此文字已使用 Salesforce 的自動翻譯系統進行翻譯。參閱我們的 調查以提供此內容的回饋意見,並告訴我們您接下來想要查看的內容。
Note
概觀
企業通常會將資料儲存在 Salesforce 和其他外部資料湖中,例如 Snowflake、Google BigQuery、Databricks、Redshift 或雲端儲存空間,例如 Amazon S3。在不同來源系統中將資料分隔,對於想要充分利用資料功能的公司來說,這是一個挑戰。
處理整合多個資料湖之間資料的結構設計師會面對關於如何最佳整合該資料的重要結構決策。Data 360 提供多個資料整合選項,每個選項都有不同的優點與缺點。
本指南提供評估哪個模式最適合您在整合資料時的延遲、成本、可擴展性、管治和複雜性需求的架構,協助您選擇何時使用資料提取、零複製資料聯合或混合式方法。此指南也會協助您在不同方法之間進行選取,這些方法皆滿足不同的需求。
將外部資料湖集與 Data 360 整合需要仔細考量資料新鮮度、管治與管道效率之間的權衡。例如,使用「零複製」資料聯合即時查詢可將資料的最新度最大化,但在您在網路上移動更多資料時,可能會降低銷售管道效率。因此,針對大多數的實作,在多雲湖區生態系統中結合取用與聯合是最佳的路徑。此混合式方法可確保可調整、受管理、可互通的結構,可順暢地支援低延遲的作業工作量,例如即時個人化和詐騙偵測,以及分析工作量,例如法規報告和歷程記錄趨勢分析。此決策指南將協助您瞭解如何瀏覽這些權衡,並選取正確的策略。
接待時間
- **Data Caption:**將資料複製到 Salesforce Data 360,建立受管理的標準資料模型。需要執行以下動作時的理想選擇:
- **建立全方位的 Customer 360:**將不同的來源統一並轉換為單一信任的設定檔。
- **符合嚴格的法規規範:**建立可稽核的集中複本,可在其中密切控制資料存取與歷程。
- **零複製聯合:**即時查詢外部來源,無須重複,並啟用即時個人化、即時顯示面板和快速來源上線。有兩個主要選項,其中包含您必須平衡的權衡:
- **即時與快取 (加速查詢):**適用於外部資料平台 (例如 Snowflake、Google BigQuery、Redshift 或 Databricks) 中資料的互動式分析和即時顯示面板。將處理推送至來源系統,以避免資料重複的速度變慢且成本高。
- **檔案聯合:**最適用於在雲端資料湖中對資料進行的大規模批次處理和 AI 模型訓練 (S3、ADLS)。透過直接以開放式表格格式查詢檔案,以解除鎖定 ETL 和資料科學工作負載的大量資料集,以避免成本高昂且速度緩慢的取用。
- **混合型號:**使用聯合功能來混合「統一設定檔」採取,以獲得最新效果、支援 Omni-Channel 參與、Agentforce 驅動的動作和 AI/ML 訓練。
重要考量事項
-
**混合結構:**經常需要混合資料採取和資料聯合。
- 針對標準資料模型和核心管理,在重要資料上使用「資料取用」。
- 透過「零複製」將所有其他資料聯合,以將建立和維護取用資料銷售管道的作業負擔降到最低。
-
**Data Capture Frequency Matters:**根據業務價值、延遲需求和營運複雜度選擇頻率。
- 針對具有時效性的工作流程 (個人化、即時顯示面板、Agentforce 動作) 使用即時。
