Le integrazioni Salesforce moderne devono supportare molto più del semplice scambio di dati. Si prevede che rafforzino le esperienze dei clienti in tempo reale, coordinino le azioni in più sistemi e operino in modo affidabile su scala aziendale, il tutto rispettando rigorosi requisiti di sicurezza e conformità. Scegliere il giusto approccio di integrazione è quindi una decisione architettonica fondamentale, non un dettaglio di implementazione. Considerare uno scenario aziendale comune. Un cliente completa un acquisto in un'app mobile, attivando un controllo dell'idoneità in tempo reale per un'offerta personalizzata. Allo stesso tempo, i dati delle transazioni devono essere registrati in un sistema ERP, gli attributi dei clienti aggiornati in Salesforce e gli elementi di Analytics trasmessi in streaming a un data lake, senza introdurre latenza, duplicazione dei dati o rischi di conformità. Scenari di questo tipo sono ormai tipici degli ambienti Salesforce moderni, dove Salesforce raramente opera in modo isolato e deve integrarsi perfettamente con un ecosistema più ampio di applicazioni e piattaforme dati. Questa guida esiste per aiutare architetti e sviluppatori a progettare queste integrazioni con chiarezza e sicurezza. Anziché concentrarsi sulle implementazioni da punto a punto, presenta una serie di modelli di integrazione collaudati che riguardano scenari aziendali ricorrenti, ad esempio l'orchestrazione dei processi, la sincronizzazione dei dati e l'accesso ai dati in tempo reale. Ogni schema enfatizza l'intento architettonico, i compromessi e i modelli di esecuzione, consentendo ai team di prendere decisioni di progettazione informate e durature. All'interno di questo documento troverai:
- Schemi di integrazione che rappresentano "archetipi" aziendali comuni in scenari di accesso a processi, dati e virtuali
- Framework di selezione degli schemi per identificare l'approccio corretto in base all'intento di integrazione e ai tempi di esecuzione
- Indicazioni pratiche su scalabilità, affidabilità, governance e considerazioni sulla sicurezza
- Procedure consigliate tratte dalle implementazioni reali di Salesforce e Data 360 L'obiettivo di questo documento è quello di fornire un linguaggio architettonico condiviso per l'integrazione, aiutando i team a progettare soluzioni che bilanciano prestazioni, flessibilità e Trust allineandosi con i dati aziendali e le strategie di governance.
Questo documento è destinato a progettisti e architetti che necessitano di integrare i dati di altre applicazioni aziendali con Salesforce Data 360 (in precedenza Data Cloud). Questo contenuto è un distillato di molte implementazioni di successo degli architetti e dei partner Salesforce. Per acquisire familiarità con le funzionalità e le opzioni di integrazione disponibili per l'adozione su larga scala di Data 360, vedere le sezioni Riepilogo schemi e Guida alla selezione degli schemi riportate di seguito. Gli architetti e gli sviluppatori dovrebbero considerare questi dettagli dello schema e le procedure consigliate durante la fase di progettazione e implementazione dei progetti di interazione dei dati in Data 360. Se implementati correttamente, questi schemi consentono di arrivare in produzione il più velocemente possibile e di avere la serie di applicazioni più stabile, scalabile ed esente da manutenzione possibile. Gli architetti consulenti Salesforce utilizzano questi schemi come punti di riferimento durante le revisioni architettoniche e li gestiscono e migliorano attivamente. Come per tutti gli schemi, questo contenuto copre la maggior parte degli scenari di integrazione, ma non tutti. Benché Salesforce consenta l'integrazione dell'interfaccia utente (interfaccia utente), ad esempio i mashup, tale integrazione esula dall'ambito di questo documento.
Ogni schema di integrazione segue una struttura coerente. Ciò offre coerenza nelle informazioni fornite in ogni schema e semplifica anche il confronto degli schemi.
- Nome: Identificatore dello schema che indica anche il tipo di integrazione contenuto nello schema.
- Context: Scenario di integrazione generale affrontato dallo schema. Il contesto fornisce informazioni su ciò che gli utenti stanno cercando di ottenere e su come l'applicazione si comporta per supportare i requisiti.
- Problema: Espresso come domanda, questo è lo scenario che lo schema è progettato per risolvere. Leggere questa sezione per capire se lo schema è appropriato per il proprio scenario di integrazione.
- Forze: I vincoli e le circostanze che rendono lo scenario dichiarato difficile da risolvere.
- Soluzione: Il modo consigliato per risolvere lo scenario di integrazione.
- Sketch: Diagramma di sequenza UML che mostra come la soluzione affronta lo scenario.
- Risultati: Spiega i dettagli di come applicare la soluzione allo scenario di integrazione e come risolvere le forze associate a quello scenario. Questa sezione contiene anche nuove sfide che possono sorgere in seguito all'applicazione dello schema.
- Intestazioni laterali: Sezioni aggiuntive correlate allo schema che contengono problemi tecnici chiave, variazioni dello schema, problemi specifici dello schema e così via.
- Esempio: Uno scenario del mondo reale che descrive come viene utilizzato lo schema di progettazione in uno scenario Salesforce del mondo reale. L'esempio spiega gli obiettivi di integrazione e come implementare lo schema per raggiungere tali obiettivi.
Utilizzare questa tabella come indice degli schemi di integrazione contenuti in questo documento.
| Schema livello1 | Schema livello2 | Schema | Secenario |
|---|---|---|---|
| Schemi di inserimento dati - Dati in entrata | Schemi di inserimento batch | Inserimento di dati in blocco da Cloud Storage | I dati vengono inseriti da una fonte di archiviazione cloud aziendale come Amazon S3, Azure Blob o Google Cloud Storage in Data 360 sotto forma di grandi batch di dati non elaborati (ad esempio transazioni o registri di prodotti). |
| Inserimento di dati in blocco da Salesforce Clouds | Data 360 riceve i dati CRM in blocco da più organizzazioni Salesforce (ad esempio Sales Cloud, Service Cloud) per creare profili cliente unificati. | ||
| Streaming e schemi di inserimento in tempo reale | Inserimento basato sugli eventi tramite l'API di inserimento--Streaming | Data 360 si abbona agli endpoint di inserimento streaming che ricevono payload di eventi continui (ad esempio, eventi di acquisto, telemetria IoT) dai sistemi aziendali per gli aggiornamenti dei profili in tempo reale. | |
| Inserimento di comportamenti Web e mobili in tempo reale | Data 360 raccoglie ed elabora i dati comportamentali in tempo reale dei siti Web e delle app mobili tramite SDK per arricchire le metriche di coinvolgimento e i modelli di personalizzazione. | ||
| Sincronizzazione CRM quasi in tempo reale tramite streaming | Data 360 riceve gli aggiornamenti dei dati CRM (ad esempio, le modifiche di referenti, casi e opportunità) quasi in tempo reale tramite stream di eventi per mantenere una visualizzazione Customer 360 sincronizzata in modo continuo. | ||
| Inserimento di stream di eventi dalle piattaforme di messaggistica cloud - Kinesis e MSK | Data 360 utilizza i dati in streaming direttamente da piattaforme di eventi cloud come AWS Kinesis o Kafka (MSK) per elaborare eventi operativi o IoT ad alta frequenza. | ||
| Schemi copia zero - In entrata e in uscita | Copia zero in entrata - Piattaforme esterne in Data 360 | Data 360 esegue query su serie di dati esterne (ad esempio Snowflake, BigQuery) su richiesta tramite l'inserimento copia zero, senza spostare fisicamente i dati in Salesforce. | |
| Copia zero in uscita - Dati 360 su piattaforme esterne | I sistemi esterni come Databricks o Tableau accedono a segmenti e approfondimenti arricchiti in Data 360 tramite connessioni Copia zero in uscita senza replica dei dati. | ||
| Piattaforma dati unificata multi-organizzazione con Data Cloud One | Data Cloud One unifica più organizzazioni Salesforce e fonti di dati esterne in un modello semantico e di metadati condiviso, offrendo Customer 360 coerente senza duplicazione dei dati. | ||
| Schemi di attivazione dei dati - Dati in uscita | Schemi di attivazione batch | Attivazione del segmento nelle piattaforme di marketing e pubblicità | Data 360 attiva i segmenti di clienti curati direttamente in Marketing Cloud, Meta, Google Ads o altre piattaforme pubblicitarie per la consegna personalizzata delle campagne |
| Esportazione di dati in Cloud Storage | Data 360 esporta le serie di dati unificate o filtrate (ad esempio, i record cliente consenzienti) come file CSV o Parquet nell'archiviazione cloud aziendale per l'analisi o l'archiviazione della conformità. | ||
| Attivazione basata su API on-demand | Integrazione di applicazioni personalizzate tramite API Connect | Le applicazioni esterne richiamano l'API Data 360 Connect in tempo reale per recuperare o attivare azioni personalizzate (ad esempio, il controllo del saldo fedeltà o la generazione di offerte AI) in base ai dati correnti dei clienti.Le applicazioni Web o mobili personalizzate recuperano gli approfondimenti armonizzati di Data 360 in modo sicuro tramite l'API REST Connect per visualizzarli nelle interfacce utente aziendali o dei partner. | |
| Completamento del recupero del profilo cliente tramite l'API Data Graph | Un sistema recupera il profilo unificato di un cliente utilizzando l'API Data Graph, restituendo una rappresentazione JSON pre-unita in tempo reale della visualizzazione completa a 360° per le decisioni o la personalizzazione. | ||
| Azioni dati in tempo reale | Azione dati in tempo reale Trasformazione dei segnali dei clienti in azione immediata | Data 360 rileva ed elabora un evento live (ad esempio, aggiornamento del consenso, trigger di acquisto) e richiama immediatamente un sistema connesso o un flusso Salesforce per un'azione a valle.Un segnale di attività del cliente (ad esempio, il rischio di abbandono rilevato) in Data 360 attiva un'azione istantanea in tempo reale, ad esempio aggiornare CRM, invocare il calcolo del punteggio Einstein o avviare un journey di fidelizzazione. |
Gli schemi di integrazione in questo documento sono classificati in tre categorie: integrazioni di dati, processi e visuali.
Gli schemi di integrazione dei dati in Data 360 riguardano lo spostamento e la sincronizzazione dei dati tra i sistemi per garantire che sia Data 360 che le piattaforme esterne dispongano di informazioni coerenti, tempestive e affidabili. Questi schemi in genere gestiscono flussi di dati su larga scala e a volume elevato e si basano su pipeline governate che impongono la coerenza dello schema, il tracciamento dei lignaggi e le regole di masterizzazione.
- Gli schemi di inserimento batch rappresentano il livello di base dell'orientamento dei dati aziendali. L'inserimento in blocco di dati da servizi di cloud storage come AWS S3, Azure Blob o Google Cloud Storage consente di caricare periodicamente serie di dati storici di grandi dimensioni in Data 360 per la risoluzione dell'identità, la segmentazione e l'analisi. Analogamente, l'inserimento in blocco da Salesforce Cloud, ad esempio Sales Cloud, Service Cloud o Marketing Cloud, utilizza connettori e stream di dati nativi per inserire i dati CRM nel livello di dati unificato, garantendo armonizzazione e continuità tra i sistemi di coinvolgimento.
- Streaming e schemi di inserimento in tempo reale estendono questo processo acquisendo dati di eventi a velocità elevata. L'inserimento basato sugli eventi tramite l'API di inserimento consente ai sistemi esterni di trasmettere continuamente l'attività dei clienti in Data 360. L'inserimento del comportamento Web e mobile in tempo reale acquisisce i dati di clickstream e di interazione direttamente dai punti di contatto digitali per favorire la personalizzazione immediata. La sincronizzazione CRM quasi in tempo reale tramite le Streaming API garantisce che gli attributi dei clienti e gli aggiornamenti del consenso si riflettano rapidamente nei vari sistemi. L'inserimento di stream di eventi da piattaforme di messaggistica come Amazon Kinesis o Confluent MSK supporta opportunità in corso di realizzazione continue ad alta produttività, allineando Data 360 alle architetture degli eventi aziendali.
- Unified Multi-Org Data Platform with Data Cloud One rappresenta un ulteriore esempio di integrazione dei dati, offrendo un ambiente consolidato per unificare i dati di più organizzazioni Salesforce e fonti esterne sotto un livello di governance e semantica comune. Ciò consente alle organizzazioni di ottenere coerenza dei dati a livello aziendale, modelli di dati condivisi e analisi scalabili.
- Nella fase di attivazione, gli schemi di attivazione batch seguono lo stesso principio di integrazione dei dati. I segmenti curati in Data 360 vengono esportati nei processi pianificati nelle piattaforme di marketing e pubblicità a valle, ad esempio Marketing Cloud, Meta Ads o Google Ads, dove attivano l'esecuzione delle campagne. Analogamente, le serie di dati possono essere esportate in destinazioni di archiviazione cloud per alimentare le opportunità di analytics e data science esterne. In tutti questi casi d'uso, Data 360 funge da fonte di dati veritieri per i dati dei clienti sincronizzati e curati.
Gli schemi di integrazione dei processi in Data 360 includono l'attivazione o l'orchestrazione di processi aziendali tra i sistemi in quasi tempo reale. Questi schemi consentono a Data 360 di partecipare attivamente ai flussi di lavoro aziendali, abilitando risposte contestuali e attivazione dinamica dei dati.
- L'attivazione basata su API abilita scenari di coinvolgimento in tempo reale. Tramite l'API Connect, le applicazioni personalizzate possono eseguire query o attivare i profili cliente direttamente da Data 360 come parte dei processi operativi, ad esempio una console agente che recupera approfondimenti unificati sui profili durante un'interazione con il cliente. Il Complete Customer Profile Retrieval via Data Graph API supporta applicazioni composite e microservizi che si basano sull'accesso basato su API al grafico entità completo di un cliente, consentendo esperienze dinamiche senza segmenti pre-stadiati.
- Le azioni dati in tempo reale spingono ulteriormente questo approccio di integrazione abilitando la reattività immediata. Quando viene rilevato un segnale cliente, ad esempio un acquisto, l'invio di un modulo o un evento di soglia, Data 360 può attivare azioni come l'aggiornamento di un record CRM, l'invocazione di un webhook esterno o l'avvio di un flusso di lavoro dell'offerta personalizzato. Questi schemi incarnano una vera e propria orchestrazione dei processi, collegando Intelligence clienti in tempo reale ed esecuzione operativa automatica.
Gli schemi di integrazione virtuali in Data 360 consentono l'accesso live a fonti di dati esterne o federate senza copiare o duplicare fisicamente i dati. Questi sono fondamentali per le aziende che necessitano di informazioni aggiornate e gestite in fase di query riducendo al minimo lo spostamento dei dati.
- Inbound Zero Copy Data Federation (External Platforms-to-Data 360) consente ai sistemi esterni, ad esempio data warehouse o data lake, di condividere le serie di dati con Data 360 tramite connessioni protette e regolamentate (ad esempio, Snowflake Secure Data Sharing). Ciò garantisce che Data 360 possa accedere e operare virtualmente sui dati esterni, preservando la freschezza ed eliminando le repliche inutili.
- Outbound Zero Copy Data Sharing (Data 360-to-External Platforms) consente a Data 360 di esporre le serie di dati curate per il consumo esterno, ad esempio modellazione AI, business intelligence o analisi avanzate, tramite meccanismi di federazione dei dati e query live sicuri. Scegliere la strategia di integrazione migliore per il proprio sistema non è banale. Ci sono molti aspetti da considerare e molti strumenti che possono essere utilizzati, con alcuni strumenti più appropriati di altri per determinate operazioni. Ogni schema affronta specifiche aree critiche, tra cui le funzionalità di ogni sistema, il volume dei dati, la gestione dei guasti e la transazionalità.
Quando si seleziona uno schema di integrazione, iniziare rispondendo a due domande fondamentali che definiscono la progettazione e il comportamento complessivi dell'integrazione. Cosa si sta integrando? — Accesso a processi, dati o virtuale Questa dimensione definisce lo scopo principale dell'integrazione.
- Le integrazioni dei processi si concentrano sull'orchestrazione dei flussi di lavoro aziendali e sul coordinamento delle azioni tra i sistemi.
- Le integrazioni dei dati si concentrano sulla sincronizzazione, l'arricchimento o la propagazione dei dati tra i sistemi.
- Le integrazioni virtuali si concentrano sull'accesso ai dati esterni in tempo reale senza copiarli o mantenerli in Salesforce o Data 360. La comprensione di questo intento consente di determinare il livello di orchestrazione, spostamento dei dati e accoppiamento richiesto tra i sistemi.
- Come deve essere eseguito? — Il metodo Sincrono o Asincrono definisce il modello di esecuzione dell'integrazione.
- Le integrazioni sincronizzate sono in tempo reale e bloccanti, in cui il chiamante si aspetta una risposta immediata, comunemente utilizzate per scenari guidati dagli utenti o di convalida.
- Le integrazioni asincrone sono non bloccanti e disaccoppiate, progettate per gestire processi su larga scala, di lunga durata, tentativi e volumi di dati elevati. Insieme, queste due dimensioni (intento di integrazione e tempistica di esecuzione) offrono un framework chiaro e coerente per selezionare lo schema di integrazione corretto bilanciando esperienza utente, scalabilità e resilienza operativa. Nota: Un'integrazione può richiedere un middleware esterno o una soluzione di integrazione (ad esempio, Enterprise Service Bus) a seconda degli aspetti validi per lo scenario di integrazione.
In questa tabella sono elencati gli schemi e i relativi aspetti chiave per consentire di determinare quale schema si adatta meglio alle proprie esigenze quando l'integrazione passa da Salesforce a un altro sistema
| Tipo | Tempistica | Considerazioni in uscita |
|---|---|---|
| Integrazione dei dati | Asynchronous | Attivazione del segmento nelle piattaforme di marketing e pubblicità |
| Integrazione processi/dati | Synchronous | Integrazione di applicazioni personalizzate tramite API Connect Completamento del recupero del profilo cliente tramite l'API Data Graph |
| Integrazione dei dati | Synchronous | Azione dati in tempo reale Trasformazione dei segnali dei clienti in azione immediata |
| Integrazione virtuale (utilizzo di copia zero) | Asynchronous | Copia zero in uscita - Dati 360 su piattaforme esterne |
| Integrazione virtuale | Asynchronous | Piattaforma dati unificata multi-organizzazione con Data Cloud One |
In questa tabella sono elencati gli schemi e i relativi aspetti chiave per consentire di determinare lo schema più adatto alle proprie esigenze quando l'integrazione avviene da un altro sistema a Salesforce.
| Tipo | Tempistica | Considerazioni in entrata |
|---|---|---|
| Integrazione dei dati | Asynchronous | Inserimento di dati in blocco da Cloud Storage Inserimento di dati in blocco da Salesforce Clouds |
| Integrazione dei dati | Asynchronous | Inserimento di stream di eventi dalle piattaforme di messaggistica cloud - Kinesis e MSK Sincronizzazione CRM quasi in tempo reale tramite streaming |
| Integrazione dei processi | Synchronous | Inserimento basato sugli eventi tramite l'API di inserimento--Streaming Inserimento di comportamenti Web e mobili in tempo reale |
| Integrazione virtuale | Asynchronous | Copia zero in entrata - Piattaforme esterne in Data 360 |
In questa tabella sono elencati alcuni termini chiave relativi al middleware e le relative definizioni in relazione a questi schemi.
| Termine | Definizione |
|---|---|
| Gestione eventi | La gestione degli eventi si riferisce alla ricezione, all'instradamento e alla risposta a occorrenze identificabili da un sistema o da un'applicazione di origine. Middleware gestisce gli eventi identificando l'endpoint di destinazione, inoltrando l'evento e attivando l'azione aziendale richiesta (ad esempio, registrazione, tentativi o attivazione di servizi a valle). Nelle architetture Data 360, la gestione degli eventi è fondamentale per l'inserimento dati in tempo reale, i trigger di attivazione e gli schemi di pubblicazione/abbonamento. Gli eventi possono provenire da sistemi esterni (Kafka, AWS Kinesis) o da eventi Salesforce Platform e vengono instradati dal middleware o dal bus degli eventi di Data 360 per l'elaborazione immediata. |
| Conversione protocollo | La conversione del protocollo consente la comunicazione tra sistemi che utilizzano standard di trasporto dati diversi. Middleware traduce protocolli proprietari o legacy (come AMQP, MQTT, FTP) in protocolli Data 360 supportati (REST, gRPC o HTTPS). Ciò garantisce l'interoperabilità tra sistemi eterogenei. Poiché Data 360 non gestisce in modo nativo la conversione del protocollo, il middleware fornisce il livello di adattamento, incapsulando o trasformando i messaggi in un formato che le API e i connettori di Data 360 possono interpretare. |
| Traduzione e trasformazione | La traduzione e la trasformazione garantiscono l'interoperabilità mappando un formato di dati o uno schema a un altro. Middleware esegue queste trasformazioni per allineare diversi payload di dati (CSV, XML, JSON) agli oggetti modello di dati (DMO) e agli oggetti livello di dati (UDLO) di Data 360. Ciò include la pulitura, l'arricchimento e l'applicazione di mappature semantiche o basate sull'ontologia prima dell'inserimento. Mentre Salesforce offre strumenti di trasformazione come i procedimenti di Preparazione dati, le trasformazioni complesse (soprattutto per l'armonizzazione semantica) sono gestite meglio nel middleware. |
| Area di attesa e buffering | L'area di attesa e il buffering si basano sul passaggio di messaggi asincroni per garantire una comunicazione resiliente e disaccoppiata. Le piattaforme middleware (ad esempio MuleSoft, Kafka o Azure Event Hub) forniscono aree di attesa persistenti che memorizzano temporaneamente i dati quando Data 360 o i sistemi a valle sono occupati o non raggiungibili. Ciò evita la perdita di dati e supporta l'inserimento o i tentativi di attivazione quasi in tempo reale. Data 360 supporta l'inserimento in streaming e la messaggistica in uscita basata sul flusso, ma le aree di attesa durevoli e la consegna garantita sono in genere gestite dal middleware. |
| Protocolli di trasporto sincroni | I protocolli di trasporto sincrono prevedono il blocco delle operazioni di richiesta/risposta in tempo reale. Il mittente attende una risposta prima di procedere. In Data 360, vengono utilizzati per attivazioni basate su API on-demand, arricchimento in tempo reale o ricerche di profili, in cui le risposte sono richieste immediatamente. Middleware garantisce l'affidabilità della connessione e gestisce i tentativi o la gestione di fallback per le chiamate API Data 360 sincrone. |
| Protocolli di trasporto asincrono | I protocolli di trasporto asincroni supportano la comunicazione non bloccante e disaccoppiata in cui il mittente continua l'elaborazione senza attendere una risposta. Middleware gestisce i flussi asincroni per le attivazioni batch, l'inserimento in streaming e l'attivazione basata sugli eventi. Ciò consente un'elevata produttività e resilienza, fondamentali per lo streaming degli eventi e gli schemi di inserimento dati quasi in tempo reale in Data 360. |
| Instradamento della mediazione | L'instradamento della mediazione definisce un flusso di messaggi complesso tra i sistemi, assicurando che i dati o gli eventi corretti raggiungano il consumatore corretto. Middleware funge da mediatore, gestendo la logica di instradamento in base a regole, intestazioni, contenuti o tipi di evento. Nelle integrazioni Data 360, la mediazione garantisce che gli eventi e gli aggiornamenti dei profili di più sistemi vengano instradati correttamente alle API di inserimento dati, agli endpoint di attivazione o ai consumatori esterni. Ciò semplifica l'orchestrazione e supporta la sincronizzazione dei dati multi-sistema. |
| Coreografia del processo e orchestrazione del servizio | La coreografia e l'orchestrazione del processo coordinano i processi multi-sistema. La coreografia supporta flussi autonomi e asincroni basati sugli eventi, in cui i sistemi agiscono in base a regole condivise senza un controller centrale. L'orchestrazione è un flusso gestito centralmente che dirige l'esecuzione del servizio. Nelle architetture Data 360, il middleware gestisce l'orchestrazione per l'inserimento e l'attivazione tra i sistemi, mentre i flussi di lavoro o i flussi di Salesforce gestiscono coreografie leggere all'interno della piattaforma. Un'orchestrazione complessa, che richiede il coordinamento delle transazioni o la gestione dello stato, è consigliata a livello middleware. |
| Transazionalità (crittografia, firma, consegna affidabile, gestione delle transazioni) | La transazionalità garantisce operazioni atomiche, coerenti, isolate e durature (ACID) in tutti i sistemi. Salesforce e Data 360 sono transazioni all'interno dei loro confini ma non supportano le transazioni distribuite tra i sistemi esterni. Middleware gestisce il controllo delle transazioni globali, incluse crittografia, firma dei messaggi, ritiro, compensazione e consegna affidabile. Per i flussi di dati mission-critical (ad esempio, aggiornamenti finanziari o consenso), il middleware garantisce l'integrità e il ripristino end-to-end in Data 360 e nei sistemi esterni. |
| Instradamento | L'instradamento specifica il flusso controllato di messaggi o dati tra i componenti. Può essere basato su intestazioni, tipo di contenuto, priorità o regole. Middleware gestisce la logica di instradamento per gli eventi e le attivazioni che coinvolgono Data 360, ad esempio l'indirizzamento di segmenti di pubblico arricchiti a diversi sistemi a valle (piattaforme pubblicitarie, magazzini, app CRM). Sebbene l'instradamento possa essere implementato in Salesforce (Apex, flussi), l'instradamento middleware è preferito per la scalabilità, la flessibilità e la governance. |
| Estrazione, trasformazione e caricamento (ETL) | ETL consiste nell'estrarre i dati dai sistemi di origine, trasformarli in uno schema coerente e caricarli in una destinazione (ad esempio Data 360). Gli strumenti middleware o ETL gestiscono queste operazioni prima dell'inserimento dei dati. Data 360 può ricevere output ETL tramite API, connettori o pipeline di inserimento in blocco e supporta anche la sincronizzazione quasi in tempo reale per l'acquisizione dati di modifica. I processi ETL middleware sono essenziali per integrare i sistemi legacy e garantire la qualità dei dati prima dell'unificazione in Data 360. |
| Sondaggio lungo | Il long polling (programmazione Comet) è un metodo per mantenere aperta la comunicazione tra i sistemi per gli aggiornamenti in tempo reale. Il client invia una richiesta e il server la mantiene finché non si verifica un evento, quindi risponde e riapre una nuova connessione. Salesforce lo utilizza nei protocolli Streaming API e CometD/Bayeux per la sincronizzazione dei dati basata sugli eventi. Middleware può abbonarsi a questi eventi e inoltrarli a Data 360 per l'inserimento in tempo reale o i trigger di attivazione, garantendo una latenza minima tra i sistemi aziendali. |
L'inserimento dati è il primo e più importante passaggio del ciclo di vita dei dati di Salesforce Data 360. È il modo in cui le informazioni non elaborate provenienti da più sistemi esterni (API CRM, ERP, Web, mobili o di terze parti) entrano nella piattaforma e diventano parte di una visualizzazione cliente unificata. Lo schema di inserimento corretto dipende dalle esigenze dell'azienda:
- Volume di dati: quanti dati vengono spostati contemporaneamente
- Latenza: quanto devono essere aggiornati i dati
- Funzionalità del sistema di origine: come il sistema può connettersi e fornire dati Data 360 supporta diverse modalità di inserimento per soddisfare queste esigenze: batch per carichi a volume elevato, streaming per aggiornamenti quasi in tempo reale, basato sugli eventi per l'immediatezza delle transazioni e inserimento Copia zero per l'accesso immediato ai dati esterni senza spostarli fisicamente. Insieme, questi schemi assicurano che ogni segnale del cliente, sia che si tratti di un evento di acquisto, di un registro clickstream o di un aggiornamento fedeltà, fluisca in Data 360 in modo efficiente, sicuro e nell'intervallo di tempo giusto per fornire dati analitici affidabili ed esperienze basate sull'intelligenza artificiale.
Gli schemi di inserimento batch sono la spina dorsale dell'orientamento dei dati su larga scala in Data 360. Sono ottimizzati per gli scenari in cui i dati vengono elaborati in blocco, in genere su base pianificata o periodica, anziché in modo continuo. Questi modelli sono più adatti per:
- Dati storici caricati per inizializzare la piattaforma con record aziendali esistenti
- Sincronizzazione regolare con sistemi di record come ERP, data warehouse o database proprietari
- Utilizzare casi in cui la freschezza in tempo reale non è fondamentale, ma la coerenza, la completezza e la possibilità di controllo sono L'inserimento batch offre prestazioni prevedibili e semplicità operativa, il che lo rende una scelta affidabile per le aziende che gestiscono terabyte di dati strutturati o semi-strutturati. Data 360 offre una serie di connettori pronti per l'uso in produzione, generalmente disponibili, che supportano l'inserimento batch in modo nativo. Questi connettori semplificano l'impostazione dell'integrazione, riducono lo sviluppo ETL personalizzato e garantiscono la qualità e la sicurezza dei dati in ogni importazione. La tabella seguente evidenzia i connettori più comuni utilizzati per l'inserimento batch su scala aziendale.
Contesto
Questo schema è progettato per gli scenari aziendali che prevedono l'inserimento di grandi volumi di dati strutturati, ad esempio file CSV o Parquet, e asset non strutturati da data lake centralizzati o drop di file pianificati. Le fonti di dati includono in genere piattaforme di archiviazione cloud come Amazon S3, Google Cloud Storage (GCS) e Archiviazione BLOB di Microsoft Azure, in cui i file vengono consegnati periodicamente nell'ambito di opportunità di data pipeline a monte o esportazioni batch.
Problema
Come può un'organizzazione stabilire un processo affidabile, sicuro e ad alta produttività per inserire serie di dati massicce basate su file dalla piattaforma di archiviazione cloud principale in Data 360 in modo prevedibile e ricorrente, senza sacrificare la governance, la scalabilità o le prestazioni?
Forze
L'inserimento di serie di dati massicce basate su file in Data 360 non è un semplice esercizio di trasferimento dati: è una sfida architetturale caratterizzata da vincoli di scala, governance e piattaforma.
Volume e scala dei dati : I connettori di inserimento Data 360 sono ottimizzati per l'affidabilità e la governance, non per la produzione in blocco arbitraria. Ad esempio, il connettore Amazon S3 supporta fino a 100 milioni di righe o 50 GB per oggetto, a seconda di quale limite viene raggiunto per primo. Per le aziende con serie di dati storiche che contengono miliardi di record, questo confine diventa un vincolo fondamentale per la progettazione. Un approccio lift-and-shift a file singolo diventa rapidamente impossibile, richiedendo strategie intelligenti di partizionamento dei dati, suddivisione in blocchi e orchestrazione per raggiungere la scalabilità senza superare i limiti dei connettori.
Definizione e manutenzione dello schema: Data 360 richiede definizioni esplicite dello schema per ogni pipeline di inserimento per garantire l'integrità semantica e strutturale. In caso di inserimento S3, un file CSV deve definire le intestazioni di colonna e una singola riga di dati rappresentativa. Questo file funge da contratto canonico tra il sistema di origine, ovvero l'archiviazione cloud, e Data 360. Qualsiasi disallineamento, nei nomi dei campi, nei tipi di dati o nella codifica, può causare errori di inserimento o danni silenziosi ai dati. Mantenere questo file schema nel controllo di versione e imporre la convalida tramite flussi di lavoro CI/CD o di governance dei dati diventa una procedura ottimale per gli ambienti di produzione.
Convenzioni di denominazione rigorose: Data 360 applica rigorose regole di denominazione per mantenere la coerenza nel grafico dei metadati.
- I nomi degli oggetti devono iniziare con una lettera e possono contenere solo lettere, numeri o caratteri di sottolineatura.
