Esse texto foi traduzido usando o sistema de tradução automatizado do Salesforce. Pegue nossa enquisa para fornecer feedback sobre esse conteúdo e diga-nos o que você gostaria de ver em seguida.
Note
Visão geral
As arquiteturas modernas do Salesforce são cada vez mais alimentadas por processamento assíncrono; não como uma conveniência, mas como um requisito estratégico de escala. Nos últimos anos, vimos mais e mais empresas enfrentando volumes de dados crescentes, integrações complexas que envolvem vários pontos de contato e o surgimento de sistemas autônomos que funcionam 24 horas por dia, 7 dias por semana. Todas essas coisas levam os arquitetos a projetar sistemas assíncronos em primeiro lugar.
O processamento assíncrono no Salesforce geralmente significa projetar em torno dos limites e da complexidade do controlador. Esses limites atuam como proteções e restrições arquitetônicas que ajudam a produzir sistemas escalonáveis e seguros em massa. Embora nenhum limite de plataforma sirva diretamente para gerenciar a complexidade, os padrões de design podem ajudar a mitigar o risco nessa frente. Interna, o Salesforce frequentemente aprofunde os limites da plataforma para testar novos recursos e automatizar processos comerciais complexos. Criamos uma Estrutura de processamento assíncrono baseada em etapas para executar trabalhos assíncronos com um número arbitrário de etapas. Cada etapa pode ser executada, tentada novamente e reiniciada de modo independente com controles de governança compartilhados e visibilidade operacional total por meio de registro centralizado. Este documento descreve os principais componentes arquitetônicos: Apex enfileirável e finalizadores, fluxo agendado, cursores do Apex, ações invocáveis e integrações com o Slack. Juntos, esses componentes fornecem uma arquitetura modular, escalonável e observável adequada para necessidades empresariais em evolução.
Principais transferências
As arquiteturas modernas do Salesforce devem adotar uma abordagem assíncrona primeiro para alcançar escala, resiliência e transparência operacional.
Dividir trabalho complexo em etapas executáveis de modo independente habilita desempenho previsível, novas tentativas mais seguras, pontuação de verificação, reversão e evolução modular sem reengenhar fluxos de trabalho principais.
A estrutura fornece uma alternativa escalonável a trabalhos em lote monolíticos e antigos, chamadas assíncronas encadeadas e fluxos profundamente aninhados, e é criada para cargas de trabalho de alto volume que devem ser dimensionadas horizontalmente dentro do Salesforce sem orquestração fora da plataforma.
A execução determinística e observ��vel garante rastreamento de progresso, monitoramento de SLA, diagnóstico de falha e transparência em nível de auditoria por meio de registro e governança centralizados.
Projetado para rigor de nível corporativo, incluindo governança unificada, conformidade e controle de estado distribuído em processos de negócios de longa duração.
Melhores práticas de plataforma
Antes de revisar os requisitos, aqui estão algumas considerações sobre quando usar uma estrutura como esta. Acima de tudo, considere qual sistema é a única fonte da verdade. Se sua organização do Salesforce depender minimamente de dados externos, mas precisar escalar de centenas a milhões de registros, considere uma estrutura assíncrona baseada em etapas.
Use essa estrutura se:
A maioria (ou todas) das informações com base nas quais realizar ações já existe em seu CRM.
O custo inicial ou contínuo de manter um trabalho de Extrair carga de transformação (ETL) para harmonizar dados externos é muito alto.
Você precisa adiar o processamento de um grande número de registros do Salesforce em uma agenda definida.
Você pode dividir o processamento em etapas separadas. Por exemplo, você pode criar um conjunto hierárquico ou baseado em árvore de registros, especialmente se o volume de dados passar pela hierarquia ou pela árvore.
Não use essa estrutura se:
Criar ou atualizar registros requer recálculo imediato.
A integração é um desafio porque os sistemas externos hospedem dados primários para atualizações de registro. (Considere enviar dados atualizados por push ao Salesforce com a API em massa.)
Considerando essas práticas, vamos revisar nossos requisitos e começar a criar.
Quebrar os requisitos
Considere a instrução de problema:
Para um trabalho que precisa ser executado diariamente, verifique se determinados registros cumprem critérios predefinidos para processamento adicional. Se eles fizerem isso, inicie esses trabalhos de processamento. Processar registros pode significar extrair dados de vários sistemas externos para realizar cálculos. As etapas nos trabalhos devem notificar as pessoas por meio do Slack de que os registros processados estão prontos para revisão. As etapas também devem escalar as notificações para gerentes e superiores na hierarquia de papéis com base em um atraso configurável após a primeira rodada de notificações.
Esse problema envolve várias etapas diferentes, algumas das quais podem ocorrer independentemente uma da outra. Há muitas maneiras de dividir o trabalho. Aqui está um agrupamento:
O agendador.
A interface da etapa e as implementações concretas que processam registros (independentemente do tipo de processamento).
Há alguma complexidade oculta na frase "delay configurable". Revisaremos essa complexidade mais adiante neste artigo.
Aqui está um diagrama definido para a estrutura integrada:
Agora, divida esse diagrama e comece a criar as peças.
Agendamento com fluxo agendado
O Fluxo agendado oferece várias vantagens como mecanismo de agendamento:
Fluxos agendados podem ser empacotados e implementados como metadados. Isso não se aplica a trabalhos agendados por meio do Apex (ou pela página Trabalhos agendados).
O elemento Aguardar é crítico para estruturas que exigem chamadas. Ao usá-lo no Fluxo, as chamadas não são necessárias na parte Invocável da estrutura.
A granularidade do agendamento atende aos requisitos: o intervalo mínimo para Fluxos agendados é diário. Se você precisar de uma frequência maior (por exemplo, por hora), reconsidere Fluxo agendado para esse requisito.
