このテキストは、Salesforce の自動翻訳システムを使用して翻訳されました。アンケートに回答して、このコンテンツに関するフィードバックを提供し、次に何を表示するかをお寄せください。
Note
概要
このドキュメントでは、高可用性とディザスタリカバリの要件を満たすためにアプリケーションを CloudHub 2.0 にリリースするための現在のオプションについて説明します。US リージョンを例として使用し、他のリージョンに適用できます。
CloudHub 2.0 は、クラウドでの MuleSoft API とインテグレーションの導入、拡張、管理を自動化することでインフラストラクチャのオーバーヘッドを排除する、完全に管理されたクラウドネイティブのインテグレーションプラットフォームです。これは、Amazon AWS インフラストラクチャで実行される MuleSoft の最新のクラウドリリースプラットフォームです。
災害復旧の要件
ほとんどの場合、CloudHub 2.0 が提供するデフォルトの高可用性 (HA) とディザスターリカバリー (DR) で十分です。CloudHub 2.0 は、地域レベルで HA と DR を提供します(詳細は、「CloudHub 2.0の停止シナリオ」を参照してください)。「CloudHub 2.0 Key Considerations(CloudHub 2.0 の主要な考慮事項)」セクションでは、CloudHub-2.0 でサポートされる HA と DR の詳細について説明します。
CloudHub 2.0 のデフォルトの可用性を超える設計を義務付ける条件は次のとおりです。
- アプリケーションは、災害シナリオ (Amazon のリージョンがダウンした場合など) でデータが失われないようにする必要があります。
- アプリケーションはオブジェクトストアに依存するため、リリースリージョンが停止した場合に継続性を確保する必要があります。
前提条件
- バックエンドシステムは同等の可用性を持つように設定されています。CloudHub 2.0 では、キューや同様のメカニズムで信頼性を提供できる場合がありますが、インテグレーションがリアルタイムか非同期かに関係なく、バックエンドシステムは同等のレベルの HA と DR をサポートする必要があります。
- AWS リージョンレベルの停止がバックエンドシステムに影響する場合、その復旧は CloudHub 2.0 の復旧と並行して実行されることが想定されます。
- 複数の地域で非公開スペースの設定が完了している。
範囲外
このガイドの設計オプションは、AWS アベイラビリティゾーン全体またはリージョンが使用できなくなった場合に CloudHub 2.0 でアプリケーションの可用性を実現するソリューションに焦点を当てています。
このガイドでは、次のリカバリ シナリオには対応していませんが、関連する箇所については言及しています。
- Anypoint CloudHub の外部 (オンプレミスまたはクラウド) で管理およびプロビジョニングされているバックエンドシステム、アプリケーション、データベース、ネットワークコンポーネント、データセンターのリカバリ。
- CloudHub 2.0 と顧客の非公開データセンター間の VPN リンク (IPsec トンネルや VPN ゲートウェイなど) の復旧。このガイドの一部の DR オプションでは、これらのシナリオに部分的に対処できます。
- インテグレーションで IP 許可リストが使用されている場合、ディザスターリカバリー中に MuleSoft 出力 IP に変更されます。このガイドの一部の DR オプションでは、これらのシナリオに部分的に対処できます。
- MuleSoft (Anypoint MQ など) または他のベンダー (AWS MSK や Heroku Kafka など) が提供する、カスタマーソリューションで使用される外部メッセージングシステム。
