毎日、数十万の企業と数百万のユーザーが、Salesforce Platform を利用するアプリケーションを使用してクラウドでビジネスを行っています。プラットフォームが成功している理由は?Trust でビジネスをサポートできる理由は?このプラットフォームは、御社のような企業にどのような独自のメリットをもたらしますか?
この技術概要では、Salesforce Platform がクラウドコンピューティング向けの独自のソフトウェアアーキテクチャを使用して、信頼性、拡張性、カスタマイズのしやすさを備えたエンドユーザーエクスペリエンスを提供する方法について説明します。この概要を読むと、Salesforce Platform がビジネスアプリケーションにとって魅力的な選択肢となる基盤となるテクノロジーについてより深く理解できます。
Salesforce Platform は、クラウドコンピューティングプラットフォームと関連アプリケーションのエコシステムの成功の最たる例です。2000 年の変わり目以降、このプラットフォームは次のことを実現する基盤となっています。
- セールスやカスタマーサービスなどの一般的な使用事例向けの一般的なビジネス目的アプリケーション多数
- 金融や医療などのより特殊な使用事例向けの業界固有アプリケーション
- 固有の使用事例に対応する数百万のカスタムアプリケーションとアプリケーション拡張
Salesforce Platform は、構築、使用、カスタマイズ、および拡張が容易なアプリケーションを独自のソフトウェアアーキテクチャでサポートし、卓越したパフォーマンスと信頼性を備えているため、そのほとんどが成功して人気があります。プラットフォームのソフトウェアアーキテクチャの中心は、そのマルチテナントのメタデータ主導の設計です。
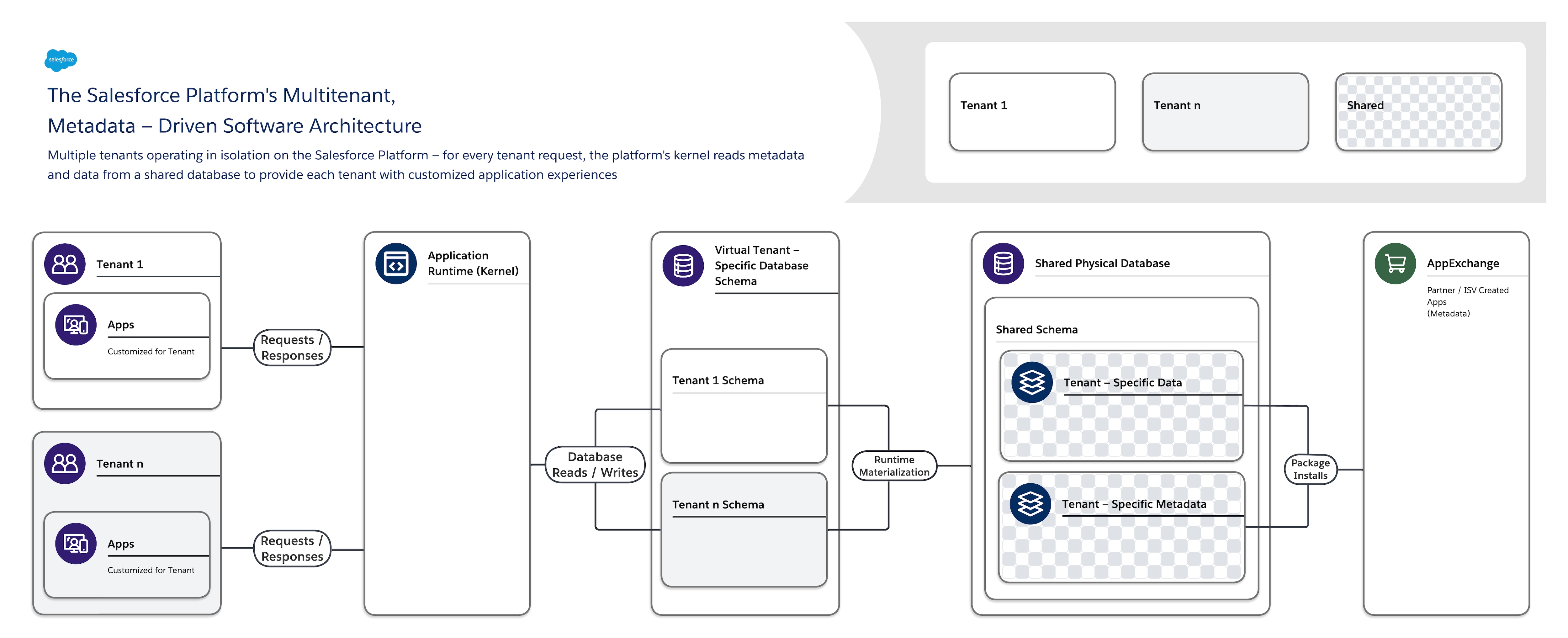
Salesforce Platform のソフトウェアアーキテクチャは次のとおりです。
- マルチテナント:多くのテナント(組織、ビジネス・ユニットなど)のさまざまな要件を分離し、同時にサポートします。
- メタデータ駆動型 — すべてのテナントは、メタデータ、つまりユーザー インターフェイス(UI)やビジネス ロジックなどの要素を記述するデータを使用して、アプリケーションとユーザー エクスペリエンスを簡単かつ迅速にカスタマイズできます。
Salesforce Platform を使用して新しいアプリケーションオブジェクトを作成したり、コードを記述したりしても、プラットフォームはデータベースに実際のテーブルを作成したり、コードをコンパイルしたりしません。代わりに、プラットフォームはメタデータを保存するだけで、実行時に仮想アプリケーションコンポーネントを動的に具体化できます。このプラットフォームにより、すべてのテナントのメタデータが非公開になり、ロックやダウンタイムなしで簡単に更新できるため、各テナントは個別にアプリケーションを構築およびカスタマイズできます。Salesforce Platform では、同じメタデータを使用してカスタム API、RESTful、および Web サービス (SOAP ベース) インターフェースが提供され、アプリケーションを他のアプリケーションや自動化プロセスと統合するために使用できます。
既成のソリューションは、プラットフォームの拡張アプリケーション市場であるAppExchangeでも使用できます。AppExchange パッケージは、信頼できるパートナーと独立系ソフトウェア・ベンダー(ISV)の広範なエコシステムによって構築されており、特定のビジネス要件を満たすために使用できる、無料または有料のアプリケーション拡張およびアプリケーション全体を説明するサードパーティのメタデータです。
この高度なカスタマイズと拡張が可能なアーキテクチャをサポートするために、Salesforce Platform の 1 つのインスタンスでは以下が使用されます。
- テナント固有のメタデータとデータを保存する単一のスキーマを持つ単一の共有マルチテナント データベース。
- メタデータとデータを参照して、実行時に各テナントのユーザーにテナント固有のアプリケーション、ビジネス ロジック、API を動的に提供するマルチテナント カーネル(アプリケーション ランタイム)。
Salesforce 管理カーネルとテナント管理メタデータが明確に分離されているため、Salesforce、テナント、ISV は干渉することなくシステムの部分を独自に進化させることができます。
この概要に基づいて、この記事の後続のセクションでは、設計の主要な側面に起因するプラットフォームの独自の機能について詳しく説明します。
- プラットフォームデータレイヤー
- プラットフォームアプリケーション開発
- 内部プラットフォーム処理
- プラットフォームインフラストラクチャ
Salesforce Platform のアプリケーションランタイムと革新的なデータレイヤーを組み合わせることで、テナント固有のデータ、スキーマのカスタマイズ、ビジネスロジックを安全に分離できます。スキーマの概要では、さまざまな使用事例がサポートされます。
- アプリケーションを作成またはカスタマイズすると、プラットフォームはすべてのテナントのメタデータを保持する共有データベーステーブルに関連メタデータを保存します。
- アプリケーションを使用してデータの読み取りまたは書き込みを行う場合、プラットフォームでは、すべてのテナントのデータを保持する共有データベーステーブルにデータが保存されます。
- また、バックグラウンドで、カーネルが実行時に要求遅延を最適化するために使用する多数のテーブルの内部メタデータも保持されます。
ただし、1 つの共有データベースとスキーマですべてのテナントのデータの非公開を維持する方法は?プラットフォーム上の各テナントは、組織、略して組織と呼ばれます。また、共有データベーステーブルのすべての組織固有のレコードに OrgID があります。カーネルはデータベースにアクセスするときに、この一意の識別子を使用して、各組織の活動を非公開にします。