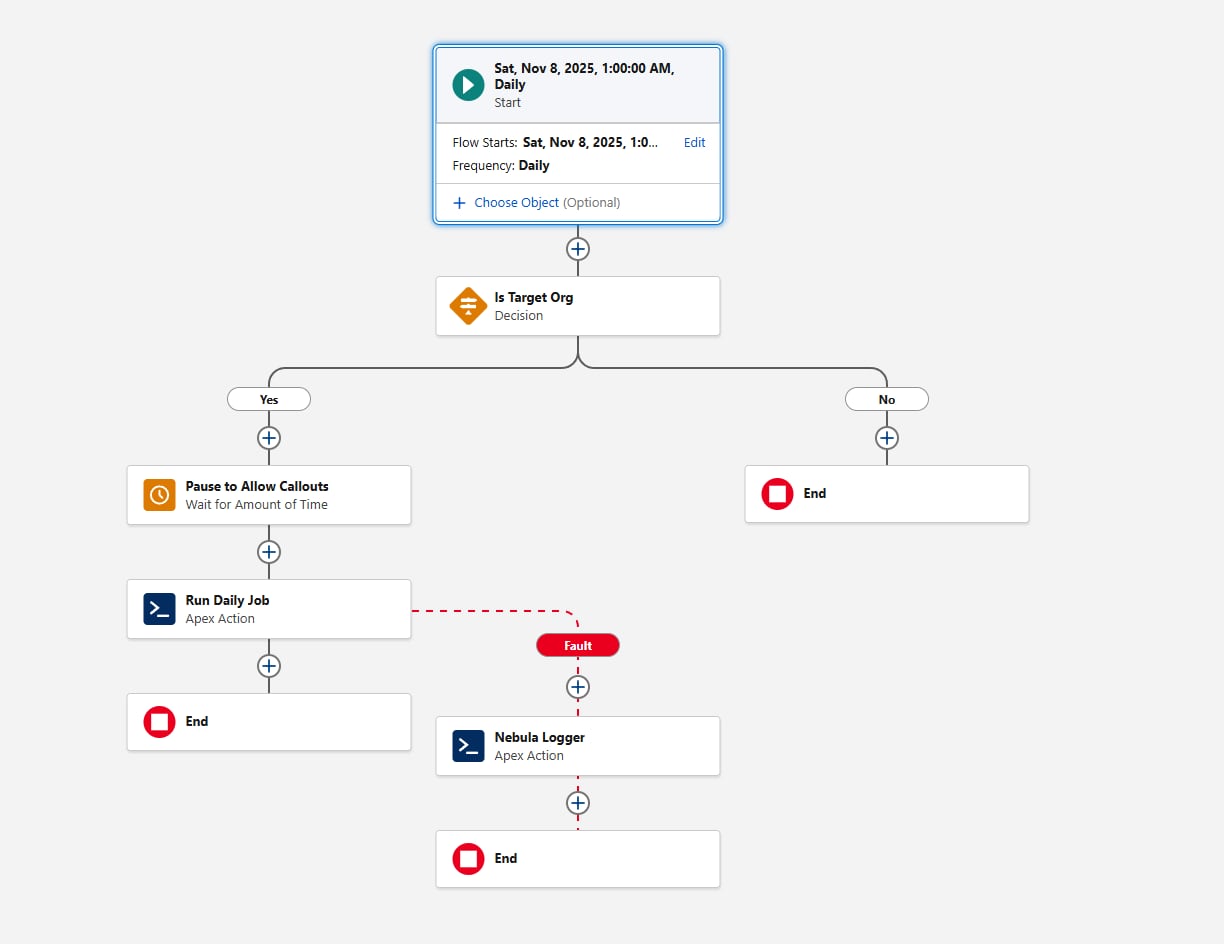
Outra consideração ao configurar o Fluxo agendado é o encaminhamento de ambiente. Antes de invocar a ação do Apex, adicione um elemento Decisão que avalie a variável {!$Api.Enterprise_Server_URL_100}. Isso garante que o trabalho seja executado apenas nos ambientes pretendidos, como UAT e Produção. Esse padrão é importante porque os sandboxes são atualizados com frequência ou recém-criados durante o SDLC, e sem uma verificação de ambiente explícita, um Fluxo agendado pode ser executado inadvertidamente em ambientes em que a estrutura não deve ser executada. Usar o operador contains no elemento Decisão torna a configuração resiliente a futuras criações de sandbox ou alterações de URL.
Por fim, considere como a estrutura deve capturar falhas. Sempre adicione um caminho de falha quando o Fluxo chamar qualquer Ação; por exemplo, você pode encaminhar falhas à ação "Adicionar entrada de registro" do Nebula Logger. Como o Nebula Logger grava registros em objetos personalizados, os clientes devem estar cientes de que os dados de registro consomem o armazenamento da organização. Por padrão, os registros são armazenados por 14 dias em uma organização e, em seguida, são limpos. Esse período de retenção é configurável. O Nebula Logger também usa os Eventos da plataforma para publicar registros, de modo que as entradas do registro são salvas independentemente da transação principal de processamento de dados – isso garante que as falhas sejam capturadas mesmo que a ação principal do Fluxo ou do Apex seja revertida. Os clientes devem avaliar os requisitos de retenção e volume de registros esperados ao considerar a adição de uma estrutura de registro.
Esta é a aparência do Fluxo:
Vamos passar para as primeiras partes do Apex code com o requisito de agendamento agora atendido.
Para este artigo, a interface de step é mostrada como uma classe externa para maior clareza. A estrutura em si é flexível – as equipes podem organizar a interface e suas implementações usando qualquer padrão de empacotamento do Apex que preferem, desde que todas as classes de Etapa façam referência à mesma interface.
Há alguns aspectos a serem considerados sobre os métodos definidos em nossa interface:
execute, embora sem argumento no momento, melhora quando passamos uma classe de State (ou interface) para orquestrar dados entre etapas quando a ordem importa.
Os getName podem retornar um valor de System.Type em vez de um String. A meta é dar à camada de orquestração uma maneira de registrar nomes de etapa sem expor outras propriedades.
Esta é a primeira implementação concreta para mostrar como essas peças se encaixam. Com uma exceção, recomendamos usar o Apex enfileirável para implementar processamento assíncrono no Apex; o Apex em lote normalmente não é necessário (e os métodos de @future são desencorajados). O Apex enfileirável é iniciado rapidamente e, com os Cursores do Apex, tem muitas vantagens em relação ao Apex em lote.
