Ежедневно сотни тысяч предприятий и миллионы пользователей работают в облачном режиме с помощью приложений, поддерживаемых Salesforce Platform. Почему платформа так успешна? Почему вы можете Trust ему поддержку бизнеса? Какие уникальные преимущества предоставляет платформа предприятиям, подобным вашему?
Данная техническая справка объясняет, как Salesforce Platform предоставляет надежные, масштабируемые и удобные для настройки взаимодействия конечного пользователя посредством уникальной архитектуры программного обеспечения для облачных вычислений. Прочитав данную справку, вы лучше поймете основные технологии, которые делают Salesforce Platform привлекательным выбором для ваших бизнес-приложений.
Salesforce Platform является ярким примером успешной платформы облачной обработки данных и связанной экосистемы приложений. С начала нового тысячелетия платформа является благоприятной основой для:
- Многие популярные бизнес-приложения для распространенных способов использования, например, продажи и обслуживание клиентов
- Отраслевые приложения для более специализированных способов использования, таких как финансы и здравоохранение
- Миллионы настраиваемых приложений и расширений приложений для уникальных способов использования
В значительной степени Salesforce Platform настолько успешна и популярна, поскольку ее уникальная архитектура программного обеспечения поддерживает приложения, которые легко создавать, использовать, настраивать и расширять с исключительной производительностью и надежностью. Сердцем архитектуры программного обеспечения платформы является ее многопользовательский дизайн на основе метаданных.
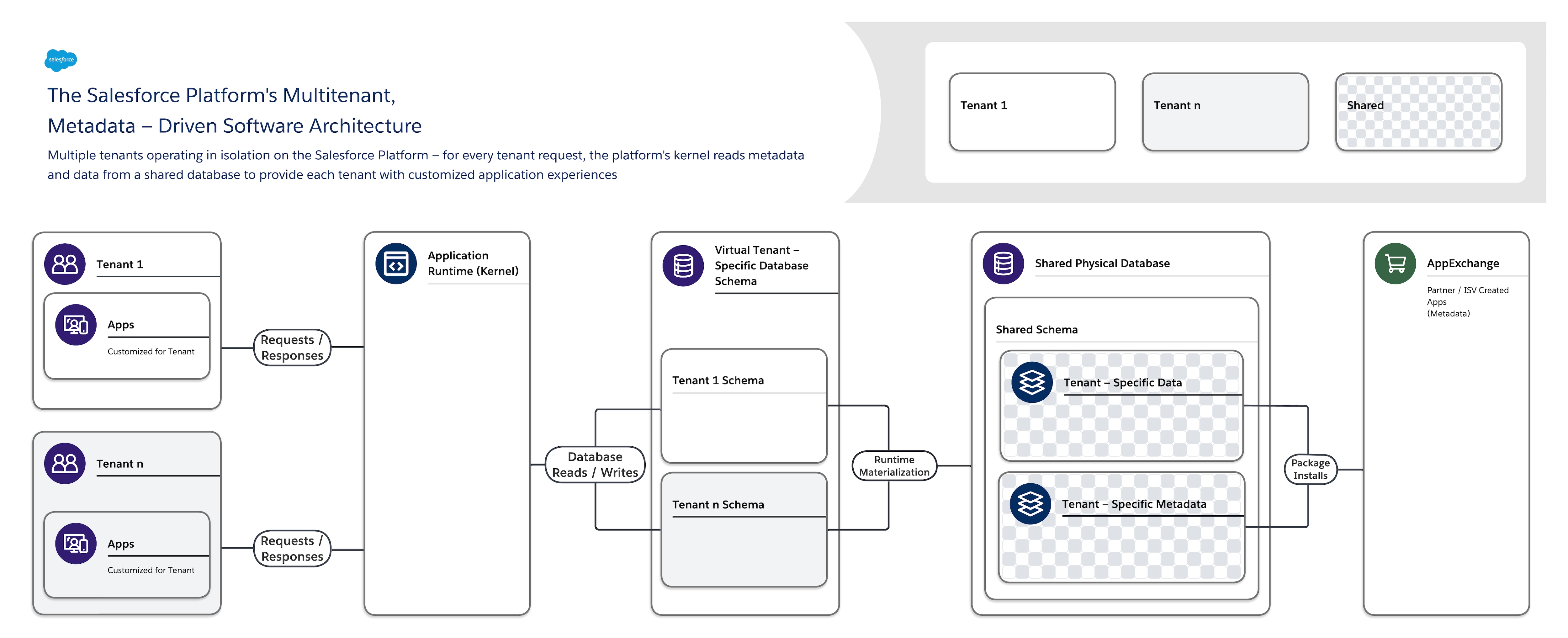
Архитектура программного обеспечения Salesforce Platform:
- «Многопользовательский сектор»: позволяет изолировать и параллельно удовлетворять различные потребности многих клиентов (организации, бизнес-единицы и т. д.).
- Метаданные — позволяют каждому клиенту легко и быстро настраивать приложения и взаимодействия пользователя посредством метаданных, данных, описывающих такие элементы, как пользовательский интерфейс (UI) и бизнес-логика.
При создании нового объекта приложения или написании кода посредством Salesforce Platform платформа не создает фактическую таблицу в базе данных и не компилирует код. Вместо этого платформа просто хранит некоторые метаданные, которые потом могут использоваться во время выполнения для динамической материализации компонентов виртуального приложения. Платформа обеспечивает конфиденциальность и простоту обновления метаданных каждого клиента без необходимости блокировки или простоя, чтобы каждый клиент мог создавать и настраивать приложения изолированно. Salesforce Platform использует те же метаданные для предоставления настраиваемых API, интерфейсов RESTful и веб- служб (на основе SOAP), которые можно использовать для интеграции приложений с другими приложениями и автоматизированными процессами.
Готовые решения также доступны в AppExchange, являющемся обширной площадкой приложения платформы. Созданный обширной экосистемой надежных партнеров и независимых поставщиков программного обеспечения (ISV), пакет AppExchange - это метаданные стороннего приложения, описывающие бесплатные или платные расширения приложений и целые приложения, которые можно использовать в соответствии с определенными бизнес-требованиями.
