Ce texte a été traduit en utilisant le système de traduction automatisé de Salesforce. Répondez à notre sondage pour nous faire part de vos commentaires sur ce contenu et nous dire ce que vous aimeriez voir ensuite.
Note
Vue d'ensemble
Les architectures Salesforce modernes sont de plus en plus pilotées par le traitement asynchrone, non pas comme une commodité, mais comme une exigence stratégique d'échelle. Ces dernières années, nous avons vu de plus en plus d'entreprises faire face à des volumes de données en augmentation, à des intégrations complexes impliquant plusieurs points de contact et à l'essor des systèmes autonomes fonctionnant 24/7/365. Toutes ces choses poussent les architectes à concevoir des systèmes qui sont d'abord asynchrones.
Le traitement asynchrone dans Salesforce implique souvent de concevoir en fonction des limites et de la complexité du gouverneur. Ces limites agissent comme des garde-fous et des contraintes architecturales qui aident à produire des systèmes évolutifs et sûrs en masse. Bien qu'aucune limite de plate-forme ne serve directement à gérer la complexité, les modèles de conception peuvent aider à atténuer les risques sur ce front. En interne, Salesforce repousse souvent les limites de la plate-forme pour tester de nouvelles fonctionnalités et automatiser des processus métiers complexes. Nous avons élaboré une infrastructure de traitement asynchrone basée sur une étape pour exécuter des tâches asynchrones avec un nombre arbitraire d'étapes. Chaque étape peut être exécutée, réessayée et redémarrée indépendamment avec des contrôles de gouvernance partagés et une visibilité opérationnelle totale via la consignation centralisée. Le présent document décrit ses principaux éléments architecturaux : Apex et finaliseurs Queueable, flux planifié, curseurs Apex, actions invocables et intégrations à Slack. Ensemble, ces composants offrent une architecture modulaire, évolutive et observable adaptée à l'évolution des besoins de l'entreprise.
Principaux points à retenir
Les architectures Salesforce modernes doivent adopter une approche asynchrone avant tout pour atteindre l'échelle, la résilience et la transparence opérationnelle.
La division d'un travail complexe en étapes exécutables indépendantes permet d'obtenir des performances prévisibles, des tentatives plus sûres, un pointage, une restauration et une évolution modulaire sans reconcevoir les workflows de base.
L'infrastructure offre une alternative évolutive aux tâches par lot monolithiques et vieillissantes, aux appels asynchrones enchaînés et aux flux profondément imbriqués, et est conçue pour les charges de travail à haut volume qui doivent évoluer horizontalement dans Salesforce sans orchestration hors plate-forme.
Une exécution déterministe et observable garantit le suivi des progrès, la surveillance des accords de niveau de service, les diagnostics d'échec et la transparence au niveau de l'audit grâce à une consignation et une gouvernance centralisées.
Conçu pour la rigueur de l'entreprise, notamment la gouvernance unifiée, la conformité et le contrôle de l'État distribué à travers des processus métiers à long terme.
Meilleures pratiques de la plate-forme
Avant de passer en revue les exigences, voici quelques recommandations à ne pas faire pour utiliser une infrastructure de ce type. Réfléchissez surtout au système qui est la source unique de vérité. Si votre organisation Salesforce s'appuie peu sur des données externes, mais doit passer de centaines à des millions d'enregistrements, envisagez une infrastructure asynchrone basée sur une étape.
**N'**utilisez cette infrastructure que si :
La plupart (ou toutes) les informations sur lesquelles agir existent déjà dans votre CRM.
Le coût initial ou permanent de la maintenance d'une tâche ETL (Extract Transform Load) pour harmoniser les données externes est trop élevé.
Vous devez reporter le traitement d'un grand nombre d'enregistrements Salesforce selon une planification définie.
Vous pouvez décomposer le traitement en étapes discrètes. Par exemple, vous pouvez créer un ensemble d'enregistrements hiérarchiques ou arborescents, en particulier si le volume de données s'étend à la hiérarchie ou à l'arborescence.
**N'**utilisez pas cette infrastructure si :
La création ou la mise à jour d'enregistrements nécessite un recalcul immédiat.
L'intégration est difficile, car les systèmes externes hébergent les données principales pour les mises à jour d'enregistrements. (vous pouvez envoyer automatiquement des données mises à jour à Salesforce avec l'API de transfert en masse).
Avec ces pratiques à l'esprit, révisons nos exigences et commençons à élaborer.
Répartition des exigences
Tenez compte de l'énoncé du problème :
Avec une tâche qui doit être exécutée quotidiennement, vérifiez si certains enregistrements remplissent des critères préétablis pour un traitement ultérieur. S'ils le font, lancez ces tâches de traitement. Le traitement d'enregistrements peut impliquer l'extraction de données de plusieurs systèmes externes pour effectuer des calculs. Les étapes des tâches doivent notifier les personnes via Slack que les enregistrements traités sont prêts à être révisés. Les étapes doivent également escalader les notifications aux responsables et aux échelons supérieurs de la hiérarchie des rôles en fonction d'un délai configurable après la première série de notifications.
Ce problème implique plusieurs étapes différentes, dont certaines peuvent se produire indépendamment les unes des autres. Il existe de nombreuses façons de répartir le travail. Voici un regroupement :
Le planificateur.
L'interface de l'étape et les implémentations concrètes qui traitent les enregistrements (quel que soit le type de traitement).
Le processeur qui organise les étapes.
L'Apex Invocable appelé par le planificateur.
L'élément de notification. On utilise le SDK Apex Slack.
L'expression « délai configurable » cache une certaine complexité. Nous allons examiner cette complexité plus loin dans cet article.
Voici un diagramme de l'infrastructure élaborée :
Maintenant, décomposez ce diagramme et commencez à construire les pièces.
Planification avec un flux planifié
Le flux planifié offre plusieurs avantages en tant que mécanisme de planification :
Les flux planifiés peuvent être empaquetés et déployés en tant que métadonnées. Ce n'est pas vrai pour les tâches planifiées via Apex (ou via la page Tâches planifiées).
L'élément Attente est essentiel pour les infrastructures qui nécessitent une légende. En l'utilisant dans Flux, les appels externes ne sont pas nécessaires dans la partie Invocable de l'infrastructure.
