Hver dag driver hundretusener av virksomheter og millioner av brukere virksomheten sin i skyen ved hjelp av applikasjoner som leveres av Salesforce Platform. Hvorfor er plattformen så vellykket? Hvorfor kan du Trust den til å støtte din virksomhet? Hvilke unike fordeler gir plattformen for virksomheter som din?
Dette tekniske kortet forklarer hvordan Salesforce Platform leverer pålitelige, skalerbare og enkle å tilpasse sluttbrukeropplevelser ved bruk av sin unike programvarearkitektur for skydatabehandling. Etter å ha lest denne brødteksten vil du bedre forstå den underliggende teknologien som gjør Salesforce Platform til et overbevisende valg for forretningsprogrammene dine.
Salesforce Platform er det fremtredende eksemplet på en vellykket skydatabehandlingsplattform og et relatert økosystem av programmer. Siden begynnelsen av millenniet har plattformen vært grunnlaget for følgende:
- Mange populære forretningsapplikasjoner for vanlige bruksområder som salg og kundeservice
- bransjespesifikke applikasjoner for mer spesialiserte bruksområder som finans og helse
- Millioner av tilpassede programmer og programutvidelser for unike brukstilfeller
I stor grad er Salesforce Platform så vellykket og populær fordi den unike programvarearkitekturen støtter programmer som er enkle å bygge, bruke, tilpasse og utvide med eksepsjonell ytelse og pålitelighet. Kjernen i plattformens programvarearkitektur er den fleransatte, metadatastyrte utformingen.
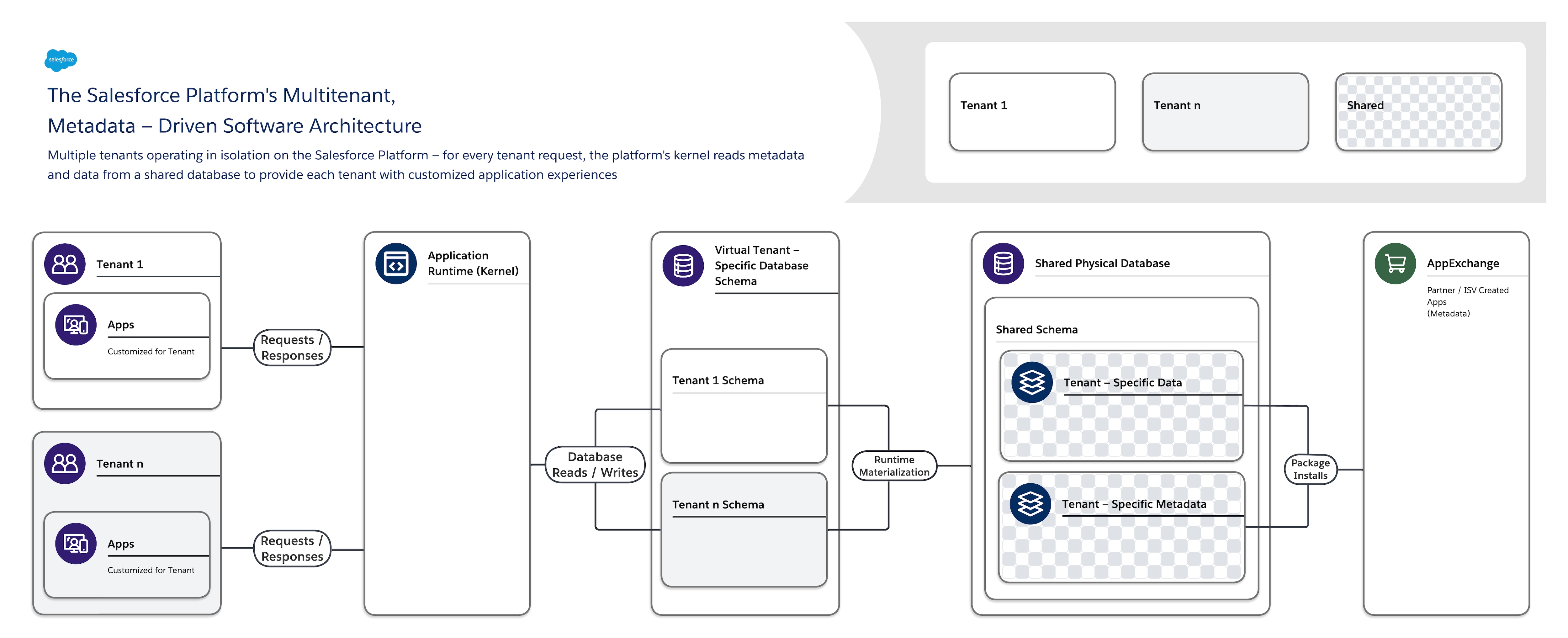
Salesforce Platforms programvarearkitektur er:
- Multitenant – Det isolerer og støtter samtidig de varierende kravene til mange leietagere (organisasjoner, forretningsenheter og så videre).
- Metadatastyrt – Det lar alle leietagere enkelt og raskt tilpasse sine apper og brukeropplevelser ved hjelp av metadata, data som beskriver elementer som brukergrensesnittet og forretningslogikk.
Når du oppretter et nytt programobjekt eller skriver en del kode med Salesforce Platform, oppretter ikke plattformen en faktisk tabell i en database eller kompilerer noen kode. I stedet lagrer plattformen bare noen metadata som den deretter kan bruke ved kjøretid for å dynamisk materialisere virtuelle programkomponenter. Plattformen sikrer at hver leietageres metadata er private og enkle å oppdatere uten låsing eller nedetid, slik at hver leietager kan bygge og tilpasse apper isolert. Salesforce Platform bruker de samme metadataene til å tilby tilpassede API-er, RESTful- og nettjenestegrensesnitt (SOAP-basert) som du kan bruke til å integrere programmene dine med andre programmer og automatiserte prosesser.
Klargjorte løsninger er også tilgjengelig i AppExchange, plattformens omfattende appmarkedsplass. Bygd av et stort økosystem av klarerte partnere og uavhengige programvareleverandører (ISV-er), er en AppExchange metadata fra en tredjepart som beskriver gratis eller betalte programutvidelser og hele programmer som du kan bruke til å oppfylle spesifikke forretningskrav.
For å støtte denne meget tilpassbare og utvidbare arkitekturen bruker en enkelt forekomst av Salesforce Platform
- En enkelt delt multitenantdatabase med ett enkelt skjema som lagrer leietakerspesifikke metadata og data.
- En multitenantkjerne (programkjøretid) som leser metadata og data for dynamisk å levere leietakerspesifikke programmer, forretningslogikk og API-er for hver leietakers brukere ved kjøretid.
