Este texto se tradujo utilizando el sistema de traducción automatizado de Salesforce. Realice nuestra encuesta para proporcionar comentarios sobre este contenido e indicarnos qué le gustaría ver a continuación.
Note
Descripción general
Salesforce Platform ha avanzado continuamente en su arquitectura de automatización para satisfacer las demandas de procesos de negocio complejos. Las generaciones anteriores (Reglas de flujo de trabajo y Process Builder) proporcionaban los pasos iniciales en la lógica dirigida por eventos, ampliando las funciones de automatización para la lógica dirigida por eventos y ampliando el alcance a una gama más amplia de generadores.
Esta evolución ha culminado en una arquitectura consolidada de alto rendimiento centrada en dos pilares complementarios: Flujo desencadenado por registro y Desencadenadores de Apex. Este documento proporciona el marco y las directrices para tomar decisiones fundamentadas al diseñar automatizaciones de desencadenadores.
Productos en ámbito
Flujo
Salesforce Flow es una potente herramienta de automatización de apuntar y hacer clic que permite a los usuarios crear procesos de negocio complejos, pantallas y lógica visualmente utilizando Flow Builder, sin redactar código. Automatiza tareas como actualizaciones de datos, envío de emails y orientación de usuarios, ofreciendo flexibilidad a través de tipos como Flujos de pantalla (interacción de usuario) y Flujos desencadenados (eventos de registro/programados).
Apex
Salesforce Apex es un lenguaje de programación patentado y orientado a objetos para la plataforma Salesforce, similar a Java, que se utiliza para crear lógica de negocio personalizada, automatizar procesos y ampliar las funciones principales de CRM más allá de las herramientas declarativas.
Comida para llevar
La creación de automatizaciones desencadenadas por registros ampliables, mantenibles y con desempeño en Salesforce Platform requiere un enfoque disciplinado dirigido por la arquitectura. La elección entre Flow y Apex, y la implementación de cada uno, se guía por un conjunto claro de principios. Estos puntos resumen estos principios y sirven como reglas fundamentales para el diseño de automatización moderno.
Seleccione la herramienta correcta para el trabajo en base a la densidad de automatización de objetos de Salesforce.
Utilice Flujo desencadenado por registro para objetos de Salesforce para automatizaciones de baja densidad.
Aumente la lógica de flujo desencadenado por registro con Apex invocable para automatizaciones de densidad media.
Utilice desencadenadores Apex para objetos de Salesforce para automatizaciones de alta densidad.
Tenga cuidado al desencadenar procesos asíncronos.
Esta regla se aplica independientemente de que esté invocando procesos asíncronos en un flujo desencadenado por registro o poniendo un trabajo colocable en cola desde Apex. Aunque este patrón puede ser tentador para descargar trabajo, puede introducir escenarios de gestión de errores complejos y aumentar el riesgo de alcanzar límites reguladores.
Utilice un punto de entrada por objeto de Salesforce.
Para un objeto de Salesforce concreto, utilice un mecanismo como su punto de entrada en la automatización. Trate de evitar mezclar desencadenadores de Flujo y Apex como puntos de entrada para el mismo Objeto.
Puntos de decisión
Implementación declarativa frente a programática
Flow y Apex comparten un conjunto común de funciones fundamentales. Cada herramienta puede consultar registros, ejecutar lógica condicional, asignar variables y realizar operaciones DML como la creación, actualización y eliminación de registros, secuenciados para ejecutarse en un orden especificado.
Sin embargo, este solapamiento funcional no implica que las herramientas sean intercambiables. La elección arquitectónica no se trata de si se puede realizar una tarea, sino de cómo se realiza y cuáles son las implicaciones a largo plazo para el desempeño, la capacidad de ampliación y la capacidad de mantenimiento. Flujo destaca en claridad declarativa y velocidad de implementación para procesos sencillos, mientras Apex proporciona el control granular y la potencia bruta necesaria para soluciones complejas.
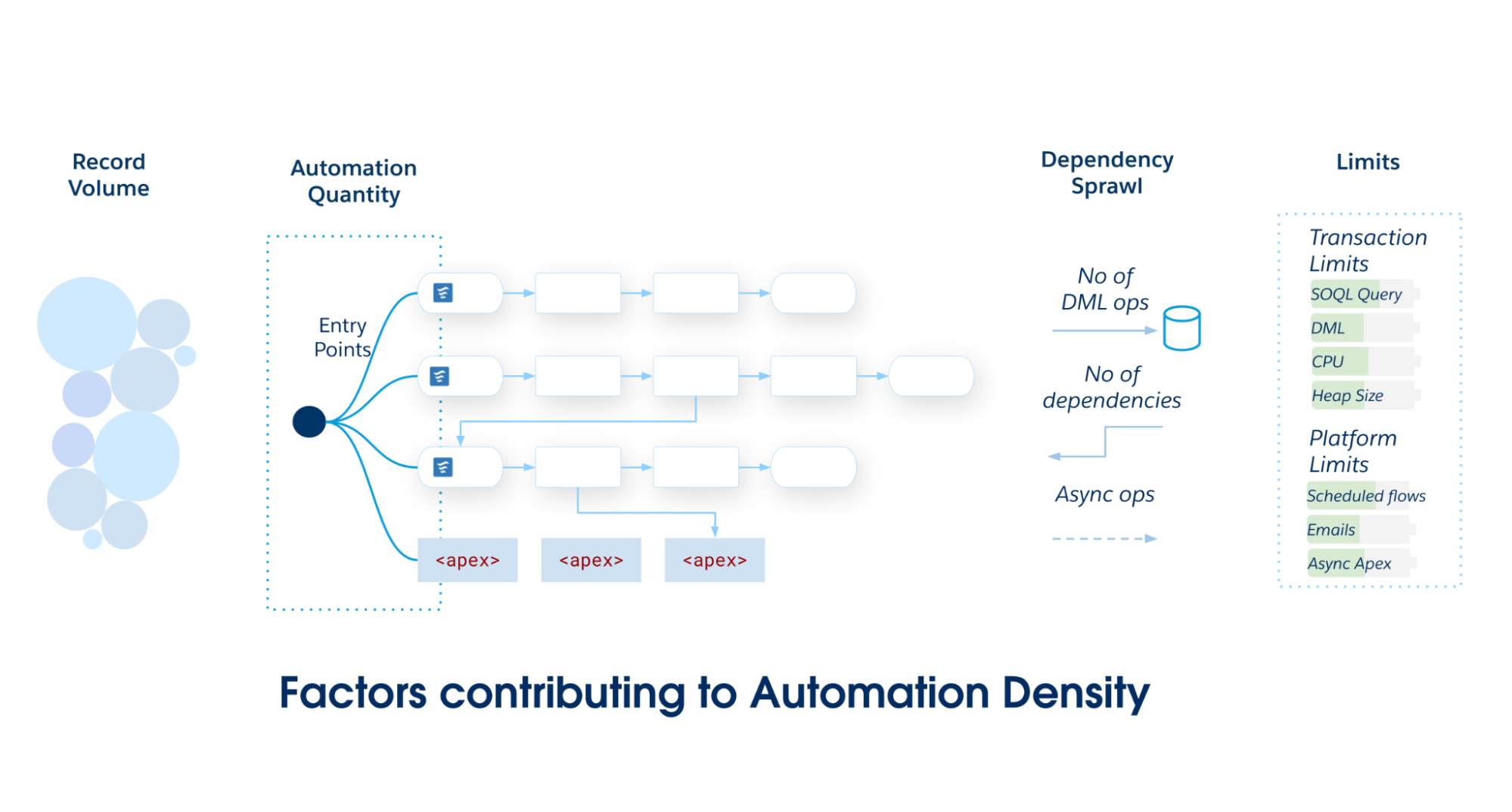
Densidad de automatización
La densidad de automatización es la carga aplicada a un objeto específico de Salesforce. Sirve como una heurística para determinar la implementación óptima del objeto. A medida que crece la densidad de automatización, aumenta la probabilidad de infringir límites de transacciones.
