Le moderne architetture Salesforce sono sempre più basate sull'elaborazione asincrona, non come comodità, ma come requisito strategico per la scalabilità. Negli ultimi anni, abbiamo visto sempre più aziende alle prese con volumi di dati crescenti, integrazioni complesse che coinvolgono più touchpoint e l'ascesa di sistemi autonomi in esecuzione 24/7/365. Tutte queste cose spingono gli architetti verso la progettazione di sistemi che sono asincroni.
L'elaborazione asincrona in Salesforce spesso implica la necessità di aggirare i limiti e la complessità del governor. Questi limiti fungono da guardrail e vincoli architetturali che aiutano a produrre sistemi scalabili e sicuri in blocco. Benché nessun limite della piattaforma serva direttamente a gestire la complessità, gli schemi di progettazione possono contribuire a mitigare i rischi su questo fronte. Internamente, Salesforce spesso supera i limiti della piattaforma per testare in avanti le nuove funzioni e automatizzare i processi aziendali complessi. Abbiamo creato un framework di elaborazione asincrona basato su fasi per l'esecuzione di processi asincroni con un numero arbitrario di passaggi. Ogni fase può essere eseguita, riprovata e riavviata in modo indipendente con controlli di governance condivisi e visibilità operativa completa tramite la registrazione centralizzata. Questo documento ne descrive i componenti architettonici chiave: Apex e finalizzatori in area di attesa, flusso pianificato, cursori Apex, azioni invocabili e integrazioni con Slack. Insieme, questi componenti offrono un'architettura modulare, scalabile e osservabile adatta alle esigenze aziendali in evoluzione.
- Le moderne architetture Salesforce dovrebbero adottare un approccio asincrono per ottenere scalabilità, affidabilità e trasparenza operativa.
- Suddividere il lavoro complesso in fasi eseguibili in modo indipendente consente prestazioni prevedibili, tentativi più sicuri, checkpointing, ritiro ed evoluzione modulare senza riprogettare i flussi di lavoro principali.
- Il framework offre un'alternativa scalabile ai processi batch monolitici e datati, alle chiamate asincrone concatenate e ai flussi profondamente nidificati ed è creato per carichi di lavoro a volume elevato che devono essere scalati orizzontalmente all'interno di Salesforce senza orchestrazione esterna alla piattaforma.
- L'esecuzione deterministica e osservabile garantisce il tracciamento dell'avanzamento, il monitoraggio degli SLA, la diagnostica dei guasti e la trasparenza a livello di controllo tramite la registrazione e la governance centralizzate.
- Progettato per un rigore di livello aziendale, che include governance unificata, conformità e controllo statale distribuito in processi aziendali di lunga durata.
Prima di rivedere i requisiti, di seguito sono riportate alcune cose da fare e da non fare per quando utilizzare un framework come questo. Soprattutto, considerare quale sistema è l'unica fonte di verità. Se l'organizzazione Salesforce si basa in minima parte su dati esterni ma deve scalare da centinaia a milioni di record, considerare un framework asincrono basato su fasi.
Utilizzare questo framework se**:**
- La maggior parte (o tutte) le informazioni su cui intervenire esistono già nel CRM.
- Il costo iniziale o continuativo del mantenimento di un processo ETL (Extract Transform Load) per armonizzare i dati esterni è troppo elevato.
- È necessario rinviare l'elaborazione di un numero elevato di record Salesforce secondo una pianificazione impostata.
- È possibile suddividere l'elaborazione in fasi discrete. Ad esempio, è possibile creare un insieme di record gerarchico o basato su albero, in particolare se il volume di dati si estende verso il basso nella gerarchia o nella struttura.
Non utilizzare questo framework se:
- La creazione o l'aggiornamento dei record richiede un ricalcolo immediato.
- L'integrazione è difficile perché i sistemi esterni ospitano i dati principali per gli aggiornamenti dei record. Considerare la possibilità di inviare i dati aggiornati a Salesforce con l'API in blocco.
