Varje dag driver hundratusentals företag och miljoner användare sin verksamhet i molnet med hjälp av program från Salesforce Platform. Varför är plattformen så framgångsrik? Varför kan du Trust it stödja din verksamhet? Vilka unika fördelar ger plattformen för verksamheter som din?
Denna tekniska sammanfattning förklarar hur Salesforce Platform levererar pålitliga, skalbara och lättanpassade slutanvändarupplevelser med sin unika programvaruarkitektur för molntjänster. Efter att du har läst denna sammanfattning kommer du bättre förstå den underliggande teknik som gör Salesforce Platform till ett övertygande val för dina verksamhetsprogram.
Salesforce Platform är det främsta exemplet på en framgångsrik molntjänstplattform och ett relaterat ekosystem av program. Sedan millennieskiftet har plattformen varit den möjliggörande grunden för:
- Många populära verksamhetsapplikationer för vanliga användningsfall som försäljning och kundservice
- Branschspecifika applikationer för mer specialiserade användningsområden som finans och hälsovård
- Miljontals egna program och programtillägg för unika användningsfall
Salesforce Platform är till stor del så framgångsrik och populär eftersom dess unika programvaruarkitektur har stöd för program som är enkla att bygga, använda, anpassa och utöka med exceptionell prestanda och pålitlighet. Hjärtat i plattformens mjukvaruarkitektur är dess multitenant, metadatadrivna design.
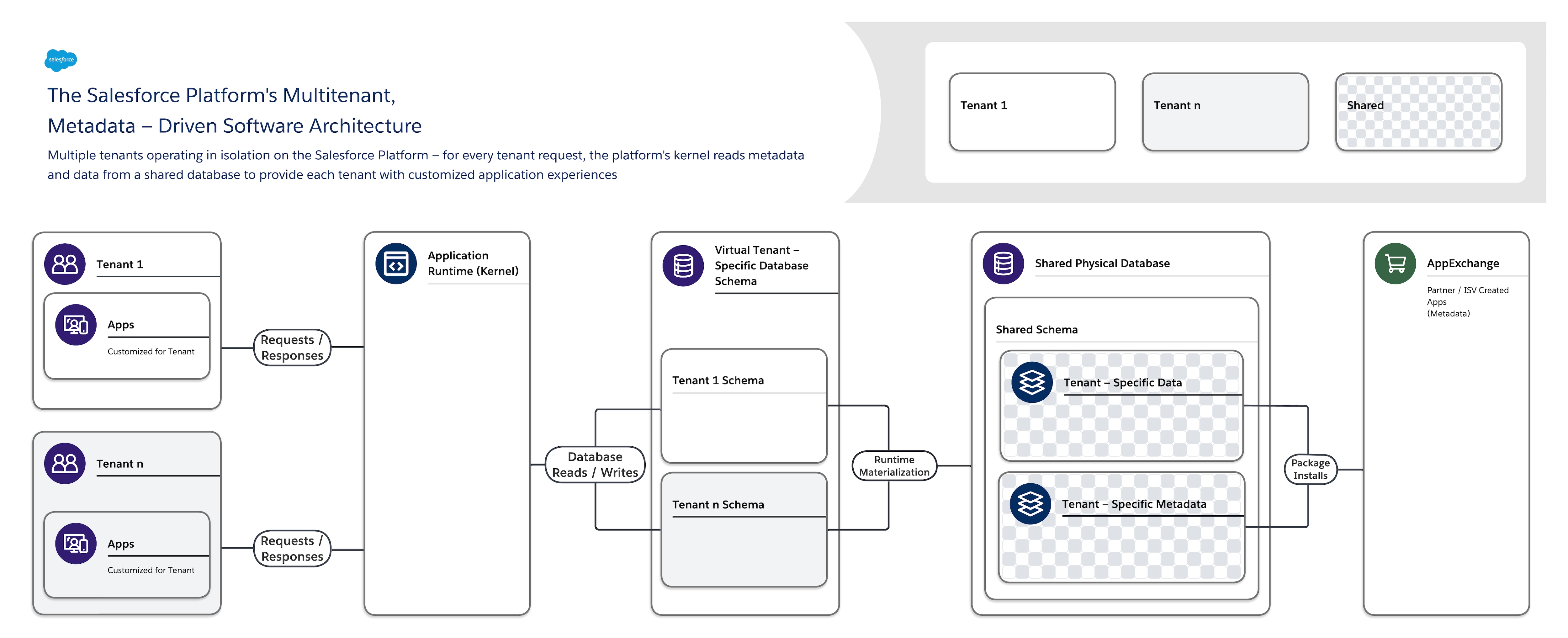
Salesforce Platforms programvaruarkitektur är:
- Multitenant — Den isolerar och stöder samtidigt de varierande kraven hos många arrendatorer (organisationer, affärsenheter och så vidare).
- Metadatadriven — Den låter alla arrendatorer enkelt och snabbt anpassa sina appar och användarupplevelser med hjälp av metadata, data som beskriver element som användargränssnitt och verksamhetslogik.
När du skapar ett nytt programobjekt eller skriver kod med Salesforce Platform skapar plattformen inte en faktisk tabell i en databas eller kompilerar någon kod. Istället lagrar plattformen bara vissa metadata som den sedan kan använda vid runtime för att dynamiskt materialisera virtuella programkomponenter. Plattformen säkerställer att varje arrendators metadata är privata och enkla att uppdatera utan att någon låsning eller nedtid krävs så att varje arrendator kan bygga och anpassa appar isolerat. Salesforce Platform använder samma metadata för att tillhandahålla egna API:n, gränssnitt för RESTful och webbtjänster (SOAP-baserade) som du kan använda för att integrera dina program med andra program och automatiserade processer.
Färdiga lösningar finns även i AppExchange, plattformens expansiva appmarknadsplats. Ett AppExchange paket är byggt av ett brett ekosystem av betrodda partners och oberoende programvaruleverantörer (ISVs) och är metadata från en tredje part som beskriver gratis eller betalda programtillägg och hela program som du kan använda för att uppfylla specifika verksamhetskrav.
För att stödja denna mycket anpassningsbara och utökningsbara arkitektur använder en enskild instans av Salesforce Platform:
- En enskild delad multitenantdatabas med ett enskilt schema som lagrar arrendatorspecifika metadata och data.
