最新の Salesforce インテグレーションでは、単純なデータ交換以上のサポートが必要です。リアルタイムのカスタマーエクスペリエンスの強化、複数のシステム間のアクションの調整、エンタープライズ規模の信頼性の高い運用を実現すると同時に、厳格なセキュリティとコンプライアンスの要件も満たすことが求められます。したがって、適切なインテグレーションアプローチを選択することは、実装の詳細ではなく、アーキテクチャ上の重要な決定事項です。 一般的なエンタープライズシナリオについて考えてみます。顧客がモバイルアプリケーションで購入を完了すると、パーソナライズされたオファーのリアルタイムの対象資格チェックがトリガーされます。同時に、トランザクションデータを ERP システムに記録し、Salesforce で顧客属性を更新し、分析をデータレイクにストリーミングする必要があります。これにより、遅延、データの重複、コンプライアンスのリスクを回避できます。このようなシナリオは、現在の Salesforce 環境では一般的です。Salesforce は、単独で運用されることがほとんどなく、アプリケーションやデータプラットフォームの広範なエコシステムとシームレスに統合する必要があります。 このガイドは、アーキテクトと開発者がこれらのインテグレーションを明確に自信を持って設計できるようにするために用意されています。ポイント・ツー・ポイントの実装に焦点を当てるのではなく、プロセスの調整、データ同期、リアルタイムのデータ・アクセスなど、繰り返し発生するエンタープライズ・シナリオに対応する一連の実証済みの統合パターンを提示します。各パターンでは、アーキテクチャの意図、トレードオフ、実行モデルが強調されるため、チームは拡張性と耐久性を備えた十分な情報に基づいた設計上の意思決定を行うことができます。 このドキュメントには、次の情報が含まれています。
- プロセス、データ、仮想アクセスのシナリオで一般的なエンタープライズの「原型」を表すインテグレーションパターン
- インテグレーションインテントと実行タイミングに基づいて適切なアプローチを識別するためのパターン選択フレームワーク
- 拡張性、耐障害性、ガバナンス、セキュリティに関する考慮事項に関する実践的なガイダンス
- Salesforce および Data 360 の実際の実装から得られたベストプラクティス このドキュメントの目標は、統合のための共通のアーキテクチャ言語を提供し、チームがエンタープライズ データおよびガバナンス戦略に合わせてパフォーマンス、柔軟性、Trust のバランスを取るソリューションを設計できるようにすることです。
このドキュメントは、社内の他のアプリケーションのデータを Salesforce Data 360 (旧 Data Cloud) と統合する必要があるデザイナーやアーキテクトを対象としています。このコンテンツは、Salesforce アーキテクトとパートナーによる多くの成功した実装を絞り込んだものです。 Data 360 の大規模な採用に使用できるインテグレーション機能とオプションについての詳細は、以下の「パターンの概要」および「パターン選択ガイド」セクションを参照してください。アーキテクトと開発者は、Data 360 へのデータインタラクションプロジェクトの設計および実装フェーズで、次のパターンの詳細とベストプラクティスを考慮する必要があります。 これらのパターンを適切に実装すれば、本番環境にできるだけ早く移行でき、可能な限り安定性と拡張性が高く、メンテナンスフリーな一連のアプリケーションを使用できます。Salesforce 独自のコンサルティングアーキテクトは、アーキテクチャレビュー時にこれらのパターンを参照点として使用し、積極的に維持および改善します。 すべてのパターンと同様に、このコンテンツではほとんどのインテグレーションシナリオがカバーされますが、すべてはカバーされません。たとえば、Salesforce ではユーザーインターフェース (UI) インテグレーションやマッシュアップが可能ですが、そのようなインテグレーションはこのドキュメントの範囲外です。
各インテグレーションパターンは一貫した構造に従います。これにより、各パターンで提供される情報の一貫性が確保され、パターンの比較も容易になります。
- 名前:パターンに含まれるインテグレーションの種別も示すパターン識別子。
- **コンテキスト:**パターンで対応する全体的なインテグレーションシナリオ。コンテキストは、ユーザーが何を達成しようとしているか、および要件をサポートするためにアプリケーションがどのように動作するかに関する情報を提供します。
- **問題:**質問として表現され、パターンで解決するように設計されたシナリオです。このセクションを読んで、パターンがインテグレーションシナリオに適しているかどうかを確認してください。
- **強制:**示されたシナリオを解決するのを困難にする制約と状況。
- **ソリューション:**インテグレーションシナリオを解決するための推奨方法。
- **スケッチ:**ソリューションがシナリオにどのように対処するかを示す UML シーケンス図。
- **結果:**ソリューションをインテグレーションシナリオに適用する方法の詳細と、そのシナリオに関連する勢力を解決する方法について説明します。このセクションでは、パターンの適用によって発生する可能性のある新しい課題についても説明します。
- **サイドバー:**主要な技術的な問題、パターンのバリエーション、パターン固有の懸念などが含まれる、パターンに関連する追加のセクション。
- **例:**実際の Salesforce シナリオでデザインパターンがどのように使用されるかを説明する実際のシナリオ。この例では、インテグレーションの目標とその目標を達成するためにパターンを実装する方法について説明します。
次の表は、このドキュメントに記載されているインテグレーションパターンの目次として使用します。
| パターンレベル1 | パターンレベル2 | パターン | シナリオ |
|---|---|---|---|
| データ取り込みパターン--データ受信 | バッチ取り込みパターン | クラウドストレージからの一括データ取り込み | データは、Amazon S3、Azure Blob、Google Cloud Storage などのエンタープライズクラウドストレージソースから、大量の未加工データ (トランザクションや商品ログなど) の形式で Data 360 に取り込まれます。 |
| Salesforce クラウドからの一括データ取り込み | Data 360 は、複数の Salesforce 組織 (Sales Cloud、Service Cloud など) から CRM データを一括で受信し、統合顧客プロファイルを作成します。 | ||
| ストリーミングおよびリアルタイム取り込みパターン | 取り込みAPIを使用したイベント駆動型取り込み--ストリーミング | Data 360 は、リアルタイムのプロファイル更新のためにエンタープライズシステムから継続的なイベントペイロード (購入イベント、IoT テレメトリーなど) を受信するストリーミング取り込みエンドポイントを登録します。 | |
| リアルタイムの Web およびモバイル動作の取り込み | Data 360 は、SDK を介してリアルタイムの Web サイトおよびモバイルアプリケーションの行動データを収集して処理し、エンゲージメント評価指標とパーソナライズモデルを強化します。 | ||
| ストリーミングによるほぼリアルタイムの CRM 同期 | Data 360は、イベントストリームを介してCRMデータの更新(取引先責任者、ケース、商談の変更など)をほぼリアルタイムで受信し、継続的に同期されたCustomer 360ビューを維持します。 | ||
| クラウドメッセージングプラットフォームからのイベントストリームの取り込み--キネシスと MSK | Data 360 では、AWS Kinesis や Kafka (MSK) などのクラウドイベントプラットフォームから直接ストリーミングデータを使用して、頻度の高い運用イベントや IoT イベントを処理します。 | ||
| ゼロコピーパターン--受信と送信 | 受信ゼロコピー--Data 360への外部プラットフォーム | Data 360 は、データを物理的に Salesforce に移動することなく、ゼロコピー取り込みを使用して外部データセット (Snowflake、BigQuery など) をオンデマンドで照会します。 | |
| 送信ゼロコピー--外部プラットフォームへのData 360 | Databricks や Tableau などの外部システムは、データレプリケーションなしで Zero Copy Outbound 接続を介して Data 360 の拡張セグメントとインサイトにアクセスします。 | ||
| Data Cloud Oneを使用した統合マルチ組織データ プラットフォーム | Data Cloud Oneは、複数のSalesforce組織と外部データソースを共有メタデータおよびセマンティック モデルの下で統合し、データの重複のない一貫したCustomer 360を提供します。 | ||
| データ有効化パターン--データ送信 | バッチ有効化パターン | マーケティングおよび広告プラットフォームへのセグメントの有効化 | Data 360 は、選定された顧客セグメントを Marketing Cloud、Meta、Google 広告、またはその他の広告プラットフォームに直接有効化して、パーソナライズされたキャンペーン配信を実現します。 |
| クラウドストレージへのデータのエクスポート | Data 360 は、統合データセットまたは絞り込まれたデータセット (同意済みの顧客レコードなど) を CSV または Parquet ファイルとして Enterprise Cloud Storage にエクスポートし、分析またはコンプライアンスアーカイブを行います。 | ||
| オンデマンド API ベースの有効化 | Connect API を使用したカスタムアプリケーションインテグレーション | 外部アプリケーションは、Data 360 Connect API をリアルタイムで呼び出して、現在の顧客データに基づいてパーソナライズされたアクション (ロイヤルティ残高チェックや AI オファーの生成など) を取得またはトリガーします。カスタム作成の Web またはモバイルアプリケーションは、Connect REST API を使用してハーモナイズされた Data 360 インサイトを安全に取得し、エンタープライズまたはパートナーの UI 内に表示します。 | |
| データグラフ API を使用した顧客プロファイルの取得の完了 | システムはデータグラフ API を使用して顧客の統合プロファイルを取得し、意思決定やパーソナライズのために 360° ビュー全体の事前結合されたリアルタイムの JSON 表現を返します。 | ||
| リアルタイムデータアクション | リアルタイムデータアクションによる顧客のシグナルのインスタントアクションへの変換 | Data 360 は、ライブイベント (同意の更新、購入トリガーなど) を検出して処理し、接続済みシステムまたは Salesforce フローをすぐに呼び出してダウンストリームアクションを実行します。Data 360 の顧客活動のシグナル (離脱リスクの検出など) によって、CRM の更新、Einstein スコアリングの呼び出し、保持ジャーニーの開始などのリアルタイムアクションがすぐにトリガーされます。 |
このドキュメントのインテグレーションパターンは、データ、プロセス、ビジュアルインテグレーションの 3 つのカテゴリに分類されます。
Data 360 のデータインテグレーションパターンは、システム全体のデータの移動と同期に対応し、Data 360 と外部プラットフォームの両方で一貫性があり、タイムリーで信頼できる情報が保持されるようにします。これらのパターンは通常、大規模で大量のデータフローを処理し、スキーマの一貫性、系統追跡、およびマスタールールを適用する管理パイプラインに依存します。
- バッチ取り込みパターンは、エンタープライズ データ オンボーディングの基盤レイヤーを表します。AWS S3、Azure Blob、Google Cloud Storage などのクラウドストレージサービスからの一括データ取り込みにより、ID 解決、セグメンテーション、分析のために、大規模な履歴データセットを定期的に Data 360 に読み込むことができます。同様に、Salesforce クラウド(Sales Cloud、Service Cloud、Marketing Cloud など)からの一括取り込みでは、ネイティブ コネクタとデータ ストリームを使用して CRM データを統合データ レイヤーに取り込み、エンゲージメント システム全体でハーモナイゼーションと継続性を確保します。
- ストリーミングおよびリアルタイム取り込みパターンでは、高速イベントデータをキャプチャすることでこれを拡張します。取り込み API を介したイベント駆動型取り込みにより、外部システムで顧客の活動を継続的に Data 360 にストリーミングできます。Web およびモバイルの行動のリアルタイム取り込みでは、デジタルタッチポイントから直接クリックストリームおよびインタラクションデータが取得され、即座にパーソナライズされます。ストリーミング API を介したほぼリアルタイムの CRM 同期により、顧客属性と同意の更新がシステム全体にすばやく反映されます。Amazon Kinesis や Confluent MSK などのメッセージングプラットフォームからのイベントストリームの取り込みでは、継続的な高スループットパイプラインがサポートされるため、Data 360 をエンタープライズイベントアーキテクチャに合わせることができます。
- Unified Multi-Org Data Platform with Data Cloud Oneは、データ統合をさらに例証し、共通のガバナンスおよびセマンティック レイヤーの下で複数の Salesforce 組織と外部ソースのデータを統合するための統合環境を提供します。これにより、組織はエンタープライズ全体のデータの一貫性、共有データモデル、および拡張性の高い分析を実現できます。
- 有効化フェーズでは、バッチ有効化パターンは同じデータ統合の原則に従います。Data 360 で選定されたセグメントは、スケジュール済みジョブで Marketing Cloud、Meta 広告、Google 広告などの下流のマーケティングおよび広告プラットフォームにエクスポートされ、そこでキャンペーンの実行がトリガーされます。同様に、データセットをクラウドストレージ対象にエクスポートして、外部分析とデータサイエンスパイプラインを強化できます。これらのすべての使用事例で、Data 360 は同期および選定された顧客データの情報源として機能します。
Data 360 のプロセスインテグレーションパターンでは、ほぼリアルタイムでシステム全体のビジネスプロセスをトリガーまたは調整します。これらのパターンにより、Data 360 はエンタープライズワークフローに積極的に参加し、状況に応じた応答と動的なデータの有効化が可能になります。
- オンデマンド API ベースの有効化により、リアルタイムのエンゲージメント シナリオが可能になります。カスタムアプリケーションは Connect API を使用して、運用プロセスの一環として Data 360 から直接顧客プロファイルを照会または有効化できます (顧客とのやりとり中にエージェントコンソールで統合プロファイルインサイトを取得する場合など)。Complete Customer Profile Retrieval via Data Graph APIでは、顧客のエンティティグラフ全体への API ベースのアクセスに依存する複合アプリケーションとマイクロサービスがサポートされるため、セグメントを事前準備することなく動的な環境を実現できます。
- リアルタイムデータアクションは、即時応答を可能にすることで、このインテグレーションアプローチをさらに推進します。購入、フォーム送信、しきい値イベントなどの顧客のシグナルが検出されると、Data 360 は CRM レコードの更新、外部 Web フックの呼び出し、パーソナライズされたオファーワークフローの起動などのアクションをトリガーできます。これらのパターンは、真のプロセス オーケストレーションを具体化し、リアルタイムの顧客インテリジェンスと自動化された業務実行を橋渡しします。
Data 360 の仮想インテグレーションパターンでは、データを物理的にコピーまたは複製することなく、外部データソースまたは統合データソースにライブアクセスできます。これらは、データの移動を最小限に抑えながら、クエリ時に管理された最新情報を必要とする企業にとって重要です。
- 受信 Zero Copy Data Federation(外部プラットフォーム-to-Data 360)では、データ ウェアハウスやデータ レイクなどの外部システムが、安全で管理された接続(Snowflake Secure Data Sharing など)を介してデータセットを Data 360 と共有できます。これにより、Data 360 は仮想的に外部データにアクセスして操作できるため、新鮮さが維持され、不要な複製が排除されます。
- **Outbound Zero Copy Data Sharing(Data 360-to-External Platforms)**により、Data 360 は安全なデータ統合とライブ クエリ メカニズムを介して、AI モデリング、ビジネス インテリジェンス、高度な分析などの外部消費用に選定されたデータセットを公開できます。 システムに最適なインテグレーション戦略を選択することは容易ではありません。考慮すべき点や使用できるツールは多数あり、ツールによっては特定の作業に適したものもあります。各パターンは、各システムの機能、データ量、障害処理、トランザクション性など、特定の重要な領域に対応します。
インテグレーションパターンを選択するときは、インテグレーションの全体的な設計と動作を形成する 2 つの基本的な質問に回答することから始めます。 何を統合しますか? — プロセス、データ、または仮想アクセス このディメンションでは、インテグレーションの主な目的を定義します。
- プロセスの統合は、ビジネス・ワークフローを調整し、システム全体のアクションを調整することに重点を置いています。
- データ統合は、システム間のデータの同期、強化、伝達に焦点を当てています。
- 仮想インテグレーションは、Salesforce や Data 360 で外部データをコピーまたは保持することなく、リアルタイムで外部データにアクセスすることに重点を置いています。 このインテントを理解することで、システム間に必要なオーケストレーション、データ移動、結合のレベルを判断できます。
- How does it need to execute? (実行方法) — 同期または非同期の方法でインテグレーションの実行モデルを定義します。
- 同期インテグレーションは、通話者が即時の応答を期待するリアルタイムのブロッキングです。これは、通常、ユーザー主導のシナリオや検証シナリオで使用されます。
- 非同期インテグレーションはノン ブロッキングで分離されており、拡張性、実行時間の長いプロセス、再試行、大量のデータを処理するように設計されています。 これらの 2 つのディメンション(インテグレーション インテントと実行タイミング)を組み合わせることで、ユーザー エクスペリエンス、拡張性、運用の耐障害性のバランスを取りながら、適切なインテグレーション パターンを選択するための明確で一貫したフレームワークが提供されます。 **注意:**インテグレーションシナリオに適用される側面に応じて、インテグレーションに外部ミドルウェアまたはインテグレーションソリューション (エンタープライズサービスバスなど) が必要になる場合があります。
次の表は、Salesforce から別のシステムへのインテグレーションの場合に要件に最も適したパターンを判断するのに役立つパターンとその主要な側面を示しています。
| タイプ | タイミング | 送信に関する考慮事項 |
|---|---|---|
| データインテグレーション | 非同期 | マーケティングおよび広告プラットフォームへのセグメントの有効化 |
| プロセス/データインテグレーション | 同期 | Connect API を使用したカスタムアプリケーションインテグレーション データグラフ API を使用した顧客プロファイルの取得の完了 |
| データインテグレーション | 同期 | リアルタイムデータアクションによる顧客のシグナルのインスタントアクションへの変換 |
| 仮想インテグレーション (ゼロコピーを使用) | 非同期 | 送信ゼロコピー--外部プラットフォームへのData 360 |
| 仮想インテグレーション | 非同期 | Data Cloud Oneを使用した統合マルチ組織データ プラットフォーム |
次の表は、別のシステムから Salesforce へのインテグレーションの場合に要件に最適なパターンを判断するのに役立つパターンとその主要な側面を示しています。
| タイプ | タイミング | 受信に関する考慮事項 |
|---|---|---|
| データインテグレーション | 非同期 | クラウドストレージからの一括データ取り込み Salesforce クラウドからの一括データ取り込み |
| データインテグレーション | 非同期 | クラウドメッセージングプラットフォームからのイベントストリームの取り込み--キネシスと MSK ストリーミングによるほぼリアルタイムの CRM 同期 |
| プロセスインテグレーション | 同期 | 取り込みAPIを使用したイベント駆動型取り込み--ストリーミング リアルタイムの Web およびモバイル動作の取り込み |
| 仮想インテグレーション | 非同期 | 受信ゼロコピー--Data 360への外部プラットフォーム |
次の表に、ミドルウェアに関連する主要な用語と、それらのパターンの定義を示します。
| 用語 | 定義 |
|---|---|
| イベント処理 | イベント処理とは、ソースシステムまたはアプリケーションからの識別可能な発生の受信、ルーティング、応答を指します。ミドルウェアは、対象エンドポイントを特定し、イベントを転送して、必要なビジネスアクション (ログの記録、再試行、ダウンストリームサービスの有効化など) をトリガーすることでイベントを処理します。Data 360 アーキテクチャでは、イベントの処理はリアルタイムのデータ取り込み、有効化トリガー、公開/登録パターンにとって重要です。イベントは外部システム (Kafka、AWS Kinesis) または Salesforce Platform イベントから発生する可能性があり、ミドルウェアまたは Data 360 イベントバスによってルーティングされ、すぐに処理されます。 |
| プロトコル変換 | プロトコル変換により、異なるデータ転送標準を使用するシステム間の通信が可能になります。ミドルウェアは、独自のプロトコルや従来のプロトコル (AMQP、MQTT、FTP など) を、サポートされている Data 360 プロトコル (REST、gRPC、HTTPS) に変換します。これにより、異種システム間の相互運用性が確保されます。Data 360 はプロトコルの変換をネイティブに処理しないため、ミドルウェアは適応レイヤーを提供し、メッセージを Data 360 API とコネクタが解釈できる形式にカプセル化または変換します。 |
| 翻訳と変換 | 翻訳と変換では、あるデータ形式またはスキーマを別のデータ形式またはスキーマに対応付けることで相互運用性を確保します。ミドルウェアは、さまざまなデータペイロード (CSV、XML、JSON) を Data 360 データモデルオブジェクト (DMO) と統合データレイヤーオブジェクト (UDLO) に合わせるために、これらの変換を実行します。これには、取り込み前のセマンティックまたはオントロジーベースの対応付けのクリーンアップ、強化、適用が含まれます。Salesforceはデータプレップレシピなどの変換ツールを提供していますが、複雑な変換(特にセマンティックハーモナイゼーション)はミドルウェアで処理するのが最適です。 |
| キューイングとバッファリング | キューイングとバッファリングは、復元性のある分離された通信を確保するために非同期メッセージパッシングに依存します。ミドルウェアプラットフォーム (MuleSoft、Kafka、Azure Event Hub など) には、Data 360 やダウンストリームシステムがビジー状態やアクセス不能な場合にデータを一時的に保存する永続的なキューが用意されています。これにより、データの損失を防止し、ほぼリアルタイムの取り込みまたは有効化の再試行をサポートします。Data 360 ではストリーミング取り込みとフローベースのアウトバウンドメッセージングがサポートされますが、耐久性のあるキューと保証された配信は通常ミドルウェアで処理されます。 |
| 同期転送プロトコル | 同期転送プロトコルには、ブロックされたリアルタイムの要求/応答操作が含まれます。送信者は返信を待ってから続行します。Data 360 では、これらはオンデマンド API ベースの有効化、リアルタイム強化、またはすぐに応答が必要なプロファイル検索に使用されます。ミドルウェアは、接続の信頼性を確保し、同期 Data 360 API コールの再試行またはフォールバック処理を管理します。 |
| 非同期転送プロトコル | 非同期転送プロトコルでは、送信者が応答を待たずに処理を続行するノンブロッキングの分離通信がサポートされます。ミドルウェアは、一括有効化、ストリーミング取り込み、イベント駆動型有効化の非同期フローを処理します。これにより、イベントストリーミングや Data 360 のほぼリアルタイムのデータ取り込みパターンに重要な高いスループットと復元性を実現できます。 |
| 仲介ルーティング | 仲介ルーティングでは、システム間の複雑なメッセージフローを定義して、適切なデータまたはイベントが適切なコンシューマーに到達するようにします。ミドルウェアはメディエーターとして機能し、ルール、ヘッダー、コンテンツ、またはイベント種別に基づいてルーティングロジックを処理します。Data 360 インテグレーションでは、メディエーションにより、複数のシステムからのイベントとプロファイルの更新がデータ取り込み API、有効化エンドポイント、または外部コンシューマーに適切に転送されます。これによりオーケストレーションが簡素化され、マルチシステムデータ同期がサポートされます。 |
| プロセス振付とサービスオーケストレーション | プロセス振付とオーケストレーションでマルチシステムプロセスを調整します。振付では、中央コントローラーを使用せずにシステムが共有ルールに基づいて動作する自律的な非同期イベント駆動型フローがサポートされます。オーケストレーションは、サービスの実行を指示する一元管理されたフローです。Data 360 アーキテクチャでは、ミドルウェアでシステム全体の取り込みと有効化のオーケストレーションを管理し、Salesforce ワークフローまたはフローでプラットフォーム内の軽量な振付を処理します。ミドルウェアレイヤーでは、トランザクションの調整や状態管理を必要とする複雑なオーケストレーションをお勧めします。 |
| トランザクション性 (暗号化、署名、信頼性の高い配信、トランザクション管理) | トランザクション性により、システム全体でアトミック、一貫性、分離、耐久性 (ACID) のある操作が保証されます。Salesforce と Data 360 は境界内でトランザクションを行いますが、外部システム間の分散トランザクションはサポートされません。ミドルウェアは、暗号化、メッセージ署名、ロールバック、補償、信頼性の高い配信など、グローバルなトランザクション制御を処理します。ミッションクリティカルなデータフロー (財務や同意の更新など) の場合、ミドルウェアにより、Data 360 と外部システム全体でエンドツーエンドの整合性とリカバリが確保されます。 |
| ルーティング | ルーティングでは、コンポーネント間のメッセージまたはデータの制御フローを指定します。ヘッダー、コンテンツタイプ、優先度、ルールに基づく場合があります。ミドルウェアは、Data 360 に関連するイベントや有効化のルーティングロジックを処理します。たとえば、強化されたオーディエンスセグメントをさまざまな下流システム (広告プラットフォーム、倉庫、CRM アプリケーション) に転送します。ルーティングはSalesforce内に実装できますが(Apex、フロー)、拡張性、柔軟性、ガバナンスの観点からミドルウェア ルーティングが推奨されます。 |
| ETL (抽出、変換、読み込み) | ETL には、ソースシステムからデータを抽出し、一貫性のあるスキーマに変換して、対象 (Data 360 など) に読み込む作業が含まれます。ミドルウェアまたは ETL ツールでは、データを取り込む前にこれらの操作が処理されます。Data 360 は API、コネクタ、または一括取り込みパイプラインを介して ETL 出力を受信でき、ほぼリアルタイムの同期を実現する変更データキャプチャ (CDC) もサポートしています。ミドルウェア ETL プロセスは、Data 360 で統合する前にレガシーシステムを統合し、データ品質を確保するために不可欠です。 |
| Long Polling | ロングポーリング (コメットプログラミング) は、リアルタイム更新のためにシステム間のオープンな通信を維持する方法です。クライアントは要求を送信し、サーバーはイベントが発生するまで要求を保持し、イベントが発生すると応答して新しい接続を再オープンします。Salesforce は、イベント駆動型データ同期のために、これをストリーミング API および CometD/Bayeux プロトコルで使用します。ミドルウェアは、これらのイベントを登録して Data 360 に転送し、リアルタイムの取り込みまたは有効化トリガーを実行できるため、エンタープライズシステム全体の遅延を最小限に抑えることができます。 |
データの取り込みは、Salesforce Data 360 のデータライフサイクルの最初で最も重要なステップです。これにより、複数の外部システム (CRM、ERP、Web、モバイル、サードパーティ API) からの未加工情報がプラットフォームに入力され、統合顧客ビューの一部になります。 適切な取り込みパターンは、ビジネスのニーズによって異なります。
- データ量 — 一度に移動されるデータ量
- レーテンシー — データをどれだけ新しくする必要があるか
- ソースシステムの機能 — システムがデータを接続して配信する方法 Data 360 では、これらのニーズを満たすために複数の取り込みモードがサポートされています。大量読み込み用のバッチ、ほぼリアルタイムの更新用のストリーミング、トランザクションの即時実行用のイベントベース、外部データを物理的に移動せずに瞬時にアクセスするための Zero Copy 取り込みです。 これらのパターンを組み合わせることで、購入イベント、クリックストリームログ、ロイヤルティ更新など、すべての顧客のシグナルが Data 360 に効率的かつ安全に適切なタイミングで取り込まれ、信頼できる分析と AI 駆動型エクスペリエンスを強化できます。
一括取り込みパターンは、Data 360 の大規模データオンボーディングのバックボーンです。これらは、データが連続的ではなく一括で (通常はスケジュール済みまたは定期的に) 処理されるシナリオに最適化されています。 次のパターンが最適です。
- 既存のエンタープライズレコードでプラットフォームを初期化するための履歴データ読み込み
- ERP、データウェアハウス、独自のデータベースなどの記録システムとの定期的な同期
- リアルタイムの新鮮さは重要でないが、一貫性、完全性、監査可能性は重要な用途 バッチ取り込みは、予測可能なパフォーマンスとシンプルな運用を提供し、テラバイト規模の構造化データまたは半構造化データを管理する企業にとって信頼できる選択肢となります。 Data 360 には、バッチの取り込みをネイティブでサポートする本番対応の正式リリース済み**コネクタ**のセットが用意されています。これらのコネクタにより、インテグレーションの設定が合理化され、カスタム ETL 開発が減り、すべてのインポートでデータ品質とセキュリティが確保されます。次の表は、エンタープライズ規模のバッチ取り込みに使用される最も一般的なコネクタを示しています。
コンテキスト
このパターンは、CSV ファイルや Parquet ファイルなどの大量の構造化データと、一元化されたデータレイクやスケジュールされたファイルの削除からの非構造化アセットの取り込みが含まれるエンタープライズシナリオ向けに設計されています。通常、データソースには、Amazon S3、Google Cloud Storage (GCS)、Microsoft Azure Blob Storage などのクラウドストレージプラットフォームが含まれます。これらのプラットフォームでは、上流データパイプラインまたはバッチエクスポートの一部としてファイルが定期的に配信されます。
問題
ガバナンス、拡張性、パフォーマンスを犠牲にすることなく、プライマリクラウドストレージプラットフォームから大量のファイルベースのデータセットを予測可能な定期的なスケジュールで Data 360 に取り込むための、信頼性が高く、安全で、高スループットのプロセスを確立する方法は?