Tenendo presenti queste procedure, rivedere i requisiti e iniziare a creare.
Considerare l'istruzione del problema:
Dato un processo che deve essere eseguito quotidianamente, verificare se alcuni record soddisfano criteri prestabiliti per un'ulteriore elaborazione. Se lo fanno, avviare quei processi di elaborazione. L'elaborazione dei record può richiedere l'estrazione di dati da più sistemi esterni per eseguire calcoli. Le fasi dei processi devono informare le persone tramite Slack che i record elaborati sono pronti per la revisione. Le fasi dovrebbero anche inoltrare le notifiche ai responsabili e ai livelli superiori della gerarchia dei ruoli in base a un ritardo configurabile dopo la prima serie di notifiche.
Questo problema comporta diversi passaggi, alcuni dei quali possono verificarsi indipendentemente l'uno dall'altro. Esistono molti modi per suddividere il lavoro. Ecco un raggruppamento:
- Il pianificatore.
- L'interfaccia della fase e le implementazioni concrete che elaborano i record (indipendentemente dal tipo di elaborazione).
- Processore che organizza le fasi.
- Apex invocabile chiamato dallo strumento di pianificazione.
- Il pezzo di notifica. Usiamo l'Apex Slack SDK.
- C'è una certa complessità nascosta nella frase "ritardo configurabile". Esamineremo questa complessità più avanti in questo articolo.
Di seguito è riportato un diagramma ponderato per il framework predefinito:
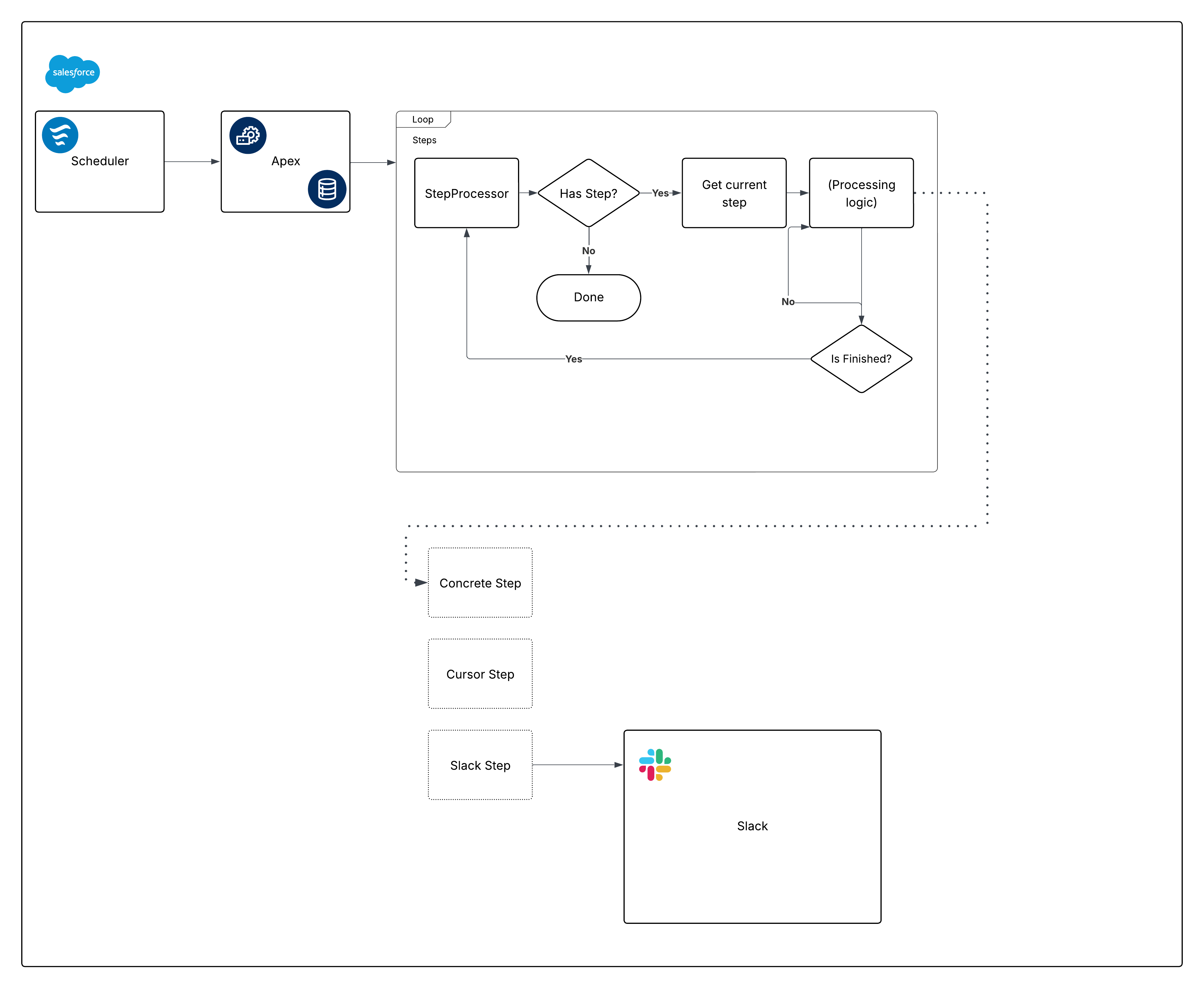 Ora, scomponi il diagramma e inizia a costruire i pezzi.
Ora, scomponi il diagramma e inizia a costruire i pezzi.
Flusso pianificato offre diversi vantaggi come meccanismo di pianificazione:
- I flussi pianificati possono essere inseriti in pacchetti e distribuiti come metadati. Questo non è vero per i processi pianificati tramite Apex (o tramite la pagina Processi pianificati).
- L'elemento Attesa è fondamentale per i framework che richiedono chiamate. Utilizzandola nel flusso, le chiamate non sono necessarie nella parte Invocabile del framework.