組織固有のオブジェクト (従来のリレーショナルデータベースと同じ考え方の think table)、項目、ストアドプロシージャ、データベーストリガーなどはすべて、_Universal Data Dictionary (_UDD) と呼ばれるいくつかのデータベーステーブルにプラットフォームが保存するメタデータによって記述される仮想構造です。
- MT_Objects は、アプリケーションに定義するオブジェクトに関するメタデータ (オブジェクトの一意の識別子 (ObjID)、組織 (OrgID)、オブジェクトに付ける名前 (ObjName) など) を保存するデータベーステーブルです。
- MT_Fields システムテーブルには、各オブジェクトに対して宣言するフィールド (列) に関するメタデータが保存されます。これには、フィールドの一意の識別子 (FieldID)、組織 (OrgID)、フィールドが含まれるオブジェクト (ObjID)、フィールドの名前 (FieldName)、フィールドのデータ型、フィールドにインデックス付けが必要かどうかを示す Boolean 値 (IsIndexed)、オブジェクト内での他のフィールドに対するフィールドの位置 (FieldNum) が含まれます。
メタデータは重要な要素であるため、プラットフォームはメタデータへのアクセスを最適化する必要があります。そうしないと、メタデータアクセスを頻繁に行うと、サービスを拡張できなくなります。この潜在的なボトルネックを念頭に置いて、プラットフォームは大規模で高度なメタデータ キャッシュを使用して、最近使用したメタデータをメモリに保持し、ディスク I/O とコードの再コンパイルのパフォーマンスの低下を回避し、アプリケーションのレスポンス タイムを向上させます。
MT_Data システムテーブルには、MT_Objects および MT_Fields のメタデータで定義されたすべての組織固有のテーブルとそのフィールドにマッピングされる、アプリケーションからアクセス可能なデータが保存されます。各行には、グローバル一意識別子 (GUID)、行を所有する組織 (OrgID)、包含オブジェクト識別子 (ObjID) などの識別項目が含まれます。MT_Data テーブルの各行には、対応するレコードの「自然名」を保存する [名前] 項目もあります。たとえば、取引先レコードでは「取引先名」、ケースレコードでは「ケース番号」などが使用されます。
Value0 ...ValueN flex 列 (スロットとも呼ばれる) には、それぞれ MT_Objects と MT_Fields で宣言されたテーブルとフィールドに対応付けられるアプリケーションデータが保存されます。すべての Flex 列は、任意の構造化された種別のアプリケーションデータ (文字列、数値、日付など) を保存できるように、可変長文字列データ型を使用します。次の図に示すように、同じオブジェクトの 2 つの項目をストレージの MT_Data の同じスロットに対応付けることはできません。ただし、各項目が異なるオブジェクトから取得されている限り、1 つのスロットで複数の項目の情報を管理できます。
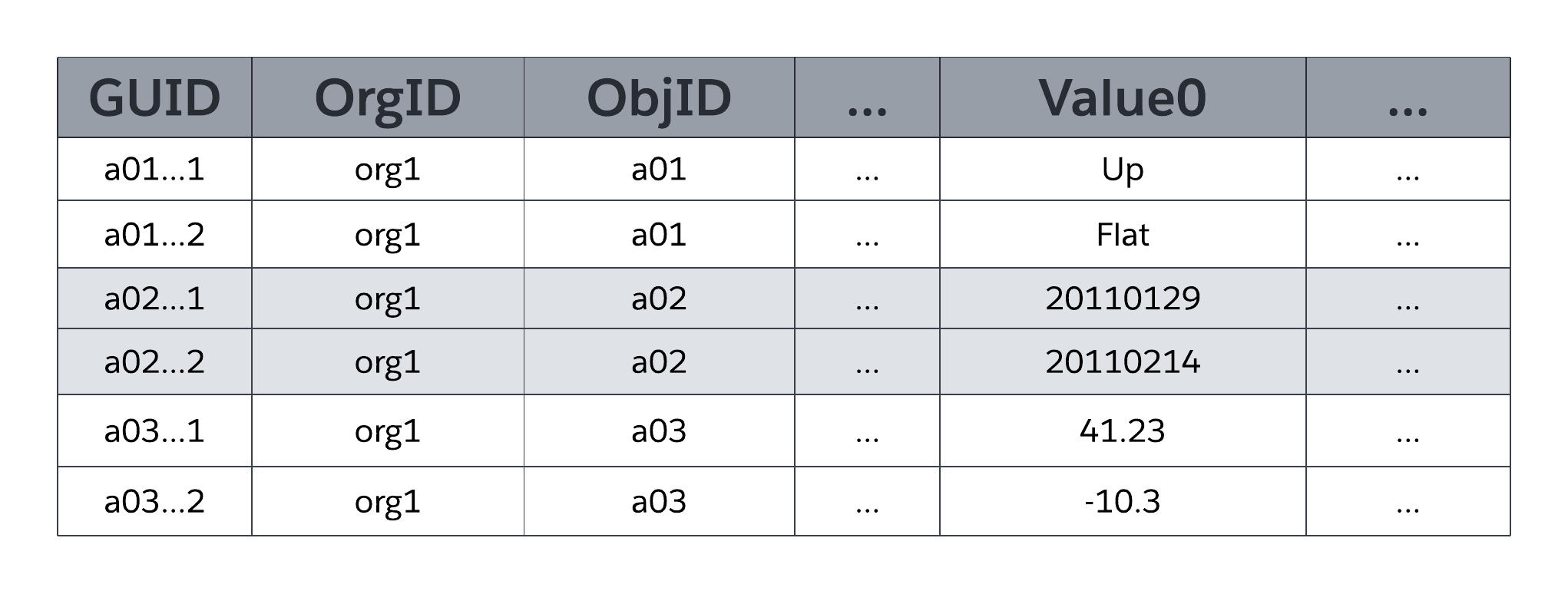
MTField では*、テキスト、数値、日付、日付/時間などの標準構造化データ型のほか、選択リスト (列挙項目)、自動採番 (自動増分、システム生成の連番)、数式 (参照のみの派生値)、主従関係 (外部キー)、チェックボックス (Boolean)、メール、URL などの特殊な用途のリッチ構造化データ型を使用でき* ます。MT_Fields は必須 (null ではない) にすることもできます。また、カスタム入力規則 (1 つの項目が別の項目よりも大きい必要があるなど) があり、どちらもプラットフォームで適用されます。
オブジェクトを宣言または変更すると、オブジェクトを定義する MT_Objects のメタデータ行がプラットフォームで管理されます。同様に、項目ごとに、対応する項目データの保存のために項目を MT_Data の特定の Flex 列に対応付けるメタデータを含む、MT_Fields の行がプラットフォームで管理されます。プラットフォームでは、オブジェクトと項目の定義が実際のデータベース構造ではなくメタデータとして管理されるため、他の組織やユーザーの同時活動をブロックすることなく、システムはオンラインのマルチテナントアプリケーションスキーマのメンテナンス作業を許容できます。一方、従来のリレーショナルデータベースシステムのオンラインテーブルの再定義では、通常、一時的なロックが必要であり、多くの場合、複雑で面倒なプロセスが発生し、アプリケーションのダウンタイムがスケジュールされます。
前の図の MT_Data の簡略化された表現が示すように、フレックス列はユニバーサルデータ型 (可変長文字列) であり、さまざまな構造化データ型 (文字列、数値、日付など) を使用する複数の項目で 1 つのフレックス列を共有できます。
プラットフォームでは、すべての Flex 列データが正規形式を使用して保存され、アプリケーションで Flex 列からデータを参照および書き込むときに、必要に応じて基盤となるデータベースシステムのデータ型変換関数 (TO_NUMBER、TO_DATE、TO_CHAR など) が使用されます。
MTData には、前の図に示されていない列も含まれます。たとえば、行を作成したユーザーとその行が作成された日時、行を最後に更新したユーザーとその行が最後に更新された日時など、監査データを管理する 4 つの列があります。MT_Data には、行が削除されたことを示すためにプラットフォームで使用される _IsDeleted 列も含まれます。
