Dagelijks exploiteren honderdduizenden ondernemingen en miljoenen gebruikers hun bedrijf in de cloud met behulp van toepassingen die worden aangestuurd door het Salesforce Platform. Waarom is het platform zo succesvol? Waarom kunt u erop Trusten dat het uw bedrijf ondersteunt? Welke unieke voordelen biedt het platform voor bedrijven zoals het uwe?
In deze technische handleiding wordt uitgelegd hoe het Salesforce Platform betrouwbare, schaalbare en eenvoudig aan te passen eindgebruikerservaringen biedt met behulp van de unieke softwarearchitectuur voor cloud computing. Na het lezen van deze samenvatting krijgt u een beter inzicht in de onderliggende technologie die het Salesforce Platform een aantrekkelijke keuze maakt voor uw bedrijfstoepassingen.
Het Salesforce Platform is een uitstekend voorbeeld van een succesvol cloudcomputingplatform en een gerelateerd ecosysteem van toepassingen. Sinds de millenniumwisseling is het platform de ondersteunende basis voor:
- Veel populaire zakelijke toepassingen voor veelvoorkomende gebruikscases zoals verkoop en klantenservice
- Branchespecifieke toepassingen voor meer gespecialiseerde gebruikscases zoals finance en gezondheidszorg
- Miljoenen aangepaste toepassingen en toepassingsextensies voor unieke gebruikscases
Het Salesforce Platform is voor een groot deel zo succesvol en populair omdat de unieke softwarearchitectuur toepassingen ondersteunt die gemakkelijk te bouwen, gebruiken, aan te passen en uit te breiden zijn met uitzonderlijke prestaties en betrouwbaarheid. Het hart van de softwarearchitectuur van het platform is het multitenant, metagegevensgestuurd ontwerp.
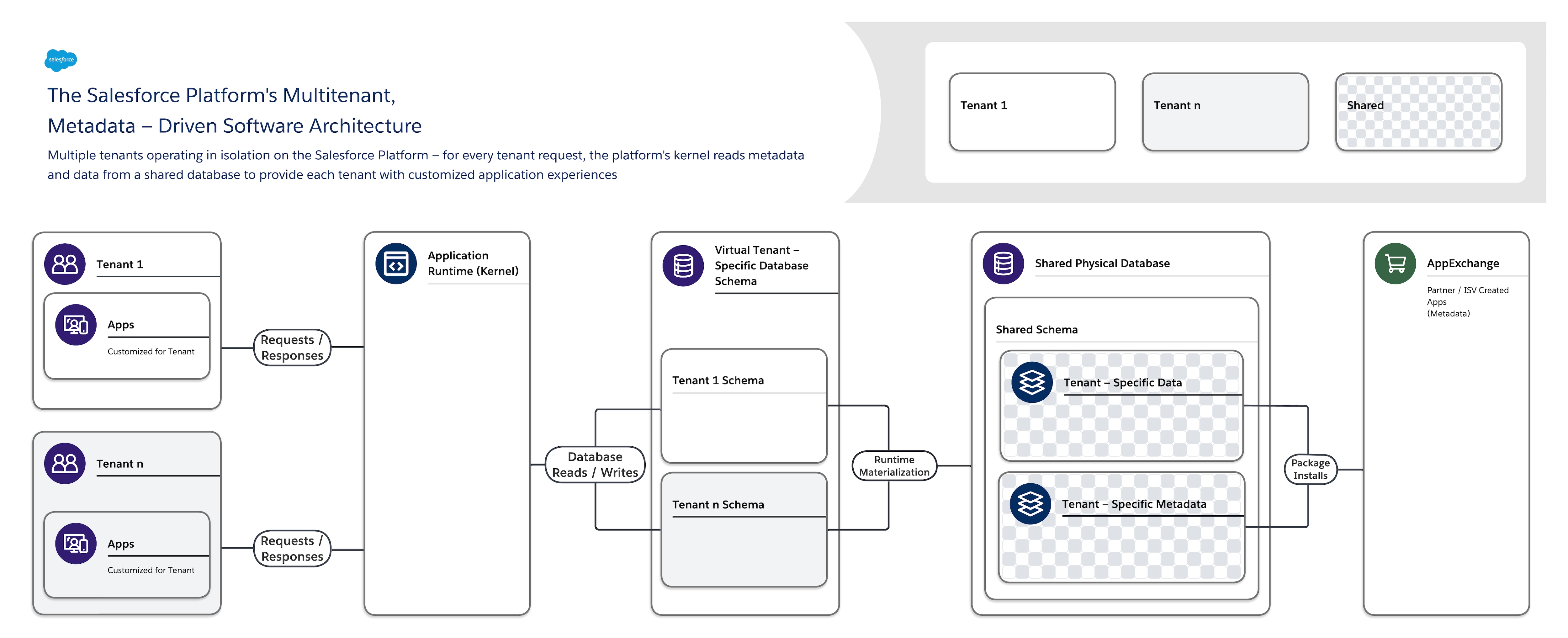
De softwarearchitectuur van het Salesforce Platform is:
- Multitenant — Het isoleert en ondersteunt tegelijkertijd de variërende behoeften van vele belanghebbenden (organisaties, bedrijfseenheden, enzovoort).
- Metagegevensgestuurd: hiermee kan elke belanghebbende gemakkelijk en snel zijn apps en gebruikerservaringen aanpassen met behulp van metagegevens, gegevens die elementen zoals de gebruikersinterface (UI) en bedrijfslogica beschrijven.
Wanneer u een nieuw toepassingsobject maakt of code schrijft met behulp van het Salesforce Platform, maakt het platform geen feitelijke tabel in een database of compileert het geen code. In plaats daarvan slaat het platform gewoon wat metagegevens op die het vervolgens tijdens run-time kan gebruiken om componenten van virtuele toepassingen dynamisch te realiseren. Het platform zorgt ervoor dat de metagegevens van elke belanghebbende privé zijn en gemakkelijk kunnen worden bijgewerkt zonder dat vergrendeling of downtime vereist is, zodat elke belanghebbende apps afzonderlijk kan samenstellen en aanpassen. Het Salesforce Platform gebruikt dezelfde metagegevens om aangepaste API's, RESTful en webservices (op SOAP gebaseerde) interfaces te bieden die u kunt gebruiken om uw toepassingen te integreren met andere toepassingen en geautomatiseerde processen.
Kant-en-klare oplossingen zijn ook beschikbaar in AppExchange, de uitgebreide appmarktplaats van het platform. Een AppExchange pakket is samengesteld door een uitgebreid ecosysteem van vertrouwde partners en onafhankelijke softwareleveranciers (ISV's). Het bestaat uit metagegevens van een externe leverancier die gratis of betaalde toepassingsextensies en complete toepassingen beschrijft die u kunt gebruiken om te voldoen aan specifieke bedrijfsvereisten.
Ter ondersteuning van deze zeer aanpasbare en uitbreidbare architectuur gebruikt één exemplaar van het Salesforce Platform:
- Eén gedeelde multitenantdatabase met één schema waarin belanghebbendenspecifieke metagegevens en gegevens worden opgeslagen.
