Questo testo è stato tradotto utilizzando il sistema di traduzione automatica di Salesforce. Partecipa al nostro sondaggio per fornire un feedback su questo contenuto e dirci cosa vorresti vedere dopo.
Le piattaforme dati si sono evolute per oltre tre decenni. Inizialmente, il settore era dominato da database operativi/OLTP locali, centralizzati e strutturati (per lo più relazionali). Questo si è esteso per includere piattaforme OLAP/Big Data per i data warehouse che sono state utilizzate principalmente per l'elaborazione analitica e sono rimaste relazionali e centralizzate. Lo storage cloud ha determinato architetture distribuite come data warehouse, lakehouse e storage disaggregato. Tuttavia, le piattaforme operative e le piattaforme analitiche sono rimaste separate. Oggi, il cloud computing e la rivoluzione dell'intelligenza artificiale stanno cambiando radicalmente l'architettura della piattaforma dati.
Le aziende investono già in piattaforme Big Data mature come Snowflake, Databricks, BigQuery e Redshift. Ma queste piattaforme fungono da silos di dati. I clienti non derivano valore aziendale dai loro dati perché non è possibile intervenire sui dati direttamente all'interno dei flussi aziendali e delle applicazioni. Queste soluzioni non dispongono di elaborazione dell'intelligenza artificiale generativa e non sono in grado di fornire l'accesso ai dati in tempo reale, quindi non sono in grado di offrire personalizzazione basata sull'intelligenza artificiale al momento del coinvolgimento dei clienti e di altre funzioni leader del settore.
Il futuro delle piattaforme dati è caratterizzato da un'infrastruttura dati unificata, flessibile, accessibile e aperta. Questa nuova architettura si basa sulle moderne tendenze di elaborazione e archiviazione (GPU, memoria di grandi dimensioni, SSD NVMe e cloud storage) per integrarsi con il cloud computing e l'intelligenza artificiale. Sono in grado di fornire approfondimenti in tempo reale, potenziare il processo decisionale autonomo e favorire le applicazioni in tempo reale. Ciò include l'aumento dell'intelligenza artificiale agente, dell'intelligenza artificiale predittiva, dell'analisi, dei database OLTP su larga scala in tempo reale, dei data lake e delle lakehouse. Queste moderne piattaforme dati sono progettate per offrire semplicità, scalabilità, agilità, prestazioni, sicurezza, disponibilità ed efficienza in termini di costi.
Le seguenti tendenze dei dati determinano l'architettura della piattaforma dati di nuova generazione.
- AI, machine learning e Analytics al centro: L'ascesa dell'intelligenza artificiale agente modificherà in modo sostanziale lo sviluppo, la distribuzione e l'utilizzo/accesso della piattaforma dati. L'intelligenza artificiale agente comprenderà l'intento della conversazione/query, pianificherà, genererà flussi di lavoro e automatizzerà il processo decisionale. La memoria agentica (a breve e a lungo termine) è basata sulla cronologia delle conversazioni per personalizzare la pianificazione e le decisioni degli agenti, la modellazione delle conversazioni in tempo reale e il supporto della personalizzazione nelle piattaforme dati. Gli agenti aiuteranno ad automatizzare "funzionalità" operative come la governance dei dati (ad esempio, sicurezza, conformità, Trust), le prestazioni (ad esempio, scalabilità automatica per concomitanza, produttività e latenza), il failover e la disponibilità e l'osservabilità e la manutenzione. Analytics, previsioni, elaborazione del linguaggio naturale (NLP) basata su AI per le domande/risposte analitiche e analisi su dati non strutturati (testo come PDF, immagini, audio, video) saranno standard, consentendo alle aziende di derivare approfondimenti più approfonditi da fonti di dati diverse.
- Decentralizzazione dei dati ma accesso ai dati unificato: Gli agenti hanno bisogno di dati aziendali per ricavare approfondimenti e prendere decisioni e automatizzare le attività aziendali. I dati sono per loro natura decentralizzati nelle aziende, in applicazioni e piattaforme dati diverse. Ma non è facile unificare senza problemi i silos tra le diverse unità operative all'interno dell'azienda e con partner esterni all'azienda. L'unificazione dei dati prevede la condivisione dei dati, tramite inserimento da fonti o federazione con fonti di dati; dati grezzi provenienti da preparazione, armonizzazione e modellazione dei dati per l'elaborazione analitica e AI; archiviazione e gestione dei dati su larga scala per un accesso efficiente con bassa CTS; e accesso ai dati tramite vari meccanismi e strumenti di query e analisi, profondamente integrati con le piattaforme di archiviazione e accesso ai dati sottostanti
- Open Lakehouse basati su cloud: Le piattaforme OLP (Big Data) basate su cloud stanno convergendo nell'adozione di formati di file aperti (Parquet) e formati di tabella (Iceberg) che abilitano la federazione dei dati (data in) e la condivisione (data out).
- Trattamento dati non: strutturati Con l'emergere, l'avanzamento e l'adozione dell'intelligenza artificiale generativa, le aziende stanno iniziando a trarre informazioni preziose e valore aziendale dal corpus di dati aziendale che costituisce grandi volumi di documenti di testo, trascrizioni audio, registrazioni video e altri media. L'elaborazione di dati non strutturati, inclusi suddivisione in blocchi, vettorializzazione, ricerca semantica e grafici Knowledge, rendono possibili questi approfondimenti. Tecniche come RAG (retrieval augmented generation) e CAG (cache augmented generation) stanno diventando i principali motori della ricerca veloce e agente in tutto il corpus di dati.
- Knowledge Management: Knowledge va oltre il semplice contenuto grezzo (documenti, articoli, video). Rappresenta l'aumento di quel contenuto derivando significato, curando i metadati e inserendolo nel contesto per sviluppare una comprensione condivisa del contenuto in un'organizzazione o in un'azienda. Knowledge stesso è generalmente strutturato. La gestione Knowledge include la gestione dei contenuti, l'estrazione Knowledge, la rappresentazione tramite modelli come i grafici e la navigazione.
- Accesso RTF ai dati: Un accesso completo ai dati significa che i dati, gli strumenti di analisi e intelligenza artificiale devono essere accessibili a una varietà di profili, inclusi utenti finali, utenti aziendali, amministratori e analisti. L'accessibilità viene raggiunta attraverso meccanismi come la query insiemi (con query relazionali, parola chiave e semantica), il linguaggio naturale per la query SQL (NL2SQL), l'accesso in tempo reale e così via.
- Elaborazione in tempo reale: Le applicazioni agenti prendono decisioni in tempo reale in base allo stato corrente e ai nuovi eventi, personalizzando le risposte e le azioni, il che richiede l'accesso, l'elaborazione e l'utilizzo di dati in tempo reale. L'elaborazione in tempo reale richiede dati aggiornati (latenza dei dati) e accesso interattivo (latenza di accesso). Tali dati e latenza di accesso richiedono che la piattaforma dati sottostante supporti l'accesso aggiornato ai dati dagli archivi operativi e analitici, l'elaborazione a bassa latenza (ricerche di punti e query), l'elevata scalabilità dei dati e l'elevata produttività.
- Sicurezza dei dati, governance e residenza: L'intelligenza artificiale agentiale e conversazionale semplifica l'interfaccia utente delle applicazioni, consentendo a chiunque, dai consumatori ai dipendenti fino ad altri agenti di intelligenza artificiale, di interagire con le applicazioni conversazionalmente utilizzando un linguaggio naturale parlato o scritto. I preziosi dati personali e dei clienti che devono essere archiviati e modellati per le applicazioni Agentic devono essere protetti e governati con policy di accesso e condivisione ben definite. Sempre più spesso, molti clienti devono rispettare i regolamenti che richiedono la residenza dei dati nel proprio paese o regione, in particolare quelli governativi o che lavorano con i governi.
Salesforce Data 360 è progettato per il futuro per gestire queste tendenze dei dati. Data 360 è una piattaforma di dati nativa per il cloud basata sui metadati che unifica i dati in silo in tutta l'azienda, consentendo alle organizzazioni di archiviare, modellare ed elaborare i propri dati per abilitare applicazioni analitiche, AI, machine learning e agenti.
Questo documento è una guida essenziale per gli architetti aziendali e i CTO. Descrive l'architettura, le funzionalità, i principi di progettazione e i casi d'uso di Data 360. Introduce i fondamenti dell'architettura Data 360 come primer, seguito da una serie di approfondimenti sui suoi principali differenziatori, come l'interoperabilità con le piattaforme dati esistenti, tra cui strategia multi-organizzazioni, sicurezza, governance e privacy, attivazione in tempo reale e camere bianche dei dati.
Salesforce Data 360 si basa su una serie di principi fondamentali che rendono i dati aziendali operativi, affidabili e in tempo reale.
- Apertura e interoperabilità: Creato per gli ecosistemi multi-cloud. Si unisce a piattaforme dati come Snowflake, Databricks, BigQuery e Redshift senza duplicazioni, estendendo Customer 360 pur preservando gli investimenti esistenti.
- Separazione memoria-calcolo: Scala l'archiviazione e l'elaborazione (batch, streaming e interattiva) in modo indipendente. Offre elasticità ed efficienza per carichi di lavoro a volume elevato e prestazioni elevate.
- Memoria ed elaborazione multimodello: Supporta diversi tipi di dati strutturati e non strutturati come testo, audio immagine e video. Offre archiviazione efficiente, elaborazione in tempo reale e in batch, indicizzazione ampliabile, ricerca unificata, query e analisi.
- Progettazione basata sui metadati: Le applicazioni sono definite dai metadati anziché dal codice. I metadati vengono trattati come asset di prima classe, consentendo una governance unificata, flessibilità e una profonda integrazione nella piattaforma Salesforce.
- Elaborazione ibrida in tempo reale: Supporta query a bassa latenza e processi decisionali istantanei, oltre all'elaborazione batch e ai carichi di lavoro analitici.
- Dati intelligenti e attivi: Inserisce, analizza e invia continuamente approfondimenti direttamente nei flussi di lavoro aziendali. Alimenta l'automazione senza codice, low-code, pro-code e basata sull'intelligenza artificiale con il contesto più attuale.
- Governance e privacy by Design: Lineage, controllo degli accessi, residenza, crittografia dei dati e conformità sono integrati. Trust e fiducia normativa sono rafforzati a ogni livello.
- Tenancy uno a molti: Un'organizzazione Data 360 centralizzata funge da singola fonte di dati per Customer 360, supportando in modo semplice gli ambienti Salesforce multi-organizzazioni ampiamente utilizzati dai clienti Salesforce.
Questi principi garantiscono che Data 360 renda i dati aperti, intelligenti e fruibili in tempo reale.
Salesforce Data 360 è una piattaforma dati moderna basata su principi di progettazione che tengono conto delle tendenze attuali dei dati. Le funzionalità dell'architettura garantiscono che i dati aziendali siano affidabili, unificati e fruibili in tempo reale, in linea con i principi guida.
- Cloud-Native Foundation: Funziona su Hyperforce, distribuito su Hyperscalers (come AWS), con un'infrastruttura immutabile basata su microservizi. Offre scalabilità elastica, sicurezza zero Trust, consegna continua e conformità globale.
- Gestione dei metadati di Salesforce (Core): I metadati sono progettati, modellati e archiviati come metadati Salesforce che consentono l'uso immediato da parte di TUTTE le applicazioni Salesforce. Tali metadati sono archiviati in un RDBMS completamente compatibile con ACID. Garantisce governance, coerenza del ciclo di vita e una profonda integrazione con Salesforce Lightning Platform.
- Stoccaggio: Lakehouse Basato su Apache Iceberg e Parquet, combina la scalabilità del data lake con la governance del magazzino che supporta l'evoluzione dello schema, i viaggi nel tempo e gli aggiornamenti a volume elevato. Data 360 archivia, modella ed elabora dati strutturati e non strutturati con un'archiviazione su larga scala con moderni standard aperti e con funzionalità complete di trasformazione ed elaborazione dati per carichi di lavoro basati su batch ed eventi.
- Opportunità dati in corso di realizzazione end-to-end con inserimento flessibile: Copre l'intero ciclo di vita (inserimento, preparazione, modellazione, unificazione, analisi e attivazione) riducendo la dipendenza da soluzioni di punti frammentate. Supporta batch, quasi in tempo reale e streaming con più di 270 connettori e MuleSoft. L'approccio ELT-first consente una rapida disponibilità dei dati con flessibilità di trasformazione a valle.
- Interoperabilità dei dati aziendali con framework aperti e federazione: Unisce i dati in silo in tutta l'azienda con la federazione bidirezionale Copia zero con Snowflake, Databricks, BigQuery e Redshift evitando la migrazione o la duplicazione dei dati.
- Classificazione, modellazione e organizzazione dei dati: Data 360 organizza i dati come dati inseriti non elaborati, dati puliti e archiviati e dati modellati in base allo schema informativo comune noto come SSOT (Single Source of Truth). Tali oggetti SSOT costituiscono la base per la definizione di modelli di dati semantici (SDM) e altri modelli curati e specifici delle applicazioni.
- Modellazione semantica incorporata per analisi estendibili con API di query semantiche aperte, che guidano Tableau Next e abilitano analisi specifiche dell'applicazione.
- Motore di query Data 360 SQL che supporta una query unificata su dati strutturati, non strutturati e grafici.
- Memorie dati a bassa latenza: Archiviazione dei valori chiave per i dati caldi con tempi di risposta in millisecondi. Abilita la personalizzazione e gli scenari basati sugli eventi in tempo reale. Raccoglie ed elabora i dati di coinvolgimento dei clienti in tempo reale. Unisce le identità, le interazioni e le conversazioni in un unico profilo Customer 360 e grafico del contesto affidabili.
- Pipeline di elaborazione dati non strutturate per un supporto flessibile ed estensibile per l'archiviazione di dati non strutturati, la suddivisione, la generazione di incorporamento (vettorializzazione), l'estrazione di metadati (aumento), il riepilogo, l'indicizzazione, l'estrazione Knowledge, l'elaborazione intelligente dei documenti, la creazione di memoria a breve e lungo termine (conversazione) e così via.
- Indicizzazione nativa parola chiave, vettore e ibrida per un accesso preciso ed efficiente ai dati non strutturati come ricerca rapida e agente, RAG, estrazione Knowledge, derivazione della memoria agente, ecc.
- Servizi Profilo, Personalizzazione, Contesto per l'abilitazione di applicazioni AI/ML e Agentic.
- Governance e sicurezza integrate a ogni livello per il tracciamento dei lignaggi, il mascheramento dei dati, la residenza dei dati e la sicurezza zero Trust per garantire conformità e Trust.
- Tessuto elastico di calcolo: Tessuto di elaborazione multi-tenant nativo di Kubernetes. Esegue Spark per l'elaborazione distribuita e Hyper per i carichi di lavoro SQL. Scala in modo elastico in processi diversi e supporta l'isolamento per l'esecuzione di codice non affidabile.
Tutto questo viene eseguito su Hyperforce, la base cloud di Salesforce. Hyperforce fornisce:
- Sicurezza Zero Trust con policy di crittografia, isolamento e privilegi minimi.
- Resilienza attraverso distribuzioni multiregione. Benché Salesforce Data 360 tragga vantaggio dalla resilienza multiregione e dalla tolleranza ai guasti a livello di piattaforma di Hyperforce, il vero disaster recovery (DR) di livello aziendale richiede un'architettura più ampia simile a qualsiasi piattaforma dati con funzionalità chiave: pipeline di inserimento riproducibili, replica e reidratazione basata sui metadati in tutti gli ecosistemi dipendenti.
- Osservabilità con monitoraggio, metriche e tracciamento integrati.
- Scala automatica e consapevolezza FinOps per l'efficienza senza overflow dei costi.
Data 360 non sostituisce gli investimenti aziendali esistenti. Data 360 rende invece i dati di cui ci si è già fidati, gestiti e fruibili, offrendo un coinvolgimento in tempo reale basato sull'intelligenza artificiale dove è più importante. In breve, Salesforce trasforma tutti i dati aziendali, inclusi i dati esterni, come oggetti basati sui metadati (Salesforce) e abilita le applicazioni Agentic per l'individuazione, il processo decisionale e l'esecuzione di azioni.
La figura seguente illustra l'architettura di riferimento di Data 360:
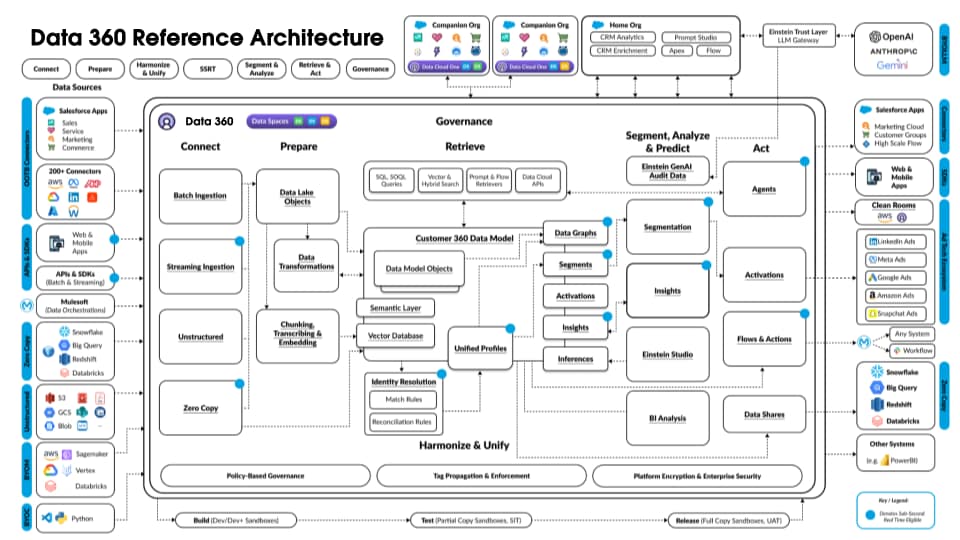
Si consideri un ipotetico Agentforce Loan Agent stratificato in Data 360 per descrivere un flusso di architettura di esempio. Si supponga che l'agente prestiti sia un agente rivolto al cliente in cui i clienti (consumatori) richiedono prestiti e ottengono approvazioni immediate dei prestiti.
Data 360 esegue questi passaggi come pianificato, preparando i dati per l'uso da parte dell'agente del prestito.
- Data 360 inserisce i dati strutturati dell'account cliente da CRM e li archivia nel data lake.
- Data 360 elabora i dati non strutturati relativi a prestiti aziendali e polizze finanziarie.
- Data 360 federa i dati personali di una fonte di dati esterna come Snowflake.
- Trasforma e modella i dati inseriti e federati in Data 360.
