데이터 플랫폼은 30년 이상 발전해 왔습니다. 처음에는 온 프레미스, 중앙 집중식, 구조화된(주로 관계형) 운영/OLTP 데이터베이스가 산업에 주도했습니다. 이는 주로 분석 처리에 사용되었으며 관계적이고 중앙 집중 상태로 유지된 데이터 웨어하우스 OLAP/Big Data 플랫폼을 포함하도록 확장되었습니다. 클라우드 저장소는 데이터 웨어하우스, 레이크하우스, 분류된 저장소와 같은 분산된 아키텍처를 구동했습니다. 그러나 운영 플랫폼과 분석 플랫폼은 별도로 유지되었습니다. 오늘날 클라우드 컴퓨팅과 AI 혁명은 데이터 플랫폼 아키텍처를 근본적으로 변경하고 있습니다.
엔터프라이즈는 이미 Snowflake, Databricks, BigQuery, Redshift와 같은 성숙한 Big Data 플랫폼에 투자하고 있습니다. 그러나 이러한 플랫폼은 데이터 분산으로 사용됩니다. 고객은 비즈니스 플로 및 응용 프로그램 내에서 직접 데이터에 대한 작업을 수행할 수 없으므로 데이터에서 비즈니스 가치를 도출하지 않습니다. 이러한 솔루션에는 생성형 에이전트 AI 처리가 없고 실시간으로 데이터 액세스를 제공할 수 없으므로 고객 참여 시점 및 기타 업계 최고의 기능에서 AI 중심 개인 설정을 제공할 수 없습니다.
데이터 플랫폼의 미래는 통합, 유연성, 액세스 가능성, 개방형 데이터 인프라스트럭처로 특징이 있습니다. 이 새로운 아키텍처는 GPU, 대용량 메모리, NVMe SSD, 클라우드 저장소 등 최신 계산 및 저장소 추세를 기반으로 구축되어 클라우드 컴퓨팅 및 AI와 통합됩니다. 실시간 인사이트를 제공하고, 자율 의사 결정을 강화하며, 실시간 신청을 구동할 수 있습니다. 여기에는 에이전트 AI, 예측 AI, 분석, 실시간 대규모 OLTP 데이터베이스, 데이터 레이크, 호수의 증가가 포함됩니다. 이러한 최신 데이터 플랫폼은 단순성, 확장성, 민첩성, 성능, 보안, 가용성, 비용 효율성을 위해 설계되었습니다.
다음 데이터 추세는 차세대 데이터 플랫폼 아키텍처를 구동합니다.
- AI, 기계 학습 및 핵심 분석: 에이전트 AI의 발전은 데이터 플랫폼 개발, 배포, 사용/액세스를 근본적으로 변경합니다. 에이전트 AI는 대화/쿼리 의도를 이해하고, 워크플로를 계획하고, 생성하고, 의사 결정을 자동화합니다. 에이전트 계획 및 결정, 실시간 대화 모델링, 데이터 플랫폼에서 중요한 개인 설정 지원을 개인 설정하기 위해 에이전트(단기 및 장기) 메모리는 대화 내역에서 구성됩니다. 에이전트는 데이터 거버넌스(예: 보안, 규정 준수, Trust), 성능(예: 동시성, 처리량 및 대기 시간에 대한 자동 확장), 페일오버 및 가용성, 관찰 가능성 및 유지 관리 등 운영 "능력"을 자동화하는 데 도움을 줄 것입니다. AI 기반 분석, 예측, 분석 Q/A용 자연어 처리(NLP), 구조화되지 않은 데이터(PDF, 이미지, 오디오, 비디오와 같은 텍스트)에 대한 분석이 표준 상태가 되므로 기업은 다양한 데이터 소스에서 자세한 인사이트를 파생할 수 있습니다.
- 데이터 분산 하지만 데이터 액세스 통합: 에이전트는 인사이트를 파생하고 결정을 내리고 비즈니스 활동을 자동화하기 위해 엔터프라이즈 데이터가 필요합니다. 데이터는 엔터프라이즈에서, 서로 다른 응용 프로그램 및 데이터 플랫폼에서 기본적으로 분산됩니다. 그러나 엔터프라이즈 내부 및 엔터프라이즈 외부의 파트너와 서로 다른 사업부에서 사일로를 원활하게 통합하는 것은 쉽지 않습니다. 데이터 통합은 소스에서 데이터를 수집하거나 데이터 소스와 통합하여 데이터를 공유하고, 분석 및 AI 처리를 위한 데이터 준비, 조합 및 모델링의 원시 데이터를 공유하고, CTS가 낮은 수준으로 데이터를 효율적으로 액세스할 수 있도록 대규모로 데이터를 저장하고 관리하며, 다양한 쿼리 및 분석 메커니즘과 도구를 통해 데이터를 액세스하고, 기본 스토리지 및 데이터 액세스 플랫폼과 깊이 통합합니다.
- Cloud-based Open LakeHouses: 클라우드 기반 빅 데이터(OLAP) 플랫폼은 오픈 파일 형식(Parquet) 및 테이블 형식(Iceberg)을 채택하여 데이터 연합(데이터 입력) 및 공유(데이터 출력)을 활성화하고 있습니다.
- 비정형 데이터 처리: 생성형 AI의 출현, 발전, 채택으로 인해 기업은 대용량 텍스트 문서, 오디오 기록, 비디오 녹음, 기타 미디어를 구성하는 데이터의 엔터프라이즈 장부에서 가치 있는 인사이트와 비즈니스 가치를 파생하기 시작합니다. 청크, 벡터화, 시맨틱 검색 및 Knowledge 그래프를 포함한 비정형 데이터 처리는 이러한 통찰력을 가능하게 합니다. RAG(검색 증강 생성) 및 CAG(캐시 증강 생성)와 같은 기술이 데이터의 본문 전체에서 빠르고 에이전트적인 검색의 메인스트림 동인으로 바뀌고 있습니다.
- Knowledge 관리: Knowledge 원시 콘텐츠 자체(문서, 기사, 비디오)를 벗어납니다. 이는 의미를 파생하고 메타데이터를 큐레이팅하고 컨텍스트에 배치하여 조직 또는 엔터프라이즈 전반에서 콘텐츠에 대한 공유 이해를 개발하여 해당 콘텐츠의 증가를 나타냅니다. Knowledge 자체는 일반적으로 구조화되어 있습니다. Knowledge 관리에는 컨텐츠 관리, Knowledge 추출, 그래프와 같은 모델을 통한 표현, 탐색이 포함됩니다.
- ** 풍부한 데이터 액세스**: 풍부한 데이터 액세스는 최종 사용자, 비즈니스 사용자, 관리자, 분석가를 비롯한 다양한 페르소나가 데이터, 분석, AI 도구에 액세스할 수 있어야 함을 의미합니다. 액세스 가능성은 앙상블 쿼리(관계, 키워드, 시맨틱 쿼리 포함), 자연어-SQL(NL2SQL) 쿼리, 실시간 액세스 등과 같은 메커니즘을 통해 달성됩니다.
- 실시간 처리: 에이전트 응용 프로그램은 현재 상태를 기반으로 새로운 이벤트, 개인 설정 응답 및 작업을 기반으로 실시간 결정을 내리며, 이를 통해 실시간 데이터에 액세스, 처리, 조치를 취해야 합니다. 실시간 처리를 위해 최신 데이터(데이터 대기 시간) 및 대화형 액세스(액세스 대기 시간)가 필요합니다. 이러한 데이터 및 액세스 대기 시간에는 기본 데이터 플랫폼이 운영 및 분석 매장에서 최신 데이터 액세스, 낮은 대기 시간 액세스(지점 조회 및 쿼리) 처리, 높은 데이터 규모, 높은 처리량을 지원해야 합니다.
- 데이터 보안, 거버넌스 및 거주: 에이전트 및 대화형 AI는 응용 프로그램 UI를 간소화하므로 소비자에서 직원, 기타 AI 에이전트에 이르기까지 모든 사람이 음성 또는 서면 자연어를 사용하여 응용 프로그램과 대화식으로 상호 작용할 수 있습니다. 에이전트 응용 프로그램에 대해 저장 및 모델링해야 하는 중요한 고객 및 개인 데이터는 정확하게 정의된 액세스 및 공유 정책을 통해 보호 및 관리해야 합니다. 점점 더 많은 고객이 해당 국가 또는 지역의 데이터 보존을 요구하는 규정을 준수해야 하며, 특히 정부에 속하거나 정부와 작업을 수행하는 고객을 대상으로 합니다.
Salesforce Data 360은 향후 데이터 추세를 해결하기 위해 고안되었습니다. Data 360은 엔터프라이즈 전반에서 사일로 데이터를 통합하여 조직에서 데이터를 저장, 모델링, 처리하여 분석, AI, 기계 학습, 에이전트 응용 프로그램을 활성화할 수 있도록 지원하는 클라우드 네이티브 메타데이터 기반 데이터 플랫폼입니다.
이 문서는 엔터프라이즈 설계자 및 CTO를 위한 필수 가이드입니다. Data 360의 아키텍처, 기능, 설계 원리, 사용 사례를 자세히 설명합니다. Data 360 아키텍처의 기본 사항을 프라이머로 소개한 다음, 다중 조직 전략, 보안, 거버넌스 및 개인 정보 보호, 실시간 활성화, 데이터 정리 룸 등 기존 데이터 플랫폼과의 상호 운용성과 같은 주요 차별화 요소에 대한 일련의 심층 분석을 진행합니다.
Salesforce Data 360은 엔터프라이즈 데이터를 실시간으로 실행하고 신뢰할 수 있도록 하는 핵심 원칙 집합을 기반으로 설계되었습니다.
- 개방성 및 상호 운용성: 다중 클라우드 에코시스템을 위해 구축됩니다. 중복 없이 Snowflake, Databricks, BigQuery, Redshift와 같은 데이터 플랫폼을 통합하여 기존 투자를 유지하면서 Customer 360 확장합니다.
- 스토리지-계산 분리: 스토리지 및 처리(배치, 스트리밍, 대화형)를 독립적으로 확장합니다. 대용량 고성능 워크로드에 유연성과 효율성을 제공합니다.
- 다중 모델 스토리지 및 처리: 텍스트, 이미지 오디오, 비디오와 같은 구조화된 다양한 비정형 데이터 유형을 지원합니다. 효율적인 저장소, 실시간 및 배치 처리, 확장 가능한 색인화, 통합 검색, 쿼리 및 분석을 제공합니다.
- 메타데이터 중심 설계: 응용 프로그램은 코드가 아닌 메타데이터로 정의됩니다. 메타데이터는 최상위 자산으로 취급되므로 Salesforce Platform에 통합된 거버넌스, 유연성, 심층 통합이 가능합니다.
- 실시간 하이브리드 프로세싱: 일괄 처리 및 분석 워크로드와 함께 대기 시간이 낮은 쿼리 및 즉각적인 의사 결정을 지원합니다.
- 인텔리전트 및 액티브 데이터: 지속적으로 인사이트를 수집, 분석하고 비즈니스 워크플로에 직접 푸시합니다. 최신 컨텍스트를 사용하여 코드 없음, 하위 코드, 프로 코드, AI 중심 자동화를 지원합니다.
- 설계를 통한 거버넌스 및 개인 정보 보호: 계보, 액세스 제어, 보존, 데이터 암호화, 규정 준수가 내장되어 있습니다. 모든 계층에서 Trust 및 규제 신뢰가 강화됩니다.
- 일대다 테넌시: 중앙 집중식 Data 360 조직은 Customer 360 신뢰할 수 있는 단일 소스로 작동하며, Salesforce 고객이 광범위하게 사용하는 다중 조직 Salesforce 환경을 원활하게 지원합니다.
이러한 원칙은 Data 360이 데이터를 실시간으로 열고 지능적으로 실행할 수 있도록 합니다.
Salesforce Data 360은 현재 데이터 추세를 해결하는 설계 원칙을 기반으로 구축된 최신 데이터 플랫폼입니다. 아키텍처 기능을 통해 엔터프라이즈 데이터가 신뢰할 수 있고 통합되며 안내 원칙에 따라 실시간으로 실행할 수 있습니다.
- Cloud-Native Foundation: 변경할 수 없는 마이크로서비스 기반 인프라가 있는 Hyperforce 실행되며, AWS와 같은 Hypercaler에 배포됩니다. 탄력적인 확장, 제로 Trust 보안, 지속적인 제공, 글로벌 규정 준수 제공
- Salesforce(핵심) 메타데이터 기반: 메타데이터는 모든 Salesforce 응용 프로그램에서 즉시 사용할 수 있도록 설계, 모델링, Salesforce 메타데이터로 저장됩니다. 해당 메타데이터는 완전히 ACID 준수 RDBMS에 저장됩니다. 거버넌스, 수명 주기 일관성, Salesforce Lightning Platform과의 깊은 통합을 보장합니다.
- 레이크하우스 저장소: 스키마 진화, 시간 이동, 대용량 업데이트를 지원하는 창고 거버넌스와 데이터 레이크 규모를 결합하는 아파치 아이세버그 및 Parquet에 구축됩니다. Data 360은 최신 개방형 표준을 사용하는 대규모 저장소와 배치 및 이벤트 중심 워크로드에 대한 풍부한 변환 및 데이터 처리 기능을 사용하여 구조화 및 비정형 데이터를 저장, 모델, 처리합니다.
- 유연한 수집이 가능한 엔드 투 엔드 데이터 파이프라인: 수집, 준비, 모델링, 통합, 분석, 활성화와 같은 전체 수명 주기를 포함하여 분할된 포인트 솔루션에 대한 의존도를 줄입니다. 배치, 거의 실시간, 270개 이상의 커넥터 및 MuleSoft를 사용하여 스트리밍을 지원합니다. ELT 우선 접근 방식은 다운스트림 변환 유연성과 함께 빠른 데이터 가용성을 제공합니다.
- Open frameworks 및 Federation과 엔터프라이즈 데이터 상호 운용성: Snowflake, Databricks, BigQuery, Redshift를 사용하여 양방향 Zero Copy 연합을 사용하여 엔터프라이즈 전반에 걸쳐 실로 데이터를 통합하여 데이터 마이그레이션 또는 중복을 방지합니다.
- 데이터 분류, 모델링 및 조직: Data 360은 데이터를 원시 수집 데이터, 정리 및 저장된 데이터, SSOT(단일 신뢰 소스)라고 하는 일반적인 정보 스키마에 따라 모델링된 데이터로 구성합니다. 이러한 SSOT 개체는 SDM(시맨틱 데이터 모델) 및 기타 큐레이팅된 응용 프로그램별 모델을 정의하는 기반입니다.
- 개방형 시맨틱 쿼리 API를 사용하여 확장 가능한 분석을 위한 내장형 시맨틱 데이터 모델링, Tableau Next를 구동하고 애플리케이션별 분석을 활성화합니다.
- 구조화된 데이터, 비정형 데이터 및 그래프 데이터에서 통합된 Data 360 SQL 쿼리를 지원하는 고성능 SQL 쿼리 엔진입니다.
- 낮은 대기 시간 데이터 저장소: 응답 시간이 밀리초인 핫 데이터의 키 값 저장소입니다. 실시간으로 개인 설정 및 이벤트 중심 시나리오를 활성화합니다. 고객 참여 데이터를 실시간으로 수집하고 처리합니다. ID, 상호 작용 및 대화를 신뢰할 수 있는 단일 Customer 360 프로필 및 컨텍스트 그래프로 통합합니다.
- 비정형 데이터 저장, 청크, 내장형 생성(벡터화), 메타데이터 추출(확대), 요약, 인덱싱, Knowledge 추출, 지능형 문서 처리, 단기 및 장기(대화) 메모리 생성 등을 위한 유연하고 확장 가능한 지원을 위한 비정형 데이터 처리 파이프라인입니다.
- 빠른 검색 및 에이전트 검색, RAG, Knowledge 추출, 에이전트 메모리 파생 등과 같은 정확하고 효율적인 비정형 데이터 액세스를 위한 네이티브 키워드, 벡터 및 하이브리드 인덱싱
- AI/ML 및 Agenttic 애플리케이션을 활성화하기 위한 프로필, 개인 설정, 컨텍스트 서비스
- 계보 추적, 데이터 마스킹, 데이터 보존, 규정 준수 및 Trust 보증을 위한 모든 계층의 내장형 거버넌스 및 보안
- Elastic Compute Fabric: Kubernetes 기본 다중 테넌트 계산 패브릭입니다. 배포된 처리용 Spark 및 SQL 워크로드용 하이퍼를 실행합니다. 다양한 작업에서 유연하게 확장하고 신뢰할 수 없는 코드를 실행할 수 있는 격리를 지원합니다.
모든 작업은 Salesforce의 클라우드 파운데이션인 Hyperforce 실행됩니다. Hyperforce 다음을 제공합니다.
- 암호화, 격리 및 최소 권한 정책이 포함된 Zero Trust 보안
- 다중 지역 배포를 통한 복구성 Salesforce Data 360은 Hyperforce 다중 지역 복원 및 플랫폼 수준 오류 허용 기능을 활용할 수 있지만, 진정한 엔터프라이즈급 재해 복구(DR)에는 모든 종속된 에코시스템 전반에서 재생 가능한 수집 파이프라인, 복제, 메타데이터 구동 재활용과 같은 주요 기능을 갖춘 모든 데이터 플랫폼과 유사한 더 광범위한 아키텍처가 필요합니다.
- 내장된 모니터링, 메트릭 및 추적 기능을 갖춘 관찰 가능성
- 자동 조정 및 FinOps 인지도를 통해 비용 과도 없이 효율성 향상
Data 360은 기존 엔터프라이즈 투자를 대체하지 않습니다. 대신 Data 360은 이미 신뢰하고 관리하고 실행 가능한 데이터를 만들어 가장 중요한 위치에서 실시간으로 AI 중심 참여를 제공합니다. 단, Salesforce는 외부 데이터를 포함한 모든 엔터프라이즈 데이터를 (Salesforce) 메타데이터 구동 개체로 전환하고 에이전트 응용 프로그램을 활성화하여 검색, 의사 결정, 조치를 취합니다.
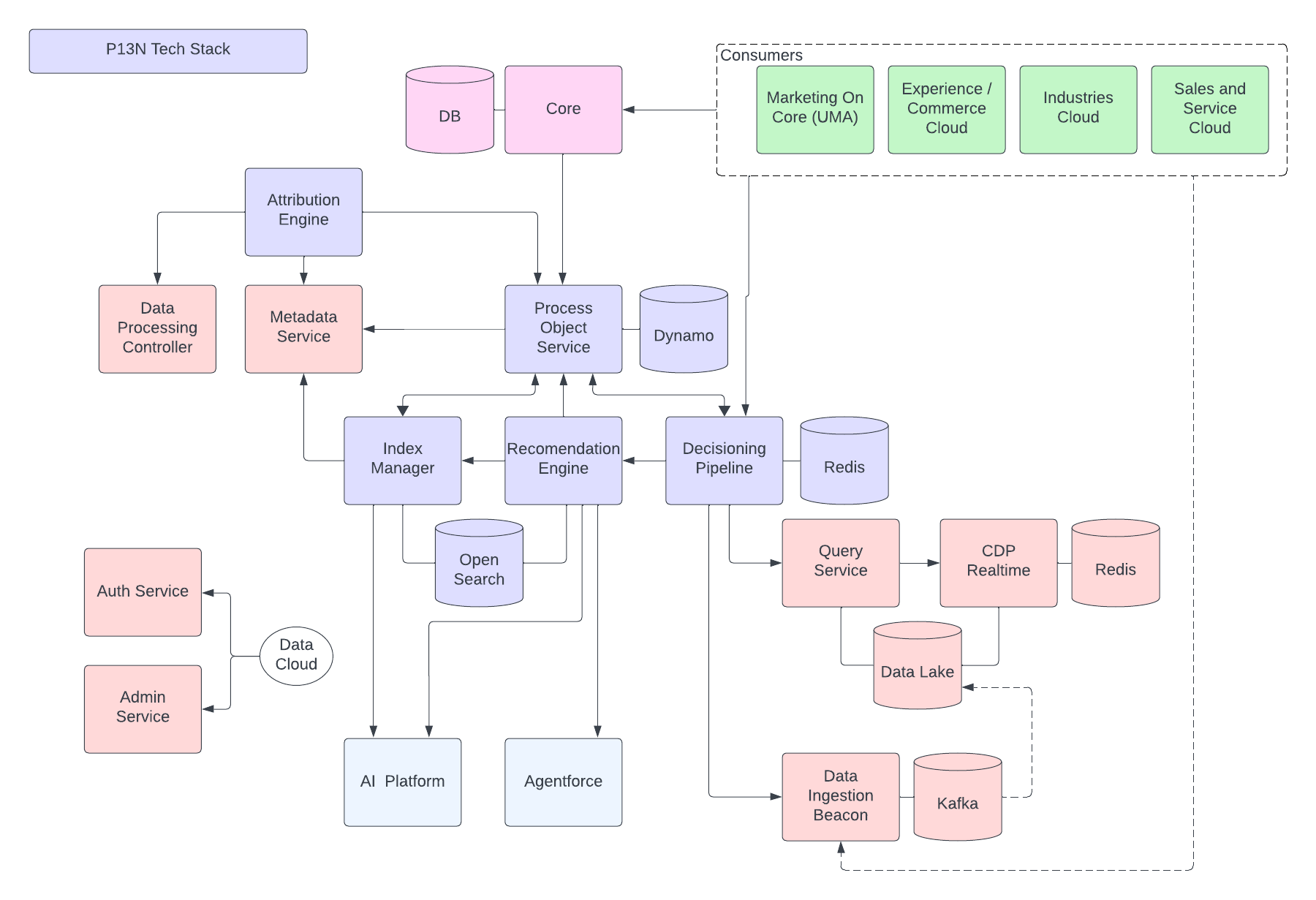
다음 그림은 Data 360 참조 아키텍처를 보여줍니다.
