このテキストは、Salesforce の自動翻訳システムを使用して翻訳されました。アンケートに回答して、このコンテンツに関するフィードバックを提供し、次に何を表示するかをお寄せください。
データプラットフォームは 30 年以上進化し続けています。当初は、この業界はオンプレミスの一元化された構造化された (主にリレーショナルの) 運用/OLTP データベースが主流でした。これは、主に分析処理に使用され、リレーショナルで一元化されたデータウェアハウス OLAP/Big Data プラットフォームを含むように拡張されました。クラウド ストレージは、データ ウェアハウス、レイクハウス、分離ストレージなどの分散アーキテクチャを推進しました。ただし、業務プラットフォームと分析プラットフォームは別々でした。今日、クラウド コンピューティングとAI革命によって、データ プラットフォーム アーキテクチャが根本的に変化しています。
企業は、Snowflake、Databricks、BigQuery、Redshift などの成熟したビッグデータプラットフォームにすでに投資しています。ただし、これらのプラットフォームはデータサイロとして機能します。データはビジネスフローやアプリケーション内で直接操作できないため、お客様はデータからビジネス価値を引き出すことはできません。これらのソリューションは生成エージェント型 AI 処理がなく、データアクセスをリアルタイムで提供できないため、顧客エンゲージメントの瞬間に AI 主導のパーソナライズや他の業界をリードする機能を提供できません。
データプラットフォームの未来は、統合され、柔軟で、アクセス可能で、オープンなデータインフラストラクチャによって特徴付けられます。この新しいアーキテクチャは、最新のコンピューティングとストレージのトレンド (GPU、大容量メモリ、NVMe SSD、クラウド ストレージ) に基づいて構築されており、クラウドコンピューティングと AI と統合します。リアルタイムのインサイトを提供し、自律的な意思決定を強化し、リアルタイムアプリケーションを促進できます。これには、エージェント型 AI、予測 AI、分析、リアルタイムの大規模 OLTP データベース、データレイク、レイクハウスの台頭が含まれます。これらの最新のデータプラットフォームは、シンプルさ、拡張性、俊敏性、パフォーマンス、セキュリティ、可用性、コスト効率を考慮して設計されています。
次のデータトレンドは、次世代データプラットフォームアーキテクチャを推進します。
- コアとなるAI、機械学習、分析:エージェント型 AI の台頭により、データプラットフォームの開発、リリース、利用状況/アクセスが根本的に変わります。エージェント型 AI が会話/クエリのインテントを理解し、計画し、ワークフローを生成し、意思決定を自動化します。エージェント的 (短期および長期) 記憶は会話履歴から構築され、エージェントの計画と意思決定、リアルタイムの会話モデリング、データプラットフォームで重要なパーソナライズサポートをパーソナライズします。エージェントは、データ ガバナンス(セキュリティ、コンプライアンス、Trust)、パフォーマンス(同時実行、スループット、レイテンシの自動拡張)、フェールオーバー、可用性、オブザーバビリティ、メンテナンスなどの運用上の「機能」の自動化を支援します。AI を駆使した分析、売上予測、分析 Q/A の自然言語処理 (NLP)、非構造化データ (PDF、画像、音声、動画などのテキスト) の分析が標準となり、企業はさまざまなデータソースからより深いインサイトを取得できます。
- データの分散と統合データアクセス:エージェントがインサイトを取得して意思決定を行い、ビジネス活動を自動化するには、エンタープライズデータが必要です。データは本質的に、企業内のさまざまなアプリケーションやデータプラットフォームで分散化されています。ただし、社内のさまざまなビジネスユニット間や社外のパートナーとシームレスにサイロを統合するのは容易ではありません。データの統合には、ソースからの取り込みまたはデータ ソースとの連携によるデータ共有、分析およびAI処理のためのデータプレップ、ハーモナイゼーション、モデリングからの未加工データ、低CTSで効率的なアクセスを実現する大規模なデータの保存と管理、基盤となるストレージおよびデータ アクセス プラットフォームと密接に統合されたさまざまなクエリおよび分析メカニズムとツールによるデータ アクセスが含まれます。
- クラウド ベースのオープン レイクハウス:クラウドベースのビッグデータ (OLAP) プラットフォームは、データの統合 (データイン) と共有 (データアウト) を可能にするオープンファイル形式 (Parquet) とテーブル形式 (Iceberg) の採用に集約されています。
- 非構造化データ処理:生成 AI の出現、進歩、採用に伴い、企業は大量のテキストドキュメント、音声トランスクリプト、動画記録などのメディアで構成されるエンタープライズコーパスから貴重なインサイトとビジネス価値を引き出し始めています。チャンク、ベクトル化、セマンティック検索、Knowledgeグラフなどの非構造化データ処理により、これらのインサイトが可能になります。RAG (取得増強生成) や CAG (キャッシュ増強生成) などの手法は、データコーパス全体の高速かつエージェント的な検索の主流となっています。
- Knowledge Management
は、未加工のコンテンツ自体(ドキュメント、記事、動画)にとどまりません。意味を導き出し、メタデータを選定し、コンテキストに配置して、組織や企業全体でコンテンツについて共通の理解を育むことで、そのコンテンツの強化を表します。Knowledge自体は一般的に構造化されています。Knowledge Managementには、コンテンツ管理、Knowledge抽出、グラフなどのモデルを使用した表示、ナビゲーションが含まれます。 - 豊富なデータアクセス:豊富なデータアクセスとは、エンドユーザー、ビジネスユーザー、システム管理者、アナリストなど、さまざまな人格がデータ、分析、AI ツールにアクセスできる必要があることを意味します。アクセシビリティは、アンサンブルクエリ (リレーショナルクエリ、キーワードクエリ、セマンティッククエリを使用)、自然言語から SQL (NL2SQL) へのクエリ、リアルタイムアクセスなどのメカニズムによって実現されます。
- リアルタイム処理:エージェントアプリケーションは、現在の状態と新しいイベントに基づいてリアルタイムの意思決定を行い、応答とアクションをパーソナライズします。アクションには、リアルタイムデータへのアクセス、処理、およびアクションが必要です。リアルタイム処理には、最新のデータ (データ遅延) と対話型アクセス (アクセス遅延) が必要です。このようなデータとアクセス遅延には、業務ストアや分析ストアからの最新データアクセス、低遅延アクセス (ポイントルックアップとクエリ) 処理、高いデータスケール、高いスループットをサポートするための基盤となるデータプラットフォームが必要です。
- データ セキュリティ、ガバナンス、レジデンシー:エージェント型 AI と会話型 AI により、アプリケーション UI が簡素化され、消費者から従業員、他の AI エージェントまで、誰もが話し言葉や記述された自然言語を使用して対話形式でアプリケーションを操作できます。Agentic アプリケーション用に保存およびモデル化する必要がある貴重な顧客および個人データは、明確に定義されたアクセスおよび共有ポリシーで保護および管理する必要があります。ますます多くの顧客が、自国の国または地域でデータレジデンシーを必要とする規制に準拠する必要があります。特に、政府関係者や政府関係者です。
Salesforce Data 360 は、これらのデータトレンドに対応する将来に向けて設計されています。Data 360 は、企業全体のサイロ化されたデータを統合するクラウドネイティブのメタデータ駆動型データプラットフォームです。これにより、組織はデータを保存、モデル化、処理して、分析、AI、機械学習、エージェントアプリケーションを有効にできます。
このドキュメントは、エンタープライズアーキテクトと CTO にとって不可欠なガイドです。Data 360 のアーキテクチャ、機能、設計原則、使用事例について詳しく説明します。Data 360 アーキテクチャの基本を入門編として紹介し、続いて、マルチ組織戦略、セキュリティ、ガバナンスとプライバシー、リアルタイム有効化、データクリーンルームなど、既存のデータプラットフォームとの相互運用性など、Data 360 アーキテクチャの主な差別化要因について詳しく説明します。
Salesforce Data 360 は、エンタープライズデータを運用、信頼、およびリアルタイムで利用できるようにするためのコア原則セットに基づいて設計されています。
- オープン性と相互運用性:マルチクラウドエコシステム向けに構築されています。Snowflake、Databricks、BigQuery、Redshiftなどのデータ プラットフォームを重複なしで統合し、既存の投資を維持しながらCustomer 360を拡張します。
- ストレージとコンピューティングの分離:ストレージと処理 (バッチ、ストリーミング、インタラクティブ) を個別に拡張します。大規模でハイ パフォーマンスのワークロードに弾力性と効率性を提供します。
- マルチモデルのストレージと処理:テキスト、画像オーディオ、動画などの構造化されたさまざまな非構造化データ型をサポートします。効率的なストレージ、リアルタイムおよびバッチ処理、拡張可能なインデックス付け、統合検索、クエリ、分析を提供します。
- メタデータ駆動設計:アプリケーションは、コードではなくメタデータで定義されます。メタデータは第一級のアセットとして扱われ、統合ガバナンス、柔軟性、Salesforce Platform への緊密な統合を実現します。
- リアルタイムハイブリッド処理:バッチ処理および分析ワークロードと共に、低レイテンシのクエリとインスタント意思決定をサポートします。
- インテリジェントでアクティブなデータ:インサイトを継続的に取り込み、分析し、ビジネスワークフローに直接転送します。最新のコンテキストを使用して、ノーコード、ローコード、プロコード、AI 駆動の自動化を強化します。
- 設計によるガバナンスとプライバシー:系統、アクセス制御、レジデンシー、データ暗号化、コンプライアンスが組み込まれています。Trustと規制の信頼性がすべてのレイヤーで強化されます。
- 1対多のテナント:一元化されたData 360組織は、Customer 360の単一の情報源として機能し、Salesforceのお客様に広く使用されている複数組織のセールスフォース環境をシームレスにサポートします。
これらの原則により、Data 360 はリアルタイムでデータをオープン、インテリジェント、アクション可能にします。
Salesforce Data 360 は、現在のデータトレンドに対応する設計原則に基づいて構築された最新のデータプラットフォームです。そのアーキテクチャ機能により、エンタープライズデータは、その指針に従ってリアルタイムで信頼性と統合され、アクションを実行できます。
- クラウド ネイティブ基盤:不変のマイクロサービス ベースのインフラストラクチャを使用して、Hyperscaler(AWSなど)に導入されるHyperforceで実行されます。柔軟な拡張、ゼロトラスト セキュリティ、継続的なデリバリ、グローバル コンプライアンスを実現します。
- Salesforce (コア) メタデータ駆動型:メタデータは、Salesforce メタデータとして設計、モデル化、保存され、すべての Salesforce アプリケーションですぐに使用できます。このようなメタデータは、完全に ACID 準拠の RDBMS に保存されます。ガバナンス、ライフサイクルの一貫性、Salesforce Lightning Platformとの緊密な統合を実現します。
- Lakehouse Storage
Iceberg と Parquet を基盤に構築され、スキーマの進化、タイムトラベル、大量の更新をサポートするデータレイクスケールとウェアハウスガバナンスを組み合わせています。Data 360 は、最新のオープンスタンダードを備えた大規模なストレージと、バッチおよびイベント駆動型ワークロード向けの豊富な変換およびデータ処理能力を使用して、構造化データと非構造化データを保存、モデル化、処理します。 - 柔軟な取り込みによるエンド ツー エンドのデータ パイプライン:ライフサイクル全体 (取り込み、準備、モデル化、統合、分析、有効化) をカバーし、断片的なポイントソリューションへの依存を軽減します。270 以上のコネクタと MuleSoft でバッチ、ほぼリアルタイム、ストリーミングをサポートします。ELT ファーストのアプローチにより、ダウンストリーム変換の柔軟性を維持しながらデータの迅速な可用性を実現できます。
- オープン フレームワークおよび統合とのエンタープライズ データの相互運用性
、Databricks、BigQuery、Redshift との双方向の Zero Copy 統合により、データの移行や重複を回避し、企業全体のサイロ化されたデータを統合します。 - データ分類、モデリング、および整理 360 では、取り込まれた未加工データ、クリーンアップおよび保存されたデータ、SSOT (Single Source of Truth) と呼ばれる一般的な情報スキーマに従ってモデル化されているデータとしてデータが整理されます。このような SSOT オブジェクトは、セマンティックデータモデル (SDM) や他の選定されたアプリケーション固有のモデルを定義するための基礎となります。
- オープン セマンティック クエリAPIを使用した拡張可能な分析のための組み込みセマンティック データ モデリングにより、Tableau Nextを推進し、アプリケーション固有の分析を可能にします。
- 構造化データ、非構造化データ、グラフデータの統合Data 360 SQLクエリをサポートするハイパフォーマンスSQLクエリエンジン。
- 低レイテンシのデータストア:ミリ秒のレスポンス タイムのホット データ用のキー バリュー ストレージ。パーソナライズとイベント駆動型シナリオをリアルタイムで有効にします。顧客エンゲージメントデータをリアルタイムで収集して処理します。ID、インタラクション、会話を1つの信頼できるCustomer 360プロファイルおよびコンテキストグラフに統合します。
- 非構造化データ処理パイプラインにより、非構造化データ・ストレージ、チャンク、埋め込み生成(ベクトル化)、メタデータ抽出(拡張)、要約、インデックス付け、Knowledge抽出、インテリジェントなドキュメント処理、短期/長期(会話)メモリ作成などに対する柔軟で拡張可能なサポートが提供されます。
- ネイティブのキーワード、ベクトル、ハイブリッド インデックスにより、高速およびエージェント検索、RAG、Knowledge抽出、エージェントによるメモリ派生などの非構造化データに正確かつ効率的にアクセスできます。
- AI/MLおよびエージェント アプリケーションを有効にするためのプロファイル、パーソナライズ、コンテキスト サービス。
