A Salesforce Platform avançou continuamente sua arquitetura de automação para atender às demandas de processos de negócios complexos. Gerações anteriores, as Regras de fluxo de trabalho e o Criador de processos, forneciam as etapas iniciais na lógica conduzida por evento, expandindo os recursos de automação para lógica conduzida por evento e ampliando o alcance para uma gama mais ampla de criadores.
Essa evolução culminou em uma arquitetura consolidada de alto desempenho centrada em dois pilares complementares: Fluxo acionado por registro e acionadores do Apex. Este documento fornece a estrutura e as diretrizes para tomar decisões fundamentadas ao projetar automações de acionador.
| Fluxo | O Fluxo Salesforce é uma ferramenta avançada de automação de apontar e clicar que permite aos usuários criar processos comerciais complexos, telas e lógica visualmente usando o Flow Builder, sem escrever código. Ele automatiza tarefas como atualizações de dados, envio de emails e orientação de usuários, oferecendo flexibilidade por meio de tipos como Fluxos de tela (interação do usuário) e Fluxos acionados (eventos de registro/agendamento). |
| Apex | O Salesforce Apex é uma linguagem de programação proprietária e orientada a objetos para a plataforma Salesforce, semelhante a Java, usada para criar lógica de negócios personalizada, automatizar processos e estender as principais funcionalidades do CRM além das ferramentas declarativas. |
A criação de automação acionada por registro escalonável, mantida e de desempenho no Salesforce Platform requer uma abordagem disciplinada e orientada por arquitetura. A escolha entre o Fluxo e o Apex, e a implementação de cada um, é guiada por um conjunto claro de princípios. Esses pontos resumem esses princípios e servem como as regras fundamentais para o design de automação moderna.
-
Escolha a ferramenta certa para o trabalho com base na densidade de automação do Salesforce Object.
-
Use o Fluxo acionado por registro para objetos do Salesforce para automações de baixa densidade.
-
Aumente a lógica de fluxo acionado por registro com o Apex invocável para automações de densidade média.
-
Use acionadores do Apex para objetos do Salesforce para automações de alta densidade.
-
-
Tome cuidado ao acionar processos assíncronos.
Essa regra se aplica se você está invocando processos assíncronos em um fluxo acionado por registro ou enfileirando um trabalho enfileirável do Apex. Embora esse padrão possa ser tentador para descarregar o trabalho, ele pode introduzir cenários complexos de tratamento de erros e aumentar o risco de atingir os limites do regulador. -
Use um ponto de entrada por objeto do Salesforce.
Para um determinado Objeto do Salesforce, use um mecanismo como seu ponto de entrada para automação. Tente evitar misturar acionadores de Fluxo e Apex como pontos de entrada para o mesmo Objeto.
O Fluxo e o Apex compartilham um conjunto comum de recursos fundamentais. Cada ferramenta pode consultar registros, executar lógica condicional, atribuir variáveis e realizar operações DML, como criar, atualizar e excluir registros, sequenciados para execução em uma ordem especificada.
No entanto, essa sobreposição funcional não implica que as ferramentas sejam intercambiáveis. A escolha da arquitetura não é sobre se uma tarefa pode ser realizada, mas sobre como ela é realizada e quais são as implicações a longo prazo para o desempenho, a escalabilidade e a capacidade de manutenção. O Fluxo se destaca em clareza declarativa e velocidade de implementação para processos simples, enquanto o Apex fornece o controle granular e a potência bruta necessárias para soluções complexas.
A densidade de automação é a carga colocada em um objeto do Salesforce específico. Ele serve como uma heurística para determinar a implementação ideal do objeto. Conforme a densidade de automação aumenta, aumenta a probabilidade de violar limites transacionais.
Calcule a densidade de automação inspecionando três dimensões específicas de volume e complexidade:
-
Quantidade de automação: O número bruto de entradas de metadados de automação exclusivas (fluxos, ações de acionador e assim por diante) que são executadas durante um único evento de Linguagem de manipulação de dados (DML).
-
Volume de registro: Os registros por transação processados por meio de carregamentos de API ou processamento em lote pesado, em que o desempenho se torna crítico.
-
Despansão da dependência: Uma medida das operações de DML a jusante acionadas pela operação CRUD inicial. Ele quantifica a profundidade do gráfico em que uma atualização se encaixa em atualizações em objetos relacionados (por exemplo, caso → conta → contato → totalização personalizada).
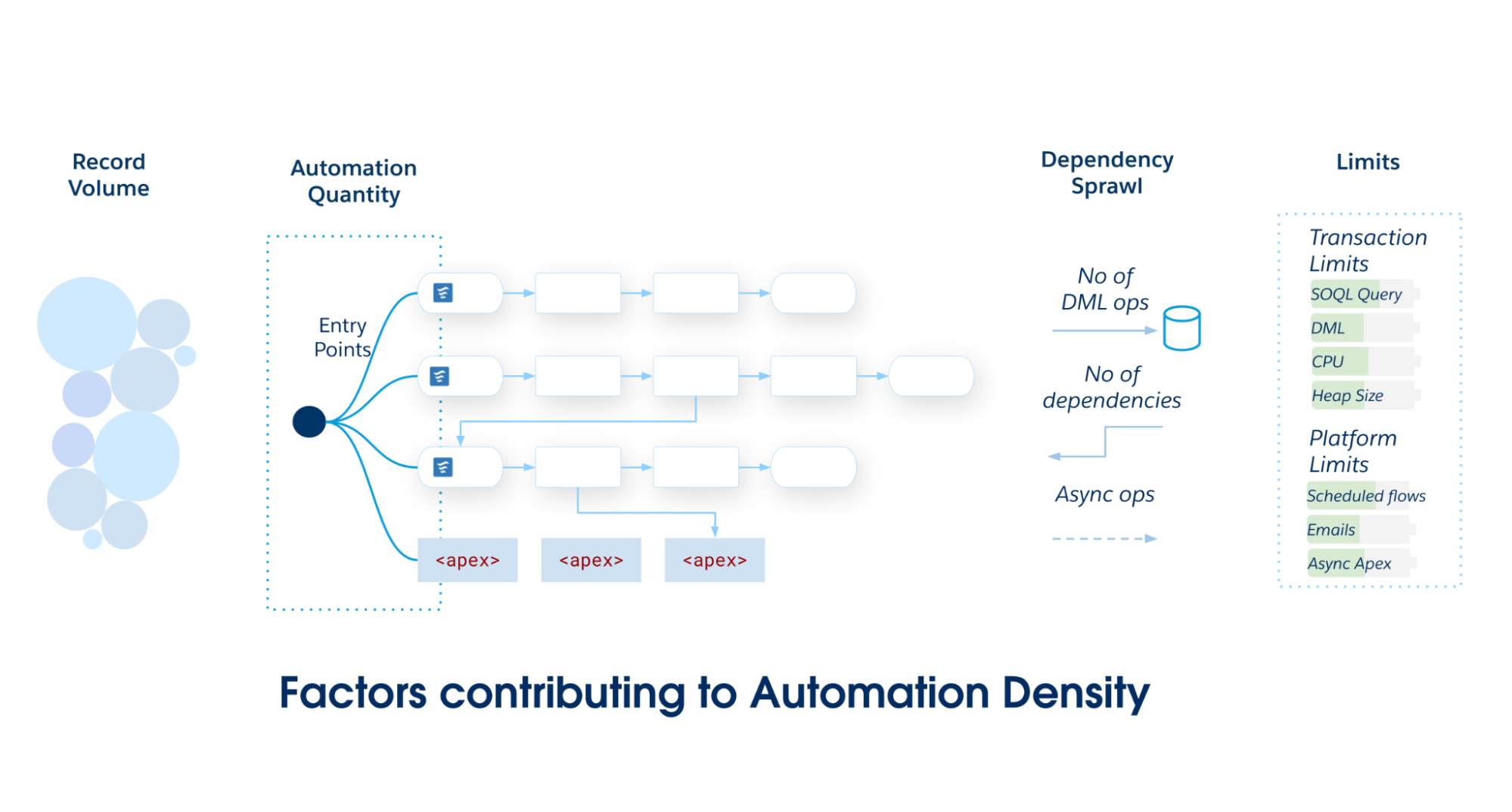
Conforme o escopo e a complexidade do seu aplicativo Salesforce aumentam, confirme-se com um único ponto de entrada principal: Fluxo acionado por registro ou Acionadores do Apex. Evite particionar automações entre vários mecanismos em um único objeto do Salesforce, pois isso leva à má capacidade de manutenção e à fragmentação da governança.
