Täglich betreiben Hunderttausende Unternehmen und Millionen von Benutzern ihre Geschäfte in der Cloud mithilfe von Salesforce Platform-gestützten Anwendungen. Warum ist die Plattform so erfolgreich? Warum können Sie Trusts zur Unterstützung Ihres Unternehmens vertrauen? Welche einzigartigen Vorteile bietet die Plattform Unternehmen wie Ihnen?
In dieser technischen Zusammenfassung wird erläutert, wie die Salesforce Platform mithilfe ihrer einzigartigen Softwarearchitektur für Cloud Computing zuverlässige, skalierbare und einfach anzupassende Endbenutzererfahrungen bereitstellt. Nachdem Sie diese Kurzbeschreibung gelesen haben, werden Sie die zugrunde liegende Technologie besser verstehen, die Salesforce Platform zu einer überzeugenden Wahl für Ihre Geschäftsanwendungen macht.
Die Salesforce Platform ist das herausragende Beispiel für eine erfolgreiche Cloud Computing-Plattform und ein entsprechendes Ökosystem von Anwendungen. Seit der Jahrtausendwende ist die Plattform die Grundlage für Folgendes:
- Viele beliebte Geschäftsanwendungen für häufige Anwendungsfälle wie Vertrieb und Kundenservice
- Branchenspezifische Anwendungen für spezialisiertere Anwendungsfälle wie Finanzen und Gesundheitswesen
- Millionen von benutzerdefinierten Anwendungen und Anwendungserweiterungen für individuelle Anwendungsfälle
Die Salesforce Platform ist zum großen Teil deshalb so erfolgreich und beliebt, weil ihre einzigartige Softwarearchitektur Anwendungen unterstützt, die einfach zu erstellen, zu verwenden, anzupassen und zu erweitern sind und eine außergewöhnliche Leistung und Zuverlässigkeit bieten. Das Herzstück der Softwarearchitektur der Plattform ist das mandantenfähige, metadatengesteuerte Design.
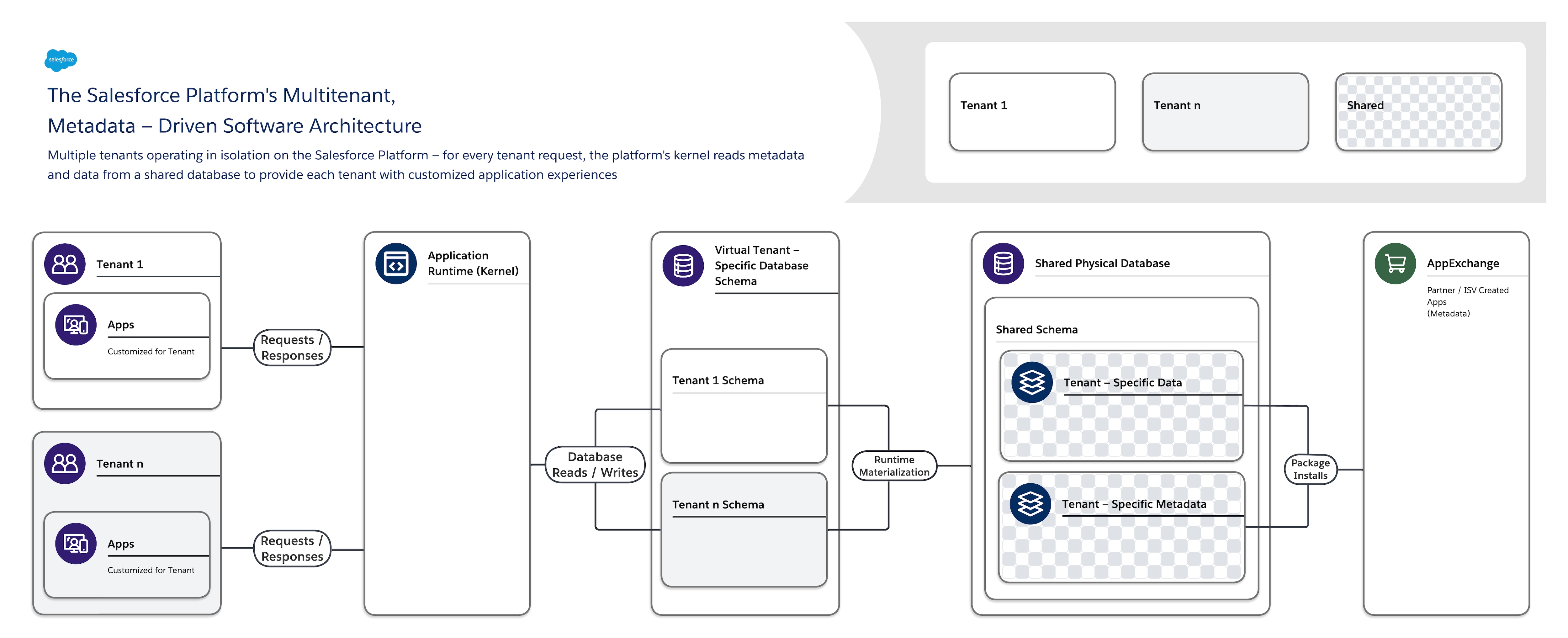
Die Softwarearchitektur der Salesforce Platform ist:
- Mandant: Er isoliert die unterschiedlichen Anforderungen vieler Mandanten (Organisationen, Geschäftseinheiten usw.) und unterstützt sie gleichzeitig.
