Les plates-formes de données évoluent depuis plus de trois décennies. Au début, l'industrie était dominée par des bases de données sur site, centralisées et structurées (surtout relationnelles) opérationnelles/OLTP. Il a été élargi pour inclure les plates-formes OLAP/Big Data des entrepôts de données qui étaient principalement utilisées pour le traitement analytique et qui restaient relationnelles et centralisées. Le stockage dans le cloud pilotait des architectures distribuées telles que des entrepôts de données, des lacs et un stockage désagrégé. Cependant, les plates-formes opérationnelles et les plates-formes analytiques sont restées séparées. Aujourd'hui, le cloud computing et la révolution de l'IA changent fondamentalement l'architecture de la plate-forme de données.
Les entreprises investissent déjà dans des plates-formes Big Data matures telles que Snowflake, Databricks, BigQuery et Redshift. Mais ces plates-formes servent de silos de données. Les clients ne tirent pas de valeur métier de leurs données, car les données ne peuvent pas être utilisées directement dans les flux métiers et les applications. Ces solutions n'ont pas de traitement IA générative Agentic et ne peuvent pas fournir l'accès aux données en temps réel. Par conséquent, elles ne peuvent pas offrir une personnalisation pilotée par l'IA au moment de l'engagement des clients et d'autres fonctionnalités de pointe.
L'avenir des plates-formes de données est caractérisé par une infrastructure de données unifiée, flexible, accessible et ouverte. Cette nouvelle architecture s'appuie sur les tendances modernes du calcul et du stockage (GPU, mémoire volumineuse, SSD NVMe et stockage cloud) pour s'intégrer au cloud computing et à l'IA. Ils peuvent fournir des connaissances en temps réel, prendre des décisions autonomes et piloter des applications en temps réel. Cela inclut l'essor de l'IA agentique, de l'IA prédictive, des analytiques, des bases de données OLTP en temps réel à grande échelle, des lacs de données et des maisons de lac. Ces plates-formes de données modernes sont conçues pour la simplicité, l'évolutivité, l'agilité, les performances, la sécurité, la disponibilité et la rentabilité.
Les tendances des données suivantes déterminent l'architecture de la plate-forme de données de nouvelle génération.
- IA, apprentissage machine et analytique au cœur: L’essor de l’IA agentique va fondamentalement changer le développement, le déploiement et l’utilisation/l’accès de la plate-forme de données. L’IA agentique comprendra l’intention de conversation/interrogation, planifiera, générera des workflows et automatisera la prise de décision. La mémoire agentique (à court et à long terme) est construite à partir de l'historique des conversations pour personnaliser la planification et les décisions des agents, la modélisation des conversations en temps réel et la prise en charge de la personnalisation, qui sont essentielles dans les plates-formes de données. Les agents aideront à automatiser les « capacités » opérationnelles telles que la gouvernance des données (c.-à-d. sécurité, conformité, Trust), les performances (c.-à-d. l'échelle automatique pour la simultanéité, le débit et la latence), le basculement et la disponibilité, ainsi que l'observabilité et la maintenance. Les analytiques pilotées par l’IA, les prévisions, le traitement en langage naturel (NLP) pour les analyses Q/R, et les analytiques sur des données non structurées (textes tels que PDF, images, audio, vidéo) seront standard, ce qui permettra aux entreprises de recueillir des connaissances approfondies à partir de diverses sources de données.
- Décentralisation des données mais accès aux données unifié: Les agents ont besoin de données d'entreprise pour recueillir des connaissances et prendre des décisions, et automatiser les activités commerciales. Les données sont par nature décentralisées dans les entreprises, dans des applications et des plates-formes de données disparates. Mais il n'est pas facile d'unifier de façon transparente les silos entre les différentes unités commerciales au sein de l'entreprise et avec des partenaires extérieurs à l'entreprise. L'unification des données implique le partage de données, soit par ingestion à partir de sources, soit par fédération avec des sources de données ; des données brutes issues de la préparation, harmonisation et modélisation des données pour le traitement analytique et IA ; le stockage et la gestion des données à l'échelle pour un accès efficace avec un faible taux de CTS ; et l'accès aux données via divers mécanismes et outils de requête et d'analyse, profondément intégrés aux plates-formes de stockage et d'accès aux données sous-jacentes
- Open Lakehouses basées sur le cloud: Les plates-formes OLAP (cloud-based Big Data) convergent vers l'adoption de formats de fichier ouverts (Parquet) et de formats de tableau (Iceberg) permettant la fédération des données (data in) et le partage (data out).
- Traitement des données non structuré: Avec l'émergence, l'avancement et l'adoption de l'IA générative, les entreprises commencent à tirer des connaissances précieuses et de la valeur métier du corpus de données de l'entreprise qui constitue de grands volumes de documents texte, de transcriptions audio, d'enregistrements vidéo et d'autres médias. Le traitement non structuré des données, notamment le segmentage, la vectorisation, la recherche sémantique et les graphiques Knowledge, permet d'obtenir ces connaissances. Des techniques telles que le RAG (retrieval augmentéd generation) et le CAG (cache augmentéd generation) deviennent des moteurs principaux de la recherche rapide et agentique dans le corpus de données.
- Knowledge Management: Knowledge dépasse le simple contenu brut lui-même (documents, articles, vidéos). Il représente une augmentation de ce contenu en dérivant le sens, en organisant les métadonnées et en les plaçant dans le contexte pour développer une compréhension partagée du contenu dans une organisation ou une entreprise. Knowledge lui-même est généralement structuré. La gestion Knowledge implique la gestion des contenus, l'extraction Knowledge, la représentation à travers des modèles tels que des graphiques et la navigation.
- Accès aux données enrichi: L'accès enrichi aux données signifie que les données, les analytiques et les outils d'IA doivent être accessibles à une variété de personnes, notamment aux utilisateurs, aux utilisateurs professionnels, aux administrateurs et aux analystes. L'accessibilité est obtenue par des mécanismes tels que l'interrogation d'ensemble (avec requête relationnelle, mot-clé et sémantique), le langage naturel à l'interrogation SQL (NL2SQL), l'accès en temps réel, etc.
- Traitement en temps réel: Les applications agents prennent des décisions en temps réel basées sur l'état actuel et sur de nouveaux événements, en personnalisant les réponses et les actions, ce qui nécessite d'accéder aux données en temps réel, de les traiter et d'agir en conséquence. Le traitement en temps réel nécessite des données actualisées (latence des données) et un accès interactif (latence d'accès). Cette latence des données et de l'accès nécessite que la plate-forme de données sous-jacente prenne en charge l'accès aux données à jour à partir de magasins opérationnels et analytiques, un faible accès en latence (références de points et requêtes), une échelle de données élevée et un débit élevé.
- Sécurité des données, gouvernance et résidence: L'IA agentique et conversationnelle simplifie l'interface utilisateur de l'application, en permettant à tout le monde, des consommateurs aux employés en passant par d'autres agents IA, d'interagir avec les applications de façon conversationnelle en utilisant un langage naturel parlé ou écrit. Les données clients et personnelles importantes qui doivent être stockées et modélisées pour les applications Agentic doivent être sécurisées et régies par des politiques d'accès et de partage bien définies. De plus en plus, de nombreux clients doivent se conformer à la réglementation qui exige la résidence des données dans leur propre pays ou région, en particulier ceux qui travaillent au gouvernement ou avec des gouvernements.
Salesforce Data 360 est conçu pour répondre aux tendances en matière de données. Data 360 est une plate-forme de données basée sur le cloud, pilotée par les métadonnées, qui unifie les données cloisonnées à travers l'entreprise, permettant aux organisations de stocker, de modéliser et de traiter leurs données pour activer les analytiques, l'IA, l'apprentissage machine et les applications Agentic.
Ce document est un guide essentiel pour les architectes d'entreprise et les directeurs techniques. Il détaille l'architecture, les capacités, les principes de conception et les cas d'utilisation de Data 360. Il présente les principes fondamentaux de l'architecture Data 360 en tant que base, suivi d'une série d'explorations approfondies de ses principaux différenciateurs tels que l'interopérabilité avec les plates-formes de données existantes, notamment la stratégie multi-organisations, la sécurité, la gouvernance et la confidentialité, l'activation en temps réel et les salles blanches de données.
Salesforce Data 360 repose sur un ensemble de principes fondamentaux qui rendent les données d'entreprise opérationnelles, fiables et en temps réel.
- Ouverture et interopérabilité: Conçu pour les écosystèmes multicloud. Fédère avec des plates-formes de données telles que Snowflake, Databricks, BigQuery et Redshift sans duplication, étendant Customer 360 tout en préservant les investissements existants.
- Séparation stockage-calcul: Adapte indépendamment le stockage et le traitement (par lot, en continu et interactif). Fournit élasticité et efficacité pour les charges de travail à haut volume et hautes performances.
- Stockage et traitement multimodèle: Prend en charge les types de données structurés et non structurés, tels que texte, image audio et vidéo. Fournit un stockage efficace, le traitement en temps réel et par lot, l'indexation extensible, la recherche unifiée, l'interrogation et l'analyse.
- Conception pilotée par les métadonnées: Les applications sont définies par des métadonnées plutôt que par un code. Les métadonnées sont traitées comme un actif de premier ordre, qui permet une gouvernance unifiée, la flexibilité et une intégration profonde à la plate-forme Salesforce.
- Traitement hybride en temps réel: Prend en charge les requêtes à faible latence et la prise de décision instantanée, ainsi que le traitement par lot et les charges de travail analytiques.
- Données intelligentes et actives: Ingère, analyse et transmet en permanence des connaissances directement dans les workflows métiers. Pilote l'automatisation sans code, à faible code, pro-code et pilotée par l'IA avec le contexte le plus récent.
- Gouvernance et confidentialité par conception: La lignée, le contrôle d'accès, la résidence, le cryptage des données et la conformité sont intégrés. Trust et confiance réglementaire sont renforcés à chaque couche.
- Location un-à-plusieurs: Une organisation Data 360 centralisée sert de Source de vérité unique pour Customer 360, prenant en charge de façon transparente les environnements Salesforce multi-organisations largement utilisés par les clients de Salesforce.
Ces principes garantissent que Data 360 rend les données ouvertes, intelligentes et actionnables en temps réel.
Salesforce Data 360 est une plate-forme de données moderne basée sur des principes de conception qui répondent aux tendances actuelles en matière de données. Ses capacités d'architecture garantissent que les données d'entreprise sont fiables, unifiées et actionnables en temps réel, conformément à ses principes directeurs.
- Cloud-Native Foundation: Exécuté sur Hyperforce, déployé sur Hyperscalers (comme AWS), avec une infrastructure immuable, basée sur des microservices. Fournit une évolutivité élastique, une sécurité zéro Trust, une livraison continue et une conformité globale.
- Salesforce (Core) piloté par les métadonnées: Les métadonnées sont conçues, modélisées et stockées en tant que métadonnées Salesforce, ce qui permet une utilisation immédiate par TOUTES les applications Salesforce. Ces métadonnées sont stockées dans un SGBDR entièrement conforme aux normes ACID. Garantit la gouvernance, la cohérence du cycle de vie et une intégration profonde à Salesforce Lightning Platform.
- Lakehouse Storage: Élaboré sur Apache Iceberg et Parquet, combinant l'échelle du lac de données à la gouvernance de l'entrepôt prenant en charge l'évolution du schéma, les déplacements temporels et les mises à jour à haut volume. Data 360 stocke, modélise et traite des données structurées et non structurées avec un stockage à grande échelle avec des normes ouvertes modernes, et des capacités de transformation et de traitement des données riches pour les charges de travail pilotées par lot et par événement.
- Encours de données de bout en bout avec ingestion flexible: Couvre le cycle de vie complet (ingérer, préparer, modéliser, unifier, analyser et activer), ce qui réduit la dépendance aux solutions ponctuelles fragmentées. Prend en charge le traitement par lot, en temps quasi réel et en streaming avec plus de 270 connecteurs et MuleSoft. L'approche ELT-first permet une disponibilité rapide des données avec la flexibilité de la transformation en aval.
- Interopérabilité des données d'entreprise avec les infrastructures ouvertes et la Fédération: Unifie les données cloisonnées dans l'entreprise avec la fédération bidirectionnelle Zero Copy avec Snowflake, Databricks, BigQuery et Redshift, en évitant la migration des données ou la duplication.
- Classification, modélisation et organisation des données: Data 360 organise les données sous forme de données ingérées brutes, de données nettoyées et stockées, et de données modélisées conformément au schéma d'information commun appelé SSOT (Single Source of Truth). Ces objets SSOT forment la base de la définition de modèles de données sémantiques (SDM) et d'autres modèles organisés et spécifiques à l'application.
- Modélisation des données sémantiques intégrée pour des analytiques extensibles avec des API de requête sémantique ouvertes, pilotant Tableau Next et activant des analytiques spécifiques à l'application.
- Moteur de requête SQL haute performance prenant en charge une requête SQL Data 360 unifiée à travers des données structurées, non structurées et graphiques.
- Magasins de données à faible latence: Stockage clé-valeur pour les données chaudes avec des temps de réponse en millisecondes. Active la personnalisation et les scénarios pilotés par l'événement en temps réel. Collecte et traite les données d'engagement client en temps réel. Unifie les identités, les interactions et les conversations dans un graphique Customer 360 Profile and Context unique et fiable.
- Pipelines de traitement des données non structurées pour la prise en charge flexible et extensible du stockage de données non structuré, Chunking, génération d'incorporation (vectorisation), extraction de métadonnées (augmentation), résumé, indexation, extraction Knowledge, traitement intelligent des documents, création de mémoire à court et à long terme (conversation), etc.
- Indexation native par mot-clé, vecteur et hybride pour un accès précis et efficace aux données non structurées telles que la recherche rapide et agentique, RAG, extraction Knowledge, dérivation de la mémoire agentique, etc.
- Services Profil, Personnalisation, Contexte pour l'activation des applications IA/ML et Agentic.
- Gouvernance et sécurité intégrées à chaque niveau pour le suivi de la lignée, le masquage des données, la résidence des données et la sécurité zéro Trust garantissant la conformité et Trust
- Tissu de calcul élastique: Tissu de calcul multilocataire natif de Kubernetes. Exécute Spark pour le traitement distribué et Hyper pour les charges de travail SQL. Évolue élastiquement entre diverses tâches et prend en charge l'isolation pour exécuter un code non fiable.
Le tout fonctionne sur Hyperforce, la fondation cloud de Salesforce. Hyperforce fournit :
- Zero Trust Security avec des stratégies de cryptage, d'isolation et de moindre privilège.
- Résilience grâce à des déploiements multirégions. Si Salesforce Data 360 bénéficie de la résilience multi-régions d'Hyperforce et de la tolérance aux pannes au niveau de la plate-forme, une véritable reprise après sinistre (DR) de niveau entreprise exige une architecture plus large similaire à n'importe quelle plate-forme de données avec des capacités clés: pipelines d'ingestion rejouables, réplication, et réhydratation pilotée par les métadonnées à travers tous les écosystèmes dépendants.
- Observabilité avec la surveillance, les métriques et le traçage intégrés.
- Échelle automatisée et sensibilisation FinOps pour plus d'efficacité sans dépassement de coût.
Data 360 ne remplace pas les investissements d'entreprise existants. À la place, Data 360 rend les données que vous avez déjà approuvées, gouvernées et actionnables, en offrant un engagement en temps réel piloté par l'IA là où cela est le plus important. En résumé, Salesforce transforme toutes les données d'entreprise, y compris les données externes, en objets pilotés par les métadonnées (Salesforce), et active les applications Agentic pour la découverte, la prise de décision et l'exécution d'actions.
La figure suivante illustre l'architecture de référence Data 360 :
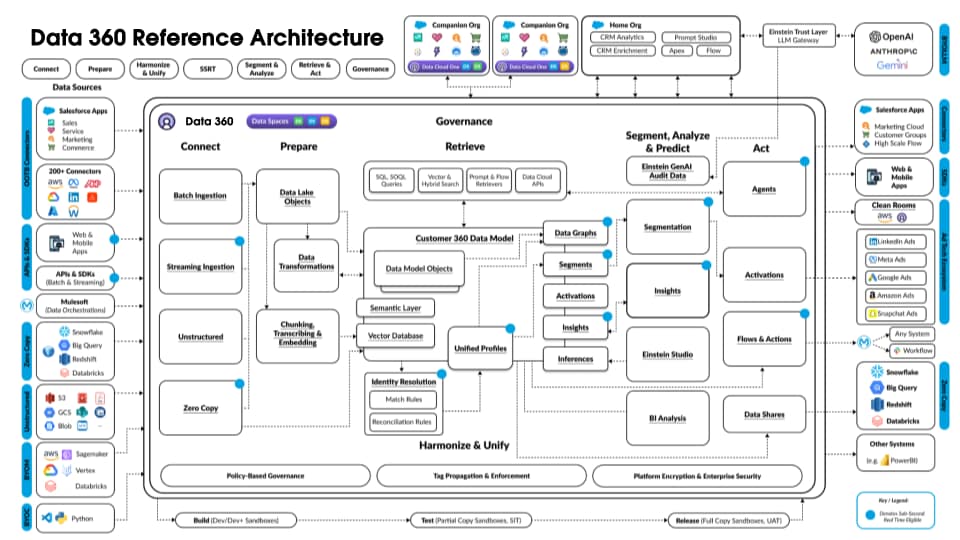
Prenons un hypothétique Agent de prêt Agentforce stratifié sur Data 360 pour décrire un exemple de flux d'architecture. Supposons que l'agent de prêt est un agent qui contacte les clients (consommateurs) pour demander des prêts et obtenir instantanément des approbations de prêt.
Data 360 exécute ces étapes comme prévu, en préparant les données à utiliser par l'agent de prêt.
- Data 360 ingère les données structurées Compte client à partir de CRM et les stocke dans le lac de données.
- Data 360 traite les données non structurées des prêts et des politiques financières de l'entreprise.
- Data 360 fédère les données personnelles à partir d'une source de données externe telle que Snowflake.
- Data 360 transforme et modélise les données ingérées et fédérées.
- Data 360 élabore et gère le graphique des données de profil.
Chaque fois qu'un client fait une demande de prêt, les actions ci-dessous sont exécutées.
