Ogni giorno, centinaia di migliaia di aziende e milioni di utenti gestiscono la propria attività nel cloud utilizzando applicazioni basate su Salesforce Platform. Perché la piattaforma ha tanto successo? Perché puoi Trust per supportare il tuo business? Quali vantaggi esclusivi offre la piattaforma per aziende come la tua?
Questo brief tecnico spiega in che modo Salesforce Platform offre esperienze utente finali affidabili, scalabili e facili da personalizzare utilizzando la sua esclusiva architettura software per il cloud computing. Dopo aver letto questo breve articolo, si comprenderà meglio la tecnologia sottostante che rende Salesforce Platform una scelta interessante per le applicazioni aziendali.
Salesforce Platform è l'esempio più importante di una piattaforma di cloud computing di successo e di un ecosistema correlato di applicazioni. Dall'inizio del millennio, la piattaforma è stata la base abilitante per:
- Molte applicazioni aziendali popolari per casi d'uso comuni come vendite e assistenza clienti
- Applicazioni specifiche del settore per casi d'uso più specializzati come finanza e assistenza sanitaria
- Milioni di applicazioni personalizzate ed estensioni per casi d'uso univoci
In gran parte, Salesforce Platform è così popolare e di successo perché la sua architettura software unica supporta applicazioni facili da creare, utilizzare, personalizzare ed estendere con prestazioni e affidabilità eccezionali. Il cuore dell'architettura software della piattaforma è il design multi-tenant basato sui metadati.
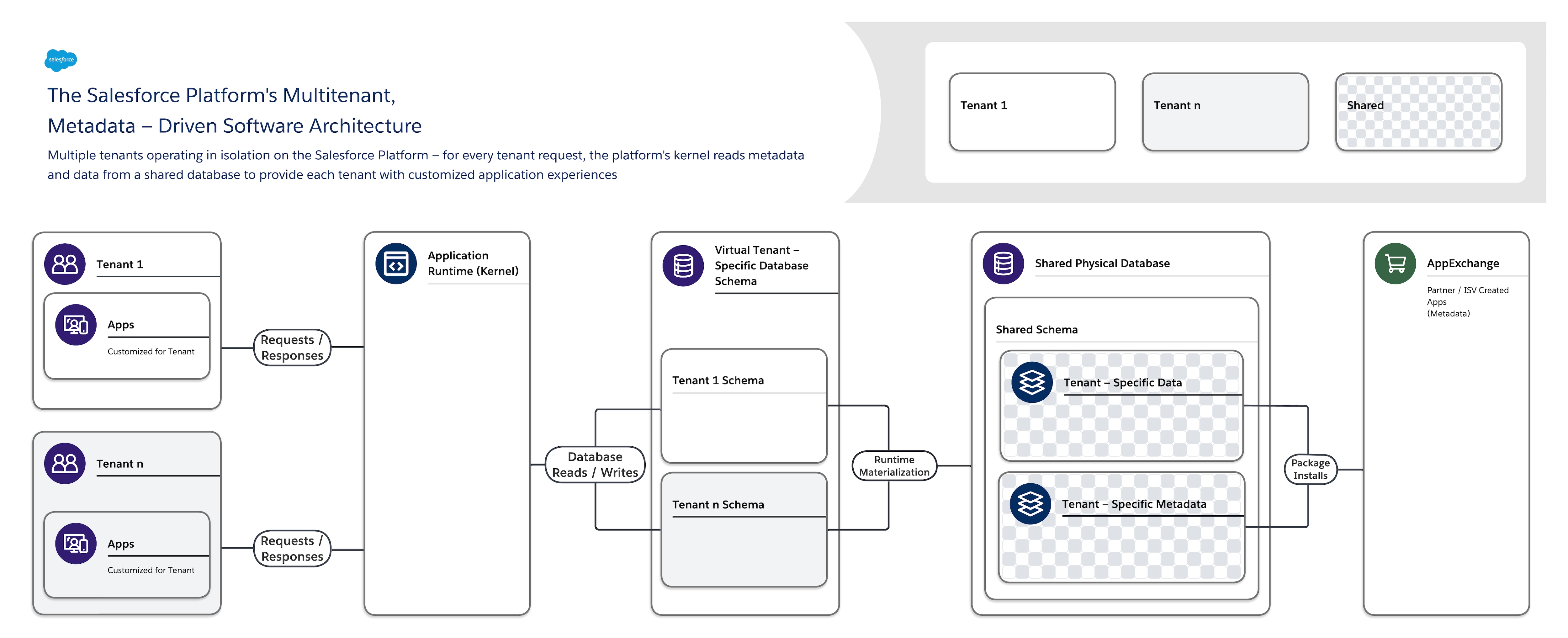
L'architettura software di Salesforce Platform è:
- Multitenant: isola e supporta contemporaneamente le diverse esigenze di molti tenant (organizzazioni, unità operative e così via).
- Basato sui metadati: consente a ogni tenant di personalizzare facilmente e rapidamente le proprie app e esperienze utente utilizzando metadati, dati che descrivono elementi come l'interfaccia utente (interfaccia utente) e la logica aziendale.
Quando si crea un nuovo oggetto applicazione o si scrive del codice utilizzando Salesforce Platform, la piattaforma non crea una tabella effettiva in un database né compila alcun codice. La piattaforma memorizza semplicemente alcuni metadati che può quindi utilizzare in fase di esecuzione per materializzare dinamicamente i componenti dell'applicazione virtuale. La piattaforma garantisce che i metadati di ogni tenant siano privati e facili da aggiornare senza alcun blocco o tempo di inattività richiesto, in modo che ogni tenant possa creare e personalizzare le app in modo isolato. Salesforce Platform utilizza gli stessi metadati per fornire API personalizzate, interfacce RESTful e Web (basate su SOAP) che è possibile utilizzare per integrare le applicazioni con altre applicazioni e processi automatizzati.
Le soluzioni pronte all’uso sono disponibili anche in AppExchange, l’ampio marketplace di app della piattaforma. Creato da un vasto ecosistema di partner affidabili e fornitori di software indipendenti (ISV), un pacchetto AppExchange è costituito da metadati di terze parti che descrivono estensioni di applicazioni gratuite o a pagamento e intere applicazioni che è possibile utilizzare per soddisfare requisiti aziendali specifici.
Per supportare questa architettura altamente personalizzabile ed estendibile, una singola istanza di Salesforce Platform utilizza:
- Un unico database multitenant condiviso con un unico schema che memorizza metadati e dati specifici del tenant.
- Kernel multi-tenant (runtime applicazione) che legge i metadati e i dati per fornire in modo dinamico applicazioni, logica aziendale e API specifiche del tenant per gli utenti di ogni tenant in fase di esecuzione.
Questa netta separazione del kernel gestito da Salesforce dai metadati gestiti dal tenant consente a Salesforce, ai tenant e agli ISV di evolvere in modo indipendente le loro parti del sistema senza interferenze.
