エンタープライズデータアーキテクチャは転換期にあります。組織は、リアルタイム AI システムのサポート、厳格化するプライバシー規制への準拠、未加工データを共有できない外部パートナーとのコラボレーションを同時に行う必要があります。これらの要件は、データプラットフォームの設計方法を根本的に変えています。
ETL パイプラインと一元化されたデータウェアハウスに基づいて構築された従来のアーキテクチャでは、これらの要求を満たすことが困難です。システム全体でデータを複製すると、遅延、コスト、ガバナンスの複雑さが増します。各コピーが新しいコンプライアンス義務となり、分散環境間での同意管理、削除要求、ポリシー適用が複雑になります。
こうした課題に対応するため、業界ではゼロコピーのポリシー適用コラボレーションモデルへの移行が進んでいます。データクリーンルームは主要なアーキテクチャ機能として登場しており、複数の組織が未加工データを公開または転送することなく、共有シグナルを分析できます。データを一元化された環境に移動する代わりに、計算は各参加者が管理するドメイン内で実行され、プライバシーに安全な結果のみが返されます。
このアーキテクチャのシフトは、さまざまな業界でますます顕著になっています。たとえば、マーケティングと広告の最大手である WPP が InfoSum を買収したことは、プライバシー保護のコラボレーションのためのインフラストラクチャとしてクリーンルームの重要性が増していることを反映しています。金融機関は、機密の基盤となるレコードを共有せずに、金融機関全体の不正行為の検出、小売業者による消費者ブランドとのプロモーションの調整、医療機関による提供者間患者コホートの分析にこれらの情報を使用します。
Salesforce Data 360は、Hyperforce上に構築されたゼロ コピー アーキテクチャによってこのモデルを運用します。データはソースシステムに残りますが、統合クエリでは実行時にプライバシー、同意、レジデンシーポリシーが適用されます。このアプローチにより、データレプリケーションによって生じるリスク表面を拡大することなく、リアルタイムのインサイト、クロスクラウドコラボレーション、AI 主導の意思決定が可能になります。
このドキュメントでは、データクリーンルームがモダンエンタープライズの基盤アーキテクチャパターンとして機能し、AI イノベーション、規制コンプライアンス、安全なドメイン間コラボレーションを同時に大規模にサポートする方法について説明します。
エンタープライズアーキテクトは、データクリーンルームが必要な理由を理解するために、まず従来のインテグレーションモデルの構造的な障害に直面しなければなりません。業界では、モノリス型の一元化されたデータリポジトリから分散型の統合エコシステムへの決定的な移行が進んでいます。ここでは、データは物理的に移動するのではなく、その場でアクセス、管理、計算されます。このシフトは増分ではありません。これは、従来のアーキテクチャでは吸収できなくなった拡張性、プライバシー、俊敏性に関するシステム上のプレッシャーに直接対応します。
企業は長年、CRM、ERP、デジタルシステムから一元化された倉庫にデータをコピーしてレポートと分析を行う ETL 駆動型アーキテクチャを使用していました。このアプローチは履歴分析に有効であることがわかりましたが、バッチ指向の低速な世界向けに設計されています。
デジタルインタラクションが加速し、AI 主導のシステムが登場すると、このモデルの限界がより明確になりました。ETL パイプラインは本質的に非同期であるため、多くの場合、イベントの発生から数時間から数日後にインサイトが到着します。このような遅延は、リアルタイムのパーソナライズ、適応型意思決定、即時のコンテキストデータを必要とする AI システムなどの最新の使用事例とますます互換性がありません。
また、レプリケーションにより、ガバナンスとセキュリティの複雑さも増します。データの新しいコピーごとに、追加のポリシー、監視、コンプライアンス管理が必要です。規制環境では、一般データ保護規則 (GDPR) などのフレームワークでは、データが存在するすべての場所で削除、同意、使用制限を管理する必要があります。これは、データセットが複数のシステムで重複している場合の運用上の課題です。
規模が大きくなると、この重複によってコストと運用オーバーヘッドが複合化します。組織は、複数のプラットフォームで取り込み、保存、セキュリティ、処理のコストを繰り返し支払う一方で、追加コピーの限界値は低下します。
その結果、最新のデータアーキテクチャは、データの移動を最小限に抑え、ソースで直接ガバナンスを適用するモデルに移行しつつあります。ゼロコピーインテグレーションと統合データアクセスにより、組織は機密データセットを複製することなくインサイトを生成できるため、エンタープライズデータコラボレーションに対する拡張性と安全性が高く、ポリシーに準拠したアプローチが実現します。
こうしたプレッシャーに対応するため、業界では次の 2 つの補完的なアーキテクチャパラダイムが統合されています。データメッシュとデータファブリック。これらを組み合わせることで、一元管理から統合ドメイン対応データアーキテクチャへの移行が実現します。
データメッシュでは、データ所有権が営業、マーケティング、サプライチェーンなど、ドメインが連携したチームに分散されます。各ドメインでは、契約、品質標準、サービスレベル目標が明確に定義された商品としてデータが扱われます。このモデルでは、説明責任とビジネスの連携が向上しますが、エンタープライズ規模では、ドメイン間の調整、相互運用性、一貫したガバナンスに関する新しい課題が生じます。
