Esse texto foi traduzido usando o sistema de tradução automatizado do Salesforce. Pegue nossa enquisa para fornecer feedback sobre esse conteúdo e diga-nos o que você gostaria de ver em seguida.
Note
Visão geral
As empresas costumam armazenar dados tanto no Salesforce quanto em outros data lakes externos, como Snowflake, Google BigQuery, Databricks, Redshift ou armazenamento em nuvem, como o Amazon S3. Esse silonamento de dados em diferentes sistemas de origem apresenta um desafio para as empresas que querem aproveitar todo o poder de seus dados.
Os arquitetos que trabalham para unir dados entre vários data lakes enfrentam decisões arquitetônicas importantes sobre como integrar melhor esses dados. O Data 360 oferece várias opções para integração de dados, cada uma oferecendo diferentes prós e contras.
Este guia fornece uma estrutura para avaliar qual padrão atende melhor aos seus requisitos de latência, custo, escalabilidade, governança e complexidade ao integrar dados, ajudando você a escolher quando usar ingestão de dados, federação de dados de Cópia zero ou uma abordagem híbrida. O guia também o ajudará a selecionar entre diferentes métodos de ingestão de dados e federação de dados, cada um dos quais preenche uma necessidade diferente.
Integrar data lakehouses externos ao Data 360 requer uma consideração cuidadosa das compensações entre a atualidade dos dados, a governança e a eficiência do pipeline. Por exemplo, usar as consultas ativas de federação de dados do Zero Copy maximizam a atualidade dos dados, mas podem reduzir a eficiência do pipeline à medida que você move mais dados pela rede. Portanto, para a maioria das implementações do mundo real, uma combinação de ingestão e federação em um ecossistema de lakehouse de várias nuvens é o caminho ideal. Essa abordagem híbrida garante uma arquitetura escalonável, governada e interoperável que dá suporte perfeitamente a cargas de trabalho operacionais de baixa latência, como personalização em tempo real e detecção de fraudes, e cargas de trabalho analíticas, como relatórios regulatórios e análise de tendências históricas. Este guia de decisão vai ajudá-lo a entender como navegar por essas compensações e selecionar a estratégia certa.
Capturas
- Ingestão de dados: Copia dados para o Salesforce Data 360, criando modelos de dados canônicos gerenciados. Ideal quando você precisa:
- Criar um Customer 360 abrangente: Unifique e transforme origens distintas em um único perfil confiável.
- Satisfazer a rigorosa conformidade regulatória: Crie uma cópia auditável centralizada em que o acesso aos dados e a linhagem possam ser controlados de perto.
- Federação de cópia zero: Consulta origens externas em tempo real sem duplicação, habilitando personalização em tempo real, painéis ativos e integração de origem rápida. Duas opções principais com compensações que você deve equilibrar:
- Ativo e cache (consulta acelerada): Melhor para análise interativa e painéis em tempo real em dados que estão em plataformas de dados externas, como Snowflake, Google BigQuery, Redshift ou Databricks. Evita duplicação de dados lenta e dispendiosa enviando o processamento para o sistema de origem.
- Federação de arquivos: Melhor para processamento em lote em grande escala e treinamento de modelo de IA em dados em seu data lake de nuvem (S3, ADLS). Evita ingestões caras e lentas consultando diretamente arquivos em formatos de tabela abertos, desbloqueando conjuntos de dados massivos para ETL e cargas de trabalho de ciência de dados.
- Modelo híbrido: Combine ingestão para Perfis unificados com federação para frescura, suporte ao engajamento do Omni-Channel, ações conduzidas pelo Agentforce e treinamento de IA/ML.
Considerações importantes
-
Arquitetura híbrida: Geralmente, é necessário combinar a ingestão de dados e a federação de dados.
- Use a Ingestão de dados em dados críticos para modelos de dados canônicos e governança principal.
- Federar todos os outros dados por meio da Cópia zero para minimizar a sobrecarga operacional de criar e manter os pipelines de dados de ingestão.
-
A frequência de ingestão de dados importa: Escolha a frequência com base no valor dos negócios, nas necessidades de latência e na complexidade operacional.
- Use em tempo real para fluxos de trabalho urgentes (personalização, painéis ativos, ações Agentforce).
- Quase em tempo real para processos moderadamente urgentes (campanhas, relatórios operacionais).
- Lote para conjuntos de dados históricos ou de baixa velocidade.
-
Combine o padrão de federação com latência e desempenho: Escolha o que melhor corresponde aos seus padrões de acesso e aos requisitos de frescura, desempenho e custo.
- Use a Consulta ativa para painéis operacionais e personalização em tempo real em que baixa latência seja crítica.
- Use o armazenamento em cache (consulta acelerada) quando as consultas forem frequentes, mas os resultados levemente obsoletos forem aceitáveis, o que equilibra o desempenho e o custo.
- Use a federação de arquivos para análises em grande escala e de alto rendimento ou cargas de trabalho em lote, ideais para conjuntos de dados históricos ou menos sensíveis ao tempo.
-
Alinhar a governança aos requisitos de residência de dados:
- Use a ingestão quando a governança centralizada for crítica.
- Use federação quando a governança descentralizada for aceitável, ao mesmo tempo que você impõe uma governança rígida na origem externa. A Cópia zero respeita políticas em nível de origem, como segurança em nível de linha (RLS) e mascaramento de dados.
