Les intégrations Salesforce modernes doivent prendre en charge bien plus que le simple échange de données. Ils sont censés piloter l'expérience client en temps réel, coordonner les actions entre plusieurs systèmes et fonctionner de façon fiable à l'échelle de l'entreprise, le tout en respectant des exigences strictes de sécurité et de conformité. Le choix de la bonne approche d'intégration est donc une décision architecturale critique, pas un détail d'implémentation. Prenons un scénario d'entreprise courant. Un client effectue un achat dans une application mobile, déclenchant un contrôle d'éligibilité en temps réel pour une offre personnalisée. Parallèlement, les données des transactions doivent être enregistrées dans un système ERP, les attributs des clients mis à jour dans Salesforce et les analytiques transmises à un lac de données, sans introduire de latence, de duplication des données ou de risque de conformité. De tels scénarios sont désormais typiques dans les environnements Salesforce modernes, où Salesforce fonctionne rarement de façon isolée et doit s'intégrer de façon transparente à un écosystème élargi d'applications et de plates-formes de données. Ce guide existe pour aider les architectes et les développeurs à concevoir ces intégrations avec clarté et confiance. Au lieu de se concentrer sur les implémentations de point à point, il présente une série de modèles d'intégration éprouvés qui répondent à des scénarios d'entreprise récurrents, tels que l'orchestration de processus, la synchronisation des données et l'accès aux données en temps réel. Chaque modèle met l'accent sur l'intention architecturale, les compromis et les modèles d'exécution, ce qui permet aux équipes de prendre des décisions de conception informées, adaptées et durables. Dans ce document, vous trouverez :
- Modèles d'intégration qui représentent des « archétypes » d'entreprise communs dans les scénarios de processus, de données et d'accès virtuel
- Un cadre de sélection de schéma pour aider à identifier l'approche appropriée basée sur l'intention d'intégration et le calendrier d'exécution
- Considérations pratiques sur l'évolutivité, la résilience, la gouvernance et la sécurité
- Meilleures pratiques tirées des implémentations Salesforce et Data 360 réelles L'objectif de ce document est de fournir un langage architectural partagé pour l'intégration, en aidant les équipes à concevoir des solutions qui concilient performance, flexibilité et Trust tout en s'alignant avec les données de l'entreprise et les stratégies de gouvernance.
Ce document s'adresse aux concepteurs et aux architectes qui doivent intégrer les données d'autres applications de leur entreprise à Salesforce Data 360 (anciennement Data Cloud). Ce contenu est une distillation de nombreuses implémentations réussies par des architectes et partenaires Salesforce. Pour vous familiariser avec les capacités d'intégration et les options disponibles pour l'adoption à grande échelle de Data 360, lisez les sections Résumé du schéma et Guide de sélection de schéma ci-dessous . Les architectes et les développeurs doivent prendre en compte ces détails de schéma et les meilleures pratiques pendant la phase de conception et d'implémentation des projets d'interaction de données dans Data 360. S'ils sont correctement implémentés, ces modèles permettent d'accéder à la production le plus rapidement possible et d'utiliser l'ensemble d'applications le plus stable, évolutif et sans maintenance possible. Les architectes-conseils Salesforce utilisent ces modèles comme points de référence lors des examens architecturaux, et les entretiennent et les améliorent activement. Comme avec tous les schémas, ce contenu couvre la plupart des scénarios d'intégration, mais pas tous. Salesforce autorise par exemple l'intégration d'interface utilisateur (interface utilisateur), mais cette intégration n'entre pas dans le champ d'application de ce document.
Chaque modèle d'intégration suit une structure cohérente. Cela permet de fournir des informations cohérentes dans chaque modèle et facilite également la comparaison.
- Nom: L'identificateur du modèle qui indique également le type d'intégration contenu dans le modèle.
- Contexte : Le scénario d'intégration global que le schéma traite. Contexte fournit des informations sur ce que les utilisateurs tentent d'accomplir et sur le comportement de l'application pour satisfaire aux exigences.
- Problème : Exprimé sous forme de question, c'est le scénario que le schéma est conçu pour résoudre. Lisez cette section pour comprendre si le schéma convient à votre scénario d'intégration.
- Forces : Les contraintes et les circonstances qui rendent le scénario énoncé difficile à résoudre.
- Solution : La méthode recommandée pour résoudre le scénario d'intégration.
- Croquis : Un diagramme de séquence UML qui montre comment la solution répond au scénario.
- Résultats : Explique comment appliquer la solution à votre scénario d'intégration et comment elle résout les forces associées à ce scénario. Cette section présente également les nouveaux défis qui peuvent survenir suite à l'application du schéma.
- Barres latérales : Sections supplémentaires liées au modèle qui contiennent des problèmes techniques clés, des variantes du modèle, des préoccupations spécifiques au modèle, etc.
- Exemple : Un scénario du monde réel qui décrit l'utilisation du modèle de conception dans un scénario Salesforce réel. L'exemple explique les objectifs d'intégration et comment implémenter le schéma pour atteindre ces objectifs.
Utilisez ce tableau comme table des matières pour les modèles d'intégration contenus dans ce document.
| Niveau de schéma1 | Niveau de schéma2 | Modèle | Scénario |
|---|---|---|---|
| Modèles d'ingestion de données - Données entrantes | Modèles d'ingestion par lot | Ingestion de données en masse depuis Cloud Storage | Les données sont ingérées dans Data 360 à partir d'une source de stockage cloud d'entreprise telle que Amazon S3, Azure Blob ou Google Cloud Storage, sous forme de lots volumineux de données brutes (par exemple, des journaux de transactions ou de produits). |
| Ingestion de données en masse depuis Salesforce Clouds | Data 360 reçoit en masse les données CRM de plusieurs organisations Salesforce (par exemple Sales Cloud, Service Cloud) pour élaborer des profils clients unifiés. | ||
| Modèles d'ingestion en continu et en temps réel | Ingestion pilotée par l'événement via l'API Ingestion--Streaming | Data 360 s'abonne aux points de terminaison d'ingestion en continu qui reçoivent des charges de travail d'événements continus (par exemple, événements d'achat, télémétrie IoT) des systèmes d'entreprise pour des mises à jour de profil en temps réel. | |
| Ingestion du comportement Web et mobile en temps réel | Data 360 collecte et traite les données comportementales en temps réel des sites Web et des applications mobiles via des kits de développement pour enrichir les métriques d'engagement et les modèles de personnalisation. | ||
| Synchronisation CRM en temps quasi réel via Streaming | Data 360 reçoit les mises à jour des données CRM (p. ex., contact, requête, changements d'opportunité) en temps quasi réel via des flux d'événements pour maintenir une vue Customer 360 synchronisée en permanence. | ||
| Ingestion de flux d'événements à partir de plates-formes de messagerie Cloud - Kinesis et MSK | Data 360 consomme des données en continu directement à partir de plates-formes d'événements cloud telles que AWS Kinesis ou Kafka (MSK) pour traiter les événements opérationnels ou Internet des objets à haute fréquence. | ||
| Zéro modèle de copie - entrant et sortant | Inbound Zero Copy - Plates-formes externes dans Data 360 | Data 360 interroge des jeux de données externes (par exemple Snowflake, BigQuery) à la demande via Zero Copy Ingestion, sans déplacer physiquement les données dans Salesforce. | |
| Copie zéro sortante - Data 360 vers des plates-formes externes | Des systèmes externes tels que Databricks ou Tableau accèdent à des segments et à des connaissances enrichis dans Data 360 via des connexions Zero Copy Outbound sans réplication des données. | ||
| Plate-forme de données multi-organisations unifiée avec Data Cloud One | Data Cloud One unifie plusieurs organisations Salesforce et sources de données externes sous un modèle sémantique et de métadonnées partagées, offrant ainsi un Customer 360 cohérent sans duplication des données. | ||
| Modèles d'activation des données - Données sortantes | Modèles d'activation par lot | Activation de segments pour des plates-formes marketing et publicitaires | Data 360 active des segments de clients organisés directement dans Marketing Cloud, Meta, Google Ads ou d'autres plates-formes publicitaires pour une diffusion de campagnes personnalisées |
| Exportation de données vers Cloud Storage | Data 360 exporte des jeux de données unifiés ou filtrés (par exemple, des enregistrements clients consentis) sous forme de fichiers CSV ou Parquet vers le stockage cloud d'entreprise pour l'archivage d'analyses ou de conformité. | ||
| Activation basée sur l'API à la demande | Intégration d'application personnalisée via l'API Connect | Les applications externes invoquent l'API Data 360 Connect en temps réel pour récupérer ou déclencher des actions personnalisées (par exemple, contrôle du solde de fidélité ou génération d'offres IA) basées sur les données clients actuelles.Des applications Web ou mobiles personnalisées récupèrent des connaissances Data 360 harmonisées en toute sécurité via l'API REST Connect pour les afficher dans des interfaces utilisateur d'entreprise ou de partenaire. | |
| Récupération complète du profil client via l'API Data Graph | Un système récupère le profil unifié d'un client en utilisant l'API Data Graph, en renvoyant une représentation JSON en temps réel pré-jointe de la vue complète à 360° pour la prise de décision ou la personnalisation. | ||
| Actions de données en temps réel | Action de données en temps réel Transformation des signaux clients en action instantanée | Data 360 détecte et traite un événement en direct (par exemple, mise à jour du consentement, déclencheur d'achat) et invoque immédiatement un système connecté ou un flux Salesforce pour une action en aval.Un signal d'activité client (par exemple, risque d'attrition détecté) dans Data 360 déclenche une action instantanée en temps réel, par exemple mettre à jour CRM, invoquer le score Einstein ou lancer un parcours de rétention. |
Les modèles d'intégration de ce document sont classés en trois catégories : données, processus et intégrations visuelles.
Les modèles d'intégration de données dans Data 360 traitent du mouvement et de la synchronisation des données entre les systèmes afin de garantir que Data 360 et les plates-formes externes contiennent des informations cohérentes, opportunes et fiables. Ces modèles gèrent généralement des flux de données à grande échelle et à haut volume, et s'appuient sur des pipelines gouvernés qui appliquent des règles de cohérence de schéma, de suivi de lignage et de mastering.
- Les modèles d'ingestion par lot représentent la couche fondamentale de l'intégration des données d'entreprise. L'ingestion de données en masse à partir de services de stockage cloud tels que AWS S3, Azure Blob ou Google Cloud Storage permet de charger périodiquement des jeux de données historiques volumineux dans Data 360 pour la résolution de l'identité, la segmentation et les analytiques. De la même façon, l'ingestion en masse à partir de Salesforce Clouds, tels que Sales, Service ou Marketing Cloud, utilise des connecteurs natifs et des flux de données pour intégrer les données CRM dans la couche de données unifiée, garantissant harmonisation et continuité entre les systèmes d'engagement.
- Les modèles d'ingestion en continu et en temps réel étendent cette fonctionnalité en capturant des données d'événements à grande vitesse. L'ingestion pilotée par l'événement via l'API Ingestion permet aux systèmes externes de diffuser en continu l'activité des clients dans Data 360. L'ingestion en temps réel du comportement Web et mobile capture les données de flux de clics et d'interaction directement depuis les points de contact numériques pour favoriser une personnalisation immédiate. La synchronisation CRM en temps quasi réel via les API Streaming permet de refléter rapidement les attributs des clients et les mises à jour du consentement dans tous les systèmes. L'ingestion de flux d'événements à partir de plates-formes de messagerie telles que Amazon Kinesis ou Confluent MSK prend en charge les pipelines à haut débit continus, alignant Data 360 avec les architectures d'événements d'entreprise.
- Unified Multi-Org Data Platform with Data Cloud One illustre davantage l'intégration de données, en fournissant un environnement consolidé pour unifier les données de plusieurs organisations Salesforce et sources externes sous une gouvernance et une couche sémantique communes. Cela permet aux organisations d'obtenir une cohérence des données à l'échelle de l'entreprise, des modèles de données partagés et des analytiques évolutives.
- Dans la phase d'activation, les modèles d'activation par lot suivent le même principe d'intégration de données. Les segments organisés dans Data 360 sont exportés dans des tâches planifiées vers des plates-formes marketing et publicitaires en aval, telles que Marketing Cloud, Meta Ads ou Google Ads, où ils déclenchent l'exécution de campagnes. De la même façon, les jeux de données peuvent être exportés vers des cibles de stockage Cloud pour alimenter les pipelines d'analyses externes et de science des données. Dans tous ces cas d'utilisation, Data 360 agit en tant que source de vérité pour les données clients synchronisées et organisées.
Les modèles d'intégration de processus dans Data 360 impliquent le déclenchement ou l'orchestration de processus métiers à travers les systèmes en temps quasi réel. Ces modèles permettent à Data 360 de participer activement aux workflows d'entreprise, en activant des réponses contextuelles et l'activation dynamique des données.
- L'activation basée sur l'API à la demande active des scénarios d'engagement en temps réel. Grâce à l'API Connect, les applications personnalisées peuvent interroger ou activer des profils clients directement depuis Data 360 dans le cadre de processus opérationnels, par exemple une console d'agent récupérant des connaissances de profil unifiées pendant une interaction avec un client. La Récupération complète du profil client via l'API Data Graph prend en charge les applications composites et les microservices qui dépendent de l'accès piloté par l'API au graphique complet des entités d'un client, ce qui permet des expériences dynamiques sans segments pré-étape.
- Les actions de données en temps réel poussent plus loin cette approche d'intégration en activant une réactivité immédiate. Lorsqu'un signal client, par exemple un achat, une soumission de formulaire ou un événement de seuil, est détecté, Data 360 peut déclencher des actions telles que la mise à jour d'un enregistrement CRM, l'invocation d'un webhook externe ou le lancement d'un workflow d'offre personnalisée. Ces schémas incarnent une véritable orchestration des processus, reliant l'Intelligence client en temps réel à l'exécution opérationnelle automatisée.
Les modèles d'intégration virtuelle dans Data 360 permettent d'accéder en direct à des sources de données externes ou fédérées sans copier ni dupliquer physiquement les données. Elles sont essentielles pour les entreprises qui ont besoin d'informations gouvernées et à jour au moment de la requête tout en limitant les mouvements de données.
- Inbound Zero Copy Data Federation (External Platforms-to-Data 360) permet à des systèmes externes, tels que des entrepôts de données ou des lacs de données, de partager des jeux de données avec Data 360 via des connexions sécurisées et régies (par exemple, Snowflake Secure Data Sharing). Cela permet à Data 360 d'accéder virtuellement à des données externes et de les exploiter, préservant ainsi leur fraîcheur et éliminant les réplications inutiles.
- Outbound Zero Copy Data Sharing (Data 360-to-External Platforms) permet à Data 360 d'exposer des jeux de données organisés pour la consommation externe, tels que la modélisation IA, l'intelligence économique ou les analytiques avancées, via des mécanismes sécurisés de fédération de données et de requête live. Choisir la meilleure stratégie d'intégration pour votre système n'est pas anodin. Il y a de nombreux aspects à prendre en compte et de nombreux outils qui peuvent être utilisés, certains outils étant plus appropriés que d'autres pour certaines tâches. Chaque modèle traite de domaines critiques spécifiques, notamment les capacités de chaque système, le volume de données, le traitement des échecs et la transactionnalité.
Lors de la sélection d'un modèle d'intégration, commencez par répondre à deux questions fondamentales qui déterminent la conception et le comportement globaux de l'intégration. Qu'est-ce que vous intégrez ? — Processus, Données ou Accès virtuel Cette dimension définit l'objectif principal de l'intégration.
- Les intégrations de processus se concentrent sur l'orchestration des workflows métiers et la coordination des actions entre les systèmes.
- Les intégrations de données se concentrent sur la synchronisation, l'enrichissement ou la propagation de données entre les systèmes.
- Les intégrations virtuelles se concentrent sur l'accès aux données externes en temps réel sans les copier ni les conserver dans Salesforce ou Data 360. Comprendre cette intention permet de déterminer le niveau d'orchestration, de mouvement des données et de couplage requis entre les systèmes.
- Comment doit-elle être exécutée ? — La méthode Synchrone ou Asynchrone définit le modèle d'exécution de l'intégration.
- Les intégrations synchrones sont en temps réel et bloquantes, où l'appelant attend une réponse immédiate, couramment utilisées pour des scénarios pilotés par l'utilisateur ou de validation.
- Les intégrations asynchrones ne sont pas bloquantes et découplées, conçues pour gérer les processus d'échelle, longs, les tentatives et les volumes de données élevés. Ensemble, ces deux dimensions (intention d'intégration et calendrier d'exécution) fournissent un cadre clair et cohérent pour sélectionner le modèle d'intégration approprié tout en équilibrant l'expérience utilisateur, l'évolutivité et la résilience opérationnelle. Note : Une intégration peut nécessiter un middleware externe ou une solution d'intégration (par exemple, Bus de service d'entreprise) selon les aspects qui s'appliquent à votre scénario d'intégration.
Le tableau ci-dessous répertorie les modèles et leurs aspects clés pour vous aider à déterminer le modèle le plus adapté à vos besoins lorsque votre intégration se fait depuis Salesforce vers un autre système.
| Type | Calendrier | Considérations sortantes |
|---|---|---|
| Intégration de données | Asynchrone | Activation de segments pour des plates-formes marketing et publicitaires |
| Intégration de processus/données | Synchrone | Intégration d'application personnalisée via l'API Connect Récupération complète du profil client via l'API Data Graph |
| Intégration de données | Synchrone | Action de données en temps réel Transformation des signaux clients en action instantanée |
| Intégration virtuelle (utilisation de Zero Copy) | Asynchrone | Copie zéro sortante - Data 360 vers des plates-formes externes |
| Intégration virtuelle | Asynchrone | Plate-forme de données multi-organisations unifiée avec Data Cloud One |
Le tableau ci-dessous répertorie les schémas et leurs principaux aspects pour vous aider à déterminer le schéma le plus adapté à vos besoins lorsque votre intégration s'effectue depuis un autre système vers Salesforce.
| Type | Calendrier | Considérations relatives aux entrées |
|---|---|---|
| Intégration de données | Asynchrone | Ingestion de données en masse depuis Cloud Storage Ingestion de données en masse depuis Salesforce Clouds |
| Intégration de données | Asynchrone | Ingestion de flux d'événements à partir de plates-formes de messagerie Cloud - Kinesis et MSK Synchronisation CRM en temps quasi réel via Streaming |
| Intégration de processus | Synchrone | Ingestion pilotée par l'événement via l'API Ingestion--Streaming Ingestion du comportement Web et mobile en temps réel |
| Intégration virtuelle | Asynchrone | Inbound Zero Copy - Plates-formes externes dans Data 360 |
Le tableau ci-dessous répertorie quelques termes clés liés au middleware et leurs définitions par rapport à ces modèles.
| Durée | Définition |
|---|---|
| Gestion des événements | Le traitement des événements désigne la réception, l'acheminement et la réponse à des occurrences identifiables à partir d'un système source ou d'une application. Middleware gère les événements en identifiant le point de terminaison cible, en transmettant l'événement et en déclenchant l'action métier requise (par exemple, consignation, tentatives ou activation de services en aval). Dans les architectures Data 360, le traitement des événements est essentiel pour l'ingestion de données en temps réel, les déclencheurs d'activation et les modèles de publication/abonnement. Les événements peuvent provenir de systèmes externes (Kafka, AWS Kinesis) ou d'événements de plate-forme Salesforce, et sont acheminés par middleware ou bus d'événement Data 360 pour un traitement immédiat. |
| Conversion du protocole | La conversion de protocole permet de communiquer entre les systèmes en utilisant différentes normes de transport de données. Middleware traduit les protocoles propriétaires ou hérités (tels que AMQP, MQTT, FTP) en protocoles Data 360 pris en charge (REST, gRPC ou HTTPS). Cela garantit l'interopérabilité entre des systèmes hétérogènes. Comme Data 360 ne gère pas nativement la conversion de protocole, middleware fournit la couche d'adaptation, encapsulant ou transformant les messages dans un format que les API et les connecteurs Data 360 peuvent interpréter. |
| Traduction et transformation | La traduction et la transformation garantissent l'interopérabilité en mappant un format de données ou un schéma avec un autre. Middleware effectue ces transformations pour aligner diverses charges de travail de données (CSV, XML, JSON) avec des objets modèle de données (DMO) Data 360 et des objets couche de données unifiée (UDLO). Cela inclut le nettoyage, l'enrichissement et l'application d'un mappage sémantique ou basé sur l'ontologie avant l'ingestion. Si Salesforce propose des outils de transformation comme les Recettes de Préparation des données, il est préférable de gérer les transformations complexes (notamment pour l'harmonisation sémantique) dans les middlewares. |
| File d'attente et tampon | La mise en file d'attente et la mise en tampon s'appuient sur la transmission de messages asynchrones pour garantir une communication résiliente et découplée. Les plates-formes middleware (par exemple, MuleSoft, Kafka ou Azure Event Hub) fournissent des files d'attente permanentes qui stockent temporairement des données lorsque Data 360 ou des systèmes en aval sont occupés ou inaccessibles. Cela évite la perte de données et prend en charge les tentatives d'ingestion ou d'activation en temps quasi réel. Data 360 prend en charge l'ingestion en continu et la messagerie sortante basée sur le flux, mais la mise en file d'attente durable et la livraison garantie sont généralement gérées par un middleware. |
| Protocoles de transport synchrones | Les protocoles de transport synchrones impliquent des opérations de blocage/réponse en temps réel. L'expéditeur attend une réponse avant de continuer. Dans Data 360, ils sont utilisés pour les activations basées sur l'API à la demande, l'enrichissement en temps réel ou les références de profil, où des réponses sont requises immédiatement. Middleware garantit la fiabilité de la connexion et gère les tentatives ou le traitement de secours pour les appels d'API Data 360 synchrones. |
| Protocoles de transport asynchrone | Les protocoles de transport asynchrones prennent en charge la communication non bloquante et découplée dans laquelle l'expéditeur poursuit le traitement sans attendre une réponse. Middleware gère les flux asynchrones pour les activations par lot, l'ingestion en continu et l'activation pilotée par l'événement. Cela permet un débit et une résilience élevés, essentiels pour la diffusion en continu d'événements et les modèles d'ingestion de données en temps quasi réel dans Data 360. |
| Acheminement de médiation | L'acheminement de la médiation définit un flux de messages complexe entre les systèmes, garantissant que les données ou les événements appropriés parviennent au consommateur approprié. Middleware agit en tant que médiateur, gérant une logique d'acheminement basée sur des règles, des en-têtes, un contenu ou un type d'événement. Dans les intégrations Data 360, la médiation garantit que les événements et les mises à jour de profil de plusieurs systèmes sont correctement acheminés vers des API Ingestion de données, des points de terminaison d'activation ou des consommateurs externes. Cela simplifie l'orchestration et prend en charge la synchronisation des données multisystème. |
| Chorégraphie de processus et orchestration de service | La chorégraphie de processus et l'orchestration coordonnent les processus multi-systèmes. La chorégraphie prend en charge des flux autonomes pilotés par un événement, où les systèmes agissent sur la base de règles partagées sans contrôleur central. Orchestration est un flux géré de façon centralisée qui dirige l'exécution du service. Dans les architectures Data 360, le middleware gère l'orchestration pour l'ingestion et l'activation à travers les systèmes, tandis que les workflows Salesforce ou les flux gèrent les chorégraphies légères sur la plate-forme. Une orchestration complexe, nécessitant une coordination des transactions ou une gestion d'état, est recommandée au niveau de la couche middleware. |
| Transactionnalité (cryptage, signature, livraison fiable, gestion des transactions) | La transactionnalité garantit des opérations atomiques, cohérentes, isolées et durables (ACID) entre les systèmes. Salesforce et Data 360 sont transactionnelles dans leurs limites, mais ne prennent pas en charge les transactions distribuées à travers des systèmes externes. Middleware gère le contrôle global des transactions, notamment le cryptage, la signature de messages, l'annulation, la compensation et la livraison fiable. Pour les flux de données critiques (par exemple, les mises à jour financières ou de consentement), le middleware garantit l'intégrité et la récupération de bout en bout dans Data 360 et les systèmes externes. |
| Acheminement | L'acheminement spécifie le flux contrôlé de messages ou de données entre les composants. Il peut être basé sur des en-têtes, un type de contenu, une priorité ou des règles. Middleware gère la logique d'acheminement des événements et des activations impliquant Data 360, par exemple l'acheminement de segments d'audience enrichis vers différents systèmes en aval (plates-formes publicitaires, entrepôts, applications CRM). Bien que l'acheminement puisse être implémenté dans Salesforce (Apex, Flux), l'acheminement middleware est préféré pour l'évolutivité, la flexibilité et la gouvernance. |
| Extraction, transformation et chargement (ETL) | ETL consiste à extraire des données de systèmes sources, à les transformer en schéma cohérent et à les charger dans une cible (telle que Data 360). Les outils middleware ou ETL gèrent ces opérations avant l'ingestion de données. Data 360 peut recevoir des sorties ETL via des API, des connecteurs, ou des pipelines d'ingestion en masse, et prend également en charge la Capture des données de modification (CDC) pour la synchronisation en temps quasi réel. Les processus ETL Middleware sont essentiels pour intégrer des systèmes hérités et garantir la qualité des données avant l'unification dans Data 360. |
| Sondage long | L'interrogation longue (programmation Comet) est une méthode qui permet de maintenir une communication ouverte entre les systèmes pour des mises à jour en temps réel. Le client envoie une requête et le serveur la conserve jusqu'à ce qu'un événement se produise, puis répond et rouvre une nouvelle connexion. Salesforce l'utilise dans l'API Streaming et les protocoles CometD/Bayeux pour la synchronisation des données pilotée par l'événement. Middleware peut s'abonner à ces événements et les transmettre à Data 360 pour des déclencheurs d'ingestion ou d'activation en temps réel, ce qui garantit une latence minimale entre les systèmes d'entreprise. |
L'ingestion de données est la première étape et la plus critique du cycle de vie des données de Salesforce Data 360. C'est ainsi que les informations brutes de plusieurs systèmes externes (CRM, ERP, Web, mobiles ou API tierces) entrent sur la plate-forme et font partie d'une vue client unifiée. Le mode d'ingestion approprié dépend des besoins de l'entreprise :
- Volume de données : quantité de données qui se déplacent à la fois
- Latence — Quelle doit être l'actualisation des données
- Capacités système source - comment le système peut connecter et livrer des données Data 360 prend en charge plusieurs modes d'ingestion pour répondre à ces besoins : par lot pour les chargements à haut volume, streaming pour les mises à jour en temps quasi réel, basé sur l'événement pour l'immédiateté transactionnelle et ingestion Zero Copy pour un accès instantané aux données externes sans les déplacer physiquement. Ensemble, ces modèles garantissent que chaque signal client, qu'il s'agisse d'un événement d'achat, d'un journal de flux de clics ou d'une mise à jour de fidélité, est transmis dans Data 360 de façon efficace, sécurisée et dans les délais appropriés afin d'optimiser les analytiques de confiance et les expériences pilotées par l'IA.
Les modèles d'ingestion par lot sont l'épine dorsale de l'intégration de données à grande échelle dans Data 360. Ils sont optimisés pour les scénarios dans lesquels les données sont traitées en masse, généralement de façon planifiée ou périodique, plutôt que de façon continue. Ces modèles sont les plus adaptés pour :
- Chargement de données historiques pour initialiser la plate-forme avec des enregistrements d'entreprise existants
- Synchronisation régulière avec des systèmes d'enregistrement tels que des ERP, des entrepôts de données ou des bases de données propriétaires
- Utilisez des cas où l'actualisation en temps réel n'est pas critique, mais la cohérence, l'exhaustivité et l'auditabilité sont L'ingestion par lot offre des performances prévisibles et une simplicité opérationnelle, ce qui en fait un choix de confiance pour les entreprises qui gèrent des téraoctets de données structurées ou semi-structurées. Data 360 fournit une série de connecteurs prêts pour la production et globalement disponibles qui prennent en charge l'ingestion par lot en natif. Ces connecteurs rationalisent la configuration de l'intégration, réduisent le développement ETL personnalisé, et garantissent la qualité et la sécurité des données à chaque importation. Le tableau ci-dessous présente les connecteurs les plus souvent utilisés pour l'ingestion par lot à l'échelle de l'entreprise.
Context
Ce schéma est conçu pour les scénarios d'entreprise qui impliquent l'ingestion de volumes importants de données structurées, telles que des fichiers CSV ou Parquet, et d'actifs non structurés à partir de lacs de données centralisés ou de dépôts de fichiers planifiés. Les sources de données comprennent généralement des plates-formes de stockage cloud telles que Amazon S3, Google Cloud Storage (GCS) et Microsoft Azure Blob Storage, où les fichiers sont périodiquement livrés dans le cadre de pipelines de données en amont ou d'exportations par lot.
Problème
Comment une organisation peut-elle établir un processus fiable, sécurisé et à haut débit pour ingérer des jeux de données volumineux, basés sur des fichiers, depuis sa plate-forme de stockage cloud principale vers Data 360 à un rythme prévisible et récurrent, sans sacrifier la gouvernance, l'évolutivité ou les performances ?
Forces
L'ingestion massive de jeux de données basés sur des fichiers dans Data 360 n'est pas un simple exercice de transfert de données, mais un défi architectural façonné par les contraintes d'échelle, de gouvernance et de plate-forme.
Volume et échelle des données : Les connecteurs d'ingestion Data 360 sont optimisés pour la fiabilité et la gouvernance, pas pour un débit en masse arbitraire. Par exemple, le connecteur Amazon S3 prend en charge jusqu'à 100 millions de lignes ou 50 Go par objet, selon la première limite atteinte. Pour les entreprises qui ont des jeux de données historiques contenant des milliards d'enregistrements, cette frontière devient une contrainte de conception clé. Une approche à fichier unique, par lift-and-shift devient rapidement impossible, nécessitant des stratégies intelligentes de partitionnement, de segmentation et d'orchestration des données pour atteindre l'échelle sans atteindre les limites du connecteur.
Définition et maintenance du schéma : Data 360 nécessite des définitions de schéma explicites pour chaque pipeline d'ingestion afin de garantir l'intégrité sémantique et structurelle. Dans le cas d'une ingestion S3, un fichier csv doit définir des en-têtes de colonne et une seule ligne de données représentative. Ce fichier agit en tant que contrat canonique entre le système source, c'est-à-dire le stockage cloud, et Data 360. Tout désalignement (dans les noms de champ, les types de données ou l'encodage) peut entraîner des échecs d'ingestion ou une corruption silencieuse des données. La gestion de ce fichier de schéma dans le contrôle de version et l'application automatique de la validation via des workflows CI/CD ou de gouvernance des données devient une meilleure pratique pour les environnements de production.
Conventions de nommage strictes : Data 360 applique des règles strictes de nommage d'objets et de champs pour maintenir la cohérence dans le graphique des métadonnées.
- Les noms d'objet doivent commencer par une lettre et ne peuvent inclure que des lettres, des chiffres ou des traits de soulignement.
- Les noms de champ doivent suivre les mêmes modèles. Les fichiers qui enfreignent ces conventions, par exemple les champs contenant des espaces, des caractères spéciaux ou des symboles non pris en charge, échouent à la validation du schéma pendant l'ingestion. Les entreprises doivent mettre en œuvre des processus d'hygiène des données préalables à l'ingestion afin d'assainir et de normaliser les structures de fichiers entrants.
Schéma d'authentification et de sécurité : Chaque connexion à un stockage externe doit respecter les normes de sécurité et de conformité de niveau entreprise.
- L'authentification est généralement gérée via l'accès AWS/clés secrètes ou l'authentification par fournisseur d'identité (IdP) fédéré.
- Les rôles IAM doivent être délimités pour appliquer le moindre privilège, en autorisant uniquement l'accès en lecture aux chemins de stockage spécifiés.
- Pour un accès sécurisé, les adresses IP sortantes doivent être directement ajoutées à la liste d'autorisations du système source. Ces contrôles en couches garantissent que chaque transfert de fichier fonctionne dans un périmètre zéro Trust et auditable, en équilibrant la conformité de l'entreprise avec la flexibilité requise pour l'ingestion à grande échelle.