- Metadatengesteuert: Damit kann jeder Mandant seine Anwendungen und Benutzererfahrungen einfach und schnell mithilfe von Metadaten anpassen, Daten, die Elemente wie die Benutzeroberfläche (UI) und Geschäftslogik beschreiben.
Wenn Sie ein neues Anwendungsobjekt erstellen oder Code mithilfe der Salesforce Platform schreiben, erstellt die Plattform keine tatsächliche Tabelle in einer Datenbank und kompiliert keinen Code. Stattdessen speichert die Plattform lediglich einige Metadaten, die sie dann zur Laufzeit verwenden kann, um Komponenten der virtuellen Anwendung dynamisch zu materialisieren. Die Plattform stellt sicher, dass die Metadaten jedes Mandanten privat sind und einfach aktualisiert werden können, ohne dass Sperren oder Ausfallzeiten erforderlich sind, sodass jeder Mandant Anwendungen isoliert erstellen und anpassen kann. Die Salesforce Platform verwendet dieselben Metadaten, um benutzerdefinierte APIs, RESTful- und Webservices-Schnittstellen (SOAP-basiert) bereitzustellen, mit denen Sie Ihre Anwendungen in andere Anwendungen und automatisierte Prozesse integrieren können.
Fertige Lösungen sind auch in AppExchange, dem umfangreichen Marktplatz für Anwendungen der Plattform, verfügbar. Ein AppExchange-Paket wurde von einem umfangreichen Ökosystem vertrauenswürdiger Partner und unabhängiger Softwareanbieter erstellt und besteht aus Metadaten eines Drittanbieters, in denen kostenlose oder kostenpflichtige Anwendungserweiterungen und ganze Anwendungen beschrieben werden, die Sie verwenden können, um bestimmte Geschäftsanforderungen zu erfüllen.
Zur Unterstützung dieser hochgradig anpassbaren und erweiterbaren Architektur verwendet eine einzelne Instanz der Salesforce Platform Folgendes:
- Eine einzelne freigegebene Mandantendatenbank mit einem einzelnen Schema, in dem mandantenspezifische Metadaten und Daten gespeichert werden.
- Ein Mandantenkernel (Anwendungslaufzeit), der Metadaten und Daten liest, um den Benutzern jedes Mandanten zur Laufzeit dynamisch mandantenspezifische Anwendungen, Geschäftslogik und APIs bereitzustellen.
Diese klare Trennung des von Salesforce verwalteten Kernels von den von Mandanten verwalteten Metadaten ermöglicht es Salesforce, Mandanten und ISVs, ihre Teile des Systems unabhängig voneinander weiterzuentwickeln.
Um auf dieser Übersicht aufzubauen, enthalten die nachfolgenden Abschnitte dieses Artikels weitere Details zu den einzigartigen Funktionen der Plattform, die sich aus wichtigen Aspekten ihres Designs ergeben, darunter:
- Die Plattformdatenebene
- Entwicklung von Plattformanwendungen
- Interne Plattformverarbeitung
- Plattforminfrastruktur
Zusammen isolieren die Anwendungslaufzeit der Salesforce Platform und die innovative Datenebene mandantenspezifische Daten, Schemaanpassungen und Geschäftslogik sicher. Auf einer hohen Ebene unterstützt das Schema eine Vielzahl von Anwendungsfällen:
- Wenn Sie eine Anwendung erstellen oder anpassen, speichert die Plattform zugehörige Metadaten in freigegebenen Datenbanktabellen, die Metadaten für alle Mandanten verwalten.
- Wenn Sie eine Anwendung zum Lesen oder Schreiben von Daten verwenden, speichert die Plattform Ihre Daten in freigegebenen Datenbanktabellen, die Daten für alle Mandanten verwalten.
- Im Hintergrund verwaltet die Plattform auch interne Metadaten in einer Reihe von Tabellen, die der Kernel zur Optimierung der Anforderungslatenz zur Laufzeit verwendet.
Aber wie kann eine einzelne freigegebene Datenbank und ein Schema die Daten jedes Mandanten privat halten? Jeder Mandant auf der Plattform wird als Organisation oder kurz Organisation bezeichnet. Und jeder organisationsspezifische Datensatz in freigegebenen Datenbanktabellen verfügt über eine OrgID. Wenn der Kernel auf die Datenbank zugreift, verwendet er diese eindeutige Kennung, um sicherzustellen, dass die Aktivitäten der einzelnen Organisationen privat sind.

