Todos os dias, centenas de milhares de empresas e milhões de usuários operam seus negócios na nuvem usando aplicativos habilitados pela Salesforce Platform. Por que a plataforma é tão bem-sucedida? Por que você pode Trust para apoiar seu negócio? Quais benefícios exclusivos a plataforma oferece para empresas como a sua?
Este resumo técnico explica como a Salesforce Platform oferece experiências de usuário final confiáveis, escalonáveis e fáceis de personalizar usando sua arquitetura de software exclusiva para computação em nuvem. Depois de ler este resumo, você entenderá melhor a tecnologia subjacente que torna a Salesforce Platform uma escolha atraente para seus aplicativos comerciais.
A Salesforce Platform é o exemplo proeminente de uma plataforma de computação em nuvem bem-sucedida e um ecossistema relacionado de aplicativos. Desde o início do milénio, a plataforma tem sido a base ativa para:
- Muitos aplicativos de negócios populares para casos de uso comuns, como vendas e atendimento ao cliente
- Aplicativos específicos do setor para casos de uso mais especializados, como finanças e saúde
- Milhões de aplicativos personalizados e extensões de aplicativo para casos de uso únicos
Em grande parte, a Salesforce Platform é tão bem-sucedida e popular porque sua arquitetura de software exclusiva suporta aplicativos fáceis de criar, usar, personalizar e estender com desempenho e confiabilidade excepcionais. O coração da arquitetura de software da plataforma é seu design baseado em metadados de vários locatários.
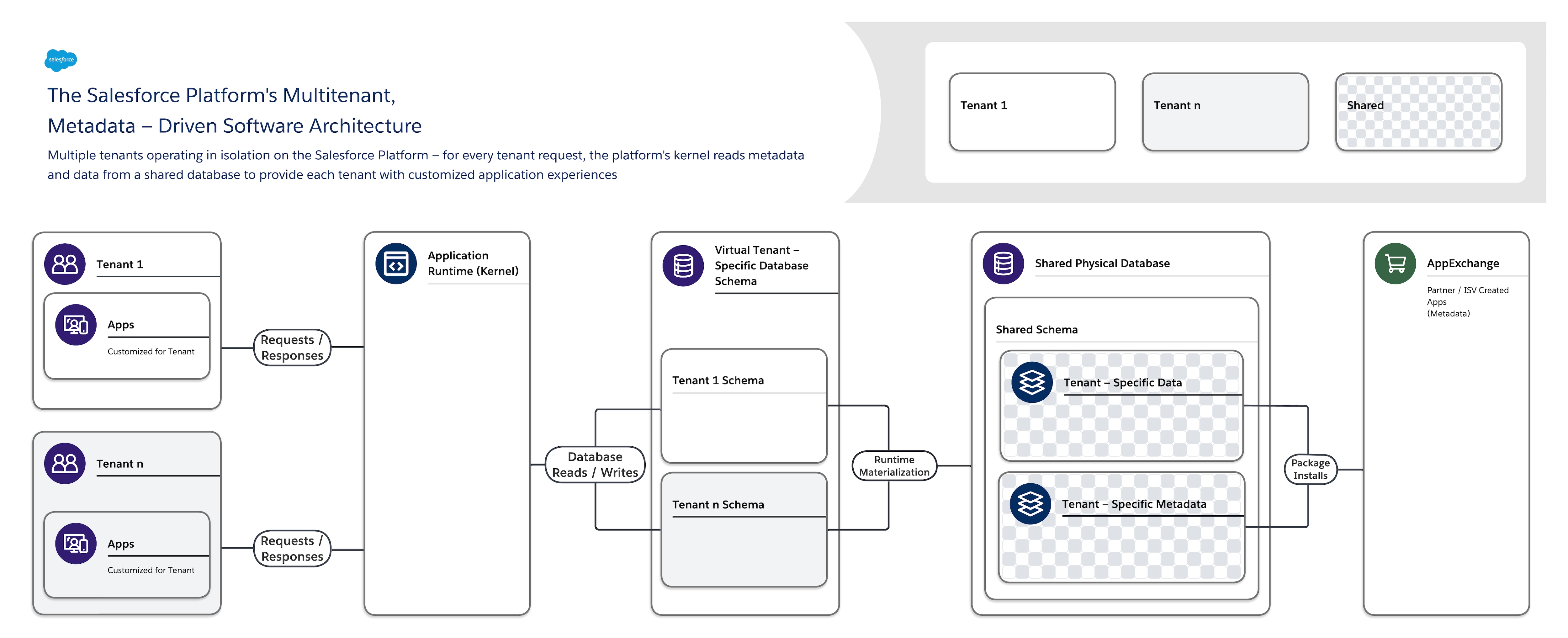
A arquitetura de software da Salesforce Platform é:
- Multitenant — Isola e suporta simultaneamente as necessidades variadas de muitos locatários (organizações, unidades de negócios, etc.).
- Acionada por metadados – Permite que cada locatário personalize facilmente e rapidamente suas experiências de aplicativos e usuários usando metadados, dados que descrevem elementos como a interface do usuário (UI) e lógica de negócios.
Quando você cria um novo objeto de aplicativo ou escreve algum código usando a Salesforce Platform, a plataforma não cria uma tabela real em um banco de dados nem compila nenhum código. Em vez disso, a plataforma simplesmente armazena alguns metadados que pode usar em tempo de execução para materializar dinamicamente componentes de aplicativo virtual. A plataforma garante que os metadados de cada locatário sejam privados e fáceis de atualizar sem nenhum bloqueio ou tempo de inatividade necessário para que cada locatário possa criar e personalizar aplicativos isoladamente. A Salesforce Platform usa os mesmos metadados para fornecer interfaces personalizadas de APIs, RESTful e serviços da Web (com base em SOAP) que você pode usar para integrar seus aplicativos a outros aplicativos e processos automatizados.
As soluções prontas também estão disponíveis no AppExchange, o amplo mercado de aplicativos da plataforma. Criado por um vasto ecossistema de parceiros confiáveis e fornecedores de software independentes (ISVs), um pacote do AppExchange é um metadado de terceiros que descreve extensões de aplicativos gratuitas ou pagas e aplicativos inteiros que você pode usar para atender a requisitos de negócios específicos.
Para oferecer suporte a essa arquitetura altamente personalizável e extensível, uma única instância da Salesforce Platform usa:
- Um único base de dados de locatário compartilhada com um único esquema que armazena metadados e dados específicos do locatário.
- Um núcleo de locatário (tempo de execução de aplicativo) que lê metadados e dados para fornecer dinamicamente aplicativos, lógica de negócios e APIs específicos do locatário para os usuários de cada locatário no tempo de execução.
Essa separação clara do kernel gerenciado pelo Salesforce dos metadados gerenciados pelo locatário permite que o Salesforce, os locatários e os ISVs evoluam de modo independente suas partes do sistema sem interferência.