Solution
Le tableau ci-dessous présente des solutions à ce problème d'intégration.
| Solution | Ajustement | Commentaires |
|---|---|---|
| Utilisation de connecteurs Native Cloud Storage (Amazon S3, Google Cloud Storage, Azure Blob Storage) | Meilleur | C'est le modèle recommandé et le plus fiable pour l'ingestion récurrente à grande échelle de fichiers dans Data 360\. Les connecteurs natifs fournissent une authentification gérée, un mappage de schémas et un mouvement sécurisé des données directement dans les objets lac de données (DLO) de Data 360. Idéal pour les chargements par lot planifiés où la latence n'est pas critique (par exemple, planification horaire ou quotidienne). |
| Traitement des jeux de données volumineux (au-delà des limites du connecteur) | Mieux avec le prétraitement | Chaque connecteur applique des limites en ingestion (par exemple, S3 : 100 M de lignes ou 50 Go par objet). Pour des jeux de données plus volumineux, implémentez une étape de prétraitement ETL afin de partitionner les données dans des fichiers/dossiers plus petits qui correspondent à ces seuils. Configurez ensuite plusieurs flux de données pour ingérer chaque partition en parallèle, puis utilisez le nœud append dans une transformation de données par lot) dans Data 360 pour recombiner les partitions dans un jeu de données unifié. |
| Sécurité et gouvernance | Meilleur | Tous les connecteurs prennent en charge l'authentification sécurisée via des méthodes natives du cloud (rôles IAM, comptes de service ou clés d'accès). Pour plus de contrôle, limitez l'accès aux plages IP Data 360 via la liste d'autorisations du fournisseur de cloud. Le transfert de données se fait sur des canaux cryptés, avec des fichiers stockés dans une couche intermédiaire temporaire et sécurisée pendant l'ingestion. |
| Quand ne pas utiliser | Suboptimal | Ce schéma n'est pas optimal pour :
|
Croquis
Ce diagramme illustre la séquence des étapes d'ingestion des données depuis le stockage Cloud vers Data 360
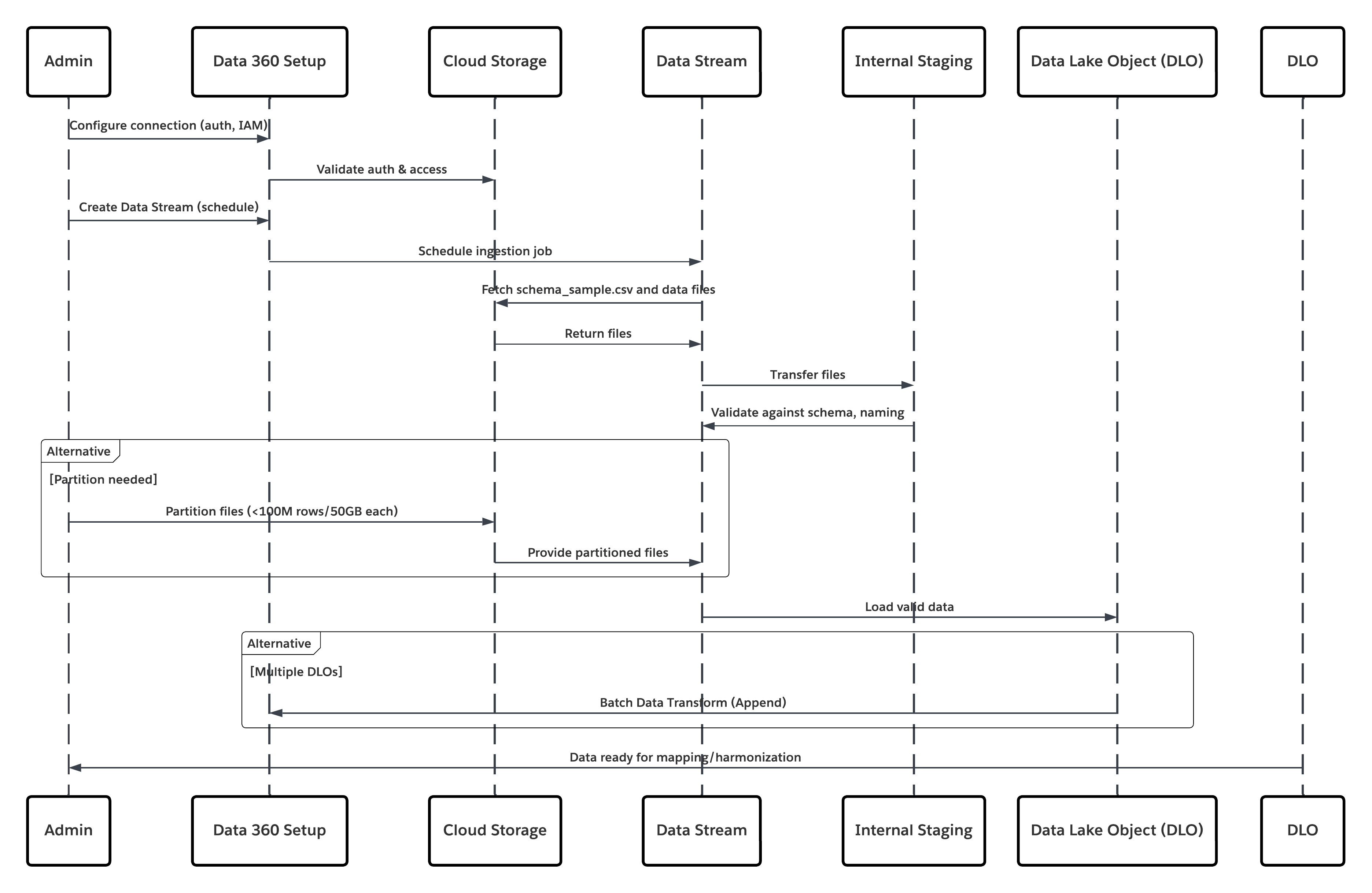
Dans ce scénario :
- L'administrateur configure une connexion au stockage cloud via l'interface de configuration de Data 360 (en spécifiant l'authentification, les détails du compartiment, les rôles IAM et la liste blanche).
- L'interface de configuration de Data Cloud s'authentifie à Cloud Storage Platform, en vérifiant les identifiants et l'accès.
- L'administrateur crée un flux de données dans Data 360, liant le flux de données à l'objet/dossier dans Cloud Storage et définissant la planification de l'ingestion.
- À la planification du déclencheur, le flux de données demande des fichiers sources (par exemple, CSV, Parquet) depuis Cloud Storage Platform.
- Cloud Storage Platform livre des fichiers, y compris les fichiers valides requis schema_sample.csv et d'autres fichiers de données conformes aux conventions de nommage.
- Le flux de données transfère des fichiers vers l'environnement intermédiaire interne dans Data 360.
- Data 360 Pipeline traite les fichiers : Utilise la définition de schéma de schema_sample.csv Valide la structure, les noms de champ et divise la charge si elle dépasse les seuils d'ingestion (100 millions de lignes/50 Go par fichier). Si des fichiers volumineux sont détectés, une étape de partitionnement préalable au traitement (notifiée à l'administrateur pour la prochaine exécution) est effectuée en externe.
- Les enregistrements sont importés depuis Staging dans un objet lac de données (DLO).
- Si nécessaire et que les données sont partitionnées, utilisez le nœud append dans une transformation de données batch pour combiner plusieurs objets lac de données.
- Data 360 consigne les réussites/échecs, met à jour le statut de surveillance et indique que les données sont prêtes pour le mappage, l'harmonisation et l'unification.
Résultats
L'application de ce schéma permet d'ingestion sécurisée, planifiée et à grande échelle de fichiers structurés ou non structurés à partir de plates-formes de stockage cloud d'entreprise dans Data 360. Le processus est automatisé, évolutif et résilient. Il livre des données brutes dans des objets lac de données (DLO) qui servent de base d'harmonisation et de mappage avec le Customer 360 Data Model.
Mécanismes d'ingestion
Le mécanisme d'ingestion dépend du connecteur et de la stratégie de planification définis dans Data 360.
| Mécanisme d'ingestion | Description |
|---|---|
| Connecteur Native Cloud Storage (Amazon S3, GCS, Azure) | Recommandé pour l'ingestion directe de fichiers au format CSV ou Parquet depuis le lac de données cloud de l'entreprise. Ces connecteurs prennent en charge les planifications d'actualisation incrémentielles et complètes. Par exemple, une banque peut configurer une synchronisation quotidienne des fichiers de transaction client depuis un compartiment S3 vers un objet lac de données. |
| Stratégie de fichiers partitionnés | Pour des jeux de données très volumineux (au-delà de 100 millions de lignes ou 50 Go par objet), les données sont partitionnées en jeux logiques plus petits (par exemple, par mois ou par région). Chaque partition est gérée comme un flux de données séparé, puis recombinée en utilisant une Transformation de données par lot avec un nœud Ajouter. |
| Synchronisation planifiée automatisée | Data 360 fournit un planificateur déclaratif (cadence horaire, quotidienne ou personnalisée) qui déclenche automatiquement des tâches d'ingestion, assurant l'actualisation des données sans intervention manuelle. |
Gestion et récupération des erreurs
Le traitement des erreurs et la récupération sont essentiels pour garantir la fiabilité des opérations d'ingestion à haut volume.
- Détection des erreurs : Chaque exécution de flux de données consigne les erreurs d'ingestion (par exemple, inadéquation du schéma, corruption de fichiers ou infractions au nommage) dans Data 360 Monitoring. Les administrateurs peuvent réviser et retraiter les lots échoués.
- Mécanisme de recouvrement: Data 360 maintient le pointage pour s'assurer que les lots échoués ne corrompent pas les ingestions précédentes. Les récupérations peuvent être configurées après avoir corrigé des problèmes sources (par exemple des fichiers CSV malformés).
- Validation du schéma: Le fichier schema_sample.csv définit les types de données et la structure. Toute modification déclenche une validation afin d'éviter une dérive silencieuse du schéma entre les exécutions.
Considérations relatives à la conception impotente
L'ingestion est idempotente par conception - le retraitement du même fichier n'entraîne pas de duplication des enregistrements. Les stratégies clés comprennent :
- Empreinte digitale du fichier : Data 360 calcule des sommes de contrôle pour identifier et ignorer les fichiers précédemment traités.
- Ingestion transactionnelle : Les données sont intermédiaires et engagées dans l'objet lac de données uniquement lorsque le traitement de tous les enregistrements réussit.
- Ajouter vs. Remplacer : Selon la logique métier, les flux peuvent ajouter ou remplacer entièrement l'objet lac de données cible, ce qui garantit des résultats déterministes et empêche le chevauchement partiel des données.
Considérations relatives à la sécurité
La sécurité fait partie intégrante du pipeline d'ingestion, de l'authentification au cryptage et au contrôle d'accès.
- Authentification et autorisation : Les connecteurs utilisent l'infrastructure d'intégration sécurisée de Salesforce, exploitant les identifiants nommés et les identifiants externes pour l'authentification sans révéler de secrets.
- Cryptage : Les données sont cryptées en transit (TLS 1.2+) et au repos (AES-256).
- Contrôles réseau : Les systèmes de stockage sources (p. ex. les compartiments S3) doivent ajouter des adresses IP Data 360 à la liste d'autorisations.
- Alignement de conformité : Prend en charge les infrastructures de protection des données d'entreprise telles que GDPR, HIPAA et les directives FFIEC lorsqu'elles sont associées à des clés gérées par le client (CMK).
- Auditabilité : Chaque tâche d'ingestion et accès aux identifiants est consigné pour la traçabilité et les rapports de conformité.
Menus latéraux
Opportunité
La rapidité dépend de la planification de l'ingestion et du volume de données.
- Les jeux de données d'entreprise volumineux (100M+ lignes) peuvent nécessiter un partitionnement pour l'ingestion parallèle.
- La latence d'ingestion typique varie de minutes à quelques heures, selon la taille du fichier et la complexité de la transformation.
- Pour l'ingestion en temps quasi réel, des connecteurs Data 360 Streaming ou basés sur l'API peuvent compléter le modèle basé sur le fichier.
Volumes de données
- Convient parfaitement à l'ingestion par lots périodique à haut volume.
- Chaque objet traité via le connecteur S3 prend en charge jusqu'à 100 millions de lignes ou 50 Go par fichier.
- Pour des systèmes à l'échelle du pétaoctet, utilisez le partitionnement des données et l'orchestration multiflux.
Prise en charge des capacités et des normes des points de terminaison
La capacité et la prise en charge standard du point de terminaison dépendent de la solution que vous choisissez.
| Type de connecteur | Exigences du point de terminaison |
|---|---|
| Connecteur Amazon S3 | Compartiment S3 avec la stratégie IAM appropriée et le fichier schema\_sample.csv définissant le schéma. |
| Connecteur Google Cloud Storage | Identifiants de compte de service et accès au compartiment avec des conventions de nommage uniformes. |
| Connecteur Azure Storage | Accéder à l'authentification basée sur la clé ou le jeton SAS ; la structure du blob ou du dossier doit respecter les conventions Data 360. |
Gestion des états
L'état est suivi à travers les flux de données et leur horodatage de dernière exécution réussie.
- Data 360 conserve automatiquement les états de synchronisation et les décalages, garantissant que seuls les fichiers nouveaux ou modifiés sont traités lors des exécutions suivantes.
- Lors de l'intégration à des outils ETL externes, des identificateurs de fichier uniques (par exemple, des UUID ou des horodatages) sont recommandés pour éviter les doublons.
Scénarios d'intégration complexes
Dans les architectures d'entreprise avancées, ce schéma peut s'intégrer à :
- Middleware ETL Pipelines (p. ex. Informatica, MuleSoft) : pour orchestrer le prétraitement, la validation et le partitionnement de fichiers avant la transmission à Data 360.
- Workflows IA/ML : les données d'objet lac de données traitées peuvent être publiées via un objet modèle de données pour modéliser des environnements d'entraînement ou des index RAG via des cibles d'activation Data 360.
- Systèmes transactionnels : les objets modèle de données harmonisés peuvent déclencher des mises à jour en aval dans Salesforce CRM ou des systèmes externes via des Actions de données ou des Événements de plate-forme.
Exemple
Une institution financière internationale stocke les données des clients et des transactions dans un lac de données AWS S3, où les fichiers Parquet partitionnés sont générés la nuit par région (États-Unis, UE et APAC). L'équipe d'architecture de données configure plusieurs flux de données dans Data 360, chacun connecté à un dossier régional, avec un schema_sample.csv partagé garantissant des en-têtes et des types de données cohérents dans toutes les partitions. Les planifications d'ingestion nocturne chargent automatiquement les données dans des objets lac de données, après quoi les Transformations de données par lot ajoutent toutes les partitions régionales dans un objet lac de données Customer_Transactions_DLO unifié. Ce jeu de données harmonisé est ensuite mappé avec le Customer 360 Data Model, ce qui permet d'activer les analytiques en aval et l'IA. L'approche fournit une ingestion automatisée et fiable à partir du lac de données existant, applique une authentification forte et un cryptage alignés sur les politiques informatiques de l'entreprise, et fournit une fondation modulaire évolutive qui prend en charge l'expansion future et l'évolution du schéma.
Context
Un cas d'utilisation principal et critique pour Data 360 est l'unification des données clients dans l'écosystème Salesforce. Ce schéma couvre l'ingestion native de données à partir des plates-formes Salesforce principales : Sales Cloud et Service Cloud (collectivement Salesforce CRM) et Marketing Cloud Engagement. Les sources comprennent des objets CRM standard et personnalisés (par exemple, Compte, Contact, Requête, Opportunité) et des extensions de données Marketing Cloud Engagement qui contiennent des événements d'engagement, des envois d'e-mails et des données de suivi.
Problème
Comment une organisation peut-elle ingérer efficacement et de façon fiable des objets CRM standard et personnalisés et des extensions de données Marketing Cloud Engagement dans Data 360 afin d'utiliser les données pour élaborer des profils clients unifiés (résolution de l'identité, Customer 360), tout en maintenant les performances, la gouvernance et une interruption minimale des systèmes sources ?
Forces
Les connecteurs natifs simplifient la tâche, mais plusieurs forces opérationnelles et architecturales doivent être gérées :
- Autorisations sources complètes : Un utilisateur connecté dédié (compte d'intégration) doit disposer des autorisations de lecture appropriées au niveau de l'objet et au niveau du champ. L'incapacité d'attribuer les ensembles d'autorisations requis (par exemple, un ensemble d'autorisations de connecteur Data 360 prédéfini) est une cause fréquente d'échec de l'ingestion.
- Modes d'actualisation des données et coût : Les connecteurs prennent en charge les modes d'actualisation complet et delta/incrémentiel. Les actualisations complètes sont plus lourdes en performances et crédits ; les extractions delta réduisent la charge, mais dépendent d'un suivi fiable des modifications dans le système source.
- Schéma personnalisé et mappage de champs : Les instances CRM contiennent souvent des objets/champs personnalisés. Un mappage précis des schémas et la gestion des champs personnalisés (noms, types) sont requis pour éviter les erreurs de mappage ou les dérives sémantiques.
- Paquets de données de démarrage vs. Mappage personnalisé : Les paquets de données de démarrage accélèrent l'intégration en présélectionnant des objets/champs typiques, mais les organisations fortement personnalisées auront besoin de définitions de flux sur mesure.
- Limites en débit et en API : Les limites en API d'organisation source et les taux d'extraction Marketing Cloud limitent l'agressivité avec laquelle vous pouvez planifier des actualisations.
- Conventions relatives à l'hygiène des données et au nommage : Les noms de champ source, le comportement nul et les types de données doivent être normalisés avant l'ingestion afin d'éviter les problèmes de mappage en aval.
- Sécurité et moindre privilège : Le connecteur s'appuie sur l'authentification sécurisée et doit respecter les modèles IAM à moindre privilège, l'auditabilité et les contrôles réseau.
Solution
Le tableau ci-dessous présente des solutions à ce problème d'intégration.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Solution adaptée | Meilleur | Utilisez le connecteur Salesforce CRM natif et le connecteur Marketing Cloud Engagement dans Data 360\. Commencez par les paquets de données de démarrage pour des cas d'utilisation standard et accélérez l'intégration. Utilisez la personnalisation manuelle des flux pour des modèles de données sur mesure ou spécifiques au domaine. |
| Gestion des instances CRM hautement personnalisées | Mieux avec l'atelier de mappage | Traitez les offres groupées de démarrage comme une référence et organisez un atelier de cartographie pour identifier : Objets et relations personnalisés. Champs de formule ou calculés. Extensions de package géré. Pour des champs de formule lourds, calculez des valeurs dans un ETL préalable à l'étape ou dans des Transformations Data 360 afin de limiter la charge d'API pour les organisations sources. |
| Quand ne pas utiliser | Scénarios sous-optimaux | Évitez ce schéma si : Vous avez besoin d'une ingestion d'événements à haute fréquence ou en temps réel (utilisez à la place Connecteurs en continu, Événements de plate-forme ou Fédération zéro copie). L'organisation source a une capacité d'API limitée et ne peut pas prendre en charge les extractions planifiées sans limitation ou délais de mise en file d'attente. |
| Sécurité et gouvernance | Contrôles obligatoires | Principe du moindre privilège : utilisez un utilisateur d'intégration dédié avec un accès en lecture minimal. N'utilisez jamais des administrateurs d'organisation. Authentification : utilisez OAuth 2.0 et des applications connectées, permutez régulièrement les secrets clients et surveillez l'utilisation de jetons d'actualisation. Audit et traçabilité : consignez toutes les exécutions d'ingestion, les changements de schéma et les événements de connecteur. Transmettez les journaux au SIEM ou aux systèmes de conformité pour la préparation à l'audit. Classification des données : appliquez le balisage PII/PHI et le Contrôle d'accès basé sur l'attribut (ABAC) en utilisant des stratégies CEDAR immédiatement après l'ingestion pour imposer le masquage, le consentement et la conformité en aval. |
Croquis
Ce diagramme illustre la séquence des étapes d'ingestion des données depuis le stockage Cloud vers Data 360
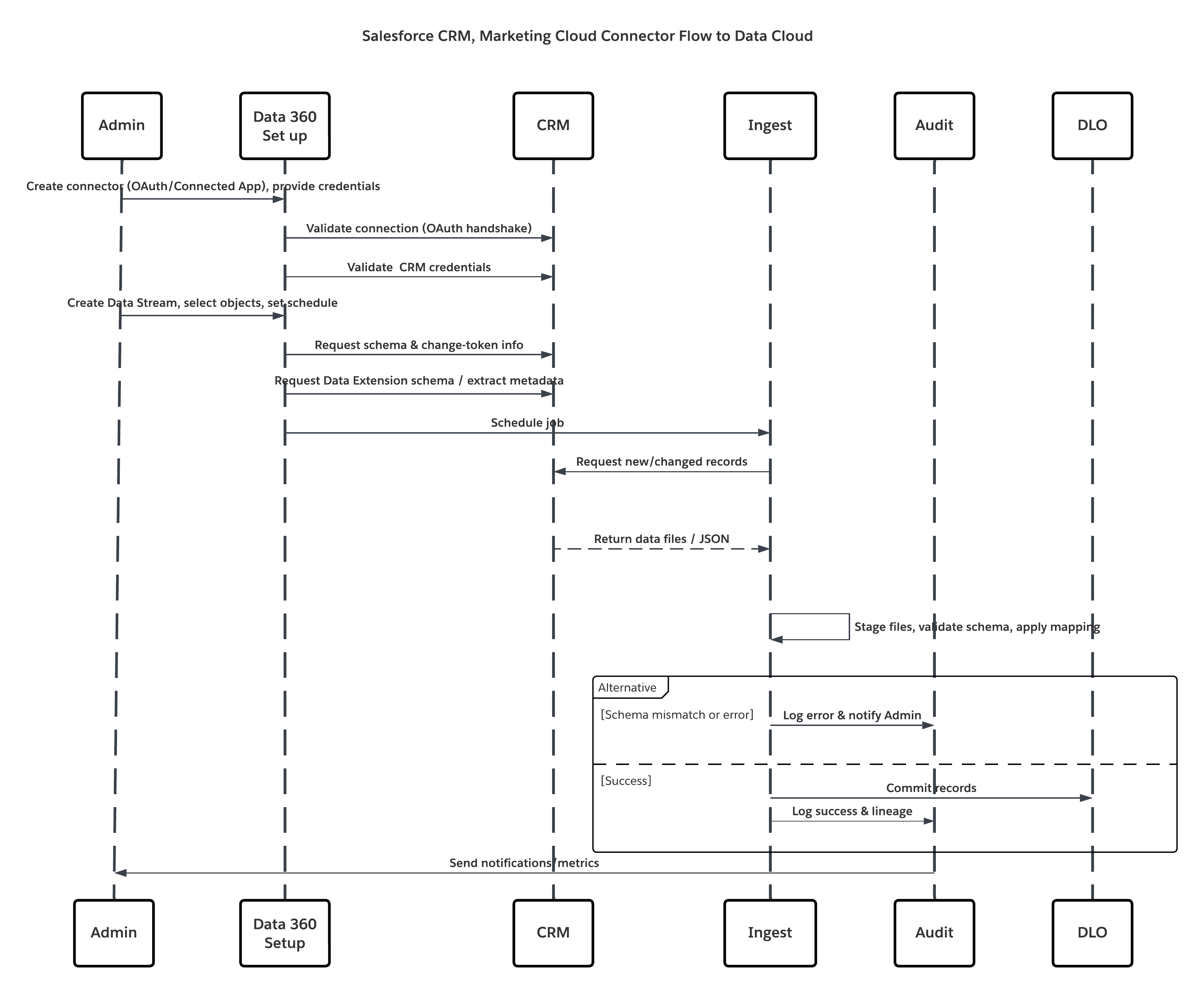
Dans ce scénario :
- L'administrateur provisionne les utilisateurs de l'intégration et attribue des ensembles d'autorisations de connecteur dans les organisations sources.
- L'administrateur configure les connecteurs dans la Configuration de Data 360 (se connecte à Salesforce CRM et Marketing Cloud via OAuth/application connectée).
- L'administrateur crée des flux de données en sélectionnant des objets et des extensions de données, choisit l'actualisation complète ou delta, et définit des planifications.
- À l'exécution planifiée, Data 360 demande des jetons de schéma et delta à la ou aux sources.
- Les systèmes sources renvoient des enregistrements (delta ou charge utile complète). Marketing Cloud peut fournir des extractions, CRM peut renvoyer des résultats JSON/Query.
- Data 360 met en scène les fichiers dans sa zone intermédiaire sécurisée interne et les valide par rapport au schéma mappé.
- Si la validation échoue, l'erreur est consignée dans les journaux d'ingestion, l'administrateur est alerté et l'engagement est interrompu. Si la validation réussit, Data 360 engage atomiquement les enregistrements dans l'objet lac de données cible.
- Les journaux de surveillance et d'audit sont mis à jour avec le lignage, la durée d'exécution, le nombre de lignes et l'utilisation des identifiants. Alertes envoyées aux administrateurs en cas de déclenchement de seuils ou d'erreurs.
Résultats
Les principales données de relation client et d'engagement marketing sont ingérées dans Data 360 en tant qu'objets lac de données (DLO). Cela renvoie :
- Jeu de données unifié contenant des profils, des requêtes, des opportunités et des métriques d'e-mail/engagement.
- Fondation pour la résolution de l'identité et la construction de profils Individu unifié.
- Préparation opérationnelle à l'harmonisation, à l'enrichissement, à la modélisation et à l'activation de l'IA en aval tout en préservant la gouvernance et l'auditabilité.
Mécanismes d'ingestion
Le mécanisme d'ingestion dépend du connecteur et de la stratégie de planification définis dans Data 360.
| Mécanisme | Quand utiliser |
|---|---|
| Connecteur Salesforce CRM (natif) | Idéal pour les objets CRM standard/personnalisés ; prend en charge l'actualisation complète et delta. |
| Connecteur Marketing Cloud Engagement (natif) | Idéal pour les extensions de données, les envois et les extractions de suivi ; prend en charge les modes full/delta. |
| Paquets de données de démarrage | Accélérez l'intégration pour les objets Sales/Service/Marketing courants. |
| Flux personnalisés + prétraitement | Utilisé lorsque des transformations complexes ou une normalisation de schéma lourde sont requises. |
Gestion et récupération des erreurs
Le traitement des erreurs et la récupération sont essentiels pour garantir la fiabilité des opérations d'ingestion à haut volume.
- Journaux par exécution : Chaque exécution de flux de données fournit des détails de réussite/échec et des erreurs au niveau de la ligne.
- Retries & Checkpointing : Les exécutions échouées peuvent être ré-essayées après avoir corrigé des problèmes sources ou de schéma ; Data 360 utilise la sémantique d'étape et d'engagement atomique.
- Alertes : Configurez des alertes en cas de dérive du schéma, d'échecs répétés ou d'écarts de séquence delta.
Considérations relatives à la conception impotente
L'ingestion est idempotente par conception - le retraitement n'entraîne pas de doublons dans les enregistrements. Les stratégies clés comprennent :
- Détection des modifications : Les extractions Delta s'appuient sur des indicateurs de changement du système source (LastModifiedDate / capture des données de changement du système). Vérifiez que la source fournit des horodatages/indicateurs fiables.
- Déduplication : Utilisez des clés métiers uniques (par exemple Contact.ExternalId) pour dédupliquer ou mettre à jour/insérer dans des objets lac de données.
- Engagement transactionnel : Les enregistrements sont intermédiaires et engagés uniquement lorsque le traitement par lot est terminé avec succès.
Considérations relatives à la sécurité
La sécurité fait partie intégrante du pipeline d'ingestion, de l'authentification au cryptage et au contrôle d'accès.
- Authentification et autorisation : Les connecteurs utilisent l'infrastructure d'intégration sécurisée de Salesforce, exploitant les identifiants nommés et les identifiants externes pour l'authentification sans révéler de secrets.
- Cryptage : Les données sont cryptées en transit (TLS 1.2+) et au repos (AES-256).
- Contrôles réseau : Les systèmes de stockage sources (p. ex. les compartiments S3) doivent ajouter des adresses IP Data 360 à la liste d'autorisations.
- Alignement de conformité : Prend en charge les infrastructures de protection des données d'entreprise telles que GDPR, HIPAA et les directives FFIEC lorsqu'elles sont associées à des clés gérées par le client (CMK).
- Auditabilité : Chaque tâche d'ingestion et accès aux identifiants est consigné pour la traçabilité et les rapports de conformité
Menus latéraux
Opportunité
La rapidité dépend de la planification de l'ingestion et du volume de données.
- La cadence idéale dépend des besoins de l'entreprise : toutes les heures pour les déclencheurs marketing en temps quasi réel, toutes les nuits pour les rapprochements importants.
- Les modes delta réduisent la charge et le coût ; les actualisations complètes sont plus lourdes et utilisées pour les chargements initiaux ou les changements de schéma majeurs.
Volumes de données
- Les connecteurs CRM sont optimisés pour les jeux de données transactionnels et à volume moyen (millions d'enregistrements).
- Pour des volumes historiques extrêmement importants, tenez compte de l'ETL intermédiaire pour partitionner et charger par étapes.
Prise en charge des capacités et des normes des points de terminaison
La capacité et la prise en charge standard du point de terminaison dépendent de la solution que vous choisissez.
| Connecteur | Exigences du point de terminaison |
|---|---|
| Connecteur Salesforce CRM | L'organisation source doit autoriser une application connectée, des jetons OAuth et un utilisateur d'intégration dédié avec des autorisations de lecture. |
| Connecteur Marketing Cloud | Identifiants d'API Marketing Cloud ou package installé ; les extensions de données doivent exposer les données via Extraits/API. |
Gestion des états
- État du connecteur : Les flux de données conservent les derniers horodatages de synchronisation réussis et les décalages delta.
- Principale stratégie clé : Préférez des identifiants métiers cohérents (ID externes) afin que le rapprochement en aval et les mises à jour/insertions soient déterministes.
Scénarios d'intégration complexes
Dans les architectures d'entreprise avancées, ce schéma peut s'intégrer à :
- Topologies hybrides : Combinez l'ingestion CRM à la diffusion en continu (événements de plate-forme) pour des mises à jour en temps quasi réel.
- Orchestration middleware : Utilisez les outils MuleSoft ou ETL lorsque l'orchestration, l'enrichissement ou la préingestion de transformation complexe est requis.
- Boucles de commentaires d'activation : Les objets modèle de données harmonisés peuvent déclencher des mises à jour en aval des systèmes sources via des Actions de données ou des API de plate-forme (attention avec les contrôles SoD).
Exemple
Un distributeur multinational regroupe les métriques d’engagement Comptes, Contacts, Requêtes, Opportunités et Marketing Cloud dans Data 360 pour créer une vue client unifiée. Le paquet de données Starter initialise les principaux objets Ventes et Service, tandis que l'équipe étend le modèle avec des champs personnalisés tels que Loyalty_Membershipc et Customer_Tierc pour capturer le contexte de fidélité. Les flux de données CRM sont exécutés toutes les heures en mode delta, et Marketing Cloud Engagement est synchronisé quotidiennement en utilisant des extractions delta pour les événements d'engagement. Ces jeux de données sont traités via des objets lac de données et la résolution de l'identité, ce qui génère un profil client unifié qui combine CRM et signaux d'engagement pour piloter la personnalisation et les modèles IA en aval.
Ces modèles sont conçus pour les scénarios où les millisecondes sont importantes, c'est-à-dire lorsque les interactions, les transactions ou les signaux des clients doivent déclencher une connaissance ou une action immédiate. Ils vont au-delà de l'ingestion par lot planifiée traditionnelle pour activer le flux de données piloté par l'événement, où les informations sont traitées dès leur génération. Dans l'écosystème Salesforce Data 360, le « temps réel » n'est pas un mode unique, mais un continuum de modèles de latence. D'un côté, la synchronisation en temps quasi réel, où les mises à jour des systèmes d'enregistrement (tels que CRM ou ERP) sont reflétées dans Data 360 en quelques secondes ou minutes. De l'autre côté, la véritable capture d'événements en temps réel, où les signaux comportementaux côté client, tels que les clics, les achats ou les interactions mobiles, sont ingérés et activés en millisecondes. Pour les architectes, la distinction est plus que sémantique. Il définit la conception des pipelines, l'invocation des API et la prise de décisions en aval. La sélection du modèle approprié (synchronisation en temps quasi réel ou ingestion d'événements en continu) garantit que le système atteint les objectifs de latence opérationnelle de l'entreprise tout en préservant l'intégrité des données, l'évolutivité et la gouvernance.
Context
Ce schéma permet à n'importe quel système externe, par exemple une application personnalisée, une plate-forme Internet des objets (IoT), un système de point de vente (POS) ou un service tiers, d'envoyer automatiquement par programmation des données d'événements dans Data 360 en temps quasi réel lorsque des événements discrets se produisent.
Problème
Comment un développeur peut-il envoyer de façon fiable des enregistrements uniques ou de petits lots asynchrones d'événements depuis une application externe vers Data 360 avec une faible latence afin que les données soient rapidement disponibles pour le traitement, la segmentation et l'activation ?
Forces
Ce schéma offre une faible latence et un meilleur contrôle du développeur, mais introduit plusieurs contraintes techniques et dépendances opérationnelles :
- Dépendance du développeur : Nécessite un effort de développeur pour implémenter des clients d'API REST authentifiés et une logique d'erreur/réessai. Ce n'est pas un connecteur par pointer-cliquer.
- Schéma strict en écriture : L'API Ingestion applique automatiquement le schéma en écriture. Un schéma précis doit être défini et chargé dans la configuration du connecteur. Toutes les charges utiles doivent être conformes ou rejetées.
