현대 Salesforce 통합은 간단한 데이터 교환 이상을 지원해야 합니다. 실시간 고객 환경을 구동하고 여러 시스템에서 조치를 조율하며 엄격한 보안 및 규정 준수 요구 사항을 충족하면서 엔터프라이즈 규모에서 안정적으로 운영할 수 있습니다. 따라서 올바른 통합 접근 방식을 선택하는 것은 구현 세부 사항이 아닌 중요한 아키텍처 결정입니다. 일반적인 엔터프라이즈 시나리오를 고려하십시오. 고객이 모바일 앱에서 구매를 완료하여 맞춤형 제안에 대한 실시간 자격 검사를 트리거합니다. 동시에 트랜잭션 데이터는 ERP 시스템에 기록되고, 고객 특성이 Salesforce에서 업데이트되고, 분석이 대기 시간, 데이터 중복 또는 규정 준수 위험을 유발하지 않고 데이터 레이크로 스트리밍되어야 합니다. 이와 같은 시나리오는 Salesforce가 분리된 상태에서 작동하는 경우가 거의 없으며 더 광범위한 응용 프로그램 및 데이터 플랫폼 에코시스템과 원활하게 통합해야 하는 현대 Salesforce 환경에서 일반적입니다. 이 가이드는 설계자 및 개발자가 명확하고 자신 있게 통합을 설계할 수 있도록 지원합니다. 지점 간 구현에 초점을 맞추지 않고 반복되는 엔터프라이즈 시나리오(예: 프로세스 오케스트레이션, 데이터 동기화, 실시간 데이터 액세스)를 해결하는 확인된 통합 패턴을 소개합니다. 각 패턴은 아키텍처 의도, 제약, 실행 모델을 강조하여 팀이 확장하고 지속되는 정보에 근거한 설계 결정을 내릴 수 있습니다. 이 문서 내에서 다음을 찾을 수 있습니다.
- 프로세스, 데이터, 가상 액세스 시나리오에서 일반적인 엔터프라이즈 "상위 유형"을 나타내는 통합 패턴
- 통합 의도 및 실행 타이밍을 기반으로 올바른 접근 방식을 식별하는 데 도움이 되는 패턴 선택 프레임워크
- 확장성, 복원력, 거버넌스, 보안 고려 사항에 대한 실용 지침
- 실제 Salesforce 및 Data 360 구현에서 얻은 모범 사례 이 문서의 목표는 통합을 위한 공유 아키텍처 언어를 제공하는 것입니다. 이를 통해 팀이 엔터프라이즈 데이터 및 거버넌스 전략에 맞춰 성능, 유연성, Trust 균형을 맞추는 솔루션을 설계할 수 있습니다.
이 문서는 엔터프라이즈의 다른 응용 프로그램의 데이터를 Salesforce Data 360(기존의 Data Cloud)과 통합해야 하는 디자이너 및 아키텍처를 위한 것입니다. 이 콘텐츠는 Salesforce 아키텍처 및 파트너가 성공적으로 구현한 수많은 구현 내용의 추출입니다. Data 360의 대규모 채택에 사용할 수 있는 통합 기능 및 옵션을 숙지하려면 아래의 패턴 요약 및 패턴 선택 가이드 섹션을 참조하십시오. 설계자 및 개발자는 Data 360에 대한 데이터 상호 작용 프로젝트의 설계 및 구현 단계에서 해당 패턴 세부 사항 및 성공 사례를 고려해야 합니다. 올바르게 구현되면 해당 패턴을 사용하면 가능한 한 빠르게 프로덕션으로 이동하고 가능한 한 안정적이고 확장 가능하며 유지보수 없이 애플리케이션 집합을 사용할 수 있습니다. Salesforce의 자체 컨설팅 아키텍처는 이러한 패턴을 아키텍처 검토 시 참조 지점으로 사용하고 적극적으로 유지 및 개선합니다. 모든 패턴과 마찬가지로 이 콘텐츠는 대부분의 통합 시나리오에 적용되지만 전부는 적용되지 않습니다. 예를 들어 Salesforce에서 사용자 인터페이스(UI) 통합을 허용하는 경우, 이러한 통합은 이 문서의 범위를 벗어납니다.
각 통합 패턴은 일관된 구조를 따릅니다. 이렇게 하면 각 패턴에 제공되는 정보가 일관되고 패턴을 더 쉽게 비교할 수 있습니다.
- 이름: 패턴에 포함된 통합 유형을 나타내는 패턴 식별자입니다.
- 컨텍스트: 패턴이 해결하는 전체 통합 시나리오입니다. 컨텍스트는 사용자가 달성하려는 작업과 응용 프로그램이 요구 사항을 지원하기 위해 동작하는 방법에 대한 정보를 제공합니다.
- 문제: 질문으로 표현하면 패턴이 해결하도록 설계된 시나리오입니다. 이 섹션을 읽어 패턴이 통합 시나리오에 적합한지 이해하십시오.
- Forces: 설명된 시나리오를 해결하기 어려운 제약 및 상황입니다.
- 솔루션: 통합 시나리오를 해결하는 권장 방법입니다.
- 스케치: 솔루션이 시나리오를 해결하는 방식을 보여주는 UML 순서 다이어그램
- 결과: 통합 시나리오에 솔루션을 적용하는 방법과 해당 시나리오와 관련된 힘을 해결하는 방법에 대한 세부 사항을 설명합니다. 이 섹션에는 패턴 적용으로 인해 발생할 수 있는 새로운 문제도 포함되어 있습니다.
- 사이드바: 주요 기술 문제, 패턴 변형, 패턴별 문제 등을 포함하는 패턴과 관련된 추가 섹션입니다.
- 예: 실제 Salesforce 시나리오에서 디자인 패턴이 사용되는 방식을 설명하는 실제 시나리오입니다. 이 예에서는 통합 목표 및 해당 목표를 달성하기 위해 패턴을 구현하는 방법을 설명합니다.
이 표를 이 문서에 포함된 통합 패턴의 목차로 사용합니다.
| 패턴 수준1 | 패턴 수준2 | 패턴 | 보조 |
|---|---|---|---|
| 데이터 수집 패턴--데이터 인바운드 | 배치 수집 패턴 | 클라우드 스토리지에서 대량 데이터 수집 | 데이터는 Amazon S3, Azure Blob 또는 Google Cloud Storage와 같은 엔터프라이즈 클라우드 저장소 소스에서 대량의 원시 데이터 배치(예: 트랜잭션 또는 제품 로그) 형태로 Data 360으로 수집됩니다. |
| Salesforce Cloud에서 대량 데이터 수집 | Data 360은 여러 Salesforce 조직(예: Sales Cloud, Service Cloud)에서 CRM 데이터를 대량으로 수신하여 통합 고객 프로필을 구축합니다. | ||
| 스트리밍 및 실시간 수집 패턴 | 수집 API를 통한 이벤트 중심 수집--스트리밍 | Data 360은 실시간 프로필 업데이트를 위해 엔터프라이즈 시스템에서 연속 이벤트 페이로드(예: 구매 이벤트, IoT Telemetry)를 수신하는 스트리밍 수집 끝점을 구독합니다. | |
| 실시간 웹 및 모바일 동작 수집 | Data 360은 SDK를 통해 실시간 웹 사이트 및 모바일 앱 동작 데이터를 수집 및 처리하여 참여 메트릭 및 개인 설정 모델을 강화합니다. | ||
| 스트리밍을 통한 거의 실시간 CRM 동기화 | Data 360은 이벤트 스트림을 통해 CRM 데이터 업데이트(예: 연락처, 사례, 기회 변경)를 거의 실시간으로 수신하여 지속적으로 동기화된 Customer 360 보기를 유지합니다. | ||
| 클라우드 메시징 플랫폼에서 이벤트 스트림 수집--Kinesis 및 MSK | Data 360은 AWS Kinesis 또는 Kafka(MSK)와 같은 클라우드 이벤트 플랫폼에서 직접 스트리밍 데이터를 사용하여 고주파 운영 또는 IoT 이벤트를 처리합니다. | ||
| 제로 복제 패턴--인바운드 및 아웃바운드 | 인바운드 제로 복제--Data 360에 대한 외부 플랫폼 | Data 360은 물리적으로 데이터를 Salesforce로 이동하지 않고도 Zero Copy 수집을 통해 요청 시 외부 데이터 집합(예: Snowflake, BigQuery)을 쿼리합니다. | |
| Outbound Zero Copy--외부 플랫폼에 대한 Data 360 | Databricks 또는 Tableau와 같은 외부 시스템은 데이터 복제 없이 Zero Copy 아웃바운드 연결을 통해 Data 360의 보강 세그먼트 및 인사이트에 액세스합니다. | ||
| Data Cloud One을 통합한 다중 조직 데이터 플랫폼 | Data Cloud One은 공유 메타데이터 및 시맨틱 모델 아래 여러 Salesforce 조직과 외부 데이터 소스를 통합하여 데이터 중복 없이 일관된 Customer 360 제공합니다. | ||
| 데이터 활성화 패턴--데이터 아웃바운드 | 배치 활성화 패턴 | 마케팅 및 광고 플랫폼에 대한 세그먼트 활성화 | Data 360은 맞춤형 캠페인 전달을 위해 Marketing Cloud, Meta, Google Ads 또는 기타 광고 플랫폼에 직접 선별된 고객 세그먼트를 활성화합니다. |
| 클라우드 저장소로 데이터 내보내기 | Data 360은 분석 또는 규정 준수 보관을 위해 통합 또는 필터링된 데이터 집합(예: 동의된 고객 레코드)을 CSV 또는 Parquet 파일로 엔터프라이즈 클라우드 저장소로 내보냅니다. | ||
| 요청형 API 기반 활성화 | Connect API를 통한 맞춤형 응용 프로그램 통합 | 외부 응용 프로그램은 Data 360 Connect API를 실시간으로 호출하여 현재 고객 데이터를 기반으로 개인 설정된 작업(예: 충성도 잔고 확인 또는 AI 제안 생성)을 검색하거나 트리거합니다.사용자 정의된 웹 또는 모바일 응용 프로그램은 Connect REST API를 통해 조화된 Data 360 인사이트를 안전하게 검색하여 엔터프라이즈 또는 파트너 UI 내에 표시합니다. | |
| 데이터 그래프 API를 통한 전체 고객 프로필 검색 | 시스템에서 데이터 그래프 API를 사용하여 고객의 통합 프로필을 검색하여 결정 또는 개인 설정을 위해 전체 360° 보기의 사전 결합된 실시간 JSON 표현을 반환합니다. | ||
| 실시간 데이터 작업 | 실시간 데이터 동작 고객 신호를 즉각적인 동작으로 전환 | Data 360은 실시간 이벤트(예: 동의 업데이트, 구매 트리거)를 감지 및 처리하고 연결된 시스템 또는 Salesforce 플로를 즉시 호출하여 다운스트림 작업을 수행합니다.Data 360의 고객 활동 신호(예: 이탈 위험 감지)는 CRM 업데이트, Einstein 점수 호출 또는 보존 여정을 시작하는 등 즉시 실시간 작업을 트리거합니다. |
이 문서의 통합 패턴은 데이터, 프로세스, 시각적 통합의 세 가지 범주로 분류됩니다.
Data 360의 데이터 통합 패턴은 Data 360 및 외부 플랫폼 모두에 일관되고 시기적절하며 신뢰할 수 있는 정보를 보관할 수 있도록 시스템 전반의 데이터 이동 및 동기화를 해결합니다. 이러한 패턴은 일반적으로 대규모 대용량 데이터 플로를 처리하고 스키마 일관성, 계보 추적, 마스터링 규칙을 적용하는 관리 파이프라인에 의존합니다.
- 배치 수집 패턴은 엔터프라이즈 데이터 온보딩의 기본 계층입니다. AWS S3, Azure Blob 또는 Google Cloud Storage와 같은 클라우드 저장소 서비스에서 대량 데이터를 수집하면 ID 확인, 세분화, 분석을 위해 대규모 내역 데이터 집합을 Data 360에 주기적으로 로드할 수 있습니다. 마찬가지로 Sales, Service 또는 Marketing Cloud와 같은 Salesforce Cloud의 대량 수집은 네이티브 커넥터 및 데이터 스트림을 사용하여 CRM 데이터를 통합된 데이터 레이어로 가져오므로 참여 시스템 간 조합 및 연속성을 보장합니다.
- 스트리밍 및 실시간 수집 패턴은 고속 이벤트 데이터를 캡처하여 이를 확장합니다. 수집 API를 통한 이벤트 중심 수집을 통해 외부 시스템에서 고객 활동을 Data 360으로 지속적으로 스트리밍할 수 있습니다. 실시간 웹 및 모바일 동작 수집은 디지털 접점에서 직접 클릭스트림 및 상호 작용 데이터를 수집하여 즉시 개인 설정을 촉진합니다. 스트리밍 API를 통해 거의 실시간으로 CRM을 동기화하면 고객 특성과 동의 업데이트가 시스템 전체에 빠르게 반영됩니다. Amazon Kinesis 또는 Confluent MSK와 같은 Messaging 플랫폼에서 이벤트 스트림 수집은 지속적인 고처리량 파이프라인을 지원하며 Data 360을 엔터프라이즈 이벤트 아키텍처에 맞춥니다.
- Unified Multi-Org Data Platform with Data Cloud One은 데이터 통합을 더욱 잘 보여주며, 여러 Salesforce 조직 및 외부 소스의 데이터를 공통 관리 및 시맨틱 계층 하에서 통합할 수 있는 통합 환경을 제공합니다. 이를 통해 조직은 엔터프라이즈 전체 데이터 일관성, 공유 데이터 모델, 확장 가능한 분석을 달성할 수 있습니다.
- 활성화 단계에서 배치 활성화 패턴은 동일한 데이터 통합 원리를 따릅니다. Data 360에서 선별된 세그먼트는 예약된 작업에서 Marketing Cloud, Meta Ads 또는 Google Ads와 같은 다운스트림 마케팅 및 광고 플랫폼으로 내보내며, 여기에서 캠페인 실행을 트리거합니다. 마찬가지로 데이터 집합을 클라우드 저장소 대상으로 내보내 외부 분석 및 데이터 과학 파이프라인을 촉진할 수 있습니다. 모든 사용 사례에서 Data 360은 동기화 및 선별된 고객 데이터의 신뢰할 수 있는 소스로 작동합니다.
Data 360의 프로세스 통합 패턴은 거의 실시간으로 시스템 전반에서 비즈니스 프로세스를 트리거하거나 오케스트레이션하는 작업을 수행합니다. 이러한 패턴을 사용하면 Data 360이 엔터프라이즈 워크플로에 적극적으로 참여하여 상황별 응답 및 동적 데이터 활성화를 활성화할 수 있습니다.
- On-Demand API 기반 활성화는 실시간 참여 시나리오를 지원합니다. Connect API를 통해 사용자 정의 응용 프로그램은 고객 상호 작용 중 통합 프로필 인사이트를 검색하는 에이전트 콘솔 등 운영 프로세스의 일부로 Data 360에서 직접 고객 프로필을 쿼리하거나 활성화할 수 있습니다. Data Graph API를 통해 전체 고객 프로필 검색은 고객의 전체 엔티티 그래프에 대한 API 기반 액세스를 기반으로 하는 복합 애플리케이션 및 마이크로서비스를 지원하므로 사전 단계 세그먼트 없이 동적 환경을 제공할 수 있습니다.
- 실시간 데이터 작업은 즉각적인 응답 기능을 제공함으로써 이 통합 접근 방식을 더욱 발전시킵니다. 구매, 양식 제출 또는 임계값 이벤트와 같은 고객 신호가 감지되면 Data 360은 CRM 레코드 업데이트, 외부 웹후크 호출 또는 맞춤형 제안 워크플로 시작과 같은 작업을 트리거할 수 있습니다. 이러한 패턴은 실시간 고객 인텔리전스 인텔리전스를 자동화된 운영 실행과 연결하는 진정한 프로세스 오케스트레이션을 구현합니다.
Data 360의 가상 통합 패턴을 사용하면 데이터를 물리적으로 복사하거나 복제하지 않고도 외부 또는 연합 데이터 소스에 실시간으로 액세스할 수 있습니다. 이는 데이터 이동을 최소화하면서 쿼리 시간에 관리되고 최신 정보를 요구하는 엔터프라이즈에 매우 중요합니다.
- **Inbound Zero Copy Data Federation(External Platforms-to-Data 360)**을 사용하면 데이터 웨어하우스 또는 데이터 레이크와 같은 외부 시스템이 안전하고 관리되는 연결(예: Snowflake 보안 데이터 공유)을 통해 Data 360과 데이터 집합을 공유할 수 있습니다. 이렇게 하면 Data 360이 외부 데이터에 가상으로 액세스하고 작업할 수 있으므로 최신 상태를 유지하고 불필요한 복제를 피할 수 있습니다.
- Outbound Zero Copy Data Sharing(Data 360-to-External Platforms)를 사용하면 Data 360이 안전한 데이터 통합 및 실시간 쿼리 메커니즘을 통해 AI 모델링, 비즈니스 인텔리전스 또는 고급 분석과 같은 외부 사용을 위해 큐레이팅된 데이터 집합을 노출할 수 있습니다. 시스템에 가장 적합한 통합 전략을 선택하는 것은 중요하지 않습니다. 고려해야 할 여러 측면과 사용할 수 있는 도구가 많으며, 일부 도구는 특정 과업에 다른 도구보다 적합합니다. 각 패턴은 각 시스템의 성능, 데이터 용량, 오류 처리, 트랜잭션성 등 특정 중요 영역을 다룹니다.
통합 패턴을 선택할 때 통합의 전반적인 디자인과 동작을 형성하는 두 가지 기본 질문에 답변하여 시작합니다. 통합 중인 항목은 무엇입니까? — 프로세스, 데이터 또는 가상 액세스 이 차원은 통합의 기본 목적을 정의합니다.
- 프로세스 통합은 비즈니스 워크플로를 오케스트레이션하고 시스템 간의 조치를 조정하는 데 초점을 맞춥니다.
- 데이터 통합은 시스템 간의 데이터 동기화, 보강 또는 전파에 중점을 둡니다.
- 가상 통합은 Salesforce 또는 Data 360에서 복사하거나 유지하지 않고 실시간으로 외부 데이터에 액세스하는 데 중점을 둡니다. 이 의도를 이해하면 시스템 간에 필요한 오케스트레이션, 데이터 이동, 커플링 수준을 결정하는 데 도움이 됩니다.
- 어떻게 실행해야 합니까? - 동기 또는 비동기 메서드는 통합의 실행 모델을 정의합니다.
- 동기식 통합은 실시간 및 차단 방식으로 호출자가 즉각적인 응답을 기대합니다. 이는 일반적으로 사용자 중심 또는 검증 시나리오에 사용됩니다.
- 비동기 통합은 차단되지 않고 분리되므로 규모가 크고 오랜 프로세스, 재시도 및 대용량 데이터를 처리할 수 있습니다. 이 두 가지 측면(통합 의도 및 실행 타이밍)은 올바른 통합 패턴을 선택할 수 있는 명확하고 일관된 프레임워크를 제공하며 사용자 경험, 확장성 및 운영 복원성의 균형을 유지합니다. 참고: 통합 시 통합 시나리오에 적용되는 측면에 따라 통합에 외부 미들웨어 또는 통합 솔루션(예: 엔터프라이즈 서비스 버스)이 필요할 수 있습니다.
이 표에는 Salesforce에서 다른 시스템으로 통합할 때 요구 사항에 가장 적합한 패턴을 결정하는 데 도움이 되는 패턴 및 주요 측면이 나열되어 있습니다.
| 유형 | 시기 | 아웃바운드 고려 사항 |
|---|---|---|
| 데이터 통합 | 비동기식 | 마케팅 및 광고 플랫폼에 대한 세그먼트 활성화 |
| 프로세스/데이터 통합 | 동기식 | Connect API를 통한 맞춤형 응용 프로그램 통합 데이터 그래프 API를 통한 전체 고객 프로필 검색 |
| 데이터 통합 | 동기식 | 실시간 데이터 동작 고객 신호를 즉각적인 동작으로 전환 |
| 가상 통합(zero Copy 사용) | 비동기식 | Outbound Zero Copy--외부 플랫폼에 대한 Data 360 |
| 가상 통합 | 비동기식 | Data Cloud One을 통합한 다중 조직 데이터 플랫폼 |
이 표에는 다른 시스템에서 Salesforce로 통합할 때 요구 사항에 가장 적합한 패턴을 결정하는 데 도움이 되는 패턴 및 주요 측면이 나열되어 있습니다.
| 유형 | 시기 | 인바운드 고려 사항 |
|---|---|---|
| 데이터 통합 | 비동기식 | 클라우드 스토리지에서 대량 데이터 수집 Salesforce Cloud에서 대량 데이터 수집 |
| 데이터 통합 | 비동기식 | 클라우드 메시징 플랫폼에서 이벤트 스트림 수집--Kinesis 및 MSK 스트리밍을 통한 거의 실시간 CRM 동기화 |
| 프로세스 통합 | 동기식 | 수집 API를 통한 이벤트 중심 수집--스트리밍 실시간 웹 및 모바일 동작 수집 |
| 가상 통합 | 비동기식 | 인바운드 제로 복제--Data 360에 대한 외부 플랫폼 |
이 표에는 미들웨어와 관련된 몇 가지 주요 용어와 해당 패턴과 관련된 정의가 나열되어 있습니다.
| 기간 | 정의 |
|---|---|
| 이벤트 처리 | 이벤트 처리는 소스 시스템 또는 응용 프로그램에서 식별 가능한 항목의 수신, 라우팅, 응답을 나타냅니다. 중간웨어는 대상 끝점을 식별하고, 이벤트를 전달하고, 필수 비즈니스 작업(예: 로깅, 재시도 또는 다운스트림 서비스 활성화)을 트리거하여 이벤트를 처리합니다. Data 360 아키텍처에서 이벤트 처리는 실시간 데이터 수집, 활성화 트리거, 게시/구독 패턴에 매우 중요합니다. 이벤트는 외부 시스템(Kafka, AWS Kinesis) 또는 Salesforce Platform 이벤트에서 생성될 수 있으며, 즉시 처리하기 위해 미들웨어 또는 Data 360 이벤트 버스에서 라우팅됩니다. |
| 프로토콜 변환 | 프로토콜 변환을 사용하면 다른 데이터 전송 표준을 사용하여 시스템 간에 통신할 수 있습니다. 중간웨어는 독점 또는 레거시 프로토콜(예: AMQP, MQTT, FTP)을 지원되는 Data 360 프로토콜(REST, gRPC 또는 HTTPS)으로 변환합니다. 이렇게 하면 이기종 시스템 전체에서 상호 운용성이 보장됩니다. Data 360은 기본적으로 프로토콜 변환을 처리하지 않으므로 미들웨어는 메시지를 Data 360 API 형식으로 캡슐화하거나 변환하고 커넥터가 해석할 수 있는 조정 레이어를 제공합니다. |
| 번역 및 변환 | 번역 및 변환은 하나의 데이터 형식 또는 스키마를 다른 데이터 형식에 매핑하여 상호 운용성을 보장합니다. 중간웨어는 이러한 변환을 수행하여 다양한 데이터 페이로드(CSV, XML, JSON)를 Data 360 데이터 모델 개체(DMO) 및 통합 데이터 레이어 개체(UDLO)에 맞춥니다. 수집 전 시맨틱 또는 본체 기반 매핑 정리, 보강, 적용이 포함됩니다. Salesforce는 Data Prep Recipes와 같은 변환 도구를 제공하지만, 복잡한 변환(특히 시맨틱 조합)은 미들웨어에서 처리하는 것이 가장 좋습니다. |
| 대기열 및 버퍼링 | 대기열 및 완충은 복원 가능한 분리된 통신을 보장하기 위해 비동기식 메시지 전달에 의존합니다. MuleSoft, Kafka 또는 Azure 이벤트 허브 등 중간웨어 플랫폼은 Data 360 또는 다운스트림 시스템이 사용 중이거나 액세스할 수 없는 경우 데이터를 일시적으로 저장하는 영구 대기열을 제공합니다. 이를 통해 데이터 손실을 방지하고 거의 실시간 수집 또는 활성화 재시도를 지원합니다. Data 360은 스트리밍 수집 및 플로 기반 아웃바운드 메시지를 지원하지만, 지속적인 대기열 및 보증 배달은 일반적으로 미들웨어에서 처리됩니다. |
| 동기식 전송 프로토콜 | 동기식 전송 프로토콜에는 차단, 실시간 요청/응답 작업이 수반됩니다. 진행하기 전에 발신자가 회신을 기다립니다. Data 360에서는 요청 시 API 기반 활성화, 실시간 보강 또는 즉시 응답이 필요한 프로필 조회에 사용됩니다. 중간웨어는 연결 신뢰성을 보장하고 동기식 Data 360 API 호출에 대한 재시도 또는 대체 처리를 관리합니다. |
| 비동기식 전송 프로토콜 | 비동기식 전송 프로토콜은 배송자가 응답을 기다리지 않고 계속 처리하는 차단되지 않은 분리된 통신을 지원합니다. 중간웨어는 배치 활성화, 스트리밍 수집, 이벤트 중심 활성화를 위한 비동기 플로를 처리합니다. 이를 통해 Data 360에서 이벤트 스트리밍 및 거의 실시간 데이터 수집 패턴에 매우 중요한 처리량과 복원을 높일 수 있습니다. |
| 중재 라우팅 | 중재 라우팅은 시스템 간 복잡한 메시지 플로를 정의하여 올바른 데이터 또는 이벤트를 올바른 소비자에게 제공합니다. 중간웨어는 중재자 역할을 하며 규칙, 머리글, 콘텐츠 또는 이벤트 유형을 기반으로 라우팅 논리를 처리합니다. Data 360 통합에서 중재를 통해 여러 시스템의 이벤트 및 프로필 업데이트가 데이터 수집 API, 활성화 끝점 또는 외부 소비자에게 제대로 라우팅됩니다. 이렇게 하면 오케스트레이션을 간소화하고 다중 시스템 데이터 동기화를 지원합니다. |
| 프로세스 작전 및 서비스 오케스트레이션 | 프로세스 통합 및 오케스트레이션은 다중 시스템 프로세스를 좌표합니다. 단계는 중앙 컨트롤러 없이 공유 규칙을 기반으로 작업하는 자동 비동기 이벤트 중심 플로를 지원합니다. 오케스트레이션은 서비스 실행을 안내하는 중앙에서 관리하는 플로입니다. Data 360 아키텍처에서 미들웨어는 시스템 전반에서 수집 및 활성화를 위한 오케스트레이션을 관리하고 Salesforce 워크플로 또는 플로는 플랫폼 내에서 가벼운 통합을 처리합니다. 중간웨어 계층에서 트랜잭션 조정 또는 상태 관리를 필요로 하는 복잡한 오케스트레이션을 사용하는 것이 좋습니다. |
| 트랜잭션성(암호화, 서명, 신뢰할 수 있는 전달, 트랜잭션 관리) | 트랜잭션성은 시스템 전반에서 원자적, 일관적인, 분리된, 내구성 있는(ACID) 작업을 보장합니다. Salesforce 및 Data 360은 경계 내에서 트랜잭션이지만 외부 시스템에서 배포된 트랜잭션은 지원하지 않습니다. 중간웨어는 암호화, 메시지 서명, 롤백, 보상, 신뢰할 수 있는 전달 등 글로벌 트랜잭션 제어를 처리합니다. 미션에 중요한 데이터 플로(예: 재무 또는 동의 업데이트)의 경우 미들웨어는 Data 360 및 외부 시스템 전반에서 종단간 무결성 및 복구를 보장합니다. |
| 라우팅 | 라우팅은 구성 요소 간에 메시지 또는 데이터의 제어 플로를 지정합니다. 머리글, 콘텐츠 유형, 우선 순위 또는 규칙을 기반으로 할 수 있습니다. 중간웨어는 Data 360과 관련된 이벤트 및 활성화에 대한 라우팅 논리를 처리합니다(예: 다양한 다운스트림 시스템(Ad Platform, 웨어하우스, CRM 앱)으로 보강된 대상 세그먼트 이동). 라우팅은 Salesforce(Apex, 플로) 내에서 구현할 수 있지만, 확장성, 유연성 및 거버넌스에 따라 미들웨어 라우팅이 선호됩니다. |
| Extract, Transform, and Load(ETL) | ETL은 소스 시스템에서 데이터를 추출하고 일관된 스키마로 변환한 후 대상(예: Data 360)에 로드하는 과정입니다. 데이터 수집 전에 Middleware 또는 ETL 도구가 이러한 작업을 처리합니다. Data 360은 API, 커넥터 또는 대량 수집 파이프라인을 통해 ETL 출력을 수신할 수 있으며, 실시간 동기화를 위해 CDC(Change 데이터 수집 지원합니다. 중간웨어 ETL 프로세스는 레거시 시스템을 통합하고 Data 360에서 통합하기 전에 데이터 품질을 보장하는 데 필수적입니다. |
| 긴 폴링 | 긴 폴링(혜성 프로그래밍)은 실시간 업데이트를 위해 시스템 간의 개방형 통신을 유지하는 방법입니다. 클라이언트가 요청을 보내고 서버가 이벤트가 발생할 때까지 요청을 유지한 후 응답하고 새 연결을 다시 엽니다. Salesforce는 이벤트 중심 데이터 동기화를 위해 스트리밍 API 및 CometD/Bayeux 프로토콜에서 이를 사용합니다. 중간웨어는 해당 이벤트를 구독하고 Data 360에 전달하여 실시간 수집 또는 활성화 트리거를 수행하여 엔터프라이즈 시스템 전반에서 대기 시간이 최소화됩니다. |
데이터 수집은 Salesforce Data 360의 데이터 수명 주기에서 가장 중요한 첫 번째 단계입니다. 이를 통해 여러 외부 시스템(CRM, ERP, 웹, 모바일 또는 타사 API)의 원시 정보가 플랫폼에 들어와 통합 고객 보기의 일부가 됩니다. 올바른 수집 패턴은 비즈니스의 요구 사항에 따라 다릅니다.
- 데이터 볼륨 — 한 번에 얼마나 많은 데이터가 이동하는지
- 대기 시간 - 데이터가 얼마나 최신이어야 하는지
- 소스 시스템 기능 — 시스템이 데이터를 연결하고 전달하는 방법 Data 360은 대용량 로드를 위한 배치, 실시간 업데이트를 위한 스트리밍, 트랜잭션 즉각성을 위한 이벤트 기반, 외부 데이터를 물리적으로 이동하지 않고 즉시 액세스할 수 있는 Zero Copy 수집과 같은 여러 수집 모드를 지원합니다. 이러한 패턴을 함께 사용하면 구매 이벤트, 클릭 스트림 로그 또는 충성도 업데이트 등 모든 고객 신호가 신뢰할 수 있는 분석 및 AI 기반 환경을 제공하기 위해 적절한 시간 범위 내에 Data 360에 효율적이고 안전하게 유입됩니다.
배치 수집 패턴은 Data 360에서 대규모 데이터 온보딩의 기반입니다. 일반적으로 데이터가 연속적으로 처리되는 대신 예약 또는 정기적으로 대량으로 처리되는 시나리오에 최적화됩니다. 다음 패턴이 가장 적합합니다.
- 기존 엔터프라이즈 레코드를 사용하여 플랫폼을 초기화하기 위한 내역 데이터 로드
- ERP, 데이터 웨어하우스 또는 독점 데이터베이스와 같은 레코드 시스템과 정기적으로 동기화
- 실시간 신선도가 중요하지 않지만 일관성, 완전성 및 감사 가능성이 중요하지 않은 사례 사용 배치 수집은 예측 가능한 성능과 운영 단순성을 제공하므로 구조화된 데이터 또는 세미 구조화된 데이터의 테라바이트를 관리하는 엔터프라이즈에서 신뢰할 수 있는 선택 항목입니다. Data 360은 기본적으로 배치 수집을 지원하는 생산 준비가 된 일반적으로 사용 가능한 **연결기**를 제공합니다. 이러한 커넥터는 통합 설정을 간소화하고, 사용자 정의 ETL 개발을 줄이고, 모든 가져오기에 걸쳐 데이터 품질과 보안을 보장합니다. 아래의 표는 엔터프라이즈 규모의 배치 수집에 사용되는 가장 일반적인 커넥터를 강조 표시합니다.
컨텍스트
이 패턴은 CSV 또는 Parquet 파일과 같은 대량의 구조화된 데이터와 중앙 집중식 데이터 레이크 또는 예약된 파일 삭제에서 구조화되지 않은 자산을 수집하는 것과 관련된 엔터프라이즈 시나리오를 위해 고안되었습니다. 일반적으로 데이터 소스에는 Amazon S3, Google Cloud Storage(GCS), Microsoft Azure Blob Storage와 같은 클라우드 저장소 플랫폼이 포함되며, 여기서 파일은 업스트림 데이터 파이프라인 또는 배치 내보내기의 일부로 주기적으로 전달됩니다.
문제
조직은 대규모 파일 기반 데이터 집합을 기본 클라우드 저장소 플랫폼에서 예측 가능한 반복 일정에 따라 Data 360으로 수집하는 신뢰할 수 있고 안전하며 고처리량 프로세스를 구축할 수 있는 방법은 무엇입니까?
Force
대규모 파일 기반 데이터 집합을 Data 360에 수집하는 것은 간단한 데이터 전송 작업이 아니라 규모, 거버넌스, 플랫폼 제약으로 인한 아키텍처 문제입니다.
데이터 용량 및 규모 : Data 360 수집 커넥터는 임의의 대량 처리량이 아닌 신뢰성 및 거버넌스를 위해 최적화되어 있습니다. 예를 들어, Amazon S3 커넥터는 최대 1억 개의 행 또는 개체당 50GB를 지원합니다. 제한에 가장 먼저 도달하는 경우 과거 데이터 집합이 수십억 개의 레코드로 실행되는 엔터프라이즈의 경우 이 경계는 주요 설계 제약이 됩니다. 단일 파일의 리프트 앤 시프트 접근 방식은 빠르게 실행되지 않으므로 커넥터 제한에 도달하지 않고 확장하려면 지능형 데이터 분할, 청크, 오케스트레이션 전략이 필요합니다.
스키마 정의 및 유지 보수 : Data 360은 시맨틱 및 구조적 무결성을 보장하기 위해 모든 수집 파이프라인에 대해 명시적인 스키마 정의를 요구합니다. S3 수집의 경우 csv 파일은 열 머리글과 단일 대표 데이터 행을 정의해야 합니다. 이 파일은 소스 시스템(예: 클라우드 저장소 및 Data 360) 간의 정규 계약 역할을 합니다. 필드 이름, 데이터 유형 또는 인코딩과 같은 정렬 오류로 인해 수집 실패 또는 자동 데이터 손상이 발생할 수 있습니다. 이 스키마 파일을 버전 관리에서 유지하고 CI/CD 또는 데이터 거버넌스 워크플로를 통해 유효성 검사를 적용하면 프로덕션 환경에 가장 좋은 방법이 됩니다.
부드러운 명명 규칙 : Data 360은 메타데이터 그래프 전체에서 일관성을 유지하기 위해 격리된 개체 및 필드 명명 규칙을 적용합니다.
- 개체 이름은 문자로 시작해야 하며 문자, 숫자 또는 밑줄만 포함할 수 있습니다.