- Een multitenant kernel (toepassingsrun-time) die metagegevens en gegevens leest om dynamisch belanghebbendespecifieke toepassingen, bedrijfslogica en API's te bieden voor de gebruikers van elke belanghebbende tijdens run-time.
Deze duidelijke scheiding tussen de door Salesforce beheerde kernel en door belanghebbenden beheerde metagegevens maakt het voor Salesforce, belanghebbenden en ISV's mogelijk om hun delen van het systeem onafhankelijk van elkaar te ontwikkelen zonder inmenging.
Om op dit overzicht voort te bouwen, geven de volgende secties van dit artikel meer details over de unieke mogelijkheden van het platform die voortvloeien uit de belangrijkste aspecten van het ontwerp, waaronder:
- De platformgegevenslaag
- Platform-toepassingsontwikkeling
- Interne platformverwerking
- Platforminfrastructuur
Samen isoleren de toepassingsrun-time en innovatieve gegevenslaag van het Salesforce Platform belanghebbendenspecifieke gegevens, schemaaanpassingen en bedrijfslogica veilig. Op hoog niveau ondersteunt het schema een verscheidenheid aan gebruikscases:
- Wanneer u een toepassing maakt of aanpast, slaat het platform gerelateerde metagegevens op in gedeelde databasetabellen die metagegevens voor alle belanghebbenden bijhouden.
- Wanneer u een toepassing gebruikt om gegevens te lezen of schrijven, slaat het platform uw gegevens op in gedeelde databasetabellen die gegevens voor alle belanghebbenden bijhouden.
- Achter de schermen houdt het platform ook interne metagegevens bij in een aantal tabellen die de kernel gebruikt om de latentie van verzoeken tijdens run-time te optimaliseren.
Maar hoe kan één gedeelde database en één schema de gegevens van elke belanghebbende privé houden? Elke belanghebbende op het platform staat bekend als een organisatie, of kortweg organisatie. En elke organisatiespecifieke record in gedeelde databasetabellen heeft een OrgID. Wanneer de kernel de database opent, gebruikt deze deze unieke identifier om ervoor te zorgen dat de activiteiten van elke organisatie privé zijn.

Organisatiespecifieke objecten (denk aan tabellen in traditionele relationele databasetaal), velden, opgeslagen procedures, databasetriggers en meer zijn allemaal virtuele constructies die worden beschreven door metagegevens die het platform opslaat in enkele databasetabellen die bekend staan als het Universal Data Dictionary (UDD).
- MT_Objects is een databasetabel waarin metagegevens worden opgeslagen over de objecten die u voor een toepassing definieert, inclusief een unieke identifier voor een object (ObjID), uw organisatie (OrgID) en de naam die u voor het object opgeeft (ObjName).
- De systeemtabel MT_Fields slaat metagegevens op over de velden (kolommen) die u voor elk object declareert, inclusief een unieke identifier voor een veld (FieldID), uw organisatie (OrgID), het object dat het veld bevat (ObjID), de naam van het veld (FieldName), het gegevenstype van het veld, een booleaanse waarde om aan te geven of het veld indexering vereist (IsIndexed) en de positie van het veld in het object ten opzichte van andere velden (FieldNum).
Omdat metagegevens een belangrijk ingrediënt zijn, moet het platform de toegang tot metagegevens optimaliseren; anders zou frequente toegang tot metagegevens verhinderen dat de service wordt opgeschaald. Met dit potentiële knelpunt in gedachten gebruikt het platform enorme en geavanceerde metagegevenscaches om de recentst gebruikte metagegevens in het geheugen te bewaren, prestatieverhogende schijf-I/O en codehercompilaties te voorkomen en reactietijden van toepassingen te verbeteren.
De systeemtabel MT_Data slaat de voor toepassingen toegankelijke gegevens op, die worden toegewezen aan alle organisatiespecifieke tabellen en hun velden, zoals gedefinieerd door metagegevens in MT_Objects en MT_Fields. Elke rij omvat identificerende velden, zoals een globale unieke identifier (GUID), de organisatie die eigenaar is van de rij (OrgID) en de omvattende objectidentifier (ObjID). Elke rij in de tabel MT_Data heeft ook een veld Naam waarin een "natuurlijke naam" voor overeenkomende records wordt opgeslagen; zo kan een accountrecord "Accountnaam" gebruiken, kan een caserecord "Casenummer" gebruiken, enzovoort.
Waarde0 ... ValueN flex-kolommen, ook wel slots genoemd, slaan toepassingsgegevens op die worden toegewezen aan de tabellen en velden die respectievelijk in MT_Objects en MT_Fields zijn gedeclareerd. Alle Flex-kolommen gebruiken een gegevenstype tekenreeks met variabele lengte, zodat ze elk gestructureerd type toepassingsgegevens (tekenreeksen, getallen, datums, enzovoort) kunnen opslaan. Zoals de volgende figuur illustreert, kunnen geen twee velden van hetzelfde object worden toegewezen aan hetzelfde tijdstip in MT_Data voor opslag. Eén tijdstip kan echter de informatie van meerdere velden beheren, zolang elk veld afkomstig is van een ander object.
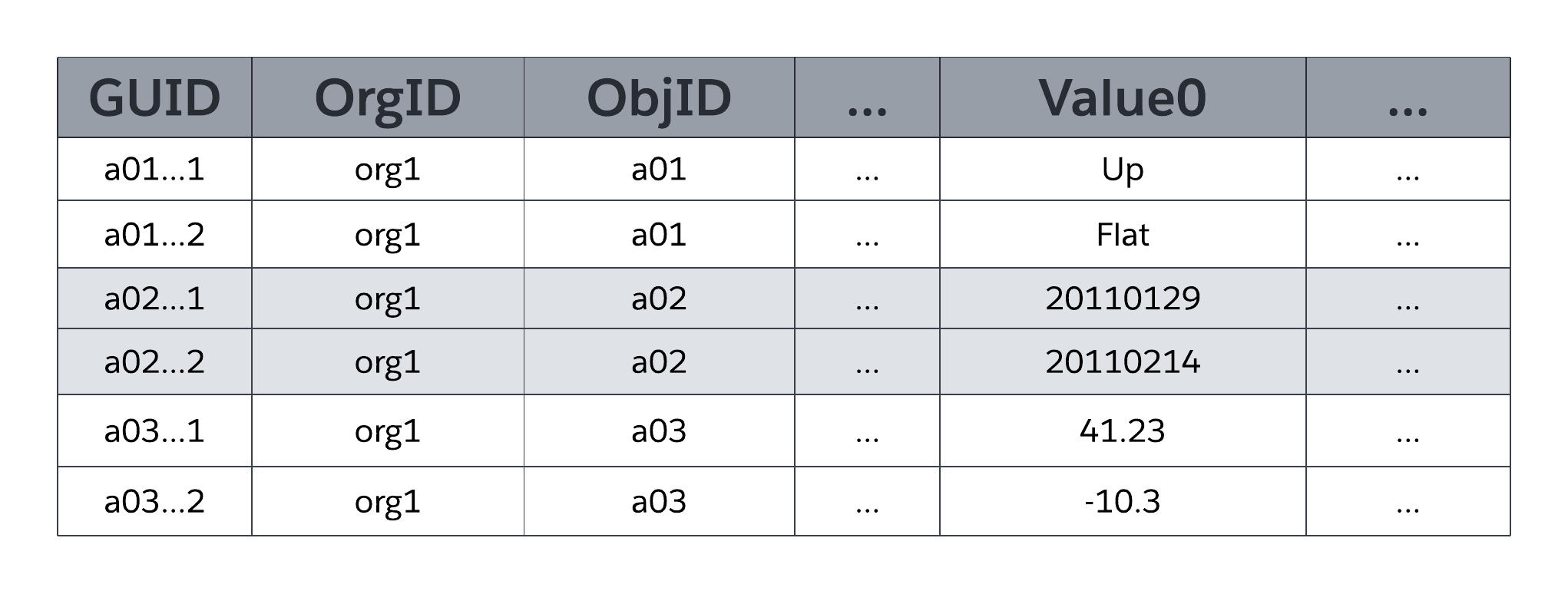
MTFields kan elk van een aantal standaard gestructureerde gegevenstypen gebruiken, zoals tekst, getal, datum en datum/tijd, evenals speciale gestructureerde gegevenstypen voor gebruik, zoals keuzelijst (genummerd veld), automatische nummering (automatisch verhoogd, door het systeem gegenereerd volgnummer), formule (alleen-lezen afgeleide waarde), hoofd-/detailrelatie (vreemde sleutel), selectievakje (booleaans), e-mail, URL en andere. MT_Fields kan ook verplicht zijn (niet null) en aangepaste validatieregels hebben (zo moet het ene veld groter zijn dan het andere), die het platform in beide gevallen afdwingt.