- Modes d'interaction double : Le même connecteur prend en charge le streaming (JSON) pour les mises à jour à faible latence, enregistrement par enregistrement, et le transfert en masse (CSV) pour les synchronisations périodiques plus importantes. Les architectes doivent choisir par cas d'utilisation.
- Authentification et sécurité : Les appels doivent être authentifiés via une application connectée Salesforce en utilisant OAuth 2.0 (p. ex. flux de porteur JWT pour serveur à serveur). La gestion des jetons, la rotation et les étendues de moindre privilège sont obligatoires.
- Visibilité opérationnelle : Les développeurs et les équipes de plate-forme doivent mettre en œuvre une surveillance des codes de réponse, des tentatives, des files d'attente en lettres mortes et des alertes de dérive de schéma.
- Graphique en temps réel requis : Pour une véritable activation instantanée (segmentation instantanée, mappage d'objets modèle de données en temps réel), l'objet modèle de données (DMO) cible doit faire partie du graphique de données en temps réel, sinon les événements traversent un pipeline à latence légèrement plus élevée.
Solution
Le tableau ci-dessous présente des solutions à ce problème d'intégration.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Solution adaptée | Meilleur pour la capture d'événements à faible latence | Utilisez l'API Data 360 Ingestion (JSON en continu) pour envoyer automatiquement des événements uniques ou des micro-batches. Configurez le connecteur d'API Ingestion avec un schéma OAS 3.0 strict (.yaml). Utilisez l'ingestion CSV en masse pour des synchronisations plus grandes et moins fréquentes. |
| Modifications du schéma de traitement | Strict / Géré | Les changements de schéma sont rompus : mettez à jour OAS .yaml, mettez le connecteur en version et effectuez des tests contractuels. Implémentez la migration du schéma glissant si les producteurs ne peuvent pas changer simultanément. |
| Quand ne pas utiliser | Suboptimal | Pas idéal si un prétraitement est nécessaire ( ex: déduplication, commande garantie etc. ) , ou pour des charges en masse extrêmement importantes (utilisez des connecteurs en masse natifs ou ETL par lot). Si la source ne peut pas produire de charges utiles valides pour le schéma ou ne peut pas s'authentifier en toute sécurité, utilisez des méthodes d'ingestion alternatives. |
| Sécurité et gouvernance | Obligatoire | Utilisez OAuth 2.0 avec des étendues à moindre privilège, permutez les clés, consignez l'utilisation de jetons. Appliquez le protocole TLS 1.2+, validez les adresses IP des clients si nécessaire et assurez-vous que les informations d'identification personnelle de la charge de travail sont balisées. Tous les événements doivent porter des métadonnées de provenance (source, horodatage, version du schéma, clé d'idempotence). |
Croquis
Ce diagramme illustre la séquence des étapes d'ingestion des données depuis l'API Ingestion vers Data 360
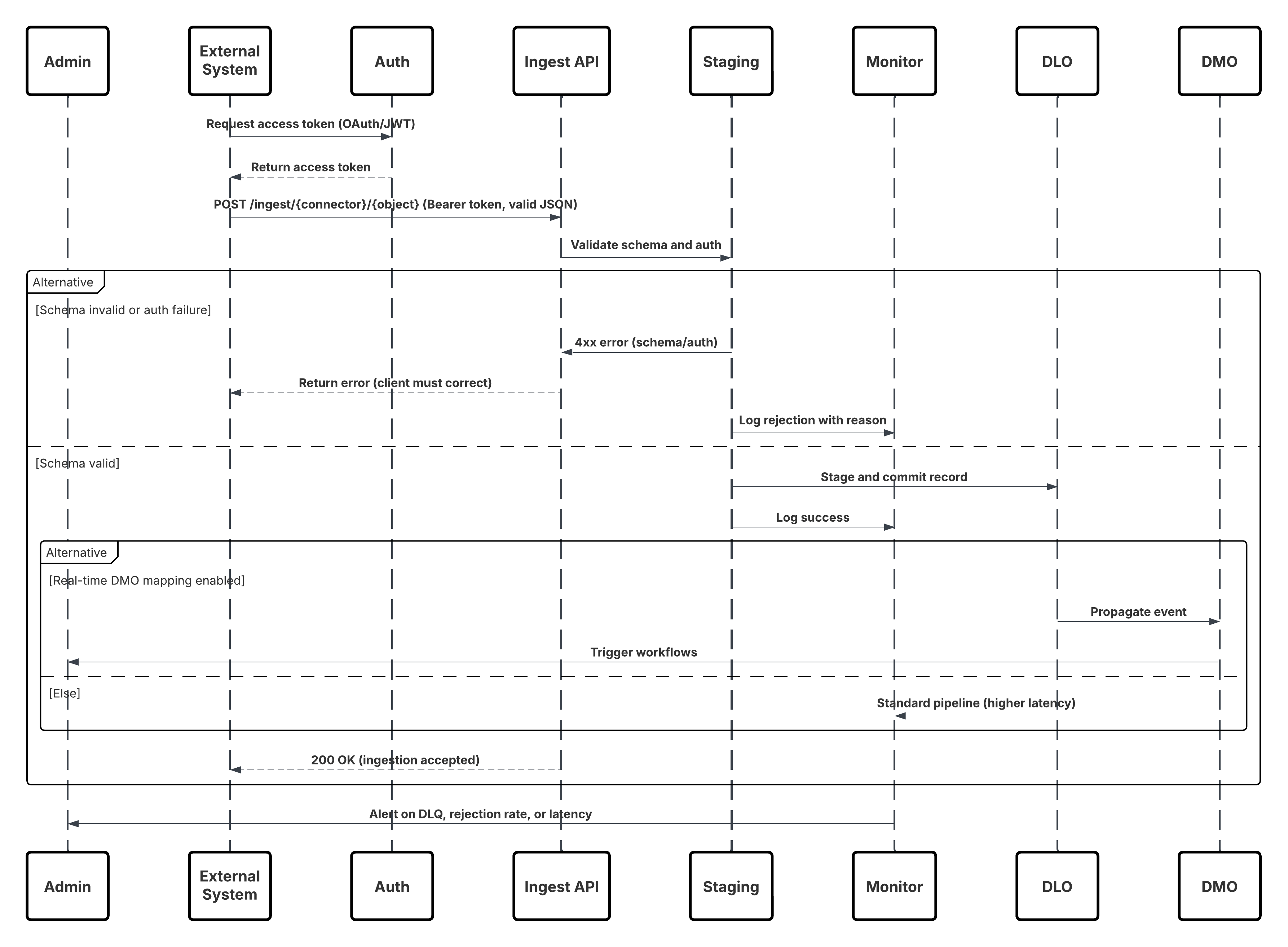
Dans ce scénario :
- Le système externe demande l'authentification via OAuth/JWT au serveur d'authentification.
- Le serveur d'authentification renvoie le jeton d'accès au système externe.
- Le système externe envoie la requête POST d'ingestion de données à l'API Ingestion Data 360 avec autorisation et charge de travail JSON.
- L'API Ingestion valide le schéma de requête et l'authentification via le module Staging & Validation.
- En cas d'échec du schéma/de l'authentification :
- Erreur renvoyée dans Système externe.
- Refus consigné pour surveillance et alerte.
- Une fois la validation réussie :
- Enregistrements mis en scène et engagés dans Objet lac de données (DLO).
- Succès consigné pour la surveillance.
- Si cette option est activée, les données sont propagées vers le Graphique de données en temps réel (DMO) qui déclenche des workflows en aval.
- Sinon, les données sont traitées par lot standard ou pipeline à latence plus élevée.
- L'API Ingestion confirme le succès du système externe.
- Les composants de surveillance alertent l'administrateur sur les files d'attente en lettres mortes, les taux de rejet ou les problèmes de latence.
Résultats
Les données d'événements externes sont ingérées dans des objets lac de données Data 360 à faible latence. Lorsque l'objet modèle de données cible fait partie du graphique en temps réel, les données sont disponibles pour la segmentation instantanée, les workflows des agents, les modèles IA et l'activation opérationnelle. Cela permet de répondre rapidement aux événements provenant de n'importe quel système connecté.
Mécanismes d'ingestion
Le mécanisme d'ingestion dépend du connecteur et de la stratégie de planification définis dans Data 360.
| Mécanisme | Quand utiliser |
|---|---|
| JSON en continu (API Ingestion) | Événements uniques, microbatches, événements comportementaux, flux de clics, télémétrie Internet des objets — lorsqu'une faible latence est requise. |
| CSV en masse (mode en masse de l'API Ingestion) | Chargements périodiques plus importants où les exigences de latence sont assouplies. |
| Edge / Middleware | Utilisez-le lorsque vous avez besoin de validation, de transformation, d'enrichissement ou de limitation de taux avant d'appliquer automatiquement l'API Ingestion. |
Gestion et récupération des erreurs
- Erreurs (de synchronisation) immédiates : Réponses 4xx pour des erreurs de schéma/authentification — le client doit corriger la charge utile ou le jeton et réessayer.
- Échecs transitoires (asynchrones) : Réponses 5xx : le client essaie avec un recul exponentiel et de la gigue.
- File d'attente lettre morte (DLQ) : Les échecs persistants sont renvoyés dans DLQ pour inspection manuelle et relecture.
- Surveillance : Suivez le taux de rejet du schéma, les échecs d'authentification, les percentiles de latence et le backlog DLQ. Alerte sur les seuils.
Considérations relatives à la conception impotente
- Clé d'immunité : Chaque événement doit inclure une clé d'identité/ID de message unique.
- Mettre à jour/insérer une stratégie : Utilisez des clés métiers (ExternalId) pour éviter les doublons lors des relectures.
- Fenêtre Dedup : L'architecte doit définir des fenêtres de déduplication et de rétention pour le suivi de l'idempotence.
Considérations relatives à la sécurité
La sécurité fait partie intégrante du pipeline d'ingestion, de l'authentification au cryptage et au contrôle d'accès.
- Authentification : OAuth 2.0 (porteur JWT) recommandé pour serveur à serveur. Limitez les étendues uniquement à l'ingestion.
- Cryptage : TLS 1.2+ pour le transport; Data 360 applique automatiquement le cryptage au repos.
- Moins de privilège : Les identifiants de l'application connectée ont des droits minimums. Permutez les secrets et les journaux d'accès aux instruments.
- Gouvernance de la charge de travail : Insérez des indicateurs de consentement/consommation dans les métadonnées des événements; appliquez les stratégies ABAC/CEDAR immédiatement après l'ingestion.
- Contrôles IP / Private Connect : Si nécessaire, limitez l'accès via des listes d'autorisations ou utilisez Private Connect pour la mise en réseau privée.
Menus latéraux
Opportunité
La rapidité dépend de la planification de l'ingestion et du volume de données. Le JSON en continu renvoie une latence de la seconde à la seconde selon le traitement et la configuration du graphique. Le fichier CSV en masse est de minutes à heures. Choisissez en fonction des accords commerciaux.
Volumes de données
La taille des événements individuels doit être petite (< quelques Ko). Pour les producteurs à haut débit, vous pouvez utiliser un traitement par lot chez le producteur ou une mémoire tampon en continu (Kafka/Kinesis) avant d'appeler l'API.
Gestion des états
- Schéma de version : Maintenir la version du schéma dans les métadonnées d'événements et utiliser la gestion des versions du connecteur lors de la mise à jour du contrat OAS.
- Décalages de connecteur : Data 360 gère la sémantique d'engagement. Les producteurs doivent suivre les clés d'idempotence et la dernière séquence réussie pour une relecture sécurisée.
Scénarios d'intégration complexes
Dans les architectures d'entreprise avancées, ce schéma peut s'intégrer à :
- Couche de validation Edge : Utilisez un middleware pour traduire des formats de producteur hétérogènes vers le contrat OAS requis, effectuer une limitation de taux et un pré-enrichissement.
- Architectures hybrides : Combinez l'API d'ingestion pour les événements et les connecteurs pour le rapprochement en masse.
- Activation de l'agent : Les événements mappés avec des objets modèle de données en temps réel peuvent déclencher des workflows Agentforce et des modèles Einstein pour la prise de décision automatisée.
Exemple
Une chaîne de magasins de détail diffuse des événements d'achat de point de vente (POS) dans Data 360 inReal-Time pour favoriser l'engagement immédiat des clients. Chaque magasin exécute un composant serveur léger qui collecte les transactions, les enrichit avec des métadonnées d'emplacement et d'appareil, et publie en toute sécurité des événements JSON en utilisant OAuth du porteur JWT avec des clés d'idempotency pour éviter les doublons. Un administrateur définit la structure de l'événement en chargeant un schéma OAS pour le point de vente et en configurant le connecteur d'API Ingestion. Les événements entrants sont ingérés dans l'objet lac de données pos_sale, mappés avec l'objet modèle de données Vente et ajoutés au graphique en temps réel. Ainsi, les achats de grande valeur sont détectés instantanément, ce qui déclenche des workflows VIP dans Agentforce et met à jour la segmentation des clients pour piloter la personnalisation en temps réel.
Context
Ce schéma permet de capturer des données d'interaction utilisateur précises et volumineuses, telles que des vues de page, des clics sur des boutons, des impressions de produits et des lectures vidéo, à partir de sites Web et d'applications mobiles en temps réel. Elle est fondamentale pour offrir une personnalisation instantanée, où chaque interaction numérique peut influencer dynamiquement l'expérience utilisateur et favoriser l'engagement.
Problème
Comment une entreprise peut-elle capturer et traiter un flux continu d'événements comportementaux à partir de propriétés numériques, couvrant des millions d'interactions utilisateur par minute, et rendre ces données immédiatement disponibles dans Data 360 pour piloter la segmentation, la personnalisation et l'activation en temps réel ?
Forces
Ce cas d'utilisation introduit plusieurs défis de conception qui nécessitent une architecture d'ingestion à faible latence spécialement conçue :
- Débit extrême : Les sites Web ou les applications mobiles à fort trafic peuvent émettre des millions d'événements par minute. La couche d'ingestion doit évoluer horizontalement pour gérer ce volume sans perte d'événement ni contre-pression, ce qui garantit une latence constante sous des charges de pointe.
- Instrumentation côté client : Contrairement aux intégrations pilotées par le serveur, ce modèle dépend des kits de développement côté client. Une balise JavaScript (Salesforce Interactions SDK) doit être incorporée à chaque page, ou un kit de développement natif intégré à des applications mobiles. Cela nécessite un déploiement client robuste, la gestion des versions et la gouvernance du schéma d'événements.
- Traitement des événements à faible latence : Les actions de l'utilisateur, telles que « ajouter au panier d'achat » ou « lecture vidéo », doivent atteindre Data 360 en quelques secondes, ce qui permet l'activation en temps réel et des réponses contextuelles (par exemple, des offres ciblées, des recommandations personnalisées).
- Harmonisation et résolution de l'identité des données : Les événements capturés contiennent souvent des identifiants anonymes (cookies, ID d'appareil, jetons de session). Pour piloter les cas d'utilisation Customer 360, ils doivent être mappés avec des profils connus via la résolution de l'identité de Data 360 et harmonisés avec le Customer 360 Data Model.
Solution
L'approche recommandée consiste à utiliser le connecteur Salesforce Marketing Cloud Personalization, un encours en continu entièrement géré et natif conçu pour l'ingestion comportementale à haut débit.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Capture d'événement basée sur le kit de développement | Meilleur | Déployez le kit de développement Salesforce Interactions (web) ou le kit de développement natif (mobile). Ces bibliothèques légères capturent et sérialisent les interactions des utilisateurs en temps réel, en joignant des métadonnées (ID de session, horodatage, contexte). |
| Event Streaming Pipeline | Meilleur | Les événements sont envoyés au service de streaming d'événements Marketing Cloud Personalization sur HTTPS sécurisé. Cette couche est évolutive horizontalement et optimisée pour la transmission à faible latence (<2s). |
| Intégration Data 360 | Meilleur | Le connecteur de personnalisation de Data 360 s'abonne au fil en continu, ingérant chaque événement dans un objet lac de données (DLO) en temps quasi réel. |
| Mappage de modèle de données | Meilleures pratiques | L'objet lac de données ingéré est mappé avec des objets modèle de données Customer 360. Cela permet de lier des utilisateurs anonymes et connus via la Résolution de l'identité. |
| Activation du graphique en temps réel | Facultatif / Recommandé | Insérez des objets modèle de données mappés dans le graphique en temps réel pour une segmentation instantanée, déclenchant des actions personnalisées via des workflows Einstein ou Agentforce. |
| Quand ne pas utiliser | Suboptimal | Ce schéma n'est pas idéal lorsque : Les données sources sont client Web et événements (utilisez à la place l'API Ingestion). L'organisation ne contrôle pas les clients Web/mobile. Le suivi du comportement en temps réel n'est pas requis (utilisez l'ingestion par lot). |
| Gestion des modifications du schéma | Évolution gérée | Les schémas d'événements évoluent à mesure que de nouvelles interactions sont ajoutées. Les kits de développement doivent versionner les définitions d'événements. Les modifications rétrocompatibles (ajout de champs facultatifs) sont sûres. Les modifications de rupture nécessitent une reconfiguration du connecteur et des tests de contrat. |
Croquis
Ce diagramme illustre la séquence des étapes d'ingestion des données de canaux Mobile et Web dans Data 360
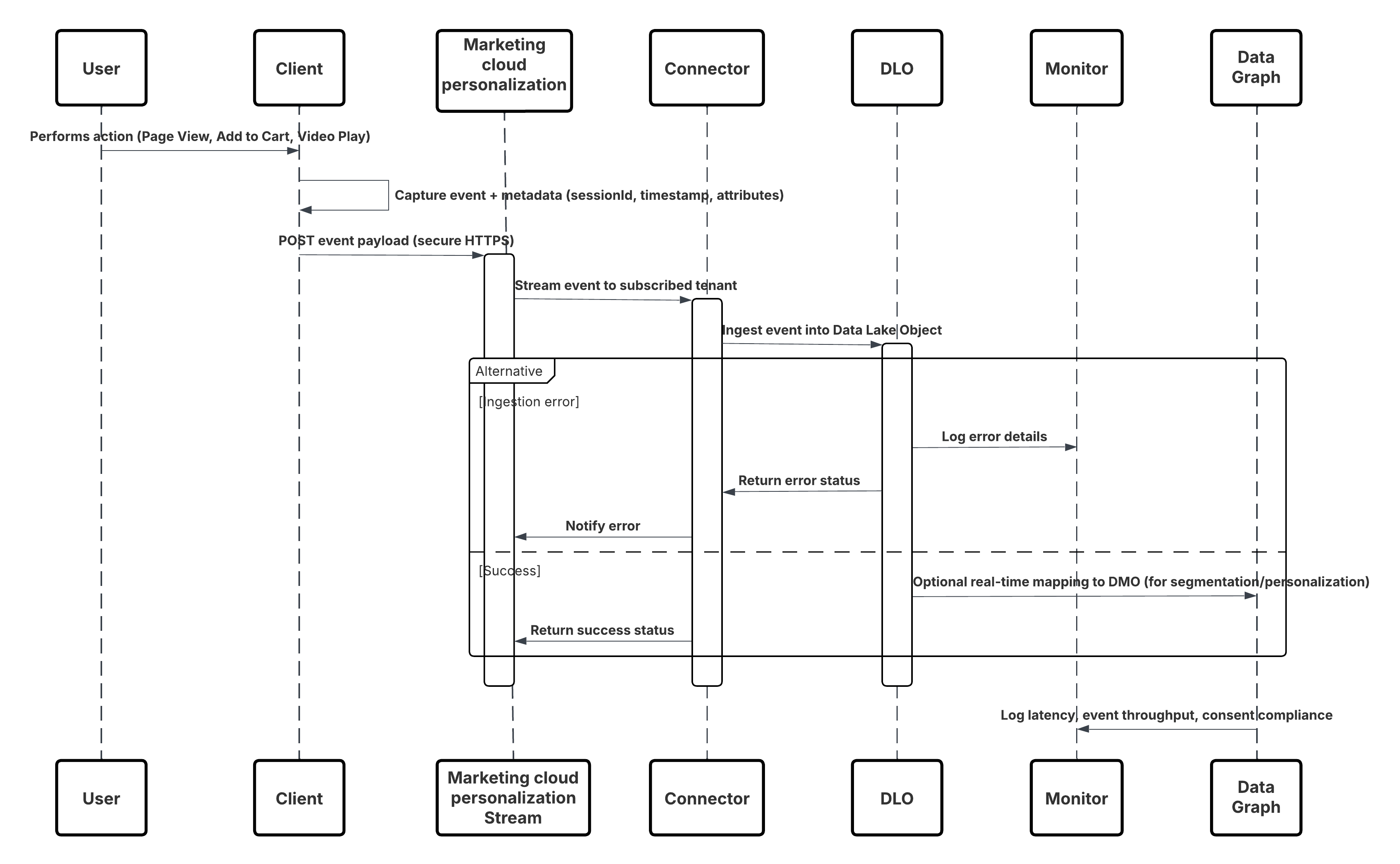
Dans ce scénario :
- Déployez le kit de développement dans des canaux Web ou mobiles (capture de l'interaction utilisateur).
- Configurez SDK avec des contrôles d'ID de locataire, d'environnement et de consentement.
- Diffusez les événements JSON capturés (métadonnées + attributs) au point de terminaison en continu Marketing Cloud.
- Dans Configuration de Data 360, créez et configurez le connecteur de personnalisation pour le locataire.
- Ingérez des événements dans un objet lac de données et mappez l'objet lac de données → objet modèle de données dans Data 360.
- Activez l'objet modèle de données dans le graphique en temps réel pour une activation immédiate.
- Surveillez la latence, la conformité du schéma, les indicateurs de consentement, le débit, les taux d'erreur.
- Déployez en production et surveillez en permanence.
Résultats
Un flux continu et à faible latence d'événements comportementaux circule depuis les canaux numériques vers Data 360. En quelques secondes, chaque action utilisateur devient disponible pour la segmentation en temps réel, la modélisation prédictive ou la personnalisation déclenchée, ce qui permet des expériences clients réellement adaptatives.
Mécanismes d'ingestion
Le mécanisme d'ingestion dépend du connecteur et de la stratégie de planification définis dans Data 360.
| Mécanisme | Quand utiliser |
|---|---|
| Interactions SDK (Web) | Capture en temps réel à partir de navigateurs Web et de SPA. |
| Mobile SDK | Capture en temps réel à partir d'applications mobiles natives. |
| Connecteur de personnalisation | Abonnement géré entre Marketing Cloud et Data 360\. |
| Mappage de graphiques en temps réel | Active l'activation immédiate dans Segmentation, Einstein et Parcours. |
Gestion et récupération des erreurs
- Tolérance aux défauts en couches : Implémentez des mécanismes de validation et de nouvel essai à plusieurs niveaux : les kits de développement client gèrent les échecs temporaires avec un recul exponentiel, tandis que la couche d'ingestion utilise des files d'attente durables et des pipelines rejouables pour éviter la perte de données.
- Schéma et gouvernance des données : Versionnez et validez des schémas d'événements en continu. Les événements non valides ou évolutifs sont acheminés vers une File d'attente de refus de schéma ou de lettre morte pour un tri et une relecture sécurisés.
- Idempotence et déduplication : Utilisez des identificateurs d'événement stables et mettez à jour/insérer la sémantique pour garantir un traitement en une seule fois, même pendant les tentatives ou les relectures.
- Automatisation de la surveillance et du recouvrement : La surveillance continue du débit, de la latence et des taux d'erreur déclenche des workflows de récupération automatisés, qui garantissent une faible latence, une livraison fiable et des résultats de personnalisation en temps réel cohérents.
Considérations relatives à la conception impotente
- Chaque événement doit porter une clé d'identité ou un ID de message unique afin de permettre la duplication des soumissions en aval.
- Utilisez des clés métiers (p. ex. sessionID + eventTimestamp + userID) pour identifier les doublons.
- Définissez une période de déduplication (par exemple 24 heures) pendant laquelle les événements dupliqués sont ignorés ou filtrés.
- Utilisez des stratégies de mise à jour/insertion au besoin (par exemple, mettez à jour les compteurs ou les indicateurs au lieu d'insérer des doublons).
Considérations relatives à la sécurité
La sécurité fait partie intégrante du pipeline d'ingestion, de l'authentification au cryptage et au contrôle d'accès.
- Cryptage du transport : TLS 1.2+ pour toutes les connexions SDK → service de streaming.
- Cryptage des données au repos dans Data 360 et le flux marketing.
- SDK respecte les indicateurs de consentement utilisateur (RGPD/CCPA) et supprime le suivi si le consentement est refusé.
- Authentification du trafic SDK : assurez-vous que seuls les locataires/clients approuvés peuvent diffuser des événements.
- Métadonnées : chaque événement doit inclure l'ID source, l'horodatage, la version du schéma, l'ID de session, la clé d'idempotence.
- Accès à moindre privilège : Points de terminaison et connecteurs SDK limités à l'étendue d'ingestion d'événements; permutez régulièrement les identifiants.
- Classification des données : Annoter les informations d'identification personnelle dans les charges de travail d'événements, appliquer des politiques immédiatement après l'ingestion
Menus latéraux
Opportunité
- La rapidité dépend de l'activité de l'utilisateur et de la configuration de la diffusion en continu des événements.
- Généralement, les événements capturés via le kit de développement Salesforce Interactions SDK et livrés via le flux Marketing Cloud Personalization atteignent une latence de moins de 2 secondes à environ 2 secondes avant d'être disponibles dans le graphique en temps réel Data 360.
- Cela permet la segmentation, la personnalisation et l'activation quasi instantanées dans les sessions utilisateur actives.
Volumes de données
Les événements comportementaux individuels (par exemple, clic, affichage, ajout au panier d'achat) sont légers, généralement de 1 à 5 Ko par charge utile. Pour des propriétés numériques à grande échelle, attendez-vous à des milliers à des millions d'événements par minute. Pour garantir le débit et la résilience :
- Utilisez les mécanismes intégrés de traitement par lot et de nouvel essai du kit de développement pour les pages à fort trafic.
- Déchargez le traitement en rafale dans la couche tampon Marketing Cloud.
- Surveillez le débit d'ingestion et les ratios d'erreur en utilisant le tableau de bord des métriques du connecteur.
Gestion des états
Chaque événement inclut des métadonnées pour le contrôle d'état et de version :
- Schéma de version : Incorporez la version du schéma à chaque événement ; versionnez le Connecteur de personnalisation lors de la mise à jour du schéma.
- Gestion de la lecture : Les événements qui échouent en raison de problèmes réseau transitoires sont automatiquement réessayés par le kit de développement avec un backoff exponentiel.
- Clés Idempotency : Des identifiants uniques (sessionId + eventType + timestamp) garantissent que les événements rejoués ne créent pas de doublons dans Data 360.
- Gestion des décalages : Data 360 suit les validations réussies. Tous les événements non traités sont remis en file d'attente par le connecteur jusqu'à leur ingestion réussie.
Scénarios d'intégration complexes
Ce schéma s'intègre de façon transparente dans les architectures d'entreprise avancées :
- Couche d'enrichissement Edge : Ajoutez un middleware (par exemple, un proxy inverse ou une fonction sans serveur) pour injecter un contexte supplémentaire, par exemple une géolocalisation, un type d'appareil ou des métadonnées de campagne, avant que les événements atteignent Marketing Cloud.
- Hybride (Streaming + Lot) : Utilisez le connecteur Marketing Cloud pour des flux en temps réel et combinez-le à des tâches ETL par lot (par exemple, des données de commande) pour le rapprochement en aval.
- Activation de l'agent : Les événements mappés avec des objets modèle de données en temps réel peuvent déclencher Personnalisation Einstein, des workflows Agentforce ou des prises de décision pilotées par l'IA pour adapter l'expérience numérique dans le moment présent.
- Gouvernance multilocataire : Utilisez des indicateurs de consentement et des métadonnées sensibles aux locataires pour appliquer la confidentialité et la conformité dans des environnements multimarques ou multirégions.
Exemple
Une entreprise mondiale de commerce électronique fournit des recommandations de produits personnalisés et des contenus dynamiques aux acheteurs qui naviguent activement sur www.retailx.com, une application à page unique basée sur React. En utilisant le kit de développement Salesforce Interactions côté client, le site capture les vues de page, les clics sur les produits, les actions de panier d'achat et les interactions vidéo en temps réel. Ces événements transitent par le flux d'événements Marketing Cloud Personalization et le connecteur Personalization dans des objets lac de données Data 360, où ils sont modélisés dans des objets modèle de données et incorporés dans le graphique en temps réel. Grâce à cette architecture, les signaux comportementaux sont instantanément disponibles pour la segmentation, la personnalisation pilotée par Einstein et l'activation Agentforce, ce qui permet des expériences client réactives et en session
Context
Pour de nombreux processus critiques de l'entreprise, il est essentiel de garder Data 360 parfaitement aligné avec les toutes dernières mises à jour des systèmes CRM de base. Les équipes du service client, des ventes et du marketing dépendent d'informations à jour pour prendre des décisions, déclencher des parcours et activer l'automatisation. Ce schéma fournit un mécanisme qui permet de synchroniser les modifications apportées aux principaux objets Salesforce CRM, tels que Contact, Compte et Requête, dans Data 360 avec un délai minimal, sans l'inefficacité ou la latence des interrogations par lot fréquentes.
Problème
Comment Data 360 peut-elle maintenir un état presque parfaitement synchronisé avec les principaux objets Salesforce CRM, en s'assurant que les analytiques en aval, la segmentation et l'activation pilotée par l'IA fonctionnent toujours sur les données les plus récentes disponibles ?
Forces
Ce schéma introduit plusieurs contraintes techniques et considérations architecturales :
- Architecture pilotée par l'événement : La synchronisation doit être réactive, pilotée par des événements de modification dans l'organisation source CRM plutôt que par des tâches par lot périodiques.
- Prise en charge sélective des objets : Les objets Salesforce standard et personnalisés ne prennent pas tous en charge la diffusion en temps réel. Les architectes doivent référencer la liste des objets pris en charge pendant la conception afin d'éviter les écarts.
- Accès et autorisations : L'activation de la diffusion en continu nécessite d'attribuer l'autorisation système « Activer les autorisations pour CRM Streaming » à l'utilisateur de l'intégration dans l'organisation source.
- Actualisation des données vs. Coût de traitement : Bien que la synchronisation en temps quasi réel améliore la réactivité, un débit d'événement excessif peut nécessiter une mise à l'échelle horizontale et des mécanismes robustes de reprise après erreur.
- Sécurité et intégration de la couche de confiance : Toutes les données d'événements doivent être conformes aux infrastructures Trust et Security de Salesforce (cryptées en transit, validées pour la conformité du schéma et traitées dans les limites Trust de l'organisation).