Data Fabric は、分散ドメインを 1 つの一貫したシステムにバインドする結合レイヤーを提供することで、これらの課題に対処します。共有メタデータ、共通セマンティクス、自動化されたポリシー適用、系統、ガバナンスが提供されるため、物理的な統合を 1 つのリポジトリに強制することなく、データの一貫した検出、アクセス、管理が可能になります。
データメッシュとデータファブリックを組み合わせることで、統合データアクセスの基盤が確立されます。しかし、重要な次の問題を解決するには、ドメインや組織の境界を越えて安全で管理されたコラボレーションを実現する必要があります。このコラボレーションでは、データをコピーしたり公開したりせずに共同で分析する必要があります。
企業データの分散が進み、プライバシー規制が厳しくなるにつれて、組織はコアアーキテクチャの課題に直面します。未加工データを共有せずにチーム、パートナー、プラットフォーム間でコラボレーションする方法は?従来のデータインテグレーションアプローチは、このレベルの配布や規制の精査を目的として設計されていないため、コラボレーションとコンプライアンスの間に緊張が生じていました。
この課題により、データクリーンルームが基本的なアーキテクチャ機能として重視されるようになりました。クリーンルームは、コラボレーションをデータ転送から管理された計算に移行します。データセットをコピーまたは交換する代わりに、メタデータを共有して、データがすでに存在する場所で分析と AI のワークロードが実行されます。クエリはプライバシー、同意、および使用ルールに対してリアルタイムで評価され、承認された集計結果のみが返されます。
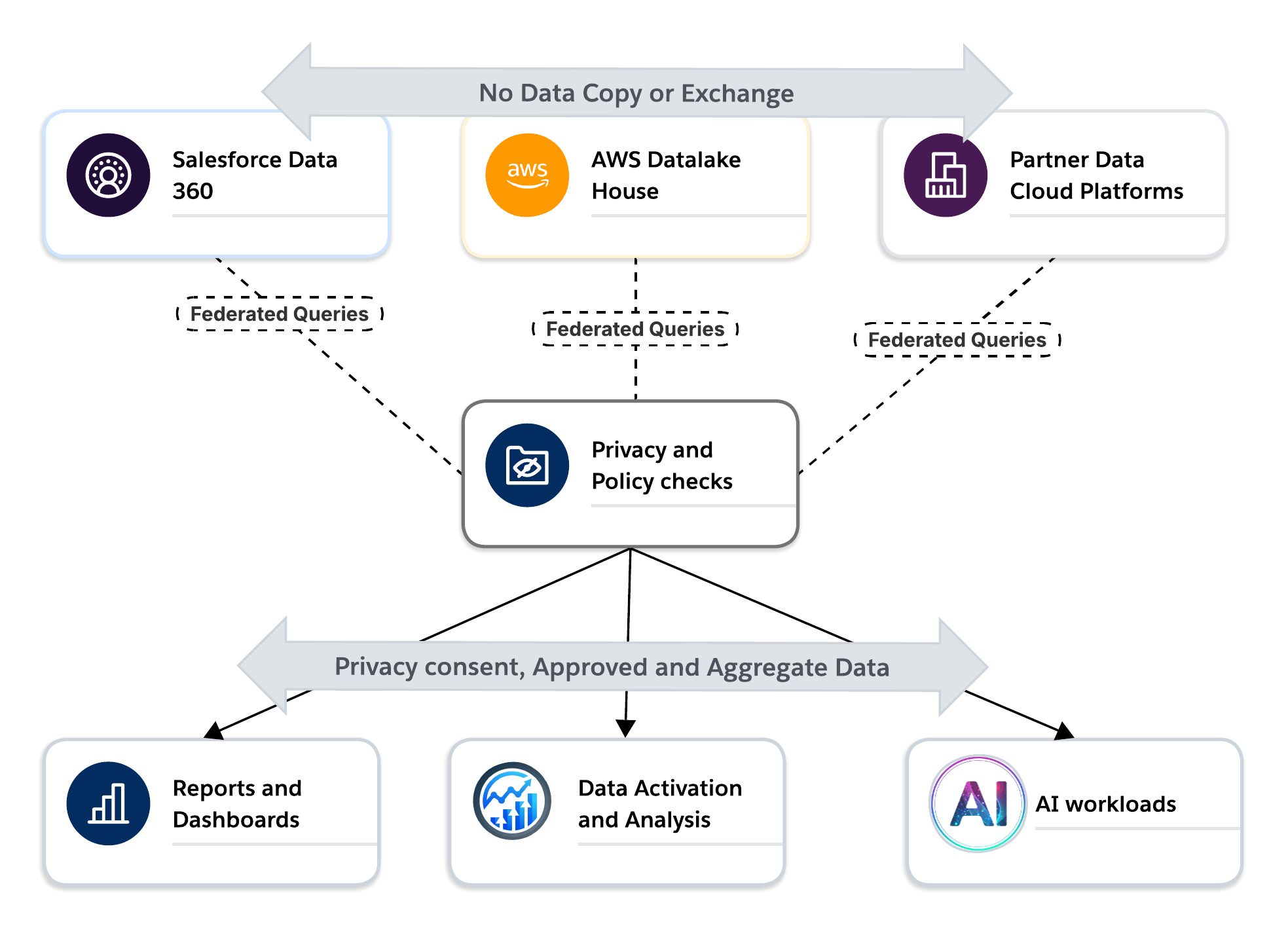
このモデルでは、データ クリーン ルームはモダン データ アーキテクチャのTrust境界として機能します。これにより、組織はデータの制御を失うことなくパートナーや関連子会社と連携し、ポリシーのみではなくシステム制御によってプライバシーと同意を適用し、データのレジデンシーと契約上の制限を尊重しながらクラウド全体で運用できます。
有効化、分析、AI の使用事例の場合、クリーンルームでは機密情報を公開することなく、外部データからインサイトを安全に生成できます。データ共有から信頼できるコラボレーションへの移行が可能になります。有効化の使用事例では、クリーンルームは許可された対象に直接有効化できる利用者を安全に生成する方法を提供します。これらはすべて、個人識別情報 (PII) をいずれの関係者にも公開することなく実現されます。これは、エンタープライズデータアーキテクチャの転換点となります。データクリーンルームはもはやニッチなツールではありません。これらは、プライバシーを保護し、AI に対応した統合データプラットフォームのコアインフラストラクチャになりつつあります。
成功するデータクリーンルームアーキテクチャは、データユーティリティ、セキュリティ、スピードの競合するプレッシャーを解決するために設計されたマルチインターフェースシステムです。3 つの主要な人格があり、基盤となる技術設計で個別の摩擦点に対処する必要があります。
プライバシーとコンプライアンスの責任者は、ガバナンスツールとしてデータクリーンルームを使用します。主な懸念事項はコンプライアンスのドリフトです。これは、外部コラボレーション環境が内部システムと同じ厳格な基準を適用できないリスクです。
- **摩擦点:**規制違反 (GDPR、CCPA、DMA) や、パートナーが詳細なクエリを繰り返してユーザーの ID を三角測量しようとする「フィッシング」攻撃。
データサイエンティストは、データクリーンルームを高度なモデリングの安全な避難所と考えています。プライバシー保護対策によってデータが統計的に無駄にならないよう、ユーティリティの維持が主な関心事です。
- **摩擦点:**機械学習 (ML)、類似モデリング、離脱予測に必要な詳細な属性への高レイテンシーと制限されたアクセス。
この人格は、タイムトゥバリュー (TTV) のみに焦点を当てています。懸念事項は、データクリーンルームプロジェクトが、数週間のデータエンジニアリングサポートを必要とする技術的なボトルネックになることです。
- **摩擦点:**複雑な設定プロセス、手動のデータクリーンアップ、単純な重複結果を得るためにコードを記述する必要があるという「空白のページ」の問題。
従来のアーキテクチャはユーザーレイヤーよりもデータレイヤーの構築に焦点を絞っていましたが、「ビジネスファースト」手法に沿った戦略的アプローチではこのモデルが逆転しています。コード不要、数回のクリックでインサイトを生成してすぐにアクションを実行できるアプローチが優先されます。
**「Insight-to-Action」ワークフロー:**このアーキテクチャは、パッシブリポジトリではなく、アクティブなワークスペースとして設計されています。使用事例テンプレート (セグメントの重複、有効化、キャンペーンパフォーマンスなど) を提供することで、ビジネスユーザーはインサイトをセルフサービスで提供できます。これにより、最適化された類似セグメントなどのインサイトをマーケティングエコシステム全体ですぐに有効化できます。データエンジニアが手動でファイルを移動する必要はありません。
**戦略的資産としてのゼロコピー統合:**TTV を最大化するために、このアーキテクチャではゼロコピーロジックを採用しています。遅延やセキュリティリスクが発生する従来の ETL プロセスではなく、このアーキテクチャではデータが存在する場所 (Snowflake、BigQuery、Amazon S3 など) へのクエリを直接統合します。これにより、組織の既存のデータ投資が戦略的な資産となり、ビジネスユーザーは最新のデータにリアルタイムで対応しながら、厳格なガバナンスを維持し、データの冗長性のコストを排除できます。
データクリーンルームは、Cookie の廃止とプライバシー規制に対応するために広告で登場しましたが、測定だけでなく、さまざまな業種の顧客分析、オーディエンスセグメンテーション、有効化の使用事例に発展しました。2025 State of Retail Media (2025 年の小売メディアの状況) レポートによると、測定可能なビジネス成果をもたらすプライバシーで安全なコラボレーションの必要性から、66% の組織がクリーンルームを一定の業務量で使用しています。 パターンはセクター全体で一貫しており、データは所有者に保持され、計算は管理され、プライバシーが保護されたインサイトのみが共有されます。