Uma implementação semelhante a cursor do Apex
Os Cursores do Apex oferecem uma alternativa moderna ao modelo Apex em lote tradicional. De modo semelhante ao processamento em lote, uma implementação de cursor pode buscar registros em blocos (até 2.000 por lote). No entanto, os cursores permitem várias busca em uma única transação, permitindo uma taxa de transferência significativamente maior para operações de grande volume.
Ao adotar cursores como parte dessa estrutura, as equipes devem estar cientes das limitações atuais de teste e simulação. Como o comportamento do cursor em testes pode ser diferente do comportamento de produção, é importante projetar estratégias de teste que evitem depender de elementos internos do cursor e validar a lógica de orquestração nos limites. Conforme a plataforma evolui, essas áreas continuarão melhorando, mas a orientação principal permanece: Os cursores proporcionam um desempenho maior e uma sobrecarga de orquestração reduzida em comparação ao Apex em lote para muitos casos de uso.
Para definir um limite claro entre o cursor fornecido pelo sistema e seu próprio código, recomendamos criar uma representação semelhante ao cursor ao implementar a interface de Step. Considere este código:
1public inherited sharing abstract class CursorStep implements Step{2 private static final Integer MAX_CHUNK_SIZE = 2000;34 protected Cursor cursor;56 private Integer chunkSize = System.Limits.getLimitDMLRows();7 private Integer position = 0;89 protected abstract Cursor getCursor();10 protected abstract void innerExecute(List<SObject>records);1112 public abstract String getName();1314 public virtual CursorStep withChunkSize(Integer chunkSize){15 this.chunkSize = chunkSize;16 return this;17}1819 public void execute(){20 this.cursor = this.cursor ?? this.getCursor();21 this.cursor.setFetchesPerTransaction(this.getFetchesPerTransaction());22 List<SObject>records = new List<SObject>();23 if(this.shouldAdvance()){24 records = this.cursor.fetch(this.position, this.chunkSize);25 this.position += this.chunkSize;26}27 this.innerExecute(records);28}2930 public virtual void finalize(){31 Logger.info('finished cursor step for ' + this.getName());32}3334 public virtual Boolean shouldRestart(){35 return this.position<this.cursor.getNumRecords();36}3738 protected virtual Integer getFetchesPerTransaction(){39 Integer maxRecordsPerFetchCall = 2000;40 if(this.chunkSize< maxRecordsPerFetchCall){41 return this.chunkSize;42}43 // Integer division rounds down44 // which is perfect for our use-case45 return this.chunkSize / maxRecordsPerFetchCall;46}4748 protected virtual Boolean shouldAdvance(){49 return true;50}51}
Observe a aula de Cursor. Os cursores do Apex são instâncias de Database.Cursor, mas nossa implementação de Cursor nos dá flexibilidade em torno das falhas dos cursores. Aqui está a implementação:
1public virtual without sharing class Cursor{2 private static final Integer MAX_FETCHES_PER_TRANSACTION = Limits.getLimitFetchCallsOnApexCursor();34 @TestVisible5 private static Integer maxRecordsPerFetchCall = 2000;67 private Integer cursorNumRecords;8 private Integer fetchesPerTransaction = MAX_FETCHES_PER_TRANSACTION;9 private final Database.Cursor cursor;1011 public Cursor(12 String finalQuery,13 Map<String, Object>bindVars,14 System.AccessLevel accessLevel15){16 try{17 this.cursor = Database.getCursorWithBinds(finalQuery, bindVars, accessLevel);18}catch(FatalCursorException e){19 Logger.newEntry(20 System.LoggingLevel.WARN,21 'Error creating cursor. This can happen if there' +22 ' are no records returned by the query: ' + e.getMessage()23);24}25}2627 public Cursor setFetchesPerTransaction(Integer possibleFetchesPerTransaction){28 // Handle accidental round downs from Integer division29 if(possibleFetchesPerTransaction == 0){30 return this;31}32 if(possibleFetchesPerTransaction > MAX_FETCHES_PER_TRANSACTION){33 Logger.newEntry(34 System.LoggingLevel.DEBUG,35 'Fetches per transaction: ' +36 possibleFetchesPerTransaction +37 ' exceeded platform max fetches per transaction: ' +38 MAX_FETCHES_PER_TRANSACTION +39 ', defaulting to platform max'40);41 possibleFetchesPerTransaction = MAX_FETCHES_PER_TRANSACTION;42}43 this.fetchesPerTransaction = possibleFetchesPerTransaction;44 return this;45}4647 @SuppressWarnings('PMD.EmptyStatementBlock')48 protected Cursor(){49}5051 public virtual List<SObject>fetch(Integer start, Integer advanceBy){52 if(this.getNumRecords() == 0){53 Logger.newEntry(54 System.LoggingLevel.DEBUG,55 'Bypassing fetch call, no records to fetch'56);57 return new List<SObject>();58}59 Integer localStart = start;60 List<SObject>results = new List<SObject>();61 while(62 Limits.getFetchCallsOnApexCursor()<this.fetchesPerTransaction &&63 results.size()<this.getNumRecords() &&64 localStart < start + advanceBy65){66 Integer actualAdvanceBy = this.getAdvanceBy(localStart, advanceBy);67 results.addAll(this.cursor?.fetch(localStart, actualAdvanceBy)?? new List<SObject>());68 localStart += actualAdvanceBy;69}70 return results;71}7273 public virtual Integer getNumRecords(){74 this.cursorNumRecords = this.cursorNumRecords ?? this.cursor?.getNumRecords()?? 0;75 return this.cursorNumRecords;76}7778 protected Integer getAdvanceBy(Integer start, Integer advanceBy){79 Integer possibleFetchSize = Math.min(advanceBy, this.getNumRecords() - start);80 if(possibleFetchSize > maxRecordsPerFetchCall){81 Logger.newEntry(82 System.LoggingLevel.DEBUG,83 'Fetch size: ' +84 possibleFetchSize +85 ' exceeded platform max fetch size of ' +86 maxRecordsPerFetchCall +87 ', defaulting to max fetch size'88);89 possibleFetchSize = maxRecordsPerFetchCall;90}else if(possibleFetchSize <0){91 possibleFetchSize = 0;92}93 return possibleFetchSize;94}95}
Para o restante deste artigo, omitimos as declarações de sharing ao fazer referência a classes do Apex. Na prática, garanta que as classes de nível superior sejam usadas explicitamente com ou sem compartilhamento para estar de acordo com seu modelo de objeto e permissões.