- La granularità della pianificazione soddisfa i requisiti: l'intervallo minimo per i flussi pianificati è giornaliero. Se è necessaria una frequenza più alta (ad esempio, oraria), riconsiderare Flusso pianificato per questo requisito.
Un'altra considerazione quando si configura il flusso pianificato è il gating dell'ambiente. Prima di invocare l'azione Apex, aggiungere un elemento Decisione che valuta la variabile {!$Api.Enterprise_Server_URL_100}. Ciò garantisce che il processo venga eseguito solo negli ambienti previsti, ad esempio UAT e Produzione. Questo schema è importante perché i Sandbox vengono aggiornati di frequente o creati di recente durante l'SDLC e, senza un controllo esplicito dell'ambiente, un flusso pianificato potrebbe essere eseguito involontariamente in ambienti in cui il framework non è progettato per l'esecuzione. L'uso dell'operatore contains nell'elemento Decisione rende l'impostazione resiliente alle future creazioni Sandbox o modifiche degli URL.
Infine, considerare in che modo il framework dovrebbe acquisire gli errori. Aggiungere sempre un percorso di errore quando il flusso chiama un'azione; ad esempio, è possibile collegare i guasti all'azione "Aggiungi voce registro" di Nebula Logger. Nebula Logger scrive i registri negli oggetti personalizzati, quindi i clienti devono sapere che i dati dei registri consumano memoria dell'organizzazione: per impostazione predefinita, i registri vengono memorizzati per 14 giorni all'interno di un'organizzazione e quindi puliti; questo periodo di conservazione è configurabile. Nebula Logger utilizza anche Eventi piattaforma per pubblicare i registri, quindi le voci di registro vengono salvate indipendentemente dalla transazione di elaborazione dati principale, in modo da garantire l'acquisizione degli errori anche se l'azione Flusso principale o Apex viene ritirata. I clienti devono valutare il volume dei registri previsto e i requisiti di conservazione quando valutano l'aggiunta di un framework di registrazione.