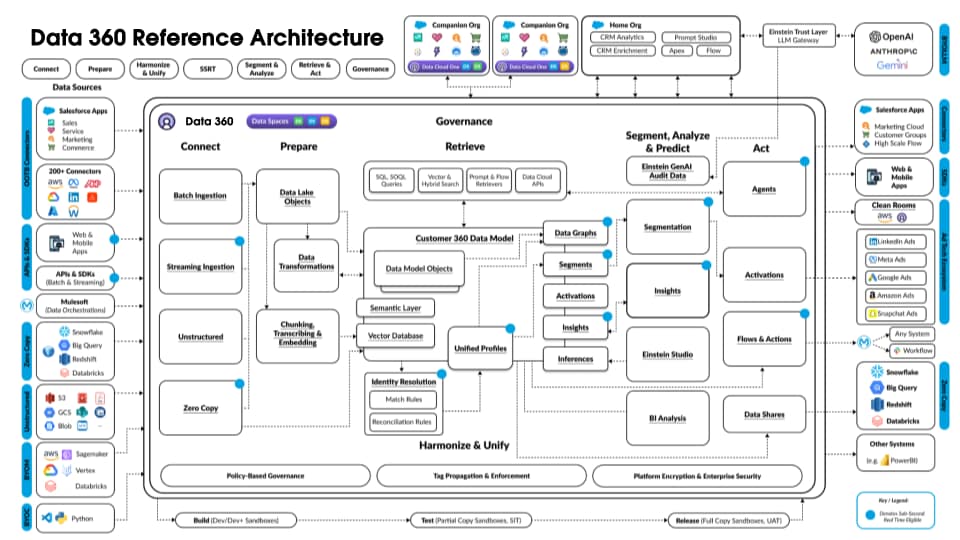
Data 360에 계층화된 가정적인 Agentforce Loan Agent를 고려하여 예제 아키텍처 흐름을 설명해 보겠습니다. 대출 에이전트가 고객(소비자)이 대출을 신청하고 즉시 대출 승인을 받을 수 있는 고객 대면 에이전트라고 가정해 보겠습니다.
Data 360은 해당 단계를 예약된 대로 수행하여 대출 에이전트가 사용할 데이터를 준비합니다.
- Data 360은 CRM에서 구조화된 고객 계정 데이터를 수집하고 데이터 레이크에 저장합니다.
- Data 360은 비정형 회사 대출 및 재무 증권 데이터를 처리합니다.
- Data 360은 Snowflake와 같은 외부 데이터 소스의 개인 데이터를 연합합니다.
- Data 360은 수집 및 연합 데이터를 변환하고 모델링합니다.
- Data 360은 프로필 데이터 그래프를 구축하고 유지합니다.
고객이 대출을 신청할 때마다 다음 작업이 수행됩니다.
- 고객이 대출 에이전트에 로그인하면 고객 세션이 실시간 레이어로 시작됩니다. 고객의 통합 프로필이 실시간 레이어로 가져옵니다.
- 고객이 필수 정보를 제공하여 대출 신청을 완료합니다.
- 고객이 비정형 데이터 처리를 위해 세금 반환, 투자, 은행 내역서와 같은 금융 문서를 Data 360에 업로드합니다.
- 업로드된 데이터는 청크되고 벡터화됩니다(포함 생성), 색인(키워드 및 벡터)이 생성됩니다.
- 그런 다음, 고객이 대출 신청 문서를 작성하고 업로드합니다. Data 360은 대출 금액 및 기간을 실시간으로 추출합니다.
- 대출 에이전트는 Data 360 쿼리 및 프로필 및 기타 사전 생성된 색인에서 하이브리드 검색을 사용하여 관련 금융 데이터를 검색합니다.
- 대출 에이전트가 대출 데이터 및 기타 금융 프로필 데이터를 사용하여 승인 에이전트를 활성화하여 대출 승인 결정을 내립니다.
- 대출 에이전트가 결정으로 고객에게 응답합니다.
- 고객과 대출 에이전트 간의 전체 상호 작용도 Data 360에 수집 및 저장됩니다.
위 예에서는 대출 에이전트와 같은 에이전트 응용 프로그램을 구축하는 데 사용되는 Data 360 아키텍처 구성 요소의 개요를 제공합니다. 다음 섹션에서는 Data 360 아키텍처 계층 및 구성 요소에 대해 설명합니다.
이 섹션에서는 Salesforce Data 360의 기본 빌딩 블록을 자세히 살펴보고, 견고한 스토리지 모델부터 이후에 데이터 연결, 수집, 준비 메커니즘을 살펴봅니다. 그런 다음, 구조화된 데이터와 비정형 데이터가 어떻게 저장되고, 모델링되고, 처리되는지 살펴보고, 조합, 통합, 검색 및 지능형 활성화 기능을 이해할 수 있습니다.
Salesforce Data 360은 레이크하우스의 강점과 실시간 저장소를 결합하는 계층화된 통합형 스토리지 모델을 기반으로 구축됩니다. 레이크하우스 레이어는 대량의 내역 및 배치 데이터에 확장 가능한 비용 효율적인 저장소를 제공하므로 고급 분석 및 기계 학습 사용 사례를 지원합니다. 반면 실시간 저장소는 대기 시간이 낮은 액세스 및 고주기 업데이트에 최적화되어 고객 상호 작용, 프로필, 참여 신호가 항상 최신 상태로 유지됩니다. 이러한 계층은 함께 원활하게 작동하므로 데이터가 내역 및 실시간 컨텍스트 간에 원활하게 이동하여 개인 설정, AI, 활성화를 위한 통합 데이터 파운데이션에서 심도와 즉각성을 모두 제공할 수 있습니다.
Data 360은 AI 및 분석 응용 프로그램에 매우 중요한 구조화된 데이터와 비정형 데이터를 모두 지원하는 배치, 스트리밍, 실시간 시나리오의 대규모 데이터 관리 및 처리를 처리하도록 설계된 Iceberg/Parquet 기반의 네이티브 레이크하우스 아키텍처를 갖추고 있습니다.
Azure, AWS 또는 GCP와 같은 클라우드 기반 데이터 레이크에서 기본 저장소는 일반적으로 폴더 및 계층으로 구성된 파일입니다. Lakehouse는 쿼리 및 AI/ML 처리와 같은 작업을 쉽게 수행할 수 있도록 더 높은 수준의 구조적 및 의미적 추상화를 도입하여 이 구조를 강화합니다. 기본 추상은 구조 및 의미론을 정의하는 메타데이터가 포함된 테이블이며, Data 360에서 추가 의미론 레이어를 추가하여 아이세버그 또는 델타 레이크와 같은 오픈 소스 프로젝트의 요소를 통합합니다.
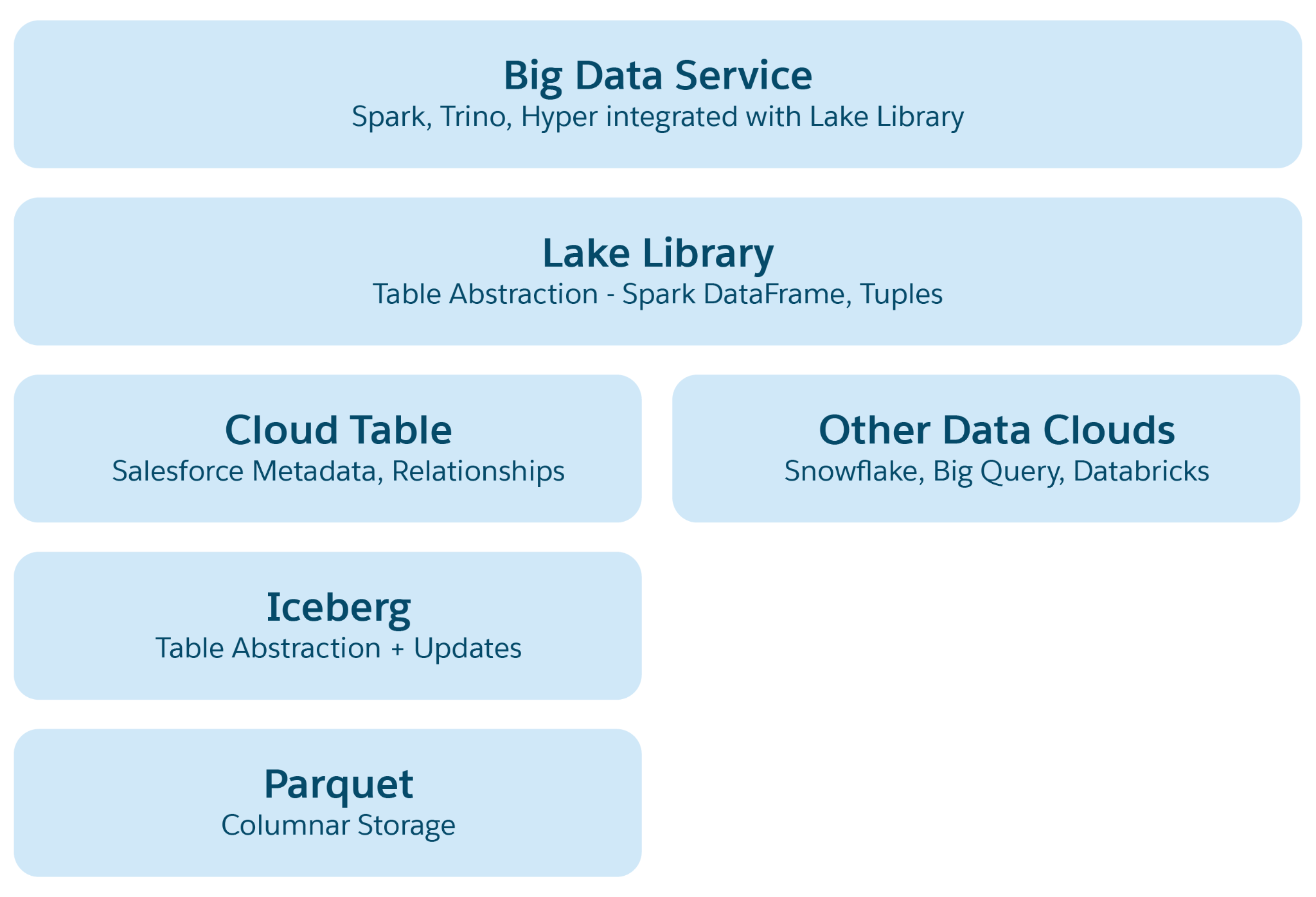
레이크하우스의 추상 레이어:
- Parquet 파일 요약: 기본적으로 저장소는 Parquet 형식의 데이터 레이크 파일(예: AWS의 S3 또는 Azure의 Blob)으로 구성됩니다. 소스 테이블의 데이터는 여러 파티션에서 Parquet 파일로 저장되며, 각 테이블은 해당 파일의 모음입니다.
- Iceberg Table Abstraction: 테이블은 폴더로 구성되며, 데이터 파티션은 해당 폴더 내에 Parquet 파일로 저장됩니다. 파티션을 수정하면 새 Parquet 파일이 스냅샷으로 표시됩니다. Iceberg는 스키마, 파티션 사양, 스냅샷을 자세히 설명하는 각 테이블의 메타데이터 파일을 관리합니다.
- Salesforce Cloud 테이블 요약: 이 레이어는 아이스버그에서 구축되며, 대상 파일 크기 및 압축과 같은 구성과 함께 열 이름 및 관계와 같은 의미 있는 메타데이터를 추가합니다. Snowflake 및 Databricks와 같은 다양한 플랫폼에서 테이블을 추상화하여 기본 스토리지 플랫폼 세부 사항으로부터 Data 360 응용 프로그램을 보호합니다.
- 레이크 액세스 도서관: 이 라이브러리는 Salesforce Cloud 테이블에 대한 액세스 권한을 제공하며, 데이터와 메타데이터를 모두 처리하고 응용 프로그램 개발자의 기본 저장 메커니즘을 추상합니다.
- Big Data Service Abstraction: 여기에는 쿼리용 하이퍼와 같은 처리 프레임워크 및 모든 클라우드 테이블 플랫폼에서 처리하는 Spark가 포함됩니다.
실시간 분석 및 에이전트 응용 프로그램을 지원하기 위해 Data 360은 레이크하우스의 대용량 데이터 저장소를 낮은 대기 시간 저장소로 늘립니다. Data 360 실시간 레이어는 메모리에서 실시간 신호 및 참여 데이터를 처리합니다. 그러나 메모리 기반 저장 용량이 제한되어 모든 데이터가 적합하지 않으며 실시간으로 처리를 수행할 수 없습니다. Data 360은 이러한 제한 사항을 제거하기 위해 낮은 대기 시간 저장소(LLS)를 추가하여 확장 가능한 실시간 처리를 활성화합니다.
저 대기 시간 저장소는 레이크하우스의 페타바이트 규모 NVMe(SSD) 저장소 계층입니다. 일부 데이터는 저 대기 시간 저장소에 보관할 필요가 없습니다. 견고한 캐시입니다. 대부분의 데이터는 결국 Lakehouse로 이동하여 장기간 유지됩니다. 실시간 레이어의 세션 내 데이터는 후속 빠른 액세스를 위해 저 대기 시간 저장소로 플러시할 수 있습니다. 예를 들어 에이전트 대화에서 메모리에 최근 메시지를 처리할 수 있으며, 오래된 메시지는 저 대기 시간 저장소로 플러시할 수 있습니다. 이전 대화가 필요한 경우 저 대기 시간 매장에서 몇 밀리초 이내에 액세스할 수 있습니다. NVMe 기반 저장소를 사용하면 대량의 데이터를 밀리초 대기 시간으로 저장하고 액세스할 수 있습니다. 데이터는 Lakehouse 클라우드 저장소로 이동하여 장기간 유지될 수 있습니다. 또한 실시간 처리에 필요한 레이크하우스의 데이터 또는 실시간 경험을 늘리기 위해 필요한 데이터가 가져와 저지연 매장에 보관됩니다. 예를 들어 고객 프로필 컨텍스트가 미리 가져오거나 레이크하우스에서 가져와 지연 시간이 낮은 매장에 캐시됩니다. 또한 세션 내 처리 시 실시간 처리에 필요한 레이크하우스 개체 및 기타 개체는 저 대기 시간 저장소에서도 캐시할 수 있습니다.
Data 360 낮은 대기 시간 저장소는 데이터가 해당 레이어 간에 원활하게 마이그레이션되는 메모리(SSD) 레이크하우스 저장소 레이어를 사용하는 실제 저장소 계층의 실시간 타이머 레이어를 활성화합니다. 이 문서에서는 나중에 Data 360 실시간 레이어에 대해 설명합니다.
Salesforce Data 360은 원시 입력을 통합된 현재 데이터 모델로 전환하는 엄격한 수명 주기에 따라 모든 고객 데이터(정형 및 비정형)를 표준화, 조화, 활성화하도록 설계되었습니다.
수명 주기는 다양한 외부 데이터 입력을 가져오고 모델링된 영구 개체로 구조화하는 데 중점을 둡니다. 모델링된 데이터를 Customer 360 통합 프로파일로 조화할 수 있습니다.
초고 수집 데이터 및 초기 변형
프로세스는 소스 시스템(CRM, 마케팅, 파일 등)에서 그대로 수집된 원시 데이터로 시작합니다. 전체 데이터 로드 및 지속적인 변경 이벤트(델타)가 포함되며, 현재 상태를 유지하기 위해 영구 데이터와 관리 및 병합됩니다.
인라인 변환(예: 트림, 정규화, 연결)은 수집 중에 즉시 적용되어 예비 데이터 품질과 순결을 보장합니다.
데이터 레이크 개체(DLO): 영구 레이어
DLO(데이터 레이크 개체)는 Data 360 내의 핵심 영구 저장 계층을 구성합니다. 깨끗하고 변환된 데이터를 저장하고 모든 고객 정보를 위한 구성된 장기 리포지토리로 사용합니다.
소스 DLO에 고급 데이터 변환(예: 조인, 집계, 계산된 인사이트)이 적용되어 새로 고도로 큐레이팅된 파생 DLO를 생성합니다.
Zero Copy 데이터 연합을 통해 사용할 수 있도록 지정된 데이터는 DLO로 직접 표시됩니다.
비정형 데이터 및 메타데이터 조직
구조화되지 않은 콘텐츠(텍스트, 미디어, 문서)의 경우 Data 360은 구조화되지 않은 데이터 레이크 개체(UDLO)라는 특정 DLO 내에서 구조화된 메타데이터를 추출하고 유지하여 데이터를 통합합니다.
이러한 전문화된 DLO는 디렉터리 테이블로 작동하여 구조화되지 않은 자산의 실제 위치 및 컨텍스트에 대한 지도를 제공합니다. 이 기능을 사용하면 아키텍처가 구조화되지 않은 데이터의 메타데이터를 구조화된 고객 데이터의 나머지 데이터와 원활하게 연결하여 통합 쿼리 및 조합 가능합니다.
데이터 모델 개체(DMO): 조화된 레이어
DMO(데이터 모델 객체)는 최종, 조화된 구조화된 데이터 레이어를 나타냅니다.
이 필드는 소스, 파생 및 비정형 메타데이터 DLO의 DLO 필드를 표준 Customer 360 데이터 모델에 매핑하여 생성됩니다.
DMO 레이어는 모든 고객 데이터에 대한 신뢰할 수 있는 단일 소스로 작동하여 광범위한 에코시스템 전반에서 통합 프로필 생성, 세분화, 활성화를 지원합니다.
데이터 공간은 모든 DLO(정형 및 비정형) 및 DMO를 포함하여 Data 360 내의 모든 데이터 및 메타데이터를 구성하기 위한 기본 논리 컨테이너입니다. 데이터 공간은 데이터 처리 및 모델링을 위한 안전하고 분리된 환경을 제공합니다.
데이터 공간은 논리적 경계와 거버넌스 경계 역할을 하며, 비즈니스 단위, 지역 또는 브랜드와 같은 고유한 엔티티에 대한 데이터를 분리하여 내부 다중 자산을 가능하게 하며, 엔터프라이즈 전체의 가시성, 계보, 규정 준수를 유지하면서 대규모 세분화된 액세스 제어를 정의하는 기반이 됩니다.
데이터 공간 내의 격리는 플랫폼의 여러 계층에 적용됩니다.
- 데이터 레벨 격리: 각 DLO/DMO는 단일 데이터 공간에 속하므로 쿼리, 변환, 개체 매핑이 명시적으로 승인되지 않는 한 데이터 공간 경계를 넘을 수 없습니다.
- 액세스 제어 통합: 권한 집합은 기본적으로 데이터 공간에 연결되어 있어 읽기, 쓰기, 관리 작업을 제어할 수 있습니다. 이렇게 하면 권한이 있는 사용자 및 서비스만 데이터 공간 내의 개체, 인사이트, 활성화에 액세스할 수 있습니다.
- 거버넌스 및 감사: 데이터 공간 내의 모든 작업은 엔터프라이즈급 감사 추적을 사용하여 기록되므로 규정 준수, 관리, 규제 보고에 대한 추적 가능성이 활성화됩니다.
