Integrações modernas do Salesforce devem oferecer suporte a muito mais do que uma simples troca de dados. É esperado que eles aprimorem as experiências do cliente em tempo real, coordenem ações em vários sistemas e operem com confiança em escala corporativa, tudo ao mesmo tempo que atendem a requisitos de segurança e conformidade rígidos. Assim, escolher a abordagem de integração certa é uma decisão arquitetônica crítica, não um detalhe da implementação. Considere um cenário corporativo comum. Um cliente conclui uma compra em um aplicativo móvel, acionando uma verificação de elegibilidade em tempo real para uma oferta personalizada. Ao mesmo tempo, os dados da transação devem ser registrados em um sistema ERP, os atributos do cliente atualizados no Salesforce e a análise transmitida para um data lake sem introduzir latência, duplicação de dados ou risco de conformidade. Cenários como esse agora são típicos em ambientes do Salesforce modernos, em que o Salesforce raramente opera isoladamente e deve se integrar perfeitamente a um ecossistema mais amplo de aplicativos e plataformas de dados. Esse guia existe para ajudar arquitetos e desenvolvedores a projetar essas integrações com clareza e confiança. Em vez de se concentrar em implementações ponto a ponto, ele apresenta um conjunto de padrões de integração comprovados que abordam cenários empresariais recorrentes, como orquestração de processos, sincronização de dados e acesso a dados em tempo real. Cada padrão enfatiza a intenção arquitetônica, as compensações e os modelos de execução, permitindo que as equipes tomem decisões de design bem informadas que tenham escala e resistência. Neste documento, você encontrará:
- Padrões de integração que representam "arquétipos" corporativos comuns em cenários de processo, dados e acesso virtual
- Uma estrutura de seleção de padrão para ajudar a identificar a abordagem certa com base na intenção de integração e no momento da execução
- Orientação prática sobre aspectos de escalabilidade, resiliência, governança e segurança
- Práticas recomendadas obtidas de implementações do Salesforce e do Data 360 no mundo real O objetivo deste documento é fornecer uma linguagem arquitetônica compartilhada para integração, ajudando as equipes a projetar soluções que equilibram o desempenho, a flexibilidade e o Trust, alinhando-as às estratégias de governança e dados corporativos.
Este documento é para designers e arquitetos que precisam integrar dados de outros aplicativos em suas empresas com o Salesforce Data 360 (antigo Data Cloud). Esse conteúdo é uma distilação de muitas implementações bem-sucedidas por arquitetos e parceiros do Salesforce. Para se familiarizar com as funcionalidades e opções de integração disponíveis para adoção em grande escala do Data 360, leia as seções Resumo do padrão e Guia de seleção de padrão abaixo. Arquitetos e desenvolvedores devem considerar esses detalhes do padrão e práticas recomendadas durante a fase de design e implementação de projetos de interação de dados no Data 360. Se implementados adequadamente, esses padrões permitem que você entre na produção o mais rápido possível e tenha o conjunto de aplicativos mais estável, escalonável e livre de manutenção possível. Os próprios arquitetos de consultoria do Salesforce usam esses padrões como pontos de referência durante revisões de arquitetura e os mantêm e melhoram ativamente. Como acontece com todos os padrões, esse conteúdo abrange a maioria dos cenários de integração, mas não todos. Embora o Salesforce permita a integração da interface do usuário (UI), mascaramentos, por exemplo, essa integração está fora do escopo desse documento.
Cada padrão de integração segue uma estrutura consistente. Isso proporciona consistência nas informações fornecidas em cada padrão e também facilita a comparação de padrões.
- Nome: O identificador de padrão que também indica o tipo de integração contido no padrão.
- Contexto: O cenário geral de integração que o padrão aborda. O contexto fornece informações sobre o que os usuários estão tentando realizar e como o aplicativo se comporta para dar suporte aos requisitos.
- Problema: Expressado como uma pergunta, esse é o cenário que o padrão foi projetado para resolver. Leia esta seção para entender se o padrão é adequado para seu cenário de integração.
- Forças: As restrições e circunstâncias que tornam o cenário declarado difícil de resolver.
- Solução: A maneira recomendada de resolver o cenário de integração.
- Esquema: Um diagrama de sequência UML que mostra como a solução lida com o cenário.
- Resultados: Explica os detalhes de como aplicar a solução ao seu cenário de integração e como ela resolve as forças associadas a esse cenário. Esta seção também contém novos desafios que podem surgir como resultado da aplicação do padrão.
- Barras laterais: Seções adicionais relacionadas ao padrão que contêm os principais problemas técnicos, variações do padrão, preocupações específicas do padrão e assim por diante.
- Exemplo: Um cenário do mundo real que descreve como o padrão de design é usado em um cenário do Salesforce do mundo real. O exemplo explica as metas de integração e como implementar o padrão para atingir essas metas.
Use esta tabela como um índice para os padrões de integração contidos neste documento.
| Nível de padrão1 | Nível de padrão2 | Padrão | Secenário |
|---|---|---|---|
| Padrões de ingestão de dados -- Entrada de dados | Padrões de ingestão de lote | Ingestão de dados em massa do armazenamento em nuvem | Os dados são ingeridos de uma fonte de armazenamento de nuvem corporativa, como Amazon S3, Azure Blob ou Google Cloud Storage, no Data 360 na forma de lotes grandes de dados brutos (por exemplo, transações ou logs de produto). |
| Ingestão de dados em massa do Salesforce Clouds | O Data 360 recebe dados de CRM em massa de várias organizações do Salesforce (por exemplo, Sales Cloud, Service Cloud) para criar perfis de cliente unificados. | ||
| Padrões de ingestão de streaming e em tempo real | Ingestão conduzida por evento via API de ingestão--Streaming | O Data 360 assina pontos de extremidade de ingestão de streaming que recebem cargas úteis de evento contínuas (por exemplo, eventos de compra, telemetria de IoT) de sistemas corporativos para atualizações de perfil em tempo real. | |
| Ingestão de comportamento Web e móvel em tempo real | O Data 360 coleta e processa dados comportamentais em tempo real de aplicativo móvel e site por meio de SDKs para aprimorar métricas de engajamento e modelos de personalização. | ||
| Sincronização de CRM quase em tempo real por streaming | O Data 360 recebe atualizações de dados do CRM (por exemplo, contato, caso, alterações de oportunidade) quase em tempo real por meio de fluxos de evento para manter uma visualização Customer 360 continuamente sincronizada. | ||
| Ingestão de fluxo de evento de plataformas de mensagens em nuvem – Kinesis e MSK | O Data 360 consome dados de streaming diretamente de plataformas de evento de nuvem, como AWS Kinesis ou Kafka (MSK), para processar eventos operacionais ou de IoT de alta frequência. | ||
| Padrões de cópia zero – entrada e saída | Inbound Zero Copy – Plataformas externas para o Data 360 | O Data 360 consulta conjuntos de dados externos (por exemplo, Snowflake, BigQuery) sob demanda por meio da Ingestão de cópia zero, sem mover fisicamente os dados para o Salesforce. | |
| Outbound Zero Copy – Data 360 para plataformas externas | Sistemas externos, como o Databricks ou o Tableau, acessam segmentos e percepções aprimorados no Data 360 por meio de conexões de saída do Zero Copy sem replicação de dados. | ||
| Plataforma de dados unificada para diversas organizações com o Data Cloud One | O Data Cloud One unifica várias organizações do Salesforce e origens de dados externas sob um modelo semântico e metadados compartilhados, proporcionando um Customer 360 consistente sem duplicação de dados. | ||
| Padrões de ativação de dados – Saída de dados | Padrões de ativação em lote | Ativação de segmento para plataformas de marketing e publicidade | O Data 360 ativa segmentos de clientes selecionados diretamente no Marketing Cloud, no Meta, no Google Ads ou em outras plataformas de anúncio para entrega de campanha personalizada |
| Exportação de dados para armazenamento na nuvem | O Data 360 exporta conjuntos de dados unificados ou filtrados (por exemplo, registros de cliente consentidos) como arquivos CSV ou Parquet para armazenamento na nuvem corporativa para análise ou arquivamento de conformidade. | ||
| Ativação baseada em API sob demanda | Integração de aplicativos personalizados via API do Connect | Os aplicativos externos chamam a API do Data 360 Connect em tempo real para recuperar ou acionar ações personalizadas (por exemplo, verificação de saldo de fidelidade ou geração de oferta de IA) com base nos dados atuais do cliente.Aplicativos móveis ou da Web personalizados recuperam percepções do Data 360 harmonizadas com segurança por meio da API REST do Connect para serem exibidos em UIs corporativas ou de parceiros. | |
| Recuperação completa do perfil do cliente por meio da API do Data Graph | Um sistema recupera o perfil unificado de um cliente usando a API do Gráfico de dados, retornando uma representação JSON em tempo real pré-juncionada da visualização completa em 360° para decisão ou personalização. | ||
| Ações de dados em tempo real | Ação de dados em tempo real transformando sinais do cliente em ação instantânea | O Data 360 detecta e processa um evento ativo (por exemplo, atualização de consentimento, acionador de compra) e chama imediatamente um sistema conectado ou o Salesforce Flow para ação a jusante.Um sinal de atividade do cliente (por exemplo, risco de rotatividade detectado) no Data 360 aciona uma ação instantânea em tempo real, como atualizar o CRM, invocar a pontuação do Einstein ou iniciar uma jornada de retenção. |
Os padrões de integração neste documento são classificados em três categorias: integrações de dados, processos e visuais.
Os padrões de integração de dados no Data 360 lidam com a movimentação e a sincronização de dados entre sistemas para garantir que o Data 360 e as plataformas externas contenham informações consistentes, oportunas e confiáveis. Esses padrões costumam lidar com fluxos de dados em grande escala e de alto volume e dependem de pipelines governados que aplicam a consistência do esquema, o rastreamento de linha e as regras de domínio.
- Os Padrões de ingestão em lote representam a camada fundamental da integração de dados corporativos. A ingestão de dados em massa de serviços de armazenamento em nuvem, como AWS S3, Azure Blob ou Google Cloud Storage, permite que grandes conjuntos de dados históricos sejam carregados periodicamente no Data 360 para resolução de identidade, segmentação e análise. Da mesma forma, a ingestão em massa de nuvens do Salesforce, como Sales, Service ou Marketing Cloud, usa conectores nativos e fluxos de dados para trazer dados de CRM para a camada de dados unificada, garantindo harmonização e continuidade entre sistemas de engajamento.
- Os Padrões de ingestão de streaming e em tempo real ampliam isso capturando dados de evento de alta velocidade. A ingestão conduzida por evento por meio da API de ingestão permite que os sistemas externos transmitam continuamente a atividade do cliente para o Data 360. A ingestão de comportamento móvel e da Web em tempo real captura dados de interação e clickstream diretamente de pontos de contato digitais para promover a personalização imediata. A sincronização quase em tempo real do CRM por meio de APIs de streaming garante que atributos do cliente e atualizações de consentimento sejam refletidos rapidamente entre sistemas. A ingestão de fluxo de evento de plataformas de mensagens, como Amazon Kinesis ou Confluent MSK, oferece suporte a pipelines contínuos de alta taxa de transferência, alinhando o Data 360 a arquiteturas de evento corporativas.
- A Plataforma de dados multiorganização unificada com o Data Cloud One exemplifica ainda mais a integração de dados, fornecendo um ambiente consolidado para unificar dados de várias organizações do Salesforce e origens externas sob uma camada semântica e de governança comum. Isso permite que as organizações obtenham consistência de dados corporativos, modelos de dados compartilhados e análises dimensionáveis.
- Na fase de ativação, os Padrões de ativação em lote seguem o mesmo princípio de integração de dados. Os segmentos selecionados no Data 360 são exportados em trabalhos agendados para plataformas de marketing e publicidade a jusante, como Marketing Cloud, Meta Ads ou Google Ads, em que acionam a execução da campanha. Da mesma forma, os conjuntos de dados podem ser exportados para destinos de armazenamento na nuvem para alimentar pipelines externos de análise e ciência de dados. Em todos esses casos de uso, o Data 360 atua como a fonte da verdade para dados do cliente sincronizados e selecionados.
Os padrões de integração de processo no Data 360 envolvem acionar ou orquestrar processos de negócios entre sistemas quase em tempo real. Esses padrões permitem que o Data 360 participe ativamente de fluxos de trabalho corporativos, habilitando respostas contextuais e ativação de dados dinâmica.
- Ativação baseada em API sob demanda permite cenários de engajamento em tempo real. Por meio da API do Connect, aplicativos personalizados podem consultar ou ativar perfis do cliente diretamente do Data 360 como parte de processos operacionais, como um console do agente que recupera percepções de perfil unificado durante uma interação com o cliente. A Recuperação completa de perfil do cliente por meio da API de gráfico de dados oferece suporte a aplicativos compostos e microsserviços que dependem de acesso orientado por API ao gráfico completo de entidade de um cliente, permitindo experiências dinâmicas sem segmentos pré-estagiados.
- As Ações de dados em tempo real impulsionam ainda mais essa abordagem de integração habilitando a responsividade imediata. Quando um sinal do cliente, como compra, envio de formulário ou evento de limite, é detectado, o Data 360 pode acionar ações como atualizar um registro do CRM, invocar um webhook externo ou iniciar um fluxo de trabalho de oferta personalizado. Esses padrões incorporam uma verdadeira orquestração de processos, conectando a Inteligência do cliente em tempo real com execução operacional automatizada.
Os padrões de integração virtual no Data 360 permitem o acesso ativo a origens de dados externas ou federadas sem copiar ou duplicar dados fisicamente. Eles são essenciais para empresas que exigem informações gerenciadas e atualizadas no momento da consulta enquanto minimizam a movimentação de dados.
- A Inbound Zero Copy Data Federation (Plataformas externas para Data 360) permite que sistemas externos, como armazéns de dados ou data lakes, compartilhem conjuntos de dados com o Data 360 por meio de conexões seguras e gerenciadas (por exemplo, o Snowflake Secure Data Sharing). Isso garante que o Data 360 possa acessar e operar em dados externos virtualmente, preservando a atualidade e eliminando a replicação desnecessária.
- O Compartilhamento de dados de cópia zero externo (Plataformas Data 360-to-External) permite que o Data 360 exponha conjuntos de dados selecionados para consumo externo, como modelagem de IA, inteligência de negócios ou análise avançada, por meio de federação de dados segura e mecanismos de consulta ativa. Escolher a melhor estratégia de integração para seu sistema não é trivial. Há muitos aspectos a serem considerados e muitas ferramentas que podem ser usadas, sendo que algumas ferramentas são mais adequadas do que outras para determinadas tarefas. Cada padrão aborda áreas críticas específicas, incluindo os recursos de cada um dos sistemas, o volume de dados, o tratamento de falhas e a transacionalidade.
Ao selecionar um padrão de integração, comece respondendo a duas perguntas fundamentais que moldam o design geral e o comportamento da integração. O que você está integrando? — Processamento, Dados ou Acesso virtual Essa dimensão define o propósito principal da integração.
- As integrações de processos focam a orquestração de fluxos de trabalho de negócios e a coordenação de ações entre sistemas.
- As integrações de dados focam a sincronização, enriquecimento ou propagação de dados entre sistemas.
- As integrações virtuais se concentram em acessar dados externos em tempo real sem copiá-los ou persisti-los no Salesforce ou no Data 360. Entender essa intenção ajuda a determinar o nível de orquestração, movimentação de dados e acoplamento necessário entre os sistemas.
- Como ele precisa ser executado? — O método síncrono ou assíncrono define o modelo de execução da integração.
- As integrações síncronas são em tempo real e de bloqueio, em que o chamador espera uma resposta imediata, comumente usada para cenários conduzidos pelo usuário ou de validação.
- As integrações assíncronas são não bloqueadoras e desacopladas, projetadas para lidar com escala, processos de longa duração, novas tentativas e grandes volumes de dados. Juntos, essas duas dimensões – a intenção de integração e o tempo de execução – fornecem uma estrutura clara e consistente para selecionar o padrão de integração certo, equilibrando a experiência do usuário, a escalabilidade e a resiliência operacional. Nota: Uma integração pode exigir um middleware externo ou uma solução de integração (por exemplo, o Enterprise Service Bus), dependendo de quais aspectos se aplicam ao seu cenário de integração.
Esta tabela lista os padrões e seus principais aspectos para ajudá-lo a determinar qual padrão atende melhor aos seus requisitos quando sua integração é do Salesforce para outro sistema
| Tipo | Tempo | Considerações de saída |
|---|---|---|
| Integração de dados | Assíncrono | Ativação de segmento para plataformas de marketing e publicidade |
| Processamento/Integração de dados | Síncrono | Integração de aplicativos personalizados via API do Connect Recuperação completa do perfil do cliente por meio da API do Data Graph |
| Integração de dados | Síncrono | Ação de dados em tempo real transformando sinais do cliente em ação instantânea |
| Integração virtual (usando a cópia zero) | Assíncrono | Outbound Zero Copy – Data 360 para plataformas externas |
| Integração virtual | Assíncrono | Plataforma de dados unificada para diversas organizações com o Data Cloud One |
Esta tabela lista os padrões e seus principais aspectos para ajudá-lo a determinar o padrão mais adequado aos seus requisitos quando sua integração for de outro sistema para o Salesforce.
| Tipo | Tempo | Considerações de entrada |
|---|---|---|
| Integração de dados | Assíncrono | Ingestão de dados em massa do armazenamento em nuvem Ingestão de dados em massa do Salesforce Clouds |
| Integração de dados | Assíncrono | Ingestão de fluxo de evento de plataformas de mensagens em nuvem – Kinesis e MSK Sincronização de CRM quase em tempo real por streaming |
| Integração de processos | Síncrono | Ingestão conduzida por evento via API de ingestão--Streaming Ingestão de comportamento Web e móvel em tempo real |
| Integração virtual | Assíncrono | Inbound Zero Copy – Plataformas externas para o Data 360 |
Esta tabela lista alguns termos-chave relacionados ao middleware e suas definições com relação a esses padrões.
| Termo | Definição |
|---|---|
| Manuseio de evento | A manipulação de eventos se refere a receber, rotear e responder a ocorrências identificáveis de um sistema de origem ou aplicativo. O Middleware lida com eventos identificando o ponto de extremidade de destino, encaminhando o evento e acionando a ação de negócios necessária (por exemplo, registro, novas tentativas ou ativação de serviços downstream). Em arquiteturas do Data 360, a manipulação de eventos é essencial para ingestão de dados em tempo real, acionadores de ativação e padrões de publicação/assinatura. Os eventos podem se originar de sistemas externos (Kafka, AWS Kinesis) ou Eventos da Salesforce Platform e são roteados pelo middleware ou pelo barramento de eventos do Data 360 para processamento imediato. |
| Conversão de protocolo | A conversão de protocolo permite a comunicação entre sistemas usando diferentes padrões de transporte de dados. O Middleware traduz protocolos proprietários ou legados (como AMQP, MQTT, FTP) em protocolos compatíveis do Data 360 (REST, gRPC ou HTTPS). Isso garante a interoperabilidade entre sistemas heterogêneos. Como o Data 360 não lida nativamente com a conversão de protocolo, o middleware fornece a camada de adaptação, encapsulando ou transformando mensagens em APIs do Data 360 em um formato que os conectores podem interpretar. |
| Tradução e Transformação | A tradução e a transformação garantem a interoperabilidade mapeando um formato de dados ou esquema para outro. O Middleware realiza essas transformações para alinhar diversas cargas úteis de dados (CSV, XML, JSON) com objetos de modelo de dados (DMOs) do Data 360 e objetos de camada de dados unificados (UDLOs). Isso inclui limpar, aprimorar e aplicar mapeamento semântico ou baseado em ontologia antes da ingestão. Embora o Salesforce ofereça ferramentas de transformação como Receitas do Preparador de dados, as transformações complexas (especialmente para harmonização semântica) são melhor tratadas em middleware. |
| Enfileiramento e buffering | O enfileiramento e o buffering dependem da passagem de mensagens assíncronas para garantir uma comunicação resiliente e desacoplada. As plataformas de middleware (por exemplo, MuleSoft, Kafka ou Azure Event Hub) fornecem filas persistentes que armazenam dados temporariamente quando o Data 360 ou sistemas downstream estão ocupados ou inacessíveis. Isso evita a perda de dados e dá suporte a novas tentativas de ingestão ou ativação quase em tempo real. O Data 360 oferece suporte à ingestão de streaming e a mensagens de saída baseadas em fluxo, mas o enfileiramento durável e a entrega garantida geralmente são tratados pelo middleware. |
| Protocolos de transporte síncrono | Os protocolos de transporte síncrono envolvem operações de bloqueio de solicitação/resposta em tempo real. O remetente espera uma resposta antes de prosseguir. No Data 360, eles são usados para ativações baseadas em API sob demanda, aprimoramento em tempo real ou pesquisas de perfil, em que as respostas são necessárias imediatamente. O Middleware garante a confiabilidade da conexão e gerencia novas tentativas ou o gerenciamento de fallback para chamadas síncronas à API do Data 360. |
| Protocolos de transporte assíncrono | Os protocolos de transporte assíncronos oferecem suporte à comunicação não bloqueada e desacoplada em que o remetente continua processando sem esperar uma resposta. O Middleware lida com fluxos assíncronos para ativações em lote, ingestão de streaming e ativação conduzida por evento. Isso permite alta taxa de transferência e resiliência, essenciais para padrões de ingestão de dados quase em tempo real e streaming de evento no Data 360. |
| Roteamento de mediação | O roteamento de mediação define o fluxo de mensagens complexo entre sistemas, garantindo que os dados ou o evento certos cheguem ao consumidor correto. O middleware atua como mediador, lidando com a lógica de roteamento com base em regras, cabeçalhos, conteúdo ou tipo de evento. Em integrações do Data 360, a mediação garante que eventos e atualizações de perfil de vários sistemas sejam roteados adequadamente para APIs de ingestão de dados, pontos de extremidade de ativação ou consumidores externos. Isso simplifica a orquestração e dá suporte à sincronização de dados de vários sistemas. |
| Coreografia de processos e orquestração de serviço | A coreografia do processo e a orquestração coordenam processos de vários sistemas. A coreografia oferece suporte a fluxos autônomos assíncronos conduzidos por evento, em que os sistemas atuam com base em regras compartilhadas sem um controlador central. A orquestração é um fluxo gerenciado centralmente que direciona a execução do serviço. Em arquiteturas do Data 360, o middleware gerencia a orquestração para ingestão e ativação entre sistemas, enquanto fluxos de trabalho ou fluxos do Salesforce gerenciam coreografias leves dentro da plataforma. Orquestração complexa, que requer coordenação de transação ou gerenciamento de estado, é recomendada na camada de middleware. |
| Transaccionalidade (criptografia, assinatura, entrega confiável, gerenciamento de transações) | A transacionalidade garante operações atômicas, consistentes, isoladas e duráveis (ACID) entre sistemas. O Salesforce e o Data 360 são transacionais dentro de seus limites, mas não oferecem suporte a transações distribuídas entre sistemas externos. O Middleware lida com o controle de transações globais, incluindo criptografia, assinatura de mensagens, reversão, compensação e entrega confiável. Para fluxos de dados críticos para a missão (por exemplo, atualizações financeiras ou de consentimento), o middleware garante a integridade completa e a recuperação em sistemas externos e do Data 360. |
| Rotagem | O roteamento especifica o fluxo controlado de mensagens ou dados entre componentes. Pode ser baseado em cabeçalhos, tipo de conteúdo, prioridade ou regras. O Middleware lida com a lógica de roteamento para eventos e ativações envolvendo o Data 360, como direcionar segmentos de público avançados para diferentes sistemas downstream (plataformas de anúncios, armazéns, aplicativos CRM). Embora o roteamento possa ser implementado no Salesforce (Apex, Fluxos), o roteamento de middleware é preferido para escalabilidade, flexibilidade e governança. |
| Extrair, transformar e carregar (ETL) | O ETL envolve extrair dados de sistemas de origem, transformá-los em um esquema consistente e carregá-los em um destino (como o Data 360). As ferramentas de middleware ou ETL lidam com essas operações antes da ingestão de dados. O Data 360 pode receber saídas ETL por meio de APIs, conectores ou pipelines de ingestão em massa e também oferece suporte à Captura de dados de alteração (CDC) para sincronização quase em tempo real. Os processos ETL do Middleware são essenciais para integrar sistemas legados e garantir a qualidade dos dados antes da unificação no Data 360. |
| Polling longo | Pesquisa longa (programas de Cometa) é um método para manter a comunicação aberta entre sistemas para atualizações em tempo real. O cliente envia uma solicitação e o servidor a mantém até que um evento ocorra, então responde e reabre uma nova conexão. O Salesforce usa isso na API de streaming e nos protocolos CometD/Bayeux para sincronização de dados conduzida por evento. O Middleware pode assinar esses eventos e encaminhá-los para o Data 360 para acionadores de ingestão ou ativação em tempo real, garantindo a latência mínima entre sistemas corporativos. |
A ingestão de dados é a primeira e mais crítica etapa do ciclo de vida de dados do Salesforce Data 360. É como as informações brutas de vários sistemas externos (CRM, ERP, Web, móvel ou APIs de terceiros) entram na plataforma e se tornam parte de uma visualização unificada do cliente. O padrão de ingestão certo depende do que a empresa precisa:
- Volume de dados — Quantos dados estão se movendo ao mesmo tempo
- Latency – quão recentes os dados devem estar
- Funcionalidades do sistema de origem – como o sistema pode conectar e entregar dados O Data 360 oferece suporte a vários modos de ingestão para atender a essas necessidades: lote para carregamentos de alto volume, streaming para atualizações quase em tempo real, baseado em evento para imediato transacional e ingestão do Zero Copy para acesso instantâneo a dados externos sem movê-los fisicamente. Juntos, esses padrões garantem que cada sinal do cliente, seja um evento de compra, um registro de fluxo de cliques ou uma atualização de fidelidade, flua para o Data 360 de modo eficiente, seguro e no período certo para habilitar análises confiáveis e experiências conduzidas por IA.
Os padrões de ingestão em lote são a base da integração de dados em grande escala no Data 360. Eles são otimizados para cenários em que os dados são processados em massa, geralmente de modo agendado ou periódico, em vez de continuamente. Estes padrões são mais adequados para:
- Carregamentos de dados históricos para inicializar a plataforma com registros empresariais existentes
- Sincronização regular com sistemas de registro, como ERPs, armazéns de dados ou bancos de dados proprietários
- Use casos em que a atualização em tempo real não é essencial, mas consistência, completude e capacidade de auditoria são A ingestão em lote oferece desempenho previsível e simplicidade operacional, tornando-a uma escolha confiável para empresas que gerenciam terabytes de dados estruturados ou semistruturados. O Data 360 fornece um conjunto de conectores disponíveis ao público em geral prontos para produção que suportam a ingestão de lote nativamente. Esses conectores simplificam a configuração da integração, reduzem o desenvolvimento de ETL personalizado e garantem a qualidade e a segurança dos dados em todas as importações. A tabela abaixo destaca os conectores mais comuns usados para ingestão em lote em escala corporativa.
Contexto
Esse padrão é projetado para cenários corporativos que envolvem a ingestão de grandes volumes de dados estruturados, como arquivos CSV ou Parquet, e ativos não estruturados de data lakes centralizados ou gotações de arquivos agendadas. As fontes de dados geralmente incluem plataformas de armazenamento em nuvem, como Amazon S3, Google Cloud Storage (GCS) e Microsoft Azure Blob Storage, em que os arquivos são entregues periodicamente como parte de pipelines de dados upstream ou exportações em lote.
Problema
Como uma organização pode estabelecer um processo confiável, seguro e de alto rendimento para ingerir conjuntos de dados baseados em arquivo de sua plataforma de armazenamento de nuvem primária para o Data 360 em uma agenda recorrente e previsível sem sacrificar a governança, a escalabilidade ou o desempenho?
Forças
Ingerir conjuntos de dados em massa baseados em arquivos no Data 360 não é um exercício simples de transferência de dados, é um desafio arquitetônico moldado por restrições de escala, governança e plataforma.
Volume e escala dos dados: Os conectores de ingestão do Data 360 são otimizados para confiabilidade e governança, não para taxa de transferência em massa arbitrária. Por exemplo, o conector do Amazon S3 oferece suporte a até 100 milhões de linhas ou 50 GB por objeto, o limite que for atingido primeiro. Para empresas com conjuntos de dados históricos executados em bilhões de registros, esse limite se torna uma principal restrição de design. Uma abordagem de aumento e mudança de arquivo único rapidamente se torna inviável, exigindo estratégias inteligentes de particionamento de dados, agrupamento e orquestração para atingir a escala sem atingir os limites do conector.
Definir esquema e manutenção : O Data 360 exige definições de esquema explícitas para cada pipeline de ingestão para garantir a integridade semântica e estrutural. No caso da ingestão do S3, um arquivo csv deve definir cabeçalhos de coluna e uma única linha de dados representativa. Esse arquivo atua como o contrato canônico entre o sistema de origem, ou seja, o armazenamento em nuvem e o Data 360. Qualquer desalinhamento (em nomes de campo, tipos de dados ou codificação) pode causar falhas de ingestão ou corrupção de dados silenciosos. Manter esse arquivo de esquema no controle de versão e impor validação por meio de fluxos de trabalho de CI/CD ou governança de dados se torna uma prática recomendada para ambientes de produção.
Convenções de nomenclatura estrita : O Data 360 aplica regras rígidas de nomenclatura de objetos e campos para manter a consistência em todo o gráfico de metadados.
- Os nomes de objeto devem começar com uma letra e podem incluir somente letras, dígitos ou sublinhados.
- Os nomes de campo devem seguir os mesmos padrões. Arquivos que violam essas convenções, por exemplo, campos contendo espaços, caracteres especiais ou símbolos sem suporte, falharão na validação do esquema durante a ingestão. As empresas devem implementar processos de higiene de dados pré-ingestão para sanitar e normalizar estruturas de arquivos de entrada.
Posição de autenticação e segurança: Cada conexão com armazenamento externo deve estar em conformidade com os padrões de conformidade e segurança corporativos.