**課題:**マーケティング担当者は、キャンペーンの効果を測定し、広告インプレッションの重複を回避し、リーチ/頻度を最適化する必要がありますが、サードパーティの Cookie やデバイス ID に依存することはできなくなりました。
クリーンルームソリューション:
- 広告主がハッシュされた顧客またはキャンペーン露出データを寄稿する
- パブリッシャーがインプレッションシグナルとエンゲージメントシグナルを寄稿する
- クリーンルームでリーチ、頻度、属性、リフトを計算
- 未加工データのエクスポートなしで承認済みプラットフォーム経由で有効化
**ビジネス結果:**クリーンルームでは、広告インプレッションを実際の取引にリンクするクローズドループ属性、真のキャンペーンリフトを分離する増分分析、チャネル間の統合メジャメントなど、従来のデジタル広告では提供できなかった機能が提供されます。
**業界の証拠:**メジャメントは、現在最も確立されたクリーンルームの使用事例であり、Pinterest、ディズニー、パラマウントなどの大手メディアネットワークが独自のクリーンルームを作成しています。
**課題:**CPG ブランドは小売メディアに多額の費用を費やしているが、購入結果を可視化していない。小売業者は豊富な POS データを所有していますが、プライバシーのコミットメントに違反しずに公開することはできません。
クリーンルームソリューション:
- 小売業者と CPG 会社は、小売店の POS データとマーケティングデータを組み合わせてプロモーション活動を最適化します。
- ブランドがハッシュされた CRM またはロイヤルティ識別子を貢献する
- 店舗内/オンライン購入へのクリーンルーム広告リンク
- 有効化は小売業者のメディアエコシステム内にとどまる
ビジネス結果:
- 小売業者は未加工の顧客情報を販売せずにファーストパーティデータを収益化
- ブランドは、どのキャンペーンが購入を促進したかを示す循環利用属性を取得します。
- プライバシーリスクのないリテールメディアネットワークの拡張 **業界の証拠:**Walmart の Luminate や Kroger Precision Marketing などのリテールメディアネットワークは、CPG ブランドが小売業者データを使用して顧客の行動を分析し、マーケティング戦略を最適化するのに役立つクリーンルームを提供しています。
**課題:**不正行為ネットワークは複数の機関で運用されていますが、GLBA や新しいプライバシー保護法などの規制により、銀行は顧客データや取引データをオープンに共有できません。
クリーンルームソリューション:
- 複数の銀行が匿名データをプールして、異常な銀行間活動などの不正行為を示すパターンを特定
- 共有された不正行為のシグナル全体で実行される統合分析またはモデル
- 別の顧客の顧客レベルのデータはどの機関にも表示されない
ビジネス結果:
- 機関間不正行為パターンの早期発見
- 豊富な信号セットによる偽陽性の減少
- 機密データを一元化せずに法規制に準拠
**業界の証拠:**Experian と TransUnion の金融サービスソリューションは、厳格なデータプライバシー管理を維持しながら、銀行と保険会社が不正行為の検出とリスク評価でコラボレーションできるようにするクリーンルームテクノロジーを提供します。
**課題:**製薬会社は医薬品開発のために実際の患者転帰を必要としていますが、データは HIPAA および同様の規制で保護された病院の EHR システムにあります。
クリーンルームソリューション:
- 医師と製薬研究者がクリーンルーム内でデータを共有することで、患者が治療にどのように反応しているかを把握できます。
- 患者データは提供者環境内に残ります。
- 研究者はクリーンルームを介して承認済みの統計分析を実行します。
- 差分プライバシーにより、再識別を防止できます。
ビジネス結果:
- 大規模で統計的に有効な実際の証拠
- 匿名化された患者データを臨床試験条件と照合し、医療プライバシー保護法に違反することなく適格な候補者を見つけることで、臨床試験の患者募集を合理化
- 制限された臨床試験母集団への依存を軽減
**業界の証拠:**Datavant のようなヘルスケアに焦点を絞ったクリーンルームは、研究者やヘルスケア組織が臨床試験や医薬品開発のために患者データを安全に分析するための HIPAA 準拠の環境を提供します。
これらの主な使用事例以外にも、クリーンルームには次の利点があります。
- **サプライチェーンの最適化:**メーカーとサプライヤーが協力して在庫の詳細、生産スケジュール、需要予測を共有することで、機密情報を保護しながら連携を強化できます。
- **M&Aデューデリジェンス:**ある企業が別の企業を買収する場合、デューデリジェンスでは機密情報を直接共有せずに財務予測と顧客データベースを調査する必要があります。クリーンルームでは、顧客セグメントのアライメントやコンプライアンスリスクなどのインサイトを明らかにします。