권한 집합을 통해 액세스 및 권한이 관리되어 세부적인 가시성, 제어 업데이트, 교차 도메인 데이터 누출 방지를 보장합니다. 데이터 공간 경계를 Data 360의 보안 및 거버넌스 아키텍처와 통합함으로써 설계자는 여러 클라우드 및 비즈니스 도메인에서 일관성을 유지하면서 중앙 집중식 및 분산형 거버넌스 전략을 모두 확신할 수 있습니다.
Data 360 계산 패브릭은 모든 주요 데이터 작업 부하를 관리하고 실행할 수 있는 통합된 계층을 제공하여 기본 인프라 복잡성을 간소화합니다. 핵심 구성 요소는 데이터 처리 컨트롤러(DPC)입니다.
DPC는 다양한 클라우드 컴퓨팅 환경에서 Job-as-a-Service(JaS) 기능을 제공하는 포괄적인 다중 작업 부하 데이터 처리 오케스트레이션 서비스입니다. 이는 인프라 복잡성을 추상하고 Spark(EC2의 EMR 및 EKS의 EMR) 및 Kubernetes 리소스 컨트롤러(KRC) 워크로드와 같은 프레임워크에 대한 작업 실행을 통합합니다. 중앙 집중식 제어 플레인 게이트웨이로 사용되므로 DPC는 여러 데이터 플레인에서 작업을 오케스트레이션, 예약 및 모니터링하여 신뢰성, 확장성, 비용 효율성, 일관된 개발자 환경을 보장합니다.
DPC의 필요성은 EMR과 같은 기본 클러스터 관리 시스템과 직접 상호 작용하는 제한으로 인해 발생합니다.
인프라 및 클라우드 추상
EMR은 클러스터, 과업 및 단계에 대한 API를 제공하지만, 프로비저닝, 확장, 성능 조정, 비용 최적화와 같은 중요한 인프라 관리 과업을 클라이언트 팀에 부담으로 합니다. DPC는 작업 제출을 위한 간소화된 플랫폼 수준 API를 제공하여 이를 해결합니다. 자동 오류 처리, 재시도, 동적 로드 밸런싱을 지원합니다. 빈팩, 스팟 및 Graviton 기반 노드를 통해 비용 효율성을 제공합니다. TLS, PKI, IAM 격리 및 자동 패치를 통해 강력한 보안을 제공합니다. 성능 향상, 보안 패치 및 기능 향상을 제공하기 위해 Spark 및 EMR 런타임 버전 업그레이드를 관리합니다.
또한 DPC는 데이터 작업을 제출하고 관리할 수 있는 클라우드와 무관한 통합 인터페이스를 제공하며, 기본 클라우드 기반의 복잡성과 독점 API(AWS, future provider)를 추상화합니다. 이렇게 하면 클라이언트 팀이 Kubernetes 및 YARN과 같은 기본 리소스 관리자의 복잡성을 추상하는 공통 Data 360 API 기반 작업 제출 인터페이스와만 상호 작용할 수 있습니다. 이렇게 하면 클라이언트 팀이 팟, 노드 풀 또는 Spark 클러스터 구성을 직접 관리할 필요 없이 간단하고 통합된 API를 통해 Spark 작업을 제출할 수 있습니다.
수동으로 Spark 매개 변수를 조정하려면 전문 기술이 필요하며, 잘못된 구성으로 인해 작업 실행이 느려질 수 있습니다. DPC 팀은 이 전문 지식을 중앙 집중화하여 일반적인 성능 문제를 방지하기 위한 최적화된 구성을 제공합니다. 이 전문 팀은 컨트롤러가 관리하는 모든 작업 부하에서 최적의 성능을 보장하기 위해 오픈 소스 커뮤니티의 Knowledge 지속적으로 통합합니다.
DPC는 Spark로 제한되지 않으며 광범위한 워크로드 배열을 지원합니다. 다음은 포함됩니다.
- 실시간 처리 워크로드
- 데이터 작업에 대한 이벤트 배달 기능
- Milvus 관리(구형화되지 않은 데이터 색인화를 위한 벡터 데이터베이스)
- 저 대기 시간 스토리지 인프라
DPC는 또한 Kubernetes 리소스 컨트롤러(KRC) 프레임워크를 활용하여 Trino for Query, Event Delivery for Data Actions, Data Extraction Jobs for Connectors, 실시간 처리와 같은 워크로드를 지원합니다. 모든 KRC 워크로드에 대해 DPC는 중앙 Job-as-a-Service 기능을 제공하며, 고급 작업 추상에서 컴퓨팅 프로비저닝, 배포, 관리를 처리합니다.
JaaS 혜택 및 아키텍처
DPC에서 제공하는 Job-as-a-Service 모델은 비용 효율적이고 복원성이 뛰어난 작업 처리 파이프라인을 보장합니다.
사용자는 클러스터 일치에 필요한 CPU, 메모리, 저장소, 인스턴스 수, 최소/최대 클러스터 수 및 태그에 초점을 맞춘 간단한 클러스터 사양을 제공합니다. 그러면 DPC가 최적의 VM SKU 선택, 인스턴스 플리트 관리, 핵심 대비 비율 결정 등 추상 인프라 세부 사항을 자동으로 관리합니다. 과업 노드 및 주문형 관리 vs. 입력을 기반으로 인스턴스를 찾습니다. 또한 가동 중지 시간 없이 EMR 및 구성 요소 버전 관리 및 업그레이드를 처리합니다.
중요한 점은 DPC가 기본적으로 Data 360 테넌시 경계 및 자원 분리를 이해하고 적용하도록 설계된 멀티테넌스를 지원합니다. 또한 Salesforce 인증 기계 이미지를 적용하고 서비스별 IAM 역할을 관리하며 운송 중 및 유휴 중 모두 암호화를 보장하여 보안 및 규정 준수를 보장합니다. 라우팅 및 수용력 제어의 경우 클러스터 태그를 사용하여 작업-클러스터 일치가 관리되고 수용력 기반 라우팅은 최대 작업 동시 설정을 사용하여 자원 활용도를 효과적으로 제어합니다.
클라우드 무시적 클라이언트 환경은 클라이언트 서비스에서 기본 클라우드 환경의 복잡성을 숨기므로 비즈니스 논리에만 집중할 수 있으므로 핵심적인 이점입니다. 이를 통해 클라우드 공급자 추상화의 목표를 달성할 수 있습니다. 마지막으로 DPC를 사용하면 사용량 및 비용을 쉽게 추적할 수 있으므로 클러스터 사용량 및 비용을 서비스별로 세분화하여 정확한 계산을 수행할 수 있습니다. 전체적으로 DPC는 플러그 가능한 아키텍처를 따르므로 새로운 실행 엔진(예: Flink, Ray) 및 클라우드 기반(GKE/Dataproc)을 사용자에게 기본 인프라 세부 사항을 노출하지 않고 원활하게 통합할 수 있습니다. 이 설계는 실행 계층에서 제어 플레인을 분리하여 백엔드와 상관없이 일관된 API 및 운영 환경을 보장합니다.
Data 360은 원시 데이터를 세분화하고 보강하여 원시 정보와 실천 가능한 비즈니스 소비 사이의 격차를 줄입니다. 정교한 활성화 및 분석을 위해 복잡한 데이터를 준비하여 데이터 개체 수명 주기를 보완합니다. Data 360은 배치 및 스트리밍 데이터 변환, 배치 및 스트리밍 계산된 인사이트, 비정형 데이터 처리, ID 확인 등 다양한 처리 유형을 지원합니다. 특히 대규모 데이터 집합에서 거의 실시간으로 다양한 작업을 효율적으로 수행하려면 데이터 변경 사항을 효과적으로 처리하는 정교한 메커니즘이 필요합니다.
특히 테라바이트 크기의 테이블과 수백만 개의 잠재적인 업데이트를 사용하여 거의 실시간으로 효율적인 데이터 처리를 수행하려면 Data 360에 혁신적인 작업이 필요했습니다. 데이터가 변경될 때 정확하게 시스템에 알림을 보내고 관련 업데이트만 업데이트될 때만 처리되도록 변경된 데이터를 효율적으로 식별해야 했습니다. 이 과제로 인해 다음과 같은 두 가지 혁신이 보완되었습니다. 변경 사항이 발생하면 알리는 기본 변경 이벤트(SNCE)를 저장하고 변경된 사항을 식별하는 데이터 피드(CDF)를 저장합니다.
저장소 네이티브 변경 이벤트(SNCE)
SNCE는 Data 360을 반응형 증분 데이터 플랫폼으로 근본적으로 변경했습니다. 이 교대 근무는 표준화된 이벤트 형식 및 고처리량 메시지 전달 시스템을 사용하여 데이터 레이크의 적극적인 폴링에서 원자 커밋 이벤트를 수동으로 모니터링하는 것으로 전환됩니다.
Iceberg 테이블에 대해 성공적으로 쓰기 작업(삽입, 업데이트, 삭제)을 수행하면 카탈로그에서 테이블의 현재 메타데이터 파일 포인터를 원자로 교체할 수 있습니다. 기본 개체 저장소 계층(S3)은 테이블의 디렉터리에 새 메타데이터 스냅샷이 작성될 때마다 S3 이벤트와 같은 기본 알림 이벤트를 전송하도록 구성됩니다.
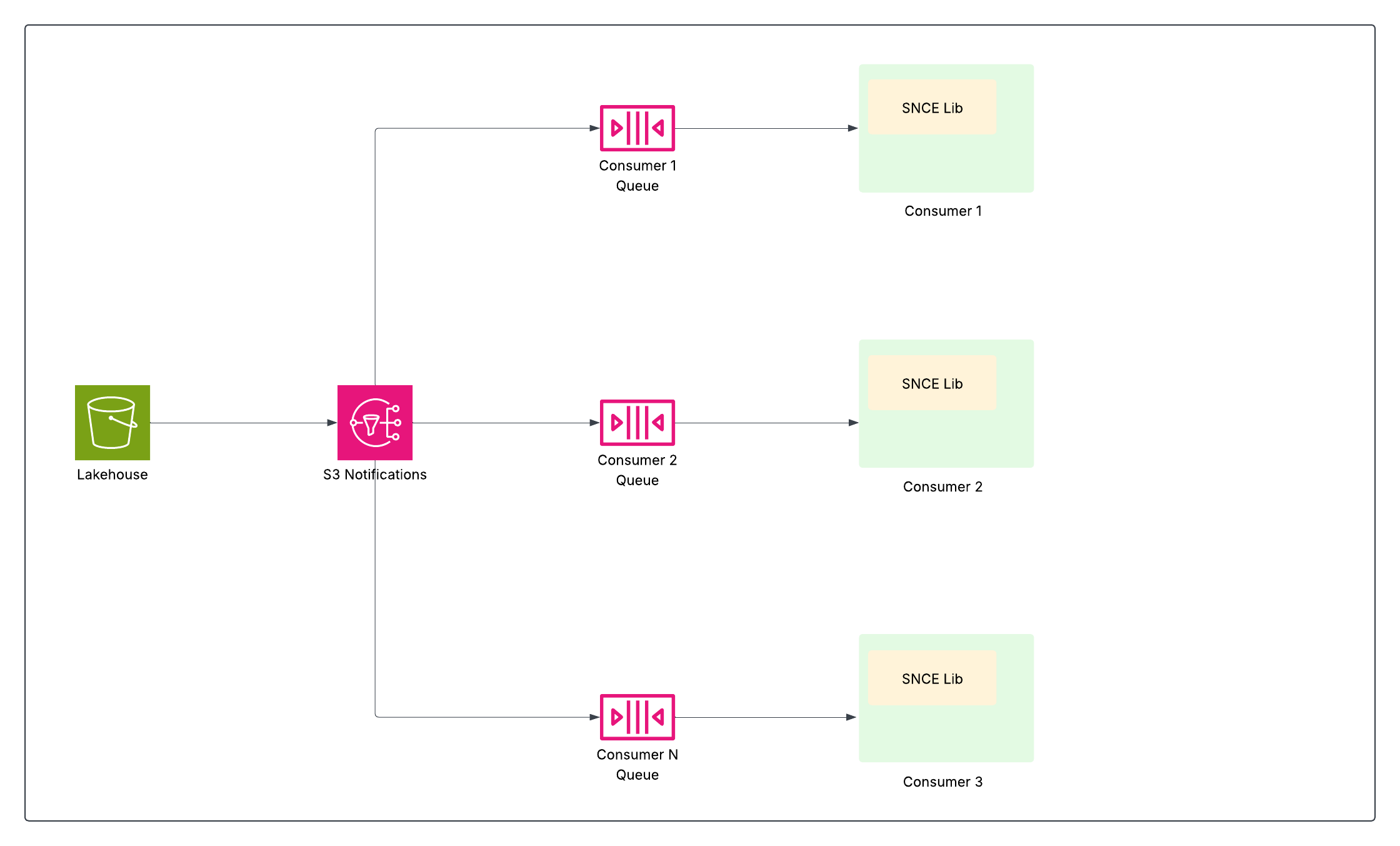
SNCE 라이브러리는 해당 이벤트를 사용하기 위한 표준화된 방법을 제공하며 요청 시 스냅샷 메타데이터로 보강할 수도 있습니다.
이렇게 하면 다운스트림 데이터 파이프라인(스트리밍 계산된 인사이트, ID 확인, 세분화 등)이 데이터가 변경된 경우에만 구독하고 조치를 취할 수 있으므로 비용이 많이 드는 전체 테이블 스캔을 피하여 효율성을 크게 높일 수 있습니다.
데이터 피드 변경(CDF)
SNCE를 기반으로 하는 변경 데이터 피드(CDF)는 변경 사항을 소비하고 증분적으로 처리하는 간소화된 메커니즘을 제공합니다.
CDF는 Iceberg 스냅샷을 활용하여 변경 사항 스트림을 효율적으로 생성합니다. 중요한 점은 Data 360의 최적화된 아이스버그 작성기가 쓰기 작업 자체의 일부로 변경 사항을 계산하고 유지하므로 CDF 생성이 매우 효율적이고 추가 오버헤드가 최소화됩니다. 이렇게 하면 처리 작업(스트리밍 변환 또는 스트리밍 계산된 인사이트 등)이 변경된 레코드만 선택적으로 처리하여 비용이 많이 드는 스냅샷 다름 계산을 피할 수 있습니다.
이 증분 전략은 비용 절감, 대기 시간 단축, 효율성 향상 등 대규모 데이터 집합에 몇 가지 이점을 제공합니다. 스트리밍 변환 및 증분 ID 확인과 같은 기능을 활성화하여 더 빠른 인사이트, 더 예측 가능한 시스템 로드, 향상된 성능, 운영 비용을 줄일 수 있습니다.
Data 360은 Salesforce 제품에 대한 기본 지원과 함께 강력한 수집 기능을 제공하여 원활한 데이터 흐름을 보장합니다. 외부 소스의 경우 270개가 넘는 커넥터, API, SDK, MuleSoft를 통해 광범위한 연결을 제공합니다. 또한 Data 360은 0-copy 연합을 사용하므로 데이터 중복 없이 BI 및 분석을 수행할 수 있습니다.
Data 360 커넥터 프레임워크(DCF)는 대부분의 Data 360 연결을 위한 기반입니다. 통합 아키텍처를 통해 수집, 연합, 추출을 활성화합니다. DCF는 설정 및 관리용 UI에서 메타데이터 지속성, 데이터 추출, 레이크하우스로 전달 또는 외부 소스에 대한 실시간 쿼리를 통해 커넥터 구축 및 관리에 대한 표준을 정의합니다. 또한 비공개 링크, VPN, 보안 터널 등 비공개 연결 옵션을 지원하여 고객 또는 파트너 환경에 연결할 때 엔터프라이즈급 데이터 보안 및 규정 준수를 보장합니다. 모든 커넥터에서 일관된 접근 방식을 제공함으로써 DCF는 확장성, 신뢰성, 안전한 통합을 보장하여 Data 360을 더 광범위한 에코시스템에 원활하게 연결할 수 있도록 지원합니다.
Data 360은 광범위한 데이터 소스 에코시스템에 강력한 연결을 제공하며 네이티브 Salesforce 제품과 다양한 외부 시스템을 모두 지원합니다. 이 광범위한 연결은 사일로 엔터프라이즈 데이터를 통합하고 AI/ML 및 에이전트 응용 프로그램을 활성화하는 데 매우 중요합니다.
Data 360은 MuleSoft, API, SDK를 통해 또는 기본적으로 270개가 넘는 커넥터를 제공하여 배치, 스트리밍 또는 실시간 수집을 통해 종단간 데이터 파이프라인 기능을 지원합니다. 이러한 커넥터는 통합하는 소스 시스템 유형별로 광범위하게 범주화할 수 있습니다.
Salesforce 기본 커넥터
이러한 커넥터는 Salesforce 제품의 원활한 기본 데이터 흐름을 보장합니다.
Salesforce CRM, Data Cloud One, Marketing Cloud Engagement, Marketing Cloud Account Engagement, B2C Commerce의 커넥터를 예로 들 수 있습니다.
외부 애플리케이션 및 SaaS
다양한 비즈니스 응용 프로그램 및 클라우드 서비스의 커넥터를 사용하면 외부 소프트웨어 플랫폼에서 데이터를 수집할 수 있습니다.
예를 들어 Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp, Airtable이 있습니다.
데이터베이스 및 데이터 웨어하우스
Data 360은 다양한 관계형 및 클라우드 기반 데이터 저장소 플랫폼에 연결됩니다.
예로는 Amazon Redshift, Amazon DynamoDB, Amazon RDS(MySQL, PostgreSQL, Oracle), Google BigQuery, Microsoft SQL Server가 있습니다.
클라우드 개체 저장소 및 파일 시스템
이러한 커넥터는 구조화된 데이터와 비정형 데이터 모두를 위한 대규모 스토리지 솔루션과 통합됩니다.
예로는 Amazon S3, Google Cloud Storage(GCS), Azure Blob Storage가 있습니다.
스트리밍 및 메시징 서비스
연속 실시간 데이터 스트림을 처리하는 커넥터는 이벤트 중심 시나리오 및 실시간 처리에 매우 중요합니다.
Amazon Kinesis 커넥터를 예로 들 수 있습니다.
통합 플랫폼
MuleSoft Anypoint 커넥터는 Anypoint Exchange를 통해 더 광범위한 응용 프로그램 및 데이터베이스와 Data 360의 도달 범위를 확장합니다.
비정형 데이터 및 클라우드 개체 저장소 커넥터
이러한 커넥터는 생성형 AI 기능을 강화하기 위해 구조화되지 않은 데이터(사전 정의된 모델이 없는 데이터)를 수집하고 참조하는 데 중요합니다.
모든 커넥터는 일관된 환경을 제공하는 Data 360 커넥터 프레임워크에 구축되어 있습니다.
데이터 변환은 Data 360의 기본 아키텍처 구성 요소로, 원시 수집된 데이터를 정리, 보강하고 Customer 360 데이터 모델에 맞춰 정규화된 실행 가능한 데이터 자산으로 형성하도록 설계되었습니다. 이 프로세스는 데이터 조합, 품질 향상 및 프로필 통합, 세분화 및 활성화와 같은 다운스트림 사용 사례에 대한 데이터 준비가 필수적입니다. 변환은 소스 데이터 레이크 개체(DLO) 및 데이터 모델 개체(DMO)를 모두 입력으로 활용하여 각각 새로운 DLO 또는 DMO에 대한 결과를 생성합니다.
Data 360은 서로 다른 데이터 속도 요구 사항인 배치 데이터 변환 및 스트리밍 데이터 변환을 해결하기 위한 두 가지 기본 변환 패러다임을 제공합니다.
배치 데이터 변환
배치 데이터 변환은 정의된 일정 또는 주문형 트리거를 기반으로 대용량 처리를 위해 고안되었습니다. 이 엔진은 복잡하고 자원 집약적인 재구축 작업을 처리하기 위해 최적화되어 있습니다.
배치 변환 프로세스는 사용자가 다단계 변환 논리를 정의할 수 있는 시각적 하위 코드 파이프라인 캔버스를 사용하여 구성됩니다. 이 엔진은 정규 데이터 모델 정렬에 중요한 복잡한 재구성 작업(데이터 구조화 및 정규화)을 고유하게 지원합니다. 여기에는 피벗(비정규화된 레코드를 여러 정규화된 레코드로 분해) 및 평면화(JSON과 같은 계층적 데이터를 구조화된 테이블로 재구축)가 포함됩니다. 시스템의 실행 모드는 전체 동기화(모든 레코드 처리) 및 고효율 증분 처리 모드를 모두 지원합니다. 증분 모드는 마지막으로 성공적으로 실행된 이후에 변경된 레코드만 처리하여 처리 시간과 리소스 소비를 크게 줄입니다. 배치 변환은 정기적 집계 및 복잡한 데이터 재구축과 같이 실시간 업데이트가 필수적이지 않은 과업에 적합합니다.