- A autenticação geralmente é processada por meio de chaves de acesso/segredo da AWS ou autenticação de provedor de identidade federado (IdP).
- Os papéis do IAM devem ter o escopo para aplicar o privilégio mínimo, permitindo apenas acesso de leitura aos caminhos de armazenamento especificados.
- Para acesso seguro, os endereços IP de saída devem ser adicionados diretamente à lista de permissões do sistema de origem. Esses controles em camadas garantem que cada transferência de arquivo funcione dentro de um perímetro de Trust zero e auditável, equilibrando a conformidade da empresa com a flexibilidade necessária para ingestão em grande escala.
Solução
Esta tabela contém soluções para esse problema de integração.
| Solução | Ajuste | Comentários |
|---|---|---|
| Usar conectores de armazenamento do Native Cloud (Amazon S3, Google Cloud Storage, Armazenamento de Blobs do Azure) | Melhor | Esse é o padrão recomendado e mais confiável para ingestão baseada em arquivo recorrente em grande escala no Data 360\. Conectores nativos fornecem autenticação gerenciada, mapeamento de esquema e movimentação segura de dados diretamente para os objetos do Data Lake (DLOs) do Data 360. Ideal para carregamentos em lote agendados em que a latência não é crítica (por exemplo, agendamento por hora ou diário). |
| Processamento de conjuntos de dados grandes (além dos limites do conector) | Melhor com pré-processamento | Cada conector impõe limites de ingestão (por exemplo, S3: 100M de linhas ou 50 GB por objeto). Para conjuntos de dados maiores, implemente uma etapa de pré-processamento de ETL para particionar dados em arquivos/pastas menores que estejam abaixo desses limites. Em seguida, configure vários fluxos de dados para ingerir cada partição em paralelo e use o nó de adição em uma transformação de dados em lote) no Data 360 para recombinar as partições em um conjunto de dados unificado. |
| Segurança e governança | Melhor | Todos os conectores oferecem suporte à autenticação segura por meio de métodos nativos da nuvem (papéis do IAM, contas de serviço ou chaves de acesso). Para maior controle, restrinja o acesso a intervalos de IP do Data 360 por meio da lista de permissões do provedor de nuvem. A transferência de dados ocorre em canais criptografados, com arquivos armazenados em uma camada de preparação temporária e segura durante a ingestão. |
| Quando não usar | Suboptimal | Esse padrão não é ideal para:
|
Esboço
Este diagrama ilustra a sequência de etapas para ingerir os dados do armazenamento na nuvem para o Data 360
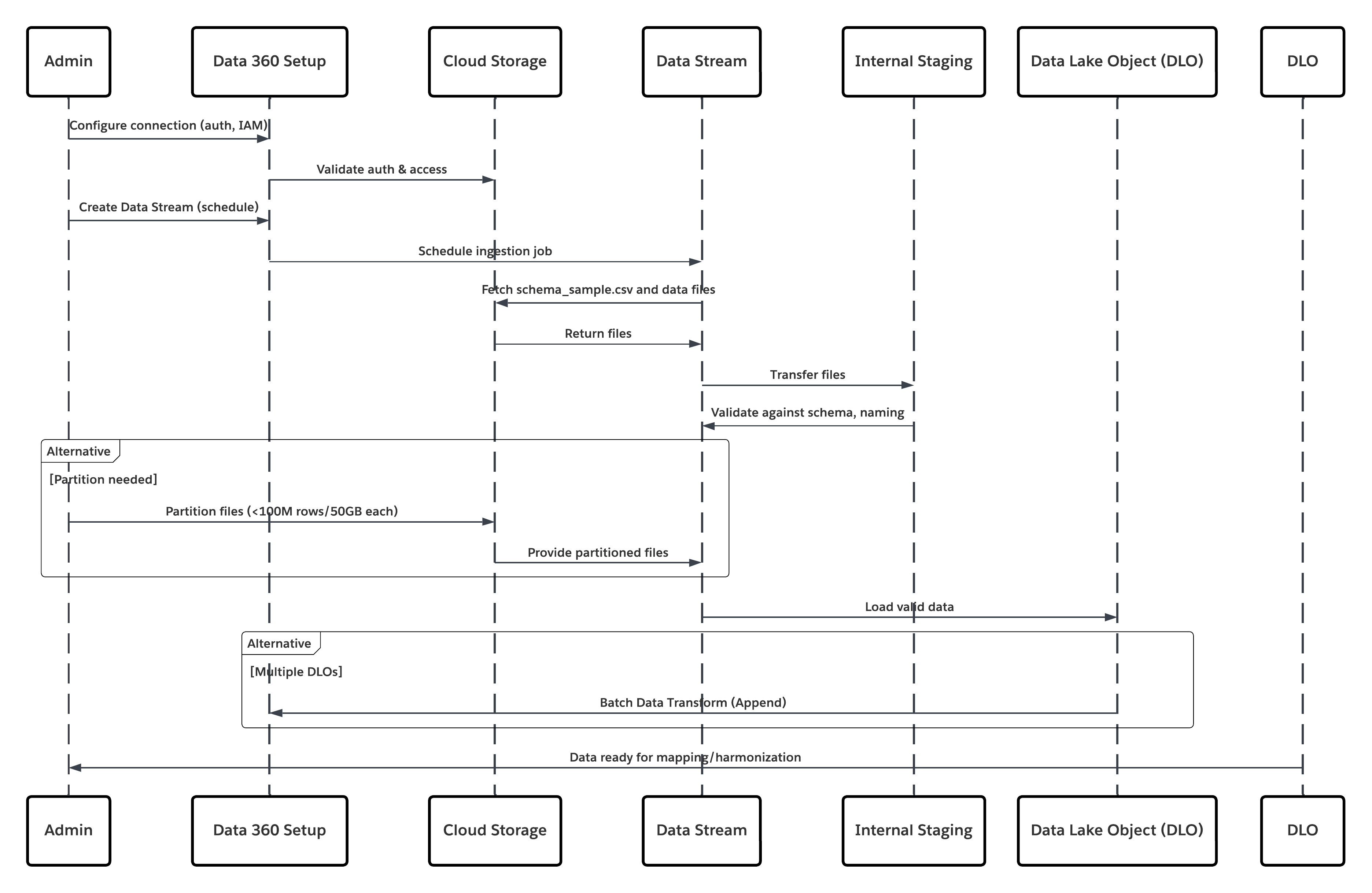
Neste cenário:
- O administrador configura uma conexão com o armazenamento na nuvem por meio da interface de Configuração do Data 360 (especificando a autenticação, os detalhes do bucket, os papéis do IAM e a lista de permissões).
- A interface de Configuração do Data Cloud autentica com a plataforma de armazenamento em nuvem, verificando as credenciais e o acesso.
- O administrador cria um fluxo de dados no Data 360, vinculando o fluxo de dados ao objeto/pasta no Armazenamento na nuvem e definindo a agenda de ingestão.
- No acionador de agenda, o fluxo de dados solicita arquivos de origem (por exemplo, CSV, Parquet) da plataforma de armazenamento em nuvem.
- A Plataforma de armazenamento em nuvem entrega arquivos, incluindo o schema_sample.csv válido obrigatório e outros arquivos de dados em conformidade com convenções de nomenclatura.
- O fluxo de dados transfere arquivos para o ambiente de preparação interno no Data 360.
- O Pipeline do Data 360 processa os arquivos: Usa a definição de esquema de schema_sample.csv Valida a estrutura, os nomes de campo e divide a carga se estiver acima dos limites de ingestão (100 milhões de linhas/50 GB por arquivo). Se arquivos grandes forem detectados, uma etapa de particionamento de pré-processamento (notificada ao administrador para a próxima execução) será realizada externamente.
- Os registros são importados da preparação para um objeto de data lake (DLO).
- Se necessário e os dados estiverem particionados, use o nó append em uma transformação de dados em lote para combinar vários DLOs.
- O Data 360 registra o sucesso/falha, atualiza o status para monitoramento e indica que os dados estão prontos para mapeamento, harmonização e unificação.
Resultados
A aplicação desse padrão permite a ingestão segura, agendada e em grande escala de arquivos estruturados ou não estruturados de plataformas de armazenamento de nuvem corporativa para o Data 360. O processo é automatizado, escalonável e resiliente, entregando dados brutos em objetos de data lake (DLOs) que servem de base para harmonização e mapeamento para o Modelo de dados Customer 360.
Mecanismos de ingestão
O mecanismo de ingestão depende do conector e da estratégia de agendamento definidos no Data 360.
| Mecanismo de ingestão | Descrição |
|---|---|
| Conector de armazenamento do Native Cloud (Amazon S3, GCS, Azure) | Recomendado para ingestão direta de arquivos no formato CSV ou Parquet do data lake de nuvem da empresa. Esses conectores oferecem suporte a agendas de atualização incrementais e completas. Por exemplo, um banco pode configurar uma sincronização diária de arquivos de transação do cliente de um bucket do S3 para um DLO. |
| Estratégia de arquivo particionado | Para conjuntos de dados muito grandes (mais de 100 milhões de linhas ou 50 GB por objeto), os dados são particionados em conjuntos lógicos menores (por exemplo, por mês ou região). Cada partição é gerenciada como um fluxo de dados separado e posteriormente recombinada usando uma transformação de dados em lote com um nó Acrescentar. |
| Sincronização agendada automatizada | O Data 360 fornece um agendador declarativo (hora, dia ou ritmo personalizado) que aciona trabalhos de ingestão automaticamente, garantindo a atualização dos dados sem intervenção manual. |
Tratamento e recuperação de erros
O tratamento e a recuperação de erros são essenciais para garantir a confiabilidade em operações de ingestão de alto volume.
- Detecção de erro: Cada execução de Fluxo de dados registra erros de ingestão (por exemplo, incompatibilidade de esquema, corrupção de arquivo ou violações de nomenclatura) no Monitoramento do Data 360. Os administradores podem revisar e reprocessar lotes com falha.
- Mecanismo de recuperação: O Data 360 mantém o apontamento de verificação para garantir que lotes com falha não corrompam ingestões anteriores. As novas tentativas podem ser configuradas depois de corrigir problemas de origem (por exemplo, CSVs malformados).
- Validação de esquema: O arquivo schema_sample.csv define tipos de dados e estrutura. Qualquer alteração aciona a validação para evitar o desvio silencioso de esquema entre execuções.
Considerações sobre design idempotente
A ingestão é idempotente por design: reprocessar o mesmo arquivo não resulta em registros duplicados. As principais estratégias incluem:
- Arquivo de impressão digital: O Data 360 calcula as somas de verificação para identificar e ignorar arquivos processados anteriormente.
- Ingestão transacional: Os dados são preparados e confirmados no DLO apenas após o processamento bem-sucedido de todos os registros.
- Adicionar vs. Substituir: Dependendo da lógica de negócios, os fluxos podem anexar ou substituir totalmente o DLO de destino; isso garante resultados determinísticos e evita sobreposições de dados parciais.
Considerações de segurança
A segurança é integral em todo o pipeline de ingestão, da autenticação à criptografia e controle de acesso.
- Autenticação & Autorização: Os conectores usam a Estrutura de integração segura do Salesforce, aproveitando Credenciais nomeadas e Credenciais externas para autenticação sem expor segredos.
- Criptografia: Os dados são criptografados em trânsito (TLS 1.2+) e em repouso (AES-256).
- Controles de rede: Os sistemas de armazenamento de origem (por exemplo, buckets do S3) devem incluir IPs do Data 360 na lista de permissões.
- Alinhamento de conformidade: Suporta estruturas de proteção de dados corporativas, como diretrizes de GDPR, HIPAA e FFIEC, quando combinadas a Chaves gerenciadas pelo cliente (CMK).
- Auditabilidade: Cada trabalho de ingestão e acesso à credencial são registrados para relatórios de rastreabilidade e conformidade.
Barras laterais
Tempo
O tempo depende da agenda de ingestão e do volume de dados.
- Grandes conjuntos de dados corporativos (100M+ linhas) podem exigir particionamento para ingestão paralela.
- A latência de ingestão típica varia de minutos a algumas horas, dependendo do tamanho do arquivo e da complexidade da transformação.
- Para ingestão quase em tempo real, os conectores baseados em API ou de streaming do Data 360 podem complementar o modelo baseado em arquivo.
Volumes de dados
- Mais adequado para ingestão de lote periódica de alto volume.
- Cada objeto processado por meio do conector do S3 oferece suporte a até 100 milhões de linhas ou 50 GB por arquivo.
- Para sistemas em escala de petabytes, use o particionamento de dados e a orquestração de vários fluxos.
Suporte a padrões e funcionalidade do ponto de extremidade
A funcionalidade e o suporte padrão para o ponto de extremidade dependem da solução escolhida.
| Tipo de conector | Requisitos de ponto de extremidade |
|---|---|
| Amazon S3 Connector | Bucket do S3 com a política de IAM adequada e o arquivo schema\_sample.csv definindo o esquema. |
| Conector do Google Cloud Storage | Credenciais da conta de serviço e acesso de bucket com convenções de nomenclatura uniformes. |
| Conector do Armazenamento do Azure | Acessar autenticação baseada em chave ou token SAS; a estrutura de blob ou pasta deve seguir as convenções do Data 360. |
Gerenciamento de estado
O estado é rastreado por meio de Fluxos de dados e seu carimbo de data e hora da última execução bem-sucedida.
- O Data 360 mantém automaticamente os estados de sincronização e os deslocamentos, garantindo que somente arquivos novos ou modificados sejam processados em execuções subsequentes.
- Ao integrar-se a ferramentas ETL externas, são recomendados identificadores de arquivo exclusivos (por exemplo, UUIDs ou carimbos de data e hora) para evitar duplicação.
Cenários de integração complexos
Em arquiteturas empresariais avançadas, esse padrão pode ser integrado a:
- Middleware ETL Pipelines (por exemplo, Informatica, MuleSoft): para orquestrar o pré-processamento, a validação e o particionamento de arquivos antes de transferir para o Data 360.
- Fluxos de trabalho AI/ML: os dados de DLO processados podem ser publicados via DMO para modelos de ambientes de treinamento ou índices RAG por meio de Destinos de ativação do Data 360.
- Sistemas transacionais: DMOs harmonizados podem acionar atualizações a jusante no Salesforce CRM ou sistemas externos por meio de Ações de dados ou Eventos de plataforma.
Exemplo
Uma instituição financeira global armazena dados do cliente e da transação em um data lake do AWS S3, em que arquivos Parquet particionados são gerados diariamente por região (como EUA, UE e APAC). A equipe de arquitetura de dados configura vários Fluxos de dados no Data 360, cada um conectado a uma pasta regional, com um esquema_sample.csv compartilhado garantindo cabeçalhos e tipos de dados consistentes em todas as partições. Agendas de ingestão noturna carregam automaticamente os dados em DLOs, após o que as Transformações de dados em lote acrescentam todas as partições regionais a um Customer_Transactions_DLO unificado. Esse conjunto de dados harmonizado é mapeado para o Customer 360 Data Model, permitindo análise a jusante e ativação de IA. A abordagem fornece uma ingestão automatizada e confiável do data lake existente, impõe uma autenticação e criptografia fortes alinhadas às políticas de TI corporativas e fornece uma base modular dimensionável que dá suporte à expansão futura e à evolução do esquema.
Contexto
Um caso de uso principal e crítico para o Data 360 é unificar dados do cliente em todo o ecossistema do Salesforce. Esse padrão abrange a ingestão nativa de dados de plataformas principais do Salesforce – Sales Cloud e Service Cloud (coletivamente Salesforce CRM) e Marketing Cloud Engagement. As origens incluem objetos de CRM padrão e personalizados (por exemplo, Conta, Contato, Caso, Oportunidade) e extensões de dados do Marketing Cloud Engagement que contêm eventos de engajamento, envios de email e dados de rastreamento.
Problema
Como uma organização pode ingerir de modo eficiente e confiável objetos de CRM padrão e personalizados e extensões de dados do Marketing Cloud Engagement no Data 360 para que os dados possam ser usados para criar perfis de cliente unificados (resolução de identidade, Customer 360), mantendo o desempenho, a governança e as interrupções mínimas dos sistemas de origem?
Forças
Conectores nativos simplificam o trabalho, mas várias forças operacionais e arquitetônicas devem ser gerenciadas:
- Permissões de origem abrangentes: Um usuário de conexão dedicado (conta de integração) deve ter as permissões de leitura adequadas em nível de objeto e de campo. A falha na atribuição dos conjuntos de permissões necessários (por exemplo, um conjunto de permissões do conector do Data 360 predefinido) é uma causa comum de falha de ingestão.
- Modos e custo de atualização de dados: Os conectores oferecem suporte aos modos de atualização completa e delta/incremental. Atualizações completas têm mais impacto no desempenho e nos créditos; as extrações de delta reduzem a carga, mas dependem de um rastreamento de alteração confiável no sistema de origem.
- Esquema personalizado e mapeamento de campo: As instâncias do CRM geralmente incluem objetos/campos personalizados. O mapeamento de esquema preciso e o tratamento de campos personalizados (nomes, tipos) são necessários para evitar erros de mapeamento ou desvio semântico.
- Pacotes de dados starter vs. Mapeamento personalizado: Pacotes de dados iniciantes aceleram a integração pré-selecionando objetos/campos típicos, mas organizações altamente personalizadas precisarão de definições de fluxo personalizadas.
- Limites de taxa de transferência e API: Os limites da API da organização de origem e as taxas de extração do Marketing Cloud restringem a agressividade com que você pode agendar atualizações.
- Convenções de higiene de dados e nomenclatura: Nomes de campo de origem, comportamento nulo e tipos de dados devem ser normalizados antes da ingestão para evitar problemas de mapeamento posterior.
- Segurança e privilégio mínimo: O conector depende de autenticação segura e deve respeitar padrões de IAM de privilégio mínimo, auditoria e controles de rede.
Solução
Esta tabela contém soluções para esse problema de integração.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Ajuste da solução | Melhor | Use o Conector nativo do Salesforce CRM e o Conector de engajamento do Marketing Cloud no Data 360\. Comece com Pacotes de dados iniciais para casos de uso padrão e acelere a integração. Use a personalização manual de fluxo para modelos de dados personalizados ou específicos do domínio. |
| Manipulação de instâncias de CRM altamente personalizadas | Melhor com a oficina de mapeamento | Trate Pacotes iniciais como uma linha de base e realize um workshop de mapeamento para identificar: Objetos personalizados e relacionamentos. Campos de fórmula ou calculados. Extensões de pacote gerenciado. Para campos de fórmula pesados, calcule valores em um ETL pré-estágio ou dentro de Transformações do Data 360 para minimizar a carga da API em organizações de origem. |
| Quando não usar | Cenários subóptimos | Evite esse padrão se: Você precisa de ingestão de evento em tempo real ou de alta frequência (em vez disso, use Conectores de streaming, Eventos de plataforma ou Federação de cópia zero). A organização de origem tem capacidade de API limitada e não pode manter extrações agendadas sem atrasos de limite ou de fila. |
| Segurança e governança | Controles obrigatórios | Princípio de privilégio mínimo - Use um usuário de integração dedicado com acesso mínimo de leitura. Nunca use administradores de toda a organização. Autenticação – Use o OAuth 2.0 e aplicativos conectados; faça a rotação regular dos segredos do cliente e monitore o uso do token de atualização. Auditoria e rastreabilidade – Registre todas as execuções de ingestão, alterações de esquema e eventos do conector. Encaminhe registros para SIEM ou sistemas de conformidade para prontidão de auditoria. Classificação de dados – Aplique marcação PII/PHI e Controle de acesso baseado em atributo (ABAC) usando políticas do CEDAR imediatamente após a ingestão para impor mascaramento, consentimento e conformidade a jusante. |
Esboço
Este diagrama ilustra a sequência de etapas para ingerir os dados do armazenamento na nuvem para o Data 360
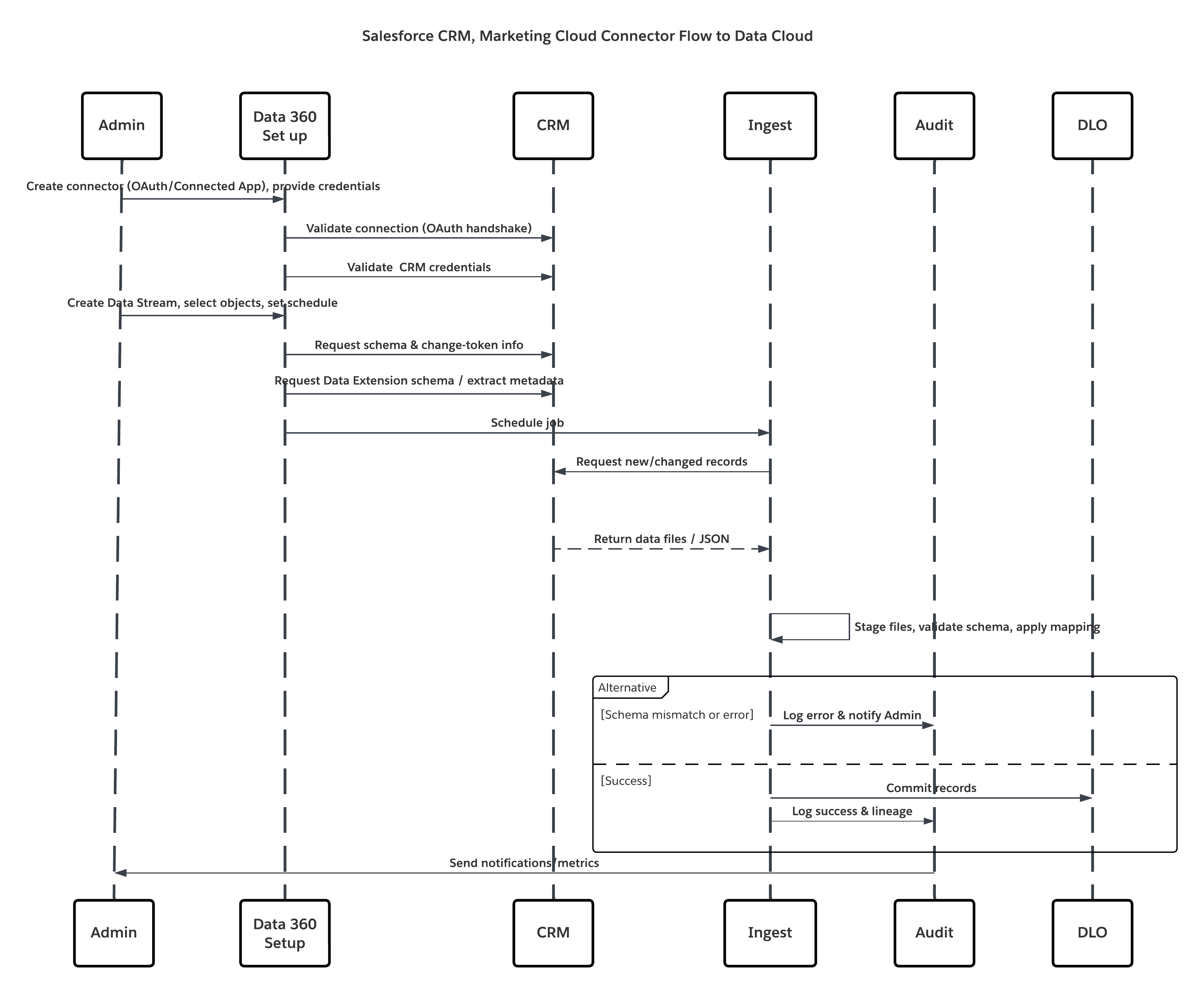
Neste cenário:
- O administrador provisiona usuários de integração e atribui conjuntos de permissões de conector em organizações de origem.
- O administrador configura os conectores na Configuração do Data 360 (conecta-se ao Salesforce CRM e ao Marketing Cloud por meio de OAuth/aplicativo conectado).
- O administrador cria Fluxos de dados selecionando objetos e Extensões de dados, escolhe atualização completa ou delta e define agendas.
- Em execução agendada, o Data 360 solicita tokens de esquema e delta da(s) origem(s).
- Os sistemas de origem retornam registros (delta ou carga útil total). O Marketing Cloud pode fornecer extrações; o CRM pode retornar resultados de JSON/Query.
- O Data 360 prepara arquivos em sua área de preparação segura interna e valida em relação ao esquema mapeado.
- Se a validação falhar, a ingestão registra o erro, alerta o administrador e interrompe a confirmação. Se a validação for bem-sucedida, o Data 360 confirmará os registros atomicamente para o DLO de destino.
- Os logs de monitoramento e auditoria são atualizados com a linhagem, a duração da execução, as contagens de linhas e o uso de credenciais. Alertas emitidos a administradores se limites ou erros foram acionados.
Resultados
Os principais dados de relacionamento com o cliente e engajamento de marketing são ingeridos no Data 360 como objetos do Data Lake (DLOs). Isso gera:
- Conjunto de dados unificado contendo perfis, casos, oportunidades e métricas de email/engajamento.
- Fundação para resolução de identidade e construção de Perfis de Indivíduo Unificados.
- Preparação operacional para harmonização a jusante, enriquecimento, modelagem de IA e ativação, preservando a governança e a capacidade de auditoria.
Mecanismos de ingestão
O mecanismo de ingestão depende do conector e da estratégia de agendamento definidos no Data 360.
| Mecanismo | Quando usar |
|---|---|
| Conector do Salesforce CRM (nativo) | Melhor para objetos padrão/personalizados do CRM; oferece suporte a atualização completa e delta. |
| Conector de engajamento do Marketing Cloud (nativo) | Melhor para extensões de dados, envios e extrações de rastreamento; oferece suporte a modos full/delta. |
| Iniciar pacotes de dados | Acelere a integração para objetos comuns de Vendas/Serviço/Marketing. |
| Fluxos personalizados + pré-processamento | Use quando transformações complexas ou normalização de esquema pesado forem necessárias. |
Tratamento e recuperação de erros
O tratamento e a recuperação de erros são essenciais para garantir a confiabilidade em operações de ingestão de alto volume.
- Logs por execução: Cada execução de Fluxo de dados fornece detalhes de sucesso/falha e erros no nível da linha.
- Retries & Checkpointing: Execuções com falha podem ser tentadas novamente depois de corrigir problemas de origem ou esquema; o Data 360 usa a semântica de preparação e confirmação atômica.
- Alertas: Configure alertas para desvio de esquema, falhas repetidas ou lacunas de sequência delta.
Considerações sobre design idempotente
A ingestão é idempotente por design: reprocessar a mesma não resulta em registros duplicados. As principais estratégias incluem:
- Detecção de alteração: As extrações de delta dependem de indicadores de alteração do sistema de origem (LastModifiedDate / captura de dados de alteração do sistema). Verifique se a origem fornece carimbos de data/hora confiáveis.
- Deduplicação: Use chaves de negócios exclusivas (por exemplo, Contact.ExternalId) para desduplicar ou inserir e atualizar em DLOs.
- Confirmação transacional: Os registros são preparados e confirmados apenas quando o processamento em lote é concluído com sucesso.
Considerações de segurança
A segurança é integral em todo o pipeline de ingestão, da autenticação à criptografia e controle de acesso.
- Autenticação & Autorização: Os conectores usam a Estrutura de integração segura do Salesforce, aproveitando Credenciais nomeadas e Credenciais externas para autenticação sem expor segredos.
- Criptografia: Os dados são criptografados em trânsito (TLS 1.2+) e em repouso (AES-256).
- Controles de rede: Os sistemas de armazenamento de origem (por exemplo, buckets do S3) devem incluir IPs do Data 360 na lista de permissões.
- Alinhamento de conformidade: Suporta estruturas de proteção de dados corporativas, como diretrizes de GDPR, HIPAA e FFIEC, quando combinadas a Chaves gerenciadas pelo cliente (CMK).
- Auditabilidade: Cada trabalho de ingestão e acesso à credencial são registrados para relatórios de rastreabilidade e conformidade
Barras laterais
Tempo
O tempo depende da agenda de ingestão e do volume de dados.
- O ritmo ideal depende da necessidade do negócio: por hora para acionadores de marketing quase em tempo real, por noite para grandes reconciliações.
- Os modos Delta reduzem a carga e o custo; atualizações completas são mais pesadas e usadas para cargas iniciais ou grandes alterações de esquema.
Volumes de dados
- Os conectores do CRM são otimizados para conjuntos de dados transacionais e de médio volume (milhões de registros).
- Para volumes históricos extremamente grandes, considere o ETL preparado para particionar e carregar em estágios.
Suporte a padrões e funcionalidade do ponto de extremidade
A funcionalidade e o suporte padrão para o ponto de extremidade dependem da solução escolhida.
| Conector | Requisitos de ponto de extremidade |
|---|---|
| Conector do Salesforce CRM | A organização de origem deve permitir um aplicativo conectado, tokens OAuth e um usuário de integração dedicado com permissões de leitura. |
| Conector do Marketing Cloud | Credenciais da API do Marketing Cloud ou pacote instalado; As Extensões de dados devem expor dados por meio de Extrações/API. |
Gerenciamento de estado
- Estado do conector: Os fluxos de dados mantêm os últimos carimbos de data e hora de sincronização bem-sucedidos e deslocamentos de delta.
- Estratégia principal chave: Prefira identificadores de negócios consistentes (IDs externos) para que a reconciliação a jusante e os upserts sejam determinísticos.
Cenários de integração complexos
Em arquiteturas empresariais avançadas, esse padrão pode ser integrado a:
- Topologias híbridas: Combine a ingestão de CRM com streaming (eventos de plataforma) para atualizações quase em tempo real.
- Orquestração de middleware: Use ferramentas MuleSoft ou ETL quando orquestração, aprimoramento ou pré-ingestão de transformação complexos forem necessários.
- Loops de feedback da ativação: DMOs harmonizados podem acionar atualizações a jusante para sistemas de origem por meio de Ações de dados ou APIs de plataforma (cuidado com controles de SOD).