Calcule la densidad de automatización inspeccionando tres dimensiones específicas de volumen y complejidad:
Cantidad de automatización: El número sin procesar de entradas de metadatos de automatización exclusivas (flujos, acciones de desencadenador, etc.) que se ejecutan durante un único evento de Lenguaje de manipulación de datos (DML).
Volumen de registro: Los registros por transacción procesados a través de cargas de API o procesamiento por lotes intenso, donde el desempeño se vuelve crítico.
Extensión de dependencia: Una medición de las operaciones DML descendentes desencadenadas por la operación CRUD inicial. Cuantifica la profundidad del gráfico donde una actualización entra en cascada en actualizaciones en objetos relacionados (por ejemplo, caso → cuenta → contacto → acumulación personalizada).
A medida que crece el ámbito y la complejidad de su aplicación de Salesforce, confirme un único punto de entrada principal: Flujo desencadenado por registro o Desencadenadores de Apex. Evite particionar automatizaciones entre múltiples mecanismos en un único objeto de Salesforce, ya que lleva a una mala capacidad de mantenimiento y una gobernanza fragmentada.
Matriz de selección de densidad
Utilice esta matriz para determinar el estándar arquitectónico requerido para su objeto de Salesforce.
Flujo desencadenado por registro es la solución preferida para baja densidad de automatización. Ofrece un equilibrio de potencia y accesibilidad ideal para automatizaciones sencillas e independientes entre sí.
El patrón híbrido (Flujo desencadenado por registro con Apex invocable) es una opción potente y mantenible para automatizaciones de densidad media con complejidad creciente. Este patrón permite a los equipos mantener la coreografía ordenada en Flujo declarativo mientras delegan operaciones con gran volumen de computación en Apex, equilibrando la accesibilidad con el desempeño.
Los desencadenadores Apex proporcionan los elementos constructivos necesarios para una base arquitectónica sólida que admita automatizaciones de alta densidad. El desempeño, el control granular y la abstracción y el polimorfismo orientados a objetos de Apex son más adecuados para gestionar la complejidad y la escala de estos escenarios.
Nivel de densidad
Cantidad de automatización
Volumen de datos (Tamaño de lote)
Extensión de dependencia
Estándar arquitectónico
Bajo
< 15
Automatizaciones
Estándar
Interacciones de la interfaz de usuario dirigidas por el usuario o pequeñas cargas de API (1 a 200 registros)
Discreta
Lógica autónoma. 0-1 operaciones DML descendentes en el mismo objeto o un objeto relacionado.
Flujo desencadenado por registro
Medio
15–30
Automatizaciones
Moderado
Procesamiento por lotes estándar (con lógica que requiere una masificación cuidadosa)
Acoplado
Principal/Secundario actualiza de 2 a 4 operaciones DML descendentes. Riesgo de recurrencia
Patrón híbrido
Flujo + Apex invocable
Alto
> 30
Automatizaciones
Alto
Grandes volúmenes de datos con cargas de API masivas (2.000 a 10.000+ registros)
Complejo y recursivo
Gráfico de dependencia profunda (5+ operaciones DML descendentes). Riesgo de bucles de recursión triangulares
Marco de metadatos desencadenado por Apex
Las decisiones arquitectónicas del mundo real requieren que sopese todas las dimensiones de la densidad de automatización de forma colectiva. Tenga en cuenta el posible ámbito futuro al seleccionar un mecanismo de automatización para un objeto de Salesforce concreto.
Además, tenga en cuenta el número total diario de operaciones DML porque Salesforce aplica la gestión de recursos compartidos en un entorno de múltiples arrendatarios y limita para evitar que las automatizaciones descontroladas monopolicen recursos compartidos. Los objetos de Salesforce con un gran volumen DML diario requieren una cuidadosa selección de automatización. Por ejemplo, los límites asíncronos de tiempo de CPU (60.000 ms) y tamaño de pila (12 MB) son superiores a los límites síncronos. Además, el límite de 24 horas de toda la organización en ejecuciones asíncronas (calculado como 250.000 o 200 veces sus licencias de usuario) requiere tener en cuenta el DML diario total en su diseño arquitectónico para evitar excepciones en tiempo de ejecución.
Comparación de productos
Flujo desencadenado por registro es la principal herramienta declarativa de la plataforma para la automatización desencadenada por registro. La facilidad de uso de Flow y las salvaguardas de plataforma integradas permiten a los equipos crear fácilmente soluciones escalables y fiables. Es la opción ideal para la mayoría de equipos que crean soluciones en Salesforce Platform.
Apex es el lenguaje de programación patentado, fuertemente tipificado y orientado a objetos de la plataforma. Utilice Apex para objetos de Salesforce con alta densidad de automatización y para casos de uso que requieren alto desempeño, lógica sofisticada o control granular sobre transacciones.
Para ayudar en el proceso de toma de decisiones, esta matriz proporciona una comparación directa de Flujo y Apex entre funciones arquitectónicas clave.
Capacidad
Flujo desencadenado por registro
Desencadenador Apex
Rápida entrega y mantenimiento
Recomendado
La interfaz de usuario visual de Flow Builder permite a los administradores y otros generadores declarativos crear y modificar automatizaciones con mayor rapidez que redactar, probar e implementar código Apex. Esta interfaz potencia una gama más amplia de miembros del equipo para entregar valor de negocio y reduce la dependencia de recursos de desarrollador especializados para tareas sencillas.
Requiere experiencia
Apex requiere desarrolladores de software debidamente cualificados para implementar, probar y mantener el código.
Modularidad
Disponible
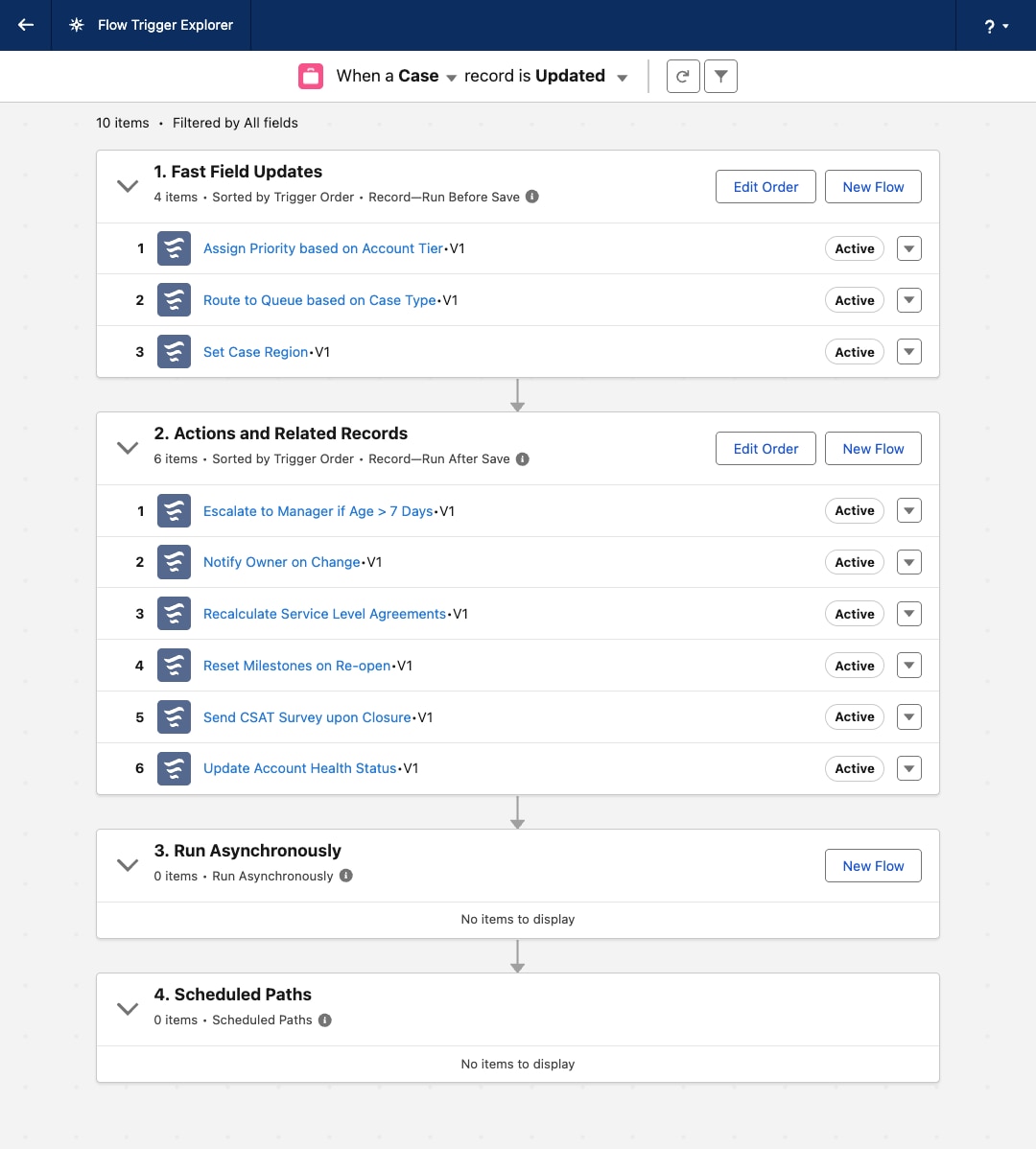
Los flujos desencadenados por registros son modulares de forma predeterminada. En vez de lógica monolítica, los equipos crean flujos discretos para requisitos específicos y los coreografíen juntos utilizando el Explorador de desencadenadores de flujos. Esta modularidad permite una modificación aislada y una ampliación sencilla, reduciendo enormemente el costo de propiedad a largo plazo.