- 適用於中度緊急流程 (行銷活動、營運報告) 的近乎即時。
- 歷程記錄或低速資料集的批次。
-
**將聯合模式與延遲與效能比對:**選擇最符合您存取模式以及更新性、效能與成本需求的資源。
- 將「即時查詢」用於低延遲十分重要的作業顯示面板和即時個人化。
- 當查詢頻繁但略有延遲的結果可接受時,請使用快取 (加速查詢),以平衡效能與成本。
- 將檔案聯合用於大規模、輸送量繁重的分析或批次工作負載,其非常適用於歷史或較不敏感的時間資料集。
-
使管治與資料落地需求保持一致:
- 在集中化監管十分重要時,請使用採取。
- 在接受去中心化監管的情況下使用聯合,同時在外部來源強制執行嚴格監管。「零複製」遵循如列層級安全性 (RLS) 和資料遮蔽等來源層級原則。
-
**為高價值工作流程排定取用優先順序:**選擇性地套用至重要流程,例如身分解析、監管報告和作業啟用。
-
**成本與複雜性驅動決策:**即時採取可能高成本且複雜。結構設計師應將上線、儲存和轉換資料的成本與直接透過零複製查詢資料的成本加權。
選擇正確的整合模式 (「資料」、「零複製」或「混合式」方法) 會直接影響多重雲端平台的延遲、管治、營運效率和成本。此決策會決定如何可靠且大規模地提供即時洞察、AI 驅動的啟用和個人化參與。
產品比較
此表格提供 Salesforce Data 360 中「資料取用」與「零複製」模式的技術比較,專注於功能、權衡和優點,以及企業使用個案和成果。結構設計師可以使用此作為設計混合式多雲端資料平台的參考,以平衡效能、成本和合規性。
| 模式類型 | 模式/工具 | 益處 | 考量事項 | 成果 |
|---|---|---|---|---|
| 資料取用 | 即時:透過具有 CDC 支援的「取用 API」進行子秒延遲。連續串流銷售管道。 | - 立即洞察 - 適用於低延遲作業和個人化使用個案的理想選擇 - 支援以事件為導向的工作流程 |
- 高成本 - 複雜結構 - 需要低延遲來源系統 - 大量來源會造成過度串流導致飽和的銷售管道 - I/O 密集 - 考慮選擇性欄位和篩選條件以減少超額 |
Agentforce: - 即時詐騙警示、零售個人化、營運警示 Analytics: - 子秒顯示面板、KPI 監視 合規性: - 持續更新受監管工作流程的客戶記錄 |
| 串流: 透過原生連接器每 1–3 分鐘進行一次微批次採取 | - 平衡成本與新鮮度 - 比即時更簡單的結構 - 支援增量更新 |
- 輕微延遲 - 可能不適用於重要子秒決策 - 批次大小會影響記憶體/計算 - I/O 為中度 - 最適用於可預測的重複更新模式 - 考慮視窗彙總以減少處理負載 |
Agentforce: - 及時的行銷活動觸發、近乎即時的參與 Analytics: - 建議引擎、近乎即時的顯示面板 合規性: - 含稽核性的頻繁更新 |
|
| 批次:透過連接器或 API 排程大量載入。支援物件儲存和 ETL/ELT 銷售管道。 | - 大量資料集的成本效益 - 易於實作 - 可靠的歷程記錄分析 |
- 資料延遲 - 不適用於時效操作 - 載入期間的 I/O 密集 - 網路輸送量可能會成為大型檔案的瓶頸 - 最適用於歷程記錄彙總或監管報告工作流程 |
Agentforce: - 資訊支援票證 (Jira/ServiceNow),彙總工作流程 Analytics: - 歷程記錄分析、趨勢評估 抱怨: - 法規報告、病患/索賠資料彙總 |
