现代 Salesforce 架构越来越多地由异步处理提供支持;异步处理不是为了方便,而是规模的战略要求。近年来,我们看到越来越多的公司面临着数据量激增、涉及多个接触点的复杂集成以及全天候运行的自主系统的兴起等问题。所有这些因素都推动架构师设计异步优先的系统。
Salesforce 上的异步处理通常意味着围绕调控器限制和复杂性进行设计。这些限制充当防护栏和架构约束,有助于生产批量安全的、可扩展的系统。虽然没有平台限制直接用于管理复杂性,但设计模式可以帮助降低这方面的风险。在内部,Salesforce 通常会推动平台向前发展,以测试新功能并自动化复杂的业务流程。我们构建了一个基于步骤的异步处理框架,用于运行具有任意数量步骤的异步作业。通过集中日志记录,每个步骤都可以独立运行、重试和重新启动,并具有共享治理控制和完全操作可见性。本文档概述了其主要架构组件:可排队 Apex 和最终确定器、计划流、Apex 光标、可调用操作以及与 Slack 的集成。这些组件共同提供了一个适合不断发展的业务需求的模块化、可扩展和可观察的架构。
- 现代 Salesforce 架构应采用异步优先的方法,以实现规模、弹性和运营透明度。
- 将复杂工作分解为独立可执行的步骤可实现可预测的性能、更安全的重试、检查点、回滚和模块化演进,而无需重新设计核心工作流。
- 该框架提供了对整体式和老化批处理作业、链式异步调用和深度嵌套流的可扩展替代方案,并专为必须在 Salesforce 中水平扩展而没有平台外编排的高用量工作负载构建。
- 确定性和可观察的执行通过集中的日志记录和治理来确保进度跟踪、SLA 监控、故障诊断和审计级透明度。
- 设计用于企业级严格性,包括跨长时间运行的业务流程的统一治理、合规性和分布式状态控制。
在查看要求之前,以下是何时使用类似框架的一些注意事项。首先,请考虑哪个系统是真理的唯一来源。如果您的 Salesforce 组织对外部数据的依赖最少,但需要从数百条记录扩展到数百万条记录,请考虑基于步骤的异步框架。
如果满足以下条件**,请**使用此框架:
- 大部分(或所有)要处理的信息已经存在于您的 CRM 中。
- 维护提取转换加载 (ETL) 作业以协调外部数据的前期或持续成本太高。
- 您需要推迟按既定计划处理大量 Salesforce 记录。
- 您可以将处理分解为离散的步骤。例如,您可以创建一组层次结构或基于树的记录,特别是如果数据量向下扇出层次结构或树。
如果出现以下情况**,请勿**使用此框架:
- 创建或更新记录需要立即重新计算。
- 集成具有挑战性,因为外部系统托管记录更新的主要数据。(考虑使用批量 API 将更新的数据推送到 Salesforce。)
请记住这些实践,让我们回顾一下我们的要求并开始构建。
考虑问题陈述:
给定需要每天运行的作业,请检查某些记录是否满足预先建立的标准,以便进一步处理。如果是,则启动这些处理作业。处理记录可能意味着从多个外部系统提取数据以执行计算。作业中的步骤应通过 Slack 通知人员已处理记录已准备好进行审核。步骤还应根据第一轮通知后的可配置延迟,将通知上报到角色层次结构中的经理和上级。
此问题涉及几个不同的步骤,其中一些步骤可以相互独立发生。拆分工作有很多方法。以下是一组:
- 计划程序。
- 处理记录的步骤界面和具体实施(无论处理类型如何)。
- 组织步骤的处理器。
- 计划程序调用的 Apex 可调用。
- 通知部分。我们使用 Apex Slack SDK。
- “可配置的延迟”短语隐藏着一些复杂性。我们将在本文后面回顾这种复杂性。
以下是构建框架的意见图:
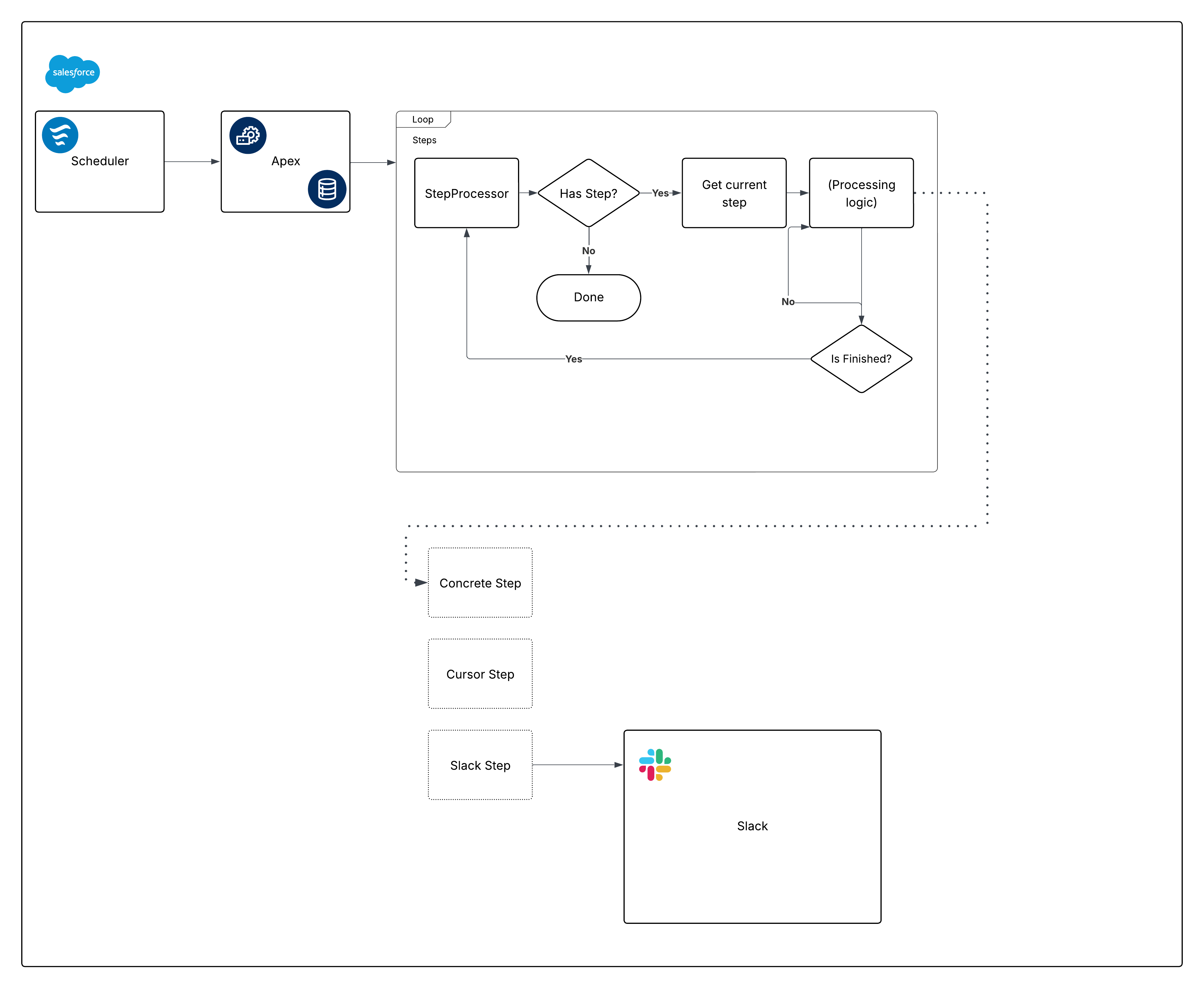 现在,分解该图表,并开始构建各个部分。
现在,分解该图表,并开始构建各个部分。
计划流作为计划机制提供了几个优势:
- 计划流可以打包并部署为元数据。对于通过 Apex(或通过计划作业页面)计划的作业,情况并非如此。
- “等待”元素对于需要标注的框架至关重要。通过在流中使用它,在框架的可调用部分中不需要标注。
- 计划粒度满足要求:计划流的最小间隔是每天。如果您需要更高的频率(例如每小时),请重新考虑此要求的计划流。
配置计划流时的另一个注意事项是环境门控。在调用 Apex 操作前,添加评估{!$Api.Enterprise_Server_URL_100}变量的决策元素。这确保了作业仅在预期的环境中运行,例如 UAT 和生产。这种模式很重要,因为 Sandbox 在 SDLC 期间经常刷新或新创建,如果没有明确的环境检查,计划流可能会无意中在框架不打算运行的环境中执行。在决策元素中使用 contains 运算符会使设置适应未来的 Sandbox 创建或 URL 更改。
最后,考虑框架应如何捕获失败。在流调用任何操作时,请始终添加错误路径;例如,您可以将错误连接到 Nebula Logger 的“添加日志条目”操作。星云日志记录器将日志写入自定义对象,因此客户应了解日志数据会消耗组织存储 — 默认情况下,日志会在组织中存储 14 天,然后进行清理;此保留期可配置。星云日志记录器还使用平台事件发布日志,因此日志条目独立于主要数据处理事务保存 — 这将确保捕获失败,即使主要流或 Apex 操作回滚。在考虑添加日志记录框架时,客户应评估预期的日志量和保留要求。
以下是流的外观:
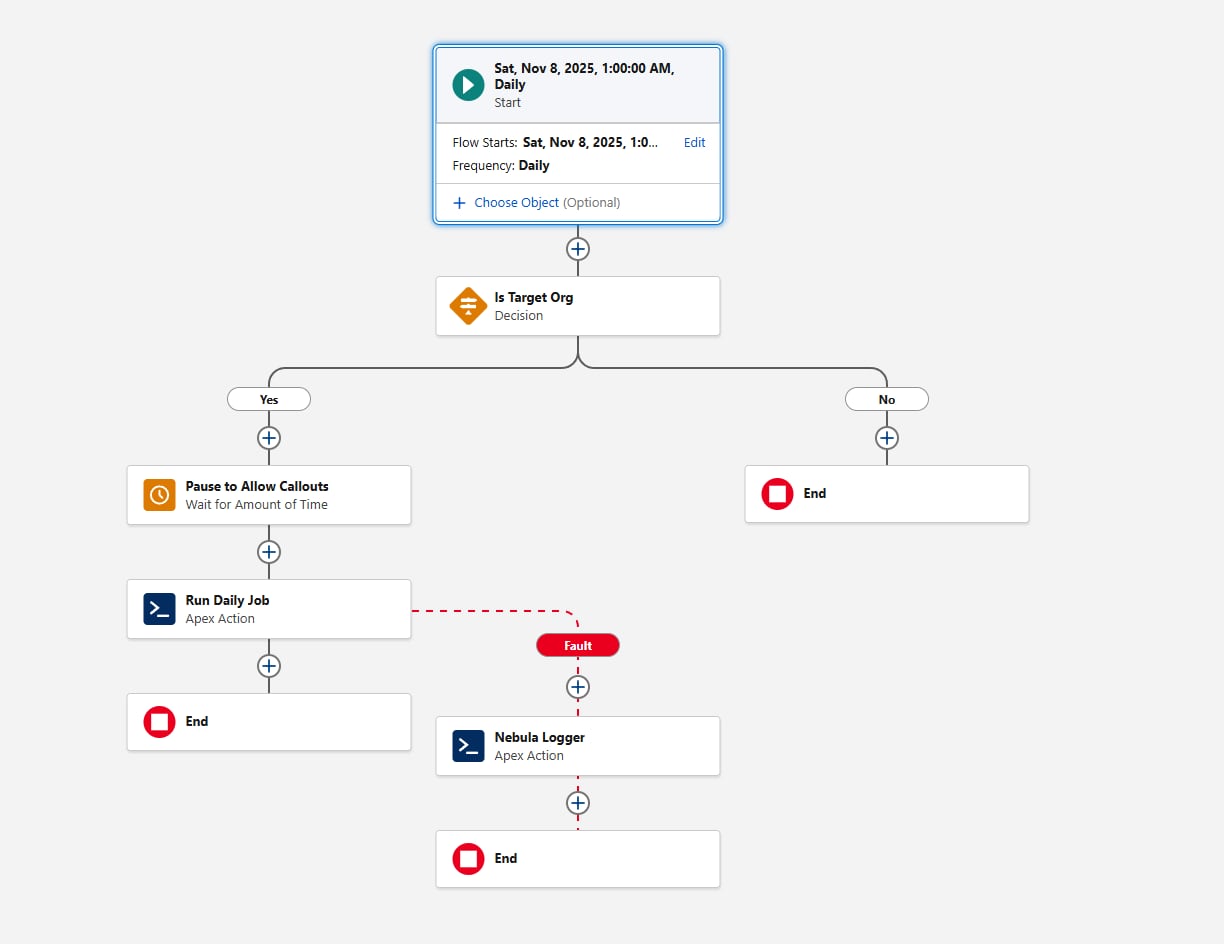
现在,让我们继续讨论 Apex 代码的第一部分,满足计划要求。
定义Step界面:
对于本文,为清楚起见,step界面显示为外部类。框架本身是灵活的 — 只要所有步骤类引用相同的界面,团队就可以使用他们喜欢的任何 Apex 打包模式来组织界面及其实施。
关于在我们的界面中定义的方法,有一些需要注意的事项:
execute目前虽然没有参数,但在我们传递State类(或接口)以在顺序重要时在步骤之间编排数据时有所改进。getName可以返回System.Type值,而不是String。目标是为编排层提供一种在不公开其他属性的情况下记录步骤名称的方法。
以下是第一个具体实施,显示了这些组件如何相互配合。除了稍后的一个例外,我们建议使用可排队 Apex 在 Apex 中实施异步处理;批量 Apex 通常是不必要的(不鼓励使用@future方法)。Queueable Apex 启动迅速,通过 Apex 光标,与批处理 Apex 相比有许多优势。
Apex 光标为传统的批量 Apex 模型提供了现代替代方案。与批处理相似,光标实施可以分块获取记录(每批最多 2,000 条)。但是,光标允许在单个事务中进行多次提取,从而为大批量操作提供了更高的吞吐量。
当将光标作为此框架的一部分时,团队应该了解当前的测试和可模拟性限制。测试中的光标行为可能与生产行为不同,因此重要的是设计测试策略,避免依赖光标内部,而是在边界处验证编排逻辑。随着平台的发展,这些领域将继续改进,但核心指导仍然是:与批处理 Apex 相比,光标在许多用例中提供了更高的性能和更低的编排开销。
要定义系统提供的光标和您自己的代码之间的明确边界,我们建议在实施Step界面时创建类似光标的表示。考虑以下代码:
请注意Cursor类。Apex 光标是Database.Cursor的实例,但我们的Cursor实施使我们对光标的缺点具有灵活性。以下是实施:
对于本文的其余部分,我们在引用 Apex 类时省略了 sharing 声明。在实践中,请确保顶级类明确使用,无论是否共享,以符合您的对象模型和权限。
另请注意,我们的Cursor实施委派到平台Database.Cursor,下面将讨论其他好处。
首先,以下是相应的测试:
通过将Cursor虚拟化,当具体的CursorStep实施不需要迭代大型记录集时,它们可以在没有Database.Cursor的情况下运行,类似于在批处理 Apex 中返回System.Iterable<T>而不是Database.QueryLocator。以下是示例:
请注意,由于该类也是抽象的,因此它将innerExecute的具体实施留给子类。
CursorLike 内部子类也有另一种选择。如果您知道像这样的步骤的具体版本不会通过其他调控器限制,您可以从 CursorLike.fetch 返回 this.records 并覆盖父CursorStep.shouldRestart()以返回 false。这允许您迭代仅受每个异步事务 12 MB 的 Apex 堆限制限制的列表。
