Chaque jour, des centaines de milliers d'entreprises et des millions d'utilisateurs exploitent leur activité dans le cloud en utilisant des applications pilotées par Salesforce Platform. Pourquoi la plate-forme est-elle si réussie ? Pourquoi pouvez-vous lui Trust pour soutenir votre entreprise? Quels avantages uniques la plate-forme offre-t-elle aux entreprises comme la vôtre ?
Ce brief technique explique comment Salesforce Platform offre des expériences utilisateur fiables, évolutives et faciles à personnaliser en utilisant son architecture logicielle unique pour le cloud computing. Après avoir lu ce brief, vous comprendrez mieux la technologie sous-jacente qui fait de Salesforce Platform un choix attrayant pour vos applications métiers.
Salesforce Platform est l'exemple prééminent d'une plate-forme cloud computing réussie et de l'écosystème d'applications associé. Depuis le début du millénaire, la plate-forme est la base habilitante pour :
- De nombreuses applications métiers populaires pour des cas d'utilisation courants tels que les ventes et le service client
- Applications spécifiques au secteur d'activité pour des cas d'utilisation plus spécialisés tels que la finance et la santé
- Des millions d'applications personnalisées et d'extensions pour des cas d'utilisation uniques
En grande partie, Salesforce Platform connaît un grand succès et est populaire parce que son architecture logicielle unique prend en charge des applications faciles à élaborer, à utiliser, à personnaliser et à étendre avec des performances et une fiabilité exceptionnelles. Le cœur de l'architecture logicielle de la plate-forme est sa conception multilocataire pilotée par les métadonnées.
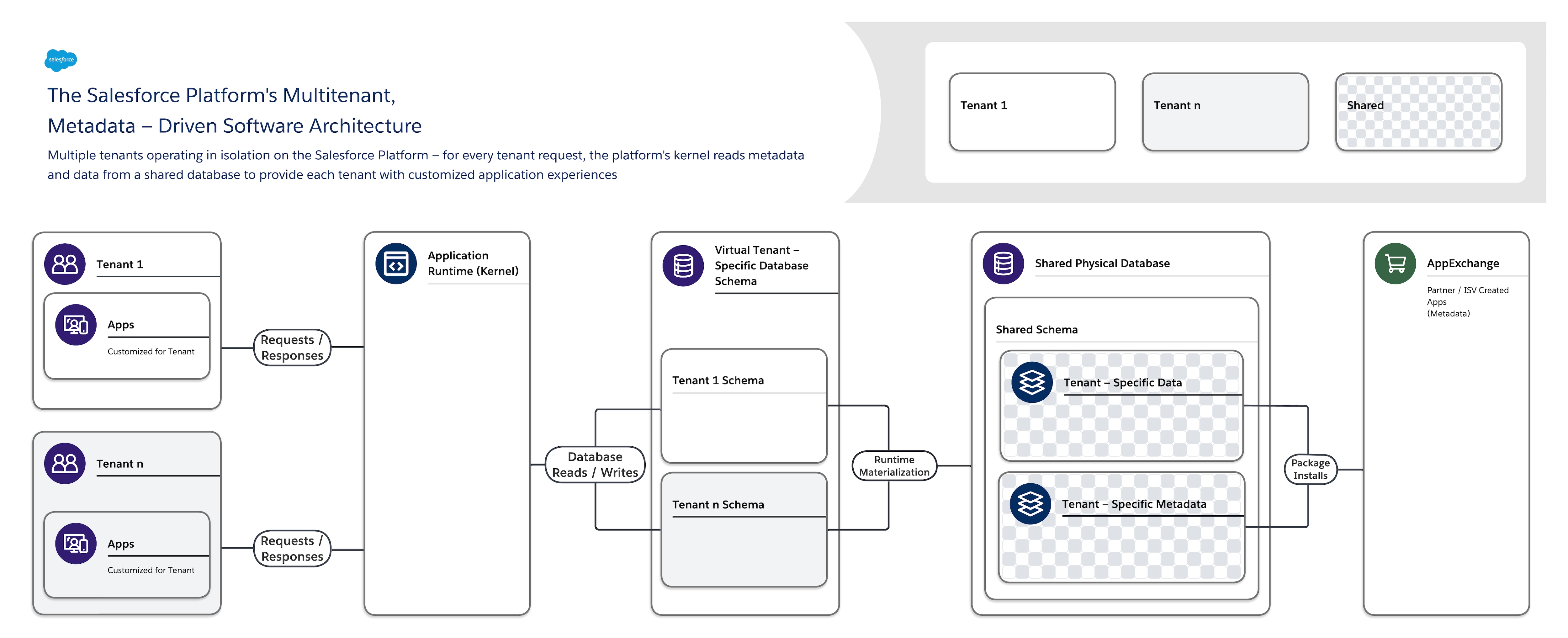
L'architecture logicielle de Salesforce Platform est la suivante :
- Multilocataire : il isole et prend en charge simultanément les exigences variables de nombreux locataires (organisations, unités commerciales, etc.).
- Métadonnées pilotées : elles permettent à chaque locataire de personnaliser facilement et rapidement ses applications et ses expériences utilisateur en utilisant des métadonnées, des données qui décrivent des éléments tels que l'interface utilisateur (UI) et la logique métier.
Lorsque vous créez un objet d'application ou écrivez un code en utilisant Salesforce Platform, la plate-forme ne crée pas de tableau réel dans une base de données et ne compile aucun code. À la place, la plate-forme stocke simplement certaines métadonnées qu'elle peut ensuite utiliser à l'exécution pour matérialiser dynamiquement des composants d'application virtuelle. La plate-forme garantit que les métadonnées de chaque locataire sont privées et faciles à mettre à jour sans verrouillage ni temps d'arrêt requis, afin que chaque locataire puisse élaborer et personnaliser des applications de façon isolée. Salesforce Platform utilise les mêmes métadonnées pour fournir des API personnalisées, des interfaces RESTful et Web (basées sur SOAP) que vous pouvez utiliser pour intégrer vos applications à d'autres applications et processus automatisés.
Des solutions toutes faites sont également disponibles dans AppExchange, la vaste place de marché des applications de la plate-forme. Élaboré par un vaste écosystème de partenaires de confiance et d'éditeurs de logiciels indépendants (ISV), un package AppExchange est une métadonnées provenant d'un tiers qui décrit des extensions d'application gratuites ou payantes et des applications complètes que vous pouvez utiliser pour répondre à des exigences métiers spécifiques.
Pour prendre en charge cette architecture hautement personnalisable et extensible, une instance unique de Salesforce Platform utilise :
- Une base de données multilocataire partagée unique avec un schéma unique qui stocke des métadonnées et des données spécifiques au locataire.
- Un noyau multitenant (exécution d'application) qui lit les métadonnées et les données afin de fournir dynamiquement des applications, une logique métier et des API spécifiques au locataire pour les utilisateurs de chaque locataire à l'exécution.
Cette séparation claire entre le noyau géré par Salesforce et les métadonnées gérées par les locataires permet à Salesforce, aux locataires et aux éditeurs de logiciels de faire évoluer indépendamment leurs parties du système sans interférence.