- En multitenantkärna (programkörning) som läser metadata och data för att dynamiskt tillhandahålla arrendatorspecifika program, verksamhetslogik och API för varje arrendatoranvändare vid körning.
Denna tydliga separation av den Salesforce-hanterade kärnan från arrendatorhanterade metadata gör det möjligt för Salesforce, arrendatorer och ISV:er att oberoende utveckla sina delar av systemet utan störningar.
För att bygga på denna översikt ger efterföljande sektioner i denna artikel mer detaljer om plattformens unika kapacitet som härrör från viktiga aspekter av dess design, inklusive:
- Plattformsdatalagret
- Utveckling av plattformsprogram
- Intern plattformsbearbetning
- Plattformsinfrastruktur
Tillsammans isolerar Salesforce Platforms programkörning och innovativa datalager säkert arrendatorspecifika data, schemaanpassningar och verksamhetslogik. På en hög nivå har schemat stöd för flera olika användningsfall:
- När du skapar eller anpassar ett program lagrar plattformen relaterade metadata i delade databastabeller som behåller metadata för alla arrendatorer.
- När du använder ett program för att läsa eller skriva data lagrar plattformen dina data i delade databastabeller som underhåller data för alla arrendatorer.
- Bakom kulisserna behåller plattformen även interna metadata i ett antal tabeller som kärnan använder för att optimera begärans latens vid runtime.
Men hur kan en enskild delad databas och schema hålla varje arrendators data privata? Varje arrendator på plattformen kallas en organisation, förkortat org. Och varje organisationsspecifik post i delade databastabeller har ett OrgID. När kärnan går till databasen använder den denna unika identifierare för att säkerställa att varje organisations aktiviteter är privata.

Organisationsspecifika objekt (tänk tabeller i traditionellt relationsdatabasspråk), fält, lagrade procedurer, databasutlösare med mera är alla virtuella konstruktioner som beskrivs av metadata som plattformen lagrar i några databastabeller som kallas Universal Data Dictionary (UDD).
- MT_Objects är en databastabell som lagrar metadata om de objekt som du definierar för ett program, inklusive en unik identifierare för ett objekt (ObjID), din organisation (OrgID) och namnet du anger för objektet (ObjName).
- Systemtabellen MT_Fields lagrar metadata om de fält (kolumner) som du deklarerar för varje objekt, inklusive en unik identifierare för ett fält (FieldID), din organisation (OrgID), objektet som innehåller fältet (ObjID), namnet på fältet (FieldName), fältets datatyp, ett booleskt värde för att indikera om fältet kräver indexering (IsIndexed) och fältets position i objektet i förhållande till andra fält (FieldNum).
Eftersom metadata är en viktig ingrediens måste plattformen optimera åtkomsten till metadata, annars skulle frekvent metadataåtkomst förhindra tjänsten från att skalas upp. Med tanke på denna potentiella flaskhals använder plattformen massiva och sofistikerade metadatacacheminnen för att upprätthålla de senast använda metadata i minnet, undvika prestandasänkande disk-I/O och kodomkompileringar och förbättra programsvarstider.
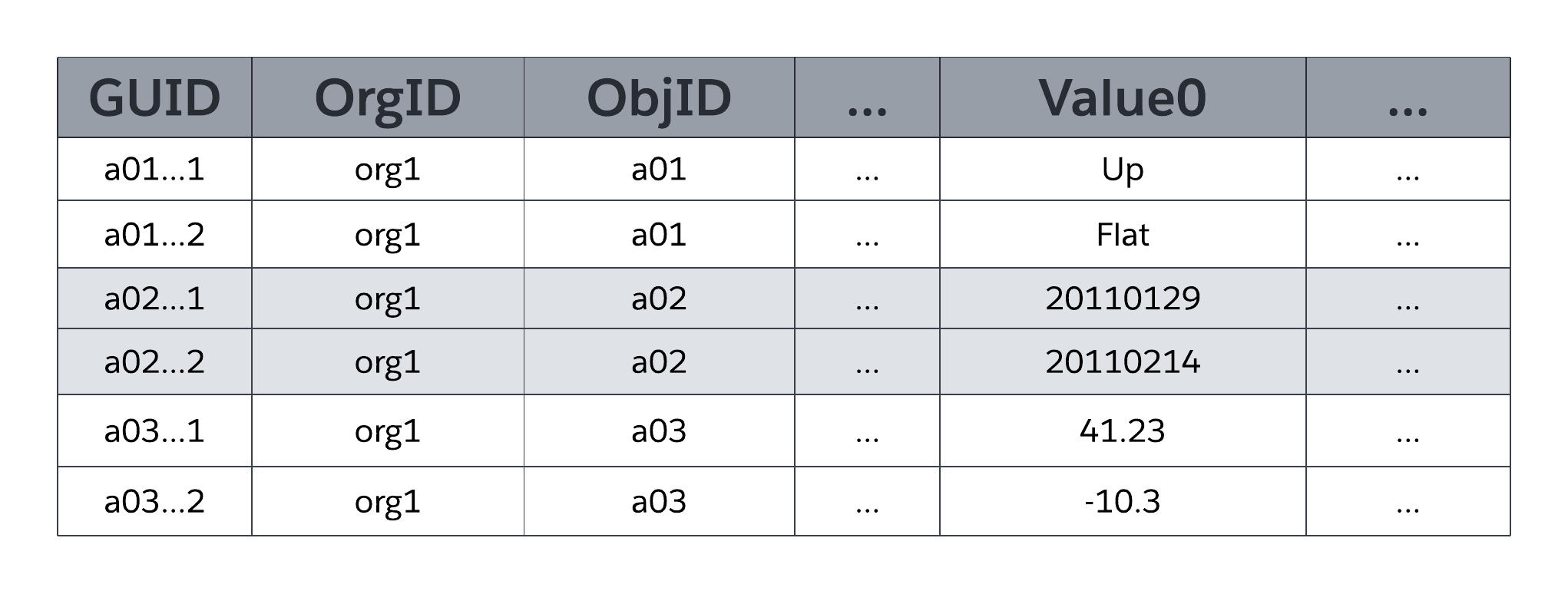
Systemtabellen MT_Data lagrar programtillgängliga data som mappar till alla organisationsspecifika tabeller och deras fält, enligt metadata i MT_Objects och MT_Fields. Varje rad innehåller identifierande fält, till exempel en global unik identifierare (GUID), organisationen som äger raden (OrgID) och den omgivande objektidentifieraren (ObjID). Varje rad i tabellen MT_Data har även ett Namn-fält som lagrar ett "naturligt namn" för motsvarande poster. Till exempel kan en kontopost använda "Kontonamn", en kundcasepost kan använda "Kundcasenummer" och så vidare.
