Every day, hundreds of thousands of enterprises and millions of users operate their business in the cloud using applications powered by the Salesforce Platform. Why is the platform so successful? Why can you trust it to support your business? What unique benefits does the platform provide for businesses like yours?
This technical brief explains how the Salesforce Platform delivers reliable, scalable, and easy-to-customize end-user experiences using its unique software architecture for cloud computing. After reading this brief, you’ll better understand the underlying technology that makes the Salesforce Platform a compelling choice for your business applications.
The Salesforce Platform is the preeminent example of a successful cloud computing platform and related ecosystem of applications. Since the turn of the millennium, the platform has been the enabling foundation for:
- Many popular business-purpose applications for common use cases such as sales and customer service
- Industry-specific applications for more specialized use cases such as finance and healthcare
- Millions of custom applications and application extensions for unique use cases
In large part, the Salesforce Platform is so successful and popular because its unique software architecture supports applications that are easy to build, use, customize, and extend with exceptional performance and reliability. The heart of the platform’s software architecture is its multitenant, metadata-driven design.
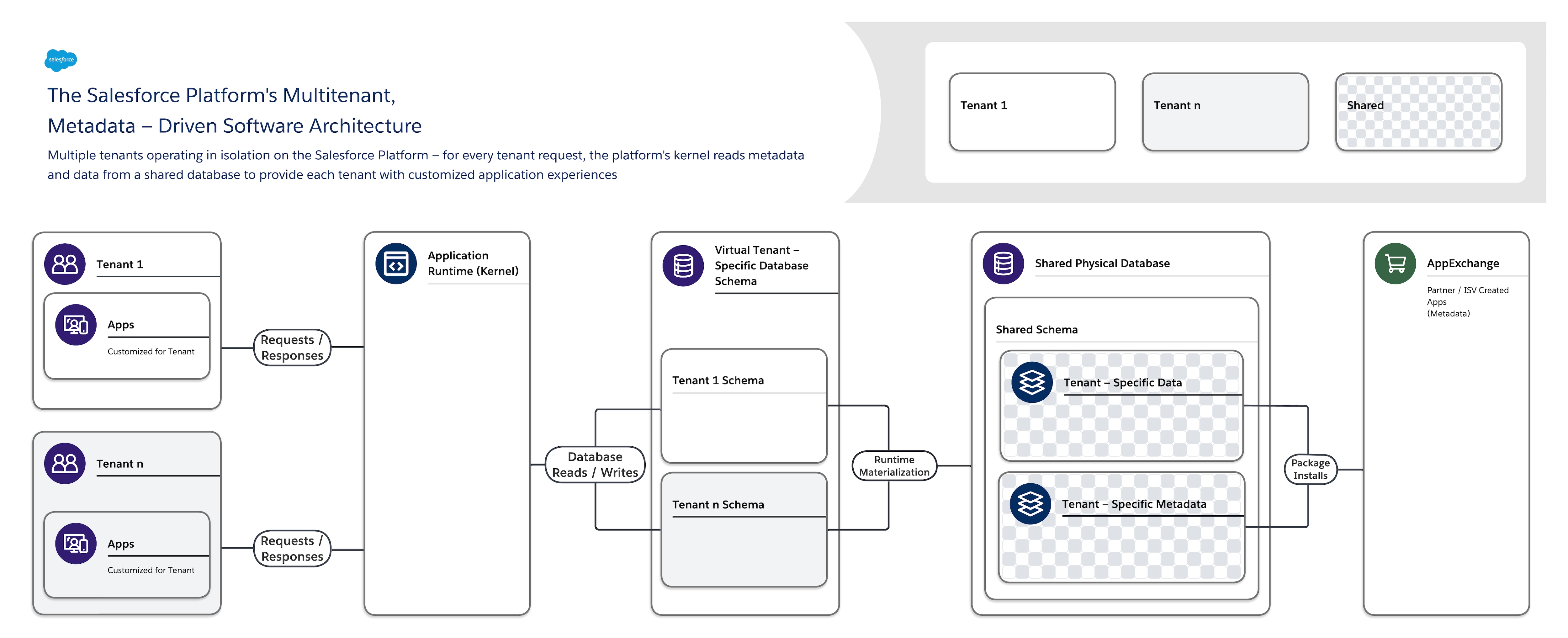
The Salesforce Platform’s software architecture is:
- Multitenant — It isolates and concurrently supports the varying requirements of many tenants (organizations, business units, and so on).
- Metadata-driven — It lets every tenant easily and quickly customize their apps and user experiences using metadata, data that describes elements such as the user interface (UI) and business logic.
When you create a new application object or write some code using the Salesforce Platform, the platform does not create an actual table in a database or compile any code. Instead, the platform simply stores some metadata that it can then use at runtime to dynamically materialize virtual application components. The platform ensures that every tenant’s metadata is private and easy to update without any locking or downtime required so that every tenant can build and customize apps in isolation. The Salesforce Platform uses the same metadata to provide custom APIs, RESTful and web services (SOAP-based) interfaces you can use to integrate your applications with other applications and automated processes.
