Moderne Salesforce-Architekturen werden zunehmend durch asynchrone Verarbeitung unterstützt, nicht als Komfort, sondern als strategische Skalierungsanforderung. In den letzten Jahren haben wir immer mehr Unternehmen erlebt, die mit steigenden Datenvolumen, komplexen Integrationen mit mehreren Kontaktpunkten und der Zunahme autonomer Systeme rund um die Uhr zu kämpfen haben. All dies drängt Architekten dazu, asynchrone Systeme zu entwickeln.
Bei der asynchronen Verarbeitung in Salesforce müssen Sie oft Obergrenzen und Komplexität berücksichtigen. Diese Obergrenzen dienen als Leitplanken und architektonische Einschränkungen, die bei der Herstellung massensicherer, skalierbarer Systeme helfen. Auch wenn keine Plattformobergrenzen direkt zur Verwaltung der Komplexität dienen, können Designmuster dazu beitragen, Risiken in dieser Hinsicht zu minimieren. Intern überschreitet Salesforce oft die Grenzen der Plattform, um neue Funktionen zu testen und komplexe Geschäftsprozesse zu automatisieren. Es wurde ein Framework für die schrittbasierte asynchrone Verarbeitung entwickelt, um asynchrone Aufträge mit einer beliebigen Anzahl von Schritten auszuführen. Jeder Schritt kann unabhängig voneinander ausgeführt, wiederholt und neu gestartet werden. Dazu gehören freigegebene Steuerungen und vollständige betriebliche Transparenz durch die zentralisierte Protokollierung. In diesem Dokument werden die wichtigsten architektonischen Komponenten beschrieben: Warteschlangenfähiger Apex und Finalizer, geplanter Flow, Apex Cursors, aufrufbare Aktionen und Integrationen in Slack. Zusammen bieten diese Komponenten eine modulare, skalierbare und beobachtbare Architektur, die sich an sich ändernde Unternehmensanforderungen anpasst.
- Moderne Salesforce-Architekturen sollten einen asynchronen Ansatz verfolgen, um Skalierbarkeit, Widerstandsfähigkeit und betriebliche Transparenz zu erreichen.
- Die Aufteilung komplexer Arbeiten in unabhängig ausführbare Schritte ermöglicht eine vorhersehbare Leistung, sichere Wiederholungen, Prüfpunkte, Rollback und modulare Weiterentwicklung, ohne die Kern-Workflows neu zu entwickeln.
- Das Framework bietet eine skalierbare Alternative zu monolithischen und alternden Batchaufträgen, verketteten asynchronen Aufrufen und tief verschachtelten Flows und wurde für Arbeitslasten mit hohem Volumen entwickelt, die horizontal innerhalb von Salesforce ohne Orchestrierung außerhalb der Plattform skaliert werden müssen.
- Die deterministische und beobachtbare Ausführung gewährleistet Fortschrittsverfolgung, SLA-Überwachung, Fehlerdiagnose und Transparenz auf Überwachungsebene durch zentralisierte Protokollierung und Governance.
- Konzipiert für die Strenge von Unternehmen, einschließlich einheitlicher Governance, Compliance und verteilter Kontrolle über den Bundesstaat in langfristigen Geschäftsprozessen.
Bevor Sie die Anforderungen überprüfen, finden Sie hier einige Tipps und Tricks für die Verwendung eines solchen Frameworks. Überlegen Sie vor allem, welches System die einzige Quelle der Wahrheit ist. Wenn Ihre Salesforce-Organisation nur minimal von externen Daten abhängig ist, jedoch von Hunderten auf Millionen Datensätze skaliert werden muss, sollten Sie ein schrittbasiertes asynchrones Framework in Betracht ziehen.
Verwenden Sie dieses Framework**,** wenn:
- Die meisten (oder alle) Informationen, auf die reagiert werden soll, sind bereits in Ihrem CRM vorhanden.
- Die Kosten für die Wartung eines Auftrags vom Typ "Extract Transform Load (ETL)" zur Harmonisierung externer Daten sind zu hoch.
- Sie müssen die Verarbeitung einer großen Anzahl von Salesforce-Datensätzen nach einem festgelegten Zeitplan zurückstellen.
- Sie können die Verarbeitung in separate Schritte unterteilen. Beispielsweise können Sie einen hierarchischen oder strukturbasierten Satz von Datensätzen erstellen, insbesondere wenn das Datenvolumen in der Hierarchie oder Struktur aufgefächert wird.