Värde0 ... ValueN flexkolumner, även kallade luckor, lagrar programdata som mappar till tabeller och fält som deklarerats i MT_Objects respektive MT_Fields. Alla flexkolumner använder en datatyp med variabel längd så att de kan lagra alla strukturerade typer av programdata (strängar, nummer, datum och så vidare). Som följande figur illustrerar kan inga två fält i samma objekt mappa till samma lucka i MT_Data för lagring. En enskild lucka kan dock hantera informationen för flera fält så länge som varje fält kommer från ett annat objekt.
MTFields kan använda vilken som helst av ett antal standardstrukturerade datatyper som text, nummer, datum och datum/tid, samt specialanvända, _rich-strukturerade datatyper som kombinationsruta (uppräknade fält), automatisk numrering (automatiskt ökat, systemskapat sekvensnummer), formel (skrivskyddat deriverat värde), huvud-detalj-relation (utländsk nyckel), kryssruta (boolesk), e-post, URL, med flera. MT_Fields kan även vara obligatoriska (inte null) och ha egna valideringsregler (till exempel måste ett fält vara större än ett annat fält), som båda tillämpas av plattformen.
När du deklarerar eller ändrar ett objekt hanterar plattformen en rad med metadata i MT_Objects som definierar objektet. På samma sätt hanterar plattformen för varje fält en rad i MT_Fields, inklusive metadata som mappar fältet till en specifik flexkolumn i MT_Data för lagring av motsvarande fältdata. Eftersom plattformen hanterar objekt- och fältdefinitioner som metadata snarare än faktiska databasstrukturer kan systemet tolerera underhållsaktiviteter för programscheman online utan att blockera samtidig aktivitet för andra organisationer och användare. Som jämförelse kräver omdefinition av onlinetabeller för traditionella relationsdatabassystem vanligtvis tillfälliga låsningar och ofta arbetsamma, komplicerade processer och schemalagd programnedtid.
Som den förenklade representationen av MT_Data i föregående figur visar är flexkolumner av en universell datatyp (sträng med variabel längd), vilket gör att plattformen kan dela en enskild flexkolumn mellan flera fält som använder olika strukturerade datatyper (strängar, nummer, datum och så vidare).
Plattformen lagrar alla flexkolumndata i ett kanoniskt format och använder underliggande datatypkonverteringsfunktioner för databassystem (till exempel TO_NUMBER, TO_DATE, TO_CHAR) enligt behov när program läser data från och skriver data till flexkolumner.
MTData innehåller även kolumner som inte visas i föregående figur. Det finns till exempel fyra kolumner för att hantera granskningsdata, inklusive vilken användare som skapade en rad och när den raden skapades, och vilken användare som senast ändrade en rad och när den raden senast ändrades. MT_Data innehåller även kolumnen _IsDeleted som plattformen använder för att indikera när en rad har tagits bort.
Plattformen har även stöd för deklaration av fält som stora teckenobjekt (CLOBs) för att tillåta lagring av långa textfält med upp till 32 000 tecken. För varje rad i MTData som har en CLOB lagrar plattformen CLOB utanför raden i en tabell som heter _MT_Clob, som systemet kan slå samman med motsvarande rader i MT_Data efter behov.
Obs! Plattformen lagrar även CLOBs i indexerad form utanför databasen för snabbtextsökningar. Se Sökningar för mer information om plattformens textsökmotor.
Plattformen indexerar automatiskt olika typer av fält för att leverera skalbar prestanda.
Traditionella databassystem förlitar sig på inbyggda databasindex för att snabbt hitta specifika rader i en databastabell som har fält som matchar ett specifikt villkor. Det är dock inte praktiskt att skapa inbyggda databasindex för flexkolumner för MTData eftersom plattformen använder en enda flexkolumn för att lagra data i många fält med varierande strukturerade datatyper. Istället hanterar plattformen ett index för MT_Data genom att synkront kopiera fältdata markerade för indexering till en lämplig kolumn i en pivottabell för _MT_Indexs.
MT_Indexes innehåller starkt skrivna, indexerade kolumner som StringValue, NumValue och DateValue som plattformen använder för att hitta fältdata för motsvarande datatyp. Till exempel skulle plattformen kopiera ett strängvärde i en MT_Data-flexkolumn till fältet StringValue i MT_Indexes, ett datumvärde till fältet DateValue, och så vidare. De underliggande indexen för MT_Indexes är standard, icke-unika databasindex. När en intern systemfråga innehåller en sökparameter som refererar till ett strukturerat fält i ett objekt använder plattformens egna sökfrågeoptimerare MT_Indexes för att hjälpa till att optimera associerade dataåtkomståtgärder.
Obs! Plattformen kan hantera sökningar på flera språk eftersom systemet använder en skiftlägesalgoritm som konverterar strängvärden till ett universellt, ej skiftlägeskänsligt format. Kolumnen StringValue i tabellen MT_Indexes lagrar strängvärden i detta format. Vid runtime bygger frågeoptimeraren automatiskt dataåtkomståtgärder så att det optimerade SQL-uttrycket filtreras på motsvarande kundcasevikta StringValue, vilket i sin tur motsvarar den littera som anges i sökbegäran.
Plattformen låter dig indikera när ett fält i ett objekt måste innehålla unika värden (skiftlägeskänsliga eller ej skiftlägeskänsliga). Med tanke på arrangemanget av MT_Data och delad användning av kolumnerna Värde för fältdata är det inte praktiskt att skapa unika databasindex för objektet. (Denna situation liknar den som diskuterades i föregående avsnitt för icke-unika index.)