Ecco come si presenta il flusso:
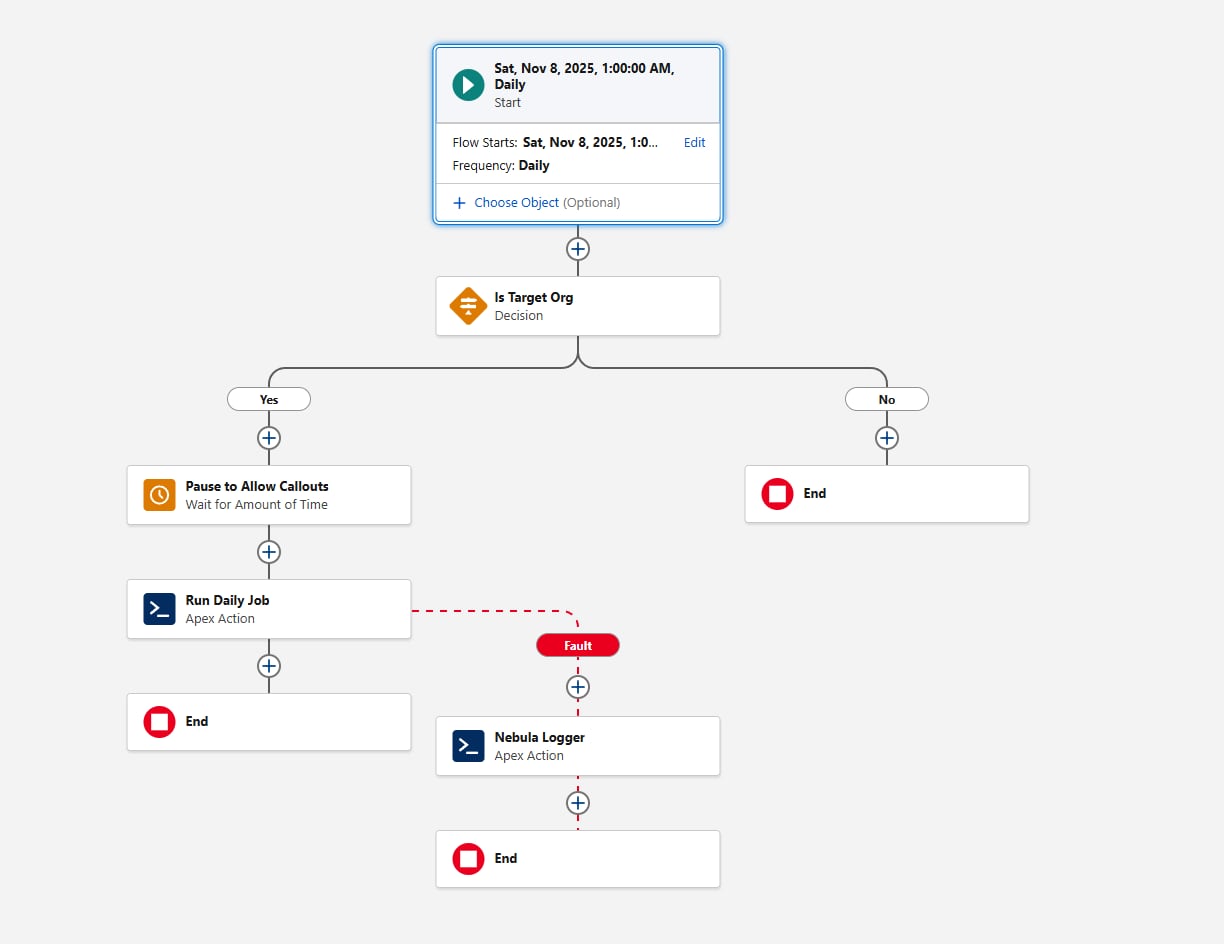
Passiamo alle prime parti di Apex Code con il requisito di pianificazione ora soddisfatto.