- Data 360 crea e gestisce il grafico dei dati del profilo.
Ogni volta che un cliente richiede un prestito, vengono eseguite queste azioni.
- Un cliente accede all'agente del prestito, che avvia una sessione del cliente nel livello in tempo reale. Il profilo unificato del cliente viene inserito nel livello in tempo reale.
- Il cliente completa una richiesta di prestito fornendo le informazioni richieste.
- Il cliente carica documenti finanziari (ad esempio dichiarazioni dei redditi, investimenti, estratti conto) in Data 360 per l'elaborazione di dati non strutturati.
- I dati caricati vengono suddivisi in blocchi e vettorializzati (generazione di incorporamento) e vengono creati gli indici (parola chiave e vettore).
- Quindi, il cliente compila il documento di richiesta di prestito e lo carica. Data 360 estrae l'ammontare e la durata del prestito in tempo reale.
- L'agente del prestito recupera i dati finanziari pertinenti utilizzando query di Data 360 e ricerca ibrida su profili e altri indici pre-creati.
- L'agente del prestito attiva un agente di approvazione con i dati del prestito e altri dati del profilo finanziario per prendere la decisione di approvazione del prestito.
- L'agente del prestito risponde al cliente con una decisione.
- Anche l'intera interazione tra il cliente e l'agente del prestito viene acquisita e archiviata in Data 360.
L'esempio precedente offre una panoramica dei componenti dell'architettura di Data 360 utilizzati per creare un'applicazione Agentic come un agente di prestito. Nella sezione successiva descriviamo i livelli e i componenti dell'architettura Data 360.
In questa sezione, approfondiremo i componenti base di Salesforce Data 360, iniziando con il suo modello di archiviazione robusto e successivamente esplorando i meccanismi di connessione, inserimento e preparazione dei dati. Esamineremo quindi come vengono memorizzati, modellati ed elaborati i dati strutturati e non strutturati, culminando in una comprensione delle loro capacità di armonizzazione, unificazione, recupero e attivazione intelligente.
Salesforce Data 360 è basato su un modello di archiviazione a livelli ma integrato che combina i punti di forza di una lakehouse con l'archiviazione in tempo reale. Il livello lakehouse offre uno spazio di archiviazione scalabile ed economico per grandi volumi di dati storici e batch, abilitando casi d'uso avanzati di analisi e machine learning. La memoria in tempo reale, invece, è ottimizzata per l'accesso a bassa latenza e gli aggiornamenti ad alta frequenza, assicurando che le interazioni con i clienti, i profili e i segnali di coinvolgimento siano sempre aggiornati. Insieme, questi livelli funzionano perfettamente, consentendo ai dati di spostarsi in modo fluido tra contesti storici e in tempo reale, offrendo profondità e immediatezza in una base di dati unificata per personalizzazione, intelligenza artificiale e attivazione.
Data 360 dispone di un'architettura lakehouse nativa basata su Iceberg/Parquet, progettata per gestire la gestione e l'elaborazione dei dati su larga scala per scenari batch, streaming e in tempo reale che supportano dati sia strutturati che non strutturati, cruciali per le applicazioni di intelligenza artificiale e analisi.
Nei data lake basati su cloud come Azure, AWS o GCP, l'unità di archiviazione fondamentale è un file, in genere organizzato in cartelle e gerarchie. Lakehouse ottimizza questa struttura introducendo astrazioni strutturali e semantiche di livello superiore per facilitare operazioni come query ed elaborazione AI/ML. L'astrazione principale è una tabella con metadati che ne definisce la struttura e la semantica, incorporando elementi di progetti open source come Iceberg o Delta Lake, con livelli semantici aggiuntivi aggiunti da Data 360.
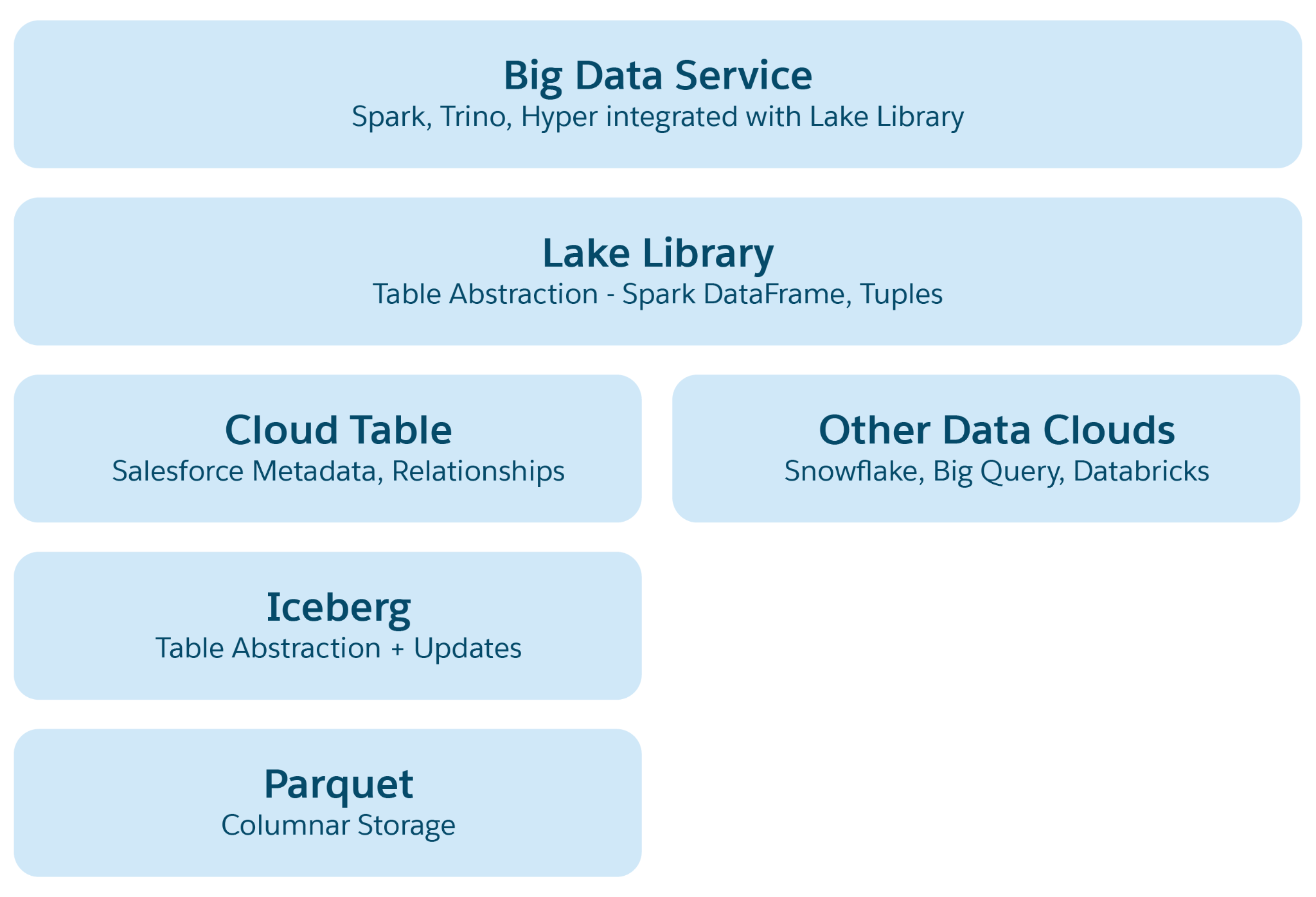
Strati di astrazione in Lakehouse:
- Astrazione file Parquet: Alla base, lo storage è costituito da file data lake (ad esempio S3 in AWS o Blob in Azure) in formato Parquet. I dati di una tabella di origine sono memorizzati in più partizioni come file Parquet, e ogni tabella è una raccolta di questi file.
- Astrazione tabella Iceberg: Le tabelle sono organizzate come cartelle, con partizioni di dati memorizzate come file Parquet all'interno di queste cartelle. Le modifiche apportate a una partizione generano nuovi file Parquet come istantanee. Iceberg gestisce un file di metadati per ogni tabella, descrivendo gli schemi, le specifiche delle partizioni e le istantanee.
- Astrazione tabella Salesforce Cloud: Basato su Iceberg, questo livello aggiunge metadati semantici come nomi e relazioni delle colonne, oltre a configurazioni come le dimensioni e la compressione dei file di destinazione. Astrae le tabelle in varie piattaforme come Snowflake e Databricks, proteggendo le applicazioni Data 360 dalle specifiche della piattaforma di archiviazione sottostante.
- Libreria di accesso al lago: Questa libreria fornisce l'accesso alla tabella Salesforce Cloud, gestendo sia i dati che i metadati e astraendo i meccanismi di archiviazione sottostanti per gli sviluppatori di applicazioni.
- Astrazione del servizio Big Data: Sono inclusi framework di elaborazione come Hyper per le query e Spark per l'elaborazione in qualsiasi piattaforma di tabelle cloud.
Per supportare applicazioni analitiche e agenti in tempo reale, Data 360 potenzia l'archiviazione Big Data di Lakehouse con Low Latency Store. Livello in tempo reale di Data 360 elabora i segnali in tempo reale e i dati di coinvolgimento in memoria. Tuttavia, poiché la capacità di memoria è limitata, tutti i dati non possono essere inseriti e l'elaborazione potrebbe non essere eseguita in tempo reale. Data 360 aggiunge un archivio a bassa latenza (LLS) per rimuovere tali limitazioni, abilitando l'elaborazione scalabile in tempo reale.
Il punto vendita a bassa latenza è un livello di memoria NVMe (SSD) con scala di petabyte in Lakehouse. Non tutti i dati devono essere conservati nell'archivio a bassa latenza. È una cache durevole. La maggior parte dei dati alla fine arriva a Lakehouse per la persistenza a lungo termine. I dati in sessione nel livello in tempo reale possono essere trasferiti all'archivio a bassa latenza per un successivo accesso rapido. Ad esempio, in una conversazione agente, i messaggi recenti possono essere elaborati in memoria; i messaggi più vecchi possono essere trasferiti nell'archivio a bassa latenza. Se è necessaria una conversazione precedente, è possibile accedervi entro pochi millisecondi dallo Store a bassa latenza. L'archiviazione basata su NVMe consente di archiviare e accedere a grandi quantità di dati a latenze di millisecondi. I dati possono arrivare allo spazio di archiviazione cloud Lakehouse per persistenza a lungo termine. Inoltre, i dati di Lakehouse necessari per l'elaborazione in tempo reale o per migliorare le esperienze in tempo reale vengono recuperati e conservati nell'archivio a bassa latenza. Ad esempio, il contesto del profilo cliente viene pre-recuperato o portato da Lakehouse e memorizzato nella cache nell'archivio a bassa latenza. Inoltre, tutti gli oggetti lakehouse e altri oggetti necessari per l'elaborazione in tempo reale durante l'elaborazione in sessione possono essere memorizzati nella cache anche nell'archivio a bassa latenza.
L'archivio a bassa latenza di Data 360 abilita il livello Real Timer in una vera gerarchia di memoria con livelli di memoria Lakehouse (SSD), con la migrazione dei dati tra questi livelli senza problemi. Il livello Real Time di Data 360 verrà descritto più avanti in questo documento.
Salesforce Data 360 è progettato per standardizzare, armonizzare e attivare tutti i dati dei clienti, strutturati e non, seguendo un rigoroso ciclo di vita che trasforma l'input non formattato in un modello di dati aggiornato e unificato.
Il ciclo di vita si concentra sull'acquisizione di vari input di dati esterni e la loro strutturazione in oggetti persistenti e modellati. I dati modellati possono essere armonizzati nei profili unificati Customer 360.
Dati inseriti non elaborati e trasformazioni iniziali
Il processo inizia con i dati non elaborati inseriti così come sono dai sistemi di origine (CRM, Marketing, file, ecc.). Sono inclusi i carichi completi di dati e gli eventi di modifica continua (delta), che vengono gestiti e uniti con dati persistenti per mantenere lo stato corrente.
Le trasformazioni in linea (ad esempio, tronca, normalizza, concatena) vengono applicate immediatamente durante l'inserimento per garantire la qualità e la pulizia preliminari dei dati.
Oggetti data lake (DLO): Il livello persistente
I DLO (Data Lake Objects) costituiscono il livello di memoria persistente centrale in Data 360. Memorizzano i dati puliti e trasformati e fungono da repository organizzato a lungo termine per tutte le informazioni sui clienti.
Le trasformazioni dati avanzate (ad esempio join, aggregazioni, approfondimenti calcolati) vengono applicate ai DLO di origine per produrre nuovi DLO derivati altamente curati.
I dati resi disponibili tramite Zero Copy Data Federation sono rappresentati direttamente come DLO.
Organizzazione di dati e metadati non strutturati
Per i contenuti non strutturati (come testo, media, documenti), Data 360 incorpora i dati estraendo e conservando i metadati strutturati all'interno di DLO specifici denominati oggetti data lake non strutturati (UDLO).
Questi DLO specializzati funzionano come tabelle di directory, fornendo una mappa alla posizione fisica e al contesto degli asset non strutturati. Questa funzionalità consente agli architetti di correlare in modo semplice i metadati dei dati non strutturati con il resto dei dati strutturati dei clienti, consentendo query unificate e armonizzazione.
Oggetti modello di dati (DMO): Il livello armonizzato
I DMO (Data Model Objects) rappresentano il livello di dati finale, armonizzato e strutturato.
Vengono creati mappando i campi DLO (dai DLO di origine, derivati e non strutturati) al modello di dati Customer 360 standard.
Il livello DMO funge da unica fonte di dati per tutti i dati dei clienti, consentendo la creazione, la segmentazione e l'attivazione unificate dei profili in tutto l'ecosistema più ampio.
Uno spazio dati è il contenitore logico fondamentale per organizzare tutti i dati e i metadati in Data 360, inclusi tutti i DLO (strutturati e non) e i DMO. Gli spazi dati offrono un ambiente sicuro e isolato per l'elaborazione e la modellazione dei dati.
Gli spazi dati fungono da confini logici e di governance, abilitando la multi-tenancy interna separando i dati per entità distinte come unità operative, regioni o marchi, pur mantenendo visibilità, discendenza e conformità a livello aziendale, fungendo da base per la definizione di un controllo degli accessi di base.
L'isolamento all'interno degli spazi dati viene applicato a più livelli della piattaforma:
- Isolamento a livello di dati: Ogni DLO/DMO appartiene a un unico spazio dati, il che garantisce che query, trasformazioni e mappature di oggetti non possano superare i confini dello spazio dati a meno che non siano esplicitamente autorizzate.
- Integrazione controllo accessi: Gli insiemi di autorizzazioni sono collegati in modo nativo agli spazi dati, consentendo il controllo sulle operazioni di lettura, scrittura e amministrazione. Ciò garantisce che solo gli utenti e i servizi autorizzati possano accedere a oggetti, approfondimenti e attivazioni all'interno di uno spazio dati.
- Governance e audit: Tutte le operazioni all'interno di uno spazio dati vengono registrate con percorsi di controllo di livello aziendale, consentendo la tracciabilità per conformità, gestione e rapporti normativi.
L'accesso e le autorizzazioni vengono gestiti tramite gli insiemi di autorizzazioni, garantendo visibilità granulare, aggiornamenti controllati e prevenzione di fughe di dati tra domini diversi. Integrando i confini dello spazio dati con l'architettura di sicurezza e governance di Data 360, gli architetti possono implementare con sicurezza strategie di governance sia centralizzate che decentralizzate, mantenendo la coerenza in più cloud e domini aziendali.
Il tessuto di elaborazione di Data 360 offre un livello unificato per la gestione e l'esecuzione di tutti i carichi di lavoro Big Data, semplificando le complessità dell'infrastruttura sottostante. Il suo componente principale è il controller di elaborazione dati (DPC).
DPC è un servizio completo di orchestrazione dell'elaborazione dati multi-carico di lavoro che offre funzionalità Job-as-a-Service (JaaS) in diversi ambienti di cloud computing. Astrae la complessità dell'infrastruttura e unifica l'esecuzione dei processi per framework come Spark (EMR su EC2 e EMR su EKS) e carichi di lavoro Kubernetes Resource Controller (KRC). Fungendo da gateway del piano di controllo centralizzato, DPC orchestra, pianifica e monitora i processi su più piani dati, garantendo affidabilità, scalabilità, efficienza dei costi e un'esperienza dello sviluppatore coerente.
L'esigenza di DPC deriva dalle limitazioni dell'interazione diretta con sistemi di gestione dei cluster nativi come EMR.
Astrazione di infrastrutture e cloud
Benché EMR offra API per cluster, operazioni e fasi, continua a gravare i team clienti su operazioni critiche di gestione dell'infrastruttura come provisioning, scalabilità, ottimizzazione delle prestazioni e ottimizzazione dei costi. DPC risolve questo problema offrendo un'API semplificata a livello di piattaforma per l'invio dei processi. Supporta la gestione automatica dei guasti, i tentativi e il bilanciamento dinamico del carico. Offre efficienza in termini di costi tramite nodi basati su binpacking, spot e gravitoni. Offre una sicurezza elevata con TLS, PKI, isolamento IAM e patching automatico. Gestisce gli aggiornamenti delle versioni runtime Spark ed EMR per offrire miglioramenti delle prestazioni, patch di sicurezza e miglioramenti delle funzioni.
Inoltre, DPC fornisce un'interfaccia unificata e indipendente dal cloud per l'invio e la gestione dei processi di dati, astraendo le complessità e le API proprietarie del substrato cloud sottostante (AWS, futuri provider). Ciò garantisce che i team client interagiscano esclusivamente con un'interfaccia di invio dei processi comune basata sull'API Data 360 che elimina le complessità dei responsabili delle risorse sottostanti come Kubernetes e YARN. Ciò consente ai team client di inviare processi Spark tramite un'API semplice e unificata senza dover gestire direttamente pod, pool di nodi o configurazioni di cluster Spark.
La regolazione manuale dei parametri Spark richiede competenze specifiche e configurazioni errate possono rallentare l'esecuzione dei processi. Il team DPC centralizza questa esperienza, fornendo configurazioni ottimizzate per evitare problemi di prestazioni comuni. Questo team specializzato integra continuamente Knowledge della comunità open source per garantire prestazioni ottimali in tutti i carichi di lavoro gestiti dal controller.
