Les entreprises stockent souvent des données dans Salesforce et dans d'autres lacs de données externes tels que Snowflake, Google BigQuery, Databricks, Redshift ou dans un stockage cloud tel que Amazon S3. Ce cloisonnement des données dans différents systèmes sources pose un défi aux entreprises qui souhaitent exploiter toute la puissance de leurs données.
Les architectes qui travaillent pour regrouper des données à travers plusieurs lacs de données doivent prendre des décisions architecturales importantes sur la meilleure façon d'intégrer ces données. Data 360 offre plusieurs options d'intégration de données, chacune offrant des avantages et des inconvénients différents.
Ce guide fournit un cadre qui permet d'évaluer le modèle le plus adapté à vos exigences en matière de latence, de coût, d'évolutivité, de gouvernance et de complexité lors de l'intégration de données, en vous aidant à choisir quand utiliser l'ingestion de données, la fédération de données Zero Copy ou une approche hybride. Le guide vous aidera également à sélectionner entre différentes méthodes d'ingestion de données et de fédération de données, chacune répondant à un besoin différent.
L'intégration de lacs de données externes à Data 360 nécessite un examen attentif des compromis entre l'actualisation des données, la gouvernance et l'efficacité du pipeline. Par exemple, l'utilisation de requêtes live de fédération de données Zero Copy optimise l'actualisation des données, mais peut réduire l'efficacité du pipeline en déplaçant davantage de données sur le réseau. Par conséquent, pour la plupart des implémentations réelles, une combinaison d'ingestion et de fédération dans un écosystème Lakehouse multicloud est la voie optimale. Cette approche hybride garantit une architecture évolutive, régie et interopérable qui prend en charge de façon transparente à la fois les charges de travail opérationnelles à faible latence telles que la personnalisation en temps réel et la détection des fraudes, et les charges de travail analytiques telles que les rapports réglementaires et l'analyse des tendances historiques. Ce guide de décision vous aidera à comprendre comment parcourir ces compromis et sélectionner la stratégie appropriée.
- Ingestion de données : Copie les données dans Salesforce Data 360, créant des modèles de données gouvernés et canoniques. Idéal lorsque vous devez :
- Élaborer un Customer 360 complet : Unifiez et transformez des sources différentes en un profil unique et de confiance.
- Satisfaire à la stricte conformité réglementaire : Créez une copie auditable et centralisée dans laquelle l'accès aux données et le lignage peuvent être étroitement contrôlés.
- Zero Copy Federation : Interroge les sources externes en temps réel sans duplication, ce qui permet une personnalisation en temps réel, des tableaux de bord live et une intégration rapide des sources. Deux options principales avec des compromis que vous devez équilibrer :
- Live et mise en cache (requête accélérée) : Idéal pour l'analyse interactive et les tableaux de bord en temps réel sur les données qui vivent sur des plates-formes de données externes telles que Snowflake, Google BigQuery, Redshift ou Databricks. Évite les duplications de données lentes et coûteuses en orientant le traitement vers le système source.
- Fédération de fichiers : Idéal pour le traitement par lot à grande échelle et la formation au modèle IA sur les données de votre lac de données Cloud (S3, ADLS). Évite l'ingestion coûteuse et lente en interrogeant directement des fichiers sous des formats de tableau ouvert, ce qui déverrouille des jeux de données massifs pour les charges de travail ETL et de science des données.
- Modèle hybride: Combinez l'ingestion pour Profils unifiés avec la fédération pour la fraîcheur, en prenant en charge l'engagement omni-canal, les actions pilotées par Agentforce et la formation IA/ML.
-
Architecture hybride : La combinaison de l'ingestion de données et de la fédération de données est souvent nécessaire.
- Utilisez Ingestion de données sur des données critiques pour des modèles de données canoniques et la gouvernance de base.
- Fédérez toutes les autres données via Zero Copy afin de limiter les coûts opérationnels liés à l'élaboration et à la maintenance des pipelines de données d'ingestion.
-
La fréquence d'ingestion des données est importante : Choisissez la fréquence en fonction de la valeur métier, des besoins en latence et de la complexité opérationnelle.
- Utilisez le temps réel pour des workflows temporels (personnalisation, tableaux de bord live, actions Agentforce).
- Temps quasi réel pour des processus modérément urgents (campagnes, rapports opérationnels).
- Lot de jeux de données historiques ou à faible vitesse.
-
Mappez le schéma de fédération avec Latence et performance : Choisissez celui qui correspond le mieux à vos modèles d'accès et aux exigences de fraîcheur, de performance et de coût.
- Utilisez Live Query pour les tableaux de bord opérationnels et la personnalisation en temps réel lorsque la faible latence est critique.
- Utilisez la mise en cache (requête accélérée) lorsque les requêtes sont fréquentes, mais que les résultats légèrement périmés sont acceptables, ce qui équilibre les performances et le coût.
- Utilisez Fédération de fichiers pour des analytiques ou des charges de travail par lot à grande échelle et lourdes en débit, idéales pour des jeux de données historiques ou moins temporels.
-
Alignement de la gouvernance avec les exigences de résidence des données :
- Utilisez l'ingestion lorsque la gouvernance centralisée est essentielle.
- Utilisez la fédération lorsque la gouvernance décentralisée est acceptable, tout en appliquant une gouvernance stricte à la source externe. Zero Copy respecte les stratégies au niveau source telles que la sécurité au niveau de la ligne (RLS) et le masquage des données.
-
Priorité à l'ingestion pour les workflows à valeur élevée : Appliquez l'ingestion de façon sélective à des processus critiques tels que la résolution de l'identité, les rapports réglementaires et l'activation opérationnelle.
