As plataformas de dados estão evoluindo há mais de três décadas. Inicialmente, o setor era dominado por bancos de dados operacionais/OLTP locais, centralizados e estruturados (principalmente relacionais). Isso se expandiu para incluir plataformas OLAP/Big Data de armazéns de dados que eram usadas principalmente para processamento analítico e permaneciam relacionais e centralizadas. O armazenamento em nuvem impulsionava arquiteturas distribuídas, como armazéns de dados, lagos e armazenamento desagregado. No entanto, plataformas de operações e plataformas analíticas permaneceram separadas. Hoje, a computação em nuvem e a revolução da IA estão mudando fundamentalmente a arquitetura da plataforma de dados.
As empresas já investem em plataformas de Big Data maduras, como Snowflake, Databricks, BigQuery e Redshift. Porém, essas plataformas servem como silos de dados. Os clientes não estão derivando valor comercial de seus dados porque os dados não podem ser usados diretamente dentro dos fluxos de negócios e aplicativos. Essas soluções não têm processamento de IA agente generativa e não podem fornecer acesso a dados em tempo real, portanto, não podem fornecer personalização conduzida por IA no momento do engajamento do cliente e outros recursos líderes do setor.
O futuro das plataformas de dados é caracterizado por uma infraestrutura de dados unificada, flexível, acessível e aberta. Essa nova arquitetura é criada com base em tendências de computação e armazenamento modernas (GPUs, memória grande, SSDs NVMe e armazenamento em nuvem) para integração com computação em nuvem e IA. Eles podem fornecer percepções em tempo real, aprimorar a tomada de decisão autônoma e promover solicitações em tempo real. Isso inclui o surgimento de IA agente, IA preditiva, análise, bancos de dados OLTP em alta escala em tempo real, data lakes e lakehouses. Essas plataformas de dados modernas são projetadas para simplicidade, escalabilidade, agilidade, desempenho, segurança, disponibilidade e economia.
As seguintes tendências de dados conduzem a arquitetura da plataforma de dados de próxima geração.
- IA, aprendizado de máquina e análise no centro: O surgimento da IA agente mudará fundamentalmente o desenvolvimento, a implantação e o uso/acesso da plataforma de dados. A IA agente entenderá a intenção de conversa/consulta, planejará, gerará fluxos de trabalho e automatizará a tomada de decisão. A memória agente (de curto e longo prazo) é criada com base no histórico de conversas para personalizar o planejamento e as decisões do agente, a modelagem de conversas em tempo real e o suporte de personalização são essenciais em plataformas de dados. Os agentes ajudarão na automação de “capacidades” operacionais, como governança de dados (ou seja, segurança, conformidade, Trust), desempenho (ou seja, escalação automática para simultaneidade, taxa de transferência e latência), failover e disponibilidade, e observabilidade e manutenção. Análise habilitada por IA, previsão, processamento de linguagem natural (NLP) para perguntas/resposta de análise e análise em dados não estruturados (texto como PDFs, imagens, áudio, vídeo) serão padrão, permitindo que as empresas derivem percepções mais profundas de diversas fontes de dados.
- Descentralização dos dados, mas acesso unificado aos dados: Os agentes precisam de dados corporativos para derivar percepções e tomar decisões e automatizar atividades de negócios. Os dados são inerentemente descentralizados em empresas, em aplicativos e plataformas de dados diferentes. Porém, não é fácil unificar perfeitamente os silos entre diferentes unidades de negócios dentro da empresa e com parceiros fora dela. Unificar dados envolve compartilhamento de dados, seja por meio de ingestão de fontes ou federação com fontes de dados; dados brutos da preparação de dados, harmonização e modelagem para processamento analítico e de IA; armazenamento e gerenciamento de dados em escala para acesso eficiente com baixo CTS; e acesso a dados por meio de vários mecanismos e ferramentas de consulta e análise, profundamente integrados com as plataformas de armazenamento e acesso de dados subjacentes
- Lacos abertos baseados em nuvem: As plataformas de Big Data (OLAP) baseadas em nuvem estão se convergindo para adotar formatos de arquivo abertos (Parquet) e formatos de tabela (Iceberg) habilitando a federação de dados (entrada de dados) e o compartilhamento (saída de dados).
- Processamento de dados não estruturados: Com o surgimento, o avanço e a adoção da IA generativa, as empresas estão começando a derivar percepções valiosas e valor comercial do corpus corporativo de dados que constituem grandes volumes de documentos de texto, transcrições de áudio, gravações de vídeo e outras mídias. Processamento de dados não estruturados, incluindo agrupamento, vetorização, pesquisa semântica e gráficos do Knowledge, tornam essas percepções possíveis. Técnicas como RAG (gerência aumentada de recuperação) e CAG (gerência aumentada de cache) estão se tornando os principais acionadores de pesquisa rápida e agente em todo o corpus de dados.
- ** Knowledge Management**: Knowledge vai além do conteúdo bruto em si (documentos, artigos, vídeos). Ele representa o aumento desse conteúdo derivando significado, selecionando metadados e colocando-os no contexto para desenvolver uma compreensão compartilhada do conteúdo em uma organização ou empresa. O Knowledge em si é geralmente estruturado. O Knowledge Management envolve gerenciamento de conteúdo, extração do Knowledge, representação por meio de modelos como gráficos e navegação.
- Acesso a ricos dados: O acesso a dados avançados significa que dados, análises e ferramentas de IA devem estar acessíveis a uma variedade de personalidades, incluindo usuários finais, usuários de negócios, administradores e analistas. A acessibilidade é alcançada por meio de mecanismos como consulta de conjunto (com consulta relacional, palavra-chave e consulta semântica), consulta de linguagem natural para SQL (NL2SQL), acesso em tempo real e assim por diante.
- Processamento em tempo real: Os aplicativos agentes tomam decisões em tempo real com base no estado atual e em novos eventos, respostas personalizadas e ações, que exigem acessar, processar e agir com base em dados em tempo real. O processamento em tempo real requer dados atualizados (latência de dados) e acesso interativo (latência de acesso). Esses dados e a latência de acesso exigem que a plataforma de dados subjacente dê suporte a acesso a dados atualizado de lojas operacionais e analíticas, acesso de baixa latência (pesquisas de pontos e consulta), processamento de alta escala de dados e alta taxa de transferência.
- Segurança de dados, governança e residência: A IA agente e conversacional simplifica a IU do aplicativo, permitindo que qualquer pessoa, de consumidores a funcionários a outros agentes de IA, interaja com aplicativos de modo conversacional usando linguagem natural falada ou escrita. Os dados valiosos do cliente e pessoais que devem ser armazenados e modelados para aplicativos do agente devem ser protegidos e controlados com políticas de acesso e compartilhamento bem definidas. Cada vez mais, muitos clientes devem cumprir regulamentos que exigem residência de dados em seu próprio país ou região, especialmente aqueles no governo ou trabalhando com governos.
O Salesforce Data 360 é arquitetado para o futuro para lidar com essas tendências de dados. O Data 360 é uma plataforma de dados orientada por metadados nativa da nuvem que unifica dados isolados em toda a empresa, permitindo que as organizações armazenem, modelem e processem seus dados para habilitar aplicativos de análise, IA, aprendizado de máquina e Agência.
Este documento é um guia essencial para arquitetos empresariais e CTOs. Ele detalha a arquitetura, os recursos, os princípios de design e os casos de uso do Data 360. Ele apresenta os fundamentos da arquitetura do Data 360 como um primer, seguido por uma série de aprofundamentos em seus principais diferenciadores, como interoperabilidade com plataformas de dados existentes, incluindo estratégia de várias organizações, segurança, governança e privacidade, ativação em tempo real e Data Clean Rooms.
O Salesforce Data 360 é projetado em torno de um conjunto essencial de princípios que tornam os dados corporativos operacionais, confiáveis e em tempo real.
- Abrilidade e interoperabilidade: Criado para ecossistemas de várias nuvens. Federa com plataformas de dados como Snowflake, Databricks, BigQuery e Redshift sem duplicação, estendendo o Customer 360 enquanto preserva os investimentos existentes.
- Storage-Computer Separation: Dimensiona o armazenamento e o processamento (lote, streaming e interativo) de modo independente. Proporciona elasticidade e eficiência para cargas de trabalho de alto volume e alto desempenho.
- Armazenamento e processamento de vários modelos: Dá suporte a tipos de dados estruturados e diversos tipos de dados não estruturados, como texto, áudio de imagem e vídeo. Fornece armazenamento eficiente, processamento em tempo real e em lote, indexação extensível, pesquisa unificada, consulta e análise.
- Design conduzido por metadados: Os aplicativos são definidos por metadados em vez de código. Os metadados são tratados como um ativo de primeira classe, permitindo a governança unificada, a flexibilidade e a integração profunda na Salesforce Platform.
- Processamento híbrido em tempo real: Dá suporte a consultas de baixa latência e tomada de decisão instantânea, junto com processamento em lote e cargas de trabalho analíticas.
- Dados inteligentes e ativos: Ingere, analisa e envia percepções continuamente diretamente para fluxos de trabalho de negócios. Aprimora a automação sem código, com baixa codificação, de código profissional e conduzida por IA com o contexto mais atual.
- Governança e privacidade por design: Linhamento, controle de acesso, residência, criptografia de dados e conformidade são integrados. A Trust e a confiança regulatória são reforçadas em todas as camadas.
- Um para muitos locatários: Uma organização centralizada do Data 360 serve como a única Fonte da verdade para Customer 360, oferecendo suporte integrado a ambientes do Salesforce de várias organizações amplamente usados pelos clientes do Salesforce.
Esses princípios garantem que o Data 360 torne os dados abertos, inteligentes e acionáveis em tempo real.
O Salesforce Data 360 é uma moderna plataforma de dados criada com base em princípios de design que lidam com as tendências de dados atuais. Seus recursos de arquitetura garantem que os dados corporativos sejam confiáveis, unificados e acionáveis em tempo real, de acordo com seus princípios diretos.
- Cloud-Native Foundation: Executa no Hyperforce, implementado em Hypercalers (como AWS), com infraestrutura baseada em microsserviços imutável. Oferece escala elástica, segurança zero Trust, entrega contínua e conformidade global.
- Salesforce (núcleo) baseado em metadados: Os metadados são projetados, modelados e armazenados como metadados do Salesforce, permitindo o uso imediato por TODOS os aplicativos Salesforce. Esses metadados são armazenados em um RDBMS totalmente compatível com ACID. Garante governança, consistência do ciclo de vida e integração profunda com a Salesforce Lightning Platform.
- Lakehouse Storage: Criado com base no Apache Iceberg e Parquet, combinando a escala do data lake com a governança de armazém com suporte para evolução de esquema, viagem de tempo e atualizações de alto volume. O Data 360 armazena, modeliza e processa dados estruturados e não estruturados com armazenamento em escala extrema com padrões abertos modernos e com recursos avançados de transformação e processamento de dados para cargas de trabalho conduzidas por evento e lote.
- Pipeline de dados completo com ingestão flexível: Cobre todo o ciclo de vida (ingerir, preparar, modelar, unificar, analisar e ativar), reduzindo a dependência de soluções de ponto fragmentadas. Suporta lote, quase em tempo real e streaming com mais de 270 conectores e MuleSoft. A abordagem ELT First permite a disponibilidade rápida de dados com flexibilidade de transformação a jusante.
- Interoperabilidade de dados corporativos com estruturas abertas e Federação: Unifica dados de silo em toda a empresa com federação bidirecional do Zero Copy com Snowflake, Databricks, BigQuery e Redshift evitando migração ou duplicação de dados.
- Classificação, modelagem e organização de dados: O Data 360 organiza dados como dados brutos ingeridos, dados limpos e armazenados e dados modelados de acordo com o esquema de informações comuns conhecido como SSOT (Fonte única da verdade). Esses objetos SSOT formam a base para definir Modelos de dados semânticos (SDM) e outros modelos selecionados e específicos do aplicativo.
- Modelação de dados semânticos integrada para análise extensível com APIs de consulta semântica aberta, acionando o Tableau Next e habilitando a análise específica do aplicativo.
- Motor de consulta SQL de alto desempenho que suporta uma consulta unificada do Data 360 SQL em dados estruturados, não estruturados e de gráfico.
- Armazéns de dados de baixa latência: Armazenamento de valor-chave para dados quentes com tempos de resposta de milissegundos. Ativa a personalização e cenários conduzidos por evento em tempo real. Coleta e processa dados de engajamento do cliente em tempo real. Unifica identidades, interações e conversas em um único gráfico de perfil e contexto do Customer 360 confiável.
- Pipelines de processamento de dados não estruturados para suporte flexível e extensível para armazenamento de dados não estruturados, particionamento, geração de integração (vectorização), extração de metadados (aumento), resumo, indexação, extração de Knowledge, processamento inteligente de documentos, criação de memória de curto e longo prazo (conversa) e assim por diante.
- Palavra-chave nativa, vetor e indexação híbrida para acesso a dados não estruturados preciso e eficiente, como pesquisa rápida e agente, RAG, extração de Knowledge, derivação de memória agente, etc.
- Serviços de perfil, personalização, contexto para habilitar aplicativos de IA/ML e agência.
- Governança integrada e segurança em cada camada para rastreamento de linha, mascaramento de dados, residência de dados e segurança de zero Trust garantindo conformidade e Trust.
- Tela Elástica Computar: Tecido computacional nativo de Kubernetes com vários locatários. Executa o Spark para processamento distribuído e cargas de trabalho do Hyper para SQL. Escala elasticamente em diversos trabalhos e dá suporte ao isolamento para executar código não confiável.
Tudo isso é executado no Hyperforce, a base de nuvem do Salesforce. O Hyperforce fornece:
- Security Trust Zero com criptografia, isolamento e políticas de privilégio mínimo.
- Resiliência por meio de implantações de várias regiões. Embora o Salesforce Data 360 beneficie da resiliência multi-região do Hyperforce e da tolerância a falhas no nível da plataforma, a verdadeira recuperação de desastres de nível empresarial (DR) exige uma arquitetura mais ampla semelhante a qualquer plataforma de dados com recursos-chave: pipelines de ingestão reproduzíveis, replicação e reidratação orientada por metadados em todos os ecossistemas dependentes.
- Observabilidade com monitoramento, métricas e rastreamento integrados.
- Escala automatizada e consciência de FinOps para eficiência sem sobrecarga de custos.
O Data 360 não substitui investimentos empresariais existentes. Em vez disso, o Data 360 torna os dados já confiáveis, controlados e acionáveis, proporcionando engajamento conduzido por IA em tempo real onde mais importa. Em suma, o Salesforce transforma todos os dados corporativos, incluindo dados externos, como objetos conduzidos por metadados (Salesforce) e habilita aplicativos Agentes para descoberta, tomada de decisão e tomada de ações.
A figura a seguir ilustra a Arquitetura de referência do Data 360:
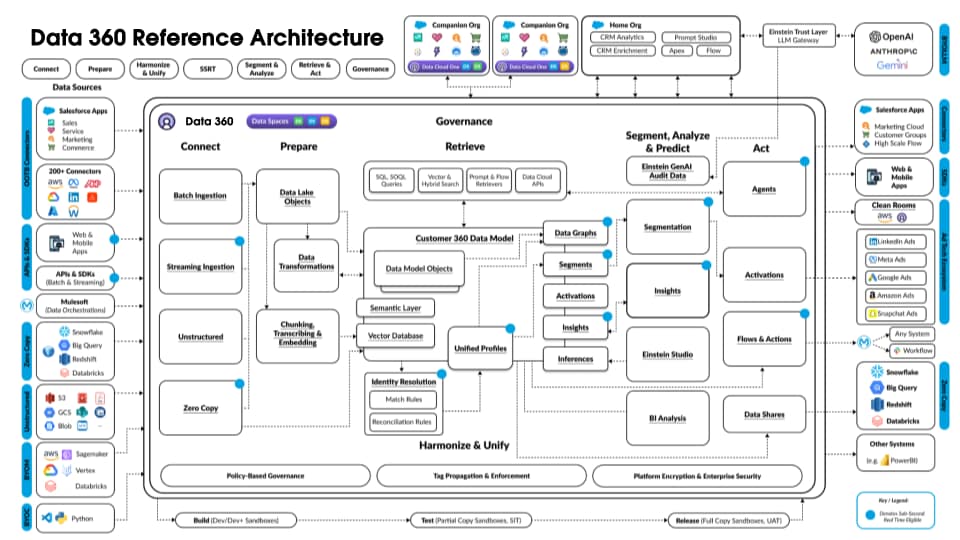
Vamos considerar um Agentforce Loan Agent hipotético estratificado no Data 360 para descrever um exemplo de fluxo de arquitetura. Digamos que o Agente de empréstimo seja um agente voltado para o cliente em que os clientes (consumidores) solicitam empréstimos e recebem aprovações de empréstimo instantâneas.
O Data 360 realiza essas etapas conforme agendado, preparando dados para uso pelo agente de empréstimo.
- O Data 360 ingere dados de Conta do cliente estruturados do CRM e os armazena no data lake.
- O Data 360 processa dados de política financeira e empréstimo da empresa não estruturados.
- O Data 360 federa dados pessoais de uma origem de dados externa, como o Snowflake.
- O Data 360 transforma e modeliza dados ingeridos e federados.
- O Data 360 cria e mantém o gráfico de dados do perfil.
Sempre que um cliente solicita um empréstimo, estas ações são realizadas.
- Um cliente faz login no Agente de empréstimo, que inicia uma sessão do cliente na camada em tempo real. O perfil unificado do cliente é capturado para a camada em tempo real.
- O cliente conclui uma solicitação de empréstimo fornecendo as informações necessárias.
- O cliente carrega documentos financeiros (como devoluções de impostos, investimentos, extratos bancários) para o Data 360 para processamento de dados não estruturado.
- Os dados carregados são divididos em blocos e vetorizados (geração de integração) e os índices (palavra-chave e vetor) são criados.
- Em seguida, o cliente preenche o documento de solicitação de empréstimo e o carrega. O Data 360 extrai o valor e a duração do empréstimo em tempo real.
- O Agente de empréstimo recupera dados financeiros relevantes usando a consulta do Data 360 e a pesquisa híbrida em perfis e outros índices pré-criados.