勢力
Data 360 への大量のファイルベースのデータセットの取り込みは、単純なデータ転送ではなく、拡張性、ガバナンス、プラットフォームの制約によって形成されるアーキテクチャ上の課題です。
**データ量と拡張性 ―**Data 360 取り込みコネクタは、任意の一括スループットではなく、信頼性とガバナンスのために最適化されています。たとえば、Amazon S3 コネクタでは、オブジェクトあたり最大 1 億行または 50 GB のいずれか先に制限に達した方がサポートされます。履歴データセットが数十億件のレコードに対応している企業では、この境界が設計上の重要な制約になります。単一ファイルのリフトアンドシフトアプローチはすぐに実現できなくなり、コネクタの制限に達することなく拡張を実現するインテリジェントなデータパーティショニング、チャンク、オーケストレーション戦略が必要になります。
**スキーマ定義とメンテナンス ―**Data 360 では、セマンティックおよび構造の整合性を確保するために、すべての取り込みパイプラインで明示的なスキーマ定義が必要です。S3 取り込みの場合、csv ファイルで列ヘッダーと 1 つの代表的なデータ行を定義する必要があります。このファイルは、ソースシステム (クラウドストレージと Data 360) 間の正規契約として機能します。項目名、データ型、または文字コードにずれがあると、取り込みに失敗したり、サイレントデータが破損したりする可能性があります。このスキーマファイルをバージョン管理で管理し、CI/CD またはデータガバナンスワークフローを使用して検証を適用することが、本番環境のベストプラクティスになります。
**厳格な命名規則 :**Data 360 では、メタデータグラフ全体の一貫性を維持するために、厳格なオブジェクトおよび項目の命名ルールが適用されます。
- オブジェクト名は文字で始まる必要があり、文字、数字、アンダースコアのみを使用できます。
- 項目名は同じパターンに従う必要があります。 これらの規則に違反するファイル (スペース、特殊文字、サポートされていない記号を含む項目など) は、取り込み時にスキーマ検証に失敗します。企業は、受信ファイル構造のサニタイズと正規化を行うために、取り込み前データ衛生プロセスを実装する必要があります。
**認証とセキュリティのポスチャ ―**外部ストレージへの各接続は、エンタープライズクラスのセキュリティおよびコンプライアンス標準に準拠する必要があります。
- 通常、認証は AWS アクセス/秘密鍵または統合 ID プロバイダー (IdP) 認証で処理されます。
- IAM ロールの範囲は、指定されたストレージパスへの参照アクセス権のみを許可する最小権限を適用する必要があります。
- 安全なアクセスを実現するには、送信 IP アドレスを直接ソースシステムの許可リストに追加する必要があります。 これらの階層化された制御により、すべてのファイル転送が監査可能なゼロ Trust 境界内で実行されるため、企業のコンプライアンスと大規模な取り込みに必要な柔軟性のバランスが保たれます。
ソリューション
次の表に、このインテグレーションの問題の解決方法を示します。
| ソリューション | 適合 | コメント |
|---|---|---|
| ネイティブクラウドストレージコネクタの使用 (Amazon S3、Google Cloud Storage、Azure Blob Storage) | 最善 | これは、Data 360\ への大規模で定期的なファイルベースの取り込みに推奨される最も信頼性の高いパターンです。ネイティブコネクタは、管理された認証、スキーママッピング、Data 360 のデータレークオブジェクト (DLO) への安全なデータ移動を直接提供します。遅延が重要ではないスケジュール済みバッチ読み込み (1 時間ごとや 1 日ごとなど) に最適です。 |
| 大きなデータセットの処理 (コネクタの制限を超える) | 前処理に最適 | 各コネクタで取り込み制限が適用されます (S3 など)。オブジェクトあたり 1 億行または 50 GB)。データセットが大きい場合は、ETL 前処理ステップを実装して、これらのしきい値に該当する小さなファイル/フォルダーにデータを分割します。次に、Data 360 内で複数のデータストリームを設定して各パーティションを並列で取り込み、一括処理データ変換で追加ノードを使用してパーティションを統合データセットに再結合します。 |
| セキュリティとガバナンス | 最善 | すべてのコネクタで、クラウドネイティブの方法 (IAM ロール、サービスアカウント、またはアクセスキー) による安全な認証がサポートされます。制御を強化するには、クラウドプロバイダーの許可リストを使用して Data 360 IP 範囲へのアクセスを制限します。データ転送は暗号化されたチャネルを介して行われ、取り込み時にファイルは一時的な安全なステージングレイヤーに保存されます。 |
| 使用しないケース | 最適ではない | このパターンは、次の場合に最適ではありません。
|
スケッチ
次の図は、クラウドストレージから Data 360 にデータを取り込む手順を示しています。
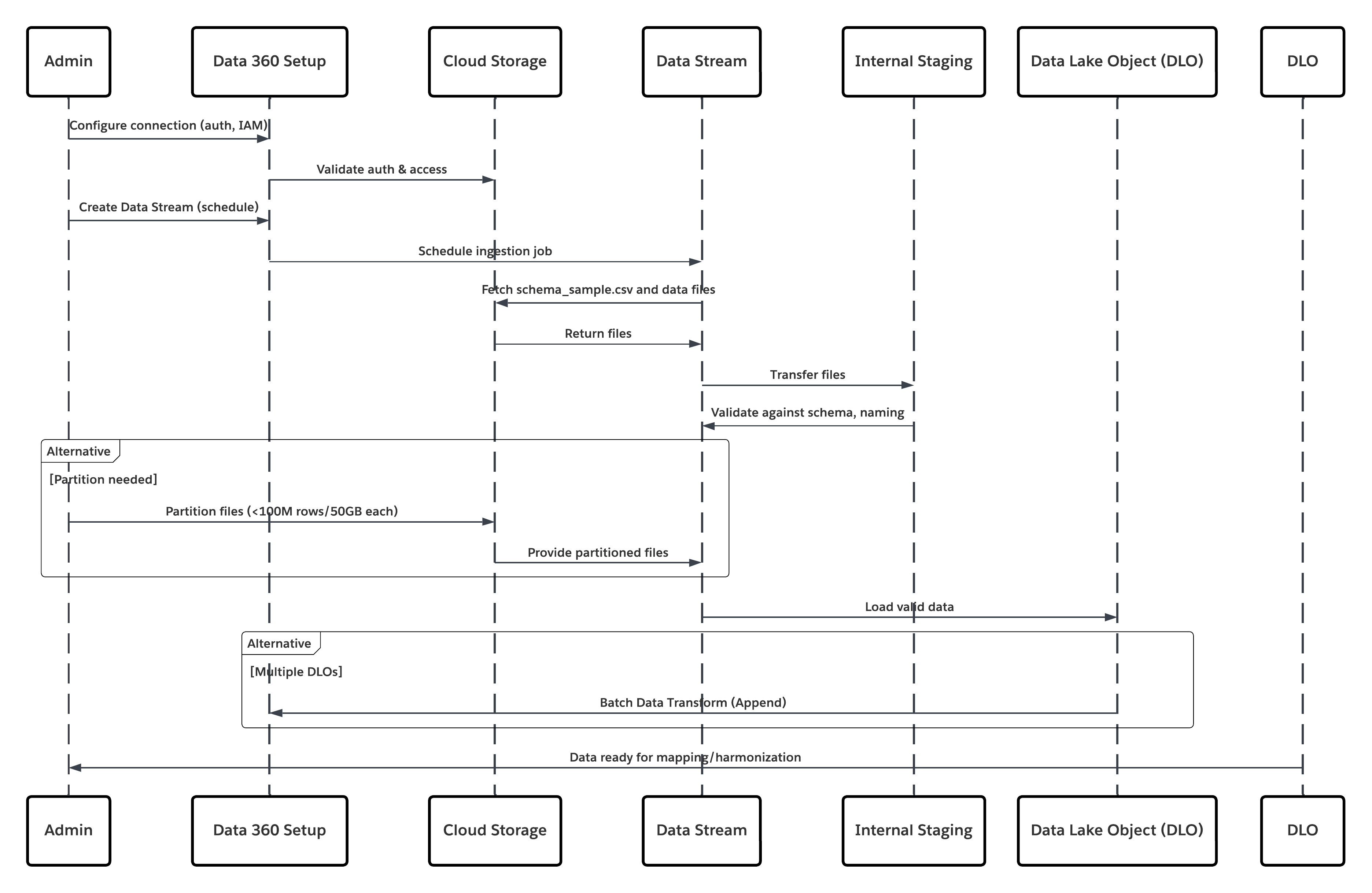
このシナリオの内容は次のとおりです。
- システム管理者は、Data 360 設定インターフェースを使用してクラウドストレージへの接続を設定します (認証、バケットの詳細、IAM ロール、ホワイトリストの指定)。
- Data Cloud 設定インターフェースは、Cloud Storage Platform で認証し、ログイン情報とアクセス権を検証します。
- システム管理者が Data 360 でデータストリームを作成し、データストリームを Cloud Storage のオブジェクト/フォルダーにリンクして取り込みスケジュールを定義します。
- スケジュールトリガー時に、データストリームは Cloud Storage Platform からソースファイル (CSV、Parquet など) を要求します。
- Cloud Storage Platform では、必要な有効な schema_sample.csv や、命名規則に準拠するその他のデータファイルなどのファイルが提供されます。
- データストリームは、Data 360 内の内部ステージング環境にファイルを転送します。
- Data 360 Pipeline でファイルが処理されます。schema_sample.csv のスキーマ定義を使用して、構造と項目名を検証し、取り込みしきい値 (1 ファイルあたり 1 億行/50 GB) を超える場合は負荷を除算します。大きなファイルが検出された場合、前処理パーティショニングステップ (次の実行のためにシステム管理者に通知) が外部で実行されます。
- レコードはステージングからデータレイクオブジェクト (DLO) にインポートされます。
- 必要に応じてデータがパーティション分割されている場合は、一括処理データ変換で追加ノードを使用して複数の DLO を結合します。
- Data 360 は成功/失敗を記録し、監視のステータスを更新して、データのマッピング、ハーモナイゼーション、統合の準備が整ったことを通知します。
結果
このパターンを適用すると、Enterprise Cloud Storage プラットフォームから Data 360 に構造化ファイルまたは非構造化ファイルを安全かつスケジュール済みで大規模に取り込むことができます。このプロセスは自動化され、拡張性と復元力を備えています。ハーモナイゼーションと Customer 360 データ モデルへのマッピングの基盤となる DLO(データ レイク オブジェクト)に未加工データを配信します。
取り込みメカニズム
取り込みメカニズムは、Data 360 内で定義されたコネクタとスケジュール戦略によって異なります。
| 取り込みメカニズム | 説明 |
|---|---|
| ネイティブクラウドストレージコネクタ (Amazon S3、GCS、Azure) | CSV 形式または Parquet 形式のファイルを企業のクラウドデータレイクから直接取り込むことをお勧めします。これらのコネクタでは、増分更新スケジュールとフル更新スケジュールがサポートされます。たとえば、銀行は S3 バケットから DLO への顧客トランザクションファイルの日次同期を設定できます。 |
| パーティション分割ファイル戦略 | データセットが非常に大きい場合 (1 億行またはオブジェクトあたり 50 GB を超える場合)、データは月別や地域別など、小さな論理セットに分割されます。各パーティションは個別のデータストリームとして管理され、後で追加ノードとの一括処理データ変換を使用して再結合されます。 |
| 自動スケジュール同期 | Data 360 には、取り込みジョブを自動的にトリガーする宣言型スケジューラー (1 時間ごと、1 日ごと、またはカスタムケイデンス) があり、手動操作なしでデータの新鮮度を確保できます。 |
エラー処理と回復
大量の取り込み操作の信頼性を確保するためには、エラー処理と復旧が不可欠です。
- **エラー検出:**データストリームを実行するたびに、Data 360 Monitoring に取り込みエラー (スキーマの不一致、ファイルの破損、命名違反など) が記録されます。管理者は失敗したバッチを確認して再処理できます。
- 回復メカニズム:Data 360 では、失敗したバッチで以前の取り込みが破損しないようにチェックポイントが管理されます。再試行は、ソースの問題 (不正な形式の CSV など) を修正した後に設定できます。
- スキーマ検証:schema_sample.csv ファイルでは、データ型と構造を定義します。実行全体でサイレントスキーマドリフトを回避するための変更トリガー検証。
Idempotent 設計に関する考慮事項
取り込みは設計上最適です。同じファイルを再処理しても、レコードが重複することはありません。 主な戦略は次のとおりです。
- **ファイルフィンガープリント:**Data 360 はチェックサムを計算して、以前に処理されたファイルを識別してスキップします。
- **トランザクションの取り込み:**データはステージングされ、すべてのレコードが正常に処理された場合にのみ DLO にコミットされます。
- **追加と置換:**ビジネスロジックに応じて、ストリームを対象 DLO に追加したり、完全に置き換えたりできます。これにより、確定的な結果が保証され、部分的なデータの重複が回避されます。
セキュリティに関する考慮事項
セキュリティは、認証から暗号化、アクセス制御まで、取り込みパイプライン全体にわたって不可欠です。
- **認証と承認:**コネクタは Salesforce のセキュアなインテグレーションフレームワークを使用し、秘密を公開せずに指定ログイン情報と外部ログイン情報を使用して認証します。
- **暗号化:**データは送信中 (TLS 1.2+) および保存中 (AES-256) に暗号化されます。
- **ネットワークコントロール:**ソースストレージシステム (S3 バケットなど) では、Data 360 IP を許可リストに登録する必要があります。
- **コンプライアンスの調整:**Customer-Managed Keys (CMK) と組み合わせることで、GDPR、HIPAA、FFIEC ガイドラインなどのエンタープライズデータ保護フレームワークをサポートします。
- **監査可能性:**すべての取り込みジョブとログイン情報アクセス権は、トレーサビリティとコンプライアンスのレポート用に記録されます。
サイドバー
適時性
適時性は、取り込みスケジュールとデータ量によって異なります。
- 大規模なエンタープライズデータセット (1 億行以上) では、並列取り込みのためにパーティション分割が必要な場合があります。
- 一般的な取り込みレーテンシーの範囲は、ファイルサイズと変換の複雑さに応じて数分から数時間です。
- ほぼリアルタイムの取り込みでは、Data 360 ストリーミングまたは API ベースのコネクタがファイルベースのモデルを補完する場合があります。
データ量
- 大量の定期的なバッチ取り込みに最適です。
- S3 コネクタを介して処理される各オブジェクトは、最大 1 億行 (ファイルあたり 50 GB) をサポートします。
- ペタバイト規模のシステムでは、データパーティショニングとマルチストリームオーケストレーションを使用します。
エンドポイントの機能と標準のサポート
エンドポイントの機能と標準サポートは、選択したソリューションによって異なります。
| コネクタ種別 | エンドポイント要件 |
|---|---|
| Amazon S3 コネクタ | 適切な IAM ポリシーとスキーマを定義する schema\_sample.csv ファイルを含む S3 バケット。 |
| Google Cloud Storage コネクタ | 統一した命名規則を使用したサービスアカウントのログイン情報とバケットアクセス。 |
| Azure Storage コネクタ | アクセスキーまたは SAS トークンベースの認証。blob またはフォルダー構造は Data 360 の規則に従う必要があります。 |
状態管理
状態は、データストリームと最後に成功した実行タイムスタンプで追跡されます。
- Data 360 では同期状態とオフセットが自動的に維持されるため、以降の実行時には新規または変更されたファイルのみが処理されます。
- 外部 ETL ツールと統合する場合、重複を避けるために一意のファイル識別子 (UUID やタイムスタンプなど) を使用することをお勧めします。
複雑なインテグレーションのシナリオ
高度なエンタープライズアーキテクチャでは、このパターンを以下と統合できます。
- ミドルウェア ETL パイプライン (例: Informatica、MuleSoft): Data 360 に渡す前の前処理、検証、ファイルパーティショニングを調整します。
- **AI/ML ワークフロー:**処理された DLO データは、DMO を介してトレーニング環境をモデル化したり、Data 360 有効化対象を介して RAG インデックスをモデル化したりできます。
- トランザクションシステム: ハーモナイズ DMO は、データアクションまたはプラットフォームイベントを介して Salesforce CRM または外部システムのダウンストリーム更新をトリガーできます。
例
あるグローバル金融機関は、顧客データとトランザクションデータを AWS S3 データレイクに保存します。このデータレイクでは、パーティション分割された Parquet ファイルが地域 (米国、EU、APAC など) ごとに夜間に生成されます。データアーキテクチャチームは、Data 360 の複数のデータストリームを設定し、それぞれが地域フォルダーに接続され、すべてのパーティションでヘッダーとデータ型の一貫性が確保されるように schema_sample.csv を共有します。夜間の取り込みスケジュールでは、データが自動的に DLO に読み込まれます。その後、一括処理データ変換ですべての地域パーティションが統合 Customer_Transactions_DLO に追加されます。次に、このハーモナイズされたデータセットが Customer 360 データ モデルにマッピングされ、下流の分析と AI の有効化が可能になります。このアプローチでは、既存のデータレークからの自動的かつ信頼性の高い取り込みを実現し、企業の IT ポリシーに沿った強力な認証と暗号化を適用し、将来の拡張とスキーマの進化をサポートするスケーラブルなモジュール式基盤を提供します。
コンテキスト
Data 360 の主な重要な使用事例は、Salesforce エコシステム全体で顧客データを統合することです。このパターンでは、Salesforce のコアプラットフォーム (Sales Cloud と Service Cloud (Salesforce CRM を総称) および Marketing Cloud Engagement) からデータをネイティブに取り込みます。ソースには、エンゲージメントイベント、メール送信、追跡データを保持する標準およびカスタム CRM オブジェクト (取引先、取引先責任者、ケース、商談など) と Marketing Cloud Engagement データエクステンションが含まれます。
問題
パフォーマンス、ガバナンスを維持し、ソース システムの中断を最小限に抑えながら、組織が標準およびカスタム CRM オブジェクトと Marketing Cloud Engagement データエクステンションを Data 360 に効率的かつ確実に取り込んで、データを使用して統合顧客プロファイル(ID 解決、Customer 360)を構築できるようにするにはどうすればよいでしょうか。
勢力
ネイティブコネクタによって作業が簡略化されますが、次のような運用面とアーキテクチャ面で管理する必要があります。
- **包括的なソース権限:**専用の接続ユーザー (インテグレーションアカウント) には、適切なオブジェクトレベルおよび項目レベルの参照権限が必要です。必要な権限セット (事前作成済み Data 360 コネクタ権限セットなど) を割り当てないと、取り込みに失敗する一般的な原因になります。
- **データ更新モードとコスト:**コネクタでは、フル更新モードとデルタ/増分更新モードがサポートされています。フル更新では、パフォーマンスとクレジットの負担が大きくなります。差分抽出により負荷が軽減されますが、ソースシステムでの信頼性の高い変更追跡に依存します。
- **カスタムスキーマおよび項目の対応付け:**CRM インスタンスには多くの場合、カスタムオブジェクト/項目が含まれます。マッピングエラーやセマンティックドリフトを回避するために、スキーマの正確なマッピングとカスタム項目 (名前、型) の処理が必要です。
- **スターターデータバンドルとカスタム対応付け:**スターターデータバンドルでは、典型的なオブジェクト/項目を事前に選択することでオンボーディングを加速しますが、高度にカスタマイズされた組織では、特注のストリーム定義が必要になります。
- **スループットと API の制限:**ソース組織の API 制限と Marketing Cloud の抽出レートによって、更新をどの程度積極的にスケジュールできるかが制限されます。
- **データ衛生と命名規則:**ソース項目名、null 動作、データ型は、ダウンストリームの対応付けの問題を回避するために、取り込み前に正規化する必要があります。
- **セキュリティと最小権限:**コネクタは安全な認証に依存し、最小権限の IAM パターン、監査可能性、およびネットワーク制御を考慮する必要があります。
ソリューション
次の表に、このインテグレーションの問題の解決方法を示します。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| ソリューション適合 | 最善 | Data 360\ でネイティブの Salesforce CRM コネクタと Marketing Cloud Engagement コネクタを使用します。標準使用事例のスターターデータバンドルから開始して、オンボーディングを加速します。特注またはドメイン固有のデータモデルでは、手動のストリームカスタマイズを使用します。 |
| 高度にカスタマイズされた CRM インスタンスの処理 | Best with Mapping Workshop (マッピングワークショップに最適) | スターターバンドルをベースラインとして扱い、マッピングワークショップを実施して以下を特定します。カスタムオブジェクトとリレーション。数式項目または計算項目。管理パッケージ拡張。数式項目が多い場合、ソース組織の API 負荷を最小限に抑えるために、事前フェーズの ETL または Data 360 変換内で値を計算します。 |
| 使用しないケース | 最適でないシナリオ | 次の場合、このパターンは避けてください。高頻度またはリアルタイムのイベントの取り込みが必要です (代わりに、ストリーミングコネクタ、プラットフォームイベント、または Zero-Copy 統合を使用します)。ソース組織の API 容量は制限されており、調整やキューの遅延なしでスケジュール済み抽出を維持することはできません。 |
| セキュリティとガバナンス | 必須コントロール | 最小権限の原則 - 参照アクセス権が最小限の専用のインテグレーションユーザーを使用します。組織の共有管理者は絶対に使用しないでください。 認証 — OAuth 2.0 と接続アプリケーションを使用します。クライアントの秘密を定期的に循環し、更新トークンの使用状況を監視します。 監査とトレーサビリティ — すべての取り込みの実行、スキーマの変更、コネクタイベントを記録します。監査準備のためにログを SIEM またはコンプライアンスシステムに転送します。 データ分類 — CEDARポリシーを使用してPII/PHIタギングとABAC(属性ベースのアクセス制御)を取り込み後すぐに適用し、マスキング、同意、ダウンストリームコンプライアンスを適用します。 |
スケッチ
次の図は、クラウドストレージから Data 360 にデータを取り込む手順を示しています。
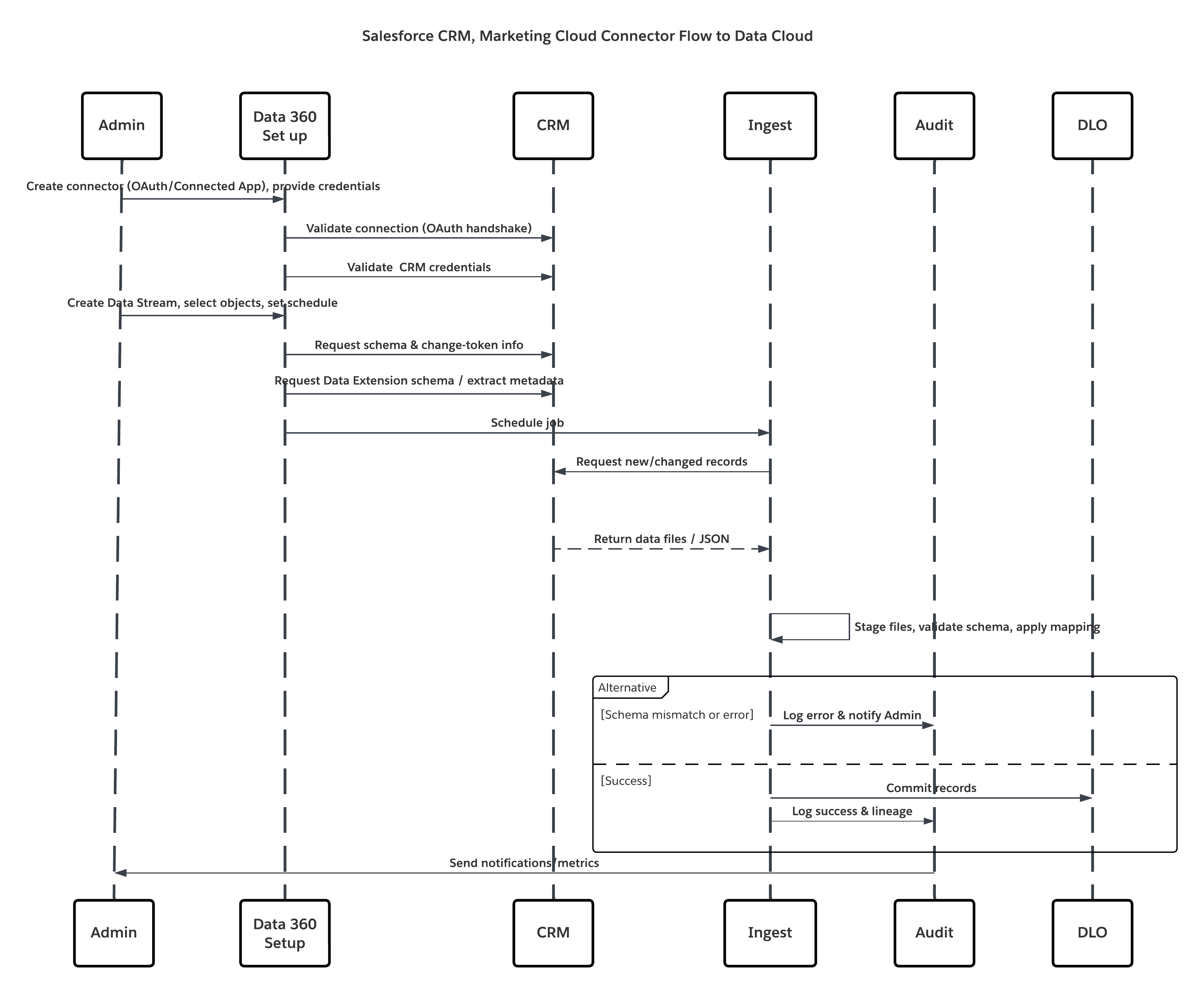
このシナリオの内容は次のとおりです。
- システム管理者がインテグレーションユーザーのプロビジョニングを行い、ソース組織でコネクタ権限セットを割り当てます。
- システム管理者は、Data 360 の [設定] でコネクタを設定します (OAuth/接続アプリケーションを介して Salesforce CRM および Marketing Cloud に接続します)。
- システム管理者は、オブジェクトとデータエクステンションを選択してデータストリームを作成し、フル更新またはデルタ更新を選択して、スケジュールを設定します。
- スケジュール済み実行時、Data 360 はソースからスキーマとデルタ トークンを要求します。
- ソースシステムはレコード (デルタまたはフルペイロード) を返します。Marketing Cloud で抽出が提供される場合もあれば、CRM で JSON/クエリ結果が返される場合もあります。
- Data 360 はファイルを内部の安全なステージング領域にステージングし、マッピングされたスキーマに対して検証します。
- 検証に失敗すると、取り込みログにエラーが記録され、管理者にアラートが送信され、コミットが停止します。検証に成功すると、Data 360 はレコードを対象 DLO にアトミックにコミットします。
- 監視および監査ログは、系統、実行期間、行数、ログイン情報の使用状況で更新されます。しきい値またはエラーがトリガーされた場合にシステム管理者に発行されるアラート。
結果
コア顧客リレーションとマーケティングエンゲージメントデータは、データレイクオブジェクト (DLO) として Data 360 に取り込まれます。これにより、次の結果が得られます。
- プロファイル、ケース、商談、メール/エンゲージメント評価指標を含む統合データセット。
- 統合個人プロファイルの ID 解決および構築の基盤。
- ガバナンスと監査性を維持しながら、ダウンストリームのハーモナイゼーション、強化、AI モデリング、有効化のための運用準備を行います。
取り込みメカニズム
取り込みメカニズムは、Data 360 内で定義されたコネクタとスケジュール戦略によって異なります。
| メカニズム | 使用するケース |
|---|---|
| Salesforce CRM コネクタ (ネイティブ) | 標準/カスタム CRM オブジェクトに最適。フル更新と差分更新をサポートします。 |
| Marketing Cloud Engagement コネクタ (ネイティブ) | データエクステンション、送信、抽出の追跡に最適。フル/デルタモードをサポート。 |
| スターターデータバンドル | 一般的なセールス/サービス/マーケティングオブジェクトのオンボーディングを加速します。 |
| カスタムストリーム + 前処理 | 複雑な変換や重いスキーマの正規化が必要な場合に使用します。 |
エラー処理と回復
大量の取り込み操作の信頼性を確保するためには、エラー処理と復旧が不可欠です。
- **実行あたりのログ数:**各データストリームの実行では、成功/失敗の詳細と行レベルのエラーが提供されます。
- **再試行 & チェックポイント:**失敗した実行は、ソースまたはスキーマの問題を修正した後に再試行できます。Data 360 では、ステージングとアトミック確定セマンティックが使用されます。
- **アラート:**スキーマドリフト、繰り返しの失敗、またはデルタシーケンスギャップに関するアラートを設定します。
Idempotent 設計に関する考慮事項
取り込みは設計上最適です。同じ処理を再実行すると、レコードが重複することはありません。 主な戦略は次のとおりです。
- **変更検出:**デルタ抽出は、ソースシステム変更インジケーター (LastModifiedDate / システム変更データキャプチャ) に依存します。ソースが信頼できるタイムスタンプ/フラグを提供していることを確認します。
- **重複排除:**一意のビジネスキー (Contact.ExternalId など) を使用して、DLO に重複排除または更新/挿入します。
- **トランザクションコミット:**レコードはステージングされ、バッチ処理が正常に完了した場合にのみ確定されます。
セキュリティに関する考慮事項
セキュリティは、認証から暗号化、アクセス制御まで、取り込みパイプライン全体にわたって不可欠です。
- **認証と承認:**コネクタは Salesforce のセキュアなインテグレーションフレームワークを使用し、秘密を公開せずに指定ログイン情報と外部ログイン情報を使用して認証します。
- **暗号化:**データは送信中 (TLS 1.2+) および保存中 (AES-256) に暗号化されます。
- **ネットワークコントロール:**ソースストレージシステム (S3 バケットなど) では、Data 360 IP を許可リストに登録する必要があります。
- **コンプライアンスの調整:**Customer-Managed Keys (CMK) と組み合わせることで、GDPR、HIPAA、FFIEC ガイドラインなどのエンタープライズデータ保護フレームワークをサポートします。
- **監査可能性:**すべての取り込みジョブとログイン情報アクセスが記録され、トレーサビリティとコンプライアンスのレポートが作成されます。
サイドバー
適時性
適時性は、取り込みスケジュールとデータ量によって異なります。
- 理想的なケイデンスは、ビジネス ニーズによって異なります。ほぼリアルタイムのマーケティング トリガーの場合は毎時、大規模な調整の場合は毎晩です。
- デルタ モードでは、負荷とコストが削減されます。フル更新は重く、初期読み込みやスキーマの大幅な変更に使用されます。
データ量
- CRM コネクタは、トランザクションデータセットとミッドボリュームデータセット (数百万レコード) 用に最適化されています。
- 履歴ボリュームが非常に大きい場合は、段階的にパーティション分割して読み込むステージングされた ETL を検討してください。
エンドポイントの機能と標準のサポート
エンドポイントの機能と標準サポートは、選択したソリューションによって異なります。
| コネクタ | エンドポイント要件 |
|---|---|
| Salesforce CRM コネクタ | ソース組織は、接続アプリケーション、OAuth トークン、および参照権限を持つ専用のインテグレーションユーザーを許可する必要があります。 |
| Marketing Cloud Connector | Marketing Cloud API ログイン情報またはインストール済みパッケージ。データエクステンションは抽出/API を使用してデータを公開する必要があります。 |
状態管理
- **コネクタの状態:**データストリームには、最後に成功した同期タイムスタンプとデルタオフセットが保持されます。
- **Master Key Strategy:**下流の調整と更新/挿入が確定的になるように、一貫したビジネス識別子 (外部 ID) を優先します。
複雑なインテグレーションのシナリオ
高度なエンタープライズアーキテクチャでは、このパターンを以下と統合できます。
- **ハイブリッド トポロジー:**CRM 取り込みをストリーミング (プラットフォームイベント) と組み合わせて、ほぼリアルタイムで更新します。
- **ミドルウェアオーケストレーション:**複雑なオーケストレーション、強化、変換の事前取り込みが必要な場合、MuleSoft または ETL ツールを使用します。
- **有効化フィードバック ループ:**ハーモナイズ DMO は、データアクションまたはプラットフォーム API を使用してソースシステムへのダウンストリーム更新をトリガーできます (SoD コントロールには注意してください)。
例
ある多国籍小売業者は、取引先、取引先責任者、ケース、商談、Marketing Cloud エンゲージメント評価指標を Data 360 に統合して、統合された顧客ビューを作成します。Starter データバンドルはコアセールスオブジェクトとサービスオブジェクトを初期化し、チームは Loyalty_Membershipc や Customer_Tierc などのカスタム項目を使用してモデルを拡張し、ロイヤルティコンテキストを取得します。CRM データストリームはデルタモードで 1 時間ごとに実行され、Marketing Cloud Engagement はエンゲージメントイベントのデルタ抽出を使用して毎日同期します。これらのデータセットは DLO と ID 解決で処理され、CRM とエンゲージメントシグナルを組み合わせてパーソナライズと下流の AI モデルを強化する統合顧客プロファイルが作成されます。
これらのパターンは、ミリ秒単位の時間を要するシナリオ (顧客とのやりとり、取引、またはシグナルによってすぐにインサイトやアクションがトリガーされる必要があるシナリオ) 用に構築されています。従来のスケジュール済みバッチ取り込みを超えて、情報が生成された瞬間に処理されるイベント駆動型データフローを実現します。 Salesforce Data 360 エコシステムでは、「リアルタイム」は 1 つのモードではなく、連続した遅延モデルです。1 つはほぼリアルタイムの同期で、レコードシステム (CRM や ERP など) からの更新が数秒から数分で Data 360 に反映されます。一方、真のリアルタイムイベントキャプチャでは、クリック、購入、モバイルインタラクションなどのクライアント側の行動シグナルがミリ秒単位で取り込まれ、有効化されます。 建築家にとって、区別は意味以上のものです。パイプラインの設計方法、API の呼び出し方法、下流の決定方法を定義します。ほぼリアルタイムの同期またはイベントストリーミングの取り込みで適切なパターンを選択することで、データの整合性、拡張性、ガバナンスを維持しながら、システムがビジネスの運用レーテンシー目標を達成できるようにします。
コンテキスト
このパターンにより、カスタムアプリケーション、IoT (モノのインターネット) プラットフォーム、POS (販売時点情報管理) システム、サードパーティサービスなどの外部システムで、個別のイベントが発生したときにほぼリアルタイムでイベントデータをプログラムで Data 360 に転送できます。
問題
開発者は、データを処理、セグメンテーション、有効化するために迅速に利用できるように、外部アプリケーションから Data 360 に単一レコードまたは小さな非同期イベントのバッチを確実に低遅延で送信できる方法は?
