Este texto se tradujo utilizando el sistema de traducción automatizado de Salesforce. Realice nuestra encuesta para proporcionar comentarios sobre este contenido e indicarnos qué le gustaría ver a continuación.
Note
Descripción general
Las arquitecturas modernas de Salesforce están cada vez más impulsadas por el procesamiento asíncrono; no como una comodidad, sino como un requisito estratégico para la escala. En los últimos años, hemos visto a más y más compañías lidiar con volúmenes de datos crecientes, integraciones complejas que implican múltiples puntos de contacto y el auge de sistemas autónomos que se ejecutan 24/7/365. Todo esto empuja a los arquitectos hacia el diseño de sistemas que son asíncronos en primer lugar.
El procesamiento asíncrono en Salesforce a menudo significa diseñar alrededor de límites reguladores y complejidad. Esos límites actúan como barandillas y restricciones arquitectónicas que ayudan a producir sistemas escalables y seguros en masa. Aunque ningún límite de plataforma sirve directamente para gestionar la complejidad, los patrones de diseño pueden ayudar a mitigar el riesgo en ese frente. Internamente, Salesforce a menudo amplía los límites de la plataforma para probar nuevas funciones y automatizar procesos de negocio complejos. Construimos un Marco de trabajo de procesamiento asíncrono basado en pasos para ejecutar trabajos asíncronos con un número arbitrario de pasos. Cada paso puede ejecutarse, reintentarse y reiniciarse de forma independiente con controles de gobernanza compartidos y visibilidad operativa completa a través del registro centralizado. Este documento describe sus componentes arquitectónicos clave: Apex y finalizadores colocables en cola, Flujo programado, Cursores Apex, Acciones invocables e integraciones con Slack. Juntos, estos componentes proporcionan una arquitectura modular, ampliable y observable adecuada para necesidades de negocio en evolución.
Conclusiones clave
Las arquitecturas modernas de Salesforce deben adoptar un enfoque asíncrono primero para alcanzar la escala, la resiliencia y la transparencia operativa.
Dividir el trabajo complejo en pasos ejecutables de forma independiente permite un desempeño predecible, reintentos más seguros, puntos de control, reversión y evolución modular sin volver a diseñar flujos de trabajo principales.
El marco de trabajo proporciona una alternativa ampliable a trabajos por lotes monolíticos y antiguos, llamadas asíncronas encadenadas y flujos profundamente anidados, y está construido para cargas de trabajo de gran volumen que deben ampliarse horizontalmente dentro de Salesforce sin orquestación fuera de la plataforma.
La ejecución determinista y observable garantiza el seguimiento del progreso, el monitoreo de SLA, el diagnóstico de fallos y la transparencia a nivel de auditoría a través del registro y la gobernanza centralizados.
Diseñado para el rigor de nivel de compañía, incluyendo la gobernanza unificada, el cumplimiento y el control de estado distribuido entre procesos de negocio de larga duración.
Mejores prácticas de plataforma
Antes de revisar los requisitos, estos son algunos de los aspectos que se deben y no se deben tener en cuenta para cuándo utilizar un marco como este. Sobre todo, considere qué sistema es la única fuente de verdad. Si su organización de Salesforce depende mínimamente de datos externos pero necesita ampliarse de cientos a millones de registros, considere un marco de trabajo asíncrono basado en pasos.
Sí utilice este marco de trabajo si:
La mayoría (o toda) la información sobre la que actuar ya existe en su CRM.
El costo inicial o continuo de mantener un trabajo Extraer carga de transformación (ETL) para armonizar datos externos es demasiado alto.
Debe aplazar el procesamiento de un gran número de registros de Salesforce en una programación establecida.
Puede desglosar el procesamiento en pasos discretos. Por ejemplo, puede crear un conjunto de registros jerárquicos o basados en árboles, especialmente si el volumen de datos se desvía de la jerarquía o el árbol.
No utilice este marco de trabajo si:
La creación o actualización de registros requiere un nuevo cálculo inmediato.
La integración es un reto porque los sistemas externos alojan datos principales para actualizaciones de registros. (Considere el envío de datos actualizados a Salesforce con la API masiva.)
Con esas prácticas en mente, revisemos nuestros requisitos y comencemos a construir.
Desglose de los requisitos
Considere la declaración de problema:
Dado un trabajo que necesita ejecutarse diariamente, compruebe si ciertos registros cumplen criterios preestablecidos para un procesamiento posterior. Si lo hacen, inicie esos trabajos de procesamiento. Procesar registros podría significar extraer datos de múltiples sistemas externos para realizar cálculos. Los pasos en trabajos deben notificar a las personas a través de Slack que los registros procesados están listos para su revisión. Los pasos también deben distribuir notificaciones a gestores y superiores en la jerarquía de funciones basándose en un retraso configurable después de la primera ronda de notificaciones.
Este problema implica varios pasos diferentes, algunos de los cuales pueden producirse independientemente entre sí. Existen muchas formas de dividir el trabajo. Esta es una agrupación:
El programador.
La interfaz de pasos e implementaciones concretas que procesan registros (independientemente del tipo de procesamiento).
Existe cierta complejidad oculta en la frase “retraso configurable”. Revisaremos esta complejidad más adelante en este artículo.
Este es un diagrama con opiniones para el marco de trabajo construido:
Ahora, desglose ese diagrama y comience a construir las piezas.