- メディアおよびエンターテインメント:パブリッシャーは購読者 ID を保護しながら広告主にオーディエンスの価値を証明し、確率的ターゲティングではなく、信頼できるメジャメントに裏打ちされたプレミアム CPM を実現します。 AdTech、小売、金融サービス、医療、メディア全体で、データ クリーン ルームはTrustインフラストラクチャの基盤となっています。これにより、以前はプライバシー、規制、または競合上の制約によってブロックされていた価値の高いコラボレーションが可能になります。クリーンルームは、安全で管理されたコラボレーションを可能にするコア アーキテクチャ コンポーネントであり、データの制御やコンプライアンスを損なうことなく、インサイトと収益化を実現します。
データクリーンルームは、未加工データを公開または交換することなく、複数の関係者が共同インサイトを生成できる安全な管理環境です。データセットを複製する代わりに、承認済みの分析、AI、有効化ワークロードが実行され、ポリシーに準拠した出力のみが返されます。有効化に個人レベルのレコードが必要な場合、データはコラボレーション関係者に公開されずに目的の宛先に直接配信されます。
アーキテクチャ上、クリーンルームはコラボレーションをデータ共有から制御された計算に移行します。各参加者はデータの管理権を保持し、ランタイム適用によってクエリの動作、出力制約、同意、使用ポリシーが制御されます。
コラボレーションは、プライバシーが保持される識別子アライメントメカニズムによってさらに有効になり、基盤となる識別子を公開することなく、さまざまな関係者のデータセットを相関させることができます。この機能は、このドキュメントの後半で詳しく説明します。 そのため、データクリーンルームは、ゼロコピーの統合データ戦略で業務を行う、プライバシーが規制されたマルチクラウドの AI 駆動型企業の基盤インフラストラクチャとして機能します。
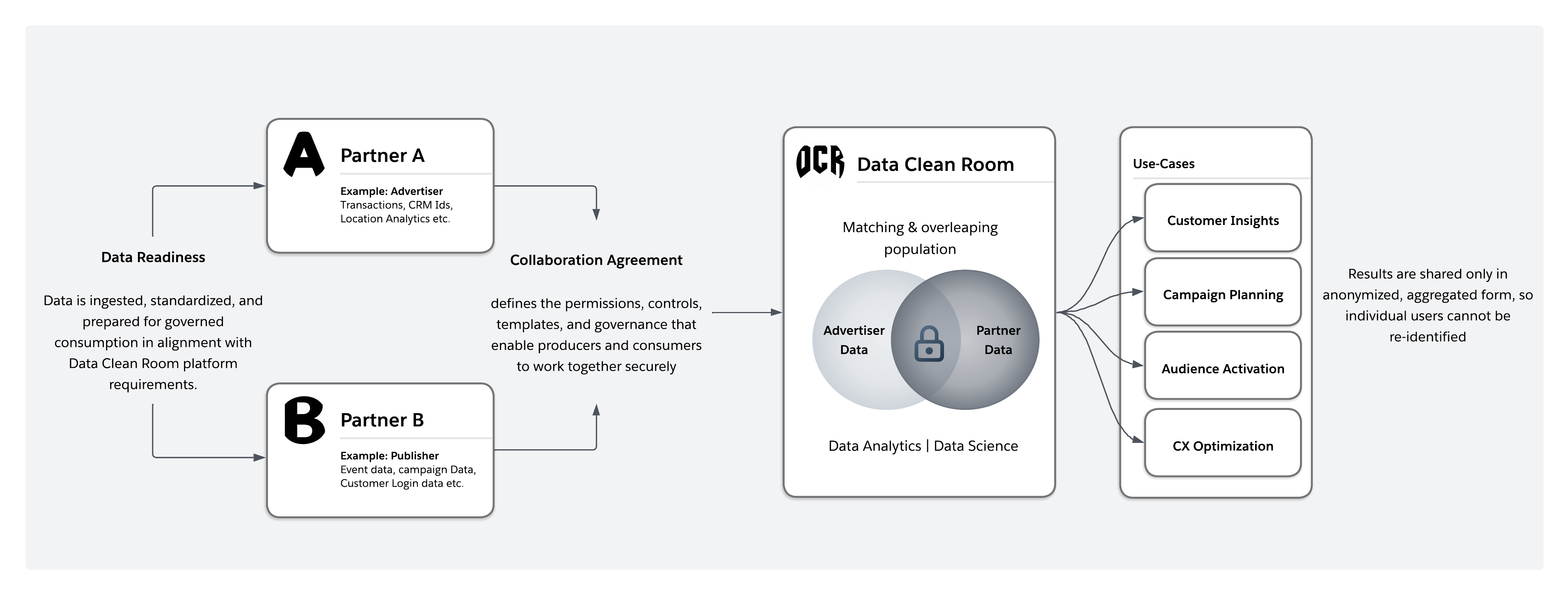
初期のデータクリーンルームは、一元化された「バンカー」モデルに従っていました。すべての参加者は、分析のために中立的なサードパーティ環境にデータをコピーする必要がありました。このアプローチは概念的には単純ですが、大きな摩擦を引き起こしました。データ移動によって遅延とコストが増加し、法規制とコンプライアンスの合意が複雑になり、組織は機密データの直接管理を断念せざるを得なくなりました。規制のある業界では、これらのトレードオフによってコラボレーションが現実的でなくなることがよくありました。
最新のデータクリーンルームは、分散型の統合モデルへと進化しました。データは所有者の環境に残り、統合クエリを使用して分析が実行されます。クリーンルーム自体は、各クエリを代行受信し、実行時にプライバシーとポリシーの制御を適用し、承認された集計出力のみを返すガバナンスレイヤーとして機能します。
| ディメンション | 従来のクリーンルーム (「バンカー」モデル) | 最新のクリーンルーム (分散/統合モデル) |
|---|---|---|
| データの場所 | データは一元化されたサードパーティ環境にコピーされる | データは所有者の環境に残る |
| データ移動 | データセットの物理的な転送と複製が必要 | 未加工データを移動せず、クエリを実行 |
| 制御と保管 | 保管がサードパーティプラットフォームに一部譲渡 | 各当事者が保持する未加工データの所有権と保管 |
| アーキテクチャモデル | 一元化された集計 | 分散統合計算 |
| ガバナンスの実施 | データの移動後に適用されるポリシー | クエリ実行時に適用されるポリシー |
| プライバシーモデル | 契約および手続き上の管理に大きく依存 | ランタイム制御と集計しきい値によって技術的に適用 |
| 遅延 | 取り込みと同期によるレイテンシの増加 | 低レイテンシ、ほぼリアルタイムの統合クエリ |
| コスト構造 | ストレージ、転送、複製のコストの増加 | 重複の削減、データが存在する場所での自動計算 |
| コンプライアンスの複雑さ | 境界を越えたデータの移動による複雑な法的合意 | データがソース境界から離れないため、コンプライアンスが簡略化される |
| 拡張性 | 拡張にはより多くのストレージとデータレプリケーションが必要 | データを重複させることなく分散コンピューティングで拡張 |
| 規制対象の業界適合 | 親権や居住権の懸念から非現実的であることが多い | 主権、同意、規制上の制約へのより適切な対応 |
Salesforce Data 360 は、この統合モデルを示しています。パブリッシャーと広告主は、未加工データがプラットフォームのセキュリティ境界から離れることなく、クラウドプラットフォーム間でコラボレーションや分析を実行できます。データの管理が保持され、リスクが軽減され、コラボレーションが迅速かつ簡単に拡張されます。
共有データから共有コンピューティングへの移行により、エンタープライズ コラボレーションのTrustが再定義されます。クリーンルームは、データが保存される場所ではなく、インサイトを安全に生成する方法を管理するシステムです。
コアアーキテクチャ機能として運用するためには、エンタープライズクラスのデータクリーンルームは、交渉の余地のない一連の要件を満たす必要があります。
データクリーンルームの最も基本的な要件は、ゼロコピーアーキテクチャです。従来のデータコラボレーションは、データを共有環境にコピーする ETL パイプラインに依存していました。これにより、機密データの未管理のコピーを複数作成しながら、レイテンシ、コスト、セキュリティリスク、規制リスクが増大します。
最新のデータクリーンルームでは、この問題が解消されます。データは、クラウドデータウェアハウス、運用プラットフォーム、SaaS アプリケーションに関係なく、元のレコードシステムに残ります。クリーンルームでは、これらの分散ソースの統合クエリが使用され、承認されたプライバシーに安全な結果のみが返されます。