また、プラットフォームでは、最大 32,000 文字のロングテキストフィールドを保存できる文字ラージオブジェクト (CLOB) としてのフィールドの宣言もサポートされています。CLOB がある MTData の各行について、プラットフォームは _MT_Clob というテーブルに行外の CLOB を保存します。このテーブルは、必要に応じて MT_Data の対応する行と結合できます。
**注意:**また、このプラットフォームでは、テキスト検索を高速化するために、データベース外のインデックス付き形式で CLOB を保存します。プラットフォームのテキスト検索エンジンについての詳細は、「検索」を参照してください。
プラットフォームでは、さまざまな種別の項目に自動的にインデックスが付けられ、スケーラブルなパフォーマンスが提供されます。
従来のデータベースシステムでは、特定の条件に一致する項目があるデータベーステーブル内の特定の行をすばやく見つけるために、ネイティブデータベースインデックスを使用します。ただし、MTData の Flex 列に対してネイティブのデータベースインデックスを作成することは現実的ではありません。プラットフォームでは、1 つの Flex 列を使用して、さまざまな構造化データ型の多数の項目のデータを保存します。代わりに、プラットフォームはインデックス付けの対象としてマークされた項目データを _MT_Indexes ピボットテーブルの適切な列に同期コピーすることで、MT_Data のインデックスを管理します。
MT_Indexes には、StringValue、NumValue、DateValue など、強く型付けされインデックス付けされた列が含まれ、プラットフォームは、対応するデータ型の項目データを検索するために使用します。たとえば、プラットフォームは MT_Data Flex 列の文字列値を MT_Indexes の StringValue 項目にコピーし、日付値を DateValue 項目にコピーします。MT_Indexes の基盤となるインデックスは、標準の一意でないデータベースインデックスです。内部システムクエリにオブジェクトの構造化項目を参照する検索パラメーターが含まれている場合、プラットフォームのカスタムクエリオプティマイザーは MT_Indexes を使用して、関連付けられたデータアクセス操作を最適化します。
注意:文字列値を大文字と小文字を区別しないユニバーサル形式に変換する大文字と小文字の折り畳みアルゴリズムが使用されるため、プラットフォームで複数の言語の検索を処理できます。MT_Indexes テーブルの StringValue 列には、次の形式で文字列値が保存されます。実行時に、クエリオプティマイザーは、最適化された SQL ステートメントが対応するケース折り畳まれた StringValue (検索要求で提供されるリテラルに対応する) で絞り込まれるように、データアクセス操作を自動的に構築します。
プラットフォームでは、オブジェクトの項目に一意の値を含める必要があるタイミング (大文字と小文字を区別しない) を指定できます。MT_Data の配置と項目データの [値] 列の共有使用を考慮すると、オブジェクトの一意のデータベースインデックスを作成するのは現実的ではありません。(この状況は、前のセクションで説明した一意でないインデックスの場合と似ています)。
カスタム項目の一意性をサポートするために、プラットフォームでは MT_Unique_Indexes ピボットテーブルが使用されます。このテーブルは MT_Indexes テーブルとよく似ていますが、MT_Unique_Indexes の基盤となるネイティブデータベースインデックスで一意性が適用されます。一意性が必要な項目にアプリケーションが重複値を挿入しようとした場合、または重複値を含む既存の項目に管理者が一意性を適用しようとした場合、プラットフォームは適切なエラーメッセージをアプリケーションに返します。
まれに、プラットフォームの外部検索エンジン (「検索」を参照) が過負荷になったり、その他の理由で使用できなくなったりして、検索要求にタイムリーに応答できない場合があります。エンドユーザーに失望させるエラーを返すのではなく、プラットフォームは二次検索メカニズムにフォールバックして妥当な検索結果を提供します。
フォールバック検索は、対象レコードの [名前] フィールドを参照する検索条件を使用する直接データベースクエリとして実装されます。コストのかかる可能性のある union クエリを実行せずにグローバルオブジェクト検索 (複数のテーブルにまたがる検索) を最適化するために、プラットフォームではすべてのレコードの名前を記録する MT_Fallback_Indexes ピボットテーブルが保持されています。MT_Fallback_Indexes の更新は、トランザクションでレコードが変更されると同期的に実行されるため、フォールバック検索では常に最新のデータベース情報にアクセスできます。
MT_Name_Denorm テーブルは、各レコードの ObjID と Name を MT_Data に保存するリーンデータテーブルです。アプリケーションで親/子リレーションに関連するレコードのリストを提供する必要がある場合、プラットフォームは MT_Name_Denorm テーブルを使用して、たとえばハイパーリンクの一部としてアプリケーションに表示するために、参照される各レコードの名前を取得する比較的簡単なクエリを実行します。
プラットフォームには、組織がテーブル間のリレーション (参照整合性) を宣言するために使用できるリレーションデータ型が用意されています。リレーション種別を使用してオブジェクトの項目を宣言すると、プラットフォームによってその項目が MT_Data の [値] 項目に対応付けられ、この項目を使用して関連オブジェクトの ObjID が保存されます。
結合操作を最適化するために、プラットフォームでは MT_Relationships ピボットテーブルが管理されています。このシステムテーブルには、必要に応じてどちらの方向のオブジェクトも効率的にトラバースできる 2 つのデータベース一意の複合インデックスがあります。
