Dieser Text wurde mit dem automatisierten Übersetzungssystem von Salesforce übersetzt. Nehmen Sie an unserer Umfrage teil, um Feedback zu diesem Inhalt zu geben und uns mitzuteilen, was Sie als Nächstes sehen möchten.
Note
Übersicht
Unternehmen speichern Daten häufig in Salesforce und anderen externen Data Lakes wie Snowflake, Google BigQuery, Databricks, Redshift oder Cloud-Speicher wie Amazon S3. Diese Isolierung von Daten in unterschiedlichen Quellsystemen stellt eine Herausforderung für Unternehmen dar, die die volle Leistungsfähigkeit ihrer Daten nutzen möchten.
Architekten, die daran arbeiten, Daten über mehrere Data Lakes hinweg zusammenzuführen, stehen vor wichtigen architektonischen Entscheidungen, wie sie diese Daten am besten integrieren können. Data 360 bietet mehrere Optionen für die Datenintegration, von denen jede unterschiedliche Vor- und Nachteile bietet.
Dieser Leitfaden bietet ein Framework, um zu bewerten, welches Muster Ihren Anforderungen an Latenz, Kosten, Skalierbarkeit, Governance und Komplexität bei der Integration von Daten am besten entspricht. So können Sie auswählen, wann die Datenaufnahme, die Zero Copy-Datenverbundorganisation oder ein hybrider Ansatz verwendet werden soll. Der Leitfaden hilft Ihnen auch bei der Auswahl zwischen verschiedenen Methoden der Datenaufnahme und der Datenzuordnung, von denen jede einen anderen Bedarf erfüllt.
Die Integration externer Data Lakehouses in Data 360 erfordert eine sorgfältige Abwägung der Kompromisse zwischen Datenaktualisierung, Governance und Pipeline-Effizienz. Wenn Sie beispielsweise Live-Abfragen des Datenverbunds Zero Copy verwenden, wird die Aktualität der Daten maximiert, die Pipeline-Effizienz kann jedoch reduziert werden, da Sie mehr Daten über das Netzwerk übertragen. Daher ist für die meisten realen Implementierungen eine Kombination aus Aufnahme und Verbund innerhalb eines Mehr-Cloud-Lakehouse-Ökosystems der optimale Weg. Dieser hybride Ansatz gewährleistet eine skalierbare, gesteuerte und interoperable Architektur, die nahtlos sowohl operative Arbeitslasten mit geringer Latenz wie Echtzeitpersonalisierung und Betrugserkennung als auch analytische Arbeitslasten wie behördliche Berichte und Analysen historischer Trends unterstützt. In diesem Entscheidungsleitfaden erfahren Sie, wie Sie in diesen Kompromissen navigieren und die richtige Strategie auswählen.
Takeaways
- Datenaufnahme: Kopiert Daten in Salesforce Data 360 und erstellt so geregelte kanonische Datenmodelle. Ideal für folgende Fälle:
- Erstellen einer umfassenden Customer 360: Vereinheitlichen und transformieren Sie ungleiche Quellen in ein einzelnes, vertrauenswürdiges Profil.
- Erfüllen Sie die strenge Einhaltung gesetzlicher Vorschriften: Erstellen Sie eine überprüfbare, zentralisierte Kopie, in der der Datenzugriff und die Herkunft streng gesteuert werden können.
- Nullkopieverbund: Fragt externe Quellen in Echtzeit ohne Duplikate ab und ermöglicht so die Echtzeitpersonalisierung, Live-Dashboards und die schnelle Einarbeitung von Quellen. Zwei primäre Optionen mit Kompromissen, die Sie abwägen müssen:
- Live & Caching (Beschleunigte Abfrage): Ideal für interaktive Analysen und Echtzeit-Dashboards zu Daten, die sich auf externen Datenplattformen wie Snowflake, Google BigQuery, Redshift oder Databricks befinden. Vermeidet langsame, kostspielige Datenduplizierungen, indem die Verarbeitung auf das Quellsystem verschoben wird.
- Dateiverbund: Bestens geeignet für die Batch-Verarbeitung im großen Umfang und für AI-Modellschulungen zu Daten in Ihrem Cloud-Data-Lake (S3, ADLS). Vermeidet eine kostspielige und langsame Aufnahme, indem Dateien in offenen Tabellenformaten direkt abgefragt werden und so umfangreiche Datensets für ETL- und Data Science-Arbeitslasten freigeschaltet werden.
- Hybrid Model: Kombinieren Sie die Aufnahme von zusammengeführten Profilen mit Verbundenheit für mehr Aktualität, unterstützen Sie Omnikanal-Engagement, Agentforce Aktionen und AI/ML-Schulungen.
Wichtige Überlegungen
-
Hybridarchitektur: Die Kombination von Datenaufnahme und Datenverbund ist häufig erforderlich.
- Verwenden Sie "Datenaufnahme" für wichtige Daten für kanonische Datenmodelle und die Kernverwaltung.
- Führen Sie alle anderen Daten über Zero Copy zusammen, um den operativen Aufwand beim Erstellen und Verwalten der Aufnahmedatenpipelines zu minimieren.
-
Wichtige Datenaufnahmehäufigkeit: Wählen Sie die Häufigkeit basierend auf Geschäftswert, Latenzanforderungen und betrieblicher Komplexität aus.
- Verwenden Sie Echtzeit für zeitkritische Workflows (Personalisierung, Live-Dashboards, Agentforce-Aktionen).
- Nahezu in Echtzeit für mäßig dringende Prozesse (Kampagnen, Betriebsberichte).
- Batch für historische oder Low-Velocity-Datensets.
-
Abgleichen des Verbundmusters mit Latenz und Leistung: Wählen Sie das aus, das Ihren Zugriffsmustern und den Anforderungen an Aktualität, Leistung und Kosten am besten entspricht.
- Verwenden Sie die Live-Abfrage für betriebliche Dashboards und Echtzeitpersonalisierungen, bei denen eine geringe Latenz entscheidend ist.
- Verwenden Sie die Zwischenspeicherung (beschleunigte Abfrage), wenn Abfragen häufig sind, aber leicht veraltete Ergebnisse akzeptiert werden, was Leistung und Kosten ins Gleichgewicht bringt.
- Verwenden Sie den Dateiverbund für umfangreiche Analysen oder Batch-Arbeitslasten, die sich ideal für historische oder weniger zeitkritische Datensets eignen.
-
Anpassen der Unternehmensführung an die Anforderungen an die Datenresidenz:
- Verwenden Sie die Aufnahme, wenn die zentralisierte Verwaltung entscheidend ist.
