Cada día, cientos de miles de empresas y millones de usuarios operan su negocio en la nube utilizando aplicaciones con tecnología de Salesforce Platform. ¿Por qué la plataforma tiene tanto éxito? ¿Por qué puede Trust it para apoyar su negocio? ¿Qué beneficios exclusivos proporciona la plataforma para negocios como el suyo?
Este resumen técnico explica cómo Salesforce Platform ofrece experiencias de usuario final fiables, ampliables y fáciles de personalizar utilizando su arquitectura de software exclusiva para computación en nube. Tras leer este resumen, comprenderá mejor la tecnología subyacente que hace de Salesforce Platform una opción atractiva para sus aplicaciones comerciales.
Salesforce Platform es el ejemplo preeminente de una plataforma de computación en nube exitosa y un ecosistema relacionado de aplicaciones. Desde el cambio de milenio, la plataforma ha sido la base propicia para:
- Muchas aplicaciones comerciales populares para casos de uso comunes como ventas y servicio al cliente
- Aplicaciones específicas del sector para casos de uso más especializados como finanzas y cuidados sanitarios
- Millones de aplicaciones personalizadas y extensiones para casos de uso exclusivos
En gran parte, Salesforce Platform es tan exitosa y popular porque su arquitectura de software exclusiva admite aplicaciones fáciles de crear, utilizar, personalizar y ampliar con un rendimiento y fiabilidad excepcionales. El núcleo de la arquitectura de software de la plataforma es su diseño dirigido por metadatos y multiusuario.
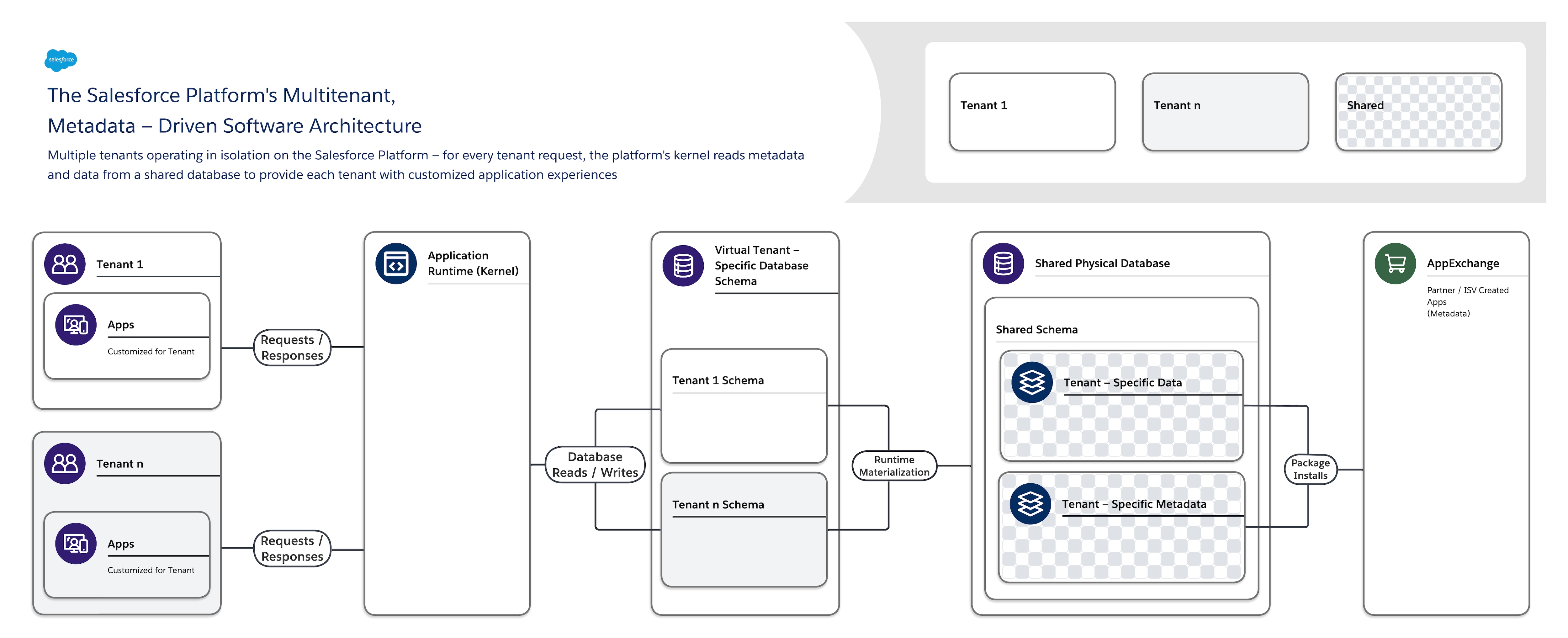
La arquitectura de software de Salesforce Platform es:
- Arrendatario múltiple: Aísla y admite simultáneamente los requisitos variables de muchos arrendatarios (organizaciones, unidades comerciales, etc.).
- Impulsado por metadatos: Permite a cada arrendatario personalizar fácil y rápidamente sus aplicaciones y experiencias de usuario utilizando metadatos, datos que describen elementos como la interfaz de usuario (UI) y la lógica comercial.
Cuando crea un nuevo objeto de aplicación o escribe algún código utilizando Salesforce Platform, la plataforma no crea una tabla real en una base de datos o compila ningún código. En su lugar, la plataforma simplemente almacena algunos metadatos que luego puede utilizar en tiempo de ejecución para materializar de forma dinámica componentes de aplicaciones virtuales. La plataforma garantiza que los metadatos de cada arrendatario sean privados y fáciles de actualizar sin ningún bloqueo o tiempo de inactividad requerido de modo que cada arrendatario pueda crear y personalizar aplicaciones de forma aislada. Salesforce Platform utiliza los mismos metadatos para proporcionar API personalizadas, interfaces RESTful y servicios web (basadas en SOAP) que puede utilizar para integrar sus aplicaciones con otras aplicaciones y procesos automatizados.
Las soluciones preparadas también están disponibles en AppExchange, el amplio mercado de aplicaciones de la plataforma. Construido por un vasto ecosistema de socios de confianza y proveedores de software independientes (ISV), un paquete AppExchange es metadatos de un tercero que describe extensiones de aplicación gratuitas o de pago y aplicaciones completas que puede utilizar para cumplir requisitos comerciales específicos.
Para dar cobertura a esta arquitectura altamente personalizable y ampliable, una única instancia de Salesforce Platform utiliza:
- Una única base de datos multiarrendatario compartida con un único esquema que almacena datos y metadatos específicos del arrendatario.
- Un núcleo multiusuario (tiempo de ejecución de la aplicación) que lee metadatos y datos para proporcionar de forma dinámica aplicaciones específicas del arrendatario, lógica comercial y API para los usuarios de cada arrendatario en tiempo de ejecución.
Esta clara separación del núcleo gestionado por Salesforce de los metadatos gestionados por el arrendatario hace posible que Salesforce, los arrendatarios y los ISV desarrollen de forma independiente sus partes del sistema sin interferencias.