- O agente de empréstimo ativa um agente de aprovação com dados de empréstimo e outros dados de perfil financeiro para tomar a decisão de aprovação do empréstimo.
- O agente de empréstimo responde ao cliente com uma decisão.
- Toda essa interação entre o cliente e o Agente de empréstimo também é capturada e armazenada no Data 360.
O exemplo acima apresenta uma visão geral dos componentes da arquitetura do Data 360 usados para criar um aplicativo Agente como um Agente de empréstimo. Na próxima seção, descrevemos as camadas e os componentes da arquitetura do Data 360.
Nesta seção, aprofundaremos-nos nos blocos de construção fundamentais do Salesforce Data 360, começando com seu modelo de armazenamento robusto e depois explorando os mecanismos para conexão, ingestão e preparação de dados. Vamos então examinar como dados estruturados e não estruturados são armazenados, modelados e processados, culminando em uma compreensão de suas capacidades de harmonização, unificação, recuperação e ativação inteligente.
O Salesforce Data 360 é baseado em um modelo de armazenamento em níveis, mas integrado, que combina os pontos fortes de um lakehouse com armazenamento em tempo real. A camada do lakehouse fornece armazenamento dimensionável e econômico para grandes volumes de dados históricos e em lote, habilitando análises avançadas e casos de uso de aprendizado de máquina. O armazenamento em tempo real, por outro lado, é otimizado para acesso de baixa latência e atualizações de alta frequência, garantindo que as interações, os perfis e os sinais de engajamento do cliente estejam sempre atualizados. Juntos, esses níveis funcionam perfeitamente, permitindo que os dados se movam fluidamente entre contextos históricos e em tempo real, proporcionando profundidade e imediato em uma base de dados unificada para personalização, IA e ativação.
O Data 360 apresenta uma arquitetura nativa do lakehouse baseada em Iceberg/Parquet, projetada para lidar com o gerenciamento e o processamento de dados em grande escala para cenários em lote, streaming e em tempo real que dão suporte a dados estruturados e não estruturados, cruciais para aplicativos de IA e análise.
Em data lakes baseados em nuvem, como Azure, AWS ou GCP, a unidade de armazenamento fundamental é um arquivo, normalmente organizado em pastas e hierarquias. O Lakehouse aprimora essa estrutura introduzindo abstrações estruturais e semânticas de nível superior para facilitar operações como consulta e processamento de IA/ML. A abstração primária é uma tabela com metadados que define sua estrutura e semântica, incorporando elementos de projetos de código aberto, como Iceberg ou Delta Lake, com camadas semânticas adicionais adicionadas pelo Data 360.
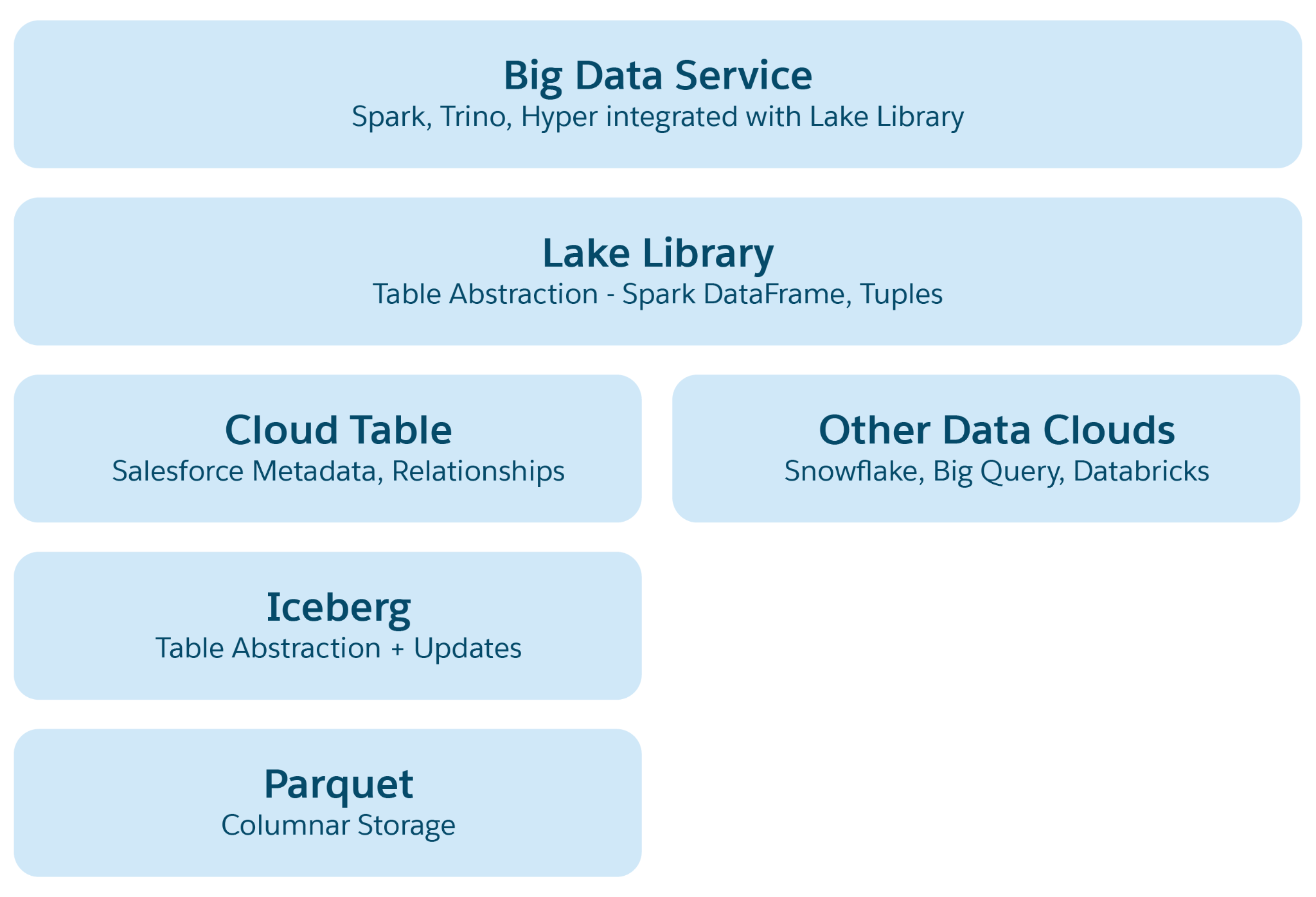
Camadas de abstração no Lakehouse:
- Abstração de arquivo Parquet: Na base, o armazenamento consiste em arquivos de data lake (por exemplo, S3 na AWS ou Blob no Azure) no formato Parquet. Os dados de uma tabela de origem são armazenados entre várias partições como arquivos Parquet, sendo que cada tabela é uma coleção desses arquivos.
- Abstração de tabela de gelo: As tabelas são organizadas como pastas, com partições de dados armazenadas como arquivos Parquet nessas pastas. As modificações em uma partição resultam em novos arquivos Parquet como instantâneos. O IceBerg gerencia um arquivo de metadados para cada tabela, detalhando esquemas, especificações de partição e instantâneos.
- Abstração de tabela do Salesforce Cloud: Com base no iceberg, essa camada adiciona metadados semânticos, como nomes de coluna e relacionamentos, junto com configurações como tamanho de arquivo de destino e compactação. Ele abstrai tabelas em várias plataformas, como o Snowflake e o Databricks, protegendo aplicativos do Data 360 dos detalhes subjacentes da plataforma de armazenamento.
- Lake Access Library: Essa biblioteca fornece acesso à Tabela do Salesforce Cloud, que lida com dados e metadados e abstrai os mecanismos de armazenamento subjacentes para desenvolvedores de aplicativos.
- Abstração de serviço de big data: Isso inclui estruturas de processamento como Hyper para consulta e Spark para processamento em qualquer plataforma de tabela de nuvem.
Para oferecer suporte a análises em tempo real e aplicativos agentes, o Data 360 aumenta o armazenamento de big data do Lakehouse com a Loja de baixa latência. A Camada em tempo real do Data 360 processa sinais em tempo real e dados de engajamento na memória. No entanto, como a capacidade de armazenamento baseado em memória é limitada, todos os dados não podem caber e o processamento pode não ser feito em tempo real. O Data 360 adiciona um armazenamento de baixa latência (LLS) para remover essas limitações, habilitando o processamento escalonável em tempo real.
O repositório de baixa latência é uma camada de armazenamento NVMe (SSD) em escala de petabytes no Lakehouse. Nem todos os dados precisam ser mantidos no repositório de baixa latência. É um cache durável. A maioria dos dados acaba chegando ao Lakehouse para persistência de longo prazo. Os dados na sessão na camada de tempo real podem ser transferidos para o armazenamento de baixa latência para acesso rápido subsequente. Por exemplo, em uma conversa agente, as mensagens recentes podem ser processadas na memória; mensagens mais antigas podem ser enviadas para o repositório de baixa latência. Se uma conversa anterior for necessária, ela poderá ser acessada em poucos milissegundos do repositório de baixa latência. O armazenamento baseado em NVMe permite que grandes quantidades de dados sejam armazenadas e acessadas em latências de milissegundos. Os dados podem entrar no armazenamento do Lakehouse Cloud para a manutenção de longo prazo. Além disso, os dados do Lakehouse necessários para processamento em tempo real ou para aumentar experiências em tempo real são buscados e mantidos no repositório de baixa latência. Por exemplo, o Contexto do perfil do cliente é pré-coletado ou trazido do Lakehouse e armazenado em cache na loja de baixa latência. Além disso, todos os objetos do Lakehouse e outros objetos necessários para processamento em tempo real durante o processamento na sessão também podem ser armazenados em cache no repositório de baixa latência.
O armazenamento de baixa latência do Data 360 habilita a camada de Tempo real em uma hierarquia de armazenamento verdadeira com camadas de armazenamento do Lakehouse de memória (SSD), com dados migrando perfeitamente entre essas camadas. Vamos discutir a camada do Data 360 em tempo real mais adiante neste documento.
O Salesforce Data 360 é projetado para padronizar, harmonizar e ativar todos os dados do cliente, estruturados e não estruturados, seguindo um ciclo de vida rigoroso que transforma a entrada bruta em um modelo de dados unificado e atual.
O ciclo de vida se concentra em obter várias entradas de dados externos e estruturá-las em objetos persistentes modelados. Os dados modelados podem ser harmonizados em perfis unificados do Customer 360.
Dados brutos ingeridos e transformações iniciais
O processo começa com dados brutos ingeridos como estão de sistemas de origem (CRM, Marketing, arquivos etc.). Isso inclui carregamentos de dados completos e eventos de alteração contínua (deltas), que são gerenciados e mesclados com dados persistentes para manter um estado atual.
As transformações inline (por exemplo, recorte, normalização, concatenação) são aplicadas imediatamente durante a ingestão para garantir a qualidade preliminar dos dados e a limpeza.
Objetos do Data Lake (DLOs): A camada persistente
Os DLOs (Objetos do Data Lake) formam a camada de armazenamento persistente central no Data 360. Eles armazenam os dados limpos e transformados e servem como o repositório organizado e de longo prazo para todas as informações do cliente.
As transformações de dados avançadas (por exemplo, junções, agregações, insights calculados) são aplicadas aos DLOs de origem para produzir novos DLOs derivados altamente selecionados.
Os dados disponibilizados por meio da Federação de dados de cópia zero são representados diretamente como DLOs.
Organização de metadados e dados não estruturados
Para conteúdo não estruturado (como texto, mídia, documentos), o Data 360 incorpora os dados extraindo e mantendo seus metadados estruturados dentro de DLOs específicos chamados de objetos de data lake não estruturados (UDLOs).
Esses DLOs especializados funcionam como tabelas de diretório, fornecendo um mapa para a localização física e o contexto dos ativos não estruturados. Essa funcionalidade permite aos arquitetos relacionar perfeitamente os metadados de dados não estruturados com o restante dos dados do cliente estruturado, permitindo consulta unificada e harmonização.
Objetos de modelo de dados (DMOs): A camada harmonizada
Os DMOs (Objetos de modelo de dados) representam a camada de dados final, harmonizada e estruturada.
Eles são criados mapeando campos de DLO (de DLOs de metadados de origem, derivados e não estruturados) para o Modelo de dados Customer 360 padrão.
A camada de DMO atua como a única fonte da verdade para todos os dados do cliente, habilitando a criação, segmentação e ativação de perfil unificados em todo o ecossistema.
Um espaço de dados é o contêiner lógico fundamental para organizar todos os dados e metadados no Data 360, incluindo todos os DLOs (estruturados e não estruturados) e DMOs. Os espaços de dados oferecem um ambiente seguro e isolado para processamento e modelagem de dados.
Os espaços de dados atuam como limites lógicos e de governança, habilitando multitarefa interna separando dados para entidades distintas, como unidades de negócios, regiões ou marcas, enquanto mantêm a visibilidade, a linhagem e a conformidade em toda a empresa, servindo como a base para definir o controle de acesso granular.
O isolamento dentro de espaços de dados é imposto em várias camadas da plataforma:
- Isolamento em nível de dados: Cada DLO/DMO pertence a um único espaço de dados, garantindo que consultas, transformações e mapeamentos de objeto não possam cruzar limites de espaço de dados, a menos que autorizados explicitamente.
- Integração de controle de acesso: Os conjuntos de permissões são vinculados nativamente a espaços de dados, permitindo o controle de operações administrativas, de leitura e gravação. Isso garante que apenas usuários e serviços autorizados possam acessar objetos, percepções e ativações em um espaço de dados.
- Governance and audit: Todas as operações em um espaço de dados são registradas com trilhas de auditoria de nível corporativo, habilitando a rastreabilidade para conformidade, orientação e relatórios regulatórios.
O acesso e as permissões são gerenciados por meio de Conjuntos de permissões, garantindo visibilidade granular, atualizações controladas e prevenção de vazamento de dados entre domínios. Ao integrar limites de espaço de dados à arquitetura de segurança e governança do Data 360, os arquitetos podem implementar com confiança estratégias de governança centralizada e descentralizada enquanto mantêm a consistência em várias nuvens e domínios de negócios.
O tecido de computação do Data 360 fornece uma camada unificada para gerenciar e executar todas as cargas de trabalho de big data, simplificando as complexidades de infraestrutura subjacentes. Seu componente principal é o controlador de processamento de dados (DPC).
O DPC é um serviço abrangente de orquestração de processamento de dados de várias cargas de trabalho que fornece funcionalidades de Trabalho como serviço (JaaS) em vários ambientes de computação em nuvem. Ele abstrai a complexidade da infraestrutura e unifica a execução de trabalhos para estruturas como Spark (EMR em EC2 e EMR em EKS) e cargas de trabalho do Controlador de recurso Kubernetes (KRC). Ao servir como um gateway de plano de controle centralizado, o DPC orquestra, agenda e monitora trabalhos em vários planos de dados, garantindo confiabilidade, escalabilidade, custo-benefício e uma experiência de desenvolvedor consistente.
A necessidade de DPC deriva das limitações de interagir diretamente com sistemas de gerenciamento de cluster nativos, como EMR.
Infraestrutura e abstração de nuvem
Embora o EMR ofereça APIs para clusters, tarefas e etapas, ele ainda carrega as equipes do cliente com tarefas críticas de gerenciamento de infraestrutura, como provisionamento, escalação, ajuste de desempenho e otimização de custo. A DPC lida com isso oferecendo uma API simplificada no nível da plataforma para envio de trabalhos. Ele oferece suporte a manuseio automático de falhas, novas tentativas e balanceamento de carga dinâmico. Fornece eficiência de custo por meio de nós com base em empacotamento, spot e graviton. Fornece segurança forte com TLS, PKI, isolamento IAM e correção automatizada. Gerencia upgrades de versão do tempo de execução do Spark e do EMR para proporcionar melhorias de desempenho, correções de segurança e aprimoramentos de recursos.
Além disso, o DPC fornece uma interface unificada agnóstica à nuvem para enviar e gerenciar trabalhos de dados, abstraindo as complexidades e as APIs proprietárias do substrato de nuvem subjacente (AWS, provedores futuros). Isso garante que as equipes do cliente interajam apenas com uma interface de envio de trabalho comum baseada na API do Data 360 que abstrai as complexidades dos gerentes de recursos subjacentes, como Kubernetes e YARN. Isso permite que as equipes do cliente enviem trabalhos do Spark por meio de uma API simples e unificada sem precisar gerenciar pods, grupos de nós ou configurações de cluster do Spark diretamente.
O ajuste manual dos parâmetros do Spark requer habilidades especializadas, e configurações incorretas podem levar à execução lenta do trabalho. A equipe de DPC centraliza esse conhecimento, fornecendo configurações otimizadas para evitar problemas comuns de desempenho. Essa equipe especializada integra continuamente o Knowledge da comunidade de código aberto para garantir um desempenho ideal em todas as cargas de trabalho gerenciadas pelo controlador.
O DPC não está limitado ao Spark; ele oferece suporte a uma ampla gama de cargas de trabalho. Essas incluem:
- Cargas de trabalho de processamento em tempo real
- Entrega de evento para recurso Ações de dados
- Gerenciamento do Milvus (o banco de dados vetorial para indexação de dados não estruturados)
- Infraestrutura de armazenamento de baixa latência
A DPC também utiliza a estrutura Kubernetes Resource Controller (KRC), que dá suporte a cargas de trabalho como Trino para consulta, Entrega de evento para ações de dados, Trabalhos de extração de dados para conectores e processamento em tempo real. Para todas as cargas de trabalho do KRC, o DPC fornece funcionalidades centrais de Trabalho como um serviço, lidando com provisionamento de computação, implantação e gerenciamento em uma abstração de trabalho de alto nível.
Benefícios e arquitetura de JaaS
O modelo de Trabalho como um serviço, fornecido pela DPC, garante um pipeline de processamento de trabalho rentável e resiliente.
Os usuários fornecem especificações de cluster simples, focando a CPU necessária, a memória, o armazenamento, as contagens de instância e as contagens mín/máx. de cluster e as marcas para correspondência de cluster. O DPC então gerencia automaticamente os detalhes da infraestrutura abstrata, incluindo selecionar SKUs de VM ideais, gerenciar frotas de instância, determinar a proporção de Núcleo vs. Nós de tarefa e gerenciamento On-Demand vs. Detectar instâncias com base em entradas. Também lida com o gerenciamento de versão de componente e EMR e upgrades sem tempo de inatividade.
