이 텍스트는 Salesforce의 자동 번역 시스템을 사용하여 번역되었습니다. 이 콘텐츠에 대한 피드백을 제공하고 다음에 원하는 내용을 알려주려면 저희의 설문 조사을 참조하십시오.
Note
개요
엔터프라이즈 데이터 아키텍처가 변화하는 시점입니다. 조직은 실시간 AI 시스템을 동시에 지원하고, 점점 엄격해지는 개인정보보호 규정을 준수하고, 원시 데이터를 공유할 수 없는 외부 파트너와 공동 작업을 수행해야 합니다. 이러한 요구 사항은 데이터 플랫폼이 설계되는 방식을 근본적으로 변경하고 있습니다.
ETL 파이프라인 및 중앙 집중식 데이터 웨어하우스를 기반으로 구축된 기존 아키텍처는 이러한 요구 사항을 충족하는 데 어려움을 겪고 있습니다. 시스템 전체에서 데이터를 복제하면 대기 시간, 비용, 거버넌스 복잡성이 증가합니다. 각 복사본은 새로운 규정 준수 의무가 되어 배포된 환경에서 동의 관리, 삭제 요청, 정책 시행이 복잡해집니다.
이러한 문제를 해결하기 위해 업계는 정책에 따라 제로 카피 공동 작업 모델로 전환하고 있습니다. 데이터 정리 룸은 주요 아키텍처 기능으로 등장하여 여러 조직에서 원시 데이터를 노출하거나 전송하지 않고도 공유 신호를 분석할 수 있습니다. 데이터를 중앙 집중화된 환경으로 이동하는 대신 계산이 각 참가자의 관리 도메인 내에서 실행되고 개인 정보 보호에 안전한 결과만 반환됩니다.
이 아키텍처 변화는 산업 전반에서 점점 더 눈에 띄고 있습니다. 예를 들어, 마케팅 및 광고 분야에서 가장 큰 회사인 WPP가 InfoSum을 인수한 것은 개인 정보 보호 안전 공동 작업을 위한 인프라로서 청결한 공간이 점점 더 중요하다는 사실을 반영합니다. 금융 기관은 이를 사용하여 기관 전체에서 사기를 감지하고 소매업체는 소비자 브랜드와 프로모션을 조율하며 헬스케어 조직은 민감한 기본 레코드를 공유하지 않고 교차 제공자 환자 코호트를 분석합니다.
Salesforce Data 360은 Hyperforce 구축된 제로 카피 아키텍처를 통해 이 모델을 운영합니다. 데이터는 소스 시스템에 남아 있지만 연합 쿼리는 런타임 시 개인 정보 보호, 동의, 보존 정책을 적용합니다. 이 접근 방식은 데이터 복제로 인해 생성되는 위험 영역을 확장하지 않고 실시간 인사이트, 클라우드 간 공동 작업, AI 중심 의사 결정을 지원합니다.
이 문서에서는 데이터 정리 룸이 현대 엔터프라이즈의 기본 아키텍처 패턴으로 작동하는 방식을 검토하여 AI 혁신, 규제 준수, 안전한 도메인 간 공동 작업을 동시에 대규모로 지원합니다.
지금 중요한 방 정리 이유
데이터 정리 공간이 필요한 이유를 이해하려면 엔터프라이즈 설계자가 먼저 기존 통합 모델의 구조적 실패를 해결해야 합니다. 업계는 중앙 집중식 단독 데이터 리포지토리에서 분산화된 연합된 에코시스템으로의 결정적인 전환을 거칩니다. 여기에서 데이터는 물리적으로 이동하는 대신 액세스, 관리, 계산됩니다. 이 교대 근무는 증분이 아닙니다. 이는 기존 아키텍처에서 더 이상 흡수할 수 없는 규모, 개인 정보 보호, 민첩성과 관련된 시스템적 압박에 대한 직접적인 대응입니다.
현대 엔터프라이즈에서 데이터 통합 재정의
수년간 기업은 보고 및 분석을 위해 CRM, ERP, 디지털 시스템의 데이터를 중앙 창고로 복사하는 ETL 기반 아키텍처에 의존했습니다. 이 접근 방식은 내역 분석에 효과적이었지만 더 느린 배치 지향 환경을 위해 고안되었습니다.
디지털 상호 작용이 가속화되고 AI 기반 시스템이 등장함에 따라 이 모델의 제한 사항이 더욱 명확해졌습니다. ETL 파이프라인은 본질적으로 비동기식이므로 이벤트가 발생한 후 몇 시간 또는 며칠 후 인사이트가 도착하는 경우가 많습니다. 이러한 대기 시간은 실시간 개인 설정, 적응형 의사 결정, 즉각적인 컨텍스트 데이터가 필요한 AI 시스템과 같은 현대 사용 사례와 점점 더 불일치합니다.
또한 복제는 증가하는 거버넌스 및 보안 복잡성을 도입합니다. 각각의 새 데이터 사본에는 추가 정책, 모니터링, 규정 준수 제어가 필요합니다. 규제된 환경에서 GDPR(일반 데이터 보호 규정)와 같은 프레임워크에서 조직은 데이터가 존재하는 모든 위치에서 삭제, 동의, 사용 제한을 관리해야 합니다. 이는 여러 시스템에서 데이터 집합이 복제되는 경우 운영상의 문제입니다.
이 중복은 규모에 따라 비용 및 운영 오버헤드가 복합됩니다. 조직은 여러 플랫폼에서 수집, 저장소, 보안, 처리 비용을 반복적으로 지불하고, 추가 사본의 여백 값은 하락합니다.
따라서 현대 데이터 아키텍처는 데이터 이동을 최소화하고 소스에 직접 관리를 적용하는 모델로 전환하고 있습니다. 제로 카피 통합 및 연합 데이터 액세스를 사용하면 조직이 민감한 데이터 집합을 복제하지 않고 인사이트를 생성하여 엔터프라이즈 데이터 공동 작업에 더욱 확장 가능하고 안전하며 정책에 부합하는 접근 방식을 제공할 수 있습니다.
데이터 메쉬 및 데이터 패브릭의 출현
이러한 압박에 대응하기 위해 업계는 두 가지 보완적인 아키텍처 패러다임, 즉 데이터 메쉬 및 데이터 패브릭. 모두 중앙 집중식 제어에서 통합된 도메인 인식 데이터 아키텍처로의 전환을 나타냅니다.
데이터 메쉬는 데이터 소유권을 세일즈, 마케팅 또는 공급망과 같은 도메인 지정 팀으로 분산합니다. 각 도메인은 계약, 품질 표준, 서비스 수준 목표가 명확하게 정의된 제품으로 데이터를 처리합니다. 이 모델은 회계 및 비즈니스 정렬을 개선하지만, 엔터프라이즈 규모에서 도메인 전반의 조정, 상호 운용성, 일관된 거버넌스와 관련된 새로운 문제를 제기합니다.
Data Fabric은 분산된 도메인을 일관된 시스템에 바인딩하는 연결 계층을 제공하여 이러한 문제를 해결합니다. 공유 메타데이터, 일반적인 의미론, 자동 정책 적용, 계보, 거버넌스를 제공하므로 물리적 통합을 단일 리포지토리로 강제 적용하지 않고 데이터를 지속적으로 검색, 액세스, 관리할 수 있습니다.
데이터 메쉬와 데이터 패브릭은 함께 연합 데이터 액세스를 위한 기반을 마련합니다. 그러나 데이터를 복사하거나 노출하지 않고 공동으로 분석해야 하는 도메인 및 조직 범위 전반에 걸쳐 안전하고 관리되는 공동 작업을 활성화하는 중요한 차선 문제를 해결하지 못합니다.
방 청소 전략 피벗
엔터프라이즈 데이터가 더욱 분산되고 개인정보보호 규정이 더욱 엄격해지므로 조직은 핵심적인 아키텍처 문제에 직면하게 됩니다. 원시 데이터를 공유하지 않고 팀, 파트너, 플랫폼에서 공동 작업을 수행하는 방법은 무엇입니까? 기존 데이터 통합 접근 방식은 이 수준의 배포 또는 규제 심사에 맞춰 설계되지 않았으므로 공동 작업과 규정 준수 간의 긴장이 발생했습니다.