- Un client se connecte à l'agent de prêt, qui commence une session client dans la couche en temps réel. Le profil unifié du client est extrait dans la couche en temps réel.
- Le client remplit une demande de prêt en fournissant les informations requises.
- Le client charge des documents financiers (tels que des déclarations fiscales, des investissements, des relevés bancaires) dans Data 360 pour un traitement de données non structuré.
- Les données chargées sont segmentées et vectorisées (génération incorporée), et des index (mot-clé et vecteur) sont créés.
- Ensuite, le client remplit le document de demande de prêt et le charge. Data 360 extrait en temps réel le montant et la durée du prêt.
- L'agent de prêt récupère les données financières pertinentes en utilisant la requête Data 360 et la recherche hybride sur le profil et d'autres index précréés.
- L'agent de prêt active un agent d'approbation avec des données de prêt et d'autres données de profil financier pour prendre la décision d'approbation de prêt.
- L'agent de prêt répond au client avec une décision.
- Cette interaction complète entre le client et l'agent de prêt est également capturée et stockée dans Data 360.
L'exemple ci-dessus présente une vue d'ensemble des composants d'architecture Data 360 utilisés pour élaborer une application Agentic telle qu'un agent de prêt. Dans la section suivante, nous décrivons les couches et les composants de l'architecture Data 360.
Dans cette section, nous allons explorer les blocs de construction de base de Salesforce Data 360, en commençant par son modèle de stockage robuste, puis en explorant les mécanismes de connexion, d'ingestion et de préparation des données. Nous examinerons ensuite comment les données structurées et non structurées sont stockées, modélisées et traitées, pour aboutir à une compréhension de leur harmonisation, unification, récupération et capacités d'activation intelligente.
Salesforce Data 360 repose sur un modèle de stockage hiérarchisé mais intégré qui combine les avantages d'une maison de lac avec le stockage en temps réel. La couche Lakehouse fournit un stockage évolutif et économique pour de grands volumes de données historiques et par lot, ce qui permet des analytiques avancées et des cas d'utilisation d'apprentissage machine. Le stockage en temps réel, quant à lui, est optimisé pour l'accès à faible latence et les mises à jour à haute fréquence, ce qui garantit que les interactions, les profils et les signaux d'engagement des clients sont toujours à jour. Ensemble, ces niveaux fonctionnent de façon transparente, ce qui permet aux données de circuler de façon fluide entre les contextes historiques et en temps réel, offrant à la fois profondeur et immédiateté dans une fondation de données unifiée pour la personnalisation, l'IA et l'activation.
Data 360 propose une architecture Lakehouse native basée sur Iceberg/Parquet, conçue pour gérer la gestion et le traitement des données à grande échelle pour des scénarios par lot, en continu et en temps réel prenant en charge des données structurées et non structurées, essentielles pour les applications d'IA et d'analyse.
Dans les lacs de données basés sur le cloud tels que Azure, AWS ou GCP, l'unité de stockage de base est un fichier, généralement organisé en dossiers et en hiérarchies. Lakehouse améliore cette structure en introduisant des abstractions structurelles et sémantiques de niveau supérieur pour faciliter des opérations telles que l'interrogation et le traitement IA/ML. L'abstraction principale est un tableau avec des métadonnées qui définit sa structure et sa sémantique, incorporant des éléments de projets open-source tels que Iceberg ou Delta Lake, avec des couches sémantiques supplémentaires ajoutées par Data 360.
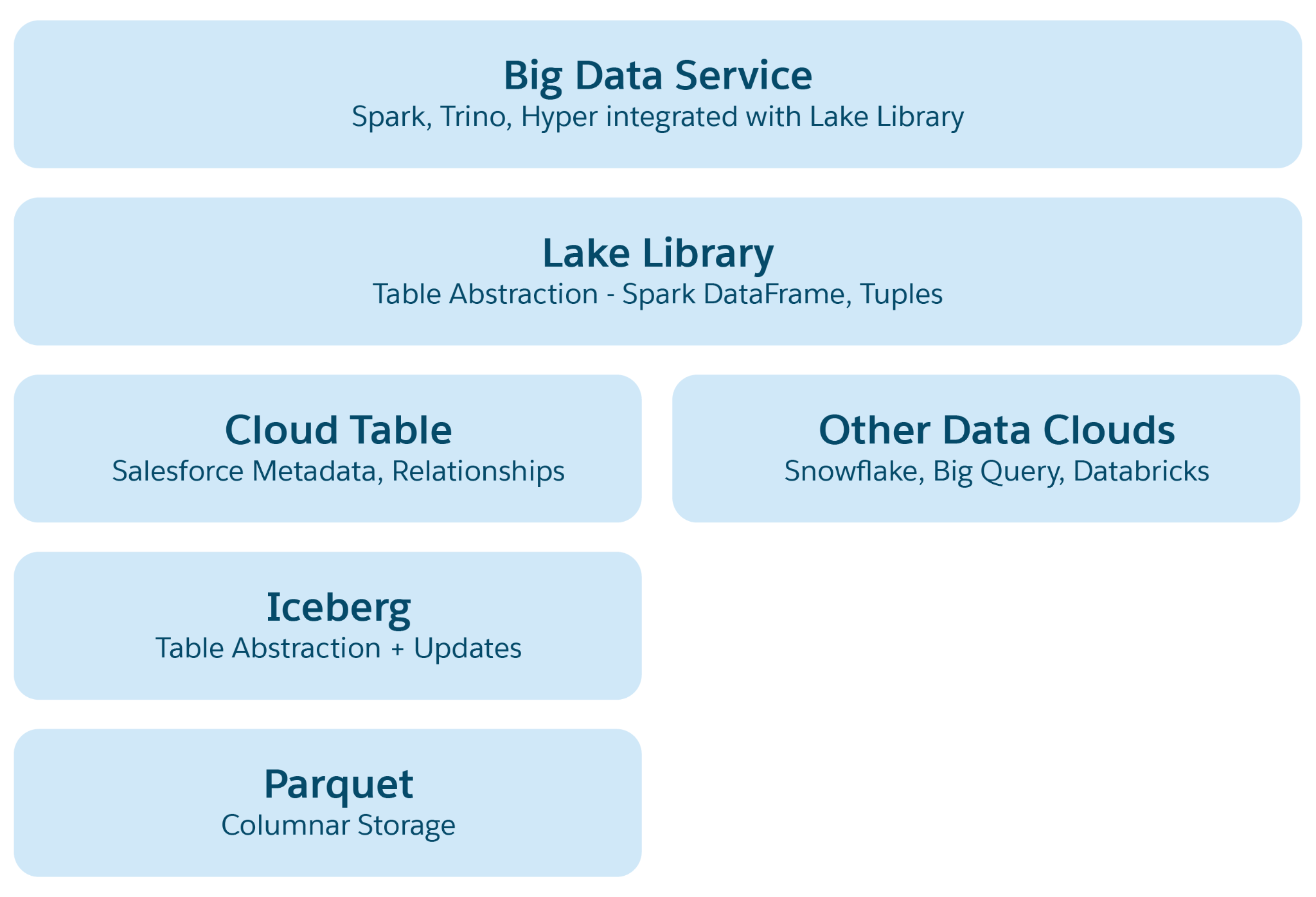
Couches d'abstraction dans Lakehouse :
- Parquet File Abstraction: À la base, le stockage est composé de fichiers lac de données (par exemple S3 dans AWS ou Blob dans Azure) au format Parquet. Les données d'un tableau source sont stockées dans plusieurs partitions sous forme de fichiers Parquet, chaque tableau étant une collection de ces fichiers.
- Abstraction de tableau iceberg: Les tableaux sont organisés en dossiers, avec des partitions de données stockées sous forme de fichiers Parquet dans ces dossiers. Les modifications apportées à une partition entraînent de nouveaux fichiers Parquet sous forme de clichés instantanés. Iceberg gère un fichier de métadonnées pour chaque tableau, détaillant des schémas, des spécifications de partition et des clichés instantanés.
- Salesforce Cloud Table Abstraction: Basée sur Iceberg, cette couche ajoute des métadonnées sémantiques telles que les noms de colonne et les relations, ainsi que des configurations telles que la taille de fichier cible et la compression. Il extrait des tableaux sur diverses plates-formes telles que Snowflake et Databricks, protégeant les applications Data 360 des spécificités de la plate-forme de stockage sous-jacente.
- Bibliothèque d'accès au lac: Cette bibliothèque permet d'accéder au tableau Salesforce Cloud, en gérant les données et les métadonnées, et d'extraire les mécanismes de stockage sous-jacents pour les développeurs d'applications.
- Big Data Service Abstraction: Cela inclut des infrastructures de traitement telles que Hyper pour l'interrogation et Spark pour le traitement sur n'importe quelle plate-forme de tableau cloud.
Pour prendre en charge les analytiques en temps réel et les applications agentiques, Data 360 augmente le stockage de Big Data Lakehouse avec Low Latency Store. Data 360 Real-Time Layer traite les signaux en temps réel et les données d'engagement en mémoire. Cependant, comme la capacité de stockage basée sur la mémoire est limitée, toutes les données ne peuvent pas tenir et le traitement peut ne pas être effectué en temps réel. Data 360 ajoute un magasin à faible latence (LLS) pour supprimer ces limitations, ce qui permet un traitement en temps réel évolutif.
Le magasin à faible latence est une couche de stockage NVMe (SSD) à l'échelle du pétaoctet dans Lakehouse. Les données ne doivent pas toutes être conservées dans le magasin à faible latence. C'est un cache durable. La plupart des données finissent par arriver à Lakehouse pour la persistance à long terme. Les données en session dans la couche temps réel peuvent être vidées vers le magasin à faible latence pour un accès rapide ultérieur. Par exemple, dans une conversation Agentic, les messages récents peuvent être traités en mémoire ; les anciens messages peuvent être vidés dans le magasin à faible latence. Si une conversation précédente est requise, elle est accessible en quelques millisecondes depuis le magasin à faible latence. Le stockage basé sur NVMe permet de stocker de grandes quantités de données et d'y accéder à des latences en millisecondes. Les données peuvent se frayer un chemin vers le stockage cloud Lakehouse pour la persistance à long terme. De plus, les données Lakehouse requises pour le traitement en temps réel ou pour augmenter les expériences en temps réel sont récupérées et conservées dans le magasin à faible latence. Par exemple, le contexte du profil client est pré-récupéré ou apporté depuis Lakehouse et mis en cache dans le magasin à faible latence. De plus, tous les objets Lakehouse et les autres objets requis pour le traitement en temps réel pendant le traitement en session peuvent également être mis en cache dans le magasin à faible latence.
Le magasin à faible latence Data 360 active la couche Real Timer dans une véritable hiérarchie de stockage avec des couches de stockage Lakehouse à mémoire (SSD), avec une migration transparente des données entre ces couches. Nous abordons la couche Data 360 Real Time plus loin dans ce document.
Salesforce Data 360 est conçu pour standardiser, harmoniser et activer toutes les données clients, structurées et non structurées, en suivant un cycle de vie rigoureux qui transforme l'entrée brute en un modèle de données unifié et actuel.
Le cycle de vie se concentre sur l'utilisation de diverses entrées de données externes et leur structuration en objets modélisés persistants. Les données modélisées peuvent être harmonisées dans des profils unifiés Customer 360.
Données brutes ingérées et transformations initiales
Le processus commence par les données brutes ingérées telles quelles à partir de systèmes sources (CRM, Marketing, fichiers, etc.). Cela inclut les chargements complets de données et les événements de modification continue (deltas), qui sont gérés et fusionnés avec des données persistantes pour maintenir un état actuel.
Les transformations en ligne (p. ex. rogner, normaliser, concaténer) sont immédiatement appliquées pendant l'ingestion afin d'assurer la qualité et la propreté préliminaires des données.
Objets lac de données (DLO) : La couche persistante
Les objets lac de données (DLO) forment la couche de stockage permanente principale dans Data 360. Ils stockent les données propres et transformées et servent de référentiel organisé à long terme pour toutes les informations sur les clients.
Des transformations de données avancées (p. ex. jointures, agrégations, connaissances calculées) sont appliquées aux objets lac de données sources pour produire de nouveaux objets lac de données dérivés hautement organisés.
Les données disponibles via la Fédération des données Zero Copy sont représentées directement sous forme d'objets lac de données.
Organisation des données et métadonnées non structurées
Pour des contenus non structurés (texte, média, documents), Data 360 incorpore les données en extrayant et en conservant ses métadonnées structurées dans des objets lac de données spécifiques appelés Objets lac de données non structurés (UDLO).
Ces objets lac de données spécialisés fonctionnent comme des tableaux d'annuaire, fournissant une carte de l'emplacement physique et du contexte des actifs non structurés. Cette capacité permet aux architectes d'associer de façon transparente les métadonnées de données non structurées avec le reste des données clients structurées, ce qui permet une interrogation et harmonisation unifiées.
Objets modèle de données (DMO) : La couche harmonisée
Les objets modèle de données (DMO) représentent la couche de données finale, harmonisée et structurée.
Ils sont créés en mappant des champs d'objet lac de données (à partir d'objets lac de données sources, dérivés et non structurés) avec le modèle standard Customer 360 Data Model.
La couche DMO agit en tant que source unique de preuve pour toutes les données des clients, permettant la création, la segmentation et l'activation de profils unifiés dans l'écosystème élargi.
Un espace de données est le conteneur logique fondamental pour organiser toutes les données et métadonnées dans Data 360, y compris tous les objets lac de données (structurés et non structurés) et les objets modèle de données. Les espaces de données offrent un environnement sécurisé et isolé pour le traitement et la modélisation des données.
Les espaces de données agissent comme des frontières logiques et de gouvernance, permettant la multilocation interne en séparant les données d'entités distinctes telles que des unités commerciales, des régions ou des marques, tout en préservant la visibilité, la lignage et la conformité à l'échelle de l'entreprise, servant de base à la définition d'un contrôle d'accès grossier.
L'isolement dans les espaces de données est appliqué à plusieurs couches de la plate-forme :
- Isolation au niveau des données: Chaque objet lac de données/objet modèle de données appartient à un espace de données unique, ce qui garantit que les requêtes, les transformations et les mappages d'objets ne peuvent pas franchir les limites de l'espace de données, sauf autorisation explicite.
- Intégration du contrôle d'accès: Les ensembles d'autorisations sont liés nativement à des espaces de données, ce qui permet de contrôler les opérations de lecture, d'écriture et administratives. Ainsi, seuls les utilisateurs et les services autorisés peuvent accéder aux objets, aux connaissances et aux activations dans un espace de données.
- Gouvernance et audit: Toutes les opérations dans un espace de données sont consignées avec des pistes d'audit de niveau entreprise, ce qui permet la traçabilité de la conformité, de la gérance et des rapports réglementaires.
L'accès et les autorisations sont gérés via des ensembles d'autorisations, ce qui garantit une visibilité précise, des mises à jour contrôlées et la prévention des fuites de données entre les domaines. En intégrant les frontières de l'espace de données à l'architecture de sécurité et de gouvernance de Data 360, les architectes peuvent implémenter en toute confiance des stratégies de gouvernance centralisées et décentralisées tout en préservant la cohérence entre plusieurs clouds et domaines métiers.
Data 360 Compute Fabric fournit une couche unifiée pour gérer et exécuter toutes les charges de travail Big Data, ce qui simplifie les complexités sous-jacentes de l'infrastructure. Son composant principal est le contrôleur de traitement des données (DPC).
DPC est un service complet d'orchestration du traitement des données à charges de travail multiples qui fournit des capacités de travail en tant que service (JaaS) dans divers environnements de calcul cloud. Il élimine la complexité de l'infrastructure et unifie l'exécution des tâches pour des infrastructures telles que Spark (EMR sur EC2 et EMR sur EKS) et les charges de travail Kubernetes Resource Controller (KRC). En servant de passerelle de plan de contrôle centralisée, DPC orchestre, planifie et surveille les tâches à travers plusieurs plans de données, garantissant fiabilité, évolutivité, rentabilité et expérience cohérente pour les développeurs.
Le besoin de DPC découle des limitations de l'interaction directe avec les systèmes de gestion de clusters natifs tels que le DME.
Abstraction de l'infrastructure et du cloud
EMR offre des API pour les clusters, les tâches et les étapes, mais il charge les équipes clientes avec des tâches de gestion d'infrastructure critiques telles que le provisionnement, la mise à l'échelle, l'ajustement des performances et l'optimisation des coûts. DPC y répond en offrant une API simplifiée au niveau de la plate-forme pour la soumission de tâches. Il prend en charge le traitement automatique des échecs, les tentatives et l'équilibrage de charge dynamique. Fournit un bon rapport coût-efficacité à travers les nœuds binpacking, spot et graviton. Fournit une sécurité renforcée avec l'isolation TLS, PKI, IAM et le correctif automatisé. Gère les mises à niveau de version d'exécution Spark et EMR pour améliorer les performances, les correctifs de sécurité et les fonctionnalités.
De plus, DPC fournit une interface cloud agnostique unifiée pour la soumission et la gestion des tâches de données, en faisant abstraction des complexités et des API propriétaires du substrat cloud sous-jacent (AWS, futurs fournisseurs). Cela garantit que les équipes clientes interagissent uniquement avec une interface de soumission de tâches basée sur l'API Data 360 commune qui élimine les complexités des gestionnaires de ressources sous-jacents tels que Kubernetes et YARN. Cela permet aux équipes clientes de soumettre des tâches Spark via une API simple et unifiée sans avoir à gérer directement les pods, les pools de nœuds ou les configurations de cluster Spark.
L'ajustement manuel des paramètres Spark nécessite des compétences spécialisées et des configurations incorrectes peuvent ralentir l'exécution des tâches. L'équipe DPC centralise cette expertise, en fournissant des configurations optimisées pour éviter les problèmes de performance courants. Cette équipe spécialisée intègre en permanence Knowledge de la communauté open-source afin de garantir des performances optimales à travers toutes les charges de travail gérées par le contrôleur.