För att stödja unikhet för egna fält använder plattformen pivottabellen MT_Unique_Indexes; denna tabell liknar mycket tabellen MT_Indexes, förutom att de underliggande inbyggda databasindexen för MT_Unique_Indexes upprätthåller unikhet. När ett program försöker infoga ett dubblettvärde i ett fält som kräver unikhet, eller en administratör försöker tillämpa unikhet i ett befintligt fält som innehåller dubblettvärden, returnerar plattformen ett lämpligt felmeddelande till programmet.
I sällsynta fall kan plattformens externa sökmotor (som förklaras i Sökningar) bli överbelastad eller på annat sätt otillgänglig och kanske inte kan svara på en sökförfrågan i tid. Istället för att returnera ett tråkigt fel till slutanvändaren återgår plattformen till en sekundär sökmekanism för att ge rimliga sökresultat.
En standardsökning implementeras som en direkt databasfråga med sökvillkor som refererar fältet Namn i målposter. För att optimera globala objektsökningar (sökningar som sträcker sig över tabeller) utan att behöva utföra potentiellt dyra unionsfrågor upprätthåller plattformen en pivottabell för MT_Fallback_Indexes som registrerar Namn på alla poster. Uppdateringar av MT_Fallback_Index sker synkront när transaktioner ändrar poster så att grundsökningar alltid har åtkomst till den senaste databasinformationen.
Tabellen MT_Name_Denorm är en mager datatabell som lagrar ObjID och Namn för varje post i MT_Data. När ett program behöver tillhandahålla en lista över poster som är involverade i en överordnad/underordnad relation använder plattformen tabellen MT_Name_Denorm för att utföra en relativt enkel sökfråga som hämtar Namn på varje refererad post för visning i appen, till exempel som en del av en hyperlänk.
Plattformen tillhandahåller relationsdatatyper som en organisation kan använda för att deklarera relationer (referensintegritet) mellan tabeller. När du deklarerar ett objekts fält med en relationstyp mappar plattformen fältet till ett värdefält i MT_Data och använder sedan detta fält för att lagra ObjID för ett relaterat objekt.
För att optimera sammanslagningsåtgärder upprätthåller plattformen pivottabellen MT_Relationships. Denna systemtabell har två underliggande unika databasindex som möjliggör effektiva objekttraverseringar i båda riktningar, efter behov.
Med bara några få musklick tillhandahåller plattformen historikspårning för alla fält. När en organisation aktiverar granskning för ett specifikt fält registrerar systemet asynkront information om de ändringar som gjorts av fältet (gamla och nya värden, ändringsdatum och så vidare) med hjälp av en intern pivottabell som en granskningslogg.
Alla plattformsdata, metadata och pivottabellstrukturer, inklusive underliggande databasindex, partitioneras fysiskt av OrgID med inbyggda partitioneringsmekanismer för databaser. Datapartitionering är en beprövad teknik som databassystem tillhandahåller för att fysiskt dela upp stora logiska datastrukturer i mindre, mer hanterbara bitar. Partitionering kan även hjälpa till att förbättra prestandan, skalbarheten och tillgängligheten för ett stort databassystem, till exempel en miljö med flera klienter. Per definition är varje plattformsfråga inriktad på en specifik organisations information, så frågeoptimeraren behöver endast överväga att öppna datapartitioner som innehåller en organisations data, snarare än en hel tabell eller index. Denna vanliga optimering kallas ibland "partitionsbeskärning".
Detta avsnitt handlar om hur apputvecklare kan skapa ett schemas underliggande metadata och sedan bygga appar som hanterar data. Dessa metadata och data lagras i plattformsdatalagret som beskrivs i föregående avsnitt.
Utvecklare kan deklarativt bygga programkomponenter på serversidan med hjälp av plattformens webbläsarbaserade utvecklingsmiljö, vanligen kallad Platform Inställningsskärmar. Konfigurationens peka-och-klicka-gränssnitt har stöd för alla aspekter av processen för att bygga programscheman, till exempel skapandet av ett programs datamodell (inklusive objekt och deras fält samt relationer), säkerhet och delningsmodell (inklusive användare, profiler och rollhierarkier), användargränssnitt (inklusive skärmlayouter, datainmatningsformulär och rapporter), deklarativ logik (arbetsflöden) och programmatisk logik (lagrade procedurer och utlösare). Salesforce-flödet gör det till exempel enkelt att automatisera ett brett spektrum av användningsfall. Inställningars Flow Builder-gränssnitt, som visas nedan, låter dig grafiskt utforma och implementera arbetsflöden som interagerar med användare, eller startas automatiskt baserat på ett schema eller när det utlöses av en händelse.
Inställningsskärmarna gör det enkelt för alla att utveckla och anpassa program med ingen (eller mycket lite) kod. Exempel:
- Plattformsinbyggda användargränssnitt är enkla att bygga utan någon kod. Bakom kulisserna har ett inbyggt appgränssnitt stöd för alla vanliga dataåtkomståtgärder, inklusive sökfrågor, infogningar, uppdateringar och borttagningar. Varje datamanipulation som utförs av inbyggda plattformsprogram kan ändra ett objekt åt gången och automatiskt överlämna varje ändring i en separat transaktion.
- När du definierar ett textfält för ett objekt som innehåller känsliga data kan du enkelt konfigurera fältet så att plattformen krypterar motsvarande data och, om du vill, använder en indatamask för att dölja skärminformation från nyfikna ögon.
- En deklarativ valideringsregel är ett enkelt sätt för en organisation att tillämpa en domänintegritetsregel utan programmering. Du kan till exempel ange en valideringsregel som säkerställer att ett LineItem-objekts fält Kvantitet alltid är större än noll.
- Ett formelfält är en deklarativ funktion i plattformen som gör det enkelt att lägga till ett beräknat fält till ett objekt. Du kan till exempel lägga till ett fält i objektet LineItem för att beräkna ett LineTotal-värde.
- Ett summeringssammanfattningsfält är ett korsobjektfält som gör det enkelt att aggregera underordnad fältinformation i ett överordnat objekt. Du kan till exempel skapa ett sammanfattningsfält för OrderTotal i objektet SalesOrder baserat på fältet LineTotal i objektet LineItem.