Definire un'interfaccia Step:
Per questo articolo, l'interfaccia step viene visualizzata come classe esterna per chiarezza. Il framework è flessibile: i team possono organizzare l'interfaccia e le relative implementazioni utilizzando qualsiasi schema di creazione pacchetti Apex preferito, a condizione che tutte le classi Fase facciano riferimento alla stessa interfaccia.
Ci sono alcune cose da notare sui metodi definiti nella nostra interfaccia:
- La
execute, anche se al momento non richiede argomenti, migliora quando si passa una classe diState(o interfaccia) per orchestrare i dati tra le fasi quando l'ordine è importante. getNamepotrebbe restituire un valoreSystem.Typeanziché unString. L'obiettivo è fornire al livello di orchestrazione un modo per registrare i nomi delle fasi senza esporre altre proprietà.
Ecco la prima implementazione concreta che mostra come questi pezzi si adattano. Con un'eccezione in seguito, si consiglia di utilizzare Queueable Apex per implementare l'elaborazione asincrona in Apex; Batch Apex è in genere inutile (e i metodi di @future sono scoraggiati). Queueable Apex si avvia rapidamente e, con i cursori Apex, presenta molti vantaggi rispetto a Batch Apex.
I cursori Apex offrono un'alternativa moderna al modello Apex batch tradizionale. Analogamente all'elaborazione batch, un'implementazione Cursore può recuperare i record in blocchi (fino a 2.000 per batch). Tuttavia, i Cursori consentono più recuperi all'interno di una singola transazione, consentendo una produttività significativamente superiore per le operazioni a volume elevato.
Quando si adottano i Cursori come parte di questo framework, i team devono essere consapevoli delle limitazioni attuali dei test e della possibilità di falsificazione. Il comportamento del cursore nei test può essere diverso dal comportamento di produzione, quindi è importante progettare strategie di test che evitino di affidarsi ai componenti interni del cursore e convalidino invece la logica di orchestrazione ai confini. Man mano che la piattaforma si evolve, queste aree continueranno a migliorare, ma le linee guida principali rimangono: I cursori offrono prestazioni superiori e un sovraccarico di orchestrazione ridotto rispetto ad Apex batch per molti casi d'uso.
Per definire un confine chiaro tra il Cursore fornito dal sistema e il proprio codice, si consiglia di creare una rappresentazione simile al Cursore quando si implementa l'interfaccia Step. Considerare questo codice:
Notare la classe Cursor. I cursori Apex sono esempi di Database.Cursor, ma la nostra implementazione di Cursor ci offre flessibilità per risolvere le carenze dei cursori. Ecco l'implementazione:
Per il resto di questo articolo, omettiamo le dichiarazioni sharing quando ci riferiamo alle classi Apex. In pratica, assicurarsi che le classi di livello superiore utilizzino esplicitamente con o senza condivisione per conformarsi al modello di oggetto e alle autorizzazioni.
Si noti inoltre che l'implementazione di Cursor delega all'Database.Cursor piattaforma, con ulteriori vantaggi descritti di seguito.
Innanzitutto, ecco i test corrispondenti:
Rendendo virtuali i Cursor, le implementazioni di CursorStep concrete possono funzionare senza Database.Cursor quando non è necessario ripetere un insieme di record di grandi dimensioni, come quando si restituisce un System.Iterable<T> anziché un Database.QueryLocator in Batch Apex. Ecco un esempio:
Tenere presente che, poiché questa classe è anche astratta, lascia l'implementazione concreta di innerExecute alle sottoclassi.