Disponible
Apex está dividido en módulos funcionales por diseño. Cada clase Apex está pensada para implementar un único módulo de funciones.
Visibilidad y gobernanza
Recomendado
La naturaleza visual de Flujo proporciona una representación intuitiva de la lógica de negocio. El Explorador de desencadenadores de flujos proporciona una vista consolidada de todos los flujos en un objeto, facilitando a los arquitectos y administradores la tarea de comprender, gobernar y solucionar problemas sin leer código.
Requiere experiencia
El uso de un marco de trabajo de metadatos para organizar desencadenadores es ventajoso, pero Apex requiere un equipo de desarrollo disciplinado para mantener el código organizado y mantenible.
Procesamiento masivo de datos de alto desempeño
No recomendado
Existe un riesgo elevado de alcanzar límites reguladores cuando se trata de lógica compleja o grandes volúmenes de datos.
Recomendado
El código Apex se ejecuta más cerca de los servicios principales de la plataforma y ofrece a los desarrolladores un control mejorado sobre la optimización de consultas, el tratamiento de datos y la eficiencia algorítmica. Esto da como resultado un mejor desempeño y escala, especialmente en escenarios complejos que implican grandes volúmenes de datos.
Lógica robusta y estructuras de datos
Disponible
El elemento Transformación de flujo puede ayudar con algunas tareas de procesamiento complejas. Sin embargo, Flow carece de estructuras de datos de asignación y conjunto nativas, lo que hace que el procesamiento de datos complejo sea engorroso e ineficiente desde el punto de vista computacional.
Recomendado
Apex proporciona acceso completo a Map, Set y bucles programáticos para una manipulación de datos altamente eficiente y segura. Como un lenguaje de programación completo, Apex también proporciona acceso a construcciones lógicas complejas, estructuras de datos y patrones de diseño que pueden ayudar a resolver problemas de negocio complejos de una manera mantenible y eficiente. Apex incluye una biblioteca estándar enriquecida de funciones avanzadas (por ejemplo, BusinessHours, Crypto) no disponible actualmente en herramientas declarativas.
Control de transacciones
No disponible
Flow no proporciona acceso a `Database.savepoint`, `Database.rollback` u operaciones DML parcialmente satisfactorias para confirmaciones o reversiones de transacciones parciales.
Disponible
Apex proporciona un control completo y granular sobre la integridad de las transacciones y escenarios de recuperación de errores complejos.
Distribución de email
Recomendado
El envío de alertas de email preconfiguradas desde un flujo desencadenado por registro es sencillo y ampliable. Las alertas de email personalizadas se pueden crear y distribuir en tiempo de ejecución. Los emails personalizados están sujetos a límites de envío diarios.
Disponible
Apex puede generar y enviar mensajes de email personalizados. Todos los emails enviados desde Apex están sujetos a los límites de envío diarios.
Aplicación de salvaguardias de plataforma
Recomendado
El flujo incluye protecciones integradas, como la masificación automática y los reintentos automáticos. Estas salvaguardas aumentan la velocidad de valorización y evitan riesgos de desempeño que requieren codificación manual compleja.
Se requiere implementación manual
Las salvaguardias como el masificado deben codificarse de forma explícita (por ejemplo, gestionando recopilaciones y evitando SOQL dentro de bucles). Los reintentos automáticos no son nativos de desencadenadores y requieren lógica personalizada compleja para implementarse.
Procesamiento asíncrono
Disponible
Flow ofrece mecanismos sencillos para automatizaciones que requieren una transacción separada en una ruta asíncrona. Estas automatizaciones están sujetas a límites diarios.
Disponible
Apex permite el control completo mediante Captura de datos de cambios y eventos colocables en cola gestionados por un suscriptor de desencadenador desvinculado.
Procesamiento programado
Recomendado
Las rutas programadas del flujo proporcionan una capacidad de programación única y potente (por ejemplo, "disparo 3 días antes de la fecha de cierre"). Esta función incluye la cancelación automática y la reprogramación si cambian los datos del registro. Estas automatizaciones están sujetas a límites diarios.
No disponible
Un desencadenador Apex no puede programar de forma nativa un evento específico de registro temporal con cancelación automática. Aunque Apex programado existe, es un mecanismo fundamentalmente diferente que se ejecuta a una hora específica y no se programa durante el procesamiento de un registro individual como parte de un desencadenador.
Ordenación y coreografía
Disponible
El Explorador de desencadenadores de flujos permite a los administradores definir un orden de ejecución relativo para múltiples flujos en el mismo objeto.
Disponible
Un marco de trabajo de desencadenador proporciona control granular sobre el orden exacto de las automatizaciones.
Actualizaciones de campos del mismo registro
Disponible (antes de guardar)
Flujo desencadenado por registro es la opción declarativa de mayor desempeño para actualizar el registro desencadenante antes de la confirmación DML inicial.
Disponible (antes de guardar)
Apex proporciona la oferta de mayor desempeño con un gasto general mínimo.
Crudo de objeto cruzado
Disponible (después de guardar)
Flujo es adecuado para operaciones DML de objetos cruzados sencillas y de baja complejidad.
Disponible (después de guardar)
Apex proporciona un control superior sobre la deduplicación, la gestión de errores y el desempeño para operaciones DML de objetos cruzados.
Deduplicación de cálculos costosos
Disponible
Flujo destaca en la eliminación de consultas redundantes y declaraciones DML a través de masificación automática. Sin embargo, el estado no se puede almacenar en caché o compartir entre diferentes desencadenadores de flujo o entre múltiples invocaciones del mismo flujo en una transacción. Esta limitación puede volverse importante en escenarios de desempeño extremo.
Recomendado
Apex proporciona mecanismos para deduplicar operaciones costosas. Los desarrolladores pueden aprovechar el almacenamiento en caché de transacciones utilizando variables y propiedades estáticas, y el almacenamiento en caché a nivel de plataforma utilizando Caché de plataforma, para almacenar y reutilizar datos. Estas técnicas son importantes para reducir el consumo de límites reguladores de transacciones, como consultas SOQL, y garantizar un alto desempeño y capacidad de ampliación.
Gestión de errores personalizados
Disponible
El elemento CustomError puede bloquear una operación de guardado y mostrar un mensaje al usuario.
Recomendado
El método addError() proporciona mensajería de error condicional y a nivel de campo flexible.
Casos de uso
Recomendaciones más ajustadas
Esta tabla proporciona recomendaciones generales "mejor ajustadas" para casos de uso generales, basándose en las funciones presentadas. En última instancia, tendrá en cuenta consideraciones adicionales para llegar a un mejor ajuste para sus escenarios particulares, como aquellos incluidos en la sección Mejores prácticas relacionadas de este documento. Allí, aprenderá más sobre cuándo una combinación concreta de Flow y Apex proporciona el mejor enfoque.