-
Priorizar ingestão para fluxos de trabalho de alto valor: Aplique a ingestão de modo seletivo a processos críticos, como resolução de identidade, relatórios regulatórios e ativação operacional.
-
Custo e complexidade levam a decisão: A ingestão em tempo real pode ser cara e complexa. Os arquitetos devem ponderar o custo de integração, armazenamento e transformação de dados em relação ao custo de consultá-los diretamente por meio do Zero Copy.
Escolher o padrão de integração certo (Ingestão de dados, Cópia zero ou abordagem híbrida) afeta diretamente a latência, a governança, a eficiência operacional e o custo em plataformas de várias nuvens. Essa decisão determina como percepções em tempo real, ativação conduzida por IA e engajamento personalizado podem ser entregues de forma confiável e em escala.
Comparação de produto
Esta tabela fornece uma comparação técnica dos padrões de Ingestão de dados e Cópia zero no Salesforce Data 360, focando recursos, compensações e benefícios, junto com casos de uso e resultados corporativos. Os arquitetos podem usar isso como referência para projetar plataformas de dados de várias nuvens híbridas que equilibram desempenho, custo e conformidade.
| Tipo de padrão | Modo/ferramenta | Benefícios | Considerações | Resultados |
|---|---|---|---|---|
| Ingestão de dados | Em tempo real: Ingestão de latência de menos de um segundo por meio de APIs de ingestão com suporte para CDC. Pipelines de streaming contínuo. | - Insights imediatos - Ideal para casos de uso operacionais e de personalização de baixa latência - Dá suporte a fluxos de trabalho conduzidos por evento |
- Custo alto - Arquitetura complexa - Requer sistemas de origem de baixa latência - Origens de alto volume podem causar streaming excessivo que leva a pipelines saturados - Intensivo de I/O - Considere campos seletivos e filtragem para reduzir a sobrecarga |
Agentforce: - Alertas de fraude em tempo real, personalização do varejo, alertas operacionais Analytics: - Painéis de subsegundo, monitoramento de KPI Conformidade: - Atualizações contínuas de registro do cliente para fluxos de trabalho regulados |
| Streaming: Ingestão de microlote a cada 1 a 3 minutos por meio de conectores nativos | - Custo equilibrado vs. frescura - Arquitetura mais simples do que em tempo real - Dá suporte a atualizações incrementais |
- Baixa latência - Pode não ser adequado para decisões críticas em menos de um segundo - O tamanho do lote afeta a memória/compute - A I/O é moderada - Melhor para padrões de atualização repetidos e previsíveis - Considere a agregação com janelas para reduzir a carga de processamento |
Agentforce: Acionadores de campanha oportunos, engajamento quase ativo Analytics: - Mecanismos de recomendação, painéis quase ativos Conformidade: - Atualizações frequentes com capacidade de auditoria |
|
| Lote: Cargas de grande volume agendadas por meio de conectores ou APIs. Suporta o armazenamento de objetos e pipelines ETL/ELT. | - Eficiente para conjuntos de dados massivos - Fácil de implementar - Confiável para análise histórica |
- Latência de dados - Não é adequado para operações que exigem tempo - Intensidade de I/O durante janelas de carregamento - A taxa de transferência de rede pode se tornar um gargalos para arquivos grandes - Melhor para agregação de histórico ou fluxos de trabalho de relatórios regulados |
Agentforce: - Pedidos de suporte de TI (Jira/ServiceNow), fluxos de trabalho agregados Analytics: - Análise histórica, avaliação de tendências Reclamação: - Relatórios regulatórios, agregação de dados de pacientes/reivindicações |
|
| Zero Copy | Consulta ao vivo: Consultas diretas em sistemas externos; esquema-on-read; sem duplicação de dados | - Máxima frescura - Sobrecarga mínima de armazenamento; dá suporte a percepções operacionais em tempo real |
- Dependendo do desempenho de origem - O alto volume de consultas pode afetar a latência - Ideal para consultas com push-down de predicado e agregação para minimizar I/O - Evite consultas não filtradas em conjuntos de dados massivos |
Agentforce: - Fluxos de trabalho dinâmicos adaptados à atividade ativa Analytics: - Painéis operacionais, relatórios ativos Conformidade: - Respeita a segurança e o mascaramento no nível da linha na origem |
| Consulta acelerada (cache): cópias locais armazenadas em cache para consultas federadas. Configurável de 15 minutos a 7 dias. Execução de consulta otimizada | - Reduz a latência - Custo menor do que consultas ativas repetidas - Melhora o desempenho para padrões de acesso frequente |
- Gerenciamento de cache obrigatório - A permanência depende do intervalo de cache - Melhor para consultas de alta frequência - Não é adequado para tomada de decisão em menos de um segundo |
Agentforce: - Métricas de engajamento pré-agregadas para uma rápida tomada de decisão Analytics: - Painéis de BI, segmentação, relatórios analíticos Conformidade: - Painéis regulados consistentes com registros de auditoria |
|
| Federação de arquivos: Acesso direto a grandes conjuntos de dados históricos em lojas de objetos ou lagos (S3, Iceberg, Google BigQuery, Redshift). | - Lida com conjuntos de dados em escala enorme - Armazenamento mínimo no Data 360 - Dá suporte a cargas de trabalho de IA/ML |
- Somente leitura - O desempenho da consulta depende da taxa de transferência do sistema externo - Otimizada para trabalhos pesados em lote com alta taxa de transferência - Não é adequado para painel em tempo real |
Agentforce: - (Não típico – lote pesado) Analytics: - Treinamento em ML/IA, análise histórica, relatórios em escala de petabyte Conformidade: - Acesso controlado a conjuntos de dados externos sem duplicação |
Padrões de integração do Data 360
Ingestão de dados
Com a ingestão de dados, os dados são copiados fisicamente para o Data 360 e totalmente controlados, diferentemente do Zero Copy em que os dados permanecem na origem. O cálculo de transformações acontece no Data 360, que permite a governança e a auditoria centralizadas.