Ready-made solutions are also available in AppExchange, the platform’s expansive app marketplace. Built by a vast ecosystem of trusted partners and independent software vendors (ISVs), an AppExchange package is metadata from a third-party that describes free or paid-for application extensions and entire applications that you can use to meet specific business requirements.
To support this highly customizable and extensible architecture, a single instance of the Salesforce Platform uses:
- A single shared multitenant database with a single schema that stores tenant-specific metadata and data.
- A multitenant kernel (application runtime) that reads metadata and data to dynamically provide tenant-specific applications, business logic, and APIs for each tenant’s users at runtime.
This clear separation of the Salesforce-managed kernel from tenant-managed metadata makes it possible for Salesforce, tenants, and ISVs to independently evolve their portions of the system without interference.
To build on this overview, subsequent sections of this article provide more detail about the unique capabilities of the platform that stem from key aspects of its design, including:
- The Platform Data Layer
- Platform Application Development
- Internal Platform Processing
- Platform Infrastructure
Together, the Salesforce Platform’s application runtime and innovative data layer safely isolate tenant-specific data, schema customizations, and business logic. At a high level, the schema supports a variety of use cases:
- When you create or customize an application, the platform stores related metadata in shared database tables that maintain metadata for all tenants.
- When you use an application to read or write data, the platform stores your data in shared database tables that maintain data for all tenants.
- Behind the scenes, the platform also maintains internal metadata in a number of tables that the kernel uses to optimize request latency at runtime.
But how can a single shared database and schema keep every tenant’s data private? Every tenant on the platform is known as an organization, or org for short. And every org-specific record in shared database tables has an OrgID. When the kernel accesses the database, it uses this unique identifier to ensure that each org’s activities are private.

Org-specific objects (think tables in traditional relational database parlance), fields, stored procedures, database triggers, and more are all virtual constructs described by metadata that the platform stores in a few database tables known as the Universal Data Dictionary (UDD).
- MT_Objects is a database table that stores metadata about the objects that you define for an application, including a unique identifier for an object (ObjID), your org (OrgID), and the name you give for the object (ObjName).
- The MT_Fields system table stores metadata about the fields (columns) that you declare for each object, including a unique identifier for a field (FieldID), your org (OrgID), the object that contains the field (ObjID), the name of the field (FieldName), the field’s data type, a Boolean value to indicate if the field requires indexing (IsIndexed), and the position of the field in the object relative to other fields (FieldNum).
Because metadata is a key ingredient, the platform must optimize access to metadata; otherwise, frequent metadata access would prevent the service from scaling. With this potential bottleneck in mind, the platform uses massive and sophisticated metadata caches to maintain the most recently used metadata in memory, avoid performance-sapping disk I/O and code recompilations, and improve application response times.
The MT_Data system table stores the application-accessible data that maps to all org-specific tables and their fields, as defined by metadata in MT_Objects and MT_Fields. Each row includes identifying fields, such as a global unique identifier (GUID), the org that owns the row (OrgID), and the encompassing object identifier (ObjID). Each row in the MT_Data table also has a Name field that stores a “natural name” for corresponding records; for example, an Account record might use “Account Name,” a Case record might use “Case Number,” and so on.
Value0 ... ValueN flex columns, also known as slots, store application data that maps to the tables and fields declared in MT_Objects and MT_Fields, respectively. All flex columns use a variable-length string data type so that they can store any structured type of application data (strings, numbers, dates, and so on). As the following figure illustrates, no two fields of the same object can map to the same slot in MT_Data for storage; however, a single slot can manage the information of multiple fields, as long as each field stems from a different object.