Esiste anche un'alternativa alla sottoclasse interna CursorLike. Se si sa che le versioni concrete di un passaggio come questo non supereranno altri limiti del governor, è possibile restituire this.records da CursorLike.fetch e sostituire il CursorStep.shouldRestart() controllante per restituire false. Ciò consente di eseguire l'iterazione su un elenco delimitato solo dal limite di heap Apex di 12 MB per transazione asincrona.
La nostra implementazione basata sul cursore offre molta flessibilità quando si esegue la paginazione su grandi quantità di dati. L'interfaccia Step, nel frattempo, ci offre la flessibilità di descrivere e incapsulare fasi di ogni tipo.
Considerare una fase basata su flusso:
Poiché i flussi non possono restituire parametri di output conformi a un tipo definito da Apex, viene verificato un parametro di output shouldRestart prima di utilizzarlo.
Alcuni passaggi potrebbero essere contrassegnati dalla funzione. È possibile implementare la logica per decidere quali fasi includere, oppure utilizzare una fase no-op per una funzione disabilitata. Lo schema Oggetto nullo è un metodo comune per ridurre la complessità all'interno del livello di orchestrazione:
Ora abbiamo un bel po' di elementi base su cui lavorare. Vediamo il livello di orchestrazione responsabile dell'iterazione delle fasi.
Il processore è un punto di flessione nell'architettura. Dobbiamo decidere chi definisce quali fasi vengono inizializzate e dove. Le opzioni includono:
- Chiedere al processore di definire le fasi da mappare alla logica aziendale. Questa opzione è semplice, ma la scalabilità è scarsa.
- Definire la mappatura con i metadati personalizzati (CMDT). I campi Relazione metadati non supportano
ApexClass, che associa in modo non preciso l'ortografia dei nomi delle classi nell'impostazione dei processi aziendali. È possibile ridurre il rischio per l'amministratore impostando il campo come elenco di selezione e convalidando l'esistenza del tipo (Type.forName()o eseguendo query suApexClass), ma poiché i record CMDT non supportano i trigger, la convalida avviene in fase di esecuzione. Questo percorso è testabile, ma gli amministratori possono comunque creare record CMDT solo in produzione. - Definire la mappatura con i record. I non amministratori possono configurare le fasi, ma le distribuzioni diventano più complesse e gli ambienti possono andare alla deriva. Procedere con cautela.
C'è una famosa citazione da Clean Code su come gestire questo particolare pezzo di complessità:
La soluzione a questo problema è seppellire la dichiarazione di
switch[per fare oggetti] nel seminterrato di una fabbrica astratta, e non farla mai vedere a nessuno.
Tenendo presente ciò, e poiché il nostro numero attuale di fasi è ben definito e difficilmente crescerà troppo, è normale che il processore di fasi sia anche la fabbrica per le fasi. Questo può utilizzare un enum per guidare l'istruzione switch:
E poi per la nostra StepProcessor:
I metodi di fabbrica visualizzati, ad esempio addTypeOneSteps(), possono delegare preoccupazioni come la segnalazione delle funzioni; cleanSteps() esegue un controllo singolo sulle fasi raccolte per assicurarsi che non vi siano fasi "vuote" prima di passare alla vera asincrona. Potrebbe essere simile a questo:
Non abbiamo più discusso della gestione degli errori dopo aver menzionato Nebula Logger nella sezione Flusso pianificato. Questo perché System.Finalizer ci consente di coprire la registrazione per tutte le condizioni di errore senza aggiungere una gestione specifica degli errori in ogni fase. Ogni Step si concentra sull'esecuzione, mentre noi registriamo e revochiamo eventuali percorsi non felici in modo che emergano nei test di unità. Questo supporta l'iterazione sicura e gli avvisi a livello di produzione (utilizzando il plug-in Slack Logger per Nebula per tutti i registri WARN ed ERROR).
