Enterprise data architecture is at an inflection point. Organizations must simultaneously support real-time AI systems, comply with increasingly strict privacy regulations, and collaborate with external partners who cannot share raw data. These requirements are fundamentally reshaping how data platforms are designed.
Traditional architectures built on ETL pipelines and centralized data warehouses struggle to meet these demands. Replicating data across systems increases latency, cost, and governance complexity. Each copy becomes a new compliance obligation, complicating consent management, deletion requests, and policy enforcement across distributed environments.
To address these challenges, the industry is shifting toward zero-copy, policy-enforced collaboration models. Data clean rooms have emerged as a key architectural capability, enabling multiple organizations to analyze shared signals without exposing or transferring raw data. Instead of moving data into centralized environments, computation executes within each participant’s governed domain, and only privacy-safe results are returned.
This architectural shift is increasingly visible across industries. For example, the acquisition of InfoSum by WPP, which is the largest company in marketing and advertising, reflects the growing importance of clean rooms as infrastructure for privacy-safe collaboration. Financial institutions use them to detect fraud across institutions, retailers to coordinate promotions with consumer brands, and healthcare organizations to analyze cross-provider patient cohorts, without sharing sensitive underlying records.
Salesforce Data 360 operationalizes this model through a zero-copy architecture built on Hyperforce. Data remains in its source systems while federated queries enforce privacy, consent, and residency policies at runtime. This approach enables real-time insights, cross-cloud collaboration, and AI-driven decisioning without expanding the risk surface created by data replication.
This document examines how data clean rooms function as a foundational architectural pattern for the modern enterprise, supporting AI innovation, regulatory compliance, and secure cross-domain collaboration simultaneously and at scale.
To understand why data clean rooms are necessary, enterprise architects must first confront the structural failure of legacy integration models. The industry is undergoing a decisive transition from monolithic, centralized data repositories to decentralized, federated ecosystems. Here, data is accessed, governed, and computed in place rather than physically moved. This shift isn’t incremental. It’s a direct response to systemic pressures around scale, privacy, and agility that traditional architectures can no longer absorb.
For years, enterprises relied on ETL-driven architectures that copied data from CRM, ERP, and digital systems into centralized warehouses for reporting and analytics. This approach proved effective for historical analysis, but it was designed for a slower, batch-oriented world.
As digital interactions accelerated and AI-driven systems emerged, the limitations of this model became more apparent. ETL pipelines are inherently asynchronous, meaning insights often arrive hours or days after events occur. Such latency is increasingly incompatible with modern use cases like real-time personalization, adaptive decision-making, and AI systems that require immediate, contextual data.
Replication also introduces growing governance and security complexity. Each new copy of data requires additional policies, monitoring, and compliance controls. In regulated environments, frameworks such as the General Data Protection Regulation (GDPR) require organizations to manage deletion, consent, and usage restrictions everywhere the data exists—an operational challenge when datasets are duplicated across multiple systems.
At scale, this duplication compounds cost and operational overhead. Organizations repeatedly pay for ingestion, storage, security, and processing across multiple platforms while the marginal value of additional copies declines.
As a result, modern data architectures are shifting toward models that minimize data movement and enforce governance directly at the source. Zero-copy integration and federated data access enable organizations to generate insights without replicating sensitive datasets, providing a more scalable, secure, and policy-aligned approach to enterprise data collaboration.
In response to these pressures, the industry has coalesced around two complementary architectural paradigms: Data Mesh and Data Fabric. Together, they represent a shift away from centralized control toward federated, domain-aware data architectures.
Data Mesh decentralizes data ownership to domain-aligned teams such as Sales, Marketing, or Supply Chain. Each domain treats its data as a product, with clearly defined contracts, quality standards, and service-level objectives. This model improves accountability and business alignment, but at enterprise scale it introduces new challenges around coordination, interoperability, and consistent governance across domains.
Data Fabric addresses these challenges by providing the connective layer that binds decentralized domains into a coherent system. It delivers shared metadata, common semantics, automated policy enforcement, lineage, and governance, enabling data to be discovered, accessed, and governed consistently without forcing physical consolidation into a single repository.
Together, Data Mesh and Data Fabric establish the foundation for federated data access. However, they stop short of solving a critical next-order problem: enabling secure, governed collaboration across domains and organizational boundaries, where data must be analyzed jointly without being copied or exposed.
As enterprise data becomes more distributed and privacy regulations grow stricter, organizations face a core architectural challenge. How do they collaborate across teams, partners, and platforms without sharing raw data? Traditional data integration approaches weren’t designed for this level of distribution or regulatory scrutiny, which created tension between collaboration and compliance.
This challenge has led to a shift toward data clean rooms as a foundational architectural capability. Clean rooms move collaboration away from data transfer and toward governed computation. Instead of copying or exchanging datasets, analytics and AI workloads run where the data already lives by sharing the metadata. Queries are evaluated in real time against privacy, consent, and usage rules, and only approved, aggregated results are returned.