Observe também que nossa implementação de Cursor delega para a plataforma Database.Cursor, com benefícios adicionais discutidos a seguir.
Primeiro, aqui estão os testes correspondentes:
1@IsTest2private class CursorTest{3 @IsTest4 static void itCapsAdvanceByArgument(){5 String accountName = 'helloWorld!';6 insert new Account(Name = accountName);7 String query = 'SELECT Name FROM Account WHERE Name = :bindVar0';8 Map<String, Object>bindVars = new Map<String, Object>{'bindVar0' => accountName };910 Cursor instance = new Cursor(query, bindVars, System.AccessLevel.SYSTEM_MODE);1112 Assert.areEqual(1, instance.getNumRecords());13 Assert.areEqual(accountName, instance.fetch(0, 1000).get(0).get('Name'));14 Assert.areEqual(1, System.Limits.getApexCursorRows());15}1617 @IsTest18 static void itCapsMaxRecordsPerFetchCall(){19 Cursor.maxRecordsPerFetchCall = 20;20 Integer oneMoreThanMaxFetch = Cursor.maxRecordsPerFetchCall + 1;2122 List<Account>accounts = new List<Account>();23 for(Integer i = 0; i < oneMoreThanMaxFetch; i++){24 accounts.add(new Account(Name = 'Fetch ' + i));25}26 insert accounts;2728 Exception ex;29 List<SObject>results;30 Cursor instance = new Cursor(31 'SELECT Id FROM Account',32 new Map<String, Object>(),33 System.AccessLevel.SYSTEM_MODE34);35 try{36 results = instance.fetch(0, oneMoreThanMaxFetch);37}catch(System.InvalidParameterValueException e){38 ex = e;39}4041 Assert.areEqual(null, ex?.getMessage());42 Assert.areEqual(2, Limits.getFetchCallsOnApexCursor());43 Assert.areEqual(oneMoreThanMaxFetch, results.size());44}4546 @IsTest47 static void itFetchesMultipleTimesPerTransactionWhenMoreThanMaxFetch(){48 Cursor.maxRecordsPerFetchCall = 20;49 List<Account>accounts = new List<Account>();50 Set<String>expectedFetchNames = new Set<String>();51 for(Integer i = 0; i <Cursor.maxRecordsPerFetchCall + 1; i++){52 String accountName = 'Fetch' + i;53 expectedFetchNames.add(accountName);54 accounts.add(new Account(Name = accountName));55}56 insert accounts;5758 Integer oneMoreThanMaxFetch = Cursor.maxRecordsPerFetchCall + 1;59 Cursor instance = new Cursor(60 'SELECT Name FROM Account',61 new Map<String, Object>(),62 System.AccessLevel.SYSTEM_MODE63);64 List<SObject>results = instance.setFetchesPerTransaction(2).fetch(0, oneMoreThanMaxFetch);6566 Assert.areEqual(Cursor.maxRecordsPerFetchCall + 1, results.size());67 Assert.areEqual(2, Limits.getFetchCallsOnApexCursor());68 Set<String>actuallyFetchedNames = new Set<String>();69 for(Account account :(List<Account>) results){70 actuallyFetchedNames.add(account.Name);71}72 Assert.areEqual(expectedFetchNames, actuallyFetchedNames);73}7475 @IsTest76 static void itFetchesMultipleTimesPerTransaction(){77 Cursor.maxRecordsPerFetchCall = 1;78 insert new List<Account>{new Account(Name = 'One'), new Account(Name = 'Two')};7980 Cursor instance = new Cursor(81 'SELECT Id FROM Account',82 new Map<String, Object>(),83 System.AccessLevel.SYSTEM_MODE84)85 .setFetchesPerTransaction(2);86 List<SObject>results = instance.fetch(0, 2);8788 Assert.areEqual(2, instance.getNumRecords());89 Assert.areEqual(2, results.size());90 results = instance.fetch(2, 1);91 Assert.areEqual(0, results.size());92}9394 @IsTest95 static void fetchesCorrectAmountOfRecords(){96 List<Account>accounts = new List<Account>();97 for(Integer i = 0; i <10; i++){98 accounts.add(new Account(Name = 'Fetch ' + i));99}100 insert accounts;101102 Cursor instance = new Cursor(103 'SELECT Id FROM Account',104 new Map<String, Object>(),105 System.AccessLevel.SYSTEM_MODE106)107 .setFetchesPerTransaction(10);108 List<SObject>results = instance.fetch(0, 2);109110 Assert.areEqual(2, results.size(), '' + results);111 Assert.areEqual(1, Limits.getFetchCallsOnApexCursor());112}113114 @IsTest115 static void doesNotExceedPlatformMaxFetch(){116 List<Account>accounts = new List<Account>();117 for(Integer i = 0; i <101; i++){118 accounts.add(new Account(Name = 'Fetch ' + i));119}120 insert accounts;121122 Test.startTest();123 Cursor instance = new Cursor(124 'SELECT Id FROM Account',125 new Map<String, Object>(),126 System.AccessLevel.SYSTEM_MODE127)128 .setFetchesPerTransaction(100);129 Integer counter = 0;130 List<SObject>results;131 while(counter <= 100){132 results = instance.fetch(counter, counter + 1);133 counter++;134}135 Test.stopTest();136137 Assert.areEqual(101, counter);138 Assert.areEqual(0, results.size());139}140}
Ao tornar as Cursor virtuais, as implementações de CursorStep concretas podem operar sem uma Database.Cursor quando não precisam de iterar um grande conjunto de registros, semelhante a retornar uma System.Iterable<T> em vez de uma Database.QueryLocator no Apex em lote. Aqui está um exemplo:
1public abstract class CursorLikeImplementation extends CursorStep{2 private final Cursor cursorLike;34 public CursorLikeImplementation(List<SObject>previouslyRetrievedRecords){5 this.cursorLike = new CursorLike(previouslyRetrievedRecords);6}78 public override String getName(){9 return CursorLikeImplementation.class.getName();10}1112 public override Cursor getCursor(){13 return this.cursorLike;14}1516 private class CursorLike extends Cursor{17 private final List<SObject>records;1819 public CursorLike(List<SObject>records){20 super();21 this.records = records;22}2324 public override List<SObject>fetch(Integer position, Integer chunkSize){25 // clone, to keep the underlying list type26 List<SObject>clonedRecords = this.records.clone();27 clonedRecords.clear();28 for(Integer i = position; i <this.getAdvanceBy(position, chunkSize); i++){29 clonedRecords.add(this.records[i]);30}31 return clonedRecords;32}3334 public override Integer getNumRecords(){35 return this.records.size();36}37}38}
Observe que, como essa classe também é abstrata, ela deixa a implementação concreta de innerExecute para subclasses.