Una nota sulla registrazione degli errori: il passaggio dell'istanza della fase nei messaggi di registro presuppone un livello di Trust in ciò che diventa visibile nei registri. Il toString() predefinito per le classi Apex include tutte le proprietà statiche e a livello di istanza nel messaggio. Questo può essere auspicabile, oppure può far trapelare informazioni sensibili. Anche se la registrazione e la sicurezza non sono al centro dell'attenzione, tenere presente che per alcuni sistemi, l'osservanza di un'interfaccia come Step può anche comportare la forzatura di una sostituzione per toString().
Tale metodo impone a ogni creatore di oggetti di decidere che cosa è consentito stampare, il che può essere auspicabile.
A livello di registrazione: a livello di StepProcessor, viene utilizzato INFO, il livello massimo senza errori. Man mano che si aumenta la granularità dell'applicazione, i livelli di registrazione dovrebbero diminuire di conseguenza. Singole fasi potrebbero utilizzare DEBUG per informazioni di alto livello, con FINE, FINER e FINEST riservati a output sempre più dettagliati. Registrare è un'arte quanto una scienza, ma seguire questi principi aiuta a mantenere i registri coerenti e utili.
Prima di procedere, riflettiamo brevemente sulla decisione di fare in modo che il nostro processore di fasi ospiti la logica per cui vengono utilizzati i passaggi. In una base di codice di grandi dimensioni, valutare la possibilità di rendere i StepProcessor virtuali o astratti e fare in modo che le sottoclassi individuino passaggi specifici per stabilire una separazione corretta delle preoccupazioni.
Lo strumento di pianificazione alla fine invoca Apex. Con il resto dell'impostazione completato, la sezione Apex invocabile può decidere quali fasi eseguire e passare il List<StepType> al processore:
Questa è una parte semplice dell'equazione: utilizzare record, dati o logica per determinare quali tipi di fasi eseguire. L'azione invocabile è semplice perché la complessità è stata incapsulata altrove. Abbiamo anche protetto da eccezioni impreviste e reso ogni pezzo facile da testare in isolamento.
L'SDK Apex Slack esula dall'ambito di questo articolo, ma vale la pena rivedere un potenziale intoppo dei requisiti: informare le persone in alto nella gerarchia dei ruoli in base a un ritardo configurabile. Sulla carta, questo è semplice e potresti (correttamente) considerare la System.enqueueJob(this) nel StepProcessor. Con System.AsyncOptions, la nostra inclinazione iniziale era di utilizzare il sovraccarico di enqueueJob per soddisfare questo requisito.
Per ora, invece, il ritardo massimo via System.AsyncOptions.MinimumQueueableDelayInMinutes è di 10 minuti. Poiché il requisito è 120 minuti, rimangono alcune opzioni. Un approccio ingenuo potrebbe essere il seguente:
In pratica, il ritardo verrebbe passato a questa classe perché è determinato dalla configurazione.
Questo approccio non è consigliabile a meno che non si sia certi che sarà sempre presente un solo tipo di notifica ritardata. Viene masterizzato in 11 processi asincroni aggiuntivi prima di iniziare (o più, se il ritardo aumenta). Quel costo potrebbe andare bene per un lavoro, non per molti. È anche necessario aggiungere un metodo all'interfaccia Step in modo che ogni fase possa indicare al processore quanto tempo attendere prima di riavviare, il che aggiunge rumore.
Questo ci lascia con due possibilità interessanti:
- È possibile inserire la fase ritardata nel framework lavorativo esistente se è già stato pianificato un processo di polling a un intervallo appropriato. Dovrebbe anche essere possibile che il ritardo specificato arrivi fino a 15 minuti dopo (15 minuti è l'intervallo di aggiornamento minimo per un'espressione CRON pianificata Apex). Corrisponde grosso modo all'esempio Apex invocabile; la pianificazione viene eseguita tramite Apex. In altre parole, è possibile riutilizzare la stessa architettura basata su
Stepper elaborare i record in base a un'indicazione oraria "Inizia dopo" e decidere quali fasi utilizzare in base a un elenco di selezione o a una mappatura elenco di selezione a selezione multipla ai valoriStepTypeenum visualizzati in precedenza. - In alternativa, se si preferisce definire una classe Apex esterna aggiuntiva, ripiegare su Batch Apex (a differenza di Queueable Apex, che supporta le classi interne, le classi Batch Apex devono essere classi esterne) utilizzando
System.scheduleBatch().