Denne tydelige skillet mellom den Salesforce-administrerte kjernen og leietageradministrerte metadata gjør det mulig for Salesforce, leietagere og ISV-er å uavhengig utvikle sine deler av systemet uten forstyrrelser.
For å bygge på denne oversikten gir de etterfølgende delene av denne artikkelen flere detaljer om plattformens unike funksjoner som kommer fra viktige aspekter ved utformingen, inkludert:
- Plattformdatalaget
- Plattformprogramutvikling
- Intern plattformbehandling
- Plattforminfrastruktur
Sammen isolerer Salesforce Platforms programkjøretid og innovative datalag trygt leietakerspesifikke data, skjematilpasninger og forretningslogikk. På et høyt nivå støtter skjemaet en rekke bruksområder:
- Når du oppretter eller tilpasser et program, lagrer plattformen relaterte metadata i delte databasetabeller som vedlikeholder metadata for alle leietagere.
- Når du bruker et program til å lese eller skrive data, lagrer plattformen dataene dine i delte databasetabeller som vedlikeholder data for alle leietagere.
- I bakgrunnen beholder plattformen også interne metadata i en rekke tabeller som kjernen bruker til å optimalisere forespørselslatens ved kjøretid.
Men hvordan kan en enkelt delt database og skjema holde alle leietagernes data private? Hver leietager på plattformen er kjent som en organisasjon, eller organisasjon for kort. Og alle organisasjonsspesifikke poster i delte databasetabeller har en OrgID. Når kjernen får tilgang til databasen, bruker den denne unike identifikatoren til å sikre at hver organisasjons aktiviteter er private.

Organisasjonsspesifikke objekter (tenk tabeller i tradisjonell relasjonsdatabasespråk), felt, lagrede prosedyrer, databaseutløsere og mer er alle virtuelle konstruksjoner beskrevet av metadata som plattformen lagrer i noen få databasetabeller kjent som Universal Data Dictionary (UDD).
- MT_Objects er en databasetabell som lagrer metadata om objektene som du definerer for et program, inkludert en unik identifikator for et objekt (ObjID), organisasjonen (OrgID) og navnet du gir for objektet (ObjName).
- Systemtabellen MT_Fields lagrer metadata om feltene (kolonnene) som du deklarerer for hvert objekt, inkludert en unik identifikator for et felt (FieldID), organisasjonen (OrgID), objektet som inneholder feltet (ObjID), navnet på feltet (FieldName), feltets datatype, en boolsk verdi for å angi om feltet krever indeksering (IsIndexed), og posisjonen til feltet i objektet i forhold til andre felt (FieldNum).
Fordi metadata er en nøkkelkomponent, må plattformen optimalisere tilgangen til metadata. Ellers vil hyppig metadatatilgang hindre at tjenesten skaleres. Med denne potensielle flaskehalsen i tankene bruker plattformen massive og sofistikerte metadatabuffere for å vedlikeholde de sist brukte metadataene i minnet, unngå ytelsesnedbrytende I/O- og koderekompilasjoner og forbedre svartider for programmer.
Systemtabellen MT_Data lagrer programtilgjengelige data som tilordnes til alle organisasjonsspesifikke tabeller og deres felt, som definert av metadata i MT_Objects og MT_Fields. Hver rad inkluderer identifiserende felt, som en global unik identifikator (GUID), organisasjonen som eier raden (OrgID) og den omsluttende objektidentifikatoren (ObjID). Hver rad i MT_Data-tabellen har også et Navn-felt som lagrer et "naturlig navn" for tilsvarende poster. En Konto-post kan for eksempel bruke Kontonavn, en Sak-post kan bruke Saksnummer og så videre.
Verdi0 ... ValueN flex-kolonner, også kjent som luker, lagrer programdata som tilordnes tabellene og feltene som er erklært i henholdsvis MT_Objects og MT_Fields. Alle fleksikolonner bruker en strengdatatype med variabellengde slik at de kan lagre hvilken som helst strukturert type programdata (strenger, tall, datoer og så videre). Som illustrert i figuren nedenfor kan ingen to felt i samme objekt tilordnes til den samme luken i MT_Data for lagring. En enkelt luken kan imidlertid behandle informasjonen for flere felt, så lenge hvert felt kommer fra et annet objekt.
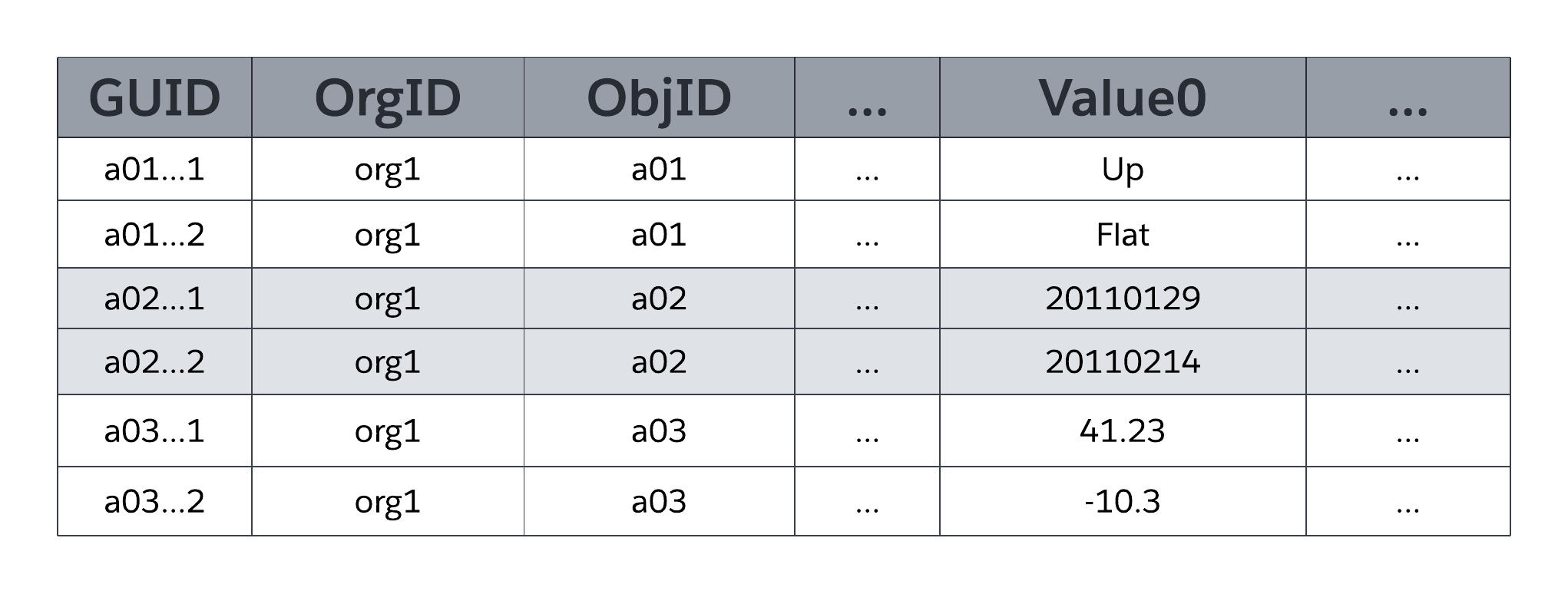
MT Felt kan bruke en hvilken som helst av en rekke standard strukturerte datatyper som tekst, tall, dato og dato/klokkeslett, samt spesielle, _rik strukturerte datatyper som valgliste (oppført felt), automatisk nummerering (automatisert, systemgenerert sekvensnummer), formel (skrivebeskyttet utledet verdi), overordnet-detalj-relasjon (fremmed nøkkel), avmerkingsboks (boolsk), e-post, URL og andre. MT_Felt kan også være nødvendige (ikke null) og ha tilpassede valideringsregler (for eksempel at ett felt må være større enn et annet felt), som plattformen håndhever begge.