-
Les coûts et la complexité déterminent la décision : L'ingestion en temps réel peut être coûteuse et complexe. Les architectes doivent évaluer le coût de l'intégration, du stockage et de la transformation des données par rapport au coût de leur interrogation directe via Zero Copy.
Le choix du modèle d'intégration approprié (Ingestion de données, Zéro copie ou approche hybride) impacte directement la latence, la gouvernance, l'efficacité opérationnelle et le coût sur les plates-formes multicloud. Cette décision détermine comment les connaissances en temps réel, l'activation pilotée par l'IA et l'engagement personnalisé peuvent être fournis de façon fiable et à grande échelle.
Le tableau ci-dessous présente une comparaison technique des modèles Ingestion de données et Zéro copie dans Salesforce Data 360, en se concentrant sur les capacités, les compromis et les avantages, ainsi que sur les cas d'utilisation et les résultats de l'entreprise. Les architectes peuvent s'en servir comme référence pour concevoir des plates-formes de données hybrides et multicloud qui concilient performance, coût et conformité.
| Type de modèle | Mode / Outil | Avantages | Considérations | Résultats |
|---|---|---|---|---|
| Ingestion de données | En temps réel : Ingestion de latence subseconde via des API Ingestion avec la prise en charge du CDC. Pipelines en continu. | - Connaissances immédiates - Idéal pour les cas d'utilisation opérationnels et de personnalisation à faible latence - Prend en charge les workflows pilotés par l'événement |
- Coût élevé - Architecture complexe - Nécessite des systèmes sources à faible latence - Les sources à haut volume peuvent entraîner une diffusion excessive conduisant à des pipelines saturés - E/S intensives - Prendre en compte les champs sélectifs et le filtrage pour réduire les frais généraux |
Agentforce : - Alertes anti-fraude en temps réel, personnalisation de la vente au détail, alertes opérationnelles Analytics : - Tableaux de bord sub-seconde, suivi des indicateurs de performance clés Conformité : - Mises à jour continues des enregistrements clients pour les workflows réglementés |
| Streaming : Ingestion par microbatch toutes les 1 à 3 minutes via des connecteurs natifs | - Coût équilibré vs fraîcheur - Une architecture plus simple que le temps réel - Prend en charge les mises à jour incrémentielles |
- Légère latence - Peut ne pas convenir à des décisions critiques de deuxième seconde - La taille du lot impacte la mémoire/calcul - E/S est modéré - Idéal pour les modèles de mise à jour prévisibles et répétés - Envisager l'agrégation fenêtrée pour réduire la charge de traitement |
Agentforce : - Déclencheurs de campagne au moment opportun, engagement en direct Analytics : - Moteurs de recommandation, tableaux de bord en quasi direct Conformité : - Mises à jour fréquentes avec auditabilité |
|
| Batch : Chargements planifiés à grand volume via des connecteurs ou des API. Prend en charge le stockage d'objets et les pipelines ETL/ELT. | - Rentable pour des jeux de données massifs - Facile à mettre en oeuvre - Fiable pour les analytiques historiques |
- Latence des données - Inadapté aux opérations temporelles - E/S intensives pendant les fenêtres de chargement - Le débit réseau peut devenir un goulot d'étranglement pour les fichiers volumineux - Idéal pour les workflows d'agrégation historique ou de rapports réglementés |
Agentforce : - tickets de support informatique (Jira/ServiceNow), workflows agrégés Analytics : - Analyse historique, évaluation des tendances Plainte : - Rapports réglementaires, agrégation des données patients/réclamations |
|
| Zéro copie | Live Query : Requêtes directes sur des systèmes externes ; schéma en lecture seule ; pas de duplication des données | - Maximum de fraîcheur - Réduction des surcharges de stockage; prend en charge les connaissances opérationnelles en temps réel |
- Selon les performances de la source - Un volume de requête élevé peut affecter la latence - Idéal pour les requêtes avec pushdown et agrégation de prédicat afin de minimiser les entrées/sorties - Éviter les requêtes non filtrées dans les jeux de données massifs |
Agentforce : - Workflows dynamiques s'adaptant à l'activité live Analytics : - Tableaux de bord opérationnels, reporting live Conformité : - Respecte la sécurité au niveau de la ligne et le masquage à la source |
| Requête accélérée (mise en cache) : copies locales mises en cache pour les requêtes fédérées. Configurable de 15 min à 7 jours. Exécution de requête optimisée | - Réduit la latence - Coût inférieur aux requêtes live répétées - Améliore les performances des modèles d'accès fréquents |
- Gestion du cache requise - L'absence dépend de l'intervalle de cache - Idéal pour les requêtes à haute fréquence - Ne convient pas à la prise de décision en sous-seconde |
Agentforce : - Métriques d'engagement préagrégées pour accélérer la prise de décision Analytics : - Tableaux de bord BI, segmentation, reporting analytique Conformité : - Tableaux de bord réglementés cohérents avec des journaux d'audit |
|
| Fédération de fichiers: accès direct aux jeux de données historiques volumineux dans les magasins d'objets ou les lacs (S3, Iceberg, Google BigQuery, Redshift). | - Gère les jeux de données à grande échelle - Stockage minimal dans Data 360 - Prend en charge les charges de travail IA/ML |
- Lecture seule - Les performances des requêtes dépendent du débit système externe - Optimisé pour les tâches lourdes en lots et gourmandes en débit - Ne convient pas aux tableaux de bord en temps réel |
Agentforce : - (pas typique — lourd en lots) Analytics : - Entraînement ML/IA, analytiques historiques, rapports à l'échelle pétaoctets Conformité : - Accès régi aux jeux de données externes sans duplication |
Avec l'ingestion de données, les données sont physiquement copiées dans Data 360 et entièrement régies, contrairement à Zero Copy où les données restent à la source. Le calcul des transformations est effectué dans Data 360, ce qui permet une gouvernance et un audit centralisés.