DPC n'est pas limité à Spark, il prend en charge un large éventail de charges de travail. Il s'agit notamment de :
- Charges de travail de traitement en temps réel
- Fonctionnalité Livraison d'événements pour Actions de données
- Gestion de Milvus (la base de données vectorielle pour l'indexation des données non structurées)
- Infrastructure de stockage à faible latence
DPC exploite également l'infrastructure Kubernetes Resource Controller (KRC), qui prend en charge des charges de travail telles que Trino pour les requêtes, Event Delivery pour les actions de données, les tâches d'extraction de données pour les connecteurs et le traitement en temps réel. Pour toutes les charges de travail KRC, DPC fournit des capacités centrales de travail en tant que service, qui gèrent le provisionnement, le déploiement et la gestion du calcul à un niveau élevé d'abstraction des tâches.
Avantages et architecture JaaS
Le modèle Job-as-a-Service, fourni par DPC, garantit un pipeline de traitement des tâches économique et résilient.
Les utilisateurs fournissent des spécifications de cluster simples, en se concentrant sur le processeur, la mémoire, le stockage, le nombre d'instances, ainsi que le nombre de clusters Min/Max et les balises de correspondance de cluster. DPC gère ensuite automatiquement les détails abstraits de l'infrastructure, notamment la sélection d'UGS de machine virtuelle optimales, la gestion des flottes d'instances, la détermination du ratio Core/SKU. Nœuds de tâche et gestion à la demande par rapport à Repérez les instances en fonction des entrées. Il gère également la gestion des DME et des versions de composants, ainsi que les mises à niveau sans temps d'arrêt.
Essentiellement, DPC prend en charge la multilocation, conçue pour comprendre et appliquer les limites de la location Data 360 et la séparation des ressources. Il garantit également la sécurité et la conformité en appliquant automatiquement les images machine certifiées Salesforce, en gérant les rôles IAM spécifiques au service et en garantissant le cryptage en transit et au repos. Pour l'acheminement et le contrôle de la capacité, la correspondance tâche à cluster est gérée en utilisant des Balises de cluster, et l'acheminement basé sur la capacité utilise un paramètre de concurrence de tâches maximum pour contrôler efficacement l'utilisation des ressources.
L'expérience client Cloud Agnostic est un avantage essentiel, car la complexité des environnements Cloud sous-jacents est masquée pour les services clients, ce qui leur permet de se concentrer uniquement sur la logique métier. Cela atteint l'objectif de l'abstraction des fournisseurs de cloud. Enfin, DPC facilite le suivi de l'utilisation et des coûts, ce qui permet de segmenter l'utilisation et les coûts des clusters par service pour une comptabilité précise. Globalement, DPC suit une architecture enfichable qui permet d'intégrer de façon transparente de nouveaux moteurs d'exécution (par exemple Flink, Ray) et des substrats cloud (GKE/Dataproc) sans exposer aux utilisateurs les détails sous-jacents de l'infrastructure. Cette conception découple le plan de contrôle de la couche d'exécution, ce qui garantit une API et une expérience opérationnelle cohérentes, quel que soit le back-end.
Data 360 affine et enrichit les données brutes, en comblant le fossé entre les informations brutes et la consommation métier actionnable. Il complète le cycle de vie des objets de données en préparant des données complexes pour une activation et une analyse sophistiquées. Data 360 prend en charge divers types de traitement, notamment les Transformations de données par lot et en continu, les Connaissances calculées par lot et en continu, le Traitement des données non structuré et la Résolution de l'identité. Pour permettre efficacement ces diverses opérations, en particulier en temps quasi réel et à travers des jeux de données massifs, un mécanisme sophistiqué est nécessaire pour gérer efficacement les modifications des données.
Pour obtenir un traitement efficace et en temps quasi réel des données, en particulier avec des tableaux de taille en téraoctets et des millions de mises à jour potentielles, Data 360 avait besoin d'une percée. Elle nécessitait un moyen de notifier les systèmes avec précision lorsque les données changeaient, puis d'identifier efficacement les données modifiées afin que seules les mises à jour pertinentes soient traitées et uniquement lorsqu'elles sont mises à jour. Ce défi a conduit à deux innovations complémentaires : Événements de modification natifs du stockage (SNCE) pour notifier une modification et Fil de données de modification (CDF) pour identifier les modifications.
Événements de modification natifs du stockage (SNCE)
SNCE a fondamentalement transformé Data 360 en une plate-forme de données réactive et incrémentielle. Ce changement implique de passer d'une interrogation active du lac de données à une surveillance passive des événements d'engagement atomique, en utilisant un format d'événement standardisé et un système de livraison de messages à haut débit.
Chaque opération d'écriture réussie (INSÉRER, METTRE À JOUR, SUPPRIMER) dans un tableau Iceberg aboutit à un échange atomique du pointeur de fichier de métadonnées actuel du tableau dans le catalogue. La couche de stockage d'objet sous-jacente (par exemple S3) est configurée pour émettre un événement de notification natif (par exemple un événement S3) chaque fois qu'un nouvel instantané de métadonnées est écrit dans le répertoire du tableau.
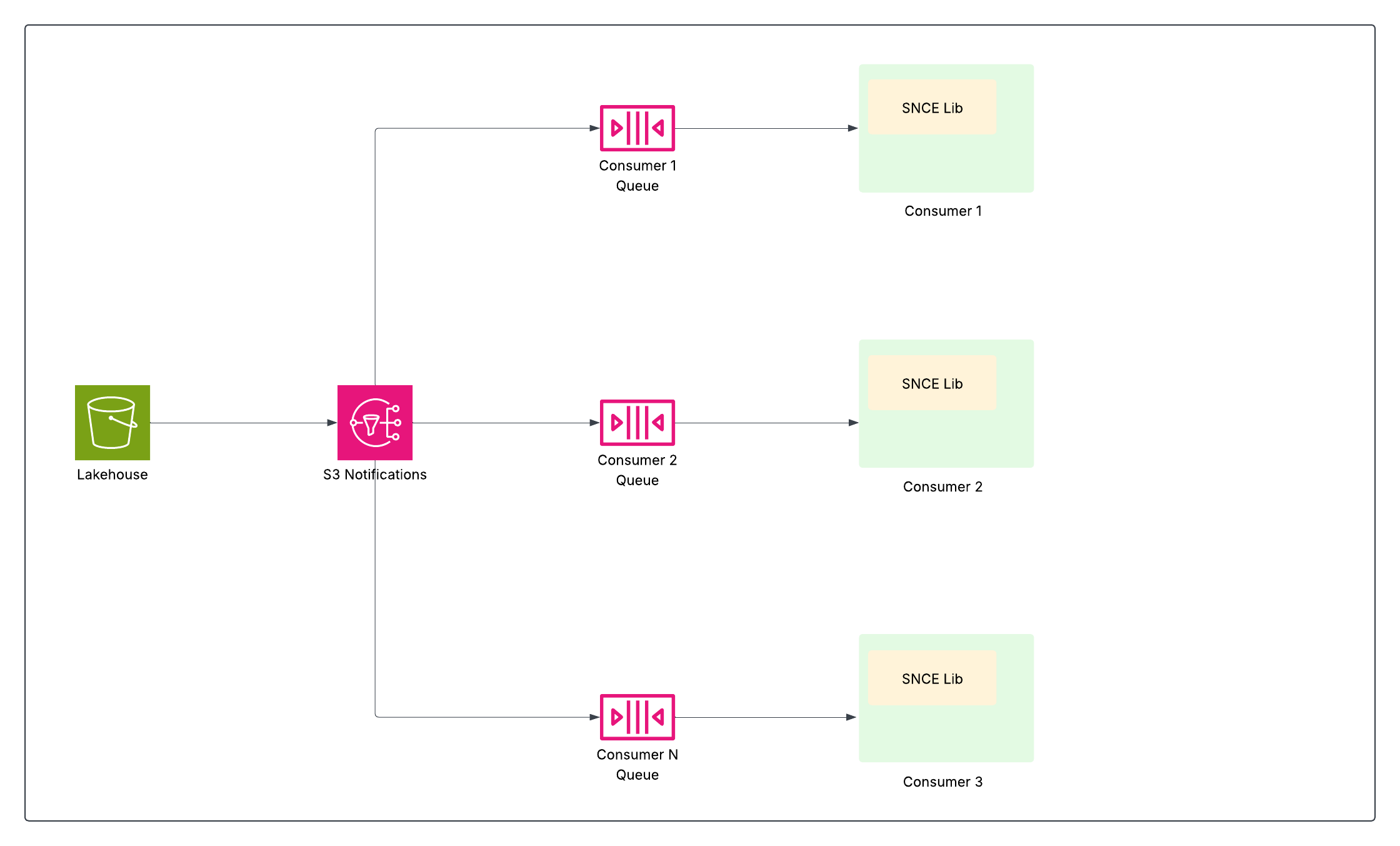
La bibliothèque SNCE offre une méthode standardisée pour consommer ces événements, et peut également les enrichir avec des métadonnées de clichés instantanés sur demande.
Cela permet aux pipelines de données en aval, tels que les connaissances calculées en continu, la résolution de l'identité et la segmentation, de s'abonner et d'agir uniquement lorsque les données ont changé, ce qui augmente considérablement l'efficacité en évitant les analyses coûteuses de tableaux complets.
Modification du fil de données (CDF)
En s'appuyant sur SNCE, le Fil de données de modification (CDF) fournit un mécanisme rationalisé pour consommer et traiter progressivement les modifications.
CDF exploite les clichés instantanés Iceberg pour générer efficacement le flux de modifications. L'éditeur Iceberg optimisé de Data 360 calcule et conserve les modifications dans le cadre de l'opération d'écriture elle-même, ce qui rend la génération de CDF très efficace et réduit les surcharges supplémentaires. Cela permet aux tâches de traitement (telles que les transformations en continu ou les connaissances calculées en continu) de traiter sélectivement uniquement les enregistrements altérés, ce qui évite le calcul coûteux des différences de clichés instantanés.
Cette stratégie incrémentielle offre plusieurs avantages pour les jeux de données volumineux, notamment des économies, une latence réduite et une efficacité accrue. Il active des fonctionnalités telles que les transformations en continu et la résolution incrémentielle de l'identité, qui entraînent à leur tour des connaissances plus rapides, des charges système plus prévisibles, des performances améliorées et une réduction des dépenses opérationnelles.
Data 360 offre des capacités d'ingestion robustes avec la prise en charge native des produits Salesforce, ce qui garantit un flux de données transparent. Pour des sources externes, il fournit une connectivité étendue via plus de 270 connecteurs, API, kits de développement et MuleSoft. De plus, Data 360 offre une fédération sans copie, ce qui permet d'effectuer des analyses analytiques sans duplication des données.
L'infrastructure de connecteur Data 360 (DCF) est la base de la plupart des connectivités Data 360. Il permet l'ingestion, la fédération et la sortie à travers une architecture unifiée. DCF définit les normes d'élaboration et de gestion des connecteurs, depuis l'interface utilisateur pour la configuration et l'administration jusqu'à la persistance des métadonnées, l'extraction et la livraison de données dans Lakehouse ou via des requêtes live avec des sources externes. Il prend également en charge les options de connectivité privées (telles que les liens privés, les VPN et les tunnels sécurisés) pour garantir la sécurité et la conformité des données de niveau entreprise lors de la connexion à des environnements clients ou partenaires. En offrant une approche cohérente à travers tous les connecteurs, DCF permet à Data 360 de se connecter de façon transparente à l'écosystème élargi en garantissant l'extensibilité, la fiabilité et l'intégration sécurisée.
Data 360 fournit une connectivité robuste à un vaste écosystème de sources de données, prenant en charge les produits Salesforce natifs et de nombreux systèmes externes. Cette connectivité étendue est cruciale pour unifier les données d'entreprise cloisonnées et activer les applications IA/ML et Agentic.
Data 360 offre plus de 270 connecteurs en natif ou via MuleSoft, des API et des kits de développement pour prendre en charge ses capacités de pipeline de données de bout en bout avec l'ingestion par lot, en continu ou en temps réel. Ces connecteurs peuvent être classés globalement par type de système source qu'ils intègrent.
Connecteurs Salesforce Native
Ces connecteurs garantissent un flux de données transparent et natif à partir des produits Salesforce.
Par exemple, les connecteurs Salesforce CRM, Data Cloud One , Marketing Cloud Engagement, Marketing Cloud Account Engagement et B2C Commerce.
Applications externes et SaaS
Les connecteurs pour diverses applications métiers et services cloud permettent l'ingestion de données à partir de plates-formes logicielles externes.
Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp et Airtable en sont des exemples.
Bases de données et entrepôts de données
Data 360 se connecte à une variété de plates-formes de stockage de données relationnelles et basées sur le cloud.
Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery et Microsoft SQL Server en sont des exemples.
Systèmes de stockage et de fichiers d'objets Cloud
Ces connecteurs s'intègrent à des solutions de stockage hyperscaler pour des données structurées et non structurées.
Amazon S3, Google Cloud Storage (GCS) et Azure Blob Storage en sont des exemples.
Services de streaming et de messagerie
Les connecteurs qui gèrent des flux de données continus et en temps réel sont essentiels pour les scénarios pilotés par l'événement et le traitement en temps réel.
Un exemple est le connecteur Amazon Kinesis.
Plateformes d'intégration
Le connecteur MuleSoft Anypoint étend la portée de Data 360 en l'intégrant à un plus grand nombre d'applications et de bases de données via Anypoint Exchange.
Connecteurs de stockage de données et d'objets Cloud non structurés
Ces connecteurs sont essentiels pour ingérer et référencer des données non structurées (données sans modèle prédéfini) afin d'alimenter les capacités d'IA générative.
Tous ces connecteurs sont construits sur l'infrastructure de connecteur Data 360 offrant une expérience cohérente.
La transformation des données est un composant architectural fondamental dans Data 360, conçu pour nettoyer, enrichir et mettre en forme les données ingérées brutes en actifs de données normalisés et actionnables alignés sur le modèle de données Customer 360. Ce processus est essentiel à l'harmonisation, à l'amélioration de la qualité et à la préparation des données pour des cas d'utilisation en aval tels que l'unification, la segmentation et l'activation de profils. Les transformations exploitent les objets lac de données sources (DLO) et les objets modèle de données (DMO) en entrée, produisant les résultats respectivement vers de nouveaux objets lac de données ou objets modèle de données.
Data 360 fournit deux paradigmes de transformation principaux pour répondre à différentes exigences de vitesse des données : les transformations de données par lot et les transformations de données en continu.
Transformations de données par lot
Les transformations de données par lot sont conçues pour le traitement à haut volume basé sur une planification définie ou un déclencheur à la demande. Ce moteur est optimisé pour gérer les opérations de restructuration complexes et gourmandes en ressources.
Le processus de transformation par lot est configuré en utilisant une zone de dessin visuelle à faible code du pipeline qui permet aux utilisateurs de définir une logique de transformation à plusieurs étapes. Ce moteur prend en charge de façon unique les opérations de restructuration complexes essentielles à l'alignement canonique des modèles de données : la structuration et la normalisation des données. Cela inclut le pivotement (décomposition des enregistrements dénormalisés en plusieurs enregistrements normalisés) et l'aplatissement (restructuration des données hiérarchiques, par exemple JSON, en tableaux structurés). Le mode d'exécution du système prend en charge la synchronisation complète (traitement de tous les enregistrements) et un mode de traitement incrémentiel très efficace. Le mode incrémentiel réduit considérablement le temps de traitement et la consommation de ressources en traitant uniquement les enregistrements qui ont changé depuis la dernière exécution réussie. Les transformations par lot sont idéales pour les tâches dans lesquelles les mises à jour en temps réel ne sont pas essentielles, par exemple les agrégations périodiques et la restructuration de données complexes.
Transformations de données en continu
Les données en continu transforment les données de traitement de façon continue et incrémentielle en temps quasi réel à mesure qu'elles entrent dans le système, ce qui les rend essentielles pour les cas d'utilisation à faible latence.
L'interface principale est une approche SQL-first, dans laquelle les transformations sont définies en tant que requête SQL SELECT qui s'exécute en permanence contre le flux entrant de modifications d'enregistrement. Ce moteur prend en charge les principales fonctions de transformation, notamment le nettoyage et la normalisation des données (par exemple, la validation des informations d'identification personnelle et la normalisation des formats de données), ainsi que l'enrichissement et la fusion des données (en utilisant des jointures et des unions). Il prend en charge les Streaming Lookup JOINS pour activer l'enrichissement des données en temps réel et les références aux données de référence statiques ou en évolution lente, ce qui garantit des mises à jour instantanées du profil. Pour optimiser le rapport coût-service, l'architecture utilise une conception de tâche Haute densité (HD), qui regroupe plusieurs définitions de transformation en continu pour un locataire unique dans une seule tâche de calcul sous-jacente, ce qui optimise l'utilisation des ressources. Les transformations en continu sont essentielles pour des cas d'utilisation tels que la surveillance des événements, la personnalisation immédiate et les mises à jour de profil en temps réel.
Data 360 révolutionne la gestion des données en prenant en charge la fédération Zero Copy et le partage de données, ce qui élimine la nécessité de déplacer ou de dupliquer les données. Cette capacité permet aux utilisateurs d'accéder de façon transparente et directe aux données de diverses sources externes et de partager des données avec des environnements externes, ce qui réduit considérablement la complexité, réduit les coûts de stockage et garantit que toutes les décisions sont basées sur les informations les plus récentes et les plus fiables.