Para basarse en esta descripción general, las secciones posteriores de este artículo proporcionan más detalles acerca de las funciones exclusivas de la plataforma que se derivan de aspectos clave de su diseño, incluyendo:
- La capa de datos de plataforma
- Desarrollo de aplicaciones de plataforma
- Procesamiento de plataforma interno
- Infraestructura de plataforma
Juntos, el tiempo de ejecución de la aplicación Salesforce Platform y la innovadora capa de datos aíslan de forma segura datos específicos del arrendatario, personalizaciones de esquemas y lógica comercial. A un alto nivel, el esquema admite una variedad de casos de uso:
- Cuando crea o personaliza una aplicación, la plataforma almacena metadatos relacionados en tablas de bases de datos compartidas que mantienen metadatos para todos los arrendatarios.
- Cuando utiliza una aplicación para leer o escribir datos, la plataforma almacena sus datos en tablas de bases de datos compartidas que mantienen datos para todos los arrendatarios.
- En segundo plano, la plataforma también mantiene metadatos internos en una serie de tablas que el núcleo utiliza para optimizar la latencia de solicitudes en tiempo de ejecución.
Pero, ¿cómo puede una única base de datos y esquema compartidos mantener los datos de cada arrendatario privados? Cada arrendatario en la plataforma se conoce como una organización u organización para abreviar. Además, cada registro específico de la organización en tablas de bases de datos compartidas tiene un Id. de organización. Cuando el núcleo accede a la base de datos, utiliza este identificador exclusivo para garantizar que las actividades de cada organización son privadas.

Los objetos específicos de la organización (piense en tablas en lenguaje de base de datos relacional tradicional), campos, procedimientos almacenados, desencadenadores de base de datos y mucho más son construcciones virtuales descritas por metadatos que la plataforma almacena en algunas tablas de base de datos conocidas como el Universal Data Dictionary (UDD).
- MT_Objects es una tabla de base de datos que almacena metadatos acerca de los objetos que define para una aplicación, incluyendo un identificador exclusivo para un objeto (ObjID), su organización (OrgID) y el nombre que da para el objeto (ObjName).
- La tabla del sistema MT_Fields almacena metadatos acerca de los campos (columnas) que declara para cada objeto, incluyendo un identificador exclusivo para un campo (FieldID), su organización (OrgID), el objeto que contiene el campo (ObjID), el nombre del campo (FieldName), el tipo de datos del campo, un valor booleano para indicar si el campo requiere indexación (IsIndexed) y la posición del campo en el objeto en relación con otros campos (FieldNum).
Debido a que los metadatos son un ingrediente clave, la plataforma debe optimizar el acceso a los metadatos; de lo contrario, el acceso frecuente a los metadatos evitaría la ampliación del servicio. Con este posible cuello de botella en mente, la plataforma utiliza memorias caché de metadatos masivas y sofisticadas para mantener los metadatos utilizados más recientemente en memoria, evitar las recompilaciones de código y E/S de disco que merman el rendimiento y mejorar los tiempos de respuesta de las aplicaciones.
La tabla del sistema MT_Data almacena los datos accesibles a la aplicación que se asignan a todas las tablas específicas de la organización y sus campos, como se define por los metadatos en MT_Objects y MT_Fields. Cada fila incluye campos de identificación, como un identificador exclusivo global (GUID), la organización propietaria de la fila (OrgID) y el identificador de objeto de inclusión (ObjID). Cada fila en la tabla MT_Data también tiene un campo Nombre que almacena un “nombre natural” para los registros correspondientes; por ejemplo, un registro Cuenta podría utilizar “Nombre de cuenta”, un registro Caso podría utilizar “Número de caso”, etc.
Valor0 ... Las columnas flexibles ValueN, también conocidas como divisiones, almacenan datos de aplicaciones que se asignan a las tablas y campos declarados en MT_Objects y MT_Fields, respectivamente. Todas las columnas flexibles utilizan un tipo de datos de cadena de longitud variable de modo que pueden almacenar cualquier tipo estructurado de datos de aplicación (cadenas, números, fechas, etc.). Como ilustra la siguiente figura, no hay dos campos del mismo objeto que puedan asignarse a la misma división en MT_Data para almacenamiento; sin embargo, una única división puede gestionar la información de múltiples campos, siempre que cada campo provenga de un objeto diferente.
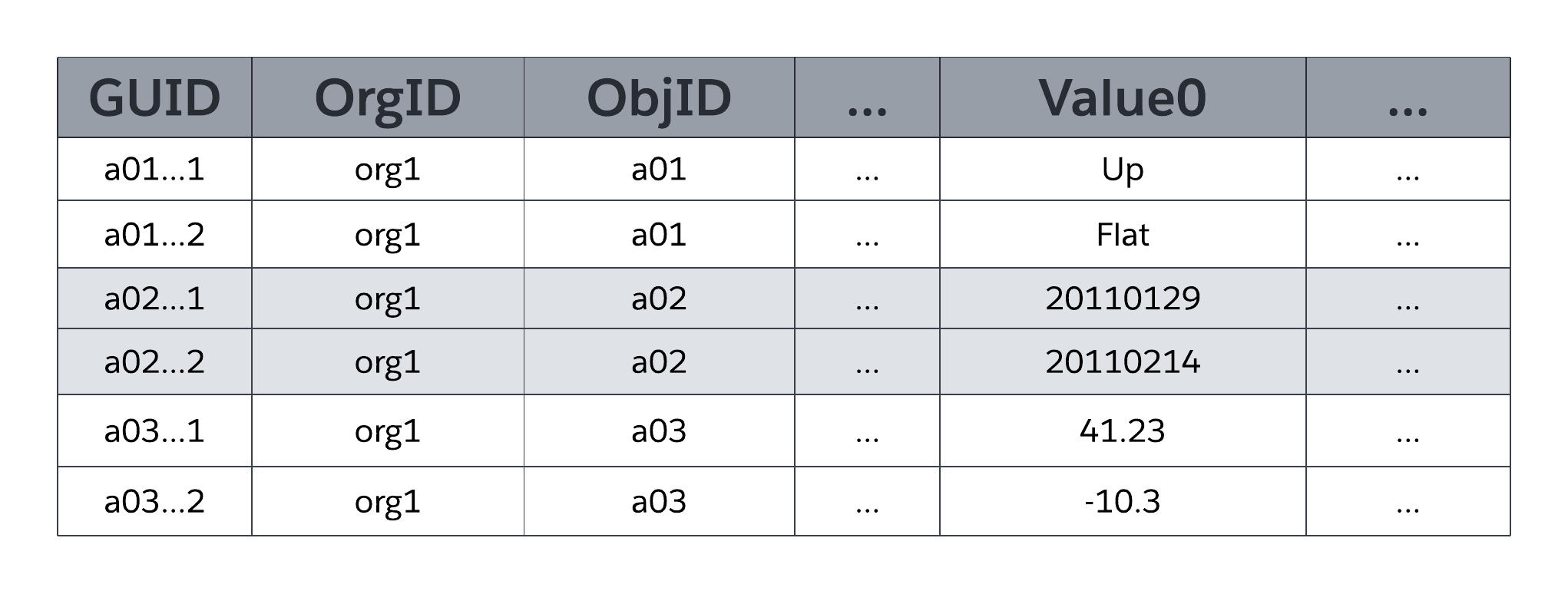
MTFields puede utilizar cualquiera de una serie de tipos de datos estructurados estándar como texto, número, fecha y fecha/hora, así como tipos de datos estructurados _rich de uso especial como lista de selección (campo enumerado), numeración automática (número de secuencia generado por el sistema e incrementado automáticamente), fórmula (valor derivado de solo lectura), relación principal-detalle (clave externa), casilla de verificación (booleana), correo electrónico, URL y otros. MT_Fields también puede ser obligatorio (no nulo) y tener reglas de validación personalizadas (por ejemplo, un campo debe ser mayor que otro campo), que la plataforma aplica.