Use essa matriz para determinar o padrão de arquitetura necessário para seu objeto do Salesforce.
-
O Fluxo acionado por registro é a solução preferida para baixa densidade de automação. Ele oferece um equilíbrio de poder e acessibilidade ideal para automações diretas e independentes umas das outras.
-
O padrão híbrido (Fluxo acionado por registro com Apex invocável) é uma escolha poderosa e manejável para automações de média densidade com complexidade crescente. Esse padrão permite que as equipes mantenham a coreografia ordenada no Fluxo declarativo enquanto delegam operações pesadas em computação ao Apex, equilibrando acessibilidade e desempenho.
-
Os acionadores Apex fornecem os blocos de construção necessários para uma base arquitetônica sólida para suportar automações de alta densidade. O desempenho, o controle granular e a abstração e o polimorfismo orientados a objetos do Apex são mais adequados para gerenciar a complexidade e a escala desses cenários.
| Nível de densidade | Quantidade de automação | Volume de dados (tamanho do lote) | Sprawl de dependência | Padrão arquitetônico |
|---|---|---|---|---|
| Baixo | < 15 Automações |
Padrão Interações de interface do usuário orientadas pelo usuário ou cargas de API pequenas (1 a 200 registros) |
Discreto Lógica independente. 0 a 1 operações de DML a jusante no mesmo objeto ou em um objeto relacionado. |
Fluxo acionado por registro |
| Médio | 15–30 Automações |
Moderar Processamento em lote padrão (com lógica que requer massificação cuidadosa) |
Acoplado Pai/filho atualiza de 2 a 4 operações de DML a jusante. Risco de recursão |
Padrão híbrido Fluxo + Apex invocável |
| Alto | > 30 Automações |
Alto Grandes volumes de dados com carregamentos de API em massa (2.000 a 10.000 registros) |
Complexo e Recursivo Gráfico de dependência profunda (5 operações DML a jusante). Risco de loops de recursão triangular |
Apex Trigger Metadata Framework |
Além disso, considere o número total diário de operações de DML, pois o Salesforce impõe o gerenciamento compartilhado de recursos em um ambiente de vários locatários e os limites de governador para evitar que as automações de fuga monopolizem recursos compartilhados. Objetos do Salesforce com alto volume diário de DML exigem seleção de automação cuidadosa. Por exemplo, limites assíncronos para tempo de CPU (60.000 ms) e tamanho de heap (12 MB) são maiores que limites síncronos. Além disso, o limite de 24 horas para toda a organização em execuções assíncronas (calculado como 250 mil, ou 200 vezes suas licenças de usuário) exige a consideração do DML diário total em seu design arquitetônico para evitar exceções de tempo de execução.
O Fluxo acionado por registro é a principal ferramenta declarativa da plataforma para automação acionada por registro. A facilidade de uso do fluxo e as proteções de plataforma integradas permitem que as equipes criem facilmente soluções escalonáveis e confiáveis. É a escolha ideal para a maioria das equipes criando soluções na plataforma Salesforce.
Apex é a linguagem de programação proprietária da plataforma, fortemente tipada e orientada a objetos. Use Apex para objetos do Salesforce com alta densidade de automação e para casos de uso que exigem alto desempenho, lógica sofisticada ou controle granular sobre transações.
Para ajudar no processo de tomada de decisão, esta matriz fornece uma comparação direta de Fluxo e Apex entre os principais recursos de arquitetura.
| Capacidade | Fluxo acionado por registro | Acionador do Apex |
|---|---|---|
| Velocidade de entrega e manutenção | Recomendado A interface de usuário visual do Flow Builder permite que administradores e outros criadores declarativos criem e modifiquem automações mais rapidamente do que escrever, testar e implementar Apex code. Essa interface permite que uma gama mais ampla de membros da equipe ofereça valor comercial e reduza a dependência de recursos de desenvolvedor especializados para tarefas simples. |
Requer conhecimento O Apex exige que desenvolvedores de software habilitados para implementar, testar e manter o código. |
| Modularidade | Disponível Fluxos acionados por registro são modulares por padrão. Em vez de lógica monolítica, as equipes criam fluxos separados para requisitos específicos e os coreografam juntas usando o Explorador do Acionador de fluxo. Essa modularidade permite a modificação isolada e a extensão simples, reduzindo significativamente o custo de propriedade de longo prazo. |
Disponível O Apex é dividido em módulos funcionais por design. Cada classe do Apex tem como objetivo implementar um único módulo de funcionalidade. |
| Visibilidade e governança | Recomendado A natureza visual do Fluxo fornece uma representação intuitiva da lógica de negócios. O Explorador do acionador de fluxo fornece uma visualização consolidada de todos os fluxos em um objeto, tornando mais fácil para arquitetos e administradores entenderem, governarem e solucionarem problemas sem lerem código. |
Requer conhecimento Usar uma estrutura de metadados para organizar acionadores é vantajoso, mas o Apex exige uma equipe de desenvolvimento disciplinada para manter o código organizado e mantido. |
| Processamento de dados em massa de alto desempenho | Não recomendado Há um maior risco de atingir os limites do controlador ao lidar com lógica complexa ou grandes volumes de dados. |
Recomendado O Apex code é executado mais próximo dos serviços centrais da plataforma e oferece aos desenvolvedores um controle aprimorado sobre a otimização de consultas, o tratamento de dados e a eficiência algorítmica. Isso resulta em melhor desempenho e escala, especialmente em cenários complexos que envolvem grandes volumes de dados. |
| Lógica robusta e estruturas de dados | Disponível O Elemento Transformação de Fluxo pode ajudar com algumas tarefas complexas de processamento. No entanto, o Fluxo não tem estruturas de dados Mapear e Definir nativas, tornando o processamento de dados complexo complicado e computacionalmente ineficiente. |
Recomendado O Apex oferece acesso total a loops Map, Set e Programmatic para manipulação de dados altamente eficiente e segura em massa. Como uma linguagem de programação com recursos completos, o Apex também oferece acesso a construções lógicas complexas, estruturas de dados e padrões de design que podem ajudar a resolver problemas de negócios complexos de forma mantida e eficiente. O Apex inclui uma rica biblioteca padrão de funções avançadas (por exemplo, BusinessHours, Crypto) que atualmente não estão disponíveis em ferramentas declarativas. |
| Controlo da transação | Não disponível O fluxo não fornece acesso a operações de DML `Database.savepoint`, `Database.rollback` ou parcialmente bem-sucedidas para confirmações ou reversões de transações parciais. |
Disponível O Apex fornece controle completo e granular sobre a integridade da transação e cenários complexos de recuperação de erros. |
| Distribuição de email | Recomendado Enviar alertas por email pré-configurados de um fluxo acionado por registro é fácil e escalonável. Alertas por email personalizados podem ser elaborados e distribuídos no tempo de execução. Emails personalizados estão sujeitos a limites diários de envio de email. |
Disponível O Apex pode gerar e enviar mensagens de email personalizadas. Todos os emails enviados do Apex estão sujeitos aos limites diários de envio de email. |
| Aplicando salvaguardas de plataforma | Recomendado O fluxo inclui proteções integradas, como massificação automática e novas tentativas automáticas. Essas proteções aumentam a velocidade de valorização e impedem armadilhas de desempenho que exigem codificação manual complexa. |