La granularité de la planification remplit les exigences : l'intervalle minimal pour les flux planifiés est quotidien. Si vous avez besoin d'une fréquence plus élevée (par exemple, toutes les heures), reconsidérez Flux planifié pour cette exigence.
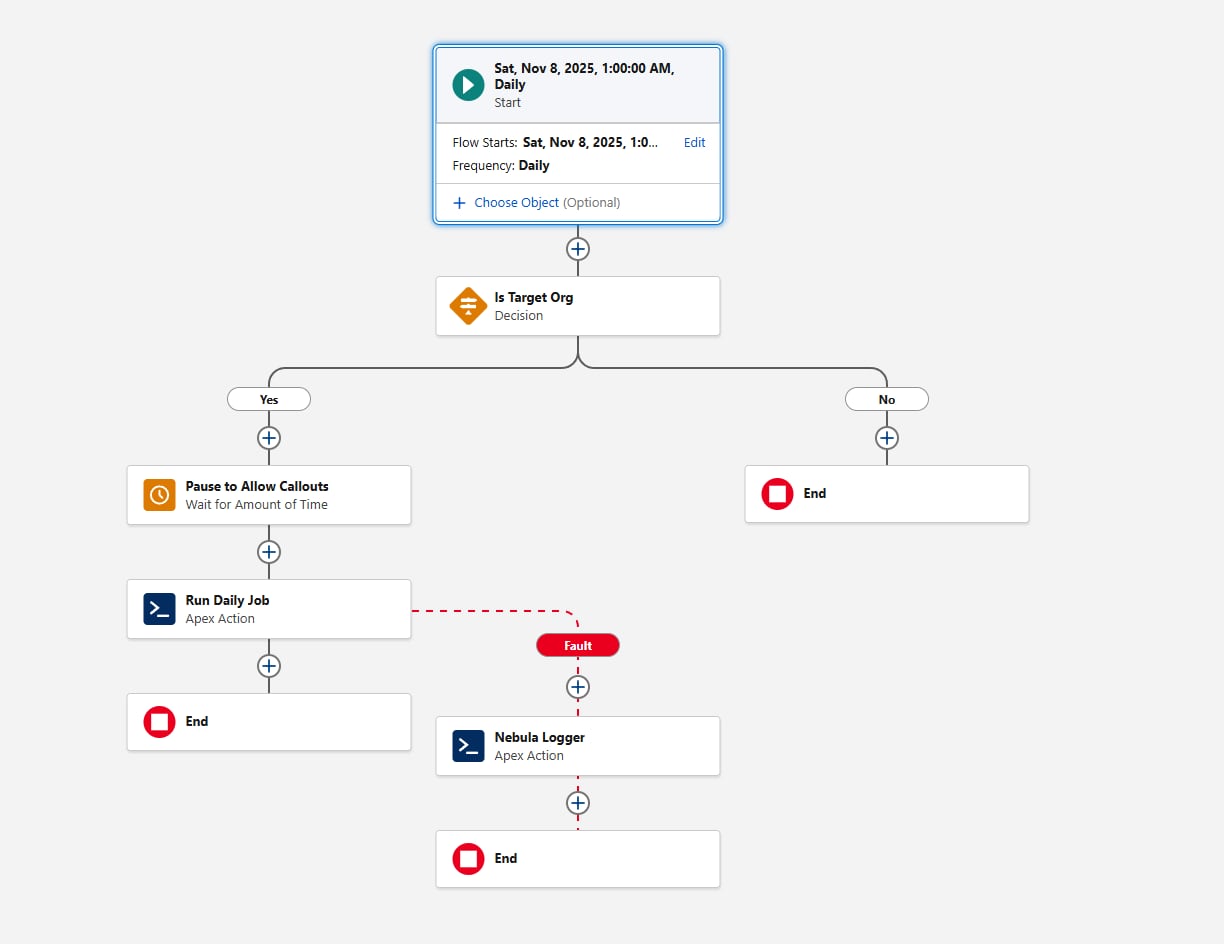
Une autre considération lors de la configuration du flux planifié est le portage de l'environnement. Avant d'invoquer l'action Apex, ajoutez un élément Décision qui évalue la variable {!$Api.Enterprise_Server_URL_100}. Cela garantit que la tâche est exécutée uniquement dans les environnements prévus, tels que UAT et Production. Ce schéma est important, car les sandbox sont fréquemment actualisées ou créées pendant le développement de l'infrastructure, et sans vérification explicite de l'environnement, un flux planifié peut involontairement être exécuté dans des environnements où l'infrastructure n'est pas conçue pour être exécutée. L'utilisation de l'opérateur contains dans l'élément Décision rend la configuration résiliente aux futures créations de sandbox ou aux changements d'URL.
Enfin, déterminez comment l'infrastructure doit capturer les échecs. Ajoutez toujours un chemin de défaut lorsque Flux appelle n'importe quelle action. Vous pouvez par exemple câbler les défauts à l'action « Ajouter une entrée au journal » de Nebula Logger. Nebula Logger écrit des journaux dans des objets personnalisés. Par conséquent, les clients doivent savoir que les données des journaux consomment du stockage dans l'organisation. Par défaut, les journaux sont stockés pendant 14 jours dans une organisation, puis nettoyés. Cette période de rétention est configurable. Nebula Logger utilise également les événements de plate-forme pour publier des journaux. Par conséquent, les entrées dans les journaux sont enregistrées indépendamment de la transaction de traitement des données principale. Cela garantit la capture des échecs, même si l'action principale Flux ou Apex est annulée. Les clients doivent évaluer le volume de consignation attendu et les exigences de rétention en envisageant l'ajout d'une infrastructure de consignation.
Le flux se présente comme suit :
Passons aux premiers bouts de code Apex avec l'exigence de planification désormais satisfaite.
Pour cet article, l'interface de step est affichée en tant que classe externe pour plus de clarté. L'infrastructure elle-même est flexible. Les équipes peuvent organiser l'interface et ses implémentations en utilisant n'importe quel modèle d'empaquetage Apex de leur choix, à condition que toutes les classes Étape référencent la même interface.
Voici quelques points à noter concernant les méthodes définies dans notre interface :
La execute, bien que sans argument pour le moment, s'améliore lorsque nous passons une classe (ou interface) de State pour orchestrer les données entre les étapes lorsque l'ordre importe.
getName peut renvoyer une valeur de System.Type au lieu d'une String. L'objectif est de fournir à la couche d'orchestration un moyen de consigner les noms d'étape sans exposer d'autres propriétés.