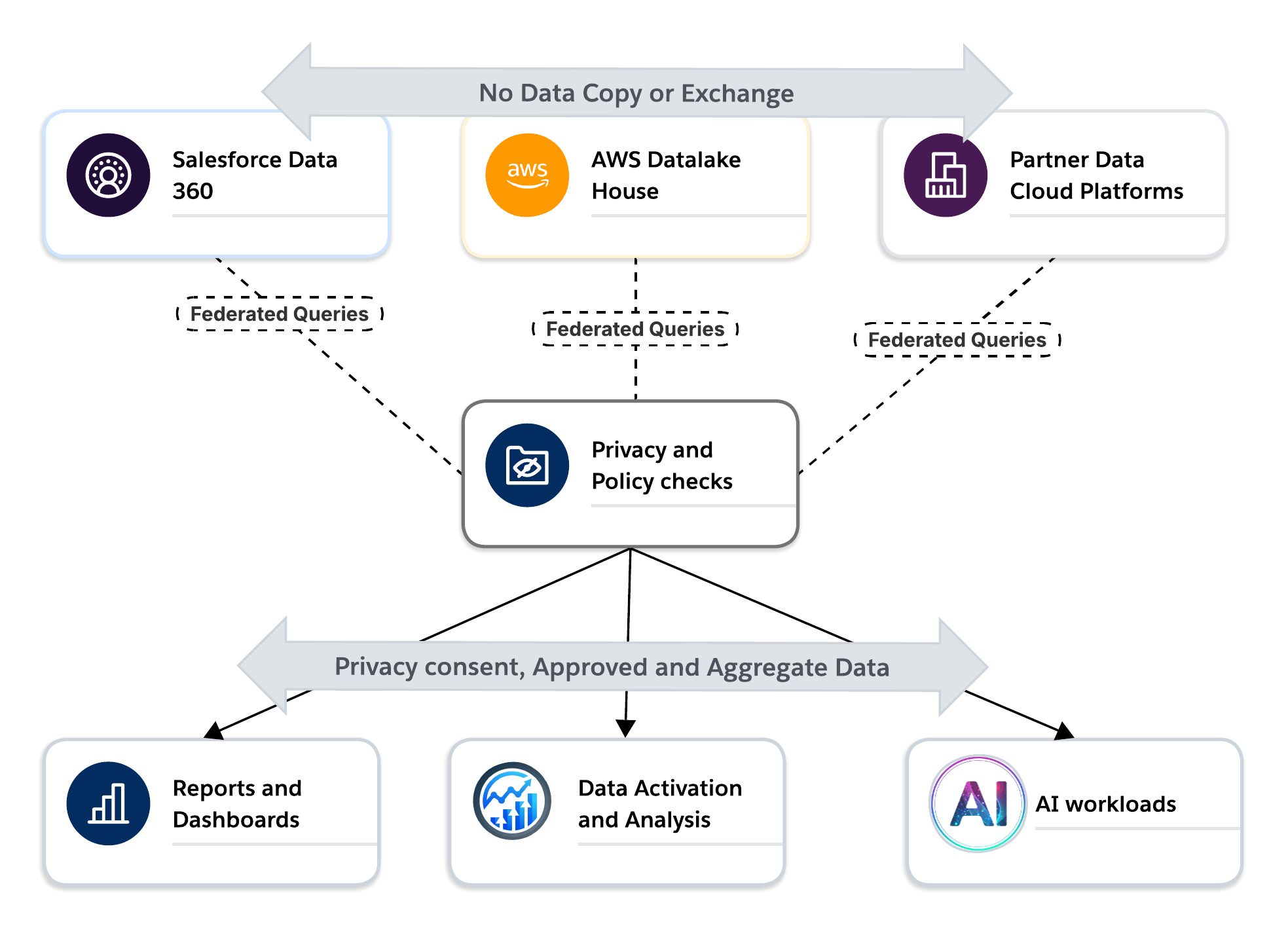
In this model, data clean rooms act as the trust boundary of modern data architectures. They allow organizations to work with partners and subsidiaries without losing control of their data, enforce privacy and consent through system controls rather than policy alone, and operate across clouds while respecting data residency and contractual limits.
For activation, analytics and AI use cases, clean rooms provide a secure way to generate insights from external data without exposing sensitive information. They enable a shift from data sharing to trusted collaboration. For Activation use cases, clean rooms provide a secure way to generate audiences that can be activated directly to an allowed destination. All this is achieved without exposing any personally identifiable information (PII) to either party.This marks a turning point in enterprise data architecture. Data clean rooms are no longer niche tools. They are becoming core infrastructure for federated, privacy-preserving, AI-ready data platforms.
A successful data clean room architecture is a multi-interface system designed to resolve the competing pressures of data utility, security, and speed. There are three primary personas whose distinct friction points must be addressed by the underlying technical design.
Privacy and compliance officers use the data clean room as a governance tool. Their primary concern is compliance drift, the risk that external collaboration environments fail to enforce the same rigorous standards as internal systems.
- Friction Points: Regulatory exposure (GDPR, CCPA, DMA) and "phishing" attacks where a partner attempts to triangulate a user's identity through repeated granular queries.
Data scientists view the data clean room as a safe haven for advanced modeling. Their primary concern is utility preservation, ensuring that privacy measures don’t render the data statistically useless.
- Friction Points: High latency and restricted access to granular attributes needed for machine learning (ML), lookalike modeling, and churn prediction.
This persona is focused exclusively on time to value (TTV). Their concern is that data clean room projects often become technical bottlenecks requiring weeks of data engineering support.
- Friction Points: Complex setup processes, manual data cleaning, and the "blank page" problem of needing to write code to get simple overlap results.
While traditional architectures focus on building the data layer before the user layer, our strategic approach, aligned with the "Business First" methodology, inverts this model. We prioritize a no-code to few-clicks approach that allows business users to generate insights and take immediate action.