Organisationsspezifische Objekte (man denke an Tabellen in traditioneller relationaler Datenbanksprache), Felder, gespeicherte Prozeduren, Datenbankauslöser usw. sind allesamt virtuelle Konstrukte, die durch Metadaten beschrieben werden, die von der Plattform in einigen Datenbanktabellen gespeichert werden, die als Universal Data Dictionary (UDD) bezeichnet werden.
- Bei MT_Objects handelt es sich um eine Datenbanktabelle, in der Metadaten zu den Objekten gespeichert werden, die Sie für eine Anwendung definieren, einschließlich einer eindeutigen Kennung für ein Objekt (ObjID), Ihrer Organisation (OrgID) und des Namens, den Sie für das Objekt angeben (ObjName).
- In der Systemtabelle MT_Fields werden Metadaten zu den Feldern (Spalten) gespeichert, die Sie für jedes Objekt deklarieren. Dazu zählen ein eindeutiger Kennzeichner für ein Feld (FieldID), Ihre Organisation (OrgID), das Objekt, das das Feld enthält (ObjID), der Name des Felds (FieldName), der Datentyp des Felds, ein boolescher Wert, der angibt, ob das Feld indiziert werden muss (IsIndexed) und die Position des Felds im Objekt relativ zu anderen Feldern (FieldNum).
Da Metadaten eine wichtige Zutat sind, muss die Plattform den Zugriff auf Metadaten optimieren. Andernfalls würde ein häufiger Metadatenzugriff die Skalierung des Service verhindern. Angesichts dieses potenziellen Engpasses verwendet die Plattform massive und komplexe Metadaten-Caches, um die zuletzt verwendeten Metadaten im Arbeitsspeicher zu speichern, leistungsmindernde Datenträger-I/O- und Code-Neukompilierungen zu vermeiden und die Antwortzeiten der Anwendung zu verbessern.
Die Systemtabelle MT_Data speichert die anwendungszugänglichen Daten, die allen organisationsspezifischen Tabellen und deren Feldern zugeordnet sind, wie durch Metadaten in MT_Objects und MT_Fields definiert. Jede Zeile enthält identifizierende Felder wie eine globale eindeutige Kennung (Global Unique Identifier, GUID), die Organisation, die Inhaber der Zeile ist (OrgID), und die umfassende Objektkennung (ObjID). Jede Zeile in der Tabelle "MT_Data" verfügt auch über ein Namensfeld, in dem ein "natürlicher Name" für entsprechende Datensätze gespeichert wird. Beispielsweise kann ein Account-Datensatz "Accountname" verwenden, ein Kundenvorgangs-Datensatz "Kundenvorgangsnummer" usw.
Wert0 ... In ValueN-Flexspalten, die auch als Zeitfenster bezeichnet werden, werden Anwendungsdaten gespeichert, die den in MT_Objects bzw. MT_Fields deklarierten Tabellen und Feldern zugeordnet werden. Alle Flex-Spalten verwenden einen Zeichenfolgen-Datentyp mit variabler Länge, sodass sie jeden strukturierten Typ von Anwendungsdaten speichern können (Zeichenfolgen, Zahlen, Datumswerte usw.). Wie die folgende Abbildung veranschaulicht, können nicht zwei Felder desselben Objekts demselben Zeitfenster in MT_Data zum Speichern zugeordnet werden. Ein einzelnes Zeitfenster kann jedoch die Informationen mehrerer Felder verwalten, solange jedes Feld aus einem anderen Objekt stammt.
