Utilisation des outils et schémas appropriés pour les architectures pilotées par les événements
Les architectures pilotées par l'événement prennent en charge la production et la consommation efficaces d'événements, qui communiquent les changements d'état du système ou de l'application. Ces architectures permettent des connexions flexibles entre les systèmes, et prennent en charge les processus et les mises à jour en temps quasi réel qui fonctionnent entre les systèmes. Les avantages des architectures pilotées par l'événement sont faciles à voir, mais les détails d'implémentation ne sont pas toujours aussi clairs. Quelles capacités devez-vous prendre en compte dans les modèles architecturaux pilotés par l'événement ? Quels problèmes spécifiques ces schémas résolvent-ils ? Quelles considérations particulières s'appliquent à vos solutions et quels sont les modèles optimaux pour les résoudre ?
Ce guide présente les modèles utilisés pour élaborer des architectures pilotées par les événements optimales lors de l'utilisation de technologies Salesforce. Il traite également des outils de concours complet disponibles dans Salesforce et fournit des recommandations d'outils pour une sélection de cas d'utilisation. Pour plus d'informations sur les intégrations au niveau des données impliquant Salesforce, consultez notre Data Integration Decision Guide.
-
Utilisez des architectures pilotées par l'événement pour les processus qui ne nécessitent pas de réponses synchrones aux requêtes. Les schémas présentés dans ce guide sont conçus pour la cohérence, l'évolutivité et la réutilisation des données, ce qui permet de réduire au minimum les dettes techniques à mesure que le paysage applicatif de votre organisation évolue. (Pour plus d'informations, consultez Bien archivé - Débit).
-
Si MuleSoft ou une autre solution Enterprise Service Bus (ESB) fait partie de votre paysage existant, utilisez-la dans la mesure du possible. Ces solutions sont spécialement conçues pour prendre en charge les modèles d'architecture pilotée par l'événement et offrent de puissantes capacités qui permettent de réutiliser les intégrations dans votre entreprise.
-
Utilisez l'API Pub/Sub pour les futurs modèles de publication/abonnement au lieu d'élaborer vos propres gestionnaires d'événements en utilisant d'autres API, notamment l'API Streaming. L'API Pub/Sub étant désormais globalement disponible, utilisez-la pour tous les nouveaux modèles de publication/abonnement. Planifiez la migration des communications d'événements existantes en utilisant d'autres API de plate-forme, telles que l'API Streaming ou des services Apex personnalisés, vers l'API Pub/Sub lorsque cela est possible.
-
Les événements de plate-forme et la Capture des données de modification (CDC) sont les mécanismes privilégiés pour publier les modifications des enregistrements et des champs qui doivent être consommés par d'autres systèmes. Nous recommandons de ne pas utiliser PushTopic et des événements génériques pour les nouvelles implémentations. Salesforce continuera de prendre en charge PushTopic et les événements génériques dans les limites des capacités fonctionnelles actuelles, mais n'envisage pas d'autres investissements dans cette technologie.
 |
Salesforce Platform est une plate-forme complète pilotée par l’IA qui unifie les employés, les agents IA autonomes, les données de l’entreprise et les applications dans un système unique et de confiance pour améliorer la productivité et l’expérience client. Il permet la création d'une "entreprise agentique" en connectant les applications Customer 360, Data Cloud, et Slack pour une automatisation de bout en bout. |
 |
MuleSoft est la plate-forme d'intégration leader de Salesforce qui permet aux organisations de connecter des applications, des données et des appareils à travers des environnements sur site et cloud. MuleSoft est une plate-forme qui fournit aux TI les plates-formes nécessaires pour déverrouiller les données entre les systèmes, développer des infrastructures d'intégration et d'automatisation évolutives, et créer rapidement des expériences connectées différenciées. |
Les architectures pilotées par l'événement (EDA) sont recommandées pour les scénarios qui nécessitent des notifications en temps quasi réel, la distribution de la charge de traitement pour les messages à haut volume ou complexes, et l'intégration de systèmes tels que l'Internet des objets et les appareils mobiles qui nécessitent une résilience de la connectivité via la mise en file d'attente. Cependant, les AED ne devraient pas être mises en oeuvre pour des processus qui nécessitent des réponses humaines immédiates et synchrones, car elles sont conçues pour une exécution asynchrone. Elles ne conviennent pas non plus si les données sources changent si rarement qu'un schéma plus simple, tel que le traitement par lot, suffit.
Voici plusieurs scénarios courants qui conviennent souvent à une architecture pilotée par l'événement :
| Point de décision | Guide |
|---|---|
| Notifications en temps quasi réel | Les modèles d'architecture pilotée par l'événement, tels que publier/s'abonner, fanout et streaming, fonctionnent généralement bien dans les scénarios où plusieurs applications doivent être notifiées en temps quasi réel des changements de statut ou des mises à jour d'enregistrement. |
| Traitement parallèle | Les modèles tels que publier/s'abonner fonctionnent généralement bien dans les scénarios où des volumes de données importants ou des messages très complexes nécessitent de distribuer la charge de traitement entre plusieurs systèmes. |
| Lectures à haut volume | Les modèles Messages transmis et File d'attente sont fréquemment utilisés dans les situations où les organisations subissent des augmentations et où le volume de messages produits peut dépasser la capacité des abonnés à les traiter immédiatement. |
| Écritures à haut volume | Les schémas Streaming et Queuing fonctionnent bien dans de nombreux scénarios où les organisations subissent une augmentation du nombre de messages produits. |
| Envoi des mêmes données à différents systèmes | Bien que publier/s'abonner tende à être une solution assez courante pour les organisations qui doivent envoyer les mêmes données à plusieurs systèmes, elle peut être traitée par la plupart des modèles couverts ici. Assurez-vous de les examiner en détail pour trouver le meilleur ajustement. |
| Introduction fréquente de nouveaux systèmes ou dispositifs | Les schémas Publier/S'abonner, Streaming et File d'attente fonctionnent généralement bien dans les scénarios où le paysage global tend à évoluer, avec de nouveaux systèmes et appareils ajoutés régulièrement. Dans ce scénario, un nouveau système ou appareil doit simplement devenir abonné au bus d'événement ou associé à une file d'attente, pour commencer à recevoir des messages plutôt que de demander une intégration point à point personnalisée. |
| Appareils Internet des objets | Les appareils Internet des objets fournissent généralement des mises à jour fréquentes et peuvent également générer une augmentation des messages dans certains scénarios. Par conséquent, les modèles Streaming et Queuing fonctionnent généralement bien lors de leur intégration dans un paysage informatique. |
| Appareils et systèmes mobiles hors ligne | Les appareils mobiles qui doivent travailler dans des zones avec un accès Internet de faible qualité ou inexistant, ou des systèmes qui peuvent être hors ligne au moment de la remise des messages, bénéficieront du modèle Queuing, qui leur permet de se connecter à leurs files d'attente et de récupérer tous les messages pertinents une fois de retour en ligne. |
La plupart des grandes organisations ont des paysages informatiques complexes qui combinent des systèmes avec différentes capacités. Il est possible, ou peut-être probable, que votre organisation ait des systèmes hérités qui ne prennent pas en charge les intégrations pilotées par l'événement. Vous pouvez également avoir des cas d'utilisation où les intégrations pilotées par l'événement ne sont pas logiques, même si les systèmes les prennent en charge (par exemple, les transferts de fichiers SFTP de tiers). Si vous prenez un peu de recul et examinez le paysage informatique de votre organisation dans son ensemble, il est probable que, comme avec d'autres solutions architecturales, vous emploierez une combinaison de modèles pour prendre en charge différents scénarios. Lorsque vous choisissez de définir l'approche pilotée par l'événement comme votre approche préférée des intégrations, considérez-la comme un autre outil dans votre boîte à outils. Elle peut et doit être utilisée dans les scénarios appropriés, mais ce n'est pas une approche à imposer à chaque système. Le développement d'une stratégie d'intégration complète vous aidera à déterminer quand les modèles décrits dans ce guide peuvent être appropriés ou non.