Há também uma alternativa à subclasse interna CursorLike. Se você souber que versões concretas de uma etapa como esta não passarão pelos outros limites do regulador, poderá retornar this.records de CursorLike.fetch e substituir o CursorStep.shouldRestart() pai para retornar falso. Isso permite que você itere em uma lista limitada apenas pelo limite de heap do Apex de 12 MB por transação assíncrona.
Outras implementações baseadas em etapa possíveis
Nossa implementação baseada em cursor nos dá muita flexibilidade ao paginar em grandes quantidades de dados. A interface de Step, entretanto, nos dá a flexibilidade de descrever e encapsular passos de todos os tipos.
Considere uma etapa baseada em fluxo:
1public virtual class FlowStep implements Step{2 private final Invocable.Action specificFlow;34 private Boolean shouldRestart = false;56 public FlowStep(String specificFlowName, Map<String, Object>inputs){7 this.specificFlow = Invocable.Action.createCustomAction('flow', specificFlowName);8 this.specificFlow.setInvocations(new List<Map<String,Object>>{ inputs });9}1011 public void execute(){12 List<Invocable.Action.Result>results = this.specificFlow.invoke();13 for(Invocable.Action.Result result : results){14 if(result.isSuccess()){15 Map<String, Object>outputParams = result.getOutputParameters();16 Object potentialShouldRestartValue = outputParams.get('shouldRestart');17 // Flow does not enforce Booleans being initialized18 // so a null check is sadly necessary here19 if(potentialShouldRestartValue != null){20 this.shouldRestart = this.shouldRestart ||21 Boolean.valueOf(potentialShouldRestartValue);22}23}else{24 List<String>errorMessages = new List<String>();25 for(Invocable.Action.Error error : result.getErrors()){26 errorMessages.add(27 'Error code: ' + error.getCode() +28 ', error message: ' + error.getMessage()29);30}31 Logger.error(32 'An error occurred within your auto-launched flow:\n' +33 String.join(errorMessages, '\n\t')34);35}36}37}3839 public virtual void finalize(){40 Logger.info(this.getName() + ' finished processing');41}4243 public String getName(){44 return FlowStep.class.getName() + ':' + this.specificFlow.getName();45}4647 public Boolean shouldRestart(){48 return this.shouldRestart;49}50}
Como os Fluxos não podem retornar parâmetros de saída que correspondam a um tipo definido pelo Apex, verificamos um parâmetro de saída de shouldRestart antes de usá-lo.
Algumas etapas podem ser sinalizadas por recurso. Você pode implementar lógica para decidir quais etapas incluir ou usar uma etapa no-op para um recurso desabilitado. O padrão de objeto nulo é uma maneira comum de reduzir a complexidade dentro da camada de orquestração:
1@SuppressWarnings('PMD.EmptyStatementBlock')2public class NoOpStep implements Step{3 // The null object pattern is commonly implemented4 // as a singleton to reduce memory consumption5 public static final NoOpStep SELF {6 get {7 SELF = SELF ?? new NoOpStep();8}9 private set;10}1112 public void execute(){13}1415 public void finalize(){16}1718 String getName(){19 return NoOpStep.class.getName();20}2122 Boolean shouldRestart(){23 return false;24}25}
Agora temos vários blocos de construção com os quais trabalhar. Vamos dar uma olhada na camada de orquestração responsável pela iteração entre etapas.
Criando um processador de etapa
O processador é um ponto de inflexão na arquitetura. Devemos decidir quem define quais etapas serão inicializadas e onde. As opções incluem:
Peça para o processador definir quais etapas são mapeadas para a lógica de negócios. Essa opção é simples, mas tem uma escala ruim para legibilidade.
Defina o mapeamento com Metadados personalizados (CMDT). Os campos Relacionamento de metadados não oferecem suporte a ApexClass, o que combina facilmente a ortografia de nomes de classe à configuração do seu processo de negócios. Você pode reduzir o risco administrativo tornando o campo uma lista de opções e validando o tipo existente (Type.forName() ou consultando ApexClass), mas como os registros CMDT não suportam acionadores, a validação ocorre no tempo de execução. Essa rota é testável, mas os administradores ainda podem criar registros CMDT apenas em produção. Continue com cuidado.
Defina o mapeamento com registros. Não administradores podem configurar etapas, mas as implementações ficam mais difíceis e os ambientes podem se desviar. Prossiga com cuidado.
Há uma famosa citação do Código Limpo sobre como lidar com essa parte específica da complexidade:
A solução para esse problema é enterrar a declaração de switch [para fazer objetos] no porão de uma fábrica abstrata, e nunca deixar ninguém vê-la.
