährleistet sind?
Kräfte
Native Konnektoren vereinfachen die Arbeit, es müssen jedoch mehrere betriebliche und architektonische Kräfte verwaltet werden:
- Umfassende Quellberechtigungen: Ein spezieller verbindender Benutzer (Integrationsaccount) muss über die entsprechenden Leseberechtigungen auf Objekt- und Feldebene verfügen. Die Nichtzuweisung der erforderlichen Berechtigungssätze (beispielsweise eines vorgefertigten Data 360-Konnektors) ist eine häufige Ursache für Aufnahmefehler.
- Datenaktualisierungsmodi und -kosten: Konnektoren unterstützen den vollständigen und den Delta-/inkrementellen Aktualisierungsmodus. Vollständige Aktualisierungen sind leistungs- und gutschriftsintensiver. Delta-Extraktionen reduzieren die Auslastung, sind jedoch auf eine zuverlässige Änderungsverfolgung im Quellsystem angewiesen.
- Benutzerdefiniertes Schema und Feldzuordnung: CRM-Instanzen enthalten oft benutzerdefinierte Objekte/Felder. Eine genaue Schemazuordnung und Verarbeitung benutzerdefinierter Felder (Namen, Typen) ist erforderlich, um Zuordnungsfehler oder semantische Abweichungen zu vermeiden.
- Starter-Datenpakete vs. Benutzerdefinierte Zuordnung: Starter-Datenpakete beschleunigen die Einarbeitung, indem typische Objekte/Felder vorab ausgewählt werden. Stark angepasste Organisationen benötigen jedoch maßgeschneiderte Stream-Definitionen.
- Obergrenzen für Durchsatz und API: API-Obergrenzen für Quellorganisationen und Marketing Cloud-Extraktionsraten schränken ein, wie aggressiv Sie Aktualisierungen planen können.
- Datenhygiene- und Benennungskonventionen: Quellfeldnamen, Nullverhalten und Datentypen müssen vor der Aufnahme normalisiert werden, um nachgelagerte Zuordnungsprobleme zu vermeiden.
- Sicherheit und geringste Berechtigung: Der Konnektor basiert auf der sicheren Authentifizierung und muss IAM-Muster mit den geringsten Berechtigungen, Überprüfbarkeit und Netzwerksteuerungen berücksichtigen.
Lösung
Diese Tabelle enthält Lösungen für dieses Integrationsproblem.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Lösungsanpassung | Best | Verwenden Sie den nativen Salesforce CRM-Konnektor und den Marketing Cloud Engagement-Konnektor in Data 360\. Beginnen Sie mit Starter-Datenpaketen für Standardanwendungsfälle und beschleunigen Sie die Einarbeitung. Verwenden Sie die manuelle Stream-Anpassung für maßgeschneiderte oder domänenspezifische Datenmodelle. |
| Umgang mit hochgradig angepassten CRM-Instanzen | Am besten mit Zuordnungsworkshop | Behandeln Sie Starter-Pakete als Grundlage und führen Sie einen Zuordnungsworkshop durch, um Folgendes zu ermitteln: Benutzerdefinierte Objekte und Beziehungen. Formel- oder berechnete Felder. Erweiterungen für verwaltete Pakete. Berechnen Sie bei schweren Formelfeldern Werte in einem vorgelagerten ETL oder in Data 360-Transformationen, um die API-Last in Quellorganisationen zu minimieren. |
| Wann nicht verwenden | Suboptimale Szenarien | Vermeiden Sie dieses Muster in folgenden Fällen: Sie benötigen die Aufnahme von Ereignissen mit hoher Häufigkeit oder in Echtzeit (verwenden Sie stattdessen Streaming-Konnektoren, Plattformereignisse oder Zero-Copy-Verbund). Die API-Kapazität der Quellorganisation ist begrenzt und geplante Extraktionen können nicht ohne Drosselung oder Warteschlangenverzögerungen unterstützt werden. |
| Sicherheit und Governance | Obligatorische Steuerelemente | Grundsatz der geringsten Berechtigung: Verwenden Sie einen dedizierten Integrationsbenutzer mit minimalem Lesezugriff. Verwenden Sie niemals organisationsweite Administratoren. Authentifizierung: Verwenden Sie OAuth 2.0 und verbundene Anwendungen, rotieren Sie Client-Geheimnisse regelmäßig und überwachen Sie die Verwendung von Aktualisierungstoken. Überprüfung und Rückverfolgbarkeit: Protokollieren Sie alle Aufnahmeausführungen, Schemaänderungen und Konnektorereignisse. Leiten Sie Protokolle zur Überprüfungsbereitschaft an SIEM- oder Compliance-Systeme weiter. Datenklassifizierung: Wenden Sie das PII/PHI-Tagging und die attributbasierte Zugriffssteuerung (ABAC) mit CEDAR-Richtlinien unmittelbar nach der Aufnahme an, um Maskierung, Einwilligung und Einhaltung nachgelagerter Vorschriften zu erzwingen. |
Skizze
In diesem Diagramm wird die Abfolge der Schritte zum Aufnehmen der Daten aus dem Cloud-Speicher in Data 360 veranschaulicht.
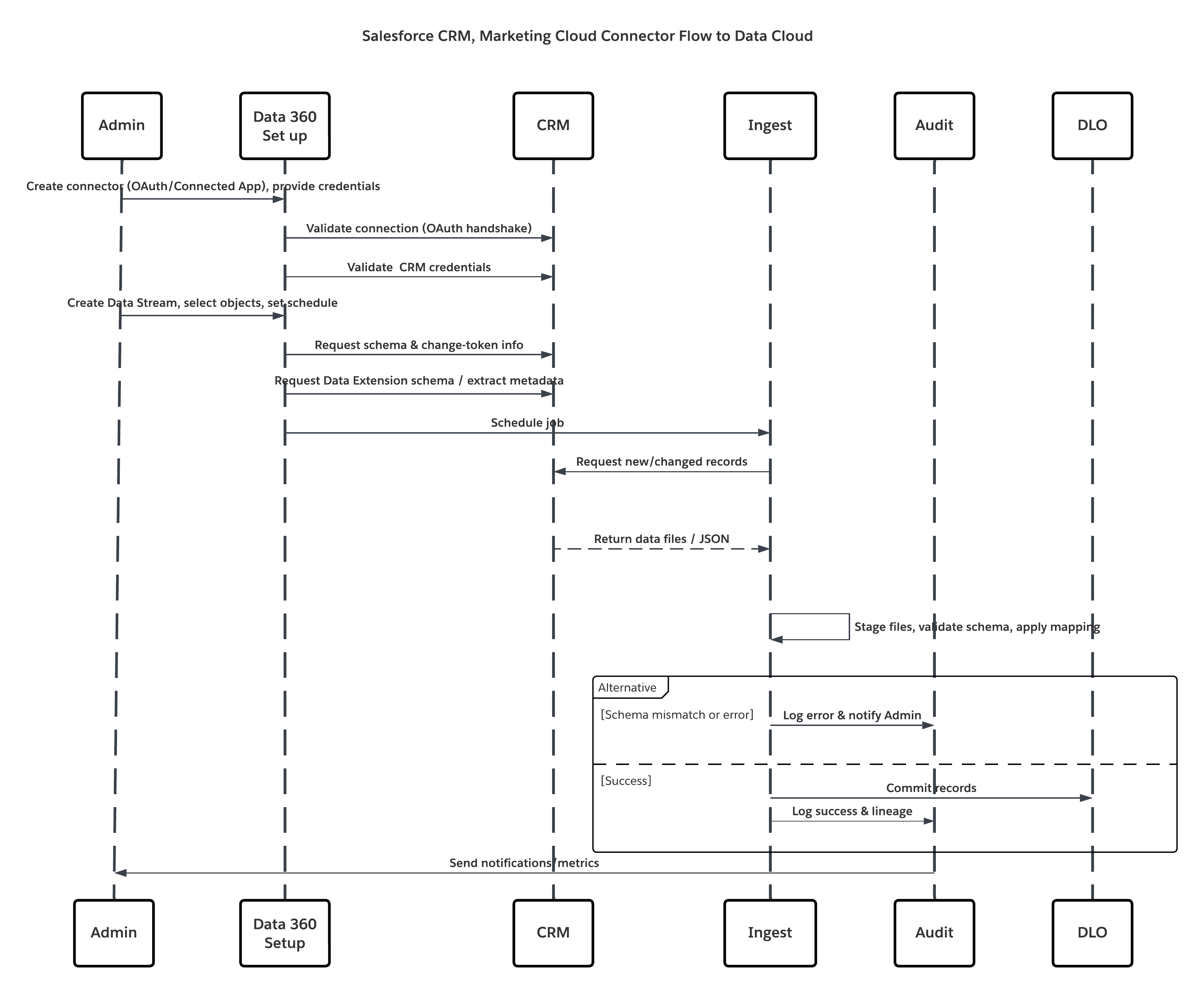
In diesem Szenario:
- Der Administrator stellt Integrationsbenutzer bereit und weist Konnektorberechtigungssätze in Quellorganisationen zu.
- Der Administrator konfiguriert Konnektoren im Setup von Data 360 (stellt über OAuth/verbundene Anwendung eine Verbindung mit Salesforce CRM und Marketing Cloud her).
- Der Administrator erstellt Datenströme, wählt Objekte und Data Extensions aus, wählt die vollständige Aktualisierung oder Delta-Aktualisierung aus und legt Zeitpläne fest.
- Bei geplanter Ausführung fordert Data 360 Schema- und Delta-Token von der/den Quelle(n) an.
- Quellsysteme geben Datensätze zurück (Delta oder vollständige Nutzlast). Marketing Cloud kann Auszüge bereitstellen. CRM kann JSON-/Abfrageergebnisse zurückgeben.
- Data 360 stellt Dateien im internen sicheren Staging-Bereich bereit und validiert sie anhand des zugeordneten Schemas.
- Wenn die Validierung fehlschlägt, wird ein Fehler bei der Aufnahme protokolliert, der Administrator wird benachrichtigt und der Commit wird angehalten. Wenn die Validierung erfolgreich ist, überträgt Data 360 Datensätze atomar an das Ziel-DLO.
- Die Überwachungs- und Prüfungsprotokolle werden mit Abstammung, Ausführungsdauer, Zeilenzahl und Anmeldeinformationen aktualisiert. Benachrichtigungen für Administratoren, wenn Schwellenwerte oder Fehler ausgelöst wurden.
Ergebnisse
Daten zu Kundenbeziehungen und Marketinginteraktionen werden als Data-Lake-Objekte (DLOs) in Data 360 aufgenommen. Daraus ergibt sich:
- Zusammengeführtes Datenset mit Profilen, Kundenvorgängen, Opportunities und Kennzahlen für E-Mail/Engagement.
- Grundlage für die Identitätsbestimmung und Erstellung von Profilen für zusammengeführte Einzelpersonen.
- Betriebsbereitschaft für die nachgelagerte Harmonisierung, Anreicherung, AI-Modellierung und Aktivierung unter Beibehaltung der Governance und Überprüfbarkeit.
Aufnahmemechanismen
Der Aufnahmemechanismus hängt vom Konnektor und der in Data 360 definierten Planungsstrategie ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| Salesforce CRM-Konnektor (nativ) | Ideal für standardmäßige/benutzerdefinierte CRM-Objekte; unterstützt vollständige und Delta-Aktualisierungen. |
| Marketing Cloud Engagement-Konnektor (nativ) | Ideal für Data Extensions, Sends und Tracking-Extraktionen; unterstützt Full/Delta-Modi. |
| Starter-Datenpakete | Beschleunigen Sie die Einarbeitung für allgemeine Sales/Service/Marketing-Objekte. |
| Benutzerdefinierte Streams + Vorverarbeitung | Wird verwendet, wenn komplexe Transformationen oder eine schwere Schemanormalisierung erforderlich ist. |
Fehlerbehandlung und -behebung
Die Fehlerbehandlung und -behebung sind wichtig, um die Zuverlässigkeit bei der Aufnahme von Daten mit hohem Volumen zu gewährleisten.
- Pro Ausführung Protokolle: Jede Ausführung des Datenstroms enthält Details zu Erfolg/Fehler und Fehler auf Zeilenebene.
- Abrufe und Prüfpunkte: Fehlgeschlagene Ausführungen können wiederholt werden, nachdem Quell- oder Schemaprobleme behoben wurden. Data 360 verwendet Staging- und Atom-Commit-Semantik.
- Warnungen: Konfigurieren Sie Benachrichtigungen für Schemaabweichungen, wiederholte Fehler oder Delta-Sequenz-Lücken.
Überlegungen zum idempotenten Design
Die Aufnahme ist vom Design her idempotent. Die erneute Verarbeitung derselben führt nicht zu doppelten Datensätzen. Zu den wichtigsten Strategien zählen:
- Änderungserkennung: Delta-Extrakte basieren auf Quellsystemänderungsindikatoren (LastModifiedDate / Datenerfassung für Systemänderungen). Überprüfen Sie, ob die Quelle zuverlässige Zeitstempel/Kennzeichnungen bereitstellt.
- Duplizierung: Verwenden Sie eindeutige Geschäftsschlüssel (z. B. Contact.ExternalId), um ein Deduplizieren oder Einfügen in DLOs vorzunehmen.
- Transaktions-Commit: Datensätze werden in Phasen unterteilt und erst übernommen, wenn die Batchverarbeitung erfolgreich abgeschlossen wurde.
Sicherheitsüberlegungen
Sicherheit ist in der gesamten Aufnahme-Pipeline von entscheidender Bedeutung, von der Authentifizierung über die Verschlüsselung bis hin zur Zugriffskontrolle.
- Authentifizierung und Autorisierung: Konnektoren verwenden das sichere Integrations-Framework von Salesforce und nutzen Anmeldeinformationen mit Namen und externe Anmeldeinformationen für die Authentifizierung, ohne Geheimnisse preiszugeben.
- Verschlüsselung: Die Daten werden während der Übertragung (TLS 1.2+) und im Leerlauf (AES-256) verschlüsselt.
- Netzwerksteuerungen: Quellspeichersysteme (z. B. S3-Buckets) müssen Data 360-IPs auf die Zulassungsliste setzen.
- Compliance-Ausrichtung: Unterstützt Enterprise-Datenschutz-Frameworks wie die DSGVO, HIPAA und FFIEC-Richtlinien in Kombination mit Customer-Managed Keys (CMK).
- Überprüfbarkeit: Jeder Aufnahmeauftrag und jeder Zugriff auf Anmeldeinformationen wird für die Rückverfolgbarkeit und Compliance-Berichte protokolliert
Randleisten
Aktualität
Die Aktualität hängt vom Aufnahmeplan und dem Datenvolumen ab.
- Der ideale Rhythmus hängt von den Geschäftsanforderungen ab – stündlich für Marketingauslöser nahezu in Echtzeit, nächtliche für große Schlichtungen.
- Die Delta-Modi reduzieren Last und Kosten. Vollständige Aktualisierungen sind schwerer und werden für anfängliche Ladevorgänge oder größere Schemaänderungen verwendet.
Datenvolumen
- CRM-Konnektoren sind für transaktionale Datensets und Datensets mit mittlerem Volumen (Millionen von Datensätzen) optimiert.
- Ziehen Sie bei extrem großen historischen Volumen die Phasen-ETL in Betracht, um sie in Phasen zu partitionieren und zu laden.
Unterstützung von Endpunktfunktionen und Standards
Die Funktionen und die Standardunterstützung für den Endpunkt hängen von der von Ihnen ausgewählten Lösung ab.
| Konnektor | Endpunktanforderungen |
|---|---|
| Salesforce CRM-Konnektor | Die Quellorganisation muss eine verbundene Anwendung, OAuth-Token und einen dedizierten Integrationsbenutzer mit Leseberechtigungen zulassen. |
| Marketing Cloud-Konnektor | Marketing Cloud-API-Anmeldeinformationen oder installiertes Paket; Data Extensions müssen Daten über Extrakte/API bereitstellen. |
Bundesstaatsverwaltung
- Konnektorstatus: Datenströme behalten die letzten erfolgreichen Synchronisierungszeitstempel und Delta-Verschiebungen bei.
- Hauptschlüsselstrategie: Bevorzugen Sie konsistente Geschäftskennzeichner (externe IDs), damit die nachgelagerte Schlichtung und das Aktualisieren und Einfügen deterministisch sind.
Komplexe Integrationsszenarien
In erweiterten Unternehmensarchitekturen kann dieses Muster integriert werden in:
- Hybridtopologien: Kombinieren Sie die CRM-Aufnahme mit Streaming (Plattformereignisse), um Aktualisierungen nahezu in Echtzeit vorzunehmen.
- Middleware-Orchestrierung: Verwenden Sie MuleSoft- oder ETL-Tools, wenn eine komplexe Orchestrierung, Anreicherung oder Transformationsvoraberfassung erforderlich ist.
- Feedbackschleifen für Aktivierungen: Harmonisierte DMOs können nachgelagerte Aktualisierungen an Quellsystemen über Datenaktionen oder Plattform-APIs auslösen (vorsichtig bei SoD-Steuerelementen).
Beispiel
Ein multinationaler Händler konsolidiert Accounts, Kontakte, Kundenvorgänge, Opportunities und Marketing Cloud-Engagementkennzahlen in Data 360, um eine einheitliche Kundenansicht zu erstellen. Das Starter-Datenpaket initialisiert die zentralen Vertriebs- und Serviceobjekte, während das Team das Modell um benutzerdefinierte Felder wie "Loyalty_Membershipc" und "Customer_Tierc" erweitert, um den Treuekontext zu erfassen. CRM-Datenströme werden stündlich im Delta-Modus ausgeführt und Marketing Cloud Engagement wird täglich mithilfe von Delta-Extrakten für Engagementereignisse synchronisiert. Diese Datensets werden über DLOs und die Identitätsbestimmung verarbeitet, was zu einem vereinheitlichten Kundenprofil führt, das CRM- und Engagementsignale kombiniert, um die Personalisierung und nachgelagerte AI-Modelle voranzutreiben.
Diese Muster wurden für Szenarien entwickelt, in denen es auf Millisekunden ankommt – wenn Kundeninteraktionen, Transaktionen oder Signale sofortige Statistiken oder Aktionen auslösen müssen. Sie gehen über die herkömmliche geplante Batch-Aufnahme hinaus, um einen ereignisgesteuerten Datenfluss zu ermöglichen, bei dem Informationen sofort verarbeitet werden. Im Salesforce Data 360-Ökosystem ist "Echtzeit" kein einzelner Modus, sondern ein Kontinuum von Latenzmodellen. An einem Ende liegt die Synchronisierung nahezu in Echtzeit, bei der Aktualisierungen aus Datensatzsystemen (wie CRM oder ERP) innerhalb von Sekunden oder Minuten in Data 360 widergespiegelt werden. Auf der anderen Seite steht die echte Echtzeit-Ereigniserfassung, bei der clientseitige Verhaltenssignale wie Klicks, Käufe oder mobile Interaktionen in Millisekunden aufgenommen und aktiviert werden. Für Architekten ist die Unterscheidung mehr als semantisch. Sie definiert, wie Pipelines konzipiert werden, wie APIs aufgerufen werden und wie nachgelagerte Entscheidungen getroffen werden. Durch die Auswahl des richtigen Musters – ob Synchronisierung nahezu in Echtzeit oder Aufnahme von Ereignis-Streaming – wird sichergestellt, dass das System die Latenzziele des Unternehmens erreicht und gleichzeitig die Datenintegrität, Skalierbarkeit und Governance gewährleistet.
Context
Mit diesem Muster können externe Systeme, beispielsweise eine benutzerdefinierte Anwendung, eine Internet-of-Things (IoT), ein Point-of-Sale (POS)-System oder ein Drittanbieterservice, Ereignisdaten nahezu in Echtzeit programmgesteuert in Data 360 übertragen, wenn diskrete Ereignisse auftreten.
Problem
Wie kann ein Entwickler zuverlässig einzelne Datensätze oder kleine asynchrone Ereignisbatches aus einer externen Anwendung mit geringer Latenz an Data 360 senden, damit die Daten schnell verarbeitet, segmentiert und aktiviert werden können?
Kräfte
Dieses Muster bietet eine geringe Latenz und eine bessere Entwicklersteuerung, führt jedoch zu mehreren technischen Einschränkungen und betrieblichen Abhängigkeiten:
- Entwicklerabhängigkeit: Erfordert Entwickleraufwand, um authentifizierte REST-API-Clients und Fehler-/Wiederholungslogik zu implementieren – es handelt sich nicht um einen Zeigen-und-Klicken-Konnektor.
- Strenges Schema beim Schreiben: Die Aufnahme-API erzwingt die Erstellung von Schemas beim Schreiben. Es muss ein genaues Schema definiert und in die Konnektorkonfiguration hochgeladen werden. Alle Nutzlasten müssen genau übereinstimmen oder abgelehnt werden.
- Doppelte Interaktionsmodi: Derselbe Konnektor unterstützt Streaming (JSON) für Aktualisierungen mit geringer Latenz, Datensatz-für-Datensatz-Aktualisierungen und Massensynchronisierung (CSV) für größere regelmäßige Synchronisierungen. Architekten müssen pro Anwendungsfall auswählen.
- Authentifizierung und Sicherheit: Aufrufe müssen über eine verbundene Salesforce-Anwendung mit OAuth 2.0 authentifiziert werden (z. B. JWT-Bearer-Flow für Server-zu-Server). Die Umfänge "Tokenverwaltung", "Rotation" und "Least-Privileges" sind obligatorisch.
- Operative Sichtbarkeit: Entwickler und Plattformteams müssen die Überwachung auf Antwortcodes, Wiederholungen, Warteschlangen mit totem Brief und Schemaabweichungswarnungen implementieren.
- Anforderung an Echtzeitdiagramme: Für eine echte sofortige Aktivierung (sofortige Segmentierung, Echtzeit-DMO-Zuordnung) muss das Ziel-Datenmodellobjekt (DMO) Teil des Echtzeit-Datendiagramms sein. Andernfalls durchlaufen Ereignisse eine Pipeline mit etwas höherer Latenz.
Lösung
Diese Tabelle enthält Lösungen für dieses Integrationsproblem.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Lösungsanpassung | Am besten für die Ereigniserfassung mit geringer Latenz | Verwenden Sie die Data 360-Aufnahme-API (Streaming-JSON) zum Pushen einzelner Ereignisse oder Mikro-Batchs. Konfigurieren Sie den Aufnahme-API-Konnektor mit einem strengen OAS 3.0-Schema (.yaml). Verwenden Sie die Massen-CSV-Aufnahme für größere, weniger häufige Synchronisierungen. |
| Verarbeitung von Schemaänderungen | Streng / Verwaltet | Schemaänderungen sind fehlerhaft: Aktualisieren Sie OAS .yaml, versionieren Sie den Konnektor und führen Sie Vertragstests durch. Implementieren Sie die Migration rollierender Schemas, wenn Hersteller nicht gleichzeitig Änderungen vornehmen können. |
| Wann nicht verwenden | Suboptimal | Nicht ideal, wenn eine Vorverarbeitung erforderlich ist (z. B. Deduplizierung, garantierter Auftrag usw.) oder wenn extrem große Massenlasten auftreten (verwenden Sie native Massenkonnektoren oder Batch-ETL). Wenn die Quelle keine schemagültigen Nutzlasten erzeugen oder sich nicht sicher authentifizieren kann, verwenden Sie alternative Aufnahmemethoden. |
| Sicherheit und Unternehmensführung | Pflichtfeld | Verwenden Sie OAuth 2.0 mit den geringsten Berechtigungsbereichen, drehen Sie Schlüssel und protokollieren Sie die Tokennutzung. Erzwingen Sie TLS 1.2+, validieren Sie bei Bedarf Client-IPs und stellen Sie das PII-Tagging für Nutzlasten sicher. Alle Ereignisse müssen Provenienz-Metadaten enthalten (Quelle, Zeitstempel, Schemaversion, Identitätsschlüssel). |
Skizze
In diesem Diagramm wird die Abfolge der Schritte zum Aufnehmen der Daten aus der Aufnahme-API in Data 360 veranschaulicht.
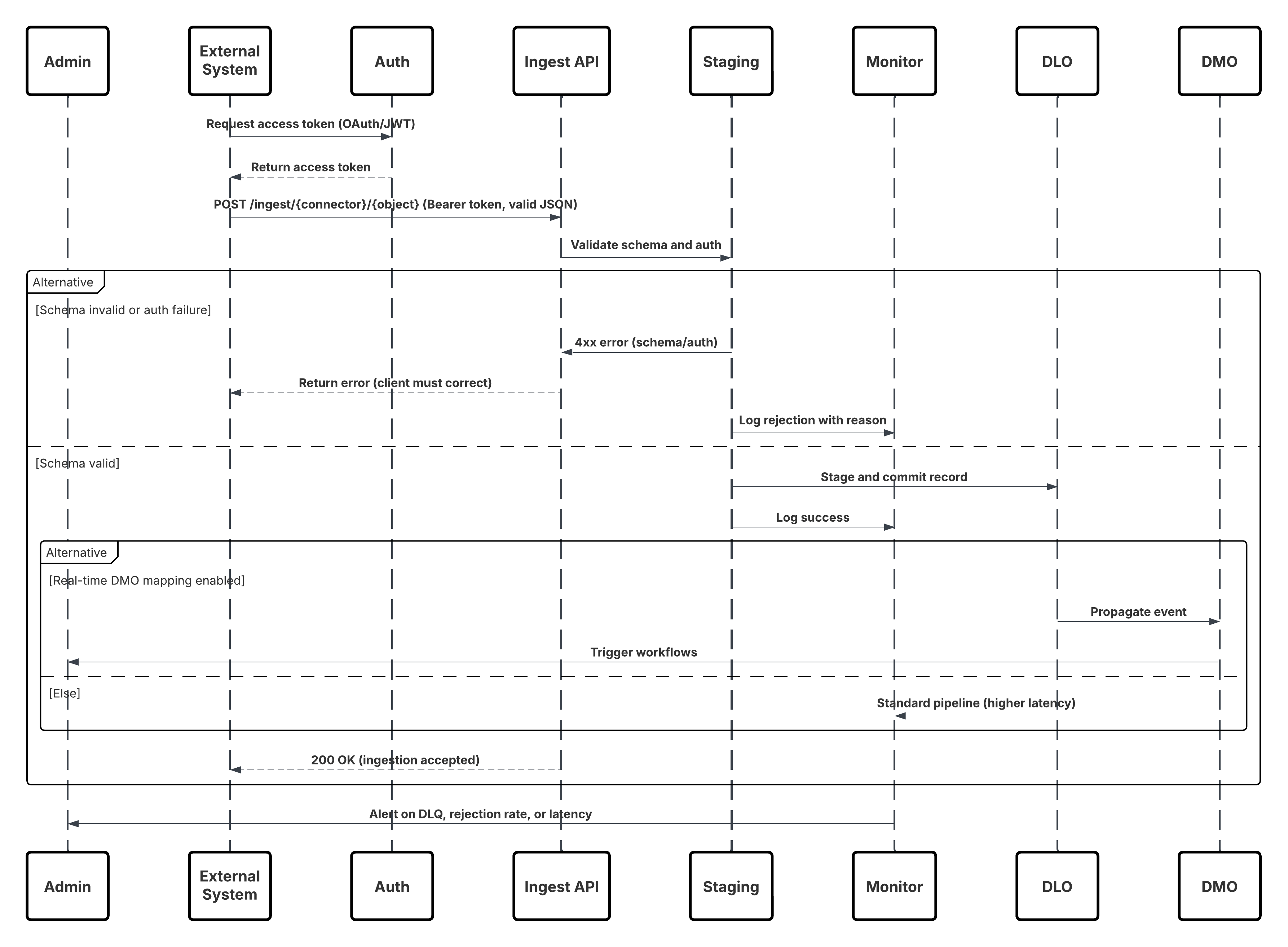
In diesem Szenario:
- Das externe System fordert die Authentifizierung über OAuth/JWT vom Auth Server an.
- Auth Server gibt Zugriffstoken an "Externes System" zurück.
- Das externe System sendet die POST-Anforderung zur Datenaufnahme mit Autorisierung und JSON-Nutzlast an die Data 360-Aufnahme-API.
- Die Aufnahme-API validiert Anforderungsschema und Authentifizierung über das Modul "Staging & Validation".
- Bei Schema-/Authentifizierungsfehlern:
- Fehler, der an "Externes System" zurückgegeben wurde.
- Ablehnung zur Überwachung und Warnung protokolliert.
- Bei erfolgreicher Validierung:
- Datensätze, die in Data Lake Object (DLO) inszeniert und übernommen wurden.
- Erfolgsprotokollierung zur Überwachung.
- Wenn diese Option aktiviert ist, werden die Daten in das Echtzeit-Datendiagramm (DMO) übernommen, wodurch nachgelagerte Workflows ausgelöst werden.
- Andernfalls werden Daten über die standardmäßige Batch-Pipeline oder die Pipeline mit höherer Latenz verarbeitet.
- Die Aufnahme-API bestätigt den Erfolg des externen Systems.
- Überwachungskomponenten benachrichtigen den Administrator bei Warteschlangen mit auslaufenden Briefen, Ablehnungsraten oder Latenzproblemen.
Ergebnisse
Externe Ereignisdaten werden mit geringer Latenz in Data 360-DLOs aufgenommen. Wenn das Ziel-DMO Teil des Echtzeitdiagramms ist, sind die Daten für die sofortige Segmentierung, Agenten-Workflows, AI-Modelle und die operative Aktivierung verfügbar. Dadurch können Sie schnell auf Ereignisse reagieren, die aus einem verbundenen System stammen.
Aufnahmemechanismen
Der Aufnahmemechanismus hängt vom Konnektor und der in Data 360 definierten Planungsstrategie ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| Streaming-JSON (Aufnahme-API) | Einzelne Ereignisse, Micro-Batchs, Verhaltensereignisse, Clickstreams, IoT-Telemetrie – wenn eine geringe Latenz erforderlich ist. |
| Massen-CSV (Aufnahme-API-Massenmodus) | Größere, regelmäßige Uploads mit gelockerten Latenzanforderungen. |
| Edge / Middleware | Wird verwendet, wenn Sie Validierung, Transformation, Anreicherung oder Ratenbegrenzung benötigen, bevor Sie die Aufnahme-API übertragen. |
Fehlerbehandlung und -behebung
- Unmittelbare (Synchronisierungs-)Fehler: 4xx-Antworten für Schema-/Authentifizierungsfehler: Der Client muss die Nutzlast oder das Token beheben und es erneut versuchen.
- Vorübergehende (asynchrone) Fehler: 5xx Antworten: Client-Wiederholungsversuche mit exponentiellem Backoff und Jitter.
- Warteschlange mit Dead-Letter (DLQ): Persistente Fehler werden in DLQ zur manuellen Inspektion und erneuten Wiedergabe angezeigt.
- Monitoring: Verfolgen Sie Schemaablehnungsrate, Authentifizierungsfehler, Latenzperzentile und DLQ-Rückstand. Warnung bei Schwellenwerten.
Überlegungen zum idempotenten Design
- Idempotenzschlüssel: Jedes Ereignis sollte einen eindeutigen Identitätsschlüssel/Nachrichten-ID enthalten.