Verwenden Sie dieses Framework nicht in folgenden Fällen:
- Für das Erstellen oder Aktualisieren von Datensätzen ist eine sofortige Neuberechnung erforderlich.
- Die Integration ist schwierig, da externe Systeme Primärdaten für Datensatzaktualisierungen hosten. (Überlegen Sie, ob aktualisierte Daten mit der Bulk-API an Salesforce übertragen werden sollen.)
Unter Berücksichtigung dieser Vorgehensweisen sollten wir unsere Anforderungen überprüfen und mit der Erstellung beginnen.
Beachten Sie die Problemanweisung:
Überprüfen Sie bei einem Auftrag, der täglich ausgeführt werden muss, ob bestimmte Datensätze vorab festgelegte Kriterien für die weitere Verarbeitung erfüllen. Falls ja, starten Sie die Verarbeitungsaufträge. Die Verarbeitung von Datensätzen kann bedeuten, dass Daten aus mehreren externen Systemen abgerufen werden, um Berechnungen durchzuführen. Schritte in Aufträgen sollten Personen über Slack benachrichtigen, dass verarbeitete Datensätze zur Überprüfung bereit sind. Die Schritte sollten auch Benachrichtigungen an Manager und übergeordnete Positionen in der Rollenhierarchie basierend auf einer konfigurierbaren Verzögerung nach der ersten Benachrichtigungsrunde eskalieren.
Dieses Problem umfasst mehrere verschiedene Schritte, von denen einige unabhängig voneinander ablaufen können. Es gibt viele Möglichkeiten, die Arbeit aufzuteilen. Hier eine Gruppierung:
- Der Planer.
- Die Schrittoberfläche und konkrete Implementierungen, die Datensätze verarbeiten (unabhängig vom Verarbeitungstyp).
- Der Prozessor, der Schritte organisiert.
- Die vom Planer aufgerufene Apex Invocable.
- Der Benachrichtigungsteil. Wir verwenden das Apex Slack SDK.
- Im Ausdruck "konfigurierbare Verzögerung" verbirgt sich etwas Komplexität. Diese Komplexität wird später in diesem Artikel beschrieben.
Im Folgenden finden Sie ein Diagramm mit Meinungsäußerungen für das integrierte Framework:
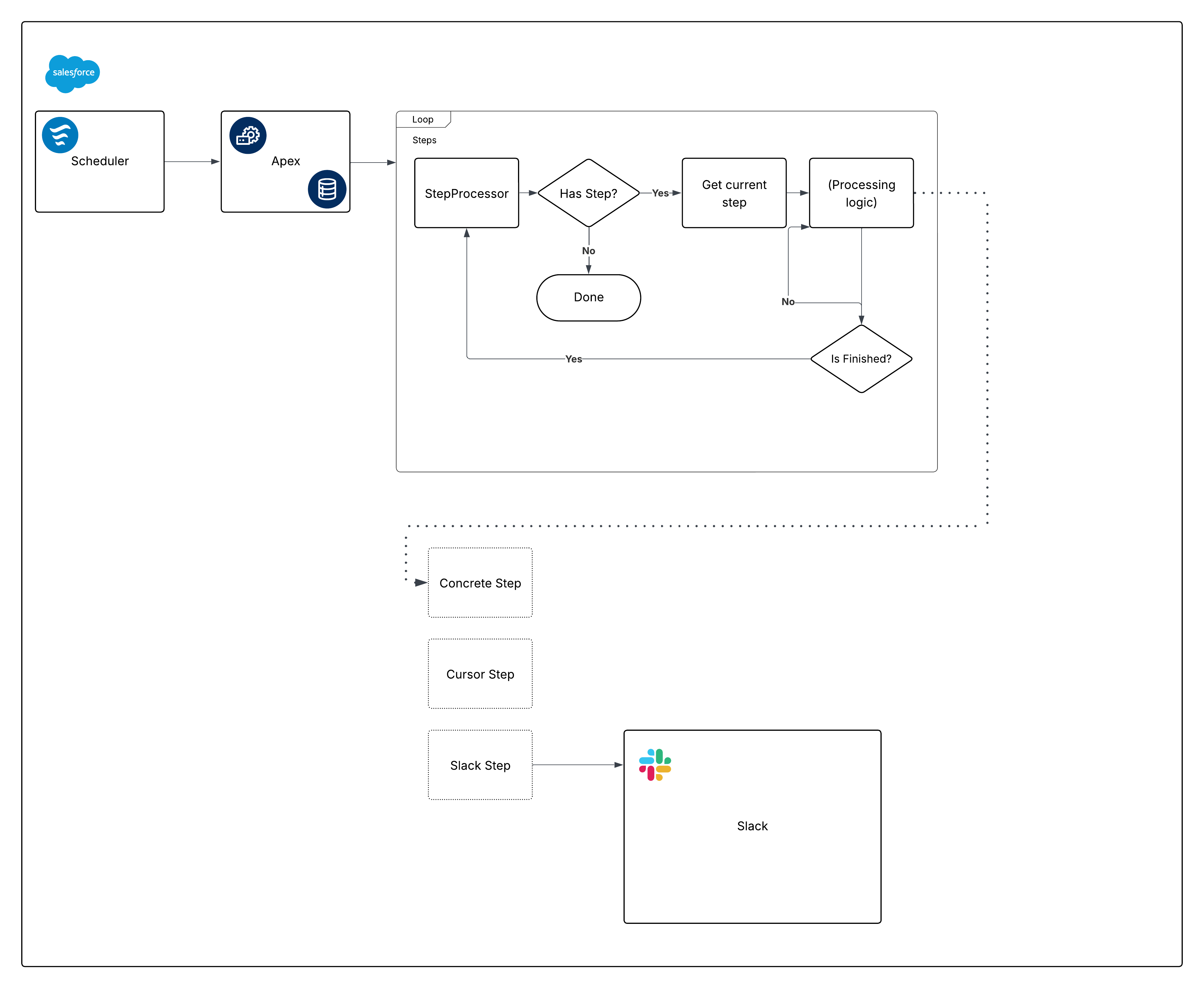 Nun schlüsseln Sie das Diagramm auf und erstellen Sie die Teile.
Nun schlüsseln Sie das Diagramm auf und erstellen Sie die Teile.
Der geplante Flow bietet als Planungsmechanismus mehrere Vorteile:
- Geplante Flows können als Metadaten in Pakete aufgenommen und bereitgestellt werden. Dies gilt nicht für Aufträge, die über Apex (oder über die Seite "Geplante Aufträge") geplant werden.