Utilisez l'ingestion de données pour stocker des jeux de données canoniques et gouvernés dans Salesforce Data 360 à des fins de conformité et de contrôle opérationnel. Utilisez l'ingestion lorsqu'un contrôle total, un audit et une traçabilité sont requis. Idéal pour les workflows réglementés ou à valeur élevée dans lesquels le calcul centralisé et la gouvernance sont essentiels.
L'ingestion est la meilleure méthode pour établir une base de confiance pour la résolution de l'identité, les rapports réglementaires, et les workflows critiques pilotés par l'IA et l'engagement des clients.

Les méthodes d'ingestion de données varient selon le connecteur que vous utilisez pour ingérer vos données. Certains connecteurs offrent diverses méthodes d'ingestion, tandis que d'autres fonctionnent uniquement en mode par lot ou streaming. Consultez Data 360 : Intégrations et connecteurs pour une liste complète des connecteurs Data 360 et leurs méthodes disponibles.
- En temps réel
- Ingestion d'une seconde en utilisant des pipelines en continu ou Capture des données de modification (CDC).
- Idéal pour les workflows temporels (détection des fraudes, personnalisation, tableaux de bord opérationnels).
- Transformations push et agrégations dans Data 360 pour réduire les entrées/sorties en aval et optimiser l'utilisation des calculs. Utilisez le CDC incrémentiel pour limiter le mélange de données.
- Streaming
- Ingestion toutes les 1 à 3 minutes par petits incréments.
- Équilibre fraîcheur et coût, adapté à l'orchestration de campagnes, à l'engagement en direct et aux rapports opérationnels.
- Utilisez des micro-batchs pour contrôler les pics d'E/S. Agrégez les données à la source si possible pour réduire les volumes de transfert et optimiser le stockage.
- Lot (chargements planifiés)
- Ingestion périodique de jeux de données volumineux (horaire, quotidien, hebdomadaire).
- Rentable et fiable pour les jeux de données historiques, les rapports réglementaires et les cas d'utilisation de conformité.
- Garantissez la localisation du calcul dans la même région que le stockage source pour optimiser les performances et les coûts.
- Cas d'utilisation pour l'ingestion de données
- Générer des profils Customer 360 unifiés : Élaboration d'une source de vérité unique pour l'identité et les attributs des clients.
- Gérer les jeux de données de conformité réglementaire : Application de la gouvernance, de la lignage et de l'auditabilité pour les données confidentielles.
- Centraliser l'orchestration des campagnes : Le marketing, les ventes et le service fonctionnent à partir de jeux de données cohérents et de confiance.
- Pratiques de conception
- Privilégiez l'ingestion par lot pour les besoins historiques ou tolérants à faible latence, par exemple les rapports d'archives ou les clichés instantanés périodiques.
- Utilisez des API CDC ou streaming pour actualiser les workflows opérationnels et de personnalisation, en garantissant des mises à jour en temps quasi réel.
- Contrôlez le stockage et calculez la croissance en appliquant des charges incrémentielles, au lieu de recharger des jeux de données complets, afin d'optimiser le coût et l'efficacité.
- Alignez les pipelines d'ingestion avec la localisation du calcul et le traitement incrémentiel afin de réduire les entrées/sorties réseau. Appliquez des transformations dans Data 360 pour éviter de déplacer inutilement des données brutes.
- Considérations relatives aux coûts
- Ingestion en temps réel : Coûts de calcul et de pipeline les plus élevés ; justifiés pour des workflows à forte valeur ajoutée et urgents tels que la personnalisation, des tableaux de bord opérationnels ou des actions pilotées par Agentforce.
- Ingestion en continu : Modérer les coûts de calcul et de stockage. Convient aux mises à jour fréquentes qui peuvent tolérer de légers retards, par exemple l'orchestration de campagnes ou la génération de rapports opérationnels.
- Ingestion par lot : Réduction des coûts de calcul, stockage prévisible, idéal pour les jeux de données historiques ou les mises à jour à basse fréquence. L'ingestion de données par lot à partir d'organisations Salesforce en utilisant certains connecteurs est gratuite.
- Mode d'actualisation : La sélection du mode Actualisation incrémentielle réduit les coûts totaux d'ingestion et de calcul. Nous recommandons d'utiliser l'actualisation incrémentielle dans la mesure du possible afin d'optimiser l'efficacité dans tous les types d'ingestion.
- Le coût est également impacté par le volume d'E/S depuis la source vers Data 360. L'optimisation de la taille des lots, des partitions et de l'alignement régional réduit les coûts de transfert et améliore les performances.
- Scénarios de secteur d'activité
- Finances : Ingérez les jeux de données requis pour connaître vos clients (KYC), Anti Money Laundering (AML) et la détection des fraudes, où l'auditabilité et la conformité ne sont pas négociables.
- Soins de santé : Utilisez l'ingestion pour la résolution de l'identité des patients et les enregistrements conformes HIPAA, ce qui permet des vues sécurisées et unifiées.