- すべてのレイヤーにガバナンスとセキュリティが組み込まれており、系統追跡、データ マスキング、データ レジデンシー、ゼロトラスト セキュリティにより、コンプライアンスと信頼性が確保されます。
- Elastic Compute Fabric
ネイティブのマルチテナントコンピューティングファブリック。分散処理の場合は Spark、SQL ワークロードの場合は Hyper を実行します。さまざまなジョブで柔軟に拡張でき、信頼できないコードの実行の分離をサポートします。
これらはすべて、Salesforceのクラウド基盤であるHyperforceで実行されます。Hyperforce は次の機能を提供します。
- 暗号化ポリシー、分離ポリシー、最小権限ポリシーによるZero-Trustセキュリティ。
- 複数リージョンの導入による耐障害性。Salesforce Data 360はHyperforceの複数リージョンの耐障害性とプラットフォーム レベルのフォールト トレランスからメリットを得ていますが、真のエンタープライズ クラスのDR(ディザスタリカバリ)では、すべての連動エコシステムで再生可能な取り込みパイプライン、レプリケーション、メタデータ主導のリハイドレーションなどの主要機能を備えた、あらゆるデータ プラットフォームに似たより広範なアーキテクチャが必要です。
- 監視、評価指標、追跡が組み込まれた可観測性。
- コスト オーバーフローのない効率性を実現する自動拡張とFinOps認識。
Data 360 は、既存のエンタープライズ投資に代わるものではありません。代わりに、Data 360 では、すでに信頼、管理、およびアクション可能なデータを使用して、最も重要な部分に AI 主導のリアルタイムエンゲージメントを提供します。つまり、Salesforce は外部データを含むすべてのエンタープライズデータを (Salesforce) メタデータ駆動型オブジェクトに変換し、エージェントアプリケーションが検出、意思決定、アクションを実行できるようにします。
次の図は、Data 360 リファレンスアーキテクチャを示しています。
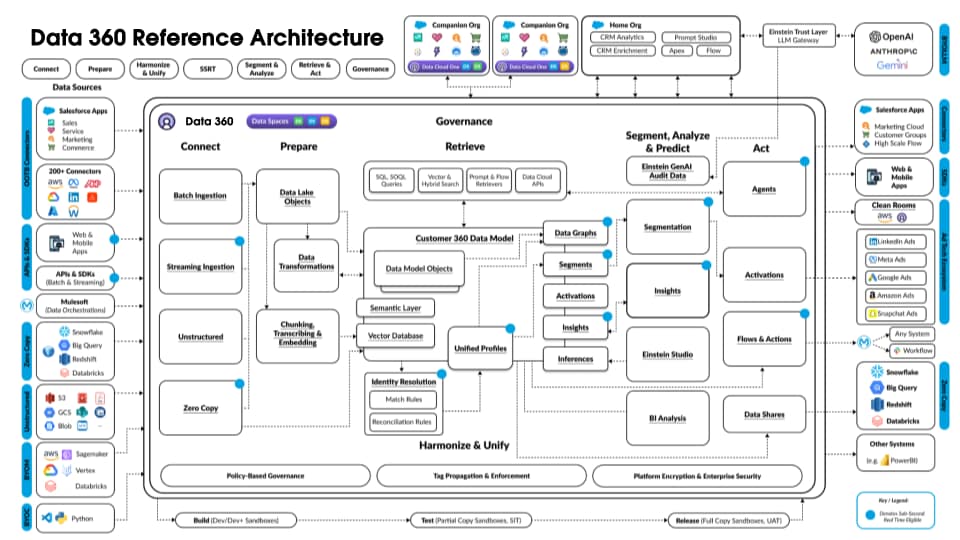
Data 360 上に階層化された仮想の Agentforce Loan Agent で、アーキテクチャフローの例を説明するとします。たとえば、ローンエージェントは、顧客 (消費者) がローンを申請し、すぐにローンの承認を受ける顧客対応エージェントです。
Data 360 はスケジュールどおりにこれらの手順を実行し、ローンエージェントが使用するデータを準備します。
- Data 360 は構造化されたカスタマー取引先データを CRM から取り込み、データレイクに保存します。
- Data 360 は、会社のローンおよび財務契約に関する非構造化データを処理します。
- Data 360 は、Snowflake などの外部データソースから個人データを統合します。
- Data 360 は、取り込まれたデータと統合データを変換およびモデル化します。
- Data 360 は、プロファイルデータグラフを作成して管理します。
顧客がローンを申請するたびに、次のアクションが実行されます。
- 顧客がローンエージェントにサインインすると、リアルタイムレイヤーで顧客セッションが開始されます。顧客の統合プロファイルがリアルタイムレイヤーに取り込まれます。
- 顧客が必要な情報を入力してローン申込を完了します。
- 顧客が非構造化データ処理のために財務ドキュメント (確定申告、投資、銀行取引明細書など) を Data 360 にアップロードします。
- アップロードされたデータはチャンク化およびベクトル化 (埋め込み生成) され、インデックス (キーワードとベクトル) が作成されます。
- 次に、顧客はローン申込ドキュメントに入力してアップロードします。Data 360 は、ローン金額と期間をリアルタイムで抽出します。
- ローンエージェントは、Data 360 クエリとプロファイルおよび他の事前作成済みインデックスを使用したハイブリッド検索を使用して、関連する財務データを取得します。
- ローンエージェントは、ローンデータとその他の財務プロファイルデータを使用して承認エージェントを有効化し、ローンの承認を決定します。
- ローンエージェントが顧客に決定で応答します。
- 顧客とローンエージェント間のこのやりとりもすべて取得され、Data 360 に保存されます。
上記の例では、ローンエージェントなどのエージェントアプリケーションを構築するために使用される Data 360 アーキテクチャコンポーネントの概要を示しています。次のセクションでは、Data 360 アーキテクチャのレイヤーとコンポーネントについて説明します。
このセクションでは、Salesforce Data 360 の基盤となるビルディングブロックについて、堅牢なストレージモデルから始めて、データの接続、取り込み、準備のメカニズムまでを掘り下げます。次に、構造化データと非構造化データの保存、モデル化、処理方法を検討し、ハーモナイゼーション、統合、取得、インテリジェントな有効化の機能を理解します。
Salesforce Data 360 は、レイクハウスの強みとリアルタイムストレージを組み合わせた階層型の統合ストレージモデルに基づいて構築されています。Lakehouse レイヤーは、大量の履歴データとバッチデータに対応する拡張性とコスト効率に優れたストレージを提供し、高度な分析と機械学習の使用事例を可能にします。一方、リアルタイムストレージは、低レイテンシのアクセスと頻繁な更新を実現するように最適化されており、顧客とのやりとり、プロファイル、エンゲージメントシグナルが常に最新の状態に保たれます。これらの階層がシームレスに連携することで、履歴コンテキストとリアルタイムコンテキスト間でデータを柔軟に移動でき、パーソナライズ、AI、有効化のための統合されたデータ基盤で深さと即時性の両方が提供されます。
Data 360 は、Iceberg/Parquet に基づくネイティブの Lakehouse アーキテクチャを特徴としており、AI および分析アプリケーションに不可欠な構造化データと非構造化データの両方をサポートするバッチ、ストリーミング、リアルタイムシナリオの大規模なデータ管理と処理を処理するように設計されています。
Azure、AWS、GCP などのクラウドベースのデータレイクでは、基本的なストレージユニットはファイルであり、通常はフォルダーと階層に整理されます。Lakehouse は、クエリや AI/ML 処理などの操作を容易にするために、より高いレベルの構造と意味の抽象化を導入することで、この構造を強化しています。プライマリ抽象化は、その構造とセマンティックを定義するメタデータを含むテーブルで、Iceberg や Delta Lake などのオープンソースプロジェクトの要素と、Data 360 によって追加されたセマンティックレイヤーが組み込まれています。
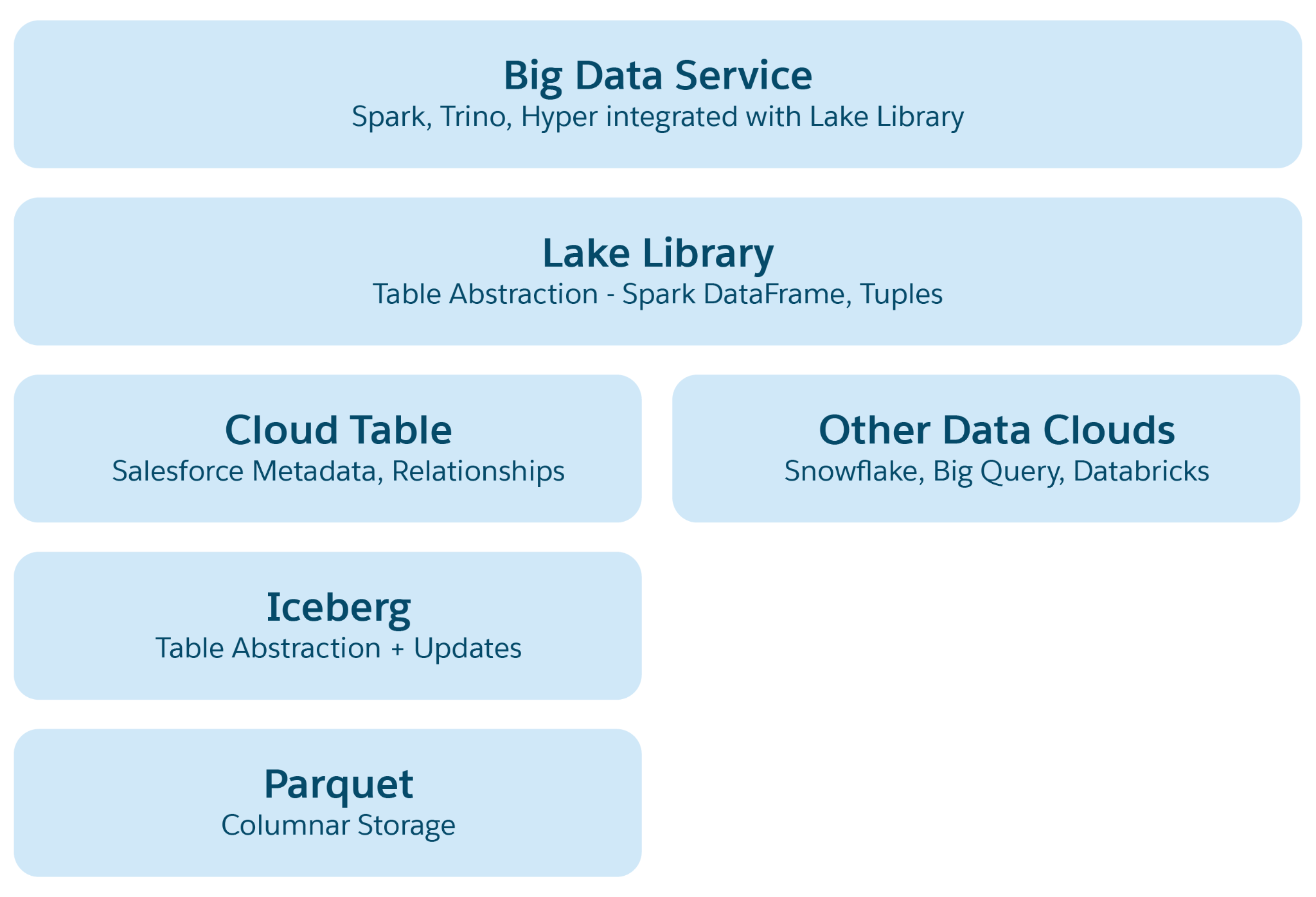
Lakehouse の抽象レイヤー:
- Parquet File Abstraction:基本のストレージは Parquet 形式のデータレイクファイル (AWS の S3 や Azure の Blob など) で構成されます。ソーステーブルのデータは Parquet ファイルとして複数のパーティションに保存され、各テーブルはこれらのファイルのコレクションになります。
- Iceberg Table Abstraction:テーブルはフォルダーとして整理され、データパーティションはこれらのフォルダー内に Parquet ファイルとして保存されます。パーティションを変更すると、新しい Parquet ファイルがスナップショットとして作成されます。Iceberg は、スキーマ、パーティション仕様、スナップショットの詳細を含む各テーブルのメタデータファイルを管理します。
- Salesforce Cloud Table Abstraction
を基盤とするこのレイヤーでは、列名やリレーションなどのセマンティックメタデータと、対象ファイルサイズや圧縮などの設定が追加されます。Snowflake や Databricks などのさまざまなプラットフォームのテーブルを抽象化し、Data 360 アプリケーションを基盤となるストレージプラットフォーム固有のものから保護します。 - Lake Access Library:このライブラリは、Salesforce Cloud テーブルへのアクセスを提供し、データとメタデータの両方を処理し、アプリケーション開発者の基盤となるストレージメカニズムを抽象化します。
- Big Dataサービスの抽象化:これには、クエリ用の Hyper や、あらゆるクラウドテーブルプラットフォームで処理するための Spark などの処理フレームワークが含まれます。
リアルタイム分析とエージェントアプリケーションをサポートするために、Data 360 は Lakehouse Big Data ストレージを低レイテンシストアで強化します。Data 360 Real-Time Layer は、メモリ内のリアルタイムシグナルとエンゲージメントデータを処理します。ただし、メモリベースのストレージ容量は限られているため、すべてのデータが収まることはなく、処理がリアルタイムで行われない可能性があります。Data 360 では、このような制限を排除するために低遅延ストア (LLS) が追加され、拡張性の高いリアルタイム処理が可能になります。
低レイテンシ ストアは、Lakehouse 上のペタバイト規模の NVMe (SSD) ストレージ レイヤーです。すべてのデータを低遅延ストアに保存する必要はありません。これは耐久性のあるキャッシュです。ほとんどのデータは、最終的に長期間保持するためにレイクハウスに保存されます。リアルタイムレイヤーのセッション中データは、後続の高速アクセスのために低レイテンシストアにフラッシュできます。たとえば、Agentic 会話では、最近のメッセージはメモリで処理でき、古いメッセージは低遅延ストアにフラッシュできます。以前の会話が必要な場合、低遅延ストアから数ミリ秒以内にアクセスできます。NVMeベースのストレージでは、大量のデータをミリ秒のレイテンシーで保存およびアクセスできます。データは、長期間保持するために Lakehouse クラウドストレージに転送される場合があります。さらに、リアルタイム処理やリアルタイムエクスペリエンスの追加に必要な Lakehouse のデータが取得され、低レイテンシストアに保持されます。たとえば、顧客のプロファイルコンテキストが Lakehouse から事前取得または取得され、低遅延ストアにキャッシュされます。また、セッション中処理中のリアルタイム処理に必要なレイクハウスオブジェクトやその他のオブジェクトも低レイテンシストアにキャッシュできます。
Data 360 低レイテンシストアでは、メモリ (SSD) Lakehouse ストレージレイヤーを使用して、真のストレージ階層のリアルタイムレイヤーを有効にし、これらのレイヤー間でデータをシームレスに移行できます。Data 360 Real Time レイヤーについては、このドキュメントの後半で説明します。
Salesforce Data 360 は、未加工の入力を統合された最新のデータモデルに変換する厳格なライフサイクルに従って、構造化および非構造化のすべての顧客データを標準化、ハーモナイズ、有効化するように設計されています。
ライフサイクルでは、さまざまな外部データ入力を取得し、永続的なモデル化されたオブジェクトに構造化することに重点を置いています。モデル化されたデータは Customer 360 統合プロファイルにハーモナイズできます。
未加工の取り込みデータと初期変換
このプロセスは、ソースシステム (CRM、マーケティング、ファイルなど) からそのまま取り込まれた未加工データから始まります。これには、現在の状態を維持するために管理され、永続的なデータにマージされるフルデータ読み込みと連続変更イベント (デルタ) が含まれます。
インライン変換(トリミング、正規化、連結など)は、暫定的なデータ品質とクリーンアップを確保するために取り込み時にすぐに適用されます。
データレークオブジェクト (DLO):永続的レイヤー
DLO(データ レイク オブジェクト)は、Data 360内のコア永続ストレージ レイヤーを形成します。クリーンな変換済みデータを保存し、すべての顧客情報の整理された長期的なリポジトリとして機能します。
高度なデータ変換(結合、集計、計算済みインサイトなど)がソースDLOに適用され、厳選された新しい派生DLOが生成されます。
Zero Copy Data Federation を介して使用可能になるデータは、DLO として直接表されます。
非構造化データとメタデータの整理
非構造化コンテンツ (テキスト、メディア、ドキュメントなど) の場合、Data 360 では、非構造化データレイクオブジェクト (UDLO) と呼ばれる特定の DLO 内で構造化メタデータを抽出して保持することでデータが取り込まれます。
これらの特殊な DLO はディレクトリテーブルとして機能し、非構造化アセットの物理的な場所とコンテキストへのマップを提供します。この機能により、アーキテクトは非構造化データのメタデータを残りの構造化された顧客データとシームレスに関連づけることができ、統合されたクエリとハーモナイゼーションが可能になります。
データモデルオブジェクト (DMO):ハーモナイズレイヤー
DMO (データモデルオブジェクト) は、最終的なハーモナイズされた構造化されたデータレイヤーを表します。
これらは、(ソース、派生、および非構造化メタデータの)DLOフィールドを標準のCustomer 360データ モデルにマッピングすることで作成されます。
DMO レイヤーは、すべての顧客データの一元化された情報源として機能し、広範なエコシステム全体で統合されたプロファイルの作成、セグメンテーション、有効化を可能にします。
データスペースは、すべての DLO (構造化および非構造化) と DMO を含む、Data 360 内のすべてのデータとメタデータを整理するための基本的な論理コンテナです。データスペースは、データ処理とモデリングのための安全で隔離された環境を提供します。
データスペースは論理境界とガバナンス境界として機能し、ビジネスユニット、地域、ブランドなどの個別のエンティティのデータを分離することで内部のマルチテナンシーを実現すると同時に、企業全体の表示、系統、コンプライアンスを維持し、きめ細かなアクセス制御を定義するための基礎となります。
データスペース内の分離は、プラットフォームの複数のレイヤーで適用されます。
- データレベルの分離:各 DLO/DMO は 1 つのデータスペースに属するため、明示的に承認されていない限り、クエリ、変換、オブジェクトマッピングがデータスペースの境界を超えることはありません。
- アクセス制御の統合:権限セットはデータスペースにネイティブに関連付けられ、参照、更新、および管理操作を制御できます。これにより、承認されたユーザーとサービスのみがデータスペース内のオブジェクト、インサイト、有効化にアクセスできます。