- 필드 이름은 같은 패턴을 따라야 합니다. 이러한 규칙을 위반하는 파일(예: 공백, 특수 문자 또는 지원되지 않는 기호가 포함된 필드)은 수집하는 동안 스키마 유효성 검사에 실패합니다. 기업은 들어오는 파일 구조를 비활성화하고 정규화하기 위해 처리 데이터 위생 프로세스를 구현해야 합니다.
인증 및 보안 조치: 외부 저장소에 대한 각 연결은 엔터프라이즈급 보안 및 규정 준수 표준을 준수해야 합니다.
- 인증은 일반적으로 AWS 액세스/암호 키 또는 연합 ID 공급자(IdP) 인증을 통해 처리됩니다.
- 지정된 저장소 경로에 대한 읽기 액세스만 허용하도록 최소 권한을 적용하려면 IAM 역할의 범위가 지정되어야 합니다.
- 보안 액세스를 위해 아웃바운드 IP 주소를 소스 시스템의 허용 목록에 직접 추가해야 합니다. 이러한 계층형 컨트롤은 모든 파일 전송이 제로 Trust, 감사 가능 경계 내에서 작동하도록 보장하며, 대규모 수집에 필요한 유연성과 엔터프라이즈 규정 준수의 균형을 맞춥니다.
솔루션
이 표에는 이 통합 문제에 대한 솔루션이 포함되어 있습니다.
| 솔루션 | 맞춤 | 댓글 |
|---|---|---|
| 기본 클라우드 저장소 커넥터 사용(Amazon S3, Google Cloud Storage, Azure Blob Storage) | 최대 | Data 360\에 대규모 반복 파일 기반 수집을 위한 가장 신뢰할 수 있는 권장 패턴입니다. 기본 커넥터는 Data 360의 데이터 레이크 개체(DLO)로 직접 관리 인증, 스키마 매핑, 안전한 데이터 이동을 제공합니다. 대기 시간이 중요하지 않은 예약된 배치 로드에 적합합니다(예: 시간별 또는 매일 예약). |
| 대규모 데이터 집합 처리(커넥터 제한 초과) | 사전 처리를 사용하는 최고 | 각 커넥터는 수집 제한을 적용합니다(예: S3: 100M 행 또는 개체당 50GB). 더 큰 데이터 집합의 경우 ETL 사전 처리 단계를 구현하여 해당 임계값 아래에 속하는 더 작은 파일/폴더로 데이터를 분할합니다. 그런 다음, 여러 데이터 스트림을 구성하여 각 파티션을 병렬로 수집하고 Data 360 내의 배치 데이터 변환에서 추가 노드를 사용하여 파티션을 통합 데이터 집합으로 다시 결합합니다. |
| 보안 및 거버넌스 | 최대 | 모든 커넥터는 클라우드 네이티브 메서드(IAM 역할, 서비스 계정 또는 액세스 키)를 통한 보안 인증을 지원합니다. 추가 제어를 위해 클라우드 공급자의 허용 목록을 통해 Data 360 IP 범위에 대한 액세스를 제한합니다. 데이터는 암호화된 채널을 통해 전송되며, 수집하는 동안 파일이 임시로 보안된 스테이징 계층에 저장됩니다. |
| 사용하지 않을 경우 | 최적화되지 않음 | 이 패턴은 다음에 적합하지 않습니다.
|
스케치
이 다이어그램은 클라우드 저장소에서 Data 360으로 데이터를 수집하는 단계 순서를 보여줍니다.
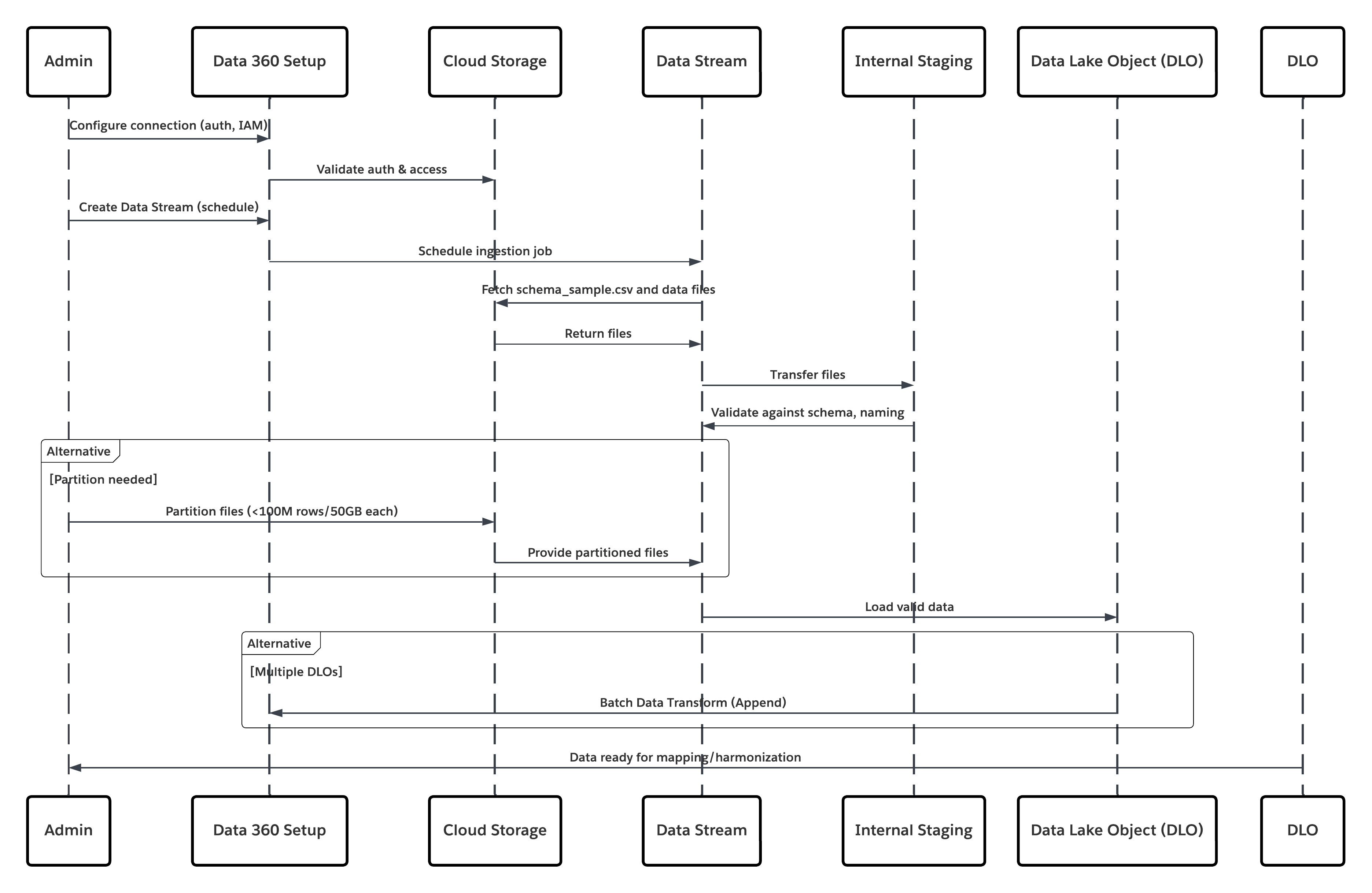
이 시나리오의 경우:
- 관리자는 Data 360 설정 인터페이스(인증, 버킷 세부 사항, IAM 역할, 화이트리스트 지정)를 통해 클라우드 저장소에 대한 연결을 구성합니다.
- Data Cloud 설정 인터페이스는 클라우드 저장소 플랫폼을 사용하여 인증하여 자격 증명 및 액세스를 확인합니다.
- 관리자가 Data 360에서 데이터 스트림을 만들고 데이터 스트림을 클라우드 저장소의 개체/폴더에 연결하고 수집 일정을 정의합니다.
- 일정 트리거에서 데이터 스트림은 클라우드 저장소 플랫폼에서 소스 파일(예: CSV, Parquet)을 요청합니다.
- Cloud Storage Platform은 필수 유효한 schema_sample.csv 및 명명 규칙을 준수하는 기타 데이터 파일을 비롯한 파일을 전달합니다.
- 데이터 스트림은 Data 360 내 내부 내부 스테이징 환경에 파일을 전송합니다.
- Data 360 파이프라인은 파일을 처리합니다. schema_sample.csv의 스키마 정의를 사용하여 구조, 필드 이름을 확인하고 수집 임계값(파일당 100만 개의 행/50GB)을 초과하는 경우 로드를 나누며, 대용량 파일이 감지된 경우 사전 처리 파티션 분할 단계(다음 실행 시 관리자에게 알림)가 외부에서 수행됩니다.
- 레코드는 스테이징에서 데이터 레이크 개체(DLO)로 가져옵니다.
- 필요한 경우 데이터가 분할된 경우 배치 데이터 변환 추가 노드를 사용하여 여러 DLO를 결합합니다.
- Data 360은 성공/실패를 기록하고 모니터링을 위해 상태를 업데이트하며 데이터를 매핑, 조합 및 통합할 준비가 되었음을 나타냅니다.
결과
이 패턴을 적용하면 엔터프라이즈 클라우드 저장소 플랫폼에서 Data 360으로 구조화되거나 구조화되지 않은 파일을 안전하게, 예약적으로, 대규모로 수집할 수 있습니다. 이 프로세스는 자동화되고 확장 가능하며 복원성이 뛰어납니다. 즉, 원시 데이터를 데이터 레이크 객체(DLO)로 전달하여 Customer 360 데이터 모델의 조합 및 매핑을 위한 기초가 됩니다.
수집 메커니즘
수집 메커니즘은 Data 360 내에 정의된 커넥터 및 예약 전략에 따라 다릅니다.
| 수집 메커니즘 | 설명 |
|---|---|
| 기본 클라우드 저장소 커넥터(Amazon S3, GCS, Azure) | 엔터프라이즈의 클라우드 데이터 레이크에서 CSV 또는 Parquet 형식의 파일을 직접 수집하는 것이 좋습니다. 이러한 커넥터는 증분 및 전체 새로 고침 일정을 지원합니다. 예를 들어, 은행은 S3 버킷에서 DLO로의 고객 트랜잭션 파일의 일일 동기화를 구성할 수 있습니다. |
| 분할된 파일 전략 | 매우 큰 데이터 집합(개체당 1억 개 이상의 행 또는 50GB 이상)의 경우 데이터가 더 작은 논리 집합(예: 월 또는 지역별)으로 분할됩니다. 각 파티션은 별도의 데이터 스트림으로 관리되고 나중에 추가 노드와 배치 데이터 변환 사용하여 다시 결합됩니다. |
| 자동화된 예약 동기화 | Data 360은 수집 작업을 자동으로 트리거하는 선언적 스케줄러(시간별, 일별 또는 사용자 정의 케이던스)를 제공하여 수동 중재 없이 데이터를 새로 고칩니다. |
오류 처리 및 복구
오류 처리 및 복구는 대용량 수집 작업의 신뢰성을 보장하는 데 매우 중요합니다.
- 오류 감지: 각 데이터 스트림 실행은 Data 360 모니터링에서 수집 오류(예: 스키마 불일치, 파일 손상 또는 명명 위반)를 기록합니다. 관리자는 실패한 배치를 검토하고 다시 처리할 수 있습니다.
- 복구 메커니즘: Data 360은 실패한 배치가 이전 수집을 손상하지 않도록 점검을 유지합니다. 소스 문제를 수정한 후에 재시도를 구성할 수 있습니다(예: 잘못된 CSV).
- 스키마 검증: schema_sample.csv 파일은 데이터 유형 및 구조를 정의합니다. 변경 사항은 실행 전반에서 자동 스키마 드리프트를 방지하기 위해 유효성 검사를 트리거합니다.
동임 설계 고려 사항
수집은 설계에 따라 동일합니다. 동일한 파일을 다시 처리해도 레코드가 중복되지 않습니다. 주요 전략은 다음과 같습니다.
- 파일 지문: Data 360은 체크 합계를 계산하여 이전에 처리된 파일을 식별하고 건너뛰습니다.
- 트랜잭션 수집: 데이터는 단계적이며 모든 레코드가 성공적으로 처리되면 DLO에만 적용됩니다.
- 추가 vs. 대체: 비즈니스 논리에 따라 스트림이 대상 DLO에 추가되거나 완전히 대체될 수 있으므로 결정적 결과를 얻고 일부 데이터 겹침을 방지할 수 있습니다.
보안 고려 사항
보안은 인증에서부터 암호화 및 액세스 제어에 이르기까지 수집 파이프라인 전반에 걸쳐 통합됩니다.
- 인증 및 인증: 커넥터는 Salesforce의 보안 통합 프레임워크를 사용하여 암호를 노출하지 않고 인증에 명명된 자격 증명 및 외부 자격 증명을 활용합니다.
- 암호화: 데이터는 전송 시(TLS 1.2+) 및 유지 시(AES-256) 암호화됩니다.
- 네트워크 제어: 소스 저장소 시스템(예: S3 버킷)은 Data 360 IP를 허용 목록으로 지정해야 합니다.
- 규정 준수: 고객 관리 키(CMK)와 페어링된 경우 GDPR, HIPAA, FFIEC 지침과 같은 엔터프라이즈 데이터 보호 프레임워크를 지원합니다.
- ** 감사 가능:** 모든 수집 작업 및 자격 증명 액세스는 추적 가능성 및 규정 준수 보고를 위해 기록됩니다.
링크 모음
시기
시기는 수집 일정 및 데이터 용량에 따라 다릅니다.
- 대규모 엔터프라이즈 데이터 집합(행 100만 개 이상)의 경우 병렬 수집을 위해 파티션이 필요할 수 있습니다.
- 일반적인 수집 지연 시간은 파일 크기 및 변환 복잡성에 따라 분에서 몇 시간 사이입니다.
- 거의 실시간 수집을 위해 Data 360 스트리밍 또는 API 기반 커넥터가 파일 기반 모델을 보완할 수 있습니다.
데이터 용량
- 대용량 정기 배치 수집에 가장 적합합니다.
- S3 커넥터를 통해 처리되는 각 개체는 최대 1억 개의 행 또는 파일당 50GB를 지원합니다.
- 페타바이트 규모의 시스템의 경우 데이터 분할 및 다중 스트림 오케스트레이션을 사용합니다.
끝점 기능 및 표준 지원
끝점에 대한 기능 및 표준 지원은 선택한 솔루션에 따라 다릅니다.
| 커넥터 유형 | 끝점 요구 사항 |
|---|---|
| Amazon S3 커넥터 | 적절한 IAM 정책과 스키마를 정의하는 schema\_sample.csv 파일이 있는 S3 버킷 |
| Google Cloud 스토리지 커넥터 | 일관된 명명 규칙을 사용하여 서비스 계정 자격 증명 및 버킷 액세스 |
| Azure Storage 커넥터 | 키 또는 SAS 토큰 기반 인증에 액세스합니다. Blob 또는 폴더 구조는 Data 360 규칙을 따라야 합니다. |
시/도 관리
상태는 데이터 스트림 및 마지막으로 성공적으로 실행된 타임스탬프를 통해 추적됩니다.
- Data 360은 동기화 상태 및 오프셋을 자동으로 유지하므로 후속 실행 시 신규 또는 수정된 파일만 처리됩니다.
- 외부 ETL 도구와 통합할 경우 중복을 방지하기 위해 고유한 파일 식별자(예: UUID 또는 타임스탬프)를 사용하는 것이 좋습니다.
복잡한 통합 시나리오
고급 엔터프라이즈 아키텍처에서 이 패턴은 다음과 통합할 수 있습니다.
- Middleware ETL 파이프라인(예: Informatica, MuleSoft): Data 360으로 전달하기 전에 사전 처리, 검증 및 파일 분할을 오케스트레이션합니다.
- AI/ML 워크플로: 처리된 DLO 데이터는 DMO를 통해 교육 환경을 모델링하거나 Data 360 활성화 타겟을 통해 RAG 인덱스를 게시할 수 있습니다.
- 트랜잭션 시스템: 조화된 DMO는 데이터 작업 또는 플랫폼 이벤트를 통해 Salesforce CRM 또는 외부 시스템에서 다운스트림 업데이트를 트리거할 수 있습니다.
예제
글로벌 금융 기관은 고객 및 트랜잭션 데이터를 AWS S3 데이터 레이크에 저장하며, 여기서 분할된 Parquet 파일은 지역별로(예: 미국, EU, APAC) 매일 밤 생성됩니다. 데이터 아키텍처 팀은 공유 schema_sample.csv를 사용하여 각각 지역 폴더에 연결된 Data 360의 여러 데이터 스트림을 구성하여 모든 파티션에서 일관된 머리글과 데이터 유형을 보장합니다. 야간 수집 일정이 데이터를 DLO에 자동으로 로드한 후 배치 데이터 변환이 모든 지역 파티션을 통합 Customer_Transactions_DLO에 추가합니다. 이 조화된 데이터 집합은 Customer 360 데이터 모델에 매핑되어 다운스트림 분석 및 AI 활성화를 지원합니다. 이 접근 방식은 기존 데이터 레이크에서 자동화되고 신뢰할 수 있는 수집을 제공하고, 엔터프라이즈 IT 정책에 따라 강력한 인증 및 암호화를 적용하며, 향후 확장 및 스키마 발전을 지원하는 확장 가능한 모듈식 기반을 제공합니다.
컨텍스트
Data 360의 기본 및 중요한 사용 사례는 Salesforce 에코시스템 전반에서 고객 데이터를 통합하는 것입니다. 이 패턴은 핵심 Salesforce Platform(Sales Cloud 및 Service Cloud(전체적으로 Salesforce CRM) 및 Marketing Cloud Engagement)에서 기본적으로 데이터를 수집하는 작업을 다룹니다. 소스에는 표준 및 사용자 정의 CRM 개체(예: 계정, 연락처, 사례, 기회)와 참여 이벤트, 이메일 전송, 추적 데이터를 보관하는 Marketing Cloud 참여 데이터 확장이 포함됩니다.
문제
조직은 어떻게 표준 및 사용자 지정 CRM 개체와 Marketing Cloud Engagement 데이터 확장을 Data 360에 효율적이고 신뢰할 수 있게 수집하여 데이터를 통합 고객 프로필(ID 확인, Customer 360)을 구축하는 데 사용할 수 있으며 성능, 규제를 유지하고 소스 시스템의 중단을 최소화할 수 있습니까?
Force
네이티브 커넥터는 작업을 간소화하지만 몇 가지 운영 및 아키텍처 요소를 관리해야 합니다.
- 전체 소스 권한: 전용 연결 사용자(통합 계정)에게 적절한 개체 및 필드 수준 읽기 권한이 있어야 합니다. 필수 권한 집합 할당 실패(예: 사전 구축된 Data 360 커넥터 권한 집합)는 수집 실패의 일반적인 원인입니다.
- 데이터 새로 고침 모드 및 비용: 커넥터는 전체 및 델타/증분 새로 고침 모드를 지원합니다. 전체 새로 고침은 성능 및 크레딧에 더 무겁습니다. 델타 추출은 부하를 줄이지만 소스 시스템에서 신뢰할 수 있는 변경 추적에 의존합니다.
- 사용자 정의 스키마 및 필드 매핑: CRM 인스턴스에는 사용자 정의 개체/필드가 포함되는 경우가 많습니다. 매핑 오류 또는 시맨틱 드리프트를 방지하기 위해 사용자 정의 필드(이름, 유형)에 대한 정확한 스키마 매핑 및 처리가 필요합니다.
- Starter 데이터 번들 vs. 사용자 지정 매핑: 스타터 데이터 번들은 일반적인 개체/필드를 미리 선택하여 온보딩을 가속화하지만 사용자 정의가 많은 조직은 맞춤형 스트림 정의가 필요합니다.
- 지출량 및 API 제한: 소스 조직 API 제한 및 Marketing Cloud 추출 비율은 새로 고침을 얼마나 적극적으로 예약할 수 있는지 제한합니다.
- 데이터 위생 및 명명 규칙: 다운스트림 매핑 문제를 방지하기 위해 수집하기 전에 소스 필드 이름, null 동작 및 데이터 유형을 정규화해야 합니다.
- 보안 및 최소 권한: 커넥터는 보안 인증에 의존하며 최소 권한 IAM 패턴, 감사 가능성, 네트워크 제어를 준수해야 합니다.
솔루션
이 표에는 이 통합 문제에 대한 솔루션이 포함되어 있습니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 솔루션 맞춤 | 최대 | Data 360\에서 기본 Salesforce CRM 커넥터 및 Marketing Cloud 참여 커넥터를 사용합니다. 표준 사용 사례의 경우 스타터 데이터 번들로 시작하고 온보딩을 가속화합니다. 사용자 정의 또는 도메인별 데이터 모델에 수동 스트림 사용자 정의를 사용합니다. |
| 고도로 사용자 정의된 CRM 인스턴스 처리 | 매핑 워크숍의 최고 기능 | 스타터 번들을 기준으로 처리하고 매핑 워크숍을 실시하여 다음을 식별합니다. 사용자 정의 개체 및 관계. 수식 또는 계산된 필드입니다. 관리 패키지 확장. 대용량 수식 필드의 경우 사전 스테이지 ETL 또는 Data 360 변환 내에서 값을 계산하여 소스 조직에 대한 API 로드를 최소화합니다. |
| 사용하지 않을 경우 | 최적화되지 않은 시나리오 | 다음과 같은 경우 이 패턴을 피하십시오. 대신 스트리밍 커넥터, 플랫폼 이벤트 또는 제로 카피 연합을 사용하여 빈도가 높은 이벤트 또는 실시간 이벤트 수집이 필요합니다. 소스 조직에 API 용량이 제한되어 있으며 조절 또는 대기열 지연 없이 예약된 추출을 유지할 수 없습니다. |
| 보안 및 거버넌스 | 필수 제어 | 최소 권한 원칙 - 최소 읽기 액세스 권한이 있는 전용 통합 사용자를 사용합니다. 조직 전체 관리자를 사용하지 마십시오. 인증 — OAuth 2.0 및 연결된 앱을 사용하고 클라이언트 암호를 정기적으로 순환하고 새로 고침 토큰 사용을 모니터링합니다. 감사 및 추적 가능성 — 모든 수집 실행, 스키마 변경 및 커넥터 이벤트 기록 감사 준비를 위해 SIEM 또는 규정 준수 시스템에 로그를 전달합니다. 데이터 분류 — 수집 후 즉시 CEDAR 정책을 사용하여 PII/PHI 태그 지정 및 특성 기반 액세스 제어(ABAC)를 적용하여 마스킹, 동의, 다운스트림 규정 준수를 적용합니다. |
스케치
이 다이어그램은 클라우드 저장소에서 Data 360으로 데이터를 수집하는 단계 순서를 보여줍니다.
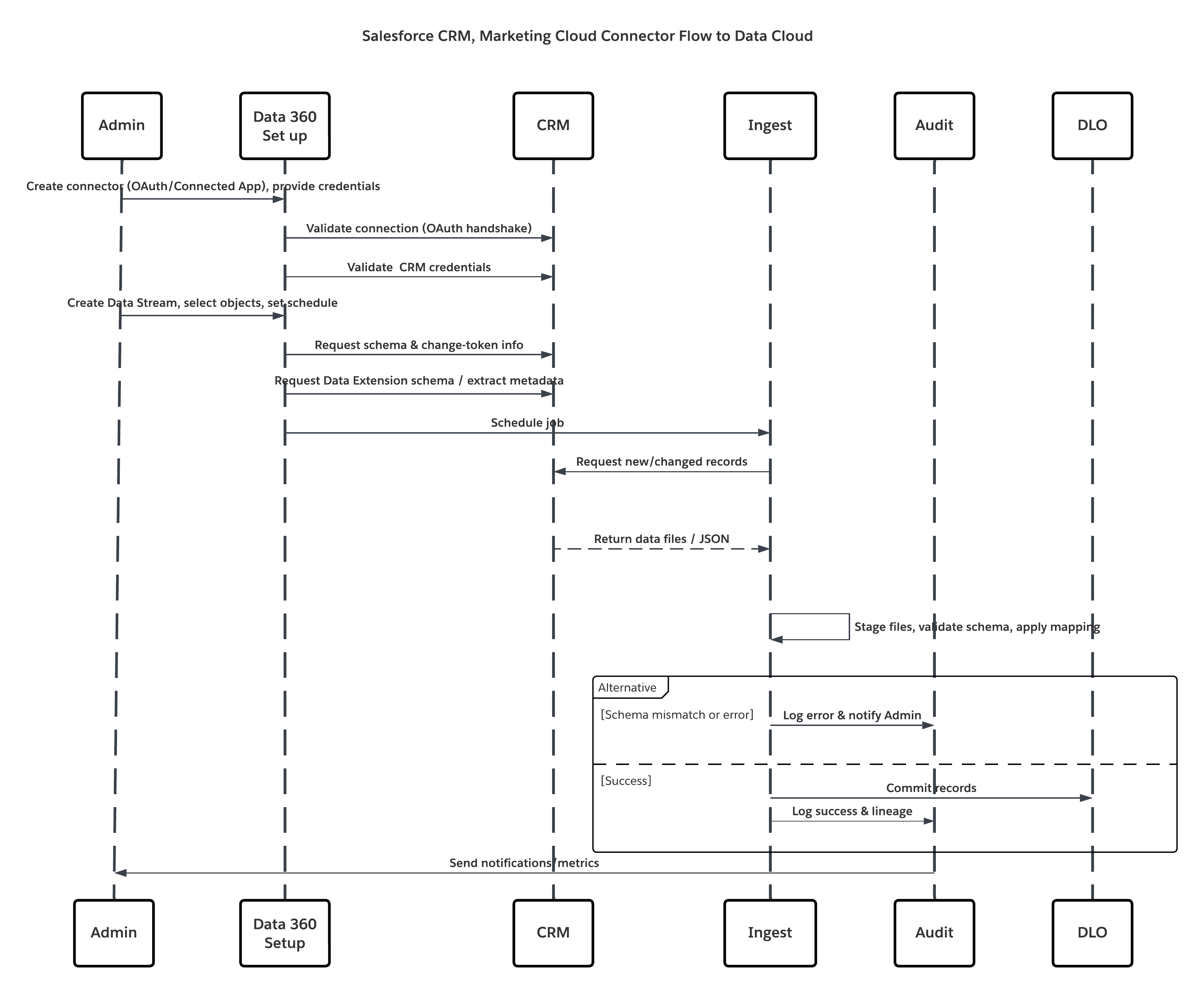
이 시나리오의 경우:
- 관리자가 소스 조직에서 통합 사용자를 프로비저닝하고 커넥터 권한 집합을 할당합니다.
- 관리자는 Data 360 설정에서 커넥터를 구성합니다(OAuth/연결된 앱을 통해 Salesforce CRM 및 Marketing Cloud에 연결).
- 관리자는 개체 및 데이터 확장을 선택하는 데이터 스트림을 만들고 전체 또는 델타 새로 고침을 선택하고 일정을 설정합니다.
- 예약 실행 시 Data 360은 소스에서 스키마 및 델타 토큰을 요청합니다.
- 소스 시스템은 레코드를 반환합니다(델타 또는 전체 페이로드). Marketing Cloud에서 추출을 제공하고 CRM에서 JSON/쿼리 결과를 반환할 수 있습니다.
- Data 360은 내부 보안 스테이징 영역에서 파일을 스테이징하고 매핑된 스키마에 대해 검증합니다.
- 확인에 실패하면 수집 로그에서 오류를 기록하고 관리자에게 경고를 보내고 커밋을 중지합니다. 확인에 성공하면 Data 360이 대상 DLO에 레코드를 원자식으로 커밋합니다.
- 모니터링 및 감사 로그는 계보, 실행 기간, 행 수 및 자격 증명 사용량에 따라 업데이트됩니다. 임계값 또는 오류가 트리거되면 관리자에게 경고가 발송됩니다.
결과
핵심 고객 관계 및 마케팅 참여 데이터는 Data 360에 DLO(데이터 레이크 개체)로 수집됩니다. 결과:
- 프로필, 사례, 기회, 이메일/참여 메트릭을 포함하는 통합 데이터 집합
- ID 확인 기초 및 통합 개인 프로필 구축
- 관리 및 감사 가능성을 유지하면서 다운스트림 조합, 보강, AI 모델링 및 활성화에 대한 운영 준비 상태
수집 메커니즘
수집 메커니즘은 Data 360 내에 정의된 커넥터 및 예약 전략에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Salesforce CRM 커넥터(네이티브) | 표준/사용자 정의 CRM 개체에 가장 적합하며, 전체 및 델타 새로 고침을 지원합니다. |
| Marketing Cloud 참여 커넥터(네이티브) | 데이터 확장, 보내기, 추적 추출에 가장 적합하며, 전체/델타 모드를 지원합니다. |
| 스타터 데이터 번들 | 일반적인 세일즈/서비스/마케팅 개체에 대한 온보딩을 가속화합니다. |
| 사용자 정의 스트림 + 사전 처리 | 복잡한 변환 또는 심각한 스키마 정규화가 필요한 경우 사용합니다. |
오류 처리 및 복구
오류 처리 및 복구는 대용량 수집 작업의 신뢰성을 보장하는 데 매우 중요합니다.
- 실행별 로그: 각 데이터 스트림 실행은 성공/실패 세부 사항 및 행 수준 오류를 제공합니다.
- 재시도 및 검사: 실패한 실행은 소스 또는 스키마 문제를 수정한 후 다시 시도할 수 있습니다. Data 360은 스테이징 및 원자 커밋 시맨틱스를 사용합니다.
- 경고: 스키마 드리프트, 반복 실패 또는 델타 시퀀스 간격에 대한 경고를 구성합니다.
동임 설계 고려 사항
수집은 설계에 따라 동일합니다. 다시 처리해도 레코드가 중복되지 않습니다. 주요 전략은 다음과 같습니다.
- 변경 감지: 델타 추출은 소스 시스템 변경 지표(LastModifiedDate / 시스템 변경 데이터 수집)에 의존합니다. 소스가 신뢰할 수 있는 타임스탬프/플래그를 제공하는지 확인합니다.
- 중복 제거: 고유한 비즈니스 키(예: Contact.ExternalId)를 사용하여 DLO로 중복 제거하거나 업서트합니다.
- 트랜잭션 커밋: 레코드는 단계적이며 배치 처리가 성공적으로 완료된 경우에만 커밋됩니다.
보안 고려 사항
보안은 인증에서부터 암호화 및 액세스 제어에 이르기까지 수집 파이프라인 전반에 걸쳐 통합됩니다.
- 인증 및 인증: 커넥터는 Salesforce의 보안 통합 프레임워크를 사용하여 암호를 노출하지 않고 인증에 명명된 자격 증명 및 외부 자격 증명을 활용합니다.
- 암호화: 데이터는 전송 시(TLS 1.2+) 및 유지 시(AES-256) 암호화됩니다.
- 네트워크 제어: 소스 저장소 시스템(예: S3 버킷)은 Data 360 IP를 허용 목록으로 지정해야 합니다.
- 규정 준수: 고객 관리 키(CMK)와 페어링된 경우 GDPR, HIPAA, FFIEC 지침과 같은 엔터프라이즈 데이터 보호 프레임워크를 지원합니다.
- ** 감사 가능:** 모든 수집 작업 및 자격 증명 액세스는 추적 및 규정 준수 보고를 위해 기록됩니다.
링크 모음
시기
시기는 수집 일정 및 데이터 용량에 따라 다릅니다.
- ** 이상적인 케이던스는** 비즈니스 요구에 따라 달라집니다. 거의 실시간 마케팅 트리거를 위해 매시간, 대규모 조정을 위해 매일 밤.
- 델타 모드은 부하와 비용을 절감합니다. 전체 업데이트는 더 무겁고 초기 부하 또는 주요 스키마 변경에 사용됩니다.
데이터 용량
- CRM 커넥터는 트랜잭션 및 중간 볼륨 데이터 집합(레코드 수백만 개)에 최적화되어 있습니다.
- 매우 큰 내역 볼륨의 경우 단계화된 ETL을 단계별로 분할하고 로드합니다.
끝점 기능 및 표준 지원
끝점에 대한 기능 및 표준 지원은 선택한 솔루션에 따라 다릅니다.
| 커넥터 | 끝점 요구 사항 |
|---|---|
| Salesforce CRM 커넥터 | 소스 조직은 연결된 앱, OAuth 토큰 및 읽기 권한이 있는 전용 통합 사용자를 허용해야 합니다. |
| Marketing Cloud 커넥터 | Marketing Cloud API 자격 증명 또는 설치된 패키지. 데이터 확장은 추출/API를 통해 데이터를 노출해야 합니다. |
시/도 관리
- 연결기 상태: 데이터 스트림은 마지막으로 성공한 동기화 타임스탬프 및 델타 오프셋을 유지합니다.
- 마스터 키 전략: 다운스트림 조정 및 업서트가 결정적으로 결정되도록 일관된 비즈니스 식별자(외부 ID)를 선호합니다.
복잡한 통합 시나리오
고급 엔터프라이즈 아키텍처에서 이 패턴은 다음과 통합할 수 있습니다.
- 하이브리드 토폴로지: CRM 수집과 스트리밍(플랫폼 이벤트)을 결합하여 거의 실시간으로 업데이트합니다.
- 중간웨어 오케스트레이션: 복잡한 오케스트레이션, 보강 또는 변환 사전 수집이 필요한 경우 MuleSoft 또는 ETL 도구를 사용합니다.
- 활성화 피드백 루프: 조화된 DMO는 데이터 작업 또는 플랫폼 API를 통해 소스 시스템에 대한 다운스트림 업데이트를 트리거할 수 있습니다(SoD 제어에 주의).
예제
다국적 소매업체는 계정, 연락처, 사례, 기회, Marketing Cloud 참여 메트릭을 Data 360에 통합하여 통합 고객 보기를 만듭니다. 스타터 데이터 번들은 핵심 세일즈 및 서비스 개체를 초기화하고, 팀은 Loyalty_Membershipc 및 Customer_Tierc와 같은 사용자 정의 필드를 사용하여 모델을 확장하여 충성도 컨텍스트를 수집합니다. CRM 데이터 스트림은 델타 모드에서 매시간 실행되며, Marketing Cloud Engagement는 참여 이벤트에 대한 델타 추출을 사용하여 매일 동기화합니다. 해당 데이터 집합은 DLO 및 ID 확인을 통해 처리되므로 CRM 및 참여 신호를 결합하여 개인 설정 및 다운스트림 AI 모델을 강화하는 통합 고객 프로필이 생성됩니다.
해당 패턴은 고객 상호 작용, 트랜잭션 또는 신호가 즉각적인 인사이트 또는 조치를 트리거해야 하는 밀리초가 중요한 시나리오에 대해 작성되었습니다. 이는 기존의 예약된 배치 수집 이상으로 이벤트 중심 데이터 플로를 활성화하며, 정보가 생성되는 순간에 처리됩니다. Salesforce Data 360 에코시스템에서 "실시간"은 단일 모드가 아니라 연속 대기 시간 모델입니다. 한쪽 끝에는 레코드 시스템의 업데이트(예: CRM 또는 ERP)가 몇 초 또는 몇 분 이내에 Data 360에 반영되는 거의 실시간 동기화가 있습니다. 다른 쪽 끝에는 클릭, 구매 또는 모바일 상호 작용과 같은 클라이언트측 동작 신호가 밀리초 단위로 수집되고 활성화되는 실제 실시간 이벤트 캡처가 있습니다. 설계자의 경우 구분은 의미론 이상입니다. 파이프라인이 설계되는 방법, API가 호출되는 방법, 다운스트림 결정을 내리는 방법을 정의합니다. 거의 실시간 동기화 또는 이벤트 스트리밍 수집과 같은 올바른 패턴을 선택하면 시스템이 데이터 무결성, 확장성, 거버넌스를 유지하면서 비즈니스의 운영 지연 시간 목표를 충족합니다.