- I nomi dei campi devono seguire gli stessi schemi. I file che violano queste convenzioni, ad esempio campi contenenti spazi, caratteri speciali o simboli non supportati, non riusciranno a convalidare lo schema durante l'inserimento. Le aziende devono implementare processi di igiene per disinfettare e normalizzare le strutture di file in entrata.
Autenticazione e comportamento di sicurezza: Ogni connessione allo storage esterno deve essere conforme agli standard di sicurezza e conformità di livello aziendale.
- L'autenticazione viene in genere gestita tramite l'autenticazione AWS Access/Secret Keys o IdP (Federated Identity Provider).
- I ruoli IAM devono avere un ambito per imporre privilegi minimi, consentendo l'accesso in sola lettura ai percorsi di archiviazione specificati.
- Per un accesso sicuro, gli indirizzi IP in uscita devono essere aggiunti direttamente all'elenco consentiti del sistema di origine. Questi controlli a livelli assicurano che ogni trasferimento di file operi in un perimetro controllabile e a zero Trust, bilanciando la conformità dell'azienda con la flessibilità necessaria per l'inserimento su larga scala.
Soluzione
Questa tabella contiene le soluzioni a questo problema di integrazione.
| Soluzione | Adatta | Commenti |
|---|---|---|
| Utilizzo di connettori di archiviazione cloud nativi (Amazon S3, Google Cloud Storage, Archiviazione BLOB di Azure) | Best | Questo è lo schema consigliato e più affidabile per l'inserimento su larga scala e ricorrente basato su file in Data 360\. I connettori nativi forniscono l'autenticazione gestita, la mappatura dello schema e lo spostamento sicuro dei dati direttamente negli oggetti data lake (DLO) di Data 360. Ideale per i carichi batch pianificati in cui la latenza non è critica (ad esempio, la pianificazione ogni ora o ogni giorno). |
| Gestione di serie di dati di grandi dimensioni (oltre i limiti del connettore) | Migliore con la preelaborazione | Ogni connettore impone dei limiti di inserimento (ad esempio, S3: 100 milioni di righe o 50 GB per oggetto). Per le serie di dati più grandi, implementare una fase di preelaborazione ETL per suddividere i dati in file/cartelle più piccoli che rientrano in queste soglie. Quindi, configurare più stream di dati per inserire ogni partizione in parallelo e utilizzare il nodo append in una trasformazione dati batch) in Data 360 per ricombinare le partizioni in una serie di dati unificata. |
| Sicurezza e governance | Best | Tutti i connettori supportano l'autenticazione protetta tramite metodi nativi cloud (ruoli IAM, account di servizio o chiavi di accesso). Per un maggiore controllo, limitare l'accesso agli intervalli IP di Data 360 tramite l'elenco consentiti del provider cloud. Il trasferimento dei dati avviene su canali crittografati, con file memorizzati in un livello di gestione temporanea e sicuro durante l'inserimento. |
| Quando non utilizzare | Non ottimale | Questo schema non è ottimale per:
|
Sketch
Questo diagramma illustra la sequenza delle fasi per inserire i dati dall'archiviazione cloud in Data 360
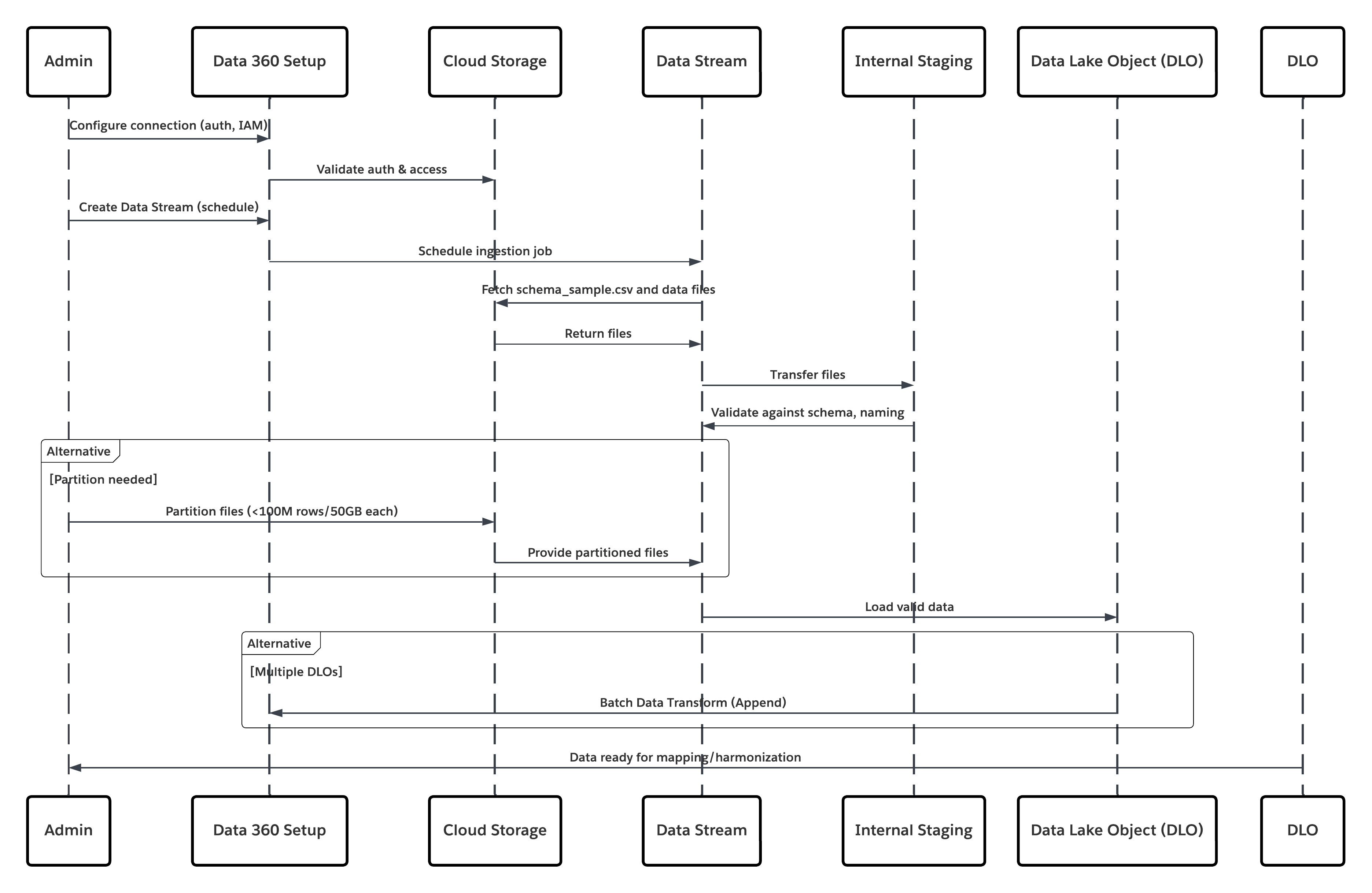
In questo scenario:
- L'amministratore configura una connessione all'archiviazione cloud tramite l'interfaccia di impostazione di Data 360 (specificando l'autenticazione, i dettagli del bucket, i ruoli IAM e la whitelist).
- L'interfaccia di impostazione di Data Cloud esegue l'autenticazione con Cloud Storage Platform, verificando le credenziali e l'accesso.
- L'amministratore crea uno stream di dati in Data 360, collegandolo all'oggetto/cartella in Cloud Storage e definendo la pianificazione dell'inserimento.
- Al trigger di pianificazione, lo stream di dati richiede i file di origine (ad esempio, CSV, Parquet) da Cloud Storage Platform.
- Cloud Storage Platform fornisce file, inclusi schema_sample.csv validi e altri file di dati conformi alle convenzioni di denominazione.
- Stream di dati trasferisce i file all'ambiente di gestione temporanea interno in Data 360.
- Pipeline di Data 360 elabora i file: Utilizza la definizione schema di schema_sample.csv Convalida la struttura, i nomi dei campi e divide il carico se supera le soglie di inserimento (100 milioni di righe/50 GB per file). Se vengono rilevati file di grandi dimensioni, viene eseguita esternamente una fase di partizionamento di preelaborazione (notificata all'amministratore per l'esecuzione successiva).
- I record vengono importati dalla gestione temporanea in un oggetto data lake (DLO).
- Se necessario e i dati sono partizionati, utilizzare il nodo append in una trasformazione dati batch per combinare più DLO.
- Data 360 registra gli esiti positivi/negativi, aggiorna lo stato per il monitoraggio e segnala che i dati sono pronti per mappatura, armonizzazione e unificazione.
Risultati
L'applicazione di questo schema consente l'inserimento sicuro, pianificato e su larga scala di file strutturati o non strutturati dalle piattaforme di archiviazione cloud aziendali in Data 360. Il processo è automatizzato, scalabile e resiliente: fornisce dati non elaborati in oggetti data lake (DLO) che fungono da base per l'armonizzazione e la mappatura al modello di dati Customer 360.
Meccanismi di inserimento
Il meccanismo di inserimento dipende dal connettore e dalla strategia di pianificazione definiti in Data 360.
| Meccanismo di inserimento | Descrizione |
|---|---|
| Connettore Cloud Storage nativo (Amazon S3, GCS, Azure) | Consigliato per l'inserimento diretto di file in formato CSV o Parquet dal data lake cloud dell'azienda. Questi connettori supportano pianificazioni di aggiornamento incrementali e complete. Ad esempio, una banca può configurare una sincronizzazione giornaliera dei file delle transazioni dei clienti da un bucket S3 a un DLO. |
| Strategia file partizionati | Per le serie di dati molto grandi (oltre 100 milioni di righe o 50 GB per oggetto), i dati vengono partizionati in serie logiche più piccole (ad esempio, per mese o regione). Ogni partizione viene gestita come stream di dati separato e in seguito ricombinata utilizzando una trasformazione dati batch con un nodo Aggiungi in coda. |
| Sincronizzazione pianificata automatica | Data 360 offre uno strumento di pianificazione dichiarativo (ogni ora, ogni giorno o cadenza personalizzata) che attiva automaticamente i processi di inserimento, garantendo la freschezza dei dati senza intervento manuale. |
Gestione e ripristino degli errori
La gestione e il ripristino degli errori sono fondamentali per garantire l'affidabilità nelle operazioni di inserimento a volume elevato.
- Rilevamento errori: Ogni esecuzione dello stream di dati registra gli errori di inserimento (ad esempio, mancata corrispondenza dello schema, danneggiamento dei file o violazioni dei nomi) in Monitoraggio di Data 360. Gli amministratori possono rivedere e rielaborare i batch non riusciti.
- Meccanismo di recupero: Data 360 mantiene il checkpointing per garantire che i batch non riusciti non danneggino gli inserimenti precedenti. I tentativi possono essere configurati dopo la correzione dei problemi di origine (ad esempio, file CSV in formato non corretto).
- Convalida dello schema: Il file schema_sample.csv definisce i tipi di dati e la struttura. Qualsiasi modifica attiva la convalida per evitare una fluttuazione silenziosa dello schema tra le esecuzioni.
Considerazioni sulla progettazione idempotente
L'inserimento è idempotente per progettazione: la rielaborazione dello stesso file non genera record duplicati. Le strategie chiave includono:
- Impronte digitali file: Data 360 calcola le checksum per identificare e ignorare i file elaborati in precedenza.
- Inserimento transazionale: I dati vengono inseriti in più passaggi e confermati nel DLO solo dopo che sono stati elaborati correttamente tutti i record.
- Append vs. Sostituisci: A seconda della logica aziendale, gli stream possono aggiungere o sostituire completamente il DLO di destinazione; ciò garantisce risultati deterministici ed evita la sovrapposizione parziale dei dati.
Considerazioni sulla sicurezza
La sicurezza è fondamentale in tutta la pipeline di inserimento, dall'autenticazione alla crittografia e al controllo degli accessi.
- Autenticazione e autorizzazione: I connettori utilizzano il framework di integrazione sicura di Salesforce, che sfrutta le credenziali denominate e le credenziali esterne per l'autenticazione senza esporre segreti.
- Crittografia: I dati vengono crittografati in transito (TLS 1.2+) e a riposo (AES-256).
- Controlli di rete: I sistemi di archiviazione di origine (ad esempio, i bucket S3) devono inserire nell'elenco consentiti gli IP di Data 360.
- Allineamento conformità: Supporta i framework di protezione dei dati aziendali come GDPR, HIPAA e le linee guida FFIEC se abbinati alle chiavi gestite dal cliente (CMK).
- Controllabilità: Ogni processo di inserimento e accesso alle credenziali vengono registrati per la tracciabilità e la creazione di rapporti sulla conformità.
Intestazioni laterali
Tempestività
La tempestività dipende dalla pianificazione dell'inserimento e dal volume dei dati.
- Serie di dati aziendali di grandi dimensioni (oltre 100 milioni di righe) possono richiedere il partizionamento per l'inserimento parallelo.
- La latenza tipica dell'inserimento varia da minuti ad alcune ore, a seconda delle dimensioni del file e della complessità della trasformazione.
- Per l'inserimento quasi in tempo reale, Streaming Data 360 o connettori basati su API possono integrare il modello basato su file.
Volumi di dati
- Più adatto per l'inserimento periodico batch a volume elevato.
- Ogni oggetto elaborato tramite il connettore S3 supporta fino a 100 milioni di righe o 50 GB per file.
- Per i sistemi su scala petabyte, utilizzare il partizionamento dei dati e l'orchestrazione multi-stream.
Supporto della capacità e degli standard degli endpoint
La funzionalità e il supporto standard per l'endpoint dipendono dalla soluzione scelta.
| Tipo di connettore | Requisiti degli endpoint |
|---|---|
| Connettore Amazon S3 | bucket S3 con policy IAM e file schema\_sample.csv appropriati che definiscono lo schema. |
| Connettore Google Cloud Storage | Credenziali account di servizio e accesso bucket con convenzioni di denominazione uniformi. |
| Connettore Azure Storage | Chiave di accesso o autenticazione basata su token SAS; la struttura dei BLOB o delle cartelle deve seguire le convenzioni di Data 360. |
Gestione statale
Lo stato viene tracciato attraverso gli stream di dati e l'indicazione oraria dell'ultima esecuzione riuscita.
- Data 360 mantiene automaticamente gli stati di sincronizzazione e gli offset, assicurando che solo i file nuovi o modificati vengano elaborati nelle esecuzioni successive.
- Quando si esegue l'integrazione con strumenti ETL esterni, si consiglia di utilizzare identificatori di file univoci (ad esempio, UUID o indicazioni orarie) per evitare la duplicazione.
Scenari di integrazione complessi
Nelle architetture aziendali avanzate, questo schema può integrarsi con:
- Pipeline ETL middleware (ad esempio Informatica, MuleSoft): per orchestrare la preelaborazione, la convalida e il partizionamento dei file prima della consegna a Data 360.
- Flussi AI/ML: i dati DLO elaborati possono essere pubblicati tramite DMO per modellare gli ambienti di addestramento o gli indici RAG tramite Destinazioni attivazione Data 360.
- Sistemi transazionali: i DMO armonizzati possono attivare aggiornamenti a valle in Salesforce CRM o in sistemi esterni tramite azioni dati o eventi piattaforma.
Esempio
Un istituto finanziario globale archivia i dati dei clienti e delle transazioni in un data lake AWS S3, dove i file Parquet partizionati vengono generati nottetempo per regione (ad esempio Stati Uniti, UE e APAC). Il team dell'architettura dei dati configura più stream di dati in Data 360, ciascuno collegato a una cartella regionale, con schema_sample.csv condiviso che garantisce intestazioni e tipi di dati coerenti in tutte le partizioni. Le pianificazioni dell'inserimento notturno caricano automaticamente i dati nei DLO, dopo di che le trasformazioni dati batch aggiungono tutte le partizioni regionali in un Customer_Transactions_DLO unificato. Questa serie di dati armonizzata viene quindi mappata al modello di dati Customer 360, abilitando l'analisi a valle e l'attivazione dell'intelligenza artificiale. L'approccio offre l'inserimento automatico e affidabile dal data lake esistente, impone l'autenticazione e la crittografia avanzate in linea con le policy IT aziendali e fornisce una base modulare scalabile che supporta l'espansione futura e l'evoluzione dello schema.
Contesto
Un caso d'uso principale e critico per Data 360 è l'unificazione dei dati dei clienti in tutto l'ecosistema Salesforce. Questo schema copre l'inserimento nativo dei dati dalle piattaforme Salesforce principali, Sales Cloud e Service Cloud (collettivamente Salesforce CRM) e Marketing Cloud Engagement. Le fonti includono oggetti CRM standard e personalizzati (ad esempio Account, Referente, Caso, Opportunità) ed estensioni dati di Marketing Cloud Engagement che contengono eventi di coinvolgimento, invii di email e dati di tracciamento.
Problema
Come può un'organizzazione inserire in modo efficiente e affidabile oggetti CRM standard e personalizzati ed estensioni dati Marketing Cloud Engagement in Data 360 in modo che i dati possano essere utilizzati per creare profili cliente unificati (risoluzione dell'identità, Customer 360), mantenendo prestazioni, governance e interruzioni minime dei sistemi di origine?
Forze
I connettori nativi semplificano il lavoro, ma è necessario gestire diverse forze operative e architettoniche:
- Autorizzazioni di origine complete: Un utente di connessione dedicato (account integrazione) deve disporre delle autorizzazioni di lettura appropriate a livello di oggetto e di campo. La mancata assegnazione degli insiemi di autorizzazioni necessari (ad esempio, un insieme di autorizzazioni predefinito del connettore Data 360) è una causa comune di errore di inserimento.
- Modalità e costo di aggiornamento dei dati: I connettori supportano le modalità di aggiornamento completo e delta/incrementale. Gli aggiornamenti completi sono più pesanti per le prestazioni e i crediti; le estrazioni delta riducono il carico ma dipendono dal tracciamento affidabile delle modifiche nel sistema di origine.
- Schema personalizzato e mappatura dei campi: Le istanze CRM spesso includono oggetti/campi personalizzati. Per evitare errori di mappatura o fluttuazioni semantiche sono necessarie una mappatura e una gestione accurate dei campi personalizzati (nomi, tipi).
- Avvia pacchetti di dati rispetto a Mappatura personalizzata: I pacchetti di dati Starter accelerano l'orientamento preselezionando oggetti/campi tipici, ma le organizzazioni molto personalizzate avranno bisogno di definizioni di stream personalizzate.
- Limite di throughput e API: I limiti dell'API dell'organizzazione di origine e le percentuali di estrazione di Marketing Cloud limitano la modalità di pianificazione degli aggiornamenti.
- Igiene dei dati e convenzioni di denominazione: I nomi dei campi di origine, il comportamento nullo e i tipi di dati devono essere normalizzati prima dell'inserimento per evitare problemi di mappatura a valle.
- Sicurezza e privilegi minimi: Il connettore si basa sull'autenticazione protetta e deve rispettare gli schemi IAM con i privilegi minimi, la possibilità di controllo e i controlli di rete.
Soluzione
Questa tabella contiene le soluzioni a questo problema di integrazione.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Soluzione adatta | Best | Utilizzare il connettore Salesforce CRM nativo e il connettore Marketing Cloud Engagement in Data 360\. Iniziare con i pacchetti di dati Starter per i casi d'uso standard e accelerare l'orientamento. Utilizzare la personalizzazione manuale degli stream per modelli di dati personalizzati o specifici del dominio. |
| Gestione delle istanze CRM altamente personalizzate | Migliori con il workshop di mappatura | Considerare i pacchetti Starter come base di riferimento e condurre un workshop di mappatura per identificare: Oggetti e relazioni personalizzati. Formula o campi calcolati. Estensioni di pacchetti gestiti. Per i campi formula pesanti, calcolare i valori in un ETL pre-fase o all'interno delle trasformazioni Data 360 per ridurre al minimo il carico API nelle organizzazioni di origine. |
| Quando non utilizzare | Scenari non ottimali | Evitare questo schema se: È necessario l'inserimento di eventi ad alta frequenza o in tempo reale (utilizzare invece Streaming Connectors, Platform Events o Zero-Copy Federation). L'organizzazione di origine ha una capacità API limitata e non può supportare le estrazioni pianificate senza limitazioni o ritardi nell'area di attesa. |
| Sicurezza e governance | Controlli obbligatori | Principio dei privilegi minimi: utilizzare un utente integrazione dedicato con accesso in lettura minimo. Non utilizzare mai gli amministratori dell'organizzazione. Autenticazione: utilizzare OAuth 2.0 e le applicazioni connesse; ruotare regolarmente i segreti client e monitorare l'utilizzo dei token di aggiornamento. Controllo e tracciabilità: registrare tutte le esecuzioni dell'inserimento, le modifiche dello schema e gli eventi del connettore. Inoltrare i registri a SIEM o ai sistemi di conformità per la preparazione al controllo. Classificazione dei dati: applicare il tag PII/PHI e il controllo dell'accesso basato sugli attributi (ABAC) utilizzando policy CEDAR immediatamente dopo l'inserimento per applicare mascheramento, consenso e conformità a valle. |
Sketch
Questo diagramma illustra la sequenza delle fasi per inserire i dati dall'archiviazione cloud in Data 360
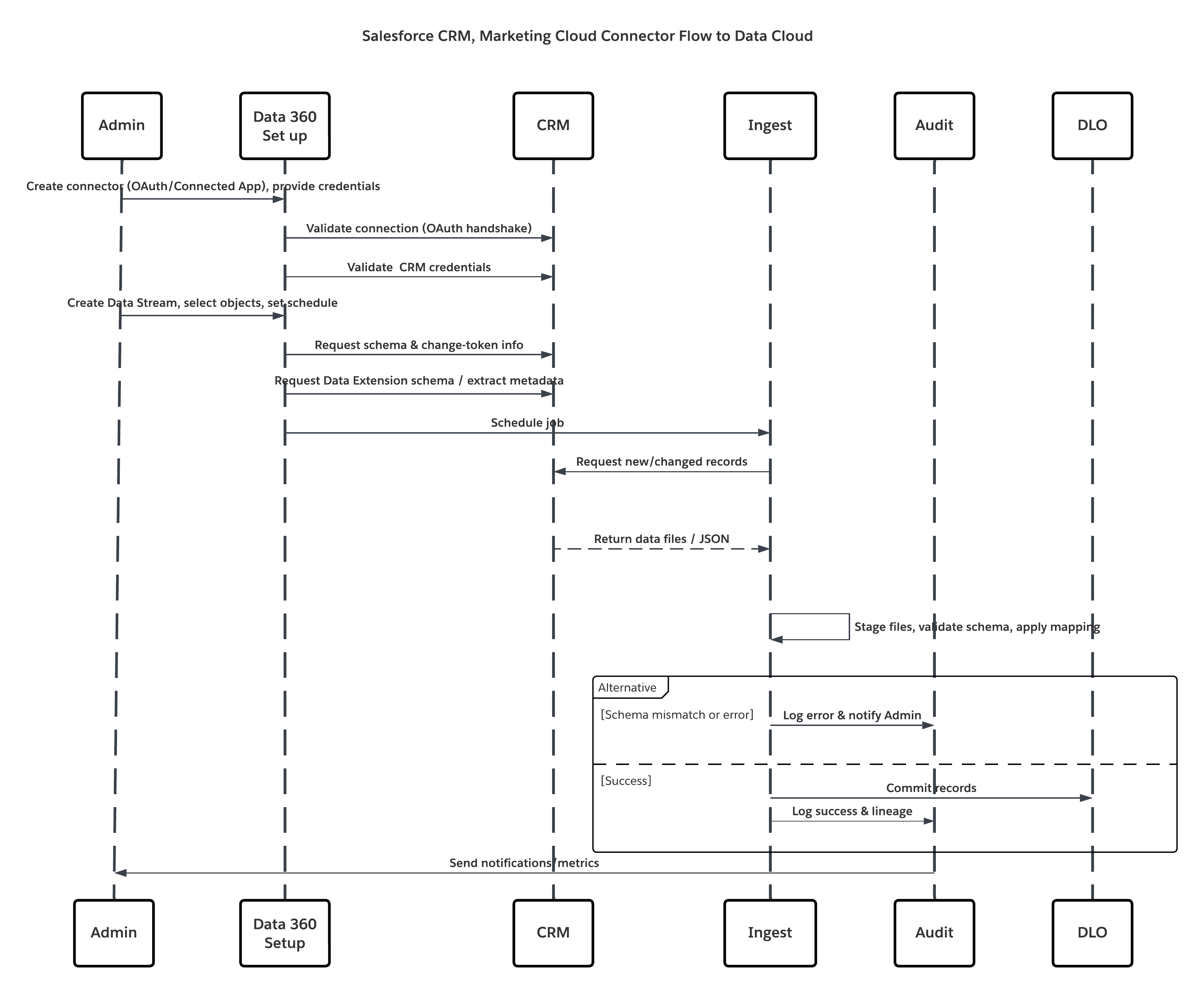
In questo scenario:
- L'amministratore esegue provisioning e assegna gli insiemi di autorizzazioni connettore nelle organizzazioni di origine.
- L'amministratore configura i connettori in Imposta in Data 360 (si connette a Salesforce CRM e Marketing Cloud tramite OAuth/applicazione connessa).
- L'amministratore crea stream di dati selezionando oggetti ed estensioni dati, sceglie l'aggiornamento completo o delta e imposta le pianificazioni.
- All'esecuzione pianificata, Data 360 richiede lo schema e i token delta alle fonti.
- I sistemi di origine restituiscono record (delta o payload completo). Marketing Cloud può fornire estratti; CRM può restituire risultati JSON/Query.
- Data 360 inserisce file nella propria area di gestione temporanea protetta interna e li convalida in base allo schema mappato.
- Se la convalida non riesce, l'inserimento registra l'errore, avvisa l'amministratore e interrompe la conferma. Se la convalida riesce, Data 360 conferma i record in modo atomico nel DLO di destinazione.
- I registri monitoraggio e controllo vengono aggiornati con discendenza, durata dell'esecuzione, conteggi delle righe e utilizzo delle credenziali. Avvisi inviati agli amministratori se vengono attivate soglie o errori.
Risultati
I dati principali sulle relazioni con i clienti e sul coinvolgimento nel marketing vengono inseriti in Data 360 come oggetti data lake (DLO). In questo modo si ottiene:
- Serie di dati contenente profili, casi, opportunità e metriche di email/coinvolgimento.
- Fondazione per la risoluzione dell'identità e la costruzione di profili Persona unificata.
- Prontezza operativa per armonizzazione, arricchimento, modellazione AI e attivazione a valle, preservando governance e controllabilità.
Meccanismi di inserimento
Il meccanismo di inserimento dipende dal connettore e dalla strategia di pianificazione definiti in Data 360.
| Meccanismo | Quando utilizzare |
|---|---|
| Connettore Salesforce CRM (nativo) | Ideale per oggetti CRM standard/personalizzati; supporta l'aggiornamento completo e delta. |
| Connettore Marketing Cloud Engagement (nativo) | Ideale per estensioni dati, invii e tracciamento delle estrazioni; supporta le modalità full/delta. |
| Pacchetti di dati Starter | Accelerare l'orientamento per gli oggetti Sales/Service/Marketing più comuni. |
| Stream personalizzati + preelaborazione | Utilizzare quando sono necessarie trasformazioni complesse o una pesante normalizzazione dello schema. |
Gestione e ripristino degli errori
La gestione e il ripristino degli errori sono fondamentali per garantire l'affidabilità nelle operazioni di inserimento a volume elevato.
- Registri per esecuzione: Ogni esecuzione dello stream di dati fornisce dettagli su esito positivo/fallimento ed errori a livello di riga.
- Tentativi e checkpoint: Le esecuzioni non riuscite possono essere riprovate dopo aver risolto i problemi di origine o schema; Data 360 utilizza la gestione temporanea e la semantica di conferma atomica.
- Avvisi: Configurare gli avvisi per fluttuazione dello schema, errori ripetuti o interruzioni della sequenza delta.
Considerazioni sulla progettazione idempotente
L'inserimento è idempotente per progettazione: la rielaborazione degli stessi non genera record duplicati. Le strategie chiave includono:
- Rilevamento modifiche: Le estrazioni delta si basano sugli indicatori di modifica del sistema di origine (LastModifiedDate / acquisizione dati di modifica del sistema). Verificare che l'origine fornisca indicazioni orarie/flag affidabili.
- Deduplicazione: Utilizzare chiavi aziendali univoche (ad esempio Contact.ExternalId) per deduplicare o inserire con aggiornamento nei DLO.
- Impegno transazionale: I record vengono impostati e confermati solo quando l'elaborazione batch viene completata correttamente.
Considerazioni sulla sicurezza
La sicurezza è fondamentale in tutta la pipeline di inserimento, dall'autenticazione alla crittografia e al controllo degli accessi.
- Autenticazione e autorizzazione: I connettori utilizzano il framework di integrazione sicura di Salesforce, che sfrutta le credenziali denominate e le credenziali esterne per l'autenticazione senza esporre segreti.
- Crittografia: I dati vengono crittografati in transito (TLS 1.2+) e a riposo (AES-256).
- Controlli di rete: I sistemi di archiviazione di origine (ad esempio, i bucket S3) devono inserire nell'elenco consentiti gli IP di Data 360.
- Allineamento conformità: Supporta i framework di protezione dei dati aziendali come GDPR, HIPAA e le linee guida FFIEC se abbinati alle chiavi gestite dal cliente (CMK).
- Controllabilità: Ogni processo di inserimento e accesso alle credenziali viene registrato per la tracciabilità e la creazione di rapporti sulla conformità
Intestazioni laterali
Tempestività
La tempestività dipende dalla pianificazione dell'inserimento e dal volume dei dati.
- La cadenza ideale dipende dalle esigenze aziendali: oraria per i trigger di marketing quasi in tempo reale, notturna per le riconciliazioni di grandi dimensioni.
- Le modalità delta riducono il carico e i costi; gli aggiornamenti completi sono più pesanti e vengono utilizzati per i caricamenti iniziali o per le modifiche principali dello schema.
Volumi di dati
- I connettori CRM sono ottimizzati per le serie di dati transazionali e a volume medio (milioni di record).
- Per volumi storici estremamente grandi, considerare l'opzione ETL in più passaggi per partizionare e caricare in più passaggi.
Supporto della capacità e degli standard degli endpoint
La funzionalità e il supporto standard per l'endpoint dipendono dalla soluzione scelta.
| Connettore | Requisiti degli endpoint |
|---|---|
| Connettore Salesforce CRM | L'organizzazione di origine deve consentire un'applicazione connessa, token OAuth e un utente integrazione dedicato con autorizzazioni di lettura. |
| Connettore Marketing Cloud | Credenziali API Marketing Cloud o pacchetto installato; le estensioni dati devono esporre i dati tramite Estrazioni/API. |
Gestione statale
- Stato connettore: Gli stream di dati mantengono le indicazioni orarie e gli offset delta dell'ultima sincronizzazione riuscita.
- Strategia chiave principale: Preferire identificatori aziendali coerenti (ID esterni) in modo che la riconciliazione a valle e gli inserimenti con aggiornamento siano deterministici.
Scenari di integrazione complessi
Nelle architetture aziendali avanzate, questo schema può integrarsi con:
- Topologie ibride: Combinare l'inserimento CRM con lo streaming (Eventi piattaforma) per aggiornamenti quasi in tempo reale.
- Orchestrazione middleware: Utilizzare gli strumenti MuleSoft o ETL quando è necessaria un'orchestrazione, un arricchimento o una pre-inserimento di trasformazioni complessi.