Voici la première mise en œuvre concrète qui montre comment ces pièces s’agencent. À une exception près plus loin, nous recommandons d'utiliser Apex Queueable pour implémenter le traitement asynchrone dans Apex; Apex par lot est généralement inutile (et les méthodes de @future sont déconseillées). Apex Queueable démarre rapidement et présente, avec les curseurs Apex, de nombreux avantages par rapport aux Apex batch.
Une implémentation Apex semblable à un curseur
Les curseurs Apex offrent une alternative moderne au modèle Apex traditionnel par lot. De la même façon qu'un traitement par lot, une implémentation de curseur peut récupérer des enregistrements par segments (jusqu'à 2000 par lot). Cependant, les curseurs autorisent plusieurs récupérations dans une seule transaction, ce qui augmente considérablement le débit pour les opérations à grand volume.
Lors de l'adoption des curseurs dans ce cadre, les équipes doivent être conscientes des limitations actuelles en matière de test et de moquabilité. Le comportement du curseur dans les tests peut différer de celui de la production. Par conséquent, il est important de concevoir des stratégies de test qui évitent de dépendre des internes du curseur et valident à la place la logique d'orchestration aux frontières. À mesure que la plate-forme évoluera, ces domaines continueront de s'améliorer, mais les orientations principales demeurent les suivantes : Les curseurs offrent des performances supérieures et réduisent les surcharges d'orchestration par rapport à Apex par lot pour de nombreux cas d'utilisation.
Pour définir une frontière claire entre le curseur fourni par le système et votre propre code, nous recommandons de créer une représentation de type curseur lors de l'implémentation de l'interface de Step. Tenez compte du code suivant :
1public inherited sharing abstract class CursorStep implements Step{2 private static final Integer MAX_CHUNK_SIZE = 2000;34 protected Cursor cursor;56 private Integer chunkSize = System.Limits.getLimitDMLRows();7 private Integer position = 0;89 protected abstract Cursor getCursor();10 protected abstract void innerExecute(List<SObject>records);1112 public abstract String getName();1314 public virtual CursorStep withChunkSize(Integer chunkSize){15 this.chunkSize = chunkSize;16 return this;17}1819 public void execute(){20 this.cursor = this.cursor ?? this.getCursor();21 this.cursor.setFetchesPerTransaction(this.getFetchesPerTransaction());22 List<SObject>records = new List<SObject>();23 if(this.shouldAdvance()){24 records = this.cursor.fetch(this.position, this.chunkSize);25 this.position += this.chunkSize;26}27 this.innerExecute(records);28}2930 public virtual void finalize(){31 Logger.info('finished cursor step for ' + this.getName());32}3334 public virtual Boolean shouldRestart(){35 return this.position<this.cursor.getNumRecords();36}3738 protected virtual Integer getFetchesPerTransaction(){39 Integer maxRecordsPerFetchCall = 2000;40 if(this.chunkSize< maxRecordsPerFetchCall){41 return this.chunkSize;42}43 // Integer division rounds down44 // which is perfect for our use-case45 return this.chunkSize / maxRecordsPerFetchCall;46}4748 protected virtual Boolean shouldAdvance(){49 return true;50}51}
Notez la classe Cursor. Les curseurs Apex sont des instances de Database.Cursor, mais notre implémentation Cursor nous donne la flexibilité nécessaire pour contourner les lacunes des curseurs. Voici l'implémentation :
1public virtual without sharing class Cursor{2 private static final Integer MAX_FETCHES_PER_TRANSACTION = Limits.getLimitFetchCallsOnApexCursor();34 @TestVisible5 private static Integer maxRecordsPerFetchCall = 2000;67 private Integer cursorNumRecords;8 private Integer fetchesPerTransaction = MAX_FETCHES_PER_TRANSACTION;9 private final Database.Cursor cursor;1011 public Cursor(12 String finalQuery,13 Map<String, Object>bindVars,14 System.AccessLevel accessLevel15){16 try{17 this.cursor = Database.getCursorWithBinds(finalQuery, bindVars, accessLevel);18}catch(FatalCursorException e){19 Logger.newEntry(20 System.LoggingLevel.WARN,21 'Error creating cursor. This can happen if there' +22 ' are no records returned by the query: ' + e.getMessage()23);24}25}2627 public Cursor setFetchesPerTransaction(Integer possibleFetchesPerTransaction){28 // Handle accidental round downs from Integer division29 if(possibleFetchesPerTransaction == 0){30 return this;31}32 if(possibleFetchesPerTransaction > MAX_FETCHES_PER_TRANSACTION){33 Logger.newEntry(34 System.LoggingLevel.DEBUG,35 'Fetches per transaction: ' +36 possibleFetchesPerTransaction +37 ' exceeded platform max fetches per transaction: ' +38 MAX_FETCHES_PER_TRANSACTION +39 ', defaulting to platform max'40);41 possibleFetchesPerTransaction = MAX_FETCHES_PER_TRANSACTION;42}43 this.fetchesPerTransaction = possibleFetchesPerTransaction;44 return this;45}4647 @SuppressWarnings('PMD.EmptyStatementBlock')48 protected Cursor(){49}5051 public virtual List<SObject>fetch(Integer start, Integer advanceBy){52 if(this.getNumRecords() == 0){53 Logger.newEntry(54 System.LoggingLevel.DEBUG,55 'Bypassing fetch call, no records to fetch'56);57 return new List<SObject>();58}59 Integer localStart = start;60 List<SObject>results = new List<SObject>();61 while(62 Limits.getFetchCallsOnApexCursor()<this.fetchesPerTransaction &&63 results.size()<this.getNumRecords() &&64 localStart < start + advanceBy65){66 Integer actualAdvanceBy = this.getAdvanceBy(localStart, advanceBy);67 results.addAll(this.cursor?.fetch(localStart, actualAdvanceBy)?? new List<SObject>());68 localStart += actualAdvanceBy;69}70 return results;71}7273 public virtual Integer getNumRecords(){74 this.cursorNumRecords = this.cursorNumRecords ?? this.cursor?.getNumRecords()?? 0;75 return this.cursorNumRecords;76}7778 protected Integer getAdvanceBy(Integer start, Integer advanceBy){79 Integer possibleFetchSize = Math.min(advanceBy, this.getNumRecords() - start);80 if(possibleFetchSize > maxRecordsPerFetchCall){81 Logger.newEntry(82 System.LoggingLevel.DEBUG,83 'Fetch size: ' +84 possibleFetchSize +85 ' exceeded platform max fetch size of ' +86 maxRecordsPerFetchCall +87 ', defaulting to max fetch size'88);89 possibleFetchSize = maxRecordsPerFetchCall;90}else if(possibleFetchSize <0){91 possibleFetchSize = 0;92}93 return possibleFetchSize;94}95}
Pour la suite de cet article, nous omettons les déclarations de sharing en faisant référence à des classes Apex. En pratique, assurez-vous que les classes de niveau supérieur sont explicitement utilisées avec ou sans partage pour être conformes à votre modèle d'objet et à vos autorisations.