Solution
L'approche recommandée consiste à utiliser le connecteur Salesforce CRM avec Streaming (Capture des données modifiées) activé. Lors de la création d'un flux de données pour un objet CRM pris en charge (par exemple Contact), les administrateurs peuvent basculer vers l'option « Activer la diffusion en continu ». Sous le capot, la plate-forme de Capture des données de modification (CDC) de Salesforce publie un message ChangeEvent chaque fois qu'un enregistrement est créé, mis à jour, supprimé ou non supprimé dans l'organisation CRM source. Le connecteur Data 360 CRM s'abonne à ces événements CDC et applique en temps quasi réel les modifications correspondantes à l'objet lac de données (DLO) mappé dans Data 360. Cela garantit une synchronisation continue entre CRM et Data 360 avec une intervention manuelle minimale.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Connecteur Streaming basé sur CDC | Meilleur | Mécanisme Salesforce natif, entièrement géré et intégré à l'infrastructure d'événements de plate-forme. |
| Abonnement et livraison d'événements | Meilleur | Le connecteur s'abonne aux canaux ChangeEvent (par exemple, /data/ContactChangeEvent) via des ID de relecture durables. |
| Mappage des données et évolution du schéma | Meilleure pratique | Mappez les charges utiles diffusées avec l'objet lac de données correspondant ; gérez la gestion des versions de schéma dans les métadonnées pour éviter les pauses dans l'ingestion. |
| Relecture et récupération de défaut | Recommandé | Utilisez des ID de relecture et des clés d'idempotence pour éviter les doublons et récupérer les erreurs temporaires. |
| Mode hybride (Streaming + Batch) | Optional | Pour des objets non pris en charge ou un chargement en masse initial, utilisez l'ingestion par lot combinée à la diffusion en continu de CDC. |
| Quand ne pas utiliser | Suboptimal | Ce schéma peut être sous-optimal lorsque : L'objet source n'est pas activé pour le CDC. Le cas d'utilisation ne nécessite pas de mise à jour en temps réel (un lot suffit). La sortie du réseau depuis l'organisation source est limitée ou les limites en événements sont dépassées. |
Croquis
Ce diagramme illustre la séquence des étapes d'ingestion des données depuis CRM vers Data 360 en temps quasi réel
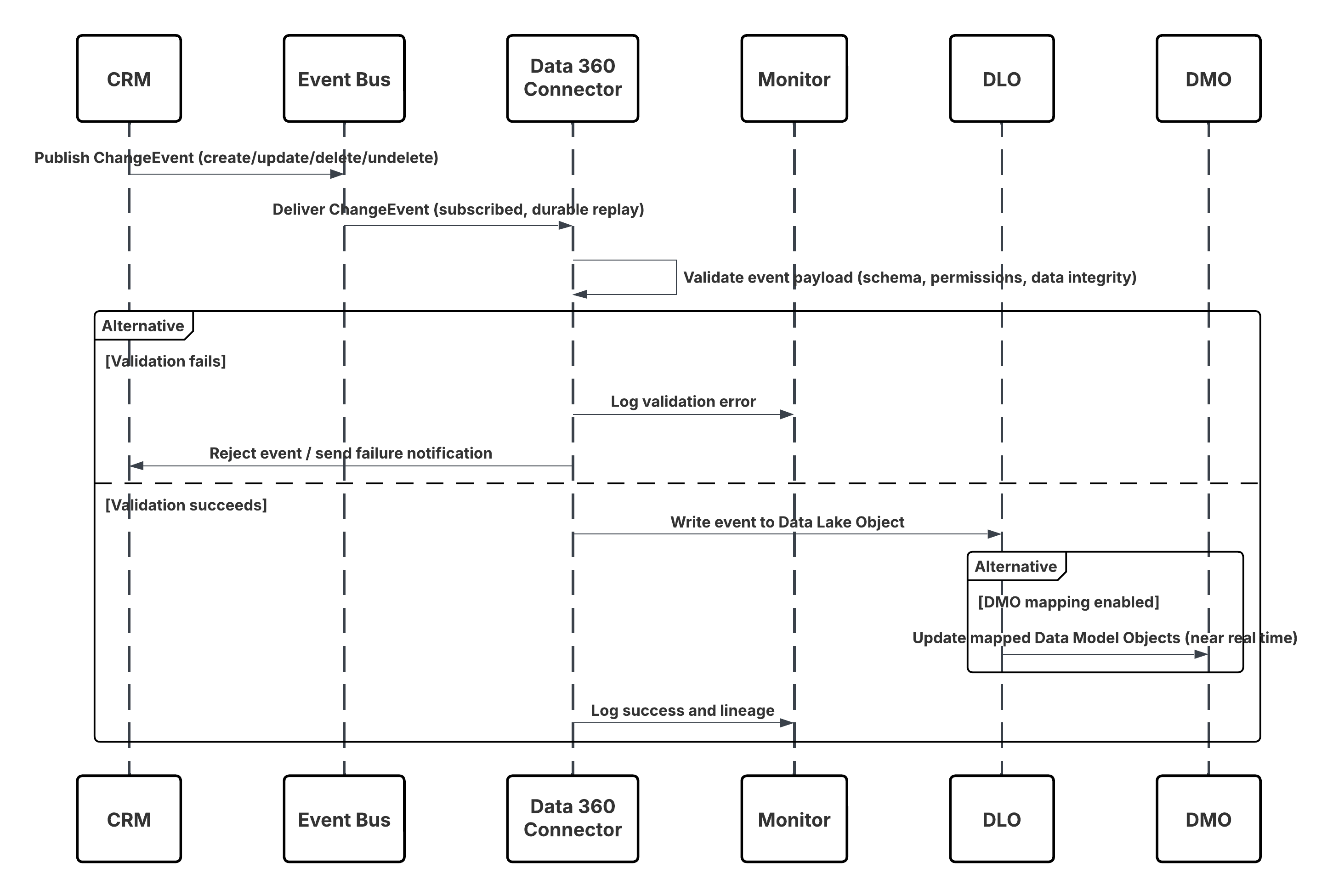
Dans ce scénario :
- La modification est effectuée dans Salesforce CRM (créer/mettre à jour/supprimer/annuler la suppression).
- CDC publie un ChangeEvent dans le Bus d'événement Salesforce interne.
- Le connecteur Data 360 CRM s'abonne au Bus d'événement en utilisant un curseur de relecture durable.
- La charge de travail des événements est validée pour le schéma, les autorisations et l'intégrité des données.
- Data 360 écrit l'événement validé dans l'objet lac de données mappé.
- Si cette option est activée, les objets modèle de données mappés sont mis à jour en temps quasi réel, ce qui favorise la segmentation et l'activation.
Résultats
Data 360 maintient un miroir synchronisé en continu des données CRM clés. Cela active :
- Déclencheurs en temps réel (par exemple, le parcours est lancé lors de la création d'une requête).
- Segmentation à jour (p. ex. déplacer les clients vers le segment « Gold » lors d'un changement de statut du compte).
- Analyses et personnalisation plus précises basées sur le contexte CRM live.
Mécanismes d'ingestion
Le mécanisme d'ingestion de ce schéma est géré en natif via le connecteur Salesforce CRM avec la Capture des données de modification (CDC) activée. Data 360 agit en tant qu'abonné au flux d'événements CDC, garantissant une synchronisation fiable et à faible latence entre l'organisation CRM source et Data 360.
| Mécanisme | Quand utiliser |
|---|---|
| Streaming via CDC (préféré) | Pour tous les objets Salesforce standard et personnalisés pris en charge dans lesquels une synchronisation en temps quasi réel est requise. |
| Mode hybride (CDC + lot) | Pour les objets qui ne sont pas encore activés par le CDC ou pour lesquels un chargement historique initial est requis. |
| Mode d'abonnement relecture | Pour la resynchronisation après un temps d'arrêt ou un déploiement. |
| Mode d'isolation d'erreur | Pour les environnements de test et de validation. |
Gestion et récupération des erreurs
- Reprise automatique des défauts : Le connecteur CRM résout automatiquement les erreurs transitoires de réseau ou de plate-forme en utilisant un backoff exponentiel et achemine les échecs persistants vers la file d'attente des lettres mortes (DLQ) pour la relecture.
- Résilience du schéma et de l'authentification : Les incohérences de schéma sont mises en quarantaine dans la File d'attente de refus du schéma pour examen par l'administrateur, tandis que des erreurs d'authentification ou d'autorisation déclenchent des tentatives contrôlées et des alertes via Data 360 Monitoring.
- Continuité garantie des événements : Les ReplayID durables garantissent l'absence de perte d'événements pendant les temps d'arrêt du connecteur. Les événements manqués sont réhydratés via des fenêtres de relecture ou des tâches de resynchronisation par lot.
- Intégrité des données et commande : L'idempotence intégrée (RecordID + SequenceNumber) empêche les doublons, et ChangeEventHeader.sequenceNumber préserve l'ordre des événements correct pour chaque enregistrement CRM.
Considérations relatives à la conception impotente
- Unicité des événements : Chaque événement CDC porte un ReplayID et ChangeEventHeader.entityName pour la déduplication déterministe.
- Mettre à jour/insérer une stratégie : Implémentez une logique UPSERT basée sur l'ID d'enregistrement pour vous assurer que les événements répétés ne créent pas de doublons.
- Gestion de la lecture : Utilisez le curseur de relecture du connecteur pour reprendre à partir du dernier décalage engagé en cas de pannes transitoires.
- **Évolution du schéma : **Gérez une version de schéma dans les métadonnées d'événements et mettez à jour les mappages d'objet lac de données lorsque le schéma CRM change.
Considérations relatives à la sécurité
La sécurité fait partie intégrante du pipeline d'ingestion, de l'authentification au cryptage et au contrôle d'accès.
- Encryption and Trust : Tous les événements sont transmis en utilisant TLS 1.2+ et stockés cryptés au repos dans Data 360.
- Contrôle d'accès : Seuls les connecteurs authentifiés qui disposent des autorisations d'intégration appropriées peuvent s'abonner à des canaux CDC.
- Validation du schéma : Chaque charge utile d'événement est validée par rapport au schéma d'objet lac de données avant l'ingestion.
- Propagation du consentement : Le consentement et les métadonnées de classification des données circulent en aval avec chaque événement afin de préserver la confidentialité et la conformité (RGPD, CCPA).
- Gouvernance opérationnelle : Les événements sont consignés, audités et surveillés pour détecter les anomalies de relecture, de rejet de schéma et de débit via Data 360 Trust Layer.
Menus latéraux
Opportunité
- Les événements CDC sont traités en temps quasi réel, généralement dans les secondes qui suivent la modification du CRM.
- La latence peut varier selon le volume d'événements et le débit du connecteur, mais Data 360 garantit une disponibilité inférieure à la minute pour les objets pris en charge.
Volumes de données
- Chaque charge utile d'événement est légère (~1 à 5 Ko).
- Pour des objets à taux de modification élevé tels que Requête ou Contact, assurez-vous que les limites en débit correspondent aux allocations d'événements Salesforce CDC.
Gestion des états
Chaque événement inclut des métadonnées pour le contrôle d'état et de version :
- ID de lecture : Utilisé pour la récupération d'événements séquentiels.
- Schéma de version : Gérez les métadonnées de version pour gérer les changements de contrat.
- Clés Idempotency : Dupliquer les relectures entre les tentatives.
- Décalage de l'engagement : Data 360 conserve l'état d'engagement après chaque lot d'événements réussi.
Scénarios d'intégration complexes
Ce schéma s'intègre de façon transparente dans les architectures d'entreprise avancées :
- Hybride (Streaming + Lot) : Utilisez CDC pour les mises à jour delta et les tâches en masse pour les actualisations complètes.
- Streaming inter-organisations : Plusieurs organisations sources peuvent diffuser dans le même locataire Data 360, unifié via des mappages d'objets modèle de données.
- Activation de l'agent : Les mises à jour d'objets en temps réel déclenchent des automatisations Einstein ou Agentforce.
- Acheminement des événements : Un middleware (par ex. MuleSoft ou Relais d'événements) peut enrichir ou acheminer les messages CDC avant l'ingestion.
Exemple
Une banque mondiale souhaite s'assurer que les modifications apportées aux données des clients dans Salesforce Sales Cloud se reflètent instantanément dans Data 360.Lorsque l'adresse d'un Contact est mise à jour dans Sales Cloud, le mécanisme de Capture des données de modification publie un ContactChangeEvent.Le Connecteur Data 360 CRM consomme cet événement, applique la mise à jour à l'objet lac de données Customer et met automatiquement à jour tous les profils Customer 360 associés. Cela déclenche une Einstein Next Best Action pour vérifier la nouvelle adresse, c'est-à-dire compléter la boucle de commentaire dans les secondes qui suivent la modification CRM d'origine.
Context
Les entreprises numériques modernes s'appuient sur des plates-formes de streaming d'événements en temps réel telles que Amazon Kinesis Data Streams et Amazon MSK (Managed Streaming for Apache Kafka) pour capturer des flux de données continus à partir d'applications distribuées, d'appareils Internet des objets et de systèmes transactionnels. Data 360 permet l'ingestion directe depuis ces plates-formes via des connecteurs natifs et internes, ce qui élimine la nécessité de solutions ETL personnalisées ou basées sur un middleware. Ce modèle est conçu pour l'ingestion de données à haut débit et à faible latence, qui alimente les connaissances en temps quasi réel, la personnalisation et l'activation pilotée par l'IA.
Problème
Comment une entreprise peut-elle connecter en toute sécurité et efficacement Data 360 à des rubriques AWS Kinesis ou AWS MSK Kafka pour ingérer en permanence des données structurées d'événements et de profils, en garantissant la conformité, l'évolutivité et la gouvernance du schéma ?
Forces
Ce schéma introduit de multiples considérations architecturales et opérationnelles :
- Disponibilité du connecteur natif : Salesforce fournit des connecteurs natifs globalement disponibles pour Amazon Kinesis et Amazon MSK. Ces connecteurs offrent une prise en charge interne et éliminent la nécessité de pipelines basés sur une API personnalisée.
- Authentification et sécurité : Chaque connecteur nécessite une authentification au niveau AWS.
- Pour Kinesis, cela utilise Clé d'accès AWS et Clé secrète, régies par des stratégies IAM.
- Pour MSK, l'authentification peut être configurée via Clé/Secret d'accès ou OpenID Connect (OIDC).
- Définition du schéma : Data 360 nécessite un schéma pour interpréter la charge de travail en continu. Pour Kinesis, le fichier de schéma est chargé lors de la configuration de la connexion, définissant la structure des événements et les mappages de champs.
- Source de configuration :
- Le connecteur Kinesis s'abonne à un nom de flux Kinesis spécifique.
- Le connecteur MSK s'abonne à une rubrique Kafka dans le cluster MSK.
- Accès réseau : Pour des environnements sécurisés, les connecteurs peuvent être configurés avec l'acheminement PrivateLink ou VPC, ce qui garantit qu'aucune donnée ne traverse l'Internet public.
- Gouvernance opérationnelle : Le débit en continu, la validation du schéma et les événements d'authentification sont surveillés au sein de Data 360 Trust Layer, ce qui garantit la conformité et la traçabilité.
Solution
La solution exploite les connecteurs Amazon Kinesis natifs ou Amazon MSK dans Data 360.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Kinesis Native Connector | Meilleur | Intégration interne à AWS Kinesis; prend en charge l'ingestion continue à haut débit. |
| Connecteur natif MSK | Meilleur | Ingestion gérée de Kafka avec la prise en charge de l'authentification OIDC et basée sur la clé. |
| Mapping et validation de schéma | Meilleure pratique | Chargez le schéma (.json/.avro) qui définit la structure des événements ; applique la cohérence pendant l'ingestion. |
| Configuration IAM | Recommandé | Attribuez un rôle IAM à moindre privilège avec un accès en lecture seule au flux Kinesis cible ou à la rubrique MSK. |
| Acheminement réseau privé | Optional | Configurez des points de terminaison PrivateLink/VPC pour un acheminement interne sécurisé. |
| Modèle hybride (Streaming + Lot) | Optional | Utilisez le streaming pour les deltas et l'ingestion par lot pour les remplissages ou les chargements historiques. |
| Mode d'isolation d'erreur | Recommandé | Acheminer les rejets de schéma et les erreurs transitoires vers DLQ pour relecture |
Croquis
Ce diagramme illustre la séquence des étapes d'ingestion des données de plates-formes d'événements telles que Kafka et Kinesis dans Data 360 en temps quasi réel
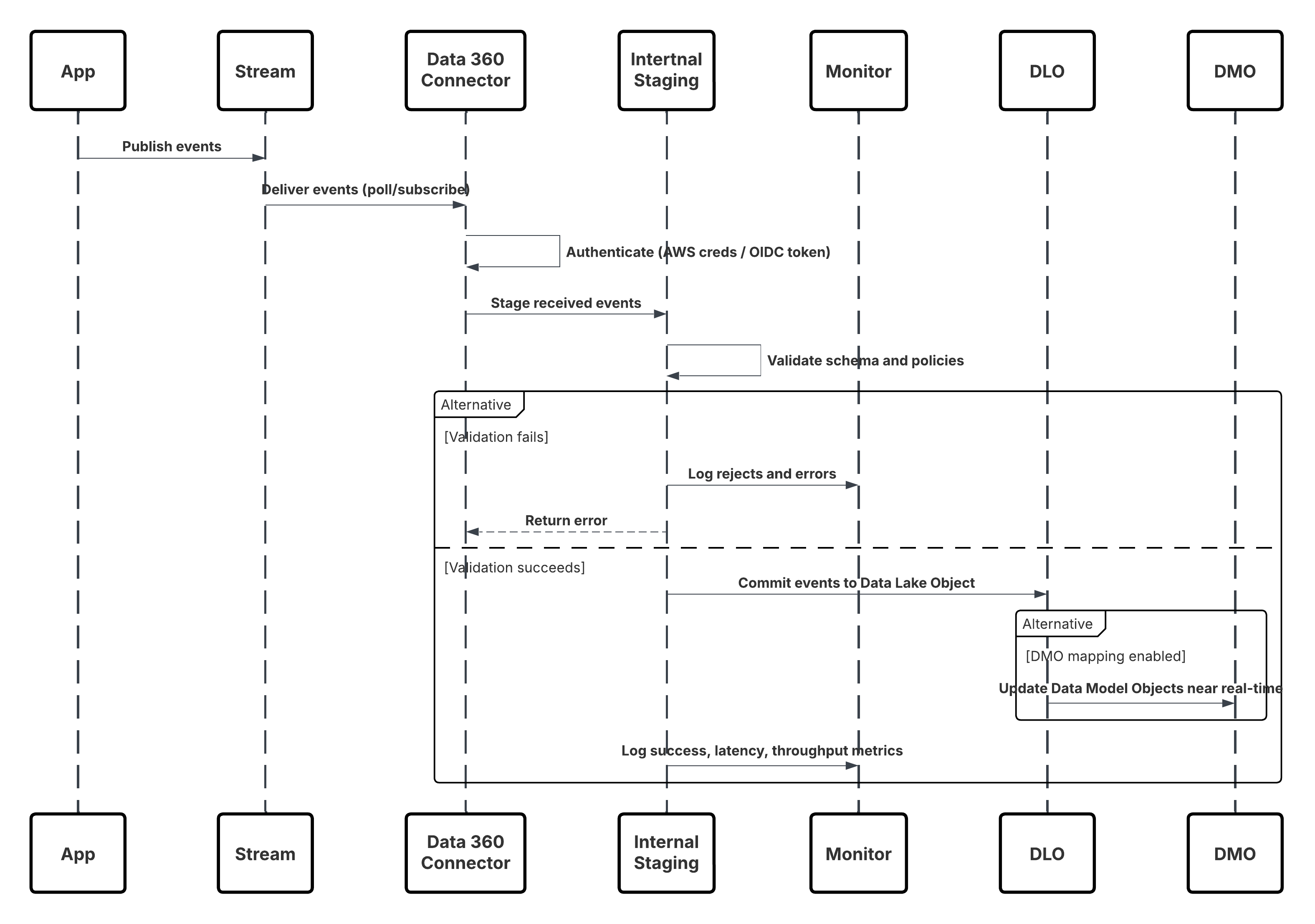
Dans ce scénario :
- Les applications ou les appareils publient des événements dans Kinesis Stream ou MSK Topic.
- Le connecteur Data 360 s'authentifie en utilisant des identifiants AWS ou un jeton OIDC.
- Le connecteur interroge ou s'abonne continuellement au flux.
- Les événements sont organisés, validés pour le schéma et la stratégie, puis engagés dans Objet lac de données (DLO).
- S'ils sont mappés, les objets modèle de données (DMO) sont mis à jour en temps quasi réel pour l'activation.
- La couche de surveillance suit les métriques, les rejets de schéma et la latence.
Résultats
Ingestion continue et à faible latence de données structurées directement depuis AWS Kinesis ou MSK dans Data 360. Les données sont immédiatement disponibles pour :
- Résolution de l'identité
- Segmentation en temps réel
- Activation IA Einstein
- Déclencheurs pilotés par Agentforce Élimine la dépendance à l'ETL par lot, en activant des architectures basées sur le flux alignées avec les conceptions pilotées par les événements d'entreprise.
Mécanismes d'ingestion
| Mécanisme | Quand utiliser |
|---|---|
| Connecteur Kinesis (préféré) | Pour les sources de streaming natives AWS nécessitant une ingestion continue de données structurées à haut volume. |
| Connecteur MSK | Pour les organisations qui exécutent des pipelines d'événements sur des plates-formes compatibles Kafka. |
| Hybride (Streaming + Batch) | Pour l'ingestion incrémentielle d'événements combinée à des charges en masse périodiques. |
Gestion et récupération des erreurs
- Récupérations automatiques : Les connecteurs réessayent les erreurs transitoires de réseau ou de plate-forme avec un backoff exponentiel.
- Refus de schéma : Les charges utiles non valides sont acheminées vers la file d'attente de rejet du schéma pour examen par l'administrateur.
- DLQ Replay : Les échecs persistants sont capturés dans des files d'attente en lettres mortes pour être retraités.
- Contrôle de l'immunité : Les clés d'événement ou les numéros de séquence garantissent la déduplication et l'ingestion ordonnée.
- Surveillance de l'intégration : Tous les échecs, tentatives et métriques de débit sont exposés dans les tableaux de bord Data 360 Monitoring.
Considérations relatives à la conception impotente
- Unicité et suivi des événements : Chaque événement est attribué à une clé unique déterministe (par exemple, PartitionKey + SequenceNumber pour Kinesis, ou Rubrique + Partition + Offset pour MSK) pour garantir l'ingestion exacte une fois.
- Contrôle du connecteur : Les connecteurs Data 360 conservent le dernier décalage traité ou numéro de séquence pour reprendre l'ingestion en toute sécurité après des échecs ou un redémarrage.
- Déduplication et logique UPSERT : Pendant les validations d'objet lac de données, les événements dupliqués sont détectés et ignorés. Les enregistrements valides sont mis à jour en utilisant la clé unique pour plus de cohérence.
- Contrôle de lecture et de récupération : Les événements échoués ou retardés sont rejoués à partir des décalages stockés via les files d'attente Lettre morte et Relecture, ce qui garantit une récupération fiable sans duplication.
Considérations relatives à la sécurité
La sécurité fait partie intégrante du pipeline d'ingestion, de l'authentification au cryptage et au contrôle d'accès.
- Authentification : Sécurisez l'échange d'identifiants en utilisant des stratégies AWS IAM ou OIDC.
- Cryptage : Données cryptées en transit (TLS 1.2+) et au repos (AES-256) dans Data 360.
- Contrôle d'accès : Rôles de moindre privilège appliqués ; connecteurs limités à des flux/rubriques spécifiques.
- Gouvernance : Métadonnées de lignage et de classification appliquées à chaque enregistrement pour une traçabilité totale.
- Sécurité réseau : Vous pouvez également déployer dans des sous-réseaux privés en utilisant AWS PrivateLink.
Menus latéraux
Opportunité
- Traitement en temps quasi réel : Les connecteurs CDC et streaming traitent les événements en quelques secondes après les modifications de la source, garantissant généralement une actualisation des données inférieure à la minute.
- Latence déterministe : Le décalage de bout en bout dépend du débit source, de la mise en lot des événements et des conditions réseau, mais Data 360 garantit une latence prévisible pilotée par le contrat de niveau de service pour les objets pris en charge.
- Échelle élastique : Le pipeline d'ingestion s'adapte automatiquement lorsque le volume d'événements est élevé, préservant ainsi l'actualité même pendant les pics de données.
- Visibilité opérationnelle : Les tableaux de bord de surveillance exposent le décalage des événements, les horodatages d'engagement et le statut de relecture pour l'assurance de latence et le dépannage.
Volumes de données
- Charges utiles légères : Les événements CDC ou streaming individuels sont compacts (1 à 5 Ko de taille typique), optimisés pour les mises à jour à haute fréquence.
- Objets à fort changement : Pour les entités volatiles (p. ex. requête, contact, commande), les architectes doivent s'assurer que les allocations du CDC et le débit des événements correspondent aux taux de mise à jour attendus.
- Flux parallèles : Data 360 prend en charge l'ingestion de flux multiples pour l'échelle horizontale entre des volumes d'objets importants ou plusieurs organisations sources.
- Traitement de la contre-pression : Les mécanismes de laminage intégrés maintiennent la stabilité de l'ingestion sous charge sans laisser tomber les événements.
Gestion des états
Chaque événement inclut des métadonnées pour le contrôle d'état et de version :
- Relecture et suivi décalé : Chaque événement contient des métadonnées d'ID de lecture et de séquence, ce qui permet la livraison commandée et la récupération basée sur un point de contrôle.
- Schéma de version : Les balises de version dans les en-têtes d'événement garantissent un traitement rétrocompatible lorsque les schémas sources évoluent.
- Clés Idempotency : Chaque événement inclut une transaction ou une clé de validation unique, ce qui permet à Data 360 de dupliquer les relectures et les tentatives en toute sécurité.
- Atomic Commit : Le pipeline d'ingestion marque les compensations comme terminées uniquement lorsque les engagements en aval dans les objets lac de données réussissent, ce qui garantit la cohérence.
Scénarios d'intégration complexes
Ce schéma s'intègre de façon transparente dans les architectures d'entreprise avancées :
- Ingestion hybride : Combinez le CDC pour les deltas incrémentiels à des flux de données en masse pour des actualisations complètes, en préservant la fraîcheur et l'exhaustivité.
- Streaming inter-organisations : Plusieurs organisations CRM ou ERP peuvent publier dans le même locataire Data 360, unifié via le mappage d'objets modèle de données et l'alignement de l'ontologie.
- Enrichissement des événements : Un middleware (par exemple, MuleSoft, Relais d'événements) peut enrichir, filtrer ou acheminer les données en continu avant qu'elles atteignent Data 360.
- Activation de l'IA et de l'agent : Les mises à jour en temps réel déclenchent une automatisation en aval, par exemple des prédictions Einstein ou des réponses Agentforce, dans les secondes qui suivent l'événement d'origine.
Exemple
Une entreprise de vente au détail mondiale utilise AWS Kinesis pour diffuser les données des points de vente et des interactions Web.Le connecteur Kinesis de Data 360 s'authentifie via des identifiants IAM et ingère en permanence des événements dans un objet lac de données Transaction.Chaque enregistrement est validé par un schéma, enrichi de métadonnées et immédiatement propagé au DMO Client.En quelques secondes, les modèles IA Einstein mettent à jour les segments clients et Agentforce déclenche des recommandations Next-Best-Offre en temps réel — réalisant ainsi une boucle de personnalisation entièrement pilotée par l'événement.
Zero Copy est plus qu'une méthode d'intégration, c'est un changement fondamental dans la façon dont les données d'entreprise se déplacent, ou plutôt ne se déplacent pas. Traditionnellement, l'intégration de données nécessitait de copier de grands volumes d'enregistrements via des pipelines ETL, créant des magasins de données redondants, des délais de synchronisation et des défis de gouvernance. Zéro copie élimine tout cela. Dans ce modèle, Data 360 se connecte directement à des plates-formes de données externes telles que Snowflake et Databricks, en lisant et en activant en toute sécurité les données en place, sans jamais les déplacer ni les dupliquer. Le résultat est un pont transparent entre votre maison de lac de données d'entreprise et l'écosystème Salesforce, offrant un accès instantané, une réduction des frais opérationnels et une gouvernance des données renforcée.
Les capacités de copie zéro entrante permettent à Data 360 d'interroger et d'harmoniser les données externes à la source (telles que les profils clients, les transactions ou les données de produits) stockées dans Snowflake ou Databricks. Au lieu d'ingérer des fichiers, Data 360 établit une connexion sécurisée et sensible aux métadonnées qui exploite les définitions de schéma et les stratégies de sécurité existantes dans l'entrepôt externe.
- Fédération directe : Data 360 lit les données en place via des requêtes sécurisées et optimisées sans réplication.
- Gouvernance unifiée : Les données restent soumises au cadre de sécurité, de contrôle d'accès et de conformité du système source.
- Efficacité opérationnelle : Élimine les duplications de frais généraux et de stockage ETL, réduisant ainsi les coûts et la complexité.
- Préparation en temps réel : Active l'harmonisation à la demande : dès que les données sont mises à jour dans Snowflake, elles peuvent être immédiatement activées dans Data 360.
Context
Les entreprises modernes pilotées par les données gèrent des pétaoctets de données clients, de transactions et de télémétrie dans des plates-formes lac de données à l'échelle du cloud telles que Snowflake et Databricks. Ces environnements sont la source unique de preuve pour les analytiques, l’IA et la conformité. Data 360 introduit Zero CopyData Federation, qui permet à Data 360 d'interroger et d'utiliser directement des jeux de données externes en place, sans copier, transformer ni stocker des données redondantes. Ce schéma permet aux organisations d'étendre le tissu Customer 360 à leur infrastructure existante d'entrepôt de données ou de Lakehouse, en réalisant une unification et une activation en temps réel avec zéro duplication, zéro latence et zéro compromis sur la gouvernance.
Problème
Comment les entreprises peuvent-elles exploiter des jeux de données enrichis déjà organisés dans Snowflake, Databricks ou des formats lac ouvert tels que Apache Iceberg — pour la segmentation, la résolution de l'identité et l'activation dans Data 360 — sans les coûts, la latence et les frais généraux de gouvernance des pipelines ETL ou du mouvement des données physiques ?
Forces
Ce schéma introduit de multiples considérations architecturales, de sécurité et de performance :
Réseau et sécurité
- Data 360 doit établir une connexion sécurisée et privée avec l'entrepôt externe ou Lakehouse.
- Généralement configuré en utilisant Salesforce Private Connect ou PrivateLink/VPC Peering, ce qui garantit que le trafic ne quitte jamais le réseau contrôlé du client.
- Les systèmes externes doivent ajouter les adresses IP Data 360 à la liste d'autorisations et appliquer le cryptage TLS 1.2+.
Authentification et contrôle d'accès
- Prend en charge l'authentification par paire de clés, OAuth 2.0 ou la délégation Trust basée sur le fournisseur d'identité (Data 360 agissant en tant que client de confiance)
- Le contrôle d'accès basé sur le rôle (RBAC) dans le système externe applique l'accès avec le moindre privilège à l'exécution de requêtes.
Performances et dépendance au calcul
- La fédération de requêtes envoie automatiquement l'exécution SQL vers le bas dans Snowflake ou Databricks, en exploitant leurs clusters de calcul.
- Les performances et l'échelle de coût avec la charge de requête externe - la latence de segmentation et le coût sont liés à la configuration du calcul externe.
Normes évolutives : Fédération de fichiers
- Un modèle de nouvelle génération, Fédération de fichiers, exploite les formats de tableau ouverts tels que Apache Iceberg ou Delta Lake, permettant à Data 360 de lire directement depuis le stockage d'objets (par ex. Amazon S3, Azure ADLS, Google Cloud Storage).
- En contournant la couche de calcul source, Fédération de fichiers réduit considérablement la latence et le coût des charges de travail analytiques lourdes en lecture tout en préservant l'intégrité du schéma.
Gouvernance et conformité
- Les données ne quittent jamais la plate-forme source. Les stratégies de conformité, de cryptage et de rétention restent appliquées à l'origine.
- Tous les attributs de métadonnées, de lignage et de consentement se propagent dans la Trust Layer de Data 360 pour garantir une traçabilité de bout en bout.
Solution
L'approche recommandée consiste à utiliser des connecteurs Zero Copy natifs pour Snowflake, Databricks ou Fédération de fichiers dans Data 360.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Connecteur Snowflake Zero Copy | Meilleur | Intégration native tierce; établit la fédération de requêtes live via les API Partage de données ou Tableau externe Snowflake. |
| Connecteur Databricks Zero Copy | Meilleur | Prend en charge l'accès direct en direct aux tableaux/vues dans Delta Lake. Les requêtes pushdown sont exécutées à l'exécution de Databricks. |
| Fédération de fichiers (Apache Iceberg / Delta / Parquet) | Meilleures pratiques émergentes | Data 360 lit directement les formats de tableau ouverts dans le stockage d'objets sans dépendance de calcul externe. Idéal pour les jeux de données massifs. |
| Configuration du réseau privé | Recommandé | Utilisez Salesforce Private Connect ou le peering VPC pour sécuriser la fédération au niveau du réseau. |
| Authentification et gestion des clés | Meilleures pratiques | Implémentez une authentification sécurisée basée sur la clé ou OAuth avec une rotation périodique et une gestion des coffres-forts. |
| Enregistrement du schéma | Obligatoire | Data 360 récupère le schéma externe et le mappe avec un objet lac de données externe (objet lac de données externe). |
| Métadonnées régies | Recommandé | Tous les objets lac de données externes héritent des métadonnées de classification, de consentement et de lignage pour la visibilité de la conformité. |
Croquis
Le diagramme ci-dessous montre comment configurer une connexion zéro copie et créer des objets lac de données externes dans Data 360.