- ガバナンスと監査:データスペース内のすべての操作がエンタープライズクラスの監査履歴で記録されるため、コンプライアンス、スチュワードシップ、規制レポートのトレーサビリティを実現できます。
アクセス権と権限は権限セットで管理されるため、詳細な表示、更新の制御、クロスドメインデータ漏洩の防止が保証されます。データスペース境界を Data 360 のセキュリティおよびガバナンスアーキテクチャと統合することで、アーキテクトは複数のクラウドおよびビジネスドメインで一貫性を維持しながら、一元化されたガバナンス戦略と分散化されたガバナンス戦略の両方を確実に実装できます。
Data 360 コンピューティングファブリックは、すべてのビッグデータワークロードを管理および実行する統合レイヤーを提供し、基盤となるインフラストラクチャの複雑さを簡素化します。そのコアコンポーネントはデータ処理コントローラー (DPC) です。
DPC は、さまざまなクラウドコンピューティング環境にサービスとしてのジョブ (JaaS) 機能を提供する包括的なマルチワークロードデータ処理オーケストレーションサービスです。インフラストラクチャの複雑さを抽象化し、Spark (EC2 上の EMR と EKS 上の EMR) や Kubernetes リソースコントローラー (KRC) ワークロードなどのフレームワークのジョブの実行を統合します。DPC は一元化されたコントロールプレーンゲートウェイとして機能することで、複数のデータプレーン間でジョブを調整、スケジュール、監視し、信頼性、拡張性、コスト効率、一貫した開発者エクスペリエンスを確保します。
DPC のニーズは、EMR などのネイティブのクラスター管理システムを直接操作するという制限に起因します。
インフラストラクチャとクラウドの抽象化
EMR では、クラスター、ToDo、ステップの API が提供されますが、プロビジョニング、拡張、パフォーマンスチューニング、コストの最適化など、重要なインフラストラクチャ管理タスクがクライアントチームに課せられます。DPC は、ジョブ登録用の簡略化されたプラットフォームレベルの API を提供することで、これに対応します。自動障害処理、再試行、動的負荷バランシングがサポートされています。ビンパッキング、スポットおよび重力ベースのノードにより、コスト効率が向上します。TLS、PKI、IAM の分離、自動パッチで強力なセキュリティを提供します。Spark および EMR ランタイムのバージョンアップグレードを管理して、パフォーマンスの向上、セキュリティパッチ、機能強化を実現します。
さらに、DPC は、データジョブを送信および管理するためのクラウドに依存しない統合インターフェースを提供し、基盤となるクラウド基盤 (AWS、将来のプロバイダー) の複雑さと独自の API を抽象化します。これにより、クライアントチームは、Kubernetes や YARN などの基盤となるリソースマネージャーの複雑さを抽象化した、Data 360 API ベースの一般的なジョブ登録インターフェースのみを操作することができます。これにより、クライアントチームはポッド、ノードプール、Spark クラスター設定を直接管理することなく、シンプルな統合 API を使用して Spark ジョブを送信できます。
Spark パラメーターを手動で調整するには特殊なスキルが必要であり、誤った設定を行うとジョブの実行が遅くなる可能性があります。DPCチームはこの専門知識を一元化し、一般的なパフォーマンスの問題を回避するために最適化された設定を提供します。この専門チームは、オープン ソース コミュニティのKnowledgeを継続的に統合し、コントローラーで管理されるすべてのワークロードで最適なパフォーマンスを確保します。
DPC は Spark に限定されず、さまざまなワークロードをサポートします。これには以下が含まれます。
- リアルタイム処理ワークロード
- データアクション機能のイベント配信
- Milvus (非構造化データインデックス付け用のベクトルデータベース) の管理
- 低レイテンシのストレージインフラストラクチャ
また、DPCは、クエリ用のTrino、データアクション用のイベント配信、コネクタ用のデータ抽出ジョブ、リアルタイム処理などのワークロードをサポートする**Kubernetesリソースコントローラ(KRC)**フレームワークも活用します。すべてのKRCワークロードに対して、DPCは一元化されたサービスとしてのジョブ機能を提供し、コンピューティングのプロビジョニング、導入、管理を高レベルのジョブ抽象化で処理します。
JaaS の利点とアーキテクチャ
DPC が提供する Job-as-a-Service モデルにより、コスト効率と復元性の高いジョブ処理パイプラインが確保されます。
ユーザーは、必要な CPU、メモリ、ストレージ、インスタンス数、最小/最大クラスター数、クラスター一致のタグに焦点を絞ったシンプルなクラスター仕様を提供します。その後、DPCは最適なVM SKUの選択、インスタンス フリートの管理、コアと仮想インフラストラクチャの比率の決定など、抽象インフラストラクチャの詳細を自動的に管理します。ToDo ノード、およびオンデマンドと入力に基づいてインスタンスを見つけます。また、EMR およびコンポーネントのバージョン管理とアップグレードもダウンタイムなしで処理します。
重要な点として、DPC は本質的にマルチテナントをサポートしており、Data 360 のテナント境界とリソースの分離を理解して適用するように設計されています。また、Salesforce 認定のマシンイメージを適用し、サービス固有の IAM ロールを管理し、転送中と保存中の両方で暗号化を保証することで、セキュリティとコンプライアンスを確保します。ルーティングと業務量制御では、ジョブとクラスターの一致はクラスタータグを使用して管理され、業務量ベースのルーティングでは最大ジョブ同時実行設定を使用してリソース使用率を効果的に制御します。
クラウドに依存しないクライアント環境は、基盤となるクラウド環境の複雑さをクライアントサービスに隠蔽し、ビジネスロジックのみに集中できるため、中核的なメリットとなります。これにより、クラウドプロバイダーの抽象化の目標が達成されます。最後に、DPC により、使用量とコストの追跡が容易になり、クラスターの稼働率とコストをサービス別にセグメント化して正確な会計を行うことができます。全体的に、DPC はプラグイン可能なアーキテクチャに従っており、基盤となるインフラストラクチャの詳細をユーザーに公開することなく、新しい実行エンジン (Flink、Ray など) とクラウド基盤 (GKE/Dataproc) をシームレスに統合できます。この設計により、コントロールプレーンが実行レイヤーから分離され、バックエンドに関係なく一貫した API と操作環境が保証されます。
Data 360 は未加工データを調整して強化し、未加工情報とアクション可能なビジネス消費のギャップを埋めます。高度な有効化と分析のために複雑なデータを準備することで、データオブジェクトのライフサイクルを補完します。Data 360 では、バッチおよびストリーミングデータ変換、バッチおよびストリーミング計算済みインサイト、非構造化データ処理、ID 解決など、さまざまな処理種別がサポートされます。特にほぼリアルタイムかつ膨大なデータセット全体でこれらの多様な操作を効率的に実行するには、データの変更を効果的に処理するための高度なメカニズムが必要です。
Data 360 は、特にテラバイト規模のテーブルと数百万の更新の可能性の高いデータで、ほぼリアルタイムの効率的なデータ処理を実現するために、画期的な方法を必要としていました。データが変更されたときに正確にシステムに通知し、どのデータが変更されたかを効率的に特定して、関連する更新のみが処理され、その更新のみが更新されるようにする必要がありました。この課題は、次の 2 つの補完的なイノベーションにつながりました。何かが変更されたら通知するストレージネイティブ変更イベント (SNCE) と、何が変更されたかを識別する変更データフィード (CDF)。
ストレージネイティブ変更イベント (SNCE)
SNCE は、Data 360 を反応型の増分データプラットフォームに根本的に変えました。この移行には、標準化されたイベント形式と高スループットのメッセージ配信システムを使用して、データレイクを積極的にポーリングする作業から、アトミック確定イベントを受動的に監視する作業への移行が含まれます。
Iceberg テーブルへの書き込み操作 (INSERT、UPDATE、DELETE) が成功すると、カタログ内のテーブルの現在のメタデータファイルポインターがアトミックに切り替わります。基盤となるオブジェクトストレージレイヤー (S3 など) は、新しいメタデータスナップショットがテーブルのディレクトリに書き込まれるたびにネイティブの通知イベント (S3 イベントなど) を送信するように構成されています。
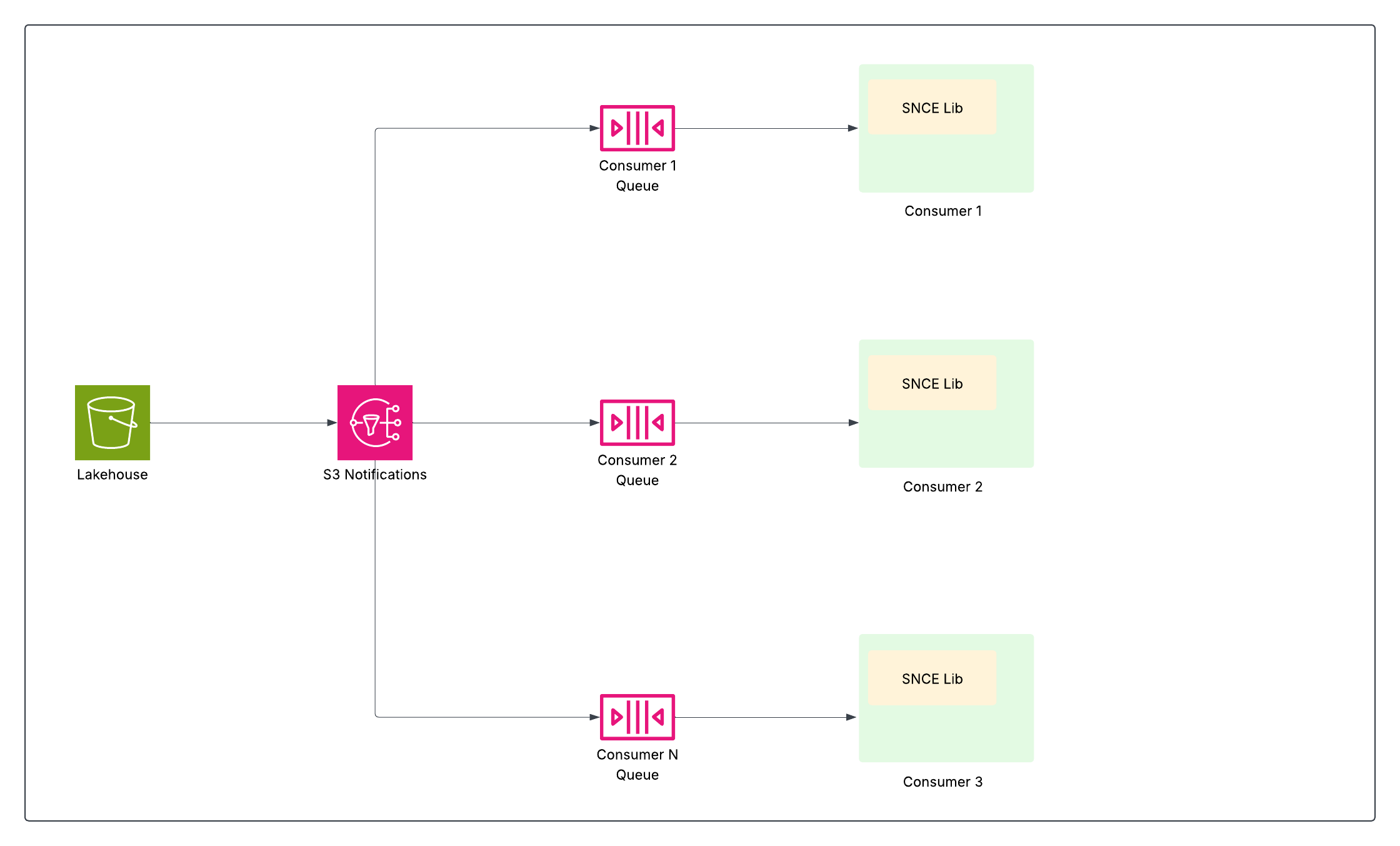
SNCE ライブラリでは、これらのイベントを使用するための標準化された方法が提供され、要求に応じてスナップショットメタデータで強化することもできます。
これにより、計算済みインサイトのストリーミング、ID 解決、セグメンテーションなどのダウンストリームデータパイプラインは、データが変更された場合にのみ登録してアクションを実行でき、コストのかかるテーブル全体のスキャンを回避して効率を大幅に向上できます。
変更データフィード (CDF)
SNCE を基盤とする変更データフィード (CDF) では、変更を消費して増分処理するための合理化されたメカニズムが提供されます。
CDF は Iceberg スナップショットを使用して、変更のストリームを効率的に生成します。Data 360 の最適化された Iceberg ライターは、書き込み操作自体の一環として変更を計算して保持するため、CDF 生成の効率が高く、追加のオーバーヘッドを最小限に抑えることができます。これにより、処理ジョブ (ストリーミング変換やストリーミング計算済みインサイトなど) は、高価なスナップショットの差分計算を回避して、変更されたレコードのみを選択的に処理できます。
この増分戦略は、大規模なデータセットにコスト削減、遅延の短縮、効率の向上など、いくつかのメリットをもたらします。これにより、ストリーミング変換や増分 ID 解決などの機能が有効になり、インサイトの迅速化、システムの読み込みの予測可能性の向上、パフォーマンスの向上、運用コストの削減につながります。
Data 360 は、Salesforce 製品のネイティブサポートにより、堅牢な取り込み機能を提供し、シームレスなデータフローを実現します。外部ソースの場合、270 を超えるコネクタ、API、SDK、MuleSoft を介して広範な接続を提供します。さらに、Data 360 にはゼロコピー統合機能があり、データの重複のない BI および分析が可能です。
Data 360 コネクタフレームワーク (DCF) は、ほとんどの Data 360 接続の基盤です。統合されたアーキテクチャを使用して、取り込み、統合、出力が可能になります。DCF では、設定と管理のための UI から、メタデータの保持、データの抽出、Lakehouse への配信、外部ソースに対するライブクエリまで、コネクタの作成と管理に関する標準が定義されています。また、プライベート接続オプション (プライベートリンク、VPN、セキュアトンネルなど) もサポートし、顧客またはパートナー環境に接続するときにエンタープライズクラスのデータセキュリティとコンプライアンスを確保します。すべてのコネクタで一貫したアプローチを提供することで、DCF は拡張性、信頼性、安全なインテグレーションを確保し、Data 360 をより広範なエコシステムにシームレスに接続します。
Data 360 は、ネイティブの Salesforce 製品と多数の外部システムの両方をサポートする、膨大なデータソースエコシステムへの堅牢な接続を提供します。この広範な接続性は、サイロ化されたエンタープライズデータを統合し、AI/ML およびエージェントアプリケーションを有効にするために不可欠です。
Data 360 は、バッチ、ストリーミング、またはリアルタイム取り込みによるエンドツーエンドのデータパイプライン機能をサポートするために、ネイティブまたは MuleSoft、API、SDK を介して 270 を超えるコネクタを提供します。これらのコネクタは、統合するソースシステムの種別によって大きく分類できます。
Salesforce ネイティブコネクタ
これらのコネクタにより、Salesforce 製品からのシームレスでネイティブなデータフローが確保されます。
たとえば、Salesforce CRM、Data Cloud One、Marketing Cloud Engagement、Marketing Cloud Account Engagement、B2C Commerce のコネクタがあります。
外部アプリケーションとSaaS
さまざまなビジネスアプリケーションとクラウドサービスのコネクタでは、外部ソフトウェアプラットフォームからデータを取得できます。
たとえば、Adobe Marketo Engage、Microsoft Dynamics 365、Mailchimp、Airtable などがあります。
データベースとデータウェアハウス
Data 360 は、さまざまなリレーショナルおよびクラウドベースのデータストレージプラットフォームに接続します。
たとえば、Amazon Redshift、Amazon DynamoDB、Amazon RDS (MySQL、PostgreSQL、Oracle)、Google BigQuery、Microsoft SQL Server などがあります。
クラウド オブジェクト ストレージとファイル システム
これらのコネクタは、構造化データと非構造化データの両方のハイパースケーラー ストレージ ソリューションと統合されます。
たとえば、Amazon S3、Google Cloud Storage (GCS)、Azure Blob Storage などがあります。
ストリーミングおよびメッセージングサービス
継続的なリアルタイムデータストリームを処理するコネクタは、イベント駆動型のシナリオとリアルタイム処理に不可欠です。
たとえば、Amazon Kinesis コネクタです。
インテグレーションプラットフォーム
MuleSoft Anypoint Connector は、Anypoint Exchange を介して幅広いアプリケーションやデータベースと統合することで、Data 360 の範囲を拡大します。
非構造化データおよびクラウド オブジェクト ストレージ コネクタ
これらのコネクタは、非構造化データ (定義済みモデルがないデータ) を取り込んで参照し、生成 AI 機能を強化するために不可欠です。
これらのコネクタはすべて、Data 360 コネクタフレームワーク上に構築されており、一貫した環境が提供されます。