Exemplo
Um varejista multinacional consolida as métricas de engajamento de Contas, Contatos, Casos, Oportunidades e Marketing Cloud no Data 360 para criar uma visualização unificada do cliente. O Pacote de dados Starter inicializa os principais objetos de Vendas e Serviço, enquanto a equipe estende o modelo com campos personalizados, como Loyalty_Membershipc e Customer_Tierc, para capturar o contexto de fidelidade. Os fluxos de dados do CRM são executados a cada hora no modo delta e o Marketing Cloud Engagement é sincronizado diariamente usando extrações de delta para eventos de engajamento. Esses conjuntos de dados são processados por meio de DLOs e resolução de identidade, resultando em um perfil de cliente unificado que combina sinais de engajamento e CRM para aprimorar a personalização e modelos de IA a jusante.
Esses padrões são criados para cenários em que milissegundos são importantes, quando interações, transações ou sinais do cliente devem acionar percepções ou ações imediatas. Eles vão além da ingestão em lote tradicional agendada para habilitar o fluxo de dados conduzido por evento, em que as informações são processadas no momento em que são geradas. No ecossistema do Salesforce Data 360, "tempo real" não é um único modo, é um continuum de modelos de latência. Em uma extremidade está a sincronização quase em tempo real, em que atualizações de sistemas de registro (como CRM ou ERP) são refletidas no Data 360 em segundos ou minutos. No outro lado está a captura de evento em tempo real, em que sinais comportamentais do lado do cliente, como cliques, compras ou interações móveis, são ingeridos e ativados em milissegundos. Para arquitetos, a distinção é mais do que semântica. Ela define como os pipelines são projetados, como as APIs são invocadas e como as decisões posteriores são tomadas. Selecionar o padrão certo, seja sincronização quase em tempo real ou ingestão de streaming de evento, garante que o sistema atenda às metas de latência operacional dos negócios enquanto mantém a integridade, a escalabilidade e a governança dos dados.
Contexto
Esse padrão permite que qualquer sistema externo, como um aplicativo personalizado, uma plataforma Internet das Coisas (IoT), um sistema de ponto de venda (POS) ou um serviço de terceiros, envie programaticamente dados de evento para o Data 360 quase em tempo real conforme ocorrem eventos separados.
Problema
Como um desenvolvedor pode enviar com confiança registros únicos ou pequenos lotes assíncronos de eventos de um aplicativo externo para o Data 360 com baixa latência para que os dados estejam disponíveis rapidamente para processamento, segmentação e ativação?
Forças
Esse padrão oferece baixa latência e melhor controle do desenvolvedor, mas introduz várias restrições técnicas e dependências operacionais:
- Dependência de desenvolvedor: Requer esforço do desenvolvedor para implementar clientes da API REST autenticados e lógica de erro/tentativa – não é um conector de apontar e clicar.
- Esquema rígido na gravação: A API de ingestão aplica o esquema-em-gravação. Um esquema preciso deve ser definido e carregado para a configuração do conector; todas as cargas úteis devem atender exatamente ou ser rejeitadas.
- Modos de interação dupla: O mesmo conector oferece suporte ao streaming (JSON) para atualizações de baixa latência, registro por registro e em massa (CSV) para sincronizações periódicas maiores – os arquitetos devem escolher por caso de uso.
- Autenticação & Segurança: As chamadas devem ser autenticadas por meio de um aplicativo conectado do Salesforce usando OAuth 2.0 (por exemplo, Fluxo do portador JWT para servidor a servidor). Escopos de gerenciamento de token, rotação e privilégio mínimo são obrigatórios.
- Visibilidade operacional: Os desenvolvedores e as equipes da plataforma devem implementar o monitoramento para códigos de resposta, novas tentativas, filas de letras inativas e alertas de desvio de esquema.
- Requisito de gráfico em tempo real: Para ativação instantânea verdadeira (segmentação instantânea, mapeamento de DMO em tempo real), o Objeto de modelo de dados (DMO) de destino deve fazer parte do gráfico de dados em tempo real; caso contrário, os eventos atravessarão um pipeline de latência ligeiramente maior.
Solução
Esta tabela contém soluções para esse problema de integração.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Ajuste da solução | Melhor para captura de evento de baixa latência | Use a API de ingestão do Data 360 (JSON de streaming) para enviar eventos únicos ou microlote. Configure o conector da API de ingestão com um esquema OAS 3.0 estrito (.yaml). Use a ingestão CSV em massa para sincronizações maiores e menos frequentes. |
| Lidar com alterações de esquema | Rígido / Gerenciado | As alterações de esquema estão em andamento: atualize o .yaml do OAS, faça a versão do conector e realize testes de contrato. Implemente a migração de esquema progressivo se os produtores não puderem alterar simultaneamente. |
| Quando não usar | Subóptimo | Não é ideal se o pré-processamento for necessário (por exemplo, desduplicação, pedido garantido etc.) ou para cargas em massa extremamente grandes (use conectores em massa nativos ou ETL em lote). Se a origem não puder produzir cargas úteis válidas para esquema ou não puder se autenticar com segurança, use métodos de ingestão alternativos. |
| Segurança e governança | Obrigatório | Use OAuth 2.0 com escopos de privilégio mínimo, chaves de rotação, uso de token de log. Imponha o TLS 1.2+, valide os IPs do cliente, se necessário, e garanta a marcação de PII da carga útil. Todos os eventos devem conter metadados de provenência (origem, carimbo de data e hora, versão do esquema, chave de idempotency). |
Esboço
Este diagrama ilustra a sequência de etapas para ingerir os dados da API de ingestão no Data 360
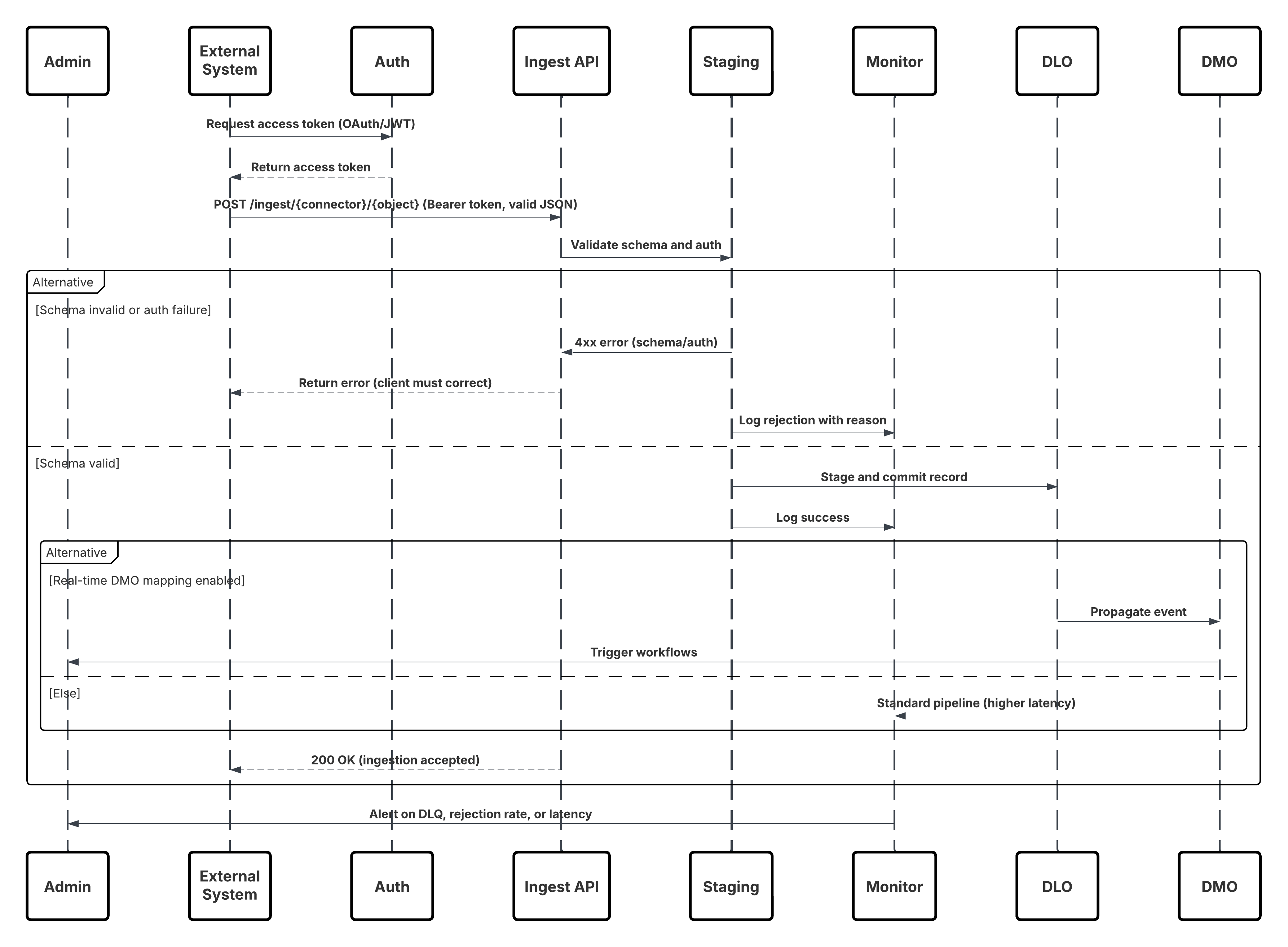
Neste cenário:
- O Sistema externo solicita autenticação por meio do OAuth/JWT do Servidor de autenticação.
- O Servidor de autenticação retorna o token de acesso ao Sistema externo.
- O Sistema externo envia uma solicitação POST de ingestão de dados para a API de ingestão do Data 360 com autorização e carga útil JSON.
- A API de ingestão valida o esquema de solicitação e a autenticação por meio do módulo Preparação e validação.
- Em falha de esquema/autenticação:
- Erro retornado para o Sistema externo.
- Rejeição registrada para monitoramento e alerta.
- Na validação bem-sucedida:
- Registros preparados e confirmados no Objeto do Data Lake (DLO).
- Sucesso registrado para monitoramento.
- Se habilitado, os dados são propagados para o Gráfico de dados em tempo real (DMO) acionando fluxos de trabalho downstream.
- Caso contrário, os dados são processados por meio de um pipeline de maior latência ou lote padrão.
- A API de ingestão confirma o sucesso para o Sistema externo.
- Os componentes de monitoramento alertam o administrador sobre filas de letras mortas, taxas de rejeição ou problemas de latência.
Resultados
Dados de evento externo são ingeridos em DLOs do Data 360 com baixa latência. Quando o DMO de destino faz parte do gráfico em tempo real, os dados estão disponíveis para segmentação instantânea, fluxos de trabalho do agente, modelos de IA e ativação operacional. Isso habilita respostas comerciais rápidas a eventos originados de qualquer sistema conectado.
Mecanismos de ingestão
O mecanismo de ingestão depende do conector e da estratégia de agendamento definidos no Data 360.
| Mecanismo | Quando usar |
|---|---|
| Streaming JSON (API de ingestão) | Eventos únicos, microlote, eventos comportamentais, fluxos de cliques, telemetria de IoT – quando baixa latência é necessária. |
| CSV em massa (modo em massa da API de ingestão) | Uploads periódicos maiores em que os requisitos de latência são relaxados. |
| Edge / Middleware | Use quando precisar de validação, transformação, aprimoramento ou limitação de taxa antes de enviar por push para a API de ingestão. |
Tratamento e recuperação de erros
- Erros imediatos (sincronização): Respostas 4xx para erros de esquema/autenticação – o cliente deve corrigir a carga útil ou o token e tentar novamente.
- Falhas temporárias (assíncronas): 5xx responses – novas tentativas de cliente com desvio exponencial e agitação.
- Fila de letras mortas (DLQ): Falhas persistentes chegam ao DLQ para inspeção manual e reprodução.
- Monitoração: Acompanhe a taxa de rejeição de esquema, falhas de autenticação, percentis de latência e pendências de DLQ. Alerta sobre limites.
Considerações sobre design idempotente
- Chave de idempotency: Cada evento deve incluir uma chave de idempotency/ID de mensagem exclusiva.
- Estratégia de inserção e atualização: Use chaves de negócios (ExternalId) para evitar duplicatas em repetições.
- Janela de desativação: O arquiteto deve definir janelas de desduplicação e retenção para rastreamento de idempotência.
Considerações de segurança
A segurança é integral em todo o pipeline de ingestão, da autenticação à criptografia e controle de acesso.
- Autenticação: OAuth 2.0 (portador JWT) recomendado para servidor a servidor. Limite escopos apenas à ingestão.
- Criptografia: TLS 1.2+ para transporte; o Data 360 impõe a criptografia em repouso.
- Privilégio mínimo: As credenciais do aplicativo conectado têm direitos mínimos; segredos de rotação e registros de acesso de instrumento.
- Governação da carga de pagamento: Inclua sinalizadores de consentimento/consumo em metadados de evento; aplique políticas ABAC/CEDAR imediatamente após a ingestão.
- Controles de IP / Conexão privada: Quando necessário, restrinja o acesso por meio de listas de permissões ou use a Conexão privada para rede privada.
Barras laterais
Tempo
O tempo depende da agenda de ingestão e do volume de dados. O JSON de streaming gera uma latência de subsegundo a segundo, dependendo do processamento e da configuração do gráfico. CSV em massa é de minutos a horas. Escolha com base em SLAs de negócios.
Volumes de dados
Os tamanhos de eventos individuais devem ser pequenos (menos de alguns KB). Para produtores de alta taxa de transferência, considere fazer o lote no produtor ou usar uma margem de streaming (Kafka/Kinesis) antes de chamar a API.
Gerenciamento de estado
- Versão do esquema: Mantenha a versão do esquema nos metadados de evento e use o controle de versão do conector ao atualizar o contrato do OAS.
- Deslocamentos do conector: O Data 360 lida com a semântica de compromisso; os produtores devem rastrear chaves de idempotency e a última sequência bem-sucedida para reprodução segura.
Cenários de integração complexos
Em arquiteturas empresariais avançadas, esse padrão pode ser integrado a:
- Caixa de validação de borda: Use o middleware para traduzir formatos de produtores heterogêneos para o contrato OAS necessário, realizar a limitação de taxa e pré-aprimoramento.
- Arquiteturas híbridas: Combine a API de ingestão para eventos e Conectores para reconciliação em massa.
- Ativação do agente: Os eventos mapeados para DMOs em tempo real podem acionar fluxos de trabalho do Agentforce e modelos do Einstein para tomada de decisão automatizada.
Exemplo
Uma rede de varejo transmite eventos de compra de ponto de venda (POS) para o Data 360 em tempo real para impulsionar o engajamento imediato do cliente. Cada loja executa um componente de servidor leve que coleta transações, aprimora-as com metadados de local e dispositivo e publica eventos JSON com segurança usando OAuth portador JWT com chaves de idempotency para evitar duplicações. Um administrador define a estrutura do evento carregando um esquema OAS para o ponto de venda e configurando o conector da API de ingestão. Os eventos recebidos são ingeridos no DLO pos_sale, mapeados para o DMO de vendas e adicionados ao gráfico em tempo real. Como resultado, as compras de alto valor são detectadas instantaneamente, acionando fluxos de trabalho VIP no Agentforce e atualizando a segmentação de clientes para promover a personalização em tempo real.
Contexto
Esse padrão permite a captura de dados de interação do usuário granulares de alto volume, como visualizações de página, cliques em botões, impressões de produto e reproduções de vídeo, de sites e aplicativos móveis em tempo real. É fundamental para oferecer personalização no momento, em que cada interação digital pode influenciar dinamicamente a experiência do usuário e promover o engajamento.
Problema
Como uma empresa pode capturar e processar um fluxo contínuo de eventos comportamentais de propriedades digitais, abrangendo milhões de interações do usuário por minuto, e disponibilizar esses dados imediatamente no Data 360 para habilitar a segmentação, a personalização e a ativação em tempo real?
Forças
Esse caso de uso apresenta vários desafios de design que exigem uma arquitetura de ingestão de baixa latência criada para fins específicos:
- Período extremo : Sites de alto tráfego ou aplicativos móveis podem emitir milhões de eventos por minuto. A camada de ingestão deve ser dimensionada horizontalmente para lidar com esse volume sem perda de evento ou contrapressão, garantindo uma latência consistente sob cargas de pico.
- Instrumentação no lado do cliente: Diferentemente das integrações conduzidas pelo servidor, esse padrão depende dos SDKs do lado do cliente. Um emblema JavaScript (SDK de Interações do Salesforce) deve ser integrado a cada página ou um SDK nativo integrado a aplicativos móveis. Isso requer implementação de cliente robusta, controle de versões e governança de esquema de evento.
- Processamento de evento de baixa latência : As ações do usuário, como "adicionar ao carrinho" ou "jogar vídeo", devem alcançar o Data 360 dentro de segundos, habilitando ativação em tempo real e respostas contextuais (por exemplo, ofertas direcionadas, recomendações personalizadas).
- Armonização de dados e resolução de identidade: Os eventos capturados geralmente incluem identificadores anônimos (cookies, IDs de dispositivo, tokens de sessão). Para habilitar os casos de uso do Customer 360, eles devem ser mapeados para perfis conhecidos por meio da resolução de identidade do Data 360 e harmonizados com o Modelo de dados do Customer 360.
Solução
A abordagem recomendada é usar o Conector de personalização do Salesforce Marketing Cloud, um pipeline de streaming nativo e totalmente gerenciado projetado para ingestão comportamental de alto rendimento.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Captura de evento baseada em SDK | Melhor | Implemente o SDK de Interações do Salesforce (web) ou o SDK nativo (móvel). Essas bibliotecas leves capturam e serializam interações do usuário em tempo real, anexando metadados (ID da sessão, carimbo de data e hora, contexto). |
| Pipeline de streaming de evento | Melhor | Os eventos são enviados ao serviço de streaming de eventos da Personalização do Marketing Cloud por HTTPS seguro. Essa camada é escalonável horizontalmente e otimizada para transmissão de baixa latência (<2s). |
| Integração do Data 360 | Melhor | O Conector de personalização do Data 360 assina o feed de streaming, ingerindo cada evento em um Objeto do Data Lake (DLO) quase em tempo real. |
| Mapeamento de modelo de dados | Práticas recomendadas | O DLO ingerido é mapeado para objetos de modelo de dados (DMOs) do Customer 360. Isso habilita a vinculação de usuários anônimos e conhecidos por meio da Resolução de identidade. |
| Habilitação de gráfico em tempo real | Opcional / Recomendado | Inclua DMOs mapeados no gráfico em tempo real para segmentação instantânea, acionando ações personalizadas por meio de fluxos de trabalho do Einstein ou Agentforce. |
| Quando Não usar | Subóptimo | Esse padrão não é ideal quando: Os dados de origem são cliente da Web e eventos (use a API de ingestão em vez disso). A organização não tem controle sobre clientes da Web/móveis. Não é necessário rastreamento de comportamento em tempo real (use ingestão em lote). |
| Lidar com as alterações do esquema | Evolução gerenciada | Os esquemas de evento evoluem conforme novas interações são adicionadas. Os SDKs devem ter definições de evento de versão. Alterações compatíveis com versões anteriores (adicionando campos opcionais) são seguras; alterar as alterações exige reconfiguração do conector e teste de contrato. |
Esboço
Este diagrama ilustra a sequência de etapas para ingerir os dados de canais móveis e da Web no Data 360
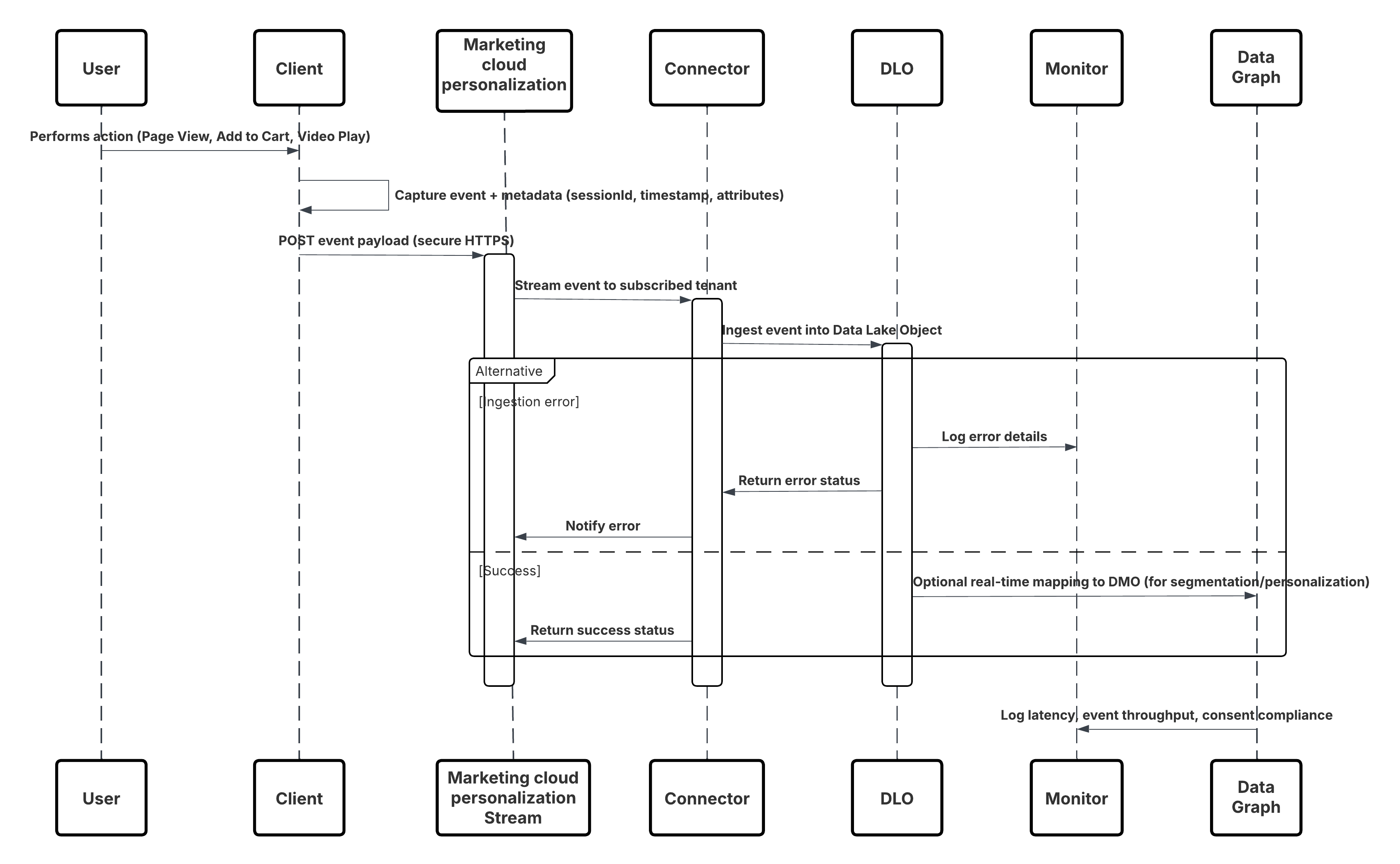
Neste cenário:
- Implemente o SDK em canais da Web ou móveis (captura de interação do usuário).
- Configure o SDK com ID do locatário, ambiente e controles de consentimento.
- Transmita eventos JSON capturados (metadados + atributos) para o ponto de extremidade de streaming do Marketing Cloud.
- Na Configuração do Data 360, crie e configure o Conector de personalização para o locatário.
- Ingira eventos em um DLO e mapeie o DLO → DMO dentro do Data 360.
- Habilite o DMO no gráfico em tempo real para ativação imediata.
- Monitore a latência, a conformidade do esquema, os sinalizadores de consentimento, a taxa de transferência e as taxas de erro.
- Implante em produção e monitore continuamente.
Resultados
Um fluxo contínuo de eventos comportamentais de baixa latência flui de canais digitais para o Data 360. Dentro de segundos, cada ação do usuário fica disponível para segmentação em tempo real, modelagem preditiva ou personalização acionada, habilitando experiências do cliente verdadeiramente adaptáveis.
Mecanismos de ingestão
O mecanismo de ingestão depende do conector e da estratégia de agendamento definidos no Data 360.
| Mecanismo | Quando usar |
|---|---|
| SDK de interações (Web) | Captura em tempo real de navegadores da Web e SPAs. |
| Mobile SDK | Captura em tempo real de aplicativos móveis nativos. |
| Conector de personalização | Assinatura gerenciada entre o Marketing Cloud e o Data 360\. |
| Mapeamento de gráfico em tempo real | Habilita a ativação imediata em Segmentação, Einstein e Jornadas. |
Tratamento e recuperação de erros
- Tolerância de falha em camadas: Implemente mecanismos de validação e repetição de vários níveis – os SDKs do cliente lidam com falhas temporárias com fallos exponenciais, enquanto a camada de ingestão usa filas duráveis e pipelines reproduzíveis para evitar a perda de dados.
- Esquema e governança de dados: Versione e valide esquemas de evento continuamente; eventos inválidos ou em evolução são roteados para uma Rejeição de esquema ou Fila de letras mortas para triagem e reprodução seguras.
- Idempotency & Deduplicação: Use identificadores de evento estáveis e semântica de inserção e atualização para garantir o processamento exato mesmo durante novas tentativas ou repetições.
- Automação de monitoramento e recuperação: O monitoramento contínuo de taxa de transferência, latência e erro aciona fluxos de trabalho de recuperação automatizados, garantindo baixa latência, entrega confiável e resultados de personalização consistentes em tempo real.
Considerações sobre design idempotente
- Cada evento deve conter uma chave de idempotency ou ID de mensagem exclusiva para que envios duplicados possam ser desduplicados a jusante.
- Use chaves de negócios (por exemplo, sessionID + eventTimestamp + userID) quando apropriado para identificar duplicados.
- Defina uma janela de desduplicação (por exemplo, 24 horas) durante a qual eventos duplicados são ignorados ou filtrados.
- Use estratégias de inserção e atualização quando apropriado (por exemplo, atualizar contadores ou sinalizadores em vez de inserir itens duplicados).
Considerações de segurança
A segurança é integral em todo o pipeline de ingestão, da autenticação à criptografia e controle de acesso.
- Criptografia de transporte: TLS 1.2+ para todas as conexões de serviço de streaming → SDK.
- Criptografia de dados em repouso no Data 360 e no fluxo de marketing.
- O SDK respeita os indicadores de consentimento do usuário (GDPR/CCPA) e suprime o rastreamento se o consentimento for negado.
- Autenticação do tráfego SDK: garanta que apenas locatários/clientes aprovados possam transmitir eventos.
- Metadados: cada evento deve incluir ID de origem, carimbo de data e hora, versão do esquema, ID da sessão, chave de idempotency.
- Acesso de privilégio mínimo: Pontos de extremidade e conectores de SDK limitados ao escopo de ingestão de evento; faça a rotação das credenciais regularmente.
- Classificação de dados: Anote PII em cargas úteis de evento, aplique políticas imediatamente após a ingestão
Barras laterais
Tempo
- O tempo depende da atividade do usuário final e da configuração de streaming de evento.
- Os eventos capturados por meio do SDK de Interações do Salesforce e entregues por meio do Fluxo de personalização do Marketing Cloud geralmente alcançam uma latência de ~2 segundos a ~2 segundos antes de ficarem disponíveis no Gráfico em tempo real do Data 360.
- Isso habilita a segmentação, a personalização e a ativação quase instantâneas em sessões de usuário ativas.
Volumes de dados
Eventos comportamentais individuais (por exemplo, clique, exibição, adição ao carrinho) são leves, geralmente de 1 a 5 KB por carga útil. Para propriedades digitais em grande escala, espere milhares a milhões de eventos por minuto. Para garantir taxa de transferência e resiliência:
- Use os mecanismos de repetição e lote integrados do SDK para páginas de alto tráfego.
- Descarregue a manipulação de explosões para a camada de buffer de streaming do Marketing Cloud.
- Monitore a taxa de ingestão e as proporções de erro usando o painel de métricas do conector.
Gerenciamento de estado
Cada evento inclui metadados para controle de estado e versão:
- Versão do esquema: Integre a versão do esquema a cada evento; configure o Conector de personalização ao atualizar o esquema.
- Manuseio de reprodução: Eventos que falham devido a problemas de rede temporários são repetidos automaticamente pelo SDK com fallos exponenciais.
- Claves de idempotency: Identificadores únicos (sessionId + eventType + timestamp) garantem que eventos repetidos não criem duplicatas no Data 360.
- Gerenciamento de deslocamento: O Data 360 rastreia confirmações bem-sucedidas; quaisquer eventos não processados são colocados novamente na fila pelo conector até serem ingeridos com sucesso.
Cenários de integração complexos
Esse padrão se integra perfeitamente a arquiteturas empresariais avançadas:
- Capa de enriquecimento de borda: Adicione middleware (por exemplo, proxy reverso ou função sem servidor) para injetar contexto adicional, como geograma, tipo de dispositivo ou metadados de campanha, antes que os eventos cheguem ao Marketing Cloud.
- Híbrido (Streaming + Lote): Use o conector do Marketing Cloud para fluxos em tempo real e combine-o com trabalhos ETL em lote (por exemplo, dados do pedido) para reconciliação downstream.
- Ativação do agente: Os eventos mapeados para DMOs em tempo real podem acionar Personalização do Einstein, fluxos de trabalho do Agentforce ou tomada de decisão orientada por IA para adaptar a experiência digital no momento.
- Governação de vários locatários: Use sinalizadores de consentimento e metadados sensíveis ao locatário para impor privacidade e conformidade em ambientes de várias marcas ou regiões.
Exemplo
Uma empresa global de comércio eletrônico fornece recomendações de produtos personalizadas e conteúdo dinâmico aos compradores enquanto eles navegam ativamente em www.retailx.com, um aplicativo de página única baseado em React. Usando o SDK de Interações do Salesforce no lado do cliente, o site captura visualizações de página, cliques em produtos, ações de carrinho e interações por vídeo em tempo real. Esses eventos fluem pelo fluxo de eventos de Personalização do Marketing Cloud e pelo conector de Personalização para DLOs do Data 360, em que são modelados em DMOs e incorporados ao gráfico em tempo real. Esta arquitetura disponibiliza sinais comportamentais instantaneamente para segmentação, personalização orientada pelo Einstein e ativação do Agentforce, permitindo experiências do cliente responsivas na sessão
Contexto
Para muitos processos essenciais para os negócios, manter o Data 360 perfeitamente alinhado às atualizações mais recentes nos principais sistemas de CRM é essencial. As equipes de atendimento ao cliente, vendas e marketing dependem de informações atualizadas para conduzir decisões, acionar jornadas e ativar automação. Esse padrão fornece um mecanismo para sincronizar alterações aos principais objetos do Salesforce CRM, como Contato, Conta e Caso, no Data 360 com o atraso mínimo, sem a ineficiência ou a latência de pesquisas em lote frequentes.