"Insight-to-Action" Workflow: The architecture is designed as an active workspace rather than as a passive repository. By providing use case templates (for example, segment overlap, activation, and campaign performance), we enable business users to self-serve insights. This ensures that an insight, such as an optimized lookalike segment, is immediately available for activation across the marketing ecosystem without the need for a data engineer to manually move files.
Zero-Copy Federation as a Strategic Asset: To maximize TTV, the architecture adopts a zero-copy logic. Instead of the traditional ETL process, which introduces latency and security risks, our architecture federates queries directly to where the data resides (for example, Snowflake, BigQuery, or Amazon S3). This turns the organization's existing data investment into a strategic asset, allowing business users to act on the most current data in real-time while maintaining strict governance and eliminating the cost of data redundancy.
Data clean rooms emerged in advertising as a response to cookie deprecation and privacy regulation, but have evolved beyond measurement into customer analytics, audience segmentation, and activation use cases across industries. According to the 2025 State of Retail Media report, 66% of organizations now use clean rooms in some capacity, driven by the need for privacy-safe collaboration that delivers measurable business outcomes. The pattern is consistent across sectors: data stays with its owner, computation is governed, and only privacy-safe insights are shared.
The Challenge: Marketers need to measure campaign effectiveness, avoid duplicate ad impressions, and optimize reach/frequency—but can no longer rely on third-party cookies or device identifiers.
The Clean Room Solution:
- Advertisers contribute hashed customer or campaign exposure data
- Publishers contribute impression and engagement signals
- Clean room computes reach, frequency, attribution, and lift
- Activation occurs via approved platforms without raw data exports
Business Outcome: Clean rooms provide closed-loop attribution linking ad impressions to actual transactions, incrementality analysis isolating true campaign lift, and unified measurement across channels —capabilities traditional digital advertising can’t offer.
Industry Evidence: Measurement is the most established clean room use case today, with major media networks like Pinterest, Disney, and Paramount creating their own clean rooms.
The Challenge: CPG brands spend heavily on retail media but lack visibility into purchase outcomes. Retailers own rich point-of-sale data but can't expose it without violating privacy commitments.
The Clean Room Solution:
- Retailers and CPG companies combine point-of-sale data from retail locations with marketing data to optimize promotional activities
- Brands contribute hashed CRM or loyalty identifiers
- Clean room links ad exposure to in-store/online purchases
- Activation stays within retailer's media ecosystem
Business Outcome:
- Retailers monetize first-party data without selling raw customer information
- Brands gain closed-loop attribution showing which campaigns drove purchases
- Retail Media Networks scale without privacy risk
Industry Evidence: Retail Media Networks like Walmart's Luminate and Kroger Precision Marketing offer clean rooms that help CPG brands analyze customer behavior and optimize marketing strategies using retailer data.
The Challenge: Fraud networks operate across institutions, but banks can’t openly share customer or transaction data due to regulations like GLBA and emerging privacy laws.
The Clean Room Solution:
- Multiple banks pool anonymized data to identify patterns indicative of fraud, such as unusual cross-bank activity
- Federated analytics or models run across shared fraud signals
- No institution sees another's customer-level data
Business Outcome:
- Earlier detection of cross-institution fraud patterns
- Fewer false positives through richer signal sets
- Regulatory compliance without centralizing sensitive data
Industry Evidence: Financial services solutions from Experian and TransUnion offer clean room technologies enabling banks and insurers to collaborate on fraud detection and risk assessment while maintaining strict data privacy controls.
The Challenge: Pharmaceutical companies need real-world patient outcomes for drug development, but data resides in hospital EHR systems protected by HIPAA and similar regulations.
The Clean Room Solution:
- Doctors and pharmaceutical researchers share data within a clean room to learn how patients are reacting to treatments.
- Patient data remains within provider environments.
- Researchers run approved statistical analyses via a clean room.
- Differential privacy prevents re-identification.
Business Outcome:
- Statistically valid real-world evidence at scale
- Streamlined patient recruitment for clinical trials by matching anonymized patient data with trial criteria, finding eligible candidates without violating healthcare privacy laws
- Reduced dependence on limited clinical trial populations
Industry Evidence: Healthcare-focused clean rooms like Datavant provide HIPAA-compliant environments for researchers and healthcare organizations to securely analyze patient data for clinical trials and drug development.
Beyond these primary use cases, clean rooms enable:
- Supply Chain Optimization: Manufacturers and suppliers collaborate to share inventory details, production schedules, and demand forecasts, enabling better coordination while protecting proprietary information.
- M&A Due Diligence: When one company acquires another, due diligence requires examining financial projections and customer databases without sharing sensitive information directly; clean rooms reveal insights like customer segment alignment and compliance risks.
- Media and Entertainment: Publishers prove audience value to advertisers while protecting subscriber identities, enabling premium CPMs backed by trusted measurement instead of probabilistic targeting
Across AdTech, retail, financial services, healthcare, and media, Data Clean Rooms have become foundational trust infrastructure. They enable high-value collaboration that was previously blocked by privacy, regulatory, or competitive constraints. Clean rooms are core architectural components that enable secure, governed collaboration—unlocking insight and monetization without surrendering data control or compliance.