データ変換は、Data 360の基本的なアーキテクチャ コンポーネントであり、取り込まれた未加工データをクリーンアップ、強化し、Customer 360データ モデルに合わせて正規化されたアクション可能なデータ資産に形成するように設計されています。このプロセスは、データのハーモナイゼーション、品質の向上、およびプロファイルの統合、セグメンテーション、有効化などのダウンストリームの使用事例に向けたデータの準備に不可欠です。変換では、入力としてソースデータレイクオブジェクト (DLO) とデータモデルオブジェクト (DMO) の両方を活用し、それぞれ新しい DLO または DMO に結果を生成します。
Data 360 では、さまざまなデータ速度要件に対応するために、一括処理データ変換とストリーミングデータ変換の 2 つの主要な変換パラダイムが提供されます。
一括処理データ変換
一括処理データ変換は、定義されたスケジュールまたはオンデマンドトリガーに基づいて大量の処理を実行するように設計されています。このエンジンは、リソースを大量に消費する複雑な再構築操作を処理するように最適化されています。
一括変換プロセスは、ユーザーが複数フェーズの変換ロジックを定義できる、視覚的なローコードパイプラインキャンバスを使用して設定されます。このエンジンは、正規データモデルのアライメントに不可欠な複雑な再構築操作 (データの構造化と正規化) を独自にサポートします。これには、ピボット (非正規化されたレコードを複数の正規化されたレコードに分解) やフラット化 (JSON などの階層データを構造化テーブルに再構築) が含まれます。システムの実行モードでは、完全同期 (すべてのレコードの処理) と効率の高い増分処理モードの両方がサポートされます。増分モードでは、前回成功した実行以降に変更されたレコードのみが処理されるため、処理時間とリソースの消費が大幅に削減されます。一括変換は、定期的な集計や複雑なデータの再構築など、リアルタイムの更新が不可欠なタスクに最適です。
ストリーミングデータ変換
ストリーミングデータ変換では、データがシステムに取り込まれるとほぼリアルタイムでデータが継続的かつ段階的に処理されるため、低レイテンシの使用事例には不可欠です。
プライマリインターフェースは SQL ファーストアプローチで、変換は、レコード変更の受信ストリームに対して継続的に実行される SQL SELECT クエリとして定義されます。このエンジンでは、データクレンジングや標準化 (PII の検証やデータ形式の標準化など)、データ強化やマージ (結合や結合を使用) などのコア変換機能がサポートされます。重要な点は、ストリーミングルックアップ結合がサポートされているため、リアルタイムのデータ強化と静的または変化の遅い参照データに対するルックアップが可能になり、プロファイルの即時更新が保証されます。提供コストを最適化するために、このアーキテクチャでは高密度 (HD) ジョブ設計を採用しています。この設計では、1 つのテナントの複数のストリーミング変換定義を 1 つの基盤となるコンピューティングジョブにまとめ、リソースの使用率を最大化します。ストリーミング変換は、イベント監視、即時パーソナライズ、リアルタイムプロファイル更新などの使用事例に不可欠です。
Data 360 では、ゼロコピー統合とデータ共有がサポートされるため、データの移動や重複が不要になり、データ管理が変革されます。この機能により、ユーザーはさまざまな外部ソースのデータにシームレスかつ直接アクセスし、外部環境とデータを共有できるため、複雑さが大幅に軽減され、ストレージコストが削減され、すべての意思決定が信頼性の高い最新の情報に基づいて行われます。
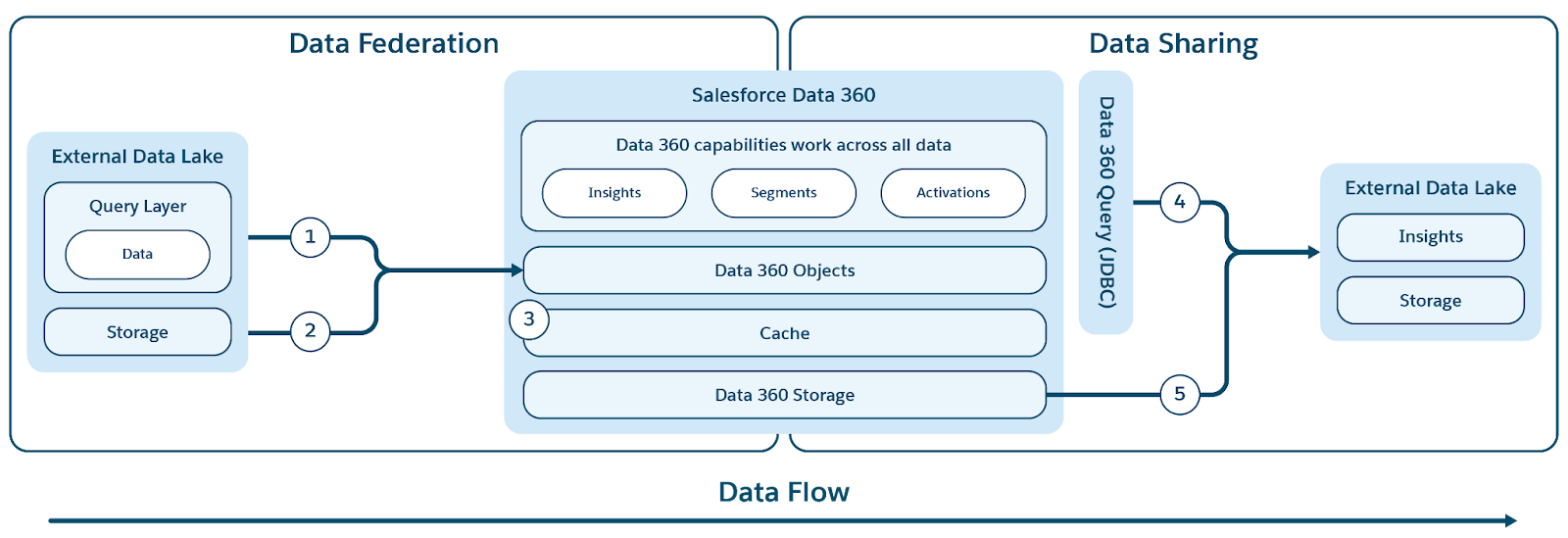
Data 360 では、外部データウェアハウス (Snowflake、Redshift)、レイクハウス (Google BigQuery、Databricks、Azure Fabric)、SQL データベース、その他の多くのソースとのゼロコピー統合がサポートされます。抽象化レイヤーにより、重複のない外部データの直接クエリが可能になり、取り込み時間、ストレージコストを削減し、最新情報を確保できます。
Data 360 は、Salesforce オブジェクトと外部オブジェクトの両方を抽象化する統合メタデータレイヤーを提供することで、外部および統合データへのアクセスを簡素化します。これにより、Salesforce Platform とそのアプリケーション全体でこのデータをシームレスに使用できます。
Data 360 では、ファイルベースとクエリベースの両方の統合がサポートされ、図に示すようにライブクエリとアクセスアクセラレーションが提供されます。
表示ラベル (1) と (2) は、外部データレイク/ウェアハウス/データソースからデータにアクセスするための Data 360 のクエリ (ライブクエリプッシュダウンを含む) とファイルベースの統合を示し、表示ラベル (3) は、外部データレイク/データソースからの統合アクセスの高速化を示します。
クエリ統合
Data 360 の統合機能の中核は、外部データにアクセスしてインテリジェントなクエリプッシュダウンを実行する複雑なプロセスを管理するクエリ統合レイヤーにあります (表示ラベル 1 を参照)。Data 360 は、JDBC プロトコルを使用してソースに接続し、ソースからデータを取得します。このプロトコルは、効率を向上させるためにロジックが追加されています。クエリ統合レイヤーは、さまざまな SQL 方言を理解して翻訳し、効率的な処理のために外部システムに転送されるクエリの最適な部分を特定し、結果を取得して、最終的なインサイトを導き出すために必要な追加処理を実行します。
キャッシュ (クエリアクセラレーション)
拡張ユーティリティの場合、Data 360 では統合機能に省略可能な高速化機能が提供されます。
アクセラレーションが有効になっている場合、Data 360 は統合データをキャッシュして、外部ソースへの繰り返しの直接アクセスを回避し、アクセスの高速化とコスト削減を実現します。このキャッシュはアクセラレーションレイヤーとして扱われ、外部ソースデータの変更をすばやく反映するように増分更新され、アクセラレーションビューがほぼリアルタイムになります。
ファイルフェデレーション
Data 360 では、外部データレイクおよびソースからデータにアクセスするためのファイルベースの統合 (表示ラベル 2 で示されています) がサポートされています。このゼロコピー機能の技術的な基盤は標準化に依存しています。基盤となるデータは Apache Parquet ファイル形式であり、Apache Iceberg 表形式を使用する必要があります。Data 360 は、Iceberg REST Catalog (IRC) を公開する任意のソースに統合してメタデータとストレージにアクセスできるため、プラットフォーム外にあるファイルへのシームレスな管理されたアクセスが保証されます。
ファイルベースの統合では、Data 360 コンピューティングは基盤となるストレージに直接アクセスするため、すべてのデータ処理を処理します。これにより、クエリベースの統合でよく必要となるクエリプッシュダウンやさまざまな SQL 方言の管理が不要になります。
これに加えて、ゼロコピー機能は、Data 360 の非構造化処理パイプラインからアクセスできるハイパースケーラーストレージソリューション (S3/GCS/Azure ストレージ)、Slack、Google ドライブなどの非構造化データソースにも拡張されます。
Data 360 では、外部データレークやウェアハウスで管理するデータのクエリベースとファイルベースの共有が促進されます (元の Figure コンテキストでは表示ラベル 4 と 5 で示されています)。
クエリベースの共有
クエリベースのデータ共有の場合、Data 360 は JDBC ドライバーを公開します。このドライバーを使用して、外部エンジンとアプリケーションはデータに安全にアクセスできます。このメカニズムにより、外部システムは Data 360 内のデータに対してライブクエリを直接接続、認証、実行できます。
ファイルベースの共有 (データ共有および DaaS)
ファイルベースの共有の主なメカニズムには、DaaS (サービスとしてのデータ) API を活用するデータ共有とデータ共有対象という 2 つの概念が含まれます。
- 詳細な制御:データ共有の概念により、外部で共有するオブジェクト (DLO、DMO、CIO など) を正確に定義できるため、意図しないデータ漏洩を防止できます。
- 安全なターゲティング:また、データ共有対象も制御し、明示的に承認された外部環境、取引先、またはパートナー組織のみがデータを使用できるようにします (特定の Redshift または Databricks インスタンスとの共有など)。
DaaS API は、外部エンジンがデータを消費するための安全で管理されたインターフェースを提供します。Data 360 のすべてのセマンティクスを保持しながら、重要なメタデータと基盤となるテーブルストレージの両方にアクセスできます。これにより、外部エンジンは一貫性のある有意義なコンテキストで安全にデータにアクセスできます。
セキュリティに敏感な顧客 (特に大企業、規制対象の業界、公共セクターの組織) の多くは、セキュリティ体制の一環として、データレイクへのすべてのインターネットアクセスを制限しています。このポリシーは、コンプライアンスとリスク軽減には不可欠ですが、Salesforce Data 360 と Agentforce がパブリックインターネットを介してこれらの環境に接続することも防止します。
これらのデータレイクのほとんどは、AWS、Azure、Google Cloud などのハイパースケーラー環境にリリースされます。Data 360 自体は AWS で実行されるため、別のクラウドプロバイダーでホストされている顧客データレイクにアクセスするには、クロスクラウドネットワーク接続が必要です。パブリック インターネットを迂回する安全なプライベート接続オプションがない場合、お客様は多くの場合、これらのデータ レイクに依存するユースケースにData 360やAgentforceを採用できないか、採用を拒否します。
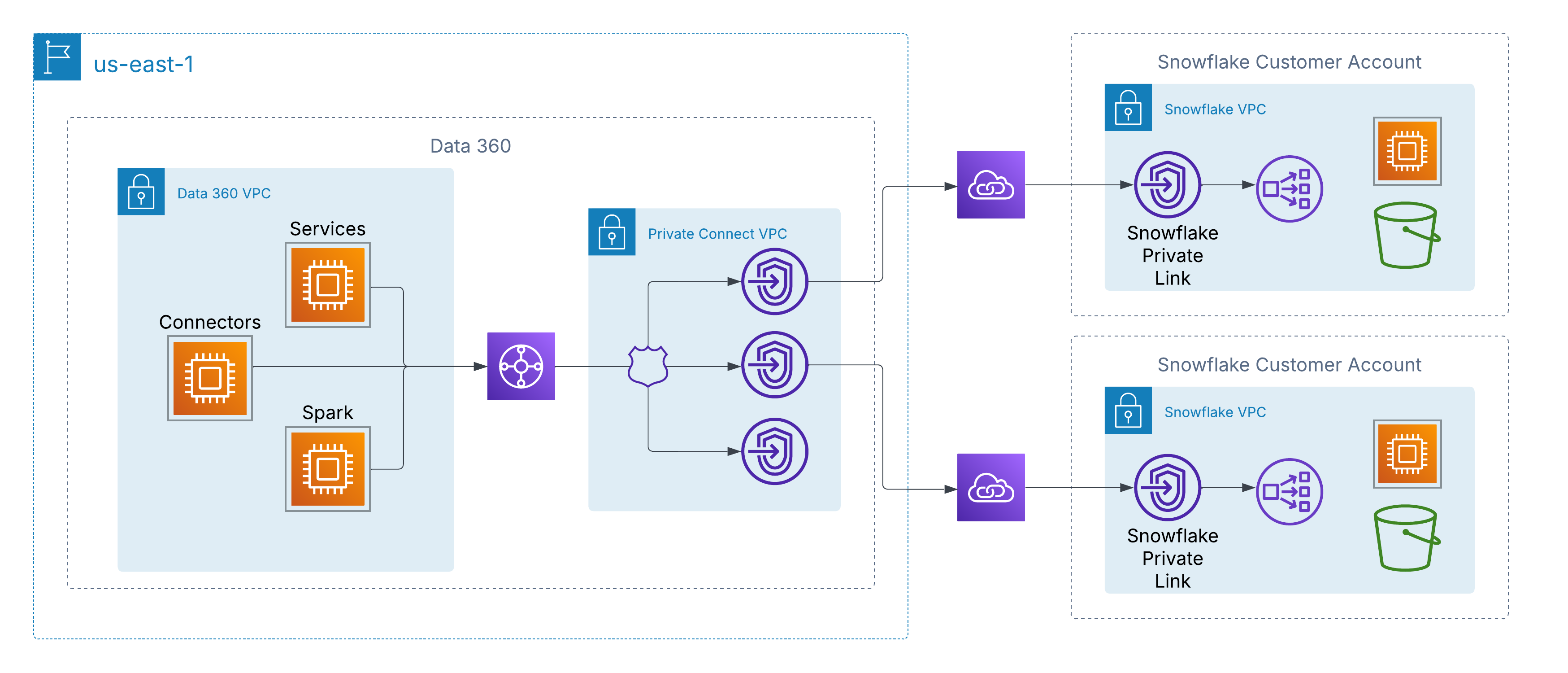
これに対応するために、Data 360 では、クラウド間で顧客が管理するデータソースへの非公開のネットワークレベルの接続がサポートされています。AWS では、これは AWS PrivateLink を介して有効になります。これにより、Data 360 は、パブリックインターネットを経由することなく、独自のアカウント内またはサードパーティのデータレイク環境 (Snowflake など) 内で、顧客がプロビジョニングしたエンドポイントに直接接続できます。
このアーキテクチャにより、プライベート IP アドレスとルーティング不可能なネットワークパスを使用して、すべてのトラフィックが AWS バックボーンに完全に保持されるため、厳格なセキュリティとコンプライアンスの要件を満たしながら、顧客データへのシームレスなアクセスが可能になります。
マルチクラウドアーキテクチャを使用するお客様のために、Data 360 ではクロスクラウド相互接続のサポートを通じてプライベート接続を AWS 以外にも拡張しています。これにより、Data 360 から Azure または Google Cloud でホストされているデータレイクやサービスへの安全なバックボーン専用ネットワークパスが可能になり、AWS PrivateLink と同じ原則 (プライベート IP アドレス、非公開ルーティング、インターネット公開ゼロ) が維持されます。
顧客は 2 つのリリースモデルのいずれかを選択できます。
-
顧客が管理する相互接続
ExpressRoute、Google Cloud Interconnect、Equinix Fabric などの既存のプライベート回線を Data 360 の VPC に直接統合します。 -
Salesforce 管理インターコネクト
がクロスクラウドリンクをプロビジョニングして操作し、対象クラウドで非公開エンドポイントを公開できる、完全に管理されたターンキー接続を使用します。
どちらのモデルでも、操作性は一貫しています。Data 360 サービスは、ハイパースケーラーを介して外部データソースにローカルであるかのように接続し、公衆インターネットを経由することなく安全に取り込み、有効化、照会できるようにします。
エンタープライズ アーキテクトにとって、堅牢なデータ ガバナンスは単なるコンプライアンス チェックボックスではなく、信頼性、拡張性、アクション可能な顧客インテリジェンスを構築するための基本的な柱です。Salesforce Data 360 は、データ品質、セキュリティ、およびデータライフサイクル全体の規制要件への遵守を保証する包括的なガバナンスフレームワークを使用して設計されています。
Data 360 は一元化されたガバナンスハブとして機能し、未加工の取り込みから有効化されたインサイトまで、すべてのデータが整合性と制御をもって管理されるようにします。
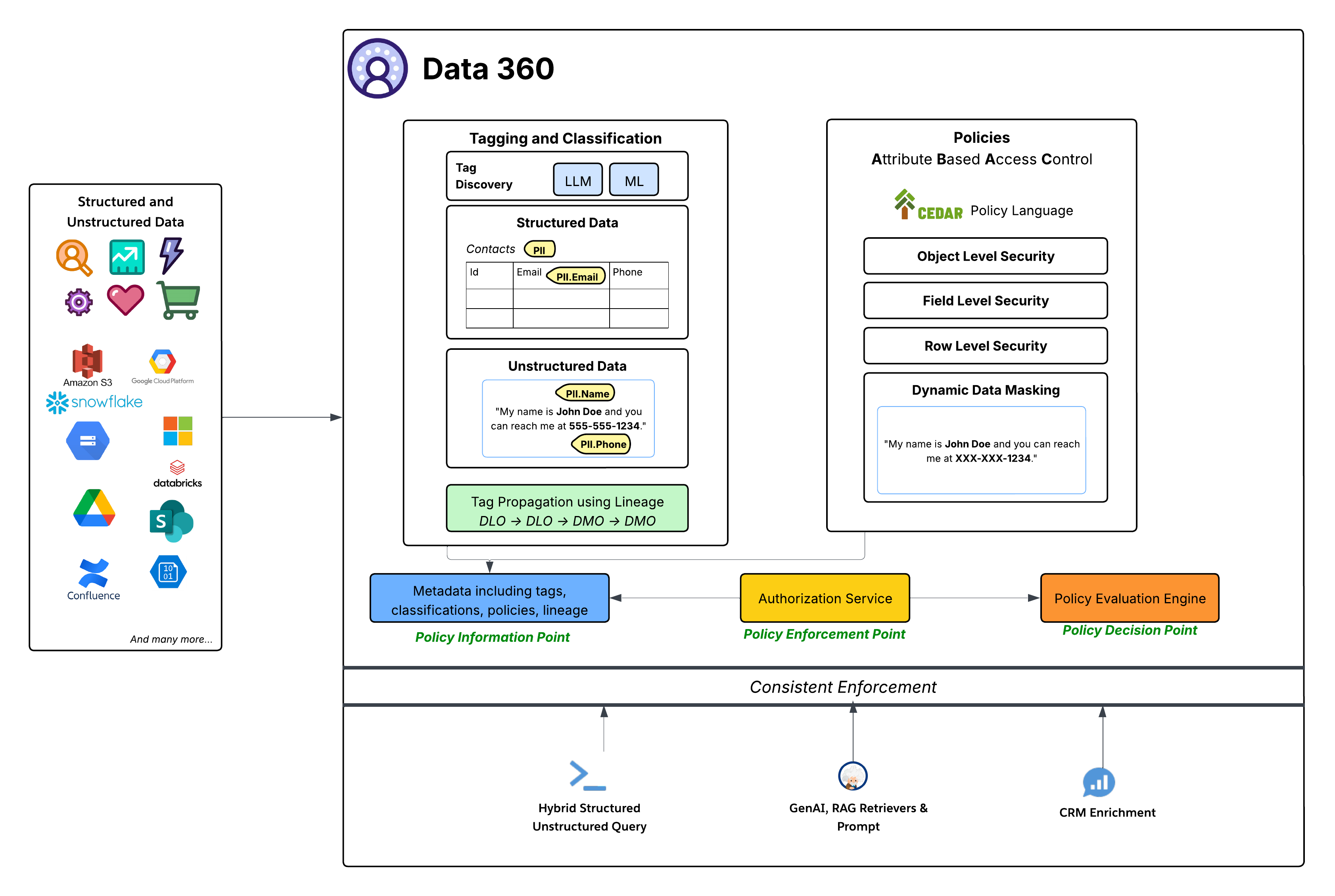
データスペースでは、データスペース内のすべてのオブジェクトへのアクセス権を決定するための粗いきめ細かいアクセス制御が提供されますが、ABAC ベースのポリシーでは、データスペース内の個々のオブジェクト、項目、行へのきめ細かなアクセス制御が提供されます。Data 360 では、きめ細かなアクセス制御を実現するため、属性ベースのアクセス制御 (ABAC) をコア認証モデルとして採用しています。この戦略的な選択により、従来のロールベースのアクセス制御 (RBAC) よりも優れた柔軟性と拡張性が提供されます。これは、大量のデータとさまざまなアクセスニーズがある動的で複雑なエンタープライズ環境で特に重要です。ABAC では、事前定義されたロールだけでなく、ユーザーの属性 (部署、ロール、場所など)、データ (PII、機密性、データスペースなど)、環境 (時間帯など) に基づいてアクセスを決定できます。これにより、データとユーザー属性の変化に応じて適応する、きめ細かいコンテキストに基づいたアクセスポリシーが可能になります。
- CEDAR ポリシー言語 360 の ABAC 実装の中心となるのは、CEDAR ポリシー言語を使用することです。この専用の正式なポリシー言語により、複雑な認証ルールを正確かつ検証可能な方法で定義できるため、ポリシーが明確になり、大規模で一貫した評価が可能になります。
Data 360 内のガバナンスシステムは、標準の堅牢な ABAC アーキテクチャに準拠しています。
- タギング、分類、ポリシーの作成 (Policy Information Point (PIP)):
- Data 360 では、LLM (Large Language Model) と ML (機械学習) を活用して、構造化データ (取引先責任者テーブルなど) と非構造化データ (Google ドライブなど) の両方で機密データカテゴリ (PII.Email、PII.Phone、PII.Name など) やその他の専用の分類 (PHI、FinancialData) を識別する自動タギングおよび分類メカニズムが提供されます。
- 重要な点として、タグの伝達はデータ系統に沿って行われ (DLO → DLO → DMO)、未加工の取り込まれたデータからハーモナイズ DMO レイヤー、プロセス定義から作成された派生データに至るまで、データ変換と派生に従って分類が自動的に行われます。
