Ce texte a été traduit en utilisant le système de traduction automatisé de Salesforce. Répondez à notre sondage pour nous faire part de vos commentaires sur ce contenu et nous dire ce que vous aimeriez voir ensuite.
Note
Vue d'ensemble
Salesforce Platform a continuellement amélioré son architecture d'automatisation pour répondre aux exigences des processus métiers complexes. Les générations précédentes – Règles de workflow et Générateur de processus – ont fourni les premières étapes de la logique pilotée par l'événement, en élargissant les capacités d'automatisation de la logique pilotée par l'événement et en élargissant la portée à un plus grand nombre de générateurs.
Cette évolution a abouti à une architecture consolidée et performante centrée sur deux piliers complémentaires : Flux déclenché par un enregistrement et déclencheurs Apex. Ce document fournit le cadre et les consignes nécessaires pour prendre des décisions informées lors de la conception d'automatisations de déclencheur.
Produits dans la portée
Flux
Salesforce Flow est un puissant outil d'automatisation par pointer-cliquer qui permet aux utilisateurs d'élaborer visuellement des processus métiers, des écrans et une logique complexes en utilisant Flow Builder, sans écrire de code. Il automatise des tâches telles que la mise à jour des données, l'envoi d'e-mails et le guidage des utilisateurs, offrant ainsi de la flexibilité à travers des types tels que Flux d'écran (interaction utilisateur) et Flux déclenchés (enregistrement/événements planifiés).
Apex
Salesforce Apex est un langage de programmation propriétaire et orienté objet pour la plate-forme Salesforce, similaire à Java, utilisé pour élaborer une logique métier personnalisée, automatiser les processus et étendre les fonctionnalités CRM de base au-delà des outils déclaratifs.
Points à retenir
L'élaboration d'une automatisation déclenchée par un enregistrement évolutive, maintenable et performante sur Salesforce Platform nécessite une approche disciplinée et pilotée par l'architecture. Le choix entre Flux et Apex, et l'implémentation de chacun, est guidé par une série de principes clairs. Ces points résument ces principes et servent de règles de base pour la conception moderne de l'automatisation.
Choisissez l'outil adapté à votre tâche en fonction de la densité d'automatisation des objets Salesforce.
Utilisez Flux déclenché par un enregistrement pour des objets Salesforce afin d'automatiser la faible densité.
Augmenter la logique de flux déclenché par un enregistrement avec Apex invocable pour des automatisations de densité moyenne.
Utilisez des déclencheurs Apex pour des objets Salesforce pour des automatisations à haute densité.
Faites preuve de prudence en déclenchant des processus asynchrones.
Cette règle s'applique que vous invoquiez des processus asynchrones dans un flux déclenché par un enregistrement ou mettiez en file d'attente une tâche depuis Apex. Bien que ce schéma puisse être tentant pour le délestage du travail, il peut introduire des scénarios complexes de traitement des erreurs et augmenter le risque d'atteindre les limites du gouverneur.
Utilisez un point d'entrée par objet Salesforce.
Pour un objet Salesforce donné, utilisez un mécanisme comme point d'entrée dans l'automatisation. Essayez d'éviter de mélanger des déclencheurs Flux et Apex comme points d'entrée d'un même Objet.
Points de décision
Implémentation déclarative par rapport à programmatique
Flux et Apex partagent un ensemble commun de capacités fondamentales. Chaque outil peut interroger des enregistrements, exécuter une logique conditionnelle, attribuer des variables et exécuter des opérations DML telles que la création, la mise à jour et la suppression d'enregistrements, séquencés pour être exécutés dans un ordre spécifié.
Cependant, ce chevauchement fonctionnel n'implique pas que les outils soient interchangeables. Le choix architectural ne concerne pas si une tâche peut être réalisée, mais comment elle est réalisée et quelles sont les implications à long terme pour les performances, l'évolutivité et la maintenabilité. Le flux excelle dans la clarté déclarative et la rapidité d'implémentation pour des processus simples, tandis qu'Apex fournit le contrôle granulaire et la puissance brute nécessaires pour des solutions complexes.
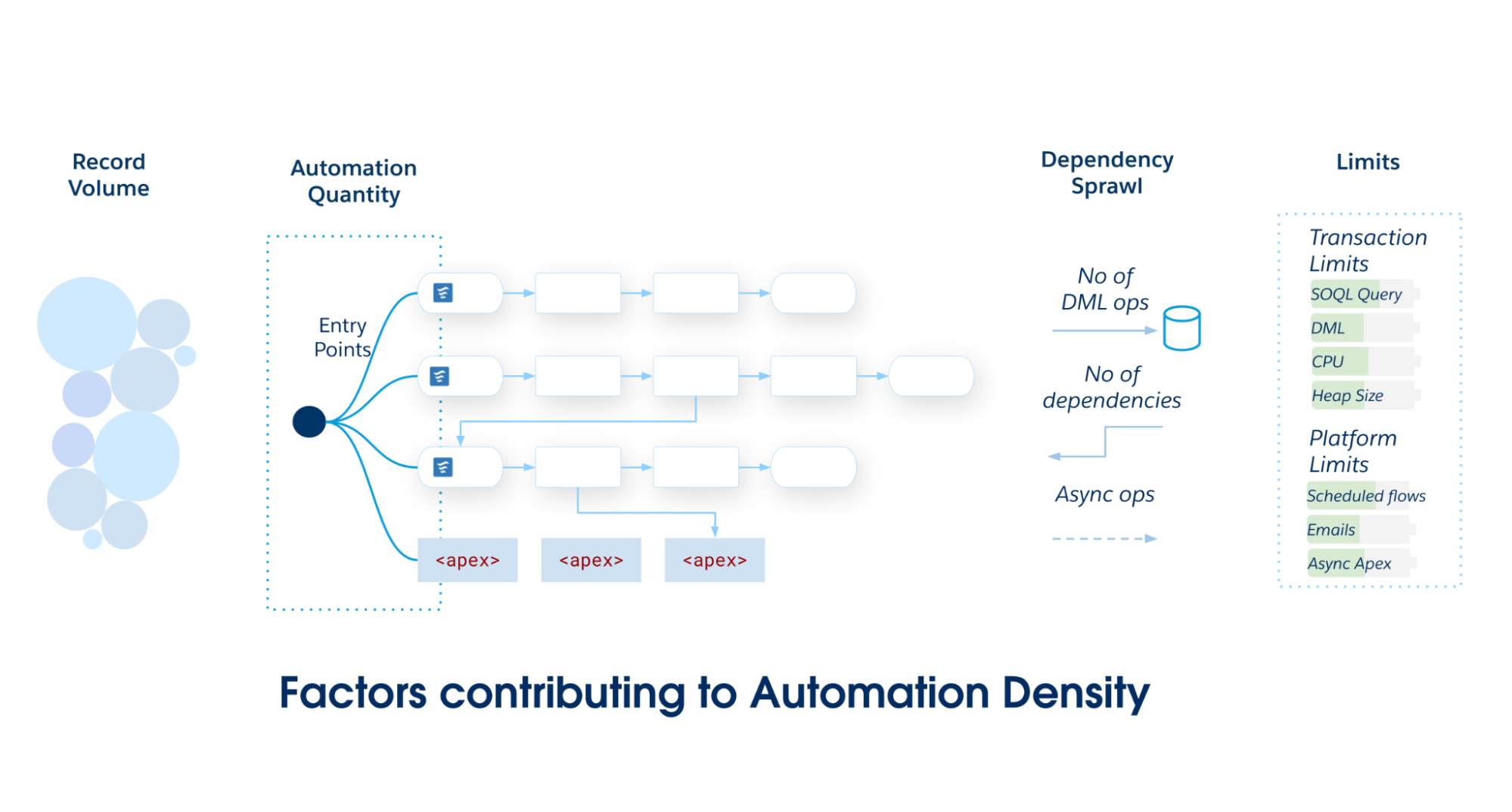
Densité d'automatisation
La densité d'automatisation est la charge imposée à un objet Salesforce spécifique. Il sert d'heuristique pour déterminer l'implémentation optimale de l'objet. À mesure que la densité de l'automatisation augmente, la probabilité d'infraction aux limites transactionnelles augmente.
Calculez la densité d'automatisation en inspectant trois dimensions spécifiques de volume et de complexité :
Quantité d'automatisation : Le nombre brut d'entrées de métadonnées d'automatisation uniques (flux, actions de déclencheur, etc.) exécutées pendant un événement DML (Data Manipulation Language) unique.