Obs! Internt implementerar plattformen formel- och summeringssammanfattningsfält med inbyggda databasfunktioner och omberäknar effektivt värden synkront som en del av pågående transaktioner.
Plattformen har flera öppna, standardbaserade API:n som utvecklare kan använda för att bygga appar. Både RESTful och webbtjänster (SOAP-baserade) API ger åtkomst till plattformens många funktioner. Med hjälp av dessa olika API:n kan ett program:
- Hantera metadata som beskriver ett programschema
- Skapa, läsa, uppdatera och ta bort (CRUD) affärsdata
- Massinläsning eller asynkron förfrågan av ett stort antal poster
- Exponera en dataström nästan i realtid på ett säkert och skalbart sätt
Appar kan använda Salesforce Object Query Language (SOQL) för att skapa enkla men kraftfulla databasfrågor. På samma sätt som SELECT-kommandot i SQL (Structured Query Language) låter SOQL dig specificera källobjektet, en lista över fält att hämta och villkor för att välja rader i källobjektet. Till exempel returnerar följande SOQL-fråga värdet för fältet Id och Namn för alla kontoposter med ett namn som är lika med strängen 'Acme'.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
Plattformen innehåller även en flerspråkig fulltextsökmotor som automatiskt indexerar alla textrelaterade fält. Appar kan använda denna förintegrerade sökmotor genom att använda Salesforce Object Search Language (SOSL) för att utföra textsökningar. Till skillnad från SOQL, som endast kan fråga ett objekt åt gången, låter SOSL dig söka text-, e-post- och telefonfält för flera objekt samtidigt. Till exempel söker följande SOSL-uttryck efter poster i objekten Lead och Kontakt som innehåller strängen 'Joe Smith' i namnfältet och returnerar namn- och telefonnummerfältet från varje post som hittas.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, som i många avseenden liknar Java, är ett kraftfullt utvecklingsspråk som utvecklare kan använda för att centralisera processlogik i sitt programschema. Apex kod kan deklarera programvariabler och konstanter, utföra traditionella flödeskontrolluttryck (if-else, loopar och så vidare), utföra datamanipulationsåtgärder (infoga, uppdatera, infoga, ta bort) och utföra transaktionskontrollåtgärder (setSavepoint, rollback).
Du kan lagra Apex program i plattformen med två olika formulär: som en namngiven Apex klass med metoder (liknande lagrade procedurer i traditionellt databasspråk) som program kör vid behov, eller som en databasutlösare som automatiskt körs före eller efter att en specifik händelse för databasmanipulation inträffar. I båda formaten kompilerar plattformen Apex kod och lagrar den som metadata i UDD. Första gången en organisation kör ett Apex program läser plattformens runtimetolk in den kompilerade versionen av programmet i en MRU-cache (senast använd) för den organisationen. Om en användare från samma organisation behöver använda samma rutin kan plattformen spara minne och undvika att kompilera om programmet igen genom att dela det körklara programmet som redan finns i minnet.
Genom att lägga till ett enkelt nyckelord här och där kan utvecklare använda Apex för att stödja många unika applikationskrav. Till exempel kan utvecklare visa en metod som ett eget RESTful- eller SOAP-baserat API-anrop, göra den asynkront schemaläggningsbar eller konfigurera den att bearbeta en stor operation i satser.
Apex är mycket mer än ”bara ett till procedurspråk”. Det är en integrerad plattformskomponent som hjälper systemet leverera pålitlig multitenans. Till exempel validerar plattformen automatiskt alla inbäddade SOQL- och SOSL-uttryck inom en klass för att förhindra kod som annars skulle misslyckas vid runtime. Plattformen behåller sedan motsvarande information om objektberoenden för giltiga klasser och använder den för att förhindra ändringar av metadata som annars skulle bryta beroende kod.
Många standard Apex klasser och systemstatiska metoder ger enkla gränssnitt till underliggande systemfunktioner. Till exempel har de systemstatiska DML-metoderna som infoga, uppdatera och ta bort en enkel boolesk parameter som utvecklare kan använda för att indikera det önskade massbearbetningsalternativet (allt eller inget, eller delvis spara); dessa metoder returnerar även ett resultatobjekt som anropsrutinen kan läsa för att avgöra vilka poster som inte behandlades och varför. Andra exempel på direkta kopplingar mellan Apex och plattformsfunktioner inkluderar de inbyggda e-postklasserna och XmlStream-klasserna.
Till stor del presterar och skalar plattformen bra eftersom Salesforce byggde den med två viktiga principer i åtanke:
- Tillhandahåll effektiv, storskalig grundläggande plattformskapacitet.
- Hjälp utvecklare göra allt så effektivt som möjligt.
Plattformen införlivar dessa principer i plattformens unika bearbetningsarkitekturer, inklusive:
- Sökfrågor
- Sökningar
- Bulkoperationer
- Schemaändring
- Multitenantisolering
- Papperskorgen
De flesta moderna databassystem avgör optimala planer för att utföra sökfrågor genom att använda en kostnadsbaserad sökfrågeoptimerare som överväger relevant statistik om måltabell- och indexdata. Konventionell, kostnadsbaserad optimerarstatistik är dock utformad för applikationer med en enda arrendator och tar inte hänsyn till dataåtkomstegenskaperna för någon användare som kör en sökfråga i en miljö med flera arrendatorer. Till exempel, en given sökfråga som riktar in sig på ett objekt med en stor mängd data skulle troligen köras mer effektivt med olika utförandeplaner för användare med hög synlighet (en chef som kan se alla rader) jämfört med användare med låg synlighet (säljare som endast kan se rader relaterade till sig själva).
För att tillhandahålla tillräcklig statistik för att avgöra optimala planer för att utföra sökfrågor i ett system med flera klienter upprätthåller plattformen en fullständig uppsättning optimerarstatistik (arrendator-, grupp- och användarnivå) för varje organisations objekt. Statistik reflekterar antalet rader som en specifik sökfråga potentiellt kan komma åt, noggrant med tanke på övergripande organisationsspecifik objektstatistik (till exempel det totala antalet rader som ägs av organisationen som helhet) samt mer detaljerad statistik (till exempel antalet rader som en specifik behörighetsgrupp eller slutanvändare potentiellt kan komma åt).