物理的なデータの移動を回避することで、ゼロコピークリーンルームは攻撃対象領域を減らし、データのレジデンシーと所有権を保持し、データファブリックと統合データアーキテクチャの原則に自然に従います。
最新のデータ戦略は、データを移動せずにコラボレーションできるかどうかにかかっています。Salesforce Data 360 は、2 つの主要なモデルを使用して、企業をグローバルデータエコシステムに接続する柔軟なフレームワークを提供します。
**ネイティブのSalesforce-to-Salesforce接続 ―**このモデルでは、コラボレーションは 2 人の Salesforce ユーザー間で直接行われます。共有メタデータレイヤーを使用すると、提供者と消費者は 簡単な設定 ですぐに接続できます。これにより、チームはデータの複製の遅延やリスクなしに共同インサイトを生成でき、元の場所で情報のセキュリティを確保できます。
**外部Salesforce-to-クラウド統合(AWSとSnowflake):**このモデルでは、Salesforce と外部クラウド環境間でコラボレーションが行われます。ゼロコピー統合により、組織はデータ移動のコストやリスクをかけずにさまざまなインフラストラクチャを連結できます。これにより、チームはデータを常駐クラウドに保持しながら、ID の断片化を解決してリーチを拡大し、一元化されたガバナンスを維持し、出力料金を排除できます。
ゼロコピーおよび統合アーキテクチャは、未加工データの移動や複製を防止しますが、それ自体がプライバシーを保証するものではありません。これらのモデルでは、主なリスクはデータストレージからデータ計算に移行します。
集計結果のみが返される場合でも、機密情報が分析出力から漏洩する可能性があります。一般的な攻撃ベクトルには、反復または重複するクエリ(差分攻撃)、ごく少数の母集団の分析、外部Knowledgeを使用した推測などがあります。そのため、プライバシーの問題はアクセス制御だけでなく、クエリ実行の動的要件にも及びます。
エンタープライズデータクリーンルームでは、プライバシー強化テクノロジー (PET) を、省略可能な分析機能やポリシーガイダンスではなく、必須のシステムレベルの制御として処理する必要があります。 アーキテクチャの観点からは、次のことを意味します。
- プライバシーはアナリストではなくプラットフォームによって適用される
- ユーザー、パートナー、ワークロード間で制御の一貫性を確保
- プライバシー保証は確定的、反復可能、監査可能
- 許可される計算、結果の形成方法、およびクエリをブロックする必要があるタイミングを定義します。
PETのコア機能
**差分プライバシー:**差分プライバシー (DP) は、個人の有無がクエリ結果に重大な影響を与えないことを数学的に保証します。実際には、これはクリーンルームが校正済みの統計ノイズを出力に自動的に挿入し、データセットごとに定義されたプライバシー予算を追跡することを意味します。すべてのクエリでこの予算の一部が消費され、消費されると、以降のクエリはブロックされます。 アーキテクトにとって DP の価値は証明可能性にあります。プライバシーリスクは定量的に制限されるため、防御可能なコンプライアンスが可能になり、主観的なポリシー解釈への依存が軽減されます。
**安全な識別子アライメント:**多くのコラボレーションシナリオでは、共有の顧客や取引先など、データセット全体で重複を特定する必要があります。raw 識別子を公開すると、データ最小化の原則に違反します。クリーンルームグレードアーキテクチャでは、代わりにクリーンルーム境界内で実行される確定的ハッシュまたはトークン化を使用します。比較は未加工の識別子を関係者に公開せずに行われるため、データ開示なしで結合のような動作が可能になります。
**集計しきい値と結果の抑制:**結果がごく少数の母集団から取得された場合、完全に匿名化された出力でも侵害される可能性があります。これを回避するには、エンタープライズデータクリーンルームで最小集計しきい値を適用し、それを下回る結果を自動的に抑制する必要があります。これらのしきい値は上書き不可にする必要があり、小さなセグメントの漏洩から一貫して保護されます。
実行レイヤーでPET(プライバシー強化テクノロジー)を適用しない場合、データ クリーン ルームは、人間の判断と契約上の合意に依存するTrustベースの環境になるリスクがあります。PET をプラットフォームに直接埋め込むことで、プライバシーは手続き上のプロパティではなく構造上のプロパティになります。これにより、Trustを再交渉することなくコラボレーションをチームやパートナー全体に拡張できます。また、規制当局やリスク チームは、主観的なポリシーではなく、客観的な数学的基準を使用して保証を評価できます。
エンタープライズアーキテクトにとって、PET はデータクリーンルームを安全な Sandbox から、エンタープライズ規模で規制対象のマルチパーティ分析と AI ワークロードをサポートできる信頼できるコラボレーションファブリックに昇格させる重要なメカニズムです。
複数パーティのコラボレーションでは、表示によって Trust が維持されます。エンタープライズクラスのデータクリーンルームでは、関係者とデータ間のすべてのやりとりの「ペーパートレイル」を提供する必要があります。
Query Logs:すべての SQL 実行が記録され、要求者の ID、タイムスタンプ、使用された特定のクエリロジックが取得されます。