데이터 변환 스트리밍
스트리밍 데이터 변환은 시스템에 흐르는 동안 거의 실시간으로 데이터를 지속적으로 증분적으로 처리하므로 대기 시간이 낮은 사용 사례에 필수적으로 적용됩니다.
기본 인터페이스는 변환이 수신되는 레코드 변경 스트림에 대해 지속적으로 실행되는 SQL SELECT 쿼리로 정의되는 SQL 우선 접근 방식입니다. 이 엔진은 데이터 정리 및 표준화(예: PII 확인 및 데이터 형식 표준화) 및 데이터 보강 및 병합(조인 및 조인 사용) 등 핵심 변환 기능을 지원합니다. 중요하게 스트리밍 조회 JOIN을 지원하여 정적 또는 느리게 변경되는 참조 데이터에 대한 실시간 데이터 보강 및 조회를 활성화하여 즉시 프로필 업데이트를 보장합니다. 서비스 비용을 최적화하기 위해 아키텍처는 단일 테넌트에 대한 여러 스트리밍 변환 정의를 단일 기본 컴퓨팅 작업으로 패키징하는 고밀도(HD) 작업 설계를 사용하여 자원 활용도를 극대화합니다. 스트리밍 변환은 이벤트 모니터링, 즉각적인 개인 설정, 실시간 프로필 업데이트와 같은 사용 사례에 필수적입니다.
Data 360은 Zero Copy 연합 및 데이터 공유를 지원하여 데이터 관리를 혁신화하므로 데이터를 이동하거나 복제할 필요가 없습니다. 이 기능을 사용하면 사용자가 다양한 외부 소스에서 데이터에 원활하게 직접 액세스하고 외부 환경과 데이터를 공유하여 복잡성을 크게 줄이고 저장소 비용을 절감하며 모든 결정을 최신의 신뢰할 수 있는 정보를 기반으로 합니다.
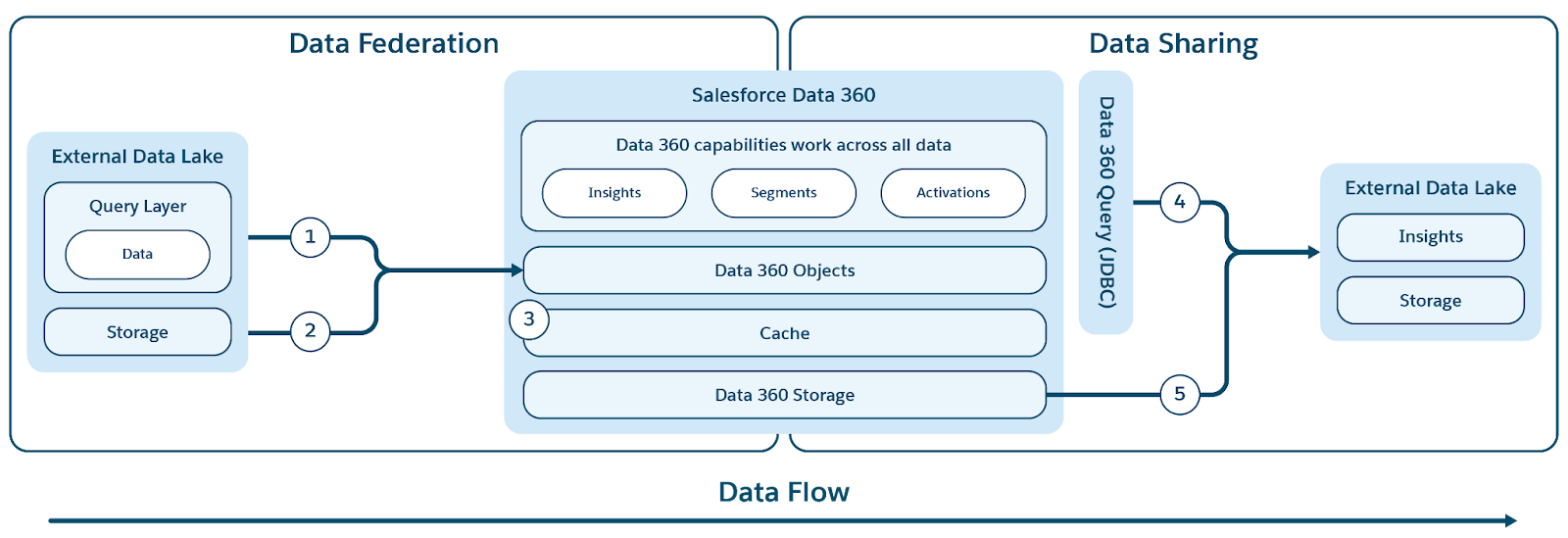
Data 360은 외부 데이터 웨어하우스(Snowflake, Redshift), 레이크하우스(Google BigQuery, Databricks, Azure Fabric), SQL 데이터베이스 및 기타 여러 소스와 함께 0-copy 연합을 지원합니다. 추상 레이어를 사용하면 중복 없이 외부 데이터를 직접 쿼리할 수 있으므로 수집 시간과 저장소 비용을 줄이고 최신 정보를 확보할 수 있습니다.
Data 360은 Salesforce 및 외부 개체를 모두 추상하는 통합 메타데이터 레이어를 제공하여 외부 및 연합 데이터에 대한 액세스를 간소화합니다. 이렇게 하면 전체 Salesforce Platform 및 응용 프로그램이 이 데이터를 원활하게 사용할 수 있습니다.
Data 360은 파일 및 쿼리 기반 연합을 모두 지원하며, 그림에 표시된 대로 실시간 쿼리 및 액세스 가속화가 가능합니다.
레이블(1) 및(2)은 외부 데이터 레이크/웨어하우스/데이터 소스에서 데이터에 액세스하기 위한 Data 360의 쿼리(실시간 쿼리 푸시다운 포함) 및 파일 기반 연합을 보여주며, 레이블(3)은 외부 데이터 레이크/데이터 소스에서 연합된 액세스 가속화를 강조합니다.
쿼리 연합
Data 360의 연합 기능의 핵심은 외부 데이터에 액세스하고 지능형 쿼리 푸시다운을 수행하는 복잡한 프로세스를 관리하는 쿼리 연합 계층에 있습니다( 레이블 1에 표시). Data 360은 효율성을 향상하기 위해 추가 논리로 향상된 JDBC 프로토콜을 사용하여 소스에서 데이터를 연결하고 검색합니다. 쿼리 연합 계층은 다양한 SQL 방언을 이해하고 번역하고 최적의 쿼리 부분을 외부 시스템으로 푸시하여 효율적으로 처리하고 결과를 검색하고 최종 인사이트를 도출하기 위해 필요한 모든 추가 처리를 수행할 책임이 있습니다.
캐싱(쿼리 가속화)
고급 유틸리티의 경우 Data 360은 연합 기능에 대한 가속 기능(옵션)을 제공합니다.
Acceleration이 활성화되면 Data 360이 연합 데이터를 캐시하여 외부 소스에 대한 반복적인 직접 액세스를 방지하여 더 빠른 액세스 및 비용을 절감합니다. 이 캐시는 가속화 레이어로 취급되며 외부 소스 데이터의 변경 사항을 빠르게 반영하도록 증분적으로 업데이트되므로 가속 보기가 실시간에 가깝게 유지됩니다.
파일 통합
Data 360은 외부 데이터 레이크 및 소스의 데이터에 액세스하기 위한 파일 기반 연합(레이블 2로 표시)을 지원합니다. 이 제로 카피 기능의 기술적 기반은 표준화에 의존합니다. 기본 데이터는 Apache Parquet 파일 형식이어야 하며 Apache Iceberg 테이블 형식을 사용해야 합니다. Data 360은 메타데이터 및 저장소 액세스를 위해 IRC(Iceberg REST Catalog)를 노출하는 모든 소스로 연합하여 플랫폼 외부에 있는 파일에 원활하고 관리되는 액세스를 보장할 수 있습니다.
파일 기반 연합을 사용하면 Data 360 컴퓨팅이 기본 저장소에 직접 액세스하므로 모든 데이터 처리를 처리합니다. 이렇게 하면 쿼리 기반 연합에 종종 필요한 다양한 SQL 방언을 쿼리 푸시다운하고 관리할 필요가 없습니다.
또한 Zero Copy 기능은 Data 360의 비정형 처리 파이프라인에서 액세스할 수 있는 대규모 스토리지 솔루션(S3/GCS/Azure 스토리지), Slack 및 Google Drive 등 비정형 데이터 소스에도 확장됩니다.
Data 360은 원래 그림 컨텍스트에서 레이블 4 및 5로 표시된 외부 데이터 레이크 및 창고와 관리하는 데이터의 쿼리 기반 및 파일 기반 공유를 쉽게 수행합니다.
쿼리 기반 공유
쿼리 기반 데이터 공유의 경우 Data 360은 데이터에 대한 보안 액세스를 얻을 수 있는 외부 엔진 및 응용 프로그램을 사용하여 JDBC 드라이버를 노출합니다. 이 메커니즘을 사용하면 외부 시스템이 Data 360 내의 데이터에 대해 직접 실시간 쿼리를 연결, 인증, 실행할 수 있습니다.
파일 기반 공유(데이터 공유 및 DaaS)
파일 기반 공유를 위한 기본 메커니즘은 DaaS(Data as a Service) API를 활용하는 두 가지 개념인 데이터 공유 및 데이터 공유 대상을 포함합니다.
- 세분화된 제어: 데이터 공유 개념을 사용하면 고객이 외부에서 공유되는 개체(DLO, DMO, CIO 등)를 정확하게 정의하여 의도하지 않은 데이터 노출을 방지할 수 있습니다.
- 보안 대상: 또한 데이터 공유 대상을 제어하여 명시적으로 승인된 외부 환경, 계정 또는 파트너 조직(예: 특정 Redshift 또는 Databricks 인스턴스와 공유)만 데이터를 사용할 수 있도록 합니다.
DaaS API는 외부 엔진이 데이터를 소비할 수 있도록 안전하고 관리되는 인터페이스를 제공합니다. 모든 Data 360 시맨틱을 유지하면서 필수 메타데이터 및 기본 테이블 저장소에 대한 액세스 권한을 부여합니다. 이렇게 하면 외부 엔진이 일관되고 의미 있는 컨텍스트에서 안전한 방식으로 데이터에 액세스할 수 있습니다.
특히 대기업, 규제된 산업, 공공 부문 조직 등 많은 보안에 민감한 고객이 보안 조치의 일부로 데이터 레이크에 대한 모든 인터넷 액세스를 제한합니다. 이 정책은 규정 준수 및 위험 감소에 필수적이지만 Salesforce Data 360 및 Agentforce 공개 인터넷을 통해 해당 환경에 연결되지 않도록 방지합니다.
대부분의 데이터 레이크는 AWS, Azure 또는 Google Cloud와 같은 하이퍼스케일러 환경에 배포됩니다. Data 360 자체가 AWS에서 실행되므로 다른 클라우드 공급자에서 호스팅되는 고객 데이터 레이크에 액세스하려면 클라우드 간 네트워크 연결이 필요합니다. 공개 인터넷을 우회하는 안전한 비공개 연결 옵션이 없으면 고객이 이러한 데이터 레이크에 의존하는 사용 사례에 Data 360 또는 Agentforce 채택할 수 없거나 원하지 않는 경우가 많습니다.
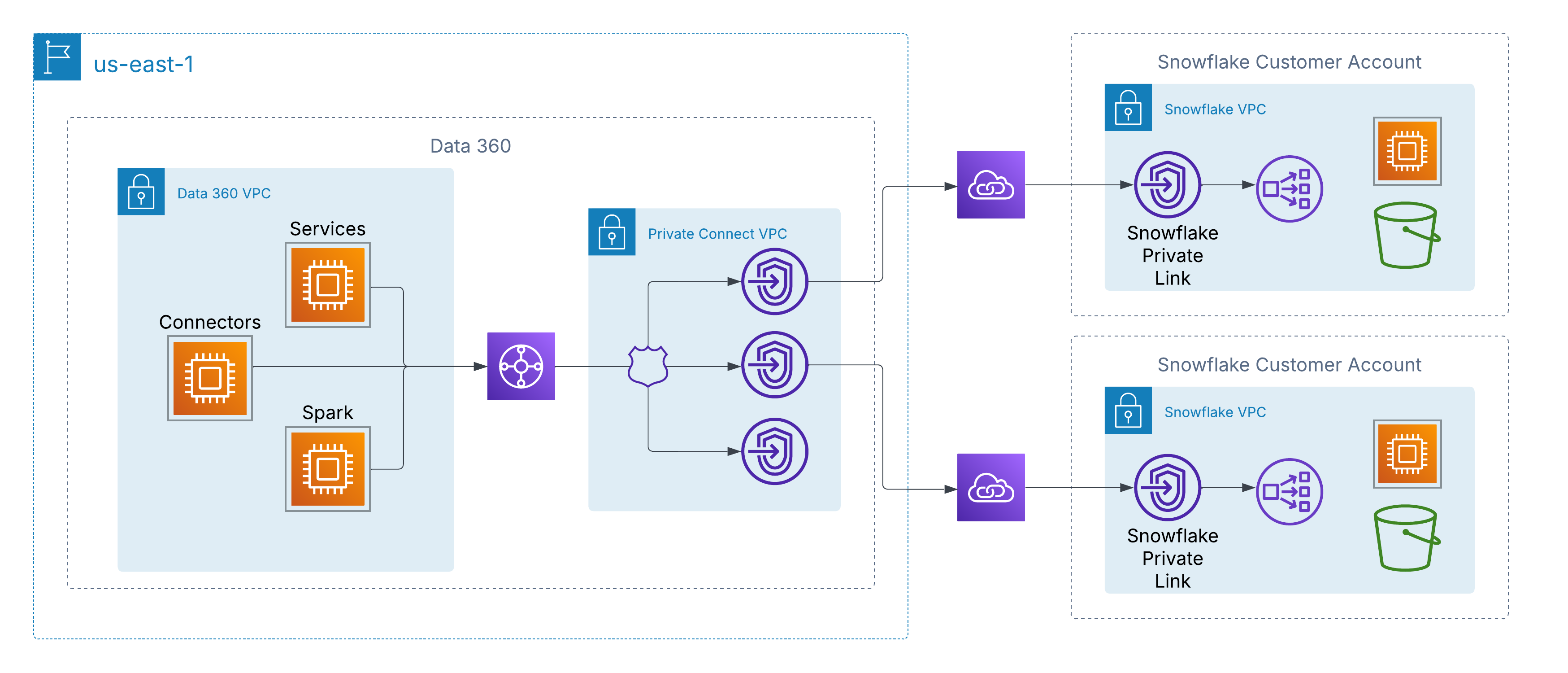
이를 해결하기 위해 Data 360은 클라우드 전반에서 고객이 관리하는 데이터 소스에 대한 비공개 네트워크 수준 연결을 지원합니다. AWS에서는 AWS PrivateLink를 통해 활성화되며, 이를 통해 Data 360은 공개 인터넷을 이동하지 않고 자체 계정 또는 타사 데이터 레이크 환경(예: Snowflake) 내에서 고객 프로비저닝 끝점에 직접 연결할 수 있습니다.
이 아키텍처는 비공개 IP 주소 지정 및 라우팅할 수 없는 네트워크 경로를 사용하여 모든 트래픽이 AWS 백본에 남아 있어 엄격한 보안 및 규정 준수 요구 사항을 충족하며 고객 데이터에 원활하게 액세스할 수 있도록 합니다.
다중 클라우드 아키텍처를 사용하는 고객의 경우 Data 360은 클라우드 간 상호 연결 지원을 통해 AWS 이상의 비공개 연결을 확장합니다. 이를 통해 Data 360에서 Azure 또는 Google Cloud에서 호스팅되는 데이터 레이크 및 서비스로의 보안 백본 전용 네트워크 경로를 활성화하고 AWS PrivateLink와 동일한 원칙(비공개 IP 주소 지정, 비공개 라우팅, 인터넷 노출 제로)을 유지할 수 있습니다.
고객은 두 가지 배포 모델 중에서 선택할 수 있습니다.
-
고객 관리형 상호 연결: Azure ExpressRoute, Google Cloud Interconnect 또는 Equinix Fabric과 같은 기존의 비공개 회로를 Data 360의 VPC와 직접 통합합니다.
-
Salesforce 관리형 상호 연결: Salesforce가 클라우드 간 링크를 프로비저닝하고 운영하는 완전 관리형 턴키 연결을 사용하여 대상 클라우드에 비공개 끝점을 노출합니다.
두 모델 모두 환경이 일관적입니다. Data 360 서비스는 하이퍼스케일러를 통해 로컬처럼 외부 데이터 소스에 연결하여 공개 인터넷을 이동하지 않고도 안전하게 수집, 활성화, 쿼리를 수행할 수 있습니다.
엔터프라이즈 아키텍처의 경우 강력한 데이터 거버넌스는 단순히 규정 준수 확인란이 아니라 신뢰할 수 있고 확장 가능하며 실행 가능한 고객 인텔리전스 구축하는 기본 기둥입니다. Salesforce Data 360은 전체 데이터 수명 주기 전반에 걸쳐 데이터 품질, 보안, 규제 요구 사항 준수를 보장하는 포괄적인 거버넌스 프레임워크로 구성되어 있습니다.
Data 360은 중앙 집중화된 거버넌스 허브 역할을 하므로 원시 수집에서 활성화된 인사이트까지 모든 데이터가 무결하고 제어적으로 관리됩니다.
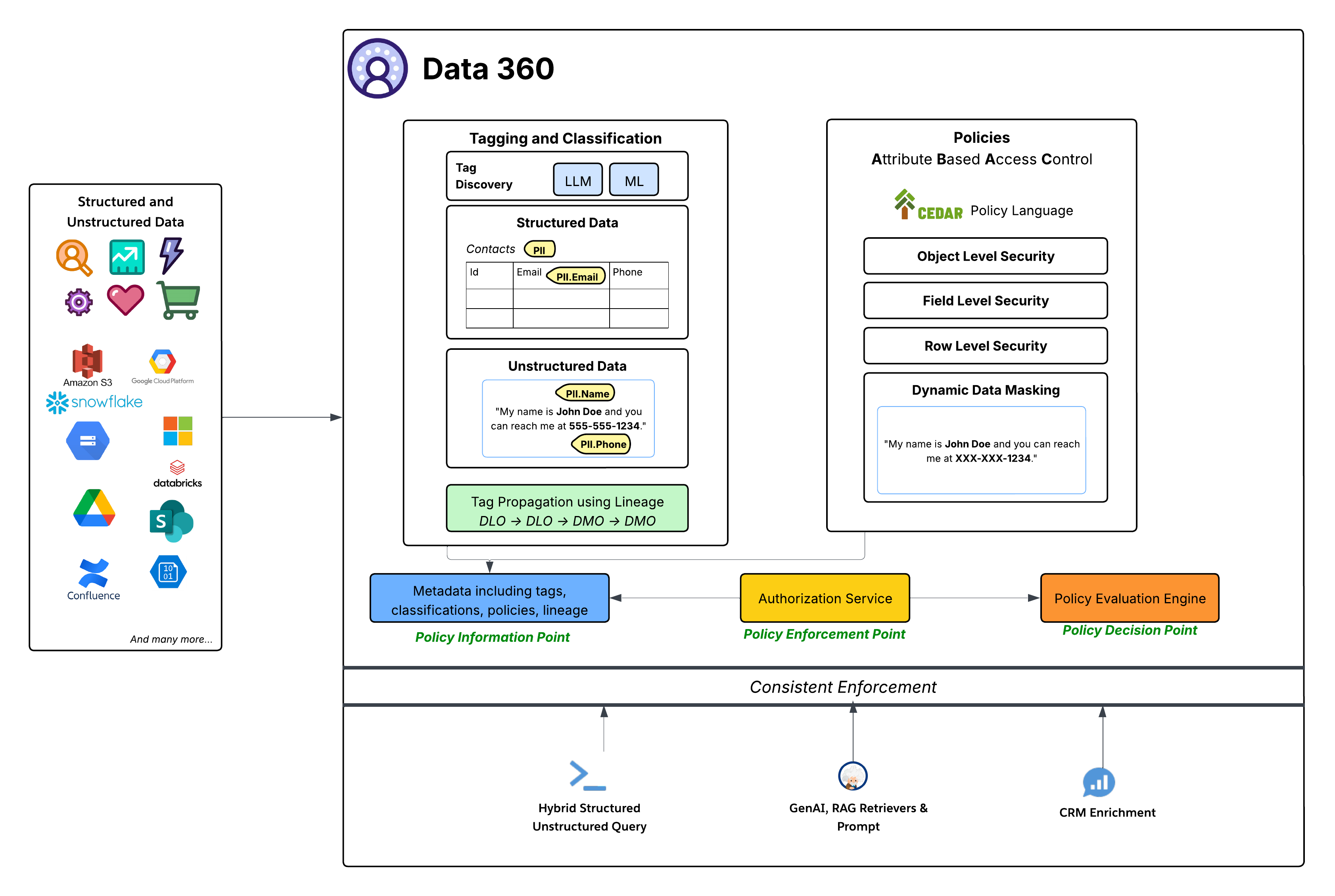
데이터 공간은 데이터 공간 내의 모든 개체에 대한 액세스 권한을 결정하는 대규모 세분화된 액세스 제어를 제공하지만 ABAC 기반 정책은 데이터 공간 내의 개별 개체, 필드 및 행에 대한 정밀 세분화된 액세스 제어를 제공합니다. Data 360은 세분화된 액세스 제어를 위한 핵심 권한 부여 모델로 특성 기반 액세스 제어(ABAC)를 채택했습니다. 이 전략적 선택은 대용량 데이터와 다양한 액세스 요구 사항이 있는 동적이고 복잡한 엔터프라이즈 환경에서 특히 중요한 기존 RBAC(역할 기반 액세스 제어)와 비교하여 탁월한 유연성과 확장성을 제공합니다. ABAC를 사용하면 미리 정의된 역할이 아닌 사용자의 특성(예: 부서, 역할, 위치), 데이터(예: PII, 민감도, 데이터 공간), 환경(예: 일과 시간)을 기반으로 액세스 결정을 내릴 수 있습니다. 이를 통해 데이터 및 사용자 특성 변경에 따라 적응하는 매우 세분화되고 상황에 맞는 액세스 정책을 사용할 수 있습니다.