Si consideri l'esempio Batch Apex. Benché in genere si raccomandi Queueable Apex per flessibilità e controllo, questo è un caso in cui Batch Apex regna ancora sovrano:
E poi, nel StepProcessor, si immagini che il metodo di addTypeOneSteps() mostrato in precedenza venga aggiornato con questo passaggio ritardato:
Anche se in genere non raccomandiamo di fare così tanti salti mortali, questo ritardo della fase diventa un altro elemento fondamentale riutilizzabile. Finché non sono consentiti ritardi più lunghi in Queueable Apex, rappresenta anche il modo più semplice per produrre questo effetto (senza un meccanismo di polling, come discusso).
Per soddisfare i requisiti, abbiamo utilizzato la progettazione orientata agli oggetti e creato un sistema che si espanderà bilanciando i costi di costruzione e manutenzione a lungo termine. Benché la dichiarazione e l'istanziazione delle fasi possano in ultima analisi superare il loro posto in StepProcessor, in questo caso l'indebitamento tecnico aggiuntivo è minimo. Con FlowStep, amministratori e sviluppatori possono decidere insieme quando le soluzioni no-code o pro-code hanno più senso.
Utilizzando l'interfaccia System.Finalizer all'interno del framework Queueable di Apex, insieme a Nebula Logger, abbiamo creato un sistema robusto e testabile che ci avvisa in caso di errori imprevisti anche se le fasi future non prevedono una registrazione esplicita. Per noi, questo sistema sta felicemente snocciolando numeri e riducendo costi e complessità. Ci ha anche fornito informazioni preziose sul comportamento dei Cursori Apex sotto carichi di lavoro reali, aiutandoci a perfezionare il nostro approccio e migliorando la funzione stessa.
Scomponendo carichi di lavoro complessi a volume elevato in fasi di esecuzione modulari, il framework di elaborazione asincrona basata su fasi trasforma i vincoli della piattaforma in vantaggi ingegnerizzati, consentendo prestazioni, osservabilità e governance prevedibili su scala aziendale. Le fasi possono essere impostate sia dagli amministratori che dagli sviluppatori e, in entrambi i casi, gli autori delle fasi possono concentrarsi tranquillamente sull'osservanza dei limiti di base del governor della piattaforma (ad esempio le righe DML e le righe di query recuperate) senza doversi preoccupare di come scalare ogni fase.
Per rendere operativo e adottare questo schema nelle implementazioni aziendali, gli architetti dovrebbero:
- Valutare le automazioni esistenti per identificare le aree in cui l'orchestrazione asincrona può contribuire a migliorare le prestazioni e l'osservabilità.
- Suddividere grandi processi in fasi eseguibili discrete e indipendenti con obiettivi di elaborazione chiari e punti autore discreti (come Flusso o Apex).
- Definire e raggruppare i tipi di fasi per accelerare il riutilizzo e la standardizzazione delle fasi nelle unità operative.
- È possibile pilotare l'approccio con nuovi processi o automazioni esistenti. Potresti essere sorpreso di scoprire quanti casi edge trovi gratuitamente a portata di mano, cura della registrazione integrata e osservabilità!
James Simone è un Principal Software Engineer di Salesforce e ha più di un decennio di esperienza di lavoro sulla piattaforma. Era un cliente Salesforce — e titolare di un prodotto — prima di passare allo sviluppo e dal 2019 scrive approfondimenti tecnici su Salesforce all’interno di The Joys Of Apex. In precedenza ha pubblicato articoli sul blog Salesforce Developer e anche sul blog Salesforce Engineering.