|
| 零複製 | 即時查詢:對外部系統進行直接查詢;結構描述即讀;無資料重複 | - 最大新鮮度 - 儲存空間負擔率最小;支援即時營運洞察 |
- 相依於來源效能 - 高查詢量可能會影響延遲 - 適用於具有述詞推送和彙總以將 I/O 最小化查詢的理想選擇 - 避免對大量資料集進行未篩選的查詢 |
Agentforce: - 適應即時活動的動態工作流程 Analytics: - 作業顯示面板、即時報告 合規性: - 遵循來源的列層級安全性與遮蔽 |
| 加速查詢 (快取): 聯合查詢的快取本機複本。可設定 15 分鐘到 7 天。最佳化查詢執行 | - 減少延遲 - 比重複即時查詢的成本更低 - 改善頻繁存取模式的效能 |
- 需要快取管理 - 延遲時間取決於快取間隔 - 最適用於高頻率查詢 - 不適用於次要決策 |
Agentforce: - 用於快速決策的預先彙總參與度量 Analytics: - BI 顯示面板、區隔、分析報告 合規性: - 具有稽核記錄的一致監管顯示面板 |
|
| 檔案聯合:直接存取物件存放區或湖中大型歷史資料集 (S3、Iceberg、Google BigQuery、Redshift)。 | - 處理大規模資料集 - Data 360 中的儲存空間下限 - 支援 AI/ML 工作量 |
- 唯讀 - 查詢效能取決於外部系統輸送量 - 針對批次繁重、輸送量密集型工作最佳化 - 不適用於即時顯示面板 |
Agentforce: - (非典型 — 批次繁重) Analytics: - ML/AI 訓練、歷程記錄分析、Peta 位元的規模報告 合規性: - 無重複的外部資料集受管理存取權 |
Data 360 整合模式
資料匯入
若要使用資料取用,則資料會實際複製到 Data 360 並完全受管理,與資料保留在來源的「零複製」不同。在 Data 360 內進行轉換的計算,進而允許集中管理和稽核。
資料取用個案
在 Salesforce Data 360 中使用資料取用來儲存標準、受管理的資料集,以達成合規性和作業控制。當需要完整控制、稽核和可追溯性時,請使用採取。適用於監管或高價值的工作流程,其中集中運算與管治十分重要。
在建立身分解析、監管報告、任務關鍵 AI 驅動工作流程和客戶參與的信任基礎上,最適合使用「採取」。

資料取用方法
系統會根據您使用的連接器,用來取用資料。某些連接器提供各式各樣的方法,而其他連接器僅在批次或串流模式中運作。請參閱 Data 360 360 連接器及其可用方法的完整清單的整合和連接器。
- 即時
- 使用串流管道或 Change 資料擷取 (CDC) 進行子秒取用。
- 最適用於具有時效性的工作流程 (詐騙偵測、個人化、作業顯示面板)。
- 在 Data 360 內推送轉換和彙總,以減少下游 I/O 並最佳化運算用量。使用增量 CDC 將資料混亂降到最低。
- 串流
- 每 1–3 分鐘以小量增量排列。
- 平衡最新與成本,適用於行銷活動協調流程、近乎即時的參與和作業報告。
- 使用微批次控制 I/O 峰值。盡可能彙總來源的資料,以減少傳輸量並最佳化儲存空間。
- 批次 (已排程載入)
- 大型資料集 (每小時、每日、每週) 會定期採取。