Для поддержки этой высоконастраиваемой и расширяемой архитектуры один экземпляр Salesforce Platform использует:
- Единая общедоступная база данных нескольких клиентов с единой схемой, хранящей метаданные и данные клиента.
- Ядро нескольких клиентов (среда выполнения приложения), которое считывает метаданные и данные для динамического предоставления приложений клиента, бизнес-логики и API для пользователей каждого клиента во время выполнения.
Это четкое разделение управляемого Salesforce ядра и метаданных под управлением клиента позволяет Salesforce, клиентам и ISV независимо развивать свои части системы без вмешательства.
Чтобы развить этот обзор, последующие разделы данной статьи предоставляют более подробную информацию об уникальных возможностях платформы, вытекающих из ключевых аспектов ее дизайна, включая:
- Слой данных платформы
- Разработка приложения платформы
- Внутренняя обработка платформы
- Инфраструктура платформы
Вместе, среда выполнения приложения Salesforce Platform и инновационный слой данных безопасно изолируют данные клиента, настройки схемы и бизнес-логику. На высоком уровне схема поддерживает разные сценарии использования:
- При создании или настройке приложения платформа сохраняет связанные метаданные в общедоступных таблицах базы данных, которые хранят метаданные для всех клиентов.
- При использовании приложения для чтения или записи данных платформа сохраняет данные в общедоступных таблицах базы данных, которые хранят данные для всех клиентов.
- В фоновом режиме платформа также сохраняет внутренние метаданные в ряде таблиц, используемых ядром для оптимизации задержки запроса во время выполнения.
Но как единая общедоступная база данных и схема могут сохранять конфиденциальность данных каждого клиента? Каждый клиент платформы называется организацией или сокращенно организацией. Каждая запись организации в общедоступных таблицах базы данных содержит OrgID. Когда ядро открывает базу данных, оно использует этот уникальный идентификатор для обеспечения конфиденциальности действий каждой организации.

Объекты организации (аналитические таблицы на традиционном языке относительной базы данных), поля, сохраненные процедуры, триггеры базы данных и прочее - это виртуальные конструкции, описанные метаданными, которые платформа хранит в нескольких таблицах базы данных, известных как Универсальный словарь данных (UDD).
- MT_Objects - это таблица базы данных, содержащая метаданные об объектах, заданных для приложения, включая уникальный идентификатор объекта (ObjID), вашей организации (OrgID) и имя, заданное для объекта (ObjName).
- Системная таблица MT_Fields содержит метаданные о полях (столбцах), объявленных для каждого объекта, включая уникальный идентификатор поля (FieldID), организации (OrgID), объекта, содержащего поле (ObjID), имя поля (FieldName), тип данных поля, логическое значение, указывающее на необходимость индексации поля (IsIndexed) и положение поля в объекте относительно других полей (FieldNum).
Поскольку метаданные являются ключевым компонентом, платформа должна оптимизировать доступ к метаданным; в противном случае, частый доступ к метаданным помешает масштабированию службы. Учитывая это потенциальное препятствие, платформа использует массивные и сложные кэши метаданных для хранения последних использованных метаданных в памяти, избежания ввода-вывода диска и повторных компиляций кода, снижающих производительность, и улучшения времени ответа приложения.
Системная таблица MT_Data сохраняет доступные приложению данные, которые соотносятся со всеми таблицами организации и их полями, как определено метаданными в MT_Objects и MT_Fields. Каждая строка содержит идентифицирующие поля, например, глобальный уникальный идентификатор (GUID), организацию, ответственную за строку (OrgID), и охватывающий идентификатор объекта (ObjID). Каждая строка таблицы MT_Data также содержит поле «Имя», содержащее «естественное имя» для соответствующих записей. Например, запись организации может использовать «Имя организации», запись обращения может использовать «Номер обращения» и т. д.
Значение0 ... Столбцы Flex ValueN, также известные как интервалы, хранят данные приложения, которые соотносятся с таблицами и полями, объявленными в MT_Objects и MT_Fields, соответственно. Все столбцы flex используют тип данных строки переменной длины, чтобы хранить любой структурированный тип данных приложения (строки, числа, даты и т. д.). Как показано на рисунке ниже, два поля одного объекта не могут соотноситься с одним интервалом в MT_Data для хранения; однако один интервал может управлять сведениями о нескольких полях, если каждое поле происходит из разных объектов.