勢力
このパターンでは、低レイテンシーと開発者による制御の向上が実現しますが、いくつかの技術的な制約と運用上の依存関係が生じます。
- **開発者の依存関係:**認証済み REST API クライアントとエラー/再試行ロジックを実装する開発者の作業が必要です。これは、ポイント & クリックコネクタではありません。
- **厳格な更新時のスキーマ:**取り込み API では、スキーマが書き込み時に適用されます。正確なスキーマを定義してコネクタ設定にアップロードする必要があります。すべてのペイロードが正確に適合しているか、拒否されている必要があります。
- **デュアルインタラクションモード:**同じコネクタで、低レイテンシーのレコードごとの更新のためのストリーミング (JSON) と、大規模な定期的な同期のための一括 (CSV) の両方がサポートされます。アーキテクトは使用事例ごとに選択する必要があります。
- **認証とセキュリティ:**通話は、OAuth 2.0 (サーバー間の JWT ベアラーフローなど) を使用して Salesforce 接続アプリケーション経由で認証する必要があります。トークン管理、循環、最小権限の範囲は必須です。
- **運用の可視性:**開発者とプラットフォームチームは、応答コード、再試行、デッドレターキュー、スキーマドリフトアラートの監視を実装する必要があります。
- **リアルタイムグラフ要件:**真のインスタント有効化 (インスタントセグメンテーション、リアルタイム DMO マッピング) を行うには、対象データモデルオブジェクト (DMO) がリアルタイムデータグラフに含まれている必要があります。含まれていない場合、イベントは若干高いレイテンシのパイプラインをトラバースします。
ソリューション
次の表に、このインテグレーションの問題の解決方法を示します。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| ソリューション適合 | 低レイテンシのイベントキャプチャに最適 | Data 360 取り込み API (ストリーミング JSON) を使用して、単一イベントまたはマイクロバッチをプッシュします。厳格な OAS 3.0 スキーマ (.yaml) を使用して取り込み API コネクタを設定します。より頻繁ではない大きな同期には、一括 CSV 取り込みを使用します。 |
| スキーマ変更の処理 | 厳格/管理 | スキーマの変更は、OAS .yaml の更新、コネクタのバージョン管理、契約テストの実行など、破壊的です。プロデューサーを同時に変更できない場合は、ローリングスキーマ移行を実装します。 |
| 使用しないケース | 準最適 | 前処理が必要な場合 (重複排除、注文の保証など) や、非常に大きなバルク積荷の場合 (ネイティブのバルクコネクタまたはバッチ ETL を使用) は理想的ではありません。ソースでスキーマが有効なペイロードを生成できない場合、または安全に認証できない場合は、別の取り込み方法を使用します。 |
| セキュリティとガバナンス | 必須 | 最小権限範囲で OAuth 2.0 を使用し、鍵を循環し、トークンの使用状況を記録します。TLS 1.2+ を適用し、必要に応じてクライアント IP を検証し、ペイロードの PII タギングを確認します。すべてのイベントでは、provinance メタデータ (ソース、タイムスタンプ、スキーマバージョン、緊急キー) を伝達する必要があります。 |
スケッチ
次の図は、取り込み API から Data 360 にデータを取り込む手順を示しています。
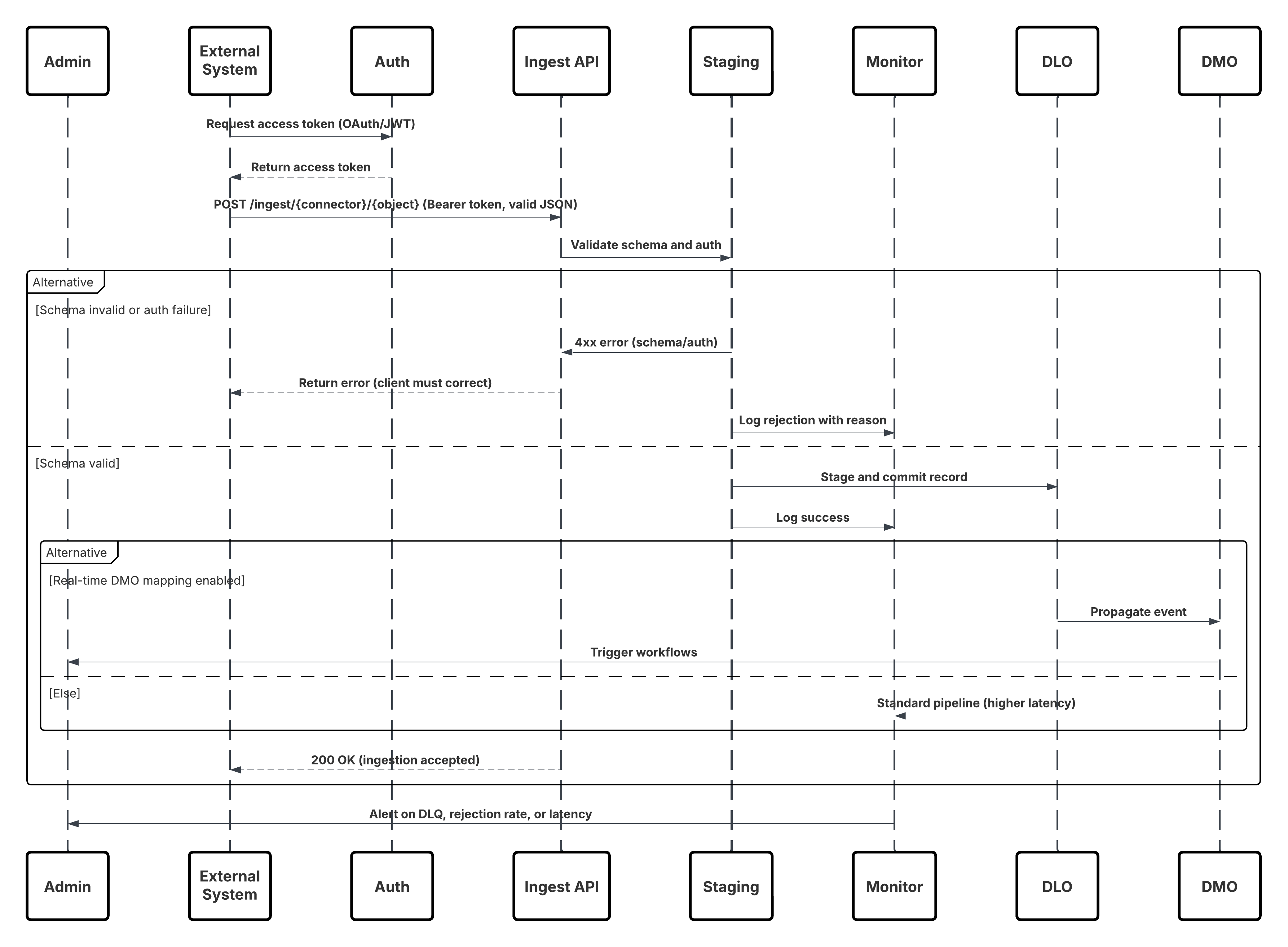
このシナリオの内容は次のとおりです。
- 外部システムは、認証サーバーから OAuth/JWT を介して認証を要求します。
- 認証サーバーがアクセストークンを外部システムに返します。
- 外部システムは、認証と JSON ペイロードを使用してデータ取り込み POST 要求を Data 360 取り込み API に送信します。
- 取り込み API は、「ステージング & 検証」モジュールを使用して要求スキーマと認証を検証します。
- スキーマ/認証に失敗した場合:
- エラーが外部システムに返されました。
- 監視とアラートのために記録された却下。
- 検証が成功した場合:
- ステージングされてデータレークオブジェクト (DLO) にコミットされたレコード。
- 監視のために記録された成功。
- 有効になっている場合、データはリアルタイムデータグラフ (DMO) に伝搬され、下流のワークフローがトリガーされます。
- それ以外の場合は、標準バッチまたは高遅延パイプラインで処理されるデータ。
- 取り込み API で外部システムへの成功が確認されます。
- 監視コンポーネントは、デッドレターキュー、却下率、または遅延の問題についてシステム管理者に警告します。
結果
外部イベントデータは、低遅延で Data 360 DLO に取り込まれます。対象 DMO がリアルタイムグラフの一部である場合、そのデータをインスタントセグメンテーション、エージェントワークフロー、AI モデル、運用の有効化で使用できます。これにより、接続システムから発生したイベントに迅速にビジネスで対応できます。
取り込みメカニズム
取り込みメカニズムは、Data 360 内で定義されたコネクタとスケジュール戦略によって異なります。
| メカニズム | 使用するケース |
|---|---|
| ストリーミング JSON (取り込み API) | 単一イベント、マイクロバッチ、行動イベント、クリックストリーム、IoT テレメトリ (低遅延が必要な場合)。 |
| Bulk CSV (取り込み API 一括モード) | 遅延要件が緩和された、より大規模な定期的なアップロード。 |
| Edge / Middleware | 取り込み API に転送する前に検証、変換、強化、またはレート制限が必要な場合に使用します。 |
エラー処理と回復
- **即時 (同期) エラー:**スキーマ/認証エラーに対する 4xx 応答 — クライアントはペイロードまたはトークンを修正して再試行する必要があります。
- **一時的な (非同期) 障害:**5xx 応答 — 指数関数的なバックオフとジッタによるクライアントの再試行。
- **Dead-Letter Queue (DLQ):**永続的な障害は、手動で検査および再生するために DLQ に転送されます。
- **監視:**スキーマ却下率、認証失敗、遅延の割合、DLQ バックログを追跡します。しきい値に関するアラート。
Idempotent 設計に関する考慮事項
- **Idempotency Key:**すべてのイベントに一意の緊急キー/メッセージ ID を含める必要があります。
- **Upsert Strategy:**リプレイの重複を回避するには、ビジネスキー (ExternalId) を使用します。
- **重複除外ウィンドウ:**アーキテクトは、緊急性追跡のための重複排除期間と保持を定義する必要があります。
セキュリティに関する考慮事項
セキュリティは、認証から暗号化、アクセス制御まで、取り込みパイプライン全体にわたって不可欠です。
- **認証:**サーバー間で OAuth 2.0 (JWT ベアラー) を推奨。範囲は取り込みのみに制限します。
- **暗号化:**転送には TLS 1.2+、保存時には Data 360 で暗号化が適用されます。
- **最小権限:**接続アプリケーションのログイン情報には最小限の権限しかないため、秘密と機器アクセスログを循環します。
- **ペイロードガバナンス:**イベントメタデータに同意/利用フラグを含め、取り込み直後に ABAC/CEDAR ポリシーを適用します。
- **IP コントロール/プライベートコネクト:**必要に応じて、許可リストを使用してアクセスを制限するか、プライベートネットワーキングにプライベートコネクトを使用します。
サイドバー
適時性
適時性は、取り込みスケジュールとデータ量によって異なります。ストリーミング JSON では、処理とグラフの設定に応じて 1 秒から 2 秒未満の遅延が発生します。一括 CSV は分~時間です。ビジネス SLA に基づいて選択します。
データ量
個々のイベントサイズは小さくする必要があります (数 KB 未満)。高スループットプロデューサーの場合、API をコールする前に、プロデューサーでバッチ処理するか、ストリーミングバッファ (Kafka/Kinesis) を使用することを検討してください。
状態管理
- **スキーマのバージョン管理:**イベントメタデータでスキーマバージョンを維持し、OAS 契約を更新するときにコネクタバージョンを使用します。
- **コネクタのオフセット:**Data 360 は確定セマンティクスを処理します。安全なリプレイのために、プロデューサーは緊急キーと最後の成功したシーケンスを追跡する必要があります。
複雑なインテグレーションのシナリオ
高度なエンタープライズアーキテクチャでは、このパターンを以下と統合できます。
- **エッジ検証レイヤー:**ミドルウェアを使用して、異種混在プロデューサー形式を必要な OAS 契約に変換し、レート制限と事前強化を実行します。
- **ハイブリッド アーキテクチャ:**イベントの取り込み API と一括調整用のコネクタを組み合わせます。
- **エージェントの有効化:**リアルタイム DMO にマッピングされたイベントは、自動決定のために Agentforce ワークフローと Einstein モデルをトリガーできます。
例
小売チェーンは、POS 購入イベントを Data 360 にリアルタイムでストリーミングし、即時の顧客エンゲージメントを強化します。各ストアでは、トランザクションを収集し、ロケーションとデバイスのメタデータで強化し、重複を防ぐために緊急キーを使用する JWT ベアラー OAuth を使用して JSON イベントを安全に投稿する軽量のサーバーコンポーネントが実行されます。システム管理者は、販売時点管理用の OAS スキーマをアップロードし、取り込み API コネクタを設定して、イベント構造を定義します。受信イベントが pos_sale DLO に取り込まれ、販売 DMO にマッピングされ、リアルタイムグラフに追加されます。その結果、価値の高い購入が即座に検出され、Agentforce の VIP ワークフローがトリガーされ、顧客のセグメンテーションが更新されてリアルタイムのパーソナライズが促進されます。
コンテキスト
このパターンにより、Web サイトやモバイルアプリケーションからページビュー、ボタンクリック、商品インプレッション、動画再生などの大量の詳細なユーザーインタラクションデータを trueReal-Time で取得できます。これは、すべてのデジタルインタラクションがユーザーエクスペリエンスに動的に影響し、エンゲージメントを促進する可能性がある、その場限りのパーソナライズを提供するための基礎となります。
問題
企業がデジタルプロパティから 1 分間に数百万件のユーザーインタラクションに及ぶ行動イベントの継続的なストリームを取得して処理し、そのデータを Data 360 ですぐに利用できるようにして、リアルタイムのセグメンテーション、パーソナライズ、有効化を強化する方法は?
勢力
この使用事例では、目的に特化した低レイテンシの取り込みアーキテクチャを必要とする設計上の課題をいくつか紹介します。
- **Extreme Throughput (スループットの向上):**トラフィック量の多い Web サイトやモバイルアプリケーションは、1 分間に何百万ものイベントが発生する可能性があります。取り込みレイヤーは、イベント損失やバックプレッシャなしでこの量を処理できるように水平に拡張する必要があり、ピーク負荷時の一貫したレイテンシを確保できます。
- **クライアント側の計測 ―**サーバー駆動型インテグレーションとは異なり、このパターンはクライアント側 SDK に依存します。JavaScript ビーコン (Salesforce Interactions SDK) を各ページに埋め込むか、モバイルアプリケーションに統合するネイティブ SDK が必要です。これには、堅牢なクライアントリリース、バージョン管理、イベントスキーマガバナンスが必要です。
- 低レイテンシイベント処理 ―「カートに追加」や「動画再生」などのユーザーアクションは、数秒以内に Data 360 に到達する必要があり、リアルタイムの有効化と状況に応じた対応 (対象を絞った提案、パーソナライズされたおすすめなど) が可能になります。
- **データハーモナイゼーションおよび ID 解決 ―**多くの場合、キャプチャされたイベントには匿名識別子 (Cookie、デバイス ID、セッショントークン) が含まれます。Customer 360 の使用事例を強化するには、Data 360 の ID 解決を介して既知のプロファイルにマッピングし、Customer 360 データ モデルにハーモナイズする必要があります。
ソリューション
推奨されるアプローチは、Salesforce Marketing Cloud Personalization コネクタを使用することです。これは、高スループット動作の取り込み用に設計されたネイティブの完全に管理されたストリーミング パイプラインです。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| SDK ベースのイベントキャプチャ | 最善 | Salesforce Interactions SDK (Web) またはネイティブ SDK (モバイル) をリリースします。これらの軽量ライブラリは、ユーザー操作をリアルタイムで取得して逐次化し、メタデータ (セッション ID、タイムスタンプ、コンテキスト) を添付します。 |
| Event Streaming Pipeline | 最善 | イベントは、セキュアな HTTPS を介して Marketing Cloud Personalization のイベントストリーミングサービスに送信されます。このレイヤーは水平方向に拡張可能で、低遅延の送信用に最適化されています (<2s)。 |
| Data 360 インテグレーション | 最善 | Data 360 の Personalization Connector はストリーミングフィードを登録し、各イベントをほぼリアルタイムでデータレイクオブジェクト (DLO) に取り込みます。 |
| データモデルマッピング | ベストプラクティス | 取り込まれた DLO は Customer 360 DMO (データモデルオブジェクト) にマッピングされます。これにより、ID 解決を使用して匿名ユーザーと既知ユーザーをリンクできます。 |
| リアルタイムグラフの有効化 | 省略可能/推奨 | マッピングされた DMO をリアルタイムのグラフに含め、Einstein または Agentforce ワークフローを介してパーソナライズされたアクションをすぐにセグメンテーションできます。 |
| 使用しないケース | 準最適 | このパターンは、次の場合には理想的ではありません。ソースデータは Web クライアントとイベントです (代わりに取り込み API を使用します)。組織は Web / モバイルクライアントを制御できない。リアルタイムの行動追跡は必要ありません (一括取り込みを使用します)。 |
| スキーマの変更の処理 | Managed Evolution | イベントスキーマは、新しいインタラクションが追加されると進化します。SDK はイベント定義のバージョンを設定する必要があります。下位互換性のある変更 (省略可能な項目の追加) は安全です。変更を破棄するには、コネクタの再設定と契約テストが必要です。 |
スケッチ
次の図は、モバイルおよび Web チャネルから Data 360 にデータを取り込む手順を示しています。
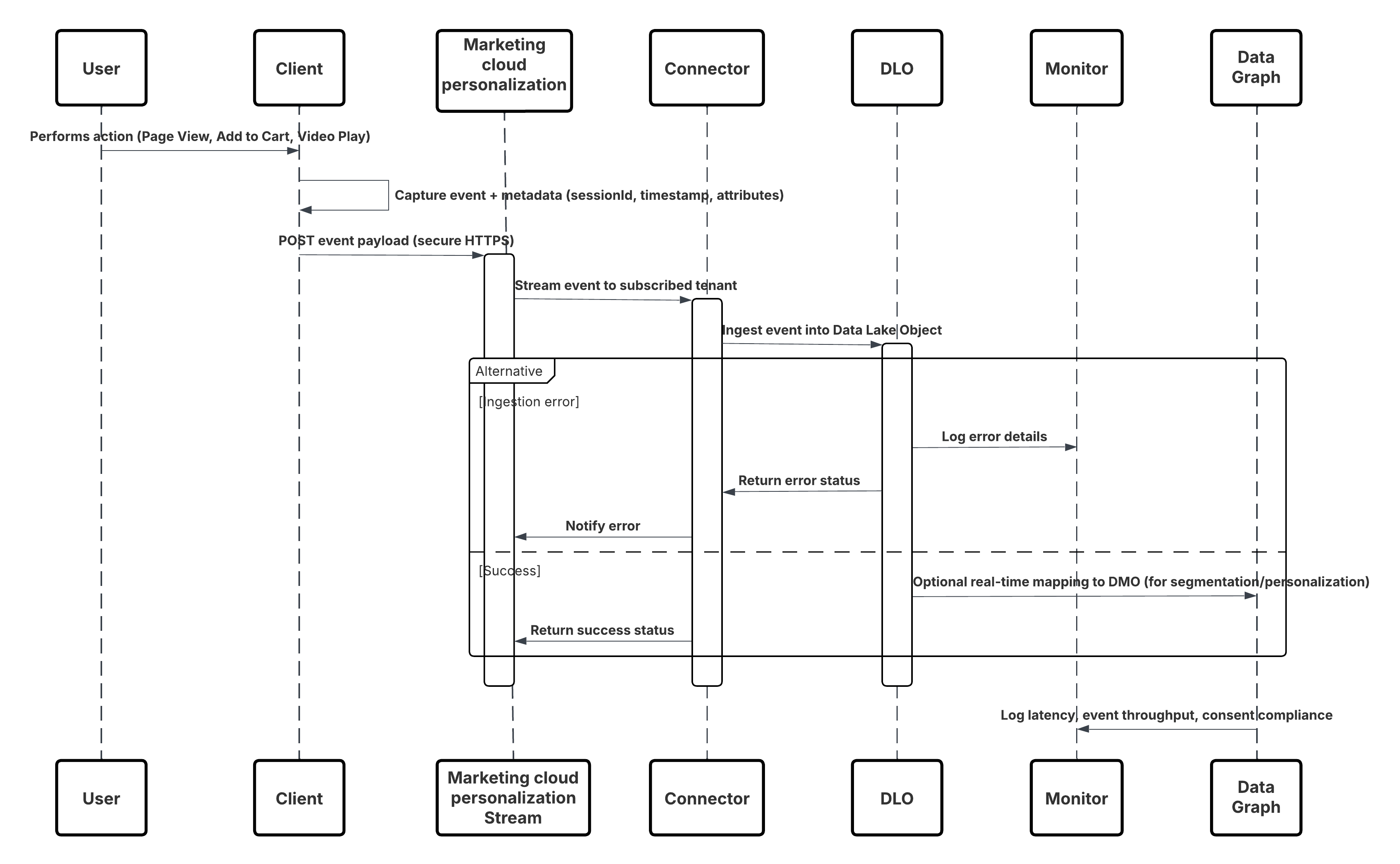
このシナリオの内容は次のとおりです。
- Web またはモバイルチャネルで SDK をリリースします (ユーザーインタラクションキャプチャ)。
- テナント ID、環境、同意コントロールを使用して SDK を設定します。
- 取得した JSON イベント (メタデータ + 属性) を Marketing Cloud ストリーミングエンドポイントにストリーミングします。
- Data 360 の [設定] で、テナントのパーソナライズコネクタを作成および設定します。
- イベントを DLO に取り込み、Data 360 内で DLO → DMO をマッピングします。
- リアルタイムグラフで DMO を有効にして、すぐに有効化します。
- 遅延、スキーマの適合性、同意フラグ、スループット、エラー率を監視します。
- 本番にリリースし、継続的に監視します。
結果
行動イベントの継続的な低遅延ストリームがデジタルチャネルから Data 360 に流れます。数秒で、各ユーザーアクションをリアルタイムセグメンテーション、予測モデリング、トリガーされたパーソナライズで使用できるようになり、真に適応したカスタマーエクスペリエンスが可能になります。
取り込みメカニズム
取り込みメカニズムは、Data 360 内で定義されたコネクタとスケジュール戦略によって異なります。
| メカニズム | 使用するケース |
|---|---|
| Interactions SDK (Web) | Web ブラウザーおよび SPA からのリアルタイムキャプチャ。 |
| Mobile SDK | ネイティブモバイルアプリケーションからのリアルタイムキャプチャ。 |
| Personalization コネクタ | Marketing Cloud と Data 360\ 間の管理サブスクリプション。 |
| リアルタイムグラフの対応付け | セグメンテーション、Einstein、ジャーニーで即時有効化を有効にします。 |
エラー処理と回復
- **階層化されたフォールト トレランス:**多層検証と再試行メカニズムを実装する — クライアント SDK は指数バックオフで一時的な失敗を処理し、取り込みレイヤーは耐久性のあるキューと再生可能なパイプラインを使用してデータの損失を防ぎます。
- **スキーマとデータ ガバナンス:**イベントスキーマのバージョン管理と検証を継続的に行います。無効なイベントや進化するイベントは、安全に優先順位を付けて再生できるようにスキーマ却下またはデッドレターキューに転送されます。
- **無力性と重複排除:**安定したイベント識別子と更新/挿入セマンティクスを使用して、再試行中またはリプレイ中であっても 1 回限りの処理を保証します。
- **監視とリカバリの自動化:**スループット、遅延、エラー率を継続的に監視することで、自動リカバリワークフローがトリガーされ、低遅延、信頼性の高い配信、一貫したリアルタイムのパーソナライズ結果が確保されます。
Idempotent 設計に関する考慮事項
- 重複する送信をダウンストリームで重複排除できるように、すべてのイベントで一意の緊急キーまたはメッセージ ID を伝達する必要があります。
- 必要に応じて、ビジネスキー (sessionID + eventTimestamp + userID など) を使用して重複を特定します。
- 重複イベントが無視または絞り込まれる重複排除期間 (24 時間など) を定義します。
- 必要に応じて、更新/挿入戦略を使用します (重複を挿入するのではなく、カウンタやフラグを更新するなど)。
セキュリティに関する考慮事項
セキュリティは、認証から暗号化、アクセス制御まで、取り込みパイプライン全体にわたって不可欠です。
- **トランスポート暗号化:**すべての SDK → ストリーミングサービス接続で TLS 1.2+。
- Data 360 およびマーケティングストリームでの保存時のデータ暗号化。
- SDK は**ユーザー同意フラグ(**GDPR/CCPA)を尊重し、同意が拒否された場合は追跡を抑制します。
- **SDK トラフィックの認証:**承認されたテナント/クライアントのみがイベントをストリーミングできることを確認します。
- メタデータ: 各イベントには、ソース ID、タイムスタンプ、スキーマバージョン、セッション ID、緊急キーが含まれている必要があります。
- **最小権限アクセス:**SDK エンドポイントとコネクタはイベントの取り込み範囲に制限され、ログイン情報は定期的に循環します。
- **データ分類:**イベントペイロードで PII にアノテーションを付与し、取り込み後にすぐにポリシーを適用
サイドバー
適時性
- 適時性は、エンドユーザーの活動とイベントストリーミング設定によって異なります。
- Salesforce Interactions SDK を介して取得され、Marketing Cloud Personalization ストリームを介して配信されるイベントでは、通常、Data 360 リアルタイムグラフで使用できるようになるまで 1 秒から 2 秒未満の遅延が発生します。
- これにより、有効なユーザーセッション内でほぼ瞬時にセグメンテーション、パーソナライズ、有効化できます。
データ量
個々の行動イベント (クリック、表示、カートに追加など) は軽量で、通常はペイロードあたり 1 ~ 5 KB です。 大規模なデジタルプロパティの場合、1 分間に数千から数百万のイベントが発生すると予想されます。 スループットと復元性を確保する
- トラフィックが多いページでは、SDK の組み込みのバッチおよび再試行メカニズムを使用します。
- バースト処理を Marketing Cloud ストリーミングバッファレイヤーにオフロードします。
- コネクタ総計値ダッシュボードを使用して、取り込みスループットとエラー率を監視します。
状態管理
各イベントには、状態およびバージョン管理のメタデータが含まれます。
- **スキーマのバージョン管理:**すべてのイベントにスキーマバージョンを埋め込みます。スキーマを更新するときに Personalization Connector のバージョンを設定します。
- **リプレイ処理:**一時的なネットワークの問題で失敗したイベントは、指数バックオフを使用して SDK によって自動的に再試行されます。
- **Idempotency Keys:**一意の識別子 (sessionId + eventType + timestamp) により、リプレイされたイベントで Data 360 に重複が発生しません。
- **オフセット管理:**Data 360 は成功した確定を追跡します。正常に取り込まれるまで、未処理のイベントはコネクタによって再キューに入れられます。
複雑なインテグレーションのシナリオ
このパターンは、高度なエンタープライズアーキテクチャにシームレスに統合されます。
- **エッジ強化レイヤー:**イベントが Marketing Cloud に到達する前に、ミドルウェア (リバースプロキシやサーバーレス関数など) を追加して、地理、デバイス種別、キャンペーンメタデータなどの追加のコンテキストを挿入します。
- **ハイブリッド(ストリーミング + バッチ):**リアルタイムストリームには Marketing Cloud コネクタを使用し、下流の調整のために一括処理 ETL ジョブ (注文データなど) と組み合わせます。
- **エージェントの有効化:**リアルタイム DMO にマッピングされたイベントは、Einstein Personalization、Agentforce ワークフロー、AI 駆動型の意思決定をトリガーして、デジタルエクスペリエンスを瞬時に適応させることができます。
- **マルチ テナント ガバナンス:**同意フラグとテナント対応メタデータを使用して、マルチブランド環境またはマルチリージョン環境でプライバシーとコンプライアンスを適用します。
例
グローバルな E コマース会社は、買い物客が React ベースの単一ページアプリケーションである www.retailx.com をアクティブに閲覧しているときに、パーソナライズされた商品のおすすめと動的コンテンツを買い物客に提供します。クライアント側で Salesforce Interactions SDK を使用して、サイトはページビュー、商品のクリック、カートアクション、動画インタラクションをリアルタイムで取得します。これらのイベントは Marketing Cloud Personalization イベントストリームと Personalization コネクタを経由して Data 360 DLO に流れ、DMO にモデル化されてリアルタイムグラフに組み込まれます。このアーキテクチャにより、セグメンテーション、Einstein 主導のパーソナライズ、Agentforce の有効化で動作シグナルを瞬時に利用できるようになり、セッション中の応答性の高いカスタマー・エクスペリエンスが実現されます。
コンテキスト
多くのビジネスクリティカルなプロセスでは、Data 360 をコア CRM システムの最新の更新に完全に一致させることが不可欠です。カスタマーサービスチーム、営業チーム、マーケティングチームは、意思決定の促進、ジャーニーのトリガー、自動化の有効化に最新情報を活用しています。このパターンでは、取引先責任者、取引先、ケースなどの主要な Salesforce CRM オブジェクトへの変更を、頻繁な一括ポーリングの非効率性や遅延なしで最小限の遅延で Data 360 に同期するメカニズムが提供されます。
問題
Data 360 で主要な Salesforce CRM オブジェクトとほぼ完全に同期された状態を維持し、下流の分析、セグメンテーション、AI 駆動の有効化が常に最新のデータで動作できるようにする方法は?