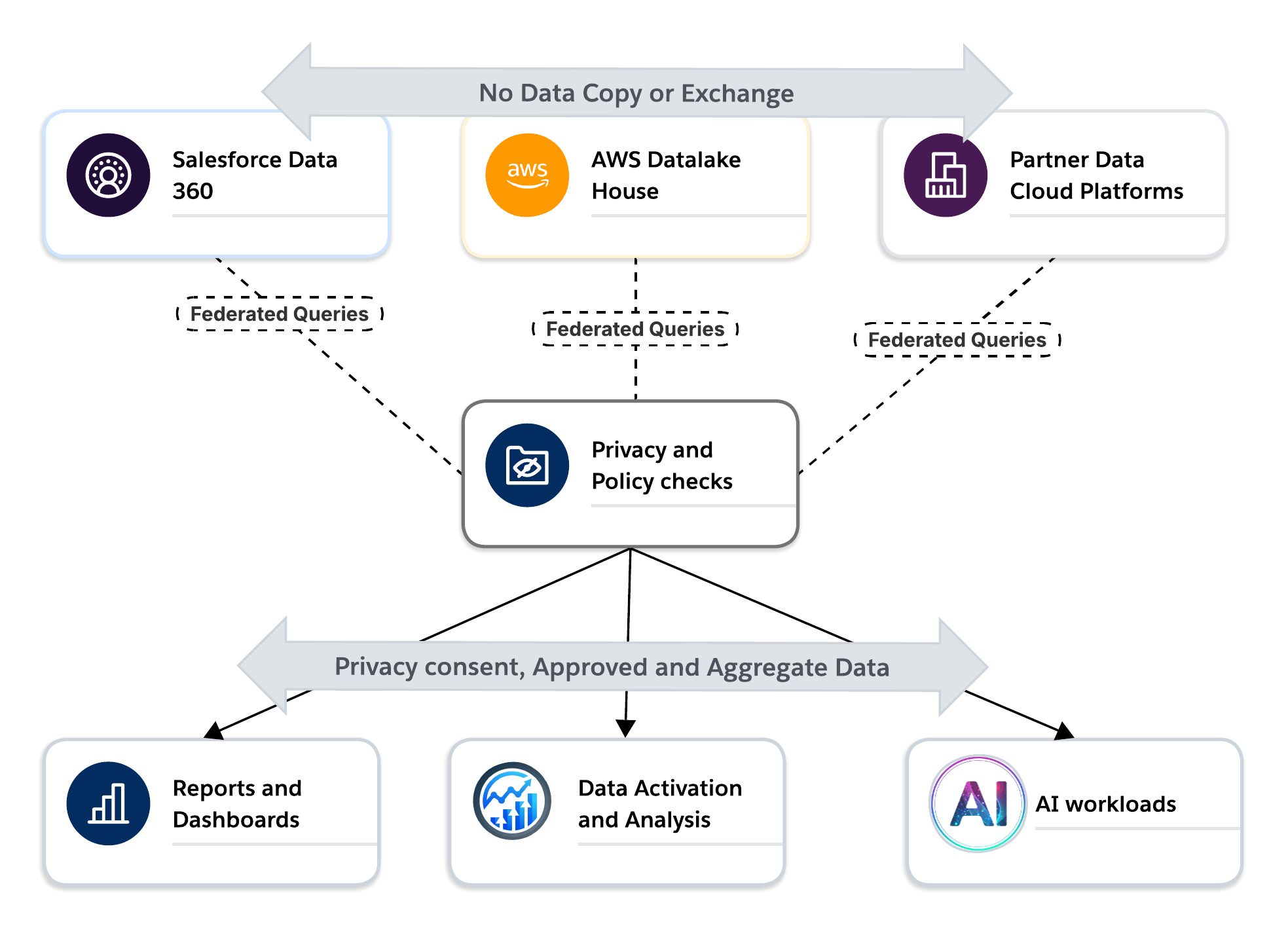
이 과제로 인해 데이터 정리 룸이 기본 아키텍처 기능으로 바뀌었습니다. 정리 룸은 데이터 전송에서 관리 계산으로의 공동 작업을 이동시킵니다. 데이터 집합을 복사하거나 교환하는 대신 분석 및 AI 워크로드가 메타데이터를 공유하여 이미 존재하는 위치에서 실행됩니다. 개인정보보호, 동의, 사용 규칙에 대해 쿼리가 실시간으로 평가되고, 승인된 집계된 결과만 반환됩니다.
이 모델에서는 데이터 클린 룸이 현대 데이터 아키텍처의 Trust 경계로 작동합니다. 이를 통해 조직이 데이터를 제어하지 않고 파트너 및 자회사와 협력하고, 정책이 아닌 시스템 제어를 통해 개인정보보호 및 동의를 적용하고, 데이터 보존 및 계약 제한을 존중하면서 클라우드 전반에서 운영할 수 있습니다.
활성화, 분석, AI 사용 사례의 경우 클린 룸은 민감한 정보를 노출하지 않고도 외부 데이터에서 인사이트를 생성할 수 있는 안전한 방법을 제공합니다. 데이터 공유에서 신뢰할 수 있는 공동 작업으로 전환할 수 있습니다. 활성화 사용 사례의 경우 정리 룸은 허용된 대상으로 바로 활성화할 수 있는 대상 그룹을 생성하는 안전한 방법을 제공합니다. 이 모든 작업은 당사자에게 개인 식별 정보(PII)를 노출하지 않고 수행됩니다. 이는 엔터프라이즈 데이터 아키텍처의 전환점입니다. 데이터 정리 룸은 더 이상 틈새 도구가 아닙니다. 이는 연합, 개인 정보 보호, AI 지원 데이터 플랫폼의 핵심 인프라가 되고 있습니다.
이해당사자 페르소나 및 기술 가드 레일
성공적인 데이터 정리 룸 아키텍처는 데이터 유틸리티, 보안 및 속도의 경쟁적 압력을 해결하도록 설계된 다중 인터페이스 시스템입니다. 기본 기술 설계에서 고유한 마찰 지점을 해결해야 하는 3개의 기본 개인 정보가 있습니다.
개인정보 보호 및 규정 준수 담당자(위험 완화자)
개인정보 보호 및 규정 준수 담당자는 데이터 정리 룸을 거버넌스 도구로 사용합니다. 이들의 주된 우려는 규정 준수 드리프트이며, 외부 공동 작업 환경이 내부 시스템과 동일한 엄격한 표준을 적용하지 못할 위험입니다.
마찰점: 규제 노출(GDPR, CCPA, DMA) 및 파트너가 반복적인 세분화된 쿼리를 통해 사용자의 ID를 삼각화하려고 하는 "피싱" 공격
데이터 과학자 및 분석가(유틸리티 최적화 프로그램)
데이터 과학자는 데이터 정리실을 고급 모델링을 위한 안전한 장소로 간주합니다. 이들의 주된 관심사는 유틸리티 보존이며, 개인 정보 보호 조치로 인해 데이터가 통계적으로 유용하지 않게 만들 수 있습니다.
마찰점: 대기 시간이 길고 기계 학습(ML), 유사 모델링, 이탈 예측에 필요한 세분화된 특성에 대한 액세스가 제한됩니다.
마케팅 및 비즈니스 사용자(가치 실현자)
이 개인 정보는 TTV(Time to Value)에만 초점을 맞춥니다. 데이터 정리 룸 프로젝트는 종종 데이터 엔지니어링 지원이 수주일 필요로 하는 기술적인 지체 지점이 됩니다.
마찰점: 복잡한 설정 프로세스, 수동 데이터 정리, 단순한 결과 겹침을 얻기 위해 코드를 작성해야 하는 "빈 페이지" 문제
"비즈니스 우선" 페르소나 모델
기존 아키텍처는 사용자 레이어보다 먼저 데이터 레이어를 구축하는 데 중점을 두지만 "비즈니스 우선" 메서드와 일치하는 전략적 접근 방식은 이 모델을 반전합니다. 비즈니스 사용자가 인사이트를 생성하고 즉각적인 조치를 취할 수 있도록 코드 없음 접근 방식을 클릭 몇 번으로 우선 적용합니다.