Pour tirer parti de cette vue d'ensemble, les sections suivantes de cet article fournissent plus de détails sur les capacités uniques de la plate-forme qui découlent des aspects clés de sa conception, notamment :
- La couche de données de la plate-forme
- Développement d'applications de plate-forme
- Traitement de la plate-forme interne
- Infrastructure de la plate-forme
Ensemble, l'exécution d'application et la couche de données innovante de Salesforce Platform isolent en toute sécurité les données spécifiques au locataire, les personnalisations de schéma et la logique métier. À un niveau élevé, le schéma prend en charge divers cas d'utilisation :
- Lorsque vous créez ou personnalisez une application, la plate-forme stocke les métadonnées associées dans des tableaux de base de données partagés qui gèrent les métadonnées de tous les locataires.
- Lorsque vous utilisez une application pour lire ou écrire des données, la plate-forme stocke vos données dans des tableaux de base de données partagés qui gèrent les données de tous les locataires.
- En arrière-plan, la plate-forme gère également les métadonnées internes dans un certain nombre de tableaux que le noyau utilise pour optimiser la latence des requêtes à l'exécution.
Mais comment une base de données et un schéma partagés uniques peuvent-ils garder les données privées de chaque locataire ? Chaque locataire de la plate-forme est appelé organisation, ou organisation en abrégé. Chaque enregistrement spécifique à une organisation dans des tableaux de base de données partagés a un OrgID. Lorsque le noyau accède à la base de données, il utilise cet identifiant unique pour s'assurer que les activités de chaque organisation sont privées.

Les objets spécifiques à l'organisation (tableaux de réflexion dans le langage traditionnel de la base de données relationnelle), les champs, les procédures stockées, les déclencheurs de base de données, et davantage, sont tous des constructions virtuelles décrites par des métadonnées que la plate-forme stocke dans quelques tableaux de base de données appelés Universal Data Dictionary (UDD).
- MT_Objects est un tableau de base de données qui stocke des métadonnées sur les objets que vous définissez pour une application, notamment un identifiant unique pour un objet (ObjID), votre organisation (OrgID) et le nom que vous donnez pour l'objet (ObjName).
- Le tableau système MT_Fields stocke des métadonnées sur les champs (colonnes) que vous déclarez pour chaque objet, notamment un identifiant unique pour un champ (FieldID), votre organisation (OrgID), l'objet qui contient le champ (ObjID), le nom du champ (FieldName), le type de données du champ, une valeur booléenne pour indiquer si le champ nécessite une indexation (IsIndexed) et la position du champ dans l'objet par rapport aux autres champs (FieldNum).
Comme les métadonnées sont un ingrédient clé, la plate-forme doit optimiser l'accès aux métadonnées, sinon un accès fréquent aux métadonnées empêcherait le service d'évoluer. Avec ce potentiel goulot d'étranglement à l'esprit, la plate-forme utilise des caches de métadonnées massives et sophistiquées pour conserver en mémoire les métadonnées récemment utilisées, éviter les entrées/sorties disque et les recompilations de code qui améliorent les performances, et améliorer les temps de réponse des applications.
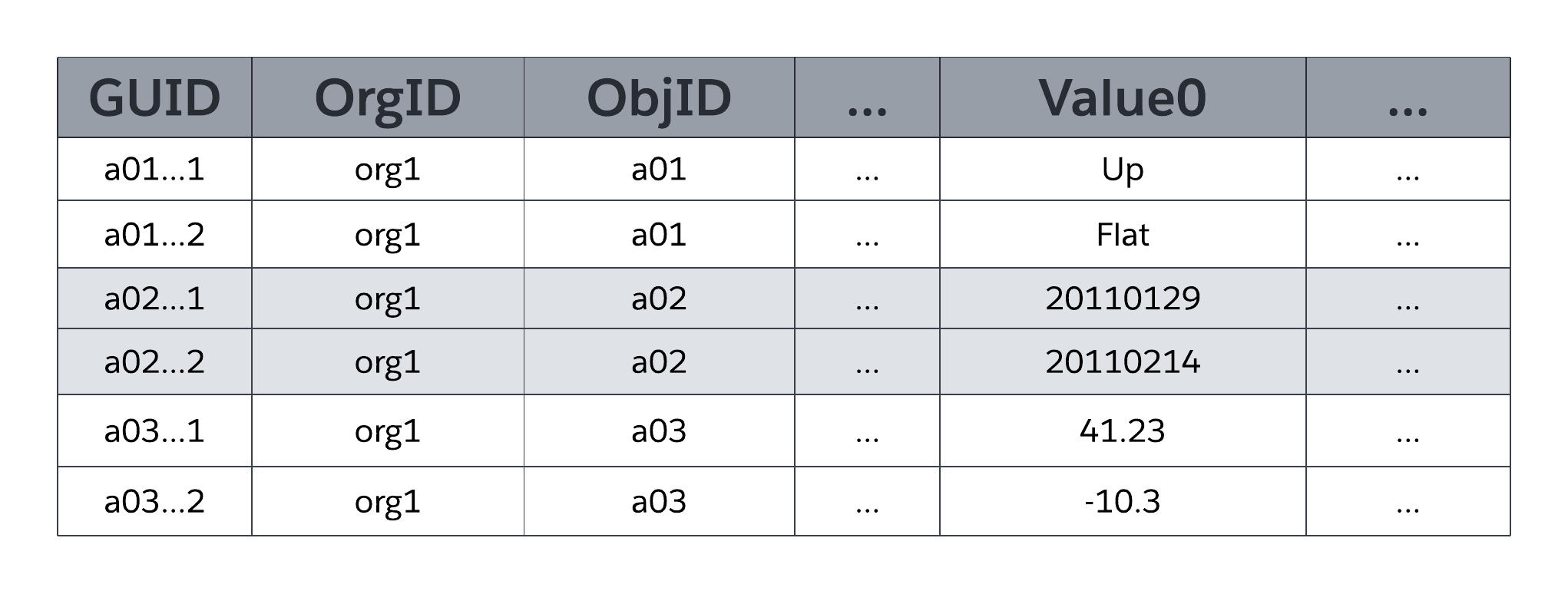
Le tableau système MT_Data stocke les données accessibles à l'application qui sont mappées avec tous les tableaux spécifiques à l'organisation et leurs champs, tels que définis par les métadonnées dans MT_Objects et MT_Fields. Chaque ligne inclut des champs d'identification, tels qu'un identifiant unique global (GUID), l'organisation propriétaire de la ligne (OrgID) et l'identificateur d'objet englobant (ObjID). Chaque ligne du tableau MT_Data contient également un champ Nom qui stocke un « nom naturel » pour les enregistrements correspondants. Par exemple, un enregistrement Compte peut utiliser « Nom du compte », un enregistrement Requête peut utiliser « Numéro de requête », etc.
