このテキストは、Salesforce の自動翻訳システムを使用して翻訳されました。アンケートに 回答して、このコンテンツに関するフィードバックを提供し、次に何を表示するかをお寄せください。
概要
Salesforce Platform は、複雑なビジネスプロセスの要求を満たすために自動化アーキテクチャを継続的に進化させてきました。旧世代 (ワークフロールールとプロセスビルダー) では、イベント駆動型ロジックの最初のステップが提供され、イベント駆動型ロジックの自動化機能が拡張され、ビルダーの範囲が広がりました。
この進化により、次の 2 つの補完的な柱を中心に、ハイパフォーマンスの統合アーキテクチャが実現しました。レコードトリガーフローおよび Apex トリガー。このドキュメントでは、トリガー自動化を設計するときに十分な情報に基づいて意思決定を行うためのフレームワークとガイドラインについて説明します。
範囲内の商品
フロー
Salesforce Flow は、強力なポイント・アンド・クリック自動化ツールです。ユーザーは、コードを記述せずに、Flow Builderを使用して複雑なビジネス・プロセス、画面、ロジックを視覚的に作成できます。データ更新、メールの送信、ユーザーへの案内などのタスクを自動化し、画面フロー (ユーザー操作) やトリガーフロー (レコード/スケジュール済みイベント) などの種別で柔軟性を提供します。
Apex
Salesforce Apex は、Java に似た Salesforce Platform 用の独自のオブジェクト指向プログラミング言語で、カスタムビジネスロジックの構築、プロセスの自動化、宣言型ツール以外のコア CRM 機能の拡張に使用されます。
ポイント
Salesforce Platform で拡張性、メンテナンス性、パフォーマンスに優れたレコードトリガー自動化を構築するには、統制の取れたアーキテクチャ主導のアプローチが必要です。フローと Apex の選択とそれぞれの実装は、明確な原則セットに従って行われます。これらのポイントはこれらの原則を要約し、最新の自動化設計の基本ルールとして機能します。
Salesforceオブジェクトの自動化密度に基づいて、ジョブに適したツールを選択します。
低密度 の自動化には、Salesforceオブジェクトのレコードトリガーフローを使用します。
呼び出し可能なApexを使用してレコード トリガー フロー ロジックを増強し、中密度 の自動化を実現します。
SalesforceオブジェクトのApexトリガーを使用して、高密度 の自動化を実現します。
非同期プロセスをトリガーするときは注意してください。
Salesforce オブジェクトごとに 1 つのエントリポイントを使用します。
決定ポイント
宣言型とプログラムによる実装
フローと Apex には、共通の基本機能セットがあります。各ツールは、レコードの照会、条件ロジックの実行、変数の割り当て、およびレコードの作成、更新、削除などの DML 操作 (指定された順序で実行) を実行できます。
ただし、この機能の重複は、ツールが交換可能であるという意味ではありません。アーキテクチャの選択は、タスクを実行できる_かどう_かではなく、タスクを_どのよう_に実行し、パフォーマンス、拡張性、および保守性に長期的な影響があるかについてです。フローは、宣言型の明確さと簡単なプロセスの実装速度に優れており、Apexは複雑なソリューションに必要な詳細な制御とロー・パワーを提供します。
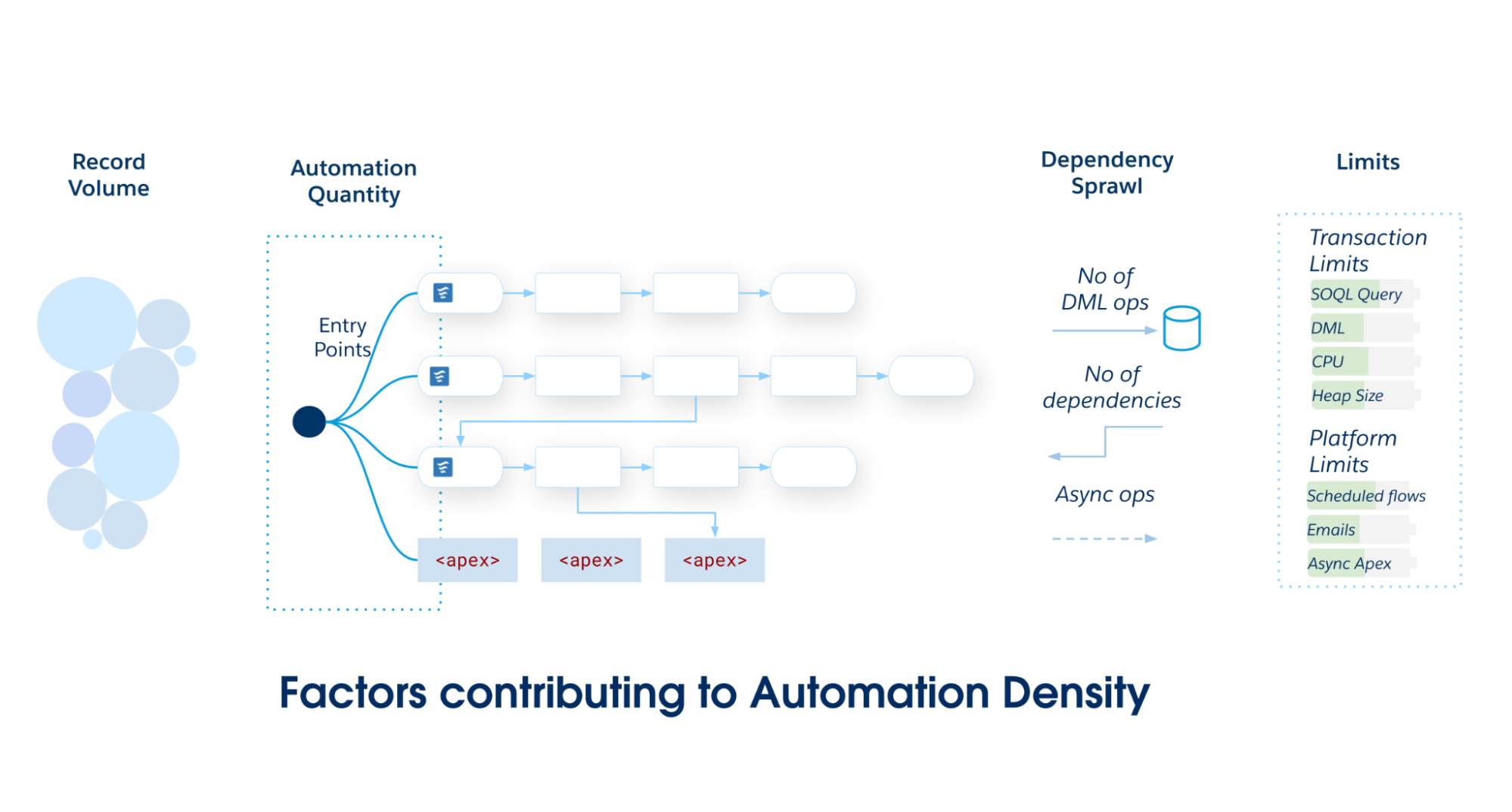
自動化密度
自動化密度 は、特定の Salesforce オブジェクトにかかる負荷です。これは、オブジェクトの最適な実装を判断するためのヒューリスティックとして機能します。自動化の密度が高まるにつれて、トランザクション制限に違反する可能性が高くなります。
量と複雑さの 3 つの特定のディメンションを調べて、自動化密度を計算します。
**自動化数量:**1 つのデータ操作言語 (DML) イベント中に実行される一意の自動化メタデータエントリ (フロー、トリガーアクションなど) の未加工数。
**レコード量:**API 読み込みまたは高負荷のバッチ処理によって処理されるトランザクションあたりのレコード数。パフォーマンスが重要になります。
**依存関係の無秩序な増加:**最初の CRUD 操作によってトリガーされる下流の DML 操作の基準。1 つの更新が関連オブジェクトの更新にカスケードされるグラフの深さを定量化します (ケース → 取引先 → 取引先責任者 → カスタム積み上げ集計など)。
Salesforceアプリケーションの範囲と複雑さが増してきたら、1つのプライマリ エントリー ポイント(レコード トリガー フローまたはApexトリガー)にコミットします。1 つの Salesforce オブジェクトで複数のメカニズムにわたって自動化をパーティション分割すると、メンテナンス性が低下し、ガバナンスが断片化してしまうため、避けてください。
密度選択マトリックス
このマトリックスを使用して、Salesforce オブジェクトに必要なアーキテクチャ標準を決定します。
レコード トリガー フロー は、自動化密度が低い場合に推奨されるソリューションです。互いに独立していてわかりやすい自動化に最適なパワーとアクセシビリティのバランスを実現します。