**ポリシー適用ログ:**照会された内容だけでなく、結果に適用されたプライバシーポリシー (集計しきい値や差分プライバシーなど) も記録する必要があります。
**ゼロ改ざんレコード:**不変監査履歴 (専用のデータモデルオブジェクト) を使用することで、データクリーンルームで関係者によるログの変更や削除を防止し、規制当局に一元化された真実を提供します。
Salesforce では、未加工のデータセットを一切共有せずにデータを分析およびコラボレーションできるようにすることで、最新のデータクリーンルームを実現します。実行時にプライバシー、同意、ガバナンスが適用されるゼロコピーの統合アーキテクチャ上に構築された Salesforce Data 360 は、インサイトのセキュリティ、コンプライアンス、および完全なアクションを可能にします。Salesforce Data 360 は、クリーンルームをエンタープライズデータライフサイクルに直接組み込むことで、ニッチな分析ツールから、AI 主導のマルチパーティコラボレーションのためのスケーラブルで信頼できるインフラストラクチャに変換します。
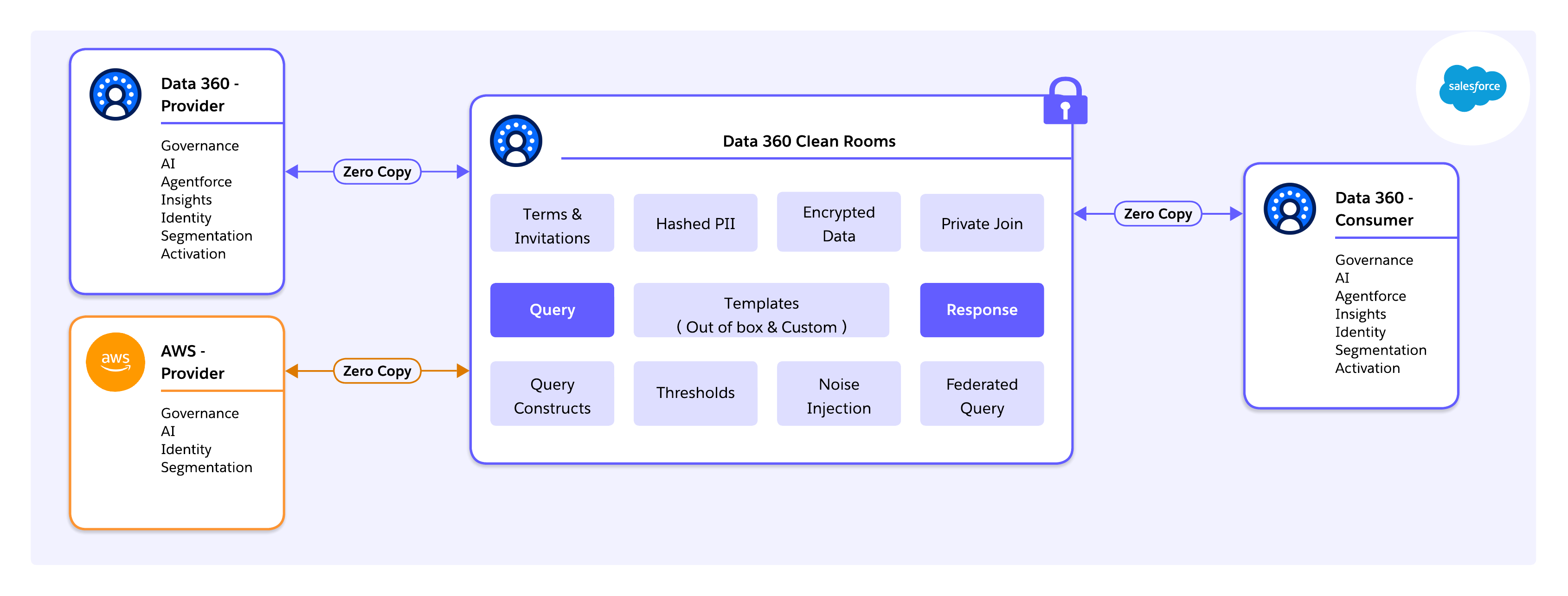
インフラストラクチャ レイヤーでは、Salesforce Data 360はHyperforceで実行されます。Hyperforceは、統合されたコントロール プレーンの背後にあるハイパースケーラー リソース(AWS、Azure、GCP)を抽象化するSalesforceのクラウド ネイティブ ランタイムです。このアーキテクチャにより、主権と居住要件を満たすためにデータを地域内に保持しながら、グローバルに管理されたクリーンルーム業務が可能になります。
重要なのは、この基盤により、AWS Clean Rooms とのネイティブの相互運用性を含め、クラウド間のクリーンルームコラボレーションが可能になることです。Data 360 をオーケストレーションおよびガバナンスレイヤーとして使用すると、企業は Salesforce が管理するストレージにデータを強制的に移行することなく、AWS で直接業務を行うパートナーとコラボレーションできます。クエリはソースに転送され、プライバシールールが一貫して適用され、準拠した集計結果のみがプラットフォーム間で交換されます。
コンプライアンスとTrustは、アプリケーション レイヤーで改良するのではなく、インフラストラクチャと実行の境界で適用されます。これにより、マルチクラウド、マルチパーティ コラボレーションの大規模な耐久性のある基盤が提供されます。
Data 360 は追跡可能なエンドツーエンドのデータパイプラインを実装し、未加工の抽出データではなく、ハーモナイズされ、管理された ID 認識データでクリーンルームの運用を実行します。 主なフェーズは次のとおりです。
- 接続:標準のコネクタ、API、SDK、MuleSoft、またはゼロコピーコネクタを使用したデータの取り込みと仮想化
- 持続:ネイティブ形式 (Parquet/Iceberg) の未加工データの保存
- Harmonize:一貫した結合のための正規データモデルオブジェクト (DMO) へのマッピング
- 統合:ID 解決によってゴールデンレコードが作成される
- インサイトの取得:計算済みインサイトは、管理境界内の集計された総計値を計算します。
- 活動:Salesforce 組織、マーケティングプラットフォーム、広告ネットワーク、外部データプラットフォーム、その他のクリーンルームへの出力フローを管理し、インサイトとアクションのループを閉じる
このパイプラインにより、クリーンルームはアドホック抽出ではなくエンタープライズクラスのデータで動作します。
個別のプロビジョニングと SQL 開発が必要なスタンドアロンのデータクリーンルームプラットフォームとは異なり、Salesforce クリーンルームは Data 360 にネイティブに組み込まれています。これにより、DMO、ID ルール、同意モデル、ガバナンスポリシーの再利用が可能になり、重複するセキュリティレイヤーが排除されます。 Salesforce のテンプレート駆動型クリーンルームモデルは、以下を使用する主要なアクセラレーターです。
- 利用者の重複、抑制、リーチ、リフト測定などの一般的なコラボレーション・パターンをサポートする標準のテンプレート。
- カスタム・テンプレートにより、アーキテクトや上級ユーザーは、未加工データやポリシーの複雑さを公開することなく、業界固有またはパートナー固有のニーズに合わせて調整された再利用可能な分析ロジックを定義できます。 このアプローチでは、コラボレーションを標準化しながら柔軟性を確保できるため、クリーンルームを 1 回限りの分析プロジェクトではなく、反復可能なエンタープライズ機能として拡張できます。
Data 360 は、従来のクリーンルームの一般的な障害モードである有効化ギャップに対処します。Golden Path フレームワークにより、未加工データをエクスポートすることなく、クリーンルーム内で生成されたインサイトをすぐに処理できます。
- 設定と検出:パートナーはスキーマメタデータを共有し、テンプレートを活用して、契約が完了する前に実現可能性を評価します。
- 分析:事前作成済みテンプレートとカスタムテンプレートにより、重複分析、抑制、類似モデリング、リフト測定がすべて管理境界内で実行されます。
- 有効化:承認されたセグメントは Marketing Cloud、広告プラットフォーム、またはパートナーシステムに直接転送され、集計された準拠の結果のみが共有されます。
テンプレートは、評価済み実行パスになり、コラボレーションが予測どおりに分析から有効化に移行します。
Salesforce Data 360 Clean Room の導入は、単なる設定作業ではなく、データの準備、ガバナンス設計、安全な接続、運用監視にわたる統制の取れたアーキテクチャワークフローです。
アーキテクトは、データまたは設定に触れる前に、以下を明確に定義する必要があります。
- どんな質問に答えようとしてるんだ?