- Loop di feedback di attivazione: I DMO armonizzati possono attivare aggiornamenti a valle dei sistemi di origine tramite azioni dati o API piattaforma (attenzione ai controlli SoD).
Esempio
Un rivenditore multinazionale consolida le metriche di coinvolgimento di Account, Referenti, Casi, Opportunità e Marketing Cloud in Data 360 per creare una visualizzazione cliente unificata. Lo Starter Data Bundle inizializza gli oggetti Sales and Service principali, mentre il team estende il modello con campi personalizzati come Loyalty_Membershipc e Customer_Tierc per acquisire il contesto fedeltà. Gli stream di dati CRM vengono eseguiti ogni ora in modalità delta e Marketing Cloud Engagement viene sincronizzato ogni giorno utilizzando le estrazioni delta per gli eventi di coinvolgimento. Queste serie di dati vengono elaborate tramite DLO e risoluzione dell'identità, creando un profilo cliente unificato che combina i segnali CRM e di coinvolgimento per potenziare la personalizzazione e i modelli di intelligenza artificiale a valle.
Questi schemi vengono creati per gli scenari in cui i millisecondi contano, ovvero quando le interazioni, le transazioni o i segnali dei clienti devono attivare approfondimenti o azioni immediate. Vanno oltre l'inserimento batch pianificato tradizionale per abilitare il flusso di dati basato sugli eventi, in cui le informazioni vengono elaborate nel momento in cui vengono generate. Nell'ecosistema Salesforce Data 360, "real-time" non è una modalità singola, ma un continuum di modelli di latenza. Da un lato si trova la sincronizzazione quasi in tempo reale, in cui gli aggiornamenti dei sistemi di registrazione (come CRM o ERP) si riflettono in Data 360 in pochi secondi o minuti. Dall'altro lato è l'acquisizione evento in tempo reale, in cui i segnali comportamentali lato client, ad esempio clic, acquisti o interazioni mobili, vengono inseriti e attivati in millisecondi. Per gli architetti, la distinzione è più che semantica. Definisce come vengono progettate le opportunità in corso di realizzazione, come vengono richiamate le API e come vengono prese le decisioni a valle. La selezione dello schema corretto, che si tratti di sincronizzazione quasi in tempo reale o inserimento di stream di eventi, garantisce che il sistema soddisfi gli obiettivi di latenza operativa dell'azienda mantenendo l'integrità, la scalabilità e la governance dei dati.
Contesto
Questo schema consente a qualsiasi sistema esterno, ad esempio un'applicazione personalizzata, una piattaforma Internet delle cose (IoT), un sistema POS o un servizio di terze parti, di inviare a livello di programmazione i dati degli eventi in Data 360 quasi in tempo reale quando si verificano eventi discreti.
Problema
Come può uno sviluppatore inviare in modo affidabile singoli record o piccoli batch asincroni di eventi da un'applicazione esterna a Data 360 con bassa latenza in modo che i dati siano disponibili rapidamente per l'elaborazione, la segmentazione e l'attivazione?
Forze
Questo schema offre una latenza bassa e un migliore controllo da parte dello sviluppatore, ma introduce diversi vincoli tecnici e dipendenze operative:
- Dipendenza sviluppatore: Richiede lo sforzo dello sviluppatore per implementare client API REST autenticati e logica di errore/riprovare: non è un connettore "point-and-click".
- Schema rigoroso in scrittura: L'API di inserimento impone lo schema in scrittura. È necessario definire uno schema preciso e caricarlo nella configurazione del connettore; tutti i payload devono essere esattamente conformi o essere rifiutati.
- Modalità di doppia interazione: Lo stesso connettore supporta sia lo streaming (JSON) per gli aggiornamenti record per record a bassa latenza, sia l'aggiornamento in blocco (CSV) per le sincronizzazioni periodiche più grandi.
- Autenticazione e sicurezza: Le chiamate devono essere autenticate tramite un'applicazione connessa Salesforce utilizzando OAuth 2.0 (ad esempio, flusso bearer JWT per server a server). La gestione dei token, la rotazione e gli ambiti con privilegi minimi sono obbligatori.
- Visibilità operativa: Gli sviluppatori e i team piattaforma devono implementare il monitoraggio per i codici di risposta, i tentativi, le aree di attesa a lettere non valide e gli avvisi di fluttuazione dello schema.
- Requisito del grafico in tempo reale: Per un'attivazione istantanea vera (segmentazione istantanea, mappatura DMO in tempo reale), l'oggetto modello di dati (DMO) di destinazione deve far parte del grafico dei dati in tempo reale; in caso contrario, gli eventi attraversano una pipeline con latenza leggermente superiore.
Soluzione
Questa tabella contiene le soluzioni a questo problema di integrazione.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Soluzione adatta | Ideale per l'acquisizione di eventi a bassa latenza | Utilizzare l'API inserimento Data 360 (JSON streaming) per inviare tramite push singoli eventi o micro batch. Configurare il connettore API di inserimento con uno schema OAS 3.0 rigoroso (.yaml). Utilizzare l'inserimento CSV in blocco per sincronizzazioni più grandi e meno frequenti. |
| Gestione delle modifiche dello schema | Rigoroso / Gestito | Le modifiche dello schema si stanno interrompendo: aggiornare il file .yaml OAS, modificare il connettore ed eseguire i test dei contratti. Implementare la migrazione dello schema continuativo se i produttori non possono modificare contemporaneamente. |
| Quando non utilizzare | Non ottimale | Non è ideale se è necessaria una preelaborazione (es:deduplicazione, ordine garantito, ecc.) o per carichi in blocco molto grandi (utilizzare connettori in blocco nativi o batch ETL). Se l'origine non è in grado di generare payload validi per lo schema o non è in grado di eseguire l'autenticazione in modo sicuro, utilizzare metodi di inserimento alternativi. |
| Sicurezza e governance | Obbligatorio | Utilizzare OAuth 2.0 con ambiti con privilegi minimi, ruotare le chiavi, registrare l'utilizzo dei token. Applicare TLS 1.2+, convalidare gli IP client se necessario e garantire la creazione di tag delle informazioni personali del payload. Tutti gli eventi devono contenere metadati di provenienza (origine, indicazione oraria, versione dello schema, chiave idempotency). |
Sketch
Questo diagramma illustra la sequenza delle fasi per inserire i dati dall'API di inserimento in Data 360
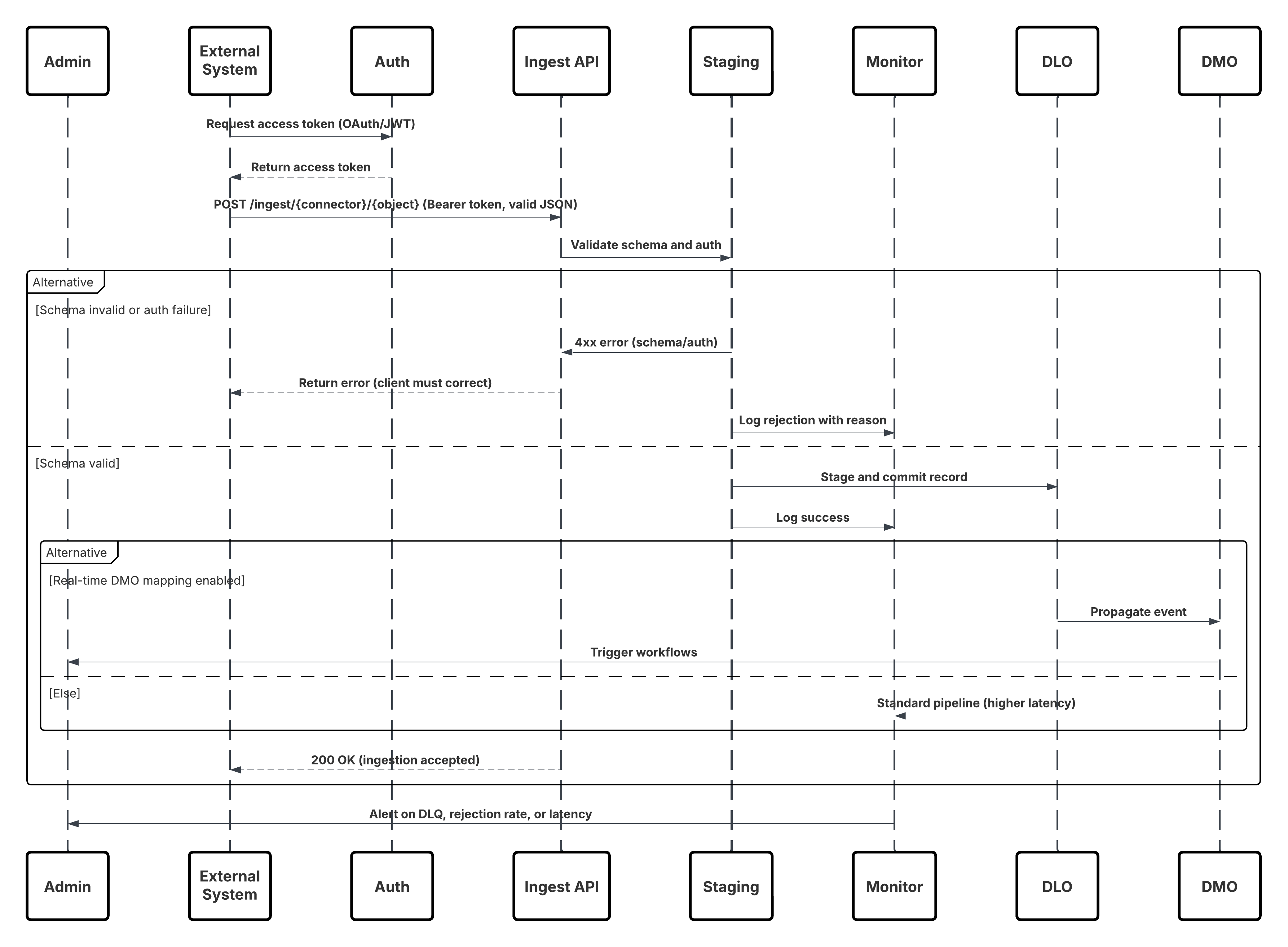
In questo scenario:
- Sistema esterno richiede l'autenticazione tramite OAuth/JWT dal server di autenticazione.
- Il server di autenticazione restituisce il token di accesso al sistema esterno.
- Sistema esterno invia la richiesta POST di inserimento dati all'API di inserimento Data 360 con autorizzazione e payload JSON.
- L'API di inserimento convalida lo schema della richiesta e l'autenticazione tramite il modulo Staging & Validation (Stage e convalida).
- In caso di errore di schema/autenticazione:
- Errore restituito al sistema esterno.
- Rifiuto registrato per il monitoraggio e l'avviso.
- In caso di convalida riuscita:
- Record inseriti e confermati nell'oggetto data lake (DLO).
- Riuscito registrato per il monitoraggio.
- Se abilitata, la propagazione dei dati al grafico dati in tempo reale (DMO) attiva flussi di lavoro a valle.
- In caso contrario, i dati elaborati tramite batch standard o pipeline a latenza più alta.
- L'API di inserimento conferma l'esito positivo di Sistema esterno.
- Avviso sui componenti di monitoraggio Amministratore in caso di aree di attesa senza risposta, percentuali di rifiuto o problemi di latenza.
Risultati
I dati degli eventi esterni vengono inseriti nei DLO di Data 360 con bassa latenza. Quando il DMO di destinazione fa parte del grafico in tempo reale, i dati sono disponibili per la segmentazione istantanea, i flussi di lavoro degli agenti, i modelli AI e l'attivazione operativa. Ciò consente risposte aziendali rapide agli eventi provenienti da qualsiasi sistema connesso.
Meccanismi di inserimento
Il meccanismo di inserimento dipende dal connettore e dalla strategia di pianificazione definiti in Data 360.
| Meccanismo | Quando utilizzare |
|---|---|
| Streaming JSON (API di inserimento) | Eventi singoli, micro batch, eventi comportamentali, stream di clic, telemetria IoT, quando è richiesta una latenza bassa. |
| CSV in blocco (modalità in blocco dell'API di inserimento) | Caricamenti periodici più ampi in cui i requisiti di latenza vengono ridotti. |
| Bordio / middleware | Utilizzare quando è necessaria la convalida, la trasformazione, l'arricchimento o la limitazione della percentuale prima di passare all'API di inserimento. |
Gestione e ripristino degli errori
- Errori immediati di (sincronizzazione): 4xx risposte per errori di schema/autenticazione: il client deve correggere il payload o il token e riprovare.
- Errori temporanei (asincroni): 5xx risposte: il client tenta di ripetere con backoff e jitter esponenziali.
- Area di attesa a lettere morte (DLQ): Gli errori persistenti vengono visualizzati in DLQ per l'ispezione manuale e il replay.
- Monitoraggio: Tenere traccia della percentuale di rifiuto dello schema, degli errori di autenticazione, dei percentili di latenza e dell'arretrato DLQ. Avviso sulle soglie.
Considerazioni sulla progettazione idempotente
- Chiave impotenza: Ogni evento deve includere una chiave idempotency/ID messaggio univoci.
- Aggiorna strategia di inserimento: Utilizzare le chiavi aziendali (ExternalId) per evitare duplicati sui replay.
- Finestra di Dundeup: L'architetto deve definire le finestre di deduplica e la conservazione per il tracciamento dell'impotenza.
Considerazioni sulla sicurezza
La sicurezza è fondamentale in tutta la pipeline di inserimento, dall'autenticazione alla crittografia e al controllo degli accessi.
- Autenticazione: OAuth 2.0 (JWT Bearer) consigliato da server a server. Limitare gli ambiti solo all'inserimento.
- Crittografia: TLS 1.2+ per il trasporto; Data 360 applica la crittografia a riposo.
- Privilegio minimo: Le credenziali dell'applicazione connessa hanno diritti minimi; ruotano i segreti e i registri di accesso agli strumenti.
- Payload Governance: Includere flag consenso/consumo nei metadati degli eventi; applicare le policy ABAC/CEDAR immediatamente dopo l'inserimento.
- Controlli IP / Private Connect: Ove necessario, limitare l'accesso tramite elenchi consentiti o utilizzare Private Connect per la rete privata.
Intestazioni laterali
Tempestività
La tempestività dipende dalla pianificazione dell'inserimento e dal volume dei dati. Il JSON in streaming restituisce una latenza da subsecondi a secondi a seconda dell'elaborazione e della configurazione del grafico. CSV in blocco è da minuti a ore. Scegliere in base agli SLA aziendali.
Volumi di dati
Le dimensioni dei singoli eventi devono essere piccole (< pochi KB). Per i produttori a elevata produttività, valutare la possibilità di creare batch presso il produttore o di utilizzare un buffer streaming (Kafka/Kinesis) prima di chiamare l'API.
Gestione statale
- Versione schema: Mantenere la versione dello schema nei metadati degli eventi e utilizzare il controllo delle versioni del connettore quando si aggiorna il contratto OAS.
- Offset connettore: Data 360 gestisce la semantica di conferma; i produttori devono tenere traccia delle chiavi di impotenza e dell'ultima sequenza riuscita per una riproduzione sicura.
Scenari di integrazione complessi
Nelle architetture aziendali avanzate, questo schema può integrarsi con:
- Livello convalida bordo: Utilizzare il middleware per tradurre formati di produttori eterogenei nel contratto OAS richiesto, eseguire la limitazione delle percentuali e il pre-arricchimento.
- Architetture ibride: Combinare l'API di inserimento per gli eventi e i connettori per la riconciliazione in blocco.
- Attivazione agente: Gli eventi mappati in DMO in tempo reale possono attivare flussi di lavoro Agentforce e modelli Einstein per le decisioni automatiche.
Esempio
Una catena di vendita al dettaglio trasmette in streaming gli eventi di acquisto POS in Data 360 in tempo reale per favorire il coinvolgimento immediato dei clienti. Ogni punto vendita esegue un componente server leggero che raccoglie le transazioni, le arricchisce con i metadati della posizione e del dispositivo e pubblica in modo sicuro eventi JSON utilizzando JWT Bearer OAuth con chiavi idempotency per evitare duplicati. Un amministratore definisce la struttura degli eventi caricando uno schema OAS per il punto vendita e configurando il connettore API di inserimento. Gli eventi in entrata vengono inseriti nel DLO pos_sale, mappati al DMO Vendita e aggiunti al grafico in tempo reale. Di conseguenza, gli acquisti di valore elevato vengono rilevati immediatamente, attivando flussi di lavoro VIP in Agentforce e aggiornando la segmentazione dei clienti per favorire la personalizzazione in tempo reale.
Contesto
Questo schema consente di acquisire dati granulari a volume elevato sulle interazioni degli utenti, ad esempio visualizzazioni di pagina, clic su pulsanti, impressioni sui prodotti e riproduzioni video, da siti Web e applicazioni mobili in trueReal-Time. È fondamentale per offrire una personalizzazione immediata, in cui ogni interazione digitale può influenzare dinamicamente l'esperienza utente e favorire il coinvolgimento.
Problema
Come può un'azienda acquisire ed elaborare un flusso continuo di eventi comportamentali dalle proprietà digitali, che coprono milioni di interazioni utente al minuto, e rendere immediatamente disponibili tali dati in Data 360 per favorire la segmentazione, la personalizzazione e l'attivazione in tempo reale?
Forze
Questo caso d'uso presenta diverse sfide di progettazione che richiedono un'architettura di inserimento appositamente creata a bassa latenza:
- Extreme Throughput : I siti Web o le app mobili a traffico elevato possono generare milioni di eventi al minuto. Lo strato di inserimento deve scalare orizzontalmente per gestire questo volume senza perdita di evento o contropressione, garantendo una latenza costante sotto i picchi di carico.
- Strumentazione lato cliente: A differenza delle integrazioni basate sul server, questo schema dipende dagli SDK lato client. In ogni pagina deve essere incorporato un beacon JavaScript (Salesforce Interactions SDK) o un SDK nativo integrato nelle app mobili. Ciò richiede una solida distribuzione client, il controllo delle versioni e la governance dello schema degli eventi.
- Elaborazione degli eventi a bassa latenza: Le azioni degli utenti, ad esempio "aggiungi al carrello" o "riproduci video", devono raggiungere Data 360 in pochi secondi, abilitando l'attivazione in tempo reale e le risposte contestuali (ad esempio offerte mirate, consigli personalizzati).
- Armonizzazione dei dati e risoluzione dell'identità: Gli eventi acquisiti spesso includono identificatori anonimi (cookie, ID dispositivo, token di sessione). Per ottimizzare i casi d'uso Customer 360, questi devono essere mappati ai profili noti tramite la risoluzione dell'identità di Data 360 e armonizzati con il modello di dati Customer 360.
Soluzione
L'approccio consigliato è utilizzare il connettore Salesforce Marketing Cloud Personalizzazione, una pipeline di streaming completamente gestita progettata per l'inserimento comportamentale ad alta produttività.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Acquisizione evento basata su SDK | Best | Distribuire Salesforce Interactions SDK (web) o SDK nativo (mobile). Queste librerie leggere acquisiscono e serializzano le interazioni degli utenti in tempo reale, allegando metadati (ID sessione, indicazione oraria, contesto). |
| Streaming di eventi in corso di realizzazione | Best | Gli eventi vengono inviati al servizio di streaming eventi di Personalizzazione Marketing Cloud su HTTPS protetto. Questo livello è scalabile orizzontalmente e ottimizzato per la trasmissione a bassa latenza (<2s). |
| Integrazione con Data 360 | Best | Il connettore Personalizzazione di Data 360 si abbona al feed in streaming, inserendo ogni evento in un oggetto data lake (DLO) in nearReal-Time. |
| Mappatura del modello di dati | Best Practice | Il DLO inserito viene mappato agli oggetti modello di dati (DMO) Customer 360. Ciò consente di collegare utenti anonimi e noti tramite la risoluzione dell'identità. |
| Abilitazione del grafico in tempo reale | Facoltativo / Consigliato | Includere i DMO mappati nel grafico in tempo reale per una segmentazione istantanea, attivando azioni personalizzate tramite flussi di lavoro Einstein o Agentforce. |
| Quando non utilizzare | Non ottimale | Questo schema non è ideale quando: I dati di origine sono client Web ed eventi (utilizzare invece l'API di inserimento). L'organizzazione non ha il controllo sui client Web/mobili. Il tracciamento del comportamento in tempo reale non è necessario (utilizzare l'inserimento batch). |
| Gestione delle modifiche dello schema | Evoluzione gestita | Gli schemi degli eventi evolvono man mano che vengono aggiunte nuove interazioni. Gli SDK devono eseguire la versione delle definizioni degli eventi. Le modifiche compatibili con le versioni precedenti (aggiunta di campi facoltativi) sono sicure; l'interruzione delle modifiche richiede la riconfigurazione del connettore e il test del contratto. |
Sketch
Questo diagramma illustra la sequenza delle fasi per inserire i dati dai canali Web e mobili in Data 360
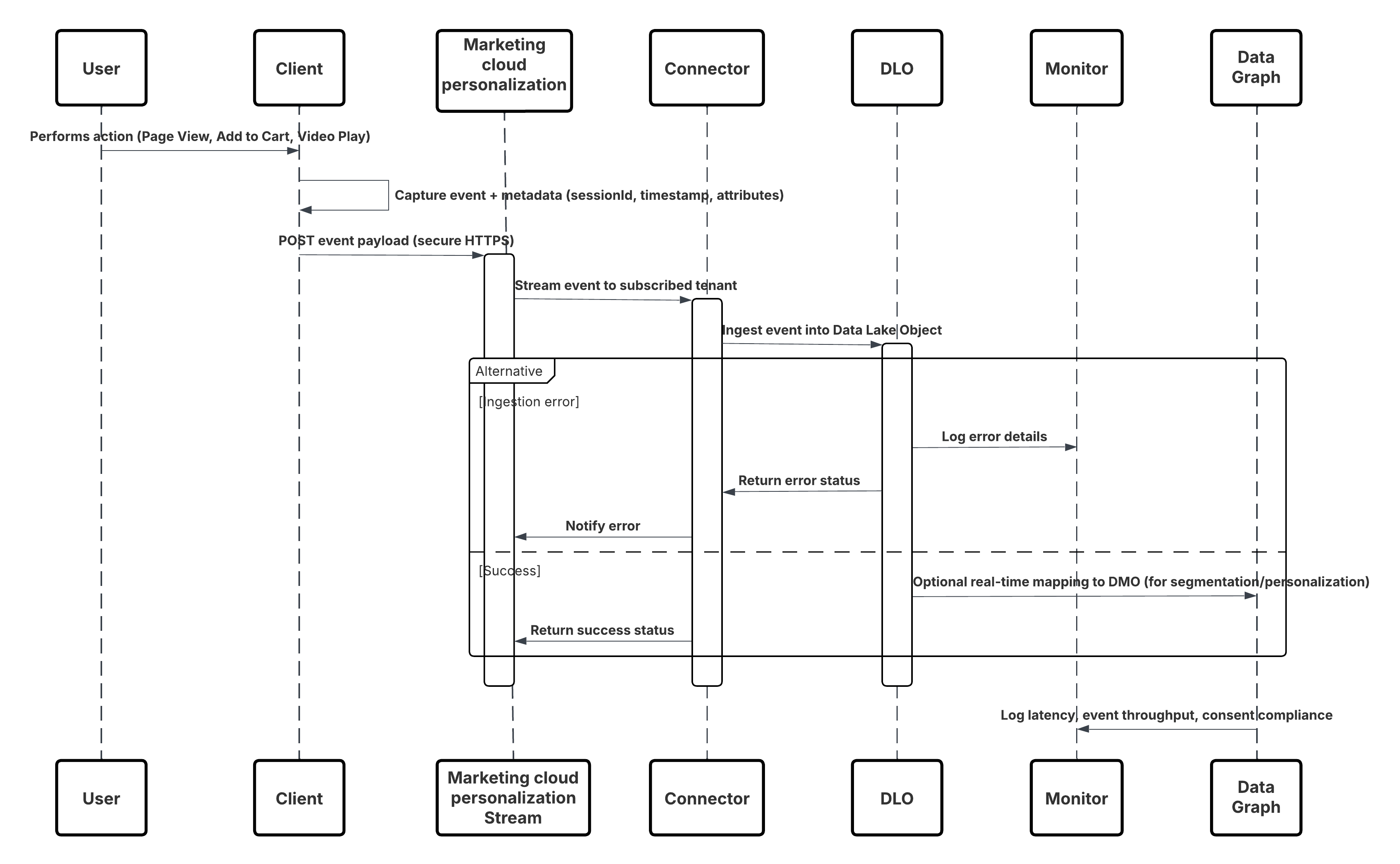
In questo scenario:
- Distribuire l'SDK nei canali Web o mobili (acquisizione dell'interazione utente).
- Configurare SDK con ID tenant, ambiente e controlli consenso.
- Inviare in streaming gli eventi JSON acquisiti (metadati + attributi) all'endpoint di streaming di Marketing Cloud.
- In Imposta in Data 360, creare e configurare il connettore Personalizzazione per il tenant.
- Inserire gli eventi in un DLO e mappare il DLO → DMO in Data 360.
- Abilitare il DMO nel grafico in tempo reale per l'attivazione immediata.
- Monitorare la latenza, la conformità dello schema, i flag di consenso, la produttività, le percentuali di errore.
- Distribuire in produzione e monitorare continuamente.
Risultati
Un flusso continuo a bassa latenza di eventi comportamentali fluisce dai canali digitali a Data 360. In pochi secondi, ogni azione utente diventa disponibile per la segmentazione in tempo reale, la modellazione predittiva o la personalizzazione attivata, abilitando esperienze cliente davvero adattive.
Meccanismi di inserimento
Il meccanismo di inserimento dipende dal connettore e dalla strategia di pianificazione definiti in Data 360.
| Meccanismo | Quando utilizzare |
|---|---|
| Interactions SDK (Web) | Acquisizione in tempo reale da browser Web e SPA. |
| SDK mobile | Acquisizione in tempo reale da applicazioni mobili native. |
| Connettore Personalizzazione | Abbonamento gestito tra Marketing Cloud e Data 360\. |
| Mappatura del grafico in tempo reale | Abilita l'attivazione immediata in Segmentazione, Einstein e Journey. |
Gestione e ripristino degli errori
- Tolleranza dei guasti a livelli: Implementare meccanismi di convalida e riprovazione a più livelli: gli SDK client gestiscono gli errori temporanei con backoff esponenziale, mentre il livello di inserimento utilizza aree di attesa durevoli e opportunità in corso di realizzazione riproducibili per evitare la perdita di dati.
- Schema e governance dei dati: Versionare e convalidare gli schemi degli eventi in modo continuo; gli eventi non validi o in evoluzione vengono instradati a un rifiuto schema o a un'area di attesa a lettere morte per un triage e un replay sicuri.
- Impotenza e deduplicazione: Utilizzare identificatori di evento stabili e semantica di inserimento con aggiornamento per garantire l'elaborazione esatta anche durante i tentativi o i replay.
- Monitoraggio e ripristino Automazione: Il monitoraggio continuo di produttività, latenza e percentuali di errore attiva flussi di lavoro di ripristino automatici, garantendo bassa latenza, consegna affidabile e risultati di personalizzazione coerenti in tempo reale.
Considerazioni sulla progettazione idempotente
- Ogni evento deve contenere una chiave di impotenza univoca o un ID messaggio in modo che gli invii duplicati possano essere deduplicati a valle.
- Utilizzare le chiavi aziendali (ad esempio sessionID + eventTimestamp + userID) ove appropriato per identificare i duplicati.
- Definire una finestra di deduplica (ad esempio, 24 ore) durante la quale gli eventi duplicati vengono ignorati o filtrati.
- Utilizzare strategie di inserimento con aggiornamento dove appropriato (ad esempio, aggiornare i contatori o i flag anziché inserire duplicati).
Considerazioni sulla sicurezza
La sicurezza è fondamentale in tutta la pipeline di inserimento, dall'autenticazione alla crittografia e al controllo degli accessi.
- Crittografia dei trasporti: TLS 1.2+ per tutte le connessioni SDK → servizio streaming.
- Crittografia dei dati a riposo in Data 360 e nello stream di marketing.
- SDK rispetta i flag consenso utente e sopprime il tracciamento se il consenso viene negato.
- Autenticazione del traffico SDK: assicurarsi che solo i tenant/client approvati possano eseguire lo streaming degli eventi.
- Metadati: ogni evento deve includere ID origine, indicazione oraria, versione schema, ID sessione, chiave idempotency.
- Accesso con privilegi minimi: Endpoint e connettori SDK limitati all'ambito di inserimento degli eventi; ruotare regolarmente le credenziali.
- Classificazione dei dati: Annotare le informazioni personali nei payload degli eventi, applicare le policy immediatamente dopo l'inserimento
Intestazioni laterali
Tempestività
- La tempestività dipende dall'attività dell'utente finale e dalla configurazione dello streaming degli eventi.
- Gli eventi acquisiti tramite Salesforce Interactions SDK e forniti tramite lo stream di personalizzazione di Marketing Cloud in genere raggiungono una latenza da sotto i secondi a ~ 2 secondi prima di diventare disponibili nel grafico in tempo reale di Data 360.
- Ciò consente la segmentazione, la personalizzazione e l'attivazione quasi istantanea all'interno delle sessioni utente attive.
Volumi di dati
I singoli eventi comportamentali (ad esempio clic, visualizzazione, aggiunta al carrello) sono leggeri, in genere da 1 a 5 KB per payload. Per le proprietà digitali su larga scala, prevedere da migliaia a milioni di eventi al minuto. Per garantire produttività e resilienza:
- Utilizzare i meccanismi di batching e di tentativo integrati nell'SDK per le pagine con traffico elevato.
- Caricare la gestione dei burst nel livello buffer streaming di Marketing Cloud.
- Monitorare la produttività dell'inserimento e i rapporti errori utilizzando il cruscotto digitale delle metriche del connettore.
Gestione statale
Ogni evento include metadati per il controllo dello stato e della versione:
- Versione schema: Incorporare la versione dello schema in ogni evento; eseguire la versione del connettore Personalizzazione quando si aggiorna lo schema.
- Gestione replay: Gli eventi che non riescono a causa di problemi di rete temporanei vengono tentati automaticamente dall'SDK con backoff esponenziale.
- Tasti impotenza: Identificatori univoci (sessionId + eventType + timestamp) assicurano che gli eventi riprodotti non creino duplicati in Data 360.
- Gestione offset: Data 360 tiene traccia delle conferme andate a buon fine; tutti gli eventi non elaborati vengono nuovamente inseriti in area di attesa dal connettore finché non vengono inseriti correttamente.
Scenari di integrazione complessi
Questo schema si integra perfettamente nelle architetture aziendali avanzate:
- Livello arricchimento bordo: Aggiungere middleware (ad esempio, proxy inverso o funzione serverless) per inserire ulteriore contesto, ad esempio metadati geografici, tipo di dispositivo o campagna, prima che gli eventi raggiungano Marketing Cloud.
- Ibrido (Streaming + batch): Utilizzare il connettore Marketing Cloud per gli stream in tempo reale e combinarlo con i processi ETL batch (ad esempio, i dati degli ordini) per la riconciliazione a valle.
- Attivazione agente: Gli eventi mappati ai DMO in tempo reale possono attivare Personalizzazione Einstein, flussi di lavoro Agentforce o decisioni basate sull'intelligenza artificiale per adattare l'esperienza digitale al momento.
- Governance multi-tenant: Utilizzare i flag di consenso e i metadati tenant-aware per imporre la privacy e la conformità in ambienti multimarca o multiregione.