Problema
Como o Data 360 pode manter um estado quase perfeitamente sincronizado com os principais objetos do Salesforce CRM, garantindo que análise a jusante, segmentação e ativação conduzida por IA sempre operem com os dados mais atuais disponíveis?
Forças
Esse padrão introduz várias restrições técnicas e considerações arquitetônicas:
- Arquitetura orientada por evento : A sincronização deve ser reativa, conduzida por eventos de alteração na organização de origem do CRM, em vez de trabalhos em lote periódicos.
- Suporte seletivo de objeto : Nem todos os objetos padrão e personalizados do Salesforce oferecem suporte à transmissão em tempo real. Os arquitetos devem consultar a lista de objetos com suporte durante o design para evitar lacunas.
- Acesso e permissões : Habilitar o streaming requer que o usuário de integração na organização de origem tenha a permissão do sistema "Habilitar permissões para streaming do CRM".
- Atualização de dados vs. Custo de processamento : Embora a sincronização quase em tempo real melhore a responsividade, a taxa de transferência de evento excessiva pode exigir escala horizontal e mecanismos robustos de recuperação de erros.
- Integração de camada de segurança e Trust : Todos os dados de evento devem estar em conformidade com as estruturas Trust e Security da Salesforce: criptografados em trânsito, validados para conformidade com esquema e processados dentro do limite de Trust da organização.
Solução
A abordagem recomendada é usar o Conector do Salesforce CRM com a opção Streaming (Alterar captura de dados) habilitada. Ao criar um fluxo de dados para um objeto do CRM com suporte (por exemplo, Contato), os administradores podem alternar a opção "Ativar streaming". Sob o capuz, a plataforma de Captura de dados de alteração (CDC) do Salesforce publica uma mensagem ChangeEvent sempre que um registro é criado, atualizado, excluído ou cancelado na organização do CRM de origem. O Conector do CRM do Data 360 assina esses eventos da CDC e aplica as alterações correspondentes ao objeto do Data Lake (DLO) mapeado no Data 360 quase em tempo real. Isso garante a sincronização contínua entre o CRM e o Data 360 com intervenção manual mínima.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Conector de streaming baseado em CDC | Melhor | Mecanismo nativo do Salesforce; totalmente gerenciado e integrado à infraestrutura de evento de plataforma. |
| Assinatura e entrega de evento | Melhor | O conector assina canais ChangeEvent (por exemplo, /data/ContactChangeEvent) por meio de IDs de reprodução duráveis. |
| Mapeamento de dados e evolução de esquema | Prática recomendada | Mapeie as cargas úteis transmitidas para o DLO correspondente; manipule o controle de versão do esquema nos metadados para evitar quebras de ingestão. |
| Replay & Recuperação de falha | Recomendado | Use IDs de reprodução e chaves de idempotency para evitar duplicação e recuperar de erros temporários. |
| Modo híbrido (Streaming + Lote) | Opcional | Para objetos sem suporte ou carregamento em massa inicial, use a ingestão em lote combinada ao streaming da CDC. |
| Quando não usar | Suboptimal | Esse padrão pode ser subótimo quando: O objeto de origem não está habilitado para CDC. O caso de uso não requer atualizações em tempo real (lote é suficiente). A saída de rede da organização de origem é restrita ou os limites de evento são excedidos. |
Esboço
Este diagrama ilustra a sequência de etapas para ingerir os dados do CRM no Data 360 quase em tempo real
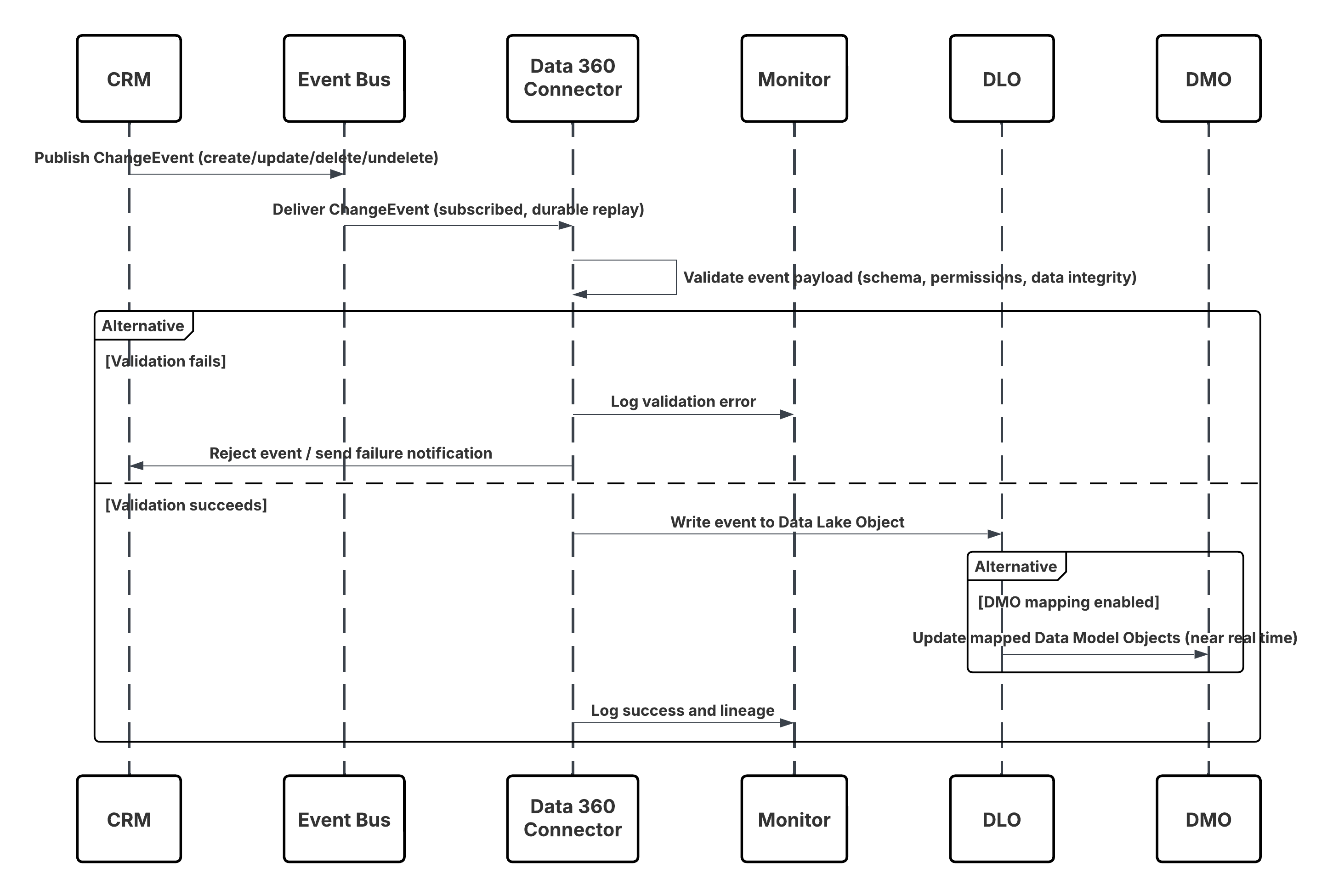
Neste cenário:
- A alteração ocorre no Salesforce CRM (criar/atualizar/excluir/não excluir).
- O CDC publica um ChangeEvent no barramento de evento interno do Salesforce.
- O Conector do CRM do Data 360 assina o barramento de evento usando um cursor de reprodução durável.
- A carga útil do evento é validada para esquema, permissões e integridade de dados.
- O Data 360 grava o evento validado no objeto Data Lake (DLO) mapeado.
- Se habilitado, os objetos de modelo de dados (DMOs) mapeados são atualizados em quase tempo real, ativando a segmentação e a ativação.
Resultados
O Data 360 mantém um espelho continuamente sincronizado dos principais dados do CRM. Isso habilita:
- Acionadores em tempo real (por exemplo, a Jornada é iniciada quando um caso é criado).
- Segmentação atualizada (por exemplo, mover clientes para o segmento "Ouro" quando o status da conta mudar).
- Análise e personalização mais precisas com base no contexto do CRM ativo.
Mecanismos de ingestão
O mecanismo de ingestão para esse padrão é gerenciado nativamente por meio do conector do Salesforce CRM com a Captura de dados de alteração (CDC) habilitada. O Data 360 atua como um assinante do fluxo de eventos da CDC, garantindo uma sincronização confiável e de baixa latência entre a organização do CRM de origem e o Data 360.
| Mecanismo | Quando usar |
|---|---|
| Streaming via CDC (Preferencial) | Para todos os objetos padrão e personalizados do Salesforce com suporte em que a sincronização quase em tempo real é necessária. |
| Modo híbrido (CDC + Lote) | Para objetos ainda não habilitados para CDC ou em que o carregamento de histórico inicial é obrigatório. |
| Modo de assinatura de repetição | Para ressincronização após tempo de inatividade ou implantação. |
| Modo de isolamento de erro | Para ambientes de teste e validação. |
Tratamento e recuperação de erros
- Recuperação automática de falhas: O Conector do CRM testa automaticamente novamente erros de rede ou plataforma temporários usando fallos exponenciais e encaminha falhas persistentes para a Fila de letras mortas (DLQ) para reprodução.
- Esquema e resiliência de autenticação: Não correspondências de esquema são colocadas em quarentena na Fila de rejeição de esquema para revisão pelo administrador, enquanto erros de autenticação ou permissão acionam novas tentativas controladas e alertas por meio do Monitoramento do Data 360.
- Continuidade do evento garantida: ReplayIDs duráveis garantem nenhuma perda de evento durante o tempo de inatividade do conector; eventos perdidos são rehidratados por meio de janelas de repetição ou trabalhos de nova sincronização em lote.
- Integridade de dados e ordem: A idempotency integrada (RecordID + SequenceNumber) evita duplicatas e ChangeEventHeader.sequenceNumber preserva a ordem de eventos correta para cada registro do CRM.
Considerações sobre design idempotente
- Exclusividade do evento: Cada evento CDC contém um ReplayID e ChangeEventHeader.entityName para deduplicação determinística.
- Estratégia de inserção e atualização: Implemente a lógica UPSERT com base no ID do registro para garantir que eventos repetidos não criem duplicatas.
- Manuseio de reprodução: Use o cursor de repetição do conector para retomar a partir do último deslocamento confirmado no caso de falhas temporárias.
- Evolução do **esquema: M **manter uma versão de esquema em metadados de evento e atualizar mapeamentos de DLO quando o esquema do CRM mudar.
Considerações de segurança
A segurança é integral em todo o pipeline de ingestão, da autenticação à criptografia e controle de acesso.
- Encryption and Trust : Todos os eventos são transmitidos usando o TLS 1.2+ e armazenados criptografados em repouso no Data 360.
- Controle de acesso: Somente conectores autenticados com permissões de integração adequadas podem assinar canais da CDC.
- Validação de esquema: Cada carga útil de evento é validada em relação ao esquema de DLO antes da ingestão.
- Propagação de consentimento: Os metadados de consentimento e classificação de dados fluem a jusante com cada evento para preservar a privacidade e a conformidade (GDPR, CCPA).
- Governança operacional: Os eventos são registrados, auditados e monitorados quanto à repetição, rejeição de esquema e anomalias de taxa de transferência por meio da Camada do Trust do Data 360.
Barras laterais
Tempo
- Os eventos de CDC são processados quase em tempo real, geralmente dentro de segundos da alteração no CRM.
- A latência pode variar conforme o volume de eventos e a taxa de transferência do conector, mas o Data 360 garante a disponibilidade de subminuto para objetos com suporte.
Volumes de dados
- Cada carga útil de evento é leve (~1 a 5 KB).
- Para objetos de alta taxa de alteração, como Caso ou Contato, garanta que os limites de taxa de transferência estejam alinhados às alocações de evento da CDC do Salesforce.
Gerenciamento de estado
Cada evento inclui metadados para controle de estado e versão:
- IDs de reprodução: Usado para recuperação de evento sequencial.
- Versão do esquema: Mantenha os metadados da versão para gerenciar alterações de contrato.
- Claves de idempotency: Desduplicar repetições entre novas tentativas.
- Compromisso de deslocamento: O Data 360 mantém o estado de compromisso após cada lote bem-sucedido de eventos.
Cenários de integração complexos
Esse padrão se integra perfeitamente a arquiteturas empresariais avançadas:
- Híbrido (Streaming + Lote): Use o CDC para atualizações em delta e trabalhos em massa para atualizações completas.
- Streaming entre organizações: Várias organizações de origem podem transmitir para o mesmo locatário do Data 360, unificadas por meio de mapeamentos de DMO.
- Ativação do agente: Atualizações de objeto em tempo real acionam automações do Einstein ou Agentforce.
- Roteamento de evento: O middleware (por exemplo, MuleSoft ou Retransmissão de evento) pode aprimorar ou encaminhar mensagens da CDC antes da ingestão.
Exemplo
Um banco global quer garantir que as alterações de dados do cliente no Salesforce Sales Cloud sejam refletidas instantaneamente no Data 360.Quando o endereço de um contato é atualizado no Sales Cloud, o mecanismo de Captura de dados de alteração publica um ContactChangeEvent.O Conector do Data 360 CRM consome esse evento, aplica a atualização ao DLO do cliente e atualiza automaticamente todos os perfis Customer 360 associados. Isso aciona o Einstein Next Best Action para verificar o novo endereço, concluindo o loop de feedback dentro de segundos da alteração do CRM original.
Contexto
Empresas digitais modernas dependem de plataformas de streaming de evento em tempo real, como Fluxos de dados do Amazon Kinesis e Amazon MSK (Gerenciado de streaming para Apache Kafka) para capturar fluxos de dados contínuos de aplicativos distribuídos, dispositivos IoT e sistemas transacionais. O Data 360 habilita a ingestão direta dessas plataformas por meio de conectores nativos de primeira parte, eliminando a necessidade de soluções baseadas em ETL ou middleware personalizadas. Esse padrão é projetado para ingestão de dados de alta taxa de transferência e baixa latência, ativação de percepções quase em tempo real, personalização e ativação conduzida por IA.
Problema
Como uma empresa pode conectar com segurança e eficiência o Data 360 a tópicos do AWS Kinesis ou do AWS MSK Kafka para ingerir continuamente dados de perfil e evento estruturados, garantindo conformidade, escalabilidade e governança do esquema?
Forças
Esse padrão apresenta várias considerações arquitetônicas e operacionais:
- Disponibilidade do conector nativo: O Salesforce fornece conectores nativos disponíveis ao público em geral para Amazon Kinesis e Amazon MSK. Esses conectores oferecem suporte de primeira parte e eliminam a necessidade de pipelines baseados em API personalizados.
- Autenticação & Segurança: Cada conector requer autenticação em nível da AWS.
- Para o Kinesis, isso usa a chave de acesso e a chave secreta da AWS, governadas pelas políticas do IAM.
- Para MSK, a autenticação pode ser configurada por meio de Chave de acesso/segredo ou OpenID Connect (OIDC).
- Definição de esquema: O Data 360 requer um esquema para interpretar a carga útil de streaming. Para Kinesis, o arquivo de esquema é carregado durante a configuração da conexão, definindo a estrutura de eventos e os mapeamentos de campo.
- Fonte de configuração:
- O conector Kinesis assina um nome específico do Fluxo de Kinesis.
- O conector MSK assina um Tópico Kafka no cluster MSK.
- Acesso à rede: Para ambientes seguros, os conectores podem ser configurados com roteamento PrivateLink ou VPC, garantindo que nenhum dado passe pela Internet pública.
- Governança operacional: A taxa de transferência de streaming, a validação de esquema e os eventos de autenticação são monitorados dentro da Camada do Trust do Data 360, garantindo a conformidade e a rastreabilidade.
Solução
A solução utiliza os conectores nativos da Amazon Kinesis ou da Amazon MSK no Data 360.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Conector nativo Kinesis | Melhor | Integração de primeira parte com a AWS Kinesis; oferece suporte a ingestão contínua de alta taxa de transferência. |
| Conector nativo MSK | Melhor | Ingestão de Kafka gerenciado com suporte para OIDC e autenticação baseada em chave. |
| Mapeamento e validação de esquema | Prática recomendada | Carregar esquema (.json/.avro) definindo a estrutura de eventos; impõe consistência durante a ingestão. |
| Configuração do IAM | Recomendado | Atribua o papel de IAM de privilégio mínimo com acesso somente leitura ao tópico de MSK ou fluxo de Kinesis de destino. |
| Roteamento de rede privada | Opcional | Configure os pontos de extremidade PrivateLink/VPC para roteamento interno seguro. |
| Padrão híbrido (Streaming + Lote) | Opcional | Use o streaming para deltas e ingestão em lote para reabastecimentos ou cargas históricas. |
| Modo de isolamento de erro | Recomendado | Rotear rejeições de esquema e erros temporários para DLQ para reprodução |
Esboço
Este diagrama ilustra a sequência de Etapas para ingerir os dados de plataformas de Evento, como Kafka e Kinesis, no Data 360 quase em tempo real
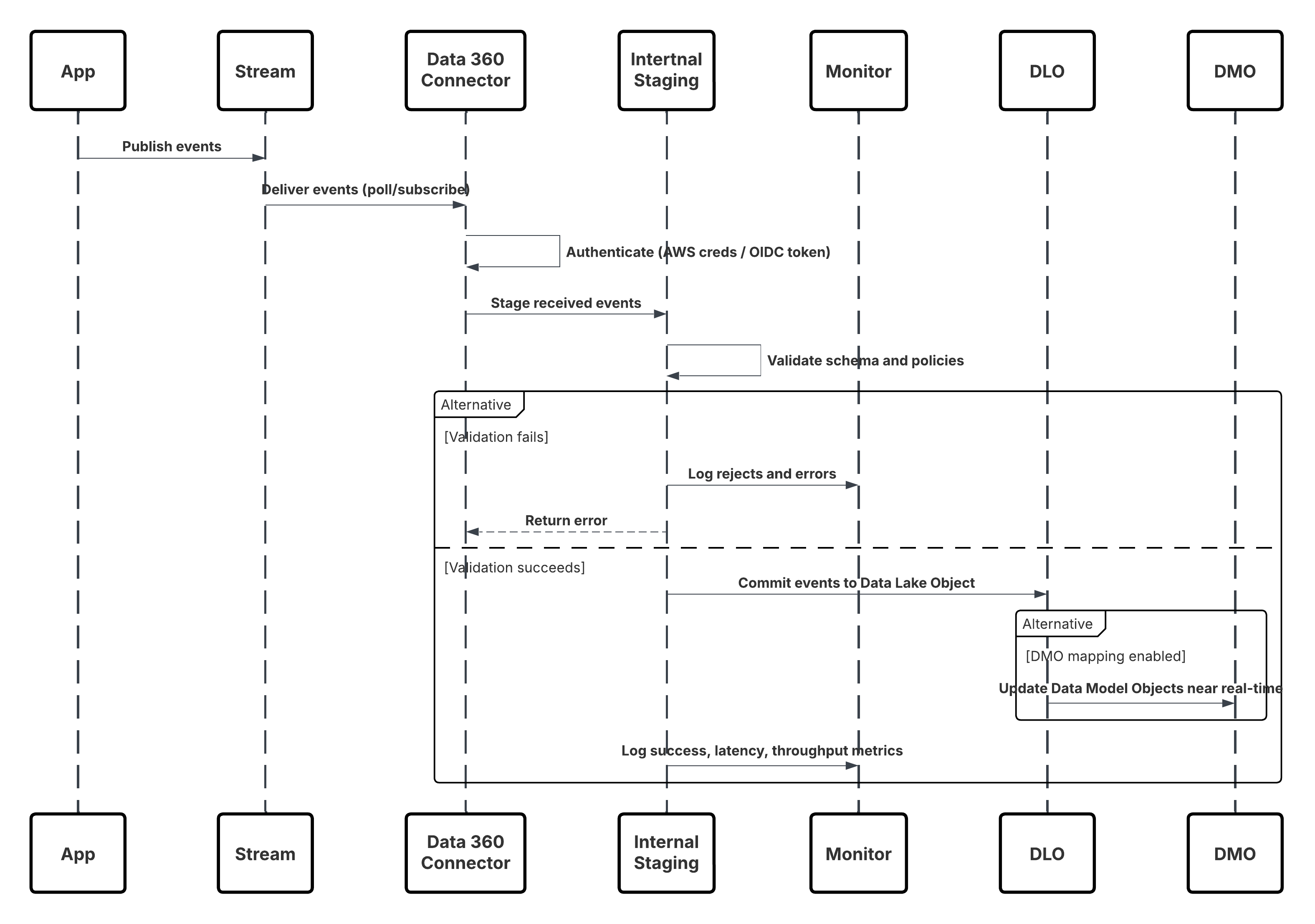
Neste cenário:
- Aplicativos ou dispositivos publicam eventos no Fluxo do Kinesis ou Tópico de MSK.
- O Conector do Data 360 autentica usando credenciais da AWS ou token OIDC.
- O conector consulta ou assina o fluxo continuamente.
- Os eventos são preparados, validados para esquema e política e confirmados para o Objeto do Data Lake (DLO).
- Se mapeado, os Objetos de modelo de dados (DMOs) são atualizados quase em tempo real para ativação.
- A Camada de monitoramento rastreia métricas, rejeições de esquema e latência.
Resultados
Ingestão contínua de dados estruturados de baixa latência diretamente do AWS Kinesis ou MSK para o Data 360. Os dados estão imediatamente disponíveis para:
- Resolução de identidade
- Segmentação em tempo real
- Ativação de IA do Einstein
- Acionadores acionados pelo Agentforce Elimina a dependência de ETL em lote, habilitando arquiteturas baseadas em fluxo alinhadas a designs conduzidos por evento corporativo.
Mecanismos de ingestão
| Mecanismo | Quando usar |
|---|---|
| Conector Kinesis (Preferencial) | Para origens de streaming nativas da AWS que exigem ingestão contínua de dados estruturados de alto volume. |
| Conector MSK | Para organizações que executam pipelines de evento em plataformas compatíveis com Kafka. |
| Híbrido(Streaming + Lote) | Para ingestão de evento incremental combinada a cargas em massa periódicas. |
Tratamento e recuperação de erros
- Automatic Retries: Os conectores tentam novamente erros de rede ou plataforma temporários com pendências exponenciais.
- Rejeições de esquema: Cargas úteis inválidas roteiam para a fila de rejeição de esquema para revisão pelo administrador.
- DLQ Replay: Falhas persistentes são capturadas em filas de letras mortas para reprocessamento.
- Idempotency Control: As chaves de evento ou os números de sequência garantem a desduplicação e a ingestão ordenada.
- Integração de monitoramento: Todas as falhas, novas tentativas e métricas de taxa de transferência são exibidas nos painéis do Monitoramento do Data 360.
Considerações sobre design idempotente
- Exclusividade do evento & rastreamento: Cada evento recebe uma chave exclusiva determinística (por exemplo, PartitionKey + SequenceNumber para Kinesis ou Topic + Partição + Deslocamento para MSK) para garantir a ingestão exata uma vez.
- Ponto de verificação do conector: Os conectores do Data 360 mantêm o último deslocamento processado ou número de sequência para retomar a ingestão com segurança após falhas ou reinicializações.
- Deduplicação & Lógica UPSERT: Durante as confirmações de DLO, eventos duplicados são detectados e ignorados; registros válidos são inseridos e atualizados usando a chave exclusiva para manter a consistência.
- Replay & Recovery Control: Eventos com falha ou atrasos são reproduzidos de deslocamentos armazenados por meio de filas de letra morta e repetição, garantindo uma recuperação confiável sem duplicação.
Considerações de segurança
A segurança é integral em todo o pipeline de ingestão, da autenticação à criptografia e controle de acesso.
- Autenticação: Troque credenciais seguras usando políticas do AWS IAM ou OIDC.
- Criptografia: Dados criptografados em trânsito (TLS 1.2+) e em repouso (AES-256) no Data 360.
- Controle de acesso: Papéis de privilégio mínimo impostos; conectores com escopo para fluxos/tópicos específicos.
- Governance: Metadados de linha e classificação aplicados a cada registro para rastreabilidade total.
- Segurança de rede: Como opção, implante em sub-rede privadas usando o AWS PrivateLink.
Barras laterais
Tempo
- Processamento quase em tempo real: CDC e conectores de streaming processam eventos dentro de segundos de alterações de origem, geralmente garantindo a atualização de dados em menos de um minuto.
- Latença determinística: O atraso de ponta a ponta depende da taxa de transferência de origem, do lote de eventos e das condições de rede, mas o Data 360 garante uma latência orientada por SLA previsível para objetos com suporte.
- Elastic Scaling: O pipeline de ingestão é escalado automaticamente sob alto volume de eventos, preservando a pontualidade mesmo durante picos de explosões de dados.
- Visibilidade operacional: Os painéis de monitoramento expõem atraso de evento, registros de data e hora de confirmação e status de reprodução para garantia de latência e solução de problemas.
Volumes de dados
- Cargas úteis ligeiras: Eventos de streaming ou CDC individuais são compactos (1 a 5 KB de tamanho típico), otimizados para atualizações de alta frequência.
- Objetos de alta mudança: Para entidades voláteis (por exemplo, Caso, Contato, Pedido), os arquitetos devem garantir que as alocações de CDC e a taxa de transferência de evento estejam alinhadas às taxas de atualização esperadas.
- Fluxos paralelos: O Data 360 oferece suporte à ingestão de vários fluxos para escala horizontal em grandes volumes de objeto ou várias organizações de origem.
- Manuseio de contrapressão: Os mecanismos de limitação integrados mantêm a estabilidade da ingestão sob carga sem cair eventos.
Gerenciamento de estado
Cada evento inclui metadados para controle de estado e versão:
- Replay & Deslocamento de rastreamento: Cada evento contém ID de reprodução e metadados de sequência, habilitando a entrega pedida e a recuperação baseada em ponto de verificação.
- Versão do esquema: As marcas de versão nos cabeçalhos de evento garantem o processamento compatível com versões anteriores quando os esquemas de origem evoluem.
- Claves de idempotency: Cada evento inclui uma transação ou chave de compromisso exclusiva, permitindo que o Data 360 desduplique repetições e novas tentativas com segurança.
- Atomic Commit: O pipeline de ingestão marca os deslocamentos como concluídos apenas depois que as confirmações a DLOs downstream são bem-sucedidas, garantindo a consistência.
Cenários de integração complexos
Esse padrão se integra perfeitamente a arquiteturas empresariais avançadas:
- Ingestão híbrida: Combine o CDC para deltas incrementais com fluxos de dados em massa para atualizações completas, mantendo a frescura e a completude.
- Streaming entre organizações: Várias organizações de CRM ou ERP podem publicar no mesmo locatário do Data 360, unificadas por meio de mapeamento de DMO e alinhamento de ontologia.
- Enriquecimento de evento: O middleware (por exemplo, MuleSoft, Retransmissão de evento) pode aprimorar, filtrar ou rotear dados de streaming antes de alcançar o Data 360.
- AI e ativação do agente: Atualizações em tempo real acionam automação a jusante, como previsões do Einstein ou respostas do Agentforce, dentro de segundos do evento de origem.
Exemplo
Uma empresa de varejo global usa o AWS Kinesis para transmitir dados de interação do ponto de venda e da Web.O conector Kinesis do Data 360 autentica por meio de credenciais IAM e ingere continuamente eventos em um DLO de transação.Cada registro é validado por esquema, aprimorado com metadados e imediatamente propagado para o DMO do cliente.Dentro de segundos, os modelos de IA do Einstein atualizam segmentos do cliente e o Agentforce aciona recomendações de próxima melhor oferta em tempo real, alcançando um loop de personalização totalmente orientado por evento.
A Cópia zero é mais do que um método de integração, é uma mudança fundamental na forma como os dados corporativos se movem, ou melhor, não se movem. Tradicionalmente, a integração de dados exigia copiar grandes volumes de registros por meio de pipelines de ETL, criando armazenamentos de dados redundantes, atrasos de sincronização e desafios de governança. A cópia zero elimina tudo isso. Nesse modelo, o Data 360 se conecta diretamente a plataformas de dados externas, como o Snowflake e o Databricks, lendo e ativando dados com segurança no lugar, sem movê-los nem duplicá-los. O resultado é uma ponte perfeita entre seu data lakehouse corporativo e o ecossistema do Salesforce, proporcionando acesso instantâneo, menor sobrecarga operacional e governança de dados mais forte.
Os recursos de cópia zero de entrada permitem que o Data 360 consulte e harmonize dados externos na origem, como perfis de clientes, transações ou dados de produto, armazenados no Snowflake ou no Databricks. Em vez de ingerir arquivos, o Data 360 estabelece uma conexão segura sensível a metadados que aproveita as definições de esquema e as políticas de segurança existentes no armazém externo.
- Federação direta: O Data 360 lê dados em vigor por meio de consultas seguras e otimizadas sem replicação.
- Governação unificada: Os dados permanecem sob a segurança, o controle de acesso e a estrutura de conformidade do sistema de origem.
- Eficiência operacional: Elimina sobrecarga de ETL e duplicação de armazenamento, reduzindo o custo e a complexidade.
- Prontidão em tempo real: Habilita harmonização sob demanda: assim que os dados forem atualizados no Snowflake, eles estarão imediatamente disponíveis para ativação no Data 360.