- 針對歷程記錄資料集、法規報告和合規性使用個案,具有成本效益且可靠性。
- 確保在與來源儲存空間相同的區域中計算地區設定,以達到效能與成本最佳化。
結構設計師手冊
- 使用個案取得資料
- **產生 Customer 360 統一設定檔:**建立客戶身分與屬性的單一事實來源。
- **維護法規合規性資料集:**強制執行敏感資料的監管、歷程和稽核能力。
- **集中行銷活動協調流程:**確保行銷、銷售和服務皆可從一致且信任的資料集中作業。
- 設計作法
- 針對歷程記錄或低延遲容忍的需求 (��如歸檔報告或定期快照) 偏好採取批次。
- 使用 CDC 或串流 API 來維持作業與個人化工作流程的最新狀態,確保近乎即時更新。
- 透過套用增量負載 (而非重新載入整個資料集),以最佳化成本和效率來控制儲存和運算成長。
- 透過運算本地性和增量處理來讓取用管道保持一致,以減少網路 I/O。在 Data 360 內套用轉換,以避免不必要地移動原始資料。
- 成本考量事項
- **即時提取:**計算和管道成本最高;對於高價值且具時間敏感性的工作流程 (例如個人化、作業顯示面板或 Agentforce 驅動的動作) 而言是正確的。
- **串流吸收:**仲裁運算和儲存成本;適用於經常更新,可容忍輕微延遲,例如行銷活動協調流程或營運報告。
- **批次接收:**較低的運算成本、可預測的儲存空間;適用於歷程記錄資料集或低頻率更新。使用特定連接器可免費從 Salesforce 組織中取用批次資料。
- **重新整理模式:**選取「增量重新整理」模式可減少整體耗用和計算成本。我們建議盡可能使用增量重新整理,以最佳化所有採取類型的效率。
- 成本也會受到來源至 Data 360 的 I/O 量影響。最佳化批次大小、分割和區域對齊方式可降低傳輸成本並改善效能。
- 行業案例
- **財務:**瞭解客戶 (KYC)、防洗錢 (AML) 和詐騙偵測所需的資料集,其中可稽核性與合規性是無法協商的。
- **醫療照護:**針對病患身分解析和 HIPAA 規範的記錄,針對取用,啟用安全且統一的檢視。
- **零售:**將銷售點 (POS)、電子商務和忠誠度計畫資料合併至統一設定檔以進行區隔和個人化
- **電信:**使用標準、受管理的訂閱者資料支援流失預防和使用量分析。
資料取用方法決策條件
| 功能 | 即時快取 | 串流捕取 | 批次提取 |
|---|---|---|---|
| 延遲與新鮮度 | 透過具有 Change 資料擷取 (CDC) 支援的「取用 API」來進行子秒延遲。提供連續串流管道。最適用於低延遲作業使用個案。 | 每 1–3 分鐘透過原生連接器進行每個 1–3 個批次的採取。支援增量更新。預期略有延遲。 | 預期資料延遲。已排程大量載入。定期攝取 (每小時、每日、每週)。不適用於具有時效性的作業。 |
| 主要使用個案 | 適用於低延遲作業和個人化使用個案的理想選擇。用於具有時效性的工作流程。支援以事件為導向的工作流程。用於即時詐騙警示和作業警示。 | 適用於中度緊急的程序。用於行銷活動協調流程、近乎即時的參與和作業報告。用於及時觸發行銷活動。 | 針對大量資料集具有成本效益。可靠以進行歷程記錄分析。用於歷程記錄彙總或監管報告工作流程。最適用於歷程記錄或低速資料集。 |