DPC non è limitato a Spark; supporta un'ampia gamma di carichi di lavoro. Questi includono:
- Carichi di lavoro di elaborazione in tempo reale
- Funzione di consegna evento per le azioni dati
- Gestione di Milvus (il database vettoriale per l'indicizzazione dei dati non strutturati)
- Infrastruttura di storage a bassa latenza
DPC sfrutta anche il framework Kubernetes Resource Controller (KRC), che supporta carichi di lavoro come Trino per Query, Event Delivery per le azioni dati, Processi di estrazione dati per i connettori ed elaborazione in tempo reale. Per tutti i carichi di lavoro del CCR, DPC offre funzionalità Job-as-a-Service centralizzate, che gestiscono il provisioning, la distribuzione e la gestione del calcolo con un'astrazione dei processi di alto livello.
Vantaggi e architettura JaaS
Il modello Job-as-a-Service, fornito da DPC, garantisce una pipeline di elaborazione dei processi conveniente e resiliente.
Gli utenti forniscono specifiche semplici per i cluster, concentrandosi su CPU, memoria, memoria, conteggi delle istanze e conteggi e tag dei cluster Min/Max necessari per la corrispondenza dei cluster. DPC gestisce automaticamente i dettagli astratti dell'infrastruttura, inclusa la selezione degli SKU VM ottimali, la gestione dei parchi istanze e la determinazione del rapporto tra Core e Core. Nodi Operazione e gestione di On-Demand vs. Individuare le istanze in base agli input. Gestisce anche la gestione delle versioni EMR e dei componenti e gli aggiornamenti senza tempi di inattività.
Fondamentalmente, il DPC supporta intrinsecamente la multi-tenancy, progettata per comprendere e applicare i confini della tenancy di Data 360 e la separazione delle risorse. Garantisce inoltre sicurezza e conformità imponendo immagini delle macchine certificate Salesforce, gestendo ruoli IAM specifici del servizio e garantendo la crittografia sia in transito che a riposo. Per l'instradamento e il controllo della capacità, l'abbinamento da processo a cluster viene gestito utilizzando i tag cluster e l'instradamento basato sulla capacità utilizza un'impostazione di concomitanza massima dei processi per controllare efficacemente l'utilizzo delle risorse.
Cloud Agnostic Client Experience è un vantaggio fondamentale, poiché la complessità degli ambienti cloud sottostanti è nascosta ai servizi client, consentendo loro di concentrarsi esclusivamente sulla logica aziendale. In questo modo si raggiunge l'obiettivo dell'astrazione del provider cloud. Infine, DPC consente un facile tracciamento dell'utilizzo e dei costi, consentendo di segmentare l'utilizzo e i costi dei cluster in base al servizio per una contabilizzazione precisa. Nel complesso, DPC segue un'architettura plug-in che consente l'integrazione senza problemi di nuovi motori di esecuzione (ad esempio Flink, Ray) e substrati cloud (GKE/Dataproc) senza esporre agli utenti i dettagli dell'infrastruttura sottostante. Questa progettazione separa il piano di controllo dal livello di esecuzione, garantendo un'API e un'esperienza operativa coerenti indipendentemente dal backend.
Data 360 perfeziona e arricchisce i dati grezzi, colmando il divario tra informazioni grezze e consumo aziendale fruibile. Integra il ciclo di vita dell'oggetto dati preparando dati complessi per un'attivazione e un'analisi sofisticate. Data 360 supporta vari tipi di elaborazione, tra cui trasformazioni dati batch e streaming, approfondimenti calcolati batch e streaming, elaborazione dati non strutturati e risoluzione dell'identità. Per consentire queste diverse operazioni in modo efficiente, soprattutto quasi in tempo reale e in serie di dati di grandi dimensioni, è necessario un meccanismo sofisticato per gestire le modifiche dei dati in modo efficace.
Per ottenere un'elaborazione dei dati efficiente e quasi in tempo reale, in particolare con tabelle di dimensioni pari a terabyte e milioni di potenziali aggiornamenti, Data 360 necessitava di una svolta. Richiedeva un modo per informare i sistemi con precisione quando i dati cambiano e quindi identificare in modo efficiente quali dati sono stati modificati in modo che vengano elaborati solo gli aggiornamenti pertinenti e solo quando vengono aggiornati. Questa sfida ha portato a due innovazioni complementari: Archiviazione degli eventi di modifica nativi (SNCE) per informare quando viene modificato qualcosa e del feed di dati di modifica (CDF) per identificare ciò che è cambiato.
Archiviazione di eventi di modifica nativi (SNCE)
SNCE ha trasformato Data 360 in una piattaforma dati reattiva e incrementale. Questo passaggio prevede il passaggio dal polling attivo del data lake al monitoraggio passivo degli eventi di conferma atomici, utilizzando un formato di evento standardizzato e un sistema di consegna dei messaggi ad alta produttività.
Ogni operazione di scrittura riuscita (INSERT, UPDATE, DELETE) in una tabella Iceberg culmina in uno scambio atomico del puntatore al file di metadati corrente della tabella nel catalogo. Il livello di memoria dell'oggetto sottostante (si supponga S3) è configurato per l'emissione di un evento di notifica nativo (ad esempio un evento S3) ogni volta che viene scritta una nuova istantanea dei metadati nella directory della tabella.
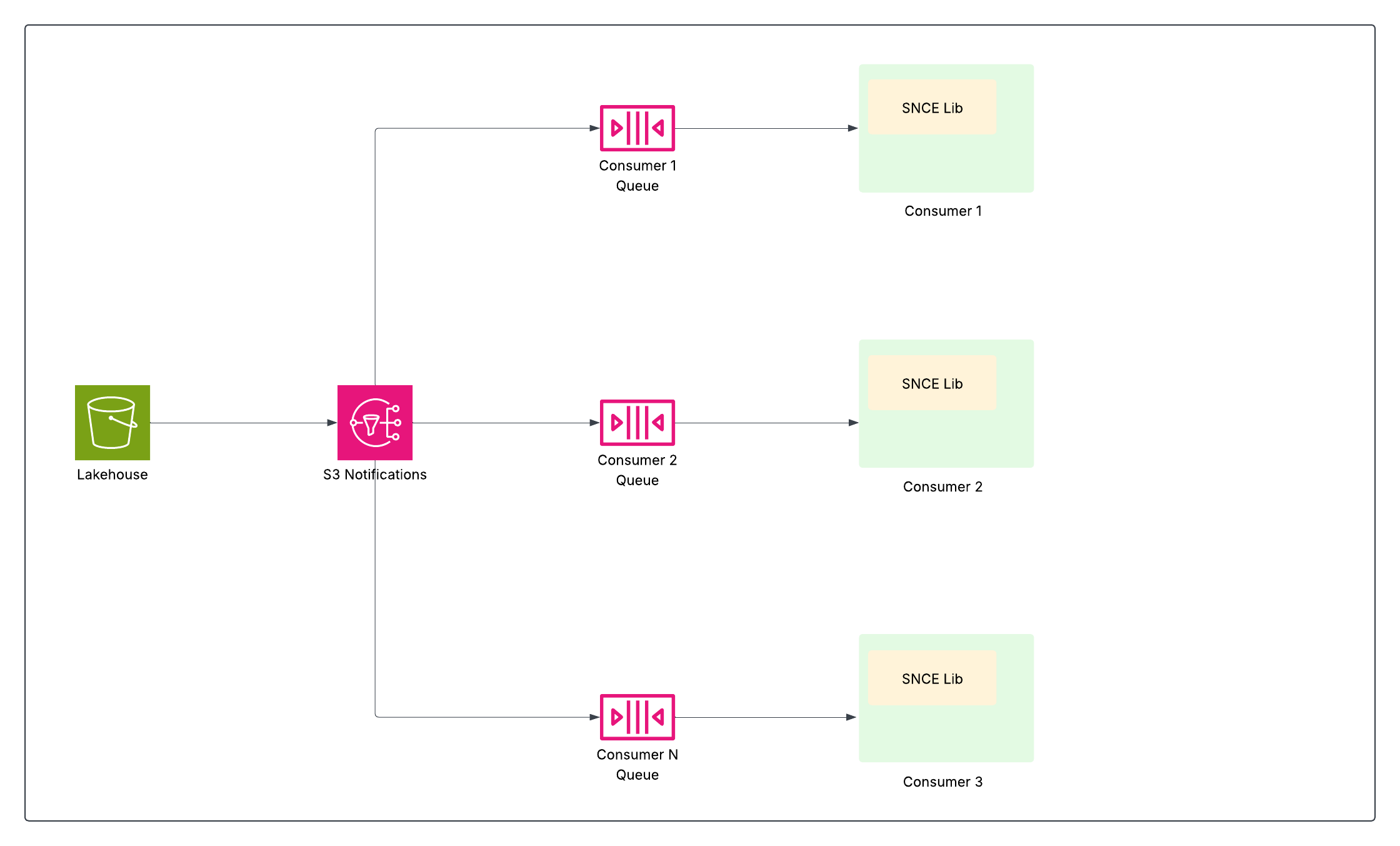
La libreria SNCE offre un metodo standardizzato per consumare questi eventi e su richiesta può anche arricchirli con metadati di istantanee.
Ciò consente alle pipeline di dati a valle, ad esempio approfondimenti calcolati in streaming, risoluzione dell'identità e segmentazione, di abbonarsi e agire solo quando i dati sono cambiati, aumentando in modo significativo l'efficienza evitando costose analisi a tabella intera.
Modifica feed di dati (CDF)
Basandosi su SNCE, il Change Data Feed (CDF) offre un meccanismo semplificato per consumare ed elaborare in modo incrementale le modifiche.
CDF sfrutta le istantanee Iceberg per generare in modo efficiente lo stream di modifiche. Il writer Iceberg ottimizzato di Data 360 calcola e mantiene le modifiche come parte dell'operazione di scrittura, rendendo la generazione di CDF estremamente efficiente e riducendo al minimo il sovraccarico aggiuntivo. Ciò consente ai processi di elaborazione (come le trasformazioni streaming o gli approfondimenti calcolati in streaming) di elaborare in modo selettivo solo i record alterati evitando il costoso calcolo delle differenze tra le istantanee.
Questa strategia incrementale offre diversi vantaggi per le serie di dati di grandi dimensioni, tra cui risparmio sui costi, latenza ridotta e maggiore efficienza. Abilita funzioni come le trasformazioni streaming e la risoluzione incrementale dell'identità, che a loro volta consentono approfondimenti più rapidi, caricamenti del sistema più prevedibili, prestazioni ottimizzate e minori spese operative.
Data 360 offre potenti funzionalità di inserimento con supporto nativo per i prodotti Salesforce, garantendo un flusso di dati senza interruzioni. Per le fonti esterne, offre un'ampia connettività attraverso oltre 270 connettori, API, SDK e MuleSoft. Inoltre, Data 360 è dotato di federazione copia zero, che consente di eseguire BI e analisi senza duplicazioni dei dati.
Il framework connettore Data 360 (DCF) è la base per la maggior parte della connettività Data 360. Consente l'inserimento, la federazione e l'uscita tramite un'architettura unificata. DCF definisce gli standard per la creazione e la gestione dei connettori, dall'interfaccia utente per l'impostazione e l'amministrazione alla persistenza dei metadati, all'estrazione dei dati e alla consegna in Lakehouse o tramite query live su fonti esterne. Supporta anche opzioni di connettività privata (ad esempio link privati, VPN e tunnel protetti) per garantire la sicurezza e la conformità dei dati di livello aziendale durante la connessione agli ambienti di clienti o partner. Fornendo un approccio coerente in tutti i connettori, DCF consente a Data 360 di connettersi perfettamente all'ecosistema più ampio garantendo estensibilità, affidabilità e integrazione sicura.
Data 360 offre una connettività affidabile a un vasto ecosistema di fonti di dati, supportando sia prodotti Salesforce nativi che numerosi sistemi esterni. Questa ampia connettività è fondamentale per unificare i dati aziendali in silo e abilitare le applicazioni AI/ML e Agentic.
Data 360 offre oltre 270 connettori in modo nativo o tramite MuleSoft, API e SDK per supportare le funzionalità end-to-end delle pipeline di dati con inserimento batch, streaming o in tempo reale. Questi connettori possono essere classificati in generale in base al tipo di sistema sorgente che integrano.
Connettori Salesforce nativi
Questi connettori garantiscono un flusso di dati nativo e senza interruzioni dai prodotti Salesforce.
Gli esempi includono connettori per Salesforce CRM, Data Cloud One, Marketing Cloud Engagement, Marketing Cloud Account Engagement e B2C Commerce.
Applicazioni esterne e SaaS
I connettori per varie applicazioni aziendali e servizi cloud consentono l'inserimento di dati da piattaforme software esterne.
Alcuni esempi sono Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp e Airtable.
Banche dati e data warehouse
Data 360 si connette a una varietà di piattaforme di archiviazione dati relazionali e basate su cloud.
Alcuni esempi sono Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery e Microsoft SQL Server.
Archiviazione oggetti cloud e file system
Questi connettori si integrano con soluzioni di archiviazione iperscala per dati strutturati e non strutturati.
Alcuni esempi sono Amazon S3, Google Cloud Storage (GCS) e Archiviazione BLOB di Azure.
Servizi di streaming e messaggistica
I connettori che gestiscono stream di dati continui in tempo reale sono fondamentali per gli scenari basati sugli eventi e l'elaborazione in tempo reale.
Un esempio è il connettore Amazon Kinesis.
Piattaforme di integrazione
Il connettore MuleSoft Anypoint estende la portata di Data 360 integrandolo con una gamma più ampia di applicazioni e database tramite Anypoint Exchange.
Connettori di archiviazione di dati non strutturati e oggetti cloud
Questi connettori sono fondamentali per inserire e fare riferimento a dati non strutturati (dati che non hanno un modello predefinito) per potenziare le funzionalità di intelligenza artificiale generativa.
Tutti questi connettori sono basati sul framework del connettore Data 360 che offre un'esperienza coerente.
La trasformazione dei dati è un componente architettonico fondamentale in Data 360, progettato per pulire, arricchire e modellare i dati inseriti non elaborati in asset di dati normalizzati e fruibili in linea con il modello di dati Customer 360. Questo processo è essenziale per l'armonizzazione dei dati, il miglioramento della qualità e la preparazione dei dati per casi d'uso a valle come l'unificazione, la segmentazione e l'attivazione dei profili. Le trasformazioni sfruttano sia gli oggetti data lake di origine (DLO) che gli oggetti modello di dati (DMO) come input, producendo i risultati rispettivamente per i nuovi DLO o DMO.
Data 360 fornisce due paradigmi di trasformazione principali per soddisfare diversi requisiti di velocità dei dati: trasformazioni dati batch e trasformazioni dati in streaming.
Trasformazioni dati batch
Le trasformazioni dati batch sono progettate per l'elaborazione a volume elevato in base a una pianificazione definita o a un trigger on-demand. Questo motore è ottimizzato per la gestione di operazioni di ristrutturazione complesse e che richiedono molte risorse.
Il processo di trasformazione batch viene configurato utilizzando un'area di disegno delle opportunità in corso di realizzazione visiva a basso codice che consente agli utenti di definire una logica di trasformazione a più fasi. Questo motore supporta in modo univoco operazioni di ristrutturazione complesse essenziali per l'allineamento del modello di dati canonico: la strutturazione e la normalizzazione dei dati. Ciò include il pivoting (decomposizione dei record denormalizzati in più record normalizzati) e l'appiattimento (ristrutturazione dei dati gerarchici, ad esempio JSON, in tabelle strutturate). La modalità di esecuzione del sistema supporta sia la sincronizzazione completa (elaborazione di tutti i record) che una modalità di elaborazione incrementale altamente efficiente. La modalità incrementale riduce in modo significativo il tempo di elaborazione e il consumo di risorse elaborando solo i record che sono cambiati dall'ultima esecuzione riuscita. Le trasformazioni batch sono ideali per le operazioni in cui gli aggiornamenti in tempo reale non sono essenziali, ad esempio aggregazioni periodiche e ristrutturazioni complesse dei dati.
Trasformazioni dati in streaming
Le trasformazioni dati in streaming elaborano i dati in modo continuo e incrementale quasi in tempo reale mentre fluiscono nel sistema, rendendoli essenziali per i casi d'uso a bassa latenza.
L'interfaccia principale è un approccio SQL-first, in cui le trasformazioni sono definite come una query SQL SELECT che viene eseguita continuamente sullo stream in entrata delle modifiche dei record. Questo motore supporta le principali funzioni di trasformazione, tra cui la pulitura e la standardizzazione dei dati (ad esempio, la convalida delle informazioni personali e la standardizzazione dei formati dei dati) e l'arricchimento e l'unione dei dati (utilizzando join e unioni). Supporta gli Streaming Lookup JOIN per abilitare l'arricchimento dei dati in tempo reale e le ricerche rispetto ai dati di riferimento statici o che cambiano lentamente, garantendo aggiornamenti istantanei dei profili. Per ottimizzare il cost-to-serve, l'architettura utilizza un processo ad alta densità (HD), che raggruppa più definizioni di trasformazione streaming per un singolo tenant in un unico processo di elaborazione sottostante, massimizzando l'utilizzo delle risorse. Le trasformazioni streaming sono essenziali per i casi d'uso come il monitoraggio degli eventi, la personalizzazione immediata e gli aggiornamenti dei profili in tempo reale.
Data 360 rivoluziona la gestione dei dati supportando la federazione Copia zero e la condivisione dei dati, eliminando la necessità di spostare o duplicare i dati. Questa funzionalità consente agli utenti di accedere in modo semplice e diretto ai dati da fonti esterne diverse e di condividere i dati con ambienti esterni, riducendo in modo significativo la complessità, riducendo i costi di archiviazione e garantendo che tutte le decisioni siano basate sulle informazioni più aggiornate e affidabili.