マウスを数回クリックするだけで、プラットフォームで任意の項目の履歴管理が提供されます。組織で特定の項目の監査を有効にすると、項目に加えられた変更 (新旧の値、変更日など) に関する情報が、内部ピボットテーブルを監査履歴として非同期に記録されます。
基盤となるデータベースインデックスを含むすべてのプラットフォームデータ、メタデータ、ピボットテーブル構造は、ネイティブのデータベースパーティショニングメカニズムを使用して、OrgID によって物理的にパーティション分割されます。データパーティショニングは、大きな論理データ構造を物理的に小さく管理しやすい部分に分割するためにデータベースシステムで提供される実証済みの手法です。パーティショニングは、マルチテナント環境などの大規模なデータベースシステムのパフォーマンス、拡張性、可用性の向上にも役立ちます。定義上、すべてのプラットフォームクエリは特定の組織の情報を対象としているため、クエリオプティマイザーはテーブル全体またはインデックス全体ではなく、組織のデータが含まれるデータパーティションへのアクセスのみを考慮する必要があります。この一般的な最適化は「パーティションプルーニング」と呼ばれることもあります。
このセクションでは、アプリケーション開発者がスキーマの基礎となるメタデータを作成し、データを管理するアプリケーションを作成する方法について説明します。このメタデータとデータは、前のセクションで説明したプラットフォームデータレイヤーに保存されます。
開発者は、プラットフォームのブラウザーベースの開発環境 (一般に「プラットフォームの設定」画面と呼ばれる) を使用して、宣言型でサーバー側アプリケーションコンポーネントを作成できます。[設定] のポイント & クリック UI では、アプリケーションのデータモデル (オブジェクトとその項目、リレーションを含む)、セキュリティと共有モデル (ユーザー、プロファイル、ロール階層を含む)、ユーザーインターフェース (画面レイアウト、データ入力フォーム、レポートを含む)、宣言型ロジック (ワークフロー)、プログラムロジック (ストアドプロシージャとトリガー) の作成など、アプリケーションスキーマの構築プロセスのすべての側面がサポートされます。たとえば、Salesforce フローを使用すると、さまざまな使用事例を簡単に自動化できます。次に示すように、[設定] の Flow Builder UI では、ユーザーとやりとりするワークフローをグラフィカルに設計して実装したり、スケジュールに基づいて自動的に起動したり、イベントによってトリガーされたりできます。
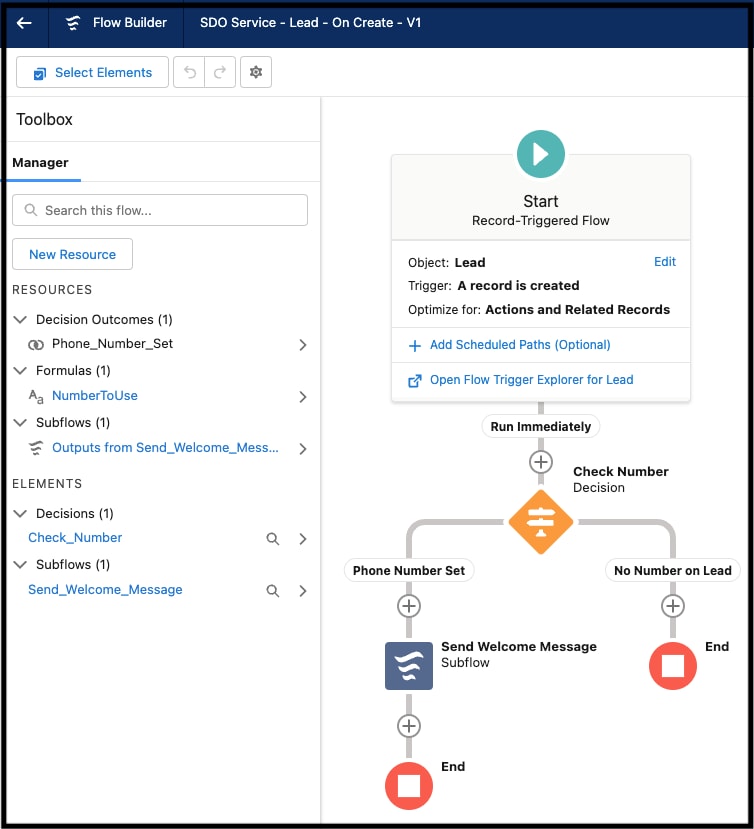
[設定] 画面では、コード不要 (またはほとんど不要) で誰でも簡単にアプリケーションを開発およびカスタマイズできます。次に例を示します。
- プラットフォームネイティブの UI は、コードなしで簡単に作成できます。ネイティブアプリケーション UI では、クエリ、挿入、更新、削除など、通常のすべてのデータアクセス操作がバックグラウンドでサポートされます。ネイティブプラットフォームアプリケーションによって実行される各データ操作では、一度に 1 つのオブジェクトを変更し、個別のトランザクションで各変更を自動的に確定できます。
- 機密データを含むオブジェクトのテキスト項目を定義する場合、対応するデータをプラットフォームで暗号化し、必要に応じて入力マスクを使用して画面情報を覗き見されないように項目を簡単に設定できます。
- 宣言型検証ルールは、プログラミングなしでドメイン整合性ルールを組織に適用する簡単な方法です。たとえば、LineItem オブジェクトの [数量] 項目が常に 0 より大きいようにする入力規則を宣言することができます。
- 数式項目は、計算項目をオブジェクトに簡単に追加できるプラットフォームの宣言型機能です。たとえば、LineItem オブジェクトに LineTotal 値を計算する項目を追加できます。
- 積み上げ集計項目は、親オブジェクトの子項目情報を簡単に集計できるクロスオブジェクト項目です。たとえば、LineItem オブジェクトの LineTotal 項目に基づいて SalesOrder オブジェクトの OrderTotal 集計項目を作成できます。
**注意:**プラットフォームの内部では、ネイティブのデータベース機能を使用して数式項目と積み上げ集計項目を実装し、進行中のトランザクションの一部として同期的に値を効率的に再計算します。
このプラットフォームには、開発者がアプリケーションの作成に使用できる、いくつかのオープンな標準ベースの API が用意されています。RESTful API と Web サービス (SOAP ベース) API のどちらも、プラットフォームの多くの機能へのアクセスを提供します。これらのさまざまな API を使用して、アプリケーションは次のことができます。
- アプリケーションスキーマを説明するメタデータの操作
- ビジネスデータの作成、参照、更新、削除 (CRUD)
- 多数のレコードを非同期で一括読み込みまたは照会
- 安全で拡張性の高い方法でほぼリアルタイムのデータストリームを公開
アプリケーションでは、Salesforce Object Query Language (SOQL) を使用して、シンプルでありながら強力なデータベースクエリを作成できます。構造化クエリ言語 (SQL) の SELECT コマンドと同様に、SOQL ではソースオブジェクト、取得する項目のリスト、ソースオブジェクトの行を選択する条件を指定できます。たとえば、次の SOQL クエリは、[名前] が文字列「Acme」のすべての取引先レコードの [Id and Name (ID と名前)] 項目の値を返します。
SELECT Id, Name FROM Account WHERE Name = 'Acme'