Plattformen upprätthåller även andra typer av statistik som visar sig vara hjälpsam med specifika sökfrågor. Till exempel upprätthåller plattformen statistik för alla egna index för att avslöja det totala antalet icke-nullvärden och unika värden i motsvarande fält, och histogram för kombinationsrutefält som avslöjar kardinaliteten för varje listvärde.
Om befintlig statistik inte finns på plats eller inte anses vara hjälpsam har plattformens optimerare några olika strategier som den använder för att hjälpa till att bygga någorlunda optimala sökfrågor. Till exempel, när en sökfråga filtrerar efter fältet Namn för ett objekt kan optimeraren använda tabellen MT_Fallback_Indexes för att effektivt hitta begärda rader. I andra scenarion kommer optimeraren att dynamiskt skapa statistik som saknas vid runtime.
Används tillsammans med optimerarstatistik förlitar sig plattformens optimerare även på interna säkerhetsrelaterade tabeller (Groups, Members, GroupBlowout och CustomShare) som upprätthåller information om säkerhetsdomänerna för en organisations användare, inklusive en användares gruppmedlemskap och egna åtkomsträttigheter för objekt och rader. Sådan information är ovärderlig för att avgöra selektiviteten för sökfrågefilter per användare. Se Platform Developer Basics Trailhead för mer information om plattformens inbäddade säkerhetsmodell.
Flödesdiagrammet i följande figur illustrerar vad som händer när plattformen bearbetar en begäran om data som finns i en av de stora heaptabellerna, till exempel MT_Data. Begäran kan komma från ett obegränsat antal källor, till exempel ett API-anrop eller en lagrad procedur. Först utför plattformen "förfrågor" som överväger den multitenant-medvetna statistiken. Baserat på de resultat som returneras av förfrågorna bygger tjänsten sedan en optimal underliggande databasfråga för utförande i den specifika inställningen.
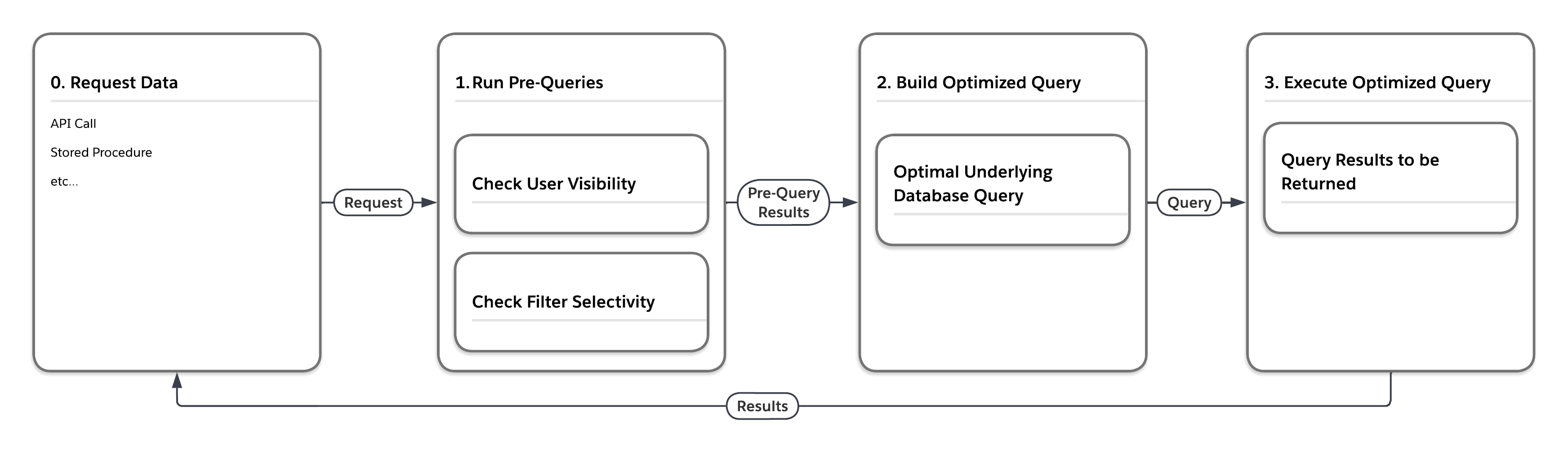
Som följande tabell visar kan plattformen köra samma sökfråga på fyra olika sätt, beroende på vilken användare som skickar in sökfrågan och selektiviteten i sökfrågans filtervillkor.
| Selektivitetsmått före förfrågan | Skriv slutgiltig databasåtkomstfråga, tvinga... | |
| Användare | Filter | |
| Låg | Låg | ... kapslade loopar slås samman, kör med vy över rader som användare kan se |
| Låg | Hög | ... användning av index relaterat till filter |
| Hög | Låg | ... beställd hashsammanslagning, kör med MT_DATA |
| Hög | Hög | ... användning av indexrelaterade filter |
Användare förväntar sig att en interaktiv sökfunktion ska skanna hela eller ett utvalt omfång av ett programs databas och returnera rangordnade resultat med svarstider på undersekunder. För att tillhandahålla denna kapacitet för plattformsprogram använder plattformen en sökmotor som är separat från dess transaktionsmotor. När du uppdaterar poster uppdaterar transaktionsmotorn kärndatabasen och vidarebefordrar även relaterade data till sökmotorn för indexering. När du söker efter poster använder sökmotorn sina index för att snabbt bearbeta sökfrågan och returnerar rangordnade resultat med länkar till relaterade databasposter.
När program uppdaterar data i textfält (CLOBs, Name och så vidare), är en pool av bakgrundsprocesser som kallas indexeringsservrar ansvariga för att asynkront uppdatera motsvarande index, som sökmotorn upprätthåller utanför huvudtransaktionsmotorn. För att optimera indexeringsprocessen kopierar plattformen synkront ändrade delar av textdata till en intern "att indexera"-tabell medan transaktioner utförs, vilket ger en relativt liten datakälla som minimerar mängden data som indexeringsservrar måste läsa från disken. Sökmotorn upprätthåller automatiskt separata index för varje organisation.