Esempio
Una società di e-commerce globale offre consigli personalizzati sui prodotti e contenuti dinamici ai clienti mentre navigano attivamente su www.retailx.com, un'applicazione a pagina singola basata su React. Utilizzando Salesforce Interactions SDK sul lato client, il sito acquisisce visualizzazioni pagina, clic sui prodotti, azioni carrello e interazioni video in tempo reale. Questi eventi passano attraverso lo stream di eventi Personalizzazione di Marketing Cloud e il connettore Personalizzazione nei DLO di Data 360, dove vengono modellati in DMO e incorporati nel grafico in tempo reale. Questa architettura rende immediatamente disponibili segnali comportamentali per segmentazione, personalizzazione basata su Einstein e attivazione Agentforce, abilitando esperienze cliente reattive in sessione
Contesto
Per molti processi business-critical, mantenere Data 360 perfettamente allineato agli ultimi aggiornamenti dei sistemi CRM principali è essenziale. I team di assistenza clienti, vendite e marketing dipendono da informazioni aggiornate per guidare le decisioni, attivare journey e attivare l'automazione. Questo schema offre un meccanismo per sincronizzare le modifiche agli oggetti Salesforce CRM chiave, ad esempio Referente, Account e Caso, in Data 360 con il minimo ritardo, senza l'inefficienza o la latenza del frequente batch polling.
Problema
In che modo Data 360 può mantenere uno stato quasi perfettamente sincronizzato con i principali oggetti Salesforce CRM, assicurando che l'analisi a valle, la segmentazione e l'attivazione basata sull'intelligenza artificiale funzionino sempre sui dati più aggiornati disponibili?
Forze
Questo schema introduce diversi vincoli tecnici e considerazioni architettoniche:
- Architettura basata sugli eventi: La sincronizzazione deve essere reattiva, determinata dagli eventi di modifica nell'organizzazione di origine CRM anziché dai processi batch periodici.
- Supporto oggetti selettivo : Non tutti gli oggetti Salesforce standard e personalizzati supportano lo streaming in tempo reale. Gli architetti devono fare riferimento all'elenco degli oggetti supportati durante la progettazione per evitare lacune.
- Accesso e autorizzazioni : L'abilitazione dello streaming richiede che all'utente integrazione nell'organizzazione di origine sia assegnata l'autorizzazione di sistema "Abilita autorizzazioni per lo streaming CRM".
- Freschezza dei dati vs. Costo di trasformazione : Mentre la sincronizzazione quasi in tempo reale migliora la reattività, un'eccessiva produttività degli eventi può richiedere la scalabilità orizzontale e meccanismi di ripristino degli errori efficaci.
- Integrazione dei livelli di sicurezza e Trust : Tutti i dati degli eventi devono essere conformi ai framework Trust e Security di Salesforce: crittografati in transito, convalidati per la conformità dello schema ed elaborati entro il confine Trust dell'organizzazione.
Soluzione
L'approccio consigliato è utilizzare Salesforce CRM Connector con Streaming (Change Acquisizione dati) abilitato. Quando si crea uno stream di dati per un oggetto CRM supportato (ad esempio Referente), gli amministratori possono attivare e disattivare l'opzione "Abilita streaming". La piattaforma CDC (Change acquisizione dati) di Salesforce pubblica un messaggio ChangeEvent ogni volta che un record viene creato, aggiornato, eliminato o annullato nell'organizzazione CRM di origine. Il connettore Data 360 CRM si abbona a questi eventi CDC e applica le modifiche corrispondenti all'oggetto data lake (DLO) mappato in Data 360 quasi in tempo reale. Ciò garantisce una sincronizzazione continua tra CRM e Data 360 con un intervento manuale minimo.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Connettore streaming basato su CDC | Best | Meccanismo Salesforce nativo; completamente gestito e integrato con l'infrastruttura degli eventi piattaforma. |
| Abbonamento e consegna evento | Best | Il connettore si abbona ai canali ChangeEvent (ad esempio, /data/ContactChangeEvent) tramite ID replay durevoli. |
| Mappatura dei dati ed evoluzione degli schemi | Procedure consigliate | Mappare i payload in streaming al DLO corrispondente; gestire il controllo delle versioni dello schema nei metadati per evitare interruzioni dell'inserimento. |
| Replay e ripristino dei guasti | Consigliato | Utilizzare replay ID e chiavi idempotency per evitare duplicazioni e ripristinare errori temporanei. |
| Modalità ibrida (streaming + batch) | Facoltativo | Per gli oggetti non supportati o il caricamento in blocco iniziale, utilizzare l'inserimento in batch in combinazione con lo streaming CDC. |
| Quando non utilizzare | Non ottimale | Questo schema può essere non ottimale quando: L'oggetto di origine non è abilitato per CDC. Il caso d'uso non richiede aggiornamenti in tempo reale (batch è sufficiente). L'uscita della rete dall'organizzazione di origine è limitata o vengono superati i limiti degli eventi. |
Sketch
Questo diagramma illustra la sequenza delle fasi per inserire i dati da CRM in Data 360 in quasi tempo reale
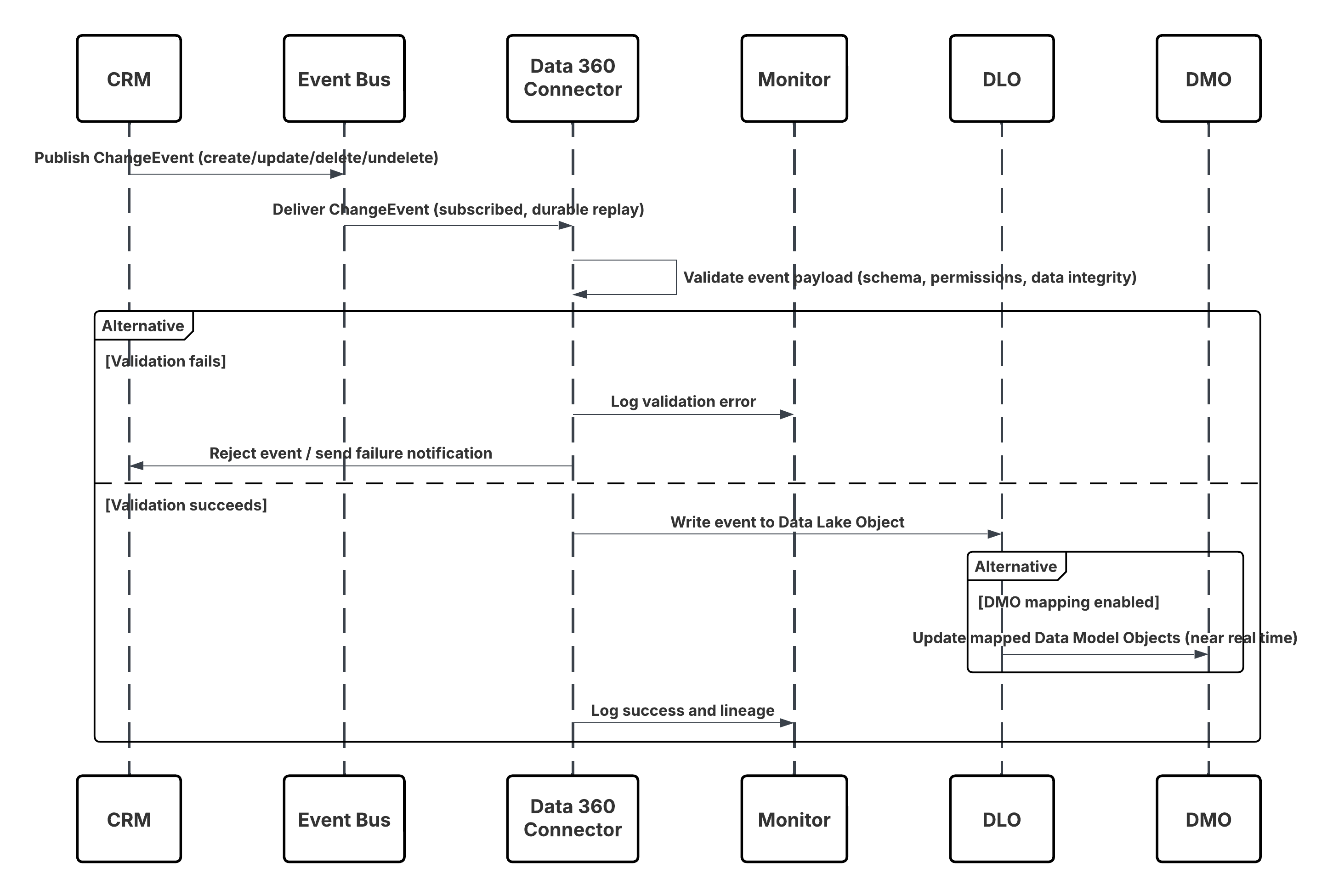
In questo scenario:
- La modifica avviene in Salesforce CRM (creazione/aggiornamento/eliminazione/annullamento eliminazione).
- CDC pubblica un ChangeEvent nel bus degli eventi Salesforce interno.
- Il connettore Data 360 CRM si abbona al bus degli eventi utilizzando un cursore di riproduzione durevole.
- Il payload evento viene convalidato per lo schema, le autorizzazioni e l'integrità dei dati.
- Data 360 scrive l'evento convalidato nel Data Lake Object (DLO) mappato.
- Se abilitati, i DMO (Data Model Objects) mappati vengono aggiornati in nearReal-Time, alimentando la segmentazione e l'attivazione.
Risultati
Data 360 mantiene un mirror continuamente sincronizzato dei dati CRM chiave. Ciò consente di:
- Trigger in tempo reale (ad esempio, il journey viene avviato quando viene creato un caso).
- Segmentazione aggiornata (ad esempio, spostare i clienti nel segmento "Oro" quando viene modificato lo stato dell'account).
- Analisi e personalizzazione più accurate in base al contesto CRM live.
Meccanismi di inserimento
Il meccanismo di inserimento di questo schema viene gestito in modo nativo tramite Salesforce CRM Connector con Acquisizione dati di modifica (CDC) abilitato. Data 360 funge da abbonato allo stream di eventi CDC, garantendo una sincronizzazione affidabile a bassa latenza tra l'organizzazione CRM di origine e Data 360.
| Meccanismo | Quando utilizzare |
|---|---|
| Streaming tramite CDC (preferito) | Per tutti gli oggetti Salesforce standard e personalizzati supportati in cui è richiesta una sincronizzazione quasi in tempo reale. |
| Modalità ibrida (CDC + batch) | Per gli oggetti non ancora abilitati per CDC o per i quali è richiesto il caricamento storico iniziale. |
| Modalità abbonamento Replay | Per la risincronizzazione dopo il tempo di inattività o la distribuzione. |
| Modalità di isolamento degli errori | Per gli ambienti di test e convalida. |
Gestione e ripristino degli errori
- Ripristino automatico dei guasti: Il connettore CRM tenta automaticamente gli errori temporanei della rete o della piattaforma utilizzando il backoff esponenziale e instrada gli errori persistenti all'area di attesa delle lettere morte (DLQ) per la riproduzione.
- Schema e resilienza dell'autenticazione: Le mancate corrispondenze degli schemi vengono poste in quarantena nell'area di attesa Rifiuto schema per la revisione da parte dell'amministratore, mentre gli errori di autenticazione o autorizzazione attivano tentativi controllati e avvisi tramite Monitoraggio di Data 360.
- Continuità evento garantita: I ReplayID durevoli non garantiscono alcuna perdita di evento durante il tempo di inattività del connettore; gli eventi mancati vengono reidratati tramite finestre di replay o processi di risincronizzazione batch.
- Integrità dei dati e ordinamento: L'impotenza incorporata (RecordID + SequenceNumber) impedisce i duplicati e ChangeEventHeader.sequenceNumber mantiene l'ordinamento degli eventi corretto per ogni record CRM.
Considerazioni sulla progettazione idempotente
- Univocità evento: Ogni evento CDC include ReplayID e ChangeEventHeader.entityName per la deduplicazione deterministica.
- Aggiorna strategia di inserimento: Implementare una logica di INSERIMENTO CON AGGIORNAMENTO basata sull'ID record per assicurarsi che gli eventi ripetuti non creino duplicati.
- Gestione replay: Utilizzare il cursore replay del connettore per riprendere dall'ultimo offset confermato in caso di errori temporanei.
- **Evoluzione schema: **Mantenere una versione dello schema nei metadati degli eventi e aggiornare le mappature dei DLO quando lo schema CRM cambia.
Considerazioni sulla sicurezza
La sicurezza è fondamentale in tutta la pipeline di inserimento, dall'autenticazione alla crittografia e al controllo degli accessi.
- Encryption and Trust : Tutti gli eventi vengono trasmessi utilizzando TLS 1.2+ e archiviati crittografati a riposo in Data 360.
- Controllo accessi: Solo i connettori autenticati con autorizzazioni di integrazione appropriate possono abbonarsi ai canali CDC.
- Convalida dello schema: Ogni payload evento viene convalidato con lo schema DLO prima dell'inserimento.
- Propagazione del consenso: Il consenso e la classificazione dei dati dei metadati fluiscono a valle con ogni evento per preservare la privacy e la conformità (GDPR, CCPA).
- Governance operativa: Gli eventi vengono registrati, controllati e monitorati per rilevare eventuali replay, rifiuto dello schema e anomalie della produttività tramite il livello Trust di Data 360.
Intestazioni laterali
Tempestività
- Gli eventi CDC vengono elaborati quasi in tempo reale, in genere entro pochi secondi dalla modifica in CRM.
- La latenza può variare in base al volume degli eventi e alla produttività del connettore, ma Data 360 garantisce la disponibilità al minuto per gli oggetti supportati.
Volumi di dati
- Ogni payload evento è leggero (~1-5 KB).
- Per gli oggetti con tasso di variazione elevato come Caso o Referente, assicurarsi che i limiti di produttività siano allineati alle allocazioni di eventi CDC Salesforce.
Gestione statale
Ogni evento include metadati per il controllo dello stato e della versione:
- Replay ID: Utilizzato per il ripristino sequenziale degli eventi.
- Versione schema: Gestire i metadati delle versioni per gestire le modifiche dei contratti.
- Tasti impotenza: Replay duplicati in più tentativi.
- Offset Commit (Impegno offset): Data 360 mantiene lo stato di conferma dopo ogni batch di eventi riuscito.
Scenari di integrazione complessi
Questo schema si integra perfettamente nelle architetture aziendali avanzate:
- Ibrido (Streaming + batch): Utilizzare CDC per gli aggiornamenti delta e i processi in blocco per gli aggiornamenti completi.
- Streaming tra organizzazioni: Più organizzazioni di origine possono eseguire lo stream nello stesso tenant di Data 360, unificato tramite mappature DMO.
- Attivazione agente: Gli aggiornamenti degli oggetti in tempo reale attivano automazioni Einstein o Agentforce.
- Instradamento evento: Middleware (ad esempio, MuleSoft o Relay evento) può arricchire o instradare i messaggi CDC prima dell'inserimento.
Esempio
Una banca globale desidera assicurarsi che le modifiche dei dati dei clienti in Salesforce Sales Cloud si riflettano immediatamente in Data 360. Quando l'indirizzo di un referente viene aggiornato in Sales Cloud, il meccanismo di acquisizione dati di modifica pubblica un ContactChangeEvent.Il connettore CRM Data 360 consuma questo evento, applica l'aggiornamento al DLO Customer e aggiorna automaticamente tutti i profili Customer 360 associati. Questo attiva un Einstein Next Best Action per verificare il nuovo indirizzo, completando il loop di feedback entro pochi secondi dalla modifica CRM originale.
Contesto
Le aziende digitali moderne si affidano a piattaforme di streaming di eventi in tempo reale come Amazon Kinesis Data Streams e Amazon MSK (Managed Streaming for Apache Kafka) per acquisire flussi di dati continui da applicazioni distribuite, dispositivi IoT e sistemi transazionali. Data 360 consente l'inserimento diretto da queste piattaforme tramite connettori nativi first party, eliminando la necessità di soluzioni basate su middleware o ETL personalizzate. Questo schema è progettato per l'inserimento di dati a bassa latenza e ad alta produttività, per fornire approfondimenti quasi in tempo reale, personalizzazione e attivazione basata sull'intelligenza artificiale.
Problema
Come può un'azienda collegare in modo sicuro ed efficiente Data 360 agli argomenti AWS Kinesis o AWS MSK Kafka per inserire in modo continuo dati strutturati di eventi e profili, garantendo la conformità, la scalabilità e la governance degli schemi?
Forze
Questo schema introduce molteplici considerazioni architettoniche e operative:
- Disponibilità connettore nativo: Salesforce fornisce connettori nativi disponibili a tutti sia per Amazon Kinesis che per Amazon MSK. Questi connettori offrono supporto first party ed eliminano la necessità di pipeline basate su API personalizzate.
- Autenticazione e sicurezza: Ogni connettore richiede l'autenticazione AWS.
- Per Kinesis, utilizza la chiave di accesso AWS e la chiave segreta, regolate dalle policy IAM.
- Per MSK, l'autenticazione può essere configurata tramite Chiave di accesso/Segreto o OpenID Connect (OIDC).
- Definizione schema: Data 360 richiede uno schema per interpretare il payload in streaming. Per Kinesis, il file dello schema viene caricato durante l'impostazione della connessione, definendo la struttura degli eventi e le mappature dei campi.
- Origine configurazione:
- Il connettore Kinesis si abbona a un nome specifico di stream Kinesis.
- Il connettore MSK si abbona a un argomento Kafka all'interno del cluster MSK.
- Accesso alla rete: Per gli ambienti sicuri, i connettori possono essere configurati con l'instradamento PrivateLink o VPC, assicurando che non vi siano dati che attraversano Internet pubblico.
- Governance operativa: La produttività dello streaming, la convalida dello schema e gli eventi di autenticazione vengono monitorati all'interno del livello Trust di Data 360, garantendo conformità e tracciabilità.
Soluzione
La soluzione sfrutta i connettori nativi Amazon Kinesis o Amazon MSK in Data 360.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Connettore nativo Kinesis | Best | Integrazione first party con AWS Kinesis; supporta l'inserimento continuo a elevata produttività. |
| Connettore nativo MSK | Best | Inserimento Kafka gestito con supporto per OIDC e autenticazione basata su chiave. |
| Mappatura e convalida degli schemi | Procedure consigliate | Carica schema (.json/.avro) che definisce la struttura degli eventi; impone la coerenza durante l'inserimento. |
| Configurazione IAM | Consigliato | Assegnare il ruolo IAM con privilegi minimi con accesso di sola lettura allo stream Kinesis di destinazione o all'argomento MSK. |
| Instradamento rete privata | Facoltativo | Configurare gli endpoint PrivateLink/VPC per un instradamento interno sicuro. |
| Schema ibrido (Streaming + batch) | Facoltativo | Utilizzare lo streaming per i delta e l'inserimento batch per i riempimenti o i carichi storici. |
| Modalità di isolamento degli errori | Consigliato | Rifiuti dello schema di instradamento ed errori temporanei a DLQ per la riproduzione |
Sketch
Questo diagramma illustra la sequenza delle fasi per inserire i dati da piattaforme Evento come Kafka e Kinesis in Data 360 quasi in tempo reale
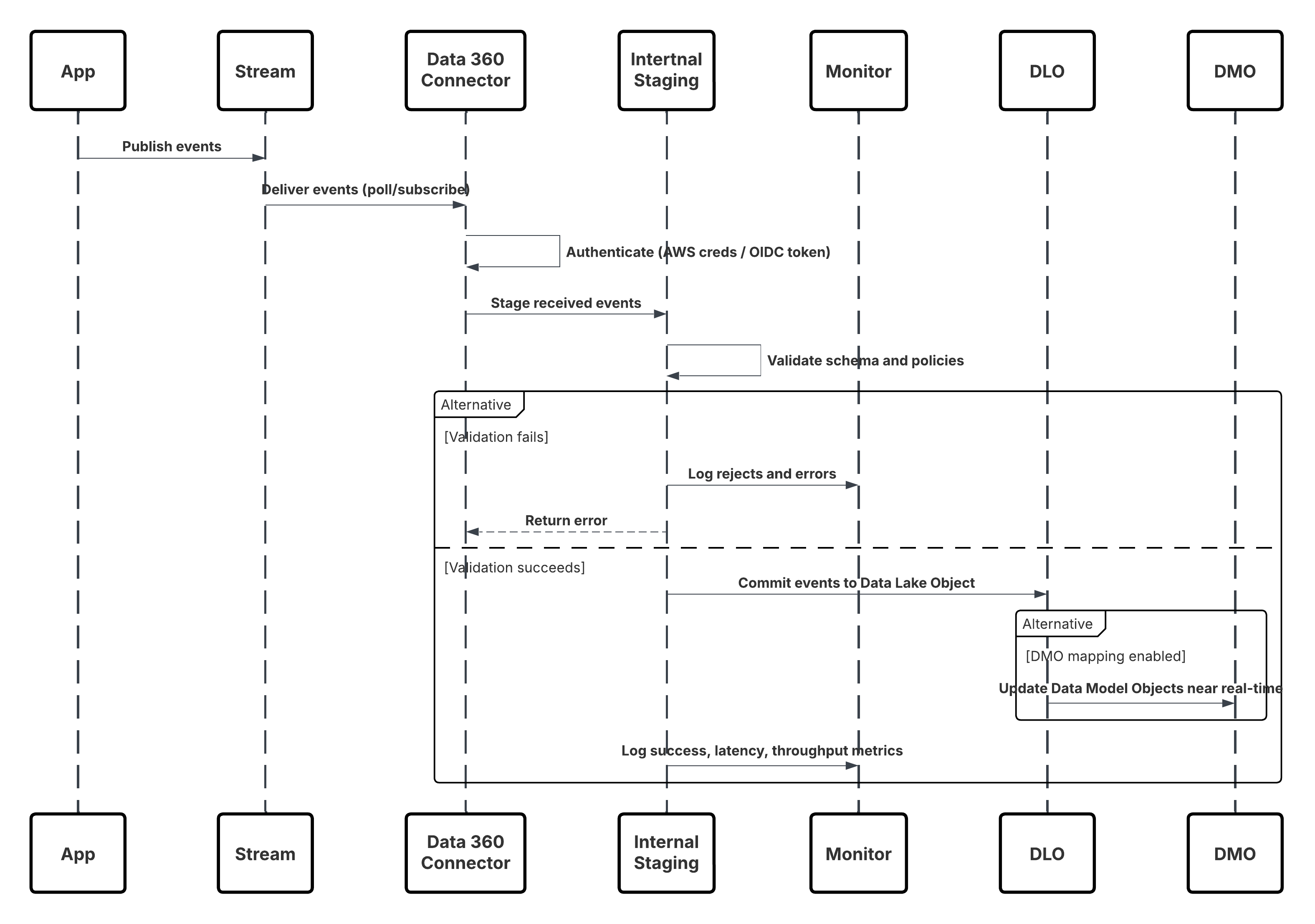
In questo scenario:
- Le applicazioni o i dispositivi pubblicano gli eventi in Kinesis Stream o Argomento MSK.
- Il connettore Data 360 esegue l'autenticazione utilizzando le credenziali AWS o il token OIDC.
- Il connettore esegue continuamente il sondaggio o si abbona allo stream.
- Gli eventi vengono messi in scena, convalidati per lo schema e la policy e quindi confermati nell'oggetto data lake (DLO).
- Se mappati, i DMO (Data Model Object) vengono aggiornati quasi in tempo reale per l'attivazione.
- Monitoring Layer tiene traccia delle metriche, degli schemi rifiutati e della latenza.
Risultati
Inserimento continuo e a bassa latenza di dati strutturati direttamente da AWS Kinesis o MSK in Data 360. I dati sono immediatamente disponibili per:
- Risoluzione dell'identità
- Segmentazione in tempo reale
- Attivazione Einstein AI
- Trigger basati su Agentforce Elimina la dipendenza da ETL batch, abilitando architetture basate su stream in linea con le strutture aziendali basate sugli eventi.
Meccanismi di inserimento
| Meccanismo | Quando utilizzare |
|---|---|
| Connettore Kinesis (preferito) | Per le fonti di streaming native AWS che richiedono l'inserimento continuo di dati strutturati a volume elevato. |
| Connettore MSK | Per le organizzazioni che eseguono opportunità in corso di realizzazione su piattaforme compatibili con Kafka. |
| Ibrido (Streaming + batch) | Per l'inserimento incrementale di eventi combinato con carichi in blocco periodici. |
Gestione e ripristino degli errori
- Riprova automaticamente: I connettori tentano di ripetere gli errori di rete o piattaforma transitori con backoff esponenziale.
- Rifiuti schema: I payload non validi vengono instradati all'area di attesa di rifiuto dello schema per la revisione da parte dell'amministratore.
- DLQ Replay: Gli errori persistenti vengono acquisiti in aree di attesa senza risposta per la rielaborazione.
- Controllo dell'impotenza: Le chiavi evento o i numeri di sequenza garantiscono la duplicazione e l'inserimento ordinato.
- Integrazione di monitoraggio: Tutti gli errori, i tentativi e le metriche di produttività vengono visualizzati nei cruscotti digitali di Monitoraggio di Data 360.
Considerazioni sulla progettazione idempotente
- Univocità e tracciamento degli eventi: A ogni evento viene assegnata una chiave univoca deterministica (ad esempio PartitionKey + SequenceNumber per Kinesis o Topic + Partition + Offset per MSK) per garantire l'inserimento di una volta esatta.
- Checkpointing connettore: I connettori Data 360 mantengono l'ultimo offset o numero di sequenza elaborato per riprendere l'inserimento in modo sicuro dopo errori o riavvii.
- Deduplicazione e logica di inserimento con aggiornamento: Durante le conferme DLO, gli eventi duplicati vengono rilevati e ignorati; i record validi vengono inseriti con aggiornamento utilizzando la chiave univoca per mantenere la coerenza.
- Controllo replay e ripristino: Gli eventi non riusciti o ritardati vengono riprodotti dagli offset memorizzati tramite le aree di attesa Dead-Letter e Replay, garantendo un ripristino affidabile senza duplicazioni.
Considerazioni sulla sicurezza
La sicurezza è fondamentale in tutta la pipeline di inserimento, dall'autenticazione alla crittografia e al controllo degli accessi.
- Autenticazione: Proteggere lo scambio di credenziali utilizzando policy AWS IAM o OIDC.
- Crittografia: Dati crittografati in transito (TLS 1.2+) e a riposo (AES-256) in Data 360.
- Controllo accessi: Ruoli con privilegi minimi imposti; connettori limitati a stream/argomenti specifici.
- Governance: Metadati di discendenza e classificazione applicati a ogni record per una tracciabilità completa.
- Sicurezza della rete: Eventualmente, distribuire all'interno di sottoreti private utilizzando AWS PrivateLink.
Intestazioni laterali
Tempestività
- Elaborazione quasi in tempo reale: I connettori CDC e streaming elaborano gli eventi entro pochi secondi dalle modifiche della fonte, garantendo in genere una freschezza dei dati inferiore al minuto.
- Latenza deterministica: Il ritardo end-to-end dipende dalla produttività della fonte, dal batch di eventi e dalle condizioni di rete, ma Data 360 garantisce una latenza basata sugli SLA prevedibile per gli oggetti supportati.
- Scala elastica: La pipeline di inserimento scala automaticamente in presenza di elevati volumi di eventi, preservando la tempestività anche durante i picchi di dati.
- Visibilità operativa: I cruscotti digitali di monitoraggio espongono il ritardo dell'evento, confermano le indicazioni orarie e lo stato di riproduzione per garantire la latenza e risolvere i problemi.
Volumi di dati
- Carichi utili leggeri: I singoli eventi CDC o streaming sono compatti (dimensioni tipiche da 1 a 5 KB), ottimizzati per gli aggiornamenti ad alta frequenza.
- Oggetti con modifiche elevate: Per le entità volatili (ad esempio, Caso, Referente, Ordine), gli architetti devono assicurarsi che le allocazioni CDC e la produttività degli eventi siano allineate alle percentuali di aggiornamento previste.
- Stream paralleli: Data 360 supporta l'inserimento multi-stream per la scalabilità orizzontale in grandi volumi di oggetti o in più organizzazioni di origine.
- Trattamento della contropressione: I meccanismi di limitazione incorporati mantengono la stabilità di inserimento sotto carico senza eventi di caduta.
Gestione statale
Ogni evento include metadati per il controllo dello stato e della versione:
- Tracciamento replay e offset: Ogni evento è dotato di metadati Replay ID e sequenza, che consentono la consegna dell'ordine e il ripristino basato su checkpoint.
- Versione schema: I tag di versione all'interno delle intestazioni evento garantiscono un'elaborazione compatibile con le versioni precedenti quando si evolvono gli schemi di origine.
- Tasti impotenza: Ogni evento include una transazione univoca o una chiave di conferma, consentendo a Data 360 di duplicare i replay e i tentativi in modo sicuro.
- Impegno atomico: La pipeline di inserimento contrassegna gli offset come completati solo dopo che le conferme a valle ai DLO sono state completate, garantendo la coerenza.
Scenari di integrazione complessi
Questo schema si integra perfettamente nelle architetture aziendali avanzate:
- Inserimento ibrido: Combinare CDC per i delta incrementali con stream di dati in blocco per aggiornamenti completi, mantenendo sia la freschezza che la completezza.
- Streaming tra organizzazioni: Più organizzazioni CRM o ERP possono pubblicare nello stesso tenant di Data 360, unificato tramite la mappatura dei DMO e l'allineamento dell'ontologia.
- Arricchimento evento: Middleware (ad esempio, MuleSoft, Relay evento) può arricchire, filtrare o instradare i dati in streaming prima che raggiungano Data 360.
- AI e attivazione degli agenti: Gli aggiornamenti in tempo reale attivano l'automazione a valle, ad esempio le previsioni Einstein o le risposte Agentforce, entro pochi secondi dall'evento di origine.
Esempio
Un'azienda di vendita al dettaglio globale utilizza AWS Kinesis per lo streaming dei dati dei punti vendita e delle interazioni Web.Il connettore Kinesis di Data 360 esegue l'autenticazione tramite le credenziali IAM e inserisce continuamente gli eventi in un DLO transazione.Ogni record viene convalidato con schema, arricchito con metadati e immediatamente propagato al DMO del cliente.In pochi secondi, i modelli Einstein AI aggiornano i segmenti di clienti e Agentforce attiva consigli Next Best Offer in tempo reale, ottenendo un loop di personalizzazione completamente basato sugli eventi.
Copia zero è più di un metodo di integrazione: è un cambiamento fondamentale nel modo in cui i dati aziendali si muovono, o meglio, non si muovono. Tradizionalmente, l'integrazione dei dati richiedeva la copia di grandi volumi di record tramite pipeline ETL, la creazione di archivi di dati ridondanti, ritardi di sincronizzazione e problemi di governance. Copia zero elimina tutto questo. In questo modello, Data 360 si connette direttamente a piattaforme dati esterne come Snowflake e Databricks, leggendo e attivando i dati in modo sicuro, senza doverli mai spostare o duplicare. Il risultato è un ponte perfetto tra la data lakehouse aziendale e l'ecosistema Salesforce, offrendo accesso immediato, costi operativi inferiori e una governance dei dati più forte.
Le funzionalità di copia zero in entrata consentono a Data 360 di eseguire query e armonizzare i dati esterni all'origine, ad esempio i profili dei clienti, le transazioni o i dati dei prodotti, archiviati in Snowflake o Databricks. Anziché inserire file, Data 360 stabilisce una connessione protetta e sensibile ai metadati che sfrutta le definizioni degli schemi e le policy di sicurezza esistenti nel warehouse esterno.
- Federazione diretta: Data 360 legge i dati sul posto tramite query protette e ottimizzate senza replica.