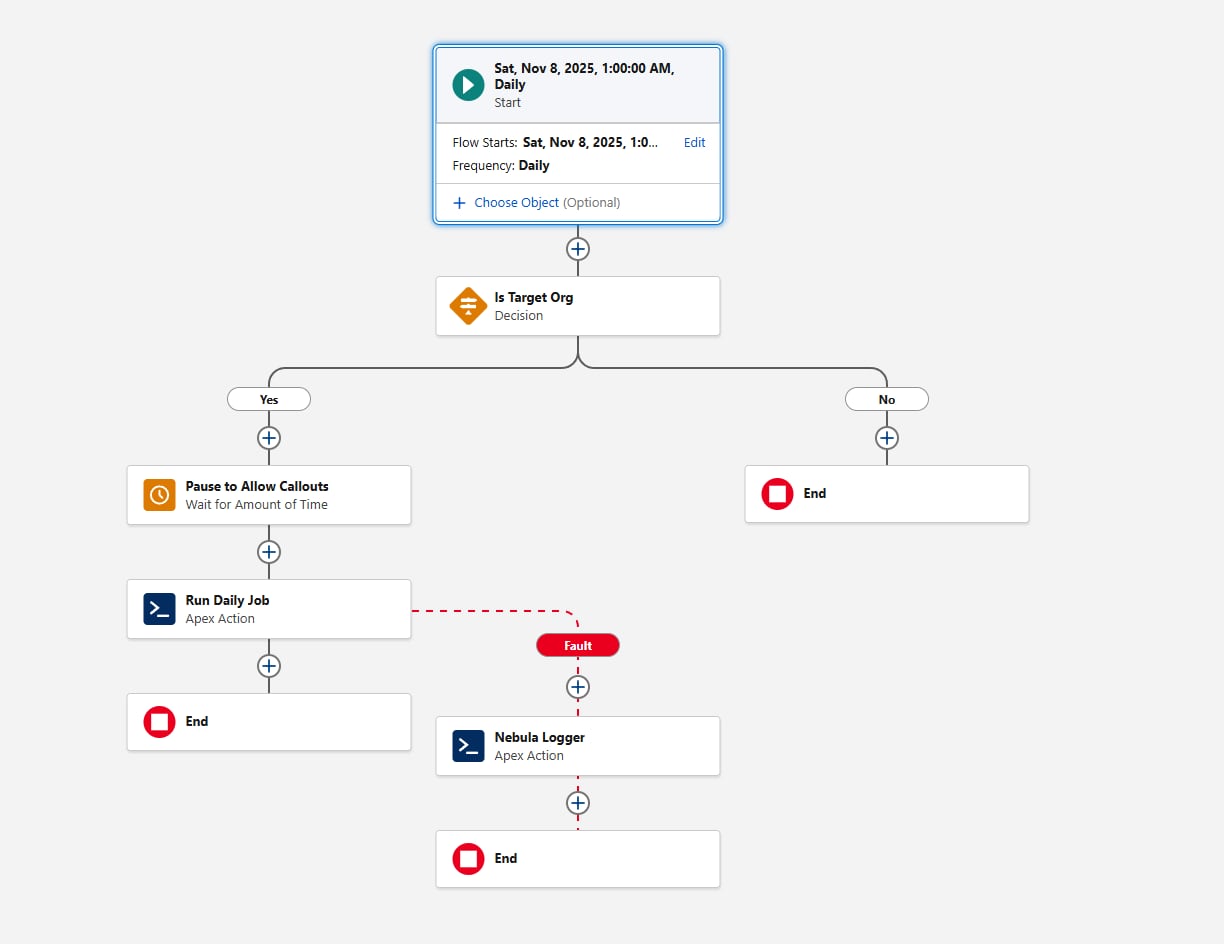
Programación con flujo programado
Flujo programado ofrece varias ventajas como mecanismo de programación:
Los flujos programados se pueden empaquetar e implementar como metadatos. Esto no es cierto para trabajos programados mediante Apex (o a través de la página Trabajos programados).
El elemento Espera es crítico para marcos de trabajo que requieren llamadas. Al utilizarlo en Flujo, las llamadas no son necesarias en la parte invocable del marco de trabajo.
La granularidad de la programación cumple los requisitos: el intervalo mínimo para Flujos programados es diario. Si necesita una frecuencia más alta (por ejemplo, cada hora), reconsidere Flujo programado para este requisito.
Otra consideración al configurar el Flujo programado es la apertura de puertas de entorno. Antes de invocar la acción Apex, agregue un elemento Decisión que evalúe la variable {!$Api.Enterprise_Server_URL_100}. Esto garantiza que el trabajo se ejecute solo en los entornos previstos, como UAT y Producción. Este patrón es importante porque los entornos sandbox se actualizan con frecuencia o se crean recientemente durante el SDLC, y sin una comprobación de entorno explícita, un Flujo programado podría ejecutarse de forma no intencionada en entornos donde el marco no está destinado a ejecutarse. El uso del operador contains en el elemento Decisión hace que la configuración sea resistente a futuras creaciones de sandbox o cambios de URL.
Finalmente, considere cómo debe capturar el marco los fallos. Agregue siempre una ruta de fallo cuando Flow llame a cualquier acción; por ejemplo, puede transferir fallos a la acción "Agregar entrada de registro" de Nebula Logger. Nebula Logger escribe registros en objetos personalizados, de modo que los clientes deben saber que los datos de registro consumen almacenamiento de la organización; de forma predeterminada, los registros se almacenan durante 14 días en una organización y luego se limpian; este periodo de retención es configurable. Nebula Logger también utiliza Eventos de plataforma para publicar registros, de modo que las entradas de registro se guardan independientemente de la transacción de procesamiento de datos principal; esto garantiza la captura de fallos incluso si la acción principal Flujo o Apex se revierte. Los clientes deben evaluar el volumen de registro esperado y los requisitos de retención cuando consideren la incorporación de un marco de trabajo de registro.
Este es el aspecto del flujo:
Pasemos a los primeros fragmentos de código Apex con el requisito de programación ahora satisfecho.
Para este artículo, la interfaz de step se muestra como una clase externa para mayor claridad. El marco en sí es flexible: los equipos pueden organizar la interfaz y sus implementaciones utilizando cualquier patrón de empaquetado Apex que prefieran, siempre que todas las clases Paso hagan referencia a la misma interfaz.
Existen algunas cosas a tener en cuenta acerca de los métodos definidos en nuestra interfaz:
execute, aunque sin argumentos por el momento, mejora cuando pasamos una clase de State (o interfaz) para orquestar datos entre pasos cuando el pedido importa.
Los getName podrían devolver un valor de System.Type en vez de un String. El objetivo es proporcionar a la capa de orquestación una forma de registrar nombres de pasos sin exponer otras propiedades.