Beroende på den aktuella belastningen och användningen av indexeringsservrar kan textindexuppdateringar släpa efter faktiska transaktioner. För att undvika oväntade sökresultat som kommer från gamla index upprätthåller plattformen även en MRU-cache med nyligen uppdaterade rader som systemet överväger när det materialiserar sökresultat i fulltext. Plattformen upprätthåller MRU-cacher per användare och per organisation för att effektivt stödja möjliga sökomfång.
Plattformens sökmotor optimerar rangordningen av poster i sökresultat med hjälp av flera metoder. Till exempel överväger systemet säkerhetsdomänen för användaren som utför en sökning och lägger mer vikt i de rader som den aktuella användaren har åtkomst till. Systemet kan även överväga ändringshistoriken för en specifik rad och rangordna mer aktivt uppdaterade rader framför de som är relativt statiska. Användaren kan välja att vikta sökresultaten efter önskemål, till exempel genom att lägga större tonvikt på nyligen ändrade rader.
Transaktionsintensiva program genererar mindre overhead och presterar mycket bättre när de kombinerar och utför repetitiva operationer i bunt. Till exempel kan ett program läsa in många nya rader på två olika sätt. Ett ineffektivt tillvägagångssätt skulle vara att använda en rutin med en loop som infogar individuella rader och gör ett API-anrop efter ett för varje radinfogning. Ett mycket mer effektivt tillvägagångssätt skulle vara att skapa en matris av rader och låta rutinen infoga dem alla med ett enda API-anrop.
Effektiv massbearbetning med plattformen är enkel för utvecklare eftersom den är inbakad i API-anrop. Internt bearbetar plattformen även alla interna steg relaterade till en explicit massoperation.
Plattformens massbearbetningsmotor tar automatiskt hänsyn till isolerade fel som uppstår under något steg på vägen. När en massåtgärd startar i delvis sparläge identifierar motorn ett känt startläge och försöker sedan utföra varje steg i processen (validera fältdata i bunt, förutlösare för massbrand, spara poster i bunt och så vidare). Om motorn upptäcker fel under något steg drar motorn tillbaka felaktiga åtgärder och alla sidoeffekter, tar bort de rader som är ansvariga för felen och fortsätter och försöker massbearbeta den återstående underuppsättningen rader. Denna process upprepas genom varje efterföljande steg tills motorn kan överlämna en underuppsättning rader utan några fel. Programmet kan undersöka ett returobjekt för att identifiera vilka rader som misslyckades och vilka undantag de skapade.
Obs! Efter eget gottfinnande är ett allt-eller-inget-läge tillgängligt för massåtgärder. Utförandet av utlösare under en massoperation är även föremål för interna styrande som begränsar mängden arbete.
Vissa typer av ändringar av definitionen av ett objekt kräver mer än enkla UDD-metadatauppdateringar. I sådana fall använder plattformen effektiva mekanismer som hjälper till att minska den övergripande prestandapåverkan på molndatabastjänsten i stort.
Tänk till exempel på vad som händer bakom kulisserna när du ändrar en kolumns datatyp från kombinationsruta till text. Plattformen allokerar först en ny lucka för kolumnens data, masskopierar kombinationsruteetiketterna som är associerade med aktuella värden och uppdaterar sedan kolumnens metadata så att den pekar till den nya luckan. Allt detta händer, men åtkomst till data är normal och program fortsätter att fungera utan någon märkbar påverkan.
Som ett annat exempel, tänk på vad som händer när du lägger till ett summeringssammanfattningsfält till ett objekt. I detta fall beräknar plattformen asynkront inledande sammanfattningar i bakgrunden med hjälp av en effektiv massoperation. Medan bakgrundsberäkningen utförs får användare som visar det nya fältet en indikation på att plattformen för närvarande beräknar fältets värde.
För att förhindra skadlig eller oavsiktlig monopolisering av delade systemresurser med flera klienter har plattformen en omfattande uppsättning styrande och resursgränser associerade med plattformskodkörning. Till exempel övervakar plattformen noggrant utförandet av ett kodskript och begränsar hur mycket CPU-tid det kan använda, hur mycket minne det kan konsumera, hur många sökfrågor och DML-uttryck det kan köra, hur många matematiska beräkningar det kan utföra, hur många utgående webbtjänstanrop det kan göra, och mycket mer. Individuella sökfrågor som plattformens optimerare anser vara för dyra att utföra ger ett runtimeundantag till anroparen. Även om sådana gränser kan låta något restriktiva är de nödvändiga för att skydda den övergripande skalbarheten och prestandan hos det delade databassystemet för alla berörda program. På lång sikt bidrar dessa åtgärder till att främja bättre kodningstekniker bland utvecklare och skapa en bättre upplevelse för alla som använder plattformen. Till exempel kommer en utvecklare som inledningsvis försöker koda en loop som ineffektivt uppdaterar tusen rader en rad åt gången att få runtimeundantag på grund av resursbegränsningar och sedan börja använda plattformens effektiva API-anrop för massbearbetning.
För att ytterligare undvika potentiella systemproblem som introduceras av dåligt skrivna program är distribueringen av ett nytt produktionsprogram en process som hanteras strikt. Innan en organisation kan överföra ett nytt program från utveckling till produktionsstatus kräver Salesforce enhetstester som validerar funktionaliteten hos programmets plattformskodrutiner. Inskickade enhetstester måste omfatta minst 75 procent av programmets källkod.
Salesforce utför inskickade enhetstester i plattformens sandboxutvecklingsmiljö för att avgöra om programkoden kommer att påverka prestandan och skalbarheten för multitenantpopulationen i stort negativt. Resultaten av ett individuellt enhetstest indikerar grundläggande information, som totalt antal rader som utförts, samt specifik information om koden som inte utförts av testet.
När ett programs kod har certifierats för produktion av Salesforce består distributionsprocessen för programmet av en enskild transaktion som kopierar programmets alla metadata till en produktionsplattforminstans och kör motsvarande enhetstester igen. Om någon del av processen misslyckas drar plattformen bara tillbaka transaktionen och returnerar undantag för att hjälpa till att felsöka problemet.
Obs! Salesforce kör enhetstesterna för varje program med varje utvecklingsutgåva av plattformen för att proaktivt få reda på om nya systemfunktioner och förbättringar bryter några befintliga program.