- 最後に、ポリシー作成ペインでは、データとユーザー属性を活用して組織の動的アクセスルールを定義するためのシンプルな環境が提供されます。
- この強化されたメタデータ (タグ、分類、ポリシー、系統など) は、ポリシー情報ポイント (PIP) に入力されます。
- 承認サービス (Policy Enforcement Point (ポリシー適用ポイント) - PEP):
- 認証サービスはポリシー適用ポイント (PEP) として機能します。さまざまな消費レイヤー (ハイブリッド構造化/非構造化クエリ、GenAI RAG Retrievers & Prompt、CRM Enrichment) からのすべてのデータアクセス要求をインターセプトし、ポリシー決定ポイントを参照してアクセスが許可されているかどうかを判断します。
- Policy Evaluation Engine(Policy Decision Point(PDP; ポリシー決定ポイント)):
- このエンジンは Policy Decision Point(PDP; ポリシー決定ポイント)として機能します。PEP のアクセス要求コンテキスト、ポリシー定義 (CEDAR 内)、および PIP の属性を取得して、権限のあるアクセスを決定します。
- 詳細なセキュリティポリシー
で定義されたポリシーは、次のようなさまざまなセキュリティレベルを適用します。 - オブジェクトレベルセキュリティ:これらのオブジェクトに関連付けられたタグに基づいて DLO 全体または DMO へのアクセスを制御する。
- 項目レベルセキュリティ:タグに基づいてオブジェクト内の特定の機密項目へのアクセスを制限する。
- 行レベルセキュリティ:特定のオブジェクトのデータを絞り込んで、ユーザー属性に基づいて関連する行のみを表示する。
- 動的データマスキング:基盤となるデータを変更せずに、アクセス ポイントで特定のデータを(タグに基づいて)動的にマスキングします。これにより、機密情報を保護しながら、広範なユーティリティを確保できます。これは、構造化データのマスキング項目と非構造化データのコンテンツに適用されます。
- 一貫した適用
フレームワーク全体では、データの直接クエリ、生成 AI アプリケーション (RAG) の取得、関連リストを使用した Salesforce CRM 環境の強化など、Data 360 のすべての消費パターンでポリシーの一貫した適用が保証されます。 - Salesforce Platformとの緊密な統合 360 のガバナンス機能は、Salesforce コアプラットフォーム内で直接定義および管理されます。このインテグレーションにより、管理者は使い慣れた Salesforce ツールを使用してアクセスポリシー、ユーザー ID、属性管理を管理できるため、Salesforce エコシステム全体で統一された一貫したガバナンスレイヤーが保証されます。
CEDAR ポリシーを使用してこの高度な ABAC フレームワークを構築することで、Data 360 はアーキテクトに比類のないレベルの制御と柔軟性を提供し、顧客データがアクション可能だけでなく、企業全体でセキュリティ、コンプライアンス、信頼性を確保できるようにします。
業界では、データ漏洩、不正アクセス、改ざん、破壊から確実に保護するために、エンドツーエンドのデータセキュリティが重要視されています。現在の Data 360 を含むほとんどのデータプラットフォームでは、ベンダーが管理する暗号化鍵を使用して保存時の暗号化が提供されます。ただし、企業 (特に規制対象セクター) は、保存データと転送データの両方について、顧客による暗号化機能の管理を義務付ける傾向が強まっています。
このモデルでは、企業は独自の暗号化鍵を制御できるため、プラットフォームレベルの侵害や不正アクセスの可能性が極めて低い場合でも、データは暗号化されて保護されます。顧客の独自の鍵がない場合、どのエンティティ (プラットフォームプロバイダーを含む) もデータを復号化または再構築できないため、完全な機密性と制御が維持されます。
Data 360 では、データの取り込み、処理、インデックス付け、クエリメカニズム全体で、構造化データ (テーブル)、半構造化データ (JSON)、非構造化データの保存と管理がシームレスにサポートされます。Data 360 では、テキスト以外のさまざまな非構造化データ型 (音声、動画、画像など) がサポートされ、データ処理と分析の範囲が広がります。次の図は、グラウンディングの両側 (取り込みと取得) を示しています。
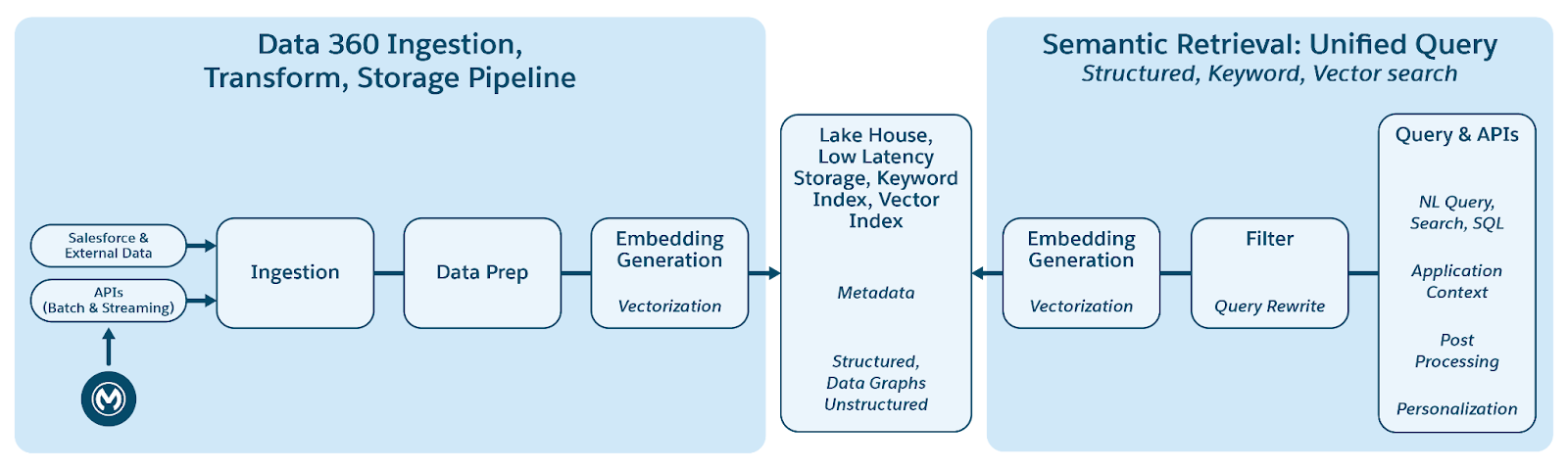
Data 360 では、非構造化データをテキストとして列に保存するか、より大きなデータセットの場合はファイルに保存して管理します。非構造化コンテンツのデータ統合をサポートしているため、複数のソースからのデータを統合および管理することができます。
その後、データが準備されてチャンクされ、埋め込みが生成され、キーワードインデックス付けとベクトルインデックス付けのために処理されます。Data 360 では、チャンク生成と埋め込み生成用の標準で接続可能な複数のモデルがホストされます。Data 360 では、後続の処理とインデックス付けのために、音声および動画コンテンツの自動的な設定可能な文字起こしがサポートされます。検索サービスはキーワードインデックス付けに使用されます。ベクトルインデックス付けの場合、Data 360 はネイティブインデックス付け (Hyper を使用) の両方をサポートし、オープンソースの Milvus などのベクトルデータベースも活用します。Data 360 は Salesforce 検索プラットフォームとも統合され、非構造化データのキーワードインデックス付けをサポートします。このような Data 360 の統合マルチモーダルインデックスにより、ドキュメントの後半の「エージェント型エンタープライズ検索」セクションで説明されているように、非構造化データの検索が強化されます。
取得のために、Data 360 には検索用の API が用意されています。ハイパーベースの統合クエリにより、構造化インデックス、キーワードインデックス、ベクトルインデックス間のアンサンブルクエリが容易になり、厳格な表示と権限が維持されるため、RAG と検索が強化されます。
Data 360 の非構造化データのインデックス付けパイプラインは、次の 5 つのコアフェーズで構成されるモジュラー型の拡張可能なアーキテクチャとして設計されています。
- 解析
- 前処理
- チャンキング
- 後処理
- 埋め込み
すべてのフェーズで LLM ベースの処理もサポートされ、顧客はカスタムプロンプトを作成できます。前処理フェーズと後処理フェーズの両方に複数の連続したステップを含めることができるため、複雑な変換を柔軟に構成できます。各フェーズは完全にメタデータ駆動型であるため、コードを変更することなくシームレスな設定と拡張が可能です。
前処理の例としては、ノイズ除去、言語の正規化、画像理解 (光学式文字認識やキャプション) などの操作があり、後処理フェーズにはメタデータ強化、セマンティックグルーピング、Raptor チャンクなどの高度な技術が含まれる場合があります。
このパイプラインでは Data 360 Code Extension が完全にサポートされているため、顧客と内部チームはどのフェーズでもカスタムロジックを組み込むことができます。コード拡張コンポーネントは軽量な Python 関数であり、そのライフサイクル (実行、スケール、障害処理) は Data 360 によって完全に管理されます。このアプローチにより、プラットフォーム全体の運用の一貫性とガバナンスを維持しながら、イノベーションとドメイン固有の処理を迅速に導入できます。
コンテキストインデックス
非構造化処理を使用して RAG を設定する場合、次の 2 つの要素が重要です。
- 迅速な反復:サンプルテストクエリを使用してすばやく検証する機能。
- 人格固有のコンテンツ:消費人格に合わせてコンテンツを設定する容量。
コンテキストインデックスは、これらの両方の側面に対処するように設計された使いやすいツールです。この対話型 UI は、以前に概説した 5 つのフェーズすべてを実行するリアルタイム (RT) パイプラインによって機能します。パイプラインでは、埋め込み生成や光学式文字認識 (OCR) などのタスクで必要な場合に GPU が使用されます。さらに、包括的なコンテンツ処理の設定をリリースする前に、エージェントを使用して RAG パイプラインをすばやくテストできます。
ドキュメント AI
Data 360 Document AI では、請求書、履歴書、ラボレポート、購入注文などのドキュメントから非構造化データまたは半構造化データを参照およびインポートできます。この機能は、一括処理だけでなく、アドホックな対話型処理もサポートします。これは、お客様のビジネスプロセスの自動化を可能にする主要な機能です。これは、LLM や ML モデルなどの人工知能によって強化されています。
企業は、Wiki、ファイル共有、コンテンツ管理システム、内部データベースなど、さまざまなシステムに分散した大量のKnowledgeを所有しています。このフラグメンテーションにより、従業員 (特にサービスエージェントと営業担当) と顧客が関連情報をすばやく効率的に見つけることが難しくなります。主な問題は次のとおりです。すべてのKnowledgeソースにわたる単一の統合された検索環境の欠如、さまざまなソースのコンテンツの表示と表示の一貫性の欠如、システムに分散している機密情報へのアクセス・ガバナンスの欠如、コア・ビジネス・ワークフロー内での信頼できるKnowledgeソースの活用の難しさ(関連記事のケースへの添付など)。
Enterprise Knowledgeは、より広範なエンタープライズ・データ・プールから手動または自動で選定されたコンテンツを表します。手動キュレーションには、Salesforce Knowledge Article の作成や外部システム内での Knowledge の開発などの慎重なアクションが含まれ、これらは取り込まれます。Salesforce エージェントや変換などのプロセスを使用して、取り込まれたデータに基づいて調整された選定されたレイヤーを生成し、構造化コンテンツと非構造化コンテンツを混在させる自動キュレーションを想定しています。手動で選定するか自動的に選定するか、Salesforce 内で選定するか、取り込み前に外部で選定するかに関係なく、結果は未加工データとは異なる付加価値コンテンツになります。
Enterprise Knowledge Hubソリューションは、Data 360の機能を活用して次のことを実現します。
- 取り込みと保存
ConnectorはSalesforce Knowledge Articleを取り込み、DCF(データコネクタフレームワーク)非構造化コネクタは未加工のコンテンツとメタデータを外部ソースから取り込みます。コンテンツは、SFDrive (ゼロコピーの場合はソース) のコンテンツへのソース固有の非構造化データレイクオブジェクト (UDLO) の対応付けに取り込まれます。 - ハーモナイゼーション & 構造化:ハーモナイゼーション パイプラインでは、UDLOとファイル データが処理され、クリーニング、正規化、強化(NLPなど)、PIIマスキング、ハーモナイゼーション中間形式への変換が実行され、SFドライブとそれにマッピングされるHUDLO(ハーモナイゼーションUDLO)に保存されます。
- インデックス付け:ハーモナイズされたコンテンツに対して非構造化パイプライン (UDS) がトリガーされ、各 HUDMO に対して検索インデックスが設定されます。
- 消費:使用するアプリケーションには、検索、取得、表示、ケースなどのビジネスオブジェクトへのリンクなどがあります。アプリケーションを使用したエンゲージメントが収集され、利用状況の分析 (クリック、レビューなど) が提供されます。
Data 360 の計算済みインサイト (CI) を使用すると、顧客はデータから集計された総計値を定義および生成できます。これらの総計値は、タイムリーな顧客エンゲージメント、分析、セグメンテーション、有効化に使用されます。CI によって計算された集計データは Lakehouse に書き込まれ、計算済みインサイトオブジェクト (CIO) として表されます。
計算済みインサイトには、主に次の 2 種類があります。
- 一括計算済みインサイト:総計値を定期的 (毎日、毎週など) に計算できる複雑で大量のデータの集計用に設計されています。
- ストリーミングインサイト:リアルタイムイベントデータから評価指標とアクションを生成する機能を提供することで、即座に低遅延の顧客エンゲージメントを実現します。
計算済みインサイトはデータモデルオブジェクト (DMO) で定義され、他の計算済みインサイトオブジェクトでも定義できます。計算済みインサイトサービスは、一括処理ジョブとストリーミングジョブの両方のオーケストレーションを管理します。
バッチインサイトとストリーミングインサイトの両方の計算で Spark が使用されます。主な違いは、ストリーミングインサイトは Spark 構造化ストリーミングを使用するのに対し、バッチ CI は定期的なスケジュール済み一括処理 Spark ジョブを使用して実行されることです。コスト効率を高めるために、計算済みインサイトサービスでは、ソースデータオブジェクトの連動関係や重複などの要素に基づいて、同じ一括処理 CI ジョブまたはストリーミング CI ジョブで CI がグループ化されます。
SNCE と CDF は、ストリーミングインサイトの計算で重要な役割を果たします。
ID 解決は、複数のソースからのさまざまなデータを 1 つの包括的な統合プロファイルに変換する役割を果たします。
統合プロファイルは「ゴールデンレコード」ではなく、ID 解決によってプロファイルの統合中に当選値が選択されたり、既存のデータが上書きされたりすることはありません。統合プロファイルは、1 つのデータソース内または複数のソースで同じエンティティに関連するすべての一致レコードを識別することで、ソースデータのロックを解除する一連のキーとして機能します。この情報を使用して、特定のビジネス使用事例で使用する適切なソースシステムデータを選択できます。
ID 解決では、個人、取引先、世帯など、さまざまなレコードタイプを統合できます。また、リードを既存の取引先と照合するためにも使用できます。統合プロセスは、完全なCustomer 360ビューを実現し、B2CとB2Bの両方のシナリオでパーソナライズされたリアルタイム エンゲージメントを促進するために不可欠です。
ID 解決パイプラインは、大量のデータを継続的に処理するように設計された、拡張性の高いクラウドネイティブフレームワーク上に構築されています。このプロセスには 3 つの主要なフェーズがあり、強力な検索インデックスを使用して一致プロセスを管理します。
- 一致 (候補の選択):一致プロセスの目標は、同じエンティティに属するレコードを検索することです。レコードは、カスタマイズ可能なルールセットに対して分析されます。各ルールセットには、どのデータをどのレベルの厳格さで照合するかを定義する一連の条件が含まれます。データストアから一致の可能性があるレコードを効率的に取得するために、次の 2 つの方法を使用して、一致する可能性が高いレコードを見つけるインデックスが生成されます。