Notez également que notre implémentation Cursor délègue à la Database.Cursor de plate-forme, avec des avantages supplémentaires discutés ci-dessous.
Pour commencer, voici les tests correspondants :
1@IsTest2private class CursorTest{3 @IsTest4 static void itCapsAdvanceByArgument(){5 String accountName = 'helloWorld!';6 insert new Account(Name = accountName);7 String query = 'SELECT Name FROM Account WHERE Name = :bindVar0';8 Map<String, Object>bindVars = new Map<String, Object>{'bindVar0' => accountName };910 Cursor instance = new Cursor(query, bindVars, System.AccessLevel.SYSTEM_MODE);1112 Assert.areEqual(1, instance.getNumRecords());13 Assert.areEqual(accountName, instance.fetch(0, 1000).get(0).get('Name'));14 Assert.areEqual(1, System.Limits.getApexCursorRows());15}1617 @IsTest18 static void itCapsMaxRecordsPerFetchCall(){19 Cursor.maxRecordsPerFetchCall = 20;20 Integer oneMoreThanMaxFetch = Cursor.maxRecordsPerFetchCall + 1;2122 List<Account>accounts = new List<Account>();23 for(Integer i = 0; i < oneMoreThanMaxFetch; i++){24 accounts.add(new Account(Name = 'Fetch ' + i));25}26 insert accounts;2728 Exception ex;29 List<SObject>results;30 Cursor instance = new Cursor(31 'SELECT Id FROM Account',32 new Map<String, Object>(),33 System.AccessLevel.SYSTEM_MODE34);35 try{36 results = instance.fetch(0, oneMoreThanMaxFetch);37}catch(System.InvalidParameterValueException e){38 ex = e;39}4041 Assert.areEqual(null, ex?.getMessage());42 Assert.areEqual(2, Limits.getFetchCallsOnApexCursor());43 Assert.areEqual(oneMoreThanMaxFetch, results.size());44}4546 @IsTest47 static void itFetchesMultipleTimesPerTransactionWhenMoreThanMaxFetch(){48 Cursor.maxRecordsPerFetchCall = 20;49 List<Account>accounts = new List<Account>();50 Set<String>expectedFetchNames = new Set<String>();51 for(Integer i = 0; i <Cursor.maxRecordsPerFetchCall + 1; i++){52 String accountName = 'Fetch' + i;53 expectedFetchNames.add(accountName);54 accounts.add(new Account(Name = accountName));55}56 insert accounts;5758 Integer oneMoreThanMaxFetch = Cursor.maxRecordsPerFetchCall + 1;59 Cursor instance = new Cursor(60 'SELECT Name FROM Account',61 new Map<String, Object>(),62 System.AccessLevel.SYSTEM_MODE63);64 List<SObject>results = instance.setFetchesPerTransaction(2).fetch(0, oneMoreThanMaxFetch);6566 Assert.areEqual(Cursor.maxRecordsPerFetchCall + 1, results.size());67 Assert.areEqual(2, Limits.getFetchCallsOnApexCursor());68 Set<String>actuallyFetchedNames = new Set<String>();69 for(Account account :(List<Account>) results){70 actuallyFetchedNames.add(account.Name);71}72 Assert.areEqual(expectedFetchNames, actuallyFetchedNames);73}7475 @IsTest76 static void itFetchesMultipleTimesPerTransaction(){77 Cursor.maxRecordsPerFetchCall = 1;78 insert new List<Account>{new Account(Name = 'One'), new Account(Name = 'Two')};7980 Cursor instance = new Cursor(81 'SELECT Id FROM Account',82 new Map<String, Object>(),83 System.AccessLevel.SYSTEM_MODE84)85 .setFetchesPerTransaction(2);86 List<SObject>results = instance.fetch(0, 2);8788 Assert.areEqual(2, instance.getNumRecords());89 Assert.areEqual(2, results.size());90 results = instance.fetch(2, 1);91 Assert.areEqual(0, results.size());92}9394 @IsTest95 static void fetchesCorrectAmountOfRecords(){96 List<Account>accounts = new List<Account>();97 for(Integer i = 0; i <10; i++){98 accounts.add(new Account(Name = 'Fetch ' + i));99}100 insert accounts;101102 Cursor instance = new Cursor(103 'SELECT Id FROM Account',104 new Map<String, Object>(),105 System.AccessLevel.SYSTEM_MODE106)107 .setFetchesPerTransaction(10);108 List<SObject>results = instance.fetch(0, 2);109110 Assert.areEqual(2, results.size(), '' + results);111 Assert.areEqual(1, Limits.getFetchCallsOnApexCursor());112}113114 @IsTest115 static void doesNotExceedPlatformMaxFetch(){116 List<Account>accounts = new List<Account>();117 for(Integer i = 0; i <101; i++){118 accounts.add(new Account(Name = 'Fetch ' + i));119}120 insert accounts;121122 Test.startTest();123 Cursor instance = new Cursor(124 'SELECT Id FROM Account',125 new Map<String, Object>(),126 System.AccessLevel.SYSTEM_MODE127)128 .setFetchesPerTransaction(100);129 Integer counter = 0;130 List<SObject>results;131 while(counter <= 100){132 results = instance.fetch(counter, counter + 1);133 counter++;134}135 Test.stopTest();136137 Assert.areEqual(101, counter);138 Assert.areEqual(0, results.size());139}140}
En rendant les Cursor virtuelles, les implémentations CursorStep concrètes peuvent fonctionner sans Database.Cursor lorsqu’elles n’ont pas besoin d’itérer un ensemble d’enregistrements volumineux, de la même façon qu’en renvoyant un System.Iterable<T> au lieu d’un Database.QueryLocator dans Apex batch. Voici un exemple :
1public abstract class CursorLikeImplementation extends CursorStep{2 private final Cursor cursorLike;34 public CursorLikeImplementation(List<SObject>previouslyRetrievedRecords){5 this.cursorLike = new CursorLike(previouslyRetrievedRecords);6}78 public override String getName(){9 return CursorLikeImplementation.class.getName();10}1112 public override Cursor getCursor(){13 return this.cursorLike;14}1516 private class CursorLike extends Cursor{17 private final List<SObject>records;1819 public CursorLike(List<SObject>records){20 super();21 this.records = records;22}2324 public override List<SObject>fetch(Integer position, Integer chunkSize){25 // clone, to keep the underlying list type26 List<SObject>clonedRecords = this.records.clone();27 clonedRecords.clear();28 for(Integer i = position; i <this.getAdvanceBy(position, chunkSize); i++){29 clonedRecords.add(this.records[i]);30}31 return clonedRecords;32}3334 public override Integer getNumRecords(){35 return this.records.size();36}37}38}
Notez que cette classe est également abstraite, elle laisse l'implémentation concrète de innerExecute à des sous-classes.
