The Salesforce Customer 360 Platform provides a powerful multitenant, metadata-driven architecture to every individual Salesforce tenant instance (aka ‘org’). This architecture basics document provides an overview of areas where the underlying architecture of the Salesforce Platform creates a key consideration for the architectures of solutions built on the platform.
There are three essential areas to understand when designing architectures on the Salesforce Platform:
On the Salesforce Platform, a transaction can be instantiated by code execution and/or a database operation. A fundamental competency for architecting on Salesforce is understanding how the platform defines and controls transactions for tenants. In order to maintain resources for all tenants, Salesforce imposes limits upon every tenant, calculated on a per transaction and per org basis.
At the transactional level, Salesforce sets governor and execution limits to ensure individual instances of code execution and database transactions don’t monopolize shared compute resources. At the org-wide level, Salesforce sets limits based on edition and feature type. Org-wide limits also include a rolling calculation of API usage across all transactions in the org, which are subject to API limits.
Let's look more closely at two key parts of transactions on the Salesforce Platform: execution context and database manipulation.
Salesforce calculates transactional limits based on a concept of execution context. It is important to understand that for Salesforce applications, this is not exclusive to executions of custom code within a single Salesforce org. Execution context is based on the platform runtime engine, and all code available to the runtime engine for a particular tenant. This means custom code defined within a tenant’s org, code from packages installed with that org, as well as code contained within Salesforce platform services can all instantiate a transaction. The platform does distinguish between different kinds of Apex code and calculates governor limits based on those distinctions.
See the Apex developer’s guide for more about Apex transaction limits.
When a transaction involves database manipulation, a built-in order of execution prescribes how different parts of your org’s configuration and code will behave. A key to understanding how to correctly use the order of execution in your Salesforce applications is understanding the robust data integrity this behavior provides for your Salesforce applications.
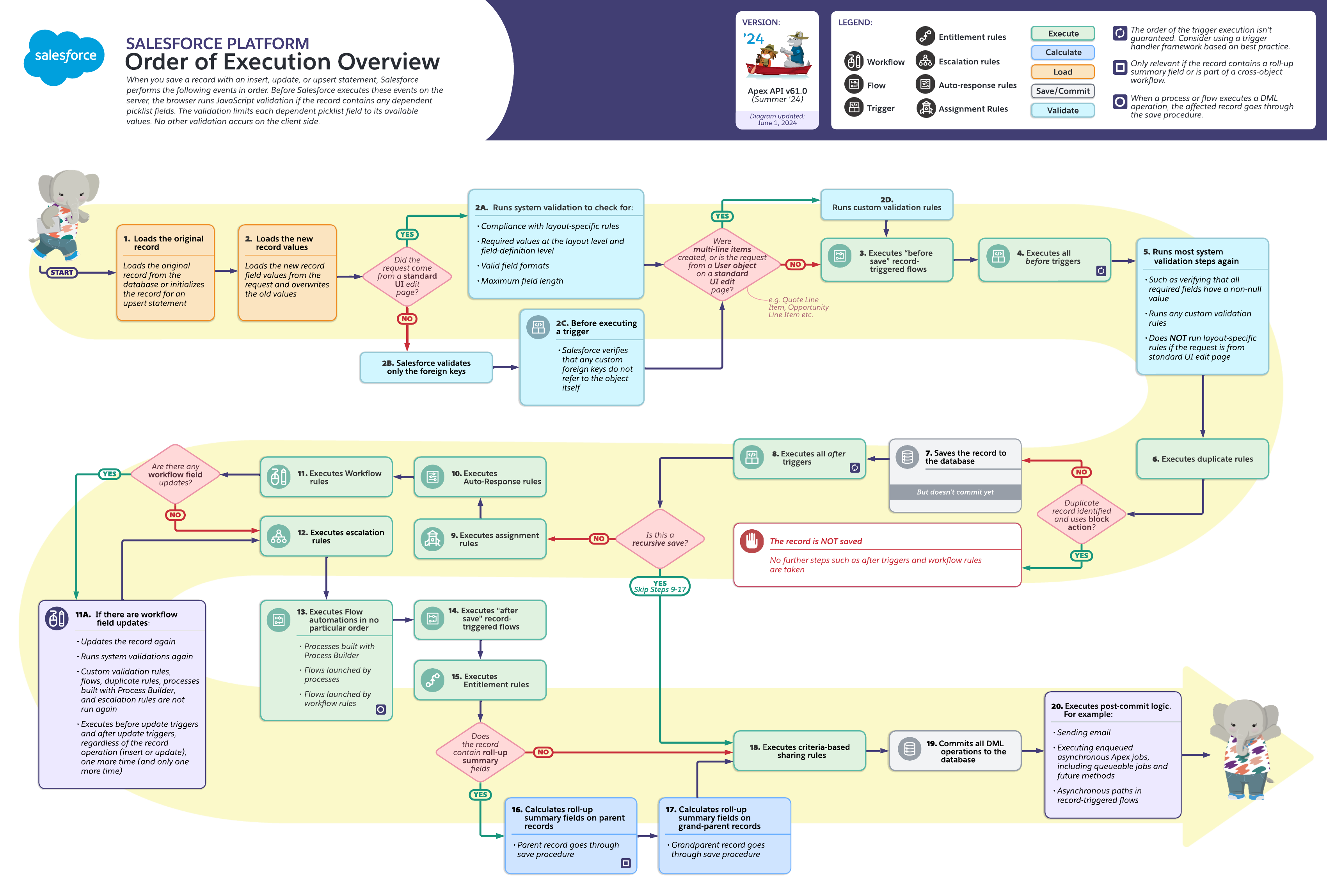
The platform exposes context variables for the state of database operations in the form of trigger context variables. It is important to understand that these trigger context variables describe runtime states for all database transactions in Salesforce org—whether or not custom Apex Triggers have been defined within that org. They are available to declarative tools like Salesforce Flow.