- Détail : Consolider les données des points de vente (POS), du commerce électronique et du programme de fidélité dans des profils unifiés pour la segmentation et la personnalisation
- Télécom : Prenez en charge la prévention des résiliations et les analytiques d'utilisation avec des données d'abonné gouvernées canoniques.
| Fonctionnalité | Ingestion en temps réel | Ingestion en continu | Ingestion par lot |
|---|---|---|---|
| Latence et fraîcheur | Ingestion de latence en une seconde via les API Ingestion avec prise en charge de la Capture des données de modification (CDC). Fournit des pipelines en continu. Idéal pour les cas d'utilisation opérationnels à faible latence. | Ingestion par microbatch toutes les 1 à 3 minutes via des connecteurs natifs. Prend en charge les mises à jour incrémentielles. Une légère latence est attendue. | Une latence des données est attendue. Chargements planifiés à grand volume. Ingestion périodique (horaire, quotidienne, hebdomadaire). Inadapté aux opérations temporelles. |
| Cas d'utilisation principaux | Idéal pour les cas d'utilisation opérationnels et de personnalisation à faible latence. Utilisé pour les workflows temporels. Prend en charge les workflows pilotés par l'événement. Utilisé pour les alertes de fraude et les alertes opérationnelles en temps réel. | Convient aux processus modérément urgents. Utilisé pour l'orchestration de campagnes, l'engagement en direct et les rapports opérationnels. Utilisé pour les déclencheurs de campagne opportuns. | Rentable pour des jeux de données massifs. Fiable pour les analytiques historiques. Utilisé pour les workflows d'agrégation historique ou de rapports réglementés. Idéal pour les jeux de données historiques ou à faible vitesse. |
| Complexité architecturale et E/S | Coût élevé et architecture complexe. Nécessite des systèmes sources à faible latence. E/S intensives. Les sources à haut volume peuvent entraîner la saturation des pipelines. | Une architecture plus simple que le temps réel. Les entrées/sorties sont modérées. Idéal pour les modèles de mise à jour prévisibles et répétés. La taille du lot impacte la mémoire/calcul. | Facile à implémenter. E/S intensives pendant les fenêtres de chargement. Le débit réseau peut devenir un goulot d'étranglement pour les lots volumineux. |
| Considérations relatives aux coûts | Coûts de calcul et de pipeline les plus élevés. Justifié uniquement pour les workflows de grande valeur et urgents. | Modérer les coûts de calcul et de stockage. Fournit une approche coût/fraîcheur équilibrée. Convient pour les mises à jour fréquentes qui peuvent tolérer de légers retards. | Réduction des coûts de calcul et stockage prévisible. Recommandé pour les jeux de données historiques ou les mises à jour à basse fréquence. L'ingestion via des pipelines internes Salesforce est gratuite. |
| Pratiques de conception | Utilisez le CDC incrémentiel pour limiter le mélange de données. Filtrez et utilisez des champs sélectifs pour réduire les frais généraux. | Utilisez des micro-batchs pour contrôler les pics d'E/S. Envisagez l'agrégation fenêtrée pour réduire la charge de traitement. | Favorisez cette option pour les rapports d'archives ou les clichés instantanés périodiques. Assurez-vous de calculer la localisation dans la même région que le stockage source pour optimiser les coûts. |
Utilisez Zero Copy pour l'interrogation en temps réel de systèmes externes sans duplication des données, ce qui permet l'agilité, la fraîcheur et l'accès évolutif à des jeux de données volumineux ou temporaires. Il est idéal pour les tableaux de bord live, les analytiques exploratoires, l'entraînement au modèle IA/ML et l'engagement client en temps réel directement via Salesforce Data 360.
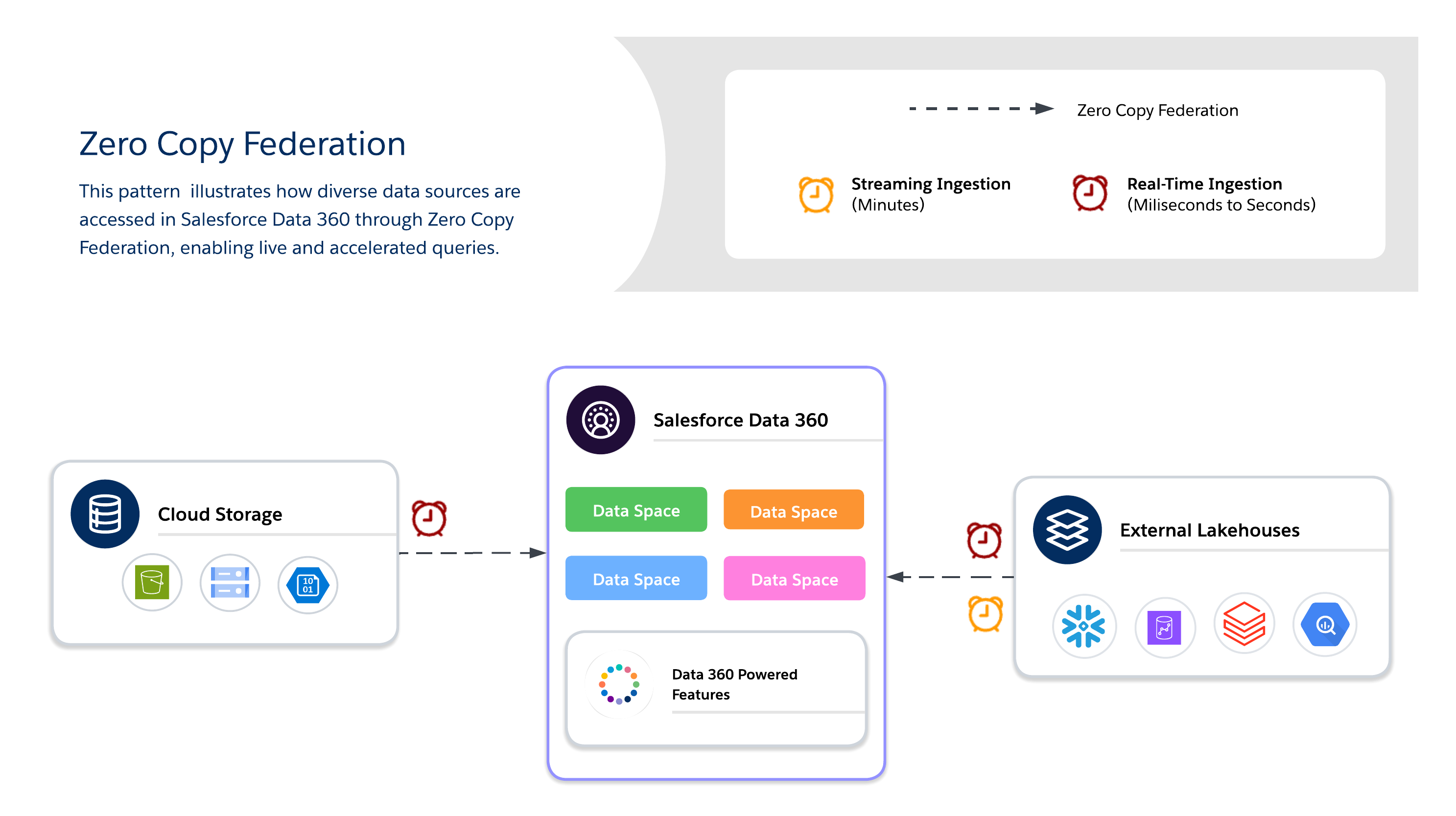