Caso de uso
Descripción
Mejor ajuste
Justificación
Procesamiento por lotes de alto desempeño
Cualquier automatización que debe procesar miles de registros de forma eficiente
Apex
Apex proporciona API enriquecidas para la interfaz con la plataforma y para la velocidad sin procesar.
Procesamiento de datos complejo
Escenarios que requieren manipulación de datos avanzada
Apex
Apex proporciona estructuras de datos, como Map y Set, que no están disponibles de forma nativa en Flow, y pueden ser críticas para redactar código de desempeño seguro y masivo.
Control de transacciones
Mecanismos de control como puntos de guardado, reversiones y confirmaciones parciales
Apex
Apex proporciona acceso a mecanismos como Database.savepoint y Database.rollback, y tiene la capacidad de procesar operaciones DML parcialmente satisfactorias.
Sofisticada validación personalizada
Validación de datos entre múltiples campos en un registro
Apex
Aunque Flujo puede evitar un guardado con el elemento `CustomError`, no está disponible en todos los tipos de flujo, incluyendo subflujos. El método Apex addError() proporciona múltiples mensajes de error específicos de campo que se pueden agregar a un registro en cualquier momento durante el procesamiento del desencadenador.
Lógica moderadamente compleja en un proceso sencillo
Manipulación de lógica y datos de complejidad moderada, simplificada por una biblioteca estándar de funciones avanzadas, que se produce como parte de un proceso sin complicaciones
Flujo + Apex
Flujo desencadenado por registro actúa como la capa de orquestación, mientras que las operaciones de alta complejidad están encapsuladas en Apex invocable.
Lógica simple a moderadamente compleja
Manipulación de datos de complejidad baja a moderada, con actualizaciones de desencadenador en los objetos de datos principales y relacionados
Flujo
Flujo es normalmente la opción a la que dirigirse, ya que se basa en un modelo declarativo que lo hace accesible tanto para administradores como desarrolladores.
Notificaciones y mensajes salientes
Envío de emails y mensajes salientes
Flujo
Flujo hace que el envío de alertas de email y mensajes salientes en cambios de registro sea sencillo y altamente escalable.
Procesamiento programado
Automatización en una fecha futura dinámica (por ejemplo, 3 días antes de una fecha de cierre)
Flujo
Las rutas programadas proporcionan una solidez única a Flujo, ya que la plataforma gestiona automáticamente la programación, cancelación y reprogramación de estas rutas si cambian los datos del registro.
Procesamiento ampliable: Casos de uso asíncronos en profundidad
La capacidad de ampliación es una consideración crítica al diseñar su implementación. Cuando la lógica de negocio de una automatización desencadenada por registro se vuelve compleja, de larga ejecución o implica altos volúmenes de datos, los límites reguladores principales de la plataforma Salesforce se convierten en una restricción arquitectónica. Las operaciones como actualizaciones de datos masivas, llamadas de API complejas o cálculos pesados aumentan el riesgo de infringir límites, como el tiempo total de CPU o el número de declaraciones DML en una sola transacción de base de datos. Un fallo en un desencadenador síncrono debido a una excepción de límite hará que se revierta toda la transacción de guardado del usuario, dando como resultado una mala experiencia del usuario y una posible pérdida de datos. Este riesgo inherente exige un patrón arquitectónico para descargar trabajo complejo.
La automatización asíncrona se vuelve esencial en este caso. Utilizando mecanismos asíncronos, los arquitectos pueden desvincular de forma efectiva el trabajo de larga duración o gran volumen de la transacción de guardado de registros síncrona principal. Guarda completo de forma rápida y fiable, mientras que el procesamiento pesado se delega a una transacción gestionada por plataforma separada que se ejecuta más adelante. La desvinculación mejora la estabilidad, evita fallos de transacciones y es clave para crear aplicaciones de negocio ampliables. La plataforma ofrece varias herramientas especializadas para esto, cada una con distintos beneficios y ventajas en cuanto a fiabilidad, volumen y complejidad.
Ruta asíncrona del flujo
La ruta Ejecutar de forma asíncrona en un flujo desencadenado por registro proporciona el mecanismo más sencillo para la lógica asíncrona "disparar y olvidar". Esta ruta se ejecuta en una transacción separada después de que la transacción de guardado de registros original se haya confirmado correctamente en la base de datos.
Caso de uso ideal: Esto es adecuado para tareas que no requieren ejecución inmediata o tratamiento de errores personalizado. Algunos ejemplos incluyen el envío de una notificación por email, la creación de una tarea de seguimiento o la realización de una llamada sencilla a un sistema externo.
Limitaciones: Este mecanismo comparte los mismos límites reguladores diarios que otras entrevistas de flujo asíncronas. No está diseñado para un procesamiento de gran volumen.
Captura de datos de cambios (CDC)
Captura de datos de cambios (CDC) es un patrón de alto rendimiento, ampliable y resistente para gestionar lógica asíncrona desencadenada por un cambio de registro en escenarios de gran volumen. En este modelo, la única responsabilidad del desencadenador es guardar el registro de forma síncrona. A continuación, la plataforma publica un mensaje de evento detallado que contiene los cambios del registro en un bus de eventos de gran volumen. Un desencadenador Apex separado y exclusivo se suscribe a este evento de cambio. Realiza trabajos complejos, de larga duración o asíncronos.
Beneficio: Este patrón desvincula el proceso asíncrono de la transacción de usuario inicial. Un fallo en el procesamiento asíncrono no provocará la reversión del guardado de registros del usuario. El patrón también proporciona una transmisión de eventos duradera que múltiples suscriptores internos o sistemas externos pueden consumir, y los eventos pueden reproducirse durante hasta 72 horas, proporcionando una fuerte resistencia.
Limitaciones: Los mensajes de eventos de CDC no contienen el estado anterior del registro, el equivalente de un Trigger.oldMap Apex. La carga de evento incluye los nuevos valores de campo, pero no los valores desde los que cambiaron. Esto dificulta la implementación de lógica basada en una transición de estado específica (por ejemplo, ejecutar solo si Status__c cambió de "Pendiente" a "Aprobado"). Puede mitigar esto consultando el historial de campos del objeto en el suscriptor del evento, pero esto agrega complejidad al proceso y el seguimiento del historial de campos podría no estar disponible para el campo de interés específico. Esto puede limitar los tipos de automatización que puede descargar en los CDC.
De forma predeterminada, CDC se puede activar en un máximo de cinco objetos de Salesforce. Las organizaciones que requieren más pueden adquirir una licencia complementaria que elimina este límite y aumenta las asignaciones de entrega de eventos.
Apex colocable en cola desde un desencadenador
Colocar un trabajo de Apex en cola directamente desde un desencadenador debe considerarse un patrón de riesgo, utilizado solo cuando se necesita el control proporcionado por Apex (por ejemplo, para lógica compleja o mecanismos de reintento personalizados), y CDC no es una opción viable.
Si se requiere Apex colocable en cola, la implementación debe incluir las salvaguardas apropiadas:
Limitar comprobaciones: El código debe comprobar el número de trabajos ya en cola en la transacción antes de intentar agregar otro.
Conciencia del contexto: El código debe detectar si se está ejecutando en un contexto asíncrono, como un trabajo por lotes (System.isBatch()), y modificar su comportamiento para cumplir el límite más estricto de un trabajo por transacción en ese contexto.
Limitar consideraciones para Apex asíncrono desencadenado
Invocar Apex asíncrono desde un desencadenador síncrono introduce riesgos de estabilidad. Para evitar la repercusión a nivel de organización (por ejemplo, superar límites), este patrón requiere un diseño y pruebas rigurosos.
El límite diario para ejecuciones asíncronas de Apex (Batch, Queueable, @Future) se comparte en toda la organización (normalmente 250.000 o un cálculo basado en licencias de usuario). Una carga de datos masiva de 20.000 registros hará que se ejecute un desencadenador en partes de 200, dando como resultado 100 invocaciones de desencadenador separadas, incluso más si el tamaño de lote masivo es inferior a 200 registros. Si cada invocación pone en cola un trabajo asíncrono, se puede consumir una parte significativa del límite diario de una única carga de datos. Este consumo puede privar potencialmente a otros procesos de negocio críticos de recursos asíncronos.