CloudHub 2.0 の主な考慮事項
ディザスタリカバリ要件について CloudHub 2.0 を評価するときは、次の主要な考慮事項を考慮してください。
AWS リージョンの可用性に対する CloudHub 2.0 の連動関係
- CloudHub 2.0 は AWS で実行され、その可用性は AWS リージョンに関連付けられます。
- リリースとアプリケーションの使用可能状況は地域ごとに整理されています。これらのリージョンは AWS リージョンに対応します。
AWS リージョン全体で障害が発生した場合、そのリージョンのアプリケーションは使用できず、他の場所に自動的に複製されません。
アプリケーションの高可用性(HA)とレプリカ管理
- CloudHub 2.0 では、ハードウェアに障害が発生すると、同じリージョン内でアプリケーションが自動的に再導入されますが、レプリカが 1 つのアプリケーションではダウンタイムが発生する可能性があります。
- 複数のレプリカを使用するアプリケーションは、デフォルトで個別の可用性ゾーンに導入され、ゾーン全体の HA が提供されます。
- 1 つのレプリカ・アプリケーションの可用性ゾーンで障害が発生した場合、そのアプリケーションは同じリージョン内の別の可用性ゾーンで自動的に起動されます。
米国東部地域固有の影響
- 米国東部地域での停止の場合:
- CloudHub 2.0 管理 UI とリリース REST サービスは使用できず、新しいアプリケーションをリリースできません。
- 他の地域のアプリケーションは、ほとんどの障害シナリオで影響を受けません。これらのアプリケーションは引き続き正常に動作しますが、停止中はコントロールプレーンを介した監視と管理機能は使用できません。
- コア CloudHub 2.0 モジュール (アプリケーション設定など) は米国東部で管理されているため、停止中は設定を編集できません。
監視とアラート
- status.mulesoft.com を使用して、可用性ゾーンまたは地域レベルの障害のアラートを設定します。
- CloudHub 2.0 の外部で別の状態チェックおよびアラートメカニズムを使用して、レプリカが失敗したりアプリケーションが応答しなくなったりした場合にチームに通知します。
データ保持 (オブジェクトストア V2)
- オブジェクトストア V2 は、アプリケーションが最初にリリースされたリージョンに関連付けられています。
- アプリケーションを別のリージョンに移動すると、オブジェクトストア V2 はデータの損失を避けるために元のリージョンに留まります。
- オブジェクトストア V2 がリリースされるリージョンで障害が発生した場合、オブジェクトストアは使用できません。
入力コントローラとプライベートスペース
- CloudHub 2.0 の入力コントローラーは、リージョンレベルで高可用性を実現します。
- 共有スペースでは、1 つのリージョンで障害が発生しても、別のリージョンの入力コントローラーは引き続き使用できますが、使用できるのは、そのリージョンにリリースされたアプリケーションのみです。
- 非公開スペースでは、リージョンに障害が発生すると、他のリージョンの入力コントローラーは、そのリージョンで事前に設定されていない限り使用できません。
- 非公開スペースの設定は地域によって異なります。地域が失敗した場合、別の地域が設定されていない限り、非公開スペースは使用できません。
CloudHub 2.0 の停止シナリオ
レプリカ/可用性ゾーン/リージョンの停止
Salesforce の責任
| コンポーネント状況 | Salesforce の責任 |
|---|---|
| Replica Down | アクション |