Cuando declara o modifica un objeto, la plataforma gestiona una fila de metadatos en MT_Objects que define el objeto. Del mismo modo, para cada campo, la plataforma gestiona una fila en MT_Fields, incluyendo metadatos que asignan el campo a una columna flexible específica en MT_Data para el almacenamiento de datos de campo correspondientes. Debido a que la plataforma gestiona definiciones de objeto y campo como metadatos en vez de estructuras de base de datos reales, el sistema puede tolerar actividades de mantenimiento de esquemas de aplicaciones de múltiples arrendatarios en línea sin bloquear la actividad simultánea de otras organizaciones y usuarios. En comparación, la redefinición de tablas en línea para sistemas de base de datos relacionales tradicionales normalmente requiere bloqueos temporales y procesos a menudo laboriosos y complicados y tiempo de inactividad de aplicación programado.
Como muestra la representación simplificada de MT_Data en la figura anterior, las columnas flexibles son de un tipo de datos universal (cadena de longitud variable), lo que permite a la plataforma compartir una única columna flexible entre múltiples campos que utilizan varios tipos de datos estructurados (cadenas, números, fechas, etc.).
La plataforma almacena todos los datos de columnas flexibles utilizando un formato canónico y utiliza funciones de conversión de tipos de datos del sistema de base de datos subyacentes (por ejemplo, TO_NUMBER, TO_DATE, TO_CHAR) según sea necesario cuando las aplicaciones leen datos y redactan datos en columnas flexibles.
MTData también contiene columnas no mostradas en la figura anterior. Por ejemplo, existen cuatro columnas para gestionar datos de auditoría, incluyendo qué usuario creó una fila y cuándo se creó esa fila, qué usuario modificó por última vez una fila y cuándo se modificó por última vez esa fila. MT_Data también contiene una columna _IsDeleted que la plataforma utiliza para indicar cuándo se ha eliminado una fila.
La plataforma también admite la declaración de campos como objetos grandes (CLOB) para permitir el almacenamiento de campos de texto largo de hasta 32.000 caracteres. Para cada fila en MT Data que tiene un CLOB, la plataforma almacena el CLOB fuera de línea en una tabla denominada _MT_Clob, que el sistema puede unir con filas correspondientes en MT_Data según sea necesario.
Nota: La plataforma también almacena CLOB en un formulario indexado fuera de la base de datos para búsquedas de texto rápidas. Consulte Búsquedas para obtener más información acerca del motor de búsqueda de texto de la plataforma.
La plataforma indexa automáticamente varios tipos de campos para ofrecer un rendimiento ampliable.
Los sistemas de base de datos tradicionales se basan en índices de base de datos nativos para localizar rápidamente filas específicas en una tabla de base de datos que tienen campos que coinciden con una condición específica. Sin embargo, no es práctico crear índices de base de datos nativos para las columnas flexibles de MTData porque la plataforma utiliza una única columna flexible para almacenar los datos de muchos campos con diferentes tipos de datos estructurados. En su lugar, la plataforma gestiona un índice de MT_Data copiando de forma síncrona datos de campo marcados para indexar a una columna apropiada en una tabla dinámica _MT_Indexes.
MT_Indexes contiene columnas indexadas fuertemente tipificadas como StringValue, NumValue y DateValue que la plataforma utiliza para localizar datos de campo del tipo de datos correspondiente. Por ejemplo, la plataforma copiaría un valor de cadena en una columna flexible MT_Data en el campo StringValue en MT_Indexes, un valor de fecha en el campo DateValue, etc. Los índices subyacentes de MT_Indexes son índices de base de datos estándar no exclusivos. Cuando una consulta interna del sistema incluye un parámetro de búsqueda que hace referencia a un campo estructurado en un objeto, el optimizador de consultas personalizado de la plataforma utiliza MT_Indexes para ayudar a optimizar las operaciones de acceso a datos asociadas.
Nota: La plataforma puede gestionar búsquedas en múltiples idiomas porque el sistema utiliza un algoritmo de plegado de casos que convierte valores de cadena a un formato universal que no distingue entre mayúsculas y minúsculas. La columna StringValue de la tabla MT_Indexes almacena valores de cadena en este formato. En tiempo de ejecución, el optimizador de consultas crea automáticamente operaciones de acceso a datos de modo que la instrucción SQL optimizada filtre en el StringValue plegado en caso correspondiente, que a su vez corresponde al literal proporcionado en la solicitud de búsqueda.
La plataforma le permite indicar cuándo un campo en un objeto debe contener valores exclusivos (distingue entre mayúsculas y minúsculas o no distingue entre mayúsculas y minúsculas). Teniendo en cuenta la disposición de MT_Data y el uso compartido de las columnas Valor para datos de campo, no es práctico crear índices de base de datos exclusivos para el objeto. (Esta situación es similar a la descrita en la sección anterior para índices no exclusivos.)
Para admitir la exclusividad para campos personalizados, la plataforma utiliza la tabla dinámica MT_Unique_Indexes; esta tabla es muy similar a la tabla MT_Indexes, excepto que los índices de base de datos nativos subyacentes de MT_Unique_Indexes aplican la exclusividad. Cuando una aplicación intenta insertar un valor duplicado en un campo que requiere exclusividad, o un administrador intenta aplicar la exclusividad en un campo existente que contiene valores duplicados, la plataforma devuelve un mensaje de error apropiado a la aplicación.
En raras circunstancias, el motor de búsqueda externo de la plataforma (explicado en Búsquedas) puede sobrecargarse o no estar disponible de otro modo, y es posible que no pueda responder a una solicitud de búsqueda de forma oportuna. En vez de devolver un error decepcionante al usuario final, la plataforma recurre a un mecanismo de búsqueda secundario para proporcionar resultados de búsqueda razonables.