Casos de uso de ingestão de dados
Use a ingestão de dados para armazenar conjuntos de dados canônicos e gerenciados no Salesforce Data 360 para conformidade e controle operacional. Use a ingestão quando controle total, auditoria e rastreabilidade forem necessários. Ideal para fluxos de trabalho regulados ou de alto valor em que computação e governança centralizadas são essenciais.
A ingestão é melhor para criar uma base confiável para resolução de identidade, relatórios regulatórios e fluxos de trabalho conduzidos por IA críticos para a missão e engajamento do cliente.

Métodos de ingestão de dados
Os métodos de ingestão de dados variam dependendo do conector que você usa para ingerir seus dados. Alguns conectores oferecem uma variedade de métodos de ingestão, enquanto outros operam apenas no modo de lote ou streaming. Consulte Data 360: Integrações e conectores para uma lista completa de conectores do Data 360 e seus métodos disponíveis.
- Em tempo real
- Ingestão de subsegundo usando pipelines de streaming ou Captura de dados de alteração (CDC).
- Melhor para fluxos de trabalho que exigem tempo (detecção de fraudes, personalização, painéis operacionais).
- Envie por push transformações e agregações no Data 360 para reduzir as I/O a jusante e otimizar o uso de computação. Use a CDC incremental para minimizar o desvio de dados.
- Streaming
- Ingestão a cada 1 a 3 minutos em pequenos incrementos.
- Equilibra frescura e custo, adequado para orquestração de campanha, engajamento quase ativo e relatórios operacionais.
- Use microlotes para controlar picos de I/O. Agregue dados na origem, se possível, para reduzir volumes de transferência e otimizar o armazenamento.
- Lote (cargas agendadas)
- Ingestão periódica de conjuntos de dados grandes (horário, diário, semanal).
- Custo e confiabilidade para conjuntos de dados históricos, relatórios regulatórios e casos de uso de conformidade.
- Garanta a localidade de computação na mesma região que o armazenamento de origem para otimização de desempenho e custo.
Manual do arquiteto
- Casos de uso para ingestão de dados
- Gerar perfis unificados do Customer 360: Crie uma única fonte da verdade para identidade e atributos do cliente.
- Manter conjuntos de dados de conformidade regulatória: Impor governança, lineagem e capacidade de auditoria para dados confidenciais.
- Orquestração de campanha centralizada: Garantir que marketing, vendas e serviço funcionem com base em conjuntos de dados consistentes e confiáveis.
- Práticas de design
- Favorecer a ingestão em lote para necessidades históricas ou com baixa tolerância de latência, como relatórios de arquivamento ou instantâneos periódicos.
- Use as APIs de streaming ou CDC para manter a atualidade dos fluxos de trabalho operacionais e de personalização, garantindo atualizações quase em tempo real.
- Controle o armazenamento e o crescimento de computação aplicando cargas incrementais, em vez de recarregar conjuntos de dados inteiros, para otimizar o custo e a eficiência.
- Alinhe os pipelines de ingestão com localidade de computação e processamento incremental para reduzir as I/O de rede. Aplique transformações dentro do Data 360 para evitar mover dados brutos desnecessariamente.
- Considerações de custo
- Ingestão em tempo real: Os maiores custos de computação e pipeline; justificados para fluxos de trabalho de alto valor e urgentes, como personalização, painéis operacionais ou ações conduzidas pelo Agentforce.
- Ingestão de streaming: Moderar os custos de computação e armazenamento; adequado para atualizações frequentes que podem tolerar pequenos atrasos, como orquestração de campanha ou relatórios operacionais.
- Ingestão de lote: Menos custos de computação, armazenamento previsível; melhor para conjuntos de dados históricos ou atualizações de baixa frequência. A ingestão de dados em lote de organizações do Salesforce usando determinados conectores é gratuita.
- Modo de atualização: Selecionar o modo Atualização incremental reduz os custos totais de ingestão e computação. Recomendamos usar atualização incremental sempre que possível para otimizar a eficiência em todos os tipos de ingestão.
- O custo também é afetado pelo volume de I/O da origem para o Data 360. Otimizar tamanhos de lote, partições e alinhamento regional reduz os custos de transferência e melhora o desempenho.
- Cenários da indústria
- Finanças: Ingira conjuntos de dados necessários para conhecer seu cliente (KYC), Anti-Lavagem de Dinheiro (AML) e detecção de fraudes, em que a auditoria e a conformidade não são negociáveis.
- Saúde: Use a ingestão para resolução de identidade do paciente e registros em conformidade com HIPAA, habilitando visualizações seguras e unificadas.
- Retail: Consolidar dados de ponto de vendas (POS), comércio eletrônico e programa de fidelidade em perfis unificados para segmentação e personalização
- Telecom: Dê suporte à prevenção de rotatividade e à análise de uso com dados canônicos de assinante regulamentados.