컨텍스트
이 패턴을 사용하면 사용자 정의 응용 프로그램, 사물 인터넷(IoT) 플랫폼, POS(Point-of-Sale) 시스템 또는 타사 서비스와 같은 모든 외부 시스템이 프로그래밍 방식으로 개별 이벤트가 발생하면 이벤트 데이터를 Data 360에 거의 실시간으로 푸시할 수 있습니다.
문제
개발자가 대기 시간이 낮은 상태에서 외부 응용 프로그램에서 단일 레코드 또는 작은 비동기 이벤트 배치를 Data 360으로 신뢰할 수 있는 방법으로 데이터를 처리, 세분화, 활성화에 빠르게 사용할 수 있습니까?
Force
이 패턴은 대기 시간이 낮고 개발자 제어가 향상되지만 몇 가지 기술적 제약과 운영 종속성이 적용됩니다.
- 개발자 의존성: 인증된 REST API 클라이언트 및 오류/재시도 논리를 구현하려면 개발자가 노력해야 합니다. 포인트 앤 클릭 커넥터가 아닙니다.
- 정밀 스키마-쓰기: 수집 API는 schema-on-write를 적용합니다. 정확한 스키마를 정의하고 커넥터 구성에 업로드해야 합니다. 모든 페이로드는 정확하게 준수하거나 거부되어야 합니다.
- 이중 상호 작용 모드: 동일한 커넥터는 저 대기 시간, 레코드별 업데이트 및 대규모 정기 동기화에 대한 대량(CSV) 스트리밍(JSON)을 모두 지원합니다. 따라서 설계자는 사용 사례별로 선택해야 합니다.
- 인증 및 보안: OAuth 2.0을 사용하여 Salesforce 연결된 앱을 통해 통화를 인증해야 합니다(예: 서버 간 JWT 전달자 플로). 토큰 관리, 순환 및 최소 권한 범위는 필수 항목입니다.
- 작업 가시성: 개발자 및 플랫폼 팀은 응답 코드, 재시도, 대기열, 스키마 드리프트 경고에 대한 모니터링을 구현해야 합니다.
- 실시간 그래프 요구 사항: 실제 인스턴스 활성화(인스턴트 세분화, 실시간 DMO 매핑)의 경우 대상 데이터 모델 개체(DMO)가 실시간 데이터 그래프의 일부여야 합니다. 그렇지 않으면 이벤트가 약간 더 긴 대기 시간 파이프라인을 거칩니다.
솔루션
이 표에는 이 통합 문제에 대한 솔루션이 포함되어 있습니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 솔루션 맞춤형 | 저지연 이벤트 캡처를 위해 최적 | Data 360 수집 API(스트리밍 JSON)를 사용하여 단일 이벤트 또는 마이크로 배치를 푸시합니다. 엄격한 OAS 3.0 스키마(.yaml)를 사용하여 수집 API 커넥터를 구성합니다. 대량 CSV 수집을 사용하여 더 큰 동기화 빈도를 줄입니다. |
| 스키마 변경 사항 처리 | 엄격 / 관리형 | 스키마가 크게 변경되었습니다. OAS .yaml 업데이트, 커넥터 버전 업데이트, 계약 테스트 수행 프로듀서가 동시에 변경할 수 없는 경우 롤링 스키마 마이그레이션을 구현합니다. |
| 사용하지 않을 때 | 비최적 | 사전 처리가 필요한 경우(예: 중복 제거, 보증 주문 등) 또는 매우 큰 대량 로드(네이티브 대량 커넥터 또는 배치 ETL 사용)에 적합하지 않습니다. 소스가 스키마 유효한 페이로드를 생성할 수 없거나 안전하게 인증할 수 없는 경우 대체 수집 방법을 사용합니다. |
| 보안 및 거버넌스 | 필수 | 최소 권한 범위의 OAuth 2.0 사용, 키 회전, 토큰 사용 로그 TLS 1.2+를 적용하고 필요한 경우 클라이언트 IP를 확인하고 페이로드 PII 태그 지정을 보장합니다. 모든 이벤트에 출처 메타데이터(소스, 타임스탬프, 스키마 버전, 균일성 키)가 포함되어야 합니다. |
스케치
이 다이어그램은 수집 API에서 Data 360으로 데이터를 수집하는 단계 순서를 보여줍니다.
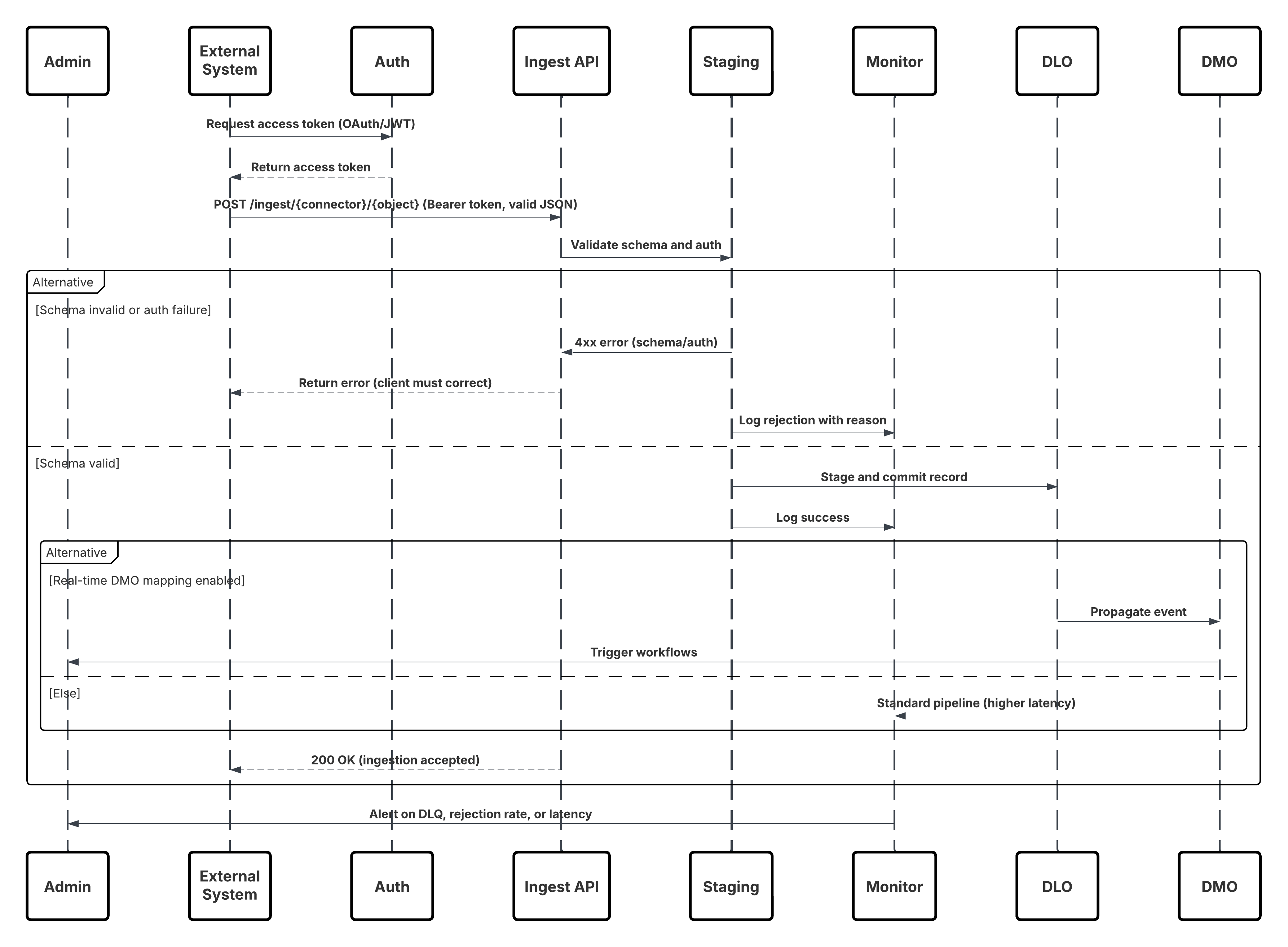
이 경우:
- 외부 시스템은 인증 서버에서 OAuth/JWT를 통한 인증을 요청합니다.
- 인증 서버가 외부 시스템에 액세스 토큰을 반환합니다.
- 외부 시스템은 인가 및 JSON 페이로드가 있는 Data 360 수집 API에 데이터 수집 POST 요청을 보냅니다.
- 수집 API는 스테이징 및 유효성 검사 모듈을 통해 요청 스키마 및 인증을 확인합니다.
- 스키마/인증 실패:
- 외부 시스템에 오류가 반환되었습니다.
- 모니터링 및 경고를 위해 로그된 거부
- 확인 성공 시:
- 데이터 레이크 개체(DLO)에 스테이징 및 커밋된 레코드입니다.
- 모니터링에 대한 성공이 기록되었습니다.
- 활성화된 경우 데이터가 실시간 데이터 그래프(DMO)로 전파되어 다운스트림 워크플로를 트리거합니다.
- 그렇지 않으면 표준 배치 또는 더 높은 대기 시간 파이프라인을 통해 데이터가 처리됩니다.
- 수집 API는 외부 시스템에 성공을 확인합니다.
- 모니터링 구성 요소는 대기열, 거부율 또는 대기 시간 문제에 대해 관리자에게 경고합니다.
결과
외부 이벤트 데이터는 대기 시간이 낮은 Data 360 DLO에 수집됩니다. 대상 DMO가 실시간 그래프의 일부인 경우 인스턴트 세분화, 에이전트 워크플로, AI 모델, 운영 활성화에 데이터를 사용할 수 있습니다. 이렇게 하면 연결된 시스템에서 시작된 이벤트에 대한 신속한 비즈니스 응답을 할 수 있습니다.
수집 메커니즘
수집 메커니즘은 Data 360 내에 정의된 커넥터 및 예약 전략에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| 스트리밍 JSON( 수집 API) | 단일 이벤트, 마이크로 배치, 동작 이벤트, 클릭 스트림, IoT Telemetry - 대기 시간이 적으면 |
| Bulk CSV( 수집 API 대량 모드) | 대기 시간 요구 사항이 완화된 대규모 정기 업로드 |
| Edge / 미들웨어 | 수집 API로 푸시하기 전에 확인, 변환, 보강 또는 속도 제한이 필요한 경우 사용합니다. |
오류 처리 및 복구
- 직접(동기화) 오류: 스키마/인증 오류에 대한 4xx 응답 - 클라이언트가 페이로드 또는 토큰을 수정하고 다시 시도해야 합니다.
- 일시적(비동기) 실패: 5xx 응답 - 기하급수 백오프 및 진동이 있는 클라이언트 재시도입니다.
- Dead-Letter Queue(DLQ): 영구 실패는 수동 검사 및 재생을 위해 DLQ에 배치됩니다.
- 모니터링: 스키마 거부율, 인증 실패, 대기 시간 백분율, DLQ 백로그를 추적합니다. 임계값에 대한 경고.
동임 설계 고려 사항
- Idempotency Key: 모든 이벤트에는 고유한 ID 역량 키/메시지 ID가 포함되어야 합니다.
- 업서트 전략: 비즈니스 키(ExternalId)를 사용하여 재발행 중복을 방지합니다.
- Dedup 창: 아키텍처는 빈도 추적을 위한 중복 제거 창 및 보존을 정의해야 합니다.
보안 고려 사항
보안은 인증에서부터 암호화 및 액세스 제어에 이르기까지 수집 파이프라인 전반에 걸쳐 통합됩니다.
- 인증: 서버 간에 OAuth 2.0(JWT 전달자)을 권장합니다. 수집으로만 범위를 제한합니다.
- 암호화: 전송을 위한 TLS 1.2+이며, Data 360은 암호화 상태를 유지합니다.
- 최소 권한: 연결된 앱 자격 증명에는 암호 순환 및 장치 액세스 로그의 권한이 최소화됩니다.
- 페이로드 거버넌스: 이벤트 메타데이터에 동의/소모 플래그를 포함하고 수집 후 즉시 ABAC/CEDAR 정책을 적용합니다.
- IP 컨트롤 / 개인 연결: 필요한 경우 허용 목록을 통해 액세스를 제한하거나 비공개 네트워킹에 비공개 연결을 사용합니다.
링크 모음
시기
시기는 수집 일정 및 데이터 용량에 따라 다릅니다. 스트리밍 JSON은 처리 및 그래프 구성에 따라 하위 초초 대기 시간을 제공합니다. 대량 CSV는 분시간입니다. 비즈니스 SLA를 기반으로 선택합니다.
데이터 용량
개별 이벤트 크기는 작아야 합니다(< 몇KB). 대량 생산자의 경우 API를 호출하기 전에 프로듀서에서 배치하거나 스트리밍 버퍼(Kafka/Kinesis)를 사용하는 것이 좋습니다.
시/도 관리
- 스키마 버전 관리: 이벤트 메타데이터에서 스키마 버전을 유지하고 OAS 계약을 업데이트할 때 커넥터 버전 관리를 사용합니다.
- 커넥터 오프셋: Data 360은 커밋 시맨틱을 처리하며, 프로듀서는 안전하게 재생할 수 있도록 역능 키 및 마지막으로 성공한 순서를 추적해야 합니다.
복잡한 통합 시나리오
고급 엔터프라이즈 아키텍처에서 이 패턴은 다음과 통합할 수 있습니다.
- Edge Validation Layer: 미들웨어를 사용하여 이기종 프로듀서 형식을 필수 OAS 계약으로 번역하고 속도 제한 및 사전 보강을 수행합니다.
- 하이브리드 아키텍처: 이벤트용 수집 API 및 대량 조정을 위한 커넥터를 결합합니다.
- 에이전트 활성화: 실시간 DMO에 매핑된 이벤트는 자동화된 의사 결정을 위한 Agentforce 워크플로 및 Einstein 모델을 트리거할 수 있습니다.
예제
리테일 체인은 POS(Point-of-Sale) 구매 이벤트를 Data 360 inReal-Time으로 스트리밍하여 즉각적인 고객 참여를 촉진합니다. 각 매장은 트랜잭션을 수집하고 위치 및 장치 메타데이터로 보강하며, 중복을 방지하기 위해 JWT 전달자 OAuth를 사용하여 안전하게 JSON 이벤트를 게시하는 경량 서버 구성 요소를 실행합니다. 관리자는 판매 지점에 대한 OAS 스키마를 업로드하고 수집 API 커넥터를 구성하여 이벤트 구조를 정의합니다. 수신 이벤트는 post_sale DLO에 수집되고, Sale DMO에 매핑되어 실시간 그래프에 추가됩니다. 따라서 중요한 구매가 즉시 감지되어 Agentforce VIP 워크플로를 트리거하고 고객 세분화를 업데이트하여 실시간 개인 설정을 촉진합니다.
컨텍스트
이 패턴을 사용하면 웹 사이트 및 모바일 응용 프로그램에서 TrueReal Time에서 페이지 보기, 버튼 클릭, 제품 인사이트, 비디오 플레이와 같은 대용량 세부적인 사용자 상호 작용 데이터를 수집할 수 있습니다. 이는 모든 디지털 상호 작용이 사용자 환경에 동적으로 영향을 미치고 참여를 촉진할 수 있는 즉각적 개인 설정을 제공하는 데 기본적입니다.
문제
디지털 속성에서 수백만 개의 사용자 상호 작용이 분당 발생하는 연속적인 동작 이벤트 스트림을 수집 및 처리하고 Data 360에서 해당 데이터를 즉시 사용할 수 있도록 하여 실시간 세분화, 개인 설정, 활성화를 지원하는 방법은 무엇입니까?
Force
이 사용 사례는 목표에 맞게 구축된 낮은 대기 시간 수집 아키텍처가 필요한 몇 가지 설계 챌린지를 소개합니다.
- Extreme Throughput : 트래픽이 많은 웹 사이트 또는 모바일 앱은 분당 수백만 개의 이벤트를 전송할 수 있습니다. 수집 레이어는 이벤트 손실 또는 역압 없이 이 볼륨을 처리하려면 수평으로 확장해야 하므로 최대 부하 시 대기 시간이 일관되도록 합니다.
- 클라이언트측 장비 : 이 패턴은 서버 구동 통합과 달리 클라이언트 측 SDK에 따라 다릅니다. JavaScript 비콘(Salesforce Interactions SDK)을 각 페이지에 포함하거나 모바일 앱에 통합된 기본 SDK를 포함해야 합니다. 이를 위해 강력한 클라이언트 배포, 버전 관리, 이벤트 스키마 관리가 필요합니다.
- 저 대기 시간 이벤트 처리: "장바구니 추가" 또는 "비디오 플레이"와 같은 사용자 작업은 Data 360에 몇 초 이내에 도달하여 실시간 활성화 및 상황별 응답(예: 대상이 지정된 제안, 맞춤형 권장 사항)을 활성화해야 합니다.
- 데이터 조합 및 ID 확인 : 수집된 이벤트에는 익명 식별자(쿠키, 장치 ID, 세션 토큰)가 포함되는 경우가 많습니다. Customer 360 사용 사례를 지원하려면 Data 360의 ID 확인을 통해 알려진 프로필에 매핑하고 Customer 360 데이터 모델에 조화되어야 합니다.
솔루션
Salesforce Marketing Cloud Personalization Connector를 사용하는 것이 좋습니다. 이는 고처리량 동작 수집을 위해 설계된 내장형 완전 관리 스트리밍 파이프라인입니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| SDK 기반 이벤트 캡처 | 최고 | Salesforce Interactions SDK(웹) 또는 네이티브 SDK(모바일)를 배포합니다. 이러한 경량 라이브러리는 메타데이터(세션 ID, 타임스탬프, 컨텍스트)를 첨부하여 실시간으로 사용자 상호 작용을 수집하고 직렬화합니다. |
| Event 스트리밍 파이프라인 | 최고 | 이벤트는 보안 HTTPS를 통해 Marketing Cloud Personalization의 이벤트 스트리밍 서비스로 전송됩니다. 이 레이어는 가로로 확장 가능하며 저 대기 시간 전송(<2s)에 최적화되어 있습니다. |
| Data 360 통합 | 최고 | Data 360의 개인 설정 커넥터는 스트리밍 피드를 구독하여 각 이벤트를 데이터 레이크 개체(DLO)에 거의 실시간으로 수집합니다. |
| 데이터 모델 매핑 | 모범 사례 | 수집된 DLO가 Customer 360 데이터 모델 개체(DMO)에 매핑됩니다. 이렇게 하면 ID 확인을 통해 익명 및 알려진 사용자를 연결할 수 있습니다. |
| 실시간 그래프 활성화 | 옵션 / 권장 | 실시간 그래프에 매핑된 DMO를 포함하여 즉시 세분화를 수행하고 Einstein 또는 Agentforce 워크플로를 통해 맞춤형 작업을 트리거합니다. |
| 사용하지 않을 때 | 비최적 | 이 패턴은 다음과 같은 경우에 적합하지 않습니다. 소스 데이터는 웹 클라이언트 및 이벤트입니다(대신 수집 API 사용). 조직은 웹/모바일 클라이언트를 제어하지 않습니다. 실시간 동작 추적은 필요하지 않습니다(배치 수집 사용). |
| 스키마 변경 사항 처리 | 관리형 진화 | 새 상호 작용이 추가되면 이벤트 스키마가 발전합니다. SDK는 버전 이벤트 정의여야 합니다. 이전 버전과 호환되는 변경 사항(옵션 필드 추가)은 안전합니다. 변경 사항을 중단하려면 커넥터 재구성 및 계약 테스트가 필요합니다. |
스케치
이 다이어그램은 모바일 및 웹 채널의 데이터를 Data 360으로 수집하는 단계 순서를 보여줍니다.
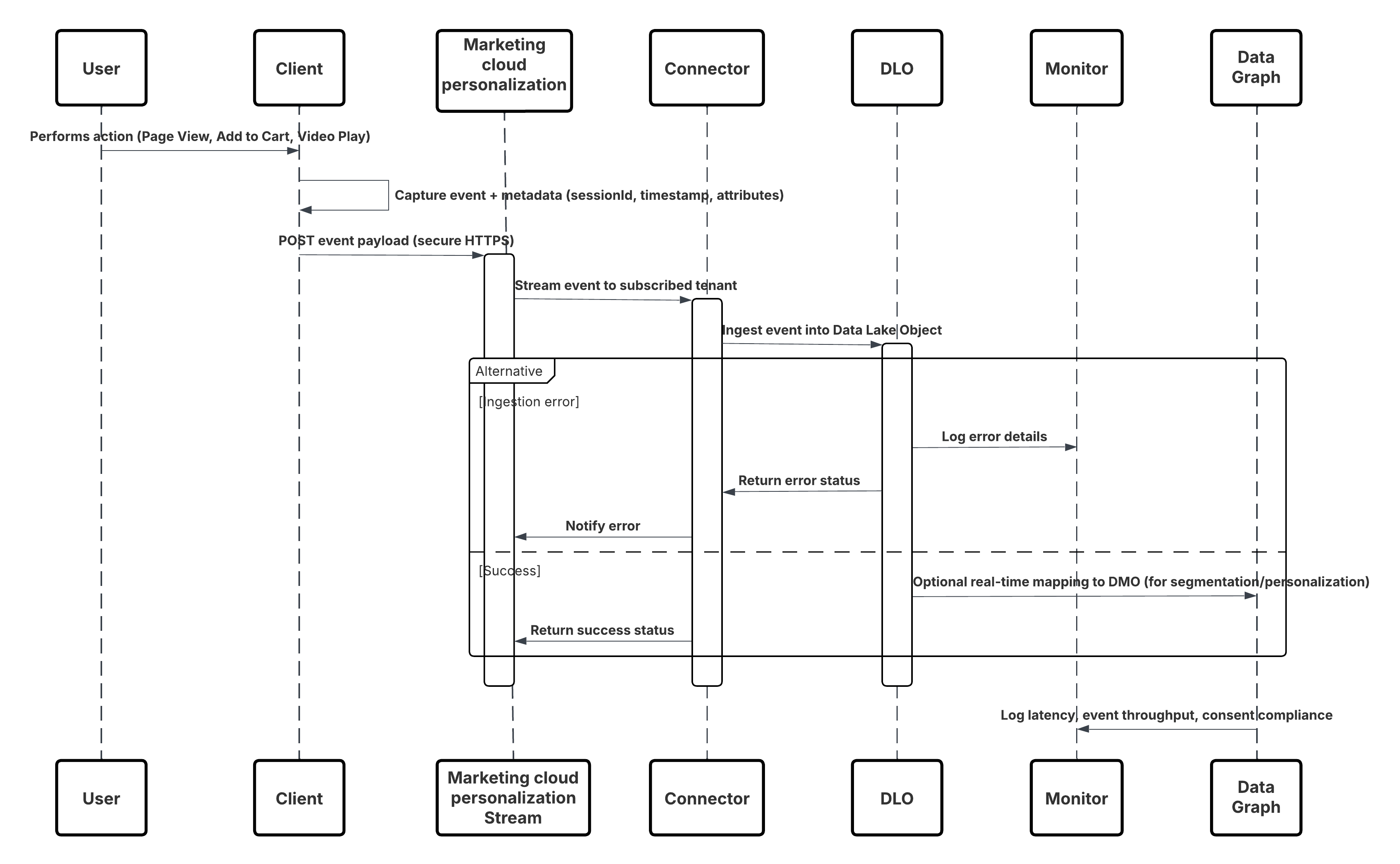
이 경우:
- 웹 또는 모바일 채널에서 SDK를 배포합니다(사용자-상호 작용 수집).
- 테넌트 ID, 환경, 동의 제어를 사용하여 SDK를 구성합니다.
- 수집된 JSON 이벤트(메타데이터 + 특성)를 Marketing Cloud 스트리밍 끝점에 스트리밍합니다.
- Data 360 설정에서 테넌트에 대한 개인 설정 커넥터를 만들고 구성합니다.
- 이벤트를 DLO에 수집하고 Data 360 내부에 DLO → DMO를 매핑합니다.
- 즉시 활성화를 위해 실시간 그래프에서 DMO를 활성화합니다.
- 대기 시간, 스키마 규정 준수, 동의 플래그, 처리량, 오류 비율을 모니터링합니다.
- 프로덕션에 배포하고 지속적으로 모니터링합니다.
결과
지속적인 지연이 낮은 동작 이벤트 스트림은 디지털 채널에서 Data 360으로 흐릅니다. 몇 초 이내에 각 사용자 작업을 실시간 세분화, 예측 모델링 또는 트리거된 개인 설정에 사용할 수 있으므로 실제로 적응 가능한 고객 환경이 가능합니다.
수집 메커니즘
수집 메커니즘은 Data 360 내에 정의된 커넥터 및 예약 전략에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Interactions SDK(웹) | 웹 브라우저 및 SPA에서 실시간으로 수집합니다. |
| Mobile SDK | 기본 모바일 응용 프로그램에서 실시간 수집 |
| 개인화 커넥터 | Marketing Cloud 및 Data 360\ 간의 관리형 구독입니다. |
| 실시간 그래프 매핑 | Segmentation, Einstein 및 Journeys에서 즉시 활성화합니다. |
오류 처리 및 복구
- 계층화된 결함 허용: 다중 계층 유효성 검사 및 재시도 메커니즘을 구현합니다. 클라이언트 SDK는 기하급수 백오프로 임시 실패를 처리하고, 수집 레이어는 내구성 있는 대기열 및 재생 가능한 파이프라인을 사용하여 데이터 손실을 방지합니다.
- 스키마 및 데이터 거버넌스: 이벤트 스키마의 버전을 지속적으로 확인하고 유효하지 않거나 진행 중인 이벤트가 스키마 거부 또는 대기열에 라우팅되어 안전하게 정렬 및 재생됩니다.
- Idempotency 및 중복 제거: 안정적인 이벤트 식별자를 사용하고 업서트 시맨틱스를 사용하여 재시도 또는 재작업 중에도 정확한 한 번 처리를 보장합니다.
- 모니터링 및 복구 자동화: 처리량, 대기 시간, 오류 비율을 지속적으로 모니터링하면 자동 복구 워크플로가 트리거되어 대기 시간이 낮고 신뢰할 수 있는 배송이 가능하며 일관적인 실시간 개인 설정 결과가 제공됩니다.
동임 설계 고려 사항
- 중복 제출이 다운스트림에서 중복 제거되도록 모든 이벤트에 고유한 ID 키 또는 메시지 ID가 포함되어 있어야 합니다.
- 중복을 식별하기 위해 필요한 경우 비즈니스 키(예: sessionID + eventTimestamp + userID)를 사용합니다.
- 중복 이벤트가 무시되거나 필터링되는 중복 제거 기간(예: 24시간)을 정의합니다.
- 적절한 경우 업서트 전략을 사용합니다(예: 중복 삽입 대신 카운터 또는 플래그 업데이트).
보안 고려 사항
보안은 인증에서부터 암호화 및 액세스 제어에 이르기까지 수집 파이프라인 전반에 걸쳐 통합됩니다.
- 전송 암호화: 모든 SDK → 스트리밍 서비스 연결의 경우 TLS 1.2+
- Data 360 및 마케팅 스트림에서 데이터 암호화가 유지됩니다.
- SDK는 **사용자 동의 플래그(GDPR/CCPA)**를 준수하고 동의가 거부되는 경우 추적을 억제합니다.
- SDK 트래픽 인증: 승인된 테넌트/클라이언트만 이벤트를 스트리밍할 수 있도록 합니다.
- 메타데이터: 각 이벤트에는 소스 ID, 타임스탬프, 스키마 버전, 세션 ID, idempotency 키가 포함되어야 합니다.
- 최소 권한 액세스: SDK 끝점 및 커넥터는 이벤트 수집 범위로 제한되며 자격 증명을 정기적으로 순환합니다.
- 데이터 분류: 이벤트 페이로드에 PII 주석 달기, 수집 후 즉시 정책 적용
링크 모음
시기
- 시기는 최종 사용자 활동 및 이벤트 스트리밍 구성에 따라 다릅니다.
- Salesforce Interactions SDK를 통해 수집되고 Marketing Cloud Personalization 스트림을 통해 전달된 이벤트는 일반적으로 Data 360 실시간 그래프에서 사용할 수 있게 되기 전에 대기 시간이 2초에서 2초까지 소요됩니다.
- 이렇게 하면 활성 사용자 세션 내에서 거의 즉시 세분화, 개인 설정, 활성화가 가능합니다.
데이터 용량
개별 동작 이벤트(예: 클릭, 보기, 장바구니 추가)는 경량(일반적으로 페이로드당 1~5KB)입니다. 대규모 디지털 속성의 경우 분당 수천에서 수백만 개의 이벤트가 발생합니다. 처리량 및 복원 보장:
- 트래픽이 많은 페이지에 SDK의 내장된 배치 및 재시도 메커니즘을 사용합니다.
- Marketing Cloud 스트리밍 버퍼 레이어에 버스트 처리를 오프로드합니다.
- 커넥터 메트릭 대시보드를 사용하여 수집 처리량 및 오류 비율을 모니터링합니다.
시/도 관리
각 이벤트에는 상태 및 버전 관리에 대한 메타데이터가 포함됩니다.
- 스키마 버전 관리: 모든 이벤트에 스키마 버전을 포함하고 스키마를 업데이트할 때 개인 설정 커넥터 버전을 지정합니다.
- 재생 처리: 일시적 네트워크 문제로 인해 실패한 이벤트는 기하급수 백오프를 사용하여 SDK에서 자동으로 다시 시도합니다.
- Idempotency 키: 고유 식별자(sessionId + eventType + 타임스탬프)는 재생된 이벤트가 Data 360에서 중복이 생성되지 않도록 합니다.
- 오프셋 관리: Data 360은 성공적인 커밋을 추적합니다. 처리되지 않은 이벤트는 성공적으로 수집될 때까지 커넥터에서 다시 대기열에 지정됩니다.
복잡한 통합 시나리오
이 패턴은 고급 엔터프라이즈 아키텍처에 원활하게 통합됩니다.
- Edge Enrichment Layer: 미들웨어(예: 역방향 프록시 또는 서버리스 함수)를 추가하여 이벤트가 Marketing Cloud에 도달하기 전에 지리적, 장치 유형 또는 캠페인 메타데이터와 같은 추가 컨텍스트를 삽입합니다.
- 하이브리드(스트리밍 + 배치): 실시간 스트림에 Marketing Cloud 커넥터를 사용하고 배치 ETL 작업(예: 주문 데이터)과 결합하여 다운스트림 조정합니다.
- 에이전트 활성화: 실시간 DMO에 매핑된 이벤트는 Einstein 개인 설정, Agentforce 워크플로 또는 AI 기반 의사 결정을 트리거하여 현재 디지털 환경을 조정할 수 있습니다.
- 다중 테넌트 거버넌스: 동의 플래그 및 테넌트 인식 메타데이터를 사용하여 다중 브랜드 또는 다중 지역 환경에서 개인정보보호 및 규정 준수를 적용합니다.
예제
글로벌 전자상거래 회사는 React 기반 단일 페이지 응용 프로그램인 www.retailx.com을 활발하게 탐색하는 동안 구매자에게 맞춤형 제품 추천과 동적 콘텐츠를 제공합니다. 클라이언트 측에서 Salesforce Interactions SDK를 사용하면 사이트에서 페이지 보기, 제품 클릭, 장바구니 작업, 비디오 상호 작용을 실시간으로 캡처합니다. 해당 이벤트는 Marketing Cloud Personalization 이벤트 스트림 및 Personalization 커넥터를 통해 Data 360 DLO로 흐릅니다. 여기서 DMO에 모델링되고 실시간 그래프에 통합됩니다. 이 아키텍처는 세분화, Einstein 기반 개인 설정 및 Agentforce 활성화를 위한 동작 신호를 즉시 사용할 수 있게 하여 세션 내 고객 경험에 반응하는 기능을 제공합니다.
컨텍스트
많은 비즈니스에 중요한 프로세스에서 핵심 CRM 시스템의 최신 업데이트와 Data 360을 완벽하게 일치시키는 것이 중요합니다. 고객 서비스, 세일즈, 마케팅 팀은 최신 정보에 의존하여 결정을 내리고 여정을 트리거하고 자동화를 활성화합니다. 이 패턴은 중요한 Salesforce CRM 개체(예: 연락처, 계정, 사례)에 대한 변경 사항을 비효율적이거나 지연되는 배치 폴링 없이 최소한의 지연 없이 Data 360으로 동기화하는 메커니즘을 제공합니다.
문제
Data 360은 주요 Salesforce CRM 개체와 거의 완벽하게 동기화된 상태를 유지하여 다운스트림 분석, 세분화, AI 중심 활성화가 항상 사용 가능한 최신 데이터에서 작동하도록 하려면 어떻게 해야 합니까?
Force
이 패턴은 다음과 같은 몇 가지 기술적 제약 사항 및 아키텍처 고려 사항을 도입합니다.
- 이벤트 중심 아키텍처: 동기화는 정기적인 배치 작업이 아닌 CRM 소스 조직의 변경 이벤트로 구동되어야 합니다.
- 선택적 객체 지원: 일부 Salesforce 표준 및 사용자 정의 개체에서는 실시간 스트리밍을 지원하지 않습니다. 설계 도중 지원되는 개체 목록을 참조하여 공백을 방지해야 합니다.
- 액세스 및 권한 : 스트리밍을 활성화하려면 소스 조직의 통합 사용자에게 "CRM 스트리밍에 대한 권한 활성화" 시스템 권한이 할당되어야 합니다.
- 데이터 신선도 vs. 처리 비용: 거의 실시간 동기화는 응답성을 향상하지만, 과도한 이벤트 처리량은 가로 조정 및 강력한 오류 복구 메커니즘이 필요할 수 있습니다.
- Security 및 Trust 계층 통합: 모든 이벤트 데이터는 Salesforce의 Trust 및 보안 프레임워크를 준수해야 합니다. 전송 시 암호화되고 스키마 규정 준수 검증되며 조직의 Trust 경계 내에서 처리됩니다.