Crucialmente, o DPC oferece suporte inerente à multitarefa, projetada para entender e impor limites de locação do Data 360 e separação de recursos. Ele também garante segurança e conformidade aplicando imagens de máquina certificadas pelo Salesforce, gerenciando papéis IAM específicos do serviço e garantindo a criptografia em trânsito e em repouso. Para roteamento e controle de capacidade, a correspondência de trabalho para grupo é gerenciada usando marcas de cluster, e o roteamento baseado em capacidade usa uma configuração de simultaneidade de trabalho máxima para controlar de modo eficaz a utilização de recursos.
A experiência de cliente agnóstica na nuvem é um benefício essencial, pois a complexidade dos ambientes de nuvem subjacentes fica oculta dos serviços ao cliente, permitindo que eles se concentrem exclusivamente na lógica de negócios. Isso atinge a meta da Abstração do provedor de nuvem. Por fim, o DPC habilita o fácil Rastreamento de uso e custo, permitindo que a utilização do cluster e os custos sejam segmentados por serviço para uma contabilidade precisa. Em geral, o DPC segue uma arquitetura plugável que permite que novos mecanismos de execução (por exemplo, Flink, Ray) e substratos de nuvem (GKE/Dataproc) sejam integrados perfeitamente sem expor detalhes de infraestrutura subjacentes aos usuários. Esse design desconecta o plano de controle da camada de execução, garantindo uma experiência operacional e de API consistente independentemente do back-end.
O Data 360 refina e aprimora dados brutos, preenchendo a lacuna entre informações brutas e consumo comercial acionável. Ele complementa o ciclo de vida do objeto de dados preparando dados complexos para ativação e análise sofisticadas. O Data 360 oferece suporte a vários tipos de processamento, incluindo Transformações de dados de streaming e lote, Insights calculados de streaming e lote, Processamento de dados não estruturado e Resolução de identidade. Para habilitar essas diversas operações de modo eficiente, especialmente em tempo quase real e em conjuntos de dados massivos, é necessário um mecanismo sofisticado para lidar com alterações de dados de modo eficaz.
Para obter um processamento de dados eficiente quase em tempo real, especialmente com tabelas de terabytes e milhões de atualizações em potencial, o Data 360 precisava de um avanço. Ele exigiu uma maneira de notificar os sistemas precisamente quando os dados mudaram e, em seguida, identificar de modo eficiente quais dados foram alterados para que somente atualizações relevantes sejam processadas e somente quando forem atualizadas. Esse desafio levou a duas inovações complementares: Armazene eventos de alteração nativos (SNCE) para notificar quando algo é alterado e Alterar feed de dados (CDF) para identificar o que mudou.
Eventos de alteração nativa de armazenamento (SNCE)
A SNCE transformou fundamentalmente o Data 360 em uma plataforma de dados reativa e incremental. Essa mudança envolve a transição da pesquisa ativa no data lake para o monitoramento passivo para compromissos atômicos, usando um formato de evento padronizado e um sistema de entrega de mensagens de alta taxa.
Cada operação de gravação bem-sucedida (INSERT, UPDATE, DELETE) em uma tabela de iceberg culmina em uma troca atômica do ponteiro do arquivo de metadados atual da tabela no catálogo. A camada de armazenamento de objeto subjacente (por exemplo, S3) é configurada para emitir um evento de notificação nativo (como um evento do S3) sempre que um novo instantâneo de metadados é gravado no diretório da tabela.
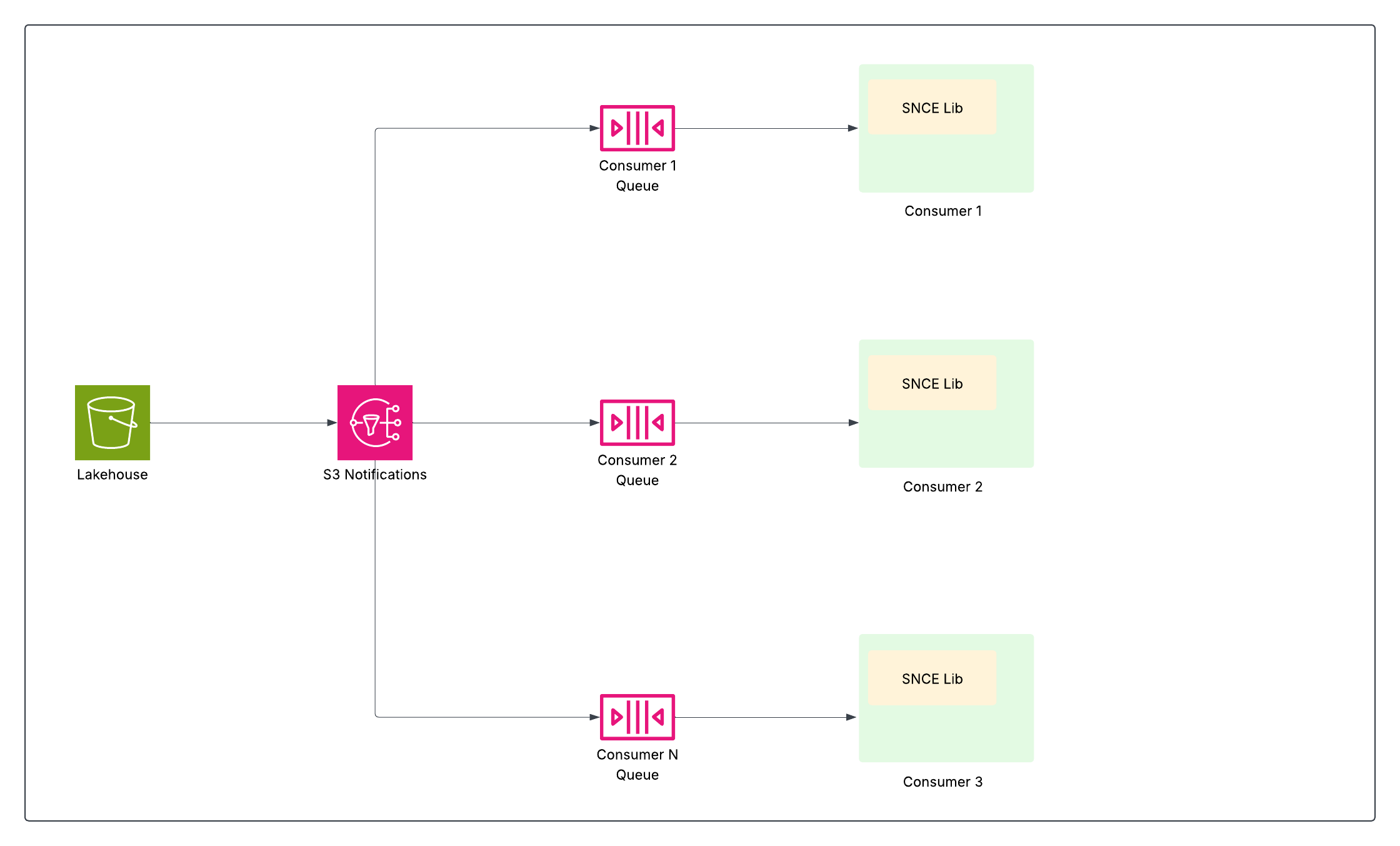
A biblioteca SNCE oferece um método padronizado para consumir esses eventos e também pode aprimorá-los com metadados de instantâneo mediante solicitação.
Isso habilita os pipelines de dados a jusante, como transmissão de percepções calculadas, resolução de identidade e segmentação, a assinar e agir apenas quando os dados mudaram, aumentando significativamente a eficiência evitando verificações de tabela completa caras.
Alterar o feed de dados (CDF)
Com base na SNCE, o Feed de alteração de dados (CDF) fornece um mecanismo simplificado para consumir e processar incrementalmente as alterações.
A CDF aproveita instantâneos do IceBerg para gerar de modo eficiente o fluxo de alterações. Crítico, o redator iceberg otimizado do Data 360 calcula e mantém as alterações como parte da própria operação de gravação, tornando a geração de CDF altamente eficiente e minimizando a sobrecarga adicional. Isso permite que trabalhos de processamento (como transformações de streaming ou percepções calculadas de streaming) processem de modo seletivo apenas os registros alterados, evitando o caro cálculo diferencial de instantâneo.
Essa estratégia incremental oferece vários benefícios para conjuntos de dados grandes, incluindo poupança de custo, menor latência e maior eficiência. Ele habilita recursos como transformações de streaming e resolução de identidade incremental, que, por sua vez, levam a percepções mais rápidas, cargas do sistema mais previsíveis, desempenho aprimorado e menores despesas operacionais.
O Data 360 oferece recursos de ingestão robustos com suporte nativo para produtos do Salesforce, garantindo um fluxo de dados contínuo. Para origens externas, ele fornece uma extensa conectividade por meio de mais de 270 conectores, APIs, SDKs e MuleSoft. Além disso, o Data 360 oferece federação de cópia zero, permitindo BI e análise sem duplicação de dados.
A estrutura do conector do Data 360 (DCF) é a base para a maior parte da conectividade do Data 360. Ele habilita a ingestão, a federação e a saída por uma arquitetura unificada. O DCF define os padrões para criar e gerenciar conectores, da IU para configuração e administração à persistência de metadados, extração de dados e entrega no Lakehouse ou por meio de consultas ativas em origens externas. Também oferece suporte a opções de conectividade privada (como links privados, VPNs e túneis seguros) para garantir a segurança e a conformidade de dados de nível corporativo ao se conectar a ambientes de clientes ou parceiros. Ao fornecer uma abordagem consistente em todos os conectores, o DCF permite que o Data 360 se conecte perfeitamente ao ecossistema mais amplo garantindo extensibilidade, confiabilidade e integração segura.
O Data 360 fornece conectividade robusta a um vasto ecossistema de fontes de dados, oferecendo suporte a produtos nativos do Salesforce e a vários sistemas externos. Essa extensa conectividade é crucial para unificar dados corporativos isolados e habilitar aplicativos de IA/ML e Agência.
O Data 360 oferece mais de 270 conectores nativamente ou por meio do MuleSoft, de APIs e de SDKs para dar suporte a seus recursos de pipeline de dados de ponta a ponta com ingestão em tempo real, streaming ou lote. Esses conectores podem ser amplamente categorizados pelo tipo de sistema de origem que eles integram.
Conectores nativos do Salesforce
Esses conectores garantem um fluxo de dados integrado e nativo de produtos do Salesforce.
Os exemplos incluem conectores para Salesforce CRM, Data Cloud One, Marketing Cloud Engagement, Account Engagement do Marketing Cloud e B2C Commerce.
Aplicativos externos e SaaS
Conectores para vários aplicativos comerciais e serviços de nuvem permitem a ingestão de dados de plataformas de software externas.
Exemplos incluem Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp e Airtable.
Bases de dados e armazéns de dados
O Data 360 se conecta a uma variedade de plataformas de armazenamento de dados relacionais e baseadas na nuvem.
Exemplos incluem Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery e Microsoft SQL Server.
Armazenamento de objetos em nuvem e sistemas de arquivos
Esses conectores se integram a soluções de armazenamento de hiperescala para dados estruturados e não estruturados.
Exemplos incluem Amazon S3, Google Cloud Storage (GCS) e Armazenamento de Blobs do Azure.
Serviços de mensagens e streaming
Conectores que lidam com fluxos de dados em tempo real contínuos são essenciais para cenários conduzidos por evento e processamento em tempo real.
Um exemplo é o Conector do Amazon Kinesis.
Plataformas de integração
O MuleSoft Anypoint Connector estende o alcance do Data 360 integrando-o a uma gama mais ampla de aplicativos e bancos de dados por meio do Anypoint Exchange.
Conectores de armazenamento de objetos de nuvem e dados não estruturados
Esses conectores são essenciais para ingerir e fazer referência a dados não estruturados (dados que não têm um modelo predefinido) para habilitar os recursos de IA generativa.
Todos esses conectores são criados na estrutura do conector do Data 360, proporcionando uma experiência consistente.
A transformação de dados é um componente arquitetônico fundamental no Data 360, projetado para limpar, enriquecer e moldar dados brutos ingeridos em ativos de dados normalizados e acionáveis alinhados ao modelo de dados Customer 360. Esse processo é essencial para harmonização de dados, melhoria da qualidade e garantia de que os dados estejam prontos para casos de uso a jusante, como unificação de perfil, segmentação e ativação. As transformações aproveitam tanto objetos de data lake de origem (DLOs) quanto objetos de modelo de dados (DMOs) como entrada, produzindo os resultados para novos DLOs ou DMOs, respectivamente.
O Data 360 fornece dois paradigmas de transformação principais para lidar com diferentes requisitos de velocidade de dados: transformações de dados em lote e transformações de dados de streaming.
Transformações de dados em lote
As Transformações de dados em lote são projetadas para processamento de alto volume com base em uma agenda definida ou acionador sob demanda. Esse mecanismo é otimizado para lidar com operações de reestruturação complexas e com uso intensivo de recursos.
O processo Transformação em lote é configurado usando uma tela de pipeline visual com pouco código que permite que os usuários definam a lógica de transformação de vários estágios. Esse mecanismo oferece suporte exclusivo a operações de reestruturação complexas vitais para o alinhamento do modelo de dados canônico: estruturação e normalização de dados. Isso inclui dinamizar (descontinuar registros não normalizados em vários registros normalizados) e nivelar (reestruturar dados hierárquicos, como JSON, em tabelas estruturadas). O modo de execução do sistema oferece suporte à sincronização completa (processando todos os registros) e a um modo de processamento incremental altamente eficiente. O modo incremental reduz significativamente o tempo de processamento e o consumo de recursos processando apenas os registros que mudaram desde a última execução bem-sucedida. As transformações em lote são ideais para tarefas em que atualizações em tempo real não são essenciais, como agregações periódicas e reestruturação de dados complexa.
Transformações de dados de streaming
Os dados de streaming processam dados de modo contínuo e incremental quase em tempo real à medida que fluem para o sistema, tornando-os essenciais para casos de uso de baixa latência.
A interface principal é uma abordagem SQL-first, em que as transformações são definidas como uma consulta SQL SELECT que é executada continuamente em relação ao fluxo de alterações de registro recebido. Esse mecanismo dá suporte a funções de transformação principais, incluindo limpeza de dados e Padronização (por exemplo, validação de PII e padronização de formatos de dados) e aprimoramento e mesclagem de dados (usando Junções e Unções). Crítico, ele oferece suporte a junções de pesquisa de streaming para habilitar o aprimoramento de dados em tempo real e pesquisas em relação a dados de referência estáticos ou que mudam lentamente, garantindo atualizações de perfil instantâneas. Para otimizar o custo para atender, a arquitetura usa um design de trabalho de alta densidade (HD), que empacota várias definições de transformação de streaming para um único locatário em um único trabalho de computação subjacente, maximizando a utilização de recursos. As transformações de streaming são essenciais para casos de uso, como monitoramento de evento, personalização imediata e atualizações de perfil em tempo real.
O Data 360 revoluciona o gerenciamento de dados com o suporte à federação e ao compartilhamento de dados de Cópia zero, o que elimina a necessidade de mover ou duplicar dados. Esse recurso permite que os usuários acessem dados de várias origens externas de modo contínuo e direto e compartilhem dados com ambientes externos, reduzindo significativamente a complexidade, reduzindo os custos de armazenamento e garantindo que todas as decisões sejam baseadas nas informações mais recentes e confiáveis.
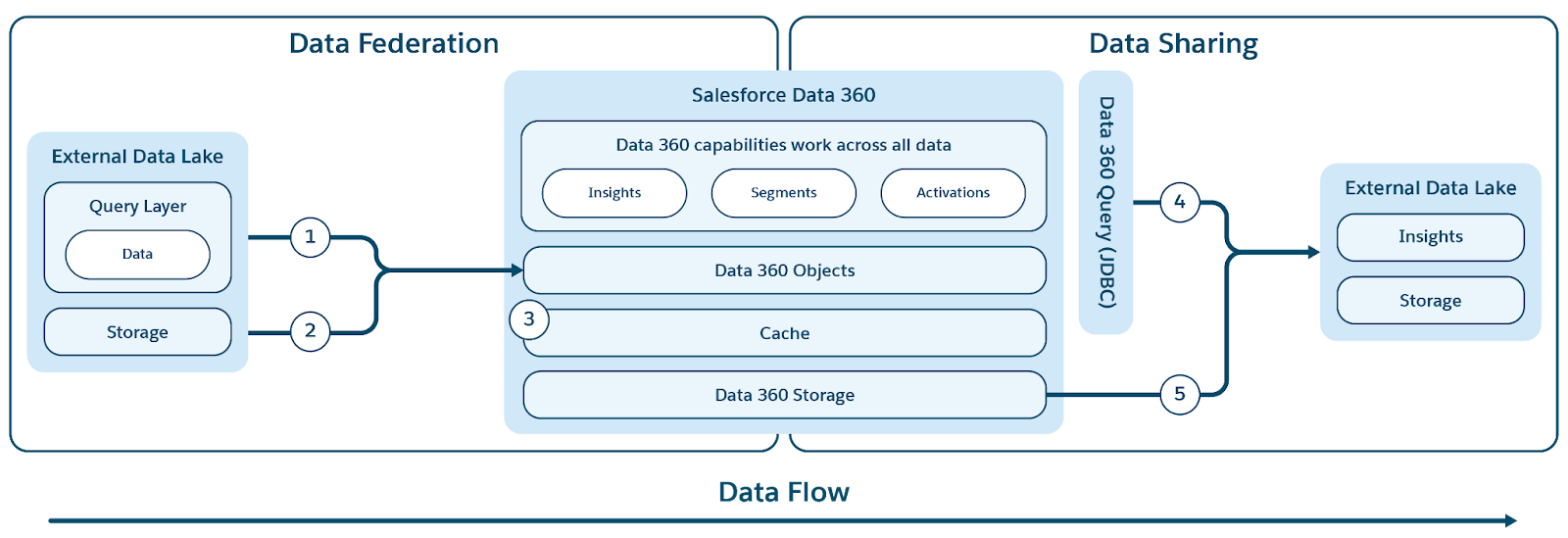
O Data 360 oferece suporte à federação de cópia zero com armazéns de dados externos (Snowflake, Redshift), lagoas (Google BigQuery, Databricks, Azure Fabric), bancos de dados SQL e muitas outras fontes. Suas camadas de abstração permitem a consulta direta de dados externos sem duplicação, reduzindo o tempo de ingestão, os custos de armazenamento e garantindo informações atualizadas.