- Das Warteelement ist wichtig für Frameworks, die Callouts erfordern. Durch die Verwendung in Flow sind Callouts im Teil "Aufrufbar" des Frameworks nicht erforderlich.
- Die Planungsgranularität erfüllt die Anforderungen: Das Mindestintervall für geplante Flows beträgt täglich. Wenn Sie eine höhere Häufigkeit benötigen (z. B. stündlich), sollten Sie den geplanten Flow für diese Anforderung überdenken.
Eine weitere Überlegung beim Konfigurieren des geplanten Flows ist das Umgebungs-Gating. Fügen Sie vor dem Aufrufen der Apex-Aktion ein Entscheidungselement hinzu, das die {!$Api.Enterprise_Server_URL_100} auswertet. Dadurch wird sichergestellt, dass der Auftrag nur in den vorgesehenen Umgebungen ausgeführt wird, z. B. in UAT und Production. Dieses Muster ist wichtig, da Sandbox-Instanzen während des SDLC häufig aktualisiert oder neu erstellt werden und ein geplanter Flow ohne explizite Umgebungsprüfung versehentlich in Umgebungen ausgeführt werden könnte, in denen das Framework nicht ausgeführt werden soll. Durch die Verwendung des contains-Operators im Entscheidungselement wird das Setup widerstandsfähig gegen künftige Sandbox-Erstellungen oder URL-Änderungen.
Überlegen Sie abschließend, wie das Framework Fehler erfassen soll. Fügen Sie immer einen Fehlerpfad hinzu, wenn Flow eine beliebige Aktion aufruft. Beispielsweise können Sie Fehler mit der Aktion "Protokolleintrag hinzufügen" verdrahten. Der Nebelprotokollierer schreibt Protokolle in benutzerdefinierte Objekte. Daher sollten sich Kunden bewusst sein, dass Protokolldaten den Speicherplatz in der Organisation belegen. Protokolle werden standardmäßig 14 Tage in einer Organisation gespeichert und dann bereinigt. Dieser Aufbewahrungszeitraum kann konfiguriert werden. Der Nebelprotokollierer verwendet auch Plattformereignisse zum Veröffentlichen von Protokollen, sodass Protokolleinträge unabhängig von der Hauptdatenverarbeitungstransaktion gespeichert werden. Auf diese Weise wird sichergestellt, dass Fehler auch dann erfasst werden, wenn die primäre Flow- oder Apex-Aktion zurückgesetzt wird. Kunden sollten das erwartete Protokollvolumen und die Aufbewahrungsanforderungen auswerten, wenn sie das Hinzufügen eines Protokollierungs-Frameworks in Erwägung ziehen.