在分页大量数据时,我们基于光标的实施为我们提供了很大的灵活性。同时 , Step 界面让我们可以灵活地描述和封装各种步骤。
考虑基于流的步骤:
因为流不能返回符合 Apex 定义类型的输出参数,所以我们在使用前要检查shouldRestart输出参数。
一些步骤可能会带有标记。您可以实施逻辑来决定要包含哪些步骤,或者对禁用的功能使用禁止步骤。空对象模式是降低编排层复杂性的常见方法:
我们现在有很多构件可以使用。让我们看看负责迭代步骤的编排层。
处理器是架构中的转折点。我们必须决定由谁定义初始化哪些步骤,以及在哪里初始化。选项包括:
- 让处理器定义哪些步骤映射到业务逻辑。此选项简单,但在可读性方面扩展性较差。
- 使用自定义元数据 (CMDT) 定义映射。元数据关系字段不支持
ApexClass,这会将类名称拼写松散地耦合到业务流程设置中。通过将字段设置为选项列表并验证类型是否存在(Type.forName()或查询ApexClass),您可以降低管理员风险,但由于 CMDT 记录不支持触发器,验证将在运行时进行。此路线可测试,但管理员仍只能在生产中创建 CMDT 记录,请谨慎操作。 - 使用记录定义映射。非管理员可以配置步骤,但部署会变得更加困难,环境也会发生变化。小心行事。
Clean Code 中有句名言介绍了如何处理这一特殊的复杂性:
这个问题的解决方案是埋在抽象工厂的地下室中[用于制作对象的]
switch语句,永远不要让任何人看到它。
请谨记这一点,因为我们当前的步骤数量定义明确,并且不太可能增长得太大,所以步骤处理器也可以成为步骤的工厂。这可以使用枚举来驱动 switch 语句:
然后为了我们的StepProcessor:
显示的工厂方法,例如 addTypeOneSteps(),可以委派功能标记等关注;cleanSteps() 对收集的步骤执行一次性检查,以确保在真正异步之前没有任何“空”步骤。这可能看起来像这样:
自从在“计划流”部分提到星云记录器以来,我们没有讨论过错误处理。这是因为 System.Finalizer 允许我们全面记录所有错误条件,而无需在每个步骤中添加特定的错误处理。每个Step侧重于运行,而我们记录并重新抛出任何不愉快的路径,以便它们在单元测试中出现。这支持安全迭代和生产级警报(对所有 WARN 和 ERROR 日志使用 Slack Logger 星云插件 ) 。
有关错误日志记录的一个注意事项:将步骤实例传递到日志消息中,假设对日志中可见的内容有一定程度的 Trust。Apex 类的默认toString()包括消息中的所有静态和实例级属性。这可能是可取的 — 也可能泄露敏感信息。虽然日志记录和安全性不是这里的重点,但是请注意对于一些系统,遵守像 Step 这样的界面也可能涉及强制覆盖toString()。