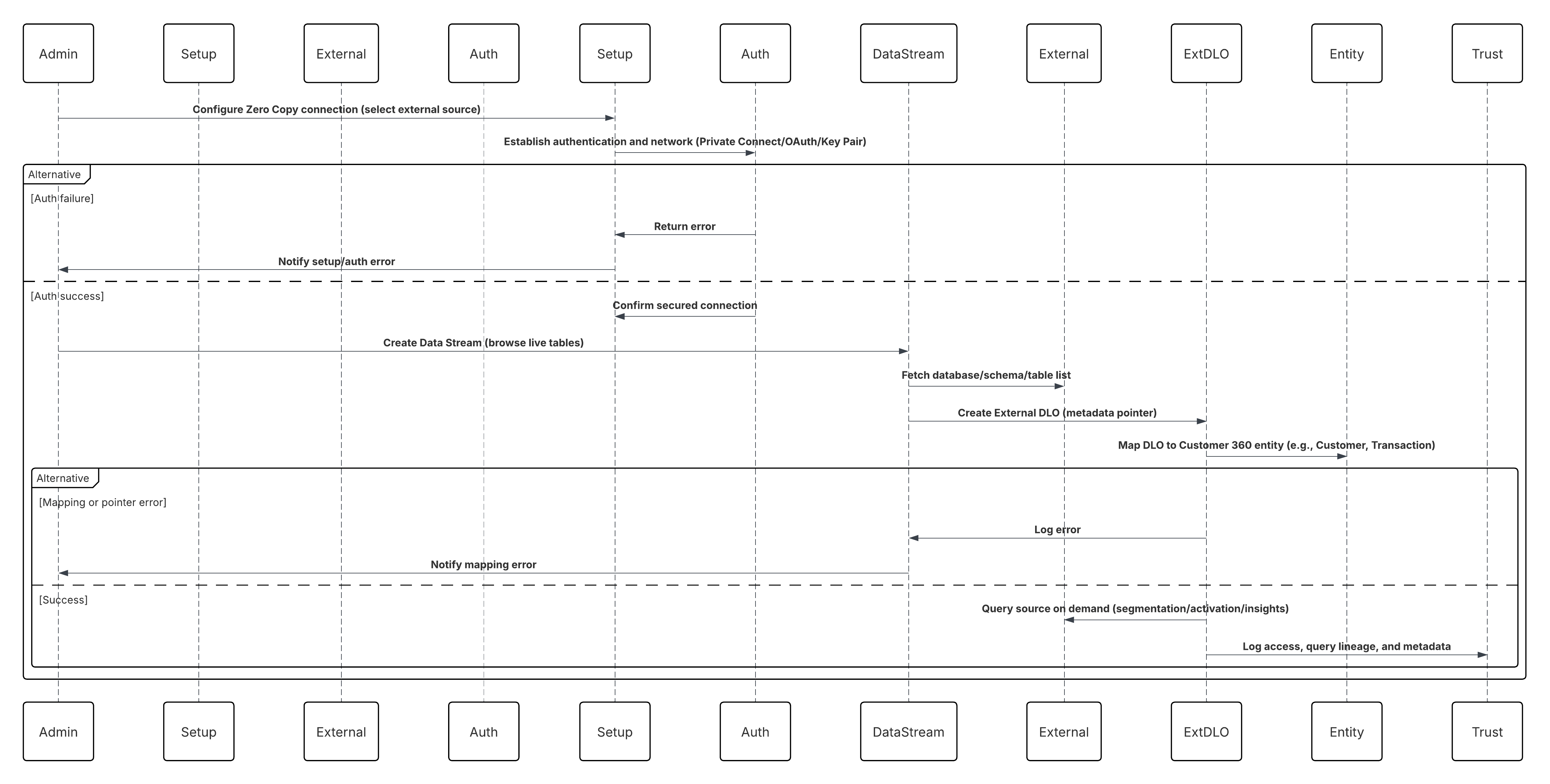
Dans ce scénario :
- L'administrateur configure une connexion Zero Copy dans la Configuration de Data 360 (Snowflake, Databricks ou Fédération de fichiers).
- L'authentification sécurisée et l'acheminement réseau sont établis (Private Connect / OAuth / Paire de clés).
- L'administrateur crée un flux de données en sélectionnant la source externe, en parcourant les bases de données live, les schémas et les tableaux.
- Au lieu de copier des données, Data 360 crée un objet lac de données externe (Objet lac de données), un pointeur de métadonnées référençant le tableau live ou le fichier Iceberg.
- Les objets lac de données externes sont mappés avec des entités Customer 360 (p. ex., Client, Transaction, Produit).
- Data 360 interroge la source en place pendant la segmentation, l'activation ou le calcul des connaissances.
- Tous les accès, lignages de requêtes et métadonnées sont audités dans Data 360 Trust Layer.
Résultats
- Les données externes sont conservées dans Snowflake, Databricks ou S3, pas d'ETL, pas de duplication, pas de stockage supplémentaire.
- Data 360 obtient un accès en temps réel et en lecture aux données de l'entreprise pour la résolution de l'identité, les connaissances calculées et l'activation.
- Les organisations gardent un contrôle total dans leurs cadres de gouvernance, de cryptage et de conformité existants.
- Ce schéma permet une véritable architecture Zero Copy, combinant les performances de l'accès local à la gouvernance du stockage fédéré.
Mécanismes d'appel
Le mécanisme d'appel dépend de la solution choisie pour implémenter ce schéma.
| Mécanisme | Quand utiliser |
|---|---|
| Snowflake Federation (préféré) | Pour une fédération de requêtes live et performante avec des entrepôts de données d'entreprise régis. |
| Databricks Federation | Pour des analytiques unifiées et des environnements Lakehouse avec des jeux de données pris en charge par Delta ou Parquet. |
| Fédération de fichiers (Apache Iceberg / Delta Lake) | Pour des jeux de données à grande échelle dans le stockage d'objets où le détachement du calcul et l'optimisation des coûts sont essentiels. |
| Mode hybride (zéro copie + ingestion) | Lorsque des données historiques nécessitent une ingestion unique, mais que les données live sont accédées via Zero Copy. |
Gestion et récupération des erreurs
- Reprise automatique et restauration des requêtes : La connectivité transitoire ou les expirations de requête sont automatiquement ré-essayées en utilisant un backoff exponentiel.
- Isolation de la non concordance du schéma : Les modifications apportées au schéma source (p. ex. nouvelles colonnes) sont consignées dans la file d'attente de rejet du schéma. Les administrateurs peuvent remapper ou actualiser les métadonnées du schéma.
- Basculement de l'authentification : Si les identifiants expirent, Data 360 tente une nouvelle connexion en utilisant des jetons d'actualisation stockés ou des stratégies de rotation de clé.
- Détection de la disponibilité du calcul : Si le cluster Snowflake ou Databricks est interrompu, Data 360 suspend les tâches de fédération et tente de nouveau de le faire lorsque le calcul reprend.
- Surveillance de l'intégration : Toutes les métadonnées d'intégrité de la connexion, de latence des requêtes et de lignage visibles dans les tableaux de bord Data 360 Monitoring.
Considérations relatives à la conception impotente
- Déterminisme de requête : Les requêtes fédérées utilisent une sémantique cohérente pour les clichés instantanés afin de garantir des lectures stables et répétitives pendant la segmentation ou l'activation.
- Versionnement DLO externe : Chaque requête fédérée inclut des métadonnées de schéma et d'horodatage pour le suivi de lignage.
- Accès sans décalage : Comme Zero Copy est en lecture seule, il ne s'appuie pas sur les décalages d'événements. La cohérence est appliquée via les garanties ACID du système externe (Snowflake/Delta Lake).
- Gestion des dérives de schéma : Maintenir les mappages de schémas avec version dans Data 360 ; actualiser les métadonnées d'objet lac de données externe sur l'évolution de la source.
Considérations relatives à la sécurité
La sécurité fait partie intégrante du modèle de fédération – sans compromis de Trust ou de conformité.
- Cryptage : Tous les échanges de données utilisent le protocole TLS 1.2+ ; les entrepôts externes cryptent au repos en utilisant AES-256.
- Contrôle d'accès : Les tableaux externes sont accédés via des rôles de moindre privilège avec des autorisations en lecture seule.
- Isolement du réseau : Les routes Private Connect ou VPC empêchent toute exposition aux points de terminaison publics.
- Flux de données régi : Les métadonnées de lignage, de consentement et de classification sont transmises dans Data 360 Trust Layer pour l'application des politiques.
- Auditabilité : Chaque requête fédérée et événement d'accès au schéma est consigné pour la traçabilité de la conformité (RGPD, CCPA, HIPAA).
Menus latéraux
Opportunité
- Les requêtes sont exécutées en direct sur l'entrepôt ou le stockage externe, ce qui garantit une visibilité en temps réel du dernier état des données.
- Les exécutions de segmentation ou d'activation reflètent les modifications à la seconde près dans les tableaux Snowflake, Databricks ou Iceberg soutenus par S3.
- La latence des requêtes dépend du niveau de performance du système source, généralement de quelques secondes à plusieurs dizaines de secondes par requête.
- Idéal pour les charges de travail analytiques et IA exigeant un accès aux données « frais, pas copié ».
Volumes de données
- Prend en charge les jeux de données à l'échelle du pétaoctet stockés nativement dans Snowflake ou Databricks sans réplication.
- Data 360 récupère uniquement les résultats, pas les jeux de données bruts, ce qui réduit les coûts réseau et de calcul.
- Fédération de fichiers optimise les analyses volumineuses grâce à l'élagage des partitions et au pushdown des colonnes.
- Évolue linéairement avec la capacité de calcul de l'entrepôt et la couche d'orchestration de requêtes fédérées de Data 360.
Gestion des états
- Les objets lac de données externes conservent les métadonnées de connexion, de schéma et de version dans Data 360.
- L'évolution du schéma est gérée automatiquement via des cycles d'actualisation des métadonnées.
- Le lignage des requêtes inclut l'horodatage, l'identité de l'utilisateur et des métriques d'exécution pour la traçabilité.
- Aucune ingestion ni compensation n'est maintenue, la cohérence est héritée des garanties ACID de la source externe.
Scénarios d'intégration complexes
- Mode hybride : Combinez Zero Copy (pour la fédération live) avec l'ingestion (pour les jeux de données historiques).
- Accès inter-entrepôts : Data 360 peut fédérer à partir de plusieurs locataires Snowflake ou Databricks dans une seule organisation.
- Interopérabilité IA/BI : Les systèmes externes (p. ex. SageMaker, Tableau, Power BI) peuvent interroger les profils enrichis de Data 360 via la copie Zero inverse.
- Extension Fédération de fichiers : Les entreprises qui adoptent les formats lac ouvert (Iceberg/Delta) peuvent unifier les données structurées et non structurées dans un seul modèle fédéré.
Exemple
Une entreprise financière internationale stocke toutes les données transactionnelles et d'interaction dans Snowflake, tout en conservant les attributs des clients et les événements marketing dans Data 360. En utilisant la fédération de données Zero Copy, Data 360 se connecte en toute sécurité à Snowflake via Private Connect.Lorsqu'une tâche de segmentation est exécutée, par exemple « Les clients qui ont dépensé plus de 10 000 € au cours des 30 derniers jours, Data 360 envoie automatiquement la requête à Snowflake, récupère les résultats agrégés et active instantanément ces profils dans Journey Builder. Aucune réplication ou ETL requise. Cet exemple utilise une intelligence fédérée en temps réel, unifiée dans l'écosystème des données d'entreprise.
La copie zéro sortante étend le même principe à l'inverse. Au lieu d'exporter ou de copier des jeux de données depuis Data 360, des systèmes externes comme Snowflake peuvent interroger directement Data 360, le traitant comme une source fédérée d'Intelligence client enrichie.
- Fédération inverse : Les analytiques externes ou les plates-formes IA peuvent accéder aux données de profil unifié de Data 360 sans les extraire.
- Activation des données à la source : Les équipes commerciales peuvent exploiter les connaissances là où résident déjà les données, que ce soit pour la modélisation IA, la génération de rapports ou la personnalisation des clients.
- Interopérabilité sans latence : Aucune exportation par lot ni tâche de synchronisation. Les connaissances circulent instantanément entre les plates-formes.
- Sémantique cohérente : Les deux systèmes partagent la même ontologie et les mêmes mappages de schémas. Par conséquent, le contexte et la signification sont préservés dans les écosystèmes. Zero copy redéfinit le rôle de Data 360 d'un référentiel de données à une couche d'activation sémantique. Elle permet aux organisations de conserver les données à l'endroit exact où elles se trouvent, dans des entrepôts gouvernés et hautement performants, tout en conservant toute leur valeur dans les limites Trust de Salesforce. Ce schéma s'aligne sur les architectures modernes de maillage de données et natives de l'IA : les données restent décentralisées, mais l'intelligence devient unifiée. Les architectes peuvent désormais élaborer des pipelines d'activation plus rapides, plus légers et plus conformes, sans aucune copie.
Context
Les entreprises modernes opèrent de plus en plus dans des écosystèmes de données multi-plate-formes, où Salesforce Data 360 pilote des profils clients unifiés et l'activation, tandis que les entrepôts de données d'entreprise tels que Snowflake ou Databricks servent d'ossature analytique pour la science des données, l'apprentissage machine et les charges de travail BI. La capacité Partage sortant Zero Copy de Salesforce Data 360 relie ces environnements de façon transparente, ce qui permet un accès gouverné, sécurisé et en temps réel aux données Data 360 harmonisées directement dans Snowflake ou Databricks, sans réplication ni ETL. Cela permet aux analystes et aux scientifiques des données d'interroger, de visualiser et de modéliser sur les mêmes données live et approuvées qui propulsent l'activation du marketing, des ventes et du service.
Problème
Comment une entreprise peut-elle exposer en toute sécurité et efficacement les profils clients unifiés et les métriques calculées de Data 360 (par exemple, Valeur de durée de vie, Risque de résiliation) à des systèmes analytiques externes, sans copier les données, rompre la gouvernance ou introduire une latence via les pipelines ETL inverses traditionnels ?
Forces
Ce schéma introduit de multiples considérations architecturales, de gouvernance et opérationnelles :
- Sécurité régie : L'accès aux données Data 360 doit être contrôlé, précis et auditable. Le partage Zero Copy utilise un accès explicite au niveau de l'objet, ce qui garantit que seuls les objets modèle de données (DMO) et les objets connaissances calculées (CIO) approuvés sont disponibles pour les consommateurs désignés.
- Sélection d'objet explicite : Les administrateurs organisent les données à partager via un Partage de données, en sélectionnant explicitement les objets à exposer. Cela préserve la gouvernance et réduit l'exposition aux risques.
- Configuration bilatérale : Data 360 et l'entrepôt externe nécessitent une configuration. Data 360 définit la Cible de partage de données (Snowflake/Databricks), alors que le système de réception doit accepter et instancier le partage.
- Modèle de fédération de requêtes : Une fois acceptée, la plate-forme externe interroge les données Data 360 live et régies via des vues fédérées, éliminant ainsi les tâches d'extraction ou les cycles d'actualisation manuels.
- Évolution des normes ouvertes : Des approches émergentes comme Fédération de fichiers exploitent les formats de tableau ouverts (par exemple, Apache Iceberg) pour activer l'accès en lecture seule à la couche de stockage, ce qui améliore l'évolutivité, les performances et l'interopérabilité entre les architectures multicloud.
Solution
La solution exploite le Partage de copie zéro natif de Salesforce Data 360 avec des plates-formes de données telles que Snowflake ou Databricks.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Création de partage de données | Meilleur | L'administrateur crée un Partage de données dans Data 360, en ajoutant les objets modèle de données et les DSI sélectionnés (par exemple Individu unifié, Score de santé client). |
| Configuration de cible | Meilleur | Créez une cible de partage de données en spécifiant les identifiants de compte et les paramètres d'authentification Snowflake ou Databricks. |
| Partager la publication | Meilleures pratiques | Liez le Partage de données à la Cible de partage de données pour le publier en toute sécurité. |
| Acceptation d'entrepôt | Obligatoire | L'administrateur externe accepte le partage et matérialise les objets partagés sous forme de vues/tableaux en lecture seule dans l'entrepôt. |
| Contrôle d'accès granulaire | Recommandé | Appliquez des autorisations basées sur l'objet et le rôle dans Data 360, alignez-vous sur le contrôle d'accès basé sur le rôle au niveau de l'entrepôt. |
| Accès aux requêtes fédérée | Meilleur | Les analystes interrogent les données partagées en direct via SQL standard, joint aux données natives de l'entrepôt pour les analytiques en aval et la ML. |
| Option Fédération de fichiers | Optional | Pour des jeux de données volumineux, exploitez la fédération basée sur Apache Iceberg pour des lectures directes S3 ou Delta Lake sans dépendance au calcul. |
Croquis
Le diagramme ci-dessous illustre un appel depuis Salesforce Data 360 vers une plate-forme de données externe.
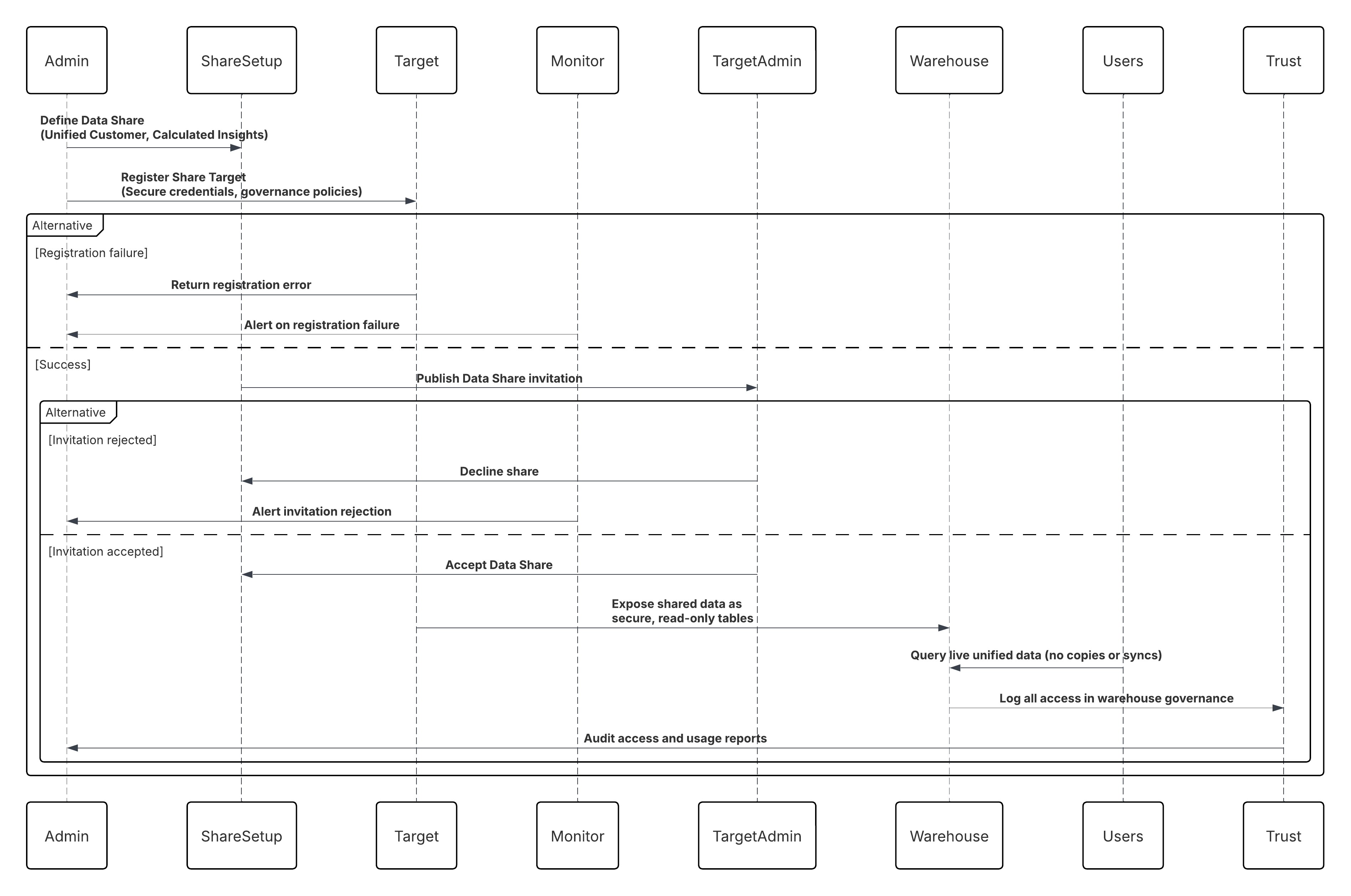
Dans ce scénario :
- L'administrateur Data 360 définit un Partage de données comprenant les objets Client unifié et Connaissances calculées.
- Une cible de partage de données (compte Snowflake ou Databricks) est enregistrée avec des identifiants sécurisés et des stratégies de gouvernance.
- Data 360 publie le partage ; les administrateurs Snowflake/Databricks l'acceptent.
- Les données partagées sont affichées sous forme de tableaux sécurisés en lecture seule dans l'entrepôt.
- Les analystes, les outils de BI ou les pipelines ML interrogent les données client live et unifiées sans les copier ni les synchroniser.
- Tous les accès sont audités dans les journaux de gouvernance de Data 360 Trust Layer et d'entrepôt.
Résultats
- Les entrepôts externes obtiennent un accès en temps réel et interrogeable aux données Data 360 harmonisées.
- Élimine les pipelines ETL inverses, réduisant ainsi la charge opérationnelle et la latence.
- Active la formation IA/ML, la modélisation prédictive et la BI avancée directement sur des données unifiées.
- Maintient l'absence de duplication, une gouvernance solide et un contrôle d'accès sécurisé par conception.
- Termine la boucle bidirectionnelle Zero Copy, dans laquelle la fédération entrante et le partage sortant coexistent sous un modèle de gouvernance unique.
Mécanismes d'appel
Le mécanisme d'appel dépend de la solution choisie pour implémenter ce schéma.
| Mécanisme | Quand utiliser |
|---|---|
| Partage de données sécurisé Snowflake (préféré) | Utilisé lorsque votre entrepôt d'entreprise est Snowflake et que vous avez besoin d'un accès live et régi aux jeux de données Data 360 harmonisés sans mouvement de données ni duplication. Idéal pour les analytiques, l'IA et les charges de travail pilotées par la conformité qui nécessitent le partage sans latence et l'application automatique de la lignage native. |
| Databricks Delta Partager | Utilisé lorsque les consommateurs en aval travaillent dans des environnements Databricks ou Delta Lake et nécessitent un accès en temps réel et en lecture seule à des jeux de données unifiés ou activés via le protocole ouvert Delta Sharing. |
| Part de table externe (Iceberg Apache / Parquet) | Utilisez-les pour gérer des architectures de format ouvert dans le stockage d'objets (S3, ADLS ou GCS) et pour utiliser le partage interopérable et économique entre des moteurs d'analyse tels que Athena, BigQuery ou Snowflake-on-Iceberg. |
| API de partage de données (accès programmatique) | Utilisé lorsque des applications personnalisées ou des middlewares (par exemple, MuleSoft) doivent découvrir, s'abonner ou consommer des jeux de données partagés en toute sécurité via des API, avec des notifications d'actualisation basées sur l'événement et un contrôle d'accès précis. |
| Partage hybride (copie nulle + partage sortant) | Utilisez-les pour implémenter des modèles d'échange bidirectionnel, en exploitant Zero Copy pour les données entrantes et Outbound Data Share pour publier des connaissances, afin de garantir la cohérence sémantique et de gouvernance entre les plans de données de l'entreprise. |
Gestion et récupération des erreurs
- Récupérations de connexion : Essais automatisés en cas d'échec de connexion ou d'authentification transitoire entre Data 360 et l'entrepôt.
- Validation du partage : Les configurations de partage non valides ou non autorisées sont mises en quarantaine dans une file d'attente de révision de l'administrateur.
- Surveillance de l'intégrité de la synchronisation : **** Data 360 expose le statut de partage en direct, la latence des requêtes et les journaux d'accès via des tableaux de bord Monitoring.
- Révocation de l'accès : Les administrateurs peuvent révoquer des partages instantanément, désactivant l'accès aux deux extrémités sans copie de données résiduelle.
- Piste d'audit régie : Toutes les modifications de configuration et d'accès sont consignées pour vérification de la conformité.
Considérations relatives à la conception impotente
- Identification de partage cohérente : Chaque paire Partage de données et Cible de partage de données a un identifiant unique, ce qui garantit une gouvernance exacte et une traçabilité de l'accès.
- Vues immuables : Les objets de données partagés sont en lecture seule. Les consommateurs ne peuvent pas muter l'état, ce qui garantit des résultats déterministes et la conformité.
- Cycle de vie de partage atomique : La publication, la révocation et les mises à jour de partage sont des opérations atomiques, entièrement terminées ou annulées.
- Cohérence de lecture : Lorsque les données Data 360 sont actualisées, les requêtes côté entrepôt renvoient toujours le dernier cliché instantané cohérent, ce qui élimine les lectures périmées.
Considérations relatives à la sécurité
La sécurité sous-tend chaque aspect du partage de copie zéro :
- Authentification: Mutual Trust établi en utilisant OAuth 2.0, échange de clés privées ou fédération d'identité (OIDC).
- Cryptage: Données cryptées en transit (TLS 1.2+) et au repos (AES-256).
- Contrôle d'accès: Les autorisations au niveau de l'objet appliquent automatiquement l'accès avec le moindre privilège, régi par Data 360 Trust Layer.
- Sécurité réseau: Les échanges de données se font via des liens réseau privés tels que Salesforce Private Connect ou les API Secure Data Exchange.
- Métadonnées de gouvernance: Chaque objet partagé inclut des attributs de lignage, de classification et de consentement pour une traçabilité totale et la conformité réglementaire.
Menus latéraux
Opportunité
- Disponibilité en temps réel : Les données partagées reflètent l'état le plus récent de Data 360 sans délais de réplication.
- Fraîcheur de la requête : Les modifications apportées aux objets modèle de données ou aux DSI se propagent instantanément aux vues d'entrepôt partagées.
- Élasticité des performances : Le pushdown des requêtes s'adapte dynamiquement aux ressources de calcul de l'entrepôt.
- Surveillance : Les tableaux de bord live exposent des métriques de performance de latence et de requête partagées pour l'assurance opérationnelle.
Volumes de données
- Partage évolutif : Prend en charge le partage de données granulaires au niveau de l'objet ou du domaine complet, selon les besoins analytiques.
- Performances de requête optimisées : Snowflake/Databricks met intelligemment en cache les données partagées afin de réduire la latence.
- Efficacité de stockage : Zéro duplication élimine les coûts de stockage redondants.
- Option Fédération de fichiers : Pour des jeux de données à l'échelle du pétaoctet, le partage direct basé sur Iceberg contourne le calcul et accélère l'accès.
Gestion des états
- Évolution du schéma : Les schémas contrôlés par version garantissent la compatibilité lorsque le modèle Data 360 évolue.
- Suivi de l'état d'accès : États de partage actifs/inactifs conservés dans Data 360 pour la gouvernance du cycle de vie.
- Synchronisation des métadonnées : Les mises à jour des définitions d'objet partagé sont automatiquement reflétées dans les catalogues d'entrepôts en aval.
- Garantie d'État immuable : Les vues d'entrepôt représentent toujours un état cohérent et temporel des données Data 360.
Scénarios d'intégration complexes
- Mode hybride : Combinez Zero Copy (pour la fédération live) avec l'ingestion (pour les jeux de données historiques).
- Accès inter-entrepôts : Data 360 peut fédérer à partir de plusieurs locataires Snowflake ou Databricks dans une seule organisation.
- Interopérabilité IA/BI : Les systèmes externes (p. ex. SageMaker, Tableau, Power BI) peuvent interroger les profils enrichis de Data 360 via la copie Zero inverse.
- Extension Fédération de fichiers : Les entreprises qui adoptent les formats lac ouvert (Iceberg/Delta) peuvent unifier les données structurées et non structurées dans un seul modèle fédéré.
Exemple
Les analyses inter-clouds permettent aux organisations de combiner des données Salesforce Data 360 régies avec des jeux de données natifs sur des plates-formes telles que Snowflake et Databricks pour offrir une vue analytique complète et complète. Grâce à l'accès multilocataire, différentes unités commerciales peuvent consommer en toute sécurité des tranches de données organisées et contrôlées par la politique via des partages séparés sans dupliquer les données. Les scientifiques des données peuvent ensuite effectuer un apprentissage IA et machine fédéré en entraînant des modèles directement sur des profils clients unifiés dans des environnements Snowflake ML ou Databricks MLflow. Tout au long de ce processus, les capacités intégrées de lignage, de gouvernance et d'audit garantissent que l'accès et l'utilisation des données restent conformes aux politiques d'entreprise et aux exigences réglementaires telles que le RGPD et HIPAA.
Data Cloud One permet aux organisations qui ont plusieurs organisations Salesforce (par exemple, en raison d'unités commerciales, de régions, de gammes de produits ou d'acquisitions) de partager une instance Data 360 unique et centrale. Cette organisation agit en tant qu'« organisation d'origine », alors que d'autres organisations, appelées « organisations d'accompagnement », peuvent accéder à ces données unifiées et agir en conséquence, sans effort minimal, sans code personnalisé et avec des contrôles de gouvernance complets.
Context
Les entreprises gèrent souvent plusieurs organisations Salesforce (par exemple, une pour les ventes, une pour le service, une autre pour le marketing ou des régions distinctes). Chaque organisation peut avoir ses propres données, configuration et processus. Avant Data Cloud One, chaque organisation nécessitait sa propre configuration Data 360 ou un code personnalisé complexe pour partager des données entre les organisations. Data Cloud One simplifie la tâche en autorisant une seule organisation « d'accueil » avec Data 360 et plusieurs organisations « d'accompagnement » qui se connectent via une configuration à faible code et le partage de métadonnées.
Problème
Comment une entreprise peut-elle permettre une utilisation cohérente des données Customer 360 unifiées (ingérées, harmonisées et gérées par Data 360 de l'organisation d'origine) dans toutes ses organisations Salesforce (afin que les ventes, le marketing, le service, etc., utilisent tous les mêmes données sous-jacentes), tout en évitant la duplication des efforts, le codage personnalisé, les instances Data 360 séparées par organisation et les écarts de gouvernance ?
Forces
Ce schéma introduit de multiples considérations architecturales, de sécurité et de performance :
- Complexité multi-organisations: L'organisation de chaque unité commerciale peut avoir des données, des objets personnalisés, une sécurité et des processus différents. Il est difficile de maintenir des vues unifiées cohérentes.
- Duplication et coût: L'exécution d'une instance Data 360 séparée par organisation entraîne une configuration supplémentaire, une gouvernance supplémentaire, des licences supplémentaires et le risque de silos de données.
- Gouvernance et contrôles de partage de données: Vous devez déterminer les données que chaque organisation partenaire peut afficher et utiliser. Vous ne pouvez pas simplement partager « tout » sans risque de gouvernance.
- Vitesse de configuration: Les équipes marketing, commerciales ou de service ne peuvent pas attendre des semaines avant qu'un code personnalisé rende les données inter-organisations disponibles, elles ont besoin de solutions de configuration par clic.
- Résidence des données, considérations régionales: Si les organisations d'origine et d'accompagnement résident dans des régions différentes, des contraintes légales ou réglementaires peuvent exister concernant l'emplacement de stockage ou le partage des données.
Solution
Le tableau ci-dessous présente diverses solutions à ce problème d'intégration.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Provisionnement d'organisation domestique | Meilleur | Désignez une organisation Salesforce en tant qu'organisation d'accueil dans laquelle Data 360 est provisionnée, qui devient le référentiel de données central et la plate-forme de gouvernance. |
| Connexion de l'organisation compagnon | Meilleur | Configurez des connexions Compagnon depuis l'organisation d'origine vers une ou plusieurs organisations Compagnon via l'application Data Cloud One, sans code personnalisé. |
| Définition d'espace de données | Meilleures pratiques | Définissez des espaces de données dans l'organisation d'origine pour segmenter logiquement les données (par exemple, Retail, Service, Marketing) et isoler les limites d'accès. |
| Partage d'espace de données | Meilleur | Partagez explicitement les Espaces de données sélectionnés depuis l'organisation d'origine vers les organisations d'accompagnement, afin de garantir une visibilité des données unifiées régie et basée sur le rôle. |
| Configuration de l'accès | Obligatoire | Dans Organisations complémentaires, activez l'application Data Cloud One et attribuez des autorisations utilisateur pour l'accès au profil, aux connaissances et au segment. |
| Gouvernance et contrôle des politiques | Recommandé | Centralisez toutes les configurations d'ingestion, de résolution de l'identité et Trust dans l'organisation d'origine, en maintenant une gouvernance de bout en bout. |
| Synchronisation multi-organisations | Meilleur | Les modifications des données et les connaissances calculées dans l'organisation d'accueil sont reflétées en temps réel dans les organisations compagnes via des pipelines de synchronisation gérés. |
| Option de déploiement hybride | Optional | Pour les grandes entreprises, plusieurs organisations compagnes peuvent se connecter à une seule organisation d'origine tout en préservant le contexte local et les limites de conformité. |
Croquis
Le diagramme ci-dessous illustre la séquence des événements dans ce schéma, où Salesforce est le maître des données.