"인사이트-작업" 워크플로: 아키텍처는 패시브 리포지토리가 아닌 활성 작업 영역으로 설계되었습니다. 사용 사례 템플릿(예: 세그먼트 겹침, 활성화, 캠페인 성과)을 제공하여 비즈니스 사용자가 셀프 서비스 인사이트를 만들 수 있습니다. 이렇게 하면 데이터 엔지니어가 파일을 수동으로 이동할 필요 없이 최적화된 유사 세그먼트와 같은 인사이트를 마케팅 에코시스템 전반에서 즉시 활성화할 수 있습니다.
전략적 자산으로서의 제로 카피 연합: TTV를 극대화하기 위해 아키텍처는 0-copy 논리를 채택합니다. 대기 시간 및 보안 위험이 발생하는 기존 ETL 프로세스 대신 아키텍처는 데이터가 있는 위치(예: Snowflake, BigQuery 또는 Amazon S3)에 쿼리를 직접 연합합니다. 이렇게 하면 조직의 기존 데이터 투자가 전략적 자산으로 전환되므로 비즈니스 사용자는 엄격한 관리를 유지하고 데이터 중복 비용을 없애는 동시에 실시간으로 최신 데이터에 대해 조치를 취할 수 있습니다.
핵심 데이터 정리 룸 사용 사례
데이터 정리 룸은 쿠키 중단 및 개인정보보호 규정에 대한 응답으로 광고에 등장했지만, 측정 이상으로 산업 전반의 고객 분석, 대상 그룹 세분화, 활성화 사용 사례로 발전했습니다. 2025년 리테일 미디어 상태 보고서에 따르면, 현재 조직의 66%가 일부 용량의 청결한 공간을 사용하고 있으며, 측정 가능한 비즈니스 결과를 제공하는 개인 정보 보호 보호 협업이 필요합니다.
패턴은 섹터 전체에서 일관되며, 데이터는 소유자와 유지되고, 계산이 관리되고, 개인 정보 보호에 안전한 인사이트만 공유됩니다.
마케팅 및 광고: 타사 쿠키 없이 측정
도전: 마케터는 캠페인 효과를 측정하고 중복 광고 인상을 피하고 도달률/주기를 최적화해야 하지만 더 이상 타사 쿠키 또는 장치 식별자를 사용하지 않아도 됩니다.
클린 룸 솔루션:
광고주가 해시된 고객 또는 캠페인 노출 데이터 제공
게시자가 인상 및 참여 신호 제공
클린 룸은 도달, 빈도, 귀속, 리프트를 계산합니다.
원시 데이터 내보내기가 없는 승인된 플랫폼을 통해 활성화
비즈니스 결과: 정리 룸은 실제 트랜잭션에 광고 인사이트를 연결하는 마감 루프 속성을 제공하고, 진정한 캠페인 리프트를 격리하는 증분성 분석을 제공하며, 기존 디지털 광고에서 제공할 수 없는 채널 전반의 통합 측정을 제공합니다.
산업 증거: 측정은 Pinterest, Disney, Paramount와 같은 주요 미디어 네트워크가 자체 깔끔한 공간을 만드는 현재 가장 확립된 청정실 사용 사례입니다.
리테일 미디어 및 Consumer Packaged Goods(CPG): 공유하지 않고 자사 데이터 수익성 조성
도전: CPG 브랜드는 리테일 미디어에 많은 비용을 지출하지만 구매 결과에 대한 가시성이 부족합니다. 소매업체는 풍부한 세일즈 지점 데이터를 소유하지만 개인정보보호 서약을 위반하지 않아도 노출할 수 없습니다.
클린 룸 솔루션:
소매업체 및 CPG 회사가 리테일 위치의 세일즈 지점 데이터와 마케팅 데이터를 결합하여 프로모션 활동 최적화
해시된 CRM 또는 충성도 식별자를 제공하는 브랜드
매장 내/온라인 구매에 대한 청소 공간 링크 광고 노출
활성화는 소매업체의 미디어 에코시스템 내에 유지됩니다.
비즈니스 결과:
소매업체는 원시 고객 정보를 판매하지 않고 자사 데이터를 활용
구매를 촉진한 캠페인을 표시하는 브랜드의 마감 루프 특성 얻기
개인 정보 보호 위험 없이 소매 미디어 네트워크 확장
산업 증거: Walmart의 Luminate 및 Kroger Precision Marketing와 같은 소매 미디어 네트워크는 CPG 브랜드가 소매업체 데이터를 사용하여 고객 동작을 분석하고 마케팅 전략을 최적화하는 데 도움이 되는 깔끔한 공간을 제공합니다.
금융 서비스: 공동 작업 사기 감지
도전: 사기 네트워크는 기관 전체에서 운영되지만 GLBA와 같은 규정 및 새로운 개인정보 보호법으로 인해 은행이 고객 또는 트랜잭션 데이터를 공개적으로 공유할 수 없습니다.
클린 룸 솔루션:
여러 은행이 익명화된 데이터를 공유하여 비정상적인 크로스 뱅크 활동과 같은 사기를 나타내는 패턴을 식별합니다.
연합 분석 또는 모델이 공유 사기 신호에서 실행됩니다.
다른 기관의 고객 수준 데이터를 볼 수 없는 경우
비즈니스 결과:
신속한 교차 기관 사기 패턴 감지
풍부한 신호 집합을 통한 위양성 감소
중요한 데이터를 중앙 집중화하지 않고 규정 준수
산업 증거: Experian 및 TransUnion의 금융 서비스 솔루션은 은행 및 보험사가 엄격한 데이터 프라이버시 제어를 유지하면서 사기 감지 및 위험 평가에 대해 공동 작업할 수 있는 청결한 공간 기술을 제공합니다.
의료 및 생명 과학: 환자 데이터 노출 없이 연구
도전: 제약 회사는 의약품 개발을 위해 실제 환자 결과가 필요하지만, 데이터는 HIPAA 및 유사한 규정에 의해 보호되는 병원 EHR 시스템에 있습니다.
클린 룸 솔루션:
의사와 의약품 연구자는 클린 룸 내에서 데이터를 공유하여 환자가 치료에 어떻게 반응하는지 알아봅니다.
환자 데이터는 제공자 환경 내에 남아 있습니다.
연구자는 클린 룸을 통해 승인된 통계 분석을 실행합니다.
개인 정보 차이로 인해 재확인되지 않습니다.
비즈니스 결과:
통계적으로 유효한 대규모 실제 증거
익명화된 환자 데이터와 평가 기준을 일치시키고 헬스케어 프라이버시 법률을 위반하지 않고 적격한 후보를 찾는 방식으로 임상 시험을 위한 환자 채용을 간소화
제한된 임상 평가 집단에 대한 종속성 감소
산업 증거: Datavant와 같은 헬스케어 중심의 청소실은 연구자 및 헬스케어 조직이 임상 시험 및 의약품 개발을 위해 환자 데이터를 안전하게 분석할 수 있는 HIPAA 준수 환경을 제공합니다.
산업 간 패턴: 공동 작업 명령
해당 기본 사용 사례 외에도 정리실은 다음을 활성화합니다.
공급망 최적화: 제조업체 및 공급업체는 재고 세부 사항, 생산 일정, 수요 예측을 공유하기 위해 공동 작업을 수행하여 독점 정보를 보호하면서 더 나은 조율을 할 수 있습니다.
M&A Due Diligence: 한 회사가 다른 회사를 인수하면 철저한 주의에 따라 민감한 정보를 직접 공유하지 않고 금융 예상 및 고객 데이터베이스를 검사해야 하며, 정리실은 고객 세그먼트 정렬 및 규정 준수 위험과 같은 인사이트를 드러냅니다.
미디어 및 엔터테인먼트: 게시자가 광고주에게 대상 그룹 가치를 입증하면서 구독��� ID를 보호하여 확률적 타겟팅 대신 신뢰할 수 있는 측정으로 지원되는 프리미엄 CPM을 활성화합니다.