Wanneer u een object declareert of wijzigt, beheert het platform een rij metagegevens in MT_Objects die het object definieert. Op soortgelijke wijze beheert het platform voor elk veld een rij in MT_Fields, inclusief metagegevens die het veld toewijzen aan een specifieke flexkolom in MT_Data voor de opslag van overeenkomende veldgegevens. Omdat het platform object- en velddefinities beheert als metagegevens in plaats van feitelijke databasestructuren, kan het systeem online onderhoudsactiviteiten voor toepassingsschema's voor meerdere belanghebbenden tolereren zonder de gelijktijdige activiteit van andere organisaties en gebruikers te blokkeren. Ter vergelijking: het opnieuw definiëren van online tabellen voor traditionele relationele databasesystemen vereist doorgaans tijdelijke vergrendelingen en vaak moeizame, complexe processen en geplande downtime van toepassingen.
Zoals de vereenvoudigde weergave van MT_Data in de vorige figuur laat zien, zijn flexkolommen van een universeel gegevenstype (tekenreeks met variabele lengte), waardoor het platform één flexkolom kan delen tussen meerdere velden die verschillende gestructureerde gegevenstypen gebruiken (tekenreeksen, getallen, datums, enzovoort).
Het platform slaat alle Flex-kolomgegevens op met behulp van een canonieke indeling en gebruikt indien nodig onderliggende conversiefuncties van het databasesysteem voor gegevenstypen (bijvoorbeeld TO_NUMBER, TO_DATE, TO_CHAR) wanneer toepassingen gegevens lezen van en schrijven naar Flex-kolommen.
MTData bevat ook kolommen die niet in de vorige figuur worden getoond. Zo zijn er vier kolommen voor het beheer van controlegegevens, waaronder welke gebruiker een rij heeft gemaakt en wanneer die rij is gemaakt, en welke gebruiker een rij het laatst heeft gewijzigd en wanneer die rij het laatst is gewijzigd. MT_Data bevat ook een kolom _IsDeleted die het platform gebruikt om aan te geven wanneer een rij is verwijderd.
Het platform ondersteunt ook de declaratie van velden als character large objects (CLOB's) om de opslag van lange-tekstvelden van maximaal 32.000 lettertekens mogelijk te maken. Voor elke rij in MTData die een CLOB heeft, slaat het platform de CLOB buiten de lijn op in een tabel met de naam _MT_Clob, die het systeem indien nodig kan samenvoegen met overeenkomende rijen in MT_Data.
Opmerking: Het platform slaat CLOB's ook op in een geïndexeerde vorm buiten de database voor zoekopdrachten met snelle tekst. Zie Zoekopdrachten voor meer informatie over de tekstzoekmachine van het platform.
Het platform indexeert automatisch verschillende typen velden om schaalbare prestaties te leveren.
Traditionele databasesystemen vertrouwen op native database-indexen om snel specifieke rijen in een databasetabel te vinden die velden hebben die overeenkomen met een specifieke voorwaarde. Het is echter niet praktisch om native database-indexen te maken voor de flexkolommen van MTData*, omdat het platform één flexkolom gebruikt om de gegevens van vele velden met verschillende gestructureerde gegevenstypen op te slaan. In plaats daarvan beheert het platform een index van MT_Data door veldgegevens die zijn gemarkeerd voor indexering, synchroon te kopiëren naar een geschikte kolom in een draaitabel _MT_Indexes*.
MT_Indexes bevat sterk getypeerde, geïndexeerde kolommen zoals StringValue, NumValue en DateValue die het platform gebruikt om veldgegevens van het overeenkomende gegevenstype te zoeken. Het platform kopieert bijvoorbeeld een tekenreekswaarde in een flexibele kolom MT_Data naar het veld StringValue in MT_Indexes, een datumwaarde naar het veld DateValue, enzovoort. De onderliggende indices van MT_Indexes zijn standaard, niet-unieke database-indices. Wanneer een interne systeemquery een zoekparameter bevat die verwijst naar een gestructureerd veld in een object, gebruikt de aangepaste queryoptimalisering van het platform MT_Indexes om gekoppelde bewerkingen voor gegevenstoegang te optimaliseren.
Opmerking: Het platform kan zoekopdrachten in meerdere talen afhandelen, omdat het systeem een hoofdlettervouwalgoritme gebruikt dat tekenreekswaarden converteert naar een universele, hoofdletterongevoelige indeling. In de kolom StringValue van de tabel MT_Indexes worden tekenreekswaarden in deze indeling opgeslagen. Tijdens run-time stelt de queryoptimaliseringsfunctie automatisch bewerkingen voor gegevenstoegang samen, zodat de geoptimaliseerde SQL-instructie filtert op de corresponderende in een case gevouwen StringValue, die op zijn beurt overeenkomt met de constanten die in de zoekaanvraag zijn opgegeven.
Met het platform kunt u aangeven wanneer een veld in een object unieke waarden (hoofdlettergevoelig of hoofdletterongevoelig) moet bevatten. Gezien de indeling van MT_Data en het gedeelde gebruik van de kolommen Waarde voor veldgegevens is het niet praktisch om unieke database-indexen voor het object te maken. (Deze situatie lijkt op de situatie die in de vorige sectie voor niet-unieke indexen is besproken.)
Om uniciteit voor aangepaste velden te ondersteunen, gebruikt het platform de draaitabel MT_Unique_Indexes. Deze tabel lijkt sterk op de tabel MT_Indexes, met dit verschil dat de onderliggende native database-indexen van MT_Unique_Indexes uniciteit afdwingen. Wanneer een toepassing probeert om een duplicaatwaarde in te voegen in een veld dat uniciteit vereist, of wanneer een beheerder probeert om uniciteit af te dwingen voor een bestaand veld dat duplicaatwaarden bevat, retourneert het platform een passend foutbericht naar de toepassing.