| 対応可能状況ゾーンのダウン | アクション:レプリカがダウンした場合と同じです。条件:デフォルト設定。Time Taken:レプリカがダウンした場合と同じです。通知:レプリカがダウンした場合と同じです。 |
| Region Down | アクション:自動リカバリなし。フェールオーバー設計が必要です。 |
顧客責任
| コンポーネント状況 | 顧客責任 |
|---|---|
| Replica Down | 通知 |
| 対応可能状況ゾーンのダウン | 通知:レプリカがダウンした場合と同じです。軽減:同じリージョンまたは異なるリージョンの複数のレプリカにアプリケーションをリリースします。**テスト/シミュレーション:**AZ ダウンシナリオのシミュレーションは困難です。考えられるテストシナリオをサポートするには、MuleSoft Engineering の関与が必要です。 |
| Region Down | 通知:レプリカがダウンした場合と同じです。また、https://status.aws.amazon.comで状況の更新も確認してください。軽減 |
VPN ゲートウェイと入力コントローラーの停止
Salesforce の責任
| コンポーネント状況 | Salesforce の責任 |
|---|---|
| VPN Gateway Down | Replica Status:実行されているが、オンプレミスでホストされ、VPN トンネルを介して到達可能なリソースに接続できない。アクション:自動リカバリなし。フェールオーバー設計が必要です。 |
| 入力コントローラ (共有スペース) のダウン | Replica Status:入力コントローラーは、アプリケーションレプリカと同様に、複数のインスタンスを含むクラスター化された設定です。アプリケーション・レプリカが失敗すると、新しいレプリカが自動的に作成され、開始されます。1 つの入力コントローラーインスタンスに障害が発生しても、他のインスタンスからアプリケーションを引き続き使用できます。入力コントローラ全体がダウンしている場合、リージョンはダウンしていると見なされます。 |
| 入力コントローラ (非公開スペース) の停止 | **レプリカのステータス:**共有スペースのダウン時の入力コントローラーと同じです。 |
顧客責任
| コンポーネント状況 | 顧客責任 |
|---|---|
| VPN ゲートウェイのダウン | 通知 |
| 入力コントローラ (共有スペース) の停止 | 通知 |
| 入力コントローラ (非公開スペース) の停止 | 通知 |
オブジェクトストアと保持キュー
概要プラットフォームサービスのダウンシナリオ – オブジェクトストア
| メモリ内オブジェクトストア | 永続的オブジェクトストア v2 | |
|---|---|---|
| データの場所 | アプリケーションに対してのみローカルです。 | MuleSoft アプリケーションが最初にリリースされた地域と同じ。 |
| レプリカ間で共有 | いいえ | あり |
| アプリケーションでのオブジェクトストアのリカバリ | データは失われます。アプリケーションの再起動、新しいリリース、またはレプリカの失敗によって、すべてのメモリ内データが失われます。 | アプリケーションが削除されない限り、データは失われません。 |
| 地域内のオブジェクトストアのリカバリ | データは失われます (上記と同様)。 | データは失われません (上記と同様)。 |
| Regional Recovery | 上記と同じです。 | データは使用できません。有効-有効 DR 設定を使用しても、オブジェクトストアは元のリリース地域でのみ使用できます。 |
| 軽減 | 地域リカバリ用にデータを外部化します。 | 元のリリース地域が使用可能である間は、データを引き続き使用できます。クロスリージョン HA または DR の場合、オブジェクトストアの外部にデータを外部化します。 |