솔루션
권장 방법은 스트리밍(데이터 수집 변경)이 활성화된 Salesforce CRM 커넥터를 사용하는 것입니다. 지원되는 CRM 개체(예: 연락처)에 대한 데이터 스트림을 만들 때 관리자가 "스트리밍 활성화" 옵션을 전환할 수 있습니다. Salesforce의 변경 데이터 수집(CDC) 플랫폼은 소스 CRM 조직에서 레코드가 생성, 업데이트, 삭제 또는 삭제 취소될 때마다 ChangeEvent 메시지를 게시합니다. Data 360 CRM 커넥터는 해당 CDC 이벤트를 구독하고 Data 360 내의 매핑된 데이터 레이크 개체(DLO)에 해당 변경 사항을 거의 실시간으로 적용합니다. 이를 통해 CRM과 Data 360 간의 지속적인 동기화를 최소한의 수동 개입으로 유지할 수 있습니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| CDC 기반 스트리밍 커넥터 | 최대 | 기본 Salesforce 메커니즘, 플랫폼 이벤트 인프라와 완전히 관리 및 통합 |
| 이벤트 가입 및 배송 | 최대 | 커넥터는 지속적인 재생 ID를 통해 ChangeEvent 채널(예: /data/ContactChangeEvent)을 구독합니다. |
| 데이터 매핑 및 스키마 진화 | 모범 사례 | 스트리밍된 페이로드를 해당 DLO에 매핑하고, 수집 중단을 방지하기 위해 메타데이터에서 스키마 버전 관리를 처리합니다. |
| 재생 및 오류 복구 | 권장 | 중복을 방지하고 일시적인 오류로부터 복구하려면 재생 ID 및 역량 키를 활용합니다. |
| 하이브리드 모드(스트리밍 + 배치) | 옵션 | 지원되지 않는 개체 또는 초기 대량 로드의 경우 CDC 스트리밍과 함께 배치 수집을 사용합니다. |
| 사용하지 않을 때 | 최적화되지 않음 | 이 패턴은 다음과 같은 경우에 비최적일 수 있습니다. 소스 개체는 CDC가 활성화되어 있지 않습니다. 사용 사례는 실시간 업데이트가 필요하지 않습니다(배치가 충분). 소스 조직의 네트워크 출력이 제한되거나 이벤트 제한이 초과됩니다. |
스케치
이 다이어그램은 CRM의 데이터를 Data 360으로 거의 실시간으로 수집하는 단계 순서를 보여줍니다.
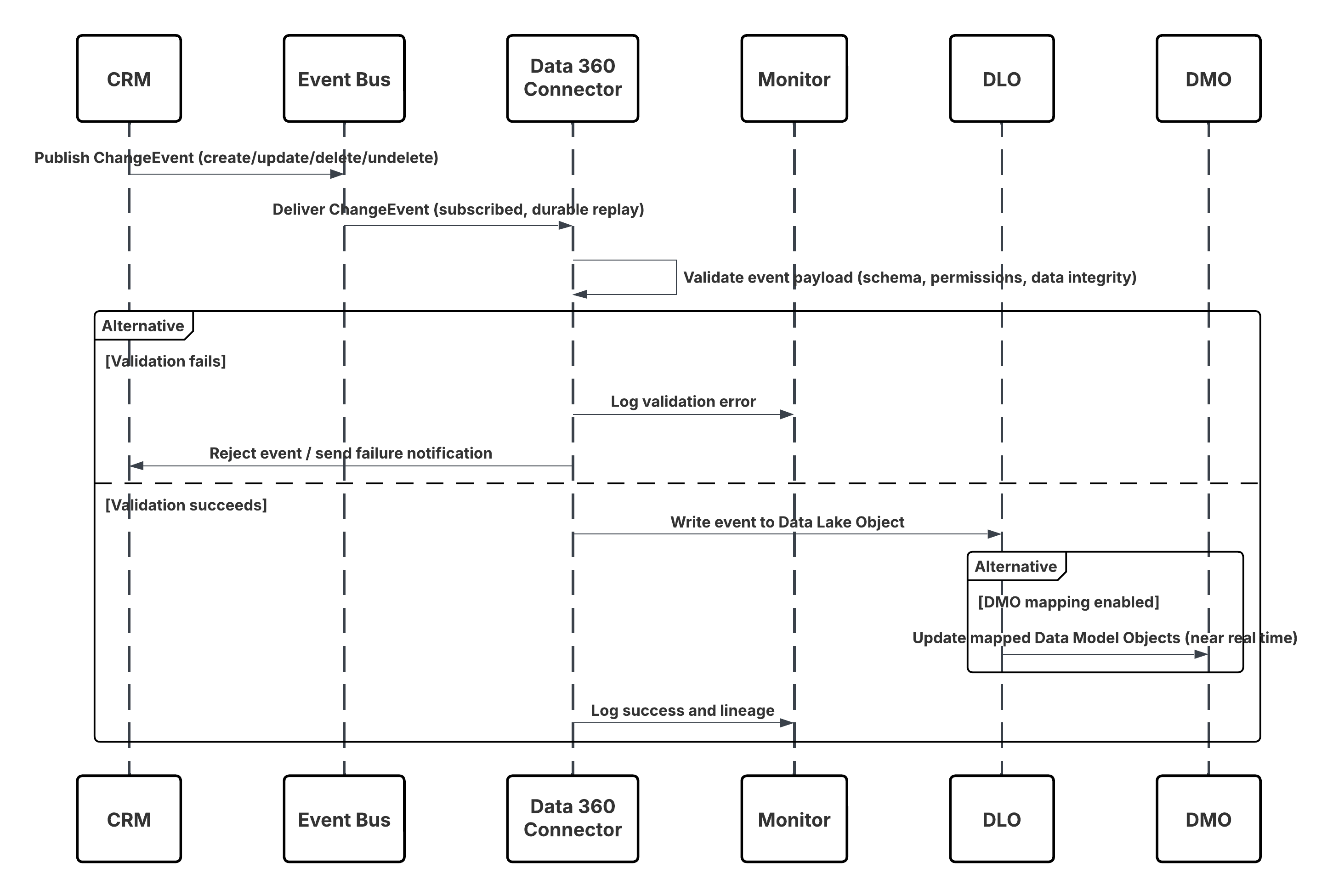
이 경우:
- 변경 사항은 Salesforce CRM(만들기/업데이트/삭제/삭제)에서 발생합니다.
- CDC가 내부 Salesforce 이벤트 버스에 ChangeEvent를 게시합니다.
- Data 360 CRM 커넥터는 지속적인 재생 커서를 사용하여 이벤트 버스를 구독합니다.
- 이벤트 페이로드가 스키마, 권한 및 데이터 무결성에 대한 유효성을 검사합니다.
- Data 360은 확인된 이벤트를 매핑된 **Data Lake Object(DLO)**에 기록합니다.
- 활성화한 경우 매핑된 **데이터 모델 개체(DMO)**가 nearReal-Time으로 업데이트되어 세분화 및 활성화를 촉진합니다.
결과
Data 360은 핵심 CRM 데이터의 지속적으로 동기화된 미러를 유지합니다. 이를 통해 다음을 수행할 수 있습니다.
- 실시간 트리거(예: 사례가 생성되면 여정이 시작됨)
- 최신 세분화(예: 계정 상태 변경 시 고객을 "골드" 세그먼트로 이동)
- 실시간 CRM 컨텍스트를 기반으로 더 정확한 분석 및 개인 설정
수집 메커니즘
이 패턴의 수집 메커니즘은 변경 데이터 수집(CDC)이 활성화된 Salesforce CRM 커넥터를 통해 기본적으로 관리됩니다. Data 360은 CDC 이벤트 스트림 구독자 역할을 하므로 소스 CRM 조직과 Data 360 간의 신뢰할 수 있고 대기 시간이 낮은 동기화를 보장합니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| CDC를 통한 스트리밍(권장) | 거의 실시간 동기화가 필요한 지원되는 모든 Salesforce 표준 및 사용자 정의 개체. |
| 하이브리드 모드(CDC + 배치) | 아직 CDC가 활성화되지 않은 개체 또는 초기 내역 로드가 필요한 경우 |
| 재생 가입 모드 | 가동 중지 시간 또는 배포 후 재동기화 |
| 오류 격리 모드 | 테스트 및 유효성 검사 환경의 경우 |
오류 처리 및 복구
- 자동 장애 복구: CRM 커넥터는 기하급수 백오프를 사용하여 임시 네트워크 또는 플랫폼 오류를 자동으로 다시 시도하고 재생할 수 있도록 영구 실패를 DLQ(Dead-Letter Queue)로 라우팅합니다.
- 스키마 및 인증 복원: 스키마 불일치는 관리자 검토를 위해 스키마 거부 대기열에서 격리되며, 인증 또는 권한 오류는 Data 360 모니터링을 통해 제어되는 재시도를 트리거하고 경고를 표시합니다.
- 이벤트 연속성 보장: 내구성 ReplayID는 커넥터 가동 중지 시 이벤트 손실을 방지합니다. 누락된 이벤트는 재생 기간 또는 배치 재동기화 작업을 통해 재수용됩니다.
- 데이터 무결성 및 주문: 내장된 idempotency(RecordID + SequenceNumber)는 중복을 방지하며, ChangeEventHeader.sequenceNumber는 모든 CRM 레코드에 대한 올바른 이벤트 순서를 유지합니다.
동임 설계 고려 사항
- 이벤트 고유성: 각 CDC 이벤트는 결정적 중복 제거를 위해 ReplayID 및 ChangeEventHeader.entityName을 포함합니다.
- 업서트 전략: 반복 이벤트가 중복되지 않도록 레코드 ID를 기반으로 UPSERT 논리를 구현합니다.
- 재생 처리: 일시적인 오류가 발생할 경우 커넥터의 재생 커서를 사용하여 마지막으로 커밋된 오프셋에서 재개합니다.
- 스키마 진화: 이벤트 메타데이터에서 스키마 버전을 유지하고 CRM 스키마가 변경되면 DLO 매핑을 업데이트합니다.
보안 고려 사항
보안은 인증에서부터 암호화 및 액세스 제어에 이르기까지 수집 파이프라인 전반에 걸쳐 통합됩니다.
- 암호화 및 Trust : 모든 이벤트는 **TLS 1.2+**를 사용하여 전송되며 Data 360에 암호화된 상태로 저장됩니다.
- 액세스 제어: 적절한 통합 권한이 있는 인증된 커넥터만 CDC 채널을 구독할 수 있습니다.
- 스키마 검증: 수집하기 전에 모든 이벤트 페이로드가 DLO 스키마에 대해 확인됩니다.
- 동의 전파: 개인정보보호 및 규정 준수(GDPR, CCPA)를 유지하기 위해 각 이벤트와 함께 동의 및 데이터 분류 메타데이터가 다운스트림됩니다.
- 운영 거버넌스: Data 360 Trust 레이어를 통해 이벤트가 기록되고 감사되고 재생, 스키마 거부 및 처리량 변칙을 모니터링됩니다.
링크 모음
시기
- CDC 이벤트는 일반적으로 CRM 변경 후 몇 초 이내에 거의 실시간으로 처리됩니다.
- 대기 시간은 이벤트 용량 및 커넥터 처리량에 따라 다를 수 있지만 Data 360은 지원되는 개체에 대해 분간 가용성을 보장합니다.
데이터 용량
- 각 이벤트 페이로드는 경량(
15KB)입니다. - 사례 또는 연락처와 같은 변경률이 높은 개체의 경우 처리량 제한이 Salesforce CDC 이벤트 할당과 일치하는지 확인하십시오.
시/도 관리
각 이벤트에는 상태 및 버전 관리에 대한 메타데이터가 포함됩니다.
- 재생 ID: 순차적인 이벤트 복구에 사용됩니다.
- 스키마 버전 관리: 버전 메타데이터를 유지하여 계약 변경 사항을 관리합니다.
- Idempotency 키: 재시도 전반에서 중복 제거를 수행합니다.
- 오프셋 커밋: Data 360은 성공적인 이벤트 배치마다 커밋 상태를 유지합니다.
복잡한 통합 시나리오
이 패턴은 고급 엔터프라이즈 아키텍처에 원활하게 통합됩니다.
- 하이브리드(스트리밍 + 배치): 델타 업데이트에 CDC를 사용하고 전체 새로 고침에 대량 작업을 사용합니다.
- Cross-Org 스트리밍: 여러 소스 조직이 DMO 매핑을 통해 통합된 동일한 Data 360 테넌트로 스트리밍할 수 있습니다.
- 에이전트 활성화: 실시간 개체 업데이트는 Einstein 또는 Agentforce 자동화를 트리거합니다.
- 이벤트 라우팅: 중간웨어(예: MuleSoft 또는 이벤트 릴레이)는 수집하기 전에 CDC 메시지를 보강하거나 라우팅할 수 있습니다.
예제
글로벌 은행은 Salesforce Sales Cloud의 고객 데이터 변경 사항이 Data 360에 즉시 반영되도록 하려고 합니다.Sales Cloud에서 연락처의 주소가 업데이트되면 변경 데이터 수집 메커니즘이 ContactChangeEvent를 게시합니다.Data 360 CRM Connector는 이 이벤트를 사용하고 고객 DLO에 업데이트를 적용하고 관련 Customer 360 프로필을 자동으로 업데이트합니다. 이렇게 하면 Einstein Next Best Action 새 주소를 확인하여 원래 CRM 변경 후 몇 초 이내에 사용자 의견 루프를 완료합니다.
컨텍스트
현대 디지털 엔터프라이즈는 Amazon Kinesis 데이터 스트림 및 Amazon MSK(Apache Kafka용 관리 스트리밍)와 같은 실시간 이벤트 스트리밍 플랫폼을 사용하여 분산된 응용 프로그램, IoT 장치, 트랜잭션 시스템에서 지속적인 데이터 플로를 캡처합니다. Data 360은 네이티브 자사 커넥터를 통해 해당 플랫폼에서 직접 수집할 수 있으므로 사용자 정의 ETL 또는 미들웨어 기반 솔루션이 필요하지 않습니다. 이 패턴은 대기 시간이 낮은 고처리 용량 데이터 수집, 실시간 인사이트, 개인 설정, AI 기반 활성화를 지원하기 위해 고안되었습니다.
문제
엔터프라이즈에서 Data 360을 AWS Kinesis 또는 AWS MSK Kafka 주제에 안전하고 효율적으로 연결하여 구조화된 이벤트 및 프로필 데이터를 지속적으로 수집하여 스키마 준수, 확장성, 거버넌스를 보장하는 방법은 무엇입니까?
Force
이 패턴은 다음과 같은 여러 아키텍처 및 운영 고려 사항을 도입합니다.
- 네이티브 커넥터 가용성: Salesforce는 Amazon Kinesis 및 Amazon MSK 모두에 정식 출시된 기본 커넥터를 제공합니다. 이러한 커넥터는 자사 지원을 제공하며 사용자 정의 API 기반 파이프라인이 필요하지 않습니다.
- 인증 및 보안: 각 커넥터는 AWS 수준 인증이 필요합니다.
- Kinesis의 경우 IAM 정책에 따라 AWS 액세스 키 및 암호 키를 사용합니다.
- MSK의 경우 액세스 키/암호 또는 OpenID Connect(OIDC)를 통해 인증을 구성할 수 있습니다.
- 스키마 정의: Data 360에는 스트리밍 페이로드를 해석하는 스키마가 필요합니다. Kinesis의 경우 연결 설정 시 스키마 파일이 업로드되어 이벤트 구조 및 필드 매핑을 정의합니다.
- 구성 소스:
- Kinesis 커넥터가 특정 Kinesis 스트림 이름을 구독합니다.
- MSK 커넥터가 MSK 클러스터 내 Kafka 주제를 구독합니다.
- 네트워크 액세스: 안전한 환경의 경우 PrivateLink 또는 VPC 라우팅을 사용하여 커넥터를 구성하여 데이터가 공용 인터넷을 이동하지 않도록 할 수 있습니다.
- 운영 거버넌스: 스트리밍 처리량, 스키마 검증 및 인증 이벤트는 Data 360 Trust 레이어 내에서 모니터링되어 규정 준수 및 추적 가능성을 보장합니다.
솔루션
이 솔루션은 Data 360 내의 Native Amazon Kinesis 또는 Amazon MSK 커넥터를 활용합니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| Kinesis 네이티브 커넥터 | 최대 | AWS Kinesis와 자사 통합, 지속적인 고처리량 수집 지원 |
| MSK 기본 커넥터 | 최대 | OIDC 및 키 기반 인증 지원을 통한 관리 Kafka 수집 |
| 스키마 매핑 및 검증 | 모범 사례 | 이벤트 구조를 정의하는 스키마 업로드(.json/.avro), 수집 중 일관성을 적용합니다. |
| IAM 구성 | 권장 | 대상 Kinesis 스트림 또는 MSK 주제에 읽기 전용 액세스 권한이 있는 최소 권한의 IAM 역할을 할당합니다. |
| 개인 네트워크 라우팅 | 옵션 | 안전한 내부 라우팅을 위해 PrivateLink/VPC 끝점을 구성합니다. |
| 하이브리드 패턴(스트리밍 + 배치) | 옵션 | 델타에 스트리밍을 사용하고 백필 또는 내역 로드에 배치 수집을 사용합니다. |
| 오류 격리 모드 | 권장 | 재생을 위해 스키마 거부 및 임시 오류를 DLQ로 라우팅 |
스케치
이 다이어그램은 Kafka 및 Kinesis와 같은 이벤트 플랫폼의 데이터를 거의 실시간으로 Data 360으로 수집하는 단계 순서를 보여줍니다.
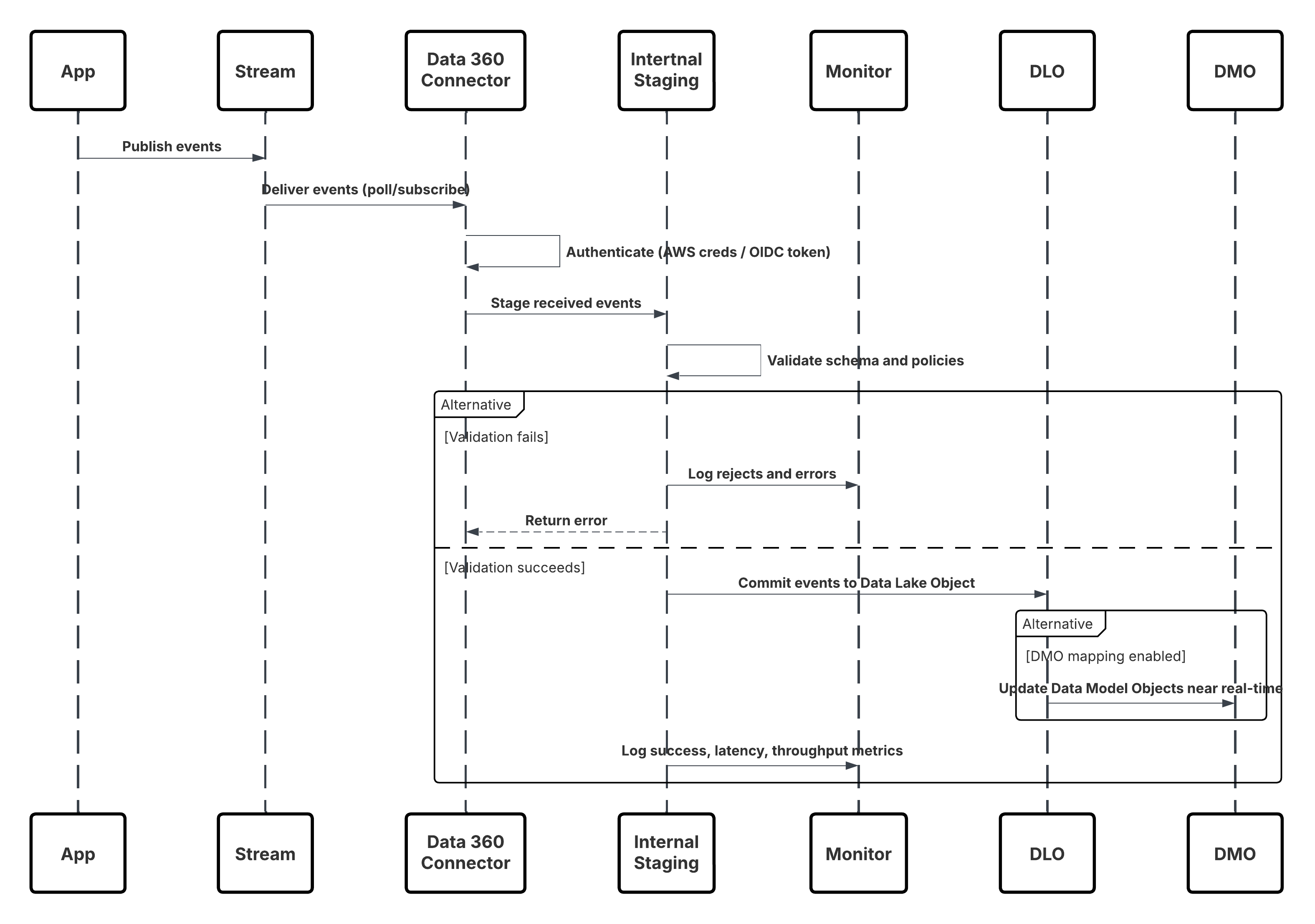
이 경우:
- 응용 프로그램 또는 장치가 Kinesis 스트림 또는 MSK 주제에 이벤트를 게시합니다.
- Data 360 커넥터는 AWS 자격 증명 또는 OIDC 토큰을 사용하여 인증합니다.
- 커넥터가 계속해서 스트림을 폴링하거나 구독합니다.
- 이벤트가 단계화되고 스키마 및 정책에 대한 유효성을 검사한 후 DLO(데이터 레이크 개체)로 커밋됩니다.
- 매핑된 경우 활성화를 위해 데이터 모델 개체(DMO)가 거의 실시간으로 업데이트됩니다.
- 모니터링 레이어는 메트릭, 스키마 거부, 대기 시간을 추적합니다.
결과
AWS Kinesis 또는 MSK에서 Data 360으로 직접 구조화된 데이터를 연속적으로 저지연하게 수집합니다. 데이터를 즉시 사용할 수 있습니다.
- ID 확인
- 실시간 세분화
- Einstein AI 활성화
- Agentforce 구동 트리거 배치 ETL에 대한 종속성을 없애 엔터프라이즈 이벤트 중심 설계에 부합하는 스트림 기반 아키텍처를 활성화합니다.
수집 메커니즘
| 메커니즘 | 사용하는 경우 |
|---|---|
| Kinesis 커넥터(권장) | 대용량의 구조화된 데이터를 지속적으로 수집해야 하는 AWS 기본 스트리밍 소스의 경우 |
| MSK 커넥터 | Kafka 호환 플랫폼에서 이벤트 파이프라인을 실행하는 조직 |
| Hybrid(스트리밍 + 배치) | 정기적인 대량 로드와 결합된 증분 이벤트 수집의 경우 |
오류 처리 및 복구
- 자동 재시도: 커넥터가 기하급수 백오프를 사용하여 임시 네트워크 또는 플랫폼 오류를 다시 시도합니다.
- 스키마 거부: 잘못된 페이로드가 관리자 검토를 위해 스키마 거부 대기열로 라우팅됩니다.
- DLQ Replay: 지속 실패는 재처리를 위해 대기열에 수집됩니다.
- Idempotency Control: 이벤트 키 또는 순서 번호는 중복 제거 및 순서가 지정된 수집을 보장합니다.
- 모니터링 통합: 모든 실패, 재시도, 처리량 메트릭이 Data 360 모니터링 대시보드에 표시됩니다.
동임 설계 고려 사항
- 이벤트 독특성 및 추적: 각 이벤트에 결정적 고유 키(예: Kinesis의 경우 PartitionKey + SequenceNumber 또는 MSK의 경우 Topic + Partition + Offset)가 할당되어 정확한 일회 수집이 가능합니다.
- 커넥터 검사: Data 360 커넥터는 마지막으로 처리된 오프셋 또는 순서 번호를 유지하여 장애 또는 재시작 후 안전하게 수집을 재개합니다.
- 중복 제거 및 업서트 논리: DLO 커밋 동안 중복 이벤트가 감지되고 건너뛰며 유효한 레코드는 일관성을 유지하기 위해 고유한 키를 사용하여 업서트됩니다.
- 재생 및 복구 제어: 실패하거나 지연된 이벤트는 Dead-Letter 및 Replay 대기열을 통해 저장된 오프셋에서 재생되므로 중복 없이 신뢰할 수 있는 복구가 가능합니다.
보안 고려 사항
보안은 인증에서부터 암호화 및 액세스 제어에 이르기까지 수집 파이프라인 전반에 걸쳐 통합됩니다.
- 인증: AWS IAM 정책 또는 OIDC를 사용하여 자격 증명 교환을 안전하게 수행합니다.
- 암호화: Data 360 내에서 암호화된 데이터 전송(TLS 1.2+) 및 유휴(AES-256)
- 액세스 제어: 최소 권한 역할 적용, 특정 스트림/주제에 대한 범위 커넥터.
- 거버넌스: 전체 추적 가능성을 위해 모든 레코드에 적용되는 계보 및 분류 메타데이터입니다.
- 네트워크 보안: 경우에 따라 AWS PrivateLink를 사용하여 개인 하위 네트워크 내에서 배포할 수 있습니다.
링크 모음
시기
- 직접 실시간 처리: CDC 및 스트리밍 커넥터는 소스 변경 후 몇 초 이내에 이벤트를 처리하므로 일반적으로 사후 시간 동안 데이터가 새로 고쳐집니다.
- 결정적 지연 시간: 종단간 지연은 소스 처리량, 이벤트 배치, 네트워크 조건에 따라 다르지만 Data 360은 지원되는 개체에 대해 예측 가능한 SLA 기반 대기 시간을 보장합니다.
- Elastic Scaling: 수집 파이프라인은 이벤트 용량이 많은 상태에서 자동으로 확장되므로 데이터가 발생하는 동안에도 시기적절성을 유지합니다.
- 작업 가시성: 대시보드 모니터링은 대기 시간 보장 및 문제 해결을 위해 이벤트 지연, 타임스탬프 커밋, 재생 상태를 표시합니다.
데이터 용량
- 경량 페이로드: 개별 CDC 또는 스트리밍 이벤트는 축소 크기(일반적인 크기 1~5KB)이며, 고주파 업데이트에 최적화되어 있습니다.
- 고변화 객체: 변동성이 있는 엔티티의 경우(예: 사례, 연락처, 주문) 설계자는 CDC 할당 및 이벤트 처리량이 예상 업데이트 비율에 부합하는지 확인해야 합니다.
- 병렬 스트림: Data 360은 대량 개체 볼륨 또는 여러 소스 조직에서 가로 확장을 위한 다중 스트림 수집을 지원합니다.
- 백압 처리: 내장된 조절 메커니즘은 이벤트를 삭제하지 않고 로드 시 수집 안정성을 유지합니다.
시/도 관리
각 이벤트에는 상태 및 버전 관리에 대한 메타데이터가 포함됩니다.
- 재생 및 오프셋 추적: 모든 이벤트에는 재생 ID 및 순서 메타데이터가 포함되어 있으므로 주문 배달 및 검사점 기반 복구가 가능합니다.
- 스키마 버전 관리: 이벤트 머리글 내의 버전 태그는 소스 스키마가 발전할 때 이전 버전과 호환되는 처리를 보장합니다.
- Idempotency 키: 각 이벤트에는 고유한 트랜잭션 또는 커밋 키가 포함되어 있어 Data 360에서 안전하게 재복제 및 재시도를 제거할 수 있습니다.
- Atomic Commit: 수집 파이프라인은 DLO에 대한 다운스트림 커밋이 성공하면 오프셋만 완료로 표시하여 일관성을 보장합니다.
복잡한 통합 시나리오
이 패턴은 고급 엔터프라이즈 아키텍처에 원활하게 통합됩니다.
- 하이브리드 수집: 증분 델타용 CDC를 대량 데이터 스트림과 결합하여 전체 새로 고침을 수행하여 신선함과 완전성을 모두 유지합니다.
- Cross-Org 스트리밍: 여러 CRM 또는 ERP 조직이 DMO 매핑 및 온토로지 정렬을 통해 통합된 동일한 Data 360 테넌트에 게시할 수 있습니다.
- 이벤트 보강: 중간웨어(예: MuleSoft, 이벤트 릴레이)는 Data 360에 도달하기 전에 스트리밍 데이터를 보강, 필터링 또는 라우팅할 수 있습니다.
- AI 및 에이전트 활성화: 실시간 업데이트는 시작 이벤트로부터 몇 초 이내에 Einstein 예측 또는 Agentforce 응답과 같은 다운스트림 자동화를 트리거합니다.
예제
글로벌 리테일 엔터프라이즈는 AWS Kinesis를 사용하여 세일즈 지점 및 웹 상호 작용 데이터를 스트리밍합니다.Data 360의 Kinesis 커넥터는 IAM 자격 증명을 통해 인증하고 트랜잭션 DLO에 이벤트를 지속적으로 수집합니다.각 레코드는 스키마 유효성 검사, 메타데이터로 보강되고 고객 DMO로 즉시 전파됩니다.Einstein AI 모델은 몇 초 이내에 고객 세그먼트를 업데이트하고 Agentforce 실시간으로 Next Best Offer 권장 사항을 트리거하여 완전히 이벤트 기반 개인 설정 루프를 달성합니다.
Zero Copy는 통합 방법 이상이며, 엔터프라이즈 데이터가 이동하는 방식 또는 이동하지 않는 방식의 기본적인 변화입니다. 일반적으로 데이터 통합을 수행하려면 ETL 파이프라인을 통해 대량의 레코드를 복사하고 중복 데이터 저장소를 만들고 동기화 지연 및 거버넌스 챌린지를 수행해야 했습니다. Zero Copy는 모든 항목을 제거합니다. 이 모델에서 Data 360은 Snowflake 및 Databricks와 같은 외부 데이터 플랫폼에 직접 연결하여 데이터를 이동하거나 복제하지 않고 데이터를 안전하게 읽고 활성화합니다. 결과적으로 엔터프라이즈 데이터 레이크하우스와 Salesforce 에코시스템 간에 원활한 연결이 이루어지며 즉각적인 액세스, 운영 오버헤드 감소, 강력한 데이터 거버넌스를 제공합니다.
인바운드 제로 복사 기능을 사용하면 Data 360이 Snowflake 또는 Databricks에 저장된 고객 프로필, 트랜잭션 또는 제품 데이터와 같은 소스에서 외부 데이터를 쿼리하고 조화시킬 수 있습니다. Data 360은 파일 수집 대신 외부 웨어하우스의 기존 스키마 정의 및 보안 정책을 활용하는 안전한 메타데이터 인식 연결을 설정합니다.
- 직접 연합: Data 360은 복제 없이 안전하고 최적화된 쿼리를 통해 즉시 데이터를 판독합니다.
- 통합 관리: 데이터는 소스 시스템의 보안, 액세스 제어, 규정 준수 프레임워크에 따라 유지됩니다.
- 운영 효율: ETL 오버헤드 및 스토리지 중복을 없애 비용과 복잡성을 줄입니다.
- 실시간 준비: On-Demand 조합 활성화합니다. Snowflake에서 데이터가 업데이트되면 Data 360에서 즉시 활성화할 수 있습니다.
컨텍스트
현대 데이터 중심 엔터프라이즈는 Snowflake 및 Databricks와 같은 클라우드 규모 데이터 레이크하우스 플랫폼 내에서 페타바이트의 고객, 트랜잭션, 텔레메트리 데이터를 관리합니다. 해당 환경은 분석, AI, 규정 준수에 대한 신뢰할 수 있는 단일 소스로 사용됩니다. Data 360은 Zero CopyData Federation을 도입하여 중복 데이터를 복사, 변환 또는 저장하지 않고도 외부 데이터 집합을 직접 쿼리하고 현장에 사용할 수 있습니다. 이 패턴을 통해 조직은 기존 데이터 웨어하우스 또는 호수 인프라에 Customer 360 패브릭을 확장할 수 있습니다. 즉, 실시간 통합 및 활성화를 실현하고 중복이 없고, 지연 시간이 없으며, 거버넌스에 대한 타협이 없습니다.
문제
Enterprise는 ETL 파이프라인 또는 물리적 데이터 이동의 비용, 대기 시간, 거버넌스 오버헤드 없이 Data 360에서 세분화, ID 확인, 활성화를 위해 Snowflake, Databricks 또는 Apache Iceberg와 같은 오픈 레이크 형식에서 이미 선별된 풍부한 데이터 집합을 어떻게 활용할 수 있습니까?
Force
이 패턴은 여러 가지 아키텍처, 보안, 성능 고려 사항을 도입합니다.
네트워크 및 보안
- Data 360은 외부 창고 또는 레이크하우스에 대한 안전한 비공개 연결을 설정해야 합니다.
- 일반적으로 Salesforce 비공개 연결 또는 PrivateLink/VPC 피어링을 사용하여 구성되어 트래픽이 고객의 제어 네트워크에서 벗어나지 않도록 합니다.
- 외부 시스템은 Data 360 IP를 허용 목록으로 지정하고 TLS 1.2+ 암호화를 적용해야 합니다.
인증 및 액세스 제어
- 키 쌍 인증, OAuth 2.0 또는 ID 공급자(IdP) 기반 Trust 위임 지원(Data 360은 신뢰할 수 있는 클라이언트 역할)
- 외부 시스템의 역할 기반 액세스 제어(RBAC)는 쿼리 실행에 대한 최소 권한 액세스를 적용합니다.
성능 및 계산 종속성
- 쿼리 연합은 SQL 실행을 Snowflake 또는 Databricks로 푸시하여 계산 클러스터를 활용합니다.
- 외부 쿼리 로드의 성능 및 비용 규모 - 세분화 대기 시간 및 비용은 외부 계산 구성과 연결됩니다.
변화하는 기준: 파일 통합
- 차세대 모델인 파일 통합 아파치 아이세버그 또는 델타 레이크와 같은 열린 테이블 형식을 활용하여 Data 360이 개체 저장소에서 직접 읽을 수 있습니다(예: Amazon S3, Azure ADLS, Google Cloud Storage).
- 소스 계산 레이어를 우회함으로써 파일 통합 스키마 무결성을 유지하면서 읽기 어려운 분석 워크로드의 대기 시간과 비용을 크게 줄입니다.
거버넌스 및 규정 준수
- 데이터는 소스 플랫폼에서 벗어나지 않으며, 규정 준수, 암호화 및 보존 정책은 원본에서 계속 적용됩니다.
- 모든 메타데이터, 계보와 동의 속성이 Data 360의 Trust 레이어로 전파되어 엔드 투 엔드 추적 가능성을 보장합니다.
솔루션
Data 360 내에서 Snowflake, Databricks 또는 파일 통합 기본 Zero Copy 커넥터를 사용하는 것이 좋습니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| Snowflake Zero Copy Connector | 최고 | 자사 네이티브 통합, Snowflake의 데이터 공유 또는 외부 테이블 API를 통해 실시간 쿼리 연합을 설정합니다. |
| Databricks Zero Copy 커넥터 | 최고 | 델타 레이크의 테이블/뷰에 대한 직접 실시간 액세스를 지원하며, 푸시다운 쿼리는 Databricks 런타임에서 실행됩니다. |
| 파일 통합 (아파치 아이스베르그 / 델타 / 파켓) | 새로운 Best Practice | Data 360은 외부 계산 종속성 없이 개체 저장소에서 열려 있는 테이블 형식을 직접 판독합니다. 대량 데이터 집합에 적합합니다. |
| 개인 네트워크 구성 | 권장 | 보안 네트워크 수준 연합을 위해 Salesforce 비공개 연결 또는 VPC 피어링을 사용합니다. |
| 인증 및 키 관리 | 모범 사례 | 정기적인 순환 및 볼트 관리를 통해 안전한 키 기반 또는 OAuth 기반 인증을 구현합니다. |
| 스키마 등록 | 필수 | Data 360이 외부 스키마를 검색하고 외부 데이터 레이크 개체(외부 DLO)에 매핑합니다. |
| 관리 메타데이터 | 권장 | 모든 외부 DLO는 규정 준수 가시성을 위해 분류, 동의, 계보 메타데이터를 상속합니다. |
스케치
다음 다이어그램은 Data 360에서 0 복사 연결을 설정하고 외부 DLO를 만드는 방법을 설명합니다.