**ハイブリッド パターン(**呼び出し可能なApexを使用したレコード トリガー フロー)は、複雑さが増している中密度の自動化に適した強力でメンテナンス可能な選択肢です。このパターンにより、チームは宣言型フローで順序付けられた振付を維持しながら、計算負荷の高い操作をApexに委任し、アクセス性とパフォーマンスのバランスを取ることができます。
Apexトリガー は、高密度の自動化をサポートする堅牢なアーキテクチャ基盤に必要なビルディング ブロックを提供します。Apexのパフォーマンス、詳細な制御、およびオブジェクト指向の抽象化と多態性は、これらのシナリオの複雑さと拡張性の管理に適しています。
密度レベル
自動化数量
データ量 (バッチサイズ)
依存関係の無秩序な増加
アーキテクチャ標準
Low (低) < 15 標準 分離 レコードトリガーフロー
Medium (中) 15–30 モデレート 結合 ハイブリッドパターン
High (高) > 30 High (高) 複雑および再帰的 Apexトリガー メタデータ フレームワーク
実際のアーキテクチャ上の意思決定では、自動化密度のすべてのディメンションをまとめて加重する必要があります。特定の Salesforce オブジェクトの自動化メカニズムを選択するときは、将来の範囲を考慮してください。
また、Salesforce はマルチテナント環境で共有リソース管理を適用し、暴走した自動化によって共有リソースが独占されないように 府の制限 を適用しているため、1 日あたりの DML 操作の合計数を考慮してください。1 日の DML 量が多い Salesforce オブジェクトでは、自動化の選択を慎重に行う必要があります。たとえば、CPU 時間 (60,000 ミリ秒) とヒープサイズ (12 MB) の非同期制限は同期制限よりも高くなります。さらに、非同期実行に関する組織の 24 時間の制限 (ユーザーライセンスの 25 万倍 (200 倍) として計算) では、実行時の例外を回避するために 1 日あたりの合計 DML をアーキテクチャ設計に組み込む必要があります。
商品比較
レコードトリガーフローは、レコードトリガー自動化のためのプラットフォームの主要な宣言型ツールです。フローの使いやすさと組み込みのプラットフォーム保護により、チームは拡張性と信頼性に優れたソリューションを簡単に構築できます。これは、Salesforce Platform でソリューションを構築するほとんどのチームにとって理想的な選択肢です。
Apex は、プラットフォーム独自の強力な型付けのオブジェクト指向プログラミング言語です。Apex は、自動化密度の高い Salesforce オブジェクトや、高パフォーマンス、高度なロジック、トランザクションの詳細な制御を必要とする使用事例に使用します。
意思決定プロセスを支援するために、このマトリックスでは主要なアーキテクチャ機能間のフローと Apex を直接比較しています。
機能
レコードトリガーフロー
Apex トリガー
デリバリとメンテナンスの迅速化 推奨 専門知識が必要
モジュール性 利用可 利用可
表示とガバナンス 推奨 専門知識が必要
高パフォーマンスの一括データ処理 非推奨 推奨
堅牢なロジックとデータ構造 利用可 フロー変換要素 は、いくつかの複雑な処理タスクに役立ちます。ただし、フローにはネイティブの Map および Set データ構造がないため、複雑なデータ処理が煩雑になり、計算効率が低下します。推奨
トランザクション制御 使用不可 利用可
メール配信 推奨 毎日のメール送信 制限が適用されます。利用可 1 日あたりのメール送信 制限が適用されます。
プラットフォーム保護の適用 推奨 手動実装が必要
非同期処理 利用可 利用可
スケジュール済み処理 推奨 使用不可
注文と振付 利用可 利用可
同じレコードの項目自動更新 使用可能 (保存前) 使用可能 (保存前)
クロスオブジェクト CRUD 使用可能 (保存後) 使用可能 (保存後)
高価な計算の重複排除 利用可 推奨
カスタムエラー処理 利用可 推奨 addError() メソッドは、柔軟な項目レベルおよび条件付きエラーメッセージングを提供します。
使用事例
最適なおすすめ
次の表に、一般的な使用事例の一般的な「最適」な推奨事項を示します。最終的には、このドキュメントの「関連するベストプラクティス 」セクションに記載されているような、特定のシナリオに最適な追加考慮事項も考慮します。ここでは、フローとApexの特定の組み合わせが最適なアプローチである場合についての詳細を説明します。
使用事例
説明
Best-Fit
根拠
高パフォーマンスのバッチ処理 何千ものレコードを効率的に処理する必要がある自動化
Apex
Apex は、プラットフォームとのインタフェースと未フォーマット時の速度を実現する豊富な API を提供します。
複雑なデータ処理 高度なデータ操作が必要なシナリオ
Apex
Apex は、Map や Set などのデータ構造を提供します。これらは、フローではネイティブに使用できず、パフォーマンスが高く一括安全なコードを記述するために不可欠です。
トランザクション制御 セーブポイント、ロールバック、部分的な確定などの制御メカニズム