高可用性とディザスタリカバリ
高可用性 (HA) は、システムコンポーネントに障害が発生した場合でもシステムへのアクセスを維持する機能の指標です。通常、HA は、複数のレベルのフォールトトレランスや負荷分散機能をシステムに組み込むことで実装されます。通常、これは有効-有効設定であり、ビジネスサービスへの影響は限定的かまったくありません。
DR(ディザスター リカバリー)は、自然災害(洪水、竜巻、地震、火災など)または人為的災害(電源障害、サーバー障害、構成ミスなど)のシナリオ後に、システムを以前の許容可能な状態にリストアするプロセスです。DR は通常、アクティブ-パッシブ構成であるため、ビジネスサービスに何らかの影響があります。
CloudHub 2.0 の地域ごとの可用性
AWS リージョンの障害発生時のビジネスへの影響を軽減するためにリージョンの高可用性またはリージョンのディザスターリカバリーが必要な場合は、MuleSoft CloudHub 2.0 でソリューションを設計するときに次の点を考慮してください。
- CloudHub 2.0 レプリカと関連機能 (プライベートスペース、入力コントローラー、Anypoint MQ 送信先) は地域固有です。
- AWS リージョン全体で障害が発生すると、そのリージョンのすべてのレプリカと関連サービスが使用できなくなります。
- 領域が回復すると設定が復元されるため、アプリケーションを再起動する必要があります。
- 米国東部地域で障害が発生した場合、Anypoint Platform サービス (アクセス管理やランタイムマネージャーなど) も使用できません。
- MuleSoft は、リージョン内のアクティブ-アクティブ構成の CloudHub 2.0 レプリカを含め、プラットフォームサービスで 99.95% の可用性を提供します。現在の詳細は、最新の MuleSoft Cloud 製品 SLA を参照してください。
- CloudHub 2.0 では、標準で複数リージョンの HA または DR はサポートされていません。使用可能なのは 1 つのリージョン内のみです。
一般的な設計ガイドライン
次の設計ガイドラインは、どの設定を選択しても適用されます。
マルチリージョンの非公開スペースの設定
次のセクションで説明するすべてのオプションでは、アプリケーションを別々の地域にリリースする必要があります。これは、災害が発生する前にプライベートスペースの設定が完了している場合にのみ可能です。プライベートスペースの設定は地域的であるため、DR 戦略では少なくとも 2 つのプライベートスペース (地域ごとに 1 つ) と、トラフィックを適切な VPN エンドポイントに切り替えるメカニズムが必要です。
地域内の高可用性プライベートスペースの設定
CloudHub 2.0 では、リージョン内の非公開スペースに障害が発生した場合の自動フェイルオーバーは提供されません。回避策は、複数の環境にまたがるアクティブ-パッシブ設定です。これには次のものが必要です。
- プライベートスペースでの複数の VPN ゲートウェイの設定。
- CloudHub 2.0 リージョンに個別の環境を設定し、それぞれに独自の非公開スペースを設定します。
- これらの環境のいずれかをパッシブ (最初にアプリケーションがリリースされず、プライマリプライベートスペースに障害が発生した場合に起動される) として指定する。
VPN ゲートウェイを単一障害点としない高可用性設定が困難な要件の場合、2 つのリージョンにリリースするのが最適なオプションです。このシナリオでの VPN ゲートウェイの障害は、プライベートスペースがすでに設定されている代替リージョンに影響を受けるリージョンをフェールオーバーすることで解決できます。
メッセージ損失ゼロ