Contexto
Empresas modernas conduzidas por dados gerenciam petabytes de dados de cliente, transação e telemetria em plataformas de data lakehouse em escala de nuvem, como o Snowflake e o Databricks. Esses ambientes servem como a única fonte da verdade para análise, IA e conformidade. O Data 360 introduz a Zero CopyData Federation, permitindo que o Data 360 consulte diretamente e use conjuntos de dados externos no lugar, sem copiar, transformar ou armazenar dados redundantes. Esse padrão permite que as organizações estendam o tecido Customer 360 em sua infraestrutura de data warehouse ou lakehouse existente, alcançando a unificação e a ativação em tempo real sem duplicação, sem latência e sem compromisso na governança.
Problema
Como as empresas podem aproveitar conjuntos de dados avançados já organizados no Snowflake, no Databricks ou em formatos de lago aberto, como o Apache Iceberg, para segmentação, resolução de identidade e ativação no Data 360, sem a sobrecarga de custo, latência e governança de pipelines ETL ou movimentação de dados físicos?
Forças
Esse padrão apresenta várias considerações arquitetônicas, de segurança e de desempenho:
Rede & Segurança
- O Data 360 deve estabelecer uma conexão segura e privada com o armazém externo ou o lakehouse.
- Geralmente configurado usando a Conexão privada do Salesforce ou a Vinculação de PrivateLink/VPC, garantindo que o tráfego nunca saia da rede controlada do cliente.
- Os sistemas externos devem incluir IPs do Data 360 na lista de permissões e aplicar a criptografia TLS 1.2+.
Autenticação e controle de acesso
- Suporta autenticação de par de chaves, OAuth 2.0 ou Delegação de Trust baseada em provedor de identidade (IdP) (o Data 360 atua como um cliente confiável)
- O controle de acesso baseado em papel (RBAC) no sistema externo impõe o acesso de privilégio mínimo para execução de consulta.
Desempenho e dependência de computação
- A federação de consulta encaminha a execução de SQL para o Snowflake ou o Databricks, aproveitando seus clusters de computação.
- Escala de desempenho e custo com carga de consulta externa – a latência de segmentação e o custo estão vinculados à configuração de computação externa.
Normes em evolução: Federação de Arquivos
- Um modelo de próxima geração, a federação de arquivos, aproveita formatos de tabela abertos, como Apache Iceberg ou Delta Lake, permitindo que o Data 360 leia diretamente do armazenamento de objetos (por exemplo, Amazon S3, Azure ADLS, Google Cloud Storage).
- Ao ignorar a camada de computação de origem, a federação de arquivos reduz drasticamente a latência e o custo para cargas de trabalho analíticas pesadas em leitura, mantendo a integridade do esquema.
Governance and Compliance
- Os dados nunca saem da plataforma de origem. Políticas de conformidade, criptografia e retenção permanecem aplicadas na origem.
- Todos os atributos de metadados, linhagem e consentimento se propagam na Camada de Trust do Data 360 para garantir a rastreabilidade completa.
Solução
A abordagem recomendada é usar conectores nativos do Zero Copy para Snowflake, Databricks ou federação de arquivos no Data 360.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Conector do Snowflake Zero Copy | Melhor | Integração nativa de primeira parte; estabelece a federação de consulta ativa por meio de APIs de tabela externa ou compartilhamento de dados do Snowflake. |
| Databricks Zero Copy Connector | Melhor | Suporta acesso ativo direto a tabelas/visualizações no Delta Lake; as consultas pop-down são executadas no tempo de execução do Databricks. |
| Federação de arquivos (Apache Iceberg / Delta / Parquet) | Práticas recomendadas emergentes | O Data 360 lê diretamente formatos de tabela abertos do armazenamento de objeto sem dependência de computação externa. Ideal para conjuntos de dados massivos. |
| Configuração de rede privada | Recomendado | Use a Conexão privada do Salesforce ou a comparação de VPC para federação segura no nível da rede. |
| Autenticação e gerenciamento de chaves | Práticas recomendadas | Implemente a autenticação segura baseada em chave ou baseada em OAuth com rotação periódica e gerenciamento de cofre. |
| Registro de esquema | Obrigatório | O Data 360 recupera o esquema externo e o mapeia para um Objeto de data lake externo (DLO externo). |
| Metadados gerenciados | Recomendado | Todos os DLOs externos herdam metadados de classificação, consentimento e linha para visibilidade de conformidade. |
Esboço
O diagrama a seguir ilustra como configurar uma conexão de cópia zero e criar DLOs externos no Data 360.
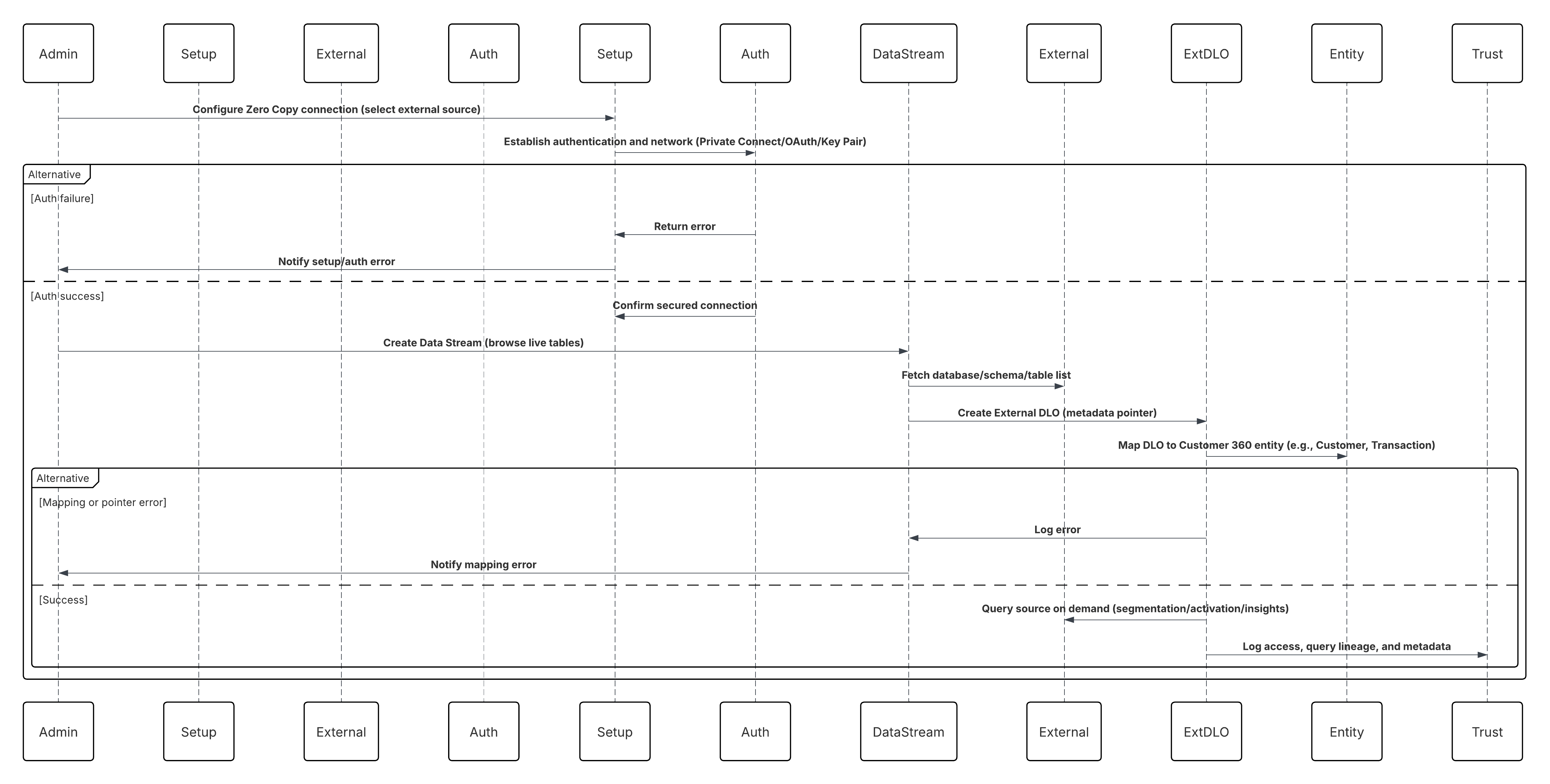
Neste cenário:
- O administrador configura uma conexão do Zero Copy na Configuração do Data 360 (Snowflake, Databricks ou Federação de arquivos).
- A autenticação segura e o roteamento de rede são estabelecidos (Conexão privada/OAuth/par de chaves).
- O administrador cria um Fluxo de dados selecionando a origem externa, navegando em bancos de dados ativos, esquemas e tabelas.
- Em vez de copiar dados, o Data 360 cria um DLO externo (Objeto de data lake) – um ponteiro de metadados que faz referência à tabela ativa ou ao arquivo Iceberg.
- DLOs externos são mapeados para entidades Customer 360 (por exemplo, Cliente, Transação, Produto).
- O Data 360 consulta a origem em vigor durante o cálculo de segmentação, ativação ou percepção.
- Todo acesso, linha de consulta e metadados são auditados dentro da Camada do Trust do Data 360.
Resultados
- Dados externos permanecem no Snowflake, no Databricks ou no S3 – sem ETL, sem duplicação, sem armazenamento adicional.
- O Data 360 obtém acesso em tempo real e de leitura a dados em escala corporativa para resolução de identidade, insights calculados e ativação.
- As organizações mantêm controle completo sob suas estruturas de governança, criptografia e conformidade existentes.
- Esse padrão habilita uma verdadeira arquitetura de Cópia zero, combinando o desempenho do acesso local com a governança do armazenamento federado.
Mecanismos de chamada
O mecanismo de chamada depende da solução escolhida para implementar esse padrão.
| Mecanismo | Quando usar |
|---|---|
| Federação do Snowflake (preferencial) | Para federação de consulta ativa e de alto desempenho com armazéns de dados corporativos gerenciados. |
| Federação de databricks | Para análise unificada e ambientes de lakehouse com conjuntos de dados com suporte Delta ou Parquet. |
| Federação de Arquivos (Apache Iceberg / Delta Lake) | Para conjuntos de dados em grande escala no armazenamento de objetos em que o desanexo de computação e a otimização de custo são essenciais. |
| Modo híbrido (cópia zero + ingestão) | Quando dados históricos precisam de ingestão única, mas os dados ativos são acessados por meio da Cópia zero. |
Tratamento e recuperação de erros
- Tentativa automática e pendências de consulta: Conexão temporária ou tempos limite de consulta são automaticamente executados novamente usando backlog exponencial.
- Isolamento de correspondência incorreta do esquema: Alterações no esquema de origem (por exemplo, novas colunas) são registradas na Fila de rejeição de esquema; os administradores podem remapear ou atualizar metadados do esquema.
- Failover de autenticação: Se as credenciais expirarem, o Data 360 tentará novamente a conexão usando tokens de atualização armazenados ou políticas de rotação de chave.
- Computar detecção de disponibilidade: Se o Snowflake ou o Databricks cluster estiver pausado, o Data 360 suspenderá trabalhos de federação e tentará novamente quando a computação for retomada.
- Integração de monitoramento: Todos os metadados de integridade da conexão, latência da consulta e linha são visíveis nos painéis do Monitoramento do Data 360.
Considerações sobre design idempotente
- Determinismo de consulta: Consultas federadas usam uma semântica de instantâneo consistente para garantir leituras estáveis e repetíveis durante a segmentação ou ativação.
- Versões de DLO externo: Cada consulta federada inclui metadados de carimbo de data e hora para rastreamento de linha.
- Acesso sem deslocamento: Como o Zero Copy é somente leitura, ele não depende de compensações de evento. A consistência é imposta por meio das garantias de ACID do sistema externo (Snowflake/Delta Lake).
- Gerenciamento de desvio de esquema: Mantenha mapeamentos de esquema com controle de versão no Data 360; atualize metadados de DLO externos na evolução de origem.
Considerações de segurança
A segurança é integral em todo o modelo de federação, garantindo que não haja compromisso em Trust ou conformidade.
- Criptografia: Todas as trocas de dados usam TLS 1.2+; armazéns externos criptografam em repouso usando AES-256.
- Controle de acesso: As tabelas externas são acessadas por meio de papéis de privilégio mínimo com permissões somente leitura.
- Isolamento de rede: As rotas VPC ou Conexão privada impedem qualquer exposição a pontos de extremidade públicos.
- Fluxo de dados gerenciado: Metadados de linhagem, consentimento e classificação fluem para a Camada do Trust do Data 360 para aplicação de políticas.
- Auditabilidade: Cada evento de acesso de esquema e consulta federada é registrado para rastreabilidade de conformidade (GDPR, CCPA, HIPAA).
Barras laterais
Tempo
- As consultas são executadas ativamente em relação ao armazém ou armazenamento externo, garantindo a visibilidade em tempo real do estado de dados mais recente.
- As execuções de segmentação ou ativação refletem alterações no Snowflake, no Databricks ou em tabelas do IceBerg com suporte no S3.
- A latência da consulta depende do nível de desempenho do sistema de origem, geralmente de segundos a dezenas de segundos por consulta.
- Ideal para cargas de trabalho de IA e análise que exigem acesso a dados "novos, não copiados".
Volumes de dados
- Dá suporte a conjuntos de dados em escala de petabytes armazenados nativamente no Snowflake ou no Databricks sem replicação.
- O Data 360 recupera apenas resultados, não conjuntos de dados brutos, minimizando os custos de rede e computação.
- A federação de arquivos otimiza grandes varreduras analíticas por meio de corte de partição e menu suspenso colunar.
- É dimensionado linearmente com a capacidade de computação do armazém e a camada de orquestração de consulta federada do Data 360.
Gerenciamento de estado
- DLOs externos mantêm metadados de conexão, esquema e versão no Data 360.
- A evolução do esquema é gerenciada automaticamente por meio de ciclos de atualização de metadados.
- A linha de consulta inclui carimbos de data e hora, identidade do usuário e métricas de execução para rastreabilidade.
- Nenhuma ingestão ou compensação de estado é mantida. A consistência é herdada das garantias de ACID da origem externa.
Cenários de integração complexos
- Modo híbrido: Combine o Zero Copy (para federação ativa) com a ingestão (para conjuntos de dados históricos).
- Acesso entre armazéns: O Data 360 pode federar de vários locatários do Snowflake ou do Databricks em uma organização.
- Interoperabilidade de IA/BI: Sistemas externos (por exemplo, SageMaker, Tableau, Power BI) podem consultar os perfis aprimorados do Data 360 de volta por meio do Zero Copy reverso.
- Extensão da federação de arquivos: Empresas que adotam formatos de open lake (Iceberg/Delta) podem unificar dados estruturados e não estruturados em um modelo federado.
Exemplo
Uma empresa financeira global armazena todos os dados transacionais e de interação no Snowflake enquanto mantém atributos do cliente e eventos de marketing no Data 360. Usando a Federação de dados de cópia zero, o Data 360 se conecta com segurança ao Snowflake por meio de Conexão privada.Quando um trabalho de segmentação é executado, por exemplo, "Clientes com US$ 10 mil gastados nos últimos 30 dias, o Data 360 envia a consulta para o Snowflake, recupera resultados agregados e ativa esses perfis instantaneamente no Journey Builder. Nenhuma replicação ou ETL necessária. Este exemplo usa inteligência federada em tempo real unificada em todo o ecossistema de dados corporativo.
A cópia zero de saída estende o mesmo princípio inversamente. Em vez de exportar ou copiar conjuntos de dados do Data 360, sistemas externos como o Snowflake podem consultar o Data 360 diretamente, tratando-o como uma fonte federada de Inteligência do cliente enriquecida.
- Federação reversa: As plataformas de análise externa ou de IA podem acessar os dados de perfil unificados do Data 360 sem extraí-los.
- Ativação de dados na fonte: As equipes de negócios podem aproveitar percepções de onde os dados já estão, seja para modelagem de IA, relatórios ou personalização do cliente.
- Interoperabilidade sem latência: Nenhuma exportação em lote ou trabalhos de sincronização; as percepções fluem instantaneamente entre plataformas.
- Semântica consistente: Como ambos os sistemas compartilham a mesma ontologia e mapeamentos de esquema, o contexto e o significado são preservados entre os ecossistemas. Zero copy redefine o papel do Data 360 de um repositório de dados para uma camada de ativação semântica. Ele permite que as organizações mantenham os dados exatamente onde eles pertencem – em armazéns de alto desempenho governados – enquanto ainda liberam todo o seu valor dentro do limite do Salesforce Trust. Esse padrão se alinha com a rede de dados moderna e arquiteturas nativas de IA: os dados permanecem descentralizados, mas a inteligência se torna unificada. Os arquitetos agora podem criar pipelines de ativação mais rápidos, flexíveis e em conformidade, sem necessidade de cópia.
Contexto
As empresas modernas operam cada vez mais em ecossistemas de dados de várias plataformas, em que o Salesforce Data 360 habilita perfis de cliente unificados e ativação, enquanto os armazéns de dados corporativos, como o Snowflake ou o Databricks, servem como pilares analíticos para ciência de dados, aprendizado de máquina e cargas de trabalho de BI. O recurso de Compartilhamento de saída de cópia zero do Salesforce Data 360 faz a ponte perfeita entre esses ambientes, permitindo acesso controlado, seguro e em tempo real a dados do Data 360 harmonizados diretamente no Snowflake ou no Databricks, sem replicação ou ETL. Isso permite que analistas e cientistas de dados consultem, visualizem e modelem os mesmos dados ativos e confiáveis que alimentam marketing, vendas e ativação de serviço.
Problema
Como uma empresa pode expor de modo seguro e eficiente os perfis de cliente unificados do Data 360 e as métricas calculadas (por exemplo, Valor da vida útil, Risco de rotatividade) a sistemas analíticos externos sem copiar dados, quebrar a governança ou introduzir latência por meio de pipelines ETL reversos tradicionais?
Forças
Esse padrão apresenta várias considerações arquitetônicas, de governança e operacionais:
- Segurança governada: O acesso aos dados do Data 360 deve ser controlado, granular e auditável. O compartilhamento de Cópia zero usa acesso em nível de objeto explícito, garantindo que apenas objetos de modelo de dados (DMOs) e objetos de insight calculado (CIOs) aprovados estejam disponíveis para os consumidores designados.
- Seleção de objeto explícito: Os administradores organizam dados compartilháveis por meio de um Compartilhamento de dados, selecionando explicitamente quais objetos expor. Isso mantém a governança e minimiza a exposição de risco.
- Configuração bi-lateral: Tanto o Data 360 quanto o armazém externo exigem configuração. O Data 360 define a Meta de compartilhamento de dados (Snowflake/Databricks), enquanto o sistema receptor deve aceitar e instanciar o compartilhamento.
- Modelo de federação de consulta: Depois de aceita, a plataforma externa consulta dados do Data 360 ativos e controlados por meio de visualizações federadas, eliminando trabalhos de extração ou ciclos de atualização manual.
- Evolução de padrões abertos: Abordagens emergentes como a federação de arquivos aproveitam formatos de tabela abertos (por exemplo, Apache Iceberg) para habilitar o acesso somente leitura na camada de armazenamento, melhorando a escalabilidade, o desempenho e a interoperabilidade entre arquiteturas de várias nuvens.
Solução
A solução aproveita o Compartilhamento de cópia zero nativo do Salesforce Data 360 com plataformas de dados como o Snowflake ou o Databricks.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Criação de compartilhamento de dados | Melhor | O administrador cria um compartilhamento de dados no Data 360, adicionando DMOs e CIOs selecionados (por exemplo, Indivíduo unificado, Pontuação de saúde do cliente). |
| Configuração de destino | Melhor | Crie uma Meta de compartilhamento de dados especificando identificadores de conta do Snowflake ou do Databricks e parâmetros de autenticação. |
| Compartilhar publicação | Práticas recomendadas | Vincule o compartilhamento de dados ao destino do compartilhamento de dados para publicar com segurança. |
| Aceitação de armazém | Obrigatório | O administrador externo aceita o compartilhamento, materializando objetos compartilhados como visualizações/tabelas somente leitura no armazém. |
| Controle de acesso granular | Recomendado | Aplique permissões baseadas em objeto e papel no Data 360; alinhe-se ao controle de acesso baseado em papel no nível do armazém. |
| Acesso à consulta federada | Melhor | Os analistas consultam dados compartilhados ativos por meio de SQL padrão; une-se a dados de armazém nativos para análise a jusante e ML. |
| Opção de federação de arquivos | Opcional | Para conjuntos de dados grandes, aproveite a federação baseada no Apache Iceberg para leituras diretas do S3 ou do Delta Lake sem dependência de computação. |
Esboço
O diagrama a seguir ilustra uma chamada do Salesforce Data 360 para uma Plataforma de dados externa.
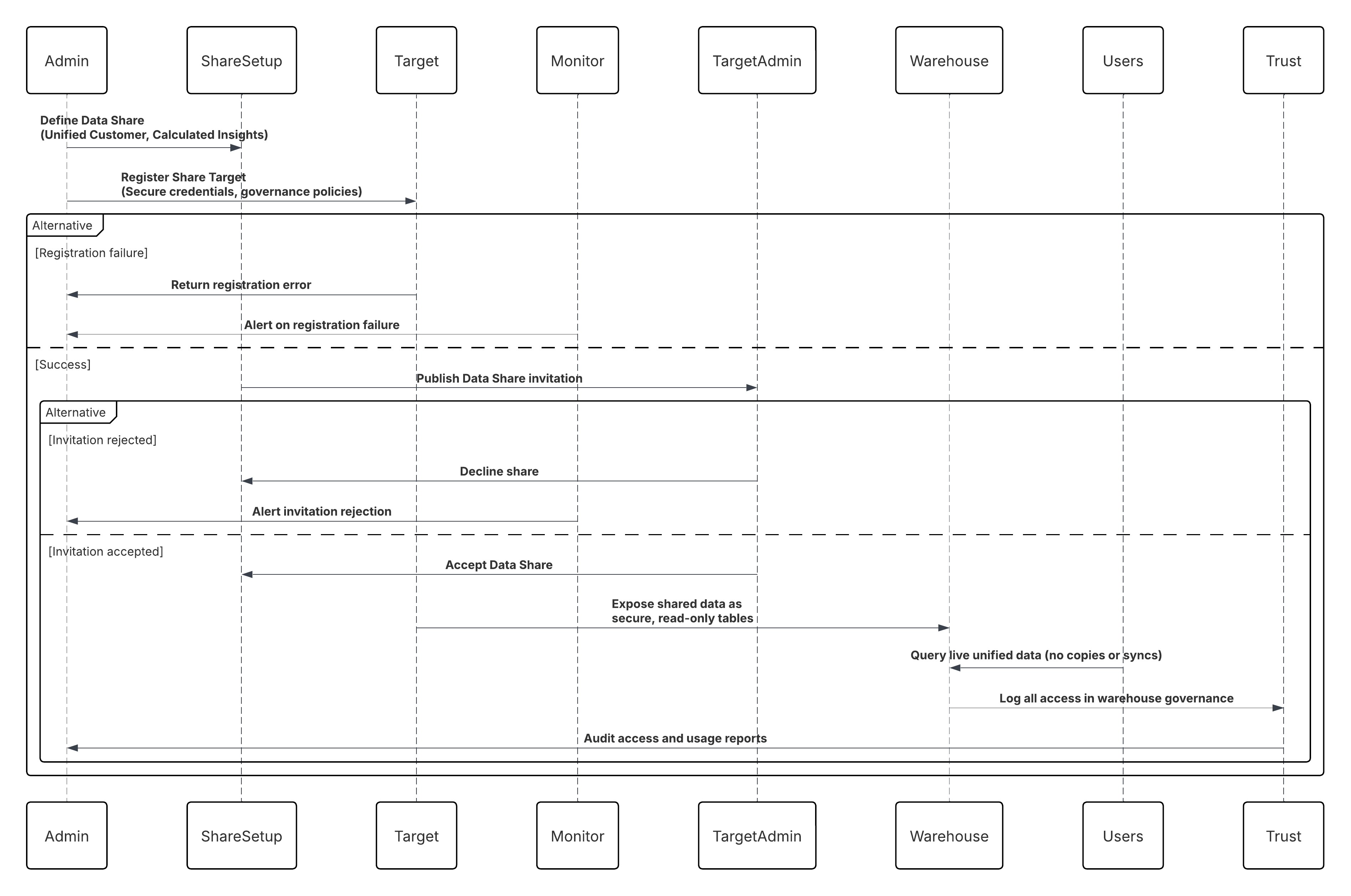
Neste cenário:
- O Administrador do Data 360 define um compartilhamento de dados incluindo os objetos Cliente unificado e Insight calculado.
- Uma Meta de compartilhamento de dados (conta do Snowflake ou Databricks) é registrada com credenciais seguras e políticas de governança.
- O Data 360 publica o compartilhamento; os administradores do Snowflake/Databricks o aceitam.
- Os dados compartilhados aparecem como tabelas somente leitura seguras no armazém.
- Analistas, ferramentas de BI ou pipelines de ML consultam os dados ativos e unificados do cliente sem copiar nem sincronizar.
- Todo o acesso é auditado dentro da Camada de Trust do Data 360 e dos logs de governança de armazém.
Resultados
- Armazéns externos obtêm acesso consultável em tempo real a dados do Data 360 harmonizados.
- Elimina pipelines de ETL reverso, reduzindo a carga operacional e a latência.
- Habilita treinamento em IA/ML, modelagem preditiva e BI avançada diretamente em dados unificados.
- Mantenha zero de duplicação, governança forte e controle de acesso seguro por design.
- Conclui o loop bidirecional de Cópia zero, em que a federação de entrada e o compartilhamento de saída coexistem sob um só modelo de governança.
Mecanismos de chamada
O mecanismo de chamada depende da solução escolhida para implementar esse padrão.
| Mecanismo | Quando usar |
|---|---|
| Compartilhamento de dados seguro do Snowflake (preferencial) | Use quando seu armazém corporativo for Snowflake e você precisar de acesso ativo e controlado a conjuntos de dados do Data 360 harmonizados sem movimentação ou duplicação de dados. Ideal para cargas de trabalho orientadas por análise, IA e conformidade que exigem compartilhamento de latência zero e imposição de linha nativa. |
| Databricks Delta Share | Use quando os consumidores a jusante operarem em ambientes Databricks ou Delta Lake e exigirem acesso somente leitura em tempo real a conjuntos de dados unificados ou ativados por meio do protocolo de compartilhamento delta aberto. |
| Compartilhamento de mesa externo (Apache Iceberg / Parquet) | Use ao manter arquiteturas de formato aberto no armazenamento de objetos (S3, ADLS ou GCS) e precisar de compartilhamento interoperável e de baixo custo entre mecanismos analíticos, como Athena, BigQuery ou Snowflake-on-Iceberg. |
| API de compartilhamento de dados (acesso programático) | Use quando aplicativos personalizados ou middleware (por exemplo, MuleSoft) precisam descobrir, assinar ou consumir conjuntos de dados compartilhados com segurança por meio de APIs, com notificações de atualização baseadas em evento e controle de acesso detalhado. |
| Compartilhamento híbrido (cópia zero + participação de saída) | Use ao implementar padrões de troca bidirecionais, aproveitando o Zero Copy para dados de entrada e o Compartilhamento de dados de saída para publicar percepções, garantindo a consistência semântica e de governança em planos de dados corporativos. |
Tratamento e recuperação de erros
- Tentativas de conexão: Novas tentativas automatizadas para conexão temporária ou falhas de autenticação entre o Data 360 e o armazém.
- Validação de compartilhamento: Configurações de compartilhamento inválidas ou não autorizadas são quarentenas em uma Fila de revisão do administrador.
- Monitoramento de saúde síncrono: O Data 360 detecta o status de compartilhamento ativo, a latência da consulta e os registros de acesso por meio de painéis de monitoramento.
- Revogação de acesso: Os administradores podem revogar compartilhamentos instantaneamente, desabilitando o acesso em ambos os lados sem cópias de dados residuais.
- Pista de auditoria governada: Todas as alterações de ajustes e acesso são registradas para verificação de conformidade.
Considerações sobre design idempotente
- Identificação de participação consistente: Cada par de Compartilhamento de dados e Meta de compartilhamento de dados tem um identificador exclusivo, garantindo a governança exata e a rastreabilidade de acesso.
- Visualizações imutáveis: Os objetos de dados compartilhados são somente leitura; os consumidores não podem mutar o estado, garantindo resultados determinísticos e conformidade.
- Ciclo de vida de compartilhamento atômico: Compartilhar publicação, revogação e atualização são operações atômicas, totalmente concluídas ou revertidas.
- Consistência de repetição: Quando os dados do Data 360 são atualizados, as consultas no lado do armazém sempre retornam o instantâneo consistente mais recente, eliminando leituras obsoletas.
Considerações de segurança
A segurança é baseada em todos os aspectos do compartilhamento de Cópia zero:
- Autenticação: Trust mútuo estabelecido usando OAuth 2.0, troca de chaves privadas ou federação de identidade (OIDC).
- Criptografia: Dados criptografados em trânsito (TLS 1.2+) e em repouso (AES-256).
- Controle de acesso: As permissões em nível de objeto aplicam o acesso de privilégio mínimo, regido pela Camada do Trust do Data 360.
- Segurança de rede: As trocas de dados ocorrem por meio de links de rede privada, como Conexão privada do Salesforce ou APIs de Troca de dados segura.
- Metadados de governança: Cada objeto compartilhado contém atributos de linhagem, classificação e consentimento para total rastreabilidade e conformidade regulatória.
Barras laterais
Tempo
- Disponibilidade em tempo real: Os dados compartilhados refletem o estado mais atual do Data 360 sem atrasos de replicação.
- Freshness da consulta: Alterações em DMOs ou CIOs se propagam instantaneamente para visualizações de armazém compartilhadas.
- Elasticidade de desempenho: O menu suspenso de consulta se adapta dinamicamente aos recursos de computação do armazém.
- Monitoração: Painéis ativos expõem métricas de desempenho de consulta e latência compartilhadas para garantia operacional.
Volumes de dados
- Compartilhamento dimensionável: Suporta compartilhamento de dados de nível de objeto granular ou de domínio completo dependendo das necessidades analíticas.
- Desempenho de consulta otimizado: O Snowflake/Databricks armazena em cache dados compartilhados de modo inteligente para minimizar a latência.