- 想定される結果 (重複分析、リフト測定、抑制、不正行為の検出など)
- 必要な集計レベルは?
- 適用される規制または契約上の制約は?
- 結果を使用する有効化パスは?
コラボレーターの目的を理解することで、結合キー、ID ルール、ガバナンスしきい値、コストモデリングなど、後続のすべてが形作られます。クリーンルームは目的に特化した環境であり、汎用的なデータ公開ではなく、定義された分析目標に基づいて設計する必要があります。
コラボレーションを開始する前に、エンタープライズデータを構造的および意味的に準備する必要があります。クリーンルームは、基礎となるデータの強みと弱みを増幅します。ゴミは入ってゴミは出て行く
**取り込み:**Salesforce CRM、Marketing Cloud、AWS S3、Google Cloud Storage などのソースシステムを Data 360 に接続します。可能な限り、ゼロコピーコネクタ (Snowflake など) を使用して、データの不要な移動や重複を回避します。
**セマンティック マッピング:**データストリームを Customer 360 データモデルにマッピングします。電話番号 (E.164 形式)、国/都道府県コード (ISO 標準)、メールアドレスなどの主要な項目を標準化します。不一致 (たとえば、「CA」と「California」を使用している関係者) があると、通知なしで結合に失敗し、一致率が低下する可能性があります。
**ID 解決:**確定的 (完全一致) ルールと確率的 (あいまい一致) ルールを設定して、統合個人 (ゴールデンレコード) を作成します。この統合エンティティは、クリーンルーム照合の表面です。 ID 解決の品質は、コラボレーションの価値に直接影響します。一致精度を上げると、重複率や分析の信頼性が高まり、偽陰性が減少します。
データをハーモナイズしたら、クリーンルーム自体をプロビジョニングしてコラボレーションの境界を定義する必要があります。
**ライセンス検証:**すべての参加組織に必要な Data 360 とクリーンルームエンタイトルメントがあることを確認します。
**データスペースの範囲設定:**クリーンルームオブジェクトの範囲は、特定のデータスペースにする必要があります。そのデータスペースに対応付けられたオブジェクトのみがクリーンルームに表示されます。これにより、クリーンルーム専用の新しいデータスペースを作成することなく、コラボレーションを論理的に分離できます。
**ガバナンスルールの定義:**クエリを実行する前に宣言的にポリシーを設定します。
- 集計しきい値: 出力あたり最低 100 件のレコードなど
- 結合キー: Email_Hash_SHA256 など
- 許可されている操作: COUNT、SUM、AVG などの集計関数のみ
- 明示的な制限: 行レベルのエクスポートをブロック (SELECT *)
ガバナンスルールは実行時に適用されるため、手順ガイダンスではなく、プライバシーとコンプライアンスのシステムレベルのプロパティになります。
多くの場合、クリーンルームは組織とプラットフォームの境界にまたがっています。接続は明示的に厳密に制御する必要があります。
取引先リンク:
- **Salesforce-to-Salesforce:**Data Cloud One または承認済みの組織間共有メカニズムを使用します。
- **マルチ クラウド シナリオ:**クエリを有効にする前に、地域の調整とレジデンシーを検証します。
**認証と承認:**最小権限の原則を使用して、専用のインテグレーションユーザーの OAuth ベースのアクセスを設定します。つまり、アクセスを必要なデータスペースに厳密に制限し、管理者権限を回避します。 多くの場合、セキュリティの失敗は、暗号化やプラットフォーム制御の脆弱性ではなく、権限が過剰なインテグレーションユーザーに起因します。
稼働開始後は、業務監視、クエリ品質、コスト管理に重点が置かれます。
**クエリ実行:**アナリストまたはワークフローは、計算済みインサイトまたは承認された SQL インターフェースを使用して重複分析と集計を実行します。すべてのクエリで集計しきい値とプライバシー制御が自動的に適用されます。
**監査とトレーサビリティ :**Salesforce Data 360 クリーンルームでは、監査データモデルオブジェクト (DMO) の形式で監査履歴が提供されます。これにより、クエリの実行者、実行日時、適用されたポリシーなど、クエリ活動に関するメタデータが取得されます。監査 DMO により、コンプライアンスレポート、ガバナンス検証、フォレンジック追跡が可能になり、コラボレーションがプライバシー保護され、レビュー可能になります。
**消費の監視:**Data Cloud では、消費ベースのクレジットモデルが使用されます。主な推進要因は次のとおりです。
- 処理行数 (例: 100 万行 = ベースラインクレジット単位)
- クエリの複雑さ
- ID 解決操作 (高い乗数)
- 一括取り込み (低い乗数)
**デジタルウォレットとアラート:**Digital Walletを使用してリアルタイムの消費を追跡し、50%、75%、90%のしきい値でアラートを設定します。急増を特定のワークロードに関連付けて、予期しないコストを回避します。 ゼロコピーでは計算コストが排除されません。物理的な重複が削除されている間は、ソース・システムで実行されます。アーキテクトは、クエリパターン、結合の選択性、実行頻度を管理して、コストとパフォーマンスを制御する必要があります。
モダン エンタープライズでは、Trustはデータ クリーン ルームに固定されません。これは建築的な結果ですSalesforce Data 360 は、ガバナンス、セキュリティ、コンプライアンスを継続的かつ自動的に適用し、クリーンルームをポリシー主導の環境からプラットフォームが管理するシステムに移行します。 実行時の制御 (ロックされた ID、監査履歴、差分プライバシー) は、コラボレーションが Salesforce 内、パートナー間、クラウド間で発生するかどうかに関係なく一貫して適用されます。
アーキテクトにとって最も重要な変化は、Trustが事前に想定されず、実行時に適用されることです。Salesforce Data 360 は、次のようないくつかのコアプラットフォームコントロールでこれを実現します。
- **ロックされた ID:**パートナーアクセスは、検証済みの Salesforce 組織の ID に暗号で関連付けられているため、なりすましや不正な参加を防止できます。
- **監査履歴:**すべてのクエリ、結合、セグメントの重複、有効化が記録され、完全な監査可能性と規制コンプライアンスが確保されます。
- **差分プライバシー:**行レベルの検査は構造的に不可能です。出力は集計され、統計的に境界があります。コラボレーターには、リーチ総計値やリフト率など、プライバシーに安全な結果のみが表示され、個々の取引や ID は表示されません。 これらの制御により、契約上のTrustが数学的保証とプラットフォーム レベルの適用に置き換えられ、運用リスクと法的リスクが軽減されます。