| 結構複雜性和 I/O | 高成本且複雜的結構。需要低延遲來源系統。I/O 密集。大量來源會造成飽和的銷售管道。 | 比即時更簡單的結構。I/O 為中。最適用於可預測的重複更新模式。批次大小會影響記憶體/計算。 | 實作簡單。載入期間的 I/O 密集。網路輸送量可能會成為大型批次的瓶頸。 |
| 成本考量事項 | 計算和管道成本最高。僅適用於高價值且具有時效性的工作流程。 | 仲裁計算和儲存成本。提供平衡成本與新鮮性的方法。適用於可承受輕微延遲的頻繁更新。 | 計算成本和可預測的儲存空間降低。建議用於歷程記錄資料集或低頻率更新。透過 Salesforce 內部銷售管道可免費使用。 |
| 設計作法 | 使用增量 CDC 將資料混亂降到最低。篩選並使用選擇性欄位來減少超額。 | 使用微批次控制 I/O 峰值。請考慮使用視窗彙總來減少處理量。 | 將此項目加入歸檔報告或定期快照。確定在與來源儲存空間相同的區域中計算地區設定,以最佳化成本。 |
零複製資料聯合
零複製使用個案
使用「零複製」來即時查詢外部系統,而無須資料重複,以啟用大型或暫時資料集的靈活性、新鮮性和可調整存取權。最適用於即時顯示面板、探索分析、AI/ML 模型訓練,以及直接透過 Salesforce Data 360 進行即時客戶參與。
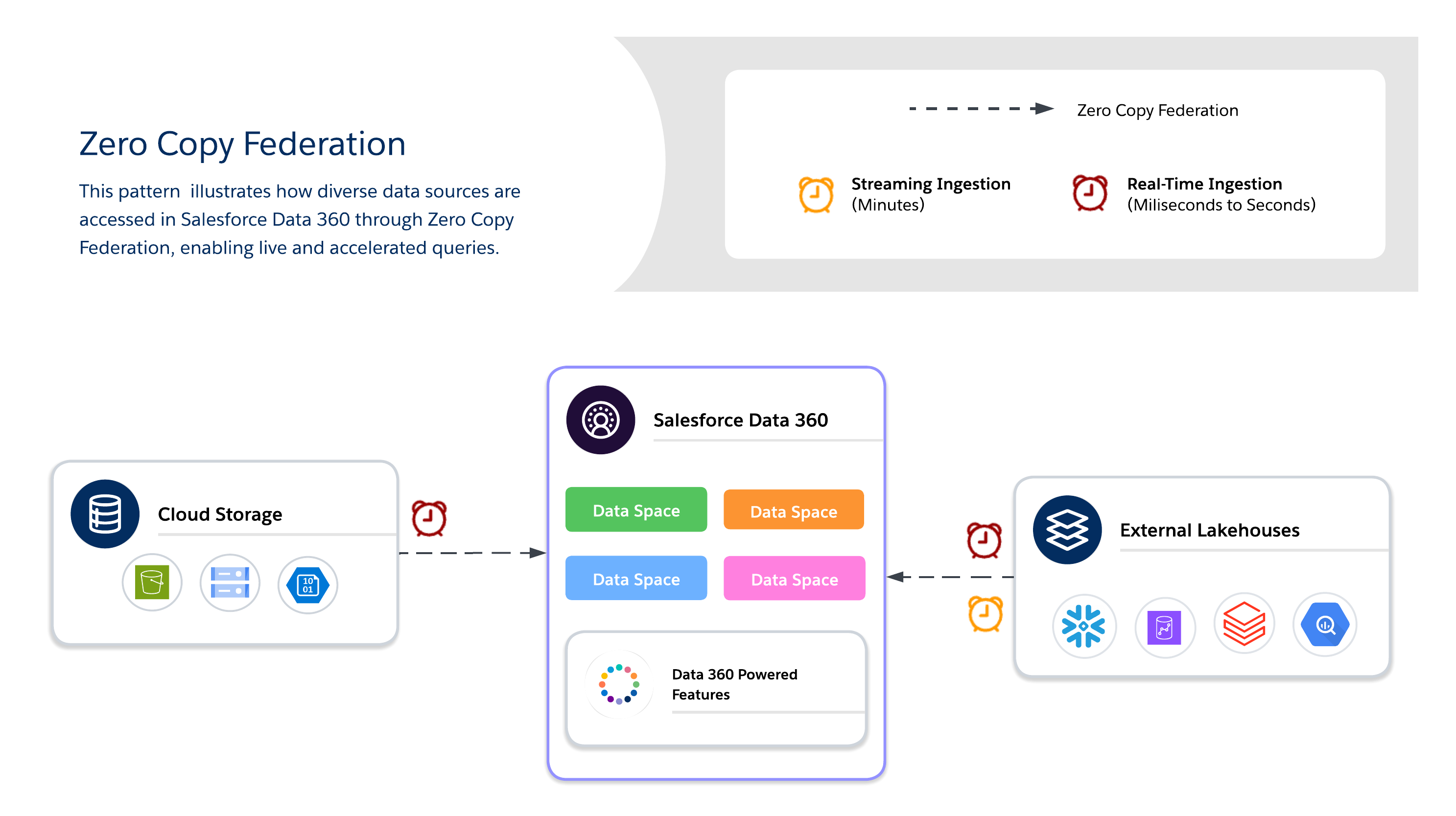
零複製方法
使用「零複製」時,結構設計師必須在三個可用的資料聯合方法之間進一步決定,每個方法都會在更新性、效能和成本之間提供自己的權衡。
- 即時查詢
- 直接針對外部系統 (Snowflake、Google BigQuery、Redshift、Databricks 等) 執行查詢,而不會重複資料。
- 當可向下推送述詞和彙總時最佳化,可將資料在網路上的移動降到最低,並降低 Salesforce Data 360 計算上的 I/O。
- 最適用於即時洞察和低延遲作業顯示面板。取決於外部系統的效能。
- 快取 (加速查詢)
- 在 Salesforce Data 360 中暫時儲存聯合資料的快取複本。
- 透過可設定的持續時間 (分鐘到天) 來減少經常存取資料集的重複查詢成本和延遲。
- 系統不會永久複製或完全管理資料;系統會透過來源的排程重新整理來管理最新狀態。
- 檔案聯合
- 提供物件存放區中大規模資料集的直接唯讀存取權 (例如 S3、GCS with Iceberg)。
- 最適用於 AI/ML 工作負載、歷程記錄分析和 petabyte 規模報告,而無須移動資料。
- 查詢效能取決於物件格式、分割和網路 I/O。若未最佳化,大型掃描可能會產生大量的 I/O。
結構設計師手冊
- 使用個案
- **即時個人化與自適應工作流程:**隨著客戶行為變更,提供動態優惠、建議和 Next Best Action。
- **即時顯示面板與作業分析:**直接從外部倉庫強化業務關鍵的顯示面板和 KPI。
- **使用大型外部資料集進行 AI/ML 模型訓練:**使用檔案聯合,無須移動即可利用資料湖和倉庫的 petabyte 級資料。
- 行業案例
- **零售/媒體:**透過聯合點閱串流或內容互動資料來啟用個人化建議和即時客戶參與。
- **財務:**透過查詢外部倉庫,而不重複敏感資料,以近乎即時執行詐騙偵測和風險評分。
- **技術/企業:**支援跨雲端報告、IT 服務顯示面板和作業分析,其中資料集位於多個系統中。
- 設計作法