Valeur0 ... Les colonnes flexibles ValueN, également appelées slots, stockent les données des applications mappées avec les tableaux et les champs déclarés respectivement dans MT_Objects et MT_Fields. Toutes les colonnes Flex utilisent un type de données de chaîne de longueur variable afin de stocker n'importe quel type structuré de données d'application (chaînes, chiffres, dates, etc.). Comme l'illustre la figure suivante, il n'y a pas deux champs d'un même objet qui peuvent être mappés avec le même slot dans MT_Data pour le stockage. Cependant, un slot unique peut gérer les informations de plusieurs champs, à condition que chaque champ provienne d'un objet différent.
Les champs MTFields peuvent utiliser n'importe quel type de données structuré standard, tel que texte, numérique, date et date/heure, ainsi que des types de données structurés à usage spécial et enrichis, tels que liste de sélection (champ énuméré), numérotation automatique (incrémenté automatiquement, numéro de séquence généré par le système), formule (valeur dérivée en lecture seule), relation principal-détails (clé étrangère), case à cocher (booléen), e-mail, URL, etc. MT_Fields peut également être obligatoire (pas nul) et avoir des règles de validation personnalisées (par exemple, un champ doit être supérieur à un autre champ), que la plate-forme applique.
Lorsque vous déclarez ou modifiez un objet, la plate-forme gère une ligne de métadonnées dans MT_Objects qui définit l'objet. De la même façon, pour chaque champ, la plate-forme gère une ligne dans MT_Fields, y compris les métadonnées qui mappent le champ avec une colonne Flex spécifique dans MT_Data pour le stockage des données de champ correspondantes. Comme la plate-forme gère les définitions d'objets et de champs en tant que métadonnées plutôt que de véritables structures de base de données, le système peut tolérer des activités de maintenance de schéma d'application multilocataire en ligne sans bloquer l'activité simultanée d'autres organisations et utilisateurs. Par comparaison, la redéfinition des tableaux en ligne pour les systèmes de base de données relationnelles traditionnels nécessite généralement des verrous temporaires et des processus souvent laborieux et complexes, ainsi que des temps d'arrêt d'application planifiés.
Comme le montre la représentation simplifiée de MT_Data dans la figure précédente, les colonnes flexibles sont de type de données universel (chaîne de longueur variable), ce qui permet à la plate-forme de partager une seule colonne flexible entre plusieurs champs qui utilisent divers types de données structurés (chaînes, chiffres, dates, etc.).
La plate-forme stocke toutes les données des colonnes flexibles en utilisant un format canonique, et utilise des fonctions de conversion de type de données système de base de données sous-jacentes (par exemple, TO_NUMBER, TO_DATE, TO_CHAR) si nécessaire lorsque les applications lisent des données à partir de colonnes flexibles et écrivent des données dans ces colonnes.
MTData contient également des colonnes qui ne sont pas affichées dans la figure précédente. Par exemple, quatre colonnes permettent de gérer les données d'audit, notamment l'utilisateur qui a créé une ligne et quand cette ligne a été créée, et l'utilisateur qui a modifié une ligne en dernier et quand cette ligne a été modifiée en dernier. MT_Data contient également une colonne _IsDeleted que la plate-forme utilise pour indiquer quand une ligne a été supprimée.
La plate-forme prend également en charge la déclaration de champs en tant que objets volumineux de caractères pour permettre le stockage de champs de texte longs contenant jusqu'à 32 000 caractères. Pour chaque ligne de MTData qui a un CLOB, la plate-forme stocke le CLOB hors ligne dans un tableau appelé _MT_Clob, que le système peut joindre aux lignes correspondantes de MT_Data si nécessaire.
Note : La plate-forme stocke également les CLOB sous une forme indexée hors de la base de données pour des recherches de texte rapides. Consultez Recherches pour plus d'informations sur le moteur de recherche textuelle de la plate-forme.
La plate-forme indexe automatiquement divers types de champ pour offrir des performances évolutives.
Les systèmes de base de données traditionnels s'appuient sur des index de base de données natifs pour localiser rapidement des lignes spécifiques dans un tableau de base de données dont les champs correspondent à une condition spécifique. Cependant, il n'est pas pratique de créer des index de base de données natifs pour les colonnes flexibles de MTData, car la plate-forme utilise une colonne flexible unique pour stocker les données de nombreux champs avec divers types de données structurés. À la place, la plate-forme gère un index de MT_Data en copiant de façon synchrone les données de champ marquées pour l'indexation dans une colonne appropriée d'un tableau croisé dynamique _MT_Indexes.
MT_Indexes contient des colonnes fortement typées et indexées, telles que StringValue, NumValue et DateValue, que la plate-forme utilise pour localiser les données de champ du type de données correspondant. Par exemple, la plate-forme copie une valeur de chaîne dans une colonne flexible MT_Data dans le champ StringValue de MT_Indexes, une valeur de date dans le champ DateValue, etc. Les index sous-jacents de MT_Indexes sont des index de base de données standard, non uniques. Lorsqu'une requête système interne inclut un paramètre de recherche qui référence un champ structuré dans un objet, l'optimiseur de requête personnalisé de la plate-forme utilise MT_Indexes pour optimiser les opérations d'accès aux données associées.
Note : La plate-forme peut gérer les recherches dans plusieurs langues, car le système utilise un algorithme de pliage qui convertit les valeurs de chaîne en un format universel insensible à la casse. La colonne StringValue du tableau MT_Indexes stocke les valeurs de chaîne sous ce format. À l'exécution, l'optimiseur de requête élabore automatiquement des opérations d'accès aux données afin de filtrer l'instruction SQL optimisée sur la valeur de chaîne de requête correspondante, qui correspond à son tour au littéral fourni dans la requête de recherche.
La plate-forme permet d'indiquer quand un champ d'un objet doit contenir des valeurs uniques (sensibles à la casse ou insensibles à la casse). Compte tenu de l'arrangement de MT_Data et de l'utilisation partagée des colonnes Valeur pour les données de champ, il n'est pas pratique de créer des index de base de données uniques pour l'objet. (Cette situation est semblable à celle décrite dans la section précédente pour les index non uniques.)
Pour prendre en charge l'unicité des champs personnalisés, la plate-forme utilise le tableau croisé dynamique MT_Unique_Indexes. Ce tableau est très similaire au tableau MT_Indexes, sauf que les index de base de données natives sous-jacents de MT_Unique_Indexes appliquent l'unicité. Lorsqu'une application tente d'insérer une valeur dupliquée dans un champ qui nécessite un caractère unique, ou lorsqu'un administrateur tente d'appliquer un caractère unique à un champ existant qui contient des valeurs dupliquées, la plate-forme renvoie un message d'erreur approprié à l'application.
Dans de rares cas, le moteur de recherche externe de la plate-forme (expliqué dans Recherches) peut être surchargé ou non disponible, et ne pas être en mesure de répondre à une demande de recherche en temps opportun. Au lieu de renvoyer une erreur décevante à l'utilisateur, la plate-forme se rabat sur un mécanisme de recherche secondaire pour fournir des résultats de recherche raisonnables.