AdTech, 소매, 금융 서비스, 의료 및 미디어에서 Data Clean Rooms는 기본 Trust 인프라스트럭처가 되었습니다. 이전에는 개인정보보호, 규제 또는 경쟁 제약으로 차단된 중요한 공동 작업을 활성화합니다. 깨끗한 공간은 데이터 제어 또는 규정 준수를 포기하지 않고 통찰력과 수익을 확보하는 안전하고 관리되는 공동 작업을 가능하게 하는 핵심 아키텍처 구성 요소입니다.
데이터 정리 룸: 신뢰할 수 있는 데이터 공동 작업의 기반
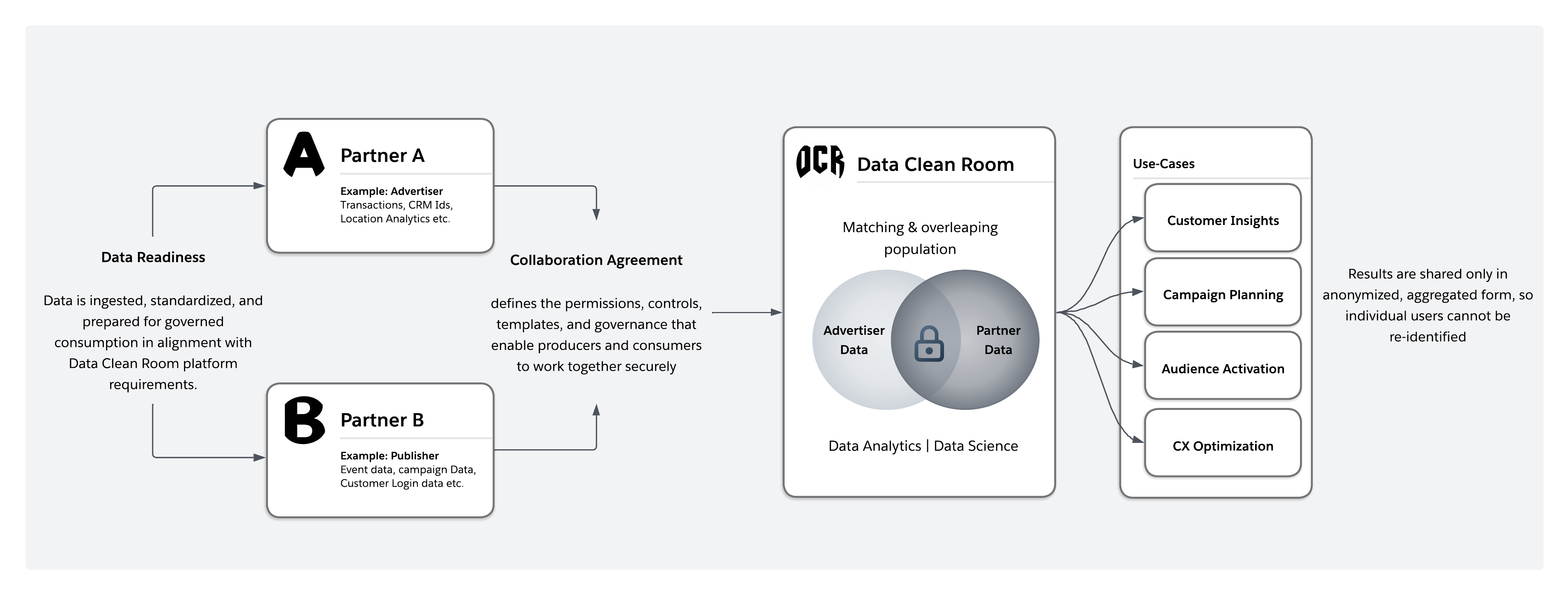
데이터 정리 룸은 여러 당사자가 원시 데이터를 노출하거나 교환하지 않고도 공동 인사이트를 생성할 수 있는 안전하고 관리되는 환경입니다. 데이터 집합을 복제하는 대신 승인된 분석, AI, 활성화 워크로드가 실행되고 정책 준수 출력만 반환됩니다. 활성화 시 개별 수준 레코드가 필요한 경우 데이터는 공동 작업 당사자에게 노출되지 않고 의도한 대상으로 바로 전달됩니다.
아키텍처적으로 깔끔한 공간은 데이터 공유에서 제어 계산으로 공동 작업을 전환합니다. 각 참가자는 데이터 보관권을 유지하고 런타임 적용은 쿼리 동작, 출력 제약, 동의, 사용 정책을 관리합니다.
개인 정보 보호 식별자 정렬 메커니즘을 통해 공동 작업이 더욱 활성화되어 있으며, 이 문서의 나중에 자세히 설명된 기능은 기본 식별자를 노출하지 않고 다른 당사자의 데이터 집합을 연관시킬 수 있습니다.
따라서 데이터 정리 룸은 제로 카피, 연합 데이터 전략을 기반으로 운영하는 개인 정보 보호 규제, 멀티 클라우드, AI 중심 엔터프라이즈의 기본 인프라로 작동합니다.
초기 데이터 정리 룸은 중앙 집중식 "번커" 모델을 따랐습니다. 모든 참가자는 분석을 위해 데이터를 중립 타사 환경에 복사해야 했습니다. 이 접근 방식은 개념이 간단하지만 상당한 마찰이 발생했습니다. 데이터 이동으로 인해 대기 시간 및 비용이 증가하고 법적 및 규정 준수 협약이 복잡해지고 조직이 민감한 데이터의 직접적인 제어를 포기하게 되었습니다. 규제화된 산업에서는 이러한 제약으로 인해 공동 작업이 실용적이지 않은 경우가 많습니다.
현대 데이터 정리 룸은 배포된 연합 모델로 발전했습니다. 데이터는 소유자의 환경에 남아 있으며, 통합 쿼리를 통해 분석이 실행됩니다. 클린 룸 자체는 각 쿼리를 가로채고 실행 시 개인 정보 및 정책 제어를 적용하며 승인된 집계된 출력만 반환하는 거버넌스 계층 역할을 합니다.
차원
일반 클린 룸("번커" 모델)
현대 클린 룸(배포/연합 모델)
데이터 위치
데이터가 중앙 집중식 타사 환경에 복사됨
소유자의 환경에 데이터 유지
데이터 이동
데이터 집합의 물리적 전송 및 복제 필요
원시 데이터 이동 없음, 쿼리가 실행됩니다.
관리 및 보관
보관이 부분적으로 타사 플랫폼에 포기됨
각 당사자가 보유한 원시 데이터 소유권 및 관리
아키텍처 모델
중앙 집중식 집계
배포된 연합 계산
거버넌스 집행
데이터 이동 후 적용되는 정책
쿼리 실행 시 적용되는 정책
개인 정보 보호 모델
계약 및 절차 제어에 크게 의존
런타임 제어 및 집계 임계값을 통해 기술적으로 적용
대기 시간
수집 및 동기화로 인한 대기 시간 증가
대기 시간이 낮아 실시간 연합 쿼리 근처
비용 구조
높은 저장소, 전송, 중복 비용
중복 감소, 데이터가 있는 위치에서 계산 발생
규정 준수 복잡성
교차 국경 데이터 이동으로 인한 복잡한 법적 계약
데이터가 소스 경계에서 나가지 않으므로 규정 준수 단순화
확장성
확장하려면 추가 저장소 및 데이터 복제가 필요합니다.
데이터 중복 없이 배포된 계산을 통해 확장
규제 산업적 적합성
보관 및 보존 문제로 인해 비실용적인 경우가 많습니다.
주체권, 동의, 규제 제약에 더 잘 부합
Salesforce Data 360은 이 연합 모델의 예입니다. 게시자 및 광고주는 원시 데이터가 플랫폼의 보안 범위를 벗어나지 않고 클라우드 플랫폼 전반에서 공동 작업하고 분석을 실행할 수 있습니다. 데이터 보관을 유지하고 위험을 줄이고 공동 작업을 더 빠르고 쉽게 확장할 수 있습니다.
공유 데이터에서 공유 계산으로의 이 전환은 엔터프라이즈 공동 작업에 대한 Trust 재정의합니다. 정리실은 더 이상 데이터가 저장되는 대상이 아니라 인사이트가 안전하게 생성되는 방식을 관리하는 시스템입니다.