De nombreux scénarios font appel à des architectures pilotées par l'événement, et dans certains cas, les architectures pilotées par l'événement fonctionnent même si elles ne sont pas adaptées. Cependant, dans certains scénarios, les architectures pilotées par l'événement ne doivent tout simplement pas être utilisées. Voici quelques questions de point de décision pour vous aider à identifier les scénarios suivants :
| Point de décision | Guide/Questions à poser |
|---|---|
| Exigences métiers | Existe-t-il un réel besoin métier pour l'une des fonctionnalités décrites dans la section [Quand utiliser une architecture pilotée par un événement] (#quand-utiliser-une-architecture-pilotée-par-un-événement) ? |
| Prescriptions techniques | L'intégration que vous concevez correspond-elle à un schéma différent, par exemple virtualisation des données, lot ou requête/réponse ? En d'autres termes, essayez-vous d'insérer une cheville carrée dans un trou rond ? |
| Processus exigeant que les humains attendent des réponses | Toute intégration impliquant un humain attendant une réponse du système cible n'est pas adaptée aux architectures pilotées par l'événement, car elles sont conçues pour une exécution asynchrone et ne peuvent pas garantir un temps de réponse. Déterminez si de tels processus sont optimaux pour votre organisation avant d'implémenter des solutions techniques. Pour plus d'informations, consultez [Well-Architected - Process Design](/docs/architect/fr-fr/well-architected/guide/automated#conception-de-processus). |
| Données sources souvent modifiées | Si les données de votre système source changent si rarement que les mises à jour périodiques sont suffisantes, vous pouvez probablement simplifier votre architecture en utilisant [batch patterns] (https://developer.salesforce.com/docs/atlas.en-us.integration_patterns_and_practices.meta/integration_patterns_and_practices/integ_pat_batch_data_sync.htm) au lieu de modèles pilotés par l'événement. |
| Exigences de mise en œuvre | La majorité des systèmes impliqués dans votre solution prennent-ils en charge les architectures pilotées par les événements ? Que faudrait-il pour utiliser des architectures pilotées par l'événement avec les systèmes qui ne les prennent pas en charge (par exemple, mises à niveau, personnalisations ou middleware) ? Quel niveau d'effort serait nécessaire pour satisfaire à ces exigences? |
| Stabilité de la structure du message | À quelle fréquence vos structures de messages doivent-elles changer ? Quels systèmes seront touchés par un tel changement et quel sera le processus d'assainissement? |
| Gouvernance organisationnelle | Avez-vous mis en place une structure de gouvernance pour vous assurer que toutes les parties prenantes sont informées des changements apportés aux structures de messages, aux déclencheurs et à d'autres décisions liées à l'architecture et aux processus, et qu'elles sont en mesure d'y contribuer ? |
| Ensembles de compétences requis | Votre personnel a-t-il de l'expérience avec les architectures pilotées par les événements et saura-t-il comment les prendre en charge ? |
Il existe divers modèles d'architecture pilotée par l'événement. Certains modèles à usage général peuvent être appliqués dans des cas d'utilisation qui n'ont pas d'exigences particulières en plus d'être pilotés par l'événement. Par exemple, consultez Bien archivé - Interopérabilité. D'autres modèles s'appliquent aux cas d'utilisation spécifiques discutés ici, tels que les intégrations impliquant des volumes de données importants ou les scénarios qui nécessitent une rétention plus longue des messages.
Le tableau ci-dessous compare les attributs des modèles décrits dans ce document. Utilisez-le comme référence rapide lorsque vous devez identifier des modèles potentiels pour un cas d'utilisation donné.
| Modèle | Temps quasi réel | Copie de message unique | Garantie de livraison | Réduire la taille du message | Transformation des données |
|---|---|---|---|---|---|
| Publier / S'abonner | ✓ | ✓ | ✓ | ||
| Fanout | ✓ | ✓ | ✓ | ||
| Messages transmis | ✓ | ✓ | ✓ | ✓ | |
| Streaming | ✓ | ✓ | ✓ | ||
| Mise en file d'attente | ✓ | ✓ | ✓ |
Salesforce offre plusieurs outils pour vous aider à gérer vos cas d'utilisation pilotés par l'événement. Le tableau ci-dessous présente une vue d'ensemble des outils disponibles.
| Outil | Description | Compétences requises | |
|---|---|---|---|
| MuleSoft | Anypoint Platform | Plate-forme qui active l'intégration de données en utilisant des couches d'API. | Pro-code |
| Connecteur Salesforce Pub/Sub | Connecteur pour l'API Pub/Sub, qui fournit une interface unique de publication et d'abonnement aux événements de plate-forme, aux événements de surveillance des événements en temps réel et aux événements de capture des données de modification. | Pro-code | |
| Connecteur MuleSoft Anypoint JMS | Connecteur qui permet d'envoyer et de recevoir des messages dans des files d'attente et des rubriques pour n'importe quel service de messagerie qui implémente la spécification Java Message Service (JMS). | Pro-code | |
| Connecteur MuleSoft Anypoint Apache Kafka | Connecteur permettant de déplacer des données entre Apache Kafka et des applications et services d'entreprise. | Pro-code | |
| MuleSoft Anypoint Solace Connecteur | Un connecteur pour les courtiers d'événements Solace PubSub+ avec une intégration d'API native utilisant le kit de développement Java JCSMP | Pro-code | |
| Connecteur MuleSoft Anypoint MQ | Un service de messagerie cloud multilocataire qui permet aux clients d'effectuer une messagerie asynchrone avancée entre leurs applications. | Pro-code | |
| Connecteur MQTT MuleSoft Anypoint | Une extension MuleSoft conforme au protocole MQTT (Message Queuing Telemetry Transport) v3.x. | Pro-code | |
| Connecteur MuleSoft Anypoint AMQP | Un connecteur qui permet à votre application de publier et de consommer des messages en utilisant un courtier conforme AMQP 0.9.1. | Pro-code | |
| API MuleSoft Anypoint Event-Driven (ASync) | Langage agnostique du secteur d'activité qui prend en charge la publication d'API pilotées par l'événement en les séparant en couches événement, canal et transport. | Pro-code | |
| MuleSoft Anypoint MQ | Service de messagerie cloud multitenant qui permet aux clients d'effectuer une messagerie asynchrone avancée entre leurs applications. | Pro-code | |
| Flux de données MuleSoft Anypoint | Infrastructure disponible dans MuleSoft Anypoint pour la publication et l'abonnement à des données en continu. | Pro-code | |
| Salesforce Platform | Apache Kafka sur Heroku | Complément Heroku qui fournit Apache Kafka en tant que service avec une intégration complète de la plate-forme à la plate-forme Heroku. | Pro-code |
| Capture des données | Journal des événements de modification, qui publie les modifications apportées aux enregistrements Salesforce. Les modifications comprennent la création d'un enregistrement, la mise à jour d'un enregistrement existant, la suppression d'un enregistrement et l'annulation de la suppression d'un enregistrement. | Code faible à code pro | |
| Messages sortants | Actions qui envoient des messages XML à des points de terminaison externes lorsque les valeurs de champ sont mises à jour dans Salesforce. | Code faible | |
| Événements de plate-forme | Messages sécurisés et évolutifs contenant des données d'événement personnalisées. | Code faible à code pro | |
| API Pub/Sub | API qui active les abonnements aux événements de plate-forme, aux événements Capture des données de modification et/ou aux événements Surveillance des événements en temps réel. | Pro-code | |
| Relais d'événements | Permet l'envoi d'événements de plate-forme et d'événements de capture des données de modification depuis Salesforce vers Amazon EventBridge. Notez que les relais d'événements se connectent uniquement à AWS Eventbridge. | Code faible | |
Lorsqu'un enregistrement critique change d'état dans une application principale (par exemple, le statut d'une commande passe de « Traitement » à « Expédié »), plusieurs autres systèmes nécessitent probablement une notification en temps quasi réel pour effectuer leurs tâches respectives. Un besoin métier spécifique survient lorsque le volume de ces changements est élevé et que les messages sont complexes, ce qui rend les intégrations point à point traditionnelles difficiles à gérer. L'établissement de connexions fragiles et personnalisées pour chaque application dépendante entraîne une dette technique et empêche l'organisation d'évoluer rapidement. Une approche d'intégration robuste est nécessaire pour gérer ces synchronisations de données fréquentes sans coupler le système source directement à chaque système consommateur.