Når du erklærer eller endrer et objekt, behandler plattformen en rad metadata i MT_Objects som definerer objektet. På samme måte behandler plattformen en rad i MT_Fields for hvert felt, inkludert metadata som tilordner feltet til en bestemt fleksikolonne i MT_Data for lagring av tilhørende feltdata. I og med at plattformen behandler objekt- og feltdefinisjoner som metadata i stedet for faktiske databasestrukturer, kan systemet tolerere vedlikeholdsaktiviteter for online skjema for flere leietagere uten å blokkere samtidig aktivitet for andre organisasjoner og brukere. Til sammenligning krever omdefinisjon av nettbaserte tabeller for tradisjonelle relasjonsdatabasesystemer vanligvis midlertidige låser og ofte omfattende, kompliserte prosesser og planlagt nedetid for programmer.
Som den forenklede representasjonen av MT_Data i forrige figur viser, er fleksikolonner av en universell datatype (streng med variabellengde), som gir plattformen mulighet til å dele en enkelt flekskolonne mellom flere felt som bruker forskjellige strukturerte datatyper (strenger, tall, datoer og så videre).
Plattformen lagrer alle flex-kolonnedata i et kanonisk format, og bruker underliggende datatypekonverteringsfunksjoner (for eksempel TO_NUMBER, TO_DATE, TO_CHAR) når programmer leser data fra og skriver data til flex-kolonner.
MTData inneholder også kolonner som ikke er vist i forrige figur. Det finnes for eksempel fire kolonner for å behandle revisjonsdata, inkludert hvilken bruker som opprettet en rad og når den raden ble opprettet, og hvilken bruker som sist endret en rad og når den raden sist ble endret. MT_Data inneholder også en _IsDeleted-kolonne som plattformen bruker til å angi når en rad har blitt slettet.
Plattformen støtter også deklarasjon av felt som tegnsstore objekter (CLOB) for å tillate lagring av lange tekstfelt på opptil 32 000 tegn. For hver rad i MTData som har en CLOB, lagrer plattformen CLOB utenfor linjen i en tabell kalt _MT_Clob, som systemet kan slå sammen med tilsvarende rader i MT_Data etter behov.
Notat: Plattformen lagrer også CLOB-er i indeksert form utenfor databasen for raske tekstsøk. Se Søk for å få mer informasjon om plattformens tekstsøkemotor.
Plattformen indekserer automatisk ulike typer felt for å levere skalerbar ytelse.
Tradisjonelle databasesystemer baserer seg på innebygde databaseindekser for å raskt finne bestemte rader i en databasetabell som har felt som samsvarer med en bestemt betingelse. Det er imidlertid ikke praktisk å opprette innebygde databaseindekser for fleksikolonnene i MTData fordi plattformen bruker en enkelt flekskolonne til å lagre dataene for mange felt med forskjellige strukturerte datatyper. I stedet administrerer plattformen en indeks for MT_Data ved å synkront kopiere feltdata som er merket for indeksering, til en passende kolonne i en pivottabell for _MT_Index.
MT_Index inneholder sterkt skrivede, indekserte kolonner som StringValue, NumValue og DateValue som plattformen bruker til å finne feltdata av den tilsvarende datatypen. Plattformen kan for eksempel kopiere en strengverdi i en MT_Data-fleksikolonne til StringValue-feltet i MT_Indexes, en datoverdi til DateValue-feltet og så videre. De underliggende indeksene for MT_Indexes er standard, ikke-unike databaseindekser. Når en intern systemspørring inkluderer en søkeparameter som refererer til et strukturert felt i et objekt, bruker plattformens tilpassede spørringsoptimalisering MT_Indexes til å bidra til å optimalisere tilknyttede datatilgangsoperasjoner.
Notat: Plattformen kan håndtere søk på tvers av flere språk fordi systemet bruker en algoritme som konverterer strengverdier til et universelt format som ikke skiller mellom små og store bokstaver. StringValue-kolonnen i MT_Index-tabellen lagrer strengverdier i dette formatet. Ved kjøretid bygger spørringsoptimaliseringen automatisk datatilgangsoperasjoner slik at den optimaliserte SQL-setningen filtrerer på den tilsvarende små og store bokstavelige StringValue, som i sin tur tilsvarer den litterale verdien i søkeforespørselen.
Plattformen lar deg angi når et felt i et objekt må inneholde unike verdier (det skilles mellom små og store bokstaver eller det skilles ikke mellom små og store bokstaver). Gitt plasseringen av MT_Data og delt bruk av Verdi-kolonnene for feltdata, er det ikke praktisk å opprette unike databaseindekser for objektet. (Denne situasjonen ligner den som ble diskutert i forrige del for ikke-unike indekser.)
For å støtte unikhet for tilpassede felt bruker plattformen pivottabellen MT_Unique_Indexes. Denne tabellen er svært lik tabellen MT_Indexes, bortsett fra at de underliggende innebygde databaseindeksene for MT_Unique_Indexes håndhever unikhet. Når et program forsøker å sette inn en duplikatverdi i et felt som krever unikhet, eller en administrator forsøker å håndheve unikhet på et eksisterende felt som inneholder duplikatverdier, returnerer plattformen en riktig feilmelding til programmet.
I sjeldne tilfeller kan plattformens eksterne søkemotor (forklart i Søk) bli overbelastet eller på annen måte utilgjengelig, og kan ikke være i stand til å svare på en søkespørsel i rett tid. I stedet for å returnere en skuffende feil til sluttbrukeren, går plattformen tilbake til en sekundær søkemekanisme for å levere rimelige søkeresultater.