엔터프라이즈급 데이터 정리 공간 구축
핵심 아키텍처 기능으로 작동하려면 엔터프라이즈급 데이터 정리 룸이 소규모 비상환 가능한 요구 사항 집합을 충족해야 합니다.
제로 카피 아키텍처
데이터 정리 공간에 대한 가장 기본적인 요구 사항은 제로 카피 아키텍처입니다. 기존 데이터 공동 작업은 데이터를 공유 환경에 복사하는 ETL 파이프라인에 의존합니다. 이렇게 하면 대기 시간, 비용, 보안 노출, 규제 위험이 증가하고 중요한 데이터의 관리되지 않는 복사본이 여러 개 생성됩니다.
최신 데이터 정리 룸은 이 문제를 해결합니다. 데이터는 클라우드 데이터 웨어하우스, 운영 플랫폼 또는 SaaS 응용 프로그램 등 원래 레코드 시스템에 남아 있습니다. 클린 룸은 해당 배포된 소스 전반에 걸쳐 연합 쿼리를 사용하고 개인 정보 보호에 안전한 승인된 결과만 반환합니다.
물리적 데이터 이동을 방지함으로써 제로 카피 정리 룸은 공격 표면을 줄이고, 데이터 보존 및 소유권을 유지하며, 데이터 패브릭 및 연합 데이터 아키텍처 원칙에 자연스럽게 부합합니다.
상호 운용 가능한 데이터 정리 룸
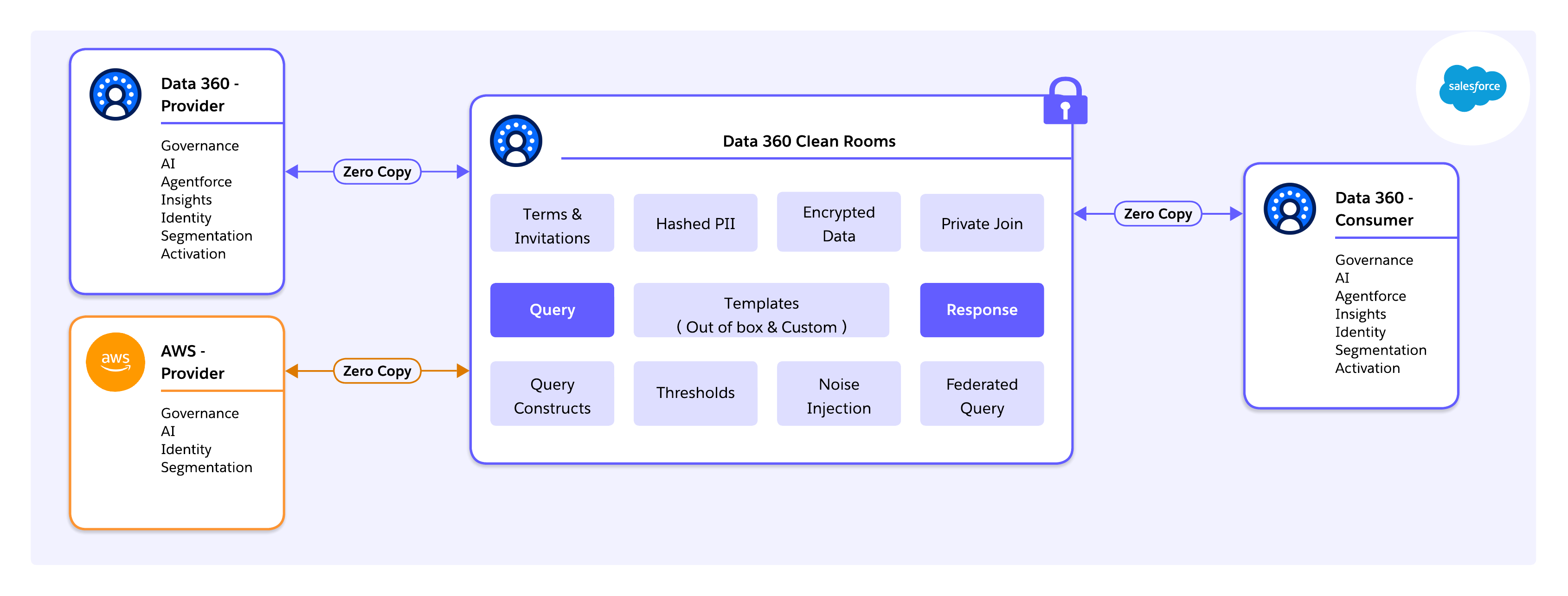
현대 데이터 전략은 데이터를 이동하지 않고 공동 작업할 수 있는 능력에 따라 다릅니다. Salesforce Data 360은 두 가지 기본 모델인
Native Salesforce-to-Salesforce 연결: 이 모델에서는 두 Salesforce 고객 간에 직접 공동 작업이 수행됩니다. 공유 메타데이터 레이어를 사용하면 제공자 및 소비자가 간단한 구성을 통해 즉시 연결할 수 있습니다. 이렇게 하면 팀이 데이터 복제 지연 또는 위험 없이 공동 인사이트를 생성할 수 있으므로 정보가 원래 위치에서 안전하게 유지됩니다.
External Salesforce-to-Cloud 통합(AWS 및 Snowflake): 이 모델에서는 Salesforce 및 외부 클라우드 환경 간 공동 작업이 수행됩니다. 제로 카피 연합을 사용하면 데이터 이동의 비용이나 위험 없이 다양한 인프라를 연결할 수 있습니다. 이렇게 하면 팀이 레지던트 클라우드에 데이터를 유지하면서 ID 분할을 해결하고 도달 범위를 확장하고 중앙 집중식 관리를 유지하고 탈퇴 수수료를 없앨 수 있습니다.
개인정보 보호 강화 기술(PET)
제로 카피 및 연합 아키텍처는 원시 데이터의 이동 또는 중복을 방지하지만, 개인 정보를 보호하는 것은 아닙니다. 이러한 모델에서 기본 위험은 데이터 저장소에서 데이터 계산으로 이동합니다.
집계된 결과만 반환되는 경우에도 중요한 정보가 계속해서 분석 출력을 통해 누출될 수 있습니다. 일반적인 공격 벡터에는 반복 또는 중복 쿼리(공격 차별화), 매우 작은 모집단 분석, 외부 Knowledge 사용한 추론이 포함됩니다. 따라서 개인정보 보호 문제는 액세스 제어를 넘어 쿼리 실행에 대한 동적 요구 사항으로 이동합니다.
엔터프라이즈 데이터 정리 룸은 옵션 분석 기능 또는 정책 지침이 아닌 필수 시스템 수준 제어로 PET(Privacy-Enhancing Technologies)를 취급해야 합니다.
아키텍처 관점에서는 다음을 의미합니다.
프라이버시는 분석가가 아닌 플랫폼에서 적용됩니다.
사용자, 파트너, 작업 부하 전체에서 일관된 제어
개인 정보 보호 보증은 결정적이며 반복 가능하며 감사 가능
시스템에서 허용되는 계산, 결과의 형태 지정, 쿼리를 차단해야 하는 시기를 정의합니다.
핵심 PET 기능
다른 개인 정보 보호: 차별 개인 정보 보호(DP)는 개인의 존재 또는 부재가 쿼리 결과에 크게 영향을 미치지 않는다는 수학적 보증을 제공합니다. 실제로는 클린 룸이 캘리브레이션된 통계적 노이즈를 출력에 자동으로 삽입하고 각 데이터 집합에 대해 정의된 개인 정보 예산을 추적함을 의미합니다. 모든 쿼리는 이 예산의 일부를 사용하며, 만료되면 추가 쿼리가 차단됩니다.
설계자의 경우 DP의 값은 확률에 있습니다. 개인정보 보호 위험은 정량적으로 제한되어 보호 가능한 규정을 준수하고 주관적 정책 해석에 대한 의존성을 줄입니다.
보안 식별자 정렬: 많은 공동 작업 시나리오에서 공유 고객 또는 계정과 같은 데이터 집합 간 겹침을 식별해야 합니다. 원시 식별자를 표시하면 데이터 최소화 원칙이 위반됩니다. 대신 클린 룸 등급 아키텍처는 클린 룸 경계 내에서 수행되는 결정적 해시 또는 토큰화에 의존합니다. 관계자에게 원시 식별자를 표시하지 않고 비교를 수행하여 데이터 공개 없이 조인 유사 동작을 활성화합니다.