リージョン全体で障害が発生した場合にメッセージ損失をゼロにするには、アプリケーションでデータ損失を防止し、次の点に対処する必要があります。
- 外部メッセージングを使用して、メッセージの信頼性を実現します。
- 本質的にトランザクションである処理中のトランザクションデータにオブジェクトストアが使用されないようにします。MuleSoft アプリケーションが最初にリリースされたリリースリージョンが停止すると、オブジェクトストアが使用できなくなります。
- オブジェクトストアの参照または書き込み操作が失敗したときに、例外処理と動作の両方で機能し続ける個別のフローまたはセクションですべてのオブジェクトストアアクセスをラップします。
メモ。ほとんどの場合、DR 要件では、災害時にメッセージの損失がゼロになるようにする必要はなく、データの損失を特定の期間 (1 時間など) よりも小さくする必要があります。
インテグレーションをステートレスに維持
一般的な設計原則として、インテグレーションが本質的にステートレスであることを確認することは常に重要です。つまり、さまざまなクライアントの呼び出しまたは実行 (スケジュール済みサービスの場合) 間でトランザクション情報は共有されません。システムの制限により一部のデータをミドルウェアで管理する必要がある場合、MuleSoft インフラストラクチャやメモリ内ではなく、データベースやメッセージングキューなどの外部ストアに保持する必要があります。特にクラウドで拡張する場合、各レプリカで使用される状態とリソースは他のレプリカから独立している必要があることに注意してください。このモデルでは、パフォーマンス、拡張性、信頼性が向上します。
複数リージョンのリリースに関する DR のその他の考慮事項
ネットワーキングおよびトラフィック管理
- バニティドメインは、地域の可用性のために必要です。地域全体のすべての入力コントローラーのグローバル DNS として機能します。
- グローバル ロード バランサーは、プライマリ領域と DR 領域のプライベート スペース間でトラフィックをルーティングします。顧客がこのコンポーネントを指定します。AWS ルート 53 またはルーティングポリシーが設定されたグローバル CDN を使用して、地域間でトラフィックを転送します。
- カスタムバニティドメインを使用して、プライマリリージョンと DR リージョンの両方で入力コントローラーを設定します。
- プライマリ領域と DR 領域の両方の非公開領域からオンプレミスアプリケーションにアクセスできるように、ファイアウォールルールと VPN トンネリングを計画および管理します。
- TLS 証明書のメンテナンスでは、シームレスな回復のためにプライマリ領域と DR 領域の両方の非公開領域を対象とする必要があります。
アプリケーションの導入と設定
- アプリケーション名は地域全体で一意である必要があります。たとえば、CI/CD パイプラインでは、リリース前にアプリケーション名にリージョン名 (またはリージョンコード) を追加して、プライマリリージョンと DR リージョン全体で一意性を維持できます。
- プライマリリージョンと DR リージョンの両方にアプリケーションをリリースするように CI/CD パイプラインを設定し、両方のリージョンですべてのアプリケーションを利用できるようにします。
インフラストラクチャと容量
パフォーマンスは、すべてのインフラストラクチャのプライマリおよび DR リージョンの容量が同じ場合に最適です。これらのインフラストラクチャの側面が同じでない場合、パフォーマンスが低下します。
データの保持と保存
- 永続ストレージは、2 つのリージョン間で定期的に同期する必要があります。ストレージレプリケーションはお客様が担当します。MuleSoft では提供していません。プライマリリージョンと DR リージョンの VPC 間で単一共有ストアを使用できますが、共有ストレージの可用性を高くする必要があります。高くしないと、両方のリージョンで単一障害点になります。