Esta es la primera implementación concreta que muestra cómo se ajustan estas piezas. Con una excepción más adelante, recomendamos utilizar Apex colocable en cola para implementar el procesamiento asíncrono en Apex; Apex por lotes es normalmente innecesario (y se desaconsejan los métodos de @future). Apex colocable en cola se inicia rápidamente y, con Apex Cursors, tiene muchas ventajas sobre Apex por lotes.
Una implementación similar a un cursor de Apex
Los cursores Apex ofrecen una alternativa moderna al modelo Apex por lotes tradicional. Al igual que el procesamiento por lotes, una implementación de Cursor puede obtener registros en partes (hasta 2.000 por lote). Sin embargo, los Cursores permiten múltiples recuperaciones en una sola transacción, lo que permite un rendimiento significativamente superior para operaciones de gran volumen.
Al adoptar Cursores como parte de este marco de trabajo, los equipos deben tener en cuenta las limitaciones de prueba y simulabilidad actuales. El comportamiento del cursor en las pruebas puede diferir del comportamiento de producción, por lo que es importante diseñar estrategias de prueba que eviten depender de los elementos internos del cursor y que validen la lógica de orquestación en los límites. A medida que evolucione la plataforma, estas áreas seguirán mejorando, pero la orientación principal sigue siendo: Los cursores proporcionan un desempeño superior y una carga de orquestación reducida en comparación con Apex por lotes para muchos casos de uso.
Para definir un límite claro entre el Cursor proporcionado por el sistema y su propio código, recomendamos crear una representación similar a Cursor al implementar la interfaz de Step. Considere este código:
1public inherited sharing abstract class CursorStep implements Step{2 private static final Integer MAX_CHUNK_SIZE = 2000;34 protected Cursor cursor;56 private Integer chunkSize = System.Limits.getLimitDMLRows();7 private Integer position = 0;89 protected abstract Cursor getCursor();10 protected abstract void innerExecute(List<SObject>records);1112 public abstract String getName();1314 public virtual CursorStep withChunkSize(Integer chunkSize){15 this.chunkSize = chunkSize;16 return this;17}1819 public void execute(){20 this.cursor = this.cursor ?? this.getCursor();21 this.cursor.setFetchesPerTransaction(this.getFetchesPerTransaction());22 List<SObject>records = new List<SObject>();23 if(this.shouldAdvance()){24 records = this.cursor.fetch(this.position, this.chunkSize);25 this.position += this.chunkSize;26}27 this.innerExecute(records);28}2930 public virtual void finalize(){31 Logger.info('finished cursor step for ' + this.getName());32}3334 public virtual Boolean shouldRestart(){35 return this.position<this.cursor.getNumRecords();36}3738 protected virtual Integer getFetchesPerTransaction(){39 Integer maxRecordsPerFetchCall = 2000;40 if(this.chunkSize< maxRecordsPerFetchCall){41 return this.chunkSize;42}43 // Integer division rounds down44 // which is perfect for our use-case45 return this.chunkSize / maxRecordsPerFetchCall;46}4748 protected virtual Boolean shouldAdvance(){49 return true;50}51}
Observe la clase de Cursor. Los cursores Apex son instancias de Database.Cursor, pero nuestra implementación de Cursor nos da flexibilidad sobre las deficiencias de Cursores. Esta es la implementación:
1public virtual without sharing class Cursor{2 private static final Integer MAX_FETCHES_PER_TRANSACTION = Limits.getLimitFetchCallsOnApexCursor();34 @TestVisible5 private static Integer maxRecordsPerFetchCall = 2000;67 private Integer cursorNumRecords;8 private Integer fetchesPerTransaction = MAX_FETCHES_PER_TRANSACTION;9 private final Database.Cursor cursor;1011 public Cursor(12 String finalQuery,13 Map<String, Object>bindVars,14 System.AccessLevel accessLevel15){16 try{17 this.cursor = Database.getCursorWithBinds(finalQuery, bindVars, accessLevel);18}catch(FatalCursorException e){19 Logger.newEntry(20 System.LoggingLevel.WARN,21 'Error creating cursor. This can happen if there' +22 ' are no records returned by the query: ' + e.getMessage()23);24}25}2627 public Cursor setFetchesPerTransaction(Integer possibleFetchesPerTransaction){28 // Handle accidental round downs from Integer division29 if(possibleFetchesPerTransaction == 0){30 return this;31}32 if(possibleFetchesPerTransaction > MAX_FETCHES_PER_TRANSACTION){33 Logger.newEntry(34 System.LoggingLevel.DEBUG,35 'Fetches per transaction: ' +36 possibleFetchesPerTransaction +37 ' exceeded platform max fetches per transaction: ' +38 MAX_FETCHES_PER_TRANSACTION +39 ', defaulting to platform max'40);41 possibleFetchesPerTransaction = MAX_FETCHES_PER_TRANSACTION;42}43 this.fetchesPerTransaction = possibleFetchesPerTransaction;44 return this;45}4647 @SuppressWarnings('PMD.EmptyStatementBlock')48 protected Cursor(){49}5051 public virtual List<SObject>fetch(Integer start, Integer advanceBy){52 if(this.getNumRecords() == 0){53 Logger.newEntry(54 System.LoggingLevel.DEBUG,55 'Bypassing fetch call, no records to fetch'56);57 return new List<SObject>();58}59 Integer localStart = start;60 List<SObject>results = new List<SObject>();61 while(62 Limits.getFetchCallsOnApexCursor()<this.fetchesPerTransaction &&63 results.size()<this.getNumRecords() &&64 localStart < start + advanceBy65){66 Integer actualAdvanceBy = this.getAdvanceBy(localStart, advanceBy);67 results.addAll(this.cursor?.fetch(localStart, actualAdvanceBy)?? new List<SObject>());68 localStart += actualAdvanceBy;69}70 return results;71}7273 public virtual Integer getNumRecords(){74 this.cursorNumRecords = this.cursorNumRecords ?? this.cursor?.getNumRecords()?? 0;75 return this.cursorNumRecords;76}7778 protected Integer getAdvanceBy(Integer start, Integer advanceBy){79 Integer possibleFetchSize = Math.min(advanceBy, this.getNumRecords() - start);80 if(possibleFetchSize > maxRecordsPerFetchCall){81 Logger.newEntry(82 System.LoggingLevel.DEBUG,83 'Fetch size: ' +84 possibleFetchSize +85 ' exceeded platform max fetch size of ' +86 maxRecordsPerFetchCall +87 ', defaulting to max fetch size'88);89 possibleFetchSize = maxRecordsPerFetchCall;90}else if(possibleFetchSize <0){91 possibleFetchSize = 0;92}93 return possibleFetchSize;94}95}
Para el resto de este artículo, omitimos las declaraciones de sharing al hacer referencia a clases Apex. En la práctica, asegúrese de que las clases de nivel superior se utilizan explícitamente con o sin colaboración para ajustarse a su modelo de objeto y permisos.