Apex
Apex は Database.savepoint や Database.rollback などのメカニズムへのアクセスを提供し、部分的に成功した DML 操作を処理する機能を備えています。
高度なカスタム検証 レコードの複数の項目のデータ検証
Apex
フローでは `CustomError` 要素を使用して保存を防ぐことができますが、サブフローを含むすべてのフロー種別で使用できるわけではありません。Apex addError() メソッドは、トリガー処理中にいつでもレコードに追加できる複数の項目固有のエラー メッセージを提供します。
単純なプロセス内のロジックがやや複雑 高度な関数の標準ライブラリによって簡略化された、中程度の複雑さのロジックとデータ操作 (複雑なプロセスの一部として発生)
フロー + Apex
レコード トリガー フローはオーケストレーション レイヤーとして機能し、高複雑度の操作は呼び出し可能Apex内にカプセル化されます。
シンプルから適度に複雑なロジック 主データオブジェクトと関連データオブジェクトの両方に対するトリガー更新による、低から中程度の複雑さのデータ操作
フロー
フローは、管理者と開発者の両方がアプローチできる宣言型モデルに基づいているため、通常はフローが適しています。
通知および送信メッセージ 送信メールおよびメッセージの送信
フロー
フローを使用すると、レコードの変更時にメールアラートと送信メッセージを送信し、容易かつ拡張性の高い方法で行うことができます。
スケジュール済み処理 将来の動的な日付 (完了予定日の 3 日前など) での自動化
フロー
スケジュール済みパスは、レコードのデータが変更された場合にプラットフォームが自動的にこれらのパスのスケジュール、キャンセル、再スケジュールを処理するため、フローに独自の強みを提供します。
スケーラブルな処理:詳細な非同期使用事例
拡張性は、実装を設計するときの重要な考慮事項です。レコードトリガーオートメーションのビジネスロジックが複雑になったり、実行時間が長くなったり、大量のデータが関係したりすると、Salesforce Platform のコアガバナ制限がアーキテクチャ上の制約になります。データの一括更新、複雑な API コールアウト、重い計算などの操作は、合計 CPU 時間や 1 つのデータベーストランザクション内の DML ステートメント数などの制限に違反するリスクを高めます。制限例外が原因で同期トリガーが失敗すると、ユーザーの保存トランザクション全体がロールバックされ、ユーザーエクスペリエンスが低下し、データが失われる可能性があります。この固有のリスクにより、複雑な作業の負荷が軽減されるアーキテクチャパターンが必要になります。
この場合、非同期自動化が不可欠です。アーキテクトは、非同期メカニズムを使用して、実行時間が長い作業や大量の作業を、同期レコード保存の主トランザクションから効果的に分離できます。迅速かつ信頼性の高い方法で保存が完了し、重い処理は後で実行される別のプラットフォーム管理トランザクションに委任されます。分離により、安定性が向上し、トランザクションの失敗が回避され、拡張性の高いエンタープライズアプリケーションを構築するために不可欠です。このプラットフォームには、信頼性、量、複雑さに関する個別の利点とトレードオフがある、このための特殊なツールがいくつか用意されています。
フローの非同期パス
レコードトリガーフローの [非同期で実行] パスは、「起動して忘れる」非同期ロジックの最もシンプルなメカニズムを提供します。このパスは、元のレコード保存トランザクションがデータベースに正常にコミットされた後、個別のトランザクションで実行されます。
変更データキャプチャ (CDC)
変更データキャプチャ (CDC) は、大規模シナリオでのレコード変更によってトリガーされる非同期ロジックを処理するための高スループット、拡張性、復元性の高いパターンです。このモデルでは、トリガーの唯一の責務はレコードの同期保存です。次に、プラットフォームは、大規模イベントバスへのレコードの変更を含む詳細なイベントメッセージを公開します。個別の専用 Apex トリガーがこの変更イベントに登録します。複雑で実行時間が長い作業や非同期の作業を実行します。
給付 :このパターンでは、非同期プロセスを最初のユーザートランザクションから分離します。非同期処理が失敗しても、ユーザーのレコード保存はロールバックされません。このパターンでは、複数の内部登録者または外部システムが使用できる耐久性のあるイベントストリームも提供され、イベントを最大 72 時間再生できるため、強力な復元力が得られます。
制限 Trigger.oldMapに相当) は含まれません。イベントペイロードには、新しい項目値が含まれますが、変更元の値は含まれません。そのため、特定の状態遷移に基づいてロジックを実装することが困難です (たとえば、Status__cが「待機中」から「承認済み」に変更された場合にのみ実行)。イベント登録者でオブジェクトの項目履歴を照会することでこれを軽減できますが、これによりプロセスが複雑になり、特定の関心項目��項目履歴管理が使用できない場合があります。これにより、CDC にオフロードできる自動化の種類が制限される場合があります。