집계 임계값 및 결과 압축: 결과가 매우 작은 모집단에서 파생된 경우 완전히 익명화된 출력도 손상될 수 있습니다. 이를 방지하려면 엔터프라이즈 데이터 정리 룸에서 최소 집계 임계값을 적용하고 아래에 속하는 결과를 자동으로 억제해야 합니다. 이러한 임계값은 재정의할 수 없어야 하므로 소규모 세그먼트 누출을 일관되게 방어할 수 있습니다.
실행 계층에서 개인정보 보호 강화 기술(PET)이 적용되지 않으면 Data Clean 룸이 인간의 판단과 계약에 의존하는 Trust 기반 환경이 될 위험이 있습니다. PET를 플랫폼에 직접 포함하면 프라이버시가 절차적 속성이 아닌 구조적 속성이 됩니다. 이를 통해 Trust 다시 협상하지 않고 팀 및 파트너 간의 공동 작업을 확장할 수 있으며, 규제 기관 및 위험 팀은 주관적인 정책이 아닌 목표적 수학적 측정값을 사용하여 보증을 평가할 수 있습니다.
엔터프라이즈 아키텍처의 경우 PET는 데이터 정리 공간을 보안 Sandbox에서 신뢰할 수 있는 공동 작업 패브릭으로 전환하는 중요한 메커니즘으로서, 규제된 다자간 분석 및 AI 워크로드를 엔터프라이즈 규모에서 지원할 수 있습니다.
감사 내역
다자간 공동 작업에서 Trust 가시성을 통해 유지됩니다. 엔터프라이즈급 데이터 정리 룸은 참가자와 데이터 간의 모든 상호 작용에 대한 "문서 추적"을 제공해야 합니다.
쿼리 로그: 모든 SQL 실행이 기���되어 요청자의 ID, 타임스탬프, 사용된 특정 쿼리 논리를 수집합니다.
정책 집행 로그: 시스템은 쿼리된 항목뿐만 아니라 결과에 적용된 개인정보 보호정책(예: 집계 임계값 또는 차별 개인정보 보호)을 기록해야 합니다.
Zero-Tamper Records: 변경 불가능 감사 내역(전용 데이터 모델 개체)을 사용하여 데이터 정리 룸은 참가자가 로그를 변경하거나 삭제할 수 없도록 하여 규제 담당자에게 신뢰할 수 있는 단일 버전을 제공합니다.
Salesforce Data 360을 사용하여 최신 데이터 정리 룸 활성화
Salesforce는 조직이 원시 데이터 집합을 공유하지 않고도 데이터를 분석하고 공동 작업할 수 있도록 하여 현대적인 데이터 정리 룸을 활성화합니다. 실행 시 개인정보보호, 동의, 거버넌스가 적용되는 제로 카피, 연합 아키텍처를 기반으로 구축된 Salesforce Data 360은 인사이트를 안전하고 규정 준수하며 실행 가능한 상태로 유지합니다. Salesforce Data 360은 깔끔한 공간을 엔터프라이즈 데이터 수명 주기에 직접 포함하여 니치 분석 도구에서 AI 중심 및 다자간 공동 작업을 위한 확장 가능한 신뢰할 수 있는 인프라로 전환합니다.
확장 가능한 데이터 정리 룸을 위한 플랫폼 기반
인프라 레이어에서 Salesforce Data 360은 통합 제어 플레인 뒤에 대규모 리소스(AWS, Azure, GCP)를 추상하는 Salesforce의 클라우드 네이티브 런타임인 Hyperforce 실행됩니다. 이 아키텍처를 사용하면 데이터가 지역 내에 유지되어 주체권 및 보존 요구 사항을 충족하는 동시에 전 세계적으로 정리 실 운영을 지원할 수 있습니다.
중요한 점은 이 파운데이션을 통해 AWS Clean Rooms와의 네이티브 상호 운용성을 비롯한 클라우드 간 클린 룸 공동 작업을 수행할 수 있습니다. Data 360을 오케스트레이션 및 거버넌스 계층으로 사용하면 Salesforce에서 관리하는 저장소로 데이터를 강제로 마이그레이션하지 않고 AWS에서 직접 작업하는 파트너와 공동 작업할 수 있습니다. 쿼리가 소스로 푸시되고 개인정보 보호 규칙이 일관되게 적용되며, 규정을 준수하고 집계된 결과만 플랫폼 간에 교환됩니다.
규정 준수 및 Trust 응용 프로그램 계층에서 세분화되지 않고 인프라 및 실행 경계에서 적용되므로 대규모로 멀티 클라우드, 다자간 공동 작업을 위한 견고한 기반을 제공합니다.
수집에서 활성화까지의 Data 360 파이프라인
Data 360은 추적 가능한 종단간 데이터 파이프라인을 구현하여 정리실 작업이 원시 추출이 아닌 조화되고 관리되는 ID 인식 데이터를 통해 실행되도록 합니다.
주요 단계는 다음과 같습니다.
연결: 기본 커넥터, API, SDK, MuleSoft 또는 제로 카피 커넥터를 통한 데이터 수집 및 가상화
유지: 원시 데이터를 네이티브 형식으로 저장(Parquet/Iceberg)
조화: 정합성 있는 조인을 위해 정규 데이터 모델 개체(DMO)에 매핑
통합: ID 확인을 통해 골든 레코드 생성
인사이트 도출: 계산된 인사이트는 관리된 경계 내에서 집계된 메트릭을 계산합니다.
작업: Salesforce 조직, 마케팅 플랫폼, 광고 네트워크, 외부 데이터 플랫폼 또는 기타 클린 룸에 대한 관리 출력 흐름으로 인사이트-작업 루프를 닫습니다.
이 파이프라인을 통해 깔끔한 룸이 특별 추출이 아닌 엔터프라이즈급 데이터에서 작동합니다.
기본 통합 및 "Clicks-Not-Code"
별도의 프로비저닝 및 SQL 개발이 필요한 독립형 데이터 정리 룸 플랫폼과 달리 Salesforce 정리 룸은 Data 360에 기본적으로 포함되어 있습니다. 이를 통해 DMO, ID 규칙, 동의 모델, 거버넌스 정책을 재사용하여 중복 보안 계층을 제거할 수 있습니다.
Salesforce의 템플릿 기반 정리 공간 모델은 다음을 사용하는 핵심 가속 요소입니다.
대상 그룹 중복, 압축, 도달, 리프트 측정과 같은 일반적인 공동 작업 패턴을 지원하는 사용 가능한 템플릿입니다.
설계자 및 고급 사용자가 원시 데이터 또는 정책 복잡성을 노출하지 않고 업계별 또는 파트너별 요구에 맞게 재사용 가능한 분석 논리를 정의할 수 있는 사용자 지정 템플릿입니다.
이 접근 방식은 유연성을 유지하면서도 공동 작업을 표준화하여 일회성 분석 프로젝트가 아닌 반복 가능한 엔터프라이즈 기능으로 클린 룸을 확장할 수 있도록 합니다.
"골든 경로" - 인사이트 작업 루프 마감
Data 360은 일반적인 청정실의 일반적인 실패 모드인 활성화 격차를 해결합니다. Golden Path 프레임워크는 원시 데이터를 내보내지 않고 클린 룸 내에서 생성된 인사이트를 즉시 조치할 수 있도록 합니다.
설정 및 검색: 파트너는 스키마 메타데이터를 공유하고 템플릿을 활용하여 계약이 완료되기 전에 실행 가능성을 평가합니다.
분석: 사전 구축된 사용자 정의 템플릿은 겹침 분석, 일시 보류, 유사 모델링, 리프트 측정을 구동하며, 모두 관리 경계 내에서 실행됩니다.
활성화: 승인된 세그먼트는 Marketing Cloud, 광고 플랫폼 또는 파트너 시스템에 직접 푸시되며, 통합된 규정 준수 결과만 공유됩니다.
템플릿이 의견이 지정된 실행 경로가 되므로 공동 작업이 분석에서 활성화까지 예측 가능한 방식으로 이동됩니다.