In zeldzame gevallen kan de externe zoekmachine van het platform (vermeld in Zoekopdrachten) overbelast raken of anderszins niet beschikbaar zijn, en mogelijk niet tijdig reageren op een zoekverzoek. In plaats van een teleurstellende fout te retourneren aan de eindgebruiker, valt het platform terug op een secundair zoekmechanisme om redelijke zoekresultaten te leveren.
Een reservezoekopdracht wordt geïmplementeerd als een directe databasequery met zoekvoorwaarden die verwijzen naar het veld Naam van doelrecords. Voor het optimaliseren van globale objectzoekopdrachten (zoekopdrachten die tabellen bestrijken) zonder potentieel dure samenvoegingsquery's te hoeven uitvoeren, onderhoudt het platform een draaitabel MT_Fallback_Indexes die de naam van alle records vastlegt. Updates van MT_Fallback_Indeexes vinden synchroon plaats wanneer transacties records wijzigen, zodat reservezoekopdrachten altijd toegang hebben tot de meest actuele databasegegevens.
De tabel MT_Name_Denorm is een magere gegevenstabel waarin de ObjID en Naam van elke record worden opgeslagen in MT_Data. Wanneer een toepassing een lijst moet bieden van records die betrokken zijn bij een bovenliggende/onderliggende relatie, gebruikt het platform de tabel MT_Name_Denorm om een relatief eenvoudige query uit te voeren die de naam van elke record waarnaar wordt verwezen ophaalt voor weergave in de app, bijvoorbeeld als onderdeel van een hyperlink.
Het platform biedt relatiegegevenstypen die een organisatie kan gebruiken om relaties (verwijzingsintegriteit) tussen tabellen te declareren. Wanneer u het veld van een object declareert met een relatietype, wijst het platform het veld toe aan een veld Waarde in MT_Data en gebruikt dit veld vervolgens om de ObjID van een gerelateerd object op te slaan.
Voor het optimaliseren van joinbewerkingen onderhoudt het platform een draaitabel MT_Relationships. Deze systeemtabel heeft twee onderliggende, unieke samengestelde database-indexen die efficiënte objectdoorgangen in beide richtingen mogelijk maken, indien nodig.
Met slechts een paar muisklikken biedt het platform historie bijhouden voor elk veld. Wanneer een organisatie controle inschakelt voor een specifiek veld, legt het systeem asynchroon informatie vast over de wijzigingen die in het veld zijn aangebracht (oude en nieuwe waarden, wijzigingsdatum, enzovoort) met behulp van een interne draaitabel als controletraject.
Alle platformgegevens, metagegevens en draaitabelstructuren, inclusief onderliggende database-indices, worden fysiek gepartitioneerd door OrgID met behulp van native databasepartitioneringsmechanismen. Gegevenspartitionering is een beproefde techniek die databasesystemen bieden om grote logische gegevensstructuren fysiek te verdelen in kleinere, beter beheersbare stukken. Partitioneren kan ook helpen om de prestaties, schaalbaarheid en beschikbaarheid van een groot databasesysteem, zoals een omgeving met meerdere belanghebbenden, te verbeteren. Per definitie is elke platformquery gericht op de informatie van een specifieke organisatie, waardoor de queryoptimalisering alleen toegang hoeft te overwegen tot gegevenspartities die de gegevens van een organisatie bevatten, in plaats van een volledige tabel of index. Deze veelvoorkomende optimalisering wordt soms "partition pruning" genoemd.
Deze sectie behandelt hoe appontwikkelaars de onderliggende metagegevens van een schema kunnen maken en vervolgens apps kunnen samenstellen die gegevens beheren. Die metagegevens en gegevens worden opgeslagen in de platformgegevenslaag die in de vorige sectie is beschreven.
Ontwikkelaars kunnen declaratief toepassingscomponenten aan de serverzijde samenstellen met behulp van de browsergebaseerde ontwikkelomgeving van het platform, doorgaans de Set-upschermen van het platform genoemd. De "point-and-click" UI van Set-up ondersteunt alle facetten van het proces van het samenstellen van toepassingsschema's, zoals het maken van het gegevensmodel van een toepassing (inclusief objecten en hun velden, alsmede relaties), het beveiligings- en deelmodel (inclusief gebruikers, profielen en rollenhiërarchieën), de gebruikersinterface (inclusief schermlay-outs, gegevensinvoerformulieren en rapporten), declaratieve logica (werkstromen) en programmatische logica (opgeslagen procedures en triggers). Salesforce Flow maakt het bijvoorbeeld gemakkelijk om een breed scala aan gebruikscases te automatiseren. Met de Flow Builder-UI van Set-up, die u hieronder ziet, kunt u werkstromen ontwerpen en implementeren die interactie hebben met gebruikers, of automatisch starten op basis van een planning of wanneer deze worden geactiveerd door een event.
De Set-upschermen maken het voor iedereen gemakkelijk om toepassingen te ontwikkelen en aan te passen zonder (of zeer weinig) code. Bijvoorbeeld:
- Platform-native UI's zijn eenvoudig te bouwen zonder enige code. Achter de schermen ondersteunt een native app-UI alle gebruikelijke bewerkingen voor gegevenstoegang, inclusief query's, invoegingen, updates en verwijderingen. Elke gegevensmanipulatiebewerking die wordt uitgevoerd door native platformtoepassingen, kan één object tegelijk wijzigen en elke wijziging automatisch in een afzonderlijke transactie vastleggen.
- Wanneer u een tekstveld definieert voor een object dat gevoelige gegevens bevat, kunt u het veld gemakkelijk dusdanig configureren dat het platform de corresponderende gegevens versleutelt en optioneel een invoermasker gebruikt om scherminformatie te verbergen voor nieuwsgierige blikken.
- Een declaratieve validatieregel is een eenvoudige manier voor een organisatie om een domeinintegriteitsregel af te dwingen zonder programmeren. Zo kunt u een validatieregel declareren die ervoor zorgt dat het veld Hoeveelheid van een LineItem-object altijd groter is dan nul.
- Een formuleveld is een declaratieve voorziening van het platform die het toevoegen van een berekend veld aan een object vergemakkelijkt. Zo kunt u een veld toevoegen aan het object LineItem om een waarde voor LineTotal te berekenen.
- Een totaaloverzichtsveld is een kruisobjectveld dat het aggregeren van onderliggende veldgegevens in een bovenliggend object vergemakkelijkt. Zo kunt u een OrderTotal-overzichtsveld maken in het object SalesOrder op basis van het veld LineTotal van het object LineItem.
Opmerking: Intern implementeert het platform formule- en totaaloverzichtsvelden met behulp van native databasevoorzieningen en berekent waarden efficiënt synchroon opnieuw als onderdeel van lopende transacties.