- Verwenden Sie einen Verbund, bei dem eine dezentrale Governance zulässig ist, und erzwingen Sie gleichzeitig eine strenge Governance an der externen Quelle. Zero Copy berücksichtigt Richtlinien auf Quellebene wie Sicherheit auf Zeilenebene und Datenmaskierung.
-
Priorisieren der Aufnahme für hochwertige Workflows: Wenden Sie die Aufnahme selektiv auf wichtige Prozesse wie die Identitätsbestimmung, behördliche Berichte und die operative Aktivierung an.
-
Kosten und Komplexität bestimmen die Entscheidung: Die Aufnahme in Echtzeit kann teuer und komplex sein. Architekten sollten die Kosten für die Einarbeitung, Speicherung und Umwandlung von Daten mit den Kosten für die direkte Abfrage über Zero Copy abwägen.
Die Auswahl des richtigen Integrationsmusters – Datenaufnahme, Nullkopie oder hybrider Ansatz – wirkt sich direkt auf Latenz, Governance, betriebliche Effizienz und Kosten auf mehreren Cloud-Plattformen aus. Diese Entscheidung bestimmt, wie Echtzeitstatistiken, AI-gestützte Aktivierung und personalisiertes Engagement zuverlässig und skalierbar bereitgestellt werden können.
Produktvergleich
In dieser Tabelle finden Sie einen technischen Vergleich der Muster für die Datenaufnahme und Nullkopie in Salesforce Data 360 mit Fokus auf Funktionen, Kompromissen und Vorteilen sowie Anwendungsfällen und Ergebnissen für Unternehmen. Architekten können dies als Referenz für die Entwicklung hybrider Multi-Cloud-Datenplattformen verwenden, die Leistung, Kosten und Compliance in Einklang bringen.
| Mustertyp | Modus / Tool | Vorteile | Überlegungen | Ergebnisse |
|---|---|---|---|---|
| Datenaufnahme | Echtzeit: Latenzaufnahme im Sekundenbereich über Aufnahme-APIs mit CDC-Unterstützung. Kontinuierliche Streaming-Pipelines. | - Sofortige Statistiken - Ideal für Anwendungsfälle mit geringer Latenz und Personalisierung - Unterstützt ereignisgesteuerte Workflows |
- Hohe Kosten - Komplexe Architektur - Erfordert Quellsysteme mit niedriger Latenz - Quellen mit hohem Volumen können zu übermäßigem Streaming führen, was zu gesättigten Pipelines führt - I/O intensiv - Ziehen Sie selektive Felder und Filter in Betracht, um den Overhead zu reduzieren |
Agentforce: - Echtzeitbetrugswarnungen, Einzelhandelspersonalisierung, operative Warnungen Analysen: - Sekundenschnelle Dashboards, KPI-Überwachung Compliance: - Kontinuierliche Kundendatensatzaktualisierungen für regulierte Workflows |
| Streaming:Aufnahme von Micro-Batch alle 1–3 Minuten über native Konnektoren | - Ausgewogene Kosten im Vergleich zur Frische - Einfachere Architektur als in Echtzeit - Unterstützt inkrementelle Aktualisierungen |
- Leichte Latenz - Kann für wichtige Entscheidungen im Sekundenbereich nicht geeignet sein - Batchgröße wirkt sich auf Speicher/Berechnung aus - I/O ist moderat - Am besten für vorhersehbare, wiederholte Aktualisierungsmuster - Ziehen Sie die Aggregation mit Fenstern in Betracht, um die Verarbeitungslast zu reduzieren |
Agentforce: - Rechtzeitige Kampagnenauslöser, Nahezu-Live-Engagement Analysen: - Empfehlungsmodule, Dashboards in Echtzeit Compliance: - Häufige Aktualisierungen mit Überprüfbarkeit |
|
| Batch: Geplante Ladevorgänge mit großem Volumen über Konnektoren oder APIs. Unterstützt Objektspeicher und ETL/ELT-Pipelines. | - Kosteneffizient für massive Datensets - Einfach zu implementieren - Zuverlässig für historische Analysen |
- Datenlatenz - Für zeitkritische Vorgänge ungeeignet - I/O intensiv bei Lastfenstern - Der Netzwerkdurchsatz kann bei großen Dateien zu einem Engpass werden - Bestens geeignet für historische Aggregations- oder regulierte Berichts-Workflows |
Agentforce: - IT-Support-Tickets (Jira/ServiceNow), aggregierte Workflows Analysen: - Verlaufsanalyse, Trendauswertung Beschwerde: - Regulatorische Berichte, Patienten-/Anspruchsdatenaggregation |
|
| Zero Copy | Live-Abfrage:Direkte Abfragen auf externen Systemen; Schema beim Lesen; keine Datenduplizierung | - Maximale Frische - Minimaler Speicheraufwand; unterstützt Echtzeit-Statistiken zum Betrieb |
- Abhängig von der Quellleistung - Hohes Abfragevolumen kann sich auf die Latenz auswirken - Ideal für Abfragen mit Prädikat-Pushdown & Aggregation zur Minimierung von E/A - Vermeiden ungefilterter Abfragen bei massiven Datensets |
Agentforce: - Dynamische Workflows zur Anpassung an Live-Aktivitäten Analysen: - Operative Dashboards, Live-Berichte Compliance: - Berücksichtigt Sicherheit auf Zeilenebene und Maskierung an der Quelle |
| Beschleunigte Abfrage (Caching): Lokale Kopien für Verbundabfragen zwischengespeichert. Konfigurierbar von 15 min bis 7 Tagen. Optimierte Abfrageausführung | - Verringert die Latenz - Geringere Kosten als wiederholte Live-Abfragen - Verbessert die Leistung bei häufigen Zugriffsmustern |
- Cache-Verwaltung erforderlich - Staleness hängt vom Cache-Intervall ab - Am besten für hochfrequente Abfragen - Nicht geeignet für Entscheidungen im Sekundenbereich |
Agentforce: - Voraggregierte Engagementkennzahlen für schnelle Entscheidungen Analysen: - BI-Dashboards, Segmentierung, analytische Berichte Compliance: - Konsistente regulierte Dashboards mit Überwachungsprotokollen |
|
| Dateiverbund:Direkter Zugriff auf große historische Datensets in Objektspeichern oder Lakes (S3, Iceberg, Google BigQuery, Redshift). | - Verarbeitet Datensets mit massivem Umfang - Minimaler Speicherplatz in Data 360 - Unterstützt AI/ML-Arbeitslasten |
- Schreibgeschützt - Die Abfrageleistung hängt vom externen Systemdurchsatz ab - Optimiert für chargenintensive, durchsatzintensive Aufträge - Nicht für Echtzeit-Dashboard geeignet |
Agentforce: - (Nicht typisch – batchlastig) Analysen: - ML/AI-Training, historische Analysen, Berichte auf Petabyte-Skala Compliance: - Gesteuerter Zugriff auf externe Datensets ohne Duplizierung |
Data 360-Integrationsmuster
Datenaufnahme
Bei der Datenaufnahme werden die Daten physisch in Data 360 kopiert und vollständig verwaltet, im Gegensatz zu Zero Copy, wo die Daten an der Quelle verbleiben. Die Berechnung von Transformationen erfolgt in Data 360, was eine zentralisierte Verwaltung und Überprüfung ermöglicht.