- CEDAR 정책 언어: Data 360의 ABAC 구현의 핵심은 CEDAR 정책 언어 사용입니다. 이 목적에 따라 구축된 공식 정책 언어는 복잡한 권한 부여 규칙을 정의하는 정확하고 확인 가능한 방법을 제공하므로 정책이 명확하고 규모에 따라 일관되게 평가할 수 있습니다.
Data 360 내의 거버넌스 시스템은 강력하고 표준 ABAC 아키텍처를 준수합니다.
- 태그 지정, 분류 및 정책 작성(정책 정보 지점 - PIP):
- Data 360은 LLM(대규모 언어 모델) 및 ML(기계 학습)을 활용하여 민감한 데이터 범주(예: PII.Email, PII.Phone, PII.Name) 및 기타 용도 구축 분류(PHI, FinancialData)를 구조화된 데이터(예: 연락처 테이블) 및 구조화되지 않은 데이터(예: Google Drive) 모두에서 식별하는 자동화된 태그 지정 및 분류 메커니즘을 제공합니다.
- 중요하게, 태그 전파는 데이터 계보(DLO -> DLO -> DMO)를 따라 발생하므로 분류가 원시 수집된 데이터에서 조화된 DMO 레이어까지 프로세스 정의에서 생성된 파생 데이터를 통해 데이터 변환 및 파생을 자동으로 따릅니다.
- 마지막으로 정책 작성 창은 데이터 및 사용자 특성을 활용하여 조직에 대한 동적 액세스 규칙을 정의하는 간단한 환경을 제공합니다.
- 이 보강된 메타데이터(태그, 분류, 정책, 계보 포함)는 정책 정보 지점(PIP)에 피드됩니다.
- 승인 서비스(정책 집행 지점 - PEP):
- 인가 서비스는 정책 집행 지점(PEP) 역할을 합니다. 다양한 소비 계층(하이브리드 구조화/비정형 쿼리, GenAI RAG 검색기 및 프롬프트, CRM 보강)의 모든 데이터 액세스 요청을 가로채고 정책 결정 지점과 상담하여 액세스 허용 여부를 결정합니다.
- 정책 평가 엔진(정책 결정 지점 - PDP):
- 이 엔진은 정책 결정 지점(PDP) 역할을 합니다. 권한 있는 액세스 결정을 내리기 위해 PEP의 액세스 요청 컨텍스트와 정책 정의(CEDAR) 및 PIP의 특성을 가져옵니다.
- 전체 보안 정책: CEDAR에 정의된 정책은 다음을 포함하여 다양한 보안 수준을 적용합니다.
- 개체 수준 보안: 해당 개체와 연결된 태그를 기반으로 전체 DLO 또는 DMO에 대한 액세스를 제어합니다.
- 현장 수준 보안: 태그를 기반으로 개체 내 특정 민감한 필드에 대한 액세스를 제한합니다.
- Row Level Security: 특정 개체의 데이터를 필터링하여 사용자 특성을 기반으로 관련 행만 표시합니다.
- 동적 데이터 마스킹: 기본 데이터를 변경하지 않고 액세스 지점에서 특정 데이터(태그 기반)를 동적으로 마스킹합니다. 이렇게 하면 민감한 정보가 보호되지만 광범위한 유틸리티를 제공할 수 있습니다. 이는 구조화된 데이터의 마스킹 필드와 비정형 데이터의 콘텐츠에 적용됩니다.
- 일관적인 적용: 전체 ABAC 프레임워크는 다이렉트 데이터 쿼리, 생성형 AI 응용 프로그램(RAG) 검색 또는 관련 목록을 통해 Salesforce CRM 환경 보강 등 모든 Data 360 소비 패턴에서 정책을 일관적으로 적용합니다.
- Salesforce Platform과의 심층적 통합: Data 360의 거버넌스 기능은 Salesforce 핵심 플랫폼 내에서 직접 정의 및 관리됩니다. 이 통합을 통해 관리자는 익숙한 Salesforce 도구를 사용하여 액세스 정책, 사용자 ID, 특성 관리를 관리하여 전체 Salesforce 에코시스템에서 일관된 통합 관리 계층을 보장할 수 있습니다.
CEDAR 정책을 사용하여 이 정교한 ABAC 프레임워크를 구축함으로써 Data 360은 설계자에게 탁월한 수준의 제어 및 유연성을 제공하여 고객 데이터가 실행 가능한 것뿐만 아니라 안전하고 규정을 준수하며 기업 전체에서 신뢰할 수 있도록 합니다.
산업 전반에서 조직은 데이터 누출, 무단 액세스, 변경 또는 파괴로부터 보호하기 위해 종단간 데이터 보안에 더욱 강조하고 있습니다. 현재 Data 360을 포함한 대부분의 데이터 플랫폼은 공급업체에서 관리하는 암호화 키를 사용하여 암호화를 유지합니다. 그러나 기업(특히 규제된 섹터에 속하는 기업)은 사용 중인 데이터와 전송 중인 데이터 모두에 대해 고객이 관리하는 암호화 기능을 점점 더 요구하고 있습니다.
이 모델을 사용하면 회사에서 자체 암호화 키를 제어하여 플랫폼 수준 위반 또는 무단 액세스가 발생할 가능성이 높지 않은 경우에도 데이터가 암호화 방식으로 보호됩니다. 고객의 독점 키가 없으면 플랫폼 공급자를 포함한 어떠한 엔티티도 데이터를 해독하거나 재구성할 수 없으므로 전체 기밀성을 유지하고 제어할 수 있습니다.
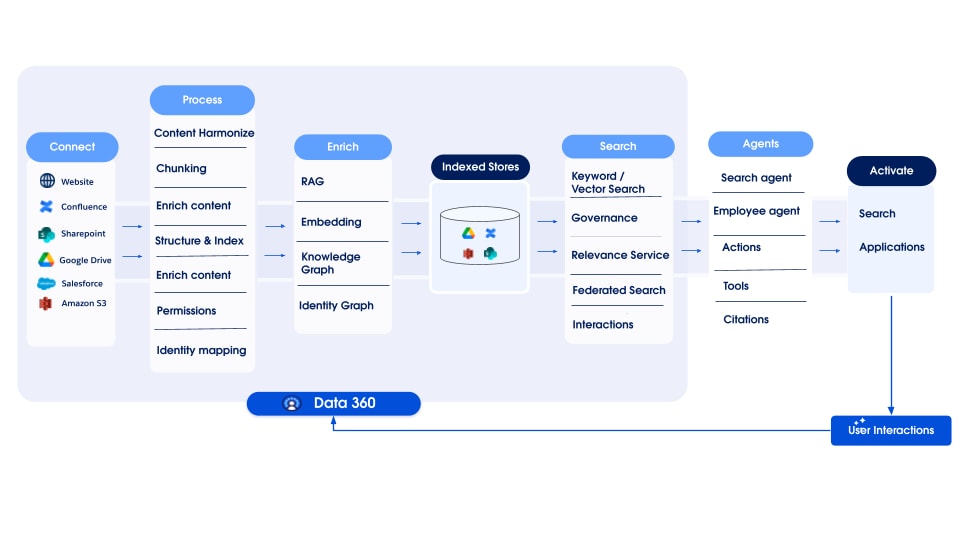
Data 360은 데이터 수집, 처리, 색인화, 쿼리 메커니즘 전반에서 원활하게 구조화(테이블), 세미 구조화(JSON), 비정형 데이터의 저장 및 관리를 지원합니다. Data 360은 오디오, 비디오, 이미지 등 텍스트 외에도 다양한 비정형 데이터 유형을 지원하여 데이터 처리 및 분석 범위를 넓힙니다. 아래 그림은 기초 교육의 양면( 수집 및 검색)을 보여줍니다.
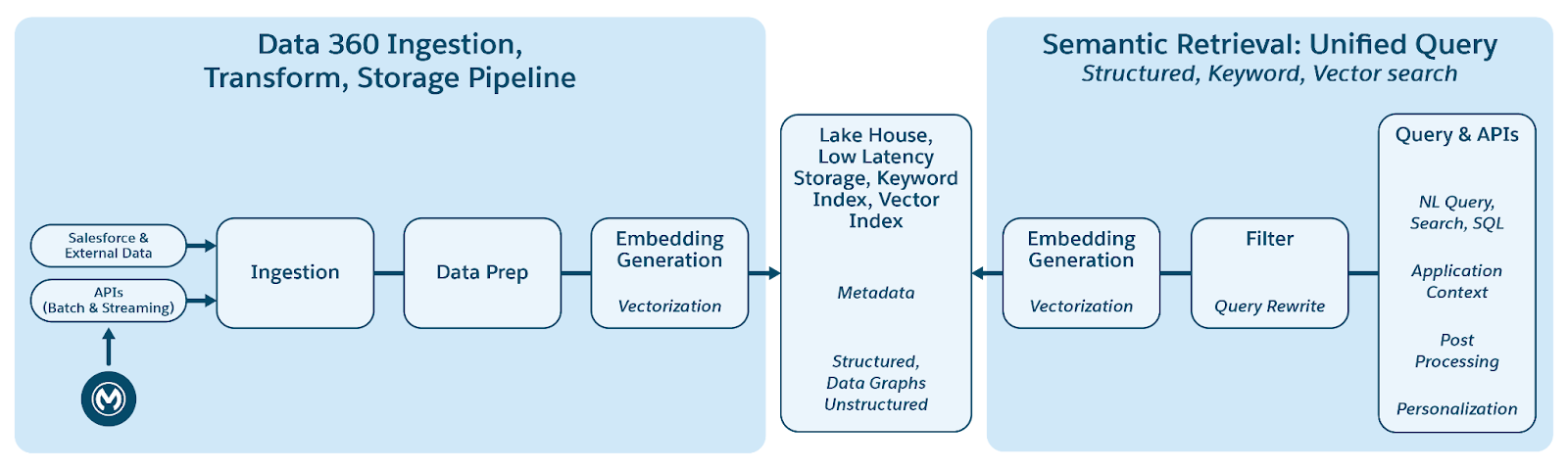
Data 360은 열에 텍스트로 저장하거나 더 큰 데이터 집합의 파일에 저장하여 비정형 데이터를 관리합니다. 구조화되지 않은 콘텐츠에 대한 데이터 연합을 지원하므로 여러 소스의 데이터를 통합하고 관리할 수 있습니다.
그런 다음, 데이터가 준비 및 청크되고, 임베딩이 생성되고, 키워드 색인화 및 벡터 색인화를 위해 처리됩니다. Data 360은 청크 및 임베딩 생성을 위한 여러 개의 기본 및 플러그 가능한 모델을 호스팅합니다. Data 360은 후속 처리 및 색인화를 위해 자동화되고 구성 가능한 오디오 및 비디오 콘텐츠 기록을 지원합니다. 검색 서비스는 키워드 색인화에 사용됩니다. 벡터 색인화의 경우 Data 360은 네이티브 색인화(하이퍼 사용)를 모두 지원하며 오픈 소스 Milvus와 같은 벡터 데이터베이스도 활용합니다. 또한 Data 360은 Salesforce Search 플랫폼과 통합되어 비정형 데이터에 대한 키워드 색인화를 지원합니다. Data 360에서 통합된 다중 모달 색인화를 사용하면 문서의 나중에 있는 에이전트 엔터프라이즈 검색 섹션에 설명된 대로 구조화되지 않은 데이터를 검색할 수 있습니다.
검색을 위해 Data 360은 검색을 위한 API를 제공합니다. 하이퍼 기반 통합 쿼리는 구조화된 키워드 색인 및 벡터 색인 전반에서 쿼리 집합을 쉽게 수행하여 엄격한 가시성과 권한을 유지하여 RAG 및 검색을 향상합니다.
Data 360의 비정형 데이터 색인화 파이프라인은 5가지 핵심 단계인 모듈식 확장 가능한 아키텍처로 설계되었습니다.
- 구문 분석
- 사전 처리
- 청크
- 후처리
- 포함
모든 스테이지에서 고객이 사용자 정의 프롬프트를 제시할 수 있는 LLM 기반 처리를 지원합니다. 사전 처리 및 사후 처리 단계 모두 여러 순차 단계를 포함할 수 있으므로 복잡한 변환을 유연하게 작성할 수 있습니다. 각 스테이지는 완전히 메타데이터 기반이므로 코드를 변경하지 않고 원활하게 구성을 수행하고 확장할 수 있습니다.
사전 처리의 예에는 소음 제거, 언어 정규화, 이미지 이해(광학 문자 인식 및 캡션)와 같은 작업이 포함되며, 사후 처리는 메타데이터 보강, 시맨틱 그룹화 또는 Raptor 청크와 같은 고급 기술을 포함할 수 있습니다.
파이프라인은 Data 360 코드 확장을 완전히 지원하므로 고객 및 내부 팀이 모든 단계에서 사용자 정의 논리를 연결할 수 있습니다. 코드 확장 구성 요소는 실행, 확장, 오류 처리 등 수명 주기가 Data 360에서 완전히 관리되는 경량 Python 함수입니다. 이 접근 방식을 통해 플랫폼 전반에서 운영 일관성 및 거버넌스를 유지하면서 혁신 및 도메인별 처리를 신속하게 도입할 수 있습니다.
컨텍스트 색인화
구조화되지 않은 처리를 사용하여 RAG를 설정하려면 다음과 같은 두 가지 중요한 요인이 중요합니다.
- 빠른 반복: 샘플 테스트 쿼리를 사용하여 신속하게 확인할 수 있는 기능
- 개인별 콘텐츠: 소비하는 개인 정보에 맞게 조정된 콘텐츠를 구성하는 수용력입니다.
컨텍스트 색인화는 이러한 두 측면을 모두 해결하기 위해 고안된 사용자에게 친숙한 도구입니다. 이 대화형 UI는 이전에 설명된 5개의 단계를 모두 실행하는 실시간(RT) 파이프라인에서 제공됩니다. 파이프라인은 생성 및 OCR(광학 문자 인식)과 같은 과업에 필요한 경우 GPU를 활용합니다. 또한 고객은 포괄적인 콘텐츠 처리를 위한 구성을 배포하기 전에 에이전트와 함께 RAG 파이프라인을 빠르게 테스트할 수 있습니다.
문서 AI
Data 360 문서 AI를 사용하면 인보이스, 이력서, 실습 보고서, 구매 주문과 같은 문서에서 비정형 또는 반정형 데이터를 읽고 가져올 수 있습니다. 이 기능은 특별 대화형 처리와 대량 배치 처리를 지원합니다. 이는 고객의 비즈니스 프로세스 자동화를 지원하는 핵심 기능입니다. 이는 LLM 및 ML 모델을 비롯한 인공 지능에 의해 제공됩니다.
엔터프라이즈는 Wiki, 파일 공유, 콘텐츠 관리 시스템, 내부 데이터베이스 등 다양한 시스템에 분산된 광범위한 Knowledge 보유하고 있습니다. 이 조각화로 인해 직원(특히 서비스 에이전트 및 세일즈 담당자) 및 고객이 빠르고 효율적으로 관련 정보를 찾기 어려워집니다. 주요 문제: 모든 Knowledge 소스에 걸쳐 단일하고 통합된 검색 경험이 없음; 다른 소스의 콘텐츠를 일관되게 표시하고 렌더링하지 않음; 시스템 간에 분산된 민감한 정보에 대한 액세스 관리가 없음; 핵심 비즈니스 워크플로 내에서 권위 있는 Knowledge 소스를 활용하는 어려움 (예: 사례에 관련 기사를 첨부).
엔터프라이즈 Knowledge 더 광범위한 엔터프라이즈 데이터 풀에서 수동 또는 자동으로 선별된 콘텐츠를 나타냅니다. 수동 큐레이션은 Salesforce Knowledge 기사를 만들거나 외부 시스템 내에서 Knowledge 개발하는 등 의도적인 조치와 함께 수행되며, 이를 통해 수집됩니다. 수집된 데이터를 통해 실행되는 Salesforce 에이전트 및 변환과 같은 프로세스를 활용하여 정교하고 선별된 레이어를 생성하고 잠재적으로 구조화된 콘텐츠와 구조화되지 않은 콘텐츠를 혼합하는 자동화된 큐레이션을 예상합니다. 수동으로 또는 자동으로, Salesforce 내부 또는 수집 전 외부로 선별되었는지 여부와 상관없이 결과는 원시 데이터와 별도의 추가 가치 콘텐츠입니다.
Enterprise Knowledge Hub 솔루션은 Data 360 기능을 활용하여 다음과 같은 작업을 수행합니다.
- 수입 및 저장: CRM Connector는 Salesforce Knowledge 기사를 수집하고, 데이터 커넥터 프레임워크(DCF) 비정형 커넥터는 외부 소스의 원시 콘텐츠와 메타데이터를 수집합니다. 콘텐츠가 소스별 비정형 데이터 레이크 개체(UDLO)에 수집되어 SFDrive의 콘텐츠(또는 0 복제의 경우 소스)에 매핑됩니다.
- 조합 및 구조화: 조합 파이프라인은 UDLO 및 파일 데이터를 처리하여 정리, 정규화, 보강(NLP 등), PII 마스킹 및 SF 드라이브에 저장된 조화된 중간 형식으로 변환하고 이를 매핑하는 조화된 UDLO(HUDLO)를 수행합니다.
- 인덱싱: 조화된 콘텐츠에서 비정형 파이프라인(UDS)이 트리거되고 각 HUDMO에 대해 검색 색인이 구성됩니다.
- 소비: 사용되는 응용 프로그램에는 사례와 같은 비즈니스 개체에 대한 검색, 검색, 렌더링, 링크가 포함됩니다. 응용 프로그램 소비 참여는 사용량 분석(예: 클릭, 검토 등)을 제공하기 위해 수집됩니다.
Data 360의 계산된 인사이트(CI)를 사용하면 고객이 데이터에서 집계된 메트릭을 정의하고 생성할 수 있습니다. 그러면 해당 메트릭이 적시에 고객 참여, 분석, 세분화, 활성화에 사용됩니다. CI가 계산한 집계 데이터는 Lakehouse에 기록되고 계산된 인사이트 개체(CIO)로 표시됩니다.
계산된 인사이트에는 다음과 같은 두 가지 주요 유형이 있습니다.
- 배치 계산된 인사이트: 메트릭을 정기적으로 계산할 수 있는 복잡한 대용량 데이터 집계(예: 매일 또는 매주)를 위해 설계되었습니다.