- Strategie zum Aktualisieren und Einfügen: Verwenden Sie Geschäftsschlüssel (ExternalId), um Duplikate bei Wiederholungen zu vermeiden.
- Dedup Window: Architekt sollte Deduplizierungsfenster und Aufbewahrung für die Identitätsverfolgung definieren.
Sicherheitsüberlegungen
Sicherheit ist in der gesamten Aufnahme-Pipeline von entscheidender Bedeutung, von der Authentifizierung über die Verschlüsselung bis hin zur Zugriffskontrolle.
- Authentifizierung: OAuth 2.0 (JWT-Bearer) wird für Server-zu-Server empfohlen. Beschränken Sie die Umfänge nur auf die Aufnahme.
- Verschlüsselung: TLS 1.2+ für den Transport; Data 360 erzwingt die Verschlüsselung im Leerlauf.
- Niedrigste Berechtigung: Anmeldeinformationen für verbundene Anwendungen verfügen über minimale Rechte. Drehen Sie Geheimnisse und Instrumentenzugriffsprotokolle.
- Nutzlast-Governance: Schließen Sie Einwilligungs-/Verbrauchskennzeichnungen in Ereignismetadaten ein. Wenden Sie ABAC-/CEDAR-Richtlinien unmittelbar nach der Aufnahme an.
- IP-Steuerelemente / Private Connect: Schränken Sie bei Bedarf den Zugriff über Zulassungslisten ein oder verwenden Sie Private Connect für private Netzwerke.
Randleisten
Aktualität
Die Aktualität hängt vom Aufnahmeplan und dem Datenvolumen ab. Die Streaming-JSON ergibt je nach Verarbeitung und Diagrammkonfiguration eine Latenz von einer Sekunde zur anderen. Die Massen-CSV beträgt Minuten bis Stunden. Wählen Sie diese Option anhand von Geschäfts-SLAs aus.
Datenvolumen
Einzelne Ereignisgrößen sollten klein sein (< wenige KB). Bei Herstellern mit hohem Durchsatz sollten Sie ggf. Batches beim Produzenten erstellen oder einen Streaming-Puffer (Kafka/Kinesis) verwenden, bevor Sie die API aufrufen.
Bundesstaatsverwaltung
- Schema Versioning: Verwalten Sie die Schemaversion in Ereignismetadaten und verwenden Sie die Konnektorversionierung beim Aktualisieren des OAS-Vertrags.
- Verschiebungen des Konnektors: Data 360-Handles übernehmen die Semantik. Produzenten sollten die Identitätsschlüssel und die letzte erfolgreiche Sequenz verfolgen, um die Wiedergabe sicher zu gestalten.
Komplexe Integrationsszenarien
In erweiterten Unternehmensarchitekturen kann dieses Muster integriert werden in:
- Kantenvalidierungsebene: Verwenden Sie Middleware, um heterogene Produzentenformate in den erforderlichen OAS-Vertrag zu übersetzen, Ratenbegrenzungen vorzunehmen und Anreicherungen vorauszusetzen.
- Hybridarchitekturen: Kombinieren Sie die Aufnahme-API für Ereignisse und Konnektoren für die Massenabstimmung.
- Agentenaktivierung: In Echtzeit-DMOs zugeordnete Ereignisse können Agentforce-Workflows und Einstein-Modelle für automatisierte Entscheidungen auslösen.
Beispiel
Eine Einzelhandelskette überträgt Point-of-Sale-Kaufereignisse in Data 360 in Echtzeit, um das sofortige Kundenengagement zu fördern. Jeder Shop führt eine kompakte Serverkomponente aus, die Transaktionen erfasst, sie mit Standort- und Gerätemetadaten anreichert und JSON-Ereignisse mithilfe von JWT Bearer OAuth mit Identitätsschlüsseln sicher postet, um Duplikate zu vermeiden. Ein Administrator definiert die Ereignisstruktur, indem er ein OAS-Schema für die Verkaufsstelle hochlädt und den Aufnahme-API-Konnektor konfiguriert. Eingehende Ereignisse werden in das DLO "pos_sale" aufgenommen, dem DMO "Sale" zugeordnet und dem Echtzeitdiagramm hinzugefügt. Dadurch werden Käufe mit hohem Wert sofort erkannt, was VIP-Workflows in Agentforce auslöst und die Kundensegmentierung aktualisiert, um die Echtzeitpersonalisierung zu fördern.
Context
Dieses Muster ermöglicht die Erfassung detaillierter Benutzerinteraktionsdaten mit hohem Volumen, beispielsweise Seitenaufrufen, Schaltflächenklicks, Produktimpressionen und Videowiedergaben, von Websites und mobilen Anwendungen in trueReal-Time. Sie ist die Grundlage für die sofortige Personalisierung, bei der jede digitale Interaktion die Benutzererfahrung dynamisch beeinflussen und das Engagement fördern kann.
Problem
Wie kann ein Unternehmen einen kontinuierlichen Strom von Verhaltensereignissen aus digitalen Eigenschaften erfassen und verarbeiten, der Millionen von Benutzerinteraktionen pro Minute umfasst, und diese Daten sofort in Data 360 zur Verfügung stellen, um die Segmentierung, Personalisierung und Aktivierung in Echtzeit zu unterstützen?
Kräfte
Dieser Anwendungsfall stellt verschiedene Designherausforderungen vor, die eine speziell entwickelte Aufnahmearchitektur mit geringer Latenz erfordern:
- Extremer Durchsatz: Websites mit hohem Datenverkehr oder mobile Anwendungen können Millionen von Ereignissen pro Minute aussenden. Die Aufnahmeebene muss horizontal skaliert werden, um dieses Volumen ohne Ereignisverlust oder Staudruck zu verarbeiten und eine konsistente Latenz unter Spitzenlasten zu gewährleisten.
- Clientseitige Instrumentierung: Im Gegensatz zu servergesteuerten Integrationen hängt dieses Muster von clientseitigen SDKs ab. Auf jeder Seite muss ein JavaScript-Beacon (Salesforce Interactions SDK) eingebettet sein oder ein natives SDK muss in mobile Anwendungen integriert sein. Dies erfordert eine zuverlässige Clientbereitstellung, Versionierung und Ereignisschema-Governance.
- Ereignisverarbeitung mit geringer Latenz: Benutzeraktionen wie "dem Einkaufswagen hinzufügen" oder "Videowiedergabe" müssen Data 360 innerhalb von Sekunden erreichen, um eine Echtzeitaktivierung und kontextbezogene Antworten (z. B. gezielte Angebote, personalisierte Empfehlungen) zu ermöglichen.
- Harmonisierung und Identitätsbestimmung von Daten: Erfasste Ereignisse enthalten oft anonyme Kennzeichner (Cookies, Geräte-IDs, Sitzungstoken). Damit Customer 360-Anwendungsfälle unterstützt werden, müssen diese über die Identitätsbestimmung von Data 360 bekannten Profilen zugeordnet und mit dem Customer 360-Datenmodell harmonisiert werden.
Lösung
Es wird empfohlen, den Salesforce Marketing Cloud Personalization-Konnektor zu verwenden, eine native, vollständig verwaltete Streaming-Pipeline, die für die Aufnahme von Verhaltensweisen mit hohem Durchsatz konzipiert ist.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| SDK-basierte Ereigniserfassung | Best | Stellen Sie das Salesforce-SDK für Interaktionen (web) oder das native SDK (mobil) bereit. Diese kompakten Bibliotheken erfassen und serialisieren Benutzerinteraktionen in Echtzeit und hängen Metadaten (Sitzungs-ID, Zeitstempel, Kontext) an. |
| Streaming-Pipeline für Ereignisse | Best | Ereignisse werden über sicheres HTTPS an den Ereignis-Streaming-Service von Marketing Cloud Personalization gesendet. Diese Ebene ist horizontal skalierbar und für die Übertragung mit geringer Latenz (< 2s) optimiert. |
| Data 360-Integration | Best | Der Personalisierungs-Konnektor von Data 360 abonniert den Streaming-Feed und nimmt jedes Ereignis nahezu in Echtzeit in ein Data-Lake-Objekt (DLO) auf. |
| Datenmodellzuordnung | Bewährte Vorgehensweisen | Das aufgenommene DLO wird Customer 360 Data Model Objects (DMOs) zugeordnet. Dadurch können anonyme und bekannte Benutzer über die Identitätsbestimmung verknüpft werden. |
| Aktivierung von Echtzeitdiagrammen | Optional / Empfohlen | Fügen Sie zugeordnete DMOs in das Echtzeitdiagramm ein, um sie sofort zu segmentieren und so personalisierte Aktionen über Einstein oder Agentforce auszulösen. |
| Wann nicht verwenden | Suboptimal | Dieses Muster ist in folgenden Fällen nicht ideal: Die Quelldaten sind Webclient und Ereignisse (verwenden Sie stattdessen die Aufnahme-API). Der Organisation fehlt die Kontrolle über webbasierte/mobile Clients. Eine Echtzeit-Verhaltensverfolgung ist nicht erforderlich (Batch-Aufnahme verwenden). |
| Verarbeitung der Schemaänderungen | Verwaltete Evolution | Ereignisschemas entwickeln sich, wenn neue Interaktionen hinzugefügt werden. SDKs sollten Ereignisdefinitionen versionieren. Abwärtskompatible Änderungen (Hinzufügen von optionalen Feldern) sind sicher. Änderungen, die fehlerhaft sind, erfordern eine Neukonfiguration des Konnektors und Vertragstests. |
Skizze
In diesem Diagramm wird die Abfolge der Schritte zum Aufnehmen der Daten aus mobilen und Webkanälen in Data 360 veranschaulicht.
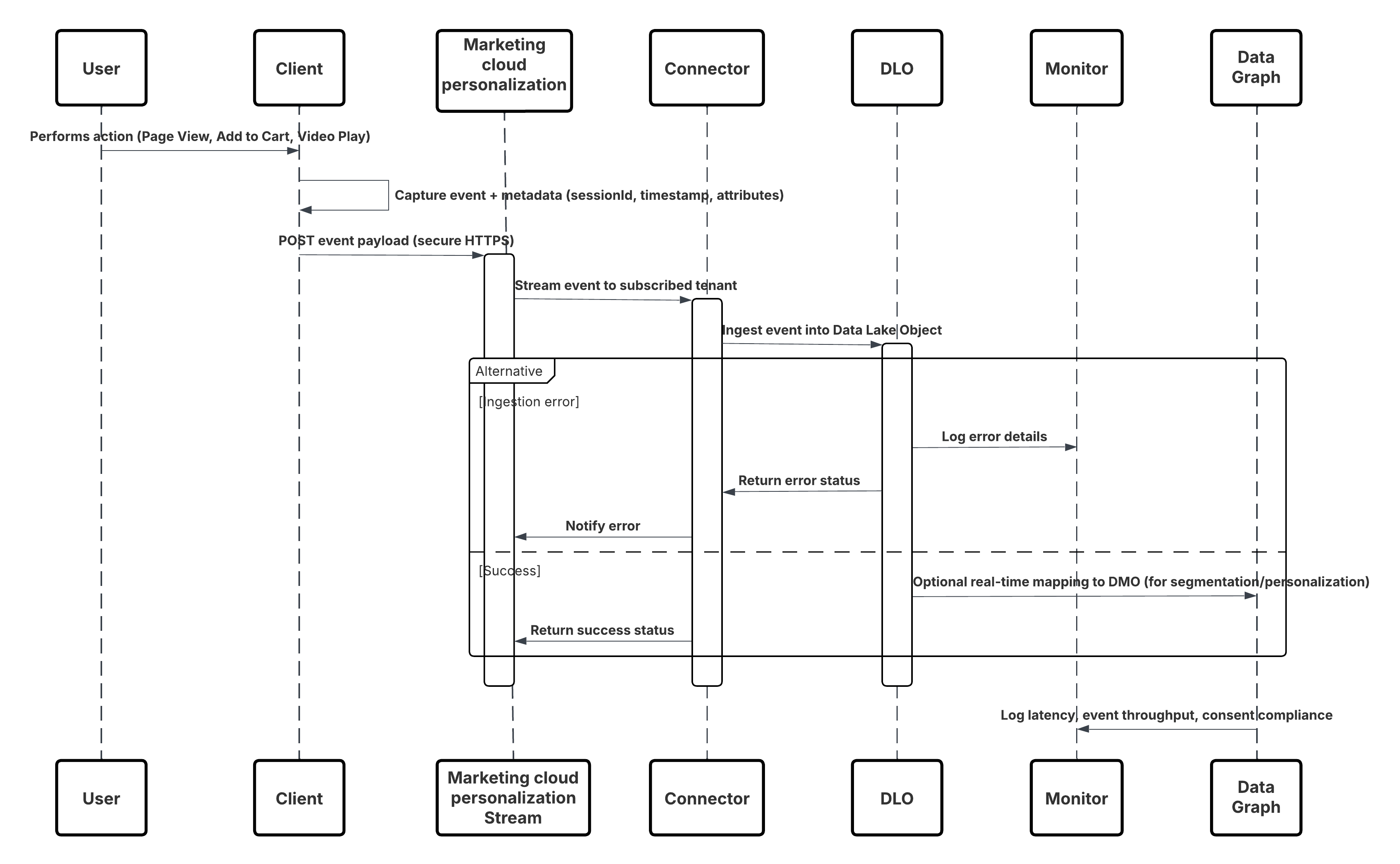
In diesem Szenario:
- Stellen Sie das SDK in Web- oder mobilen Kanälen bereit (Benutzerinteraktionserfassung).
- Konfigurieren Sie das SDK mit Steuerelementen für Mandanten-ID, Umgebung und Einwilligung.
- Streamen Sie erfasste JSON-Ereignisse (Metadaten + Attribute) an den Marketing Cloud-Streaming-Endpunkt.
- Erstellen und konfigurieren Sie im Setup von Data 360 den Personalisierungskonnektor für den Mandanten.
- Nehmen Sie Ereignisse in ein DLO auf und ordnen Sie das DLO → DMO in Data 360 zu.
- Aktivieren Sie das DMO im Echtzeitdiagramm für die sofortige Aktivierung.
- Überwachen Sie Latenz, Schemakonformität, Einwilligungskennzeichnungen, Durchsatz und Fehlerraten.
- Stellen Sie die Bereitstellung in der Produktion bereit und überwachen Sie sie kontinuierlich.
Ergebnisse
Ein kontinuierlicher Stream mit Verhaltensereignissen mit geringer Latenz fließt aus digitalen Kanälen in Data 360. Innerhalb von Sekunden ist jede Benutzeraktion für die Echtzeitsegmentierung, die Prognosemodellierung oder die ausgelöste Personalisierung verfügbar, was eine wirklich adaptive Kundenerfahrung ermöglicht.
Aufnahmemechanismen
Der Aufnahmemechanismus hängt vom Konnektor und der in Data 360 definierten Planungsstrategie ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| SDK für Interaktionen (Web) | Echtzeiterfassung über Webbrowser und SPAs. |
| Mobile SDK | Echtzeiterfassung aus nativen mobilen Anwendungen. |
| Personalisierungs-Konnektor | Verwaltetes Abonnement zwischen Marketing Cloud und Data 360\. |
| Echtzeitdiagrammzuordnung | Aktiviert die sofortige Aktivierung in Segmentierung, Einstein und Journeys. |
Fehlerbehandlung und -behebung
- Schichtweise Fehlertoleranz: Implementieren Sie mehrstufige Validierungs- und Wiederholungsmechanismen: Client-SDKs verarbeiten vorübergehende Fehler mit exponentieller Absicherung, während die Aufnahmeebene dauerhafte Warteschlangen und wiedergebbare Pipelines verwendet, um Datenverluste zu verhindern.
- Schema & Data Governance: Versionieren und validieren Sie Ereignisschemas kontinuierlich. Ungültige oder sich entwickelnde Ereignisse werden an eine Schemaablehnungs- oder Dead-Letter-Warteschlange weitergeleitet, um eine sichere Triage und erneute Wiedergabe zu ermöglichen.
- Idempotenz und Duplizierung: Verwenden Sie stabile Ereigniskennzeichner und die Semantik zum Aktualisieren und Einfügen, um eine genaue Verarbeitung auch bei Wiederholungen oder Wiederholungen zu gewährleisten.
- Überwachungs- und Wiederherstellungsautomatisierung: Die kontinuierliche Überwachung von Durchsatz, Latenz und Fehlerraten löst automatisierte Wiederherstellungs-Workflows aus und gewährleistet eine geringe Latenz, zuverlässige Zustellung und konsistente Personalisierungsergebnisse in Echtzeit.
Überlegungen zum idempotenten Design
- Jedes Ereignis muss einen eindeutigen Identitätsschlüssel oder eine Nachrichten-ID aufweisen, damit doppelte Einreichungen nachgelagert dedupliziert werden können.
- Verwenden Sie ggf. Geschäftsschlüssel (z. B. sessionID + eventTimestamp + userID), um Duplikate zu identifizieren.
- Definieren Sie ein Deduplizierungsfenster (z. B. 24 Stunden), in dem doppelte Ereignisse ignoriert oder gefiltert werden.
- Verwenden Sie ggf. Strategien zum Aktualisieren und Einfügen (z. B. Aktualisieren von Zählern oder Kennzeichnungen, statt Duplikate einzufügen).
Sicherheitsüberlegungen
Sicherheit ist in der gesamten Aufnahme-Pipeline von entscheidender Bedeutung, von der Authentifizierung über die Verschlüsselung bis hin zur Zugriffskontrolle.
- Transportverschlüsselung: TLS 1.2+ für alle SDK → Streaming-Service-Verbindungen.
- Datenverschlüsselung im Leerlauf in Data 360 und im Marketing-Stream.
- Das SDK berücksichtigt Benutzereinwilligungskennzeichnungen (DSGVO/CCPA) und unterdrückt die Verfolgung, wenn die Einwilligung verweigert wird.
- Authentifizierung des SDK-Datenverkehrs: Stellen Sie sicher, dass nur genehmigte Mandanten/Clients Ereignisse streamen können.
- Metadaten: Jedes Ereignis muss Quell-ID, Zeitstempel, Schemaversion, Sitzungs-ID und Identitätsschlüssel enthalten.
- Zugriff mit den geringsten Berechtigungen: SDK-Endpunkte und -Konnektoren, die auf den Umfang der Ereignisaufnahme beschränkt sind; rotieren Sie die Anmeldeinformationen regelmäßig.
- Datenklassifizierung: Versehen von Ereignisnutzlasten mit Anmerkungen zu personenbezogenen Daten, sofortiges Erzwingen von Richtlinien nach der Aufnahme
Randleisten
Aktualität
- Die Aktualität hängt von der Endbenutzeraktivität und der Ereignis-Streaming-Konfiguration ab.
- Ereignisse, die über das Salesforce-SDK für Interaktionen erfasst und über den Marketing Cloud-Personalisierungsstrom bereitgestellt werden, erreichen in der Regel Latenzen von Sekunden bis zu etwa 2 Sekunden, bevor sie im Data 360-Echtzeitdiagramm verfügbar werden.
- Dies ermöglicht eine nahezu sofortige Segmentierung, Personalisierung und Aktivierung innerhalb aktiver Benutzersitzungen.
Datenvolumen
Einzelne verhaltensbasierte Ereignisse (z. B. Klicken, Anzeigen, Hinzufügen zum Einkaufswagen) sind leicht – in der Regel 1–5 KB pro Nutzlast. Bei digitalen Immobilien im großen Umfang ist mit Tausenden bis Millionen von Ereignissen pro Minute zu rechnen. Sicherstellen von Durchsatz und Widerstandsfähigkeit:
- Verwenden Sie die integrierten Batch- und Wiederholungsmechanismen des SDK für Seiten mit hohem Datenverkehr.
- Laden Sie die Burst-Handhabung auf die Marketing Cloud-Streaming-Pufferebene herunter.
- Überwachen Sie den Aufnahmedurchsatz und die Fehlerquoten mithilfe des Dashboards für Konnektorkennzahlen.
Bundesstaatsverwaltung
Jedes Ereignis enthält Metadaten für die Status- und Versionskontrolle:
- Schema Versioning: Betten Sie die Schemaversion in jedes Ereignis ein. Version des Personalisierungskonnektors beim Aktualisieren des Schemas.
- Wiedergabeverarbeitung: Ereignisse, die aufgrund vorübergehender Netzwerkprobleme fehlschlagen, werden vom SDK mit exponentieller Sicherung automatisch wiederholt.
- Idempotenzschlüssel: Eindeutige Kennzeichner (sessionId + eventType + Zeitstempel) stellen sicher, dass bei wiedergegebenen Ereignissen keine Duplikate in Data 360 erstellt werden.
- Offsetverwaltung: Data 360 verfolgt erfolgreiche Commits. Nicht verarbeitete Ereignisse werden vom Konnektor erneut in die Warteschlange gestellt, bis sie erfolgreich aufgenommen werden.
Komplexe Integrationsszenarien
Dieses Muster lässt sich nahtlos in erweiterte Unternehmensarchitekturen integrieren:
- Edge Enrichment Layer: Fügen Sie Middleware (z. B. Reverse-Proxy oder serverlose Funktion) hinzu, um zusätzlichen Kontext einzufügen, beispielsweise Geo-, Gerätetyp- oder Kampagnen-Metadaten, bevor Ereignisse Marketing Cloud erreichen.
- Hybrid (Streaming + Batch): Verwenden Sie den Marketing Cloud-Konnektor für Echtzeit-Streams und kombinieren Sie ihn mit Batch-ETL-Aufträgen (z. B. Auftragsdaten) für die nachgelagerte Schlichtung.
- Agentenaktivierung: Ereignisse, die Echtzeit-DMOs zugeordnet sind, können Einstein-Personalisierung, Agentforce-Workflows oder AI-gestützte Entscheidungen zur Anpassung der digitalen Erfahrung auslösen.
- Multi-Mandant-Governance: Verwenden Sie Einwilligungskennzeichnungen und mandantenbewusste Metadaten, um Datenschutz und Compliance in Umgebungen mit mehreren Marken oder Regionen zu erzwingen.
Beispiel
Ein globales E-Commerce-Unternehmen stellt Käufern personalisierte Produktempfehlungen und dynamische Inhalte bereit, während sie aktiv www.retailx.com, eine auf React basierende Einzelseitenanwendung, durchsuchen. Mit dem Salesforce-SDK für Interaktionen auf der Client-Seite erfasst die Site Seitenaufrufe, Produktklicks, Einkaufswagenaktionen und Videointeraktionen in Echtzeit. Diese Ereignisse werden über den Ereignis-Stream "Marketing Cloud Personalization" und den Personalisierungs-Konnektor in Data 360-DLOs übertragen, wo sie in DMOs modelliert und in das Echtzeitdiagramm integriert werden. Durch diese Architektur sind Verhaltenssignale sofort für die Segmentierung, die Einstein Personalisierung und die Agentforce-Aktivierung verfügbar und ermöglichen reaktionsschnelle Kundenerfahrungen in der Sitzung
Context
Bei vielen geschäftskritischen Prozessen ist es wichtig, Data 360 perfekt auf die neuesten Aktualisierungen in zentralen CRM-Systemen abzustimmen. Kundendienst-, Vertriebs- und Marketingteams sind auf aktuelle Informationen angewiesen, um Entscheidungen zu treffen, Journeys auszulösen und die Automatisierung zu aktivieren. Dieses Muster bietet einen Mechanismus, mit dem Änderungen an wichtigen Salesforce CRM-Objekten wie "Kontakt", "Account" und "Kundenvorgang" mit minimaler Verzögerung in Data 360 synchronisiert werden können, ohne dass häufige Batch-Abfragen ineffizient oder latent sind.
Problem
Wie kann Data 360 einen nahezu perfekt synchronisierten Zustand mit wichtigen Salesforce CRM-Objekten beibehalten und sicherstellen, dass nachgelagerte Analysen, Segmentierungen und AI-gestützte Aktivierungen immer mit den neuesten verfügbaren Daten funktionieren?
Kräfte
Dieses Muster führt mehrere technische Einschränkungen und architektonische Überlegungen ein:
- Ereignisgesteuerte Architektur: Die Synchronisierung muss reaktiv sein – gesteuert durch Änderungsereignisse in der CRM-Quellorganisation und nicht durch regelmäßige Batchaufträge.
- Unterstützung für selektive Objekte: Nicht alle standardmäßigen und benutzerdefinierten Salesforce-Objekte unterstützen Echtzeit-Streaming. Architekten müssen während des Entwurfs auf die unterstützte Objektliste verweisen, um Lücken zu vermeiden.
- Zugriff und Berechtigungen: Zum Aktivieren von Streaming muss dem Integrationsbenutzer in der Quellorganisation die Systemberechtigung "Berechtigungen für CRM Streaming aktivieren" zugewiesen sein.
- Datenaktualisierung vs. Verarbeitungskosten: Während die Synchronisierung nahezu in Echtzeit die Reaktionsfähigkeit verbessert, kann ein übermäßiger Ereignisdurchsatz horizontale Skalierung und zuverlässige Fehlerbehebungsmechanismen erfordern.
- Integration von Sicherheits- und Trust Layern: Alle Ereignisdaten müssen mit den Trust and Security Frameworks von Salesforce übereinstimmen. Sie werden während der Übertragung verschlüsselt, auf Schemakonformität überprüft und innerhalb der Trust Grenze der Organisation verarbeitet.
Lösung
Es wird empfohlen, den Salesforce CRM-Konnektor mit aktiviertem Streaming (Datenerfassung ändern) zu verwenden. Beim Erstellen eines Datenstroms für ein unterstütztes CRM-Objekt (z. B. Kontakt) können Administratoren die Option "Streaming aktivieren" aktivieren. Jedes Mal, wenn ein Datensatz in der CRM-Quellorganisation erstellt, aktualisiert, gelöscht oder rückgängig gemacht wird, veröffentlicht die CDC-Plattform von Salesforce eine ChangeEvent-Meldung. Der Data 360 CRM-Konnektor abonniert diese CDC-Ereignisse und wendet die entsprechenden Änderungen nahezu in Echtzeit auf das zugeordnete Data Lake-Objekt (DLO) in Data 360 an. Dadurch wird eine kontinuierliche Synchronisierung zwischen CRM und Data 360 mit minimalen manuellen Eingriffen gewährleistet.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| CDC-basierter Streaming-Konnektor | Best | Nativer Salesforce-Mechanismus, vollständig verwaltet und in die Plattformereignisinfrastruktur integriert. |
| Ereignisabonnement und -zustellung | Best | Der Konnektor abonniert ChangeEvent-Kanäle (z. B. /data/ContactChangeEvent) über dauerhafte IDs für die erneute Wiedergabe. |
| Datenzuordnung und Schemaentwicklung | Bewährte Vorgehensweisen | Ordnen Sie gestreamte Nutzlasten dem entsprechenden DLO zu. Verarbeiten Sie die Schemaversionierung in Metadaten, um Aufnahmeunterbrechungen zu vermeiden. |
| Wiedergabe und Fehlerbehebung | Empfohlen | Verwenden Sie IDs für die erneute Wiedergabe und Identitätsschlüssel, um Duplikate zu vermeiden und vorübergehende Fehler zu beheben. |
| Hybridmodus (Streaming + Batch) | Optional | Verwenden Sie bei nicht unterstützten Objekten oder beim anfänglichen Massenladen die Batch-Aufnahme in Kombination mit CDC-Streaming. |
| Wann nicht verwenden | Suboptimal | Dieses Muster kann in folgenden Fällen suboptimal sein: Das Quellobjekt ist nicht CDC-fähig. Für den Anwendungsfall sind keine Echtzeitaktualisierungen erforderlich (Batch ist ausreichend). Der Netzwerkaustritt aus der Quellorganisation wird eingeschränkt oder Ereignisobergrenzen werden überschritten. |
Skizze
In diesem Diagramm wird die Abfolge der Schritte zum Aufnehmen der Daten aus CRM in Data 360 in nahezu Echtzeit veranschaulicht.
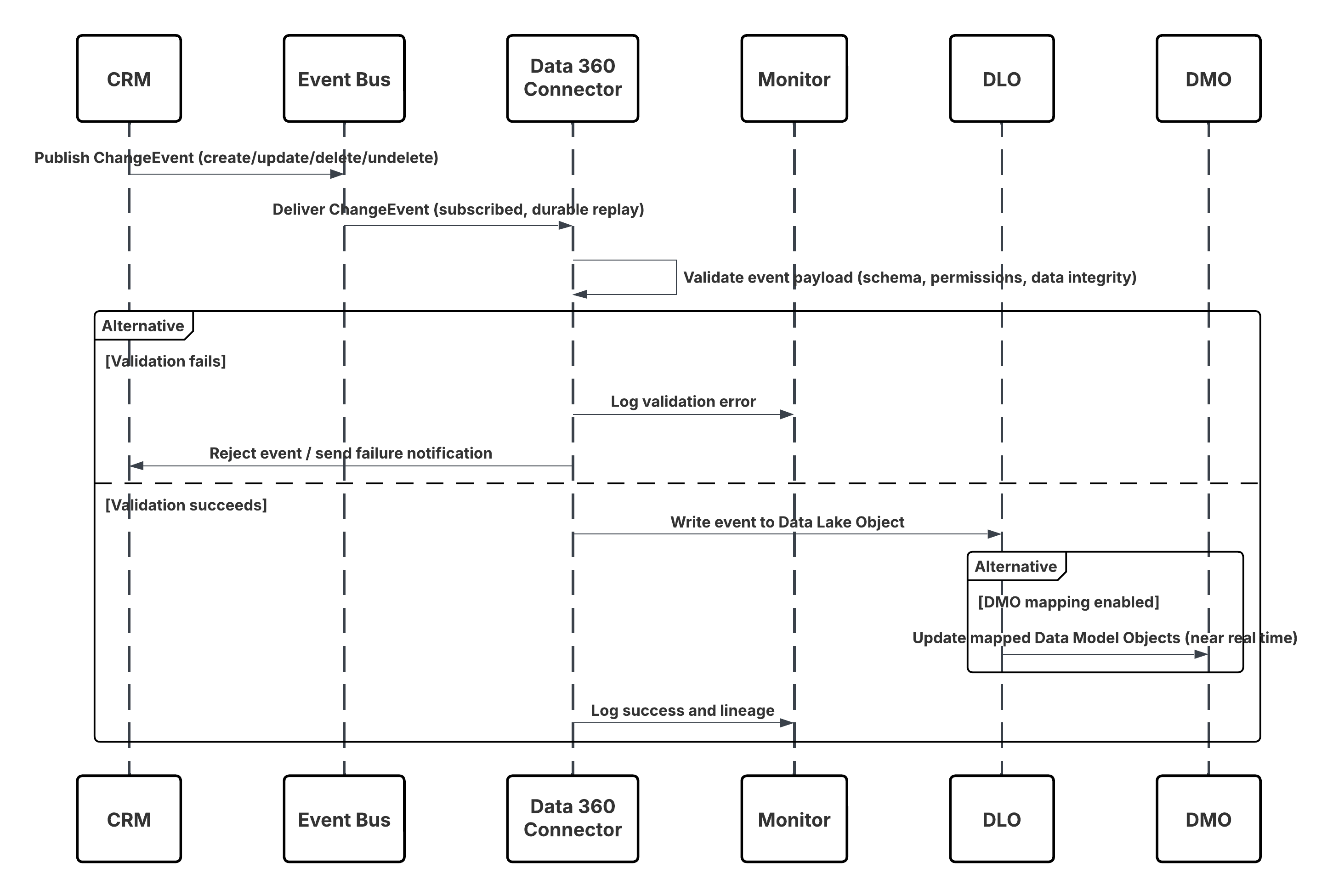
In diesem Szenario:
- Die Änderung erfolgt in Salesforce CRM (Erstellen/Aktualisieren/Löschen/Rückgängigmachen).