Critérios de decisão do método de ingestão de dados
| Recurso | Ingestão em tempo real | Ingestão de streaming | Ingestão em lote |
|---|---|---|---|
| Latency e frescura | Ingestão de latência de subsegundo por meio de APIs de ingestão com suporte para Captura de dados de alteração (CDC). Fornece pipelines de streaming contínuos. Melhor para casos de uso operacionais de baixa latência. | Ingestão de microlote a cada 1 a 3 minutos por meio de conectores nativos. Dá suporte a atualizações incrementais. É esperada uma pequena latência. | A latência de dados é esperada. Cargas de grande volume agendadas. Ingestão periódica (horária, diária, semanal). Não é adequado para operações que exigem tempo. |
| Casos de uso primários | Ideal para casos de uso operacionais e de personalização de baixa latência. Usado para fluxos de trabalho urgentes. Dá suporte a fluxos de trabalho conduzidos por evento. Usado para alertas de fraude em tempo real e alertas operacionais. | Adequado para processos moderadamente urgentes. Usado para orquestração de campanha, engajamento quase ativo e relatórios operacionais. Usado para acionadores de campanha oportunos. | Eficiente para conjuntos de dados massivos. Confiável para análise histórica. Usado para agregação de histórico ou fluxos de trabalho de relatórios regulados. Melhor para conjuntos de dados históricos ou de baixa velocidade. |
| Complexidade arquitetônica e I/O | Arquitetura complexa e de alto custo. Requer sistemas de origem de baixa latência. Intensivo de I/O. Origens de alto volume podem causar pipelines saturados. | Arquitetura mais simples do que em tempo real. O I/O é moderado. Melhor para padrões de atualização repetidos e previsíveis. O tamanho do lote afeta a memória/compute. | Fácil de implementar. Intensivo de I/O durante janelas de carregamento. A taxa de transferência de rede pode se tornar um gargalos para lotes grandes. |
| Considerações de custo | Custos de pipeline e computação mais altos. Justificado apenas para fluxos de trabalho de alto valor e urgentes. | Moderar os custos de computação e armazenamento. Fornece uma abordagem de custo equilibrado versus frescura. Adequado para atualizações frequentes que podem tolerar pequenos atrasos. | Menos custos de computação e armazenamento previsível. Recomendado para conjuntos de dados históricos ou atualizações de baixa frequência. A ingestão por meio de pipelines internos do Salesforce é gratuita. |
| Práticas de design | Use a CDC incremental para minimizar o desvio de dados. Filtre e use campos seletivos para reduzir a sobrecarga. | Use microlotes para controlar picos de I/O. Considere a agregação com janelas para reduzir a carga de processamento. | Favorecer isso para relatórios de arquivamento ou instantâneos periódicos. Certifique-se de que a localidade de computação esteja na mesma região que o armazenamento de origem para otimização de custo. |
Federação de dados de cópia zero
Casos de uso de cópia zero
Use o Zero Copy para consulta em tempo real de sistemas externos sem duplicação de dados, permitindo agilidade, frescura e acesso escalonável a conjuntos de dados grandes ou temporários. É melhor para painéis ativos, análise exploratória, treinamento de modelo de IA/ML e engajamento do cliente em tempo real diretamente por meio do Salesforce Data 360.
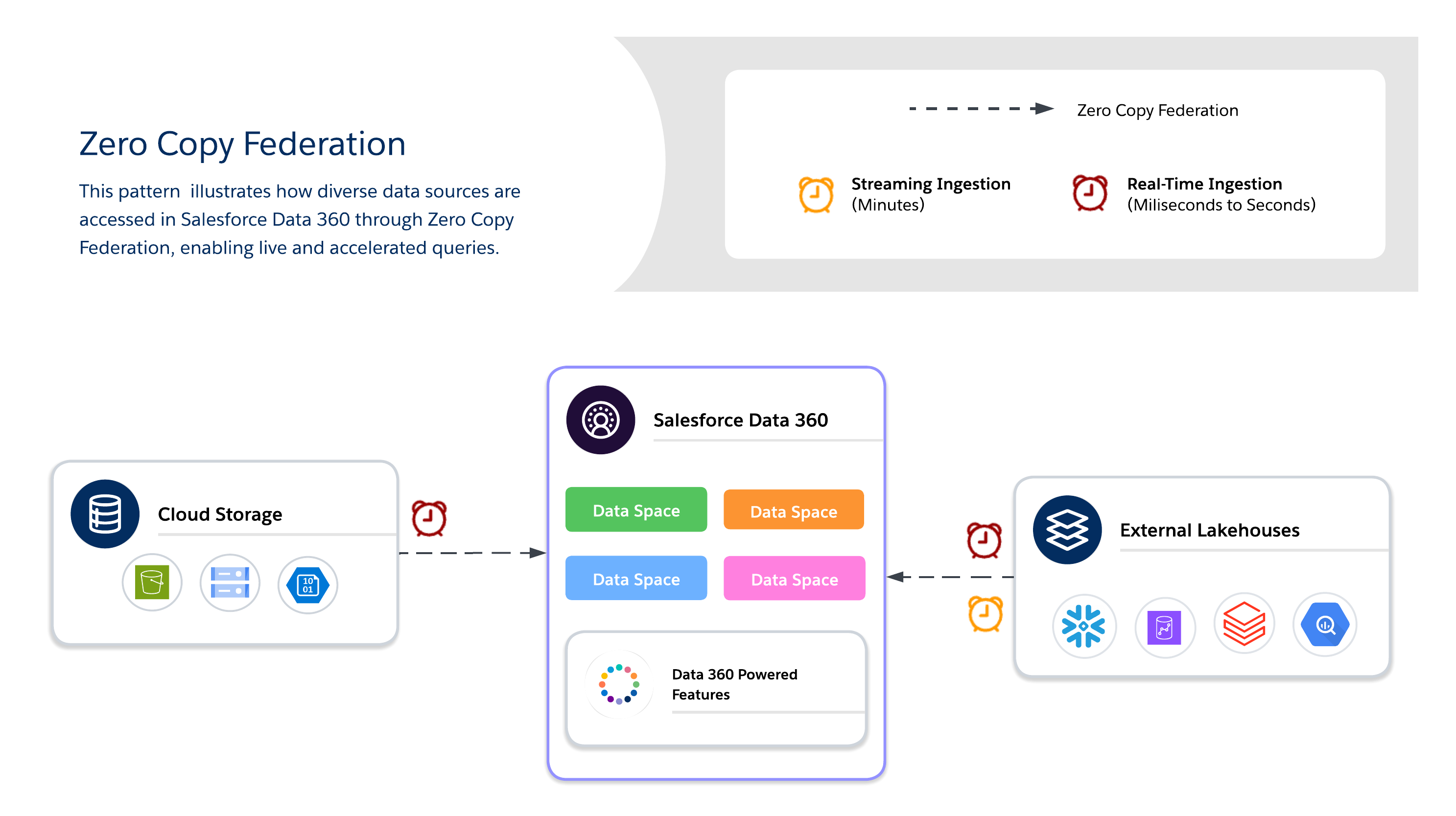
Métodos de cópia zero