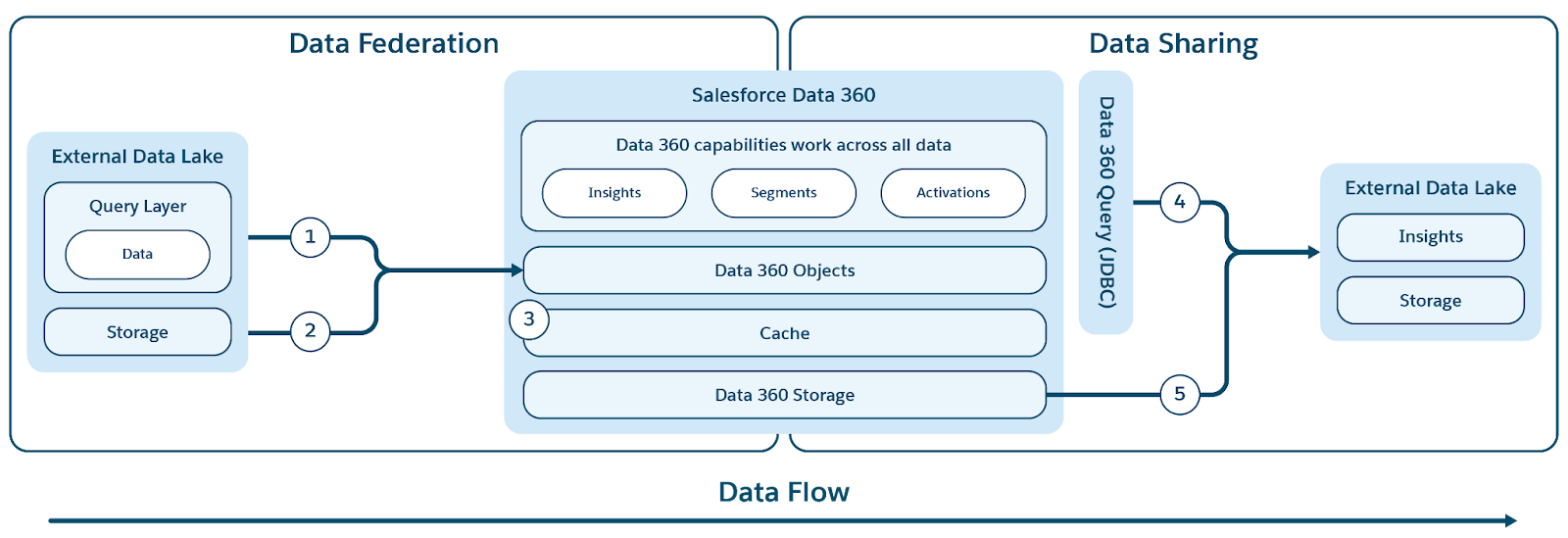
Data 360 supporta la federazione copia zero con data warehouse esterni (Snowflake, Redshift), lakehouse (Google BigQuery, Databricks, Azure Fabric), database SQL e molte altre fonti. I livelli di astrazione consentono di eseguire query dirette sui dati esterni senza duplicazioni, riducendo i tempi di inserimento, i costi di archiviazione e garantendo informazioni aggiornate.
Data 360 semplifica l'accesso ai dati esterni e federati offrendo un livello di metadati unificato che astrae sia Salesforce che gli oggetti esterni. Ciò consente all'intera piattaforma Salesforce e alle relative applicazioni di utilizzare senza problemi questi dati.
Data 360 supporta la federazione basata su file e query, con query live e accelerazione dell'accesso come mostrato nella figura.
Le etichette (1) e (2) illustrano la query di Data 360 (inclusi i pushdown delle query live) e la federazione basata su file per l'accesso ai dati da data lake/warehouse/fonti di dati esterne; l'etichetta (3) evidenzia l'accelerazione dell'accesso federato da data lake/fonti di dati esterne.
Federazione delle query
Il cuore della funzionalità di federazione di Data 360 risiede nel suo livello di federazione delle query, che gestisce il complesso processo di accesso ai dati esterni e l'esecuzione di pushdown intelligenti delle query (illustrato dall'etichetta 1). Data 360 si connette e recupera i dati dalle fonti utilizzando il protocollo JDBC, ottimizzato con logica aggiuntiva per una maggiore efficienza. Il Query Federation Layer è responsabile della comprensione e della traduzione dei diversi dialetti SQL, della definizione della parte più ottimale della query da inviare ai sistemi esterni per un'elaborazione efficiente, del recupero dei risultati e dell'esecuzione di ogni ulteriore elaborazione necessaria per derivare approfondimenti finali.
Caching (accelerazione delle query)
Per l'utilità ottimizzata, Data 360 offre una funzione di accelerazione facoltativa per le sue funzionalità federate.
Quando è attivata l'accelerazione, Data 360 memorizza nella cache i dati federati per ottenere un accesso più rapido e costi inferiori, evitando accessi diretti e ripetuti a fonti esterne. Questa cache viene trattata come un livello di accelerazione e viene aggiornata in modo incrementale per riflettere rapidamente eventuali modifiche nei dati di origine esterni, assicurando che la visualizzazione accelerata rimanga quasi in tempo reale.
Federazione file
Data 360 supporta la federazione basata su file (illustrata dall'etichetta 2) per l'accesso ai dati da data lake e fonti esterne. La base tecnica di questa funzionalità di copia zero si basa sulla standardizzazione: i dati sottostanti devono essere nel formato di file Apache Parquet e utilizzare il formato tabulare Apache Iceberg. Data 360 può essere federato in qualsiasi fonte che espone un IRC (Iceberg REST Catalog) per l'accesso ai metadati e all'archiviazione, garantendo un accesso senza interruzioni e regolamentato ai file che risiedono all'esterno della piattaforma.
Con la federazione basata su file, Data 360 compute gestisce tutta l'elaborazione dei dati perché accede direttamente all'archiviazione sottostante. Ciò elimina la necessità di eseguire query pushdown e gestire vari dialetti SQL, che spesso sono richiesti con la federazione basata su query.
Oltre a questo, la funzionalità Copia zero si estende anche a fonti di dati non strutturate come le soluzioni di archiviazione hyperscaler (archiviazione S3/GCS/Azure), Slack e Google Drive, a cui è possibile accedere dalle pipeline di elaborazione non strutturate di Data 360.
Data 360 facilita sia la condivisione basata su query che su file dei dati che gestisce con data lake e warehouse esterni (illustrata dalle etichette 4 e 5 nel contesto della figura originale).
Condivisione basata su query
Per la condivisione dei dati basata su query, Data 360 espone un driver JDBC che consente a motori e applicazioni esterni di accedere in modo sicuro ai dati. Questo meccanismo consente ai sistemi esterni di connettersi, autenticarsi ed eseguire query live direttamente sui dati in Data 360.
Condivisione basata su file (condivisione dati e DaaS)
Il meccanismo principale per la condivisione basata su file prevede due concetti: condivisione dati e destinazione condivisione dati, che sfruttano l'API DaaS (Data as a Service).
- Controllo granulare: Il concetto di condivisione dati consente ai clienti di definire con precisione gli oggetti (DLO, DMO, CIO, ecc.) condivisi esternamente, impedendo l'esposizione involontaria dei dati.
- Targetizzazione sicura: Controlla anche la destinazione della condivisione dati, assicurando che i dati siano resi disponibili solo ad ambienti esterni, account o organizzazioni partner esplicitamente autorizzati (ad esempio, la condivisione con un'istanza specifica di Redshift o Databricks).
L'API DaaS fornisce un'interfaccia sicura e gestita per i motori esterni per l'utilizzo dei dati. Concede l'accesso sia ai metadati essenziali che all'archiviazione della tabella sottostante, conservando tutta la semantica di Data 360. Ciò garantisce che i motori esterni accedano ai dati in un contesto coerente e significativo in modo sicuro.
Molti clienti sensibili alla sicurezza, in particolare le grandi aziende, i settori regolamentati e le organizzazioni del settore pubblico, limitano l'accesso a Internet ai propri data lake come parte del loro comportamento di sicurezza. Questa policy, pur essendo essenziale per la conformità e la riduzione dei rischi, impedisce anche a Salesforce Data 360 e Agentforce di connettersi a tali ambienti tramite Internet pubblico.
La maggior parte di questi data lake viene distribuita in ambienti hyperscaler come AWS, Azure o Google Cloud. Poiché Data 360 viene eseguito su AWS, l'accesso ai data lake dei clienti ospitati su un provider cloud diverso richiede una connessione di rete tra cloud. Senza un'opzione di connettività privata sicura che ignori Internet pubblico, i clienti spesso non possono o non vogliono adottare Data 360 o Agentforce per i casi d'uso basati su tali data lake.
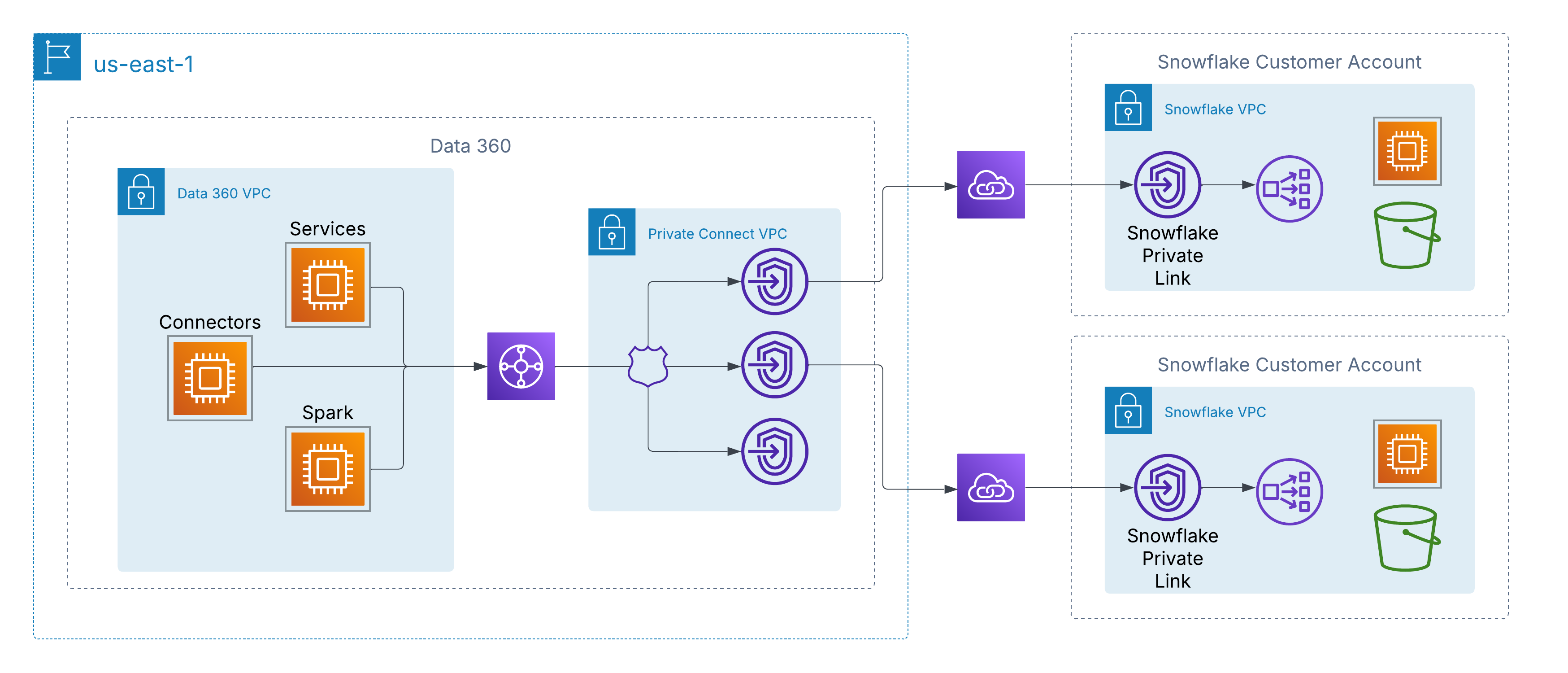
Per risolvere questo problema, Data 360 supporta la connettività privata a livello di rete alle fonti di dati gestite dai clienti nei cloud. In AWS, questo è abilitato tramite AWS PrivateLink, che consente a Data 360 di connettersi direttamente agli endpoint forniti dai clienti, sia all'interno dei propri account che all'interno di ambienti data lake di terze parti (ad esempio Snowflake), senza dover navigare su Internet pubblico.
Questa architettura garantisce che tutto il traffico rimanga interamente sulla backbone AWS, utilizzando indirizzi IP privati e percorsi di rete non instradabili, soddisfacendo così rigidi requisiti di sicurezza e conformità e consentendo al contempo un accesso senza interruzioni ai dati dei clienti.
Per i clienti con architetture multi-cloud, Data 360 estende la connettività privata oltre AWS tramite il supporto dell'interconnessione tra cloud. Ciò consente percorsi di rete sicuri e solo backbone da Data 360 ai data lake e ai servizi ospitati in Azure o Google Cloud, mantenendo gli stessi principi di AWS PrivateLink: indirizzamento IP privato, instradamento non pubblico e zero esposizione a Internet.
I clienti possono scegliere tra due modelli di distribuzione:
-
Interconnessione gestita dal cliente: Integrare circuiti privati esistenti come Azure ExpressRoute, Google Cloud Interconnect o Equinix Fabric direttamente con i VPC di Data 360.
-
Interconnessione gestita da Salesforce: Utilizzare una connessione chiavi in mano completamente gestita in cui Salesforce esegue il provisioning e il funzionamento del collegamento tra cloud, esponendo gli endpoint privati nel cloud di destinazione.
In entrambi i modelli, l'esperienza è coerente: I servizi Data 360 si connettono a fonti di dati esterne tramite hyperscaler come se fossero locali, abilitando l'inserimento, l'attivazione e l'esecuzione di query sicure senza navigare in Internet pubblico.
Per gli architetti aziendali, una governance dei dati efficace non è solo una casella di controllo della conformità, ma un pilastro fondamentale per creare Intelligence clienti affidabile, scalabile e fruibile. Salesforce Data 360 è progettato con un framework di governance completo che garantisce la qualità dei dati, la sicurezza e l'osservanza dei mandati normativi in tutto il ciclo di vita dei dati.
Data 360 funziona come un hub di governance centralizzato, garantendo che tutti i dati, dall'inserimento non formattato agli approfondimenti attivati, siano gestiti con integrità e controllo.
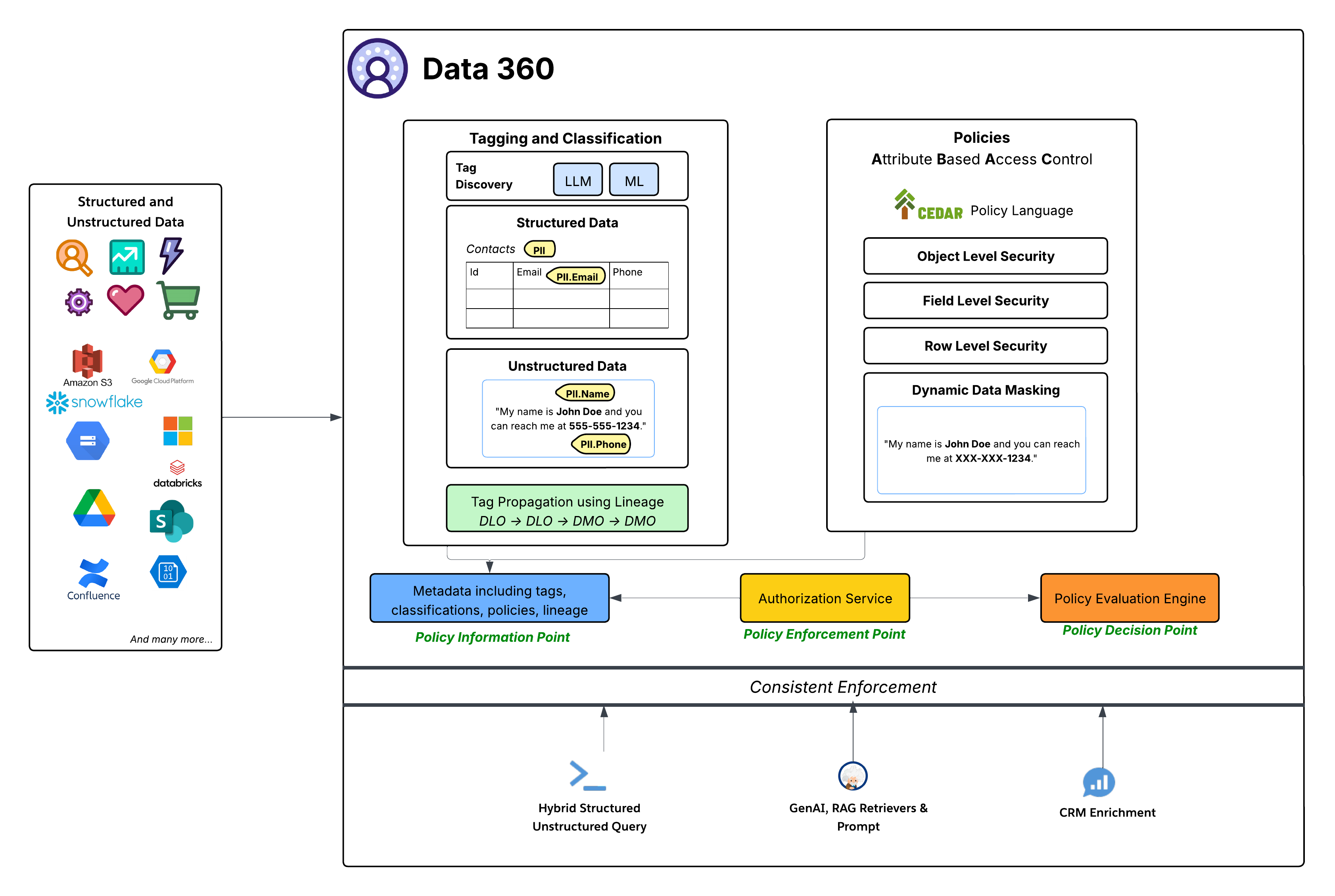
Mentre lo spazio dati fornisce un controllo dell'accesso a livello di dettaglio per determinare l'accesso a tutti gli oggetti all'interno di uno spazio dati, le policy basate su ABAC forniscono un controllo dell'accesso a livello di dettaglio a singoli oggetti, campi e righe all'interno di uno spazio dati. Data 360 ha adottato l'ABAC (Attribute-Based Access Control) come modello di autorizzazione principale per il controllo degli accessi a grana fine. Questa scelta strategica offre una flessibilità e una scalabilità superiori rispetto al tradizionale controllo dell'accesso basato sui ruoli (RBAC), particolarmente cruciale per ambienti aziendali dinamici e complessi con grandi quantità di dati e diverse esigenze di accesso. ABAC consente alle decisioni di accesso di basarsi sugli attributi dell'utente (ad esempio, reparto, ruolo, posizione), sui dati (ad esempio, informazioni personali, sensibilità, spazio dati) e sull'ambiente (ad esempio, ora del giorno), anziché solo sui ruoli predefiniti. Ciò consente policy di accesso altamente granulari e contestuali che si adattano al variare dei dati e degli attributi utente.
- Lingua: della policy CEDAR Il cuore dell'implementazione ABAC di Data 360 è l'uso del linguaggio della policy CEDAR. Questo linguaggio formale appositamente creato per le policy offre un modo preciso e verificabile per definire regole di autorizzazione complesse, assicurando che le policy siano univoche e possano essere valutate in modo coerente su larga scala.