Una búsqueda de reserva se implementa como una consulta de base de datos directa con condiciones de búsqueda que hacen referencia al campo Nombre de registros de destino. Para optimizar las búsquedas de objetos globales (búsquedas que abarcan tablas) sin necesidad de ejecutar consultas de unión potencialmente costosas, la plataforma mantiene una tabla dinámica MT_Fallback_Indexes que registra el Nombre de todos los registros. Las actualizaciones en MT_Fallback_Indexes se producen de forma síncrona a medida que las transacciones modifican registros de modo que las búsquedas de reserva siempre tienen acceso a la información de base de datos más actualizada.
La tabla MT_Name_Denorm es una tabla de datos delgados que almacena el ObjID y el Nombre de cada registro en MT_Data. Cuando una aplicación necesita proporcionar una lista de registros implicados en una relación principal/secundario, la plataforma utiliza la tabla MT_Name_Denorm para ejecutar una consulta relativamente sencilla que recupera el Nombre de cada registro de referencia para mostrar en la aplicación, por ejemplo como parte de un hipervínculo.
La plataforma proporciona tipos de datos de relación que una organización puede utilizar para declarar relaciones (integridad referencial) entre tablas. Cuando declara el campo de un objeto con un tipo de relación, la plataforma asigna el campo a un campo Valor en MT_Data y luego utiliza este campo para almacenar el ObjID de un objeto relacionado.
Para optimizar las operaciones de unión, la plataforma mantiene una tabla dinámica MT_Relationships. Esta tabla del sistema tiene dos índices compuestos exclusivos de la base de datos subyacentes que permiten desplazamientos de objetos eficientes en cualquier dirección, según sea necesario.
Con solo unos clics de ratón, la plataforma proporciona seguimiento del historial para cualquier campo. Cuando una organización activa la auditoría para un campo específico, el sistema registra asíncronamente información acerca de los cambios realizados en el campo (valores antiguos y nuevos, fecha de cambio, etc.) utilizando una tabla dinámica interna como seguimiento de auditoría.
Todos los datos de plataforma, metadatos y estructuras de tabla dinámica, incluyendo índices de base de datos subyacentes, se particionan físicamente por OrgID utilizando mecanismos de partición de base de datos nativos. La partición de datos es una técnica probada que los sistemas de base de datos proporcionan para dividir físicamente grandes estructuras de datos lógicos en partes más pequeñas y manejables. La partición también puede ayudar a mejorar el rendimiento, la capacidad de ampliación y la disponibilidad de un sistema de base de datos de gran tamaño, como un entorno multiusuario. Por definición, cada consulta de plataforma apunta a la información de una organización específica, de modo que el optimizador de consultas solo necesita considerar acceder a particiones de datos que contienen datos de una organización, en vez de una tabla o índice completos. Esta optimización común se conoce a veces como “podado de partición”.
Esta sección trata cómo los desarrolladores de aplicaciones pueden crear los metadatos subyacentes de un esquema y luego crear aplicaciones que gestionan datos. Esos metadatos y datos se almacenan en la capa de datos de plataforma descrita en la sección anterior.
Los desarrolladores pueden crear componentes de aplicación del lado del servidor de forma declarativa utilizando el entorno de desarrollo basado en navegador de la plataforma, comúnmente conocido como las pantallas de Configuración de plataforma. La interfaz de usuario de apuntar y hacer clic de Configuración admite todas las facetas del proceso de creación de esquemas de aplicación, como la creación del modelo de datos de una aplicación (incluyendo objetos y sus campos así como relaciones), el modelo de seguridad y colaboración (incluyendo usuarios, perfiles y jerarquías de funciones), la interfaz de usuario (incluyendo formatos de pantalla, formularios de entrada de datos e informes), la lógica declarativa (flujos de trabajo) y la lógica programática (procedimientos y desencadenadores almacenados). Por ejemplo, Salesforce Flow facilita la automatización de una amplia gama de casos de uso. La interfaz de usuario de Flow Builder de Configuración, que se muestra a continuación, le permite diseñar e implementar gráficamente flujos de trabajo que interactúan con usuarios, o se inician automáticamente basándose en una programación o cuando se desencadenan por un evento.
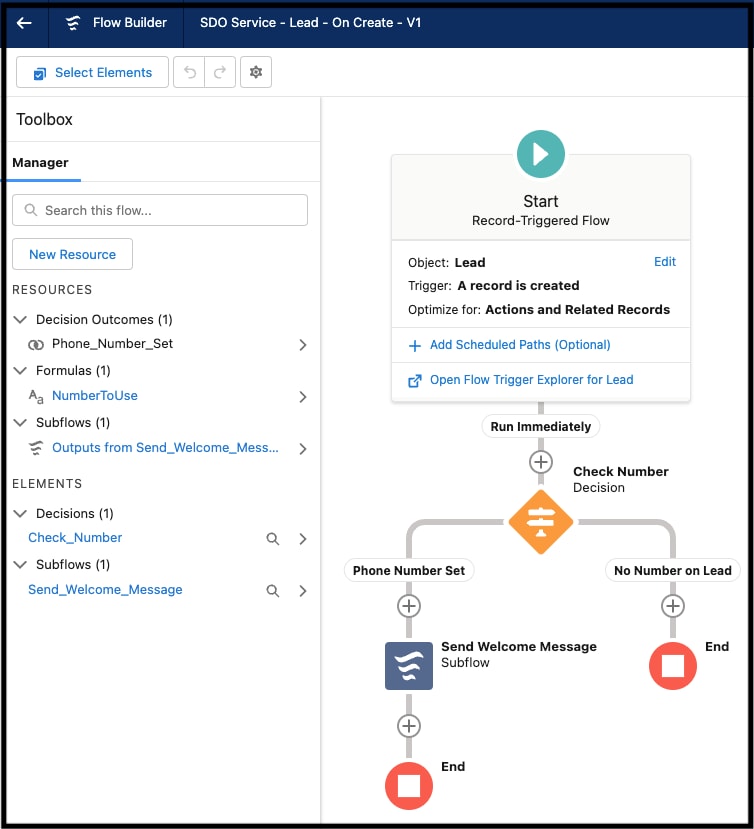
Las pantallas Configuración facilitan a cualquiera el desarrollo y la personalización de aplicaciones sin código (o con muy poco). Por ejemplo:
- Las interfaces de usuario nativas de plataforma son fáciles de crear sin ningún código. En segundo plano, una interfaz de usuario de aplicación nativa admite todas las operaciones de acceso a datos habituales, incluyendo consultas, inserciones, actualizaciones y eliminaciones. Cada operación de manipulación de datos realizada por aplicaciones de plataforma nativas puede modificar un objeto a la vez y confirmar automáticamente cada cambio en una transacción separada.
- Al definir un campo de texto para un objeto que contiene datos confidenciales, puede configurar fácilmente el campo de modo que la plataforma cifre los datos correspondientes y, opcionalmente, utilice una máscara de entrada para ocultar información de pantalla a miradas indiscretas.