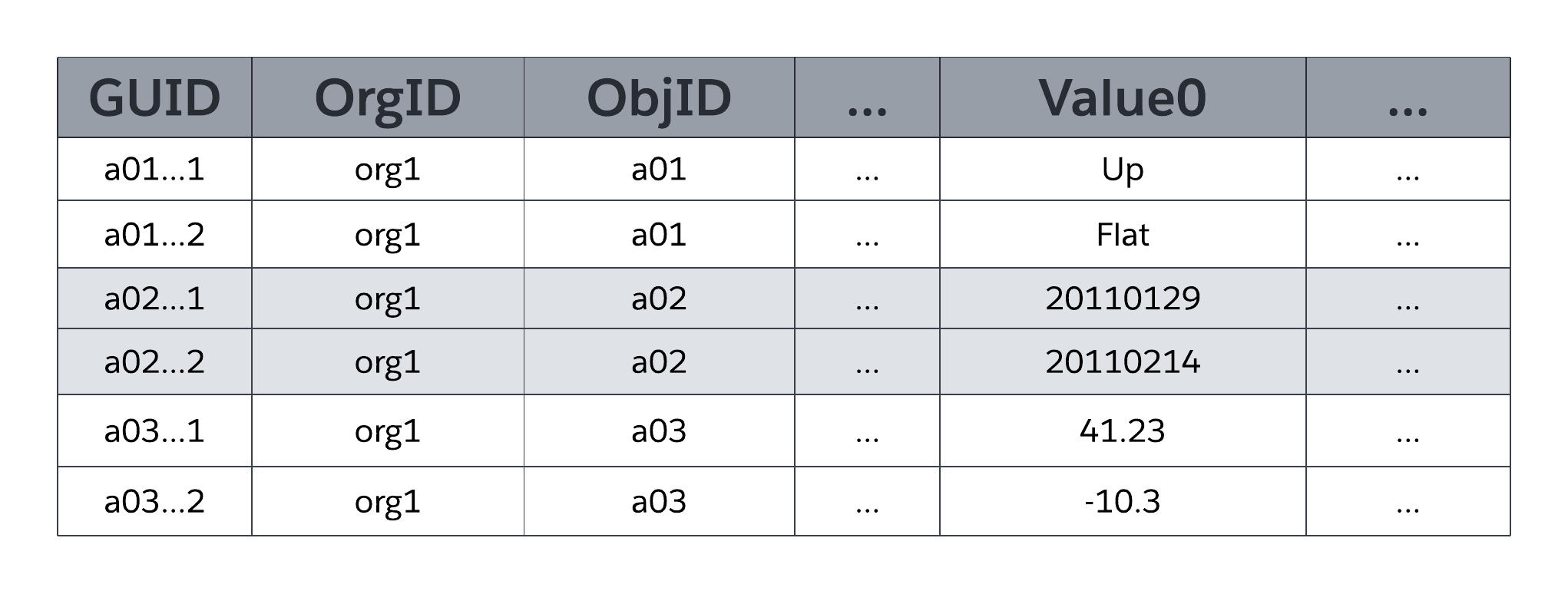
MTF-Felder können eine Reihe von standardmäßigen strukturierten Datentypen wie Text, Zahl, Datum und Datum/Uhrzeit sowie speziell verwendete strukturierte Datentypen wie Auswahlliste (aufgezähltes Feld), automatische Nummerierung (automatisch inkrementiert, vom System generierte Sequenznummer), Formel (schreibgeschützter abgeleiteter Wert), Master-Detail-Beziehung (Fremdschlüssel), Kontrollkästchen (boolesch), E-Mail, URL und andere verwenden. MT_Fields kann auch erforderlich sein (nicht null) und benutzerdefinierte Validierungsregeln aufweisen (beispielsweise muss ein Feld größer sein als ein anderes Feld), die beide von der Plattform erzwungen werden.
Wenn Sie ein Objekt deklarieren oder ändern, verwaltet die Plattform eine Metadatenzeile in "MT_Objects", die das Objekt definiert. Ebenso verwaltet die Plattform für jedes Feld eine Zeile in MT_Fields, einschließlich Metadaten, die das Feld einer bestimmten Flex-Spalte in MT_Data zuordnen, um die entsprechenden Felddaten zu speichern. Da die Plattform Objekt- und Felddefinitionen als Metadaten und nicht als tatsächliche Datenbankstrukturen verwaltet, kann das System Online-Mandanten-Anwendungsschema-Wartungsaktivitäten tolerieren, ohne die gleichzeitige Aktivität anderer Organisationen und Benutzer zu blockieren. Im Vergleich dazu erfordert die Neudefinition von Online-Tabellen für traditionelle relationale Datenbanksysteme in der Regel temporäre Sperren und oft mühsame, komplizierte Prozesse sowie geplante Ausfallzeiten für Anwendungen.
Wie die vereinfachte Darstellung von MT_Data in der vorigen Abbildung zeigt, sind Flexspalten von einem universellen Datentyp (Zeichenfolge mit variabler Länge), wodurch die Plattform eine einzelne Flexspalte für mehrere Felder freigeben kann, die verschiedene strukturierte Datentypen (Zeichenfolgen, Zahlen, Datumswerte usw.) verwenden.
Die Plattform speichert alle Flex-Spaltendaten in einem kanonischen Format und verwendet bei Bedarf die zugrunde liegenden Datenbanksystem-Datentypkonvertierungsfunktionen (z. B. TO_NUMBER, TO_DATE, TO_CHAR), wenn Anwendungen Daten aus Flex-Spalten lesen und in sie schreiben.
MTData* enthält auch Spalten, die in der vorherigen Abbildung nicht dargestellt sind. Beispielsweise gibt es vier Spalten zum Verwalten von Überwachungsdaten, einschließlich des Benutzers, der eine Zeile erstellt hat und wann diese Zeile erstellt wurde, des Benutzers, der eine Zeile zuletzt geändert hat und wann diese Zeile zuletzt geändert wurde. MT_Data enthält auch die Spalte _IsDeleted*, die die Plattform verwendet, um anzugeben, wann eine Zeile gelöscht wurde.
Die Plattform unterstützt auch die Deklaration von Feldern als _große Zeichenobjekte (_CLOBs), damit lange Textfelder mit bis zu 32.000 Zeichen gespeichert werden können. Für jede Zeile in MTData, die über einen CLOB verfügt, speichert die Plattform den CLOB out of line in einer Tabelle namens _MT_Clob, die das System bei Bedarf mit den entsprechenden Zeilen in MT_Data verknüpfen kann.