- CDC veröffentlicht ein ChangeEvent im internen Salesforce-Ereignis-Bus.
- Der Data 360 CRM-Konnektor abonniert den Ereignis-Bus mit einem dauerhaften Cursor für die erneute Wiedergabe.
- Die Ereignisnutzlast wird auf Schema, Berechtigungen und Datenintegrität überprüft.
- Data 360 schreibt das validierte Ereignis in das zugeordnete Data-Lake-Objekt (DLO).
- Wenn diese Option aktiviert ist, werden zugeordnete Datenmodellobjekte (DMOs) in nahezu Echtzeit aktualisiert, was die Segmentierung und Aktivierung unterstützt.
Ergebnisse
Data 360 behält einen kontinuierlich synchronisierten Spiegel wichtiger CRM-Daten bei. Dadurch wird Folgendes ermöglicht:
- Echtzeitauslöser (z. B. Journey wird gestartet, wenn ein Kundenvorgang erstellt wird).
- Aktuelle Segmentierung (z. B. Übertragen von Kunden in das Segment "Gold" bei Accountstatusänderung).
- Genauere Analysen und Personalisierung basierend auf dem Live-CRM-Kontext.
Aufnahmemechanismen
Der Aufnahmemechanismus für dieses Muster wird nativ über den Salesforce CRM-Konnektor mit aktivierter Datenerfassung verwaltet. Data 360 fungiert als Abonnent des CDC-Ereignisstroms und gewährleistet eine zuverlässige Synchronisierung mit geringer Latenz zwischen der CRM-Quellorganisation und Data 360.
| Mechanismus | Wann zu verwenden |
|---|---|
| Streaming über CDC (bevorzugt) | Für alle unterstützten standardmäßigen und benutzerdefinierten Salesforce-Objekte, bei denen eine Synchronisierung nahezu in Echtzeit erforderlich ist. |
| Hybrid Mode (CDC + Batch) | Bei Objekten, die noch nicht CDC-fähig sind oder bei denen ein anfänglicher historischer Ladevorgang erforderlich ist. |
| Abonnementmodus erneut wiedergeben | Für die Neusynchronisierung nach Ausfallzeiten oder Bereitstellungen. |
| Fehlerisolationsmodus | Für Test- und Validierungsumgebungen. |
Fehlerbehandlung und -behebung
- Automatische Fehlerbehebung: Der CRM-Konnektor wiederholt vorübergehende Netzwerk- oder Plattformfehler automatisch mithilfe einer exponentiellen Sicherung und leitet persistente Fehler zur erneuten Wiedergabe an die Dead-Letter-Warteschlange weiter.
- Schema- und Authentifizierungsresistenz: Schemainkongruenzen werden in der Schemaablehnungswarteschlange zur Administratorüberprüfung in Quarantäne gestellt, während Authentifizierungs- oder Berechtigungsfehler gesteuerte Wiederholungen und Warnungen über die Data 360-Überwachung auslösen.
- Gewährleistete Ereigniskontinuität: Dauerhafte ReplayIDs stellen sicher, dass während der Konnektorausfallzeit keine Ereignisse verloren gehen. Verpasste Ereignisse werden durch Replay-Fenster oder Batch-Resync-Aufträge neu synchronisiert.
- Datenintegrität und -bestellung: Die integrierte idempotency (RecordID + SequenceNumber) verhindert Duplikate und ChangeEventHeader.sequenceNumber behält die richtige Ereignisreihenfolge für jeden CRM-Datensatz bei.
Überlegungen zum idempotenten Design
- Ereigniseindeutigkeit: Jedes CDC-Ereignis trägt eine ReplayID und ChangeEventHeader.entityName für die deterministische Deduplizierung.
- Strategie zum Aktualisieren und Einfügen: Implementieren Sie die Logik UPSERT basierend auf der Datensatz-ID, um sicherzustellen, dass wiederholte Ereignisse keine Duplikate verursachen.
- Wiedergabeverarbeitung: Verwenden Sie den Cursor für die erneute Wiedergabe des Konnektors, um bei vorübergehenden Fehlern mit der zuletzt übernommenen Verschiebung fortzufahren.
- **Schema Evolution: **Verwalten Sie eine Schemaversion in Ereignismetadaten und aktualisieren Sie DLO-Zuordnungen, wenn sich das CRM-Schema ändert.
Sicherheitsüberlegungen
Sicherheit ist in der gesamten Aufnahme-Pipeline von entscheidender Bedeutung, von der Authentifizierung über die Verschlüsselung bis hin zur Zugriffskontrolle.
- Encryption and Trust: Alle Ereignisse werden mit TLS 1.2+ übertragen und im Leerlauf verschlüsselt in Data 360 gespeichert.
- Zugriffssteuerung: Nur authentifizierte Konnektoren mit entsprechenden Integrationsberechtigungen können CDC-Kanäle abonnieren.
- Schemavalidierung: Jede Ereignisnutzlast wird vor der Aufnahme mit dem DLO-Schema abgeglichen.
- Einwilligungsübernahme: Der Metadatenfluss für Einwilligungen und Datenklassifizierungen wird für jedes Ereignis nachgelagert, um Datenschutz und Compliance zu gewährleisten (DSGVO, CCPA).
- Operative Governance: Über die Data 360 Trust Layer werden Ereignisse protokolliert, überprüft und auf Wiederholungen, Schemaablehnungen und Durchsatzanomalien überwacht.
Randleisten
Aktualität
- CDC-Ereignisse werden nahezu in Echtzeit verarbeitet – in der Regel innerhalb von Sekunden nach der Änderung von CRM.
- Die Latenz kann je nach Ereignisvolumen und Konnektordurchsatz variieren. Data 360 garantiert jedoch die Verfügbarkeit von unterstützten Objekten in wenigen Minuten.
Datenvolumen
- Jede Ereignisnutzlast ist gering (~1–5 KB).
- Stellen Sie bei Objekten mit hoher Änderungsrate wie "Kundenvorgang" oder "Kontakt" sicher, dass die Durchsatzobergrenzen mit den Salesforce CDC-Ereigniszuteilungen übereinstimmen.
Bundesstaatsverwaltung
Jedes Ereignis enthält Metadaten für die Status- und Versionskontrolle:
- Wiedergabe-IDs: Wird für die sequenzielle Ereigniswiederherstellung verwendet.
- Schema Versioning: Verwalten Sie Versionsmetadaten, um Vertragsänderungen zu verwalten.
- Idempotenzschlüssel: Duplizieren Sie Wiederholungen über Wiederholungen hinweg.
- Verschiebungs-Commit: Data 360 behält den Commit-Status nach jedem erfolgreichen Batch von Ereignissen bei.
Komplexe Integrationsszenarien
Dieses Muster lässt sich nahtlos in erweiterte Unternehmensarchitekturen integrieren:
- Hybrid (Streaming + Batch): Verwenden Sie CDC für Delta-Aktualisierungen und Massenaufträge für vollständige Aktualisierungen.
- Organisationsübergreifendes Streaming: Mehrere Quellorganisationen können über DMO-Zuordnungen vereinheitlicht in denselben Data 360-Mandanten streamen.
- Agentenaktivierung: Echtzeit-Objektaktualisierungen lösen Automatisierungen von Einstein oder Agentforce aus.
- Ereignisweiterleitung: Middleware (z. B. MuleSoft oder Event Relay) kann CDC-Nachrichten vor der Aufnahme anreichern oder weiterleiten.
Beispiel
Eine globale Bank möchte sicherstellen, dass Kundendatenänderungen in Salesforce Sales Cloud sofort in Data 360 berücksichtigt werden.Wenn die Adresse eines Kontakts in Sales Cloud aktualisiert wird, veröffentlicht der Mechanismus zur Datenerfassung ein ContactChangeEvent.Der Data 360 CRM-Konnektor verwendet dieses Ereignis, wendet die Aktualisierung auf das Kunden-DLO an und aktualisiert automatisch alle zugeordneten Customer 360-Profile. Dadurch wird eine Einstein Next Best Action ausgelöst, um die neue Adresse zu überprüfen und die Feedbackschleife innerhalb von Sekunden nach der ursprünglichen CRM-Änderung abzuschließen.
Context
Moderne digitale Unternehmen setzen auf Echtzeit-Ereignis-Streaming-Plattformen wie Amazon Kinesis-Datenströme und Amazon MSK (Managed Streaming for Apache Kafka), um kontinuierliche Datenflüsse aus verteilten Anwendungen, IoT-Geräten und Transaktionssystemen zu erfassen. Data 360 ermöglicht die direkte Aufnahme von diesen Plattformen über native Erstanbieter-Konnektoren, wodurch benutzerdefinierte ETL- oder Middleware-basierte Lösungen entfallen. Dieses Muster wurde für die Aufnahme von Daten mit hohem Durchsatz und geringer Latenz entwickelt und bietet nahezu in Echtzeit Statistiken, Personalisierung und AI-gestützte Aktivierung.
Problem
Wie kann ein Unternehmen Data 360 sicher und effizient mit AWS Kinesis- oder AWS MSK Kafka-Themen verbinden, um kontinuierlich strukturierte Ereignis- und Profildaten aufzunehmen und so die Schemakonformität, Skalierbarkeit und Governance zu gewährleisten?
Kräfte
Dieses Muster führt mehrere architektonische und betriebliche Überlegungen ein:
- Native Konnektorverfügbarkeit: Salesforce bietet allgemein verfügbare native Konnektoren für Amazon Kinesis und Amazon MSK. Diese Konnektoren bieten Erstanbieter-Support und machen benutzerdefinierte API-basierte Pipelines überflüssig.
- Authentifizierung und Sicherheit: Für jeden Konnektor ist eine Authentifizierung auf AWS-Ebene erforderlich.
- Bei Kinesis werden dafür AWS-Zugriffsschlüssel und geheimer Schlüssel verwendet, die durch IAM-Richtlinien geregelt werden.
- Bei MSK kann die Authentifizierung über Zugriffsschlüssel/Geheimnis oder OpenID Connect (OIDC) konfiguriert werden.
- Schema Definition: Für Data 360 ist ein Schema zur Interpretation der Streaming-Nutzlast erforderlich. Bei Kinesis wird die Schemadatei während des Verbindungs-Setups hochgeladen und definiert die Ereignisstruktur und Feldzuordnungen.
- Konfigurationsquelle:
- Der Kinesis-Konnektor abonniert einen bestimmten Kinesis-Stream-Namen.
- Der MSK-Konnektor abonniert ein Kafka-Thema im MSK-Cluster.
- Netzwerkzugriff: Für sichere Umgebungen können Konnektoren mit PrivateLink- oder VPC-Weiterleitung konfiguriert werden, um sicherzustellen, dass keine Daten über das öffentliche Internet gelangen.
- Operative Governance: Der Streaming-Durchsatz, die Schemavalidierung und Authentifizierungsereignisse werden innerhalb der Data 360 Trust Layer überwacht, um die Einhaltung und Rückverfolgbarkeit zu gewährleisten.
Lösung
Die Lösung nutzt die nativen Amazon Kinesis- oder **Amazon MSK-**Konnektoren in Data 360.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Nativer Kinesis-Konnektor | Best | First-Party-Integration in AWS Kinesis; unterstützt die kontinuierliche Aufnahme mit hohem Durchsatz. |
| MSK Native-Konnektor | Best | Verwaltete Kafka-Aufnahme mit OIDC und schlüsselbasierter Authentifizierungsunterstützung. |
| Schemazuordnung und -validierung | Bewährte Vorgehensweisen | Hochladeschema (.json/.avro), das die Ereignisstruktur definiert; erzwingt die Konsistenz während der Aufnahme. |
| IAM-Konfiguration | Empfohlen | Weisen Sie die IAM-Rolle mit den geringsten Berechtigungen und Lesezugriff auf den Kinesis-Ziel-Stream oder das MSK-Thema zu. |
| Private Netzwerkweiterleitung | Optional | Konfigurieren Sie PrivateLink/VPC-Endpunkte für die sichere interne Weiterleitung. |
| Hybridmuster (Streaming + Batch) | Optional | Verwenden Sie Streaming für Deltas und die Batch-Aufnahme für Backfills oder historische Ladevorgänge. |
| Fehlerisolationsmodus | Empfohlen | Schemaablehnungen und vorübergehende Fehler zur erneuten Wiedergabe an DLQ weiterleiten |
Skizze
In diesem Diagramm wird die Abfolge der Schritte veranschaulicht, mit denen die Daten aus Ereignisplattformen wie Kafka und Kinesis nahezu in Echtzeit in Data 360 aufgenommen werden
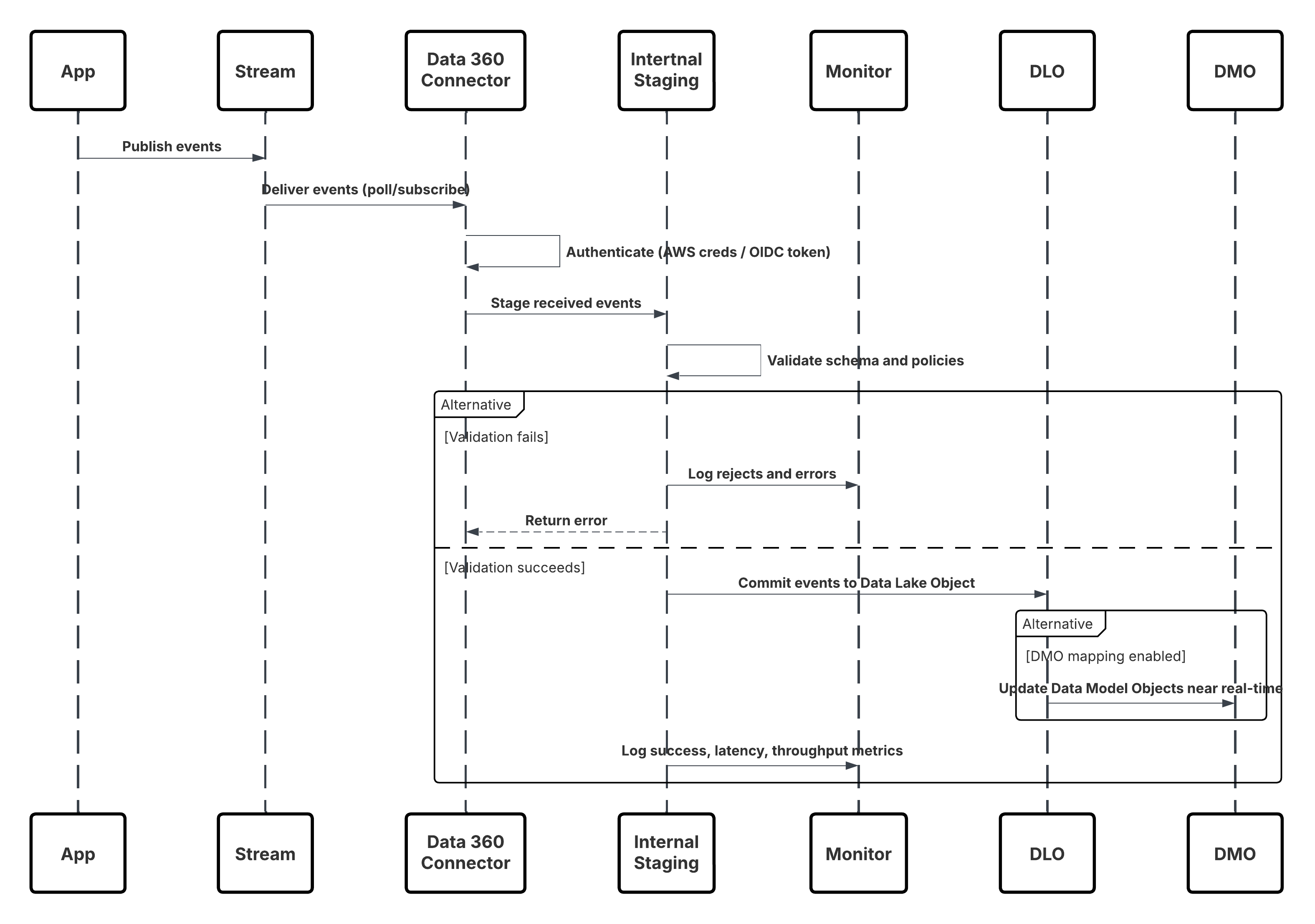
In diesem Szenario:
- Anwendungen oder Geräte veröffentlichen Ereignisse im Kinesis-Stream oder MSK-Thema.
- Der Data 360-Konnektor authentifiziert sich mit AWS-Anmeldeinformationen oder OIDC-Token.
- Der Konnektor ruft den Stream kontinuierlich ab oder abonniert ihn.
- Ereignisse werden inszeniert, für Schemas und Richtlinien validiert und dann in das Data-Lake-Objekt (DLO) übernommen.
- Wenn sie zugeordnet sind, werden Datenmodellobjekte (DMOs) zur Aktivierung nahezu in Echtzeit aktualisiert.
- Die Überwachungsebene verfolgt Kennzahlen, Schemaablehnungen und Latenz.
Ergebnisse
Kontinuierliche Aufnahme strukturierter Daten mit geringer Latenz direkt aus AWS Kinesis oder MSK in Data 360. Daten sind sofort verfügbar für:
- Identitätsbestimmung
- Echtzeitsegmentierung
- Aktivierung von Einstein AI
- Agentforce Auslöser Eliminiert die Abhängigkeit von Batch-ETL und ermöglicht streambasierte Architekturen, die auf ereignisgesteuerte Unternehmensdesigns abgestimmt sind.
Aufnahmemechanismen
| Mechanismus | Wann zu verwenden |
|---|---|
| Kinesis-Konnektor (bevorzugt) | Für AWS-native Streaming-Quellen, die eine kontinuierliche Aufnahme von strukturierten Daten mit hohem Volumen erfordern. |
| MSK-Konnektor | Für Organisationen, die Ereignis-Pipelines auf Kafka-kompatiblen Plattformen ausführen. |
| Hybrid (Streaming + Batch) | Für die inkrementelle Ereignisaufnahme in Kombination mit periodischen Massenlasten. |
Fehlerbehandlung und -behebung
- Automatische Abrufe: Konnektoren versuchen, vorübergehende Netzwerk- oder Plattformfehler mit exponentieller Sicherung zu wiederholen.
- Schemaablehnungen: Ungültige Nutzlasten werden zur Administratorüberprüfung an die Schemaablehnungswarteschlange weitergeleitet.
- DLQ-Wiedergabe: Persistente Fehler werden in Warteschlangen mit toten Briefen zur erneuten Verarbeitung erfasst.
- Idempotenzkontrolle: Ereignisschlüssel oder Sequenznummern stellen die Deduplizierung und die geordnete Aufnahme sicher.
- Überwachen der Integration: Alle Kennzahlen zu Fehlern, Wiederholungen und Durchsätzen werden in Data 360 Monitoring-Dashboards angezeigt.
Überlegungen zum idempotenten Design
- Ereigniseindeutigkeit und -verfolgung: Jedem Ereignis wird ein deterministischer eindeutiger Schlüssel zugewiesen (z. B. PartitionKey + SequenceNumber for Kinesis oder Topic + Partition + Offset for MSK), um eine genaue einmalige Aufnahme zu gewährleisten.
- Konnektorprüfung: Data 360-Konnektoren behalten die zuletzt verarbeitete Offset- oder Sequenznummer bei, um die Aufnahme nach Fehlern oder Neustarts sicher fortzusetzen.
- Duplizierung und UPSERT-Logik: Während DLO-Commits werden doppelte Ereignisse erkannt und übersprungen. Gültige Datensätze werden mithilfe des eindeutigen Schlüssels aktualisiert, um die Konsistenz zu wahren.
- Steuerung für Wiedergabe und Wiederherstellung: Fehlgeschlagene oder verzögerte Ereignisse werden über Dead-Letter- und Replay-Warteschlangen aus gespeicherten Verschiebungen wiedergegeben, um eine zuverlässige Wiederherstellung ohne Duplikate zu gewährleisten.
Sicherheitsüberlegungen
Sicherheit ist in der gesamten Aufnahme-Pipeline von entscheidender Bedeutung, von der Authentifizierung über die Verschlüsselung bis hin zur Zugriffskontrolle.
- Authentifizierung: Schützen Sie den Austausch von Anmeldeinformationen mithilfe von AWS IAM-Richtlinien oder OIDC.
- Verschlüsselung: Daten, die während der Übertragung (TLS 1.2+) und im Leerlauf (AES-256) in Data 360 verschlüsselt werden.
- Zugriffssteuerung: Erzwungene Rollen mit den geringsten Berechtigungen; Konnektoren, die auf bestimmte Streams/Themen beschränkt sind.
- Governance: Metadaten zur Abstammung und Klassifizierung, die für die vollständige Rückverfolgbarkeit auf jeden Datensatz angewendet werden.
- Netzwerksicherheit: Optional können Sie die Bereitstellung in privaten Subnetzen mithilfe von AWS PrivateLink vornehmen.
Randleisten
Aktualität
- Verarbeitung nahezu in Echtzeit: CDC- und Streaming-Konnektoren verarbeiten Ereignisse innerhalb von Sekunden nach Quelländerungen, wodurch in der Regel die Aktualisierung der Daten in wenigen Minuten gewährleistet wird.
- Deterministische Latenz: Die durchgängige Verzögerung hängt vom Quelldurchsatz, dem Ereignis-Batch und den Netzwerkbedingungen ab. Data 360 garantiert jedoch eine vorhersehbare SLA-gesteuerte Latenz für unterstützte Objekte.
- Elastische Skalierung: Die Aufnahme-Pipeline wird bei hohem Ereignisvolumen automatisch skaliert, sodass die Aktualität auch bei Spitzendatenausbrüchen erhalten bleibt.
- Operative Sichtbarkeit: Überwachungs-Dashboards zeigen Ereignisverzögerungen, Commit-Zeitstempel und den Status der erneuten Wiedergabe zur Latenzsicherung und Fehlerbehebung an.
Datenvolumen
- Leichte Nutzlasten: Einzelne CDC- oder Streaming-Ereignisse sind kompakt (typische Größe von 1–5 KB), optimiert für Aktualisierungen mit hoher Häufigkeit.
- Objekte mit hohen Änderungen: Bei volatilen Einheiten (z. B. Kundenvorgang, Kontakt, Auftrag) müssen Architekten sicherstellen, dass CDC-Zuteilungen und Ereignisdurchsatz mit den erwarteten Aktualisierungsraten übereinstimmen.
- Parallel Streams: Data 360 unterstützt die Aufnahme mehrerer Streams für die horizontale Skalierung über große Objektvolumen oder mehrere Quellorganisationen hinweg.
- Gegendruckverarbeitung: Integrierte Drosselmechanismen sorgen für eine stabile Aufnahme unter Last, ohne Ereignisse zu verwerfen.
Bundesstaatsverwaltung
Jedes Ereignis enthält Metadaten für die Status- und Versionskontrolle:
- Wiedergabe und Verschiebungsverfolgung: Jedes Ereignis enthält die Metadaten "Wiedergabe-ID" und "Sequenz", was die geordnete Zustellung und die prüfpunktbasierte Wiederherstellung ermöglicht.
- Schema Versioning: Versions-Tags in Ereigniskopfzeilen gewährleisten eine abwärtskompatible Verarbeitung, wenn sich Quellschemas weiterentwickeln.
- Idempotenzschlüssel: Jedes Ereignis enthält einen eindeutigen Transaktions- oder Commit-Schlüssel, wodurch Data 360 Wiederholungen und Wiederholungen sicher deduplizieren kann.
- Atom-Commit: Die Aufnahme-Pipeline markiert Verschiebungen erst dann als abgeschlossen, wenn die nachgelagerten Commits für DLOs erfolgreich sind, was die Konsistenz gewährleistet.
Komplexe Integrationsszenarien
Dieses Muster lässt sich nahtlos in erweiterte Unternehmensarchitekturen integrieren:
- Hybridaufnahme: Kombinieren Sie CDC für inkrementelle Deltas mit Massendatenströmen für vollständige Aktualisierungen, wobei die Aktualität und Vollständigkeit erhalten bleiben.
- Organisationsübergreifendes Streaming: Mehrere CRM- oder ERP-Organisationen können im selben Data 360-Mandanten veröffentlicht werden, der durch die DMO-Zuordnung und die Ontologieausrichtung vereinheitlicht wird.
- Ereignisanreicherung: Middleware (z. B. MuleSoft, Event Relay) kann Streaming-Daten anreichern, filtern oder weiterleiten, bevor sie Data 360 erreichen.
- AI und Agentenaktivierung: Echtzeitaktualisierungen lösen nachgelagerte Automatisierungen wie Einstein-Prognosen oder Agentforce-Antworten innerhalb von Sekunden nach dem ursprünglichen Ereignis aus.
Beispiel
Ein globales Einzelhandelsunternehmen verwendet AWS Kinesis zum Streamen von Point-of-Sale- und Webinteraktionsdaten.Der Kinesis-Konnektor von Data 360 authentifiziert sich über IAM-Anmeldeinformationen und nimmt Ereignisse kontinuierlich in ein Transaktions-DLO auf.Jeder Datensatz wird schemavalidiert, mit Metadaten angereichert und sofort in das Kunden-DMO übernommen.Innerhalb von Sekunden aktualisieren Einstein AI-Modelle Kundensegmente und Agentforce löst Empfehlungen für das nächste Angebot in Echtzeit aus.
Zero Copy ist mehr als eine Integrationsmethode – es ist eine grundlegende Änderung in Bezug darauf, wie sich Unternehmensdaten bewegen oder besser gesagt nicht. In der Regel erforderte die Datenintegration das Kopieren großer Datensatzmengen durch ETL-Pipelines, das Erstellen redundanter Datenspeicher, Synchronisierungsverzögerungen und Governance-Herausforderungen. Mit der Nullkopie wird all das beseitigt. In diesem Modell stellt Data 360 eine direkte Verbindung mit externen Datenplattformen wie Snowflake und Databricks her und liest und aktiviert Daten sicher, ohne sie jemals verschieben oder duplizieren zu müssen. Das Ergebnis ist eine nahtlose Brücke zwischen Ihrem Data Lakehouse für Unternehmen und dem Salesforce-Ökosystem, die sofortigen Zugriff, geringeren Betriebsaufwand und eine stärkere Datenverwaltung bietet.
Mit Funktionen für eingehende Nullkopien kann Data 360 externe Daten an der Quelle abfragen und harmonisieren, beispielsweise Kundenprofile, Transaktionen oder Produktdaten, die in Snowflake oder Databricks gespeichert sind. Anstatt Dateien aufzunehmen, stellt Data 360 eine sichere, metadatenbasierte Verbindung her, die vorhandene Schemadefinitionen und Sicherheitsrichtlinien im externen Lagerhaus nutzt.
- Direkter Verbund: Data 360 liest die vorhandenen Daten über sichere, optimierte Abfragen ohne Abgleich.
- Einheitliche Unternehmensführung: Die Daten unterliegen weiterhin dem Sicherheits-, Zugriffssteuerungs- und Compliance-Framework des Quellsystems.
- Betriebseffizienz: Eliminiert ETL-Overhead- und -Speicherduplikate und reduziert so Kosten und Komplexität.
- Echtzeitbereitschaft: Aktiviert die On-Demand-Harmonisierung. Sobald Daten in Snowflake aktualisiert werden, können sie sofort in Data 360 aktiviert werden.
Context
Moderne datengestützte Unternehmen verwalten Petabyte an Kunden-, Transaktions- und Telemetriedaten auf Cloud-basierten Data-Lakehouse-Plattformen wie Snowflake und Databricks. Diese Umgebungen dienen als zentrale Informationsquelle für Analysen, AI und Compliance. Data 360 führt Zero CopyData Federation ein, wodurch Data 360 externe Datensets direkt abfragen und verwenden kann, ohne redundante Daten kopieren, umwandeln oder speichern zu müssen*.* Mit diesem Muster können Unternehmen die Customer 360-Struktur auf ihre vorhandene Data Warehouse- oder Lakehouse-Infrastruktur erweitern und so eine Vereinheitlichung und Aktivierung in Echtzeit ohne Duplikate, Latenz und Kompromisse bei der Unternehmensführung erreichen.
Problem
Wie können Unternehmen Multimedia-Datensets, die bereits in Snowflake, Databricks oder Open-Lake-Formaten wie Apache Iceberg zusammengestellt wurden, für die Segmentierung, Identitätsbestimmung und Aktivierung in Data 360 nutzen, ohne dass ETL-Pipelines oder physische Datenbewegungen Kosten, Latenz und Governance verursachen?
Kräfte
Bei diesem Muster werden mehrere architektonische, Sicherheits- und Leistungsüberlegungen eingeführt:
Netzwerk und Sicherheit
- Data 360 muss eine sichere private Verbindung mit dem externen Lagerhaus oder Lakehouse herstellen.
- In der Regel mit Salesforce Private Connect oder PrivateLink/VPC Peering konfiguriert, um sicherzustellen, dass der Datenverkehr das kontrollierte Netzwerk des Kunden niemals verlässt.
- Externe Systeme müssen Data 360-IPs auf die Zulassungsliste setzen und die TLS 1.2+-Verschlüsselung erzwingen.
Authentifizierung und Zugriffssteuerung
- Unterstützt die Schlüsselpaarauthentifizierung, OAuth 2.0 oder Identity Provider (IdP)-basierte Trust Delegation (Data 360 fungiert als vertrauenswürdiger Client)
- Die rollenbasierte Zugriffssteuerung im externen System erzwingt den Zugriff mit den geringsten Berechtigungen für die Abfrageausführung.
Leistung und Berechnungsabhängigkeit
- Der Abfrageverbund verschiebt die SQL-Ausführung in Snowflake oder Databricks und nutzt deren Rechencluster.
- Leistung und Kostenskala mit externer Abfragelast – Segmentierungslatenz und -kosten sind an die Konfiguration externer Berechnungen gebunden.
Evolvierende Standards: Dateiverbund
- Ein Modell der nächsten Generation, der Dateiverbund, nutzt offene Tabellenformate wie Apache Iceberg oder Delta Lake, sodass Data 360 direkt aus dem Objektspeicher gelesen werden kann (z. B. Amazon S3, Azure ADLS, Google Cloud Storage).
- Durch das Umgehen der Quellberechnungsebene reduziert der Dateiverbund die Latenz und die Kosten für leseintensive analytische Arbeitslasten drastisch und behält gleichzeitig die Schemaintegrität bei.
Governance und Compliance
- Die Daten verlassen die Quellplattform niemals. Compliance-, Verschlüsselungs- und Aufbewahrungsrichtlinien bleiben beim Ursprung erzwungen.