Implementação manual necessária Proteções como massificação devem ser codificadas explicitamente (por exemplo, gerenciar coleções e evitar SOQL dentro de loops). As novas tentativas automáticas não são nativas de acionadores e exigem a implementação de uma lógica personalizada complexa. |
| Processamento assíncrono | Disponível O Fluxo oferece mecanismos fáceis para automações que exigem uma transação separada em um caminho assíncrono. Essas automações estão sujeitas a limites diários. |
Disponível O Apex permite o controle total por meio da Captura de dados de alteração e eventos enfileiráveis que são tratados por um assinante de acionador desacoplado. |
| Processamento agendado | Recomendado Os caminhos agendados do fluxo fornecem uma funcionalidade de agendamento exclusiva e eficiente (por exemplo, "desligar 3 dias antes da data de fechamento"). Essa funcionalidade inclui cancelamento automático e reagendamento se os dados do registro mudarem. Essas automações estão sujeitas a limites diários. |
Não disponível Um acionador do Apex não pode agendar nativamente um evento temporal específico do registro com cancelamento automático. Embora o Apex agendado exista, é um mecanismo fundamentalmente diferente que é executado em um horário específico e não é agendado durante o processamento de um registro individual como parte de um acionador. |
| Ordenamento e coreografia | Disponível O Explorador do acionador de fluxo permite que os administradores definam uma ordem de execução relativa para vários fluxos no mesmo objeto. |
Disponível Uma estrutura de acionador fornece controle granular sobre a ordem exata das automações. |
| Atualizações de campo de mesmo registro | Disponível (antes de salvar) O Fluxo acionado por registro é a opção declarativa de melhor desempenho para atualizar o registro acionador antes da confirmação DML inicial. |
Disponível (antes de salvar) O Apex oferece o melhor desempenho com pouca sobrecarga. |
| CRUD de objeto cruzado | Disponível (depois de salvar) O fluxo é adequado para operações de DML de objeto cruzado simples e de baixa complexidade. |
Disponível (depois de salvar) O Apex oferece controle superior sobre a remoção de duplicação, o tratamento de erros e o desempenho para operações DML entre objetos. |
| Deduplicação de cálculos caros | Disponível O fluxo se destaca na eliminação de consultas redundantes e instruções DML por meio de massificação automática. No entanto, o estado não pode ser armazenado em cache ou compartilhado entre diferentes acionadores de fluxo ou entre várias invocações do mesmo fluxo em uma transação. Essa limitação pode se tornar importante em cenários de desempenho extremo. |
Recomendado O Apex fornece mecanismos para desduplicar operações caras. Os desenvolvedores podem aproveitar o armazenamento em cache transacional usando propriedades e variáveis estáticas e o armazenamento em cache no nível da plataforma usando o Cache da plataforma para armazenar e reutilizar dados. Essas técnicas são importantes para reduzir o consumo de limites de controlador transacional, como consultas SOQL, e garantir alto desempenho e escalabilidade. |
| Tratamento de erros personalizados | Disponível O elemento CustomError pode bloquear uma operação de salvamento e exibir uma mensagem ao usuário. |
Recomendado O método addError() fornece mensagens de erro condicionais e em nível de campo flexíveis. |
Esta tabela fornece recomendações gerais de "melhor ajuste" para casos de uso gerais com base nos recursos apresentados. Finalmente, você considerará considerações adicionais para chegar a um melhor ajuste para seus cenários específicos, como aqueles incluídos na seção Melhores práticas relacionadas deste documento. Lá, você aprenderá mais sobre quando uma determinada combinação de Fluxo e Apex fornece a melhor abordagem.
| Caso de uso | Descrição | Melhor ajuste | Racionalidade |
|---|---|---|---|
| Processamento em lote de alto desempenho | Qualquer automação que precise processar milhares de registros de maneira eficiente | Apex | O Apex fornece APIs avançadas para interface com a plataforma e velocidade bruta. |
| Processamento de dados complexo | Cenários que exigem manipulação de dados avançada | Apex | O Apex fornece estruturas de dados, como Mapa e Conjunto, que não estão disponíveis nativamente no Fluxo e podem ser essenciais para escrever um código de alto desempenho e seguro em massa. |
| Controle transacional | Controlar mecanismos como pontos de salvamento, reversões e confirmações parciais | Apex | O Apex fornece acesso a mecanismos como Database.savepoint e Database.rollback e tem a capacidade de processar operações DML parcialmente bem-sucedidas. |
| Validação personalizada sofisticada | Validação de dados em vários campos em um registro | Apex | Embora o Fluxo possa impedir uma gravação com o elemento `CustomError', ele não está disponível em todos os tipos de fluxo, incluindo subfluxos. O método Apex addError() fornece várias mensagens de erro específicas do campo que podem ser adicionadas a um registro a qualquer momento durante o processamento do acionador. |
| Lógica moderadamente complexa em um processo simples | Lógica e manipulação de dados de complexidade moderada, simplificada por uma biblioteca padrão de funções avançadas, que ocorre como parte de um processo não complicado | Fluxo + Apex | O Fluxo acionado por registro atua como a camada de orquestração, enquanto operações de alta complexidade são encapsuladas no Apex invocável. |
| Lógica simples a moderadamente complexa | Manipulação de dados de baixa a moderada complexidade, com atualizações de acionador para os objetos de dados primários e relacionados | Fluxo | O fluxo costuma ser a opção recomendada, pois é baseado em um modelo declarativo que o torna acessível a administradores e desenvolvedores. |
| Notificações e mensagens de saída | Enviar emails e mensagens de saída | Fluxo | O fluxo torna o envio de alertas por email e mensagens de saída em alterações de registro fácil e altamente escalonável. |
| Processamento agendado | Automação em uma data futura e dinâmica (por exemplo, três dias antes de uma data de fechamento) | Fluxo | Os caminhos agendados fornecem um poder exclusivo ao Fluxo, pois a plataforma gerencia automaticamente o agendamento, o cancelamento e o reagendamento desses caminhos se os dados do registro mudarem. |
A escalabilidade é uma consideração crítica ao projetar sua implementação. Quando a lógica de negócios de uma automação acionada por registro se torna complexa, de longa duração ou envolve grandes volumes de dados, os limites principais do controlador da Salesforce Platform se tornam uma restrição arquitetônica. Operações como atualizações de dados em massa, chamadas de API complexas ou cálculos pesados aumentam o risco de violar limites, como o tempo total de CPU ou o número de instruções DML em uma única transação de banco de dados. Uma falha em um acionador síncrono devido a uma exceção de limite fará com que toda a transação de salvamento do usuário seja revertida, resultando em má experiência do usuário e possível perda de dados. Esse risco inerente exige um padrão arquitetônico para descarregar trabalho complexo.
A automação assíncrona se torna essencial nesse caso. Usando mecanismos assíncronos, os arquitetos podem efetivamente desconectar o trabalho de longa duração ou de alto volume da transação de salvamento de registro síncrona principal. Salva com rapidez e confiabilidade, enquanto o processamento pesado é delegado a uma transação gerenciada por plataforma separada que é executada mais tarde. A desacoplamento melhora a estabilidade, evita falhas de transação e é essencial para criar aplicativos corporativos dimensionáveis. A plataforma oferece várias ferramentas especializadas para isso, cada uma com benefícios e compensações distintos em termos de confiabilidade, volume e complexidade.