- 스트리밍 인사이트: 실시간 이벤트 데이터에서 메트릭 및 작업을 생성할 수 있는 기능을 제공하여 지연 시간이 낮은 즉각적인 고객 참여를 지원합니다.
계산된 인사이트는 데이터 모델 개체(DMO)에 정의되며, 다른 계산된 인사이트 개체에서도 정의할 수 있습니다. 계산된 인사이트 서비스는 배치 및 스트리밍 작업의 오케스트레이션을 모두 관리합니다.
배치 및 스트리밍 인사이트 계산 모두 Spark를 사용합니다. 스트리밍 인사이트는 Spark 구조 스트리밍을 활용하고 배치 CI는 정기적으로 예약된 배치 Spark 작업을 사용하여 실행됩니다. 비용 효율성을 위해 계산된 인사이트 서비스는 종속성 및 소스 데이터 개체의 겹침과 같은 요소를 기반으로 동일한 배치 CI 작업 또는 스트리밍 CI 작업에서 함께 계산할 CIs를 그룹화합니다.
SNCE 및 CDF는 스트리밍 인사이트 계산에 중요한 역할을 합니다.
ID 확인은 여러 소스의 서로 다른 데이터를 하나의 포괄적인 통합 프로필로 변환합니다.
통합 프로필은 "골든 레코드"가 아니며, ID 확인은 프로필을 통합하는 동안 수주 값을 선택하거나 기존 데이터를 재정의하지 않는다는 점을 이해해야 합니다. 통합 프로필은 단일 데이터 소스 또는 여러 소스에서 동일한 엔티티와 관련된 일치하는 모든 레코드를 식별하여 소스 데이터의 잠금을 해제하는 키 집합 역할을 합니다. 이 정보를 사용하면 해당 비즈니스 사용 사례에 사용할 올바른 소스 시스템 데이터를 선택할 수 있습니다.
ID 확인은 개인, 계정 및 가구를 포함하여 다양한 레코드 유형을 통합할 수 있습니다. 리드를 기존 계정에 연결하는 데도 사용할 수 있습니다. 통합 프로세스는 전체 Customer 360 뷰를 달성하고 B2C 및 B2B 시나리오 모두에서 맞춤형 실시간 참여를 유도하는 데 필수적입니다.
ID 확인 파이프라인은 대용량 데이터를 지속적으로 처리하도록 설계된 확장성이 높은 클라우드 네이티브 프레임워크를 기반으로 구축됩니다. 이 프로세스에는 세 가지 핵심 단계가 포함되어 있으며, 강력한 검색 색인 의존하여 일치 프로세스를 관리합니다.
- 일치(선택 후보): 일치 프로세스의 목표는 동일한 엔티티에 속할 수 있는 레코드를 검색하는 것입니다. 레코드는 사용자 정의 가능한 규칙 집합에 대해 분석되며, 각 규칙에는 특정 엄격도 수준에서 일치시킬 데이터를 정의하는 기준 집합이 포함됩니다. 데이터 저장소에서 잠재적 일치 항목을 효율적으로 검색하기 위해 다음 두 가지 방법을 사용하여 가능한 일치하는 레코드를 찾는 색인을 생성합니다.
- 차단 키: 차단 키는 잠재적으로 유사한 레코드를 함께 그룹화하기 위해 레코드의 데이터 및 일치 규칙(예: 이름의 처음 몇 자, 정규화된 전화 번호 등)에서 생성된 값입니다. 각 레코드에는 색인화되고 역 색인으로 저장되는 여러 개의 차단 키가 있으므로 시스템에서 전체 데이터 집합이 아닌 소규모 레코드 그룹에 대한 자세한 비교만 수행합니다.
- Locality Sensitive Hashing(LSH): 퍼지 일치가 있는 일치 규칙의 경우 교육된 모델의 내장형을 기반으로 해시가 생성됩니다.
- 딥 매칭: 후보 선택 단계가 잠재적 일치 항목의 더 작은 그룹을 생성하면 시스템에서 더 자세한 비교를 시작합니다. 이 단계에서 AI 모델 및 고급 알고리즘은 각 레코드 쌍을 분석하여 확률적 일치 점수를 계산합니다. 이 점수는 자주 오타, 변형 또는 형식 차이를 포함하는 필드를 지능적으로 비교하여 두 레코드가 동일한 엔티티를 참조할 가능성을 수량화합니다.
- 클러스터링 및 통합: 후보에서 일치하는 레코드를 식별하면 클러스터로 그룹화됩니다. 이 프로세스에는 중요하게 전달 일치 확인이 포함됩니다. 예를 들어 레코드 A가 레코드 B와 일치하고 레코드 B가 레코드 C와 일치하는 경우 A와 C가 직접 비교되지 않은 경우에도 세 가지가 모두 동일한 클러스터에 연결됩니다. 이러한 전체 클러스터는 통합 프로필의 기본 구조를 구성합니다. 이 클러스터링 프로세스를 통해 모든 관련 소스 레코드가 단일 지속 식별자 아래에 올바르게 연결됩니다.
- 조정: 모든 클러스터링된 소스 레코드의 데이터 값은 정의된 조정 규칙(예: 가장 자주 사용되는 규칙, 가장 최근 사용 또는 소스 우선 순위)을 사용하여 결과 통합 프로필을 프로필 데이터의 발췌으로 작성합니다. 조정은 통합 프로필에 연결된 키를 사용하여 모든 소스 데이터를 사용할 수 있으므로 기존 데이터를 덮어쓰지 않습니다.
아키텍처는 다양한 사용 사례를 처리하기 위해 여러 엔티티 유형의 해결을 지원합니다.
- 개별 일치: 하나의 개인에 알려진 모든 개인 식별자(이메일, 전화 번호, 충성도 ID, 쿠키)를 연결하는 통합 개인 프로필을 만드는 데 중점을 둡니다.
- 계정 일치: 계정에 대한 데이터를 연결하는 통합 계정 프로필 만들기에 중점을 둡니다. 회사 이름을 일치시키는 경우 엔진이 퍼지 일치 시 정밀 조정된 모델을 사용합니다.
- 가구 일치: 일치 논리를 확장하여 통합 개인 레코드를 관련 개인의 그룹으로 집계합니다.
- Cross Entity Matching: 통합 외에도 ID 확인은 동일한 일치 규칙을 사용하여 프로필 개체 간 링크를 생성합니다. 예를 들어, 계정 이름에서 퍼지 일치를 사용하여 리드를 계정에 연결할 수 있습니다.
통합 프로필이 항상 최신 상태로 유지되도록 ID 확인 엔진은 거의 실시간 아키텍처로 작동합니다. 이 클라우드 최적화 아키텍처는 지속적인 처리를 위해 고급 처리 시간을 달성하도록 설계되었습니다. 처리 속도는 소스 데이터가 수신되는 방식에 따라 다르지만, ID 확인을 통해 15분마다 작은 변경 사항 배치를 처리할 수 있습니다.
시스템에서 모든 소스 레코드 ID를 해당하는 통합 프로필 ID에 매핑하는 ID 링크 개체를 유지합니다. 이 기본 데이터 구조를 사용하면 엔진이 관계를 효율적으로 추적하고 통합 프로필에 변경 사항 및 업데이트를 빠르게 전파하여 웹 사이트 개인 설정, Next Best Action 권장 사항, 세분화와 같은 고객 환경이 항상 최신 사용 가능한 고객 데이터를 활용할 수 있도록 합니다.
세분화는 통합 고객 프로필을 실천 가능한 대상 그룹으로 전환하는 핵심 프로세스입니다. 이 기능은 마케팅, 상거래, 서비스 채널 전반에서 맞춤형 환경을 제공하는 데 매우 중요합니다. Salesforce Data 360 세분화 플랫폼은 대규모 작업을 위해 고안되었습니다. 수천 개의 개체 및 관계로 구성된 데이터 모델을 사용하여 복잡한 메타데이터를 관리합니다. 플랫폼은 복잡한 규칙, 집계 기반 필터, 윈도우 기반 순위를 모두 지원하며 페타바이트 규모에서 빠르고 신뢰할 수 있는 계산을 보장합니다.
Data 360은 다양한 세그먼트 유형을 지원하여 속도, 복잡성, 계층에 대한 고유한 비즈니스 요구 사항을 충족합니다.
- 표준 세그먼트: 배치 처리된 기본 세그먼트 유형입니다. 최소 12시간
24시간의 표준 게시 케이던스 또는 최근 참여 데이터에 최적화된 1시간4시간의 빠른 빠른 게시 케이던스를 사용하여 사용자 정의 가능한 일정에 따라 게시합니다. - 실시간 세그먼트: 이 세그먼트는 최신 이벤트 및 프로필 데이터를 기반으로 즉각적인 조치를 취할 수 있도록 주문형 작업을 밀리초 단위로 완료합니다. 즉각적인 개인 설정에 최적화되었지만, 제외 기준 또는 중첩된 세그먼트를 활용할 수 없습니다.
- 폭포 구간: 고객이 여러 기준에 맞는 경우 고객의 우선 순위를 가장 중요한 단일 세그먼트로 지정하는 데 사용되는 하위 세그먼트의 계층 구조입니다.
- Nested Segment: 이렇게 하면 기존 세그먼트를 더 구체적인 새로운 세그먼트(기본 세그먼트의 세분화)의 필터로 재사용할 수 있으며, 상위 세그먼트의 일정을 상속할 수 있습니다.
세분화 엔진은 속도, 규모, 복원 능력을 보장하는 강력한 클라우드 네이티브 아키텍처에서 작동합니다.
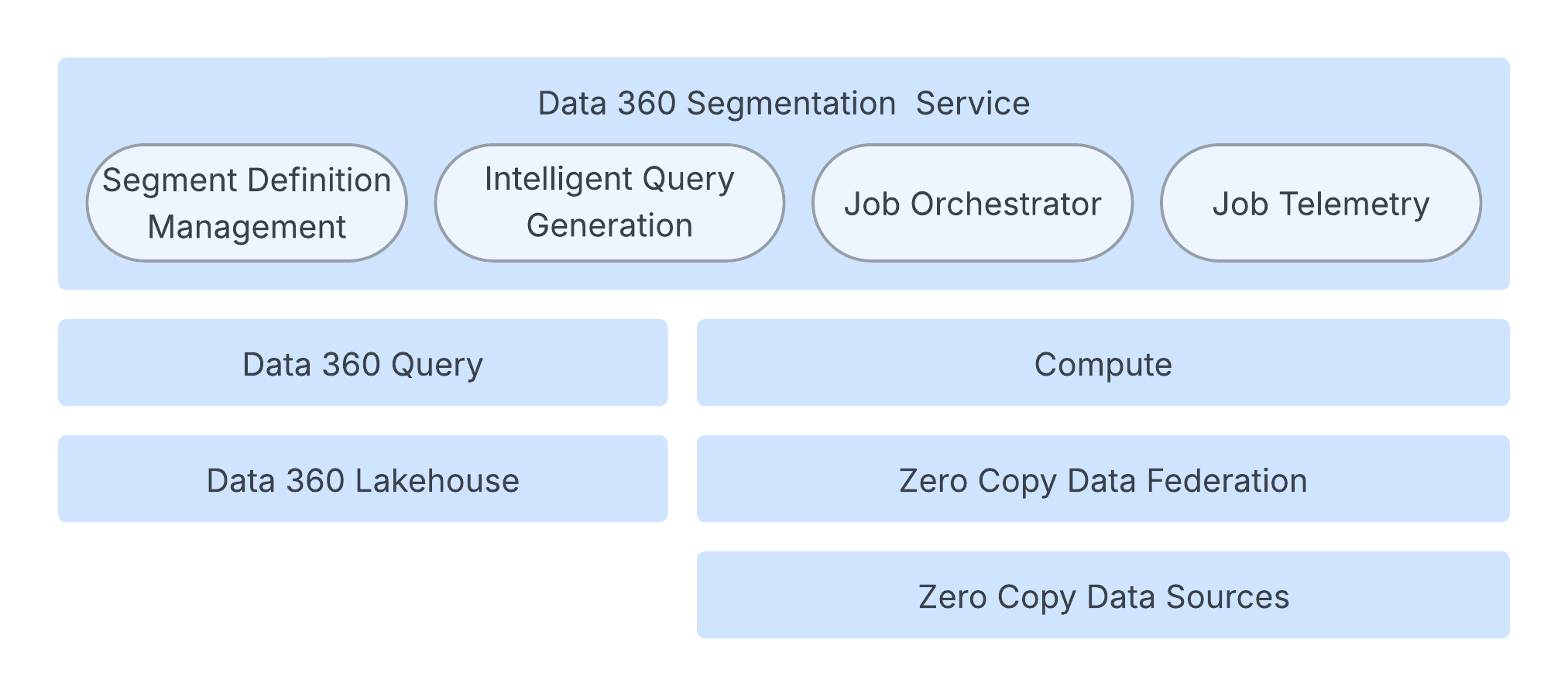
핵심 프로세스는 세그먼트의 수명 주기를 제어하여 필수 작업 구성을 생성하고 실행을 트리거하는 작업 오케스트레이션 서비스에 의해 관리됩니다. 이 오케스트레이션 레이어는 확장성을 위해 분할된 데이터베이스에서 상태 및 메타데이터를 유지합니다.
Data 360 쿼리는 세분화 개수 계산을 처리하지만 Spark 계산 계층은 실제 세그먼트 멤버십을 계산할 책임이 있습니다. Spark 응용 프로그램은 광범위한 고객 데이터에 대해 Spark SQL 쿼리를 실행합니다. 이 데이터는 Data 360 레이크하우스, Zero Copy 데이터 연합을 통한 외부 시스템 또는 둘 모두의 조합에 있을 수 있습니다.
인텔리전트 쿼리 생성을 통해 시스템이 매우 최적화되어 기본 Spark SQL 쿼리를 세분화합니다. 여기에는 데이터 스캔을 최소화하고 중복 하위 표현식을 제거하는 지능형 파티션 자르기와 같은 기법이 포함됩니다. 서비스 신뢰성을 보장하기 위해 아키텍처는 작업 부하 크기 및 복잡성을 기반으로 계산 자원을 동적으로 조정하는 어댑티브 자원 관리를 제공합니다. 또한 SLO 준수는 적응형 기간 및 재시도 논리를 사용하여 사전에 관리됩니다. 빠른 사용자 환경을 위해 가속 세그먼트 수는 샘플링 기반 접근 방식을 사용하여 세그먼트를 만드는 동안 빠른 크기 예측을 제공하므로 전체 쿼리가 실행되지 않습니다.
마지막으로 포괄적인 Spark 실행 메트릭과 자동화된 오류 분류(예: 고객 측 및 시스템 문제)를 통해 관찰 가능성 및 근본 원인 특성에 중점을 두고 진단 시간을 크게 단축하고 복원성이 높은 데이터 플랫폼을 보장합니다.
활성화는 Data 360 수명 주기의 중요한 마지막 단계입니다. 핵심 기능은 정적이고 세분화된 통합 고객 프로필을 실천 가능한 보강 데이터로 변환하고 이 데이터를 내부 및 외부 끝점(예: Marketing Cloud, Commerce Cloud, Adtech 플랫폼)에 전달하는 것입니다. 이 프로세스는 맞춤형 고객 여정과 실시간에 가까운 상호 작용을 트리거하기 위해 고안되었습니다. 관련 특성, 활성화 멤버십 필터링, 동의 필터링, 제한, 순위와 같은 고급 기능을 지원합니다.
활성화는 외부 전달 및 채널 규정 준수를 위한 세 가지 고유한 방법을 제공합니다.
- 배치 활성화: 대규모 이메일 캠페인 및 광고 대상 그룹 새로 고침과 같은 대용량 예약된 작업을 위해 고안되었습니다. 데이터는 보안 내부 버킷(클라우드 개체 저장소)에 스테이징하거나 보안 파일 전송을 통해 전달된 다음, 대상 시스템에서 시작한 API 수집 프로세스를 통해 전달됩니다. 배치 활성화는 특수 새로 고침 모드(증분)를 사용하여 Salesforce 파트너에게 전송 및 처리되는 볼륨을 줄일 수 있습니다.
- 스트리밍 활성화: 이벤트 중심 자동화가 필요한 거의 실시간 사용 사례에 최적화됩니다. 배달은 대상 끝점에 전송된 직접 API 호출을 통해 이루어집니다.
- 활성화 트리거 플로: 이 고도로 플랫폼화된 채널은 대상 그룹 데이터를 수백 개의 고객 API가 활성화된 참여 플랫폼과 통합하기 위한 코드가 없는/하위 코드 접근 방식을 제공합니다. 활성화가 완료되면 Data 360이 대상 그룹 DMO를 채운 다음, 대규모 플로를 트리거합니다. 이후 플로 엔진은 대상 그룹 데이터를 사용하고 외부 서비스 및 Mule 아웃바운드 대상과 같은 플랫폼 기능을 활용하여 최종 API 기반 대상에 호출합니다. 이 방법은 새 활성화 타겟을 온보딩하는 데 필요한 시간을 크게 줄입니다.
활성화는 작업 관리, 배포된 실행, 모니터링에 대해 세분화와 동일한 패턴을 사용합니다. 여기에는 수명 주기 관리를 위한 작업 오케스트레이션 서비스의 원리와 처리를 위한 계산 계층(Spark)이 포함되며 성능 관찰 가능성 및 서비스 수준 목표(SLO) 준수에 대한 작업 Telemetry를 사용합니다.
이 외에도 활성화에는 다음과 같은 기능이 있습니다.
활성화 대상 관리는 모든 대상 끝점의 보안 연결, 자격 증명 및 구성을 감독합니다. 데이터 형식 및 보안 프로토콜이 표준화되어 Marketing Cloud, Adtech 파트너, 기타 외부 응용 프로그램 등 다양한 플랫폼에 신뢰할 수 있는 아웃바운드 전달을 보장합니다.
활성화하면 페이로드가 특정 대상에 맞게 조정됩니다. Salesforce Marketing Cloud의 경우 사업부(BU) 인식 필터링, 다중 EID 지원, 교차 관개 제어가 포함됩니다.
커뮤니케이션 거버넌스는 고객의 선호도 및 법적 요구 사항을 준수하는 데이터 사용 및 통신을 보장합니다. 중앙 집중식 동의 모델은 전역 수신 거부에서 채널 및 목적별 동의에 이르기까지 모든 고객 기본 설정을 통합하며 통합 개인 프로필에 저장됩니다. 실행하는 동안 플랫폼은 제외 필터링을 사용하여 최종 페이로드에서 동의하지 않는 개인을 자동으로 제거하여 이러한 정책을 엄격하게 적용합니다. 또한 시스템에서 연락관 선택 규칙을 적용하여 데이터를 전송하기 전에 의도한 채널에 대해 가장 규정을 준수하고 선호하는 단일 연락관을 사용합니다. 이 적용 메커니즘은 동적 데이터 마스킹 및 액세스 제어와 같은 보호 조치를 채택하여 활성화 프로세스 전반에서 중요한 데이터 필드를 보호하는 기본 거버넌스 프레임워크에 의해 보호됩니다.
통합 데이터 플랫폼의 진정한 가치는 원본 또는 구조에 관계없이 모든 데이터 자산에 간편하고 일관된 액세스를 제공하는 기능에 있습니다. Salesforce Data 360의 통합 쿼리 기능은 이를 제공하기 위해 정확하게 설계되었으며, 다양한 데이터 저장소의 기본 복잡성을 추상하여 강력한 단일 쿼리 인터페이스를 제공합니다.
통합 쿼리 레이어는 다양한 소비 패턴에 대한 정교한 액세스를 제공합니다.
- 하이브리드 구조화 및 비정형 질의: 구조화된 데이터와 구조화되지 않은 데이터의 구조화된 메타데이터를 모두 원활하게 쿼리할 수 있는 광범위한 SQL 지원을 제공합니다. 테이블 함수를 통한 연산자 확장성이 향상되어 텍스트, 이미지, 공간 유형 전반에 걸쳐 특수 검색이 가능합니다.
- Hyper로 성능 가속화: 고성능 메모리 내 엔진인 Hyper를 활용하는 Data 360은 복잡한 분석 쿼리 및 대화형 대시보드를 가속화하여 대규모 데이터 집합에서 거의 즉각적인 응답을 제공합니다.
- AI 및 개인 설정에 대한 통합 접근법: 이 통합 액세스는 표적화된 맞춤형 결과를 생성하는 데 매우 중요하며, 풍부한 엔터프라이즈 데이터에 AI 모델을 기반으로 RAG(검색 증분 생성)를 사용하여 더욱 정밀한 LLM 응답을 직접 지원합니다.