Para se basear nessa visão geral, as seções subsequentes deste artigo fornecem mais detalhes sobre os recursos exclusivos da plataforma que se originam dos principais aspectos de seu design, incluindo:
- A Camada de dados da plataforma
- Desenvolvimento de aplicativo de plataforma
- Processamento de plataforma interna
- Infraestrutura de plataforma
Juntos, o tempo de execução do aplicativo da Salesforce Platform e a camada de dados inovadora isolam com segurança dados específicos do locatário, personalizações de esquema e lógica de negócios. Em alto nível, o esquema oferece suporte a vários casos de uso:
- Quando você cria ou personaliza um aplicativo, a plataforma armazena metadados relacionados em tabelas de banco de dados compartilhadas que mantêm metadados para todos os locatários.
- Quando você usa um aplicativo para ler ou gravar dados, a plataforma armazena seus dados em tabelas de banco de dados compartilhadas que mantêm dados para todos os locatários.
- Nos bastidores, a plataforma também mantém metadados internos em várias tabelas que o kernel usa para otimizar a latência da solicitação no tempo de execução.
Porém, como um único banco de dados compartilhado e esquema podem manter os dados de cada locatário privados? Cada locatário na plataforma é conhecido como uma organização, ou organização em suma. E cada registro específico da organização em tabelas de banco de dados compartilhadas tem um OrgID. Quando o kernel acessa o banco de dados, ele usa esse identificador exclusivo para garantir que as atividades de cada organização sejam privadas.

Objetos específicos da organização (pensar tabelas em linguagem de banco de dados relacional tradicional), campos, procedimentos armazenados, acionadores de banco de dados e muito mais são todas construções virtuais descritas por metadados que a plataforma armazena em algumas tabelas de banco de dados conhecidas como o Dicionário Universal de Dados (UDD).
- MT_Objects é uma tabela de banco de dados que armazena metadados sobre os objetos que você define para um aplicativo, incluindo um identificador exclusivo para um objeto (ObjID), sua organização (OrgID) e o nome que você fornece para o objeto (ObjName).
- A tabela do sistema MT_Fields armazena metadados sobre os campos (colunas) que você declara para cada objeto, incluindo um identificador exclusivo para um campo (FieldID), sua organização (OrgID), o objeto que contém o campo (ObjID), o nome do campo (FieldName), o tipo de dados do campo, um valor booleano para indicar se o campo requer indexação (IsIndexed) e a posição do campo no objeto em relação a outros campos (FieldNum).
Como os metadados são um componente essencial, a plataforma deve otimizar o acesso aos metadados; caso contrário, o acesso frequente aos metadados impediria a escala do serviço. Com esse possível gargalos em mente, a plataforma usa cache de metadados maciços e sofisticados para manter os metadados usados mais recentemente na memória, evitar I/O de disco e recompilações de código que prejudicam o desempenho e melhorar os tempos de resposta do aplicativo.
A tabela do sistema MT_Data armazena os dados acessíveis ao aplicativo que são mapeados para todas as tabelas específicas da organização e seus campos, conforme definido por metadados em MT_Objects e MT_Fields. Cada linha inclui campos de identificação, como um identificador exclusivo global (GUID), a organização proprietária da linha (OrgID) e o identificador de objeto abrangente (ObjID). Cada linha na tabela MT_Data também tem um campo Nome que armazena um "nome natural" para registros correspondentes; por exemplo, um registro de Conta pode usar "Nome da conta", um registro de Caso pode usar "Número do caso" e assim por diante.
Value0... As colunas flexíveis ValueN, também conhecidas como slots, armazenam dados de aplicativo que mapeiam para as tabelas e campos declarados em MT_Objects e MT_Fields, respectivamente. Todas as colunas flexíveis usam um tipo de dados de string de comprimento variável para que possam armazenar qualquer tipo estruturado de dados de aplicativo (strings, números, datas etc.). Como ilustra a figura a seguir, nenhum dos dois campos do mesmo objeto pode ser mapeado para o mesmo slot no MT_Data para armazenamento; no entanto, um único slot pode gerenciar as informações de vários campos, desde que cada campo seja derivado de um objeto diferente.
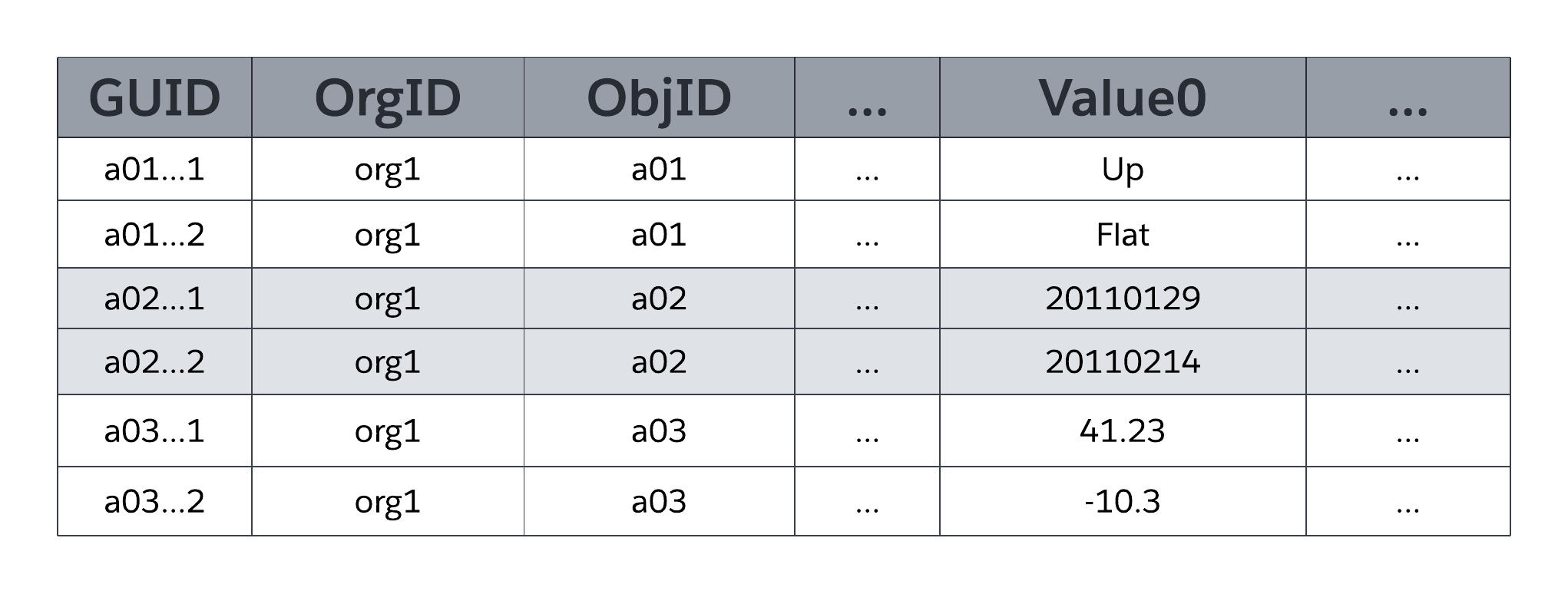
Os campos de MT podem usar qualquer um de vários tipos de dados estruturados padrão, como texto, número, data e data/hora, bem como tipos de dados _rich-structured de uso especial, como lista de opções (campo enumerado), numeração automática (número de sequência gerado automaticamente pelo sistema), fórmula (valor derivado somente leitura), relacionamento entre mestre e detalhes (chave estrangeira), caixa de seleção (booleano), email, URL e outros. MT_Fields também podem ser obrigatórios (não nulos) e ter regras de validação personalizadas (por exemplo, um campo deve ser maior que outro campo), ambas aplicadas pela plataforma.