- Alle Metadaten-, Abstammungs- und Einwilligungsattribute werden in die Trust Layer von Data 360 übernommen, um die durchgängige Rückverfolgbarkeit zu gewährleisten.
Lösung
Es wird empfohlen, native Zero Copy-Konnektoren für Snowflake, Databricks oder Dateiverbund in Data 360 zu verwenden.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Snowflake Zero Copy Connector | Best | Native Integration von Erstanbietern: Stellt den Live-Abfrageverbund über die Datenfreigabe-API oder die externe Tabellen-API von Snowflake her. |
| Databricks Zero Copy-Konnektor | Best | Unterstützt direkten Live-Zugriff auf Tabellen/Ansichten in Delta Lake. Pushdown-Abfragen werden in der Databricks-Laufzeit ausgeführt. |
| Dateiverbund (Apache Iceberg / Delta / Parquet) | Neue bewährte Vorgehensweisen | Data 360 liest offene Tabellenformate direkt aus dem Objektspeicher, ohne dass eine externe Berechnungsabhängigkeit besteht. Ideal für massive Datensets. |
| Private Netzwerkkonfiguration | Empfohlen | Verwenden Sie Salesforce Private Connect oder VPC Peering für eine sichere Verbundorganisation auf Netzwerkebene. |
| Authentifizierung und Schlüsselverwaltung | Bewährte Vorgehensweisen | Implementieren Sie die sichere schlüsselbasierte oder OAuth-basierte Authentifizierung mit regelmäßiger Rotation und Tresorverwaltung. |
| Schemaregistrierung | Erforderlich | Data 360 ruft ein externes Schema ab und ordnet es einem externen Data-Lake-Objekt (External DLO) zu. |
| Gesteuerte Metadaten | Empfohlen | Alle externen DLOs übernehmen Klassifizierungs-, Einwilligungs- und Abstammungsmetadaten für die Compliance-Sichtbarkeit. |
Skizze
Im folgenden Diagramm wird veranschaulicht, wie Sie eine Zero-Copy-Verbindung einrichten und externe DLOs in Data 360 erstellen.
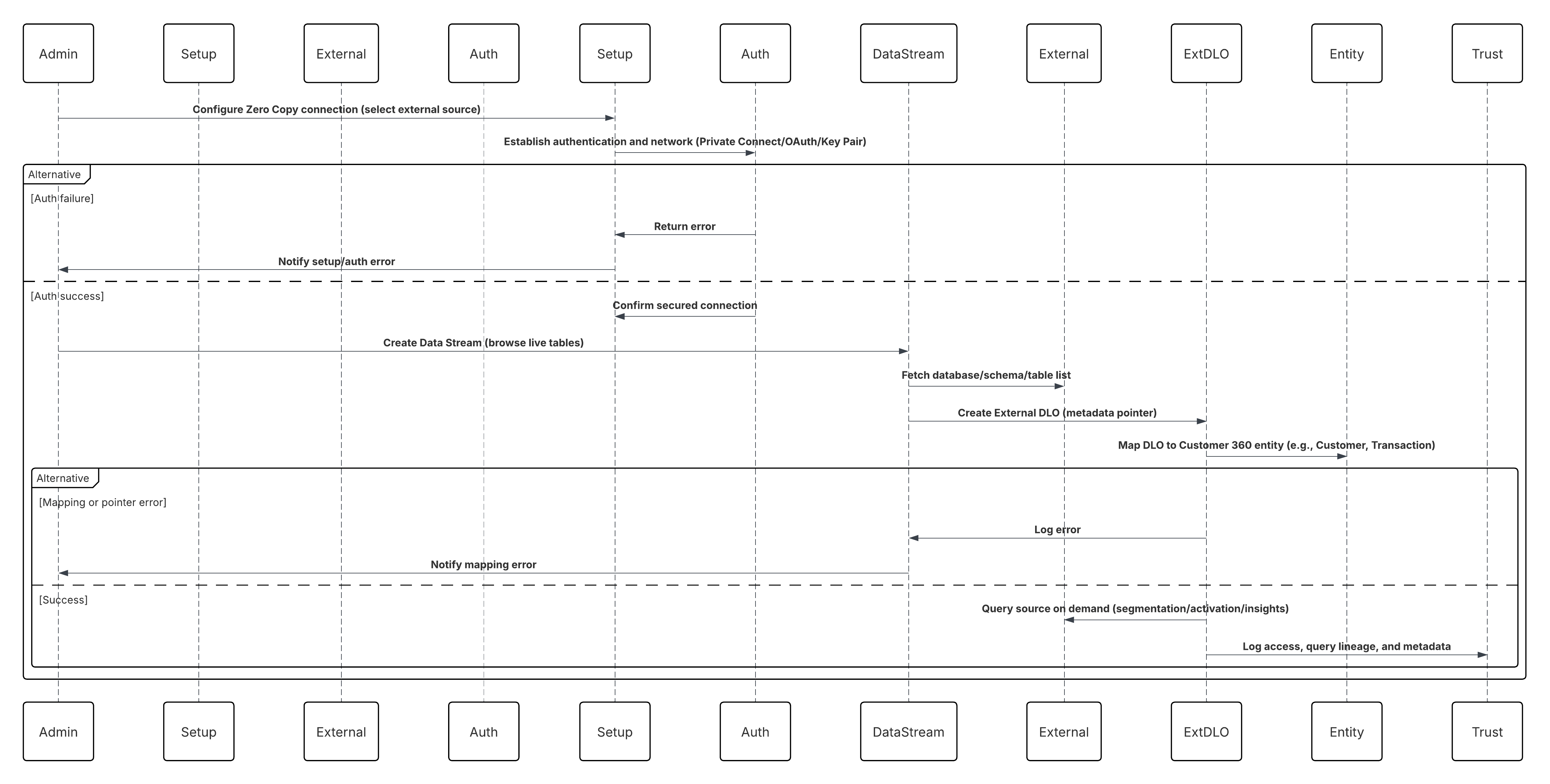
In diesem Szenario:
- Der Administrator konfiguriert im Setup von Data 360 (Snowflake, Databricks oder Dateiverbund) eine Zero Copy-Verbindung.
- Die sichere Authentifizierung und die Netzwerkweiterleitung werden eingerichtet (Private Connect / OAuth / Schlüsselpaar).
- Der Administrator erstellt einen Datenstrom, der die externe Quelle auswählt und Live-Datenbanken, Schemas und Tabellen durchsucht.
- Statt Daten zu kopieren, erstellt Data 360 ein externes DLO (Data Lake Object) – einen Metadatenzeiger, der auf die Live-Tabelle oder die Iceberg-Datei verweist.
- Externe DLOs werden Customer 360 Einheiten zugeordnet (z. B. Kunde, Transaktion, Produkt).
- Data 360 fragt die vorhandene Quelle während der Segmentierung, Aktivierung oder Statistikberechnung ab.
- Alle Zugriffs-, Abfragestamm- und Metadaten werden innerhalb der Data 360 Trust Layer überprüft.
Ergebnisse
- Externe Daten verbleiben in Snowflake, Databricks oder S3 – kein ETL, kein Duplikat und kein zusätzlicher Speicher.
- Data 360 erhält Echtzeit-Lesezugriff auf Daten im Unternehmensmaßstab für die Identitätsbestimmung, berechnete Statistiken und Aktivierung.
- Organisationen behalten die vollständige Kontrolle über ihre vorhandenen Governance-, Verschlüsselungs- und Compliance-Frameworks.
- Dieses Muster ermöglicht eine echte Zero Copy-Architektur, die die Leistung des lokalen Zugriffs mit der Verwaltung des Verbundspeichers kombiniert.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Lösung ab, die zur Implementierung dieses Musters ausgewählt wurde.
| Mechanismus | Wann zu verwenden |
|---|---|
| Snowflake-Verbund (bevorzugt) | Für den Live-Abfrageverbund mit verwalteten Enterprise Data Warehouses. |
| Databricks-Verbund | Für vereinheitlichte Analysen und Lakehouse-Umgebungen mit Delta- oder Parquet-gestützten Datensets. |
| Dateiverbund (Apache-Eisberg / Deltasee) | Für umfangreiche Datensets im Objektspeicher, bei denen die Berechnungstrennung und die Kostenoptimierung entscheidend sind. |
| Hybridmodus (Nullkopie + Aufnahme) | Wenn Verlaufsdaten einmalig aufgenommen werden müssen, jedoch über Zero Copy auf Live-Daten zugegriffen wird. |
Fehlerbehandlung und -behebung
- Automatische Wiederholung und Abfragesicherung: Transiente Verbindungs- oder Abfragezeitüberschreitungen, die automatisch mit exponentieller Sicherung wiederholt werden.
- Schemaabweichungsisolation: Änderungen am Quellschema (z. B. neue Spalten) werden in der Schemaablehnwarteschlange protokolliert. Administratoren können Schemametadaten neu zuordnen oder aktualisieren.
- Authentifizierungs-Failover: Wenn Anmeldeinformationen ablaufen, versucht Data 360, die Verbindung mithilfe gespeicherter Aktualisierungstoken oder Schlüsselrotationsrichtlinien erneut herzustellen.
- Verfügbarkeitserkennung berechnen: Wenn der Snowflake- oder Databricks-Cluster angehalten wird, setzt Data 360 Verbundaufträge aus und versucht es erneut, wenn die Berechnung fortgesetzt wird.
- Überwachen der Integration: Alle Metadaten zum Verbindungsstatus, zur Abfragelatenz und zur Abstammung sind in Dashboards vom Typ "Data 360 Monitoring" sichtbar.
Überlegungen zum idempotenten Design
- Abfragedeterminismus: Verbundabfragen verwenden eine konsistente Snapshot-Semantik, um stabile, wiederholbare Lesevorgänge während der Segmentierung oder Aktivierung zu gewährleisten.
- Externe DLO-Versionierung: Jede Verbundabfrage enthält Schema- und Zeitstempel-Metadaten für die Abstammungsverfolgung.
- Zugriff ohne Verschiebung: Da Zero Copy schreibgeschützt ist, ist es nicht auf Ereignisverschiebungen angewiesen. Die Konsistenz wird über die ACID-Garantien des externen Systems (Snowflake/Delta Lake) erzwungen.
- Schema Drift Management: Verwalten Sie versionierte Schemazuordnungen in Data 360 und aktualisieren Sie externe DLO-Metadaten zur Quellentwicklung.
Sicherheitsüberlegungen
Die Sicherheit ist im gesamten Verbundmodell von entscheidender Bedeutung, um keine Kompromisse bei Trust oder Compliance einzugehen.
- Verschlüsselung: Alle Datenaustausche verwenden TLS 1.2+; externe Lagerhäuser werden im Leerlauf mit AES-256 verschlüsselt.
- Zugriffssteuerung: Der Zugriff auf externe Tabellen erfolgt über Rollen mit den geringsten Berechtigungen mit schreibgeschützten Berechtigungen.
- Netzwerkisolation: Private Connect- oder VPC-Routen verhindern die Offenlegung öffentlicher Endpunkte.
- Gesteuerter Datenfluss: Metadaten zu Herkunft, Einwilligung und Klassifizierung werden zur Erzwingung von Richtlinien in die Data 360 Trust Layer integriert.
- Überprüfbarkeit: Alle Verbundabfrage- und Schemazugriffsereignisse werden für die Compliance-Verfolgbarkeit (DSGVO, CCPA, HIPAA) protokolliert.
Randleisten
Aktualität
- Abfragen werden live für das externe Lagerhaus oder den externen Speicher ausgeführt, wodurch eine Echtzeitsichtbarkeit des aktuellen Datenstatus gewährleistet wird.
- Segmentierungs- oder Aktivierungsausführungen berücksichtigen sekundengenaue Änderungen an Snowflake-, Databricks- oder S3-gestützten Iceberg-Tabellen.
- Die Abfragelatenz hängt von der Leistungsstufe des Quellsystems ab – in der Regel Sekunden bis hin zu mehreren zehn Sekunden pro Abfrage.
- Ideal für Analyse- und AI-Arbeitslasten, die "frischen, nicht kopierten" Datenzugriff erfordern.
Datenvolumen
- Unterstützt Datensets auf Petabyte-Skala, die nativ in Snowflake oder Databricks gespeichert sind, ohne Abgleich.
- Data 360 ruft nur Ergebnisse – keine Rohdatensets – ab, wodurch Netzwerk- und Rechenkosten minimiert werden.
- Dateiverbund optimiert große Analysescans durch Partitionsschnitt und Spalten-Pushdown.
- Die Skalierung erfolgt linear mit der Lagerhausberechnungskapazität und der Verbundabfrageorchestrierungsebene von Data 360.
Bundesstaatsverwaltung
- Externe DLOs behalten Verbindungs-, Schema- und Versionsmetadaten in Data 360 bei.
- Die Schemaentwicklung wird automatisch über Metadatenaktualisierungszyklen verwaltet.
- Die Abfragelinie enthält Zeitstempel, Benutzeridentität und Ausführungskennzahlen für die Rückverfolgbarkeit.
- Es werden keine zustandsgesteuerte Aufnahme oder Verschiebungen beibehalten. Die Konsistenz wird von den ACID-Garantien der externen Quelle übernommen.
Komplexe Integrationsszenarien
- Hybridmodus: Kombinieren Sie Zero Copy (für Live-Verbund) mit der Aufnahme (für historische Datensets).
- Lagerübergreifender Zugriff: Data 360 kann aus mehreren Snowflake- oder Databricks-Mandanten in einer Organisation zusammengeführt werden.
- AI/BI-Interoperabilität: Externe Systeme (z. B. SageMaker, Tableau, Power BI) können die angereicherten Profile von Data 360 per Reverse Zero Copy zurückfragen.
- Dateiverbund: Unternehmen, die Open-Lake-Formate (Iceberg/Delta) verwenden, können strukturierte und unstrukturierte Daten in einem Verbundmodell vereinheitlichen.
Beispiel
Ein globales Finanzunternehmen speichert alle Transaktions- und Interaktionsdaten in Snowflake und verwaltet gleichzeitig Kundenattribute und Marketingereignisse in Data 360. Mit der Zero Copy Data Federation stellt Data 360 über Private Connect eine sichere Verbindung mit Snowflake her.Wenn ein Segmentierungsauftrag ausgeführt wird, beispielsweise "Kunden mit einem Ausgabenvolumen von >100.000 EUR in den letzten 30 Tagen, überträgt Data 360 die Abfrage in Snowflake, ruft aggregierte Ergebnisse ab und aktiviert diese Profile sofort in Journey Builder. Kein Abgleich oder ETL erforderlich. In diesem Beispiel wird die Verbundintelligenz in Echtzeit verwendet, die im gesamten Unternehmensdaten-Ökosystem vereinheitlicht wird.
Bei der ausgehenden Nullkopie wird dasselbe Prinzip umgekehrt erweitert. Statt Datensets aus Data 360 zu exportieren oder zu kopieren, können externe Systeme wie Snowflake Data 360 direkt abfragen und als Verbundquelle für erweiterte Kundenintelligenz behandeln.
- Umgekehrte Zuordnung: Externe Analytics- oder AI-Plattformen können auf die vereinheitlichten Profildaten von Data 360 zugreifen, ohne sie zu extrahieren.
- Datenaktivierung bei Quelle: Geschäftsteams können Statistiken dort nutzen, wo sich die Daten bereits befinden – ob für die AI-Modellierung, die Berichterstellung oder die Kundenpersonalisierung.
- Latenzfreie Interoperabilität: Keine Batch-Exporte oder Synchronisierungsaufträge; Statistiken fließen sofort zwischen Plattformen.
- Konsistente Semantik: Da beide Systeme dieselbe Ontologie und dieselben Schemazuordnungen verwenden, bleiben Kontext und Bedeutung in allen Ökosystemen erhalten. Die Nullkopie definiert die Rolle von Data 360 von einem Datenrepository zu einer semantischen Aktivierungsebene neu. Sie ermöglicht es Organisationen, Daten genau dort zu speichern, wo sie hingehören – in verwalteten Hochleistungs-Warehouses – und dennoch ihren vollen Wert innerhalb der Trust Grenze von Salesforce zu nutzen. Dieses Muster entspricht modernen Datenmaschen- und AI-nativen Architekturen: Daten bleiben dezentral, die Intelligenz wird jedoch vereinheitlicht. Architekten können nun Aktivierungs-Pipelines erstellen, die schneller, schlanker und kompatibler sind – ohne Kopieren.
Context
Moderne Unternehmen arbeiten zunehmend in Datenökosystemen mit mehreren Plattformen, in denen Salesforce Data 360 zusammengeführte Kundenprofile und Aktivierungen unterstützt, während Enterprise Data Warehouses wie Snowflake oder Databricks als analytisches Rückgrat für Data Science-, maschinelles Lernen und BI-Arbeitslasten dienen. Die Zero Copy Outbound Sharing-Funktion von Salesforce Data 360 verbindet diese Umgebungen nahtlos und ermöglicht den kontrollierten, sicheren und Echtzeitzugriff auf harmonisierte Data 360-Daten direkt in Snowflake oder Databricks, ohne Abgleich oder ETL. Dadurch können Analysten und Datenwissenschaftler dieselben vertrauenswürdigen Live-Daten abfragen, visualisieren und modellieren, die Marketing, Vertrieb und Serviceaktivierung unterstützen.
Problem
Wie kann ein Unternehmen die vereinheitlichten Kundenprofile und berechneten Kennzahlen von Data 360 sicher und effizient externen Analysesystemen zur Verfügung stellen (z. B. "Lebensdauerwert", "Abwanderungsrisiko") – ohne Daten zu kopieren, die Unternehmensführung zu brechen oder Latenzzeiten über herkömmliche Reverse-ETL-Pipelines einzuführen?
Kräfte
Bei diesem Muster werden mehrere architektonische, Governance- und betriebliche Überlegungen eingeführt:
- Geregelte Sicherheit: Der Zugriff auf Data 360-Daten muss kontrolliert, granular und überprüfbar sein. Die Zero Copy-Freigabe verwendet expliziten Zugriff auf Objektebene, um sicherzustellen, dass nur genehmigte Datenmodellobjekte (DMOs) und Objekte der berechneten Statistik (CIOs) für angegebene Verbraucher verfügbar sind.
- Explizite Objektauswahl: Administratoren pflegen freigabefähige Daten über eine Datenfreigabe und wählen explizit aus, welche Objekte verfügbar gemacht werden sollen. Dadurch wird die Governance beibehalten und das Risiko minimiert.
- Bilaterale Konfiguration: Data 360 und das externe Lagerhaus müssen eingerichtet werden. Data 360 definiert das Datenfreigabeziel (Snowflake/Databricks), während das empfangende System die Freigabe akzeptieren und instanziieren muss.
- Abfrageverbundmodell: Nach der Annahme fragt die externe Plattform Live-Daten über Verbundansichten ab, wodurch Extraktionsaufträge oder manuelle Aktualisierungszyklen entfallen.
- Entwicklung offener Standards: Neue Ansätze wie der Dateiverbund nutzen offene Tabellenformate (z. B. Apache Iceberg), um den schreibgeschützten Zugriff auf der Speicherebene zu ermöglichen und so die Skalierbarkeit, Leistung und Interoperabilität in mehreren Cloud-Architekturen zu verbessern.
Lösung
Die Lösung nutzt die native Zero Copy Sharing von Salesforce Data 360 für Datenplattformen wie Snowflake oder Databricks.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Erstellung von Datenfreigaben | Best | Der Administrator erstellt eine Datenfreigabe in Data 360 und fügt ausgewählte DMOs und CIOs hinzu (z. B. "Zusammengeführte Einzelperson", "Kundengesundheitsbewertung"). |
| Zielkonfiguration | Best | Erstellen Sie ein Datenfreigabeziel, das Snowflake- oder Databricks-Accountkennzeichner und Authentifizierungsparameter angibt. |
| Freigabeveröffentlichung | Bewährte Vorgehensweisen | Verknüpfen Sie die Datenfreigabe mit dem Datenfreigabeziel, um sie sicher zu veröffentlichen. |
| Lagerannahme | Erforderlich | Der externe Administrator akzeptiert die Freigabe und materialisiert freigegebene Objekte als schreibgeschützte Ansichten/Tabellen im Lagerhaus. |
| Granulare Zugriffssteuerung | Empfohlen | Wenden Sie objekt- und rollenbasierte Berechtigungen in Data 360 an. Passen Sie sich an die rollenbasierte Zugriffssteuerung auf Lagerhausebene an. |
| Zugriff auf Verbundabfragen | Best | Analysten fragen freigegebene Live-Daten über standardmäßiges SQL ab. Verknüpft mit nativen Lagerhausdaten für nachgelagerte Analysen und ML. |
| Option 'Dateiverbund' | Optional | Nutzen Sie für große Datensets die Apache Iceberg-basierte Verbundfunktion für direkte S3- oder Delta Lake-Lesungen ohne Rechenabhängigkeit. |
Skizze
Im folgenden Diagramm wird ein Aufruf von Salesforce Data 360 an eine externe Data Platform veranschaulicht.
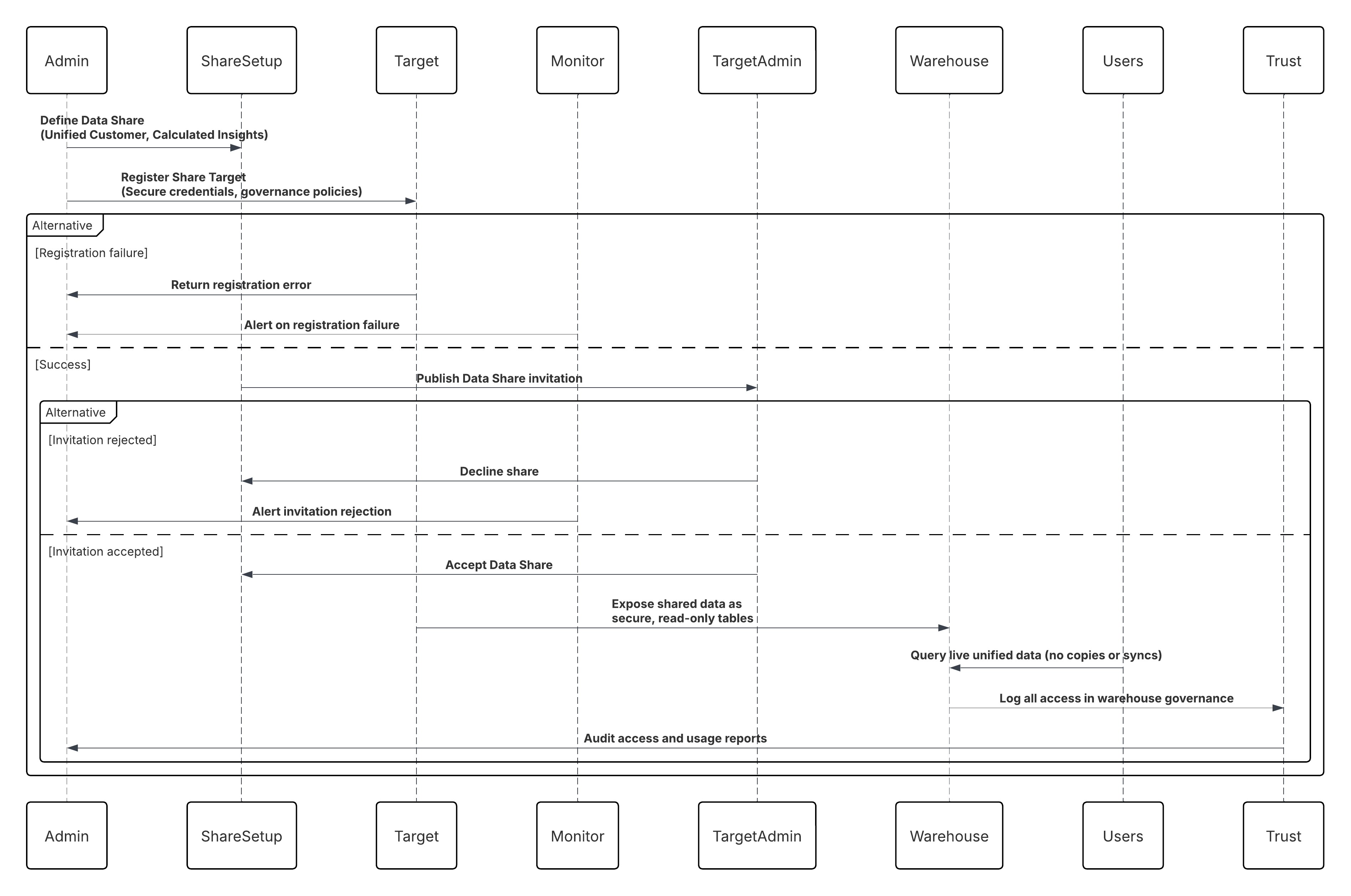
In diesem Szenario:
- Data 360-Administrator definiert eine Datenfreigabe, einschließlich der Objekte "Zusammengeführter Kunde" und "Berechnete Statistik".
- Ein Datenfreigabeziel (Snowflake- oder Databricks-Account) wird mit sicheren Anmeldeinformationen und Governance-Richtlinien registriert.
- Data 360 veröffentlicht die Freigabe. Snowflake/Databricks-Administratoren akzeptieren sie.
- Freigegebene Daten werden als sichere, schreibgeschützte Tabellen im Lagerhaus angezeigt.
- Analysten, BI-Tools oder ML-Pipelines fragen die zusammengeführten Live-Kundendaten ab, ohne sie kopieren oder synchronisieren zu müssen.
- Der gesamte Zugriff wird innerhalb der Data 360 Trust Layer- und Lagerhausverwaltungsprotokolle überprüft.
Ergebnisse
- Externe Lagerhäuser erhalten in Echtzeit abfragbaren Zugriff auf harmonisierte Data 360-Daten.
- Eliminiert umgekehrte ETL-Pipelines, wodurch der Betriebsaufwand und die Latenz reduziert werden.
- Aktiviert AI/ML-Training, Prognosemodellierung und erweiterte BI direkt für vereinheitlichte Daten.
- Bewahrt keine Duplikate, eine starke Governance und eine sichere Zugriffskontrolle nach Design auf.
- Schließt die bidirektionale Zero Copy-Schleife ab, bei der die eingehende Verbundfreigabe und die ausgehende Freigabe unter einem einzigen Governance-Modell nebeneinander vorhanden sind.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Lösung ab, die zur Implementierung dieses Musters ausgewählt wurde.
| Mechanismus | Wann zu verwenden |
|---|---|
| Snowflake-sichere Datenfreigabe (bevorzugt) | Wird verwendet, wenn Ihr Unternehmens-Warehouse Snowflake ist und Sie Live-Zugriff auf harmonisierte Data 360-Datensets ohne Datenverschiebung oder Duplikate benötigen. Ideal für Analysen, AI und Compliance-gestützte Arbeitslasten, die eine Freigabe ohne Latenz und die Erzwingung nativer Abstammung erfordern. |
| Databricks Delta Freigeben | Wird verwendet, wenn nachgelagerte Verbraucher in Databricks- oder Delta Lake-Umgebungen arbeiten und über das offene Delta-Freigabeprotokoll schreibgeschützten Echtzeitzugriff auf zusammengeführte oder aktivierte Datensets benötigen. |
| Freigabe für externe Tabellen (Apache Iceberg / Parquet) | Wird verwendet, wenn offene Architekturen im Objektspeicher (S3, ADLS oder GCS) verwaltet werden und eine interoperable, kostengünstige Freigabe über Analysemodule wie Athena, BigQuery oder Snowflake-on-Iceberg hinweg erforderlich ist. |
| API für Datenfreigabe (programmgesteuerter Zugriff) | Wird verwendet, wenn benutzerdefinierte Anwendungen oder Middleware (z. B. MuleSoft) freigegebene Datensets sicher über APIs entdecken, abonnieren oder verwenden müssen, mit ereignisbasierten Aktualisierungsbenachrichtigungen und einer detaillierten Zugriffssteuerung. |
| Hybridfreigabe (Nullkopie + ausgehende Freigabe) | Verwenden Sie diese Option bei der Implementierung von Mustern für den bidirektionalen Austausch, indem Sie Zero Copy für eingehende Daten und die Freigabe ausgehender Daten für die Veröffentlichung von Statistiken verwenden und so die semantische Konsistenz und Governance auf allen Unternehmensdatenebenen gewährleisten. |
Fehlerbehandlung und -behebung
- Verbindungsabrufe: Automatische Wiederholungen bei vorübergehenden Verbindungs- oder Authentifizierungsfehlern zwischen Data 360 und dem Lagerhaus.
- Freigabevalidierung: Ungültige oder nicht autorisierte Freigabekonfigurationen werden in einer Warteschlange für Administratorüberprüfungen unter Quarantäne gestellt.
- Synchronisierungszustandsüberwachung: Data 360 zeigt Live-Freigabestatus, Abfragelatenz und Zugriffsprotokolle über Überwachungs-Dashboards an.
- Widerruf des Zugriffs: Administratoren können Freigaben sofort widerrufen und den Zugriff an beiden Enden ohne Restdatenkopien deaktivieren.
- Governed Audit Trail (Gesteuerter Prüfpfad): Alle Konfigurations- und Zugriffsänderungen werden zur Konformitätsüberprüfung protokolliert.
Überlegungen zum idempotenten Design
- Konsistente Freigabeidentifikation: Jedes Paar "Datenfreigabe" und "Datenfreigabeziel" verfügt über eine eindeutige Kennung, die eine genaue Governance und Zugriffsverfolgung gewährleistet.
- Unveränderliche Ansichten: Freigegebene Datenobjekte sind schreibgeschützt. Verbraucher können den Status nicht stummschalten, was deterministische Ergebnisse und Compliance gewährleistet.
- Lebenszyklus der atomischen Freigabe: Freigabeveröffentlichung, Widerruf und Aktualisierungen sind atomare Vorgänge – entweder vollständig abgeschlossen oder zurückgesetzt.
- Konsistenz der erneuten Wiedergabe: Wenn Data 360-Daten aktualisiert werden, geben lagerhausseitige Abfragen immer den neuesten konsistenten Snapshot zurück, wodurch veraltete Messwerte vermieden werden.
Sicherheitsüberlegungen
Die Sicherheit untermauert jeden Aspekt der Zero Copy Sharing:
- Authentifizierung: Mit OAuth 2.0, privatem Schlüsselaustausch oder Identitätsverbund (Identity Federation, OIDC) eingerichteter gegenseitiger Trust.
- Verschlüsselung: Daten, die während der Übertragung (TLS 1.2+) und im Leerlauf (AES-256) verschlüsselt werden.
- Zugriffssteuerung: Berechtigungen auf Objektebene erzwingen den Zugriff mit den geringsten Berechtigungen, der durch die Data 360 Trust Layer geregelt wird.
- Netzwerksicherheit: Der Datenaustausch erfolgt über private Netzwerk-Links wie Salesforce Private Connect oder Secure Data Exchange APIs.
- Governance-Metadaten: Jedes freigegebene Objekt enthält Abstammungs-, Klassifizierungs- und Einwilligungsattribute für die vollständige Rückverfolgbarkeit und Einhaltung gesetzlicher Vorschriften.
Randleisten
Aktualität
- Echtzeitverfügbarkeit: Freigegebene Daten entsprechen dem aktuellen Status von Data 360 ohne Verzögerungen beim Abgleich.