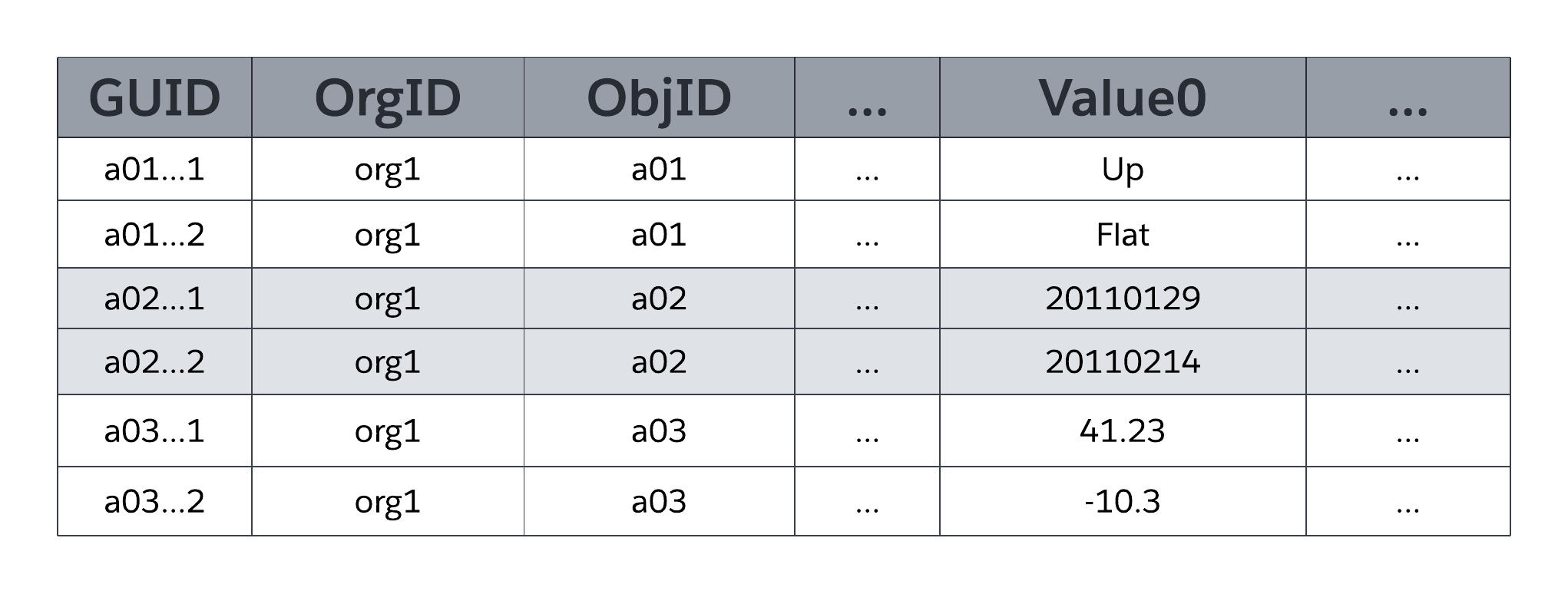
MTFields может использовать любой из нескольких стандартных типов структурированных данных, например, текст, число, дата и дата/время, а также специальные типы данных с обогащенной структурой, например, раскрывающийся список (нумерованное поле), автонумерация (автоматически инкрементируемый системный порядковый номер), формула (производное значение только для чтения), взаимосвязь «Основная — подробная» (внешний ключ), поле с флажком (логическое значение), электронная почта, URL-адрес и другие. MT_Fields также могут быть обязательными (не нулевыми) и содержать настраиваемые правила проверки (например, одно поле должно быть больше другого), которые применяются платформой.
При объявлении или изменении объекта платформа управляет строкой метаданных в MT_Objects, определяющей объект. Таким же образом, для каждого поля платформа управляет строкой в MT_Fields, включительно с метаданными, которые соотносят поле с определенным столбцом flex в MT_Data для хранения соответствующих данных поля. Поскольку платформа управляет определениями объектов и полей как метаданными, а не фактическими структурами базы данных, система может терпеть действия по обслуживанию схемы многопользовательского приложения онлайн, не блокируя параллельные действия других организаций и пользователей. Для сравнения, переопределение онлайн-таблицы для традиционных систем относительных баз данных обычно требует временных блокировок и часто трудоемких, сложных процессов и запланированного простоя приложения.
Как показано на предыдущем рисунке, столбцы flex являются универсальными типами данных (строка переменной длины), что позволяет платформе предоставлять общий доступ к одному столбцу flex нескольким полям, использующим разные типы структурированных данных (строки, числа, даты и т. д.).
Платформа сохраняет все данные столбцов flex посредством канонического формата и использует базовые функции преобразования типов данных системы базы данных (например, TO_NUMBER, TO_DATE, TO_CHAR), когда приложения считывают данные из столбцов flex и записывают данные в них.
MTData также содержит столбцы, не отображаемые на предыдущем рисунке. Например, существуют четыре столбца для управления данными аудита, включительно с пользователем, создавшим строку и временем создания строки, а также пользователем, который последним изменил строку и когда она была изменена. MT_Data также содержит столбец _IsDeleted, используемый платформой для обозначения времени удаления строки.
Платформа также поддерживает объявление полей крупными символами, позволяющее хранить поля подробного текста размером до 32 000 символов. Для каждой строки в MT Data, содержащей CLOB, платформа сохраняет CLOB вне строки в таблице под названием _MT_Clob, которую система может объединить с соответствующими строками в MT_Data.
Примечание: Платформа также сохраняет CLOB в индексированном виде за пределами базы данных для быстрого поиска текста. Дополнительную информацию о текстовом поисковике платформы см. в разделе «Поиски».
Платформа автоматически индексирует разные типы полей для обеспечения масштабируемой производительности.
Традиционные системы базы данных используют собственные индексы базы данных для быстрого обнаружения определенных строк в таблице базы данных, содержащих поля, соответствующие определенному условию. Однако создание собственных индексов базы данных для гибких столбцов MTData нецелесообразно, поскольку платформа использует один гибкий столбец для хранения данных многих полей с различными структурированными типами данных. Вместо этого, платформа управляет индексом MT_Data, синхронно копируя данные полей, помеченные для индексации, в соответствующий столбец сводной таблицы _MT_Indexes.
MT_Indexes содержит сильно типизированные индексированные столбцы, например, StringValue, NumValue и DateValue, используемые платформой для обнаружения данных полей соответствующего типа данных. Например, платформа может скопировать строковое значение в столбце flex MT_Data в поле StringValue в MT_Indexes, значение даты в поле DateValue и т. д. Базовые индексы MT_Indexes являются стандартными, не уникальными индексами базы данных. Если внутренний системный запрос содержит параметр поиска, ссылающийся на структурированное поле в объекте, настраиваемый оптимизатор запросов платформы использует MT_Indexes для оптимизации связанных операций доступа к данным.
Примечание: Платформа может обрабатывать поиски на нескольких языках, поскольку система использует алгоритм фальцевания обращений, преобразующий строковые значения в универсальный формат, не чувствительный к регистру. Столбец StringValue таблицы MT_Indexes сохраняет строковые значения в этом формате. Во время выполнения оптимизатор запроса автоматически создает операции доступа к данным, чтобы оптимизированное оператор SQL фильтровало по соответствующему значению StringValue, сложенному в обращении, что, в свою очередь, соответствует литералу, предоставленному в запросе поиска.