Het platform biedt diverse open, op standaarden gebaseerde API's die ontwikkelaars kunnen gebruiken om apps te bouwen. Zowel RESTful als webservices (op SOAP gebaseerde) API's bieden toegang tot de vele voorzieningen van het platform. Met behulp van deze verschillende API's kan een toepassing:
- Metagegevens manipuleren die een toepassingsschema beschrijven
- Bedrijfsgegevens maken, lezen, bijwerken en verwijderen (CRUD)
- Een groot aantal records asynchroon in bulk laden of bevragen
- Een vrijwel real-time stroom gegevens op een veilige en schaalbare manier zichtbaar maken
Apps kunnen de Salesforce Object Query Language (SOQL) gebruiken om eenvoudige maar krachtige databasequery's samen te stellen. Net als met de opdracht SELECT in de Structured Query Language (SQL) kunt u met SOQL het bronobject, een lijst van op te halen velden en voorwaarden voor het selecteren van rijen in het bronobject opgeven. Zo retourneert de volgende SOQL-query de waarde van het veld Id en Naam voor alle accountrecords met een naam die gelijk is aan de tekenreeks 'Acme'.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
Het platform omvat ook een meertalige zoekmachine met volledige tekst die automatisch alle aan tekst gerelateerde velden indexeert. Apps kunnen deze vooraf geïntegreerde zoekmachine gebruiken door middel van de Salesforce Object Search Language (SOSL) om tekstzoekopdrachten uit te voeren. In tegenstelling tot SOQL, dat slechts één object tegelijk kan bevragen, kunt u met SOSL tekst-, e-mail- en telefoonvelden zoeken naar meerdere objecten tegelijk. Zo zoekt de volgende SOSL-instructie naar records in de objecten Lead en Contactpersoon die de tekenreeks 'Joe Smith' in het naamveld bevatten en retourneert het naam- en telefoonnummerveld van elke gevonden record.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, dat in veel opzichten lijkt op Java, is een krachtige ontwikkeltaal die ontwikkelaars kunnen gebruiken om procedurelogica te centraliseren in hun toepassingsschema. Apex code kan programmavariabelen en constanten declareren, traditionele stroomregelingsinstructies uitvoeren (if-else, lussen, enzovoort), gegevensmanipulatiebewerkingen uitvoeren (insert, update, upsert, delete) en transactiecontrolebewerkingen uitvoeren (setSavepoint, rollback).
U kunt Apex programma's in het platform opslaan met behulp van twee verschillende vormen: als een benoemde Apex klasse met methoden (net als opgeslagen procedures in traditionele database parlance) die toepassingen uitvoeren indien nodig, of als een databasetrigger die automatisch wordt uitgevoerd vóór of na een specifieke database manipulatie-event. In beide vormen compileert het platform Apex code en slaat deze op als metagegevens in de UDD. De eerste keer dat een organisatie een Apex programma uitvoert, laadt de run-time interpreter van het platform de gecompileerde versie van het programma in een MRU (meest recent gebruikt) cachegeheugen voor die organisatie. Wanneer een gebruiker uit dezelfde organisatie dezelfde routine moet gebruiken, kan het platform geheugen besparen en de overhead van het opnieuw compileren van het programma vermijden door het reeds in het geheugen aanwezige programma te delen.
Door hier en daar een eenvoudig trefwoord toe te voegen kunnen ontwikkelaars Apex gebruiken om vele unieke toepassingsvereisten te ondersteunen. Ontwikkelaars kunnen een methode bijvoorbeeld zichtbaar maken als een aangepaste RESTful- of SOAP-gebaseerde API-aanroep, deze asynchroon plannen of configureren om een grote bewerking in batches te verwerken.
Apex is veel meer dan “zomaar een proceduretaal”. Het is een integrale platformcomponent die het systeem helpt betrouwbare multitenancy te leveren. Zo valideert het platform automatisch alle ingebedde SOQL- en SOSL-instructies binnen een klasse om code te voorkomen die anders tijdens run-time zou mislukken. Het platform onderhoudt vervolgens overeenkomende objectafhankelijkheidsgegevens voor geldige klassen en gebruikt deze om wijzigingen in metagegevens te voorkomen die anders afhankelijke code zouden breken.
Veel standaard Apex klassen en systeem statische methoden bieden eenvoudige interfaces naar onderliggende systeemvoorzieningen. Zo hebben de statische DML-methoden van het systeem zoals insert, update en delete een eenvoudige booleaanse parameter die ontwikkelaars kunnen gebruiken om de gewenste bulkverwerkingsoptie aan te geven (alles of niets, of gedeeltelijk opslaan); deze methoden retourneren ook een resultaatobject dat de aanroeproutine kan lezen om te bepalen welke records niet met succes zijn verwerkt en waarom. Andere voorbeelden van de directe banden tussen Apex en platformvoorzieningen zijn de ingebouwde e-mailklassen en XmlStream-klassen.
Het platform presteert en schaalt voor een groot deel goed omdat Salesforce het heeft gebouwd met twee belangrijke principes in gedachten:
- Efficiënte, grootschalige basisplatformmogelijkheden bieden.
- Help ontwikkelaars alles zo efficiënt mogelijk te doen.
Het platform neemt deze principes op in de unieke verwerkingsarchitecturen van het platform, waaronder:
- Query's
- Zoekopdrachten
- Bulkbewerkingen
- Schemawijziging
- Isolatie van meerdere belanghebbenden
- De prullenbak
De meeste moderne databasesystemen bepalen optimale query-uitvoeringsplannen door middel van een op kosten gebaseerde queryoptimalisering die rekening houdt met relevante statistieken over doeltabel- en indexgegevens. Conventionele, op kosten gebaseerde optimaliseringsstatistieken zijn echter ontworpen voor toepassingen met één belanghebbende en houden geen rekening met de gegevenstoegangskenmerken van een bepaalde gebruiker die een query uitvoert in een omgeving met meerdere belanghebbenden. Zo zou een gegeven query die is gericht op een object met een groot volume aan gegevens, hoogstwaarschijnlijk efficiënter worden uitgevoerd met behulp van verschillende uitvoeringsplannen voor gebruikers met een hoge zichtbaarheid (een manager die alle rijen kan zien) ten opzichte van gebruikers met een lage zichtbaarheid (verkopers die alleen rijen kunnen zien die aan zichzelf zijn gerelateerd).
Om voldoende statistieken te bieden voor het bepalen van optimale query-uitvoeringsplannen in een systeem met meerdere belanghebbenden, houdt het platform een volledige set optimaliseringsstatistieken (tenant-, groeps- en gebruikersniveau) bij voor de objecten van elke organisatie. Statistieken weerspiegelen het aantal rijen waartoe een bepaalde query potentieel toegang heeft, waarbij zorgvuldig rekening wordt gehouden met algemene organisatiespecifieke objectstatistieken (bijvoorbeeld het totale aantal rijen dat eigendom is van de organisatie als geheel) en met meer gedetailleerde statistieken (bijvoorbeeld het aantal rijen waartoe een specifieke machtigingengroep of eindgebruiker potentieel toegang heeft).
Het platform onderhoudt ook andere typen statistieken die nuttig blijken bij bepaalde query's. Zo houdt het platform statistieken bij voor alle aangepaste indices om het totale aantal niet-null-waarden en unieke waarden in het overeenkomende veld te tonen, en histogrammen voor keuzelijstvelden die de kardinaliteit van elke lijstwaarde tonen.