Une recherche de secours est implémentée en tant que requête de base de données directe avec des conditions de recherche qui référencent le champ Nom des enregistrements cibles. Pour optimiser les recherches d'objets globales (qui couvrent des tableaux) sans avoir à exécuter des requêtes Union potentiellement coûteuses, la plate-forme gère un tableau croisé dynamique MT_Fallback_Indexes qui enregistre le Nom de tous les enregistrements. Les mises à jour de MT_Fallback_Indexes sont effectuées de façon synchrone lorsque les transactions modifient les enregistrements, ce qui permet aux recherches de remplacement d'accéder aux informations les plus récentes de la base de données.
Le tableau MT_Name_Denorm est un tableau de données allégé qui stocke l'ObjID et le Nom de chaque enregistrement dans MT_Data. Lorsqu'une application doit fournir une liste d'enregistrements impliqués dans une relation parent/enfant, la plate-forme utilise le tableau MT_Name_Denorm pour exécuter une requête relativement simple qui récupère le Nom de chaque enregistrement référencé pour l'afficher dans l'application, par exemple dans le cadre d'un lien hypertexte.
La plate-forme fournit des types de données de relation qu'une organisation peut utiliser pour déclarer des relations (intégrité référentielle) entre des tableaux. Lorsque vous déclarez le champ d'un objet avec un type de relation, la plate-forme mappe le champ avec un champ Valeur dans MT_Data, puis utilise ce champ pour stocker l'ObjID d'un objet associé.
Pour optimiser les opérations de jointure, la plate-forme maintient un tableau croisé dynamique MT_Relationships. Ce tableau système contient deux index composites uniques de base de données sous-jacents qui permettent des traversées d'objet efficaces dans les deux sens, si nécessaire.
En quelques clics de souris seulement, la plate-forme fournit le suivi historique de n'importe quel champ. Lorsqu'une organisation active l'audit pour un champ spécifique, le système enregistre de façon asynchrone des informations sur les modifications apportées au champ (anciennes et nouvelles valeurs, date de modification, etc.) en utilisant un tableau croisé dynamique interne comme piste d'audit.
Toutes les données, métadonnées et structures de tableaux croisés dynamiques de la plate-forme, y compris les index de base de données sous-jacents, sont physiquement partitionnées par OrgID en utilisant des mécanismes de partitionnement de base de données natifs. Le partitionnement des données est une technique éprouvée que les systèmes de base de données fournissent pour diviser physiquement les grandes structures de données logiques en plus petites parties plus faciles à gérer. Le partitionnement peut également améliorer les performances, l'évolutivité et la disponibilité d'un système de base de données volumineux, par exemple un environnement multilocataire. Par définition, chaque requête de plate-forme cible les informations d'une organisation spécifique. Par conséquent, l'optimiseur de requête doit seulement envisager d'accéder aux partitions de données qui contiennent les données d'une organisation, plutôt qu'à un tableau ou un index complet. Cette optimisation courante est parfois appelée « taille de partition ».
Cette section présente comment les développeurs d'applications peuvent créer les métadonnées sous-jacentes d'un schéma, puis élaborer des applications qui gèrent les données. Ces métadonnées et données sont stockées dans la couche de données de la plate-forme décrite dans la section précédente.
Les développeurs peuvent élaborer par déclaration des composants d'application côté serveur en utilisant l'environnement de développement basé sur le navigateur de la plate-forme, communément appelé écrans de configuration de la plate-forme. L'interface utilisateur par pointer-cliquer de la Configuration prend en charge toutes les facettes du processus d'élaboration de schéma d'application, notamment la création du modèle de données d'une application (y compris les objets et leurs champs ainsi que les relations), le modèle de sécurité et de partage (y compris les utilisateurs, les profils et les hiérarchies de rôles), l'interface utilisateur (y compris les présentations d'écran, les formulaires de saisie de données et les rapports), la logique déclarative (workflows) et la logique programmatique (procédures stockées et déclencheurs). Par exemple, Salesforce Flow facilite l'automatisation d'un large éventail de cas d'utilisation. L'interface utilisateur de Flow Builder, présentée ci-dessous, permet de concevoir et d'implémenter graphiquement des workflows qui interagissent avec les utilisateurs, ou qui se lancent automatiquement en fonction d'une planification ou lorsqu'ils sont déclenchés par un événement.
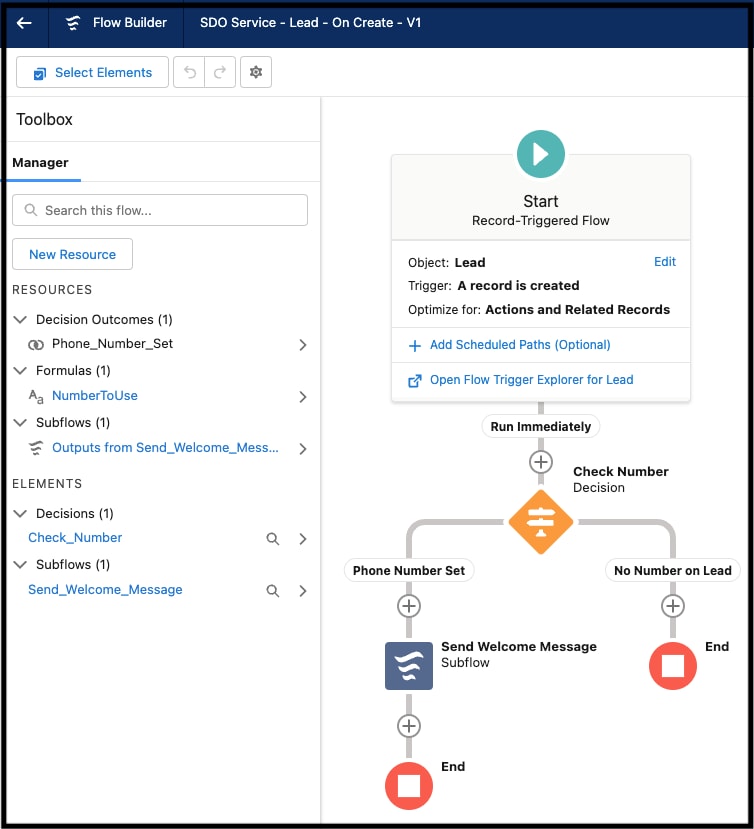
Les écrans de configuration facilitent le développement et la personnalisation d'applications sans (ou très peu) de code. Par exemple :
- Les interfaces utilisateur natives de la plate-forme sont faciles à élaborer sans code. En arrière-plan, une interface utilisateur d'application native prend en charge toutes les opérations d'accès aux données habituelles, notamment les requêtes, les insertions, les mises à jour et les suppressions. Chaque opération de manipulation de données effectuée par des applications de plate-forme natives peut modifier un objet à la fois et valider automatiquement chaque modification dans une transaction séparée.
- Lors de la définition d'un champ de texte pour un objet qui contient des données confidentielles, vous pouvez aisément configurer le champ afin que la plate-forme crypte les données correspondantes et, éventuellement, utilise un masque d'entrée pour masquer les informations d'écran aux regards indiscrets.