O caminho Executar de modo assíncrono em um fluxo acionado por registro fornece o mecanismo mais simples para lógica assíncrona "apagar e esquecer". Esse caminho é executado em uma transação separada depois que a transação de salvamento de registro original foi confirmada com sucesso no banco de dados.
-
Caso de uso ideal: Isso é adequado para tarefas que não exigem execução imediata ou tratamento de erros personalizados. Exemplos incluem enviar uma notificação por email, criar uma tarefa de acompanhamento ou fazer uma chamada simples para um sistema externo.
-
Limitações: Esse mecanismo compartilha os mesmos limites de controlador diários de outras entrevistas de fluxo assíncronas. Ele não foi projetado para processamento de alto volume.
A Captura de dados de alteração (CDC) é um padrão de alto rendimento, escalonável e resiliente para lidar com lógica assíncrona acionada por uma mudança de registro em cenários de alto volume. Nesse modelo, a única responsabilidade do acionador é salvar o registro de modo síncrono. A plataforma então publica uma mensagem de evento detalhada que contém as alterações do registro em um barramento de evento de alto volume. Um acionador do Apex dedicado separado assina esse evento de alteração. Ele realiza trabalhos complexos, de longa duração ou assíncronos.
-
Benefício: Esse padrão desconecta o processo assíncrono da transação do usuário inicial. Uma falha no processamento assíncrono não fará com que o salvamento do registro do usuário seja revertido. O padrão também fornece um fluxo de eventos durável que vários assinantes internos ou sistemas externos podem consumir, e os eventos podem ser repetidos por até 72 horas, proporcionando uma forte resiliência.
-
Limitações: As mensagens de evento CDC não contêm o estado anterior do registro, o equivalente a um
Trigger.oldMapdo Apex. A carga útil do evento inclui os novos valores de campo, mas não os valores dos quais ele mudou. Isso torna difícil implementar lógica com base em uma transição de estado específica (por exemplo, executar apenas se oStatus__cmudou de "Pensando" para "Aprovado"). Você pode mitigar isso consultando o histórico de campo do objeto no assinante do evento, mas isso aumenta a complexidade do processo e o rastreamento de histórico de campo pode não estar disponível para o campo específico de interesse. Isso pode limitar os tipos de automação que você pode descarregar para a CDC.
Por padrão, o CDC pode ser habilitado em no máximo cinco objetos do Salesforce. As organizações que precisam de mais podem comprar uma licença complementar que remova esse limite e aumenta as alocações de entrega de eventos.
Encolher um trabalho do Apex enfileirável diretamente de um acionador deve ser considerado um padrão arriscado, usado apenas quando o controle fornecido pelo Apex é necessário (por exemplo, para lógica complexa ou mecanismos de repetição personalizados), e o CDC não é uma opção viável.
Se o Apex enfileirável for necessário, a implementação deverá incluir salvaguardas adequadas:
-
Verificações de limite: O código deve verificar o número de trabalhos já enfileirados na transação antes de tentar adicionar outro.
-
Contextualização: O código deve detectar se está sendo executado em um contexto assíncrono, como um trabalho em lote (
System.isBatch()), e modificar seu comportamento para cumprir o limite mais rígido de um trabalho por transação nesse contexto.
A invocação do Apex assíncrono de um acionador síncrono introduz riscos de estabilidade. Para evitar o impacto no nível da organização (por exemplo, exceder limites), esse padrão requer um design e testes rigorosos.
-
O limite diário para execuções assíncronas do Apex (
Batch,Queueable,@Future) é compartilhado entre a organização (geralmente 250.000 ou um cálculo baseado em licenças de usuário). Um carregamento de dados em massa de 20 mil registros fará com que um acionador seja executado em blocos de 200, resultando em 100 invocações de acionador separadas, ainda mais se o tamanho do lote em massa for inferior a 200 registros. Se cada chamada enfileirar um trabalho assíncrono, uma parte significativa do limite diário de um único carregamento de dados poderá ser consumida. Esse consumo pode prejudicar outros processos de negócios críticos de recursos assíncronos. -
Os limites do controlador para enfileirar trabalhos são drasticamente diferentes dependendo do contexto. A partir de um acionador acionado por uma ação do usuário na interface do usuário (uma transação síncrona), até 50 trabalhos enfileiráveis podem ser enfileirados. No entanto, a partir de um acionador acionado no método de
executede uma classe do Apex em lote (uma transação assíncrona), apenas um trabalho enfileirável pode ser enfileirado. Não levar em conta essa diferença é um ponto de falha comum e crítico, levando a erros deLimitExceptiondurante operações de dados grandes. -
Chamar Apex programável (
System.schedule) ou Apex em lote (Database.executeBatch) diretamente de um contexto de acionador constitui um antipadrão. Esses métodos não foram projetados para serem chamados do contexto do acionador. Isso levará a um consumo rápido da alocação assíncrona do Apex, resultando em exceções de limite.
Cada mecanismo assíncrono tem compensações específicas em relação ao desempenho, limites do controlador e confiabilidade. Use essa árvore de decisão como guia para ajudá-lo a navegar por essas opções e escolher o mecanismo certo para seu caso de uso.
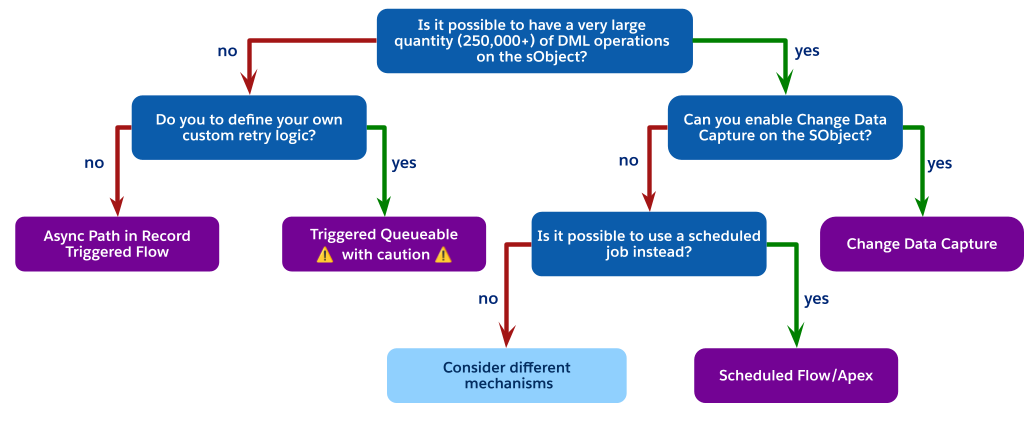
Como o fluxograma indica, quando você está enfrentando operações de DML de alto volume, mas não pode usar a Captura de dados de alteração (talvez devido a limites de objeto), a melhor escolha arquitetônica é muitas vezes evitar um processo invocado por acionador completamente.
Em vez disso, considere usar um processo agendado. Isso pode ser um Fluxo agendado ou Apex agendado. As etapas necessárias são:
-
Realize uma atualização simples e de baixo custo no acionador síncrono. Por exemplo, defina um campo de
Status__ccomo "processamento pendente" ou insira um registro relacionado a baixo custo, como uma publicação do Chatter, para indicar que o registro precisa ser processado. -
Crie um trabalho agendado, seja um fluxo agendado ou Apex agendado, que é executado periodicamente, como a cada 15 minutos ou a cada hora.
-
Tenha a consulta de trabalho agendada para todos os registros no estado pendente, execute a lógica complexa em um contexto controlado e de alto volume e atualize os registros conforme processados.