- ブロックキー:ブロックキーとは、レコードのデータから生成される値であり、類似する可能性のあるレコードをグループ化するための一致ルール (名前の最初の数文字、標準化された電話番号など) です。各レコードには複数のブロックキーがあり、インデックス付けされて転置インデックスとして保存されるため、データセット全体ではなく、小さなレコードグループでのみ詳細な比較が実行されます。
- Locality Sensitive Hashing (LSH):あいまい一致を使用する一致ルールの場合、ハッシュはトレーニング済みモデルからの埋め込みに基づいて生成されます。
- ディープマッチング:候補選択ステップで一致する可能性のある小さなグループが作成されると、より詳細な比較が開始されます。このフェーズでは、AI モデルと高度なアルゴリズムが各レコードのペアを分析して、確率的一致スコアを計算します。このスコアは、スペルミス、バリエーション、書式設定の違いが頻繁に発生する項目をインテリジェントに比較することで、2 つのレコードが同じエンティティを参照している可能性を定量化します。
- クラスタリングと統合:候補から一致するレコードが識別されると、それらはクラスターにグループ化されます。このプロセスには、推移的な一致の解決が不可欠です。たとえば、レコード A がレコード B に一致し、レコード B がレコード C に一致する場合、A と C が直接比較されなくても、3 つはすべて同じクラスタにリンクされます。これらの完全なクラスターは、統合プロファイルの基本構造を形成します。このクラスター化プロセスにより、すべての関連ソースレコードが 1 つの永続的な識別子で正しくリンクされます。
- 調整:クラスター化されたすべてのソース レコードのデータ値は、プロファイル データの抜粋を結果の統合プロファイルに入力する定義済みの調整ルール([Most Frequent (最も頻繁)]、[Most Recent (最新)]、[_Source Priority (_ソース優先度)] など)を使用して評価されます。統合プロファイルにリンクされたキーを使用してすべてのソースデータを使用できるため、調整によって既存のデータが上書きされることはありません。
このアーキテクチャでは、さまざまな使用事例を満たすために複数のエンティティ種別の解決がサポートされます。
- 個人照合:すべての既知の個人識別子 (メール、電話番号、ロイヤルティ ID、Cookie) を 1 人の個人にリンクする統合個人プロファイルの作成に焦点を絞ります。
- 取引先照合:取引先に関するデータをリンクする統合取引先プロファイルの作成に焦点を絞ります。会社名を照合する場合、あいまい一致ではエンジンで微調整されたモデルが使用されます。
- 世帯照合:一致ロジックを拡張して、統合個人レコードを関連する個人のグループに集計します。
- Cross Entity Matching
解決では、統合とは別に、同じ一致ルールを使用してプロファイルオブジェクト間のリンクも作成されます。たとえば、取引先名のあいまい一致を使用してリードを取引先にリンクできます。
統合プロファイルが常に最新になるように、ID 解決エンジンはほぼリアルタイムのアーキテクチャで動作します。このクラウドに最適化されたアーキテクチャは継続的な処理を目的として設計されており、処理時間が短縮されます。処理速度はソースデータの受信方法によって異なりますが、小さな変更のバッチは 15 分ごとに ID 解決で処理できます。
すべてのソースレコード ID を対応する統合プロファイル ID に対応付ける ID リンクオブジェクトが保持されます。この基本的なデータ構造により、エンジンでリレーションを効率的に追跡し、変更や更新を統合プロファイルにすばやく反映できるため、カスタマーエクスペリエンス (Web サイトのパーソナライズ、Next Best-Action のおすすめ、セグメンテーションなど) で常に最新の顧客データを活用できます。
セグメンテーションは、統合顧客プロファイルをアクション可能な利用者に変換するためのコアプロセスです。この機能は、マーケティング、コマース、サービスチャネル全体でパーソナライズされたエクスペリエンスを強化するために不可欠です。Salesforce Data 360 セグメンテーションプラットフォームは、大規模な運用向けに設計されています。何千ものオブジェクトとリレーションで構成されるデータモデルを使用して、複雑なメタデータを管理します。このプラットフォームでは、複雑なルール、集計ベースの検索条件、ウィンドウベースのランキングをすべてサポートしながら、ペタバイト規模の高速で信頼性の高い計算を実現します。
Data 360 は、速度、複雑さ、階層に関する個別のビジネス要件を満たすために、さまざまなセグメント種別をサポートしています。
- 標準セグメント:バッチ処理されたプライマリセグメント種別。標準公開のケイデンスは最小で 12 時間から最大 24 時間、高速公開のケイデンスは 1 ~ 4 時間で、カスタマイズ可能なスケジュールで公開されます。これは最近のエンゲージメントデータ用に最適化されています。
- リアルタイムセグメント:このセグメントは、最近のイベントとプロファイルデータに基づいてすぐにアクションを実行するためにミリ秒でオンデマンドで完了します。インスタントパーソナライズ用に高度に最適化されていますが、除外条件やネストされたセグメントは使用できません。
- 滝の区分:複数の条件に該当する場合に、顧客を 1 つの最も価値のあるセグメントに優先順位付けするために使用するサブセグメントの階層構造。
- ネストされたセグメント:これにより、親セグメントのスケジュールを継承して、既存のセグメントをより具体的な新しいセグメント (ベースセグメントの絞り込み) の検索条件として再利用できます。
セグメンテーションエンジンは、スピード、拡張性、復元性を保証する堅牢なクラウドネイティブアーキテクチャで動作します。
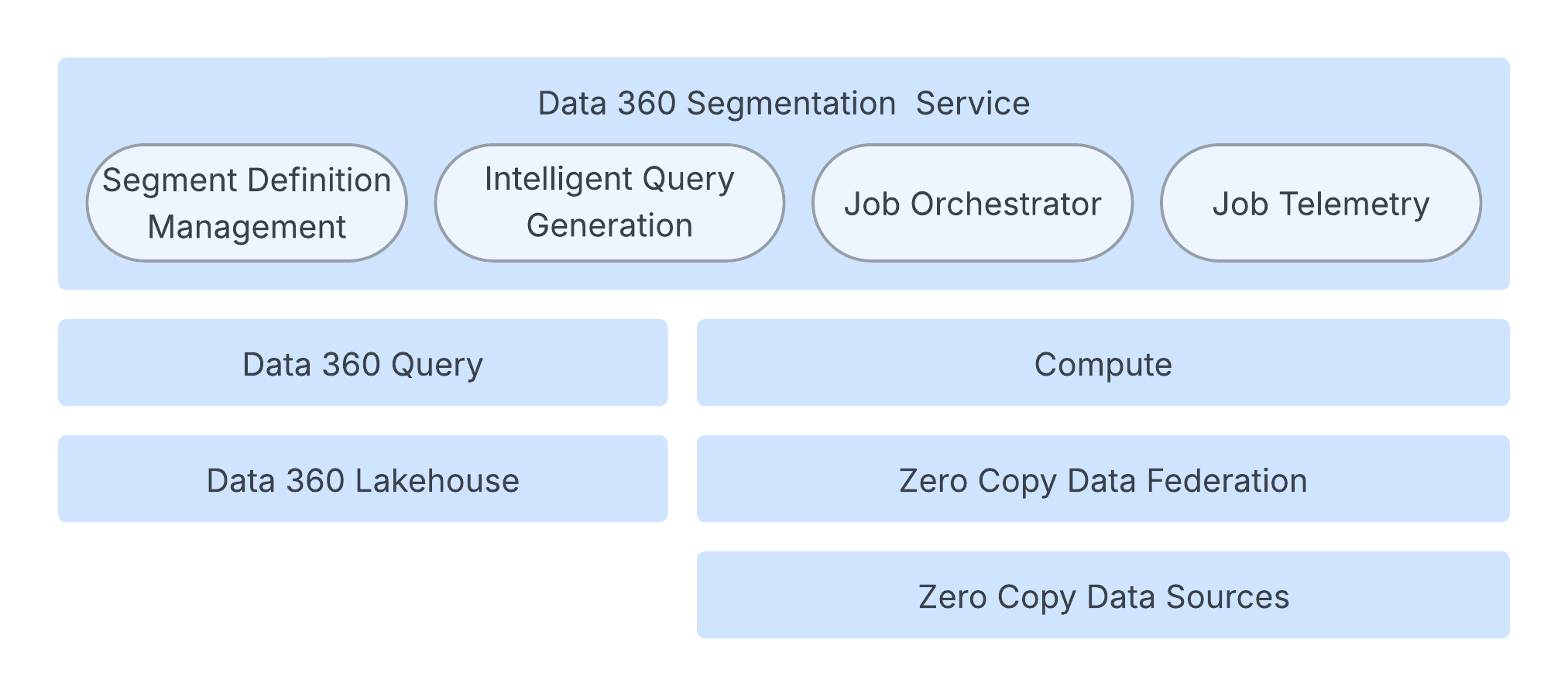
コアプロセスは、セグメントのライフサイクルを制御するジョブオーケストレーションサービスによって管理され、必要なジョブ設定が生成されて実行がトリガーされます。このオーケストレーションレイヤーでは、拡張性のために状態とメタデータがシャーディングされたデータベースに保持されます。
Data 360 クエリではセグメンテーション数の計算が処理されますが、実際のセグメントメンバーシップの計算は Spark 計算レイヤーが行います。Spark アプリケーションは、広範な顧客データに対して Spark SQL クエリを実行します。このデータは、Data 360 Lakehouse、または Zero Copy データフェデレーションを介した外部システム、あるいはその両方の組み合わせに存在できます。
システムは、基盤となる Spark SQL クエリを調整するインテリジェントなクエリ生成によって高度に最適化されています。これには、データスキャンを最小限に抑え、冗長なサブ式を排除するインテリジェントなパーティションプルーニングなどの技術が含まれます。サービスの信頼性を確保するために、このアーキテクチャにはワークロードのサイズと複雑さに基づいてコンピューティングリソースを動的に調整する適応型リソース管理が備わっています。さらに、SLO 遵守は適応期間と再試行ロジックでプロアクティブに管理されます。高速ユーザーエクスペリエンスを実現するために、セグメント数の高速化では、サンプリングベースのアプローチを使用してセグメントの作成時にサイズを迅速に推定し、クエリの実行全体を回避します。
最後に、包括的な Spark 実行評価指標とエラー (顧客側またはシステムの問題など) の自動分類により、観察可能性と根本原因の属性に深い焦点が当てられ、診断時間が大幅に短縮され、復元性の高いデータプラットフォームが確保されます。
有効化は、Data 360 ライフサイクルの重要な最終ステップです。そのコア機能は、静的でセグメント化された統合顧客プロファイルをアクション可能で強化されたデータに変換し、そのデータを内部および外部のエンドポイント (Marketing Cloud、Commerce Cloud、Adtech プラットフォームなど) に提供することです。このプロセスは、パーソナライズされたカスタマージャーニーとほぼリアルタイムのインタラクションをトリガーするように設計されています。関連属性、有効化メンバーシップの絞り込み、同意の絞り込み、制限、ランキングなどの高度な機能がサポートされます。
有効化では、外部配信とチャネルコンプライアンスの 3 つの異なる方法が提供されます。
- バッチの有効化:大規模なメールキャンペーンや広告オーディエンスの更新など、大規模でスケジュールされた業務向けに設計されています。データは、セキュアな内部バケット (クラウドオブジェクトストレージ) にステージングするか、セキュアなファイル転送を介して配信され、その後、ターゲットシステムによって API 取り込みプロセスが開始します。一括有効化では、特殊な更新モード (増分) を使用して、Salesforce パートナーに送信および処理される量を削減できます。
- ストリーミングの有効化:イベント駆動型の自動化を必要とするほぼリアルタイムの使用事例向けに最適化されています。配信は、送信先エンドポイントに送信される直接 API コールを介して実現されます。
- アクティベーショントリガーフロー:この高度にプラットフォーム化されたチャネルでは、オーディエンスデータを数百もの顧客 API 対応エンゲージメントプラットフォームと統合するためのノーコード/ローコードアプローチが提供されます。有効化が完了すると、Data 360 によってオーディエンス DMO が入力され、高スケールフローがトリガーされます。その後、フローエンジンは利用者データを使用し、外部サービスや Mule Outbound 送信先などのプラットフォーム機能を使用して、最終的な API ベースの送信先へのコールを実行します。この方法では、新しい有効化対象のオンボーディングに必要な時間が大幅に短縮されます。
有効化では、ジョブ管理、分散実行、監視でセグメンテーションと同じパターンが使用されます。これには、ライフサイクル管理用のジョブオーケストレーションサービスの原則と処理用のコンピューティングレイヤー (Spark) が含まれ、パフォーマンスの可観測性とサービスレベル目標 (SLO) の遵守のためにジョブテレメトリが利用されます。
これに加えて、有効化には - があります。
有効化対象管理は、すべての宛先エンドポイントの安全な接続、ログイン情報、設定を監視します。これにより、データ形式とセキュリティプロトコルが標準化され、Marketing Cloud、Adtech パートナー、その他の外部アプリケーションなど、さまざまなプラットフォームへの信頼性の高いアウトバウンド配信が保証されます。
有効化では、ペイロードが特定の対象に合わせて調整されます。Salesforce Marketing Cloud の場合、これにはビジネスユニット (BU) 対応絞り込み、マルチ EID サポート、受粉制御が含まれます。
コミュニケーション ガバナンスはゲートキーパーとして機能し、データ使用量とコミュニケーションが顧客の設定と法的要件に準拠するようにします。一元化された同意モデルでは、グローバルオプトアウトからチャネルおよび目的固有の同意まで、すべての顧客設定が統合され、統合個人プロファイルに保存されます。実行時に、プラットフォームは除外フィルターを使用して同意していない個人を最終ペイロードから自動的に削除することで、これらのポリシーを厳格に適用します。さらに、データが送信される前に、目的のチャネルで 1 つの最も準拠性の高い優先連絡先が使用されるように連絡先選択ルールが適用されます。この適用メカニズムは、有効化プロセス全体で機密データ項目を保護するための動的データマスキングやアクセス制御などの保護手段を使用する、基盤となるガバナンスフレームワークによって保護されます。
統合データプラットフォームの真の価値は、その発生源や構造に関係なく、すべてのデータアセットに容易で一貫したアクセスを提供できることです。Salesforce Data 360 の統合クエリ機能は、これを実現するために厳密に設計されており、さまざまなデータストアの基盤となる複雑さを抽象化して、1 つの強力なクエリインターフェースを提供します。
統合クエリレイヤーでは、さまざまな消費パターンに対して高度なアクセスが提供されます。
- ハイブリッド構造化および非構造化クエリ:構造化データと非構造化データの構造化メタデータの両方をシームレスに照会するための広範な SQL サポートが提供されます。これは、テーブル関数による演算子の拡張性によって強化され、テキスト、画像、空間種別を横断する特殊な検索が可能になります。
- Hyper によるパフォーマンスの向上 360 は、ハイパフォーマンスのインメモリエンジンである Hyper を活用して複雑な分析クエリと対話型ダッシュボードを高速化し、大規模なデータセットに対してほぼ瞬時に応答します。
- AIとパーソナライズの統合アプローチ:この統合アクセスは、対象を絞ったパーソナライズされた結果を生成するために不可欠であり、リッチなエンタープライズデータで AI モデルをグラウンディングすることで、取得拡張生成 (RAG) を使用してより正確な LLM 応答を直接促進します。
- ダウンストリーム消費との統合
駆動型エクスペリエンス、堅牢な API、生成 AI ワークフロー、CRM 強化の基盤データアクセスレイヤーとして機能し、データを有効化にシームレスに接続します。
Data 360 の統合クエリでは、単一のインテリジェントでパフォーマンスの高いクエリインターフェースが提供されるため、アーキテクトはあらゆる顧客情報を最大限に活用する俊敏なデータ駆動型アプリケーションを構築できます。
Data 360 は、データイベントに応じてパイプラインを有効化できる有効なプラットフォームです。たとえば、顧客の口座残高の減少などの重要なイベントが発生すると、Salesforce フローがトリガーされ、対応するアクションが調整されます。同様に、生涯費用などの主要な評価指標の更新は、関連するアプリケーションに自動的に反映できます。
データアクションでは、ストレージネイティブ変更イベント (SNCE) と変更データフィード (CDF) を使用して、増分データの変更を継続的に監視します。このデータは、しきい値の監視や状態の変更など、顧客が設定したアクションルールに対して評価されます。これらのルールが満たされると、データアクションイベントが生成されます。このイベントは追加情報 (顧客ロイヤルティ状況など) で強化され、設定された宛先 (Salesforce フローや外部アプリケーションなど) にすぐに送信され、ビジネスオーケストレーションがトリガーされます。