Volume d'enregistrement : Les enregistrements par transaction traités via des chargements d'API ou un traitement par lot lourd, où les performances deviennent critiques.
Étendue de la dépendance : Une mesure des opérations DML en aval déclenchées par l'opération CRUD initiale. Il quantifie la profondeur du graphique où une mise à jour est mise à jour en cascade dans des objets associés (par exemple, requête → compte → contact → cumul personnalisé).
À mesure que l'étendue et la complexité de votre application Salesforce augmentent, engagez-vous vers un point d'entrée principal unique, soit Flux déclenché par un enregistrement, soit Déclencheurs Apex. Évitez de partitionner les automatisations entre plusieurs mécanismes dans un seul objet Salesforce, car cela entraîne une mauvaise maintenabilité et une gouvernance fragmentée.
Matrice de sélection de la densité
Utilisez cette matrice afin de déterminer la norme architecturale requise pour votre objet Salesforce.
Le flux déclenché par un enregistrement est la solution préférée pour une faible densité d'automatisation. Il offre un équilibre de puissance et d'accessibilité idéal pour des automatisations simples et indépendantes les unes des autres.
Le schéma hybride (flux déclenché par un enregistrement avec Apex invocable) est un choix puissant et maintenable pour les automatisations à densité moyenne avec une complexité croissante. Ce schéma permet aux équipes de maintenir une chorégraphie ordonnée dans Flux déclaratif tout en déléguant des opérations lourdes en calcul à Apex, en équilibrant l'accessibilité avec les performances.
Les déclencheurs Apex fournissent les blocs de construction nécessaires à une fondation architecturale solide pour soutenir les automatisations à haute densité. Les performances, le contrôle granulaire, ainsi que l'abstraction orientée objet et le polymorphisme d'Apex sont mieux adaptés pour gérer la complexité et l'échelle de ces scénarios.
Niveau de densité
Quantité d'automatisation
Volume de données (taille du lot)
Sprawl de dépendance
Norme architecturale
Faible
< 15
Automatisations
Standard
Interactions de l'interface utilisateur pilotées par l'utilisateur ou petites charges d'API (1 à 200 enregistrements)
Discret
Logique autonome. 0 à 1 opérations DML en aval sur le même objet ou un objet associé.
Flux déclenché par un enregistrement
Moyen
15–30
Automatisations
Modérer
Traitement par lot standard (avec une logique nécessitant un traitement en masse minutieux)
Couplé
Parent/Enfant met à jour 2 à 4 opérations DML en aval. Risque de récursion
Modèle hybride
Flux + Apex invocable
Élevée
> 30
Automatisations
Élevée
Volumes de données importants avec des chargements d'API en masse (2 000 à plus de 10 000 enregistrements)
Complexe et récursif
Graphique de dépendance profonde (5+ opérations DML en aval). Risque de boucles de récursion triangulaires
Infrastructure de métadonnées de déclencheur Apex
Les décisions architecturales réelles nécessitent de peser collectivement toutes les dimensions de la densité de l'automatisation. Tenez compte de l'étendue future potentielle en sélectionnant un mécanisme d'automatisation pour un objet Salesforce donné.
Tenez également compte du nombre total d'opérations DML quotidiennes, car Salesforce applique automatiquement la gestion des ressources partagées dans un environnement multilocataire et les limites du gouverneur afin d'empêcher les automatisations galopantes de monopoliser les ressources partagées. Les objets Salesforce avec un volume DML quotidien élevé nécessitent une sélection rigoureuse de l'automatisation. Par exemple, les limites en temps processeur (60 000 ms) et en taille de tas (12 Mo) sont supérieures aux limites synchrones. De plus, la limite en exécutions asynchrones sur 24 heures à l'échelle de l'organisation (calculée à 250 000, soit 200 fois vos licences utilisateur) nécessite de prendre en compte le DML total quotidien dans votre conception architecturale afin d'éviter les exceptions à l'exécution.
Comparaison des produits
Le flux déclenché par un enregistrement est le principal outil déclaratif de la plate-forme pour l'automatisation déclenchée par un enregistrement. La facilité d'utilisation de Flow et les garanties de plate-forme intégrées permettent aux équipes d'élaborer aisément des solutions évolutives et fiables. C'est le choix idéal pour la plupart des équipes qui élaborent des solutions sur Salesforce Platform.
Apex est le langage de programmation propriétaire, fortement typé et orienté objet de la plate-forme. Utilisez Apex pour les objets Salesforce à forte densité d'automatisation, et pour les cas d'utilisation qui nécessitent des performances élevées, une logique sophistiquée ou un contrôle granulaire des transactions.
Pour faciliter le processus de prise de décision, cette matrice fournit une comparaison directe de Flux et Apex entre les capacités architecturales clés.
Capacité
Flux déclenché par un enregistrement
Déclencheur Apex
Rapidité de livraison et d'entretien
Recommandé
L'interface utilisateur visuelle de Flow Builder permet aux administrateurs et autres générateurs déclaratifs de créer et de modifier des automatisations plus rapidement que l'écriture, le test et le déploiement d'un code Apex. Cette interface permet à un plus grand nombre de membres de l'équipe d'offrir de la valeur métier et réduit la dépendance aux ressources spécialisées pour les développeurs pour de simples tâches.
Expertise requise
Apex nécessite des développeurs de logiciels correctement qualifiés pour implémenter, tester et maintenir le code.
Modularité
Disponible
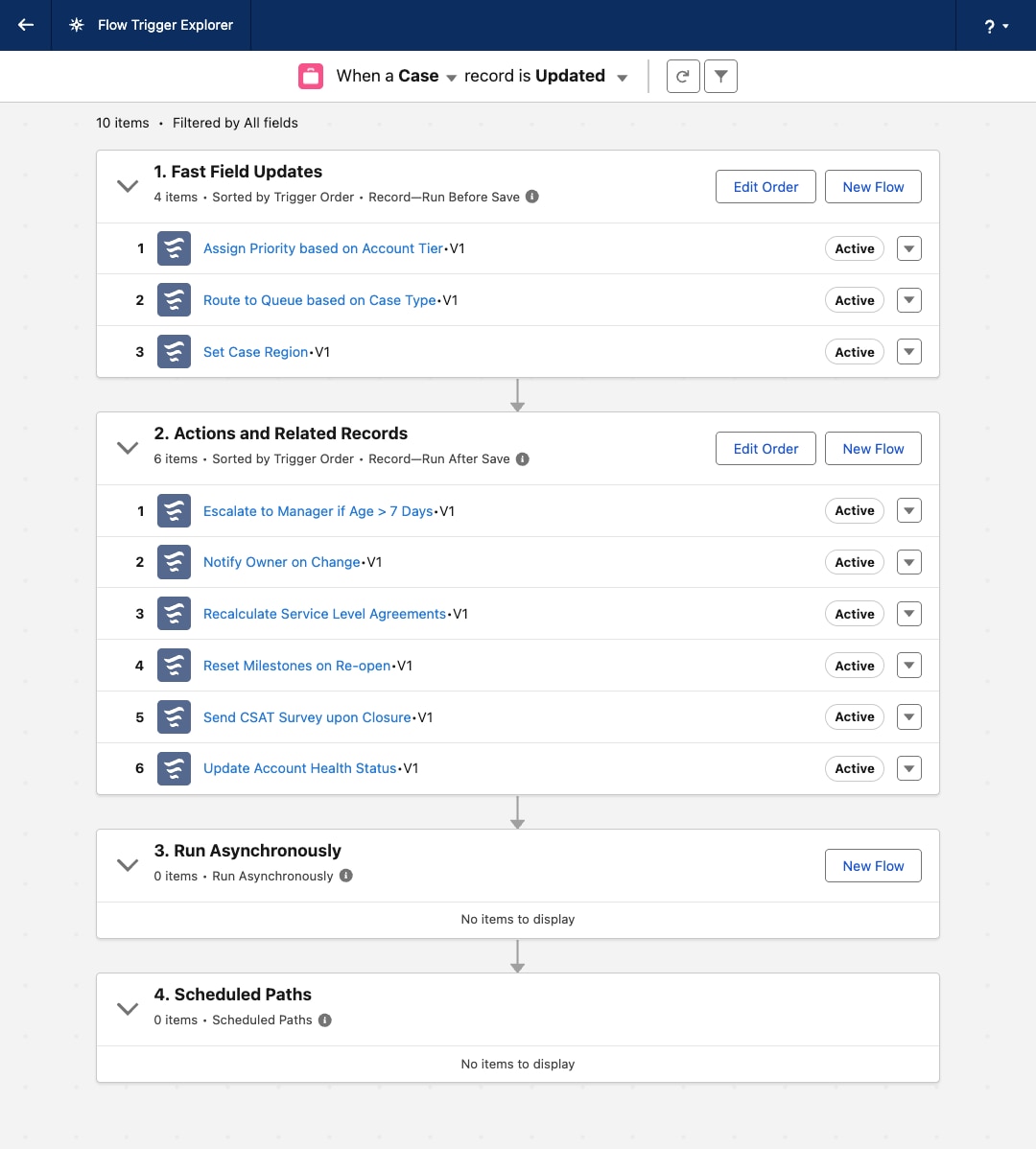
Les flux déclenchés par un enregistrement sont modulaires par défaut. Au lieu d'une logique monolithique, les équipes élaborent des flux discrets pour des exigences spécifiques et les chorégraphient ensemble en utilisant l'Explorateur de déclencheur de flux. Cette modularité permet une modification isolée et une extension simple, réduisant considérablement le coût à long terme de propriété.