Et tilbakesøk implementeres som en direkte databasespørring med søkebetingelser som refererer til Navn-feltet i målposter. For å optimalisere globale objektsøk (søk som spenner over tabeller) uten å måtte utføre potensielt kostbare forbundsspørringer, vedlikeholder plattformen en pivottabell MT_Fallback_Indexes som registrerer Navn på alle poster. Oppdateringer av MT_Fallback_Indexes skjer synkront etter hvert som transaksjoner endrer poster, slik at tilbakesøk alltid har tilgang til den nyeste databaseinformasjonen.
Tabellen MT_Name_Denorm er en lean-datatabell som lagrer ObjID og Navn på hver post i MT_Data. Når et program trenger å oppgi en liste over poster som er involvert i en overordnet/underordnet-relasjon, bruker plattformen tabellen MT_Name_Denorm til å utføre en relativt enkel spørring som henter navnet på hver post det refereres til, for visning i appen, for eksempel som en del av en hyperlenke.
Plattformen tilbyr datatyper for relasjoner som en organisasjon kan bruke til å erklære relasjoner (referanseintegritet) mellom tabeller. Når du erklærer et objekts felt med en relasjonstype, tilordner plattformen feltet til et Verdi-felt i MT_Data, og deretter bruker du dette feltet til å lagre ObjID for et relatert objekt.
For å optimalisere koblingsoperasjoner opprettholder plattformen en MT_Relationships-pivottabell. Denne systemtabellen har to underliggende unike sammensatte indekser for databasen som muliggjør om nødvendig effektive objektgjennomganger i begge retninger.
Med bare noen få museklikk sørger plattformen for historikksporing for alle felt. Når en organisasjon aktiverer revisjon for et bestemt felt, registrerer systemet asynkront informasjon om endringene som er gjort i feltet (eldre og nye verdier, endringsdato og så videre) ved å bruke en intern pivottabell som revisjonsspor.
Alle plattformdata, metadata og pivottabellstrukturer, inkludert underliggende databaseindekser, partisjoneres fysisk av OrgID ved bruk av innebygde databasepartisjonsmekanismer. Datapartisjonering er en bevisst teknikk som databasesystemer tilbyr for å fysisk dele opp store logiske datastrukturer i mindre, mer administrerbare biter. Partisjonering kan også bidra til å forbedre ytelsen, skalerbarheten og tilgjengeligheten til et stort databasesystem, som et miljø for flere leietagere. Hver plattformspørring er som definisjon rettet mot en bestemt organisasjons informasjon, så spørringsoptimaliseringen må bare vurdere å få tilgang til datapartisjoner som inneholder en organisasjons data, i stedet for en hel tabell eller indeks. Denne vanlige optimaliseringen refereres noen ganger til som "partisjonssnitt".
Denne delen dekker hvordan apputviklere kan opprette et skjemas underliggende metadata og deretter bygge apper som behandler data. Disse metadataene og dataene lagres i plattformdatalaget som er beskrevet i forrige del.
Utviklere kan deklarativt bygge programkomponenter på serversiden ved å bruke plattformens nettleserbaserte utviklingsmiljø, vanligvis referert til som plattformens oppsettskjermer. Oppsettets pek-og-klikk-grensesnitt støtter alle fasetter i prosessen med å bygge programskjemaer, som opprettelse av et programs datamodell (inkludert objekter og deres felt samt relasjoner), sikkerhets- og delingsmodell (inkludert brukere, profiler og rollehierarkier), brukergrensesnitt (inkludert skjermoppsett, datarapporter og rapporter), deklarativ logikk (arbeidsflyter) og programmatisk logikk (lagrede prosedyrer og utløsere). Salesforce-flyt gjør det for eksempel enkelt å automatisere et bredt spekter av brukstilfeller. Med Flow Builder-grensesnittet i Oppsett, vist nedenfor, kan du grafisk utforme og implementere arbeidsflyter som samhandler med brukere, eller starte automatisk basert på en tidsplan eller når utløses av en hendelse.
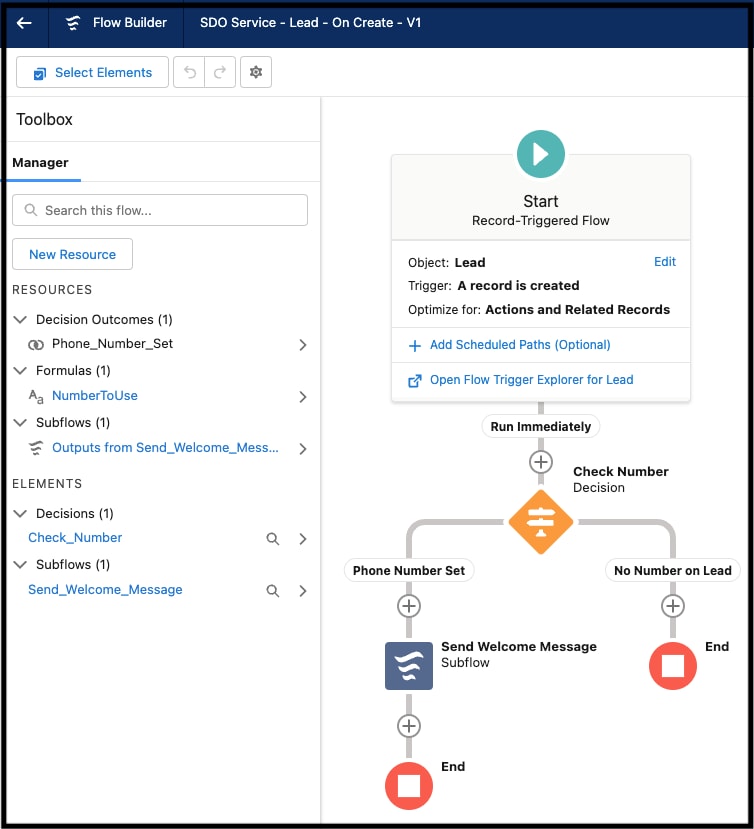
Oppsett-skjermene gjør det enkelt for alle å utvikle og tilpasse programmer uten (eller svært lite) kode. For eksempel:
- Plattforminnebygde brukergrensesnitt er enkle å bygge uten noen kode. I bakgrunnen støtter et innebygd appgrensesnitt alle vanlige datatilgangsoperasjoner, inkludert spørringer, innsetting, oppdatering og sletting. Hver datamanipuleringsoperasjon som utføres av innebygde plattformprogrammer, kan endre ett objekt om gangen og automatisk bekrefte hver endring i en separat transaksjon.
- Når du definerer et tekstfelt for et objekt som inneholder sensitive data, kan du enkelt konfigurere feltet slik at plattformen krypterer de tilsvarende dataene og eventuelt bruker en inndatamaske til å skjule skjerminformasjon for forvirrende øyne.