Lors de l'utilisation de Zero Copy, les architectes doivent choisir entre trois méthodes de fédération de données disponibles, chacune offrant ses propres compromis entre fraîcheur, performance et coût.
- Requête live
- Exécute des requêtes directement sur des systèmes externes (Snowflake, Google BigQuery, Redshift, Databricks, etc.) sans duplication de données.
- Optimal lorsque les prédicats et les agrégations peuvent être poussés vers le bas, ce qui réduit les mouvements de données sur le réseau et réduit les entrées/sorties dans le calcul Salesforce Data 360.
- Idéal pour les connaissances en temps réel et les tableaux de bord opérationnels à faible latence. Selon les performances du système externe.
- Mise en cache (requête accélérée)
- Stocke temporairement des copies mises en cache de données fédérées dans Salesforce Data 360.
- Réduit les coûts des requêtes répétées et la latence des jeux de données fréquemment accédés, avec une durée configurable (minutes à jours).
- Les données ne sont pas copiées de façon permanente ni entièrement régies. La fraîcheur est gérée par des actualisations planifiées à partir de la source.
- Fédération de fichiers
- Fournit un accès direct en lecture seule aux jeux de données à grande échelle dans les magasins d'objets (par exemple, S3, GCS avec Iceberg).
- Idéal pour les charges de travail IA/ML, les analytiques historiques et les rapports à l'échelle du pétaoctet sans déplacer les données.
- Les performances des requêtes dépendent fortement du format des objets, du partitionnement et des entrées/sorties réseau. Les analyses volumineuses peuvent générer des entrées/sorties importantes si elles ne sont pas optimisées.
- Cas d'utilisation
- Personnalisation en temps réel et workflows adaptatifs : Proposez des offres dynamiques, des recommandations et des actions Next Best lorsque le comportement des clients change.
- Tableaux de bord live et analytiques opérationnelles : Pilotez des tableaux de bord et des indicateurs de performance clés critiques pour l'entreprise directement depuis des entrepôts externes.
- Entraînement au modèle IA/ML avec de grands jeux de données externes : Exploitez les données à l'échelle du pétaoctet des lacs de données et des entrepôts en utilisant la fédération de fichiers sans les déplacer.
- Scénarios de secteur d'activité
- Retail/Media: Activez des recommandations personnalisées et l'engagement client en temps réel en fédérant les données de flux de clics ou d'interaction de contenus.
- Finances : Exécutez la détection des fraudes et le score de risque en temps quasi réel en interrogeant des entrepôts externes sans dupliquer les données confidentielles.
- Tech/Entreprise : Prenez en charge les rapports inter-clouds, les tableaux de bord de service TI et les analytiques opérationnelles lorsque les jeux de données résident dans plusieurs systèmes.
- Pratiques de conception
- Requête live
- Utilisé pour les requêtes à QPS élevé et à faible latence lorsque la fraîcheur est critique.
- Envoyez automatiquement des prédicats et des agrégations au système externe afin de réduire le transfert de données sur le réseau.
- Évitez les requêtes qui analysent inutilement des volumes de données massifs. Pensez à l'élagage des partitions et aux filtres.
- Fédération de fichiers
- Accédez aux jeux de données à l'échelle du pétaoctet dans les magasins d'objets sans ingestion.
- Gardez le stockage d'objets dans la même zone cloud que Salesforce compute afin de limiter les coûts de latence et de sortie.
- Utilisez des formats partitionnés et colonnaires (Parquet/ORC) et des filtres pushdown pour réduire les entrées/sorties et le transfert réseau.
- Exploitez les requêtes et les prédicats pushdown pour filtrer et agréger les données à la source, réduisant ainsi le mouvement des données.
- Évitez l'accès aux données entre les régions, sauf si nécessaire, car cela augmente les entrées/sorties, la latence et les coûts.