Платформа позволяет указать, когда поле в объекте должно содержать уникальные значения (чувствительные к регистру или регистру). Учитывая организацию MT_Data и совместное использование столбцов «Значение» для данных полей, создание уникальных индексов базы данных для объекта нецелесообразно. (Эта ситуация аналогична ситуации, рассмотренной в предыдущем разделе для неуникальных индексов.)
Для поддержки уникальности настраиваемых полей платформа использует сводную таблицу MT_Unique_Indexes; эта таблица очень похожа на таблицу MT_Indexes, за исключением того, что базовые собственные индексы базы данных MT_Unique_Indexes внедряют уникальность. Если приложение пытается вставить повторяющееся значение в поле, требующее уникальности, или администратор пытается внедрить уникальность в существующее поле, содержащее повторяющиеся значения, платформа возвращает соответствующее сообщение об ошибке приложению.
В редких случаях внешняя поисковая система платформы (о которой говорится в разделе «Поиски») может оказаться перегруженной или недоступной иным образом, а также неспособной своевременно ответить на запрос о поиске. Вместо возврата обидной ошибки конечному пользователю, платформа возвращается к дополнительному механизму поиска для предоставления разумных результатов поиска.
Резервный поиск выполняется в виде прямого запроса к базе данных с условиями поиска, ссылающимися на поле «Имя» целевых записей. Чтобы оптимизировать глобальный поиск объектов (поиски, охватывающие таблицы) без необходимости выполнения потенциально дорогостоящих запросов объединения, платформа поддерживает сводную таблицу MT_Fallback_Indexes, содержащую имя всех записей. Обновления MT_Fallback_Indexes выполняются синхронно, поскольку транзакции изменяют записи, поэтому резервные поиски всегда имеют доступ к последним сведениям базы данных.
Таблица MT_Name_Denorm — это таблица данных, содержащая поля ObjID и Name каждой записи в MT_Data. Если приложению нужно предоставить список записей, связанных с взаимосвязью «родительский-дочерний», платформа использует таблицу MT_Name_Denorm для выполнения относительно простого запроса, который извлекает «Имя каждой ссылочной записи» для отображения в приложении, например, как часть гиперссылки.
Платформа предоставляет типы данных о взаимосвязях, которые организация может использовать для описания взаимосвязей (ссылочная целостность) между таблицами. При объявлении поля объекта с типом взаимосвязи платформа соотносит поле с полем «Значение» в MT_Data, а потом использует это поле для сохранения объекта ObjID связанного объекта.
Для оптимизации операций присоединения платформа поддерживает сводную таблицу MT_Relationships. Эта системная таблица содержит два базовых уникальных составных индекса базы данных, которые позволяют при необходимости эффективно преодолевать объекты в любом направлении.
Всего несколькими щелчками мыши платформа предоставляет отслеживание журнала для любого поля. Если организация включает аудит для определенного поля, система асинхронно записывает сведения об изменениях, внесенных в поле (старые и новые значения, дата изменения и т. д.), используя внутреннюю сводную таблицу в качестве контрольного журнала.
Все данные платформы, метаданные и структуры сводных таблиц, включая базовые индексы базы данных, физически разделены OrgID посредством собственных механизмов разделения базы данных. Разделение данных — это проверенный метод, предоставляемый системами базы данных для физического разделения больших логических структур данных на более мелкие и управляемые части. Разделение также может помочь повысить производительность, масштабируемость и доступность большой системы баз данных, например, многопользовательской среды. По определению, каждый запрос платформы нацелен на сведения об определенной организации, поэтому оптимизатору запроса нужно учитывать только доступ к разделам данных, содержащим данные организации, а не к целой таблице или индексу. Эту распространенную оптимизацию иногда называют «обрезкой раздела».
В этом разделе описано, как разработчики приложения могут создать базовые метаданные схемы, а потом создать приложения, управляющие данными. Эти метаданные и данные хранятся в слое данных платформы, описанном в предыдущем разделе.
Разработчики могут декларативно создавать компоненты серверного приложения посредством среды разработки платформы на основе обозревателя, обычно называемой экранами настройки платформы. Пользовательский интерфейс настройки поддерживает все грани процесса создания схемы приложения, например, создание модели данных приложения (включая объекты и их поля, а также взаимосвязи), модель безопасности и общего доступа (включая пользователей, профили и иерархии ролей), пользовательский интерфейс (включая макеты окон, формы ввода данных и отчеты), декларативную логику (бизнес-правила) и программную логику (сохраненные процедуры и триггеры). Например, Salesforce Flow упрощает автоматизацию широкого диапазона способов использования. Пользовательский интерфейс Flow Builder настройки, показанный ниже, позволяет графически проектировать и внедрять бизнес-правила, взаимодействующие с пользователями или запускаемые автоматически на основе расписания или при запуске событием.
Экраны настройки упрощают разработку и настройку приложений без кода (или без него). Например:
- Пользовательские интерфейсы платформы легко создать без кода. В фоновом режиме пользовательский интерфейс собственного приложения поддерживает все обычные операции доступа к данным, включительно с запросами, вставками, обновлениями и удалениями. Каждая операция манипуляции данными, выполняемая нативными приложениями платформы, может изменить один объект за раз и автоматически подтвердить каждое изменение в отдельной транзакции.
- При определении текстового поля для объекта, содержащего конфиденциальные данные, можно легко настроить поле, чтобы платформа шифровала соответствующие данные и, по желанию, использовала маску ввода для скрытия экранных данных от посторонних глаз.
- Декларативное правило проверки — это простой способ внедрения правила целостности домена без программирования. Например, можно объявить правило проверки, которое обеспечивает, что поле объекта LineItem «Количество» всегда больше нуля.
- Поле формулы - это декларативная функция платформы, которая упрощает добавление вычисляемого поля к объекту. Например, можно добавить поле к объекту LineItem для вычисления значения LineTotal.
- Поле сводного резюмирования — это поле кросс-объекта, позволяющее быстро агрегировать сведения о дочернем поле родительского объекта. Например, создайте поле сводки OrderTotal в объекте SalesOrder на основе поля LineTotal объекта LineItem.