デフォルトでは、CDC は最大 5 つの Salesforce オブジェクトで有効にできます。追加が必要な組織は、この制限を削除し、イベント配信の割り当てを増やすアドオンライセンスを購入できます。
トリガーからのキュー可能 Apex
Queueable Apex ジョブをトリガーから直接キューに入れることは、リスクの高いパターンと見なす必要があります。これは、Apex による制御が必要な場合 (複雑なロジックやカスタム再試行メカニズムなど) にのみ使用され、CDC は実行可能なオプションではありません。
Queueable Apex が必要な場合は、実装に適切な保護を含める必要があります。
トリガーされた非同期 Apex の制限に関する考慮事項
同期トリガーから非同期 Apex を呼び出すと、安定性のリスクが生じます。組織レベルの影響 (制限を超えるなど) を回避するために、このパターンには厳格な設計とテストが必要です。
非同期Apex実行の1日あたりの制限(Batch、Queueable、@Future)は、組織全体で共有されます(通常は25万件、またはユーザー・ライセンスに基づく計算)。20,000 レコードの一括データ読み込みでは、トリガーが 200 のチャンクで実行され、100 の個別のトリガー呼び出しが発生します。一括バッチサイズが 200 レコード未満の場合、さらに多くなります。各呼び出しで非同期ジョブがキューに入れられると、1 つのデータ読み込みによる 1 日あたりの制限のかなりの部分が消費される可能性があります。この消費により、非同期リソースの他の重要なビジネスプロセスが飢餓になる可能性があります。
ジョブをキューに入れるためのガバナ制限は、コンテキストによって大幅に異なります。UI のユーザーアクション (_同期_トランザクション) によって起動されるトリガーから、最大 50 個のキュー可能なジョブをキューに追加できます。ただし、バッチ Apex クラスの execute メソッド内 (非_同期_トランザクション) で起動されたトリガーから、キューに入れることができるジョブは 1 つのみです。この違いを考慮しないと、大規模データ操作中にLimitExceptionエラーが発生する、一般的で重大な障害点になります。
トリガー コンテキストから直接 Schedulable Apex(System.schedule)または Batch Apex(Database.executeBatch)をコールすると、アンチパターンになります。これらのメソッドは、トリガーコンテキストから呼び出すようには設計されていません。これを行うと、非同期 Apex 割り当てが急速に消費され、制限例外が発生します。
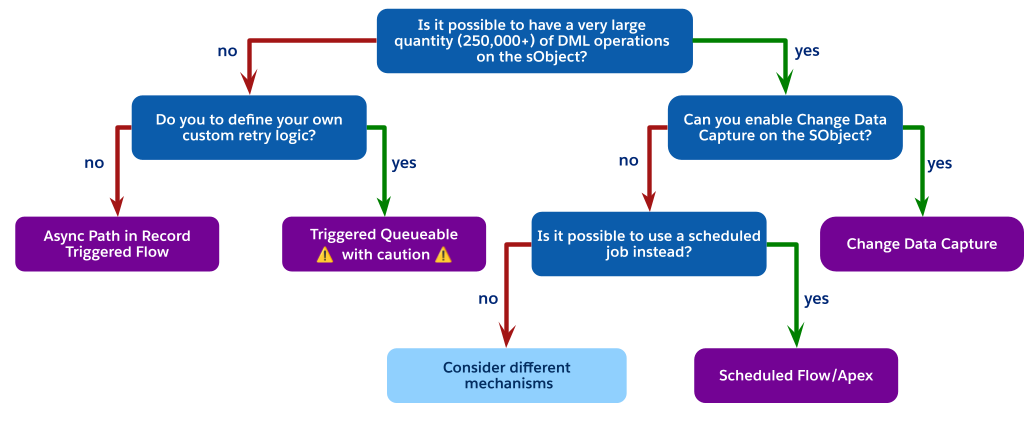
適切な非同期パターンの選択
各非同期メカニズムには、パフォーマンス、ガバナ制限、信頼性に関する特定のトレードオフがあります。このディシジョンツリーをガイドとして使用して、これらのオプションを操作し、使用事例に適したメカニズムを選択してください。
スケジュール済みジョブの代替
フローチャートが示すように、大規模な DML 操作に直面しているが (オブジェクトの制限などにより) 変更データキャプチャを使用できない場合、多くの場合、最適なアーキテクチャの選択はトリガーで呼び出されるプロセスを完全に回避することです。
代わりに、スケジュール済みプロセスを使用することを検討してください。これは、スケジュール済みフローまたはスケジュール済み Apex のいずれかです。必要な手順は次のとおりです。
同期トリガーでシンプルで低コストの更新を実行します。たとえば、Status__c フィールドを「処理待機中」に設定したり、Chatter投稿などの低コストの関連レコードを挿入して、レコードの処理が必要であることを示します。
15 分ごとや 1 時間ごとなど、定期的に実行されるスケジュール済みジョブ (スケジュール済みフローまたはスケジュール済み Apex) を作成します。
スケジュール済みジョブで待機中の状態のすべてのレコードを照会し、制御された大量のコンテキストで複雑なロジックを実行して、レコードを処理済みとして更新します。
このパターンは、重い処理をユーザーの同期保存から完全に分離し、トリガー起動バッチのトランザクションあたり 1 つのジョブの制限を受けず、非リアルタイム要件に対応する拡張性とガバナンスに優れたソリューションを提供します。
スケジュール済みジョブの遅延がビジネス要件で許容されず、CDC またはトリガー起動キューの使用が引き続き制限されている場合は、アーキテクチャの重大な不一致を示します。この時点で、異なるメカニズムを考慮する必要があります。コアアプリケーション設計を再評価すると、次のような特定の結論に達する可能性があります。
機能以外の考慮事項
複雑さ
実装の複雑さのレベルは、ソリューションの総所有コストだけでなく、変化するビジネス要件に適応する能力にも影響します。ベストプラクティスに従わないと、実装が複雑になる可能性があります。このドキュメントの「Related Best Practices (関連するベストプラクティス)」セクションでは、ソリューションの複雑さを軽減するための推奨事項を次に示します。
プロセスと標準