- Governance unificata: I dati rimangono sotto il framework di sicurezza, controllo dell'accesso e conformità del sistema di origine.
- Efficienza operativa: Elimina l'overhead ETL e la duplicazione dello storage, riducendo i costi e la complessità.
- Prontezza in tempo reale: Abilita l'armonizzazione on-demand: non appena i dati vengono aggiornati in Snowflake, sono immediatamente disponibili per l'attivazione in Data 360.
Contesto
Le moderne aziende basate sui dati gestiscono petabyte di dati di clienti, transazioni e telemetria all'interno di piattaforme data lake su scala cloud come Snowflake e Databricks. Questi ambienti sono l'unica fonte di dati per analisi, intelligenza artificiale e conformità. Data 360 introduce Zero CopyData Federation, che consente a Data 360 di eseguire query e utilizzare direttamente le serie di dati esterne in uso, senza copiare, trasformare o archiviare dati ridondanti. Questo schema consente alle organizzazioni di estendere il tessuto Customer 360 nell'infrastruttura di data warehouse o lakehouse esistente, ottenendo un'unificazione e un'attivazione in tempo reale senza duplicazioni, latenza e compromessi sulla governance.
Problema
Come possono le aziende sfruttare serie di dati complete già curate in Snowflake, Databricks o formati open lake come Apache Iceberg per segmentare, risolvere l'identità e attivare in Data 360, senza il costo, la latenza e il sovraccarico di governance delle pipeline ETL o dello spostamento dei dati fisici?
Forze
Questo schema introduce diverse considerazioni su architettura, sicurezza e prestazioni:
Rete e sicurezza
- Data 360 deve stabilire una connessione privata protetta al magazzino esterno o al lakehouse.
- In genere configurato utilizzando Salesforce Private Connect o il peering PrivateLink/VPC, per garantire che il traffico non esca mai dalla rete controllata del cliente.
- I sistemi esterni devono inserire nell'elenco consentiti gli IP di Data 360 e applicare la crittografia TLS 1.2+.
Autenticazione e controllo dell'accesso
- Supporta l'autenticazione a coppie di chiavi, OAuth 2.0 o la delega Trust basata su provider di identità (IdP) (Data 360 funge da client affidabile)
- Il controllo dell'accesso basato sui ruoli (RBAC) nel sistema esterno impone l'accesso con privilegi minimi per l'esecuzione delle query.
Prestazioni e dipendenza dal calcolo
- La federazione delle query limita l'esecuzione di SQL in Snowflake o Databricks, sfruttando i relativi cluster di elaborazione.
- Scalabilità delle prestazioni e dei costi con caricamento delle query esterne: latenza e costo della segmentazione sono legati alla configurazione di elaborazione esterna.
Evoluzione degli standard: Federazione file
- Un modello di nuova generazione, Federazione file, sfrutta formati di tabelle aperte come Apache Iceberg o Delta Lake, abilitando la lettura di Data 360 direttamente dall'archiviazione degli oggetti (ad esempio, Amazon S3, Azure ADLS, Google Cloud Storage).
- Ignorando il livello di elaborazione sorgente, Federazione file riduce drasticamente la latenza e i costi per i carichi di lavoro analitici di lettura elevata mantenendo l'integrità dello schema.
Governance e conformità
- I dati non lasciano mai la piattaforma di origine: le policy di conformità, crittografia e conservazione rimangono applicate all'origine.
- Tutti i metadati, la discendenza e gli attributi di consenso si propagano nel Trust Layer di Data 360 per garantire la tracciabilità end-to-end.
Soluzione
L'approccio consigliato è utilizzare connettori Zero Copy nativi per Snowflake, Databricks o Federazione file in Data 360.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Snowflake Zero Copy Connector | Best | Integrazione nativa first party; stabilisce la federazione delle query live tramite le API di condivisione dati o tabelle esterne Snowflake. |
| Connettore Databricks Zero Copy | Best | Supporta l'accesso live diretto alle tabelle/visualizzazioni in Delta Lake; le query pushdown vengono eseguite in fase di esecuzione di Databricks. |
| Federazione file (Apache Iceberg / Delta / Parquet) | Best practice emergenti | Data 360 legge direttamente i formati delle tabelle aperte dalla memoria degli oggetti senza dipendenza di elaborazione esterna. Ideale per serie di dati di grandi dimensioni. |
| Configurazione di rete privata | Consigliato | Utilizzare Salesforce Private Connect o VPC peering per una federazione protetta a livello di rete. |
| Autenticazione e gestione delle chiavi | Best Practice | Implementare l'autenticazione protetta basata su chiave o OAuth con rotazione periodica e gestione del vault. |
| Registrazione schema | Obbligatorio | Data 360 recupera lo schema esterno e lo mappa a un oggetto data lake esterno (DLO esterno). |
| Metadati gestiti | Consigliato | Tutti i DLO esterni ereditano i metadati di classificazione, consenso e discendenza per la visibilità della conformità. |
Sketch
Lo schema seguente illustra come impostare una connessione copia zero e creare DLO esterni in Data 360.
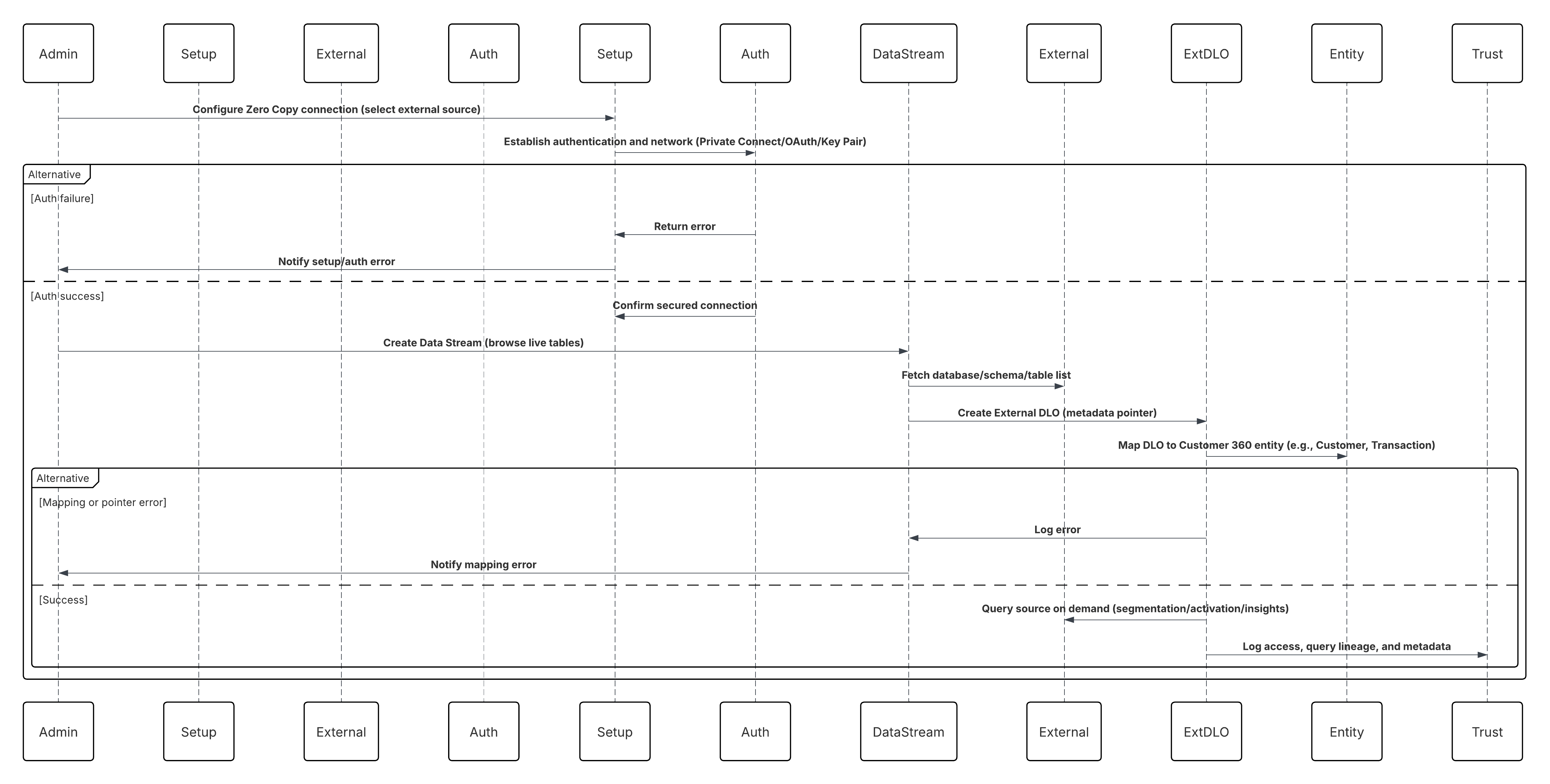
In questo scenario:
- L'amministratore configura una connessione Copia zero nell'impostazione di Data 360 (Snowflake, Databricks o Federazione file).
- Vengono stabiliti l'autenticazione protetta e l'instradamento di rete (Private Connect / OAuth / coppia di chiavi).
- L'amministratore crea uno stream di dati selezionando l'origine esterna, ovvero esplorando database, schemi e tabelle live.
- Anziché copiare i dati, Data 360 crea un DLO esterno (oggetto data lake), un puntatore ai metadati che fa riferimento alla tabella live o al file Iceberg.
- I DLO esterni vengono mappati alle entità Customer 360 (ad esempio, Cliente, Transazione, Prodotto).
- Data 360 esegue una query sulla fonte durante la segmentazione, l'attivazione o il calcolo degli approfondimenti.
- Tutti gli accessi, la discendenza delle query e i metadati vengono controllati all'interno del livello Trust di Data 360.
Risultati
- I dati esterni rimangono in Snowflake, Databricks o S3: nessun ETL, nessuna duplicazione, nessuna memoria aggiuntiva.
- Data 360 ottiene l'accesso in tempo reale e in lettura ai dati su scala aziendale per la risoluzione dell'identità, gli approfondimenti calcolati e l'attivazione.
- Le organizzazioni mantengono il controllo completo nei framework di governance, crittografia e conformità esistenti.
- Questo schema consente una vera e propria architettura Zero Copy, che combina le prestazioni dell'accesso locale con la governance dello storage federato.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla soluzione scelta per implementare questo schema.
| Meccanismo | Quando utilizzare |
|---|---|
| Snowflake Federation (Preferito) | Per la federazione delle query live e ad alte prestazioni con data warehouse aziendali gestiti. |
| Federazione Databricks | Per gli ambienti di analisi unificata e lakehouse con serie di dati Delta o Parquet. |
| Federazione file (Apache Iceberg / Delta Lake) | Per le serie di dati su larga scala nell'archiviazione di oggetti in cui lo scollamento del calcolo e l'ottimizzazione dei costi sono fondamentali. |
| Modalità ibrida (copia zero + inserimento) | Quando i dati storici richiedono un inserimento singolo ma l'accesso ai dati live avviene tramite Copia zero. |
Gestione e ripristino degli errori
- Backoff automatico di tentativi e query: Timeout di connettività transitori o query tentati automaticamente utilizzando il backoff esponenziale.
- Isolamento non corrispondente dello schema: Le modifiche nello schema di origine (ad esempio, nuove colonne) vengono registrate nell'area di attesa Rifiuto schema; gli amministratori possono rimappare o aggiornare i metadati dello schema.
- Failover autenticazione: Se le credenziali scadono, Data 360 tenta nuovamente la connessione utilizzando i token di aggiornamento memorizzati o le policy di rotazione delle chiavi.
- Calcola rilevamento disponibilità: Se Snowflake o il cluster Databricks viene messo in pausa, Data 360 sospende i processi di federazione e riprova alla ripresa del calcolo.
- Integrazione di monitoraggio: Tutti i metadati relativi allo stato della connessione, alla latenza delle query e alla discendenza visibili nei cruscotti digitali di Monitoraggio di Data 360.
Considerazioni sulla progettazione idempotente
- Determinismo delle query: Le query federate utilizzano una semantica delle istantanee coerente per garantire letture stabili e ripetibili durante la segmentazione o l'attivazione.
- Controllo versioni DLO esterno: Ogni query federata include metadati di schema e indicazione oraria per il tracciamento delle discendenze.
- Accesso senza offset: Poiché Copia zero è di sola lettura, non si basa sugli offset degli eventi: la coerenza viene imposta tramite le garanzie ACID del sistema esterno (Snowflake/Delta Lake).
- Gestione della deriva dello schema: Mantenere le mappature degli schemi con versione in Data 360; aggiornare i metadati DLO esterno sull'evoluzione della fonte.
Considerazioni sulla sicurezza
La sicurezza è parte integrante di tutto il modello di federazione, senza compromessi in termini di Trust o conformità.
- Crittografia: Tutti gli scambi di dati utilizzano TLS 1.2+; i warehouse esterni eseguono la crittografia a riposo utilizzando AES-256.
- Controllo accessi: Alle tabelle esterne si accede tramite ruoli con privilegi minimi con autorizzazioni di sola lettura.
- Isolamento della rete: I percorsi Private Connect o VPC impediscono qualsiasi esposizione agli endpoint pubblici.
- Flusso di dati governato: I metadati di discendenza, consenso e classificazione confluiscono nel livello Trust di Data 360 per l'applicazione delle policy.
- Controllabilità: Ogni query federata e ogni evento di accesso allo schema vengono registrati per la tracciabilità della conformità (GDPR, CCPA, HIPAA).
Intestazioni laterali
Tempestività
- Le query vengono eseguite in tempo reale nel magazzino o nello storage esterno, garantendo la visibilità in tempo reale dello stato dei dati più recente.
- Le esecuzioni di segmentazione o attivazione riflettono le modifiche al secondo nelle tabelle Snowflake, Databricks o Iceberg supportate da S3.
- La latenza delle query dipende dal livello di prestazioni del sistema di origine, in genere da secondi a decine di secondi per query.
- Ideale per i carichi di lavoro di analisi e intelligenza artificiale che richiedono un accesso ai dati "fresco e non copiato".
Volumi di dati
- Supporta le serie di dati su scala petabyte memorizzate in modo nativo in Snowflake o Databricks senza replica.
- Data 360 recupera solo i risultati, non le serie di dati non elaborate, riducendo al minimo i costi di rete e di calcolo.
- Federazione file ottimizza le analisi di grandi dimensioni tramite la potatura delle partizioni e il pushdown colonnare.
- Scala in modo lineare con la capacità di calcolo del magazzino e il livello di orchestrazione delle query federato di Data 360.
Gestione statale
- I DLO esterni mantengono i metadati di connessione, schema e versione in Data 360.
- L'evoluzione dello schema viene gestita automaticamente tramite cicli di aggiornamento dei metadati.
- La discendenza delle query include indicazioni orarie, identità utente e metriche di esecuzione per la tracciabilità.
- Non vengono mantenuti né l'inserimento né gli offset statici: la coerenza viene ereditata dalle garanzie ACID della fonte esterna.
Scenari di integrazione complessi
- Modalità ibrida: Combinare Copia zero (per la federazione live) con l'inserimento (per le serie di dati storiche).
- Accesso al magazzino trasversale: Data 360 può essere federato da più tenant Snowflake o Databricks all'interno di una sola organizzazione.
- Interoperabilità AI/BI: I sistemi esterni (ad esempio, SageMaker, Tableau, Power BI) possono eseguire query sui profili arricchiti di Data 360 tramite Copia zero inversa.
- Estensione federazione file: Le aziende che adottano formati open lake (Iceberg/Delta) possono unificare dati strutturati e non strutturati in un unico modello federato.
Esempio
Un'azienda finanziaria globale archivia tutti i dati delle transazioni e delle interazioni in Snowflake, mantenendo gli attributi dei clienti e gli eventi di marketing in Data 360. Utilizzando Zero Copy Data Federation, Data 360 si connette in modo sicuro a Snowflake tramite Private Connect. Quando viene eseguito un processo di segmentazione, ad esempio "I clienti con una spesa di > 10.000 dollari negli ultimi 30 giorni, Data 360 invia la query a Snowflake, recupera i risultati aggregati e attiva immediatamente tali profili in Journey Builder. Nessuna replica o ETL necessario. Questo esempio utilizza l'intelligenza federata in tempo reale unificata in tutto l'ecosistema di dati aziendali.
Copia zero in uscita estende lo stesso principio al contrario. Anziché esportare o copiare serie di dati da Data 360, i sistemi esterni come Snowflake possono eseguire query direttamente su Data 360, trattandolo come una fonte federata di Intelligence clienti arricchita.
- Federazione inversa: Piattaforme analitiche esterne o di intelligenza artificiale possono accedere ai dati del profilo unificato di Data 360 senza estrarli.
- Attivazione dei dati alla fonte: I team aziendali possono sfruttare gli approfondimenti dove già risiedono i dati, sia per la modellazione AI, la creazione di rapporti o la personalizzazione dei clienti.
- Interoperabilità senza latenza: Nessuna esportazione batch o processo di sincronizzazione; gli approfondimenti vengono visualizzati immediatamente tra le piattaforme.
- Semantica coerente: Poiché entrambi i sistemi condividono la stessa ontologia e le stesse mappature dello schema, il contesto e il significato vengono preservati in tutti gli ecosistemi. Copia zero ridefinisce il ruolo di Data 360 da un archivio di dati a un livello di attivazione semantica. Consente alle organizzazioni di mantenere i dati esattamente dove appartengono, in magazzini gestiti e ad alte prestazioni, sbloccando tutto il loro valore all'interno del confine Trust di Salesforce. Questo schema è in linea con le moderne architetture basate su mesh di dati e AI: i dati rimangono decentralizzati, ma l'intelligenza diventa unificata. Gli architetti possono ora creare opportunità di attivazione in corso di realizzazione più veloci, snelle e conformi, senza necessità di copia.
Contesto
Le aziende moderne operano sempre più spesso in ecosistemi di dati multipiattaforma, dove Salesforce Data 360 supporta i profili cliente e l'attivazione unificati, mentre i data warehouse aziendali come Snowflake o Databricks fungono da colonne portanti analitiche per la scienza dei dati, il machine learning e i carichi di lavoro di BI. La funzionalità Zero Copy Outbound Sharing di Salesforce Data 360 collega perfettamente questi ambienti, consentendo un accesso governato, sicuro e in tempo reale ai dati armonizzati di Data 360 direttamente in Snowflake o Databricks, senza replica o ETL. Ciò consente ad analisti e data scientist di eseguire query, visualizzare e modellare gli stessi dati affidabili e live che favoriscono l'attivazione di marketing, vendite e servizi.
Problema
Come può un'azienda esporre in modo sicuro ed efficiente i profili cliente unificati e le metriche calcolate di Data 360 (ad esempio, Valore durata, Rischio di abbandono) a sistemi di analisi esterni, senza copiare i dati, interrompere la governance o introdurre latenza tramite le tradizionali pipeline ETL inverse?
Forze
Questo schema introduce diverse considerazioni di tipo architettonico, di governance e operativo:
- Sicurezza governata: L'accesso ai dati di Data 360 deve essere controllato, granulare e controllabile. La condivisione copia zero utilizza l'accesso esplicito a livello di oggetto, garantendo che solo gli oggetti modello di dati (DMO) e gli oggetti approfondimento calcolato (CIO) approvati siano disponibili per i consumatori designati.
- Selezione oggetto esplicito: Gli amministratori gestiscono i dati condivisibili tramite una condivisione dati, selezionando esplicitamente gli oggetti da esporre. Ciò mantiene la governance e riduce al minimo l'esposizione al rischio.
- Configurazione Bi-Laterale: Sia Data 360 che il warehouse esterno richiedono l'impostazione. Data 360 definisce la destinazione condivisione dati (Snowflake/Databricks), mentre il sistema ricevente deve accettare e istanziare la condivisione.
- Modello di federazione delle query: Una volta accettata, la piattaforma esterna esegue query live sui dati di Data 360 gestiti tramite visualizzazioni federate, eliminando processi di estrazione o cicli di aggiornamento manuali.
- Evoluzione degli standard aperti: Approcci emergenti come Federazione file sfruttano i formati di tabelle aperte (ad esempio, Apache Iceberg) per abilitare l'accesso in sola lettura a livello di archiviazione, migliorando la scalabilità, le prestazioni e l'interoperabilità tra architetture multi-cloud.
Soluzione
La soluzione sfrutta la condivisione Zero Copy nativa di Salesforce Data 360 con piattaforme dati come Snowflake o Databricks.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Creazione di condivisioni dati | Best | L'amministratore crea una condivisione dati in Data 360, aggiungendo DMO e CIO selezionati (ad esempio, Persona unificata, Punteggio di salute del cliente). |
| Configurazione target | Best | Creare una destinazione condivisione dati specificando gli identificatori account Snowflake o Databricks e i parametri di autenticazione. |
| Condivisione pubblicazione | Best Practice | Collegare la condivisione dati alla destinazione condivisione dati per pubblicare in modo sicuro. |
| Accettazione magazzino | Obbligatorio | L'amministratore esterno accetta la condivisione, materializzando gli oggetti condivisi come visualizzazioni/tabelle di sola lettura nel magazzino. |
| Controllo dell'accesso granulare | Consigliato | Applicare le autorizzazioni basate su oggetti e ruoli in Data 360; allinearsi al controllo dell'accesso basato sui ruoli a livello di magazzino. |
| Accesso federato alle query | Best | Gli analisti eseguono query sui dati condivisi in tempo reale tramite SQL standard; join con i dati nativi del magazzino per analisi e ML a valle. |
| Opzione federazione file | Facoltativo | Per le serie di dati di grandi dimensioni, utilizzare la federazione basata su Apache Iceberg per le letture dirette S3 o Delta Lake senza dipendenza di calcolo. |
Sketch
Lo schema seguente illustra una chiamata da Salesforce Data 360 a una piattaforma dati esterna.
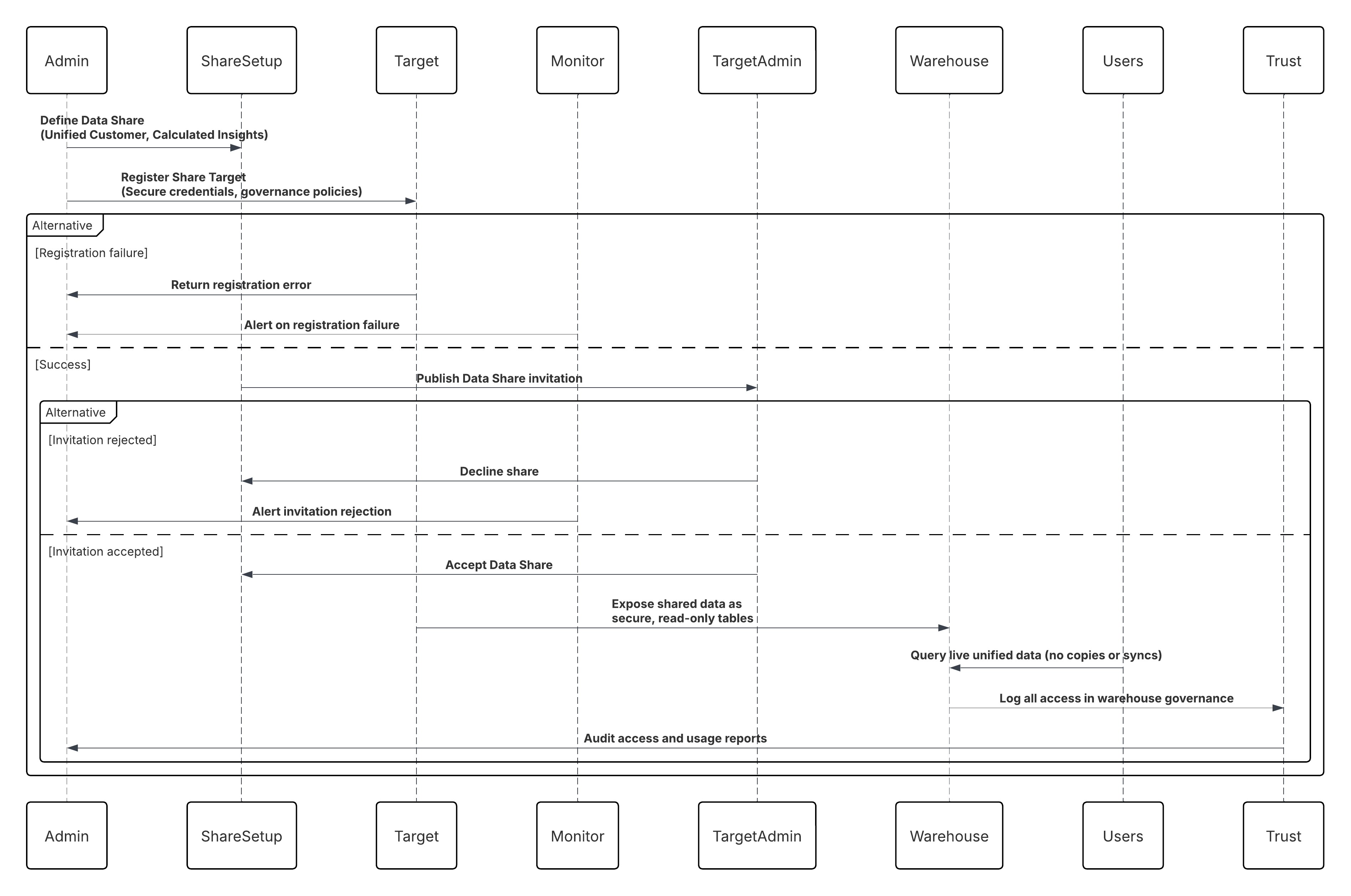
In questo scenario:
- L'amministratore di Data 360 definisce una condivisione dati che include gli oggetti Cliente unificato e Approfondimento calcolato.
- Viene registrata una destinazione condivisione dati (account Snowflake o Databricks) con credenziali e policy di governance protette.
- Data 360 pubblica la condivisione; gli amministratori Snowflake/Databricks la accettano.
- I dati condivisi vengono visualizzati come tabelle protette di sola lettura all'interno del magazzino.
- Analisti, strumenti di BI o pipeline ML eseguono query sui dati live unificati dei clienti senza copiare o sincronizzare.
- Tutto l'accesso viene controllato all'interno del Trust Layer di Data 360 e dei registri di governance del magazzino.
Risultati
- I warehouse esterni ottengono l'accesso in tempo reale e interrogabile ai dati armonizzati di Data 360.
- Elimina le pipeline ETL inverse, riducendo il carico operativo e la latenza.
- Consente l'addestramento AI/ML, la modellazione predittiva e la BI avanzata direttamente sui dati unificati.
- Mantiene zero duplicazioni, governance forte e controllo dell'accesso secure-by-design.
- Completa il loop bidirezionale Copia zero, in cui federazione in entrata e condivisione in uscita coesistono sotto un unico modello di governance.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla soluzione scelta per implementare questo schema.
| Meccanismo | Quando utilizzare |
|---|---|
| Condivisione dati protetta Snowflake (preferita) | Utilizzare quando il warehouse aziendale è Snowflake e si necessita di un accesso live e controllato alle serie di dati Data 360 armonizzate senza spostamento o duplicazione dei dati. Ideale per carichi di lavoro basati su analisi, intelligenza artificiale e conformità che richiedono la condivisione a latenza zero e l'imposizione di linee native. |
| Databricks Delta Share | Utilizzare quando i consumatori a valle operano in ambienti Databricks o Delta Lake e richiedono l'accesso in tempo reale in sola lettura alle serie di dati unificate o attivate tramite il protocollo di condivisione Delta aperto. |
| Condivisione tabella esterna (Apache Iceberg / Parquet) | Utilizzare quando si gestiscono architetture in formato aperto nell'archiviazione di oggetti (S3, ADLS o GCS) e si necessita di una condivisione interoperabile e a basso costo tra motori di analisi come Athena, BigQuery o Snowflake-on-Iceberg. |
| API condivisione dati (accesso programmatico) | Utilizzare quando le app personalizzate o il middleware (ad esempio MuleSoft) devono scoprire, abbonarsi o utilizzare le serie di dati condivise in modo sicuro tramite le API, con notifiche di aggiornamento basate sugli eventi e un controllo dell'accesso preciso. |
| Condividi ibrida (Zero copie + Condividi in uscita) | Utilizzare quando si implementano schemi di scambio bidirezionali: sfruttare Copia zero per i dati in entrata e Quota dati in uscita per pubblicare approfondimenti, garantendo la coerenza semantica e di governance tra i piani dati aziendali. |
Gestione e ripristino degli errori
- Tentativi di connessione: Tentativi automatici di connessione temporanea o errori di autenticazione tra Data 360 e warehouse.
- Convalida condivisione: Le configurazioni di condivisione non valide o non autorizzate vengono messe in quarantena in un'area di attesa.
- Monitoraggio dello stato di sincronizzazione: Data 360 mette in evidenza lo stato delle condivisioni live, la latenza delle query e i registri di accesso tramite i cruscotti digitali di monitoraggio.
- Revoca accesso: Gli amministratori possono revocare immediatamente le condivisioni, disabilitando l'accesso a entrambe le estremità senza copie dei dati residue.
- Percorso di controllo governato: Tutte le modifiche di configurazione e accesso vengono registrate per la verifica della conformità.
Considerazioni sulla progettazione idempotente
- Identificazione condivisione coerente: Ogni coppia Condivisione dati e Destinazione condivisione dati ha un identificatore univoco, che garantisce una governance esatta e la tracciabilità dell'accesso.
- Visualizzazioni immutabili: Gli oggetti dati condivisi sono di sola lettura; i consumatori non possono modificare lo stato, garantendo risultati deterministici e conformità.
- Ciclo di vita della condivisione atomica: La pubblicazione, la revoca e gli aggiornamenti delle condivisioni sono operazioni atomiche, completate o ritirate.
- Coerenza di riproduzione: Quando i dati di Data 360 vengono aggiornati, le query lato warehouse restituiscono sempre l'istantanea coerente più recente, eliminando le letture non aggiornate.
Considerazioni sulla sicurezza
La sicurezza è alla base di ogni aspetto di Zero Copy Sharing:
- Autenticazione: Trust reciproco stabilito utilizzando OAuth 2.0, scambio di chiavi private o federazione di identità (OIDC).
- Crittografia: Dati crittografati in transito (TLS 1.2+) e a riposo (AES-256).
- Controllo accessi: Le autorizzazioni a livello di oggetto impongono l'accesso con privilegi minimi; sono regolate dal livello Trust di Data 360.
- Sicurezza della rete: Gli scambi di dati avvengono tramite link di rete privati come Salesforce Private Connect o le API Secure Data Exchange.
- Metadati di governance: Ogni oggetto condiviso è dotato di attributi di discendenza, classificazione e consenso per una completa tracciabilità e conformità alle normative.
Intestazioni laterali
Tempestività
- Disponibilità in tempo reale: I dati condivisi riflettono lo stato più attuale di Data 360 senza ritardi di replica.
- Freschezza della query: Le modifiche nei DMO o nei CIO si propagano immediatamente alle visualizzazioni magazzino condivise.
- Elasticità delle prestazioni: Il pushdown delle query si adatta dinamicamente alle risorse di calcolo del magazzino.
- Monitoraggio: I cruscotti digitali live espongono le metriche di latenza condivise e delle prestazioni delle query per garantire la sicurezza operativa.
Volumi di dati
- Condivisione scalabile: Supporta la condivisione granulare dei dati a livello di oggetto o di dominio completo a seconda delle esigenze analitiche.
- Prestazioni delle query ottimizzate: Snowflake/Databricks memorizza i dati condivisi nella cache in modo intelligente per ridurre al minimo la latenza.
- Efficienza di stoccaggio: La duplicazione zero elimina i costi di archiviazione ridondanti.