- En deklarativ valideringsregel er en enkel måte for en organisasjon å håndheve en domeneintegritetsregel på uten noen programmering. Du kan for eksempel erklære en valideringsregel som sikrer at et LineItem-objektets Mengde-felt alltid er større enn null.
- Et formelfelt er en deklarativ funksjon i plattformen som gjør det enkelt å legge til et beregnet felt i et objekt. Du kan for eksempel legge til et felt i LineItem-objektet for å beregne en LineTotal-verdi.
- Et felt for samlet oppsummering er et felt på tvers av objekter som gjør det enkelt å aggregere informasjon om underordnede felt i et overordnet objekt. Du kan for eksempel opprette et OrderTotal-sammendragsfelt i SalesOrder-objektet basert på LineTotal-feltet i LineItem-objektet.
Notat: Intern implementerer plattformen formelfelt og felt for samlet oppsummering ved bruk av innebygde databasefunksjoner og beregner verdier effektivt på nytt synkront som en del av pågående transaksjoner.
Plattformen tilbyr flere åpne, standardbaserte API-er som utviklere kan bruke til å bygge apper. Både RESTful og web services (SOAP-basert) APIer gir tilgang til plattformens mange funksjoner. Ved å bruke disse ulike API-ene kan et program
- Manipulere metadata som beskriver et programskjema
- Opprette, lese, oppdatere og slette (CRUD)-forretningsdata
- Masseinnlasting eller spørring mot et stort antall poster asynkront
- Eksponer en nær sanntidsstrøm med data på en sikker og skalerbar måte
Apper kan bruke Salesforce Object Query Language (SOQL) til å konstruere enkle, men kraftige databasespørringer. På samme måte som SELECT-kommandoen i SQL (Structured Query Language) lar SOQL deg angi kildeobjektet, en liste over felt som skal hentes, og betingelser for valg av rader i kildeobjektet. Følgende SOQL-spørring returnerer for eksempel verdien i Id- og Name-feltet for alle Konto-poster med et navn lik strengen Acme.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
Plattformen inkluderer også en flerspråklig søkemotor med full tekst som automatisk indekserer alle tekstrelaterte felt. Apper kan bruke denne forhåndsintegrerte søkemotoren ved å bruke Salesforce Object Search Language (SOSL) til å utføre tekstsøk. Til forskjell fra SOQL, som kan spørre bare ett objekt om gangen, gir SOSL deg muligheten til å søke i tekst-, e-post- og telefonfelt for flere objekter samtidig. Følgende SOSL-setning søker for eksempel etter poster i Salgsemne- og Kontakt-objektene som inneholder strengen Joe Smith i navnefeltet, og returnerer navnet og telefonnummerfeltet fra hver post som ble funnet.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, som på mange måter ligner Java, er et kraftig utviklingsspråk som utviklere kan bruke til å sentralisere prosedyrelogikk i sitt programskjema. Apex kan erklære programvariabler og konstanter, utføre tradisjonelle flytkontrollsetninger (hvis ikke sløyfer og så videre), utføre datamanipuleringsoperasjoner (innsette, oppdatere, oppdatere, slette) og utføre transaksjonskontrolloperasjoner (setSavepoint, tilbakestilling).
Du kan lagre Apex-programmer i plattformen i to forskjellige former: som en navngitt Apex-klasse med metoder (lik som lagrede prosedyrer i tradisjonell databasespråk) som programmer utfører når det er nødvendig, eller som en databasutløser som utføres automatisk før eller etter en bestemt databasemanipuleringshendelse. I begge formene kompilerer plattformen Apex og lagrer den som metadata i UDD. Første gang en organisasjon utfører et Apex, laster plattformens kjøretidstolker den kompilerte versjonen av programmet inn i en MRU (nyligste brukte) buffer for den organisasjonen. Når deretter alle brukere fra samme organisasjon trenger å bruke den samme rutinen, kan plattformen lagre minne og unngå overskuddet ved å kompilere programmet på nytt ved å dele det kjøreklargjorte programmet som allerede er i minnet.
Ved å legge til et enkelt nøkkelord her og der, kan utviklere bruke Apex til å støtte mange unike programkrav. Utviklere kan for eksempel vise en metode som et tilpasset RESTful- eller SOAP-basert API-kall, gjøre den asynkront planleggbar eller konfigurere den til å behandle en stor operasjon i batcher.
Apex er mye mer enn bare et annet prosedyrespråk. Det er en integrert plattformkomponent som hjelper systemet med å levere pålitelig flerlån. Plattformen validerer for eksempel automatisk alle innebygde SOQL- og SOSL-setninger i en klasse for å hindre kode som ellers ville mislykkes ved kjøretid. Plattformen beholder deretter tilsvarende objektavhengighetsinformasjon for gyldige klasser og bruker den til å hindre endringer i metadata som ellers ville brutt avhengig kode.
Mange standard Apex og systemstatiske metoder gir enkle grensesnitt til underliggende systemfunksjoner. De statiske DML-metodene for systemet, som sett inn, oppdater og slett, har for eksempel en enkel boolsk parameter som utviklere kan bruke til å angi det ønskede alternativet for massebehandling (alt eller ingenting eller delvis lagring). Disse metodene returnerer også et resultatobjekt som oppkallrutinen kan lese for å bestemme hvilke poster som ble mislyktes behandlet og hvorfor. Andre eksempler på direkte koblinger mellom Apex og plattformfunksjoner inkluderer de innebygde e-postklassene og XmlStream-klassene.
I stor grad gjør plattformen det og skalerer godt fordi Salesforce bygde den med to viktige prinsipper i tankene:
- Sørg for effektive, grunnleggende plattformfunksjoner i stor skala.
- Hjelp utviklere med å gjøre alt så effektivt som mulig.
Plattformen innlemmer disse prinsippene i plattformens unike behandlingsarkitekturer, inkludert:
- Spørringer
- Søk
- Masseoperasjoner
- Skjemaendring
- Multitenant-isolering
- Papirkurven
De fleste moderne databasesystemer bestemmer optimale spørringsutførelsesplaner ved å bruke en kostnadsbasert spørringsoptimalisering som vurderer relevant statistikk om måltabell- og indeksdata. Konvensjonell, kostnadsbasert optimaliseringsstatistikk er imidlertid utformet for enkeltleietagerprogrammer og tar ikke hensyn til datatilgangskarakteristikkene til en gitt bruker som utfører en spørring i et miljø for flere leietagere. En gitt spørring som er rettet mot et objekt med et stort datavolum, vil for eksempel mest sannsynlig utføres mer effektivt ved å bruke forskjellige utførelsesplaner for brukere med høy synlighet (en leder som kan se alle radene) i forhold til brukere med lav synlighet (selger personer som bare kan se rader relatert til seg selv).