Il sistema di governance di Data 360 aderisce a un'architettura ABAC standard e robusta:
- Tag, classificazione e creazione di policy (Policy Information Point - PIP):
- Data 360 offre meccanismi automatici di creazione di tag e classificazione, sfruttando LLM (modello di linguaggio grande) e ML (apprendimento automatico) per identificare le categorie di dati sensibili (ad esempio, PII.Email, PII.Phone, PII.Name) e altre tassonomie create appositamente (PHI, FinancialData) sia in Dati strutturati (ad esempio, tabella Referenti) che in Dati non strutturati (ad esempio, da Google Drive).
- Fondamentalmente, la propagazione dei tag avviene lungo la discendenza dei dati (DLO -> DLO -> DMO), assicurando che le classificazioni seguano automaticamente le trasformazioni e le derivazioni dei dati, dai dati non elaborati inseriti al livello DMO armonizzato e attraverso i dati derivati creati a partire dalle definizioni dei processi.
- Infine, il riquadro di creazione della policy offre un'esperienza semplice per sfruttare i dati e gli attributi utente per definire regole di accesso dinamiche per un'organizzazione.
- Questi metadati arricchiti (inclusi tag, classificazioni, policy e discendenza) vengono inseriti nel Punto di informazione sulla policy (PIP).
- Servizio di autorizzazione (Policy Enforcement Point - PEP):
- Il servizio di autorizzazione funge da punto di applicazione della policy (PEP). Intercetta tutte le richieste di accesso ai dati da vari livelli di consumo (Query strutturata/non strutturata ibrida, GenAI RAG Retrievers & Prompt, CRM Enrichment) e consulta il Policy Decision Point per determinare se l'accesso è consentito.
- Motore di valutazione delle policy (punto di decisione delle policy - PDP):
- Questo motore funge da punto di decisione della policy (PDP). Prende il contesto della richiesta di accesso dal PEP, insieme alle definizioni delle policy (in CEDAR) e agli attributi dal PIP, per prendere una decisione di accesso autorevole.
- Polizze di sicurezza granulari: Le policy definite in CEDAR impongono vari livelli di sicurezza, tra cui:
- Protezione a livello di oggetto: Controllo dell'accesso a interi DLO o DMO in base ai tag associati a questi oggetti.
- Protezione a livello: di campo Limitazione dell'accesso a campi sensibili specifici all'interno di un oggetto in base ai tag.
- Protezione livello riga: Filtrare i dati su oggetti specifici per visualizzare solo le righe pertinenti in base agli attributi utente.
- Mascheramento dati dinamico: È possibile mascherare in modo dinamico alcuni dati (in base ai tag) nel punto di accesso, senza alterare i dati sottostanti. Ciò garantisce che le informazioni sensibili siano protette pur consentendo un'ampia utilità. Questo vale per il mascheramento dei campi nei dati strutturati e dei contenuti nei dati non strutturati.
- Coerente applicazione: L'intero framework ABAC garantisce l'applicazione coerente delle policy in tutti gli schemi di consumo di Data 360, ad esempio tramite query dirette sui dati, recupero per applicazioni Generative AI (RAG) o arricchimento delle esperienze Salesforce CRM tramite gli elenchi correlati.
- Profonda integrazione con Salesforce Platform: Le funzionalità di governance di Data 360 vengono definite e amministrate direttamente nella piattaforma centrale Salesforce. Questa integrazione consente agli amministratori di gestire le policy di accesso, le identità degli utenti e la gestione degli attributi utilizzando strumenti Salesforce familiari, garantendo un livello di governance unificato e coerente in tutto l'ecosistema Salesforce.
Con la creazione di questo sofisticato framework ABAC con policy CEDAR, Data 360 offre agli architetti un livello di controllo e flessibilità senza pari, assicurando che i dati dei clienti non siano solo fruibili ma anche sicuri, conformi e affidabili in tutta l'azienda.
In tutti i settori, le organizzazioni stanno ponendo maggiore enfasi sulla sicurezza dei dati end-to-end per garantire la protezione da fughe di dati, accesso non autorizzato, manomissione o distruzione. La maggior parte delle piattaforme dati, incluso Data 360, fornisce la crittografia a riposo utilizzando una chiave di crittografia gestita dal fornitore. Tuttavia, le imprese (in particolare quelle dei settori regolamentati) richiedono sempre più capacità di crittografia gestite dai clienti sia per i dati a riposo che per quelli in transito.
Questo modello consente alle aziende di controllare le proprie chiavi di crittografia, assicurando che anche nell'eventualità altamente improbabile di una violazione a livello di piattaforma o di un accesso non autorizzato, i dati rimangano protetti crittograficamente. Senza la chiave proprietaria del cliente, nessuna entità (incluso il fornitore della piattaforma) può decrittografare o ricostruire i dati, mantenendo così la massima riservatezza e controllo.
Data 360 supporta l'archiviazione e la gestione di dati strutturati (tabelle), semi-strutturati (JSON) e non strutturati in modo semplice nei meccanismi di inserimento, elaborazione, indicizzazione e query dei dati. Data 360 supporta diversi tipi di dati non strutturati oltre al testo, inclusi audio, video e immagini, ampliando l'ambito della gestione e dell'analisi dei dati. La figura sotto illustra i due lati della messa a terra (inserimento e recupero).
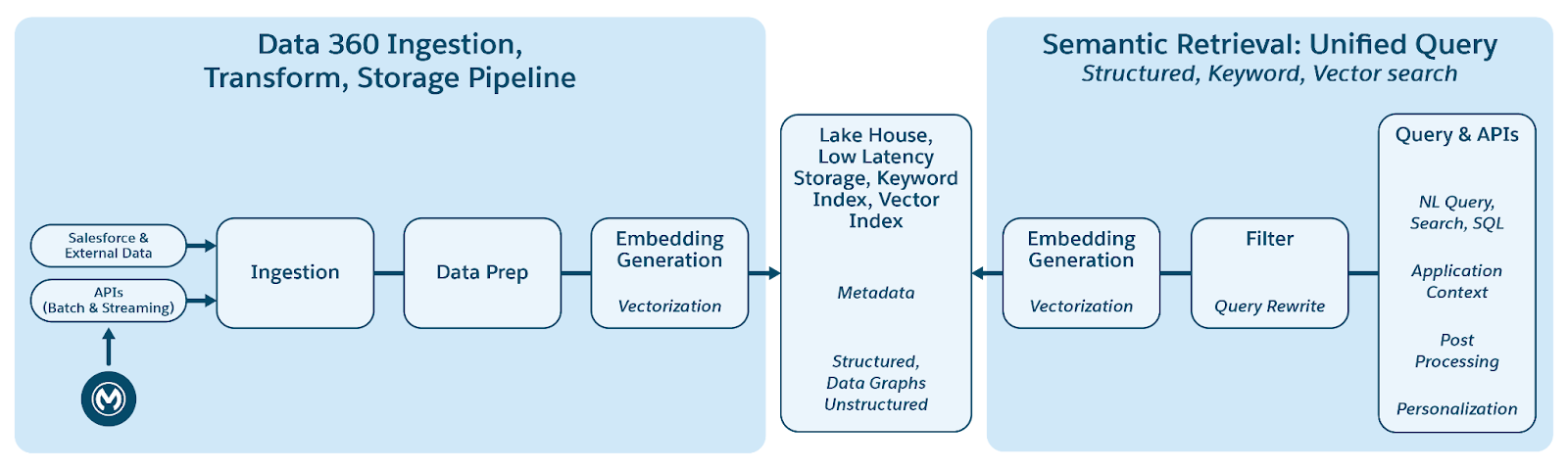
Data 360 gestisce i dati non strutturati archiviandoli in colonne come testo o in file per serie di dati più grandi. Supporta la federazione dei dati per i contenuti non strutturati, che consente l'integrazione e la gestione dei dati provenienti da più fonti.
I dati vengono quindi preparati e suddivisi in blocchi, gli incorporamenti vengono generati ed elaborati per l'indicizzazione delle parole chiave e l'indicizzazione vettoriale. Data 360 ospita più modelli pronti all'uso e collegabili per la generazione di blocchi e incorporamento. Data 360 supporta la trascrizione automatica e configurabile di contenuti audio e video per l'elaborazione e l'indicizzazione successive. Il servizio di ricerca viene utilizzato per l'indicizzazione delle parole chiave. Per l'indicizzazione vettoriale, Data 360 supporta sia l'indicizzazione nativa (con Hyper) che database vettoriali come Milvus open source. Data 360 si integra anche con la piattaforma di ricerca Salesforce per supportare l'indicizzazione delle parole chiave sui dati non strutturati. Questa indicizzazione multimodale integrata in Data 360 consente la ricerca su tutti i dati non strutturati, come descritto nella sezione Ricerca aziendale agente più avanti nel documento.
Per il recupero, Data 360 fornisce API per la ricerca. La query unificata Hyper-based facilita le query complessive in indici strutturati, indici di parole chiave e vettoriali, mantenendo visibilità e autorizzazioni rigorose, ottimizzando così RAG e Ricerca.
La pipeline di indicizzazione dei dati non strutturati di Data 360 è progettata come un'architettura modulare e ampliabile che comprende cinque fasi centrali:
- Analisi
- Pre-elaborazione
- Suddivisione
- Post-elaborazione
- Incorporamento
Tutte le fasi supportano anche l'elaborazione basata su LLM che consente ai clienti di creare prompt personalizzati. Sia la fase di pre-elaborazione che la fase di post-elaborazione possono includere più fasi sequenziali, consentendo la composizione flessibile di trasformazioni complesse. Ogni fase è interamente basata sui metadati, consentendo una configurazione e un'estensione senza interruzioni senza modifiche del codice.
Gli esempi di pre-elaborazione includono operazioni come l'eliminazione del rumore, la normalizzazione del linguaggio e la comprensione delle immagini (riconoscimento ottico dei caratteri e sottotitoli), mentre le fasi di post-elaborazione possono includere l'arricchimento dei metadati, il raggruppamento semantico o tecniche avanzate come la suddivisione in blocchi di Raptor.
La pipeline supporta completamente l'estensione Data 360 Code, consentendo ai clienti e ai team interni di inserire logica personalizzata in qualsiasi fase. I componenti dell'estensione codice sono funzioni Python leggere il cui ciclo di vita (esecuzione, scalabilità e gestione degli errori) è completamente gestito da Data 360. Questo approccio garantisce che l'innovazione e l'elaborazione specifica del dominio possano essere introdotte rapidamente mantenendo la coerenza operativa e la governance in tutta la piattaforma.
Indicizzazione contesto
Per impostare RAG con elaborazione non strutturata, due fattori critici sono fondamentali:
- Iterazione rapida: Possibilità di convalidare rapidamente con query di test di esempio.
- Contenuto specifico: Capacità di configurare contenuti su misura per il profilo consumatore.
L'indicizzazione del contesto è uno strumento intuitivo progettato per gestire entrambi questi aspetti. Questa interfaccia utente interattiva è basata su una pipeline in tempo reale che esegue tutte e cinque le fasi descritte in precedenza. La pipeline utilizza le GPU quando necessario per operazioni come la generazione di incorporamento e il riconoscimento ottico dei caratteri (OCR). Inoltre, consente ai clienti di testare rapidamente la pipeline RAG con un agente prima di distribuire la configurazione per un'elaborazione completa dei contenuti.
AI documento
L'intelligenza artificiale dei documenti di Data 360 consente di leggere e importare dati non strutturati o semi-strutturati da documenti come fatture, curriculum, rapporti di laboratorio e ordini di acquisto. Questa funzione supporta l'elaborazione interattiva ad hoc e l'elaborazione batch in blocco. Questa è una funzionalità chiave che consente l'automazione dei processi aziendali per i nostri clienti. Questo è basato sull'intelligenza artificiale che include LLM e modelli ML.
Le aziende possiedono grandi quantità di Knowledge sparse in diversi sistemi come wiki, condivisioni di file, sistemi di gestione dei contenuti, database interni e altro ancora. Questa frammentazione rende difficile per i dipendenti (soprattutto per gli agenti dell'assistenza e di vendita) e i clienti trovare le informazioni pertinenti in modo rapido ed efficiente. I problemi principali includono: Mancanza di un'unica esperienza di ricerca unificata in tutte le fonti Knowledge; presentazione e rendering incoerenti di contenuti provenienti da fonti diverse; mancanza di governance dell'accesso alle informazioni sensibili sparse nei sistemi; difficoltà a utilizzare fonti Knowledge autorevoli all'interno dei flussi di lavoro aziendali principali (ad esempio, allegare articoli pertinenti a un caso).
Enterprise Knowledge rappresenta il contenuto che è stato curato, manualmente o automaticamente, dalla più ampia serie di dati aziendali. La cura manuale prevede azioni deliberate, ad esempio la creazione di articoli Salesforce Knowledge o lo sviluppo di Knowledge all'interno di sistemi esterni che vengono quindi inseriti. Prevediamo una gestione automatizzata che utilizza processi, come gli agenti e le trasformazioni Salesforce, che eseguono i dati inseriti per generare livelli raffinati e curati, potenzialmente mescolando contenuti strutturati e non strutturati. Sia che vengano modificati manualmente o automaticamente, internamente a Salesforce o esternamente prima dell'inserimento, il risultato è un contenuto a valore aggiunto distinto dai dati non elaborati.
La soluzione Enterprise Knowledge Hub sfrutta le funzionalità di Data 360 per:
- Inserimento e memorizzazione: CRM Connector inserisce articoli di Salesforce Knowledge e i connettori non strutturati DCF (Data Connector Framework) inseriscono contenuti non elaborati e metadati da fonti esterne. Il contenuto viene inserito in oggetti data lake non strutturati (UDLO) specifici della fonte mappati al contenuto in SFDrive (o origine in caso di copia zero).
- Armonizzazione e strutturazione: Armonizzazione in corso di realizzazione elabora i dati UDLO e file, eseguendo operazioni di pulitura, normalizzazione, arricchimento (NLP, ecc.), mascheramento delle informazioni personali e trasformazione nel formato intermedio armonizzato, memorizzato in SF Drive e in un UDLO armonizzato (HUDLO) che vi viene mappato.
- Indicizzazione: Pipeline non strutturate (UDS) viene attivato sopra il contenuto armonizzato e gli indici di ricerca vengono configurati per ogni HUDMO.
- Consumo: Le applicazioni che consumano includono la ricerca, il recupero, il rendering e il collegamento a oggetti aziendali come Caso. Il coinvolgimento da parte delle applicazioni consumate viene raccolto per fornire analisi dell'utilizzo (ad esempio clic, recensioni, ecc.)
Gli approfondimenti calcolati in Data 360 consentono ai clienti di definire e generare metriche aggregate dai loro dati. Queste metriche vengono quindi utilizzate per il coinvolgimento, l'analisi, la segmentazione e l'attivazione puntuali dei clienti. I dati aggregati calcolati dagli approfondimento calcolato vengono scritti in Lakehouse e rappresentati come oggetto approfondimento calcolato (CIO).
Esistono due tipi principali di approfondimenti calcolati:
- Approfondimenti calcolati in batch: Progettato per l'aggregazione di dati complessi a volume elevato, in cui le metriche possono essere calcolate periodicamente (ad esempio, quotidianamente o settimanalmente).
- Approfondimenti streaming: Offrire la possibilità di generare metriche e azioni dai dati degli eventi in tempo reale, abilitando il coinvolgimento immediato dei clienti a bassa latenza.
Gli approfondimenti calcolati sono definiti per gli oggetti modello di dati (DMO) e possono essere definiti anche per altri oggetti approfondimento calcolato. Il servizio di approfondimenti calcolati gestisce l'orchestrazione dei processi batch e streaming.
Sia i calcoli batch che quelli degli approfondimenti streaming utilizzano Spark. La differenza principale è che gli approfondimenti streaming utilizzano Spark Structured Streaming, mentre gli IC batch vengono eseguiti utilizzando processi Spark batch periodici e pianificati. Per ottimizzare i costi, il servizio Approfondimenti calcolati raggruppa gli IC da calcolare insieme nello stesso processo batch CI o streaming CI, in base a fattori come le dipendenze e la sovrapposizione degli oggetti dati di origine.
SNCE e CDF svolgono un ruolo significativo nel calcolo degli approfondimenti streaming.
La risoluzione dell'identità è responsabile della trasformazione di dati diversi provenienti da più fonti in un unico profilo unificato completo.
È importante capire che un profilo unificato non è un "golden record" e che la risoluzione dell'identità non seleziona i valori vincenti né sostituisce i dati esistenti durante l'unificazione dei profili. I profili unificati fungono da serie di chiavi che sbloccano i dati di origine identificando tutti i record corrispondenti correlati alla stessa entità, all'interno di una sola fonte di dati o in più fonti. Con queste informazioni è possibile selezionare i dati del sistema di origine giusti da utilizzare per un determinato caso d'uso aziendale.
La risoluzione dell'identità può consolidare una varietà di tipi di record, tra cui Persone, Account e Famiglie. Può essere utilizzato anche per abbinare i lead agli account esistenti. Il processo di unificazione è essenziale per ottenere una visualizzazione Customer 360 completa e favorire il coinvolgimento personalizzato in tempo reale in scenari sia B2C che B2B.
La pipeline di risoluzione dell'identità è basata su un framework nativo del cloud altamente scalabile progettato per gestire volumi elevati di dati in modo continuo. Il processo prevede tre fasi chiave, affidandosi a un potente indice di ricerca per gestire il processo di corrispondenza:
- Corrispondenza (selezione candidato): L'obiettivo del processo di corrispondenza è cercare i record che possono appartenere alla stessa entità. I record vengono analizzati in base a una serie di regole personalizzabili, ciascuna delle quali contiene una serie di criteri che definiscono i dati da soddisfare a quale livello di rigore. Per recuperare in modo efficiente le potenziali corrispondenze dall'archivio dati, il sistema genera indici per trovare i record corrispondenti probabili utilizzando due tecniche:
- Chiavi di blocco: Una chiave di blocco è un valore generato dai dati e dalle regole di corrispondenza di un record (ad esempio le prime lettere di un nome, un numero di telefono normalizzato, ecc.) per raggruppare record potenzialmente simili. Ogni record ha più chiavi di blocco che vengono indicizzate e memorizzate come indice invertito, garantendo che il sistema esegua confronti dettagliati solo su piccoli gruppi di record, anziché sull'intera serie di dati.
- Hashing sensibile alla località (LSH): Per le regole di corrispondenza con corrispondenza "fuzzy", gli hash vengono generati in base agli incorporamenti di modelli addestrati.