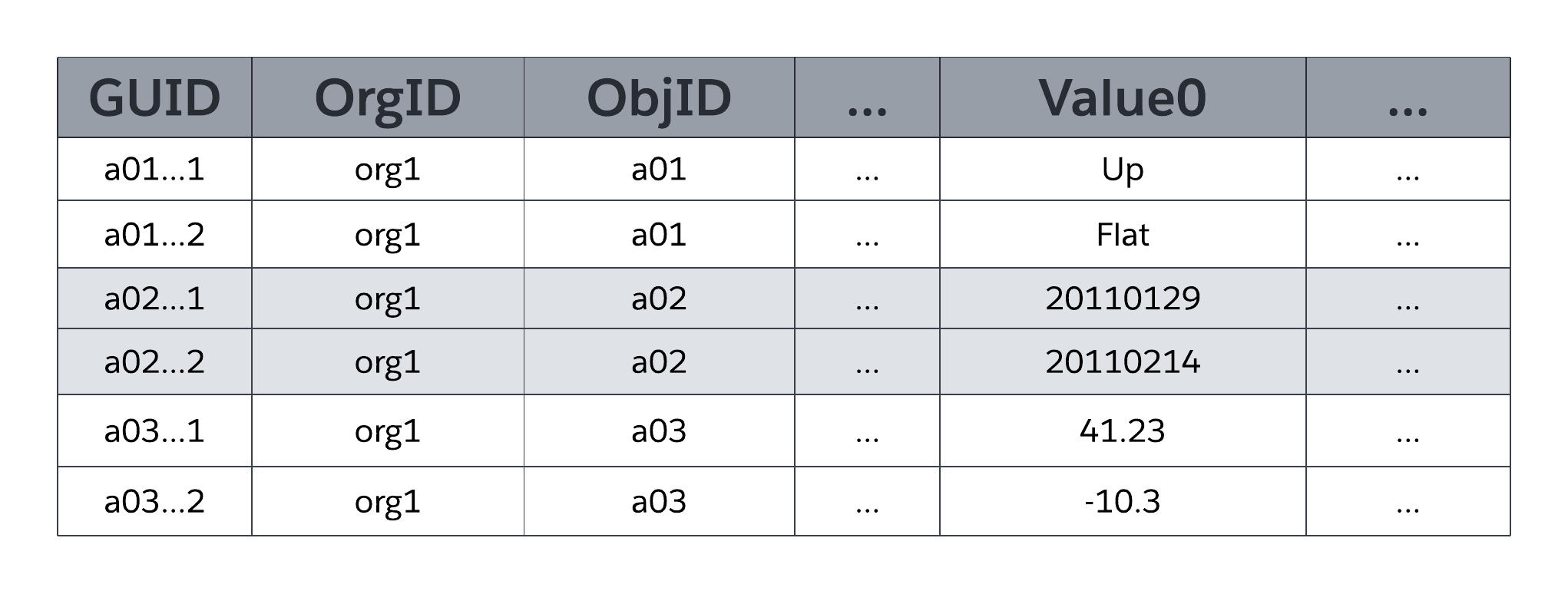
MTFields can use any one of a number of standard structured data types such as text, number, date, and date/time, as well as special-use, _rich-structured data types such as picklist (enumerated field), auto-number (auto-incremented, system-generated sequence number), formula (read-only derived value), master-detail relationship (foreign key), checkbox (Boolean), email, URL, and others. MT_Fields can also be required (not null) and have custom validation rules (for example, one field must be greater than another field), both of which the platform enforces.
When you declare or modify an object, the platform manages a row of metadata in MT_Objects that defines the object. Likewise, for each field, the platform manages a row in MT_Fields, including metadata that maps the field to a specific flex column in MT_Data for the storage of corresponding field data. Because the platform manages object and field definitions as metadata rather than actual database structures, the system can tolerate online multitenant application schema maintenance activities without blocking the concurrent activity of other orgs and users. By comparison, online table redefinition for traditional relational database systems typically requires temporary locks and often laborious, complicated processes and scheduled application downtime.
As the simplified representation of MT_Data in the previous figure shows, flex columns are of a universal data type (variable-length string), which enables the platform to share a single flex column among multiple fields that use various structured data types (strings, numbers, dates, and so on).
The platform stores all flex column data using a canonical format, and uses underlying database system data type conversion functions (for example, TO_NUMBER, TO_DATE, TO_CHAR) as necessary when applications read data from and write data to flex columns.
MTData also contains columns not shown in the previous figure. For example, there are four columns to manage auditing data, including which user created a row and when that row was created, and which user last modified a row and when that row was last modified. MT_Data also contains an _IsDeleted column that the platform uses to indicate when a row has been deleted.
The platform also supports the declaration of fields as character large objects (CLOBs) to permit the storage of long text fields of up to 32,000 characters. For each row in MTData that has a CLOB, the platform stores the CLOB out of line in a table called _MT_Clob, which the system can join with corresponding rows in MT_Data as necessary.
Note: The platform also stores CLOBs in an indexed form outside of the database for fast text searches. See Searches for more information about the platform’s text search engine.
The platform automatically indexes various types of fields to deliver scalable performance.
Traditional database systems rely on native database indexes to quickly locate specific rows in a database table that have fields matching a specific condition. However, it is not practical to create native database indexes for the flex columns of MTData because the platform uses a single flex column to store the data of many fields with varying structured data types. Instead, the platform manages an index of MT_Data by synchronously copying field data marked for indexing to an appropriate column in an _MT_Indexes pivot table.
MT_Indexes contains strongly typed, indexed columns such as StringValue, NumValue, and DateValue that the platform uses to locate field data of the corresponding data type. For example, the platform would copy a string value in an MT_Data flex column to the StringValue field in MT_Indexes, a date value to the DateValue field, and so on. The underlying indexes of MT_Indexes are standard, non-unique database indexes. When an internal system query includes a search parameter that references a structured field in an object, the platform’s custom query optimizer uses MT_Indexes to help optimize associated data access operations.
Note: The platform can handle searches across multiple languages because the system uses a case-folding algorithm that converts string values to a universal, case-insensitive format. The StringValue column of the MT_Indexes table stores string values in this format. At runtime, the query optimizer automatically builds data access operations so that the optimized SQL statement filters on the corresponding case-folded StringValue, which in turn corresponds to the literal provided in the search request.