For å gi tilstrekkelig statistikk for å bestemme optimale spørringsutførelsesplaner i et multitenantsystem opprettholder plattformen et komplett sett med optimaliseringsstatistikk (leietager-, gruppe- og brukernivå) for hver organisasjons objekter. Statistikk gjenspeiler antall rader som en bestemt spørring potensielt kan få tilgang til, med omhyggelig vurdering av generell organisasjonsspesifikk objektstatistikk (for eksempel totalt antall rader som eies av organisasjonen som helhet), i tillegg til mer detaljert statistikk (for eksempel antall rader som en bestemt tillatelsesgruppe eller sluttbruker potensielt kan få tilgang til).
Plattformen vedlikeholder også andre typer statistikk som viser seg nyttig med bestemte spørringer. Plattformen vedlikeholder for eksempel statistikk for alle tilpassede indekser for å avdekke totalt antall ikke-null-verdier og unike verdier i det tilsvarende feltet, og histogrammer for valglistefelt som viser kardinaliteten til hver listeverdi.
Når eksisterende statistikk ikke er på plass eller ikke anses som nyttig, har plattformens optimalisering noen få forskjellige strategier den bruker til å bidra til å bygge rimelig optimale spørringer. Når en spørring for eksempel filtrerer på Navn-feltet for et objekt, kan optimaliseringen bruke tabellen MT_Fallback_Indexes til å effektivt finne forespurte rader. I andre scenarier vil optimaliseringen dynamisk generere manglende statistikk ved kjøretid.
Brukes sammen med optimaliseringsstatistikk, baserer plattformens optimalisering seg også på interne sikkerhetsrelaterte tabeller (Groups, Members, GroupBlowout og CustomShare) som beholder informasjon om sikkerhetsdomenene til en organisasjons brukere, inkludert en gitt brukers gruppemedlemskap og tilpassede tilgangsrettigheter for objekter og rader. Slik informasjon er uvurderlig for å bestemme selektiviteten til spørringsfiltre per bruker. Se Platform Developer Basics Trailhead for å få mer informasjon om plattformens innebygde sikkerhetsmodell.
Flytdiagrammet i følgende figur illustrerer hva som skjer når plattformen behandler en forespørsel om data som er i en av de store heap-tabellene, som MT_Data. Forespørselen kan komme fra et hvilket som helst antall kilder, som et API-kall eller en lagret prosedyre. Først utfører plattformen "forhåndsspørringer" som vurderer statistikk som er oppmerksom på flere leietagere. Basert på resultatene som returneres av forespørslene, bygger deretter tjenesten en optimal underliggende databasespørring for utføring i den bestemte innstillingen.
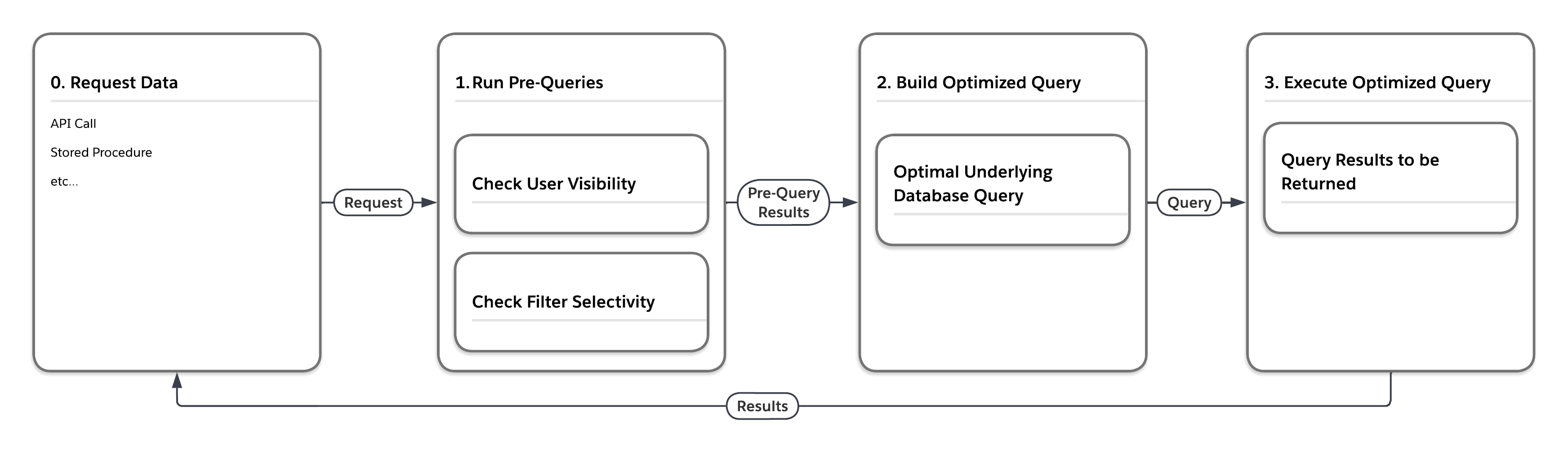
Som tabellen nedenfor viser, kan plattformen utføre den samme spørringen på fire forskjellige måter avhengig av brukeren som sender spørringen, og hvor selektiv spørringens filterbetingelser er.
| Pre-Query Selectivity-målinger | Skrive en endelig databasetilgangspørring, tvinge... | |
| Bruker | Filter | |
| Lavt | Lavt | ... nestede sløyfer kobler sammen, kjør ved bruk av visning av rader som brukeren kan se |
| Lavt | Høyt | ... bruk av indeks relatert til filter |
| Høyt | Lavt | ... ordnet hash-kobling, kjør med MT_DATA |
| Høyt | Høyt | ... bruk av indeksrelatert filter |
Brukere forventer at en interaktiv søkefunksjon skanner hele eller et valgt omfang av et programs database og returnerer rangerte resultater med svartider på under sekunder. For å gi denne muligheten til plattformapplikasjoner bruker plattformen en søkemotor som er atskilt fra transaksjonsmotoren. Når du oppdaterer poster, oppdaterer transaksjonsmotoren kjernedatabasen og videresender også relaterte data til søkemotoren for indeksering. Når du søker etter poster, bruker søkemotoren sine indekser til å behandle spørringen raskt og returnerer rangerte resultater med lenker til relaterte databaseposter.
Etter hvert som programmer oppdaterer data i tekstfelt (CLOB-er, Navn og så videre), er en gruppe bakgrunnsprosesser kalt indekseringsserverer ansvarlig for asynkron oppdatering av tilsvarende indekser, som søkemotoren vedlikeholder utenfor kjernetransaksjonsmotoren. For å optimalisere indekseringsprosessen kopierer plattformen synkront endrede biter av tekstdata til en intern tabell som skal indekseres etter hvert som transaksjoner bekreftes, og gir dermed en relativt liten datakilde som minimerer mengden data som indekseringsserverne må lese fra disken. Søkemotoren vedlikeholder automatisk separate indekser for hver organisasjon.