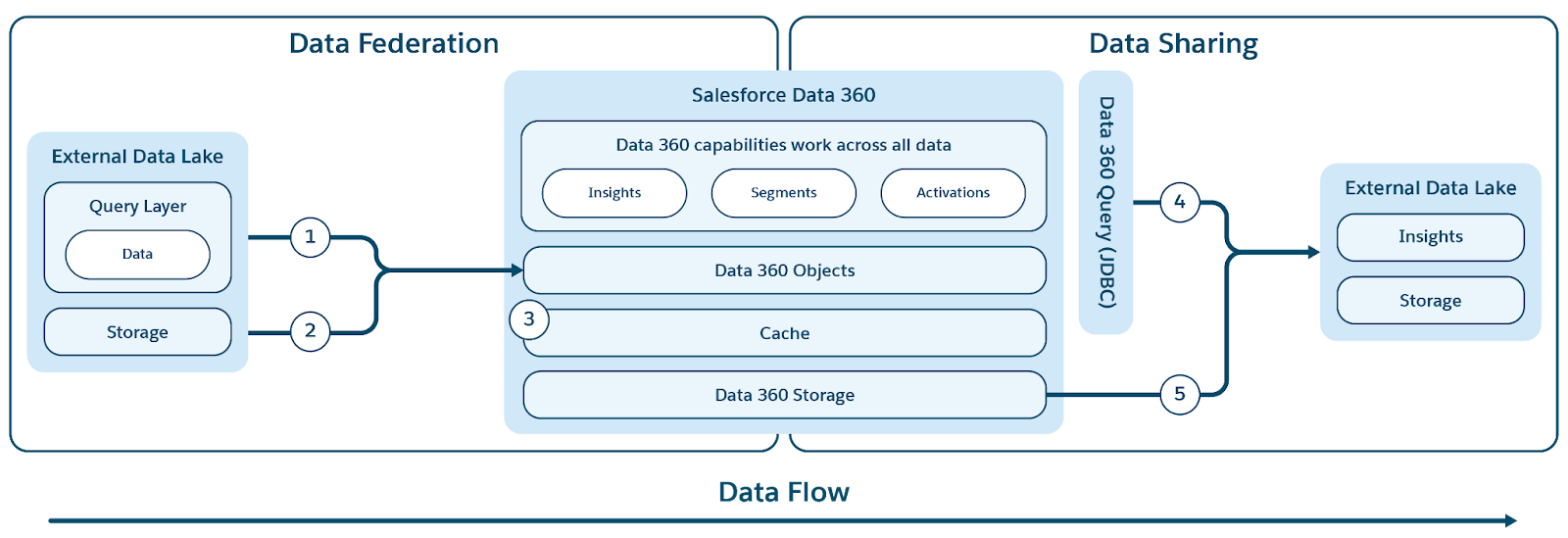
Data 360 prend en charge la fédération zéro copie avec des entrepôts de données externes (Snowflake, Redshift), des Lakehouses (Google BigQuery, Databricks, Azure Fabric), des bases de données SQL et de nombreuses autres sources. Ses couches d'abstraction permettent d'interroger directement des données externes sans duplication, ce qui réduit les temps d'ingestion, les coûts de stockage et garantit des informations à jour.
Data 360 simplifie l'accès aux données externes et fédérées en fournissant une couche de métadonnées unifiée qui extrait à la fois Salesforce et des objets externes. Cela permet à toute la plate-forme Salesforce et à ses applications d'utiliser ces données de façon transparente.
Data 360 prend en charge la fédération basée sur le fichier et la requête, avec une accélération de la requête live et de l'accès comme illustré sur la figure.
Les étiquettes (1) et (2) illustrent la requête de Data 360 (y compris les requêtes pushdown live) et la fédération basée sur un fichier pour accéder aux données de lacs de données externes/entrepôts/sources de données. L'étiquette (3) souligne l'accélération de l'accès fédéré à partir de lacs de données externes/sources de données.
Fédération de requêtes
Le cœur de la capacité de fédération de Data 360 réside dans sa couche de fédération de requêtes, qui gère le processus complexe d'accès aux données externes et d'exécution de pushdowns de requête intelligents (illustré par l'étiquette 1). Data 360 se connecte et récupère des données à partir de sources en utilisant le protocole JDBC, optimisé avec une logique supplémentaire pour plus d'efficacité. La couche de fédération de requêtes est responsable de la compréhension et de la traduction des différents dialectes SQL, de la définition de la partie la plus optimale de la requête à envoyer vers des systèmes externes pour un traitement efficace, de la récupération des résultats et de l'exécution des traitements supplémentaires nécessaires pour obtenir des connaissances finales.
Mise en cache (accélération des requêtes)
Pour une utilité avancée, Data 360 fournit une fonctionnalité d'accélération facultative pour ses capacités fédérées.
Lorsque l'Accélération est activée, Data 360 met en cache les données fédérées pour accélérer l'accès et réduire les coûts, ce qui évite l'accès direct et répété à des sources externes. Ce cache est traité comme une couche d'accélération et est mis à jour de façon incrémentielle pour refléter rapidement toutes les modifications apportées aux données sources externes, ce qui garantit que la vue accélérée reste en temps quasi réel.
Fédération de fichiers
Data 360 prend en charge la fédération basée sur le fichier (illustrée par l'étiquette 2) pour accéder aux données de lacs de données et de sources externes. La base technique de cette capacité zéro copie repose sur la normalisation : les données sous-jacentes doivent être au format de fichier Apache Parquet et utiliser le format tabulaire Apache Iceberg. Data 360 peut se fédérer dans n'importe quelle source qui expose un Iceberg REST Catalog (IRC) pour l'accès aux métadonnées et au stockage, garantissant un accès transparent et régi aux fichiers résidant hors de la plate-forme.
Avec la fédération basée sur le fichier, Data 360 calcul traite tous les traitements de données, car ils accèdent directement au stockage sous-jacent. Cela élimine le besoin de pushdown des requêtes et de gérer divers dialectes SQL, qui sont souvent requis avec la fédération basée sur la requête.
En plus de cela, la capacité Zero Copy s'étend également aux sources de données non structurées telles que les solutions de stockage hyperscaler (stockage S3/GCS/Azure), Slack et Google Drive, qui sont accessibles par les pipelines de traitement non structurés de Data 360.
Data 360 facilite le partage de données basées sur des requêtes et des fichiers qu'il gère avec des lacs de données et des entrepôts externes (illustrés par les étiquettes 4 et 5 dans le contexte de la figure d'origine).
Partage basé sur la requête
Pour le partage de données basé sur des requêtes, Data 360 expose un pilote JDBC à l'aide duquel les moteurs et les applications externes peuvent obtenir un accès sécurisé aux données. Ce mécanisme permet aux systèmes externes de connecter, d'authentifier et d'exécuter des requêtes live directement sur les données dans Data 360.
Partage basé sur le fichier (partage de données et DaaS)
Le principal mécanisme de partage basé sur un fichier implique deux concepts : le partage de données et la cible de partage de données, qui exploitent l'API DaaS (Data as a Service).
- Contrôle granulaire : Le concept de partage de données permet aux clients de définir avec précision les objets (objets lac de données, objets modèle de données, DSI, etc.) partagés en externe, ce qui évite toute exposition involontaire aux données.
- Ciblage sécurisé : Il contrôle également la cible de partage de données, en s'assurant que les données sont disponibles uniquement pour des environnements externes, des comptes ou des organisations partenaires explicitement autorisés (par exemple, le partage avec une instance Redshift ou Databricks spécifique).
L'API DaaS fournit une interface sécurisée et régie permettant aux moteurs externes de consommer des données. Il accorde l'accès aux métadonnées essentielles et au stockage de tableau sous-jacent tout en préservant toute la sémantique Data 360. Cela garantit que les moteurs externes accèdent aux données dans un contexte cohérent et pertinent de manière sécurisée.
De nombreux clients sensibles à la sécurité, en particulier les grandes entreprises, les industries réglementées et les organisations du secteur public, limitent tous les accès Internet à leurs lacs de données dans le cadre de leur dispositif de sécurité. Cette stratégie, bien qu'essentielle pour la conformité et la réduction des risques, empêche également Salesforce Data 360 et Agentforce de se connecter à ces environnements sur l'Internet public.
La plupart de ces lacs de données sont déployés dans des environnements hyperscaler tels que AWS, Azure ou Google Cloud. Data 360 fonctionne sur AWS. Par conséquent, l'accès aux lacs de données clients hébergés sur un autre fournisseur de cloud nécessite une connexion réseau inter-clouds. Sans option de connectivité privée sécurisée qui contourne l'Internet public, les clients ne peuvent souvent pas ou ne veulent pas adopter Data 360 ou Agentforce pour des cas d'utilisation qui s'appuient sur ces lacs de données.
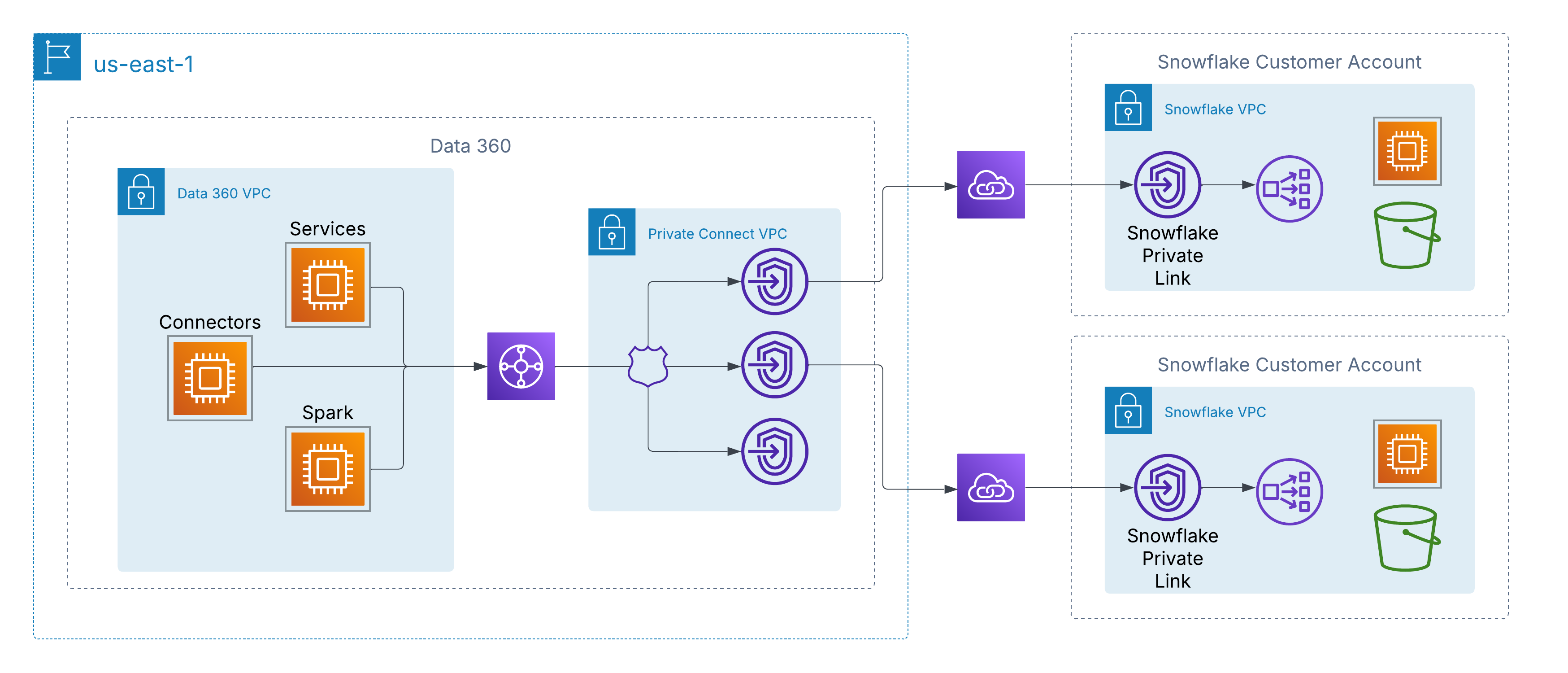
Pour y remédier, Data 360 prend en charge la connectivité privée au niveau du réseau avec des sources de données gérées par les clients à travers les clouds. Dans AWS, cette fonctionnalité est activée via AWS PrivateLink, qui permet à Data 360 de se connecter directement à des points de terminaison provisionnés par le client, soit dans ses propres comptes, soit dans des environnements de lac de données tiers (par exemple Snowflake), sans passer par l'Internet public.
Cette architecture garantit que tout le trafic reste entièrement sur le backbone AWS, en utilisant l'adressage IP privé et des chemins réseau non-routiers, satisfaisant ainsi aux exigences strictes de sécurité et de conformité tout en permettant un accès transparent aux données des clients.
Pour les clients qui ont des architectures multicloud, Data 360 étend la connectivité privée au-delà d'AWS grâce à la prise en charge de l'interconnexion inter-clouds. Cela permet de sécuriser les chemins réseau backbone uniquement depuis Data 360 vers des lacs de données et des services hébergés dans Azure ou Google Cloud, en préservant les mêmes principes que AWS PrivateLink : adressage IP privé, acheminement non public et exposition à Internet nulle.
Les clients peuvent choisir entre deux modèles de déploiement :
-
Interconnexion gérée par les clients: Intégrez des circuits privés existants tels que Azure ExpressRoute, Google Cloud Interconnect ou Equinix Fabric directement aux VPC de Data 360.
-
Interconnexion gérée par Salesforce: Utilisez une connexion clé en main entièrement gérée dans laquelle Salesforce provisionne et exploite la liaison inter-clouds, exposant les points de terminaison privés dans le cloud cible.
Dans les deux modèles, l'expérience est cohérente : Les services Data 360 se connectent à des sources de données externes à travers des hyperscalers comme s'ils étaient locaux, ce qui permet une ingestion, une activation et une interrogation sécurisées sans passer par l'Internet public.
Pour les architectes d'entreprise, une gouvernance des données robuste n'est pas seulement une case à cocher de conformité mais un pilier fondamental pour élaborer une Intelligence client fiable, évolutive et actionnable. Salesforce Data 360 est conçu avec un cadre de gouvernance complet qui garantit la qualité des données, la sécurité et le respect des mandats réglementaires tout au long de leur cycle de vie.
Data 360 fonctionne comme une plate-forme de gouvernance centralisée, garantissant que toutes les données, depuis l'ingestion brute jusqu'aux connaissances activées, sont gérées avec intégrité et contrôle.
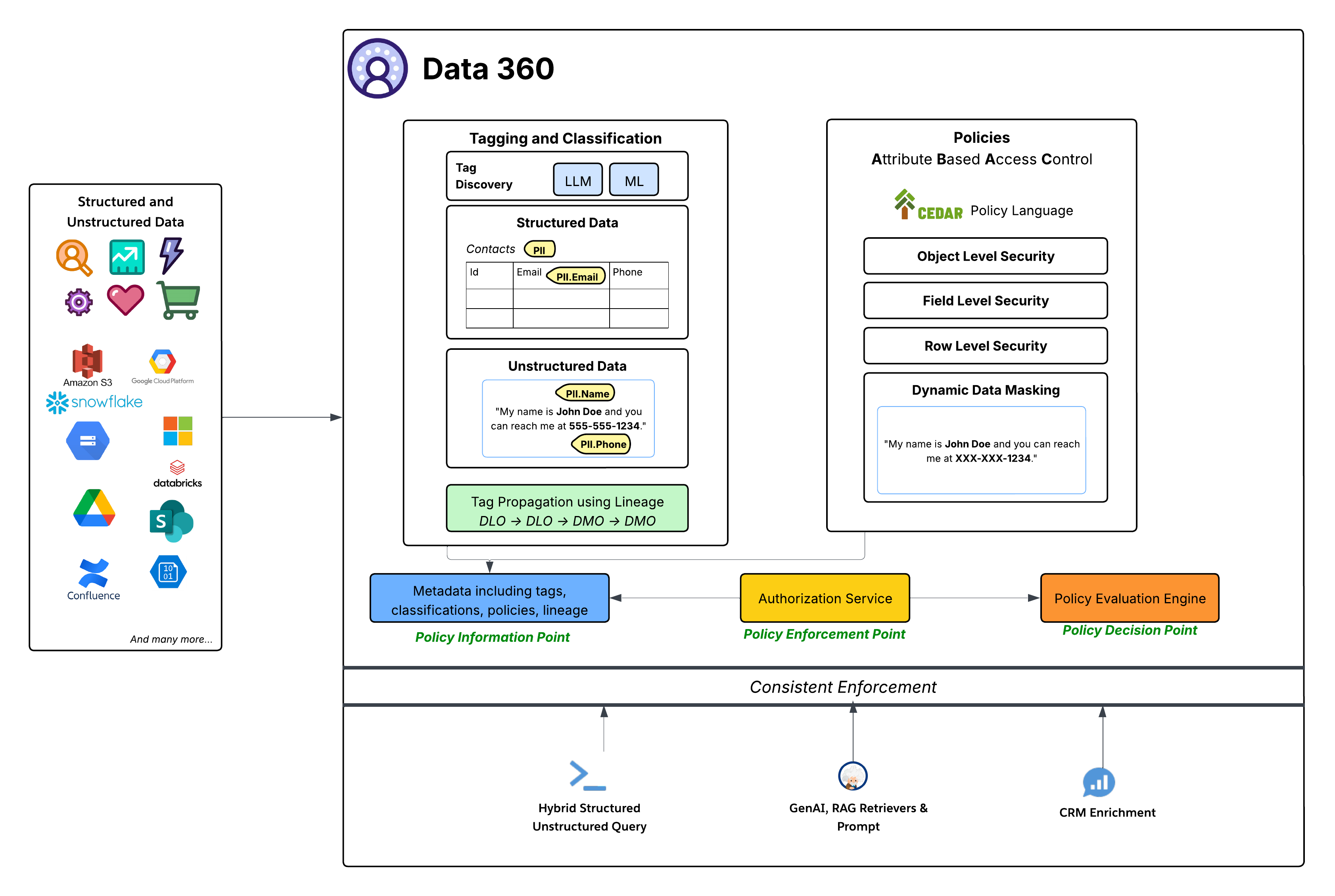
Alors que l'espace de données fournit un contrôle d'accès approximatif pour déterminer l'accès à tous les objets d'un espace de données, les stratégies basées sur ABAC fournissent un contrôle d'accès précis aux objets, aux champs et aux lignes individuels d'un espace de données. Data 360 a adopté le Contrôle d'accès basé sur l'attribut (ABAC) comme modèle d'autorisation principal pour le contrôle d'accès précis. Ce choix stratégique offre une flexibilité et une évolutivité supérieures au Contrôle d'accès basé sur le rôle (RBAC) traditionnel, particulièrement crucial pour les environnements d'entreprise dynamiques et complexes avec de grandes quantités de données et des besoins d'accès variés. ABAC permet de prendre des décisions en matière d'accès en fonction des attributs de l'utilisateur (p. ex., service, rôle, emplacement), des données (p. ex., informations d'identification personnelle, sensibilité, espace de données) et de l'environnement (p. ex., heure du jour), plutôt que de simples rôles prédéfinis. Cela permet des stratégies d'accès très précises et contextuelles qui s'adaptent à mesure que les données et les attributs utilisateur changent.