このプラットフォームには、すべてのテキスト関連項目に自動的にインデックスを付ける全文検索の多言語検索エンジンも含まれます。アプリケーションは、Salesforce Object Search Language (SOSL) を使用してテキスト検索を実行することで、この事前統合済み検索エンジンを利用できます。一度に 1 つのオブジェクトのみを照会できる SOQL とは異なり、SOSL では複数のオブジェクトのテキスト項目、メール項目、電話項目を同時に検索できます。たとえば、次の SOSL ステートメントは、名前項目に文字列「Joe Smith」を含むリードオブジェクトと取引先責任者オブジェクトのレコードを検索し、見つかった各レコードから名前と電話番号項目を返します。
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex は、多くの点で Java に似ていますが、開発者がアプリケーションスキーマで手続きロジックを一元化するために使用できる強力な開発言語です。Apex コードでは、プログラム変数および定数の宣言、従来のフロー制御ステートメントの実行 (if-else、loops など)、データ操作の実行 (insert、update、upsert、delete)、トランザクション制御操作の実行 (setSavepoint、rollback) ができます。
Apex プログラムをプラットフォームに保存するには、2 つの異なる形式を使用します。名前付き Apex クラスとして、また、必要に応じてアプリケーションが実行するメソッド (従来のデータベース用語でのストアドプロシージャに類似) と、特定のデータベース操作イベントが発生する前後に自動的に実行されるデータベーストリガーとして保存できます。どちらの形式でも、プラットフォームで Apex コードがコンパイルされ、メタデータとして UDD に保存されます。組織が初めて Apex プログラムを実行するときに、プラットフォームのランタイム インタープリタは、プログラムのコンパイル済みバージョンをその組織の MRU (最近使用したデータ) キャッシュに読み込みます。その後、同じ組織のユーザーが同じルーチンを使用する必要がある場合、プラットフォームは、メモリを節約し、すでにメモリにあるすぐに実行できるプログラムを共有することで、プログラムの再コンパイルのオーバーヘッドを回避できます。
シンプルなキーワードがあちこちに追加されているため、開発者は Apex を使用して多くの固有のアプリケーション要件をサポートできます。たとえば、開発者はメソッドをカスタム RESTful または SOAP ベースの API コールとして公開したり、非同期でスケジュール可能にしたり、大規模な操作を一括で処理するように設定したりできます。
Apex は「単なる別の手続き言語」ではありません。これは、システムが信頼性の高いマルチテナンシーを実現するのに役立つ不可欠なプラットフォームコンポーネントです。たとえば、クラス内のすべての組み込み SOQL および SOSL ステートメントがプラットフォームによって自動的に検証され、実行時に失敗するコードが回避されます。その後、プラットフォームは有効なクラスの対応するオブジェクトの連動関係情報を保持し、連動コードが破損するようなメタデータの変更を防止するために使用します。
多くの標準 Apex クラスとシステム静的メソッドは、基盤となるシステム機能への簡単なインタフェースを提供します。たとえば、insert、update、delete などのシステム静的 DML メソッドには、開発者が目的の一括処理オプション (all or nothing、または partial save) を示すために使用できる簡単な Boolean パラメーターがあります。これらのメソッドは、結果オブジェクトも返します。結果オブジェクトは、呼び出しルーチンで読み取ることができ、処理に失敗したレコードとその理由を判断できます。Apex とプラットフォーム機能を直接結び付けるその他の例として、組み込みのメール・クラスや XmlStream クラスがあります。
Salesforce は次の 2 つの重要な原則を念頭に置いてプラットフォームを構築しているため、プラットフォームのパフォーマンスと拡張性は優れています。
- 効率的で大規模な基盤プラットフォーム機能を提供します。
- 開発者がすべてをできるだけ効率的に実行できるようにします。
このプラットフォームでは、次の原則がプラットフォーム独自の処理アーキテクチャに組み込まれています。
- Queries (クエリ)
- 検索
- 一括処理
- スキーマの変更
- マルチテナントの分離
- ごみ箱
ほとんどの最新のデータベースシステムでは、対象テーブルとインデックスデータに関連する統計を考慮するコストベースのクエリオプティマイザーを使用して、最適なクエリ実行プランを決定します。ただし、従来のコストベースのオプティマイザー統計はシングルテナントアプリケーション用に設計されており、マルチテナント環境でクエリを実行する特定のユーザーのデータアクセス特性を考慮していません。たとえば、大量のデータがあるオブジェクトを対象とする特定のクエリでは、可視性の高いユーザー (すべての行を表示できるマネージャー) と可視性の低いユーザー (自分に関連する行のみを表示可能な営業担当) で異なる実行計画を使用して、より効率的に実行される可能性が高くなります。
マルチテナントシステムで最適なクエリ実行プランを判断するのに十分な統計を提供するために、プラットフォームでは、すべての組織のオブジェクトの完全なオプティマイザー統計セット (テナントレベル、グループレベル、ユーザーレベル) が保持されます。統計には、特定のクエリがアクセスできる可能性のある行数が反映されます。これには、全体的な組織固有のオブジェクト統計 (組織全体が所有する行の合計数など) と、より詳細な統計 (特定の権限グループまたはエンドユーザーがアクセスできる可能性のある行数など) が慎重に考慮されます。
プラットフォームでは、特定のクエリに役立つ他の種別の統計も管理されます。たとえば、プラットフォームでは、対応する項目の null 以外の一意の値の合計数を表示するすべてのカスタムインデックスの統計や、各リスト値のカーディナリティを表示する選択リスト項目のヒストグラムが保持されます。