- Abfrageaktualisierung: Änderungen an DMOs oder CIOs werden sofort in freigegebene Lagerhausansichten übernommen.
- Leistungselastizität: Der Abfrage-Pushdown wird dynamisch an die Ressourcen der Lagerhausberechnung angepasst.
- Monitoring: Live-Dashboards stellen Kennzahlen zur freigegebenen Latenz und Abfrageleistung zur Sicherung des Betriebs bereit.
Datenvolumen
- Skalierbare Freigabe: Unterstützt die Freigabe von Daten auf Objektebene oder in voller Domäne je nach Analysebedarf.
- Optimierte Abfrageleistung: Snowflake/Databricks zwischenspeichert freigegebene Daten intelligent, um die Latenz zu minimieren.
- Speichereffizienz: Durch die Nullduplizierung entfallen redundante Speicherkosten.
- Option 'Dateiverbund': Bei Datensets auf Petabyte-Skala umgeht die direkte Iceberg-basierte Freigabe die Berechnung und beschleunigt den Zugriff.
Bundesstaatsverwaltung
- Schema Evolution: Versionsgesteuerte Schemas stellen die Kompatibilität bei der Weiterentwicklung des Data 360-Modells sicher.
- Zugriffsstatusverfolgung: Aktive/inaktive Freigabestatus, die in Data 360 für die Lebenszyklusverwaltung beibehalten werden.
- Metadatensynchronisierung: Aktualisierungen an freigegebenen Objektdefinitionen werden automatisch in nachgelagerten Lagerhauskatalogen berücksichtigt.
- Unveränderliche staatliche Garantie: Lagerhausansichten stellen immer einen konsistenten Zeitpunkt für Data 360-Daten dar.
Komplexe Integrationsszenarien
- Hybridmodus: Kombinieren Sie Zero Copy (für Live-Verbund) mit der Aufnahme (für historische Datensets).
- Lagerübergreifender Zugriff: Data 360 kann aus mehreren Snowflake- oder Databricks-Mandanten in einer Organisation zusammengeführt werden.
- AI/BI-Interoperabilität: Externe Systeme (z. B. SageMaker, Tableau, Power BI) können die angereicherten Profile von Data 360 per Reverse Zero Copy zurückfragen.
- Dateiverbund: Unternehmen, die Open-Lake-Formate (Iceberg/Delta) verwenden, können strukturierte und unstrukturierte Daten in einem Verbundmodell vereinheitlichen.
Beispiel
Cloudübergreifende Analysen ermöglichen es Organisationen, verwaltete Salesforce Data 360-Daten mit nativen Datensets auf Plattformen wie Snowflake und Databricks zu kombinieren, um eine vollständige 360-Grad-Analyseansicht bereitzustellen. Durch den mandantenfähigen Zugriff können verschiedene Geschäftseinheiten verwaltete und richtliniengesteuerte Datenslices über separate Freigaben sicher nutzen, ohne Daten zu duplizieren. Datenwissenschaftler können dann Verbund-AI und maschinelles Lernen durchführen, indem sie Modelle direkt in zusammengeführten Kundenprofilen in Snowflake ML- oder Databricks MLflow-Umgebungen trainieren. Während dieses Prozesses stellen integrierte Funktionen für Abstammung, Unternehmensführung und Überprüfung sicher, dass der gesamte Datenzugriff und die gesamte Datennutzung mit Unternehmensrichtlinien und regulatorischen Anforderungen wie DSGVO und HIPAA konform bleiben.
Mit Data Cloud One können Organisationen mit mehreren Salesforce-Organisationen (beispielsweise aufgrund von Geschäftseinheiten, Regionen, Produktlinien oder Übernahmen) eine einzelne zentrale Data 360-Instanz freigeben. Diese Organisation fungiert als "Startorganisation", während andere Organisationen, die als "Begleitorganisationen" bezeichnet werden, mit minimalem Aufwand, ohne benutzerdefinierten Code und vollständiger Governance-Kontrolle auf diese zusammengeführten Daten zugreifen und darauf reagieren können.
Context
Unternehmen führen oft mehrere Salesforce-Organisationen aus (beispielsweise eine für den Vertrieb, eine für den Service, eine für Marketing oder unterschiedliche Regionen). Jede Organisation kann über ihre eigenen Daten, Konfigurationen und Prozesse verfügen. Vor Data Cloud One war für jede Organisation entweder ein eigenes Data 360-Setup oder komplexer benutzerdefinierter Code erforderlich, um Daten organisationsübergreifend freizugeben. Data Cloud One vereinfacht dies, indem es eine einzelne "Startorganisation" mit Data 360 und mehrere "Begleitorganisationen" zulässt, die über Low-Code-Konfiguration und Metadatenfreigabe eine Verbindung herstellen.
Problem
Wie kann ein Unternehmen die einheitliche Nutzung der vereinheitlichten Customer 360-Daten – die von den Data 360-Daten der Startseite erfasst, harmonisiert und verwaltet werden – in allen Salesforce-Organisationen ermöglichen (so dass Vertrieb, Marketing, Service usw. alle dieselben zugrunde liegenden Daten verwenden) und gleichzeitig Doppelarbeit, benutzerdefinierte Codierung, separate Data 360-Instanzen pro Organisation und Führungslücken vermeiden?
Kräfte
Bei diesem Muster werden mehrere architektonische, Sicherheits- und Leistungsüberlegungen eingeführt:
- Komplexität mehrerer Organisationen: Die Organisation der einzelnen Geschäftseinheiten kann unterschiedliche Daten, benutzerdefinierte Objekte, Sicherheit und Prozesse aufweisen. Die Aufrechterhaltung einheitlicher einheitlicher Ansichten ist schwierig.
- Duplizierung & Kosten: Die Ausführung einer separaten Data 360-Instanz pro Organisation bedeutet zusätzliche Einrichtung, zusätzliche Governance, zusätzliche Lizenzierung und das Risiko von Datensilos.
- Steuerelemente für Governance und Datenfreigabe: Sie müssen entscheiden, welche Daten jede Begleitorganisation anzeigen und auf welche Weise sie reagieren kann. Sie können nicht einfach "alles" ohne Governance-Risiko freigeben.
- Geschwindigkeit der Einrichtung: Marketing-, Vertriebs- oder Serviceteams können nicht wochenlang auf benutzerdefinierten Code warten, um organisationsübergreifende Daten verfügbar zu machen. Sie benötigen Click-Config-Lösungen.
- Datenresidenz, regionale Überlegungen: Wenn sich Startseiten- und Begleitorganisationen in unterschiedlichen Regionen befinden, kann es zu rechtlichen oder behördlichen Einschränkungen hinsichtlich der Speicherorte oder der Art der Datenfreigabe kommen.
Lösung
Die folgende Tabelle enthält verschiedene Lösungen für dieses Integrationsproblem.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Bereitstellung der Startseitenorganisation | Best | Legen Sie eine Salesforce-Organisation als "Startorganisation" fest, in der Data 360 bereitgestellt wird. Dies wird zum zentralen Datenspeicher und Governance-Zentrum. |
| Verbindung der Begleitorganisation | Best | Konfigurieren Sie Companion-Verbindungen über die Startseite einer oder mehrerer Companion-Organisationen über die Data Cloud One-Anwendung – kein benutzerdefinierter Code erforderlich. |
| Datenbereichsdefinition | Bewährte Vorgehensweisen | Definieren Sie Datenbereiche innerhalb der Startseite, um Daten logisch zu segmentieren (z. B. Einzelhandel, Service, Marketing) und Zugriffsgrenzen zu isolieren. |
| Freigabe von Datenbereichen | Best | Geben Sie ausgewählte Datenbereiche aus der Heimatorganisation explizit für Begleitorganisationen frei, um eine geregelte, rollenbasierte Sichtbarkeit der zusammengeführten Daten zu gewährleisten. |
| Zugriffskonfiguration | Erforderlich | Aktivieren Sie in Begleitorganisationen die Data Cloud One-Anwendung und weisen Sie Benutzerberechtigungen für den Profil-, Statistik- und Segmentzugriff zu. |
| Governance und Richtlinienkontrolle | Empfohlen | Zentralisieren Sie alle Aufnahme-, Identitätsbestimmungs- und Trust Konfigurationen in der Startseitenorganisation und behalten Sie die durchgängige Verwaltung bei. |
| Synchronisierung mehrerer Organisationen | Best | Datenänderungen und berechnete Statistiken in der Startseitenorganisation werden in Echtzeit in Begleitorganisationen über verwaltete Synchronisierungspipelines berücksichtigt. |
| Hybridbereitstellungsoption | Optional | Bei großen Unternehmen können mehrere Begleitorganisationen eine Verbindung zu einer einzelnen Home-Organisation herstellen und gleichzeitig lokale Kontext- und Compliance-Grenzen beibehalten. |
Skizze
Das folgende Diagramm veranschaulicht die Abfolge der Ereignisse in diesem Muster, wobei Salesforce der Datenmaster ist.
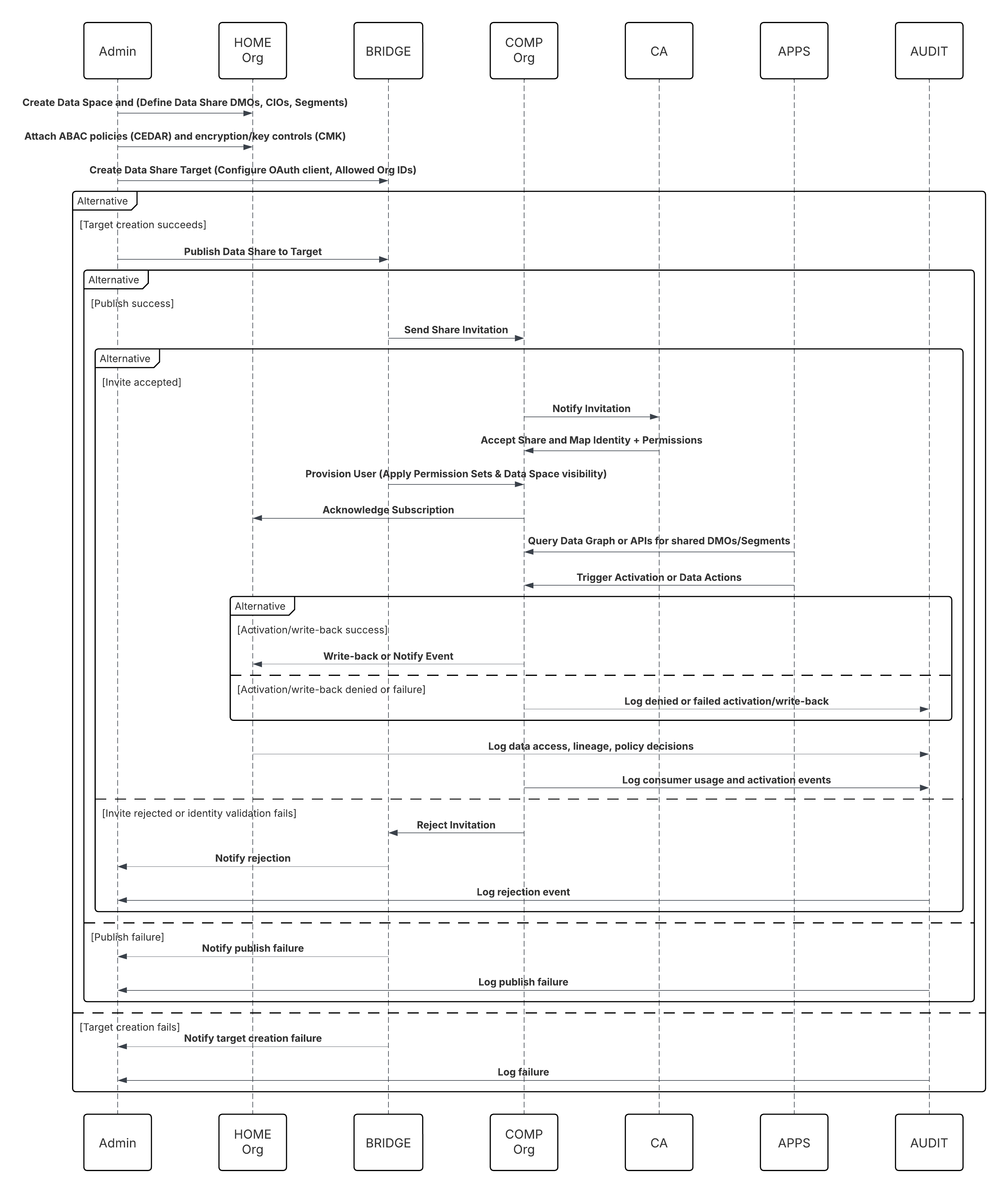
In diesem Szenario:
- Startadministrator: Erstellen Sie Datenbereiche und definieren Sie Datenfreigaben (wählen Sie DMOs/CIOs, Segmente aus).
- Startadministrator: Erstellen Sie Datenfreigabeziel für Begleitorganisationen und konfigurieren Sie Trust (OAuth-Client, zulässige Organisations-IDs).
- Startseite Administrator: Veröffentlichen Sie die Datenfreigabe im Ziel; hängen Sie ABAC-Richtlinien (CEDAR) und Verschlüsselungs-/Schlüsselsteuerungen (CMK) an, falls erforderlich.
- Begleitorganisationsadministrator: Erhält eine Einladung, validiert die Identitätszuordnung und akzeptiert Freigaben.
- Begleitorganisation: Data Cloud One Bridge stellt einen Data Cloud One-Benutzer bereit und wendet die Sichtbarkeit von Berechtigungssätzen und Datenbereichen an.
- Anwendungen für Begleitorganisationen (Flows / Einstein / Apex): Fragen Sie ein Datendiagramm ab oder rufen Sie Data Cloud One-APIs auf, um freigegebene DMOs oder Segmente zu lesen.
- Aktivierung: Die Begleitorganisation löst die Aktivierung aus oder schreibt über Datenaktionen zurück (sofern zulässig).
Ergebnisse
- Eine einzige Quelle der Wahrheit für Kundendaten (Customer 360) in allen verbundenen Organisationen – keine redundanten Data 360-Instanzen.
- Eine schnellere Bewertungszeit. Begleitorganisationen können in wenigen Minuten auf zusammengeführte Daten und Data 360-gestützte Funktionen zugreifen, statt wochenlang benutzerdefinierte Codierungen vorzunehmen.
- Gesteuerte Datenfreigabe. Nur autorisierte Datenbereiche werden freigegeben, wodurch Sicherheit und Governance gewahrt bleiben und gleichzeitig die geschäftliche Agilität ermöglicht wird.
- Geschäftsfunktionen (Vertrieb, Service, Marketing) basieren auf derselben einheitlichen Datengrundlage und ermöglichen konsistente Kennzahlen, Aktivierungen und Statistiken im gesamten Unternehmen.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Lösung ab, die zur Implementierung dieses Musters ausgewählt wurde.
| Mechanismus | Wann zu verwenden |
|---|---|
| Native Data Cloud One-Freigabe (bevorzugt) | Wird verwendet, wenn mehrere Salesforce-Organisationen (Vertrieb, Service oder Industry Cloud) Echtzeitzugriff auf zusammengeführte Kundendaten direkt über Data 360 benötigen. Dadurch werden Abgleiche vermieden und der Zugriff auf Goldene Datensätze, Segmente und berechnete Statistiken ohne Latenz ermöglicht. |
| Freigabe über Data Cloud One-Brücke | Wird verwendet, wenn mehrere Geschäftseinheiten oder Tochtergesellschaften in separaten Salesforce-Organisationen arbeiten, jedoch über eine zentrale Data 360-Instanz gemeinsam auf gemeinsame Kundendaten und Segmente zugreifen müssen. Ideal für Unternehmen mit mehreren Organisationen, die unabhängige Betriebssysteme unterhalten. |
| Plattformabfrage-APIs für Einstein 1 | Wird verwendet, wenn Salesforce-Anwendungen, Flow oder Einstein Copilot Data 360-Daten programmgesteuert abfragen oder aktivieren müssen. Ermöglicht das Abrufen von zusammengeführten Profilen, Kennzahlen oder Aktivierungsergebnissen in Echtzeit in andere Salesforce-Anwendungen ohne Batch-Exporte. |
| Aktivierung in Salesforce-Kanälen | Wird verwendet, wenn Data 360-Daten (Segmente, Statistiken oder Attribute) für Marketing Cloud, Service Cloud oder Commerce Cloud aktiviert werden müssen, um Personalisierungs-, Kampagnenausführungs- oder Agentenunterstützungserfahrungen zu ermöglichen. |
| Datendiagrammzugriff (semantische Abfrageebene) | Wird verwendet, wenn Sie über das Salesforce-Datendiagramm auf semantischer Ebene auf das vereinheitlichte Datenmodell zugreifen müssen und Copilot, AI-Workflows und cloudübergreifende Analysen in Echtzeit ohne manuelle Verknüpfungen oder Transformationen unterstützen. |
Fehlerbehandlung und -behebung
- Organisationsübergreifende Synchronisierungsresistenz: Data Cloud One wiederholt fehlgeschlagene Synchronisierungsaufträge zwischen "Startseite" und "Begleitorganisationen" automatisch mithilfe einer exponentiellen Sicherung für vorübergehende Netzwerk- oder Plattformfehler.
- Teilweise Batch-Isolierung: Fehlgeschlagene Datensatz-Batchs werden in einer Warteschlange für Wiederholungen innerhalb der Organisation "Zuhause" in Quarantäne gesetzt, bis die Abstimmung erfolgreich ist, wodurch Datendivergenzen verhindert werden.
- Governance für Schemaablehnungen: Schemas oder Zuordnungsinkongruenzen werden zur Administratorüberprüfung und -korrektur an die Warteschlange für Schemaablehnungen weitergeleitet.
- Wiedergeben und Fortsetzen der Kontinuität: Jeder Synchronisierungsauftrag behält Verschiebungsprüfpunkte bei, sodass der Abgleich ab dem letzten erfolgreichen Commit ohne Duplikat fortgesetzt werden kann.
- Integrierte Überwachung: Alle Fehler, Wiederholungen und Wiederherstellungskennzahlen werden im Trust Layer Monitoring-Dashboard erfasst, um die Sichtbarkeit und SLA-Sicherung zu gewährleisten.
Überlegungen zum idempotenten Design
- Deterministische Identitätsschlüssel: Jedes Synchronisierungsereignis enthält einen eindeutigen Schlüssel (Organisations-ID + Datensatz-ID + Versionsnummer), um eine genaue Verarbeitung zu gewährleisten.
- Wiedergabesicherheit: Doppelte oder wiedergegebene Ereignisse werden zum Commit-Zeitpunkt gefiltert, um konsistente nachgelagerte DMO- und CIO-Aktualisierungen sicherzustellen.
- Semantik des atomischen Commits: Begleitorganisationen markieren Daten erst nach erfolgreichen nachgelagerten Schreibvorgängen als "Commited" (Gebunden), wobei die organisationsübergreifende transaktionale Integrität gewahrt bleibt.
- Konfliktlösung: Aktualisierungen mit mehreren Quellen folgen der zuletzt gewonnenen Schreib- oder Richtlinien-gesteuerten Zusammenführungslogik, wodurch die Abstammung und Konsistenz gewahrt bleiben.
- Prüfpunktpersistenz: Bei Synchronisierungsaufträgen werden die zuletzt verarbeiteten Verschiebungen und der Status innerhalb der Trust Layer beibehalten, um die Wiederherstellung und erneute Wiedergabe zu gewährleisten.
Sicherheitsüberlegungen
- Starke Authentifizierung: Verbindungen zwischen Startseiten- und Begleitorganisationen verwenden OAuth 2.0 mit automatisch rotierten Token, die über verbundene Anwendungen verwaltet werden.
- Granulare Autorisierung: Begleitorganisationen können nur auf bestimmte Datenbereiche, Datenmodellobjekte oder CIOs zugreifen, die explizit über geregelte Datenfreigaberichtlinien freigegeben werden.
- Verschlüsselung überall: Die Daten werden bei der Übertragung (TLS 1.2+) und im Leerlauf (AES-256) über die Home- und Companion-Organisationen hinweg verschlüsselt.
- Grundsatz der geringsten Berechtigung: Integrationsbenutzer sind nur auf die erforderlichen Objekte beschränkt. Es werden keine Berechtigungen auf Verwaltungs- oder Systemebene übernommen.
- Sichtbarkeit von Audits und Compliance: Alle Synchronisierungsereignisse, Schemaänderungen, Anmeldeinformationen und Zugriffsgewährungen werden in der Data 360 Trust Layer protokolliert, um die vollständige Rückverfolgbarkeit zu gewährleisten.
- Private Netzwerkisolation: Mit der Option "Private Connect" oder "Privater Link" von Salesforce wird sichergestellt, dass die Datenreplikation nur über sichere interne Kanäle erfolgt.
Randleisten
Aktualität
- Die Synchronisierung zwischen der Startseite und Begleitorganisationen erfolgt nahezu in Echtzeit, in der Regel innerhalb von Sekunden nach einer Datenänderung in der Quellorganisation.
- Die Zero Copy-Architektur stellt sicher, dass freigegebene Daten sofort in allen teilnehmenden Organisationen abgefragt werden können – ohne Abgleichs- oder Batch-Verzögerungen.
- Bei Aktivierungs- und Segmentierungsaufträgen werden automatisch die neuesten Aktualisierungen aus einer verbundenen Organisation berücksichtigt, wodurch die betriebliche Aktualität erhalten bleibt.
- Die durchgängige Latenz ist deterministisch und wird durch die Orchestrierungs-Pipeline von Data Cloud One gesteuert, wodurch auch unter Last eine konsistente organisationsübergreifende Aktualität gewährleistet wird.
Datenvolumen
- Konzipiert für die mandantenübergreifende hyperskalierte Datensynchronisierung über Regionen und Geschäftseinheiten hinweg, die Milliarden von Datensätzen pro Organisation verwalten kann.
- Die Daten werden referenziert und nicht dupliziert, wodurch die Speicherkapazität reduziert und gleichzeitig die globale Abfragebarkeit gewahrt wird.
- Streaming-Deltas und Metadatenkompaktierung optimieren die Bandbreite und übernehmen den Overhead für Objekte mit hoher Änderungsrate (z. B. Kontakt, Auftrag).
- Skaliert horizontal über mehrere Begleitorganisationen hinweg mit adaptivem Lastausgleich und Orchestrierung über die Trust Layer.
Bundesstaatsverwaltung
- Jedes synchronisierte Datenset behält die Metadatenherkunft, die Version und den Kontext der Organisationsinhaberschaft bei, um die durchgängige Rückverfolgbarkeit zu gewährleisten.
- Die Prüfpunktpersistenz erfasst zuletzt synchronisierte Verschiebungen zwischen Organisationen und ermöglicht so die Wiederherstellung ohne Duplikate.
- Die organisationsübergreifende Schemaversionierung und semantische Ausrichtung werden automatisch durch Trust Layers geregelt.
- Es sind keine manuellen Statuszurücksetzungen erforderlich. Der Synchronisierungsstatus wird über den Data Cloud One-Orchestrierungsservice beibehalten.
Komplexe Integrationsszenarien
- Organisationsübergreifender Verbund: Ermöglicht eine nahtlose Abfrage und Aktivierung über mehrere Data 360-Mandanten oder -Regionen hinweg unter einem einheitlichen Governance-Modell.
- Hybridsynchronisierung: Kombiniert den Abgleich nahezu in Echtzeit für Transaktionsaktualisierungen mit der geplanten Synchronisierung für Massen- oder Archivdaten.
- Multi-Region Governance: Unterstützt die geografisch verteilte Datenfreigabe unter Berücksichtigung der Grenzen für Wohnsitz, Einwilligung und Compliance.
- AI und Automatisierungsaktivierung: Synchronisierte Daten unterstützen sofort organisationsübergreifend Einstein AI, Agentforce oder benutzerdefinierte ML-Modelle und ermöglichen so organisationsübergreifende Echtzeitinformationen.
Beispiel
Eine globale Einzelhandelsorganisation verfügt über drei Salesforce-Organisationen: eine für Verbrauchereinzelhandel, eine für Premium-Marken und eine für internationale Märkte. Sie stellen Data 360 in der Organisation "Verbrauchereinzelhandel" (und damit als "Startorganisation") bereit. Mit Data Cloud One richten sie Begleitverbindungen zu den Organisationen "Premium Brands" und "International Markets" ein. Für jede Begleitorganisation werden nur die entsprechenden Datenbereiche (z. B. "Customer 360 – Einzelhandelsprofile" und "Customer 360 – Premiumprofile") freigegeben. In der Organisation "Premium Brands" (Premiummarken) können Marketingteams zusammengeführte Kundenprofile anzeigen, Segmente anhand berechneter Statistiken erstellen (z. B. Premium-Kundenlebenszeitwert) und Marketingautomatisierungen auslösen – alles unterstützt durch die Data 360-Instanz der Startseite, ohne benutzerdefinierte Codierung oder Datenduplizierung.
Bei der Datenaktivierung kommt der Wert von Salesforce Data 360 zum Tragen. Dabei handelt es sich um den Prozess, bei dem die vereinheitlichten, angereicherten und verwalteten Daten, die sich innerhalb der Plattform befinden, unternehmensweit verwendet werden. In der Praxis bedeutet dies, dass zusammengestellte Segmente, berechnete Statistiken und Kontextattribute aus Data 360 sicher in die Systeme bereitgestellt werden, die Kunden einbinden – unabhängig davon, ob es sich um Marketingautomatisierung, Servicekonsolen, Vertriebsaktivierung, Analysen oder AI-Modelle handelt. Aus technischer Sicht definieren Aktivierungsmuster, wie sich diese Daten bewegen: welche Kanäle ausgelöst werden, welche Transformationen oder Zuordnungen vorgenommen werden und wie Richtlinien dabei erzwungen werden. Bei diesen Mustern geht es nicht nur um das Exportieren von Daten, sondern auch um die Orchestrierung richtlinienbewusster Datenflüsse in Echtzeit, die messbare Geschäftsergebnisse erzielen. Jede Aktivierungsroute verwandelt Customer 360 in einen operativen Live-Datenbestand, der Personalisierung, Prognoseentscheidungen und kontinuierliches Lernen an jedem Kontaktpunkt unterstützt.
Die Batch-Aktivierung ist nach wie vor die am weitesten verbreitete und einsatzbereite Methode zum Exportieren von Daten aus Data 360. Sie arbeitet in einem geplanten Rhythmus und veröffentlicht in regelmäßigen Abständen vordefinierte Zielgruppensegmente oder Attributsätze auf nachgelagerten Plattformen. Dieses Muster eignet sich ideal für Marketing- und Engagement-Workflows, die auf einer konsistenten Zielgruppenzustellung mit hohem Volumen und nicht auf sofortigen Aktualisierungen basieren. Typische Anwendungsfälle sind die Unterstützung von E-Mail-Journeys, Direktmail-Kampagnen oder Zielgruppen-Uploads in digitale Werbenetzwerke. Bei jeder Aktivierungsausführung wird das qualifizierte Segment aus dem vereinheitlichten Profildiagramm von Data 360 extrahiert, Governance- und Einwilligungsrichtlinien angewendet und die Ausgabe sicher an das Zielsystem übertragen. Architektonisch bietet die Batch-Aktivierung einen vorhersehbaren, überprüfbaren und kosteneffizienten Ansatz für die Datenverteilung – zwischen betrieblicher Einfachheit und Zuverlässigkeit auf Unternehmensebene. Sie ist das Rückgrat der groß angelegten Kampagnenausführung, bei der die richtigen Daten, die rechtzeitig und unter Kontrolle bereitgestellt werden, die messbaren Geschäftsauswirkungen steigern.
Context
Moderne Marketingexperten arbeiten über mehrere Engagementkanäle hinweg – E-Mail, Werbung, Mobilgeräte und Web – und fordern jeweils präzise, zeitnahe und personalisierte Kundenzielgruppen. Data 360 dient als einheitliche Grundlage für diese Zielgruppen und kombiniert Kundendaten aus jedem System zu umfangreichen, handlungsrelevanten Segmenten. Die Batch-Aktivierung ist das häufigste Aktivierungsmuster, das verwendet wird, um diese Segmente aus Data 360 auf nachgelagerte Marketing- oder Werbeplattformen zu exportieren. Typische Ziele sind Marketing Cloud Engagement, Google Ads, Meta Custom Audiences oder LinkedIn Ads, wo Kampagnen direkt für diese zusammengestellten Zielgruppen ausgeführt werden können.
Problem
Wie kann ein Marketingteam eine genau definierte Zielgruppe – die mithilfe von vereinheitlichten und angereicherten Daten in Data 360 erstellt wurde – zur Aktivierung in externen Marketing- oder Werbesystemen bereitstellen? Stellen Sie sich beispielsweise das Segment vor: "Kunden mit hohem Wert, die in den letzten 90 Tagen nicht eingekauft, aber kürzlich auf der Website interagiert haben." Marketingexperten müssen sicherstellen, dass diese Zielgruppe genau übertragen, mit relevanten Attributen (z. B. Treuestufe, Region oder prognostizierter CLV) angereichert und in regelmäßigen Abständen aktualisiert wird, um die Relevanz und Effektivität der Kampagne aufrechtzuerhalten.
Kräfte
Verschiedene technische und betriebliche Faktoren prägen das Muster der Batchaktivierung:
- Identitätszuordnung: Für eine genaue Zielgruppenzustellung ist es erforderlich, die ID der zusammengeführten Einzelperson von Data 360 dem entsprechenden Kennzeichner im Zielsystem zuzuordnen, beispielsweise einem Abonnentenschlüssel in Marketing Cloud oder einer gehashten E-Mail für digitale Anzeigenplattformen. Dadurch wird eine genaue Übereinstimmung gewährleistet und Zielfehler werden vermieden.
- Attributauswahl und -anreicherung: Marketingexperten müssen über IDs hinausgehen und zusätzliche Profildaten wie Vorname, Treuestatus, CLV oder andere personalisierte Attribute einbeziehen, um die nachgelagerte Personalisierung und Analyse zu ermöglichen.
- Zielplattformkonfiguration: Jedes Ziel muss in Data 360 als Aktivierungsziel registriert sein, einschließlich Verbindungsdetails, Authentifizierung und Datenfeldzuordnungen. Diese einmalige Einrichtung definiert die sichere Verbindung und steuert, welche Systeme aktivierte Daten empfangen können.
- Governance und Compliance: Bei der Datenaktivierung müssen Einwilligungsmetadaten, Datenschutzrichtlinien (z. B. DSGVO oder CCPA) und Marketingberechtigungen eingehalten werden, die im zusammengeführten Profil gespeichert sind. Durch die Aktivierung mit Einwilligungsbewusstsein wird sichergestellt, dass Daten nur für autorisierte Zwecke verwendet werden.
- Planung und Leistung: Aktivierungen werden oft täglich oder stündlich geplant, um nachgelagerte Zielgruppen auf dem aktuellen Stand zu halten. Das System muss große Volumen und inkrementelle Aktualisierungen ohne Duplikate oder Datenverluste effizient verarbeiten.