The platform lets you indicate when a field in an object must contain unique values (case-sensitive or case-insensitive). Considering the arrangement of MT_Data and shared usage of the Value columns for field data, it is not practical to create unique database indexes for the object. (This situation is similar to the one discussed in the previous section for non-unique indexes.)
To support uniqueness for custom fields, the platform uses the MT_Unique_Indexes pivot table; this table is very similar to the MT_Indexes table, except that the underlying native database indexes of MT_Unique_Indexes enforce uniqueness. When an application attempts to insert a duplicate value into a field that requires uniqueness, or an administrator attempts to enforce uniqueness on an existing field that contains duplicate values, the platform returns an appropriate error message to the application.
In rare circumstances, the platform’s external search engine (explained in Searches) can become overloaded or otherwise unavailable, and may not be able to respond to a search request in a timely manner. Rather than returning a disappointing error to the end user, the platform falls back to a secondary search mechanism to furnish reasonable search results.
A fall-back search is implemented as a direct database query with search conditions that reference the Name field of target records. To optimize global object searches (searches that span tables) without having to execute potentially expensive union queries, the platform maintains a MT_Fallback_Indexes pivot table that records the Name of all records. Updates to MT_Fallback_Indexes happen synchronously as transactions modify records so that fall-back searches always have access to the most current database information.
The MT_Name_Denorm table is a lean data table that stores the ObjID and Name of each record in MT_Data. When an application needs to provide a list of records involved in a parent/child relationship, the platform uses the MT_Name_Denorm table to execute a relatively simple query that retrieves the Name of each referenced record for display in the app, for example as part of a hyperlink.
The platform provides relationship data types that an org can use to declare relationships (referential integrity) among tables. When you declare an object’s field with a relationship type, the platform maps the field to a Value field in MT_Data, and then uses this field to store the ObjID of a related object.
To optimize join operations, the platform maintains an MT_Relationships pivot table. This system table has two underlying database unique composite indexes that allow for efficient object traversals in either direction, as necessary.
With just a few mouse clicks, the platform provides history tracking for any field. When an org enables auditing for a specific field, the system asynchronously records information about the changes made to the field (old and new values, change date, and so on) using an internal pivot table as an audit trail.
All the platform data, metadata, and pivot table structures, including underlying database indexes, are physically partitioned by OrgID using native database partitioning mechanisms. Data partitioning is a proven technique that database systems provide to physically divide large logical data structures into smaller, more manageable pieces. Partitioning can also help to improve the performance, scalability, and availability of a large database system, such as a multitenant environment. By definition, every platform query targets a specific org’s information, so the query optimizer need only consider accessing data partitions that contain an org’s data, rather than an entire table or index. This common optimization is sometimes referred to as “partition pruning.”
This section covers how app developers can create a schema’s underlying metadata and then build apps that manage data. That metadata and data is stored in the platform data layer described in the previous section.
Developers can declaratively build server-side application components using the platform’s browser-based development environment, commonly referred to as the platform Setup screens. Setup’s point-and-click UI supports all facets of the application schema building process, such as the creation of an application’s data model (including objects and their fields as well as relationships), security and sharing model (including users, profiles, and role hierarchies), user interface (including screen layouts, data entry forms, and reports), declarative logic (workflows), and programmatic logic (stored procedures and triggers). For example, Salesforce Flow makes it easy to automate a wide range of use cases. Setup’s Flow Builder UI, shown below, lets you graphically design and implement workflows that interact with users, or launch automatically based on a schedule or when triggered by an event.
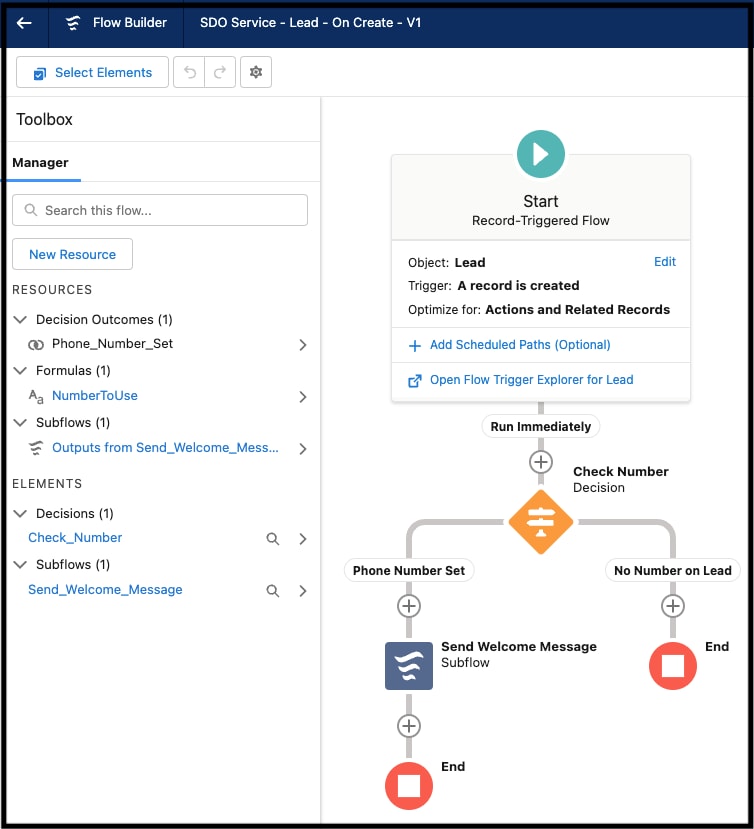
The Setup screens make it easy for anyone to develop and customize applications with no (or very little) code. For example:
- Platform-native UIs are easy to build without any code. Behind the scenes, a native app UI supports all the usual data access operations, including queries, inserts, updates, and deletes. Each data manipulation operation performed by native platform applications can modify one object at a time and automatically commit each change in a separate transaction.