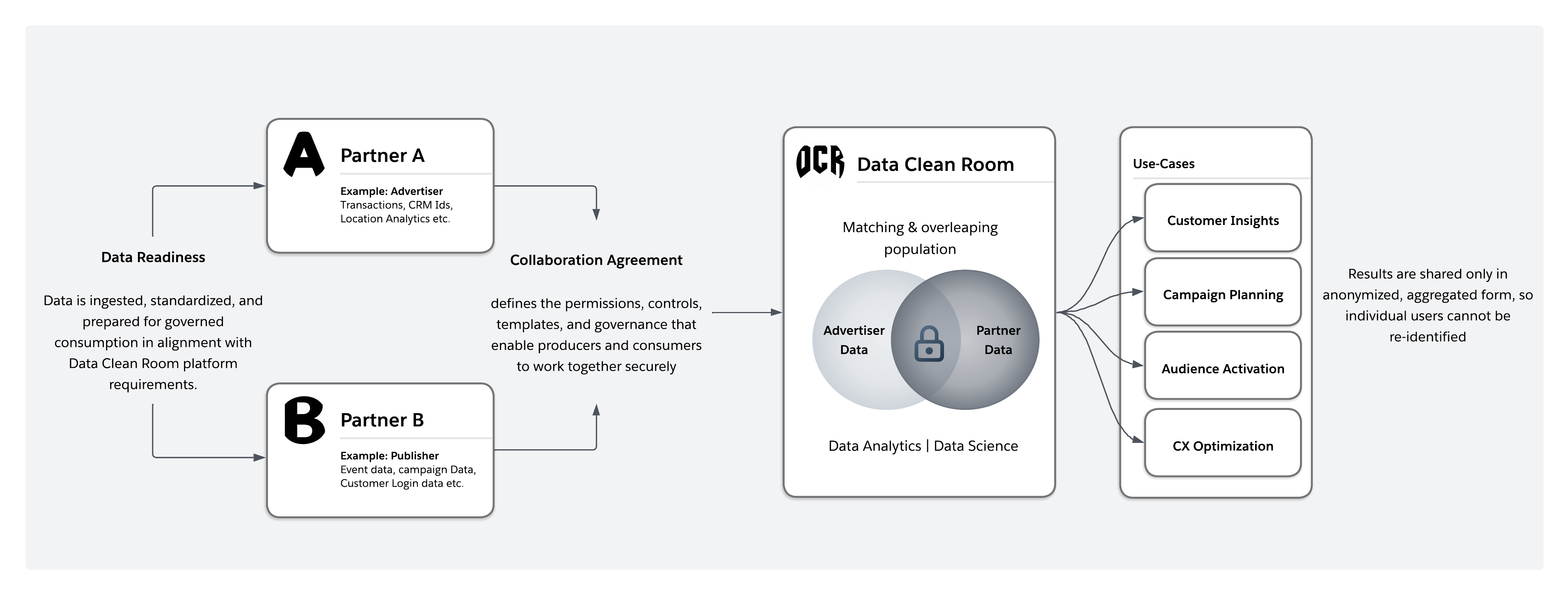
A data clean room is a secure, governed environment that enables multiple parties to generate joint insights without exposing or exchanging raw data. Instead of replicating datasets, approved analytics, AI, and activation workloads execute in place, and only policy-compliant outputs are returned. Where activation requires individual-level records, data is delivered directly to the intended destination without being exposed to collaborating parties.
Architecturally, clean rooms shift collaboration from data sharing to controlled computation. Each participant retains custody of their data, while runtime enforcement governs query behavior, output constraints, consent, and usage policies.
Collaboration is further enabled through privacy-preserving identifier alignment mechanisms, allowing datasets from different parties to be correlated without exposing the underlying identifiers—a capability explained in more detail later in this document. As a result, data clean rooms serve as foundational infrastructure for privacy-regulated, multi-cloud, AI-driven enterprises operating on zero-copy, federated data strategies.
Early data clean rooms followed a centralized “bunker” model. All participants were required to copy data into a neutral third-party environment for analysis. While straightforward in concept, this approach introduced significant friction. Data movement increased latency and cost, complicated legal and compliance agreements, and forced organizations to give up direct control of sensitive data. In regulated industries, these tradeoffs often made collaboration impractical.
Modern data clean rooms have evolved toward a distributed, federated model. Data remains in the owner’s environment, and analytics are executed in place through federated queries. The clean room itself functions as a governance layer that intercepts each query, enforces privacy and policy controls at execution time, and returns only approved, aggregated outputs.
| Dimension | Traditional Clean Room ("Bunker" Model) | Modern Clean Room (Distributed/Federated Model) |
|---|---|---|
| Data Location | Data is copied into a centralized third-party environment | Data remains in the owner's environment |
| Data Movement | Requires physical transfer and duplication of datasets | No raw data movement, queries run in place |
| Control and Custody | Custody partially relinquished to third-party platform | Raw data ownership and custody retained by each party |
| Architecture Model | Centralized aggregation | Distributed, federated computation |
| Governance Enforcement | Policies applied after data is moved | Policies enforced at query execution time |
| Privacy Model | Relies heavily on contractual and procedural controls | Enforced technically through runtime controls and aggregation thresholds |
| Latency | Higher latency due to ingestion and synchronization | Lower latency, near real-time federated queries |
| Cost Structure | Higher storage, transfer, and duplication costs | Reduced duplication, ascompute occurs where data resides |
| Compliance Complexity | Complex legal agreements due to cross-boundary data movement | Simplified compliance since data doesn't leave source boundary |
| Scalability | Scaling requires more storage and data replication | Scales through distributed compute without duplicating data |
| Regulated Industry Fit | Often impractical due to custody and residency concerns | Better aligned with sovereignty, consent, and regulatory constraints |
Salesforce Data 360 exemplifies this federation model. Publishers and advertisers can collaborate and run analyses across cloud platforms without raw data ever leaving the security boundary of the platform. Data custody is preserved, risk is reduced, and collaboration becomes faster and easier to scale.