Disponible
Apex est divisé en modules fonctionnels par conception. Chaque classe Apex est destinée à implémenter un seul module de fonctionnalité.
Visibilité et gouvernance
Recommandé
La nature visuelle de Flux offre une représentation intuitive de la logique métier. L'Explorateur de déclencheur de flux fournit une vue consolidée de tous les flux d'un objet, ce qui facilite la compréhension, la gouvernance et le dépannage des architectes et des administrateurs sans lire de code.
Expertise requise
L'utilisation d'une infrastructure de métadonnées pour organiser les déclencheurs est avantageuse, mais Apex nécessite une équipe de développement disciplinée pour garder le code organisé et maintenable.
Traitement en masse des données haute performance
Non recommandé
Le risque d'atteindre les limites du gouverneur est élevé lorsqu'il s'agit d'une logique complexe ou de volumes de données importants.
Recommandé
Le code Apex exécute au plus près des services de base de la plate-forme et offre aux développeurs un contrôle renforcé sur l'optimisation des requêtes, le traitement des données et l'efficacité algorithmique. Cela améliore les performances et l'échelle, en particulier dans les scénarios complexes impliquant des volumes de données importants.
Logique robuste et structures de données
Disponible
L'élément Transformation de flux peut faciliter certaines tâches de traitement complexes. Cependant, Flow n'a pas de structures de données Map et Set natives, ce qui rend le traitement des données complexes lourd et inefficace sur le plan informatique.
Recommandé
Apex fournit un accès complet aux boucles Map, Set et programmatic pour une manipulation des données très efficace et sécurisée en masse. En tant que langage de programmation complet, Apex permet également d'accéder à des constructions logiques complexes, des structures de données et des modèles de conception qui peuvent aider à résoudre des problèmes métiers complexes de manière maintenable et efficace. Apex inclut une riche bibliothèque standard de fonctions avancées (par exemple, BusinessHours, Crypto) qui n'est pas disponible actuellement dans les outils déclaratifs.
Contrôle des transactions
Non disponible
Le flux ne fournit aucun accès à `Database.savepoint`, `Database.rollback` ou aux opérations DML partiellement réussies pour des validations de transaction partielles ou des annulations.
Disponible
Apex fournit un contrôle complet et précis de l'intégrité des transactions et des scénarios complexes de reprise après erreur.
Distribution des e-mails
Recommandé
L'envoi d'alertes par e-mail préconfigurées à partir d'un flux déclenché par un enregistrement est facile et évolutif. Des alertes par e-mail personnalisées peuvent être élaborées et distribuées à l'exécution. Les e-mails personnalisés sont soumis à des limites quotidiennes en envois.
Disponible
Apex peut générer et envoyer des e-mails personnalisés. Tous les e-mails envoyés depuis Apex sont soumis aux limites quotidiennes en envois.
Application des garanties de la plate-forme
Recommandé
Le flux inclut des protections intégrées, telles que la mise en masse automatique et les tentatives automatiques. Ces mesures augmentent la vitesse de valorisation et évitent les problèmes de performance qui nécessitent un codage manuel complexe.
Application manuelle requise
Les mesures de protection telles que le traitement en masse doivent être explicitement codées (par exemple, gérer les collections et éviter le SOQL dans les boucles). Les tentatives automatiques ne sont pas natives de déclencheurs et nécessitent une logique personnalisée complexe à implémenter.
Traitement asynchrone
Disponible
Le flux offre des mécanismes faciles pour les automatisations qui nécessitent une transaction séparée dans un parcours asynchrone. Ces automatisations sont soumises à des limitations quotidiennes.
Disponible
Apex permet un contrôle total via la Capture des données de modification et les événements qui peuvent être mis en file d'attente et qui sont gérés par un abonné au déclencheur découplé.
Traitement planifié
Recommandé
Les parcours planifiés du flux offrent une capacité de planification unique et puissante (par exemple, « déclencher 3 jours avant la date de fermeture »). Cette capacité inclut l'annulation et la replanification automatiques si les données de l'enregistrement changent. Ces automatisations sont soumises à des limitations quotidiennes.
Non disponible
Un déclencheur Apex ne peut pas planifier nativement un événement temporel, spécifique à un enregistrement, avec une annulation automatique. Apex planifié existe, mais il s'agit d'un mécanisme fondamentalement différent qui est exécuté à une heure spécifique et qui n'est pas planifié pendant le traitement d'un enregistrement individuel dans le cadre d'un déclencheur.
Commande et chorégraphie
Disponible
L'Explorateur de déclencheur de flux permet aux administrateurs de définir un ordre d'exécution relatif pour plusieurs flux dans le même objet.
Disponible
Une infrastructure de déclencheur permet de contrôler avec précision l'ordre exact des automatisations.
Mises à jour du même champ d'enregistrement
Disponible (avant la sauvegarde)
Le flux déclenché par un enregistrement est l'option déclarative la plus performante pour mettre à jour l'enregistrement déclenchant avant l'engagement DML initial.
Disponible (avant la sauvegarde)
Apex fournit l'offre la plus performante avec un minimum de frais généraux.
CRUD inter-objets
Disponible (après la sauvegarde)
Le flux convient aux opérations DML inter-objets simples et peu complexes.
Disponible (après la sauvegarde)
Apex offre un contrôle supérieur de la déduplication, du traitement des erreurs et des performances pour les opérations DML inter-objets.
Déduplication du calcul coûteux
Disponible
Le flux excelle dans l'élimination des requêtes redondantes et des instructions DML via le traitement en masse automatique. Cependant, l'état ne peut pas être mis en cache ou partagé entre différents déclencheurs de flux ou entre plusieurs invocations du même flux dans une seule transaction. Cette limitation peut devenir importante dans des scénarios de performance extrême.
Recommandé
Apex fournit des mécanismes de déduplication des opérations coûteuses. Les développeurs peuvent exploiter la mise en cache transactionnelle en utilisant des propriétés et des variables statiques, et la mise en cache au niveau de la plate-forme en utilisant Cache de la plate-forme, pour stocker et réutiliser des données. Ces techniques sont importantes pour réduire la consommation des limites du gouverneur transactionnel, telles que les requêtes SOQL, et garantir des performances et une évolutivité élevées.
Gestion des erreurs personnalisées
Disponible
L'élément CustomError peut bloquer une opération d'enregistrement et afficher un message pour l'utilisateur.
Recommandé
La méthode addError() fournit un message d'erreur flexible au niveau du champ et conditionnel.
Cas d'utilisation
Recommandations les plus adaptées
Le tableau ci-dessous présente des recommandations générales « les plus adaptées » pour les cas d'utilisation généraux, en fonction des capacités présentées. En fin de compte, vous prendrez en compte d'autres considérations afin d'arriver à la meilleure adéquation à vos scénarios particuliers, par exemple ceux inclus dans la section Meilleures pratiques connexes du présent document. Vous y apprendrez quand une combinaison particulière de flux et Apex fournit la meilleure approche.