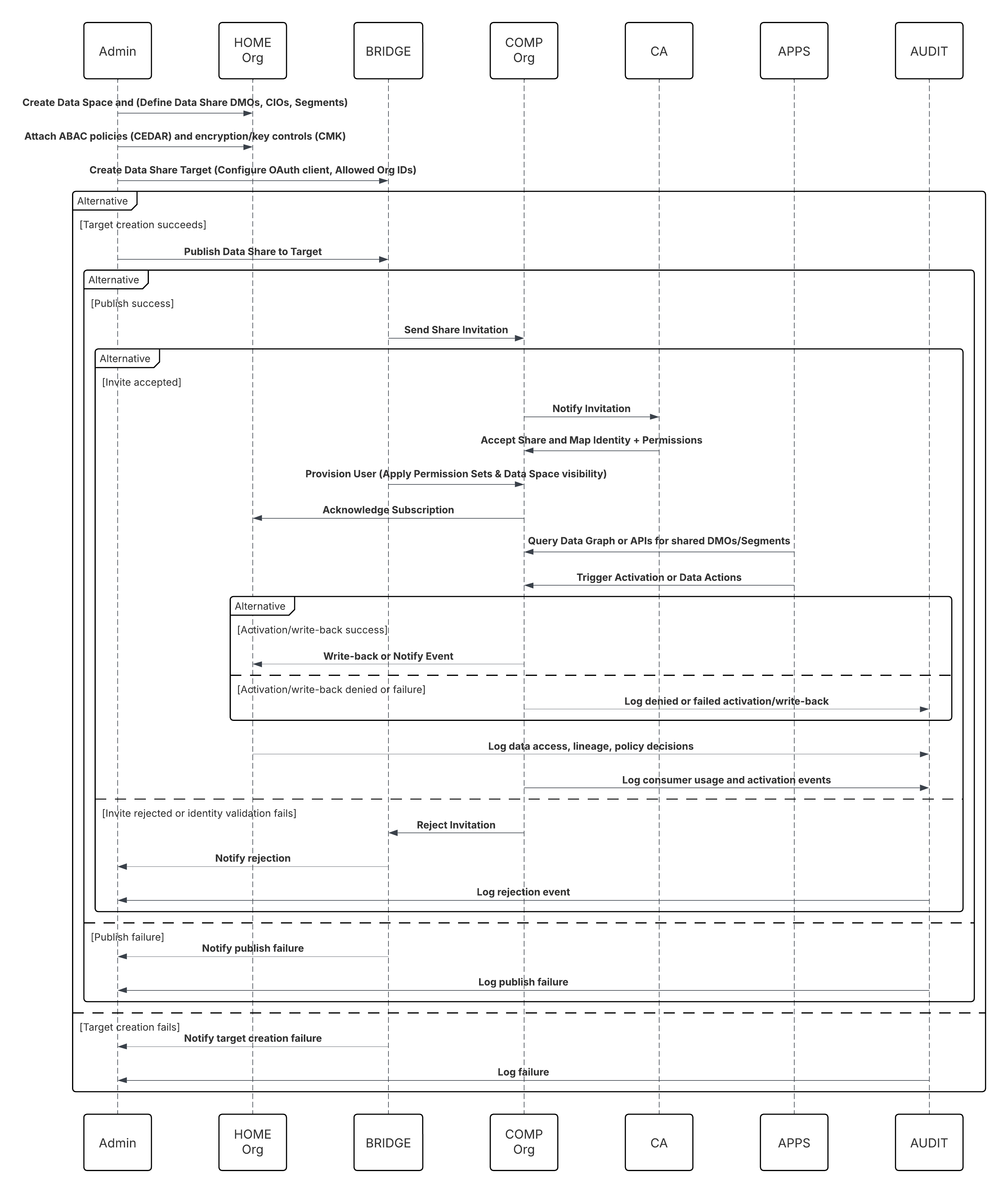
Dans ce scénario :
- Administrateur à domicile : créez un espace de données et définissez Partage de données (sélectionnez DMO/CIO, segments).
- Administrateur à domicile : créer Cible de partage de données pour les organisations compagnes et configurer Trust (client OAuth, ID d'organisation autorisés).
- Administrateur d'accueil : publiez Partage de données sur cible, joignez des stratégies ABAC (CEDAR) et des contrôles de cryptage/clé (CMK si nécessaire).
- Administrateur de l'organisation compagne : reçoit l'invitation, valide le mappage d'identité et accepte le partage.
- Organisation Compagnon: Data Cloud One Bridge provisionne un utilisateur Data Cloud One et applique la visibilité Ensembles d'autorisations et Espace de données.
- Applications d'organisation complémentaire (flux / Einstein / Apex): Interrogez un graphique de données ou appelez les API Data Cloud One pour lire des objets modèle de données ou des segments partagés.
- Activation: L'organisation compagne déclenche l'activation ou réécrit via des actions de données (si autorisé).
Résultats
- Une source unique de vérité pour les données clients (Client 360) dans toutes les organisations connectées — pas d'instances Data 360 redondantes.
- Les organisations compagnes peuvent accéder à des données unifiées et aux fonctionnalités pilotées par Data 360 en quelques minutes, pas en semaines de codage personnalisé.
- Partage de données contrôlé. Seuls les espaces de données autorisés sont partagés, ce qui préserve la sécurité et la gouvernance tout en permettant l'agilité métier.
- Les fonctions commerciales (ventes, service, marketing) fonctionnent sur la même fondation de données unifiée, ce qui permet des métriques, une activation et des connaissances cohérentes dans l'ensemble de l'entreprise.
Mécanismes d'appel
Le mécanisme d'appel dépend de la solution choisie pour implémenter ce schéma.
| Mécanisme | Quand utiliser |
|---|---|
| Partage natif Data Cloud One (préféré) | Utilisé lorsque plusieurs organisations Salesforce (Sales, Service ou Industry Cloud) ont besoin d'un accès en temps réel aux données clients unifiées directement depuis Data 360\. Cela élimine la réplication et active l'accès sans latence aux enregistrements Golden, aux segments et aux connaissances calculées. |
| Partage d'organisation à organisation via un pont Data Cloud One | Utilisé lorsque plusieurs unités commerciales ou filiales opèrent dans des organisations Salesforce distinctes, mais doivent avoir un accès partagé aux données et segments clients communs à partir d'une instance Data 360 centrale. Idéal pour les entreprises multi-organisations qui gèrent des systèmes opérationnels indépendants. |
| API Einstein 1 Platform Query | Utilisé lorsque les applications Salesforce, Flow ou Einstein Copilot doivent interroger ou activer des données Data 360 par programmation. Permet de récupérer en temps réel des profils, des métriques ou des résultats d'activation unifiés dans d'autres applications Salesforce sans exportation par lot. |
| Activation dans les canaux Salesforce | Utilisé lorsque les données Data 360 (segments, connaissances ou attributs) doivent être activées dans Marketing Cloud, Service Cloud ou Commerce Cloud pour des expériences de personnalisation, d'exécution de campagnes ou d'assistance des agents. |
| Accès aux graphiques de données (couche de requête sémantique) | Utilisé lorsque vous avez besoin d'un accès au niveau sémantique au modèle de données unifié via le Graphique de données Salesforce, qui prend en charge Copilot, les workflows IA et les analytiques inter-clouds en temps réel, sans jointures ni transformations manuelles. |
Gestion et récupération des erreurs
- Résilience de synchronisation inter-organisations : Data Cloud One essaie automatiquement les tâches de synchronisation échouées entre les organisations d'accueil et les organisations d'accompagnement en utilisant un backoff exponentiel pour les erreurs transitoires de réseau ou de plate-forme.
- Isolement partiel du lot : Les lots d'enregistrements échoués sont mis en quarantaine dans une File d'attente de nouvelle tentative au sein de l'organisation d'origine jusqu'à ce que le rapprochement réussisse, ce qui évite la divergence des données.
- Gouvernance du rejet du schéma : Les incohérences de schéma ou de mappage sont acheminées vers la file d'attente de refus du schéma pour examen et correction par l'administrateur.
- Continuité de lecture et de reprise : Chaque tâche de synchronisation conserve des points de contrôle décalés afin de permettre la reprise de la réplication depuis le dernier engagement réussi sans duplication.
- Surveillance intégrée : Tous les échecs, tentatives et métriques de reprise sont capturés dans le tableau de bord Trust Layer Monitoring pour la visibilité et l'assurance d'accord de niveau de service.
Considérations relatives à la conception impotente
- Clés d'idée-force déterministes : Chaque événement de synchronisation porte une clé unique (ID d'organisation + ID d'enregistrement + Numéro de version) pour garantir un traitement unique.
- Sécurité de lecture : Les événements dupliqués ou rejoués sont filtrés au moment de l'engagement, ce qui garantit des mises à jour cohérentes en aval des objets modèle de données et du DSI.
- Sémantique de validation atomique : Les organisations compagnes marquent les données comme engagées uniquement après des écritures en aval réussies, préservant ainsi l'intégrité transactionnelle inter-organisations.
- Résolution des conflits : Les mises à jour multisources suivent une logique de fusion en dernière écriture ou pilotée par une politique, en préservant la lignage et la cohérence.
- Persistance du point de contrôle : Les tâches de synchronisation conservent les décalages et l'état des derniers traitements dans la Trust Layer pour une récupération et une relecture sécurisées.
Considérations relatives à la sécurité
- Authentification forte : Les connexions entre les organisations d'accueil et les organisations d'accompagnement utilisent OAuth 2.0 mutuelles avec des jetons à rotation automatique gérés via des applications connectées.
- Autorisation granulaire : Les organisations compagnes peuvent accéder uniquement à des espaces de données, des objets modèle de données ou des DSI spécifiques explicitement partagés via des stratégies de partage de données régies.
- Cryptage partout : Les données sont cryptées en transit (TLS 1.2+) et au repos (AES-256) dans les organisations domestiques et les organisations complémentaires.
- Principe du moindre privilège : Les utilisateurs de l'intégration sont limités aux objets requis. Aucune autorisation administrative ou au niveau système n'est propagée.
- Visibilité d'audit et de conformité : Tous les événements de synchronisation, les modifications de schéma, les mises à jour d'identifiants et les autorisations d'accès sont consignés dans Data 360 Trust Layer pour une traçabilité totale.
- Isolation du réseau privé : En option, Salesforce Private Connect ou Private Link garantit la réplication des données uniquement sur des canaux internes sécurisés.
Menus latéraux
Opportunité
- La synchronisation entre les organisations d'accueil et les organisations d'accompagnement est effectuée en temps quasi réel, généralement quelques secondes après une modification des données dans l'organisation source.
- L'architecture Zero Copy garantit que les données partagées peuvent être instantanément interrogées dans toutes les organisations participantes, sans délai de réplication ni de lot.
- Les tâches d'activation et de segmentation reflètent automatiquement les toutes dernières mises à jour de n'importe quelle organisation connectée, préservant ainsi la fraîcheur opérationnelle.
- La latence de bout en bout est déterministe et régie par le pipeline d'orchestration de Data Cloud One, ce qui garantit une actualité inter-organisations cohérente, même en charge.
Volumes de données
- Conçu pour la synchronisation des données multi-locataires à grande échelle entre les régions et les unités commerciales, capable de gérer des milliards d'enregistrements par organisation.
- Les données sont référencées, pas dupliquées, ce qui réduit l'empreinte de stockage tout en préservant l'interrogation globale.
- Les deltas en continu et le compactage des métadonnées optimisent la bande passante et engagent les frais généraux pour les objets à taux de modification élevé (par exemple, Contact, Commande).
- Évolue horizontalement entre plusieurs organisations compagnes avec l'équilibrage de charge adaptatif et l'orchestration via la Trust Layer.
Gestion des états
- Chaque jeu de données synchronisé conserve le lignage des métadonnées, la version et le contexte de propriété de l'organisation pour garantir une traçabilité de bout en bout.
- La persistance des points de contrôle capture les décalages de dernière synchronisation entre les organisations, ce qui permet une récupération sans duplication.
- La gestion des versions de schéma et l'alignement sémantique entre les organisations sont automatiquement régis par les Trust Layers.
- Aucune réinitialisation manuelle de l'état n'est requise. L'état de synchronisation est conservé via le service d'orchestration Data Cloud One.
Scénarios d'intégration complexes
- Fédération inter-organisations : Active l'interrogation et l'activation transparentes entre plusieurs locataires ou régions Data 360 dans un modèle de gouvernance unifié.
- Synchronisation hybride : Combine la réplication en temps quasi réel pour les mises à jour transactionnelles et la synchronisation planifiée pour les données en masse ou archivistiques.
- Gouvernance multirégionale : Prend en charge le partage de données géographiquement distribué tout en respectant les frontières de résidence, de consentement et de conformité.
- Activation de l'IA et de l'automatisation : Les données synchronisées propulsent instantanément Einstein AI, Agentforce ou des modèles ML personnalisés entre les organisations, ce qui permet une intelligence inter-organisations en temps réel.
Exemple
Une organisation de vente au détail mondiale possède trois organisations Salesforce : une pour Consumer Retail, une pour Premium Brands et une autre pour International Markets. Ils provisionnent Data 360 dans l'organisation Consumer Retail (ce qui en fait l'organisation d'origine). Avec Data Cloud One, ils configurent des connexions compagnes avec les organisations Premium Brands et International Markets. Ils partagent uniquement les espaces de données appropriés (par exemple, « Customer 360 – Retail Profiles » et « Customer 360 – Premium Profiles ») avec chaque organisation partenaire. Dans l'organisation Premium Brands, les équipes marketing peuvent afficher des profils clients unifiés, élaborer des segments basés sur des connaissances calculées (par exemple, une valeur de durée de vie client supérieure) et déclencher des automatisations marketing, le tout piloté par l'instance Data 360 de l'organisation d'origine, sans code personnalisé ni duplication des données.
L'activation des données permet de donner vie à la valeur de Salesforce Data 360. Il s'agit du processus qui consiste à récupérer les données unifiées, enrichies et régies qui vivent sur la plate-forme et à les faire fonctionner dans l'ensemble de l'entreprise. En pratique, cela signifie fournir en toute sécurité des segments organisés, des connaissances calculées et des attributs contextuels depuis Data 360 vers les systèmes qui interagissent avec les clients, que ce soit l'automatisation marketing, les consoles de service, l'activation des ventes, les analytiques ou les modèles IA. D'un point de vue technique, les modèles d'activation définissent le déplacement de ces données : quels canaux sont déclenchés, quelles transformations ou quels mappages sont effectués, et comment les politiques sont appliquées en cours de route. Ces schémas ne se limitent pas à l'exportation de données, ils consistent à orchestrer des flux de données en temps réel et sensibles aux politiques qui génèrent des résultats métiers mesurables. Chaque itinéraire d'activation transforme le Customer 360 en actif opérationnel en direct. Il propulse la personnalisation, la prise de décision prédictive et l'apprentissage continu à chaque point de contact.
L'activation par lot reste la méthode la plus utilisée et la plus éprouvée sur le plan opérationnel pour exporter des données depuis Data 360. Il fonctionne selon une cadence planifiée, en publiant à intervalles réguliers des segments d'audience ou des ensembles d'attributs prédéfinis sur des plates-formes en aval. Ce modèle est idéal pour les workflows marketing et d'engagement qui s'appuient sur une diffusion d'audience cohérente et à haut volume plutôt que sur des mises à jour instantanées. Les cas d'utilisation typiques comprennent l'alimentation de parcours par e-mail, de campagnes de publipostage ou de chargements d'audience sur des réseaux publicitaires numériques. Chaque exécution d'activation extrait le segment qualifié du graphique de profil unifié de Data 360, applique des stratégies de gouvernance et de consentement, et transmet en toute sécurité la sortie au système cible. D'un point de vue architectural, l'activation par lot offre une approche prévisible, auditable et économique de la distribution des données, en équilibrant la simplicité opérationnelle et la fiabilité au niveau de l'entreprise. C'est l'épine dorsale de l'exécution de campagnes à grande échelle, où les données appropriées, livrées à temps et sous contrôle, génèrent un impact métier mesurable.
Context
Les marketeurs modernes opèrent sur plusieurs canaux d'engagement (e-mail, publicité, mobile et Web), chacun exigeant des audiences clients précises, opportunes et personnalisées. Data 360 sert de fondation unifiée pour ces audiences, en combinant les données clients de chaque système dans des segments riches et actionnables. L'activation par lot est le schéma d'activation le plus souvent utilisé pour exporter ces segments depuis Data 360 vers des plates-formes marketing ou publicitaires en aval. Les destinations typiques comprennent Marketing Cloud Engagement, Google Ads, Meta Custom Audiences ou LinkedIn Ads, où les campagnes peuvent être exécutées directement contre ces audiences organisées.
Problème
Comment une équipe marketing peut-elle prendre une audience précisément définie, élaborée à partir de données unifiées et enrichies dans Data 360, et la rendre disponible pour activation dans des systèmes marketing ou publicitaires externes ? Prenons par exemple le segment : « Les clients importants qui n'ont pas acheté au cours des 90 derniers jours, mais qui se sont récemment engagés sur le site Web. » Les marketeurs doivent s'assurer que cette audience est transférée avec précision, enrichie avec des attributs pertinents (par exemple, niveau de fidélité, région ou CLV prédit), et actualisée à intervalles réguliers pour maintenir la pertinence et l'efficacité des campagnes.
Forces
Plusieurs facteurs techniques et opérationnels déterminent le schéma d'activation par lot :
- Mappage d'identité : Une diffusion précise de l'audience nécessite de mapper l'ID d'individu unifié de Data 360 avec l'identificateur correspondant dans le système de destination, par exemple une Clé d'abonné dans Marketing Cloud ou un e-mail haché pour les plates-formes publicitaires numériques. Cela garantit une correspondance précise et élimine les erreurs de ciblage.
- Sélection et enrichissement d'attributs : Les marketeurs doivent aller au-delà des ID et inclure des données de profil supplémentaires (telles que le prénom, le statut de fidélité, le CLV ou d'autres attributs personnalisés) pour activer la personnalisation et les analytiques en aval.
- Configuration de la plate-forme cible : Chaque destination doit être enregistrée dans Data 360 en tant que cible d'activation, y compris les détails de connexion, l'authentification et les mappages de champs de données. Cette configuration unique définit la connectivité sécurisée et détermine quels systèmes peuvent recevoir des données activées.
- Gouvernance et conformité : L'activation des données doit respecter les métadonnées de consentement, les politiques de confidentialité (par exemple, RGPD ou CCPA) et les autorisations marketing stockées dans le profil unifié. L'activation consciente du consentement garantit que les données sont utilisées uniquement à des fins autorisées.
- Planification et performance : Les activations sont souvent planifiées tous les jours ou toutes les heures pour tenir les audiences en aval informées. Le système doit gérer efficacement les volumes importants et les actualisations incrémentielles sans duplication ni perte de données.
Solution
Le processus d'activation par lot dans Data 360 suit un workflow guidé qui réduit les frictions techniques pour les marketeurs tout en préservant la gouvernance et l'évolutivité :
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Création de segments | Meilleur | Un marketeur ou un analyste élabore un segment dans la zone de dessin de segmentation visuelle en appliquant des filtres à n'importe quel objet modèle de données (DMO) ou objet connaissances calculées (CIO). Cela définit l'audience cible pour l'activation. |
| Configuration de l'activation | Meilleur | L'utilisateur crée une activation et sélectionne le segment qu'il vient d'élaborer en tant que source. Cela définit l'audience que Data 360 exportera vers des systèmes en aval. |
| Sélection de la cible d'activation | Meilleures pratiques | Le marketeur sélectionne une cible d'activation préconfigurée (par exemple Marketing Cloud, Google Ads, LinkedIn Ads). Chaque cible est enregistrée dans Data 360 avec des identifiants d'authentification et des mappages de champs. |
| Définition de charge utile | Obligatoire | Le marketeur définit la charge utile en choisissant des identifiants de contact (e-mail, appareil mobile, ID haché) et en sélectionnant des attributs de profil supplémentaires (prénom, niveau de fidélité ou CLV) pour l'enrichissement dans le système de destination. |
| Planification et fréquence | Recommandé | L'exécution des activations peut être planifiée une fois ou de façon récurrente (par exemple, quotidienne ou hebdomadaire). La planification garantit que les audiences en aval restent synchronisées et à jour. |
| Exécution et exportation | Meilleur | Lors de l'exécution de la tâche d'activation, Data 360 interroge le segment, collecte les attributs sélectionnés, applique des filtres de consentement et exporte les données vers la plate-forme cible. Pour Marketing Cloud, cela entraîne généralement la création ou la mise à jour d'une extension de données partagées. |
| Gouvernance et conformité | Obligatoire | La Trust Layer applique automatiquement la validation du schéma, les métadonnées de consentement et les contrôles de politique pour garantir la conformité aux réglementations relatives à la protection des données et au marketing (par ex. RGPD, CCPA). |
| Surveillance et auditabilité | Meilleures pratiques | Chaque exécution d'activation est suivie avec des métriques de réussite/échec, des journaux d'exécution et la visibilité de la lignée dans le tableau de bord Trust Layer Monitoring, ce qui permet la transparence opérationnelle et l'assurance SLA. |
Croquis
Voici le résumé des étapes :
- Élaborer un segment : Un marketeur ou un analyste crée un segment en utilisant un outil de segmentation visuelle, combinant des filtres à travers n'importe quel objet de données unifié.
- Créer une activation : Ils sélectionnent le segment comme source et choisissent une destination préconfigurée (telle que Marketing Cloud ou Google Ads).
- Définir la charge utile : L'identifiant du contact et d'autres attributs de profil sont choisis pour l'exportation d'audience et la génération de rapports.
- Livraison planifiée : L'activation est planifiée pour être exécutée une fois ou de façon récurrente, ce qui permet de tenir l'audience de la destination informée.
- Exécution : Au déclencheur, Data 360 interroge le segment, élabore la charge utile, applique des filtres pour le consentement et envoie automatiquement le résultat au système de destination.
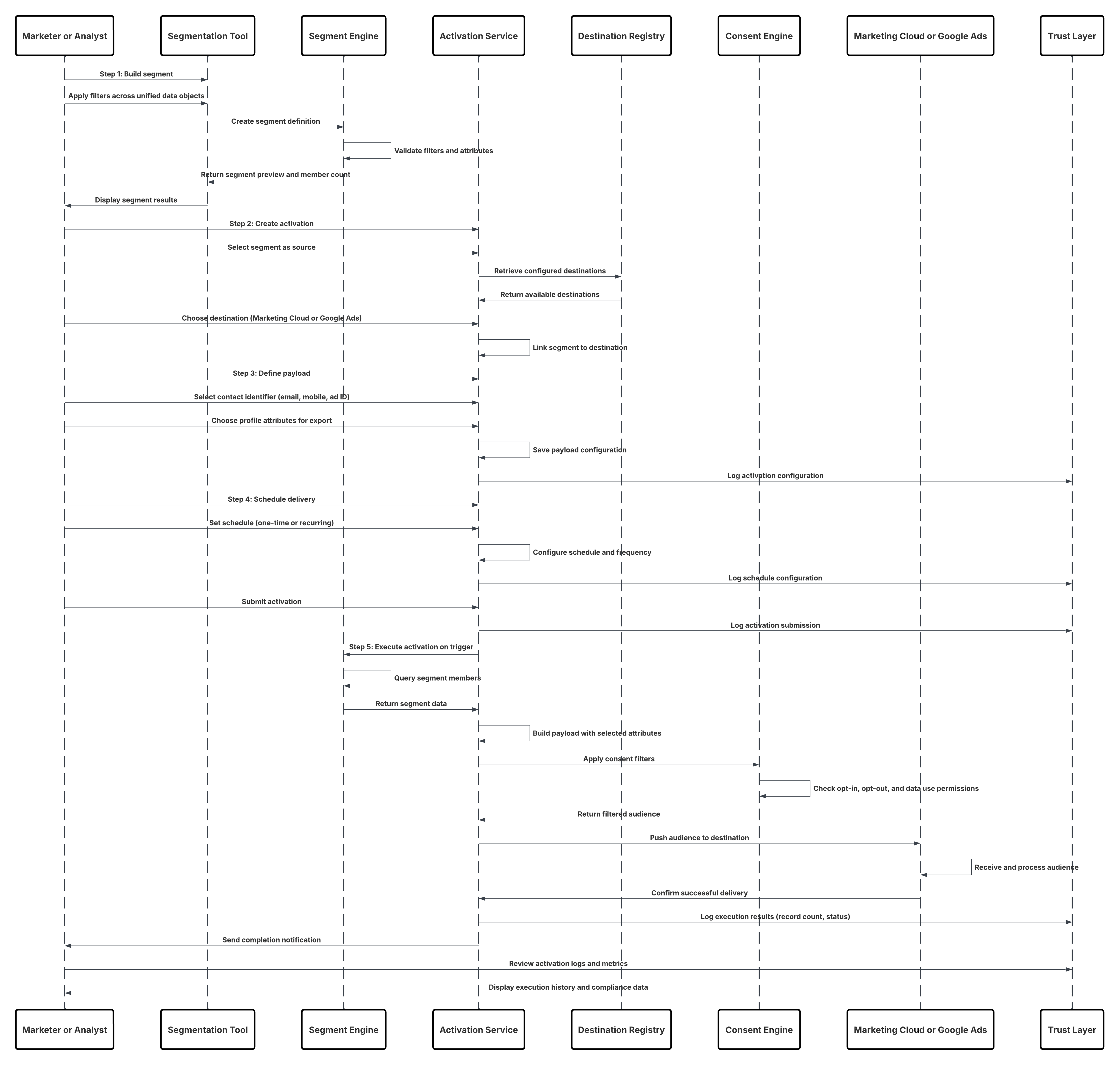
Résultats
- Les segments d'audience ciblés et enrichis de Data 360 sont disponibles directement sur les plates-formes marketing et publicitaires en aval.
- Les audiences sont automatiquement actualisées et synchronisées avec les toutes dernières données clients unifiées, ce qui maintient la pertinence des campagnes en temps réel.
- Les marketeurs peuvent utiliser ces audiences activées comme sources d'entrée pour des parcours Marketing Cloud, des campagnes par e-mail ou des audiences personnalisées dans des plates-formes publicitaires numériques telles que Google Ads, Meta ou LinkedIn Ads.
- Chaque exécution d'activation maintient la lignée de bout en bout, garantissant la conformité, la traçabilité et la cohérence entre Data 360 et les systèmes externes.
- Les utilisateurs professionnels peuvent offrir des expériences hautement personnalisées pilotées par les données, pilotées par une vue Customer 360 complète et approuvée.
Mécanismes d'appel
Le mécanisme d'appel dépend de la plate-forme de destination et de la configuration de la cible d'activation.
| Mécanisme | Quand utiliser |
|---|---|
| Activation de Marketing Cloud Engagement (préféré) | Utilisé lors de l'exécution d'e-mails ou de parcours intercanaux qui nécessitent des segments dynamiques, des attributs personnalisés et des mises à jour en temps réel dans Marketing Cloud. Data 360 exporte directement dans Extensions de données partagées pour l'activation de campagnes. |
| Activation de la plate-forme publicitaire (Google Ads, LinkedIn Ads, Meta Ads) | Utilisé lors de l'activation de segments Data 360 en tant qu'audiences personnalisées dans des plates-formes publicitaires pour le reciblage ou la modélisation similaire. Prend en charge les identifiants hachés et la livraison consciente du consentement. |
| Activation CRM (Sales ou Service Cloud) | Utilisé lors du partage de données clients enrichies, de connaissances ou de scores de propension avec des utilisateurs CRM pour des interactions d'engagement commercial ou de service personnalisées. Les données sont disponibles sous forme d'enregistrements ou de connaissances enrichis via des Actions de données ou des composants Profil unifié. |
| Activation externe via MuleSoft ou l'API | Utilisé lorsque l'activation doit atteindre des systèmes non-Salesforce tels que des entrepôts de fidélité, d'e-commerce ou de données tiers. MuleSoft ou l'API d'activation Data 360 garantit une livraison sécurisée et régie par une stratégie avec des options d'actualisation basées sur l'événement. |
| Activation hybride (batch + déclenchée par un événement) | Utilisé lors de la combinaison d'activations par lot planifiées avec des déclencheurs basés sur l'événement, qui activent la personnalisation « toujours activée » pour des campagnes urgentes telles que des alertes de panier d'achat abandonné ou de risque d'attrition. |
Gestion et récupération des erreurs
- Isolation des défauts au niveau du travail : Chaque exécution d'activation est exécutée en tant que tâche distincte et traçable dans la couche d'orchestration Data 360. Les exécutions échouées sont automatiquement mises en quarantaine sans impact sur les autres activations ou définitions de segment.
- Récupération par lot partielle : Si certains enregistrements échouent à l'exportation (p. ex., en raison de différences d'identifiants ou de limites en taux d'API), le système les essaie en utilisant des files d'attente delta incrémentielles avec une restauration exponentielle et parallèle.
- Erreurs de validation de schéma : Lorsque les attributs de charge utile sortants ne correspondent plus au schéma cible (par exemple, un attribut supprimé ou un champ renommé), la tâche achemine les enregistrements affectés vers la File d'attente de refus du schéma pour examen par l'administrateur.
- Relecture et reprise du support : Chaque tâche d'activation conserve un jeton de point de contrôle, qui capture le dernier lot réussi. Lors de la récupération, le traitement reprend à partir du point de contrôle, ce qui garantit l'absence de duplication ou de perte de données.
- Surveillance globale : Tous les événements d'activation, toutes les tentatives et toutes les métriques de livraison sont consignés dans Trust Layer Monitoring, ce qui active le suivi des accords de niveau de service, l'analyse des causes premières et les alertes automatisées via les API Event Monitoring.
Considérations relatives à la conception impotente
- Clés d'activation déterministes : Chaque exécution d'activation utilise une clé d'identabilité composée, combinant ID de segment, ID d'activation et ID de système cible, pour garantir une livraison unique.
- Replay Detection : Le service d'activation Data 360 inspecte les charges utiles entrantes par rapport aux hachages de tâches précédents afin de détecter et de supprimer les relectures.
- Atomic Export s'engage : Les charges utiles sont engagées dans le système cible uniquement après une confirmation d'écriture réussie, ce qui empêche les mises à jour partielles ou le double comptage.
- Résolution de l'identité cohérente : Comme les activations dépendent d'ID unifiés (p. ex. Individu unifié), les relectures ou tentatives ciblent toujours le même enregistrement doré, ce qui maintient la cohérence sémantique.
- Persistance de l'état d'activation : La couche d'orchestration conserve les métadonnées d'état d'activation (horodatages, codes de statut et jetons de séquence) pour un retraitement déterministe si nécessaire.
Considérations relatives à la sécurité
- Authentification forte : Chaque cible d'activation (par exemple Marketing Cloud, Ads ou CRM) utilise OAuth 2.0 avec une rotation de jeton et une étendue spécifique au locataire pour empêcher l'exportation non autorisée de données.
- Gouvernance au niveau de l'attribut : Seuls les attributs approuvés du Profil unifié sont éligibles pour l'activation, appliquée par les stratégies de partage de données et les modèles d'activation.
- Cryptage en transit et au repos : Toutes les charges utiles sont cryptées en utilisant TLS 1.2+ pendant le transfert et AES-256 au repos dans Data 360 et la plate-forme cible.
- Consentement et application des politiques : Les tâches d'activation respectent les Objets de consentement et les Stratégies de données stockées dans la Trust Layer de Data 360. Les enregistrements sans métadonnées de consentement valides sont automatiquement exclus de l'exportation.
- Audit et consignation de la conformité : Chaque exécution d'activation capture qui l'a initiée, quelles données ont été envoyées et vers quelle destination, ce qui permet d'accéder à des parcours d'audit réglementaire complets (RGPD, CCPA) dans le tableau de bord Trust Layer.
- Accès à moindre privilège : Les utilisateurs de l'intégration de chaque cible sont limités à des étendues spécifiques à l'activation, sans privilège administratif ni accès en écriture à des systèmes non associés.
Menus latéraux
Opportunité
- Conçu pour les exportations par lot planifiées ou en temps quasi réel (latence minutes à heures).
- Prend en charge les actualisations temporelles alignées sur les calendriers de campagne.
- Les tâches d'activation peuvent être séquencées avec des marqueurs de préparation des données pour garantir l'actualisation des données.
- Convient mieux aux scénarios d'activation non interactifs dans lesquels la précision des données l'emporte sur l'immédiateté.
Volumes de données
- Gère les jeux de données à grande échelle (millions d'enregistrements par exécution).
- Évolue horizontalement à travers le partitionnement des segments et les canaux d'exportation parallèles.
- Utilise le traitement par lots basé sur des segments pour éviter les expirations et optimiser le débit.
- Idéal pour les pipelines de données d'entreprise dans lesquels l'exhaustivité des données est essentielle.
Gestion des états
- Gère les objets d'état d'activation qui enregistrent les ID de tâche, les horodatages et les jetons de séquence.
- Utilise le checkpointing pour la redémarrabilité et la reprise après défaut.
- Les définitions de segment avec version garantissent la reproductibilité entre les cycles d'activation.
- Active la traçabilité des lignages entre le segment source, les attributs d'objet modèle de données et les charges utiles cibles.
Scénarios d'intégration complexes
- S'intègre de façon transparente à Salesforce CRM, Marketing Cloud et à des systèmes externes via des connecteurs prédéfinis.
- Prend en charge les activations multicibles, qui distribuent simultanément des données à différentes destinations (par exemple CRM + Ads).