O Data 360 simplifica o acesso a dados externos e federados fornecendo uma camada de metadados unificada que abstrai tanto o Salesforce quanto objetos externos. Isso permite que toda a Salesforce Platform e seus aplicativos usem esses dados perfeitamente.
O Data 360 oferece suporte à federação baseada em arquivo e consulta, com a aceleração de acesso e consulta ativa, conforme mostrado na figura.
Os rótulos (1) e (2) ilustram a consulta do Data 360 (incluindo push-downs de consulta ativa) e a federação baseada em arquivo para acessar dados de data lakes / warehouses / origens de dados externas; e o rótulo (3) destaca a aceleração do acesso federado de data lakes / origens de dados externas.
Federação de consulta
O núcleo da funcionalidade de federação do Data 360 está na camada de federação de consulta, que gerencia o processo complexo de acessar dados externos e realizar push-ups de consulta inteligentes (ilustrado pelo rótulo 1). O Data 360 se conecta e recupera dados de origens usando o protocolo JDBC, aprimorado com lógica adicional para maior eficiência. A Camada de federação de consulta é responsável por entender e traduzir diferentes dialetos SQL, descobrir a parte mais ideal da consulta a ser enviada para sistemas externos para processamento eficiente, recuperar os resultados e realizar qualquer processamento adicional necessário para derivar percepções finais.
Armazenamento em cache (aceleração de consulta)
Para utilitários aprimorados, o Data 360 fornece um recurso de aceleração opcional para seus recursos federados.
Quando a Aceleração é ativada, o Data 360 armazena em cache os dados federados para obter acesso mais rápido e custos menores, pois evita acesso repetido e direto a origens externas. Esse cache é tratado como uma camada de aceleração e é atualizado incrementalmente para refletir rapidamente quaisquer alterações nos dados de origem externos, garantindo que a visualização acelerada permaneça quase em tempo real.
Federação de arquivos
O Data 360 oferece suporte à federação baseada em arquivo (ilustrada pelo rótulo 2) para acessar dados de data lakes e origens externas. A base técnica para esse recurso de cópia zero depende da padronização: os dados subjacentes devem estar no formato de arquivo Apache Parquet e usar o formato tabular do Apache Iceberg. O Data 360 pode se federar em qualquer origem que expõe um Catálogo REST do Iceberg (IRC) para acesso a metadados e armazenamento, garantindo acesso contínuo e controlado a arquivos que residem fora da plataforma.
Com a federação baseada em arquivo, os computadores do Data 360 lidam com todo o processamento de dados porque acessam diretamente o armazenamento subjacente. Isso elimina a necessidade de consulta adicional e gerenciar vários dialetos SQL, que costumam ser necessários com federação baseada em consulta.
Além disso, a funcionalidade de Cópia zero também se estende a fontes de dados não estruturadas, como soluções de armazenamento em hiperescala (armazenamento S3/GCS/Azure), Slack e Google Drive, que podem ser acessadas pelos pipelines de processamento não estruturados do Data 360.
O Data 360 facilita o compartilhamento baseado em consulta e baseado em arquivo de dados que ele gerencia com data lakes e armazéns externos (ilustrados pelos rótulos 4 e 5 no contexto da figura original).
Compartilhamento baseado em consulta
Para compartilhamento de dados baseado em consulta, o Data 360 expõe um driver JDBC usando o qual mecanismos e aplicativos externos podem obter acesso seguro aos dados. Esse mecanismo permite que sistemas externos conectem, autentiquem e executem consultas ativas diretamente com relação aos dados no Data 360.
Compartilhamento baseado em arquivos (compartilhamento de dados e DaaS)
O mecanismo primário para compartilhamento baseado em arquivo envolve dois conceitos: compartilhamento de dados e destino de compartilhamento de dados, que aproveitam a API DaaS (Dados como um serviço).
- Controle granular: O conceito de compartilhamento de dados permite que os clientes definam com precisão quais objetos (DLOs, DMOs, CIOs etc.) são compartilhados externamente, evitando a exposição inadvertida de dados.
- Direcionamento seguro: Ele também controla o destino do compartilhamento de dados, garantindo que os dados sejam disponibilizados apenas a ambientes externos, contas ou organizações parceiras explicitamente autorizadas (por exemplo, compartilhamento com uma instância específica do Redshift ou do Databricks).
A API DaaS fornece uma interface segura e gerenciada para mecanismos externos consumirem dados. Ele concede acesso aos metadados essenciais e ao armazenamento de tabela subjacente enquanto preserva toda a semântica do Data 360. Isso garante que os mecanismos externos acessem os dados em um contexto consistente e relevante de maneira segura.
Muitos clientes sensíveis à segurança, especialmente grandes empresas, setores regulamentados e organizações do setor público, restringem todo o acesso à Internet aos seus data lakes como parte de sua postura de segurança. Essa política, embora seja essencial para a conformidade e redução de riscos, também impede que o Salesforce Data 360 e Agentforce se conectem a esses ambientes por meio da Internet pública.
A maioria desses data lakes é implementada em ambientes de hiperescala, como AWS, Azure ou Google Cloud. Como o Data 360 em si é executado na AWS, acessar data lakes do cliente hospedados em um provedor de nuvem diferente requer uma conexão de rede entre nuvens. Sem uma opção de conectividade segura e privada que ignora a Internet pública, os clientes geralmente não conseguem ou não estão dispostos a adotar o Data 360 ou Agentforce para casos de uso que dependem desses data lakes.
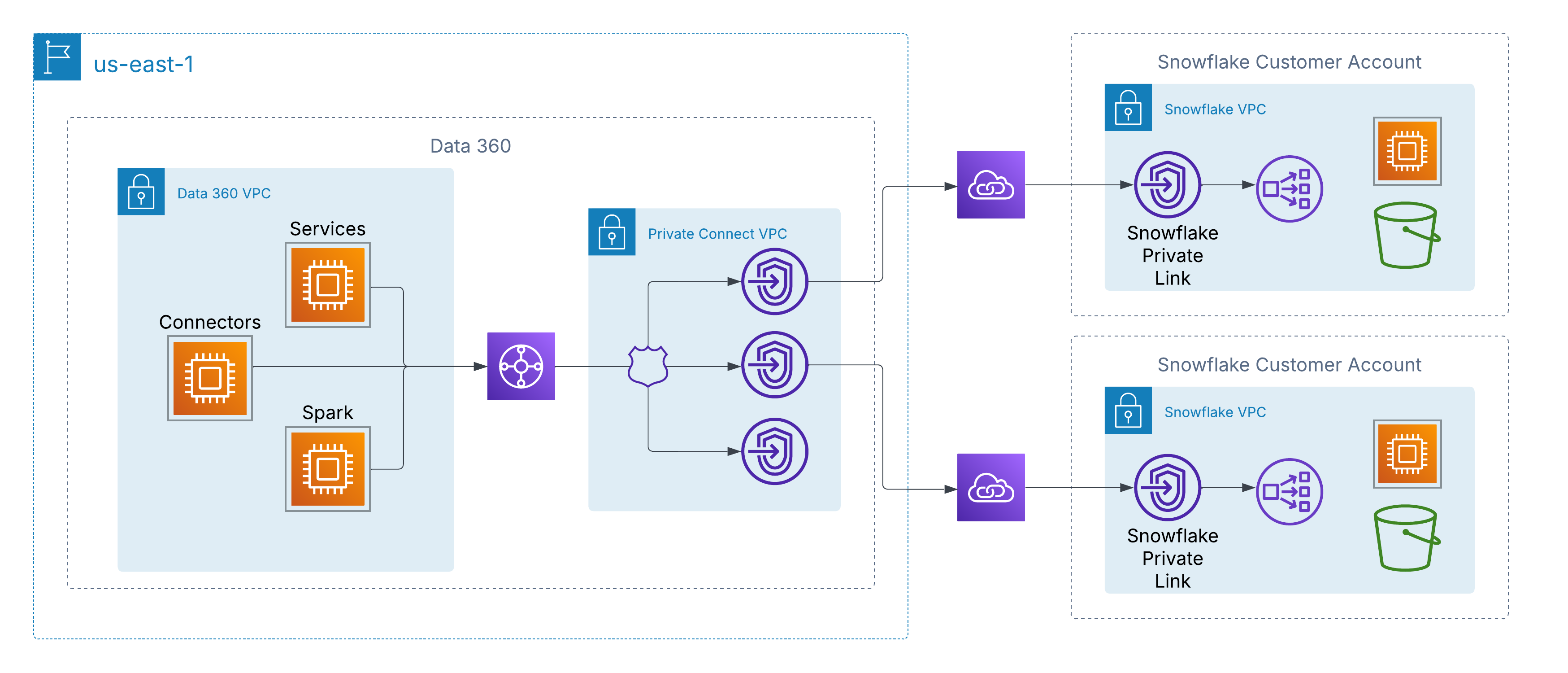
Para lidar com isso, o Data 360 oferece suporte à conectividade privada em nível de rede com fontes de dados gerenciadas pelo cliente em nuvens. Na AWS, isso é habilitado por meio do AWS PrivateLink, que permite que o Data 360 se conecte diretamente a pontos de extremidade provisionados pelo cliente, seja em suas próprias contas ou em ambientes de data lake de terceiros (por exemplo, Snowflake), sem atravessar a Internet pública.
Essa arquitetura garante que todo o tráfego permaneça inteiramente na base da AWS, usando endereço IP privado e caminhos de rede não roteáveis, satisfazendo, assim, os requisitos de segurança e conformidade rígidos e permitindo o acesso contínuo aos dados do cliente.
Para clientes com arquiteturas de várias nuvens, o Data 360 está estendendo a conectividade privada além da AWS por meio do suporte à interconexão entre nuvens. Isso habilita caminhos de rede seguros apenas de backbone do Data 360 para data lakes e serviços hospedados no Azure ou Google Cloud, preservando os mesmos princípios do AWS PrivateLink: endereço IP privado, roteamento não público e nenhuma exposição à Internet.
Os clientes podem escolher entre dois modelos de implementação:
-
Interconexão gerenciada pelo cliente: Integre circuitos privados existentes, como Azure ExpressRoute, Google Cloud Interconnect ou Equinix Fabric diretamente com as VPCs do Data 360.
-
Interconexão gerenciada pelo Salesforce: Use uma conexão totalmente gerenciada em que o Salesforce provisiona e opera o link entre nuvens, expondo pontos de extremidade privados na nuvem de destino.
Em ambos os modelos, a experiência é consistente: Os serviços do Data 360 se conectam a origens de dados externas em hiperescalers como se fossem locais, permitindo a ingestão, a ativação e consulta seguras sem atravessar a Internet pública.
Para os arquitetos empresariais, uma governança de dados robusta não é apenas uma caixa de seleção de conformidade, mas um pilar fundamental para criar Inteligência do cliente confiável, dimensionável e acionável. O Salesforce Data 360 é arquitetado com uma estrutura de governança abrangente que garante a qualidade, a segurança e a adesão a mandatos regulatórios em todo o ciclo de vida dos dados.
O Data 360 funciona como um hub de governança centralizado, garantindo que todos os dados, da ingestão bruta às percepções ativadas, sejam gerenciados com integridade e controle.
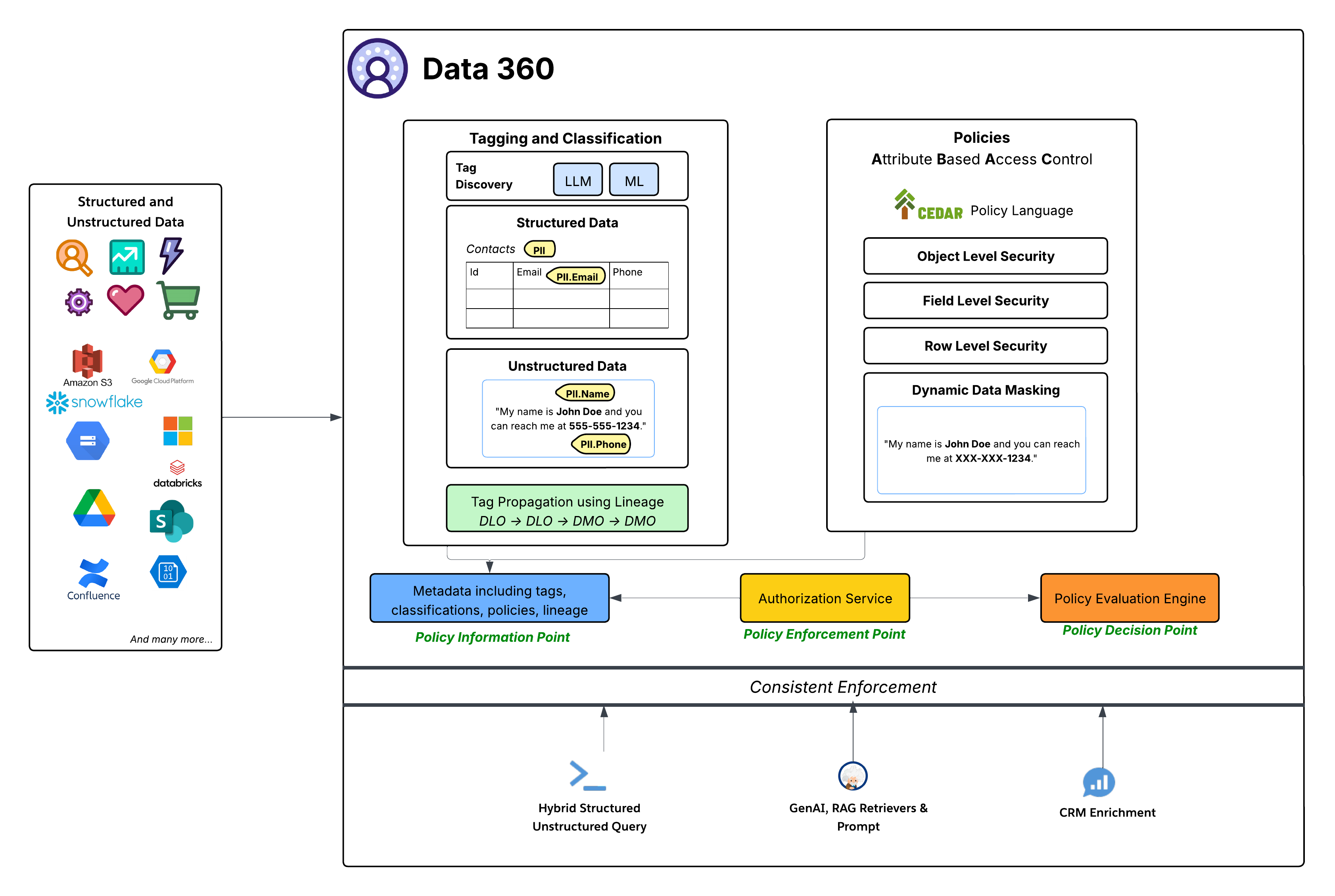
Embora o dataspace forneça controle de acesso granular para determinar o acesso a todos os objetos em um espaço de dados, as políticas baseadas em ABAC fornecem controle de acesso granular para objetos, campos e linhas individuais em um espaço de dados. O Data 360 adotou o Controle de acesso baseado em atributo (ABAC) como seu modelo de autorização principal para o controle de acesso granular. Essa opção estratégica oferece flexibilidade e escalabilidade superiores em comparação ao Controle de acesso baseado em papel (RBAC) tradicional, particularmente crucial para ambientes empresariais dinâmicos e complexos com grandes quantidades de dados e necessidades de acesso variadas. O ABAC permite que as decisões de acesso sejam baseadas em atributos do usuário (por exemplo, departamento, papel, local), os dados (por exemplo, PII, confidencialidade, espaço de dados) e o ambiente (por exemplo, hora do dia), em vez de apenas papéis predefinidos. Isso habilita políticas de acesso altamente granulares e contextuais que se adaptam à medida que os dados e os atributos do usuário mudam.
- Linguagem da política do CEDAR: No centro da implementação de ABAC do Data 360 está o uso da linguagem de política CEDAR. Essa linguagem de política formal criada com finalidade fornece uma maneira precisa e verificável de definir regras de autorização complexas, garantindo que as políticas sejam inequívocas e possam ser avaliadas de modo consistente em escala.
O sistema de governança no Data 360 adere a uma arquitetura ABAC padrão e robusta:
- Marcação, classificação e elaboração de políticas (Ponto de informações sobre políticas – PIP):
- O Data 360 fornece mecanismos automatizados de Marcação e Classificação, aproveitando o LLM (Grande Modelo de Idiomas) e o ML (Aprendizado de Máquina) para identificar categorias de dados confidenciais (por exemplo, PII.Email, PII.Phone, PII.Name) e outras taxonomias criadas para fins específicos (PHI, FinancialData) em Dados estruturados (por exemplo, tabela de Contatos) e Dados não estruturados (por exemplo, do Google Drive).
- Crucialmente, a Propagação de marcação ocorre ao longo da Linha de dados (DLO -> DLO -> DMO), garantindo que as classificações sigam automaticamente transformações e derivações de dados, de dados brutos ingeridos para a camada de DMO harmonizada e por meio de dados derivados criados de definições de processo.
- Por fim, o painel de criação de política oferece uma experiência simples para aproveitar os dados e os atributos de usuário para definir regras de acesso dinâmico para uma organização.
- Esses metadados aprimorados (incluindo marcas, classificações, políticas e linhagem) são alimentados no Ponto de informações da política (PIP).
- Serviço de Autorização (Ponto de Aplicação de Políticas - PEP):
- O Serviço de autorização atua como o Ponto de imposição de apólice (PEP). Ele intercepta todas as solicitações de acesso a dados de várias camadas de consumo (consulta estruturada/não estruturada híbrida, GenAI RAG Recuperadores e prompts, aprimoramento de CRM) e consulta o Ponto de decisão da política para determinar se o acesso é permitido.