- 다운스트림 소비와의 통합: 이는 UI 구동 환경, 강력한 API, 생성형 AI 워크플로, CRM 보강을 위한 기본 데이터 액세스 계층으로서 데이터를 활성화에 원활하게 연결합니다.
Data 360의 통합 쿼리는 지능적이고 고성능의 단일 쿼리 인터페이스를 제공하여 설계자가 고객 정보의 전체 스펙트럼을 최대한 활용하는 민첩한 데이터 중심 응용 프로그램을 구축할 수 있도록 지원합니다.
Data 360은 데이터 이벤트에 대한 파이프라인 활성화를 지원하는 활성 플랫폼입니다. 예를 들어, 고객의 계정 잔고가 떨어지는 등 중요한 이벤트가 Salesforce 플로를 트리거하여 해당 작업을 오케스트레이션할 수 있습니다. 마찬가지로 평생 소비와 같은 주요 메트릭에 대한 업데이트가 관련 응용 프로그램에 자동으로 전파될 수 있습니다.
데이터 작업은 저장소 네이티브 변경 이벤트(SNCE) 및 변경 데이터 피드(CDF)를 사용하여 변경 사항에 대한 증분 데이터를 지속적으로 모니터링합니다. 이 데이터는 임계값 모니터링 또는 상태 변경과 같은 고객이 구성한 작업 규칙에 대해 평가됩니다. 해당 규칙이 충족되면 데이터 작업 이벤트가 생성됩니다. 이 이벤트는 추가 정보(예: 고객 충성도 상태)로 보강되고 Salesforce 플로 또는 외부 응용 프로그램과 같은 구성된 대상으로 즉시 전송되어 비즈니스 오케스트레이션을 트리거합니다.
Data 360은 고급 ID 확인 기능과 포괄적인 참여 내역과 함께 통합 개인 식별자 및 프로필 생성과 같은 기본 CDP(고객 데이터 플랫폼) 기능을 지원합니다. 이 플랫폼은 위에 설명된 것처럼 정확한 일치 규칙과 퍼지 일치 규칙을 모두 사용하는 ID 확인 및 ID 그래프를 지원하여 B2B(B2B) 및 B2C(B2C) 프레임워크를 모두 처리하는 데 숙련되어 있습니다. 이러한 ID 그래프는 다양한 채널의 참여 데이터로 보강되므로 중요한 분석 인사이트 및 세그먼트가 포함된 자세한 프로필 그래프를 작성하는 데 도움이 됩니다.
고객 프로필을 지원하는 핵심 컨셉은 데이터 그래프입니다. Data 360은 다양한 레이크하우스 테이블 및 상호 관계에서 파생된 비정규화 개체인 JSON 형식의 엔터프라이즈 데이터 그래프를 제공합니다. 여기에는 개인의 구매 및 탐색 내역, 사례 내역, 제품 사용, 기타 계산된 인사이트를 포괄하는 CDP에서 만든 "프로필" 데이터 그래프가 포함되며 고객 및 파트너가 확장할 수 있습니다. 해당 데이터 그래프 특정 응용 프로그램에 맞게 조정되며 관련 고객 또는 사용자 컨텍스트를 제공하여 생성형 AI 프롬프트 정확성을 향상합니다. Data 360의 실시간 레이어는 프로필 그래프를 활용하여 실시간 개인 설정 및 세분화를 수행합니다. 대화, 세션, 에이전트 메모리를 데이터 그래프 포함하는 Agentforce 컨텍스트 모델링을 예상합니다.
또한 CDP를 사용하면 Salesforce의 Marketing Cloud, Facebook, Google 등 다양한 플랫폼에서 효과적으로 세분화 및 활성화할 수 있습니다. 즉시 의사 결정을 내리고 개인 설정을 할 수 있도록 배치, 거의 실시간, 실시간으로 고객 프로필을 처리합니다. 이 기능은 B2C 및 B2B 시나리오 모두에서 상호 작용을 강화하여 비즈니스가 고객의 요구와 행동에 빠르고 정확하게 대응할 수 있도록 합니다.
Data 360의 실시간 레이어는 Data 360 CDP에서 지원되며 실시간 사용 사례에 대한 개념을 확장합니다. Data 360의 실시간 레이어는 웹 및 모바일 클릭 스트림, 방문, 장바구니 데이터, 결제와 같은 이벤트를 밀리초 대기 시간으로 처리하도록 설계되어 고객 경험 개인 설정을 향상합니다. 고객 참여를 지속적으로 모니터링하고 Customer 360 고객 프로필을 실시간 참여 데이터, 세그먼트, 계산을 사용하여 즉시 개인 설정합니다.
예를 들어, 소비자가 쇼핑 웹 사이트에서 항목을 구매하면 실시간 레이어가 이 이벤트를 빠르게 감지 및 수집하고, 소비자를 식별하고, 업데이트된 평생 지출 정보로 프로필을 보강합니다. 이를 통해 사이트에서 몇 초 이내에 환경을 개인 설정할 수 있습니다. 또한 이 계층에는 실시간 트리거 및 응답 기능이 포함되어 있어 고객 상호 작용을 기반으로 즉각적인 조치를 취할 수 있습니다.
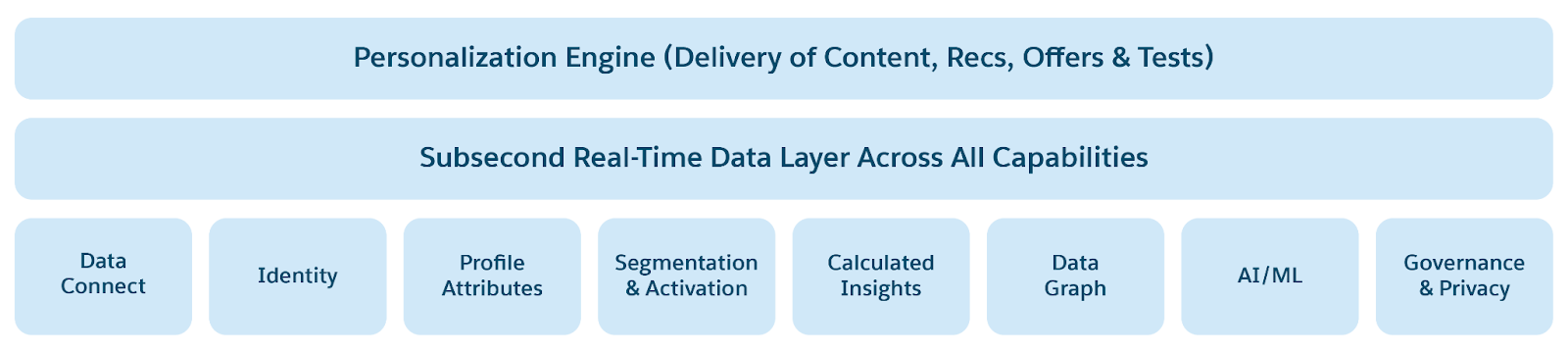
Sub-Second Real-Time 플랫폼은 다음과 같은 몇 가지 주요 기능을 통해 이 변환을 제공합니다.
- 실시간 데이터 그래프: Customer 360 프로필은 브랜드와 가장 관련된 주요 객체 및 필드를 포함하는 비정규화 그래프를 사용하여 작성됩니다. 해당 데이터 그래프 실시간 데이터 처리를 지원하고 실행 가능한 콘텐츠 및 인사이트를 밀리초 이내에 전달합니다.
- 실시간 수집 및 변환: 웹 및 모바일 소스에서 사용자 이벤트 및 프로필을 밀리초 단위로 수집합니다.
- 실시간 ID 확인: 장치 전체에서 고객 프로필을 병합하여 알 수 없는 사용자와 알려진 사용자를 즉시 통합합니다.
- 실시간 계산된 인사이트: 수명 값(LTV) 또는 사용자 방문 내역과 같은 메트릭을 밀리초 단위로 계산하여 웹, ChatBot 또는 서비스 에이전트 개인 설정 또는 제안을 활성화합니다.
- 실시간 세분화: 즉시 대상 그룹을 세분화하여 메시지 및 상호 작용을 실시간으로 개인 설정합니다.
- 실시간 작업: 브랜드가 모든 사용자 참여를 평가하고 Salesforce 플로 또는 기타 관련 커뮤니케이션 채널을 통해 조치를 취할 수 있도록 합니다.
Data 360에서 실시간 파이프라인, 낮은 대기 시간 저장소, 초초 미만 데이터 처리 계층이 포함된 새로운 실시간 플랫폼을 구축했습니다. 웹 및 모바일 채널에서 빠른 대화형 데이터가 수집되므로 일련의 빠른 프로세스를 거칩니다.
웹 및 모바일 SDK 및 실시간 API는 향후 에이전트 상호 작용에서 웹/모바일 응용 프로그램의 데이터를 수집하고 비콘 서버로 보냅니다. 이 데이터는 실시간 레이어로 라우팅되어 밀리초 처리하고 배치/스트림 데이터와 통합하기 위해 레이크하우스 레이어로 라우팅됩니다. 실시간 레이어는 세션 내, 실시간 개인 설정을 위해 사용자 총 지출 또는 평생 가치 등 사용자 프로필(익명 또는 로그인됨)의 컨텍스트에서 들어오는 실시간 데이터를 처리합니다. 실시간 레이어는 실시간 데이터 및 고객 프로필을 저장하기 위해 기본 메모리 및 NVme(SSD) 저장소에서 지원됩니다. 데이터가 실시간 레이어에 있으면 실시간 데이터 그래프로 업데이트하기 전에 다음 프로세스를 거칩니다.
- 단순 수집 및 변형: 추가 처리를 위해 데이터가 수집되고 변환됩니다.
- ID 확인: 정확히 일치 규칙은 프로필과 모든 기존 일치 규칙 집합을 통합하기 위해 적용되므로 데이터 인식 전문가는 특별히 실시간으로 새 ID 확인 규칙 집합을 만들 필요가 없습니다.
- 계산된 인사이트: 모든 참여가 평가되고, 합계 및 밀리초 단위의 개수와 같은 간단한 계산이 실행되고, 데이터가 실시간 데이터 그래프로 업데이트됩니다.
- 실시간 세그먼트: 모든 참여 데이터가 평가되어 정의된 실시간 세그먼트에 대한 기준을 충족하는지 여부를 판단하고 사용자가 밀리초 단위로 적합한 세그먼트에 추가됩니다.
- 실시간 작업 및 트리거: 정의된 규칙에 대해 모든 참여가 평가되어 규칙이 밀리초 이내에 충족될 때 실시간으로 다양한 대상에 대한 작업을 트리거합니다.
- 실시간 데이터 그래프 및 API: 실시간 API도 포함된 실시간 데이터 그래프를 사용하면 브랜드가 각 사용자에 대해 업데이트된 JSON 형식 데이터를 검색하여 모든 고객 상호 작용에 최신 데이터로 정보를 제공할 수 있습니다.
개인 설정은 대상을 지정할 사람, 관련 콘텐츠 및 권장 사항을 전달할 시기 및 위치, 언급할 내용 및 빈도를 파악하는 것입니다. 개인 설정 서비스 플랫폼은 맞춤형 환경을 통해 목표 달성률을 최적화하기 위해 결정되는 사항의 오케스트레이터입니다.
개인화 서비스는 다음 기능을 제공합니다.
- Data 360에서 프로필, 활동, 자산 데이터를 해석하는 일관된 모델 집합 및 방법
- 플랫폼 통합 실험(A/B/n, 다중 암 밴디트)
- 설계 시간(구성), ML 교육 시간 및 런타임 시 목표 통합(ML 추론)
- B2C 확장 실시간 및 배치 상호 작용 지원(익명 사용자, 대화형 실시간 외부 대량, 대용량 내부 배치)
- Data 360을 통한 Analytics 구동
- 다른 당사자(내부 및 외부)의 AI 모델 및 서비스 통합 패턴
- 핵심 메타데이터 에코시스템에 통합(PLATE 특성)
- 가치가 높은 AI 중심 사용 사례의 OOTB 구현(프로모션/콘텐츠 선택, 제품 권장 사항, 가격 책정 결정 등을 위한 컨텍스트 범주 등 다양한 ML 알고리즘을 사용하는 권장 사항/결정)
- 결정 파이프라인
- 프로필 증가, 실험, 권장 사항 등 개인 설정 결정에 대한 외부 요청을 제공합니다.
- 권장 사항 엔진
- 규칙 또는 ML 기반 권장 사항의 런타임 서비스.
- 인덱스 관리자
- 권장 모델용 ML 교육 등 비동기 프로세스에 대한 워크플로 관리/오케스트레이션
- 프로세스 개체 서비스
- 핵심 및 비핵심 간 개인 설정 메타데이터 동기화 책임자
- 속성 엔진 및 실험
- 개인 설정 권장 사항의 Analytics 특성 및 실험
Data 360은 특별히 신규 에이전트 환경을 지원하기 위해 강력하고 풍부한 플랫폼으로 설계되었습니다. 다양한 기존 Data 360 서비스를 기반으로 구축하고 Agentforce 긴밀하게 통합하여 이러한 기능을 달성합니다.
에이전트 엔터프라이즈 검색에 대한 접근 방식은 다음 원칙을 기반으로 합니다.
- 엔터프라이즈 데이터는 액세스에 필요한 보안 권한이 있는 사일로 서비스 또는 매장에 보관됩니다. 소스 권한을 유지하면서 이 데이터에 액세스하고 처리하는 기능은 Trust 보장하는 데 있어 매우 중요합니다.
- 전체 데이터의 순위 및 관련성을 통해 더 나은 결과를 얻을 수 있으므로 에이전트 환경에 더 나은 컨텍스트를 제공할 수 있습니다.
해당 환경을 제공하기 위해 에이전트 엔터프라이즈 검색은 다음 핵심 아키텍처 구성 요소를 기반으로 구축됩니다.
- 커넥터: Data 360에서 사용할 수 있는 광범위한 커넥터 집합을 사용하면 다양한 소스에서 데이터에 액세스하고 데이터를 수집할 수 있습니다.
- 비정형 데이터 처리: 이는 비테이블 형식 콘텐츠를 처리하는 데 기본이므로 시스템에서 다양한 데이터에서 의미와 컨텍스트를 도출할 수 있습니다.
- 거버넌스: 검색에서 사용되는 모든 데이터에 대해 엔터프라이즈급 보안, 규정 준수, 액세스 제어를 보장합니다. 소스 가시성 권한을 지원하면 간단한 검색 및 에이전트 환경 모두에서 권한이 있는 사용자만 데이터에 액세스할 수 있습니다. 신속한 검색을 위해 보안 권한이 가장 빠른 데이터 액세스 단계에서 검색 백엔드에서 기본적으로 평가되고 적용됩니다.
- 통합 검색 계층: 사일로 데이터의 문제를 해결하기 위해 커넥터가 포괄적인 통합 검색 계층에 피드됩니다. 이 레이어는 연합 검색을 통해 액세스된 외부 시스템에 남아 있거나 0-copy 및 수집된 데이터의 고급 색인을 통해 기본적으로 관리되는지 여부와 상관없이 모든 데이터에 단일 액세스 지점을 제공합니다.
- 인텔리전트 쿼리 이해: 검색 전에 시스템에서 AI 기반 메커니즘을 사용하여 사용자 의도를 해석합니다. 시맨틱 벡터 일치에 대한 쿼리 표현을 포함하는 것 외에도 키워드 기반 검색을 다시 작성하고 확장하여 정확도를 향상할 수 있습니다.
- 하이브리드 검색 및 고급 쿼리: 가장 관련성이 높은 정보를 찾기 위해 플랫폼은 여러 전략을 동시에 사용합니다. 하이브리드 검색은 최적화된 데이터 청크에서 시맨틱 벡터 검색과 일치하는 정확한 키워드를 제공하고, 전체 레코드 검색은 전체 문서를 동시에 검색합니다. 두 가지 모두 시맨틱한 관련성과 전체 콘텐츠 적용 범위를 모두 보장하기 위해 결합됩니다.
- 계층 순위: 데이터를 검색하면 다단계 계층 순위 아키텍처가 모든 소스 및 메서드의 결과에 점수를 매기고 병합하고 순서를 변경합니다. 이 프로세스는 사용자 또는 에이전트에 가장 관련성이 높은 정보를 표시하는 단일 통합 목록을 만듭니다.
생성형 AI는 엔터프라이즈 검색의 기본 소비자를 인간 사용자에서 대규모 언어 모델(LLM)으로 전환하고 있습니다. Data 360 Search는 모두 제공되도록 처음부터 설계되었습니다. 에이전트의 더 길고 복잡한 쿼리를 처리하고 프로그래밍 사용 및 추론 루프에 필요한 풍부한 컨텍스트 결과를 반환하도록 최적화되어 있습니다. 동시에 시스템은 인간 사용자에 대해 일반적으로 사용되는 빈번하고 모호한 쿼리를 처리하여 UI에서 빠른 평가를 위해 코드 조각 및 강조 표시와 같은 기능을 제공할 수 있습니다.
에이전트 검색 환경의 최종 전달은 두 가지 접근 방식을 결합합니다.
- 직접 검색 결과: 응용 프로그램은 Data 360 통합 검색 기반에 구축된 메타데이터 기반 API를 사용하여 순위가 지정된 결과의 기존 목록을 표시할 수 있습니다.
- 자동 대화형 답변: Agentforce와 네이티브 통합을 통해 구현됩니다. 이 대화 환경은 작업 및 쿼리를 오케스트레이션하는 기본 에이전트가 구동하여 모든 정보 검색 과업을 내부 검색 에이전트에 위임합니다.
이 전문 검색 에이전트는 엔터프라이즈 정보 검색에 최적화되어 있습니다. 이는 논리 루프를 사용하여 병렬 검색을 수립하고 실행하여 사용자의 요청의 다양한 패싯을 탐색합니다. 모든 데이터 유형에 대한 Data 360 통합 검색 및 구조화된 쿼리 언어 등 강력한 도구 집합을 활용하여 테이블 및 엔티티에서 정확한 데이터를 검색합니다.
이 아키텍처 합성을 통해 Data 360은 맥락에 맞는 매우 지능적인 실행 가능한 에이전트 엔터프라이즈 검색 환경을 만들 수 있습니다.
확장성은 Salesforce Platform의 핵심 기능입니다. 코드 확장은 Data 360에서 확장성을 제공하므로 프로 코드 사용자가 Data 360 환경 내에서 직접 사용자 정의 Python 논리를 실행할 수 있으므로 서식 있는 선언적 및 하위 코드 기능을 보완합니다. 코드 확장을 사용하면 사용자가 변환 및 비정형 데이터 파이프라인(사용자 정의 청크)과 같은 Data 360 핵심 기능을 안전하게 확장할 수 있습니다.
코드 확장 설계는 유연성, 보안, 효율성, 간소화된 개발자 환경에 우선 순위를 두고 있습니다. 각각 특정 아키텍처 요구에 맞게 조정된 두 가지 기본 실행 모델을 지원합니다.
- Script 모델:
- 목적: Data 360 레이크하우스와 직접 상호 작용해야 하는 포괄적인 사용자 정의 논리의 경우
- 기능: 고객은 코드 확장 SDK를 사용하여 전체 파이썬 스크립트를 작성하여 SDK API를 통해 Lakehouse에 대한 읽기 및 쓰기 액세스를 활성화합니다. 사용자 정의/복합 데이터 준비 또는 맞춤형 데이터 조작에 이상적입니다.
- 격리 및 보안: 스크립트가 레이크하우스에 액세스하는 동안 실행은 Data 360 런타임 내에서 안전하고 분리된 환경으로 제한되어 다른 프로세스 또는 무단 시스템 액세스를 방지합니다.
- ** 기능 모델**:
- 목적: 기존 Data 360 파이프라인에서 호출된 모듈식 상태가 없는 계산의 경우(예: 비정형 파이프라인의 사용자 정의 청크) 서버리스 함수와 유사합니다.
- 기능: 고객이 제공하는 함수는 입력을 가져오고, 계산하고, 출력을 반환합니다.
- 격리 및 보안: 해당 기능은 엄격한 격리로 설계되었으며, 레이크하우스에 직접 액세스할 수 없습니다. 실행은 Sandbox, 상태가 없는 상태, 자원 제약이므로 중점을 두고 상태가 없는 처리 단계에 적합하며, 보안, 예측 가능한 실행, 폭발 반경 최소화를 보장합니다.