- CEDAR Policy Language: L'utilisation du langage de stratégie CEDAR est au cœur de l'implémentation ABAC de Data 360. Ce langage de politique formel spécialement conçu fournit une méthode précise et vérifiable pour définir des règles d'autorisation complexes, garantissant que les politiques sont sans ambiguïté et peuvent être évaluées de façon cohérente à l'échelle.
Le système de gouvernance de Data 360 respecte une architecture ABAC robuste et standard :
- Marquage, classification et rédaction de politiques (point d'information sur les politiques - PEP):
- Data 360 fournit des mécanismes automatisés de balisage et de classification, en exploitant le LLM (grand modèle de langage) et le ML (apprentissage machine) pour identifier des catégories de données confidentielles (par exemple, PII.Email, PII.Phone, PII.Name) et d'autres taxonomies spécialement conçues (PHI, FinancialData) à la fois dans les Données structurées (par exemple, tableau Contacts) et dans les Données non structurées (par exemple depuis Google Drive).
- Essentiellement, la propagation des balises se produit le long du Lignage de données (DLO -> DLO -> DMO), ce qui garantit que les classifications suivent automatiquement les transformations et les dérivations des données, depuis les données ingérées brutes jusqu'à la couche DMO harmonisée et via les données dérivées créées à partir de définitions de processus.
- Enfin, le volet de création de stratégies offre une expérience simple qui permet d'exploiter les données et les attributs utilisateur afin de définir des règles d'accès dynamiques pour une organisation.
- Ces métadonnées enrichies (y compris les balises, les classifications, les politiques et la lignée) alimentent le Point d'information sur les politiques (PIP).
- Service d'autorisation (Policy Enforcement Point - PEP):
- Le service d'autorisation agit en tant que point d'application de la politique (PEP). Il intercepte toutes les requêtes d'accès aux données de diverses couches de consommation (Requête structurée/non structurée hybride, Récupérateurs et invites GenAI RAG, Enrichissement CRM) et consulte le Point de décision de la politique pour déterminer si l'accès est autorisé.
- Moteur d'évaluation des politiques (point de décision de politique - PDP):
- Ce moteur sert de point de décision stratégique (PDP). Il prend le contexte de la demande d'accès du PPE, avec les définitions de politique (dans CEDAR) et les attributs du PEP, pour prendre une décision d'accès faisant autorité.
- Stratégies de sécurité granulaire: Les politiques définies dans CEDAR appliquent divers niveaux de sécurité, notamment :
- Sécurité au niveau objet: Contrôle de l'accès à des objets lac de données ou objets modèle de données complets en fonction des balises associées à ces objets.
- Sécurité au niveau champ: Limitation de l'accès à des champs sensibles spécifiques dans un objet en fonction des balises.
- Sécurité au niveau: ligne Filtrage des données sur des objets spécifiques pour afficher uniquement les lignes pertinentes en fonction des attributs utilisateur.
- Masquage dynamique des données: Masquez dynamiquement certaines données (basées sur des balises) au point d'accès, sans altérer les données sous-jacentes. Cela garantit la protection des informations confidentielles tout en permettant une large utilité. Cela s'applique au masquage de champs dans des données structurées ainsi que de contenus dans des données non structurées.
- Application cohérente: L'infrastructure ABAC complète garantit l'application cohérente des politiques dans tous les modèles de consommation de Data 360, qu'il s'agisse d'interrogation directe de données, de récupération pour des applications d'IA générative (RAG) ou d'enrichissement des expériences Salesforce CRM via des listes associées, par exemple.
- Intégration approfondie à Salesforce Platform: Les capacités de gouvernance de Data 360 sont définies et administrées directement depuis la plate-forme principale de Salesforce. Cette intégration permet aux administrateurs de gérer les stratégies d'accès, l'identité des utilisateurs et la gestion des attributs en utilisant des outils Salesforce familiers, ce qui garantit une couche de gouvernance unifiée et cohérente dans l'ensemble de l'écosystème Salesforce.
En élaborant cette infrastructure ABAC sophistiquée avec des politiques CEDAR, Data 360 offre aux architectes un niveau de contrôle et de flexibilité inégalé, garantissant que les données des clients sont non seulement actionnables, mais également sécurisées, conformes et fiables dans l'ensemble de l'entreprise.
Dans tous les secteurs d'activité, les organisations mettent davantage l'accent sur la sécurité des données de bout en bout afin d'assurer la protection contre les fuites de données, les accès non autorisés, l'altération ou la destruction. La plupart des plates-formes de données, y compris Data 360 aujourd'hui, fournissent le cryptage au repos en utilisant une clé de cryptage gérée par le fournisseur. Cependant, les entreprises (en particulier celles des secteurs réglementés) exigent de plus en plus des capacités de cryptage gérées par les clients pour les données au repos et en transit.
Ce modèle permet aux entreprises de contrôler leurs propres clés de cryptage, ce qui garantit que même dans le cas très improbable d'une violation au niveau de la plate-forme ou d'un accès non autorisé, les données restent protégées cryptographiquement. Sans la clé propriétaire du client, aucune entité (y compris le fournisseur de la plate-forme) ne peut décrypter ou reconstruire les données, préservant ainsi une confidentialité et un contrôle complets.
Data 360 prend en charge le stockage et la gestion des données structurées (tableaux), semi-structurées (JSON) et non structurées de façon transparente à travers les mécanismes d'ingestion, de traitement, d'indexation et de requête des données. Data 360 prend en charge divers types de données non structurés au-delà du texte, notamment le son, la vidéo et les images, ce qui élargit la portée du traitement et de l'analyse des données. La figure ci-dessous illustre les deux côtés de l'ancrage (ingestion et récupération).
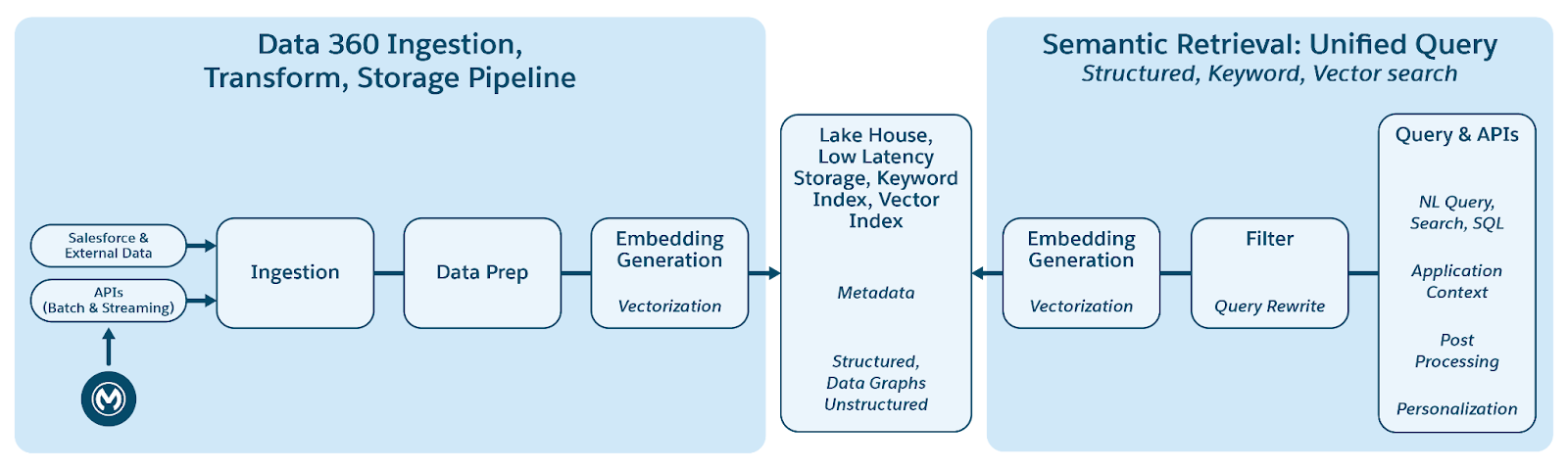
Data 360 gère les données non structurées en les stockant dans des colonnes sous forme de texte ou dans des fichiers pour des jeux de données plus volumineux. Il prend en charge la fédération de données pour les contenus non structurés, ce qui permet d'intégrer et de gérer les données de plusieurs sources.
Les données sont ensuite préparées et découpées, les incorporations sont générées et traitées pour l'indexation par mot-clé et l'indexation vectorielle. Data 360 héberge plusieurs modèles prêts à l'emploi et enfichables pour la segmentation et la génération d'encastrement. Data 360 prend en charge la transcription automatisée et configurable de contenus audio et vidéo pour un traitement et une indexation ultérieurs. Le service de recherche est utilisé pour l'indexation par mot-clé. Pour l'indexation vectorielle, Data 360 prend en charge l'indexation native (avec Hyper) et exploite également des bases de données vectorielles telles que Milvus open-source. Data 360 s'intègre également à la plate-forme de recherche Salesforce pour prendre en charge l'indexation par mot-clé dans les données non structurées. Cette indexation multimodale intégrée dans Data 360 permet de rechercher dans toutes les données non structurées, comme indiqué dans la section Recherche d'entreprise agentique plus loin dans le document.
Pour la récupération, Data 360 fournit des API pour la recherche. Notre requête unifiée Hyper-based facilite les requêtes d'ensemble à travers des index structurés, de mots-clés et vectoriels, en maintenant une visibilité et des autorisations strictes, améliorant ainsi le RAG et la Recherche.
Le pipeline d'indexation de données non structuré de Data 360 est conçu comme une architecture modulaire et extensible comprenant cinq étapes principales :
- Analyse
- Traitement préalable
- Chunking
- Post-traitement
- Incorporation
Toutes les étapes prennent également en charge le traitement basé sur le LLM, ce qui permet aux clients de générer des invites personnalisées. Les phases de pré-traitement et de post-traitement peuvent inclure plusieurs étapes séquentielles, ce qui permet de composer des transformations complexes avec flexibilité. Chaque étape est entièrement pilotée par les métadonnées, ce qui permet une configuration et une extension transparentes sans changement de code.
Parmi les exemples de prétraitement figurent des opérations telles que l'élimination du bruit, la normalisation du langage et la compréhension de l'image (reconnaissance optique des caractères et sous-titrage), tandis que les étapes de post-traitement peuvent inclure l'enrichissement des métadonnées, le regroupement sémantique ou des techniques avancées telles que la segmentation Raptor.
Le pipeline prend entièrement en charge l'extension de code Data 360, ce qui permet aux clients et aux équipes internes de brancher une logique personnalisée à n'importe quelle étape. Les composants d'extension de code sont des fonctions Python légères dont le cycle de vie (exécution, mise à l'échelle et gestion des échecs) est entièrement géré par Data 360. Cette approche permet d'introduire rapidement l'innovation et le traitement spécifique au domaine tout en préservant la cohérence opérationnelle et la gouvernance à travers la plate-forme.
Indexation du contexte
Pour configurer le RAG avec un traitement non structuré, deux facteurs critiques sont essentiels :
- Itération rapide: La possibilité de valider rapidement avec des exemples de requête de test.
- Contenus spécifiques: La capacité de configurer des contenus adaptés à la personne qui consomme.
L'indexation du contexte est un outil convivial conçu pour traiter ces deux aspects. Cette interface utilisateur interactive est pilotée par un pipeline en temps réel (RT) qui exécute les cinq étapes précédemment décrites. Le pipeline utilise des GPU lorsque nécessaire pour des tâches telles que la génération d'incorporation et la reconnaissance optique de caractères (OCR). De plus, il permet aux clients de tester rapidement le pipeline RAG avec un Agent avant de déployer la configuration pour un traitement complet des contenus.
Document AI
Data 360 Document AI permet de lire et d'importer des données non structurées ou semi-structurées à partir de documents tels que des factures, des CV, des rapports de laboratoire et des bons de commande. Cette fonctionnalité prend en charge le traitement interactif ad hoc ainsi que le traitement par lot en masse. Cette capacité clé permet l'automatisation des processus métiers pour nos clients. Il est propulsé par l'intelligence artificielle, y compris les modèles LLM et ML.
Les entreprises possèdent de vastes quantités de Knowledge réparties dans des systèmes disparates tels que des wikis, des partages de fichiers, des systèmes de gestion de contenu, des bases de données internes, et plus encore. Cette fragmentation empêche les employés (en particulier les agents de service et les commerciaux) et les clients de trouver rapidement et efficacement des informations pertinentes. Les principaux problèmes comprennent : Absence d'une expérience de recherche unique et unifiée dans toutes les sources Knowledge; Présentation et restitution incohérentes du contenu provenant de différentes sources; Absence de gouvernance de l'accès à des informations confidentielles dispersées entre les systèmes; et difficulté à exploiter la source Knowledge faisant autorité dans les workflows métiers de base (p. ex. joindre des articles pertinents à une requête).
Enterprise Knowledge représente le contenu qui a été organisé, manuellement ou automatiquement, à partir du pool élargi de données d'entreprise. La curation manuelle implique des actions délibérées, telles que la création d'articles Salesforce Knowledge ou le développement Knowledge dans des systèmes externes qui sont ensuite ingérés. Nous envisageons une curation automatisée qui utilise des processus, tels que des agents Salesforce et des transformations, qui exécutent sur des données ingérées pour générer des couches affinées et organisées, combinant potentiellement des contenus structurés et non structurés. Que ce soit organisé manuellement ou automatiquement, en interne dans Salesforce ou en externe avant l'ingestion, le résultat est un contenu à valeur ajoutée distinct des données brutes.
La solution Enterprise Knowledge Hub exploite les capacités de Data 360 pour:
- Ingestion et conservation: Le connecteur CRM ingère des articles Salesforce Knowledge, et les connecteurs non structurés Data Connector Framework (DCF) ingèrent du contenu brut et des métadonnées à partir de sources externes. Le contenu est ingéré dans des objets lac de données non structurés (UDLO) spécifiques à la source, mappés avec le contenu sur SFDrive (ou source en cas de copie nulle).
- Harmonisation & structuration: L'Harmonization Pipeline traite les données UDLO et des fichiers, effectuant le nettoyage, la normalisation, l'enrichissement (NLP, etc.), le masquage des informations d'identification personnelle, et la transformation dans le format intermédiaire harmonisé, stocké dans SF Drive et un UDLO harmonisé (HUDLO) qui le mappe.
- Indexation: Un pipeline non structuré (UDS) est déclenché sur le contenu harmonisé et des index de recherche sont configurés pour chaque HUDMO.
- Consommation: Les applications de consommation comprennent la recherche, la récupération, la restitution et la liaison à des objets métiers tels que Requête. L'engagement en consommant des applications est collecté pour fournir des analytiques d'utilisation (par exemple des clics, des avis, etc.)
Les connaissances calculées (CI) dans Data 360 permettent aux clients de définir et de générer des métriques agrégées à partir de leurs données. Ces métriques sont ensuite utilisées pour l'engagement, l'analyse, la segmentation et l'activation rapides des clients. Les données agrégées calculées par les CI sont écrites dans Lakehouse et représentées sous forme d'objet connaissances calculées (CIO).
Il existe deux principaux types de connaissances calculées :
- Connaissances calculées par lot: Conçu pour l'agrégation de données complexes et à haut volume, où des métriques peuvent être calculées périodiquement (par ex. quotidiennes ou hebdomadaires).
- Connaissances en continu: Offrez la possibilité de générer des métriques et des actions à partir de données d'événements en temps réel, ce qui permet un engagement client immédiat et à faible latence.
Les connaissances calculées sont définies dans des objets modèle de données (DMO) et peuvent également être définies dans d'autres objets connaissances calculées. Le service de connaissances calculées gère l'orchestration des tâches par lot et en continu.
Les calculs de connaissances par lot et en continu utilisent Spark. La principale différence est que les connaissances en continu utilisent Spark Structured Streaming, alors que les CI par lot sont exécutées en utilisant des tâches Spark par lot périodiques et planifiées. Pour plus de rentabilité, le service de connaissances calculées regroupe les CI à calculer ensemble dans la même tâche de CI par lot ou tâche de CI en continu, en fonction de facteurs tels que les dépendances et le chevauchement des objets de données sources.
SNCE et CDF jouent un rôle important dans le calcul des connaissances en continu.
La résolution de l'identité est responsable de la transformation des données disparates de plusieurs sources en un profil unifié unique et complet.
Il est important de comprendre qu'un profil unifié n'est pas un « enregistrement en or » et que la résolution de l'identité ne sélectionne pas de valeurs gagnantes et ne remplace aucune donnée existante tout en unifiant les profils. Les profils unifiés servent de jeu de clés qui déverrouillent vos données sources en identifiant tous les enregistrements correspondants associés à la même entité, dans une seule source de données ou dans de nombreuses sources. Ces informations permettent de sélectionner les données système source appropriées à utiliser pour un cas d'utilisation métier donné.
La résolution de l'identité peut consolider divers types d'enregistrement, notamment Individus, Comptes et Foyers. Il peut également être utilisé pour mapper des pistes avec des comptes existants. Le processus d'unification est essentiel pour obtenir une vue Customer 360 complète et piloter un engagement personnalisé et en temps réel dans les scénarios B2C et B2B.
Le pipeline de résolution de l'identité repose sur une infrastructure cloud native hautement évolutive conçue pour gérer en continu des volumes de données massifs. Le processus comporte trois étapes clés, s'appuyant sur un puissant index de recherche pour gérer le processus de correspondance:
- Matching (Candidate Selection): Le but du processus de correspondance est de rechercher des enregistrements qui peuvent appartenir à la même entité. Les enregistrements sont analysés par rapport à un ensemble de règles personnalisables, chacune contenant un ensemble de critères qui définissent les données correspondant à quel niveau de rigueur. Pour récupérer efficacement les correspondances potentielles dans le magasin de données, le système génère des index pour rechercher les enregistrements correspondants probables en utilisant deux techniques :
- Clés de blocage: Une clé de blocage est une valeur générée à partir des données et des règles de correspondance d'un enregistrement (telles que les premières lettres d'un nom, un numéro de téléphone normalisé, etc.) pour regrouper des enregistrements potentiellement similaires. Chaque enregistrement a plusieurs clés de blocage qui sont indexées et stockées sous forme d'index inversé, ce qui garantit que le système effectue des comparaisons détaillées uniquement sur de petits groupes d'enregistrements, plutôt que sur l'ensemble du jeu de données.