Cas d'utilisation
Description
Best-Fit
Justification
Traitement par lot hautement performant
Toute automatisation qui doit traiter efficacement des milliers d'enregistrements
Apex
Apex fournit des API riches pour l'interface avec la plate-forme et pour la vitesse brute.
Traitement complexe des données
Scénarios qui nécessitent une manipulation avancée des données
Apex
Apex fournit des structures de données, telles que Map et Set, qui ne sont pas disponibles en natif dans Flow, et peuvent être critiques pour écrire un code performant et sécurisé en masse.
Contrôle transactionnel
Mécanismes de contrôle tels que les points de sauvegarde, les annulations et les validations partielles
Apex
Apex permet d'accéder à des mécanismes tels que Database.savepoint et Database.rollback, et a la possibilité de traiter les opérations DML partiellement réussies.
Validation personnalisée sophistiquée
Validation des données dans plusieurs champs d'un enregistrement
Apex
Bien que Flux puisse empêcher l'enregistrement avec l'élément `CustomError`, il n'est pas disponible dans tous les types de flux, y compris les flux secondaires. La méthode Apex addError() fournit plusieurs messages d'erreur spécifiques à un champ qui peuvent être ajoutés à un enregistrement à tout moment pendant le traitement du déclencheur.
Logique moyennement complexe dans un processus simple
Logique et manipulation de données de complexité modérée, simplifiée par une bibliothèque standard de fonctions avancées, survenant dans le cadre d'un processus simple
Flux + Apex
Le flux déclenché par un enregistrement agit en tant que couche d'orchestration, tandis que les opérations hautement complexes sont encapsulées dans Apex invocable.
Logique simple à moyennement complexe
Manipulation de données de complexité faible à modérée, avec des mises à jour de déclencheur pour les objets de données principaux et associés
Flux
Le flux est généralement l'option incontournable, car il est basé sur un modèle déclaratif qui le rend accessible aux administrateurs et aux développeurs.
Notifications et messages sortants
Envoi d'e-mails et de messages sortants
Flux
Le flux facilite et adapte considérablement l'envoi d'alertes par e-mail et de messages sortants lors de modifications d'enregistrement.
Traitement planifié
Automatisation à une date future et dynamique (par exemple, 3 jours avant une date de fermeture)
Flux
Les parcours planifiés offrent une force unique à Flux, car la plate-forme gère automatiquement la planification, l'annulation et la replanification de ces parcours si les données de l'enregistrement changent.
Traitement évolutif : Cas d'utilisation asynchrones en profondeur
L'évolutivité est une considération essentielle lors de la conception de votre implémentation. Lorsque la logique métier d'une automatisation déclenchée par un enregistrement devient complexe, longue ou implique des volumes de données importants, les limites du gouverneur principal de Salesforce Platform deviennent une contrainte architecturale. Des opérations telles que des mises à jour de données en masse, des appels d'API complexes ou des calculs lourds augmentent le risque de dépassement des limites, par exemple le temps processeur total ou le nombre d'instructions DML dans une seule transaction de base de données. Un échec d'un déclencheur synchrone dû à une exception de limite entraîne l'annulation de la transaction d'enregistrement complète de l'utilisateur, ce qui entraîne une mauvaise expérience utilisateur et une perte potentielle de données. Ce risque inhérent exige un modèle architectural pour décharger des travaux complexes.
L'automatisation asynchrone devient dans ce cas indispensable. En utilisant des mécanismes asynchrones, les architectes peuvent efficacement dissocier le travail de longue durée ou à haut volume de la transaction principale et synchrone d'enregistrement. Les enregistrements sont effectués rapidement et de façon fiable, tandis que le traitement lourd est délégué à une transaction séparée gérée par la plate-forme qui est exécutée plus tard. Le découplage améliore la stabilité, évite les échecs de transaction et est essentiel pour élaborer des applications d'entreprise évolutives. La plate-forme offre plusieurs outils spécialisés pour cela, chacun avec des avantages et des compromis distincts en termes de fiabilité, de volume et de complexité.
Chemin asynchrone du flux
Le parcours Exécuter de façon asynchrone dans un flux déclenché par un enregistrement fournit le mécanisme le plus simple pour la logique asynchrone « feu et oubli ». Ce chemin est exécuté dans une transaction séparée lorsque la transaction d'enregistrement d'origine a été engagée avec succès dans la base de données.
Cas d'utilisation idéal: Il convient parfaitement aux tâches qui ne nécessitent pas d'exécution immédiate ou de traitement personnalisé des erreurs. Par exemple, envoyer une notification par e-mail, créer une tâche de suivi ou passer un simple appel externe à un système externe.
Limites: Ce mécanisme partage les mêmes limites quotidiennes du gouverneur que les autres interviews de flux asynchrones. Il n'est pas conçu pour le traitement à très haut volume.
Capture des données de modification (CDC)
La Capture des données de modification (CDC) est un modèle à haut débit, évolutif et résilient qui permet de gérer une logique asynchrone déclenchée par un changement d'enregistrement dans des scénarios à haut volume. Dans ce modèle, la seule responsabilité du déclencheur est d'enregistrer l'enregistrement de façon synchrone. La plate-forme publie ensuite un message d'événement détaillé qui contient les modifications apportées à l'enregistrement dans un bus d'événement à haut volume. Un déclencheur Apex séparé et dédié s'abonne à cet événement de modification. Il effectue des tâches complexes, longues ou asynchrones.
Avantage: Ce schéma découple le processus asynchrone de la transaction utilisateur initiale. Un échec du traitement asynchrone n'entraîne pas l'annulation de l'enregistrement de l'utilisateur. Le modèle fournit également un flux d'événements durable que plusieurs abonnés internes ou systèmes externes peuvent consommer, et les événements peuvent être rejoués pendant 72 heures, offrant une forte résilience.
Limites: Les messages d'événement du CDC ne contiennent pas l'état antérieur de l'enregistrement - l'équivalent d'un Trigger.oldMap Apex. La charge de travail de l'événement inclut les nouvelles valeurs de champ, mais pas les valeurs à partir desquelles elles ont changé. Il est donc difficile d'implémenter une logique basée sur une transition d'état spécifique (par exemple, exécutée uniquement si la Status__c change de « En attente » à « Approuvé »). Vous pouvez atténuer ce problème en interrogeant l'historique des champs de l'objet dans l'abonné à l'événement, mais cela ajoute de la complexité au processus, et le suivi de l'historique des champs peut ne pas être disponible pour le champ d'intérêt spécifique. Cela peut limiter les types d'automatisation que vous pouvez décharger vers le CDC.
Par défaut, le CDC peut être activé dans cinq objets Salesforce maximum. Les organisations qui en ont besoin peuvent acheter une licence complémentaire qui retire cette limite et augmente les allocations de livraison d'événements.
Apex Queueable à partir d'un déclencheur
La mise en file d'attente d'une tâche Apex Queueable directement à partir d'un déclencheur doit être considérée comme un schéma risqué, utilisé uniquement lorsque le contrôle fourni par Apex est nécessaire (par exemple, pour une logique complexe ou des mécanismes de nouvelle tentative personnalisés), et CDC n'est pas une option viable.
Si Apex Queueable est requis, l'implémentation doit inclure les garanties appropriées:
Limiter les contrôles: Le code doit vérifier le nombre de tâches déjà mises en file d'attente dans la transaction avant de tenter d'en ajouter une autre.
Connaissance du contexte: Le code doit détecter s'il est exécuté dans un contexte asynchrone, par exemple une tâche par lot (System.isBatch()), et modifier son comportement pour respecter la limite plus stricte d'une tâche par transaction dans ce contexte.
Considérations relatives aux limites pour Apex asynchrone déclenché
Invoquer Apex asynchrone à partir d'un déclencheur synchrone introduit des risques de stabilité. Pour éviter l'impact au niveau de l'organisation (par exemple, dépassement des limites), ce schéma nécessite une conception et des tests rigoureux.
La limite quotidienne en exécutions Apex asynchrones (Batch, Queueable, @Future) est partagée entre l'organisation (généralement 250 000 ou un calcul basé sur les licences utilisateur). Un chargement de données en masse de 20 000 enregistrements entraînera l'exécution d'un déclencheur par segments de 200, entraînant 100 invocations de déclencheur séparées - encore plus si la taille du lot en masse est inférieure à 200 enregistrements. Si chaque invocation met en file d'attente une tâche asynchrone, une partie importante de la limite quotidienne d'un chargement de données unique peut être consommée. Cette consommation peut potentiellement affamer d'autres processus métiers critiques des ressources asynchrones.