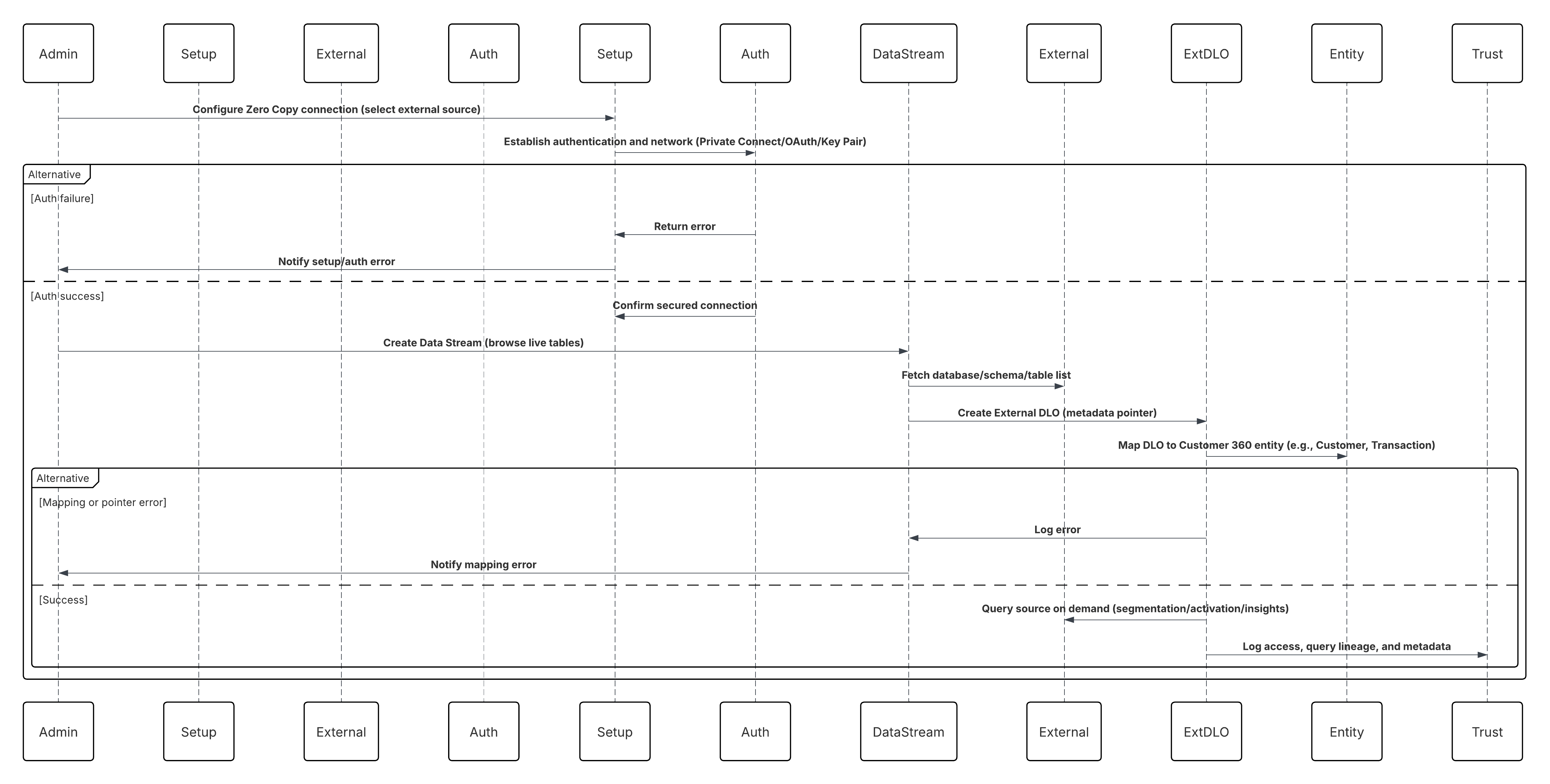
이 시나리오의 경우:
- 관리자는 Data 360 설정에서 Zero Copy 연결(Snowflake, Databricks 또는 파일 통합)을 구성합니다.
- 안전한 인증 및 네트워크 라우팅이 설정됩니다(비공개 연결/OAuth/키 쌍).
- 관리자가 실시간 데이터베이스, 스키마, 테이블을 찾아 외부 소스를 선택하는 데이터 스트림을 만듭니다.
- 데이터를 복사하는 대신 Data 360은 실시간 테이블 또는 아이스버그 파일을 참조하는 메타데이터 포인터인 외부 DLO(데이터 레이크 개체)를 만듭니다.
- 외부 DLO는 Customer 360 엔티티(예: 고객, 트랜잭션, 제품)에 매핑됩니다.
- Data 360은 세분화, 활성화 또는 인사이트 계산 중에 위치한 소스를 쿼리합니다.
- 모든 액세스, 쿼리 계보, 메타데이터는 Data 360 Trust 계층 내에서 감사됩니다.
결과
- 외부 데이터는 Snowflake, Databricks 또는 S3에 남아 있습니다(ETL, 중복, 추가 저장소 없음).
- Data 360은 ID 확인, 계산된 인사이트, 활성화를 위해 엔터프라이즈 규모의 데이터에 대한 실시간 읽기 시간 액세스를 확보합니다.
- 조직은 기존의 거버넌스, 암호화, 규정 준수 프레임워크에서 완벽한 제어를 유지합니다.
- 이 패턴은 로컬 액세스의 성능과 연합 스토리지의 관리 기능을 결합하는 진정한 Zero Copy 아키텍처를 활성화합니다.
메커니즘 호출
호출 메커니즘은 이 패턴을 구현하기 위해 선택한 솔루션에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Snowflake 연합(권장) | 관리되는 엔터프라이즈 데이터 웨어하우스를 사용하는 실시간 고성능 쿼리 연합. |
| Databricks 연합 | 델타 또는 Parquet 지원 데이터 집합이 있는 통합 분석 및 레이크하우스 환경 |
| 파일 통합 (아파치 아이스베르그 / 델타 레이크) | 계산 분리 및 비용 최적화가 핵심인 개체 저장소의 대규모 데이터 집합 |
| 하이브리드 모드(영제 복사 + 수집) | 내역 데이터는 일회성 수집이 필요하지만 실시간 데이터는 Zero Copy를 통해 액세스됩니다. |
오류 처리 및 복구
- 자동 재시도 및 쿼리 백오프: 임시 연결 또는 쿼리 시간 초과는 기하급수 백오프를 사용하여 자동으로 재시도됩니다.
- 스키마 불일치 격리: 소스 스키마의 변경 사항(예: 새 열)은 스키마 거부 대기열에 기록되며, 관리자가 스키마 메타데이터를 다시 매핑하거나 새로 고칠 수 있습니다.
- 인증 페일오버: 자격 증명이 만료되면 Data 360은 저장된 새로 고침 토큰 또는 키 순환 정책을 사용하여 연결을 재시도합니다.
- 가용성 감지 계산: Snowflake 또는 Databricks 클러스터가 일시 중지된 경우 Data 360은 재시작을 계산할 때 연합 작업 및 재시도를 정지합니다.
- 모니터링 통합: Data 360 모니터링 대시보드에 표시되는 모든 연결 상태, 쿼리 대기 시간, 계보드 메타데이터
동임 설계 고려 사항
- 쿼리 결정론: 연합 쿼리는 일관된 스냅샷 시맨틱을 사용하여 세분화 또는 활성화 시 안정적이고 반복 가능한 판독을 보장합니다.
- 외부 DLO 버전 지정: 각 연합 쿼리는 계보 추적을 위한 스키마 및 타임스탬프 메타데이터를 포함합니다.
- 오프셋 없는 액세스: Zero Copy는 읽기 전용이므로 이벤트 오프셋에 의존하지 않습니다. 일관성은 외부 시스템의 ACID 보증(Snowflake/Delta Lake)을 통해 적용됩니다.
- 스키마 드리프트 관리: Data 360에서 버전이 지정된 스키마 매핑을 유지하고 소스 진화에 대한 외부 DLO 메타데이터를 새로 고칩니다.
보안 고려 사항
보안은 연합 모델 전체에서 필수적인 요소로, Trust 또는 규정 준수에 대한 타협을 보장하지 않습니다.
- 암호화: 모든 데이터 교환은 TLS 1.2+를 사용하며 외부 웨어하우스는 AES-256를 사용하여 암호화 상태를 유지합니다.
- 액세스 제어: 외부 테이블은 읽기 전용 권한이 있는 최소 권한 역할을 통해 액세스할 수 있습니다.
- 네트워크 격리: 비공개 연결 또는 VPC 경로를 사용하면 공개 끝점에 노출되지 않습니다.
- 관리 데이터 흐름: 정책 집행을 위해 Data 360 Trust 계층에 계보, 동의 및 분류 메타데이터가 흐릅니다.
- ** 감사 가능:** 모든 연합 쿼리 및 스키마 액세스 이벤트는 규정 준수 추적 가능성을 위해 기록됩니다(GDPR, CCPA, HIPAA).
링크 모음
시기
- 쿼리는 외부 웨어하우스 또는 저장소에 대해 실시간으로 실행되므로 최신 데이터 상태를 실시간으로 확인할 수 있습니다.
- 세분화 또는 활성화 실행은 Snowflake, Databricks 또는 S3 지원 아이스버그 테이블에서 최대 1초의 변경 사항을 반영합니다.
- 쿼리 대기 시간은 소스 시스템의 성능 계층에 따라 다릅니다(일반적으로 쿼리당 초~수십초).
- “새롭고 복사되지 않은” 데이터 액세스를 요구하는 분석 및 AI 워크로드에 적합합니다.
데이터 용량
- 복제 없이 Snowflake 또는 Databricks에 기본적으로 저장된 페타바이트 규모의 데이터 집합을 지원합니다.
- Data 360은 원시 데이터 집합이 아닌 결과만 검색하여 네트워크 및 계산 비용을 최소화합니다.
- 파일 통합 파티션 자르기 및 열로 푸시다운을 통해 대규모 분석 스캔을 최적화합니다.
- 웨어하우스 컴퓨팅 용량 및 Data 360의 연합 쿼리 오케스트레이션 레이어를 사용하여 선형으로 확장합니다.
시/도 관리
- 외부 DLO는 Data 360에서 연결, 스키마, 버전 메타데이터를 유지합니다.
- 스키마 발전은 메타데이터 새로 고침 주기를 통해 자동으로 관리됩니다.
- 쿼리 계보에는 추적 가능성을 위한 타임스탬프, 사용자 ID, 실행 메트릭이 포함됩니다.
- 상태별 수집 또는 오프셋은 유지되지 않으며, 일관성은 외부 소스의 ACID 보증에서 승계됩니다.
복잡한 통합 시나리오
- 하이브리드 모드: Zero Copy(실시간 연합용)와 수집(내역 데이터 집합용)을 결합합니다.
- 교차 창고 액세스: Data 360은 단일 조직 내의 여러 Snowflake 또는 Databricks 테넌트에서 연합할 수 있습니다.
- AI/BI 상호 운용성: 외부 시스템(예: SageMaker, Tableau, Power BI)은 역 Zero Copy를 통해 Data 360의 보강 프로필을 다시 쿼리할 수 있습니다.
- 파일 통합 확장자: 개방형 레이크 형식(Iceberg/Delta)을 채택하는 엔터프라이즈는 하나의 연합 모델 아래에서 구조화된 데이터와 비정형 데이터를 통합할 수 있습니다.
예제
글로벌 금융 기업은 모든 트랜잭션 및 상호 작용 데이터를 Snowflake에 저장하고 Data 360에서 고객 특성 및 마케팅 이벤트를 유지합니다. 제로 복사 데이터 연합을 사용하면 Data 360이 비공개 연결을 통해 Snowflake에 안전하게 연결됩니다.예: "지난 30일 동안 지출이 $10,000 이상인 고객은 Data 360이 쿼리를 Snowflake로 푸시하고 집계된 결과를 검색한 후 Journey Builder에서 해당 프로필을 즉시 활성화합니다. 복제 또는 ETL이 필요하지 않습니다. 이 예에서는 엔터프라이즈 데이터 에코시스템 전체에서 통합된 실시간 연합 인텔리전스를 사용합니다.
아웃바운드 0 복사본은 반대로 동일한 원칙을 확장합니다. Snowflake와 같은 외부 시스템은 Data 360을 내보내거나 Data 360에서 데이터 집합을 복사하는 대신 직접 Data 360을 쿼리하여 강화된 고객 인텔리전스 연합 소스로 취급할 수 있습니다.
- 역연합: 외부 분석 또는 AI 플랫폼은 Data 360의 통합 프로필 데이터를 추출하지 않고 액세스할 수 있습니다.
- 소스에서 데이터 활성화: 비즈니스 팀은 AI 모델링, 보고 또는 고객 개인 설정 등 이미 데이터가 있는 위치에서 인사이트를 활용할 수 있습니다.
- 지연 없이 상호 운용성: 배치 내보내기 또는 동기화 작업이 없으며 플랫폼 간에 인사이트가 즉시 흐릅니다.
- Consistent Semantics: 두 시스템 모두 동일한 본문학 및 스키마 매핑을 공유하므로 컨텍스트와 의미가 에코시스템 전체에서 유지됩니다. Zero copy은 Data 360의 역할을 데이터 저장소에서 심리적 활성화 계층으로 재정의합니다. 이를 통해 조직은 관리되는 고성능 웨어하우스에서 데이터를 정확하게 보관하고 Salesforce의 Trust 범위 내에서 전체 가치를 확보할 수 있습니다. 이 패턴은 현대 데이터 메쉬 및 AI 기본 아키텍처와 일치합니다. 데이터는 분산 상태를 유지하지만 인텔리전스는 통합됩니다. 이제 설계자는 복사할 필요 없이 더욱 빠르고 세련되고 규정을 준수할 수 있는 활성화 파이프라인을 구축할 수 있습니다.
컨텍스트
Salesforce Data 360은 통합 고객 프로필 및 활성화를 지원하며, Snowflake 또는 Databricks와 같은 엔터프라이즈 데이터 웨어하우스는 데이터 과학, 기계 학습, BI 워크로드에 대한 분석 백본 역할을 합니다. Salesforce Data 360의 제로 카피 아웃바운드 공유 기능은 이러한 환경을 원활하게 연결하여 복제 또는 ETL 없이 Snowflake 또는 Databricks 내에서 직접 조화된 Data 360 데이터에 대한 관리, 보안, 실시간 액세스를 허용합니다. 이를 통해 분석가 및 데이터 과학자가 마케팅, 세일즈, 서비스 활성화를 지원하는 같은 실시간 신뢰할 수 있는 데이터를 쿼리, 시각화, 모델링할 수 있습니다.
문제
Data 360의 통합 고객 프로필 및 계산된 메트릭(예: 평생 가치, 이탈 위험)을 데이터 복사, 거부 관리 또는 기존의 역 ETL 파이프라인을 통해 대기 시간을 도입하지 않고 엔터프라이즈에서 안전하고 효율적으로 외부 분석 시스템에 어떻게 노출할 수 있습니까?
Force
이 패턴은 여러 가지 아키텍처, 거버넌스, 운영 고려 사항을 도입합니다.
- 관리 보안: Data 360 데이터에 대한 액세스는 제어되고 세분화되고 감사할 수 있어야 합니다. Zero Copy 공유는 명시적 개체 수준 액세스를 사용하므로 지정된 소비자에게는 승인된 데이터 모델 개체(DMO) 및 계산된 인사이트 개체(CIO)만 제공됩니다.
- 명시적 객체 선택: 관리자는 데이터 공유를 통해 공유 가능한 데이터를 큐레이팅하여 노출할 개체를 명시적으로 선택합니다. 이를 통해 거버넌스를 유지하고 위험 노출을 최소화할 수 있습니다.
- Bilateral 구성: Data 360 및 외부 웨어하우스 모두 설정이 필요합니다. Data 360은 데이터 공유 대상을 정의하고(Snowflake/Databricks), 수신 시스템은 공유를 수락하고 인스턴스화해야 합니다.
- 쿼리 연합 모델: 수락되면 외부 플랫폼이 연합 보기를 통해 실시간으로 관리되는 Data 360 데이터를 쿼리하여 추출 작업 또는 수동 새로 고침 주기를 제거합니다.
- Open Standards Evolution: 파일 통합 같은 새로운 접근 방식은 오픈 테이블 형식(예: Apache Iceberg)을 활용하여 스토리지 계층에서 읽기 전용 액세스를 활성화하여 다중 클라우드 아키텍처 전반에서 확장성, 성능, 상호 운용성을 향상합니다.
솔루션
이 솔루션은 Snowflake 또는 Databricks와 같은 데이터 플랫폼과 Salesforce Data 360의 네이티브 Zero Copy 공유를 활용합니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 데이터 공유 생성 | 최고 | 관리자가 Data 360 내에서 데이터 공유를 만들어 선택한 DMO 및 CIO(예: 통합 개인, 고객 건강 점수)를 추가합니다. |
| 목표 구성 | 최고 | Snowflake 또는 Databricks 계정 식별자 및 인증 매개 변수를 지정하는 데이터 공유 대상을 만듭니다. |
| 공유 게시 | 모범 사례 | 데이터 공유를 데이터 공유 대상에 연결하여 안전하게 게시합니다. |
| 스토리지 수용 | 필수 | 외부 관리자가 공유를 수락하여 공유 개체를 창고의 읽기 전용 보기/테이블로 구체화합니다. |
| Granular Access Control | 권장 | Data 360 내에서 개체 및 역할 기반 권한을 적용하고 웨어하우스 수준 역할 기반 액세스 제어에 부합합니다. |
| 연합 쿼리 액세스 | 최고 | 분석가는 표준 SQL을 통해 실시간 공유 데이터를 쿼리하며 다운스트림 분석 및 ML을 위해 기본 웨어하우스 데이터와 조인합니다. |
| 파일 통합 옵션 | 옵션 | 대용량 데이터 집합의 경우 계산 종속성이 없는 직접 S3 또는 델타 레이크 판독을 위해 Apache Iceberg 기반 연합을 활용합니다. |
스케치
다음 다이어그램은 Salesforce Data 360에서 외부 데이터 플랫폼으로의 호출을 보여줍니다.
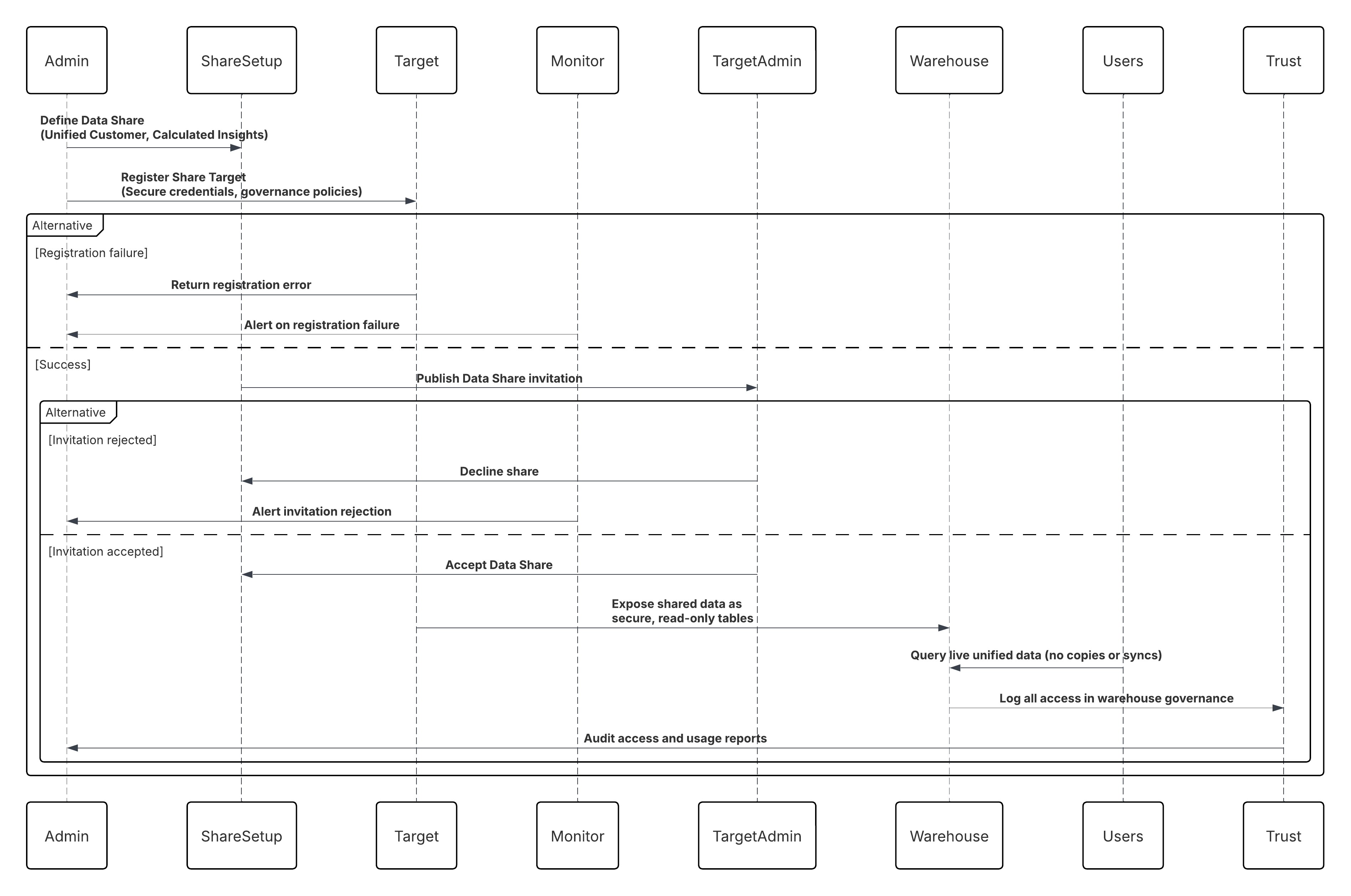
이 경우:
- Data 360 관리자는 통합 고객 및 계산된 인사이트 개체를 포함하는 데이터 공유를 정의합니다.
- 데이터 공유 대상(Snowflake 또는 Databricks 계정)이 보안 자격 증명 및 거버넌스 정책으로 등록됩니다.
- Data 360에서 공유를 게시하며 Snowflake/Databricks 관리자가 수락합니다.
- 공유된 데이터는 창고 내에서 안전한 읽기 전용 테이블로 표시됩니다.
- 분석가, BI 도구 또는 ML 파이프라인은 복사하거나 동기화하지 않고 실시간 통합 고객 데이터를 쿼리합니다.
- 모든 액세스는 Data 360 Trust Layer 및 창고 거버넌스 로그 내에서 감사됩니다.
결과
- 외부 웨어하우스는 조화된 Data 360 데이터에 실시간으로 쿼리 가능한 액세스할 수 있습니다.
- 역 ETL 파이프라인을 제거하여 운영 부담 및 대기 시간을 줄입니다.
- 통합 데이터에서 직접 AI/ML 교육, 예측 모델링, 고급 BI를 활성화합니다.
- 중복 제한, 강력한 거버넌스, 안전한 설계별 액세스 제어를 유지합니다.
- 단일 거버넌스 모델 아래 인바운드 연합과 아웃바운드 공유가 공존하는 양방향 0 Copy 루프를 완료합니다.
메커니즘 호출
호출 메커니즘은 이 패턴을 구현하기 위해 선택한 솔루션에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Snowflake 보안 데이터 공유(권장) | 엔터프라이즈 웨어하우스가 Snowflake이고 데이터 이동 또는 중복 없이 조화된 Data 360 데이터 집합에 대한 실시간 관리 액세스 권한이 필요한 경우 사용합니다. 제로 대기 공유 및 네이티브 계보 집행이 필요한 분석, AI, 규정 준수 중심 워크로드에 적합합니다. |
| Databricks 델타 점유율 | 다운스트림 소비자가 Databricks 또는 Delta Lake 환경에서 운영하고 열려 있는 델타 공유 프로토콜을 통해 통합 또는 활성화된 데이터 집합에 대한 실시간 읽기 전용 액세스 권한이 필요한 경우 사용합니다. |
| 외부 테이블 공유 (아파치 아이스베르크 / 파켓) | 개체 저장소(S3, ADLS 또는 GCS)에서 오픈 형식 아키텍처를 유지하고 Athena, BigQuery 또는 Snowflake-on-Iceberg와 같은 분석 엔진 간의 상호 운용 가능한 저렴한 비용 공유가 필요한 경우 사용합니다. |
| 데이터 공유 API(프로그래밍 액세스) | 사용자 정의 앱 또는 미들웨어(예: MuleSoft)가 이벤트 기반 새로 고침 알림 및 세분화된 액세스 제어를 통해 API를 통해 공유 데이터 집합을 안전하게 검색, 구독 또는 사용해야 하는 경우 사용합니다. |
| 하이브리드 공유(제로 복제 + 아웃바운드 공유) | 양방향 교환 패턴을 구현할 때 사용합니다. 인바운드 데이터의 경우 Zero Copy를 활용하고 인사이트를 게시하는 경우 아웃바운드 데이터 공유를 활용하여 엔터프라이즈 데이터 플레인 전반에서 시맨틱 및 거버넌스 일관성을 보장합니다. |
오류 처리 및 복구
- 연결 재시도: Data 360과 창고 간의 임시 연결 또는 인증 실패를 자동으로 다시 시도합니다.
- 공유 검증: 잘못되었거나 권한이 없는 공유 구성은 관리자 검토 대기열에서 격리됩니다.
- 동기 상태 모니터링: Data 360은 모니터링 대시보드를 통해 실시간 공유 상태, 쿼리 대기 시간, 액세스 로그를 표시합니다.
- 액세스 취소: 관리자는 공유를 즉시 취소하여 잔차 데이터 사본 없이 양쪽 끝에 대한 액세스를 비활성화할 수 있습니다.
- 관리 감사 내역: 모든 구성 및 액세스 변경 사항은 규정 준수 확인을 위해 기록됩니다.
동임 설계 고려 사항
- 일관적인 공유 식별: 각 데이터 공유 및 데이터 공유 대상 쌍에는 정확한 거버넌스 및 액세스 추적 가능성을 보장하는 고유한 식별자가 있습니다.
- 변경할 수 없는 보기: 공유된 데이터 개체는 읽기 전용이며, 소비자는 상태를 변경할 수 없으므로 결정적 결과 및 규정 준수가 보장됩니다.
- Atomic Share Lifecycle: 공유 게시, 취소, 업데이트는 완료 또는 롤백된 원자 작업입니다.
- 재생 일관성: Data 360 데이터가 새로 고쳐지면 웨어하우스 측 쿼리는 항상 최신 일관된 스냅샷을 반환하므로 오래된 읽기가 없어집니다.
보안 고려 사항
보안은 제로 카피 공유의 모든 측면에 기반합니다.
- 인증: OAuth 2.0, 비공개 키 교환 또는 ID 연합(OIDC)을 사용하여 설정된 상호 Trust.
- 암호화: 전송 중(TLS 1.2+) 및 유지 중(AES-256)으로 암호화된 데이터
- 액세스 제어: 개체 수준 권한은 Data 360 Trust 계층에 따라 최소 권한 액세스를 적용합니다.
- 네트워크 보안: 데이터 교환은 Salesforce 비공개 연결 또는 보안 데이터 교환 API와 같은 비공개 네트워크 링크를 통해 이루어집니다.
- 거버넌스 메타데이터: 모든 공유 개체에는 추적 가능성 및 규정 준수를 위해 계보, 분류, 동의 특성이 포함되어 있습니다.
링크 모음
시기
- 실시간 가용성: 공유된 데이터는 복제 지연 없이 Data 360의 최신 상태를 반영합니다.
- 쿼리 신선도: DMO 또는 CIO의 변경 사항이 공유 웨어하우스 보기에 즉시 전파됩니다.
- 성능 탄력성: 쿼리 푸시다운은 창고 계산 리소스에 동적으로 조정됩니다.
- 모니터링: 실시간 대시보드는 운영 보증을 위한 공유 대기 시간 및 쿼리 성능 메트릭을 표시합니다.
데이터 용량
- 확장 가능한 공유: 분석 요구에 따라 세분화된 개체 수준 또는 전체 도메인 데이터 공유를 지원합니다.
- 최적화된 쿼리 성능: Snowflake/Databricks는 공유 데이터를 지능적으로 캐시하여 대기 시간을 최소화합니다.
- 스토리지 효율: 중복 제거는 중복 저장소 비용을 제거합니다.
- 파일 통합 옵션: 페타바이트 규모의 데이터 집합의 경우 Direct Iceberg 기반 공유는 계산을 우회하고 액세스를 가속화합니다.
시/도 관리
- 스키마 진화: 버전 제어 스키마는 Data 360 모델이 발전할 때 호환성을 보장합니다.
- 액세스 상태 추적: 수명 주기 관리를 위해 Data 360 내에서 유지되는 활성/비활성 공유 상태입니다.
- 메타데이터 동기화: 공유 개체 정의 업데이트는 다운스트림 웨어하우스 카탈로그에 자동으로 반영됩니다.
- 변경할 수 없는 국가 보증: 웨어하우스 보기는 항상 Data 360 데이터의 일관된 시점 상태를 나타냅니다.
복잡한 통합 시나리오
- 하이브리드 모드: Zero Copy(실시간 연합용)와 수집(내역 데이터 집합용)을 결합합니다.
- 교차 창고 액세스: Data 360은 단일 조직 내의 여러 Snowflake 또는 Databricks 테넌트에서 연합할 수 있습니다.
- AI/BI 상호 운용성: 외부 시스템(예: SageMaker, Tableau, Power BI)은 역 Zero Copy를 통해 Data 360의 보강 프로필을 다시 쿼리할 수 있습니다.
- 파일 통합 확장자: 개방형 레이크 형식(Iceberg/Delta)을 채택하는 엔터프라이즈는 하나의 연합 모델 아래에서 구조화된 데이터와 비정형 데이터를 통합할 수 있습니다.
예제
클라우드 간 분석을 사용하면 조직에서 Snowflake 및 Databricks와 같은 플랫폼에서 관리되는 Salesforce Data 360 데이터와 네이티브 데이터 집합을 결합하여 포괄적인 분석 보기를 제공할 수 있습니다. 다중 테넌트 액세스를 통해 다양한 사업부가 데이터를 복제하지 않고 별도의 공유를 통해 선별된 정책 제어 데이터 조각을 안전하게 소비할 수 있습니다. 그러면 데이터 과학자는 Snowflake ML 또는 Databricks MLflow 환경 내 통합 고객 프로필에서 직접 모델을 교육하여 연합형 AI 및 기계 학습을 수행할 수 있습니다. 이 프로세스 동안 내장된 계보, 거버넌스, 감사 기능을 통해 모든 데이터 액세스 및 사용이 GDPR 및 HIPAA와 같은 엔터프라이즈 정책 및 규제 요구 사항을 계속 준수합니다.
Data Cloud One을 사용하면 여러 Salesforce 조직(예: 사업부, 지역, 제품 라인 또는 인수)이 있는 조직에서 단일 중앙 Data 360 인스턴스를 공유할 수 있습니다. 이 조직은 "홈 조직"으로 작동하며, "공동 조직"이라는 다른 조직은 최소한의 노력과 사용자 정의 코드 없이 완전한 거버넌스 제어를 사용하여 통합 데이터에 액세스하고 작업을 수행할 수 있습니다.
컨텍스트
기업은 두 개 이상의 Salesforce 조직(예: 세일즈용, 서비스용, 마케팅용 또는 고유 지역용)을 실행하는 경우가 많습니다. 각 조직에 자체 데이터, 구성, 프로세스가 있을 수 있습니다. Data Cloud One 이전에는 각 조직에 자체 Data 360 설정 또는 복잡한 사용자 정의 코드가 있어야만 조직 전체에서 데이터를 공유할 수 있었습니다. Data Cloud One은 Data 360을 사용하는 단일 "홈" 조직과 하위 코드 구성 및 메타데이터 공유를 통해 연결되는 여러 "동료" 조직을 허용하여 이를 간소화합니다.
문제
비즈니스는 홈 조직의 Data 360에서 수집, 조화 및 관리하는 통합된 Customer 360 데이터를 모든 Salesforce 조직에서 일관되게 사용할 수 있도록 하며, 동일한 기본 데이터를 모두 사용하도록 할 수 있으며, 중복 작업, 사용자 정의 코딩, 조직당 별도의 Data 360 인스턴스 및 거버넌스 공백을 방지할 수 있습니다.
Force
이 패턴은 여러 가지 아키텍처, 보안, 성능 고려 사항을 도입합니다.
- 다중 조직 복잡성: 각 사업부의 조직에 서로 다른 데이터, 사용자 정의 개체, 보안, 프로세스가 있을 수 있으므로 일관된 통합 보기를 유지하기가 어렵습니다.
- 중복 및 비용: 조직당 별도의 Data 360 인스턴스를 실행하면 추가 설정, 추가 관리, 추가 라이센스, 데이터 실패 위험이 발생합니다.
- 거버넌스 및 데이터 공유 제어: 각 동료 조직이 볼 수 있고 조치를 취할 수 있는 데이터를 결정해야 합니다. 관리 위험 없이 단순히 "모두"를 공유할 수는 없습니다.
- 설정 속도: 마케팅, 세일즈 또는 서비스 팀은 클릭 구성 솔루션이 필요하므로 사용자 정의 코드를 통해 교차 조직 데이터를 사용할 수 있을 때까지 수주를 기다릴 수 없습니다.
- 데이터 레지던스, 지역적 고려 사항: 가정 및 동료 조직이 다른 지역에 있는 경우 데이터가 저장되는 위치 또는 공유 방법에 대한 법적 또는 규제 제약이 있을 수 있습니다.
솔루션
다음 표에는 이 통합 문제에 대한 다양한 솔루션이 포함되어 있습니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 홈 조직 프로비저닝 | 최고 | 하나의 Salesforce 조직을 Data 360이 프로비저닝되는 홈 조직으로 지정합니다. 이는 중앙 데이터 리포지토리 및 거버넌스 허브가 됩니다. |
| Companion Org 연결 | 최고 | Data Cloud One 앱을 통해 홈 조직에서 하나 이상의 동료 조직에 대한 동료 연결을 구성합니다. 사용자 정의 코드가 필요하지 않습니다. |
| 데이터 공간 정의 | 모범 사례 | 홈 조직 내의 데이터 공간을 정의하여 데이터(예: 리테일, 서비스, 마케팅)를 논리적으로 분할하고 액세스 경계를 격리합니다. |
| 데이터 공간 공유 | 최고 | 홈 조직에서 동료 조직으로 선택한 데이터 공간을 명시적으로 공유하여 통합 데이터의 관리 기반 역할 기반 가시성을 보장합니다. |
| 액세스 구성 | 필수 | 동료 조직에서 Data Cloud One 앱을 활성화하고 프로필, 인사이트, 세그먼트 액세스에 대한 사용자 권한을 할당합니다. |
| 거버넌스 및 정책 관리 | 권장 | 홈 조직에서 모든 수집, ID 확인 및 Trust 구성을 중앙 집중화하고 종단간 관리를 유지합니다. |
| 다중 조직 동기화 | 최고 | 홈 조직의 데이터 변경 사항 및 계산된 인사이트는 관리 동기화 파이프라인을 통해 동료 조직 전체에서 실시간으로 반영됩니다. |
| 하이브리드 배포 옵션 | 옵션 | 대기업의 경우 여러 동료 조직이 로컬 컨텍스트 및 규정 준수 경계를 유지하면서 단일 홈 조직에 연결할 수 있습니다. |
스케치
다음 다이어그램은 Salesforce가 데이터 마스터인 이 패턴의 이벤트 순서를 보여줍니다.