Esse padrão desconecta totalmente o processamento pesado do salvamento síncrono do usuário, não está sujeito ao limite de um trabalho por transação de um lote acionado pelo acionador e fornece uma solução altamente escalonável e regulável para requisitos não em tempo real.
Se a latência de um trabalho agendado não for aceitável para os requisitos de negócios e você ainda estiver impedido de usar o CDC ou uma fila acionada pelo acionador, isso indicará uma incompatibilidade arquitetônica significativa. Nesse ponto, diferentes mecanismos devem ser considerados. Reavaliar o design do aplicativo principal pode levar a determinadas conclusões, como:
-
Comprar o complemento para remover limites de objeto da CDC.
-
Desafiar fundamentalmente o requisito de negócios para determinar se o processamento quase em tempo real é realmente um "must-have" ou se a latência de um trabalho agendado é uma compensação aceitável para a estabilidade da plataforma.
O nível de complexidade em uma implementação faz parte do custo total de propriedade de uma solução, bem como sua capacidade de se adaptar a mudanças nos requisitos de negócios. A complexidade pode afetar qualquer implementação se as práticas recomendadas não forem seguidas. Na seção Práticas recomendadas relacionadas deste documento, há recomendações para reduzir a complexidade da sua solução, incluindo estes padrões:
-
Padrão híbrido: Apex invocável para lógica complexa no fluxo
-
Usando uma estrutura de metadados para acionadores do Apex
-
Mega-fluxos vs. Vários fluxos
A documentação é tão importante quanto a automação em si. Não apenas garante a capacidade de manutenção, mas também é essencial para IA e ferramentas baseadas em agente. A documentação ajuda você a entender e gerenciar seus processos de negócios.
Em fluxo
-
Estabeleça uma convenção de nomenclatura consistente para todos os elementos e variáveis.
-
Use o campo Descrição do fluxo para explicar seu propósito geral, critérios de acionador e resultado pretendido.
-
Use o campo Descrição em cada elemento individual (por exemplo,
Get Records,Action,Transform). Essa prática é a melhor maneira de transmitir a intenção. É especialmente importante para ações e subfluxos invocáveis, em que a descrição é o principal lugar para explicar a lógica complexa realizada pela ação.
No Apex
-
Comente seu código claramente para explicar o porquê por trás de sua lógica, não apenas o o quê.
-
Se estiver usando uma estrutura conduzida por metadados, garanta que seus registros de metadados incluam e preencham um campo de Descrição legível por humanos para explicar o que cada classe de manipulador faz e quando ela deve ser executada.
DevOps e controle de origem fazem parte de um ciclo de vida de desenvolvimento maduro. Sempre use uma ferramenta de controle de código-fonte, como Git para projetos do Salesforce. As classes do Apex e os Fluxos do Salesforce são metadados que definem sua lógica de negócios e devem ser controlados e gerenciados com controle de versão.
No contexto do gerenciamento de automações acionadas por registro, um pipeline DevOps moderno oferece benefícios essenciais.
-
Verificações de qualidade automatizadas: Ferramentas como o Salesforce Code Analyzer podem ser configuradas para ser executadas automaticamente em seu pipeline. A análise estática pode detectar padrões problemáticos em ambas as ferramentas de automação antes de serem promovidas, sinalizando problemas como elementos de
Get Recordsineficientes dentro de um loop de Fluxo ou consultas deSOQLdentro de um loop do Apex, que são causas comuns de degradação do desempenho. -
Prevenção de regressão: Conforme sua densidade de automação aumenta, uma mudança para um Fluxo ou classe do Apex pode ter consequências indesejadas para outras automações no mesmo objeto. Uma estratégia de teste DevOps robusta, em que os testes automatizados do Apex são executados em relação a qualquer alteração proposta, é a maneira mais confiável de garantir que uma nova versão do Fluxo não quebre a lógica do Apex existente (e vice-versa).
-
Colaboração e visibilidade: O controle de origem é a "única fonte da verdade". Permite que administradores e desenvolvedores trabalhem em automação para o mesmo objeto em paralelo. Ele também fornece uma trilha de auditoria inestimável: quando um processo de produção é interrompido, você pode ver instantaneamente quem mudou a automação, quando mudou e — através de mensagens de compromisso — por que mudou.
Para equipes com uma combinação de administradores e desenvolvedores, o DevOps Center fornece uma interface unificada para ajudar a organizar todas essas etapas, tornando um processo de desenvolvimento escalonável e baseado em controle de código-fonte acessível a todos na equipe.
Essa disciplina combinada de documentação e DevOps garante a integridade e a manutenção de longo prazo da sua organização, o que beneficiará todos os arquitetos e administradores que o seguem.
O guia de decisão acima é melhor usado antes de planejar sua implementação. Ele tem como objetivo ajudá-lo a escolher o melhor produto para seus casos de uso. Após a seleção do produto, é importante entender as práticas recomendadas existentes para sua implementação.
O princípio Uma ferramenta por objeto é crucial para gerenciar a automação de alta densidade, mas não o interprete como uma escolha binária entre uma pilha puramente declarativa ou puramente programática. Um padrão arquitetônico mais eficaz e mantido aproveita um modelo híbrido: posicione o Fluxo acionado por registro como a camada de orquestração, encapsulando operações de alta complexidade no Apex invocável.
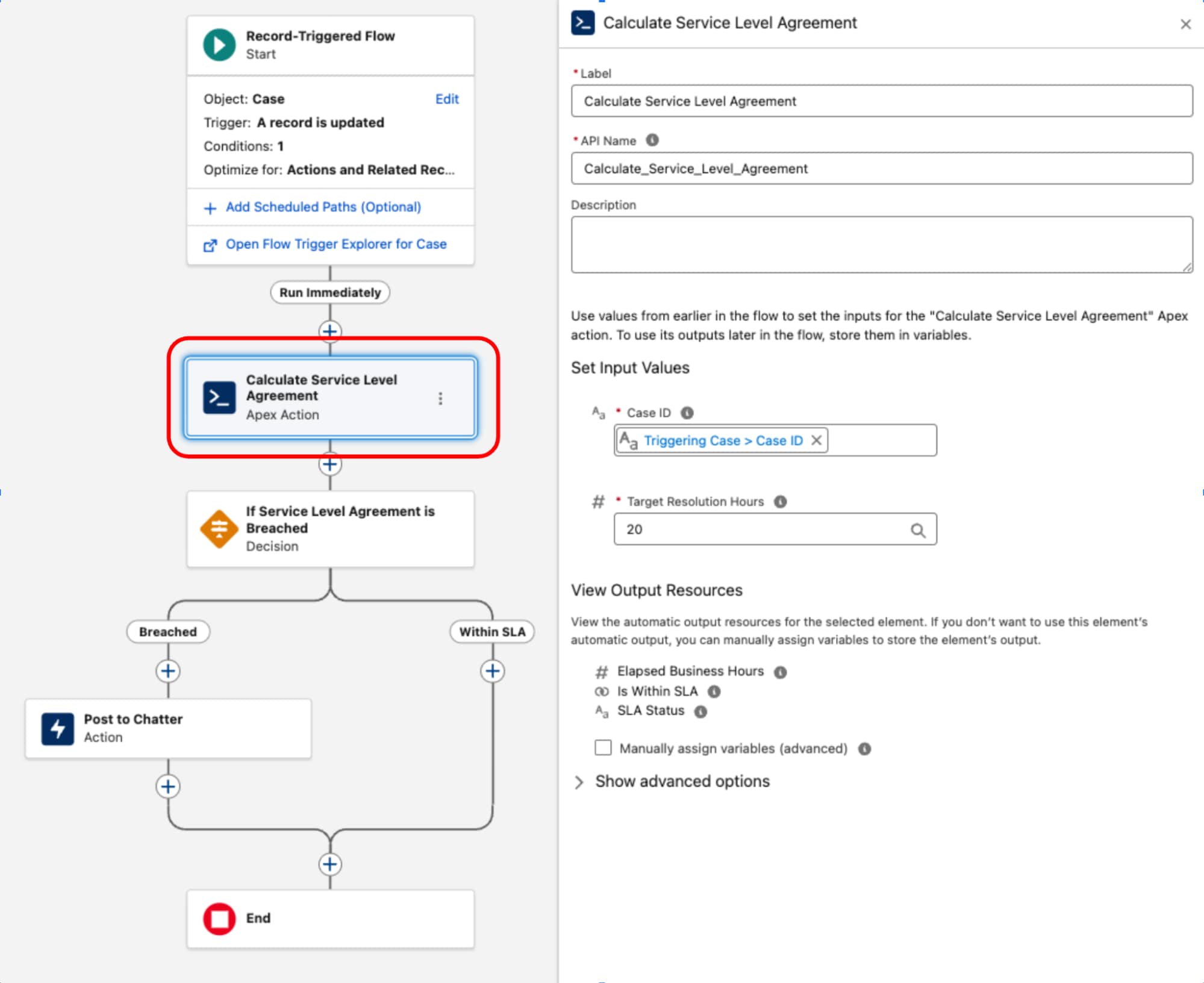
O Fluxo acionado por registro serve como a camada de orquestração para o processo de negócios. Ele é o proprietário dos critérios de entrada e do contexto de execução (o o que e quando). Ao reter a lógica de decisão e o roteamento nessa camada, a topologia de processo da arquitetura permanece transparente e gerenciável por meio do Explorador do acionador de fluxo, impedindo que a lógica de negócios crítica seja ocultada no código.