既存の統計が適切に配置されていない場合や役に立たないとみなされる場合、プラットフォームのオプティマイザーには、適度に最適なクエリを作成するのに役立ついくつかの異なる戦略があります。たとえば、クエリがオブジェクトの [名前] 項目で絞り込む場合、オプティマイザーは MT_Fallback_Indexes テーブルを使用して、要求された行を効率的に検索できます。それ以外のシナリオでは、オプティマイザーは実行時に欠落している統計を動的に生成します。
プラットフォームのオプティマイザーは、オプティマイザー統計と連動して使用され、組織のユーザーのセキュリティドメインに関する情報 (特定のユーザーのグループメンバーシップやオブジェクトおよび行のカスタムアクセス権など) を保持する内部セキュリティ関連テーブル (Groups、Members、GroupBlowout、CustomShare) も使用します。このような情報は、ユーザーごとにクエリ検索条件の選択性を判断する上で非常に重要です。プラットフォームの組み込みセキュリティモデルの詳細については、「Platform Developer Basics Trailhead」を参照してください。
次の図のフロー図は、MT_Data などの大きなヒープテーブルの 1 つに含まれるデータの要求をプラットフォームで処理したときの動作を示しています。要求は、API コールやストアドプロシージャーなど、任意の数のソースから発生する可能性があります。まず、プラットフォームはマルチテナント対応統計を考慮する「事前クエリ」を実行します。次に、事前クエリで返された結果に基づいて、特定の設定での実行に最適な基礎となるデータベースクエリがサービスによって作成されます。
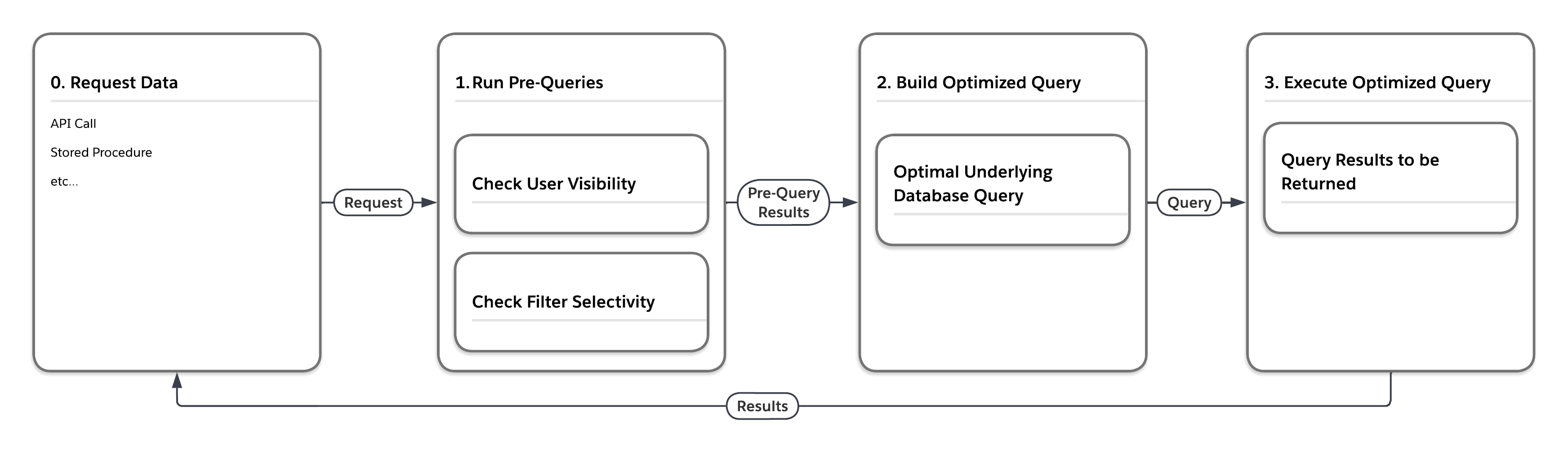
次の表に示すように、プラットフォームでは、クエリを送信するユーザーとクエリの検索条件の選択性に応じて、同じクエリを 4 つの異なる方法で実行できます。
| 事前クエリ選択性メジャメント | 最終的なデータベースアクセスクエリを記述します。強制... | |
| User | 検索条件 | |
| Low | Low | ...ネストされたループが結合され、ユーザーに表示される行のビューを使用してドライブ |
| Low | High (高) | ...検索条件に関連するインデックスの使用 |
| High (高) | Low | ...順序付きハッシュ結合、MT_DATA を使用したドライブ |
| High (高) | High (高) | ... インデックス関連検索条件の使用 |
ユーザーは、アプリケーションのデータベースのすべてまたは選択した範囲をスキャンし、1 秒未満の応答時間でランク付けされた結果を返す対話型の検索機能を期待しています。プラットフォームアプリケーションでこの機能を提供するために、プラットフォームはトランザクションエンジンとは別の検索エンジンを使用します。レコードを更新すると、トランザクションエンジンによってコアデータベースが更新され、インデックス付けのために関連データが検索エンジンに転送されます。レコードを検索すると、検索エンジンはそのインデックスを使用してクエリをすばやく処理し、関連データベースレコードへのリンクを含むランク付けされた結果を返します。
アプリケーションがテキスト項目 (CLOB、名前など) のデータを更新すると、インデックスサーバーと呼ばれるバックグラウンドプロセスのプールが対応するインデックスを非同期で更新します。このインデックスは、検索エンジンがコアトランザクションエンジン外で保持します。インデックス付けプロセスを最適化するために、プラットフォームはトランザクションの確定時に、変更されたテキストデータのチャンクを「インデックス付け対象」の内部テーブルに同期コピーします。これにより、インデックス付けサーバーがディスクから読み取る必要があるデータ量を最小限に抑える比較的小さなデータソースが提供されます。検索エンジンでは、組織ごとに個別のインデックスが自動的に維持されます。
インデックス付けサーバーの現在の負荷と使用状況によっては、テキストインデックスの更新が実際のトランザクションよりも遅れる可能性があります。古いインデックスから予期しない検索結果が返されるのを回避するために、プラットフォームでは、全文検索結果を具体化するときに考慮される最近更新された行の MRU キャッシュも保持されます。プラットフォームでは、可能な検索範囲を効率的にサポートするために、ユーザーごとおよび組織ごとに MRU キャッシュが保持されます。
プラットフォームの検索エンジンは、いくつかの方法を使用して検索結果内のレコードのランキングを最適化します。たとえば、検索を実行するユーザーのセキュリティ・ドメインが考慮され、現在のユーザーがアクセスできる行に加重されます。また、特定の行の変更履歴を考慮し、よりアクティブに更新された行を比較的静的な行より前にランク付けすることもできます。ユーザーは、必要に応じて検索結果の加重を選択できます。たとえば、最近変更した行をより強調できます。
トランザクション集約型アプリケーションでは、反復操作をまとめて実行すると、オーバーヘッドが少なくなり、パフォーマンスが大幅に向上します。たとえば、アプリケーションが多くの新しい行を読み込む 2 つの方法を対比します。個々の行を挿入するループでルーチンを使用し、行を挿入するたびに API コールを 1 つずつ実行することは非効率的です。より効率的な方法は、行の配列を作成し、ルーチンで 1 回の API コールでそのすべてを挿入することです。
プラットフォームは API コールに組み込まれているため、開発者にとって効率的な一括処理は簡単です。内部では、明示的な一括操作に関連するすべての内部ステップも一括処理されます。