Anwendungsfälle für die Datenaufnahme
Verwenden Sie die Datenaufnahme, um kanonische, geregelte Datensets in Salesforce Data 360 zu speichern, um die Compliance und die betriebliche Kontrolle zu gewährleisten. Verwenden Sie die Aufnahme, wenn vollständige Kontrolle, Überprüfung und Rückverfolgbarkeit erforderlich sind. Ideal für regulierte oder hochwertige Workflows, bei denen die zentrale Berechnung und Verwaltung entscheidend sind.
Die Aufnahme eignet sich am besten, um eine vertrauenswürdige Grundlage für die Identitätsbestimmung, behördliche Berichte und geschäftskritische AI-gestützte Workflows und Kundenengagement zu schaffen.

Methoden zur Datenaufnahme
Die Methoden zur Datenaufnahme variieren je nachdem, welchen Konnektor Sie zur Aufnahme Ihrer Daten verwenden. Einige Konnektoren bieten eine Vielzahl von Aufnahmemethoden, während andere nur im Batch- oder Streaming-Modus arbeiten. Siehe Data 360: Integrationen und Konnektoren für eine vollständige Liste der Data 360-Konnektoren und ihrer verfügbaren Methoden.
- Echtzeit
- Aufnahme im Sekundenbereich mithilfe von Streaming-Pipelines oder der Datenerfassung ändern (CDC).
- Ideal für zeitkritische Workflows (Betrugserkennung, Personalisierung, betriebliche Dashboards).
- Übertragen Sie Transformationen und Aggregationen in Data 360, um die nachgelagerten Ein- und Ausgänge zu reduzieren und die Rechennutzung zu optimieren. Verwenden Sie die inkrementelle CDC, um die Datenvermischung zu minimieren.
- Streaming
- Aufnahme alle 1–3 Minuten in kleinen Schritten.
- Gleicht Frische und Kosten aus und eignet sich für die Kampagnenorchestrierung, die Interaktion beinahe live und für operative Berichte.
- Verwenden Sie Micro-Batchs zum Steuern von E/A-Spitzen. Aggregieren Sie Daten nach Möglichkeit an der Quelle, um das Übertragungsvolumen zu reduzieren und den Speicher zu optimieren.
- Batch (Geplante Ladungen)
- Regelmäßige Aufnahme großer Datensets (stündlich, täglich, wöchentlich).
- Kosteneffizient und zuverlässig für historische Datensets, behördliche Berichte und Compliance-Anwendungsfälle.
- Stellen Sie sicher, dass die Gebietsschemata in derselben Region wie der Quellspeicher liegen, um die Leistung und die Kosten zu optimieren.
Architect Playbook (Playbook für Architekten)
- Anwendungsfälle für die Datenaufnahme
- Zusammengeführte Customer 360 Profile generieren: Erstellen einer einzigen Datenquelle für die Identität und Attribute von Kunden.
- Verwalten von Datensets zur Einhaltung gesetzlicher Vorschriften: Erzwingung von Governance, Abstammung und Überprüfbarkeit für sensible Daten.
- Kampagnenorchestrierung zentralisieren: Sicherstellen, dass Marketing, Vertrieb und Service alle über konsistente, vertrauenswürdige Datensets funktionieren.
- Designpraktiken
- Bevorzugen Sie die Batch-Aufnahme für historische oder latenzarme Anforderungen, beispielsweise Archivberichte oder regelmäßige Snapshots.
- Verwenden Sie CDC- oder Streaming-APIs, um die Aktualität für Betriebs- und Personalisierungs-Workflows aufrechtzuerhalten und Aktualisierungen nahezu in Echtzeit sicherzustellen.
- Steuern Sie das Speicher- und Berechnungswachstum, indem Sie inkrementelle Lasten anwenden, statt ganze Datensets neu zu laden, um Kosten und Effizienz zu optimieren.
- Passen Sie Aufnahme-Pipelines an die Rechenlokalität und die inkrementelle Verarbeitung an, um die Netzwerk-I/O zu reduzieren. Wenden Sie Transformationen in Data 360 an, um unnötige Verschiebungen von Rohdaten zu vermeiden.
- Überlegungen zu Kosten
- Echtzeitaufnahme: Höchste Rechen- und Pipeline-Kosten; gerechtfertigt für hochwertige, zeitkritische Workflows wie Personalisierung, betriebliche Dashboards oder Agentforce Aktionen.
- Streaming-Aufnahme: Moderate Rechen- und Speicherkosten; geeignet für häufige Aktualisierungen, die leichte Verzögerungen tolerieren können, beispielsweise Kampagnenorchestrierung oder operative Berichte.
- Batch-Aufnahme: Geringere Rechenkosten, vorhersehbarer Speicherplatz; am besten für historische Datensets oder Aktualisierungen mit geringer Häufigkeit. Die Aufnahme von Batch-Daten aus Salesforce-Organisationen mit bestimmten Konnektoren ist kostenlos.
- Aktualisierungsmodus: Durch Auswahl des Modus "Inkrementelle Aktualisierung" werden die Gesamtaufnahme- und Berechnungskosten reduziert. Es wird empfohlen, nach Möglichkeit eine inkrementelle Aktualisierung zu verwenden, um die Effizienz über alle Aufnahmetypen hinweg zu optimieren.
- Die Kosten werden auch durch das E/A-Volumen von der Quelle zu Data 360 beeinflusst. Die Optimierung von Batchgrößen, Partitionen und regionaler Ausrichtung reduziert die Übertragungskosten und verbessert die Leistung.
- Branchenszenarien
- Finanzen: Nehmen Sie Datensets auf, die für die Kenntnis Ihres Kunden, die Bekämpfung der Geldwäsche und die Betrugserkennung erforderlich sind, wobei Überprüfbarkeit und Compliance nicht verhandelbar sind.