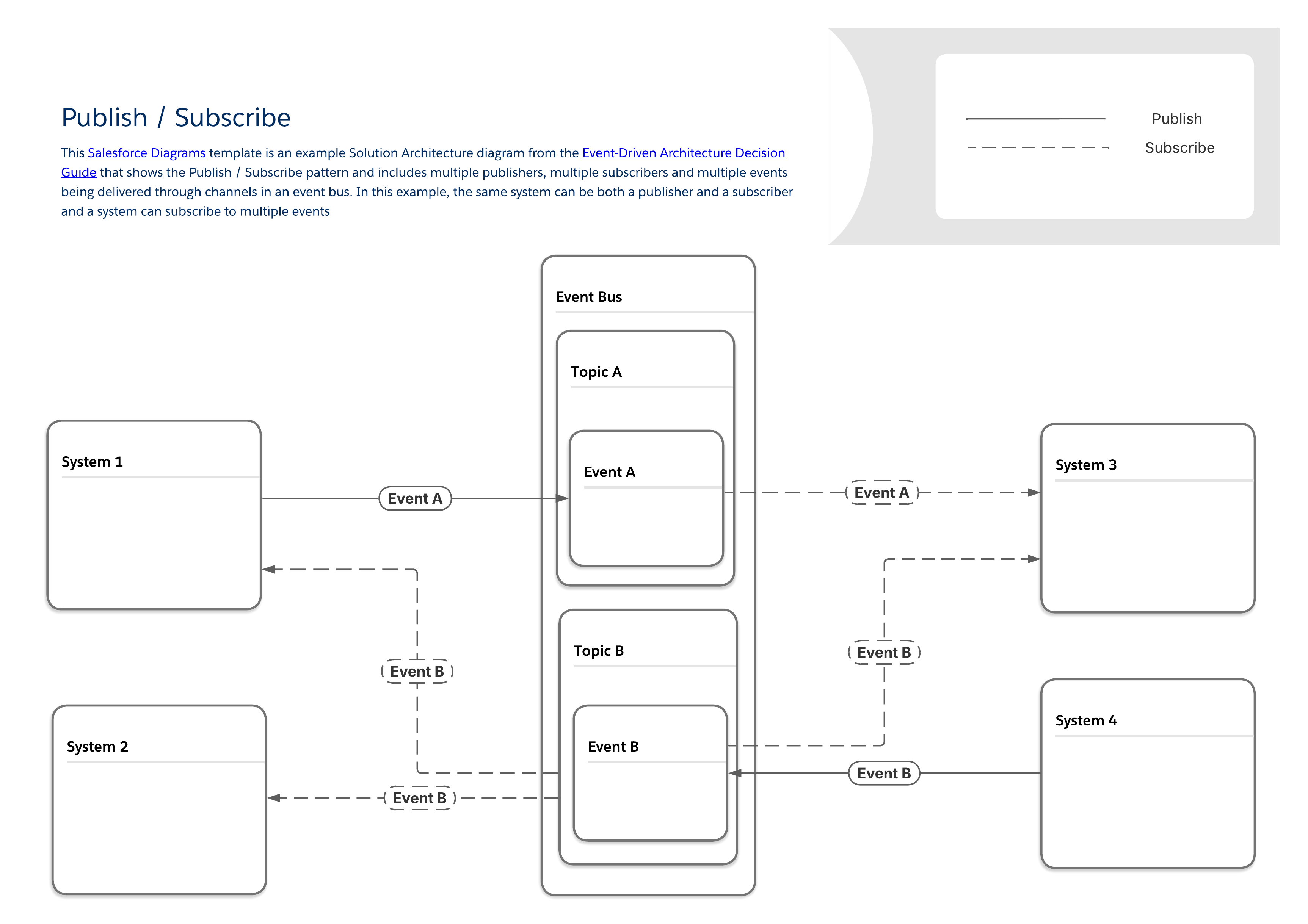
Le diagramme ci-dessous montre un modèle typique de publication/abonnement avec plusieurs éditeurs et abonnés qui partagent des données via un bus d'événement. Ce schéma de base constitue la base des schémas plus spécifiques que l'on peut trouver dans le reste de ce guide. Voici quelques caractéristiques clés de ce schéma :
-
Il n'existe aucun lien direct entre les éditeurs et les abonnés. Les éditeurs envoient simplement des messages à un bus d'événement, qui les diffuse vers tout autre système qui souhaite les écouter.
-
Le même système peut être à la fois éditeur et abonné.
-
Les systèmes peuvent publier ou s'abonner à plusieurs types d'événement.
-
Comme avec tous les modèles de ce guide, le modèle publier/s'abonner appartient à une catégorie générale de modèle d'intégration appelée invocation de procédure à distance (RPI) ou simplement « virer et oublier ».