ドキュメントはオートメーション自体と同じくらい重要です。メンテナンス性が確保されるだけでなく、AI やエージェントベースのツールにとっても重要です。ドキュメントは、ビジネスプロセスの理解と管理に役立ちます。
In Flow
すべての要素と変数に一貫した命名規則を設定します。
フローの [説明] 項目を使用して、フローの全体的な目的、トリガー条件、意図した結果を説明します。
個々の要素 (Get Records、Action、Transform など) で [説明] 項目を使用します。これは、意図を伝えるための最良の方法です。これは、呼び出し可能なアクションとサブフローで特に重要であり、説明はアクションによって実行される複雑なロジックを説明する主要な場所です。
In Apex
DevOps とソース管理は、成熟した開発ライフサイクルの一部です。Salesforce プロジェクトでは、Git などのソース管理ツールを常に使用します。Apex クラスと Salesforce フローはどちらもビジネス ロジックを定義するメタデータであり、バージョン管理する必要があります。
レコードトリガー自動化の管理のコンテキストでは、最新の DevOps パイプラインには不可欠な利点があります。
自動化された品質チェック: Salesforce Code Analyzer などのツールは、パイプラインで自動的に実行するように設定できます。静的分析では、昇格前に両方の自動化ツールの問題パターンを検出し、パフォーマンス低下の一般的な原因である、フロー ループ内の非効率的なGet Records要素やループのApex内のSOQLクエリなどの問題にフラグを設定できます。
**回帰防止:**自動化密度が高まるにつれて、1 つのフローまたは Apex クラスを変更すると、同じオブジェクトの他の自動化に意図しない結果が生じる可能性があります。提案された変更に対して自動化されたApexテストを実行する堅牢なDevOpsテスト戦略は、新しいフロー バージョンで既存のApexロジックが破損しないこと(およびその逆)を確認する最も信頼性の高い方法です。
**コラボレーションと表示:**ソース管理は「唯一の情報源」です。これにより、システム管理者と開発者は同じオブジェクトの自動化に並行して取り組むことができます。また、貴重な監査証跡も提供されます。本番プロセスが中断すると、自動化を変更した_ユーザー_、自動化を変更した_タイミング_、および(確定メッセージを介して)自動化を変更した_理由_をすぐに確認できます。
管理者と開発者が混在するチームの場合、DevOps Center では、これらのすべてのステップをコレオグラフィーするのに役立つ統合インターフェイスが提供され、拡張性の高いソース制御ベースの開発プロセスをチームの全員が利用できるようになります。
ドキュメントと DevOps のこの組み合わせにより、組織の長期的な健全性とメンテナンス性が確保され、フォローするすべてのアーキテクトとシステム管理者にメリットがもたらされます。
関連するベストプラクティス
上記の決定ガイドは、実装を計画する前に使用することをお勧めします。使用事例に最適な製品を選択できるようにすることを目的としています。製品を選択したら、実装の既存のベストプラクティスを理解することが重要です。
ハイブリッドパターンの活用:フローでの複雑なロジックの呼び出し可能な Apex
_オブジェクトあたり1_つのツールの原則は、高密度の自動化を管理するために重要ですが、それを純粋に宣言型か純粋にプログラム スタックかの二者択一として解釈しないでください。より効果的で管理しやすいアーキテクチャ・パターンでは、ハイブリッド・モデルを活用します。つまり、レコード・トリガー・フローをオーケストレーション・レイヤーとして配置しながら、呼び出し可能なApex内で高複雑度の操作がカプセル化されます。
オーケストレーションレイヤー:フロー
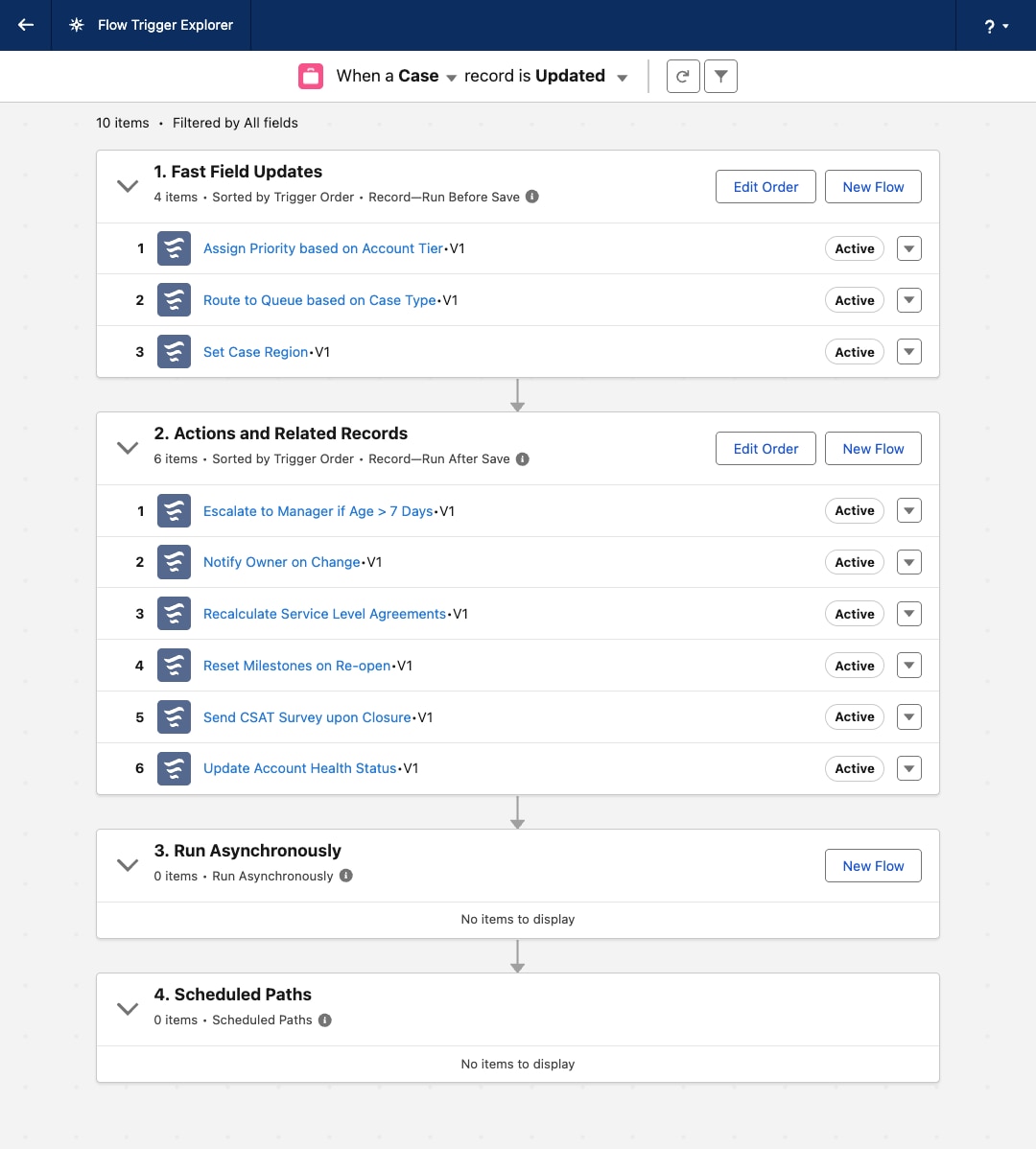
レコードトリガーフローは、ビジネスプロセスのオーケストレーションレイヤーとして機能します。エントリ条件と実行コンテキスト (何_と_いつ ) を所有します。このレイヤー内で決定ロジックとルーティングを保持することで、フロートリガーエクスプローラーでアーキテクチャのプロセストポロジーを透過的かつ管理可能にし、重要なビジネスロジックがコード内で不明瞭にならないようにします。
複合コンポーネント:呼び出し可能な Apex
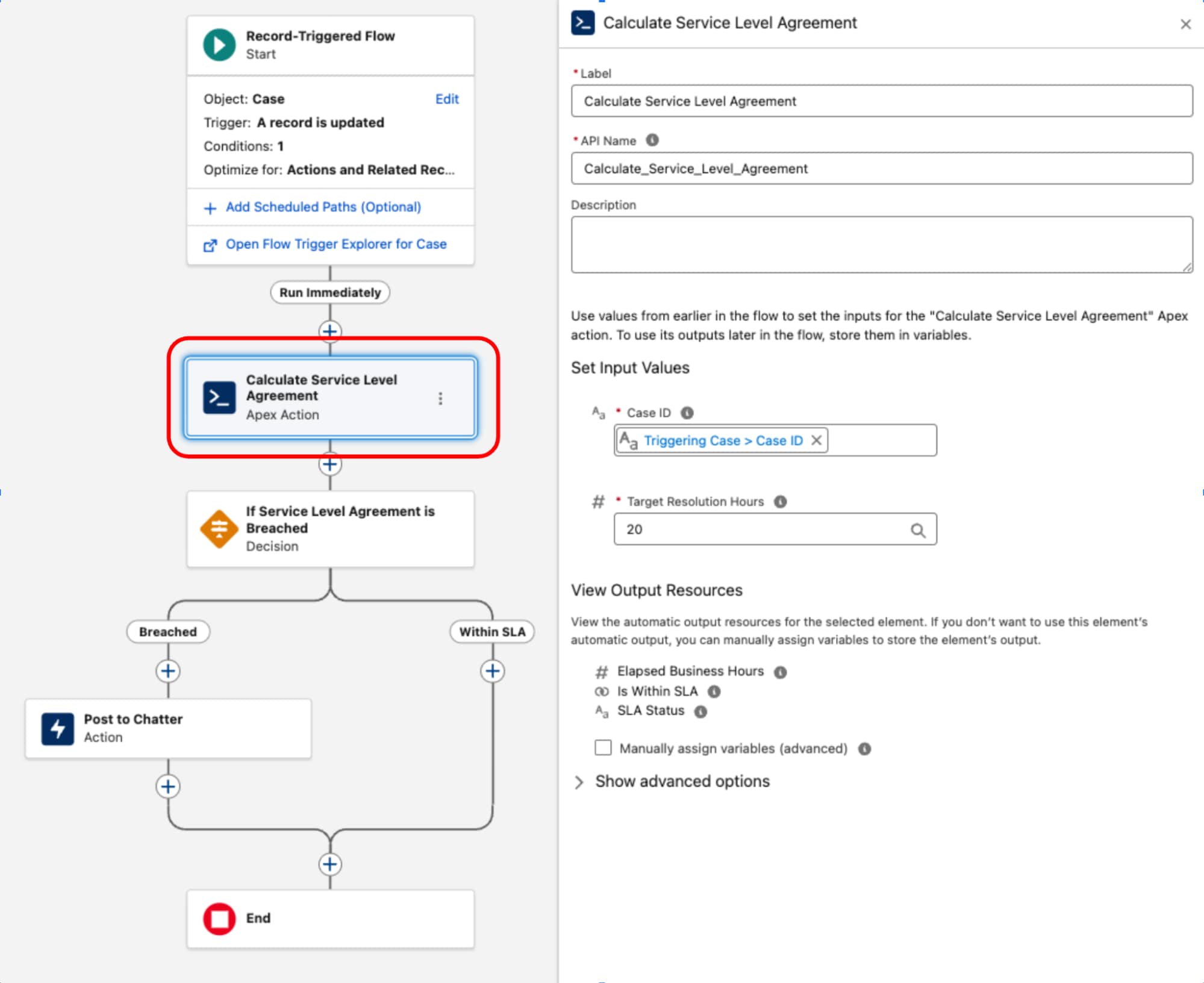
複雑なコンポーネントの一般的な例として、ケースレコードのサービスレベル契約 (SLA) の計算の実装があります。BusinessHours オブジェクトとその関連ロジックは、非勤務時間と休日を除外する正確な計算に不可欠ですが、フローではネイティブにアクセスできないため、専用の Apex クラスが使用されます。このクラスは、多くの場合 ServiceLevelAgreementCalculator などと呼ばれ、@InvocableMethod で注釈が付けられた 1 つの静的メソッドを使用して設計され、経過した営業時間を計算し、SLA が「目標内」か「違反」かを判断し、構造化された出力を返します。このアプローチでは、Apexの複雑で高パフォーマンスのロジックをカプセル化しながら、レコード・トリガー・フローの宣言型オーケストレーション・レイヤーにシームレスに実行して統合できます。