- Gesundheitswesen: Verwenden Sie die Aufnahme für die Patientenidentitätsbestimmung und HIPAA-konforme Datensätze, um sichere, vereinheitlichte Ansichten zu ermöglichen.
- Einzelhandel: Konsolidieren von Point of Sale (POS), E-Commerce und Treueprogrammdaten in vereinheitlichten Profilen zur Segmentierung und Personalisierung
- Telecom: Unterstützen Sie Abwanderungsprävention und Nutzungsanalysen mit kanonischen, geregelten Abonnentendaten.
Entscheidungskriterien für die Datenaufnahmemethode
| Funktion | Echtzeitaufnahme | Streaming-Aufnahme | Batchaufnahme |
|---|---|---|---|
| Latenz und Frische | Aufnahme von Latenzzeiten im Sekundenbereich über Aufnahme-APIs mit Unterstützung der Datenerfassung (CDC). Bietet kontinuierliche Streaming-Pipelines. Ideal für operative Anwendungsfälle mit geringer Latenz. | Micro-Batch-Aufnahme alle 1–3 Minuten über native Konnektoren. Unterstützt inkrementelle Aktualisierungen. Es wird eine leichte Latenz erwartet. | Es wird eine Datenlatenz erwartet. Geplante Ladungen mit großem Volumen. Regelmäßige Aufnahme (stündlich, täglich, wöchentlich). Für zeitkritische Vorgänge ungeeignet. |
| Primäre Anwendungsfälle | Ideal für Anwendungsfälle mit geringer Latenz und Personalisierung. Wird für zeitkritische Workflows verwendet. Unterstützt ereignisgesteuerte Workflows. Wird für Echtzeitbetrugswarnungen und operative Warnungen verwendet. | Geeignet für mäßig dringende Prozesse. Wird für die Kampagnenorchestrierung, die Interaktion beinahe live und für operative Berichte verwendet. Wird für zeitnahe Kampagnenauslöser verwendet. | Kosteneffizient für massive Datensets. Zuverlässig für historische Analysen. Wird für historische Aggregations- oder regulierte Berichts-Workflows verwendet. Bestens geeignet für historische Datensets oder Datensets mit geringer Geschwindigkeit. |
| Architekturkomplexität und I/O | Hohe Kosten und komplexe Architektur. Erfordert Quellsysteme mit geringer Latenz. I/O-intensiv. Quellen mit hohem Volumen können zu gesättigten Pipelines führen. | Einfachere Architektur als in Echtzeit. I/O ist moderat. Bestens geeignet für vorhersehbare, wiederholte Aktualisierungsmuster. Die Batchgröße wirkt sich auf den Speicher/die Berechnung aus. | Einfach zu implementieren. I/O-intensiv bei Lastfenstern. Der Netzwerkdurchsatz kann bei großen Batches zu einem Engpass werden. |
| Überlegungen zu Kosten | Höchste Rechen- und Pipeline-Kosten. Nur für hochwertige, zeitkritische Workflows gerechtfertigt. | Moderieren Sie Berechnungs- und Speicherkosten. Bietet einen ausgewogenen Ansatz für Kosten und Frische. Geeignet für häufige Aktualisierungen, die leichte Verzögerungen vertragen. | Geringere Rechenkosten und vorhersehbarer Speicher. Empfohlen für historische Datensets oder Aktualisierungen mit geringer Häufigkeit. Die Aufnahme über interne Salesforce-Pipelines ist kostenlos. |
| Designpraktiken | Verwenden Sie die inkrementelle CDC, um die Datenvermischung zu minimieren. Filtern und verwenden Sie selektive Felder, um den Overhead zu reduzieren. | Verwenden Sie Micro-Batchs zum Steuern von E/A-Spitzen. Ziehen Sie die Aggregation mit Fenstern in Betracht, um die Verarbeitungslast zu reduzieren. | Bevorzugen Sie dies für Archivberichte oder regelmäßige Snapshots. Stellen Sie sicher, dass die Berechnungslokalität in derselben Region wie der Quellspeicher liegt, um die Kosten zu optimieren. |
Zero Copy Data Federation (Zero Copy-Datenverbund)
Zero Copy-Anwendungsfälle
Verwenden Sie Zero Copy für Echtzeitabfragen externer Systeme ohne Datenduplizierung, um Agilität, Aktualität und skalierbaren Zugriff auf große oder vorübergehende Datensets zu ermöglichen. Sie eignet sich am besten für Live-Dashboards, explorative Analysen, AI/ML-Modellschulungen und Echtzeit-Kundenengagement direkt über Salesforce Data 360.