- Mecanismo de avaliação de políticas (Ponto de decisão de políticas - PDP):
- Esse mecanismo serve como o Ponto de decisão de política (PDP). Ele usa o contexto da solicitação de acesso do PEP, junto com as definições de política (no CEDAR) e atributos do PIP, para tomar uma decisão de acesso de autoridade.
- Políticas de Segurança Granular: As políticas definidas no CEDAR aplicam vários níveis de segurança, incluindo:
- Segurança em nível de objeto: Controle o acesso a DLOs ou DMOs inteiros com base em marcas associadas a esses objetos.
- Segurança em nível de campo: Restringir o acesso a campos confidenciais específicos em um objeto com base em marcas.
- Segurança em nível de linha: Filtrar dados em objetos específicos para mostrar apenas linhas relevantes com base nos atributos do usuário.
- Mascaramento dinâmico de dados: Mascare dinamicamente determinados dados (com base em marcas) no ponto de acesso sem alterar os dados subjacentes. Isso garante que as informações confidenciais sejam protegidas enquanto ainda permitem um utilitário amplo. Isso se aplica ao mascaramento de campos em dados estruturados, bem como conteúdo em dados não estruturados.
- Imposição consistente: Toda a estrutura ABAC garante a imposição consistente de políticas em todos os padrões de consumo do Data 360, seja consultas de dados diretas, recuperação para aplicativos de IA generativa (RAG) ou aprimoramento de experiências do Salesforce CRM por meio de Listas relacionadas, por exemplo.
- Integração profunda com a Salesforce Platform: Os recursos de governança do Data 360 são definidos e administrados diretamente na plataforma principal do Salesforce. Essa integração permite que os administradores gerenciem políticas de acesso, identidades de usuário e gerenciamento de atributos usando ferramentas familiares do Salesforce, garantindo uma camada de governança unificada e consistente em todo o ecossistema do Salesforce.
Ao criar essa estrutura ABAC sofisticada com políticas CEDAR, o Data 360 fornece aos arquitetos um nível inigualável de controle e flexibilidade, garantindo que os dados do cliente não sejam apenas acionáveis, mas também seguros, em conformidade e confiáveis em toda a empresa.
Em todos os setores, as organizações estão colocando maior ênfase na segurança de dados completa para garantir a proteção contra vazamento de dados, acesso não autorizado, adulteração ou destruição. A maioria das plataformas de dados, incluindo o Data 360 hoje, fornece criptografia em repouso usando uma chave de criptografia gerenciada pelo fornecedor. No entanto, as empresas (especialmente aquelas em setores regulamentados) estão cada vez mais exigindo recursos de criptografia gerenciada pelo cliente para dados em repouso e em trânsito.
Esse modelo permite que as empresas controlem suas próprias chaves de criptografia, garantindo que, mesmo no caso altamente improvável de uma violação no nível da plataforma ou acesso não autorizado, os dados permaneçam criptograficamente protegidos. Sem a chave proprietária do cliente, nenhuma entidade (incluindo o provedor da plataforma) pode descriptografar ou reconstruir os dados, mantendo a confidencialidade e o controle completos.
O Data 360 oferece suporte ao armazenamento e ao gerenciamento de dados estruturados (tabelas), semiestruturados (JSON) e não estruturados de modo contínuo em todos os mecanismos de ingestão, processamento, indexação e consulta de dados. O Data 360 oferece suporte a vários tipos de dados não estruturados além do texto, incluindo áudio, vídeo e imagens, ampliando o escopo do tratamento e da análise de dados. A figura abaixo ilustra os dois lados da fundamentação (ingestão e recuperação).
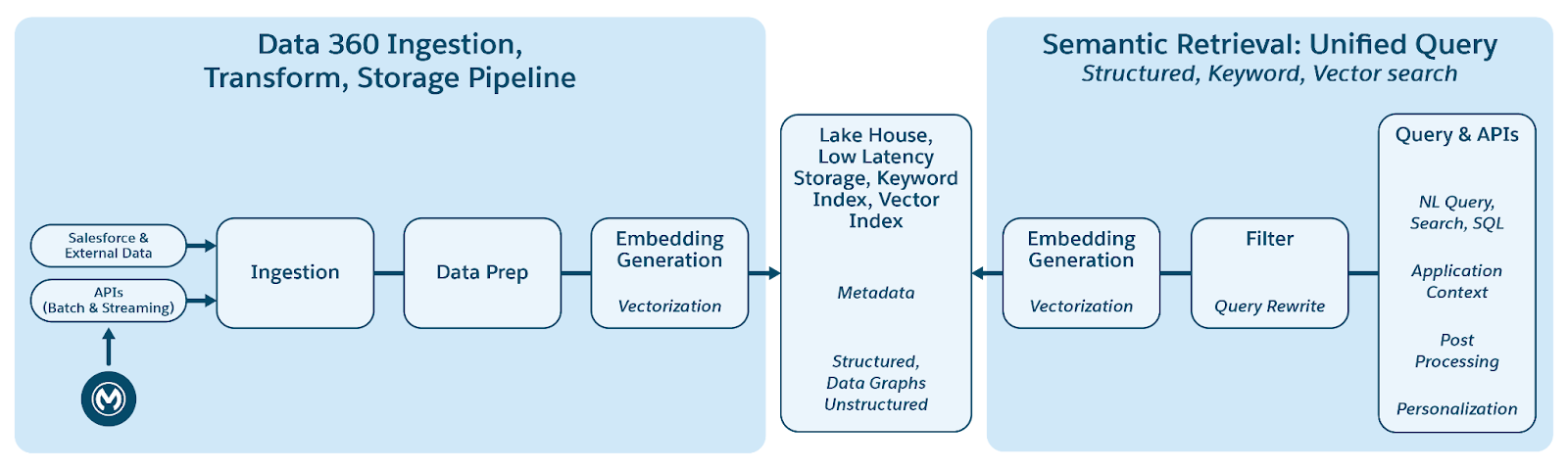
O Data 360 gerencia dados não estruturados armazenando-os em colunas como texto ou em arquivos para conjuntos de dados maiores. Ele oferece suporte à federação de dados para conteúdo não estruturado, o que permite a integração e o gerenciamento de dados de várias origens.
Os dados então são preparados e divididos em blocos, as integrações são geradas e processadas para indexação por palavra-chave e indexação vetorial. O Data 360 hospeda vários modelos prontos para uso e plugáveis para geração em blocos e integração. O Data 360 oferece suporte à transcrição automatizada e configurável de conteúdo de áudio e vídeo para processamento e indexação subsequentes. O serviço de pesquisa é usado para indexação de palavra-chave. Para indexação de vetores, o Data 360 oferece suporte à indexação nativa (com Hyper) e também utiliza bancos de dados vetoriais, como o Milvus de código aberto. O Data 360 também se integra à plataforma do Salesforce Search para dar suporte à indexação de palavras-chave em dados não estruturados. Essa indexação multimodal integrada no Data 360 permite pesquisar em qualquer dado não estruturado, conforme discutido na seção Pesquisa comercial do agente mais adiante no documento.
Para recuperação, o Data 360 fornece APIs para pesquisa. Nossa consulta unificada baseada em hiper facilita consultas de conjunto em índices estruturados, de palavra-chave e de vetores, mantendo a visibilidade e as permissões estritas, aprimorando assim o RAG e a pesquisa.
O pipeline de indexação de dados não estruturado do Data 360 é projetado como uma arquitetura modular e extensível com cinco estágios principais:
- Analisando
- Pré-processamento
- Particionamento
- Pós-processamento
- Integração
Todos os estágios também oferecem suporte ao processamento baseado em LLM, que permite que os clientes criem avisos personalizados. As fases pré-processamento e pós-processamento podem incluir várias etapas sequenciais, permitindo que transformações complexas sejam compostas de modo flexível. Cada estágio é totalmente orientado por metadados, permitindo uma configuração e uma extensão perfeitas sem alterações de código.
Exemplos de pré-processamento incluem operações como eliminação de ruído, normalização de linguagem e compreensão de imagem (reconhecimento e legenda de caracteres ópticos), enquanto os estágios de pós-processamento podem incluir aprimoramento de metadados, agrupamento semântico ou técnicas avançadas, como agrupamento em blocos Raptor.
O pipeline oferece suporte total à Extensão de código do Data 360, permitindo que clientes e equipes internas conectem lógica personalizada em qualquer estágio. Os componentes de extensão de código são funções do Python leves cujo ciclo de vida (execução, escala e tratamento de falha) é totalmente gerenciado pelo Data 360. Essa abordagem garante que a inovação e o processamento específico do domínio possam ser introduzidos rapidamente enquanto mantêm a consistência operacional e a governança em toda a plataforma.
Indexação de contexto
Para configurar RAG com processamento não estruturado, dois fatores críticos são essenciais:
- Iteração rápida: A capacidade de validar rapidamente com consultas de teste de amostra.
- Conteúdo específico da pessoa: A capacidade de configurar conteúdo personalizado para a persona consumidora.
A Indexação de contexto é uma ferramenta fácil de usar projetada para lidar com ambos os aspectos. Essa IU interativa é ativada por um pipeline em tempo real (RT) que executa todos os cinco estágios descritos anteriormente. O pipeline utiliza GPUs quando necessário para tarefas como geração de integração e reconhecimento de caracteres óptico (OCR). Além disso, ele permite que os clientes testem rapidamente o pipeline RAG com um agente antes de implementar a configuração para processamento de conteúdo abrangente.
IA do documento
A IA de documento do Data 360 permite ler e importar dados não estruturados ou semiestruturados de documentos como faturas, currículos, relatórios de laboratório e pedidos de compra. Esse recurso dá suporte ao processamento interativo ad hoc, bem como ao processamento em lote em massa. Essa é uma funcionalidade essencial que habilita a automação de processos de negócios para nossos clientes. Isso é desenvolvido com inteligência artificial, incluindo LLMs e modelos de ML.
As empresas possuem grandes quantidades de Knowledge espalhadas por sistemas diferentes, como wikis, compartilhamentos de arquivos, sistemas de gerenciamento de conteúdo, bancos de dados internos e muito mais. Essa fragmentação dificulta que funcionários (especialmente agentes de serviço e representantes de vendas) e clientes encontrem informações relevantes de forma rápida e eficiente. Os principais problemas incluem: Falta de uma única experiência de busca unificada em todas as fontes do Knowledge; apresentação e renderização inconsistentes de conteúdos de diferentes fontes; falta de governança de acesso a informações confidenciais espalhadas entre sistemas; e dificuldade de aproveitar fontes de Knowledge autoritárias dentro dos fluxos de trabalho essenciais (por exemplo, anexar artigos relevantes a um caso).
O Enterprise Knowledge representa o conteúdo que foi selecionado, seja manualmente ou automaticamente, a partir do conjunto mais amplo de dados empresariais. A criação manual envolve ações deliberadas, como criar artigos do Salesforce Knowledge ou desenvolver Knowledge dentro de sistemas externos que são então ingeridos. Nós imaginamos a seleção automatizada que utiliza processos, como agentes e transformações do Salesforce, que executam dados ingeridos para gerar camadas refinadas e selecionadas, possivelmente misturando conteúdo estruturado e não estruturado. Seja selecionado manualmente ou automaticamente, internamente no Salesforce ou externamente antes da ingestão, o resultado é conteúdo de valor agregado diferente dos dados brutos.
A solução Enterprise Knowledge Hub aproveita os recursos do Data 360 para:
- Ingestão e Armazenamento: O CRM Connector está ingerindo artigos do Salesforce Knowledge, e os conectores não estruturados do Framework do conector de dados (DCF) ingerem conteúdo bruto e metadados de fontes externas. O conteúdo é ingerido no mapeamento de objetos de data lake não estruturados (UDLOs) específicos da origem para o conteúdo no SFDrive (ou origem no caso de cópia zero).
- Harmonização e estruturação: O pipeline de harmonização processa dados de UDLO e arquivo, realizando limpeza, normalização, enriquecimento (NLP, etc.), mascaramento de PII e transformação no formato intermediário harmonizado, armazenado no SF Drive e um UDLO harmonizado (HUDLO) que mapeia para ele.
- Indexação: O Pipeline não estruturado (UDS) é acionado no conteúdo harmonizado e os índices de pesquisa são configurados para cada HUDMO.
- Consumo: Os aplicativos consumidores incluem pesquisa, recuperação, renderização e vinculação a objetos de negócios como Caso. O engajamento consumindo aplicativos é coletado para fornecer análises de uso (como cliques, análises etc.)
Insights calculados (CIs) no Data 360 permitem que os clientes definam e gerem métricas agregadas com base em seus dados. Essas métricas então são usadas para engajamento, análise, segmentação e ativação oportunos do cliente. Os dados agregados calculados por CIs são gravados no Lakehouse e representados como um objeto de percepção calculada (CIO).
Há dois tipos principais de percepções calculadas:
- Insights calculados em lote: Projetado para agregação de dados complexo e de alto volume, em que as métricas podem ser calculadas periodicamente (por exemplo, diariamente ou semanalmente).
- Insights de streaming: Forneça a capacidade de gerar métricas e ações de dados de evento em tempo real, habilitando o engajamento imediato do cliente com baixa latência.
As percepções calculadas são definidas em objetos de modelo de dados (DMOs) e também podem ser definidas em outros objetos de percepção calculada. O serviço de percepções calculadas gerencia a orquestração de trabalhos em lote e de streaming.
Os cálculos de percepções em lote e de streaming usam o Spark. A principal diferença é que as percepções de streaming usam o Streaming estruturado do Spark, enquanto as CIs em lote são executadas usando trabalhos do Spark em lote periódicos agendados. Para eficiência de custo, os Insights de serviço calculados agrupam as CIs a serem calculadas juntas no mesmo trabalho de CI em lote ou trabalho de CI de streaming com base em fatores como dependências e sobreposição de objetos de dados de origem.
A SNCE e a CDF desempenham um papel significativo no cálculo de Insights de streaming.
A resolução de identidade é responsável por transformar dados diferentes de várias origens em um único Perfil unificado abrangente.
É importante entender que um perfil unificado não é um "registro de ouro" e que a resolução de identidade não seleciona valores vencedores nem substitui dados existentes ao unificar perfis. Os perfis unificados servem como um conjunto de chaves que desbloqueiam seus dados de origem identificando todos os registros correspondentes relacionados à mesma entidade, dentro de uma fonte de dados ou entre várias fontes. Com essas informações, você pode selecionar os dados do sistema de origem certos a serem usados para um determinado caso de uso de negócios.
A resolução de identidade pode consolidar uma variedade de tipos de registro, incluindo Indivíduos, Contas e Famílias. Também pode ser usado para combinar leads a contas existentes. O processo de unificação é essencial para obter uma visualização completa do Customer 360 e promover engajamento personalizado em tempo real em cenários B2C e B2B.
O pipeline de resolução de identidade é criado em uma estrutura nativa da nuvem altamente escalonável projetada para lidar com volumes enormes de dados continuamente. O processo envolve três etapas principais, dependendo de um poderoso índice de pesquisa para gerenciar o processo de correspondência:
- Correspondência (Seleção de candidatos): O objetivo do processo de correspondência é pesquisar registros que podem pertencer à mesma entidade. Os registros são analisados em relação a um conjunto de regras personalizável, cada um contendo um conjunto de critérios que definem quais dados correspondem a qual nível de rigor. Para recuperar de modo eficiente possíveis correspondências do armazenamento de dados, o sistema gera índices para localizar registros correspondentes prováveis usando duas técnicas:
- Bloquear chaves: Uma chave de bloqueio é um valor gerado dos dados e regras de correspondência de um registro (como as primeiras letras de um nome, número de telefone normalizado etc.) para agrupar registros potencialmente semelhantes. Cada registro tem várias chaves de bloqueio que são indexadas e armazenadas como um índice invertido, garantindo que o sistema realize apenas comparações detalhadas em pequenos grupos de registros, em vez de em todo o conjunto de dados.
- Locality Sensitive Hashing (LSH): Para regras de correspondência com correspondência parcial, os hashes são gerados com base em integrações de modelos treinados.
- Deep Matching: Depois que a etapa de seleção de candidato cria grupos menores de possíveis correspondências, o sistema inicia uma comparação mais detalhada. Nesse estágio, modelos de IA e algoritmos avançados analisam cada par de registros para calcular uma pontuação de correspondência probabilística. Essa pontuação quantifica a probabilidade de dois registros se referirem à mesma entidade comparando de modo inteligente campos que geralmente contêm erros de ortografia, variações ou diferenças de formatação.
- Agrupamento e unificação: Depois que registros correspondentes são identificados entre os candidatos, eles são agrupados em um cluster. Esse processo inclui criticamente a resolução de correspondências transitivas. Por exemplo, se o Registro A corresponder ao Registro B e o Registro B corresponder ao Registro C, todos os três serão vinculados ao mesmo cluster mesmo que A e C nunca tenham sido comparados diretamente. Esses grupos completos formam a estrutura básica do Perfil unificado. Esse processo de agrupamento garante que todos os registros de origem relacionados sejam vinculados corretamente sob um único identificador persistente.
- Reconciliação: Os valores de dados de todos os registros de origem agrupados são avaliados usando regras de reconciliação definidas (por exemplo, Most Frequent, Most Recent, ou Source Priority) para preencher o Perfil unificado resultante com um trecho de dados de perfil. A reconciliação não sobrescreve nenhum dado existente, pois todos os dados de origem estão disponíveis usando as chaves vinculadas ao perfil unificado.
A arquitetura dá suporte à resolução de vários tipos de entidade para atender a uma variedade de casos de uso.
- Correspondência individual: Concentra-se na criação de perfis de Indivíduo unificado, que vinculam todos os identificadores pessoais conhecidos (email, números de telefone, IDs de fidelidade, cookies) a uma única pessoa.
- Correspondência de conta: Concentra-se na criação de perfis de Conta unificada, que vinculam dados sobre contas. Ao fazer a correspondência nos nomes da empresa, o mecanismo usa um modelo ajustado quando há correspondência parcial.
- Combinar família: Estende a lógica de correspondência para agregar registros de Indivíduo unificado em grupos de indivíduos relacionados.