| Flux et comportement des événements | Considérations relatives à la charge de travail | ||||||
|---|---|---|---|---|---|---|---|
| Outils disponibles | Compétences requises | Publier via | S'abonner via | Période de relecture | Structure de la charge utile | Limites de charge utile | |
| MuleSoft | Anypoint Platform | Pro-code | API | API | Configuré | Utilisateur défini | Aucun |
| Connecteur Salesforce Pub/Sub | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint JMS | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint Apache Kafka | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| MuleSoft Anypoint Solace Connecteur | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint MQ | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MQTT MuleSoft Anypoint | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint AMQP | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| API MuleSoft Anypoint Event-Driven (ASync) | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| MuleSoft Anypoint MQ | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Salesforce Platform | Apache Kafka sur Heroku | Pro-code | API, changements d'enregistrement dans Heroku Postgres | S.O. | 1 à 6 semaines | Utilisateur défini | Utilisateur défini |
| Capture des données | Code faible à code pro | Modifications d'enregistrement | Apex, API, Composants Web Lightning (LWC) | 3 jours | Prédéfini | 1 MB | |
| Messages sortants* | Code faible | Règles de flux et de workflow | S.O. | 24 heures | Utilisateur défini | 100 notifications par message | |
| Événements de plate-forme | Code faible à code pro | API, Apex, Flux | Apex, API, flux, LWC | 3 jours | Utilisateur défini | 1 MB | |
| API Pub/Sub | Pro-code | API Pub/Sub ou API, Apex, Flux | API Pub/Sub | 3 jours | Utilisateur défini | 1 MB | |
| Relais d'événements** | Code faible | Événements de plate-forme, Capture des données de modification | API | 3 jours | Utilisateur défini | 1 MB | |
| *Salesforce continuera de prendre en charge les messages sortants dans les limites des capacités fonctionnelles actuelles, mais n'envisage pas d'autres investissements dans cette technologie. **Les relais d'événements se connectent uniquement à AWS Eventbridge | |||||||
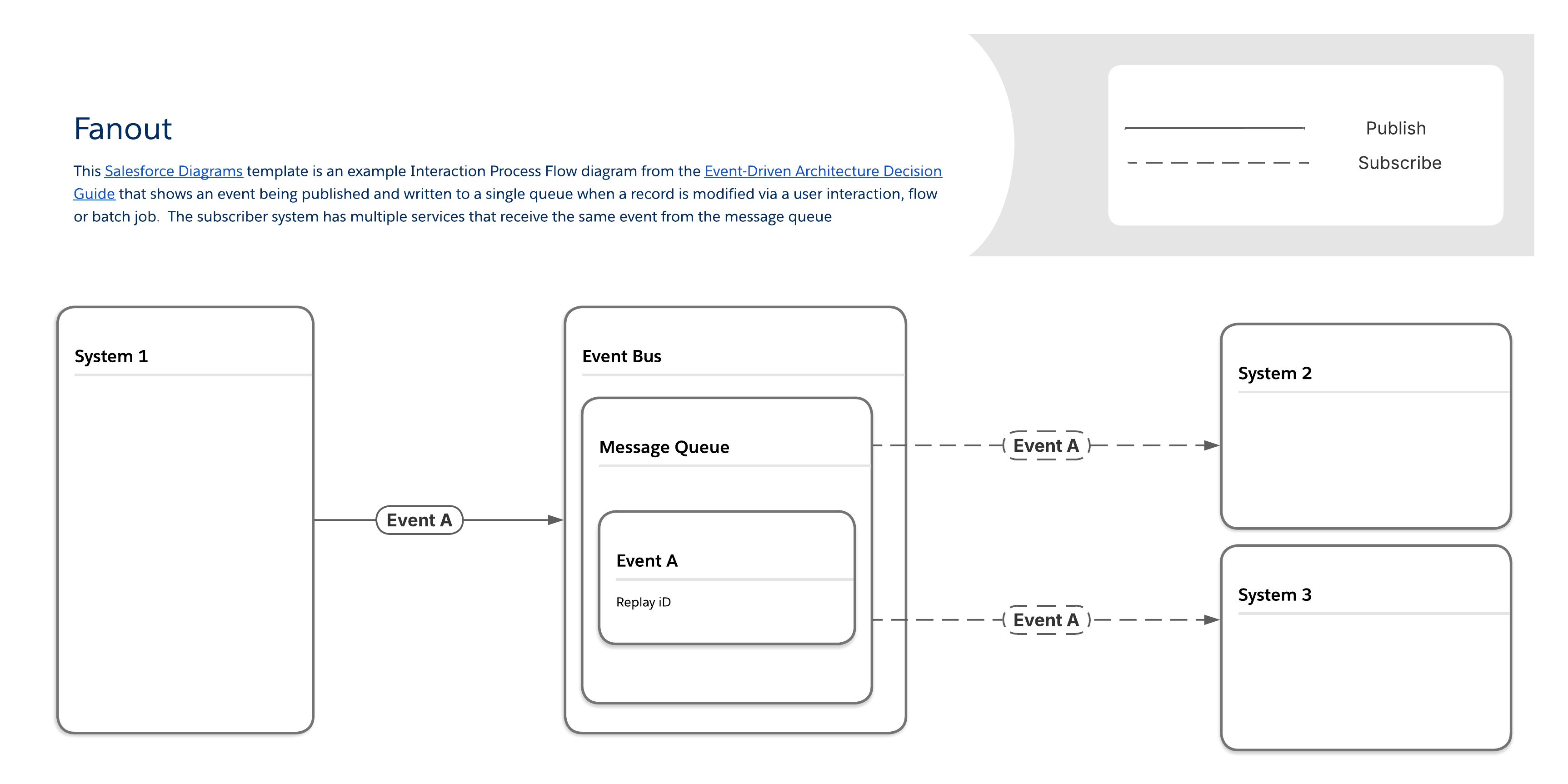
Lorsqu'une organisation doit envoyer des mises à jour instantanées à un grand nombre d'applications clientes, par exemple des notifications push ou des SMS sur des appareils mobiles, le processus traditionnel de création de transmissions uniques pour chaque destinataire devient rapidement un obstacle à l'évolutivité. Dans ce cas, le besoin métier principal est la distribution rapide et performante d'un seul élément d'information, par exemple une alerte de compte ou un avis de changement de service critique, simultanément à de nombreuses applications de point de terminaison. Une approche rationalisée pour satisfaire à cette exigence consiste à acheminer tous les messages à travers une file d'attente unique, qui agit comme le point central des informations sur les événements pour tous les systèmes consommateurs. Cette approche améliore les performances en éliminant la nécessité de gérer de nombreuses copies de messages séparées.
Avec le modèle fanout, les messages sont livrés à une ou plusieurs destinations (c'est-à-dire des clients ou des abonnés à l'écoute) via une file d'attente de messages unique. Les abonnés récupèrent le même message dans la file d'attente, plutôt que leur propre copie unique. (Notez que même si cela améliore les performances, il peut également être plus difficile de vérifier si un abonné particulier a reçu ou non le message).
| Flux et comportement des événements | Considérations relatives à la charge de travail | ||||||
|---|---|---|---|---|---|---|---|
| Outils disponibles | Compétences requises | Publier via | S'abonner via | Période de relecture | Structure de la charge utile | Limites de charge utile | |
| MuleSoft | Connecteur MuleSoft Anypoint JMS | Pro-code | API | API | Configuré | Utilisateur défini | Aucun |
| Connecteur Salesforce Pub/Sub | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint Apache Kafka | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| MuleSoft Anypoint Solace Connecteur | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint MQ | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MQTT MuleSoft Anypoint | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint AMQP | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| MuleSoft Anypoint MQ | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Salesforce Platform | Apache Kafka sur Heroku | Pro-code | API, changements d'enregistrement dans Heroku Postgres | S.O. | 1 à 6 semaines | Utilisateur défini | Utilisateur défini |
| Capture des données | Code faible à code pro | Modifications d'enregistrement | Apex, API, Composants Web Lightning (LWC) | 3 jours | Prédéfini | 1 MB | |
| Événements de plate-forme | Code faible à code pro | API, Apex, Flux | Apex, API, flux, LWC | 3 jours | Utilisateur défini | 1 MB | |
| API Pub/Sub | Pro-code | API Pub/Sub ou Apex, API, flux | API Pub/Sub | 3 jours | Utilisateur défini | 1 MB | |
| Relais d'événements* | Code faible | Événements de plate-forme, Capture des données de modification | API | 3 jours | Utilisateur défini | 1 MB | |
| *Les relais d'événements envoient uniquement des données à AWS Eventbridge | |||||||
Certains scénarios d'événement sont caractérisés par un afflux important de volume de messages qui menace de submerger la capacité des processus de synchronisation et de transformation, ou par une logique complexe à plusieurs étapes requise pour traiter et transformer les données d'événements.