- Une règle de validation déclarative est un moyen simple pour une organisation d'appliquer une règle d'intégrité de domaine sans aucune programmation. Par exemple, vous pouvez déclarer une règle de validation qui garantit que le champ Quantité d'un objet LineItem est toujours supérieur à zéro.
- Un champ de formule est une fonctionnalité déclarative de la plate-forme qui facilite l'ajout d'un champ calculé à un objet. Par exemple, vous pouvez ajouter un champ à l'objet LineItem pour calculer une valeur LineTotal.
- Un champ récapitulatif de cumul est un champ inter-objets qui facilite l'agrégation des informations des champs enfants dans un objet parent. Par exemple, vous pouvez créer un champ récapitulatif OrderTotal dans l'objet SalesOrder basé sur le champ LineTotal de l'objet LineItem.
Note : En interne, la plate-forme implémente des champs récapitulatifs de formule et de cumul en utilisant les fonctionnalités natives de la base de données, et recalcule efficacement les valeurs de façon synchrone dans le cadre des transactions en cours.
La plate-forme fournit plusieurs API basées sur des normes ouvertes que les développeurs peuvent utiliser pour élaborer des applications. Les API RESTful et Web services (basées sur SOAP) permettent d'accéder aux nombreuses fonctionnalités de la plate-forme. En utilisant ces diverses API, une application peut :
- Manipuler des métadonnées qui décrivent un schéma d'application
- Créer, lire, mettre à jour et supprimer des données métiers (CRUD)
- Chargement en masse ou interrogation asynchrone d'un grand nombre d'enregistrements
- Exposer un flux de données en temps quasi réel de façon sécurisée et évolutive
Les applications peuvent utiliser le Salesforce Object Query Language (SOQL) pour construire des requêtes de base de données simples mais puissantes. De la même façon que la commande SELECT dans le langage SQL (Structured Query Language), SOQL permet de spécifier l'objet source, la liste des champs à récupérer et les conditions de sélection des lignes dans l'objet source. Par exemple, la requête SOQL suivante renvoie la valeur du champ ID et Nom de tous les enregistrements Compte avec un Nom égal à la chaîne 'Acme'.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
La plate-forme inclut également un moteur de recherche multilingue en texte intégral qui indexe automatiquement tous les champs liés au texte. Les applications peuvent utiliser ce moteur de recherche préintégré en utilisant le Salesforce Object Search Language (SOSL) pour effectuer des recherches textuelles. Contrairement à SOQL, qui ne peut interroger qu'un seul objet à la fois, SOSL permet de rechercher simultanément des champs de texte, d'e-mail et de téléphone pour plusieurs objets. Par exemple, l'instruction SOSL suivante recherche dans les objets Piste et Contact les enregistrements qui contiennent la chaîne 'Joe Smith' dans le champ Nom, et renvoie le champ Nom et Numéro de téléphone de chaque enregistrement trouvé.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, qui est similaire à Java à de nombreux égards, est un langage de développement puissant que les développeurs peuvent utiliser pour centraliser la logique procédurale dans leur schéma d'application. Un code Apex peut déclarer des variables et des constantes de programme, exécuter des instructions de contrôle de flux traditionnelles (if-else, loops, etc.), effectuer des opérations de manipulation de données (insert, update, upsert, delete) et effectuer des opérations de contrôle de transaction (setSavepoint, rollback).
Vous pouvez stocker des programmes Apex sur la plate-forme en utilisant deux formes différentes: en tant que classe Apex nommée avec des méthodes (comme des procédures stockées dans le langage traditionnel de la base de données) que les applications exécutent lorsque nécessaire, ou en tant que déclencheur de base de données qui s'exécute automatiquement avant ou après un événement spécifique de manipulation de la base de données. Dans les deux cas, la plate-forme compile le code Apex et le stocke sous forme de métadonnées dans l'UDD. La première fois qu'une organisation exécute un programme Apex, l'interpréteur d'exécution de la plate-forme charge la version compilée du programme dans un cache MRU (dernier utilisé) de cette organisation. Par la suite, lorsqu'un utilisateur de la même organisation doit utiliser la même routine, la plate-forme peut économiser la mémoire et éviter les frais de recompilation du programme en partageant le programme prêt à exécuter qui est déjà en mémoire.
Avec l'ajout d'un simple mot-clé ici et là, les développeurs peuvent utiliser Apex pour prendre en charge de nombreuses exigences d'application uniques. Par exemple, les développeurs peuvent exposer une méthode en tant qu'appel d'API RESTful ou basée sur SOAP personnalisé, la rendre planifiable de façon asynchrone ou la configurer pour traiter une opération volumineuse par lots.
Apex est bien plus qu’un « langage procédural de plus ». C'est un composant de plate-forme intégral qui aide le système à offrir une multilocation fiable. Par exemple, la plate-forme valide automatiquement toutes les instructions SOQL et SOSL incorporées dans une classe afin d'éviter un code qui échouerait à l'exécution. La plate-forme conserve ensuite les informations de dépendance d'objet correspondantes pour les classes valides et les utilise afin d'empêcher les modifications des métadonnées qui pourraient rompre un code dépendant.
De nombreuses classes Apex standard et méthodes statiques système fournissent des interfaces simples aux fonctionnalités système sous-jacentes. Par exemple, les méthodes DML statiques système telles que insert, update et delete ont un simple paramètre booléen que les développeurs peuvent utiliser pour indiquer l'option de traitement en masse souhaitée (tout ou rien, ou enregistrement partiel). Ces méthodes renvoient également un objet résultat que la routine d'appel peut lire pour déterminer quels enregistrements ont été traités sans succès et pourquoi. Parmi les autres exemples de liens directs entre Apex et les fonctionnalités de la plate-forme figurent les classes de messagerie intégrées et les classes XmlStream.
En grande partie, la plate-forme est performante et évolutive, car Salesforce l'a élaborée en tenant compte de deux principes importants :
- Offrez des capacités de plate-forme de base efficaces et à grande échelle.
- Aidez les développeurs à tout faire aussi efficacement que possible.
La plate-forme intègre ces principes dans ses architectures de traitement uniques, notamment :
- Requêtes
- Recherches
- Opérations en masse
- Modification du schéma
- Isolation multilocataire
- La corbeille
La plupart des systèmes de base de données modernes déterminent les plans d'exécution de requête optimaux en utilisant un optimiseur de requête basé sur le coût qui prend en compte les statistiques pertinentes sur les données des tableaux cibles et des index. Cependant, les statistiques d'optimiseur classiques basées sur le coût sont conçues pour les applications monolocataires et ne tiennent pas compte des caractéristiques d'accès aux données d'un utilisateur donné qui exécute une requête dans un environnement multilocataire. Par exemple, une requête donnée qui cible un objet avec un volume de données important serait probablement exécutée plus efficacement en utilisant des plans d'exécution différents pour les utilisateurs avec une visibilité élevée (un responsable qui peut afficher toutes les lignes) et les utilisateurs avec une visibilité faible (les commerciaux qui peuvent afficher uniquement les lignes associées à eux-mêmes).