- Correspondência entre entidades: Além da unificação, a resolução de identidade também cria links entre objetos de perfil usando as mesmas regras de correspondência. Por exemplo, um Lead pode ser vinculado a uma Conta usando correspondência parcial em Nome da conta.
Para garantir que o Perfil unificado esteja sempre atualizado, o mecanismo de resolução de identidade opera com uma arquitetura quase em tempo real. Essa arquitetura otimizada para nuvem é projetada para processamento contínuo, alcançando tempos de processamento rápidos. Embora a velocidade de processamento varie dependendo de como os dados de origem são recebidos, pequenos lotes de alterações podem ser processados pela resolução de identidade com frequência de 15 minutos.
O sistema mantém objetos de link de identidade que mapeiam cada ID de registro de origem para o ID de perfil unificado correspondente. Essa estrutura de dados básica permite que o mecanismo rastreie de modo eficiente relacionamentos e propague rapidamente alterações e atualizações para o Perfil unificado, garantindo que as experiências do cliente, como personalização do site, recomendações de próxima melhor ação e segmentação, sempre aproveitem os dados mais recentes do cliente disponíveis.
A segmentação é o processo central de transformar perfis de clientes unificados em públicos acionáveis. Essa funcionalidade é essencial para habilitar experiências personalizadas em canais de marketing, comércio e serviço. A plataforma de Segmentação do Salesforce Data 360 é projetada para operações em grande escala. Gerencia metadados complexos, trabalhando com um modelo de dados que inclui milhares de objetos e relacionamentos. A plataforma oferece suporte a regras complexas, filtros baseados em agregação e classificação baseada em janela, tudo ao mesmo tempo que garante um cálculo rápido e confiável em escala de petabytes.
O Data 360 oferece suporte a vários tipos de segmento para atender a diferentes requisitos de negócios de velocidade, complexidade e hierarquia:
- Segmento padrão: O tipo de segmento processado em lote primário. Ele publica em uma agenda personalizável, com um ritmo de Publicação padrão de no mínimo 12 horas até 24 horas, ou um ritmo de Publicação rápida mais rápido de 1 a 4 horas, otimizado para dados de engajamento recentes.
- Segmento em tempo real: Esse segmento é concluído sob demanda em milissegundos para ação imediata com base em eventos recentes e dados de perfil. Ele é altamente otimizado para personalização instantânea, mas não pode utilizar critérios de exclusão ou segmentos aninhados.
- Segmento de cascata: Uma estrutura hierárquica de subsegmentos usada para priorizar um cliente em um único segmento mais valioso se ele se qualificar para vários critérios.
- Segmento aninhado: Isso permite reutilizar um segmento existente como um filtro para um segmento novo e mais específico (um refinamento de um segmento de base), herdam a agenda do segmento pai.
O mecanismo de segmentação opera em uma arquitetura robusta nativa da nuvem que garante velocidade, escala e resiliência.
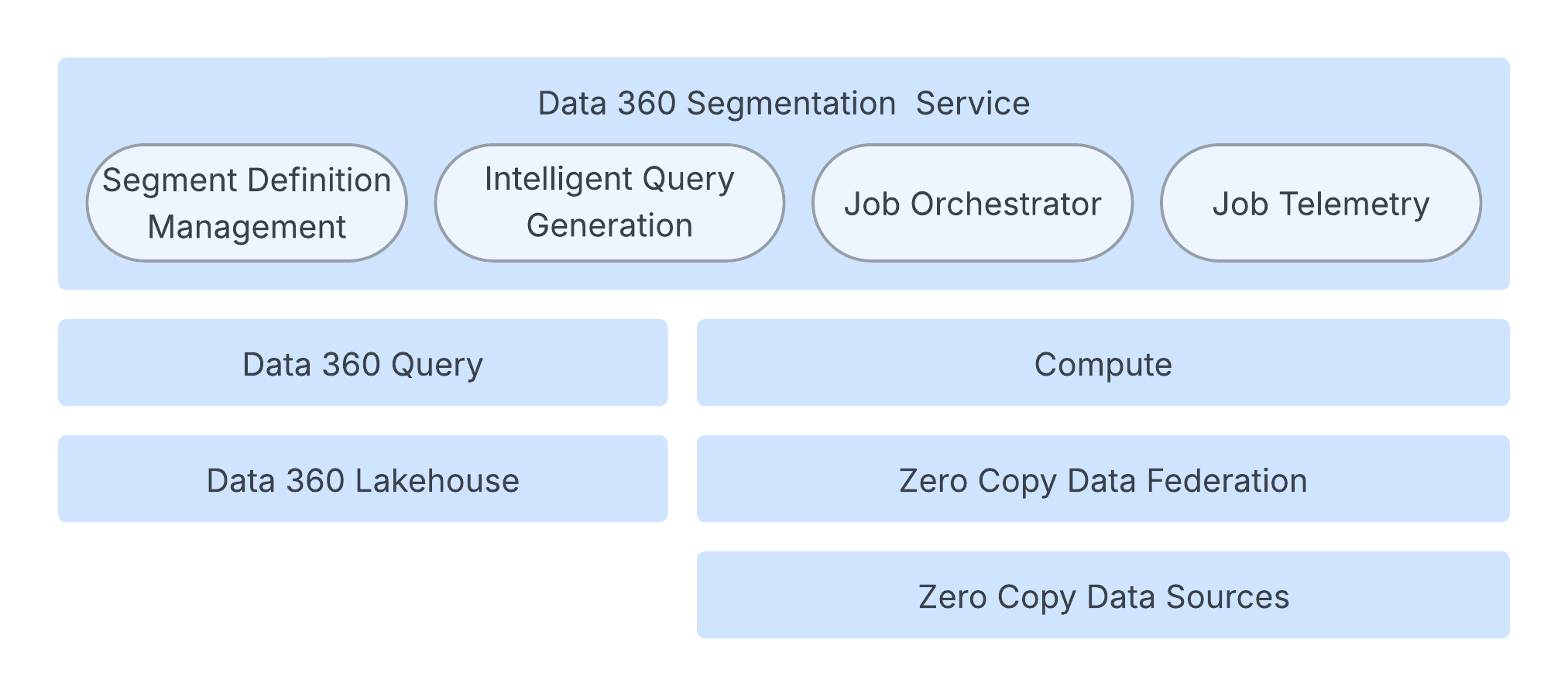
O processo principal é gerenciado por um serviço de orquestração de trabalho que controla o ciclo de vida do segmento, gerando a configuração de trabalho necessária e acionando a execução. Essa camada de orquestração mantém estado e metadados em um banco de dados particionado para escalabilidade.
Embora a Consulta do Data 360 lidar com cálculos de contagem de segmentação, a camada de computação do Spark é responsável por calcular a associação real do segmento. O aplicativo Spark executa consultas SQL do Spark em dados extensos do cliente. Esses dados podem residir no Data 360 Lakehouse, em sistemas externos por meio da federação de dados do Zero Copy ou em uma combinação de ambos.
O sistema é altamente otimizado por meio da geração de consulta inteligente, que refina a consulta SQL do Spark subjacente. Isso inclui técnicas como corte de partição inteligente para minimizar a leitura de dados e a eliminação de subexpressões redundantes. Para garantir a confiabilidade do serviço, a arquitetura oferece o gerenciamento de recursos adaptável que ajusta dinamicamente os recursos de computação com base no tamanho e na complexidade da carga de trabalho. Além disso, a adesão de SLO é gerenciada de modo proativo com durações adaptativas e lógica de nova tentativa. Para uma experiência de usuário rápida, as contagens de segmentos aceleradas usam uma abordagem baseada em amostragem para fornecer estimativas de tamanho rápidas durante a criação do segmento, evitando uma execução de consulta completa.
Por fim, um profundo foco na observabilidade e na atribuição de causa raiz é mantido por meio de métricas abrangentes de execução do Spark e classificação automatizada de erros (por exemplo, problemas do lado do cliente vs. do sistema), reduzindo significativamente o tempo de diagnóstico e garantindo uma plataforma de dados altamente resiliente.
A ativação é a etapa final crítica no ciclo de vida do Data 360. Sua função principal é transformar perfis de cliente estáticos, segmentados e unificados em dados acionáveis e aprimorados e entregar esses dados a pontos de extremidade internos e externos (como Marketing Cloud, Commerce Cloud e plataformas Adtech). Esse processo é projetado para acionar jornadas do cliente personalizadas e interações quase em tempo real. Ele oferece suporte a recursos avançados como atributos relacionados, filtragem de associação da ativação, filtragem de consentimento, limitação e classificação.
A ativação oferece três métodos distintos para entrega externa e conformidade de canal:
- Ativação de lote: Projetado para operações agendadas de alto volume, como campanhas de email em grande escala e atualizações de público de publicidade. Os dados são entregues preparando-os para os buckets internos seguros (Armazenamento de objetos na nuvem) ou por meio da Transferência segura de arquivos, seguidos por um processo de ingestão de API iniciado pelo sistema de destino. Ativações em lote podem usar um modo de atualização especial (incremental) para reduzir volumes enviados e processados por parceiros do Salesforce.
- Ativação de streaming: Otimizada para casos de uso quase em tempo real que exigem automação conduzida por evento. A entrega é realizada por meio de chamadas de API diretas enviadas ao ponto de extremidade de destino.
- Fluxos acionados por ativação: Esse canal altamente platformizado fornece uma abordagem sem código/baixo código para integrar Dados do público a centenas de plataformas de engajamento habilitadas para API do cliente. Após a conclusão da ativação, o Data 360 preenche um DMO de Público, que então aciona um Fluxo de alta escala. O mecanismo de Fluxo subsequentemente consome os dados do público e utiliza recursos de plataforma como Serviços externos e Destinos de saída do Mule para fazer chamadas ao destino final baseado em API. Esse método reduz significativamente o tempo necessário para integrar novos destinos da ativação.
A ativação usa os mesmos padrões de segmentação para gerenciamento de trabalhos, execução distribuída e monitoramento. Isso inclui os princípios do serviço de orquestração de trabalho para gerenciamento de ciclo de vida e da camada computacional (Spark) para processamento e depende da telemetria de trabalho para a observabilidade do desempenho e adesão ao objetivo de nível de serviço (SLO).
Além desses, a ativação tem -
O Gerenciamento de destino da ativação supervisiona as conexões, credenciais e configurações seguras para todos os pontos de extremidade de destino. Ela garante que os formatos de dados e os protocolos de segurança sejam padronizados, garantindo a entrega confiável de várias plataformas, incluindo Marketing Cloud, parceiros do Adtech e outros aplicativos externos.
A ativação ajusta a carga útil para metas específicas. Para o Salesforce Marketing Cloud, isso inclui Filtragem consciente da unidade de negócios (BU), suporte a vários EID e controles de polinização cruzada.
A Communication Governance atua como um gateway, garantindo que o uso e a comunicação de dados estejam de acordo com as preferências do cliente e requisitos legais. O modelo de consentimento centralizado unifica todas as preferências do cliente, desde recusas globais até consentimento específico de canal e finalidade, e é armazenado no Perfil de indivíduo unificado. Durante a execução, a plataforma impõe estritamente essas políticas usando a filtragem de exclusão para remover automaticamente indivíduos que não consentiram na carga útil final. Além disso, o sistema aplica regras de seleção de ponto de contato para garantir que ele use o ponto de contato único, mais compatível e preferencial para o canal pretendido antes de qualquer dado ser transmitido. Esse mecanismo de imposição é protegido pela estrutura de governança subjacente, que usa medidas de proteção, como mascaramento de dados dinâmico e controles de acesso, para proteger campos de dados confidenciais em todo o processo de ativação.
O verdadeiro valor de uma plataforma de dados unificada reside na sua capacidade de fornecer acesso consistente e sem esforço a todos os seus ativos de dados, independentemente de sua origem ou estrutura. O recurso Consulta unificada do Salesforce Data 360 foi projetado com precisão para oferecer isso, abstraindo as complexidades subjacentes de vários repositórios de dados para fornecer uma única e eficiente interface de consulta.
A camada Consulta unificada oferece acesso sofisticado para vários padrões de consumo:
- Consulta estruturada e não estruturada híbrida: Ele oferece amplo suporte a SQL para consultar de modo aprimorado tanto os dados estruturados quanto os metadados estruturados de dados não estruturados. Isso é aprimorado pela extensibilidade do operador por meio de funções de tabela, habilitando a pesquisa especializada em tipos de texto, imagem e espaço.
- Desempenho acelerado com Hyper: Aproveitando o Hyper, um mecanismo de alto desempenho na memória, o Data 360 acelera consultas analíticas complexas e painéis interativos, fornecendo respostas quase instantâneas em conjuntos de dados massivos.
- Abordagem unificada para IA e personalização: Esse acesso unificado é crucial para gerar resultados direcionados e personalizados, facilitando diretamente respostas de LLM mais precisas usando a Geração aumentada de recuperação (RAG) baseando modelos de IA em dados corporativos avançados.
- Integração com o consumo a jusante: Ele serve como a camada de acesso a dados básica para experiências conduzidas por UI, APIs robustas, fluxos de trabalho de IA generativa e aprimoramento de CRM, conectando dados perfeitamente à ativação.
Ao fornecer uma única interface de consulta inteligente e de alto desempenho, a consulta unificada do Data 360 capacita os arquitetos a criar aplicativos ágeis orientados por dados que aproveitam totalmente todo o espectro de informações do cliente.
O Data 360 é uma plataforma ativa que dá suporte à ativação de pipelines em resposta a eventos de dados. Por exemplo, um evento significativo, como uma queda no saldo da conta de um cliente, pode acionar um Salesforce Flow para orquestrar uma ação correspondente. Da mesma forma, as atualizações nas principais métricas, como o gasto da vida útil, podem ser propagadas automaticamente para aplicativos relevantes.
Ações de dados monitoram continuamente dados incrementais para alterações usando eventos de alteração nativos (SNCE) de armazenamento e feed de alteração de dados (CDF). Esses dados são avaliados em relação às regras de ação configuradas pelo cliente, como monitoramento de limite ou alterações de estado. Quando essas regras são atendidas, um evento de ação de dados é gerado. Esse evento é aprimorado com informações adicionais (por exemplo, status de fidelidade do cliente) e enviado imediatamente para seu destino configurado, como o Salesforce Flow ou um aplicativo externo, para acionar orquestrações de negócios.
O Data 360 oferece suporte a recursos nativos da CDP (Plataforma de dados do cliente), incluindo recursos avançados de resolução de identidade e criação de identificadores e perfis de indivíduo unificados junto com históricos de engajamento abrangentes. Essa plataforma é capaz de lidar com estruturas Business-to-Business (B2B) e Business-to-Consumer (B2C) com suporte para resolução de identidade e gráficos de identidade que usam regras de correspondência exatas e parciais, conforme descrito acima. Esses gráficos de identidade são aprimorados com dados de engajamento de vários canais, o que ajuda a criar gráficos de perfil detalhados com percepções e segmentos analíticos valiosos.
Um conceito-chave que dá suporte ao perfil do cliente é o gráfico de dados. O Data 360 oferece um gráfico de dados corporativos no formato JSON, que é um objeto não normalizado derivado de várias tabelas do Lakehouse e suas interrelações. Isso inclui um gráfico de dados "Perfil" criado pela CDP que engloba o histórico de compra e navegação de uma pessoa, o histórico de caso, o uso do produto e outras percepções calculadas e é extensível por clientes e parceiros. Esses Gráficos de dados são adaptados a aplicações específicas e melhoram a precisão do aviso de IA generativa fornecendo contexto relevante para o cliente ou o usuário. A camada em tempo real do Data 360 usa o gráfico de perfil para personalização e segmentação em tempo real. Imaginamos modelar o Contexto do Agentforce que engloba Conversas, Sessões e Memória do agente como Gráficos de dados.
Além disso, a CDP habilita a segmentação e ativação eficazes em diferentes plataformas, como o Marketing Cloud do Salesforce, o Facebook e o Google. Ele processa perfis do cliente em lote, quase em tempo real e em tempo real, o que permite tomada de decisão e personalização imediatas. Essa funcionalidade aprimora interações em cenários B2C e B2B, garantindo que as empresas possam responder de modo rápido e preciso às necessidades e comportamentos dos clientes.
A camada em tempo real do Data 360 é suportada pela CDP do Data 360 e estende seus conceitos para casos de uso em tempo real. A camada em tempo real do Data 360 é projetada para processar eventos como fluxos de cliques da Web e móveis, visitas, dados do carrinho e checkouts em latências de milissegundos, aprimorando a personalização da experiência do cliente. Ele monitora continuamente o engajamento do cliente e atualiza o perfil do cliente do Customer 360 com dados de engajamento em tempo real, segmentos e cálculos para personalização imediata.
Por exemplo, quando um consumidor compra um item em um site de compras, a camada em tempo real rapidamente detecta e ingere esse evento, identifica o consumidor e aprimora seu perfil com informações atualizadas sobre o gasto na vida útil. Isso permite a personalização da experiência deles no site em menos de segundos. Além disso, essa camada inclui recursos para acionamento e respostas em tempo real, habilitando ações imediatas com base nas interações com o cliente.
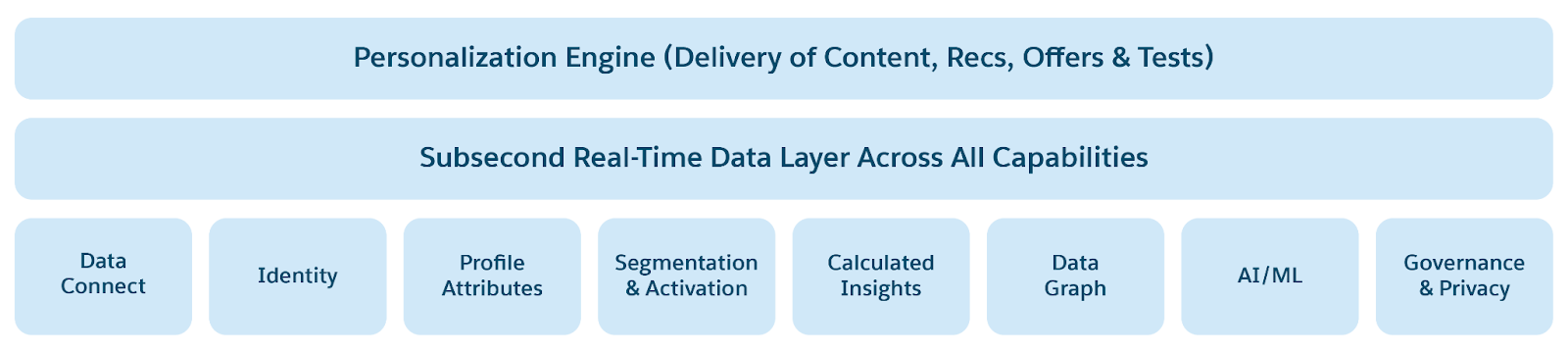
A plataforma Subsegundo em tempo real habilita essa transformação por meio de vários recursos importantes:
- Gráficos de dados em tempo real: Um perfil do Customer 360 é criado usando um gráfico desnormalizado que inclui os principais objetos e campos mais relevantes para as marcas. Esses Gráficos de dados permitem processamento de dados em tempo real e fornecem conteúdo e percepções acionáveis em milissegundos
- Ingestão e transformação em tempo real: Ingira eventos e perfis do usuário em milissegundos de fontes da Web e móveis.