Voici quelques exemples :
-
Pics de volume saisonniers : Il peut y avoir des pics de volume que les détaillants en ligne connaissent lorsqu'une sélection de leurs produits sont « en saison ». Lorsqu'un grand nombre de clients effectuent des achats en même temps, le nombre d'événements générés peut temporairement dépasser la capacité des processus de synchronisation et de transformation. Pour plus d'informations, consultez Bien archivé - Traitement des données.
-
Gestion des requêtes ou des réclamations : Les entreprises basées sur des services peuvent rencontrer des augmentations du nombre de requêtes ou de déclarations pendant les pannes.
-
Transformations de données complexes : Les organisations qui nécessitent une logique complexe pour transformer les messages craignent souvent que les événements soient générés plus rapidement qu'ils ne peuvent être transformés.
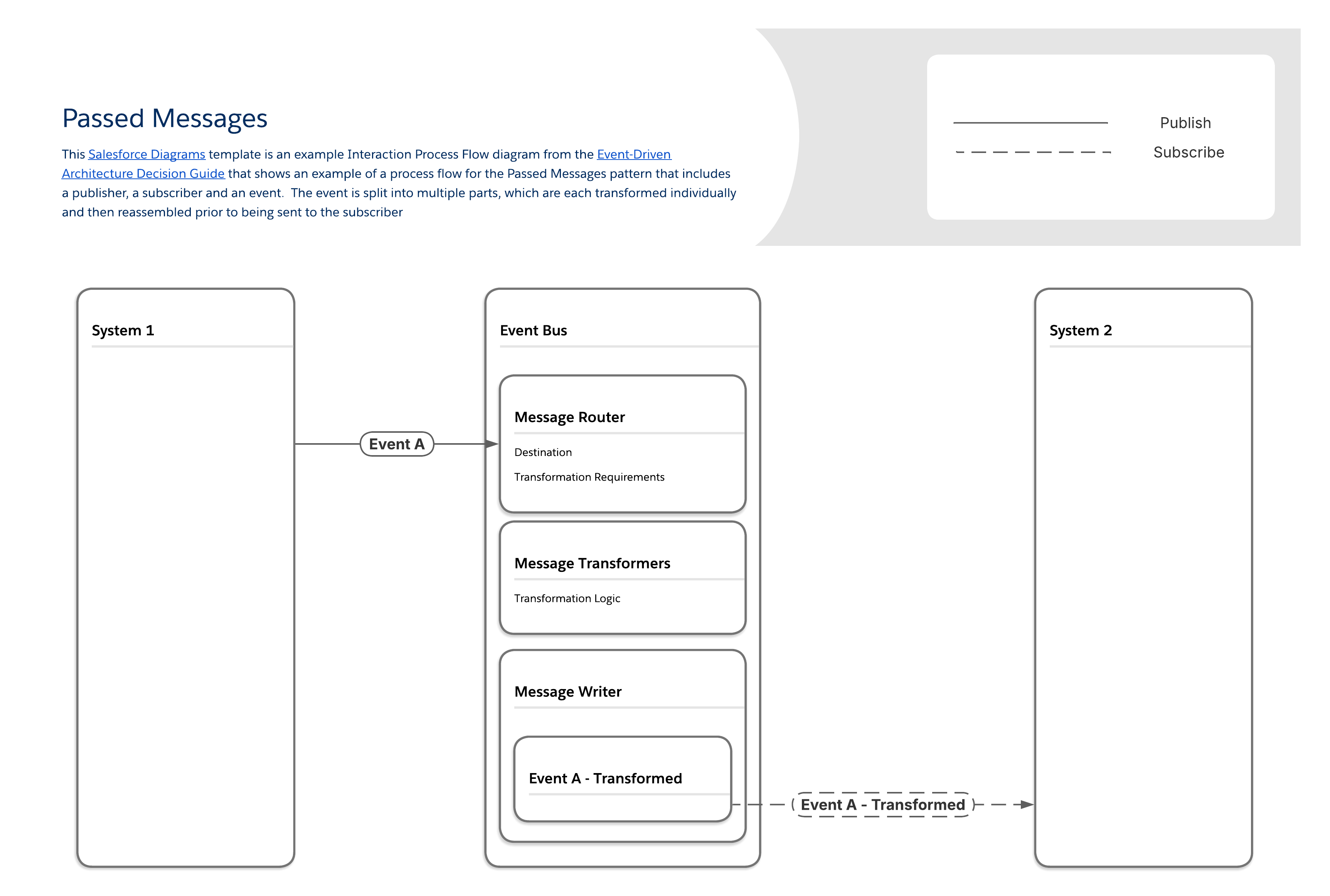
Ce schéma répond au défi de générer des messages plus rapidement qu'ils ne peuvent être transformés. Il garantit que les volumes importants de messages et les manipulations de données requises peuvent être traités de façon fiable, en incorporant une plate-forme de messagerie en continu et en segmentant la logique de traitement des messages dans des composants dédiés.
Le modèle Messages transmis fonctionne en segmentant la logique de traitement des messages en plusieurs composants :
-
Un composant gère l'acheminement des messages, détermine les transformations requises et la destination finale.
-
Un ensemble séparé de composants gère différentes couches de transformation de message (par exemple, mappages de champs, relations d'objet, etc.).
-
Le dernier composant écrit le message final modifié.
| Flux et comportement des événements | Considérations relatives à la charge de travail | ||||||
|---|---|---|---|---|---|---|---|
| Outils disponibles | Compétences requises | Publier via | S'abonner via | Période de relecture | Structure de la charge utile | Limites de charge utile | |
| MuleSoft | Connecteur MuleSoft Anypoint Apache Kafka | Pro-code | API | API | Configuré | Utilisateur défini | Aucun |
| Connecteur Salesforce Pub/Sub | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Salesforce Platform | Apache Kafka sur Heroku | Pro-code | API, changements d'enregistrement dans Heroku Postgres | S.O. | 1 à 6 semaines | Utilisateur défini | Utilisateur défini |
| Capture des données | Code faible à code pro | Modifications d'enregistrement | Apex, API, Composants Web Lightning (LWC) | 3 jours | Prédéfini | 1 MB | |
| Événements de plate-forme | Code faible à code pro | API, Apex, Flux | Apex, API, flux, LWC | 3 jours | Utilisateur défini | 1 MB | |
| API Pub/Sub | Pro-code | API Pub/Sub ou API, flux Apex | API Pub/Sub | 3 jours | Utilisateur défini | 1 MB | |
| Relais d'événements* | Code faible | Événements de plate-forme, Capture des données de modification | API | 3 jours | Utilisateur défini | 1 MB | |
| *Les relais d'événements envoient uniquement des données à AWS Eventbridge | |||||||
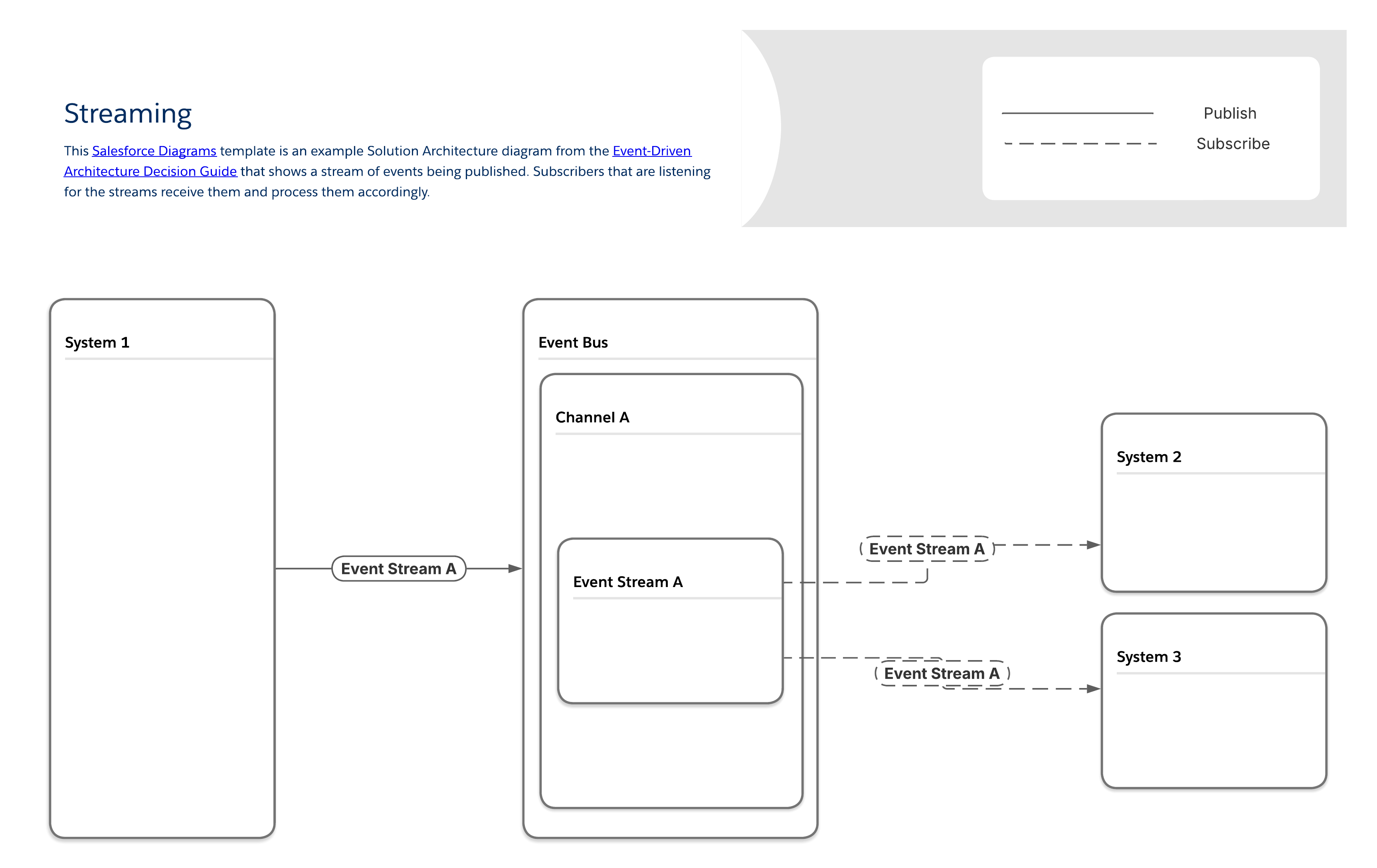
Certains producteurs génèrent un flux continu d'événements. Un exemple courant est le streaming média, qui implique des interactions utilisateur qui se produisent naturellement sous forme d'événements discrets. Plusieurs systèmes doivent réagir simultanément au même comportement des utilisateurs sans bloquer l'expérience principale de diffusion en continu.
Tenez compte des événements d'une plate-forme de streaming musical. Il peut s'agir de :
-
Suivre les événements démarrés/interrompus/ignorés
-
Événements de session d'écoute avec horodatage