Quando você declara ou modifica um objeto, a plataforma gerencia uma linha de metadados em MT_Objects que define o objeto. Da mesma forma, para cada campo, a plataforma gerencia uma linha em MT_Fields, incluindo metadados que mapeiam o campo para uma coluna flexível específica em MT_Data para armazenamento de dados de campo correspondentes. Como a plataforma gerencia definições de objeto e campo como metadados, em vez de estruturas de banco de dados reais, o sistema pode tolerar atividades de manutenção de esquema de aplicativo multilocatário online sem bloquear a atividade concomitante de outras organizações e usuários. Por comparação, a redefinição de tabela online para sistemas de banco de dados relacionais tradicionais geralmente requer bloqueios temporários e, muitas vezes, processos trabalhosos e complicados e tempo de inatividade agendado do aplicativo.
Como a representação simplificada de MT_Data na figura anterior mostra, as colunas flexíveis são de um tipo de dados universal (string de comprimento de variável), que permite à plataforma compartilhar uma única coluna flexível entre vários campos que usam vários tipos de dados estruturados (strings, números, datas e assim por diante).
A plataforma armazena todos os dados de coluna flexível usando um formato canônico e usa funções subjacentes de conversão de tipo de dados do sistema de banco de dados (por exemplo, TO_NUMBER, TO_DATE, TO_CHAR) conforme necessário quando os aplicativos leem dados de colunas flexíveis e gravam dados.
MTData também contém colunas não mostradas na figura anterior. Por exemplo, há quatro colunas para gerenciar dados de auditoria, incluindo qual usuário criou uma linha e quando ela foi criada, qual usuário modificou uma linha pela última vez e quando ela foi modificada pela última vez. MT_Data também contém uma coluna _IsDeleted que a plataforma usa para indicar quando uma linha foi excluída.
A plataforma também suporta a declaração de campos como objetos grandes de caracteres (CLOBs) para permitir o armazenamento de campos de texto longo de até 32.000 caracteres. Para cada linha em MTData que tem um CLOB, a plataforma armazena o CLOB fora da linha em uma tabela chamada _MT_Clob, que o sistema pode unir com linhas correspondentes em MT_Data conforme necessário.
Nota: A plataforma também armazena CLOBs em um formato indexado fora do banco de dados para pesquisas de texto rápido. Consulte Pesquisas para obter mais informações sobre o mecanismo de pesquisa de texto da plataforma.
A plataforma indexa automaticamente vários tipos de campos para proporcionar desempenho escalonável.
Os sistemas de banco de dados tradicionais dependem de índices de banco de dados nativos para localizar rapidamente linhas específicas em uma tabela de banco de dados que tenham campos que correspondam a uma condição específica. No entanto, não é prático criar índices de banco de dados nativos para as colunas flexíveis de MTData porque a plataforma usa uma única coluna flexível para armazenar os dados de muitos campos com tipos de dados estruturados diferentes. Em vez disso, a plataforma gerencia um índice de MT_Data copiando de modo síncrono dados de campo marcados para indexação para uma coluna apropriada em uma tabela dinâmica _MT_Indexes.
MT_Indexes contém colunas fortemente digitadas e indexadas, como StringValue, NumValue e DateValue, que a plataforma usa para localizar dados de campo do tipo de dados correspondente. Por exemplo, a plataforma copiaria um valor de string em uma coluna flexível MT_Data para o campo StringValue em MT_Indexes, um valor de data para o campo DateValue e assim por diante. Os índices subjacentes de MT_Indexes são índices de banco de dados padrão e não exclusivos. Quando uma consulta do sistema interno inclui um parâmetro de pesquisa que faz referência a um campo estruturado em um objeto, o otimizador de consulta personalizado da plataforma usa MT_Indexes para ajudar a otimizar as operações de acesso a dados associadas.
Nota: A plataforma pode lidar com pesquisas em vários idiomas porque o sistema usa um algoritmo de dobra de casos que converte valores de string em um formato universal, sem distinção entre maiúsculas e minúsculas. A coluna StringValue da tabela MT_Indexes armazena valores de string nesse formato. No tempo de execução, o otimizador de consulta cria automaticamente operações de acesso a dados para que a instrução SQL otimizada filtre o StringValue de multiplicação de maiúsculas e minúsculas correspondente, que, por sua vez, corresponde ao literal fornecido na solicitação de pesquisa.
A plataforma permite que você indique quando um campo em um objeto deve conter valores exclusivos (diferencia maiúsculas de minúsculas ou não diferencia maiúsculas de minúsculas). Considerando a disposição de MT_Data e o uso compartilhado das colunas de Valor para dados de campo, não é prático criar índices de banco de dados exclusivos para o objeto. (Essa situação é semelhante à discutida na seção anterior para índices não exclusivos.)
Para oferecer suporte à exclusividade de campos personalizados, a plataforma usa a tabela dinâmica MT_Unique_Indexes; essa tabela é muito similar à tabela MT_Indexes, exceto que os índices de banco de dados nativos subjacentes de MT_Unique_Indexes impõem a exclusividade. Quando um aplicativo tenta inserir um valor duplicado em um campo que requer exclusividade ou quando um administrador tenta impor exclusividade em um campo existente que contém valores duplicados, a plataforma retorna uma mensagem de erro adequada ao aplicativo.
Em circunstâncias raras, o mecanismo de busca externo da plataforma (explicado em pesquisas) pode ficar sobrecarregado ou de outra forma indisponível, e pode não ser capaz de responder a uma solicitação de pesquisa em tempo hábil. Em vez de retornar um erro decepcionante ao usuário final, a plataforma volta para um mecanismo de pesquisa secundário para fornecer resultados de pesquisa razoáveis.