När ett produktionsprogram är live analyserar plattformens inbyggda prestandaprofilerare det automatiskt och ger associerad feedback till administratörer. Prestandaanalysrapporter innehåller information om långsamma sökfrågor, datamanipulationer och underrutiner som du kan granska och använda för att finjustera programfunktioner. Systemet loggar och returnerar även information om runtimeundantag till administratörer för att hjälpa dem felsöka sina program.
När en app tar bort en post från ett objekt markerar plattformen bara raden för borttagning genom att ändra radens IsDeleted-fält i MTData. Denna åtgärd placerar raden i vad som kallas _Papperskorgen. plattformen låter dig återställa valda rader från Papperskorgen i upp till 15 dagar innan du permanent tar bort dem från MT_Data. Plattformen begränsar det totala antalet poster den upprätthåller för en organisation baserat på lagringsgränserna för den organisationen.
När en operation tar bort en överordnad post som är involverad i en huvud-detalj-relation tar plattformen automatiskt bort alla relaterade underordnade poster, förutsatt att detta inte bryter mot några befintliga referensintegritetsregler. Till exempel, när du tar bort en SalesOrder kaskadar plattformen automatiskt borttagningen till beroende LineItems. Om du senare återställer en överordnad post från papperskorgen återställer systemet automatiskt även alla underordnade poster.
Om du istället tar bort en refererad överordnad post som är involverad i en sökrelation ställer plattformen automatiskt in alla beroende nycklar till null. Om du sedan återställer den överordnade posten återställer plattformen automatiskt de tidigare nullade sökrelationerna, förutom relationerna som omtilldelades mellan borttagningen och återställningen.
Papperskorgen lagrar även släppta fält och deras data tills en organisation permanent tar bort dem eller ett fast antal dagar har gått, beroende på vilket som inträffar först. Fram till dess är hela fältet och alla dess data tillgängliga för återställning.
Smidighet är nyckeln till framgång i vår moderna värld. Salesforce Platforms underliggande lager hjälper dina verksamhetsprogram att snabbt anpassa sig till nya utmaningar så att du kan fortsätta fokusera på din verksamhet istället för infrastruktur.
Infrastruktur (till exempel grundläggande tjänster och datorresurser) är dold, underliggande teknik som stöder övre lager i Salesforce Platform. Hyperforce är Salesforce Platforms infrastruktur, byggd på 100 % förnybar energi och nettonoll, som löser viktiga kundutmaningar, inklusive efterlevnad, Trust och skalbarhet.
Företag som är verksamma på flera geografiska platser måste följa nya, växande och varierande föreskrifter för datahantering. Eftersom Salesforce distribuerar Hyperforce i ett växande antal länder, som för närvarande baseras på tillgänglighet i AWS-regioner, kan plattformsprogram och användare köra sina känsliga arbetsbelastningar på sätt som uppfyller strikta standarder för datalagring eller dataskydd. Till exempel, med Salesforces arbetsområde för Europeiska unionen (EU) som drivs av Hyperforce kan EU-företag enkelt behålla sina data i EU.
Säkerhet, pålitlighet och tillgänglighet är icke-funktionella krav som alla företagsprogram måste överväga för att uppfylla löftet om Trust till sina slutanvändare. Med Hyperforce låter Salesforce Platform företag enkelt leverera betrodda verksamhetsprogram.
- Säkerhet – Hyperforce har inbyggd end-to-end-kryptering av kunddata vid vila och transitering. Hyperforces Zero Trust Architecture tillämpar en strikt process för identitetsbekräftelse som säkerställer att det inte finns någon underförstådd åtkomst till resurser. Hyperforce använder principen om minsta privilegium för att säkerställa att åtgärder godkänns för precis rätt tid med rätt åtkomst.
- Tillförlitlighet – Varje instans av Hyperforce använder flera molntillgänglighetszoner och moderniserade metoder som snabbar på incidentsvar för att leverera en mycket tillgänglig och motståndskraftig plattform.
- Tillgänglighet – Hyperforces moderna CI/CD-pipeline och blå/gröna programutgåvor minimerar programunderhållsperioder till endast en minut per år.
Som grund för appar som Sales Cloud och Service Cloud är Salesforce en beprövad plattform för programutveckling där enskilda företag och tjänsteleverantörer har byggt miljontals affärsprogram för olika användningsfall, inklusive hantering av leveranskedjan, fakturering, redovisning, handel, efterlevnadsspårning, personalhantering och anspråkshantering. Plattformens unika, multitenant, metadatadrivna arkitektur är utformad specifikt för molnet och har tillförlitligt och säkert stöd för verksamhetskritiska program i internetskala. Med hjälp av standardbaserade API:n och inbyggda utvecklingsverktyg kan plattformsutvecklare enkelt bygga alla komponenter i en modern webb- eller mobilapp, inklusive appens datamodell (inklusive objekt och relationer), verksamhetslogik (inklusive arbetsflöden och valideringar), integreringar med andra program, med mera.
Sedan starten har plattformen optimerats av Salesforces tekniker för multitenancy, med funktioner som låter plattformsprogram skalas upp för att uppfylla ändrade verksamhetsbehov. Integrerade systemfunktioner — som massdatabearbetnings-API, Apex, en sökmotor i fulltext och en unik sökfrågeoptimerare — hjälper till att göra beroende program mycket effektiva och skalbara med liten eller ingen ansträngning från utvecklare.
Salesforces hanterade metod för distribuering av produktionsprogram säkerställer utmärkt prestanda, skalbarhet och pålitlighet för alla program som förlitar sig på plattformen. Salesforce övervakar och samlar kontinuerligt in operativ information från plattformsprogram för att hjälpa till att driva inkrementella förbättringar och nya systemfunktioner som omedelbart gynnar befintliga och nya program.
Steve Bobrowski är en framgångsrik entreprenör och teknikledare som har arbetat för många ledande programvaruföretag, inklusive olika roller i Salesforce sedan 2008. Idag arbetar Steve på Salesforces CTO-kontor för att hjälpa till med företagets strategier för teknikarkitektur.
Tom Leddy är arkitektevangelist på Salesforce. Han stöder den globala Salesforce Architect Community genom att hjälpa till att skapa resurser, verktyg och råd som hjälper arkitekter att göra sitt bästa. Kom i kontakt med Tom på Twitter.