- Corrispondenza profonda: Dopo che la fase di selezione del candidato ha creato gruppi più piccoli di potenziali corrispondenze, il sistema avvia un confronto più dettagliato. In questa fase, i modelli AI e gli algoritmi avanzati analizzano ogni coppia di record per calcolare un punteggio di corrispondenza probabilistico. Questo punteggio quantifica la probabilità che due record facciano riferimento alla stessa entità confrontando in modo intelligente i campi che spesso contengono errori di ortografia, variazioni o differenze di formattazione.
- Clustering e unificazione: Una volta identificati i record corrispondenti dai candidati, vengono raggruppati in un cluster. Questo processo include in modo critico la risoluzione delle corrispondenze transitive. Ad esempio, se il record A corrisponde al record B e il record B corrisponde al record C, tutti e tre sono collegati nello stesso cluster anche se A e C non sono mai stati confrontati direttamente. Questi cluster completi costituiscono la struttura di base del Profilo unificato. Questo processo di clustering garantisce che tutti i record di origine correlati siano collegati correttamente sotto un unico identificatore persistente.
- Conciliazione: I valori dei dati di tutti i record di origine raggruppati in cluster vengono valutati utilizzando regole di riconciliazione definite (ad esempio, Più frequente, Più recente o Priorità fonte) che compilano il Profilo unificato risultante con un estratto dei dati del profilo. La riconciliazione non sovrascrive alcun dato esistente, poiché tutti i dati di origine sono disponibili utilizzando le chiavi collegate al profilo unificato.
L'architettura supporta la risoluzione di più tipi di entità per soddisfare una varietà di casi d'uso.
- Corrispondenza individuale: Si concentra sulla creazione dei profili Persona unificata, che collegano tutti gli identificativi personali noti (email, numeri di telefono, ID fedeltà, cookie) a una singola persona.
- Corrispondenza account: Si concentra sulla creazione dei profili Account unificato, che collegano i dati sugli account. Quando esegue la corrispondenza in base ai nomi delle società, il motore utilizza un modello finemente ottimizzato quando esegue la corrispondenza "fuzzy".
- Corrispondenza famiglia: Estende la logica di corrispondenza per aggregare i record Persona unificata in gruppi di persone correlate.
- Corrispondenza tra entità: Oltre all'unificazione, la risoluzione dell'identità crea anche link tra gli oggetti profilo utilizzando le stesse regole di corrispondenza. Ad esempio, un lead può essere collegato a un account utilizzando la corrispondenza "fuzzy" su Nome account.
Per garantire che il Profilo unificato sia sempre aggiornato, il motore di risoluzione dell'identità funziona con un'architettura quasi in tempo reale. Questa architettura ottimizzata per il cloud è progettata per l'elaborazione continua, con tempi di elaborazione rapidi. Mentre la velocità di elaborazione varia a seconda del modo in cui vengono ricevuti i dati di origine, piccoli batch di modifiche possono essere elaborati con la risoluzione dell'identità ogni 15 minuti.
Il sistema mantiene gli oggetti link identità che mappano ogni ID record di origine all'ID profilo unificato corrispondente. Questa struttura di dati di base consente al motore di tenere traccia in modo efficiente delle relazioni e di propagare rapidamente modifiche e aggiornamenti al Profilo unificato, assicurando che le esperienze dei clienti, ad esempio la personalizzazione del sito Web, i consigli Next Best Action e la segmentazione, sfruttino sempre i dati dei clienti più aggiornati disponibili.
La segmentazione è il processo fondamentale per trasformare i profili cliente unificati in pubblici fruibili. Questa funzionalità è fondamentale per offrire esperienze personalizzate nei canali di marketing, commercio e assistenza. La piattaforma di segmentazione di Salesforce Data 360 è progettata per le operazioni su larga scala. Gestisce metadati complessi, utilizzando un modello di dati che comprende migliaia di oggetti e relazioni. La piattaforma supporta regole complesse, filtri basati su aggregazione e classificazione basata su finestre, il tutto garantendo un calcolo rapido e affidabile su scala petabyte.
Data 360 supporta diversi tipi di segmento per soddisfare requisiti aziendali distinti per velocità, complessità e gerarchia:
- Segmento standard: Tipo di segmento principale elaborato in batch. La pubblicazione avviene secondo una pianificazione personalizzabile, con una cadenza di pubblicazione standard da un minimo di 12 ore a 24 ore o una cadenza di pubblicazione rapida più rapida da 1 a 4 ore, ottimizzata per i dati di coinvolgimento recenti.
- Segmento in tempo reale: Questo segmento viene completato on-demand in millisecondi per un'azione immediata in base agli eventi recenti e ai dati del profilo. È altamente ottimizzato per la personalizzazione immediata ma non può utilizzare criteri di esclusione o segmenti nidificati.
- Segmento cascata: Struttura gerarchica di sottosegmenti utilizzata per assegnare la priorità a un cliente in un unico segmento di maggior valore se soddisface più criteri.
- Segmento nidificato: Ciò consente di riutilizzare un segmento esistente come filtro per un nuovo segmento più specifico (perfezionamento di un segmento di base), ereditando la pianificazione del segmento controllante.
Il motore di segmentazione opera su un'architettura robusta e nativa del cloud che garantisce velocità, scalabilità e resilienza.
Il processo centrale è gestito da un servizio di orchestrazione processi che controlla il ciclo di vita del segmento, generando la configurazione del processo necessaria e attivando l'esecuzione. Questo livello di orchestrazione mantiene lo stato e i metadati in un database shard per la scalabilità.
Benché Query Data 360 gestisca i calcoli del conteggio della segmentazione, il livello di calcolo Spark è responsabile del calcolo dell'effettiva appartenenza ai segmenti. L'applicazione Spark esegue query Spark SQL su dati completi dei clienti. Questi dati possono risiedere in Data 360 Lakehouse, in sistemi esterni tramite la federazione dei dati Copia zero o in una combinazione di entrambi.
Il sistema è altamente ottimizzato tramite la generazione di query intelligenti, che perfeziona la query Spark SQL sottostante. Ciò include tecniche come la potatura intelligente delle partizioni per ridurre al minimo la scansione dei dati e l'eliminazione delle sottoespressioni ridondanti. Per garantire l'affidabilità del servizio, l'architettura dispone di una gestione adattiva delle risorse che regola dinamicamente le risorse di calcolo in base alle dimensioni e alla complessità del carico di lavoro. Inoltre, l'osservanza degli SLO viene gestita in modo proattivo con durate adattive e logica di tentativo. Per un'esperienza utente rapida, i conteggi accelerati dei segmenti utilizzano un approccio basato sul campionamento per fornire stime rapide delle dimensioni durante la creazione del segmento, evitando un'esecuzione completa delle query.
Infine, viene mantenuta una profonda attenzione all'osservabilità e all'attribuzione delle cause principali attraverso metriche di esecuzione Spark complete e la classificazione automatica degli errori (ad esempio, problemi lato cliente e problemi di sistema), riducendo in modo significativo i tempi di diagnosi e garantendo una piattaforma dati altamente resiliente.
L'attivazione è il passaggio finale fondamentale del ciclo di vita di Data 360. La sua funzione principale è trasformare i profili cliente statici, segmentati e unificati in dati fruibili e arricchiti e fornire questi dati a endpoint interni ed esterni (ad esempio, piattaforme Marketing Cloud, Commerce Cloud e Adtech). Questo processo è progettato per attivare customer journey personalizzati e interazioni quasi in tempo reale. Supporta funzionalità avanzate come gli attributi correlati, i filtri di appartenenza all'attivazione, i filtri del consenso, la limitazione e la classificazione.
L'attivazione offre tre metodi distinti per la consegna esterna e la conformità del canale:
- Attivazione batch: Progettato per operazioni pianificate a volume elevato, ad esempio campagne email su larga scala e aggiornamenti del pubblico pubblicitario. I dati vengono forniti eseguendo la gestione temporanea in bucket interni protetti (Cloud Object Storage) o tramite Trasferimento file protetto, seguito da un processo di inserimento API avviato dal sistema di destinazione. Le attivazioni batch possono utilizzare una modalità di aggiornamento speciale, incrementale, per ridurre i volumi inviati ed elaborati dai partner Salesforce.
- Attivazione streaming: Ottimizzato per i casi d'uso quasi in tempo reale che richiedono un'automazione basata sugli eventi. La consegna avviene tramite chiamate API dirette inviate all'endpoint di destinazione.
- Flussi attivati da attivazione: Questo canale altamente piattaforma offre un approccio senza codice/low-code per integrare i dati del pubblico con centinaia di piattaforme di coinvolgimento abilitate per l'API del cliente. Al termine dell'attivazione, Data 360 compila un DMO Pubblico che attiva un flusso su larga scala. Il motore di flusso successivamente consuma i dati del pubblico e utilizza funzionalità della piattaforma come Servizi esterni e destinazioni Mule Outbound per effettuare chiamate alla destinazione finale basata su API. Questo metodo riduce in modo significativo il tempo necessario per l'inserimento di nuove destinazioni attivazione.
L'attivazione utilizza gli stessi schemi della segmentazione per la gestione dei processi, l'esecuzione distribuita e il monitoraggio. Ciò include i principi del servizio di orchestrazione dei processi per la gestione del ciclo di vita e del livello di elaborazione (Spark) e si basa sulla telemetria dei processi per l'osservabilità delle prestazioni e l'osservanza degli obiettivi del livello di servizio (SLO).
Oltre a quelli, l'attivazione ha -
Gestione destinazioni attivazione supervisiona le connessioni, le credenziali e le configurazioni protette per tutti gli endpoint di destinazione. Garantisce che i formati dei dati e i protocolli di sicurezza siano standardizzati, garantendo una consegna in uscita affidabile a varie piattaforme, inclusi Marketing Cloud, partner Adtech e altre applicazioni esterne.
L'attivazione personalizza il payload per target specifici. Per Salesforce Marketing Cloud, sono inclusi i filtri sensibili alle unità operative (BU), il supporto multi-EID e i controlli dell'impollinazione incrociata.
La governance delle comunicazioni agisce da gatekeeper, garantendo che l'utilizzo dei dati e la comunicazione siano conformi alle preferenze dei clienti e ai requisiti legali. Il modello di consenso centralizzato unifica tutte le preferenze dei clienti, dal rifiuto esplicito globale al consenso specifico del canale e dello scopo, e vengono memorizzati nel profilo Persona unificata. Durante l'esecuzione, la piattaforma applica rigorosamente queste policy utilizzando i filtri di esclusione per rimuovere automaticamente le persone non consenzienti dal payload finale. Inoltre, il sistema applica regole di selezione del punto di contatto per garantire che utilizzi il punto di contatto unico, più conforme e preferito per il canale previsto prima che vengano trasmessi i dati. Questo meccanismo di applicazione è protetto dal framework di governance sottostante, che utilizza misure di protezione come il mascheramento dinamico dei dati e i controlli di accesso per proteggere i campi di dati sensibili durante tutto il processo di attivazione.
Il vero valore di una piattaforma di dati unificata risiede nella sua capacità di fornire un accesso semplice e coerente a tutti i suoi asset di dati, indipendentemente dalla loro origine o struttura. La funzionalità Query unificata di Salesforce Data 360 è stata progettata appositamente per offrire questo risultato, astraendo le complessità sottostanti di archivi di dati diversi per fornire un'unica e potente interfaccia di query.
Il livello Query unificata offre un accesso sofisticato per diversi modelli di consumo:
- Query strutturate e non strutturate ibride: Fornisce un ampio supporto SQL per eseguire query senza problemi sia sui dati strutturati che sui metadati strutturati dei dati non strutturati. Ciò è ottimizzato dall'estendibilità dell'operatore tramite le funzioni di tabella, abilitando la ricerca specializzata in tipi di testo, immagine e spazio.
- Prestazioni accelerate con Hyper: Sfruttando Hyper, un motore in memoria ad alte prestazioni, Data 360 accelera query analitiche complesse e cruscotti digitali interattivi, offrendo risposte quasi istantanee su serie di dati di grandi dimensioni.
- Approccio unificato per AI e personalizzazione: Questo accesso unificato è fondamentale per generare risultati mirati e personalizzati, facilitando direttamente risposte LLM più precise utilizzando la generazione aumentata di recupero (RAG) basando i modelli AI su dati aziendali completi.
- Integrazione con il consumo a valle: Funge da livello di accesso ai dati di base per esperienze basate sull'interfaccia utente, API efficaci, flussi di lavoro di intelligenza artificiale generativi e arricchimento CRM, collegando facilmente i dati all'attivazione.
Fornendo un'unica interfaccia di query intelligente e altamente performante, la query unificata di Data 360 consente agli architetti di creare applicazioni agili basate sui dati che sfruttano al meglio la gamma completa di informazioni sui clienti.
Data 360 è una piattaforma attiva che supporta l'attivazione di opportunità in corso di realizzazione in risposta a eventi dati. Ad esempio, un evento significativo, ad esempio un calo del saldo account di un cliente, può attivare un flusso Salesforce per orchestrare un'azione corrispondente. Analogamente, gli aggiornamenti alle metriche chiave, ad esempio la spesa per tutta la vita, possono essere propagati automaticamente alle applicazioni pertinenti.
Le azioni dati monitorano continuamente i dati incrementali per le modifiche utilizzando gli eventi di modifica nativi (SNCE) e il feed di dati di modifica (CDF). Questi dati vengono valutati in base alle regole di azione configurate dal cliente, ad esempio il monitoraggio della soglia o le modifiche dello stato. Quando vengono soddisfatte queste regole, viene generato un evento azione dati. Questo evento viene arricchito con informazioni aggiuntive (ad esempio, lo stato fedeltà del cliente) e inviato immediatamente alla destinazione configurata, ad esempio Flusso Salesforce o un'applicazione esterna, per attivare le orchestrazioni aziendali.
Data 360 supporta funzioni native CDP (Customer Data Platform), tra cui funzionalità avanzate di risoluzione dell'identità e la creazione di identificatori e profili persona unificati, oltre a cronologie complete del coinvolgimento. Questa piattaforma è in grado di gestire sia framework business-to-business (B2B) che business-to-consumer (B2C) supportando la risoluzione dell'identità e i grafici dell'identità che utilizzano regole di corrispondenza esatte e "fuzzy", come descritto sopra. Questi grafici dell'identità sono arricchiti con dati di coinvolgimento di vari canali, che consentono di creare grafici dettagliati dei profili con approfondimenti analitici e segmenti preziosi.
Un concetto chiave che supporta il profilo del cliente è il grafico dei dati. Data 360 offre un grafico dei dati aziendali in formato JSON, ovvero un oggetto denormalizzato derivato da varie tabelle Lakehouse e dalle relative interrelazioni. Questo include un grafico dei dati "Profilo" creato da CDP che include la cronologia degli acquisti e della navigazione di una persona, la cronologia dei casi, l'utilizzo dei prodotti e altri approfondimenti calcolati ed è ampliabile da clienti e partner. Questi Grafici dati sono personalizzati per applicazioni specifiche e migliorano la precisione dei prompt generativi AI fornendo il contesto pertinente del cliente o dell'utente. Il livello in tempo reale di Data 360 utilizza il grafico Profilo per la personalizzazione e la segmentazione in tempo reale. È prevista la modellazione del contesto Agentforce che includa conversazioni, sessioni e memoria agente come Grafici dati.
Inoltre, il CDP consente una segmentazione e un'attivazione efficaci in diverse piattaforme, ad esempio Marketing Cloud, Facebook e Google di Salesforce. Elabora i profili dei clienti in batch, quasi in tempo reale e in tempo reale, consentendo decisioni e personalizzazioni immediate. Questa funzionalità migliora le interazioni sia negli scenari B2C che B2B, assicurando che le aziende possano rispondere in modo rapido e preciso alle esigenze e ai comportamenti dei clienti.
Il livello in tempo reale di Data 360 è supportato dal CDP di Data 360 e ne estende i concetti per i casi d'uso in tempo reale. Il livello in tempo reale di Data 360 è progettato per elaborare eventi come clickstream Web e mobili, visite, dati del carrello e pagamenti con latenze al millisecondo, migliorando la personalizzazione dell'esperienza dei clienti. Monitora continuamente il coinvolgimento dei clienti e aggiorna il profilo cliente da Customer 360 con dati, segmenti e calcoli di coinvolgimento in tempo reale per una personalizzazione immediata.
Ad esempio, quando un consumatore acquista un articolo su un sito Web di acquisto, il livello in tempo reale rileva e inserisce rapidamente questo evento, identifica il consumatore e arricchisce il suo profilo con informazioni aggiornate sulla spesa per tutta la vita. Ciò consente la personalizzazione della loro esperienza sul sito in pochi secondi. Inoltre, questo livello include funzionalità per l'attivazione e le risposte in tempo reale, abilitando azioni immediate basate sulle interazioni con i clienti.
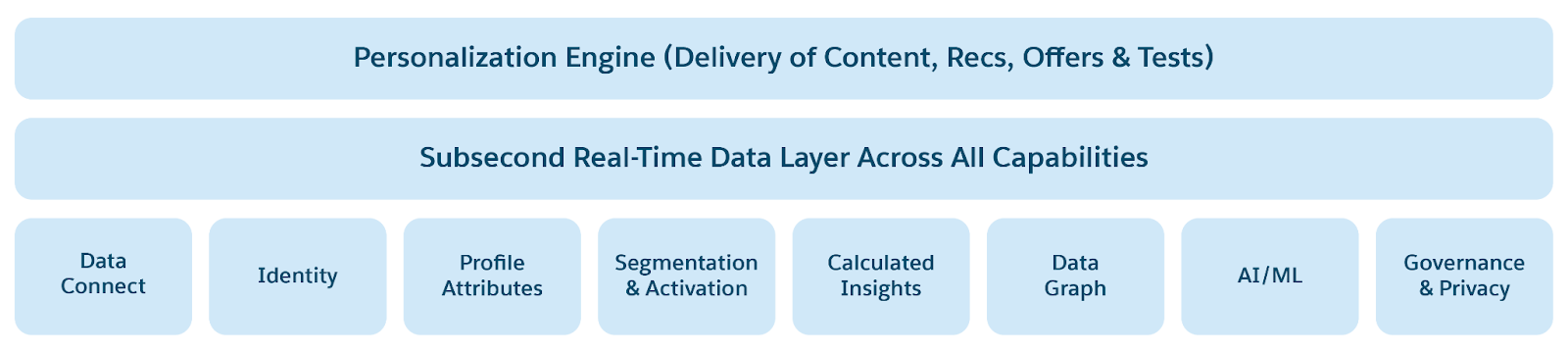
La piattaforma in tempo reale Sub-Second potenzia questa trasformazione attraverso diverse funzioni chiave:
- Grafici dati in tempo reale: Un profilo Customer 360 viene creato utilizzando un grafico denormalizzato che include gli oggetti chiave e i campi più pertinenti ai marchi. Questi Grafici dati consentono l'elaborazione dei dati in tempo reale e offrono contenuti e approfondimenti di immediato valore pratico in pochi millisecondi
- Inserimento e trasformazione in tempo reale: Inserire eventi e profili utente in millisecondi da fonti Web e mobili.