Per partire da questa panoramica, le sezioni successive di questo articolo offrono maggiori dettagli sulle funzionalità uniche della piattaforma che derivano da aspetti chiave della sua progettazione, tra cui:
- Livello di dati piattaforma
- Sviluppo di applicazioni piattaforma
- Elaborazione piattaforma interna
- Infrastruttura piattaforma
Insieme, il runtime delle applicazioni e l'innovativo livello di dati di Salesforce Platform isolano in modo sicuro i dati specifici del tenant, le personalizzazioni dello schema e la logica aziendale. A livello generale, lo schema supporta una varietà di casi d'uso:
- Quando si crea o si personalizza un'applicazione, la piattaforma memorizza i metadati correlati in tabelle di database condivise che gestiscono i metadati per tutti i tenant.
- Quando si utilizza un'applicazione per leggere o scrivere dati, la piattaforma memorizza i dati in tabelle di database condivise che conservano i dati per tutti i tenant.
- Dietro le quinte, la piattaforma mantiene anche i metadati interni in una serie di tabelle utilizzate dal kernel per ottimizzare la latenza delle richieste in fase di esecuzione.
Ma come può un singolo database e schema condiviso mantenere privati i dati di ogni tenant? Ogni tenant della piattaforma è noto come organizzazione, in breve organizzazione. Inoltre, ogni record specifico dell'organizzazione nelle tabelle di database condivise ha un OrgID. Quando accede al database, il kernel utilizza questo identificatore univoco per garantire che le attività di ogni organizzazione siano private.

Oggetti specifici dell'organizzazione (tabelle di pensiero nel linguaggio tradizionale dei database relazionali), campi, stored procedure, trigger di database e altro ancora sono tutti costrutti virtuali descritti da metadati che la piattaforma memorizza in alcune tabelle di database note come Universal Data Dictionary (UDD).
- MT_Objects è una tabella di database che memorizza i metadati sugli oggetti definiti per un'applicazione, incluso un identificatore univoco per un oggetto (ObjID), l'organizzazione (OrgID) e il nome assegnato all'oggetto (ObjName).
- La tabella di sistema MT_Fields memorizza i metadati sui campi (colonne) dichiarati per ogni oggetto, incluso un identificatore univoco per un campo (FieldID), l'organizzazione (OrgID), l'oggetto che contiene il campo (ObjID), il nome del campo (FieldName), il tipo di dati del campo, un valore booleano per indicare se il campo richiede l'indicizzazione (IsIndexed) e la posizione del campo nell'oggetto rispetto ad altri campi (FieldNum).
Poiché i metadati sono un ingrediente chiave, la piattaforma deve ottimizzare l'accesso ai metadati; in caso contrario, un accesso frequente ai metadati impedirebbe la scalabilità del servizio. Tenendo presente questo potenziale collo di bottiglia, la piattaforma utilizza cache di metadati massicce e sofisticate per mantenere in memoria i metadati utilizzati più di recente, evitare I/O disco e ricompilazioni di codice che compromettono le prestazioni e migliorare i tempi di risposta delle applicazioni.
La tabella di sistema MT_Data memorizza i dati accessibili alle applicazioni che vengono mappati a tutte le tabelle specifiche dell'organizzazione e ai relativi campi, come definito dai metadati in MT_Objects e MT_Fields. Ogni riga include campi identificativi, ad esempio un identificatore univoco globale (GUID), l'organizzazione titolare della riga (OrgID) e l'identificatore oggetto comprensivo (ObjID). Ogni riga della tabella MT_Data include anche un campo Nome che memorizza un "nome naturale" per i record corrispondenti; ad esempio, un record Account potrebbe utilizzare "Nome account", un record Caso potrebbe utilizzare "Numero caso" e così via.
Value0 ... Le colonne Flex ValueN, note anche come finestre, memorizzano i dati delle applicazioni che vengono mappati alle tabelle e ai campi dichiarati rispettivamente in MT_Objects e MT_Fields. Tutte le colonne Flex utilizzano un tipo di dati stringa di lunghezza variabile in modo da poter memorizzare qualsiasi tipo strutturato di dati dell'applicazione (stringhe, numeri, date e così via). Come illustrato nella figura seguente, non è possibile mappare due campi dello stesso oggetto alla stessa finestra temporale in MT_Data per l'archiviazione; tuttavia, una singola finestra temporale può gestire le informazioni di più campi, a condizione che ogni campo provenga da un oggetto diverso.
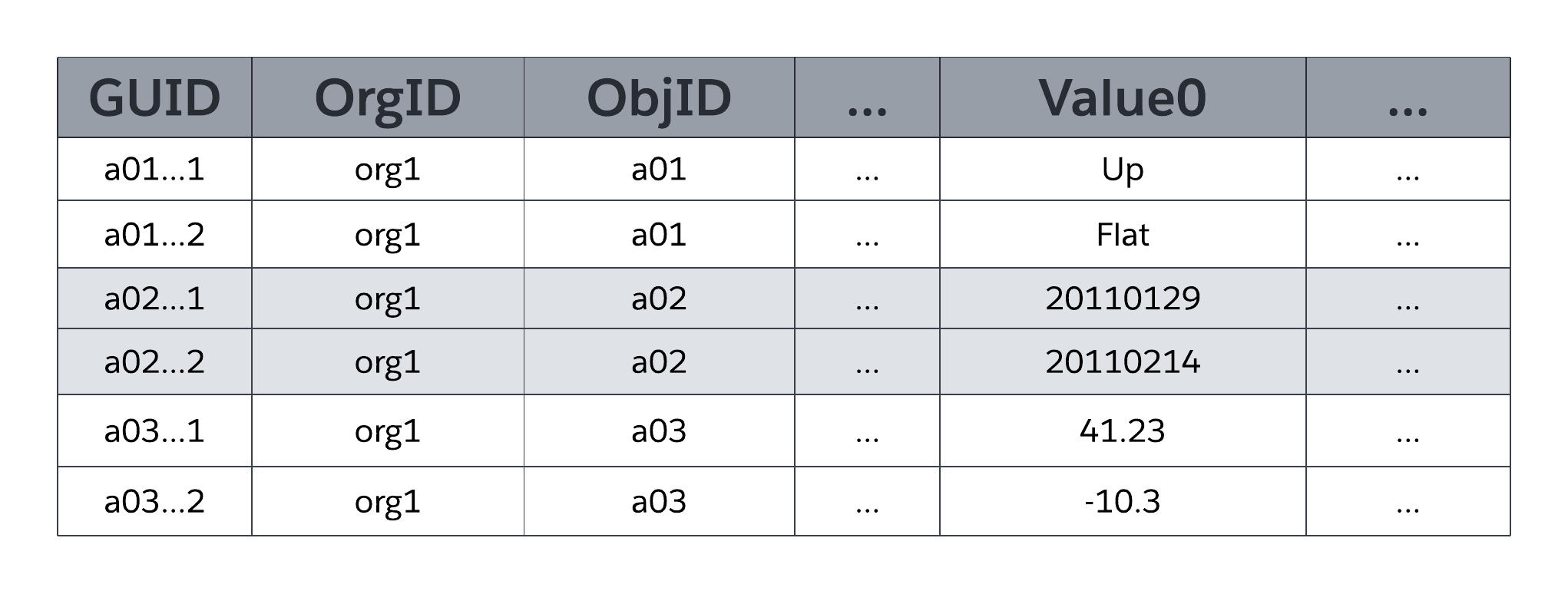
MTFields può utilizzare qualsiasi tipo di dati strutturati standard, ad esempio testo, numero, data e data/ora, nonché tipi di dati strutturati _ricchi di uso speciale, ad esempio elenco di selezione (campo enumerato), numerazione automatica (numero di sequenza incrementato automaticamente generato dal sistema), formula (valore derivato di sola lettura), relazione record principale-record dettaglio (chiave esterna), casella di controllo (booleano), email, URL e altri. MT_Fields può anche essere obbligatorio (non nullo) e avere regole di convalida personalizzate (ad esempio, un campo deve essere maggiore di un altro campo), entrambe applicate dalla piattaforma.