This shift from shared data to shared computation redefines trust in enterprise collaboration. Clean rooms are no longer destinations where data is stored, but systems that govern how insight is safely produced.
To operate as a core architectural capability, an enterprise-grade data clean room must meet a small set of non-negotiable requirements.
The most fundamental requirement for data clean rooms is zero-copy architecture. Traditional data collaboration relies on ETL pipelines that copy data into shared environments. This increases latency, cost, security exposure, and regulatory risk, while creating multiple unmanaged copies of sensitive data.
A modern data clean room eliminates this problem. Data remains in its original system of record, whether it’s a cloud data warehouse, operational platform, or SaaS application. The clean room uses federated queries across these distributed sources and returns only approved, privacy-safe results.
By avoiding physical data movement, zero-copy clean rooms reduce attack surface, preserve data residency and ownership, and align naturally with data fabric and federated data architecture principles.
Modern data strategy depends on the ability to collaborate without moving data. Salesforce Data 360 provides a flexible framework that connects your enterprise to the global data ecosystem through two primary models:
Native Salesforce-to-Salesforce Connectivity : In this model, collaboration occurs directly between two Salesforce customers. A shared metadata layer allows providers and consumers to connect instantly through simple configuration . This enables teams to generate joint insights without the delay or risk of replicating data, ensuring that information remains secure in its original location.
External Salesforce-to-Cloud Integration (AWS and Snowflake): In this model, collaboration occurs between Salesforce and external cloud environments. A zero-copy federation allows organizations to bridge different infrastructures without the cost or risk of data movement. This enables teams to resolve identity fragmentation and expand reach while keeping data in its resident cloud, maintaining centralized governance and eliminating egress fees.
Zero-copy and federated architectures prevent raw data from being moved or duplicated, but they don't, by themselves, guarantee privacy. In these models, the primary risk shifts from data storage to data computation.
Sensitive information can still leak through analytical outputs, even when only aggregated results are returned. Common attack vectors include repeated or overlapping queries (differencing attacks), analysis of very small populations, and inference using external knowledge. As a result, privacy concerns move beyond access control to a dynamic requirement for query execution.
Enterprise Data clean rooms must treat Privacy-Enhancing Technologies (PETs) as mandatory, system-level controls, not optional analytics features or policy guidance. From an architectural perspective, this means:
- Privacy is enforced by the platform, not by analysts
- Controls are consistent across users, partners, and workloads
- Privacy guarantees are deterministic, repeatable, and auditable
- The system defines which computations are allowed, how results are shaped, and when queries must be blocked
Core PET Capabilities
Differential Privacy: Differential privacy (DP) provides a mathematical guarantee that the presence or absence of any individual doesn’t materially affect query results. In practice, this means the clean room automatically injects calibrated statistical noise into outputs and tracks a defined privacy budget for each dataset. Every query consumes part of this budget, and once it is exhausted, further queries are blocked. For architects, the value of DP lies in provability. Privacy risk is quantitatively bounded, enabling defensible compliance and reducing reliance on subjective policy interpretation.
Secure Identifier Alignment: Many collaboration scenarios require identifying overlap across datasets, such as shared customers or accounts. Exposing raw identifiers would violate data minimization principles. A clean-room-grade architecture instead relies on deterministic hashing or tokenization performed within the cleanroom boundary. Comparisons occur without revealing raw identifiers to any party, enabling join-like behavior without data disclosure.
Aggregation Thresholds and Result Suppression: Even fully anonymized outputs can be compromised when results are derived from very small populations. To prevent this, an enterprise data clean room must enforce minimum aggregation thresholds and automatically suppress results that fall below them. These thresholds must be non-overridable, ensuring consistent protection against small-segment leakage.
Without Privacy-Enhancing Technologies (PETs) enforced at the execution layer, Data Clean rooms risk becoming trust-based environments that rely on human judgment and contractual agreements. By embedding PETs directly into the platform, privacy becomes a structural property rather than a procedural one. This enables collaboration to scale across teams and partners without renegotiating trust, while regulators and risk teams can evaluate guarantees using objective, mathematical measures rather than subjective policies.
For enterprise architects, PETs are the critical mechanism that elevates a data clean room from a secure sandbox to a trusted collaboration fabric, capable of supporting regulated, multi-party analytics and AI workloads at enterprise scale.
In a multi-party collaboration, trust is maintained through visibility. An enterprise-grade data clean room must provide a "paper trail" of every interaction between the participants and the data.
Query Logs: Every SQL execution is logged, capturing the identity of the requester, the timestamp, and the specific query logic used.
Policy Enforcement Logs: The system must record not just what was queried, but which privacy policies (e.g. aggregation thresholds or Differential Privacy) were applied to the results.
Zero-Tamper Records: Using an Immutable Audit Trail (dedicated data model object), the data clean room ensures that logs can't be altered or deleted by any participant, providing a single version of truth for regulators.