Tenga en cuenta también que nuestra implementación de Cursor delega en el Database.Cursor de plataforma, con beneficios adicionales discutidos a continuación.
En primer lugar, estas son las pruebas correspondientes:
1@IsTest2private class CursorTest{3 @IsTest4 static void itCapsAdvanceByArgument(){5 String accountName = 'helloWorld!';6 insert new Account(Name = accountName);7 String query = 'SELECT Name FROM Account WHERE Name = :bindVar0';8 Map<String, Object>bindVars = new Map<String, Object>{'bindVar0' => accountName };910 Cursor instance = new Cursor(query, bindVars, System.AccessLevel.SYSTEM_MODE);1112 Assert.areEqual(1, instance.getNumRecords());13 Assert.areEqual(accountName, instance.fetch(0, 1000).get(0).get('Name'));14 Assert.areEqual(1, System.Limits.getApexCursorRows());15}1617 @IsTest18 static void itCapsMaxRecordsPerFetchCall(){19 Cursor.maxRecordsPerFetchCall = 20;20 Integer oneMoreThanMaxFetch = Cursor.maxRecordsPerFetchCall + 1;2122 List<Account>accounts = new List<Account>();23 for(Integer i = 0; i < oneMoreThanMaxFetch; i++){24 accounts.add(new Account(Name = 'Fetch ' + i));25}26 insert accounts;2728 Exception ex;29 List<SObject>results;30 Cursor instance = new Cursor(31 'SELECT Id FROM Account',32 new Map<String, Object>(),33 System.AccessLevel.SYSTEM_MODE34);35 try{36 results = instance.fetch(0, oneMoreThanMaxFetch);37}catch(System.InvalidParameterValueException e){38 ex = e;39}4041 Assert.areEqual(null, ex?.getMessage());42 Assert.areEqual(2, Limits.getFetchCallsOnApexCursor());43 Assert.areEqual(oneMoreThanMaxFetch, results.size());44}4546 @IsTest47 static void itFetchesMultipleTimesPerTransactionWhenMoreThanMaxFetch(){48 Cursor.maxRecordsPerFetchCall = 20;49 List<Account>accounts = new List<Account>();50 Set<String>expectedFetchNames = new Set<String>();51 for(Integer i = 0; i <Cursor.maxRecordsPerFetchCall + 1; i++){52 String accountName = 'Fetch' + i;53 expectedFetchNames.add(accountName);54 accounts.add(new Account(Name = accountName));55}56 insert accounts;5758 Integer oneMoreThanMaxFetch = Cursor.maxRecordsPerFetchCall + 1;59 Cursor instance = new Cursor(60 'SELECT Name FROM Account',61 new Map<String, Object>(),62 System.AccessLevel.SYSTEM_MODE63);64 List<SObject>results = instance.setFetchesPerTransaction(2).fetch(0, oneMoreThanMaxFetch);6566 Assert.areEqual(Cursor.maxRecordsPerFetchCall + 1, results.size());67 Assert.areEqual(2, Limits.getFetchCallsOnApexCursor());68 Set<String>actuallyFetchedNames = new Set<String>();69 for(Account account :(List<Account>) results){70 actuallyFetchedNames.add(account.Name);71}72 Assert.areEqual(expectedFetchNames, actuallyFetchedNames);73}7475 @IsTest76 static void itFetchesMultipleTimesPerTransaction(){77 Cursor.maxRecordsPerFetchCall = 1;78 insert new List<Account>{new Account(Name = 'One'), new Account(Name = 'Two')};7980 Cursor instance = new Cursor(81 'SELECT Id FROM Account',82 new Map<String, Object>(),83 System.AccessLevel.SYSTEM_MODE84)85 .setFetchesPerTransaction(2);86 List<SObject>results = instance.fetch(0, 2);8788 Assert.areEqual(2, instance.getNumRecords());89 Assert.areEqual(2, results.size());90 results = instance.fetch(2, 1);91 Assert.areEqual(0, results.size());92}9394 @IsTest95 static void fetchesCorrectAmountOfRecords(){96 List<Account>accounts = new List<Account>();97 for(Integer i = 0; i <10; i++){98 accounts.add(new Account(Name = 'Fetch ' + i));99}100 insert accounts;101102 Cursor instance = new Cursor(103 'SELECT Id FROM Account',104 new Map<String, Object>(),105 System.AccessLevel.SYSTEM_MODE106)107 .setFetchesPerTransaction(10);108 List<SObject>results = instance.fetch(0, 2);109110 Assert.areEqual(2, results.size(), '' + results);111 Assert.areEqual(1, Limits.getFetchCallsOnApexCursor());112}113114 @IsTest115 static void doesNotExceedPlatformMaxFetch(){116 List<Account>accounts = new List<Account>();117 for(Integer i = 0; i <101; i++){118 accounts.add(new Account(Name = 'Fetch ' + i));119}120 insert accounts;121122 Test.startTest();123 Cursor instance = new Cursor(124 'SELECT Id FROM Account',125 new Map<String, Object>(),126 System.AccessLevel.SYSTEM_MODE127)128 .setFetchesPerTransaction(100);129 Integer counter = 0;130 List<SObject>results;131 while(counter <= 100){132 results = instance.fetch(counter, counter + 1);133 counter++;134}135 Test.stopTest();136137 Assert.areEqual(101, counter);138 Assert.areEqual(0, results.size());139}140}
Al hacer que las Cursor sean virtuales, las implementaciones de CursorStep concretas pueden operar sin un Database.Cursor cuando no necesitan iterar un conjunto de registros grande, similar a devolver un System.Iterable<T> en vez de un Database.QueryLocator en Apex por lotes. Este es un ejemplo:
1public abstract class CursorLikeImplementation extends CursorStep{2 private final Cursor cursorLike;34 public CursorLikeImplementation(List<SObject>previouslyRetrievedRecords){5 this.cursorLike = new CursorLike(previouslyRetrievedRecords);6}78 public override String getName(){9 return CursorLikeImplementation.class.getName();10}1112 public override Cursor getCursor(){13 return this.cursorLike;14}1516 private class CursorLike extends Cursor{17 private final List<SObject>records;1819 public CursorLike(List<SObject>records){20 super();21 this.records = records;22}2324 public override List<SObject>fetch(Integer position, Integer chunkSize){25 // clone, to keep the underlying list type26 List<SObject>clonedRecords = this.records.clone();27 clonedRecords.clear();28 for(Integer i = position; i <this.getAdvanceBy(position, chunkSize); i++){29 clonedRecords.add(this.records[i]);30}31 return clonedRecords;32}3334 public override Integer getNumRecords(){35 return this.records.size();36}37}38}
Tenga en cuenta que como esta clase también es abstracta, deja la implementación concreta de innerExecute a subclases.
