最新の Salesforce アーキテクチャは、利便性ではなく、拡張性の戦略的な要件として非同期処理によって強化されつつあります。近年、データ量の急増、複数のタッチポイントを伴う複雑なインテグレーション、24 時間 365 日稼働する自律システムの台頭に取り組む企業が増えています。これらすべての要素により、アーキテクトは非同期ファーストのシステム設計に取り組むようになります。
Salesforce での非同期処理では、多くの場合、ガバナの制限と複雑さを考慮して設計する必要があります。これらの制限は、一括で安全で拡張可能なシステムを生成するのに役立つガードレールとアーキテクチャの制約として機能します。プラットフォームの制限は複雑さの管理に直接役立ちませんが、設計パターンを使用すると、リスクを軽減できます。Salesforce の内部では、新機能のフォワードテストや複雑なビジネスプロセスの自動化にプラットフォームの限界を押し広げています。任意のステップ数で非同期ジョブを実行するためのステップベースの非同期処理フレームワークを構築しました。各ステップは、共有ガバナンス制御と一元化されたログ記録による完全な操作の可視化により、個別に実行、再試行、再起動できます。このドキュメントでは、その主要なアーキテクチャコンポーネントの概要を説明します。キュー可能な Apex およびファイナライザー、スケジュール済みフロー、Apex カーソル、呼び出し可能なアクション、Slack とのインテグレーション。これらのコンポーネントを組み合わせることで、進化するエンタープライズニーズに適したモジュラー型で拡張性が高く、監視可能なアーキテクチャが提供されます。
- 最新の Salesforce アーキテクチャでは、拡張性、耐障害性、運用の透明性を実現するために、非同期優先のアプローチを採用する必要があります。
- 複雑な作業を個々に実行可能なステップに分割することで、コアワークフローを再設計することなく、予測可能なパフォーマンス、より安全な再試行、チェックポイント、ロールバック、モジュールの進化を実現できます。
- このフレームワークは、モノリシックで経年劣化した一括処理ジョブ、チェーンされた非同期コール、深くネストされたフローに代わるスケーラブルな代替手段を提供し、プラットフォーム外でオーケストレーションすることなく Salesforce 内で水平に拡張する必要がある大規模ワークロード向けに構築されています。
- 確定的で観察可能な実行により、一元的なログとガバナンスを通じて、進行状況の追跡、SLA の監視、障害診断、監査レベルの透明性が確保されます。
- 長期にわたるビジネスプロセスの統合ガバナンス、コンプライアンス、分散状態制御など、エンタープライズ クラスの厳格さを実現するように設計されています。
要件を確認する前に、次のようなフレームワークを使用する場合の推奨事項と推奨事項を次に示します。何よりも、どのシステムが唯一の情報源であるかを検討します。Salesforce 組織が外部データに最小限しか依存していないが、数百件から数百万件のレコードに拡張する必要がある場合は、ステップベースの非同期フレームワークを検討します。
このフレームワークは、次の場合に使用します。
- アクションを実行する情報のほとんど (またはすべて) が CRM にすでに存在します。
- 外部データをハーモナイズするための抽出変換負荷 (ETL) ジョブの維持にかかる先行コストまたは継続的なコストが高すぎる。