Il existe également une alternative à la sous-classe interne CursorLike. Si vous savez que les versions concrètes d'une étape comme celle-ci ne brûleront pas à travers les autres limites du gouverneur, vous pouvez renvoyer this.records depuis CursorLike.fetch et remplacer le CursorStep.shouldRestart() parent pour renvoyer false. Cela permet d'itérer sur une liste limitée uniquement par la limite en heap Apex de 12 Mo par transaction asynchrone.
Autres implémentations basées sur une étape possibles
Notre implémentation basée sur le curseur nous offre beaucoup de flexibilité lors de la pagination sur de grandes quantités de données. L'interface de Step, quant à elle, nous offre la flexibilité nécessaire pour décrire et encapsuler toutes sortes d'étapes.
Prenons une étape basée sur un flux :
1public virtual class FlowStep implements Step{2 private final Invocable.Action specificFlow;34 private Boolean shouldRestart = false;56 public FlowStep(String specificFlowName, Map<String, Object>inputs){7 this.specificFlow = Invocable.Action.createCustomAction('flow', specificFlowName);8 this.specificFlow.setInvocations(new List<Map<String,Object>>{ inputs });9}1011 public void execute(){12 List<Invocable.Action.Result>results = this.specificFlow.invoke();13 for(Invocable.Action.Result result : results){14 if(result.isSuccess()){15 Map<String, Object>outputParams = result.getOutputParameters();16 Object potentialShouldRestartValue = outputParams.get('shouldRestart');17 // Flow does not enforce Booleans being initialized18 // so a null check is sadly necessary here19 if(potentialShouldRestartValue != null){20 this.shouldRestart = this.shouldRestart ||21 Boolean.valueOf(potentialShouldRestartValue);22}23}else{24 List<String>errorMessages = new List<String>();25 for(Invocable.Action.Error error : result.getErrors()){26 errorMessages.add(27 'Error code: ' + error.getCode() +28 ', error message: ' + error.getMessage()29);30}31 Logger.error(32 'An error occurred within your auto-launched flow:\n' +33 String.join(errorMessages, '\n\t')34);35}36}37}3839 public virtual void finalize(){40 Logger.info(this.getName() + ' finished processing');41}4243 public String getName(){44 return FlowStep.class.getName() + ':' + this.specificFlow.getName();45}4647 public Boolean shouldRestart(){48 return this.shouldRestart;49}50}
Les flux ne peuvent pas renvoyer des paramètres de sortie conformes à un type défini par Apex. Par conséquent, nous vérifions la présence d'un paramètre de sortie shouldRestart avant de l'utiliser.
Certaines étapes peuvent être signalées par une fonctionnalité. Vous pouvez implémenter une logique pour décider des étapes à inclure ou utiliser une étape sans option pour une fonctionnalité désactivée. Le modèle Objet nul est un moyen courant de réduire la complexité dans la couche d'orchestration :
1@SuppressWarnings('PMD.EmptyStatementBlock')2public class NoOpStep implements Step{3 // The null object pattern is commonly implemented4 // as a singleton to reduce memory consumption5 public static final NoOpStep SELF {6 get {7 SELF = SELF ?? new NoOpStep();8}9 private set;10}1112 public void execute(){13}1415 public void finalize(){16}1718 String getName(){19 return NoOpStep.class.getName();20}2122 Boolean shouldRestart(){23 return false;24}25}
Nous avons maintenant plusieurs blocs de construction à travailler. Examinons la couche d'orchestration responsable de l'itération des étapes.
Création d'un processeur d'étape
Le processeur est un point d'inflexion dans l'architecture. Nous devons décider qui définit les étapes à initialiser et où. Les options comprennent :
Demandez au processeur de définir les étapes à mapper avec une logique métier. Cette option est simple, mais son échelle est faible pour la lisibilité.
Définissez le mappage avec des métadonnées personnalisées (CMDT). Les champs Relation des métadonnées ne prennent pas en charge les ApexClass, qui couplent vaguement l'orthographe du nom de classe dans la configuration de vos processus métiers. Vous pouvez réduire le risque administrateur en définissant le champ en tant que liste de sélection et en validant l'existence du type (Type.forName() ou en interrogeant des ApexClass), mais comme les enregistrements CMDT ne prennent pas en charge les déclencheurs, la validation est effectuée à l'exécution. Cet itinéraire peut être testé, mais les administrateurs peuvent créer des enregistrements CMDT uniquement en production.
Définissez le mappage avec des enregistrements. Les non-administrateurs peuvent configurer des étapes, mais les déploiements deviennent plus difficiles et les environnements peuvent dériver. Procédez avec précaution.
Il y a une citation célèbre de Clean Code sur la façon de gérer cette partie particulière de complexité :
La solution à ce problème est d'enterrer l'instruction switch [pour fabriquer des objets] dans le sous-sol d'une usine abstraite, et de ne jamais laisser personne la voir.