ApexServiceLevelAgreementCalculator・クラスが定義されると、レコード・トリガー・フロー内で使用できるようになります。
このパターンは、懸念の厳格な分離を示しています。宣言型レイヤーはトランザクションライフサイクルとオーケストレーションの管理に使用され、コードは高複雑度の実行に使用されます。コードを基盤ではなく機能的なユーティリティとして扱うことで、パフォーマンスとメンテナンス性のバランスを取ります。
ハイブリッドパターンの主な利点
モジュール性 :決定は、プロセス全体で Apex またはフローを使用するという単一性からそれます。代わりに、アーキテクチャでは複雑なロジックが個別の一括安全ユニットと個別にテスト可能なユニットにカプセル化されます。これらのユニットは宣言型レイヤーで使用される再利用可能なコンポーネントとして機能し、アーキテクチャ設計を複雑にすることなく自動化を拡張できます。
再利用性 :ロジックはトリガーイベントから分離されます。適切に設計されたコード ユニット(InvocableMethodなど)は、1回のみ記述されますが、複数のエントリー ポイントで利用されます。レコードトリガーフロー、画面フロー、外部インテグレーション。このコードの再利用により、冗長な開発が排除されます。
メンテナンス性 :プロセスフローロジックは、宣言型フロー内で引き続き表示および管理できます。この一元化により、デバッグのオーバーヘッドが大幅に削減され、システムの実行順序が確定的で透過的になります。
ハイブリッドパターンの制限とトレードオフ
フローから呼び出し可能な Apex を使用するハイブリッド モデルは強力ですが、汎用的なアプローチではありません。アーキテクトは、ハイブリッド ソリューションに取り組む前に、特定の制限とトレードオフを認識しておく必要があります。
保存前サポートなし :これは最も重要な制限です。呼び出し可能なアクションは、保存後コンテキスト (アクションと関連レコードのフロー) でのみ使用できます。高パフォーマンスの保存前コンテキスト (項目の高速更新のフロー) では使用できません。そのため、このパターンを使用して同じレコードの項目自動更新を委任することはできません。保存前フローまたはコンテキスト前Apexトリガー内でネイティブのフロー要素を使用して、高パフォーマンスの作業を実行します。
**復元後のサポートなし:**現在、レコードトリガーフローでは、削除後の復元コンテキストはサポートされていません。Salesforce オブジェクトに、ごみ箱からレコードを復元するときに自動化を実行するというビジネス要件がある場合、Apex トリガーが唯一のソリューションです。
**大規模シナリオのパフォーマンス・オーバーヘッド:**フロー ランタイムから Apex ランタイムへの移行は、ゼロ コストの運用ではありません。一般に高速ですが、フローのランタイムから呼び出し可能アクションにドロップする動作は、Apex トリガー内に完全に収まるネイティブ実行ほど計算速度は速くありません。ほとんどの中密度の自動化では、このマイクロオーバーヘッドはアクセシビリティの向上にとって無視できるほどの価値があります。ただし、非常に高パフォーマンスで大量のシナリオでは、Apexのみのフレームワークの方が未フォーマット時の計算速度の点で有利です。
従来の自動化の戦略
自動化密度ヒューリスティックは新しいグリーンフィールドアーキテクチャの決定的な指針となりますが、エンタープライズ Salesforce 環境の現実は多くの場合、より微妙な違いがあります。成熟した組織では、同じ Salesforce オブジェクトで動作するレコードトリガーフローと Apex トリガーを見つけるのが一般的です。このシナリオは、前に説明したハイブリッド パターンとは異なります。ここでは、フローと Apex トリガーが結合されておらず、連携するように設計されていません。
この共存は、多くの場合、プラットフォーム機能の進化や従来の技術的負債が原因です。これは許容される運用状態ですが、アーキテクトは最終状態ではなく計算されたトレードオフとして処理する必要があります。
オーケストレーションが断片化することで、ガバナンスとメンテナンスのオーバーヘッドが大きくなり、開発、テスト、インシデント処理の作業がバラバラになり、煩雑になります。これにより、解決までの時間 (TTR) が増加し、運用が複雑になります。
Apex トリガーでのメタデータフレームワークの使用
Salesforce Platform での組織のビジネスプロセスが成熟するにつれて、レコードトリガー自動化の量と複雑さは必然的に増加します。基本的なベストプラクティスは、_ApexトリガーをSalesforceオブジェクト_ごとに1つ管理することです。プラットフォームでは、同じイベントに対して同じオブジェクトに対する複数のトリガーの実行順序が保証されないため、このルールは非常に重要です。この制限により、動作が不安定になったり、競合状態になったり、デバッグが困難になったりする可能性があります。
ただし、_ワン トリガー_の原則に従うと、アーキテクチャ上の課題が生じます。つまり、その1つのエントリー ポイントから呼び出されるすべてのビジネス ロジックを、メンテナンス可能で拡張可能な方法で管理およびオーケストレーションする方法です。