Um exemplo comum de um componente complexo é a implementação de cálculos de Acordo de nível de serviço (SLA) para registros de Caso. Como o objeto BusinessHours e sua lógica relacionada, essenciais para cálculos precisos que excluem horas de trabalho e feriados, não estão acessíveis nativamente no Fluxo, uma classe do Apex dedicada é usada. Essa classe, muitas vezes chamada de algo como ServiceLevelAgreementCalculator, é projetada com um único método estático, anotado com @InvocableMethod, para calcular o horário comercial decorrido, determinar se o SLA é "Dentro da meta" ou "Fechado" e retornar uma saída estruturada. Essa abordagem encapsula a lógica complexa e de alto desempenho no Apex, ao mesmo tempo que permite que ela seja executada e integrada na camada de orquestração declarativa de um fluxo acionado por registro.
Depois que a classe ServiceLevelAgreementCalculator do Apex for definida, ela estará disponível para uso em um fluxo acionado por registro:
Esse padrão demonstra uma separação rígida das preocupações. A camada declarativa é usada para gerenciar o ciclo de vida da transação e a orquestração enquanto o código é usado para execução de alta complexidade. Ao tratar o código como um utilitário funcional em vez da base, equilibramos o desempenho e a capacidade de manutenção.
Modularidade: A decisão afasta-se da singularidade de usar o Apex ou o Fluxo para todo o processo. Em vez disso, a arquitetura encapsula a lógica complexa em unidades separadas, seguras em massa e testáveis de modo independente. Essas unidades funcionam como componentes reutilizáveis consumidos pela camada declarativa, garantindo as escalas de automação sem complicar o design arquitetônico.
Reusabilidade: A lógica é desacoplada do evento de acionador. Uma unidade de código bem projetada (como uma InvocableMethod) é escrita uma vez, mas aproveitada em vários pontos de entrada: Fluxos acionados por registro, fluxos de tela ou integrações externas. Essa reutilização de código elimina o desenvolvimento redundante.
Manutenção: A lógica de fluxo de processo permanece visível e gerenciável no Fluxo declarativo. Essa centralização reduz drasticamente a sobrecarga de depuração e garante que a ordem de execução do sistema seja determinista e transparente.
Embora o modelo híbrido de usar o Apex invocável do fluxo seja poderoso, não é uma abordagem unidimensional. Os arquitetos devem estar cientes das limitações e compensações específicas antes de se comprometerem com uma solução híbrida.
-
Nenhum suporte antes de salvar: Esta é a limitação mais crítica. Ações invocáveis estão disponíveis apenas no contexto após salvar (fluxos para ações e registros relacionados). Eles não podem ser usados no contexto de alto desempenho antes de salvar (fluxos para atualizações de campo rápido). Portanto, esse padrão não pode ser usado para delegar atualizações de campo do mesmo registro. Faça esse trabalho de alto desempenho usando elementos de Fluxo nativos em um fluxo antes de salvar ou em um acionador do Apex antes do contexto.
-
Sem suporte após a exclusão cancelada: Atualmente, o Fluxo acionado por registro não oferece suporte ao contexto após a exclusão cancelada. Se um objeto do Salesforce tiver um requisito de negócio para executar a automação quando um registro for restaurado da lixeira, um acionador do Apex será a única solução.
-
** Sobrecarga de desempenho em cenários de alto volume:** A transição do tempo de execução do Fluxo para o tempo de execução do Apex não é uma operação de custo zero. Embora geralmente seja rápido, o ato de cair em uma Ação invocável do tempo de execução do Fluxo não é tão rápido computacionalmente quanto a execução nativa que permanece inteiramente dentro de um acionador do Apex. Para a maioria das automações de média densidade, essa sobrecarga é uma compensação insignificante e útil para a maior acessibilidade. No entanto, para cenários de alto desempenho e alto volume, uma estrutura somente do Apex terá uma vantagem de velocidade de computação bruta.
Embora a heurística de densidade de automação forneça orientação definitiva para uma arquitetura de greenfield mais recente, a realidade dos ambientes corporativos do Salesforce costuma ser mais detalhada. Em organizações maduras, é comum encontrar fluxos acionados por registro e acionadores do Apex que operam no mesmo objeto do Salesforce. Este cenário é diferente do padrão híbrido explicado anteriormente: aqui, os fluxos e acionadores do Apex não estão acoplados nem projetados para trabalharem juntos.
Essa coexistência geralmente é resultado de funcionalidades de plataforma em evolução ou débito técnico legado. Embora esse seja um estado operacional tolerado, os arquitetos devem tratá-lo como uma compensação calculada em vez de um estado final.
A orquestração fragmentada gera uma sobrecarga significativa de governança e manutenção, tornando as atividades de desenvolvimento, teste e tratamento de incidentes desagrupadas e complicadas. Isso leva a um maior Tempo para resolução (TTR) e complexidade operacional.
-
Para novos objetos do Salesforce, siga o princípio de densidade de automação como o guia principal.
-
Para Objetos do Salesforce existentes com uma pegada híbrida e acionador Apex duplo e pontos de entrada de fluxo acionados por registro, avalie a densidade e, em seguida, arquite para o refator para um estado híbrido mantido.
-
Para baixa densidade, o Apex refator aciona fluxos acionados por registro e especifica a ordem de execução, levando-os a um único ponto de entrada de automação.
-
Para densidade média, o complexo do refator faz megafluxos em um subconjunto de fluxos com a ordem de execução certa. Introduza acionadores do Apex apenas quando absolutamente necessário, por exemplo, para dar suporte após a exclusão de contexto cancelada.
-
Para alta densidade, implemente acionadores do Apex.