Les limites du gouverneur pour la mise en file d'attente des tâches sont radicalement différentes selon le contexte. Depuis un déclencheur déclenché par une action utilisateur dans l'interface utilisateur (une transaction synchrone), jusqu'à 50 tâches pouvant être mises en file d'attente peuvent être mises en file d'attente. Cependant, à partir d'un déclencheur déclenché par la méthode execute d'une classe Apex par lot - une transaction asynchrone - une seule tâche pouvant être mise en file d'attente peut être mise en file d'attente. Ne pas tenir compte de cette différence est un point d'échec commun et critique, qui entraîne des erreurs de LimitException lors d'opérations de données volumineuses.
Appeler Apex planifiable (System.schedule) ou Apex par lot (Database.executeBatch) directement à partir d'un contexte de déclenchement constitue un antischéma. Ces méthodes ne sont pas conçues pour être invoquées à partir du contexte du déclencheur. Cela entraînera une consommation rapide de votre allocation Apex asynchrone, entraînant des exceptions de limite.
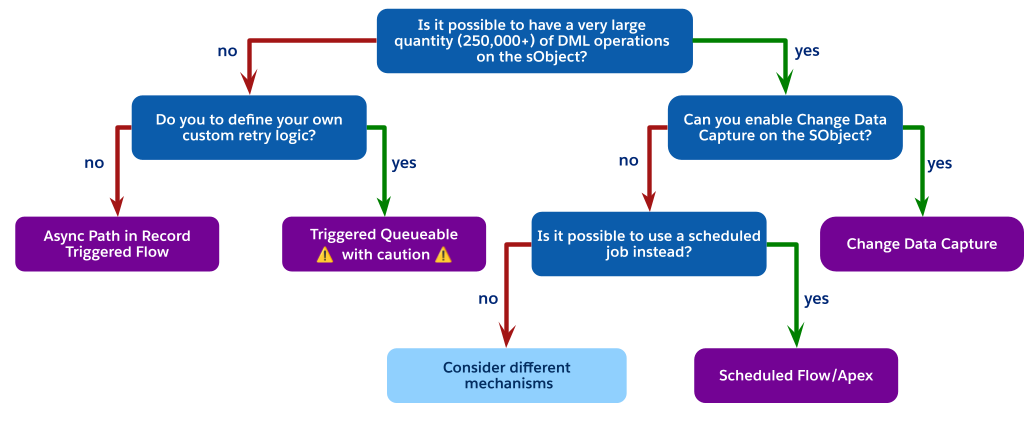
Choix du modèle asynchrone approprié
Chaque mécanisme asynchrone a des compromis spécifiques en termes de performance, de limites du gouverneur et de fiabilité. Utilisez cet arbre de décision comme guide pour vous aider à parcourir ces options et à choisir le mécanisme adapté à votre cas d'utilisation.
Alternative de tâche planifiée
Comme l'indique le diagramme, lorsque vous êtes confronté à des opérations DML à haut volume, mais que vous ne pouvez pas utiliser la Capture des données de modification (peut-être en raison des limitations des objets), le meilleur choix architectural est souvent d'éviter entièrement un processus invoqué par le déclencheur.
Vous pouvez à la place utiliser un processus planifié. Cela peut être soit un flux planifié, soit Apex planifié. Les étapes requises sont :
Effectuez une mise à jour simple et économique dans le déclencheur synchrone. Par exemple, définissez un champ de Status__c sur « traitement en attente » ou insérez un enregistrement associé peu coûteux, par exemple une publication Chatter, pour indiquer que l'enregistrement doit être traité.
Créez une tâche planifiée, soit un flux planifié ou Apex planifié, qui est exécutée périodiquement, par exemple toutes les 15 minutes ou toutes les heures.
Définissez la requête de tâche planifiée pour tous les enregistrements à l'état en attente, exécutez la logique complexe dans un contexte contrôlé à haut volume, puis mettez à jour les enregistrements tels qu'ils sont traités.
Ce schéma découple totalement le traitement lourd de l'enregistrement synchrone de l'utilisateur, n'est pas soumis à la limite d'une tâche par transaction d'un lot déclenché par un déclencheur, et offre une solution hautement évolutive et gouvernable pour les exigences en temps réel.
Si la latence d'une tâche planifiée n'est pas acceptable pour les exigences métiers, et que vous êtes toujours contraint d'utiliser CDC ou une file d'attente déclenchée par un déclencheur, cela indique un décalage architectural important. À ce stade, différents mécanismes doivent être envisagés. La réévaluation de la conception de l'application principale peut conduire à certaines conclusions, notamment :
Achat du complément pour retirer les limites en objets CDC.
Défiant fondamentalement l'exigence métier de déterminer si le traitement en temps quasi réel est vraiment un « must-have » ou si la latence d'une tâche planifiée est un compromis acceptable pour la stabilité de la plate-forme.
Considérations non fonctionnelles
Complexité
Le niveau de complexité d'une implémentation fait partie du coût total de possession d'une solution, ainsi que de sa capacité à s'adapter aux exigences métiers changeantes. La complexité peut impacter n'importe quelle implémentation si les meilleures pratiques ne sont pas respectées. La section Meilleures pratiques connexes de ce document contient des recommandations pour réduire la complexité de votre solution, notamment les modèles suivants :
Modèle hybride : Apex invocable pour une logique complexe dans un flux
Utilisation d'une infrastructure de métadonnées pour les déclencheurs Apex
Mega-Flows vs. Flux multiples
Processus et normes
La documentation est aussi importante que l'automatisation elle-même. Il garantit non seulement la maintenabilité, mais il est également essentiel pour l'IA et les outils basés sur l'agent. La documentation vous aide à comprendre et à gérer vos processus métiers.
Dans Flux
Établissez une convention de nommage cohérente pour tous les éléments et variables.
Utilisez le champ Description du flux pour expliquer son objet global, les critères de déclenchement et le résultat escompté.
Utilisez le champ Description de chaque élément individuel (par exemple, Get Records, Action, Transform). Cette pratique est la meilleure façon de transmettre l'intention. Elle est particulièrement importante pour les actions invocables et les flux secondaires, où la description est l'emplacement principal pour expliquer la logique complexe exécutée par l'action.
Dans Apex
Commentez clairement votre code pour expliquer le pourquoi de votre logique, pas seulement le quoi.
Si vous utilisez une infrastructure pilotée par les métadonnées, assurez-vous que vos enregistrements de métadonnées contiennent et remplissent un champ Description lisible par l'utilisateur pour expliquer ce que fait chaque classe gestionnaire et quand elle doit être exécutée.
Le DevOps et le contrôle du code source font partie d'un cycle de vie de développement mature. Utilisez toujours un outil de contrôle de code source tel que Git pour des projets Salesforce. Les classes Apex et les flux Salesforce sont des métadonnées qui définissent votre logique métier, et ils doivent être contrôlés et gérés par version.
Dans le contexte de la gestion des automatisations déclenchées par un enregistrement, un pipeline DevOps moderne offre des avantages essentiels.
Contrôles de qualité automatisés : Des outils tels que Salesforce Code Analyzer peuvent être configurés pour être exécutés automatiquement dans votre pipeline. L ' analyse statique peut détecter des modèles problématiques dans les deux outils d ' automatisation avant qu ' ils ne soient promus, en signalant des problèmes tels que des éléments de Get Records inefficaces dans une boucle de flux ou des requêtes SOQL dans une boucle Apex for, qui sont des causes courantes de dégradation des performances.
Prévention de la régression : À mesure que votre densité d'automatisation augmente, un changement vers une classe Flux ou Apex peut avoir des conséquences involontaires sur d'autres automatisations dans le même objet. Une stratégie de test DevOps robuste, dans laquelle des tests Apex automatisés sont exécutés contre toute modification proposée, est la méthode la plus fiable pour s'assurer qu'une nouvelle version de flux ne rompe pas la logique Apex existante (et inversement).
Collaboration et visibilité : Le contrôle de la source est la « source unique de vérité ». Il permet aux administrateurs et aux développeurs de travailler en parallèle sur l'automatisation d'un même objet. Il fournit également une piste d'audit inestimable : lorsqu'un processus de production est rompu, vous pouvez déterminer instantanément qui a modifié l'automatisation, quand ils l'ont modifiée et - via des messages d'engagement - pourquoi ils l'ont modifiée.