So sieht der Flow aus:
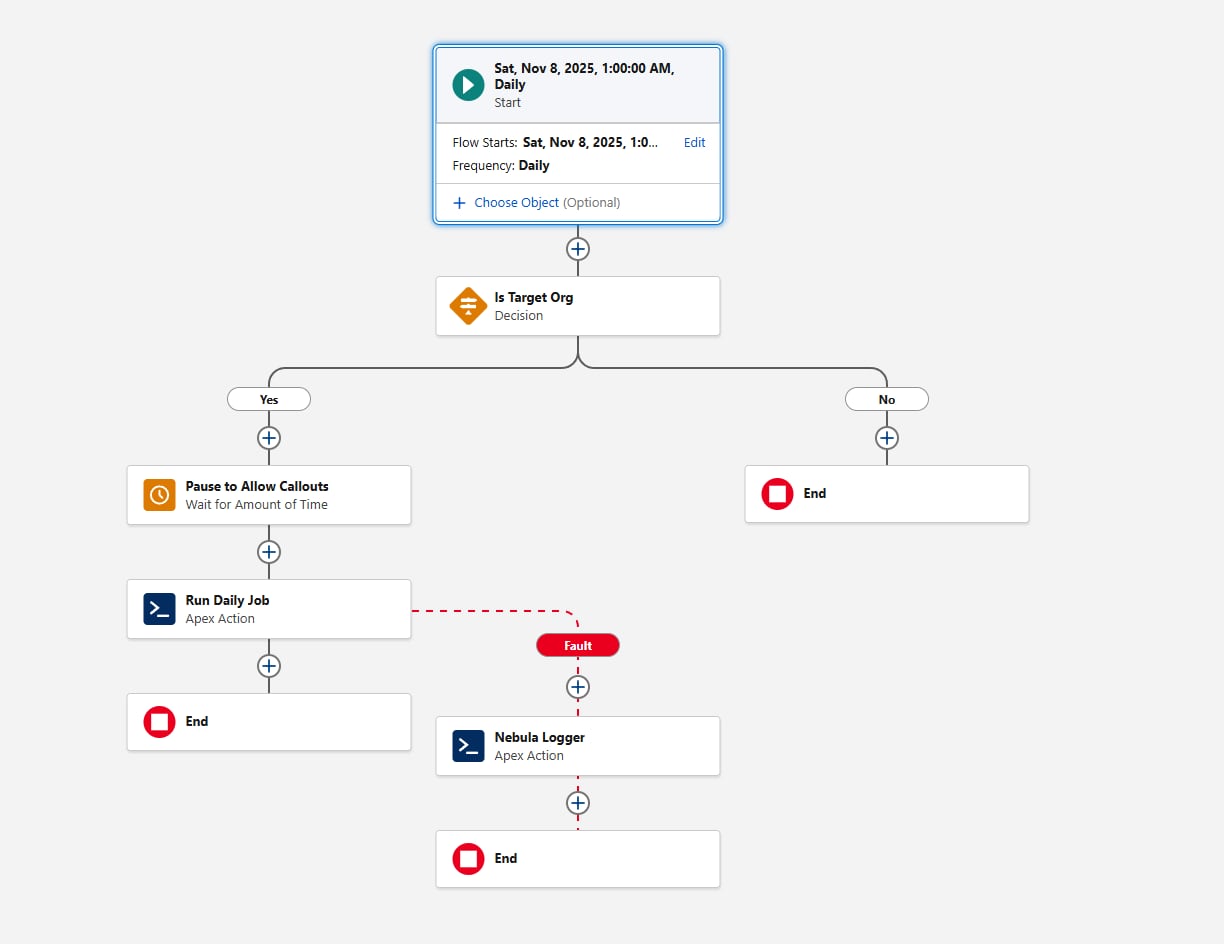
Gehen wir nun zu den ersten Teilen des Apex Codes über, wobei die Planungsanforderung nun erfüllt ist.
Definieren einer Step:
In diesem Artikel wird die step der Übersichtlichkeit halber als äußere Klasse angezeigt. Das Framework selbst ist flexibel. Teams können die Oberfläche und ihre Implementierungen mithilfe eines beliebigen Apex-Paketerstellungsmusters organisieren, sofern alle Schrittklassen auf dieselbe Oberfläche verweisen.