勢力
このパターンでは、いくつかの技術的な制約とアーキテクチャ上の考慮事項があります。
- **イベント駆動型アーキテクチャ :**同期は、定期的な一括処理ジョブではなく、CRM ソース組織の変更イベントによって実行される事後対応型である必要があります。
- **選択的なオブジェクトのサポート :**すべての Salesforce 標準オブジェクトとカスタムオブジェクトでリアルタイムストリーミングがサポートされているわけではありません。アーキテクトは、ギャップを回避するために設計時にサポートされるオブジェクトリストを参照する必要があります。
- **アクセスと権限 ―**ストリーミングを有効にするには、ソース組織のインテグレーションユーザーに「CRM ストリーミングの権限の有効化」システム権限が割り当てられている必要があります。
- **データの新鮮度と Processing Cost (処理コスト):**ほぼリアルタイムの同期により応答性は向上しますが、イベントスループットが過度に高すぎると、水平スケーリングと堅牢なエラー回復メカニズムが必要になる場合があります。
- **セキュリティと信頼レイヤーの統合 ―**すべてのイベント データは、Salesforce の Trust および Security フレームワークに準拠する必要があります。つまり、送信中に暗号化され、スキーマ コンプライアンスが検証され、組織の Trust 境界内で処理されます。
ソリューション
推奨される方法は、ストリーミング (変更データキャプチャ) が有効になっている Salesforce CRM コネクタを使用することです。サポートされている CRM オブジェクト (取引先責任者など) のデータストリームを作成する場合、システム管理者は [ストリーミングを有効化] オプションを切り替えることができます。内部的には、Salesforce の変更データキャプチャ (CDC) プラットフォームは、ソース CRM 組織でレコードが作成、更新、削除、または削除されるたびに ChangeEvent メッセージを公開します。 Data 360 CRM コネクタは、次の CDC イベントに登録し、ほぼリアルタイムで Data 360 内のマッピングされたデータレイクオブジェクト (DLO) に対応する変更を適用します。これにより、CRM と Data 360 間の継続的な同期を最小限の手動操作で実現できます。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| CDC ベースのストリーミングコネクタ | 最善 | ネイティブの Salesforce メカニズム。完全に管理され、プラットフォームイベントインフラストラクチャと統合されています。 |
| イベント登録および配信 | 最善 | コネクタは、耐久性のある再生 ID を使用して ChangeEvent チャネル (/data/ContactChangeEvent など) を登録します。 |
| データマッピングとスキーマの進化 | ベストプラクティス | ストリーミングされたペイロードを対応する DLO に対応付けます。取り込みが中断されないようにメタデータでスキーマバージョンを管理します。 |
| リプレイと障害復旧 | 推奨 | リプレイ ID と緊急キーを使用して重複を回避し、一時的なエラーから回復します。 |
| ハイブリッドモード (ストリーミング + バッチ) | 省略可能 | サポートされないオブジェクトまたは最初の一括読み込みの場合、一括取り込みを CDC ストリーミングと組み合わせて使用します。 |
| 使用しないケース | 最適ではない | このパターンは、次の場合に最適ではない場合があります。ソースオブジェクトが CDC 対応ではありません。この使用事例では、リアルタイムの更新は必要ありません (バッチで十分)。ソース組織からのネットワーク出力が制限されているか、イベント制限を超えている。 |
スケッチ
次の図は、ほぼリアルタイムで CRM から Data 360 にデータを取り込む手順を示しています。
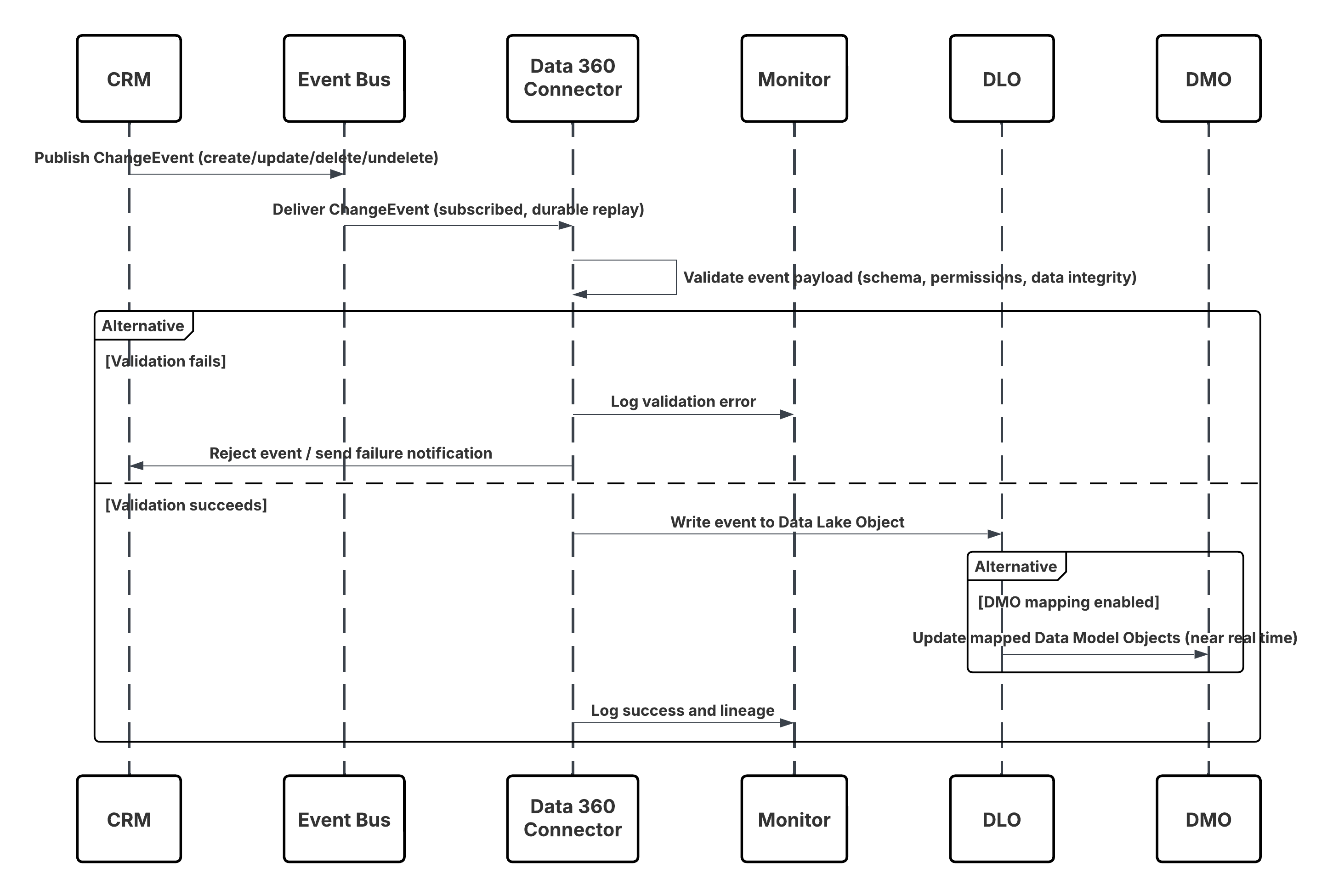
このシナリオの内容は次のとおりです。
- Salesforce CRM で変更が行われる (作成/更新/削除/復元)。
- CDC が ChangeEvent を内部 Salesforce イベントバスに公開します。
- Data 360 CRM コネクタは、耐久性のあるリプレイカーソルを使用してイベントバスを登録します。
- イベントペイロードは、スキーマ、権限、およびデータの整合性が検証されます。
- Data 360 は、検証済みイベントをマッピングされたデータレークオブジェクト (DLO) に書き込みます。
- 有効にすると、マッピングされたデータモデルオブジェクト (DMO) がほぼリアルタイムで更新され、セグメンテーションと有効化が強化されます。
結果
Data 360 では、主要な CRM データの継続的な同期ミラーが維持されます。 これにより、次のことが可能になります。
- リアルタイムトリガー (ケースが作成されたときに Journey が起動するなど)。
- 最新のセグメンテーション (取引先状況の変更時に顧客を「ゴールド」セグメントに移動するなど)。
- ライブ CRM コンテキストに基づくより正確な分析とパーソナライズ。
取り込みメカニズム
このパターンの取り込みメカニズムは、変更データキャプチャ (CDC) が有効になっている Salesforce CRM コネクタでネイティブに管理されます。Data 360 は CDC イベントストリームの登録者として機能し、ソース CRM 組織と Data 360 間の信頼性の高い低遅延の同期を保証します。
| メカニズム | 使用するケース |
|---|---|
| CDC を介したストリーミング (優先) | ほぼリアルタイムの同期が必要な、サポートされているすべての Salesforce 標準オブジェクトおよびカスタムオブジェクト。 |
| ハイブリッドモード (CDC + バッチ) | まだ CDC 対応ではないオブジェクト、または初期履歴読み込みが必要なオブジェクト。 |
| 登録モードをリプレイ | ダウンタイムまたはリリース後の再同期用。 |
| エラー分離モード | テストおよび検証環境用。 |
エラー処理と回復
- **自動障害復旧:**CRM コネクタは、指数バックオフを使用して一時的なネットワークエラーまたはプラットフォームエラーを自動的に再試行し、永続的なエラーをデッドレターキュー (DLQ) に転送してリプレイします。
- **スキーマと認証の復元:**スキーマの不一致は、システム管理者によるレビューのためにスキーマ却下キューで隔離されますが、認証エラーまたは権限エラーは Data 360 Monitoring で制御された再試行とアラートをトリガーします。
- **保証されたイベント継続性:**耐久性のあるリプレイ ID により、コネクタのダウンタイム中にイベントが失われることがありません。失敗したイベントはリプレイウィンドウまたは一括再同期ジョブで再開されます。
- **データの整合性と順序:**組み込みのイデムポテンシー (RecordID + SequenceNumber) によって重複が回避され、ChangeEventHeader.sequenceNumber によって各 CRM レコードの正しいイベント順序が保持されます。
Idempotent 設計に関する考慮事項
- **イベントの一意性:**各 CDC イベントでは、確定的重複排除のために ReplayID と ChangeEventHeader.entityName が伝達されます。
- **Upsert Strategy:**レコード ID に基づいて更新/挿入ロジックを実装し、繰り返しイベントによって重複が発生しないようにします。
- **リプレイ処理:**一時的な失敗の場合に最後に確定されたオフセットから再開するには、コネクタの再生カーソルを使用します。
- スキーマの進化:イベントメタデータのスキーマバージョンを維持し、CRM スキーマが変更されたときに DLO マッピングを更新します。
セキュリティに関する考慮事項
セキュリティは、認証から暗号化、アクセス制御まで、取り込みパイプライン全体にわたって不可欠です。
- **Encryption and Trust :**すべてのイベントは TLS 1.2+ を使用して送信され、保存時に暗号化されて Data 360 に保存されます。
- **アクセス制御:**CDC チャネルに登録できるのは、適切なインテグレーション権限を持つ認証済みコネクタのみです。
- **スキーマ検証:**すべてのイベントペイロードは、取り込み前に DLO スキーマに対して検証されます。
- **同意伝達:**プライバシーとコンプライアンスを維持するために、同意とデータ分類メタデータがイベントごとに下流に流れます (GDPR、CCPA)。
- **オペレーショナル ガバナンス:**イベントは、Data 360 Trust Layer を介して、リプレイ、スキーマの却下、スループットの異常について記録、監査、監視されます。
サイドバー
適時性
- CDC イベントは、ほぼリアルタイムで処理されます。通常は、CRM での変更後数秒以内に処理されます。
- 遅延はイベント量とコネクタスループットによって異なる場合がありますが、Data 360 ではサポートされるオブジェクトで 1 分未満の可用性が保証されます。
データ量
- 各イベントペイロードは軽量 (1 ~ 5 KB) です。
- ケースや取引先責任者など、変更頻度の高いオブジェクトの場合、スループット制限が Salesforce CDC イベントの割り当てに従っていることを確認します。
状態管理
各イベントには、状態およびバージョン管理のメタデータが含まれます。
- **Replay IDs:**順次イベント回復に使用されます。
- **スキーマのバージョン管理:**バージョンメタデータを保持して契約の変更を管理します。
- **Idempotency Keys:**再試行全体でリプレイの重複排除を行います。
- **Offset Commit:**Data 360 では、イベントが成功するたびに確定状態が維持されます。
複雑なインテグレーションのシナリオ
このパターンは、高度なエンタープライズアーキテクチャにシームレスに統合されます。
- **ハイブリッド(ストリーミング + バッチ):**CDC を使用してデルタ更新を行い、一括ジョブを使用してフル更新を行います。
- **組織間ストリーミング:**複数のソース組織を同じ Data 360 テナントにストリーミングでき、DMO マッピングを介して統合されます。
- **エージェントの有効化:**リアルタイムのオブジェクト更新により、Einstein または Agentforce の自動化がトリガーされます。
- **イベントルーティング:**ミドルウェア (MuleSoft や Event Relay など) では、取り込み前に CDC メッセージを強化または転送できます。
例
あるグローバル銀行は、Salesforce Sales Cloud の顧客データの変更が Data 360 にすぐに反映されるようにしたいと考えています。Sales Cloud で取引先責任者の住所が更新されると、変更データキャプチャによって ContactChangeEvent が公開されます。Data 360 CRM コネクタはこのイベントを使用して、更新を Customer DLO に適用し、関連付けられたすべての Customer 360 プロファイルを自動的に更新します。これにより、Einstein Next Best Action がトリガーされ、新しい住所が確認されます。つまり、元の CRM の変更から数秒でフィードバックループが完了します。
コンテキスト
現代のデジタル企業は、Amazon Kinesis Data Streams や Amazon MSK (Managed Streaming for Apache Kafka) などのリアルタイムイベントストリーミングプラットフォームを使用して、分散アプリケーション、IoT デバイス、トランザクションシステムから継続的なデータフローを取得します。Data 360 では、ネイティブのファーストパーティコネクタを介してこれらのプラットフォームから直接取り込むことができるため、カスタム ETL やミドルウェアベースのソリューションは必要ありません。このパターンは、ほぼリアルタイムのインサイト、パーソナライズ、AI 駆動の有効化を強化する高スループット、低レイテンシのデータ取り込み用に設計されています。
問題
企業が Data 360 を AWS Kinesis または AWS MSK Kafka トピックに安全かつ効率的に接続して、構造化されたイベントおよびプロファイルデータを継続的に取り込み、スキーマのコンプライアンス、拡張性、ガバナンスを確保する方法は?
勢力
このパターンでは、アーキテクチャと運用に関する複数の考慮事項が導入されます。
- **ネイティブコネクタの可用性:**Salesforce では、Amazon Kinesis と Amazon MSK の両方に正式リリースされたネイティブコネクタを提供しています。これらのコネクタはファーストパーティサポートを提供し、カスタム API ベースのパイプラインは必要ありません。
- 認証とセキュリティ:各コネクタにはAWS レベルの認証が必要です。
- Kinesis の場合、IAM ポリシーによって管理される AWS アクセスキーと秘密鍵が使用されます。
- MSK の場合、アクセスキー/秘密または OpenID Connect (OIDC) を使用して認証を設定できます。
- **スキーマ定義:**Data 360 では、ストリーミングペイロードを解釈するためのスキーマが必要です。 Kinesis の場合、スキーマファイルは接続の設定時にアップロードされ、イベント構造と項目の対応付けが定義されます。
- 設定ソース:
- Kinesis コネクタは、特定の Kinesis ストリーム名を登録します。
- MSK コネクタは、MSK クラスタ内の Kafka トピックを登録します。
- **ネットワークアクセス:**安全な環境では、PrivateLink または VPC ルーティングを使用してコネクタを設定し、データがパブリックインターネットを経由しないようにできます。
- **オペレーショナル ガバナンス:**ストリーミング スループット、スキーマ検証、認証イベントは Data 360 Trust Layer 内で監視され、コンプライアンスとトレーサビリティが確保されます。
ソリューション
このソリューションでは、Data 360 内のネイティブ Amazon Kinesis または Amazon MSK コネクタを活用します。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| Kinesis ネイティブコネクタ | 最善 | AWS Kinesis とのファーストパーティインテグレーション。継続的な高スループット取り込みをサポートします。 |
| MSK ネイティブコネクタ | 最善 | OIDC と鍵ベースの認証のサポートによる Kafka の管理取り込み。 |
| スキーマの対応付けと検証 | ベストプラクティス | イベント構造を定義するスキーマ (.json/.avro) をアップロードし、取り込み時に一貫性を適用します。 |
| IAM 設定 | 推奨 | 対象 Kinesis ストリームまたは MSK トピックへの参照のみのアクセス権を持つ最小権限の IAM ロールを割り当てます。 |
| プライベートネットワークルーティング | 省略可能 | セキュアな内部ルーティングのために PrivateLink/VPC エンドポイントを設定します。 |
| ハイブリッドパターン (ストリーミング + バッチ) | 省略可能 | 差分にはストリーミングを使用し、バックフィルや履歴読み込みには一括取り込みを使用します。 |
| エラー分離モード | 推奨 | リプレイのためにスキーマ却下と一時的なエラーを DLQ に転送 |
スケッチ
次の図は、Kafka や Kinesis などのイベントプラットフォームからデータをほぼリアルタイムで Data 360 に取り込む手順を示しています。
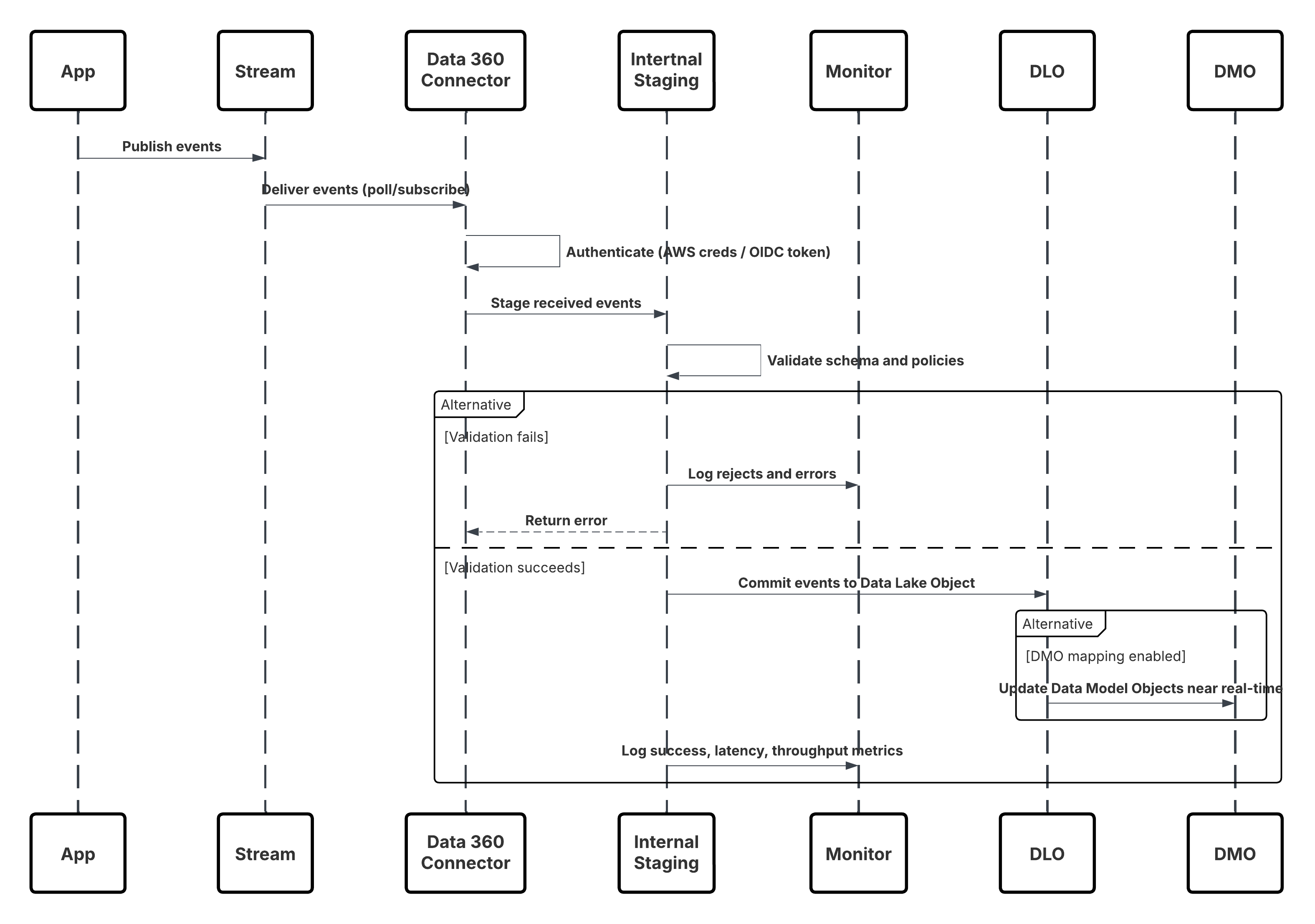
このシナリオの内容は次のとおりです。
- アプリケーションまたはデバイスは、イベントを Kinesis ストリームまたは MSK トピックに公開します。
- Data 360 コネクタは、AWS ログイン情報または OIDC トークンを使用して認証します。
- コネクタがストリームを継続的にポーリングまたは登録する。
- イベントがステージングされ、スキーマとポリシーが検証され、データレークオブジェクト (DLO) にコミットされます。
- マッピングされている場合、データモデルオブジェクト (DMO) は有効化のためにほぼリアルタイムで更新されます。
- 監視レイヤーは、総計値、スキーマ却下、遅延を追跡します。
結果
AWS Kinesis または MSK から Data 360 への構造化データの継続的な低遅延取り込み。データは、次の場合にすぐに使用できます。
- ID 解決
- リアルタイムセグメンテーション
- Einstein AI 有効化
- Agentforce 駆動型トリガー バッチ ETL への依存を排除し、エンタープライズイベント駆動型設計に準拠したストリームベースのアーキテクチャを実現します。
取り込みメカニズム
| メカニズム | 使用するケース |
|---|---|
| Kinesis コネクタ (優先) | 大量の構造化データの継続的な取り込みが必要な AWS ネイティブストリーミングソース用。 |
| MSK Connector | Kafka 互換プラットフォームでイベントパイプラインを実行している組織向け。 |
| ハイブリッド(ストリーミング + バッチ) | 増分イベントの取り込みと定期的な一括読み込みの組み合わせの場合。 |
エラー処理と回復
- **自動再試行:**コネクタは、指数バックオフで一時的なネットワークエラーまたはプラットフォームエラーを再試行します。
- **スキーマ却下:**無効なペイロードは、管理者による確認のためにスキーマ却下キューに転送されます。
- **DLQ リプレイ:**永続的な失敗は、再処理のためにデッドレターキューに取り込まれます。
- **Idempotency Control:**イベントキーまたはシーケンス番号により、重複排除と順序付き取り込みが保証されます。
- **監視インテグレーション:**すべての失敗、再試行、スループット総計値は、Data 360 Monitoring ダッシュボードに表示されます。
Idempotent 設計に関する考慮事項
- **イベントの一意性と追跡:**各イベントには確定的な一意のキー (Kinesis の場合は PartitionKey + SequenceNumber、MSK の場合は Topic + Partition + Offset) が割り当てられ、完全に 1 回のみ取り込まれます。
- **コネクタチェックポイント:**Data 360 コネクタは、失敗または再起動後に安全に取り込みを再開できるように、最後に処理されたオフセットまたはシーケンス番号を保持します。
- **重複排除および更新/挿入ロジック:**DLO の確定時に重複イベントが検出されてスキップされ、一貫性を維持するために一意のキーを使用して有効なレコードが更新挿入されます。
- **リプレイとリカバリの制御:**失敗または遅延したイベントは、デッドレターキューとリプレイキューを介して保存されたオフセットから再生されるため、重複のない信頼性の高いリカバリが保証されます。
セキュリティに関する考慮事項
セキュリティは、認証から暗号化、アクセス制御まで、取り込みパイプライン全体にわたって不可欠です。
- **認証:**AWS IAM ポリシーまたは OIDC を使用して、ログイン情報の交換を保護します。
- 暗号化:Data 360 内の送信中(TLS 1.2 以上)および保存中(AES-256)の暗号化データ。
- **アクセス制御:**適用される最小権限ロール。コネクタの範囲は特定のストリーム/トピックです。
- **ガバナンス:**完全なトレーサビリティのためにすべてのレコードに適用される系統および分類メタデータ。
- ネットワークセキュリティ:必要に応じて、AWS PrivateLink を使用してプライベートサブネット内にリリースします。
サイドバー
適時性
- **ほぼリアルタイムの処理:**CDC およびストリーミングコネクタは、ソースの変更後数秒でイベントを処理し、通常は 1 分未満のデータ新鮮度を保証します。
- **確定的レイテンシ:**エンドツーエンドの遅延はソーススループット、イベントバッチ、ネットワーク条件によって異なりますが、Data 360 ではサポートされるオブジェクトの予測可能な SLA 主導の遅延が保証されます。
- **柔軟な拡張性:**取り込みパイプラインは、大量のイベントが発生すると自動的に拡張され、ピーク時のデータバースト時でもタイムリーに維持されます。
- **運用の可視性:**監視ダッシュボードでは、遅延の保証とトラブルシューティングのためにイベント遅延、確定タイムスタンプ、リプレイ状況が公開されます。
データ量
- **軽量ペイロード:**個々の CDC またはストリーミングイベントはコンパクト (標準サイズは 1 ~ 5 KB) で、頻繁な更新に最適化されています。
- **変更の多いオブジェクト:**不安定なエンティティ (ケース、取引先責任者、注文など) の場合、アーキテクトは CDC の割り当てとイベントスループットが予測される更新レートと一致することを確認する必要があります。
- **並列ストリーム:**Data 360 では、大規模なオブジェクトボリュームや複数のソース組織にまたがる水平スケーリングでマルチストリーム取り込みがサポートされます。
- **バックプレッシャ処理:**組み込みの調整メカニズムにより、イベントをドロップすることなく、負荷がかかっても取り込みの安定性が維持されます。
状態管理
各イベントには、状態およびバージョン管理のメタデータが含まれます。
- **リプレイおよびオフセット追跡:**すべてのイベントでリプレイ ID とシーケンスメタデータが伝達され、順序付けられた配信とチェックポイントベースのリカバリが可能になります。
- **スキーマのバージョン管理:**イベントヘッダー内のバージョンタグにより、ソーススキーマが進化するときに下位互換性のある処理が保証されます。
- **Idempotency Keys:**各イベントには一意のトランザクションまたは確定キーが含まれているため、Data 360 はリプレイと再試行を安全に重複排除できます。
- **アトミックコミット:**取り込みパイプラインでは、DLO へのダウンストリームコミットが成功した場合にのみオフセットが完了としてマークされ、一貫性が確保されます。
複雑なインテグレーションのシナリオ
このパターンは、高度なエンタープライズアーキテクチャにシームレスに統合されます。
- **ハイブリッド取り込み:**増分差分用の CDC とフル更新用の一括データストリームを組み合わせて、新鮮さと完全性の両方を維持します。
- **組織間ストリーミング:**複数の CRM 組織または ERP 組織が同じ Data 360 テナントに公開でき、DMO マッピングとオントロジーアライメントを介して統合されます。
- **イベント強化:**ミドルウェア (MuleSoft、Event Relay など) では、ストリーミングデータが Data 360 に到達する前に、ストリーミングデータの強化、絞り込み、転送を行うことができます。
- **AI とエージェントの有効化:**リアルタイムの更新により、発信イベントの発生から数秒以内に下流の自動化 (Einstein 予測や Agentforce 応答など) がトリガーされます。
例
グローバルな小売企業は AWS Kinesis を使用して、POS と Web インタラクションのデータをストリーミングします。Data 360 の Kinesis コネクタは IAM ログイン情報を介して認証し、継続的にイベントをトランザクション DLO に取り込みます。各レコードはスキーマが検証され、メタデータで強化され、カスタマー DMO にすぐに伝播されます。Einstein AI モデルは数秒で顧客セグメントを更新し、Agentforce によってリアルタイムで Next Best- Offer のおすすめがトリガーされ、完全にイベント駆動型のパーソナライズ ループを実現します。
ゼロコピーは、単なるインテグレーション方法ではありません。これは、エンタープライズデータの移動方法、つまり移動しない方法の基本的なシフトです。これまで、データインテグレーションでは、ETL パイプラインを介して大量のレコードをコピーする必要があり、冗長なデータストア、同期の遅延、ガバナンスの課題が発生していました。ゼロコピーでは、そのすべてが排除されます。 このモデルでは、Data 360 は Snowflake や Databricks などの外部データプラットフォームに直接接続し、データを移動したり複製したりすることなく、その場で安全にデータを参照して有効化します。その結果、エンタープライズデータレイクハウスと Salesforce エコシステム間のシームレスなブリッジが実現し、インスタントアクセス、運用オーバーヘッドの低減、データガバナンスの強化を実現できます。
受信ゼロコピー機能を使用すると、Data 360 は Snowflake または Databricks に保存されているソースの外部データ (顧客プロファイル、取引、商品データなど) を照会してハーモナイズできます。ファイルを取り込む代わりに、Data 360 は外部倉庫の既存のスキーマ定義とセキュリティポリシーを利用する安全なメタデータ対応接続を確立します。
- **直接統合:**Data 360 は、レプリケーションなしで安全で最適化されたクエリを使用して、データを読み取ります。
- **統合ガバナンス:**データはソースシステムのセキュリティ、アクセス制御、コンプライアンスフレームワークの下に残ります。
- **運用効率:**ETL のオーバーヘッドとストレージの重複を排除し、コストと複雑さを軽減します。
- **リアルタイムの準備状況:**オンデマンド ハーモナイゼーションを有効にします。Snowflake でデータが更新されると、Data 360 ですぐに有効化できます。
コンテキスト
最新のデータ主導型企業では、Snowflake や Databricks などのクラウドスケールのデータレイクハウスプラットフォーム内でペタバイト規模の顧客データ、トランザクションデータ、テレメトリデータを管理しています。これらの環境は、分析、AI、コンプライアンスの一元化された情報源として機能します。 Data 360 では、ゼロコピーデータ統合が導入されており、冗長なデータをコピー、変換、保存することなく、Data 360 で外部データセットを直接クエリして使用できます。 このパターンにより、組織は既存のデータ ウェアハウスまたはレイクハウス インフラストラクチャに Customer 360 ファブリックを拡張でき、重複やレイテンシーがなく、ガバナンスを損なうことなく、リアルタイムの統合と有効化を実現できます。
問題
ETL パイプラインや物理データ移動のコスト、レイテンシ、ガバナンスのオーバーヘッドなしで、Snowflake、Databricks、または Apache Iceberg などのオープンレイク形式で選定された豊富なデータセットを、Data 360 でのセグメンテーション、ID 解決、有効化にどのように活用できますか?