Data 360 では、高度な ID 解決機能、包括的なエンゲージメント履歴と共に統合個人 ID とプロファイルの作成など、ネイティブの CDP (Customer Data Platform) 機能がサポートされます。このプラットフォームは、前述のように完全一致ルールとあいまい一致ルールの両方を使用する ID 解決と ID グラフをサポートすることで、企業間 (B2B) および企業間 (B2C) の両方のフレームワークの処理に適しています。これらの ID グラフは、さまざまなチャネルからのエンゲージメントデータで強化されており、貴重な分析インサイトとセグメントを含む詳細なプロファイルグラフを作成するのに役立ちます。
顧客プロファイルをサポートする主要な概念はデータグラフです。Data 360 では、さまざまな Lakehouse テーブルとその相互関係から派生した非正規化オブジェクトである JSON 形式のエンタープライズデータグラフが提供されます。これには、CDP によって作成された、個人の購入および閲覧履歴、ケース履歴、商品の使用状況、その他の計算済みインサイトを含む「プロファイル」データグラフが含まれ、顧客やパートナーが拡張できます。これらのデータグラフは特定のアプリケーションに合わせて調整されており、関連する顧客またはユーザー コンテキストを提供することで生成AIプロンプトの精度を高めます。Data 360 のリアルタイムレイヤーでは、プロファイルグラフを使用してリアルタイムのパーソナライズとセグメンテーションを行います。会話、セッション、およびエージェント記憶をデータグラフとして含む Agentforce コンテキストのモデル化を想定しています。
さらに、CDP により、Salesforce の Marketing Cloud、Facebook、Google など、さまざまなプラットフォームで効果的なセグメンテーションと有効化が可能になります。顧客プロファイルはバッチ、ほぼリアルタイム、リアルタイムで処理されるため、即時の意思決定とパーソナライズが可能です。この機能により、B2C と B2B の両方のシナリオでインタラクションが強化され、企業が顧客のニーズや行動に迅速かつ正確に対応できるようになります。
Data 360 のリアルタイムレイヤーは、Data 360 CDP によってサポートされ、リアルタイムの使用事例に合わせてその概念を拡張しています。Data 360 のリアルタイムレイヤーは、Web およびモバイルのクリックストリーム、訪問、カートデータ、チェックアウトなどのイベントをミリ秒の遅延で処理するように設計されており、カスタマーエクスペリエンスのパーソナライズを強化します。顧客エンゲージメントを継続的に監視し、リアルタイムのエンゲージメントデータ、セグメント、計算で Customer 360 から顧客プロファイルを更新して、すぐにパーソナライズします。
たとえば、消費者がショッピング Web サイトで商品を購入すると、リアルタイムレイヤーはこのイベントをすばやく検出して取り込み、消費者を識別して、更新された生涯支出情報でプロファイルを強化します。これにより、サイトでのエクスペリエンスを数秒でパーソナライズできます。さらに、このレイヤーにはリアルタイムのトリガーと応答の機能が含まれており、顧客とのやりとりに基づいてすぐにアクションを実行できます。
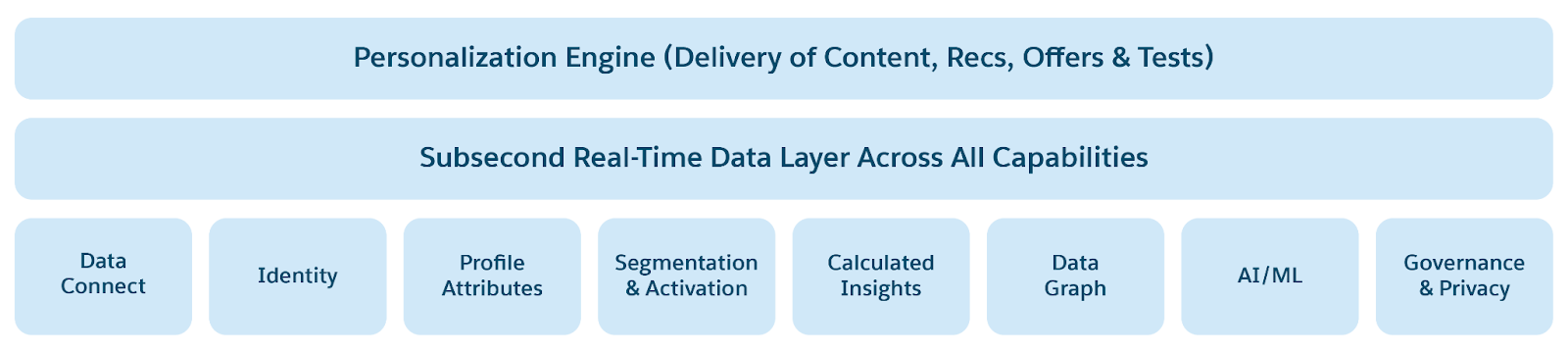
Sub-Second Real-Time Platform は、次の主要な機能によってこの変換を強化します。
- リアルタイムデータグラフ
360プロファイルは、ブランドに最も関連する主要なオブジェクトと項目を含む非正規化されたグラフを使用して作成されます。これらのデータグラフにより、リアルタイムのデータ処理が可能になり、アクション可能なコンテンツとインサイトをミリ秒以内に提供できます。 - リアルタイム取り込みおよび変換
およびモバイルソースからユーザーイベントとプロファイルをミリ秒単位で取り込みます。 - リアルタイム ID 解決:デバイス間で顧客プロファイルをマージし、不明なユーザーと既知のユーザーをすぐに統合します。
- リアルタイムの計算済みインサイト:生涯価値(LTV)やユーザー訪問履歴などの評価指標をミリ秒単位で計算して、Web、チャットボット、サービスエージェントのパーソナライズまたは提案を有効にします。
- リアルタイムセグメンテーション:オーディエンスをその場でセグメント化し、メッセージとインタラクションをリアルタイムでパーソナライズします。
- リアルタイムアクション
フローまたはその他の関連するコミュニケーションチャネルを使用して、ブランドがすべてのユーザーエンゲージメントを評価し、アクションを実行できるようにします。
Data 360 では、リアルタイムパイプライン、低レイテンシストレージ、1 秒未満のデータ処理レイヤーを備えた新しいリアルタイムプラットフォームを構築しました。Web およびモバイルチャネルから高速インタラクティブデータが取り込まれると、一連の高速プロセスが実行されます。
Web およびモバイル SDK とリアルタイム API は、Web/モバイルアプリケーション (今後の Agentic インタラクション) からデータを収集し、ビーコンサーバーに送信します。その後、このデータはミリ秒処理のためにリアルタイムレイヤーに転送され、バッチ/ストリーミングデータと統合するために Lakehouse レイヤーに転送されます。リアルタイムレイヤーは、ユーザープロファイル (匿名またはログイン済み) のコンテキストで受信リアルタイムデータを処理し、セッション中のリアルタイムパーソナライズのためにユーザーの総支出や生涯価値などを更新します。リアルタイムレイヤーは、メインメモリと NVme (SSD) ストレージによってサポートされ、リアルタイムデータと顧客プロファイルを保存します。データがリアルタイムレイヤーに取り込まれると、リアルタイムデータグラフに更新される前に次のプロセスが実行されます。
- 単純な取り込みと変換:データが取り込まれ、さらに処理できるように変換されます。
- ID 解決:完全一致ルールは、プロファイルを既存のすべての一致ルールセットと統合するために適用されるため、データアウェアスペシャリストはリアルタイム専用の新しい ID 解決ルールセットを作成する必要はありません。
- 計算済みインサイト:すべてのエンゲージメントが評価され、sum や count in milliseconds などの簡単な計算が実行され、リアルタイムデータグラフのデータが更新されます。
- リアルタイムセグメント:すべてのエンゲージメントデータは、定義されたリアルタイムセグメントの条件を満たすかどうかを判断するために評価され、ユーザーはミリ秒単位で対象セグメントに追加されます。
- リアルタイムアクションおよびトリガー:すべてのエンゲージメントは定義済みのルールに対して評価され、ルールがミリ秒単位で満たされたときにリアルタイムでアクションがトリガーされます。
- リアルタイムデータグラフおよび API:リアルタイムデータグラフにはリアルタイム API も含まれており、ブランドは各ユーザーの更新された JSON 形式のデータを取得できます。これにより、すべての顧客とのやりとりに最新のデータが提供されます。
パーソナライズは、誰を対象にするか、関連するコンテンツとおすすめをいつどこで提供するか、何を話すか、どの頻度を使用するかを理解することがすべてです。Personalization Services Platform は、パーソナライズされた環境を通じて目標達成を最適化するためにどのような意思決定を行うかを調整するオーケストレーターです。
Personalization Servicesには次の機能があります。
- Data 360 のプロファイル、活動、アセットデータを解釈するための一貫したモデルと方法のセット
- プラットフォーム統合実験 (A/B/n、マルチアームバンディット)
- 設計時 (設定)、ML トレーニング時、実行時 (ML 推測) の目標の統合
- B2C スケールのリアルタイムおよびバッチインタラクションのサポート (匿名ユーザー、大量のリアルタイム/インタラクティブ外部、大量の内部バッチ)
- Data 360 で実行される分析
- AI モデルと他の関係者 (内部と外部) のサービスを統合するパターン
- コアメタデータエコシステムへの統合 (PLATE の特性)
- 価値の高い AI 駆動型使用事例の OOTB 実装 (プロモーション/コンテンツ選択のためのコンテキスト盗賊、商品のおすすめ、価格設定の決定など、さまざまな ML アルゴリズムを使用したおすすめ/決定)
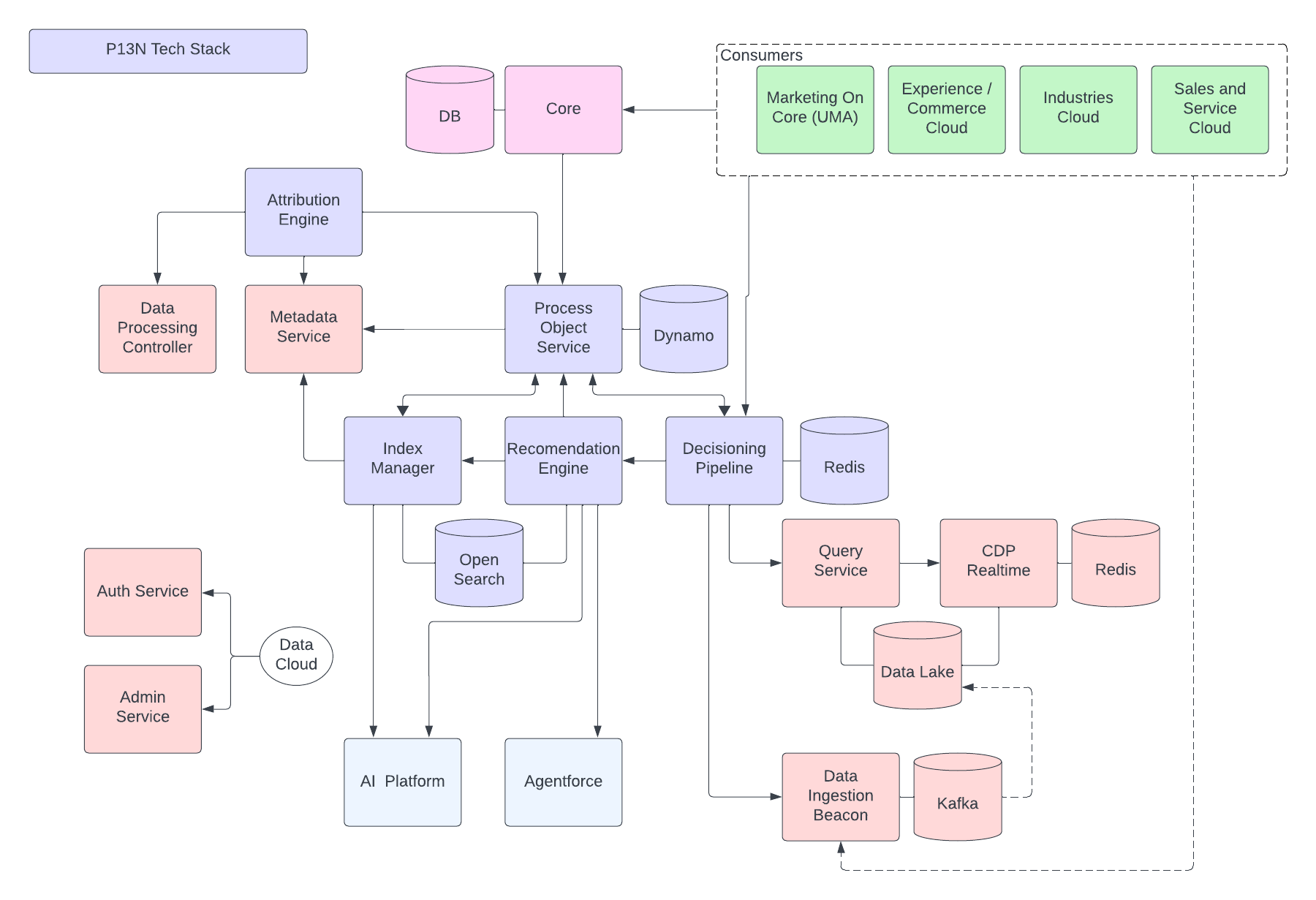
- Decisioning Pipeline
- プロファイルの追加、実験、おすすめなど、パーソナライズの決定に関する外部要求に対応する。
- おすすめエンジン
- ルールまたは ML ベースのおすすめの実行時サービス。
- Index Manager
- おすすめモデルの ML トレーニングを含む非同期プロセスのワークフローを管理/オーケストレーションする
- プロセスオブジェクトサービス
- コアとオフコア間でパーソナライズメタデータを同期する
- 属性エンジンと実験
- Analytics の属性設定とパーソナライズレコメンデーションの実験
Data 360 は、新しいエージェント環境をサポートするための堅牢で豊富なプラットフォームとして設計されています。これらの機能は、さまざまな既存のData 360サービスを基盤とし、Agentforceとの緊密な統合によって実現しています。
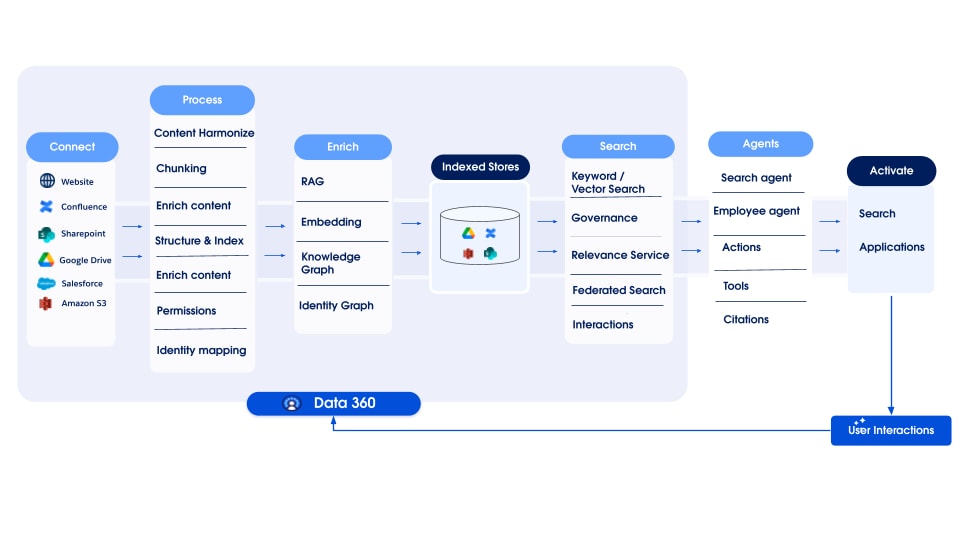
エージェント型エンタープライズ検索へのアプローチは、次の原則に基づいています。
- エンタープライズデータはサイロ化されたサービスまたはストアに保存され、アクセスに必要な安全な権限が付与されます。Trustを確保するためには、ソース権限を維持しながらこのデータにアクセスして処理する機能が不可欠です。
- データの完全なコーパス全体でのクロスランキングと関連性により、より適切な結果を得られ、エージェントエクスペリエンスのコンテキストも改善されます。
これらの環境を提供するために、エージェント型エンタープライズ検索は次の主要なアーキテクチャコンポーネント上に構築されています。
- コネクタ 360 で使用できる幅広いコネクタセットにより、さまざまなソースからデータにアクセスして取り込むことができます。
- 非構造化データ処理:これは、表形式以外のコンテンツを処理するための基礎であり、システムが多様なデータから意味とコンテキストを抽出できるようにします。
- ガバナンス:検索で消費されるすべてのデータのエンタープライズクラスのセキュリティ、コンプライアンス、アクセス制御を確保します。ソース表示権限がサポートされているため、簡単な検索とエージェント操作の両方で、承認されたユーザーのみがデータにアクセスできます。迅速に取得できるように、セキュリティ権限はデータアクセスの最も早い段階で検索バックエンドによってネイティブに評価され、適用されます。
- 統合取得レイヤー:サイロ化されたデータの課題に対応するために、コネクタは包括的な統合取得レイヤーにフィードされます。このレイヤーは、統合検索でアクセスする外部システムにデータを保持する場合でも、ゼロコピーおよび取り込まれたデータの高度なインデックスでネイティブに管理される場合でも、すべてのデータへの単一のアクセスポイントを提供します。
- インテリジェントなクエリの理解:取得前に、システムは AI を駆使したメカニズムを使用してユーザーのインテントを解釈します。セマンティックベクトル照合用のクエリの表現を埋め込むことができるだけでなく、キーワードベースの検索を書き換えて拡張し、精度を向上させることができます。
- ハイブリッド検索と高度なクエリ:最も関連性の高い情報を見つけるために、プラットフォームでは複数の戦略が並行して使用されます。ハイブリッド検索では、最適化されたデータチャンクのセマンティックベクトル検索でキーワードの正確な一致が提供されますが、フルレコード検索ではドキュメント全体が同時に取得されます。両方を組み合わせて、セマンティックな関連性とコンテンツの完全なカバー率を確保します。
- 階層ランキング:データが取得されると、複数フェーズの階層ランキングアーキテクチャによって、すべてのソースおよびメソッドの結果のスコアリング、マージ、再ランク付けが行われます。このプロセスでは、ユーザーまたはエージェントにとって最も関連性の高い情報が表示される 1 つの統合リストが作成されます。
生成 AI は、エンタープライズ検索の主要な消費者を人間のユーザーから大規模言語モデル (LLM) に移行しています。Data 360 Search は、その両方に対応するようにゼロから設計されています。エージェントからのより長く複雑なクエリを処理し、プログラムでの消費および推論ループに必要な豊富なコンテキスト結果を返すように最適化されています。同時に、このシステムは人間のユーザーにありがちな短くあいまいなクエリを処理でき、スニペットや強調表示などの機能を提供して UI ですばやく評価できます。
エージェントによる検索エクスペリエンスの究極の提供では、次の両方のアプローチを組み合わせます。
- 直接検索結果: アプリケーションは、Data 360 統合検索基盤上に構築されたメタデータ駆動型 API を使用して、ランク付けされた従来の結果のリストを表示できます。
- エージェントによる複数ターンの対話形式の回答: エージェントによる回答は、Agentforce とのネイティブ統合によって実装されます。この会話環境は、アクションとクエリを調整し、すべての情報取得タスクを専門の社内検索エージェントに委任する主エージェントによって促進されます。
この特殊な検索エージェントは、エンタープライズ情報の取得用に最適化されています。推論ループを使用して並列検索を策定して実行し、ユーザーの要求のさまざまな側面を探索します。すべてのデータ型に対応する Data 360 統合検索や、テーブルやエンティティから正確なデータを取得する構造化されたクエリ言語などの強力なツールセットを使用します。
このアーキテクチャの統合により、Data 360 は高度にインテリジェントでコンテキストを認識し、アクション可能なエージェント型のエンタープライズ検索環境の作成を強化します。
拡張性は、Salesforce Platform の主要な機能です。Code Extension は Data 360 の拡張性を提供し、プロコードユーザーは Data 360 環境内でカスタム Python ロジックを直接実行でき、その豊富な宣言型機能とローコード機能を補完します。コードエクステンションを使用すると、ユーザーは変換や非構造化データパイプライン (カスタムチャンク) などの Data 360 コア機能を安全に拡張できます。
コードエクステンションの設計では、柔軟性、セキュリティ、効率性、合理化された開発者エクスペリエンスが優先されます。それぞれ特定のアーキテクチャニーズに合わせて調整された 2 つの主実行モデルがサポートされます。
- スクリプトモデル:
- 目的 360 Lakehouse を直接操作する必要がある包括的なカスタムロジックの場合。
- 機能:顧客は Code Extension SDK を使用して完全な Python スクリプトを作成し、SDK API を介して Lakehouse への参照および更新アクセス権を有効にします。カスタム/複雑なデータプレップや、特注のデータ操作に最適です。