Zu den auf unserer Oberfläche definierten Methoden gibt es einige Hinweise:
- Die
executewird verbessert, wenn eineState(oder Schnittstelle) übergeben wird, um Daten zwischen Schritten zu orchestrieren, wenn es auf die Reihenfolge ankommt. getNamekann anstelle einesStringeinenSystem.Typezurückgeben. Ziel ist es, der Orchestrierungsebene eine Möglichkeit zu geben, Schrittnamen zu protokollieren, ohne andere Eigenschaften offenzulegen.
Im Folgenden finden Sie die erste konkrete Implementierung, die zeigt, wie diese Teile zusammenpassen. Mit einer Ausnahme später wird empfohlen, warteschlangenfähigen Apex zu verwenden, um eine asynchrone Verarbeitung in Apex zu implementieren; Batch Apex ist in der Regel nicht erforderlich (und @future werden abgeraten). Warteschlangenfähiger Apex startet schnell und bietet mit Apex Cursors viele Vorteile gegenüber Batch Apex.
Apex Cursors bieten eine moderne Alternative zum herkömmlichen Batch Apex Modell. Ähnlich wie bei der Batch-Verarbeitung kann eine Cursor-Implementierung Datensätze in Blöcken abrufen (bis zu 2.000 pro Batch). Cursors ermöglichen jedoch mehrere Abrufe innerhalb einer einzelnen Transaktion und ermöglichen so einen deutlich höheren Durchsatz für Vorgänge mit großem Volumen.
Wenn Teams Cursors als Teil dieses Frameworks übernehmen, sollten sie die aktuellen Einschränkungen bei Tests und der Mockability beachten. Das Cursorverhalten in Tests kann sich vom Produktionsverhalten unterscheiden. Daher ist es wichtig, Teststrategien zu entwerfen, die vermeiden, dass sich Cursorinterna auf sie verlassen, und stattdessen die Orchestrierungslogik an den Grenzen zu validieren. Im Zuge der Weiterentwicklung der Plattform werden sich diese Bereiche weiter verbessern, die zentrale Anleitung bleibt jedoch: Cursors bieten im Vergleich zu Batch Apex in vielen Anwendungsfällen eine höhere Leistung und einen geringeren Orchestrierungsaufwand.
Wenn Sie eine klare Grenze zwischen dem vom System bereitgestellten Cursor und Ihrem eigenen Code definieren möchten, sollten Sie beim Implementieren der Step eine Cursor-ähnliche Darstellung erstellen. Beachten Sie diesen Code:
Beachten Sie die Cursor-Klasse. Apex-Cursors sind Database.Cursor, aber unsere Cursor-Implementierung bietet uns Flexibilität hinsichtlich der Mängel von Cursors. Folgende Implementierung:
Für den Rest dieses Artikels werden die sharing-Deklarationen beim Verweis auf Apex-Klassen weggelassen. Stellen Sie in der Praxis sicher, dass Klassen der obersten Ebene explizit mit oder ohne Freigabe verwendet werden, um Ihrem Objektmodell und Ihren Berechtigungen gerecht zu werden.
Beachten Sie auch, dass unsere Cursor-Implementierung an die Plattform-Database.Cursor delegiert wird, wobei die zusätzlichen Vorteile als Nächstes diskutiert werden.
Zunächst die entsprechenden Tests:
Indem Cursor virtuell wird, können konkrete CursorStep-Implementierungen ohne Database.Cursor ausgeführt werden, wenn sie keinen großen Datensatz wiederholen müssen – ähnlich wie die Rückgabe eines System.Iterable<T> anstelle eines Database.QueryLocator in Batch Apex. Hier ein Beispiel:
Beachten Sie, dass diese Klasse ebenfalls abstrakt ist und die konkrete Implementierung von innerExecute Unterklassen überlässt.
Es gibt auch eine Alternative zur inneren Unterklasse CursorLike. Wenn Sie wissen, dass konkrete Versionen eines solchen Schritts andere Obergrenzen nicht überschreiten, können Sie this.records aus CursorLike.fetch zurückgeben und die übergeordnete CursorStep.shouldRestart() überschreiben, um false zurückzugeben. Dadurch können Sie eine Liste durchlaufen, die nur durch die Apex Heap-Obergrenze von 12 MB pro asynchroner Transaktion begrenzt ist.
Unsere Cursor-basierte Implementierung bietet uns viel Flexibilität beim Paginieren großer Datenmengen. Die Step bietet uns die Flexibilität, Schritte aller Art zu beschreiben und zu kapseln.