Salesforce enables modern data clean rooms by allowing organizations to analyze and collaborate on data without ever sharing raw datasets. Built on a zero-copy, federated architecture with privacy, consent, and governance enforced at execution, Salesforce Data 360 ensures that insights are secure, compliant, and fully actionable. By embedding clean rooms directly into the enterprise data lifecycle, Salesforce Data 360 transforms them from niche analytical tools into scalable, trusted infrastructure for AI-driven and multi-party collaboration.
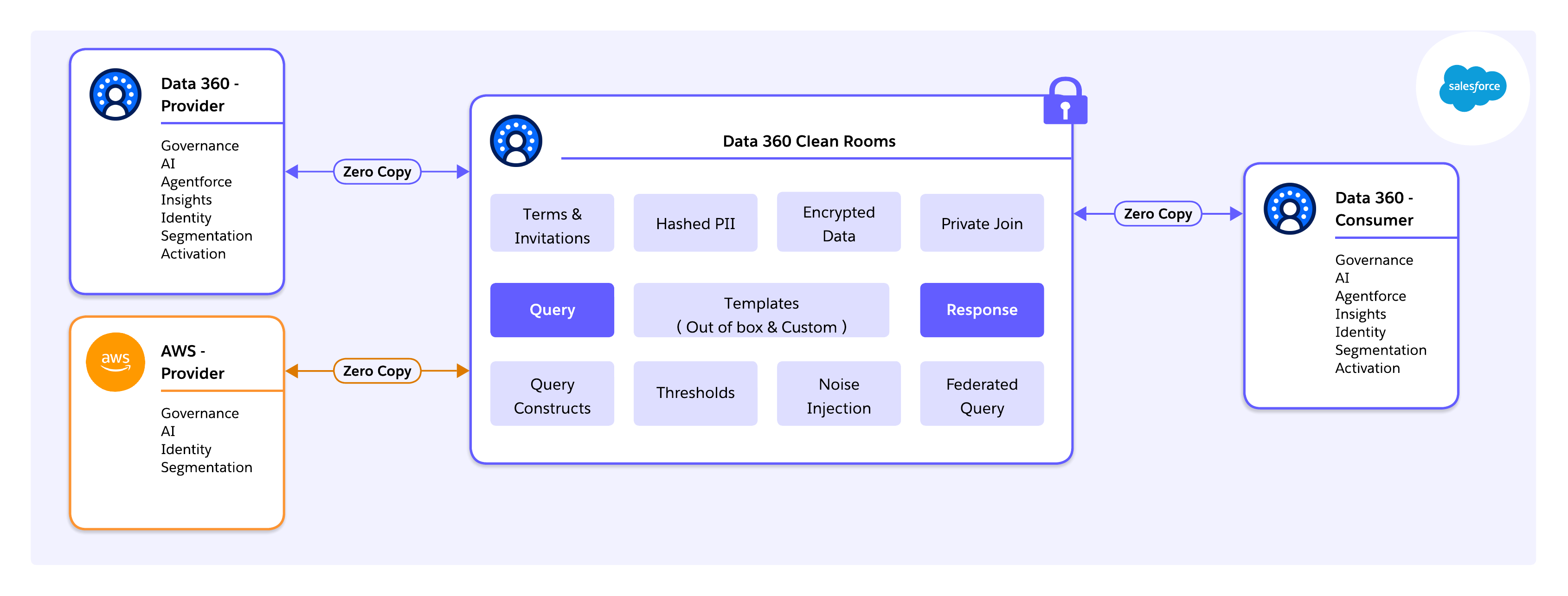
At the infrastructure layer, Salesforce Data 360 runs on Hyperforce, Salesforce’s cloud-native runtime that abstracts hyperscaler resources (AWS, Azure, GCP) behind a unified control plane. This architecture allows data to remain in-region to satisfy sovereignty and residency requirements, while enabling governed clean room operations globally.
Critically, this foundation enables cross-cloud clean room collaboration, including native interoperability with AWS Clean Rooms. Using Data 360 as the orchestration and governance layer, enterprises can collaborate with partners operating directly on AWS without forcing data migration into Salesforce-managed storage. Queries are pushed down to the source, privacy rules are enforced consistently, and only compliant, aggregated results are exchanged across platforms.
Compliance and trust are enforced at the infrastructure and execution boundary, rather than retrofitted at the application layer—providing a durable foundation for multi-cloud, multi-party collaboration at scale.
Data 360 implements a traceable, end-to-end data pipeline, ensuring that clean room operations run over harmonized, governed, and identity-aware data rather than raw extracts. Key stages include:
- Connect: Data ingestion and virtualization via out-of-the-box connectors, APIs, SDKs, MuleSoft, or zero-copy connectors
- Persist: Storage of raw data in native formats (Parquet / Iceberg)
- Harmonize: Mapping to canonical Data Model Objects (DMOs) for consistent joins
- Unify: Identity resolution creates Golden Records
- Derive Insights: Calculated insights compute aggregated metrics inside the governed boundary
- Act: Governed outputs flow to Salesforce Orgs, marketing platforms, ad networks, external data platforms, or other clean rooms, closing the insight-to-action loop
This pipeline ensures clean rooms operate on enterprise-grade data, not ad-hoc extracts.
Unlike standalone data clean room platforms that require separate provisioning and SQL development, Salesforce clean rooms are natively embedded into Data 360. This enables reuse of DMOs, identity rules, consent models, and governance policies, eliminating duplicate security layers. Salesforce’s template-driven clean room model is a key accelerator, using:
- Out-of-the-box templates to support common collaboration patterns such as audience overlap, suppression, reach, and lift measurement.