Uma pesquisa retroativa é implementada como uma consulta de banco de dados direta com condições de pesquisa que fazem referência ao campo Nome dos registros de destino. Para otimizar pesquisas de objeto globais (pesquisas que abrangem tabelas) sem ter que executar consultas de união potencialmente caras, a plataforma mantém uma tabela dinâmica MT_Fallback_Indexes que registra o Nome de todos os registros. As atualizações em MT_Fallback_Indexes acontecem de modo síncrono à medida que as transações modificam registros para que as pesquisas de fallback sempre tenham acesso às informações de banco de dados mais atuais.
A tabela MT_Name_Denorm é uma tabela de dados magnéticos que armazena o ObjID e o Nome de cada registro em MT_Data. Quando um aplicativo precisa fornecer uma lista de registros envolvidos em um relacionamento pai/filho, a plataforma usa a tabela MT_Name_Denorm para executar uma consulta relativamente simples que recupera o Nome de cada registro referenciado para exibição no aplicativo, por exemplo, como parte de um hiperlink.
A plataforma fornece tipos de dados de relacionamento que uma organização pode usar para declarar relacionamentos (integridade referencial) entre tabelas. Quando você declara o campo de um objeto com um tipo de relacionamento, a plataforma mapeia o campo para um campo de Valor em MT_Data e então usa esse campo para armazenar o ObjID de um objeto relacionado.
Para otimizar operações de junção, a plataforma mantém uma tabela dinâmica MT_Relationships. Essa tabela do sistema tem dois índices compostos exclusivos de banco de dados subjacentes que permitem cruzar objetos de modo eficiente em qualquer direção, conforme necessário.
Com apenas alguns cliques do mouse, a plataforma fornece rastreamento de histórico para qualquer campo. Quando uma organização habilita a auditoria para um campo específico, o sistema registra de modo assíncrono informações sobre as alterações feitas no campo (valores novos e antigos, data de alteração etc.) usando uma tabela dinâmica interna como uma trilha de auditoria.
Todos os dados da plataforma, metadados e estruturas de tabela dinâmica, incluindo índices de banco de dados subjacentes, são particionados fisicamente pelo OrgID usando mecanismos de particionamento de banco de dados nativos. O particionamento de dados é uma técnica comprovada que os sistemas de banco de dados fornecem para dividir fisicamente grandes estruturas de dados lógicas em partes menores e mais gerenciáveis. O particionamento também pode ajudar a melhorar o desempenho, a escalabilidade e a disponibilidade de um grande sistema de banco de dados, como um ambiente de vários locatários. Por definição, cada consulta de plataforma tem como alvo as informações de uma organização específica, portanto, o otimizador de consulta precisa apenas considerar acessar as partições de dados que contêm os dados de uma organização, em vez de uma tabela ou índice inteiro. Essa otimização comum às vezes é chamada de "pedaço de partição".
Esta seção abrange como os desenvolvedores de aplicativos podem criar os metadados subjacentes de um esquema e, em seguida, criar aplicativos que gerenciam dados. Esses metadados e dados são armazenados na camada de dados da plataforma descrita na seção anterior.
Os desenvolvedores podem criar de forma declarativa componentes de aplicativo no lado do servidor usando o ambiente de desenvolvimento baseado em navegador da plataforma, comumente referido como as telas de Configuração da plataforma. A IU de apontar e clicar da Configuração dá suporte a todas as facetas do processo de criação de esquema de aplicativo, como a criação do modelo de dados de um aplicativo (incluindo objetos e seus campos, bem como relacionamentos), modelo de segurança e compartilhamento (incluindo usuários, perfis e hierarquias de papéis), interface do usuário (incluindo layouts de tela, formulários de entrada de dados e relatórios), lógica declarativa (fluxos de trabalho) e lógica programática (procedimentos armazenados e acionadores). Por exemplo, o Salesforce Flow facilita a automação de uma ampla gama de casos de uso. A IU do Flow Builder da configuração, mostrada abaixo, permite que você projete e implemente graficamente fluxos de trabalho que interagem com os usuários ou são iniciados automaticamente com base em uma agenda ou quando acionados por um evento.
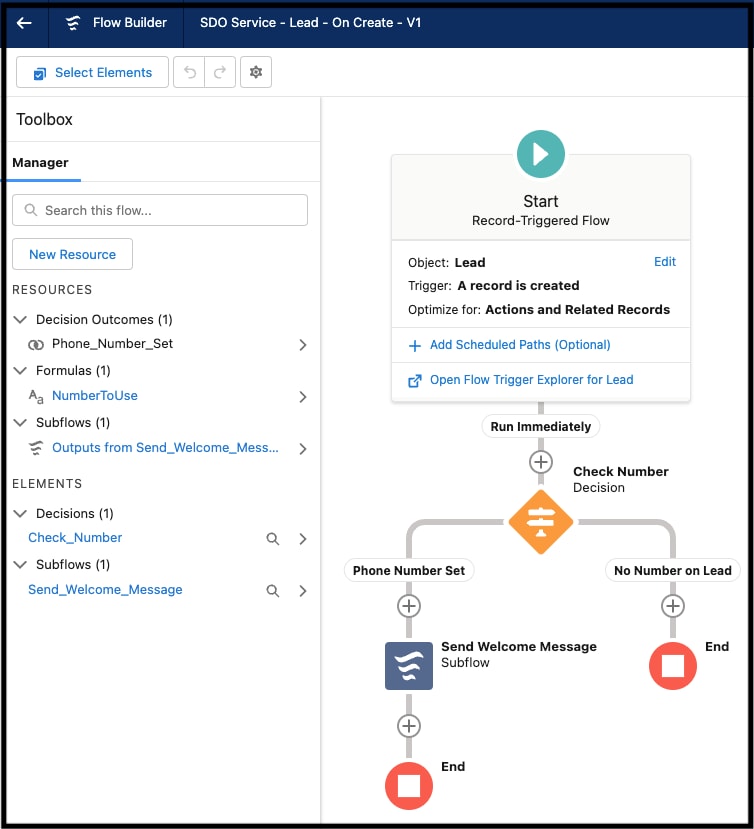
As telas de Configuração tornam fácil para qualquer pessoa desenvolver e personalizar aplicativos sem (ou muito pouco) código. Por exemplo:
- As UIs nativas da plataforma são fáceis de criar sem nenhum código. Nos bastidores, uma IU nativa do aplicativo oferece suporte a todas as operações de acesso a dados comuns, incluindo consultas, inserções, atualizações e exclusões. Cada operação de manipulação de dados realizada por aplicativos de plataforma nativos pode modificar um objeto por vez e confirmar automaticamente cada alteração em uma transação separada.
- Ao definir um campo de texto para um objeto que contém dados confidenciais, você pode configurá-lo facilmente para que a plataforma criptografe os dados correspondentes e, opcionalmente, use uma máscara de entrada para ocultar as informações da tela de olhos curiosos.