-
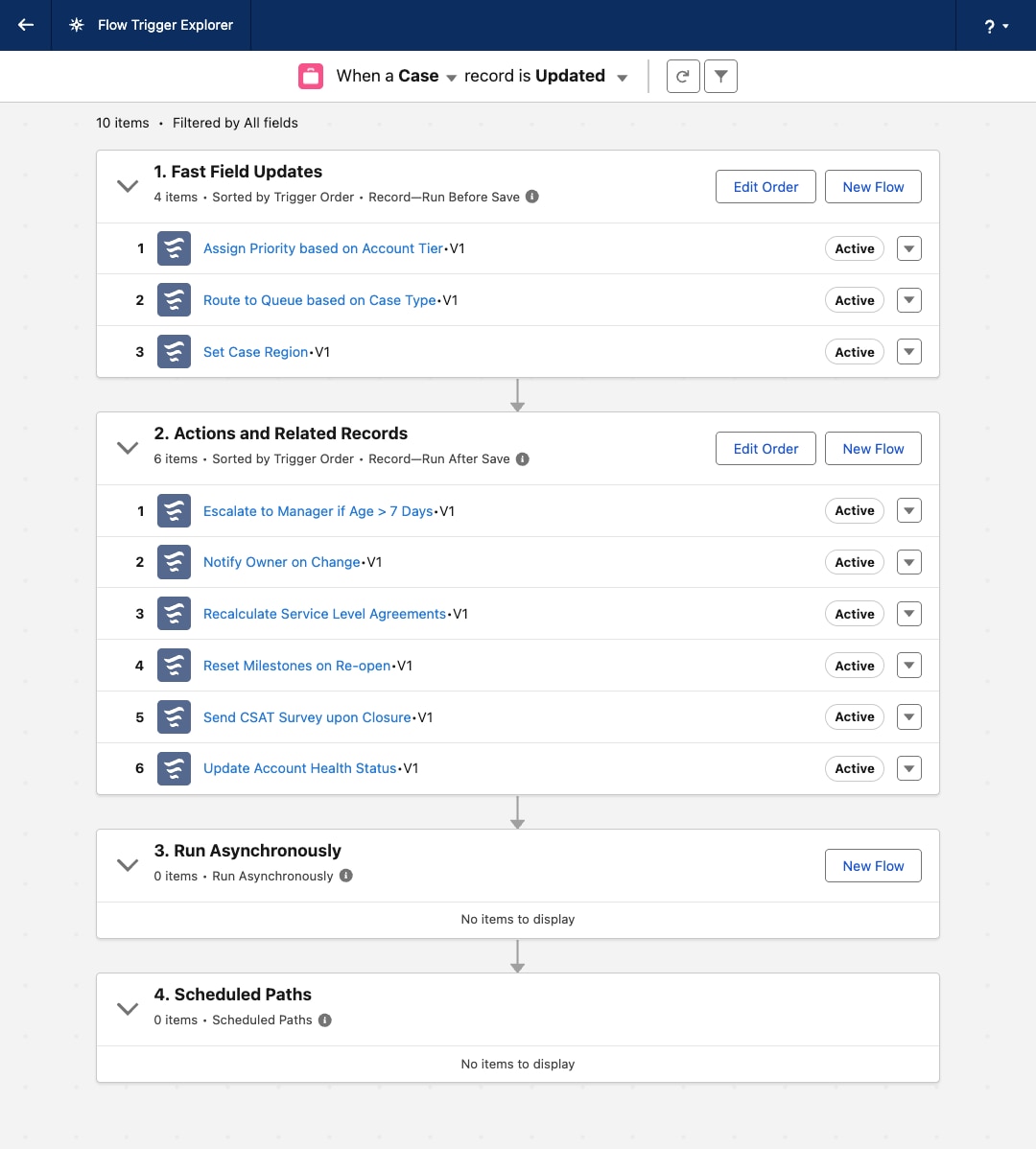
Conforme os processos de negócios de uma organização na Salesforce Platform amadurecem, o volume e a complexidade da automação acionada por registro aumentam inevitavelmente. Uma prática recomendada fundamental é manter um acionador do Apex por objeto do Salesforce. Essa regra é crítica porque a plataforma não garante a ordem de execução de vários acionadores no mesmo objeto para o mesmo evento. Essa limitação pode levar a comportamentos não deterministas, condições de corrida e problemas de depuração difíceis.
No entanto, aderir ao princípio de um acionador introduz um desafio arquitetônico: como gerenciar e orquestrar toda a lógica de negócios invocada desse ponto de entrada único de uma maneira mantida e escalonável.
A primeira evolução dessa arquitetura foi o padrão do Manipulador de acionador clássico. Nesta abordagem, o acionador Apex único delega toda a sua lógica a uma classe de manipulador correspondente (por exemplo, OpportunityTriggerHandler). Esse método separa a lógica do arquivo de acionador e fornece aos desenvolvedores controle determinístico sobre a ordem de execução dentro dos métodos da classe manipuladora (por exemplo, afterInsert()).
Embora seja uma melhoria, esse padrão geralmente leva a classes de manipulador monolíticas. Ao longo do tempo, à medida que mais requisitos de negócios são adicionados, a classe se torna grande, difícil de gerenciar e difícil de testar em isolamento. A ordem de execução de todos os processos individuais é codificada em um único método, tornando a classe propensas a conflitos de mesclagem, aumentando dramaticamente a sobrecarga de governança e manutenção em um ambiente corporativo grande.
Para resolver os problemas centrais da modularidade e da orquestração, os arquitetos mudam para uma Quadro do acionador conduzido por metadados. Este é um salto arquitetônico significativo que separa a própria lógica de automação da configuração de como e quando ela é executada.
Essa estrutura é baseada em três principais vantagens:
-
Particionamento: Em vez de uma única classe de manipulador, a lógica de negócios principal é dividida em classes do Apex pequenas e atômicas (por exemplo, uma classe de
RecalculateAccountValuesou uma classe deNotifySalesLeads), com cada classe aderindo ao Princípio de Responsabilidade Única. Essa modularidade facilita o teste, a depuração e a compreensão da lógica isoladamente. -
Ordem e coreografia: A ordem de execução não é mais codificada no Apex. Em vez disso, é definido declarativamente por registros de configuração, geralmente armazenados em um tipo de metadados personalizado (por exemplo,
TriggerAction__mdt). Isso permite que os administradores reordene, adicione ou remova ações de automação simplesmente modificando um registro de metadados, o que não requer uma implantação ou alteração de código. -
Funcionalidade de bypass: A estrutura fornece uma funcionalidade de desvio granular padronizada. Cada ação de automação pode ser configurada por meio de seu registro de metadados para ser desativada globalmente ou ignorada para usuários administrativos específicos referenciando uma permissão personalizada.
O acionador Apex único para o objeto então serve apenas como um supervisor dinâmico. Ele não contém lógica de negócios, mas instancia uma classe central de MetadataTriggerHandler. Esse manipulador consulta os registros de metadados personalizados para determinar dinamicamente a sequência de execução e invocar as classes atômicas Apex corretas na ordem prescrita. A automação é unificada sob uma única camada transparente e governável.
Uma vantagem importante do uso do Apex em uma estrutura robusta é a capacidade de gerenciar o estado transacional e otimizar o desempenho eliminando o trabalho redundante. Conforme a lógica se acumula, é comum que diferentes automações no pedido de salvamento executem de modo independente as mesmas operações caras, consumindo limites valiosos do regulador e aumentando o tempo de operação de DML.