Classic トリガーハンドラーの制限
このアーキテクチャの最初の進化は Classic トリガーハンドラーパターンでした。この方法では、1 つの Apex トリガーですべてのロジックが対応するハンドラ クラス(OpportunityTriggerHandler など)に委任されます。このメソッドにより、ロジックがトリガーファイルから分離され、開発者はハンドラクラスのメソッド (afterInsert() など) 内の実行順序を決定的に制御できます。
このパターンは改善されていますが、多くの場合、ハンドラークラスがモノリシックになります。ビジネス要件が追加されるにつれ、クラスは大規模になり、管理が難しくなり、単独でテストすることも困難になります。すべての個々のプロセスの実行順序が 1 つのメソッド内でハードコードされるため、クラスがマージの競合を起こしやすく、大規模なエンタープライズ環境でのガバナンスとメンテナンスのオーバーヘッドが大幅に増加します。
解決策:メタデータ駆動型トリガーフレームワーク
モジュール性とオーケストレーションのコア問題を解決するために、アーキテクトはメタデータ駆動型トリガー フレームワーク に移行します。これは、自動化ロジック自体を実行_方法_と実行_タイミング_の設定から分離する、アーキテクチャ上の重要な飛躍です。
このフレームワークは、次の 3 つの主要な利点に基づいて構築されています。
**パーティショニング:**1 つのハンドラ クラスではなく、コア ビジネス ロジックは小さな原子 Apex クラス(RecalculateAccountValues クラスや NotifySalesLeads クラスなど)に分割され、各クラスは_単一責任原則_に従います。このモジュール化により、ロジックをテスト、デバッグ、および理解しやすくなっています。
**順序と振付:**実行順序が Apex でハードコードされなくなりました。代わりに、通常はカスタムメタデータ型 (TriggerAction__mdt など) に保存されている設定レコードによって宣言的に定義されます。これにより、管理者はリリースやコードの変更を必要としないメタデータレコードを変更するだけで、自動化アクションの並び替え、追加、削除ができます。
**バイパス機能:**このフレームワークでは、標準化された詳細なバイパス機能が提供されます。各自動化アクションは、そのメタデータレコードを使用してグローバルに無効にするか、カスタム権限を参照して特定の管理ユーザーに対してスキップするように設定できます。
オブジェクトの単一の Apex トリガーは、動的ディスパッチャーとしてのみ機能します。ビジネスロジックが含まれておらず、代わりに中央MetadataTriggerHandlerクラスがインスタンス化されます。このハンドラは、カスタムメタデータレコードを照会して実行順序を動的に決定し、指定された順序で正しいアトミック Apex クラスを呼び出します。自動化は、1 つの透過的で管理可能なレイヤーで統合されます。
トランザクションでの高価な操作の重複排除
堅牢なフレームワークでApexを使用する重要なメリットは、トランザクションの状態を管理でき、重複作業を排除してパフォーマンスを最適化できることです。ロジックが蓄積されると、保存順序内のさまざまな自動化が同じコストのかかる操作を個別に実行し、貴重なガバナ制限を消費して DML 操作時間が増加することがよくあります。
このフレームワークは、次の 2 つの主要な戦略でこれに対処するように設計されています。
**共有状態管理:**1つのApexトランザクションの範囲内で、静的プロパティと変数を使用してデータをキャッシュします。これにより、設定のSOQLクエリなどの高価な操作は、トリガーの異なるレコードまたはフェーズで自動化ロジックが複数回呼び出された場合でも、1 回のみ実行されます。トランザクション制限の消費が大幅に削減されます。
**プラットフォーム・キャッシュ使用率:**単純なトランザクション内キャッシュを超えるには、プラットフォームキャッシュを使用して、データベース全体で特定のデータを照会しないようにします。この管理対象のメモリ内キャッシュは、非プリミティブで、コードベース全体で頻繁に参照され、トランザクション全体 (プロファイル、ロール、営業時間など) で不変のデータを取得する場合に最適です。Cache.CacheBuilder インターフェイスを使用して、システムは最初にキャッシュを確認し、データが存在しない場合にのみデータベースクエリを実行するため、パフォーマンスと拡張性が最大限に高まります。
同じレコードの更新で保存前を使用
オートメーションでトランザクションを開始するレコードの項目値のみを変更する必要がある場合は、必ず保存前更新を使用してください。これは、フローの高速項目自動更新 (保存前に実行) と Apex トリガーのコンテキスト前ロジック (挿入前、更新前) の両方に適用されます。
このパターンは、2 回目の DML 操作と再帰的な保存サイクルが回避されるため、どのツールを使用してもパフォーマンスは優れています。変更は、データベースにコミット_される前_にメモリ内のレコードに対して行われ、元のトランザクションの一部として保存されます。保存順序全体を再実行し、すべての自動化を再度実行する 2 回目の保存のオーバーヘッドが排除されます。