- 設定されたスケジュールで多数の Salesforce レコードの処理を延期する必要があります。
- 処理を個別のステップに分割できます。たとえば、階層またはツリーベースのレコードセットを作成できます。特に、データ量が階層またはツリーの下位にある場合に便利です。
次の場合は、このフレームワークを使用しないでください。
- レコードを作成または更新するには、すぐに再計算する必要があります。
- 外部システムでレコード更新の主データがホストされているため、インテグレーションが困難です。(Bulk API を使用して更新されたデータを Salesforce に転送することを検討してください)。
これらのプラクティスを念頭に置いて、要件を確認して構築を開始しましょう。
問題ステートメントについて考えてみます。
毎日実行する必要があるジョブがある場合、特定のレコードが追加処理のために事前設定された条件を満たしているかどうかを確認します。その場合は、これらの処理ジョブを開始します。レコードの処理では、複数の外部システムからデータを取得して計算を実行する必要がある場合があります。ジョブのステップでは、処理済みのレコードを確認する準備が整ったことを Slack 経由でユーザーに通知する必要があります。また、最初の通知のラウンド後に設定可能な遅延に基づいて、ロール階層内のマネージャー以上のユーザーに通知をエスカレーションする必要があります。
この問題には複数の異なるステップが含まれ、それぞれ独立して発生する場合もあります。作業を分割する方法は多数あります。1 つのグルーピングを次に示します。
- スケジューラー。
- (処理の種別に関係なく) レコードを処理するステップインターフェースと具体的な実装。
- ステップを整理するプロセッサー。
- スケジューラによって呼び出される Apex 呼び出し可能。
- 通知部分。Apex Slack SDKを使用します。
- 「設定可能な遅延」という語句には複雑さが隠されています。この複雑さについては、この記事で後ほど説明します。
組み込みフレームワークの意見を示した図を次に示します。
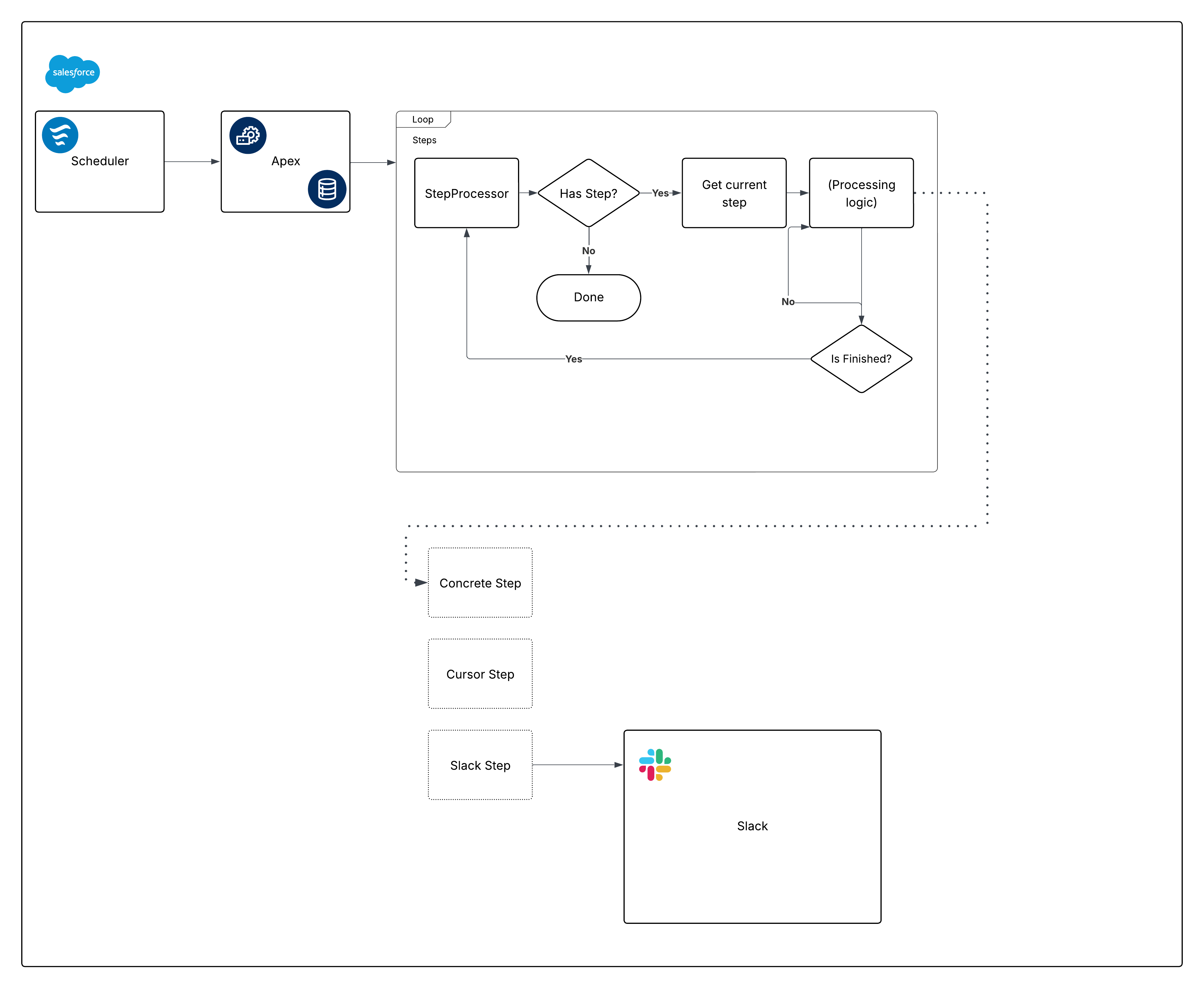 では、その図を分解して、ピースの作成を開始します。
では、その図を分解して、ピースの作成を開始します。
スケジュール済みフローには、スケジュールメカニズムとして次のような利点があります。
- スケジュール済みフローは、メタデータとしてパッケージ化してリリースできます。これは、Apex (または [スケジュール済みジョブ] ページ) でスケジュールされたジョブには適用されません。
- 待機要素は、コールアウトが必要なフレームワークにとって重要です。フローで使用すると、フレームワークの呼び出し可能部分でコールアウトが不要になります。
- スケジュールの粒度は要件を満たしています。スケジュール済みフローの最小間隔は毎日です。より高い頻度 (毎時など) が必要な場合は、この要件のスケジュール済みフローを再検討してください。
スケジュール済みフローを設定するときのもう 1 つの考慮事項は、環境管理です。Apex アクションを呼び出す前に、{!$Api.Enterprise_Server_URL_100}変数を評価する決定要素を追加します。これにより、UAT や本番など、意図した環境でのみジョブが実行されます。Sandbox は SDLC 中に頻繁に更新または新規作成されるため、このパターンは重要です。明示的な環境チェックを行わないと、フレームワークの実行が意図されていない環境でスケジュール済みフローが意図せずに実行される可能性があります。決定要素で contains 演算子を使用すると、今後の Sandbox の作成や URL の変更に対して設定が復元されます。