Hinweis: Die Plattform speichert CLOBs auch in einer indizierten Form außerhalb der Datenbank für schnelle Textsuchen. Weitere Informationen zur Textsuchmaschine der Plattform finden Sie unter Suchvorgänge.
Die Plattform indiziert automatisch verschiedene Feldtypen, um eine skalierbare Leistung zu bieten.
Herkömmliche Datenbanksysteme basieren auf nativen Datenbankindizes, um bestimmte Zeilen in einer Datenbanktabelle schnell zu finden, deren Felder einer bestimmten Bedingung entsprechen. Es ist jedoch nicht sinnvoll, native Datenbankindizes für die Flexspalten von MTData zu erstellen, da die Plattform eine einzige Flexspalte verwendet, um die Daten vieler Felder mit unterschiedlich strukturierten Datentypen zu speichern. Stattdessen verwaltet die Plattform einen Index von MT_Data, indem sie die für die Indizierung markierten Felddaten synchron in eine entsprechende Spalte in einer Pivottabelle vom Typ _MT_Indexes kopiert.
MT_Indexes enthält stark typisierte, indizierte Spalten wie StringValue, NumValue und DateValue, die von der Plattform zum Suchen nach Felddaten des entsprechenden Datentyps verwendet werden. Beispielsweise würde die Plattform einen Zeichenfolgenwert in einer Flex-Spalte vom Typ "MT_Data" in das Feld "StringValue" in "MT_Indizes", einen Datumswert in das Feld "DateValue" usw. kopieren. Die zugrunde liegenden Indizes von MT_Indizes sind standardmäßige, nicht eindeutige Datenbankindizes. Wenn eine interne Systemabfrage einen Suchparameter enthält, der auf ein strukturiertes Feld in einem Objekt verweist, verwendet die benutzerdefinierte Abfrageoptimierung der Plattform MT_Indizes, um die zugehörigen Datenzugriffsvorgänge zu optimieren.
Hinweis: Die Plattform kann Suchvorgänge in mehreren Sprachen verarbeiten, da das System einen Algorithmus zum Falten von Groß- und Kleinschreibung verwendet, der Zeichenfolgenwerte in ein universelles Format konvertiert, bei dem die Groß- und Kleinschreibung nicht berücksichtigt wird. In der Spalte "StringValue" der Tabelle "MT_Indexes" werden Zeichenfolgenwerte in diesem Format gespeichert. Zur Laufzeit erstellt die Abfrageoptimierung automatisch Datenzugriffsvorgänge, sodass die optimierte SQL-Anweisung nach dem entsprechenden StringValue filtert, der wiederum dem in der Suchanforderung angegebenen Literal entspricht.
Auf der Plattform können Sie angeben, wann ein Feld in einem Objekt eindeutige Werte enthalten muss (wobei zwischen Groß- und Kleinschreibung unterschieden wird). Angesichts der Anordnung von MT_Data und der gemeinsamen Nutzung der Wertspalten für Felddaten ist es nicht sinnvoll, eindeutige Datenbankindizes für das Objekt zu erstellen. (Diese Situation ähnelt der im vorherigen Abschnitt für nicht eindeutige Indizes beschriebenen.)
Um die Eindeutigkeit für benutzerdefinierte Felder zu unterstützen, verwendet die Plattform die Pivottabelle "MT_Unique_Indexes". Diese Tabelle ähnelt sehr der Tabelle "MT_Indexes", mit dem Unterschied, dass die zugrunde liegenden nativen Datenbankindizes von "MT_Unique_Indices" die Eindeutigkeit erzwingen. Wenn eine Anwendung versucht, einen doppelten Wert in ein Feld einzufügen, für das Eindeutigkeit erforderlich ist, oder ein Administrator versucht, Eindeutigkeit für ein vorhandenes Feld zu erzwingen, das doppelte Werte enthält, gibt die Plattform eine entsprechende Fehlermeldung an die Anwendung zurück.
In seltenen Fällen kann die externe Suchmaschine der Plattform (erläutert unter Suchvorgänge) überlastet oder anderweitig nicht verfügbar sein und möglicherweise nicht rechtzeitig auf eine Suchanfrage antworten. Statt dem Endbenutzer einen enttäuschenden Fehler zurückzugeben, greift die Plattform auf einen sekundären Suchmechanismus zurück, um vernünftige Suchergebnisse bereitzustellen.
Eine Ausweichsuche wird als direkte Datenbankabfrage mit Suchbedingungen implementiert, die auf das Feld Name von Zieldatensätzen verweisen. Damit die globalen Objektsuchen (Suchvorgänge, die sich über Tabellen erstrecken) optimiert werden, ohne dass potenziell teure Union-Abfragen ausgeführt werden müssen, verwaltet die Plattform eine Pivottabelle vom Typ MT_Fallback_Indexes, in der der Name aller Datensätze aufgezeichnet wird. Aktualisierungen an MT_Fallback_Indizes erfolgen synchron, wenn Transaktionen Datensätze ändern, sodass Ausweichsuchen immer auf die neuesten Datenbankinformationen zugreifen können.