- Mise en cache (requête accélérée)
- Mettez en cache les jeux de données fréquemment accédés pour équilibrer les coûts et les performances.
- Configurez des intervalles d'actualisation pour équilibrer la fraîcheur et le coût des requêtes.
- Conformité : Appliquez la gouvernance à la source en exploitant la sécurité au niveau de la ligne (RLS) et en masquant les stratégies directement dans les systèmes fédérés. Voici les meilleures pratiques pour uniformiser le RLS et le masquage entre les plates-formes.
- Utiliser un ID d'entreprise centralisé : Mappez des utilisateurs et des entités dans Salesforce Data 360 avec un identifiant d'entreprise unique et centralisé qui correspond aux identités dans des systèmes externes.
- Aligner les stratégies de sécurité : Assurez-vous que les stratégies de sécurité et de masquage au niveau de la ligne dans les systèmes fédérés sont appliquées en fonction de l'identité mappée. Cela préserve la conformité lors de l'interrogation de données externes.
- Schémas d'identité normalisés : Maintenez des attributs d'identité cohérents (e-mail, ID d'utilisateur, ID de client, etc.) entre toutes les sources de données afin d'éviter les incohérences et les violations d'accès.
- Requête live
- Considérations relatives aux coûts
- Live Query : Modèle de paiement par requête : les coûts s'accumulent dans le calcul externe de Lakehouse et peuvent augmenter avec un QPS élevé. Idéal pour les cas d'utilisation critiques pour la fraîcheur où la valeur est supérieure à la variabilité du coût.
- Requête accélérée (mise en cache) : Réduit le coût des requêtes par rapport à Live Query en réduisant les accès au système source, mais augmente les coûts d'ingestion de données par lot pour remplir et actualiser le cache. Idéal pour les jeux de données fréquemment accédés.
- Fédération de fichiers : L'option de stockage la moins chère en tant que données dans Object Store, mais les coûts de requête dépendent de la taille du fichier, du partitionnement et de l'élagage. Idéal pour les données historiques ou en masse à l'échelle du pétaoctet.
| Point de décision | Live Query | Mise en cache (requête accélérée) | Fédération de fichiers |
|---|---|---|---|
| Emplacement de la source de données | Lakehouses de données externes (Snowflake, Google BigQuery, Redshift, Databricks). | Lakehouses de données externes (Snowflake, Google BigQuery, Redshift, Databricks) | Stocks d'objets ou lacs de données cloud (S3, ADLS, GCS), souvent en utilisant des formats de tableau ouverts tels que Iceberg. |
| Objectif/cas d'utilisation | Idéal pour l'analyse interactive et les tableaux de bord en temps réel. Idéal pour la personnalisation en temps réel et les workflows dynamiques. | Idéal lorsque les requêtes sont fréquentes, mais que les résultats légèrement périmés sont acceptables. Convient pour les tableaux de bord BI et la segmentation. | Idéal pour le traitement par lot à grande échelle et l'entraînement au modèle IA/ML. Idéal pour les analytiques historiques et les rapports à l'échelle du pétaoctet. |
| Fraîcheur/Latence | Une fraîcheur maximale ; les requêtes sont exécutées directement en temps réel. Prend en charge la prise de décision sub-seconde. | Les résultats légèrement périmés sont acceptables. La fraîcheur dépend de l'intervalle de cache, configurable de 15 minutes à 7 jours. | Optimisé pour les tâches lourdes en lots et exigeantes en débit. Ne convient pas aux tableaux de bord en temps réel. |
| Modèle d'accès | Idéal pour les requêtes peu fréquentes ou ponctuelles. Utilisé pour les requêtes à QPS élevé (requête par seconde) et à faible latence dans lesquelles la fraîcheur est critique. | Idéal pour les scénarios de lecture à haute fréquence. Améliore les performances des modèles d'accès fréquents. | Accès en lecture seule. Convient aux jeux de données à l'échelle du pétaoctet sans ingestion. |
| Performance Drivers | Très dépendant des performances du système source externe. Optimisé lorsque les prédicats et les agrégations peuvent être automatiquement dirigés vers la source. | Réduit la latence par rapport aux requêtes live répétées. Les performances dépendent de la gestion du cache et de l'intervalle. | Les performances dépendent fortement du format de l'objet, du partitionnement et du débit système externe. Utilisez des formats partitionnés et colonnaires (Parquet/ORC). |
| Incidences sur les coûts | Modèle de paiement par requête. Les coûts s'accumulent dans le calcul externe Lakehouse. Rentable pour les requêtes peu fréquentes, mais les dépenses peuvent augmenter avec un volume de requêtes par seconde (QPS) élevé. | Coût inférieur aux requêtes live répétées. Réduit la nécessité d'interroger régulièrement la source externe. Ajoute le stockage en cache et l'actualisation. | Option de stockage la moins chère. Les coûts de requête dépendent de la taille du fichier et du partitionnement. |
| Considérations clés | Évitez les requêtes non filtrées qui analysent inutilement des volumes de données importants. | Nécessite la gestion du cache. Ne convient pas à la prise de décision sub-seconde. | Les performances des requêtes dépendent fortement de l'optimisation via le partitionnement et la pushdown des prédicats. |
Les architectures hybrides permettent aux architectes d'ancrer des jeux de données critiques dans Data 360 pour une gouvernance centralisée tout en exploitant les requêtes fédérées pour plus d'actualité, réduire les duplications et un accès évolutif aux jeux de données externes volumineux. Cette approche concilie les exigences d'E/S, de localisation du calcul, de coût et de conformité.