Lösung
Der Batch-Aktivierungsprozess in Data 360 folgt einem geführten Workflow, der die technischen Reibungen für Marketingexperten minimiert und gleichzeitig die Governance und Skalierbarkeit gewährleistet:
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Segmenterstellung | Best | Ein Marketingexperte oder Analyst erstellt ein Segment im Zeichenbereich der visuellen Segmentierung, indem er Filter auf ein beliebiges Datenmodellobjekt (DMO) oder ein Objekt der berechneten Statistik (CIO) anwendet. Dadurch wird die Zielgruppe für die Aktivierung definiert. |
| Aktivierungs-Setup | Best | Der Benutzer erstellt eine Aktivierung und wählt das Segment aus, das er gerade erstellt hat. Dadurch wird definiert, welche Zielgruppe Data 360 in nachgelagerte Systeme exportiert. |
| Aktivierungszielauswahl | Bewährte Vorgehensweisen | Der Marketingexperte wählt ein vorkonfiguriertes Aktivierungsziel aus (z. B. Marketing Cloud, Google Ads, LinkedIn Ads). Jedes Ziel ist in Data 360 mit Authentifizierungsanmeldeinformationen und Feldzuordnungen registriert. |
| Nutzlastdefinition | Erforderlich | Der Marketingexperte definiert die Nutzlast, indem er Kontaktkennzeichner (z. B. E-Mail, Mobilgerät, gehashte ID) und zusätzliche Profilattribute (z. B. Vorname, Treuestufe oder CLV) zur Anreicherung im Zielsystem auswählt. |
| Planung und Häufigkeit | Empfohlen | Aktivierungen können so geplant werden, dass sie einmalig oder wiederkehrend (z. B. täglich oder wöchentlich) ausgeführt werden. Durch die Planung wird sichergestellt, dass nachgelagerte Zielgruppen synchronisiert und aktuell bleiben. |
| Ausführung und Export | Best | Wenn der Aktivierungsauftrag ausgeführt wird, fragt Data 360 das Segment ab, erfasst die ausgewählten Attribute, wendet Einwilligungsfilter an und exportiert die Daten auf die Zielplattform. Bei Marketing Cloud führt dies in der Regel zur Erstellung oder Aktualisierung einer freigegebenen Data Extension. |
| Governance und Compliance | Erforderlich | Die Trust Layer erzwingt Schemavalidierungen, Einwilligungsmetadaten und Richtlinienkontrollen, um die Einhaltung von Datenschutz- und Marketingbestimmungen (z. B. DSGVO, CCPA) sicherzustellen. |
| Überwachung und Überprüfbarkeit | Bewährte Vorgehensweisen | Im Trust Layer Monitoring-Dashboard wird jede Aktivierungsausführung mit Erfolgs-/Fehlerkennzahlen, Ausführungsprotokollen und Abstammungssichtbarkeit verfolgt, was betriebliche Transparenz und SLA-Sicherung ermöglicht. |
Skizze
Hier die Zusammenfassung der Schritte:
- Build Segment (Segment erstellen): Ein Marketingexperte oder Analyst erstellt ein Segment mithilfe eines visuellen Segmentierungstools und kombiniert Filter für alle Objekte der zusammengeführten Daten.
- Aktivierung erstellen: Sie wählen das Segment als Quelle und ein vorkonfiguriertes Ziel (z. B. Marketing Cloud oder Google Ads) aus.
- Nutzlast definieren: Der Kontaktkennzeichner und andere Profilattribute werden für den Zielgruppenexport und die Berichterstellung ausgewählt.
- Planzustellung: Die Aktivierung soll einmalig oder wiederkehrend ausgeführt werden, damit die Zielgruppe im Ziel auf dem neuesten Stand bleibt.
- Ausführung: Beim Auslöser fragt Data 360 das Segment ab, erstellt die Nutzlast, wendet Filter für die Einwilligung an und überträgt das Ergebnis an das Zielsystem.
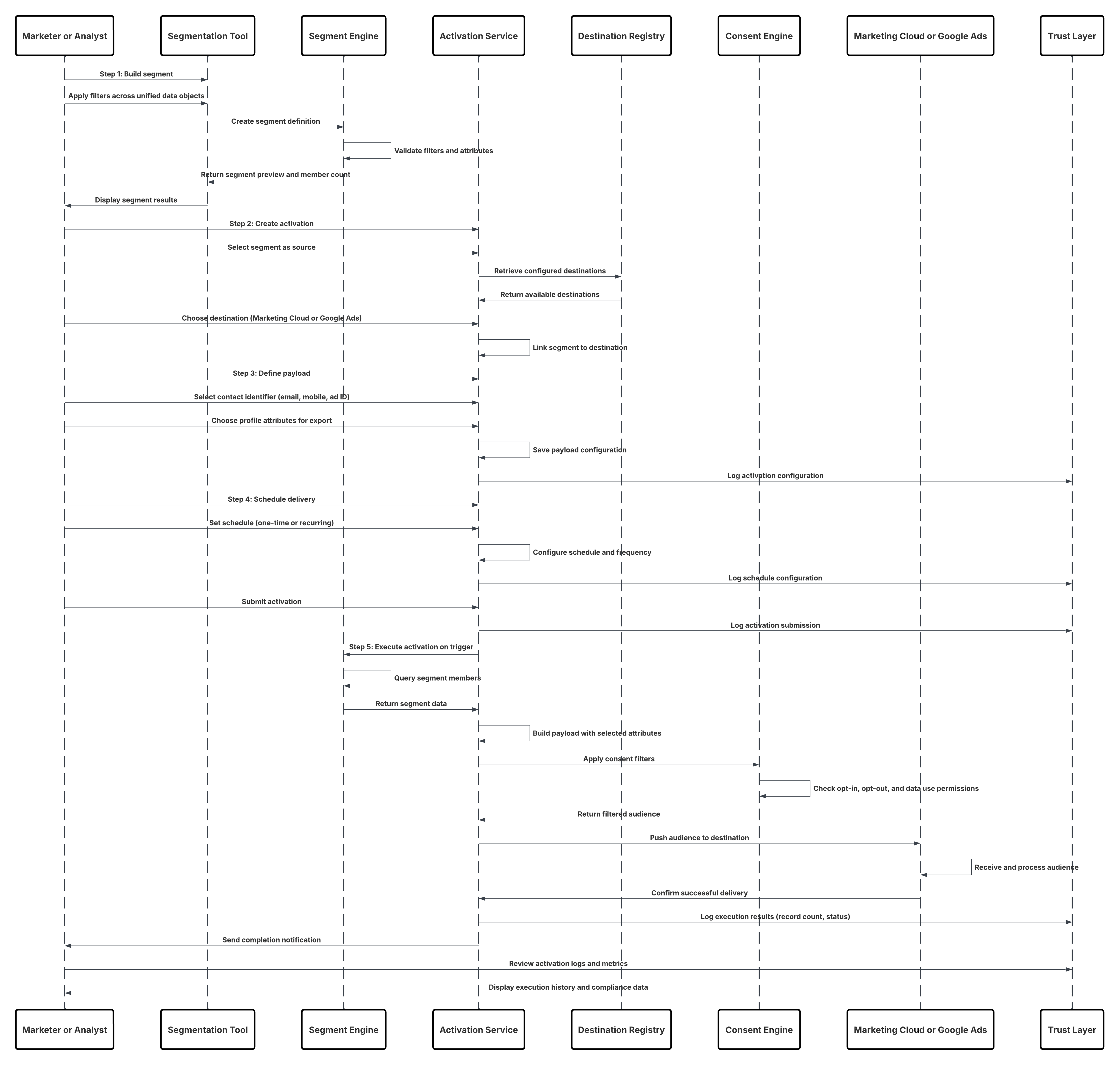
Ergebnisse
- Gezielte, angereicherte Zielgruppensegmente aus Data 360 werden direkt auf nachgelagerten Marketing- und Werbeplattformen zur Verfügung gestellt.
- Zielgruppen werden automatisch aktualisiert und mit den neuesten zusammengeführten Kundendaten synchronisiert, wodurch die Kampagnenrelevanz in Echtzeit erhalten bleibt.
- Marketingexperten können diese aktivierten Zielgruppen als Eingangsquellen für Marketing Cloud-Journeys, E-Mail-Kampagnen oder benutzerdefinierte Zielgruppen auf digitalen Anzeigenplattformen wie Google Ads, Meta oder LinkedIn Ads verwenden.
- Bei jeder Aktivierungsausführung wird die durchgängige Abstammung beibehalten, wodurch die Compliance, die Rückverfolgbarkeit und die Konsistenz zwischen Data 360 und externen Systemen gewährleistet werden.
- Geschäftsbenutzer können mithilfe einer vollständigen und vertrauenswürdigen Customer 360-Ansicht hochgradig personalisierte, datengesteuerte Erfahrungen bereitstellen.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Zielplattform und der Aktivierungszielkonfiguration ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| Marketing Cloud Engagement Activation (Preferred) | Wird bei der Ausführung von E-Mail- oder kanalübergreifenden Journeys verwendet, die dynamische Segmente, personalisierte Attribute und Echtzeitaktualisierungen in Marketing Cloud erfordern. Data 360 wird zur Kampagnenaktivierung direkt in freigegebene Data Extensions exportiert. |
| Anzeigenplattformaktivierung (Google Ads, LinkedIn Ads, Meta Ads) | Wird verwendet, wenn Data 360-Segmente als benutzerdefinierte Zielgruppen auf Werbeplattformen für das Retargeting oder die Ähnlichkeitsmodellierung aktiviert werden. Unterstützt gehashte Kennzeichner und die Zustellung mit Einwilligungsbewusstsein. |
| CRM-Aktivierung (Vertrieb oder Service Cloud) | Wird verwendet, wenn Sie angereicherte Kundendaten, Statistiken oder Neigungsbewertungen für CRM-Benutzer für personalisierte Vertriebsengagements oder Serviceinteraktionen freigeben. Daten werden als angereicherte Datensätze oder Statistiken über Datenaktionen oder Komponenten des zusammengeführten Profils zur Verfügung gestellt. |
| Externe Aktivierung über MuleSoft oder API | Wird verwendet, wenn die Aktivierung Nicht-Salesforce-Systeme wie Treue-, E-Commerce- oder Drittanbieter-Data Warehouses erreichen muss. MuleSoft oder die Data 360-Aktivierungs-API gewährleisten eine sichere, richtliniengesteuerte Zustellung mit ereignisbasierten Aktualisierungsoptionen. |
| Hybridaktivierung (Batch + durch Ereignis ausgelöst) | Wird verwendet, wenn geplante Batch-Aktivierungen mit ereignisbasierten Auslösern kombiniert werden. Dadurch wird die Personalisierung für zeitkritische Kampagnen wie Warnungen zu verlassenen Einkaufswagen oder Abwanderungsrisiken immer aktiviert. |
Fehlerbehandlung und -behebung
- Fehlerisolation auf Auftragsebene: Jede Aktivierungsausführung wird in der Data 360-Orchestrierungsebene als eindeutiger, verfolgbarer Auftrag ausgeführt. Fehlgeschlagene Ausführungen werden automatisch in Quarantäne gestellt, ohne dass sich dies auf andere Aktivierungen oder Segmentdefinitionen auswirkt.
- Teilweise Batchwiederherstellung: Wenn bestimmte Datensätze nicht exportiert werden können (z. B. aufgrund von Kennzeichnerabweichungen oder API-Ratenobergrenzen), versucht das System, sie mithilfe von inkrementellen Delta-Warteschlangen mit exponentieller Sicherung und paralleler Wiederherstellung erneut zu exportieren.
- Schemavalidierungsfehler: Wenn ausgehende Nutzlastattribute nicht mehr mit dem Zielschema übereinstimmen (z. B. ein gelöschtes Attribut oder ein umbenanntes Feld), leitet der Auftrag betroffene Datensätze zur Administratorüberprüfung an die Schemaablehnungswarteschlange weiter.
- Wiedergeben und Fortsetzen der Unterstützung: Bei jedem Aktivierungsauftrag wird ein Prüfpunkttoken gespeichert, das den letzten erfolgreichen Batch erfasst. Nach der Wiederherstellung wird die Verarbeitung am Prüfpunkt fortgesetzt, sodass keine Duplikate oder Datenverluste auftreten.
- Umfassende Überwachung: Alle Aktivierungsereignisse, Wiederholungen und Zustellungskennzahlen werden in der Trust Layer Monitoring protokolliert, wodurch die SLA-Verfolgung, die Ursachenanalyse und die automatische Benachrichtigung über die Ereignisüberwachungs-APIs aktiviert werden.
Überlegungen zum idempotenten Design
- Deterministische Aktivierungsschlüssel: Bei jeder Aktivierungsausführung wird ein zusammengesetzter Identitätsschlüssel verwendet, der Segment-ID, Aktivierungs-ID und Zielsystem-ID kombiniert, um eine exakte Zustellung zu gewährleisten.
- Wiedergabeerkennung: Der Data 360-Aktivierungsservice untersucht eingehende Nutzlasten mit vorherigen Auftrags-Hashes, um Wiederholungen zu erkennen und zu unterdrücken.
- Commits für den Atomexport: Nutzlasten werden erst nach erfolgreicher Schreibbestätigung in das Zielsystem übernommen, wodurch Teilaktualisierungen oder doppelte Zählung verhindert werden.
- Konsistente Identitätsbestimmung: Da Aktivierungen von zusammengeführten IDs abhängen (z. B. "Zusammengeführte Einzelperson"), zielen Wiederholungen oder Wiederholungen immer auf denselben goldenen Datensatz ab, um die semantische Konsistenz zu wahren.
- Aktivierungsstatus-Persistenz: Auf der Orchestrierungsebene werden Metadaten zum Aktivierungsstatus – Zeitstempel, Statuscodes und Sequenztoken – beibehalten, um sie bei Bedarf erneut deterministisch zu verarbeiten.
Sicherheitsüberlegungen
- Starke Authentifizierung: Jedes Aktivierungsziel (z. B. Marketing Cloud, Ads oder CRM) verwendet OAuth 2.0 mit Tokenrotation und mandantenspezifischer Begrenzung, um den nicht autorisierten Datenexport zu verhindern.
- Governance auf Attributebene: Nur genehmigte Attribute aus dem zusammengeführten Profil können aktiviert werden, was durch Datenfreigaberichtlinien und Aktivierungsvorlagen erzwungen wird.
- Verschlüsselung im Transit und im Leerlauf: Alle Nutzlasten werden mit TLS 1.2+ während der Übertragung und AES-256 im Leerlauf in Data 360 und der Zielplattform verschlüsselt.
- Einwilligung und Richtlinienerzwingung: Bei Aktivierungsaufträgen werden die in der Trust Layer von Data 360 gespeicherten Einwilligungsobjekte und Datenrichtlinien berücksichtigt. Datensätze ohne gültige Einwilligungsmetadaten werden automatisch vom Export ausgeschlossen.
- Aktivierungs- und Compliance-Protokollierung: Bei jeder Aktivierungsausführung wird erfasst, wer sie initiiert hat, welche Daten an welches Ziel gesendet wurden. Auf diese Weise werden vollständige regulatorische Prüfprotokolle (DSGVO, CCPA) im Trust Layer-Dashboard ermöglicht.
- Zugriff mit den geringsten Berechtigungen: Integrationsbenutzer für jedes Ziel sind auf aktivierungsspezifische Umfänge beschränkt – ohne administrative Berechtigungen oder Schreibzugriff auf nicht zugehörige Systeme.
Randleisten
Aktualität
- Konzipiert für geplante Batch-Exporte oder Batch-Exporte nahezu in Echtzeit (Latenz zwischen Minuten und Stunden).
- Unterstützt Aktualisierungen mit Zeitfenstern, die an Kampagnenkalendern ausgerichtet sind.
- Aktivierungsaufträge können mit Datenbereitschaftsmarkierungen sequenziert werden, um die Datenaktualisierung zu gewährleisten.
- Bestens geeignet für nicht interaktive Aktivierungsszenarien, in denen die Datengenauigkeit die Unmittelbarkeit überwiegt.
Datenvolumen
- Verarbeitet umfangreiche Datensets (Millionen von Datensätzen pro Ausführung).
- Skaliert horizontal durch Segmentpartitionierung und parallele Exportkanäle.
- Verwendet stückbasierte Batches, um Zeitüberschreitungen zu vermeiden und den Durchsatz zu optimieren.
- Ideal für Datenpipelines auf Unternehmensebene, bei denen die Datenvollständigkeit entscheidend ist.
Bundesstaatsverwaltung
- Verwaltet Aktivierungsstatusobjekte, die Auftrags-IDs, Zeitstempel und Sequenztoken aufzeichnen.
- Verwendet Prüfpunkte für die Neustartbarkeit und Fehlerbehebung.
- Versionierte Segmentdefinitionen gewährleisten die Reproduzierbarkeit über Aktivierungszyklen hinweg.
- Ermöglicht die Verfolgung der Abstammung zwischen Quellsegment, DMO-Attributen und Zielnutzlasten.
Komplexe Integrationsszenarien
- Kann über vorgefertigte Konnektoren nahtlos in Salesforce CRM, Marketing Cloud und externe Systeme integriert werden.
- Unterstützt Aktivierungen mit mehreren Zielen und verteilt Daten gleichzeitig an verschiedene Ziele (z. B. CRM + Ads).
- Kann zusammengesetzte Workflows auslösen, z. B. Batch-Export gefolgt von nachgelagerten API-Aufrufen oder AI-Bewertungen.
- Verarbeitet die Schemaentwicklung über die Datenmodellverwaltungsebene anmutig.
Beispiel
Eine globale Einzelhandelsmarke möchte inaktive Kunden aus den letzten 90 Tagen erneut ansprechen. Mit Data 360 definiert der Datenarchitekt ein Segment "Dormante Käufer", das mit Kaufverlaufs-, Treuestufen- und Einwilligungsmetadaten angereichert ist. Der Batch-Aktivierungsauftrag wird nachts ausgeführt und überträgt dieses Segment an Marketing Cloud Engagement, um eine personalisierte E-Mail-Kampagne vom Typ "Wir vermissen Sie" auszulösen, und an Ad Studio für das Retargeting. Der Auftrag nutzt die idempotente Zustellung, um sicherzustellen, dass es keine Duplikate bei Wiederholungen gibt, und alle Ereignisse werden in der Trust Layer protokolliert, um die Einhaltung der Prüfvorschriften zu gewährleisten.
Context
Unternehmen benötigen oft einen geregelten Mechanismus, um zusammengeführte oder segmentierte Daten aus Salesforce Data 360 in ein Standarddateiformat (z. B. CSV oder Parquet) zu exportieren, um sie zu archivieren, zu konformisieren oder nachzugelagert zu integrieren. Dieses Muster ermöglicht den Export von Data 360 in die Cloud, sodass vertrauenswürdige Kundendaten sicher in Enterprise Data Lakes oder Analytics-Pipelines fließen können, die in Amazon S3, Azure Blob oder Google Cloud Storage (GCS) gehostet werden. Typische Anwendungsfälle sind:
- Regelmäßige Archivierung der Datensets für zugestimmte Kunden zur behördlichen Aufbewahrung.
- Exportieren von zusammengestellten Segmenten für analytische Arbeitslasten außerhalb von Salesforce (z. B. Tableau, Databricks oder Power BI).
- Aktivieren externer Modelle für maschinelles Lernen, für die strukturierte CSV- oder Parquet-Dateien als Eingabe erforderlich sind.
Problem
Wie kann eine Organisation ein verwaltetes Segment oder Datenset aus Data 360 in einen Cloud-Speicher-Bucket (z. B. Amazon S3) exportieren – auf kontrollierte, sichere und automatisierte Weise – und gleichzeitig die Schemaintegrität und die Compliance-Kontrollen aufrechterhalten? Ein Compliance-Team muss beispielsweise: "Extrahieren Sie alle aktiven Kunden in der EU-Region mit gültiger Einwilligung und exportieren Sie die Daten wöchentlich an einen S3-Standort für externe Audits und Berichte." Dazu ist eine wiederholbare und richtlinienbewusste Export-Pipeline erforderlich, die das richtige Dateiformat, die richtigen Zugriffsberechtigungen und den richtigen Zustellungsplan sicherstellt – ohne manuelle Eingriffe oder nicht übernommene Datenbewegungen.
Kräfte
Dieses Exportmuster wird durch mehrere betriebliche und architektonische Faktoren bestimmt:
- Authentifizierung und Autorisierung: Beim Export muss das IAM-Modell des Cloud-Anbieters (z. B. AWS IAM Roles oder Azure Service Principals) berücksichtigt werden, um sicherzustellen, dass nur autorisierte Systeme in den Ziel-Bucket schreiben können.
- Schema Alignment: Das ausgehende Schema muss der erwarteten Struktur und dem erwarteten Format des Zielsystems (CSV, Parquet oder JSON) entsprechen.
- Datenschutz und Einwilligung: Exportierte Datensets müssen alle Datensätze herausfiltern, in denen gültige Einwilligungsmetadaten fehlen.
- Planung & Aktualisierung: Viele Exporte erfolgen regelmäßig (täglich, wöchentlich oder monatlich) und müssen mit den Zyklen der Unternehmensdatenaktualisierung übereinstimmen.
- Governance & Monitoring: Jeder Export muss mit vollständiger Abstammungssichtbarkeit überprüfbar sein, um die Einhaltung von Datenaufbewahrungs- und behördlichen Vorschriften (z. B. DSGVO, CCPA) sicherzustellen.
Lösung
Das Muster "Dateiexportaktivierung" verwendet dieselben sicheren Cloud-Speicher-Konnektoren, die für die Aufnahme verwendet werden, jedoch für den Datenaustritt konfiguriert sind. Administratoren registrieren zunächst die Cloud-Speicherplattform (z. B. Amazon S3, Azure Blob Storage oder GCS) als Aktivierungsziel in Data 360. Anschließend konfigurieren und führen Benutzer einen Aktivierungs-Workflow aus, um das gewünschte Segment in den angegebenen Dateispeicherpfad zu exportieren.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Segmentauswahl | Best | Analysten wählen eine vorhandene Segment- oder Abfragedefinition in Data 360\ aus. Das Segment bestimmt, welche Datensätze und Attribute exportiert werden. |
| Aktivierungs-Setup | Best | Benutzer erstellen eine neue Aktivierung und wählen das Segment als Quelle und das Cloud-Speicherziel (z. B. S3) als Ziel aus. |
| Aktivierungszielkonfiguration | Erforderlich | Administratoren konfigurieren das Ziel mit Anmeldeinformationen, IAM-Rollen und Ausgabepfad vor. Zu den unterstützten Formaten zählen CSV, Parquet und JSON. |
| Nutzlastdefinition | Bewährte Vorgehensweisen | Definieren Sie das Exportschema, indem Sie die erforderlichen Attribute auswählen (z. B. ID, Name, E-Mail, Region, Einwilligungskennzeichnung). Das System erzwingt die Verwaltung auf Attributebene. |
| Planung und Häufigkeit | Empfohlen | Exporte können in einem definierten Rhythmus (täglich, wöchentlich, monatlich) geplant oder bei Bedarf manuell ausgelöst werden. |
| Ausführung & Zustellung | Best | Bei der Ausführung fragt Data 360 das Segment ab, kompiliert die Exportdatei, verschlüsselt sie und schreibt sie mithilfe der API des Cloud-Anbieters in den konfigurierten Bucket/Ordner. |
| Governance und Compliance | Erforderlich | Die Trust Layer von Data 360 stellt sicher, dass alle Exporte Einwilligungsrichtlinien, Schemavalidierungen und Compliance-Filter einhalten. |
| Überwachung und Überprüfbarkeit | Bewährte Vorgehensweisen | Jeder Export wird im Trust Layer Monitoring-Dashboard mit Status-, Ausführungsprotokoll- und Abstammungsmetadaten verfolgt. |
Skizze
Im Folgenden finden Sie die Zusammenfassung der Schritte.
- Segment auswählen: Ein Analyst oder Datenverwalter wählt das zusammengeführte Segment aus, das exportiert werden soll.
- Aktivierung erstellen: Sie erstellen einen neuen Aktivierungsauftrag und wählen das registrierte Cloud-Speicherziel aus.
- Nutzlast definieren: Geben Sie ein Exportschema, eine Attributliste und ein Dateiformat (z. B. CSV) an.
- Planexport: Wählen Sie einen einmaligen oder wiederkehrenden Zeitplan aus.
- Auftrag ausführen: Data 360 generiert und stellt die Datei sicher im angegebenen Bucket-Pfad bereit.
- Überwachen und überprüfen: Ergebnisse und Protokolle werden in der Trust Layer auf Validierung und Einhaltung überprüft.
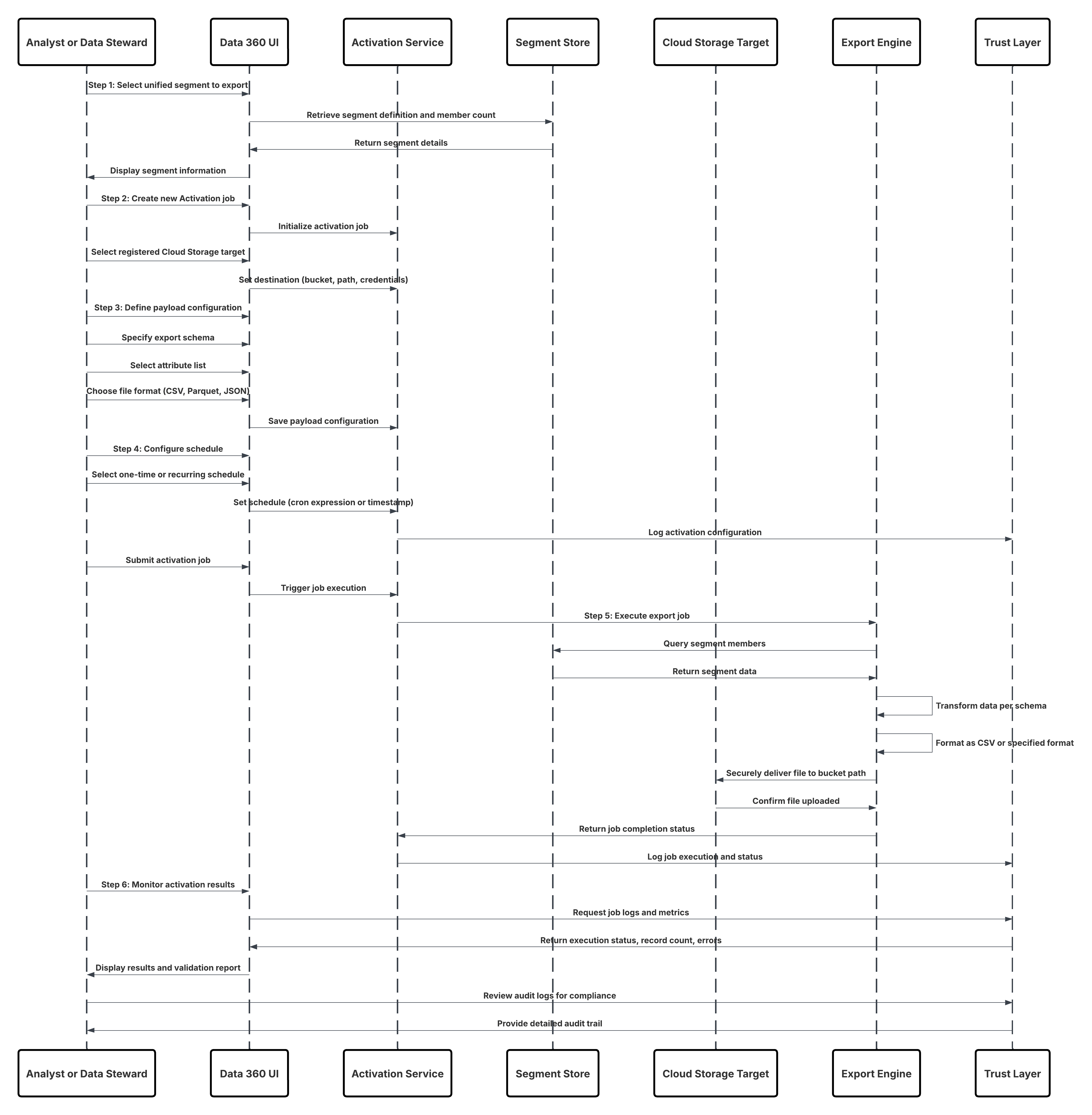
Ergebnisse
- Gezielte, angereicherte Zielgruppensegmente aus Data 360 werden direkt auf nachgelagerten Marketing- und Werbeplattformen zur Verfügung gestellt.
- Zielgruppen werden automatisch aktualisiert und mit den neuesten zusammengeführten Kundendaten synchronisiert, wodurch die Kampagnenrelevanz in Echtzeit erhalten bleibt.
- Marketingexperten können diese aktivierten Zielgruppen als Eingangsquellen für Marketing Cloud-Journeys, E-Mail-Kampagnen oder benutzerdefinierte Zielgruppen auf digitalen Anzeigenplattformen wie Google Ads, Meta oder LinkedIn Ads verwenden.
- Bei jeder Aktivierungsausführung wird die durchgängige Abstammung beibehalten, wodurch die Compliance, die Rückverfolgbarkeit und die Konsistenz zwischen Data 360 und externen Systemen gewährleistet werden.
- Geschäftsbenutzer können mithilfe einer vollständigen und vertrauenswürdigen Customer 360-Ansicht hochgradig personalisierte, datengesteuerte Erfahrungen bereitstellen.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Ziel-Cloud-Speicherplattform und der Aktivierungskonfiguration ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| Amazon S3-Aktivierung | Wird verwendet, wenn Ihr Unternehmens-Data-Lake in AWS gehostet wird. Data 360 schreibt mithilfe von IAM-Rollen oder temporären Anmeldeinformationen direkt in einen S3-Bucket und gewährleistet so einen sicheren und skalierbaren Export. |
| Azurblaue Blob-Speicheraktivierung | Wird verwendet, wenn Ihre Organisation Microsoft Azure verwendet. Data 360 verwendet SAS-Token oder Serviceprinzipale, um verschlüsselte Dateien in Blob-Container zu schreiben. |
| Google Cloud Storage (GCS) Activation | Wird verwendet, wenn Ihre Data Science- oder Analytics-Arbeitslasten mit GCP ausgeführt werden. Data 360 verwendet OAuth-Anmeldeinformationen, um Dateien in GCS-Buckets im CSV- oder Parquet-Format zu exportieren. |
| SFTP oder externes Datei-Gateway | Wird verwendet, wenn gesetzliche oder ältere Systeme eine sichere Dateizustellung über SFTP-Endpunkte oder von Unternehmen verwaltete Dateiübertragungsplattformen erfordern. |
| Hybridexport (Datei + API) | Wird verwendet, wenn eine nachgelagerte Anwendung sowohl einen dateibasierten Export für Analysen als auch einen API-Auslöser für die Workflow-Orchestrierung benötigt (z. B. MuleSoft-Flow). |
Fehlerbehandlung und -behebung
- Isolierung auf Auftragsebene: Jeder Export wird als diskreter Auftrag ausgeführt. Fehlgeschlagene Aufträge werden in Quarantäne gestellt und unabhängig wiederholt.