Los límites reguladores para los trabajos en cola son drásticamente diferentes dependiendo del contexto. Desde un desencadenador activado por una acción de usuario en la interfaz de usuario (una transacción síncrona), se pueden poner en cola hasta 50 trabajos colocables en cola. Sin embargo, desde un desencadenador activado dentro del método execute de una clase Apex por lotes (una transacción asíncrona), solo se puede poner en cola un trabajo colocable en cola. No tener en cuenta esta diferencia es un punto de fallo común y crítico, que lleva a errores de LimitException durante operaciones de datos de gran tamaño.
Llamar Apex programable (System.schedule) o Apex por lotes (Database.executeBatch) directamente desde un contexto de desencadenador constituye un antipatrón. Estos métodos no están diseñados para invocarse desde contexto de desencadenador. Al hacerlo se producirá un consumo rápido de su asignación de Apex asíncrona, lo que dará como resultado excepciones de límite.
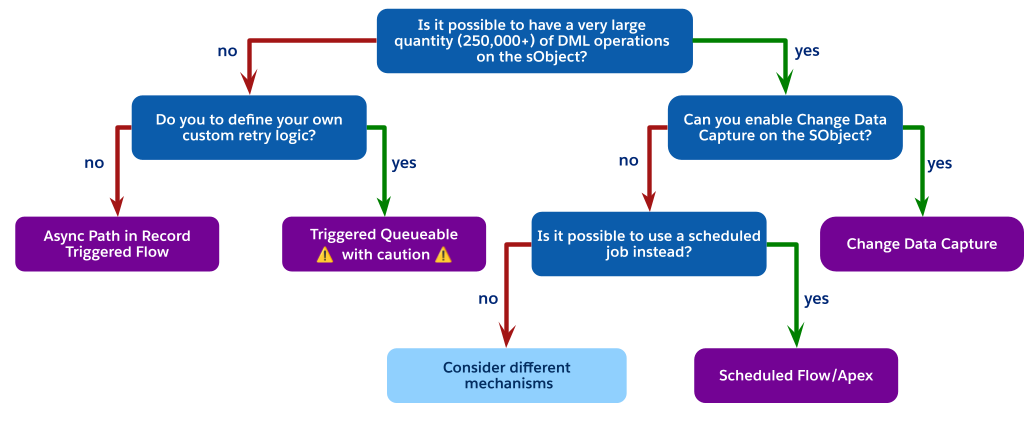
Selección del patrón asíncrono correcto
Cada mecanismo asíncrono tiene ventajas específicas en cuanto al desempeño, los límites reguladores y la fiabilidad. Utilice este árbol de decisiones como guía para ayudarle a navegar por estas opciones y elegir el mecanismo correcto para su caso de uso.
La alternativa de trabajo programado
Como indica el gráfico de flujo, cuando se enfrenta a operaciones DML de gran volumen pero no puede utilizar Captura de datos de cambios (quizás debido a límites de objetos), la mejor opción arquitectónica es a menudo evitar un proceso invocado por desencadenador completamente.
En su lugar, considere utilizar un proceso programado. Este puede ser un Flujo programado o Apex programado. Los pasos requeridos son:
Realice una actualización sencilla y de bajo costo en el desencadenador síncrono. Por ejemplo, establezca un campo de Status__c en "procesamiento pendiente" o inserte un registro relacionado de bajo costo, como una publicación de Chatter, para indicar que el registro necesita procesamiento.
Cree un trabajo programado, ya sea un flujo programado o Apex programado, que se ejecuta periódicamente, como cada 15 minutos o cada hora.
Tenga la consulta de trabajo programada para todos los registros en el estado pendiente, ejecute la lógica compleja en un contexto controlado de gran volumen y luego actualice los registros como procesados.
Este patrón desvincula completamente el procesamiento pesado del guardado síncrono del usuario, no está sujeto al límite de un trabajo por transacción de un lote desencadenado y proporciona una solución altamente ampliable y gobernable para requisitos que no son en tiempo real.
Si la latencia de un trabajo programado no es aceptable para los requisitos de negocio y aún está restringido a utilizar CDC o una cola desencadenada, esto indica un desajuste arquitectónico significativo. En este punto, deben considerarse diferentes mecanismos. La reevaluación del diseño de la aplicación principal puede llevar a ciertas conclusiones, como:
Adquisición del complemento para eliminar límites de objetos de CDC.
Fundamentalmente, desafiar el requisito de negocio para determinar si el procesamiento casi en tiempo real es realmente una necesidad o si la latencia de un trabajo programado es una ventaja aceptable para la estabilidad de la plataforma.
Consideraciones no funcionales
Complejidad
El nivel de complejidad en una implementación forma parte del costo total de propiedad de una solución, así como su capacidad de adaptarse a los requisitos de negocio cambiantes. La complejidad puede afectar a cualquier implementación si no se siguen las mejores prácticas. En la sección Mejores prácticas relacionadas de este documento, existen recomendaciones para reducir la cantidad de complejidad en su solución, incluyendo estos patrones:
Patrón híbrido: Apex invocable para lógica compleja en flujo
Uso de un marco de trabajo de metadatos para desencadenadores Apex
Megaflujos frente a Flujos múltiples
Procesos y estándares
La documentación es tan importante como la automatización en sí. No solo garantiza la capacidad de mantenimiento, también es clave para la IA y las herramientas basadas en agentes. La documentación le ayuda a comprender y gestionar sus procesos de negocio.
En flujo
Establezca una convención de nomenclatura coherente para todos los elementos y variables.
Utilice el campo Descripción para el flujo para explicar su propósito general, criterios de desencadenador y resultado previsto.
Utilice el campo Descripción en cada elemento individual (por ejemplo, Get Records, Action, Transform). Esta práctica es la mejor forma de transmitir la intención. Es especialmente importante para acciones y subflujos invocables, donde la descripción es el lugar principal para explicar la lógica compleja realizada por la acción.
En Apex
Comente su código claramente para explicar el por qué detrás de su lógica, no solo el qué.
Si utiliza un marco de trabajo dirigido por metadatos, asegúrese de que sus registros de metadatos incluyen y rellenan un campo Descripción legible para explicar qué hace cada clase de controlador y cuándo debe ejecutarse.
DevOps y el control de origen forman parte de un ciclo de vida de desarrollo maduro. Utilice siempre una herramienta de control de origen como Git para proyectos de Salesforce. Tanto las clases Apex como Salesforce Flows son metadatos que definen su lógica de negocio, y deben versionarse y gestionarse.
En el contexto de la gestión de automatizaciones desencadenadas por registros, una canalización de DevOps moderna proporciona beneficios esenciales.
Comprobaciones de calidad automatizadas: Herramientas como Salesforce Code Analyzer se pueden configurar para ejecutarse automáticamente en sus oportunidades en curso. El análisis estático puede detectar patrones problemáticos en ambas herramientas de automatización antes de promocionarse, marcando problemas como elementos de Get Records ineficientes dentro de un bucle de flujo o consultas de SOQL dentro de un bucle de Apex for, que son causas comunes de degradación del desempeño.
Prevención de regresión: A medida que crece su densidad de automatización, un cambio en una clase de Flujo o Apex puede tener consecuencias no deseadas para otras automatizaciones en el mismo objeto. Una estrategia de pruebas de DevOps sólida, donde las pruebas de Apex automatizadas se ejecutan contra cualquier cambio propuesto, es la forma más fiable de garantizar que una nueva versión de Flow no rompe la lógica Apex existente (y viceversa).
Colaboración y visibilidad: El control de origen es la "fuente única de verdad". Permite a los administradores y desarrolladores trabajar en la automatización para el mismo objeto en paralelo. También proporciona un seguimiento de auditoría inestimable: cuando se interrumpe un proceso de producción, puede ver al instante quién cambió la automatización, cuándo la cambió y, a través de mensajes de confirmación, por qué la cambió.