Utilisez une approche hybride pour une gouvernance équilibrée, la fraîcheur et l'efficacité opérationnelle en combinant l'ingestion de données et la copie zéro pour fournir des connaissances en temps réel et actionnables. Utilisez l'ingestion pour des jeux de données réglementés de grande valeur où la traçabilité, le RLS et le masquage sont requis, et la fédération pour des jeux de données éphémères ou à haut volume où la fraîcheur et les performances sont essentielles.
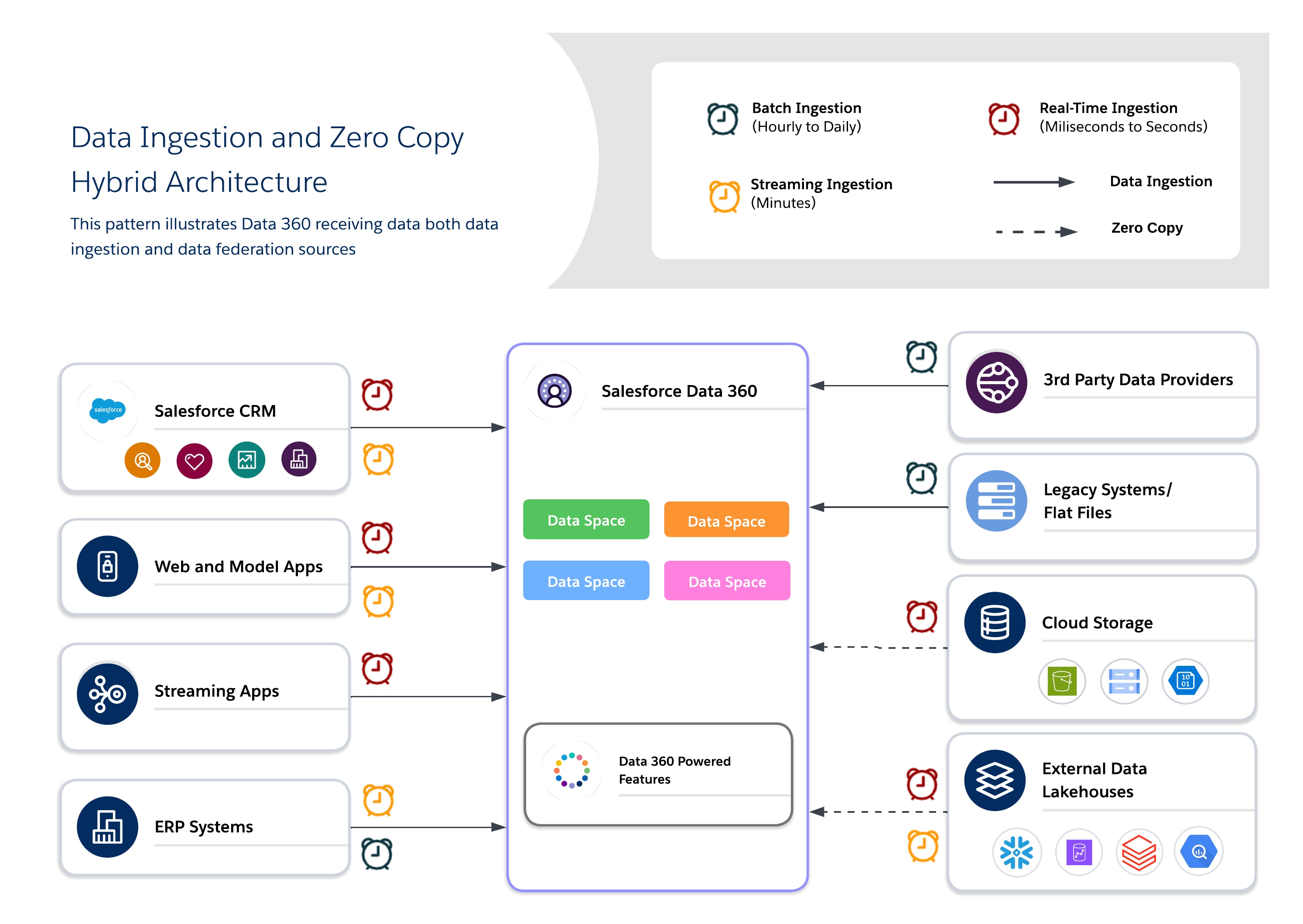
- Cas d'utilisation
- Engagement Omni-channel : Combinez les données clients historiques avec un comportement en temps réel pour offrir des expériences cohérentes et sensibles au contexte.
- Encours IA/ML : Entraînez les modèles sur des jeux de données organisés et canoniques tout en les enrichissant avec des signaux bruts ou en temps réel provenant de sources externes.
- Besoins mixtes de conformité et d'agilité : Appliquez une gouvernance stricte pour les données confidentielles, mais fédérez pour plus d'agilité opérationnelle.
- Scénarios de secteur d'activité
- Détail : Utilisez l'ingestion pour la résolution de l'identité et l'unification des profils, fédérez pour les offres en temps réel et la personnalisation.
- Soins de santé : Gérez les enregistrements de patient dorés via l'ingestion tout en fédérant les flux d'appareils Internet des objets et les données des capteurs pour un contexte immédiat.
- Services financiers : Ingérez des données réglementées dans un lac régi par la conformité tout en fédérant des requêtes externes pour la détection des fraudes et la surveillance des risques.
- Pratiques de conception
- Ancrage de la gouvernance avec l'ingestion : Ingérez des données de grande valeur ou réglementées dans des modèles canoniques pour garantir Trust et conformité.