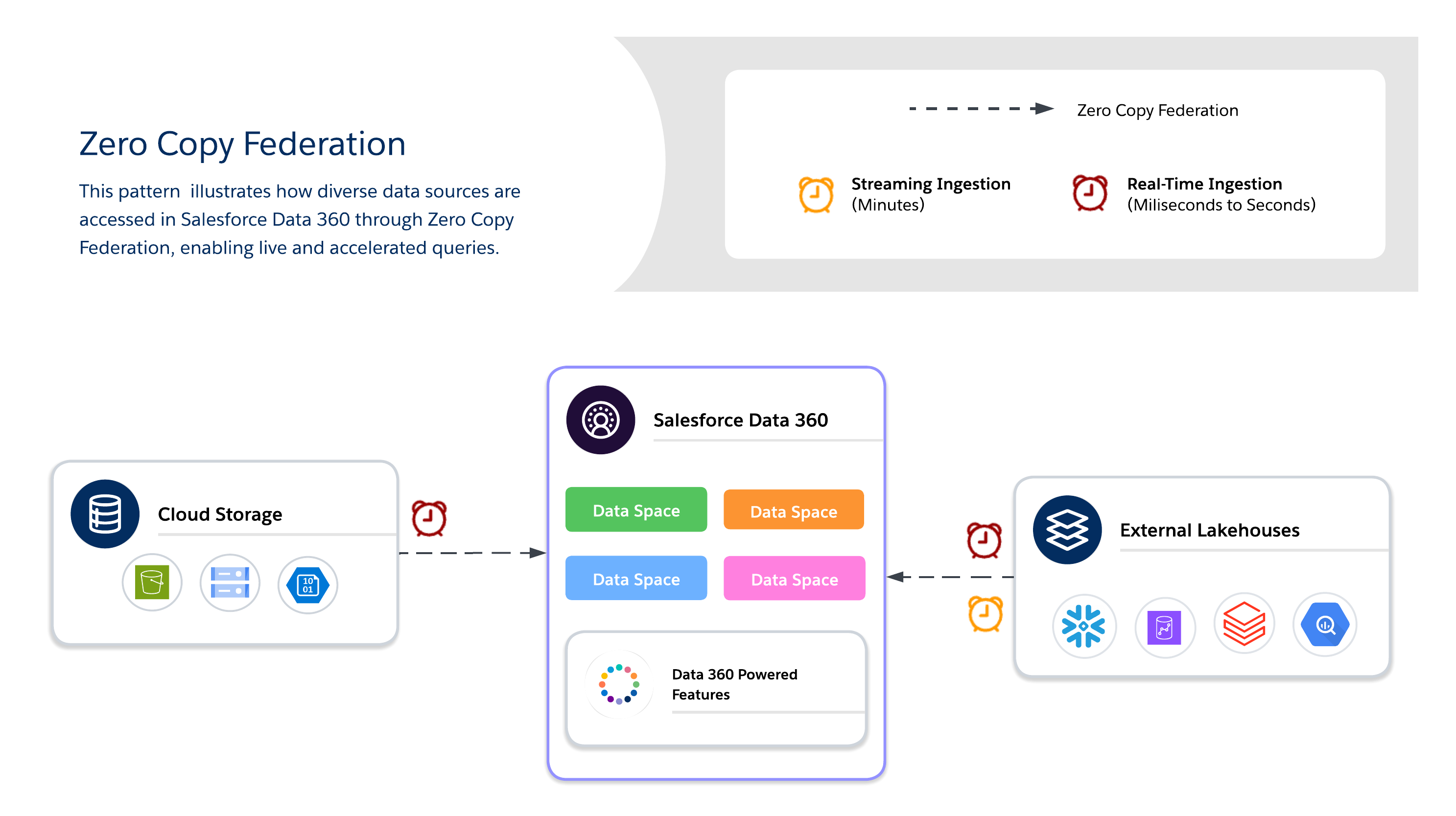
Nullkopiemethoden
Bei Verwendung von Zero Copy müssen Architekten sich zudem zwischen drei verfügbaren Datenverbundmethoden entscheiden, von denen jede ihre eigenen Kompromisse zwischen Frische, Leistung und Kosten bietet.
- Live-Abfrage
- Führt Abfragen direkt gegen externe Systeme (Snowflake, Google BigQuery, Redshift, Databricks usw.) ohne Datenduplizierung aus.
- Optimal, wenn Prädikate und Aggregationen nach unten geschoben werden können, wodurch die Datenbewegung über das Netzwerk minimiert und die Ein-/Ausgaben für den Salesforce Data 360-Berechnungsvorgang reduziert werden.
- Bestens geeignet für Echtzeitstatistiken und betriebliche Dashboards mit geringer Latenz. Abhängig von der Leistung des externen Systems.
- Zwischenspeicherung (beschleunigte Abfrage)
- Speichert temporär zwischengespeicherte Kopien von Verbunddaten in Salesforce Data 360.
- Reduziert wiederholte Abfragekosten und Latenzzeiten für häufig aufgerufene Datensets mit konfigurierbarer Dauer (Minuten bis Tage).
- Die Daten werden nicht dauerhaft kopiert oder vollständig verwaltet. Die Aktualisierung wird über geplante Aktualisierungen aus der Quelle verwaltet.
- Dateiverbund
- Bietet direkten schreibgeschützten Zugriff auf umfangreiche Datensets in Objektspeichern (z. B. S3, GCS mit Iceberg).
- Ideal für AI/ML-Arbeitslasten, historische Analysen und Berichte auf Petabyte-Skala, ohne Daten verschieben zu müssen.
- Die Abfrageleistung hängt stark vom Objektformat, der Partitionierung und der Netzwerk-I/O ab. Große Scans können erhebliche E/A generieren, wenn sie nicht optimiert sind.
Architect Playbook (Playbook für Architekten)
- Anwendungsfälle
- Echtzeitpersonalisierung und adaptive Workflows: Stellen Sie dynamische Angebote, Empfehlungen und Next-Best-Aktionen bereit, wenn sich das Kundenverhalten ändert.
- Live-Dashboards und Betriebsanalysen: Stellen Sie geschäftskritische Dashboards und KPIs direkt aus externen Lagerhäusern bereit.
- AI/ML-Modelltraining mit großen externen Datensets: Nutzen Sie Petabyte-Skalierungsdaten aus Data Lakes und Lagerhäusern mithilfe des Dateiverbunds, ohne sie zu verschieben.
- Branchenszenarien
- Einzelhandel/Medien: Aktivieren Sie personalisierte Empfehlungen und Kundenengagement in Echtzeit, indem Sie Clickstream- oder Inhaltsinteraktionsdaten verknüpfen.
- Finanzen: Führen Sie Betrugserkennung und Risikobewertung nahezu in Echtzeit aus, indem Sie externe Lagerhäuser abfragen, ohne sensible Daten zu duplizieren.
- Tech/Enterprise: Unterstützen Sie cloudübergreifende Berichte, IT-Service-Dashboards und betriebliche Analysen, bei denen sich Datensets in mehreren Systemen befinden.
- Designpraktiken
- Live-Abfrage
- Wird für Abfragen mit hoher QPS und geringer Latenz verwendet, wenn die Aktualisierung wichtig ist.
- Übertragen Sie Prädikate und Aggregationen an das externe System, um die Datenverlagerung über das Netzwerk zu reduzieren.
- Vermeiden Sie Abfragen, die unnötig große Datenvolumen scannen. Ziehen Sie Partitionszuschnitte und Filter in Betracht.
- Dateiverbund
- Greifen Sie ohne Aufnahme auf Datensets im Petabyte-Bereich in Objektspeichern zu.
- Behalten Sie den Objektspeicher in derselben Cloud-Region wie Salesforce compute bei, um Latenz- und Ausgangskosten zu minimieren.
- Verwenden Sie partitionierte Spaltenformate (Parquet/ORC) und Pushdown-Filter, um die E/A- und Netzwerkübertragung zu reduzieren.
- Nutzen Sie den Pushdown für Abfragen und Prädikate, um Daten an der Quelle zu filtern und zu aggregieren und so die Datenbewegung zu reduzieren.
- Vermeiden Sie bei Bedarf regionsübergreifenden Datenzugriff, da er die Ein-/Ausgabe, die Latenz und die Kosten erhöht.