- オブジェクトストア V2 は地域性があり、Mule アプリケーションが最初にリリースされた地域でのみ使用できます。アプリケーションを別のリージョンに移動すると、オブジェクトストア V2 はデータの損失を避けるために元のリージョンに残ります。マルチリージョン DR 戦略には、他の永続ストレージを使用します。
テストおよび操作手順
正式な DR テスト戦略を採用し、定期的な DR ドリルを実行します。アクティブ-アクティブ DR の場合、カナリアリリース戦略を使用して両方の地域を検証します。
パフォーマンスおよびサービスレベル契約 (SLA)
DR リージョンがプライマリリージョンよりもエンドユーザーやバックエンドシステムから遠いため、パフォーマンスが低下する場合があります。DR SLA を定義して関係者に伝えます。
リカバリモードの動作 (コンテキストに関する注意)
active-active モードでは、プライマリリージョンから DR リージョンのプライベートスペースへのフェールオーバーは高速です。グローバルロードバランサーはプライマリが正常でないことを検出して、トラフィックを正常 (DR) リージョンにルーティングします。アクティブ-パッシブモードでは、災害が発生したときにアプリケーションを DR リージョンの非公開領域にリリースする必要があります。
地域の対応可能状況オプション
DR レベルの可用性を高めるには、次の 3 つのオプションがあります。
有効-有効設定は、外部ロードバランサーを使用して 2 つのインスタンス間でトラフィックを転送し、地域に分散した有効な作業員に基づきます。
ウォームスタンバイ設定
アクティブ-パッシブ設定は、ある地域の有効な作業員と別の地域の受動作業員に基づきます。パッシブリージョンは、必要に応じて開始されます。
非公開スペース、VPN、中継ゲートウェイ接続など、パッシブリージョンの一部の要素は、フェイルオーバーのために有効なままであるか、事前に設定する必要があります。
上記のとおり、レプリカと入力コントローラーは、フェールオーバー時に完全に自動化された DevOps プロセスを介して 2 つ目のリージョンにプロビジョニングされます。非公開スペース、VPN、中継ゲートウェイ接続など、パッシブリージョンの一部の要素は、フェールオーバーのために有効なままである必要があります。
高可用性のためのバニティドメイン
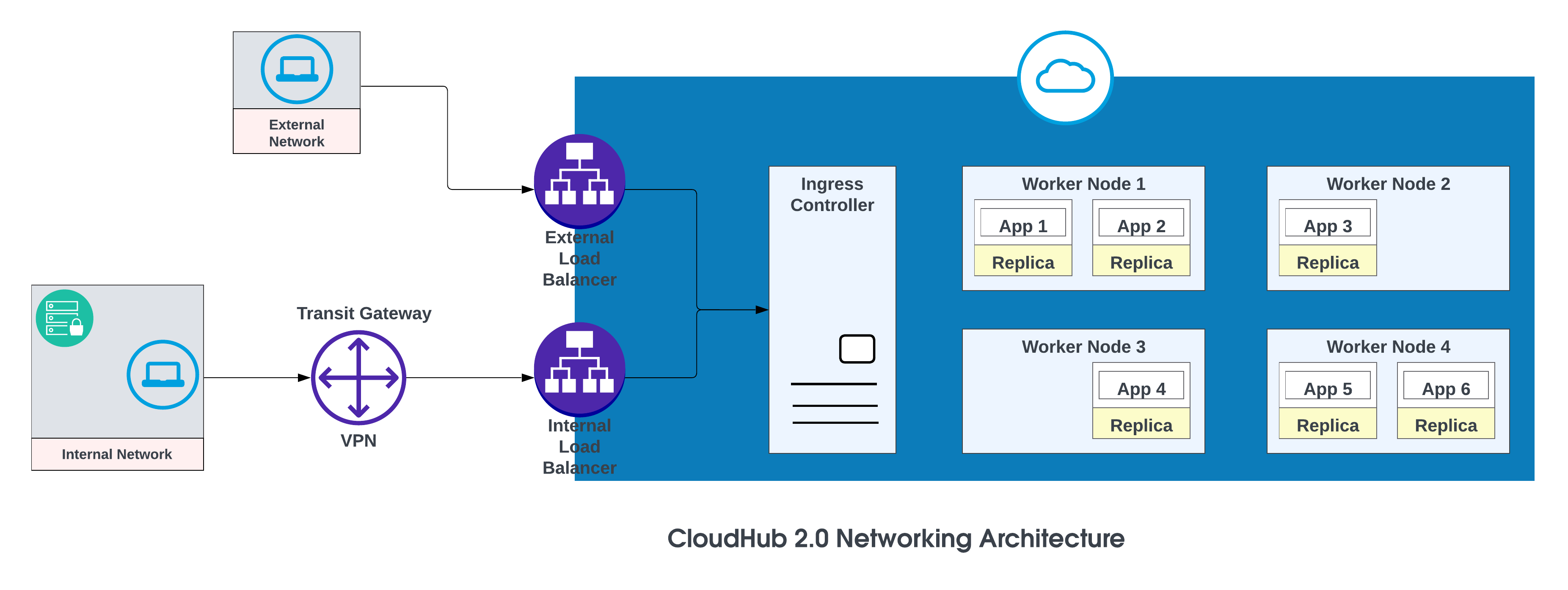
CloudHub 2.0 ネットワークアーキテクチャの基本コンポーネントは次のとおりです。
- HTTP ロードバランサー
- Mule レプリカ DNS レコード
- 非公開スペース
- 地域サービス
詳細については、「CloudHub 2.0 Networking Architecture」を参照してください。
Vanity Domains
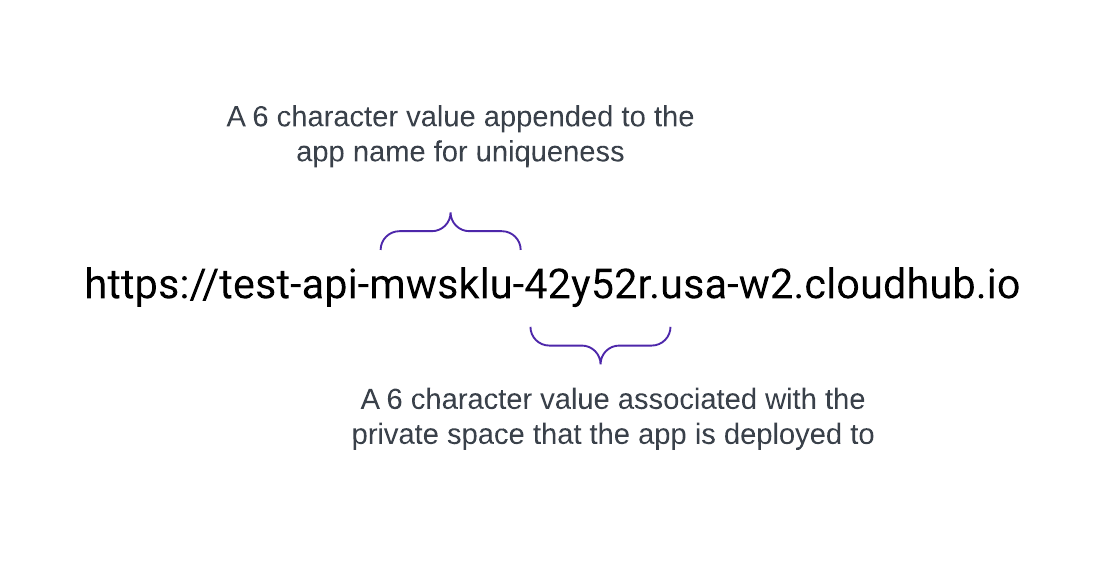
非公開スペースが作成されると、<space-id>.<region>.cloudhub.io の形式で DNS 対象名を受け取ります。この非公開スペースに test-api という名前のアプリケーションをリリースすると、エンドポイントは次の形式に従います。
CloudHub 2.0 では、TLS コンテキストと DNS レコードを使用して非公開スペース内で設定することで、カスタムドメイン (虚栄心) もサポートされます。非公開スペースのランタイムマネージャーで TLS コンテキストを作成するには、公開証明書と非公開鍵をアップロードし、そのドメインを使用するようにアプリケーションの設定にカスタムエンドポイントを追加します。バニティドメインが非公開スペースのデフォルトホスト名を参照する DNS レコード (CNAME など) を作成します。