Com isso em mente, e como nosso número atual de etapas é bem definido e provavelmente não crescerá demais, o processador de etapas também pode ser a fábrica das etapas. Isso pode usar uma enumeração para conduzir a instrução switch:
1public StepProcessor implements System.Queueable, System.Finalizer,2 Database.AllowsCallouts{3 private final List<Step>steps = new List<Step>();45 private Step currentStep;67 public StepProcessor setSteps(List<StepType> stepTypes){8 for(StepType type : stepTypes){9 switch on type {10 WHEN TYPE_ONE {11 this.addTypeOneSteps();12}13 WHEN TYPE_TWO {14 this.addTypeTwoSteps();15}16 // ... etc17}18}19 this.cleanSteps();20 return this;21}2223 public void execute(System.QueueableContext context){24 this.currentStep = this.currentStep ?? this.steps.remove(0);25 if(context != null){26 System.attachFinalizer(this);27 Logger.setAsyncContext(context);28}29 Logger.info('Executing step ' + this.currentStep.getName());30 try{31 this.currentStep.execute();32}catch(Exception e){33 Logger.exception('Unexpected exception', e);34}35 Logger.info('Finished executing step ' + this.currentStep.getName());36 Logger.saveLog();37}3839 public void execute(System.FinalizerContext context){40 Logger.info('Executing finalizer for step ' + this.currentStep.getName());41 Logger.setAsyncContext(context);42 switch on context?.getResult(){43 when UNHANDLED_EXCEPTION {44 // see the note below about this logging paradigm45 Logger.warn(46 'Failed to run on step' + this.currentStep,47 context?.getException()48);49}50 when else{51 this.currentStep.finalize();52 if(this.currentStep.shouldRestart()){53 this.kickoff();54}else if(this.steps.isEmpty() == false){55 this.currentStep = this.steps.remove(0);56 this.kickoff();57}else{58 Logger.info('Finished executing steps');59}60}61}62 Logger.info(63 'Finished executing finalizer for step ' +64 this.currentStep.getName()65);66 Logger.saveLog();67}6869 public String kickoff(){70 return this.steps.isEmpty()? null : System.enqueueJob(this);71}7273 private void cleanSteps(){74 for(Integer reverseIndex = this.steps.size() - 1;75 reverseIndex >= 0; reverseIndex--){76 if(this.steps[reverseIndex]instanceof NoOpStep){77 this.steps.remove(reverseIndex);78}79}80}8182 private void addTypeOneSteps(){83 this.steps.addAll(84 new List<Step>{85 new ExampleCursorStepOne(),86 new ExampleCursorStepTwo()87}88);89}9091 private void addTypeTwoSteps(){92 this.steps.addAll(93 new List<Step>{94 new FlowStep('95 ExampleInvocableName',96 new Map<String, Object>('exampleParameter' =>true)97),98 new ExampleCursorStepThree()99}100);101}102}
Os métodos de fábrica mostrados, como o addTypeOneSteps(), podem delegar preocupações como a sinalização de recursos; o cleanSteps() realiza uma verificação única das etapas coletadas para garantir que não haja etapas “vazias” antes de ir realmente assíncrono. Isso pode se parecer com isto:
Não discutimos o tratamento de erros desde a menção ao Nebula Logger na seção Fluxo agendado. Isso ocorre porque o System.Finalizer permite que o registro de todas as condições de erro seja abrangido sem adicionar tratamento de erros específico em cada etapa. Cada Step se concentra na corrida, enquanto registramos e recuperamos caminhos infelizes para que apareçam em testes de unidade. Isso dá suporte à iteração segura e ao alerta em nível de produção (usando o plug-in Slack Logger para Nebula para todos os logs WARN e ERROR).
Uma nota sobre o registro de erros: passar a instância da etapa para mensagens de log assume um nível de Trust no que fica visível nos logs. A toString() padrão para classes do Apex inclui todas as propriedades estáticas e no nível da instância na mensagem. Isso pode ser desejável ou pode vazar informações confidenciais. Embora o registro e a segurança não sejam o foco aqui, observe que, para alguns sistemas, a adesão a uma interface como Step também pode envolver forçar uma substituição para toString().
Esse método coloca a responsabilidade de cada criador de objeto decidir o que é permitido imprimir, o que pode ser desejável.
Nos níveis de desmatamento: no nível da StepProcessor, utilizamos o INFO, o nível mais elevado sem erros. Conforme você fica mais granular no aplicativo, os níveis de registro devem diminuir de acordo. As etapas individuais podem usar DEBUG para informações de alto nível, com FINE, FINER e FINEST reservados para resultados cada vez mais detalhados. Registrar é tanto uma arte quanto uma ciência, mas seguir esses princípios ajuda a manter os registros consistentes e úteis.
Manipulação de complexidade adicional no processador de etapa
Antes de avançar, vamos refletir brevemente sobre a decisão de fazer com que nosso processador de etapas hospede a lógica para a qual as etapas são usadas. Em uma grande base de códigos, considere tornar as StepProcessor virtuais ou abstratas e faça com que as subclasses identifiquem etapas específicas para estabelecer uma separação adequada das preocupações.
A Camada invocável do Apex
O agendador eventualmente chama o Apex. Com o restante da configuração concluída, a seção Apex invocável pode decidir quais etapas devem ser executadas e passar o List<StepType> para o processador:
1public class DailyJobExecutor{2 @InvocableMethod(label='Execute Daily Job')3 public static void executeJob(){4 Logger.info('Executing daily Job');56 List<StepType>correspondingTypes = new List<StepType>();7 // based on [business logic], determine which step types8 // should be included for any daily invocation910 if(correspondingTypes.isEmpty() == false){11 try{12 new StepProcessor().setSteps(correspondingTypes).kickoff();13}catch(Exception ex){14 Logger.exception('Error starting job', ex);15}16}17}1819 Logger.saveLog();20}
Esta é uma parte simples da equação: usando registros, dados ou lógica para determinar quais tipos de etapa executar. A Ação invocável é simples porque encapsulamos a complexidade em outro lugar. Também protegemos contra exceções inesperadas e facilitamos o teste de cada peça em isolamento.
Lidar com atrasos antes de chamar o Slack
O Apex Slack SDK está além do escopo deste artigo, mas um possível problema dos requisitos é revisitar: notificar as pessoas para cima na hierarquia de papéis com base em um atraso configurável. No papel, isso é simples, e você pode (corretamente) considerar a System.enqueueJob(this) na StepProcessor. Com o System.AsyncOptions, nossa inclinação inicial era usar a sobrecarga de enqueueJob para satisfazer esse requisito.