DevanOps Center fournit une interface unifiée qui facilite la chorégraphie de toutes ces étapes pour permettre à tous les membres de l ' équipe d ' accéder à un processus de développement évolutif, basé sur le contrôle des sources.
Cette discipline combinée de documentation et de DevOps garantit la santé et la maintenance à long terme de votre organisation, ce qui profitera à chaque architecte et administrateur qui vous suit.
Meilleures pratiques associées
Le guide de décision ci-dessus est préférable avant de planifier votre implémentation. Il vise à vous aider à choisir le meilleur produit pour vos cas d'utilisation. Après la sélection du produit, il est important de comprendre les meilleures pratiques existantes pour votre implémentation.
Exploitez le modèle hybride : Apex invocable pour une logique complexe dans un flux
Le principe Un outil par objet est essentiel pour gérer l'automatisation à haute densité, mais ne l'interprètez pas comme un choix binaire entre une pile purement déclarative ou purement programmatique. Un schéma architectural plus efficace et plus maintenable exploite un modèle Hybride: positionnez Flux déclenché par un enregistrement en tant que couche d'orchestration, tout en encapsulant les opérations hautement complexes au sein d'Apex invocable.
La couche Orchestration : Flux
Le flux déclenché par un enregistrement sert de couche orchestrative au processus métier. Il est propriétaire des critères d'entrée et du contexte d'exécution (le quoi et quand). En conservant la logique de décision et l'acheminement au sein de cette couche, la topologie des processus de l'architecture reste transparente et gérable via l'Explorateur de déclencheur de flux, ce qui évite que la logique métier critique soit masquée dans le code.
Le composant Complexe : Apex invocable
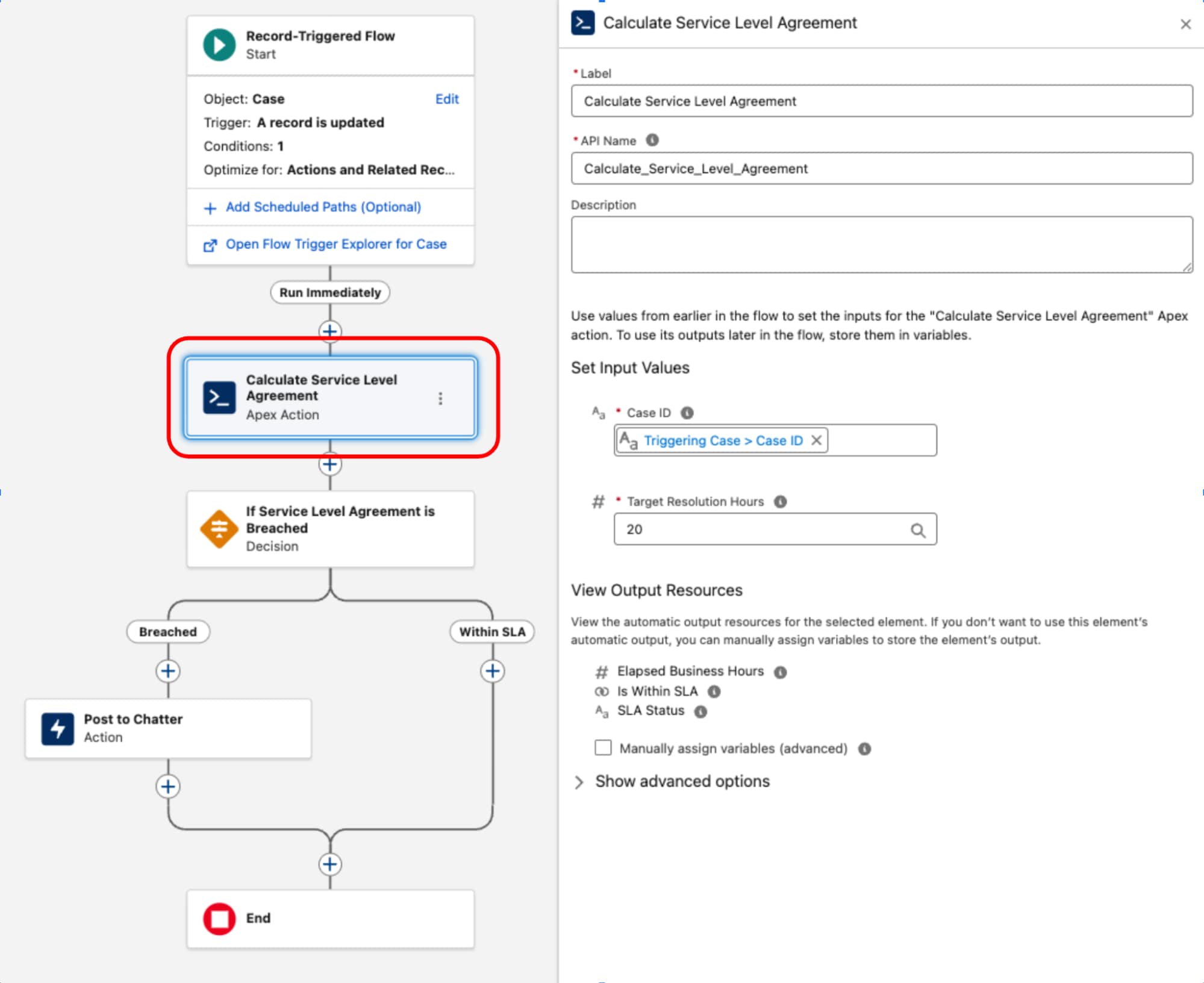
Un exemple courant de composant complexe est l'implémentation de calculs d'accord de niveau de service (SLA) pour des enregistrements Requête. Comme l'objet BusinessHours et sa logique associée — critique pour des calculs précis qui excluent les heures non travaillées et les congés — n'est pas accessible en natif dans Flux, une classe Apex dédiée est utilisée. Cette classe, souvent appelée ServiceLevelAgreementCalculator, est conçue avec une méthode statique unique, annotée avec @InvocableMethod, pour calculer les heures ouvrables écoulées, déterminer si l'accord de niveau de service est « Dans les limites de l'objectif » ou « Atteint », et renvoyer une sortie structurée. Cette approche encapsule la logique complexe et performante dans Apex tout en permettant son exécution transparente et son intégration dans la couche d'orchestration déclarative d'un flux déclenché par un enregistrement.
Une fois la classe ServiceLevelAgreementCalculator Apex définie, elle peut être utilisée dans un flux déclenché par un enregistrement :
Ce schéma démontre une stricte séparation des préoccupations. La couche déclarative est utilisée pour gérer le cycle de vie et l'orchestration des transactions, tandis que le code est utilisé pour l'exécution complexe. En traitant le code comme un utilitaire fonctionnel plutôt que comme la fondation, nous équilibrons les performances et la maintenabilité.
Principaux gains avec le schéma hybride
Modularité: La décision pivote loin de la singularité d'utiliser Apex ou Flux pour l'ensemble du processus. À la place, l'architecture encapsule une logique complexe dans des unités discrètes, sûres en masse et testables indépendamment. Ces unités fonctionnent comme des composants réutilisables consommés par la couche déclarative, assurant les échelles d'automatisation sans compliquer la conception architecturale.
Réutilisabilité: La logique est découplée de l'événement déclencheur. Une unité de code bien conçue (telle qu'une InvocableMethod) est écrite une seule fois, mais exploitée à travers plusieurs points d'entrée : Flux déclenchés par un enregistrement, flux d'écran ou intégrations externes. Cette réutilisation de code élimine les développements redondants.
Maintenabilité: La logique de flux de processus reste visible et gérable dans le flux déclaratif. Cette centralisation réduit considérablement les frais de débogage et garantit que l'ordre d'exécution du système est déterministe et transparent.
Limitations et compromis du modèle hybride
Bien que le modèle hybride d'utilisation Apex invocable de Flux soit puissant, il ne s'agit pas d'une approche unique. Les architectes doivent être conscients des limitations et des compromis spécifiques avant de s'engager dans une solution hybride.