Pour fournir des statistiques suffisantes afin de déterminer les plans d'exécution de requête optimaux dans un système multilocataire, la plate-forme gère une série complète de statistiques d'optimiseur (au niveau locataire, groupe et utilisateur) pour les objets de chaque organisation. Les statistiques reflètent le nombre de lignes auxquelles une requête particulière peut potentiellement accéder, en examinant attentivement les statistiques générales d'objets spécifiques à l'organisation (par exemple, le nombre total de lignes appartenant à l'organisation dans son ensemble), ainsi que des statistiques plus précises (par exemple, le nombre de lignes auxquelles un groupe de privilèges spécifique ou un utilisateur peut potentiellement accéder).
La plate-forme gère également d'autres types de statistiques qui s'avèrent utiles avec des requêtes particulières. Par exemple, la plate-forme gère des statistiques pour tous les index personnalisés afin de révéler le nombre total de valeurs non nulles et uniques dans le champ correspondant, et des histogrammes pour les champs de liste de sélection qui révèlent la cardinalité de chaque valeur de liste.
Lorsque les statistiques existantes ne sont pas en place ou ne sont pas considérées comme utiles, l'optimiseur de la plate-forme utilise quelques stratégies différentes pour aider à élaborer des requêtes raisonnablement optimales. Par exemple, lorsqu'une requête filtre sur le champ Nom d'un objet, l'optimiseur peut utiliser le tableau MT_Fallback_Indexes pour retrouver efficacement les lignes demandées. Dans d'autres scénarios, l'optimiseur génère dynamiquement des statistiques manquantes à l'exécution.
Utilisé conjointement avec les statistiques de l'optimiseur, l'optimiseur de la plate-forme s'appuie également sur des tableaux liés à la sécurité interne (Groupes, Membres, GroupBlowout et CustomShare) qui gèrent des informations sur les domaines de sécurité des utilisateurs d'une organisation, notamment les appartenances à un groupe donné et les droits d'accès personnalisés pour les objets et les lignes. Ces informations sont précieuses pour déterminer la sélectivité des filtres de requête par utilisateur. Pour plus d’informations sur le modèle de sécurité incorporé de la plate-forme, consultez le Platform Developer Basics Trailhead.
Le diagramme de flux de la figure ci-dessous illustre ce qui se passe lorsque la plate-forme traite une requête de données dans l'un des grands tableaux heap tels que MT_Data. La requête peut provenir de plusieurs sources, par exemple un appel d'API ou une procédure stockée. Tout d'abord, la plate-forme exécute des « pré-requêtes » qui prennent en compte les statistiques sensibles aux locataires multiples. Ensuite, en fonction des résultats renvoyés par les pré-requêtes, le service élabore une requête de base de données sous-jacente optimale pour l'exécution dans le paramètre spécifique.
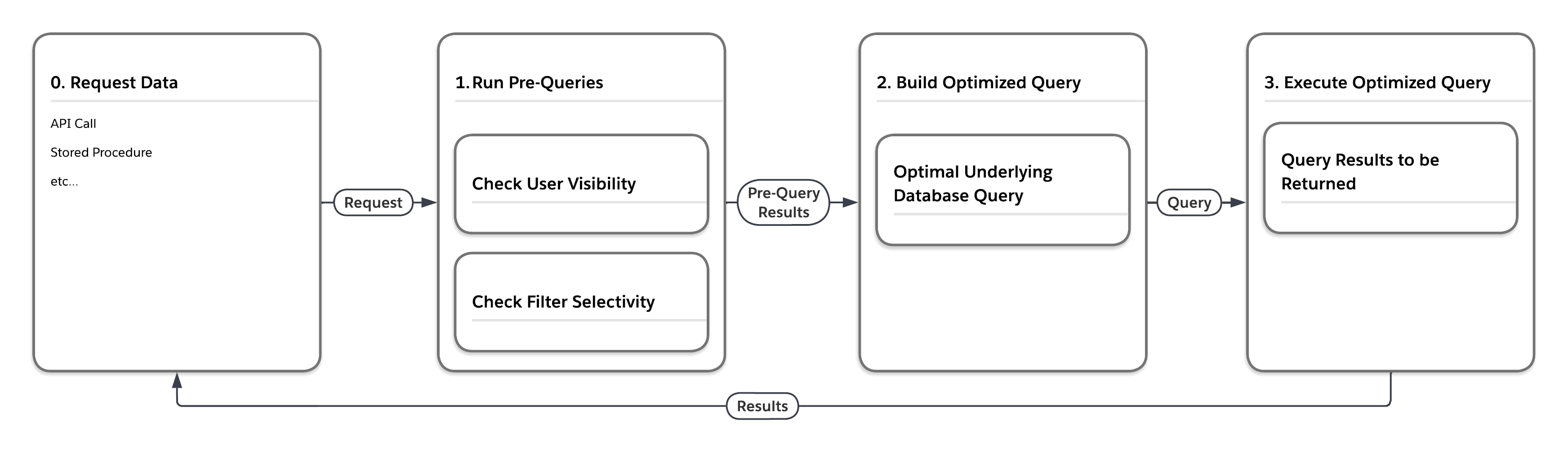
Comme le montre le tableau ci-dessous, la plate-forme peut exécuter la même requête de quatre façons différentes, selon l'utilisateur qui soumet la requête et la sélectivité des conditions de filtrage de la requête.
| Mesures de sélectivité préalables aux requêtes | Écrire une requête d'accès final à la base de données, forçant... | |
| Utilisateur | Filtre | |
| Faible | Faible | ... boucles imbriquées joindre, conduire en utilisant la vue des lignes que l'utilisateur peut voir |
| Faible | Élevée | ... utilisation de l'index associé au filtre |
| Élevée | Faible | ... jointure de hachage ordonnée, conduire en utilisant MT_DATA |
| Élevée | Élevée | ... utilisation du filtre associé à l'index |
Les utilisateurs s'attendent à ce qu'une capacité de recherche interactive analyse tout ou partie de la base de données d'une application et renvoie des résultats classés avec des temps de réponse inférieurs à la seconde. Pour fournir cette capacité aux applications de plate-forme, la plate-forme utilise un moteur de recherche distinct de son moteur de transaction. Lorsque vous mettez à jour des enregistrements, le moteur de transaction met à jour la base de données principale et transmet également les données associées au moteur de recherche pour indexation. Lorsque vous recherchez des enregistrements, le moteur de recherche utilise ses index pour traiter rapidement la requête et renvoie des résultats classés avec des liens vers des enregistrements de base de données associés.
Lorsque les applications mettent à jour des données dans des champs de texte (CLOB, Name, etc.), un pool de processus en arrière-plan appelé serveurs d'indexation est responsable de la mise à jour asynchrone des index correspondants, que le moteur de recherche gère hors du moteur de transaction principal. Pour optimiser le processus d'indexation, la plate-forme copie de façon synchrone des parties modifiées de données textuelles dans un tableau interne « à indexer » à mesure que les transactions s'engagent, fournissant ainsi une source de données relativement petite qui réduit la quantité de données que les serveurs d'indexation doivent lire sur le disque. Le moteur de recherche gère automatiquement des index séparés pour chaque organisation.