Avec cela à l'esprit, et parce que notre nombre actuel d'étapes est bien défini et qu'il est peu probable qu'il augmente trop, il est correct que le processeur d'étape soit également l'usine pour les étapes. Cela peut utiliser une énumération pour piloter l'instruction switch :
1public StepProcessor implements System.Queueable, System.Finalizer,2 Database.AllowsCallouts{3 private final List<Step>steps = new List<Step>();45 private Step currentStep;67 public StepProcessor setSteps(List<StepType> stepTypes){8 for(StepType type : stepTypes){9 switch on type {10 WHEN TYPE_ONE {11 this.addTypeOneSteps();12}13 WHEN TYPE_TWO {14 this.addTypeTwoSteps();15}16 // ... etc17}18}19 this.cleanSteps();20 return this;21}2223 public void execute(System.QueueableContext context){24 this.currentStep = this.currentStep ?? this.steps.remove(0);25 if(context != null){26 System.attachFinalizer(this);27 Logger.setAsyncContext(context);28}29 Logger.info('Executing step ' + this.currentStep.getName());30 try{31 this.currentStep.execute();32}catch(Exception e){33 Logger.exception('Unexpected exception', e);34}35 Logger.info('Finished executing step ' + this.currentStep.getName());36 Logger.saveLog();37}3839 public void execute(System.FinalizerContext context){40 Logger.info('Executing finalizer for step ' + this.currentStep.getName());41 Logger.setAsyncContext(context);42 switch on context?.getResult(){43 when UNHANDLED_EXCEPTION {44 // see the note below about this logging paradigm45 Logger.warn(46 'Failed to run on step' + this.currentStep,47 context?.getException()48);49}50 when else{51 this.currentStep.finalize();52 if(this.currentStep.shouldRestart()){53 this.kickoff();54}else if(this.steps.isEmpty() == false){55 this.currentStep = this.steps.remove(0);56 this.kickoff();57}else{58 Logger.info('Finished executing steps');59}60}61}62 Logger.info(63 'Finished executing finalizer for step ' +64 this.currentStep.getName()65);66 Logger.saveLog();67}6869 public String kickoff(){70 return this.steps.isEmpty()? null : System.enqueueJob(this);71}7273 private void cleanSteps(){74 for(Integer reverseIndex = this.steps.size() - 1;75 reverseIndex >= 0; reverseIndex--){76 if(this.steps[reverseIndex]instanceof NoOpStep){77 this.steps.remove(reverseIndex);78}79}80}8182 private void addTypeOneSteps(){83 this.steps.addAll(84 new List<Step>{85 new ExampleCursorStepOne(),86 new ExampleCursorStepTwo()87}88);89}9091 private void addTypeTwoSteps(){92 this.steps.addAll(93 new List<Step>{94 new FlowStep('95 ExampleInvocableName',96 new Map<String, Object>('exampleParameter' =>true)97),98 new ExampleCursorStepThree()99}100);101}102}
Les méthodes d'usine affichées, par exemple addTypeOneSteps(), peuvent déléguer des problèmes tels que le marquage des fonctionnalités. cleanSteps() effectue un contrôle unique des étapes rassemblées pour s'assurer qu'il n'y a pas d'étapes « vides » avant la synchronisation. Ça pourrait ressembler à ça :
Nous n'avons pas abordé le traitement des erreurs depuis que nous avons mentionné Nebula Logger dans la section Flux planifié. En effet, System.Finalizer nous permet de couvrir la consignation de toutes les conditions d'erreur sans ajouter de traitement spécifique des erreurs à chaque étape. Chaque Step se concentre sur la course à pied, tandis que nous consignons et renversons tous les chemins malheureux afin qu'ils soient exposés dans des tests unitaires. Cela prend en charge l'itération sécurisée et les alertes au niveau de la production (en utilisant le plug-in Slack Logger pour Nebula pour tous les journaux WARN et ERROR).
Une remarque concernant la consignation des erreurs: transmettre l'instance de l'étape dans des messages de consignation suppose un niveau de Trust dans ce qui devient visible dans les journaux. La toString() par défaut des classes Apex inclut dans le message toutes les propriétés statiques et au niveau de l'instance. Cela peut être souhaitable — ou cela peut divulguer des informations confidentielles. Bien que la consignation et la sécurité ne soient pas au centre des préoccupations ici, notez que pour certains systèmes, l'adhésion à une interface telle que Step peut également impliquer de forcer un remplacement pour toString().
Une telle méthode impose à chaque créateur d'objet de décider ce qui est autorisé à imprimer, ce qui peut être souhaitable.
Au niveau de la consignation : au niveau StepProcessor, nous utilisons INFO, le niveau sans erreur le plus élevé. À mesure que vous gagnez en précision dans l'application, les niveaux de consignation devraient diminuer en conséquence. Les étapes individuelles peuvent utiliser des DEBUG pour des informations générales, les FINE, FINER et FINEST étant réservés à des produits de plus en plus détaillés. La consignation est autant un art qu'une science, mais suivre ces principes permet de garder les journaux cohérents et utiles.
Traitement de complexité supplémentaire dans le processeur de l'étape
Avant de passer à autre chose, réfléchissons brièvement à la décision de laisser notre processeur d'étape héberger la logique pour laquelle les étapes sont utilisées. Dans une vaste base de codes, vous pouvez définir des StepProcessor virtuelles ou abstraites, et demander aux sous-classes d'identifier des étapes spécifiques pour établir une séparation appropriée des préoccupations.
La couche invocable Apex
Le planificateur finit par invoquer Apex . Une fois le reste de la configuration terminée, la section Apex invocable peut décider quelles étapes doivent être exécutées et transmettre le List<StepType> au processeur :
1public class DailyJobExecutor{2 @InvocableMethod(label='Execute Daily Job')3 public static void executeJob(){4 Logger.info('Executing daily Job');56 List<StepType>correspondingTypes = new List<StepType>();7 // based on [business logic], determine which step types8 // should be included for any daily invocation910 if(correspondingTypes.isEmpty() == false){11 try{12 new StepProcessor().setSteps(correspondingTypes).kickoff();13}catch(Exception ex){14 Logger.exception('Error starting job', ex);15}16}17}1819 Logger.saveLog();20}
Il s'agit d'une partie simple de l'équation, qui utilise des enregistrements, des données ou une logique pour déterminer les types d'étape à exécuter. L'action invocable est simple, car nous avons encapsulé la complexité ailleurs. Nous avons également protégé contre les exceptions inattendues et facilité le test de chaque pièce isolée.