Wanneer bestaande statistieken niet aanwezig zijn of als nuttig worden beschouwd, heeft de optimaliseringsfunctie van het platform een aantal verschillende strategieën die worden gebruikt om redelijk optimale query's samen te stellen. Wanneer een query bijvoorbeeld filtert op het veld Naam van een object, kan de optimizer de tabel MT_Fallback_Indexes gebruiken om aangevraagde rijen efficiënt te vinden. In andere scenario's genereert de optimalisering dynamisch ontbrekende statistieken tijdens run-time.
De optimaliseringsfunctie van het platform wordt gebruikt in combinatie met statistieken van de optimalisering en maakt ook gebruik van interne beveiligingsgerelateerde tabellen (Groepen, Leden, GroupBlowout en CustomShare) die informatie bijhouden over de beveiligingsdomeinen van de gebruikers van een organisatie, inclusief de groepslidmaatschappen van een bepaalde gebruiker en aangepaste toegangsrechten voor objecten en rijen. Dergelijke informatie is van onschatbare waarde voor het bepalen van de selectiviteit van queryfilters per gebruiker. Zie de Platform Developer Basics Trailhead voor meer informatie over het ingebedde beveiligingsmodel van het platform.
Het stroomdiagram in de volgende figuur illustreert wat er gebeurt wanneer het platform een verzoek om gegevens verwerkt dat voorkomt in een van de grote heaptabellen zoals MT_Data. Het verzoek kan afkomstig zijn uit een willekeurig aantal bronnen, zoals een API-aanroep of opgeslagen procedure. Eerst voert het platform 'pre-query's' uit die rekening houden met de statistieken voor meerdere belanghebbenden. Op basis van de resultaten die worden geretourneerd door de pre-query's, stelt de service vervolgens een optimale onderliggende databasequery samen voor uitvoering in de specifieke instelling.
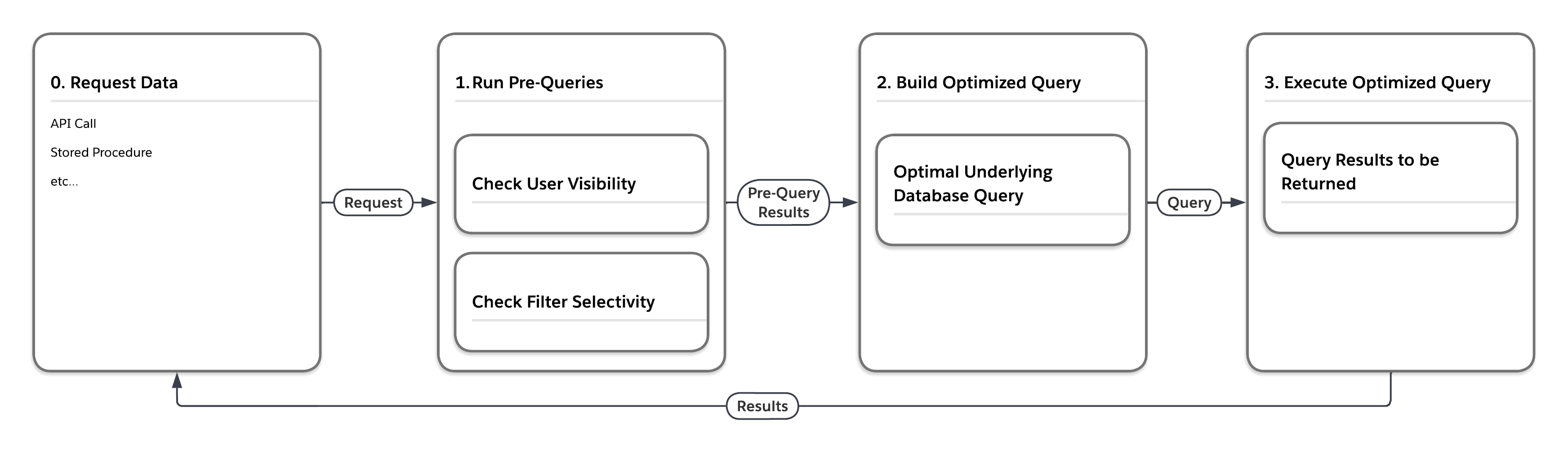
Zoals de volgende tabel laat zien, kan het platform dezelfde query op vier verschillende manieren uitvoeren, afhankelijk van de gebruiker die de query indient en de selectiviteit van de filtervoorwaarden van de query.
| Selectiviteitsmetingen vóór query | Definitieve databasetoegangsquery schrijven, afdwingen... | |
| Gebruiker | Filteren | |
| Laag | Laag | ... geneste lussen join, rijden met behulp van weergave van rijen die de gebruiker kan zien |
| Laag | Hoog | ... gebruik van index gerelateerd aan filter |
| Hoog | Laag | ... hashjoin besteld, rijden met behulp van MT_DATA |
| Hoog | Hoog | ...gebruik van aan index gerelateerd filter |
Gebruikers verwachten dat een interactieve zoekfunctie de gehele database of een geselecteerd bereik van een toepassing scant en gerangschikte resultaten retourneert met reactietijden van minder dan een seconde. Om deze mogelijkheid te bieden voor platformtoepassingen gebruikt het platform een zoekmachine die losstaat van de transactie-engine. Wanneer u records bijwerkt, werkt de transactie-engine de kerndatabase bij en stuurt gerelateerde gegevens ook door naar de zoekmachine voor indexering. Wanneer u naar records zoekt, gebruikt de zoekmachine de bijbehorende indices om de query snel te verwerken en retourneert deze gerangschikte resultaten met koppelingen naar gerelateerde databaserecords.
Terwijl toepassingen gegevens bijwerken in tekstvelden (CLOB's, Naam, enzovoort), is een pool van achtergrondprocessen, indexeringsservers genaamd, verantwoordelijk voor het asynchroon bijwerken van overeenkomende indexen, die de zoekmachine onderhoudt buiten de kerntransactie-engine. Om het indexeringsproces te optimaliseren kopieert het platform synchroon gewijzigde blokken tekstgegevens naar een interne "te indexeren" tabel terwijl transacties worden vastgelegd, waardoor een relatief kleine gegevensbron wordt geboden die de hoeveelheid gegevens minimaliseert die indexeringsservers van schijf moeten lezen. De zoekmachine houdt automatisch afzonderlijke indexen bij voor elke organisatie.
Afhankelijk van de huidige belasting en inzet van indexeringsservers kunnen updates van tekstindexen achterlopen op feitelijke transacties. Om onverwachte zoekresultaten te voorkomen die afkomstig zijn uit verouderde indexen, houdt het platform ook een MRU-cache bij van recent bijgewerkte rijen waarmee het systeem rekening houdt bij het realiseren van zoekresultaten met volledige tekst. Het platform onderhoudt MRU-caches per gebruiker en per organisatie om mogelijke zoekbereiken efficiënt te ondersteunen.
De zoekmachine van het platform optimaliseert de plaatsing van records binnen zoekresultaten met behulp van verschillende methoden. Zo houdt het systeem rekening met het beveiligingsdomein van de gebruiker die een zoekopdracht uitvoert, en legt het meer gewicht in de rijen waartoe de huidige gebruiker toegang heeft. Het systeem kan ook rekening houden met de wijzigingshistorie van een bepaalde rij en actiever bijgewerkte rijen rangschikken boven die welke relatief statisch zijn. De gebruiker kan ervoor kiezen om zoekresultaten naar wens te wegen, bijvoorbeeld door meer nadruk te leggen op recent gewijzigde rijen.