- Hachage sensible à la localisation (LSH): Pour des règles de correspondance avec une correspondance partielle, des hachages sont générés en fonction des incorporations de modèles entraînés.
- Correspondance profonde: Lorsque l'étape de sélection du candidat crée de plus petits groupes de correspondances potentielles, le système commence une comparaison plus détaillée. À cette étape, les modèles IA et les algorithmes avancés analysent chaque paire d'enregistrements pour calculer un score de correspondance probabiliste. Ce score quantifie la probabilité que deux enregistrements référencent la même entité en comparant intelligemment les champs qui contiennent souvent des fautes d'orthographe, des variations ou des différences de mise en forme.
- Clustering and Unification: Une fois que les enregistrements correspondants sont identifiés à partir des candidats, ils sont regroupés dans un cluster. Ce processus inclut la résolution des correspondances transitives. Par exemple, si l'enregistrement A correspond à l'enregistrement B et que l'enregistrement B correspond à l'enregistrement C, les trois sont liés au même cluster, même si A et C n'ont jamais été comparés directement. Ces clusters complets forment la structure de base du Profil unifié. Ce processus de clustering garantit que tous les enregistrements sources associés sont correctement liés sous un identifiant unique et permanent.
- Réconciliation: Les valeurs de données de tous les enregistrements sources en cluster sont évaluées en utilisant des règles de rapprochement définies (par exemple, Plus fréquentes, Plus récentes ou Priorité source) pour remplir le profil unifié généré avec un extrait des données du profil. Le rapprochement ne remplace aucune donnée existante, car toutes les données sources sont disponibles en utilisant les clés liées au profil unifié.
L'architecture prend en charge la résolution de plusieurs types d'entité pour répondre à divers cas d'utilisation.
- Correspondance individuelle: Met l'accent sur la création de profils Individu unifié, qui lient tous les identifiants personnels connus (e-mails, numéros de téléphone, ID de fidélité, cookies) à une seule personne.
- Correspondance du compte: Met l'accent sur la création de profils Compte unifié, qui lient les données des comptes. Lors de la correspondance sur les noms de société, le moteur utilise un modèle finement ajusté lors de la correspondance partielle.
- Correspondance du foyer: Étend la logique de correspondance pour agréger les enregistrements Individu unifié dans des groupes d'individus associés.
- Correspondance inter-entités: Outre l'unification, la résolution de l'identité crée également des liens entre les objets de profil en utilisant les mêmes règles de correspondance. Par exemple, une piste peut être liée à un compte en utilisant la correspondance partielle dans Nom du compte.
Pour s'assurer que le profil unifié est toujours à jour, le moteur de résolution de l'identité fonctionne avec une architecture en temps quasi réel. Cette architecture optimisée pour le cloud est conçue pour le traitement continu, ce qui accélère les temps de traitement. Bien que la vitesse de traitement varie selon la réception des données sources, de petits lots de modifications peuvent être traités par la résolution de l'identité toutes les 15 minutes.
Le système conserve les objets de lien d'identité qui mappent chaque ID d'enregistrement source avec son ID de profil unifié correspondant. Cette structure de données de base permet au moteur de suivre efficacement les relations et de propager rapidement les modifications et les mises à jour dans le Profil unifié, en s'assurant que les expériences client, telles que la personnalisation du site Web, les recommandations Next Best Action et la segmentation, tirent toujours parti des toutes dernières données clients disponibles.
La segmentation est le processus central de transformation des profils clients unifiés en audiences actionnables. Cette capacité est essentielle pour optimiser les expériences personnalisées à travers les canaux marketing, de commerce et de service. La plate-forme Salesforce Data 360 Segmentation est conçue pour les opérations à grande échelle. Il gère des métadonnées complexes, en travaillant avec un modèle de données comprenant des milliers d'objets et de relations. La plate-forme prend en charge des règles complexes, des filtres basés sur l'agrégation et un classement basé sur la fenêtre, le tout en garantissant un calcul rapide et fiable à l'échelle du pétaoctet.
Data 360 prend en charge divers types de segment pour répondre à des exigences métiers distinctes en matière de vitesse, de complexité et de hiérarchie :
- Segment standard: Le type de segment principal traité par lot. Il publie selon une planification personnalisable, avec une cadence de publication standard d'au moins 12 heures à 24 heures, ou une cadence de publication rapide plus rapide de 1 à 4 heures, optimisée pour les données d'engagement récentes.
- Segment en temps réel: Ce segment se termine à la demande en millisecondes pour une action immédiate basée sur les événements récents et les données de profil. Il est hautement optimisé pour la personnalisation instantanée, mais ne peut pas utiliser des critères d'exclusion ou des segments imbriqués.
- Segment cascade: Une structure hiérarchique de sous-segments utilisée pour prioriser un client dans un segment unique et précieux s'il remplit plusieurs critères.
- Segment imbriqué: Cela permet de réutiliser un segment existant en tant que filtre pour un nouveau segment plus spécifique (affinement d'un segment de base), héritant de la planification du segment parent.
Le moteur de segmentation fonctionne sur une architecture cloud native robuste qui garantit vitesse, évolutivité et résilience.
Le processus principal est géré par un service d'orchestration de tâches qui contrôle le cycle de vie du segment, générant la configuration de tâches nécessaire et déclenchant l'exécution. Cette couche d'orchestration conserve l'état et les métadonnées dans une base de données sharded pour l'évolutivité.
Bien que Data 360 Query gère les calculs de décompte de segmentation, la couche de calcul Spark est responsable du calcul de l'appartenance réelle au segment. L'application Spark exécute des requêtes Spark SQL sur de nombreuses données clients. Ces données peuvent résider dans Data 360 Lakehouse, dans des systèmes externes via la fédération de données Zero Copy, ou dans une combinaison des deux.
Le système est hautement optimisé grâce à la génération intelligente de requêtes, qui affine la requête Spark SQL sous-jacente. Cela inclut des techniques telles que l'élagage intelligent des partitions afin de minimiser l'analyse des données et l'élimination des sous-expressions redondantes. Pour garantir la fiabilité du service, l'architecture offre une gestion adaptative des ressources qui ajuste dynamiquement les ressources de calcul en fonction de la taille et de la complexité de la charge de travail. De plus, l'adhésion à la SLO est gérée proactivement avec des durées adaptatives et une logique de nouvelle tentative. Pour une expérience utilisateur rapide, les décomptes de segments accélérés utilisent une approche basée sur l'échantillonnage afin de fournir des estimations de taille rapides pendant la création de segments, évitant ainsi une exécution de requête complète.
Enfin, l'accent est mis sur l'observabilité et l'attribution des causes premières grâce à des métriques d'exécution Spark complètes et à la classification automatisée des erreurs (par exemple, problèmes côté client ou système), ce qui réduit considérablement le temps de diagnostic et garantit une plate-forme de données hautement résiliente.
L'activation est la dernière étape critique du cycle de vie de Data 360. Sa fonction principale est de transformer des profils clients statiques, segmentés et unifiés en données actionnables et enrichies, et de livrer ces données à des points de terminaison internes et externes (tels que Marketing Cloud, Commerce Cloud et les plates-formes Adtech). Ce processus est conçu pour déclencher des parcours clients personnalisés et des interactions en temps quasi réel. Il prend en charge des capacités avancées telles que les attributs associés, le filtrage des appartenances d'activation, le filtrage du consentement, la limitation et le classement.
L'activation offre trois méthodes distinctes pour la livraison externe et la conformité du canal :
- Activation par lot: Conçu pour les opérations planifiées à haut volume, telles que les campagnes par e-mail à grande échelle et les actualisations d'audience publicitaire. Les données sont livrées en les organisant dans des compartiments internes sécurisés (Cloud Object Storage) ou via un transfert de fichiers sécurisé, suivi d'un processus d'ingestion d'API initié par le système cible. Les activations par lot peuvent utiliser un mode d'actualisation spécial - incrémentiel - pour réduire les volumes envoyés à et traités par les partenaires Salesforce.
- Activation en continu: Optimisé pour les cas d'utilisation en temps quasi réel nécessitant une automatisation pilotée par l'événement. La livraison est réalisée par des appels d'API directs envoyés au point de terminaison de destination.
- Flux déclenchés par l'activation: Ce canal hautement plate-forme fournit une approche sans code/code faible pour intégrer les données d'audience à des centaines de plates-formes d'engagement activées par l'API client. Une fois l'activation terminée, Data 360 remplit un objet modèle de données Audience, qui déclenche ensuite un flux à grande échelle. Le moteur de flux consomme ensuite les données d'audience et utilise les capacités de la plate-forme telles que les Services externes et les destinations Mule Outbound pour passer des appels vers la destination finale basée sur l'API. Cette méthode réduit considérablement le temps nécessaire pour intégrer de nouvelles cibles d'activation.
L'activation utilise les mêmes modèles que la segmentation pour la gestion des tâches, l'exécution distribuée et la surveillance. Cela inclut les principes du service d'orchestration des tâches pour la gestion du cycle de vie et de la couche de calcul (Spark) pour le traitement, et s'appuie sur la télémétrie des tâches pour l'observabilité des performances et l'adhésion aux objectifs de niveau de service (SLO).
En plus de cela, l'activation a -
Activation Target Management supervise les connexions, les identifiants et les configurations sécurisés pour tous les points de terminaison de destination. Il garantit la normalisation des formats de données et des protocoles de sécurité, ce qui garantit une livraison sortante fiable à diverses plates-formes, notamment Marketing Cloud, des partenaires Adtech et d'autres applications externes.
L'activation adapte la charge de travail à des objectifs spécifiques. Pour Salesforce Marketing Cloud, cela inclut le filtrage sensible aux unités commerciales (BU), la prise en charge des ID multiples et les contrôles de pollinisation croisée.
La Gouvernance des communications agit en tant que gardienne, en veillant à ce que l'utilisation et la communication des données soient conformes aux préférences des clients et aux exigences légales. Le modèle de consentement centralisé unifie toutes les préférences des clients, depuis le désabonnement global jusqu'au consentement spécifique au canal et à l'objet, et sont stockées dans le profil Individu unifié. Pendant l'exécution, la plate-forme applique strictement ces stratégies en utilisant le filtrage d'exclusion pour retirer automatiquement les individus non consentants de la charge utile finale. De plus, le système applique des règles de sélection de points de contact pour s'assurer d'utiliser le point de contact unique, le plus conforme et le plus préféré pour le canal prévu avant la transmission des données. Ce mécanisme d'application est sécurisé par le cadre de gouvernance sous-jacent, qui utilise des mesures de protection telles que le masquage dynamique des données et des contrôles d'accès afin de sécuriser les champs de données confidentielles tout au long du processus d'activation.
La véritable valeur d'une plate-forme de données unifiée réside dans sa capacité à fournir un accès cohérent et sans effort à tous ses actifs de données, quelle que soit leur origine ou leur structure. La capacité Requête unifiée de Salesforce Data 360 est précisément conçue pour fournir cette fonctionnalité, en éliminant les complexités sous-jacentes des divers magasins de données pour fournir une interface de requête unique et puissante.
La couche Requête unifiée offre un accès sophistiqué à divers modèles de consommation :
- Interrogation hybride structurée et non structurée: Il fournit une prise en charge SQL étendue pour interroger de façon transparente à la fois les données structurées et les métadonnées structurées de données non structurées. L'extensibilité de l'opérateur via des fonctions de tableau permet d'effectuer des recherches spécialisées dans les types de texte, d'image et d'espace.
- Accélération des performances avec Hyper: Exploitant Hyper, un moteur en mémoire très performant, Data 360 accélère les requêtes analytiques complexes et les tableaux de bord interactifs, en fournissant des réponses quasi instantanées sur des jeux de données massifs.
- Approche unifiée pour l’IA et la personnalisation: Cet accès unifié est crucial pour générer des résultats ciblés et personnalisés, facilitant directement des réponses LLM plus précises en utilisant la génération augmentée de récupération (RAG) en ancrant les modèles IA dans des données d’entreprise enrichies.
- Intégration à la consommation en aval: Il sert de couche d'accès aux données de base pour les expériences pilotées par l'interface utilisateur, les API robustes, les workflows d'IA générative et l'enrichissement CRM, en connectant de façon transparente les données à l'activation.
En fournissant une interface de requête unique, intelligente et très performante, la requête unifiée de Data 360 permet aux architectes de créer des applications agiles pilotées par les données qui exploitent pleinement leur éventail complet d'informations sur les clients.
Data 360 est une plate-forme active qui prend en charge l'activation de pipelines en réponse à des événements de données. Par exemple, un événement important, par exemple une baisse du solde du compte d'un client, peut déclencher un flux Salesforce pour orchestrer une action correspondante. De la même façon, les mises à jour des métriques clés, telles que la durée de vie, peuvent être automatiquement propagées aux applications appropriées.
Les Actions de données surveillent en permanence les données incrémentielles des modifications en utilisant les événements de modification natifs du stockage (SNCE) et le fil de données de modification (CDF). Ces données sont évaluées par rapport aux règles d'action configurées par le client, telles que la surveillance du seuil ou les changements d'état. Lorsque ces règles sont remplies, un événement d'action de données est généré. Cet événement est enrichi d'informations supplémentaires (par exemple, le statut de fidélité client) et immédiatement envoyé à sa destination configurée, par exemple Salesforce Flow ou une application externe, pour déclencher des orchestrations métiers.
Data 360 prend en charge les fonctionnalités natives de CDP (Customer Data Platform), notamment les capacités avancées de résolution de l'identité, la création d'identifiants et de profils individuels unifiés, ainsi que des historiques d'engagement complets. Cette plate-forme est capable de gérer les infrastructures entreprise à entreprise (B2B) et entreprise à consommateur (B2C) en prenant en charge la résolution de l'identité et les graphiques d'identité qui utilisent des règles de correspondance exactes et partielles, comme décrit ci-dessus. Ces graphiques d'identité sont enrichis avec les données d'engagement de divers canaux, ce qui aide à élaborer des graphiques de profil détaillés avec des connaissances analytiques et des segments précieux.
Un concept clé qui prend en charge le profil client est le graphique des données. Data 360 offre un graphique de données d'entreprise au format JSON, qui est un objet dénormalisé dérivé de divers tableaux Lakehouse et de leurs interrelations. Cela inclut un graphique de données « Profil » créé par CDP qui inclut l'historique d'achat et de navigation, l'historique des requêtes, l'utilisation des produits et d'autres connaissances calculées d'une personne, et qui est extensible par les clients et les partenaires. Ces Graphiques de données sont adaptés à des applications spécifiques et améliorent la précision des invites d'IA générative en fournissant un contexte client ou utilisateur pertinent. La couche en temps réel de Data 360 utilise le graphique Profil pour la personnalisation et la segmentation en temps réel. Nous envisageons de modéliser Contexte Agentforce qui englobe sous forme de Graphiques de données Conversations, Sessions et Mémoire Agentique.
De plus, le CDP permet une segmentation et une activation efficaces sur différentes plates-formes telles que Marketing Cloud, Facebook et Google de Salesforce. Il traite les profils clients par lot, en temps quasi réel et en temps réel, ce qui permet une prise de décision et une personnalisation immédiates. Cette fonctionnalité améliore les interactions dans les scénarios B2C et B2B, ce qui permet aux entreprises de répondre rapidement et avec précision aux besoins et aux comportements des clients.
La couche temps réel de Data 360 est soutenue par Data 360 CDP et étend ses concepts pour des cas d'utilisation en temps réel. La couche en temps réel de Data 360 est conçue pour traiter des événements tels que les flux de clics Web et mobiles, les visites, les données de panier d'achat et les paiements à des latences en millisecondes, ce qui améliore la personnalisation de l'expérience client. Il surveille en permanence l'engagement des clients et met à jour le profil client depuis Customer 360 avec des données d'engagement en temps réel, des segments, et des calculs pour une personnalisation immédiate.
Par exemple, lorsqu'un consommateur achète un article sur un site Web d'achat, la couche en temps réel détecte et ingère rapidement cet événement, identifie le consommateur et enrichit son profil avec des informations actualisées sur les dépenses à vie. Cela permet de personnaliser leur expérience sur le site en quelques secondes. De plus, cette couche inclut des capacités de déclenchement et de réponse en temps réel, qui permettent des actions immédiates basées sur les interactions des clients.
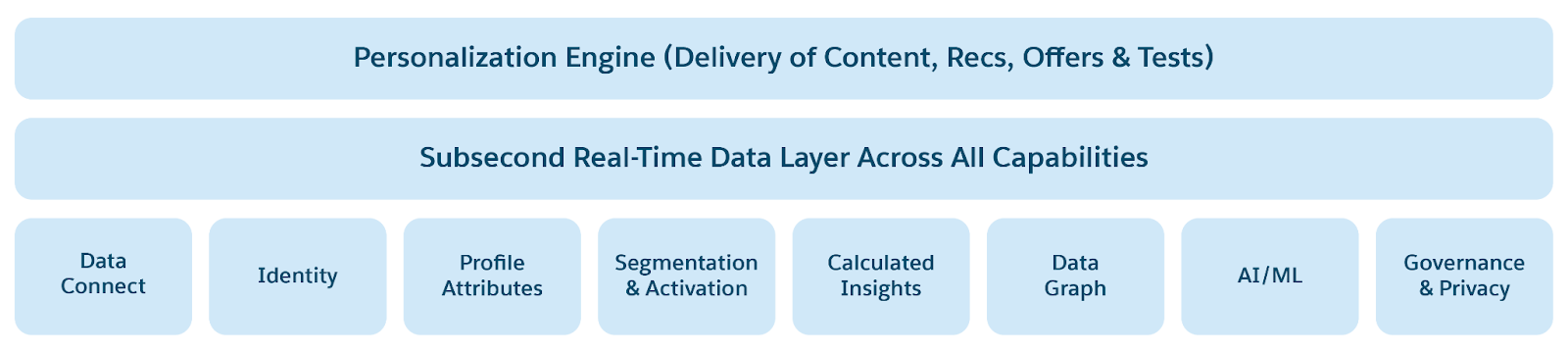
La plate-forme Sub-Second Real-Time pilote cette transformation à travers plusieurs fonctionnalités clés :
- Graphiques de données en temps réel: Un profil Customer 360 est construit en utilisant un graphique dénormalisé qui inclut les objets clés et les champs les plus pertinents pour les marques. Ces Graphiques de données permettent le traitement des données en temps réel et fournissent des contenus et des connaissances actionnables en quelques millisecondes
- Ingestion et transformation en temps réel: Ingérez des événements utilisateur et un profil en millisecondes à partir de sources Web et mobiles.