Para equipos con una combinación de administradores y desarrolladores, DevOps Center proporciona una interfaz unificada para ayudar a coreografiar todos estos pasos, haciendo accesible un proceso de desarrollo escalable basado en el control de origen para todos los miembros del equipo.
Esta disciplina combinada de documentación y DevOps garantiza el estado y la capacidad de mantenimiento a largo plazo de su organización, lo que beneficiará a cada arquitecto y administrador que le siga.
Mejores prácticas relacionadas
La guía de decisiones anterior se utiliza mejor antes de planificar su implementación. Está dirigido a ayudarle a elegir el mejor producto para sus casos de uso. Tras la selección del producto, es importante comprender las mejores prácticas existentes para su implementación.
Explotar el patrón híbrido: Apex invocable para lógica compleja en flujo
El principio Una herramienta por objeto es crítico para gestionar la automatización de alta densidad, pero no lo interprete como una opción binaria entre una pila puramente declarativa o programática. Un patrón arquitectónico más efectivo y mantenible aprovecha un modelo Híbrido: posicione Flujo desencadenado por registro como la capa de orquestación, mientras encapsula operaciones de alta complejidad en Apex invocable.
La capa de orquestación: Flujo
Flujo desencadenado por registro sirve como la capa de orquestación para el proceso de negocio. Posee los criterios de entrada y el contexto de ejecución (el qué y el cuándo). Al mantener la lógica de decisiones y el enrutamiento en esta capa, la topología de procesos de la arquitectura permanece transparente y gestionable a través del Explorador de desencadenadores de flujos, evitando que la lógica de negocio crítica se oculte en el código.
El componente Complejo: Apex invocable
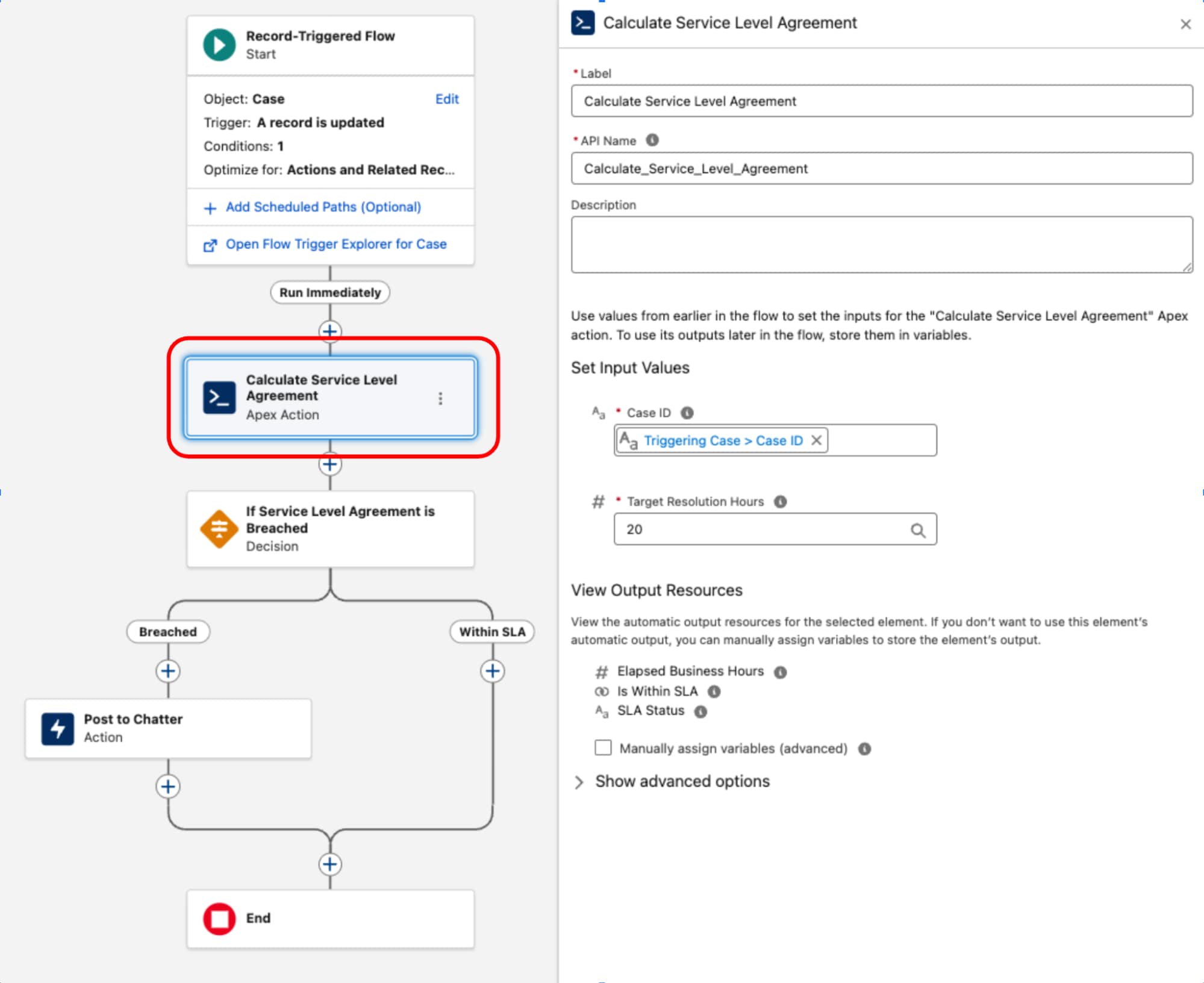
Un ejemplo común de un componente complejo es la implementación de cálculos de Acuerdo de nivel de servicio (SLA) para registros Caso. Puesto que el objeto BusinessHours y su lógica relacionada (crítica para cálculos precisos que excluyen horarios no laborales y festivos) no es accesible de forma nativa en Flow, se utiliza una clase de Apex dedicada. Esta clase, a menudo denominada algo así como ServiceLevelAgreementCalculator, está diseñada con un único método estático, anotado con @InvocableMethod, para calcular el horario laboral transcurrido, determinar si el SLA está "Dentro del objetivo" o "Incumplido" y devolver un resultado estructurado. Este enfoque encapsula la lógica compleja y de alto desempeño en Apex permitiendo al mismo tiempo su ejecución e integración transparentes en la capa de orquestación declarativa de un flujo desencadenado por registro.
Una vez definida la clase de ServiceLevelAgreementCalculator Apex, está disponible para su uso en un flujo desencadenado por registro:
Este patrón demuestra una estricta separación de preocupaciones. La capa declarativa se utiliza para gestionar el ciclo de vida y la orquestación de transacciones mientras que el código se utiliza para la ejecución de alta complejidad. Al tratar el código como una utilidad funcional en vez de la base, equilibramos el desempeño y la capacidad de mantenimiento.
Ganancias clave con el patrón híbrido
Modularidad: La decisión se aleja de la singularidad de utilizar Apex o Flow para todo el proceso. En su lugar, la arquitectura encapsula lógica compleja en unidades discretas, seguras de forma masiva y comprobables de forma independiente. Estas unidades funcionan como componentes reutilizables consumidos por la capa declarativa, garantizando las escalas de automatización sin complicar el diseño arquitectónico.
Reutilización: La lógica está desvinculada del evento desencadenador. Una unidad de código bien diseñada (como un InvocableMethod) se escribe una vez pero se aprovecha en múltiples puntos de entrada: Flujos desencadenados por registro, flujos de pantalla o integraciones externas. Esta reutilización de código elimina el desarrollo redundante.
Mantenibilidad: La lógica de flujo de proceso permanece visible y gestionable en el Flujo declarativo. Esta centralización reduce drásticamente los gastos generales de depuración y garantiza que el orden de ejecución del sistema sea determinista y transparente.
Limitaciones y ventajas del patrón híbrido
Aunque el modelo híbrido de utilizar Apex invocable desde Flow es potente, no es un enfoque de talla única. Los arquitectos deben ser conscientes de las limitaciones y las ventajas específicas antes de comprometerse con una solución híbrida.