Quando si dichiara o si modifica un oggetto, la piattaforma gestisce una riga di metadati in MT_Objects che definisce l'oggetto. Analogamente, per ogni campo, la piattaforma gestisce una riga in MT_Fields, inclusi i metadati che mappano il campo a una colonna Flex specifica in MT_Data per l'archiviazione dei dati dei campi corrispondenti. Poiché la piattaforma gestisce le definizioni di oggetti e campi come metadati anziché come strutture di database effettive, il sistema può tollerare le attività di manutenzione degli schemi delle applicazioni multitenant online senza bloccare l'attività simultanea di altre organizzazioni e utenti. Per confronto, la ridefinizione delle tabelle online per i sistemi di database relazionali tradizionali richiede in genere blocchi temporanei e spesso processi complessi e laboriosi e tempi di inattività pianificata delle applicazioni.
Come mostra la rappresentazione semplificata di MT_Data nella figura precedente, le colonne Flex sono di tipo dati universale (stringa di lunghezza variabile), il che consente alla piattaforma di condividere una singola colonna Flex tra più campi che utilizzano vari tipi di dati strutturati (stringhe, numeri, date e così via).
La piattaforma memorizza tutti i dati delle colonne Flex utilizzando un formato canonico e utilizza le funzioni di conversione dei tipi di dati del sistema di database sottostanti (ad esempio, TO_NUMBER, TO_DATE, TO_CHAR) in base alle esigenze quando le applicazioni leggono i dati e scrivono i dati nelle colonne Flex.
MTData* contiene anche colonne non visualizzate nella figura precedente. Ad esempio, sono presenti quattro colonne per gestire i dati di controllo, tra cui l'utente che ha creato una riga e la data di creazione della riga, l'utente che ha apportato l'ultima modifica a una riga e la data dell'ultima modifica. MT_Data contiene anche una colonna _IsDeleted* che la piattaforma utilizza per indicare quando una riga è stata eliminata.
La piattaforma supporta anche la dichiarazione dei campi come oggetti di grandi dimensioni per consentire la memorizzazione di campi di testo lungo fino a 32.000 caratteri. Per ogni riga in MTData con un CLOB, la piattaforma memorizza il CLOB fuori riga in una tabella denominata _MT_Clob, che il sistema può unire alle righe corrispondenti in MT_Data in base alle esigenze.
Nota: La piattaforma memorizza anche i CLOB in un formato indicizzato all'esterno del database per ricerche di testo veloce. Per ulteriori informazioni sul motore di ricerca testuale della piattaforma, vedere Ricerche.
La piattaforma indicizza automaticamente vari tipi di campi per offrire prestazioni scalabili.
I sistemi di database tradizionali si basano su indici di database nativi per individuare rapidamente righe specifiche in una tabella di database che contengono campi che corrispondono a una condizione specifica. Tuttavia, non è pratico creare indici di database nativi per le colonne Flex di MTData* poiché la piattaforma utilizza una singola colonna Flex per memorizzare i dati di molti campi con tipi di dati strutturati diversi. La piattaforma gestisce invece un indice di MT_Data copiando in modo sincrono i dati dei campi contrassegnati per l'indicizzazione in una colonna appropriata in una tabella pivot _MT_Indexes*.
MT_Indexes contiene colonne fortemente tipizzate e indicizzate come StringValue, NumValue e DateValue che la piattaforma utilizza per individuare i dati dei campi del tipo di dati corrispondente. Ad esempio, la piattaforma copierebbe un valore stringa in una colonna Flex MT_Data nel campo StringValue in MT_Indexes, un valore data nel campo DateValue e così via. Gli indici sottostanti di MT_Indexes sono indici di database standard non univoci. Quando una query di sistema interna include un parametro di ricerca che fa riferimento a un campo strutturato in un oggetto, il programma di ottimizzazione query personalizzato della piattaforma utilizza MT_Indexes per ottimizzare le operazioni di accesso ai dati associate.
Nota: La piattaforma è in grado di gestire le ricerche in più lingue poiché il sistema utilizza un algoritmo di distinzione tra maiuscole e minuscole che converte i valori di stringa in un formato universale senza distinzione tra maiuscole e minuscole. La colonna StringValue della tabella MT_Indexes memorizza i valori di stringa in questo formato. In fase di esecuzione, l'ottimizzazione delle query crea automaticamente le operazioni di accesso ai dati in modo che l'istruzione SQL ottimizzata filtri in base al StringValue con maiuscole e minuscole corrispondente al valore letterale fornito nella richiesta di ricerca.
La piattaforma consente di indicare quando un campo di un oggetto deve contenere valori univoci (con distinzione tra maiuscole e minuscole o senza distinzione tra maiuscole e minuscole). Considerando la disposizione di MT_Data e l'utilizzo condiviso delle colonne Valore per i dati dei campi, non è pratico creare indici di database univoci per l'oggetto. (Questa situazione è simile a quella descritta nella sezione precedente per gli indici non univoci.)
Per supportare l'univocità per i campi personalizzati, la piattaforma utilizza la tabella pivot MT_Unique_Indexes; questa tabella è molto simile alla tabella MT_Indexes, tranne per il fatto che gli indici di database nativi sottostanti di MT_Unique_Indexes impongono l'univocità. Quando un'applicazione tenta di inserire un valore duplicato in un campo che richiede univocità o quando un amministratore tenta di imporre univocità su un campo esistente che contiene valori duplicati, la piattaforma restituisce un messaggio di errore appropriato all'applicazione.
In rare circostanze, il motore di ricerca esterno della piattaforma (spiegato in Ricerche) può diventare sovraccarico o non disponibile in altro modo e potrebbe non essere in grado di rispondere a una richiesta di ricerca in modo tempestivo. Anziché restituire un errore deludente all'utente finale, la piattaforma ricorre a un meccanismo di ricerca secondario per fornire risultati di ricerca ragionevoli.
Una ricerca di fall-back viene implementata come query di database diretta con condizioni di ricerca che fanno riferimento al campo Nome dei record di destinazione. Per ottimizzare le ricerche di oggetti globali (ricerche che si estendono su tabelle) senza dover eseguire query di unione potenzialmente costose, la piattaforma gestisce una tabella pivot MT_Fallback_Indexes che registra il Nome di tutti i record. Gli aggiornamenti di MT_Fallback_Indexes avvengono in modo sincrono man mano che le transazioni modificano i record in modo che le ricerche di fall-back abbiano sempre accesso alle informazioni più aggiornate del database.