Aucun support avant la sauvegarde: C'est la limite la plus critique. Les actions invocables sont disponibles uniquement dans le contexte après la sauvegarde (flux d'actions et d'enregistrements associés). Ils ne peuvent pas être utilisés dans le contexte très performant avant la sauvegarde (flux de mises à jour de champ rapides). Par conséquent, ce modèle ne peut pas être utilisé pour déléguer les mises à jour de champ du même enregistrement. Exécutez ce travail très performant en utilisant des éléments Flux natifs dans un flux avant la sauvegarde ou dans un déclencheur Apex avant le contexte.
Aucun support after-undelete : Actuellement, le flux déclenché par un enregistrement ne prend pas en charge le contexte after-undelete. Si un Objet Salesforce a une exigence métier pour exécuter une automatisation lorsqu'un enregistrement est restauré depuis la corbeille, un déclencheur Apex est la seule solution.
Frais généraux de performance dans les scénarios à haut volume : Le passage de l'exécution Flux à l'exécution Apex n'est pas une opération à coût nul. Bien que généralement rapide, l'action de tomber dans une Action invocable à partir de l'exécution de Flux n'est pas aussi rapide en calcul que l'exécution native qui reste entièrement dans un déclencheur Apex. Pour la plupart des automatisations à densité moyenne, ce micro-coût est un compromis négligeable et intéressant pour l'accessibilité accrue. Cependant, pour des scénarios extrêmement performants et à haut volume, une infrastructure Apex uniquement pure aura un avantage de vitesse de calcul brute.
Stratégies pour l'automatisation héritée
Bien que l'heuristique de densité de l'automatisation fournisse des orientations définitives pour une architecture nouvelle, la réalité des environnements Salesforce d'entreprise est souvent plus nuancée. Dans les organisations matures, il est courant de trouver des flux déclenchés par un enregistrement et des déclencheurs Apex fonctionnant sur le même Objet Salesforce. Ce scénario est distinct du schéma hybride expliqué précédemment: ici, les flux et les déclencheurs Apex ne sont pas couplés ni conçus pour fonctionner ensemble.
Cette coexistence est souvent le résultat de l'évolution des capacités de la plate-forme ou de la dette technique héritée. Bien que cet état opérationnel soit toléré, les architectes doivent le traiter comme un compromis calculé plutôt que comme un état final.
L'orchestration fragmentée entraîne des coûts de gouvernance et de maintenance importants, ce qui rend les activités de développement, de test et de gestion des incidents difficiles et complexes. Cela entraîne une augmentation du délai de résolution (TTR) et de la complexité opérationnelle.
Pour les nouveaux objets Salesforce, suivez le principe de densité d'automatisation comme guide principal.
Pour les objets Salesforce existants avec une empreinte hybride et un déclencheur Apex double et des points d'entrée de flux déclenchés par un enregistrement, évaluez la densité, puis architectez pour refactoriser à un état hybride maintenable.
Pour une faible densité, refactorisez Apex déclenche des flux déclenchés par un enregistrement, et spécifiez l'ordre d'exécution, en les amenant à un point d'entrée d'automatisation unique.
Pour une densité moyenne, refactorisez les méga-flux complexes dans un sous-ensemble de flux, avec le bon ordre d'exécution. Introduisez des déclencheurs Apex uniquement lorsque cela est absolument nécessaire, par exemple pour prendre en charge le contexte after undelete.
Pour une densité élevée, privilégiez l'implémentation de déclencheurs Apex.
Utilisation d'une infrastructure de métadonnées pour les déclencheurs Apex
À mesure que les processus métiers d'une organisation sur Salesforce Platform mûrissent, le volume et la complexité de l'automatisation déclenchée par un enregistrement augmentent inévitablement. Une meilleure pratique fondamentale consiste à maintenir un déclencheur Apex par objet Salesforce. Cette règle est critique, car la plate-forme ne garantit pas l'ordre d'exécution de plusieurs déclencheurs sur le même objet pour le même événement. Cette limitation peut entraîner un comportement non déterministe, des conditions de course et des problèmes difficiles à déboguer.
Cependant, adhérer au principe du unique déclencheur introduit un défi architectural: comment gérer et orchestrer de manière maintenable et évolutive toute la logique métier invoquée à partir de ce point d'entrée unique.
Limitations des gestionnaires de déclencheur Classic
La première évolution de cette architecture a été le modèle Classic Trigger Handler. Dans cette approche, le déclencheur Apex unique délègue toute sa logique à une classe gestionnaire correspondante (par exemple, OpportunityTriggerHandler). Cette méthode sépare la logique du fichier déclencheur et fournit aux développeurs un contrôle déterministe sur l'ordre d'exécution dans les méthodes de la classe gestionnaire (par exemple, afterInsert()).
Bien qu'une amélioration, ce modèle conduit souvent à des classes de gestionnaire monolithiques. Au fil du temps, à mesure que les exigences métiers augmentent, la classe devient grande, difficile à gérer et difficile à tester isolément. L'ordre d'exécution de tous les processus individuels est codé en dur dans une seule méthode, ce qui rend la classe sujette aux conflits de fusion, augmentant considérablement les coûts de gouvernance et de maintenance dans un environnement de grande entreprise.
La solution : Infrastructure de déclencheurs pilotés par les métadonnées
Pour résoudre les problèmes fondamentaux de modularité et d'orchestration, les architectes adoptent une infrastructure de déclencheurs pilotée par les métadonnées. Il s'agit d'un saut architectural important qui dissocie la logique d'automatisation elle-même de la configuration de son exécution et de sa date d'exécution.
Ce cadre repose sur trois avantages clés :
Partitionnement : Au lieu d ' une seule classe gestionnaire, la logique métier de base est divisée en petites classes Apex atomiques (par exemple, une classe RecalculateAccountValues ou une classe NotifySalesLeads), chaque classe adhérant au principe de responsabilité unique. Cette modularité facilite le test, le débogage et la compréhension isolés de la logique.
Ordre et chorégraphie : L'ordre d'exécution n'est plus codé en dur dans Apex. À la place, il est défini par déclaration par des enregistrements de configuration, généralement stockés dans un type de métadonnées personnalisées (par exemple, TriggerAction__mdt). Cela permet aux administrateurs de réorganiser, d'ajouter ou de retirer des actions d'automatisation simplement en modifiant un enregistrement de métadonnées, ce qui ne nécessite pas de déploiement ni de changement de code.
Contourner la fonctionnalité : L'infrastructure fournit une fonctionnalité de contournement standardisée et précise. Chaque action d'automatisation peut être configurée via son enregistrement de métadonnées pour être désactivée globalement, ou contournée pour des utilisateurs administratifs spécifiques en référençant une autorisation personnalisée.
Le déclencheur Apex unique de l'objet sert alors uniquement de répartiteur dynamique. Il ne contient aucune logique métier, mais instancie à la place une classe MetadataTriggerHandler centrale. Ce gestionnaire interroge les enregistrements de métadonnées personnalisées pour déterminer dynamiquement la séquence d'exécution et invoquer les classes Apex atomiques correctes dans l'ordre prescrit. L'automatisation est unifiée sous une couche unique, transparente et gouvernable.
Déduplication des opérations coûteuses dans la transaction
Un avantage important de l'utilisation Apex dans une infrastructure robuste est la possibilité de gérer l'état transactionnel et d'optimiser les performances en éliminant le travail redondant. À mesure que la logique s'accumule, il est fréquent que différentes automatisations dans l'ordre d'enregistrement exécutent indépendamment les mêmes opérations coûteuses, ce qui consomme des limites importantes du gouverneur et augmente le temps d'opération DML.
Le cadre est conçu pour répondre à ce besoin avec deux stratégies principales :
Gestion d'état partagée : Dans le cadre d'une transaction Apex unique, les propriétés et les variables statiques sont exploitées pour mettre en cache les données. Ainsi, une opération coûteuse, par exemple une requête SOQL pour un paramètre de configuration, n'est exécutée qu'une seule fois, même si la logique d'automatisation est invoquée plusieurs fois dans différents enregistrements ou phases du déclencheur. La consommation de limites transactionnelles est considérablement réduite.
Utilisation du cache de la plate-forme : Pour aller au-delà de la simple mise en cache intra-transaction, utilisez le cache de la plate-forme afin d'éviter d'interroger certaines données dans la base de données complète. Ce cache géré en mémoire est idéal pour récupérer des données non primitives, lues fréquemment dans la base de code et immuables tout au long d'une transaction (par exemple, profils, rôles, heures ouvrables). En utilisant l'interface Cache.CacheBuilder, le système vérifie d'abord le cache et exécute la requête de base de données uniquement si les données sont absentes, ce qui optimise les performances et l'évolutivité.