Sin asistencia antes de guardar: Esta es la limitación más crítica. Las acciones invocables solo están disponibles en el contexto después del guardado (flujos para acciones y registros relacionados). No se pueden utilizar en el contexto de alto desempeño antes del guardado (flujos para actualizaciones de campo rápidas). Por lo tanto, este patrón no se puede utilizar para delegar actualizaciones de campos del mismo registro. Realice ese trabajo de alto desempeño utilizando elementos Flujo nativos en un flujo antes de guardar o dentro de un desencadenador Apex antes de contexto.
Sin compatibilidad después de la eliminación: Flujo desencadenado por registro actualmente no admite el contexto posterior a la eliminación. Si un objeto de Salesforce tiene un requisito de negocio para ejecutar la automatización cuando se restaura un registro desde la papelera, un desencadenador Apex es la única solución.
Carga de desempeño en escenarios de gran volumen: La transición del tiempo de ejecución de Flujo al tiempo de ejecución de Apex no es una operación de costo cero. Aunque generalmente es rápido, el acto de soltar en una acción invocable desde el tiempo de ejecución de Flow no es tan rápido como la ejecución nativa que permanece completamente dentro de un desencadenador Apex. Para la mayoría de las automatizaciones de densidad media, esta microcarga es una ventaja insignificante y valiosa para la accesibilidad aumentada. Sin embargo, para escenarios de alto desempeño y gran volumen extremos, un marco de trabajo solo de Apex puro tendrá una ventaja de velocidad de cálculo sin procesar.
Estrategias para la automatización heredada
Aunque la heurística de densidad de automatización proporciona directrices definitivas para una arquitectura de campo nuevo más reciente, la realidad de los entornos de Salesforce de negocio suele ser más matizada. En organizaciones maduras, es común encontrar flujos desencadenados por registros y desencadenadores Apex operando en el mismo objeto de Salesforce. Este escenario es distinto del patrón híbrido explicado anteriormente: aquí, los flujos y desencadenadores Apex no están acoplados ni diseñados para funcionar juntos.
Esta coexistencia es a menudo el resultado de la evolución de las funciones de la plataforma o de deudas técnicas heredadas. Aunque este es un estado operativo tolerado, los arquitectos deben tratarlo como una compensación calculada en vez de un estado final.
La orquestación fragmentada causa una carga de trabajo de mantenimiento y regulación significativa, haciendo que las actividades de desarrollo, pruebas y gestión de incidentes sean inconexas y engorrosas. Esto lleva a un aumento del Tiempo de resolución (TTR) y la complejidad operativa.
Para nuevos objetos de Salesforce, respete el principio de densidad de automatización como la guía principal.
Para Objetos de Salesforce existentes con una huella híbrida y un desencadenador Apex dual y puntos de entrada de flujo desencadenados por registro, evalúe la densidad y luego cree arquitectos para refactorizar a un estado híbrido mantenible.
Para baja densidad, vuelva a factorizar desencadenadores Apex en flujos desencadenados por registros y especifique el orden de ejecución, llevándolos a un único punto de entrada de automatización.
Para densidad media, vuelva a factorizar megaflujos complejos en un subconjunto de flujos, con el orden de ejecución correcto. Introduzca desencadenadores Apex solo cuando sea absolutamente necesario, por ejemplo para dar cobertura después de cancelar la eliminación de contexto.
Para alta densidad, favor de implementar desencadenadores Apex.
Uso de un marco de trabajo de metadatos para desencadenadores Apex
A medida que maduran los procesos de negocio de una organización en Salesforce Platform, el volumen y la complejidad de la automatización desencadenada por registros aumentan inevitablemente. Una mejor práctica fundamental es mantener un desencadenador Apex por objeto de Salesforce. Esta regla es crítica porque la plataforma no garantiza el orden de ejecución de múltiples desencadenadores en el mismo objeto para el mismo evento. Esta limitación puede llevar a comportamientos no deterministas, condiciones de raza y problemas difíciles de depurar.
Sin embargo, la adhesión al principio de desencadenador único presenta un reto arquitectónico: cómo gestionar y orquestar toda la lógica de negocio invocada desde ese punto de entrada único de una forma ampliable y mantenible.
Las limitaciones de los controladores de desencadenadores Classic
La primera evolución de esta arquitectura fue el patrón Classic Trigger Handler. En este enfoque, el desencadenador Apex único delega toda su lógica a una clase de controlador correspondiente (por ejemplo, OpportunityTriggerHandler). Este método separa la lógica del archivo desencadenador y proporciona a los desarrolladores un control determinista sobre el orden de ejecución dentro de los métodos de la clase de controlador (por ejemplo, afterInsert()).
Aunque es una mejora, este patrón a menudo lleva a clases de controlador monolítico. Con el tiempo, a medida que se agregan más requisitos de negocio, la clase se vuelve grande, difícil de gestionar y difícil de probar de forma aislada. El orden de ejecución de todos los procesos individuales está codificado en un único método, lo que hace que la clase sea propensa a combinar conflictos, lo que aumenta drásticamente la regulación y los gastos generales de mantenimiento en un entorno de grandes compañías.
La solución: Un marco de trabajo de desencadenador dirigido por metadatos
Para resolver los problemas principales de modularidad y orquestación, los arquitectos cambian a un Marco de trabajo de desencadenador dirigido por metadatos. Este es un salto arquitectónico significativo que desvincula la lógica de automatización en sí de la configuración de cómo y cuándo se ejecuta.
Este marco se basa en tres ventajas clave:
Partición: En vez de una única clase de gestor, la lógica de negocio principal se divide en clases de Apex atómicas pequeñas (por ejemplo, una clase de RecalculateAccountValues o una clase de NotifySalesLeads), respetando cada clase el principio de responsabilidad única. Esta modularidad facilita la tarea de probar, depurar y comprender la lógica de forma aislada.
Orden y coreografía: La orden de ejecución ya no está codificada en Apex. En su lugar, se define declarativamente por registros de configuración, normalmente almacenados en un tipo de metadatos personalizados (por ejemplo, TriggerAction__mdt). Esto permite a los administradores reordenar, agregar o eliminar acciones de automatización simplemente modificando un registro de metadatos, que no requiere una implementación o cambio de código.
Omitir funciones: El marco de trabajo proporciona funciones de omisión granulares estandarizadas. Cada acción de automatización puede configurarse a través de su registro de metadatos para desactivarse de forma global o omitirse para usuarios administrativos específicos haciendo referencia a un permiso personalizado.
El desencadenador de Apex único para el objeto sirve solo como un despachador dinámico. No contiene lógica de negocio, pero en su lugar crea una instancia de una clase de MetadataTriggerHandler central. Este controlador consulta los registros de metadatos personalizados para determinar dinámicamente la secuencia de ejecución e invocar las clases Apex atómicas correctas en el orden prescrito. La automatización está unificada bajo una capa única, transparente y gobernable.
Desduplicación de operaciones costosas en la transacción
Un beneficio importante de utilizar Apex en un marco de trabajo sólido es la capacidad de gestionar el estado de las transacciones y optimizar el desempeño eliminando el trabajo redundante. A medida que se acumula la lógica, es común que diferentes automatizaciones en la orden de guardado ejecuten de forma independiente las mismas operaciones costosas, consumiendo límites reguladores valiosos y aumentando el tiempo de operación DML.
El marco está diseñado para abordar esto con dos estrategias principales:
Gestión de estado compartido: Dentro del ámbito de una única transacción Apex, las propiedades estáticas y las variables se aprovechan para almacenar en caché datos. Esto garantiza que una operación costosa, como una consulta de SOQL para un parámetro de configuración, solo se ejecute una vez, incluso si la lógica de automatización se invoca varias veces entre diferentes registros o fases del desencadenador. El consumo de límites de transacciones se reduce significativamente.
Utilización de caché de plataforma: Para ir más allá del simple almacenamiento en caché intratransacción, utilice la caché de plataforma para evitar consultar la base de datos completa para ciertos datos. Esta caché en memoria gestionada es ideal para recuperar datos que no son primitivos, leídos frecuentemente en la base de códigos e inmutables en el transcurso de una transacción (por ejemplo, perfiles, funciones, horarios laborales). Utilizando la interfaz de Cache.CacheBuilder, el sistema comprueba la caché primero y solo realiza la consulta de la base de datos si los datos no están presentes, maximizando el desempeño y la capacidad de ampliación.