Ao usar o Zero Copy, os arquitetos devem decidir ainda mais entre três métodos de federação de dados disponíveis, cada um oferecendo seus próprios prós e contras entre frescura, desempenho e custo.
- Consulta ativa
- Executa consultas diretamente em sistemas externos (Snowflake, Google BigQuery, Redshift, Databricks etc.) sem duplicação de dados.
- Otimizado quando predicados e agregações podem ser enviados para baixo, minimizando a movimentação de dados na rede e reduzindo o E/S no computador do Salesforce Data 360.
- Melhor para percepções em tempo real e painéis operacionais de baixa latência. Dependendo do desempenho do sistema externo.
- Cache (consulta acelerada)
- Armazena temporariamente cópias em cache de dados federados no Salesforce Data 360.
- Reduz os custos de consulta repetida e a latência para conjuntos de dados acessados com frequência, com duração configurável (minutos a dias).
- Os dados não são copiados permanentemente nem totalmente controlados; a atualidade é gerenciada por meio de atualizações agendadas da origem.
- Federação de arquivos
- Fornece acesso direto somente leitura a conjuntos de dados em grande escala em lojas de objetos (por exemplo, S3, GCS com iceberg).
- Melhor para cargas de trabalho de IA/ML, análise histórica e relatórios em escala de petabytes sem mover dados.
- O desempenho da consulta depende muito do formato do objeto, do particionamento e das I/O de rede. As verificações grandes podem gerar I/O substanciais se não forem otimizadas.
Manual do arquiteto
- Casos de uso
- Personalizar em tempo real e fluxos de trabalho adaptáveis: Entregue ofertas dinâmicas, recomendações e próximas melhores ações conforme o comportamento do cliente muda.
- Painéis ativos e análise operacional: Aprimore painéis e KPIs essenciais para os negócios diretamente de armazéns externos.
- Trenamento de modelo de IA/ML com grandes conjuntos de dados externos: Aproveite dados em escala de petabytes de data lakes e armazéns usando federação de arquivos sem movê-los.
- Cenários da indústria
- Retail/Media: Habilite recomendações personalizadas e engajamento do cliente em tempo real federando dados de interação de conteúdo ou fluxo de cliques.
- Finanças: Execute a detecção de fraudes e a pontuação de risco quase em tempo real consultando armazéns externos sem duplicar dados confidenciais.
- Tech/Enterprise: Dê suporte a relatórios entre nuvens, painéis de serviço de TI e análise operacional em que os conjuntos de dados residem em vários sistemas.
- Práticas de design
- Consulta ativa
- Use para consultas de alta QPS e baixa latência quando a frescura for crítica.
- Envie por push predicados e agregações para o sistema externo para reduzir o desvio de dados na rede.
- Evite consultas que verificam volumes de dados enormes desnecessariamente; considere cortar partições e filtros.
- Federação de arquivos
- Acesse conjuntos de dados em escala de petabytes em lojas de objetos sem ingestão.
- Mantenha o armazenamento de objeto na mesma região de nuvem que a computação do Salesforce para minimizar os custos de latência e saída.
- Use formatos particionados em coluna (Parquet/ORC) e filtros de menu suspenso para reduzir a transferência de I/O e rede.
- Aproveite a consulta e o menu suspenso de predicado para filtrar e agregar dados na origem, reduzindo a movimentação dos dados.
- Evite o acesso a dados entre regiões, a menos que necessário, pois isso aumenta o E/S, a latência e os custos.