勢力
このパターンでは、アーキテクチャ、セキュリティ、およびパフォーマンスに関する複数の考慮事項が導入されます。
ネットワークとセキュリティ
- Data 360 は、外部倉庫またはレイクハウスへの安全な非公開接続を確立する必要があります。
- 通常、Salesforce プライベートコネクトまたは PrivateLink/VPC ピアリングを使用して設定し、トラフィックが顧客の制御ネットワークから送信されないようにします。
- 外部システムは Data 360 IP を許可リストに登録し、TLS 1.2+ 暗号化を適用する必要があります。
認証とアクセス制御
- キー ペア認証、OAuth 2.0、ID プロバイダー(IdP)ベースの Trust 委任をサポート(信頼できるクライアントとして動作する Data 360)
- 外部システムのロールベースのアクセス制御 (RBAC) では、クエリの実行に必要な最小限の権限のみが適用されます。
パフォーマンスと計算の連動関係
- クエリ統合では、SQL の実行を Snowflake または Databricks に転送し、コンピューティングクラスターを活用します。
- 外部クエリ負荷によるパフォーマンスとコストの拡張性 — セグメンテーションの遅延とコストは、外部コンピューティング設定に関連付けられます。
進化する標準:ファイルフェデレーション
- 次世代モデルのファイルフェデレーションでは、Apache Iceberg や Delta Lake などのオープンなテーブル形式を活用して、Data 360 をオブジェクトストレージ(Amazon S3、Azure ADLS、Google Cloud Storage など)から直接読み取ることができます。
- ソース コンピューティング レイヤーをバイパスすることで、ファイルフェデレーションはスキーマの整合性を維持しながら、読み取りの多い分析ワークロードのレイテンシとコストを大幅に削減します。
ガバナンスとコンプライアンス
- データがソースプラットフォーム外に出ることはありません。コンプライアンス、暗号化、保持ポリシーは発生時に適用されたままです。
- すべてのメタデータ、系統、同意属性が Data 360 の Trust Layer に伝搬され、エンドツーエンドのトレーサビリティが確保されます。
ソリューション
推奨されるアプローチは、Data 360 内の Snowflake、Databricks、ファイルフェデレーションにネイティブのゼロ コピー コネクタを使用することです。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| Snowflake Zero Copy Connector | 最善 | ファーストパーティネイティブインテグレーション。Snowflake のデータ共有または外部テーブル API を使用してライブクエリ統合を確立します。 |
| Databricks Zero Copyコネクタ | 最善 | Delta Lake のテーブル/ビューへの直接ライブアクセスがサポートされ、プッシュダウンクエリは Databricks ランタイムで実行されます。 |
| ファイルフェデレーション(Apache Iceberg/Delta/Parquet) | 新しいベストプラクティス | Data 360 は、外部コンピューティングの連動関係なしに、オブジェクトストレージから開いているテーブル形式を直接読み取ります。大量のデータセットに最適です。 |
| プライベートネットワーク設定 | 推奨 | Salesforce プライベートコネクトまたは VPC ピアリングを使用して、安全なネットワークレベルの統合を実現します。 |
| 認証と鍵の管理 | ベストプラクティス | 定期的な循環と保管庫管理を使用して、安全な鍵ベースまたは OAuth ベースの認証を実装します。 |
| スキーマ登録 | 必須 | Data 360 は外部スキーマを取得して、外部データレークオブジェクト (外部 DLO) にマッピングします。 |
| 管理メタデータ | 推奨 | すべての外部 DLO は、コンプライアンス表示のために分類、同意、系統メタデータを継承します。 |
スケッチ
次の図は、Data 360 でゼロコピー接続を設定して外部 DLO を作成する方法を示しています。
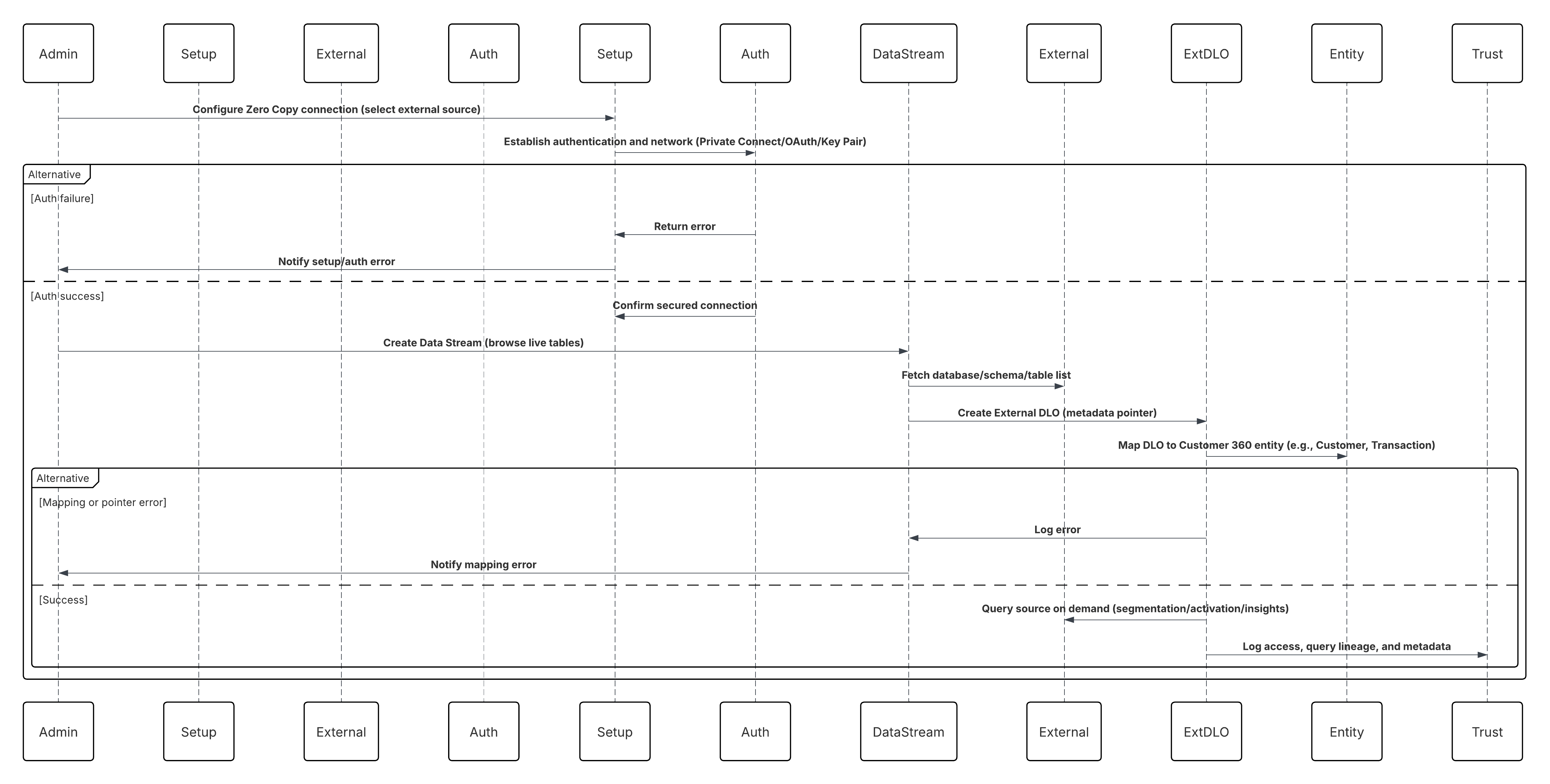
このシナリオの内容は次のとおりです。
- 管理者は、Data 360 の[設定](Snowflake、Databricks、またはファイルフェデレーション)でゼロ コピー接続を設定します。
- セキュアな認証とネットワークルーティングが確立されている (プライベートコネクト/OAuth/鍵のペア)。
- システム管理者は、外部ソース (ライブデータベース、スキーマ、テーブルの参照) を選択してデータストリームを作成します。
- Data 360 では、データをコピーする代わりに、外部 DLO (データレイクオブジェクト) が作成されます。これは、ライブテーブルまたは Iceberg ファイルを参照するメタデータポインタです。
- 外部 DLO は Customer 360 エンティティ(Customer、Transaction、Product など)にマッピングされます。
- Data 360 は、セグメンテーション、有効化、またはインサイト計算中にソースを照会します。
- すべてのアクセス、クエリの系統、メタデータは、Data 360 Trust Layer 内で監査されます。
結果
- 外部データは Snowflake、Databricks、または S3 に残ります。ETL、重複、追加ストレージはありません。
- Data 360 では、ID 解決、計算済みインサイト、有効化のためにエンタープライズ規模のデータにリアルタイムで参照できます。
- 組織は、既存のガバナンス、暗号化、およびコンプライアンスフレームワークの下で完全に制御できます。
- このパターンにより、ローカルアクセスのパフォーマンスと統合ストレージのガバナンスを組み合わせた、真のゼロコピーアーキテクチャが可能になります。
コールメカニズム
コールメカニズムは、このパターンを実装するために選択されたソリューションによって異なります。
| メカニズム | 使用するケース |
|---|---|
| Snowflake 統合 (優先) | 管理対象のエンタープライズデータウェアハウスを使用したライブのハイパフォーマンスクエリ統合。 |
| データブリックス連盟 | Delta または Parquet で支援されるデータセットを使用する統合分析および Lakehouse 環境用。 |
| ファイルフェデレーション(Apache Iceberg/Delta Lake) | コンピューティングの分離とコストの最適化が重要なオブジェクトストレージの大規模データセット用。 |
| ハイブリッドモード (ゼロコピー + 取り込み) | 履歴データに 1 回のみ取り込む必要があるが、ライブデータには Zero Copy を使用してアクセスする場合。 |
エラー処理と回復
- **自動再試行 & クエリのバックオフ:**一時的な接続またはクエリタイムアウトは、指数バックオフを使用して自動的に再試行されます。
- **スキーマの不一致の切り分け:**ソーススキーマの変更 (新しい列など) はスキーマ却下キューに記録されます。管理者はスキーマメタデータを再対応付けまたは更新できます。
- **認証フェイルオーバー:**ログイン情報が期限切れになると、Data 360 は保存されている更新トークンまたは鍵の循環ポリシーを使用して接続を再試行します。
- **可用性検出の計算:**Snowflake または Databricks クラスターが一時停止している場合、Data 360 は統合ジョブをサスペンドし、コンピューティングが再開されたときに再試行します。
- **監視インテグレーション:**Data 360 Monitoring ダッシュボードに表示されるすべての接続状態、クエリ遅延、系統メタデータ。
Idempotent 設計に関する考慮事項
- **クエリ確定性:**統合クエリでは、一貫したスナップショットセマンティクスを使用して、セグメンテーションまたは有効化中に安定した反復可能な読み取りが保証されます。
- **外部 DLO バージョン設定:**各統合クエリには、系統追跡用のスキーマとタイムスタンプメタデータが含まれます。
- **オフセットなしのアクセス:**Zero Copy は参照のみであるため、イベントオフセットに依存しません。整合性は外部システムの ACID 保証 (Snowflake/Delta Lake) を介して適用されます。
- **スキーマドリフト管理:**Data 360 でバージョン管理されたスキーマの対応付けを維持し、ソースの進化に関する外部 DLO メタデータを更新します。
セキュリティに関する考慮事項
セキュリティは、フェデレーション モデル全体にわたって不可欠であり、Trust やコンプライアンスを損なうことはありません。
- **暗号化:**すべてのデータ交換で TLS 1.2+ が使用され、外部倉庫では保存時に AES-256 を使用して暗号化されます。
- **アクセス制御:**外部テーブルには、参照のみの権限を持つ最小権限ロールでアクセスします。
- **ネットワークの分離:**プライベートコネクトまたは VPC ルートにより、公開エンドポイントへの公開が防止されます。
- **管理データフロー:**系統、同意、分類のメタデータが Data 360 Trust Layer に取り込まれ、ポリシーが適用されます。
- **監査可能性:**すべての統合クエリおよびスキーマアクセスイベントは、コンプライアンスのトレーサビリティ (GDPR、CCPA、HIPAA) のために記録されます。
サイドバー
適時性
- クエリは外部倉庫またはストレージに対してライブで実行され、最新のデータ状態をリアルタイムで確認できます。
- セグメンテーションまたは有効化の実行には、Snowflake、Databricks、または S3 が支援する Iceberg テーブルの最新の変更が反映されます。
- クエリ遅延は、ソースシステムのパフォーマンス階層によって異なります (通常はクエリあたり数秒から数十秒)。
- 「コピーではなく更新」データアクセスを必要とする分析および AI ワークロードに最適です。
データ量
- レプリケーションなしで Snowflake または Databricks にネイティブに保存されているペタバイト規模のデータセットをサポートします。
- Data 360 では、未加工のデータセットではなく結果のみが取得されるため、ネットワークコストと計算コストが最小限に抑えられます。
- ファイルフェデレーションは、パーティションプルーニングと列プッシュダウンによって大規模な分析スキャンを最適化します。
- 倉庫の計算容量と Data 360 の統合クエリオーケストレーションレイヤーを使用して直線的に拡張できます。
状態管理
- 外部 DLO は、Data 360 で接続、スキーマ、バージョンのメタデータを保持します。
- スキーマの進化は、メタデータの更新サイクルによって自動的に管理されます。
- クエリの系統には、タイムスタンプ、ユーザー ID、トレーサビリティの実行総計値が含まれます。
- ステートフルな取り込みやオフセットは維持されず、整合性は外部ソースの ACID 保証から継承されます。
複雑なインテグレーションのシナリオ
- **ハイブリッドモード:**Zero Copy (ライブフェデレーション用) と取り込み (履歴データセット用) を組み合わせます。
- **倉庫間アクセス:**Data 360 は、1 つの組織内の複数の Snowflake または Databricks テナントから統合できます。
- **AI/BI の相互運用性:**外部システム (SageMaker、Tableau、Power BI など) は、リバース Zero Copy を使用して Data 360 の拡張プロファイルを照会できます。
- **ファイルフェデレーション拡張子:**オープンレイク形式 (Iceberg/Delta) を採用している企業は、構造化データと非構造化データを 1 つの統合モデルに統合できます。
例
グローバル金融企業では、すべてのトランザクションデータとインタラクションデータを Snowflake に保存しながら、顧客属性とマーケティングイベントを Data 360 で管理しています。Zero Copy Data Federation を使用して、Data 360 は Private Connect を介して Snowflake に安全に接続します。たとえば、セグメンテーションジョブが実行されると、Data 360 はクエリを Snowflake に転送し、集計結果を取得して、Journey Builder でそれらのプロファイルをすぐに有効化します。複製や ETL は不要です。この例では、エンタープライズデータエコシステム全体で統合されたリアルタイムの統合インテリジェンスを使用します。
送信ゼロコピーは同じ原則を逆に拡張します。Data 360 からデータセットをエクスポートまたはコピーする代わりに、Snowflake などの外部システムは Data 360 を直接照会し、Data 360 を強化された顧客インテリジェンスの統合ソースとして処理できます。
- **逆統合:**外部分析または AI プラットフォームは、Data 360 の統合プロファイルデータを抽出せずにアクセスできます。
- **ソースでのデータ有効化:**ビジネスチームは、AI モデリング、レポート、顧客のパーソナライズなど、データがすでに存在する場所でインサイトを利用できます。
- **レイテンシのない相互運用性:**一括エクスポートや同期ジョブはありません。インサイトはプラットフォーム間ですぐに転送されます。
- **一貫したセマンティック:**どちらのシステムも同じオントロジーとスキーマの対応付けを共有しているため、コンテキストと意味はエコシステム全体で保持されます。 ゼロ コピーにより、Data 360 のロールがデータ リポジトリからセマンティック アクティベーション レイヤーに再定義されます。これにより、組織は、データをそのデータが属する正確な場所(管理された高パフォーマンスの倉庫)に保持しながら、Salesforce の Trust 境界内でその価値を最大限に引き出すことができます。 このパターンは、最新のデータメッシュおよび AI ネイティブアーキテクチャに準拠しており、データは分散したまま、インテリジェンスは統合されます。アーキテクトは、より高速で無駄がなく、コンプライアンスの高い有効化パイプラインを構築できるようになりました。コピーは不要です。
コンテキスト
現代の企業は、Salesforce Data 360 が統合顧客プロファイルと有効化を強化し、Snowflake や Databricks などのエンタープライズデータウェアハウスがデータサイエンス、機械学習、BI ワークロードの分析バックボーンとして機能するマルチプラットフォームデータエコシステムで運用することが増えています。 Salesforce Data 360 のゼロコピーアウトバウンド共有機能は、これらの環境をシームレスに橋渡しします。これにより、レプリケーションや ETL を使用せずに、Snowflake または Databricks 内でハーモナイズされた Data 360 データに直接、管理され、安全でリアルタイムなアクセスが可能になります。 これにより、アナリストとデータサイエンティストは、マーケティング、営業、サービスの有効化に役立つ同じライブの信頼できるデータを照会、視覚化、モデル化できます。
問題
従来のリバース ETL パイプラインでデータをコピーしたり、ガバナンスに違反したり、レイテンシを導入したりすることなく、Data 360 の統合顧客プロファイルと計算済み評価指標 (生涯価値、離脱リスクなど) を外部分析システムに安全かつ効率的に公開する方法は?
勢力
このパターンでは、アーキテクチャ、ガバナンス、運用に関する複数の考慮事項が導入されます。
- **管理対象セキュリティ:**Data 360 データへのアクセスは、制御、詳細化、監査可能でなければなりません。ゼロコピー共有では、明示的なオブジェクトレベルのアクセス権が使用されるため、承認されたデータモデルオブジェクト (DMO) と計算済みインサイトオブジェクト (CIO) のみが指定されたコンシューマーに提供されます。
- **明示的なオブジェクト選択:**管理者は、データ共有を介して共有可能なデータを選定して、公開するオブジェクトを明示的に選択します。これにより、ガバナンスが維持され、リスクにさらされるリスクが最小限に抑えられます。
- **バイラテラル構成:**Data 360 と外部倉庫の両方を設定する必要があります。Data 360 では、データ共有対象 (Snowflake/Databricks) を定義しますが、受信システムは共有を受け入れてインスタンス化する必要があります。
- **クエリ統合モデル:**受け入れると、外部プラットフォームは統合ビューを介してライブで管理された Data 360 データを照会するため、抽出ジョブや手動更新サイクルが不要になります。
- **Open Standards Evolution:**ファイルフェデレーションなどの新しいアプローチでは、オープン テーブル形式(Apache Iceberg など)を活用してストレージ レイヤーでの参照のみアクセスを可能にし、マルチクラウド アーキテクチャ全体の拡張性、パフォーマンス、相互運用性を向上させます。
ソリューション
このソリューションは、Snowflake や Databricks などのデータプラットフォームで Salesforce Data 360 のネイティブのゼロコピー共有を活用します。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| データ共有の作成 | 最善 | 管理者は Data 360 内にデータ共有を作成し、選択した DMO と CIO (統合個人、顧客の正常性スコアなど) を追加します。 |
| 対象設定 | 最善 | Snowflake または Databricks のアカウント識別子と認証パラメーターを指定して、データ共有対象を作成します。 |
| 共有公開 | ベストプラクティス | データ共有をデータ共有対象にリンクして安全に公開します。 |
| 倉庫受け入れ | 必須 | 外部管理者は共有を受け入れ、共有オブジェクトを倉庫内の参照のみのビュー/テーブルとして具体化します。 |
| 詳細なアクセス制御 | 推奨 | Data 360 内でオブジェクトおよびロールベースの権限を適用し、倉庫レベルのロールベースのアクセス制御に従います。 |
| 統合クエリアクセス | 最善 | アナリストは標準 SQL を使用してライブ共有データを照会し、ネイティブの倉庫データと結合して下流の分析と ML を実行します。 |
| ファイルフェデレーションオプション | 省略可能 | 大規模なデータセットの場合、Apache Iceberg ベースの統合を使用して、コンピューティングに依存しない S3 または Delta Lake の直接読み取りを行います。 |
スケッチ
次の図は、Salesforce Data 360 から外部データプラットフォームへのコールを示しています。
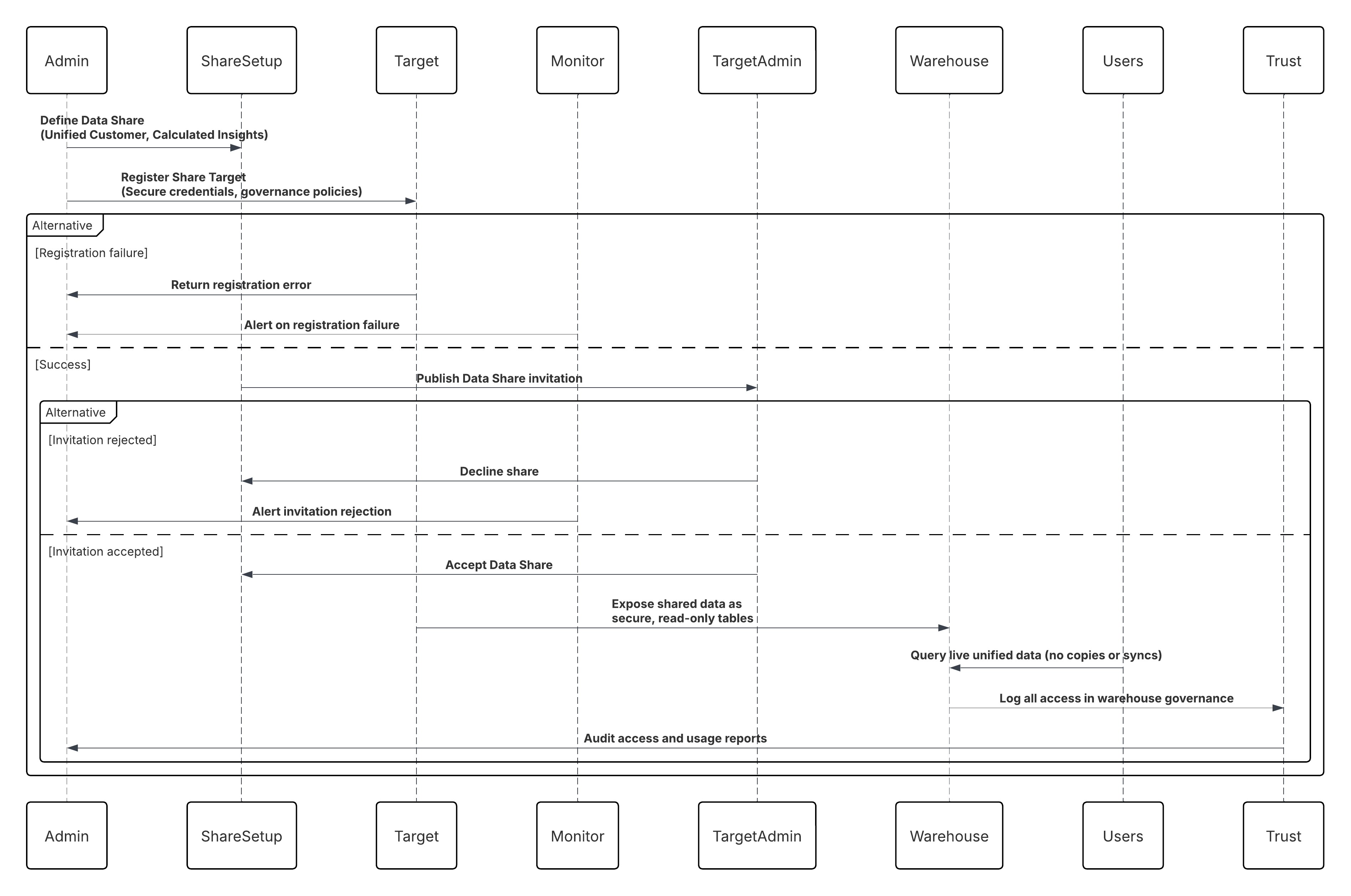
このシナリオの内容は次のとおりです。
- Data 360 管理者は、統合顧客オブジェクトと計算済みインサイトオブジェクトを含むデータ共有を定義します。
- データ共有対象 (Snowflake または Databricks アカウント) が安全なログイン情報とガバナンスポリシーで登録されている。
- Data 360 は共有を公開し、Snowflake/Databricks の管理者は共有を受け入れます。
- 共有データは、倉庫内の安全な参照のみのテーブルとして表示されます。
- アナリスト、BI ツール、または ML パイプラインは、コピーや同期を行わずにライブの統合顧客データを照会します。
- すべてのアクセスは、Data 360 Trust Layer およびウェアハウス ガバナンス ログ内で監査されます。
結果
- 外部倉庫は、ハーモナイズされた Data 360 データにリアルタイムでクエリ可能にアクセスできます。
- Reverse ETL パイプラインを排除し、運用負荷と遅延を軽減します。
- 統合データで直接 AI/ML トレーニング、予測モデリング、高度な BI を有効にします。
- 重複ゼロ、強力なガバナンス、安全な設計によるアクセス制御を維持します。
- 1 つのガバナンスモデルで受信統合と共有送信が共存する双方向のゼロコピーループを完了します。
コールメカニズム
コールメカニズムは、このパターンを実装するために選択されたソリューションによって異なります。
| メカニズム | 使用するケース |
|---|---|
| Snowflake Secure Data Share (優先) | エンタープライズウェアハウスが Snowflake で、データの移動や重複なしでハーモナイズされた Data 360 データセットへのライブで管理されたアクセスが必要な場合に使用します。ゼロレイテンシーの共有とネイティブの系統適用を必要とする分析、AI、コンプライアンス主導のワークロードに最適です。 |
| Databricks Delta Share | 下流のコンシューマーが Databricks または Delta Lake 環境で操作し、オープンなデルタ共有プロトコルを使用して統合データセットまたは有効化されたデータセットへのリアルタイムの参照のみアクセスを必要とする場合に使用します。 |
| 外部テーブル共有 (Apache Iceberg / Parquet) | オブジェクトストレージ (S3、ADLS、または GCS) でオープン形式のアーキテクチャを維持し、Athena、BigQuery、Snowflake-on-Iceberg などの分析エンジン間で相互運用可能で低コストの共有が必要な場合に使用します。 |
| データ共有 API (プログラムによるアクセス) | カスタムアプリケーションまたはミドルウェア (MuleSoft など) で、API を使用してイベントベースの更新通知と詳細なアクセス制御を使用して、共有データセットを安全に検出、登録、消費する必要がある場合に使用します。 |
| ハイブリッド共有 (ゼロコピー + 送信共有) | 双方向の交換パターンを実装するときに使用します。受信データには Zero Copy、インサイトを公開するには Outbound Data Share を使用し、エンタープライズデータプレーン全体でセマンティックとガバナンスの一貫性を確保します。 |
エラー処理と回復
- **接続再試行:**Data 360 とウェアハウス間の一時的な接続または認証失敗の自動再試行。
- **共有の検証:**無効な共有設定または未承認の共有設定は、管理レビューキューで隔離されます。
- **Sync Health Monitoring:**Data 360 では、監視ダッシュボードを介してライブ共有状況、クエリ遅延、およびアクセスログが表示されます。
- **アクセスの取り消し:**管理者は共有をすぐに取り消して、データコピーが残らない両端のアクセスを無効にできます。
- **管理監査履歴:**コンプライアンス検証のために、すべての設定とアクセスの変更が記録されます。
Idempotent 設計に関する考慮事項
- **一貫した共有 ID:**各データ共有とデータ共有対象のペアには一意の識別子があり、正確なガバナンスとアクセスのトレーサビリティが確保されます。
- **不変ビュー:**共有データオブジェクトは参照のみです。コンシューマーは状態を変更できないため、確定的な結果とコンプライアンスが保証されます。
- **アトミック共有ライフサイクル:**共有の公開、取り消し、更新は、完全に完了するかロールバックされるアトミック操作です。
- **リプレイの整合性:**Data 360 データを更新すると、倉庫側のクエリで常に最新の一貫したスナップショットが返されるため、古い読み取りが排除されます。
セキュリティに関する考慮事項
セキュリティは、ゼロコピー共有のあらゆる側面を支えます。
- 認証:Mutual Trust established using OAuth 2.0, private key exchange, or ID Federation (OIDC) (OAuth 2.0、非公開鍵交換、または ID 統合 (OIDC) を使用して確立された相互信頼)。
- 暗号化:転送中および保存中の暗号化データ (TLS 1.2+) (AES-256)。
- アクセス制御:オブジェクトレベルの権限では、最小限の権限でアクセスします。Data 360 Trust Layer によって管理されます。
- ネットワークセキュリティ:データ交換は、Salesforce Private Connect や Secure Data Exchange API などのプライベートネットワークリンクを介して行われます。
- ガバナンスメタデータ:すべての共有オブジェクトには、トレーサビリティと規制コンプライアンスを完全に満たすために、系統、分類、同意属性が含まれます。
サイドバー
適時性
- **リアルタイムの可用性:**共有データには、レプリケーション遅延のない Data 360 の最新の状態が反映されます。
- **クエリの新鮮度:**DMO または CIO の変更は、共有倉庫ビューにすぐに反映されます。
- **パフォーマンスの弾力性:**クエリプッシュダウンは、倉庫の計算リソースに動的に適応します。
- **監視:**ライブダッシュボードでは、運用保証のために共有遅延とクエリパフォーマンス総計値が公開されます。
データ量
- **拡張性の高い共有:**分析ニーズに応じて、詳細なオブジェクトレベルまたはフルドメインデータ共有をサポートします。
- **最適化されたクエリ・パフォーマンス:**Snowflake/Databricks は、共有データをインテリジェントにキャッシュして遅延を最小限に抑えます。
- **ストレージ効率:**重複を排除することで、冗長なストレージコストを排除します。
- **ファイルフェデレーションオプション:**ペタバイト規模のデータセットの場合、Iceberg ベースの直接共有は計算をスキップし、アクセスを高速化します。
状態管理
- **スキーマの進化:**バージョン管理されたスキーマにより、Data 360 モデルが進化しても互換性が維持されます。
- **アクセス状態の追跡:**ライフサイクルガバナンスのために Data 360 内で維持される有効な共有/無効な共有状態。
- **メタデータ同期:**共有オブジェクト定義の更新は、下流の倉庫カタログに自動的に反映されます。
- **不変状態保証:**倉庫ビューは、常に Data 360 データの一貫したポイントインタイム状態を表します。
複雑なインテグレーションのシナリオ
- **ハイブリッドモード:**Zero Copy (ライブフェデレーション用) と取り込み (履歴データセット用) を組み合わせます。
- **倉庫間アクセス:**Data 360 は、1 つの組織内の複数の Snowflake または Databricks テナントから統合できます。
- **AI/BI の相互運用性:**外部システム (SageMaker、Tableau、Power BI など) は、リバース Zero Copy を使用して Data 360 の拡張プロファイルを照会できます。
- **ファイルフェデレーション拡張子:**オープンレイク形式 (Iceberg/Delta) を採用している企業は、構造化データと非構造化データを 1 つの統合モデルに統合できます。
例
クロスクラウド分析を使用すると、組織は管理対象の Salesforce Data 360 データを Snowflake や Databricks などのプラットフォームのネイティブデータセットと組み合わせて、あらゆる角度から分析できます。マルチテナントアクセスにより、さまざまなビジネスユニットが、データを重複することなく、個別の共有を介して選定されたポリシーで制御されたデータスライスを安全に消費できます。その後、データサイエンティストは Snowflake ML または Databricks MLflow 環境内の統合顧客プロファイルでモデルをトレーニングすることで、統合 AI と機械学習を直接実行できます。このプロセス全体を通して、組み込みの系統、ガバナンス、監査機能により、すべてのデータアクセスと使用がエンタープライズポリシーと規制要件 (GDPR や HIPAA など) に準拠していることが保証されます。
Data Cloud One を使用すると、複数の Salesforce 組織 (ビジネスユニット、地域、製品ライン、買収など) がある組織は、1 つの中央 Data 360 インスタンスを共有できます。この組織は「ホーム組織」として機能しますが、他の組織 (「コンパニオン組織」と呼ばれる) は最小限の労力で統合データにアクセスし、カスタムコードを使用せずに完全なガバナンス制御を実行できます。
コンテキスト
多くの場合、企業では複数の Salesforce 組織 (営業、サービス、マーケティング、地域など) が稼働しています。各組織には、独自のデータ、設定、プロセスがある場合があります。Data Cloud One 以前は、組織間でデータを共有するには、各組織に独自の Data 360 設定または複雑なカスタムコードが必要でした。Data Cloud One では、Data 360 を使用する 1 つの「ホーム」組織と、ローコード設定とメタデータ共有を介して接続する複数の「コンパニオン」組織を許可することで、これを簡素化します。