- Una regla de validación declarativa es una forma sencilla para una organización de aplicar una regla de integridad de dominio sin ninguna programación. Por ejemplo, puede declarar una regla de validación que garantiza que el campo Cantidad de un objeto LineItem sea siempre superior a cero.
- Un campo de fórmula es una función declarativa de la plataforma que facilita agregar un campo calculado a un objeto. Por ejemplo, puede agregar un campo al objeto LineItem para calcular un valor LineTotal.
- Un campo de resumen es un campo de objeto cruzado que facilita agregar información de campo secundario en un objeto principal. Por ejemplo, puede crear un campo de resumen OrderTotal en el objeto SalesOrder basándose en el campo LineTotal del objeto LineItem.
Nota: Internamente, la plataforma implementa campos de fórmula y resumen utilizando funciones de base de datos nativas y vuelve a calcular valores de forma eficiente de forma síncrona como parte de transacciones en curso.
La plataforma proporciona varias API basadas en estándares abiertas que los desarrolladores pueden utilizar para crear aplicaciones. Tanto las API RESTful como las de servicios web (basadas en SOAP) proporcionan acceso a muchas funciones de la plataforma. Utilizando estas diversas API, una aplicación puede:
- Manipular metadatos que describen un esquema de aplicación
- Crear, leer, actualizar y eliminar datos comerciales (CRUD)
- Cargar de forma masiva o consultar un gran número de registros de forma asíncrona
- Exponer una transmisión de datos casi en tiempo real de una forma segura y ampliable
Las aplicaciones pueden utilizar el Lenguaje de consulta de objetos de Salesforce (SOQL) para crear consultas de base de datos sencillas pero potentes. Al igual que el comando SELECT en Structured Query Language (SQL), SOQL le permite especificar el objeto de origen, una lista de campos para recuperar y condiciones para seleccionar filas en el objeto de origen. Por ejemplo, la siguiente consulta SOQL devuelve el valor del campo Id. y Nombre para todos los registros de Cuenta con un Nombre igual a la cadena 'Acme'.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
La plataforma también incluye un motor de búsqueda multilingüe de texto completo que indexa automáticamente todos los campos relacionados con el texto. Las aplicaciones pueden hacer uso de este motor de búsqueda preintegrado utilizando el Lenguaje de búsqueda de objetos de Salesforce para realizar búsquedas de texto. A diferencia de SOQL, que solo puede consultar un objeto a la vez, SOSL le permite buscar campos de texto, correo electrónico y teléfono para múltiples objetos de forma simultánea. Por ejemplo, la siguiente instrucción SOSL busca registros en los objetos Candidato y Contacto que contienen la cadena 'Joe Smith' en el campo de nombre y devuelve el campo de nombre y número de teléfono de cada registro encontrado.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, que es similar a Java en muchos aspectos, es un potente lenguaje de desarrollo que los desarrolladores pueden utilizar para centralizar la lógica de procedimientos en su esquema de aplicación. El código Apex puede declarar variables y constantes de programa, ejecutar declaraciones de control de flujo tradicionales (si es el caso, bucles, etc.), realizar operaciones de manipulación de datos (insertar, actualizar, alterar, eliminar) y realizar operaciones de control de transacciones (setSavepoint, reversión).
Puede almacenar programas Apex en la plataforma utilizando dos formas diferentes: como una clase Apex nombrada con métodos (similares a procedimientos almacenados en lenguaje de base de datos tradicional) que las aplicaciones ejecutan cuando es necesario, o como un desencadenador de base de datos que se ejecuta automáticamente antes o después de que se produzca un evento de manipulación de base de datos específico. En cualquier forma, la plataforma compila código Apex y lo almacena como metadatos en la UDD. La primera vez que una organización ejecuta un programa Apex, el intérprete de tiempo de ejecución de la plataforma carga la versión compilada del programa en una caché MRU (utilizada más recientemente) para esa organización. A partir de entonces, cuando cualquier usuario de la misma organización necesita utilizar la misma rutina, la plataforma puede ahorrar memoria y evitar el gasto de volver a compilar el programa de nuevo compartiendo el programa listo para ejecutar que ya está en memoria.
Con la incorporación de una palabra clave sencilla aquí y allá, los desarrolladores pueden utilizar Apex para admitir muchos requisitos de aplicación exclusivos. Por ejemplo, los desarrolladores pueden exponer un método como una llamada de API basada en RESTful o SOAP personalizada, hacer que sea programable de forma asíncrona o configurarlo para procesar una operación de gran tamaño en lotes.
Apex es mucho más que “un lenguaje de procedimiento más”. Es un componente de plataforma integral que ayuda al sistema a entregar multiarrendamiento confiable. Por ejemplo, la plataforma valida automáticamente todas las declaraciones SOQL y SOSL integradas en una clase para evitar que falle el código en tiempo de ejecución. A continuación, la plataforma mantiene la información de dependencia de objeto correspondiente para clases válidas y la utiliza para evitar cambios en metadatos que de lo contrario romperían el código dependiente.
Muchas clases Apex estándar y métodos estáticos del sistema proporcionan interfaces sencillas a funciones del sistema subyacentes. Por ejemplo, los métodos DML estáticos del sistema como insertar, actualizar y eliminar tienen un parámetro booleano sencillo que los desarrolladores pueden utilizar para indicar la opción de procesamiento masivo deseada (todo o nada, o guardado parcial); estos métodos también devuelven un objeto de resultado que la rutina de llamada puede leer para determinar qué registros se procesaron sin éxito y por qué. Otros ejemplos de vínculos directos entre Apex y funciones de plataforma incluyen las clases de correo electrónico integradas y las clases de XmlStream.
En gran parte, la plataforma tiene un buen rendimiento y escala porque Salesforce la creó teniendo en cuenta dos principios importantes:
- Proporcione funciones de plataforma fundacional eficientes y de alta escala.
- Ayude a los desarrolladores a hacer todo lo más eficientemente posible.
La plataforma incorpora estos principios en las arquitecturas de procesamiento exclusivas de la plataforma, incluyendo:
- Consultas
- Búsquedas
- Operaciones masivas
- Modificación de esquema
- Aislamiento de múltiples arrendatarios
- La papelera
La mayoría de los sistemas de base de datos modernos determinan planes de ejecución de consultas óptimos empleando un optimizador de consultas basado en costes que tiene en cuenta estadísticas relevantes acerca de datos de índice y tabla de objetivos. Sin embargo, las estadísticas de optimizador basadas en costes convencionales están diseñadas para aplicaciones de un solo arrendatario y no tienen en cuenta las características de acceso a datos de cualquier usuario concreto que ejecuta una consulta en un entorno multiarrendatario. Por ejemplo, una consulta concreta dirigida a un objeto con un gran volumen de datos probablemente se ejecutaría de forma más eficiente utilizando diferentes planes de ejecución para usuarios con alta visibilidad (un gestor que puede ver todas las filas) frente a usuarios con baja visibilidad (personas de ventas que solo pueden ver filas relacionadas consigo mismas).