AIエージェントがクリーン ルーム データを操作することが増えるにつれて、SalesforceはEinstein Trust Layerを導入しました。これは、企業の機密データと外部 LLM 間のアーキテクチャ上のエアロックとして機能します。これにより、クリーンルームのインサイトは、基礎となるデータを公開することなく、AI 主導の意思決定を安全に促進できます。
主な機能:
- **データ保存ゼロ:**LLM に送信されるデータは一時的です。モデルプロバイダーは、トレーニング用のプロンプトや応答を保存できません。
- **有害言語検出と PII マスキング:**入力と出力は自動的にスキャンされ、Data 360 で設定されたデータマスキングポリシーに従って PII がマスキングされます。
データスペースは、組織内で論理的に分離され、次のような規制、地域、パートナーシップの境界に合わせる必要があります。
- EU データスペース
- 北米データスペース
データスペースに割り当てられたデータセットのみがクリーンルーム内に表示されるため、偶発的な越境漏洩を防止できます。 権限セットでは、クリーンルームの作成や管理、クエリの実行、セグメントの有効化ができるユーザーを詳細に制御できます。データアウェア権限では、データモデルオブジェクト内に項目レベルの制限が適用されます。たとえば、マーケティング担当者にはセグメント名とオーディエンスサイズは表示されますが、収入や健康インジケーターは表示されません。 セキュリティはセマンティックレイヤーで適用されるため、IT 部門が常に監視することなく、ビジネスユーザーが安全にセルフサービスを行うことができます。
同意シグナルは Data 360 を介してクリーンルームの実行に自動的に伝搬されます。同意を取り消したユーザーは、デフォルトで分析と有効化から除外されます。これにより、コンプライアンスが手動でポリシングされるのではなく、システムによって適用されます。
Salesforce Data 360 では、ガバナンス、セキュリティ、コンプライアンスは、省略可能なアドオンではなく、第一級のアーキテクチャプリミティブとして扱われます。実行時の監査可能性、ロックされたID、差分プライバシー、データ スペース、同意認識ID解決、Einstein Trust Layerを組み合わせることで、企業は、Trust、プライバシー、規制コンプライアンスを損なうことなく、パートナー、マルチクラウド システム、AI主導のワークロード間でクリーン ルーム コラボレーションを拡張できます。
データクリーンルームの価値をすべて把握するには、アーキテクトはデータを分離された分析ツールではなく、コアアーキテクチャインフラストラクチャとして取り扱う必要があります。次の優先度により、実用的で拡張性の高いパスが定義されます。 **コラボレーションを第一級のアーキテクチャ上の懸念事項にする ―**外部データコラボレーションは、内部インテグレーションと同じ厳格さで設計する必要があります。クリーンルームは、データプラットフォーム、インテグレーションレイヤー、AI システムと共にエンタープライズリファレンスアーキテクチャ内に組み込む必要があり、アドホックな拡張機能としてリリースすることはできません。相互運用性の拡大 (Data 360 クリーンルームと AWS クリーンルームの統合や将来のクリーンルーム間の互換性など) に伴い、アーキテクトは単一ベンダーのサイロではなく、マルチプラットフォームエコシステムを見据えたコラボレーションパターンを設計する必要があります。
デフォルトで取得されるプライバシーの設計
Data Fluidityの設計 ―アーキテクトは、デフォルトで重いETLと一元的なレプリケーションを使用するのではなく、まずフェデレーションとゼロ コピー アクセスを検討する必要があります。必要に応じて計算をデータに移行すると、不要な重複が減り、コストが削減され、情報源の整合性が維持されます。「Connect vs. Copy」は、継承された習慣ではなく、意識的なアーキテクチャ上の決定である必要があります。
**インサイトとアクションのギャップの解消 :**分析で停止したクリーンルームでは、ビジネス価値を提供できません。アーキテクチャでは、クリーンルームの出力を有効化システムと AI ワークフローにネイティブに接続する必要があります。フィードバックループ、パフォーマンス測定、下流の実行は最初から設計する必要があります。
**Agentic Enterprise の準備 ―**AI エージェントによるエンタープライズデータの使用が増加するにつれて、クリーンルームは未加工データを公開せずにエージェントが操作できる制御された実行環境として機能します。クリーン ルーム戦略をAIガバナンスおよびTrustフレームワークと連携させるアーキテクトは、この次のフェーズに最適な位置づけになります。
モダンデータクリーンルームは、エンタープライズデータアーキテクチャの根本的な変化を表します。データ漏洩のないコラボレーションを実現することで、データユーティリティとプライバシーの長年の緊張を解決します。
Salesforce Data 360 などのアーキテクチャは、このトレードオフが「どちらか」または「どちらか」の考慮事項ではないことを示しています。ゼロコピーパターンによってデータストレージの有効化を切り離し、プライバシー強化テクノロジーを実行に直接組み込むことで、企業はデータの制御を放棄することなく、価値の高い分析でコラボレーションできます。プライバシーは契約上の義務からアーキテクチャ上の保証に移行します。
最も重要なのは、クリーンルームによってデータが静的でサイロ化されたアセットから、管理されたアクション可能なリソースに変換されることです。有効化レイヤーと AI レイヤーにネイティブに接続されている場合、ダッシュボードでインサイトが停止しなくなります。意思決定、キャンペーン、自律システムに直接取り込まれ、エンタープライズ規模でデータ、アクション、結果間のループを閉じます。
Yugandhar Boraは、Salesforceのソフトウェアエンジニアリングアーキテクトで、データおよびインテリジェンスアプリケーションプラットフォーム内のデータアーキテクチャを専門としています。データガバナンスと統合データモデルに焦点を絞ったエンタープライズアーキテクチャレビューボード (EARB) イニシアチブを主導しながら、自動化プラットフォームプロビジョニングソリューションに貢献しています。
Birendra Kumar Singhはテクニカル スタッフのプリンシパル メンバーであり、SalesforceのData 360内のプラットフォームとデータ アーキテクチャを専門としています。有効化プラットフォームの中心メンバーであり、Data 360 の顧客へのデータクリーンルームインフラストラクチャの提供に重点を置いたクリーンルームイニシアチブを主導しています。
Priyanka Kshirsagarは、Salesforceのシニア プロダクト マネージャーであり、Data 360 Clean Roomsを率いています。Data 360 Clean Roomsは、エンタープライズ環境のお客様がプライバシーを保持しながらファースト パーティ データでコラボレーションできるようにするためにゼロから構築した機能です。クリーンルームでの類似モデリングや ID 強化など、エージェント型 AI と ML を駆使した使用事例のビジョンを推進し、製品の正式リリースと Tier-1 Dreamforce のリリースを実現しました。