- Opzione federazione file: Per le serie di dati su scala petabyte, la condivisione diretta basata su Iceberg ignora il calcolo e accelera l'accesso.
Gestione statale
- Evoluzione schema: Gli schemi controllati dalla versione garantiscono la compatibilità quando il modello Data 360 si evolve.
- Tracciamento stato di accesso: Stati condivisione attivi/inattivi gestiti in Data 360 per la governance del ciclo di vita.
- Sincronizzazione dei metadati: Gli aggiornamenti alle definizioni degli oggetti condivisi si riflettono automaticamente nei cataloghi di magazzino a valle.
- Garanzia statale immutabile: Le visualizzazioni magazzino rappresentano sempre uno stato coerente e puntuale dei dati di Data 360.
Scenari di integrazione complessi
- Modalità ibrida: Combinare Copia zero (per la federazione live) con l'inserimento (per le serie di dati storiche).
- Accesso al magazzino trasversale: Data 360 può essere federato da più tenant Snowflake o Databricks all'interno di una sola organizzazione.
- Interoperabilità AI/BI: I sistemi esterni (ad esempio, SageMaker, Tableau, Power BI) possono eseguire query sui profili arricchiti di Data 360 tramite Copia zero inversa.
- Estensione federazione file: Le aziende che adottano formati open lake (Iceberg/Delta) possono unificare dati strutturati e non strutturati in un unico modello federato.
Esempio
L'analisi cross-cloud consente alle organizzazioni di combinare i dati di Salesforce Data 360 gestiti con serie di dati native in piattaforme come Snowflake e Databricks per offrire una visualizzazione analitica completa a 360 gradi. Grazie all'accesso multi-tenant, le diverse unità operative possono utilizzare sezioni di dati curate e controllate dalle policy in modo sicuro tramite condivisioni separate senza duplicare i dati. I data scientist possono quindi eseguire modelli federati di intelligenza artificiale e machine learning addestrando direttamente i profili cliente unificati all'interno degli ambienti Snowflake ML o Databricks MLflow. Durante tutto questo processo, le funzionalità incorporate di lignaggio, governance e controllo assicurano che tutto l'accesso e l'utilizzo dei dati rimangano conformi alle policy aziendali e ai requisiti normativi come GDPR e HIPAA.
Data Cloud One consente alle organizzazioni con più organizzazioni Salesforce (ad esempio, a causa di unità operative, regioni, linee di prodotti o acquisizioni) di condividere un'unica istanza centrale di Data 360. Questa organizzazione funge da "organizzazione di origine", mentre le altre organizzazioni, denominate "organizzazioni di supporto", possono accedere e agire sui dati unificati, senza sforzo, senza codice personalizzato e con controlli di governance completi.
Contesto
Le aziende spesso gestiscono più di un'organizzazione Salesforce (ad esempio, una per le vendite, una per l'assistenza, una per il marketing o regioni distinte). Ogni organizzazione può avere dati, configurazioni e processi diversi. Prima di Data Cloud One, ogni organizzazione richiedeva la propria impostazione di Data 360 o codice personalizzato complesso per condividere i dati tra le organizzazioni. Data Cloud One semplifica questa operazione consentendo una singola organizzazione "home" con Data 360 e più organizzazioni "companion" che si connettono tramite configurazione low-code e condivisione dei metadati.
Problema
Come può un'azienda consentire un uso coerente dei dati Customer 360 unificati, inseriti, armonizzati e gestiti da Data 360 dell'organizzazione di origine, in tutte le sue organizzazioni Salesforce (in modo che vendite, marketing, assistenza, ecc. utilizzino tutti gli stessi dati sottostanti), evitando al contempo la duplicazione delle attività, la creazione di codici personalizzati, istanze di Data 360 separate per organizzazione e lacune di governance?
Forze
Questo schema introduce diverse considerazioni su architettura, sicurezza e prestazioni:
- Complessità multi-organizzazioni: L'organizzazione di ogni unità operativa può avere dati, oggetti personalizzati, protezione e processi diversi: è difficile mantenere visualizzazioni unificate coerenti.
- Duplicazione & costo: L'esecuzione di un'istanza di Data 360 separata per organizzazione comporta una configurazione aggiuntiva, una governance aggiuntiva, licenze aggiuntive e il rischio di silos di dati.
- Controlli di governance e condivisione dei dati: È necessario decidere quali dati ogni organizzazione partner può visualizzare e utilizzare: non è possibile condividere semplicemente "tutto" senza rischi di governance.
- Velocità di impostazione: I team di marketing, vendita o assistenza non possono attendere settimane prima che il codice personalizzato renda disponibili i dati tra organizzazioni: hanno bisogno di soluzioni di configurazione basate su clic.
- Data Residency, Considerazioni regionali: Se le organizzazioni di residenza e le organizzazioni associate si trovano in regioni diverse, potrebbero esserci vincoli legali o normativi relativi alla posizione in cui vengono archiviati i dati o al modo in cui vengono condivisi.
Soluzione
La tabella seguente contiene varie soluzioni a questo problema di integrazione.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Provisioning organizzazione iniziale | Best | Designare un'organizzazione Salesforce come organizzazione di residenza in cui viene eseguito il provisioning di Data 360, che diventa l'archivio dati centrale e l'hub di governance. |
| Connessione organizzazione compagna | Best | Configurare le connessioni aziendali dall'organizzazione di residenza a una o più organizzazioni aziendali tramite l'app Data Cloud One: non è necessario alcun codice personalizzato. |
| Definizione spazio dati | Best Practice | Definire gli spazi dati all'interno dell'organizzazione di residenza per segmentare logicamente i dati (ad esempio Retail, Service, Marketing) e isolare i confini di accesso. |
| Condivisione spazio dati | Best | Condividere in modo esplicito spazi dati selezionati dall'organizzazione di residenza alle organizzazioni di compagnia, garantendo una visibilità dei dati unificati governata e basata sui ruoli. |
| Configurazione dell'accesso | Obbligatorio | Nelle organizzazioni partner, abilitare l'app Data Cloud One e assegnare le autorizzazioni utente per l'accesso a profili, approfondimenti e segmenti. |
| Governance e controllo delle policy | Consigliato | Centralizzare tutte le configurazioni di inserimento, risoluzione dell'identità e Trust nell'organizzazione Home, mantenendo una governance end-to-end. |
| Sincronizzazione multi-organizzazione | Best | Le modifiche dei dati e gli approfondimenti calcolati nell'organizzazione di origine si riflettono in tempo reale nelle organizzazioni partner tramite le opportunità di sincronizzazione gestite. |
| Opzione di distribuzione ibrida | Facoltativo | Per le grandi aziende, più organizzazioni partner possono connettersi a una singola organizzazione di residenza mantenendo il contesto locale e i limiti di conformità. |
Sketch
Il diagramma seguente illustra la sequenza degli eventi in questo schema, in cui Salesforce è il master dei dati.
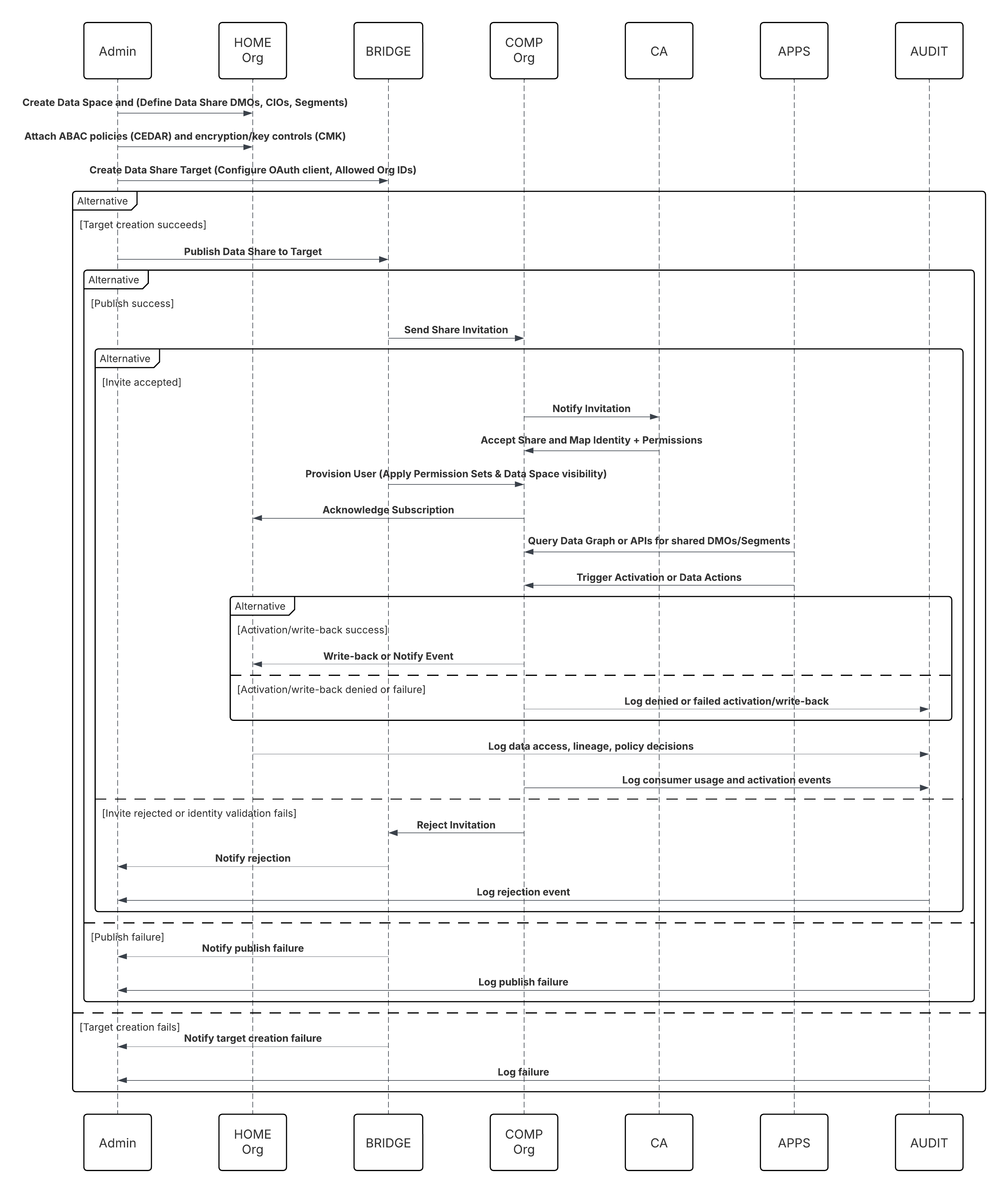
In questo scenario:
- Home Admin: creare lo spazio dati e definire la condivisione dati (selezionare DMO/CIO, segmenti).
- Home Admin: creare la destinazione condivisione dati per le organizzazioni partner e configurare Trust (client OAuth, ID organizzazione consentiti).
- Home Admin: pubblicare la condivisione dati nella destinazione; allegare policy ABAC (CEDAR) e controlli di crittografia/chiave (CMK, se necessario).
- Companion Org Admin: riceve l'invito, convalida la mappatura dell'identità e accetta la condivisione.
- Organizzazione di compagnia: Data Cloud One Bridge esegue il provisioning di un utente Data Cloud One e applica la visibilità Insiemi di autorizzazioni e spazio dati.
- App dell'organizzazione compagna (flussi / Einstein / Apex): Eseguire una query su un grafico dati o chiamare le API Data Cloud One per leggere i DMO o i segmenti condivisi.
- Attivazione: L'organizzazione compagna attiva l'attivazione o esegue il writeback tramite azioni dati (se consentito).
Risultati
- Un'unica fonte di dati per i dati dei clienti (Customer 360) in tutte le organizzazioni connesse, senza istanze di Data 360 ridondanti.
- Tempo più rapido per il calcolo: le organizzazioni associate possono accedere ai dati unificati e alle funzioni basate su Data 360 in pochi minuti, non in settimane di codice personalizzato.
- Condivisione controllata dei dati. Vengono condivisi solo gli spazi dati autorizzati, preservando la sicurezza e la governance e abilitando l'agilità aziendale.
- Le funzioni aziendali (vendite, assistenza, marketing) operano sulla stessa base di dati unificata, consentendo metriche, attivazioni e approfondimenti coerenti in tutta l'azienda.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla soluzione scelta per implementare questo schema.
| Meccanismo | Quando utilizzare |
|---|---|
| Data Cloud One Native Share (Preferito) | Utilizzare quando più organizzazioni Salesforce (Sales, Service o Industry Cloud) necessitano dell'accesso in tempo reale ai dati unificati dei clienti direttamente da Data 360\. In questo modo si eliminano le repliche e si abilita l'accesso a latenza zero a Golden Record, segmenti e approfondimenti calcolati. |
| Condivisione da organizzazione a organizzazione tramite Data Cloud One Bridge | Utilizzare quando più unità operative o società controllate operano in organizzazioni Salesforce separate ma necessitano di un accesso condiviso ai dati e ai segmenti comuni dei clienti da un'istanza centrale di Data 360. Ideale per le aziende multi-organizzazioni che gestiscono sistemi operativi indipendenti. |
| API di query piattaforma Einstein 1 | Utilizzare quando le app Salesforce, Flusso o Einstein Copilot devono eseguire query o attivare i dati di Data 360 a livello di programmazione. Consente il recupero in tempo reale di profili, metriche o risultati di attivazione unificati in altre applicazioni Salesforce senza esportazioni batch. |
| Attivazione ai canali Salesforce | Utilizzare quando è necessario attivare i dati di Data 360 (segmenti, approfondimenti o attributi) in Marketing Cloud, Service Cloud o Commerce Cloud per la personalizzazione, l'esecuzione di campagne o le esperienze di assistenza agli agenti. |
| Accesso grafico dati (livello query semantica) | Utilizzare quando è necessario l'accesso a livello semantico al modello di dati unificato tramite il grafico dati Salesforce, supportando Copilota, flussi di lavoro AI e analisi cross-cloud in tempo reale, senza join o trasformazioni manuali. |
Gestione e ripristino degli errori
- Resilienza delle sincronizzazioni tra organizzazioni: Data Cloud One tenta automaticamente di ripetere i processi di sincronizzazione non riusciti tra le organizzazioni Home e Companion utilizzando il backoff esponenziale per gli errori temporanei di rete o piattaforma.
- Isolamento batch parziale: I batch di record non riusciti vengono messi in quarantena in un'Area di attesa Riprova all'interno dell'organizzazione di origine fino a quando la riconciliazione non riesce, impedendo la divergenza dei dati.
- Governance del rifiuto dello schema: Le mancate corrispondenze degli schemi o delle mappature vengono instradate all'Area di attesa Rifiuto schema per la revisione e la correzione da parte dell'amministratore.
- Replay e ripresa della continuità: Ogni processo di sincronizzazione mantiene i checkpoint di offset in modo che la replica possa riprendere dall'ultima conferma riuscita senza duplicazioni.
- Monitoraggio integrato: Tutti gli errori, i tentativi e le metriche di ripristino vengono acquisiti nel cruscotto digitale Trust Layer Monitoring (Monitoraggio livello Trust) per la visibilità e la garanzia degli SLA.
Considerazioni sulla progettazione idempotente
- Chiavi deterministiche dell'impotenza: Ogni evento di sincronizzazione include una chiave univoca (ID organizzazione + ID record + Numero di versione) per garantire l'elaborazione esattamente una volta.
- Sicurezza di riproduzione: Gli eventi duplicati o riprodotti vengono filtrati al momento della conferma, garantendo aggiornamenti DMO e CIO coerenti a valle.
- Semantica impegno atomico: Le organizzazioni partner contrassegnano i dati come confermati solo dopo che le scritture a valle sono state completate correttamente, preservando l'integrità delle transazioni tra organizzazioni.
- Risoluzione dei conflitti: Gli aggiornamenti multifonte seguono una logica di unione basata sull'ultima scrittura o sulla policy, mantenendo la discendenza e la coerenza.
- Persistenza checkpoint: I processi di sincronizzazione persistono negli ultimi offset elaborati e nello stato all'interno del livello Trust per un ripristino e una riproduzione sicuri.
Considerazioni sulla sicurezza
- Autenticazione forte: Le connessioni tra le organizzazioni Home e Companion utilizzano OAuth 2.0 reciproco con token a rotazione automatica gestiti tramite applicazioni connesse.
- Autorizzazione granulare: Le organizzazioni di supporto possono accedere solo a spazi dati, DMO o CIO specifici esplicitamente condivisi tramite le policy di condivisione dei dati governate.
- Crittografia ovunque: I dati vengono crittografati in transito (TLS 1.2+) e a riposo (AES-256) tra le organizzazioni Home e Companion.
- Principio dei privilegi minimi: Gli utenti integrazione sono limitati agli oggetti richiesti; non vengono propagate autorizzazioni amministrative o a livello di sistema.
- Visibilità audit e conformità: Tutti gli eventi di sincronizzazione, le modifiche dello schema, gli aggiornamenti delle credenziali e le concessioni di accesso vengono registrati nel livello Trust di Data 360 per una tracciabilità completa.
- Isolamento rete privata: Salesforce Private Connect o Private Link facoltativo garantisce che la replica dei dati avvenga solo su canali interni protetti.
Intestazioni laterali
Tempestività
- La sincronizzazione tra le organizzazioni di origine e di compagnia avviene quasi in tempo reale, in genere entro pochi secondi da una modifica dei dati nell'organizzazione di origine.
- L'architettura Zero Copy garantisce che i dati condivisi siano immediatamente interrogabili in tutte le organizzazioni partecipanti, senza replica o ritardi batch.
- I processi di attivazione e segmentazione riflettono automaticamente gli ultimi aggiornamenti di qualsiasi organizzazione connessa, mantenendo la freschezza operativa.
- La latenza end-to-end è deterministica e regolata dalla pipeline di orchestrazione di Data Cloud One, garantendo una tempestività tra organizzazioni coerente anche sotto carico.
Volumi di dati
- Progettato per la sincronizzazione dei dati multi-tenant su iperscala tra regioni e unità operative, in grado di gestire miliardi di record per organizzazione.
- I dati sono referenziati, non duplicati, riducendo l'ingombro della memoria e mantenendo la possibilità di eseguire query globali.
- I delta streaming e la compattazione dei metadati ottimizzano la larghezza di banda e confermano l'overhead per gli oggetti con velocità di modifica elevata (ad esempio, Referente, Ordine).
- Scala orizzontalmente in più organizzazioni partner con bilanciamento del carico adattivo e orchestrazione tramite il livello Trust.
Gestione statale
- Ogni serie di dati sincronizzata mantiene la discendenza dei metadati, la versione e il contesto di proprietà dell'organizzazione per garantire la tracciabilità end-to-end.
- La persistenza del checkpoint acquisisce gli ultimi offset sincronizzati tra le organizzazioni, consentendo il ripristino senza duplicazioni.
- Il controllo delle versioni dello schema e l'allineamento semantico tra le organizzazioni sono regolati automaticamente dai Trust Layer.
- Non sono necessarie reimpostazioni manuali dello stato: lo stato di sincronizzazione viene mantenuto tramite il servizio di orchestrazione Data Cloud One.
Scenari di integrazione complessi
- Federazione tra organizzazioni: Abilita query e attivazione senza problemi in più tenant o regioni di Data 360 in un modello di governance unificato.
- Sincronizzazione ibrida: Combina la replica quasi in tempo reale per gli aggiornamenti delle transazioni con la sincronizzazione pianificata per i dati in blocco o di archivio.
- Governance multiregionale: Supporta la condivisione dei dati distribuita geograficamente rispettando i limiti di residenza, consenso e conformità.
- AI e attivazione dell'automazione: I dati sincronizzati supportano istantaneamente modelli Einstein AI, Agentforce o ML personalizzati in tutte le organizzazioni, abilitando l'intelligenza tra organizzazioni in tempo reale.
Esempio
Un'organizzazione di vendita al dettaglio globale dispone di tre organizzazioni Salesforce: una per Consumer Retail, una per Premium Brands e una per i Mercati internazionali. Fornisce Data 360 nell'organizzazione Consumer Retail (che la rende l'organizzazione di origine). Con Data Cloud One, impostano connessioni secondarie alle organizzazioni Premium Brands e Mercati internazionali. Condividono solo spazi dati appropriati (ad esempio, "Customer 360 – Retail Profiles" e "Customer 360 – Premium Profiles") con ogni organizzazione associata. Nell'organizzazione Premium Brands, i team di marketing possono visualizzare i profili cliente unificati, creare segmenti in base agli approfondimenti calcolati (ad esempio, il valore premium della durata del cliente) e attivare automazioni di marketing, il tutto basato sull'istanza di Data 360 dell'organizzazione di origine, senza codifica personalizzata o duplicazione dei dati.
L'attivazione dei dati è il punto in cui il valore di Salesforce Data 360 prende vita. È il processo che consiste nel prelevare i dati unificati, arricchiti e governati che vivono all'interno della piattaforma e nel farli funzionare in tutta l'azienda. In pratica, ciò significa fornire in modo sicuro segmenti curati, approfondimenti calcolati e attributi contestuali da Data 360 ai sistemi che coinvolgono i clienti, che si tratti di automazione del marketing, Service Console, abilitazione alle vendite, analisi o modelli AI. Da un punto di vista tecnico, gli schemi di attivazione definiscono come si muovono i dati: quali canali vengono attivati, quali trasformazioni o mappature si verificano e come vengono applicate le policy lungo il percorso. Questi schemi non riguardano solo l'esportazione dei dati, ma anche l'orchestrazione di flussi di dati in tempo reale e sensibili alle policy che determinano risultati aziendali misurabili. Ogni percorso di attivazione trasforma Customer 360 in un asset operativo live, potenziando la personalizzazione, le decisioni predittive e l'apprendimento continuo in ogni punto di contatto.
L'attivazione batch rimane il metodo più utilizzato e collaudato a livello operativo per esportare i dati da Data 360. Opera con cadenza pianificata, pubblicando segmenti di pubblico predefiniti o insiemi di attributi nelle piattaforme a valle a intervalli regolari. Questo schema è ideale per i flussi di lavoro di marketing e coinvolgimento che si basano su consegne di pubblico coerenti e a volume elevato anziché su aggiornamenti istantanei. I casi d'uso tipici includono l'ottimizzazione dei journey email, delle campagne di direct mailing o dei caricamenti di pubblico nelle reti pubblicitarie digitali. Ogni esecuzione attivazione estrae il segmento qualificato dal grafico del profilo unificato di Data 360, applica policy di governance e consenso e trasmette l'output in modo sicuro al sistema di destinazione. A livello architettonico, l'attivazione in batch offre un approccio alla distribuzione dei dati prevedibile, controllabile ed economico, bilanciando la semplicità operativa con l'affidabilità di livello aziendale. È la spina dorsale dell'esecuzione di campagne su larga scala, dove i dati corretti, forniti in tempo e sotto controllo, determinano un impatto misurabile sul business.
Contesto
Gli esperti di marketing moderni operano su più canali di coinvolgimento (email, pubblicità, dispositivi mobili e Web), ognuno dei quali richiede pubblici di clienti precisi, tempestivi e personalizzati. Data 360 funge da base unificata per questi pubblici, combinando i dati dei clienti di ogni sistema in segmenti completi e fruibili. L'attivazione batch è lo schema di attivazione più comune utilizzato per esportare tali segmenti da Data 360 a piattaforme di marketing o pubblicitarie a valle. Le destinazioni tipiche includono Marketing Cloud Engagement, Google Ads, Pubblico meta personalizzato o LinkedIn Ads, dove le campagne possono essere eseguite direttamente contro questi pubblici curati.
Problema
Come può un team di marketing acquisire un pubblico definito con precisione, creato utilizzando dati unificati e arricchiti in Data 360, e renderlo disponibile in sistemi di marketing o pubblicità esterni per l'attivazione? Si consideri ad esempio il segmento: “Clienti di alto valore che non hanno acquistato negli ultimi 90 giorni ma hanno recentemente partecipato al sito Web.” Gli esperti di marketing devono assicurarsi che questo pubblico venga trasferito in modo preciso, arricchito con attributi pertinenti (ad esempio, livello di fedeltà, regione o CLV previsto) e aggiornato a intervalli regolari per mantenere la pertinenza e l'efficacia della campagna.
Forze
Diversi fattori tecnici e operativi modellano lo schema di attivazione batch:
- Mappatura dell'identità: Una consegna accurata del pubblico richiede la mappatura dell'ID persona unificata di Data 360 all'identificatore corrispondente nel sistema di destinazione, ad esempio una chiave abbonato in Marketing Cloud o un'email con hashing per le piattaforme pubblicitarie digitali. Ciò garantisce una corrispondenza precisa ed elimina gli errori di destinazione.
- Selezione e arricchimento attributi: Gli esperti di marketing devono andare oltre gli ID e includere ulteriori dati del profilo, ad esempio nome, stato fedeltà, CLV o altri attributi personalizzati, per consentire la personalizzazione e l'analisi a valle.
- Configurazione piattaforma di destinazione: Ogni destinazione deve essere registrata in Data 360 come destinazione attivazione, inclusi i dettagli della connessione, l'autenticazione e le mappature dei campi dati. Questa impostazione singola definisce la connettività protetta e determina quali sistemi possono ricevere i dati attivati.
- Governance e conformità: L'attivazione dei dati deve rispettare i metadati del consenso, le policy sulla privacy (ad esempio, GDPR o CCPA) e le autorizzazioni marketing memorizzate nel profilo unificato. L'attivazione sensibile al consenso garantisce che i dati vengano utilizzati solo per scopi autorizzati.
- Pianificazione e prestazioni: Le attivazioni vengono spesso pianificate ogni giorno o ogni ora per mantenere aggiornati i pubblici a valle. Il sistema deve gestire in modo efficiente volumi elevati e aggiornamenti incrementali senza duplicazioni o perdite di dati.
Soluzione
Il processo di attivazione batch in Data 360 segue un flusso di lavoro guidato che riduce al minimo le difficoltà tecniche per gli esperti di marketing, preservando la governance e la scalabilità:
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Creazione segmento | Best | Un esperto di marketing o un analista crea un segmento nell'area di disegno di segmentazione visiva applicando filtri a qualsiasi oggetto modello di dati (DMO) o oggetto approfondimento calcolato (CIO). Definisce il pubblico di destinazione per l'attivazione. |
| Impostazione attivazione | Best | L'utente crea un'attivazione e seleziona il segmento appena creato come origine. Questo definisce il pubblico che Data 360 esporterà nei sistemi a valle. |
| Selezione della destinazione attivazione | Best Practice | L'esperto di marketing seleziona una destinazione attivazione preconfigurata (ad esempio, Marketing Cloud, Google Ads, LinkedIn Ads). Ogni destinazione è registrata in Data 360 con credenziali di autenticazione e mappature di campi. |
| Definizione payload | Obbligatorio | L'esperto di marketing definisce il payload scegliendo identificatori di referente (ad esempio, email, cellulare, ID con hashing) e selezionando attributi di profilo aggiuntivi (ad esempio, nome, livello di fedeltà o CLV) per l'arricchimento nel sistema di destinazione. |
| Pianificazione e frequenza | Consigliato | L'esecuzione delle attivazioni può essere pianificata una sola volta o su base ricorrente (ad esempio, giornaliera o settimanale). La pianificazione garantisce che i pubblici a valle rimangano sincronizzati e aggiornati. |
| Esecuzione ed esportazione | Best | Quando viene eseguito il processo di attivazione, Data 360 esegue una query sul segmento, raccoglie gli attributi selezionati, applica filtri di consenso ed esporta i dati nella piattaforma di destinazione. Per Marketing Cloud, ciò si traduce in genere nella creazione o nell'aggiornamento di un'estensione dati condivisa. |
| Governance e conformità | Obbligatorio | Il Trust Layer applica la convalida dello schema, i metadati del consenso e i controlli delle policy per garantire la conformità ai regolamenti sulla protezione dei dati e il marketing (ad esempio, GDPR, CCPA). |
| Monitoraggio e verificabilità | Best Practice | Ogni esecuzione di attivazione viene monitorata con metriche di successo/fallimento, registri esecuzioni e visibilità delle discendenze nel cruscotto digitale Trust Layer Monitoring (Monitoraggio livello trust), abilitando la trasparenza operativa e la garanzia degli accordi sul livello di servizio. |
Sketch
Ecco il riepilogo dei passaggi:
- Crea segmento: Un esperto di marketing o un analista crea un segmento utilizzando uno strumento di segmentazione visiva, combinando i filtri in tutti gli oggetti dati unificati.
- Crea attivazione: Selezionano il segmento come origine e scelgono una destinazione preconfigurata (ad esempio Marketing Cloud o Google Ads).
- Definisci payload: L'identificatore del referente e altri attributi del profilo vengono scelti per l'esportazione e la generazione di rapporti del pubblico.
- Consegna pianificata: L'attivazione è pianificata in modo da essere eseguita una sola volta o su base ricorrente, mantenendo aggiornato il pubblico nella destinazione.
- Esecuzione: Al trigger, Data 360 esegue una query sul segmento, crea il payload, applica filtri per il consenso e invia il risultato al sistema di destinazione.
Risultati
- I segmenti di pubblico mirati e arricchiti di Data 360 vengono resi disponibili direttamente nelle piattaforme di marketing e pubblicità a valle.
- I pubblici vengono automaticamente aggiornati e sincronizzati con i dati unificati più recenti dei clienti, mantenendo la pertinenza della campagna in tempo reale.
- Gli esperti di marketing possono utilizzare questi pubblici attivati come fonti di accesso per journey di Marketing Cloud, campagne email o pubblici personalizzati nelle piattaforme pubblicitarie digitali come Google Ads, Meta o LinkedIn Ads.
- Ogni esecuzione di attivazione mantiene una discendenza end-to-end, garantendo conformità, tracciabilità e coerenza tra Data 360 e i sistemi esterni.
- Gli utenti aziendali possono offrire esperienze altamente personalizzate e basate sui dati basate su una visualizzazione Customer 360 completa e affidabile.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla piattaforma di destinazione e dalla configurazione della destinazione attivazione.
| Meccanismo | Quando utilizzare |
|---|---|
| Attivazione di Marketing Cloud Engagement (preferito) | Utilizzare quando si eseguono journey email o tra canali che richiedono segmenti dinamici, attributi personalizzati e aggiornamenti in tempo reale in Marketing Cloud. Data 360 viene esportato direttamente nelle estensioni dati condivise per l'attivazione delle campagne. |
| Attivazione piattaforma pubblicitaria (Google Ads, LinkedIn Ads, Meta Ads) | Utilizzare quando si attivano segmenti di Data 360 come pubblici personalizzati nelle piattaforme pubblicitarie per il retargeting o la modellazione lookalike. Supporta gli identificatori con hashing e la consegna sensibile al consenso. |
| Attivazione CRM (Vendite o Service Cloud) | Utilizzare per condividere dati, approfondimenti o punteggi di propensione arricchiti dei clienti con gli utenti CRM per interazioni personalizzate di coinvolgimento nelle vendite o assistenza. I dati vengono resi disponibili come record o approfondimenti arricchiti tramite Azioni dati o Componenti profilo unificato. |
| Attivazione esterna tramite MuleSoft o API | Utilizzare quando l'attivazione deve raggiungere sistemi non Salesforce come i data warehouse fedeltà, eCommerce o di terze parti. MuleSoft o l'API di attivazione di Data 360 garantisce una consegna sicura e basata sulle policy con opzioni di aggiornamento basate sugli eventi. |
| Attivazione ibrida (batch + attivata da evento) | Utilizzare quando si combinano attivazioni batch pianificate con trigger basati sugli eventi, abilitando la personalizzazione "sempre attiva" per le campagne sensibili al tempo come gli avvisi di carrello abbandonato o di rischio di abbandono. |
Gestione e ripristino degli errori
- Isolamento guasto a livello di processo: Ogni esecuzione attivazione viene eseguita come processo distinto e tracciabile nel livello orchestrazione di Data 360. Le esecuzioni non riuscite vengono automaticamente messe in quarantena senza influire su altre attivazioni o definizioni di segmento.