Selon la charge et l'utilisation actuelles des serveurs d'indexation, les mises à jour de l'index de texte peuvent être en retard par rapport aux transactions réelles. Pour éviter les résultats de recherche inattendus provenant d'index périmés, la plate-forme maintient également un cache MRU de lignes récemment mises à jour que le système prend en compte lors de la matérialisation des résultats de recherche en texte intégral. La plate-forme gère les caches MRU par utilisateur et par organisation pour prendre en charge efficacement les étendues de recherche possibles.
Le moteur de recherche de la plate-forme optimise le classement des enregistrements dans les résultats de recherche en utilisant plusieurs méthodes. Par exemple, le système prend en compte le domaine de sécurité de l'utilisateur effectuant une recherche et accorde plus de poids aux lignes auxquelles l'utilisateur actuel peut accéder. Le système peut également prendre en compte l'historique des modifications d'une ligne particulière et classer les lignes mises à jour plus activement avant celles qui sont relativement statiques. L'utilisateur peut choisir de pondérer les résultats de recherche comme il le souhaite, par exemple en insistant davantage sur les lignes récemment modifiées.
Les applications gourmandes en transactions génèrent moins de frais généraux et sont beaucoup plus performantes lorsqu'elles combinent et exécutent en masse des opérations répétitives. Par exemple, une application peut charger de nombreuses nouvelles lignes de deux façons. Une approche inefficace consisterait à utiliser une routine avec une boucle qui insère des lignes individuelles, en passant un appel d'API après l'autre pour chaque insertion de ligne. Une approche beaucoup plus efficace serait de créer un tableau de lignes et d'insérer toutes ces lignes avec un seul appel d'API.
Un traitement en masse efficace avec la plate-forme est simple pour les développeurs, car il est intégré dans des appels d'API. En interne, la plate-forme traite également en masse toutes les étapes internes associées à une opération en masse explicite.
Le moteur de traitement en masse de la plate-forme prend automatiquement en compte les défauts isolés rencontrés à chaque étape du parcours. Lorsqu'une opération en masse démarre en mode d'enregistrement partiel, le moteur identifie un état de démarrage connu, puis tente d'exécuter chaque étape du processus (validation en masse des données de champ, pré-déclenchements d'incendie en masse, enregistrements d'enregistrement d'enregistrement en masse, etc.). Si le moteur détecte des erreurs à une étape quelconque, il annule les opérations incriminées et tous les effets secondaires, retire les lignes responsables des défauts et continue en tentant de traiter en masse le sous-ensemble de lignes restant. Ce processus itère à travers chaque étape successive jusqu'à ce que le moteur puisse engager un sous-ensemble de lignes sans erreur. L'application peut examiner un objet de retour pour identifier les lignes échouées et les exceptions qu'elles ont soulevées.
Note : À votre discrétion, un mode tout ou rien est disponible pour les opérations en masse. De plus, l'exécution de déclencheurs pendant une opération en masse est soumise à des gouverneurs internes qui limitent la quantité de travail.
Certains types de modification de la définition d'un objet nécessitent plus que de simples mises à jour de métadonnées UDD. Dans ce cas, la plate-forme utilise des mécanismes efficaces qui contribuent à réduire l'impact global sur les performances du service de base de données Cloud dans son ensemble.
Par exemple, tenez compte des conséquences en arrière-plan lorsque vous modifiez le type de données d'une colonne de liste de sélection à texte. La plate-forme commence par allouer un nouveau créneau pour les données de la colonne, copie en masse les étiquettes de liste de sélection associées aux valeurs actuelles, puis met à jour les métadonnées de la colonne pour pointer vers le nouveau créneau. Tout cela se produit, mais l'accès aux données est normal et les applications continuent de fonctionner sans impact notable.
Autre exemple, tenez compte de ce qui se passe lorsque vous ajoutez un champ récapitulatif de cumul à un objet. Dans ce cas, la plate-forme calcule de façon asynchrone les résumés initiaux en arrière-plan en utilisant une opération en masse efficace. Pendant le calcul en arrière-plan, les utilisateurs qui visualisent le nouveau champ reçoivent une indication indiquant que la plate-forme calcule actuellement la valeur du champ.
Pour empêcher la monopolisation malveillante ou involontaire de ressources système partagées et multilocataires, la plate-forme a un ensemble étendu de gouverneurs et de limites en ressources associés à l'exécution de code de plate-forme. Par exemple, la plate-forme surveille de près l'exécution d'un script de code et limite le temps processeur qu'elle peut utiliser, la quantité de mémoire qu'elle peut consommer, le nombre de requêtes et d'instructions DML qu'elle peut exécuter, le nombre de calculs mathématiques qu'elle peut effectuer, le nombre d'appels de services Web sortants qu'elle peut passer, et bien plus encore. Les requêtes individuelles que l'optimiseur de la plate-forme considère comme trop coûteuses à exécuter renvoient une exception d'exécution à l'appelant. Bien que ces limites puissent sembler quelque peu restrictives, elles sont nécessaires pour protéger l'évolutivité et les performances générales du système de base de données partagée pour toutes les applications concernées. À long terme, ces mesures contribuent à promouvoir de meilleures techniques de codage chez les développeurs et à créer une meilleure expérience pour tous ceux qui utilisent la plate-forme. Par exemple, un développeur qui tente initialement de coder une boucle qui met à jour inefficacement mille lignes une ligne à la fois reçoit des exceptions d'exécution en raison des limitations en ressources, puis commence à utiliser les appels d'API de traitement en masse efficaces de la plate-forme.
Pour éviter les problèmes système potentiels introduits par des applications mal écrites, le déploiement d'une nouvelle application de production est un processus strictement géré. Avant qu'une organisation puisse passer d'un statut de développement à un statut de production, Salesforce exige des tests unitaires qui valident la fonctionnalité des routines de code de plate-forme de l'application. Les tests unitaires soumis doivent couvrir au moins 75 pour cent du code source de l'application.
Salesforce exécute les tests unitaires soumis dans l'environnement de développement sandbox de la plate-forme afin de déterminer si le code de l'application affectera négativement les performances et l'évolutivité de la population multilocataire en général. Les résultats d'un test unitaire individuel indiquent des informations de base, telles que le nombre total de lignes exécutées, ainsi que des informations spécifiques sur le code qui n'a pas été exécuté par le test.
Une fois le code d'une application certifié en production par Salesforce, le processus de déploiement de l'application consiste en une transaction unique qui copie toutes les métadonnées de l'application dans une instance de plate-forme de production et réexécute les tests unitaires correspondants. Si une partie du processus échoue, la plate-forme annule simplement la transaction et renvoie des exceptions pour faciliter le dépannage du problème.
Note : Salesforce réexécute les tests unitaires pour chaque application avec chaque version de développement de la plate-forme afin de déterminer proactivement si de nouvelles fonctionnalités système et des améliorations rompent les applications existantes.