- Peut déclencher des workflows composés, par exemple une exportation par lot suivie d'un appel d'API en aval ou d'un score IA.
- Gère gracieusement l'évolution du schéma via la couche de gouvernance du modèle de données.
Exemple
Une enseigne de distribution mondiale souhaite réengager les clients inactifs des 90 derniers jours. En utilisant Data 360, l'architecte de données définit un segment « Consommateurs dormants » enrichi avec l'historique des achats, le niveau de fidélité et les métadonnées de consentement. La tâche d'activation par lot est exécutée tous les soirs, ce segment est automatiquement envoyé à Marketing Cloud Engagement pour déclencher une campagne par e-mail personnalisée « Vous nous manquez » et à Ad Studio pour le reciblage. La tâche exploite la livraison idempotente, ce qui évite les doublons entre les tentatives, et tous les événements sont consignés dans la Trust Layer pour la conformité aux audits.
Context
Les entreprises ont souvent besoin d'un mécanisme régi pour exporter des données unifiées ou segmentées depuis Salesforce Data 360 vers un format de fichier standard (par exemple, CSV ou Parquet) pour l'archivage, la conformité ou l'intégration en aval. Ce modèle permet l'exportation de stockage Data 360 vers le cloud, ce qui permet aux données clients de confiance de circuler en toute sécurité dans des lacs de données d'entreprise ou des pipelines d'analyse hébergés sur Amazon S3, Azure Blob ou Google Cloud Storage (GCS). Les cas d'utilisation typiques comprennent :
- Archivage périodique des jeux de données clients consentis pour la rétention réglementaire.
- Exportation de segments organisés pour des charges de travail analytiques non-Salesforce (par exemple Tableau, Databricks ou Power BI).
- Activation de modèles d'apprentissage machine externes qui nécessitent des fichiers CSV ou Parquet structurés en entrée.
Problème
Comment une organisation peut-elle exporter un segment ou un jeu de données organisé depuis Data 360 vers un compartiment de stockage cloud (par exemple Amazon S3), de manière régie, sécurisée et automatisée, tout en maintenant les contrôles d'intégrité et de conformité du schéma ? Par exemple, une équipe de conformité peut avoir à : « Extrayez tous les clients actifs dans la région de l’UE avec un consentement valide et exportez les données toutes les semaines vers un emplacement S3 pour un audit externe et des rapports. » Cela nécessite un pipeline d'exportation répétitif et sensible aux stratégies qui garantit le format de fichier, les autorisations d'accès et le calendrier de livraison appropriés, sans intervention manuelle ni mouvement de données non régi.
Forces
Plusieurs facteurs opérationnels et architecturaux régissent ce modèle d'exportation :
- Authentification et autorisation: Les exportations doivent respecter le modèle IAM du fournisseur de cloud (par exemple, Rôles IAM AWS ou Principals de service Azure) pour s'assurer que seuls les systèmes autorisés peuvent écrire dans le compartiment cible.
- Alignement du schéma: Le schéma sortant doit correspondre à la structure et au format attendus du système cible (CSV, Parquet ou JSON).
- Confidentialité des données et consentement: Les jeux de données exportés doivent exclure tous les enregistrements qui ne contiennent pas de métadonnées de consentement valides.
- Planification et fraîcheur: De nombreuses exportations sont périodiques (quotidiennes, hebdomadaires ou mensuelles) et doivent correspondre aux cycles d'actualisation des données d'entreprise.
- Gouvernance & Monitoring: Chaque exportation doit pouvoir être auditée avec une visibilité complète de la lignée, ce qui garantit la conformité avec la rétention des données et les mandats réglementaires (p. ex. RGPD, CCPA).
Solution
Le modèle Activation de l'exportation de fichiers réutilise les mêmes connecteurs de stockage cloud sécurisés utilisés pour l'ingestion, mais configurés pour la sortie des données. Les administrateurs enregistrent d'abord la plate-forme de stockage cloud (par exemple Amazon S3, Azure Blob Storage ou GCS) en tant que cible d'activation dans Data 360. Les utilisateurs configurent et exécutent ensuite un workflow d'activation pour exporter le segment de leur choix vers le chemin de stockage de fichiers désigné.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Sélection du segment | Meilleur | Les analystes sélectionnent une définition de segment ou de requête existante dans Data 360\. Le segment détermine les enregistrements et les attributs exportés. |
| Configuration de l'activation | Meilleur | Les utilisateurs créent une nouvelle Activation, en choisissant le Segment comme source et la Cible de stockage Cloud (par exemple, S3) comme destination. |
| Configuration de la cible d'activation | Obligatoire | Les administrateurs préconfigurent la cible avec des identifiants, des rôles IAM et un chemin de sortie. Les formats pris en charge comprennent CSV, Parquet et JSON. |
| Définition de charge utile | Meilleures pratiques | Définissez le schéma d'exportation en sélectionnant les attributs requis (par exemple, ID, Nom, Adresse e-mail, Région, Indicateur de consentement). Le système applique automatiquement la gouvernance au niveau de l'attribut. |
| Planification et fréquence | Recommandé | L'exécution des exportations peut être planifiée sur une cadence définie (quotidienne, hebdomadaire, mensuelle) ou déclenchée manuellement si nécessaire. |
| Exécution et livraison | Meilleur | Lors de l'exécution, Data 360 interroge le segment, compile le fichier d'exportation, le crypte et l'écrit dans le compartiment/dossier configuré en utilisant l'API du fournisseur de cloud. |
| Gouvernance et conformité | Obligatoire | La Trust Layer de Data 360 garantit que toutes les exportations respectent les stratégies de consentement, la validation du schéma et les filtres de conformité. |
| Surveillance et auditabilité | Meilleures pratiques | Chaque exportation est suivie dans le tableau de bord Trust Layer Monitoring avec les métadonnées de statut, d'exécution et de lignage. |
Croquis
Voici le résumé des étapes.
- Sélectionner un segment : Un analyste ou un gestionnaire de données choisit le segment unifié à exporter.
- Créer une activation : Ils créent une nouvelle tâche Activation et sélectionnent la cible Cloud Storage enregistrée.
- Définir la charge utile : Spécifiez le schéma d'exportation, la liste d'attributs et le format de fichier (par exemple, CSV).
- Planifier l'exportation : Choisissez une planification unique ou récurrente.
- Exécuter la tâche : Data 360 génère et livre en toute sécurité le fichier au chemin du compartiment désigné.
- Surveiller et vérifier : Les résultats et les journaux sont examinés dans la Trust Layer pour la validation et la conformité.
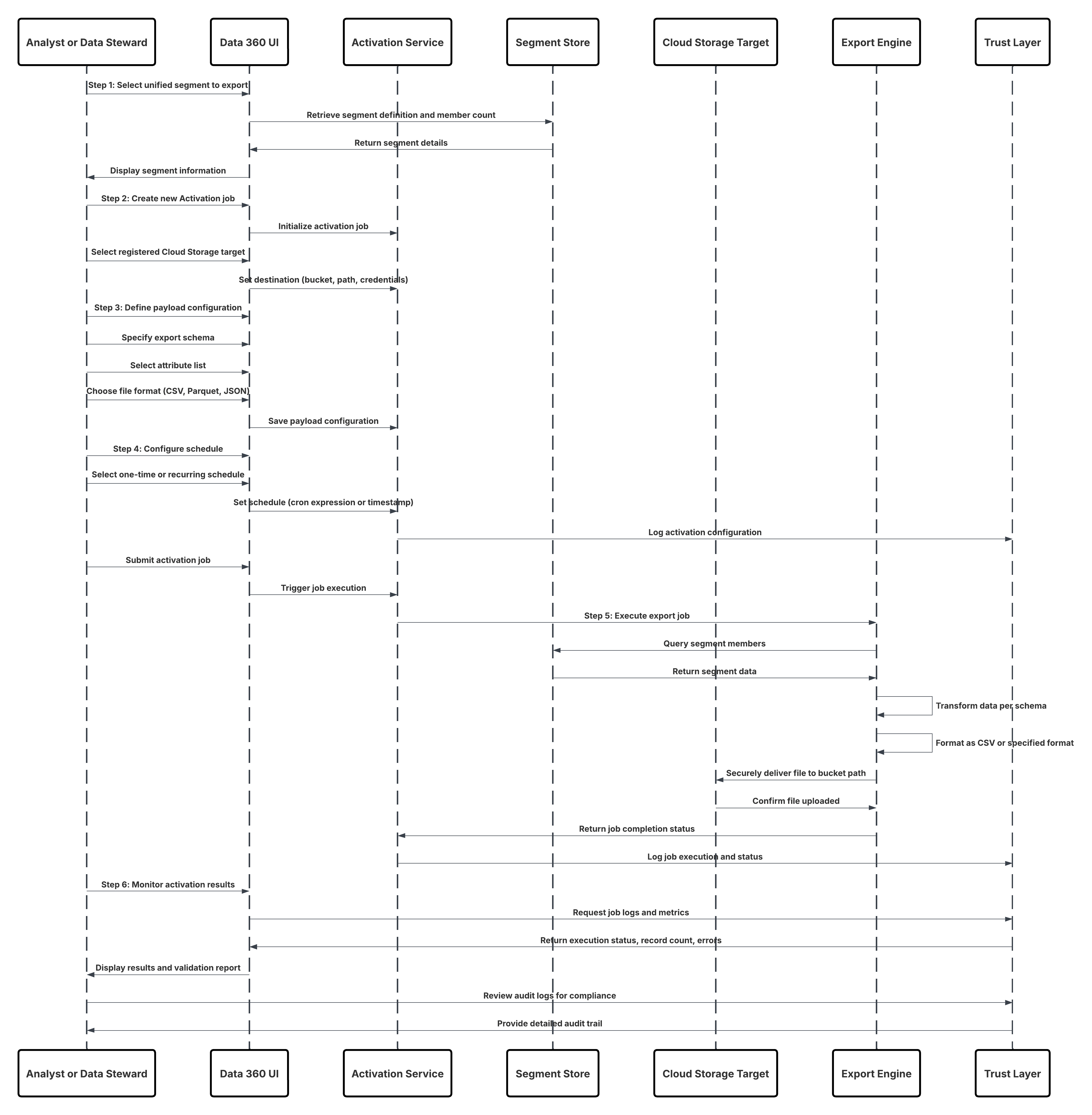
Résultats
- Les segments d'audience ciblés et enrichis de Data 360 sont disponibles directement sur les plates-formes marketing et publicitaires en aval.
- Les audiences sont automatiquement actualisées et synchronisées avec les toutes dernières données clients unifiées, ce qui maintient la pertinence des campagnes en temps réel.
- Les marketeurs peuvent utiliser ces audiences activées comme sources d'entrée pour des parcours Marketing Cloud, des campagnes par e-mail ou des audiences personnalisées dans des plates-formes publicitaires numériques telles que Google Ads, Meta ou LinkedIn Ads.
- Chaque exécution d'activation maintient la lignée de bout en bout, garantissant la conformité, la traçabilité et la cohérence entre Data 360 et les systèmes externes.
- Les utilisateurs professionnels peuvent offrir des expériences hautement personnalisées pilotées par les données, pilotées par une vue Customer 360 complète et approuvée.
Mécanismes d'appel
Le mécanisme d'appel dépend de la plate-forme de stockage cloud cible et de la configuration d'activation.
| Mécanisme | Quand utiliser |
|---|---|
| Activation Amazon S3 | Utilisé lorsque votre lac de données d'entreprise est hébergé sur AWS. Data 360 écrit directement dans un compartiment S3 en utilisant des rôles IAM ou des identifiants temporaires, ce qui garantit une exportation sécurisée et évolutive. |
| Activation du stockage Azure Blob | Utilisé lorsque votre organisation fonctionne sur Microsoft Azure. Data 360 utilise des jetons SAS ou des principaux de service pour écrire des fichiers cryptés dans des conteneurs Blob. |
| Activation de Google Cloud Storage (GCS) | Utilisé lorsque vos charges de travail de science des données ou d'analyse sont exécutées sur GCP. Data 360 utilise des identifiants OAuth pour exporter des fichiers vers des compartiments GCS au format CSV ou Parquet. |
| SFTP ou passerelle de fichiers externe | Utilisé lorsque des systèmes réglementaires ou hérités nécessitent une livraison sécurisée de fichiers via des points de terminaison SFTP ou des plates-formes de transfert de fichiers gérées par l'entreprise. |
| Exportation hybride (fichier + API) | Utile lorsqu'une application en aval a besoin à la fois d'une exportation basée sur un fichier pour les analytiques et d'un déclencheur d'API pour l'orchestration de workflow (p. ex. flux MuleSoft). |
Gestion et récupération des erreurs
- Isolement au niveau de l'emploi : Chaque exportation est exécutée en tant que tâche discrète. Les tâches échouées sont mises en quarantaine et rejugées indépendamment.
- Réessai de fichier partiel : Si certains lots ne sont pas chargés (p. ex., en raison d'interruptions du réseau), le système essaie de nouveau ces segments en utilisant un backoff exponentiel.
- Traitement des écarts de schéma : Toute dérive de schéma ou incohérence de champ achemine les enregistrements vers la File d'attente de rejet du schéma pour examen.
- Point de contrôle et reprise : Les tâches d'exportation conservent les métadonnées des points de contrôle, ce qui permet de reprendre sans duplication depuis la dernière écriture réussie.
- Surveillance intégrée : Les échecs et les tentatives sont consignés dans le tableau de bord Trust Layer pour la visibilité et la conformité SLA.
Considérations relatives à la conception impotente
- Clés d'exportation déterministes : Chaque tâche d'exportation inclut un ID unique composé de ID de segment + ID de cible + Horodatage.
- Sécurité de lecture : Les exécutions de tâches dupliquées sont détectées en utilisant des hachages de tâches et ignorées afin d'éviter les exportations redondantes.
- Garantie d'écriture atomique : Data 360 n'engage les fichiers dans le compartiment cible qu'une fois l'exécution complète et la validation de la somme de contrôle terminée.
- Versions cohérentes du schéma : Les définitions d'exportation sont contrôlées par version pour garantir la cohérence du schéma entre les exécutions.
- Persistance du point de contrôle : Les tâches d'exportation conservent l'état de récupération déterministe et de retraitement si nécessaire
Considérations relatives à la sécurité
- Authentification forte : Les connecteurs Cloud utilisent OAuth 2.0, des rôles IAM ou des principaux de service pour les écritures authentifiées.
- Cryptage partout : Les données sont cryptées en transit (TLS 1.2+) et au repos (AES-256).
- Exportation consciente du consentement : Seuls les enregistrements avec un consentement valide sont exportés, appliqués par les stratégies Trust Layer.
- Principe du moindre privilège : Les utilisateurs exportateurs et les comptes de service sont limités à leurs chemins de stockage désignés.
- Consignation d'audit complète : Chaque exportation enregistre des métadonnées, y compris l'initiateur, le schéma, la destination et l'horodatage des rapports de conformité.
Menus latéraux
Opportunité
- Conçu pour une activation immédiate pilotée par l'événement avec une latence inférieure à la seconde.
- Idéal pour les scénarios qui nécessitent une personnalisation instantanée, une recommandation ou une prise de décision.
- Fonctionne en mode streaming : les déclencheurs sont déclenchés dès que des modifications de données qualifiantes se produisent dans Data 360.
- Garantit une réactivité continue sans attendre les planifications par lot ou le recalcul du segment.
Volumes de données
- Gère les jeux de données à grande échelle (millions d'enregistrements par exécution).
- Évolue horizontalement à travers le partitionnement des segments et les canaux d'exportation parallèles.
- Utilise le traitement par lots basé sur des segments pour éviter les expirations et optimiser le débit.
- Idéal pour les pipelines de données d'entreprise dans lesquels l'exhaustivité des données est essentielle.
Gestion des états
- Chaque action d'événement conserve son propre jeton d'événement et ID de relecture pour le traitement idempotent.
- Prend en charge la persistance du point de contrôle pour reprendre à partir du dernier événement engagé en cas d'échec transitoire.
- Inclut une logique de déduplication intégrée et des fenêtres de lecture pour garantir une sémantique d'activation exacte une fois.
- Les résultats des actions (réussite/échec) sont consignés en temps réel et exposés via le tableau de bord d'observabilité Trust Layer.
Scénarios d'intégration complexes
- Intègre directement aux flux Salesforce, aux événements de plate-forme Einstein 1 ou aux webhooks externes pour des chaînes de réponse instantanées.
- Peut déclencher des automatisations en aval, par exemple des mises à jour instantanées d'enregistrement CRM, un score IA ou des envois de messages Marketing Cloud.
- Prend en charge l'orchestration composable: les déclencheurs d'événements peuvent appeler des Actions Data 360, des invocations Apex, ou des API externes.
- Conçu pour les modèles d'entreprise agentsiques et adaptatifs dans lesquels des réponses sensibles au contexte doivent se produire instantanément.
Exemple
Une entreprise de vente au détail mondiale doit livrer une exportation hebdomadaire de son segment « Membres de fidélité actifs » pour l'analyse dans Databricks. L'administrateur Data 360 configure Amazon S3 en tant que cible d'activation et planifie une exportation CSV hebdomadaire vers le chemin d's3://enterprise-analytics/loyalty/weekly_exports/. La tâche d'exportation est exécutée tous les dimanches, générant un fichier filtré par consentement avec plus de 2M enregistrements. Tous les événements, définitions de schéma et lignage sont enregistrés dans le tableau de bord Trust Layer, ce qui garantit la transparence, l'auditabilité et la conformité.
L'activation basée sur l'API à la demande est une approche en temps réel pilotée par les événements qui permet de rendre les connaissances Data 360 actionnables dès qu'elles sont utiles, sans attendre les tâches par lot ou les exportations planifiées. Au lieu de publier des segments prédéfinis sur une cadence fixe, ce modèle permet aux systèmes externes, aux applications Salesforce ou aux agents IA d'appeler directement les API Data 360 pour récupérer ou activer des segments d'audience, des attributs clients ou des connaissances spécifiques à la demande. Ce modèle est conçu pour des expériences interactives basées sur un déclencheur, par exemple lorsqu'un utilisateur se connecte à un portail, qu'un agent ouvre un enregistrement client ou qu'un Copilot IA initie une requête Next Best Action. Au lieu de dépendre d'exportations précalculées, le système interroge ou active dynamiquement les données régies les plus récentes de Data 360 inReal-Time. L'avantage clé est l'immédiateté et la précision:
- Chaque appel d'API accède à l'Intelligence client la plus récente dans le graphique de profil unifié et sensible au consentement de Data 360.
- Les activations sont idempotentes et auditables, conformes aux exigences de Trust et de conformité de l'entreprise.
- Les intégrations peuvent être déclenchées directement depuis des flux Salesforce, Apex ou des systèmes externes via des API de plate-forme Einstein 1, des API Connect ou des API d'activation. Cette approche prend en charge les cas d'utilisation où la latence et la personnalisation sont les plus importantes, par exemple :
- Déclenchement d'une offre produit personnalisée pendant un appel de service.
- Générer des audiences de campagne dynamiques basées sur des événements comportementaux live.
- Alimentation des décisions en temps réel dans des modèles IA ou ML qui fonctionnent au moment de l'engagement.
Context
Les entreprises doivent souvent exposer des connaissances Data 360 harmonisées et en temps réel dans des applications personnalisées, telles que des portails Web internes, des applications mobiles ou des expériences Web avec des partenaires. Ce schéma permet aux développeurs d'élaborer des solutions sécurisées, centrées sur l'interface utilisateur, qui consomment et affichent des données clients unifiées avec Salesforce CRM et d'autres systèmes contextuels, le tout via un accès gouverné et basé sur l'API. Les cas d'utilisation typiques comprennent :
- Incorporation de connaissances Data 360 à des tableaux de bord internes des employés ou à des applications mobiles.
- Création de portails partenaires ou concessionnaires avec la visibilité des clients et des transactions.
- Intégration de données Data 360 dans des applications Web tierces ou des couches d'expérience.
- Affichage de recommandations personnalisées en temps réel pilotées par Data 360 et Einstein 1.
Problème
Comment un développeur peut-il élaborer une application personnalisée et orientée interface utilisateur qui accède et affiche en toute sécurité des données Data 360 harmonisées, souvent avec d'autres sources de données Salesforce, sans dupliquer ni exporter des informations confidentielles ? Par exemple, une entreprise peut avoir besoin d'élaborer un portail client qui affiche des profils clients unifiés, des interactions et des connaissances calculées à partir de Data 360. Cela nécessite une couche d'API unique, sécurisée et performante qui peut piloter l'expérience frontale, gérer l'authentification et garantir la gouvernance, tout en éliminant la complexité du modèle de données interne de Data 360.
Forces
De multiples considérations architecturales et opérationnelles influencent ce schéma :
- Accès UI-Centric : L'objectif principal est d'exposer des données dans des expériences frontales personnalisées (web ou mobile), pas d'effectuer des extractions par lot ou des synchronisations back-end.
- Passerelle sécurisée : L'API choisie doit servir de point d'entrée sécurisé et évolutif pour les applications et les utilisateurs authentifiés, en appliquant des contrôles d'accès de niveau entreprise.
- Contexte des données unifiées : Les applications doivent pouvoir combiner de façon transparente des données Data 360 (par exemple, des profils unifiés, des connaissances calculées) avec des données CRM, ERP ou d'objet personnalisé.
- Developer Simplicity : Les API doivent renvoyer des charges de travail prêtes pour la présentation qui réduisent le traitement back-end ou le mappage de schéma dans la couche client.
- Gouvernance et observation : Tous les accès doivent transiter par des canaux de confiance et auditables, avec un lignage clair, l'authentification et l'application des politiques.
Solution
La solution consiste à utiliser l'API REST Salesforce Connect comme passerelle d'intégration principale pour élaborer des applications personnalisées pilotées par les données au-dessus de Data 360. L'API Connect fournit un accès RESTful aux données Salesforce, y compris les profils harmonisés, les segments et les connaissances calculées de Data 360, sous des formats de réponse optimisés pour la consommation d'interface utilisateur (basés sur JSON, légers et adaptés aux appareils mobiles). Les développeurs s'authentifient via une application connectée, obtiennent des jetons OAuth 2.0 et appellent des ressources de l'API Connect telles que /query, /Chatter ou /data pour exposer des données unifiées directement dans leurs interfaces d'application. En arrière-plan, l'API Connect sert de fondation de transport pour d'autres API — telles que l'API Query, l'API Data Graph et les API Einstein 1 Platform — permettant aux développeurs de combiner plusieurs sources de données sous un même schéma d'accès unifié.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Authentification et enregistrement d'application | Obligatoire | Créez une application connectée dans Salesforce pour l'authentification basée sur OAuth 2.0. Configurez des étendues pour l'accès à l'API Data 360. |
| Accès aux données (profils, segments, connaissances) | Meilleur | Utilisez les points de terminaison de l'API Connect (/services/data/vXX.X/connect) pour interroger des données Data 360 harmonisées, des profils unifiés et des connaissances calculées. |
| Intégration de l'interface utilisateur | Meilleur | Les applications frontales (React, Angular, iOS, Android) appellent l'API Connect pour restituer les données Data 360 dans des tableaux de bord, des portails ou des interfaces mobiles. |
| Interrogation de Data Graph | Recommandé | Combinez l'API Connect à l'API Data Graph pour des requêtes de niveau sémantique qui simplifient les jointures et les relations complexes. |
| Actualisation en temps réel | Optional | Utilisez l'API Connect avec WebSocket ou des extensions de streaming pour les mises à jour de données live. |
| Sécurité et gouvernance | Obligatoire | Appliquez la visibilité des données en utilisant les étendues OAuth, les stratégies Data 360 et l'infrastructure d'audit Trust Layer. |
Croquis
Voici le résumé des étapes.
- Enregistrer l'application connectée : définissez les étendues OAuth et les autorisations d'API pour l'authentification de l'application externe.
- Obtenir le jeton d'accès : l'application externe effectue l'authentification OAuth 2.0 pour recevoir un jeton d'accès Data 360.
- Invoquer l'API Connect : l'application passe des appels d'API REST pour récupérer des données de profil, de segment ou de connaissances unifiées.
- Restitution des données dans l'interface utilisateur : les réponses sont analysées et présentées aux utilisateurs dans un portail de marque ou une interface mobile.
- Traitement des erreurs et des jetons d'actualisation : les applications implémentent une logique de nouvelle tentative et une actualisation automatique des jetons pour la continuité de la session.
- Accès Surveillance et Audit - Tous les appels d'API sont consignés dans la Trust Layer pour plus de visibilité et de conformité.
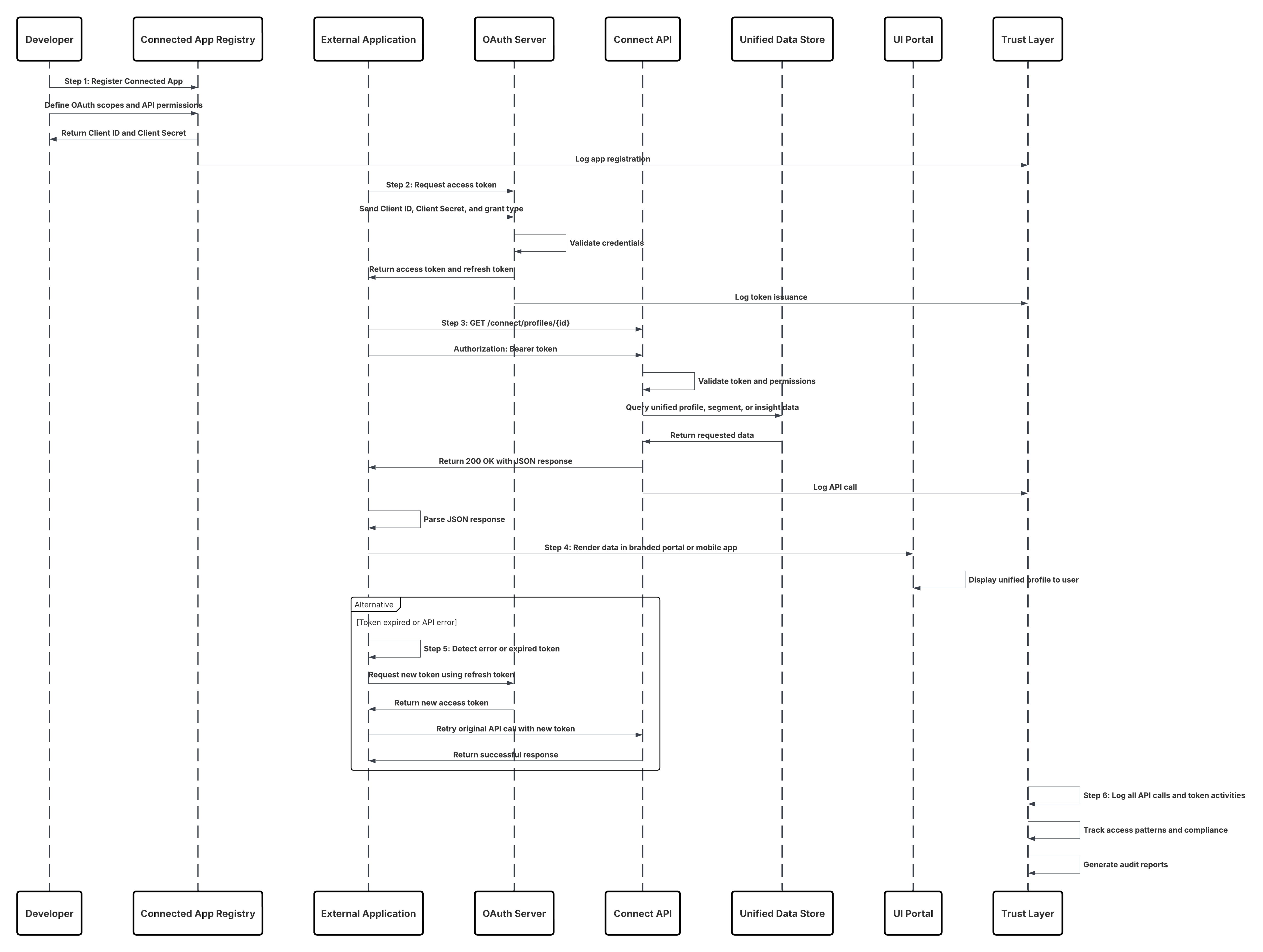
Résultats
Les développeurs peuvent créer des applications sécurisées et personnalisées étroitement intégrées à Data 360. Ces applications peuvent :
- Exposer des profils et des connaissances clients harmonisés en temps réel.
- Affichez les données Data 360 avec des objets CRM ou personnalisés via des API unifiées.
- Tirez parti de contrôles d'authentification, d'autorisation et d'audit cohérents via la Trust Layer.
- Offrez aux utilisateurs professionnels ou aux partenaires un accès transparent et régi à Intelligence client fiable à travers les expériences.
Mécanismes d'appel
Le mécanisme d'appel dépend de la plate-forme de stockage cloud cible et de la configuration d'activation.
| Mécanisme | Quand utiliser |
|---|---|
| API REST Connect (préféré) | Utilisez-les pour élaborer des applications Web, mobiles ou tierces qui nécessitent un accès en temps réel aux données Data 360 sous un format JSON convivial pour l'interface utilisateur. |
| API Data Graph | Utilisé lorsque l'application doit effectuer des requêtes de niveau sémantique à travers plusieurs objets (par exemple, Client → Transactions → Campagnes). |
| API de requête | Utilisez-les lors de l'exécution de requêtes de type SOQL pour récupérer des jeux de données harmonisés avec une grande précision. |
| API Einstein 1 Platform | Utilisez-les pour intégrer des connaissances pilotées par l’IA ou des recommandations générées par Copilot dans des interfaces utilisateur personnalisées. |
| MuleSoft ou Apex Gateway Wrappers | Utilisée lorsque l'orchestration, la mise en cache ou l'application de stratégies supplémentaires sont requises entre l'application et l'API Connect. |
Gestion et récupération des erreurs
- Demande de limitation : Retire et essaie automatiquement les appels d'API sous les limites de taux.
- Protection contre les dérives de schéma : utilise la découverte de métadonnées de schéma GraphQL ou REST pour s'adapter aux modifications du schéma.
- Gestion de l'expiration des jetons : les applications actualisent automatiquement les jetons OAuth pour éviter les interruptions de session.
- Isolation des défauts d'API : les appels d'API échoués sont consignés et réessayés sans impact sur les sessions simultanées.
- Confiance Layer Observability − Les taux de réussite/échec d ' API et les journaux d ' accès sont visibles dans le tableau de bord Trust Layer.
Considérations relatives à la conception impotente
- ID de requête déterministes: Chaque requête d'API inclut un ID de corrélation pour un traitement sans risque de relecture.
- En-têtes de validation du cache : Les en-têtes ETag et Last-Modified empêchent les récupérations de données redondantes.
- Opérations de lecture atomique : L'API Connect garantit que chaque réponse reflète un cliché instantané cohérent des données unifiées.
- Protection contre la lecture : les appels d'API dupliqués sont filtrés en utilisant des signatures de requête et des horodatages.
Considérations de sécurité
- Authentification OAuth 2.0 : Tous les appels d'API utilisent des jetons d'accès OAuth sécurisés et de courte durée via des applications connectées.
- Accès à moindre privilège : Les étendues d'API sont limitées aux objets et aux champs nécessaires.
- Cryptage partout : TLS 1.2+ en transit ; cryptage AES-256 au repos pour les réponses mises en cache ou stockées.
- Accès aux données conscient du consentement: Data 360 garantit que tous les enregistrements récupérés respectent les politiques de consentement et de gouvernance.
- Consignation d'audit complète : Chaque interaction d'API est enregistrée avec les métadonnées utilisateur, application et horodatage dans la Trust Layer.
Menus latéraux
Opportunité
- Conçu pour l'accès API en temps réel et à faible latence.
- Idéal pour les applications interactives qui nécessitent une restitution immédiate des données.
- Prend en charge les temps de réponse aux requêtes quasi instantanés via des sources Data 360 mises en cache et indexées.
- Aucune dépendance aux planifications par lot ou aux cycles d'activation asynchrones.
Volumes de données
- Optimisé pour les cas d'utilisation interactifs récupérant des jeux de données de petite à moyenne taille (par exemple, profils, connaissances ou transactions récentes).
- Gère les résultats paginés avec grâce à la pagination basée sur le curseur.
- Non destiné aux exportations en masse à haut volume, utilisez des modèles d'exportation par lot ou de fichier pour des jeux de données volumineux.
Gestion des états
- Les applications conservent un état de session léger avec des jetons OAuth et un cache local.
- L'API Connect prend en charge les requêtes conditionnelles et l'actualisation partielle pour plus d'efficacité.
- Les réponses d'API incluent des marqueurs de version pour la cohérence du schéma entre les versions.
Scénarios d'intégration complexes
- Combinez l'API Connect à l'API Data Graph pour des requêtes sémantiques dans plusieurs domaines.