Por enquanto, no entanto, o atraso máximo via System.AsyncOptions.MinimumQueueableDelayInMinutes é de 10 minutos. Como o requisito é de 120 minutos, restam algumas opções. Uma abordagem ingénua pode se parecer com esta:
1public class ExampleDelayedNotifier implements Step{2 private final List<Slack.ChatPostMessageRequest>notifications = new List<Slack.ChatPostMessageRequest>();3 private final Slack.BotClient botClient = Slack.App4 .getAppByKey('some-slack-app-key')5 .getBotClientForTeam('slack team id');67 // account for the initial delay,8 // so 120 - 10 = 1109 private Integer delayMinutes = 110;1011 public void execute(){12 if(this.delayInMinutes>0){13 return;14}1516 Integer maximumAllowedCallouts = 100;17 while(this.notifications.isEmpty() == false && maximumAllowedCallouts >0){18 this.botClient.chatPostMessage(this.notifications.remove(0));19 maximumAllowedCallouts--;20}21}2223 public void finalize(){24 this.delayInMinutes -= 10;25}2627 public String getName(){28 return ExampleDelayedNotifier.class.getName();29}3031 public Boolean shouldRestart(){32 return this.delayInMinutes>0 || this.notifications.isEmpty() == false;33}34}
Na prática, o atraso seria passado para essa classe porque o atraso é conduzido por configuração.
Não recomendamos essa abordagem, a menos que você tenha certeza de que haverá apenas um tipo de notificação atrasada. Ele executa 11 trabalhos assíncronos adicionais antes do início (ou mais, se o atraso aumentar). Esse custo pode ser bom para um trabalho, não para muitos. Você também precisaria adicionar um método à interface de Step para que cada etapa possa dizer ao processador quanto tempo esperar antes de reiniciar, o que aumenta o ruído.
Isso nos deixa com duas possibilidades interessantes:
Você poderá inserir a etapa atrasada na estrutura de trabalho existente se já tiver um trabalho de pesquisa agendado em um intervalo adequado. Você também deve estar certo com o atraso especificado atingindo até 15 minutos mais tarde (15 minutos é o intervalo mínimo de atualização para uma expressão CRON agendada pelo Apex). Isso corresponde aproximadamente ao exemplo do Apex invocável; o agendamento é realizado por meio do Apex. Em outras palavras, você pode reutilizar a mesma arquitetura baseada em Step para processar registros com base em um carimbo de data e hora "Iniciar após" e decidir quais etapas usar com base em um mapeamento de lista de opções ou de lista de opções de seleção múltipla de volta aos valores de enumeração de StepType mostrados anteriormente.
Como alternativa, se você se sentir à vontade definindo uma classe do Apex externa extra, volte para o Apex em lote (ao contrário do Apex enfileirável, que suporta classes internas, as classes do Apex em lote devem ser classes externas) usando o System.scheduleBatch().
Considere o exemplo do Apex em lote. Embora geralmente recomendamos o Apex enfileirável para flexibilidade e controle, este é um caso em que o Apex em lote ainda domina:
1public class DelayedNotifier implements Database.Batchable<Object>{2 private final StepProcessor processor = new StepProcessor();34 public Iterable<Object>start(Database.BatchableContext bc){5 return new List<Object>();6}78 @SuppressWarnings('PMD.EmptyStatementBlock')9 public void execute(Database.BatchableContext bc, Object scope){10 // we don't need to actually do anything in execute,11 // we just need to start up the processor in finish12}1314 public void finish(Database.BatchableContext bc){15 try{16 // you can imagine Notifier as an elided,17 // simpler version of the naive implementation18 // we showed above, now only focused on sending messages19 this.processor.setSteps(new List<Step>{new Notifier()}).kickoff();20}catch(Exception ex){21 Logger.exception('Unexpected error', ex);22}finally{23 Logger.saveLog();24}25}26}
E então, na StepProcessor, imagine que o método addTypeOneSteps() mostrado anteriormente seja atualizado com esta etapa atrasada:
1public StepProcessor implements System.Queueable, System.Finalizer,2 Database.AllowsCallouts{3 // .... unchanged top of class elided45 private void addTypeOneSteps(){6 this.steps.addAll(7 new List<Step>{8 new ExampleCursorStepOne(),9 new ExampleCursorStepTwo(),10 new DelayedNotifierStep()11}12);13}1415 // ...1617 private class DelayedNotifierStep implements Step{18 private final DelayedNotifier delayedNotifier = new DelayedNotifier();19 // again — in practice this value would also be passed in20 private final Integer delayInMinutes = 120;2122 public void execute(){23 System.scheduleBatch(24 this.delayedNotifier,25 'Delayed notifier: ' + System.now().getTime(),26 this.delayInMinutes27);28}2930 public void finalize(){31 Logger.debug('Nothing to finalize, batch scheduled');32}3334 public String getName(){35 return DelayedNotifierStep.class.getName();36}3738 public Boolean shouldRestart(){39 return false;40}41}42}
Embora geralmente não recomendássemos esse tipo de salto, esse atraso de etapa se torna outro bloco de criação reutilizável. Até que atrasos mais longos sejam permitidos no Apex enfileirável, também representa a maneira mais fácil de produzir esse efeito (sem um mecanismo de consulta, como discutido).
Conclusão
Usamos o design orientado a objetos para atender aos requisitos e criamos um sistema que será dimensionado enquanto equilibra o custo de construção e manutenção de longo prazo. Embora a declaração de etapas e a instanciação possam, por fim, ultrapassar o seu lugar na StepProcessor, há pouca dívida técnica adicional aqui. Com a FlowStep, administradores e desenvolvedores podem decidir juntos quando as soluções sem código ou pro-código fazem mais sentido.