In Salesforce, data is not committed (nor are data transactions finalized) until the final after trigger behaviors described in the order of execution have completed successfully. This means that any fatal errors or disqualifying behaviors during a data transaction that occur in before contexts or after contexts will cause the platform to roll back all data operations within the transaction. Requested changes to record data are not committed to the database, and no post-commit logic is executed. (Apex does expose database methods to allow for more granular control of savepoints and rollback behavior.)
A key anti-pattern to avoid in your Salesforce architecture is attempting to short cut or supersede the platform’s built-in order of execution behavior.
For a deeper look at the logic behind these built-in data integrity behaviors, see Inside and Out: Transactions on the Salesforce Engineering blog.
When choosing how you customize and extend within a Salesforce org, it is important to understand what will be considered data and what will be considered metadata from the point of view of the Salesforce Platform. For a deep-dive into the underlying architecture behind this data/metadata distinction, in the Platform Multitenant Architecture fundamentals doc.
This distinction will affect many aspects of the development lifecycle for your application, such as: whether or not an artifact will be copied over into sandbox development environments, how it can be migrated to other environments, whether or not it can be part of a package.
The table below offers a quick comparison of the performance of data vs. metadata as it relates to key parts of the application lifecycle:
| Behavior | Data | Metadata |
|---|---|---|
| Copied from production into sandbox environments | No* | Yes |
| Migrate by Metadata API | No | Yes** |
| Migrate by data load | Yes | No |
| Can be included in packages | No | Yes** |
| Counts against data storage limits | Yes | No |
| *Full copy and partial copy sandboxes allow for data replication from production. **Some metadata types are not available for use with the Metadata API and/or packages. You can find exceptions in the Metadata Coverage Report. |
||
Sometimes this distinction is fairly obvious. For example, individual records in a Salesforce org are data. The various sObjects in an org are metadata.
Distinctions can be more complex when it comes to org configuration features. A key example is Custom Settings vs Custom Metadata Types. Both of these features allow you to configure information in an org so that it is easily available at runtime, and can be manipulated and managed in ways that are similar to database records. Both features are intended to allow for loosely coupled, highly flexible design patterns in code and automation. However, Custom Settings are stored in an org as data and Custom Metadata Types are stored as metadata.
You can determine if something is metadata by seeing if it appears in the Metadata Coverage Report. This report will also tell you about key development and deployment behaviors for a particular type of metadata.
There are many Salesforce Platform APIs. Salesforce Platform APIs support different data formats and protocols, various operation types and timings. Some APIs allow you to interact with the data in a Salesforce org, while others support interactions with the metadata in a given org. Some APIs are built specifically to handle large transaction volumes, others are not. Salesforce updates the version number for all Salesforce Platform APIs with every release.
A key part of sound application architecture is making sure application developers use the correct API (and API version) for a given use case. You will need to consider the built-in API limits for your Salesforce orgs, many of which are determined by edition and feature activation. The Salesforce Platform APIs support backwards compatible usage, which means implementations with a particular version should perform with stability and consistency, even as new API versions are released. If you want to incorporate new or changed functionality from a new API version, you may need to refactor your app before upgrading references to the new API version.
The many different Salesforce Platform APIs, along with the speed of Salesforce API versions, adds significant complexity to the lifecycle of any applications that use Salesforce APIs. You will need to plan for regular evaluations of the Salesforce Platform API references in your applications and prioritize planned API maintenance cycles to keep applications running predictably and properly.