Avhengig av gjeldende innlasting og utnyttelse av indekseringsservere kan tekstindeksoppdateringer ligge etter faktiske transaksjoner. For å unngå uventede søkeresultater som kommer fra foreldede indekser, vedlikeholder plattformen også en MRU-buffer med nylig oppdaterte rader som systemet vurderer når det materialiserer fulltekstsøkeresultater. Plattformen vedlikeholder MRU-buffere per bruker og per organisasjon for å effektivt støtte mulige søkeomfang.
Plattformens søkemotor optimaliserer rangeringen av poster i søkeresultater med flere metoder. Systemet vurderer for eksempel sikkerhetsdomenet til brukeren som utfører et søk, og legger mer vekt på radene som gjeldende bruker kan få tilgang til. Systemet kan også vurdere endringshistorikken for en bestemt rad og rangere mer aktivt oppdaterte rader foran de som er relativt statiske. Brukeren kan velge å vekte søkeresultatene etter ønske, for eksempel ved å legge mer vekt på nylig endrede rader.
Transaksjonsintensive programmer genererer mindre overhead og gjør det mye bedre når de kombinerer og utfører gjentagende operasjoner samlet. Du kan for eksempel sammenligne to måter et program kan laste inn mange nye rader på. En ineffektiv løsning ville være å bruke en rutine med en sløyfe som setter inn individuelle rader, og utføre ett API-kall etter et annet for hver radinnsetting. En mye mer effektiv løsning ville være å opprette en matrise med rader og få rutinen til å sette inn alle med ett enkelt API-kall.
Effektiv massebehandling med plattformen er enkelt for utviklere fordi den er baket inn i API-kall. Intern behandler plattformen også alle interne trinn som er relatert til en eksplisitt masseoperasjon.
Plattformens massebehandlingsmotor tar automatisk hensyn til isolerte feil som oppstår under et hvilket som helst trinn underveis. Når en masseoperasjon starter i delvis lagringsmodus, identifiserer motoren en kjent starttilstand og forsøker deretter å utføre hvert trinn i prosessen (massevalider feltdata, masseutløsere av brann, masselagringsposter og så videre). Hvis motoren oppdager feil under et hvilket som helst trinn, ruller motoren tilbake overtrådende operasjoner og alle bivirkninger, fjerner radene som er ansvarlige for feilene, og fortsetter, og forsøker å masseprosessere det gjenværende delsettet av rader. Denne prosessen gjentas gjennom hver etterfølgende fase til motoren kan bekrefte et delsett av rader uten feil. Programmet kan undersøke et returobjekt for å identifisere hvilke rader som mislyktes, og hvilke unntak de oppga.
Notat: Etter eget skjønn er en alt-eller-alt-modus tilgjengelig for masseoperasjoner. Utføringen av utløsere under en masseoperasjon er også underlagt interne styringer som begrenser mengden arbeid.
Enkelte typer endringer i definisjonen av et objekt krever mer enn enkle UDD-metadataoppdateringer. I slike tilfeller bruker plattformen effektive mekanismer som bidrar til å redusere den generelle innvirkningen på ytelsen til skydatabasetjenesten generelt.
Tenk deg for eksempel hva som skjer i bakgrunnen når du endrer datatypen til en kolonne fra valgliste til tekst. Plattformen tildeler først en ny tidsluke for kolonnens data, massekopierer valglisteetikettene som er knyttet til gjeldende verdier, og oppdaterer deretter kolonnens metadata slik at den peker til den nye tidsluken. Selv om alt dette skjer, er tilgang til data normalt, og programmer fortsetter å fungere uten noen merkbar innvirkning.
Som et annet eksempel kan du vurdere hva som skjer når du legger til et felt for samlet oppsummering i et objekt. I dette tilfellet beregner plattformen asynkront innledende sammendrag i bakgrunnen ved bruk av en effektiv masseoperasjon. Mens bakgrunnsberegningen skjer, får brukere som viser det nye feltet, en indikasjon på at plattformen for øyeblikket beregner feltets verdi.
For å hindre skadelig eller utilsiktet monopolisering av delte systemressurser for flere leietagere har plattformen et omfattende sett av styrere og ressursgrenser knyttet til utføring av plattformkode. Plattformen overvåker for eksempel nøye utførelsen av et kodeskript og begrenser hvor mye CPU-tid den kan bruke, hvor mye minne den kan bruke, hvor mange spørringer og DML-setninger den kan utføre, hvor mange matematiske beregninger den kan utføre, hvor mange utgående nettjenestekall den kan utføre, og mye mer. Individuelle spørringer som plattformens optimalisering anser for dyre til å utføres, avgir et kjøretidsunntak til anroperen. Selv om slike grenser kan høres litt restriktive ut, er de nødvendige for å beskytte den generelle skalerbarheten og ytelsen til det delte databasesystemet for alle aktuelle programmer. På lang sikt bidrar disse målingene til å fremme bedre kodeteknikker blant utviklere og skape en bedre opplevelse for alle som bruker plattformen. En utvikler som for eksempel først prøver å kode en sløyfe som ineffektivt oppdaterer tusen rader om gangen, vil motta kjøretidsunntak på grunn av ressursgrenser, og deretter begynne å bruke plattformens effektive massebehandlings-API-kall.
For å unngå potensielle systemproblemer som introduseres av dårlig skrivede programmer, er distribusjon av et nytt produksjonsprogram en prosess som administreres strengt. Før en organisasjon kan overføre et nytt program fra utvikling til produksjonsstatus, krever Salesforce enhetstester som validerer funksjonaliteten til programmets plattformkoderutiner. Sendte enhetstester må dekke ikke mindre enn 75 prosent av programvarens kildekode.
Salesforce utfører sendte enhetstester i plattformens Sandbox-utviklingsmiljø for å finne ut om programkoden vil påvirke ytelsen og skalerbarheten til flerleietagerpopulasjonen generelt. Resultatene av en individuell enhetstest angir grunnleggende informasjon, som totalt antall utførte linjer, i tillegg til spesifikk informasjon om koden som ikke ble utført av testen.
Når koden til et program er sertifisert for produksjon av Salesforce, består distribusjonsprosessen for programmet av en enkelt transaksjon som kopierer alle programmets metadata til en produksjonsplattformforekomst og kjører de tilsvarende enhetstestene på nytt. Hvis en del av prosessen mislykkes, ruller plattformen bare tilbake transaksjonen og returnerer unntak for å bidra til å feilsøke problemet.
Notat: Salesforce kjører enhetstestene på nytt for hvert program med hver utviklingsutgivelse av plattformen for å proaktivt finne ut om nye systemfunksjoner og forbedringer bryter med eksisterende programmer.