-
Événements de création/modification de listes de lecture
-
Événements de partage social
-
Télécharger pour l'écoute hors ligne
Dans le schéma Streaming, les abonnés accèdent à chaque flux d'événements et traitent les événements dans l'ordre exact de réception. Des copies uniques de chaque flux de messages sont envoyées à chaque abonné, ce qui permet de livrer des contenus spécifiques à l'abonné et d'identifier les abonnés qui reçoivent les flux.
| Flux et comportement des événements | Considérations relatives à la charge de travail | ||||||
|---|---|---|---|---|---|---|---|
| Outils disponibles | Compétences requises | Publier via | S'abonner via | Période de relecture | Structure de la charge utile | Limites de charge utile | |
| MuleSoft | Flux de données MuleSoft Anypoint | Pro-code | API | API | Configuré | Utilisateur défini | Aucun |
| Connecteur Salesforce Pub/Sub | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint Apache Kafka | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Salesforce Platform | Apache Kafka sur Heroku | Pro-code | API, changements d'enregistrement dans Heroku Postgres | S.O. | 1 à 6 semaines | Utilisateur défini | Utilisateur défini |
| API Pub/Sub | Pro-code | API Pub/Sub ou API, flux Apex | API Pub/Sub | 3 jours | Utilisateur défini | 1 MB | |
Pour qu'un flux soit pertinent, tous ses événements et leurs messages associés doivent être dans l'ordre approprié. Si vous générez les données dans un flux à partir de différents systèmes, vous devez incorporer une logique de commande supplémentaire dans le processus de conception.
Les cas d'utilisation de mise en file d'attente sont omniprésents. Exemples :
-
Connexions Internet de faible qualité: Les organisations d'assistance sur site ou les autres organisations dans lesquelles les équipes avec des appareils mobiles doivent travailler dans des zones avec un accès Internet de mauvaise qualité ou intermittent bénéficient de la mise en file d'attente, car les applications sur ces appareils peuvent se connecter à leurs files d'attente et récupérer tous les messages pertinents lorsque la connectivité est rétablie.
-
Tamponnage du message : Lorsque le volume de messages dépasse occasionnellement la capacité de traitement d'un abonné et que l'augmentation de la latence ne crée pas de problèmes supplémentaires, les files d'attente peuvent servir de tampon pour stocker les messages excédentaires et éviter la perte de données.
-
Gestion des transports : Les organisations logistiques qui doivent surveiller leur flotte peuvent utiliser ce modèle pour visualiser les itinéraires que chaque véhicule suit en temps quasi réel et s'assurer que les conducteurs sont aussi efficaces que possible.
-
Appareils Internet des objets : Les fabricants utilisent souvent des systèmes qui génèrent des flux de données rapides, et ces flux peuvent avoir des effets en aval sur des systèmes supplémentaires. Ce schéma peut être utilisé pour identifier des séquences d'événements qui nécessitent une intervention humaine avant que des pannes catastrophiques ne surviennent dans plusieurs systèmes.
Dans le schéma File d'attente, les producteurs envoient des messages aux files d'attente, qui conservent les messages jusqu'à ce que les abonnés les récupèrent. La plupart des files d'attente de messages suivent l'ordre premier entré, premier sorti (FIFO) et suppriment chaque message une fois récupéré. Chaque abonné a une file d'attente unique, qui nécessite des étapes de configuration supplémentaires mais permet de garantir la livraison et d'identifier les abonnés qui ont reçu les messages.