Примечание: Внутренне платформа внедряет поля формулы и сводного резюмирования посредством собственных функций базы данных и эффективно пересчитывает значения синхронно как часть текущих транзакций.
Платформа предоставляет несколько открытых стандартных API, которые разработчики могут использовать для создания приложений. Как RESTful, так и web services (SOAP) API предоставляют доступ к многим функциям платформы. Используя эти разные API, приложение может:
- Манипулирование метаданными, описывающими схему приложения
- Создание, чтение, обновление и удаление бизнес-данных (CRUD)
- Пакетная загрузка или запрос большого количества записей асинхронно
- Отображение потока данных в близком к реальному режиме времени безопасным и масштабируемым способом
Приложения могут использовать объектный язык запросов Salesforce для создания простых, но мощных запросов к базе данных. Как и команда SELECT в структурированном языке запросов (SQL), SOQL позволяет указать исходный объект, список полей для извлечения и условия выбора строк в исходном объекте. Например, следующий запрос SOQL возвращает значение поля «Код» и «Имя» для всех записей организации с именем, равным строке 'Acme'.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
Платформа также содержит полнотекстовый многоязычный поисковый механизм, который автоматически индексирует все текстовые поля. Приложения могут использовать эту предварительно интегрированную поисковую систему, используя SOSL для выполнения текстового поиска. В отличие от SOQL, который может запрашивать только один объект одновременно, SOSL позволяет одновременно искать текст, электронную почту и телефонные поля для нескольких объектов. Например, следующее оператор SOSL ищет записи в объектах «Интерес» и «Контакт», содержащие строку «Джо Смит» в поле имени, и возвращает поле имени и номера телефона из каждой найденной записи.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, который во многих отношениях аналогичен Java, является мощным языком разработки, который разработчики могут использовать для централизации процедурной логики в схеме приложения. Код Apex может объявлять переменные и константы программы, выполнять традиционные операторы управления потоком (если-иначе, циклы и так далее), выполнять операции манипуляции данными (вставка, обновление, обновление, вставка, удаление) и выполнять операции управления транзакциями (setSavepoint, откат).
Программы Apex можно хранить на платформе посредством двух разных форм: в качестве именованного класса Apex с методами (подобно сохраненным процедурам на традиционном языке базы данных), которые приложения выполняют при необходимости, или в качестве триггера базы данных, который автоматически выполняется до или после наступления определенного события манипуляции базой данных. В любом виде платформа компилирует код Apex и сохраняет его в качестве метаданных в UDD. При первом выполнении организацией программы Apex переводчик среды выполнения платформы загружает скомпилированную версию программы в кэш MRU (последний использованный) для этой организации. После этого, когда любому пользователю из той же организации нужно использовать одинаковую рутину, платформа может сберечь память и избежать накладок повторной компиляции программы, предоставив общий доступ к готовой программе, которая уже находится в памяти.
С помощью добавления простого ключевого слова то там, то там разработчики могут использовать Apex для поддержки многих уникальных требований к приложениям. Например, разработчики могут открыть метод в виде настраиваемого вызова RESTful или SOAP API, сделать его асинхронно планируемым или настроить на обработку большой операции пакетами.
Apex - это гораздо больше, чем «просто другой процедурный язык». Это неотъемлемый компонент платформы, который помогает системе обеспечить надежную мультиаренду. Например, платформа автоматически проверяет все встроенные операторы SOQL и SOSL в классе, чтобы предотвратить сбой кода при выполнении. Платформа потом сохраняет соответствующие сведения о зависимости объекта для действительных классов и использует их для предотвращения изменений метаданных, которые в противном случае нарушат зависимый код.
Многие стандартные классы Apex и системные статические методы предоставляют простые интерфейсы к основным функциям системы. Например, системные статические методы DML, например, insert, update и delete, имеют простой логический параметр, который разработчики могут использовать для обозначения нужного параметра пакетной обработки (все или ничего, или частичное сохранение); эти методы также возвращают объект результата, который может прочитать алгоритм вызова для определения записей, обработанных неудачно и причин. Другие примеры прямых связей между функциями Apex и платформы включают встроенные классы электронной почты и классы XmlStream.
В значительной степени платформа работает и масштабируется хорошо, поскольку Salesforce создал ее с учетом двух важных принципов:
- Предоставьте эффективные и широкомасштабные базовые возможности платформы.
- Помогите разработчикам сделать все максимально эффективно.
Платформа использует следующие принципы в уникальных архитектурах обработки платформы:
- Запросы
- Поиски
- Пакетные операции
- Изменение схемы
- Многопользовательская изоляция
- Корзина
Большинство современных систем базы данных определяют оптимальные планы выполнения запросов, используя оптимизацию запросов на основе стоимости, которая учитывает актуальные статистические данные о данных целевой таблицы и индекса. Однако, обычная статистика оптимизаторов на основе стоимости разработана для приложений с одним клиентом и не учитывает характеристики доступа к данным любого пользователя, выполняющего запрос в среде с несколькими клиентами. Например, данный запрос, нацеленный на объект с большим объемом данных, скорее всего, будет выполняться более эффективно, используя разные планы выполнения для пользователей с высокой видимостью (менеджер, который видит все строки) по сравнению с пользователями с низкой видимостью (торговцы, которые могут видеть только строки, связанные с собой).
Чтобы предоставить достаточную статистику для определения оптимальных планов выполнения запросов в многопользовательской системе, платформа поддерживает полный набор статистики оптимизаторов (на уровне клиента, группы и пользователя) для всех объектов организации. Статистика отображает количество строк, к которым может получить доступ определенный запрос, тщательно изучая общую статистику объектов организации (например, общее количество строк, принадлежащих организации в целом), а также более детализированную статистику (например, количество строк, к которым может получить доступ определенная группа привилегий или конечный пользователь).