- Uma regra de validação declarativa é uma maneira simples de uma organização impor uma regra de integridade de domínio sem nenhuma programação. Por exemplo, você pode declarar uma regra de validação que garanta que o campo Quantidade de um objeto LineItem sempre seja maior que zero.
- Um campo de fórmula é um recurso declarativo da plataforma que facilita a adição de um campo calculado a um objeto. Por exemplo, você pode adicionar um campo ao objeto LineItem para calcular um valor LineTotal.
- Um campo de resumo de totalização é um campo de objeto cruzado que facilita a agregação de informações de campo filho em um objeto pai. Por exemplo, você pode criar um campo de resumo OrderTotal no objeto SalesOrder com base no campo LineTotal do objeto LineItem.
Nota: Interna, a plataforma implementa campos de resumo de fórmula e totalização usando recursos de banco de dados nativos e recalcula de modo síncrono os valores de modo eficiente como parte de transações em andamento.
A plataforma oferece várias APIs abertas e baseadas em padrões que os desenvolvedores podem usar para criar aplicativos. Tanto as APIs RESTful quanto Web Services (baseado em SOAP) fornecem acesso aos muitos recursos da plataforma. Usando essas várias APIs, um aplicativo pode:
- Manipule metadados que descrevem um esquema de aplicativo
- Criar, ler, atualizar e excluir dados comerciais (CRUD)
- Carregar em massa ou consultar um grande número de registros de modo assíncrono
- Expor um fluxo quase em tempo real de dados de maneira segura e escalonável
Os aplicativos podem usar a Salesforce Object Query Language (SOQL) para criar consultas de banco de dados simples, mas eficientes. Assim como o comando SELECT na Structured Query Language (SQL), o SOQL permite que você especifique o objeto de origem, uma lista de campos a serem recuperados e condições para selecionar linhas no objeto de origem. Por exemplo, a seguinte consulta SOQL retorna o valor do campo ID e Nome para todos os registros de Conta com um Nome igual à string "Acme".
SELECT Id, Name FROM Account WHERE Name = 'Acme'
A plataforma também inclui um mecanismo de pesquisa multilíngue de texto completo que indexa automaticamente todos os campos relacionados a texto. Os aplicativos podem usar esse mecanismo de pesquisa pré-integrado usando a Linguagem de pesquisa de objeto do Salesforce (SOSL) para realizar pesquisas de texto. Diferentemente do SOQL, que pode consultar apenas um objeto por vez, o SOSL permite pesquisar campos de texto, email e telefone para vários objetos simultaneamente. Por exemplo, a instrução SOSL a seguir pesquisa registros nos objetos Lead e Contato que contêm a string "Joe Smith" no campo name e retorna o campo name e number de cada registro encontrado.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
O Apex, que é semelhante ao Java em muitos aspectos, é uma linguagem de desenvolvimento poderosa que os desenvolvedores podem usar para centralizar a lógica procedural em seu esquema de aplicativos. O Apex code pode declarar variáveis e constantes do programa, executar instruções de controle de fluxo tradicionais (se-else, loops e assim por diante), realizar operações de manipulação de dados (insert, update, upsert, delete) e realizar operações de controle de transação (setSavepoint, rollback).
Você pode armazenar programas do Apex na plataforma usando duas formas diferentes: como uma classe do Apex nomeada com métodos (como os procedimentos armazenados na linguagem de banco de dados tradicional) que as aplicações executam quando necessário, ou como um acionador de banco de dados que é executado automaticamente antes ou depois de um evento de manipulação de banco de dados específico ocorrer. Em qualquer forma, a plataforma compila o Apex code e armazena-o como metadados no UDD. Na primeira vez que uma organização executa um programa do Apex, o interpretador de tempo de execução da plataforma carrega a versão compilada do programa em um cache MRU (usuado mais recentemente) para essa organização. Depois disso, quando qualquer usuário da mesma organização precisar usar a mesma rotina, a plataforma poderá salvar a memória e evitar a sobrecarga de recompilar o programa novamente compartilhando o programa pronto para execução que já está na memória.
Com a adição de uma palavra-chave simples aqui e ali, os desenvolvedores podem usar o Apex para suportar muitos requisitos de aplicativo exclusivos. Por exemplo, os desenvolvedores podem expor um método como uma chamada de API personalizada baseada em SOAP ou RESTful, torná-lo assíncrono agendável ou configurá-lo para processar uma operação grande em lotes.
O Apex é muito mais do que “apenas outra linguagem procedural”. É um componente integral da plataforma que ajuda o sistema a oferecer um multitarefa confiável. Por exemplo, a plataforma valida automaticamente todas as instruções SOQL e SOSL integradas em uma classe para evitar que o código falhe no tempo de execução. A plataforma então mantém as informações de dependência de objeto correspondentes para classes válidas e as usa para evitar alterações nos metadados que, caso contrário, quebrariam o código dependente.
Muitas classes padrão do Apex e métodos estáticos do sistema fornecem interfaces simples para os recursos subjacentes do sistema. Por exemplo, os métodos DML estáticos do sistema, como inserir, atualizar e excluir, têm um parâmetro booleano simples que os desenvolvedores podem usar para indicar a opção de processamento em massa desejada (tudo ou nada ou salvamento parcial); esses métodos também retornam um objeto de resultado que a rotina de chamada pode ler para determinar quais registros foram processados com falha e por quê. Outros exemplos de vínculos diretos entre recursos do Apex e da plataforma incluem as classes de email integradas e as classes XmlStream.
Em grande parte, a plataforma tem um bom desempenho e escala porque o Salesforce a criou com dois princípios importantes em mente:
- Forneça recursos de plataforma básica eficientes e de alta escala.
- Ajude os desenvolvedores a fazer tudo da maneira mais eficiente possível.
A plataforma incorpora esses princípios às arquiteturas de processamento exclusivas da plataforma, incluindo:
- Consultas
- Pesquisas
- Operações em massa
- Modificação de esquema
- Isolamento de multilocatário
- A lixeira
A maioria dos sistemas de banco de dados modernos determina planos ideais de execução de consulta empregando um otimizador de consulta baseado em custo que considera estatísticas relevantes sobre dados de índice e tabela de destino. No entanto, as estatísticas convencionais do otimizador baseadas em custo são projetadas para aplicativos de locatário único e não levam em conta as características de acesso a dados de qualquer determinado usuário que execute uma consulta em um ambiente de vários locatários. Por exemplo, uma determinada consulta direcionada a um objeto com um grande volume de dados provavelmente será executada com mais eficiência usando diferentes planos de execução para usuários com alta visibilidade (um gerente que pode ver todas as linhas) versus usuários com baixa visibilidade (pessoas de vendas que podem ver apenas linhas relacionadas a si mesmas).