- Risoluzione dell'identità in tempo reale: È possibile unire i profili dei clienti tra i vari dispositivi, unificando immediatamente gli utenti sconosciuti e noti.
- Approfondimenti calcolati in tempo reale: Calcolare metriche come il valore di durata (LTV) o la cronologia delle visite degli utenti in millisecondi per abilitare Personalizzazione o Offerte per Web, ChatBot o agente dell'assistenza.
- Segmentazione in tempo reale: Segmentare i pubblici al volo, personalizzando messaggi e interazioni in tempo reale.
- Azioni in tempo reale: Consentire ai marchi di valutare ogni coinvolgimento degli utenti e di intraprendere azioni tramite il flusso Salesforce o altri canali di comunicazione pertinenti.
In Data 360, abbiamo creato una nuova piattaforma in tempo reale con opportunità in corso di realizzazione in tempo reale, memoria a bassa latenza e un livello di elaborazione dati inferiore al secondo. Poiché i dati interattivi veloci vengono inseriti dai canali Web e Mobile, vengono sottoposti a una serie di processi rapidi.
I nostri SDK Web e Mobile e le API in tempo reale raccolgono i dati dalle applicazioni Web/mobili (nelle future interazioni degli agenti) e li inviano al nostro server beacon. Questi dati vengono quindi instradati al livello in tempo reale per l'elaborazione in millisecondi e al livello Lakehouse per l'integrazione con i dati batch/streaming. Il livello Real-Time elabora i dati in entrata in tempo reale nel contesto di un profilo utente (anonimo o connesso), ad esempio aggiornando la spesa totale o il valore durata dell'utente, ecc. per la personalizzazione in tempo reale in sessione. Il livello in tempo reale è supportato dalla memoria principale e dalla memoria di archiviazione NVme (SSD) per l'archiviazione di dati in tempo reale e profili cliente. Una volta inseriti nel Livello in tempo reale, i dati vengono sottoposti ai seguenti processi prima di essere aggiornati nel Grafico dati in tempo reale:
- Inserimento semplice e trasformazioni: I dati vengono inseriti e trasformati per un'ulteriore elaborazione.
- Risoluzione dell'identità: Le regole di corrispondenza esatta vengono applicate per unificare i profili con tutti gli insiemi di regole di corrispondenza esistenti, in modo che gli specialisti data-aware non debbano creare nuovi insiemi di regole di risoluzione dell'identità appositamente per il tempo reale.
- Approfondimenti calcolati: Ogni coinvolgimento viene valutato, vengono eseguiti calcoli semplici come somma e conteggio in millisecondi e i dati vengono aggiornati nel grafico dei dati in tempo reale.
- Segmenti in tempo reale: Ogni dato di coinvolgimento viene valutato per determinare se soddisfa i criteri per i segmenti in tempo reale definiti e gli utenti vengono aggiunti ai segmenti qualificanti in millisecondi.
- Azioni e trigger in tempo reale: Ogni coinvolgimento viene valutato in base a regole definite per attivare azioni su una serie di target in tempo reale quando le regole vengono soddisfatte in millisecondi.
- Grafico dati in tempo reale e API: Il grafico dei dati in tempo reale, che include anche un'API in tempo reale, consente ai marchi di recuperare dati in formato JSON aggiornati per ogni utente, assicurando che tutte le interazioni con i clienti siano informate dai dati più aggiornati.
La personalizzazione consiste nel sapere a chi rivolgersi, quando e dove fornire contenuti e consigli pertinenti, cosa dire e quale frequenza. Personalization Services Platform è l'orchestratore delle decisioni prese per ottimizzare il raggiungimento degli obiettivi attraverso esperienze personalizzate.
I Servizi di personalizzazione offrono le seguenti funzionalità:
- Insieme coerente di modelli e modi per interpretare i dati di profili, attività e asset in Data 360
- Sperimentazione integrata piattaforma (A/B/n, Bandito multibraccio)
- Integrazione degli obiettivi in fase di progettazione (configurazione), tempo di addestramento ML e runtime (inferenza ML)
- Supporto dell'interazione in tempo reale e batch con scala B2C (utenti anonimi, esterno interattivo/in tempo reale a volume elevato, batch interno a volume elevato)
- Analytics guidata da Data 360
- Schemi per integrare il modello AI e il servizio di altre parti (interne ed esterne)
- Integrazione nell'ecosistema dei metadati Core (caratteristiche PLATE)
- Implementazioni OOTB di casi d'uso basati sull'intelligenza artificiale di alto valore (consigli/decisioni con vari algoritmi ML, inclusi banditi contestuali per la selezione di promozioni/contenuti, consigli sui prodotti, decisioni sui prezzi, ecc.)
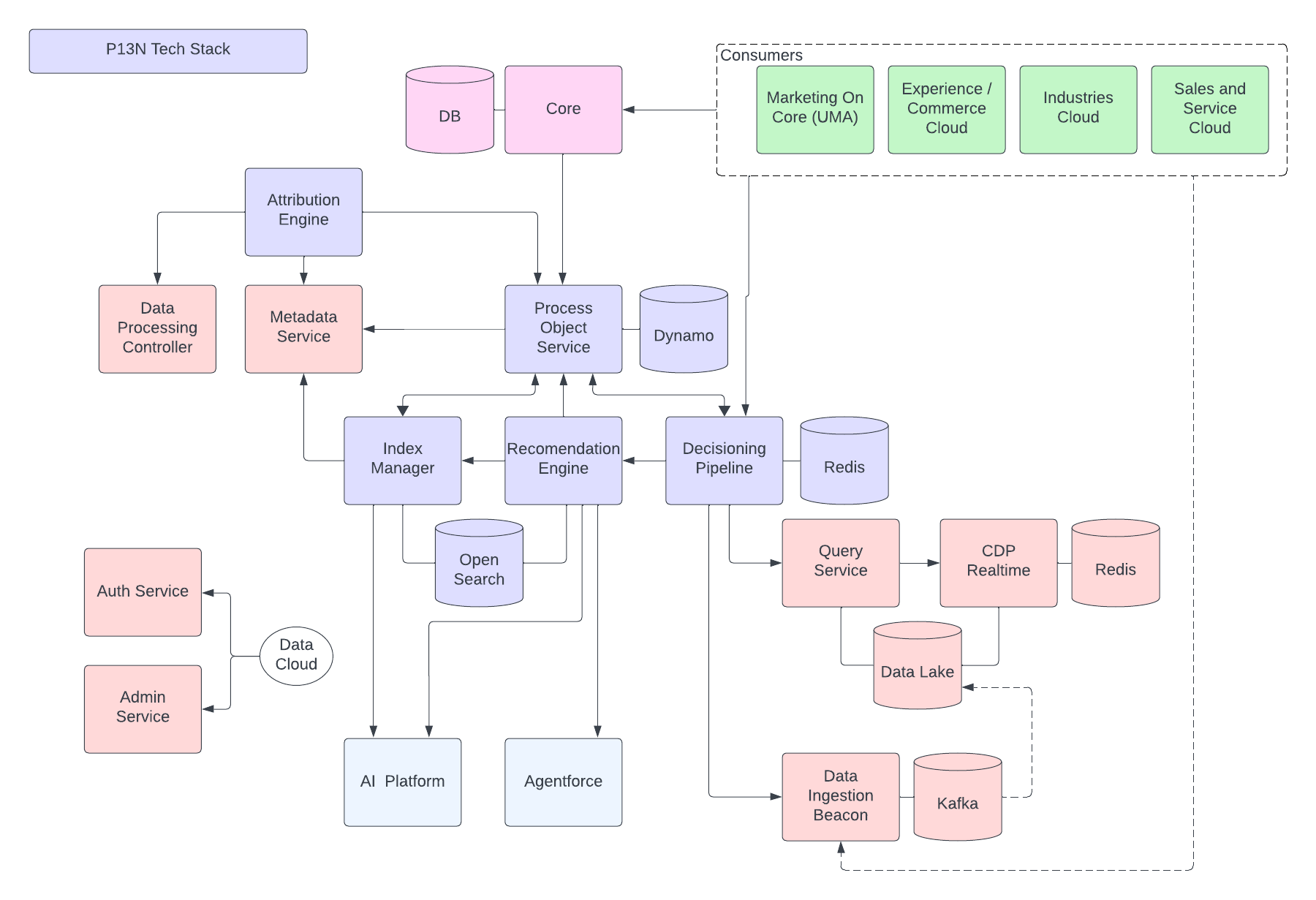
- Decisione in corso di realizzazione
- Gestione delle richieste esterne per le decisioni di personalizzazione, inclusi l'aumento dei profili, la sperimentazione e i consigli.
- Motore di consigli
- Servizio in fase di esecuzione di consigli basati su regole o ML.
- Index Manager
- Gestisce/orchestra il flusso di lavoro per i processi asincroni, inclusi i corsi di ML per i modelli di consiglio
- Servizio oggetto processo
- Responsabile della sincronizzazione dei metadati di personalizzazione tra core e off-core
- Motore di attribuzione e sperimentazione
- Attribuzione Analytics e sperimentazione dei consigli di personalizzazione
Data 360 è progettato come una piattaforma solida e completa specificamente per supportare le esperienze degli agenti emergenti. Queste funzionalità si ottengono utilizzando vari servizi Data 360 esistenti e grazie a una profonda integrazione con Agentforce.
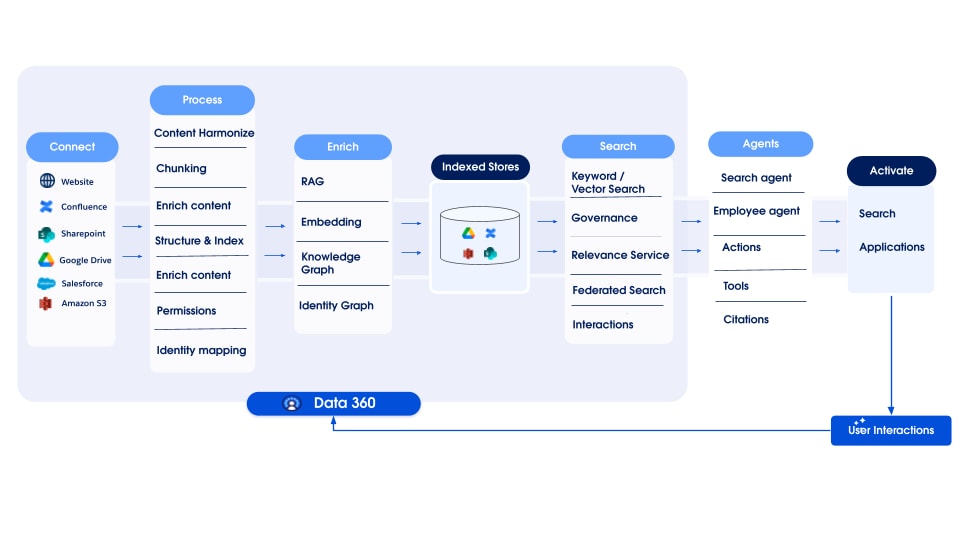
Il nostro approccio alla ricerca aziendale agentica si basa sui seguenti principi:
- I dati aziendali vengono conservati in servizi o punti vendita in silo, con autorizzazioni protette necessarie per l'accesso. La possibilità di accedere a questi dati ed elaborarli mantenendo le autorizzazioni di origine è fondamentale per garantire Trust.
- La classificazione incrociata e la pertinenza nell'intero corpus di dati consentono risultati migliori, che a loro volta possono fornire un contesto migliore per le esperienze degli agenti.
Per offrire queste esperienze, Agentic Enterprise Search si basa sui seguenti componenti architetturali chiave:
- Connettori: L'ampia gamma di connettori disponibili in Data 360 consente di accedere e inserire dati da un'ampia varietà di fonti.
- Trattamento dati non: strutturati Questo è fondamentale per la gestione dei contenuti non tabulari, consentendo al sistema di derivare significato e contesto da dati diversi.
- Governance: Garantire sicurezza, conformità e controlli di accesso di livello aziendale per tutti i dati consumati dalla ricerca. Il supporto per le autorizzazioni di visibilità sorgente garantisce che i dati siano accessibili solo agli utenti autorizzati, sia per le esperienze di ricerca semplice che per quelle degli agenti. Per garantire un recupero rapido, le autorizzazioni di protezione vengono valutate e applicate in modo nativo dai backend di ricerca nella prima fase dell'accesso ai dati.
- Livello di recupero unificato: Per affrontare la sfida dei dati in silo, i connettori vengono inseriti in un livello di recupero unificato completo. Questo livello fornisce un unico punto di accesso a tutti i dati, sia che rimangano in sistemi esterni a cui si accede tramite Ricerca federata o che vengano gestiti in modo nativo tramite indici avanzati per i dati a copia zero e inseriti.
- Comprensione delle query intelligenti: Prima del recupero, il sistema utilizza meccanismi basati sull'intelligenza artificiale per interpretare l'intento dell'utente. Oltre a incorporare rappresentazioni della query per la corrispondenza semantica vettoriale, può riscrivere ed espandere le ricerche basate su parole chiave per migliorare la precisione.
- Ricerca ibrida e query avanzate: Per trovare le informazioni più pertinenti, la piattaforma utilizza più strategie in parallelo. La ricerca ibrida offre una corrispondenza precisa delle parole chiave con la ricerca vettoriale semantica su blocchi di dati ottimizzati, mentre la ricerca record completo recupera contemporaneamente interi documenti. Entrambi sono combinati per garantire sia la pertinenza semantica che la copertura completa del contenuto.
- Classifica gerarchica: Dopo il recupero dei dati, un'architettura di classificazione gerarchica a più fasi calcola il punteggio, unisce e riclassifica i risultati di ogni fonte e metodo. Questo processo crea un unico elenco unificato che mette in evidenza le informazioni più pertinenti per l'utente o l'agente.
L'intelligenza artificiale generativa sta spostando il consumatore principale della ricerca aziendale dagli utenti umani ai modelli di linguaggio di grandi dimensioni (LLM). Data 360 Search è progettato da zero per servire entrambi. È ottimizzato per gestire le query più lunghe e complesse degli agenti e restituire i risultati completi e contestuali necessari per il consumo a livello di programmazione e i loop di ragionamento. Allo stesso tempo, il sistema è in grado di gestire le query più brevi, spesso ambigue, tipiche degli utenti umani, fornendo funzioni come gli snippet e l'evidenziazione per una valutazione rapida in un'interfaccia utente.
L'offerta finale di esperienze di ricerca agenti combina entrambi gli approcci:
- Risultati della ricerca diretta: l'applicazione può visualizzare un elenco tradizionale di risultati classificati utilizzando un'API basata sui metadati basata sulla ricerca unificata di Data 360.
- Risposte conversazionali agentiche a più turni: le risposte agentiche vengono implementate tramite l'integrazione nativa con Agentforce. Questa esperienza di conversazione è guidata da un agente principale che orchestra le azioni e le query, delegando tutte le operazioni di recupero delle informazioni a un agente di ricerca interno specializzato.
Questo Search Agent specializzato è ottimizzato per il recupero delle informazioni aziendali. Utilizza un loop di ragionamento per formulare ed eseguire ricerche parallele per esplorare diversi aspetti della richiesta di un utente. Utilizza un potente insieme di strumenti, tra cui la ricerca unificata di Data 360 per tutti i tipi di dati e i linguaggi di query strutturati per recuperare dati precisi da tabelle ed entità.
Attraverso questa sintesi architettonica, Data 360 consente la creazione di esperienze di ricerca aziendale altamente intelligenti, sensibili al contesto e fruibili da parte degli agenti.
L'estensibilità è una funzione chiave della piattaforma Salesforce. Code Extension offre estendibilità in Data 360, consentendo agli utenti pro-code di eseguire logica Python personalizzata direttamente nell'ambiente Data 360, integrando le sue funzionalità dichiarative e low-code. Utilizzando l'estensione codice, gli utenti possono estendere in modo sicuro le funzionalità principali di Data 360 come le trasformazioni e le opportunità in corso di realizzazione di dati non strutturati (chunking personalizzato).
La progettazione di Code Extension dà priorità a flessibilità, sicurezza, efficienza e a un'esperienza utente semplificata. Supporta due modelli di esecuzione principali, ciascuno personalizzato per esigenze architettoniche specifiche:
- Modello di script:
- Scopo: Per una logica personalizzata completa che richiede un'interazione diretta con Data 360 Lakehouse.
- Funzionalità: I clienti scrivono script Python completi utilizzando Code Extension SDK, abilitando l'accesso in lettura e scrittura a Lakehouse tramite le API SDK. Ideale per la preparazione di dati personalizzati/complessi o per la manipolazione dei dati su misura.
- Isolamento e sicurezza: Mentre gli script accedono a Lakehouse, la loro esecuzione è confinata in un ambiente sicuro e isolato all'interno del runtime di Data 360, impedendo interferenze con altri processi o accessi non autorizzati al sistema.
- Modello di funzione:
- Scopo: Analogamente a una funzione serverless, per i calcoli modulari senza stato richiamati dalle pipeline Data 360 esistenti (ad esempio, la suddivisione personalizzata in una pipeline non strutturata).
- Funzionalità: Le funzioni fornite dal cliente accettano input, calcolano e restituiscono output.
- Isolamento e sicurezza: Queste funzioni sono progettate per un rigoroso isolamento; non hanno accesso diretto a Lakehouse. La loro esecuzione è in modalità Sandbox, stateless e con risorse limitate, il che li rende adatti a fasi di elaborazione mirate e stateless, garantendo sicurezza, esecuzione prevedibile e riducendo al minimo il raggio di esplosione.