- 即時查詢
- 當新鮮度十分重要時,用於高 QPS、低延遲的查詢。
- 將述詞和彙總推送至外部系統,以減少網路上的資料混亂。
- 避免進行不必要掃描大量資料的查詢;請考慮裁切分割與篩選。
- 檔案聯合
- 在物件存放區中存取 petabyte 級資料集,而無須取用。
- 將物件儲存空間保持在與 Salesforce 計算相同的雲端區域中,以將延遲和輸出成本降到最低。
- 使用分割的資料欄格式 (Parquet/ORC) 和推送式篩選條件來減少 I/O 和網路傳輸。
- 利用查詢和述詞推送功能來篩選和彙總來源的資料,減少資料移動。
- 除非有必要,否則請避免跨區域資料存取,因為這會增加 I/O、延遲和成本。
- 快取 (加速查詢)
- 快取經常存取的資料集以平衡成本與效能。
- 設定重新整理間隔以平衡更新與查詢成本。
- **合規性:**透過利用列層級安全性 (RLS) 並直接在聯邦系統內遮蔽原則,強制執行來源管理。以下是統一 RLS 和跨平台遮蔽的最佳作法。
- **使用集中化企業識別碼:**將 Salesforce Data 360 中的使用者與實體對應至與外部系統中身分對應的唯一集中企業識別碼。
- **Align 安全性原則:**確保聯合系統中根據對應的身分套用列層級安全性與遮蔽原則。這可在查詢外部資料時保留合規性。
- **標準化身分結構描述:**在所有資料來源之間維護一致的身分屬性 (電子郵件、使用者識別碼、客戶識別碼等),以避免不相符和存取違規。
- 即時查詢
- 成本考量事項
- **即時查詢:**每查詢付費模型—在外部湖家計算中產生的成本,且可以高 QPS 激增。最適用於價值大於成本變異性的清新度關鍵使用個案。
- **加速查詢 (快取):**透過減少對來源系統的點擊次數,降低查詢成本 (相較於 Live Query),但會增加填入和重新整理快取的批次資料取用成本。最適用於經常存取的資料集。
- 檔案聯合:「物件商店」中資料的最便宜儲存選項,但查詢成本取決於檔案大小、分割和裁切。最適用於 Petabyte 級的歷程記錄或大量資料。
零複製方法決策條件
| 決策點 | 即時查詢 | 快取 (加速查詢) | 檔案聯合 |
|---|---|---|---|
| 資料來源位置 | 外部資料湖 (Snowflake、Google BigQuery、Redshift、Databricks)。 | 外部資料湖 (Snowflake、Google BigQuery、Redshift、Databricks) | 物件存放區或雲端資料湖 (S3、ADLS、GCS),通常使用如 Iceberg 等開放式表格格式。 |
| 用途/使用個案 | 互動式分析與即時顯示面板的理想選擇。最適用於即時個人化和動態工作流程。 | 最適用於查詢頻繁但略過時的結果可接受時。適用於 BI 顯示面板與區段。 | 最適用於大規模批次處理和 AI/ML 模型訓練。適用於歷程記錄分析和 petabyte 級報告。 |
| 新鮮度/延遲性 | 最新度最大;查詢會直接即時執行。支援次要決策。 | 可接受略過時的結果。更新性取決於快取間隔,可設定為 15 分鐘到 7 天。 | 針對批次繁重、輸送量密集型工作最佳化。不適用於即時顯示面板。 |