Платформа также поддерживает другие типы статистики, которые помогают с определенными запросами. Например, платформа сохраняет статистику для всех настраиваемых индексов, чтобы отобразить общее количество не нулевых и уникальных значений в соответствующем поле, и гистограммы для полей раскрывающегося списка, которые отображают кардинальность каждого значения списка.
Если текущая статистика отсутствует или не считается полезной, у оптимизатора платформы есть несколько разных стратегий, используемых для создания достаточно оптимальных запросов. Например, если запрос фильтруется по полю «Имя» объекта, оптимизатор может использовать таблицу MT_Fallback_Indexes для эффективного поиска запрошенных строк. В других сценариях оптимизатор динамически создаст отсутствующую статистику во время выполнения.
Используемый совместно со статистикой оптимизатора, оптимизатор платформы также использует внутренние таблицы безопасности («Группы», «Участники», GroupBlowout и CustomShare), которые хранят сведения о доменах безопасности пользователей организации, включая участников группы данного пользователя и настраиваемые права доступа для объектов и строк. Такая информация бесценна при определении избирательности фильтров запросов на основе каждого пользователя. Дополнительные сведения о встроенной модели безопасности платформы см. в разделе Platform Developer Basics Trailhead.
Диаграмма потока на следующем рисунке иллюстрирует, что происходит, когда платформа обрабатывает запрос данных, находящихся в одной из больших таблиц куч, например, MT_Data. Запрос может исходить из любого количества источников, например, вызов API или сохраненная процедура. Сперва платформа выполняет «предварительные запросы», учитывающие статистику с участием многих клиентов. Потом, на основе результатов, возвращенных предварительными запросами, служба создает оптимальный базовый запрос базы данных для выполнения в определенном параметре.
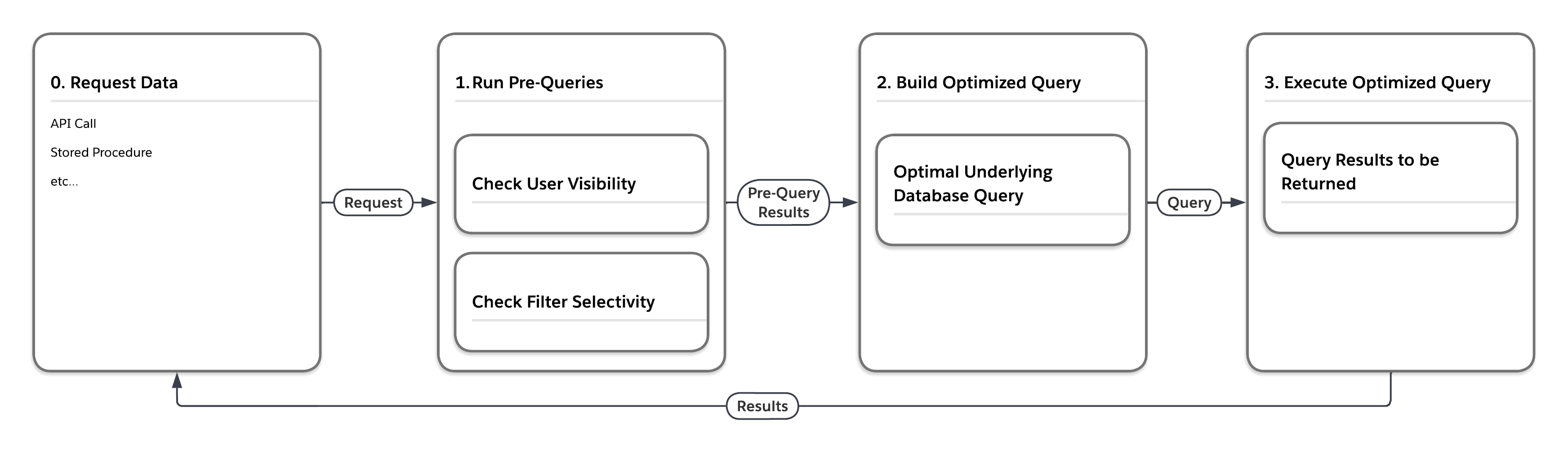
Как показано в таблице ниже, платформа может выполнить один и тот же запрос четырьмя разными способами, в зависимости от пользователя, отправившего запрос, и выборочности условий фильтрации запроса.
| Предварительные выборочные измерения запроса | Напишите окончательный запрос доступа к базе данных, принудительно... | |
| Пользователь | Фильтр | |
| Низкий | Низкий | ... вложенные циклы присоединяются, двигаются с помощью представления строк, отображаемых пользователю |
| Низкий | Высокий | ... использование индекса, связанного с фильтром |
| Высокий | Низкий | ... заказанное хэш-присоединение, диск посредством MT_DATA |
| Высокий | Высокий | ... использование фильтра, связанного с индексом |
Пользователи ожидают, что интерактивная возможность поиска просканирует всю или выбранную область базы данных приложения и вернет ранжированные результаты с промежуточным временем ответа. Чтобы предоставить эту возможность для приложений платформы, платформа использует поисковую систему, отделенную от механизма транзакций. При обновлении записей механизм транзакций обновляет базовую базу данных, а также перенаправляет связанные данные в поисковую систему для индексации. При поиске записей поисковая система использует свои индексы для быстрой обработки запроса и возвращает ранжированные результаты со ссылками на связанные записи базы данных.
Когда приложения обновляют данные в текстовых полях (CLOBs, Name и т. д.), пул фоновых процессов, называемых серверами индексации, отвечает за асинхронное обновление соответствующих индексов, которые поисковая система ведет вне базовой системы транзакций. Чтобы оптимизировать процесс индексации, платформа синхронно копирует измененные фрагменты текстовых данных во внутреннюю таблицу «для индексации» по мере подтверждения транзакций, предоставляя таким образом относительно небольшой источник данных, который минимизирует объем данных, которые серверы индексации должны считывать с диска. Поисковая система автоматически поддерживает отдельные индексы для каждой организации.