A estrutura é arquitetada para lidar com isso com duas estratégias principais:
-
Gerenciamento de estado compartilhado: No escopo de uma única transação do Apex, propriedades estáticas e variáveis são aproveitadas para armazenar dados em cache. Isso garante que uma operação cara, como uma consulta de
SOQLpara uma configuração de configuração, seja executada apenas uma vez, mesmo que a lógica de automação seja invocada várias vezes em diferentes registros ou fases do acionador. O consumo dos limites transacionais é significativamente reduzido. -
Utilização de cache da plataforma: Para ir além do simples armazenamento em cache dentro da transação, use o cache da plataforma para evitar consultar todo o banco de dados para determinados dados. Esse cache gerenciado na memória é ideal para recuperar dados que não sejam primitivos, sejam lidos com frequência na base de códigos e sejam imutáveis ao longo de uma transação (por exemplo, perfis, papéis, horário comercial). Usando a interface de
Cache.CacheBuilder, o sistema verifica o cache primeiro e realiza a consulta de banco de dados apenas se os dados não estiverem presentes, maximizando o desempenho e a escalabilidade.
Sempre use uma atualização antes de salvar quando sua automação precisar apenas alterar os valores de campo no registro que inicia a transação. Isso se aplica tanto a atualizações de campo rápido no Fluxo (que são executadas antes de salvar) quanto à lógica antes do contexto nos Acionadores do Apex (antes da inserção, antes da atualização).
Esse padrão tem desempenho, independentemente da ferramenta usada, pois evita uma segunda operação DML e um ciclo de salvamento recursivo. As alterações são feitas no registro na memória antes de ele ser vinculado ao banco de dados e são salvas como parte da transação original. A sobrecarga de um segundo salvamento, que, caso contrário, reexecutaria todo o pedido de salvamento e acionaria toda a automação novamente, é eliminada.
A recursão não controlada é uma armadilha comum em acionadores após a atualização, em que a lógica de um acionador realiza uma atualização de DML que, por sua vez, faz o mesmo acionador ser disparado novamente. Isso cria um loop infinito que termina com uma exceção de limite do regulador. Embora sinalizadores booleanos estáticos ou coleções de IDs de registro processados tenham sido usados historicamente para evitar essa recursão, um padrão mais preciso e robusto é criar a lógica por meio da comparação de valores de campo entre as versões novas e antigas do próprio registro.
Execute a lógica apenas se um campo específico de interesse tiver realmente mudado. Isso impede que o acionador execute sua lógica em operações de DML subsequentes na mesma transação em que os dados críticos permanecem inalterados.
Em um fluxo acionado por registro, evite a recursão não controlada definindo o fluxo para ser executado apenas quando o registro for atualizado para atender aos requisitos de condição:

Se você optar por usar uma fórmula de critérios de entrada em seu fluxo, poderá evitar a recursão de escape comparando a variável global $Record (que representa os novos valores) com a variável global $RecordPrior (que representa os valores originais antes do salvamento). Por exemplo, para garantir que um fluxo seja executado apenas se o campo Valor em uma oportunidade tiver sido alterado, use isto nos critérios de entrada:
Compare os valores de campo da nova versão do registro, Trigger.new, com os valores de campo da versão antiga do registro, Trigger.oldMap, para ver se a alteração específica que você está procurando ocorreu. Essa abordagem garante que a automação seja idempotente e seja executada apenas quando necessário, tornando o sistema mais eficiente e evitando loops recursivos catastróficos.
Uma organização do Salesforce bem arquitetada requer um mecanismo consistente e confiável para contornar a automação. Esse não é um recurso opcional, mas um requisito operacional essencial para manter a integridade dos dados e habilitar tarefas administrativas.
Uma estrutura de desvio é essencial para alguns cenários:
-
Ao carregar grandes volumes de dados, acionar acionadores para cada registro pode desacelerar drasticamente o processo, causar exceções de limite e criar registros relacionados e notificações incorretos. Um desvio permite que os dados sejam inseridos de maneira limpa e eficiente.
-
Um usuário de integração pode precisar sincronizar dados de um sistema externo de registro. A automação que normalmente é acionada para uma alteração iniciada pelo usuário (por exemplo, enviar um email, criar uma tarefa) pode ser indesejável ou redundante quando a alteração se origina de outro sistema.
-
Os administradores ou a equipe de suporte podem precisar realizar atualizações corretivas em registros. Um mecanismo de ignorar permite que eles façam essas alterações sem acionar a automação de negócios padrão, o que pode ter consequências indesejadas.
Permissões personalizadas: O padrão moderno e escalonável para implementar a lógica de desvio é permissões personalizadas. Esses métodos são superiores aos métodos mais antigos por diversos motivos:
-
Flexibilidade: As permissões personalizadas podem ser atribuídas aos usuários por meio de conjuntos de permissões. Essa prática está alinhada ao moderno modelo de segurança e acesso do Salesforce, permitindo uma atribuição granular e flexível. Um desvio pode ser concedido a um usuário específico ou mesmo temporariamente com uma data/hora de expiração específica.
-
Manutenção: O uso de permissões personalizadas evita que perfis de codificação permanente ou usuários entrem na lógica de automação. Se o papel de um usuário mudar ou um novo perfil precisar ignorar o acesso, a alteração será uma simples atribuição de Conjunto de permissões, não uma modificação de código ou fluxo que exija uma implantação.
-
Escalabilidade: As permissões personalizadas fornecem uma estrutura dimensionável para gerenciar exceções em uma base de usuários complexa. Eles podem ser atribuídos a usuários por meio de conjuntos de permissões, grupos de conjuntos de permissões ou perfis. Sua associação a um conjunto de permissões ou perfil também é representável nos metadados de origem.
Padrões de implementação: Aplique um padrão de desvio consistente a todas as automações acionadas por registro na organização.
Pular um fluxo acionado por registro: A maneira mais eficiente de ignorar um fluxo é impedi-lo de ser executado. Isso é feito adicionando uma condição aos critérios de entrada do fluxo.
-
No elemento Iniciar do fluxo acionado por registro, defina Requisitos da condição como Fórmula avaliada como verdadeira.
-
No construtor de fórmula, incorpore uma verificação para a permissão personalizada usando a variável global
$Permission. Combine a verificação com seus critérios de entrada existentes.- Padrão de fórmula:
-
Esse padrão garante que o fluxo seja executado somente se o usuário não tiver a permissão personalizada especificada atribuída. Essa verificação é realizada antes mesmo da criação da entrevista de fluxo, tornando-a a abordagem com melhor desempenho.
-
Excluindo uma estrutura de acionador do Apex: No Apex, integre a lógica de desvio diretamente na estrutura de acionador orientada por metadados, permitindo um controle granular.
-
O tipo de metadados personalizados
TriggerAction__mdtdeve incluir um campo de texto, por exemplo,BypassPermission__c.-
Na classe
MetadataTriggerHandler, antes de executar uma ação dinamicamente, o código deve ler o valor desse campo. -
Se o campo for preenchido, o manipulador usará o método
FeatureManagement.checkPermission()para determinar se o usuário em execução atual tem a permissão personalizada especificada. -
Se
checkPermission()retornar verdadeiro, o manipulador ignora essa ação específica e avança para a próxima na sequência. -
Esse padrão é poderoso porque permite tanto um bypass global (se todos os registros de
TriggerAction__mdtreferenciarem a mesma permissão) quanto um bypass granular por ação (se diferentes registros referenciarem permissões diferentes ou se alguns não tiverem permissão de bypass).
-
É um antipadrão consolidar toda a automação de um objeto em um único megafluxo maciço. Consolidar em um fluxo versus dividir a lógica em vários fluxos bem condicionados não tem um impacto significativo no desempenho. Os ganhos de desempenho mais significativos vêm de:
-
Usar fluxos antes de salvar para atualizações de campo do mesmo registro.
-
Escrever condições de entrada precisas para garantir que os fluxos sejam excluídos da execução em alterações que não afetam seu caso de uso específico.
O Flow Trigger Explorer permite atribuir um valor de ordem a cada fluxo em um objeto, garantindo uma ordem de execução sequencial.
| Apex | Fluxo | Operações |
|---|---|---|