También existe una alternativa a la subclase interna CursorLike. Si sabe que las versiones concretas de un paso como este no superarán otros límites reguladores, puede devolver this.records desde CursorLike.fetch y sustituir la CursorStep.shouldRestart() principal para devolver false. Eso le permite iterar sobre una lista limitada solo por el límite de pila de Apex de 12 MB por transacción asíncrona.
Otras posibles implementaciones basadas en pasos
Nuestra implementación basada en cursores nos proporciona mucha flexibilidad al paginar grandes cantidades de datos. La interfaz de Step, por su parte, nos proporciona la flexibilidad de describir y encapsular pasos de todo tipo.
Considere un paso basado en flujo:
1public virtual class FlowStep implements Step{2 private final Invocable.Action specificFlow;34 private Boolean shouldRestart = false;56 public FlowStep(String specificFlowName, Map<String, Object>inputs){7 this.specificFlow = Invocable.Action.createCustomAction('flow', specificFlowName);8 this.specificFlow.setInvocations(new List<Map<String,Object>>{ inputs });9}1011 public void execute(){12 List<Invocable.Action.Result>results = this.specificFlow.invoke();13 for(Invocable.Action.Result result : results){14 if(result.isSuccess()){15 Map<String, Object>outputParams = result.getOutputParameters();16 Object potentialShouldRestartValue = outputParams.get('shouldRestart');17 // Flow does not enforce Booleans being initialized18 // so a null check is sadly necessary here19 if(potentialShouldRestartValue != null){20 this.shouldRestart = this.shouldRestart ||21 Boolean.valueOf(potentialShouldRestartValue);22}23}else{24 List<String>errorMessages = new List<String>();25 for(Invocable.Action.Error error : result.getErrors()){26 errorMessages.add(27 'Error code: ' + error.getCode() +28 ', error message: ' + error.getMessage()29);30}31 Logger.error(32 'An error occurred within your auto-launched flow:\n' +33 String.join(errorMessages, '\n\t')34);35}36}37}3839 public virtual void finalize(){40 Logger.info(this.getName() + ' finished processing');41}4243 public String getName(){44 return FlowStep.class.getName() + ':' + this.specificFlow.getName();45}4647 public Boolean shouldRestart(){48 return this.shouldRestart;49}50}
Como los flujos no pueden devolver parámetros de salida que se ajusten a un tipo definido por Apex, comprobamos si hay un parámetro de salida de shouldRestart antes de utilizarlo.
Algunos pasos podrían estar marcados con funciones. Puede implementar lógica para decidir qué pasos incluir o utilizar un paso sin operación para una función desactivada. El patrón Objeto nulo es una forma común de reducir la complejidad en la capa de orquestación:
1@SuppressWarnings('PMD.EmptyStatementBlock')2public class NoOpStep implements Step{3 // The null object pattern is commonly implemented4 // as a singleton to reduce memory consumption5 public static final NoOpStep SELF {6 get {7 SELF = SELF ?? new NoOpStep();8}9 private set;10}1112 public void execute(){13}1415 public void finalize(){16}1718 String getName(){19 return NoOpStep.class.getName();20}2122 Boolean shouldRestart(){23 return false;24}25}
Ahora tenemos bastantes elementos constructivos con los que trabajar. Veamos la capa de orquestación responsable de iterar sobre pasos.
Creación de un procesador de pasos
El procesador es un punto de inflexión en la arquitectura. Debemos decidir quién define qué pasos se inicializan y dónde. Las opciones incluyen:
Haga que el procesador defina qué pasos asignar a la lógica de negocio. Esta opción es sencilla, pero se amplía poco para facilitar la lectura.
Defina la asignación con Metadatos personalizados (CMDT). Los campos Relación de metadatos no admiten ApexClass, lo que combina la ortografía de nombres de clases en su configuración de procesos de negocio. Puede reducir el riesgo de administrador convirtiendo el campo en una lista de selección y validando el tipo que existe (Type.forName() o consultando ApexClass), pero como los registros CMDT no admiten desencadenadores, la validación se produce en tiempo de ejecución. Esta ruta es comprobable, pero los administradores aún pueden crear registros CMDT solo en producción: continúe con cuidado.
Defina la asignación con registros. Los no administradores pueden configurar pasos, pero las implementaciones se vuelven más difíciles y los entornos pueden desviarse. Proceda con precaución.
Existe una cita famosa de Clean Code acerca de cómo gestionar esta complejidad en particular:
La solución a este problema es enterrar la declaración switch [para crear objetos] en el sótano de una fábrica abstracta, y nunca dejar que nadie la vea.