Salesforce Data 360 Clean Rooms용 플레이북
Salesforce Data 360 Clean Room 배포는 단순한 구성 연습이 아니라 데이터 준비, 거버넌스 설계, 보안 연결, 운영 모니터링을 포괄하는 규제화된 아키텍처 워크플로입니다.
1단계: 공동 작업 사용 사례 정의(의도로 시작)
데이터 또는 구성을 다루기 전에 설계자가 다음을 명확하게 정의해야 합니다.
답변하려는 질문은 무엇입니까?
예상되는 결과는 무엇입니까?(예: 겹침 분석, 리프트 측정, 억제, 사기 감지)
어떤 수준의 집계가 필요합니까?
적용되는 규제 또는 계약상의 제약은 무엇입니까?
결과를 사용하는 활성화 경로는 무엇입니까?
공동 작업자의 목표를 이해하면 조인 키, ID 규칙, 거버넌스 임계값, 비용 모델링과 같은 다음과 같은 모든 사항이 결정됩니다. 정리 룸은 용도로 구축된 환경입니다. 일반 데이터 노출이 아닌 정의된 분석 목표를 중심으로 설계해야 합니다.
2단계: Clean Room 공동 작업을 위한 데이터 준비
공동 작업을 시작하려면 먼저 엔터프라이즈 데이터를 구조적으로, 의미적으로 준비해야 합니다. 정리 룸은 기본 데이터의 강점과 약점 모두를 증폭합니다. 여기에는 휴지통이 들어오고 휴지통이 나옵니다.
수입: Salesforce CRM, Marketing Cloud, AWS S3, Google Cloud Storage와 같은 소스 시스템을 Data 360에 연결합니다. 가능한 경우 데이터를 불필요하게 이동하거나 중복하지 않도록 제로 카피 커넥터(예: Snowflake)를 사용하십시오.
세맨틱 매핑: 데이터 스트림을 Customer 360 데이터 모델에 매핑합니다. 전화 번호(E.164 형식), 국가/시/도 코드(ISO 표준), 이메일 주소와 같은 주요 필드를 표준화합니다. 정렬이 잘못되면(예: "CA"를 사용하는 한 당사자와 "캘리포니아"를 사용하는 다른 당사자) 조인이 자동으로 실패하고 일치율이 낮아질 수 있습니다.
ID 확인: 결정적(정확히 일치) 및 확률적( 퍼지 일치) 규칙을 구성하여 통합 개인(골든 레코드)을 만듭니다. 이 통합 엔티티는 정리 룸 일치를 위한 표면입니다.
ID 확인의 품질은 공동 작업 가치에 직접적으로 영향을 미칩니다. 일치 정확도가 높으면 겹침률, 분석 신뢰도 향상되고 거짓 음수가 줄어듭니다.
3단계: 클린 룸 프로비저닝
데이터가 조화되면 공동 작업 경계를 정의하기 위해 클린 룸 자체를 프로비저닝해야 합니다.
라이센스 검증: 모든 참가 조직에 필요한 Data 360 및 정리 공간 권한이 있는지 확인합니다.
데이터 공간 범위 지정: 정리 공간 개체는 특정 데이터 공간에 대한 범위를 지정해야 합니다. 해당 데이터 공간에 매핑된 개체만 클린 룸에 표시됩니다. 이를 통해 깔끔한 공간에 대해서만 새 데이터 공간을 만들 필요 없이 논리적으로 공동 작업을 분리할 수 있습니다.
거버넌스 규칙 정의: 쿼리를 실행하기 전에 선언적으로 정책을 설정합니다.
집계 임계값: 예를 들어 출력당 최소 100개의 레코드
결합 키: 예를 들어, Email_Hash_SHA256
허용되는 작업: COUNT, SUM, AVG와 같은 집계 함수만
명시 제한: 블록 행 수준 내보내기(선택 *)
거버넌스 규칙은 실행 시 적용되므로 절차 지침이 아닌 개인 정보 보호 및 규정 준수 시스템 수준 속성을 만듭니다.
4단계: 보안 다자간 연결 설정
정리 룸은 조직 및 플랫폼 경계에 걸쳐 있습니다. 연결은 명시적이고 엄격하게 제어되어야 합니다.
계정 연결:
Salesforce-Salesforce: Data Cloud One 또는 승인된 교차 조직 공유 메커니즘을 사용합니다.
다중 클라우드 시나리오: 쿼리가 활성화되기 전에 지역 정렬 및 상주를 확인합니다.
인증 및 인증: 최소 권한 원칙을 사용하여 전용 통합 사용자에 대한 OAuth 기반 액세스를 구성합니다. 필요한 데이터 공간에 대한 액세스를 엄격하게 제한하고 관리 권한을 피합니다.
보안 실패는 암호화 또는 플랫폼 제어의 약점이 아닌 권한이 지나친 통합 사용자로 인해 발생하는 경우가 많습니다.
5단계: 정리실 작업 부하 실행, 모니터링, 제어
활성화되면 운영 감독, 쿼리 품질, 비용 관리에 대한 교대 근무에 초점을 맞춥니다.
쿼리 실행: 분석가 또는 워크플로는 계산된 인사이트 또는 승인된 SQL 인터페이스를 통해 겹침 분석 및 집계를 수행합니다. 모든 쿼리에서 집계 임계값 및 개인 정보 보호 제어가 자동으로 적용됩니다.
** 감사 및 추적 가능성 :** Salesforce Data 360 정리 룸은 감사 데이터 모델 개체(DMO) 형태로 감사 내역을 제공합니다. 이렇게 하면 쿼리를 실행한 사람, 실행 시기, 적용된 정책 등 쿼리 활동에 대한 메타데이터가 수집됩니다. 감사 DMO는 규정 준수 보고, 거버넌스 검증, 포렌식 추적 가능성을 활성화하여 공동 작업이 개인 정보 보호 및 검토 가능하도록 합니다.
소모 모니터링: Data Cloud는 소비 기반 신용 모델을 사용합니다. 핵심 동인:
처리된 행(예: 1M 행 = 기준 신용 단위)
쿼리 복잡성
ID 확인 작업(높은 승수)
배치 수집(하위 승수)
Digital Wallet 및 경고: Digital Wallet 사용하여 실시간 소비를 추적하고 50%, 75% 및 90% 임계값에서 경고를 구성합니다. 급증과 특정 작업 부하를 연결하여 예기치 않은 비용을 피합니다.
제로 카피는 계산 비용을 절감하지 않습니다. 물리적 중복이 제거되는 동안 소스 시스템에서 실행이 발생합니다. 설계자는 쿼리 패턴, 조인 선택성, 실행 주기를 관리하여 비용 및 성능을 제어해야 합니다.
거버넌스, 보안, 규정 준수
대규모 Trust 위한 깔끔한 공간 설계
현대 엔터프라이즈에서는 Trust 데이터 정리 공간에 고정되지 않습니다. 이는 아키텍처 결과입니다. Salesforce Data 360은 지속적으로 자동으로 거버넌스, 보안, 규정 준수를 적용하여 정책 중심 환경에서 플랫폼 관리 시스템으로 깔끔한 공간을 전환합니다.
실행 시간 제어(잠긴 ID, 감사 추적, 차이 프라이버시)는 Salesforce 내, 파트너 간 또는 클라우드 간에 공동 작업이 발생하는지 여부와 상관없이 일관되게 적용됩니다.
Execution-Time Trust 및 거버넌스
아키텍처에게 가장 중요한 변화는 사전에 가정하지 않고 실행 중에 Trust 적용되는 것입니다. Salesforce Data 360은 다음과 같은 여러 핵심 플랫폼 제어를 통해 이를 달성합니다.
잠긴 ID: 파트너 액세스는 확인된 Salesforce 조직 ID와 암호화 방식으로 연결되어 스푸핑 또는 무단 참여를 방지합니다.
** 감사 내역:** 모든 쿼리, 조인, 세그먼트 겹침, 활성화가 로그되어 완전한 감사 가능성 및 규정 준수를 위해 기록됩니다.
다른 개인 정보 보호: 행 수준 검사는 구조적으로 불가능합니다. 출력이 집계되고 통계적으로 경계됩니다. 공동작업자는 개인 트랜잭션이나 ID가 아닌 달성률 또는 리프트율과 같은 개인 정보 보호에 안전한 결과만 볼 수 있습니다.