問題
ホーム組織の Data 360 によって取り込まれ、ハーモナイズされ、管理される統合 Customer 360 データを、すべての Salesforce 組織で一貫して使用しながら(セールス、マーケティング、サービスなどで同じ基礎データが使用されるように)、作業の重複、カスタム コーディング、組織ごとの個別の Data 360 インスタンス、ガバナンスのギャップを回避するには、どうすればよいでしょうか。
勢力
このパターンでは、アーキテクチャ、セキュリティ、およびパフォーマンスに関する複数の考慮事項が導入されます。
- 複数組織の複雑さ:各ビジネスユニットの組織には、異なるデータ、カスタムオブジェクト、セキュリティ、プロセスが含まれている可能性があり、一貫した統合ビューを維持することは困難です。
- 重複とコスト:組織ごとに個別の Data 360 インスタンスを実行すると、設定、ガバナンス、ライセンス、データサイロのリスクが高まります。
- ガバナンスおよびデータ共有コントロール:各コンパニオン組織で参照および操作できるデータを決定する必要があります。ガバナンス リスクなしで「すべて」をシンプルに共有することはできません。
- 設定の迅速化:マーケティングチーム、営業チーム、またはサービスチームは、カスタムコードで組織間データを使用できるまで数週間待つことはできません。そのためには、クリック設定ソリューションが必要です。
- データレジデンシー、地域の考慮事項:自宅組織とコンパニオン組織が異なる地域にある場合、データの保存場所や共有方法に関する法的または規制上の制約がある可能性があります。
ソリューション
次の表に、このインテグレーション問題のさまざまな解決策を示します。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| ホーム組織のプロビジョニング | 最善 | Data 360 がプロビジョニングされるホーム組織として 1 つの Salesforce 組織を指定します。これが中央データリポジトリおよびガバナンスハブになります。 |
| コンパニオン組織の接続 | 最善 | Data Cloud One アプリケーションを使用して、ホーム組織から 1 つ以上のコンパニオン組織へのコンパニオン接続を設定します。カスタムコードは必要ありません。 |
| データスペース定義 | ベストプラクティス | 自宅組織内でデータスペースを定義して、データ (小売、サービス、マーケティングなど) を論理的に区分し、アクセス境界を分離します。 |
| データスペース共有 | 最善 | 選択したデータスペースをホーム組織からコンパニオン組織まで明示的に共有し、統合データをロールベースで管理します。 |
| アクセス設定 | 必須 | コンパニオン組織で、Data Cloud One アプリケーションを有効にし、プロファイル、インサイト、セグメントアクセスのユーザー権限を割り当てます。 |
| ガバナンスとポリシーの管理 | 推奨 | すべての取り込み、ID解決、Trust設定をホーム組織で一元化し、エンド・ツー・エンドのガバナンスを維持します。 |
| 複数組織同期 | 最善 | ホーム組織のデータ変更と計算済みインサイトは、管理された同期パイプラインを介してコンパニオン組織全体でリアルタイムに反映されます。 |
| ハイブリッド導入オプション | 省略可能 | 大企業の場合、ローカルコンテキストとコンプライアンスの境界を維持しながら、複数のコンパニオン組織を 1 つの自宅組織に接続できます。 |
スケッチ
次の図は、Salesforce がデータマスターであるこのパターンの一連のイベントを示しています。
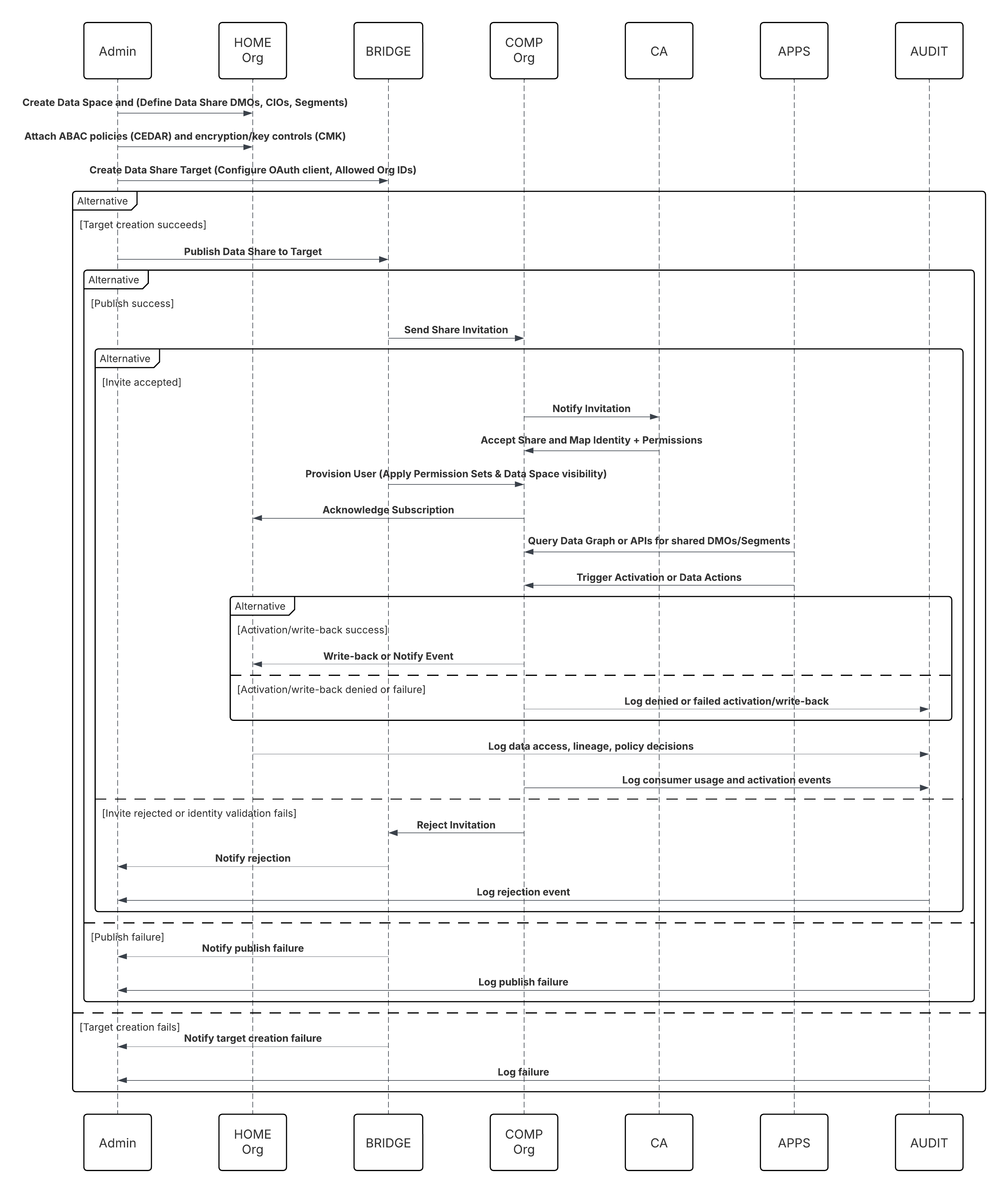
このシナリオの内容は次のとおりです。
- ホーム管理者: データスペースを作成し、データ共有を定義します (DMO/CIO、セグメントを選択)。
- ホーム管理者:コンパニオン組織のデータ共有対象を作成し、Trust(OAuth クライアント、許可された組織 ID)を設定します。
- ホーム管理者: データ共有をターゲットに公開し、ABAC ポリシー (CEDAR) と暗号化/鍵制御 (必要に応じて CMK) を添付します。
- 組織管理者: 招待を受信し、ID の対応付けを検証し、共有を受け入れます。
- コンパニオン組織:Data Cloud One Bridge は、Data Cloud One ユーザーをプロビジョニングし、権限セットとデータスペースの表示を適用します。
- コンパニオン組織アプリケーション(フロー/Einstein/Apex):データグラフを照会するか、Data Cloud One API をコールして共有 DMO またはセグメントを参照します。
- 有効化:コンパニオン組織は、有効化をトリガーするか、データアクションを使用して書き戻します (許可されている場合)。
結果
- すべての接続組織で顧客データ(Customer 360)の一元管理が可能:冗長な Data 360 インスタンスはありません。
- タイム トゥ バリュー**を短縮。**コンパニオン組織は、数週間のカスタム コーディングではなく、数分で統合データと Data 360 の機能にアクセスできます。
- **制御されたデータ共有。**承認されたデータスペースのみが共有されるため、セキュリティとガバナンスを維持しながら、ビジネスの機敏性を実現できます。
- ビジネス機能 (セールス、サービス、マーケティング) は同じ統合データ基盤で動作し、企業全体で一貫した評価指標、有効化、インサイトを実現します。
コールメカニズム
コールメカニズムは、このパターンを実装するために選択されたソリューションによって異なります。
| メカニズム | 使用するケース |
|---|---|
| Data Cloud One ネイティブ共有 (優先) | 複数の Salesforce 組織 (Sales Cloud、Service Cloud、Industry Cloud) で Data 360\ から直接統合顧客データにリアルタイムにアクセスする必要がある場合に使用します。これにより、複製が不要になり、ゴールデンレコード、セグメント、計算済みインサイトへのゼロレーテンシーアクセスが可能になります。 |
| Data Cloud One Bridge を介した組織間の共有 | 複数のビジネスユニットまたは関連子会社が別々の Salesforce 組織で業務を行っているが、中央の Data 360 インスタンスから共通の顧客データおよびセグメントへの共有アクセスが必要な場合に使用します。独立した運用システムを維持している複数組織の企業に最適です。 |
| Einstein 1プラットフォーム クエリAPI | Salesforce アプリケーション、フロー、または Einstein Copilot がプログラムで Data 360 データを照会または有効化する必要がある場合に使用します。一括エクスポートなしで、統合プロファイル、評価指標、有効化結果を他の Salesforce アプリケーションにリアルタイムで取得できるようにします。 |
| Salesforce チャネルへの有効化 | パーソナライズ、キャンペーンの実行、またはエージェント支援環境のために Marketing Cloud、Service Cloud、または Commerce Cloud に対して Data 360 データ (セグメント、インサイト、属性) を有効化する必要がある場合に使用します。 |
| データグラフアクセス (セマンティッククエリレイヤー) | Salesforce データグラフを使用して統合データモデルにセマンティックレベルでアクセスする必要がある場合に使用します。手動の結合や変換を行うことなく、リアルタイムで Copilot、AI ワークフロー、クロスクラウド分析がサポートされます。 |
エラー処理と回復
- **組織間同期の復元性:**Data Cloud One は、一時的なネットワークエラーまたはプラットフォームエラーの指数バックオフを使用して、ホーム組織とコンパニオン組織間の失敗した同期ジョブを自動的に再試行します。
- **部分的なバッチ分離:**失敗したレコードバッチは、調整が成功するまでホーム組織内の再試行キューに隔離され、データの乖離が防止されます。
- **スキーマ却下ガバナンス:**スキーマまたは対応付けの不一致は、システム管理者が確認および修正できるようにスキーマ却下キューに転送されます。
- **リプレイと再開の継続性:**各同期ジョブではオフセットチェックポイントが維持されるため、複製は重複なしで最後に成功した確定から再開できます。
- **統合監視:**すべての失敗、再試行、および復旧メトリックが Trust Layer Monitoring ダッシュボードに取得され、可視化と SLA 保証が実現します。
Idempotent 設計に関する考慮事項
- **Deterministic Idempotency Keys:**同期イベントごとに一意のキー (組織 ID + レコード ID + バージョン番号) が伝達され、1 回限りの処理が保証されます。
- **リプレイの安全性:**重複またはリプレイされたイベントは確定時に絞り込まれ、下流の DMO と CIO の更新の一貫性が確保されます。
- **Atomic Commit Semantics:**コンパニオン組織では、ダウンストリーム書き込みが成功した後にのみデータがコミット済みとしてマークされるため、組織間のトランザクションの整合性が維持されます。
- **競合の解決:**マルチソース更新は、last-write-wins またはポリシー駆動のマージロジックに従って、系統と一貫性を維持します。
- **Checkpoint Persistence:**同期ジョブは、安全にリカバリおよび再生できるように、Trust Layer 内で最終処理されたオフセットと状態を保持します。
セキュリティに関する考慮事項
- **強力な認証:**自宅組織とコンパニオン組織間の接続では、接続アプリケーションを介して管理される自動循環トークンで相互 OAuth 2.0 が使用されます。
- **詳細認証:**コンパニオン組織は、管理されたデータ共有ポリシーによって明示的に共有された特定のデータスペース、DMO、または CIO にのみアクセスできます。
- **あらゆる場所での暗号化:**データは、自宅組織とコンパニオン組織の両方で転送中 (TLS 1.2+) および保存中 (AES-256) に暗号化されます。
- **最小権限の原則:**インテグレーションユーザーの範囲は必要なオブジェクトのみに制限され、管理者権限やシステムレベルの権限は反映されません。
- **監査とコンプライアンスの表示:**完全なトレーサビリティのために、すべての同期イベント、スキーマの変更、ログイン情報の更新、アクセス許可が Data 360 Trust Layer に記録されます。
- **プライベート・ネットワークの分離:**オプションの Salesforce プライベートコネクトまたはプライベートリンクを使用すると、安全な内部チャネルでのみデータレプリケーションを実行できます。
サイドバー
適時性
- ホーム組織とコンパニオン組織間の同期は、ほぼリアルタイムで行われます。通常は、ソース組織でデータが変更されてから数秒以内に行われます。
- Zero Copy アーキテクチャにより、すべての参加組織で共有データをすぐに照会でき、レプリケーションやバッチの遅延が発生しません。
- 有効化ジョブとセグメンテーションジョブには、接続組織からの最新の更新が自動的に反映され、業務の新鮮さが維持されます。
- エンドツーエンドの遅延は確定的であり、Data Cloud One のオーケストレーションパイプラインによって管理されるため、負荷がかかっても組織間で一貫したタイムラインが維持されます。
データ量
- 地域やビジネスユニット間のマルチテナントのハイパースケールデータ同期用に設計されており、組織ごとに数十億件のレコードを管理できます。
- データは重複することなく参照されるため、ストレージ占有領域を削減しながら、グローバルなクエリ性を維持できます。
- ストリーミング差分とメタデータ圧縮により、変更率の高いオブジェクト (取引先責任者、注文など) の帯域幅とコミットオーバーヘッドが最適化されます。
- Trust レイヤーを使用した適応型ロード バランシングとオーケストレーションにより、複数のコンパニオン組織にわたって水平に拡張できます。
状態管理
- すべての同期データセットでメタデータの系統、バージョン、および組織の所有権コンテキストが維持され、エンドツーエンドのトレーサビリティが確保されます。
- チェックポイントの保持では、組織間で最後に同期されたオフセットが取得されるため、重複のないリカバリが可能です。
- 組織全体のスキーマのバージョン管理とセマンティックアライメントは、Trust Layers によって自動的に管理されます。
- 状態を手動でリセットする必要はありません。同期状態は Data Cloud One オーケストレーションサービスを介して維持されます。
複雑なインテグレーションのシナリオ
- **組織間統合:**統合ガバナンスモデルで複数の Data 360 テナントまたは地域間でシームレスなクエリと有効化を可能にします。
- **ハイブリッド同期:**トランザクション更新のためのほぼリアルタイムのレプリケーションと、一括またはアーカイブデータのスケジュール済み同期を組み合わせます。
- **マルチ リージョン ガバナンス:**レジデンシー、同意、コンプライアンスの境界を遵守しながら、地理的に分散されたデータ共有をサポートします。
- **AI と自動化の有効化:**同期されたデータは、組織全体の Einstein AI、Agentforce、またはカスタム ML モデルに即座に対応し、リアルタイムの組織間インテリジェンスを実現します。
例
グローバル小売組織には、コンシューマー小売、プレミアムブランド、国際市場の 3 つの Salesforce 組織があります。コンシューマー小売組織で Data 360 をプロビジョニングします (ホーム組織にします)。Data Cloud One を使用して、プレミアムブランド組織と国際市場組織へのコンパニオン接続を設定します。適切なデータスペース(「Customer 360 – Retail Profiles」や「Customer 360 – Premium Profiles」など)のみを各コンパニオン組織と共有します。プレミアムブランド組織では、マーケティングチームはカスタムコーディングやデータの重複なしで、統合顧客プロファイルの表示、計算済みインサイトに基づくセグメントの作成 (プレミアム顧客生涯価値など)、マーケティングオートメーションのトリガーをすべてホーム組織の Data 360 インスタンスで実行できます。
データの有効化は、Salesforce Data 360 の価値が真に発揮される場所です。プラットフォーム内に存在する統合、強化、管理されたデータを取得し、ビジネス全体で機能させるプロセスです。実際には、選定されたセグメント、計算済みインサイト、コンテキスト属性を Data 360 から、マーケティングオートメーション、サービスコンソール、セールスイネーブルメント、分析、AI モデルなど、顧客を引き付けるシステムに安全に配信します。 技術的な観点では、有効化パターンによって、このデータの移動方法 (トリガーされるチャネル、発生する変換またはマッピング、途中でのポリシーの適用方法) が定義されます。これらのパターンは、単にデータをエクスポートするだけでなく、測定可能なビジネス成果を促進するリアルタイムのポリシー対応データフローを調整します。各有効化ルートにより、Customer 360 が稼働中の資産となり、パーソナライズ、予測的判断、およびすべてのタッチポイントにわたる継続的な学習が強化されます。
一括有効化は、Data 360 からデータをエクスポートするための最も広く使用され、運用実績のある方法です。スケジュールされたケイデンスで動作し、定義済みの利用者セグメントまたは属性セットを下流プラットフォームに定期的に公開します。このパターンは、一貫性のある大量のオーディエンス配信を必要とするマーケティングおよびエンゲージメントワークフローに最適です。 一般的な使用事例には、メールジャーニー、ダイレクトメールキャンペーン、デジタル広告ネットワークへの利用者のアップロードの強化などがあります。有効化の実行ごとに、Data 360 の統合プロファイルグラフから適格なセグメントが抽出され、ガバナンスと同意ポリシーが適用され、出力がターゲットシステムに安全に送信されます。 アーキテクチャ的には、一括有効化により、予測可能、監査可能、コスト効率に優れたデータ配信アプローチが提供され、運用のシンプルさとエンタープライズクラスの信頼性のバランスが保たれます。これは、大規模なキャンペーンの実行のバックボーンであり、適切なデータがスケジュールどおりに管理された状態で提供され、測定可能なビジネスインパクトを促進します。
コンテキスト
現代のマーケターは、メール、広告、モバイル、Web など、複数のエンゲージメントチャネルにまたがって活動しており、それぞれが正確かつタイムリーでパーソナライズされた顧客オーディエンスを求めています。Data 360 はこれらの利用者のための統合基盤として機能し、すべてのシステムの顧客データを豊富でアクション可能なセグメントにまとめます。 一括有効化は、Data 360 から下流のマーケティングまたは広告プラットフォームにセグメントをエクスポートするために使用される最も一般的な有効化パターンです。一般的な対象には、Marketing Cloud Engagement、Google 広告、Meta Custom Audiences、LinkedIn 広告などがあり、選定されたオーディエンスに対してキャンペーンを直接実行できます。
問題
マーケティングチームは、Data 360 の統合および強化されたデータを使用して構築された正確に定義された利用者を、外部のマーケティングシステムや広告システムで有効化するためにどのように利用できますか? たとえば、次の区分について考えてみます。「過去 90 日間購入していないが、最近 Web サイトでエンゲージした価値の高い顧客」。 マーケティング担当者は、キャンペーンの関連性と効果を維持するために、このオーディエンスを正確に移行し、関連属性 (ロイヤルティランク、地域、予測 CLV など) で強化し、定期的に更新する必要があります。
勢力
一括有効化パターンは、いくつかの技術的および運用的な要因によって形成されます。
- **ID マッピング:**オーディエンスを正確に配信するには、Data 360 の統合個人 ID を対象システムの対応する識別子 (Marketing Cloud の購読者キーやデジタル広告プラットフォームのハッシュメールなど) に対応付ける必要があります。これにより、正確な一致が保証され、ターゲティングエラーがなくなります。
- **属性の選択と強化:**マーケティング担当者は、ID を超えて、名、ロイヤルティ状況、CLV、その他のパーソナライズされた属性などの追加のプロファイルデータを含めて、下流のパーソナライズと分析を有効にする必要があります。
- **対象プラットフォーム構成:**各送信先は、接続の詳細、認証、データ項目の対応付けを含め、有効化対象として Data 360 に登録されている必要があります。この 1 回限りの設定では、安全な接続を定義し、有効化されたデータを受信できるシステムを制御します。
- **ガバナンスとコンプライアンス:**データの有効化は、統合プロファイルに保存されている同意メタデータ、プライバシーポリシー (GDPR や CCPA など)、マーケティング権限に準拠する必要があります。同意を認識する有効化により、データは承認された目的にのみ使用されます。
- **スケジュールとパフォーマンス:**多くの場合、有効化は下流の利用者を最新の状態に維持するために毎日または 1 時間ごとにスケジュールされます。システムは、重複やデータ損失のない大量の更新や増分更新を効率的に処理する必要があります。
ソリューション
Data 360 の一括有効化プロセスは、ガバナンスと拡張性を維持しながらマーケティング担当者の技術的な摩擦を最小限に抑えるガイド付きワークフローに従います。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| セグメント作成 | 最善 | マーケティング担当者またはアナリストは、データモデルオブジェクト (DMO) または計算済みインサイトオブジェクト (CIO) 全体に検索条件を適用して、ビジュアルセグメンテーションキャンバスでセグメントを作成します。これにより、有効化の対象利用者を定義します。 |
| 有効化の設定 | 最善 | ユーザーは有効化を作成し、作成したばかりのセグメントを取得元として選択します。これにより、Data 360 で下流システムにエクスポートする利用者を定義します。 |
| 有効化対象の選択 | ベストプラクティス | マーケティング担当者は事前設定された有効化対象 (Marketing Cloud、Google 広告、LinkedIn 広告など) を選択します。各対象は、認証ログイン情報と項目の対応付けを使用して Data 360 に登録されます。 |
| ペイロード定義 | 必須 | マーケティング担当者は、取引先責任者識別子 (メール、モバイル、ハッシュ ID など) を選択し、対象システムで強化する追加のプロファイル属性 (名、ロイヤルティランク、CLV など) を選択してペイロードを定義します。 |
| スケジュールと頻度 | 推奨 | 有効化は 1 回のみ実行することも、繰り返し実行 (毎日、毎週など) することもできます。スケジュール設定により、下流の利用者は常に最新の状態に同期されます。 |
| 実行とエクスポート | 最善 | 有効化ジョブが実行されると、Data 360 はセグメントを照会し、選択した属性を収集し、同意検索条件を適用して、対象プラットフォームにデータをエクスポートします。Marketing Cloud では、通常、共有データエクステンションが作成または更新されます。 |
| ガバナンスとコンプライアンス | 必須 | Trust Layerは、スキーマ検証、同意メタデータ、ポリシー制御を適用して、データ保護とマーケティングの規制(GDPR、CCPAなど)へのコンプライアンスを確保します。 |
| 監視と監査機能 | ベストプラクティス | すべての有効化の実行は、Trust Layer Monitoringダッシュボードの成功/失敗評価指標、実行ログ、系統表示を使用して追跡され、運用の透明性とSLA保証を実現します。 |
スケッチ
手順の概要を次に示します。
- **区分を作成:**マーケティング担当者またはアナリストは、ビジュアルセグメンテーションツールを使用してセグメントを作成し、統合データオブジェクトの検索条件を組み合わせます。
- **有効化の作成:**取得元としてセグメントを選択し、事前設定された取得先 (Marketing Cloud や Google 広告など) を選択します。
- **ペイロードの定義:**取引先責任者識別子とその他のプロファイル属性は、利用者のエクスポートとレポートで選択されます。
- **配信のスケジュール:**有効化は 1 回のみ、または定期的に実行するようにスケジュールされており、目的地の利用者を常に最新の状態に保ちます。
- **実行:**トリガー時に、Data 360 はセグメントを照会し、ペイロードを作成して同意の検索条件を適用し、結果を対象システムに転送します。
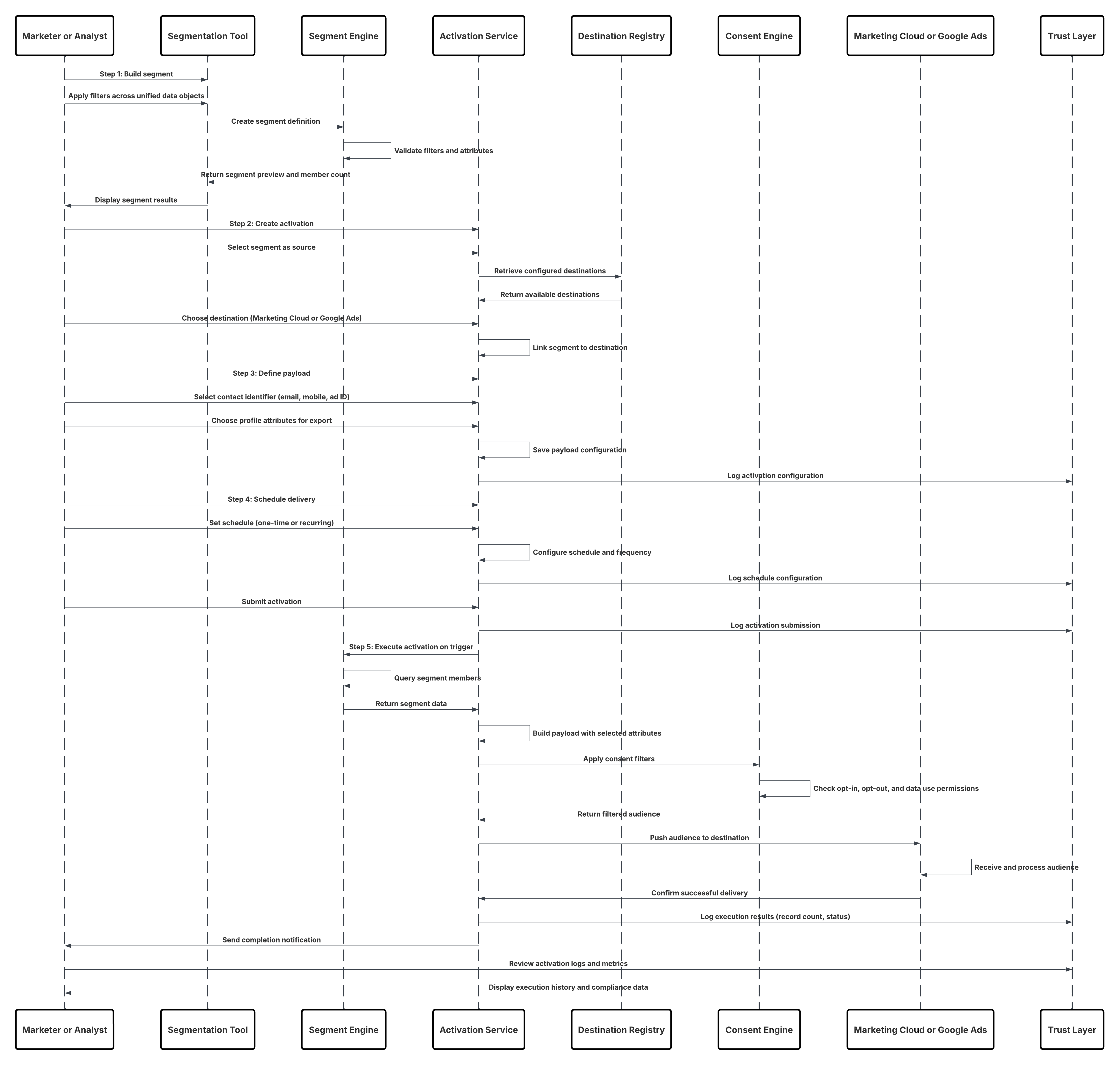
結果
- Data 360 の対象を絞った強化されたオーディエンスセグメントは、下流のマーケティングおよび広告プラットフォームで直接使用できます。
- オーディエンスは自動的に更新され、最新の統合顧客データと同期されるため、リアルタイムのキャンペーン関連性が維持されます。
- マーケティング担当者は、有効化されたオーディエンスを Marketing Cloud ジャーニー、メールキャンペーン、または Google 広告、Meta、LinkedIn 広告などのデジタル広告プラットフォームのカスタムオーディエンスのエントリソースとして使用できます。
- 有効化の実行ごとにエンドツーエンドの系統が維持され、Data 360 と外部システム間のコンプライアンス、トレーサビリティ、一貫性が確保されます。
- ビジネス ユーザーは、完全で信頼できる Customer 360 ビューにより、高度にパーソナライズされたデータ主導のエクスペリエンスを提供できます。
コールメカニズム
コールメカニズムは、対象プラットフォームと有効化対象の設定によって異なります。
| メカニズム | 使用するケース |
|---|---|
| Marketing Cloud Engagement の有効化 (推奨) | Marketing Cloud で動的セグメント、パーソナライズされた属性、リアルタイムの更新が必要なメールジャーニーまたはクロスチャネルジャーニーを実行する場合に使用します。Data 360 は、キャンペーンを有効化するために共有データエクステンションに直接エクスポートします。 |
| 広告プラットフォームの有効化 (Google 広告、LinkedIn 広告、メタ広告) | リターゲティングまたは類似モデリング用の広告プラットフォームで Data 360 セグメントをカスタムオーディエンスとして有効化するときに使用します。ハッシュされた識別子と同意認識配信をサポートします。 |
| CRM の有効化 (Sales Cloud または Service Cloud) | パーソナライズされたセールスエンゲージメントやサービスインタラクションのために、充実した顧客データ、インサイト、傾向スコアを CRM ユーザーと共有するときに使用します。データは、データアクションまたは統合プロファイルコンポーネントを使用して、強化されたレコードまたはインサイトとして使用できます。 |
| MuleSoft または API を使用した外部有効化 | ロイヤルティ、e コマース、サードパーティデータウェアハウスなど、Salesforce 以外のシステムに有効化する必要がある場合に使用します。MuleSoft または Data 360 Activation API により、イベントベースの更新オプションを使用して、ポリシーに基づいた安全な配信が保証されます。 |
| ハイブリッド有効化(バッチ + イベントトリガー) | スケジュール済みバッチ有効化をイベントベースのトリガーと組み合わせる場合に使用します。これにより、放棄カートや離脱リスクアラートなど、時間的制約のあるキャンペーンで「常時」パーソナライズが可能になります。 |
エラー処理と回復
- **ジョブレベルの障害の分離:**各有効化の実行は、Data 360 オーケストレーションレイヤーで個別の追跡可能なジョブとして実行されます。失敗した実行は、他の有効化やセグメント定義に影響を与えることなく自動的に隔離されます。
- **部分的なバッチ・リカバリ:**特定のレコードのエクスポートに失敗した場合 (ID の不一致や API レート制限など)、システムは指数関数的なバックオフと並列リカバリを備えた増分デルタキューを使用してレコードを再試行します。
- **スキーマ検証エラー:**送信ペイロード属性が対象スキーマと一致しなくなった場合 (削除された属性や名前が変更された項目など)、ジョブは影響を受けるレコードをスキーマ却下キューに転送し、管理者による確認を求めます。
- **リプレイと再開のサポート:**各有効化ジョブでは、チェックポイントトークン (成功した最後のバッチを取得) が保持されます。リカバリ時にチェックポイントから処理が再開され、重複やデータの損失がなくなります。
- **包括的な監視:**すべてのアクティベーション イベント、再試行、配信メトリックが Trust Layer Monitoring に記録され、SLA の追跡、根本原因の分析、Event Monitoring API を介した自動アラートが可能になります。
Idempotent 設計に関する考慮事項
- **確定的有効化キー:**有効化の実行ごとに、セグメント ID、有効化 ID、対象システム ID を組み合わせた複合緊急キーを使用して、1 回限りの配信を保証します。
- **リプレイ検出:**Data 360 Activation Service は、受信したペイロードを以前のジョブハッシュと比較して検査し、リプレイを検出して抑制します。
- **Atomic Export Commits:**ペイロードは、書き込み確認が成功した後にのみターゲットシステムにコミットされ、部分的な更新や二重に計数されることを防ぎます。
- **一貫した ID 解決:**有効化は統合 ID (統合個人など) に依存するため、リプレイや再試行では常に同じゴールデンレコードが対象となり、セマンティックの一貫性が維持されます。
- **有効化状態の保持:**オーケストレーションレイヤーは、必要に応じて確定的再処理のために有効化状態のメタデータ (タイムスタンプ、状況コード、シーケンストークン) を保持します。
セキュリティに関する考慮事項
- **強力な認証:**各有効化対象 (Marketing Cloud、広告、CRM など) では、トークンの循環とテナント固有の範囲設定を使用して、不正なデータエクスポートを防止します。
- **属性レベルのガバナンス:**データ共有ポリシーと有効化テンプレートによって適用される有効化の対象となるのは、統合プロファイルの承認済み属性のみです。
- **転送中および保存中の暗号化:**すべてのペイロードは、Data 360 と対象プラットフォームの両方で、転送中は TLS 1.2+、保存時は AES-256 を使用して暗号化されます。