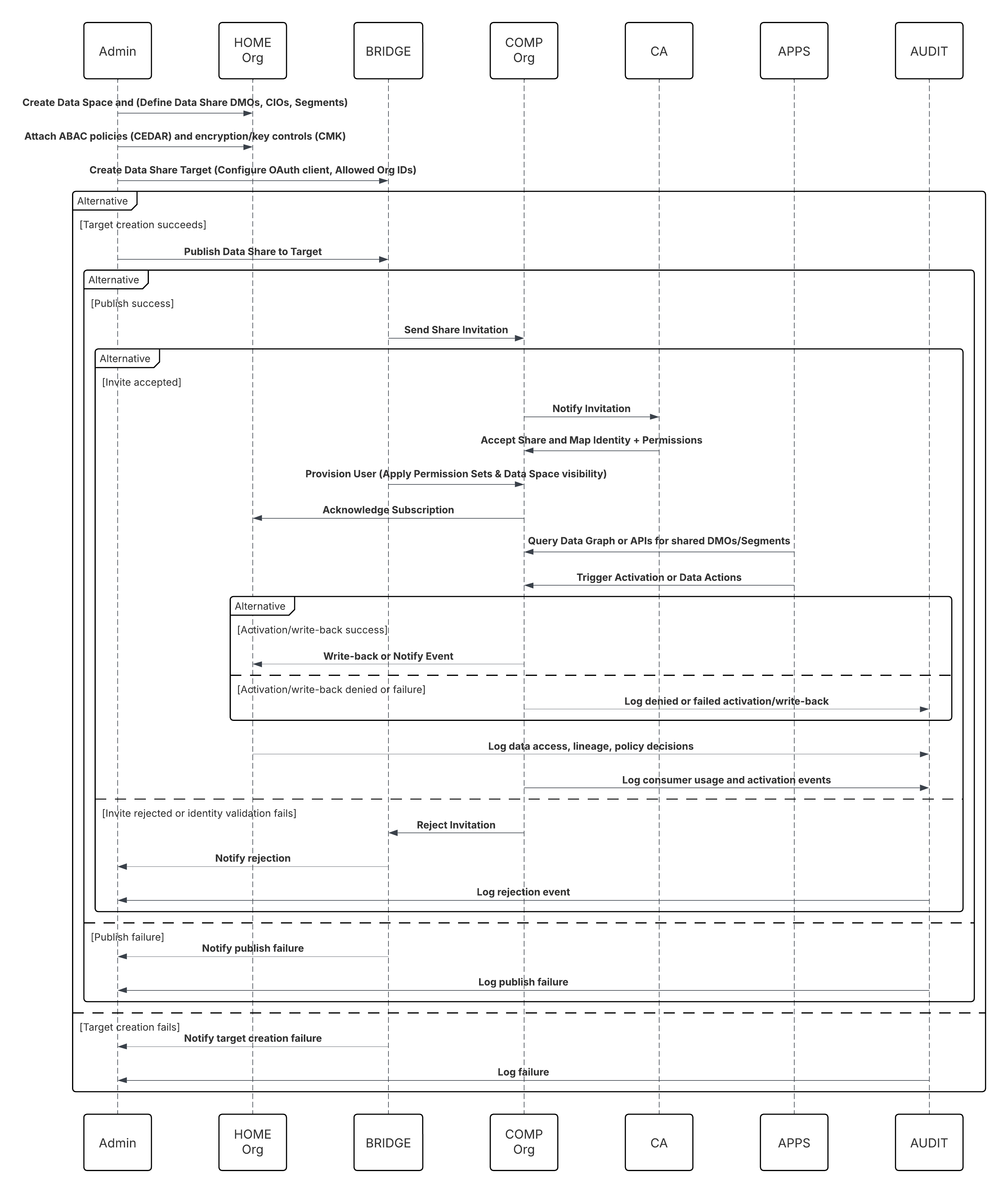
이 경우:
- 홈 관리자: 데이터 공간을 만들고 데이터 공유를 정의합니다(선택한 DMO/CIO, 세그먼트).
- 홈 관리자: 동료 조직에 대한 데이터 공유 대상을 만들고 Trust(OAuth 클라이언트, 허용된 조직 ID)를 구성합니다.
- 홈 관리자: 대상에 데이터 공유를 게시하고 ABAC 정책(CEDAR) 및 암호화/키 제어(필요한 경우 CMK)를 첨부합니다.
- 공동 조직 관리자: 초대를 수신하고, ID 매핑을 확인하고, 공유를 수락합니다.
- Companion Org: Data Cloud One Bridge는 Data Cloud One 사용자를 프로비저닝하고 권한 집합 및 데이터 공간 가시성을 적용합니다.
- Companion Org 앱(플로스 / Einstein / Apex): 데이터 그래프를 쿼리하거나 Data Cloud One API를 호출하여 공유 DMO 또는 세그먼트를 읽습니다.
- 활성화: 동료 조직이 활성화를 트리거하거나 데이터 작업을 통해 다시 쓸 수 있습니다(허용되는 경우).
결과
- 연결된 모든 조직에서 고객 데이터(Customer 360)에 대한 단일 진실 소스 - 중복 Data 360 인스턴스가 없습니다.
- 가치 실현 시간을 단축합니다. 동료 조직은 몇 주간의 사용자 정의 코딩이 아닌 몇 분 만에 통합 데이터 및 Data 360 지원 기능에 액세스할 수 있습니다.
- 제어된 데이터 공유. 승인된 데이터 공간만 공유되므로 보안 및 거버넌스를 유지하고 비즈니스 유연성을 활성화합니다.
- 비즈니스 기능(세일즈, 서비스, 마케팅)은 동일한 통합 데이터 파운데이션에서 작동하여 엔터프라이즈 전반에서 일관된 메트릭, 활성화, 인사이트를 제공합니다.
메커니즘 호출
호출 메커니즘은 이 패턴을 구현하기 위해 선택한 솔루션에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Data Cloud One 네이티브 공유(권장) | 여러 Salesforce 조직(Sales, Service 또는 Industry Cloud)이 Data 360\에서 직접 통합 고객 데이터에 실시간으로 액세스해야 하는 경우 사용합니다. 이렇게 하면 복제가 해제되고 골든 레코드, 세그먼트, 계산된 인사이트에 대한 제로 대기 시간 액세스가 활성화됩니다. |
| Data Cloud One Bridge를 통한 조직 간 공유 | 여러 사업부 또는 자회사가 별도의 Salesforce 조직에서 운영되지만 중앙 Data 360 인스턴스에서 공통 고객 데이터 및 세그먼트에 대한 공유 액세스 권한이 필요한 경우 사용합니다. 독립 운영 체제를 유지하는 다중 조직 엔터프라이즈에 적합합니다. |
| Einstein 1 플랫폼 쿼리 API | Salesforce 앱, 플로 또는 Einstein Copilot Data 360 데이터를 프로그래밍 방식으로 쿼리하거나 활성화해야 하는 경우 사용합니다. 배치 내보내기를 사용하지 않고 다른 Salesforce 응용 프로그램에 통합 프로필, 메트릭 또는 활성화 결과를 실시간으로 검색할 수 있습니다. |
| Salesforce 채널 활성화 | 개인 설정, 캠페인 실행 또는 에이전트 지원 환경을 위해 Marketing Cloud, Service Cloud 또는 Commerce Cloud에 Data 360 데이터(세그먼트, 인사이트 또는 특성)를 활성화해야 하는 경우 사용합니다. |
| 데이터 그래프 액세스(시맨틱 쿼리 레이어) | 수동 조인 또는 변환 없이 Copilot, AI 워크플로, 실시간 클라우드 간 분석을 지원하는 Salesforce 데이터 그래프를 통해 통합 데이터 모델에 시맨틱 수준으로 액세스해야 하는 경우 사용합니다. |
오류 처리 및 복구
- 교차 조직 동기화 복원성: Data Cloud One은 임시 네트워크 또는 플랫폼 오류에 대해 기하급수적 백오프를 사용하여 홈 및 동료 조직 간에 실패한 동기화 작업을 자동으로 다시 시도합니다.
- 일부 배치 절연: 실패한 레코드 배치는 조정에 성공할 때까지 홈 조직 내의 재시도 대기열에서 격리되어 데이터 분산을 방지합니다.
- 스키마 거부 거버넌스: 관리자가 검토하고 수정할 수 있도록 스키마 또는 매핑 불일치가 스키마 거부 대기열로 라우팅됩니다.
- 재생 및 재개 연속성: 각 동기화 작업은 오프셋 검사점을 유지하므로 복제가 중복되지 않고 마지막으로 성공적으로 커밋된 후 다시 시작할 수 있습니다.
- 통합 모니터링: 모든 실패, 재시도 및 복구 메트릭은 가시성 및 SLA 보증을 위해 Trust 계층 모니터링 대시보드에 수집됩니다.
동임 설계 고려 사항
- 결정적 동일성 키: 모든 동기화 이벤트에는 정확한 일회성 처리를 보장하기 위해 고유한 키(조직 ID + 레코드 ID + 버전 번호)가 포함되어 있습니다.
- 재생 안전: 중복 또는 재생된 이벤트는 커밋 시 필터링되어 다운스트림 DMO 및 CIO 업데이트가 일관되도록 합니다.
- Atomic Commit Semantics: 동료 조직은 성공적인 다운스트림 작성 후에만 데이터를 커밋됨으로 표시하여 교차 조직 트랜잭션 무결성을 유지합니다.
- 전쟁 해결: 다중 소스 업데이트는 마지막 쓰기-수주 또는 정책 중심 병합 논리를 따르며 계보와 일관성을 유지합니다.
- 검사점 지속성: 동기화 작업은 안전한 복구 및 재생을 위해 마지막으로 처리된 오프셋 및 Trust 레이어 내 상태를 유지합니다.
보안 고려 사항
- 강력한 인증: 가정 및 동료 조직 간의 연결은 연결된 앱을 통해 관리되는 자동 순환 토큰과 함께 상호 OAuth 2.0을 사용합니다.
- 전체 승인: 동료 조직은 관리되는 데이터 공유 정책을 통해 명시적으로 공유된 특정 데이터 공간, DMO 또는 CIO에만 액세스할 수 있습니다.
- 모든 곳에 암호화: 데이터는 전송(TLS 1.2+) 및 유지(AES-256) 시 홈 및 동료 조직 모두에서 암호화됩니다.
- 최소 권한 원칙: 통합 사용자는 필수 개체에만 범위를 지정하며, 관리 또는 시스템 수준 권한은 전파되지 않습니다.
- ** 감사 및 규정 준수 가시성:** 모든 동기화 이벤트, 스키마 변경 사항, 자격 증명 업데이트 및 액세스 권한 부여가 Data 360 Trust 레이어에 기록되어 완벽한 추적 가능성을 제공합니다.
- 개인 네트워크 격리: Salesforce 비공개 연결 또는 비공개 링크(옵션)는 안전한 내부 채널에서만 데이터 복제를 보장합니다.
링크 모음
시기
- 홈 및 동료 조직 간의 동기화는 일반적으로 소스 조직에서 데이터가 변경된 후 몇 초 이내에 거의 실시간으로 수행됩니다.
- Zero Copy 아키텍처는 복제 또는 배치 지연 없이 모든 참가 조직에서 공유 데이터를 즉시 쿼리할 수 있도록 합니다.
- 활성화 및 세분화 작업에 연결된 조직의 최신 업데이트가 자동으로 반영되므로 운영 체계가 최신 상태로 유지됩니다.
- 종단간 대기 시간은 결정적이며 Data Cloud One의 오케스트레이션 파이프라인에 따라 관리되므로 로드 중에도 일관된 교차 조직 시간을 보장합니다.
데이터 용량
- 조직당 수십억 개의 레코드를 관리할 수 있도록 지역 및 사업부 전반에 걸쳐 다중 테넌트의 대규모 데이터 동기화를 위해 고안되었습니다.
- 데이터가 중복되지 않고 참조되므로 전역 쿼리 가능성을 유지하면서 저장소 이력이 줄어듭니다.
- 스트리밍 델타 및 메타데이터 압축은 대역폭을 최적화하고 변경 속도가 높은 개체(예: 연락처, 주문)에 대한 커밋 오버헤드를 제공합니다.
- Trust 계층을 통해 어댑티브 로드 밸런싱 및 오케스트레이션을 통해 여러 동료 조직에서 가로로 확장합니다.
시/도 관리
- 동기화된 모든 데이터 집합은 메타데이터 계보, 버전, 조직 소유권 컨텍스트를 유지하여 전체 추적 가능성을 보장합니다.
- 검사점 지속성은 조직 간에 마지막으로 동기화된 오프셋을 수집하여 중복 없이 복구할 수 있습니다.
- 조직 간의 스키마 버전 지정 및 시맨틱 정렬은 Trust 레이어에 의해 자동으로 관리됩니다.
- 수동 상태 재설정은 필요하지 않습니다. 동기화 상태는 Data Cloud One 오케스트레이션 서비스를 통해 유지됩니다.
복잡한 통합 시나리오
- Cross-Org Federation: 통합 관리 모델 아래 여러 Data 360 테넌트 또는 지역에서 원활한 쿼리 및 활성화를 활성화합니다.
- 하이브리드 동기화: 트랜잭션 업데이트를 위한 거의 실시간 복제를 대량 또는 보관 데이터에 대해 예약된 동기화와 결합합니다.
- 다중 지역 거버넌스: 상주, 동의, 규정 준수 경계를 존중하면서 지리적으로 분산된 데이터 공유를 지원합니다.
- AI 및 자동화 활성화: 동기화된 데이터는 조직 전체에서 Einstein AI, Agentforce 또는 사용자 지정 ML 모델을 즉시 구동하여 실시간으로 교차 조직 인텔리전스를 제공합니다.
예제
글로벌 리테일 조직에는 Consumer Retail, Premium Brands, International Markets와 같은 세 가지 Salesforce 조직이 있습니다. Consumer Retail 조직에서 Data 360을 프로비저닝합니다(가정 조직으로 지정). Data Cloud One을 사용하여 프리미엄 브랜드 및 국제 시장 조직에 대한 동료 연결을 설정합니다. 각 동료 조직과만 적절한 데이터 공간(예: “Customer 360 – Retail Profiles” 및 “Customer 360 – Premium Profiles”)을 공유합니다. 프리미엄 브랜드 조직에서 마케팅 팀은 통합 고객 프로필을 보고, 계산된 인사이트(예: 프리미엄 고객 생애 가치)를 기반으로 세그먼트를 구축하고, 사용자 정의 코딩 또는 데이터 중복 없이 홈 조직의 Data 360 인스턴스에서 제공되는 마케팅 자동화를 트리거할 수 있습니다.
데이터 활성화는 Salesforce Data 360의 가치를 실제로 생성하는 과정입니다. 플랫폼 내에 존재하는 통합, 보강, 관리 데이터를 가져와 비즈니스 전체에서 작동하도록 만드는 프로세스입니다. 실제로는 마케팅 자동화, 서비스 콘솔, 세일즈 활성화, 분석 또는 AI 모델 등 Data 360에서 고객을 참여시키는 시스템에 선별된 세그먼트, 계산된 인사이트, 컨텍스트 특성을 안전하게 전달하는 것을 의미합니다. 기술적 관점에서 활성화 패턴은 트리거되는 채널, 발생하는 변환 또는 매핑, 정책이 적용되는 방법 등 이 데이터가 이동하는 방식을 정의합니다. 이러한 패턴은 단순히 데이터를 내보내는 것이 아니라 측정 가능한 비즈니스 결과를 촉진하는 정책 인식 데이터 플로를 실시간으로 오케스트레이션하는 것입니다. 각 활성화 경로는 Customer 360 실시간 운영 자산으로 전환하며, 모든 접점에서 개인 설정, 예측 결정, 지속적인 학습을 제공합니다.
배치 활성화는 Data 360에서 데이터를 내보내는 데 가장 널리 사용되고 운영적으로 검증된 방법으로 남아 있습니다. 예약된 케이던스에서 작동하며, 정기적으로 다운스트림 플랫폼에 미리 정의된 대상 세그먼트 또는 특성 집합을 게시합니다. 이 패턴은 일관된 대량 대상 그룹 전달이 아닌 즉각적인 업데이트에 의존하는 마케팅 및 참여 워크플로에 이상적입니다. 일반적인 사용 사례에는 이메일 여정, 직접 메일 캠페인 또는 디지털 광고 네트워크에 대한 대상 업로드가 포함됩니다. 각 활성화 실행은 Data 360의 통합 프로필 그래프에서 적격 세그먼트를 추출하고, 거버넌스 및 동의 정책을 적용하고, 출력을 대상 시스템에 안전하게 전송합니다. 아키텍처적으로 배치 활성화는 예측 가능, 감사 가능, 비용 효율적인 데이터 배포 접근 방식을 제공하며, 운영 단순성과 엔터프라이즈급 신뢰도에 균형을 맞춥니다. 적시에 전달되고 제어된 올바른 데이터가 측정 가능한 비즈니스 영향을 미치는 대규모 캠페인 실행의 기반입니다.
컨텍스트
현대 마케터는 이메일, 광고, 모바일, 웹 등 여러 참여 채널에서 작업하며, 각각 정확하고 시기 적절하며 맞춤화된 고객 대상을 요구합니다. Data 360은 이러한 대상 그룹을 위한 통합 기반 역할을 하며 모든 시스템의 고객 데이터를 실행 가능한 풍부한 세그먼트로 결합합니다. 배치 활성화는 Data 360에서 다운스트림 마케팅 또는 광고 플랫폼으로 세그먼트를 내보내는 데 사용되는 가장 일반적인 활성화 패턴입니다. 일반적인 대상에는 Marketing Cloud Engagement, Google Ads, Meta 사용자 정의 대상 그룹 또는 LinkedIn Ads가 포함되며, 여기에서 캠페인을 선별된 대상 그룹에 직접 실행할 수 있습니다.
문제
마케팅 팀이 Data 360의 통합 및 보강 데이터를 사용하여 구축된 정밀하게 정의된 대상 그룹을 사용하여 외부 마케팅 또는 광고 시스템에서 활성화할 수 있도록 만드는 방법은 무엇입니까? 예를 들어 세그먼트: "지난 90일 동안 구매하지 않았지만 최근에 웹 사이트에 참여한 중요한 고객" 마케터는 캠페인의 관련성과 효과를 유지하기 위해 이 대상 그룹이 정확하게 전송되고 관련 특성(예: 충성도 계층, 지역 또는 예측 CLV)으로 보강되고 정기적으로 새로 고쳐야 합니다.
Force
배치 활성화 패턴을 구성하는 몇 가지 기술 및 운영 요소:
- ID 매핑: 정확한 대상 그룹 전달을 위해서는 Data 360의 통합 개인 ID를 Marketing Cloud의 구독자 키 또는 디지털 광고 플랫폼의 해시 이메일 등 대상 시스템의 해당 식별자에 매핑해야 합니다. 이를 통해 정확한 일치를 보장하고 대상 지정 오류를 방지할 수 있습니다.
- 속성 선택 및 보강: 마케터는 ID를 벗어나 이름(성 없이), 충성도 상태, CLV 또는 기타 개인 설정된 특성과 같은 추가 프로필 데이터를 포함하여 다운스트림 개인 설정 및 분석을 활성화해야 합니다.
- 목표 플랫폼 구성: 각 대상은 연결 세부 사항, 인증, 데이터 필드 매핑을 포함하여 Data 360에 활성화 대상으로 등록되어야 합니다. 이 일회성 설정은 보안 연결을 정의하고 활성화된 데이터를 수신할 수 있는 시스템을 관리합니다.
- 거버넌스 및 규정 준수: 데이터 활성화는 동의 메타데이터, 개인정보 보호정책(예: GDPR 또는 CCPA) 및 통합 프로필에 저장된 마케팅 권한을 준수해야 합니다. 동의 인식 활성화를 통해 데이터가 승인된 목적으로만 사용됩니다.
- 예약 및 성과: 활성화는 다운스트림 대상 그룹을 최신 상태로 유지하기 위해 주로 매일 또는 매시간 예약됩니다. 중복 또는 데이터 손실 없이 대용량 및 증분 새로 고침을 효율적으로 처리해야 합니다.
솔루션
Data 360의 배치 활성화 프로세스는 마케터의 기술적 마찰을 최소화하면서도 관리성과 확장성을 유지하는 안내 워크플로를 따릅니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 세그먼트 생성 | 최고 | 마케터 또는 분석가가 데이터 모델 개체(DMO) 또는 계산된 인사이트 개체(CIO)에서 필터를 적용하여 시각적 세분화 캔버스에서 세그먼트를 구축합니다. 이렇게 하면 활성화 대상 그룹이 정의됩니다. |
| 활성화 설정 | 최고 | 사용자가 활성화를 만들고 소스로 방금 구축한 세그먼트를 선택합니다. 이를 통해 다운스트림 시스템으로 Data 360을 내보낼 대상 그룹이 정의됩니다. |
| 활성화 대상 선택 | 모범 사례 | 마케터가 사전 구성된 활성화 대상을 선택합니다(예: Marketing Cloud, Google Ads, LinkedIn Ads). 각 대상은 인증 자격 증명 및 필드 매핑을 사용하여 Data 360에 등록됩니다. |
| Payload 정의 | 필수 | 마케터는 연락처 식별자(예: 이메일, 모바일, 해시 ID)를 선택하고 대상 시스템에서 보강할 추가 프로필 특성(예: 이름(성 없이), 충성도 계층 또는 CLV)을 선택하여 페이로드를 정의합니다. |
| 예약 및 빈도 | 권장 | 활성화를 한 번 또는 반복적으로 실행하도록 예약할 수 있습니다(예: 매일 또는 매주). 예약을 통해 다운스트림 대상 그룹이 동기화되고 최신 상태로 유지됩니다. |
| 실행 및 내보내기 | 최고 | 활성화 작업이 실행되면 Data 360이 세그먼트를 쿼리하고, 선택한 특성을 수집하고, 동의 필터를 적용하고, 데이터를 대상 플랫폼으로 내보냅니다. Marketing Cloud의 경우 일반적으로 공유 데이터 확장이 생성되거나 업데이트됩니다. |
| 거버넌스 및 규정 준수 | 필수 | Trust 계층은 데이터 보호 및 마케팅 규정(예: GDPR, CCPA)을 준수하기 위해 스키마 검증, 동의 메타데이터 및 정책 제어를 적용합니다. |
| 모니터링 및 감사 기능 | 모범 사례 | 모든 활성화 실행은 성공/실패 메트릭, 실행 로그 및 계보 가시성을 통해 Trust 계층 모니터링 대시보드에서 추적되므로 운영 투명성과 SLA 보증이 가능합니다. |
스케치
다음은 단계의 요약입니다.
- 구축 부분: 마케터 또는 분석가가 시각적 세분화 도구를 사용하여 세그먼트를 만들고 통합 데이터 개체 전체의 필터를 결합합니다.
- 활성화 만들기: 세그먼트를 소스로 선택하고 사전 구성된 대상을 선택합니다(예: Marketing Cloud 또는 Google Ads).
- 페이로드 정의: 대상 그룹 내보내기 및 보고에 연락처 식별자 및 기타 프로필 특성이 선택됩니다.
- 제공 일정: 활성화가 한 번 또는 반복적으로 실행되도록 예약되어 대상의 대상이 최신 상태로 유지됩니다.
- 실행: 트리거 시 Data 360이 세그먼트를 쿼리하고 페이로드를 구축하고 동의 필터를 적용한 후 결과를 대상 시스템으로 푸시합니다.
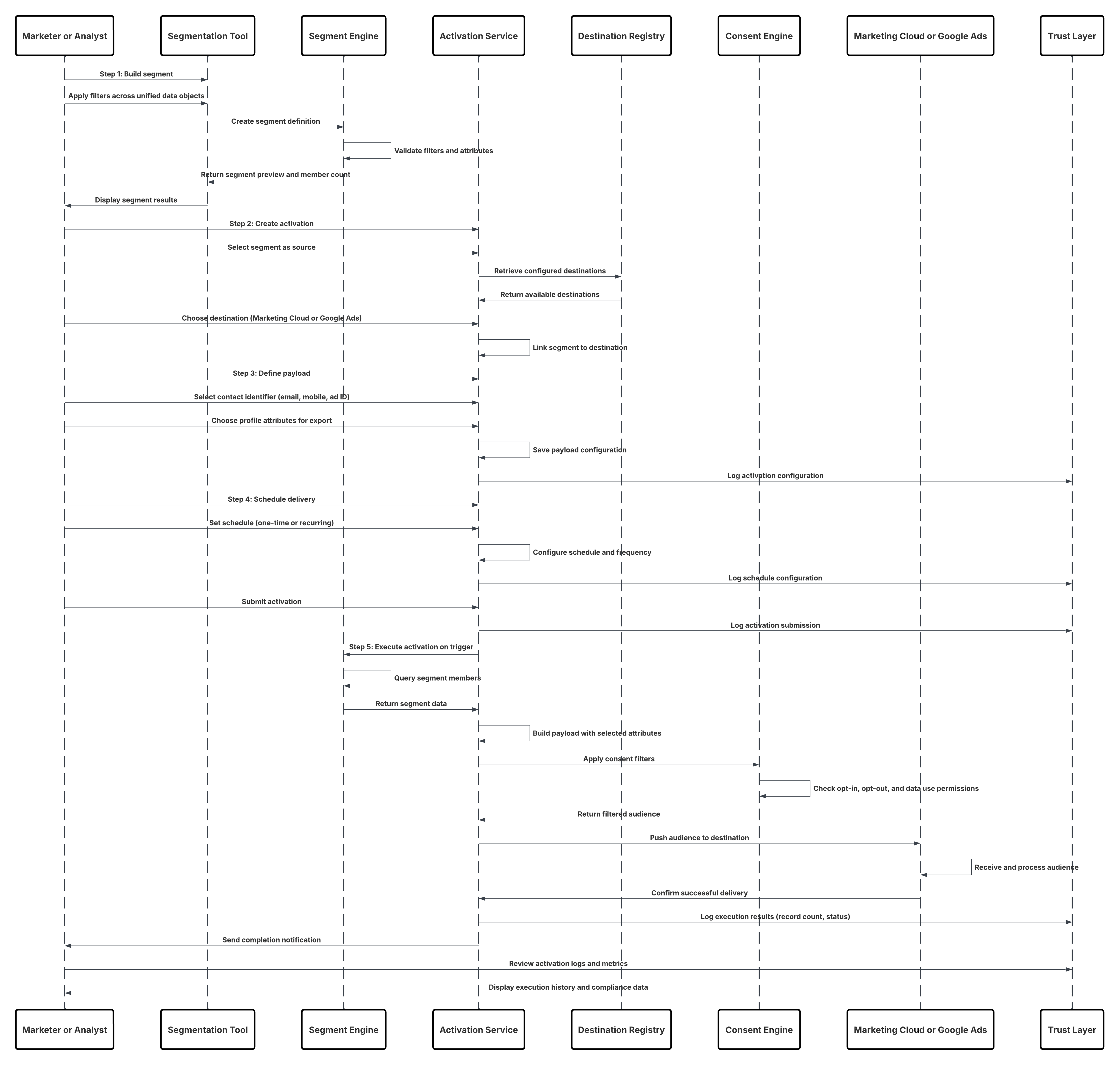
결과
- Data 360의 대상 그룹 세그먼트를 다운스트림 마케팅 및 광고 플랫폼에서 바로 사용할 수 있습니다.
- 대상 그룹이 자동으로 새로 고쳐 최신 통합 고객 데이터와 동기화되어 실시간 캠페인 관련성을 유지합니다.
- 마케터는 활성화된 대상 그룹을 Google Ads, Meta 또는 LinkedIn Ads와 같은 디지털 광고 플랫폼에서 Marketing Cloud Journeys, 이메일 캠페인 또는 사용자 정의 대상 그룹의 입력 소스로 사용할 수 있습니다.
- 모든 활성화 실행은 종단간 계보를 유지하여 Data 360과 외부 시스템 간의 규정 준수, 추적 가능성, 일관성을 보장합니다.
- 비즈니스 사용자는 완벽하고 신뢰할 수 있는 Customer 360 뷰를 통해 고도로 맞춤화된 데이터 중심 환경을 제공할 수 있습니다.
메커니즘 호출
호출 메커니즘은 대상 플랫폼 및 활성화 대상 구성에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Marketing Cloud 참여 활성화(권장) | Marketing Cloud에서 동적 세그먼트, 맞춤형 특성, 실시간 업데이트가 필요한 이메일 또는 교차 채널 여정을 실행할 때 사용합니다. Data 360은 캠페인 활성화를 위해 공유 데이터 확장으로 직접 내보냅니다. |
| Ad Platform 활성화(Google Ads, LinkedIn Ads, Meta Ads) | 재타겟팅 또는 유사 모델링을 위해 Data 360 세그먼트를 광고 플랫폼의 사용자 정의 대상 그룹으로 활성화할 때 사용합니다. 해시 식별자 및 동의 인식 전달을 지원합니다. |
| CRM 활성화(Sales 또는 Service Cloud) | 맞춤형 세일즈 참여 또는 서비스 상호 작용을 위해 CRM 사용자와 보강된 고객 데이터, 인사이트 또는 성향 점수를 공유할 때 사용합니다. 데이터는 데이터 작업 또는 통합 프로필 구성 요소를 통해 보강된 레코드 또는 인사이트로 사용할 수 있습니다. |
| MuleSoft 또는 API를 통한 외부 활성화 | 충성도, 전자상거래 또는 타사 데이터 웨어하우스와 같은 비Salesforce 시스템에 활성화해야 하는 경우 사용합니다. MuleSoft 또는 Data 360 활성화 API는 이벤트 기반 새로 고침 옵션과 함께 안전한 정책 관리 전달을 보장합니다. |
| 하이브리드 활성화(배치 + 이벤트 트리거형) | 예약된 배치 활성화를 이벤트 기반 트리거와 결합하는 경우 사용합니다. 중단된 장바구니 또는 이탈 위험 경고와 같은 시간이 중요한 캠페인에 대해 "항상" 개인 설정을 활성화합니다. |
오류 처리 및 복구
- 작업 수준 오류 격리: 각 활성화 실행은 Data 360 오케스트레이션 계층에서 고유하고 추적 가능한 작업으로 실행됩니다. 실패한 실행은 다른 활성화 또는 세그먼트 정의에 영향을 미치지 않고 자동으로 격리됩니다.
- 일부 배치 복구: 특정 레코드를 내보내지 못할 경우(예: 식별자 불일치 또는 API 속도 제한으로 인해) 증분 백오프 및 병렬 복구를 통해 증분 델타 대기열을 사용하여 다시 시도합니다.
- 스키마 유효성 검사 오류: 아웃바운드 페이로드 특성이 더 이상 대상 스키마와 일치하지 않는 경우(예: 삭제된 특성 또는 이름이 변경된 필드) 작업이 영향을 받는 레코드를 관리자 검토를 위해 스키마 거부 대기열로 라우팅합니다.
- 재생 및 재개 지원: 각 활성화 작업은 마지막으로 성공한 배치를 수집하는 검사점 토큰을 유지합니다. 복구 시 검사점에서 처리가 다시 시작되어 중복 또는 데이터 손실이 발생하지 않습니다.
- 전체 모니터링: 모든 활성화 이벤트, 재시도 및 전달 메트릭은 Trust Layer Monitoring에 기록되므로 이벤트 모니터링 API를 통해 SLA 추적, 근본 원인 분석 및 자동 경고가 가능합니다.
동임 설계 고려 사항
- 결정적 활성화 키: 모든 활성화 실행은 세그먼트 ID, 활성화 ID, 대상 시스템 ID를 결합하는 복합 ID능력 키를 사용하여 정확한 일회성 배달을 보장합니다.
- 재생 감지: Data 360 활성화 서비스는 이전 작업 해시에 대해 수신 페이로드를 검사하여 재배치를 감지하고 억제합니다.
- Atomic Export Commits: 페이로드는 쓰기 확인 후에만 대상 시스템에 적용되므로 부분 업데이트 또는 이중 계산이 방지됩니다.
- 일관적인 ID 확인: 활성화는 통합 ID(예: 통합 개인)에 종속되므로 재작성 또는 재시도는 항상 동일한 골든 레코드를 대상으로 하므로 의미 있는 일관성이 유지됩니다.
- 활성화 상태 지속성: 오케스트레이션 계층은 필요한 경우 결정적 재처리를 위해 활성화 상태 메타데이터(타임스탬프, 상태 코드, 순서 토큰)를 유지합니다.
보안 고려 사항
- 강력한 인증: 각 활성화 대상(예: Marketing Cloud, Ads 또는 CRM)은 토큰 순환 및 테넌트별 범위와 함께 OAuth 2.0을 사용하여 무단 데이터 내보내기를 방지합니다.
- 속성 수준 거버넌스: 데이터 공유 정책 및 활성화 템플릿에 의해 적용되는 통합 프로필의 승인된 특성만 활성화할 수 있습니다.
- 교통 및 휴무 중 암호화: 전송 중에 모든 페이로드가 TLS 1.2+를 사용하여 암호화되고 Data 360 및 대상 플랫폼 모두에서 AES-256를 사용하여 암호화됩니다.
- 계약 및 정책 시행: 활성화 작업은 Data 360의 Trust 레이어에 저장된 동의 개체 및 데이터 정책을 준수합니다. 유효한 동의 메타데이터가 없는 레코드는 내보내기에 자동으로 제외됩니다.
- ** 감사 및 규정 준수 로깅:** 각 활성화 실행은 누가 시작했는지, 어떤 데이터가 전송되었는지, 어떤 대상으로 이동했는지 수집하여 Trust 계층 대시보드 내에서 전체 규제 감사 추적(GDPR, CCPA)을 활성화합니다.
- 최소 권한 액세스: 각 대상에 대한 통합 사용자는 활성화별 범위로 제한됩니다(관리 권한 또는 관련 없는 시스템에 대한 쓰기 액세스 권한 없음).
링크 모음
시기
- 예약 또는 거의 실시간 배치 내보내기를 위해 고안되었습니다(분-시간 대기 시간).
- 캠페인 캘린더에 맞춰 시간 초과 새로 고침을 지원합니다.
- 활성화 작업은 데이터 준비 마커를 사용하여 순서대로 처리하여 데이터를 새로 고칠 수 있습니다.
- 데이터 정확도가 즉각성보다 큰 비대화형 활성화 시나리오에 가장 적합합니다.
데이터 용량
- 대규모 데이터 집합(실행당 수백만 개의 레코드)을 처리합니다.
- 세그먼트 분할 및 병렬 내보내기 채널을 통해 수평으로 확장합니다.
- 시간 초과를 방지하고 처리량을 최적화하기 위해 청크 기반 배치를 사용합니다.
- 데이터 완결성이 중요한 엔터프라이즈급 데이터 파이프라인에 적합합니다.