Para proporcionar estadísticas suficientes para determinar planes de ejecución de consultas óptimos en un sistema de múltiples arrendatarios, la plataforma mantiene un conjunto completo de estadísticas de optimizador (nivel de arrendatario, grupo y usuario) para los objetos de cada organización. Las estadísticas reflejan el número de filas a las que una consulta concreta puede acceder potencialmente, teniendo en cuenta cuidadosamente las estadísticas generales de objetos específicos de la organización (por ejemplo, el número total de filas propiedad de la organización en su conjunto), así como estadísticas más granulares (por ejemplo, el número de filas a las que un grupo de privilegios específico o usuario final puede acceder potencialmente).
La plataforma también mantiene otros tipos de estadísticas que resultan útiles con consultas concretas. Por ejemplo, la plataforma mantiene estadísticas para todos los índices personalizados para revelar el número total de valores no nulos y exclusivos en el campo correspondiente, e histogramas para campos de lista de selección que revelan la cardinalidad de cada valor de lista.
Cuando las estadísticas existentes no están establecidas o no se consideran útiles, el optimizador de la plataforma tiene algunas estrategias diferentes que utiliza para ayudar a crear consultas razonablemente óptimas. Por ejemplo, cuando una consulta filtra en el campo Nombre de un objeto, el optimizador puede utilizar la tabla MT_Fallback_Indexes para encontrar filas solicitadas de forma eficiente. En otros escenarios, el optimizador generará de forma dinámica estadísticas que faltan en tiempo de ejecución.
Utilizado en tándem con estadísticas del optimizador, el optimizador de la plataforma también se basa en tablas relacionadas con la seguridad interna (Grupos, Miembros, GroupBlowout y CustomShare) que mantienen información acerca de los dominios de seguridad de los usuarios de una organización, incluyendo las pertenencias a grupos de un usuario específico y los derechos de acceso personalizado para objetos y filas. Dicha información es inestimable para determinar la selectividad de filtros de consulta por usuario. Consulte Platform Developer Basics Trailhead para obtener más información acerca del modelo de seguridad integrado de la plataforma.
El diagrama de flujo de la siguiente figura ilustra lo que sucede cuando la plataforma procesa una solicitud de datos que está en una de las tablas de gran tamaño como MT_Data. La solicitud puede originarse desde cualquier número de orígenes, como una llamada de API o un procedimiento almacenado. En primer lugar, la plataforma ejecuta “consultas previas” que tienen en cuenta las estadísticas de múltiples arrendatarios. A continuación, basándose en los resultados devueltos por las consultas previas, el servicio crea una consulta de base de datos subyacente óptima para su ejecución en la configuración específica.
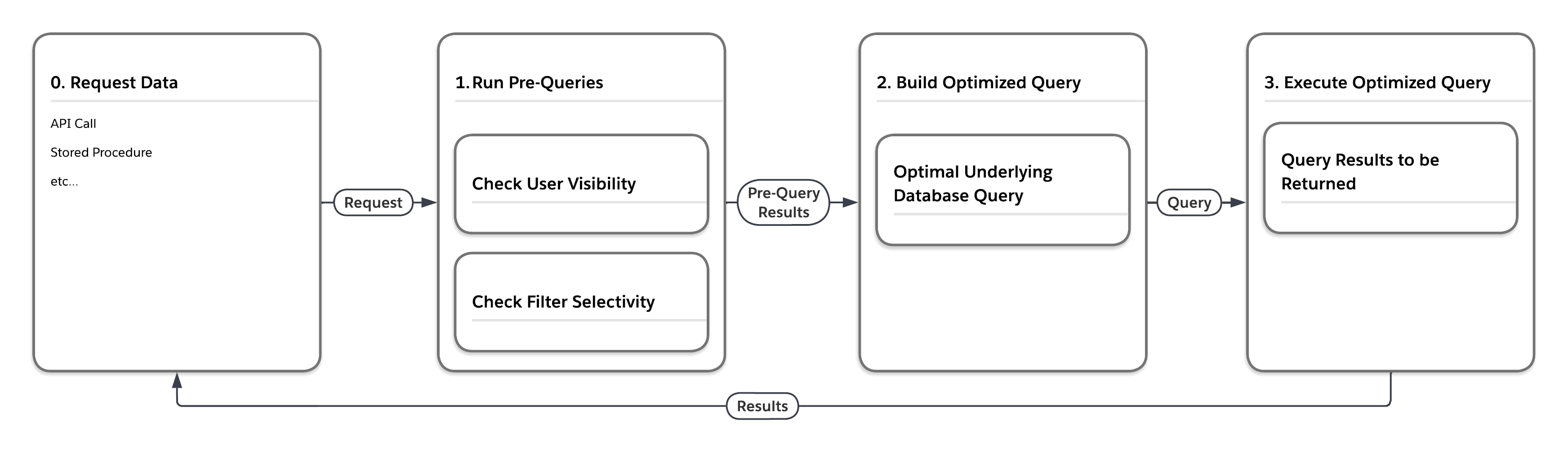
Como se muestra en la siguiente tabla, la plataforma puede ejecutar la misma consulta de cuatro formas diferentes, dependiendo del usuario que envía la consulta y la selectividad de las condiciones de filtro de la consulta.
| Medición de selectividad previa a la consulta | Escribir consulta final de acceso a la base de datos, forzando... | |
| Usuario | Filtro | |
| Bajo | Bajo | ... bucles anidados unir, conducir utilizando vista de filas que el usuario puede ver |
| Bajo | Alto | ... uso de índice relacionado con filtro |
| Alto | Bajo | ... unión de hash ordenado, conducción utilizando MT_DATA |
| Alto | Alto | ... uso de filtro relacionado con índice |
Los usuarios esperan una función de búsqueda interactiva para explorar todo o un ámbito seleccionado de la base de datos de una aplicación y devolver resultados clasificados con tiempos de respuesta inferiores a los segundos. Para proporcionar esta función para aplicaciones de plataforma, la plataforma utiliza un motor de búsqueda separado de su motor de transacciones. Cuando actualiza registros, el motor de transacciones actualiza la base de datos principal y también reenvía datos relacionados al motor de búsqueda para su indexación. Cuando busca registros, el motor de búsqueda utiliza sus índices para procesar la consulta rápidamente y devuelve resultados clasificados con vínculos a registros de base de datos relacionados.
A medida que las aplicaciones actualizan datos en campos de texto (CLOB, Nombre, etc.), un grupo de procesos en segundo plano denominados servidores de indexación se encargan de actualizar de forma asíncrona los índices correspondientes, que el motor de búsqueda mantiene fuera del motor de transacciones principal. Para optimizar el proceso de indexación, la plataforma copia de forma síncrona fragmentos modificados de datos de texto en una tabla interna “a indexar” a medida que se confirman las transacciones, proporcionando así una fuente de datos relativamente pequeña que minimiza la cantidad de datos que los servidores de indexación deben leer desde el disco. El motor de búsqueda mantiene automáticamente índices separados para cada organización.