- 分離とセキュリティ:スクリプトが Lakehouse にアクセスする間、スクリプトの実行は Data 360 ランタイム内の安全で隔離された環境に制限されるため、他のプロセスへの干渉や不正なシステムアクセスが防止されます。
- 機能モデル:
- 目的:既存の Data 360 パイプライン (非構造化パイプラインのカスタムチャンクなど) から呼び出されるモジュール型のステートレス計算の場合、サーバーレス関数に似ています。
- 機能:顧客が指定した関数は、入力、計算、出力を返します。
- 分離とセキュリティ:これらの関数は厳密に分離するように設計されており、Lakehouse に直接アクセスすることはできません。実行は Sandbox でステートレスであり、リソースが制限されているため、集中したステートレスな処理ステップに適しており、セキュリティ、予測可能な実行、ブラスト半径の最小化を実現します。
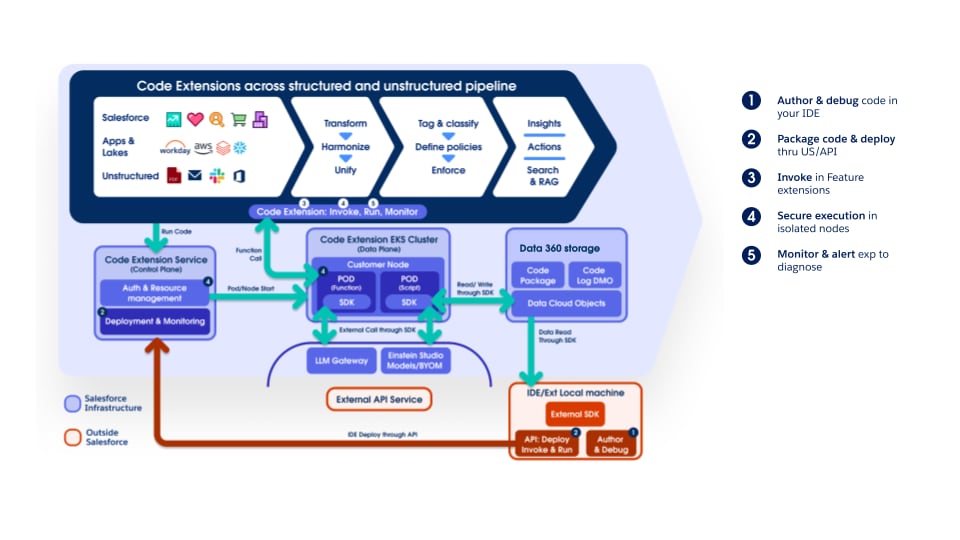
スクリプトモデルと関数モデルのどちらも、顧客のコードを安全に実行し、あるテナントのコードが他のテナントに影響を与えたり、他のテナントのデータ、Salesforce リソース、外部リソースに不正にアクセスしたりすることを防止することを目的としています。このセキュリティは、階層型 (多層防御) アーキテクチャによって実現されます。このアーキテクチャでは、さまざまなガードレールが組み込まれ、各テナントのカスタムコードに対して分離された実行環境が提供されます。これには、Kubernetes (K8) レベルでの論理的な分離、ネットワークの分離、実行時の Sandbox、最小限の権限などが含まれ、さらに、運用監視とインシデント対応の準備状況によって検出と対応が補完されます。
堅牢な開発ライフサイクルをサポートするために、Code Extension には次の機能があります。
- 外部作成およびデバッグ:開発者は、VSCode などの使い慣れた環境で SDK を使用して Python コードを作成してデバッグできます。
- 柔軟な導入
ユーティリティ、Data 360 UI、または API を使用してカスタムコードをパッケージ化してリリースできるため、CI/CD に統合できます。
操作ログ:詳細な実行ログにアクセスできるため、透明性が高く、本番でのトラブルシューティングに役立ちます。
Data 360 は、これらの安全で柔軟なコード拡張機能を提供することで、アーキテクトが最もユニークで複雑なデータ処理要件に合わせてプラットフォームを調整し、拡張可能なエンタープライズデータファブリックとしての役割を真に強固なものにします。
企業が AI の採用を加速するにつれ、そのほとんどは Amazon SageMaker、Google Vertex AI、カスタム Python ベースの環境など、信用リスクスコアリング、離脱傾向、商品のおすすめ、Next Best Action の決定など、ミッションクリティカルな予測を促進するモデルをホストする異種混在 ML エコシステムを維持しています。
これまで、これらの外部モデルを Salesforce に統合するには、専用の API レイヤー、ETL パイプライン、ミドルウェアオーケストレーションが必要でした。そのため、データの重複、ガバナンスオーバーヘッド、レイテンシ、運用の複雑さが発生し、統合的でコンプライアンスに準拠したリアルタイムの Customer Data Platform (CDP) ビジョンと相反する課題が生じていました。
Bring Your Own Model (BYOM) 360のEinstein Studioを介して提供されるため、データを移動したりレプリケートしたりすることなく、Salesforceワークフロー、Apexロジック、自動化ツール内で外部トレーニングを受けたモデルを直接呼び出すことができるため、これらの課題に対処できます。ゼロ コピー統合により、Data 360は管理された単一の情報源として機能し、ハーモナイズされたCustomer 360データを外部エンドポイントで推測できるようにします。予測出力はリアルタイムで戻されるため、拡張性の高いインテリジェンスでビジネスプロセスを強化できます。
BYOM は、モデル開発、管理データ、消費レイヤーを分離することで、データサイエンスと業務実行の間のギャップを効果的に埋めます。プラットフォームの独立性が維持され、インテグレーションの複雑さが軽減され、AI の導入が迅速化され、機密データのガバナンスが維持されます。
このアーキテクチャは次のように動作します。Data 360は統合されたCustomer 360データ基盤を提供し、Einstein Studioは外部MLプラットフォーム(SageMaker、Vertex AI、カスタム エンドポイント)への接続を調整します。外部モデルは、リアルタイム、バッチ、またはストリーミングモードで推測を実行します。Salesforceレイヤー(フロー、Apex、クエリAPI)では、出力を使用して、Sales Cloud、Service Cloud、Marketing Cloud、Industry Cloudでパーソナライズされた自動分析インサイトを提供します。
エンタープライズの観点から見ると、BYOM には次の利点があります。
- データの整合性とガバナンス:制御されていないデータコピーを排除し、ポリシーコンプライアンスを適用します。
- AIの民主化:技術者以外のユーザーが Salesforce ツールを使用して複雑なモデルにアクセスできるようにします。
- タイム トゥ バリューの短縮:外部モデルは、Salesforce プロセス内ですぐに有効化されます。
- 拡張性とハイブリッド アーキテクチャのサポート
ワークロードのマルチクラウドリリースを有効にします。 - 未来志向のAIアーキテクチャ:構成可能な AI 戦略をサポートし、データ、モデル、消費レイヤーを分離することで、運用の俊敏性を実現します。
Bring Your Own LLM (BYO-LLM):生成モデルに同じ拡張性メカニズムを提供します。外部 LLM の直接呼び出しを有効にすることで、顧客は Salesforce が提供するモデルの代わりに Agentforce Platform で外部 LLM を使用できます。エンタープライズの場合、BYO-LLM では次のことができます。
- 微調整されたモデルへのアクセス
- 現在 Salesforce で提供されていないモデルのインテグレーション
- 顧客が指定した取引先でのモデルの使用
モダン エンタープライズは、2 つの主要なアーキテクチャ上の課題によって特徴付けられる複雑なデータ ランドスケープ内で運用されます。
- 企業内フラグメンテーション:大規模な組織では、複数の Salesforce 組織 (多くの場合、地域、ビジネスユニット、または過去の買収履歴でセグメント化) やその他の多数のデータシステムが頻繁に使用されます。このフラグメンテーションにより、内部データサイロが作成されるため、ビジネス全体でリアルタイムのエンゲージメントを行うための顧客の 1 つの信頼できる統合ビューを確立できなくなります。課題は、すべてのシステムでデータを物理的に統合または複製せずにこのデータを統合し、ガバナンスを確実に維持することです。
- 企業間コラボレーション:多くの場合、企業は共同マーケティング、メジャメント、ビジネスインテリジェンスのためにパートナーやサプライヤーとデータを共有する必要があります。課題は、機密性の高い独自データを保護し、GDPR や CCPA などのプライバシー規制や競争障壁を遵守しながら、このコラボレーションを実現することです。
Salesforce Data 360は、データの移動や複製ではなく、アクセスとインサイトの共有の原則に基づいて構築されたゼロ コピーのTrust-by-Designフレームワークでこれらの課題に対処します。
Salesforce Data 360 は、Data Cloud One、Data 360 間のデータ共有、プライバシー優先のデータクリーンルームを使用して、データの断片化とコラボレーションの課題に対処します。これらのソリューションは、顧客データを統合し、安全なデータ交換を可能にし、プライバシー保護に関するインサイトを提供します。ゼロ コピーのTrust by Designアプローチにより、組織はリアルタイムのエンゲージメント、強化されたパートナーシップ、インテリジェントな意思決定のためにデータの可能性を引き出すことができます。これらのデータコラボレーションオプションの目的はそれぞれ異なります。
Data Cloud One を使用した内部エンタープライズイネーブルメント
Data Cloud One は、複数の Salesforce 組織を運用しているエンタープライズ向けの基本的なアーキテクチャソリューションです。その目的は単なるデータ共有にとどまらず、単一の信頼できる顧客ビューを確立し、組織全体で Data 360 プラットフォームのすべての機能を実現するように設計されています。
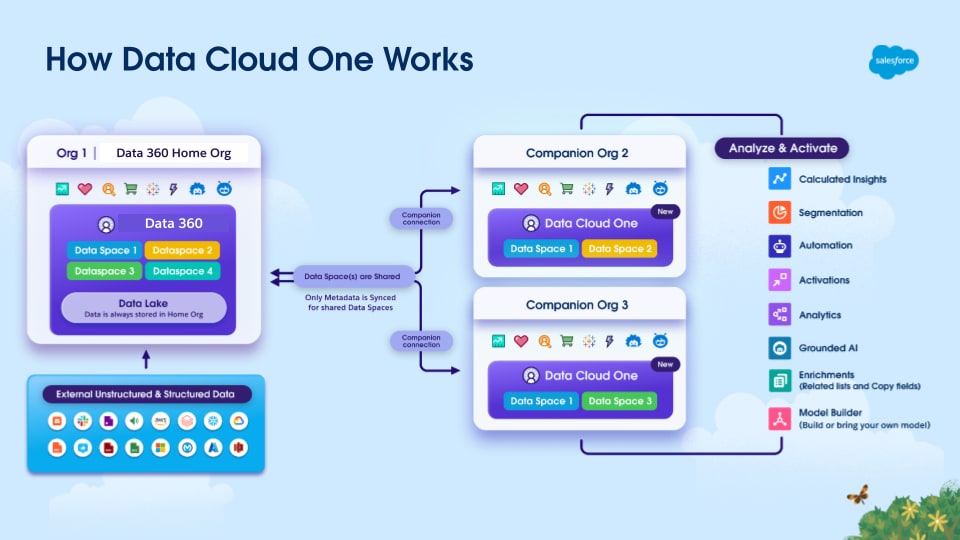
このメカニズムは、指定された Home Org Data 360 インスタンスを中心に機能します。このインスタンスは、データ管理と統合顧客プロファイルの作成の中心機関として機能します。ホーム組織は、Data 360 がプロビジョニングされている組織です。Data 360 と他の Salesforce 組織 (コンパニオン組織) の間に Data Cloud One 接続が確立されます。Data Cloud One 接続の一環として、Data 360 は各コンパニオン組織と 1 つ以上のデータスペースを共有し、各共有データスペースのデータとメタデータの両方へのアクセスを提供します。これは、ゼロコピー統合モデルと組織間メタデータ同期によって実現されます。
Data Cloud One では、コンパニオン組織で自宅の組織の Data 360 インスタンスを活用して、独自の有効化、パーソナライズ、インテリジェンスのニーズにも対応できます。この戦略は、内部データの断片化を排除し、すべてのビジネスユニットが同じ管理対象の統合顧客プロファイルに対して有効化され、コア Data 360 実装の ROI を最大化するために不可欠です。
Data 360 組織間でのデータ共有
Data 360-to-Data 360 データ共有では、分散内部環境 (完全な一元化が不可能) や信頼できる外部パートナーとのコラボレーションのために、独立した Data 360 インスタンスが接続されます。
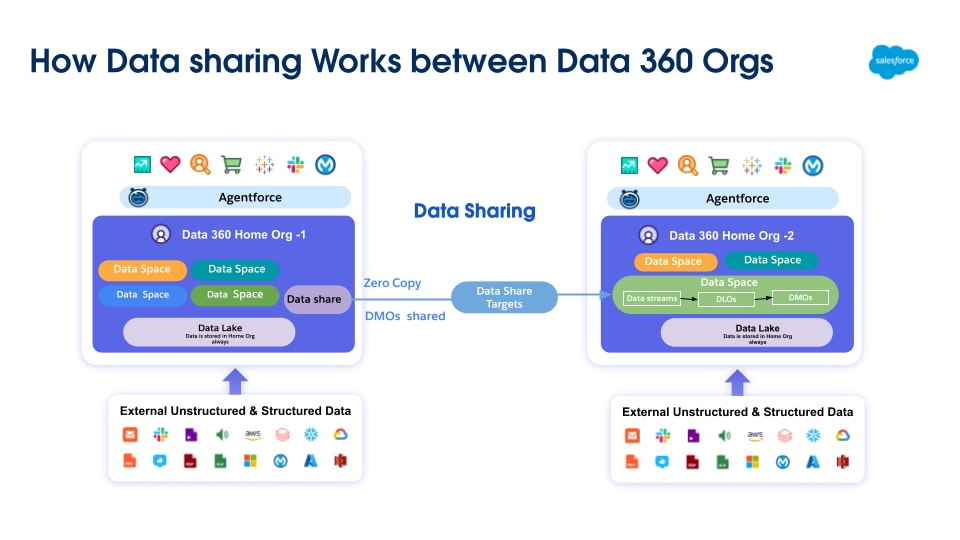
このゼロコピー共有モデルでは、データオブジェクト (DLO、DMO、CIO) の安全な交換を目的として、異なる Salesforce 組織にプロビジョニングされた別々の Data 360 テナント間の接続が確立されます。接続すると、受信者の Data 360 でデータオブジェクト全体にアクセスできるようになります。受信者 Data 360 の管理者は、このデータへのユーザーアクセスを管理するガバナンスルールを設定できます。
Data 360 Clean Room Collaboration を使用したプライバシー優先のコラボレーション
コラボレーションで最高レベルのプライバシーとコンプライアンスが必要な場合や、競合上の懸念から未加工データの共有が禁止されている場合は、Data 360 Clean Rooms のアーキテクチャが義務付けられています。
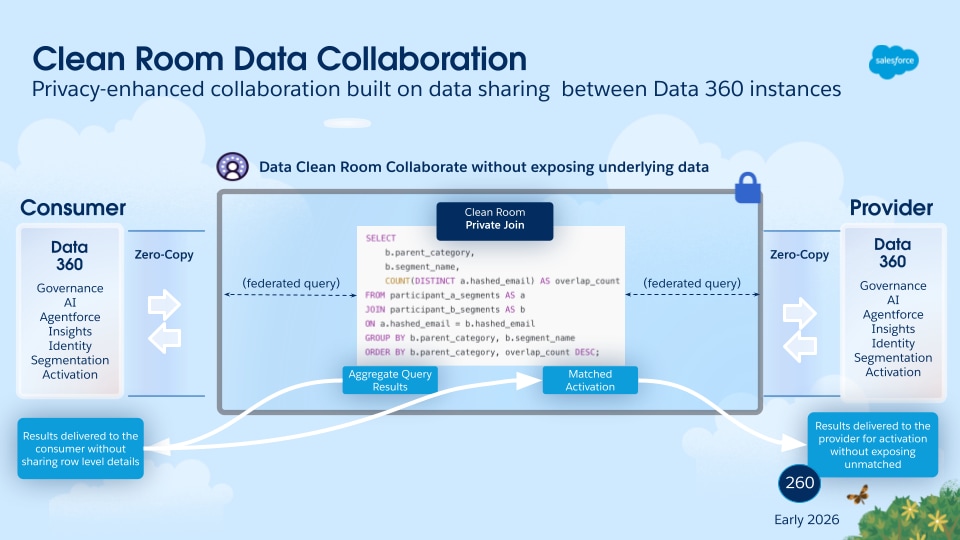
アーキテクチャ的には、Data 360 クリーンルームコラボレーションは、Data 360-to-Data 360 データ共有で使用されるゼロコピー共有フレームワーク上に構築されていますが、ガバナンスと計算上の制約が一層追加されています。Data 360 クリーンルームは、関係者が匿名化された鍵に基づいてデータセットを結合できる安全で制御されたコンピューティング環境を提供します。その主な目的は、基盤となる独自データを公開することなく、共同分析とインサイト生成を可能にすることです。環境では、最小集計しきい値やエクスポートできない識別子などの厳格でプログラム可能なルールが適用されます。これらのルールにより、承認されたインサイト、プライバシーを強化するインサイト、集計されたインサイトのみが取得および共有されます。これにより、クロスプラットフォームキャンペーンメジャメントや機密性の高いオーディエンスの重複分析などの使用事例でクリーンルームが不可欠になります。
Data 360 は、次世代の AI を強化するために必要な、インテリジェントで拡張可能な信頼できるデータファブリックとして設計されています。そのアーキテクチャ設計により、断片化されたデータの問題に対処し、組織は Zero Copy Data Federation を使用して、すべての顧客データを大規模に統合、処理、有効化して効率を確保できます。
その堅牢なデータ整理により、パーティション分割されたデータスペース内で保護されている DLO (非構造化データを含む) から DMO までのハーモナイズビューが確立されます。Data 360 の汎用性の高いデータ処理能力 (バッチ変換、ストリーミング変換、計算済みインサイト、非構造化データ処理、ID 解決など) は、増分 SNCE および CDF アーキテクチャによって強化され、効率的でほぼリアルタイムの処理と大幅なコスト削減を実現します。
拡張性は、コードエクステンションアーキテクチャによって提供され、スクリプトまたは独立した関数を使用して、固有の要件に合わせてカスタム Python ロジックを安全に有効化します。さらに、CEDAR ポリシーを使用した属性ベースのアクセス制御 (ABAC) を基盤とする包括的なデータガバナンスフレームワークにより、詳細なセキュリティ、動的データマスキング、およびすべてのデータ消費の一貫した適用が保証されます。これにより、高度なセグメンテーションと有効化機能が実現し、統合された顧客プロファイルがリアルタイムの応答性を備えた動的なマルチチャネルエンゲージメント戦略に変換されます。
重要な点として、インテリジェント AI エージェントを強化するには、Data 360 の膨大で多様なデータの統合、統合クエリによるリアルタイムのコンテキストの提供 (ハイブリッド構造化/非構造化検索、ハイパーアクセラレーションなど)、厳格なガバナンスの適用が不可欠です。RAG(生成AIワークフロー)をグラウンディングし、Agentforceを利用するエージェントの複数ターンのアクション指向の機能を強化するために必要な、信頼性の高い最新の関連データが提供され、エージェントが正確かつ正確に操作できるようにします。
Data 360 は、ソースデータをアクション可能なインサイトに変換する将来を見据えたプラットフォームを提供することで、エージェント型のカスタマーエクスペリエンスを構築する組織に不可欠なアーキテクチャ基盤として機能します。顧客データを、今日の組織の成功を促進する洗練されたパーソナライズされたカスタマーエクスペリエンスに変換する重要なバックボーンです。