시/도 관리
- 작업 ID, 타임스탬프, 순서 토큰을 기록하는 활성화 상태 개체를 유지합니다.
- 재시작 가능성 및 오류 복구에 점검을 사용합니다.
- 버전이 지정된 세그먼트 정의는 활성화 주기 전반에 걸쳐 재현성을 보장합니다.
- 소스 세그먼트, DMO 특성, 대상 페이로드 간의 계보 추적 가능성을 활성화합니다.
복잡한 통합 시나리오
- 사전 구축 커넥터를 통해 Salesforce CRM, Marketing Cloud, 외부 시스템과 원활하게 통합합니다.
- 다중 대상 활성화를 지원하며 여러 대상(예: CRM + 광고)에 데이터를 동시에 배포합니다.
- 복합 워크플로(예: 배치 내보내기 후 다운스트림 API 호출 또는 AI 점수 매기기)를 트리거할 수 있습니다.
- 데이터 모델 거버넌스 계층을 통해 스키마 진화를 정상적으로 처리합니다.
예제
지난 90일간 비활성 고객을 다시 참여시키려는 글로벌 리테일 브랜드 Data 360을 사용하여 데이터 아키텍처는 구매 내역, 충성도 계층, 동의 메타데이터로 보강된 "고정 쇼핑객" 세그먼트를 정의합니다. 배치 활성화 작업은 매일 밤 실행되며, 이 세그먼트를 Marketing Cloud Engagement로 푸시하여 맞춤형 "We Miss You" 이메일 캠페인을 트리거하고, 리타겟팅을 위해 Ad Studio로 푸시합니다. 이 작업은 동일한 전달 기능을 활용하여 재시도 간 중복을 방지하며 모든 이벤트는 감사 준수에 대해 Trust 계층에 기록됩니다.
컨텍스트
기업은 보관, 규정 준수 또는 다운스트림 통합을 위해 Salesforce Data 360에서 통합 또는 세분화된 데이터를 표준 파일 형식(예: CSV 또는 Parquet)으로 내보내려면 관리 메커니즘이 필요합니다. 이 패턴을 사용하면 신뢰할 수 있는 고객 데이터가 Amazon S3, Azure Blob 또는 Google Cloud Storage(GCS)에서 호스팅되는 엔터프라이즈 데이터 레이크 또는 분석 파이프라인으로 안전하게 유입되도록 Data 360을 클라우드 간 저장소로 내보낼 수 있습니다. 일반적인 사용 사례에는 다음이 포함됩니다.
- 규제 보존을 위해 동의된 고객 데이터 집합을 정기적으로 보관합니다.
- 비Salesforce 분석 워크로드(예: Tableau, Databricks 또는 Power BI)에 대해 선별된 세그먼트를 내보냅니다.
- 입력으로 구조화된 CSV 또는 Parquet 파일이 필요한 외부 기계 학습 모델을 활성화합니다.
문제
조직이 스키마 무결성 및 규정 준수 제어를 유지하면서 관리, 안전, 자동화된 방식으로 Data 360에서 클라우드 스토리지 버킷(예: Amazon S3)으로 선별된 세그먼트 또는 데이터 집합을 내보낼 수 있는 방법은 무엇입니까? 예를 들어, 규정 준수 팀은 다음을 수행해야 할 수 있습니다. "유효한 동의를 가지고 EU 지역의 모든 활성 고객을 추출하고 외부 감사 및 보고를 위해 매주 S3 위치로 데이터를 내보냅니다." 이를 위해 수동 개입 또는 비관리 데이터 이동 없이 올바른 파일 형식, 액세스 권한 및 배달 일정을 보장하는 반복 가능한 정책 인식 내보내기 파이프라인이 필요합니다.
Force
여러 운영 및 아키텍처 요인에 따라 이 내보내기 패턴이 적용됩니다.
- 인증 및 인증: 인증된 시스템만 대상 버킷에 쓸 수 있도록 하려면 내보내기는 클라우드 공급자의 IAM 모델(예: AWS IAM 역할 또는 Azure 서비스 주체)을 준수해야 합니다.
- 스키마 정렬: 아웃바운드 스키마는 대상 시스템의 예상 구조와 형식(CSV, Parquet 또는 JSON)과 일치해야 합니다.
- 데이터 개인 정보 보호 및 동의: 내보낸 데이터 집합은 유효한 동의 메타데이터가 없는 레코드를 필터링해야 합니다.
- 예약 및 신선함: 많은 내보내기는 정기적으로 수행되며(매일, 매주 또는 매월), 엔터프라이즈 데이터 새로 고침 주기와 일치해야 합니다.
- 거버넌스 및 모니터링: 모든 내보내기는 전체 계보 가시성을 통해 감사할 수 있어야만 데이터 보존 및 규제 요구 사항(예: GDPR, CCPA)을 준수할 수 있습니다.
솔루션
파일 내보내기 활성화 패턴은 수집에 사용되었지만 데이터 출력에 대해 구성된 같은 보안 클라우드 저장소 커넥터를 재사용합니다. 관리자는 먼저 클라우드 저장소 플랫폼(예: Amazon S3, Azure Blob Storage 또는 GCS)을 Data 360의 활성화 대상으로 등록합니다. 그런 다음, 사용자가 활성화 워크플로를 구성하고 실행하여 원하는 세그먼트를 지정된 파일 저장소 경로로 내보냅니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 세그먼트 선택 | 최고 | 분석가가 Data 360\ 내에서 기존 세그먼트 또는 쿼리 정의를 선택합니다. 세그먼트에 따라 내보낼 레코드 및 특성이 결정됩니다. |
| 활성화 설정 | 최고 | 사용자가 세그먼트를 소스로 선택하고 클라우드 저장소 대상을 대상으로 선택하는 새 활성화를 만듭니다(예: S3). |
| 활성화 대상 구성 | 필수 | 관리자가 자격 증명, IAM 역할 및 출력 경로를 사용하여 대상을 미리 구성합니다. 지원되는 형식에는 CSV, Parquet, JSON이 포함됩니다. |
| Payload 정의 | 모범 사례 | 필수 특성(예: ID, 이름, 이메일, 지역, 동의 플래그)을 선택하여 내보내기 스키마를 정의합니다. 시스템에서 특성 수준 관리를 적용합니다. |
| 예약 및 빈도 | 권장 | 정의된 케이던스(매일, 매주, 매달)에서 실행되도록 내보내기를 예약하거나 필요에 따라 수동으로 트리거할 수 있습니다. |
| 실행 및 배달 | 최고 | 실행 시 Data 360은 세그먼트를 쿼리하고 내보내기 파일을 컴파일하고 암호화한 후 클라우드 공급자의 API를 사용하여 구성된 버킷/폴더에 작성합니다. |
| 거버넌스 및 규정 준수 | 필수 | Data 360의 Trust 레이어는 모든 내보내기가 동의 정책, 스키마 검증 및 규정 준수 필터를 준수하도록 합니다. |
| 모니터링 및 감사 기능 | 모범 사례 | 각 내보내기는 Trust 계층 모니터링 대시보드에서 상태, 실행 로그 및 계보 메타데이터와 함께 추적됩니다. |
스케치
다음은 단계의 요약입니다.
- 세그먼트 선택: 분석가 또는 데이터 관리자가 내보낼 통합 세그먼트를 선택합니다.
- 활성화 만들기: 새 활성화 작업을 만들고 등록된 클라우드 저장소 대상을 선택합니다.
- 페이로드 정의: 내보내기 스키마, 특성 목록 및 파일 형식을 지정합니다(예: CSV).
- 예약 내보내기: 일회성 또는 반복 일정을 선택합니다.
- 작업 실행: Data 360은 지정된 버킷 경로에 파일을 생성하고 안전하게 전달합니다.
- 모니터링 및 확인: 결과 및 로그는 Trust 계층에서 검토하여 검증 및 규정 준수 여부를 확인합니다.
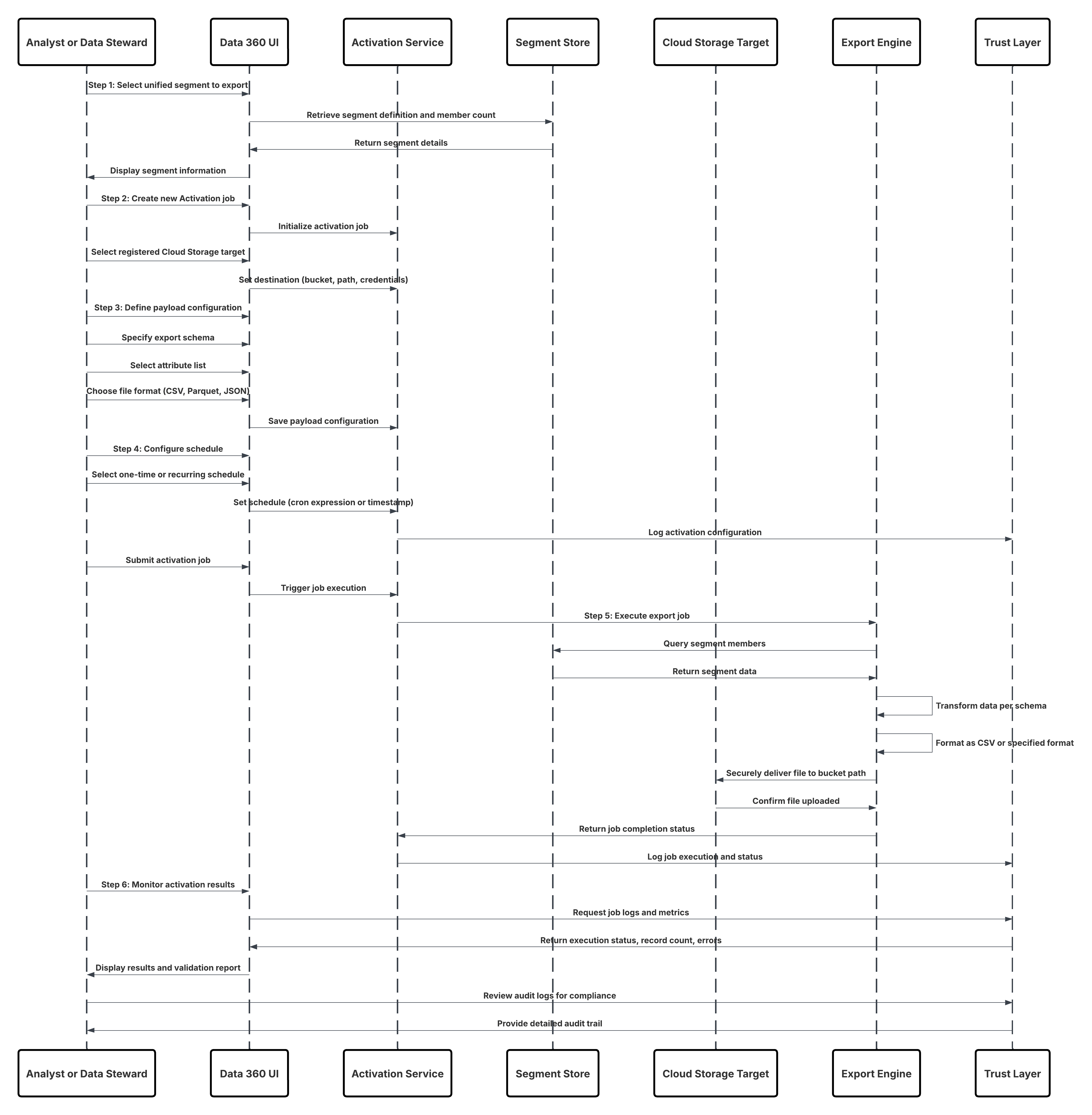
결과
- Data 360의 대상 그룹 세그먼트를 다운스트림 마케팅 및 광고 플랫폼에서 바로 사용할 수 있습니다.
- 대상 그룹이 자동으로 새로 고쳐 최신 통합 고객 데이터와 동기화되어 실시간 캠페인 관련성을 유지합니다.
- 마케터는 활성화된 대상 그룹을 Google Ads, Meta 또는 LinkedIn Ads와 같은 디지털 광고 플랫폼에서 Marketing Cloud Journeys, 이메일 캠페인 또는 사용자 정의 대상 그룹의 입력 소스로 사용할 수 있습니다.
- 모든 활성화 실행은 종단간 계보를 유지하여 Data 360과 외부 시스템 간의 규정 준수, 추적 가능성, 일관성을 보장합니다.
- 비즈니스 사용자는 완벽하고 신뢰할 수 있는 Customer 360 뷰를 통해 고도로 맞춤화된 데이터 중심 환경을 제공할 수 있습니다.
메커니즘 호출
호출 메커니즘은 target Cloud 스토리지 플랫폼 및 활성화 구성에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Amazon S3 활성화 | 엔터프라이즈 데이터 레이크가 AWS에서 호스팅되는 경우 사용합니다. Data 360은 IAM 역할 또는 임시 자격 증명을 사용하여 S3 버킷에 직접 작성하여 안전하고 확장 가능한 내보내기를 보장합니다. |
| Azure Blob 스토리지 활성화 | 조직이 Microsoft Azure에서 운영하는 경우 사용합니다. Data 360은 SAS 토큰 또는 서비스 주체를 사용하여 Blob 컨테이너에 암호화된 파일을 작성합니다. |
| Google Cloud Storage(GCS) 활성화 | 데이터 과학 또는 분석 워크로드가 GCP에서 실행되는 경우 사용합니다. Data 360은 OAuth 자격 증명을 사용하여 CSV 또는 Parquet 형식의 GCS 버킷으로 파일을 내보냅니다. |
| SFTP 또는 외부 파일 게이트웨이 | 규제 또는 레거시 시스템에서 SFTP 끝점 또는 엔터프라이즈 관리 파일 전송 플랫폼을 통해 안전한 파일 전달이 필요한 경우 사용합니다. |
| 하이브리드 내보내기(파일 + API) | 다운스트림 응용 프로그램에 분석을 위한 파일 기반 내보내기와 워크플로 오케스트레이션을 위한 API 트리거(예: MuleSoft 플로)가 모두 필요한 경우 사용합니다. |
오류 처리 및 복구
- 작업 수준 격리: 각 내보내기는 개별 작업으로 실행됩니다. 실패한 작업은 독립적으로 격리 및 재시도됩니다.
- 일부 파일 재시도: 특정 배치가 업로드에 실패할 경우(예: 네트워크 중단으로 인해) 기하율 백오프를 사용하여 해당 청크를 다시 시도합니다.
- 스키마 불일치 처리: 스키마 드리프트 또는 필드 불일치가 스키마 거부 대기열에 레코드를 라우팅하여 검토합니다.
- Checkpoint & Resume: 내보내기 작업은 검사점 메타데이터를 유지하므로 중복 없이 마지막으로 성공적으로 쓰기를 다시 시작할 수 있습니다.
- 통합 모니터링: 실패 및 재시도는 가시성 및 SLA 규정 준수를 위해 Trust 계층 대시보드에 기록됩니다.
동임 설계 고려 사항
- 결정적 내보내기 키: 각 내보내기 작업에는 세그먼트 ID + 대상 ID + 타임스탬프로 구성된 고유 ID가 포함되어 있습니다.
- 재생 안전: 중복 작업 실행은 작업 해시를 사용하여 감지되고 중복 내보내기를 방지하기 위해 건너뛰습니다.
- Atomic 쓰기 보증: Data 360은 전체 완료 및 체크섬 유효성 검사 후에만 대상 버킷에 파일을 커밋합니다.
- 일관적인 스키마 버전 관리: 내보내기 정의는 실행 전반에서 스키마 일관성을 보장하기 위해 버전이 제어됩니다.
- 검사점 지속성: 필요한 경우 결정적 복구 및 재처리를 위해 작업 내보내기 상태 유지
보안 고려 사항
- 강력한 인증: 클라우드 커넥터는 OAuth 2.0, IAM 역할 또는 서비스 책임자를 인증된 쓰기에 사용합니다.
- 모든 곳에 암호화: 데이터는 전송 중(TLS 1.2+) 및 유지 중(AES-256) 모두 암호화됩니다.
- Consent-Aware 내보내기: 유효한 동의가 있는 레코드만 내보내며 Trust Layer 정책에 따라 적용됩니다.
- 최소 권한 원칙: 사용자 및 서비스 계정 내보내기는 지정된 저장소 경로로 제한됩니다.
- 전체 감사 로깅: 모든 내보내기 레코드 메타데이터(이니시에이터, 스키마, 대상, 규정 준수 보고 타임스탬프 포함).
링크 모음
시기
- 대기 시간이 초 미만인 즉각적인 이벤트 중심 활성화를 위해 고안되었습니다.
- 즉시 개인 설정, 권장 사항 또는 결정이 필요한 시나리오에 적합합니다.
- 스트리밍 모드에서 작동 - Data 360에서 유효한 데이터 변경 사항이 발생하는 즉시 트리거가 실행됩니다.
- 배치 일정 또는 세그먼트 재계산을 기다리지 않고 지속적인 응답을 보장합니다.
데이터 용량
- 대규모 데이터 집합(실행당 수백만 개의 레코드)을 처리합니다.
- 세그먼트 분할 및 병렬 내보내기 채널을 통해 수평으로 확장합니다.
- 시간 초과를 방지하고 처리량을 최적화하기 위해 청크 기반 배치를 사용합니다.
- 데이터 완결성이 중요한 엔터프라이즈급 데이터 파이프라인에 적합합니다.
시/도 관리
- 각 이벤트 작업은 자체 이벤트 토큰 및 재생 ID를 유지하여 동일한 처리를 수행합니다.
- 임시 실패 시 마지막으로 커밋된 이벤트에서 재개할 수 있는 검사점 지속성을 지원합니다.
- 정확한 한 번 활성화 시맨틱스를 보장하기 위해 내장된 중복 제거 논리와 재생 구간을 포함합니다.
- 작업 결과(성공/실패)는 실시간으로 기록되고 Trust 계층 관찰 가능성 대시보드를 통해 표시됩니다.
복잡한 통합 시나리오
- 즉각적인 응답 체인을 위한 Salesforce 플로, Einstein 1 플랫폼 이벤트 또는 외부 웹후크와 직접 통합
- 즉시 CRM 레코드 업데이트, AI 점수 매기기 또는 Marketing Cloud 메시지 전송 등 다운스트림 자동화를 트리거할 수 있습니다.
- 구성 가능한 오케스트레이션 지원: 이벤트 트리거는 Data 360 작업, Apex 호출 또는 외부 API를 호출할 수 있습니다.
- 컨텍스트 인식 응답이 즉시 발생해야 하는 에이전트 및 적응형 엔터프라이즈 패턴을 위해 고안되었습니다.
예제
글로벌 리테일 엔터프라이즈는 Databricks에서 분석을 위해 "활성 충성도 구성원" 세그먼트의 주간 내보내기를 제공해야 합니다. Data 360 관리자는 Amazon S3를 활성화 대상으로 구성하고 주간 CSV 내보내기를 s3://enterprise-analytics/loyalty/weekly_exports/ 경로로 예약합니다. 내보내기 작업은 매주 일요일 실행되며 2M+ 레코드가 포함된 동의 필터링 파일이 생성됩니다. 모든 이벤트, 스키마 정의 및 계보는 Trust 계층 대시보드에 기록되어 투명성, 감사 가능성 및 규정 준수 여부를 보장합니다.
주문형 API 기반 활성화는 배치 작업 또는 예약된 내보내기를 기다리지 않고 Data 360 인사이트를 필요한 시기에 실행할 수 있는 실시간 이벤트 기반 접근 방식입니다. 이 패턴을 사용하면 고정 케이던스에 미리 작성된 세그먼트를 게시하는 대신 외부 시스템, Salesforce 앱 또는 AI 에이전트가 Data 360 API를 직접 호출하여 요청 시 특정 대상 그룹 조각, 고객 특성 또는 인사이트를 가져오거나 활성화할 수 있습니다. 이 패턴은 사용자가 포털에 로그인하거나, 에이전트가 고객 레코드를 열거나, AI Copilot이 Next Best Action 쿼리를 시작하는 등 대화형 트리거 기반 환경을 위해 고안되었습니다. 시스템은 사전 계산된 내보내기를 사용하지 않고 Data 360에서 실시간으로 가장 최신 관리 데이터를 동적으로 쿼리하거나 활성화합니다. 주요 장점은 즉각성과 정밀도입니다.
- 모든 API 호출은 Data 360의 통합 동의 인식 프로필 그래프 내에서 최신 고객 인텔리전스 액세스합니다.
- 활성화는 동일하고 감사 가능하며 엔터프라이즈 Trust 및 규정 준수 요구 사항에 부합합니다.
- Einstein 1 플랫폼 API, Connect API 또는 활성화 API를 통해 Salesforce 플로, Apex 또는 외부 시스템에서 직접 통합을 트리거할 수 있습니다. 이 접근 방식은 대기 시간 및 개인 설정이 가장 중요한 사용 사례(예:
- 서비스 통화 도중 맞춤형 제품 제안 트리거
- 실시간 동작 이벤트를 기반으로 동적 캠페인 대상 그룹을 생성합니다.
- 참여 시점에 작동하는 AI 또는 ML 모델에 실시간 결정을 제공합니다.
컨텍스트
기업은 내부 웹 포털, 모바일 앱 또는 파트너 대면 웹 환경과 같은 사용자 정의 구축 응용 프로그램 내에서 조화된 실시간 Data 360 인사이트를 표시해야 하는 경우가 많습니다. 이 패턴을 사용하면 개발자가 관리 및 API 기반 액세스를 통해 Salesforce CRM 및 기타 컨텍스트 시스템과 함께 통합 고객 데이터를 소비하고 표시하는 UI 중심의 안전한 솔루션을 구축할 수 있습니다. 일반적인 사용 사례에는 다음이 포함됩니다.
- 내부 직원 대시보드 또는 모바일 앱에 Data 360 인사이트를 포함합니다.
- 고객 및 트랜잭션 가시성을 사용하여 파트너 또는 딜러 포털을 만듭니다.
- Data 360 데이터를 타사 웹 응용 프로그램 또는 환경 계층에 통합합니다.
- Data 360 및 Einstein 1에서 제공하는 실시간 맞춤형 권장 사항 표시
문제
개발자는 민감한 정보를 복제하거나 내보내지 않고 다른 Salesforce 데이터 소스와 함께 조화된 Data 360 데이터에 안전하게 액세스하고 표시하는 사용자 정의 UI 중심 응용 프로그램을 구축할 수 있는 방법은 무엇입니까? 예를 들어, Data 360에서 통합 고객 프로필, 상호 작용, 계산된 인사이트를 표시하는 고객 포털을 구축해야 할 수 있습니다. 이를 위해서는 프런트엔드 환경을 구동하고 인증을 처리하고 거버넌스를 보장하는 동시에 Data 360의 내부 데이터 모델의 복잡성을 추상화하는 단일 안전하고 성능이 뛰어난 API 계층이 필요합니다.
Force
다양한 아키텍처 및 운영 고려 사항이 이 패턴에 영향을 미칩니다.
- UI 중심 액세스: 기본 목표는 배치 추출 또는 백엔드 동기화를 수행하지 않고 사용자 정의 프런트엔드 환경(웹 또는 모바일) 내에서 데이터를 표시하는 것입니다.
- Secure Gateway : 선택한 API는 인증된 응용 프로그램 및 사용자에 대해 안전하고 확장 가능한 진입점으로 작동하여 엔터프라이즈급 액세스 제어를 적용해야 합니다.
- 통합 데이터 컨텍스트 : 응용 프로그램은 Data 360 데이터(예: 통합 프로필, 계산된 인사이트)를 CRM, ERP 또는 사용자 정의 개체 데이터와 원활하게 결합할 수 있어야 합니다.
- 개발자 단순성: API는 클라이언트 계층에서 백엔드 처리 또는 스키마 매핑을 최소화하는 프레젠테이션 지원 페이로드를 반환해야 합니다.
- 거버넌스 및 관찰 가능성 : 모든 액세스는 명확한 계보, 인증, 정책 집행을 통해 신뢰할 수 있고 감사 가능한 채널을 통해 진행해야 합니다.
솔루션
솔루션은 Data 360 위에 맞춤형 데이터 중심 애플리케이션을 구축하기 위한 기본 통합 게이트웨이로 Salesforce Connect REST API를 사용하는 것입니다. Connect API는 Data 360의 조화된 프로필, 세그먼트, 계산된 인사이트 등 UI 사용에 최적화된 응답 형식(JSON 기반, 경량, 모바일 지원)으로 Salesforce 데이터에 대한 RESTful 액세스를 제공합니다. 개발자는 연결된 앱을 통해 인증하고 OAuth 2.0 토큰을 가져오고 /query, /chatter 또는 /data와 같은 Connect API 리소스를 호출하여 응용 프로그램 인터페이스에 통합 데이터를 직접 표시합니다. Connect API는 Query API, Data Graph API 및 Einstein 1 플랫폼 API와 같은 다른 API의 전송 기초 역할을 하므로 개발자가 하나의 통합 액세스 패턴에 따라 여러 데이터 소스를 결합할 수 있습니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 인증 및 앱 등록 | 필수 | Salesforce에서 OAuth 2.0 기반 인증을 위한 연결된 앱을 만듭니다. Data 360 API 액세스에 대한 범위를 구성합니다. |
| 데이터 액세스(프로필, 세그먼트, 인사이트) | 최대 | Connect API 끝점(/services/data/vXX.X/connect)을 사용하여 조화된 Data 360 데이터, 통합 프로필, 계산된 인사이트를 쿼리합니다. |
| UI 통합 | 최대 | 프런트엔드 앱(반응형, 각도, iOS, Android)은 Connect API를 호출하여 대시보드, 포털 또는 모바일 인터페이스에서 Data 360 데이터를 렌더링합니다. |
| 데이터 그래프 쿼리 | 권장 | 복잡한 조인 및 관계를 간소화하는 시맨틱 수준 쿼리에 대해 Connect API와 데이터 그래프 API를 결합합니다. |
| 실시간 새로 고침 | 옵션 | 라이브 데이터 업데이트를 위해 Connect API와 WebSocket 또는 스트리밍 확장을 사용합니다. |
| 보안 및 거버넌스 | 필수 | OAuth 범위, Data 360 정책 및 Trust 계층 감사 프레임워크를 사용하여 데이터 가시성을 적용합니다. |
스케치
다음은 단계의 요약입니다.
- 연결된 앱 등록 — 외부 앱 인증을 위한 OAuth 범위 및 API 권한을 정의합니다.
- 액세스 토큰 가져오기 — 외부 앱이 OAuth 2.0 인증을 수행하여 Data 360 액세스 토큰을 수신합니다.
- Invoke Connect API — 앱이 REST API 호출을 만들어 통합 프로필, 세그먼트 또는 인사이트 데이터를 검색합니다.
- UI에서 데이터 렌더링 — 응답은 브랜딩 포털 또는 모바일 인터페이스에서 사용자에게 분석되고 표시됩니다.
- Handle Errors & Refresh Tokens — 앱은 세션 연속성을 위해 재시도 논리 및 자동 토큰 새로 고침을 구현합니다.
- 모니터링 및 감사 액세스 — 모든 API 호출은 가시성 및 규정 준수를 위해 Trust 레이어에 기록됩니다.
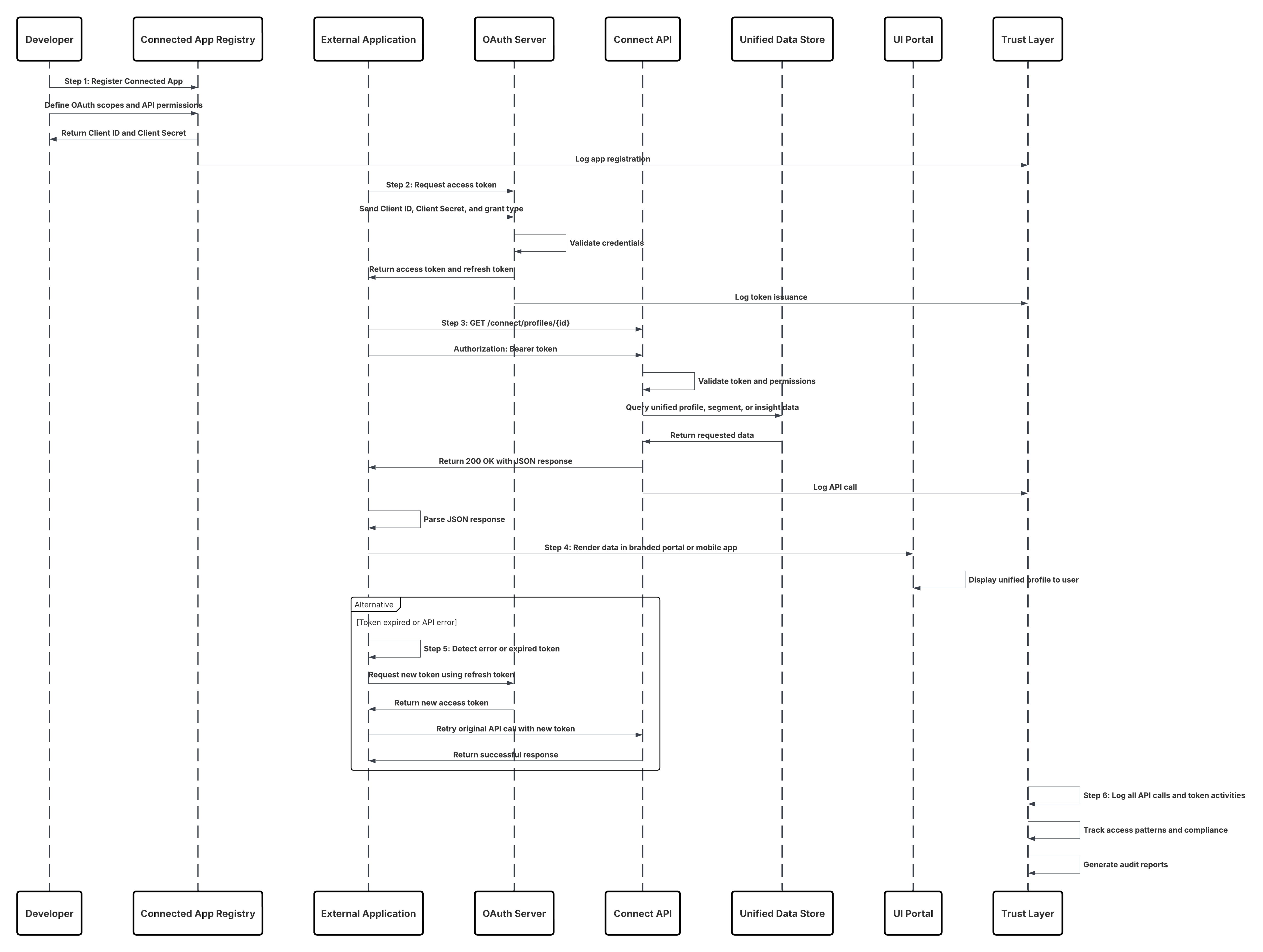
결과
개발자는 Data 360과 긴밀하게 통합되는 안전한 사용자 정의 브랜딩 응용 프로그램을 만들 수 있습니다. 이러한 앱은 다음을 수행할 수 있습니다.
- 실시간으로 조화된 고객 프로필 및 인사이트를 표시합니다.
- 통합 API를 통해 CRM 또는 사용자 정의 개체와 함께 Data 360 데이터를 표시합니다.
- Trust 계층을 통해 일관된 인증, 인가, 감사 제어를 활용합니다.
- 비즈니스 사용자 또는 파트너에게 환경 전반에서 신뢰할 수 있는 고객 인텔리전스 대한 원활하고 관리되는 액세스 권한을 제공합니다.
메커니즘 호출
호출 메커니즘은 target Cloud 스토리지 플랫폼 및 활성화 구성에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| Connect REST API(권장) | UI 친화적인 JSON 형식으로 Data 360 데이터에 실시간 액세스해야 하는 웹, 모바일 또는 타사 앱을 구축할 때 사용합니다. |
| 데이터 그래프 API | 앱이 여러 개체(예: 고객 → 트랜잭션 → 캠페인)에서 시맨틱 수준 쿼리를 수행해야 하는 경우 사용합니다. |
| 쿼리 API | SOQL과 유사한 쿼리를 실행할 때 사용하여 전체적으로 조화된 데이터 집합을 검색합니다. |
| Einstein 1 플랫폼 API | 사용자 정의 UI 내에서 AI 기반 인사이트 또는 Copilot 생성 권장 사항을 통합하는 경우 사용합니다. |
| MuleSoft 또는 Apex 게이트웨이 래퍼 | 앱과 Connect API 간에 추가 오케스트레이션, 캐싱 또는 정책 적용이 필요한 경우 사용합니다. |
오류 처리 및 복구
- 요청 Throttling: 속도 제한 아래에서 API 호출을 자동으로 백업하고 다시 시도합니다.
- 스키마 드리프트 보호: GraphQL 스키마 버전 관리 또는 REST 메타데이터 검색을 사용하여 스키마 변경에 적응합니다.
- 토큰 만료 관리 – 애플리케이션은 세션 중단을 방지하기 위해 OAuth 토큰을 자동으로 새로 고칩니다.
- API 오류 격리 – 실패한 API 호출이 동시 세션에 영향을 미치지 않고 기록되고 다시 시도됩니다.
- Trust Layer Observability – API 성공률/실패율 및 액세스 로그가 Trust Layer 대시보드에 표시됩니다.
동임 설계 고려 사항
- 결정적 요청 ID: 각 API 요청에는 재생 안전한 처리를 위한 상관 관계 ID가 포함되어 있습니다.
- 캐시 검증 헤더: ETag 및 최종 수정 머리글은 중복 데이터 가져오기를 방지합니다.
- 원자 읽기 작업: Connect API를 사용하면 각 응답이 일관된 통합 데이터 스냅샷을 반영합니다.
- 재생 보호 – 중복 API 호출은 요청 서명 및 타임스탬프를 사용하여 필터링됩니다.
보안 고려 사항
- OAuth 2.0 인증: 모든 API 호출은 연결된 앱을 통해 안전한 단기간 OAuth 액세스 토큰을 사용합니다.
- 최소 권한 액세스: API 범위는 필수 개체 및 필드로만 제한됩니다.
- 모든 곳에 암호화: 전송 중인 TLS 1.2+ 및 캐시되거나 저장된 응답에 대한 AES-256 암호화가 유지됩니다.
- 동의 인식 데이터 액세스: Data 360은 검색된 모든 레코드가 동의 및 거버넌스 정책을 준수하도록 합니다.
- 전체 감사 로깅: 모든 API 상호 작용은 사용자, 앱 및 Trust 계층의 타임스탬프 메타데이터로 기록됩니다.
링크 모음
시기
- 대기 시간이 낮고 실시간 API 액세스를 위해 설계되었습니다.
- 즉시 데이터 렌더링이 필요한 대화형 응용 프로그램에 적합합니다.
- 캐시 및 색인화된 Data 360 소스를 통해 거의 즉각적인 쿼리 응답 시간을 지원합니다.
- 배치 일정 또는 비동기 활성화 주기에 종속되지 않습니다.
데이터 용량
- 소규모에서 중간 크기의 데이터 집합(예: 프로필, 인사이트 또는 최근 트랜잭션)을 가져오는 대화형 사용 사례에 최적화됩니다.
- 커서 기반 페이지 매김을 통해 페이지 매김된 결과를 정상적으로 처리합니다.