- When defining a text field for an object that contains sensitive data, you can easily configure the field so that the platform encrypts the corresponding data and, optionally, uses an input mask to hide screen information from prying eyes.
- A declarative validation rule is a simple way for an org to enforce a domain integrity rule without any programming. For example, you might declare a validation rule that makes sure that a LineItem object’s Quantity field is always greater than zero.
- A formula field is a declarative feature of the platform that makes it easy to add a calculated field to an object. For example, you might add a field to the LineItem object to calculate a LineTotal value.
- A roll-up summary field is a cross-object field that makes it easy to aggregate child field information in a parent object. For example, you might create an OrderTotal summary field in the SalesOrder object based on the LineTotal field of the LineItem object.
Note: Internally, the platform implements formula and roll-up summary fields using native database features and efficiently recalculates values synchronously as part of ongoing transactions.
The platform provides several open, standards-based APIs that developers can use to build apps. Both RESTful and web services (SOAP-based) APIs provide access to the platform’s many features. Using these various APIs, an application can:
- Manipulate metadata that describes an application schema
- Create, read, update, and delete (CRUD) business data
- Bulk-load or query a large number of records asynchronously
- Expose a near real-time stream of data in a secure and scalable way
Apps can use the Salesforce Object Query Language (SOQL) to construct simple but powerful database queries. Similar to the SELECT command in the Structured Query Language (SQL), SOQL enables you to specify the source object, a list of fields to retrieve, and conditions for selecting rows in the source object. For example, the following SOQL query returns the value of the Id and Name field for all Account records with a Name equal to the string 'Acme'.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
The platform also includes a full-text, multilingual search engine that automatically indexes all text-related fields. Apps can make use of this pre-integrated search engine by using the Salesforce Object Search Language (SOSL) to perform text searches. Unlike SOQL, which can only query one object at a time, SOSL enables you to search text, email, and phone fields for multiple objects simultaneously. For example, the following SOSL statement searches for records in the Lead and Contact objects that contain the string 'Joe Smith' in the name field and returns the name and phone number field from each record found.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, which is similar to Java in many respects, is a powerful development language that developers can use to centralize procedural logic in their application schema. Apex code can declare program variables and constants, execute traditional flow control statements (if-else, loops, and so on), perform data manipulation operations (insert, update, upsert, delete), and perform transaction control operations (setSavepoint, rollback).
You can store Apex programs in the platform using two different forms: as a named Apex class with methods (akin to stored procedures in traditional database parlance) that applications execute when necessary, or as a database trigger that automatically executes before or after a specific database manipulation event occurs. In either form, the platform compiles Apex code and stores it as metadata in the UDD. The first time that an org executes an Apex program, the platform’s runtime interpreter loads the compiled version of the program into an MRU (most recently used) cache for that org. Thereafter, when any user from the same org needs to use the same routine, the platform can save memory and avoid the overhead of recompiling the program again by sharing the ready-to-run program that is already in memory.
With the addition of a simple keyword here and there, developers can use Apex to support many unique application requirements. For example, developers can expose a method as a custom RESTful or SOAP-based API call, make it asynchronously schedulable, or configure it to process a large operation in batches.
Apex is much more than “just another procedural language.” It’s an integral platform component that helps the system deliver reliable multitenancy. For example, the platform automatically validates all embedded SOQL and SOSL statements within a class to prevent code that would otherwise fail at runtime. The platform then maintains corresponding object dependency information for valid classes and uses it to prevent changes to metadata that would otherwise break dependent code.
Many standard Apex classes and system static methods provide simple interfaces to underlying system features. For example, the system static DML methods such as insert, update, and delete have a simple Boolean parameter that developers can use to indicate the desired bulk processing option (all or nothing, or partial save); these methods also return a result object that the calling routine can read to determine which records were unsuccessfully processed and why. Other examples of the direct ties between Apex and platform features include the built-in email classes and XmlStream classes.
In large part, the platform performs and scales well because Salesforce built it with two important principles in mind:
- Provide efficient, high-scale foundational platform capabilities.