最後に、フレームワークで失敗をどのように捉えるかを検討します。フローでアクションをコールするときは、必ず障害パスを追加します。たとえば、Nebula Logger の「Add Log Entry」アクションに障害を配線できます。Nebula Logger はログをカスタムオブジェクトに書き込むため、ログデータは組織のストレージを消費します。デフォルトでは、ログは組織内で 14 日間保存され、その後クリーンアップされます。この保持期間は設定可能です。Nebula Logger はプラットフォームイベントを使用してログも公開するため、ログエントリはメインのデータ処理トランザクションから独立して保存されます。これにより、プライマリフローまたは Apex アクションがロールバックされた場合でも、障害を確実に捕捉できます。ログフレームワークの追加を検討する場合は、予想されるログ量と保持要件を評価する必要があります。
フローは次のようになります。
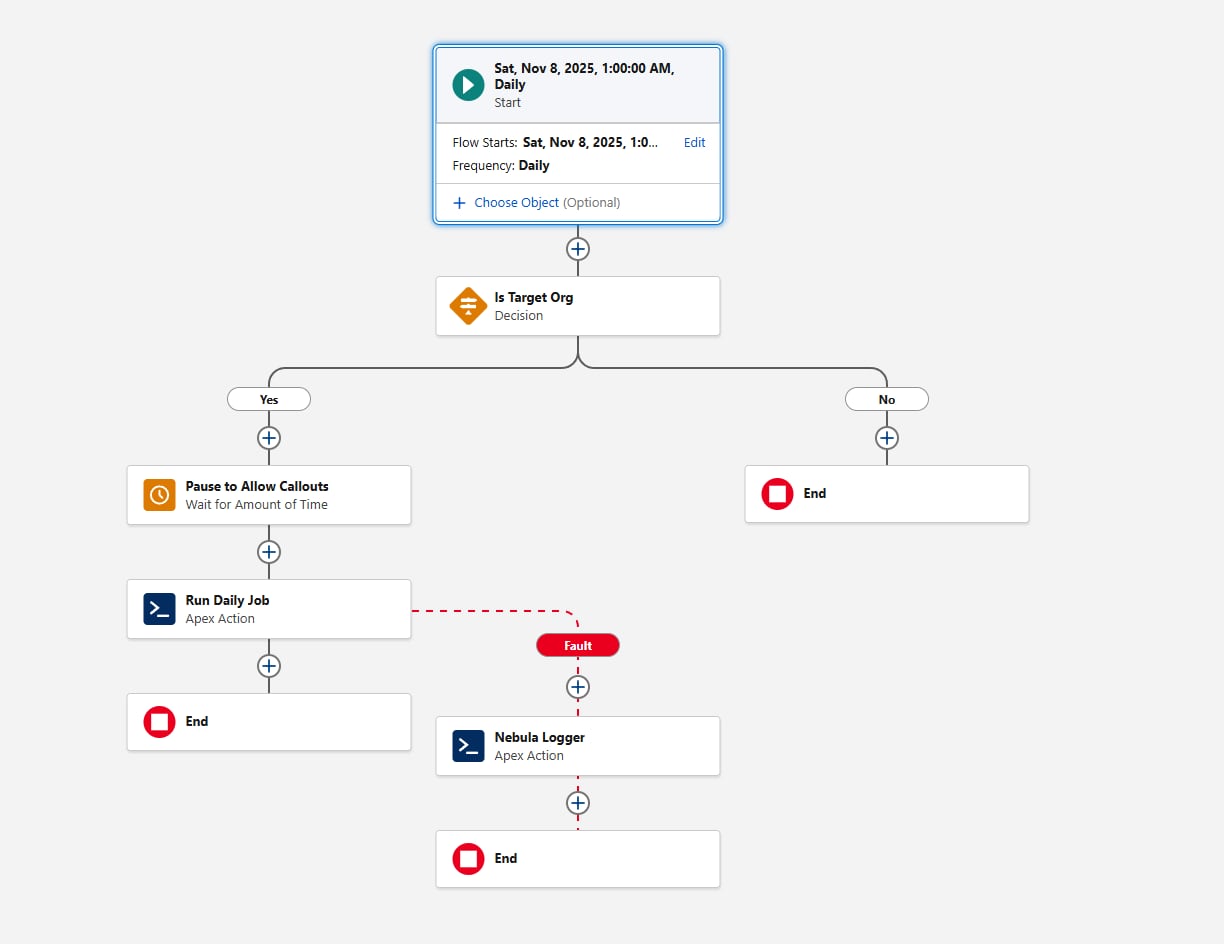
スケジュール要件が満たされた最初のApexコードに進みましょう。
Step インターフェイスを定義します。
この記事では、わかりやすくするために step インタフェースを外部クラスとして示します。フレームワーク自体は柔軟性が高く、すべてのステップ・クラスが同じインタフェースを参照していれば、チームは任意のApexパッケージ・パターンを使用してインタフェースとその実装を編成できます。
インターフェース内で定義されたメソッドについては、いくつかの注意事項があります。
executeは、現時点では引数なしで済みますが、順序が重要な場合にステップ間でデータをオーケストレーションするためにStateクラス(またはインターフェイス)を渡すと改善されます。getNameは、System.Type値ではなくString値を返す可能性があります。目的は、オーケストレーションレイヤーで他のプロパティを公開せずにステップ名を記録する方法を提供することです。
これらの要素がどのように組み合わされるかを示す最初の具体的な実装を次に示します。後で 1 つの例外を除いて、キュー可能 Apex を使用して Apex 内に非同期処理を実装することをお勧めします。通常、バッチ Apex は不要です (@future メソッドは使用しない)。Queueable Apex はすばやく開始でき、Apex カーソルを使用すると、バッチ Apex よりも多くの利点があります。
Apexカーソルは、従来のバッチApexモデルに代わる最新の機能を提供します。一括処理と同様に、カーソル実装ではレコードをチャンク (バッチあたり最大 2,000 件) で取得できます。ただし、カーソルでは 1 つのトランザクション内で複数の取得が許可されるため、大量の操作のスループットが大幅に向上します。