Traitement des délais avant d'appeler Slack
Le Kit de développement Apex Slack dépasse le cadre de cet article, mais il convient de revenir sur l ' un des problèmes potentiels liés aux exigences : notifier les personnes de rang supérieur dans la hiérarchie des rôles en fonction d ' un délai configurable. Sur le papier, c'est simple, et vous pourriez (correctement) considérer la System.enqueueJob(this) dans le StepProcessor. Avec System.AsyncOptions, notre penchant initial était d'utiliser la surcharge de enqueueJob pour satisfaire cette exigence.
Pour le moment, cependant, le délai maximal via System.AsyncOptions.MinimumQueueableDelayInMinutes est de 10 minutes. Comme l'exigence est de 120 minutes, il reste quelques options. Une approche naïve pourrait ressembler à ceci :
1public class ExampleDelayedNotifier implements Step{2 private final List<Slack.ChatPostMessageRequest>notifications = new List<Slack.ChatPostMessageRequest>();3 private final Slack.BotClient botClient = Slack.App4 .getAppByKey('some-slack-app-key')5 .getBotClientForTeam('slack team id');67 // account for the initial delay,8 // so 120 - 10 = 1109 private Integer delayMinutes = 110;1011 public void execute(){12 if(this.delayInMinutes>0){13 return;14}1516 Integer maximumAllowedCallouts = 100;17 while(this.notifications.isEmpty() == false && maximumAllowedCallouts >0){18 this.botClient.chatPostMessage(this.notifications.remove(0));19 maximumAllowedCallouts--;20}21}2223 public void finalize(){24 this.delayInMinutes -= 10;25}2627 public String getName(){28 return ExampleDelayedNotifier.class.getName();29}3031 public Boolean shouldRestart(){32 return this.delayInMinutes>0 || this.notifications.isEmpty() == false;33}34}
En pratique, le délai serait transmis dans cette classe, car il est piloté par la configuration.
Nous recommandons cette approche, sauf si vous êtes certain qu'il n'y aura jamais qu'un seul type de notification retardée. Il brûle 11 tâches asynchrones supplémentaires avant de démarrer (ou plus, si le délai augmente). Ce coût peut convenir pour un seul travail, pas pour beaucoup. Vous devez également ajouter une méthode à l'interface de Step afin que chaque étape indique au processeur le temps d'attente avant le redémarrage, ce qui ajoute du bruit.
Cela nous laisse deux possibilités intéressantes :
Vous pouvez insérer l'étape retardée dans votre infrastructure de travail existante si vous avez déjà planifié une tâche d'interrogation à un intervalle approprié. Vous devriez également être d'accord avec le délai spécifié frappant jusqu'à 15 minutes plus tard (15 minutes est l'intervalle d'actualisation minimum pour une expression CRON planifiée Apex). Cela correspond à peu près à l'exemple Apex invocable; la planification est effectuée à la place via Apex. En d'autres termes, vous pouvez réutiliser la même architecture basée sur l'Step pour traiter les enregistrements basés sur un horodatage « Commencer après » et choisir les étapes à utiliser en fonction d'un mappage de liste de sélection ou de liste à sélection multiple avec les valeurs d'énumération StepType précédemment affichées.
Alternativement, si vous êtes à l’aise pour définir une classe Apex externe supplémentaire, rabattez-vous sur Apex par lot (contrairement à Apex Queueable, qui prend en charge les classes internes, les classes Apex par lot doivent être des classes externes) en utilisant System.scheduleBatch().
Prenons l'exemple Apex par lot. Bien que nous recommandons généralement Apex Queueable pour la flexibilité et le contrôle, c'est un cas où Apex Batch règne toujours en maître:
1public class DelayedNotifier implements Database.Batchable<Object>{2 private final StepProcessor processor = new StepProcessor();34 public Iterable<Object>start(Database.BatchableContext bc){5 return new List<Object>();6}78 @SuppressWarnings('PMD.EmptyStatementBlock')9 public void execute(Database.BatchableContext bc, Object scope){10 // we don't need to actually do anything in execute,11 // we just need to start up the processor in finish12}1314 public void finish(Database.BatchableContext bc){15 try{16 // you can imagine Notifier as an elided,17 // simpler version of the naive implementation18 // we showed above, now only focused on sending messages19 this.processor.setSteps(new List<Step>{new Notifier()}).kickoff();20}catch(Exception ex){21 Logger.exception('Unexpected error', ex);22}finally{23 Logger.saveLog();24}25}26}
Imaginez ensuite, dans le StepProcessor, que la méthode de addTypeOneSteps() précédemment montrée soit mise à jour avec cette étape retardée :
1public StepProcessor implements System.Queueable, System.Finalizer,2 Database.AllowsCallouts{3 // .... unchanged top of class elided45 private void addTypeOneSteps(){6 this.steps.addAll(7 new List<Step>{8 new ExampleCursorStepOne(),9 new ExampleCursorStepTwo(),10 new DelayedNotifierStep()11}12);13}1415 // ...1617 private class DelayedNotifierStep implements Step{18 private final DelayedNotifier delayedNotifier = new DelayedNotifier();19 // again — in practice this value would also be passed in20 private final Integer delayInMinutes = 120;2122 public void execute(){23 System.scheduleBatch(24 this.delayedNotifier,25 'Delayed notifier: ' + System.now().getTime(),26 this.delayInMinutes27);28}2930 public void finalize(){31 Logger.debug('Nothing to finalize, batch scheduled');32}3334 public String getName(){35 return DelayedNotifierStep.class.getName();36}3738 public Boolean shouldRestart(){39 return false;40}41}42}
Nous recommandons généralement de ne pas sauter autant, mais ce délai d'étape devient un autre bloc de construction réutilisable. Tant que des délais plus longs ne sont pas autorisés dans Apex Queueable, cela représente également la méthode la plus simple pour produire cet effet (sans mécanisme d'interrogation, comme discuté).
Conclusion
Nous avons utilisé la conception orientée objet pour répondre aux exigences et créé un système qui s'adapte tout en équilibrant les coûts à long terme de construction et de maintenance. Bien que la déclaration et l'instanciation d'étapes finissent par l'emporter sur leur place dans le StepProcessor, il n'y a guère de dette technique supplémentaire ici. Avec FlowStep, les administrateurs et les développeurs peuvent décider ensemble quand les solutions sans code ou pro-code sont les plus pertinentes.