- Help developers do everything as efficiently as possible.
The platform incorporates these principles into the unique processing architectures of the platform, including:
- Queries
- Searches
- Bulk operations
- Schema modification
- Multitenant isolation
- The recycle bin
Most modern database systems determine optimal query execution plans by employing a cost-based query optimizer that considers relevant statistics about target table and index data. However, conventional, cost-based optimizer statistics are designed for single-tenant applications and fail to account for the data access characteristics of any given user executing a query in a multitenant environment. For example, a given query that targets an object with a large volume of data would most likely execute more efficiently using different execution plans for users with high visibility (a manager that can see all rows) versus users with low visibility (sales people that can only see rows related to themselves).
To provide sufficient statistics for determining optimal query execution plans in a multitenant system, the platform maintains a complete set of optimizer statistics (tenant-, group-, and user-level) for every org’s objects. Statistics reflect the number of rows that a particular query can potentially access, carefully considering overall org-specific object statistics (for example, the total number of rows owned by the org as a whole), as well as more granular statistics (for example, the number of rows that a specific privilege group or end user can potentially access).
The platform also maintains other types of statistics that prove helpful with particular queries. For example, the platform maintains statistics for all custom indexes to reveal the total number of non-null and unique values in the corresponding field, and histograms for picklist fields that reveal the cardinality of each list value.
When existing statistics are not in place or are not considered helpful, the platform’s optimizer has a few different strategies it uses to help build reasonably optimal queries. For example, when a query filters on the Name field of an object, the optimizer can use the MT_Fallback_Indexes table to efficiently find requested rows. In other scenarios, the optimizer will dynamically generate missing statistics at runtime.
Used in tandem with optimizer statistics, the platform’s optimizer also relies on internal security-related tables (Groups, Members, GroupBlowout, and CustomShare) that maintain information about the security domains of an org’s users, including a given user’s group memberships and custom access rights for objects and rows. Such information is invaluable in determining the selectivity of query filters on a per-user basis. See the Platform Developer Basics Trailhead for more information about the platform’s embedded security model.
The flow diagram in the following figure illustrates what happens when the platform processes a request for data that is in one of the large heap tables such as MT_Data. The request might originate from any number of sources, such as an API call or stored procedure. First, the platform executes “pre-queries” that consider the multitenant-aware statistics. Then, based on the results returned by the pre-queries, the service builds an optimal underlying database query for execution in the specific setting.
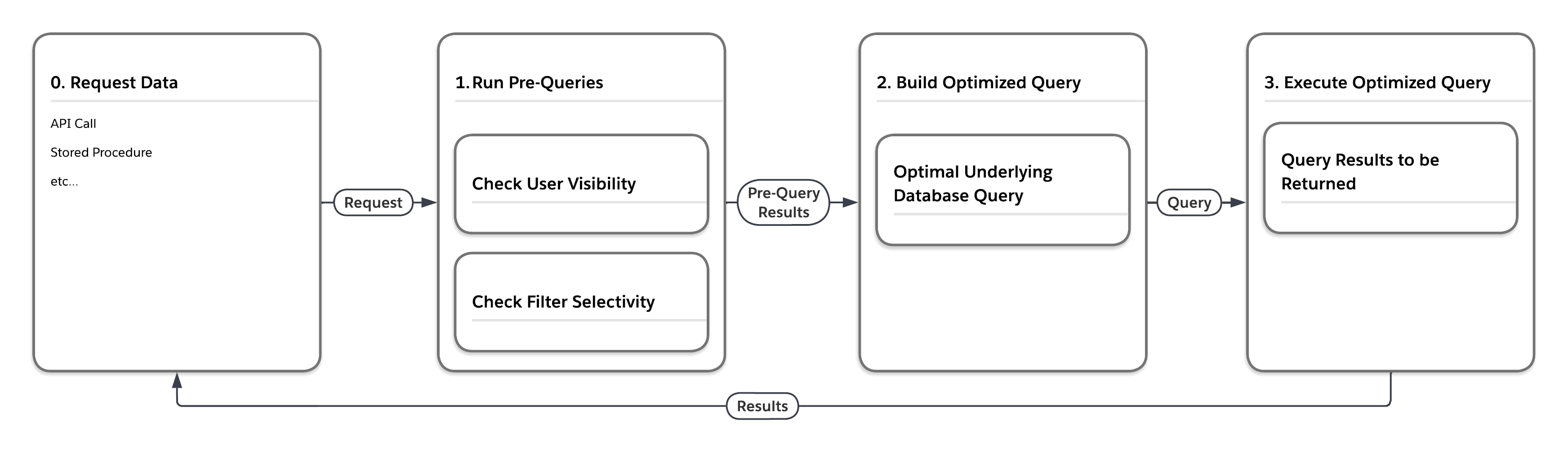
As the following table shows, the platform can execute the same query four different ways, depending on the user that submits the query and the selectivity of the query’s filter conditions.
| Pre-Query Selectivity Measurements | Write final database access query, forcing... | |
| User | Filter | |
| Low | Low | ... nested loops join, drive using view of rows that user can see |
| Low | High | ... use of index related to filter |
| High | Low | ... ordered hash join, drive using MT_DATA |
| High | High | ... use of index related filter |
Users expect an interactive search capability to scan all or a selected scope of an application’s database and return ranked results with sub-second response times. To provide this capability for platform applications, the platform uses a search engine that is separate from its transaction engine. When you update records, the transaction engine updates the core database and also forwards related data to the search engine for indexing. When you search for records, the search engine uses its indexes to process the query quickly and returns ranked results with links to related database records.