このフレームワークの一部としてカーソルを採用する場合、チームは現在のテストとモック可能性の制限を認識しておく必要があります。テストでのカーソルの動作は本番の動作とは異なる可能性があるため、カーソルの内部に依存しないようにテスト戦略を設計し、境界でオーケストレーションロジックを検証することが重要です。プラットフォームが進化するにつれて、次の領域は引き続き改善されますが、主要な指針は引き続き維持されます。カーソルを使用すると、多くの使用事例でバッチApexよりもパフォーマンスが向上し、オーケストレーションのオーバーヘッドが軽減されます。
システムが提供するカーソルと独自のコードの間に明確な境界を定義するには、Step インターフェースを実装するときにカーソルのような表現を作成することをお勧めします。次のコードについて考えてみます。
Cursor クラスに注目してください。Apex カーソルはDatabase.Cursorのインスタンスですが、Cursor の実装により、カーソルの欠点を柔軟に回避できます。実装は次のようになります。
この記事では、Apex クラスを参照するときに sharing 宣言を省略します。実際には、オブジェクトモデルと権限に準拠するために、最上位クラスで共有の有無に関係なく明示的に使用してください。
また、Cursorの実装はプラットフォーム Database.Cursorに委任され、その他のメリットについては次に説明します。
まず、対応するテストを次に示します。
Cursorを仮想化することで、大規模なレコード・セットを繰り返す必要がない場合でも、具体的なCursorStepの実装をDatabase.Cursorなしで実行できます。これは、バッチApexでDatabase.QueryLocatorではなくSystem.Iterable<T>を返す場合と同様です。次に例を示します。
このクラスも抽象クラスであるため、innerExecuteの具体的な実装はサブクラスに任せます。
CursorLike の内部サブクラスの代替法もあります。このようなステップの具体的なバージョンが他のガバナ制限で焼き付けられないことがわかっている場合は、CursorLike.fetch からthis.recordsを返し、親CursorStep.shouldRestart()を上書きして false を返すことができます。これにより、非同期トランザクションあたり12 MBのApexヒープ制限のみによって制限されたリストを反復処理できます。
カーソルベースの実装では、大量のデータをページングするときに十分な柔軟性が得られます。一方、Stepインターフェイスでは、あらゆる種類のステップを記述してカプセル化できる柔軟性があります。
フローベースのステップを考えてみましょう。
フローでは Apex で定義されたタイプに準拠する出力パラメータを返すことができないため、使用前にshouldRestart出力パラメータが確認されます。
一部のステップは機能フラグが付けられている場合があります。含めるステップを決定するロジックを実装したり、無効化された機能に no-op ステップを使用したりできます。Null オブジェクトパターンは、オーケストレーションレイヤー内の複雑さを軽減する一般的な方法です。
今では、多くのビルディングブロックで作業できます。ステップの反復を担当するオーケストレーションレイヤーを見てみましょう。
プロセッサーはアーキテクチャの転換点となります。誰がどのステップをどこで初期化するかを決定する必要があります。次のオプションがあります。
- ビジネスロジックに対応付けるステップをプロセッサーで定義します。このオプションはシンプルですが、読みやすく拡張性に欠けます。