- Eficiência de armazenamento: A duplicação zero elimina custos de armazenamento redundantes.
- Opção de federação de arquivos: Para conjuntos de dados em escala de petabytes, o compartilhamento direto baseado em iceberg ignora o cálculo e acelera o acesso.
Gerenciamento de estado
- Evolução do esquema: Os esquemas com controle de versão garantem a compatibilidade quando o modelo do Data 360 evolui.
- Rastreamento de estado de acesso: Estados de compartilhamento ativos/inativos mantidos no Data 360 para governança de ciclo de vida.
- Sincronização de metadados: As atualizações em definições de objeto compartilhadas são refletidas automaticamente nos catálogos de armazém a jusante.
- Garantia estatal imutável: As visualizações de armazém sempre representam um estado de ponto no tempo consistente dos dados do Data 360.
Cenários de integração complexos
- Modo híbrido: Combine o Zero Copy (para federação ativa) com a ingestão (para conjuntos de dados históricos).
- Acesso entre armazéns: O Data 360 pode federar de vários locatários do Snowflake ou do Databricks em uma organização.
- Interoperabilidade de IA/BI: Sistemas externos (por exemplo, SageMaker, Tableau, Power BI) podem consultar os perfis aprimorados do Data 360 de volta por meio do Zero Copy reverso.
- Extensão da federação de arquivos: Empresas que adotam formatos de open lake (Iceberg/Delta) podem unificar dados estruturados e não estruturados em um modelo federado.
Exemplo
A análise entre nuvens permite que as organizações combinem dados gerenciados do Salesforce Data 360 com conjuntos de dados nativos em plataformas como o Snowflake e o Databricks para oferecer uma visualização analítica completa e completa. Por meio do acesso de vários locatários, diferentes unidades de negócios podem consumir com segurança fatias de dados selecionadas e controladas por apólice por meio de compartilhamentos separados sem duplicar dados. Os cientistas de dados então podem realizar a IA federada e o aprendizado de máquina treinando modelos diretamente em perfis de cliente unificados nos ambientes do ML do Snowflake ou do Databricks MLflow. Ao longo desse processo, os recursos integrados de lineagem, governança e auditoria garantem que todo o acesso e uso de dados permaneçam em conformidade com as políticas corporativas e requisitos regulatórios, como GDPR e HIPAA.
O Data Cloud One permite que organizações com várias organizações do Salesforce (por exemplo, devido a unidades de negócios, regiões, linhas de produto ou aquisições) compartilhem uma única instância central do Data 360. Essa organização atua como a "organização inicial", enquanto outras organizações, chamadas de "organizações parceiras", podem acessar e agir com base nesses dados unificados, com esforço mínimo, sem código personalizado e controles de governança completos.
Contexto
As empresas costumam executar mais de uma organização do Salesforce (por exemplo, uma para vendas, uma para serviço, uma para marketing ou regiões distintas). Cada organização pode ter seus próprios dados, configuração e processos. Antes do Data Cloud One, cada organização exigia sua própria configuração do Data 360 ou código personalizado complexo para compartilhar dados entre organizações. O Data Cloud One simplifica isso permitindo uma única organização "início" com o Data 360 e várias organizações "companheiras" que se conectam por meio de configuração de baixa codificação e compartilhamento de metadados.
Problema
Como uma empresa pode permitir o uso consistente dos dados unificados do Customer 360 – ingeridos, harmonizados e gerenciados pelo Data 360 da organização de origem – em todas as suas organizações do Salesforce (para que vendas, marketing, serviço, etc., todos usem os mesmos dados subjacentes), evitando duplicação de esforços, codificação personalizada, instâncias separadas do Data 360 por organização e lacunas de governança?
Forças
Esse padrão apresenta várias considerações arquitetônicas, de segurança e de desempenho:
- Complexidade de várias organizações: A organização de cada unidade de negócios pode ter dados, objetos personalizados, segurança e processos diferentes. É difícil manter visualizações unificadas consistentes.
- Duplicação & Custo: Executar uma instância separada do Data 360 por organização significa configuração extra, governança extra, licenciamento extra e risco de silos de dados.
- Governança e controles de compartilhamento de dados: Você precisa decidir quais dados cada organização companheira pode ver e agir com base nisso – você não pode simplesmente compartilhar “tudo” sem risco de governança.
- Velocidade de configuração: Equipes de marketing, vendas ou serviço não podem esperar semanas para que o código personalizado disponibilize dados entre organizações. Elas precisam de soluções de click-config.
- Residência de dados, Considerações regionais: Se as organizações de origem e companheiras estiverem em regiões diferentes, talvez haja restrições legais ou regulatórias sobre onde os dados são armazenados ou como eles são compartilhados.
Solução
A tabela a seguir contém várias soluções para esse problema de integração.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Home Organização de provisionamento | Melhor | Designe uma organização do Salesforce como a organização inicial em que o Data 360 está provisionado; isso se torna o repositório de dados central e o hub de governança. |
| Conexão da organização companheira | Melhor | Configure as Conexões de companheiro da organização inicial para uma ou mais Organizações de companheiro por meio do aplicativo Data Cloud One, sem necessidade de código personalizado. |
| Definição de espaço de dados | Práticas recomendadas | Defina espaços de dados na organização inicial para segmentar dados de modo lógico (por exemplo, varejo, serviço, marketing) e isolar limites de acesso. |
| Compartilhamento de espaço de dados | Melhor | Compartilhe explicitamente espaços de dados selecionados da organização inicial para organizações companheiras, garantindo a visibilidade governada e baseada em papel dos dados unificados. |
| Configuração de acesso | Obrigatório | Em Organizações de companheiro, habilite o aplicativo Data Cloud One e atribua permissões de usuário para acesso a perfil, percepção e segmento. |
| Governança e controle de política | Recomendado | Centralize todas as configurações de ingestão, resolução de identidade e Trust na organização inicial, mantendo a governança completa. |
| Sincronização de várias organizações | Melhor | Alterações de dados e percepções calculadas na organização inicial são refletidas em tempo real em organizações de companheiro por meio de pipelines de sincronização gerenciados. |
| Opção de implantação híbrida | Opcional | Para grandes empresas, várias organizações de companheiro podem se conectar a uma única organização inicial enquanto mantêm o contexto local e os limites de conformidade. |
Esboço
O diagrama a seguir ilustra a sequência de eventos nesse padrão, em que o Salesforce é o mestre de dados.
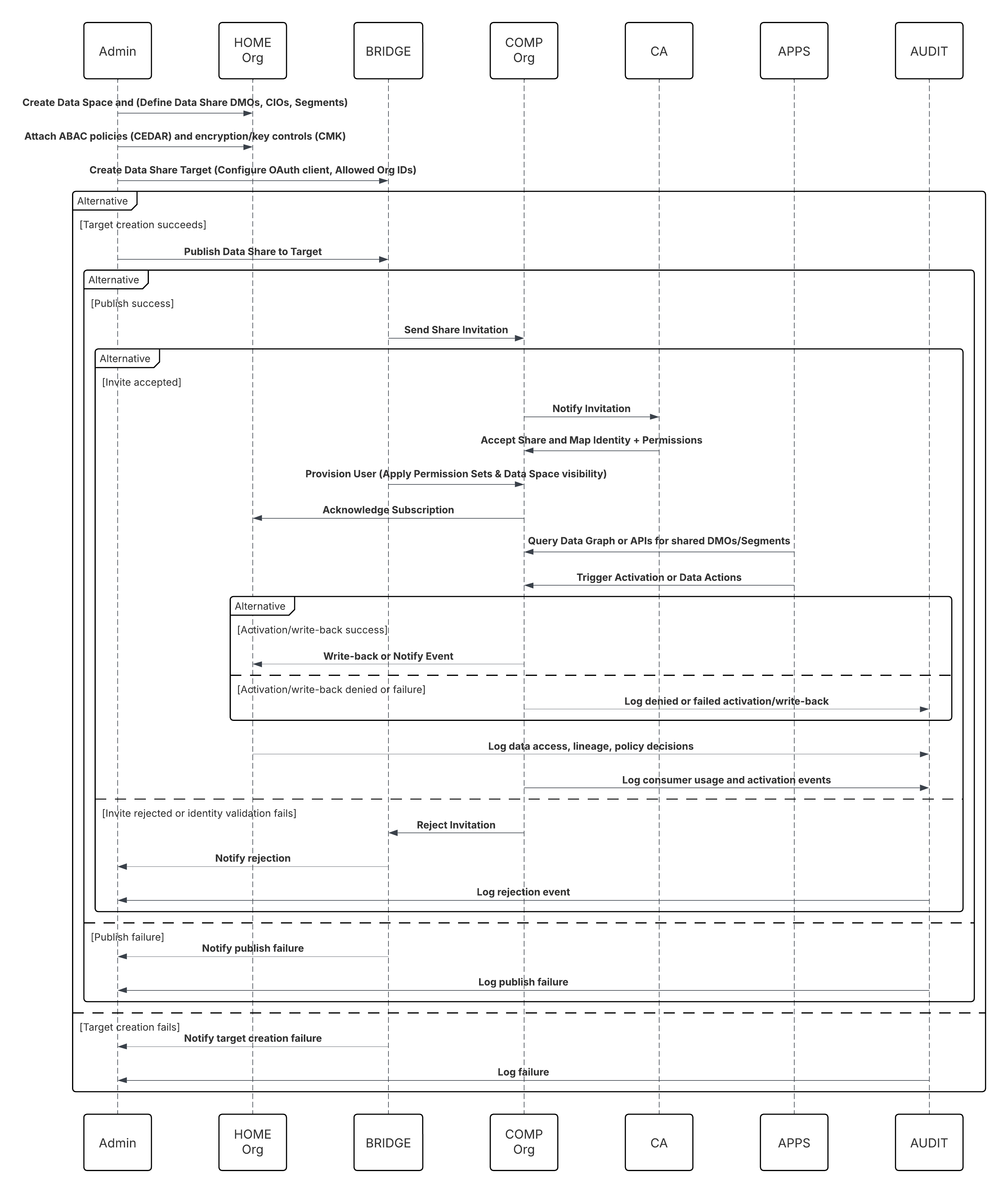
Neste cenário:
- Home Admin: crie Espaço de dados e defina o Compartilhamento de dados (selecione DMOs/CIOs, segmentos).
- Home Admin: crie um destino de compartilhamento de dados para organizações parceiras e configure o Trust (cliente OAuth, IDs de organização permitidos).
- Home Admin: publicar o Data Share para o destino; anexar políticas ABAC (CEDAR) e controles de criptografia/chave (CMK, se necessário).
- Administrador da organização companheira: recebe convite, valida o mapeamento de identidade e aceita compartilhamento.
- Organização companheira: A Ponte do Data Cloud One provisiona um usuário do Data Cloud One e aplica a visibilidade de Conjuntos de permissões e Espaço de dados.
- Aplicativos da organização companheira (fluxos / Einstein / Apex): Consulte um gráfico de dados ou chame as APIs do Data Cloud One para ler segmentos ou DMOs compartilhados.
- Ativação: A organização do companheiro aciona a ativação ou grava novamente por meio de ações de dados (se permitido).
Resultados
- Uma única fonte de verdade para dados do cliente (Customer 360) em todas as organizações conectadas, sem instâncias redundantes do Data 360.
- Um tempo de valorização mais rápido. As organizações parceiras podem acessar dados unificados e recursos desenvolvidos com o Data 360 em minutos, em vez de semanas de codificação personalizada.
- Compartilhamento de dados controlado. Somente espaços de dados autorizados são compartilhados, preservando a segurança e a governança enquanto habilita a agilidade dos negócios.
- Funções de negócios (vendas, serviço, marketing) operam na mesma base de dados unificada, permitindo métricas, ativação e percepções consistentes em toda a empresa.
Mecanismos de chamada
O mecanismo de chamada depende da solução escolhida para implementar esse padrão.
| Mecanismo | Quando usar |
|---|---|
| Compartilhamento nativo do Data Cloud One (preferencial) | Use quando várias organizações do Salesforce (Vendas, Serviço ou Industry Clouds) precisarem de acesso em tempo real a dados unificados do cliente diretamente do Data 360\. Isso elimina a replicação e habilita o acesso de latência zero a registros dourados, segmentos e percepções calculadas. |
| Compartilhamento organizacional por meio do Data Cloud One Bridge | Use quando várias unidades de negócios ou subsidiárias operam em organizações do Salesforce separadas, mas precisam de acesso compartilhado a dados e segmentos comuns do cliente de uma instância central do Data 360. Ideal para empresas de várias organizações que mantêm sistemas operacionais independentes. |
| APIs de consulta de plataforma Einstein 1 | Use quando os aplicativos Salesforce, o Fluxo ou o Einstein Copilot precisarem consultar ou ativar dados do Data 360 programaticamente. Permite a recuperação em tempo real de perfis unificados, métricas ou resultados da ativação para outros aplicativos do Salesforce sem exportações em lote. |
| Ativação para canais do Salesforce | Use quando os dados do Data 360 (segmentos, percepções ou atributos) precisarem ser ativados no Marketing Cloud, no Service Cloud ou no Commerce Cloud para personalização, execução de campanha ou experiências de assistência do agente. |
| Acesso ao gráfico de dados (camada de consulta semântica) | Use quando precisar de acesso em nível de semântica ao modelo de dados unificado por meio do Salesforce Data Graph, com suporte para Copilot, fluxos de trabalho de IA e análise entre nuvens em tempo real, sem junções ou transformações manuais. |
Tratamento e recuperação de erros
- Resiliência de sincronização entre organizações: O Data Cloud One repetiu automaticamente os trabalhos de sincronização com falha entre Organizações iniciais e Organizações de companheiro usando backlog exponencial para erros de rede ou plataforma temporários.
- Isolamento parcial do lote: Os lotes de registro com falha são colocados em quarentena em uma Fila de nova tentativa na organização inicial até que a reconciliação seja bem-sucedida, evitando divergências de dados.
- Governação de rejeição de esquema: Não correspondências de esquema ou mapeamento são roteadas para a Fila de rejeição de esquema para revisão e correção pelo administrador.
- Continuidade de repetição e retomada: Cada trabalho de sincronização mantém pontos de verificação de deslocamento para que a replicação possa ser retomada da última confirmação bem-sucedida sem duplicação.
- Monitoramento integrado: Todas as falhas, novas tentativas e métricas de recuperação são capturadas no Trust Layer Monitoring Dashboard para visibilidade e garantia de SLA.
Considerações sobre design idempotente
- Chaves de Idempotência determinística: Cada evento de sincronização contém uma chave exclusiva (ID da organização + ID do registro + Número da versão) para garantir o processamento exato uma vez.
- Segurança de reprodução: Eventos duplicados ou repetidos são filtrados no tempo de confirmação, garantindo atualizações consistentes de DMO e CIO a jusante.
- Semântica de confirmação atômica: Organizações parceiras marcam dados como confirmados apenas após gravações bem-sucedidas a jusante, preservando a integridade transacional entre organizações.
- Resolução de conflitos: Atualizações de múltiplas fontes seguem a lógica de mesclagem conduzida por política ou última gravação e ganho, mantendo a linhagem e a consistência.
- Persistência do ponto de verificação: Os trabalhos de sincronização persistem nos últimos deslocamentos processados e estão dentro da Camada Trust para recuperação e reprodução seguras.
Considerações de segurança
- Autenticação forte: As conexões entre organizações Início e Companion usam OAuth 2.0 mútuo com tokens de rotação automática gerenciados por meio de Aplicativos conectados.
- Autorização granular: Organizações parceiras podem acessar apenas espaços de dados, DMOs ou CIOs específicos explicitamente compartilhados por meio de políticas de compartilhamento de dados governadas.
- Criptografia em qualquer lugar: Os dados são criptografados em trânsito (TLS 1.2+) e em repouso (AES-256) em organizações Início e Companheiro.
- Princípio de privilégio mínimo: Os usuários de integração têm o escopo definido apenas para os objetos necessários; nenhuma permissão administrativa ou no nível do sistema é propagada.
- Visibilidade de auditoria e conformidade: Todos os eventos de sincronização, alterações de esquema, atualizações de credenciais e concessões de acesso são registrados na Camada do Trust do Data 360 para rastreabilidade total.
- Isolamento de rede privada: A opção Conexão privada ou Link privado do Salesforce garante que a replicação de dados ocorra apenas em canais seguros e internos.
Barras laterais
Tempo
- A sincronização entre organizações Início e Companheiro ocorre quase em tempo real, geralmente dentro de segundos de uma alteração de dados na organização de origem.
- A arquitetura de Cópia zero garante que os dados compartilhados sejam instantaneamente consultáveis em todas as organizações participantes, sem atrasos de replicação ou lote.
- Os trabalhos de ativação e segmentação refletem automaticamente as atualizações mais recentes de qualquer organização conectada, mantendo a frescura operacional.
- A latência de ponta a ponta é determinística e regulada pelo pipeline de orquestração do Data Cloud One, garantindo um tempo entre organizações consistente mesmo sob carga.
Volumes de dados
- Projetado para sincronização de dados em hiperescala de vários locatários entre regiões e unidades de negócios, capaz de gerenciar bilhões de registros por organização.
- Os dados são referenciados, não duplicados, reduzindo a pegada de armazenamento enquanto mantêm a capacidade de consulta global.
- Os deltas de streaming e a compactação de metadados otimizam a largura de banda e confirmam a sobrecarga para objetos de alta taxa de alteração (por exemplo, Contato, Pedido).
- Escala horizontalmente em várias Organizações Companheiras com balanceamento de carga adaptável e orquestração por meio da Camada de Trust.
Gerenciamento de estado
- Cada conjunto de dados sincronizado mantém a linhagem de metadados, a versão e o contexto de propriedade da organização para garantir o rastreamento de ponta a ponta.
- A persistência do ponto de verificação captura deslocamentos sincronizados pela última vez entre organizações, permitindo a recuperação sem duplicação.
- O controle de versões do esquema e o alinhamento semântico entre organizações são automaticamente regidos pelas Camadas Trust.
- Nenhuma redefinição de estado manual é necessária – o estado da sincronização é mantido por meio do Serviço de orquestração do Data Cloud One.
Cenários de integração complexos
- Federação entre organizações: Habilita a consulta e a ativação perfeitas em vários locatários do Data 360 ou regiões em um modelo de governança unificado.
- Sincronização híbrida: Combina a replicação quase em tempo real para atualizações transacionais com a sincronização agendada para dados em massa ou arquivos.
- Governança de várias regiões: Dá suporte ao compartilhamento de dados distribuídos geograficamente enquanto respeita os limites de residência, consentimento e conformidade.
- AI e ativação de automação: Dados sincronizados alimentam instantaneamente a IA do Einstein, Agentforce ou modelos de ML personalizados entre organizações, habilitando inteligência entre organizações em tempo real.
Exemplo
Uma organização de varejo global tem três organizações do Salesforce: uma para o varejo do consumidor, outra para marcas premium e outra para mercados internacionais. Eles provisionam o Data 360 na organização do varejo do consumidor (o que o torna a organização de origem). Com o Data Cloud One, eles configuram conexões de companheiro com as organizações de Marcas premium e Mercados internacionais. Compartilham apenas espaços de dados apropriados (por exemplo, "Customer 360 – Perfis de varejo" e "Customer 360 – Perfis premium") com cada organização parceira. Na organização de Marcas premium, as equipes de marketing podem visualizar perfis de cliente unificados, criar segmentos com base em percepções calculadas (por exemplo, valor da vida útil do cliente premium) e acionar automações de marketing, tudo desenvolvido pela instância do Data 360 da organização de origem, sem codificação personalizada ou duplicação de dados.
É na ativação de dados que o valor do Salesforce Data 360 ganha vida. É o processo de obter os dados unificados, aprimorados e governados que estão dentro da plataforma e torná-los úteis em todos os negócios. Na prática, isso significa entregar com segurança segmentos selecionados, percepções calculadas e atributos contextuais do Data 360 para os sistemas que engajam os clientes, sejam eles automação de marketing, consoles de serviço, capacitação de vendas, análise ou modelos de IA. De uma perspectiva técnica, os padrões de ativação definem como esses dados se movem: quais canais são acionados, quais transformações ou mapeamentos ocorrem e como as políticas são aplicadas ao longo do caminho. Esses padrões não se referem apenas à exportação de dados, mas à orquestração de fluxos de dados em tempo real sensíveis à política que geram resultados de negócios mensuráveis. Cada rota de ativação transforma o Customer 360 em um ativo operacional ativo – acionando personalização, tomada de decisão preditiva e aprendizado contínuo em todos os pontos de contato.
A ativação em lote continua sendo o método mais usado e comprovado operacionalmente para exportar dados do Data 360. Ele opera em um ritmo agendado, publicando segmentos de público predefinidos ou conjuntos de atributos em plataformas a jusante a intervalos regulares. Esse padrão é ideal para fluxos de trabalho de marketing e engajamento que dependem de entrega de público consistente e de alto volume em vez de atualizações instantâneas. Os casos de uso típicos incluem habilitar jornadas de email, campanhas de email direto ou carregamentos de público em redes de publicidade digital. Cada execução de ativação extrai o segmento qualificado do gráfico de perfil unificado do Data 360, aplica políticas de governança e consentimento e transmite com segurança a saída para o sistema de destino. Arquitetonicamente, a ativação em lote oferece uma abordagem previsível, auditável e econômica à distribuição de dados, equilibrando a simplicidade operacional com a confiabilidade em nível corporativo. É a base da execução de campanha em grande escala, em que os dados certos, entregues a tempo e sob controle, geram impacto comercial mensurável.
Contexto
Os profissionais de marketing modernos operam em vários canais de engajamento (email, publicidade, dispositivos móveis e Web) exigindo públicos de clientes precisos, oportunos e personalizados. O Data 360 serve como a base unificada para esses públicos, combinando dados do cliente de cada sistema em segmentos avançados e acionáveis. A ativação em lote é o padrão de ativação mais comum usado para exportar esses segmentos do Data 360 para plataformas de marketing ou publicidade a jusante. Destinos típicos incluem Marketing Cloud Engagement, Google Ads, Meta Custom Audiences ou LinkedIn Ads, em que as campanhas podem ser executadas diretamente em relação a esses públicos selecionados.
Problema
Como uma equipe de marketing pode obter um público definido com precisão, criado usando dados unificados e aprimorados no Data 360, e disponibilizá-lo em sistemas de marketing ou publicidade externos para ativação? Por exemplo, considere o segmento: "Clientes de alto valor que não compraram nos últimos 90 dias, mas se engajaram recentemente no site". Os profissionais de marketing precisam garantir que esse público seja transferido com precisão, aprimorado com atributos relevantes (por exemplo, nível de fidelidade, região ou CLV previsto) e atualizado a intervalos regulares para manter a relevância e a eficácia da campanha.
Forças
Vários fatores técnicos e operacionais moldam o padrão de Ativação em lote:
- Mapeamento de identidade: A entrega de público precisa exige mapear o ID de indivíduo unificado do Data 360 para o identificador correspondente no sistema de destino, como uma Chave de assinante no Marketing Cloud ou um email com hash para plataformas de anúncio digital. Isso garante uma correspondência precisa e elimina erros de direcionamento.
- Seleção de atributo e aprimoramento: Os profissionais de marketing devem ir além dos IDs e incluir dados de perfil adicionais, como primeiro nome, status de fidelidade, CLV ou outros atributos personalizados, para habilitar a personalização e a análise a jusante.
- Configuração da plataforma de destino: Cada destino deve ser registrado no Data 360 como um Destino da ativação, incluindo detalhes da conexão, autenticação e mapeamentos de campo de dados. Essa configuração única define a conectividade segura e controla quais sistemas podem receber dados ativados.
- Governance and Compliance: A ativação de dados deve cumprir metadados de consentimento, políticas de privacidade (por exemplo, GDPR ou CCPA) e permissões de marketing armazenadas no perfil unificado. A ativação sensível ao consentimento garante que os dados sejam usados apenas para fins autorizados.
- Agendamento e desempenho: As ativações costumam ser agendadas diariamente ou de hora em hora para manter os públicos a jusante atualizados. O sistema deve lidar com eficiência com grandes volumes e atualizações incrementais sem duplicação ou perda de dados.
Solução
O processo de ativação em lote no Data 360 segue um fluxo de trabalho guiado que minimiza o atrito técnico para os profissionais de marketing, preservando a governança e a escalabilidade:
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Criação de segmento | Melhor | Um profissional de marketing ou analista cria um segmento na tela de segmentação visual aplicando filtros em qualquer objeto de modelo de dados (DMO) ou objeto de Insight calculado (CIO). Isso define o público-alvo para ativação. |
| Configuração de ativação | Melhor | O usuário cria uma ativação e seleciona o segmento que acaba de criar como origem. Isso define qual público o Data 360 exportará para sistemas downstream. |
| Seleção de destino da ativação | Práticas recomendadas | O profissional de marketing seleciona um destino da ativação pré-configurado (por exemplo, Marketing Cloud, Google Ads, LinkedIn Ads). Cada destino é registrado no Data 360 com credenciais de autenticação e mapeamentos de campo. |
| Definição de carga de pagamento | Obrigatório | O profissional de marketing define a carga útil escolhendo identificadores de contato (por exemplo, email, celular, ID com hash) e selecionando atributos de perfil adicionais (por exemplo, primeiro nome, nível de fidelidade ou CLV) para aprimoramento no sistema de destino. |
| Agendamento e frequência | Recomendado | As ativações podem ser agendadas para execução uma vez ou de forma recorrente (por exemplo, diária ou semanal). O agendamento garante que os públicos a jusante permaneçam sincronizados e atualizados. |
| Execução e exportação | Melhor | Quando o trabalho de ativação é executado, o Data 360 consulta o segmento, coleta os atributos selecionados, aplica filtros de consentimento e exporta os dados para a plataforma de destino. Para o Marketing Cloud, isso geralmente resulta na criação ou atualização de uma Extensão de dados compartilhada. |
| Governance & Compliance | Obrigatório | A Camada de Trust aplica validação de esquema, metadados de consentimento e controles de política para garantir a conformidade com os regulamentos de proteção de dados e marketing (por exemplo, GDPR, CCPA). |
| Monitoramento & Auditabilidade | Práticas recomendadas | Cada execução de ativação é rastreada com métricas de sucesso/falha, registros de execução e visibilidade de linha no painel de monitoramento da camada do Trust, permitindo transparência operacional e garantia de SLA. |
Esboço
Aqui está o resumo das etapas:
- Criar segmento: Um profissional de marketing ou analista cria um segmento usando uma ferramenta de segmentação visual, combinando filtros em qualquer objeto de dados unificado.
- Criar ativação: Eles selecionam o segmento como origem e escolhem um destino pré-configurado (como o Marketing Cloud ou o Google Ads).
- Definir carga útil: O identificador de contato e outros atributos de perfil são escolhidos para exportação e relatório de público.
- Agendar entrega: A ativação está agendada para ser executada uma vez ou de modo recorrente, mantendo o público no destino atualizado.
- Execução: No acionador, o Data 360 consulta o segmento, cria a carga útil, aplica filtros para consentimento e envia o resultado para o sistema de destino.
Resultados
- Segmentos de público avançados e direcionados do Data 360 são disponibilizados diretamente em plataformas de marketing e publicidade a jusante.
- Os públicos são atualizados e sincronizados automaticamente com os dados do cliente unificado mais recentes, mantendo a relevância da campanha em tempo real.
- Os profissionais de marketing podem usar esses públicos ativados como fontes de entrada para jornadas do Marketing Cloud, campanhas por email ou públicos personalizados em plataformas de anúncio digital, como Google Ads, Meta ou LinkedIn Ads.
- Cada execução de ativação mantém a linha de ponta a ponta, garantindo conformidade, rastreabilidade e consistência entre o Data 360 e sistemas externos.
- Os usuários de negócios podem oferecer experiências altamente personalizadas orientadas por dados com uma visualização completa e confiável do Customer 360.
Mecanismos de chamada
O mecanismo de chamada depende da plataforma de destino e da configuração de destino da ativação.
| Mecanismo | Quando usar |
|---|---|
| Ativação de engajamento do Marketing Cloud (preferencial) | Use ao executar jornadas de email ou entre canais que exigem segmentos dinâmicos, atributos personalizados e atualizações em tempo real no Marketing Cloud. O Data 360 é exportado diretamente para extensões de dados compartilhadas para ativação de campanha. |
| Ativação da plataforma de anúncios (Google Ads, LinkedIn Ads, Meta Ads) | Use ao ativar segmentos do Data 360 como públicos personalizados em plataformas de publicidade para modelagem de similaridade ou redirecionamento. Dá suporte a identificadores com hash e entrega sensível ao consentimento. |
| Ativação do CRM (Vendas ou Service Cloud) | Use ao compartilhar dados, percepções ou pontuações de propensão do cliente aprimorados com usuários do CRM para engajamento de vendas personalizado ou interações de serviço. Os dados são disponibilizados como registros aprimorados ou percepções por meio de Ações de dados ou Componentes de perfil unificado. |
| Ativação externa via MuleSoft ou API | Use quando a ativação precisar alcançar sistemas que não sejam do Salesforce, como armazenamentos de dados de terceiros, comércio eletrônico ou fidelidade. O MuleSoft ou a API de ativação do Data 360 garantem a entrega segura e governada por política com opções de atualização baseadas em evento. |
| Ativação híbrida (Lote + acionado por evento) | Use ao combinar ativações em lote agendadas com acionadores baseados em evento, habilitando a personalização "sempre ativa" para campanhas urgentes, como carrinho abandonado ou alertas de risco de rotatividade. |
Tratamento e recuperação de erros
- Isolamento de falha no nível do trabalho: Cada execução de ativação é executada como um trabalho distinto e rastreável na Camada de orquestração do Data 360. As execuções com falha são automaticamente quarentenas sem afetar outras ativações ou definições de segmento.
- Recuperação parcial em lote: Se determinados registros falharem na exportação (por exemplo, devido a discrepâncias de identificador ou limites de taxa de API), o sistema os tentará novamente usando filas de delta incrementais com recuperação exponencial e paralela.