Dependiendo de la carga actual y la utilización de servidores de indexación, las actualizaciones de índices de texto pueden estar a la zaga de las transacciones reales. Para evitar resultados de búsqueda inesperados originados en índices obsoletos, la plataforma también mantiene una memoria caché de MRU de filas actualizadas recientemente que el sistema tiene en cuenta al materializar resultados de búsqueda de texto completo. La plataforma mantiene cachés de MRU por usuario y organización para dar cobertura de forma eficiente a posibles ámbitos de búsqueda.
El motor de búsqueda de la plataforma optimiza la clasificación de registros dentro de los resultados de búsqueda utilizando varios métodos. Por ejemplo, el sistema tiene en cuenta el dominio de seguridad del usuario que realiza una búsqueda y pone más peso en las filas a las que puede acceder el usuario actual. El sistema también puede considerar el historial de modificación de una fila en particular y clasificar filas actualizadas de forma más activa por delante de aquellas que son relativamente estáticas. El usuario puede elegir ponderar los resultados de búsqueda según desee, por ejemplo, poniendo más énfasis en filas modificadas recientemente.
Las aplicaciones intensivas en transacciones generan menos gastos generales y tienen un rendimiento mucho mejor cuando combinan y ejecutan operaciones repetitivas de forma masiva. Por ejemplo, contraste dos formas en que una aplicación podría cargar muchas filas nuevas. Un enfoque ineficiente sería utilizar una rutina con un bucle que inserta filas individuales, realizando una llamada de API tras otra para cada inserción de fila. Un enfoque mucho más eficiente sería crear una matriz de filas y tener la rutina insertándolas todas con una sola llamada de API.
El procesamiento masivo eficiente con la plataforma es sencillo para los desarrolladores porque se integra en llamadas de API. Internamente, la plataforma también procesa de forma masiva todos los pasos internos relacionados con una operación masiva explícita.
El motor de procesamiento masivo de la plataforma tiene en cuenta automáticamente fallos aislados encontrados durante cualquier paso en el camino. Cuando una operación masiva se inicia en modo de guardado parcial, el motor identifica un estado de inicio conocido y luego intenta ejecutar cada paso en el proceso (validar de forma masiva datos de campo, desencadenadores previos de disparo masivo, registros de guardado masivo, etc.). Si el motor detecta errores durante cualquier paso, el motor revierte las operaciones ofensivas y todos los efectos secundarios, elimina las filas responsables de los fallos y continúa intentando procesar de forma masiva el subconjunto restante de filas. Este proceso itera por cada etapa sucesiva hasta que el motor puede confirmar un subconjunto de filas sin ningún error. La aplicación puede examinar un objeto de devolución para identificar qué filas fallaron y qué excepciones plantearon.
Nota: A su discreción, un modo todo o nada está disponible para operaciones masivas. Además, la ejecución de desencadenadores durante una operación masiva está sujeta a reguladores internos que restringen la cantidad de trabajo.
Algunos tipos de modificaciones en la definición de un objeto requieren más que simples actualizaciones de metadatos UDD. En estos casos, la plataforma utiliza mecanismos eficientes que ayudan a reducir la repercusión general del rendimiento en el servicio de base de datos en la nube en general.
Por ejemplo, considere lo que sucede en segundo plano cuando modifica el tipo de datos de una columna de lista de selección a texto. La plataforma asigna primero una nueva división para los datos de la columna, copia de forma masiva las etiquetas de lista de selección asociadas con valores actuales y luego actualiza los metadatos de la columna de modo que apunten a la nueva división. Mientras todo esto sucede, el acceso a los datos es normal y las aplicaciones continúan funcionando sin ningún impacto notable.
Como otro ejemplo, considere lo que sucede cuando agrega un campo de resumen a un objeto. En este caso, la plataforma calcula de forma asíncrona resúmenes iniciales en segundo plano utilizando una operación masiva eficiente. Mientras se realiza el cálculo en segundo plano, los usuarios que visualizan el nuevo campo reciben una indicación de que la plataforma está calculando el valor del campo.
Para evitar la monopolización maliciosa o no intencionada de recursos del sistema compartidos y multiusuario, la plataforma tiene un amplio conjunto de reguladores y límites de recursos asociados con la ejecución de código de plataforma. Por ejemplo, la plataforma supervisa de cerca la ejecución de una secuencia de comandos de código y limita el tiempo de CPU que puede utilizar, la cantidad de memoria que puede consumir, el número de consultas y declaraciones DML que puede ejecutar, el número de cálculos matemáticos que puede realizar, el número de llamadas de servicios web salientes que puede realizar y mucho más. Las consultas individuales que el optimizador de la plataforma considera demasiado caras para ejecutar arrojan una excepción de tiempo de ejecución al llamante. Aunque esos límites pueden parecer algo restrictivos, son necesarios para proteger la capacidad de ampliación y el rendimiento generales del sistema de base de datos compartido para todas las aplicaciones interesadas. A largo plazo, estas medidas ayudan a promover mejores técnicas de codificación entre los desarrolladores y crear una mejor experiencia para todos los usuarios de la plataforma. Por ejemplo, un desarrollador que inicialmente intenta codificar un bucle que actualiza de forma ineficiente mil filas una fila a la vez recibirá excepciones de tiempo de ejecución debido a límites de recursos y luego comenzará a utilizar las llamadas de API de procesamiento masivo eficientes de la plataforma.
Para evitar aún más posibles problemas del sistema introducidos por aplicaciones mal escritas, la implementación de una nueva aplicación de producción es un proceso estrictamente gestionado. Antes de que una organización pueda realizar la transición de una nueva aplicación del estado de desarrollo al de producción, Salesforce requiere pruebas de unidad que validen la funcionalidad de las rutinas de código de plataforma de la aplicación. Las pruebas de unidad enviadas deben cubrir al menos el 75 por ciento del código fuente de la aplicación.
Salesforce ejecuta pruebas de unidad enviadas en el entorno de desarrollo de sandbox de la plataforma para determinar si el código de aplicación afectará negativamente al rendimiento y la capacidad de ampliación de la población de múltiples arrendatarios en general. Los resultados de una prueba de unidad individual indican información básica, como el número total de líneas ejecutadas, así como información específica sobre el código que no se ejecutó por la prueba.
Una vez que Salesforce certifica la producción del código de una aplicación, el proceso de implementación de la aplicación consta de una única transacción que copia todos los metadatos de la aplicación en una instancia de plataforma de producción y vuelve a ejecutar las pruebas de unidad correspondientes. Si cualquier parte del proceso falla, la plataforma simplemente revierte la transacción y devuelve excepciones para ayudar a solucionar el problema.
Nota: Salesforce vuelve a ejecutar las pruebas de unidad para cada aplicación con cada versión de desarrollo de la plataforma para obtener información proactiva sobre si las nuevas funciones y mejoras del sistema interrumpen cualquier aplicación existente.