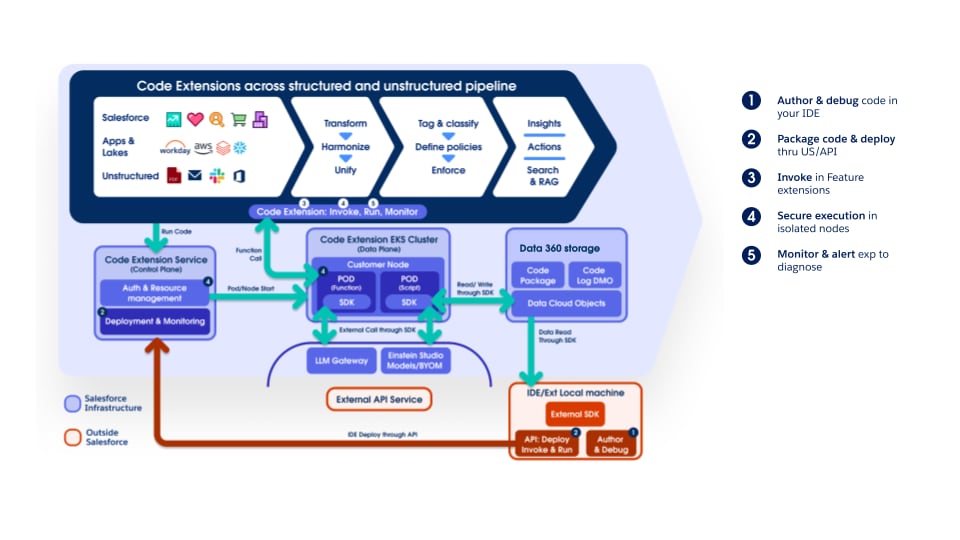
Sia il modello Script che il modello Function mirano a eseguire in modo sicuro il codice del cliente, evitando che il codice di un tenant influisca su altri o ottenga l'accesso non autorizzato ai dati di altri tenant, alle risorse Salesforce o alle risorse esterne. Questa sicurezza è ottenuta attraverso un'architettura a livelli (difesa in profondità). Questa architettura fornisce un ambiente di esecuzione isolato per il codice personalizzato di ogni tenant, incorporando vari guardrail. Questi includono l'isolamento logico a livello di Kubernetes (K8s), l'isolamento della rete, il Sandboxing in fase di esecuzione e le autorizzazioni con privilegi minimi, il tutto completato dal monitoraggio operativo e dalla preparazione alla risposta agli incidenti per il rilevamento e la risposta.
Per supportare un ciclo di vita di sviluppo efficiente, Code Extension offre:
- Creazione esterna e debug: Gli sviluppatori possono creare ed eseguire il debug del codice Python in ambienti familiari come VSCode, utilizzando l'SDK.
- Distribuzione flessibile: Il codice personalizzato può essere inserito in un pacchetto e distribuito utilizzando le utilità SDK, l'interfaccia utente di Data 360 o l'API, abilitando l'integrazione in CI/CD.
Registri operativi: L'accesso a registri esecuzioni dettagliati offre trasparenza e facilita la risoluzione dei problemi in produzione.
Offrendo queste funzionalità di estensione codice sicura e flessibile, Data 360 consente agli architetti di adattare la piattaforma ai loro requisiti di elaborazione dati più specifici e complessi, consolidando davvero il suo ruolo di tessuto di dati aziendale estendibile.
Man mano che le aziende accelerano l'adozione dell'intelligenza artificiale, la maggior parte gestisce ecosistemi ML eterogenei, inclusi Amazon SageMaker, Google Vertex AI e ambienti Python personalizzati, che ospitano modelli che guidano previsioni mission-critical, come il calcolo del punteggio del rischio di credito, la propensione all'abbandono, i consigli sui prodotti e le decisioni Next Best Action.
Tradizionalmente, l'integrazione di questi modelli esterni in Salesforce richiedeva livelli API personalizzati, pipeline ETL o orchestrazione middleware, introducendo la duplicazione dei dati, l'overhead di governance, la latenza e la complessità operativa, sfide che contrastano con una visione CDP (Customer Data Platform) unificata, conforme e in tempo reale.
Porta il tuo modello (BYOM): Fornito tramite Einstein Studio in Data 360, risolve queste sfide abilitando la chiamata diretta di modelli addestrati esternamente nei flussi di lavoro, nella logica Apex e negli strumenti di automazione di Salesforce, senza spostare o replicare i dati. Tramite la federazione copia zero, Data 360 funge da singola fonte di dati controllata, esponendo i dati Customer 360 armonizzati per l'inferenza in endpoint esterni. Gli output delle previsioni ritornano in tempo reale, potenziando i processi aziendali con un'intelligenza scalabile.
BYOM colma efficacemente il divario tra scienza dei dati ed esecuzione operativa separando lo sviluppo del modello, i dati governati e i livelli di consumo. Mantiene l'indipendenza della piattaforma, riduce la complessità dell'integrazione, accelera la distribuzione dell'intelligenza artificiale e mantiene la governance sui dati sensibili.
L'architettura funziona come segue: Data 360 fornisce una base di dati Customer 360 unificata, mentre Einstein Studio orchestra le connessioni alle piattaforme ML esterne (SageMaker, Vertex AI o endpoint personalizzati). I modelli esterni eseguono l'inferenza in tempo reale, in batch o in streaming. I livelli Salesforce (API Flusso, Apex e Query) utilizzano gli output per offrire approfondimenti personalizzati, automatizzati e analitici in Sales Cloud, Service Cloud, Marketing e Industry Cloud.
Dal punto di vista aziendale, BYOM offre:
- Integrità e governance dei dati: Elimina le copie dei dati non controllate e impone la conformità alle policy.
- Democratizzazione: AI Rende accessibili i modelli complessi agli utenti non tecnici tramite gli strumenti Salesforce.
- Accelerazione time-to-value: I modelli esterni si attivano immediatamente all'interno dei processi Salesforce.
- Supporto della scalabilità e dell'architettura ibrida: Abilita la distribuzione multi-cloud dei carichi di lavoro AI.
- Architettura AI pronta per il futuro: Supporta strategie di intelligenza artificiale componibili, separando i livelli di dati, modello e consumo per l'agilità operativa.
Porta il tuo LLM (BYO-LLM): Offre lo stesso meccanismo di estensibilità ma per i modelli generativi. Abilitando la chiamata diretta di LLM esterni, consentiamo ai clienti di utilizzarli in Agentforce Platform al posto dei modelli forniti da Salesforce. Per le imprese BYO-LLM consente:
- Accesso ai modelli perfezionati
- Integrazione di modelli attualmente non forniti da Salesforce
- Utilizzo dei modelli negli account forniti dai clienti
Le aziende moderne operano all'interno di un panorama di dati complesso caratterizzato da due principali sfide architettoniche:
- Frammentazione intra-aziendale: Le grandi organizzazioni utilizzano spesso più organizzazioni Salesforce (spesso segmentate per regione, unità operativa o acquisizione storica) e numerosi altri sistemi di dati. Questa frammentazione crea silos di dati interni, rendendo impossibile stabilire una visualizzazione unificata, affidabile e unificata del cliente per il coinvolgimento in tempo reale in tutta l'azienda. La sfida è unificare questi dati senza consolidarli fisicamente o duplicarli in tutti i sistemi, garantendo che la governance rimanga intatta.
- Collaborazione tra imprese: Le aziende spesso hanno bisogno di condividere i dati con partner e fornitori per attività congiunte di marketing, misurazione e business intelligence. La sfida è abilitare questa collaborazione proteggendo i dati sensibili e proprietari e rispettando regolamenti sulla privacy come GDPR e CCPA, oltre alle barriere competitive.
Salesforce Data 360 affronta queste sfide con un framework Trust by Design a copia zero basato sul principio di condivisione dell'accesso e degli approfondimenti anziché spostare o duplicare i dati.
Salesforce Data 360 affronta le sfide legate alla frammentazione dei dati e alla collaborazione con Data Cloud One, la condivisione dei dati tra Data 360 e le Data Clean Room con priorità alla privacy. Queste soluzioni unificano i dati dei clienti, consentono lo scambio sicuro dei dati e offrono approfondimenti che salvaguardano la privacy. Con un approccio Trust by Design a copia zero, le organizzazioni possono sbloccare il potenziale dei dati per il coinvolgimento in tempo reale, partnership ottimizzate e processi decisionali intelligenti. Ciascuna di queste opzioni di collaborazione sui dati ha scopi diversi.
Abilitazione di Internal Enterprise con Data Cloud One
Data Cloud One è la soluzione architettonica di base per le aziende che gestiscono più organizzazioni Salesforce. Il suo scopo va oltre la semplice condivisione dei dati; è progettato per stabilire una visualizzazione cliente unica e affidabile e abilitare le funzionalità complete della piattaforma Data 360 in tutta l'organizzazione.
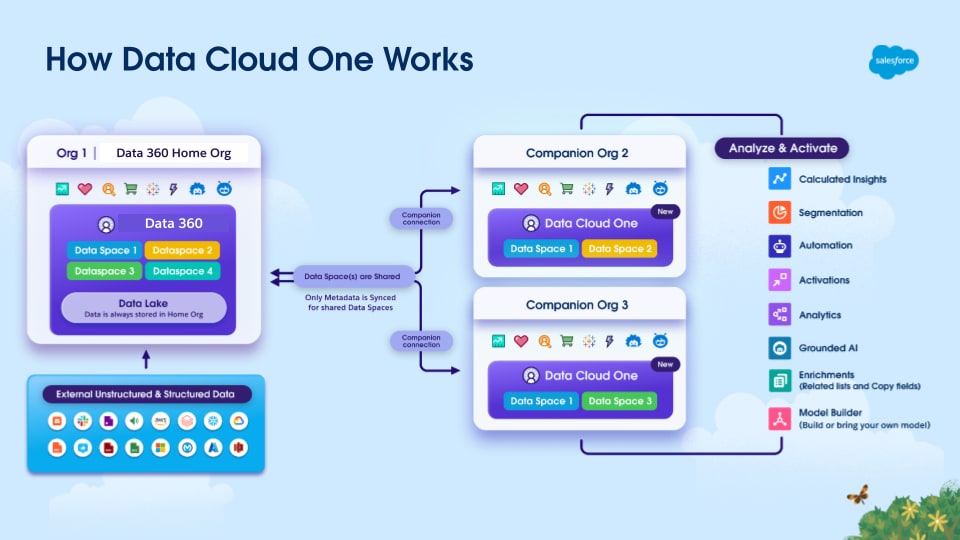
Questo meccanismo si basa su un'istanza designata di Home Org Data 360, che funge da autorità centrale per la gestione dei dati e la creazione del profilo cliente unificato. L'organizzazione iniziale è l'organizzazione di cui viene eseguito il provisioning di Data 360. Viene stabilita una connessione a Data Cloud One tra Data 360 e altre organizzazioni Salesforce, denominate organizzazioni partner. Come parte della connessione a Data Cloud One, Data 360 condivide uno o più dei suoi spazi dati con ogni organizzazione associata, fornendo l'accesso sia ai dati che ai metadati in ogni spazio dati condiviso. Questo viene ottenuto tramite un modello di federazione a copia zero e la sincronizzazione dei metadati tra organizzazioni.
Data Cloud One consente anche alle organizzazioni di supporto di sfruttare l'istanza Data 360 dell'organizzazione di residenza per le proprie esigenze di attivazione, personalizzazione e intelligenza. Questa strategia è essenziale per eliminare la frammentazione dei dati interni e garantire che tutte le unità operative si attivino in base allo stesso profilo cliente, governato e unificato, massimizzando il ROI dell'implementazione di Data 360 principale.
Condivisione dei dati tra organizzazioni Data 360
Per gli ambienti interni distribuiti (in cui la centralizzazione completa non è possibile) e per la collaborazione con partner esterni affidabili, la condivisione dei dati da Data 360 a Data 360 collega istanze di Data 360 indipendenti.
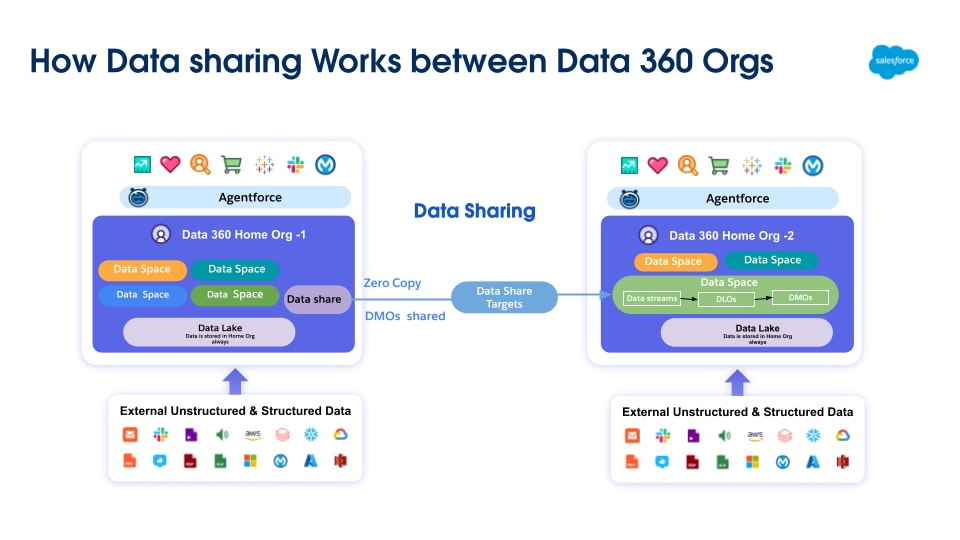
Questo modello di condivisione copia zero stabilisce una connessione tra tenant di Data 360 separati forniti in organizzazioni Salesforce diverse allo scopo di uno scambio sicuro di oggetti dati (DLO, DMO e CIO). Una volta connesso, l'intero oggetto dati diventa accessibile nel destinatario Data 360. L'amministratore di Data 360 del destinatario può quindi impostare regole di governance per gestire l'accesso degli utenti a questi dati.
Collaborazione Privacy-First con Data 360 Clean Room
Quando la collaborazione richiede i massimi livelli di privacy e conformità o quando le preoccupazioni della concorrenza impediscono la condivisione di dati non elaborati, le camere bianche di Data 360 sono architetturalmente obbligatorie.
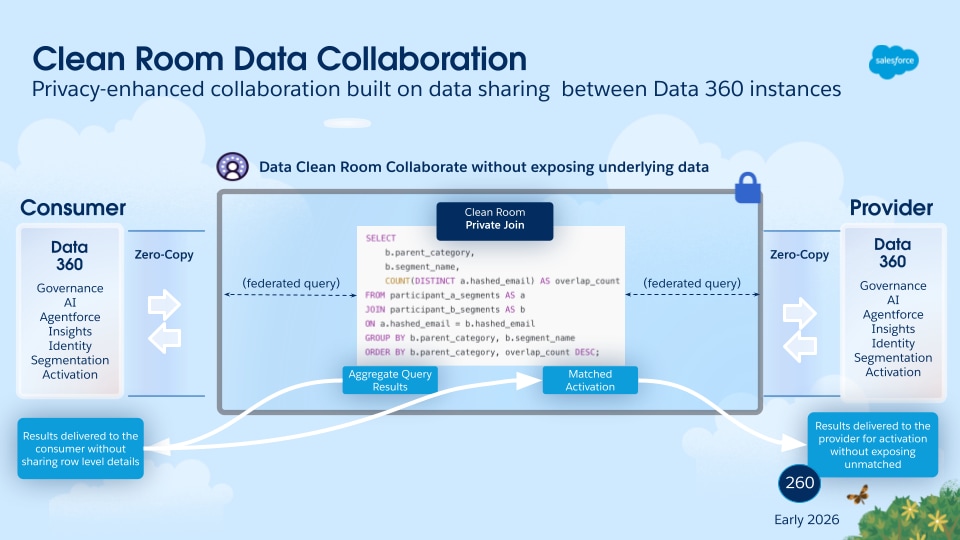
Dal punto di vista architettonico, Data 360 Clean Room Collaboration è basato sul framework di condivisione Zero-Copy utilizzato dalla condivisione dei dati da Data 360 a Data 360, ma con ulteriori livelli di governance e vincoli computazionali applicati. La Clean Room di Data 360 offre un ambiente di elaborazione sicuro e controllato in cui le parti possono unire le proprie serie di dati in base a chiavi anonime. Il suo scopo principale è consentire l'analisi congiunta e la generazione di approfondimenti senza esporre i dati proprietari sottostanti. L'ambiente applica regole rigorose e programmabili, ad esempio soglie minime di aggregazione e identificatori non esportabili. Queste regole garantiscono che solo gli approfondimenti approvati, che tutelano la privacy e aggregati vengano derivati e condivisi. Ciò rende le camere bianche essenziali per casi d'uso come la misurazione delle campagne multipiattaforma e l'analisi sensibile della sovrapposizione del pubblico.
Data 360 è progettato come un data fabric intelligente, ampliabile e affidabile necessario per potenziare l'intelligenza artificiale di prossima generazione. La sua progettazione architettonica affronta il problema della frammentazione dei dati, consentendo alle organizzazioni di unificare, elaborare e attivare tutti i dati dei clienti su larga scala, utilizzando Zero Copy Data Federation per garantire l'efficienza.
La sua organizzazione dei dati affidabile stabilisce una visualizzazione armonizzata dai DLO (inclusi i dati non strutturati) ai DMO, tutti protetti all'interno di spazi dati partizionati. Le versatili funzionalità di elaborazione dati di Data 360, tra cui trasformazioni batch e streaming, approfondimenti calcolati, elaborazione dati non strutturati e risoluzione dell'identità, si basano sull'architettura SNCE e CDF incrementale, garantendo un'elaborazione efficiente quasi in tempo reale e un significativo risparmio sui costi.
L'estendibilità è garantita dall'architettura Code Extension, che abilita in modo sicuro la logica Python personalizzata tramite script o funzioni isolate per esigenze specifiche. Inoltre, un framework di governance dei dati completo, basato sul controllo dell'accesso basato sugli attributi (ABAC) con policy CEDAR, garantisce una sicurezza granulare, un mascheramento dinamico dei dati e un'applicazione coerente in tutto il consumo di dati. Ciò si traduce in sofisticate funzionalità di segmentazione e attivazione, che traducono i profili cliente unificati in strategie di coinvolgimento dinamiche multicanale con reattività in tempo reale.
Fondamentalmente, la capacità di Data 360 di unificare dati vasti e diversificati, fornire contesto in tempo reale tramite la query unificata (inclusa la ricerca ibrida strutturata/non strutturata e l'accelerazione Hyper) e imporre una governance rigorosa è fondamentale per potenziare gli agenti di intelligenza artificiale intelligenti. Fornisce i dati affidabili, aggiornati e pertinenti necessari per mettere a terra i flussi di lavoro di intelligenza artificiale generativa (RAG) e per alimentare le funzionalità multi-turno orientate all'azione degli agenti basati su Agentforce, assicurando che funzionino con precisione e accuratezza.
Fornendo una piattaforma a prova di futuro in cui i dati di origine vengono trasformati in approfondimenti di immediato valore pratico, Data 360 funge da base architettonica indispensabile per le organizzazioni che creano esperienze cliente Agentic. È la spina dorsale fondamentale che trasforma i dati dei clienti in esperienze cliente sofisticate e personalizzate che guidano il successo delle organizzazioni moderne di oggi.