- カスタムメタデータ (CMDT) を使用して対応付けを定義します。メタデータリレーションフィールドでは、クラス名のスペルをビジネスプロセス設定と疎結合にする
ApexClassはサポートされません。項目を選択リストにしてその種別が存在することを検証 (Type.forName()またはApexClassを照会) することで、管理者のリスクを軽減できますが、CMDT レコードではトリガーがサポートされないため、検証は実行時に行われます。このルートはテスト可能ですが、システム管理者は本番でのみ CMDT レコードを作成できます。慎重に進めてください。 - レコードとの対応付けを定義します。システム管理者以外もステップを設定できますが、リリースが難しくなり、環境がドリフトする可能性があります。慎重に進め
Clean Code には、この特定の複雑さを処理する方法に関する有名な引用があります。
この問題の解決方法は、(オブジェクトを作成するための)
switchステートメントを抽象工場の地下に埋めて、誰にも見せないことです。
この点を考慮して、現在のステップ数は明確に定義されており、大きくなりすぎることはないため、ステッププロセッサーをステップの工場にすることもできます。これは、switch ステートメントの実行に Enum を使用できます。
そして、私たちのStepProcessor:のために
表示されたファクトリメソッド (addTypeOneSteps() など) は、機能のフラグ設定などの懸念事項を委任できます。cleanSteps() は、収集されたステップに対して 1 回チェックを実行し、「空の」ステップがないことを確認してから、実際に非同期にします。これは次のようになります。
[スケジュール済みフロー] セクションで Nebula Logger に言及して以来、エラー処理については説明していません。これは、System.Finalizerを使用すると、各ステップで特定のエラー処理を追加することなく、すべてのエラー条件のログを包括的にカバーできるためです。各Stepは実行に焦点を絞りますが、単体テストで問題のあるパスがあれば記録して再スローします。これにより、安全な反復と本番レベルのアラートがサポートされます(すべてのWARNログとERRORログでNebula用Slack Loggerプラグインを使用)。
エラーログに関する 1 つの注意事項: ログメッセージにステップインスタンスを渡すと、ログに表示される内容のTrust性が想定されます。Apexクラスのデフォルト toString()には、すべての静的プロパティとインスタンス レベル プロパティがメッセージに含まれます。これは望ましいことですが、機密情報が漏洩する可能性もあります。ここではロギングとセキュリティは重視しませんが、一部のシステムでは、Step などのインターフェイスに準拠するために、toString()の上書きを強制することもあります。
このような方法では、各オブジェクト作成者に責任を負わせて、印刷を許可する内容を決定します。
ログ レベル:StepProcessor レベルでは、エラーでない最も高いレベルであるINFOが使用されます。アプリケーション内の詳細度が高くなると、それに応じてログレベルも低下します。個々のステップでは、概要レベルの情報に DEBUG を使用し、より詳細な出力用に FINE、FINER、FINEST を予約できます。ロギングは科学と同じくらい技術ですが、これらの原則に従うことでログの一貫性と有用性を保つことができます。