- Résolution de l'identité en temps réel: Fusionnez les profils clients entre les appareils, en unifiant instantanément les utilisateurs inconnus et connus.
- Connaissances calculées en temps réel: Calculez des métriques telles que la valeur de durée de vie (LTV) ou l'historique des visites utilisateur en millisecondes pour activer Personnalisation ou Offres pour le Web, ChatBot ou Agent de service.
- Segmentation en temps réel: Segmentez les audiences en temps réel, en personnalisant les messages et les interactions.
- Actions en temps réel: Permettez aux marques d'évaluer chaque engagement des utilisateurs et de prendre des mesures via Salesforce Flow ou d'autres canaux de communication appropriés.
Dans Data 360, nous avons élaboré une nouvelle plate-forme en temps réel avec un pipeline en temps réel, un stockage à faible latence et une couche de traitement des données de moins de deux secondes. Comme les données interactives rapides sont ingérées à partir de canaux Web et mobiles, elles passent par une série de processus rapides.
Nos kits de développement Web et mobiles et nos API en temps réel collectent les données d'applications Web/mobiles (dans les futures interactions Agentic) et les envoient à notre serveur de balise. Ces données sont ensuite acheminées vers la couche Temps réel pour le traitement en millisecondes et la couche Lakehouse pour l'intégration à des données par lot/streaming. La couche Temps réel traite les données en temps réel entrantes dans le contexte d'un profil utilisateur (anonyme ou connecté), par exemple la mise à jour de la dépense totale ou de la valeur de durée de vie de l'utilisateur, etc., pour une personnalisation en session et en temps réel. La couche en temps réel est soutenue par la mémoire principale et le stockage NVme (SSD) pour stocker des données en temps réel et des profils clients. Une fois les données dans la couche Temps réel, elles suivent les processus suivants avant d'être mises à jour dans le graphique de données en temps réel :
- Ingestion simple et transformations: Les données sont ingérées et transformées pour un traitement ultérieur.
- Résolution de l'identité: Des règles de correspondance exactes sont appliquées pour unifier les profils avec tous les jeux de règles de correspondance existants. Par conséquent, les spécialistes des données n'ont pas à créer de nouveaux jeux de règles de résolution de l'identité spécialement conçus pour le temps réel.
- Connaissances calculées: Chaque engagement est évalué, de simples calculs tels que la somme et le nombre en millisecondes sont exécutés, et les données sont mises à jour dans le graphique des données en temps réel.
- Segments en temps réel: Chaque donnée d'engagement est évaluée pour déterminer si elle remplit les critères des segments en temps réel définis, et les utilisateurs sont ajoutés aux segments qualifiants en millisecondes.
- Actions et déclencheurs en temps réel: Chaque engagement est évalué par rapport à des règles définies afin de déclencher des actions sur une plage de cibles en temps réel lorsque les règles sont remplies en millisecondes.
- Graphique de données et API en temps réel: Le graphique des données en temps réel, qui inclut également une API en temps réel, permet aux marques de récupérer des données au format JSON mises à jour pour chaque utilisateur, ce qui garantit que toutes les interactions des clients sont informées par les données les plus récentes.
La personnalisation consiste à savoir qui cibler, quand et où livrer des contenus et des recommandations pertinents, quoi dire et à quelle fréquence. La Plate-forme des services de personnalisation est l'orchestre des décisions prises pour optimiser l'atteinte des objectifs grâce à des expériences personnalisées.
Les Services de personnalisation offrent les capacités suivantes :
- Ensemble cohérent de modèles et de méthodes d'interprétation des données de profil, d'activité et d'actif dans Data 360
- Expérimentation intégrée de la plate-forme (A/B/n, Multi-Arm Bandit)
- Intégration d'objectifs lors de la conception (configuration), temps d'entraînement ML et exécution (inférence ML)
- Prise en charge des interactions en temps réel et par lot à l'échelle B2C (utilisateurs anonymes, externe interactif/temps réel haut volume, lot interne haut volume)
- Analytics pilotée par Data 360
- Modèles d’intégration du modèle IA et du service d’autres parties (internes et externes)
- Intégration à l'écosystème de métadonnées de base (caractéristiques de PLATE)
- Implémentations OOTB de cas d’utilisation pilotés par l’IA à haute valeur ajoutée (Recommandations/décisions avec divers algorithmes ML, y compris des bandits contextuels pour la promotion/sélection de contenus, recommandations de produits, décisions de tarification, etc.)
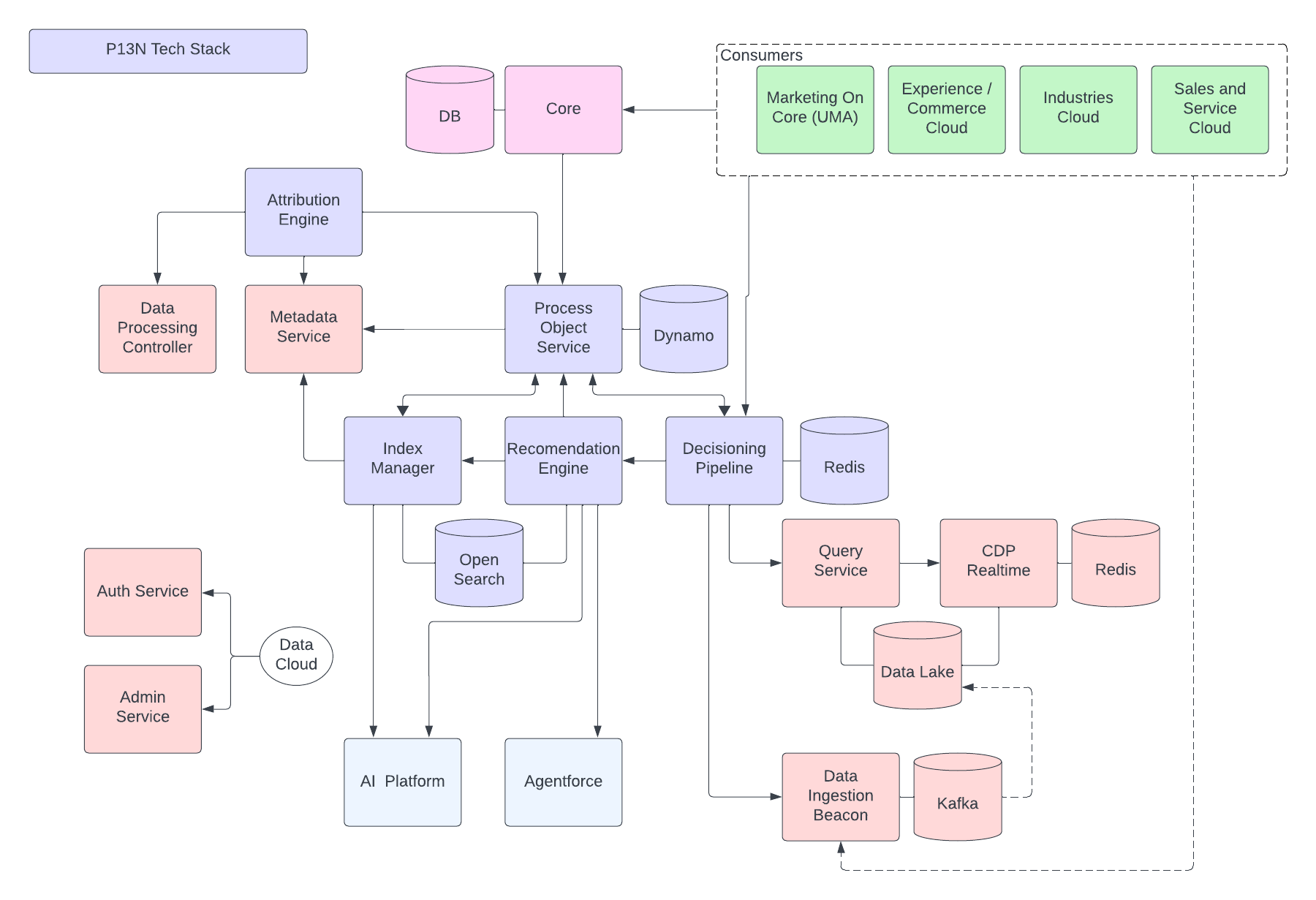
- Encours décisionnel
- Servir les demandes externes de décisions de personnalisation, notamment l'augmentation du profil, l'expérimentation et les recommandations.
- Moteur de recommandation
- Service à l'exécution de recommandations basées sur des règles ou ML.
- Gestionnaire d'index
- Gère/Orchestre le workflow pour les processus asynchrones, y compris les formations ML pour les modèles de recommandation
- Service d'objet de processus
- Responsable de la synchronisation des métadonnées de personnalisation entre core et off-core
- Moteur d'attribution et expérimentation
- Attribution Analytics et expérimentation de recommandations de personnalisation
Data 360 est conçue comme une plate-forme robuste et riche spécifiquement pour prendre en charge les expériences agentiques émergentes. Nous réalisons ces capacités en nous appuyant sur divers services Data 360 existants et grâce à une intégration profonde avec Agentforce.
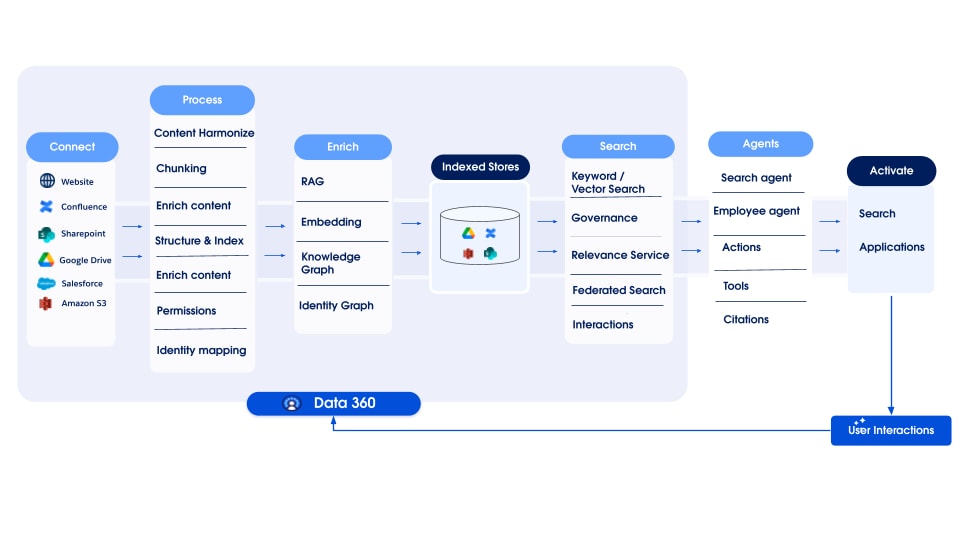
Notre approche de la Recherche d'entreprise Agentic repose sur les principes suivants :
- Les données d'entreprise sont conservées dans des services ou des magasins cloisonnés, avec les autorisations sécurisées requises pour l'accès. La possibilité d'accéder à ces données et de les traiter tout en conservant les autorisations sources est vitale pour garantir Trust.
- Le classement croisé et la pertinence dans le corpus complet de données permettent d'obtenir de meilleurs résultats, ce qui peut à son tour fournir un meilleur contexte pour les expériences des agents.
Pour offrir ces expériences, la Recherche d'entreprise Agentic s'appuie sur les principaux composants architecturaux suivants :
- Connecteurs: Le large ensemble de connecteurs disponibles dans Data 360 permet d'accéder à et d'ingérer des données à partir d'une grande variété de sources.
- Traitement des données non structuré: Ceci est fondamental pour gérer les contenus non tabulaires, permettant au système de dériver un sens et un contexte à partir de diverses données.
- Gouvernance: Garantir la sécurité, la conformité et les contrôles d'accès de niveau entreprise pour toutes les données consommées par la recherche. La prise en charge des autorisations de visibilité de la source garantit que les données sont accessibles uniquement aux utilisateurs autorisés, aussi bien pour la simple recherche que pour les expériences des agents. Pour accélérer la récupération, les autorisations de sécurité sont évaluées et appliquées nativement par les back-ends de recherche dès la première étape de l'accès aux données.
- Couche de récupération unifiée: Pour relever le défi des données cloisonnées, les connecteurs alimentent une couche complète de récupération unifiée. Cette couche fournit un point d'accès unique à toutes les données, qu'elles restent dans des systèmes externes accédés via la Recherche fédérée ou qu'elles soient gérées nativement via des index avancés pour des données sans copie et ingérées.
- Compréhension intelligente des requêtes: Avant la récupération, le système utilise des mécanismes pilotés par l'IA pour interpréter l'intention de l'utilisateur. En plus d'incorporer des représentations de la requête pour la correspondance vectorielle sémantique, il peut réécrire et élargir les recherches basées sur des mots-clés pour plus de précision.
- Recherche hybride et interrogation avancée: Pour trouver les informations les plus pertinentes, la plate-forme utilise plusieurs stratégies en parallèle. La recherche hybride fournit une correspondance précise par mot-clé avec la recherche vectorielle sémantique sur des segments de données optimisés, tandis que la recherche complète récupère simultanément des documents complets. Les deux sont combinés pour garantir à la fois la pertinence sémantique et une couverture complète des contenus.
- Classement hiérarchique: Une fois les données récupérées, une architecture de classement hiérarchique à plusieurs étapes calcule le score, fusionne et reclasse les résultats de chaque source et méthode. Ce processus crée une liste unique et unifiée qui présente les informations les plus pertinentes pour l'utilisateur ou l'agent.
L’IA générative déplace le principal consommateur de la recherche en entreprise des utilisateurs humains vers les grands modèles de langage (LLM). La recherche Data 360 est entièrement conçue pour servir les deux. Il est optimisé pour gérer les requêtes plus longues et plus complexes des agents et renvoyer les résultats contextuels enrichis nécessaires pour les boucles de consommation et de raisonnement par programmation. En même temps, le système peut gérer les requêtes plus courtes et souvent ambiguës typiques des utilisateurs humains, en fournissant des fonctionnalités telles que des extraits de code et en surlignant pour une évaluation rapide dans une interface utilisateur.
La livraison ultime d'expériences de recherche d'agents combine les deux approches :
- Résultats de recherche directe : l'application peut afficher une liste traditionnelle de résultats classés en utilisant une API pilotée par les métadonnées élaborée sur la fondation de recherche unifiée Data 360.
- Réponses conversationnelles multiples : les réponses sont implémentées par l'intégration native à Agentforce. Cette expérience conversationnelle est pilotée par un agent principal qui orchestre les actions et les requêtes, déléguant toutes les tâches de récupération d'informations à un agent de recherche interne spécialisé.
Cet agent de recherche spécialisé est optimisé pour la récupération d'informations d'entreprise. Il utilise une boucle de raisonnement pour formuler et exécuter des recherches parallèles afin d'explorer différentes facettes de la requête d'un utilisateur. Il utilise un ensemble puissant d'outils, notamment la recherche unifiée Data 360 pour tous les types de données et les langages de requête structurés pour récupérer des données précises à partir de tableaux et d'entités.
Grâce à cette synthèse architecturale, Data 360 permet de créer des expériences de recherche d'entreprise hautement intelligentes, sensibles au contexte et actionnables.
L'extensibilité est une fonctionnalité clé de Salesforce Platform. L'extension de code offre l'extensibilité dans Data 360, permettant aux utilisateurs pro-code d'exécuter une logique Python personnalisée directement dans l'environnement Data 360, en plus de ses fonctionnalités déclaratives enrichies et à faible code. En utilisant l'extension de code, les utilisateurs peuvent étendre en toute sécurité les capacités de base de Data 360, notamment Transformations et Pipelines de données non structurés (chunking personnalisé).
Notre conception de l'extension Code privilégie la flexibilité, la sécurité, l'efficacité et une expérience de développement rationalisée. Il prend en charge deux modèles d'exécution principaux, chacun adapté à des besoins architecturaux spécifiques :
- Modèle de script:
- Objet: Pour une logique personnalisée complète nécessitant une interaction directe avec Data 360 Lakehouse.
- Fonctionnalité: Les clients écrivent des scripts Python complets en utilisant le kit de développement Code Extension SDK, qui permet d'accéder en lecture et en écriture à Lakehouse via des API SDK. Idéal pour la préparation de données personnalisées/complexes, ou la manipulation de données sur mesure.
- Isolement et sécurité: Lorsque les scripts accèdent à Lakehouse, leur exécution est limitée à un environnement sécurisé et isolé pendant l'exécution de Data 360, ce qui empêche toute interférence avec d'autres processus ou accès système non autorisé.
- Modèle de fonction:
- Objet: Analogue à une fonction sans serveur, pour des calculs modulaires sans état invoqués à partir de pipelines Data 360 existants (par exemple, segmentation personnalisée dans un pipeline non structuré).
- Fonctionnalité: Les fonctions fournies par le client prennent l'entrée, calculent et renvoient la sortie.
- Isolement et sécurité: Ces fonctions sont conçues pour une isolation stricte; elles n'ont pas d'accès direct à Lakehouse. Leur exécution est sandbox, sans état et limitée en ressources, ce qui les rend adaptés à des étapes de traitement ciblées et sans état, garantissant la sécurité, une exécution prévisible et réduisant le rayon d'explosion.