- Ripristino batch parziale: Se l'esportazione di alcuni record non riesce (ad esempio, a causa di non corrispondenze degli identificatori o limiti di traffico API), il sistema li riprova utilizzando aree di attesa delta incrementali con backoff esponenziale e ripristino parallelo.
- Errori di convalida dello schema: Quando gli attributi del payload in uscita non corrispondono più allo schema di destinazione (ad esempio, un attributo eliminato o un campo rinominato), il processo instrada i record interessati all'Area di attesa Rifiuto schema per la revisione da parte dell'amministratore.
- Supporto per riproduzione e ripresa: Ogni processo di attivazione mantiene un token checkpoint, acquisendo l'ultimo batch riuscito. Al ripristino, l'elaborazione riprende dal checkpoint, evitando duplicati o perdite di dati.
- Monitoraggio completo: Tutti gli eventi di attivazione, i tentativi e le metriche di consegna vengono registrati in Trust Layer Monitoring, abilitando il tracciamento degli SLA, l'analisi delle cause principali e gli avvisi automatici tramite le API di Monitoraggio evento.
Considerazioni sulla progettazione idempotente
- Chiavi di attivazione deterministica: Ogni esecuzione di attivazione utilizza una chiave di impotenza composita, che combina ID segmento, ID attivazione e ID sistema di destinazione, per garantire la consegna una volta esatta.
- Rilevamento replay: Il servizio di attivazione di Data 360 esamina i payload in entrata alla ricerca di hash dei processi precedenti per rilevare e sopprimere i replay.
- Committi di esportazione atomici: I payload vengono confermati nel sistema di destinazione solo dopo la corretta conferma in scrittura, impedendo aggiornamenti parziali o il doppio conteggio.
- Risoluzione coerente dell'identità: Poiché le attivazioni dipendono dagli ID unificati (ad esempio, Persona unificata), i replay o i rettry hanno sempre come destinazione lo stesso golden record, mantenendo la coerenza semantica.
- Persistenza stato di attivazione: Il livello di orchestrazione mantiene i metadati dello stato di attivazione (indicazioni orarie, codici di stato e token di sequenza) per la rielaborazione deterministica, se necessario.
Considerazioni sulla sicurezza
- Autenticazione forte: Ogni destinazione attivazione (ad esempio Marketing Cloud, Ads o CRM) utilizza OAuth 2.0 con rotazione del token e definizione degli ambiti specifica del tenant per impedire l'esportazione non autorizzata dei dati.
- Governance a livello di attributo: Solo gli attributi approvati dal profilo unificato sono idonei per l'attivazione, imposti dalle policy di condivisione dati e dai modelli di attivazione.
- Crittografia in transito e a riposo: Tutti i payload vengono crittografati utilizzando TLS 1.2+ durante il trasferimento e AES-256 a riposo sia in Data 360 che nella piattaforma di destinazione.
- Consenso e applicazione delle policy: I processi di attivazione rispettano gli oggetti consenso e le policy sui dati archiviati nel Trust Layer di Data 360. I record senza metadati di consenso validi vengono automaticamente esclusi dall'esportazione.
- Controllo e registrazione della conformità: Ogni esecuzione di attivazione acquisisce chi l'ha avviata, quali dati sono stati inviati e a quale destinazione, abilitando percorsi di controllo normativi completi (GDPR, CCPA) all'interno del cruscotto digitale Trust Layer.
- Accesso con privilegi minimi: Gli utenti integrazione per ogni destinazione sono limitati agli ambiti specifici dell'attivazione, senza privilegi amministrativi o accesso in scrittura a sistemi non correlati.
Intestazioni laterali
Tempestività
- Progettato per esportazioni batch pianificate o quasi in tempo reale (latenza da minuti a ore).
- Supporta aggiornamenti con finestre temporali allineate ai calendari delle campagne.
- I processi di attivazione possono essere sequenziati con indicatori di preparazione ai dati per garantire la freschezza dei dati.
- Più adatto per gli scenari di attivazione non interattivi in cui la precisione dei dati supera l'immediatezza.
Volumi di dati
- Gestisce serie di dati su larga scala (milioni di record per esecuzione).
- Scala orizzontalmente attraverso il partizionamento dei segmenti e i canali di esportazione parallela.
- Utilizza il batching basato su blocchi per evitare timeout e ottimizzare la produttività.
- Ideale per le pipeline di dati di livello aziendale in cui la completezza dei dati è fondamentale.
Gestione statale
- Mantiene gli oggetti stato di attivazione che registrano ID processo, indicazioni orarie e token sequenza.
- Utilizza il checkpointing per riavviabilità e ripristino dei guasti.
- Le definizioni segmento con versione garantiscono la riproducibilità tra i cicli di attivazione.
- Consente la tracciabilità della discendenza tra segmento di origine, attributi DMO e payload di destinazione.
Scenari di integrazione complessi
- Si integra perfettamente con Salesforce CRM, Marketing Cloud e sistemi esterni tramite connettori predefiniti.
- Supporta le attivazioni multi-target, distribuendo i dati contemporaneamente a destinazioni diverse (ad esempio CRM + Ads).
- Può attivare flussi di lavoro compositi, ad esempio l'esportazione in batch seguita da una chiamata API a valle o dal calcolo del punteggio AI.
- Gestisce l'evoluzione dello schema in modo fluido tramite il livello di governance del modello di dati.
Esempio
Un marchio retail globale vuole coinvolgere nuovamente i clienti inattivi degli ultimi 90 giorni. Utilizzando Data 360, l'architetto dei dati definisce un segmento "Clienti dormienti" arricchito con cronologia acquisti, livello di fedeltà e metadati del consenso. Il processo di attivazione batch viene eseguito di notte, inviando questo segmento a Marketing Cloud Engagement per attivare una campagna email personalizzata "Ci manchi" e ad Ad Studio per il retargeting. Il processo sfrutta una consegna idempotente, garantendo che non vengano eseguite duplicazioni tra i vari tentativi e che tutti gli eventi vengano registrati nel Trust Layer per la conformità del controllo.
Contesto
Le aziende spesso richiedono un meccanismo governato per esportare dati unificati o segmentati da Salesforce Data 360 in un formato di file standard (ad esempio, CSV o Parquet) per l'archiviazione, la conformità o l'integrazione a valle. Questo schema abilita l'esportazione dello spazio di archiviazione da Data 360 a cloud, consentendo ai dati affidabili dei clienti di fluire in modo sicuro in data lake aziendali o pipeline di analisi ospitate in Amazon S3, Azure Blob o Google Cloud Storage (GCS). I casi d'uso tipici includono:
- Archiviazione periodica delle serie di dati dei clienti consentite per la conservazione ai fini normativi.
- Esportazione di segmenti curati per carichi di lavoro analitici non Salesforce (ad esempio Tableau, Databricks o Power BI).
- Abilitazione di modelli di machine learning esterni che richiedono file CSV o Parquet strutturati come input.
Problema
Come può un'organizzazione esportare un segmento o una serie di dati curata da Data 360 in un bucket di archiviazione cloud (ad esempio Amazon S3) in modo governato, sicuro e automatico, mantenendo l'integrità dello schema e i controlli di conformità? Ad esempio, un team di conformità potrebbe avere la necessità di: "Estrarre tutti i clienti attivi nella regione UE con un consenso valido ed esportare i dati ogni settimana in una posizione S3 per il controllo esterno e la generazione di rapporti." Ciò richiede una pipeline di esportazione ripetibile e attenta alle policy che garantisca il formato di file, le autorizzazioni di accesso e la pianificazione di consegna corretti, senza interventi manuali o movimenti di dati non regolati.
Forze
Più fattori operativi e architettonici regolano questo modello di esportazione:
- Autenticazione e autorizzazione: Le esportazioni devono rispettare il modello IAM del provider di cloud (ad esempio, Ruoli IAM AWS o Enti di servizio Azure) per garantire che solo i sistemi autorizzati possano scrivere nel bucket di destinazione.
- Allineamento schema: Lo schema in uscita deve corrispondere alla struttura e al formato previsti per il sistema di destinazione (CSV, Parquet o JSON).
- Privacy dei dati e consenso: Le serie di dati esportate devono escludere tutti i record privi di metadati di consenso validi.
- Pianificazione e freschezza: Molte esportazioni sono periodiche (giornaliere, settimanali o mensili) e devono essere allineate ai cicli di aggiornamento dei dati aziendali.
- Governance e monitoraggio: Ogni esportazione deve essere controllabile con piena visibilità della discendenza, garantendo la conformità alla conservazione dei dati e ai mandati normativi (ad esempio, GDPR, CCPA).
Soluzione
Lo schema Attivazione esportazione file riutilizza gli stessi connettori di archiviazione cloud protetti utilizzati per l'inserimento ma configurati per l'uscita dati. Gli amministratori registrano innanzitutto la piattaforma di cloud storage (ad esempio Amazon S3, Archiviazione BLOB di Azure o GCS) come destinazione attivazione in Data 360. Quindi, gli utenti configurano ed eseguono un flusso di lavoro di attivazione per esportare il segmento desiderato nel percorso di archiviazione file designato.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Selezione segmento | Best | Gli analisti selezionano una definizione di segmento o query esistente in Data 360\. Il segmento determina quali record e attributi vengono esportati. |
| Impostazione attivazione | Best | Gli utenti creano una nuova attivazione, scegliendo il segmento come origine e la destinazione Cloud Storage (ad esempio, S3). |
| Configurazione della destinazione attivazione | Obbligatorio | Gli amministratori preconfigurano la destinazione con credenziali, ruoli IAM e percorso di output. I formati supportati sono CSV, Parquet e JSON. |
| Definizione payload | Best Practice | Definire lo schema di esportazione selezionando gli attributi richiesti (ad esempio ID, Nome, Email, Regione, Flag di consenso). Il sistema applica la governance a livello di attributo. |
| Pianificazione e frequenza | Consigliato | L'esecuzione delle esportazioni può essere pianificata secondo una cadenza definita (giornaliera, settimanale, mensile) o attivata manualmente in base alle esigenze. |
| Esecuzione & consegna | Best | All'esecuzione, Data 360 esegue una query sul segmento, compila il file di esportazione, lo crittografa e lo scrive nel bucket/cartella configurato utilizzando l'API del provider cloud. |
| Governance e conformità | Obbligatorio | Trust Layer di Data 360 garantisce che tutte le esportazioni rispettino le policy di consenso, la convalida dello schema e i filtri di conformità. |
| Monitoraggio e verificabilità | Best Practice | Ogni esportazione viene tracciata nel cruscotto digitale Trust Layer Monitoring (Monitoraggio livello Trust) con lo stato, i registri esecuzioni e i metadati dei lignaggi. |
Sketch
Di seguito è riportato il riepilogo dei passaggi.
- Seleziona segmento: Un analista o uno steward dei dati sceglie il segmento unificato da esportare.
- Crea attivazione: Crea un nuovo processo di attivazione e seleziona la destinazione Cloud Storage registrata.
- Definisci payload: Specificare lo schema di esportazione, l'elenco degli attributi e il formato del file (ad esempio, CSV).
- Pianificazione dell'esportazione: Scegliere una pianificazione singola o ricorrente.
- Esegui processo: Data 360 genera e consegna in modo sicuro il file al percorso bucket designato.
- Monitoraggio e verifica: I risultati e i registri vengono esaminati nel livello Trust per verificarne la convalida e la conformità.
Risultati
- I segmenti di pubblico mirati e arricchiti di Data 360 vengono resi disponibili direttamente nelle piattaforme di marketing e pubblicità a valle.
- I pubblici vengono automaticamente aggiornati e sincronizzati con i dati unificati più recenti dei clienti, mantenendo la pertinenza della campagna in tempo reale.
- Gli esperti di marketing possono utilizzare questi pubblici attivati come fonti di accesso per journey di Marketing Cloud, campagne email o pubblici personalizzati nelle piattaforme pubblicitarie digitali come Google Ads, Meta o LinkedIn Ads.
- Ogni esecuzione di attivazione mantiene una discendenza end-to-end, garantendo conformità, tracciabilità e coerenza tra Data 360 e i sistemi esterni.
- Gli utenti aziendali possono offrire esperienze altamente personalizzate e basate sui dati basate su una visualizzazione Customer 360 completa e affidabile.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla piattaforma di archiviazione cloud di destinazione e dalla configurazione di attivazione.
| Meccanismo | Quando utilizzare |
|---|---|
| Attivazione di Amazon S3 | Utilizzare quando il data lake aziendale è ospitato in AWS. Data 360 scrive direttamente in un bucket S3 utilizzando ruoli IAM o credenziali temporanee, garantendo un'esportazione sicura e scalabile. |
| Attivazione di Archiviazione BLOB Azure | Utilizzare quando l'organizzazione opera in Microsoft Azure. Data 360 utilizza token SAS o entità di servizio per scrivere file crittografati nei contenitori Blob. |
| Attivazione di Google Cloud Storage (GCS) | Utilizzare quando i carichi di lavoro di data science o analytics vengono eseguiti su GCP. Data 360 utilizza le credenziali OAuth per esportare i file in bucket GCS in formato CSV o Parquet. |
| SFTP o gateway file esterno | Utilizzare quando i sistemi normativi o legacy richiedono la consegna sicura dei file tramite endpoint SFTP o piattaforme di trasferimento file gestite dall'azienda. |
| Esportazione ibrida (File + API) | Utilizzare quando un'applicazione a valle richiede sia l'esportazione basata su file per l'analisi che un trigger API per l'orchestrazione del flusso di lavoro (ad esempio, il flusso MuleSoft). |
Gestione e ripristino degli errori
- Isolamento a livello di processo: Ogni esportazione viene eseguita come processo discreto. I processi non riusciti vengono messi in quarantena e riprovati in modo indipendente.
- Riprova file parziale: Se alcuni batch non vengono caricati (ad esempio, a causa di interruzioni della rete), il sistema tenta nuovamente questi blocchi utilizzando il backoff esponenziale.
- Gestione non corrispondenza schema: Qualsiasi fluttuazione dello schema o mancata corrispondenza dei campi instrada i record all'area di attesa Rifiuto schema per la revisione.
- Checkpoint e ripresa: I processi di esportazione mantengono i metadati del checkpoint, abilitando la ripresa dall'ultima scrittura riuscita senza duplicazioni.
- Monitoraggio integrato: Gli errori e i nuovi tentativi vengono registrati nel cruscotto digitale Trust Layer per la visibilità e la conformità agli SLA.
Considerazioni sulla progettazione idempotente
- Chiavi deterministiche di esportazione: Ogni processo di esportazione include un ID univoco composto da ID segmento + ID destinazione + Indicazione oraria.
- Sicurezza di riproduzione: Le esecuzioni di processi duplicati vengono rilevate utilizzando gli hash e ignorate per evitare esportazioni ridondanti.
- Garanzia di scrittura atomica: Data 360 conferma i file nel bucket di destinazione solo dopo il completamento completo e la convalida del checksum.
- Versione schema coerente: Le definizioni di esportazione sono controllate dalla versione per garantire la coerenza dello schema tra le esecuzioni.
- Persistenza checkpoint: I processi di esportazione persistono per il recupero deterministico e la rielaborazione, se necessario
Considerazioni sulla sicurezza
- Autenticazione forte: I connettori cloud utilizzano OAuth 2.0, ruoli IAM o entità di servizio per le scritture autenticate.
- Crittografia ovunque: I dati vengono crittografati sia in transito (TLS 1.2+) che a riposo (AES-256).
- Esportazione sensibile al consenso: Vengono esportati solo i record con consenso valido, imposti dalle policy Trust Layer.
- Principio dei privilegi minimi: Gli utenti export e gli account di servizio sono limitati ai percorsi di archiviazione designati.
- Registrazione di controllo completa: Ogni esportazione registra i metadati, inclusi iniziatore, schema, destinazione e indicazioni orarie per la generazione di rapporti sulla conformità.
Intestazioni laterali
Tempestività
- Progettato per l'attivazione immediata basata sugli eventi con latenza inferiore ai secondi.
- Ideale per gli scenari che richiedono personalizzazione immediata, consigli o decisioni.
- Funziona in modalità streaming: i trigger vengono attivati non appena si verificano modifiche dei dati qualificanti in Data 360.
- Garantisce una reattività continua senza dover attendere pianificazioni batch o ricalcoli di segmenti.
Volumi di dati
- Gestisce serie di dati su larga scala (milioni di record per esecuzione).
- Scala orizzontalmente attraverso il partizionamento dei segmenti e i canali di esportazione parallela.
- Utilizza il batching basato su blocchi per evitare timeout e ottimizzare la produttività.
- Ideale per le pipeline di dati di livello aziendale in cui la completezza dei dati è fondamentale.
Gestione statale
- Ogni azione evento mantiene il proprio token evento e ID replay per un'elaborazione idempotente.
- Supporta la persistenza del checkpoint per riprendere dall'ultimo evento confermato in caso di errore temporaneo.
- Include una logica di deduplica incorporata e finestre di riproduzione per garantire una semantica di attivazione esatta.
- I risultati dell'azione (successo/fallimento) vengono registrati in tempo reale e presentati attraverso il cruscotto digitale di osservabilità Trust Layer.
Scenari di integrazione complessi
- Si integra direttamente con i flussi Salesforce, gli eventi piattaforma Einstein 1 o i webhook esterni per le catene di risposta istantanea.
- Può attivare automazioni a valle, ad esempio aggiornamenti istantanei dei record CRM, calcolo del punteggio AI o invii di messaggi di Marketing Cloud.
- Supporta l'orchestrazione componibile: i trigger di evento possono chiamare azioni Data 360, chiamate Apex o API esterne.
- Progettato per gli schemi aziendali agentici e adattivi in cui le risposte sensibili al contesto devono verificarsi immediatamente.
Esempio
Un'azienda di vendita al dettaglio globale deve fornire un'esportazione settimanale del segmento "Membri fedeltà attivi" per l'analisi in Databricks. L'amministratore di Data 360 configura Amazon S3 come destinazione attivazione e pianifica un'esportazione CSV settimanale nel percorso s3://enterprise-analytics/loyalty/weekly_exports/. Il processo di esportazione viene eseguito ogni domenica, generando un file filtrato per il consenso con oltre 2 milioni di record. Tutti gli eventi, le definizioni dello schema e la discendenza vengono registrati nel cruscotto digitale Trust Layer, garantendo trasparenza, verificabilità e conformità.
L'attivazione basata su API on-demand è un approccio basato sugli eventi in tempo reale per rendere fruibili gli approfondimenti di Data 360 nel momento in cui sono necessari, senza attendere processi batch o esportazioni pianificate. Anziché pubblicare segmenti predefiniti con una cadenza fissa, questo schema consente ai sistemi esterni, alle app Salesforce o agli agenti AI di chiamare direttamente le API Data 360 per recuperare o attivare sezioni di pubblico, attributi dei clienti o approfondimenti specifici su richiesta. Questo schema è progettato per esperienze interattive basate su trigger, ad esempio quando un utente accede a un portale, un agente apre un record cliente o un copilota AI avvia una query Next Best Action. Anziché affidarsi a esportazioni precalcolate, il sistema esegue query o attiva in modo dinamico i dati più aggiornati e gestiti da Data 360 in tempo reale. Il vantaggio principale è l'immediatezza e la precisione:
- Ogni chiamata API accede all'Intelligence clienti più aggiornata all'interno del grafico del profilo unificato e sensibile al consenso di Data 360.
- Le attivazioni sono idempotenti e controllabili, in linea con i requisiti di Enterprise Trust e conformità.
- Le integrazioni possono essere attivate direttamente da flussi Salesforce, Apex o sistemi esterni tramite API piattaforma Einstein 1, API Connect o API di attivazione. Questo approccio supporta i casi d'uso in cui latenza e personalizzazione sono più importanti, ad esempio:
- Attivazione di un'offerta di prodotti personalizzata durante una chiamata di assistenza.
- Generazione di pubblici campagna dinamici basati su eventi comportamentali live.
- Inserire decisioni in tempo reale nei modelli AI o ML che operano al momento del coinvolgimento.
Contesto
Le aziende spesso hanno bisogno di presentare approfondimenti armonizzati e in tempo reale su Data 360 all'interno di applicazioni personalizzate, ad esempio portali Web interni, app mobili o esperienze Web rivolte ai partner. Questo schema consente agli sviluppatori di creare soluzioni sicure e incentrate sull'interfaccia utente che utilizzano e visualizzano dati unificati dei clienti insieme a Salesforce CRM e ad altri sistemi contestuali, il tutto tramite l'accesso governato e basato su API. I casi d'uso tipici includono:
- Incorporare approfondimenti di Data 360 nei cruscotti digitali interni dei dipendenti o nelle app mobili.
- Creazione di portali partner o concessionari con visibilità sui clienti e sulle transazioni.
- Integrazione dei dati di Data 360 in applicazioni Web o livelli di esperienza di terze parti.
- Visualizzazione di consigli personalizzati in tempo reale basati su Data 360 ed Einstein 1.
Problema
Come può uno sviluppatore creare un'applicazione personalizzata e incentrata sull'interfaccia utente che accede e visualizza in modo sicuro i dati armonizzati di Data 360, spesso insieme ad altre fonti di dati Salesforce, senza duplicare o esportare informazioni sensibili? Ad esempio, un'azienda può avere la necessità di creare un Portale Clienti che mostra profili cliente unificati, interazioni e approfondimenti calcolati da Data 360. Ciò richiede un unico livello API sicuro e performante in grado di potenziare l'esperienza front-end, gestire l'autenticazione e garantire la governance, eliminando al contempo la complessità del modello di dati interno di Data 360.
Forze
Molteplici considerazioni architettoniche e operative influenzano questo schema:
- Accesso interfaccia utente: L'obiettivo principale è rendere visibili i dati all'interno di esperienze front-end personalizzate (web o mobile), non eseguire estrazioni batch o sincronizzazioni backend.
- Gateway sicuro: L'API scelta deve fungere da punto di ingresso sicuro e scalabile per le applicazioni e gli utenti autenticati, imponendo controlli di accesso di livello aziendale.
- Contesto dati unificato: Le applicazioni devono essere in grado di combinare facilmente i dati di Data 360 (ad esempio profili unificati, approfondimenti calcolati) con i dati CRM, ERP o di oggetti personalizzati.
- Developer Simplicity : Le API devono restituire payload pronti per la presentazione che riducono al minimo l'elaborazione del backend o la mappatura dello schema nel livello client.
- Governance e osservabilità: Tutto l'accesso dovrebbe passare attraverso canali affidabili e controllabili con chiara discendenza, autenticazione e applicazione delle policy.
Soluzione
La soluzione consiste nell'utilizzare l'API REST Salesforce Connect come gateway di integrazione principale per creare applicazioni personalizzate basate sui dati su Data 360. L'API Connect offre un accesso RESTful ai dati Salesforce, inclusi i profili armonizzati, i segmenti e gli approfondimenti calcolati di Data 360, in formati di risposta ottimizzati per il consumo dell'interfaccia utente (basati su JSON, leggeri e adatti ai dispositivi mobili). Gli sviluppatori eseguono l'autenticazione tramite un'applicazione connessa, ottengono token OAuth 2.0 e chiamano risorse API Connect come /query, /Chatter o /data per rendere visibili i dati unificati direttamente nelle interfacce delle loro applicazioni. Dietro le quinte, l'API Connect funge da base di trasporto per altre API, ad esempio l'API Query, l'API Data Graph e le API Einstein 1 Platform, consentendo agli sviluppatori di combinare più fonti di dati in un unico schema di accesso unificato.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Autenticazione e registrazione app | Obbligatorio | Creare un'applicazione connessa in Salesforce per l'autenticazione basata su OAuth 2.0. Configurare gli ambiti per l'accesso all'API Data 360. |
| Accesso ai dati (profili, segmenti, approfondimenti) | Best | Utilizzare gli endpoint API Connect (/services/data/vXX.X/connect) per eseguire query sui dati armonizzati di Data 360, sui profili unificati e sugli approfondimenti calcolati. |
| Integrazione dell'interfaccia utente | Best | Le app front-end (React, Angular, iOS, Android) chiamano l'API Connect per visualizzare i dati di Data 360 in cruscotti digitali, portali o interfacce mobili. |
| Query sul grafico dati | Consigliato | Combinare l'API Connect con l'API grafico dati per query a livello semantico che semplificano join e relazioni complessi. |
| Aggiornamento in tempo reale | Facoltativo | Utilizzare l'API Connect con estensioni WebSocket o streaming per gli aggiornamenti dei dati live. |
| Sicurezza e governance | Obbligatorio | Applicare la visibilità dei dati utilizzando gli ambiti OAuth, le policy Data 360 e il framework di controllo Trust Layer. |
Sketch
Di seguito è riportato il riepilogo dei passaggi.
- Registra applicazione connessa: definire gli ambiti OAuth e le autorizzazioni API per l'autenticazione delle applicazioni esterne.
- Obtain Access Token (Ottieni token di accesso): l'app esterna esegue l'autenticazione OAuth 2.0 per ricevere un token per l'accesso a Data 360.
- API Invoca Connect — L'app effettua chiamate API REST per recuperare i dati di profilo, segmento o approfondimento unificati.
- Renderizzazione dei dati nell'interfaccia utente: le risposte vengono analizzate e presentate agli utenti in un portale con immagine aziendale o in un'interfaccia mobile.
- Gestisci errori e token di aggiornamento: le app implementano la logica di tentativo e l'aggiornamento automatico dei token per garantire la continuità della sessione.
- Monitor & Audit Access — Tutte le chiamate API vengono registrate nel Trust Layer per visibilità e conformità.
Risultati
Gli sviluppatori possono creare applicazioni protette con immagine aziendale personalizzata strettamente integrate con Data 360. Queste app possono:
- È possibile presentare profili cliente e approfondimenti armonizzati in tempo reale.
- Visualizzare i dati di Data 360 insieme a oggetti CRM o personalizzati tramite API unificate.
- Sfruttare controlli di autenticazione, autorizzazione e controllo coerenti tramite il livello Trust.
- Offrire a utenti aziendali o partner un accesso senza interruzioni e regolamentato a Intelligence clienti affidabile in tutte le esperienze.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla piattaforma di archiviazione cloud di destinazione e dalla configurazione di attivazione.
| Meccanismo | Quando utilizzare |
|---|---|
| API REST Connect (preferita) | Utilizzare quando si creano app Web, mobili o di terze parti che richiedono l'accesso in tempo reale ai dati di Data 360 in un formato JSON intuitivo. |
| API grafico dati | Utilizzare quando l'app deve eseguire query a livello semantico su più oggetti (ad esempio, Cliente → Transazioni → Campagne). |
| API Query | Utilizzare quando si eseguono query simili a SOQL per recuperare serie di dati armonizzate con elevata precisione. |
| API piattaforma Einstein 1 | Utilizzare quando si integrano approfondimenti basati sull'intelligenza artificiale o consigli generati da Copilota all'interno di interfacce utente personalizzate. |
| Wrapper di gateway MuleSoft o Apex | Utilizzare quando è necessaria un'ulteriore orchestrazione, caching o applicazione delle policy tra l'app e l'API Connect. |
Gestione e ripristino degli errori
- Limitazione della richiesta: Esegue automaticamente la retromarcia e riprova le chiamate API entro i limiti di traffico.
- Protezione dalla fluttuazione degli schemi: utilizza il controllo delle versioni dello schema GraphQL o l'individuazione dei metadati REST per adattarsi alle modifiche dello schema.
- Gestione scadenza token: le applicazioni aggiornano automaticamente i token OAuth per evitare interruzioni della sessione.
- API Fault Isolation: le chiamate API non riuscite vengono registrate e riprovate senza influire sulle sessioni simultanee.
- Osservabilità livello Trust – Le percentuali di successo/fallimento dell’API e i registri di accesso sono visibili nel cruscotto digitale Trust Layer.
Considerazioni sulla progettazione idempotente
- ID richiesta deterministica: Ogni richiesta API include un ID correlazione per un'elaborazione sicura per il replay.
- Intestazioni convalida cache: Le intestazioni ETag e Ultima modifica impediscono recuperi di dati ridondanti.
- Operazioni di lettura atomica: L'API Connect garantisce che ogni risposta rifletta un'istantanea coerente dei dati unificati.
- Protezione dai replay: le chiamate API duplicate vengono filtrate utilizzando le firme e le indicazioni orarie delle richieste.
Considerazioni sulla sicurezza
- Autenticazione OAuth 2.0: Tutte le chiamate API utilizzano token di accesso OAuth protetti e di breve durata tramite le applicazioni connesse.
- Accesso con privilegi minimi: Gli ambiti API sono limitati solo agli oggetti e ai campi necessari.
- Crittografia ovunque: TLS 1.2+ in transito; crittografia AES-256 a riposo per le risposte memorizzate nella cache o memorizzate.
- Accesso ai dati sensibili al consenso: Data 360 garantisce che tutti i record recuperati rispettino le policy di consenso e governance.
- Registrazione di controllo completa: Ogni interazione API viene registrata con i metadati di utenti, app e indicazioni orarie nel livello Trust.
Intestazioni laterali
Tempestività
- Progettato per l'accesso API in tempo reale a bassa latenza.
- Ideale per applicazioni interattive che richiedono un rendering immediato dei dati.
- Supporta tempi di risposta alle query quasi istantanei tramite fonti Data 360 memorizzate nella cache e indicizzate.
- Nessuna dipendenza dalle pianificazioni batch o dai cicli di attivazione asincroni.
Volumi di dati
- Ottimizzato per i casi d'uso interattivi che recuperano serie di dati di piccole e medie dimensioni (ad esempio profili, approfondimenti o transazioni recenti).
- Gestisce i risultati impaginati in modo fluido tramite la paginazione basata sul cursore.
- Non destinato alle esportazioni in blocco a volume elevato: utilizzare schemi di esportazione batch o file per serie di dati di grandi dimensioni.
Gestione statale
- Le applicazioni mantengono uno stato di sessione leggero con token OAuth e cache locale.
- L'API Connect supporta le richieste condizionali e l'aggiornamento parziale per l'efficienza.
- Le risposte API includono indicatori di versione per la coerenza dello schema tra i rilasci.
Scenari di integrazione complessi
- Combinare l'API Connect con l'API Data Graph per le query semantiche su più domini.
- È possibile integrarsi con API copilota o AI Einstein 1 per esperienze di conversazione predittive.
- Utilizzare Experience Cloud o i componenti Web Lightning per lo sviluppo dell'interfaccia utente ibrida.
- Estensione tramite MuleSoft per orchestrare l'arricchimento dei dati o le ricerche di sistemi esterni in tempo reale.
Esempio
Una società di assicurazioni multinazionale crea un portale self-service per i clienti che consente agli assicurati di visualizzare i loro profili unificati, le richieste recenti e le offerte personalizzate. L'app front-end basata su eact esegue l'autenticazione tramite OAuth 2.0 e recupera i dati utilizzando l'API REST Connect e l'API Data Graph. Tutti i dati vengono visualizzati in tempo reale, sensibili al consenso e gestiti tramite il livello Trust di Data 360. Gli sviluppatori monitorano le chiamate API e gli itinerari di controllo direttamente all'interno di Salesforce, garantendo la piena conformità e osservabilità.