La tabella MT_Name_Denorm è una tabella di dati snella che memorizza ObjID e Name di ogni record in MT_Data. Quando un'applicazione deve fornire un elenco dei record coinvolti in una relazione controllante/controllato, la piattaforma utilizza la tabella MT_Name_Denorm per eseguire una query relativamente semplice che recupera il Nome di ogni record a cui si fa riferimento per la visualizzazione nell'app, ad esempio come parte di un collegamento ipertestuale.
La piattaforma fornisce tipi di dati di relazione che un'organizzazione può utilizzare per dichiarare le relazioni (integrità referenziale) tra le tabelle. Quando si dichiara il campo di un oggetto con un tipo di relazione, la piattaforma mappa il campo a un campo Valore in MT_Data e quindi utilizza questo campo per memorizzare l'ObjID di un oggetto correlato.
Per ottimizzare le operazioni di join, la piattaforma gestisce una tabella pivot MT_Relationships. Questa tabella di sistema ha due indici compositi univoci del database sottostanti che consentono di attraversare gli oggetti in modo efficiente in entrambe le direzioni, in base alle esigenze.
Con pochi clic del mouse, la piattaforma fornisce il tracciamento della cronologia per qualsiasi campo. Quando un'organizzazione abilita il controllo per un campo specifico, il sistema registra in modo asincrono le informazioni sulle modifiche apportate al campo (vecchi e nuovi valori, data di modifica e così via) utilizzando una tabella pivot interna come itinerario di controllo.
Tutti i dati della piattaforma, i metadati e le strutture delle tabelle pivot, inclusi gli indici del database sottostanti, sono fisicamente partizionati da OrgID utilizzando meccanismi di partizionamento del database nativi. Il partizionamento dei dati è una tecnica collaudata fornita dai sistemi di database per suddividere fisicamente strutture di dati logiche di grandi dimensioni in parti più piccole e gestibili. Il partizionamento può anche contribuire a migliorare le prestazioni, la scalabilità e la disponibilità di un sistema di database di grandi dimensioni, ad esempio un ambiente multi-tenant. Per definizione, ogni query piattaforma riguarda le informazioni di un'organizzazione specifica, quindi l'ottimizzazione delle query deve solo considerare l'accesso alle partizioni di dati che contengono i dati di un'organizzazione, anziché un'intera tabella o indice. Questa ottimizzazione comune è a volte chiamata "potatura delle partizioni".
Questa sezione descrive come gli sviluppatori di app possono creare i metadati sottostanti di uno schema e quindi creare app che gestiscono i dati. I metadati e i dati sono memorizzati nel livello di dati della piattaforma descritto nella sezione precedente.
Gli sviluppatori possono creare componenti di applicazioni lato server in modo dichiarativo utilizzando l'ambiente di sviluppo basato su browser della piattaforma, comunemente chiamato schermate di impostazione della piattaforma. L'interfaccia utente "point-and-click" di Imposta supporta tutti gli aspetti del processo di creazione dello schema dell'applicazione, ad esempio la creazione del modello di dati di un'applicazione (inclusi gli oggetti e i relativi campi, nonché le relazioni), il modello di protezione e condivisione (inclusi utenti, profili e gerarchie dei ruoli), l'interfaccia utente (inclusi layout schermata, moduli di immissione dati e rapporti), la logica dichiarativa (flussi di lavoro) e la logica programmatica (stored procedure e trigger). Ad esempio, Flusso Salesforce semplifica l'automazione di un'ampia gamma di casi d'uso. L'interfaccia utente di Flow Builder di Imposta, illustrata di seguito, consente di progettare e implementare graficamente flussi di lavoro che interagiscono con gli utenti o che vengono avviati automaticamente in base a una pianificazione o quando vengono attivati da un evento.
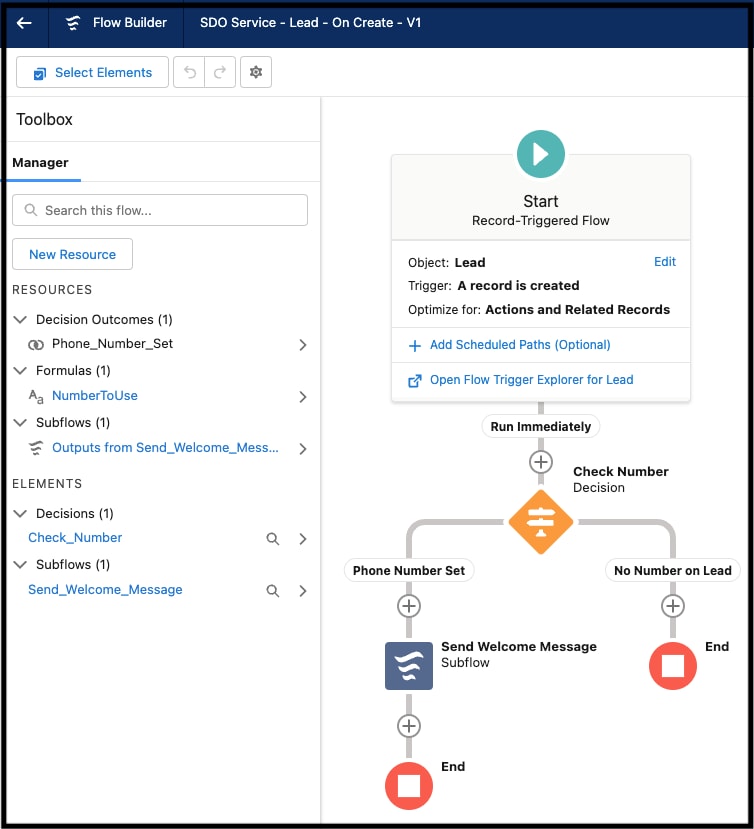
Le schermate di impostazione semplificano lo sviluppo e la personalizzazione di applicazioni senza (o pochissimo) codice. Ad esempio:
- Le interfacce utente native della piattaforma sono facili da creare senza codice. Dietro le quinte, un'interfaccia utente nativa dell'app supporta tutte le normali operazioni di accesso ai dati, incluse query, inserimenti, aggiornamenti ed eliminazioni. Ogni operazione di manipolazione dei dati eseguita dalle applicazioni native della piattaforma può modificare un oggetto alla volta e confermare automaticamente ogni modifica in una transazione separata.
- Quando si definisce un campo di testo per un oggetto che contiene dati sensibili, è possibile configurare facilmente il campo in modo che la piattaforma crittografi i dati corrispondenti e, se si desidera, utilizzi una maschera di input per nascondere le informazioni sullo schermo da occhi indiscreti.
- Una regola di convalida dichiarativa è un modo semplice per un'organizzazione di applicare una regola di integrità del dominio senza alcuna programmazione. Ad esempio, è possibile dichiarare una regola di convalida che fa in modo che il campo Quantità di un oggetto LineItem sia sempre maggiore di zero.