这种方法让每个对象创建者负责决定允许打印的内容,这可能是可取的。
在日志记录级别:在StepProcessor级别,我们使用 INFO,即最高的非错误级别。随着您在应用程序中变得越来越细,日志级别应该相应地降低。单个步骤可能会将DEBUG用于高级信息,并将FINE、FINER和FINEST保留给越来越详细的输出。记录既是一门艺术,也是一门科学,但遵循这些原则有助于保持日志的一致性和有用性。
在继续之前,让我们简要地考虑一下让我们的步骤处理器托管使用步骤的逻辑的决定。在大型代码库中,考虑使StepProcessor成为虚拟或抽象的,并让子类确定具体步骤来建立适当的关注点分离。
计划程序最终会调用 Apex。在其余设置完成后,可调用 Apex 部分可以决定哪些步骤应运行并将List<StepType>传递给处理器:
这是等式的简单部分 — 使用记录、数据或逻辑来确定要运行哪个步骤类型。可调用操作很简单,因为我们在其他地方封装了复杂性。我们还防止了意外异常,并使每个部分易于单独测试。
Apex Slack SDK超出了本文的范围,但需求中的一个潜在障碍值得重新审视:根据可配置的延迟通知角色层次结构中的上级人员。从纸面上讲,这很简单,您可能(正确地)考虑在StepProcessor中System.enqueueJob(this)。对于 System.AsyncOptions,我们最初倾向于使用enqueueJob过载来满足这一要求。
但目前通过System.AsyncOptions.MinimumQueueableDelayInMinutes的最大延迟为 10 分钟。因为要求是 120 分钟,所以还有一些选项。一种幼稚的方法可能看起来像这样:
实际上,延迟会传递到该类,因为延迟是配置驱动的。
除非您确定只有一个延迟通知类型,否则我们不建议使用这种方法。在开始之前,它会烧掉 11 个额外的异步作业(或者更多,如果延迟增加)。对于一个工作来说,这个成本可能还不错 — 对许多人来说不是。您还需要向Step界面添加方法,以便每个步骤可以告诉处理器在重新启动之前需要等待多长时间,这会增加噪音。
这给我们留下了两个有趣的可能性:
- 如果您已经以适当的时间间隔计划了轮询作业,您可以将延迟的步骤插入到现有作业框架中。指定的延迟在 15 分钟后到达(15 分钟是 Apex 计划 CRON 表达式的最小刷新间隔),您也应该可以。这大致匹配可调用 Apex 示例;计划改为通过 Apex 执行。换句话说,您可以重复使用相同的基于
Step的架构来根据“开始于”时间戳处理记录,并根据选项列表或映射到之前显示的StepType枚举值的多选选项列表决定使用哪些步骤。 - 或者,如果您愿意定义额外的外部 Apex 类,请回到使用