- Utilisez Federation for Freshness : Laissez les maisons de lac externes fournir un accès aux données en temps réel ou à grande échelle sans duplication.
- Coût d'équilibre vs. Performance : Profilez les charges de travail pour décider ce que vous ingérez par rapport à fédérer, en réduisant les coûts inutiles de stockage ou de requête.
- Appliquer la gouvernance en couches : Appliquer la gouvernance centralisée pour les données ingérées, tout en tirant parti des propres contrôles de sécurité des systèmes fédérés (par exemple, RLS, masquage).
- Lors de la conception de pipelines hybrides, assurez l'ingestion incrémentielle de jeux de données historiques et envoyez automatiquement des agrégations ou des filtres à des sources fédérées afin d'optimiser les entrées/sorties et l'utilisation des calculs.
- Considérations relatives aux coûts
- Optimisez le coût total par rapport aux performances en combinant l'ingestion pour la conformité ou des données critiques avec la fédération lorsque la fraîcheur est nécessaire.
- Tenez compte des entrées/sorties et calculez la distribution en mélangeant l'ingestion et la fédération. Pour réduire les coûts de calcul dans les systèmes sources de requêtes répétées, utilisez la mise en cache (requête accélérée) pour les jeux de données fédérés fréquemment accédés et lus.
Voici des archétypes courants qui illustrent comment appliquer cette logique.
- L'archétype « Source unique de vérité » : Centraliser et gouverner
- Scénario : Vous devez élaborer des profils Customer 360 conformes et unifiés pour l'ensemble de votre entreprise mondiale. Les données proviennent d’une douzaine de systèmes différents, doivent respecter les réglementations strictes du GDPR et de la CCPA, et serviront de source de confiance pour toutes les interactions marketing et de service.
- Modèle recommandé : Ingestion de données. La priorité est gouvernance, Trust et contrôle. L'ingestion des données dans Data 360 est le seul moyen de créer un profil canonique entièrement auditable, isolé des systèmes sources.
- L'archétype « Connaissances en temps réel » : Analyser sans bouger
- Scénario : Votre équipe de science des données doit exécuter des requêtes exploratoires sur un tableau de transactions massif et constamment mis à jour dans Snowflake. En même temps, votre équipe de direction souhaite un tableau de bord live BI piloté par ces mêmes données. Le déplacement quotidien de pétaoctets de données est trop lent et coûteux.
- Modèle recommandé : Zero Copy Federation. La priorité est la rapidité, l'agilité et la rentabilité à l'échelle. Zero Copy vous permet de tirer parti de l'immense puissance de votre entrepôt de données existant pour les requêtes en temps réel sans les surcharges et la latence de la duplication des données.
- L'archétype « Intelligence hybride » : Gouvernance du cœur, fédération de l’avantage
- Scénario : Vous souhaitez enrichir vos profils clients gouvernés et ingérés avec des signaux comportementaux en temps réel (par exemple des clics sur un site Web) à partir d'un lac de données. Vous avez besoin de la stabilité du profil principal, mais de l'immédiateté des données live pour piloter la personnalisation instantanée.
- Modèle recommandé : A Hybrid Approach. Utilisez Ingestion de données pour créer le noyau stable et gouverné de vos données clients. Utilisez ensuite Zero Copy pour fédérer les données « edge » volatiles en temps réel, en les joignant au moment de la requête pour une vue complète et actualisée.
La stratégie de données d'entreprise ne consiste plus à choisir un modèle d'intégration unique, mais à concevoir une flexibilité contrôlée dans un écosystème de données interopérable. La sélection de la méthode d'intégration de données appropriée pour chaque système de données source en fonction des besoins métiers conduit souvent à une approche hybride qui combine les forces de l'ingestion de données et de la fédération de données.
- Ingérez des jeux de données gouvernés critiques dans Salesforce Data 360 pour la conformité, la résolution de l'identité et les workflows opérationnels.
- Fédérez des données via Zero Copy pour des analytiques live, exploratoires et pilotées par l'IA sans dupliquer le stockage.
Salesforce Data 360 sur Hyperforce offre une résilience et une évolutivité multi-régions. s open lakehouse avec des tableaux Iceberg permet la séparation des calculs et l'interopérabilité avec des plates-formes telles que Snowflake, Databricks et S3 Iceberg, formant l'épine dorsale d'un écosystème de données multicloud véritablement interopérable.
À mesure que les écosystèmes de données évoluent, conciliez en permanence fraîcheur, coût, performance et conformité pour préserver l'agilité architecturale. Préservez votre plate-forme en unifiant les données ingérées et régies avec un accès fédéré. Cela permet l'intelligence en temps réel, l'activation de l'IA et la personnalisation à l'échelle de l'entreprise à travers les clouds, les régions et les domaines métiers.
Les solutions universelles ne conviennent pas à la plupart des entreprises. La stratégie optimale mappe le modèle approprié avec le moteur métier approprié.
Yugandhar Bora est architecte en génie logiciel chez Salesforce, spécialisé dans l'architecture de données au sein de la plate-forme Data & Intelligence Applications. Il dirige les initiatives du comité d'examen de l'architecture d'entreprise (EARB) axées sur la gouvernance des données et les modèles de données unifiés, tout en contribuant aux solutions de provisionnement de plate-forme automatisé.
Jan Fernando est architecte principal au bureau de l'architecte en chef chez Salesforce. Il a rejoint Salesforce en 2012, apportant une riche expérience de son passage dans l’écosystème des startups. Avant de se joindre au Bureau de l'architecte en chef, il a passé plus d'une décennie au sein de l'organisation Platform, où il a dirigé plusieurs transformations technologiques clés.