- Teilweiser Dateiversuch: Wenn bestimmte Batches nicht hochgeladen werden können (z. B. aufgrund von Netzwerkunterbrechungen), versucht das System, diese Blöcke mithilfe von exponentieller Sicherung erneut zu erstellen.
- Schema Mismatch Handling: Schemaabweichungen oder Feldinkongruenzen leiten Datensätze zur Überprüfung an die Schemaablehnungswarteschlange weiter.
- Prüfpunkt & Fortsetzung: Bei Exportaufträgen werden Prüfpunkt-Metadaten beibehalten, sodass die Fortsetzung nach dem letzten erfolgreichen Schreiben ohne Duplikate möglich ist.
- Integrierte Überwachung: Fehler und Wiederholungen werden im Trust Layer-Dashboard protokolliert, um die Sichtbarkeit und SLA-Konformität zu gewährleisten.
Überlegungen zum idempotenten Design
- Deterministische Exportschlüssel: Jeder Exportauftrag enthält eine eindeutige ID, die aus Segment-ID + Ziel-ID + Zeitstempel besteht.
- Wiedergabesicherheit: Doppelte Auftragsausführungen werden mithilfe von Auftrags-Hashes erkannt und übersprungen, um redundante Exporte zu verhindern.
- Atomare Schreibsicherheit: Data 360 überträgt Dateien erst nach vollständigem Abschluss und Prüfsummenvalidierung in den Ziel-Bucket.
- Konsistente Schemaversionierung: Exportdefinitionen werden versionsgesteuert, um die Schemakonsistenz über alle Ausführungen hinweg sicherzustellen.
- Prüfpunktpersistenz: Exportaufträge bleiben im Status für deterministische Wiederherstellung und erneute Verarbeitung, falls erforderlich
Sicherheitsüberlegungen
- Starke Authentifizierung: Cloud-Konnektoren verwenden OAuth 2.0, IAM-Rollen oder Serviceprinzipale für authentifizierte Schreibvorgänge.
- Verschlüsselung überall: Die Daten werden sowohl während der Übertragung (TLS 1.2+) als auch im Leerlauf (AES-256) verschlüsselt.
- Export mit Einwilligungsbewusstsein: Nur Datensätze mit gültiger Einwilligung werden exportiert und durch Trust Layer-Richtlinien erzwungen.
- Grundsatz der geringsten Berechtigung: Exportbenutzer und Serviceaccounts sind auf ihre angegebenen Speicherpfade beschränkt.
- Umfassende Auditprotokollierung: Jeder Export speichert Metadaten, einschließlich Initiator, Schema, Ziel und Zeitstempel für Compliance-Berichte.
Randleisten
Aktualität
- Konzipiert für die sofortige, ereignisgesteuerte Aktivierung mit Latenzzeiten unter einer Sekunde.
- Ideal für Szenarien, in denen sofortige Personalisierung, Empfehlungen oder Entscheidungen erforderlich sind.
- Funktioniert im Streaming-Modus: Auslöser werden ausgelöst, sobald qualifizierende Datenänderungen in Data 360 vorgenommen werden.
- Stellt die kontinuierliche Reaktionsfähigkeit sicher, ohne auf Batchpläne oder Segmentneuberechnung zu warten.
Datenvolumen
- Verarbeitet umfangreiche Datensets (Millionen von Datensätzen pro Ausführung).
- Skaliert horizontal durch Segmentpartitionierung und parallele Exportkanäle.
- Verwendet stückbasierte Batches, um Zeitüberschreitungen zu vermeiden und den Durchsatz zu optimieren.
- Ideal für Datenpipelines auf Unternehmensebene, bei denen die Datenvollständigkeit entscheidend ist.
Bundesstaatsverwaltung
- Jede Ereignisaktion behält ihr eigenes Ereignistoken und ihre eigene ID für die erneute Wiedergabe für die idempotente Verarbeitung bei.
- Unterstützt die Beibehaltung von Prüfpunkten, um sie im Falle eines vorübergehenden Fehlers ab dem letzten übernommenen Ereignis fortzusetzen.
- Enthält eine integrierte Deduplizierungslogik und Fenster für die erneute Wiedergabe, um eine exakte Aktivierungssemantik zu gewährleisten.
- Aktionsergebnisse (Erfolg/Fehler) werden in Echtzeit protokolliert und über das Dashboard für die Beobachtbarkeit der Trust Layer angezeigt.
Komplexe Integrationsszenarien
- Kann direkt in Salesforce-Flows, Einstein 1 Platform-Ereignisse oder externe Webhooks für sofortige Antwortketten integriert werden.
- Kann nachgelagerte Automatisierungen auslösen, beispielsweise sofortige CRM-Datensatzaktualisierungen, AI-Bewertungen oder Marketing Cloud-Nachrichtensendungen.
- Unterstützt die zusammengesetzte Orchestrierung: Ereignisauslöser können Data 360-Aktionen, Apex-Aufrufe oder externe APIs aufrufen.
- Konzipiert für agentische und adaptive Unternehmensmuster, bei denen kontextbezogene Antworten sofort erfolgen müssen.
Beispiel
Ein globales Einzelhandelsunternehmen muss einen wöchentlichen Export seines Segments "Aktive Treuemitglieder" für die Analyse in Databricks bereitstellen. Der Data 360-Administrator konfiguriert Amazon S3 als Aktivierungsziel und plant einen wöchentlichen CSV-Export in den s3://enterprise-analytics/loyalty/weekly_exports/. Der Exportauftrag wird jeden Sonntag ausgeführt und generiert eine einwilligungsgefilterte Datei mit 2M+-Datensätzen. Alle Ereignisse, Schemadefinitionen und Abstammungen werden im Trust Layer-Dashboard aufgezeichnet, um Transparenz, Überprüfbarkeit und Compliance zu gewährleisten.
Die API-basierte On-Demand-Aktivierung ist ein ereignisgesteuerter Ansatz in Echtzeit, um Data 360-Statistiken in dem Moment handlungsfähig zu machen, in dem sie benötigt werden, ohne auf Batchaufträge oder geplante Exporte warten zu müssen. Statt vorgefertigte Segmente in einem festen Rhythmus zu veröffentlichen, ermöglicht dieses Muster externen Systemen, Salesforce-Anwendungen oder AI-Agenten, Data 360-APIs direkt aufzurufen, um spezifische Zielgruppen-Slices, Kundenattribute oder Statistiken nach Bedarf abzurufen oder zu aktivieren. Dieses Muster wurde für interaktive, auslöserbasierte Erfahrungen entwickelt, beispielsweise wenn sich ein Benutzer bei einem Portal anmeldet, ein Agent einen Kundendatensatz öffnet oder ein AI-Copilot eine Next-Best-Action-Abfrage initiiert. Anstatt sich auf vorberechnete Exporte zu verlassen, fragt das System die aktuellsten gesteuerten Daten aus Data 360 in Echtzeit dynamisch ab oder aktiviert sie. Der entscheidende Vorteil ist die Unmittelbarkeit und Präzision:
- Jeder API-Aufruf greift auf die neueste Kundenintelligenz im vereinheitlichten Profildiagramm für Einwilligungen von Data 360 zu.
- Aktivierungen sind idempotent und überprüfbar und entsprechen den Anforderungen an Enterprise Trust und Compliance.
- Integrationen können über Einstein 1-Plattform-APIs, Connect-APIs oder Aktivierungs-APIs direkt über Salesforce-Flows, Apex oder externe Systeme ausgelöst werden. Dieser Ansatz unterstützt Anwendungsfälle, in denen Latenz und Personalisierung am wichtigsten sind, beispielsweise:
- Auslösen eines personalisierten Produktangebots während eines Serviceanrufs.
- Generieren dynamischer Kampagnenzielgruppen auf der Grundlage von Live-Verhaltensereignissen.
- Einspeisen von Echtzeitentscheidungen in AI- oder ML-Modelle, die zum Zeitpunkt des Engagements ausgeführt werden.
Context
Unternehmen müssen häufig harmonisierte Data 360-Statistiken in Echtzeit in benutzerdefinierten Anwendungen anzeigen, beispielsweise in internen Webportalen, mobilen Anwendungen oder Partner-Weberfahrungen. Dieses Muster ermöglicht es Entwicklern, sichere, benutzeroberflächenorientierte Lösungen zu erstellen, die zusammen mit Salesforce CRM und anderen Kontextsystemen zusammengeführte Kundendaten nutzen und anzeigen – und das alles über geregelten und API-basierten Zugriff. Typische Anwendungsfälle sind:
- Einbetten von Data 360-Statistiken in interne Mitarbeiter-Dashboards oder mobile Anwendungen.
- Erstellen von Partner- oder Händlerportalen mit Kunden- und Transaktionssichtbarkeit.
- Integrieren von Data 360-Daten in Drittanbieter-Webanwendungen oder Erfahrungsebenen.
- Zeigt personalisierte Empfehlungen in Echtzeit an, die auf Data 360 und Einstein 1 basieren.
Problem
Wie kann ein Entwickler eine benutzerdefinierte, auf die Benutzeroberfläche ausgerichtete Anwendung erstellen, die häufig zusammen mit anderen Salesforce-Datenquellen sicher auf harmonisierte Data 360-Daten zugreift und sie anzeigt, ohne sensible Informationen zu duplizieren oder zu exportieren? Beispielsweise muss ein Unternehmen möglicherweise ein Kundenportal erstellen, das zusammengeführte Kundenprofile, Interaktionen und berechnete Statistiken aus Data 360 anzeigt. Dazu ist eine einzige, sichere und leistungsfähige API-Ebene erforderlich, die die Front-End-Erfahrung unterstützen, die Authentifizierung verarbeiten und die Governance sicherstellen kann. Gleichzeitig wird die Komplexität des internen Datenmodells von Data 360 abstrahiert.
Kräfte
Mehrere architektonische und betriebliche Überlegungen beeinflussen dieses Muster:
- Benutzeroberflächenzentrierter Zugriff: Das primäre Ziel besteht darin, Daten in benutzerdefinierten Front-End-Erfahrungen (web oder mobil) anzuzeigen und keine Batch-Extraktion oder Backend-Synchronisierungen durchzuführen.
- Sicheres Gateway: Die ausgewählte API muss als sicherer und skalierbarer Einstiegspunkt für authentifizierte Anwendungen und Benutzer dienen und Zugriffssteuerungen auf Unternehmensebene erzwingen.
- Zusammengeführter Datenkontext: Anwendungen sollten Data 360-Daten (z. B. zusammengeführte Profile, berechnete Statistiken) nahtlos mit CRM-, ERP- oder benutzerdefinierten Objektdaten kombinieren können.
- Entwicklereinfachheit: APIs sollten für Präsentationen geeignete Nutzlasten zurückgeben, die die Backend-Verarbeitung oder die Schemazuordnung auf Client-Ebene minimieren.
- Governance und Beobachtbarkeit: Der gesamte Zugriff sollte über vertrauenswürdige, überprüfbare Kanäle mit klarer Abstammung, Authentifizierung und Richtlinienerzwingung erfolgen.
Lösung
Die Lösung besteht darin, die Salesforce Connect REST-API als primäres Integrations-Gateway zum Erstellen von benutzerdefinierten datengesteuerten Anwendungen auf Data 360 zu verwenden. Die Connect-API bietet RESTful-Zugriff auf Salesforce-Daten – einschließlich der harmonisierten Profile, Segmente und berechneten Statistiken von Data 360 – in Antwortformaten, die für den Benutzeroberflächenverbrauch optimiert sind (JSON-basiert, leichtgewichtig und für Mobilgeräte geeignet). Entwickler authentifizieren sich über eine verbundene Anwendung, rufen OAuth 2.0-Token ab und rufen Connect-API-Ressourcen wie /query, /Chatter oder /data auf, um zusammengeführte Daten direkt auf ihren Anwendungsoberflächen anzuzeigen. Im Hintergrund dient die Connect-API als Transportgrundlage für andere APIs wie die Abfrage-API, die Datendiagramm-API und die Einstein 1-Plattform-APIs. Dadurch können Entwickler mehrere Datenquellen unter einem einheitlichen Zugriffsmuster kombinieren.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Authentifizierung und Anwendungsregistrierung | Erforderlich | Erstellen Sie eine verbundene Anwendung in Salesforce für die OAuth 2.0-basierte Authentifizierung. Konfigurieren Sie Umfänge für den Data 360-API-Zugriff. |
| Datenzugriff (Profile, Segmente, Statistiken) | Best | Verwenden Sie Connect-API-Endpunkte (/services/data/vXX.X/connect), um harmonisierte Data 360-Daten, zusammengeführte Profile und berechnete Statistiken abzufragen. |
| Benutzeroberflächenintegration | Best | Front-End-Anwendungen (React, Angular, iOS, Android) rufen die Connect-API auf, um Data 360-Daten in Dashboards, Portalen oder mobilen Oberflächen darzustellen. |
| Datendiagrammabfrage | Empfohlen | Kombinieren Sie die Connect-API mit der Datendiagramm-API für Abfragen auf semantischer Ebene, die komplexe Verknüpfungen und Beziehungen vereinfachen. |
| Echtzeitaktualisierung | Optional | Verwenden Sie die Connect-API mit WebSocket oder Streaming-Erweiterungen für Live-Datenaktualisierungen. |
| Sicherheit und Unternehmensführung | Erforderlich | Erzwingen Sie die Datensichtbarkeit mithilfe von OAuth-Geltungsbereichen, Data 360-Richtlinien und dem Trust Layer-Audit-Framework. |
Skizze
Im Folgenden finden Sie die Zusammenfassung der Schritte.
- Verbundene Anwendung registrieren: Definieren Sie OAuth-Geltungsbereiche und API-Berechtigungen für die Authentifizierung externer Anwendungen.
- Zugriffstoken abrufen: Die externe Anwendung führt die OAuth 2.0-Authentifizierung durch, um ein Token für den Data 360-Zugriff zu erhalten.
- Invoke Connect API (Connect-API aufrufen): Die Anwendung führt REST-API-Aufrufe durch, um zusammengeführte Profil-, Segment- oder Statistikdaten abzurufen.
- Daten auf Benutzeroberfläche darstellen: Antworten werden analysiert und Benutzern in einem Portal mit Branding oder auf einer mobilen Oberfläche angezeigt.
- Verarbeitung von Fehlern und Aktualisierungstoken: Anwendungen implementieren Wiederholungslogik und automatische Tokenaktualisierung für die Sitzungskontinuität.
- Überwachungs- und Prüfungszugriff: Alle API-Aufrufe werden in der Trust Layer protokolliert, um Sichtbarkeit und Compliance zu gewährleisten.
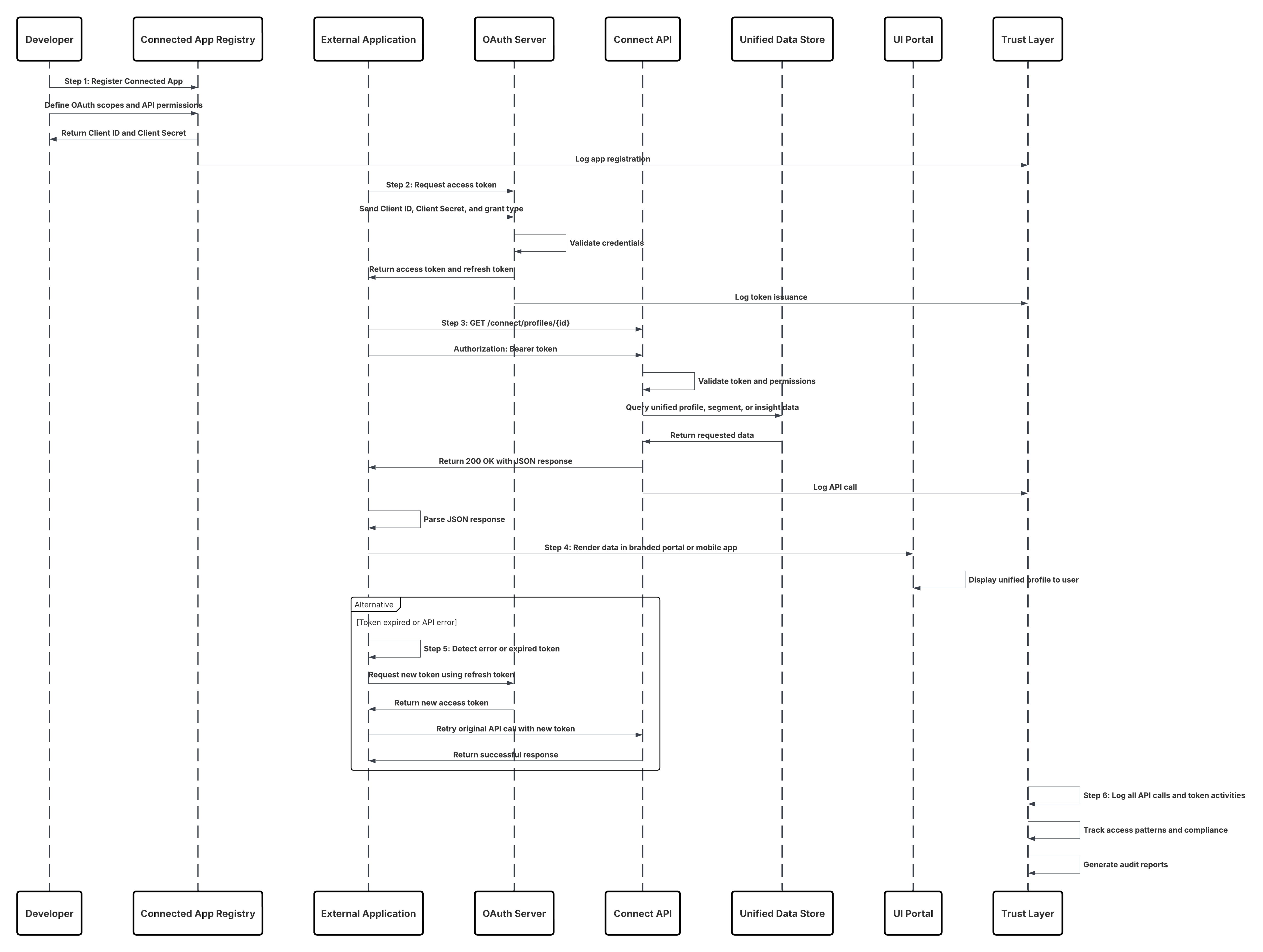
Ergebnisse
Entwickler können sichere Anwendungen mit benutzerdefiniertem Branding erstellen, die eng in Data 360 integriert sind. Diese Anwendungen können:
- Zeigen Sie harmonisierte Kundenprofile und Statistiken in Echtzeit an.
- Zeigen Sie Data 360-Daten zusammen mit CRM oder benutzerdefinierten Objekten über vereinheitlichte APIs an.
- Nutzen Sie konsistente Authentifizierungs-, Autorisierungs- und Überwachungssteuerungen über die Trust Layer.
- Bieten Sie Geschäftsbenutzern oder Partnern nahtlosen, gesteuerten Zugriff auf vertrauenswürdige Kundenintelligenz über mehrere Erfahrungen hinweg.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Ziel-Cloud-Speicherplattform und der Aktivierungskonfiguration ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| Connect-REST-API (bevorzugt) | Wird beim Erstellen von Web-, mobilen oder Drittanbieteranwendungen verwendet, die Echtzeitzugriff auf Data 360-Daten in einem benutzerfreundlichen JSON-Format erfordern. |
| Datendiagramm-API | Wird verwendet, wenn die Anwendung Abfragen auf semantischer Ebene über mehrere Objekte hinweg ausführen muss (z. B. Kunde → Transaktionen → Kampagnen). |
| Abfrage-API | Wird beim Ausführen von SOQL-ähnlichen Abfragen verwendet, um harmonisierte Datensets mit hoher Genauigkeit abzurufen. |
| Plattform-APIs für Einstein 1 | Wird verwendet, wenn AI-gestützte Statistiken oder von Copilot generierte Empfehlungen in benutzerdefinierte Benutzeroberflächen integriert werden. |
| MuleSoft oder Apex Gateway Wrapper | Wird verwendet, wenn eine zusätzliche Orchestrierung, Zwischenspeicherung oder Richtlinienerzwingung zwischen der Anwendung und der Connect-API erforderlich ist. |
Fehlerbehandlung und -behebung
- Anforderungsdrosselung: Wird automatisch zurückgesetzt und wiederholt API-Aufrufe unter Ratenobergrenzen.
- Schemaabweichungsschutz: Verwendet die GraphQL-Schemaversionierung oder die REST-Metadatenerkennung zur Anpassung an Schemaänderungen.
- Tokenablaufverwaltung: Anwendungen aktualisieren OAuth-Token automatisch, um Sitzungsunterbrechungen zu vermeiden.
- API Fault Isolation (API-Fehlerisolierung): Fehlgeschlagene API-Aufrufe werden protokolliert und wiederholt, ohne dass sich dies auf gleichzeitige Sitzungen auswirkt.
- Trust Layer Observability (Beobachtbarkeit der Trust Layer): API-Erfolgs-/Fehlerraten und Zugriffsprotokolle sind im Trust Layer-Dashboard sichtbar.
Überlegungen zum idempotenten Design
- IDs der deterministischen Anforderung: Jede API-Anforderung enthält eine Korrelations-ID für die wiedergabesichere Verarbeitung.
- Cache-Validierungskopfzeilen: ETag- und Zuletzt geänderte Kopfzeilen verhindern redundante Datenabrufe.
- Atomische Lesevorgänge: Die Connect-API stellt sicher, dass jede Antwort einen einheitlichen Snapshot der zusammengeführten Daten widerspiegelt.
- Wiedergabeschutz: Doppelte API-Aufrufe werden anhand von Anforderungssignaturen und Zeitstempeln gefiltert.
Sicherheitsüberlegungen
- OAuth 2.0-Authentifizierung: Alle API-Aufrufe verwenden sichere, kurzlebige OAuth-Zugriffstoken über verbundene Anwendungen.
- Zugriff mit den geringsten Berechtigungen: API-Geltungsbereiche sind nur auf erforderliche Objekte und Felder beschränkt.
- Verschlüsselung überall: TLS 1.2+ im Transit; AES-256-Verschlüsselung im Leerlauf für zwischengespeicherte oder gespeicherte Antworten.
- Zugriff auf Daten mit Einwilligungsbewusstsein: Data 360 stellt sicher, dass alle abgerufenen Datensätze die Einwilligungs- und Governance-Richtlinien einhalten.
- Umfassende Auditprotokollierung: Jede API-Interaktion wird mit Benutzer-, Anwendungs- und Zeitstempel-Metadaten in der Trust Layer aufgezeichnet.
Randleisten
Aktualität
- Konzipiert für API-Zugriff mit geringer Latenz in Echtzeit.
- Ideal für interaktive Anwendungen, die ein sofortiges Daten-Rendering erfordern.
- Unterstützt nahezu sofortige Antwortzeiten auf Abfragen über zwischengespeicherte und indizierte Data 360-Quellen.
- Keine Abhängigkeit von Batchplänen oder asynchronen Aktivierungszyklen.
Datenvolumen
- Optimiert für interaktive Anwendungsfälle, die kleine bis mittlere Datensets abrufen (z. B. Profile, Statistiken oder aktuelle Transaktionen).
- Verarbeitet paginierte Ergebnisse anmutig durch die cursorbasierte Paginierung.
- Nicht für Massenexporte mit hohem Volumen vorgesehen: Verwenden Sie Batch- oder Dateiexportmuster für große Datensets.
Bundesstaatsverwaltung
- Anwendungen behalten einen leichten Sitzungsstatus mit OAuth-Token und lokalem Cache bei.
- Die Connect-API unterstützt bedingte Anforderungen und Teilaktualisierungen zur Effizienzsteigerung.
- API-Antworten enthalten Versionsmarkierungen für die Schemakonsistenz zwischen Versionen.
Komplexe Integrationsszenarien
- Kombinieren Sie die Connect-API mit der Datendiagramm-API für semantische Abfragen in mehreren Domänen.
- Integrieren Sie Einstein 1 in Copilot- oder AI-APIs für prognostizierte Unterhaltungen.
- Verwenden Sie sie zusammen mit Experience Cloud oder Lightning Web Components für die Entwicklung hybrider Benutzeroberflächen.
- Erweitern Sie die Funktion über MuleSoft, um die Datenanreicherung oder externe Systemnachschlagevorgänge in Echtzeit zu orchestrieren.
Beispiel
Ein multinationales Versicherungsunternehmen erstellt ein Self-Service-Portal für Kunden, über das Versicherungsnehmer ihre zusammengeführten Profile, aktuellen Ansprüche und personalisierten Angebote anzeigen können. Die eact-basierte Front-End-Anwendung authentifiziert sich über OAuth 2.0 und ruft Daten über die Connect-REST-API und die Datendiagramm-API ab. Alle Daten werden in Echtzeit angezeigt, sind einwilligungsbewusst und werden über die Data 360 Trust Layer verwaltet. Entwickler überwachen API-Aufrufe und -Aktivierungsprotokolle direkt in Salesforce und stellen so die vollständige Einhaltung und Beobachtbarkeit sicher.
Context
Unternehmen benötigen zunehmend sofortigen Zugriff auf ein vollständiges Kundenprofil für Echtzeit-Entscheidungssysteme wie Servicekonsolen, Empfehlungsmodule oder Personalisierungsplattformen. Mit diesem Muster können Anwendungen vorausberechnete, vereinheitlichte Ansichten der Daten eines Kunden nahezu in Echtzeit mithilfe der Datendiagramm-API von Data 360 abrufen und so Antwortzeiten in Sekundenschnelle für interaktive Erfahrungen bereitstellen. Typische Anwendungsfälle sind:
- Anzeigen einer 360-Grad-Kundenansicht in einer Kundendienst- oder Sales Console.
- Unterstützung von AI-basierten Empfehlungen für "Next Best Action" oder "Next Best Offer" (Next bestes Angebot).
- Bereitstellen hyperpersonalisierter Web- oder mobiler Erfahrungen zum Zeitpunkt des Ladens der Seite.
- Unterstützung von Entscheidungen in Sitzungen in Agenten- oder Self-Service-Umgebungen.
Problem
Wie kann eine Anwendung eine vollständige, vorausberechnete zusammengeführte Kundenansicht sofort abrufen, statt zur Laufzeit langsame Abfragen mit mehreren Objekten auszuführen? Beispielsweise muss ein Webpersonalisierungsmodul den vollständigen Kundenkontext (demografische Daten, Voreinstellungen, Transaktionen und berechnete Statistiken) innerhalb von Millisekunden laden, um ein personalisiertes Angebot auszuwählen. Herkömmliche relationale Abfragen erfordern möglicherweise mehrere Verknüpfungen und führen zu einer inakzeptablen Latenz. Dazu ist eine API erforderlich, die denormalisierte, sofort einsatzbereite Profildaten bereitstellt, die über einen einzelnen Schlüsselnachschlagevorgang abgerufen werden können – und Geschwindigkeit, Vollständigkeit und Governance kombinieren.
Kräfte
Mehrere betriebliche und Leistungsfaktoren beeinflussen dieses Muster:
- Geschwindigkeit: Die Antwortzeit muss nearReal-Time sein. Die API muss innerhalb von Millisekunden ein vollständiges Profil zurückgeben, um synchrone Interaktionen zu unterstützen.
- Vollständigkeit: Die Antwort muss alle relevanten Attribute, Beziehungen und berechneten Statistiken enthalten – idealerweise in einer einzelnen Nutzlast.
- Nachschlageeffizienz: Profile sollten über Kennzeichner wie customerId, contactKey oder E-Mail abgerufen werden können, sodass Abfragen in mehreren Schritten vermieden werden.
- Datenaktualisierung vs. Latenz: Einige Anwendungsfälle bevorzugen vorausberechnete (zwischengespeicherte) Daten für die Geschwindigkeit. Andere benötigen Live-Daten, um eine höhere Latenz zu akzeptieren.
- Governance und Sicherheit: Der Zugriff muss über Salesforce Trust Layer-Richtlinien gesteuert werden, um die Einhaltung der Datensichtbarkeit und Einwilligungsregeln zu gewährleisten.
Lösung
Die Lösung besteht darin, die Salesforce-Datendiagramm-API zu verwenden, um vorab berechnete, denormalisierte Kundenansichten abzurufen, die als Datendiagramm-Datensätze gespeichert sind. Ein Datendiagramm ist eine materialisierte semantische Ansicht, die mehrere Datenmodellobjekte (DMOs) wie "Einzelperson", "Transaktion" und "ProductInterest" in einem einzelnen schreibgeschützten Datensatz kombiniert, der häufig als JSON-Blob dargestellt wird. Entwickler können REST-Endpunkte wie die folgenden verwenden: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} um einen vollständigen Datensatz anhand seiner eindeutigen Kennung abzurufen. Bei dynamischen Szenarien unterstützt die API einen Parameter live=true, der den materialisierten Cache umgeht und eine Echtzeitabfrage in Data 360 ausführt, wobei die Latenz minimal für die neuesten Daten ist. Dadurch können Entwickler je nach Geschäftsanforderung zwischen sofortigen (zwischengespeicherten) und aktuellen (live) Profilabrufen auswählen.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Datendiagrammdefinition | Erforderlich | Architekten definieren ein Datendiagramm, das mehrere DMOs in einer einzigen semantischen Einheit kombiniert (z. B. "UnifiedCustomerProfile"). |
| Profil-Nachschlageabruf | Best | Anwendungen rufen GET /api/v1/dataGraph/{entity}/{id} auf, um vollständige denormalisierte Profile nach eindeutiger ID oder Schlüssel abzurufen. |
| Live-Parameternutzung | Optional | Hängen Sie ?live=true an, um eine neue Berechnung anstelle eines zwischengespeicherten Abrufs zu erzwingen. Dies eignet sich für Entscheidungen mit hohem Wert. |
| Authentifizierung | Erforderlich | Verwenden Sie OAuth 2.0 über verbundene Anwendungen, um API-Aufrufe sicher zu authentifizieren. |
| Antwortanalyse | Bewährte Vorgehensweisen | Anwendungen analysieren die JSON-Antwort direkt auf ihrer Benutzeroberfläche oder in ihrem Entscheidungsmodul. Es sind keine weiteren Verknüpfungen erforderlich. |
| Cache-Strategie | Empfohlen | Implementieren Sie die kurzfristige lokale Zwischenspeicherung (z. B. im Arbeitsspeicher oder CDN) für wiederholte Profilnachschlagevorgänge. |
| Überwachung und Beobachtbarkeit | Erforderlich | Verwenden Sie Trust Layer-Dashboards, um die Abfrageleistung, die Antwortzeiten und die Richtlinieneinhaltung zu überwachen. |
Skizze
Hier die Zusammenfassung des Implementierungs-Flows:
- Datendiagramm definieren: Datenarchitekten erstellen ein Datendiagramm, das eine einheitliche Kundenansicht über mehrere DMOs hinweg modelliert.
- Verbundene Anwendung registrieren: Entwickler konfigurieren OAuth-Anmeldeinformationen für den sicheren API-Zugriff.
- Datendiagramm-API aufrufen: Die Anwendung stellt eine GET-Anforderung mit dem Namen des Datendiagramms und der Datensatz-ID aus.
- Prozessantwort: Die API gibt eine vollständige JSON-Darstellung des Kundenprofils zurück.