Teniendo esto en cuenta, y como nuestro número actual de pasos está bien definido y es poco probable que crezca demasiado, está bien que el procesador de pasos sea también la fábrica de pasos. Esto puede utilizar una enumeración para dirigir la declaración switch:
1public StepProcessor implements System.Queueable, System.Finalizer,2 Database.AllowsCallouts{3 private final List<Step>steps = new List<Step>();45 private Step currentStep;67 public StepProcessor setSteps(List<StepType> stepTypes){8 for(StepType type : stepTypes){9 switch on type {10 WHEN TYPE_ONE {11 this.addTypeOneSteps();12}13 WHEN TYPE_TWO {14 this.addTypeTwoSteps();15}16 // ... etc17}18}19 this.cleanSteps();20 return this;21}2223 public void execute(System.QueueableContext context){24 this.currentStep = this.currentStep ?? this.steps.remove(0);25 if(context != null){26 System.attachFinalizer(this);27 Logger.setAsyncContext(context);28}29 Logger.info('Executing step ' + this.currentStep.getName());30 try{31 this.currentStep.execute();32}catch(Exception e){33 Logger.exception('Unexpected exception', e);34}35 Logger.info('Finished executing step ' + this.currentStep.getName());36 Logger.saveLog();37}3839 public void execute(System.FinalizerContext context){40 Logger.info('Executing finalizer for step ' + this.currentStep.getName());41 Logger.setAsyncContext(context);42 switch on context?.getResult(){43 when UNHANDLED_EXCEPTION {44 // see the note below about this logging paradigm45 Logger.warn(46 'Failed to run on step' + this.currentStep,47 context?.getException()48);49}50 when else{51 this.currentStep.finalize();52 if(this.currentStep.shouldRestart()){53 this.kickoff();54}else if(this.steps.isEmpty() == false){55 this.currentStep = this.steps.remove(0);56 this.kickoff();57}else{58 Logger.info('Finished executing steps');59}60}61}62 Logger.info(63 'Finished executing finalizer for step ' +64 this.currentStep.getName()65);66 Logger.saveLog();67}6869 public String kickoff(){70 return this.steps.isEmpty()? null : System.enqueueJob(this);71}7273 private void cleanSteps(){74 for(Integer reverseIndex = this.steps.size() - 1;75 reverseIndex >= 0; reverseIndex--){76 if(this.steps[reverseIndex]instanceof NoOpStep){77 this.steps.remove(reverseIndex);78}79}80}8182 private void addTypeOneSteps(){83 this.steps.addAll(84 new List<Step>{85 new ExampleCursorStepOne(),86 new ExampleCursorStepTwo()87}88);89}9091 private void addTypeTwoSteps(){92 this.steps.addAll(93 new List<Step>{94 new FlowStep('95 ExampleInvocableName',96 new Map<String, Object>('exampleParameter' =>true)97),98 new ExampleCursorStepThree()99}100);101}102}
Los métodos de fábrica mostrados, como addTypeOneSteps(), pueden delegar preocupaciones como el marcado de funciones; cleanSteps() realiza una comprobación puntual en los pasos recopilados para asegurarse de que no hay ningún paso “vacío” antes de ser verdaderamente asíncrono. Podría tener este aspecto:
No hemos debatido el tratamiento de errores desde que mencionamos el Registrador de nebulosas en la sección Flujo programado. Esto se debe a que la System.Finalizer nos permite cubrir el registro de todas las condiciones de error sin agregar la gestión de errores específica en cada paso. Cada Step se centra en la ejecución, mientras registramos y volvemos a lanzar cualquier ruta insatisfecha de modo que aflore en pruebas de unidad. Esto admite la iteración segura y las alertas a nivel de producción (utilizando el complemento Slack Logger para Nebula para todos los registros WARN y ERROR).
Una nota acerca del registro de errores: pasar la instancia del paso a mensajes de registro asume un nivel de Trust en lo que se hace visible en los registros. El toString() predeterminado para clases Apex incluye todas las propiedades estáticas y a nivel de instancia en el mensaje. Eso puede ser deseable, o puede filtrar información confidencial. Aunque el registro y la seguridad no son el enfoque aquí, tenga en cuenta que para algunos sistemas, la adhesión a una interfaz como Step también puede implicar forzar una sustitución para toString().
Este método impone a cada creador de objetos la responsabilidad de decidir qué se puede imprimir, lo que puede ser deseable.
En niveles de registro: a nivel de StepProcessor, utilizamos INFO, el nivel de no error más alto. A medida que se vuelve más granular en la aplicación, los niveles de registro deben disminuir en consecuencia. Los pasos individuales podrían utilizar DEBUG para información de alto nivel, con FINE, FINER y FINEST reservados para resultados cada vez más detallados. El registro es tanto un arte como una ciencia, pero seguir estos principios ayuda a mantener los registros coherentes y útiles.
Gestión de complejidad adicional dentro del procesador de pasos
Antes de continuar, reflexionemos brevemente sobre la decisión de que nuestro procesador de pasos aloje la lógica para la que se utilizan los pasos. En una base de código grande, considere hacer que los StepProcessor sean virtuales o abstractos y haga que las subclases identifiquen pasos específicos para establecer una separación apropiada de las preocupaciones.
La capa invocable Apex
El programador eventualmente invoca Apex. Con el resto de la configuración completa, la sección Apex invocable puede decidir qué pasos se deben ejecutar y pasar el List<StepType> al procesador:
1public class DailyJobExecutor{2 @InvocableMethod(label='Execute Daily Job')3 public static void executeJob(){4 Logger.info('Executing daily Job');56 List<StepType>correspondingTypes = new List<StepType>();7 // based on [business logic], determine which step types8 // should be included for any daily invocation910 if(correspondingTypes.isEmpty() == false){11 try{12 new StepProcessor().setSteps(correspondingTypes).kickoff();13}catch(Exception ex){14 Logger.exception('Error starting job', ex);15}16}17}1819 Logger.saveLog();20}
Esta es una parte sencilla de la ecuación: el uso de registros, datos o lógica para determinar qué tipos de pasos ejecutar. La acción invocable es sencilla porque encapsulamos la complejidad en otro lugar. También nos hemos protegido contra excepciones inesperadas y hemos hecho que cada pieza sea fácil de probar de forma aislada.