プラットフォームの一括処理エンジンでは、途中のステップで発生した分離された障害が自動的に考慮されます。一括操作が部分保存モードで開始されると、エンジンは既知の開始状態を識別し、プロセスの各ステップ (項目データの一括検証、事前トリガーの一括起動、レコードの一括保存など) の実行を試みます。ステップ中にエラーが検出されると、エンジンは問題のある操作とすべての副作用をロールバックし、障害の原因となっている行を削除して続行し、残りの行のサブセットを一括処理しようとします。このプロセスは、エンジンがエラーなしで行のサブセットをコミットできるようになるまで、各フェーズを反復処理します。アプリケーションは、返品オブジェクトを調べて、失敗した行と発生した例外を識別できます。
**注意:**一括操作では、任意でオールオアナッシングモードを使用できます。また、一括操作中のトリガーの実行には、作業量を制限する内部ガバナが適用されます。
オブジェクト定義に対する特定の種別の変更では、単純な UDD メタデータの更新以上のものが必要です。このような場合、プラットフォームでは、クラウドデータベースサービス全体に対する全体的なパフォーマンスへの影響を軽減する効率的なメカニズムが使用されます。
たとえば、列のデータ型を選択リストからテキストに変更したときにバックグラウンドで何が起こるかを考えてみます。プラットフォームは、まず列のデータの新しい時間枠を割り当て、現在の値に関連付けられている選択リストの表示ラベルを一括コピーし、新しい時間枠を参照するように列のメタデータを更新します。これらすべてが発生する間、データへのアクセスは正常であり、アプリケーションは重大な影響もなく機能し続けます。
別の例として、積み上げ集計項目をオブジェクトに追加するとどうなるかを考えてみましょう。この場合、プラットフォームは効率的な一括操作を使用してバックグラウンドで初期集計を非同期で計算します。バックグラウンド計算の実行中、新しい項目を参照するユーザーは、プラットフォームで項目の値が現在計算中であることを示す通知を受け取ります。
共有マルチテナントシステムリソースの悪意のある独占や意図しない独占を防止するために、プラットフォームにはプラットフォームコード実行に関連付けられた広範なガバナとリソース制限のセットがあります。たとえば、プラットフォームはコードスクリプトの実行を詳細に監視し、使用できる CPU 時間、消費できるメモリ量、実行できるクエリと DML ステートメントの数、実行できる算術計算の数、実行できる送信 Web サービスコールの数などを制限します。プラットフォームのオプティマイザーが実行には高すぎると判断した個々のクエリは、呼び出し元にランタイム例外をスローします。このような制限は、やや制限に聞こえるかもしれませんが、関連するすべてのアプリケーションの共有データベースシステム全体の拡張性とパフォーマンスを保護するために必要です。長期的には、これらの対策は開発者間のコーディング技術の向上を促進し、プラットフォームを使用するすべてのユーザーの環境を改善するのに役立ちます。たとえば、最初に 1,000 行を 1 行ずつ非効率的に更新するループをコーディングしようとした開発者は、リソース制限による実行時例外を受け取り、プラットフォームの効率的な一括処理 API コールの使用を開始します。
適切に記述されていないアプリケーションによって発生する可能性のあるシステムの問題をさらに回避するために、新しい本番アプリケーションの導入は厳密に管理されるプロセスです。組織が新しいアプリケーションを開発状況から本番状況に移行できるようにするには、アプリケーションのプラットフォームコードルーチンの機能を検証する単体テストが必要です。送信される単体テストは、アプリケーションのソースコードの 75% 以上を対象とする必要があります。
Salesforce は、送信された単体テストをプラットフォームの Sandbox 開発環境で実行し、アプリケーションコードがマルチテナント母集団全体のパフォーマンスと拡張性に悪影響を及ぼすかどうかを判断します。個々の単体テストの結果には、実行された合計行数などの基本情報と、テストで実行されなかったコードに関する具体的な情報が表示されます。
アプリケーションのコードが Salesforce によって本番用に認定されると、アプリケーションのリリースプロセスは、アプリケーションのすべてのメタデータを本番プラットフォームインスタンスにコピーし、対応する単体テストを再実行する 1 つのトランザクションで構成されます。プロセスの一部が失敗した場合、プラットフォームはトランザクションをロールバックし、問題のトラブルシューティングに役立つ例外を返します。
**注意:**Salesforce は、プラットフォームの開発リリースごとにアプリケーションごとに単体テストを再実行し、新しいシステム機能と機能強化によって既存のアプリケーションが破損していないかどうかを積極的に把握します。
本番アプリケーションが稼働したら、プラットフォームの組み込みパフォーマンスプロファイラーが自動的に分析し、関連付けられたフィードバックを管理者に提供します。パフォーマンス分析レポートには、クエリの遅延、データ操作、サブルーチンに関する情報が含まれ、アプリケーション機能を確認して調整するために使用できます。また、実行時例外に関する情報が記録され、システム管理者に返され、アプリケーションのデバッグに役立ちます。
アプリケーションがオブジェクトからレコードを削除する場合、プラットフォームは MTData の行の IsDeleted フィールドを変更して、その行を削除するようにマークします。このアクションにより、行は事実上、_ごみ箱に配置されます。プラットフォームでは、選択した行をごみ箱から最大 15 日間復元してから、MT_Data から完全に削除できます。プラットフォームでは、組織のストレージ制限に基づいて、組織で管理するレコードの合計数が制限されます。