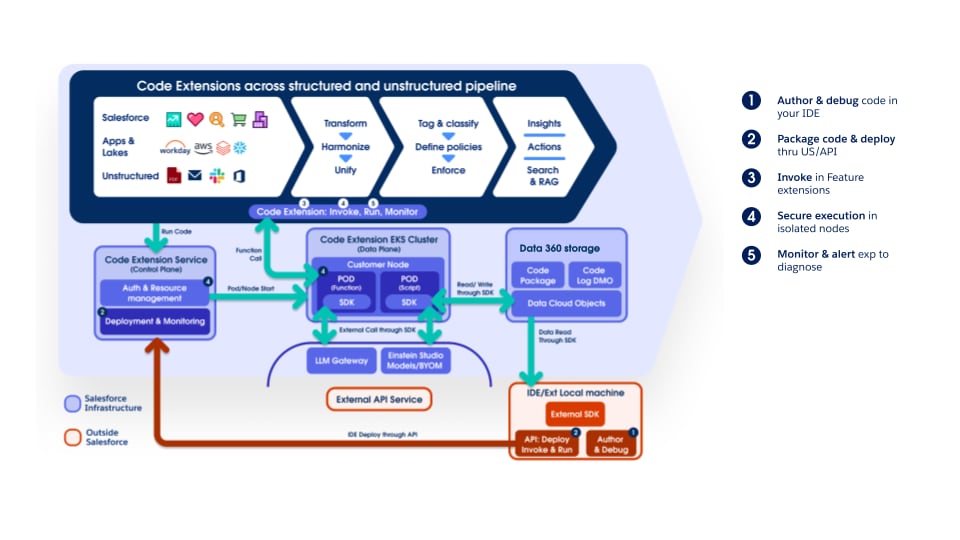
Les modèles Script et Fonction visent à exécuter en toute sécurité un code client, en empêchant le code d'un locataire d'affecter d'autres locataires ou d'obtenir un accès non autorisé aux données, aux ressources Salesforce ou aux ressources externes d'autres locataires. Cette sécurité est obtenue grâce à une architecture en couches (défense en profondeur). Cette architecture fournit un environnement d'exécution isolé pour le code personnalisé de chaque locataire, incorporant divers garde-fous. Il s'agit notamment de l'isolation logique au niveau des Kubernetes (K8), de l'isolation du réseau, de l'exécution sandbox et des autorisations de moindre privilège, le tout complété par une surveillance opérationnelle et une préparation aux incidents pour la détection et la réponse.
Pour prendre en charge un cycle de vie de développement robuste, Code Extension offre :
- Rédaction et débogage externes: Les développeurs peuvent élaborer et déboguer du code Python dans des environnements familiers tels que VSCode, en exploitant le kit de développement.
- Déploiement flexible: Un code personnalisé peut être empaqueté et déployé en utilisant des utilitaires SDK, l'interface utilisateur Data 360 ou l'API, ce qui permet l'intégration dans CI/CD.
Journaux opérationnels: L'accès à des journaux d'exécution détaillés offre de la transparence et facilite le dépannage en production.
En offrant ces capacités d'extension de code sécurisées et flexibles, Data 360 permet aux architectes d'adapter la plate-forme à leurs exigences de traitement des données les plus uniques et complexes, renforçant ainsi véritablement son rôle de tissu de données d'entreprise extensible.
À mesure que les entreprises accélèrent l'adoption de l'IA, la plupart gèrent des écosystèmes ML hétérogènes, notamment Amazon SageMaker, Google Vertex AI et des environnements Python personnalisés, qui hébergent des modèles qui pilotent des prédictions critiques, telles que le score de risque de crédit, la propension à l'attrition, les recommandations de produits et les décisions Next Best Action.
Traditionnellement, l'intégration de ces modèles externes dans Salesforce nécessitait des couches d'API sur mesure, des pipelines ETL ou une orchestration middleware, introduisant la duplication des données, les frais généraux de gouvernance, la latence et la complexité opérationnelle, des défis qui sont en conflit avec une vision Customer Data Platform (CDP) unifiée, conforme et en temps réel.
Apportez votre propre modèle (BYOM): Proposé via Einstein Studio dans Data 360, répond à ces défis en activant l'invocation directe de modèles formés en externe dans les workflows Salesforce, la logique Apex et les outils d'automatisation, sans déplacer ni répliquer les données. Grâce à la fédération zéro copie, Data 360 agit en tant que source unique de vérité régie, exposant les données Customer 360 harmonisées pour l'inférence à des points de terminaison externes. Les sorties de prédiction remontent en temps réel, alimentant les processus métiers avec une intelligence évolutive.
BYOM réduit efficacement l'écart entre la science des données et l'exécution opérationnelle en découplant le développement de modèles, les données régies et les couches de consommation. Il préserve l'indépendance de la plate-forme, réduit la complexité de l'intégration, accélère le déploiement de l'IA et maintient la gouvernance sur les données confidentielles.
L'architecture fonctionne comme suit : Data 360 fournit une fondation de données Customer 360 unifiée, tandis qu'Einstein Studio orchestre les connexions à des plates-formes ML externes (SageMaker, Vertex AI, ou des points de terminaison personnalisés). Les modèles externes exécutent l'inférence en temps réel, par lot ou en mode streaming. Les couches Salesforce (API Flow, Apex et Query) consomment des sorties pour fournir des connaissances personnalisées, automatisées et analytiques dans Sales Cloud, Service Cloud, Marketing Cloud et Industry Cloud.
D'un point de vue d'entreprise, BYOM offre :
- Intégrité des données et gouvernance: Élimine les copies de données incontrôlées et applique la conformité aux politiques.
- Démocratisation IA: Rendre les modèles complexes accessibles aux utilisateurs non techniques via des outils Salesforce.
- Accélération du temps de mise en valeur: Les modèles externes sont immédiatement activés dans les processus Salesforce.
- Prise en charge de l'évolutivité et de l'architecture hybride: Active le déploiement multicloud des charges de travail IA.
- Architecture IA prête pour le futur: Prend en charge les stratégies IA composables, le découplage des couches données, modèle et consommation pour plus d’agilité opérationnelle.
Bring Your Own LLM (BYO-LLM): Offre le même mécanisme d'extensibilité que pour les modèles génératifs. En activant l'invocation directe de LLM externes, nous permettons aux clients de les utiliser dans Agentforce Platform à la place des modèles fournis par Salesforce. Pour les entreprises BYO-LLM permet:
- Accès aux modèles ajustés
- Intégration de modèles non fournis actuellement par Salesforce
- Utilisation de modèles dans des comptes fournis par des clients
Les entreprises modernes opèrent dans un paysage de données complexe caractérisé par deux défis architecturaux majeurs :
- Fragmentation intra-entreprise: Les grandes organisations utilisent fréquemment plusieurs organisations Salesforce (souvent segmentées par région, unité commerciale ou acquisition historique) et de nombreux autres systèmes de données. Cette fragmentation crée des silos de données internes, rendant impossible l'établissement d'une vue unique, fiable et unifiée du client pour un engagement en temps réel dans l'ensemble de l'entreprise. Le défi consiste à unifier ces données sans les consolider ni les dupliquer physiquement dans tous les systèmes, afin de préserver la gouvernance.
- Collaboration inter-entreprises: Les entreprises ont souvent besoin de partager des données avec des partenaires et des fournisseurs pour des activités conjointes de marketing, de mesure et de veille économique. Le défi est de permettre cette collaboration tout en protégeant les données confidentielles et propriétaires et en adhérant aux réglementations relatives à la protection de la vie privée telles que le RGPD et la CCPA, ainsi qu’aux obstacles concurrentiels.
Salesforce Data 360 répond à ces défis avec une infrastructure Trust by Design zéro copie construite sur le principe du partage de l'accès et des connaissances plutôt que de déplacer ou dupliquer les données.
Salesforce Data 360 résout les problèmes de fragmentation des données et de collaboration avec Data Cloud One, le Partage de données entre Data 360 et les Salles blanches de données. Ces solutions unifient les données des clients, permettent un échange de données sécurisé et fournissent des connaissances sur la protection de la vie privée. Avec une approche Trust by Design sans copie, les organisations peuvent exploiter le potentiel des données pour un engagement en temps réel, des partenariats renforcés et une prise de décision intelligente. Chacune de ces options de collaboration de données sert des objectifs différents.
Activation interne de l'entreprise avec Data Cloud One
Data Cloud One est la solution architecturale de base pour les entreprises qui exploitent plusieurs organisations Salesforce. Son objectif va au-delà du simple partage de données. Il est conçu pour établir une vue client unique et de confiance et activer toutes les capacités de la plate-forme Data 360 dans toute l'organisation.
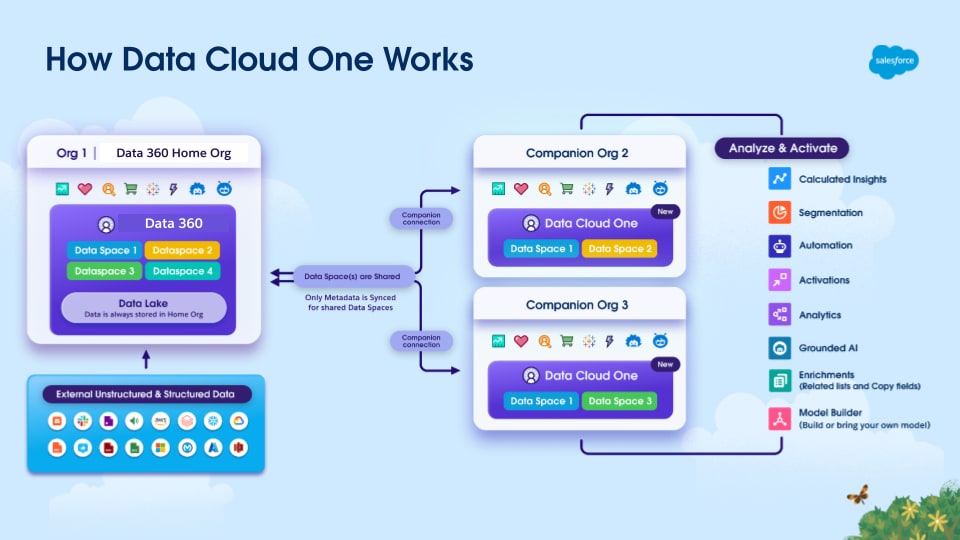
Ce mécanisme est centré sur une instance Home Org Data 360 désignée, qui sert d'autorité centrale pour la gestion des données et l'élaboration du profil client unifié. L'organisation d'accueil est l'organisation dans laquelle Data 360 est provisionnée. Une connexion Data Cloud One est établie entre Data 360 et d'autres organisations Salesforce, appelées Organisations Compagnons. Dans le cadre de la connexion Data Cloud One, Data 360 partage un ou plusieurs de ses espaces de données avec chaque organisation partenaire, ce qui permet d'accéder aux données et aux métadonnées de chaque espace de données partagé. Cela est possible grâce à un modèle de fédération sans copie et à la synchronisation des métadonnées inter-organisations.
Data Cloud One permet également aux organisations compagnes d'exploiter l'instance Data 360 de l'organisation d'origine pour leurs propres besoins en activation, personnalisation et intelligence. Cette stratégie est essentielle pour éliminer la fragmentation des données internes et garantir que toutes les unités commerciales s'activent avec le même profil client, gouverné et unifié, afin d'optimiser le retour sur investissement de l'implémentation principale de Data 360.
Partage de données entre des organisations Data 360
Pour les environnements internes distribués (où la centralisation complète n'est pas possible) et pour la collaboration avec des partenaires externes de confiance, le partage de données Data 360 vers Data 360 connecte des instances Data 360 indépendantes.
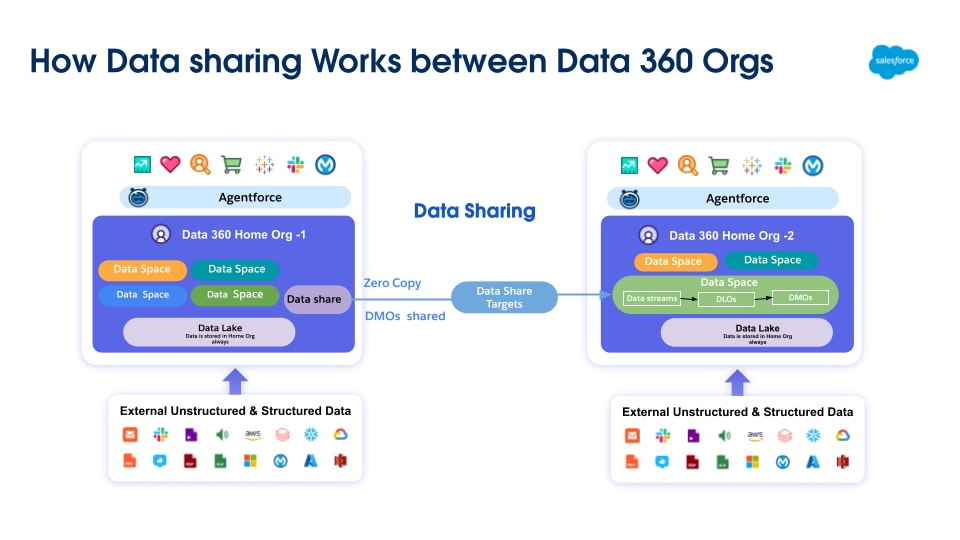
Ce modèle de partage sans copie établit une connexion entre des locataires Data 360 distincts provisionnés dans différentes organisations Salesforce afin de sécuriser l'échange d'objets de données (DLO, DMO et CIO). Une fois connecté, l'objet de données complet devient accessible dans Data 360 destinataire. L'administrateur de Data 360 destinataire peut ensuite définir des règles de gouvernance pour gérer l'accès des utilisateurs à ces données.
Collaboration Priorité à la confidentialité avec Data 360 Clean Room
Lorsque la collaboration nécessite les plus hauts niveaux de confidentialité et de conformité, ou lorsque des préoccupations concurrentielles interdisent le partage de données brutes, les salles blanches Data 360 sont architecturalement mandatées.
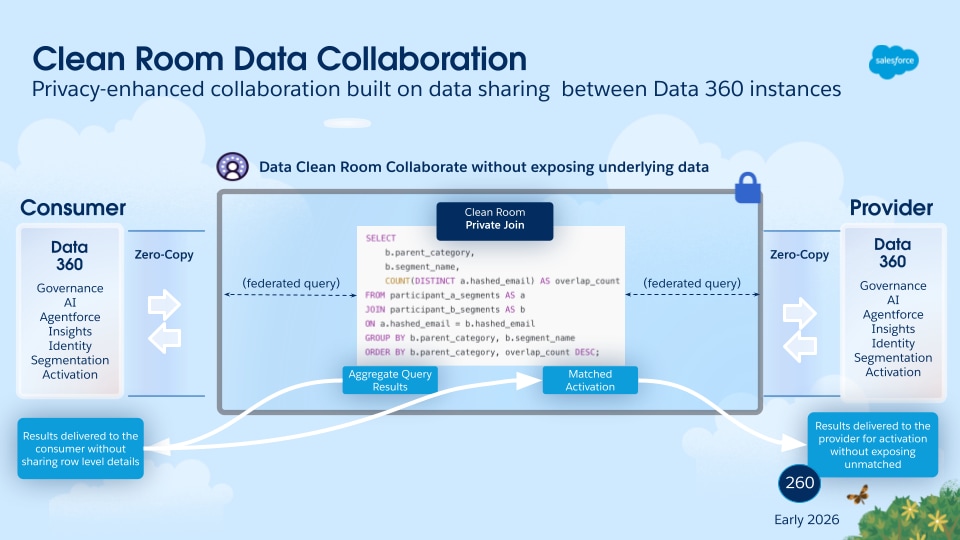
D'un point de vue architectural, la collaboration en salle blanche Data 360 repose sur l'infrastructure de partage zéro copie utilisée par le partage de données Data 360 vers Data 360, mais avec des couches supplémentaires de contraintes de gouvernance et de calcul appliquées. La salle blanche Data 360 offre un environnement de calcul sécurisé et contrôlé dans lequel les parties peuvent joindre leurs jeux de données sur la base de clés anonymisées. Son objectif principal est de permettre une analyse conjointe et la génération de connaissances sans exposer les données propriétaires sous-jacentes. L'environnement applique des règles strictes et programmables telles que des seuils d'agrégation minimum et des identifiants non exportables. Ces règles garantissent que seules les connaissances approuvées, améliorant la confidentialité et agrégées sont dérivées et partagées. Cela rend les Salles blanches essentielles pour des cas d'utilisation tels que la mesure de campagnes multiplate-forme et l'analyse des chevauchements d'audience sensibles.
Data 360 est conçu comme un tissu de données intelligent, extensible et fiable nécessaire pour piloter l’IA de nouvelle génération. Sa conception architecturale répond au problème de la fragmentation des données, permettant aux organisations d'unifier, de traiter et d'activer toutes les données clients à l'échelle, en utilisant la Fédération de données Zero Copy pour garantir l'efficacité.
Son organisation robuste des données établit une vue harmonisée des objets lac de données (y compris les données non structurées) aux objets modèle de données, le tout sécurisé dans des espaces de données partitionnés. Les capacités polyvalentes de traitement des données de Data 360, notamment les transformations par lot et en continu, les connaissances calculées, le traitement des données non structuré et la résolution de l'identité, sont pilotées par l'architecture incrémentielle SNCE et CDF, ce qui garantit un traitement efficace et en temps quasi réel et des économies importantes.
L'extensibilité est fournie par l'architecture Code Extension, qui active en toute sécurité une logique Python personnalisée via des scripts ou des fonctions isolées pour des exigences uniques. De plus, un cadre de gouvernance des données complet, basé sur le contrôle d'accès basé sur l'attribut (ABAC) avec des politiques CEDAR, garantit une sécurité granulaire, un masquage dynamique des données et une application cohérente dans l'ensemble de la consommation de données. Cela aboutit à des capacités sophistiquées de segmentation et d'activation, qui traduisent des profils clients unifiés en stratégies d'engagement multicanal dynamiques et réactives en temps réel.
La capacité de Data 360 à unifier des données vastes et diverses, à fournir un contexte en temps réel via sa requête unifiée (y compris la recherche structurée/non structurée hybride et l'accélération Hyper) et à appliquer une gouvernance stricte est essentielle pour piloter les agents IA intelligents. Il fournit les données fiables, actualisées et pertinentes nécessaires pour ancrer les workflows IA générative (RAG) et pour alimenter les capacités multitours orientées action des agents pilotés par Agentforce, en garantissant leur fonctionnement avec précision et précision.
En fournissant une plate-forme à l'épreuve du temps où les données sources sont transformées en connaissances actionnables, Data 360 est une fondation architecturale indispensable pour les organisations qui élaborent des expériences client Agentic. C'est l'épine dorsale vitale qui transforme les données des clients en expériences client sophistiquées et personnalisées qui favorisent la réussite des organisations modernes d'aujourd'hui.