- Un campo formula è una funzione dichiarativa della piattaforma che semplifica l'aggiunta di un campo calcolato a un oggetto. Ad esempio, è possibile aggiungere un campo all'oggetto LineItem per calcolare un valore LineTotal.
- Un campo di riepilogo di roll-up è un campo oggetti incrociato che semplifica l'aggregazione delle informazioni dei campi secondari in un oggetto controllante. Ad esempio, è possibile creare un campo di riepilogo OrderTotal nell'oggetto SalesOrder basato sul campo LineTotal dell'oggetto LineItem.
Nota: Internamente, la piattaforma implementa i campi formula e riepilogo di roll-up utilizzando funzioni native del database e ricalcola in modo efficiente i valori in modo sincrono nell'ambito delle transazioni in corso.
La piattaforma fornisce diverse API basate su standard aperte che gli sviluppatori possono utilizzare per creare app. Sia le API RESTful che Web (basate su SOAP) forniscono l'accesso alle numerose funzionalità della piattaforma. Utilizzando queste varie API, un'applicazione può:
- Manipolare i metadati che descrivono uno schema dell'applicazione
- Creazione, lettura, aggiornamento ed eliminazione di dati aziendali (CRUD)
- Caricare in blocco o eseguire query su un numero elevato di record in modo asincrono
- Esporre uno stream di dati quasi in tempo reale in modo sicuro e scalabile
Le app possono utilizzare il linguaggio di query a oggetti Salesforce per creare query di database semplici ma efficaci. Analogamente al comando SELECT nel linguaggio di query strutturato (SQL), SOQL consente di specificare l'oggetto di origine, un elenco di campi da recuperare e le condizioni per la selezione delle righe nell'oggetto di origine. Ad esempio, la query SOQL seguente restituisce il valore del campo Id e Name per tutti i record Account con Nome uguale alla stringa 'Acme'.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
La piattaforma include anche un motore di ricerca multilingue full-text che indicizza automaticamente tutti i campi correlati al testo. Le app possono utilizzare questo motore di ricerca preintegrato utilizzando Salesforce Object Search Language per eseguire ricerche di testo. A differenza di SOQL, che può eseguire query su un solo oggetto alla volta, SOSL consente di cercare contemporaneamente più oggetti nei campi di testo, email e telefono. Ad esempio, la seguente istruzione SOSL cerca i record negli oggetti Lead e Referente che contengono la stringa 'Joe Smith' nel campo nome e restituisce il campo nome e numero di telefono di ogni record trovato.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, simile a Java per molti aspetti, è un potente linguaggio di sviluppo che gli sviluppatori possono utilizzare per centralizzare la logica procedurale nello schema delle loro applicazioni. Apex Code può dichiarare variabili e costanti del programma, eseguire istruzioni di controllo del flusso tradizionali (if-else, loop e così via), eseguire operazioni di manipolazione dei dati (inserimento, aggiornamento, inserimento con aggiornamento, eliminazione) ed eseguire operazioni di controllo delle transazioni (setSavepoint, rollback).
È possibile memorizzare programmi Apex nella piattaforma utilizzando due forme diverse: come classe Apex denominata con metodi (simili alle stored procedure nel linguaggio tradizionale dei database) che le applicazioni eseguono quando necessario o come trigger di database che viene eseguito automaticamente prima o dopo che si sia verificato un evento di manipolazione del database specifico. In entrambi i casi, la piattaforma compila Apex Code e lo archivia come metadati nell'UDD. La prima volta che un'organizzazione esegue un programma Apex, l'interprete di runtime della piattaforma carica la versione compilata del programma in una cache MRU (utilizzata più di recente) per l'organizzazione. In seguito, quando un utente della stessa organizzazione deve utilizzare la stessa routine, la piattaforma può risparmiare memoria ed evitare il sovraccarico di ricompilazione del programma condividendo il programma pronto per l'esecuzione già presente in memoria.
Con l'aggiunta di una semplice parola chiave qua e là, gli sviluppatori possono utilizzare Apex per supportare molti requisiti specifici delle applicazioni. Ad esempio, gli sviluppatori possono esporre un metodo come chiamata API RESTful o basata su SOAP personalizzata, renderlo pianificabile in modo asincrono o configurarlo per elaborare un'operazione di grandi dimensioni in batch.
Apex è molto più di un “semplice linguaggio procedurale”. È un componente piattaforma integrale che consente al sistema di offrire una multitenancy affidabile. Ad esempio, la piattaforma convalida automaticamente tutte le istruzioni SOQL e SOSL incorporate all'interno di una classe per evitare codice che altrimenti non riuscirebbe in fase di esecuzione. La piattaforma mantiene quindi le informazioni sulle dipendenze degli oggetti corrispondenti per le classi valide e le utilizza per impedire modifiche ai metadati che altrimenti interromperebbero il codice dipendente.
Molte classi Apex standard e metodi statici di sistema offrono interfacce semplici alle funzioni di sistema sottostanti. Ad esempio, i metodi DML statici del sistema come insert, update ed delete hanno un semplice parametro booleano che gli sviluppatori possono utilizzare per indicare l'opzione di elaborazione in blocco desiderata (tutto o niente o salvataggio parziale); questi metodi restituiscono anche un oggetto risultato che la routine di chiamata può leggere per determinare quali record sono stati elaborati in modo non corretto e perché. Altri esempi di legami diretti tra Apex e le funzioni della piattaforma sono le classi email incorporate e le classi XmlStream.
In gran parte, la piattaforma funziona e si adatta bene perché Salesforce l'ha creata tenendo presenti due principi importanti:
- Offrire funzionalità di piattaforma di base efficienti e su larga scala.
- Aiutare gli sviluppatori a fare tutto nel modo più efficiente possibile.
La piattaforma incorpora questi principi nelle architetture di elaborazione esclusive della piattaforma, tra cui:
- Query
- Ricerche
- Operazioni in blocco
- Modifica dello schema
- Isolamento multi-tenant
- Il cestino
La maggior parte dei sistemi di database moderni determina piani di esecuzione delle query ottimali utilizzando un ottimizzatore delle query basato sui costi che considera le statistiche pertinenti sui dati delle tabelle di destinazione e degli indici. Tuttavia, le statistiche di ottimizzazione convenzionali basate sui costi sono progettate per le applicazioni a tenant singolo e non tengono conto delle caratteristiche di accesso ai dati di un determinato utente che esegue una query in un ambiente multi-tenant. Ad esempio, una determinata query destinata a un oggetto con un volume elevato di dati molto probabilmente verrebbe eseguita in modo più efficiente utilizzando piani di esecuzione diversi per gli utenti con alta visibilità (un responsabile che può visualizzare tutte le righe) rispetto agli utenti con bassa visibilità (gli addetti alle vendite che possono visualizzare solo le righe correlate a se stessi).