Transactie-intensieve toepassingen genereren minder overhead en presteren veel beter wanneer ze herhalende bewerkingen in bulk combineren en uitvoeren. Zo kunt u twee manieren vergelijken waarop een toepassing mogelijk veel nieuwe rijen laadt. Een inefficiënte benadering zou zijn om een routine te gebruiken met een lus die afzonderlijke rijen invoegt, waarbij de ene API-aanroep na de andere wordt uitgevoerd voor elke rijinvoeging. Een veel efficiëntere benadering zou zijn om een array van rijen te maken en deze allemaal door de routine te laten invoegen met één API-aanroep.
Efficiënte bulkverwerking met het platform is eenvoudig voor ontwikkelaars, omdat het is ingebakken in API-aanroepen. Intern verwerkt het platform ook in bulk alle interne stappen die zijn gerelateerd aan een expliciete bulkbewerking.
De bulkverwerkingsengine van het platform houdt automatisch rekening met geïsoleerde fouten die zich tijdens elke stap voordoen. Wanneer een bulkbewerking start in de gedeeltelijke opslagmodus, identificeert de engine een bekende startstatus en probeert vervolgens elke stap in het proces uit te voeren (veldgegevens in bulk valideren, pre-triggers voor bulkbranden, records in bulk opslaan, enzovoort). Als de engine tijdens een stap fouten detecteert, draait de engine de betreffende bewerkingen en alle bijwerkingen terug, verwijdert de rijen die verantwoordelijk zijn voor de fouten, en gaat door met een poging om de resterende subset van rijen in bulk te verwerken. Dit proces herhaalt elke opeenvolgende fase totdat de engine een subset van rijen kan vastleggen zonder fouten. De toepassing kan een retourobject onderzoeken om te bepalen welke rijen zijn mislukt en welke uitzonderingen ze hebben veroorzaakt.
Opmerking: Naar eigen inzicht is een alles-of-niets-modus beschikbaar voor bulkbewerkingen. Ook is de uitvoering van triggers tijdens een bulkbewerking onderworpen aan interne beheerders die de hoeveelheid werk beperken.
Bepaalde typen wijzigingen in de definitie van een object vereisen meer dan alleen updates van UDD-metagegevens. In dergelijke gevallen maakt het platform gebruik van efficiënte mechanismen die de algehele impact op de prestaties van de clouddatabaseservice in het algemeen helpen verminderen.
Denk bijvoorbeeld aan wat er achter de schermen gebeurt wanneer u het gegevenstype van een kolom wijzigt van keuzelijst in tekst. Het platform wijst eerst een nieuw tijdstip toe voor de gegevens van de kolom, kopieert in bulk de keuzelijstlabels die zijn gekoppeld aan huidige waarden, en werkt vervolgens de metagegevens van de kolom bij zodat deze naar het nieuwe tijdstip verwijst. Terwijl dit allemaal gebeurt, is toegang tot gegevens normaal en blijven toepassingen functioneren zonder merkbare gevolgen.
Denk bijvoorbeeld eens aan wat er gebeurt wanneer u een totaaloverzichtsveld toevoegt aan een object. In dit geval berekent het platform asynchroon initiële samenvattingen op de achtergrond met behulp van een efficiënte bulkbewerking. Terwijl de achtergrondberekening wordt uitgevoerd, krijgen gebruikers die het nieuwe veld weergeven, een indicatie dat het platform momenteel de waarde van het veld berekent.
Om kwaadwillige of onbedoelde monopolisering van gedeelde systeemresources met meerdere belanghebbenden te voorkomen, heeft het platform een uitgebreide set beheerfuncties en resourcelimieten die zijn gekoppeld aan de uitvoering van platformcode. Zo bewaakt het platform de uitvoering van een codescript op de voet en beperkt het de CPU-tijd die het kan gebruiken, hoeveel geheugen het kan verbruiken, hoeveel query's en DML-instructies het kan uitvoeren, hoeveel wiskundige berekeningen het kan uitvoeren, hoeveel uitgaande webservices het kan aanroepen, en nog veel meer. Afzonderlijke query's die de optimaliseringsfunctie van het platform als te duur beschouwt om uit te voeren, leiden tot een run-time uitzondering voor de aanroeper. Hoewel dergelijke limieten enigszins beperkend klinken, zijn ze noodzakelijk om de algehele schaalbaarheid en prestaties van het gedeelde databasesysteem voor alle betrokken toepassingen te beschermen. Op de lange termijn helpen deze maatregelen om betere codeertechnieken bij ontwikkelaars te bevorderen en een betere ervaring te creëren voor iedereen die het platform gebruikt. Een ontwikkelaar die bijvoorbeeld in eerste instantie probeert om een lus te coderen die op inefficiënte wijze duizend rijen tegelijk bijwerkt, krijgt run-time uitzonderingen vanwege resourcelimieten en kan vervolgens de efficiënte API-aanroepen voor bulkverwerking van het platform gaan gebruiken.
Om potentiële systeemproblemen als gevolg van slecht geschreven toepassingen verder te voorkomen, is de implementatie van een nieuwe productietoepassing een proces dat strikt wordt beheerd. Voordat een organisatie een nieuwe toepassing kan laten overstappen van ontwikkelings- naar productiestatus, vereist Salesforce eenheidstests die de functionaliteit van de platformcoderoutines van de toepassing valideren. Ingediende eenheidstests moeten minstens 75 procent van de broncode van de toepassing bestrijken.
Salesforce voert ingediende eenheidstests uit in de sandboxontwikkelomgeving van het platform om te bepalen of de toepassingscode een negatieve invloed heeft op de prestaties en schaalbaarheid van de populatie van meerdere belanghebbenden in het algemeen. De resultaten van een afzonderlijke eenheidstest geven basisgegevens aan, zoals het totale aantal regels dat is uitgevoerd, alsmede specifieke informatie over de code die niet is uitgevoerd door de test.
Zodra de code van een toepassing is gecertificeerd voor productie door Salesforce, bestaat het implementatieproces voor de toepassing uit één transactie die alle metagegevens van de toepassing kopieert naar een productieplatformexemplaar en de bijbehorende eenheidstests opnieuw uitvoert. Als een deel van het proces mislukt, draait het platform de transactie gewoon terug en retourneert het uitzonderingen om het probleem op te lossen.
Opmerking: Salesforce voert de eenheidstests voor elke toepassing opnieuw uit bij elke ontwikkelingsrelease van het platform om proactief te achterhalen of nieuwe systeemvoorzieningen en uitbreidingen bestaande toepassingen verstoren.
Nadat een productietoepassing live is, analyseert de ingebouwde prestatieprofiler van het platform deze automatisch en geeft deze gekoppelde feedback aan beheerders. Prestatieanalyserapporten bevatten informatie over langzame query's, gegevensmanipulaties en subroutines die u kunt controleren en gebruiken om de functionaliteit van toepassingen af te stemmen. Het systeem registreert ook gegevens over run-time uitzonderingen en retourneert deze aan beheerders om ze te helpen fouten op te sporen in hun toepassingen.