- Zwischenspeicherung (beschleunigte Abfrage)
- Zwischenspeichern häufig aufgerufener Datensets, um Kosten und Leistung in Einklang zu bringen.
- Konfigurieren Sie Aktualisierungsintervalle, um die Frische im Vergleich zu den Abfragekosten auszugleichen.
- Compliance: Erzwingen Sie die Governance an der Quelle, indem Sie Sicherheitsrichtlinien auf Zeilenebene und Maskierungsrichtlinien direkt in Verbundsystemen nutzen. Im Folgenden finden Sie bewährte Vorgehensweisen für einheitliches RLS und Maskierung über mehrere Plattformen hinweg.
- Verwenden einer zentralisierten Unternehmens-ID: Ordnen Sie Benutzer und Einheiten in Salesforce Data 360 einer eindeutigen, zentralisierten Unternehmenskennung zu, die Identitäten in externen Systemen entspricht.
- Ausrichten von Sicherheitsrichtlinien: Stellen Sie sicher, dass Sicherheits- und Maskierungsrichtlinien auf Zeilenebene in Verbundsystemen basierend auf der zugeordneten Identität angewendet werden. Dadurch wird die Compliance beim Abfragen externer Daten beibehalten.
- Standardisieren von Identitätsschemas: Verwalten Sie konsistente Identitätsattribute (E-Mail, Benutzer-ID, Kunden-ID usw.) über alle Datenquellen hinweg, um Inkonsistenzen und Zugriffsverletzungen zu vermeiden.
- Live-Abfrage
- Überlegungen zu Kosten
- Live-Abfrage: Pay-per-Query-Modell: Kosten fallen bei der Berechnung externer Lakehouse-Rechner an und können bei hoher QPS in die Höhe schnellen. Ideal für frischekritische Anwendungsfälle, in denen der Wert größer ist als die Kostenvariabilität.
- Beschleunigte Abfrage (Zwischenspeicherung): Senkt die Abfragekosten im Vergleich zur Live-Abfrage, indem Treffer im Quellsystem reduziert werden, erhöht jedoch die Kosten für die Batch-Datenaufnahme beim Füllen und Aktualisieren des Cache. Bestens geeignet für häufig aufgerufene Datensets.
- Dateiverbund: Günstigste Speicheroption als Daten im Objektspeicher, die Abfragekosten hängen jedoch von der Dateigröße, der Partitionierung und dem Zuschnitt ab. Ideal für historische Daten oder Massendaten im Petabyte-Bereich.
Entscheidungskriterien für Nullkopiemethode
| Entscheidungspunkt | Live-Abfrage | Zwischenspeicherung (beschleunigte Abfrage) | Dateiverbund |
|---|---|---|---|
| Datenquellenstandort | Externe Data Lakehouses (Snowflake, Google BigQuery, Redshift, Databricks). | Externe Data Lakehouses (Snowflake, Google BigQuery, Redshift, Databricks) | Objektspeicher oder Cloud-Data-Lakes (S3, ADLS, GCS) verwenden häufig offene Tabellenformate wie Iceberg. |
| Zweck/Anwendungsfall | Ideal für interaktive Analysen und Echtzeit-Dashboards. Bestens geeignet für Echtzeitpersonalisierung und dynamische Workflows. | Am besten geeignet für häufige Abfragen, aber leicht veraltete Ergebnisse. Geeignet für BI-Dashboards und Segmentierung. | Bestens geeignet für die Batchverarbeitung im großen Umfang und für AI/ML-Modellschulungen. Ideal für historische Analysen und Berichte auf Petabyte-Skala. |
| Frisch/Latenz | Maximale Aktualität; Abfragen werden direkt in Echtzeit ausgeführt. Unterstützt Entscheidungen in Sekundenschnelle. | Etwas veraltete Ergebnisse sind akzeptabel. Die Aktualisierung hängt vom Cache-Intervall ab, das zwischen 15 Minuten und 7 Tagen konfiguriert werden kann. | Optimiert für chargenintensive, durchsatzintensive Aufträge. Nicht für Echtzeit-Dashboards geeignet. |
| Zugriffsmuster | Ideal für seltene oder Ad-hoc-Abfragen. Wird für Abfragen mit hoher Qualität (Abfrage pro Sekunde) und geringer Latenz verwendet, bei denen die Aktualität entscheidend ist. | Ideal für Szenarien mit hoher Lesehäufigkeit. Verbessert die Leistung bei häufigen Zugriffsmustern. | Schreibgeschützter Zugriff. Geeignet für Datensets im Petabyte-Bereich ohne Aufnahme. |
| Leistungstreiber | Stark von der Leistung des externen Quellsystems abhängig. Optimiert, wenn Prädikate und Aggregationen in die Quelle übertragen werden können. | Verringert die Latenz im Vergleich zu wiederholten Live-Abfragen. Die Leistung hängt von der Cache-Verwaltung und dem Intervall ab. | Die Leistung hängt stark vom Objektformat, der Partitionierung und dem externen Systemdurchsatz ab. Verwenden Sie partitionierte, spaltenförmige Formate (Parquet/ORC). |
| Kostenauswirkungen | Pay-per-Query-Modell. Die Kosten fallen bei der Berechnung externer Lakehouse-Instanzen an. Kostengünstig für seltene Abfragen, aber die Ausgaben können bei hohem Query per Second-Volumen (QPS) steigen. | Geringere Kosten als bei wiederholten Live-Abfragen. Verringert die Notwendigkeit, die externe Quelle wiederholt abzufragen. Fügt Cache-Speicher und Aktualisierungs-Overhead hinzu. | Günstigste Speicheroption. Die Abfragekosten hängen von der Dateigröße und der Partitionierung ab. |
| Wichtige Überlegungen | Vermeiden Sie ungefilterte Abfragen, die unnötig große Datenvolumen scannen. | Erfordert die Cache-Verwaltung. Nicht für Entscheidungen im Sekundenbereich geeignet. | Die Abfrageleistung hängt stark von der Optimierung über Partitionierung und Pushdown-Prädikate ab. |
Hybridansatz
Mit hybriden Architekturen können Architekten wichtige Datensets in Data 360 für eine zentralisierte Verwaltung verankern und Verbundabfragen für Aktualität, reduzierte Duplikate und skalierbaren Zugriff auf große externe Datensets nutzen. Bei diesem Ansatz werden die Anforderungen an E/A, Berechnungslokalität, Kosten und Compliance abgewogen.