- Resolução de identidade em tempo real: Mescle perfis do cliente entre dispositivos, unificando usuários desconhecidos e conhecidos instantaneamente.
- Insights calculados em tempo real: Calcule métricas como valor da vida útil (LTV) ou histórico de visitas do usuário em milissegundos para habilitar Personalização ou ofertas para Web, ChatBot ou agente de serviços.
- Segmentação em tempo real: Segmente públicos rapidamente, personalizando mensagens e interações em tempo real.
- Ações em tempo real: Permita que as marcas avaliem cada engajamento do usuário e realizem ações por meio do Salesforce Flow ou outros canais de comunicação relevantes.
No Data 360, criamos uma nova plataforma em tempo real com pipeline em tempo real, armazenamento de baixa latência e uma camada de processamento de dados de menos de um segundo. Conforme dados interativos rápidos são ingeridos de canais da Web e móveis, eles passam por uma série de processos rápidos.
Nossos SDKs da Web e móveis e APIs em tempo real coletam dados de aplicativos da Web/móvel (em interações futuras do agente) e os enviam para nosso servidor de sinalizadores. Esses dados então são roteados para a Camada em tempo real para processamento de milissegundo e para a Camada do Lakehouse para integração a dados em lote/fluxo. A camada em tempo real processa os dados recebidos em tempo real no contexto de um perfil de usuário (anônimo ou conectado), como atualizar o gasto total do usuário ou o valor da vida útil, etc., para personalização em tempo real na sessão. A Camada em tempo real é suportada pelo armazenamento de armazenamento de memória principal e NVme (SSD) para armazenar dados em tempo real e perfis do cliente. Quando os dados estão na Camada em tempo real, eles passam pelos seguintes processos antes de serem atualizados para o Gráfico de dados em tempo real:
- Ingestão simples e transformações: Os dados são ingeridos e transformados para processamento adicional.
- Resolução de identidade: As regras de correspondência exata são aplicadas para unificar perfis com todos os conjuntos de regras de correspondência existentes, de modo que os especialistas com conhecimento em dados não precisam criar novos conjuntos de regras de resolução de identidade especificamente para tempo real.
- Insights computados: Cada engajamento é avaliado, cálculos simples, como soma e contagem em milissegundos, são executados e os dados são atualizados no Gráfico de dados em tempo real.
- Segmentos em tempo real: Cada dado de engajamento é avaliado para determinar se ele atende aos critérios para segmentos em tempo real definidos e os usuários são adicionados a segmentos qualificados em milissegundos.
- Ações e acionadores em tempo real: Cada engajamento é avaliado em relação a regras definidas para acionar ações para uma variedade de metas em tempo real quando as regras são atendidas em milissegundos.
- Gráfico de dados em tempo real e API: O gráfico de dados em tempo real, que também inclui uma API em tempo real, permite que as marcas recuperem dados atualizados no formato JSON para cada usuário, garantindo que todas as interações com o cliente sejam informadas pelos dados mais recentes.
A personalização envolve saber para quem focar, quando e onde entregar conteúdo e recomendações relevantes, o que dizer e qual frequência. A Plataforma de serviços de personalização é o orquestrador das decisões tomadas para otimizar a realização da meta por meio de experiências personalizadas.
Os Serviços de Personalização oferecem as seguintes funcionalidades:
- Conjunto consistente de modelos e maneiras de interpretar dados de perfil, atividade e ativo no Data 360
- Experimentação integrada de plataforma (A/B/n, bandido de vários braços)
- Integração de Metas no momento do design (configuração), tempo de treinamento de ML e tempo de execução (inferência de ML)
- Suporte à interação em tempo real e em lote em escala B2C (usuários anônimos, externo interativo em tempo real de alto volume, lote interno de alto volume)
- Analytics conduzido pelo Data 360
- Padrões para integrar o modelo de IA e o serviço de outras partes (interna e externa)
- Integração ao ecossistema de metadados principais (características PLATE)
- Implementações de OOTB de casos de uso conduzidos por IA de alto valor (Recomendações/decisões com vários algoritmos de ML, incluindo bandidos contextuais para promoção/seleção de conteúdo, recomendações de produto, decisões de precificação etc.)
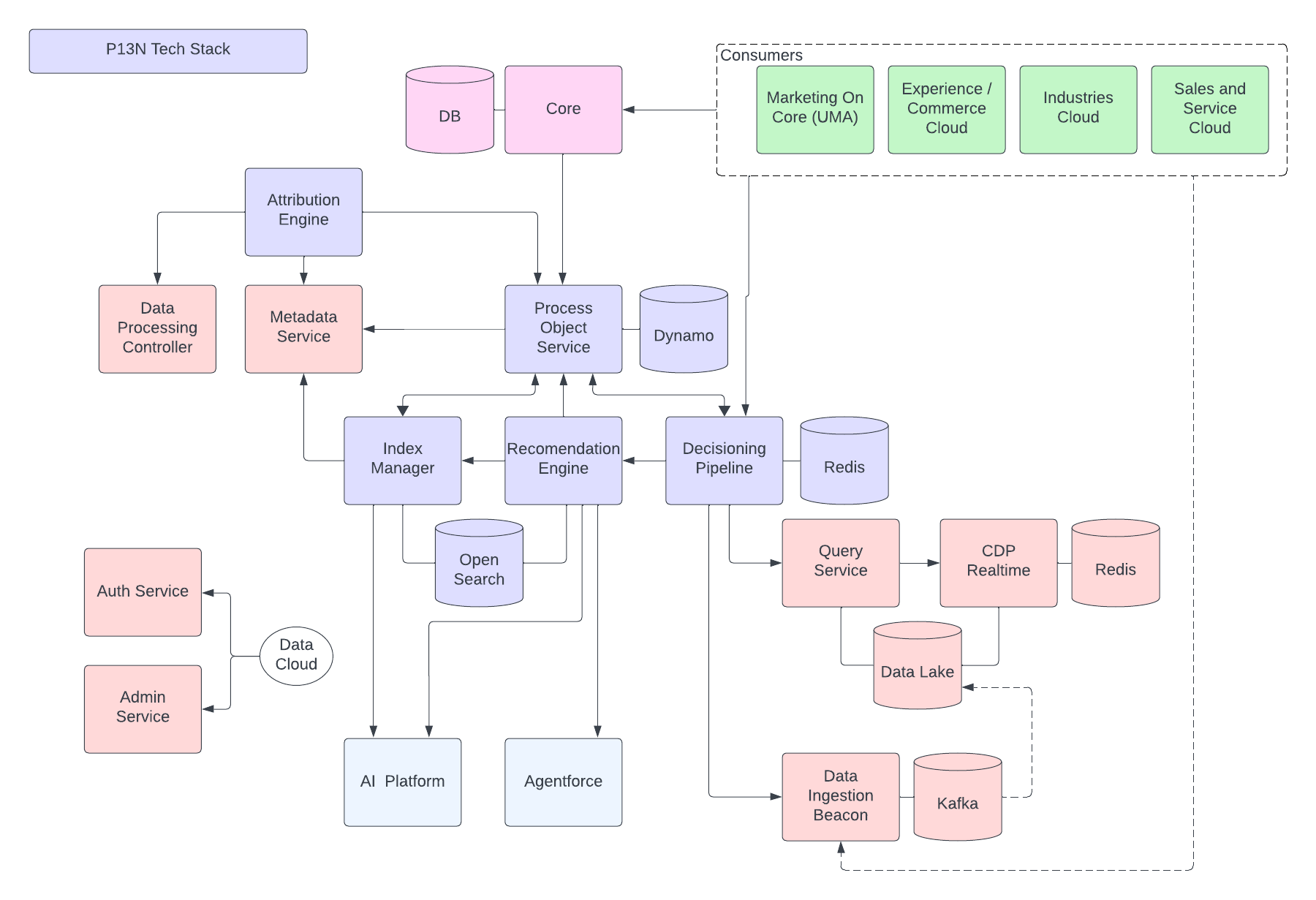
- Pipeline de decisão
- Atender solicitações externas para decisões de personalização, incluindo aumento de perfil, experimentação e recomendações.
- Mecanismo de recomendação
- Serviço de tempo de execução de recomendações baseadas em regra ou ML.
- Gerenciador de índice
- Gerencia/Orquestra o fluxo de trabalho para processos assíncronos, incluindo treinamentos de ML para modelos de recomendação
- Serviço de objeto de processo
- Responsável por sincronizar metadados de personalização entre o núcleo e fora dele
- Mecanismo de Atribuição e Experimentação
- Atribuição e experimentação de recomendações de personalização do Analytics
O Data 360 é projetado como uma plataforma robusta e avançada especificamente para dar suporte às experiências agentes emergentes. Nós alcançamos esses recursos com base em vários serviços existentes do Data 360 e através de uma profunda integração com Agentforce.
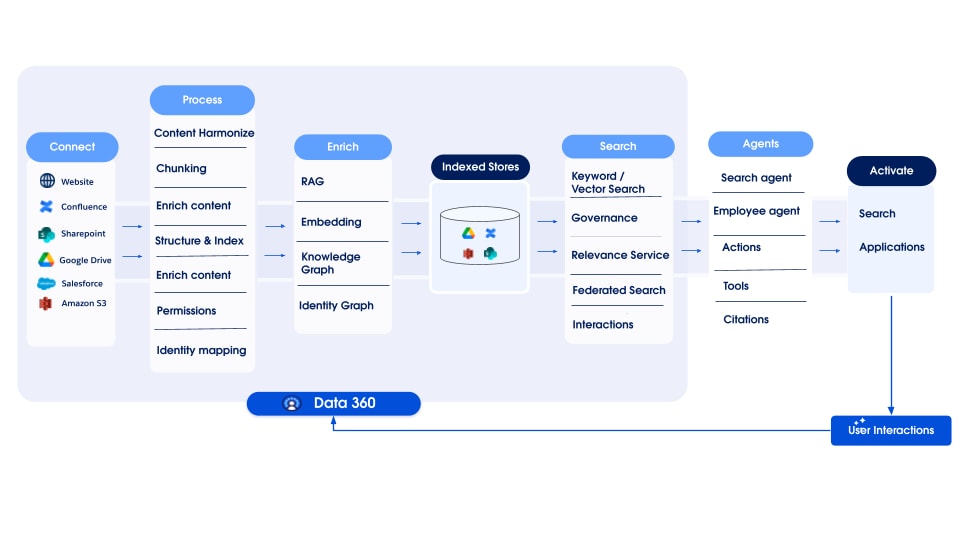
Nossa abordagem da Pesquisa comercial agendada é baseada nos seguintes princípios:
- Os dados corporativos são mantidos em serviços ou lojas isoladas, com permissões seguras necessárias para acesso. A capacidade de acessar esses dados e processá-los enquanto mantém as permissões de origem é vital para garantir o Trust.
- A classificação cruzada e a relevância em todo o corpus completo de dados permitem resultados melhores, o que, por sua vez, pode fornecer um contexto melhor para experiências agentes.
Para oferecer essas experiências, a Pesquisa comercial de agência é criada com base nestes principais componentes arquitetônicos:
- Conectores: O amplo conjunto de conectores disponíveis no Data 360 permite que você acesse e ingira dados de uma ampla variedade de origens.
- Processamento de dados não estruturados: Isso é fundamental para lidar com conteúdo não tabular, permitindo que o sistema derive significado e contexto de dados diversos.
- Governance: Garanta a segurança, a conformidade e os controles de acesso em nível corporativo para todos os dados consumidos pela pesquisa. O suporte para permissões de visibilidade de origem garante que os dados estejam acessíveis apenas a usuários autorizados, tanto para experiências de pesquisa simples quanto para experiências agentes. Para garantir a recuperação rápida, as permissões de segurança são avaliadas e impostas nativamente pelos backends de pesquisa no primeiro estágio de acesso aos dados.
- Caixa de recuperação unificada: Para lidar com o desafio de dados isolados, os conectores alimentam uma camada abrangente de Recuperação unificada. Essa camada fornece um único ponto de acesso a todos os dados, estejam eles permanecendo em sistemas externos acessados por meio da Pesquisa federada ou gerenciados nativamente por meio de índices avançados para dados de cópia zero e dados ingeridos.
- Compreensão inteligente de consulta: Antes da recuperação, o sistema usa mecanismos habilitados por IA para interpretar a intenção do usuário. Além de incorporar representações da consulta para correspondência de vetor semântico, ele pode reescrever e expandir pesquisas baseadas em palavra-chave para melhorar a precisão.
- Pesquisa híbrida e consulta avançada: Para localizar as informações mais relevantes, a plataforma usa várias estratégias em paralelo. A pesquisa híbrida fornece uma correspondência precisa de palavras-chave com a pesquisa vetorial semântica em partes de dados otimizadas, enquanto a pesquisa de registro completo recupera simultaneamente documentos inteiros. Ambos são combinados para garantir a relevância semântica e a cobertura completa do conteúdo.
- Classificação hierárquica: Depois que os dados são recuperados, uma arquitetura de classificação hierárquica de vários estágios pontua, mescla e classifica novamente os resultados de cada origem e método. Esse processo cria uma única lista unificada que detecta as informações mais relevantes para o usuário ou agente.
A IA generativa está mudando o consumidor principal da pesquisa corporativa de usuários humanos para Modelos de idioma grande (LLMs). O Data 360 Search foi desenvolvido do zero para atender a ambos. Ele é otimizado para lidar com consultas mais longas e complexas dos agentes e retornar os resultados contextuais avançados necessários para loops de consumo programático e raciocínio. Ao mesmo tempo, o sistema pode lidar com as consultas mais curtas, muitas vezes ambíguas, típicas de usuários humanos, fornecendo recursos como snippets e destaques para avaliação rápida em uma IU.
A entrega definitiva de experiências de pesquisa agente combina ambas as abordagens:
- Resultados de pesquisa diretos: o aplicativo pode exibir uma lista tradicional de resultados classificados usando uma API orientada por metadados criada na base de pesquisa unificada do Data 360.
- Respostas conversacionais de múltiplos turnos: as respostas agentes são implementadas por meio da integração nativa com Agentforce. Essa experiência conversacional é conduzida por um agente principal que orquestra ações e consultas, delegando todas as tarefas de recuperação de informações a um agente de pesquisa interno especializado.
Esse agente de pesquisa especializado é otimizado para recuperação de informações corporativas. Ele usa um loop de raciocínio para formular e executar pesquisas paralelas para explorar diferentes facetas da solicitação de um usuário. Ele utiliza um conjunto eficiente de ferramentas, incluindo a pesquisa unificada do Data 360 para todos os tipos de dados e idiomas de consulta estruturados para recuperar dados precisos de tabelas e entidades.
Por meio dessa síntese arquitetônica, o Data 360 capacita a criação de experiências de pesquisa corporativas altamente inteligentes, sensíveis ao contexto e acionáveis.
A extensibilidade é um dos principais recursos da Salesforce Platform. A Extensão de código fornece extensibilidade no Data 360, permitindo que usuários de código profissional executem lógica do Python personalizada diretamente no ambiente do Data 360, complementando suas funcionalidades declarativas avançadas e de baixa codificação. Usando a Extensão de código, os usuários podem estender com segurança os recursos principais do Data 360, como Transformações e Pipelines de dados não estruturados (partilhamento personalizado).
Nosso design para Extensão de código prioriza flexibilidade, segurança, eficiência e uma experiência de desenvolvedor simplificada. Ele oferece suporte a dois modelos de execução primários, cada um personalizado para necessidades arquitetônicas específicas:
- Modelo de script:
- Objetivo: Para lógica personalizada abrangente que requer interação direta com o Data 360 Lakehouse.
- Funcionalidade: Os clientes escrevem scripts completos do Python usando o SDK Extensão de código, habilitando o acesso de leitura e gravação ao Lakehouse por meio de APIs do SDK. Ideal para preparação de dados personalizados/complexos ou manipulação de dados personalizada.
- Isolamento e Segurança: Enquanto os scripts acessam o Lakehouse, sua execução é limitada a um ambiente seguro e isolado dentro do tempo de execução do Data 360, impedindo interferência com outros processos ou acesso não autorizado ao sistema.
- Modelo de função:
- Objetivo: Análogo a uma função sem servidor, para cálculos modulares sem estado chamados de pipelines do Data 360 existentes (por exemplo, agrupamento personalizado em um pipeline não estruturado).
- Funcionalidade: Funções fornecidas pelo cliente recebem entrada, calculam e retornam saída.
- Isolamento e Segurança: Essas funções são projetadas para isolamento estrito; elas não têm acesso direto ao Lakehouse. Sua execução é de sandbox, sem estado e restrita a recursos, tornando-as adequadas para etapas de processamento focadas sem estado, garantindo segurança, execução previsível e minimizando o raio de explosão.