非制御の再帰の防止
非制御再帰は、更新後のトリガーでよく発生する落とし穴で、トリガーのロジックによって DML 更新が実行され、同じトリガーが再度起動されます。これにより、ガバナ制限例外で終了する無限ループが作成されます。これまで、静的 Boolean フラグや処理済みレコード ID のコレクションは、このような再帰を防ぐために使用されてきましたが、より正確で堅牢なパターンは、レコード自体の新しいバージョンと古いバージョン間で項目値を比較してロジックをゲートすることです。
ロジックは、関心のある特定の項目が実際に変更された場合にのみ実行します。これにより、重要なデータが変更されない同じトランザクション内の後続の DML 操作でトリガーのロジックが実行されなくなります。
レコードトリガーフローでの再帰の制御
レコードトリガーフローでは、条件の要件を満たすようにレコードが更新されたときにのみ実行されるようにフローを設定することで、非制御の再帰を防止します。
フローで入力条件数式を使用する場合、$Record グローバル変数 (新しい値を表す) と $RecordPrior グローバル変数 (保存前の元の値を表す) を比較することで、暴走を回避できます。たとえば、商談の [金額] 項目が変更された場合にのみフローが実行されるようにするには、次のように入力条件で使用します。
1 $Record.Amount != $Record__Prior.Amount Apex での再帰の制御
新しいバージョンのレコード Trigger.new の項目値と古いバージョンのレコード Trigger.oldMap の項目値を比較し、探している特定の変更が行われているかどうかを確認します。このアプローチにより、自動化が即効性を発揮し、必要な場合にのみ実行されるため、システムの効率が向上し、破滅的な再帰ループを回避できます。
自動化のスキップ
適切に設計された Salesforce 組織では、自動化をスキップするための一貫した信頼性の高いメカニズムが必要です。これは省略可能な機能ではなく、データの整合性を維持し、管理タスクを有効にするためのコア業務要件です。
次のようなシナリオでは、バイパスフレームワークが不可欠です。
大量のデータを読み込む場合、レコードごとにトリガーをトリガーすると、プロセスが大幅に遅くなり、制限例外が発生し、誤った関連レコードと通知が作成される可能性があります。バイパスを使用すると、データをクリーンかつ効率的に挿入できます。
インテグレーションユーザーは、外部の記録システムからデータを同期する必要がある場合があります。ユーザーが開始した変更 (メールの送信、ToDo の作成など) で通常起動される自動化は、変更が別のシステムから行われた場合に望ましくない場合や冗長になる場合があります。
システム管理者またはサポートスタッフは、レコードの修正更新を実行する必要がある場合があります。バイパスメカニズムを使用すると、意図しない結果になる可能性がある標準のビジネス自動化をトリガーせずにこれらの変更を行うことができます。
カスタム権限 :バイパスロジックを実装するための最新のスケーラブルな標準はカスタム権限です。これらは、いくつかの理由で古い方法よりも優れています。
**柔軟性:**カスタム権限は、権限セットを使用してユーザーに割り当てることができます。この手法は、最新の Salesforce セキュリティおよびアクセスモデルに準拠しているため、きめ細かく柔軟な割り当てが可能です。バイパスは特定のユーザーに付与することも、特定の有効期限で一時的に付与することもできます。
**メンテナンス性:**カスタム権限を使用すると、プロファイルやユーザーを自動化ロジックにハードコードすることを回避できます。ユーザーのロールが変更されたり、新しいプロファイルにアクセスをバイパスする必要がある場合、変更は単純な権限セットの割り当てであり、リリースを必要とするコードやフローの変更ではありません。
**拡張性:**カスタム権限は、複雑なユーザーベース全体で例外を管理するためのスケーラブルなフレームワークを提供します。権限セット、権限セットグループ、またはプロファイルを使用してユーザーに割り当てることができます。権限セットまたはプロファイルへの関連付けもソースメタデータで表現できます。
実装パターン :一貫したバイパスパターンを組織内のすべてのレコードトリガー自動化に適用します。
レコードトリガーフローのバイパス :フローを迂回する最も効率的な方法は、フローがまったく実行されないようにすることです。これは、フローのエントリ条件に条件を追加することで実現されます。
Apex トリガーフレームワークのバイパス
メガフローと複数のフロー
これは、オブジェクトのすべての自動化を 1 つの巨大なフローに統合するためのアンチパターンです。ロジックを複数の適切な条件のフローに分割するよりも 1 つのフローに統合する方がパフォーマンスに大きな影響を与えません。パフォーマンスの最も重要な向上は、次の点にあります。
フロートリガーエクスプローラー では、オブジェクトの各フローに順序値を割り当てて、順次実行順序を保証できます。
リソース