Per fornire statistiche sufficienti per determinare i piani di esecuzione delle query ottimali in un sistema multi-tenant, la piattaforma gestisce una serie completa di statistiche di ottimizzazione (a livello di tenant, gruppo e utente) per gli oggetti di ogni organizzazione. Le statistiche riflettono il numero di righe a cui una determinata query può potenzialmente accedere, considerando attentamente le statistiche complessive sugli oggetti specifiche dell'organizzazione (ad esempio, il numero totale di righe di cui l'organizzazione è titolare nel suo complesso) e le statistiche più granulari (ad esempio, il numero di righe a cui un gruppo di privilegi o un utente finale specifico può potenzialmente accedere).
La piattaforma gestisce anche altri tipi di statistiche che si rivelano utili con query specifiche. Ad esempio, la piattaforma gestisce statistiche per tutti gli indici personalizzati per rivelare il numero totale di valori non nulli e univoci nel campo corrispondente e istogrammi per i campi elenco di selezione che rivelano la cardinalità di ogni valore elenco.
Quando le statistiche esistenti non sono disponibili o non sono considerate utili, l'ottimizzazione della piattaforma utilizza diverse strategie per creare query ragionevolmente ottimali. Ad esempio, quando una query filtra in base al campo Nome di un oggetto, l'ottimizzazione può utilizzare la tabella MT_Fallback_Indexes per trovare in modo efficiente le righe richieste. In altri scenari, l'ottimizzazione genererà in modo dinamico le statistiche mancanti in fase di esecuzione.
Utilizzato in combinazione con le statistiche di ottimizzazione, l'ottimizzazione della piattaforma si basa anche sulle tabelle relative alla sicurezza interna (Gruppi, Membri, GroupBlowout e CustomShare) che conservano le informazioni sui domini di sicurezza degli utenti di un'organizzazione, incluse le appartenenze ai gruppi di un determinato utente e i diritti di accesso personalizzati per oggetti e righe. Tali informazioni sono preziose per determinare la selettività dei filtri di query per utente. Vedere il Platform Developer Basics Trailhead per ulteriori informazioni sul modello di sicurezza incorporato della piattaforma.
Il diagramma di flusso nella figura seguente illustra ciò che accade quando la piattaforma elabora una richiesta di dati che si trova in una delle tabelle heap di grandi dimensioni come MT_Data. La richiesta può provenire da qualsiasi numero di fonti, ad esempio una chiamata API o una stored procedure. Innanzitutto, la piattaforma esegue delle "pre-query" che considerano le statistiche sensibili al multi-tenant. Quindi, in base ai risultati restituiti dalle pre-query, il servizio crea una query di database sottostante ottimale per l'esecuzione nell'impostazione specifica.
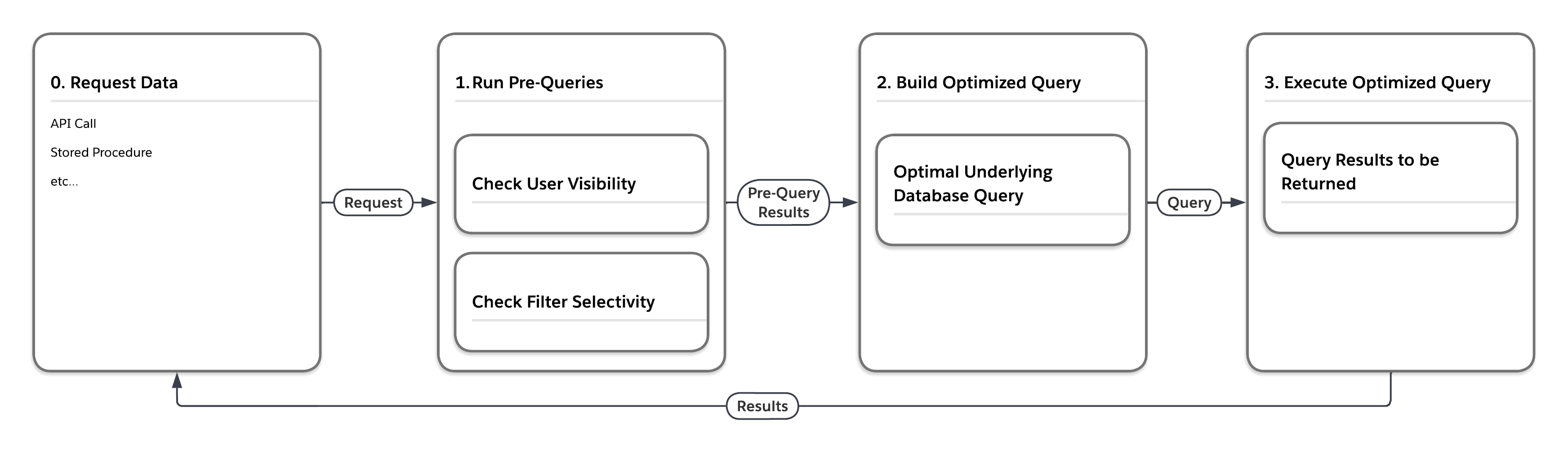
Come indicato nella tabella seguente, la piattaforma può eseguire la stessa query in quattro modi diversi, a seconda dell'utente che invia la query e della selettività delle condizioni di filtro della query.
| Misure della selettività pre-query | Scrittura della query finale di accesso al database, forzando... | |
| Utente | Filtro | |
| Basso | Basso | ... loop nidificati join, drive utilizzando la visualizzazione delle righe che l'utente può vedere |
| Basso | Alto | ... utilizzo dell'indice correlato al filtro |
| Alto | Basso | ... join hash ordinato, drive con MT_DATA |
| Alto | Alto | ... utilizzo del filtro correlato all'indice |
Gli utenti si aspettano che una funzionalità di ricerca interattiva esegua la scansione di tutto o di un ambito selezionato del database di un'applicazione e restituisca risultati classificati con tempi di risposta inferiori al secondo. Per fornire questa funzionalità alle applicazioni piattaforma, la piattaforma utilizza un motore di ricerca separato dal motore di transazione. Quando si aggiornano i record, il motore di transazione aggiorna il database centrale e inoltra i dati correlati al motore di ricerca per l'indicizzazione. Quando si cercano record, il motore di ricerca utilizza i propri indici per elaborare rapidamente la query e restituisce risultati classificati con link a record di database correlati.
Man mano che le applicazioni aggiornano i dati nei campi di testo (CLOB, Nome e così via), un pool di processi in background chiamati server di indicizzazione è responsabile dell'aggiornamento asincrono degli indici corrispondenti, che il motore di ricerca gestisce all'esterno del motore di transazione principale. Per ottimizzare il processo di indicizzazione, la piattaforma copia in modo sincrono blocchi di dati di testo modificati in una tabella interna "da indicizzare" durante la conferma delle transazioni, fornendo così una fonte di dati relativamente piccola che riduce al minimo la quantità di dati che i server di indicizzazione devono leggere dal disco. Il motore di ricerca gestisce automaticamente indici separati per ogni organizzazione.