- 대용량 대량 내보내기에 사용할 수 없으며 대규모 데이터 집합에 배치 또는 파일 내보내기 패턴을 사용합니다.
시/도 관리
- 응용 프로그램은 OAuth 토큰 및 로컬 캐시를 사용하여 경량 세션 상태를 유지합니다.
- Connect API는 효율성을 위해 조건부 요청 및 부분 새로 고침을 지원합니다.
- API 응답에는 릴리스 전반의 스키마 일관성을 위한 버전 마커가 포함되어 있습니다.
복잡한 통합 시나리오
- 여러 도메인에서 시맨틱 쿼리를 위해 Connect API와 데이터 그래프 API를 결합합니다.
- 예측 가능한 대화형 환경을 위해 Einstein 1 Copilot 또는 AI API와 통합합니다.
- 하이브리드 UI 개발을 위해 Experience Cloud 또는 Lightning 웹 구성 요소와 함께 사용합니다.
- MuleSoft를 통해 확장하여 실시간으로 데이터 보강 또는 외부 시스템 조회를 오케스트레이션합니다.
예제
다국적 보험 회사는 보험사가 통합 프로필, 최근 청구, 맞춤형 제안을 볼 수 있도록 고객 셀프 서비스 포털을 구축합니다. 프런트엔드 eact 기반 앱은 OAuth 2.0을 통해 인증하고 Connect REST API 및 데이터 그래프 API를 사용하여 데이터를 검색합니다. 모든 데이터는 실시간으로 표시되고, 동의에 따라 표시되며, Data 360 Trust 계층을 통해 관리됩니다. 개발자는 Salesforce 내에서 직접 API 호출 및 감사 추적을 모니터링하여 완벽한 규정 준수 및 관찰 가능성을 보장합니다.
컨텍스트
엔터프라이즈에서는 서비스 콘솔, 권장 사항 엔진 또는 개인 설정 플랫폼과 같은 실시간 결정 시스템에 대한 전체 고객 프로필에 대한 즉각적인 액세스 권한이 점점 더 필요합니다. 이 패턴을 통해 애플리케이션이 Data 360의 Data Graph API를 사용하여 사전 계산된 통합된 고객 데이터 보기를 거의 실시간으로 검색하여 대화형 환경에 2초 이내의 응답 시간을 제공할 수 있습니다. 일반적인 사용 사례에는 다음이 포함됩니다.
- 고객 서비스 또는 Sales Console 내에서 전체적인 고객 보기를 표시합니다.
- AI 기반 "Next Best Action" 또는 "Next Best Offer" 권장 사항을 제공합니다.
- 페이지 로드 시간에 고개인화된 웹 또는 모바일 환경을 제공합니다.
- 에이전트 또는 셀프 서비스 환경에서 세션 내 결정 지원
문제
응용 프로그램이 런타임 시 느린 다중 개체 쿼리를 실행하는 대신 사전 계산된 전체 통합 고객 보기를 즉시 검색할 수 있는 방법은 무엇입니까? 예를 들어, 맞춤형 제안을 선택하려면 웹 개인 설정 엔진이 전체 고객 컨텍스트(인구 통계, 기본 설정, 트랜잭션, 계산된 인사이트)를 밀리초 이내에 로드해야 합니다. 기존 관계 쿼리는 여러 조인이 필요할 수 있으며, 이를 통해 허용되지 않는 대기 시간이 발생할 수 있습니다. 따라서 속도, 완전성 및 관리를 결합하는 단일 키 검색을 통해 검색할 수 있는 비정규화된 즉시 사용할 수 있는 프로필 데이터를 제공하는 API가 필요합니다.
Force
여러 운영 및 성능 요소가 이 패턴에 영향을 미칩니다.
- 속도: 응답 시간은 실시간에 근접해야 합니다. API가 동기식 상호 작용을 지원하려면 전체 프로필을 밀리초 이내에 반환해야 합니다.
- 완전성: 응답에 모든 관련 특성, 관계, 계산된 인사이트가 포함되어야 하며, 이상적으로 단일 페이로드에 포함되어야 합니다.
- 검색 효율: 프로필은 customerId, contactKey 또는 이메일과 같은 식별자를 통해 검색할 수 있어 다단계 쿼리가 없어야 합니다.
- 데이터 신선도 vs. 지연 시간: 일부 사용 사례는 속도를 위해 사전 계산(캐시)된 데이터를 선호하며, 다른 경우 실시간 데이터가 필요하며 대기 시간이 더 길어집니다.
- 거버넌스 및 보안: Salesforce Trust Layer 정책을 통해 액세스 권한을 유지하여 데이터 가시성 및 동의 규칙을 준수해야 합니다.
솔루션
솔루션은 Salesforce 데이터 그래프 API를 사용하여 데이터 그래프 레코드로 저장된 미리 계산된 비정규화 고객 보기를 검색하는 것입니다. 데이터 그래프는 개인, 트랜잭션, ProductInterest와 같은 여러 데이터 모델 개체(DMO)를 하나의 읽기 전용 레코드로 결합하는 구체화된 시맨틱 보기이며, 이는 JSON 블롭으로 표시되는 경우가 많습니다. 개발자는 다음과 같은 REST 끝점을 사용할 수 있습니다. GET /api/v1/dataGraph/{dataGraphEntityName}/{id} 고유 식별자별로 전체 레코드를 검색합니다. 동적 시나리오의 경우 API는 구체화된 캐시를 우회하고 Data 360 전반에서 실시간 쿼리를 실행하고 최신 데이터에 대한 최소 대기 시간을 트레이딩하는 live=true 매개 변수를 지원합니다. 이를 통해 개발자는 비즈니스 요구에 따라 즉각적(캐시됨) 및 최신(실시간) 프로필 검색을 선택할 수 있습니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 데이터 그래프 정의 | 필수 | 설계자는 여러 DMO를 하나의 시맨틱 엔티티(예: UnifiedCustomerProfile)로 결합하는 데이터 그래프를 정의합니다. |
| 프로필 검색 검색 | 최대 | 애플리케이션은 GET /api/v1/dataGraph/{entity}/{id}를 호출하여 고유한 ID 또는 키로 전체 비정규화 프로필을 검색합니다. |
| 실시간 매개 변수 사용 | 옵션 | ?live=true를 추가하여 캐시된 검색이 아닌 새 계산을 강제 적용합니다. 중요한 결정에 적합합니다. |
| 인증 | 필수 | 연결된 앱을 통해 OAuth 2.0을 사용하여 API 호출을 안전하게 인증합니다. |
| 응답 구문 분석 | 모범 사례 | 응용 프로그램이 JSON 응답을 UI 또는 결정 엔진에 직접 구문 분석하며 추가 조인이 필요하지 않습니다. |
| 캐싱 전략 | 권장 | 반복 프로필 조회를 위해 단기 로컬 캐싱(예: 메모리 내 또는 CDN)을 구현합니다. |
| 모니터링 및 관찰 가능성 | 필수 | Trust 계층 대시보드를 사용하여 쿼리 성능, 응답 시간 및 정책 준수를 모니터링합니다. |
스케치
다음은 구현 플로의 요약입니다.
- 데이터 그래프 정의 — 데이터 아키텍처는 여러 DMO에서 통합 고객 보기를 모델링하는 데이터 그래프를 만듭니다.
- 연결된 앱 등록 — 개발자가 보안 API 액세스를 위한 OAuth 자격 증명을 구성합니다.
- Data Graph API 호출 - 응용 프로그램이 Data Graph 이름 및 레코드 ID가 포함된 GET 요청을 발행합니다.
- 프로세스 응답 — API는 고객 프로필의 전체 JSON 표현을 반환합니다.
- Render or Act — 사용하는 앱(UI 또는 엔진)은 개인 설정, 권장 사항 또는 서비스 작업에 통합된 데이터를 사용합니다.
- 모니터링 및 조정 — 성능 메트릭과 액세스 로그는 Trust 계층 관찰 콘솔을 통해 검토됩니다.
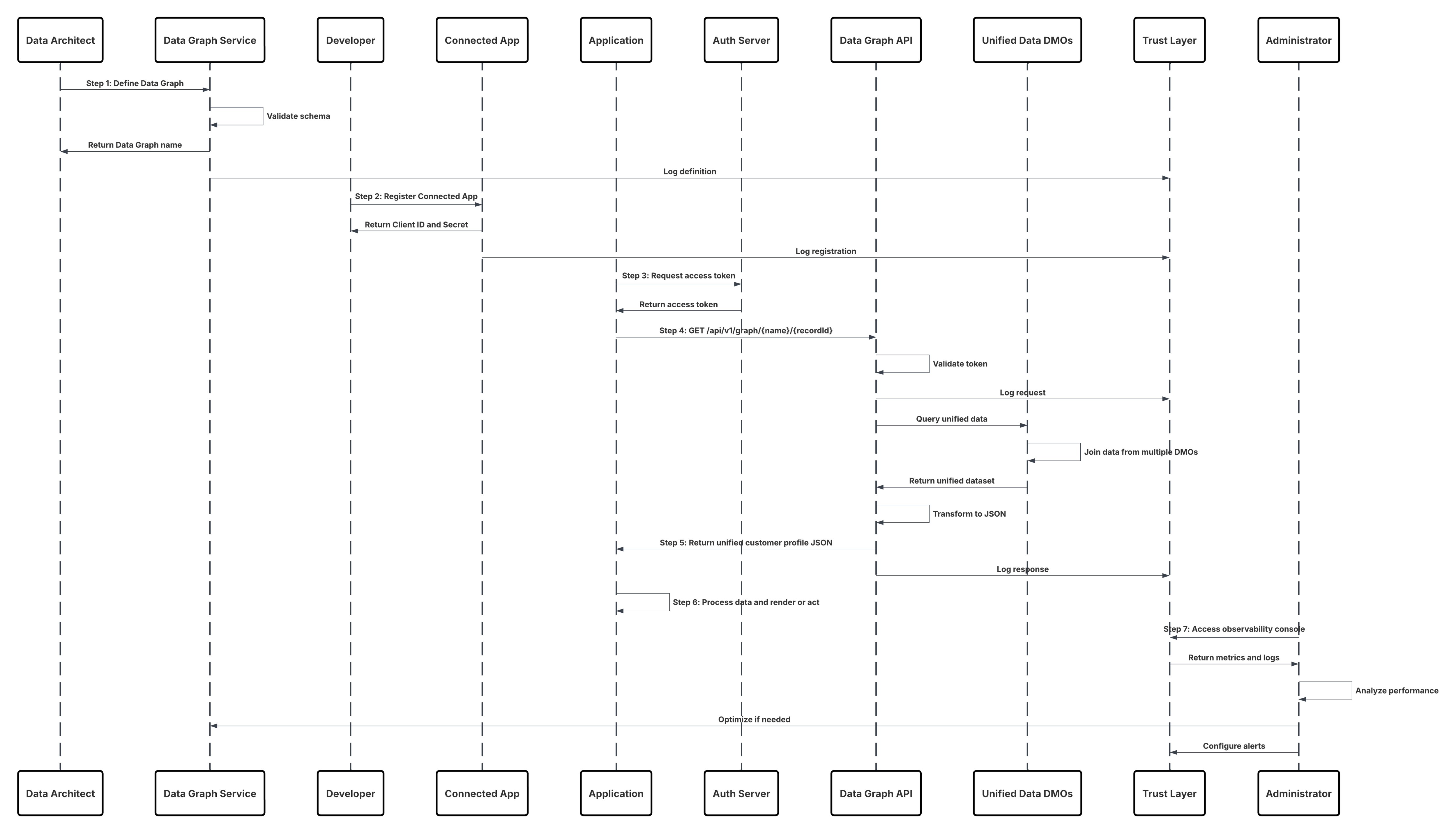
결과
이제 응용 프로그램이 사전 결합된 전체 고객 프로필을 즉시 검색하여 개인 설정, 서비스, 의사 결정 자동화와 같은 실시간 상호 작용을 제공할 수 있습니다. 이 패턴은 다음을 보장합니다.
- 즉시 결정에 대한 초과 응답 시간입니다.
- Data 360 시맨틱 모델에 맞춰 일관되고 관리되는 데이터 검색
- 간소화된 응용 프로그램 논리 - 조인, 스키마 조정 없음
- 감사 및 관찰성을 위해 Trust 계층을 통해 추적 가능한 규정 준수 액세스
메커니즘 호출
호출 메커니즘은 target Cloud 스토리지 플랫폼 및 활성화 구성에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| 데이터 그래프 API(권장) | ID 또는 키로 사전 구체화된 전체 프로필을 즉시 검색하는 데 사용합니다. |
| live=true를 사용하는 데이터 그래프 API | 최신 데이터가 필요한 가치가 높은 사용 사례(예: 사기 감지, 실시간 제안)에서 약간 더 높은 대기 시간을 허용합니다. |
| Connect API(폴백) | 데이터 그래프 검색을 다른 Salesforce 데이터와 결합하는 복합 앱 시나리오에 사용합니다. |
| 쿼리 API | 즉각적인 프로필 검색 대신 임시 쿼리 또는 분석 판독을 구성할 때 사용합니다. |
| MuleSoft API Proxy | 엔터프라이즈 게이트웨이를 통해 데이터 그래프 호출을 라우팅하거나 추가 오케스트레이션/정책을 적용해야 하는 경우 사용합니다. |
오류 처리 및 복구
- 기타 – 실시간 쿼리가 실패하거나 시간 초과 임계값을 초과하면 캐시된 데이터 그래프 검색으로 자동으로 되돌립니다.
- 시간 초과 관리 – 고 부하의 API 호출에 대해 재시도 및 회로 차단기 논리를 구현합니다.
- 유효하지 않은 ID 처리 – 표준 404를 반환하지 않음 프로필 키가 없음에 대한 응답을 찾을 수 없습니다. UI에서 편리하게 처리합니다.
- 스키마 버전 유효성 검사 – 스키마가 발전할 때 불일치를 방지하기 위해 데이터 그래프 버전 메타데이터를 검증합니다.
- 관찰성 통합 – SLA 모니터링을 위해 Trust 계층 대시보드 내의 모든 오류, 재시도 및 지연을 기록합니다.
동임 설계 고려 사항
- 결정적 키 – 각 프로필 검색은 예측 가능한 재생 안전한 쿼리를 보장하는 안정적인 ID(예: IndividualId)를 사용합니다.
- 캐시 일관성 – 조건부 검색 및 캐시 검증에 ETag 또는 최종 수정 머리글을 사용합니다.
- Atomic Retrieval – 각 API 응답은 구체화된 데이터 그래프 레코드의 일관된 스냅샷을 나타냅니다.
- 재생 보호 – 클라이언트 응용 프로그램이 상관 관계 ID 및 타임스탬프를 통해 중복 검색을 감지합니다.
보안 고려 사항
- 강력한 인증 – 연결된 앱을 통한 OAuth 2.0은 보안 토큰 기반 액세스를 적용합니다.
- 동의 인식 검색 – 동의된 특성만 반환됩니다. 동의 필터는 Trust 계층에서 자동으로 적용됩니다.
- 현장 수준 거버넌스 – Data 360의 메타데이터 및 정책 정의를 통해 속성에 대한 액세스를 제어합니다.
- 교통 및 중지 중 암호화 – 모든 응답은 TLS 1.2+ 및 AES-256로 암호화됩니다.
- ** 감사 및 추적 가능성** – 모든 프로필 검색 이벤트는 식별자, 타임스탬프 및 정책 컨텍스트로 기록됩니다.
링크 모음
시기
- 즉각적인 검색을 위해 설계되었습니다.
- 대기 시간이 약간 더 높은 최신 데이터에 대한 실시간 쿼리를 지원합니다(초 미만).
- 동기 의사 결정 및 대화형 응용 프로그램에 최적화됩니다.
- 배치 전 활성화 또는 세그먼트 재계산이 필요하지 않습니다.
데이터 용량
- 요청당 단일 레코드 검색 또는 소규모 세트(십~백 개)에 이상적입니다.
- 대규모 대량 검색에 최적화되어 있지 않으며 대용량 읽기에 배치 또는 쿼리 API를 사용합니다.
- 속도를 위해 가로로 확장 가능한 캐싱 및 사전 구체화를 사용합니다.
시/도 관리
- 경량 상태가 없는 액세스를 유지합니다. 각 요청은 독립적입니다.
- 재생 안전한 검색을 위해 캐싱 머리글을 지원합니다.
- 응용 프로그램에서 로컬 캐시 또는 단기 세션 저장소를 유지하여 반복 조회를 줄일 수 있습니다.
복잡한 통합 시나리오
- 복합 데이터 환경을 위해 Einstein 1, Connect API 및 MuleSoft와 원활하게 통합합니다.
- 즉각적인 컨텍스트 인식을 필요로 하는 액티컬 시스템(예: Copilot 또는 AI 추론 엔진)을 구동할 수 있습니다.
- 검색 또는 상태 변경 시 실시간 트리거를 위해 데이터 작업과 결합
- 성능이나 거버넌스를 저하하지 않고도 규모 맞춤화 가능
예제
글로벌 전자상거래 플랫폼은 Data 360의 Data Graph API를 사용하여 추천 엔진에 대한 통합 고객 프로필을 실시간으로 검색합니다. 사용자가 로그인하면 응용 프로그램이 데이터 그래프 끝점을 호출하여 해당 고객의 UnifiedCustomerProfile을 가져오고 인구 통계 특성, 동작 신호 및 계산된 인사이트를 단일 JSON 페이로드로 반환합니다. 개인 설정 엔진은 활성 세션 동안 "Next Best Offer"를 결정하고 표시하기 위해 이 응답을 밀리초 이내에 사용합니다. 모든 요청은 Trust Layer를 통해 관리되고 기록되므로 상호 작용 전반에서 완벽한 가시성, 정책 집행 및 규정 준수가 보장됩니다.
실시간 데이터 작업을 사용하면 Data 360에서 변경되는 즉시 고객 데이터를 즉시 활성화할 수 있습니다. 해당 작업은 예약된 배치 내보내기를 기다리는 대신 업데이트, 인사이트 또는 트리거를 Salesforce 또는 외부 시스템에 직접 밀리초 만에 푸시합니다. 고객의 상태, 동의 또는 참여 메트릭이 Data 360에서 업데이트되면 해당 신호는 맞춤형 제안을 즉시 강화하거나 Service Cloud 자동화를 트리거하거나 충성도 계층을 업데이트하여 모든 고객 경험이 가장 최신 통합된 사실을 반영합니다. 이 패턴은 맞춤형 웹 환경, 사기 감지 경고, Next-Best Action 권장 사항 또는 실시간 CRM 업데이트와 같은 높은 영향과 지연에 민감한 사용 사례에 이상적입니다. 데이터 인사이트와 비즈니스 작업 간의 격차를 해소하여 통합 데이터를 즉각적인 인텔리전스로 전환합니다.
컨텍스트
현대 디지털 환경과 운영 워크플로우는 이벤트가 발생하는 순간 즉각적인 상황에 맞는 조치를 요구합니다. 예를 들어, Checkout 중에 고객 레코드를 업데이트하거나 반품을 스캔할 때 재고를 조정하거나 사용자가 장바구니를 떠날 순간 맞춤형 프로모션을 제공합니다. 실시간 데이터 작업을 통해 시스템이 통합 Data 360 프로필과 계산된 인사이트를 초 초 초에서 초까지 지연하여 호출, 보강 및 조치를 취할 수 있으므로 대화형 개인 설정, 운영 자동화 및 즉각적인 의사 결정이 가능합니다.
문제
런타임 시 응용 프로그램, UI 상호 작용 플로 또는 미들웨어가 Data 360을 호출하여 예약된 배치 작업 또는 중량 파이프라인을 기다리지 않고 단일 통합 프로필을 읽고, 계산하거나 업데이트하거나 작업(예: 제안 보내기, CRM 업데이트, 워크플로 시작)을 트리거할 수 있는 방법은 무엇입니까?
Force
다음과 같은 몇 가지 기술, 운영, 거버넌스 부서가 이 패턴을 구성합니다.
- 저 대기 시간 요구 사항: 통화는 우수한 UX를 유지하거나 운영 SLA를 충족하려면 초 초에서 몇 초 범위까지 완료해야 합니다.
- 결정적 정체성 해결: 요청은 신속하고 신뢰할 수 있는 올바른 통합 개인 프로필(골든 레코드)으로 해결해야 합니다.
- 세분화된 승인: 실시간 통화는 요청 시 특성 수준 정책 및 동의 검사를 적용해야 합니다.
- 페이로드 최소화: 실시간 페이로드는 작고 집중해야 합니다(단일 프로필 또는 소규모 특성 집합) 대기 시간 및 비용을 줄이십시오.
- 개발자 경험: API는 개발자 친화적이어야 합니다(REST/gRPC/GraphQL), 명확한 스키마와 안정적인 프로덕션 사용 계약이 있어야 합니다.
- ** 감사 및 추적 가능성:** 규정을 준수하기 위해 모든 실시간 작업은 계보, 사용자 ID, 정책 결정과 함께 기록되어야 합니다.
솔루션
Data 360의 실시간 데이터 작업 인터페이스(API + SDK)를 가장자리 캐싱 및 필요한 경우 최소한의 컴퓨팅 변환과 결합하여 사용하는 것이 좋습니다. 통합은 데이터 작업 끝점을 호출하여 프로필 특성을 읽거나 쓰거나 인사이트를 계산하거나 오케스트레이션을 시작합니다. 페이로드를 반환하거나 작업을 실행하기 전에 정책 적용 지점에서 실시간 정책 확인(CEDAR) 및 동적 마스킹이 적용됩니다.
| 솔루션 영역 | 맞춤 | 댓글/구현 세부 사항 |
|---|---|---|
| 실시간 데이터 액션 | 최고 | 단일 레코드 읽기/쓰기 및 작업 트리거에 대한 끝점을 표시합니다. OAuth/JWT를 통해 인증합니다. |
| ID 확인 | 필수 | 수신 식별자(email, externalId, 쿠키)를 통합 개인 ID 인라인으로 확인합니다. 캐시와 함께 결정적 확인자를 사용합니다. |
| 정책 집행(CEDAR) | 모범 사례 | 요청 시 동의, ABAC, 마스킹 정책을 평가하고 정책 결정당 필드를 거부하거나 마스킹합니다. |
| Edge/Cache 레이어 | 권장 | 프로필 조각 및 계산된 인사이트에 짧은 TTL 캐시를 사용하여 대기 시간을 줄이고 변경 이벤트에 대해 무효화합니다. |
| 경량 변형 | 권장 | 작업 경로에 간단한 보강 또는 계산된 필드를 적용합니다. 대량 변환은 사전 계산해야 합니다. |
| 작업 오케스트레이션 | 최고 | 복잡한 플로에 대해 동기식 단일 단계 작업(예: 반품 제공 토큰) 및 비동기식 오케스트레이션(대기열 \+ 웹후크)을 지원합니다. |
| 관찰성 & 추적 | 필수 | 감사 및 디버깅을 위해 요청/응답, 정책 결정 및 계보를 Trust Layer/SIEM에 기록합니다. |
| 레이트 제한 & Throttling | 필수 | 트래픽이 많은 순간에 클라이언트 할당량 및 정상적인 저하 전략을 적용합니다. |
스케치
다음은 단계의 요약입니다.
- 클라이언트(UI/미들웨어/POS)는 식별자 및 작업 유형과 함께 인증된 데이터 작업 요청을 보냅니다.
- API 게이트웨이는 토큰, 속도 제한, Data 360 작업 서비스에 대한 전달을 확인합니다.
- 작업 서비스에서 식별자 → 통합 개인 ID를 확인합니다(빠른 경로 캐시, 그래프 조회 대체).
- 정책 집행(PDP)은 PIP 및 요청 컨텍스트의 특성을 사용하여 CEDAR 정책을 평가합니다.
- 허용되는 경우 작업 서비스가 모든 필수 프로필 특성/인사이트를 읽고 Light Transforms를 수행합니다.
- 작업 서비스는 동기식으로 응답(예: 제공 토큰, 업데이트된 특성)을 반환하거나 비동기 오케스트레이션을 대기열에 지정하고 확인을 반환합니다.
- 모든 이벤트, 결정 및 페이로드는 Trust 레이어에 기록되고 선택적으로 SIEM에 전달됩니다.
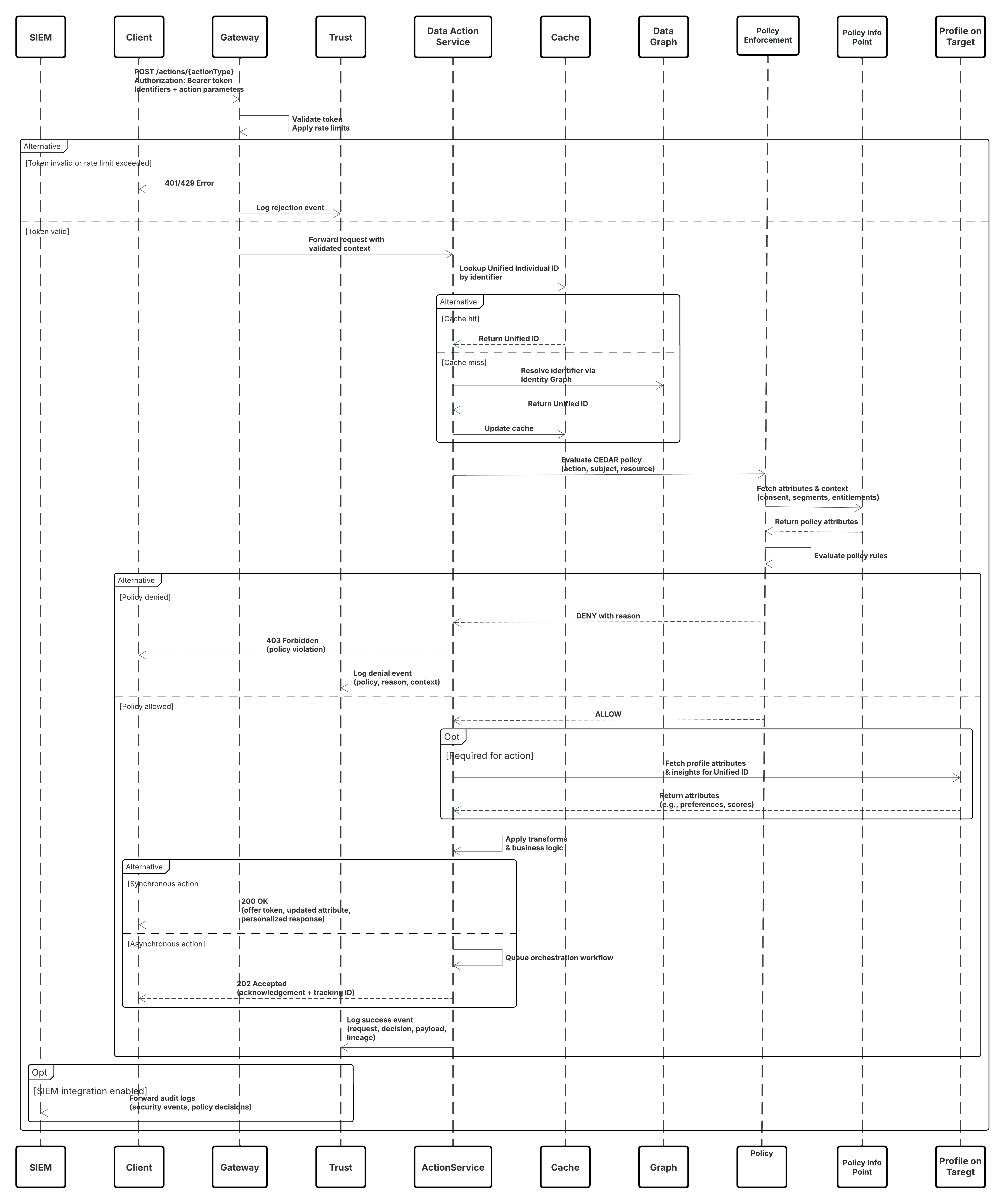
결과
- 응용 프로그램은 하위 초~초 대기 시간으로 통합 프로필 읽기/쓰기 및 작업 트리거에 즉시 정책 관리 액세스할 수 있습니다.
- 배치 지연 없이 실시간 개인 설정, 결정, 운영 워크플로(예: 제안, 에이전트 지원, 재고 업데이트)가 활성화됩니다.
- 모든 작업은 감사 가능하고 동의에 근거하며 개인 정보 보호 및 규정 준수를 유지하기 위해 특성 수준 마스킹을 적용합니다.
메커니즘 호출
호출 메커니즘은 대상 플랫폼 및 활성화 대상 구성에 따라 다릅니다.
| 메커니즘 | 사용하는 경우 |
|---|---|
| RESTful 데이터 작업 API | 동기 프로필 읽기 또는 작업 응답이 필요한 웹/모바일 앱 및 미들웨어에 기본 설정됩니다. |
| gRPC / Binary RPC | 대기 시간이 매우 낮은 엔터프라이즈 서비스 또는 지속적인 연결이 있는 내부 마이크로 서비스에 사용합니다. |
| GraphQL 단일 레코드 쿼리 | 클라이언트에게 유연한 필드 선택이 필요하고 페이로드를 최소화하려는 경우 사용합니다. |
| 이벤트 트리거형 웹후크 | 작업이 다운스트림 프로세스를 트리거하는 비동기 워크플로에 사용합니다(예: 여정 시작). |
| 플랫폼 이벤트 / PubSub | 여러 시스템이 단일 작업 이벤트에 반응해야 하는 팬 아웃 시나리오에 사용합니다. |
| Edge SDK(클라이언트 라이브) | 프로필 조각을 캐시하고 필요한 경우에만 데이터 작업 API를 호출하는 대기 시간이 낮은 클라이언트에 사용합니다. |
오류 처리 및 복구
- 동기 오류: 사람이 읽을 수 있는 메시지 및 균일성 토큰을 사용하여 구조화된 오류 코드를 반환합니다.
- 일시 재시도: 클라이언트는 429/5xx 응답에서 기하급수 백오프를 사용하여 긍정적인 요청을 다시 시도해야 합니다.
- Policy Deny Handling: 거부는 명확한 이유 코드를 반환합니다. 정책 실패 시 중요한 데이터는 반환되지 않습니다.
- 비동기 오케스트레이션 실패: 오케스트레이션 작업은 DLQ로 이동하여 재생할 수 있으며, 작업 상태 API를 사용하면 클라이언트가 콜백을 폴링하거나 받을 수 있습니다.
- 폴백 전략: ID 확인에 실패할 경우 결정적 오류와 경우에 따라 제안된 수정(예: externalId 필요)을 반환합니다.
동임 설계 고려 사항
- Idempotency Key: 클라이언트가 작업을 변형할 수 있도록 ID 키(UUID + 클라이언트 네임스페이스)를 제공합니다.
- 결정적 키: 복합 키(UnifiedIndividualId + ActionType + TimestampWindow)를 사용하여 중복을 감지합니다.
- 안전한 재시도: 측면 효과를 방지하거나 블라인드 삽입 대신 업서트를 수행하도록 작업을 설계합니다.
- 재생 보호: 재생을 방지하기 위해 비즈니스 기간 이후에 처리된 ID 긍정 키를 유지하고 TTL을 유지합니다.
- 무국성: 가능한 경우 동기화 작업을 상태가 없는 상태로 유지하고 비동기 워크플로의 최소 상태를 유지합니다.
보안 고려 사항
- 인증: OAuth 2.0(서비스 계정의 경우 JWT 전달자 또는 mTLS), 단기간 토큰 및 새로 고침 순환.
- 권한 부여: 정책 결정 지점은 요청당 특성 기반 액세스 제어(CEDAR) 및 동의 검사를 적용합니다.
- 전송 및 저장 암호화: 전송 중인 TLS 1.2+ 및 캐시된 조각 또는 감사 로그에 대해 AES-256가 유지됩니다.
- 최소 권한: 최소 권한 범위가 지정된 API 클라이언트, 읽기 및 쓰기와 오케스트레이션에 대해 구분된 역할
- 데이터 최소화: 요청 및 동의된 특성만 반환하고 PII/PHI에 동적 마스킹을 적용합니다.
- 네트워크 제어: 경우에 따라 고위험 작업에 대해 비공개 네트워크(Private Connect, IP 허용 목록)의 호출이 필요합니다.
- ** 감사 및 모니터링:** 요청 메타데이터, 정책 결정, 요청자 ID, 응답 해시를 Trust Layer 및 SIEM에 기록합니다.
링크 모음
시기
- 동기식 작업의 하위 초에서 낮은 단일 초 범위의 평균 대기 시간을 위해 고안되었습니다.
- 에지 캐시(짧은 TTL) 및 사전 계산된 인사이트는 순차 이동을 줄입니다.
- 비동기 경로는 어려운 과업에 대한 백그라운드 처리를 통해 거의 즉각적인 확인을 제공합니다.
데이터 용량
- 단일 레코드 또는 소규모 배치 상호 작용에 최적화됩니다(레코드 1~100개).
- 대량 내보내기를 위한 것이 아닙니다. 대량에는 배치 활성화를 사용합니다.
- 처리량이 높은 경우 풀링/연결 재사용 및 병렬 오케스트레이션 대기열을 사용합니다.
시/도 관리
- 동기식 통화의 경우 상태가 없는 요청 모델이며, 기부금/트랜잭션에 대해 최소 작업 상태로 유지됩니다.
- 변경 이벤트로 인한 캐시 무효화 - TTL 및 무효화 신호가 캐시를 최신 상태로 유지합니다.
- 오케스트레이션 작업은 Trust 계층에 저장된 영구 상태(jobId, 상태, 재시도)를 유지합니다.
복잡한 통합 시나리오
- 에이전트 지원: 에이전트의 경우 실시간 프로필 조회 + 계산된 성향이 하위 초에 Service Console에 반환됩니다.
- POS / Edge 장치: 프로모션 또는 충성도 상태 확인을 위한 로컬 SDK + 임시 데이터 작업
- 하이브리드 흐름: 결정 + 비동기 오케스트레이션에 대한 데이터 동기화 작업을 사용하여 다운스트림 시스템을 업데이트하고 캠페인을 트리거합니다.
- 타사 미들웨어: MuleSoft 또는 API 게이트웨이는 인증을 조정하고, 컨텍스트를 강화하고, 추가 정책 검사를 적용할 수 있습니다.
예제
소매 모바일 앱은 구매자가 쇼핑객의 이메일 및 장바구니 컨텍스트와 함께 제안 적격성 데이터 작업을 호출하여 쇼핑객이 체크아웃을 누를 때 맞춤형 인스턴트 쿠폰을 표시할지 여부를 결정합니다. 요청은 API 게이트웨이에서 확인되고 데이터 작업 서비스에 전달되며, 이는 캐시 일치를 사용하여 이메일을 통합 개인 ID로 확인하고 PDP를 통해 마케팅 동의를 확인하고 고객 생애 가치 및 최근 구매를 기반으로 자격을 평가합니다. 쇼핑객이 자격을 갖추면 서비스에서 서명된 쿠폰 토큰을 반환하고 결정을 기록합니다. 쿠폰 발행 시 재고 예약이 필요한 경우 비동기식 오케스트레이션이 트리거되어 재고를 예약하고 CRM 시스템에 알립니다. 앱은 쿠폰을 즉시 표시하고 다운스트림 업데이트는 백그라운드에서 완료되며 Trust Layer는 관리 및 규정 준수에 대한 전체 감사 추적을 캡처합니다.