Wanneer een app een record verwijdert uit een object, markeert het platform de rij voor verwijdering door het veld IsDeleted van de rij in MTData* te wijzigen. Met deze actie wordt de rij effectief in de zogenaamde Prullenbak geplaatst*. Met het platform kunt u geselecteerde rijen uit de Prullenbak gedurende maximaal 15 dagen herstellen voordat u ze permanent verwijdert uit MT_Data. Het platform beperkt het totale aantal records dat het onderhoudt voor een organisatie op basis van de opslaglimieten voor die organisatie.
Wanneer een bewerking een bovenliggende record verwijdert die betrokken is bij een hoofd-/detailrelatie, verwijdert het platform automatisch alle gerelateerde onderliggende records, op voorwaarde dat dit geen regels voor verwijzingsintegriteit zou schenden. Wanneer u bijvoorbeeld een SalesOrder verwijdert, trapt het platform het verwijderen automatisch toe op afhankelijke regelitems. Als u vervolgens een bovenliggende record herstelt vanuit de Prullenbak, herstelt het systeem automatisch ook alle onderliggende records.
Wanneer u daarentegen een bovenliggende record verwijdert waarnaar wordt verwezen in een opzoekrelatie, stelt het platform automatisch alle afhankelijke sleutels in op null. Als u de bovenliggende record vervolgens herstelt, herstelt het platform automatisch de eerder nulde opzoekrelaties, behalve de relaties die opnieuw zijn toegewezen tussen de bewerkingen voor verwijderen en herstellen.
De Prullenbak slaat ook gevallen velden en hun gegevens op totdat een organisatie ze permanent verwijdert of totdat een ingesteld aantal dagen is verstreken, afhankelijk van wat het eerst gebeurt. Tot die tijd is het gehele veld en alle gegevens ervan beschikbaar voor herstel.
Wendbaarheid is essentieel voor ondernemingen om succesvol te zijn in onze moderne wereld. De onderliggende lagen van het Salesforce Platform helpen uw bedrijfstoepassingen zich snel aan te passen aan nieuwe uitdagingen, zodat u zich kunt blijven richten op uw bedrijf in plaats van op de infrastructuur.
De infrastructuur (bijvoorbeeld basisservices en computerresources) is verborgen, onderliggende technologie die de bovenste lagen van het Salesforce Platform ondersteunt. Hyperforce is de Salesforce Platform-infrastructuur, gebouwd op 100% hernieuwbare energie en netto-nul, die de belangrijkste uitdagingen van klanten oplost, waaronder naleving, Trust en schaalbaarheid
Ondernemingen die op meerdere geografische locaties actief zijn, moeten voldoen aan nieuwe, veranderende en variërende regelgeving voor gegevensbeheer. Omdat Salesforce Hyperforce in een groeiend aantal landen implementeert, momenteel gebaseerd op beschikbaarheid van AWS-regio's, kunnen platformtoepassingen en gebruikers hun gevoelige werkbelasting uitvoeren op manieren die voldoen aan strenge normen voor gegevensopslag of gegevensbescherming. Met bijvoorbeeld Salesforce's European Union (EU) Operating Zone powered by Hyperforce kunnen EU-bedrijven hun gegevens gemakkelijk in de EU houden.
Beveiliging, betrouwbaarheid en beschikbaarheid zijn niet-functionele vereisten die elke bedrijfstoepassing in overweging moet nemen om de belofte van Trust aan hun eindgebruikers waar te maken. Met Hyperforce kunnen ondernemingen met het Salesforce Platform eenvoudig vertrouwde bedrijfstoepassingen leveren.
- Beveiliging — Hyperforce heeft native end-to-end encryptie van klantgegevens tijdens rust en transport. Hyperforce Zero Trust Architecture dwingt een strikt identiteitsverificatieproces af dat ervoor zorgt dat er geen impliciete toegang tot resources is. En Hyperforce gebruikt het principe van minste rechten, waardoor bewerkingen voor precies de juiste hoeveelheid tijd met de juiste hoeveelheid toegang worden goedgekeurd.
- Betrouwbaarheid — Elk exemplaar van Hyperforce gebruikt meerdere cloudbeschikbaarheidszones en gemoderniseerde benaderingen die incidentrespons versnellen om een hoog beschikbaar en veerkrachtig platform te leveren.
- Beschikbaarheid — Hyperforce's moderne CI/CD-pijplijnen en blauw/groene toepassingsreleases reduceren de onderhoudsperiode van toepassingen tot slechts één minuut per jaar.
Salesforce is de basis voor apps zoals Sales Cloud en Service Cloud en is een bewezen platform voor het ontwikkelen van toepassingen waarop afzonderlijke ondernemingen en serviceproviders miljoenen bedrijfstoepassingen hebben gebouwd voor verschillende gebruikscases, waaronder supply chain management, facturering, boekhouding, handel, naleving bijhouden, personeelsbeheer en claimverwerking. De unieke, multitenant, metagegevensgestuurde architectuur van het platform is specifiek ontworpen voor de cloud en ondersteunt betrouwbaar en veilig missiekritieke toepassingen op internetschaal. Met behulp van op standaarden gebaseerde API's en native ontwikkeltools kunnen platformontwikkelaars gemakkelijk alle componenten van een moderne web- of mobiele toepassing samenstellen, inclusief het gegevensmodel van de toepassing (inclusief objecten en relaties), bedrijfslogica (inclusief werkstromen en validaties), integraties met andere toepassingen en meer.
Sinds de oprichting is het platform door de engineers van Salesforce geoptimaliseerd voor multitenancy, met voorzieningen waarmee platformtoepassingen kunnen worden opgeschaald om te voldoen aan veranderende zakelijke behoeften. Integrale systeemvoorzieningen — zoals de bulk-API voor gegevensverwerking, Apex, een full-text zoekmachine en een unieke queryoptimalisering — helpen afhankelijke toepassingen zeer efficiënt en schaalbaar te maken zonder dat ontwikkelaars daar veel of weinig moeite voor hoeven te doen.
De beheerde aanpak van Salesforce voor de implementatie van productietoepassingen garandeert uitstekende prestaties, schaalbaarheid en betrouwbaarheid voor alle toepassingen die afhankelijk zijn van het platform. Salesforce bewaakt en verzamelt continu operationele informatie van platformtoepassingen om incrementele verbeteringen en nieuwe systeemvoorzieningen te stimuleren die direct ten goede komen aan bestaande en nieuwe toepassingen.
Steve Bobrowski is een succesvolle ondernemer en technologieleider die sinds 2008 voor vele toonaangevende softwarebedrijven voor de onderneming heeft gewerkt, waaronder verschillende rollen in Salesforce. Vandaag werkt Steve in het Salesforce Office of the CTO om te helpen bij de strategieën voor de technologische architectuur van het bedrijf.
Tom Leddy is architect-evangelist bij Salesforce. Hij ondersteunt de wereldwijde Salesforce Architect Community door te helpen bij het maken van resources, tools en begeleiding waarmee architecten hun beste werk kunnen doen. Verbind met Tom via Twitter.