Gestión de retrasos antes de llamar a Slack
El SDK Apex Slack está más allá del ámbito de este artículo, pero un posible inconveniente de los requisitos merece una revisión: notificar a las personas en la jerarquía de funciones basándose en un retraso configurable. Sobre el papel, esto es sencillo y es posible que considere (correctamente) System.enqueueJob(this) en la StepProcessor. Con System.AsyncOptions, nuestra inclinación inicial era utilizar la sobrecarga de enqueueJob para satisfacer este requisito.
Por ahora, sin embargo, la demora máxima a través de System.AsyncOptions.MinimumQueueableDelayInMinutes es de 10 minutos. Como el requisito es de 120 minutos, quedan algunas opciones. Un enfoque ingenuo podría tener este aspecto:
1public class ExampleDelayedNotifier implements Step{2 private final List<Slack.ChatPostMessageRequest>notifications = new List<Slack.ChatPostMessageRequest>();3 private final Slack.BotClient botClient = Slack.App4 .getAppByKey('some-slack-app-key')5 .getBotClientForTeam('slack team id');67 // account for the initial delay,8 // so 120 - 10 = 1109 private Integer delayMinutes = 110;1011 public void execute(){12 if(this.delayInMinutes>0){13 return;14}1516 Integer maximumAllowedCallouts = 100;17 while(this.notifications.isEmpty() == false && maximumAllowedCallouts >0){18 this.botClient.chatPostMessage(this.notifications.remove(0));19 maximumAllowedCallouts--;20}21}2223 public void finalize(){24 this.delayInMinutes -= 10;25}2627 public String getName(){28 return ExampleDelayedNotifier.class.getName();29}3031 public Boolean shouldRestart(){32 return this.delayInMinutes>0 || this.notifications.isEmpty() == false;33}34}
En la práctica, el retraso se pasaría a esta clase porque el retraso está dirigido por la configuración.
No recomendamos este enfoque a menos que esté seguro de que solo habrá un tipo de notificación retrasada. Se quema en 11 trabajos asíncronos adicionales antes de comenzar (o más, si el retraso aumenta). Ese costo podría estar bien para un trabajo, no para muchos. También necesitaría agregar un método a la interfaz de Step de modo que cada paso pueda indicar al procesador cuánto tiempo esperar antes de reiniciar, lo que agrega ruido.
Eso nos deja dos posibilidades interesantes:
Puede dividir el paso retrasado en su marco de trabajo existente si ya tiene un trabajo de sondeo programado en un intervalo apropiado. También debería estar de acuerdo con que el retraso especificado llegue hasta 15 minutos después (15 minutos es el intervalo de actualización mínimo para una expresión de CRON programada por Apex). Esto coincide aproximadamente con el ejemplo de Apex invocable; la programación se realiza mediante Apex en su lugar. En otras palabras, puede reutilizar la misma arquitectura basada en Step para procesar registros basándose en una marca de tiempo “Iniciar después” y decidir qué pasos utilizar basándose en una lista de selección o asignación de lista de selección múltiple a los valores de enumeración de StepType mostrados anteriormente.
De manera alternativa, si está cómodo definiendo una clase de Apex externa adicional, vuelva a Apex por lotes (a diferencia de Apex colocable en cola, que admite clases internas, las clases Apex por lotes deben ser clases externas) utilizando System.scheduleBatch().
Considere el ejemplo de Apex por lotes. Aunque generalmente recomendamos Apex colocable en cola por flexibilidad y control, este es un caso donde Apex por lotes aún reina:
1public class DelayedNotifier implements Database.Batchable<Object>{2 private final StepProcessor processor = new StepProcessor();34 public Iterable<Object>start(Database.BatchableContext bc){5 return new List<Object>();6}78 @SuppressWarnings('PMD.EmptyStatementBlock')9 public void execute(Database.BatchableContext bc, Object scope){10 // we don't need to actually do anything in execute,11 // we just need to start up the processor in finish12}1314 public void finish(Database.BatchableContext bc){15 try{16 // you can imagine Notifier as an elided,17 // simpler version of the naive implementation18 // we showed above, now only focused on sending messages19 this.processor.setSteps(new List<Step>{new Notifier()}).kickoff();20}catch(Exception ex){21 Logger.exception('Unexpected error', ex);22}finally{23 Logger.saveLog();24}25}26}
Luego, en la StepProcessor, imagine que el método de addTypeOneSteps() mostrado anteriormente se actualiza con este paso retrasado:
1public StepProcessor implements System.Queueable, System.Finalizer,2 Database.AllowsCallouts{3 // .... unchanged top of class elided45 private void addTypeOneSteps(){6 this.steps.addAll(7 new List<Step>{8 new ExampleCursorStepOne(),9 new ExampleCursorStepTwo(),10 new DelayedNotifierStep()11}12);13}1415 // ...1617 private class DelayedNotifierStep implements Step{18 private final DelayedNotifier delayedNotifier = new DelayedNotifier();19 // again — in practice this value would also be passed in20 private final Integer delayInMinutes = 120;2122 public void execute(){23 System.scheduleBatch(24 this.delayedNotifier,25 'Delayed notifier: ' + System.now().getTime(),26 this.delayInMinutes27);28}2930 public void finalize(){31 Logger.debug('Nothing to finalize, batch scheduled');32}3334 public String getName(){35 return DelayedNotifierStep.class.getName();36}3738 public Boolean shouldRestart(){39 return false;40}41}42}
Aunque normalmente no recomendamos esta cantidad de saltos, este retraso de paso se convierte en otro elemento constructivo reutilizable. Hasta que se permitan demoras más largas en Apex colocable en cola, también representa la forma más sencilla de producir este efecto (sin un mecanismo de sondeo, como se discutió).
Conclusión
Utilizamos el diseño orientado a objetos para cumplir los requisitos y creamos un sistema que se ampliará mientras equilibra el costo a largo plazo de la construcción y el mantenimiento. Aunque la declaración de pasos y la creación de instancias pueden en última instancia superar su lugar en StepProcessor, hay poca deuda técnica adicional aquí. Con FlowStep, los administradores y desarrolladores pueden decidir juntos cuándo tienen más sentido las soluciones sin código o procódigo.