- Custom templates that allow architects and advanced users to define reusable analytical logic tailored to industry-specific or partner-specific needs—without exposing raw data or policy complexity.
This approach standardizes collaboration while still allowing flexibility, enabling clean rooms to scale as a repeatable enterprise capability, not a one-off analytics project.
Data 360 addresses a common failure mode of traditional clean rooms: the Activation Gap. Its Golden Path framework ensures that insights generated inside a clean room can be acted upon immediately, without exporting raw data.
- Setup and Discovery: Partners share schema metadata and leverage templates to evaluate feasibility before contracts are finalized.
- Analysis: Pre-built and custom templates drive overlap analysis, suppression, lookalike modeling, and lift measurement, all executed inside the governed boundary.
- Activation: Approved segments are pushed directly into Marketing Cloud, ad platforms, or partner systems, with only aggregate, compliant results shared.
Templates become opinionated execution paths, ensuring collaboration moves predictably from analysis to activation.
Deploying a Salesforce Data 360 Clean Room isn't just a configuration exercise—it is a disciplined architectural workflow spanning data readiness, governance design, secure connectivity, and operational monitoring.
Before touching data or configuration, architects must clearly define:
- What question are we trying to answer?
- What outcome is expected? (e.g., overlap analysis, lift measurement, suppression, fraud detection)
- What level of aggregation is required?
- What regulatory or contractual constraints apply?
- What activation path will consume the results?
Understanding the collaborator’s objective shapes everything that follows – join keys, identity rules, governance thresholds, and cost modeling. Clean Rooms are purpose-built environments. hey should be designed around a defined analytical goal, not generic data exposure.
Before collaboration can begin, enterprise data must be structurally and semantically prepared. Clean rooms amplify both strengths and weaknesses in underlying data. Garbage in, garbage out is all the more true here.
Ingestion: Connect source systems such as Salesforce CRM, Marketing Cloud, AWS S3, and Google Cloud Storage to Data 360. Wherever possible, use zero-copy connectors (for example, Snowflake) to avoid unnecessary movement or duplication of data.
Semantic Mapping: Map data streams to the Customer 360 data model. Standardize key fields like phone numbers (E.164 format), country/state codes (ISO standards), and email addresses. Misalignment (for example, one party using “CA” and another “California”) can silently fail joins and reduce match rates.
Identity Resolution: Configure deterministic (exact match) and probabilistic (fuzzy match) rules to create a Unified Individual (Golden Record). This unified entity is the surface for clean room matching. The quality of identity resolution directly impacts collaboration value. Higher match accuracy increases overlap rates, analytical confidence, and reduces false negatives.
Once data is harmonized, the clean room itself must be provisioned to define collaboration boundaries.
License Validation: Confirm that all participating organizations have the necessary Data 360 and clean room entitlements.
Data Space Scoping: Clean room objects must be scoped to a specific data space. Only objects mapped to that data space are visible to the clean room. This ensures collaboration is logically isolated without requiring the creation of a new data space solely for clean rooms.
Define Governance Rules: Establish policies declaratively before queries are executed:
- Aggregation Thresholds: for example, a minimum of 100 records per output
- Join Keys: for example, Email_Hash_SHA256
- Allowed Operations: only aggregate functions such as COUNT, SUM, AVG
- Explicit Restrictions: block row-level exports (SELECT *)
Governance rules are enforced at execution time, making privacy and compliance system-level properties rather than procedural guidance.
Clean rooms often span organizational and platform boundaries. Connectivity must be explicit and tightly controlled.
Account Linking:
- Salesforce-to-Salesforce: Use Data Cloud One or approved cross-org sharing mechanisms.
- Multi-cloud scenarios: Validate region alignment and residency before queries are enabled.
Authentication and Authorization: Configure OAuth-based access for dedicated integration users with the Principle of Least Privilege—limit access strictly to necessary data spaces and avoid administrative permissions. Security failures often result from over-permissioned integration users rather than weaknesses in cryptography or platform controls.
Once live, focus shifts to operational oversight, query quality, and cost management.
Query Execution: Analysts or workflows perform overlap analysis and aggregations via Calculated Insights or approved SQL interfaces. All queries automatically enforce aggregation thresholds and privacy controls.
Audit and Traceability : Salesforce Data 360 clean rooms provide audit trails in the form of an audit data model object (DMO). This captures metadata about query activity, including who executed the query, when it was run, and what policies were applied. Audit DMO enables compliance reporting, governance validation, and forensic traceability — ensuring collaboration is both privacy-safe and reviewable.
Consumption Monitoring: Data Cloud uses a consumption-based credit model. Key drivers include:
- Rows processed (for example, 1M rows = baseline credit unit)
- Query complexity
- Identity resolution operations (higher multiplier)
- Batch ingestion (lower multiplier)
Digital Wallet and Alerts: Use Digital Wallet to track real-time consumption and configure alerts at 50%, 75%, and 90% thresholds. Correlate spikes with specific workloads to avoid unexpected costs. Note that zero-copy doesn’t eliminate compute costs. While physical duplication is removed, execution occurs at the source system. Architects must manage query patterns, join selectivity, and execution frequency to control cost and performance.
In modern enterprises, trust isn't bolted onto a data clean room. It is an architectural outcome. Salesforce Data 360 enforces governance, security, and compliance continuously and automatically, shifting clean rooms from policy-driven environments to platform-governed systems. Execution-time controls (locked identities, audit trails, and differential privacy) apply consistently whether collaboration occurs within Salesforce, across partners, or across clouds.