- Intégrez à Einstein 1 Copilot ou aux API IA pour des expériences prédictives et conversationnelles.
- Utilisez-les aux côtés des composants Experience Cloud ou Web Lightning pour le développement d'interfaces utilisateur hybrides.
- Étendez-vous via MuleSoft pour orchestrer l'enrichissement des données ou des références système externes en temps réel.
Exemple
Une multinationale d'assurances crée un portail en libre-service pour les clients, qui permet aux assurés d'afficher leur profil unifié, les déclarations récentes et les offres personnalisées. L'application frontale basée sur eact s'authentifie via OAuth 2.0 et récupère les données en utilisant l'API REST Connect et l'API Data Graph. Toutes les données sont affichées en temps réel, sensibles au consentement et régies par la couche Trust Data 360. Les développeurs surveillent les appels d'API et les pistes d'audit directement dans Salesforce, ce qui garantit une conformité et une observabilité totales.
Context
Les entreprises ont de plus en plus besoin d'accéder instantanément à un profil client complet pour les systèmes de décision en temps réel, tels que les consoles de service, les moteurs de recommandation ou les plates-formes de personnalisation.Ce modèle permet aux applications de récupérer des vues précalculées et unifiées des données d'un client en temps quasi réel en utilisant l'API Data Graph de Data 360, qui fournit des temps de réponse inférieurs à la seconde pour des expériences interactives. Les cas d'utilisation typiques comprennent :
- Affichage d'une vue client complète au sein d'un Customer Service ou Sales Console.
- Alimentation des recommandations « Next Best Action » ou « Next Best Offer » basées sur l’IA.
- Offrir des expériences Web ou mobiles hyper personnalisées au chargement de la page.
- Prise en charge de la prise de décision en session dans des environnements d'agent ou en libre-service.
Problème
Comment une application peut-elle récupérer instantanément une vue client complète, précalculée et unifiée, au lieu d'exécuter des requêtes lentes et multi-objets à l'exécution ? Par exemple, un moteur de personnalisation Web doit charger le contexte client complet (données démographiques, préférences, transactions et connaissances calculées) en quelques millisecondes pour sélectionner une offre personnalisée. Les requêtes relationnelles traditionnelles peuvent nécessiter plusieurs jointures et entraîner une latence inacceptable. Cela nécessite une API qui fournit des données de profil dénormalisées et prêtes à l'emploi, récupérables via une référence clé unique, combinant rapidité, exhaustivité et gouvernance.
Forces
Plusieurs facteurs opérationnels et de performance influencent ce modèle :
- Vitesse : Le temps de réponse doit être en temps quasi réel. L'API doit renvoyer un profil complet en quelques millisecondes pour prendre en charge les interactions synchrones.
- Exhaustivité : La réponse doit inclure tous les attributs pertinents, les relations et les connaissances calculées, idéalement dans une seule charge utile.
- Efficacité de référence : Les profils doivent pouvoir être récupérés via des identifiants tels que customerId, contactKey ou email, ce qui élimine les requêtes à plusieurs étapes.
- Actualisation des données vs. Latence : Certains cas d'utilisation préfèrent les données précalculées (mises en cache) pour plus de rapidité ; d'autres nécessitent des données live, acceptant une latence plus élevée.
- Gouvernance et sécurité : L'accès doit rester régi par des stratégies Salesforce Trust Layer, garantissant le respect des règles de visibilité et de consentement des données.
Solution
La solution consiste à utiliser l'API Salesforce Data Graph pour récupérer des vues clients précalculées et dénormalisées stockées en tant qu'enregistrements Data Graph. Un Data Graph est une vue sémantique matérialisée qui combine plusieurs objets modèle de données (DMO) (tels que Individu, Transaction et ProductInterest) dans un enregistrement en lecture seule unique, souvent représenté sous forme de blob JSON. Les développeurs peuvent utiliser des points de terminaison REST tels que : GET /api/v1/dataGraph/{dataGraphEntityName}/{id} pour récupérer un enregistrement complet par son identifiant unique. Pour des scénarios dynamiques, l'API prend en charge un paramètre live=true qui contourne le cache matérialisé, en exécutant une requête en temps réel à travers Data 360, en échangeant une latence minimale contre les données les plus récentes. Cela permet aux développeurs de sélectionner entre les récupérations de profil instantanées (mises en cache) et à jour (en direct) selon les besoins de l'entreprise.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Définition du graphique de données | Obligatoire | Les architectes définissent un Data Graph qui combine plusieurs objets modèle de données en une seule entité sémantique (par exemple, UnifiedCustomerProfile). |
| Récupération de référence de profil | Meilleur | Les applications appellent GET /api/v1/dataGraph/{entity}/{id} pour récupérer des profils complets et dénormalisés par ID ou clé unique. |
| Utilisation des paramètres live | Optional | Ajoutez ?live=true pour forcer un nouveau calcul plutôt qu'une récupération mise en cache; adapté aux décisions importantes. |
| Authentification | Obligatoire | Utilisez OAuth 2.0 via des applications connectées pour authentifier les appels d'API en toute sécurité. |
| Analyse des réponses | Meilleure pratique | Les applications analysent la réponse JSON directement dans leur interface utilisateur ou leur moteur de décision. Aucune jointure supplémentaire n'est requise. |
| Stratégie de mise en cache | Recommandé | Implémentez la mise en cache locale à court terme (par exemple en mémoire ou CDN) pour les références de profil répétées. |
| Monitoring & Observability | Obligatoire | Utilisez les tableaux de bord Trust Layer pour surveiller les performances des requêtes, les temps de réponse et l'adhésion aux stratégies. |
Croquis
Voici un résumé du flux d'implémentation :
- Define Data Graph : les architectes de données créent un Data Graph qui modélise une vue client unifiée à travers plusieurs objets modèle de données.
- Enregistrer l'application connectée : les développeurs configurent les identifiants OAuth pour un accès API sécurisé.
- Invoquer l'API Data Graph : l'application émet une requête GET avec le nom et l'ID d'enregistrement Data Graph.
- Réponse du processus : l'API renvoie une représentation JSON complète du profil client.
- Rendu ou Act : l'application consommatrice (interface utilisateur ou moteur) utilise les données unifiées pour la personnalisation, les recommandations ou les actions de service.
- Surveiller et ajuster - Les métriques de performance et les journaux d'accès sont examinés dans la console d'observabilité Trust Layer.
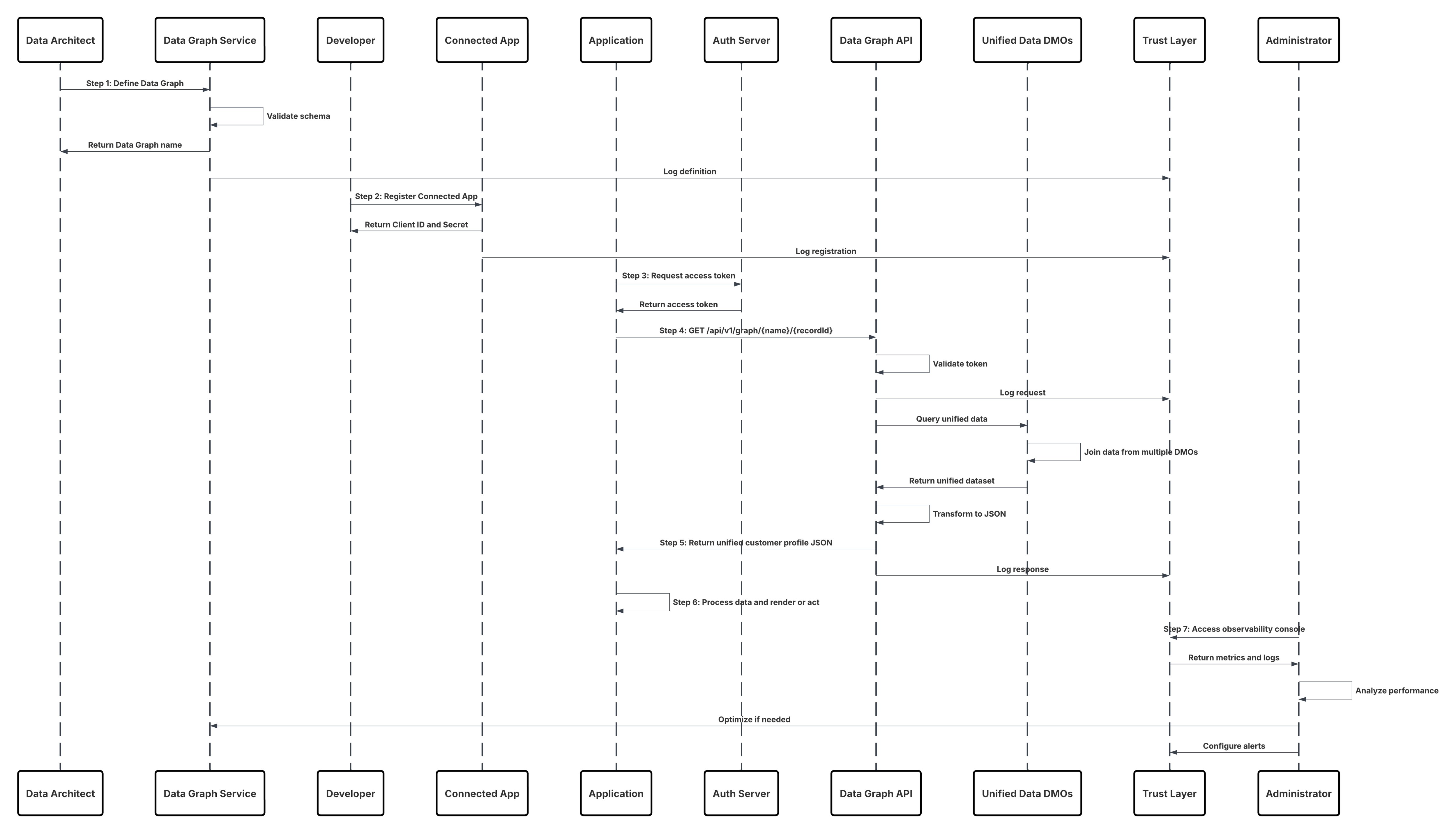
Résultats
Les applications peuvent désormais récupérer instantanément un profil client complet et pré-joint, ce qui permet des interactions en temps réel telles que la personnalisation, le service et l'automatisation des décisions. Ce schéma garantit :
- Temps de réponse inférieur à la seconde pour la prise de décision instantanée.
- Récupération de données cohérente et régie alignée sur le modèle sémantique Data 360.
- Logique d'application simplifiée : aucune jointure, aucun rapprochement de schéma.
- Accès traçable et conforme via la Trust Layer pour l'audit et l'observabilité.
Mécanismes d'appel
Le mécanisme d'appel dépend de la plate-forme de stockage cloud cible et de la configuration d'activation.
| Mécanisme | Quand utiliser |
|---|---|
| API Data Graph (préféré) | Utilisé pour récupérer instantanément des profils prématérialisés complets par ID ou clé. |
| API Data Graph avec live=true | Utilisez-le pour des cas d'utilisation à valeur élevée (p. ex. détection de fraude, offres live) dans lesquels les données les plus récentes sont requises, en acceptant une latence légèrement plus élevée. |
| API Connect (Fallback) | Utilisé pour des scénarios d'application composite combinant des récupérations de Data Graph à d'autres données Salesforce. |
| API de requête | Utilisé lors de la construction de requêtes ad hoc ou de lectures analytiques plutôt que de la récupération instantanée de profils. |
| MuleSoft API Proxy | Utilisé lors de l'acheminement des appels Data Graph via des passerelles d'entreprise ou lorsqu'une orchestration/application de politiques supplémentaires est requise. |
Gestion et récupération des erreurs
- Retour gratuit : si les requêtes live échouent ou dépassent les seuils d'expiration, restaurez automatiquement les récupérations Data Graph en cache.
- Gestion du délai d'expiration : implémentez une nouvelle logique et un disjoncteur pour les appels d'API soumis à une charge élevée.
- Traitement des ID non valides – renvoient les réponses standard 404 Not Found pour les clés de profil inexistantes. Gérez-les avec élégance dans l'interface utilisateur.
- Validation de version du schéma : validez les métadonnées de version du graphique de données afin d'éviter les incohérences lorsque le schéma évolue.
- Intégration de l’observabilité : consignez toutes les erreurs, tentatives et latences dans les tableaux de bord Trust Layer pour la surveillance des accords de niveau de service.
Considérations relatives à la conception impotente
- Clés déterministes : chaque récupération de profil utilise un ID stable (p. ex. IndividualId) qui garantit des requêtes prévisibles et sans risque de relecture.
- Cohérence du cache : utilisez l'en-tête ETag ou Last-Modified pour les récupérations conditionnelles et la validation du cache.
- Récupération atomique : chaque réponse d'API représente un cliché instantané cohérent de l'enregistrement Data Graph matérialisé.
- Protection contre la lecture : assurez-vous que les applications clientes détectent les récupérations dupliquées via des ID de corrélation et des horodatages.
Considérations relatives à la sécurité
- Authentification forte – OAuth 2.0 via des applications connectées applique automatiquement l'accès sécurisé basé sur un jeton.
- Récupération consciente du consentement - Seuls les attributs consentis sont renvoyés; les filtres de consentement sont automatiquement appliqués par la Trust Layer.
- Gouvernance au niveau du champ : l'accès aux attributs est contrôlé via les métadonnées et les définitions de stratégie de Data 360.
- Cryptage en transit et au repos : toutes les réponses sont cryptées avec TLS 1.2+ et AES-256.
- Audit et traçabilité : chaque événement de récupération de profil est consigné avec des identifiants, des horodatages et le contexte de la stratégie.
Menus latéraux
Opportunité
- Conçu pour la récupération instantanée.
- Prend en charge les requêtes live pour des données à jour avec une latence légèrement plus élevée (sub-seconde).
- Optimisé pour la prise de décision synchrone et les applications interactives.
- Élimine la nécessité d'une activation préalable au lot ou d'un recalcul de segment.
Volumes de données
- Idéal pour les références à enregistrement unique ou les petits ensembles (dizaines à centaines) par requête.
- Non optimisé pour la récupération en masse à grande échelle. Utilisez des API Batch ou Query pour les lectures à haut volume.
- Utilise la mise en cache et la pré-matérialisation évolutives horizontales pour plus de rapidité.
Gestion des états
- Maintient un accès léger et sans apatride ; chaque requête est indépendante.
- Prend en charge la mise en cache des en-têtes pour une récupération sans risque de relecture.
- Les applications peuvent conserver un espace cache local ou un espace de stockage de session à court terme afin de réduire les références répétées.
Scénarios d'intégration complexes
- Intègre de façon transparente à Einstein 1, à l'API Connect et à MuleSoft pour des expériences de données composées.
- Peut piloter des systèmes agents (par ex. Copilot ou des moteurs de raisonnement IA) qui nécessitent une sensibilisation instantanée et contextuelle.
- Combiné à des actions de données pour des déclencheurs en temps réel lors de la récupération ou d'un changement d'état.
- Permet la personnalisation à grande échelle sans compromettre les performances ou la gouvernance.
Exemple
Une plate-forme d'e-commerce mondiale utilise l'API Data Graph de Data 360 pour récupérer en temps réel des profils clients unifiés pour son moteur de recommandation. Lorsqu'un utilisateur se connecte, l'application invoque le point de terminaison Data Graph pour récupérer le UnifiedCustomerProfile de ce client, en renvoyant des attributs démographiques, des signaux comportementaux et des connaissances calculées dans une charge de travail JSON unique. Le moteur de personnalisation consomme cette réponse en quelques millisecondes pour déterminer et afficher la « Next Best Offer » pendant la session active. Toutes les requêtes sont régies et consignées par la Couche Trust, ce qui garantit la visibilité, l ' application des politiques et le respect des règles dans l ' ensemble de l ' interaction.
Les actions de données en temps réel activent l'activation instantanée des données clients dès qu'elles changent dans Data 360. Au lieu d'attendre les exportations par lot planifiées, ces actions envoient automatiquement des mises à jour, des connaissances ou des déclencheurs directement à Salesforce ou à des systèmes externes en quelques millisecondes. Lorsque le statut, le consentement ou la métrique d'engagement d'un client est mis à jour dans Data 360, ce signal peut immédiatement alimenter des offres personnalisées, déclencher des automatisations Service Cloud ou mettre à jour les niveaux de fidélité, afin de garantir que chaque expérience client reflète la vérité la plus récente et unifiée. Ce modèle est idéal pour les cas d'utilisation sensibles à l'impact et à la latence, tels que les expériences Web personnalisées, les alertes de détection de fraude, les recommandations Next Best Action ou les mises à jour CRM en temps réel. Il réduit l'écart entre les connaissances des données et l'action commerciale, transformant les données unifiées en intelligence instantanée.
Context
Les expériences numériques modernes et les workflows opérationnels nécessitent des actions immédiates et contextuelles dès qu'un événement se produit, par exemple, mettre à jour un enregistrement client pendant un Checkout, ajuster l'inventaire lorsqu'un retour est scanné ou offrir une promotion personnalisée dès qu'un utilisateur abandonne un panier d'achat. Les actions de données en temps réel permettent aux systèmes d'invoquer, d'enrichir et d'agir sur des profils Data 360 unifiés et des connaissances calculées avec une latence inférieure à la seconde, ce qui permet la personnalisation interactive, l'automatisation opérationnelle et la prise de décision instantanée.
Problème
Comment des applications, des flux d'interaction d'interface utilisateur ou des middlewares peuvent-ils appeler Data 360 à l'exécution pour lire, calculer ou mettre à jour un profil unifié unique ou déclencher une action (par exemple envoyer une offre, mettre à jour CRM, démarrer un workflow) avec une faible latence, une forte cohérence et des contrôles de gouvernance, sans attendre les tâches par lot planifiées ou les pipelines lourds ?
Forces
Plusieurs forces techniques, opérationnelles et de gouvernance façonnent ce schéma :
- Exigence de faible latence : Les appels doivent être effectués en quelques secondes ou en quelques secondes pour préserver un bon niveau d'expérience utilisateur ou respecter les accords de niveau de service opérationnels.
- Résolution déterministe de l'identité : Les requêtes doivent être résolues avec le profil Individu unifié correct (enregistrement doré) de façon fiable et rapide.
- Autorisation précise : Les appels en temps réel doivent appliquer des stratégies au niveau de l'attribut et des contrôles de consentement à la demande.
- Minimalisme de la charge de travail : Les charges utiles en temps réel doivent être petites et ciblées (profil unique ou petit ensemble d'attributs) afin de réduire la latence et les coûts.
- Expérience du développeur : Les API doivent être adaptées aux développeurs (REST/gRPC/GraphQL), avec des schémas clairs et des contrats stables pour l'utilisation en production.
- Auditabilité et traçabilité : Chaque action en temps réel doit être consignée avec le lignage, l'identité de l'utilisateur et les décisions de politique de conformité.
Solution
La solution recommandée est d'utiliser l'interface Actions de données en temps réel (API + SDK) de Data 360 combinée à la mise en cache des bords et à un minimum de transformations de calcul si nécessaire. Les intégrations invoquent un point de terminaison d'actions de données pour lire ou écrire des attributs de profil, calculer des connaissances ou initier des orchestrations. Les contrôles de stratégie en temps réel (CEDAR) et le masquage dynamique sont appliqués au point d'application de la politique avant le renvoi de la charge utile ou l'exécution de l'action.
| Zone de solution | Ajustement | Commentaires / Détails d'implémentation |
|---|---|---|
| Action Données en temps réel | Meilleur | Point de terminaison d'exposition pour les déclencheurs de lecture/écriture et d'action à enregistrement unique. Authentifiez-vous via OAuth/JWT. |
| Résolution de l'identité | Obligatoire | Résolvez les identifiants entrants (e-mail, externalId, cookie) dans ID d'individu unifié en ligne. Utilisez un résolveur déterministe avec cache. |
| Application des politiques (CEDAR) | Meilleures pratiques | Évaluez les politiques de consentement, d'ABAC et de masquage à la demande, refusez ou masquez les champs par décision de politique. |
| Couche Bord/Cache | Recommandé | Utilisez des caches TTL courts pour les fragments de profil et les connaissances calculées afin de réduire la latence; invalidez lors d'événements de modification. |
| Transformations légères | Recommandé | Appliquez de simples enrichissements ou des champs calculés dans le parcours d'action ; les transformations lourdes doivent être précalculées. |
| Orchestration d'action | Meilleur | Prenez en charge les actions synchrones à une étape (par exemple, jeton d'offre de retour) et les orchestrations asynchrones (file d'attente \+ webhook) pour les flux complexes. |
| Observabilité et traçabilité | Obligatoire | Consignez les demandes/réponses, les décisions stratégiques et la lignée dans la Trust Layer/SIEM pour vérification et débogage. |
| Limitation tarifaire et limitation | Obligatoire | Appliquez des quotas clients et des stratégies de dégradation gracieuses pour les moments à fort trafic. |
Croquis
Voici le résumé des étapes.
- Le client (interface utilisateur / middleware / point de vente) envoie des requêtes Action de données authentifiées avec des identifiants et un type d'action.
- La passerelle API valide les limites en jetons, en taux et en transferts vers le service d'action Data 360.
- Action Service résout l'identificateur → ID d'individu unifié (cache du chemin rapide ; repli vers la référence Graphique).
- L'application des politiques (PDP) évalue les politiques CEDAR en utilisant les attributs de PEP et le contexte de la demande.
- Si autorisé, Action Service lit tous les attributs/connaissances de profil requis et effectue des transformations légères.
- Action Service renvoie la réponse de façon synchrone (par exemple, jeton d'offre, attribut mis à jour) ou met en file d'attente l'orchestration asynchrone et renvoie l'accusé de réception.
- Tous les événements, décisions et charges utiles sont consignés dans Trust Layer et éventuellement transmis à SIEM.
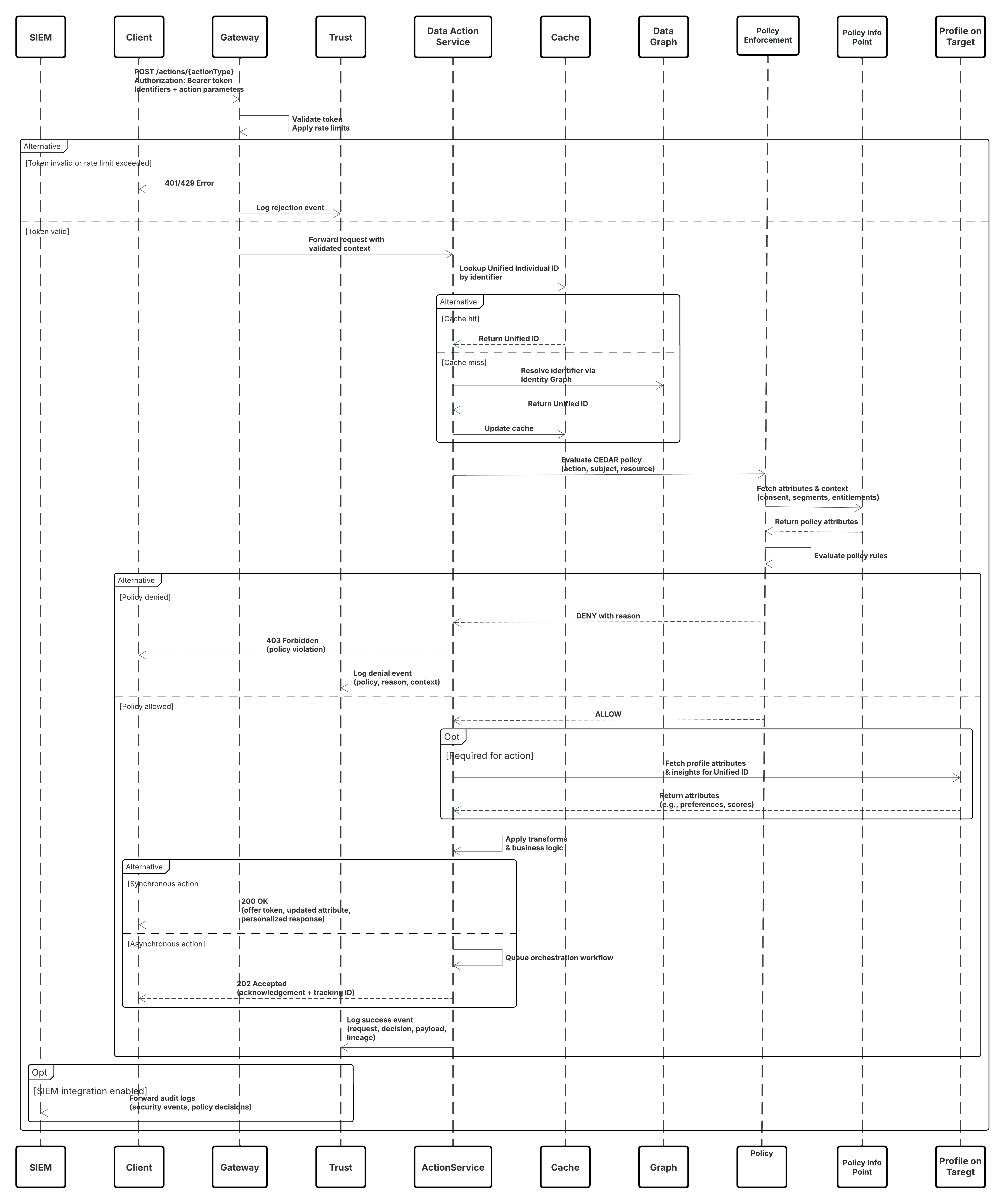
Résultats
- Les applications reçoivent un accès immédiat, régi par la politique, aux lectures/écritures de profil unifié et aux déclencheurs d'action avec une latence de la seconde à la seconde.
- La personnalisation en temps réel, la prise de décision et les workflows opérationnels (p. ex. offres, assistance de l'agent, mises à jour d'inventaire) sont activés sans délai par lot.
- Toutes les actions peuvent être auditées, sont sensibles au consentement et appliquent automatiquement le masquage au niveau de l'attribut pour préserver la confidentialité et la conformité.
Mécanismes d'appel
Le mécanisme d'appel dépend de la plate-forme de destination et de la configuration de la cible d'activation.
| Mécanisme | Quand utiliser |
|---|---|
| API RESTful Data Actions | Préféré pour les applications Web/mobiles et les middlewares qui nécessitent des lectures de profil ou des réponses d'action synchrones. |
| gRPC / Binary RPC | Utilisé pour les services d'entreprise à très faible latence ou les microservices internes avec des connexions permanentes. |
| Requêtes GraphQL à enregistrement unique | Utile lorsque les clients doivent sélectionner des champs flexibles et souhaitent réduire les charges utiles. |
| Webhooks déclenchés par un événement | Utilisé pour les workflows asynchrones dans lesquels une action déclenche des processus en aval (par exemple, démarrer un parcours). |
| Événements de plate-forme / PubSub | Utilisé pour les scénarios de déploiement dans lesquels plusieurs systèmes doivent réagir à un événement d'action unique. |
| Edge SDK (libs client) | Utilisé pour les clients à faible latence qui mettent en cache les fragments de profil et appellent l'API Actions de données uniquement en cas de besoin. |
Gestion et récupération des erreurs
- Erreurs synchrones : Renvoyez des codes d'erreur structurés avec des messages lisibles par l'utilisateur et des jetons d'idempotence.
- Nouvelle tentative transitoire : Les clients doivent réessayer les requêtes idempotentes avec un recul exponentiel sur les réponses 429/5xx.
- Traitement des refus de politique : Les refus renvoient des codes de motif clairs ; les données confidentielles ne sont jamais renvoyées en cas d'échec de la stratégie.
- Échecs d'orchestration asynchrone : Les tâches d'orchestration sont déplacées vers DLQ et rejouables. Une API de statut de tâche permet aux clients d'interroger ou de recevoir des rappels.
- Stratégies de repli : Si la résolution de l'identité échoue, renvoyez une erreur déterministe et éventuellement une mesure corrective suggérée (par exemple, exiger externalId).
Considérations relatives à la conception impotente
- Clé d'immunité : Les clients fournissent une clé d'idempotence (UUID + espace de noms client) pour les actions de mutation.
- Clés déterministes : Utilisez des clés composées (UnifiedIndividualId + ActionType + TimestampWindow) pour détecter les doublons.
- Récupérations sécurisées : Concevez des actions tolérant les effets secondaires ou effectuez des mises à jour/insertions au lieu d'insertions aveugles.
- Protection contre la lecture : Maintenez les clés d'idempotence traitées et TTL-les après la fenêtre métier pour éviter les relectures.
- Apatridie : Gardez les actions synchrones sans état d'apatridie si possible, et maintenez un état minimal pour les workflows asynchrones.
Considérations relatives à la sécurité
- Authentification : OAuth 2.0 (porteur JWT ou mTLS pour les comptes de service); jetons de courte durée et rotation de l'actualisation.
- Autorisation : Le point de décision de politique applique automatiquement le contrôle d'accès basé sur l'attribut (CEDAR) et les contrôles de consentement par requête.
- Transport & Storage Encryption : TLS 1.2+ en transit; AES-256 au repos pour tous les fragments mis en cache ou journaux d'audit.
- Moins de privilège : Clients d'API limités à des autorisations minimales ; rôles séparés pour la lecture et l'écriture et l'orchestration.
- Réduction des données : Renvoyez uniquement les attributs demandés et consentis ; appliquez le masquage dynamique pour PII/PHI.
- Contrôles réseau : Vous pouvez également exiger des appels à partir de réseaux privés (Private Connect, listes d'autorisations IP) pour des actions à haut risque.
- Audit et surveillance : Consignez les métadonnées des requêtes, les décisions stratégiques, l'identité du demandeur et les hachages de réponse dans Trust Layer et SIEM.
Menus latéraux
Opportunité
- Conçu pour les latences moyennes dans la plage inférieure à la seconde et inférieure à une seconde pour les actions synchrones.
- Les caches Edge (TTL court) et les connaissances précalculées réduisent les allers-retours.
- Les parcours asynchrones fournissent un accusé de réception quasi instantané avec un traitement en arrière-plan pour les tâches lourdes.
Volumes de données
- Optimisé pour les interactions à enregistrement unique ou par petits lots (1 à 100 enregistrements).
- Pas destiné aux exportations en masse : utilisez l'activation par lot pour les volumes importants.
- Le débit élevé utilise la réutilisation de la mise en commun/connexion et des files d'attente d'orchestration parallèles.
Gestion des états
- Modèle de requête apatride pour les appels synchrones ; état d'action minimal persistant pour les subventions/transactions.
- Invalidation du cache pilotée par les événements de modification : assurez-vous que les TTL et les signaux d'invalidation gardent le cache à jour.
- Les tâches d'orchestration conservent un état durable (jobId, statut, tentatives) stocké dans la Trust Layer.
Scénarios d'intégration complexes
- Assistance de l'agent : Référence de profil en temps réel + propension calculée renvoyée à la console de service en moins de seconde pour les agents.
- POS / Edge Devices: Kit de développement local + action de données occasionnelle pour valider des promotions ou le statut de fidélité.
- Flux hybrides : Synchronisez Action de données pour l'orchestration Décision + asynchrone afin de mettre à jour les systèmes en aval et de déclencher des campagnes.
- Intergiciel tiers : Les passerelles MuleSoft ou API peuvent servir de médiateur pour l'authentification, enrichir le contexte et appliquer des contrôles de stratégie supplémentaires.
Exemple
Une application mobile de vente au détail détermine si un coupon instantané personnalisé doit être affiché lorsqu’un consommateur touche Checkout en invoquant l’action de données d’**éligibilité à l’**offre dans le contexte de l’adresse e-mail et du panier d’achat du consommateur. La requête est validée par la passerelle d'API et transmise au service d'action de données, qui résout l'e-mail vers un ID d'individu unifié en utilisant un accès cache, vérifie le consentement marketing via le PDP, et évalue l'éligibilité en fonction de la valeur de durée de vie du client et de la récence d'achat récente. Si le consommateur est éligible, le service renvoie un jeton de coupon signé et consigne la décision. Lorsque l'émission d'un coupon nécessite une réservation d'inventaire, une orchestration asynchrone est déclenchée pour réserver l'inventaire et notifier les systèmes CRM. L'application affiche immédiatement le coupon, tandis que les mises à jour en aval sont terminées en arrière-plan et que la Trust Layer capture un journal d'audit complet pour la gouvernance et la conformité.
- Connecteurs et intégration
- Web & Mobile SDK
- Ingestion en temps réel inférieure à la seconde
- Bring Your Own Lake (Requête zéro copie)
- Bring Your Own Lake (fichier sans copie)
- Graphiques de données
- Activation : Engagement MC
- Activation : Personnalisation MC
- Activation : B2C Commerce
- Partage de données (copie nulle)
- Activation : Stockage de fichiers
- Actions de données
- Actions de données en temps réel sub-second
- Plate-forme d'activation externe