System.scheduleBatch()的批处理 Apex(与支持内部类的 Queueable Apex 不同,批处理 Apex 类必须是外部类)。
考虑批处理 Apex 示例。虽然我们通常建议使用 Queueable Apex 来实现灵活性和控制性,但这是 Batch Apex 仍然占主导地位的一个情况:
然后,在StepProcessor中,假设之前显示的addTypeOneSteps()方法使用此延迟步骤进行更新:
虽然我们通常不会建议这么多的跳转,但这个步骤延迟会成为另一个可重用的构建块。在 Queueable Apex 中允许更长的延迟之前,这也是产生这种效果的最简单方法(如讨论的那样,没有轮询机制)。
我们使用面向对象的设计来满足要求,并创建了一个系统来扩展,同时平衡长期的建筑和维护成本。虽然步骤声明和实例化最终可能会超出其在StepProcessor中的地位,但几乎没有额外的技术债务。通过FlowStep,管理员和开发人员可以共同决定何时无代码或专业代码解决方案最有意义。
通过在 Apex 可排队框架中使用System.Finalizer界面以及星云日志记录器,我们构建了一个强大的可测试系统,即使未来的步骤缺乏明确的日志记录,也能提醒我们意外的失败。对于我们来说,这个系统很高兴地压缩了数字,降低了成本和复杂性。它还为我们提供了有关 Apex 光标在实际工作负载下的行为的宝贵见解,帮助我们在改进功能的同时完善了我们的方法。
通过将复杂的高用量工作负载分解为模块化执行步骤,基于步骤的异步处理框架框架将平台约束转化为工程优势,实现了企业级的可预测性能、可观察性和治理。管理员和开发人员都可以设置步骤,无论哪种情况,步骤作者都可以安全地专注于遵守基本平台调控器限制(例如 DML 行和检索的查询行),而不必担心如何扩展每个步骤。
为了在企业实施中操作和采用这种模式,架构师应该:
- 评估现有自动化,确定异步编排可帮助改善性能和增强可观察性的领域。
- 将大型进程细分为离散的、独立可执行的步骤,具有明确的处理目标和离散的作者点(例如 Flow 或 Apex)。
- 定义和分组步骤类型,以加速步骤重用和跨业务部门的标准化。
- 通过新流程或现有自动化试用该方法。您可能会惊讶地发现,在步骤中免费找到多少边缘个案,关心您的内置日志记录和可观察性!
James Simone 是 Salesforce 的首席软件工程师,拥有十多年的平台工作经验。在进入开发阶段之前,他是 Salesforce 的客户和产品所有者,自 2019 年以来一直在 The Joys Of Apex 中撰写有关 Salesforce 的技术文章。他之前在 Salesforce 开发人员博客和 Salesforce 工程博客上发表了文章。