En utilisant l'interface System.Finalizer dans l'infrastructure Queueable d'Apex, avec Nebula Logger, nous avons construit un système robuste et testable qui nous alerte des échecs imprévus même si les étapes futures n'ont pas de consignation explicite. Pour nous, ce système réduit heureusement les chiffres et réduit les coûts et la complexité. Il nous a également fourni des connaissances précieuses sur le comportement des curseurs Apex sous de réelles charges de travail, nous aidant à affiner notre approche tout en améliorant la fonctionnalité elle-même.
En décomposant les charges de travail complexes et à haut volume en étapes d'exécution modulaires, l'infrastructure de traitement asynchrone basé sur des étapes transforme les contraintes de la plate-forme en avantages techniques, ce qui permet des performances prévisibles, l'observabilité et la gouvernance à l'échelle de l'entreprise. Les étapes peuvent être configurées par les administrateurs et les développeurs, et dans les deux cas, les auteurs d'étapes peuvent se concentrer en toute sécurité sur le respect des limites du gouverneur de plate-forme de base (par exemple les lignes DML et les lignes de requête récupérées) sans se soucier de la mise à l'échelle de chaque étape.
Chemin à suivre
Pour rendre opérationnel et adopter ce schéma dans toutes les implémentations d'entreprise, les architectes doivent :
Évaluez les automatisations existantes afin d'identifier les zones dans lesquelles l'orchestration asynchrone peut aider à améliorer les performances et l'observabilité.
Décomposez les grands processus en étapes exécutables discrètes et indépendantes avec des objectifs de traitement clairs et des points d'auteur discrets (comme Flow ou Apex).
Définissez et regroupez les types d'étape pour accélérer la réutilisation et la normalisation des étapes entre les unités commerciales.
Pilote l'approche avec de nouveaux processus ou des automatisations existantes. Vous serez peut-être surpris de constater le nombre de cas de bord que vous trouvez gratuitement dans les étapes, les soins de votre consignation intégrée et l'observabilité !
À propos de l'auteur
James Simone est ingénieur logiciel principal chez Salesforce et possède plus d'une décennie d'expérience sur la plate-forme. Il était client de Salesforce – et propriétaire de produits – avant de se lancer dans le développement, et écrit des plongées techniques approfondies sur Salesforce depuis 2019 dans Les Joies d’Apex. Il a déjà publié des articles sur le blog Salesforce Developer et le blog Salesforce Engineering également.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.
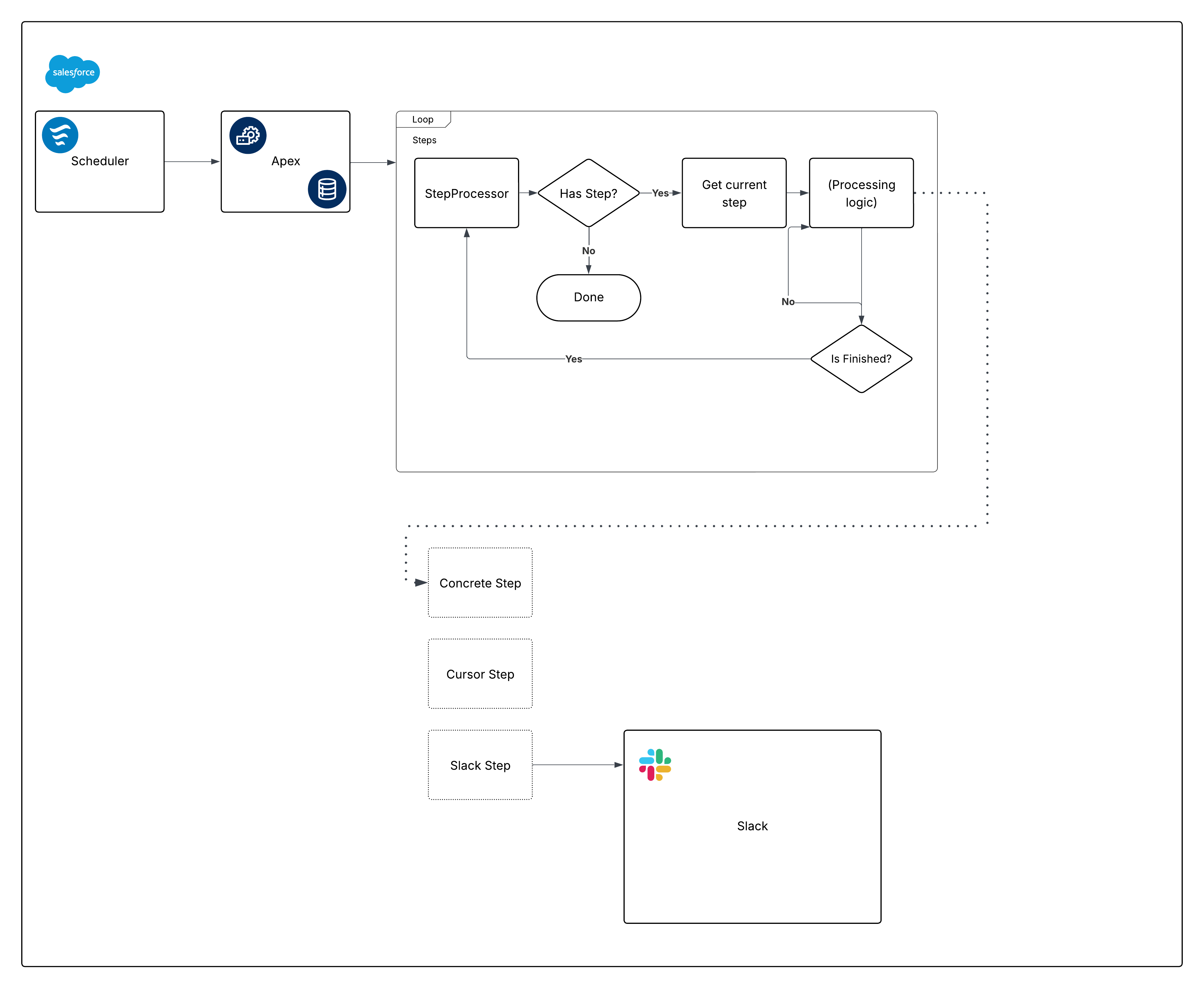 Maintenant, décomposez ce diagramme et commencez à construire les pièces.
Maintenant, décomposez ce diagramme et commencez à construire les pièces.