| 存取模式 | 適用於不常見或臨時查詢。用於高 QPS (每秒查詢)、低延遲查詢,其中重新整理十分重要。 | 最適用於高頻率讀取情況。改善頻繁存取模式的效能。 | 唯讀存取權。適用於不需要採取的 petabyte 級資料集。 |
| 效能驅動因素 | 高度依賴外部來源系統的效能。當可將述詞和彙總向下推送至來源時,已最佳化。 | 與重複的即時查詢相比,減少延遲。效能取決於快取管理和間隔。 | 效能取決於物件格式、分割和外部系統輸送量。使用分割的資料欄格式 (Parquet/ORC)。 |
| 成本影響 | 每查詢付款模式。外部湖家計算產生的成本。對於不常見的查詢而言,成本效益高,但成本可能會因每秒高查詢量 (QPS) 量而高峰。 | 比重複即時查詢的成本更低。減少重複查詢外部來源的需求。新增快取儲存空間和重新整理負擔。 | 最便宜的儲存空間選項。查詢成本取決於檔案大小與分割。 |
| 重要考量事項 | 避免未經篩選的查詢不必要地掃描大量資料。 | 需要快取管理。不適用於次要決策。 | 查詢效能主要依賴透過分割和述詞推送功能表進行最佳化。 |
混合式方法
混合式結構可讓結構設計師將重要資料集固定在 Data 360 中,以進行集中管理,同時運用聯合查詢以獲得最新狀態、減少重複,並可擴充存取大型外部資料集。此方法會平衡 I/O、計算地區設定、成本和合規性需求。
混合式使用個案
使用混合式方法來結合資料取用和零複製,以提供即時且可採取動作的洞察,以達到平衡的管治、新鮮性和營運效率。針對需要可追蹤性、RLS 和遮蔽的高價值、受監管的資料集,並針對最新性和效能為關鍵的暫時或大量資料集使用同盟。
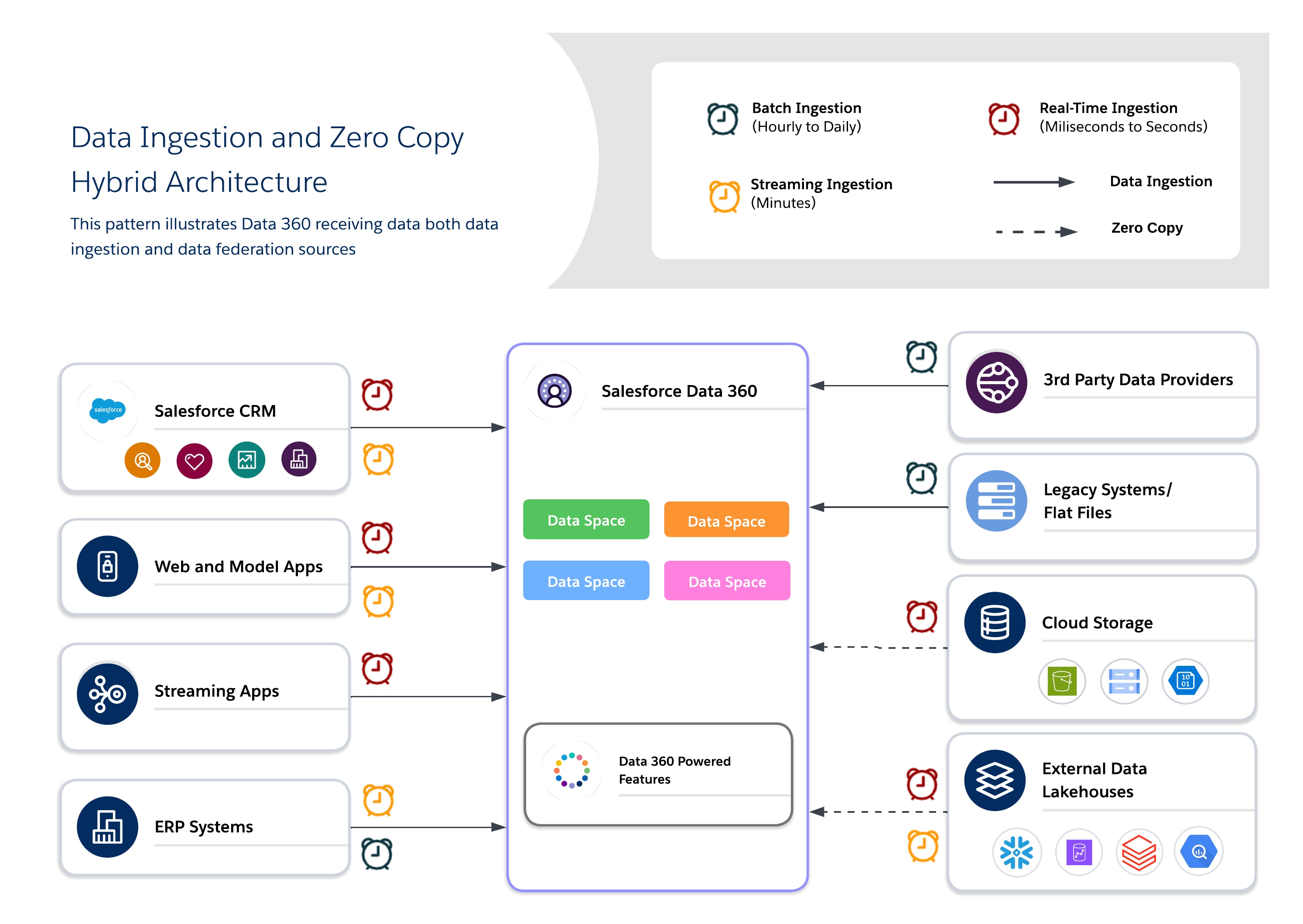
結構設計師手冊
- 使用個案
- **Omni-Channel 參與:**將歷程記錄客戶資料與即時行為混合在一起,以提供一致且感知內容的體驗。
- **AI/ML 銷售管道:**針對精密設計的標準資料集訓練模型,同時使用來自外部來源的原始或即時訊號來增強模型。
- **混合合規性和靈活性需求:**對敏感資料套用嚴格的監管,但聯合以獲得營運靈活性。
- 行業案例
- **零售:**針對身分解析與設定檔統一,請使用採取;針對即時優惠與個人化,請使用聯合。
- **醫療照護:**透過採取來維護金級病患記錄,同時聯合 IoT 裝置串流和感應器資料以取得立即內容。
- **金融服務:**將受監管的資料匯入合規管理湖,同時聯合外部查詢以進行詐騙偵測和風險監視。
- 設計作法
- ** 含採取的節點管理:**將高價值或受監管的資料匯入標準模型,以確保 Trust 與合規性。
- **使用聯合提升新鮮度:**讓外部湖舍提供即時或大規模的資料存取,而不會重複。
- **餘額成本與績效:**設定檔工作量以決定要採取的項目與聯合的項目,以將不必要的儲存空間或查詢成本降到最低。
- **套用階層管理:**強制執行集中化管治,同時利用聯邦系統自己的安全性控制 (例如 RLS、遮蔽)。
- 設計混合式銷售管道時,請確保對歷程記錄資料集進行增量式採取,並將彙總或篩選推送至聯合來源,以最佳化 I/O 和運算用量。
- 成本考量事項
- 將合規性或關鍵資料與必要時的同盟結合,以最佳化總成本與效能。
- 當混合採取和聯合時,考量 I/O 和計算散佈。若要減少重複查詢來源系統中的運算成本,請針對高讀取率且經常存取的聯合資料集使用快取 (加速查詢)。
使用個案決策指南
以下是常見的原型,說明如何套用此邏輯。