- Erros de validação de esquema: Quando os atributos de carga útil de saída não correspondem mais ao esquema de destino (por exemplo, um atributo excluído ou um campo renomeado), o trabalho encaminha os registros afetados para a Fila de rejeição do esquema para revisão pelo administrador.
- Replay e retomar suporte: Cada trabalho de ativação mantém um token de ponto de verificação, capturando o último lote bem-sucedido. Após a recuperação, o processamento é retomado no ponto de verificação, garantindo nenhuma duplicação ou perda de dados.
- Monitorização abrangente: Todos os eventos de ativação, novas tentativas e métricas de entrega são registradas no Trust Layer Monitoring, habilitando o rastreamento de SLA, a análise de causa-raiz e o alerta automatizado por meio das APIs de Monitoramento de evento.
Considerações sobre design idempotente
- Claves de ativação determinísticas: Cada execução de ativação usa uma chave de idempotency composta (combinando ID do segmento, ID da ativação e ID do sistema de destino) para garantir a entrega exata uma vez.
- Detecção de reprodução: O Serviço de ativação do Data 360 inspeciona as cargas úteis recebidas em relação a hashs de trabalho anteriores para detectar e suprimir repetições.
- Compromissos de exportação atômica: As cargas úteis são confirmadas no sistema de destino apenas após a confirmação de gravação bem-sucedida, impedindo atualizações parciais ou contagem dupla.
- Resolução de identidade consistente: Como as ativações dependem de IDs unificados (por exemplo, Indivíduo unificado), as repetições ou as novas tentativas sempre têm como alvo o mesmo registro de ouro, mantendo a consistência semântica.
- Persistência do estado de ativação: A camada de orquestração mantém metadados de estado de ativação (carimbos de data e hora, códigos de status e tokens de sequência) para reprocessamento determinístico, se necessário.
Considerações de segurança
- Autenticação forte: Cada destino da ativação (por exemplo, Marketing Cloud, Ads ou CRM) usa OAuth 2.0 com rotação de token e delimitação específica do locatário para evitar a exportação não autorizada de dados.
- Governação em nível de atributo: Somente atributos aprovados do Perfil unificado são elegíveis para ativação, impostos por Políticas de compartilhamento de dados e Modelos de ativação.
- Criptografia em trânsito e em repouso: Todas as cargas úteis são criptografadas usando TLS 1.2+ durante a transferência e AES-256 em repouso tanto no Data 360 quanto na plataforma de destino.
- Consentimento e aplicação da política: Os trabalhos de ativação respeitam Objetos de consentimento e Políticas de dados armazenados na Camada de Trust do Data 360. Registros sem metadados de consentimento válidos são excluídos automaticamente da exportação.
- Auditoria e registro de conformidade: Cada execução de ativação captura quem a iniciou, quais dados foram enviados e para qual destino, habilitando trilhas de auditoria regulatória completa (GDPR, CCPA) no painel Camada de Trust.
- Acesso de privilégio mínimo: Os usuários de integração para cada destino são restritos a escopos específicos da ativação, sem privilégios administrativos ou acesso de gravação a sistemas não relacionados.
Barras laterais
Tempo
- Projetado para exportações em lote agendadas ou quase em tempo real (latência de minutos para horas).
- Dá suporte a atualizações com janela de tempo alinhadas a calendários de campanha.
- Os trabalhos de ativação podem ser sequenciados com marcadores de prontidão de dados para garantir a atualidade dos dados.
- Mais adequado para cenários de ativação não interativos em que a precisão dos dados supera a imediatez.
Volumes de dados
- Lida com conjuntos de dados em grande escala (milhões de registros por execução).
- Escala horizontalmente por meio de particionamento de segmento e canais de exportação paralelos.
- Usa lote baseado em bloco para evitar tempos limite e otimizar a taxa de transferência.
- Ideal para pipelines de dados corporativos em que a completude dos dados é crítica.
Gerenciamento de estado
- Mantenha os objetos de estado de ativação registrando IDs de trabalho, carimbos de data e hora e tokens de sequência.
- Usa a ponte de seleção para reinicialização e recuperação de falha.
- Definições de segmento com controle de versão garantem a reprodutibilidade entre os ciclos de ativação.
- Habilita o rastreamento de linha entre segmentos de origem, atributos de DMO e cargas úteis de destino.
Cenários de integração complexos
- Integra-se perfeitamente ao Salesforce CRM, ao Marketing Cloud e a sistemas externos por meio de conectores predefinidos.
- Dá suporte a ativações de vários destinos, distribuindo dados simultaneamente para diferentes destinos (por exemplo, CRM + Ads).
- Pode acionar fluxos de trabalho compostos, por exemplo, exportação em lote seguida por chamada à API downstream ou pontuação de IA.
- Lida com a evolução do esquema com facilidade por meio da Camada de governança do modelo de dados.
Exemplo
Uma marca de varejo global quer interagir novamente com clientes inativos dos últimos 90 dias. Usando o Data 360, o arquiteto de dados define um segmento de "Compradores dormientes" aprimorado com o histórico de compras, o nível de fidelidade e os metadados de consentimento. O Trabalho de ativação em lote é executado durante a noite, enviando esse segmento para o Marketing Cloud Engagement para acionar uma campanha de email personalizada "Nós sinto sua falta" e para o Ad Studio para redirecionamento. O trabalho aproveita a entrega idempotente, garantindo nenhuma duplicação entre novas tentativas, e todos os eventos são registrados na Camada de Trust para conformidade de auditoria.
Contexto
As empresas geralmente exigem um mecanismo regulado para exportar dados unificados ou segmentados do Salesforce Data 360 para um formato de arquivo padrão (por exemplo, CSV ou Parquet) para arquivamento, conformidade ou integração a jusante. Esse padrão habilita a exportação de armazenamento do Data 360 para nuvem, permitindo que dados confiáveis do cliente fluam com segurança para data lakes corporativos ou pipelines de análise hospedados no Amazon S3, Azure Blob ou Google Cloud Storage (GCS). Os casos de uso típicos incluem:
- Arquivamento periódico de conjuntos de dados do cliente consentidos para retenção regulatória.
- Exportação de segmentos selecionados para cargas de trabalho analíticas não do Salesforce (por exemplo, Tableau, Databricks ou Power BI).
- Habilitar modelos de aprendizado de máquina externos que exigem arquivos CSV ou Parquet estruturados como entrada.
Problema
Como uma organização pode exportar um segmento ou conjunto de dados selecionado do Data 360 para um bucket de armazenamento em nuvem (por exemplo, o Amazon S3) de maneira governada, segura e automatizada enquanto mantém a integridade do esquema e os controles de conformidade? Por exemplo, uma equipe de conformidade pode precisar: "Extraia todos os clientes ativos na região da UE com consentimento válido e exporte os dados semanalmente para um local do S3 para auditoria e relatórios externos." Isso exige um pipeline de exportação repetível e sensível à política que garanta o formato de arquivo correto, as permissões de acesso e a agenda de entrega, sem intervenção manual ou movimentação de dados não gerenciada.
Forças
Vários fatores operacionais e arquitetônicos controlam esse padrão de exportação:
- Autenticação e autorização: As exportações devem respeitar o modelo IAM do provedor de nuvem (por exemplo, Papéis do AWS IAM ou Entidades de serviço do Azure) para garantir que apenas sistemas autorizados possam gravar no bucket de destino.
- Alinhamento de esquema: O esquema de saída deve corresponder à estrutura e ao formato esperados do sistema de destino (CSV, Parquet ou JSON).
- Privacidade de dados e consentimento: Os conjuntos de dados exportados devem filtrar todos os registros sem metadados de consentimento válidos.
- Agendamento & Freshness: Muitas exportações são periódicas (diária, semanal ou mensal) e devem estar alinhadas aos ciclos de atualização de dados corporativos.
- Governance & Monitoring: Todas as exportações devem ser auditáveis com visibilidade de linhagem completa, garantindo a conformidade com a retenção de dados e mandatos regulatórios (por exemplo, GDPR, CCPA).
Solução
O padrão de Ativação de exportação de arquivo reutiliza os mesmos conectores de armazenamento de nuvem segura usados para ingestão, mas configurados para saída de dados. Os administradores primeiro registram a plataforma de armazenamento em nuvem (por exemplo, Amazon S3, Azure Blob Storage ou GCS) como um Destino da ativação no Data 360. Em seguida, os usuários configuram e executam um Fluxo de trabalho de ativação para exportar o segmento desejado para o caminho de armazenamento de arquivos designado.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Seleção de segmento | Melhor | Os analistas selecionam uma definição de Segmento ou Consulta existente no Data 360\. O segmento determina quais registros e atributos são exportados. |
| Configuração de ativação | Melhor | Os usuários criam uma nova Ativação, escolhendo o Segmento como a origem e o Destino do armazenamento em nuvem (por exemplo, S3) como o destino. |
| Configuração de destino da ativação | Obrigatório | Os administradores pré-configuram o destino com credenciais, papéis do IAM e caminho de saída. Os formatos com suporte incluem CSV, Parquet e JSON. |
| Definição de carga de pagamento | Práticas recomendadas | Defina o esquema de exportação selecionando os atributos necessários (por exemplo, ID, Nome, Email, Região, Sinalizador de consentimento). O sistema impõe a governança em nível de atributo. |
| Agendamento & Frequência | Recomendado | As exportações podem ser agendadas para serem executadas em um ritmo definido (diário, semanal, mensal) ou acionadas manualmente conforme necessário. |
| Execução & Entrega | Melhor | Na execução, o Data 360 consulta o segmento, compila o arquivo de exportação, o criptografa e o grava no bucket/pasta configurado usando a API do provedor de nuvem. |
| Governance & Compliance | Obrigatório | A Camada de Trust do Data 360 garante que todas as exportações cumpram políticas de consentimento, validação de esquema e filtros de conformidade. |
| Monitoramento & Auditabilidade | Práticas recomendadas | Cada exportação é rastreada no Painel de monitoramento de camada de Trust com status, registros de execução e metadados de linha. |
Esboço
Aqui está o resumo das etapas.
- Selecionar segmento: Um analista ou administrador de dados escolhe o segmento unificado a exportar.
- Criar ativação: Ele cria um novo trabalho de Ativação e seleciona o destino do Armazenamento na nuvem registrado.
- Definir carga útil: Especifique o esquema de exportação, a lista de atributos e o formato de arquivo (por exemplo, CSV).
- Exportação de agenda: Escolha uma agenda única ou recorrente.
- Executar trabalho: O Data 360 gera e entrega com segurança o arquivo para o caminho de grupo designado.
- Monitor & Verificar: Os resultados e os registros são revisados na Camada de Trust para validação e conformidade.
Resultados
- Segmentos de público avançados e direcionados do Data 360 são disponibilizados diretamente em plataformas de marketing e publicidade a jusante.
- Os públicos são atualizados e sincronizados automaticamente com os dados do cliente unificado mais recentes, mantendo a relevância da campanha em tempo real.
- Os profissionais de marketing podem usar esses públicos ativados como fontes de entrada para jornadas do Marketing Cloud, campanhas por email ou públicos personalizados em plataformas de anúncio digital, como Google Ads, Meta ou LinkedIn Ads.
- Cada execução de ativação mantém a linha de ponta a ponta, garantindo conformidade, rastreabilidade e consistência entre o Data 360 e sistemas externos.
- Os usuários de negócios podem oferecer experiências altamente personalizadas orientadas por dados com uma visualização completa e confiável do Customer 360.
Mecanismos de chamada
O mecanismo de chamada depende da plataforma de armazenamento de nuvem de destino e da configuração de ativação.
| Mecanismo | Quando usar |
|---|---|
| Ativação do Amazon S3 | Use quando seu data lake corporativo estiver hospedado na AWS. O Data 360 grava diretamente em um bucket do S3 usando papéis IAM ou credenciais temporárias, garantindo uma exportação segura e escalonável. |
| Ativação do Armazenamento de Blobs do Azure | Use quando sua organização opera no Microsoft Azure. O Data 360 usa tokens SAS ou entidades de serviço para gravar arquivos criptografados em contêineres Blob. |
| Ativação do Google Cloud Storage (GCS) | Use quando suas cargas de trabalho de análise ou ciência de dados forem executadas no GCP. O Data 360 usa credenciais do OAuth para exportar arquivos para buckets do GCS no formato CSV ou Parquet. |
| SFTP ou Gateway de arquivo externo | Use quando sistemas regulatórios ou legados exigem entrega segura de arquivos por meio de pontos de extremidade de SFTP ou plataformas de transferência de arquivos gerenciadas pela empresa. |
| Exportação híbrida (Arquivo + API) | Use quando um aplicativo downstream precisar tanto de exportação baseada em arquivo para análise quanto de um acionador de API para orquestração de fluxo de trabalho (por exemplo, fluxo do MuleSoft). |
Tratamento e recuperação de erros
- Isolamento em nível de trabalho: Cada exportação é executada como um trabalho distinto. Os trabalhos com falha são quarentena e tentados novamente de forma independente.
- Tentativa de novo arquivo parcial: Se determinados lotes falharem no carregamento (por exemplo, devido a interrupções de rede), o sistema tentará novamente esses blocos usando backlow exponencial.
- Manuseio de correspondência incorreta do esquema: Qualquer desvio de esquema ou falta de correspondência de campo encaminha registros para a Fila de rejeição de esquema para revisão.
- Ponto de verificação e retomada: Os trabalhos de exportação mantêm metadados de ponto de verificação, habilitando a retomada da última gravação bem-sucedida sem duplicação.
- Monitoramento integrado: Falhas e novas tentativas são registradas no painel Camada de Trust para visibilidade e conformidade com SLA.
Considerações sobre design idempotente
- Chaves de exportação determinística: Cada trabalho de exportação inclui um ID exclusivo composto por ID do segmento + ID do destino + Carimbo de data e hora.
- Segurança de reprodução: Execuções de trabalhos duplicados são detectadas usando hashes de trabalho e ignoradas para evitar exportações redundantes.
- Garantia de gravação atômica: O Data 360 confirma arquivos no bucket de destino apenas após a conclusão completa e a validação de soma de verificação.
- Versão de esquema consistente: As definições de exportação são controladas por versão para garantir a consistência do esquema entre execuções.
- Persistência do ponto de verificação: Os trabalhos de exportação persistem no estado para recuperação determinística e reprocessamento, se necessário
Considerações de segurança
- Autenticação forte: Os conectores de nuvem usam papéis do OAuth 2.0, IAM ou entidades de serviço para gravações autenticadas.
- Criptografia em qualquer lugar: Os dados são criptografados tanto em trânsito (TLS 1.2+) quanto em repouso (AES-256).
- Exportação com conhecimento em consentimento: Somente registros com consentimento válido são exportados, impostos pelas políticas da Camada de Trust.
- Princípio de privilégio mínimo: Exportar usuários e contas de serviço é restrito aos seus caminhos de armazenamento designados.
- Registro de auditoria abrangente: Todas as exportações registram metadados, incluindo acionador, esquema, destino e carimbos de data e hora para relatórios de conformidade.
Barras laterais
Tempo
- Projetado para ativação imediata acionada por evento com latência de menos de um segundo.
- Ideal para cenários que exigem personalização instantânea, recomendação ou tomada de decisão.
- Opera no modo de streaming – os acionadores são disparados assim que alterações de dados qualificadas ocorrem no Data 360.
- Garante a responsividade contínua sem aguardar agendas em lote ou recálculo de segmento.
Volumes de dados
- Lida com conjuntos de dados em grande escala (milhões de registros por execução).
- Escala horizontalmente por meio de particionamento de segmento e canais de exportação paralelos.
- Usa lote baseado em bloco para evitar tempos limite e otimizar a taxa de transferência.
- Ideal para pipelines de dados corporativos em que a completude dos dados é crítica.
Gerenciamento de estado
- Cada ação de evento mantém seu próprio token de evento e ID de reprodução para processamento idempotente.
- Dá suporte à persistência do ponto de verificação para ser retomada do último evento confirmado no caso de falha temporária.
- Inclui lógica de desduplicação integrada e janelas de reprodução para garantir a semântica de ativação exata uma vez.
- Os resultados da ação (sucesso/falha) são registrados em tempo real e detectados por meio do painel de capacidade de observação da Camada de Trust.
Cenários de integração complexos
- Integra-se diretamente a Fluxos do Salesforce, Eventos da plataforma Einstein 1 ou webhooks externos para cadeias de resposta instantâneas.
- Pode acionar automações a jusante, por exemplo, atualizações de registro instantâneas do CRM, pontuação de IA ou envios de mensagens do Marketing Cloud.
- Suporta orquestração composível: os acionadores de evento podem chamar ações do Data 360, invocações do Apex ou APIs externas.
- Projetado para padrões empresariais agentes e adaptáveis em que respostas sensíveis ao contexto devem ocorrer instantaneamente.
Exemplo
Uma empresa de varejo global precisa fornecer uma exportação semanal de seu segmento "Membros ativos de fidelidade" para análise no Databricks. O administrador do Data 360 configura o Amazon S3 como um destino da ativação e agenda uma exportação CSV semanal para o caminho de s3://enterprise-analytics/loyalty/weekly_exports/. O trabalho de exportação é executado todos os domingos, gerando um arquivo filtrado por consentimento com registros 2M+. Todos os eventos, as definições de esquema e a linhagem são registrados no painel Camada de Trust, garantindo transparência, auditoria e conformidade.
A Ativação baseada em API sob demanda é uma abordagem orientada por evento em tempo real para tornar percepções do Data 360 acionáveis no momento em que são necessárias, sem esperar trabalhos em lote ou exportações agendadas. Em vez de publicar segmentos predefinidos em um ritmo fixo, esse padrão permite que sistemas externos, aplicativos Salesforce ou agentes de IA chamem APIs do Data 360 diretamente para buscar ou ativar fatias de público específicas, atributos do cliente ou percepções sob demanda. Esse padrão é projetado para experiências interativas baseadas em acionador, como quando um usuário faz login em um portal, um agente abre um registro de cliente ou um Copiloto de IA inicia uma consulta de Next Best Action. Em vez de depender de exportações pré-computadas, o sistema consulta ou ativa dinamicamente os dados mais atuais e controlados do Data 360 em tempo real. A principal vantagem é a imediatez e a precisão:
- Cada chamada de API acessa a Inteligência do cliente mais atualizada no gráfico de perfil unificado e sensível ao consentimento do Data 360.
- As ativações são idempotentes e auditáveis, alinhando-se aos requisitos de conformidade e Trust da empresa.
- As integrações podem ser acionadas diretamente de Fluxos do Salesforce, Apex ou sistemas externos por meio de APIs da plataforma Einstein 1, APIs do Connect ou APIs de ativação. Essa abordagem oferece suporte a casos de uso em que a latência e a personalização são mais importantes, por exemplo:
- Acionar uma oferta de produto personalizada durante uma chamada de serviço.
- Gerar públicos de campanha dinâmicos com base em eventos comportamentais ativos.
- alimentar decisões em tempo real em modelos de IA ou ML que operam no momento do engajamento.
Contexto
As empresas costumam precisar apresentar percepções harmonizadas do Data 360 em tempo real em aplicativos personalizados, como portais da Web internos, aplicativos móveis ou experiências da Web voltadas para o parceiro. Esse padrão permite que os desenvolvedores criem soluções seguras centradas em interface do usuário que consomem e exibem dados unificados do cliente junto com o Salesforce CRM e outros sistemas contextuais, tudo por meio de acesso baseado em API e governado. Os casos de uso típicos incluem:
- Integrar percepções do Data 360 a painéis internos de funcionários ou aplicativos móveis.
- Criar portais do parceiro ou do revendedor com visibilidade do cliente e da transação.
- Integrar dados do Data 360 a aplicativos da Web de terceiros ou camadas de experiência.
- Exibindo recomendações personalizadas em tempo real habilitadas pelo Data 360 e Einstein 1.
Problema
Como um desenvolvedor pode criar um aplicativo personalizado com foco na IU que acessa e exibe com segurança dados do Data 360 harmonizados, muitas vezes junto com outras fontes de dados do Salesforce, sem duplicar ou exportar informações confidenciais? Por exemplo, uma empresa pode precisar criar um portal de clientes que mostre perfis de clientes unificados, interações e percepções calculadas do Data 360. Isso requer uma única camada de API segura e de desempenho que possa alimentar a experiência de front-end, lidar com a autenticação e garantir a governança, ao mesmo tempo que abstrai a complexidade do modelo de dados interno do Data 360.
Forças
Várias considerações arquitetônicas e operacionais influenciam esse padrão:
- Acesso centrado em UI : A meta principal é detectar dados em experiências de front-end personalizadas (web ou móvel), não realizar extrações em lote ou sincronizações de back-end.
- Secure Gateway : A API escolhida deve servir como um ponto de entrada seguro e escalonável para aplicativos e usuários autenticados, aplicando controles de acesso de nível corporativo.
- Contexto de dados unificado : Os aplicativos devem poder combinar dados do Data 360 (por exemplo, perfis unificados, percepções calculadas) com dados de objeto personalizado, ERP ou CRM.
- Simplicidade do desenvolvedor : As APIs devem retornar cargas úteis prontas para apresentação que minimizam o processamento de back-end ou o mapeamento de esquema na camada do cliente.
- Governance and Observability : Todo o acesso deve fluir por canais confiáveis e auditáveis com linha clara, autenticação e imposição de políticas.
Solução
A solução é usar a API REST do Salesforce Connect como o principal gateway de integração para criar aplicativos personalizados orientados por dados com base no Data 360. A API do Connect fornece acesso RESTful a dados do Salesforce, incluindo perfis, segmentos e percepções calculadas harmonizados do Data 360, em formatos de resposta otimizados para consumo da IU (com base em JSON, leve e compatível com dispositivos móveis). Os desenvolvedores se autenticam por meio de um aplicativo conectado, obtêm tokens do OAuth 2.0 e chamam recursos da API do Connect, como /query, /chatter ou /data, para exibir dados unificados diretamente em suas interfaces de aplicativo. Nos bastidores, a API do Connect serve como a base de transporte para outras APIs, como a API de consulta, a API do Data Graph e as APIs da Plataforma Einstein 1, permitindo que os desenvolvedores combinem várias fontes de dados sob um padrão de acesso unificado.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Autenticação e registro de aplicativo | Obrigatório | Crie um aplicativo conectado no Salesforce para autenticação baseada em OAuth 2.0. Configure escopos para acesso à API do Data 360. |
| Acesso a dados (perfis, segmentos, percepções) | Melhor | Use os pontos de extremidade da API do Connect (/services/data/vXX.X/connect) para consultar dados do Data 360 harmonizados, perfis unificados e percepções calculadas. |
| Integração de UI | Melhor | Aplicativos de front-end (React, Angular, iOS, Android) chamam a API do Connect para renderizar dados do Data 360 em painéis, portais ou interfaces móveis. |
| Consulta de gráfico de dados | Recomendado | Combine a API do Connect com a API do Data Graph para consultas em nível de semântica que simplificam junções e relacionamentos complexos. |
| Atualização em tempo real | Opcional | Use a API do Connect com WebSocket ou extensões de streaming para atualizações de dados ativas. |
| Segurança e governança | Obrigatório | Imponha a visibilidade de dados usando escopos do OAuth, políticas do Data 360 e a estrutura de auditoria da Camada de Trust. |
Esboço
Aqui está o resumo das etapas.
- Registro de aplicativo conectado – Defina escopos de OAuth e permissões de API para autenticação de aplicativo externo.
- Obter token de acesso – o aplicativo externo realiza a autenticação do OAuth 2.0 para receber um token para acesso ao Data 360.
- Invoke a API do Connect – o aplicativo faz chamadas à API REST para recuperar dados de perfil, segmento ou percepção unificados.
- Renderizar dados na IU – as respostas são analisadas e apresentadas aos usuários em um portal ou interface móvel com marca.
- Gerenciar erros e tokens de atualização — Os aplicativos implementam lógica de nova tentativa e atualização automática de token para a continuidade da sessão.
- Acesso de monitoramento e auditoria — Todas as chamadas à API são registradas na Camada de confiança para maior visibilidade e conformidade.
Resultados
Os desenvolvedores podem criar aplicativos seguros com identidade visual personalizada que estejam fortemente integrados ao Data 360. Esses aplicativos podem:
- Detecte perfis e percepções do cliente harmonizados em tempo real.
- Exiba dados do Data 360 junto com objetos personalizados ou do CRM por meio de APIs unificadas.
- Aproveite os controles consistentes de autenticação, autorização e auditoria por meio da Camada de Trust.
- Forneça aos usuários de negócios ou parceiros acesso contínuo e controlado à Inteligência do cliente confiável em todas as experiências.
Mecanismos de chamada
O mecanismo de chamada depende da plataforma de armazenamento de nuvem de destino e da configuração de ativação.
| Mecanismo | Quando usar |
|---|---|
| Conectar a API REST (preferencial) | Use ao criar aplicativos da Web, móveis ou de terceiros que exigem acesso em tempo real a dados do Data 360 em um formato JSON compatível com a interface do usuário. |
| API de gráfico de dados | Use quando o aplicativo precisar realizar consultas em nível de semântica em vários objetos (por exemplo, Cliente → Transações → Campanhas). |
| API de consulta | Use ao executar consultas semelhantes a SOQL para recuperar conjuntos de dados harmonizados com alta precisão. |
| APIs da plataforma Einstein 1 | Use ao integrar percepções conduzidas por IA ou recomendações geradas pelo Copilot em UIs personalizadas. |
| MuleSoft ou Apex Gateway Wrappers | Use quando orquestração, armazenamento em cache ou imposição de políticas adicionais forem necessários entre o aplicativo e a API do Connect. |
Tratamento e recuperação de erros
- Encadeamento de solicitação: Recupera e repetiu automaticamente as chamadas à API nos limites de frequência.
- Proteção de desvio de esquema: Usa controle de versão de esquema do GraphQL ou descoberta de metadados REST para se adaptar às alterações de esquema.
- Gerenciamento de expiração de token – Os aplicativos atualizam os tokens OAuth automaticamente para evitar interrupções de sessão.
- Isolamento de falha da API: as chamadas à API com falha são registradas e repetidas sem afetar sessões simultâneas.
- Observabilidade da camada Trust – As taxas de sucesso/falha da API e os logs de acesso estão visíveis no painel Camada Trust.
Considerações sobre design idempotente
- IDs de solicitação determinística: Cada solicitação de API inclui um ID de correlação para processamento seguro de reprodução.
- Cabeçalhos de validação de cache: Os cabeçalhos ETag e Última modificação impedem busca de dados redundantes.
- Operações de leitura atômica: A API do Connect garante que cada resposta reflita um instantâneo consistente dos dados unificados.
- Proteção contra reprodução – Chamadas à API duplicadas são filtradas usando assinaturas de solicitação e carimbos de data e hora.
Considerações de segurança
- Autenticação OAuth 2.0: Todas as chamadas à API usam tokens de acesso OAuth seguros de curta duração por meio de Aplicativos conectados.
- Acesso de privilégio mínimo: Os escopos de API são restritos apenas a objetos e campos necessários.
- Criptografia em qualquer lugar: TLS 1.2+ em trânsito; criptografia AES-256 em repouso para respostas armazenadas ou armazenadas em cache.
- Acesso a dados com conhecimento em consentimento: O Data 360 garante que todos os registros recuperados cumpram as políticas de governança e consentimento.
- Registro de auditoria abrangente: Todas as interações da API são registradas com metadados de usuário, aplicativo e carimbo de data e hora na Camada de Trust.
Barras laterais
Tempo
- Projetado para acesso à API em tempo real com baixa latência.
- Ideal para aplicativos interativos que exigem renderização de dados imediata.
- Dá suporte a tempos de resposta de consulta quase instantâneos por meio de fontes do Data 360 indexadas e armazenadas em cache.
- Sem dependência de agendas em lote ou ciclos de ativação assíncronos.
Volumes de dados
- Otimizada para casos de uso interativos que buscam conjuntos de dados pequenos a médios (por exemplo, perfis, percepções ou transações recentes).
- Lida com resultados paginados com facilidade por meio da paginação baseada no cursor.
- Não destinado a exportações em massa de alto volume – use os padrões de Exportação de arquivo ou lote para conjuntos de dados grandes.
Gerenciamento de estado
- Os aplicativos mantêm um estado de sessão leve com tokens OAuth e cache local.
- A API do Connect oferece suporte a solicitações condicionais e atualização parcial para eficiência.
- As respostas da API incluem marcadores de versão para consistência do esquema entre versões.
Cenários de integração complexos
- Combine a API do Connect com a API do Data Graph para consultas semânticas em vários domínios.
- Integre-se ao Einstein 1 Copilot ou às APIs de IA para experiências preditivas e conversacionais.
- Use junto com o Experience Cloud ou Componentes da Web Lightning para desenvolvimento de interface do usuário híbrida.
- Estenda por meio do MuleSoft para orquestrar o aprimoramento de dados ou pesquisas do sistema externo em tempo real.
Exemplo
Uma seguradora multinacional cria um portal de autoatendimento ao cliente permitindo que os titulares de apólice visualizem seus perfis unificados, reivindicações recentes e ofertas personalizadas. O aplicativo de front-end baseado em eact autentica por meio do OAuth 2.0 e recupera dados usando a API REST do Connect e a API do Data Graph. Todos os dados são exibidos em Tempo real, sensíveis ao consentimento e controlados por meio da camada Trust do Data 360. Os desenvolvedores monitoram chamadas à API e trilhas de auditoria diretamente no Salesforce, garantindo total conformidade e capacidade de observação.
Contexto
As empresas exigem cada vez mais acesso instantâneo a um perfil de cliente completo para sistemas de decisão em tempo real, como consoles de serviço, mecanismos de recomendação ou plataformas de personalização.Esse padrão permite que os aplicativos recuperem visualizações pré-calculadas e unificadas dos dados de um cliente quase em tempo real usando a API do Data Graph do Data 360, fornecendo tempos de resposta de menos de um segundo para experiências interativas. Os casos de uso típicos incluem:
- Exibir uma visão completa do cliente em um Atendimento ao cliente ou Sales Console.
- Acionando recomendações de "Next Best Action" ou "Next Best Offer" baseadas em IA.