- **同意とポリシーの適用:**有効化ジョブでは、Data 360 の Trust Layer に保存されている同意オブジェクトとデータ ポリシーが考慮されます。有効な同意メタデータのないレコードは、エクスポートから自動的に除外されます。
- **監査とコンプライアンスのログ:**有効化の実行ごとに、誰が有効化したか、どのデータがどの宛先に送信されたかが取得されるため、Trust Layer ダッシュボード内で規制監査履歴(GDPR、CCPA)を完全に利用できます。
- **最小権限アクセス:**各対象のインテグレーションユーザーは、有効化固有の範囲に制限されます。管理者権限や、関連しないシステムへの書き込みアクセス権はありません。
サイドバー
適時性
- スケジュール済みまたはほぼリアルタイムのバッチエクスポート (数分から数時間の遅延) 用に設計されています。
- キャンペーンカレンダーに合わせた期間指定の更新をサポートします。
- 有効化ジョブは、データ準備状況マーカーを使用して順序付けすることで、データの新鮮さを確保できます。
- データの精度が即時性よりも優先される非対話型の有効化シナリオに最適です。
データ量
- 大規模なデータセット (実行あたり数百万件のレコード) を処理します。
- セグメントパーティショニングチャネルと並列エクスポートチャネルで水平に拡張します。
- チャンクベースのバッチ処理を採用してタイムアウトを回避し、スループットを最適化します。
- データの完全性が重要なエンタープライズクラスのデータパイプラインに最適です。
状態管理
- ジョブ ID、タイムスタンプ、シーケンストークンを記録する有効化状態オブジェクトを保持します。
- 再開可能性と障害回復のためにチェックポイントを使用します。
- バージョン管理されたセグメント定義により、有効化サイクル全体の再現性が確保されます。
- ソースセグメント、DMO 属性、対象ペイロード間の系統トレーサビリティを有効にします。
複雑なインテグレーションのシナリオ
- 事前作成済みコネクタを使用して、Salesforce CRM、Marketing Cloud、および外部システムとシームレスに統合します。
- 複数対象有効化がサポートされ、データを異なる対象 (CRM + 広告など) に同時に配信できます。
- 複合ワークフローをトリガーできます。たとえば、バッチエクスポートの後に下流の API コールや AI スコアリングをトリガーできます。
- データモデルガバナンスレイヤーでスキーマの進化を正常に処理します。
例
グローバル小売ブランドは、過去 90 日間の無効な顧客を再びエンゲージしたいと考えています。データアーキテクトは Data 360 を使用して、購入履歴、ロイヤルティランク、同意メタデータで強化された「休止中の買い物客」セグメントを定義します。一括有効化ジョブは夜間に実行され、このセグメントを Marketing Cloud Engagement に転送してパーソナライズされた「We Miss You」メールキャンペーンをトリガーし、Ad Studio に転送してリターゲティングします。このジョブでは、最適な配信を活用して再試行の重複を回避し、監査コンプライアンスのためにすべてのイベントを Trust Layer に記録します。
コンテキスト
多くの場合、アーカイブ、コンプライアンス、ダウンストリームインテグレーションのために、Salesforce Data 360 から統合データまたはセグメント化されたデータを標準ファイル形式 (CSV や Parquet など) にエクスポートするための管理メカニズムが必要です。このパターンにより、Data 360 からクラウドストレージへのエクスポートが可能になり、Amazon S3、Azure Blob、または Google Cloud Storage (GCS) でホストされているエンタープライズデータレイクまたは分析パイプラインに信頼できる顧客データを安全に取り込むことができます。 一般的な使用事例を次に示します。
- 同意済みの顧客データセットを規制対象として定期的にアーカイブする。
- Salesforce 以外の分析ワークロード (Tableau、Databricks、Power BI など) の選定されたセグメントのエクスポート。
- 構造化された CSV または Parquet ファイルを入力として必要とする外部機械学習モデルの有効化。
問題
スキーマの整合性とコンプライアンス管理を維持しながら、選定されたセグメントまたはデータセットを統制され、安全で自動化された方法で Data 360 からクラウドストレージバケット (Amazon S3 など) にエクスポートする方法は?たとえば、コンプライアンスチームは次のことを行う必要があります。「有効な同意に基づいて EU 地域のすべての有効な顧客を抽出し、外部監査および報告のために毎週データを S3 ロケーションにエクスポートします。」そのためには、手動操作や管理されていないデータ移動を行わずに、正しいファイル形式、アクセス権限、配信スケジュールを保証する、繰り返し可能なポリシー対応エクスポートパイプラインが必要です。
勢力
このエクスポートパターンは、複数の運用要素とアーキテクチャ要素によって制御されます。
- 認証および承認:エクスポートでは、承認されたシステムのみが対象バケットに書き込めるように、クラウドプロバイダーの IAM モデル (AWS IAM ロールや Azure サービスプリンシパルなど) を考慮する必要があります。
- スキーマアライメント:送信スキーマは、ターゲットシステムで想定されている構造と形式 (CSV、Parquet、または JSON) と一致する必要があります。
- データプライバシーと同意:エクスポートされたデータセットでは、有効な同意メタデータがないレコードを除外する必要があります。
- スケジュールと新鮮さ:多くのエクスポートは定期的 (毎日、毎週、または毎月) であり、企業のデータ更新サイクルに合わせる必要があります。
- ガバナンスと監視:すべてのエクスポートは、データ保持と規制要件 (GDPR、CCPA など) へのコンプライアンスを確保するために、完全な系統表示で監査可能でなければなりません。
ソリューション
[File Export Activation (ファイルのエクスポートの有効化)] パターンでは、取り込みで使用され、データ出力で設定されたセキュアクラウドストレージコネクタが再利用されます。管理者は最初に、クラウドストレージプラットフォーム (Amazon S3、Azure Blob Storage、GCS など) を Data 360 の有効化対象として登録します。次に、ユーザーは目的のセグメントを指定されたファイルストレージパスにエクスポートする有効化ワークフローを設定して実行します。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| セグメントの選択 | 最善 | アナリストは Data 360\ 内の既存のセグメントまたはクエリ定義を選択します。セグメントによって、エクスポートするレコードと属性が決まります。 |
| 有効化の設定 | 最善 | ユーザーが新しい有効化を作成し、取得元としてセグメント、取得先としてクラウドストレージ対象 (S3 など) を選択します。 |
| 有効化対象設定 | 必須 | システム管理者は、ログイン情報、IAM ロール、出力パスを使用して対象を事前設定します。サポートされる形式には、CSV、Parquet、JSON などがあります。 |
| ペイロード定義 | ベストプラクティス | 必要な属性 (ID、名前、メール、地域、同意フラグなど) を選択して、エクスポートスキーマを定義します。属性レベルのガバナンスが適用されます。 |
| スケジュールと頻度 | 推奨 | エクスポートは、定義された頻度 (毎日、毎週、毎月) で実行するようにスケジュールするか、必要に応じて手動でトリガーできます。 |
| 実行 & デリバリ | 最善 | 実行時に、Data 360 はセグメントを照会し、エクスポートファイルをコンパイルして暗号化し、クラウドプロバイダーの API を使用して設定されたバケット/フォルダーに書き込みます。 |
| ガバナンスとコンプライアンス | 必須 | Data 360のTrust Layerにより、すべてのエクスポートが同意ポリシー、スキーマ検証、コンプライアンス・フィルタに準拠します。 |
| 監視と監査機能 | ベストプラクティス | 各エクスポートは、状況、実行ログ、系統メタデータと共に Trust Layer Monitoring ダッシュボードで追跡されます。 |
スケッチ
手順の概要を次に示します。
- **セグメントを選択:**アナリストまたはデータスチュワードがエクスポートする統合セグメントを選択します。
- **有効化の作成:**新しい有効化ジョブを作成し、登録済みのクラウドストレージ対象を選択します。
- **ペイロードの定義:**エクスポートスキーマ、属性リスト、ファイル形式 (CSV など) を指定します。
- **エクスポートのスケジュール:**1 回限りまたは定期的なスケジュールを選択します。
- **ジョブの実行:**Data 360 によってファイルが生成され、指定されたバケットパスに安全に配信されます。
- **監視と検証:**結果とログは Trust Layer で検証とコンプライアンスのためにレビューされます。
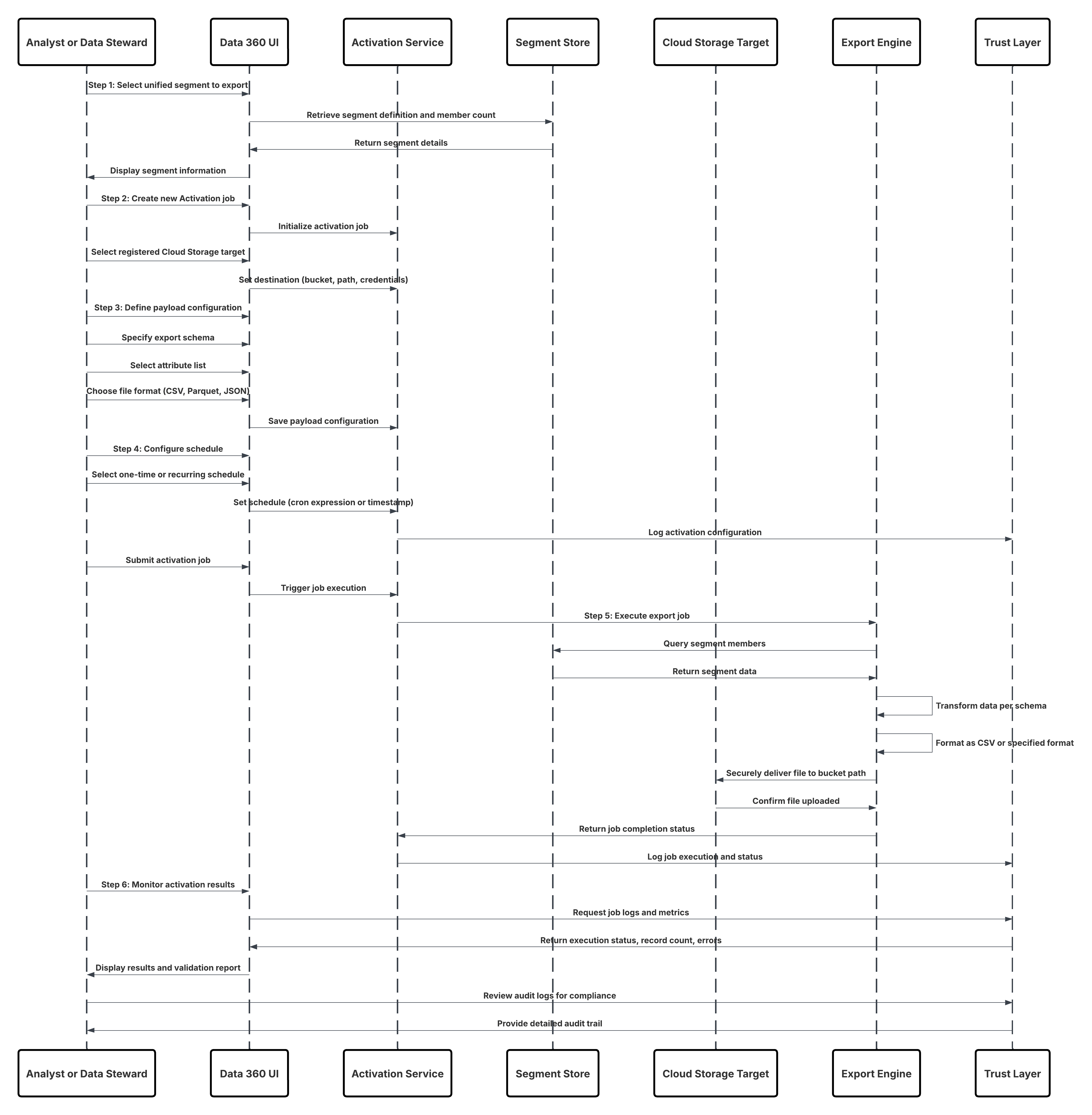
結果
- Data 360 の対象を絞った強化されたオーディエンスセグメントは、下流のマーケティングおよび広告プラットフォームで直接使用できます。
- オーディエンスは自動的に更新され、最新の統合顧客データと同期されるため、リアルタイムのキャンペーン関連性が維持されます。
- マーケティング担当者は、有効化されたオーディエンスを Marketing Cloud ジャーニー、メールキャンペーン、または Google 広告、Meta、LinkedIn 広告などのデジタル広告プラットフォームのカスタムオーディエンスのエントリソースとして使用できます。
- 有効化の実行ごとにエンドツーエンドの系統が維持され、Data 360 と外部システム間のコンプライアンス、トレーサビリティ、一貫性が確保されます。
- ビジネス ユーザーは、完全で信頼できる Customer 360 ビューにより、高度にパーソナライズされたデータ主導のエクスペリエンスを提供できます。
コールメカニズム
コールメカニズムは、対象クラウドストレージプラットフォームと有効化設定によって異なります。
| メカニズム | 使用するケース |
|---|---|
| Amazon S3 の有効化 | エンタープライズデータレイクが AWS でホストされている場合に使用します。Data 360 は、IAM ロールまたは一時的なログイン情報を使用して S3 バケットに直接書き込むため、安全でスケーラブルなエクスポートが保証されます。 |
| Azure Blobストレージの有効化 | 組織が Microsoft Azure で運用している場合に使用します。Data 360 は SAS トークンまたはサービスプリンシパルを使用して、暗号化されたファイルを Blob コンテナに書き込みます。 |
| Google Cloud Storage (GCS) の有効化 | データサイエンスまたは分析ワークロードが GCP で実行される場合に使用します。Data 360 は OAuth ログイン情報を使用して、CSV または Parquet 形式でファイルを GCS バケットにエクスポートします。 |
| SFTP または外部ファイルゲートウェイ | 規制やレガシーシステムで SFTP エンドポイントまたはエンタープライズ管理ファイル転送プラットフォームを介した安全なファイル転送が必要な場合に使用します。 |
| ハイブリッドエクスポート (ファイル + API) | 下流アプリケーションで分析用のファイルベースのエクスポートとワークフローオーケストレーション用の API トリガーの両方が必要な場合に使用します (MuleSoft フローなど)。 |
エラー処理と回復
- **ジョブレベルの分離:**各エクスポートは個別のジョブとして実行されます。失敗したジョブは隔離され、個別に再試行されます。
- **部分的なファイルの再試行:**特定のバッチのアップロードに失敗した場合 (ネットワークの中断など)、システムは指数バックオフを使用してそれらのチャンクを再試行します。
- **スキーマの不一致の処理:**スキーマのずれや項目の不一致があると、レコードがスキーマ却下キューに転送されて確認されます。
- **Checkpoint & Resume:**エクスポートジョブではチェックポイントメタデータが保持されるため、重複のない最後に成功した書き込みから再開できます。
- **統合監視:**失敗と再試行は、可視性と SLA 準拠のために Trust Layer ダッシュボードに記録されます。
Idempotent 設計に関する考慮事項
- **確定的エクスポートキー:**各エクスポートジョブには、セグメント ID + 対象 ID + タイムスタンプで構成される一意の ID が含まれます。
- **リプレイの安全性:**重複するジョブの実行はジョブハッシュを使用して検出され、重複するエクスポートを回避するためにスキップされます。
- **アトミック書き込み保証:**Data 360 は、完全な完了とチェックサムの検証後にのみファイルを対象バケットにコミットします。
- **一貫したスキーマバージョン管理:**エクスポート定義は、実行全体でスキーマの一貫性を確保するためにバージョン管理されます。
- **Checkpoint Persistence:**必要に応じて確定的リカバリと再処理を行うためにエクスポートジョブの状態が保持される
セキュリティに関する考慮事項
- **強力な認証:**クラウドコネクタは、認証済み書き込みに OAuth 2.0、IAM ロール、またはサービスプリンシパルを使用します。
- **あらゆる場所での暗号化:**データは送信中 (TLS 1.2+) と保存中 (AES-256) の両方で暗号化されます。
- **同意に基づくエクスポート:**Trust Layer ポリシーによって適用され、有効な同意があるレコードのみがエクスポートされます。
- **最小権限の原則:**エクスポートユーザーとサービスアカウントは、指定されたストレージパスに制限されます。
- **包括的な監査ログ:**すべてのエクスポートで、コンプライアンスレポート用の開始者、スキーマ、対象、タイムスタンプなどのメタデータが記録されます。
サイドバー
適時性
- 1 秒未満のレイテンシーで即座に有効化できるイベント駆動型です。
- 即座のパーソナライズ、おすすめ、判断が必要なシナリオに最適です。
- ストリーミングモードで動作します。トリガーは、Data 360 で対象データが変更されるとすぐに起動されます。
- バッチスケジュールやセグメントの再計算を待つことなく、継続的な応答性を確保します。
データ量
- 大規模なデータセット (実行あたり数百万件のレコード) を処理します。
- セグメントパーティショニングチャネルと並列エクスポートチャネルで水平に拡張します。
- チャンクベースのバッチ処理を採用してタイムアウトを回避し、スループットを最適化します。
- データの完全性が重要なエンタープライズクラスのデータパイプラインに最適です。
状態管理
- 各イベントアクションは、適切な処理のために独自のイベントトークンとリプレイ ID を保持します。
- 一時的な障害が発生した場合に、最後にコミットされたイベントから再開するためのチェックポイントの保持をサポートします。
- 組み込みの重複排除ロジックとリプレイウィンドウにより、有効化のセマンティックが 1 回限りになります。
- アクションの結果(成功/失敗)は、Real-Time に記録され、Trust Layer observability ダッシュボードに表示されます。
複雑なインテグレーションのシナリオ
- Salesforce フロー、Einstein 1 プラットフォーム イベント、外部 Web フックと直接統合して、即時応答チェーンを実現します。
- 下流の自動化 (CRM レコードのインスタント更新、AI スコアリング、Marketing Cloud メッセージの送信など) をトリガーできます。
- 構成可能なオーケストレーションをサポート:イベント トリガーで Data 360 アクション、Apex 呼び出し、外部 API をコールできます。
- コンテキスト対応応答をすぐに実行する必要があるエージェント型および適応型のエンタープライズパターン向けに設計されています。
例
グローバル小売企業は、Databricks で分析するために「有効なロイヤルティメンバー」セグメントのエクスポートを毎週配信する必要があります。Data 360 管理者は、Amazon S3 を有効化対象として設定し、s3://enterprise-analytics/loyalty/weekly_exports/パスへの毎週の CSV エクスポートをスケジュールします。エクスポートジョブは毎週日曜日に実行され、200 万件以上のレコードを含む同意条件が絞り込まれたファイルが生成されます。 すべてのイベント、スキーマ定義、系統が Trust Layer ダッシュボードに記録され、透明性、監査可能性、コンプライアンスが確保されます。
オンデマンド API ベースの有効化は、一括処理ジョブやスケジュール済みエクスポートを待たずに、必要なときに Data 360 インサイトをアクション可能にするためのリアルタイムのイベント駆動型アプローチです。このパターンでは、固定された頻度で事前作成済みセグメントを公開するのではなく、外部システム、Salesforce アプリケーション、AI エージェントが Data 360 API を直接コールして、特定のオーディエンススライス、顧客属性、インサイトをオンデマンドで取得または有効化できます。 このパターンは、ユーザーがポータルにログインしたとき、エージェントが顧客レコードを開いたとき、AI Copilot が Next Best-Action クエリを開始したときなど、対話型のトリガーベースの環境向けに設計されています。事前計算されたエクスポートを使用するのではなく、Data 360 から最新の管理データをリアルタイムに照会または有効化します。 主な利点は、即時性と精度です。
- すべての API コールは、Data 360 の統合され、同意を認識するプロファイルグラフ内の最新の顧客インテリジェンスにアクセスします。
- 有効化は、エンタープライズの Trust およびコンプライアンス要件に合致した、即効性のある監査可能なものです。
- インテグレーションは、Einstein 1 Platform API、Connect API、有効化 API を使用して、Salesforce フロー、Apex、外部システムから直接トリガーできます。 このアプローチでは、次のような、遅延とパーソナライズが最も重要な使用事例がサポートされます。
- サービスコール中にパーソナライズされた商品オファーをトリガーする。
- ライブ行動イベントに基づいて動的なキャンペーンオーディエンスを生成する。
- エンゲージメントの瞬間で動作する AI または ML モデルにリアルタイムの意思決定を取り込みます。
コンテキスト
多くの場合、企業は社内 Web ポータル、モバイルアプリケーション、パートナー向け Web 環境などのカスタム作成アプリケーション内で、ハーモナイズされたリアルタイムの Data 360 インサイトを表示する必要があります。このパターンにより、開発者は Salesforce CRM や他のコンテキストシステムと共に統合顧客データを使用および表示する安全な UI 中心のソリューションを、すべて管理された API ベースのアクセスを介して構築できます。 一般的な使用事例を次に示します。
- Data 360 インサイトを内部従業員ダッシュボードまたはモバイルアプリケーションに埋め込みます。
- 顧客と取引を表示可能なパートナーポータルまたは販売業者ポータルの作成。
- Data 360 データをサードパーティの Web アプリケーションまたはエクスペリエンスレイヤーに統合する。
- Data 360 および Einstein 1 によりパーソナライズされたリアルタイムのおすすめを表示します。
問題
開発者は、機密情報を複製したりエクスポートしたりすることなく、ハーモナイズされた Data 360 データに安全にアクセスして他の Salesforce データソースと一緒に表示する UI 重視のカスタムアプリケーションをどのように構築できますか? たとえば、企業は Data 360 の統合顧客プロファイル、インタラクション、計算済みインサイトを表示するカスタマーポータルを作成する必要がある場合があります。 これには、Data 360 の内部データモデルの複雑さを抽象化しながら、フロントエンドエクスペリエンスの強化、認証の処理、ガバナンスの確保を行うことができる、安全でパフォーマンスの高い単一の API レイヤーが必要です。
勢力
このパターンには、複数のアーキテクチャと運用上の考慮事項が影響します。
- **UI 中心のアクセス ―**主な目標は、バッチ抽出やバックエンド同期を実行するのではなく、カスタムフロントエンド環境 (Web またはモバイル) 内でデータを表示することです。
- **セキュアゲートウェイ ―**選択した API は、認証済みアプリケーションとユーザーの安全でスケーラブルなエントリポイントとして機能し、エンタープライズクラスのアクセス制御を適用する必要があります。
- **統合データコンテキスト ―**アプリケーションは、Data 360 データ (統合プロファイル、計算済みインサイトなど) を CRM、ERP、またはカスタムオブジェクトデータとシームレスに組み合わせることができる必要があります。
- **開発者のシンプルさ :**API は、クライアントレイヤーでのバックエンド処理またはスキーマの対応付けを最小限に抑えるプレゼンテーション対応のペイロードを返す必要があります。
- **ガバナンスとオブザーバビリティ :**すべてのアクセスは、系統、認証、ポリシー適用が明確で信頼できる監査可能なチャネルを経由する必要があります。
ソリューション
ソリューションは、Salesforce Connect REST API をプライマリ統合ゲートウェイとして使用し、Data 360 上にカスタムのデータ駆動型アプリケーションを構築することです。 Connect API では、UI 消費用に最適化された応答形式 (JSON ベース、軽量、モバイル対応) で、Data 360 のハーモナイズプロファイル、セグメント、計算済みインサイトなどの Salesforce データに RESTful でアクセスできます。 開発者は接続アプリケーションを介して認証し、OAuth 2.0 トークンを取得して、/query、/Chatter、/data などの Connect API リソースをコールし、統合データをアプリケーション インターフェイスに直接表示します。 Connect API は、他の API(クエリ API、データグラフ API、Einstein 1 プラットフォーム API など)の転送基盤としてバックグラウンドで機能し、開発者は複数のデータソースを 1 つの統合されたアクセス パターンにまとめることができます。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| 認証とアプリケーションの登録 | 必須 | OAuth 2.0 ベースの認証用の接続アプリケーションを Salesforce で作成します。Data 360 API アクセスの範囲を設定します。 |
| データアクセス (プロファイル、セグメント、インサイト) | 最善 | Connect API エンドポイント (/services/data/vXX.X/connect) を使用して、ハーモナイズされた Data 360 データ、統合プロファイル、計算済みインサイトを照会します。 |
| UI インテグレーション | 最善 | フロントエンドアプリケーション (React、Angular、iOS、Android) は Connect API をコールして、ダッシュボード、ポータル、またはモバイルインターフェースで Data 360 データを表示します。 |
| データグラフの照会 | 推奨 | Connect API をデータグラフ API と組み合わせて、複雑な結合とリレーションを簡略化するセマンティックレベルのクエリを実行します。 |
| リアルタイム更新 | 省略可能 | ライブデータ更新には、WebSocket またはストリーミング拡張機能で Connect API を使用します。 |
| セキュリティとガバナンス | 必須 | OAuth範囲、Data 360ポリシー、Trust Layer監査フレームワークを使用して、データの表示を適用します。 |
スケッチ
手順の概要を次に示します。
- 接続アプリケーションを登録 — 外部アプリケーション認証の OAuth 範囲と API 権限を定義します。
- アクセストークンの取得 — 外部アプリケーションは OAuth 2.0 認証を実行して、Data 360 アクセスのトークンを受信します。
- Connect API の呼び出し — アプリケーションは、REST API コールを実行して、統合プロファイル、セグメント、またはインサイトデータを取得します。
- Render Data in UI (UI でデータを表示) — 応答が解析され、ブランド設定されたポータルまたはモバイルインターフェースでユーザーに表示されます。
- エラーと更新トークンの処理 — アプリケーションでは、セッションの継続性のために再試行ロジックと自動トークン更新が実装されています。
- Monitor & Audit Access (監視および監査アクセス) — 可視性とコンプライアンスのために、すべての API コールが Trust Layer に記録されます。
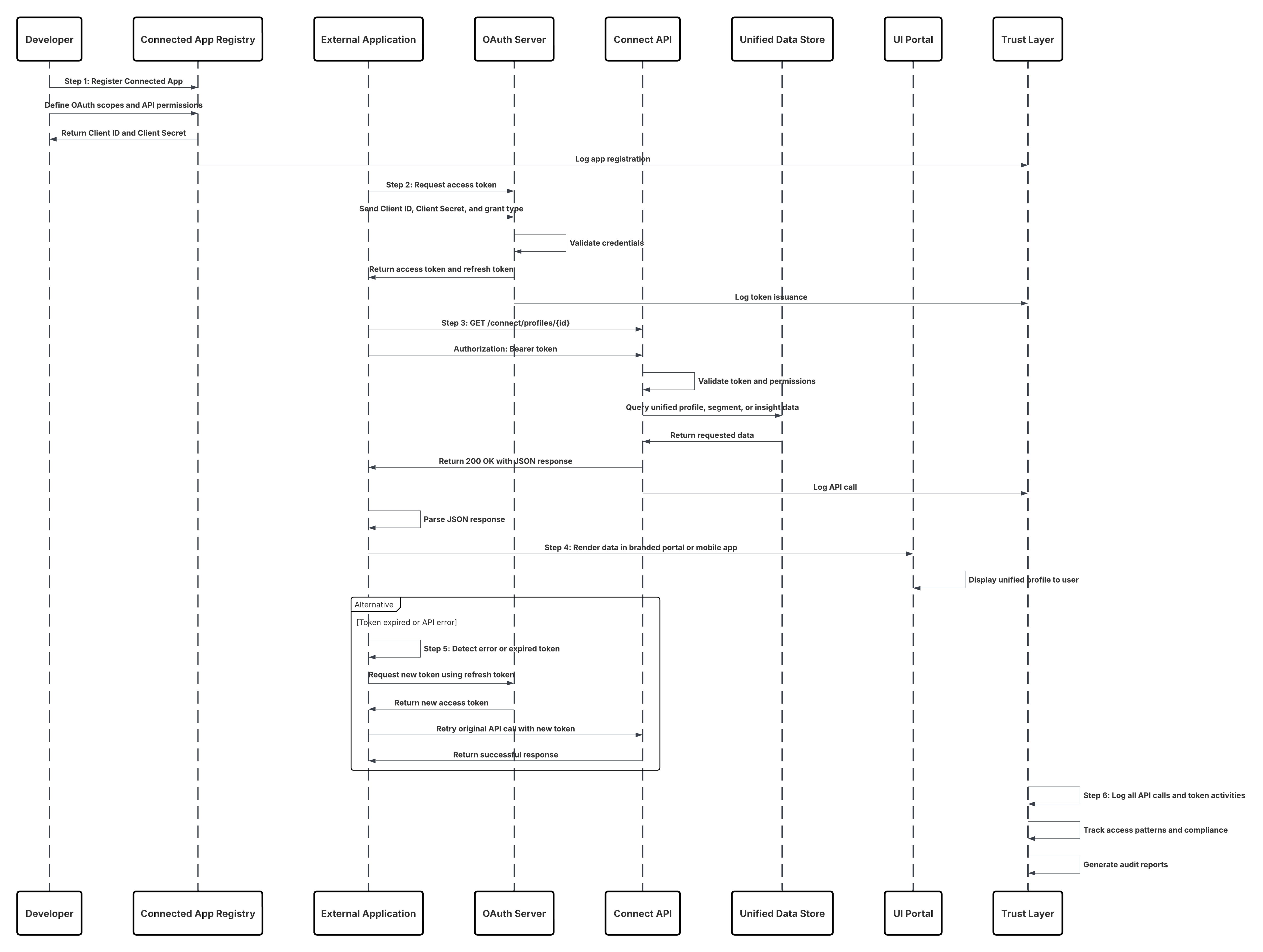
結果
開発者は、Data 360 と緊密に統合された安全なカスタムブランドアプリケーションを作成できます。次のアプリケーションを実行できます。
- ハーモナイズされた顧客プロファイルとインサイトをリアルタイムに表示します。
- 統合 API を使用して、CRM またはカスタムオブジェクトと共に Data 360 データを表示します。
- Trust Layer を介した一貫した認証、承認、監査コントロールを活用します。
- ビジネス ユーザーまたはパートナーに、エクスペリエンス全体で信頼できる顧客インテリジェンスへのシームレスで管理されたアクセスを提供します。
コールメカニズム
コールメカニズムは、対象クラウドストレージプラットフォームと有効化設定によって異なります。
| メカニズム | 使用するケース |
|---|---|
| Connect REST API (優先) | UI に適した JSON 形式で Data 360 データにリアルタイムでアクセスする必要がある Web アプリケーション、モバイルアプリケーション、またはサードパーティアプリケーションを作成する場合に使用します。 |
| データグラフ API | アプリケーションが複数のオブジェクト間でセマンティックレベルのクエリを実行する必要がある場合に使用します (例: 顧客 → トランザクション → キャンペーン)。 |
| Query API | SOQL のようなクエリを実行するときに使用し、ハーモナイズされたデータセットを高い精度で取得します。 |
| Einstein 1プラットフォームAPI | AI 駆動のインサイトまたは Copilot で生成されたおすすめをカスタム UI 内で統合するときに使用します。 |
| MuleSoft または Apex ゲートウェイラッパー | アプリケーションと Connect API 間で追加のオーケストレーション、キャッシュ、またはポリシー適用が必要な場合に使用します。 |
エラー処理と回復
- **Request Throttling:**レート制限の下で自動的に API コールを取り消して再試行します。
- スキーマドリフト保護:GraphQL スキーマバージョン設定または REST メタデータ検出を使用して、スキーマの変更に対応します。
- トークン有効期限管理 – アプリケーションが OAuth トークンを自動的に更新してセッションの中断を回避します。
- API 障害の分離 – 失敗した API コールが記録され、同時セッションに影響を与えることなく再試行されます。
- Trust Layer Observability:API の成功率/失敗率とアクセス ログが Trust Layer ダッシュボードに表示されます。
Idempotent 設計に関する考慮事項
- 確定的要求 ID:各 API 要求には、リプレイセーフな処理のための相関関係 ID が含まれます。
- **キャッシュ検証ヘッダー:**ETag および Last-Modified ヘッダーにより、重複するデータ取得が防止されます。
- **アトミック読み取り操作:**Connect API を使用すると、各応答に、一貫性のある統合データのスナップショットが反映されます。
- リプレイ保護:重複する API コールは、要求の署名とタイムスタンプを使用してフィルタリングされます。
セキュリティに関する考慮事項
- **OAuth 2.0 認証:**すべての API コールで、接続アプリケーションを介した安全で有効期限の短い OAuth アクセストークンが使用されます。
- **最小権限アクセス:**API 範囲は、必要なオブジェクトと項目のみに制限されます。