- 「單一事實來源」架構類型:集中與控管
- **案例:**您需要為整個全球企業建立合規性的統一 Customer 360 設定檔。資料來自十幾個不同的系統,必須遵循嚴格的 GDPR 和 CCPA 法規,並且會作為所有行銷和服務互動的信任來源。
- **建議模式:****Data Capture.**優先順序為監管、Trust 和控制。在 Data 360 中將資料提取是建立可完全稽核且與來源系統隔離的標準設定檔的唯一方法。
- 「即時洞察」架構類型:不移動分析
- **案例:**您的資料科學小組需要對 Snowflake 中大量且不斷更新的交易表格執行探索查詢。同時,您的管理小組想要由相同資料提供的即時 BI 顯示面板。每天移動 petabyte 的資料速度太慢且成本太高。
- **建議模式:****零複製聯邦.**優先順序為速度、靈活性和大規模成本效益。「零複製」可讓您利用現有資料倉庫的強大功能來進行即時查詢,而不會造成資料重複的負擔和延遲。
- 「混合智慧」架構類型:管理核心、聯合邊緣
- **案例:**您想要使用來自資料湖的即時行為訊號 (例如點擊網站) 來增強受管理且已採取的客戶設定檔。您需要核心設定檔的穩定性,但需要即時資料的立即性才能提供即時個人化功能。
- **建議模式:****混合式方法。**使用「資料取用」建立客戶資料的穩定、受管理核心。接著使用「零複製」將波動式即時「邊緣」資料聯合在一起,並在查詢時間聯結,以取得完整且即時的檢視。
前進路徑
企業資料策略不再是關於選擇單一整合模式,而是關於在可互通資料生態系統內架構受控制的彈性。根據業務需求為每個來源資料系統選取正確的資料整合方法,通常會導致混合式方法,結合資料取用和資料聯合的優勢。
- 將任務關鍵且受管理的資料集用於合規性、身分解析和營運工作流程,以便在 Salesforce Data 360 中移入。
- 透過「零複製」聯合資料,以進行即時、探索性和 AI 驅動的分析,而無須重複儲存空間。
Hyperforce 上的 Salesforce Data 360 提供多區域彈性與延展性。具有 Iceberg 表格的 open lakehouse 可與 Snowflake、Databricks 和 S3 Iceberg 等平台進行運算分隔和互通,形成真正可互通的多雲資料生態系統的基礎。
隨著資料生態系統的發展,會持續平衡新鮮度、成本、效能和合規性,以維持結構靈活性。透過使用聯合存取權來統一獲取的受管理資料,讓您的平台有未來考量。這可在雲端、區域和業務網域之間啟用即時情報、AI 啟用和企業規模個人化。
一體適合所有解決方案不適合大多數企業。最佳策略會將正確的模式對應至正確的業務驅動因素。
關於作者
Yugandhar Bora 是 Salesforce 的「軟體工程結構設計師」,專門在「資料與情報應用程式」平台內進行資料結構。他負責領導企業結構審查委員會 (EARB) 計畫,專注於資料管理和統一資料模型,同時為自動平台佈建解決方案做出貢獻。
Jan Fernando 是 Salesforce 首席結構設計師辦公室的首席結構設計師。他於 2012 年加入 Salesforce,從入門生態系統中獲得豐富的經驗。在加入首席結構設計師辦公室之前,他在平台組織中花費了十多年的時間,在��組織領導了數項關鍵技術轉型。
 j
j2 minute read