Die Tabelle MT_Name_Denorm ist eine Tabelle mit schlanken Daten, in der die ObjID und der Name jedes Datensatzes in MT_Data gespeichert werden. Wenn eine Anwendung eine Liste der Datensätze bereitstellen muss, die an einer Über-/Unterordnungsbeziehung beteiligt sind, verwendet die Plattform die Tabelle MT_Name_Denorm, um eine relativ einfache Abfrage auszuführen, die den Namen jedes referenzierten Datensatzes zur Anzeige in der Anwendung abruft, beispielsweise als Teil eines Hyperlinks.
Die Plattform stellt Beziehungsdatentypen bereit, mit denen eine Organisation Beziehungen (referenzielle Integrität) zwischen Tabellen deklarieren kann. Wenn Sie das Feld eines Objekts mit einem Beziehungstyp deklarieren, ordnet die Plattform das Feld einem Wertfeld in MT_Data zu und verwendet dieses Feld dann zum Speichern der ObjID eines verwandten Objekts.
Zum Optimieren von Verknüpfungsvorgängen führt die Plattform eine Pivottabelle MT_Relationships. Dieser Systemtabelle liegen zwei eindeutige zusammengesetzte Datenbankindizes zugrunde, die bei Bedarf effiziente Objekttraversierungen in beide Richtungen ermöglichen.
Mit nur wenigen Mausklicks bietet die Plattform eine Verlaufsverfolgung für jedes Feld. Wenn eine Organisation die Überprüfung für ein bestimmtes Feld aktiviert, zeichnet das System asynchron Informationen über die am Feld vorgenommenen Änderungen (alte und neue Werte, Änderungsdatum usw.) auf und verwendet dazu eine interne Pivottabelle als Überprüfungsprotokoll.
Alle Plattformdaten, Metadaten und Pivottabellenstrukturen, einschließlich der zugrunde liegenden Datenbankindizes, werden physisch durch OrgID mithilfe von nativen Datenbankpartitionierungsmechanismen partitioniert. Die Datenpartitionierung ist eine bewährte Technik, die Datenbanksysteme bereitstellen, um große logische Datenstrukturen physisch in kleinere, besser verwaltbare Teile zu unterteilen. Die Partitionierung kann auch dazu beitragen, die Leistung, Skalierbarkeit und Verfügbarkeit eines großen Datenbanksystems, beispielsweise einer mandantenfähigen Umgebung, zu verbessern. Jede Plattformabfrage zielt definitionsgemäß auf die Informationen einer bestimmten Organisation ab. Daher muss die Abfrageoptimierung nur den Zugriff auf Datenpartitionen in Betracht ziehen, die die Daten einer Organisation enthalten, statt auf eine gesamte Tabelle oder einen Index. Diese allgemeine Optimierung wird manchmal als "Partitionsschnitt" bezeichnet.
In diesem Abschnitt wird beschrieben, wie Anwendungsentwickler die zugrunde liegenden Metadaten eines Schemas erstellen und dann Anwendungen erstellen können, die Daten verwalten. Diese Metadaten und Daten werden in der im vorherigen Abschnitt beschriebenen Plattformdatenebene gespeichert.
Entwickler können serverseitige Anwendungskomponenten deklarativ mithilfe der browserbasierten Entwicklungsumgebung der Plattform erstellen, die häufig als Bildschirme für das Setup der Plattform bezeichnet wird. Die Zeigen-und-Klicken-Benutzeroberfläche des Setups unterstützt alle Bereiche des Prozesses zur Erstellung von Anwendungsschemas, beispielsweise die Erstellung des Datenmodells einer Anwendung (einschließlich Objekten und deren Feldern sowie Beziehungen), das Sicherheits- und Freigabemodell (einschließlich Benutzern, Profilen und Rollenhierarchien), die Benutzeroberfläche (einschließlich Bildschirmlayouts, Dateneingabeformularen und Berichten), die deklarative Logik (Arbeitsabläufe) und die programmgesteuerte Logik (gespeicherte Prozeduren und Auslöser). Salesforce-Flow erleichtert beispielsweise die Automatisierung einer Vielzahl von Anwendungsfällen. Mit der unten gezeigten Flow Builder-Benutzeroberfläche von Setup können Sie Workflows grafisch entwerfen und implementieren, die mit Benutzern interagieren oder automatisch anhand eines Zeitplans oder durch ein Ereignis ausgelöst gestartet werden.