主従関係に含まれる親レコードが操作で削除されると、プラットフォームは、すべての関連する子レコードを自動的に削除します。ただし、その場合でも、保持されている参照整合性ルールは破られません。たとえば、SalesOrder を削除すると、プラットフォームによって自動的に連動品目に削除がカスケードされます。その後、ごみ箱から親レコードを復元すると、すべての子レコードも自動的に復元されます。
一方、参照関係に含まれる参照先の親レコードを削除すると、プラットフォームによって連動キーがすべて自動的に null に設定されます。その後、親レコードを復元すると、削除操作と復元操作の間に再割り当てされたリレーションを除き、以前にヌル化された参照関係が自動的に復元されます。
ごみ箱には、削除された項目とそのデータが、組織で完全に削除されるか、設定された日数が経過するまで保存されます。それまでは、項目全体とそのすべてのデータを復元できます。
俊敏性は、企業が現代世界で成功するための鍵です。Salesforce Platform の基盤レイヤーにより、ビジネスアプリケーションが新しい課題にすばやく適応できるため、インフラストラクチャではなくビジネスに集中し続けることができます。
インフラストラクチャ(たとえば、基盤サービスやコンピューティングリソース)は、Salesforce Platform の上位レイヤーをサポートする隠れた基盤となるテクノロジーです。Hyperforceは、100%再生可能エネルギーとネットゼロで構築された Salesforce Platform インフラストラクチャであり、コンプライアンス、Trust、拡張性など、お客様の主要な課題を解決します。
複数の地理的な場所で事業を展開する企業は、データ管理の新しく、進化し、変化する規制に準拠する必要があります。Salesforce は、現在 AWS リージョンの可用性に基づいて Hyperforce を導入する国を増やしているため、プラットフォーム アプリケーションとユーザーは、厳格なデータ ストレージまたはデータ保護基準を満たす方法で機密ワークロードを実行できます。たとえば、Hyperforce を利用した*Salesforce の EU(*欧州連合)オペレーティング ゾーンを使用すると、EU の企業はデータを簡単に EU 内に保持できます。
セキュリティ、信頼性、可用性は、すべてのビジネス アプリケーションがエンド ユーザーに Trust の約束を果たすために考慮する必要がある機能以外の要件です。Hyperforce を使用すると、Salesforce Platform で企業は信頼性の高いビジネス アプリケーションを簡単に提供できます。
- セキュリティ — Hyperforce は、保存中および転送中の顧客データをネイティブのエンドツーエンドで暗号化します。Hyperforce の Zero Trust アーキテクチャでは、リソースへの暗黙的なアクセスがないように厳格な ID 検証プロセスが適用されます。Hyperforce は最小権限の原則を使用して、適切なアクセス量で適切な時間だけ業務が承認されるようにします。
- 信頼性 — Hyperforce のすべてのインスタンスでは、複数のクラウド可用性ゾーンと最新のアプローチを使用してインシデント対応時間を短縮し、高可用性と耐障害性に優れたプラットフォームを実現します。
- 可用性 — Hyperforce の最新の CI/CD パイプラインと青/緑のアプリケーション リリースにより、アプリケーションのメンテナンス期間が年に 1 分に短縮されます。
Salesforce は、Sales Cloud や Service Cloud などのアプリケーションの基盤として、個々の企業やサービスプロバイダーがサプライチェーン管理、請求、会計、コマース、コンプライアンス追跡、人材管理、請求処理など、さまざまな使用事例に対応する数百万のビジネスアプリケーションを構築してきた実績あるアプリケーション開発プラットフォームです。プラットフォームの独自のマルチテナントのメタデータ駆動型アーキテクチャは、クラウド専用に設計されており、ミッションクリティカルなインターネット規模のアプリケーションを信頼性と安全性でサポートします。プラットフォーム開発者は、標準ベースの API とネイティブ開発ツールを使用して、アプリケーションのデータモデル (オブジェクトやリレーションを含む)、ビジネスロジック (ワークフローや検証を含む)、他のアプリケーションとのインテグレーションなど、最新の Web またはモバイルアプリケーションのすべてのコンポーネントを簡単に作成できます。
プラットフォームは、その開始以来、Salesforce のエンジニアによってマルチテナント用に最適化されており、変化するビジネスニーズに合わせてプラットフォームアプリケーションを拡張できる機能を備えています。一括データ処理 API、Apex、全文検索エンジン、独自のクエリオプティマイザーなどの不可欠なシステム機能により、開発者の手をほとんど借りずに、連動アプリケーションの効率性と拡張性を高めることができます。
本番アプリケーションの導入に関する Salesforce の管理アプローチにより、プラットフォームに依存するすべてのアプリケーションで優れたパフォーマンス、拡張性、信頼性が保証されます。Salesforce はプラットフォームアプリケーションから運用情報を継続的に監視および収集し、既存および新規アプリケーションにすぐにメリットをもたらす段階的な改善と新しいシステム機能を促進します。
Steve Bobrowski は、2008 年から Salesforce 全体のさまざまな役割を含め、多くの主要なエンタープライズソフトウェア企業で働いてきた成功した起業家であり、テクノロジーリーダーです。現在、Steve は Salesforce の CTO オフィスで、同社のテクノロジーアーキテクチャ戦略を支援しています。
Tom Leddy は、Salesforce のアーキテクトエバンジェリストです。アーキテクトが最高の仕事をできるようにするリソース、ツール、ガイダンスの作成を支援することで、グローバルな Salesforce アーキテクトコミュニティをサポートしています。Twitter で Tom とつながります。