Betrachten Sie einen Flow-basierten Schritt:
Da Flows keine Ausgabeparameter zurückgeben können, die einem Apex-definierten Typ entsprechen, wird vor der Verwendung nach einem shouldRestart-Ausgabeparameter gesucht.
Einige Schritte sind möglicherweise funktionsgekennzeichnet. Sie können Logik implementieren, um zu entscheiden, welche Schritte einbezogen werden sollen, oder einen No-op-Schritt für eine deaktivierte Funktion verwenden. Das Muster "Null Object" ist eine gängige Möglichkeit, die Komplexität innerhalb der Orchestrierungsebene zu reduzieren:
Es gibt nun einige Bausteine, mit denen wir arbeiten müssen. Sehen wir uns die Orchestrierungsebene an, die für das Durchlaufen von Schritten verantwortlich ist.
Der Prozessor ist ein Wendepunkt in der Architektur. Wir müssen entscheiden, wer definiert, welche Schritte initialisiert werden und wo. Zu den Optionen zählen:
- Lassen Sie den Prozessor definieren, welche Schritte der Geschäftslogik zugeordnet werden. Diese Option ist einfach, wird jedoch zur besseren Lesbarkeit schlecht skaliert.
- Definieren Sie die Zuordnung mit benutzerdefinierten Metadaten (Custom Metadata, CMDT). Metadatenbeziehungsfelder unterstützen keine
ApexClass, wodurch die Klassennamenschreibweise locker in Ihr Geschäftsprozess-Setup integriert wird. Sie können das Administratorrisiko reduzieren, indem Sie das Feld als Auswahlliste festlegen und den vorhandenen Typ validieren (Type.forName()oderApexClassabfragen). Da CMDT-Datensätze jedoch keine Auslöser unterstützen, erfolgt die Validierung zur Laufzeit. Diese Route kann getestet werden. Administratoren können jedoch weiterhin nur CMDT-Datensätze in der Produktion erstellen. - Definieren Sie die Zuordnung mit Datensätzen. Nicht-Administratoren können Schritte konfigurieren, Bereitstellungen werden jedoch schwieriger und Umgebungen können abweichen. Gehen Sie mit Bedacht vor.
Es gibt ein berühmtes Zitat aus Clean Code über die Handhabung dieser besonderen Komplexität:
Die Lösung dieses Problems besteht darin, die
switch-Anweisung [zum Erstellen von Objekten] im Keller einer abstrakten Fabrik zu vergraben und sie niemals jemandem anzeigen zu lassen.
In diesem Sinne und da unsere aktuelle Anzahl an Schritten genau definiert ist und nicht zu groß wird, ist es in Ordnung, dass der Schrittprozessor auch die Fabrik für Schritte ist. Dadurch kann eine Enumeration zum Steuern der switch-Anweisung verwendet werden:
Und dann für unsere StepProcessor:
Die angezeigten Werksmethoden können wie addTypeOneSteps() Bedenken wie die Kennzeichnung von Funktionen delegieren. cleanSteps() führt eine einmalige Überprüfung der erfassten Schritte durch, um sicherzustellen, dass keine "leeren" Schritte vorhanden sind, bevor es wirklich asynchron wird. Das könnte wie folgt aussehen:
Die Fehlerbehandlung wurde seit der Erwähnung des Nebelprotokollierers im Abschnitt "Geplanter Flow" nicht mehr diskutiert. Das liegt daran, dass wir mit System.Finalizer die Protokollierung für alle Fehlerbedingungen abdecken können, ohne in jedem Schritt eine spezifische Fehlerbehandlung hinzuzufügen. Jeder Step konzentriert sich auf die Ausführung, während alle unzufriedenen Pfade protokolliert und neu geworfen werden, damit sie in Einheitentests angezeigt werden. Dies unterstützt die sichere Iteration und Warnungen auf Produktionsebene (mit dem Slack Logger-Plugin für Nebula für alle WARN- und ERROR-Protokolle).
Hinweis zur Fehlerprotokollierung: Die Übergabe der Schrittinstanz an Protokollmeldungen setzt ein Maß an Trust voraus, was in Protokollen sichtbar wird. Die Standard-toString() für Apex-Klassen enthält alle statischen und instanzspezifischen Eigenschaften in der Meldung. Dies kann wünschenswert sein oder vertrauliche Informationen preisgeben. Auch wenn Protokollierung und Sicherheit hier nicht im Mittelpunkt stehen, sollten Sie beachten, dass die Einhaltung einer Schnittstelle wie Step bei einigen Systemen auch das Erzwingen einer Überschreibung für toString() beinhalten kann.