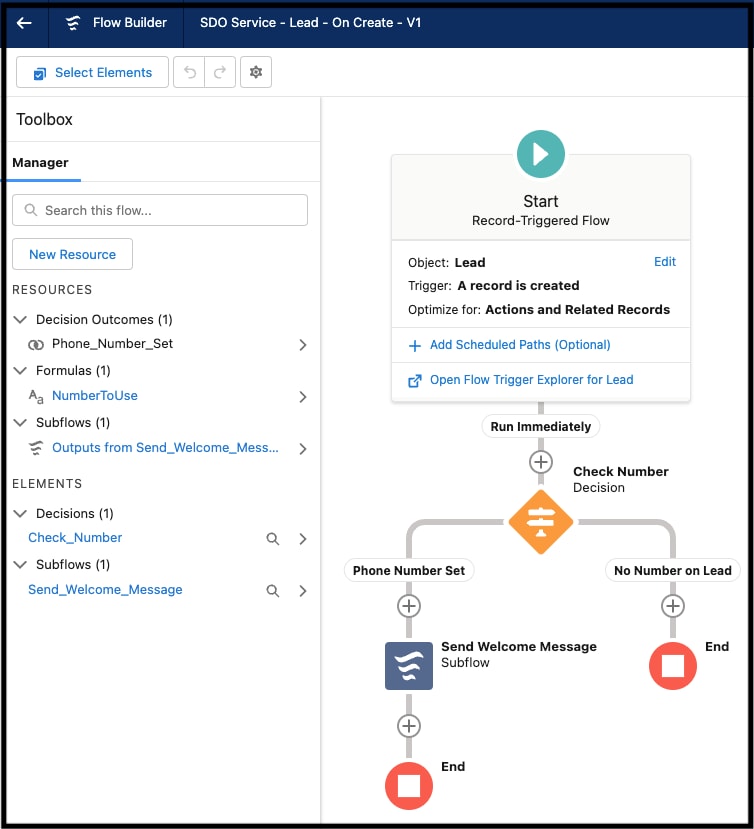
Mit den Setup-Bildschirmen können Benutzer Anwendungen ohne (oder mit sehr wenig) Code einfach entwickeln und anpassen. Beispiel:
- Plattformeigene Benutzeroberflächen können ohne Code einfach erstellt werden. Im Hintergrund unterstützt eine Benutzeroberfläche der nativen Anwendung alle gängigen Datenzugriffsvorgänge, einschließlich Abfragen, Einfügungen, Aktualisierungen und Löschungen. Jeder Datenänderungsvorgang, der von nativen Plattformanwendungen ausgeführt wird, kann jeweils ein Objekt ändern und jede Änderung automatisch in einer separaten Transaktion übernehmen.
- Wenn Sie ein Textfeld für ein Objekt definieren, das sensible Daten enthält, können Sie das Feld einfach so konfigurieren, dass die Plattform die entsprechenden Daten verschlüsselt und optional eine Eingabemaske verwendet, um Bildschirminformationen vor neugierigen Blicken zu verbergen.
- Eine deklarative Validierungsregel ist eine einfache Möglichkeit für eine Organisation, eine Domänenintegritätsregel ohne Programmierung zu erzwingen. Beispielsweise können Sie eine Validierungsregel deklarieren, die sicherstellt, dass das Feld "Menge" eines LineItem-Objekts immer größer als null ist.
- Ein Formelfeld ist eine deklarative Funktion der Plattform, mit der ein berechnetes Feld einem Objekt einfach hinzugefügt werden kann. Beispielsweise können Sie dem Objekt "LineItem" ein Feld hinzufügen, um einen LineTotal-Wert zu berechnen.
- Bei einem Rollup-Zusammenfassungsfeld handelt es sich um ein objektübergreifendes Feld, mit dem Informationen zu untergeordneten Feldern in einem übergeordneten Objekt einfach aggregiert werden können. Beispielsweise können Sie ein Zusammenfassungsfeld "OrderTotal" im Objekt "SalesOrder" erstellen, das auf dem Feld "LineTotal" des Objekts "LineItem" basiert.
Hinweis: Intern implementiert die Plattform Formel- und Rollup-Zusammenfassungsfelder mithilfe von nativen Datenbankfunktionen und berechnet Werte synchron im Rahmen laufender Transaktionen effizient neu.
Die Plattform bietet mehrere offene, standardbasierte APIs, mit denen Entwickler Anwendungen erstellen können. Sowohl RESTful- als auch Webservices (SOAP-basiert) bieten Zugriff auf die vielen Funktionen der Plattform. Mithilfe dieser verschiedenen APIs kann eine Anwendung:
- Bearbeiten von Metadaten, die ein Anwendungsschema beschreiben
- Erstellen, Lesen, Aktualisieren und Löschen (CRUD) von Geschäftsdaten
- Massenladen oder Abfragen einer großen Anzahl asynchroner Datensätze
- Bereitstellen eines Datenstroms nahezu in Echtzeit auf sichere und skalierbare Weise
Anwendungen können die Salesforce Object Query Language (SOQL) verwenden, um einfache, aber leistungsstarke Datenbankabfragen zu erstellen. Ähnlich wie beim SELECT-Befehl in der strukturierten Abfragesprache (SQL) können Sie mit SOQL das Quellobjekt, eine Liste der abzurufenden Felder und Bedingungen für die Auswahl von Zeilen im Quellobjekt angeben. Die folgende SOQL-Abfrage gibt beispielsweise den Wert des Felds "ID" und "Name" für alle Accountdatensätze mit dem Namen "Acme" zurück.