As applications update data in text fields (CLOBs, Name, and so on), a pool of background processes called indexing servers are responsible for asynchronously updating corresponding indexes, which the search engine maintains outside the core transaction engine. To optimize the indexing process, the platform synchronously copies modified chunks of text data to an internal “to-be-indexed” table as transactions commit, thus providing a relatively small data source that minimizes the amount of data that indexing servers must read from disk. The search engine automatically maintains separate indexes for each org.
Depending on the current load and utilization of indexing servers, text index updates may lag behind actual transactions. To avoid unexpected search results originating from stale indexes, the platform also maintains an MRU cache of recently updated rows that the system considers when materializing full-text search results. The platform maintains MRU caches on a per-user and per-org basis to efficiently support possible search scopes.
The platform’s search engine optimizes the ranking of records within search results using several methods. For example, the system considers the security domain of the user performing a search and puts more weight in the rows that the current user can access. The system can also consider the modification history of a particular row, and rank more actively updated rows ahead of those that are relatively static. The user can choose to weight search results as desired, for example, placing more emphasis on recently modified rows.
Transaction-intensive applications generate less overhead and perform much better when they combine and execute repetitive operations in bulk. For example, contrast two ways an application might load many new rows. An inefficient approach would be to use a routine with a loop that inserts individual rows, making one API call after another for each row insert. A much more efficient approach would be to create an array of rows and have the routine insert all of them with a single API call.
Efficient bulk processing with the platform is simple for developers because it is baked into API calls. Internally, the platform also bulk processes all internal steps related to an explicit bulk operation.
The platform’s bulk processing engine automatically accounts for isolated faults encountered during any step along the way. When a bulk operation starts in partial save mode, the engine identifies a known start state and then attempts to execute each step in the process (bulk validate field data, bulk fire pre-triggers, bulk save records, and so on). If the engine detects errors during any step, the engine rolls back offending operations and all side effects, removes the rows that are responsible for the faults, and continues, attempting to bulk process the remaining subset of rows. This process iterates through each successive stage until the engine can commit a subset of rows without any errors. The application can examine a return object to identify which rows failed and what exceptions they raised.
Note: At your discretion, an all-or-nothing mode is available for bulk operations. Also, the execution of triggers during a bulk operation is subject to internal governors that restrict the amount of work.
Certain types of modifications to the definition of an object require more than simple UDD metadata updates. In such cases, the platform uses efficient mechanisms that help reduce the overall performance impact on the cloud database service at large.
For example, consider what happens behind the scenes when you modify a column’s data type from picklist to text. The platform first allocates a new slot for the column’s data, bulk-copies the picklist labels associated with current values, and then updates the column’s metadata so that it points to the new slot. While all of this happens, access to data is normal and applications continue to function without any noticeable impact.
As another example, consider what happens when you add a roll-up summary field to an object. In this case, the platform asynchronously calculates initial summaries in the background using an efficient bulk operation. While the background calculation is happening, users who view the new field receive an indication that the platform is currently calculating the field’s value.
To prevent malicious or unintentional monopolization of shared, multitenant system resources, the platform has an extensive set of governors and resource limits associated with platform code execution. For example, the platform closely monitors the execution of a code script and limits how much CPU time it can use, how much memory it can consume, how many queries and DML statements it can execute, how many math calculations it can perform, how many outbound web services calls it can make, and much more. Individual queries that the platform’s optimizer regards as too expensive to execute throw a runtime exception to the caller. Although such limits might sound somewhat restrictive, they are necessary to protect the overall scalability and performance of the shared database system for all concerned applications. In the long term, these measures help to promote better coding techniques among developers and create a better experience for everyone that uses the platform. For example, a developer who initially tries to code a loop that inefficiently updates a thousand rows one row at a time will receive runtime exceptions due to resource limits and then begin using the platform’s efficient bulk processing API calls.
To further avoid potential system problems introduced by poorly written applications, the deployment of a new production application is a process that is strictly managed. Before an org can transition a new application from development to production status, Salesforce requires unit tests that validate the functionality of the application’s platform code routines. Submitted unit tests must cover no less than 75 percent of the application’s source code.
Salesforce executes submitted unit tests in the platform’s sandbox development environment to determine if the application code will adversely affect the performance and scalability of the multitenant population at large. The results of an individual unit test indicate basic information, such as the total number of lines executed, as well as specific information about the code that wasn’t executed by the test.