Usando a interface de System.Finalizer na estrutura Queueable do Apex, juntamente com o Nebula Logger, criamos um sistema robusto e testável que nos alerta sobre falhas imprevistas, mesmo que as etapas futuras não tenham registro explícito. Para nós, esse sistema está felizmente aumentando os números e reduzindo o custo e a complexidade. Ele também nos deu percepções valiosas sobre o comportamento dos cursores do Apex sob cargas de trabalho reais, ajudando-nos a refinar nossa abordagem enquanto melhora o próprio recurso.
Ao dividir cargas de trabalho complexas de alto volume em etapas de execução modulares, a estrutura de Estrutura de processamento assíncrono baseada em etapas transforma restrições de plataforma em vantagens de engenharia, permitindo desempenho previsível, observabilidade e governança em escala corporativa. As etapas podem ser configuradas por administradores e desenvolvedores, e em ambos os casos, os autores de etapas podem se concentrar com segurança em observar os limites básicos do controlador de plataforma (como linhas DML e linhas de consulta recuperadas) sem precisar se preocupar com a escala de cada etapa.
Caminho para frente
Para operacionalizar e adotar esse padrão em implementações corporativas, os arquitetos devem:
Avaliar as automações existentes para identificar áreas em que a orquestração assíncrona pode ajudar a melhorar o desempenho e melhorar a visibilidade.
Divida grandes processos em etapas separadas e executáveis de forma independente com metas de processamento claras e pontos de autor separados (como Fluxo ou Apex).
Defina e agrupe tipos de etapas para acelerar a reutilização de etapas e a padronização entre unidades de negócios.
Pilote a abordagem com novos processos ou automações existentes. Você pode se surpreender ao encontrar quantos casos de ponta você encontra gratuitamente dentro de etapas, cuidando de seu registro integrado e capacidade de observação!
Sobre o autor
James Simone é engenheiro de software principal na Salesforce e tem mais de uma década de experiência trabalhando na plataforma. Ele era um cliente da Salesforce — e proprietário do produto — antes de se mudar para o desenvolvimento, e está escrevendo detalhes técnicos sobre o Salesforce desde 2019 no The Joys Of Apex. Ele publicou artigos anteriormente no blog Salesforce Developer e também no blog Salesforce Engineering.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.
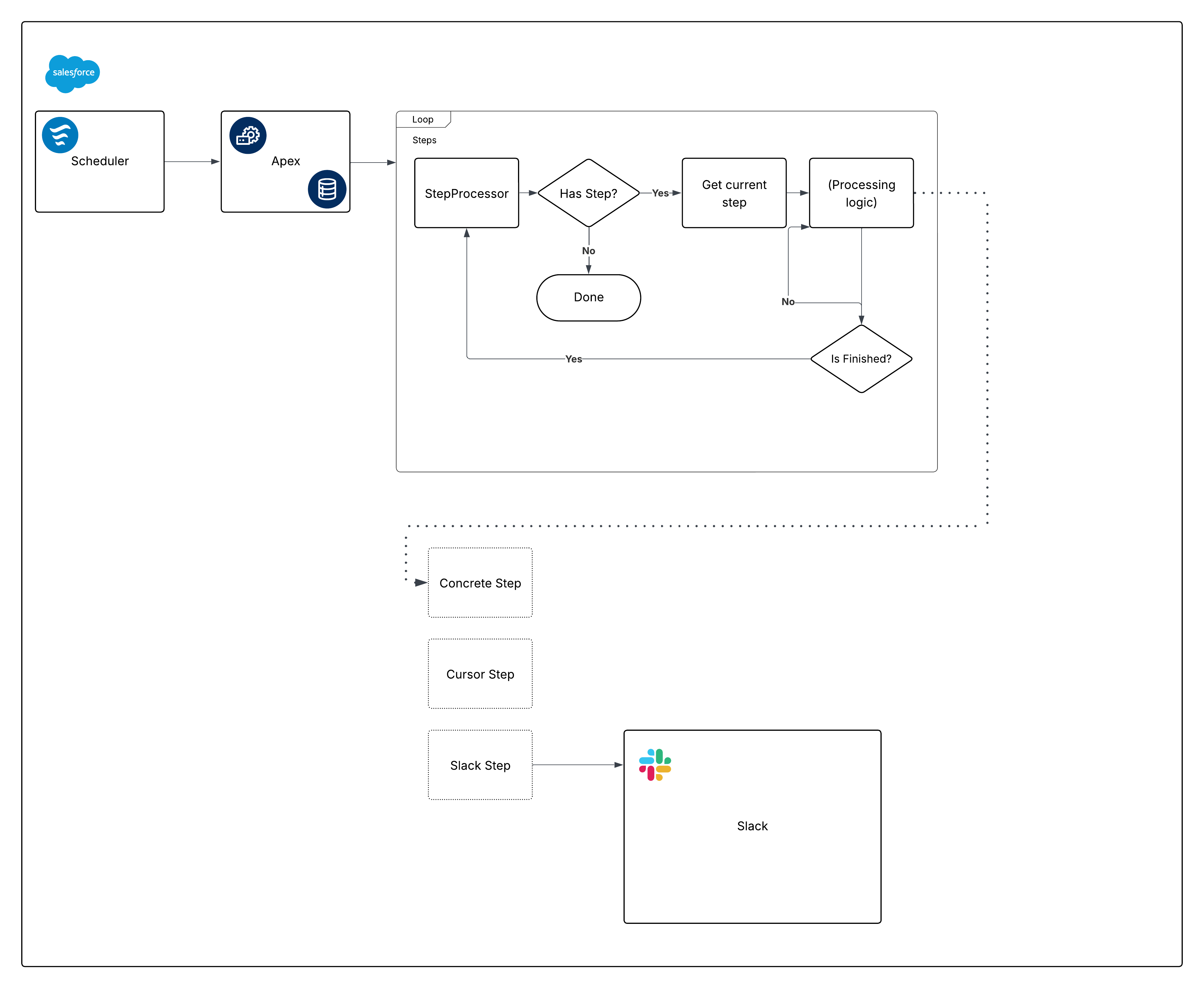 Agora, divida esse diagrama e comece a criar as peças.
Agora, divida esse diagrama e comece a criar as peças.