이러한 제어는 계약 Trust 수학적 보증 및 플랫폼 수준 적용으로 대체하여 운영 및 법적 위험을 줄입니다.
Einstein Trust 계층을 통한 AI 거버넌스
AI 에이전트가 Clean Room 데이터와 점점 더 상호 작용함에 따라 Salesforce는 Einstein Trust 레이어를 도입합니다. 중요한 엔터프라이즈 데이터와 외부 LLM 간의 아키텍처 공급 장치 역할을 합니다. 그러면 깔끔한 공간 인사이트가 기본 데이터를 노출하지 않고 AI 기반 의사 결정을 안전하게 강화할 수 있습니다.
** 핵심 기능:**
데이터 보존 제로: LLM에 전송되는 데이터는 간단합니다. 모델 공급자는 교육을 위해 프롬프트 또는 응답을 저장할 수 없습니다.
독성 언어 탐지 및 PII 마스킹: 입력 및 출력이 자동으로 스캔되고 Data 360에 구성된 데이터 마스킹 정책에 따라 PII가 마스킹됩니다.
데이터 공간 및 권한 집합을 통한 논리적 격리
데이터 공간은 조직 내에서 논리적으로 격리되며, 다음과 같은 규제, 지리 및 파트너십 경계에 맞춰야 합니다.
EU 데이터 공간
북미 데이터 공간
데이터 공간에 할당된 데이터 집합만 클린 룸 내에 표시되므로 우발적인 교차 경계 노출이 방지됩니다.
권한 집합은 정리된 공간을 만들거나 관리하거나, 쿼리를 실행하거나, 세그먼트를 활성화할 수 있는 사람을 정밀하게 제어합니다. 데이터 인식 권한은 데이터 모델 개체 내에서 필드 수준 제한을 적용합니다. 예를 들어 마케터는 세그먼트 이름과 대상 그룹 크기를 볼 수 있지만 수입 또는 건강 지표는 볼 수 없습니다.
보안은 시맨틱 계층에서 적용되므로 지속적인 IT 감독 없이 비즈니스 사용자에게 안전한 셀프 서비스를 제공할 수 있습니다.
설계를 통한 규정 준수 및 동의
동의 신호는 Data 360을 통해 자동으로 정리실 실행으로 전파됩니다. 동의를 취소하는 사용자는 기본적으로 분석 및 활성화에서 제외되므로 규정을 수동으로 적용하지 않고 시스템에서 규정을 준수합니다.
Salesforce Data 360은 관리, 보안, 규정 준수를 옵션 추가 기능이 아닌 최상위 아키텍처 기본값으로 취급합니다. 실행 시간 감사 가능성, 잠긴 ID, 차별화된 개인 정보 보호, 데이터 공간, 동의 인식 ID 확인 및 Einstein Trust 계층을 결합하여 파트너, 멀티 클라우드 시스템, AI 기반 워크로드 간의 클린 룸 공동 작업을 확장할 수 있으며, 이는 Trust, 개인 정보 보호 또는 규정 준수에 영향을 미치지 않고도 가능합니다.
결론 및 진행 경로
설계자를 위한 실용적인 진행 경로
데이터 정리 룸의 가치를 모두 수집하려면 설계자가 격리된 분석 도구가 아닌 핵심 아키텍처 인프라로 처리해야 합니다. 다음 우선 순위는 실용적이고 확장 가능한 경로를 정의합니다.
공동 작업을 최상의 건축 문제로 만들기 : 외부 데이터 공동 작업은 내부 통합과 같은 엄격함으로 설계해야 합니다. 정리 공간은 데이터 플랫폼, 통합 계층 및 AI 시스템과 함께 엔터프라이즈 참조 아키텍처 내에 포함되어야 하며, 특별 확장으로 배포되지 않아야 합니다. 상호 운용성이 확대되면(예: Data 360 클린 룸과 AWS 클린 룸 통합 및 향후 교차 룸 호환성) 설계자는 단일 공급업체가 아닌 다중 플랫폼 생태계를 예상하는 공동 작업 패턴을 설계해야 합니다.
소스에서 기본적으로 개인정보보호 설계
데이터 유동성 설계: 기본값이 큰 ETL과 중앙 복제를 사용하는 대신 아키텍처는 먼저 통합 및 제로 복제 액세스를 고려해야 합니다. 데이터로 계산을 전환하면(해당하는 경우) 불필요한 중복을 줄이고 비용을 절감하며 신뢰할 수 있는 소스 무결성을 유지할 수 있습니다. "연결 및 복사"는 상속된 습관이 아닌 의도한 아키텍처 결정이어야 합니다.
인사이트-작업 간격 닫기 : 분석 시 중지하는 정리실은 비즈니스 가치를 제공하지 못합니다. 아키텍처는 활성화 시스템 및 AI 워크플로에 정리 공간 출력을 기본적으로 연결해야 합니다. 사용자 의견 루프, 성능 측정, 다운스트림 실행은 처음부터 설계해야 합니다.
에이전트 엔터프라이즈 준비 : AI 에이전트가 점점 더 많은 엔터프라이즈 데이터를 사용하므로 클린 룸은 에이전트가 원시 데이터를 노출하지 않고 작업할 수 있는 제어 실행 환경으로 작동합니다. 클린 룸 전략과 AI 거버넌스 및 Trust 프레임워크를 조율하는 아키텍처는 다음 단계에 가장 적합합니다.
결론
현대 데이터 정리 룸은 엔터프라이즈 데이터 아키텍처의 근본적인 변화입니다. 데이터 노출 없이 공동 작업을 활성화하여 데이터 유틸리티와 개인 정보 보호 간의 오래된 긴장을 해결합니다.
Salesforce Data 360과 같은 아키텍처는 이 제약이 "또는" 고려 사항이 아니라는 사실을 보여줍니다. 데이터 저장소를 활성화에서 제로 복사 패턴으로 분리하고 개인 정보 보호 향상 기술을 실행에 직접 포함하여 기업은 데이터 제어를 포기하지 않고도 중요한 분석에 대한 공동 작업을 수행할 수 있습니다. 개인 정보 보호는 계약상 의무에서 아키텍처 보증으로 이동합니다.
무엇보다 클린 룸은 정적이고 사일로된 자산의 데이터를 실천 가능한 관리 자원으로 변환합니다. 활성화 및 AI 레이어에 기본적으로 연결되면 더 이상 대시보드에서 인사이트가 중단되지 않습니다. 이를 통해 결정, 캠페인 및 자율 시스템에 직접 유입되어 데이터, 작업, 결과 간에 엔터프라이즈 규모의 루프를 닫습니다.
작성자 정보
Yugandhar Bora는 Salesforce의 소프트웨어 엔지니어링 아키텍처로, 데이터 및 인텔리전스 애플리케이션 플랫폼 내 데이터 아키텍처를 전문으로 합니다. 그는 데이터 거버넌스 및 통합 데이터 모델에 초점을 맞춘 EARB(Enterprise Architecture Review Board) 이니셔티브를 이끌고 자동화된 플랫폼 프로비저닝 솔루션에 기여합니다.
Birendra Kumar Singh는 Salesforce의 Data 360 내에서 플랫폼 및 데이터 아키텍처를 전문으로 하는 주요 기술 직원입니다. 활성화 플랫폼의 핵심 구성원이며 Data 360 고객에게 데이터 정리 공간 인프라를 제공하는 데 중점을 둔 청소 공간 이니셔티브를 이끌고 있습니다.
Salesforce의 수석 제품 관리자인 Priyanka Kshirsagar는 Data 360 Clean Rooms를 선도하며, 엔터프라이즈 고객이 개인 정보를 보호하는 환경에서 자사 데이터에 대해 공동 작업할 수 있도록 처음부터 구축한 기능입니다. 클린 룸에서 유사 모델링 및 ID 보강 등 에이전트 AI 및 ML 기반 사용 사례에 대한 비전을 구동하고 일반 가용성 및 계층 1 Dreamforce 출시를 통해 제품을 도입했습니다.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.