Bei einer solchen Methode müssen die einzelnen Objektersteller entscheiden, was gedruckt werden darf, was wünschenswert sein kann.
Auf Protokollierungsebenen: Auf StepProcessor wird INFO verwendet, die höchste Nicht-Fehler-Ebene. Wenn Sie in der Anwendung genauer werden, sollten die Protokollierungsebenen entsprechend reduziert werden. Bei einzelnen Schritten werden möglicherweise DEBUG für allgemeine Informationen verwendet, wobei FINE, FINER und FINEST für eine immer detailliertere Ausgabe reserviert sind. Protokollierung ist ebenso eine Kunst wie eine Wissenschaft, aber diese Prinzipien zu befolgen, hilft, Protokolle konsistent und nützlich zu halten.
Bevor wir fortfahren, sollten wir kurz über die Entscheidung nachdenken, dass unser Schrittprozessor die Logik hosten soll, für die Schritte verwendet werden. Ziehen Sie in einer großen Codebasis in Erwägung, StepProcessor virtuell oder abstrakt zu gestalten, und lassen Sie Unterklassen bestimmte Schritte identifizieren, um eine ordnungsgemäße Trennung von Bedenken zu erreichen.
Der Planer ruft schließlich Apex auf. Nach Abschluss des restlichen Setups kann der Abschnitt "Aufrufbares Apex" entscheiden, welche Schritte ausgeführt werden sollen, und die List<StepType> an den Prozessor übergeben:
Dies ist ein einfacher Teil der Gleichung: Verwenden Sie Datensätze, Daten oder Logik, um zu bestimmen, welche Schritttypen ausgeführt werden sollen. Die aufrufbare Aktion ist einfach, da die Komplexität an anderer Stelle gekapselt wurde. Wir haben uns auch vor unerwarteten Ausnahmen geschützt und jedes Stück für sich genommen einfach getestet.
Das Apex Slack-SDK liegt außerhalb des Geltungsbereichs dieses Artikels, aber ein potenzieller Haken an den Anforderungen besteht darin, Personen anhand einer konfigurierbaren Verzögerung nach oben in der Rollenhierarchie zu benachrichtigen. Auf dem Papier ist dies einfach und Sie könnten (richtig) System.enqueueJob(this) in der StepProcessor berücksichtigen. Bei System.AsyncOptions bestand unsere anfängliche Neigung darin, die enqueueJob-Überlastung zu verwenden, um diese Anforderung zu erfüllen.
Derzeit beträgt die maximale Verzögerung über System.AsyncOptions.MinimumQueueableDelayInMinutes jedoch 10 Minuten. Da die Anforderung 120 Minuten beträgt, bleiben einige Optionen. Ein naiver Ansatz könnte wie folgt aussehen:
In der Praxis würde die Verzögerung an diese Klasse weitergegeben, da die Verzögerung konfigurationsgesteuert ist.
Dieser Ansatz wird nur empfohlen, wenn Sie sicher sind, dass es immer nur einen verzögerten Benachrichtigungstyp gibt. Es werden 11 zusätzliche asynchrone Aufträge durchgebrannt, bevor gestartet wird (oder mehr, wenn die Verzögerung zunimmt). Diese Kosten können für einen Auftrag in Ordnung sein – nicht für viele. Außerdem müssen Sie der Step-Oberfläche eine Methode hinzufügen, damit der Prozessor bei jedem Schritt feststellen kann, wie lange vor dem Neustart gewartet werden muss, was zu zusätzlichen Störungen führt.
Dadurch bleiben uns zwei interessante Möglichkeiten:
- Sie können den verzögerten Schritt in Ihr vorhandenes Auftrags-Framework einfügen, wenn Sie bereits über einen in einem angemessenen Intervall geplanten Abstimmungsauftrag verfügen. Sie sollten auch damit einverstanden sein, dass die angegebene Verzögerung bis zu 15 Minuten später auftritt (15 Minuten sind das Mindestaktualisierungsintervall für einen Apex CRON-Ausdruck). Dies entspricht ungefähr dem Beispiel "Aufrufbares Apex". Die Planung erfolgt stattdessen über Apex. Anders ausgedrückt, Sie könnten dieselbe
StepArchitektur wiederverwenden, um Datensätze anhand eines Zeitstempels vom Typ "Start nach" zu verarbeiten und anhand einer Auswahlliste oder Mehrfachauswahllistenzuordnung zurück zu den zuvor angezeigtenStepTypezu entscheiden, welche Schritte verwendet werden sollen. - Wenn Sie eine zusätzliche äußere Apex-Klasse definieren möchten, können Sie alternativ mithilfe von
System.scheduleBatch()auf Batch Apex zurückgreifen (anders als warteschlangenfähiges Apex, das innere Klassen unterstützt, müssen Batch Apex Klassen äußere Klassen sein).