たとえば、デフォルトの DNS が 42y52r.usa-w2.cloudhub.io で us-west-2 にリリースされた test-api という名前のアプリケーションの API エンドポイントは次のようになります。
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
この URL では、バニティまたはカスタムドメインは使用されません。API URL が https://test-api.acme.com として表示されるように acme.com を使用するには、次の手順に従います。
- Runtime Manager で公開鍵と非公開鍵を使用して TLS コンテキストを作成します。
- アプリケーションの設定でバニティドメインを追加して、そのドメインを使用します。
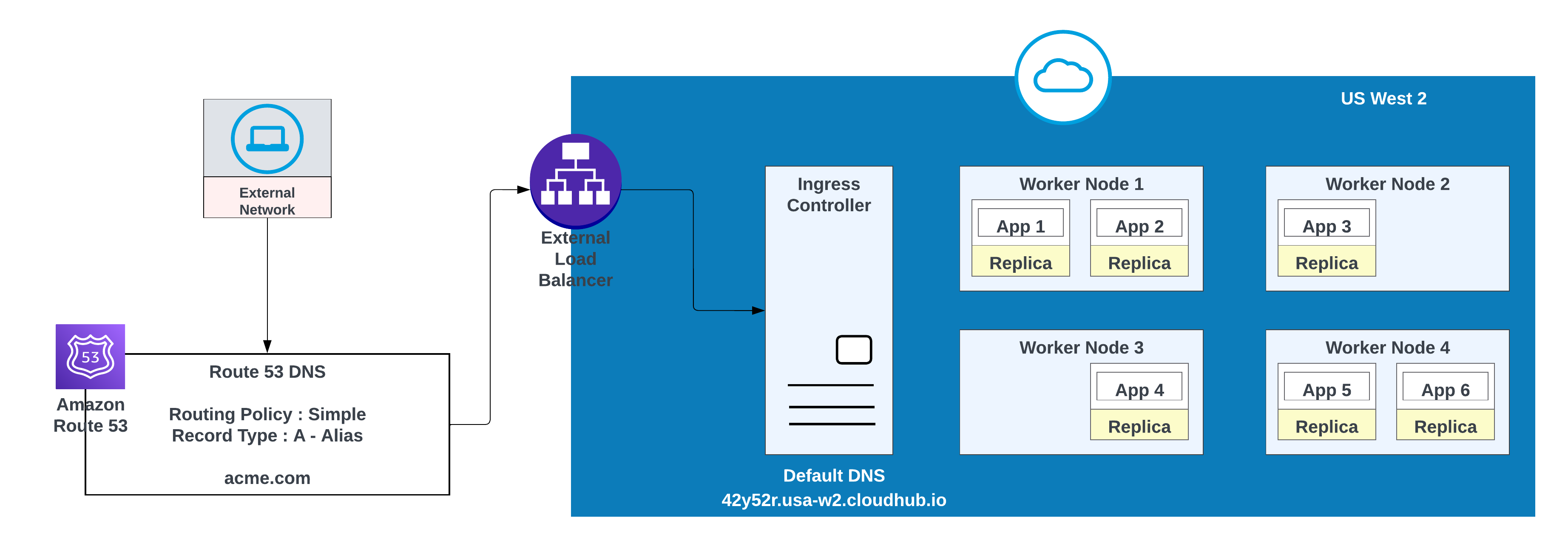
- AWS ルート 53 で DNS レコードを作成し、バニティドメインがプライベートスペースのデフォルトホスト名に解決されるように簡単なルーティングポリシー (CNAME など) を設定します。
カスタムドメインの場合、AWS ルート 53 またはルーティングポリシーを使用するその他のグローバル CDN サービスを使用できます。次の図では、AWS ルート 53 が「シンプル」なルーティングポリシーで使用されています。パブリック (外部) ネットワークのコンシューマーが acme.com を要求すると、AWS ルート 53 はその要求を MuleSoft 非公開スペース入力コントローラーに転送します。
フェールオーバー戦略
このオプションは、アプリケーションでフェイルオーバーが必要な場合に使用します。1 つのインスタンスをプライマリ領域 (us-west-2 など) にリリースし、別のインスタンスをセカンダリ領域 (us-east-1 など) にリリースします。
可能な場合はセカンダリリージョンで既存の環境を使用します。新しい環境を作成するには、追加の作業が必要です。
1 つのリージョンに導入されるアプリケーションの例(米国西部 2)と別のリージョンへのフェイルオーバーの例(米国東部 1)
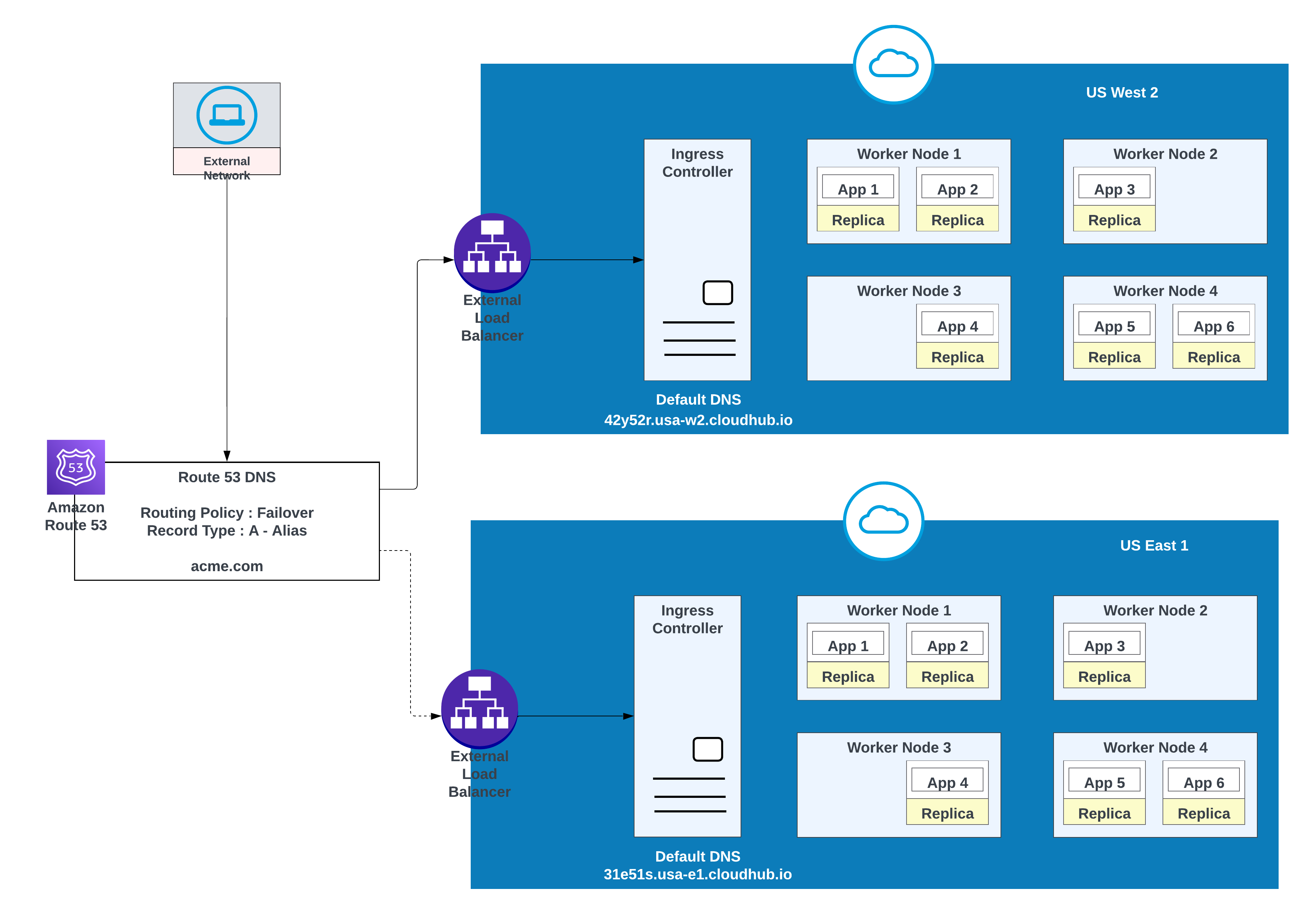
| レコード名 | Value/Route Traffic To (値/トラフィックの転送先) | ルーティングポリシー | 状態チェック ID |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | フェールオーバー | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | フェールオーバー | 43e131s131sq |
この設定では、AWS ルート 53 がトラフィックを米国西部 2 と米国東部 1 のプライベートスペースの入力コントローラーにルーティングします。フェールオーバールーティングポリシーが状態チェックで設定されている。
高可用性と低遅延
高可用性と共に低遅延を実現するには、図で説明されているリリース戦略を使用します。この戦略では、アプリケーションを 2 つのリージョン (この例では us-west-2 と us-east-1) にリリースできます。
AWS ルート 53 の遅延ルーティングポリシーを使用して、高可用性を維持しながら、遅延が最も少ないリージョンに要求を転送します。 AWS ルート 53 の「遅延」ルーティングポリシーを使用して、高可用性を維持しながら、遅延が最も少ないリージョンに要求を転送します。
アプリケーション レイテンシと高可用性を実現するため、両方の地域(米国西部 2 と米国東部 1)に導入