Para fornecer estatísticas suficientes para determinar planos ideais de execução de consulta em um sistema multilocatário, a plataforma mantém um conjunto completo de estatísticas de otimizador (em nível de locatário, grupo e usuário) para os objetos de cada organização. As estatísticas refletem o número de linhas que uma consulta específica pode acessar, considerando cuidadosamente as estatísticas gerais de objeto específicas da organização (por exemplo, o número total de linhas de propriedade da organização como um todo), bem como estatísticas mais granulares (por exemplo, o número de linhas que um grupo de privilégios específico ou usuário final pode acessar potencialmente).
A plataforma também mantém outros tipos de estatísticas que se revelam úteis com determinadas consultas. Por exemplo, a plataforma mantém estatísticas para todos os índices personalizados para revelar o número total de valores não nulos e exclusivos no campo correspondente e histogramas para campos de lista de opções que revelam a cardinalidade de cada valor de lista.
Quando as estatísticas existentes não estão em vigor ou não são consideradas úteis, o otimizador da plataforma tem algumas estratégias diferentes que ele usa para ajudar a criar consultas razoavelmente ideais. Por exemplo, quando uma consulta filtra no campo Nome de um objeto, o otimizador pode usar a tabela MT_Fallback_Indexes para localizar com eficiência as linhas solicitadas. Em outros cenários, o otimizador gerará dinamicamente estatísticas ausentes no tempo de execução.
Usado junto com as estatísticas do otimizador, o otimizador da plataforma também depende de tabelas internas relacionadas à segurança (Grupos, Membros, GroupBlowout e CustomShare) que mantêm informações sobre os domínios de segurança dos usuários de uma organização, incluindo as associações de grupo de um determinado usuário e direitos de acesso personalizados para objetos e linhas. Essas informações são valiosas para determinar a seletividade dos filtros de consulta por usuário. Consulte o Trailhead Platform Developer Basics para obter mais informações sobre o modelo de segurança integrado da plataforma.
O fluxograma na figura a seguir ilustra o que acontece quando a plataforma processa uma solicitação de dados que está em uma das tabelas de heap grandes, como MT_Data. A solicitação pode se originar de qualquer quantidade de origens, como uma chamada à API ou um procedimento armazenado. Primeiro, a plataforma executa "pré-consultas" que consideram as estatísticas sensíveis ao multilocatário. Em seguida, com base nos resultados retornados pelas consultas anteriores, o serviço cria uma consulta de banco de dados ideal subjacente para execução na configuração específica.
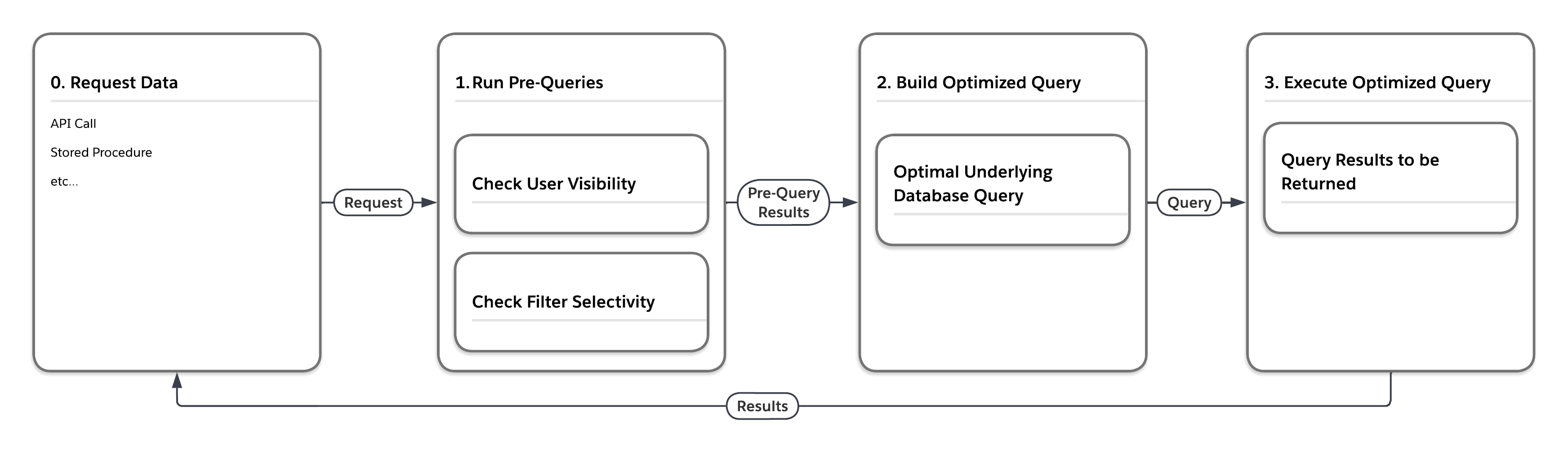
Como mostra a tabela a seguir, a plataforma pode executar a mesma consulta de quatro maneiras diferentes, dependendo do usuário que envia a consulta e da seletividade das condições de filtro da consulta.
| Medidas de seleção pré-consulta | Escrever consulta de acesso ao banco de dados final, forçando... | |
| Usuário | Filtro | |
| Baixo | Baixo | ... junção de loops aninhados, acionando usando a visualização das linhas que o usuário pode ver |
| Baixo | Alto | ... uso do índice relacionado ao filtro |
| Alto | Baixo | ... junção de hash ordenada, acionando usando MT_DATA |
| Alto | Alto | ... uso do filtro relacionado a índice |
Os usuários esperam que um recurso de pesquisa interativa verifique todo ou um escopo selecionado do banco de dados de um aplicativo e retorne resultados classificados com tempos de resposta de menos de um segundo. Para fornecer essa capacidade para aplicativos de plataforma, a plataforma usa um mecanismo de pesquisa separado do seu mecanismo de transação. Quando você atualiza registros, o mecanismo de transação atualiza o banco de dados principal e também encaminha dados relacionados ao mecanismo de pesquisa para indexação. Quando você pesquisa registros, o mecanismo de pesquisa usa seus índices para processar a consulta rapidamente e retorna resultados classificados com links para registros de banco de dados relacionados.
Conforme os aplicativos atualizam dados em campos de texto (CLOBs, Name e assim por diante), um grupo de processos em segundo plano chamado servidores de indexação é responsável por atualizar de modo assíncrono os índices correspondentes, que o mecanismo de pesquisa mantém fora do mecanismo de transação principal. Para otimizar o processo de indexação, a plataforma copia de modo síncrono partes de dados de texto modificados para uma tabela interna "para ser indexada" conforme as transações são confirmadas, fornecendo assim uma origem de dados relativamente pequena que minimiza a quantidade de dados que os servidores de indexação devem ler do disco. O mecanismo de pesquisa mantém automaticamente índices separados para cada organização.