Utilizar antes del guardado para actualizaciones del mismo registro
Utilice siempre una actualización antes del guardado cuando su automatización solo necesite cambiar valores de campo en el registro que inicia la transacción. Esto se aplica a actualizaciones de campo rápido en Flujo (que se ejecutan antes de guardar) y lógica antes de contexto en Desencadenadores Apex (antes de insertar, antes de actualizar).
Este patrón es de desempeño, independientemente de la herramienta que se utilice, porque evita una segunda operación DML y un ciclo de guardado recursivo. Los cambios se realizan en el registro en memoria antes de que se confirme en la base de datos y se guardan como parte de la transacción original. Se elimina la sobrecarga de un segundo guardado, que de lo contrario volvería a ejecutar la orden de guardado completa e iniciaría toda la automatización de nuevo.
Evitar la repetición no controlada
La recursión no controlada es un problema común en desencadenadores posteriores a la actualización, donde la lógica de un desencadenador realiza una actualización DML que a su vez provoca que el mismo desencadenador se active de nuevo. Esto crea un bucle infinito que termina finalmente con una excepción de límite regulador. Aunque históricamente se han utilizado indicadores booleanos estáticos o recopilaciones de Id. de registros procesados para evitar dicha repetición, un patrón más preciso y sólido es portar la lógica comparando valores de campo entre las versiones nueva y antigua del registro en sí.
Ejecute la lógica solo si un campo de interés específico cambió realmente. Esto evita que el desencadenador ejecute su lógica en operaciones DML posteriores en la misma transacción donde los datos críticos permanecen sin cambios.
Control de la recurrencia en flujos desencadenados por registros
En un flujo desencadenado por registro, evite la repetición no controlada estableciendo el flujo para ejecutarse solo cuando se actualiza el registro para cumplir los requisitos de condición:
Si elige utilizar una fórmula de criterios de entrada en su flujo, puede evitar la repetición desbocada comparando la variable global de $Record (representando los nuevos valores) con la variable global de $RecordPrior (representando los valores originales antes del guardado). Por ejemplo, para asegurarse de que un flujo solo se ejecuta si el campo Importe en una oportunidad cambió, utilice esto en los criterios de entrada:
1$Record.Amount != $Record__Prior.Amount
Control de la recurrencia en Apex
Compare valores de campo de la nueva versión del registro, Trigger.new, con los valores de campo de la versión antigua del registro, Trigger.oldMap, para ver si se produjo el cambio específico que está buscando. Este enfoque garantiza que la automatización sea idempotente y solo se ejecute cuando sea necesario, haciendo que el sistema sea más eficiente y evitando bucles recursivos catastróficos.
Omitir la automatización
Una organización de Salesforce bien diseñada requiere un mecanismo coherente y fiable para omitir la automatización. Esta no es una función opcional, sino un requisito operativo principal para mantener la integridad de los datos y activar tareas administrativas.
Un marco de trabajo de omisión es esencial para algunos escenarios:
Cuando se cargan grandes volúmenes de datos, la activación de desencadenadores para cada registro puede ralentizar drásticamente el proceso, provocar excepciones de límite y crear notificaciones y registros relacionados erróneos. Una omisión permite insertar los datos de forma limpia y eficiente.
Un usuario de integración puede necesitar sincronizar datos desde un sistema de registro externo. La automatización que normalmente se desencadena para un cambio iniciado por el usuario (por ejemplo, el envío de un email, la creación de una tarea) puede ser indeseable o redundante cuando el cambio se origina desde otro sistema.
Es posible que los administradores o el personal de asistencia necesiten realizar actualizaciones correctivas en registros. Un mecanismo de omisión les permite realizar estos cambios sin desencadenar la automatización de negocio estándar, lo que podría tener consecuencias no deseadas.
Permisos personalizados: El estándar moderno y ampliable para la implementación de la lógica de omisión son los permisos personalizados. Estos métodos son superiores a los antiguos por varias razones:
Flexibilidad: Los permisos personalizados se pueden asignar a usuarios a través de conjuntos de permisos. Esta práctica se alinea con el modelo moderno de acceso y seguridad de Salesforce, permitiendo una asignación granular y flexible. Se puede otorgar una omisión a un usuario específico, o incluso temporalmente con una fecha/hora de caducidad específica.
Mantenibilidad: El uso de permisos personalizados evita codificar perfiles o usuarios en lógica de automatización. Si la función de un usuario cambia o un nuevo perfil necesita omitir el acceso, el cambio es una asignación de Conjunto de permisos sencilla, no una modificación de flujo o código que requiere una implementación.
Escalabilidad: Los permisos personalizados proporcionan un marco de trabajo ampliable para gestionar excepciones en una base de usuarios compleja. Se pueden asignar a usuarios a través de conjuntos de permisos, grupos de conjuntos de permisos o perfiles. Su asociación a un conjunto de permisos o perfil también es representable en metadatos de origen.
Patrones de implementación: Aplique un patrón de omisión coherente a todas las automatizaciones desencadenadas por registros en la organización.
Omitir un flujo desencadenado por registro: La forma más eficiente de omitir un flujo es evitar que se ejecute. Esto se logra agregando una condición a los criterios de entrada del flujo.
En el elemento Inicio del flujo desencadenado por registro, establezca los Requisitos de condición en La fórmula se evalúa como Verdadero.
En el generador de fórmulas, incorpore una comprobación para el permiso personalizado utilizando la variable global $Permission. Combine la comprobación con sus criterios de entrada existentes.
Patrón de fórmula:
1( ) && NOT($Permission.Bypass_This_Flow)
Este patrón garantiza que el flujo solo se ejecute si el usuario no tiene el permiso personalizado especificado asignado. Esta comprobación se realiza incluso antes de que se cree la entrevista de flujo, lo que la convierte en el enfoque con mayor desempeño.
Omitir un marco de trabajo desencadenador Apex: En Apex, integre la lógica de omisión directamente en el marco de desencadenador dirigido por metadatos, permitiendo un control granular.
El tipo de metadatos personalizados de TriggerAction__mdt debe incluir un campo de texto, por ejemplo, BypassPermission__c.
En la clase MetadataTriggerHandler, antes de ejecutar una acción de forma dinámica, el código debe leer el valor de este campo.
Si el campo se rellena, el controlador utiliza el método FeatureManagement.checkPermission() para determinar si el usuario que ejecuta actualmente tiene el permiso personalizado especificado.
Si checkPermission() devuelve true, el controlador omite esa acción específica y continúa con la siguiente en la secuencia.
Este patrón es potente porque permite una omisión global (si todos los registros de TriggerAction__mdt hacen referencia al mismo permiso) y una omisión granular por acción (si diferentes registros hacen referencia a diferentes permisos, o algunos no tienen ningún permiso de omisión).
Megaflujos frente a Flujos múltiples
Es un antipatrón para consolidar toda la automatización de un objeto en un único flujo masivo. La consolidación en un flujo frente a la división de la lógica en múltiples flujos bien acondicionados no tiene un impacto importante en el desempeño. Las ganancias de desempeño más significativas provienen de:
Uso de flujos antes de guardar para actualizaciones de campos del mismo registro.
Redactar condiciones de entrada precisas para garantizar que los flujos no se ejecutan en cambios que no afectan a su caso de uso específico.
Flow Trigger Explorer le permite asignar un valor de pedido a cada flujo en un objeto, garantizando un orden de ejecución secuencial.
We use cookies on our website to improve website performance, to analyze website usage and to tailor content and offers to your interests.
Advertising and functional cookies are only placed with your consent. By clicking “Accept All Cookies”, you consent to us placing these cookies. By clicking “Do Not Accept”, you reject the usage of such cookies. We always place required cookies that do not require consent, which are necessary for the website to work properly.
For more information about the different cookies we are using, read the Privacy Statement. To change your cookie settings and preferences, click the Cookie Consent Manager button.
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.