- Cache (consulta acelerada)
- Armazene em cache conjuntos de dados acessados com frequência para equilibrar custo e desempenho.
- Configure intervalos de atualização para equilibrar a frescura versus o custo da consulta.
- Conformidade: Imponha a governança na origem aproveitando a segurança em nível de linha (RLS) e mascarando políticas diretamente em sistemas federados. Aqui estão as práticas recomendadas para RLS uniforme e mascaramento entre plataformas.
- Usar um ID corporativo centralizado: Mapeie usuários e entidades no Salesforce Data 360 para um identificador corporativo único e centralizado que corresponda a identidades em sistemas externos.
- Align Políticas de segurança: Garanta que a segurança em nível de linha e as políticas de mascaramento em sistemas federados sejam aplicadas com base na identidade mapeada. Isso preserva a conformidade ao consultar dados externos.
- Padronizar esquemas de identidade: Mantenha atributos de identidade consistentes (email, ID do usuário, ID do cliente etc.) em todas as fontes de dados para evitar incompatibilidades e violações de acesso.
- Consulta ativa
- Considerações de custo
- Consulta ao vivo: Modelo de pagamento por consulta – os custos se acumulam no cálculo externo do lakehouse e podem aumentar com QPS alto. Melhor para casos de uso críticos de frescura em que o valor é maior que a variabilidade de custo.
- Consulta acelerada (cache): Reduz o custo da consulta em comparação à Consulta ativa reduzindo as consultas ao sistema de origem, mas aumenta os custos de ingestão de dados em lote para preenchimento e atualização do cache. Melhor para conjuntos de dados acessados com frequência.
- Federação de arquivos: Opção de armazenamento mais barata como dados na Loja de objetos, mas os custos de consulta dependem do tamanho do arquivo, do particionamento e da redução. Melhor para dados históricos ou em massa em escala de petabytes.
Critérios de decisão do método de cópia zero
| Ponto de decisão | Consulta ativa | Armazenamento em cache (consulta acelerada) | Federação de arquivos |
|---|---|---|---|
| Local da fonte de dados | Lagos de dados externos (Snowflake, Google BigQuery, Redshift, Databricks). | Lagos de dados externos (Snowflake, Google BigQuery, Redshift, Databricks) | Armazéns de objetos ou data lakes de nuvem (S3, ADLS, GCS), geralmente usando formatos de tabela abertos, como IceBerg. |
| Objetivo/Caso de uso | Ideal para análise interativa e painéis em tempo real. Melhor para personalização em tempo real e fluxos de trabalho dinâmicos. | Melhor para quando as consultas são frequentes, mas os resultados levemente obsoletos são aceitáveis. Adequado para painéis de BI e segmentação. | Melhor para processamento em lote em grande escala e treinamento de modelo de IA/ML. Ideal para análise histórica e relatórios em escala de petabytes. |
| Freshness/Latency | Máxima atualidade; as consultas são executadas diretamente em tempo real. Dá suporte à tomada de decisão em subsegundo. | Resultados levemente obsoletos são aceitáveis. A atualidade depende do intervalo de cache, configurável de 15 minutos a 7 dias. | Otimizada para trabalhos pesados em lote com alta taxa de transferência. Não é adequado para painel em tempo real. |
| Padrão de acesso | Melhor para consultas infrequentes ou ad-hoc. Use para consultas de QPS alto (consulta por segundo), de baixa latência em que a frescura é crítica. | Melhor para cenários de leitura de alta frequência. Melhora o desempenho para padrões de acesso frequente. | Acesso somente leitura. Adequado para conjuntos de dados em escala de petabytes sem ingestão. |
| Drivers de desempenho | Altamente dependente do desempenho do sistema de origem externo. Otimizado quando predicados e agregações podem ser enviados para baixo para a origem. | Reduz a latência em comparação a consultas ativas repetidas. O desempenho depende do gerenciamento de cache e do intervalo. | O desempenho depende muito do formato do objeto, do particionamento e da taxa de transferência do sistema externo. Use formatos particionados em colunas (Parquet/ORC). |
| Implicações dos custos | Modelo Pagar por consulta. Os custos se acumulam no computador de lakehouse externo. Custo-benefício para consultas pouco frequentes, mas as despesas podem aumentar com alto volume de consultas por segundo (QPS). | Custo menor do que consultas ativas repetidas. Reduz a necessidade de consultar a origem externa repetidamente. Adiciona armazenamento em cache e sobrecarga de atualização. | Opção de armazenamento mais barata. Os custos de consulta dependem do tamanho e do particionamento do arquivo. |
| Consideração principal | Evite consultas não filtradas que verificam volumes de dados enormes desnecessariamente. | Requer gerenciamento de cache. Não é adequado para tomada de decisão em menos de um segundo. | O desempenho da consulta depende fortemente da otimização por meio de particionamento e menu suspenso de predicado. |
Abordagem híbrida
As arquiteturas híbridas permitem que os arquitetos ancorem conjuntos de dados críticos no Data 360 para governança centralizada enquanto aproveitam consultas federadas para atualização, redução da duplicação e acesso escalonável a conjuntos de dados externos grandes. Essa abordagem balanceia os requisitos de I/O, localidade de computação, custo e conformidade.