Sehen Sie sich das Beispiel für Batch Apex an. Obwohl Queueable Apex im Allgemeinen für Flexibilität und Kontrolle empfohlen wird, ist dies ein Fall, in dem Batch-Apex weiterhin die Oberhand behält:
Stellen Sie sich dann im StepProcessor vor, dass die zuvor angezeigte addTypeOneSteps() mit diesem verzögerten Schritt aktualisiert wird:
Obwohl wir normalerweise nicht so viel Hoop-Jumping empfehlen würden, wird diese Schrittverzögerung zu einem weiteren wiederverwendbaren Baustein. Bis längere Verzögerungen in Queueable Apex zulässig sind, stellt dies auch die einfachste Möglichkeit dar, diesen Effekt zu erzeugen (ohne einen Abfragemechanismus, wie diskutiert).
Wir haben objektorientiertes Design verwendet, um die Anforderungen zu erfüllen, und ein System entwickelt, das skaliert und gleichzeitig die langfristigen Kosten für Gebäude und Wartung abwägt. Während die Schrittdeklaration und -instanziierung letztlich ihren Platz in der StepProcessor übersteigen können, gibt es hier wenig zusätzliche technische Schulden. Mit FlowStep können Administratoren und Entwickler gemeinsam entscheiden, wann No-Code- oder Pro-Code-Lösungen am sinnvollsten sind.
Durch die Verwendung der System.Finalizer-Schnittstelle im Queueable-Framework von Apex wurde zusammen mit Nebula Logger ein robustes, testbares System entwickelt, das uns auf unvorhergesehene Fehler hinweist, selbst wenn künftige Schritte keine explizite Protokollierung erfordern. Für uns ist dieses System ein glücklicher Zahlenschlag und reduziert Kosten und Komplexität. Außerdem erhalten wir wertvolle Statistiken zum Verhalten von Apex Cursors unter realen Arbeitslasten, wodurch wir unseren Ansatz optimieren und gleichzeitig die Funktion selbst verbessern können.
Indem komplexe Arbeitslasten mit hohem Volumen in modulare Ausführungsschritte zerlegt werden, wandelt das Framework für die schrittbasierte asynchrone Verarbeitung Plattformeinschränkungen in technische Vorteile um, die eine vorhersehbare Leistung, Beobachtbarkeit und Governance im Unternehmensmaßstab ermöglichen. Schritte können sowohl von Administratoren als auch von Entwicklern eingerichtet werden. In beiden Fällen können sich Schrittautoren auf die Einhaltung der grundlegenden Plattformobergrenzen (wie DML-Zeilen und abgerufene Abfragezeilen) konzentrieren, ohne sich Gedanken über die Skalierung jedes Schritts machen zu müssen.
Damit dieses Muster in Unternehmensimplementierungen operationalisiert und übernommen werden kann, sollten Architekten:
- Bewertung vorhandener Automatisierungen, um Bereiche zu identifizieren, in denen die asynchrone Orchestrierung zur Leistungssteigerung und zur Verbesserung der Beobachtbarkeit beitragen kann.
- Unterteilen Sie große Prozesse in diskrete, unabhängig ausführbare Schritte mit klaren Verarbeitungszielen und diskreten Autorenpunkten (wie Flow oder Apex).
- Definieren und gruppieren Sie Schritttypen, um die Wiederverwendung und Standardisierung von Schritten über Geschäftseinheiten hinweg zu beschleunigen.
- Pilotieren Sie den Ansatz mit neuen Prozessen oder vorhandenen Automatisierungen. Sie werden überrascht sein, wie viele Edge-Kundenvorgänge Sie innerhalb von Schritten kostenlos finden, was Ihre integrierte Protokollierung und Beobachtbarkeit gewährleistet!
James Simone ist Principal Software Engineer bei Salesforce und verfügt über mehr als ein Jahrzehnt Erfahrung in der Arbeit an der Plattform. Er war Salesforce-Kunde – und Produktinhaber –, bevor er in die Entwicklung einstieg, und schreibt seit 2019 in The Joys Of Apex technische Details zu Salesforce. Zuvor hat er Artikel im Salesforce Developer Blog und im Salesforce Engineering Blog veröffentlicht.