- Darstellen oder Aktualisieren: Die verbrauchende Anwendung (Benutzeroberfläche oder Modul) verwendet die zusammengeführten Daten für Personalisierungs-, Empfehlungs- oder Serviceaktionen.
- Monitor and Tune (Überwachen und Abstimmen): Leistungskennzahlen und Zugriffsprotokolle werden über die Trust Layer Observability Console überprüft.
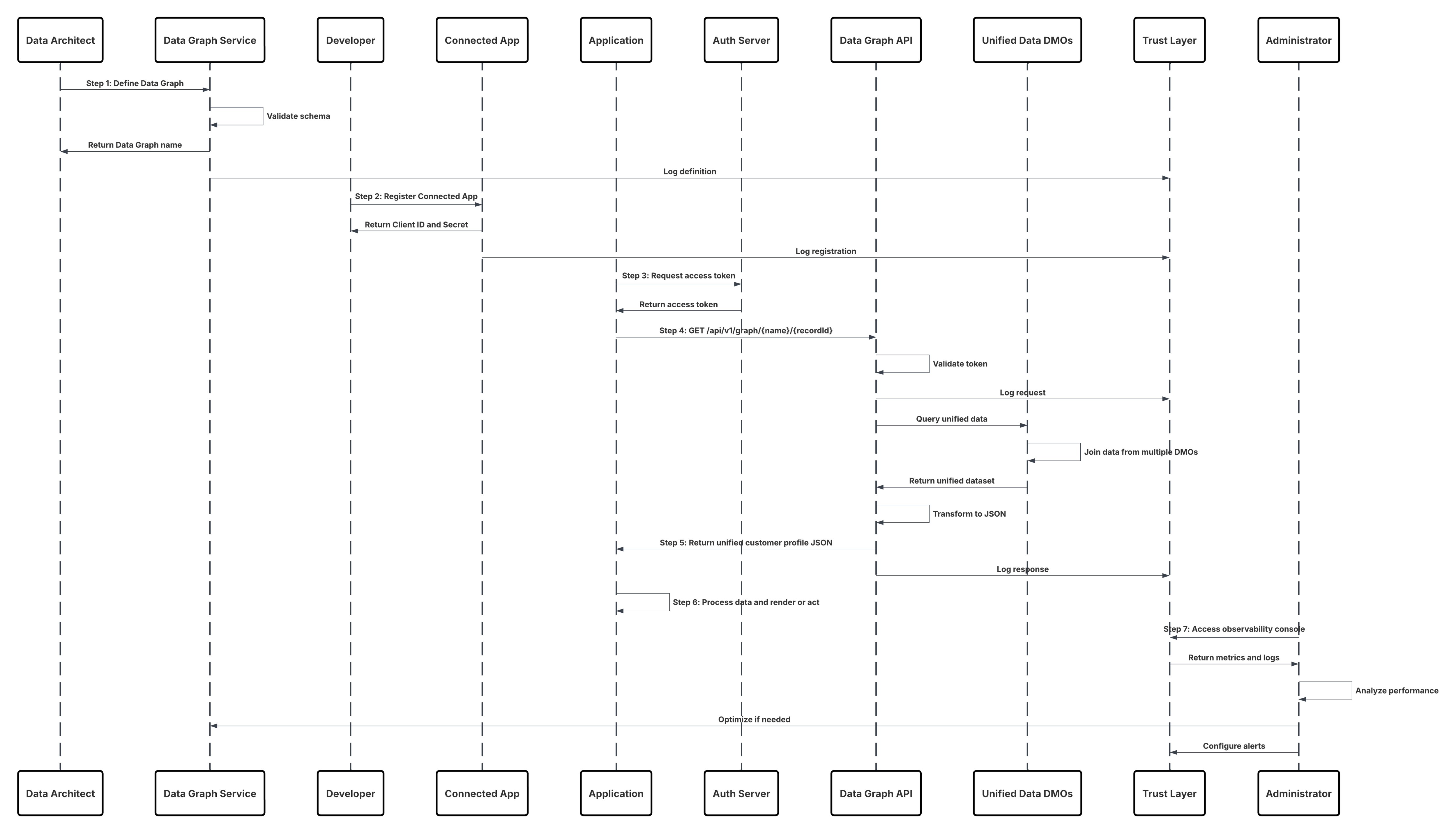
Ergebnisse
Anwendungen können nun sofort ein vollständiges, vorverknüpftes Kundenprofil abrufen und so Echtzeitinteraktionen wie Personalisierung, Service und Entscheidungsautomatisierung unterstützen. Dieses Muster gewährleistet Folgendes:
- Antwortzeiten innerhalb von Sekunden für die sofortige Entscheidungsfindung.
- Konsistenter, gesteuerter Datenabruf, der auf das semantische Data 360-Modell abgestimmt ist.
- Vereinfachte Anwendungslogik: Keine Verknüpfungen, keine Schemaabstimmung.
- Verfolgen und konformer Zugriff über die Trust Layer für Überprüfung und Beobachtbarkeit.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Ziel-Cloud-Speicherplattform und der Aktivierungskonfiguration ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| Datendiagramm-API (bevorzugt) | Wird zum sofortigen Abrufen vollständiger, vormaterialisierter Profile nach ID oder Schlüssel verwendet. |
| Datendiagramm-API mit live=true | Wird für Anwendungsfälle mit hohem Wert (z. B. Betrugserkennung, Live-Angebote) verwendet, in denen die neuesten Daten benötigt werden, wobei eine etwas höhere Latenz akzeptiert wird. |
| Connect-API (Fallback) | Wird für Szenarien zusammengesetzter Anwendungen verwendet, in denen Datendiagrammabrufe mit anderen Salesforce-Daten kombiniert werden. |
| Abfrage-API | Wird beim Erstellen von Ad-hoc-Abfragen oder analytischen Lesevorgängen anstelle des sofortigen Profilabrufs verwendet. |
| MuleSoft API Proxy | Wird verwendet, wenn Datendiagrammaufrufe über Unternehmens-Gateways weitergeleitet werden oder wenn eine zusätzliche Orchestrierung/Erzwingung von Richtlinien erforderlich ist. |
Fehlerbehandlung und -behebung
- Anmutige Ausweichmöglichkeiten: Wenn Live-Abfragen fehlschlagen oder Zeitüberschreitungsschwellenwerte überschreiten, kehren Sie automatisch zu zwischengespeicherten Datendiagrammabrufen zurück.
- Zeitüberschreitungsverwaltung: Implementieren Sie Logik für Wiederholungen und Leistungsschalter für API-Aufrufe unter hoher Last.
- Verarbeitung ungültiger IDs: Gibt standardmäßige Antworten vom Typ 404 "Nicht gefunden" für nicht vorhandene Profilschlüssel zurück.
- Schemaversionsvalidierung: Validieren Sie Datendiagrammversions-Metadaten, um Fehlübereinstimmungen bei der Entwicklung des Schemas zu vermeiden.
- Beobachtbarkeitsintegration: Protokollieren Sie alle Fehler, Wiederholungen und Latenzen in Trust Layer-Dashboards für die SLA-Überwachung.
Überlegungen zum idempotenten Design
- Deterministische Schlüssel: Jeder Profilabruf verwendet eine stabile ID (z. B. IndividualId), um vorhersehbare und wiedergabesichere Abfragen zu gewährleisten.
- Cache-Konsistenz: Verwenden Sie ETag- oder Zuletzt geänderte Kopfzeilen für bedingte Abrufe und die Cache-Validierung.
- Atomic Retrieval (Atomischer Abruf): Jede API-Antwort stellt einen konsistenten Snapshot des materialisierten Datendiagramm-Datensatzes dar.
- Wiedergabeschutz: Stellen Sie sicher, dass Client-Anwendungen doppelte Abrufe über Korrelations-IDs und Zeitstempel erkennen.
Sicherheitsüberlegungen
- Starke Authentifizierung – OAuth 2.0 über verbundene Anwendungen erzwingt sicheren, tokenbasierten Zugriff.
- Abruf mit Einwilligungsbewusstsein: Es werden nur Attribute mit Einwilligung zurückgegeben. Einwilligungsfilter werden von der Trust Layer automatisch angewendet.
- Field-Level Governance: Der Zugriff auf Attribute wird über die Metadaten und Richtliniendefinitionen von Data 360 gesteuert.
- Verschlüsselung im Transit und im Leerlauf: Alle Antworten werden mit TLS 1.2+ und AES-256 verschlüsselt.
- Aktivierung und Rückverfolgbarkeit: Jedes Profilabrufereignis wird mit Kennzeichnern, Zeitstempeln und Richtlinienkontext protokolliert.
Randleisten
Aktualität
- Konzipiert für den sofortigen Abruf.
- Unterstützt Live-Abfragen für aktuelle Daten mit etwas höherer Latenz (Sekunde).
- Optimiert für synchrone Entscheidungen und interaktive Anwendungen.
- Es ist keine Aktivierung vor dem Batch oder Segmentneuberechnung erforderlich.
Datenvolumen
- Ideal für Nachschlagevorgänge mit einem Datensatz oder kleine Sätze (zehn bis hunderte) pro Anforderung.
- Nicht für den Massenabruf in großem Umfang optimiert. Verwenden Sie Batch- oder Abfrage-APIs für Lesevorgänge mit hohem Volumen.
- Verwendet horizontal skalierbare Zwischenspeicherung und Vormaterialisierung für Geschwindigkeit.
Bundesstaatsverwaltung
- Behält den einfachen Zugriff ohne Status bei. Jede Anforderung ist unabhängig.
- Unterstützt das Zwischenspeichern von Kopfzeilen für den sicheren Abruf.
- Anwendungen können den lokalen Cache oder den kurzfristigen Sitzungsspeicher verwalten, um wiederholte Nachschlagevorgänge zu reduzieren.
Komplexe Integrationsszenarien
- Kann nahtlos in Einstein 1, die Connect-API und MuleSoft für zusammengesetzte Datenerfahrungen integriert werden.
- Kann Agentensysteme (z. B. Copilot oder AI Reasoning Engines) unterstützen, die sofortiges Kontextbewusstsein erfordern.
- Kombiniert mit Datenaktionen für Echtzeitauslöser beim Abruf oder bei Statusänderungen.
- Ermöglicht die Personalisierung in großem Umfang, ohne die Leistung oder die Unternehmensführung zu beeinträchtigen.
Beispiel
Eine globale E-Commerce-Plattform verwendet die Datendiagramm-API von Data 360, um zusammengeführte Kundenprofile in Echtzeit für ihr Empfehlungsmodul abzurufen. Wenn sich ein Benutzer anmeldet, ruft die Anwendung den Datendiagramm-Endpunkt auf, um das UnifiedCustomerProfile für diesen Kunden abzurufen und demografische Attribute, Verhaltenssignale und berechnete Statistiken als einzelne JSON-Nutzlast zurückzugeben. Das Personalisierungsmodul verbraucht diese Antwort innerhalb von Millisekunden, um das "Next Best Offer" (Next bestes Angebot) während der aktiven Sitzung zu ermitteln und anzuzeigen. Alle Anforderungen werden über die Trust Layer gesteuert und protokolliert, wodurch die vollständige Transparenz, die Durchsetzung von Richtlinien und die Einhaltung von Vorschriften in der gesamten Interaktion gewährleistet werden.
Echtzeit-Datenaktionen ermöglichen die sofortige Aktivierung von Kundendaten, sobald sie sich in Data 360 ändern. Statt auf geplante Batch-Exporte zu warten, übertragen diese Aktionen Aktualisierungen, Statistiken oder Auslöser in Millisekunden direkt an Salesforce oder externe Systeme. Wenn die Status-, Einwilligungs- oder Interaktionskennzahl eines Kunden in Data 360 aktualisiert wird, kann dieses Signal sofort personalisierte Angebote unterstützen, Service Cloud-Automatisierungen auslösen oder Treuestufen aktualisieren und sicherstellen, dass jede Kundenerfahrung die neueste einheitliche Wahrheit widerspiegelt. Dieses Muster eignet sich ideal für Anwendungsfälle mit hoher Auswirkung, die auf Latenz reagieren, beispielsweise personalisierte Weberfahrungen, Betrugserkennungswarnungen, Next-Best-Action-Empfehlungen oder CRM-Aktualisierungen in Echtzeit. Sie schließt die Lücke zwischen Datenstatistiken und Geschäftsaktionen und verwandelt zusammengeführte Daten in sofortige Intelligenz.
Context
Moderne digitale Erfahrungen und betriebliche Workflows erfordern sofortige kontextbezogene Aktionen, sobald ein Ereignis auftritt. Dazu zählen beispielsweise das Aktualisieren eines Kundendatensatzes während eines Checkouts, das Anpassen des Inventars beim Scannen einer Rückgabe oder das Bereitstellen eines personalisierten Sonderangebots, sobald ein Benutzer einen Einkaufswagen verlässt. Mit Echtzeit-Datenaktionen können Systeme vereinheitlichte Data 360-Profile und berechnete Statistiken mit Latenz zwischen Sekunden und Sekunden aufrufen, anreichern und darauf reagieren. Dies ermöglicht interaktive Personalisierung, betriebliche Automatisierung und sofortige Entscheidungen.
Problem
Wie können Anwendungen, Benutzeroberflächeninteraktions-Flows oder Middleware zur Laufzeit in Data 360 aufgerufen werden, um ein einzelnes zusammengeführtes Profil zu lesen, zu berechnen oder zu aktualisieren oder eine Aktion auszulösen (z. B. ein Angebot zu senden, CRM zu aktualisieren, einen Workflow zu starten) mit geringer Latenz, starker Konsistenz und Steuerungssteuerungen, ohne auf geplante Batchaufträge oder schwere Pipelines zu warten?
Kräfte
Mehrere technische, operative und Governance-Kräfte prägen dieses Muster:
- Niedrige Latenzanforderung: Anrufe müssen im Sekundenbereich von wenigen Sekunden abgeschlossen werden, um eine gute Benutzeroberfläche zu erhalten oder operative SLAs zu erfüllen.
- Deterministische Identitätsbestimmung: Anforderungen müssen zuverlässig und schnell in das richtige Profil "Zusammengeführte Einzelperson" (Goldener Datensatz) aufgelöst werden.
- Genauere Autorisierung: Bei Echtzeitanrufen müssen Richtlinien auf Attributebene und Einwilligungsprüfungen zur Anforderungszeit erzwungen werden.
- Nutzlastminimismus: Echtzeit-Nutzlasten sollten klein und fokussiert sein (einzelnes Profil oder kleiner Attributsatz), um Latenz und Kosten zu reduzieren.
- Entwicklererfahrung: APIs müssen entwicklerfreundlich (REST/gRPC/GraphQL) sein, mit klaren Schemas und stabilen Verträgen für die Produktionsnutzung.
- Überprüfbarkeit und Rückverfolgbarkeit: Jede Echtzeitaktion muss mit Abstammung, Benutzeridentität und Richtlinienentscheidungen protokolliert werden, um die Einhaltung zu gewährleisten.
Lösung
Die empfohlene Lösung besteht darin, die Echtzeit-Datenaktionsoberfläche (APIs + SDKs) von Data 360 in Kombination mit Kantenzwischenspeicherung und minimalen Berechnungstransformationen zu verwenden. Integrationen rufen einen Endpunkt für Datenaktionen auf, um Profilattribute zu lesen oder zu schreiben, Statistiken zu berechnen oder Orchestrierungen zu initiieren. Echtzeit-Richtlinienüberprüfungen (CEDAR) und dynamische Maskierung werden am Erzwingungspunkt für Policen angewendet, bevor eine Nutzlast zurückgegeben oder eine Aktion ausgeführt wird.
| Lösungsbereich | Fit | Kommentare / Implementierungsdetails |
|---|---|---|
| Echtzeit-Datenaktion | Best | Stellen Sie den Endpunkt für Lese-/Schreibzugriff und Aktionsauslöser mit einem Datensatz bereit. Authentifizieren über OAuth/JWT. |
| Identitätsbestimmung | Erforderlich | Lösen Sie eingehende Kennzeichner (E-Mail, externalId, Cookie) inline in die ID der zusammengeführten Einzelperson auf. Verwenden Sie einen deterministischen Resolver mit Cache. |
| Policenerzwingung (CEDAR) | Bewährte Vorgehensweisen | Evaluieren Sie Einwilligungs-, ABAC- und Maskierungsrichtlinien zur Anforderungszeit. Verweigern oder maskieren Sie Felder pro Richtlinienentscheidung. |
| Edge/Cache Layer | Empfohlen | Verwenden Sie Kurz-TTL-Caches für Profilfragmente und berechnete Statistiken, um die Latenz zu reduzieren und bei Änderungsereignissen ungültig zu machen. |
| Leichtbautransformationen | Empfohlen | Wenden Sie einfache Anreicherungen oder berechnete Felder im Aktionspfad an. Schwere Transformationen sollten vorausberechnet werden. |
| Aktionsorchestrierung | Best | Unterstützen Sie synchrone Einzelschrittaktionen (z. B. Rückgabeangebotstoken) und asynchrone Orchestrierungen (Warteschlange \+ Webhook) für komplexe Flows. |
| Beobachtbarkeit und Verfolgung | Erforderlich | Protokollieren Sie Anforderungen/Antworten, Richtlinienentscheidungen und die Abstammung zur Trust Layer/ SIEM für die Überprüfung und das Debugging. |
| Ratenbegrenzung und -drosselung | Erforderlich | Erzwingen Sie Kundenquoten und anmutige Verschlechterungsstrategien für Momente mit hohem Datenverkehr. |
Skizze
Im Folgenden finden Sie die Zusammenfassung der Schritte.
- Client (Benutzeroberfläche / Middleware / POS) sendet authentifizierte Datenaktionsanforderungen mit Kennzeichnern und Aktionstyp.
- Das API-Gateway validiert Token, Ratenobergrenzen und leitet sie an den Data 360-Aktionsservice weiter.
- Der Aktionsservice löst Kennzeichner → ID der zusammengeführten Einzelperson auf (Cache für schnellen Pfad; Ausweichmöglichkeit für Diagrammsuche).
- Die Richtlinienerzwingung wertet CEDAR-Richtlinien anhand von Attributen aus PIP und Anforderungskontext aus.
- Sofern zulässig, liest der Aktionsservice alle erforderlichen Profilattribute/-statistiken und führt leichte Transformationen durch.
- Der Aktionsservice gibt die Antwort synchron zurück (z. B. Angebotstoken, aktualisiertes Attribut) oder stellt die asynchrone Orchestrierung in Warteschlangen und gibt eine Bestätigung zurück.
- Alle Ereignisse, Entscheidungen und Nutzlasten werden in Trust Layer protokolliert und optional an SIEM weitergeleitet.
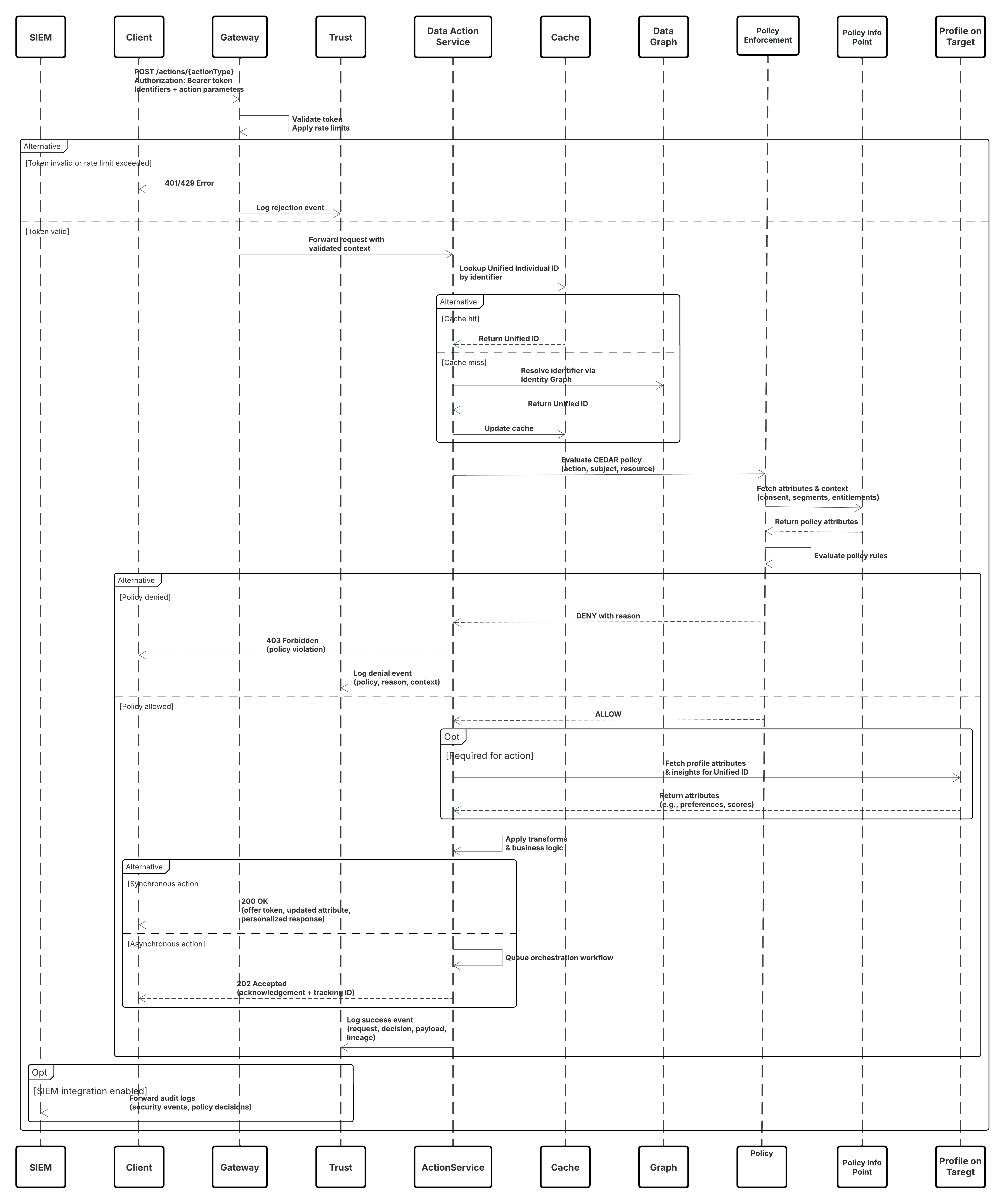
Ergebnisse
- Anwendungen erhalten sofortigen, richtliniengesteuerten Zugriff auf Lese-/Schreibzugriff auf zusammengeführte Profile und Aktionsauslöser mit Latenz zwischen Sekunden und Sekunden.
- Personalisierungs-, Entscheidungs- und betriebliche Workflows in Echtzeit (z. B. Angebote, Agentenunterstützung, Inventaraktualisierungen) werden ohne Batch-Verzögerungen aktiviert.
- Alle Aktionen sind überprüfbar, stimmen zu und erzwingen Maskierungen auf Attributebene, um Datenschutz und Compliance zu gewährleisten.
Aufrufmechanismen
Der Aufrufmechanismus hängt von der Zielplattform und der Aktivierungszielkonfiguration ab.
| Mechanismus | Wann zu verwenden |
|---|---|
| API für RESTful-Datenaktionen | Bevorzugt für Web-/Mobilanwendungen und Middleware, die synchrone Profillesungen oder Aktionsantworten benötigen. |
| gRPC / Binär-RPC | Wird für Enterprise-Services mit extrem niedriger Latenz oder interne Microservices mit persistenten Verbindungen verwendet. |
| GraphQL-Einzeldatensatzabfragen | Wird verwendet, wenn Kunden eine flexible Feldauswahl benötigen und Nutzlasten minimieren möchten. |
| Durch Ereignisse ausgelöste Webhooks | Wird für asynchrone Workflows verwendet, bei denen Aktionen nachgelagerte Prozesse auslösen (z. B. eine Journey starten). |
| Plattformereignisse / PubSub | Wird für Fan-Out-Szenarien verwendet, in denen mehrere Systeme auf ein einzelnes Aktionsereignis reagieren müssen. |
| Edge SDK (Client-Bibliotheken) | Wird für Clients mit geringer Latenz verwendet, die Profilfragmente zwischenspeichern und die API für Datenaktionen nur bei Bedarf aufrufen. |
Fehlerbehandlung und -behebung
- Synchronous Errors: Geben Sie strukturierte Fehlercodes mit für Menschen lesbaren Nachrichten und Identitäts-Token zurück.
- Vorübergehender Wiederholungsversuch: Clients sollten idempotente Anforderungen mit exponentieller Absicherung für 429/5xx-Antworten wiederholen.
- Policy Deny Handling (Policy – Handhabung ablehnen): Ablehnungen geben eindeutige Ursachencodes zurück. Bei Policenfehlern werden keine sensiblen Daten zurückgegeben.
- Asynchrone Orchestrierungsfehler: Orchestrierungsaufträge werden in DLQ verschoben und können wiedergegeben werden. Über eine Auftragsstatus-API können Kunden abstimmen oder Rückmeldungen erhalten.
- Fallback Strategies: Wenn die Identitätsbestimmung fehlschlägt, geben Sie einen deterministischen Fehler und optional eine vorgeschlagene Korrektur zurück (z. B. externalId erforderlich).
Überlegungen zum idempotenten Design
- Idempotenzschlüssel: Clients stellen einen Identitätsschlüssel (UUID + Client-Namespace) für Mutierungsaktionen bereit.
- Deterministische Schlüssel: Verwenden Sie zusammengesetzte Schlüssel (UnifiedIndividualId + ActionType + TimestampWindow), um Duplikate zu erkennen.
- Sichere Wiederholungen: Entwerfen Sie Aktionen, die Nebenwirkungen tolerant sind, oder führen Sie Aktualisierungen und Einfügungen anstelle von Blindeinfügungen aus.
- Wiedergabeschutz: Verarbeitete Identitätsschlüssel beibehalten und nach dem Geschäftsfenster per TTL eingrenzen, um Wiederholungen zu vermeiden.
- Statelessness: Halten Sie synchrone Aktionen nach Möglichkeit zustandslos und behalten Sie den Minimalstatus für asynchrone Workflows bei.
Sicherheitsüberlegungen
- Authentifizierung: OAuth 2.0 (JWT Bearer oder mTLS für Serviceaccounts); kurzlebige Token und Aktualisierungsrotation.
- Autorisierung: Der Richtlinienentscheidungspunkt erzwingt die attributbasierte Zugriffssteuerung (CEDAR) und Einwilligungsprüfungen pro Anforderung.
- Transport- und Speicherverschlüsselung: TLS 1.2+ im Transit; AES-256 im Leerlauf für zwischengespeicherte Fragmente oder Überwachungsprotokolle.
- Niedrigste Berechtigung: API-Clients, die auf minimale Berechtigungen beschränkt sind; Rollen getrennt für "Lesen" und "Schreiben" und "Orchestrieren".
- Datenminimierung: Geben Sie nur angeforderte und zugestimmte Attribute zurück. Wenden Sie dynamische Maskierungen für personenbezogene Daten/PHI an.
- Netzwerksteuerungen: Optional können Sie Aufrufe aus privaten Netzwerken (Private Connect, IP-Zulassungslisten) für Aktionen mit hohem Risiko anfordern.
- Aktivierung und Überwachung: Protokollieren Sie Anforderungsmetadaten, Richtlinienentscheidungen, die Identität des Anforderers und Antwort-Hashes in Trust Layer und SIEM.
Randleisten
Aktualität
- Konzipiert für mittlere Latenzen im Sekunden- bis Sekundenbereich für synchrone Aktionen.
- Edge-Caches (kurze TTL) und vorberechnete Statistiken reduzieren die Anzahl der Fahrten.
- Asynchrone Pfade bieten nahezu sofortige Bestätigung mit Hintergrundverarbeitung für schwere Aufgaben.
Datenvolumen
- Optimiert für Einzeldatensatz- oder Klein-Batch-Interaktionen (1–100 Datensätze).
- Nicht für Massenexporte vorgesehen: Verwenden Sie die Batch-Aktivierung für große Mengen.
- Bei hohem Durchsatz werden Pooling/Verbindungswiederverwendung und parallele Orchestrierungswarteschlangen verwendet.
Bundesstaatsverwaltung
- Statusloses Anforderungsmodell für synchrone Aufrufe; minimaler Aktionsstatus für Fördermittel/Transaktionen beibehalten.
- Cache-Ungültigkeit, die durch Änderungsereignisse gesteuert wird: Stellen Sie sicher, dass TTLs und Ungültigkeitssignale die Caches auf dem neuesten Stand halten.
- Bei Orchestrierungsaufträgen wird der dauerhafte Status (jobId, status, retries) in der Trust Layer gespeichert.
Komplexe Integrationsszenarien
- Agentenunterstützung: Echtzeit-Profilsuche + berechnete Tendenz, die Agenten in Sekundenschnelle zur Servicekonsole zurückgegeben werden.
- POS / Edge Devices: Lokales SDK + gelegentliche Datenaktion zum Validieren von Sonderangeboten oder Treuestatus.
- Hybrid-Flows: Aktion 'Daten synchronisieren' für die Entscheidungs- und asynchrone Orchestrierung, um nachgelagerte Systeme zu aktualisieren und Kampagnen auszulösen.
- Drittanbieter-Middleware: MuleSoft- oder API-Gateways können die Authentifizierung vermitteln, den Kontext erweitern und zusätzliche Richtlinienüberprüfungen erzwingen.
Beispiel
Eine mobile Einzelhandelsanwendung bestimmt, ob ein personalisierter Sofortgutschein angezeigt werden soll, wenn ein Käufer auf Checkout tippt, indem die Datenaktion für die Angebotsberechtigung mit dem E-Mail- und Einkaufswagenkontext des Käufers aufgerufen wird. Die Anforderung wird vom API-Gateway validiert und an den Datenaktionsservice weitergeleitet, der die E-Mail mithilfe eines Cache-Treffers in eine ID einer zusammengeführten Einzelperson auflöst, die Marketingeinwilligung über das PDP überprüft und die Berechtigung anhand des Kundenlebenszeitwerts und der aktuellen Kaufaktualität auswertet. Wenn sich der Käufer qualifiziert, gibt der Service ein signiertes Gutscheintoken zurück und protokolliert die Entscheidung. Wenn für die Ausstellung von Gutscheinen eine Inventarreservierung erforderlich ist, wird eine asynchrone Orchestrierung ausgelöst, um Inventar zu reservieren und CRM-Systeme zu benachrichtigen. Die Anwendung zeigt den Gutschein sofort an, während nachgelagerte Aktualisierungen im Hintergrund abgeschlossen werden und die Trust Layer einen vollständigen Überprüfungspfad für die Verwaltung und Compliance erfasst.
- Konnektoren und Integration
- Web & Mobile SDK
- Untergeordnete Aufnahme in Echtzeit
- Bring Your Own Lake (Nullkopieabfrage)
- Bring Your Own Lake (Zero Copy File)
- Datendiagramme
- Aktivierung: MC Engagement
- Aktivierung: MC-Personalisierung
- Aktivierung: B2C Commerce
- Datenfreigabe (Nullkopie)
- Aktivierung: Dateispeicher
- Datenaktionen
- Aktionen für untergeordnete Daten in Echtzeit
- Externe Aktivierungsplattform