Dependendo do carregamento e da utilização atuais dos servidores de indexação, as atualizações de índice de texto podem ficar atrás das transações reais. Para evitar resultados de pesquisa inesperados originados de índices obsoletos, a plataforma também mantém um cache de MRU de linhas atualizadas recentemente que o sistema considera ao materializar resultados de pesquisa de texto completo. A plataforma mantém os cache de MRU por usuário e por organização para dar suporte de modo eficiente a possíveis escopos de pesquisa.
O mecanismo de pesquisa da plataforma otimiza a classificação de registros nos resultados da pesquisa usando vários métodos. Por exemplo, o sistema considera o domínio de segurança do usuário que está realizando uma pesquisa e coloca mais peso nas linhas que o usuário atual pode acessar. O sistema também pode considerar o histórico de modificação de uma linha específica e classificar linhas atualizadas mais ativamente antes das linhas relativamente estáticas. O usuário pode optar por ponderar os resultados da pesquisa conforme desejado, por exemplo, colocando mais ênfase em linhas modificadas recentemente.
Os aplicativos com uso intensivo de transações geram menos sobrecarga e apresentam um desempenho muito melhor quando combinam e executam operações repetitivas em massa. Por exemplo, contraste duas maneiras como um aplicativo pode carregar muitas linhas novas. Uma abordagem ineficiente seria usar uma rotina com um loop que insere linhas individuais, fazendo uma chamada de API após outra para cada inserção de linha. Uma abordagem muito mais eficiente seria criar uma matriz de linhas e fazer a inserção de rotina de todas elas com uma única chamada de API.
O processamento em massa eficiente com a plataforma é simples para desenvolvedores porque é integrado a chamadas à API. Interna, a plataforma também processa em massa todas as etapas internas relacionadas a uma operação em massa explícita.
O mecanismo de processamento em massa da plataforma considera automaticamente falhas isoladas encontradas durante qualquer etapa ao longo do caminho. Quando uma operação em massa começa no modo de salvamento parcial, o mecanismo identifica um estado de início conhecido e então tenta executar cada etapa no processo (dados de campo de validação em massa, pré-acionadores de incêndio em massa, registros de salvamento em massa etc.). Se o mecanismo detectar erros durante qualquer etapa, ele reverterá as operações com infração e todos os efeitos colaterais, removerá as linhas responsáveis pelas falhas e continuará, tentando processar em massa o subconjunto restante de linhas. Esse processo itera em cada estágio sucessivo até que o mecanismo possa confirmar um subconjunto de linhas sem erros. O aplicativo pode examinar um objeto de retorno para identificar quais linhas falharam e quais exceções eles geraram.
Nota: A seu critério, um modo de tudo ou nada está disponível para operações em massa. Além disso, a execução de acionadores durante uma operação em massa está sujeita a controladores internos que restringem a quantidade de trabalho.
Determinados tipos de modificações na definição de um objeto exigem mais do que atualizações de metadados UDD simples. Nesses casos, a plataforma usa mecanismos eficientes que ajudam a reduzir o impacto geral de desempenho no serviço de banco de dados de nuvem em geral.
Por exemplo, considere o que acontece nos bastidores quando você modifica o tipo de dados de uma coluna da lista de opções para texto. A plataforma primeiro aloca um novo período para os dados da coluna, copia em massa os rótulos da lista de opções associados aos valores atuais e atualiza os metadados da coluna para apontar para o novo período. Embora tudo isso aconteça, o acesso aos dados é normal e os aplicativos continuam funcionando sem nenhum impacto perceptível.
Como outro exemplo, considere o que acontece quando você adiciona um campo de resumo de totalização a um objeto. Nesse caso, a plataforma calcula de modo assíncrono os resumos iniciais em segundo plano usando uma operação em massa eficiente. Enquanto o cálculo em segundo plano está acontecendo, os usuários que visualizam o novo campo recebem uma indicação de que a plataforma está calculando o valor do campo no momento.
Para evitar monopolização mal-intencionada ou mal-intencionada de recursos do sistema multilocatário compartilhados, a plataforma tem um amplo conjunto de controladores e limites de recursos associados à execução de código da plataforma. Por exemplo, a plataforma monitora de perto a execução de um script de código e limita quanto tempo de CPU ela pode usar, quanto memória ela pode consumir, quantas consultas e instruções DML ela pode executar, quantos cálculos matemáticos ela pode realizar, quantas chamadas de serviços da Web de saída ela pode fazer e muito mais. Consultas individuais que o otimizador da plataforma considera caras demais para executar geram uma exceção de tempo de execução ao chamador. Embora esses limites possam parecer um pouco restritivos, eles são necessários para proteger a escalabilidade geral e o desempenho do sistema de banco de dados compartilhado para todos os aplicativos afetados. No longo prazo, essas medidas ajudam a promover melhores técnicas de codificação entre desenvolvedores e criar uma melhor experiência para todos que usam a plataforma. Por exemplo, um desenvolvedor que inicialmente tente codificar um loop que atualize de modo ineficiente mil linhas de uma linha por vez receberá exceções de tempo de execução devido a limites de recursos e, em seguida, começará a usar as chamadas de API de processamento em massa eficientes da plataforma.
Para evitar ainda mais possíveis problemas do sistema introduzidos por aplicativos mal escritos, a implantação de um novo aplicativo de produção é um processo estritamente gerenciado. Para que uma organização possa migrar um novo aplicativo do status de desenvolvimento para o de produção, o Salesforce exige testes de unidade que validam a funcionalidade das rotinas de código de plataforma do aplicativo. Os testes de unidade enviados devem cobrir não menos de 75% do código-fonte do aplicativo.
O Salesforce executa os testes de unidade enviados no ambiente de desenvolvimento de sandbox da plataforma para determinar se o código do aplicativo afetará negativamente o desempenho e a escalabilidade da população de multilocatários em geral. Os resultados de um teste de unidade individual indicam informações básicas, como o número total de linhas executadas, bem como informações específicas sobre o código que não foi executado pelo teste.
Depois que o código de um aplicativo é certificado para produção pelo Salesforce, o processo de implementação do aplicativo consiste em uma única transação que copia todos os metadados do aplicativo para uma instância da plataforma de produção e executa novamente os testes de unidade correspondentes. Se qualquer parte do processo falhar, a plataforma simplesmente reverte a transação e retorna exceções para ajudar a solucionar o problema.
Nota: O Salesforce executa novamente os testes de unidade para cada aplicativo a cada versão de desenvolvimento da plataforma para saber proativamente se novos recursos e aprimoramentos do sistema interrompem quaisquer aplicativos existentes.