Utilizando la interfaz de System.Finalizer en el marco de trabajo Colocable en cola de Apex, junto con Nebula Logger, construimos un sistema sólido y comprobable que nos alerta de fallos imprevistos incluso si los pasos futuros carecen de registro explícito. Para nosotros, este sistema está felizmente ajustando números y reduciendo costos y complejidad. También nos ha proporcionado perspectivas valiosas sobre el comportamiento de los Cursores Apex bajo cargas de trabajo reales, ayudándonos a perfeccionar nuestro enfoque mientras mejoramos la función en sí.
Al descomponer cargas de trabajo complejas y de gran volumen en pasos de ejecución modulares, el marco de trabajo de procesamiento asíncrono basado en pasos transforma las restricciones de plataforma en ventajas de ingeniería, permitiendo desempeño, observabilidad y gobernanza predecibles a escala de la compañía. Los pasos pueden configurarse por administradores y desarrolladores, y en cualquier caso, los autores de pasos pueden centrarse de forma segura en la observación de los límites reguladores de plataforma básicos (como filas DML y filas de consulta recuperadas) sin tener que preocuparse por cómo ampliar cada paso.
Ruta a seguir
Para poner en marcha y adoptar este patrón en implementaciones de negocio, los arquitectos deben:
Evalúe automatizaciones existentes para identificar áreas donde la orquestación asíncrona puede ayudar a mejorar el desempeño y la observabilidad.
Divida procesos grandes en pasos discretos ejecutables de forma independiente con objetivos de procesamiento claros y puntos de autor discretos (como Flujo o Apex).
Defina y agrupe tipos de pasos para acelerar la estandarización y la reutilización de pasos entre unidades de negocio.
Pilote el enfoque con nuevos procesos o automatizaciones existentes. ¡Es posible que se sorprenda al descubrir cuántos casos Edge encontrará de forma gratuita en cuestión de pasos, cuidando su registro integrado y observabilidad!
Acerca del autor
James Simone es ingeniero de software principal en Salesforce y tiene más de una década de experiencia trabajando en la plataforma. Era cliente de Salesforce (y propietario de productos) antes de pasar al desarrollo, y ha estado redactando inmersiones técnicas profundas sobre Salesforce desde 2019 en The Joys Of Apex. Anteriormente publicó artículos en el blog Salesforce Developer y también en el blog Salesforce Engineering.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.
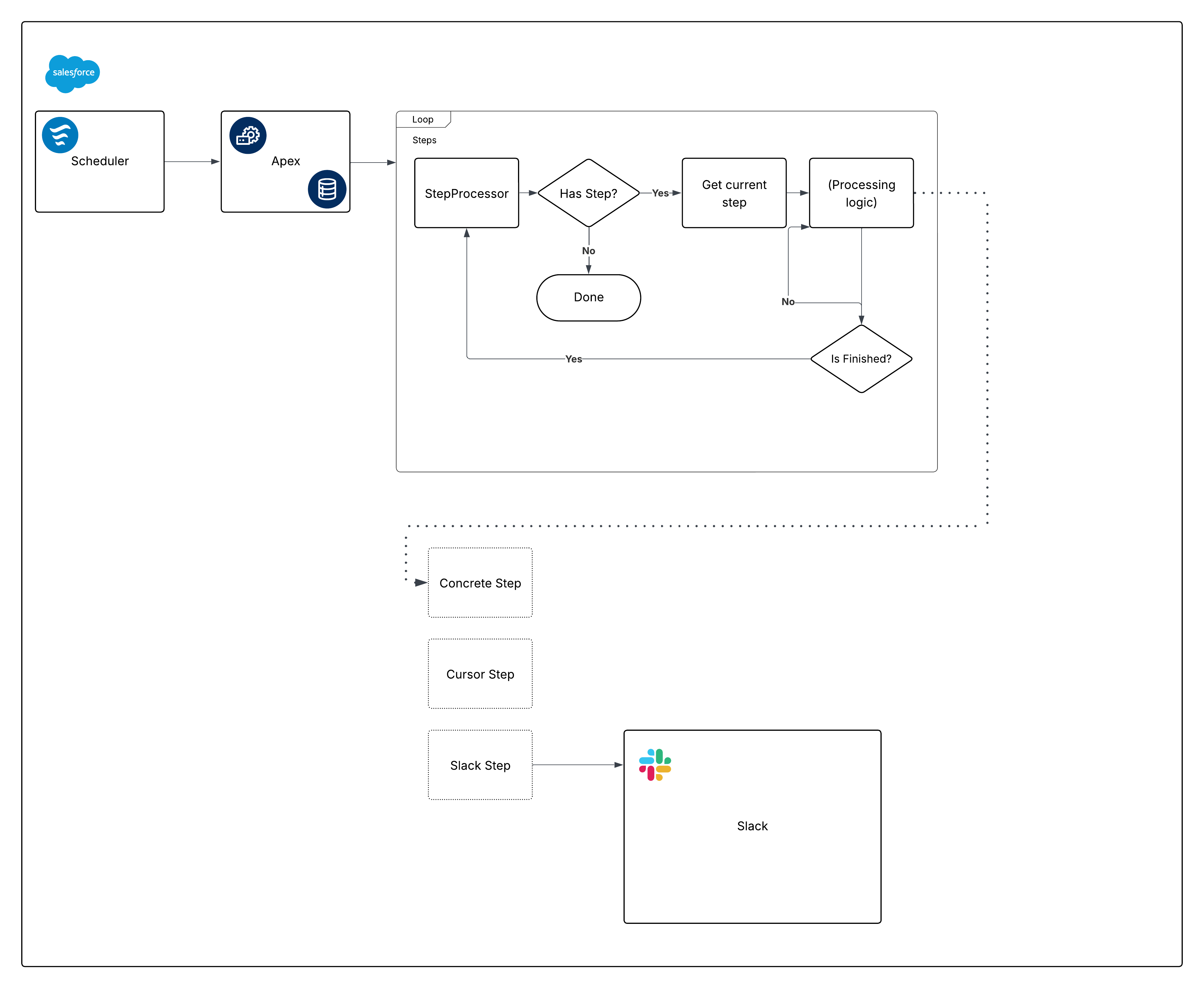 Ahora, desglose ese diagrama y comience a construir las piezas.
Ahora, desglose ese diagrama y comience a construir las piezas.