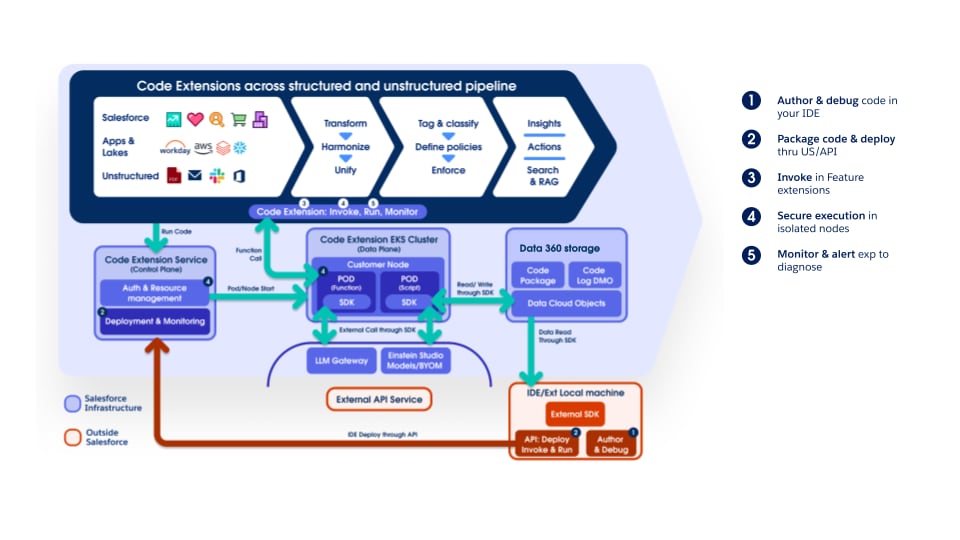
Os modelos Script e Function visam executar com segurança o código do cliente, impedindo que o código de um locatário afete outros ou obtenha acesso não autorizado a dados de outros locatários, recursos do Salesforce ou recursos externos. Essa segurança é alcançada por meio de uma arquitetura em camadas (defense-in-depth). Essa arquitetura fornece um ambiente de execução isolado para o código personalizado de cada locatário, incorporando várias proteções. Eles incluem isolamento lógico no nível de Kubernetes (K8s), isolamento de rede, sandbox de tempo de execução e permissões de privilégio mínimo, tudo complementado por monitoramento operacional e prontidão para resposta e detecção de incidentes.
Para oferecer suporte a um ciclo de vida de desenvolvimento robusto, a Extensão de código oferece:
- Autoria externa e depuração: Os desenvolvedores podem elaborar e depurar o código do Python em ambientes familiares, como VSCode, aproveitando o SDK.
- Implantação flexível: O código personalizado pode ser empacotado e implementado usando utilitários SDK, a IU do Data 360 ou a API, habilitando a integração ao CI/CD.
Registros operacionais: O acesso a registros de execução detalhados proporciona transparência e ajuda na solução de problemas na produção.
Ao oferecer esses recursos de extensão de código seguros e flexíveis, o Data 360 capacita os arquitetos a personalizar a plataforma para seus requisitos de processamento de dados mais exclusivos e complexos, realmente solidificando seu papel como um tecido de dados corporativo extensível.
Conforme as empresas aceleram a adoção da IA, a maioria mantém ecossistemas de ML heterogêneos, incluindo Amazon SageMaker, Google Vertex AI e ambientes baseados em Python personalizados, hospedando modelos que conduzem previsões críticas para a missão, como pontuação de risco de crédito, propensão de rotatividade, recomendações de produto e decisões de próxima melhor ação.
Tradicionalmente, a integração desses modelos externos ao Salesforce exigiu camadas de API personalizadas, pipelines de ETL ou orquestração de middleware, introduzindo duplicação de dados, sobrecarga de governança, latência e complexidade operacional – desafios que entram em conflito com uma visão unificada, em conformidade e em tempo real da Plataforma de dados do cliente (CDP).
Traga o teu modelo (BYOM): Entregue por meio do Einstein Studio no Data 360, ele lida com esses desafios permitindo a invocação direta de modelos treinados externamente em fluxos de trabalho do Salesforce, lógica do Apex e ferramentas de automação sem mover ou replicar dados. Por meio da federação de cópia zero, o Data 360 atua como a única fonte de verdade governada, expondo dados do Customer 360 harmonizados para inferência em pontos finais externos. Saídas de previsão fluem de volta em tempo real, alimentando processos de negócios com inteligência dimensionável.
O BYOM elimina de modo eficaz a lacuna entre a ciência de dados e a execução operacional desacoplando o desenvolvimento de modelo, os dados governados e as camadas de consumo. Ela preserva a independência da plataforma, reduz a complexidade da integração, acelera a implantação de IA e mantém a governança sobre dados confidenciais.
A arquitetura opera da seguinte maneira: O Data 360 fornece uma base de dados unificada do Customer 360, enquanto o Einstein Studio orquestra conexões a plataformas ML externas (SageMaker, Vertex AI ou pontos de extremidade personalizados). Modelos externos executam a inferência em modos em tempo real, em lote ou de streaming. As camadas do Salesforce – APIs de Fluxo, Apex e Consulta – consomem saídas para fornecer percepções personalizadas, automatizadas e analíticas em Sales, Service, Marketing e Industry Clouds.
Do ponto de vista empresarial, o BYOM oferece:
- Integridade dos dados e governança: Elimina cópias de dados não controladas e impõe a conformidade da política.
- Democratização da IA: Torna modelos complexos acessíveis a usuários não técnicos por meio de ferramentas do Salesforce.
- Aceleração de tempo para valor: Modelos externos são ativados imediatamente em processos do Salesforce.
- Suporte para escalabilidade e arquitetura híbrida: Habilita a implantação em várias nuvens de cargas de trabalho de IA.
- Arquitetura de IA pronta para o futuro: Dá suporte a estratégias de IA composível, desacoplamentando camadas de dados, modelo e consumo para agilidade operacional.
Traga o seu próprio LLM (BYO-LLM): Oferece o mesmo mecanismo de extensibilidade, mas para modelos generativos. Ao habilitar a invocação direta de LLMs externos, permitimos que os clientes os usem na Plataforma Agentforce em vez de modelos fornecidos pela Salesforce. Para empresas, o BYO-LLM permite:
- Acesso a modelos ajustados
- Integração de modelos não fornecidos atualmente pelo Salesforce
- Uso de modelos em contas fornecidas pelo cliente
As empresas modernas operam em um panorama de dados complexo caracterizado por dois desafios arquitetônicos importantes:
- Fragmentação intra-empresarial: Organizações grandes costumam usar várias organizações do Salesforce (geralmente segmentadas por região, unidade de negócios ou aquisição histórica) e vários outros sistemas de dados. Essa fragmentação cria silos de dados internos, tornando impossível estabelecer uma visualização única, confiável e unificada do cliente para engajamento em tempo real em todo o negócio. O desafio é unificar esses dados sem consolidá-los fisicamente ou duplicá-los em todos os sistemas, garantindo que a governança permaneça intacta.
- Colaboração entre empresas: As empresas costumam precisar compartilhar dados com parceiros e fornecedores para marketing, medição e inteligência de negócios conjuntos. O desafio é habilitar essa colaboração enquanto protege dados confidenciais e proprietários e cumpre normas de privacidade, como GDPR e CCPA, bem como barreiras da concorrência.
O Salesforce Data 360 lida com esses desafios com uma estrutura de Trust por design de cópia zero baseada no princípio de compartilhar acesso e percepções, em vez de mover ou duplicar dados.
O Salesforce Data 360 lida com os desafios de fragmentação de dados e colaboração com o Data Cloud One, o Compartilhamento de dados entre o Data 360s e o Data Clean Rooms prioritário para a privacidade. Essas soluções unificam dados do cliente, permitem trocas de dados seguras e fornecem percepções de privacidade. Com uma abordagem de Trust por design de cópia zero, as organizações podem desbloquear o potencial de dados para engajamento em tempo real, parcerias aprimoradas e tomada de decisão inteligente. Cada uma dessas opções de colaboração de dados tem fins diferentes.
Habilitação corporativa interna com o Data Cloud One
O Data Cloud One é a solução de arquitetura básica para empresas que operam várias organizações do Salesforce. Sua finalidade vai além do simples compartilhamento de dados; é projetada para estabelecer uma única visualização do cliente confiável e habilitar recursos completos da plataforma Data 360 em toda a organização.
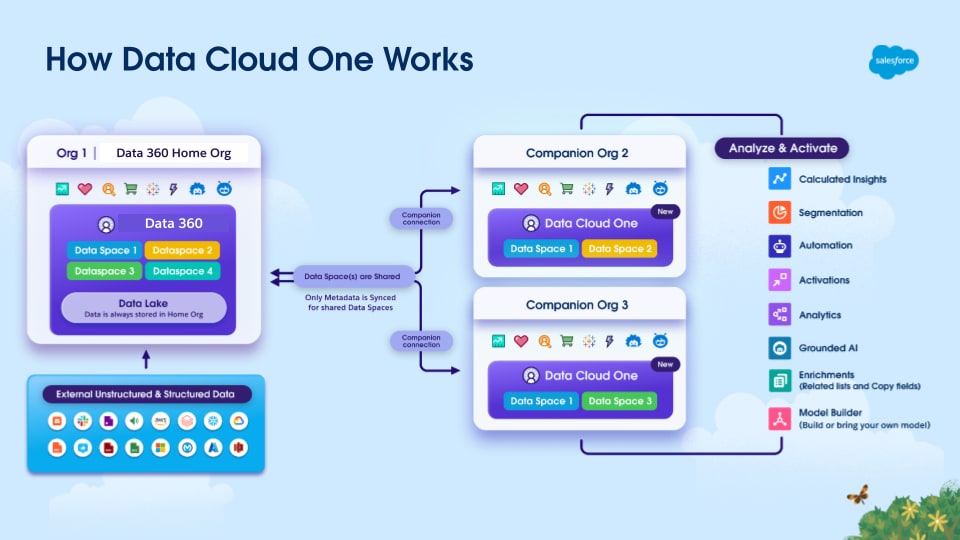
Esse mecanismo centraliza uma instância do Data 360 da organização inicial designada, que serve como a autoridade central para gerenciamento de dados e criação do perfil do cliente unificado. A organização inicial é a organização na qual o Data 360 está provisionado. Uma conexão do Data Cloud One é estabelecida entre o Data 360 e outras organizações do Salesforce, chamada de Organizações de companheiro. Como parte da conexão do Data Cloud One, o Data 360 compartilha um ou mais de seus espaços de dados com cada organização companheira, fornecendo acesso a dados e metadados em cada espaço de dados compartilhado. Isso é feito por meio de um modelo de federação de cópia zero e sincronização de metadados entre organizações.
O Data Cloud One também permite que as Organizações parceiras aproveitem a instância do Data 360 da organização inicial para suas próprias necessidades de ativação, personalização e inteligência. Essa estratégia é essencial para eliminar a fragmentação de dados internos e garantir que todas as unidades de negócios sejam ativadas em relação ao mesmo perfil de cliente unificado, regulamentado e unificado, maximizando o retorno sobre o investimento da implementação principal do Data 360.
Compartilhamento de dados entre organizações do Data 360
Para ambientes internos distribuídos (em que a centralização completa não é viável) e para colaboração com parceiros externos confiáveis, o compartilhamento de dados do Data 360-to-Data 360 conecta instâncias independentes do Data 360.
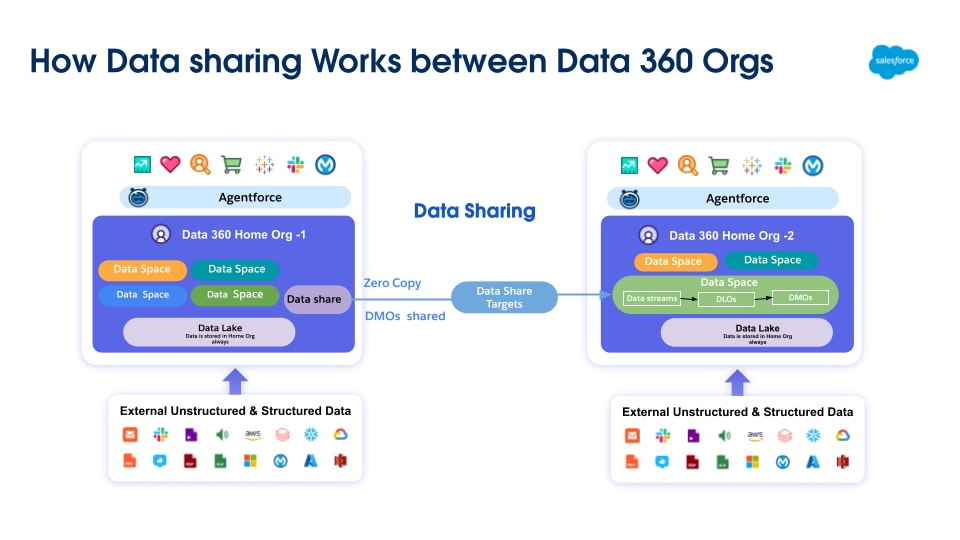
Esse modelo de compartilhamento de cópia zero estabelece uma conexão entre locatários separados do Data 360 provisionados em diferentes organizações do Salesforce para fins de troca segura de objetos de dados (DLOs, DMOs e CIOs). Depois de conectado, todo o objeto de dados fica acessível no Data 360 do destinatário. O administrador do Data 360 do destinatário pode então definir regras de governança para gerenciar o acesso do usuário a esses dados.
Colaboração com prioridade em privacidade com a Colaboração do Data 360 Clean Room
Quando a colaboração requer os mais altos níveis de privacidade e conformidade ou quando preocupações de concorrência proíbem o compartilhamento de dados brutos, o Data 360 Clean Rooms é arquitetonicamente obrigatório.
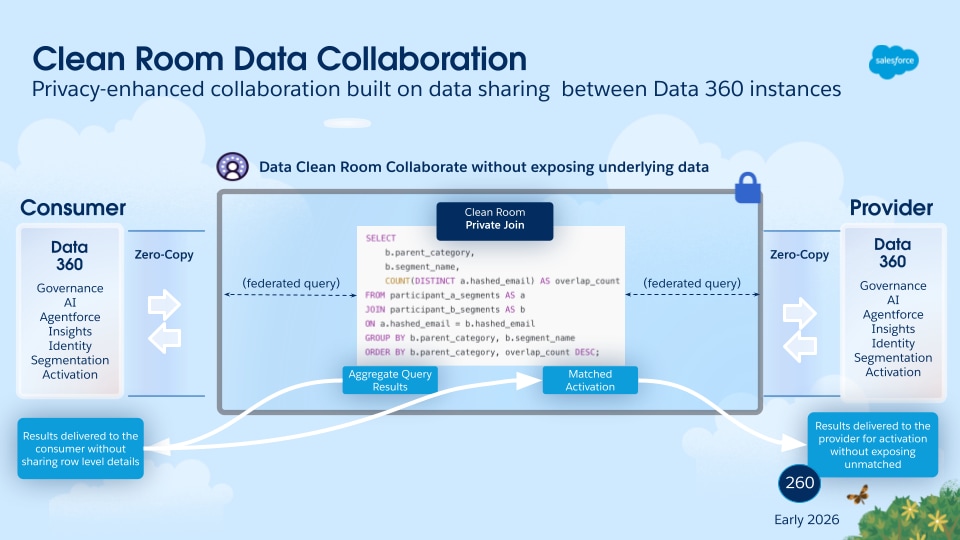
Arquitetonicamente, a Colaboração do Data 360 Clean Room é criada com base na estrutura de compartilhamento de cópia zero usada pelo compartilhamento de dados do Data 360-to-Data 360, mas com camadas adicionais de governança e restrições computacionais aplicadas. O Data 360 Clean Room fornece um ambiente de computação seguro e controlado em que as partes podem unir seus conjuntos de dados com base em chaves anonimizadas. Seu objetivo principal é permitir a análise conjunta e a geração de percepções sem expor os dados proprietários subjacentes. O ambiente aplica regras estritas e programáveis, como limites mínimos de agregação e identificadores não exportáveis. Essas regras garantem que apenas percepções aprovadas, aprimorando a privacidade e agregadas sejam derivadas e compartilhadas. Isso torna as salas limpas essenciais para casos de uso, como medição de campanha entre plataformas e análise de sobreposição de público confidencial.
O Data 360 é projetado como um tecido de dados inteligente, extensível e confiável necessário para habilitar a IA de próxima geração. Seu design arquitetônico lida com o problema de dados fragmentados, permitindo que as organizações unifiquem, processem e ativem todos os dados do cliente em escala, usando a Federação de dados de cópia zero para garantir a eficiência.
Sua organização de dados robusta estabelece uma visualização harmonizada de DLOs (incluindo dados não estruturados) para DMOs, todos protegidos dentro de espaços de dados particionados. Os recursos versáteis de processamento de dados do Data 360, incluindo transformações em lote e streaming, percepções calculadas, processamento de dados não estruturado e resolução de identidade, são alimentados pela arquitetura incremental SNCE e CDF, garantindo processamento eficiente quase em tempo real e poupança significativa de custos.
A extensibilidade é fornecida pela arquitetura Extensão de código, habilitando com segurança a lógica do Python personalizada por meio de scripts ou funções isoladas para requisitos exclusivos. Além disso, uma estrutura abrangente de governança de dados, criada com base no controle de acesso baseado em atributo (ABAC) com políticas do CEDAR, garante segurança granular, mascaramento de dados dinâmico e imposição consistente em todo o consumo de dados. Isso culmina em recursos sofisticados de segmentação e ativação, convertendo perfis de clientes unificados em estratégias de engajamento dinâmicas de vários canais com responsividade em tempo real.
Crucialmente, a capacidade do Data 360 de unificar dados vastos e diversificados, fornecer contexto em tempo real por meio de sua consulta unificada (incluindo pesquisa estruturada/não estruturada híbrida e hiperaceleração) e aplicar uma governança rígida é fundamental para capacitar agentes inteligentes de IA. Ele fornece os dados confiáveis, recentes e relevantes necessários para estabelecer fluxos de trabalho de IA generativa (RAG) e alimentar as capacidades de múltiplos turnos e orientadas a ações dos agentes acionados pelo Agentforce, garantindo que eles operem com precisão e precisão.
Ao fornecer uma plataforma pronta para o futuro em que os dados de origem são transformados em percepções acionáveis, o Data 360 serve como uma base arquitetônica indispensável para as organizações criarem experiências do cliente Agente. É a base vital que transforma os dados do cliente nas experiências sofisticadas e personalizadas do cliente que conduzem ao sucesso das organizações modernas de hoje.