Hybride Anwendungsfälle
Verwenden Sie einen hybriden Ansatz für ausgewogene Verwaltung, Aktualität und betriebliche Effizienz, indem Sie Datenaufnahme und Nullkopie kombinieren, um handlungsrelevante Statistiken in Echtzeit bereitzustellen. Verwenden Sie die Aufnahme für hochwertige, regulierte Datensets, bei denen Rückverfolgbarkeit, RLS und Maskierung erforderlich sind, und die Zuordnung für vorübergehende Datensets oder Datensets mit hohem Volumen, bei denen Aktualität und Leistung entscheidend sind.
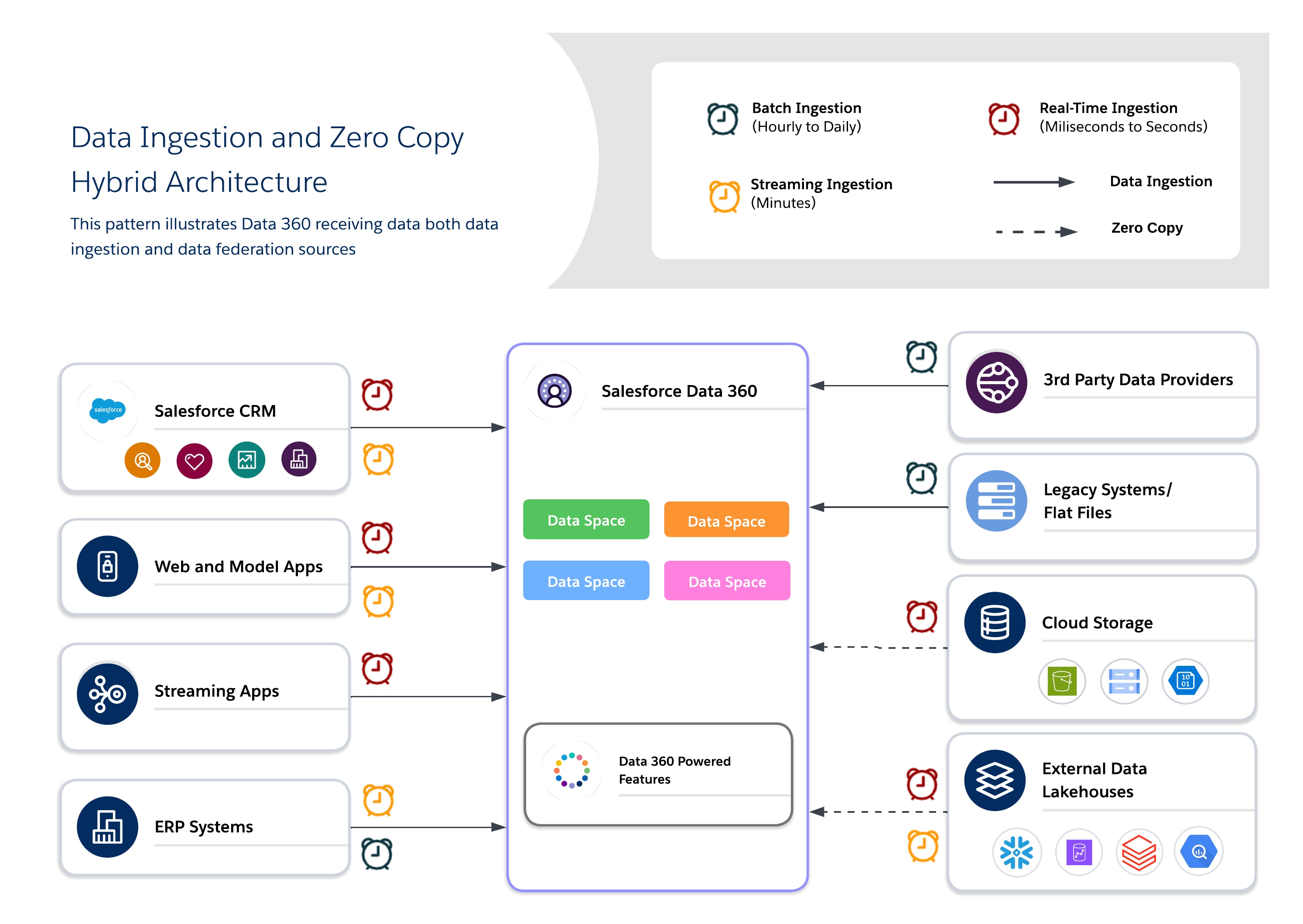
Architect Playbook (Playbook für Architekten)
- Anwendungsfälle
- Omnikanal-Engagement: Kombinieren Sie historische Kundendaten mit Echtzeitverhalten, um konsistente, kontextbezogene Erfahrungen bereitzustellen.
- AI/ML-Pipelines: Trainieren Sie Modelle für zusammengestellte kanonische Datensets und reichern Sie sie mit Roh- oder Echtzeitsignalen aus externen Quellen an.
- Kombinierte Compliance- und Agilitätsanforderungen: Wenden Sie strenge Governance-Vorschriften für sensible Daten an, schließen Sie sich jedoch für die betriebliche Agilität zusammen.
- Branchenszenarien
- Einzelhandel: Verwenden Sie die Aufnahme für die Identitätsbestimmung und die Profilvereinheitlichung. Verbinden Sie sie für Echtzeitangebote und Personalisierungen.
- Gesundheitswesen: Verwalten Sie goldene Patientenakten über die Aufnahme, während Sie IoT-Geräteströme und Sensordaten verknüpfen, um einen unmittelbaren Kontext zu erhalten.
- Financial Services: Nehmen Sie regulierte Daten in einen konformitätsgesteuerten See auf, während Sie externe Abfragen zur Betrugserkennung und Risikoüberwachung verknüpfen.
- Designpraktiken
- Anker-Governance mit Aufnahme: Nehmen Sie hochwertige oder regulierte Daten in kanonische Modelle auf, um Trust und Compliance zu gewährleisten.
- Verbund für Frische verwenden: Ermöglichen Sie es externen Lakehouses, Datenzugriff in Echtzeit oder in großem Umfang ohne Duplikate bereitzustellen.
- Balance Cost vs. Leistung: Profilieren Sie Arbeitslasten, um zu entscheiden, was im Vergleich zum Verbund aufgenommen werden soll, wodurch unnötige Speicher- oder Abfragekosten minimiert werden.
- Anwenden der mehrschichtigen Unternehmensführung: Erzwingen Sie die zentralisierte Verwaltung für aufgenommene Daten und nutzen Sie gleichzeitig die eigenen Sicherheitssteuerungen von Verbundsystemen (z. B. RLS, Maskierung).