В зависимости от текущей загрузки и использования серверов индексации, обновления текстовых индексов могут отставать от фактических транзакций. Во избежание непредвиденных результатов поиска из устаревших индексов, платформа также поддерживает кэш MRU недавно обновленных строк, учитываемый системой при материализации результатов полнотекстового поиска. Платформа обслуживает кэши MRU на основе отдельного пользователя и организации для эффективной поддержки возможных областей поиска.
Поисковая система платформы оптимизирует ранжирование записей в результатах поиска несколькими методами. Например, система учитывает домен безопасности пользователя, выполняющего поиск, и придает больше значения строкам, доступным текущему пользователю. Система также может учитывать журнал изменений отдельной строки и ранжировать более активно обновленные строки, опережая относительно статичные. Пользователь может выбрать взвешивание результатов поиска, например, уделяя больше внимания недавно измененным строкам.
Транзакционноемкие приложения создают меньше накладных расходов и работают намного лучше, если они объединяют и выполняют повторяющиеся операции в пакете. Например, приложение может загрузить много новых строк двумя способами. Неэффективным подходом было бы использование рутины с циклом, вставляющим отдельные строки, выполняя один вызов API за другим для каждой вставки строки. Гораздо более эффективным подходом было бы создание массива строк и вставка всех строк посредством одного вызова API.
Эффективная пакетная обработка с помощью платформы проста для разработчиков, поскольку она дополняется вызовами API. Внутренне платформа также обрабатывает все внутренние этапы, связанные с явной пакетной операцией.
Механизм пакетной обработки платформы автоматически учитывает отдельные ошибки, возникающие на любом этапе пути. Когда пакетная операция запускается в режиме частичного сохранения, механизм определяет известное состояние начала, а потом пытается выполнить каждый этап процесса (пакетная проверка данных поля, предварительные триггеры пакетного пожара, записи пакетного сохранения и т. д.). Если двигатель обнаруживает ошибки во время любого этапа, он откатывает нарушающие операции и все побочные эффекты, удаляет строки, ответственные за ошибки, и продолжает, пытаясь обработать оставшийся поднабор строк. Этот процесс повторяется на каждом последующем этапе, пока механизм не сможет подтвердить поднабор строк без ошибок. Приложение может изучить объект возврата, чтобы определить, какие строки не удались и какие исключения они сделали.
Примечание: По вашему усмотрению, режим «Все или ничего» доступен для пакетных операций. Также выполнение триггеров во время пакетной операции подчиняется внутренним регуляторам, ограничивающим объем работы.
Некоторые типы изменений определения объекта требуют большего, чем простые обновления метаданных UDD. В таких случаях платформа использует эффективные механизмы, которые помогают снизить общее влияние производительности на облачную службу базы данных в целом.
Например, обратите внимание на фоновые изменения типа данных столбца из раскрывающегося списка в текст. Сначала платформа выделяет новый интервал для данных столбца, пакетно копирует метки раскрывающегося списка, связанные с текущими значениями, а потом обновляет метаданные столбца, чтобы они указывали на новый интервал. Хотя все это происходит, доступ к данным нормальный, и приложения продолжают функционировать без какого-либо заметного влияния.
В качестве еще одного примера можно привести действия, которые происходят при добавлении поля сводного резюмирования к объекту. В этом случае платформа асинхронно рассчитывает начальные сводки в фоновом режиме посредством эффективной пакетной операции. Пока выполняется расчет фона, пользователи, просматривающие новое поле, получают сигнал о том, что платформа в данный момент вычисляет значение поля.
Чтобы предотвратить злонамеренную или ненамеренную монополизацию общедоступных многопользовательских системных ресурсов, платформа использует широкий набор управляющих и ограничений ресурсов, связанных с выполнением кода платформы. Например, платформа внимательно отслеживает выполнение сценария кода и ограничивает объем используемого процессорного времени, объем памяти, объем запросов и операторов DML, объем математических расчетов, объем исходящих вызовов веб-служб и многое другое. Отдельные запросы, которые оптимизатор платформы считает слишком дорогими для выполнения, добавляют исключение среды выполнения абоненту. Хотя такие ограничения могут звучать несколько ограничительно, они необходимы для защиты общей масштабируемости и производительности системы общедоступных баз данных для всех соответствующих приложений. В долгосрочной перспективе эти меры помогают продвигать лучшие методы кодирования среди разработчиков и создавать лучшее взаимодействие для всех, кто использует платформу. Например, разработчик, который изначально пытается запрограммировать цикл, который неэффективно обновляет тысячу строк за раз, получит исключения среды выполнения из-за ограничений ресурсов, а потом начнет использовать эффективные вызовы API пакетной обработки платформы.
Во избежание потенциальных проблем системы, связанных с неправильными приложениями, развертывание нового производственного приложения является процессом, который строго контролируется. Прежде чем организация сможет перевести новое приложение из статуса разработки в статус производственного, Salesforce требует единичных тестов, проверяющих функциональность процедур кода платформы приложения. Отправленные единичные тесты должны охватывать не менее 75% исходного кода приложения.
Salesforce выполняет отправленные единичные тесты в среде разработки безопасной среды платформы для определения отрицательного влияния кода приложения на производительность и масштабируемость многопользовательской среды в целом. Результаты тестирования отдельной единицы обозначают основные сведения, например, общее количество выполненных строк, а также конкретные сведения о коде, не выполненном тестом.
Как только код приложения сертифицирован для производства Salesforce, процесс развертывания приложения состоит из одной транзакции, которая копирует все метаданные приложения в экземпляр производственной платформы и повторно выполняет соответствующие единичные тесты. Если какая-либо часть процесса не удается, платформа просто откатывает транзакцию и возвращает исключения, чтобы помочь устранить проблему.
Примечание: Salesforce повторно запускает единичные тесты для каждого приложения с каждым выпуском разработки платформы, чтобы активно узнать, не ломают ли новые функции и расширения системы существующие приложения.
После активации производственного приложения встроенное средство профилирования производительности платформы автоматически анализирует его и предоставляет связанный отзыв администраторам. Отчеты по анализу производительности содержат сведения о медленных запросах, манипуляциях с данными и подпрограммах, которые можно просмотреть и использовать для настройки функций приложения. Система также регистрирует и возвращает администраторам сведения об исключениях среды выполнения, чтобы помочь им отладить приложения.