先に進む前に、ステッププロセッサーでステップを使用するロジックをホストするという決定について簡単に振り返ってみましょう。大規模なコードベースでは、StepProcessorを仮想または抽象にすることを検討し、サブクラスに特定のステップを特定させて、適切な懸念の分離を確立します。
スケジューラは最終的に Apex を呼び出します。残りの設定が完了したら、「呼び出し可能な Apex」セクションで実行するステップを決定し、List<StepType>をプロセッサーに渡すことができます。
これは、レコード、データ、またはロジックを使用して実行するステップ種別を決定するという、方程式の簡単な部分です。呼び出し可能なアクションは、他の場所で複雑さをカプセル化しているためシンプルです。また、予期しない例外から保護され、各ピースを個別に簡単にテストできるようになりました。
Apex Slack SDK はこの記事の範囲外ですが、要件に関する潜在的な問題として、ロール階層の上位にあるユーザーへの設定可能な遅延に基づく通知を再確認する必要があります。書類上、これは単純であり、StepProcessorのSystem.enqueueJob(this)を(正しく)考慮する可能性があります。System.AsyncOptions では、この要件を満たすためにenqueueJobオーバーロードを使用するのが最初の傾向でした。
ただし、現時点では、System.AsyncOptions.MinimumQueueableDelayInMinutes 経由の最大遅延は 10 分です。要件は 120 分であるため、いくつかのオプションが残っています。ナイーブなアプローチは次のようになります。
実際には、遅延は設定駆動であるため、このクラスに遅延が渡されます。
遅延通知種別が 1 つしかないことが確実な場合を除き、この方法はお勧めしません。開始前に 11 個の追加非同期ジョブが実行されます (遅延が増加した場合はそれ以上)。そのコストは、1 つの作業で十分かもしれませんが、多くの作業では必要ありません。また、Step インタフェースにメソッドを追加して、各ステップで再起動までの待機時間をプロセッサーに指示できるようにする必要があります。これにより、ノイズが増加します。
次の 2 つの興味深い可能性が考えられます。
- ポーリングジョブがすでに適切な間隔でスケジュールされている場合、既存のジョブフレームワークに遅延ステップを挿入できます。また、指定した遅延が最大 15 分経過しても問題ありません(15 分は Apex でスケジュールされた CRON 式の最小更新間隔)。これは、呼び出し可能な Apex の例にほぼ一致し、代わりに Apex を介してスケジュールが実行されます。つまり、同じ
Stepベースのアーキテクチャを再利用して、[Start After]タイムスタンプに基づいてレコードを処理し、前に表示したStepType列挙値への選択リストまたは複数選択リストの対応付けに基づいて使用するステップを決定できます。 - または、追加の外部 Apex クラスを定義する場合は、
System.scheduleBatch()を使用して一括 Apex にフォールバックします(内部クラスをサポートする Queueable Apex とは異なり、一括 Apex クラスは外部クラスである必要があります)。
Batch Apexの例を考えてみましょう。一般的に、柔軟性と制御性のために Queueable Apex をお勧めしますが、これはバッチ Apex が依然として優位なケースの 1 つです。