The most important shift for architects is that trust is enforced during execution, not assumed beforehand. Salesforce Data 360 achieves this through a number of core platform controls:
- Locked Identity: Partner access is cryptographically tied to verified Salesforce Org identities, preventing spoofing or unauthorized participation.
- Audit Trails: Every query, join, segment overlap, and activation is logged for full auditability and regulatory compliance.
- Differential Privacy: Row-level inspection is structurally impossible. Outputs are aggregated and statistically bounded. Collaborators see only privacy-safe results, such as reach metrics or lift percentages, never individual transactions or identities.
These controls replace contractual trust with mathematical guarantees and platform-level enforcement, reducing operational and legal risk.
As AI agents increasingly interact with Clean Room data, Salesforce introduces the Einstein Trust Layer. It acts as an architectural airlock between sensitive enterprise data and external LLMs. This ensures clean room insights can safely power AI-driven decisioning without exposing underlying data.
Key capabilities:
- Zero Data Retention: Data sent to LLMs is ephemeral. Model providers can't store prompts or responses for training.
- Toxic Language Detection and PII Masking: Inputs and outputs are automatically scanned, and PII is masked according to Data Masking Policies configured in Data 360.
Data spaces provide logical isolation within an org and should align with regulatory, geographic, and partnership boundaries like:
- EU Data Space
- North America Data Space
Only datasets assigned to a data space are visible within its clean rooms, preventing accidental cross-boundary exposure. Permission sets offer fine-grained control over who can create or manage clean rooms, execute queries, or activate segments. Data-aware permissions enforce field-level restrictions within data model objects—for example, marketers may see segment names and audience size but not income or health indicators. Security is enforced at the semantic layer, allowing safe self-service for business users without constant IT oversight.
Consent signals propagate automatically through Data 360 into clean room execution. Users who revoke consent are excluded from analysis and activation by default—ensuring compliance is system-enforced, not manually policed.
Salesforce Data 360 treats governance, security, and compliance as first-class architectural primitives, not optional add-ons. By combining execution-time auditability, locked identities, differential privacy, data spaces, consent-aware identity resolution, and the Einstein Trust Layer, enterprises can scale clean room collaboration across partners, multi-cloud systems, and AI-driven workloads—all without compromising trust, privacy, or regulatory compliance.
To capture the full value of data clean rooms, architects must treat them as core architectural infrastructure, not as isolated analytics tools. The following priorities define a pragmatic and scalable path forward: Make Collaboration a First-Class Architectural Concern : External data collaboration should be designed with the same rigor as internal integration. Clean rooms should be embedded within enterprise reference architectures alongside data platforms, integration layers, and AI systems—not deployed as ad hoc extensions. As interoperability expands (for example, Data 360 clean room integration with AWS clean rooms and future cross-clean-room compatibility), architects must design collaboration patterns that anticipate multi-platform ecosystems rather than single-vendor silos.
Design for Privacy by Default at Source
Design for Data Fluidity : Rather than defaulting to heavy ETL and central replication, architects should first consider federation and zero-copy access. Moving computation to data (when appropriate) reduces unnecessary duplication, lowers cost, and preserves source-of-truth integrity. “Connect vs. copy” should be a conscious architectural decision, not an inherited habit.
Close the Insight-to-Action Gap : Clean rooms that stop at analysis fail to deliver business value. Architectures must natively connect clean room outputs to activation systems and AI workflows. Feedback loops, performance measurement, and downstream execution must be designed from the outset.
Prepare for the Agentic Enterprise : As AI agents increasingly use enterprise data, clean rooms will serve as controlled execution environments where agents can operate without exposing raw data. Architects who align clean room strategy with AI governance and trust frameworks will be best positioned for this next phase.
Modern data clean rooms represent a fundamental shift in enterprise data architecture. They resolve the long-standing tension between data utility and privacy by enabling collaboration without data exposure.
Architectures such as Salesforce Data 360 demonstrate that this tradeoff is not an “either-or” consideration. By decoupling data storage from activation through zero-copy patterns, and by embedding privacy-enhancing technologies directly into execution, enterprises can collaborate on high-value analytics without relinquishing control of their data. Privacy moves from contractual obligation to architectural guarantee.
Most importantly, clean rooms transform data from a static, siloed asset into a governed, actionable resource. When connected natively to activation and AI layers, insights no longer stall in dashboards. They flow directly into decisions, campaigns, and autonomous systems—closing the loop between data, action, and outcomes at enterprise scale.
Yugandhar Bora is a Software Engineering Architect at Salesforce, specializing in data architecture within the Data and Intelligence Applications platform. He leads enterprise architecture review board (EARB) initiatives focused on data governance and unified data models, while contributing to automated platform provisioning solutions.
Birendra Kumar Singh is a Principal Member of Technical Staff, specializing in platform and data architecture within the Data 360 at Salesforce. He is a core member of the Activation Platform and leads the Clean Room initiative focused on providing data clean room infrastructure to Data 360 customers.
Priyanka Kshirsagar is a Senior Product Manager at Salesforce, leading Data 360 Clean Rooms — a capability she built from the ground up to enable enterprise customers to collaborate on first-party data in a privacy-preserving environment. She drives the vision for agentic AI and ML-powered use cases, including lookalike modeling and identity enrichment on clean rooms, and has taken the product through General Availability and a Tier-1 Dreamforce launch.