Когда приложение удаляет запись из объекта, платформа просто отмечает строку для удаления, изменив поле строки IsDeleted в MTData. Это действие фактически помещает строку в так называемую _корзину. платформа позволяет восстановить выбранные строки из корзины до 15 дней, прежде чем необратимо удалить их из MT_Data. Платформа ограничивает общее количество записей, обслуживаемых для организации, в зависимости от ограничений хранилища для этой организации.
Когда операция удаляет родительскую запись, связанную с взаимосвязью «Основная — подробная», платформа автоматически удаляет все связанные дочерние записи, при условии, что это не нарушит действующих правил целостности регистрационных данных. Например, при удалении SalesOrder платформа автоматически каскадирует удаление в зависимые LineItems. При последующем восстановлении родительской записи из корзины система автоматически восстанавливает также все дочерние записи.
В отличие от этого, при удалении ссылочной родительской записи, участвующей во взаимосвязи поиска, платформа автоматически устанавливает все зависимые ключи на нулевое значение. При последующем восстановлении родительской записи платформа автоматически восстанавливает ранее обнуленные взаимосвязи поиска, за исключением взаимосвязей, переназначенных между операциями удаления и восстановления.
В корзине также хранятся удаленные поля и их данные до необратимого удаления или истечения заданного количества дней, в зависимости от того, что произойдет раньше. До этого времени все поле и все его данные доступны для восстановления.
Проворство является ключом к успеху предприятий в современном мире. Базовые слои Salesforce Platform помогают бизнес-приложениям быстро адаптироваться к новым задачам, чтобы вы могли продолжать фокусироваться на бизнесе, а не на инфраструктуре.
Инфраструктура (например, базовые услуги и вычислительные ресурсы) скрыта, что является основой технологии, поддерживающей верхние уровни в Salesforce Platform. Hyperforce - это инфраструктура Salesforce Platform, построенная на 100% возобновляемой энергии и чистом нуле, которая решает ключевые задачи клиентов, включая соответствие требованиям, Trust и масштабируемость
Предприятия, работающие в нескольких географических точках, должны соответствовать новым, развивающимся и различным регламентам управления данными. Поскольку Salesforce внедряет Hyperforce во все большем количестве стран, в настоящее время в зависимости от доступности региона AWS, приложения платформы и пользователи могут выполнять конфиденциальные рабочие нагрузки в соответствии со строгими стандартами хранения данных или защиты данных. Например, поскольку операционная зона Европейского союза (ЕС) Salesforce работает на Hyperforce, предприятия ЕС могут легко хранить свои данные в ЕС.
Безопасность, надежность и доступность - это нефункциональные требования, которые каждое бизнес-приложение должно учитывать, чтобы выполнить обещание Trust перед конечными пользователями. С помощью Hyperforce Salesforce Platform позволяет предприятиям легко поставлять надежные бизнес-приложения.
- Безопасность — Hyperforce использует собственное сквозное шифрование данных клиентов в дежурном режиме и в пути. Архитектура Zero Trust Hyperforce применяет строгий процесс проверки подлинности, обеспечивающий отсутствие скрытого доступа к ресурсам. Hyperforce использует принцип наименьших привилегий, обеспечивая одобрение операций на нужное время с соответствующим количеством доступа.
- Надежность — Каждый экземпляр Hyperforce использует несколько зон облачной доступности и модернизированные подходы, ускоряющие реагирование на частоту инцидентов для предоставления высокодоступной и устойчивой платформы.
- Доступность: современные ожидаемые продажи CI/CD Hyperforce и выпуски синих/зеленых приложений позволяют сократить периоды обслуживания приложения до одной минуты в год.
Будучи основой для таких приложений, как Sales Cloud и Service Cloud, Salesforce является проверенной платформой разработки приложений, на которой отдельные предприятия и поставщики услуг создали миллионы бизнес-приложений для разных способов использования, включительно с управлением цепочками поставок, выставлением счетов, учетом, коммерцией, отслеживанием соответствия, управлением людскими ресурсами и обработкой претензий. Уникальная многопользовательская архитектура платформы, управляемая метаданными, разработана специально для облака и надежно и безопасно поддерживает важные приложения в Интернете. Используя стандартные API и собственные инструменты разработки, разработчики платформы могут легко создать все компоненты современного веб- или мобильного приложения, включая модель данных приложения (включая объекты и взаимосвязи), бизнес-логику (включая бизнес-правила и проверки), интеграции с другими приложениями и прочее.
С момента создания платформа была оптимизирована инженерами Salesforce для мультитенденциальности, с функциями, которые позволяют приложениям платформы масштабироваться в соответствии с изменяющимися бизнес-требованиями. Интегральные функции системы — например, API для пакетной обработки данных, Apex, полнотекстовый поисковик и уникальный оптимизатор запросов — помогают сделать зависимые приложения высокоэффективными и масштабируемыми практически без усилий разработчиков.
Управляемый подход Salesforce к развертыванию производственных приложений обеспечивает отличную производительность, масштабируемость и надежность для всех приложений, зависящих от платформы. Salesforce постоянно отслеживает и собирает оперативную информацию из приложений платформы, чтобы стимулировать инкрементные улучшения и новые функции системы, которые немедленно приносят пользу существующим и новым приложениям.
Стив Бобровски — успешный предприниматель и технологический лидер, который с 2008 года работал во многих ведущих компаниях по производству корпоративного программного обеспечения, включая различные роли в Salesforce. Сегодня Стив работает в офисе Salesforce по техническим вопросам, помогая с стратегиями технологической архитектуры компании.
Том Ледди - евангелист-архитектор в Salesforce. Он поддерживает глобальное сообщество архитекторов Salesforce, помогая создавать ресурсы, инструменты и рекомендации, которые помогают архитекторам делать свою лучшую работу. Свяжитесь с Томом в Twitter.