- **あらゆる場所での暗号化:**転送中の TLS 1.2 以上、キャッシュされた応答または保存された応答の保存時の AES-256 暗号化。
- 同意対応データアクセス:Data 360 では、取得されたすべてのレコードが同意とガバナンスポリシーに準拠します。
- **包括的な監査ログ:**すべての API インタラクションは、ユーザー、アプリケーション、タイムスタンプのメタデータと共に Trust Layer に記録されます。
サイドバー
適時性
- 低遅延のリアルタイム API アクセス用に設計されています。
- 即時のデータ表示が必要なインタラクティブアプリケーションに最適です。
- キャッシュおよびインデックス付けされた Data 360 ソースを介したほぼ即時のクエリ応答時間をサポートします。
- バッチスケジュールや非同期有効化サイクルに依存しません。
データ量
- 中小規模のデータセット (プロファイル、インサイト、最近のトランザクションなど) を取得する対話型の使用事例に最適化されています。
- カーソルベースのページネーションでページ設定された結果を正常に処理します。
- 大量の一括エクスポートは目的としていません。大規模なデータセットには一括エクスポートまたはファイルエクスポートパターンを使用します。
状態管理
- アプリケーションは、OAuth トークンとローカルキャッシュを使用して軽量なセッション状態を維持します。
- Connect API では、効率化のために条件付き要求と部分更新がサポートされています。
- API 応答には、リリース間でスキーマの一貫性を保つためのバージョンマーカーが含まれます。
複雑なインテグレーションのシナリオ
- Connect API とデータグラフ API を組み合わせて、複数のドメインでセマンティッククエリを実行します。
- Einstein 1 Copilot または AI API と統合して、予測的な会話環境を実現します。
- Experience Cloud または Lightning Web コンポーネントと組み合わせて、ハイブリッド UI を開発できます。
- MuleSoft を介して拡張し、データ強化や外部システム参照をリアルタイムで調整します。
例
ある多国籍保険会社は、保険契約者が統合プロファイル、最近の請求、パーソナライズされた提案を参照できる顧客セルフサービスポータルを構築しています。フロントエンドのファクトベースのアプリケーションは、OAuth 2.0 を使用して認証し、Connect REST API とデータグラフ API を使用してデータを取得します。すべてのデータは、同意を認識してリアルタイムで表示され、Data 360 Trust レイヤーを介して管理されます。開発者は API コールと監査履歴を Salesforce 内で直接監視し、完全なコンプライアンスと可観測性を確保します。
コンテキスト
サービスコンソール、レコメンデーションエンジン、パーソナライズプラットフォームなど、リアルタイムの意思決定システムのために、完全な顧客プロファイルへの瞬時のアクセスが企業からますます要求されています。このパターンにより、アプリケーションは Data 360 のデータグラフ API を使用して、事前計算されたほぼリアルタイムの顧客データの統合ビューを取得でき、インタラクティブなエクスペリエンスの応答時間を 1 秒未満に抑えることができます。 一般的な使用事例を次に示します。
- Customer Service または Sales Console 内での全方位的な顧客ビューの表示。
- AI ベースの「Next Best Action」または「Next Best Offer」レコメンデーションの強化。
- ページ読み込み時に高度にパーソナライズされた Web またはモバイル環境を提供します。
- エージェント環境またはセルフサービス環境でのセッション中の決定のサポート。
問題
実行時に低速の複数オブジェクトクエリを実行するのではなく、事前計算された完全な統合顧客ビューをアプリケーションで即座に取得する方法は?たとえば、Web パーソナライズエンジンでは、パーソナライズされたオファーを選択するためにミリ秒以内に完全な顧客コンテキスト (デモグラフィック、設定、トランザクション、計算済みインサイト) を読み込む必要があります。従来のリレーショナルクエリでは、複数の結合が必要であり、許容できない遅延が発生する可能性があります。これには、速度、完全性、ガバナンスを組み合わせた 1 つの鍵参照で取得可能な非正規化されたすぐに使用できるプロファイルデータを提供する API が必要です。
勢力
このパターンには、複数の運用要素とパフォーマンス要素が影響します。
- **速度:**応答時間は nearReal-Time である必要があります。同期インタラクションをサポートするには、API がミリ秒以内に完全なプロファイルを返す必要があります。
- **完全性:**応答には、関連するすべての属性、リレーション、計算済みインサイトが 1 つのペイロードに含まれている必要があります。
- **参照効率:**プロファイルは customerId、contactKey、email などの識別子で取得可能で、複数ステップのクエリが排除されている必要があります。
- **データの新鮮度と遅延:**使用事例によっては、速度のために事前計算された (キャッシュされた) データが必要な場合もあれば、より高いレイテンシーを受け入れるライブデータが必要な場合もあります。
- **ガバナンスとセキュリティ:**アクセスは引き続き Salesforce Trust Layer ポリシーで管理し、データの表示ルールと同意ルールへのコンプライアンスを確保する必要があります。
ソリューション
解決策は、Salesforce データグラフ API を使用して、データグラフレコードとして保存されている事前計算済みの非正規化された顧客ビューを取得することです。データグラフは、複数のデータモデルオブジェクト (DMO) (個人、トランザクション、ProductInterest など) を 1 つの参照のみのレコード (多くの場合 JSON Blob として表される) に結合する具体化されたセマンティックビューです。 開発者は次のような REST エンドポイントを使用できます。 GET /api/v1/dataGraph/{dataGraphEntityName}/{id} 一意の識別子を使用して完全なレコードを取得します。動的シナリオの場合、API では、具体化されたキャッシュをバイパスする live=true パラメーターがサポートされ、Data 360 全体でリアルタイムクエリが実行され、最新のデータに対して最小限の遅延が取引されます。 これにより、開発者はビジネスニーズに応じて、瞬時のプロファイル取得 (キャッシュ) と最新のプロファイル取得 (ライブ) を選択できます。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| データグラフ定義 | 必須 | アーキテクトは、複数の DMO を 1 つのセマンティックエンティティ (UnifiedCustomerProfile など) にまとめるデータグラフを定義します。 |
| プロファイルルックアップの取得 | 最善 | アプリケーションは GET /api/v1/dataGraph/{entity}/{id} をコールして、一意の ID またはキーで非正規化された完全なプロファイルを取得します。 |
| ライブパラメーターの利用状況 | 省略可能 | キャッシュされた取得ではなく、新しい計算を強制するには ?live=true を付加します。重要な決定に適しています。 |
| 認証 | 必須 | API コールを安全に認証するには、接続アプリケーションを介して OAuth 2.0 を使用します。 |
| 応答解析 | ベストプラクティス | アプリケーションは JSON 応答を UI または決定エンジンに直接解析します。それ以上の結合は必要ありません。 |
| キャッシュ戦略 | 推奨 | プロファイルの参照を繰り返すために短期ローカルキャッシュ (メモリ内や CDN など) を実装します。 |
| 監視とオブザーバビリティ | 必須 | Trust Layerダッシュボードを使用して、クエリのパフォーマンス、応答時間、ポリシー遵守を監視します。 |
スケッチ
実装フローの概要を次に示します。
- データグラフを定義 — データアーキテクトは、複数の DMO にわたる統合顧客ビューをモデル化するデータグラフを作成します。
- 接続アプリケーションを登録 — 開発者は安全な API アクセスのために OAuth ログイン情報を設定します。
- データグラフの呼び出し API — アプリケーションは、データグラフ名とレコード ID を使用して GET 要求を発行します。
- プロセス応答 — API は、顧客プロファイルの完全な JSON 表現を返します。
- 表示または操作 — 消費アプリケーション (UI またはエンジン) は、パーソナライズ、おすすめ、またはサービスアクションに統合データを使用します。
- 監視と調整 — パフォーマンス評価指標とアクセス ログは Trust Layer の可観測性コンソールで確認できます。
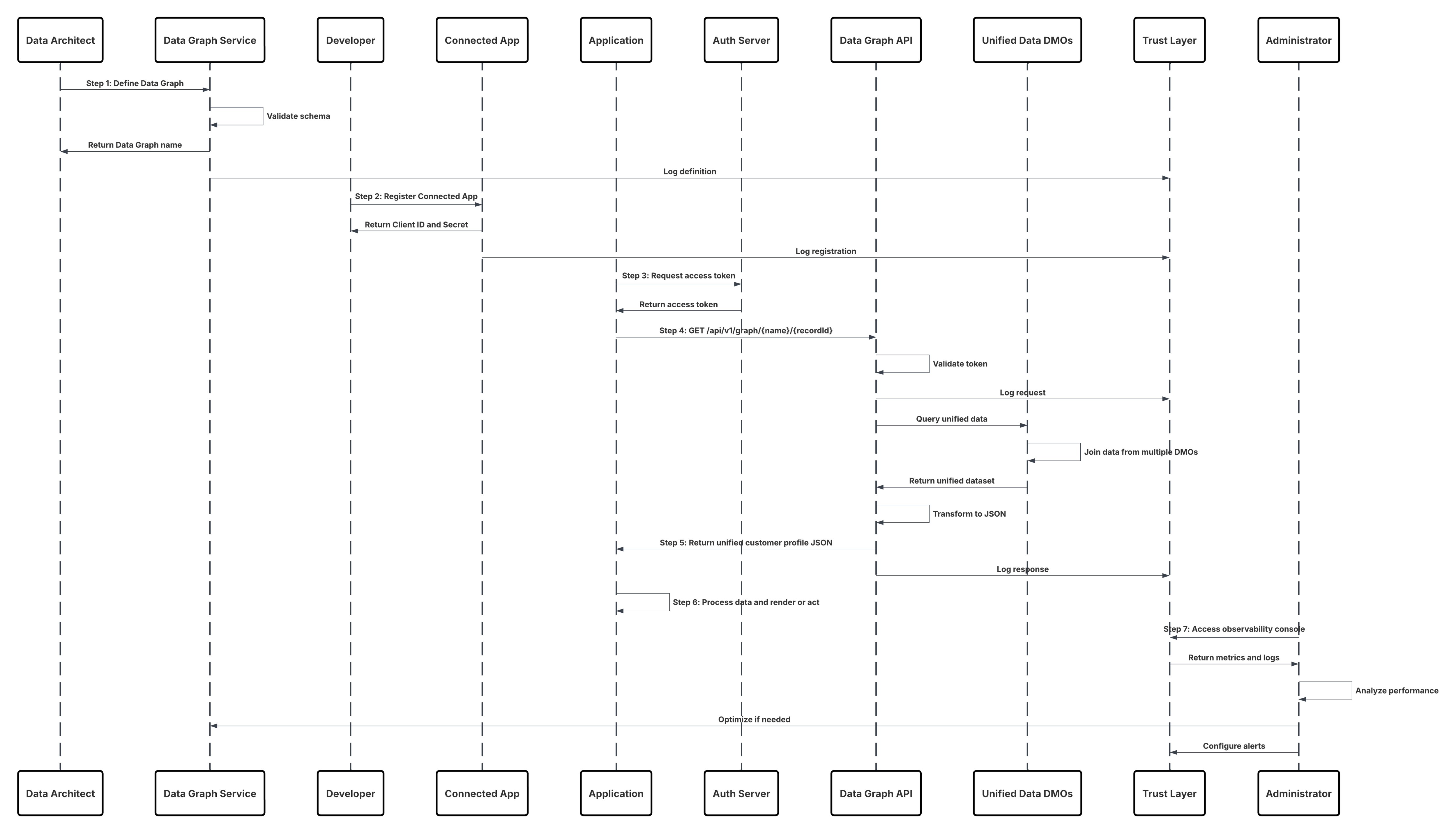
結果
アプリケーションは、事前参加済みの完全な顧客プロファイルをすぐに取得できるようになり、パーソナライズ、サービス、意思決定の自動化などのリアルタイムインタラクションを強化できます。 このパターンにより、次のことが保証されます。
- 瞬時の意思決定のための 1 秒未満の応答時間。
- Data 360 セマンティックモデルに準拠した一貫性のある管理されたデータ取得。
- アプリケーションロジックの簡略化 — 結合やスキーマの調整が不要。
- Trust Layer を介した追跡可能でコンプライアンスに準拠したアクセスにより、監査と監視が可能になります。
コールメカニズム
コールメカニズムは、対象クラウドストレージプラットフォームと有効化設定によって異なります。
| メカニズム | 使用するケース |
|---|---|
| データグラフ API (優先) | ID または鍵で完全な事前具体化されたプロファイルをすぐに取得するために使用します。 |
| live=true のデータグラフ API | 最新のデータが必要で、若干高いレイテンシを受け入れる、価値の高い使用事例 (不正行為の検出、ライブオファーなど) に使用します。 |
| Connect API (フォールバック) | データグラフの取得と他の Salesforce データを組み合わせた複合アプリケーションのシナリオに使用します。 |
| Query API | プロファイルのインスタント取得ではなく、アドホッククエリまたは分析読み取りを作成する場合に使用します。 |
| MuleSoft API Proxy | エンタープライズゲートウェイを介してデータグラフコールを転送する場合や、追加のオーケストレーション/ポリシー適用が必要な場合に使用します。 |
エラー処理と回復
- グレースフルフォールバック – ライブクエリが失敗したかタイムアウトしきい値を超えた場合、自動的にキャッシュされたデータグラフの取得に戻ります。
- タイムアウト管理 – 高負荷時の API コールの再試行およびサーキットブレーカーロジックを実装します。
- 無効な ID 処理 – 存在しないプロファイル キーに対して標準の 404 Not Found 応答を返します。UI で適切に処理します。
- スキーマバージョン検証 – データグラフバージョンのメタデータを検証して、スキーマが進化するときの不一致を防止します。
- Observability Integration(オブザーバビリティ統合) – Trust Layer ダッシュボード内のすべてのエラー、再試行、および遅延を記録して、SLA を監視します。
Idempotent 設計に関する考慮事項
- 確定的鍵 – 各プロファイル取得では、安定した ID (IndividualId など) を使用して、予測可能でリプレイセーフなクエリを保証します。
- キャッシュの一貫性 – 条件取得とキャッシュ検証に ETag または Last-Modified ヘッダーを使用します。
- アトミック取得 – 各 API 応答は、マテリアライズドデータグラフレコードの一貫したスナップショットを表します。
- リプレイ保護 – クライアント アプリケーションが相関関係 ID とタイムスタンプを使用して重複する取得を検出します。
セキュリティに関する考慮事項
- 強力な認証 – 接続アプリケーションを介した OAuth 2.0 により、安全なトークン ベースのアクセスが適用されます。
- 同意認識取得 – 同意済み属性のみが返されます。同意フィルタは Trust Layer によって自動的に適用されます。
- 項目レベルガバナンス – 属性へのアクセスは、Data 360 のメタデータとポリシー定義を使用して制御されます。
- 転送中および保存中の暗号化 – すべての応答が TLS 1.2+および AES-256 で暗号化されます。
- 監査とトレーサビリティ – すべてのプロファイル取得イベントが識別子、タイムスタンプ、ポリシー コンテキストと共に記録されます。
サイドバー
適時性
- 即時取得用に設計されています。
- 若干高い遅延 (1 秒未満) で最新のデータに対するライブクエリをサポートします。
- 同期的な判断と対話型のアプリケーション向けに最適化されています。
- 事前バッチの有効化やセグメントの再計算が不要になります。
データ量
- 要求あたりの単一レコード検索または小規模なセット (数十から数百) に最適です。
- 大規模な一括取得には最適化されていません。大量の読み取りには、バッチまたはクエリ API を使用します。
- 水平方向に拡張可能なキャッシュと事前具体化を採用して高速化。
状態管理
- 軽量でステートレスなアクセスを維持します。各要求は独立しています。
- リプレイセーフな取得のためのヘッダーのキャッシュをサポートします。
- アプリケーションは、ローカルキャッシュまたは短期セッションストレージを保持して、繰り返し参照を減らすことができます。
複雑なインテグレーションのシナリオ
- Einstein 1、Connect API、MuleSoftとシームレスに統合して複合データ環境を実現します。
- 瞬時のコンテキスト認識を必要とするエージェント システム(Copilot や AI 推論エンジンなど)を強化できます。
- データアクションと組み合わせて、取得時または状態変更時にリアルタイムトリガー。
- パフォーマンスやガバナンスを損なうことなく、大規模にパーソナライズできます。
例
グローバルな E コマースプラットフォームでは、Data 360 のデータグラフ API を使用して、レコメンデーションエンジンの統合顧客プロファイルをリアルタイムで取得します。ユーザーがログインすると、アプリケーションはデータグラフエンドポイントを呼び出してその顧客の UnifiedCustomerProfile を取得し、デモグラフィック属性、行動シグナル、計算済みインサイトを 1 つの JSON ペイロードとして返します。パーソナライズエンジンはミリ秒以内にこの応答を使用して、有効なセッション中に「Next Best Offer」を判断して表示します。すべての要求はTrust Layerを介して管理および記録され、インタラクション全体の完全な表示、ポリシーの適用、コンプライアンスが保証されます。
リアルタイムデータアクションにより、Data 360 で顧客データが変更された瞬間にすぐに有効化できます。これらのアクションは、スケジュールされたバッチエクスポートを待機するのではなく、更新、インサイト、トリガーを Salesforce または外部システムに直接ミリ秒で転送します。Data 360 で顧客の状況、同意、またはエンゲージメント評価指標が更新されると、そのシグナルによってパーソナライズされたオファーをすぐに強化したり、Service Cloud の自動化をトリガーしたり、ロイヤルティランクを更新したりできるため、すべてのカスタマーエクスペリエンスに最新の統合された真実が反映されます。 このパターンは、パーソナライズされた Web 環境、不正行為検出アラート、Next Best-Action のおすすめ、リアルタイム CRM 更新など、影響が大きく、レイテンシの影響を受けやすい使用事例に最適です。データインサイトとビジネスアクション間のギャップを埋め、統合データを一瞬のインテリジェンスに変換します。
コンテキスト
最新のデジタル エクスペリエンスと運用ワークフローでは、イベントが発生した瞬間にコンテキストに基づいたアクションをすぐに実行する必要があります。たとえば、Checkout 中に顧客レコードを更新したり、返品がスキャンされたときに在庫を調整したり、ユーザーがカートを破棄したときにパーソナライズされたプロモーションを提供したりします。**リアルタイム データ アクション**により、システムは統合 Data 360 プロファイルと計算済みインサイトを 1 秒から 2 秒未満のレイテンシで呼び出し、強化し、アクションを実行できるため、対話型のパーソナライズ、運用の自動化、即時の意思決定が可能になります。
問題
アプリケーション、UI インタラクションフロー、またはミドルウェアを実行時に Data 360 にコールして、スケジュールされた一括処理ジョブや重量級パイプラインを待たずに、1 つの統合プロファイルを参照、計算、更新したり、低レイテンシー、強力な一貫性、ガバナンス制御でアクション (提案の送信、CRM の更新、ワークフローの開始など) をトリガーしたりする方法は?
勢力
このパターンは、複数の技術、運用、ガバナンスの部門によって形成されます。
- **低レイテンシの要件:**優れた UX を維持するため、または業務 SLA を満たすために、通話は 1 秒未満から数秒の範囲で完了する必要があります。
- **確定的 ID 解決:**要求は、正しい統合個人プロファイル (ゴールデンレコード) に確実かつ迅速に解決する必要があります。
- **きめ細かな認証:**リアルタイムコールでは、要求時に属性レベルのポリシーと同意チェックを適用する必要があります。
- **ペイロード最小化:**リアルタイムペイロードは、遅延とコストを削減するために、小さくて焦点を絞る必要があります (1 つのプロファイルまたは小さな属性セット)。
- **開発者エクスペリエンス:**API は、明確なスキーマと本番で使用する安定した契約があり、開発者にとって使いやすいものである必要があります (REST/gRPC/GraphQL)。
- **監査性とトレーサビリティ:**すべてのリアルタイムアクションは、コンプライアンスのために系統、ユーザー ID、およびポリシー決定を使用して記録する必要があります。
ソリューション
推奨されるソリューションは、Data 360 のリアルタイム データ アクション インターフェイス(API + SDK)を、必要に応じてエッジ キャッシュと最小限のコンピューティング変換と組み合わせて使用することです。インテグレーションは、データアクションエンドポイントを呼び出して、プロファイル属性の読み取りまたは書き込み、インサイトの計算、オーケストレーションの開始を行います。ペイロードが返されたりアクションが実行されたりする前に、リアルタイムポリシーチェック (CEDAR) と動的マスキングがポリシー適用ポイントに適用されます。
| ソリューション領域 | 適合 | コメント/実装の詳細 |
|---|---|---|
| リアルタイムデータアクション | 最善 | 単一レコードの参照・更新トリガーとアクショントリガーのエンドポイントを公開します。OAuth/JWT を使用して認証します。 |
| ID 解決 | 必須 | 受信識別子 (メール、externalId、Cookie) をインラインで統合個人 ID に解決します。キャッシュで確定的リゾルバーを使用します。 |
| ポリシー適用 (CEDAR) | ベストプラクティス | 要求時に同意、ABAC、マスキングポリシーを評価し、ポリシーの決定ごとに項目を拒否またはマスキングします。 |
| Edge/Cache Layer | 推奨 | プロファイルフラグメントと計算済みインサイトの短い TTL キャッシュを使用して、遅延を減らし、変更イベントで無効化します。 |
| 軽量変換 | 推奨 | アクションパスに単純な強化または計算項目を適用します。重い変換は事前に計算する必要があります。 |
| アクションオーケストレーション | 最善 | 複雑なフローの同期シングルステップアクション (返品提案トークンなど) と非同期オーケストレーション (キュー \+ Web フック) をサポートします。 |
| オブザーバビリティと追跡 | 必須 | 要求/レスポンス、ポリシーの決定、系統を監査とデバッグのためにTrust Layer/SIEMに記録します。 |
| レート制限および調整 | 必須 | トラフィックが多い瞬間にクライアント割り当てとグレースフルデグラデーション戦略を適用します。 |
スケッチ
手順の概要を次に示します。
- クライアント (UI/ミドルウェア/POS) は、ID とアクション種別を使用して認証済みデータアクション要求を送信します。
- API ゲートウェイは、トークン、レート制限を検証し、Data 360 Action Service に転送します。
- アクションサービスで識別子を解決 → 統合個人 ID (高速パスキャッシュ、グラフルックアップへのフォールバック)。
- Policy Enforcement (PDP) では、PIP および要求コンテキストの属性を使用して CEDAR ポリシーが評価されます。
- 許可されている場合、アクションサービスは必要なプロファイル属性/インサイトを読み取り、簡易変換を実行します。
- アクションサービスは、応答 (オファートークン、更新された属性など) を同期的に返すか、非同期オーケストレーションをキューに入れて確認応答を返します。
- すべてのイベント、決定、ペイロードは Trust Layer に記録され、必要に応じて SIEM に転送されます。
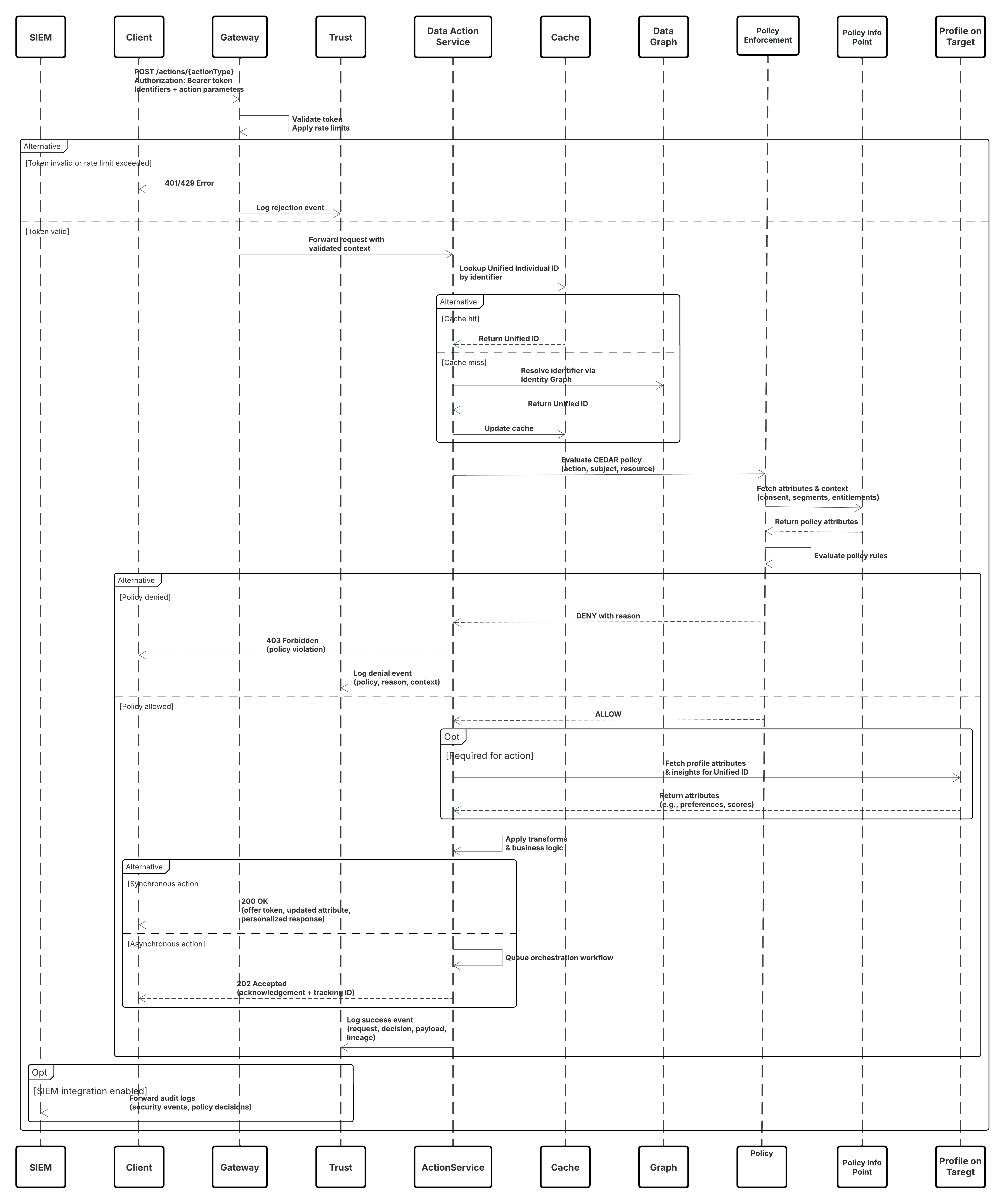
結果
- アプリケーションは、1 秒から 2 秒未満のレイテンシーで、統合プロファイルの読み取り/書き込みとアクショントリガーへのポリシーで管理されたアクセス権をすぐに取得できます。
- リアルタイムのパーソナライズ、判断、業務ワークフロー (提案、エージェント支援、在庫の更新など) がバッチ遅延なしで有効になります。
- すべてのアクションは監査可能で同意を認識し、プライバシーとコンプライアンスを維持するために属性レベルのマスキングを適用します。
コールメカニズム
コールメカニズムは、対象プラットフォームと有効化対象の設定によって異なります。
| メカニズム | 使用するケース |
|---|---|
| RESTful データアクション API | 同期プロファイル読み取りまたはアクション応答が必要な Web/モバイルアプリケーションおよびミドルウェアに適しています。 |
| gRPC/バイナリRPC | 永続的な接続を使用する超低レイテンシのエンタープライズサービスまたは内部マイクロサービスに使用します。 |
| GraphQL 単一レコードクエリ | クライアントが柔軟な項目選択を必要とし、ペイロードを最小限に抑えたい場合に使用します。 |
| イベントトリガー Web フック | アクションによって下流プロセスがトリガーされる非同期ワークフロー (ジャーニーの開始など) に使用します。 |
| プラットフォームイベント/PubSub | 複数のシステムが 1 つのアクションイベントに反応する必要があるファンアウトシナリオに使用します。 |
| Edge SDK (クライアントライブラリ) | プロファイルフラグメントをキャッシュし、必要な場合にのみデータアクション API をコールする低遅延クライアントに使用します。 |
エラー処理と回復
- **同期エラー:**人間が判読可能なメッセージと緊急トークンを使用して構造化されたエラーコードを返します。
- **一時的な再試行:**クライアントは、429/5xx 応答の指数バックオフを使用して緊急要求を再試行する必要があります。
- **Policy Deny Handling:**拒否されると明確な理由コードが返されます。機密データはポリシー違反時に返されません。
- **Async Orchestration Failures:**オーケストレーションジョブは DLQ に移動し、再生可能です。ジョブ状況 API を使用すると、クライアントはコールバックをポーリングまたは受信できます。
- **フォールバック戦略:**ID 解決に失敗した場合は、確定的エラーと、必要に応じて推奨の是正措置 (externalId が必要など) を返します。
Idempotent 設計に関する考慮事項
- **Idempotency Key:**クライアントは、アクションを変更するための緊急キー (UUID + クライアント名前空間) を提供します。
- **確定的キー:**複合キー (UnifiedIndividualId + ActionType + TimestampWindow) を使用して重複を検出します。
- **安全な再試行:**アクションは、副作用に寛容であるか、ブラインド挿入ではなく更新/挿入を実行するように設計します。
- **リプレイ保護:**リプレイを回避するために、処理済みの緊急キーを保持し、営業時間後に TTL 処理します。
- **ステートレス:**可能な場合は同期アクションをステートレスのままにし、非同期ワークフローの場合は最小限の状態を維持します。
セキュリティに関する考慮事項
- **認証:**OAuth 2.0 (サービスアカウントの JWT ベアラーまたは mTLS)、有効期間の短いトークンと更新の循環。
- **承認:**Policy Decision Point は、要求ごとに属性ベースのアクセス制御 (CEDAR) と同意チェックを適用します。
- **トランスポートとストレージの暗号化:**転送中の TLS 1.2+。キャッシュされたフラグメントまたは監査ログの保存時は AES-256。
- **最小権限:**API クライアントの範囲は最小限の権限のみ。ロールは参照と更新、オーケストレーションで区別されます。
- **データの最小化:**要求された属性と同意済みの属性のみを返します。PII/PHI には動的マスキングを適用します。
- **ネットワークコントロール:**必要に応じて、高リスクのアクションのためにプライベートネットワーク (プライベートコネクト、IP 許可リスト) からのコールを要求します。
- **監査と監視:**要求メタデータ、ポリシーの決定、要求者の ID、応答ハッシュを Trust Layer と SIEM に記録します。
サイドバー
適時性
- 同期アクションで 1 秒未満から 1 秒未満までの平均遅延に対応するように設計されています。
- エッジキャッシュ (短い TTL) と事前計算済みインサイトにより、ラウンドトリップが減少します。
- 非同期パスでは、重いタスクのバックグラウンド処理でほぼ即座に確認応答が提供されます。
データ量
- 単一レコードまたは少量のバッチインタラクション (1 ~ 100 レコード) に最適化されています。
- 一括エクスポートは目的としていません。大量の場合は一括有効化を使用します。
- 高スループットでは、プーリング/接続の再利用と並列オーケストレーション キューが使用されます。
状態管理
- 同期コールのステートレスな要求モデル。助成金/トランザクションで保持される最小限のアクション状態。
- 変更イベントによるキャッシュ無効化 — TTL と無効化シグナルによってキャッシュが最新に保たれるようにします。
- オーケストレーション ジョブは、Trust Layer に保存された耐久性のある状態(jobId、status、retries)を維持します。
複雑なインテグレーションのシナリオ
- **エージェント支援:**リアルタイムのプロファイルルックアップ + エージェントが 1 秒以内にサービスコンソールに返される計算済み傾向。
- **POS/エッジ デバイス:**ローカル SDK + プロモーションまたはロイヤルティ状況を検証する臨時データアクション。
- **ハイブリッド フロー:**意思決定 + 非同期オーケストレーション用の同期データアクションでダウンストリームシステムを更新し、キャンペーンをトリガーします。
- **サード・パーティ製ミドルウェア:**MuleSoft または API ゲートウェイは、認証の仲介、コンテキストの強化、追加のポリシーチェックの適用を行うことができます。
例
小売モバイル アプリケーションは、買い物客のメールおよびカート コンテキストを使用してオファー対象資格データ アクションを呼び出すことで、買い物客が Checkout をタップすると、パーソナライズされたインスタント クーポンを表示するかどうかを決定します。要求は API ゲートウェイによって検証され、データアクションサービスに転送されます。データアクションサービスは、キャッシュヒットを使用してメールを統合個人 ID に解決し、PDP を介してマーケティングの同意を検証し、顧客の生涯価値と最近の購入履歴に基づいて対象資格を評価します。買い物客が対象である場合、サービスは署名済みクーポントークンを返し、決定を記録します。クーポンの発行で在庫予約が必要な場合、在庫を予約して CRM システムに通知するための非同期オーケストレーションがトリガーされます。アプリケーションはクーポンをすぐに表示します。ダウンストリームの更新はバックグラウンドで完了し、Trust Layer はガバナンスとコンプライアンスのための完全な監査履歴を取得します。