Once an application’s code is certified for production by Salesforce, the deployment process for the application consists of a single transaction that copies all the application’s metadata into a production platform instance and reruns the corresponding unit tests. If any part of the process fails, the platform simply rolls back the transaction and returns exceptions to help troubleshoot the problem.
Note: Salesforce reruns the unit tests for every application with each development release of the platform to proactively learn whether new system features and enhancements break any existing applications.
After a production application is live, the platform’s built-in performance profiler automatically analyzes it and provides associated feedback to administrators. Performance analysis reports include information about slow queries, data manipulations, and subroutines that you can review and use to tune application functionality. The system also logs and returns information about runtime exceptions to administrators to help them debug their applications.
When an app deletes a record from an object, the platform simply marks the row for deletion by modifying the row’s IsDeleted field in MTData. This action effectively places the row in what is known as the _Recycle Bin. the platform lets you restore selected rows from the Recycle Bin for up to 15 days before permanently removing them from MT_Data. The platform limits the total number of records it maintains for an org based on the storage limits for that org.
When an operation deletes a parent record involved in a master-detail relationship, the platform automatically deletes all related child records, provided that doing so would not break any referential integrity rules in place. For example, when you delete a SalesOrder, the platform automatically cascades the delete to dependent LineItems. Should you subsequently restore a parent record from the Recycle Bin, the system automatically restores all child records as well.
In contrast, when you delete a referenced parent record involved in a lookup relationship, the platform automatically sets all dependent keys to null. If you subsequently restore the parent record, the platform automatically restores the previously nulled lookup relationships, except for the relationships that were reassigned between the delete and restore operations.
The Recycle Bin also stores dropped fields and their data until an org permanently deletes them or a set number of days has elapsed, whichever happens first. Until that time, the entire field and all its data is available for restoration.
Agility is key for enterprises to be successful in our modern world. The Salesforce Platform’s underlying layers help your business applications quickly adapt to new challenges so you can continue to focus on your business rather than infrastructure.
Infrastructure (for example, foundational services and computing resources) is hidden, underlying technology that supports upper layers in the Salesforce Platform. Hyperforce is the Salesforce Platform infrastructure, built on 100% renewable energy and net-zero, that solves key customer challenges including compliance, trust, and scalability
Enterprises that operate in multiple geographical locations need to comply with new, evolving, and varying regulations for data management. Because Salesforce is deploying Hyperforce in an expanding number of countries, currently based on AWS region availability, platform applications and users can run their sensitive workloads in ways that meet strict data storage or data protection standards. For example, with Salesforce’s European Union (EU) Operating Zone powered by Hyperforce, EU businesses can easily keep their data in the EU.
Security, reliability, and availability are non-functional requirements that every business application must consider to deliver on the promise of trust to their end users. With Hyperforce, the Salesforce Platform lets enterprises deliver trusted business applications easily.
- Security — Hyperforce has native end-to-end encryption of customer data at-rest and in-transit. Hyperforce’s Zero Trust Architecture enforces a strict identity verification process that ensures there is no implicit access to resources. And Hyperforce uses the principle of least privilege, ensuring operations are approved for just the right amount of time with the right amount of access.
- Reliability — Every instance of Hyperforce uses multiple cloud availability zones and modernized approaches that speed incidence response to deliver a highly available and resilient platform.
- Availability — Hyperforce’s modern CI/CD pipelines and blue/green application releases minimize application maintenance periods to just one minute a year.
As the foundation for apps like Sales Cloud and Service Cloud, Salesforce is a proven application development platform on which individual enterprises and service providers have built millions of business applications for varying use cases, including supply chain management, billing, accounting, commerce, compliance tracking, human resource management, and claims processing. The platform’s unique, multitenant, metadata-driven architecture is engineered specifically for the cloud, and reliably and securely supports mission-critical, internet-scale applications. Using standards-based APIs and native development tools, platform developers can easily build all components of a modern web or mobile application, including the application’s data model (including objects and relationships), business logic (including workflows and validations), integrations with other applications, and more.
Since its inception, the platform has been optimized by Salesforce’s engineers for multitenancy, with features that let platform applications scale to meet changing business demands. Integral system features — such as the bulk data-processing API, Apex, a full-text search engine, and a unique query optimizer — help make dependent applications highly efficient and scalable with little or no effort from developers.
Salesforce’s managed approach for the deployment of production applications ensures excellent performance, scalability, and reliability for all applications that rely on the platform. Salesforce continually monitors and gathers operational information from platform applications to help drive incremental improvements and new system features that immediately benefit existing and new applications.
Steve Bobrowski is a successful entrepreneur and technology leader who has worked for many leading enterprise software companies, including various roles across Salesforce since 2008. Today, Steve works in Salesforce’s Office of the CTO to help with the company’s technology architecture strategies.
Tom Leddy is an Architect Evangelist at Salesforce. He supports the global Salesforce Architect Community by helping to create resources, tools & guidance that help enable architects to do their best work. Connect with Tom on Twitter.