- Stellen Sie beim Entwerfen von hybriden Pipelines sicher, dass historische Datensets inkrementell aufgenommen werden, und übertragen Sie Aggregationen oder Filter an Verbundquellen, um die E/A- und Berechnungsnutzung zu optimieren.
- Überlegungen zu Kosten
- Optimieren Sie die Gesamtkosten im Vergleich zur Leistung, indem Sie die Aufnahme für Compliance- oder wichtige Daten mit dem Verbund kombinieren, wenn eine Aktualisierung erforderlich ist.
- Berücksichtigen Sie die E/A- und Berechnungsverteilung beim Mischen von Aufnahme und Verbund. Verwenden Sie zum Reduzieren der Rechenkosten in Quellsystemen wiederholter Abfragen die Zwischenspeicherung (beschleunigte Abfrage) für Verbunddatensets mit hohem Lesezugriff.
Leitfaden zur Anwendungsfallentscheidung
Im Folgenden finden Sie allgemeine Archetypen, die die Anwendung dieser Logik veranschaulichen.
- Der Archetyp "Single Source of Truth" (Einzelne Datenquelle): Zentralisieren und Verwalten
- Szenario: Sie müssen kompatible, vereinheitlichte Customer 360 Profile für Ihr gesamtes globales Unternehmen erstellen. Die Daten stammen aus einem Dutzend verschiedener Systeme, müssen strenge DSGVO- und CCPA-Vorschriften einhalten und dienen als vertrauenswürdige Quelle für alle Marketing- und Serviceinteraktionen.
- Empfohlenes Muster: Datenaufnahme. Die Priorität liegt auf Governance, Trust und Kontrolle. Die Aufnahme der Daten in Data 360 ist die einzige Möglichkeit, ein vollständig überprüfbares, kanonisches Profil zu erstellen, das von den Quellsystemen isoliert ist.
- Der Archetyp "Echtzeitstatistiken": Analysieren ohne Verschieben
- Szenario: Ihr Data Science-Team muss Erkundungsabfragen für eine massive, ständig aktualisierte Transaktionstabelle in Snowflake ausführen. Gleichzeitig möchte Ihr Führungsteam ein Live-BI-Dashboard, das auf denselben Daten basiert. Das tägliche Verschieben von Petabyte Daten ist zu langsam und teuer.
- Empfohlenes Muster: Zero Copy Federation. Priorität haben Geschwindigkeit, Agilität und Kosteneffizienz im richtigen Maßstab. Zero Copy ermöglicht es Ihnen, die immense Leistungsfähigkeit Ihres vorhandenen Data Warehouse für Echtzeitabfragen zu nutzen, ohne den Aufwand und die Latenz der Datenduplizierung zu erhöhen.
- Der Archetyp "Hybridintelligenz": Verwalten des Kerns, Zusammenführen des Kerns
- Szenario: Sie möchten Ihre verwalteten, aufgenommenen Kundenprofile mit Echtzeit-Verhaltenssignalen (wie Website-Klicks) aus einem Data Lake anreichern. Sie benötigen die Stabilität des Kernprofils, aber die Unmittelbarkeit der Live-Daten, um die sofortige Personalisierung zu unterstützen.
- Empfohlenes Muster: Ein hybrider Ansatz. Verwenden Sie die Datenaufnahme, um den stabilen, geregelten Kern Ihrer Kundendaten zu erstellen. Verwenden Sie dann Zero Copy, um die volatilen Echtzeit-"Edge"-Daten zu verknüpfen und sie zur Abfragezeit zu verknüpfen, um eine vollständige, sekundengenaue Ansicht zu erhalten.
Der Weg nach vorn
Bei der Unternehmensdatenstrategie geht es nicht mehr darum, ein einzelnes Integrationsmuster auszuwählen, sondern darum, kontrollierte Flexibilität in einem interoperablen Datenökosystem zu entwickeln. Die Auswahl der richtigen Datenintegrationsmethode für jedes Quelldatensystem auf der Grundlage der Geschäftsanforderungen führt häufig zu einem hybriden Ansatz, der die Stärken der Datenaufnahme und der Datenverknüpfung kombiniert.
- Nehmen Sie geschäftskritische, geregelte Datensets in Salesforce Data 360 auf, um Compliance, Identitätsbestimmung und betriebliche Workflows zu gewährleisten.
- Verbinden Sie Daten über Zero Copy für Live-, explorative und AI-gestützte Analysen, ohne Speicherplatz zu duplizieren.
Salesforce Data 360 in Hyperforce bietet Widerstandsfähigkeit und Skalierbarkeit für mehrere Regionen. Das offene Lakehouse mit Iceberg-Tabellen ermöglicht die Berechnungstrennung und Interoperabilität mit Plattformen wie Snowflake, Databricks und S3 Iceberg und bildet das Rückgrat eines wirklich interoperablen Datenökosystems mit mehreren Clouds.
Während sich Datenökosysteme weiterentwickeln, halten Sie Aktualisierung, Kosten, Leistung und Compliance kontinuierlich im Gleichgewicht, um die architektonische Agilität aufrechtzuerhalten. Sorgen Sie dafür, dass Ihre Plattform zukunftssicher ist, indem Sie erfasste, geregelte Daten mit Verbundzugriff vereinheitlichen. Dies ermöglicht Echtzeitintelligenz, AI-Aktivierung und Personalisierung im Unternehmensbereich über Clouds, Regionen und Geschäftsdomänen hinweg.
Lösungen, die für alle geeignet sind, eignen sich für die meisten Unternehmen nicht. Die optimale Strategie ordnet das richtige Muster dem richtigen Geschäftstreiber zu.
Über die Autoren
Yugandhar Bora ist Software Engineering Architekt bei Salesforce und spezialisiert sich auf die Datenarchitektur innerhalb der Plattform für Daten- und Intelligenzanwendungen. Er leitet Initiativen des Enterprise Architecture Review Board (EARB), die sich auf die Datenverwaltung und vereinheitlichte Datenmodelle konzentrieren, und trägt gleichzeitig zu automatisierten Plattformbereitstellungslösungen bei.
Jan Fernando ist Principal Architect im Büro des Chief Architect bei Salesforce. Seit 2012 ist er bei Salesforce tätig und verfügt über umfangreiche Erfahrungen aus seiner Zeit im Startup-Ökosystem. Bevor er in das Büro des Chefarchitekten eintrat, verbrachte er über ein Jahrzehnt in der Plattformorganisation, wo er mehrere wichtige Technologietransformationen leitete.
 j
j21 minute read