Utilisation de Before-Save pour les mises à jour du même enregistrement
Utilisez toujours une mise à jour avant la sauvegarde lorsque votre automatisation doit modifier uniquement les valeurs de champ dans l'enregistrement qui démarre la transaction. Cela s'applique aussi bien aux mises à jour de champ rapide dans Flux (qui s'exécutent avant la sauvegarde) qu'à la logique avant le contexte dans Déclencheurs Apex (avant l'insertion, avant la mise à jour).
Ce schéma est performant, quel que soit l'outil utilisé, car il évite une deuxième opération DML et un cycle d'enregistrement récursif. Les modifications sont apportées à l'enregistrement en mémoire avant son engagement dans la base de données et sont enregistrées dans le cadre de la transaction d'origine. Les frais généraux d'une deuxième sauvegarde, qui autrement réexécuterait l'ordre de sauvegarde complet et déclencherait de nouveau toute l'automatisation, sont éliminés.
Prévention de la récursion incontrôlée
La récursion non contrôlée est un piège courant dans les déclencheurs après mise à jour, où la logique d'un déclencheur effectue une mise à jour DML qui entraîne à son tour le déclenchement du même déclencheur. Cela crée une boucle infinie qui se termine par une exception de limite du gouverneur. Bien que des indicateurs booléens statiques ou des collections d'ID d'enregistrement traités aient toujours été utilisés pour empêcher une telle récursion, un modèle plus précis et plus robuste consiste à lier la logique en comparant les valeurs de champ entre la nouvelle et l'ancienne version de l'enregistrement lui-même.
Exécutez la logique uniquement si un champ d'intérêt spécifique a changé. Cela empêche le déclencheur d'exécuter sa logique sur les opérations DML suivantes dans la même transaction où les données critiques restent inchangées.
Contrôle de la récursion dans un flux déclenché par un enregistrement
Dans un flux déclenché par un enregistrement, empêchez la récursion incontrôlée en définissant l'exécution du flux uniquement lorsque l'enregistrement est mis à jour pour remplir les conditions requises :
Si vous choisissez d'utiliser une formule de critères d'entrée dans votre flux, vous pouvez empêcher une récursion galopante en comparant la variable globale $Record (représentant les nouvelles valeurs) à la variable globale $RecordPrior (représentant les valeurs d'origine avant l'enregistrement). Par exemple, pour vous assurer qu'un flux est exécuté uniquement si le champ Montant d'une opportunité a changé, utilisez-le dans les critères d'entrée :
1$Record.Amount != $Record__Prior.Amount
Contrôle de la récursion dans Apex
Comparez les valeurs de champ de la nouvelle version de l'enregistrement, Trigger.new, aux valeurs de champ de l'ancienne version de l'enregistrement, Trigger.oldMap, pour déterminer si la modification spécifique que vous recherchez s'est produite. Cette approche garantit que l'automatisation est idempotente et exécutée uniquement lorsque nécessaire, ce qui rend le système plus efficace et évite les boucles récursives catastrophiques.
Contournement de l'automatisation
Une organisation Salesforce bien architecturée nécessite un mécanisme cohérent et fiable pour contourner l'automatisation. Il ne s'agit pas d'une fonctionnalité facultative, mais d'une exigence opérationnelle essentielle pour préserver l'intégrité des données et activer les tâches administratives.
Un cadre de contournement est essentiel pour certains scénarios :
Lors du chargement de volumes de données importants, le déclenchement de déclencheurs pour chaque enregistrement peut ralentir considérablement le processus, entraîner des exceptions de limite et créer des enregistrements et des notifications associés erronés. Un contournement permet d'insérer les données proprement et efficacement.
Un utilisateur de l'intégration peut avoir besoin de synchroniser des données à partir d'un système d'enregistrement externe. L'automatisation normalement déclenchée pour une modification initiée par l'utilisateur (par exemple, envoyer un e-mail, créer une tâche) peut être indésirable ou redondante lorsque la modification provient d'un autre système.
Les administrateurs ou le personnel de support peuvent avoir à effectuer des mises à jour correctives sur les enregistrements. Un mécanisme de contournement leur permet d'effectuer ces modifications sans déclencher l'automatisation métier standard, ce qui pourrait avoir des conséquences inattendues.
Autorisations personnalisées: La norme moderne et évolutive pour l'implémentation d'une logique de contournement est celle des autorisations personnalisées. Elles sont supérieures aux anciennes méthodes pour plusieurs raisons :
Flexibilité : Des autorisations personnalisées peuvent être attribuées à des utilisateurs via des ensembles d'autorisations. Cette pratique s'aligne sur le modèle moderne de sécurité et d'accès de Salesforce, ce qui permet une attribution granulaire et flexible. Un contournement peut être accordé à un utilisateur spécifique, ou même temporairement avec une date/heure d'expiration spécifique.
Maintenabilité : L'utilisation d'autorisations personnalisées évite de coder en dur des profils ou des utilisateurs dans une logique d'automatisation. Si le rôle d'un utilisateur change ou si un nouveau profil doit contourner l'accès, la modification est une simple attribution d'ensemble d'autorisations, pas une modification de code ou de flux qui nécessite un déploiement.
Évolutivité : Les autorisations personnalisées offrent une infrastructure évolutive pour gérer les exceptions dans une base d'utilisateurs complexe. Ils peuvent être attribués à des utilisateurs via un ensemble d'autorisations, des groupes d'ensembles d'autorisations ou des profils. Leur association à un ensemble d'autorisations ou à un profil peut également être représentée dans les métadonnées sources.
Schémas d'implémentation: Appliquez un modèle de contournement cohérent à toutes les automatisations déclenchées par un enregistrement dans l'organisation.
Contournement d'un flux déclenché par un enregistrement: La méthode la plus efficace pour contourner un flux est d'empêcher son exécution. Pour ce faire, ajoutez une condition aux critères d'entrée du flux.
Dans l'élément Démarrer du flux déclenché par l'enregistrement, définissez Exigences de condition sur Formule évalue sur True.
Dans le générateur de formule, incorporez une vérification de l'autorisation personnalisée en utilisant la variable globale $Permission. Combinez la vérification à vos critères d'entrée existants.
Modèle de formule :
1( ) && NOT($Permission.Bypass_This_Flow)
Ce modèle garantit que le flux est exécuté uniquement si l'utilisateur _n'_a pas l'autorisation personnalisée spécifiée attribuée. Ce contrôle est effectué avant même la création de l'interview de flux, ce qui en fait l'approche la plus performante.
Contournement d'une infrastructure de déclencheurs Apex: Dans Apex, intégrez la logique de contournement directement à l'infrastructure de déclencheur pilotée par les métadonnées, ce qui permet un contrôle granulaire.
Le type de métadonnées personnalisées TriggerAction__mdt doit inclure un champ de texte, par exemple BypassPermission__c.
Dans la classe MetadataTriggerHandler, avant d'exécuter dynamiquement une action, le code doit lire la valeur de ce champ.
Si le champ est rempli, le gestionnaire utilise la méthode FeatureManagement.checkPermission() pour déterminer si l'utilisateur actif actuel dispose de l'autorisation personnalisée spécifiée.
Si checkPermission() renvoie true, le gestionnaire ignore cette action spécifique et passe à la suivante dans la séquence.
Ce modèle est puissant, car il permet à la fois un contournement global (si tous les enregistrements TriggerAction__mdt référencent la même autorisation) et un contournement granulaire par action (si différents enregistrements référencent différentes autorisations, ou si certains n'ont aucune autorisation de contournement du tout).
Mega-Flows vs. Flux multiples
C'est un anti-schéma pour consolider toute l'automatisation d'un objet en un seul méga-flux massif. La consolidation en un seul flux par opposition à la séparation d'une logique en plusieurs flux bien conditionnés n'a pas d'impact majeur sur les performances. Les gains de performance les plus importants proviennent des éléments suivants :
Utilisation de flux avant la sauvegarde pour les mises à jour de champ du même enregistrement.
Écriture de conditions d'entrée précises afin d'empêcher l'exécution de flux avec des modifications qui n'impactent pas leur cas d'utilisation spécifique.
L'Explorateur de déclencheur de flux permet d'attribuer une valeur d'ordre à chaque flux d'un objet, garantissant ainsi un ordre d'exécution séquentiel.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.