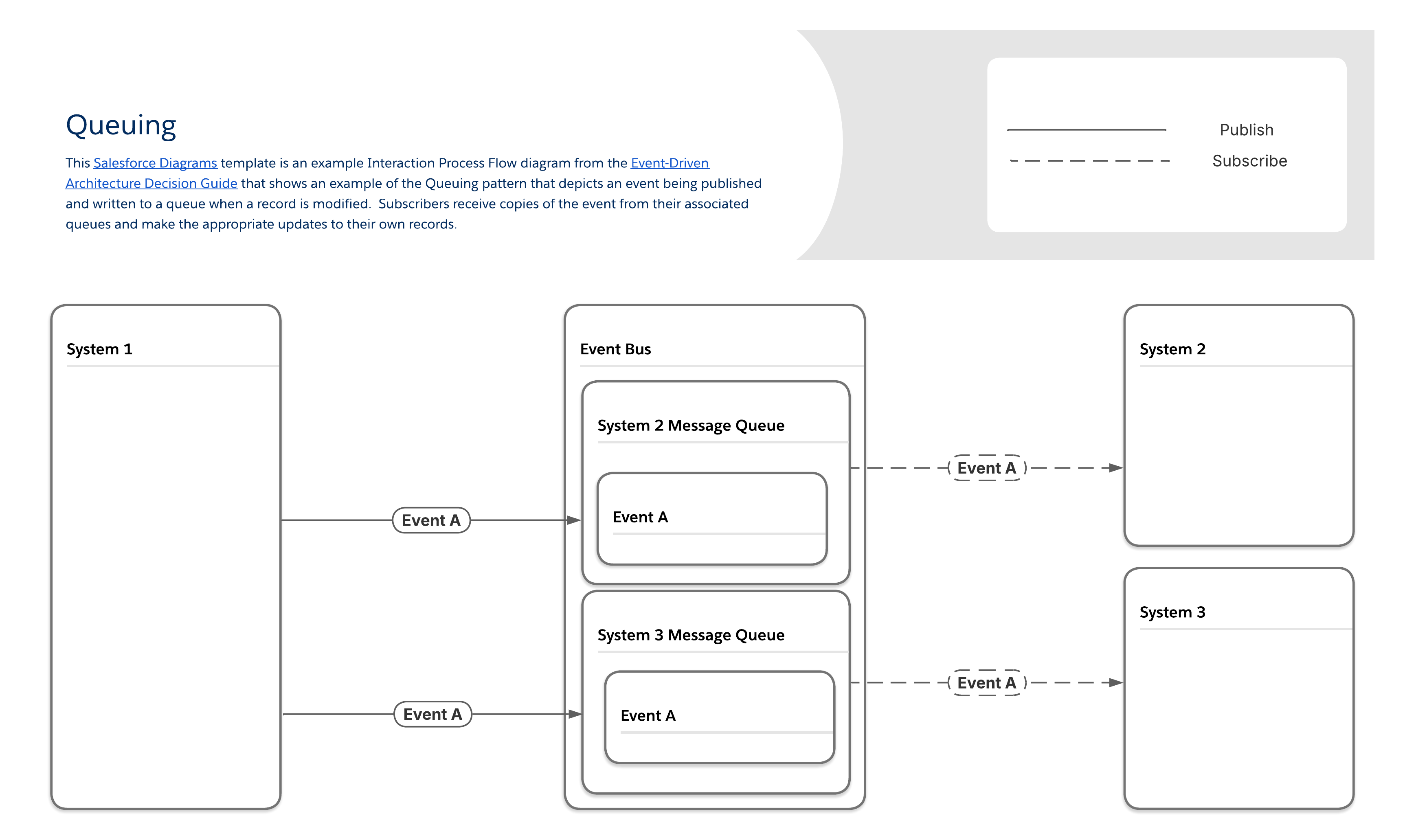
| Flux et comportement des événements | Considérations relatives à la charge de travail | ||||||
|---|---|---|---|---|---|---|---|
| Outils disponibles | Compétences requises | Publier via | S'abonner via | Période de relecture | Structure de la charge utile | Limites de charge utile | |
| MuleSoft | MuleSoft Anypoint MQ | Pro-code | API | API | Configuré | Utilisateur défini | Aucun |
| Connecteur Salesforce Pub/Sub | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint Apache Kafka | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint MQ | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MQTT MuleSoft Anypoint | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Connecteur MuleSoft Anypoint AMQP | Pro-code | API | API | Configuré | Utilisateur défini | Aucun | |
| Salesforce Platform | Apache Kafka sur Heroku | Pro-code | API, changements d'enregistrement dans Heroku Postgres | S.O. | 1 à 6 semaines | Utilisateur défini | Utilisateur défini |
| Capture des données | Code faible à code pro | Modifications d'enregistrement | Apex, API, Composants Web Lightning (LWC) | 3 jours | Prédéfini | 1 MB | |
| Événements de plate-forme | Code faible à code pro | API, Apex, Flux | Apex, API, flux, LWC | 3 jours | Utilisateur défini | 1 MB | |
| API Pub/Sub | Pro-code | API Pub/Sub ou API, Apex, Flux | API Pub/Sub | 3 jours | Utilisateur défini | 1 MB | |
| Relais d'événements* | Code faible | Événements de plate-forme, Capture des données de modification | API | 3 jours | Utilisateur défini | 1 MB | |
| *Les relais d'événements envoient uniquement des données à AWS Eventbridge | |||||||
En raison de la nature asynchrone du modèle Queuing, un délai important peut exister entre l'ajout d'un message à une file d'attente et sa récupération. Les files d'attente nécessitent de la mémoire ou de l'espace de stockage pour contenir leurs messages. Par conséquent, elles ne peuvent pas s'allonger indéfiniment, ce qui signifie qu'un abonné hors ligne indéfiniment peut entraîner un échec si suffisamment de messages s'accumulent dans la file d'attente. La mise en mémoire tampon des messages peut avoir le même effet si les temps de traitement des abonnés deviennent trop longs, ce qui entraîne l'accumulation de volumes importants de messages dans leurs files d'attente. Pour atténuer ces risques, effectuez une analyse approfondie des besoins en stockage de toutes les files d'attente de messages et, si nécessaire, concevez des processus qui purgent et désactivent les files d'attente si les messages ne sont pas récupérés dans un délai donné ou lorsqu'ils atteignent un volume prédéterminé.
Même si vous êtes convaincu qu'une architecture pilotée par l'événement convient à votre organisation, vous commencez peut-être par un paysage qui contient déjà un grand nombre d'intégrations de point à point. Obtenir le financement d'un projet pour remplacer toutes vos intégrations à la fois peut s'avérer difficile, et il peut même ne pas être possible d'utiliser une architecture pilotée par l'événement directement avec certains systèmes hérités. Dans ces scénarios, vous pouvez adopter une approche incrémentielle pour migrer vers une architecture plus vaguement couplée en convertissant d'abord les applications les plus critiques de l'entreprise, puis en convertissant d'autres systèmes à mesure qu'ils sont mis à jour ou remplacés dans de futurs projets. Cette approche facilite l'ajout de nouvelles applications au bus d'événements, et permet à votre paysage informatique global de rester évolutif et résilient à mesure que les systèmes s'ajoutent au fil du temps.
En tant qu'architectes, nous savons que chaque architecture est associée à des compromis. Une architecture pilotée par l'événement ne fait pas exception. Bien qu'un paysage rempli de systèmes peu couplés soit hautement évolutif et résilient, il y a aussi quelques compromis à prendre en compte :
-
Stratégie globale d'intégration : Quels que soient les outils et les modèles que vous choisissez d'utiliser, il est important de commencer par créer une stratégie pour le partage des données entre les divers systèmes du paysage de votre organisation. Cette stratégie doit inclure les objectifs de votre organisation concernant ses données, la façon dont les données peuvent être partagées et les modèles utilisés, ainsi que les sources de données, les cibles, les structures, et les exigences de propriété et d'accès.
-
Prise en charge des systèmes hérités : Votre organisation peut avoir des systèmes hérités qui ne prennent tout simplement pas en charge les modèles d'architecture pilotée par l'événement. Bien qu'il soit possible d'élaborer des contournements (par exemple, avec un processus qui agit comme une transmission en s'abonnant à des événements, puis en envoyant la sortie au système cible via un autre moyen de transfert de données), vous pouvez envisager d'autres méthodes d'intégration dans ce cas.