Casos de uso híbridos
Use uma abordagem híbrida para uma governança equilibrada, frescura e eficiência operacional combinando ingestão de dados e cópia zero para fornecer percepções acionáveis em tempo real. Use a ingestão para conjuntos de dados regulados de alto valor em que rastreabilidade, RLS e mascaramento são necessários e federação para conjuntos de dados efetivos ou de alto volume em que a atualização e o desempenho são essenciais.
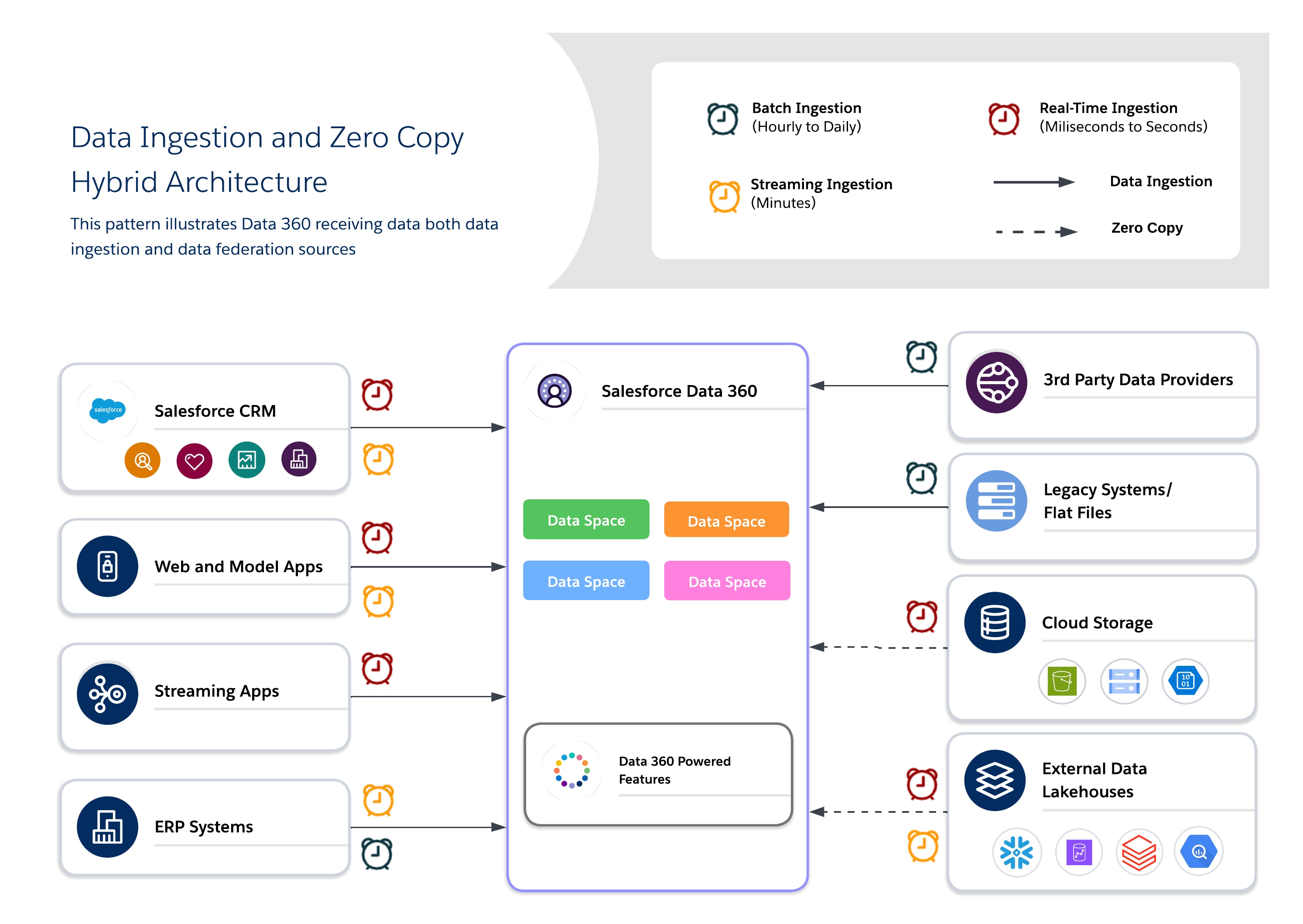
Manual do arquiteto
- Casos de uso
- Engajamento do Omni-Channel: Combine dados históricos do cliente com comportamento em tempo real para proporcionar experiências consistentes sensíveis ao contexto.
- Pipelines de IA/ML: Treine modelos em conjuntos de dados canônicos selecionados enquanto os aprimora com sinais brutos ou em tempo real de fontes externas.
- Necessidades de conformidade e agilidade mistas: Aplique uma governança rígida a dados confidenciais, mas federar para agilidade operacional.
- Cenários da indústria
- Retail: Use ingestão para resolução de identidade e unificação de perfil; federar para ofertas e personalização em tempo real.
- Saúde: Mantenha registros do paciente dourados por meio de ingestão enquanto federa fluxos de dispositivo de IoT e dados de sensor para contexto imediato.
- Serviços financeiros: Ingira dados regulados em um lago de conformidade enquanto federa consultas externas para detecção de fraudes e monitoramento de risco.
- Práticas de design
- Ancora governança com ingestão: Ingira dados de alto valor ou regulados em modelos canônicos para garantir Trust e conformidade.
- Use Federação para frescura: Permita que os lagos externos forneçam acesso a dados em tempo real ou em grande escala sem duplicação.