次に、StepProcessor で、前に示した addTypeOneSteps() メソッドがこの遅延ステップで更新されたとします。
通常、この程度のフープジャンプはお勧めしませんが、このステップの遅延がもう 1 つの再利用可能なビルディングブロックになります。Queueable Apex で長い遅延が許可されるまでは、この方法は、この効果を生成する最も簡単な方法でもあります(ポーリング メカニズムを使用しない場合については後述)。
要件を満たすためにオブジェクト指向設計を使用し、長期的な構築コストとメンテナンスコストのバランスを取りながら拡張できるシステムを作成しました。ステップの宣言とインスタンス化は最終的にStepProcessorでの位置を超える可能性がありますが、技術的な負債はほとんどありません。FlowStepを使用すると、システム管理者と開発者は、ノーコード ソリューションまたはプロコード ソリューションが最も合理的なタイミングを一緒に決定できます。
Apexのキュー可能フレームワーク内のSystem.Finalizer・インタフェースをNebula Loggerとともに使用することで、今後のステップで明示的なログ記録が欠落している場合でも、予期しない障害を警告する堅牢でテスト可能なシステムを構築しました。当社にとって、このシステムはコストと複雑さを軽減し、楽しく数字を計算できます。また、実際のワークロードでのApexカーソルの動作に関する貴重なインサイトが得られ、機能自体を改善しながらアプローチを改善できるようになりました。
ステップベースの非同期処理フレームワークフレームワークは、複雑で大量のワークロードをモジュール化された実行ステップに分解することで、プラットフォームの制約をエンジニアリング上のメリットに変換し、エンタープライズ規模の予測可能なパフォーマンス、可観測性、ガバナンスを実現します。ステップはシステム管理者と開発者の両方が設定でき、いずれの場合もステップ作成者は各ステップの拡張方法を心配することなく、プラットフォームの基本的なガバナ制限 (DML 行や取得されるクエリ行など) の遵守に集中できます。
エンタープライズ実装全体でこのパターンを運用して採用するには、アーキテクトは次の要件を満たす必要があります。
- 既存の自動化を評価して、非同期オーケストレーションがパフォーマンスの向上と可観測性の向上に役立つ領域を特定します。
- 明確な処理目標と個別の作成者ポイント(フロー、Apexなど)を使用して、大きなプロセスを個別に実行可能なステップに分割します。
- ステップ種別を定義してグループ化し、ビジネスユニット間でのステップの再利用と標準化を促進します。
- 新しいプロセスまたは既存の自動化を使用してアプローチをパイロットします。ステップ内で無料で見つけることができるエッジケースの数に驚くかもしれません。
James Simone は Salesforce のプリンシパルソフトウェアエンジニアであり、このプラットフォームで 10 年以上働いた経験があります。開発に移行する前はSalesforceのお客様であり、製品所有者でした。また、2019年からThe Joys Of ApexでSalesforceに関する技術的な詳細を執筆されています。以前にはSalesforce開発者ブログとSalesforceエンジニアリングブログでも記事を公開しています。