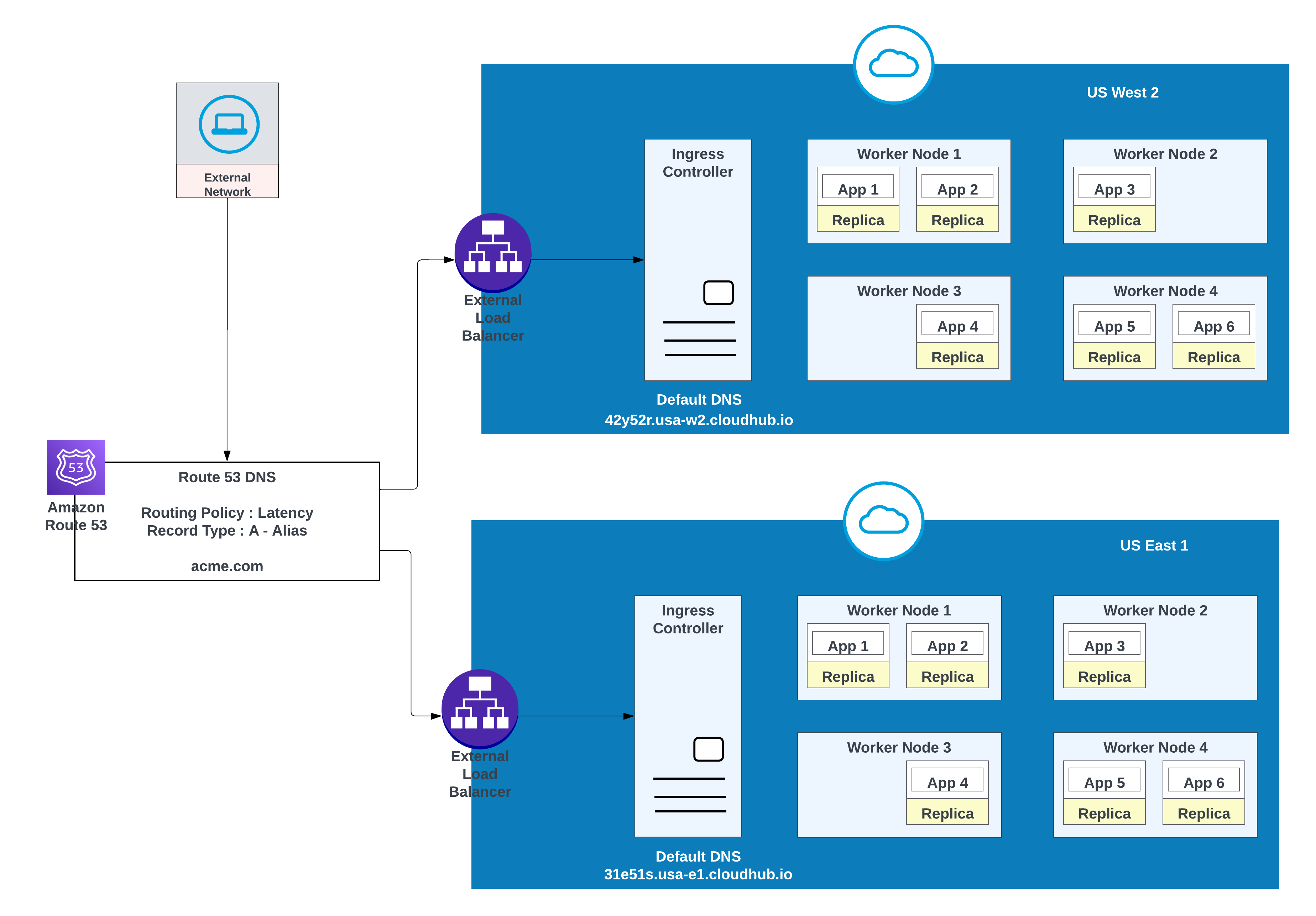
| レコード名 | 値/トラフィックの転送先 | ルーティングポリシー | 状態チェック ID |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | 遅延 | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | 遅延 | 43e131s131sq |
結論
MuleSoft CloudHub 2.0 は、主に自動レプリカ冗長性とインテリジェントなロードバランシングを活用して、リージョン内レジリエンスの堅牢な基盤を提供します。1 つのクラウド領域内で複数のレプリカを使用するアプリケーションを導入することで、1 つのインスタンスに障害が発生しても、他のユーザーがすぐにワークロードを引き継ぐことができます。統合されたロードバランサーにより、受信トラフィックがこれらの正常なレプリカに効率的に分散されるため、ダウンタイムが最小限に抑えられ、通常の運用条件での継続的なサービス可用性が確保されます。
ただし、この単一リージョンアーキテクチャのみに依存すると、冗長性が高くても、広範囲にわたる壊滅的な地域停止が発生する重大なリスクがあります。歴史が示すとおり、最も信頼性が高く、技術的に高度なクラウド プロバイダーであっても、地理的な地域全体に影響する可能性のある破壊的なインシデントが発生しやすくなります。これらの単一障害点は、まれではありますが、次のようなさまざまなイベントによって発生する可能性があります。
- 大規模なインフラストラクチャインシデント
- 重大な停電
- 広範囲のネットワーク中断
したがって、真の高可用性 (HA) とディザスターリカバリー (DR) を実現するには、単一リージョンモデルの制限を超えるアーキテクチャを設計する必要があります。推奨される戦略は、地理的に異なる複数の地域にリリースすることです。このリージョン間の復元性により、予期しない災害によってクラウドリージョン全体が使用できなくなった場合でも、影響を受けない別のリージョンで実行されているアプリケーションインスタンスにトラフィックをシームレスにフェールオーバーできるため、サービスの中断を最小限に抑え、アップタイムの目標を達成できます。
参照
CloudHub 2.0 Networking Architecture
著者について
Gulal Kumar は、Salesforce のソフトウェアエンジニアリングアーキテクトで、データおよびインテグレーションアーキテクチャに重点を置いています。インテグレーションと API、モダナイゼーションプログラム、セキュリティ、AIML イニシアチブで 20 年以上の経験があり、豊富な専門知識を備えています。Gulal は、ビジネス変革イニシアチブを推進し、セキュリティと耐障害性を強化し、アーキテクチャの卓越性を促進し、さまざまなドメインで AIML イニシアチブをリードしてきました。
Ajay Nagaraju は、MuleSoft のエンタープライズアーキテクト兼シニアディ���クターで、エンタープライズアーキテクチャ、システムインテグレーション、大規模なデジタルトランスフォーメーションの分野で 28 年以上の経験があります。また、API 主導の接続、SOA、クラウドテクノロジー、エンタープライズインテグレーションパターンに関する深い専門知識を持ち、Fortune 100 および Fortune 500 の組織で数百万ドルの複雑なプログラムのアーキテクチャと提供を主導してきました。Ajay は、ビジネスプロセス、データプラットフォーム、インテグレーションエコシステムを最新化するために経営陣と密接に連携し、拡張性の高いアーキテクチャの構築、チームの指導、テクノ��ジーによる測定可能なビジネス成果の促進に取り組んでいます。
 j
j3 minute read