- Custo do saldo vs. Desempenho: Faça o perfil das cargas de trabalho para decidir o que ingerir vs. federar, minimizando custos desnecessários de armazenamento ou consulta.
- Aplicar governança em camadas: Imponha a governança centralizada para dados ingeridos enquanto aproveita os próprios controles de segurança dos sistemas federados (por exemplo, RLS, mascaramento).
- Ao projetar pipelines híbridos, garanta a ingestão incremental para conjuntos de dados históricos e envie agregações ou filtros por push para fontes federadas para otimizar o uso de I/O e computação.
- Considerações de custo
- Otimize o custo total versus o desempenho combinando a ingestão de dados críticos ou de conformidade com a federação quando a atualização for necessária.
- Considere a distribuição de I/O e computação ao combinar ingestão e federação. Para reduzir o custo de computação em sistemas de origem de consultas repetidas, use o armazenamento em cache (consulta acelerada) para conjuntos de dados federados de alta leitura acessados com frequência.
Usar o Guia de decisão de caso
Abaixo estão os arquetípicos comuns que ilustram como aplicar essa lógica.
- O Arquétipo da "Fonte Única da Verdade": Centralizar e governar
- Cenário: Você precisa criar perfis unificados e compatíveis do Customer 360 para toda a sua empresa global. Os dados vêm de uma dúzia de sistemas diferentes, devem cumprir normas rigorosas de GDPR e CCPA e servirão como a fonte confiável para todas as interações de marketing e serviço.
- Padrão recomendado: Ingestão de dados. A prioridade é governança, Trust e controle. Ingerir os dados no Data 360 é a única maneira de criar um perfil canônico totalmente auditável que seja isolado dos sistemas de origem.
- O Arquiteto de Insights em tempo real: Analisar sem se mover
- Cenário: Sua equipe de ciência de dados precisa executar consultas exploratórias em uma tabela de transações massiva e constantemente atualizada no Snowflake. Ao mesmo tempo, sua equipe executiva quer um painel de BI ativo habilitado pelos mesmos dados. Mover petabytes de dados por dia é muito lento e caro.
- Padrão recomendado: Federação de cópia zero. A prioridade é velocidade, agilidade e custo-benefício em escala. A Cópia zero permite que você aproveite o enorme poder do seu armazém de dados existente para consultas em tempo real sem o sobrecarregamento e a latência da duplicação de dados.
- O Arquétipo de Inteligência Híbrida: Governar o núcleo, Federar a borda
- Cenário: Você deseja aprimorar seus perfis de cliente administrados e ingeridos com sinais comportamentais em tempo real (como cliques no site) de um data lake. Você precisa da estabilidade do perfil principal, mas da imediatez dos dados ativos para habilitar a personalização no momento.
- Padrão recomendado: Uma abordagem híbrida. Use a Ingestão de dados para criar o núcleo estável e governado dos dados do cliente. Em seguida, use a Cópia zero para federar os dados de "frente" em tempo real e voláteis, unindo-os no tempo da consulta para uma visualização completa atualizada por segundo.
O caminho para frente
A estratégia de dados corporativos não é mais sobre escolher um único padrão de integração, é sobre arquitetar flexibilidade controlada em um ecossistema de dados interoperável. Selecionar o método de integração de dados certo para cada sistema de dados de origem com base nas necessidades de negócios geralmente leva a uma abordagem híbrida que combina os pontos fortes da ingestão de dados e da federação de dados.:
- Ingira conjuntos de dados governados essenciais para a missão no Salesforce Data 360 para conformidade, resolução de identidade e fluxos de trabalho operacionais.
- Federar dados por meio do Zero Copy para análise ativa, exploratória e conduzida por IA sem armazenamento duplicado.
O Salesforce Data 360 no Hyperforce proporciona resiliência e escalabilidade multi-região. O lakehouse aberto com tabelas de iceberg permite a separação de computação e a interoperabilidade com plataformas como Snowflake, Databricks e S3 Iceberg, formando a espinha dorsal de um ecossistema de dados multi-nuvem verdadeiramente interoperável.
Conforme os ecossistemas de dados evoluem, equilibre continuamente a atualidade, o custo, o desempenho e a conformidade para manter a agilidade arquitetônica. Proteja sua plataforma para o futuro unificando dados ingeridos e controlados com acesso federado. Isso habilita a inteligência em tempo real, a ativação de IA e a personalização em escala corporativa em nuvens, regiões e domínios de negócios.
Soluções unidimensionais adequadas a todos não são adequadas à maioria das empresas. A estratégia ideal mapeia o padrão certo para o motor de negócios certo.
Sobre os autores
Yugandhar Bora é um arquiteto de engenharia de software na Salesforce, especializado em arquitetura de dados na plataforma de Aplicativos de dados e inteligência. Ele lidera iniciativas do Conselho de revisão de arquitetura corporativa (EARB) focadas na governança de dados e modelos de dados unificados, ao mesmo tempo que contribui para soluções de provisionamento de plataforma automatizadas.
Jan Fernando é um arquiteto principal no escritório do arquiteto principal no Salesforce. Ele entrou para a Salesforce em 2012, trazendo uma vasta experiência de seu tempo no ecossistema de startup. Antes de ingressar no Escritório do Arquiteto Chefe, ele passou mais de uma década na organização da plataforma, onde liderou várias transformações tecnológicas importantes.
 j
j26 minute read