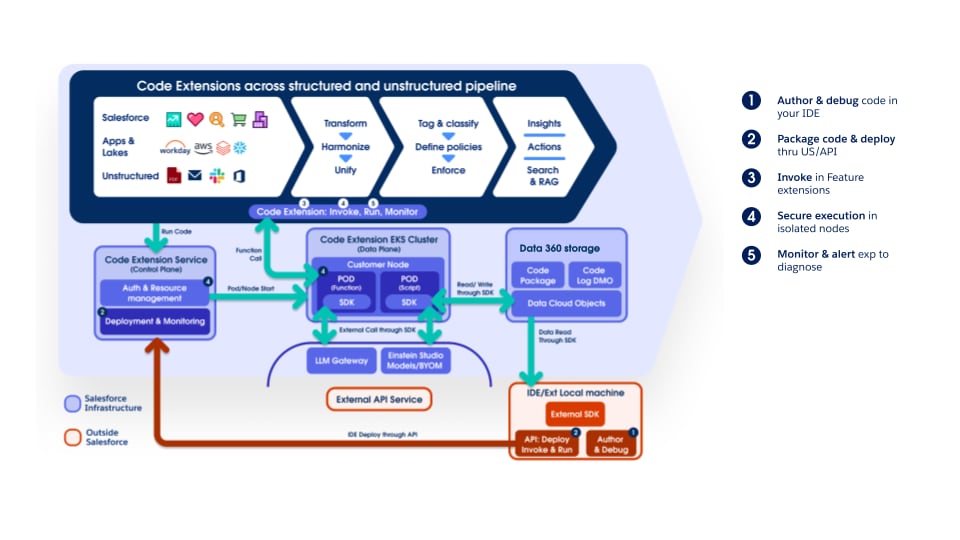
스크립트 및 함수 모델 모두 고객 코드를 안전하게 실행하여 한 테넌트의 코드가 다른 테넌트에 영향을 미치거나 다른 테넌트의 데이터, Salesforce 자원 또는 외부 자원에 대한 무단 액세스를 방지합니다. 이 보안은 계층화된 (보조 방어) 아키텍처를 통해 달성됩니다. 이 아키텍처는 다양한 가드 레일을 통합하여 각 테넌트의 사용자 정의 코드에 대해 분리된 실행 환경을 제공합니다. 여기에는 Kubernetes(K8s) 수준의 논리적 격리, 네트워크 격리, 런타임 Sandbox, 최소 권한 권한이 모두 포함되며, 감지 및 응답을 위한 운영 모니터링 및 사고 응답 준비가 보완됩니다.
강력한 개발 수명 주기를 지원하기 위해 코드 확장은 다음을 제공합니다.
- 외부 작성 및 디버깅: 개발자는 SDK를 활용하여 VSCode와 같은 친숙한 환경에서 Python 코드를 작성하고 디버그할 수 있습니다.
- 유연한 구축: 사용자 정의 코드는 SDK 유틸리티, Data 360 UI 또는 API를 사용하여 패키지화하고 배포하여 CI/CD에 통합할 수 있습니다.
작업 로그: 자세한 실행 로그에 대한 액세스는 투명성을 제공하고 프로덕션에서 문제 해결에 도움이 됩니다.
Data 360은 이러한 안전하고 유연한 코드 확장 기능을 제공함으로써 설계자가 가장 고유하고 복잡한 데이터 처리 요구 사항에 맞게 플랫폼을 조정할 수 있도록 지원하여 확장 가능한 엔터프라이즈 데이터 패브릭 역할을 강화할 수 있습니다.
기업이 AI 채택을 가속화함에 따라 대부분 Amazon SageMaker, Google Vertex AI, 사용자 정의 Python 기반 환경 등 이기종 ML 에코시스템을 유지하며, 신용 위험 점수 매기기, 이탈 성향, 제품 추천, Next Best Action 결정과 같은 미션 크리티컬 예측을 촉진하는 모델을 호스팅합니다.
일반적으로 이러한 외부 모델을 Salesforce에 통합하려면 사용자 정의된 API 계층, ETL 파이프라인 또는 미들웨어 오케스트레이션이 필요하며 데이터 중복, 거버넌스 오버헤드, 대기 시간, 운영 복잡성이 도입되어 통합, 규정 준수, 실시간 고객 데이터 플랫폼(CDP) 비전과 충돌하는 문제입니다.
Bring Your Own Model (BYOM): Data 360의 Einstein Studio를 통해 제공되며 데이터를 이동하거나 복제하지 않고 Salesforce 워크플로, Apex 논리 및 자동화 도구 내에서 외부에서 교육된 모델을 직접 호출할 수 있도록 지원함으로써 이러한 과제를 해결합니다. 제로 카피 연합을 통해 Data 360은 관리되는 단일 진실 소스로 작동하며, 외부 엔드포인트에서 추론할 수 있도록 조화된 Customer 360 데이터를 노출합니다. 예측 출력이 실시간으로 다시 흐르므로 비즈니스 프로세스에 확장 가능한 인텔리전스를 제공합니다.
BYOM은 모델 개발, 관리 데이터, 소비 계층을 분리하여 데이터 과학 및 운영 실행 간의 격차를 효과적으로 해소합니다. 플랫폼 독립성을 유지하고, 통합 복잡성을 줄이고, AI 배포를 가속화하며, 중요한 데이터에 대한 거버넌스를 유지합니다.
아키텍처는 다음과 같이 작동합니다. Data 360은 통합된 Customer 360 데이터 파운데이션을 제공하고 Einstein Studio는 외부 ML 플랫폼(SageMaker, Vertex AI 또는 사용자 정의 엔드포인트)에 대한 연결을 오케스트레이션합니다. 외부 모델은 실시간, 배치 또는 스트리밍 모드에서 추론을 실행합니다. Salesforce 계층(플로, Apex, 쿼리 API)은 출력을 사용하여 세일즈, 서비스, 마케팅, 산업 클라우드 전체에서 맞춤형, 자동화된 분석 인사이트를 제공합니다.
엔터프라이즈 관점에서 BYOM은 다음을 제공합니다.
- 데이터 무결성 및 거버넌스: 제어되지 않는 데이터 사본을 제거하고 정책 준수를 적용합니다.
- AI 민주화: Salesforce 도구를 통해 비기술 사용자가 복잡한 모델에 액세스할 수 있도록 합니다.
- Time-to-Value 가속화: 외부 모델은 Salesforce 프로세스 내에서 즉시 활성화됩니다.
- 확장성 및 하이브리드 아키텍처 지원: AI 워크로드의 다중 클라우드 배포를 활성화합니다.
- 미래에 적합한 AI 아키텍처: 운영 유연성을 위해 구성 가능한 AI 전략을 지원하고 데이터, 모델, 소비 계층을 분리합니다.
자신의 LLM 가져오기 (BYO-LLM): 생성형 모델의 경우에도 동일한 확장성 메커니즘을 제공합니다. 외부 LLM의 직접 호출을 활성화함으로써 고객은 Salesforce에서 제공하는 모델 대신 Agentforce Platform에서 해당 모델을 사용할 수 있습니다. 엔터프라이즈의 경우 BYO-LLM은 다음을 허용합니다.
- 정밀 조정된 모델에 액세스
- 현재 Salesforce에서 제공하지 않는 모델의 통합
- 고객이 제공한 계정의 모델 사용
현대 기업은 두 가지 주요 아키텍처 문제인 복잡한 데이터 환경 내에서 운영합니다.
- 기업 내 분할: 대규모 조직은 여러 Salesforce 조직(주로 지역, 사업부 또는 내역 인수별로 세분화됨)과 다양한 기타 데이터 시스템을 자주 활용합니다. 이러한 조각화로 인해 내부 데이터가 사라지므로 비즈니스 전반에서 실시간 참여를 위해 신뢰할 수 있는 단일하고 통합된 고객 보기를 설정할 수 없습니다. 모든 시스템에서 물리적으로 통합하거나 복제하지 않고 이 데이터를 통합하여 거버넌스를 그대로 유지하는 과제입니다.
- 기업 간 협업: 회사는 공동 마케팅, 측정, 비즈니스 인텔리전스를 위해 파트너 및 공급업체와 데이터를 공유해야 하는 경우가 많습니다. 중요한 독점 데이터를 보호하고 GDPR 및 CCPA와 같은 개인정보보호 규정을 준수하며 경쟁 장벽을 보호하면서 이러한 공동 작업을 활성화하는 것이 문제입니다.
Salesforce Data 360은 데이터를 이동하거나 복제하지 않고 액세스 및 인사이트를 공유하는 원칙에 기반한 제로 복제, Trust by Design 프레임워크를 통해 이러한 과제를 해결합니다.
Salesforce Data 360은 Data Cloud One, Data 360 간 데이터 공유, 프라이버시 우선 데이터 정리 룸을 사용하여 데이터 조각화 및 공동 작업 문제를 해결합니다. 이러한 솔루션은 고객 데이터를 통합하고, 안전한 데이터 교환을 활성화하며, 개인 정보를 보호하는 인사이트를 제공합니다. 제로 카피, Trust by Design 접근 방식을 통해 조직은 실시간 참여, 향상된 파트너십, 지능형 의사 결정을 위한 데이터 잠재력을 확보할 수 있습니다. 이러한 각 데이터 공동 작업 옵션은 서로 다른 목적으로 사용됩니다.
Data Cloud One을 통한 내부 엔터프라이즈 활성화
Data Cloud One은 여러 Salesforce 조직을 운영하는 엔터프라이즈를 위한 기본 아키텍처 솔루션입니다. 단순한 데이터 공유를 벗어나 신뢰할 수 있는 단일 고객 보기를 구축하고 전체 조직에서 전체 Data 360 플랫폼 기능을 활성화하도록 설계되었습니다.
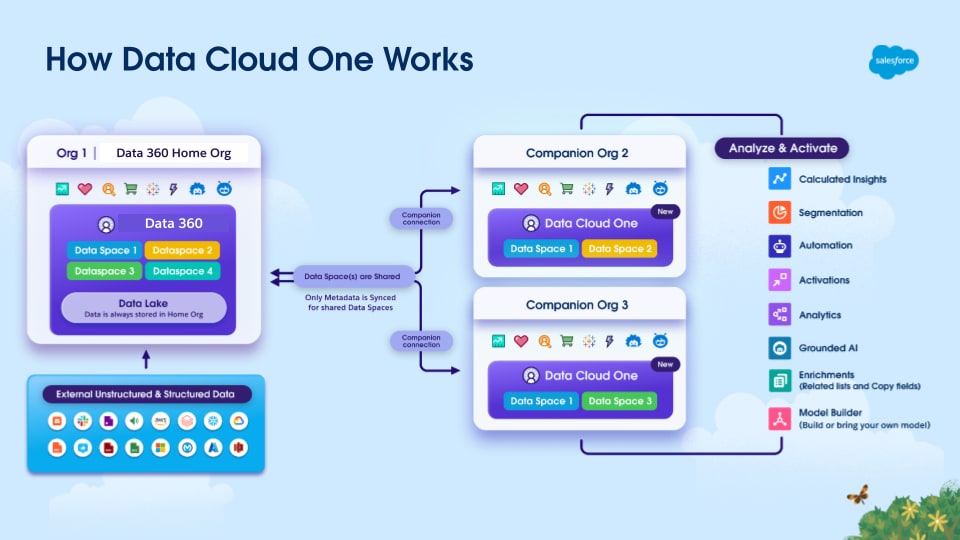
이 메커니즘은 데이터 관리 및 통합 고객 프로필 구축을 위한 중앙 기관 역할을 하는 지정된 홈 조직 Data 360 인스턴스에 중점을 두고 있습니다. 홈 조직은 Data 360이 프로비저닝되는 조직입니다. Data 360과 다른 Salesforce 조직 간에 동료 조직이라는 Data Cloud One 연결이 설정됩니다. Data Cloud One 연결의 일부로 Data 360은 각 동료 조직과 하나 이상의 데이터 공간을 공유하여 각 공유 데이터 공간의 데이터와 메타데이터에 모두 액세스할 수 있습니다. 이는 제로 카피 연합 모델 및 교차 조직 메타데이터 동기화를 통해 이루어집니다.
Data Cloud One을 사용하면 동료 조직이 자체 활성화, 개인 설정, 인텔리전스 요구에 맞게 홈 조직의 Data 360 인스턴스를 활용할 수도 있습니다. 이 전략은 내부 데이터 분할을 없애고 모든 사업부가 같은 관리 및 통합 고객 프로필에 대해 활성화되어 핵심 Data 360 구현의 ROI를 극대화하는 데 필수적입니다.
Data 360 조직 간 데이터 공유
분산된 내부 환경(완전한 중앙 집중화가 불가능한 경우) 및 신뢰할 수 있는 외부 파트너와의 공동 작업을 위해 Data 360-to-Data 360 데이터 공유는 독립 Data 360 인스턴스를 연결합니다.
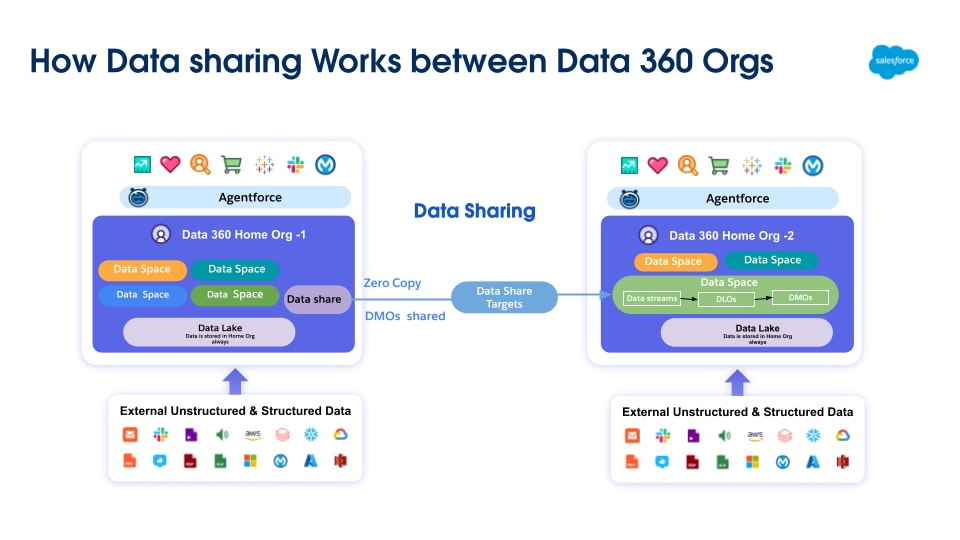
이 제로 카피 공유 모델은 데이터 개체(DLO, DMO, CIO)를 안전하게 교환하기 위해 다른 Salesforce 조직에서 프로비저닝된 별도의 Data 360 테넌트 간 연결을 설정합니다. 연결되면 수신자 Data 360에서 전체 데이터 개체에 액세스할 수 있습니다. 그러면 수신자 Data 360의 관리자가 이 데이터에 대한 사용자 액세스를 관리하는 거버넌스 규칙을 설정할 수 있습니다.
Data 360 Clean Room 공동 작업을 통한 개인정보 보호-첫 번째 공동 작업
공동 작업 시 가장 높은 수준의 개인 정보 보호 및 규정 준수가 필요하거나 경쟁 문제로 인해 원시 데이터 공유가 금지되는 경우 Data 360 Clean Rooms는 아키텍처에 따라 필수 항목입니다.
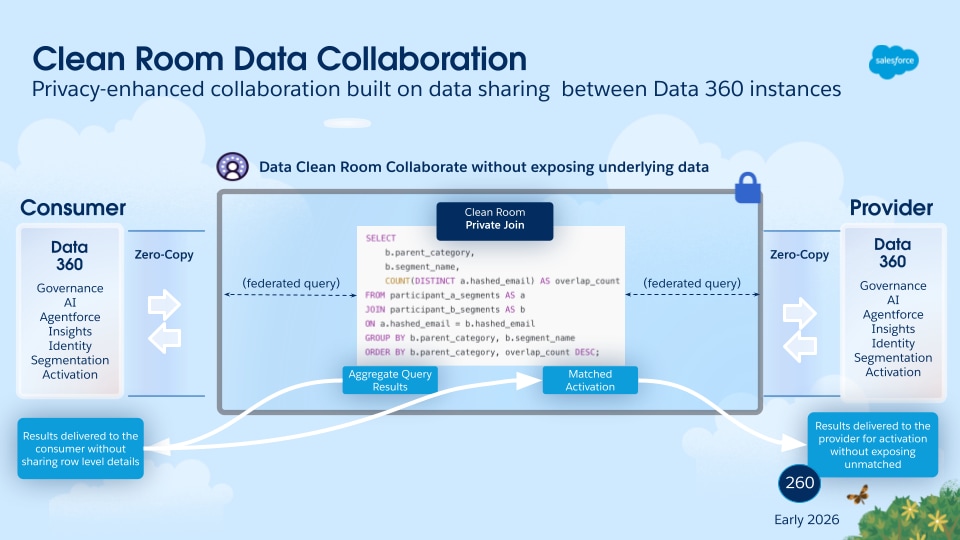
아키텍처적으로 Data 360 Clean Room 공동 작업은 Data 360-to-Data 360 데이터 공유에 사용되는 제로 카피 공유 프레임워크의 상단에 구축되었지만 추가적인 관리 계층 및 계산 제약이 적용됩니다. Data 360 Clean Room은 당사자가 익명화된 키를 기반으로 데이터 집합을 조인할 수 있는 안전하고 제어되는 컴퓨팅 환경을 제공합니다. 핵심적인 목적은 기본 독점 데이터를 노출하지 않고도 공동 분석 및 인사이트 생성을 허용하는 것입니다. 환경은 최소 집계 임계값 및 내보내기가 불가능한 식별자와 같은 프로그래밍 가능한 엄격한 규칙을 적용합니다. 이러한 규칙을 통해 승인된 개인 정보 보호 및 집계된 인사이트만 파생 및 공유됩니다. 이를 통해 클린 룸은 플랫폼 간 캠페인 측정 및 민감한 대상 겹침 분석과 같은 사용 사례에 필수적으로 적용됩니다.
Data 360은 차세대 AI를 구동하는 데 필요한 지능적이고 확장 가능하며 신뢰할 수 있는 데이터 패브릭으로 설계되었습니다. 아키텍처 설계는 분할된 데이터의 문제를 해결하여 조직에서 효율성을 보장하기 위해 Zero Copy Data Federation을 사용하여 모든 고객 데이터를 대규모로 통합, 처리, 활성화할 수 있도록 합니다.
강력한 데이터 조직은 DLO(정형화되지 않은 데이터 포함)에서 DMO로의 조화된 보기를 설정하며, 모두 분할된 데이터 공간 내에서 보호됩니다. 배치 및 스트리밍 변환, 계산된 인사이트, 비정형 데이터 처리, ID 확인 등 Data 360의 다양한 데이터 처리 기능은 증분 SNCE 및 CDF 아키텍처에 의해 제공되므로 효율적이고 실시간에 가까운 처리를 수행하고 상당한 비용을 절감할 수 있습니다.
확장성은 코드 확장 아키텍처에서 제공되며, 고유한 요구 사항에 대해 스크립트 또는 분리된 함수를 통해 사용자 정의 파이썬 논리를 안전하게 활성화합니다. 또한 CEDAR 정책과 함께 특성 기반 액세스 제어(ABAC)를 기반으로 구축된 포괄적인 데이터 거버넌스 프레임워크는 세분화된 보안, 동적 데이터 마스킹, 모든 데이터 사용 전반에 걸쳐 일관된 적용을 보장합니다. 이는 정교한 세분화 및 활성화 기능으로 끝나고, 통합 고객 프로필을 실시간 반응형 동적 다중 채널 참여 전략으로 전환합니다.
중요한 점은 Data 360이 광범위하고 다양한 데이터를 통합하고, 통합 쿼리를 통해 실시간 컨텍스트를 제공하는 기능(하이브리드 구조화/비정형 검색 및 하이퍼 가속 포함), 엄격한 관리를 적용하는 기능이 지능형 AI 에이전트를 강화하는 데 매우 중요합니다. Agentforce 지원 에이전트의 생성형 AI 워크플로(RAG)를 기반으로 신뢰할 수 있고 신선하고 관련성이 높은 데이터를 제공하고 다중 전환 작업 지향 기능을 제공하므로 정확하고 정확하게 작동합니다.
소스 데이터가 실천 가능한 인사이트로 변환되는 미래 보장 플랫폼을 제공함으로써 Data 360은 에이전트 고객 경험을 구축하는 조직에 필수 아키텍처 기반 역할을 합니다. 이는 고객 데이터를 현대 조직의 성공을 촉진하는 정교하고 맞춤형 고객 경험으로 전환하는 중요한 기초입니다.