Después de que una aplicación de producción esté en vivo, el perfilador de rendimiento integrado de la plataforma la analiza automáticamente y proporciona comentarios asociados a los administradores. Los informes de análisis de rendimiento incluyen información sobre consultas lentas, manipulaciones de datos y subrutinas que puede revisar y utilizar para ajustar la funcionalidad de la aplicación. El sistema también registra y devuelve información acerca de excepciones de tiempo de ejecución a administradores para ayudarles a depurar sus aplicaciones.
Cuando una aplicación elimina un registro de un objeto, la plataforma simplemente marca la fila para su eliminación modificando el campo IsDeleted de la fila en MTData. Esta acción coloca de forma efectiva la fila en lo que se conoce como la _Papelera. la plataforma le permite restaurar filas seleccionadas desde la Papelera durante un máximo de 15 días antes de eliminarlas permanentemente de MT_Data. La plataforma limita el número total de registros que mantiene para una organización basándose en los límites de almacenamiento para esa organización.
Cuando una operación elimina un registro principal implicado en una relación principal-detalle, la plataforma elimina automáticamente todos los registros secundarios relacionados, siempre que hacerlo no rompa ninguna regla de integridad referencial vigente. Por ejemplo, cuando elimina un SalesOrder, la plataforma pone en cascada automáticamente la eliminación en LineItems dependientes. Si posteriormente restaura un registro principal desde la Papelera, el sistema restaura automáticamente todos los registros secundarios también.
Por el contrario, cuando elimina un registro principal de referencia implicado en una relación de búsqueda, la plataforma establece automáticamente todas las claves dependientes como nulas. Si posteriormente restaura el registro principal, la plataforma restaura automáticamente las relaciones de búsqueda anuladas anteriormente, excepto para las relaciones que se reasignaron entre las operaciones de eliminación y restauración.
La Papelera también almacena campos descartados y sus datos hasta que una organización los elimine permanentemente o haya transcurrido un número establecido de días, lo que ocurra primero. Hasta ese momento, todo el campo y todos sus datos están disponibles para la restauración.
La agilidad es clave para que las empresas tengan éxito en nuestro mundo moderno. Las capas subyacentes de Salesforce Platform ayudan sus aplicaciones comerciales a adaptarse rápidamente a nuevos retos de modo que pueda continuar centrándose en su negocio en vez de en la infraestructura.
La infraestructura (por ejemplo, servicios fundacionales y recursos informáticos) está oculta, tecnología subyacente que admite capas superiores en Salesforce Platform. Hyperforce es la infraestructura de Salesforce Platform, construida sobre energía 100% renovable y cero neto, que resuelve retos clave de los clientes, incluyendo cumplimiento, Trust y escalabilidad.
Las empresas que operan en múltiples ubicaciones geográficas necesitan cumplir con leyes nuevas, en evolución y variables para la gestión de datos. Debido a que Salesforce está implementando Hyperforce en un número creciente de países, actualmente basándose en la disponibilidad de la región de AWS, las aplicaciones de plataforma y los usuarios pueden ejecutar sus cargas de trabajo confidenciales de formas que cumplen estrictos estándares de almacenamiento o protección de datos. Por ejemplo, con la Zona Operativa de la Unión Europea (UE) de Salesforce con Hyperforce, las empresas de la UE pueden mantener fácilmente sus datos en la UE.
Seguridad, fiabilidad y disponibilidad son requisitos no funcionales que cada aplicación comercial debe tener en cuenta para cumplir la promesa de Trust a sus usuarios finales. Con Hyperforce, Salesforce Platform permite a las empresas entregar aplicaciones comerciales de confianza fácilmente.
- Seguridad: Hyperforce tiene cifrado nativo de extremo a extremo de datos de clientes en tiempo de inactividad y en tránsito. Zero Trust Architecture de Hyperforce aplica un estricto proceso de verificación de identidad que garantiza que no haya acceso implícito a los recursos. Hyperforce utiliza el principio de menor privilegio, garantizando que las operaciones se aprueben durante el tiempo correcto con el acceso correcto.
- Fiabilidad: Cada instancia de Hyperforce utiliza múltiples zonas de disponibilidad en la nube y enfoques modernizados que aceleran la respuesta de incidencia para entregar una plataforma altamente disponible y resistente.
- Disponibilidad: las modernas oportunidades en curso de CI/CD de Hyperforce y las versiones de aplicaciones de color azul/verde minimizan los periodos de mantenimiento de las aplicaciones a solo un minuto al año.
Como base para aplicaciones como Sales Cloud y Service Cloud, Salesforce es una plataforma de desarrollo de aplicaciones probada en la que las empresas individuales y los proveedores de servicio han creado millones de aplicaciones comerciales para casos de uso diferentes, incluyendo la gestión de la cadena de suministro, facturación, contabilidad, comercio, seguimiento de cumplimiento, gestión de recursos humanos y procesamiento de reclamaciones. La arquitectura única, multiusuario y dirigida por metadatos de la plataforma está diseñada específicamente para la nube y admite de forma fiable y segura aplicaciones de escala de Internet de misión crítica. Utilizando API basadas en estándares y herramientas de desarrollo nativas, los desarrolladores de plataforma pueden crear fácilmente todos los componentes de una aplicación web o móvil moderna, incluyendo el modelo de datos de la aplicación (incluyendo objetos y relaciones), lógica comercial (incluyendo flujos de trabajo y validaciones), integraciones con otras aplicaciones y mucho más.
Desde su creación, la plataforma ha sido optimizada por los ingenieros de Salesforce para el multiarrendamiento, con funciones que permiten a las aplicaciones de plataforma ampliarse para satisfacer las cambiantes demandas comerciales. Las funciones integrales del sistema, como la API de procesamiento masivo de datos, Apex, un motor de búsqueda de texto completo y un optimizador de consultas exclusivo, ayudan a hacer que las aplicaciones dependientes sean altamente eficientes y ampliables con poco o ningún esfuerzo de los desarrolladores.
El enfoque gestionado de Salesforce para la implementación de aplicaciones de producción garantiza un excelente rendimiento, capacidad de ampliación y fiabilidad para todas las aplicaciones que se basan en la plataforma. Salesforce supervisa y recopila continuamente información operativa de aplicaciones de plataforma para ayudar a dirigir mejoras incrementales y nuevas funciones del sistema que benefician inmediatamente a aplicaciones existentes y nuevas.
Steve Bobrowski es un exitoso empresario y líder tecnológico que ha trabajado para muchas empresas de software empresarial líderes, incluyendo varias funciones en Salesforce desde 2008. Hoy en día, Steve trabaja en la Oficina del CTO de Salesforce para ayudar con las estrategias de arquitectura tecnológica de la empresa.
Tom Leddy es Arquitecto Evangelista de Salesforce. Apoya a la comunidad global de arquitectos de Salesforce ayudando a crear recursos, herramientas y directrices que ayudan a los arquitectos a hacer su mejor trabajo. Conecta con Tom en Twitter.