- Proporcionar experiências móveis ou da Web hiperpersonalizadas no tempo de carregamento de página.
- Suporte à tomada de decisão na sessão em ambientes de agente ou autoatendimento.
Problema
Como um aplicativo pode recuperar uma visualização do cliente unificada completa e pré-calculada instantaneamente, em vez de executar consultas de vários objetos lentas em tempo de execução? Por exemplo, um mecanismo de personalização da Web deve carregar o contexto completo do cliente (demografia, preferências, transações e percepções calculadas) em milissegundos para selecionar uma oferta personalizada. Consultas relacionais tradicionais podem exigir várias junções e resultar em latência inaceitável. Isso exige uma API que forneça dados de perfil não normalizados prontos para uso, recuperáveis por meio de uma única pesquisa de chave, combinando velocidade, completude e governança.
Forças
Vários fatores operacionais e de desempenho influenciam esse padrão:
- Velocidade: O tempo de resposta deve ser próximo aReal-Time. A API deve retornar um perfil completo dentro de milissegundos para dar suporte a interações síncronas.
- Completeness: A resposta deve incluir todos os atributos, relacionamentos e percepções calculadas relevantes, idealmente em uma única carga útil.
- Eficiência de pesquisa: Os perfis devem ser recuperáveis por meio de identificadores como customerId, contactKey ou email, eliminando consultas de várias etapas.
- Atualização de dados vs. Latência: Alguns casos de uso preferem dados pré-calculados (arquivados) para velocidade; outros precisam de dados ativos, aceitando uma latência maior.
- Governance and Security: O acesso deve permanecer regulado por meio das políticas da Camada de Trust do Salesforce, garantindo a conformidade com as regras de visibilidade de dados e consentimento.
Solução
A solução é usar a API de Gráfico de dados do Salesforce para recuperar visualizações de cliente não normalizadas e pré-calculadas armazenadas como registros de Gráfico de dados. Um Gráfico de dados é uma visualização semântica materializada que combina vários objetos de modelo de dados (DMOs), como Individual, Transação e ProductInterest, em um único registro somente leitura, geralmente representado como um blob JSON. Os desenvolvedores podem usar pontos de extremidade REST, como: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} para recuperar um registro completo por seu identificador exclusivo. Para cenários dinâmicos, a API oferece suporte a um parâmetro live=true que ignora o cache materializado, executando uma consulta em tempo real no Data 360, negociando a latência mínima para os dados mais recentes. Isso permite que os desenvolvedores selecionem entre recuperações de perfil instantâneas (arquivadas) e atualizadas (ativas) dependendo da necessidade de negócios.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Definição de gráfico de dados | Obrigatório | Os arquitetos definem um Gráfico de dados que combina vários DMOs em uma única entidade semântica (por exemplo, UnifiedCustomerProfile). |
| Recuperação de pesquisa de perfil | Melhor | As aplicações chamam GET /api/v1/dataGraph/{entity}/{id} para recuperar perfis completos e não normalizados por ID ou chave exclusiva. |
| Uso do parâmetro ativo | Opcional | Adicione ?live=true para forçar cálculos recentes em vez de recuperação em cache; adequado para decisões de alto valor. |
| Autenticação | Obrigatório | Use o OAuth 2.0 por meio de aplicativos conectados para autenticar chamadas à API com segurança. |
| Análise de resposta | Prática recomendada | Os aplicativos analisam a resposta JSON diretamente na IU ou no mecanismo de decisão; nenhuma junção adicional é necessária. |
| Estratégia de cache | Recomendado | Implemente o armazenamento em cache local de curto prazo (por exemplo, na memória ou na CDN) para pesquisas de perfil repetidas. |
| Monitoramento e observabilidade | Obrigatório | Use os painéis da Camada de Trust para monitorar o desempenho da consulta, os tempos de resposta e a adesão à política. |
Esboço
Aqui está o resumo do fluxo de implementação:
- Definir gráfico de dados — Os arquitetos de dados criam um gráfico de dados que modelam uma visualização unificada do cliente em vários DMOs.
- Registro de aplicativo conectado – os desenvolvedores configuram as credenciais do OAuth para acesso à API seguro.
- Invocar a API de gráfico de dados – o aplicativo emite uma solicitação GET com o nome do gráfico de dados e o ID do registro.
- Resposta do processo – A API retorna uma representação JSON completa do perfil do cliente.
- Renderizar ou agir — O aplicativo consumidor (UI ou mecanismo) usa os dados unificados para personalização, recomendações ou ações de serviço.
- Monitor e ajuste – as métricas de desempenho e os registros de acesso são revisados por meio do console de observabilidade da Camada de confiança.
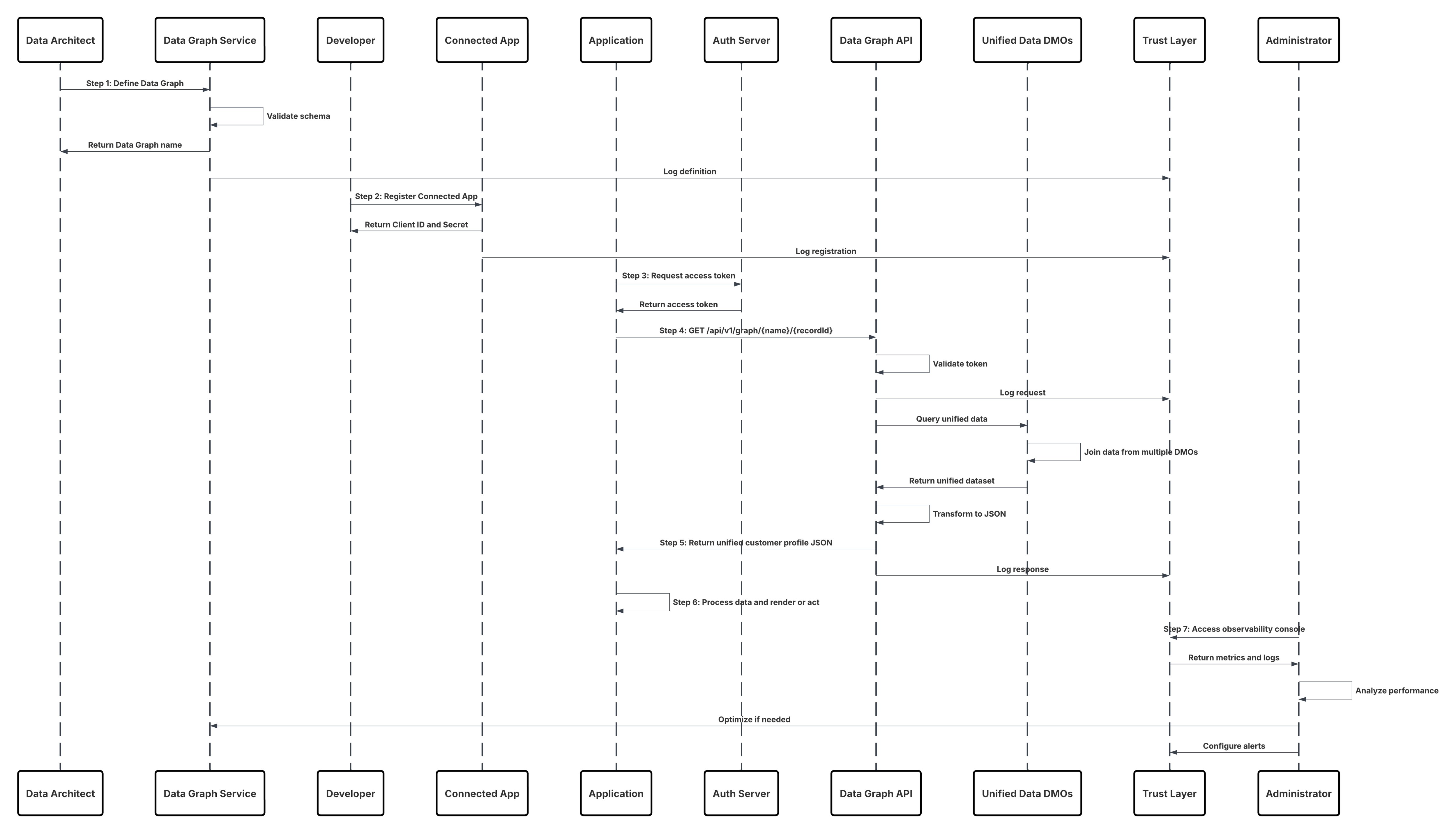
Resultados
Os aplicativos agora podem recuperar um perfil de cliente completo e pré-juncionado instantaneamente, ativando interações em tempo real, como personalização, serviço e automação de decisão. Esse padrão garante que:
- Tempos de resposta de subsegundo para tomada de decisão no momento.
- Recuperação de dados consistente e controlada alinhada ao modelo semântico do Data 360.
- Lógica de aplicativo simplificada – nenhuma junção, nenhuma reconciliação de esquema.
- Acesso rastreável e compatível por meio da Camada de Trust para auditoria e observabilidade.
Mecanismos de chamada
O mecanismo de chamada depende da plataforma de armazenamento de nuvem de destino e da configuração de ativação.
| Mecanismo | Quando usar |
|---|---|
| API de gráfico de dados (preferencial) | Use para recuperar perfis completos e pré-materializados instantaneamente por ID ou chave. |
| API de gráfico de dados com live=true | Use para casos de uso de alto valor (por exemplo, detecção de fraudes, ofertas ativas) em que os dados mais atuais são necessários, aceitando uma latência levemente maior. |
| API do Connect (Fallback) | Use para cenários de aplicativo composto combinando recuperações de gráfico de dados a outros dados do Salesforce. |
| API de consulta | Use ao construir consultas ad hoc ou leituras analíticas em vez de recuperação de perfil instantânea. |
| MuleSoft API Proxy | Use ao rotear chamadas do Gráfico de dados por meio de gateways corporativos ou quando a imposição de orquestração/política adicional for necessária. |
Tratamento e recuperação de erros
- Infelizes fallbacks – Se as consultas ativas falharem ou excederem os limites de tempo limite, reverta automaticamente para recuperações do Data Graph armazenadas em cache.
- Gerenciamento de tempo limite – Implemente uma nova tentativa e lógica de interruptor para chamadas à API sob alta carga.
- Manuseio de ID inválido – Retornar padrão 404 Não encontramos respostas para chaves de perfil inexistentes; lidar com facilidade na UI.
- Validação de versão do esquema – Valide metadados de versão do Gráfico de dados para evitar incompatibilidades quando o esquema evolui.
- Integração de observabilidade – registre todos os erros, novas tentativas e latências nos painéis da Camada de confiança para monitoramento de SLA.
Considerações sobre design idempotente
- Chaves determinísticas – Cada recuperação de perfil usa um ID estável (por exemplo, IndividualId) garantindo consultas previsíveis e seguras de reprodução.
- Consistência de cache – Use cabeçalhos ETag ou Last-Modified para recuperações condicionais e validação de cache.
- Recuperação atômica – Cada resposta da API representa um instantâneo consistente do registro do Gráfico de dados materializado.
- Proteção de reprodução – Garanta que os aplicativos cliente detectem recuperações duplicadas por meio de IDs de correlação e carimbos de data e hora.
Considerações de segurança
- Autenticação forte – O OAuth 2.0 via Aplicativos conectados impõe acesso seguro baseado em token.
- Recuperação consciente do consentimento – Apenas atributos consentidos são retornados; os filtros de consentimento são aplicados automaticamente pela Camada de confiança.
- Governação em nível de campo – O acesso aos atributos é controlado por meio das definições de metadados e políticas do Data 360.
- Criptografia em trânsito e em repouso – Todas as respostas são criptografadas com TLS 1.2+ e AES-256.
- Auditoria e rastreabilidade – Cada evento de recuperação de perfil é registrado com identificadores, carimbos de data e hora e contexto da política.
Barras laterais
Tempo
- Projetado para recuperação instantânea.
- Dá suporte a consultas ativas para dados atualizados com uma latência levemente maior (subsegundo).
- Otimizada para tomada de decisão síncrona e aplicativos interativos.
- Elimina a necessidade de ativação pré-lote ou recálculo de segmento.
Volumes de dados
- Ideal para pesquisas de registro único ou conjuntos pequenos (dezenas a centenas) por solicitação.
- Não otimizado para recuperação em massa em grande escala; use APIs de consulta ou lote para leituras de alto volume.
- Usa armazenamento em cache e pré-materialização escalonáveis horizontalmente para velocidade.
Gerenciamento de estado
- Mantenha o acesso sem estado leve; cada solicitação é independente.
- Suporta o armazenamento em cache de cabeçalhos para recuperação segura de reprodução.
- Os aplicativos podem manter o armazenamento de cache local ou de sessão de curto prazo para reduzir as pesquisas repetidas.
Cenários de integração complexos
- Integra-se perfeitamente ao Einstein 1, à API do Connect e ao MuleSoft para experiências de dados compostos.
- Pode alimentar sistemas acionáveis (por exemplo, Copilot ou mecanismos de raciocínio de IA) que exigem consciência instantânea e contextual.
- Combinado com Ações de dados para acionadores em tempo real na recuperação ou alteração de estado.
- Permite a personalização em escala sem comprometer o desempenho ou a governança.
Exemplo
Uma plataforma global de comércio eletrônico usa a API Data Graph do Data 360 para recuperar perfis de clientes unificados em tempo real para seu mecanismo de recomendação. Quando um usuário faz login, o aplicativo chama o ponto de extremidade do Data Graph para buscar o UnifiedCustomerProfile desse cliente, retornando atributos demográficos, sinais comportamentais e percepções calculadas como uma única carga útil JSON. O mecanismo de personalização consome essa resposta em milissegundos para determinar e exibir a opção "Next Best Offer" durante a sessão ativa. Todas as solicitações são controladas e registradas por meio da Camada de Trust, garantindo visibilidade total, imposição de políticas e conformidade em toda a interação.
Ações de dados em tempo real permitem a ativação instantânea de dados do cliente no momento em que eles mudam no Data 360. Em vez de esperar por exportações em lote agendadas, essas ações enviam atualizações, percepções ou acionadores diretamente para o Salesforce ou sistemas externos em milissegundos. Quando o status, o consentimento ou a métrica de engajamento de um cliente são atualizados no Data 360, esse sinal pode ativar imediatamente ofertas personalizadas, acionar automações do Service Cloud ou atualizar níveis de fidelidade, garantindo que cada experiência do cliente reflita a verdade unificada mais atual. Esse padrão é ideal para casos de uso de alto impacto sensíveis à latência, como experiências da Web personalizadas, alertas de detecção de fraudes, recomendações de próxima melhor ação ou atualizações de CRM em tempo real. Ele fecha a lacuna entre percepção de dados e ação de negócios, transformando dados unificados em inteligência no momento.
Contexto
As experiências digitais modernas e os fluxos de trabalho operacionais exigem ações contextuais imediatas no momento em que um evento ocorre – por exemplo, atualizar um registro de cliente durante um Checkout, ajustar o estoque quando uma devolução é verificada ou entregar uma promoção personalizada no momento em que um usuário abandona um carrinho. As ações de dados em tempo real permitem aos sistemas invocar, aprimorar e agir com base em perfis unificados do Data 360 e percepções calculadas com latência de subsegundo a segundo, permitindo personalização interativa, automação operacional e tomada de decisão instantânea.
Problema
Como aplicativos, fluxos de interação da IU ou middleware podem chamar o Data 360 no tempo de execução para ler, calcular ou atualizar um único perfil unificado ou acionar uma ação (por exemplo, enviar uma oferta, atualizar o CRM, iniciar um fluxo de trabalho) com baixa latência, consistência forte e controles de governança sem esperar trabalhos em lote agendados ou pipelines pesados?
Forças
Várias forças técnicas, operacionais e de governança moldam esse padrão:
- Requisito de baixa latência: As chamadas devem ser concluídas em um intervalo de menos de um segundo a alguns segundos para preservar uma boa UX ou cumprir os SLAs operacionais.
- Resolução de identidade determinista: As solicitações devem ser resolvidas para o perfil de Indivíduo unificado correto (registro Ouro) de modo confiável e rápido.
- Autorização de granulação fina: Chamadas em tempo real devem aplicar políticas de nível de atributo e verificações de consentimento no momento da solicitação.
- Minimalismo de carga: As cargas úteis em tempo real devem ser pequenas e focadas (perfil único ou conjunto de atributos pequeno) para reduzir a latência e o custo.
- Experiência do desenvolvedor: As APIs devem ser fáceis para o desenvolvedor (REST/gRPC/GraphQL), com esquemas claros e contratos estáveis para uso de produção.
- Auditabilidade e rastreabilidade: Todas as ações em tempo real devem ser registradas com lineagem, identidade do usuário e decisões de política para conformidade.
Solução
A solução recomendada é usar a interface de Ações de dados em tempo real do Data 360 (APIs + SDKs) combinada com cache de borda e transformações computacionais mínimas quando necessário. As integrações chamam um ponto de extremidade de ações de dados para ler ou gravar atributos de perfil, calcular percepções ou iniciar orquestrações. As verificações de política em tempo real (CEDAR) e o mascaramento dinâmico são aplicados no Ponto de imposição da política antes de qualquer carga útil ser retornada ou a ação ser executada.
| Área de solução | Ajuste | Comentários/Detalhes da implementação |
|---|---|---|
| Ação de dados em tempo real | Melhor | Exponha o ponto de extremidade para acionadores de ação e leitura/gravação de registro único. Autenticar por meio de OAuth/JWT. |
| Resolução de identidade | Obrigatório | Resolva identificadores recebidos (email, externalId, cookie) para ID de indivíduo unificado em linha. Use um resolvedor determinístico com cache. |
| Política de Aplicação (CEDAR) | Práticas recomendadas | Avaliar políticas de consentimento, ABAC e mascaramento no momento da solicitação; negar ou mascarar campos por decisão de política. |
| Edge/Cache Layer | Recomendado | Use caches TTL curtos para fragmentos de perfil e percepções calculadas para reduzir a latência; invalide em eventos de alteração. |
| Transformações leves | Recomendado | Aplique aprimoramentos simples ou campos calculados no caminho de ação; as transformações pesadas devem ser pré-calculadas. |
| Orquestração de ação | Melhor | Dê suporte a ações síncronas de etapa única (por exemplo, token de oferta de devolução) e orquestrações assíncronas (fila \+ webhook) para fluxos complexos. |
| Observabilidade & Rastreamento | Obrigatório | Registre solicitação/resposta, decisões de política e lineagem para a Camada de Trust/SIEM para auditoria e depuração. |
| Limitação de taxa & Throttling | Obrigatório | Imponha cotas do cliente e estratégias de degradação elegantes para momentos de alto tráfego. |
Esboço
Aqui está o resumo das etapas.
- O Client (UI/middleware/POS) envia solicitações de Ação de dados autenticadas com identificadores e tipo de ação.
- O Gateway de API valida token, limites de frequência e encaminha para o Serviço de ação do Data 360.
- O Serviço de ação resolve identificador → ID de indivíduo unificado (cache de caminho rápido; fallback para pesquisa de Gráfico).
- A Imposição de apólice (PDP) avalia as apólices do CEDAR usando atributos do contexto de PIP e solicitação.
- Se permitido, o Serviço de ação lê todos os atributos/insights de perfil obrigatórios e realiza transformações light.
- O Serviço de ação retorna a resposta de modo síncrono (por exemplo, token de oferta, atributo atualizado) ou coloca na fila orquestração assíncrona e retorna confirmação.
- Todos os eventos, decisões e cargas úteis são registrados na Camada de Trust e, opcionalmente, encaminhados ao SIEM.
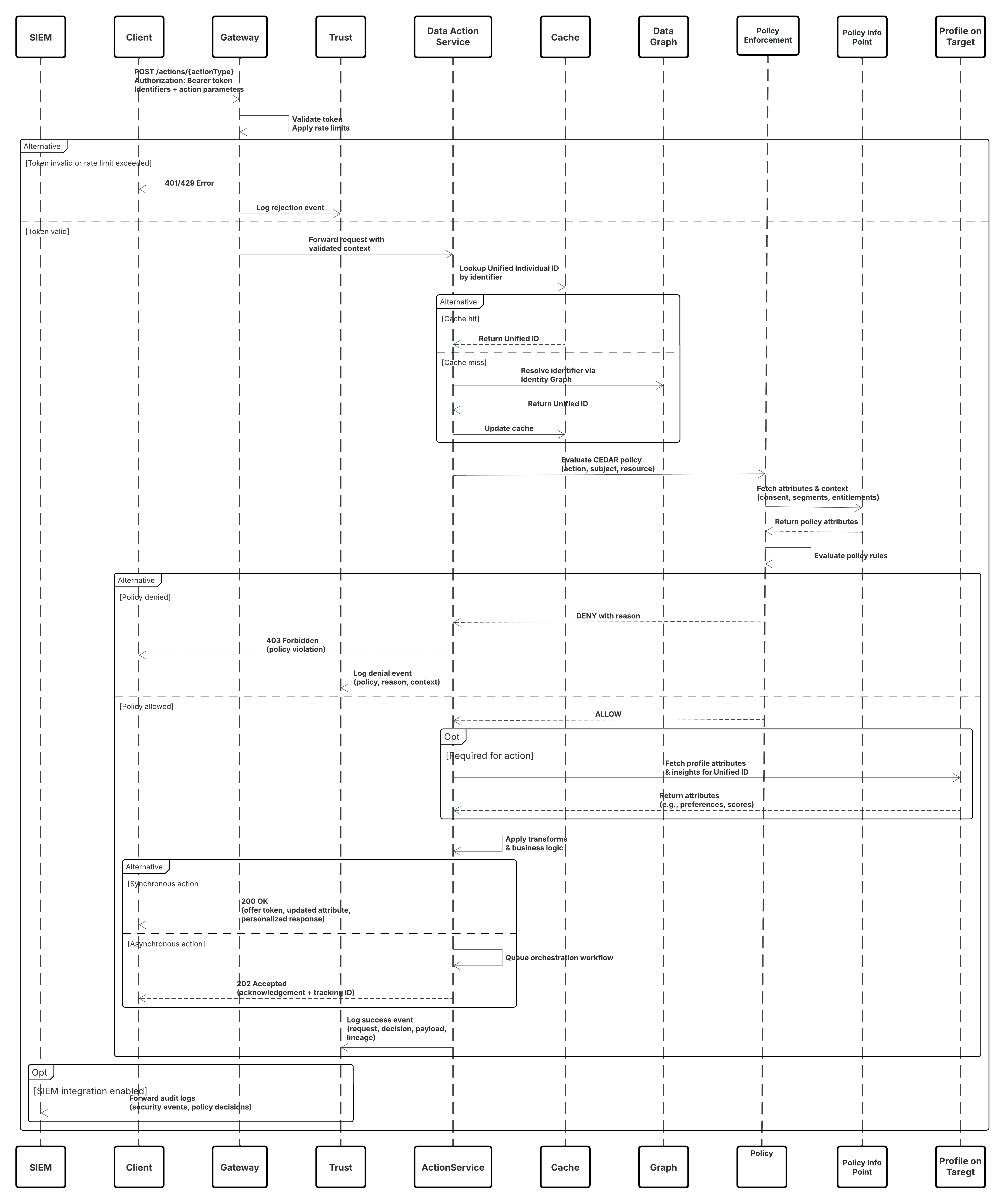
Resultados
- Os aplicativos recebem acesso imediato governado por política a leituras/gravações de perfil unificadas e acionadores de ação com latência de subsegundo a segundo.
- Personalização em tempo real, tomada de decisão e fluxos de trabalho operacionais (por exemplo, ofertas, assistência do agente, atualizações de inventário) são habilitados sem atrasos em lote.
- Todas as ações são auditáveis, sensíveis ao consentimento e aplicam o mascaramento em nível de atributo para manter a privacidade e a conformidade.
Mecanismos de chamada
O mecanismo de chamada depende da plataforma de destino e da configuração de destino da ativação.
| Mecanismo | Quando usar |
|---|---|
| API RESTful Data Actions | Preferencial para aplicativos da Web/móveis e middleware que precisam de leituras de perfil síncronas ou respostas de ação. |
| gRPC/RPC binário | Use para serviços corporativos de latência ultra baixa ou microsserviços internos com conexões persistentes. |
| Consultas de registro único do GraphQL | Use quando os clientes precisarem de seleção de campo flexível e quiserem minimizar as cargas úteis. |
| Webhooks acionados por evento | Use para fluxos de trabalho assíncronos em que a ação aciona processos a jusante (por exemplo, iniciar uma jornada). |
| Plataforma Eventos / PubSub | Use para cenários de desativação em que vários sistemas precisam reagir a um único evento de ação. |
| Edge SDK (client libs) | Use para clientes de baixa latência que armazenam fragmentos de perfil em cache e chamam a API de Ações de dados apenas quando necessário. |
Tratamento e recuperação de erros
- Erros síncronos: Retorne códigos de erro estruturados com mensagens legíveis por humanos e tokens de idempotency.
- Tentativa transitória: Os clientes devem tentar novamente solicitações idempotentes com pendências exponenciais em respostas 429/5xx.
- Tratamento de negação de política: Negativas retornam códigos de motivo claros; dados confidenciais nunca são retornados quando a política falha.
- Falhas de orquestração assíncrona: Os trabalhos de orquestração passam para DLQ e são reproduzíveis; uma API de status de trabalho permite que os clientes pesquisem ou recebam retornos de chamada.
- Estratégias de fallback: Se a resolução de identidade falhar, retorne um erro determinístico e, opcionalmente, uma remediação sugerida (por exemplo, exigir externalId).
Considerações sobre design idempotente
- Chave de idempotency: Os clientes fornecem uma chave de idempotency (UUID + namespace do cliente) para ações de mutação.
- Chaves deterministas: Use chaves compostas (UnifiedIndividualId + ActionType + TimestampWindow) para detectar itens duplicados.
- Safe Retries: Projete ações para serem tolerantes a efeitos colaterais ou para realizar inserções e atualizações em vez de inserções cegas.
- Proteção de reprodução: Persista chaves de idempotency processadas e TTL-as após a janela de negócios para evitar repetições.
- Apatria: Mantenha as ações síncronas sem estado quando possível; mantenha o estado mínimo para fluxos de trabalho assíncronos.
Considerações de segurança
- Autenticação: OAuth 2.0 (Portador do JWT ou mTLS para contas de serviço); tokens de curta duração e rotação de atualização.
- Autorização: O Ponto de decisão da política aplica o Controle de acesso baseado em atributo (CEDAR) e verificações de consentimento por solicitação.
- Transporte e criptografia de armazenamento: TLS 1.2+ em trânsito; AES-256 em repouso para quaisquer fragmentos em cache ou registros de auditoria.
- Privilégio mínimo: Clientes de API com escopo de permissões mínimas; papéis separados para leitura vs. gravação vs. orquestração.
- Minimizar dados: Retorne apenas atributos solicitados e consentidos; aplique mascaramento dinâmico para PII/PHI.
- Controles de rede: Opcionalmente, exija chamadas de redes privadas (Conexão privada, listas de permissões de IP) para ações de alto risco.
- Auditoria & Monitoramento: Registre metadados de solicitação, decisões de política, identidade do solicitante e hashs de resposta com a Camada de Trust e o SIEM.
Barras laterais
Tempo
- Projetado para latências médias no intervalo de menos de um segundo a menos de um segundo para ações síncronas.
- Cache do Edge (TTL curto) e percepções pré-calculadas reduzem as viagens de ida e volta.
- Os caminhos assíncronos fornecem confirmação quase instantânea com processamento em segundo plano para tarefas pesadas.
Volumes de dados
- Otimizada para interações de registro único ou de lote pequeno (1 a 100 registros).
- Não destinado a exportações em massa – use ativação em lote para grandes volumes.
- A alta taxa de transferência usa reutilização de agrupamento/conexão e filas de orquestração paralelas.
Gerenciamento de estado
- Modelo de solicitação sem estado para chamadas síncronas; estado de ação mínima persistiu para concessões/transações.
- Invalidação de cache conduzida por eventos de alteração: garanta que TTLs e sinais de invalidação mantenham os cache atualizados.
- Os trabalhos de orquestração mantêm o estado durável (jobId, status, retries) armazenado na Camada Trust.
Cenários de integração complexos
- Agente Assistente: Pesquisa de perfil em tempo real + propensão calculada retornada ao console de serviço em menos de um segundo para agentes.
- Dispositivos POS/Edge: SDK local + ação de dados ocasional para validar promoções ou status de fidelidade.
- Fluxos híbridos: Ação de sincronização de dados para orquestração de decisão + assíncrona para atualizar sistemas downstream e acionar campanhas.
- Middleware de terceiros: Os gateways de API ou MuleSoft podem mediar a autenticação, aprimorar o contexto e impor verificações de política extras.
Exemplo
Um aplicativo móvel de varejo determina se um cupom instantâneo personalizado será exibido quando um comprador tocar em Checkout invocando a ação de dados de equivalencia da oferta com o contexto do email e do carrinho do comprador. A solicitação é validada pelo Gateway da API e encaminhada para o Serviço de ação de dados, que resolve o email para um ID de indivíduo unificado usando um hit de cache, verifica o consentimento de marketing por meio do PDP e avalia a elegibilidade com base no valor da vida útil do cliente e na compra recente. Se o comprador se qualificar, o serviço retornará um token de cupom assinado e registrará a decisão. Quando a emissão de cupom requer reserva de inventário, uma orquestração assíncrona é acionada para reservar o inventário e notificar os sistemas de CRM. O aplicativo exibe o cupom imediatamente, enquanto as atualizações a jusante são concluídas em segundo plano e a Camada de Trust captura uma trilha de auditoria completa para governança e conformidade.
- Conectores & Integração
- SDK Web e móvel
- Ingestão em tempo real de subsegundo
- Traga o seu próprio lago (consulta de cópia zero)
- Traga o seu próprio lago (Arquivo de cópia zero)
- Gráficos de dados
- Ativação: Engajamento do MC
- Ativação: Personalização MC
- Ativação: B2C Commerce
- Compartilhamento de dados (cópia zero)
- Ativação: Armazenamento de arquivos
- Ações de dados
- Ações de dados de subsegundo em tempo real
- Plataforma de ativação externa