Contesto
Le aziende richiedono sempre più spesso l'accesso immediato a un profilo cliente completo per i sistemi decisionali in tempo reale, ad esempio Service Console, Motori di consiglio o Piattaforme di personalizzazione. Questo schema consente alle applicazioni di recuperare visualizzazioni unificate precalcolate dei dati di un cliente quasi in tempo reale utilizzando l'API Data Graph di Data 360, offrendo tempi di risposta inferiori ai secondi per le esperienze interattive. I casi d'uso tipici includono:
- Visualizzazione di una visualizzazione a 360 gradi dei clienti all'interno di un Servizio clienti o Sales Console.
- Potenziamento dei consigli basati su AI "Next Best Action" o "Next Best Offer".
- Offrire esperienze Web o mobili iper-personalizzate in fase di caricamento delle pagine.
- Supporto delle decisioni in sessione negli ambienti degli agenti o self-service.
Problema
Come può un'applicazione recuperare istantaneamente una visualizzazione cliente completa, pre-calcolata e unificata, anziché eseguire query lente multi-oggetto in fase di esecuzione? Ad esempio, un motore di personalizzazione Web deve caricare il contesto completo del cliente (dati demografici, preferenze, transazioni e approfondimenti calcolati) in millisecondi per selezionare un'offerta personalizzata. Le query relazionali tradizionali possono richiedere più join e causare una latenza inaccettabile. Ciò richiede un'API che fornisca dati di profilo denormalizzati e pronti all'uso, recuperabili tramite una singola ricerca della chiave, combinando velocità, completezza e governance.
Forze
Più fattori operativi e di prestazione influenzano questo schema:
- Velocità: Il tempo di risposta deve essere nearReal-Time. L'API deve restituire un profilo completo in millisecondi per supportare le interazioni sincrone.
- Completezza: La risposta deve includere tutti gli attributi, le relazioni e gli approfondimenti calcolati pertinenti, idealmente in un unico payload.
- Efficienza di ricerca: I profili devono essere recuperabili tramite identificatori come customerId, contactKey o email, eliminando le query in più fasi.
- Freschezza dei dati vs. Latenza: Alcuni casi d'uso preferiscono i dati precalcolati (con cache) per la velocità; altri necessitano di dati live, accettando latenza più elevata.
- Governance e sicurezza: L'accesso deve rimanere regolato dalle policy Salesforce Trust Layer, garantendo la conformità alle regole di visibilità dei dati e consenso.
Soluzione
La soluzione consiste nell'utilizzare l'API Salesforce Data Graph per recuperare le visualizzazioni cliente precalcolate e denormalizzate memorizzate come record Grafico dati. Un grafico dati è una visualizzazione semantica materializzata che combina più oggetti modello di dati (DMO), ad esempio Persona, Transazione e ProductInterest, in un unico record di sola lettura, spesso rappresentato come blob JSON. Gli sviluppatori possono utilizzare endpoint REST come: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} per recuperare un record completo in base al relativo identificatore univoco. Per gli scenari dinamici, l'API supporta un parametro live=true che ignora la cache materializzata, eseguendo una query in tempo reale in Data 360, scambiando la latenza minima con i dati più aggiornati. Ciò consente agli sviluppatori di scegliere tra recuperi di profili istantanei (con cache) e aggiornati (live) a seconda delle esigenze aziendali.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Definizione grafico dati | Obbligatorio | Gli architetti definiscono un grafico dei dati che combina più DMO in un'unica entità semantica (ad esempio, UnifiedCustomerProfile). |
| Recupero ricerca profilo | Best | Le applicazioni chiamano GET /api/v1/dataGraph/{entity}/{id} per recuperare profili completi e denormalizzati in base a ID o chiave univoci. |
| Utilizzo dei parametri live | Facoltativo | Aggiungere ?live=true per forzare il calcolo anziché il recupero nella cache; adatto per decisioni di valore elevato. |
| Autenticazione | Obbligatorio | Utilizzare OAuth 2.0 tramite applicazioni connesse per autenticare le chiamate API in modo sicuro. |
| Analisi delle risposte | Procedure consigliate | Le applicazioni analizzano la risposta JSON direttamente nell'interfaccia utente o nel motore decisionale; non sono necessari ulteriori join. |
| Strategia di caching | Consigliato | Implementare il caching locale a breve termine (ad esempio, in memoria o CDN) per ricerche ripetute di profili. |
| Monitoraggio e osservabilità | Obbligatorio | Utilizzare i cruscotti digitali Trust Layer per monitorare le prestazioni delle query, i tempi di risposta e l'osservanza delle policy. |
Sketch
Di seguito è riportato il riepilogo del flusso di implementazione:
- Definisci grafico dati: gli architetti di dati creano un grafico dati che modella una visualizzazione cliente unificata in più DMO.
- Registra applicazione connessa: gli sviluppatori configurano le credenziali OAuth per l'accesso API sicuro.
- API Invoca grafico dati: l'applicazione emette una richiesta GET con il nome del grafico dati e l'ID record.
- Risposta del processo: l'API restituisce una rappresentazione JSON completa del profilo del cliente.
- Render o Act: l'app che consuma (interfaccia utente o motore) utilizza i dati unificati per personalizzazione, consigli o azioni di servizio.
- Monitor and Tune — Le metriche delle prestazioni e i registri di accesso vengono esaminati tramite la console di osservabilità Trust Layer.
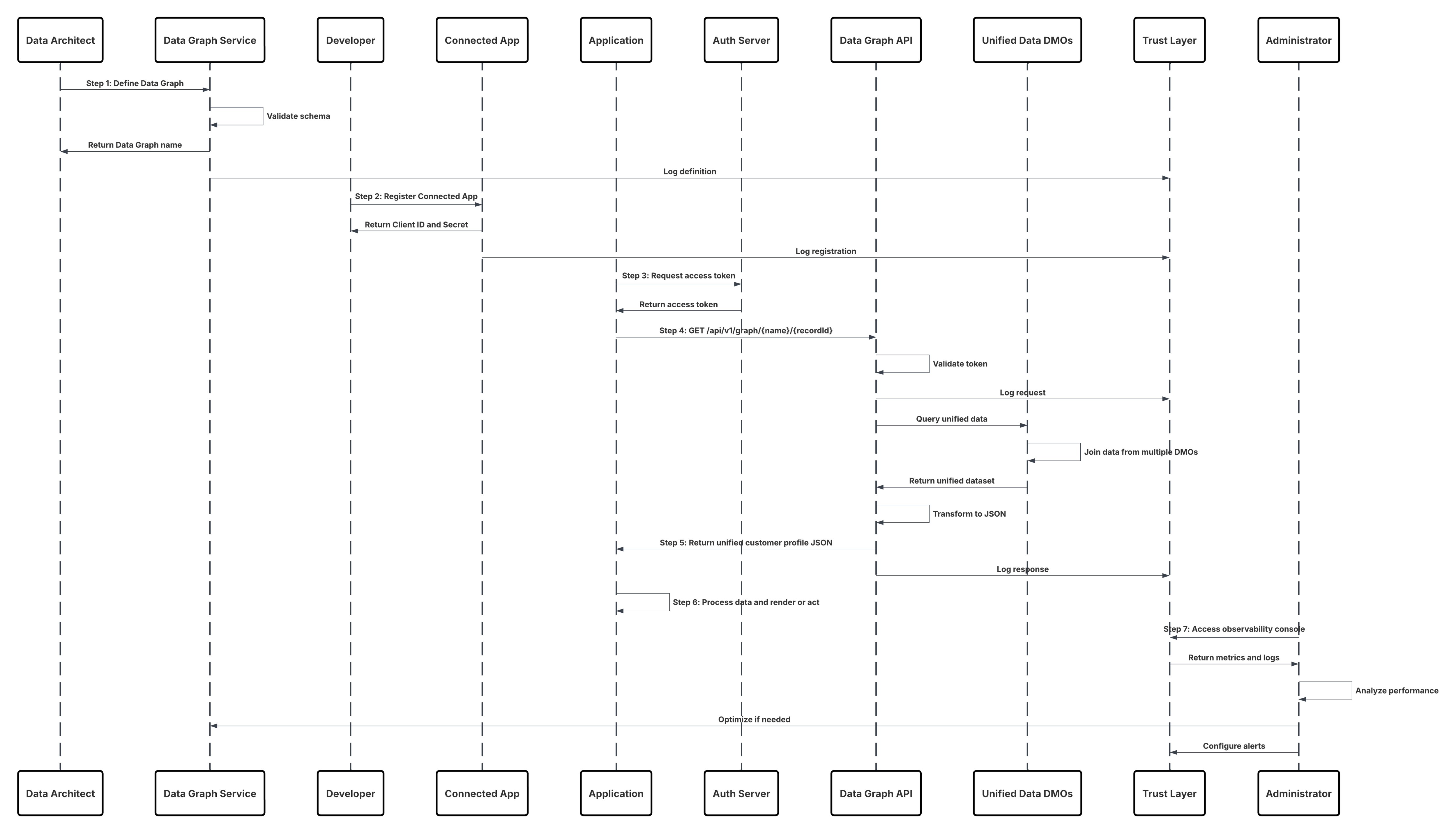
Risultati
Le applicazioni ora possono recuperare istantaneamente un profilo cliente completo e pre-unito, ottimizzando interazioni in tempo reale come personalizzazione, assistenza e automazione delle decisioni. Questo schema garantisce:
- Tempi di risposta inferiori al secondo per le decisioni sul momento.
- Recupero dei dati gestito coerente e in linea con il modello semantico di Data 360.
- Logica di applicazione semplificata: nessun join, nessuna riconciliazione dello schema.
- Accesso tracciabile e conforme tramite il Trust Layer per controllo e osservabilità.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla piattaforma di archiviazione cloud di destinazione e dalla configurazione di attivazione.
| Meccanismo | Quando utilizzare |
|---|---|
| API grafico dati (preferita) | Utilizzare per recuperare istantaneamente profili completi e pre-materializzati in base all'ID o alla chiave. |
| API grafico dati con live=true | Utilizzare per casi d'uso di valore elevato (ad esempio, rilevamento di frodi, offerte live) in cui sono necessari i dati più aggiornati, accettando una latenza leggermente superiore. |
| API Connect (Fallback) | Utilizzare per scenari di applicazioni composte che combinano i recuperi di Grafico dati con altri dati Salesforce. |
| API Query | Utilizzare quando si creano query ad hoc o letture analitiche anziché recuperare istantaneamente i profili. |
| Proxy API MuleSoft | Utilizzare quando si instradano le chiamate di Data Graph attraverso gateway aziendali o quando è necessaria un'ulteriore orchestrazione/imposizione delle policy. |
Gestione e ripristino degli errori
- Fallback graziosi: se le query live non riescono o superano le soglie di timeout, vengono ripristinati automaticamente i recuperi del grafico dati memorizzati nella cache.
- Gestione timeout: implementare la logica dei tentativi e degli interruttori automatici per le chiamate API con carichi elevati.
- Gestione ID non valido: restituire le risposte standard 404 Non trovato per chiavi di profilo inesistenti; gestire con eleganza nell'interfaccia utente.
- Convalida versione schema: convalida i metadati della versione del grafico dati per evitare mancate corrispondenze quando lo schema si evolve.
- Integrazione osservabilità: registrare tutti gli errori, i tentativi e le latenze nei cruscotti digitali Trust Layer per il monitoraggio degli SLA.
Considerazioni sulla progettazione idempotente
- Chiavi deterministiche: ogni recupero di profilo utilizza un ID stabile (ad esempio IndividualId) che garantisce query prevedibili e sicure per la riproduzione.
- Coerenza della cache: utilizzare le intestazioni ETag o Ultima modifica per i recuperi condizionali e la convalida della cache.
- Recupero atomico: ogni risposta API rappresenta un'istantanea coerente del record Grafico dati materializzato.
- Protezione dai replay: assicurarsi che le applicazioni client rilevino i recuperi duplicati tramite ID correlazione e indicazioni orarie.
Considerazioni sulla sicurezza
- Autenticazione avanzata: OAuth 2.0 tramite applicazioni connesse impone un accesso sicuro basato su token.
- Consent-Aware Retrieval (Recupero consapevole del consenso): vengono restituiti solo gli attributi consenzienti; i filtri del consenso vengono applicati automaticamente dal livello Trust.
- Governance a livello di campo: l'accesso agli attributi è controllato tramite i metadati e le definizioni delle policy di Data 360.
- Crittografia in transito e a riposo: tutte le risposte vengono crittografate con TLS 1.2+ e AES-256.
- Controllo e tracciabilità: ogni evento di recupero del profilo viene registrato con identificatori, indicazioni orarie e contesto della policy.
Intestazioni laterali
Tempestività
- Progettato per il recupero istantaneo.
- Supporta le query live per i dati aggiornati con latenza leggermente superiore (sottosecondo).
- Ottimizzato per le decisioni sincrone e le applicazioni interattive.
- Elimina la necessità di attivazione pre-batch o ricalcolo del segmento.
Volumi di dati
- Ideale per ricerche di singoli record o piccoli insiemi (da decine a centinaia) per richiesta.
- Non ottimizzato per il recupero in blocco su larga scala; utilizzare API batch o Query per letture a volume elevato.
- Utilizza il caching scalabile orizzontalmente e la pre-materializzazione per la velocità.
Gestione statale
- Mantiene un accesso leggero e senza stato; ogni richiesta è indipendente.
- Supporta il caching delle intestazioni per un recupero sicuro per il replay.
- Le applicazioni possono mantenere la cache locale o la memoria di sessione a breve termine per ridurre le ricerche ripetute.
Scenari di integrazione complessi
- Si integra perfettamente con Einstein 1, l'API Connect e MuleSoft per esperienze dati composte.
- Può alimentare sistemi agenti (ad esempio, motori di ragionamento copilota o AI) che richiedono una consapevolezza immediata e contestuale.
- Combinato con Azioni dati per trigger in tempo reale al recupero o alla modifica dello stato.
- Consente la personalizzazione su larga scala senza compromettere le prestazioni o la governance.
Esempio
Una piattaforma di e-commerce globale utilizza l'API Data Graph per recuperare i profili cliente unificati in tempo reale per il motore di consigli. Quando un utente esegue l'accesso, l'applicazione richiama l'endpoint Grafico dati per recuperare il ProfiloUnifiedCustomer per quel cliente, restituendo attributi demografici, segnali comportamentali e approfondimenti calcolati come singolo payload JSON. Il motore di personalizzazione utilizza questa risposta in millisecondi per determinare e visualizzare la "Next Best Offer" durante la sessione attiva. Tutte le richieste vengono governate e registrate tramite il Truste Layer, garantendo visibilità completa, applicazione delle policy e conformità in tutta l'interazione.
Le azioni dati in tempo reale consentono l'attivazione immediata dei dati dei clienti nel momento in cui cambiano in Data 360. Anziché attendere le esportazioni batch pianificate, queste azioni inviano aggiornamenti, approfondimenti o trigger direttamente a Salesforce o a sistemi esterni in pochi millisecondi. Quando lo stato, il consenso o la metrica di coinvolgimento di un cliente vengono aggiornati in Data 360, quel segnale può alimentare immediatamente le offerte personalizzate, attivare automazioni di Service Cloud o aggiornare i livelli di fedeltà, assicurando che ogni esperienza del cliente rifletta la verità più aggiornata e unificata. Questo schema è ideale per casi d'uso sensibili alla latenza come esperienze Web personalizzate, avvisi di rilevamento frodi, consigli Next Best Action o aggiornamenti CRM in tempo reale. Colma il divario tra l'approfondimento dei dati e l'azione aziendale, trasformando i dati unificati in intelligenza sul momento.
Contesto
Le moderne esperienze digitali e i flussi di lavoro operativi richiedono azioni immediate e contestuali nel momento in cui si verifica un evento, ad esempio aggiornare il record di un cliente durante un Checkout, modificare l'inventario quando viene eseguita la scansione di un reso o fornire una promozione personalizzata nel momento in cui un utente abbandona un carrello. Le azioni dati in tempo reale consentono ai sistemi di invocare, arricchire e agire sui profili Data 360 unificati e sugli approfondimenti calcolati con latenza da subsecondi a secondi, consentendo la personalizzazione interattiva, l'automazione operativa e la decisione immediata.
Problema
In che modo le applicazioni, i flussi di interazione dell'interfaccia utente o il middleware possono chiamare in Data 360 in fase di esecuzione per leggere, calcolare o aggiornare un singolo profilo unificato o per attivare un'azione (ad esempio, inviare un'offerta, aggiornare CRM, avviare un flusso di lavoro) con bassa latenza, elevata coerenza e controlli di governance, senza attendere processi batch pianificati o opportunità in corso di realizzazione?
Forze
Diverse forze tecniche, operative e di governance modellano questo schema:
- Requisito di bassa latenza: Le chiamate devono essere completate in un intervallo da sottosecondi a pochi secondi per mantenere una buona UX o soddisfare gli SLA operativi.
- Risoluzione deterministica dell'identità: Le richieste devono passare al profilo Persona unificata corretto (golden record) in modo affidabile e rapido.
- Autorizzazione fine-grained: Le chiamate in tempo reale devono applicare policy a livello di attributo e controlli del consenso al momento della richiesta.
- Minimalismo payload: I payload in tempo reale devono essere piccoli e mirati (singolo profilo o piccolo insieme di attributi) per ridurre la latenza e i costi.
- Developer Experience: Le API devono essere facili da usare per gli sviluppatori (REST/gRPC/GraphQL), con schemi chiari e contratti stabili per l'uso in produzione.
- Controllabilità e tracciabilità: Ogni azione in tempo reale deve essere registrata con discendenza, identità utente e decisioni della policy per garantire la conformità.
Soluzione
La soluzione consigliata è utilizzare l'interfaccia Real-Time Data Actions (API + SDK) di Data 360 combinata con il caching edge e trasformazioni di elaborazione minime, ove necessario. Le integrazioni invocano un endpoint azioni dati per leggere o scrivere attributi di profilo, calcolare approfondimenti o avviare orchestrazioni. I controlli delle policy in tempo reale (CEDAR) e il mascheramento dinamico vengono applicati al punto di applicazione delle policy prima che venga restituito qualsiasi payload o eseguita un'azione.
| Area soluzioni | Adatta | Commenti / Dettagli implementazione |
|---|---|---|
| Azione dati in tempo reale | Best | Esporre l'endpoint per i trigger di lettura/scrittura e azione a record singolo. Autenticazione tramite OAuth/JWT. |
| Risoluzione dell'identità | Obbligatorio | Risolvere gli identificatori in entrata (email, externalId, cookie) in ID persona unificata in linea. Utilizzare un risolutore deterministico con cache. |
| Applicazione delle policy (CEDAR) | Best Practice | Valutare il consenso, l'ABAC e le policy di mascheramento al momento della richiesta; negare o mascherare i campi in base alle decisioni delle policy. |
| Livello Edge/Cache | Consigliato | Utilizzare cache TTL brevi per i frammenti di profilo e gli approfondimenti calcolati per ridurre la latenza; invalidare gli eventi di modifica. |
| Trasformazioni Lightweight | Consigliato | Applicare arricchimenti semplici o campi calcolati nel percorso azione; le trasformazioni pesanti devono essere precalcolate. |
| Orchestrazione azione | Best | Supportare le azioni sincrone a fase singola (ad esempio, il token di offerta restituito) e le orchestrazioni asincrone (webhook area di attesa \+) per i flussi complessi. |
| Osservabilità e tracciamento | Obbligatorio | Registrare le richieste/risposte, le decisioni delle policy e la discendenza nel Trust Layer/SIEM per il controllo e il debug. |
| Limitazione e limitazione delle tariffe | Obbligatorio | Applicare le quote dei clienti e strategie di degrado graziose per i momenti di traffico elevato. |
Sketch
Di seguito è riportato il riepilogo dei passaggi.
- Client (interfaccia utente / middleware / POS) invia richieste di azioni dati autenticate con identificatori e tipo di azione.
- Gateway API convalida il token, i limiti di traffico e lo inoltra a Data 360 Action Service.
- Il servizio azioni risolve l'identificatore → ID persona unificata (cache percorso veloce; fallback alla ricerca del grafico).
- Policy Enforcement (PDP) valuta le policy CEDAR utilizzando attributi di PIP e contesto della richiesta.
- Se consentito, Action Service legge tutti gli attributi/approfondimenti del profilo richiesti ed esegue trasformazioni luminose.
- Action Service restituisce la risposta in modo sincrono (ad esempio, token di offerta, attributo aggiornato) o accoda l'orchestrazione asincrona e restituisce la conferma.
- Tutti gli eventi, le decisioni e i payload vengono registrati in Trust Layer ed eventualmente inoltrati a SIEM.
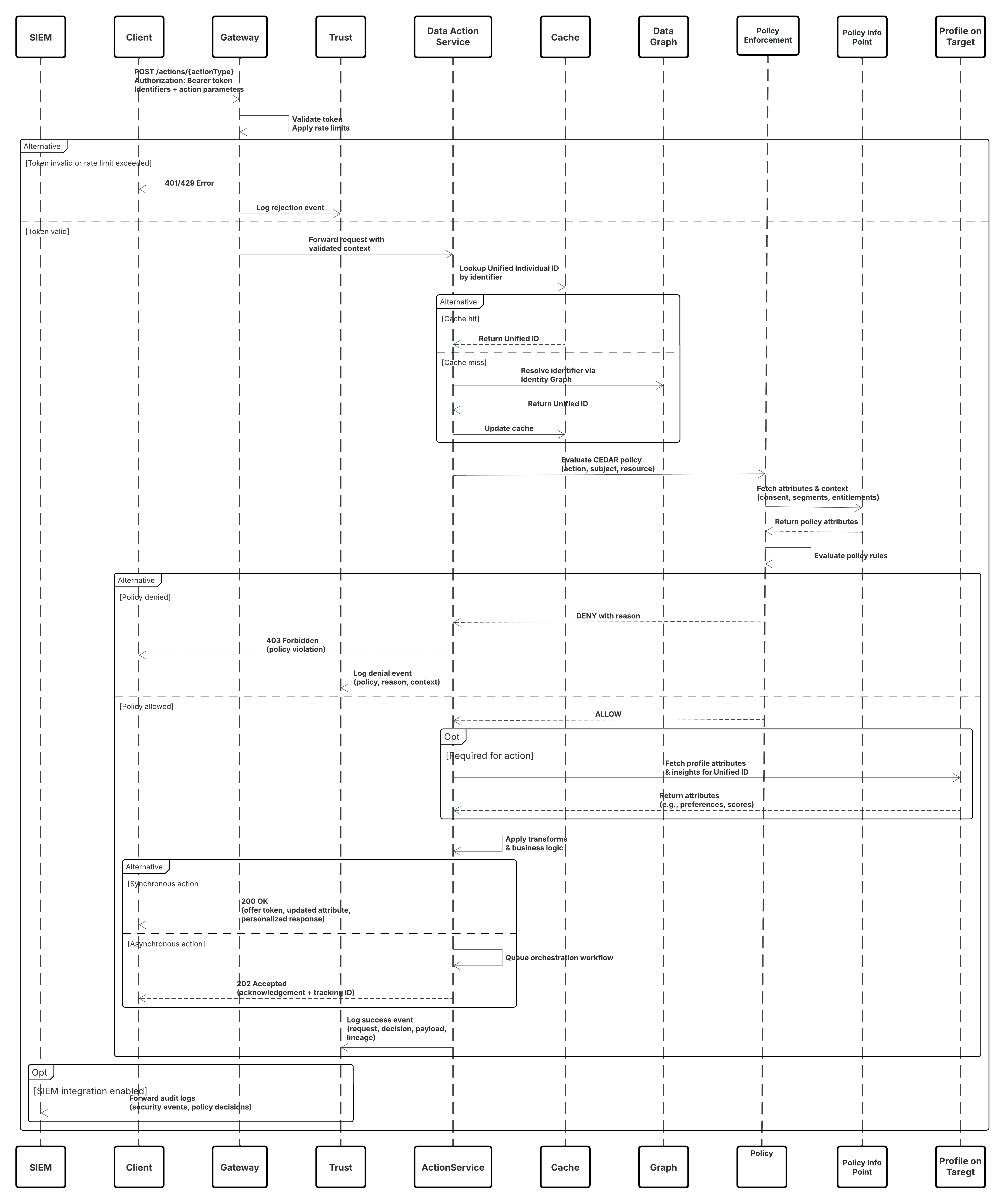
Risultati
- Le applicazioni ricevono l'accesso immediato e regolato dalle policy alle letture/scritture unificate dei profili e ai trigger di azione con latenza da subseconda a seconda.
- Personalizzazione in tempo reale, decisioni e flussi di lavoro operativi (ad esempio offerte, assistenza agli agenti, aggiornamenti dell'inventario) vengono abilitati senza ritardi batch.
- Tutte le azioni sono controllabili, sensibili al consenso e impongono il mascheramento a livello di attributo per mantenere la privacy e la conformità.
Meccanismi di chiamata
Il meccanismo di chiamata dipende dalla piattaforma di destinazione e dalla configurazione della destinazione attivazione.
| Meccanismo | Quando utilizzare |
|---|---|
| API Azioni dati RESTful | Preferito per app Web/mobili e middleware che richiedono letture di profili sincroni o risposte azioni. |
| gRPC / Binary RPC | Utilizzare per i servizi aziendali a latenza ultra bassa o i microservizi interni con connessioni persistenti. |
| Query a record singolo GraphQL | Utilizzare quando i clienti necessitano di una selezione flessibile dei campi e desiderano ridurre al minimo i payload. |
| Webhook attivati da eventi | Utilizzare per i flussi di lavoro asincroni in cui l'azione attiva processi a valle (ad esempio, avvia un journey). |
| Platform Events / PubSub | Utilizzare per scenari di fan-out in cui più sistemi devono reagire a un singolo evento azione. |
| Edge SDK (librerie client) | Utilizzare per i client a bassa latenza che memorizzano nella cache i frammenti di profilo e chiamano l'API Azioni dati solo quando necessario. |
Gestione e ripristino degli errori
- Errori sincroni: Restituire codici di errore strutturati con messaggi in formato leggibile e token di impotenza.
- Tentativo transitorio: I client devono riprovare le richieste idempotenti con backoff esponenziale sulle risposte 429/5xx.
- Gestione rifiuto policy: I rifiuti restituiscono codici motivo chiari; i dati sensibili non vengono mai restituiti in caso di errore della policy.
- Errori dell'orchestrazione asincrona: I processi di orchestrazione vengono spostati in DLQ e sono riproducibili; un'API stato processo consente ai client di eseguire il polling o ricevere richiamate.
- Strategie di fallback: Se la risoluzione dell'identità non riesce, restituire un errore deterministico e, se si desidera, una correzione suggerita (ad esempio, richiedere externalId).
Considerazioni sulla progettazione idempotente
- Chiave impotenza: I client forniscono una chiave idempotency (UUID + spazio dei nomi client) per le azioni di modifica.
- Chiavi deterministiche: Utilizzare le chiavi composte (UnifiedIndividualId + ActionType + TimestampWindow) per rilevare i duplicati.
- Tentativi sicuri: Progettare le azioni per essere tolleranti agli effetti collaterali o per eseguire inserimenti con aggiornamento anziché inserimenti ciechi.
- Protezione dal replay: Persistere con le chiavi impotenza elaborate e TTL dopo la finestra aziendale per evitare riproduzioni.
- Apolidia: Ove possibile, mantenere le azioni sincrone stateless; mantenere lo stato minimo per i flussi di lavoro asincroni.
Considerazioni sulla sicurezza
- Autenticazione: OAuth 2.0 (JWT Bearer o mTLS per gli account di servizio); token di breve durata e rotazione di aggiornamento.
- Autorizzazione: Policy Decision Point applica il controllo dell'accesso basato sugli attributi (CEDAR) e i controlli del consenso per richiesta.
- Transport & Storage Encryption (Crittografia trasporto e stoccaggio): TLS 1.2+ in transito; AES-256 a riposo per eventuali frammenti memorizzati nella cache o registri di controllo.
- Privilegio minimo: Client API limitati a autorizzazioni minime; ruoli separati per lettura e scrittura e orchestrazione.
- Minimizzazione dei dati: Restituire solo gli attributi richiesti e consentiti; applicare il mascheramento dinamico per le informazioni personali/le informazioni personali.
- Controlli di rete: Se si desidera, richiedere chiamate da reti private (Private Connect, elenchi IP consentiti) per le azioni ad alto rischio.
- Controllo e monitoraggio: Registrare i metadati delle richieste, le decisioni delle policy, l'identità del richiedente e gli hash di risposta in Trust Layer e SIEM.
Intestazioni laterali
Tempestività
- Progettato per latenze medie nell'intervallo da sottosecondo a basso secondo per le azioni sincrone.
- Le cache edge (TTL breve) e gli approfondimenti precalcolati riducono i viaggi di andata e ritorno.
- I percorsi asincroni offrono un riconoscimento quasi istantaneo con l'elaborazione in background per le operazioni pesanti.
Volumi di dati
- Ottimizzato per interazioni a singolo record o a piccoli batch (1–100 record).
- Non destinato alle esportazioni in blocco: utilizzare l'attivazione in batch per volumi elevati.
- L'alta produttività utilizza il riutilizzo in pool/connessione e le aree di attesa di orchestrazione parallele.
Gestione statale
- Modello di richiesta stateless per le chiamate sincrone; stato di azione minimo mantenuto per le sovvenzioni/transazioni.
- L'invalidazione della cache causata da eventi di modifica: assicurarsi che i TTL e i segnali di invalidazione mantengano aggiornate le cache.
- I processi di orchestrazione mantengono lo stato duraturo (jobId, stato, tentativi) memorizzato nel livello Trust.
Scenari di integrazione complessi
- Assistente agente: Ricerca del profilo in tempo reale + propensione calcolata restituita a Service Console in un sottosecondo per gli agenti.
- POS / dispositivi Edge: SDK locale + azione dati occasionale per la convalida delle promozioni o dello stato fedeltà.
- Flussi ibridi: Sincronizzare l'azione dati per l'orchestrazione decisione + asincrona per aggiornare i sistemi a valle e attivare le campagne.
- Middleware di terze parti: I gateway MuleSoft o API possono mediare l'autenticazione, arricchire il contesto e imporre controlli delle policy aggiuntivi.
Esempio
Un'app mobile per la vendita al dettaglio determina se visualizzare un coupon istantaneo personalizzato quando un cliente tocca Checkout invocando l'azione dati di idoneità dell'offerta con l'email e il contesto del carrello del cliente. La richiesta viene convalidata dal gateway API e inoltrata al servizio di azione dati, che risolve l'email a un ID persona unificato utilizzando un hit della cache, verifica il consenso al marketing tramite il PDP e valuta l'idoneità in base al valore di durata del cliente e alla frequenza degli acquisti recenti. Se il cliente è idoneo, il servizio restituisce un token coupon firmato e registra la decisione. Quando l'emissione di coupon richiede la prenotazione dell'inventario, viene attivata un'orchestrazione asincrona per prenotare l'inventario e informare i sistemi CRM. L'app visualizza immediatamente il coupon, mentre gli aggiornamenti a valle vengono completati in background e il livello Trust acquisisce un itinerario di controllo completo per la governance e la conformità.
- Connettori e integrazione
- SDK Web e mobile
- Inserimento in tempo reale sub-secondo
- Bring Your Own Lake (Query senza copia)
- Bring Your Own Lake (File copia zero)
- Grafici dati
- Attivazione: Coinvolgimento MC
- Attivazione: Personalizzazione MC
- Attivazione: B2C Commerce
- Condivisione dati (copia zero)
- Attivazione: Archiviazione file
- Azioni dati
- Azioni dati subsecondi in tempo reale
- Piattaforma di attivazione esterna