Lorsqu'une application de production est en ligne, le profileur de performance intégré de la plate-forme l'analyse automatiquement et fournit des commentaires associés aux administrateurs. Les rapports d'analyse des performances contiennent des informations sur les requêtes lentes, les manipulations de données et les sous-programmes que vous pouvez consulter et utiliser pour ajuster les fonctionnalités de l'application. Le système consigne et renvoie également aux administrateurs des informations sur les exceptions d'exécution pour les aider à déboguer leurs applications.
Lorsqu'une application supprime un enregistrement d'un objet, la plate-forme marque simplement la ligne à supprimer en modifiant le champ IsDeleted de la ligne dans MTData. Cette action place effectivement la ligne dans ce qu'on appelle la _Corbeille. La plate-forme permet de restaurer les lignes sélectionnées de la Corbeille pendant 15 jours maximum avant de les retirer définitivement de MT_Data. La plate-forme limite le nombre total d'enregistrements qu'elle conserve pour une organisation en fonction des limites en stockage de cette organisation.
Lorsqu'une opération supprime un enregistrement parent impliqué dans une relation principal-détails, la plate-forme supprime automatiquement tous les enregistrements enfants associés, à condition que cela n'enfreigne aucune règle d'intégrité référentielle en place. Par exemple, lorsque vous supprimez une commande SalesOrder, la plate-forme applique automatiquement la suppression en cascade aux LineItems dépendants. Si vous restaurez ensuite un enregistrement parent depuis la Corbeille, le système restaure également automatiquement tous les enregistrements enfants.
Par contre, lorsque vous supprimez un enregistrement parent référencé impliqué dans une relation de référence, la plate-forme définit automatiquement toutes les clés dépendantes sur null. Si vous restaurez ensuite l'enregistrement parent, la plate-forme restaure automatiquement les relations de référence précédemment nulles, à l'exception des relations qui ont été réattribuées entre les opérations de suppression et de restauration.
La Corbeille stocke également les champs abandonnés et leurs données jusqu'à ce qu'une organisation les supprime définitivement ou jusqu'à l'expiration d'un délai défini, selon le premier de ces événements. En attendant, le champ complet et toutes ses données peuvent être restaurés.
L'agilité est essentielle pour la réussite des entreprises dans notre monde moderne. Les couches sous-jacentes de Salesforce Platform aident vos applications métiers à s'adapter rapidement aux nouveaux défis afin de vous concentrer sur votre activité plutôt que sur l'infrastructure.
L'infrastructure (par exemple, les services de base et les ressources informatiques) est une technologie sous-jacente masquée qui prend en charge les couches supérieures dans Salesforce Platform. Hyperforce est l'infrastructure de Salesforce Platform, construite sur 100% d'énergie renouvelable et net-zero, qui résout les principaux défis des clients, notamment la conformité, Trust et l'évolutivité
Les entreprises qui opèrent dans plusieurs emplacements géographiques doivent se conformer à des réglementations nouvelles, évolutives et variables en matière de gestion des données. Comme Salesforce déploie Hyperforce dans un nombre croissant de pays, actuellement en fonction de la disponibilité de la région AWS, les applications de plate-forme et les utilisateurs peuvent exécuter leurs charges de travail confidentielles de manière à respecter des normes strictes de stockage des données ou de protection des données. Par exemple, avec la zone opérationnelle Union européenne (UE) propulsée par Hyperforce, les entreprises de l’UE peuvent aisément conserver leurs données dans l’UE.
La sécurité, la fiabilité et la disponibilité sont des exigences non fonctionnelles que chaque application métier doit prendre en compte pour tenir la promesse de Trust à ses utilisateurs finaux. Avec Hyperforce, Salesforce Platform permet aux entreprises de fournir aisément des applications métiers de confiance.
- Sécurité — Hyperforce crypte de bout en bout les données des clients au repos et en transit. L'architecture Zero Trust d'Hyperforce applique un processus strict de vérification de l'identité qui garantit l'absence d'accès implicite aux ressources. Hyperforce utilise le principe du moindre privilège, s'assurant que les opérations sont approuvées pour la durée appropriée avec le droit d'accès approprié.
- Fiabilité - Chaque instance d'Hyperforce utilise plusieurs zones de disponibilité dans le cloud et des approches modernisées qui accélèrent la réponse en incidence pour offrir une plate-forme hautement disponible et résiliente.
- Disponibilité — Les pipelines CI/CD modernes d’Hyperforce et les versions d’application bleues/vertes réduisent les périodes de maintenance des applications à une minute par an seulement.
En tant que base d'applications telles que Sales Cloud et Service Cloud, Salesforce est une plate-forme de développement d'applications éprouvée sur laquelle des entreprises individuelles et des fournisseurs de services ont élaboré des millions d'applications métiers pour divers cas d'utilisation, notamment la gestion de la chaîne d'approvisionnement, la facturation, la comptabilité, le commerce, le suivi de la conformité, la gestion des ressources humaines et le traitement des réclamations. L'architecture unique, multilocataire et pilotée par les métadonnées de la plate-forme est spécialement conçue pour le cloud, et prend en charge de façon fiable et sécurisée les applications critiques à l'échelle d'Internet. En utilisant des API basées sur des normes et des outils de développement natifs, les développeurs de plate-forme peuvent aisément élaborer tous les composants d'une application Web ou mobile moderne, y compris le modèle de données de l'application (y compris les objets et les relations), la logique métier (y compris les workflows et les validations), les intégrations à d'autres applications, et plus encore.
Depuis sa création, la plate-forme a été optimisée par les ingénieurs de Salesforce pour la multilocation, avec des fonctionnalités qui permettent aux applications de la plate-forme de s'adapter à l'évolution des demandes métiers. Des fonctionnalités système intégrées — telles que l'API de traitement des données en masse, Apex, un moteur de recherche en texte intégral et un optimiseur de requête unique — aident à rendre les applications dépendantes très efficaces et évolutives sans effort ou presque des développeurs.
L'approche gérée de Salesforce pour le déploiement d'applications de production garantit d'excellentes performances, l'évolutivité et la fiabilité de toutes les applications qui s'appuient sur la plate-forme. Salesforce surveille et recueille en permanence des informations opérationnelles à partir des applications de plate-forme afin de favoriser des améliorations incrémentielles et de nouvelles fonctionnalités système qui profitent immédiatement aux applications existantes et nouvelles.
Steve Bobrowski est un entrepreneur à succès et un leader technologique qui a travaillé pour de nombreuses grandes sociétés de logiciels d'entreprise, y compris divers rôles dans Salesforce depuis 2008. Aujourd'hui, Steve travaille au bureau du directeur technique de Salesforce pour aider à définir les stratégies d'architecture technologique de l'entreprise.
Tom Leddy est architecte évangéliste chez Salesforce. Il soutient la communauté internationale des architectes Salesforce en aidant à créer des ressources, des outils et des guides qui aident les architectes à faire de leur mieux. Contactez Tom sur Twitter.