A seconda del carico e dell'utilizzo correnti dei server di indicizzazione, gli aggiornamenti degli indici di testo possono essere in ritardo rispetto alle transazioni effettive. Per evitare risultati di ricerca imprevisti provenienti da indici non aggiornati, la piattaforma mantiene anche una cache MRU di righe aggiornate di recente che il sistema considera quando materializza i risultati di ricerca a testo pieno. La piattaforma gestisce le cache MRU per utente e per organizzazione per supportare in modo efficiente i possibili ambiti di ricerca.
Il motore di ricerca della piattaforma ottimizza la classificazione dei record all'interno dei risultati di ricerca utilizzando diversi metodi. Ad esempio, il sistema considera il dominio di sicurezza dell'utente che esegue una ricerca e inserisce un peso maggiore nelle righe a cui l'utente corrente può accedere. Il sistema può anche considerare la cronologia delle modifiche di una determinata riga e classificare le righe aggiornate più attivamente prima di quelle relativamente statiche. L'utente può scegliere di ponderare i risultati della ricerca in base alle proprie esigenze, ad esempio ponendo maggiore enfasi sulle righe modificate di recente.
Le applicazioni ad alta intensità di transazioni generano meno sovraccarico e offrono prestazioni molto migliori quando combinano ed eseguono operazioni ripetitive in blocco. Ad esempio, è possibile contrapporre due modi in cui un'applicazione potrebbe caricare molte nuove righe. Un approccio inefficiente sarebbe quello di utilizzare una routine con un loop che inserisce singole righe, effettuando una chiamata API dopo l'altra per ogni inserimento di riga. Un approccio molto più efficiente sarebbe quello di creare una matrice di righe e fare in modo che la routine le inserisca tutte con una singola chiamata API.
L'elaborazione in blocco efficiente con la piattaforma è semplice per gli sviluppatori perché è integrata nelle chiamate API. Internamente, la piattaforma elabora anche in blocco tutte le fasi interne correlate a un'operazione in blocco esplicita.
Il motore di elaborazione in blocco della piattaforma tiene automaticamente conto dei guasti isolati riscontrati durante qualsiasi fase del processo. Quando un'operazione in blocco si avvia in modalità di salvataggio parziale, il motore identifica uno stato di avvio noto e quindi tenta di eseguire ogni fase del processo (convalida in blocco dei dati sul campo, pre-attivazioni in blocco, record di salvataggio in blocco e così via). Se il motore rileva errori durante una qualsiasi fase, ritira le operazioni offensive e tutti gli effetti collaterali, rimuove le righe responsabili dei guasti e continua tentando di elaborare in blocco il sottoinsieme di righe rimanente. Questo processo si ripete in ogni fase successiva finché il motore non conferma un sottoinsieme di righe senza errori. L'applicazione può esaminare un oggetto reso per identificare le righe non riuscite e le eccezioni che hanno generato.
Nota: A discrezione dell'utente, è disponibile una modalità "tutto o niente" per le operazioni in blocco. Inoltre, l'esecuzione dei trigger durante un'operazione in blocco è soggetta a governor interni che limitano la quantità di lavoro.
Alcuni tipi di modifiche alla definizione di un oggetto richiedono più del semplice aggiornamento dei metadati UDD. In questi casi, la piattaforma utilizza meccanismi efficienti che consentono di ridurre l'impatto complessivo sulle prestazioni del servizio di database cloud in generale.
Ad esempio, considerare ciò che accade dietro le quinte quando si modifica il tipo di dati di una colonna da elenco di selezione a testo. La piattaforma alloca innanzitutto una nuova finestra temporale per i dati della colonna, copia in blocco le etichette degli elenchi di selezione associate ai valori correnti e quindi aggiorna i metadati della colonna in modo che punti alla nuova finestra temporale. Mentre tutto questo accade, l'accesso ai dati è normale e le applicazioni continuano a funzionare senza alcun impatto significativo.
Come altro esempio, considerare cosa accade quando si aggiunge un campo di riepilogo di roll-up a un oggetto. In questo caso, la piattaforma calcola in modo asincrono i riepiloghi iniziali in background utilizzando un'efficiente operazione in blocco. Durante il calcolo dello sfondo, gli utenti che visualizzano il nuovo campo ricevono un'indicazione che indica che la piattaforma sta attualmente calcolando il valore del campo.
Per impedire la monopolizzazione dannosa o involontaria delle risorse di sistema multi-tenant condivise, la piattaforma dispone di un ampio insieme di governor e limiti delle risorse associati all'esecuzione di codice piattaforma. Ad esempio, la piattaforma monitora attentamente l'esecuzione di uno script di codice e limita il tempo CPU che può utilizzare, la memoria che può consumare, il numero di query e istruzioni DML che può eseguire, il numero di calcoli matematici che può eseguire, il numero di chiamate ai servizi Web in uscita che può effettuare e molto altro ancora. Le singole query che l'ottimizzazione della piattaforma considera troppo costose da eseguire inviano un'eccezione in fase di esecuzione al chiamante. Sebbene tali limiti possano sembrare alquanto restrittivi, sono necessari per proteggere la scalabilità e le prestazioni complessive del sistema di database condiviso per tutte le applicazioni interessate. A lungo termine, queste misure aiutano a promuovere migliori tecniche di codifica tra gli sviluppatori e a creare un'esperienza migliore per tutti coloro che utilizzano la piattaforma. Ad esempio, uno sviluppatore che tenta inizialmente di codificare un loop che aggiorna in modo inefficiente un migliaio di righe una alla volta riceverà eccezioni in fase di esecuzione a causa dei limiti delle risorse e quindi inizierà a utilizzare le efficienti chiamate API di elaborazione in blocco della piattaforma.
Per evitare ulteriormente potenziali problemi di sistema introdotti da applicazioni scritte in modo non corretto, la distribuzione di una nuova applicazione di produzione è un processo gestito rigorosamente. Prima che un'organizzazione possa passare una nuova applicazione dallo stato di sviluppo a quello di produzione, Salesforce richiede test di unità che convalidino la funzionalità delle routine del codice piattaforma dell'applicazione. I test di unità inviati devono coprire non meno del 75% del codice sorgente dell'applicazione.
Salesforce esegue i test di unità inviati nell'ambiente di sviluppo Sandbox della piattaforma per determinare se il codice dell'applicazione influirà negativamente sulle prestazioni e sulla scalabilità della popolazione multi-tenant in generale. I risultati di un singolo test di unità indicano informazioni di base, ad esempio il numero totale di righe eseguite, nonché informazioni specifiche sul codice non eseguito dal test.
Dopo che il codice di un'applicazione è stato certificato per la produzione da Salesforce, il processo di distribuzione dell'applicazione consiste in una singola transazione che copia tutti i metadati dell'applicazione in un'istanza della piattaforma di produzione ed esegue nuovamente i test di unità corrispondenti. Se una qualsiasi parte del processo non riesce, la piattaforma ritira semplicemente la transazione e restituisce le eccezioni per aiutare a risolvere il problema.
Nota: Salesforce riesegue i test di unità per ogni applicazione con ogni rilascio di sviluppo della piattaforma per scoprire in modo proattivo se le nuove funzioni di sistema e le ottimizzazioni interrompono le applicazioni esistenti.