Depois que um aplicativo de produção estiver ativo, o perfil de desempenho integrado da plataforma o analisará automaticamente e fornecerá feedback associado aos administradores. Os relatórios de análise de desempenho incluem informações sobre consultas lentas, manipulações de dados e subrotinas que você pode revisar e usar para ajustar a funcionalidade do aplicativo. O sistema também registra e retorna informações sobre exceções de tempo de execução aos administradores para ajudá-los a depurar seus aplicativos.
Quando um aplicativo exclui um registro de um objeto, a plataforma simplesmente marca a linha para exclusão modificando o campo IsDeleted da linha em MTData. Esta ação efetivamente coloca a linha no que é conhecido como a Lixeira _. a plataforma permite que você restaure linhas selecionadas da Lixeira por até 15 dias antes de removê-las permanentemente do MT_Data. A plataforma limita o número total de registros que mantém para uma organização com base nos limites de armazenamento para essa organização.
Quando uma operação exclui um registro pai envolvido em um relacionamento entre mestre e detalhes, a plataforma exclui automaticamente todos os registros filho relacionados, desde que isso não quebre nenhuma regra de integridade referencial em vigor. Por exemplo, quando você exclui um SalesOrder, a plataforma encadeia automaticamente a exclusão para LineItems dependentes. Se você restaurar posteriormente um registro pai da Lixeira, o sistema também restaurará automaticamente todos os registros filho.
Por outro lado, quando você exclui um registro pai referenciado envolvido em um relacionamento de pesquisa, a plataforma define automaticamente todas as chaves dependentes como nulas. Se você restaurar posteriormente o registro pai, a plataforma restaurará automaticamente os relacionamentos de pesquisa anulados anteriormente, exceto os relacionamentos que foram reatribuídos entre as operações de exclusão e restauração.
A Lixeira também armazena campos descartados e seus dados até que uma organização os exclua permanentemente ou um determinado número de dias tenha decorrido, o que ocorrer primeiro. Até esse momento, todo o campo e todos os seus dados estarão disponíveis para restauração.
Agilidade é fundamental para que as empresas tenham sucesso no nosso mundo moderno. As camadas subjacentes da Salesforce Platform ajudam seus aplicativos de negócios a se adaptar rapidamente a novos desafios para que você possa continuar se concentrando em seus negócios, em vez de em sua infraestrutura.
A infra-estrutura (por exemplo, serviços básicos e recursos de computação) é uma tecnologia oculta e subjacente que suporta camadas superiores na Salesforce Platform. O Hyperforce é a infraestrutura da Salesforce Platform, construída com 100% de energia renovável e zero líquido, que resolve os principais desafios do cliente, incluindo conformidade, Trust e escalabilidade
As empresas que operam em vários locais geográficos precisam cumprir normas novas, em evolução e variadas para gerenciamento de dados. Como a Salesforce está implantando o Hyperforce em um número crescente de países, atualmente, com base na disponibilidade da região da AWS, aplicativos de plataforma e usuários podem executar suas cargas de trabalho confidenciais de maneiras que atendem aos padrões rigorosos de armazenamento de dados ou proteção de dados. Por exemplo, com a zona operacional da União Europeia (UE) da Salesforce alimentada pelo Hyperforce, as empresas da UE podem facilmente manter seus dados na UE.
Segurança, confiabilidade e disponibilidade são requisitos não funcionais que cada aplicativo de negócios deve considerar para cumprir a promessa de Trust para seus usuários finais. Com o Hyperforce, a Salesforce Platform permite que as empresas entreguem facilmente aplicativos comerciais confiáveis.
- Segurança – o Hyperforce tem criptografia completa nativa de dados do cliente em repouso e em trânsito. A Arquitetura Zero Trust do Hyperforce aplica um processo de verificação de identidade rigoroso que garante que não haja acesso implícito aos recursos. E o Hyperforce usa o princípio de privilégio mínimo, garantindo que as operações sejam aprovadas na quantidade certa de tempo com a quantidade certa de acesso.
- Confiabilidade — Cada instância do Hyperforce usa várias zonas de disponibilidade na nuvem e abordagens modernizadas que aceleram a resposta de incidência para proporcionar uma plataforma altamente disponível e resiliente.
- Disponibilidade — Os pipelines CI/CD modernos do Hyperforce e as versões de aplicativo azul/verde minimizam os períodos de manutenção de aplicativos para apenas um minuto por ano.
Como a base para aplicativos como o Sales Cloud e o Service Cloud, o Salesforce é uma plataforma de desenvolvimento de aplicativos comprovada na qual empresas individuais e provedores de serviços criaram milhões de aplicativos de negócios para diferentes casos de uso, incluindo gerenciamento de cadeia de abastecimento, faturamento, contabilidade, comércio, rastreamento de conformidade, gerenciamento de recursos humanos e processamento de declarações. A arquitetura exclusiva acionada por metadados de vários locatários da plataforma é projetada especificamente para a nuvem e dá suporte de modo confiável e seguro a aplicativos de escala da Internet críticos para a missão. Usando APIs baseadas em padrões e ferramentas de desenvolvimento nativas, os desenvolvedores de plataforma podem facilmente criar todos os componentes de um aplicativo móvel ou da Web moderno, incluindo o modelo de dados do aplicativo (incluindo objetos e relacionamentos), lógica de negócios (incluindo fluxos de trabalho e validações), integrações com outros aplicativos e muito mais.
Desde a sua criação, a plataforma foi otimizada pelos engenheiros da Salesforce para multitarefa, com recursos que permitem a escala de aplicativos de plataforma para atender às mudanças nas demandas de negócios. Recursos integrados do sistema, como a API de processamento de dados em massa, Apex, um mecanismo de pesquisa de texto completo e um otimizador de consulta exclusivo, ajudam a tornar os aplicativos dependentes altamente eficientes e escalonáveis com pouco ou nenhum esforço dos desenvolvedores.
A abordagem gerenciada do Salesforce para a implantação de aplicativos de produção garante desempenho, escalabilidade e confiabilidade excelentes para todos os aplicativos que dependem da plataforma. O Salesforce monitora e coleta continuamente informações operacionais de aplicativos de plataforma para ajudar a promover melhorias incrementais e novos recursos do sistema que beneficiam imediatamente aplicativos novos e existentes.
Steve Bobrowski é um empresário e líder de tecnologia bem-sucedido que trabalhou para muitas das principais empresas de software corporativo, incluindo vários papéis no Salesforce desde 2008. Hoje, Steve trabalha no Escritório do CTO da Salesforce para ajudar com as estratégias de arquitetura de tecnologia da empresa.
Tom Leddy é um arquiteto evangelista no Salesforce. Ele dá suporte à comunidade global de arquitetos do Salesforce ajudando a criar recursos, ferramentas e orientações que ajudam os arquitetos a fazerem o melhor de seu trabalho. Conecte-se com Tom no Twitter.