Når et produksjonsprogram er aktivt, analyserer plattformens innebygde ytelsesprofil automatisk det og gir tilknyttede tilbakemeldinger til administratorer. Ytelsesanalyserapporter inkluderer informasjon om trege spørringer, datamanipulasjoner og underrutiner som du kan se gjennom og bruke til å justere programfunksjonaliteten. Systemet logger også og returnerer informasjon om kjøretidsunntak til administratorer for å hjelpe dem med å feilsøke sine programmer.
Når en app sletter en post fra et objekt, merker plattformen bare raden for sletting ved å endre radens IsDeleted-felt i MTData. Denne handlingen plasserer raden effektivt i det som kalles papirkurven. plattformen lar deg gjenopprette valgte rader fra papirkurven i opptil 15 dager før du fjerner dem permanent fra MT_Data. Plattformen begrenser totalt antall poster den vedlikeholder for en organisasjon, basert på lagringsgrensene for denne organisasjonen.
Når en operasjon sletter en overordnet post som er involvert i en overordnet-detalj-relasjon, sletter plattformen automatisk alle relaterte underordnede poster, forutsatt at det ikke bryter noen referanseintegritetsregler på plass. Når du for eksempel sletter en SalesOrder, fører plattformen automatisk slettingen gjennom hverandre til avhengige LineItems. Hvis du senere gjenoppretter en overordnet post fra papirkurven, gjenoppretter systemet også automatisk alle underordnede poster.
Når du i motsetning til dette sletter en overordnet post som det refereres til, som er involvert i en oppslagsrelasjon, setter plattformen automatisk alle avhengige nøkler til null. Hvis du senere gjenoppretter den overordnede posten, gjenoppretter plattformen automatisk de tidligere null-oppslagsrelasjonene, bortsett fra relasjonene som ble tildelt på nytt mellom slette- og gjenopprettingsoperasjonene.
Papirkurven lagrer også utelatte felt og deres data til en organisasjon sletter dem permanent eller et angitt antall dager har gått, avhengig av hva som skjer først. Frem til da vil hele feltet og alle tilhørende data være tilgjengelig for gjenoppretting.
Agilitet er nøkkelen for at bedrifter skal lykkes i vår moderne verden. Salesforce Platforms underliggende lag hjelper forretningsprogrammene med å raskt tilpasse seg nye utfordringer, slik at du kan fortsette å fokusere på virksomheten i stedet for infrastrukturen.
Infrastruktur (for eksempel grunnleggende tjenester og databehandlingsressurser) er skjult, underliggende teknologi som støtter øvre lag i Salesforce Platform. Hyperforce er Salesforce Platform-infrastrukturen, bygget på 100 % fornybar energi og netto null, som løser viktige kundeutfordringer, inkludert samsvar, Trust og skalerbarhet
Virksomheter som opererer på flere geografiske steder, må overholde nye, utviklende og varierende forskrifter for databehandling. Fordi Salesforce distribuerer Hyperforce i et økende antall land, kan plattformprogrammer og brukere kjøre sine sensitive arbeidsbelastninger på måter som oppfyller strenge datalagrings- eller datasikringsstandarder. For eksempel, med Salesforces EU-operasjonssone drevet av Hyperforce, kan virksomheter i EU enkelt beholde dataene sine i EU.
Sikkerhet, pålitelighet og tilgjengelighet er ikke-funksjonelle krav som alle forretningsapplikasjoner må vurdere for å oppfylle løftet om Trust til sluttbrukerne. Med Hyperforce kan Salesforce Platform gjøre det enkelt for virksomheter å levere klarerte forretningsprogrammer.
- Sikkerhet – Hyperforce har innebygd ende-til-ende-kryptering av kundedata under lagring og i transitt. Hyperforces Zero Trust Architecture håndhever en streng identitetsbekreftelsesprosess som sikrer at det ikke er noen implisitt tilgang til ressurser. Og Hyperforce bruker prinsippet om minst rettigheter, slik at operasjoner godkjennes for akkurat den riktige tiden med den riktige tilgangsmengden.
- Pålitelighet – Hver forekomst av Hyperforce bruker flere skytilgjengelighetssoner og moderniserte tilnærminger som akselererer respons på forekomst for å levere en svært tilgjengelig og fleksibel plattform.
- Tilgjengelighet – Hyperforces moderne CI/CD pipelines og blå/grønn applikasjonsutgivelser minimerer applikasjonsvedlikeholdsperioder til bare ett minutt i året.
Som grunnlaget for apper som Sales Cloud og Service Cloud er Salesforce en godt utprøvet programutviklingsplattform der individuelle bedrifter og tjenesteleverandører har bygd millioner av forretningsapplikasjoner for forskjellige bruksområder, inkludert behandling av forsyningskjeder, fakturering, regnskap, handel, samsvarssporing, behandling av menneskelige ressurser og behandling av krav. Plattformens unike, flerleietagerbaserte, metadatastyrte arkitektur er utviklet spesielt for skyen, og støtter pålitelig og sikkert oppgavekritiske programmer i internettskala. Ved å bruke standardbaserte API-er og innebygde utviklingsverktøy kan plattformutviklere enkelt bygge alle komponenter i et moderne nett- eller mobilprogram, inkludert programmets datamodell (inkludert objekter og relasjoner), forretningslogikk (inkludert arbeidsflyter og valideringer), integrasjoner med andre programmer og mer.
Siden oppstarten har plattformen blitt optimalisert av Salesforces ingeniører for flerlån, med funksjoner som lar plattformprogrammer skaleres for å møte endrede forretningsmessige behov. Integrerte systemfunksjoner, som Bulk Data Processing API, Apex, en søkemotor med full tekst og en unik spørringsoptimalisering, bidrar til å gjøre avhengige programmer svært effektive og skalerbare med lite eller ingen innsats fra utviklere.
Salesforces administrerte tilnærming til distribusjon av produksjonsprogrammer sikrer utmerket ytelse, skalerbarhet og pålitelighet for alle programmer som avhenger av plattformen. Salesforce overvåker og samler kontinuerlig inn driftsinformasjon fra plattformprogrammer for å bidra til trinnvise forbedringer og nye systemfunksjoner som umiddelbart gir fordeler for eksisterende og nye programmer.
Steve Bobrowski er en vellykket entreprenør og teknologileder som har jobbet for mange ledende firmaets programvareselskaper, inkludert ulike roller på tvers av Salesforce siden 2008. I dag arbeider Steve i Salesforces CTO-kontor for å hjelpe til med firmaets teknologiregistreringsstrategier.
Tom Leddy er arkitektutvikler hos Salesforce. Han støtter det globale Salesforce-arkitektsamfunnet ved å bidra til å opprette ressurser, verktøy og veiledning som hjelper arkitekter med å gjøre sitt beste. Kontakt Tom på Twitter.