Dopo che un'applicazione di produzione è stata resa disponibile, il profiler delle prestazioni integrato nella piattaforma la analizza automaticamente e fornisce un feedback associato agli amministratori. I rapporti di analisi delle prestazioni includono informazioni su query lente, manipolazioni dei dati e subroutine che è possibile esaminare e utilizzare per ottimizzare le funzionalità dell'applicazione. Il sistema inoltre registra e restituisce informazioni sulle eccezioni in fase di esecuzione agli amministratori per aiutarli a eseguire il debug delle loro applicazioni.
Quando un'app elimina un record da un oggetto, la piattaforma contrassegna semplicemente la riga per l'eliminazione modificando il campo IsDeleted della riga in MTData*. Questa azione posiziona efficacemente la riga nel cosiddetto _Cestino*. La piattaforma consente di ripristinare le righe selezionate dal Cestino per un massimo di 15 giorni prima di rimuoverle definitivamente da MT_Data. La piattaforma limita il numero totale di record che mantiene per un'organizzazione in base ai limiti di memoria per quell'organizzazione.
Quando un'operazione elimina un record controllante coinvolto in una relazione record principale-record dettaglio, la piattaforma elimina automaticamente tutti i record secondari correlati, a condizione che ciò non infranga alcuna regola di integrità referenziale. Ad esempio, quando si elimina un SalesOrder, la piattaforma inserisce automaticamente l'eliminazione in LineItems dipendenti. Se in seguito si ripristina un record controllante dal Cestino, il sistema ripristina automaticamente anche tutti i record secondari.
Al contrario, quando si elimina un record controllante con riferimenti coinvolto in una relazione di ricerca, la piattaforma imposta automaticamente tutte le chiavi dipendenti su null. Se successivamente si ripristina il record controllante, la piattaforma ripristina automaticamente le relazioni di ricerca annullate in precedenza, ad eccezione delle relazioni riassegnate tra le operazioni di eliminazione e ripristino.
Il Cestino memorizza anche i campi eliminati e i relativi dati finché un'organizzazione non li elimina in modo definitivo o finché non è trascorso un determinato numero di giorni, a seconda di quale evento si verifica per primo. Fino a quel momento, l'intero campo e tutti i relativi dati sono disponibili per il ripristino.
L'agilità è fondamentale per il successo delle aziende nel nostro mondo moderno. I livelli sottostanti di Salesforce Platform consentono alle applicazioni aziendali di adattarsi rapidamente alle nuove sfide, in modo da poter continuare a concentrarsi sul business anziché sull'infrastruttura.
L'infrastruttura (ad esempio, i servizi di base e le risorse di calcolo) è nascosta e la tecnologia sottostante supporta i livelli superiori in Salesforce Platform. Hyperforce è l'infrastruttura Salesforce Platform, basata al 100% su energia rinnovabile e net-zero, che risolve le principali sfide dei clienti, tra cui conformità, Trust e scalabilità.
Le aziende che operano in più aree geografiche devono rispettare i nuovi regolamenti in evoluzione e variabili per la gestione dei dati. Poiché Salesforce sta distribuendo Hyperforce in un numero crescente di paesi, attualmente in base alla disponibilità nella regione AWS, le applicazioni piattaforma e gli utenti possono eseguire i loro carichi di lavoro sensibili in modo da soddisfare rigidi standard di archiviazione e protezione dei dati. Ad esempio, con la zona operativa Hyperforce, le aziende dell’UE possono facilmente conservare i propri dati nell’UE.
Sicurezza, affidabilità e disponibilità sono requisiti non funzionali che ogni applicazione aziendale deve considerare per mantenere la promessa di Trust agli utenti finali. Con Hyperforce, Salesforce Platform consente alle aziende di fornire facilmente applicazioni aziendali affidabili.
- Sicurezza: Hyperforce dispone di una crittografia end-to-end nativa dei dati dei clienti a riposo e in transito. L'architettura Zero Trust di Hyperforce impone un rigoroso processo di verifica dell'identità che garantisce che non vi sia alcun accesso implicito alle risorse. E Hyperforce usa il principio dei privilegi minimi, assicurando che le operazioni vengano approvate per la giusta quantità di tempo con la giusta quantità di accesso.
- Affidabilità: ogni istanza di Hyperforce utilizza più zone di disponibilità cloud e approcci modernizzati che velocizzano la risposta all'incidenza per offrire una piattaforma altamente disponibile e resiliente.
- Disponibilità: le moderne pipeline CI/CD di Hyperforce e i rilasci di applicazioni blu/verdi riducono i periodi di manutenzione delle applicazioni a un solo minuto all'anno.
Salesforce è la base per app come Sales Cloud e Service Cloud, una piattaforma di sviluppo di applicazioni collaudata su cui le singole aziende e i fornitori di servizi hanno creato milioni di applicazioni aziendali per diversi casi d'uso, tra cui gestione della supply chain, fatturazione, contabilità, commercio, monitoraggio della conformità, gestione delle risorse umane ed elaborazione delle richieste. L'architettura unica, multi-tenant e basata sui metadati della piattaforma è progettata specificamente per il cloud e supporta in modo affidabile e sicuro le applicazioni mission-critical su scala Internet. Utilizzando API basate su standard e strumenti di sviluppo nativi, gli sviluppatori di piattaforme possono creare facilmente tutti i componenti di un'applicazione Web o mobile moderna, inclusi il modello di dati dell'applicazione (inclusi oggetti e relazioni), la logica aziendale (inclusi flussi di lavoro e convalide), le integrazioni con altre applicazioni e altro ancora.
Fin dalla sua istituzione, la piattaforma è stata ottimizzata dai tecnici Salesforce per la multitenancy, con funzionalità che consentono alle applicazioni della piattaforma di scalare per soddisfare le esigenze aziendali in continua evoluzione. Le funzioni di sistema integrate, come l'API di elaborazione dati in blocco, Apex, un motore di ricerca full-text e un ottimizzatore di query esclusivo, contribuiscono a rendere le applicazioni dipendenti altamente efficienti e scalabili con uno sforzo minimo o nullo da parte degli sviluppatori.
L'approccio gestito di Salesforce per la distribuzione delle applicazioni di produzione garantisce prestazioni, scalabilità e affidabilità eccellenti per tutte le applicazioni che si basano sulla piattaforma. Salesforce monitora e raccoglie continuamente informazioni operative dalle applicazioni piattaforma per favorire miglioramenti incrementali e nuove funzionalità di sistema che apportano vantaggi immediati alle applicazioni esistenti e nuove.
Steve Bobrowski è un imprenditore di successo e leader tecnologico che ha lavorato per molte aziende leader nel software aziendale, inclusi vari ruoli in Salesforce dal 2008. Oggi, Steve lavora nell'ufficio del CTO di Salesforce per aiutare con le strategie dell'architettura tecnologica dell'azienda.
Tom Leddy è un Architect Evangelist di Salesforce. Supporta la comunità globale di architetti Salesforce contribuendo a creare risorse, strumenti e indicazioni che consentono agli architetti di svolgere al meglio il loro lavoro. Connettiti con Tom su Twitter.