-
Modifications structurelles des messages : Une fois la structure initiale des messages définie et acceptée entre les éditeurs et les abonnés, il peut être difficile de la modifier, en particulier si les abonnés sont externes. Il existe plusieurs façons de résoudre ce problème. Vous pouvez utiliser des points de terminaison versionnés, mais assurez-vous de définir et de communiquer un cycle de vie clair pour chaque version afin d'éviter à vos développeurs de gérer un trop grand nombre de versions simultanément. Si Apache Kafka on Heroku fait partie de votre paysage, vous pouvez également envisager un registre de schéma ou un outil similaire, mais assurez-vous que les autres systèmes de votre paysage le prennent en charge (et l'utilisent également).
-
Manque de visibilité entre les éditeurs et les abonnés : Dans la plupart des modèles d'architecture pilotée par l'événement, les éditeurs ne connaissent pas le statut de leurs abonnés. Par conséquent, si un éditeur envoie un message critique alors que tous les abonnés sont hors ligne, le message peut ne jamais être remis. Vous pouvez résoudre ce problème en utilisant la fonctionnalité de relecture ou en ajoutant des abonnés redondants exécutés sur des serveurs séparés pour tous les messages critiques.
-
Goulots d'étranglement des performances : À mesure qu'une architecture pilotée par l'événement évolue, le bus d'événement peut devenir un goulot d'étranglement pour la remise de messages s'il est submergé par un trop grand nombre d'éditeurs qui tentent d'envoyer simultanément des messages à un trop grand nombre d'abonnés. Vous pouvez y remédier en augmentant la mémoire et les ressources de traitement allouées au bus d'événement ou en utilisant plusieurs bus d'événement pour traiter différents types de message en parallèle.
Avant d'implémenter une architecture pilotée par l'événement, déterminez si vous devez vraiment l'utiliser. La section précédente décrit des scénarios métiers courants adaptés à chaque modèle d'architecture pilotée par l'événement. Vous pouvez également lire plus dans Bien Architecté - Interopérabilité. Examinez les défis à prendre en compte lors de l'implémentation d'architectures pilotées par l'événement afin de déterminer si les modèles que vous envisagez conviennent le mieux à vos cas d'utilisation spécifiques.
Notez que bien que la majorité des scénarios présentés dans ce guide impliquent des intégrations, les architectures pilotées par l'événement peuvent également être utilisées pour envoyer des messages dans une seule organisation Salesforce en utilisant par exemple des événements de plate-forme. Assurez-vous de tenir compte des limites en allocations d'événements applicables lors de la conception de processus qui utilisent des événements de plate-forme en tant que système de messagerie interne.
Souvent, les anti-modèles autour des architectures pilotées par l'événement proviennent de l'utilisation d'événements comme contournement pour les communications internes dans une organisation Salesforce. Les anti-modèles courants comprennent :
-
La publication d'événements à partir de déclencheurs Apex associés au même objet événement: Cela entraînera une boucle de déclenchement infinie.
-
La publication d'événements depuis Apex avant la fin d'une transaction DML: Si une transaction échoue et est annulée, tous les événements publiés qui ont le comportement Publier immédiatement ne sont pas inclus dans le comportement d'annulation.
-
Publication d'événements dans Flux pour orchestrer une automatisation ultérieure : Pour coordonner la logique entre plusieurs automatisations, la meilleure méthode consiste à utiliser des flux secondaires ou des Orchestrateurs de flux.
-
Création de dépendances d'exécution : Ne publiez pas d'événements pour faciliter la communication entre les packages sans prendre les mesures appropriées pour éliminer les dépendances à l'exécution.
-
Charges utiles inutilement importantes : Lors de requêtes, il est préférable d'envoyer et de recevoir le plus petit volume de données possible dans la charge utile. Chaque action d'un utilisateur peut potentiellement générer plusieurs requêtes, et il est important que celles-ci soient traitées efficacement. L'envoi d'un plus grand nombre de données que nécessaire peut ralentir le transport et augmenter le temps de traitement.
-
Traitement non sélectif des événements d'application : Lorsque plusieurs composants écoutent un événement d'application, les développeurs doivent s'assurer que le gestionnaire d'événements est exécuté uniquement lorsque cela est réellement souhaité et utile. Par exemple, dans Lightning Console, les composants contenus dans des onglets qui ne sont pas au point peuvent toujours être en écoute même s'ils ne sont pas visibles. Un développeur peut utiliser diverses techniques, par exemple utiliser un élément utilitaire en arrière-plan comme seul auditeur, ou appeler getEnclosingTabId() pour déterminer si cette instance du composant est incluse dans l'onglet ciblé afin de s'assurer que chaque événement est géré uniquement lorsqu'il est prévu.
-
Le comportement de publication des événements de plate-forme est incorrect : Les événements de plate-forme ont deux comportements de publication : Publier immédiatement et Publier après validation. Il peut être utile d'utiliser des événements de plate-forme en temps réel pour des cas d'utilisation tels que la consignation, dans lesquels vous souhaitez publier l'événement de consignation, que la transaction réussisse ou non et qu'elle s'engage. Cependant, utilisez Publier immédiatement avec précaution avec des événements de plate-forme en temps réel. Les événements peuvent être consommés par les abonnés dans la même transaction et entraîner des verrouillages de ligne ou d'autres conditions de course.
Lors de l'implémentation d'une architecture pilotée par l'événement, l'une des clés du succès est de définir des normes pour la conception des événements eux-mêmes. Les détails varient selon les cas d'utilisation de votre organisation, mais voici quelques consignes générales :
-
Déterminez la structure optimale pour vos charges de travail d'événements. Bien que les tailles de message plus petites réduisent les temps de traitement, bombarder les abonnés avec des volumes massifs de messages peut entraîner des blocages dans les performances. Il peut être nécessaire d'itérer sur vos tailles et structures de charge utile pour trouver le bon équilibre. MuleSoft et les outils ESB similaires permettent de concevoir des charges de travail personnalisées dans les messages associés à vos événements, ce qui peut vous aider à visualiser les structures de données pour améliorer les performances côté abonné. (pour plus d'informations, consultez Bien archivé - Gestion des API).
-
Pensez à vos processus de bout en bout. Assurez-vous de ne pas créer de scénarios de « boucle sans fin », qui peuvent être difficiles à retrouver une fois les intégrations déployées. Par exemple, deux systèmes publient des événements lorsque les enregistrements sont mis à jour, tout en écoutant les événements de l'autre, qui déclenchent des événements publiés supplémentaires lorsqu'ils sont traités.
Vous pouvez corriger ce type d'anti-modèle en ajoutant une logique aux deux systèmes qui garantit que les modifications effectuées suite à un événement consommé n'entraînent pas la publication d'un nouvel événement. Assurez-vous également de documenter tous vos événements, leurs déclencheurs associés et les systèmes en aval qui peuvent être affectés. Utilisez cette documentation comme référence pendant les sessions de conception pour identifier le plus tôt possible des boucles interminables et des scénarios similaires. (Pour plus d'informations, consultez Bien archivé - Conception de processus).
-
Utilisez des conventions de nommage communes entre les systèmes. Des conventions de nommage cohérentes sont une meilleure pratique pour tous les développements de logiciels, y compris les architectures pilotées par les événements. Prenez le temps de documenter une série de normes pour les noms d'événements, les structures, les objets associés et les processus de traitement des erreurs afin de garantir la cohérence entre les systèmes. (Pour plus d'informations, consultez Bien archivé - Normes de conception).