SELECT Id, Name FROM Account WHERE Name = 'Acme'
Die Plattform enthält auch eine mehrsprachige Volltextsuchmaschine, die alle textbezogenen Felder automatisch indiziert. Anwendungen können diese vorintegrierte Suchmaschine verwenden, indem sie die Salesforce Object Search Language (SOSL) verwenden, um Textsuchen durchzuführen. Anders als SOQL, das jeweils nur ein Objekt abfragen kann, können Sie mit SOSL Text-, E-Mail- und Telefonfelder für mehrere Objekte gleichzeitig durchsuchen. Die folgende SOSL-Anweisung sucht beispielsweise nach Datensätzen in den Lead- und Kontaktobjekten, die die Zeichenfolge "Joe Smith" im Namensfeld enthalten, und gibt den Namen und das Telefonnummernfeld jedes gefundenen Datensatzes zurück.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, das in vielerlei Hinsicht Java ähnelt, ist eine leistungsstarke Entwicklungssprache, mit der Entwickler Verfahrenslogik in ihrem Anwendungsschema zentralisieren können. Apex Code kann Programmvariablen und -konstanten deklarieren, traditionelle Anweisungen zur Flow-Steuerung (falls vorhanden, Schleifen usw.) ausführen, Datenmanipulationsvorgänge (Einfügen, Aktualisieren, Aktualisieren, Einfügen, Löschen) und Transaktionssteuerungsvorgänge (SetSavepoint, Rollback) ausführen.
Sie können Apex-Programme auf der Plattform in zwei verschiedenen Formen speichern: als benannte Apex-Klasse mit Methoden (die in traditioneller Datenbanksprache gespeicherten Prozeduren entsprechen), die Anwendungen bei Bedarf ausführen, oder als Datenbankauslöser, der automatisch ausgeführt wird, bevor oder nachdem ein bestimmtes Datenbankmanipulationsereignis auftritt. In beiden Fällen kompiliert die Plattform Apex Code und speichert ihn als Metadaten in der UDD. Wenn eine Organisation ein Apex Programm zum ersten Mal ausführt, lädt der Laufzeitinterpreter der Plattform die kompilierte Version des Programms in einen MRU-Cache (zuletzt verwendet). Wenn ein Benutzer aus derselben Organisation dieselbe Routine verwenden muss, kann die Plattform Speicher sparen und den Aufwand für die erneute Kompilierung des Programms vermeiden, indem das bereits vorhandene einsatzbereite Programm freigegeben wird.
Wenn Entwickler hier und da ein einfaches Stichwort hinzufügen, können sie Apex verwenden, um viele individuelle Anwendungsanforderungen zu unterstützen. Beispielsweise können Entwickler eine Methode als benutzerdefinierten RESTful- oder SOAP-basierten API-Aufruf bereitstellen, sie asynchron planen oder so konfigurieren, dass ein großer Vorgang in Batches verarbeitet wird.
Apex ist viel mehr als "nur eine weitere Verfahrenssprache". Es ist eine integrale Plattformkomponente, mit der das System zuverlässige Mandantenfunktionen bereitstellen kann. Beispielsweise validiert die Plattform automatisch alle eingebetteten SOQL- und SOSL-Anweisungen innerhalb einer Klasse, um Code zu verhindern, der andernfalls zur Laufzeit fehlschlagen würde. Die Plattform behält dann die entsprechenden Objektabhängigkeitsinformationen für gültige Klassen bei und verwendet sie, um Änderungen an Metadaten zu verhindern, die andernfalls den abhängigen Code beschädigen würden.
Viele standardmäßige Apex-Klassen und statische Systemmethoden bieten einfache Schnittstellen zu den zugrunde liegenden Systemfunktionen. Beispielsweise verfügen die systemstatischen DML-Methoden wie insert, update und delete über einen einfachen booleschen Parameter, den Entwickler verwenden können, um die gewünschte Massenverarbeitungsoption (alle oder nichts oder Teilspeicherung) anzugeben. Diese Methoden geben auch ein Ergebnisobjekt zurück, das die aufrufende Routine lesen kann, um zu bestimmen, welche Datensätze nicht erfolgreich verarbeitet wurden und warum. Weitere Beispiele für die direkten Verbindungen zwischen Apex und Plattformfunktionen sind die integrierten E-Mail-Klassen und XmlStream-Klassen.
Zum großen Teil funktioniert die Plattform gut und kann gut skaliert werden, da Salesforce zwei wichtige Prinzipien berücksichtigt:
- Stellen Sie effiziente, hochskalierte grundlegende Plattformfunktionen bereit.
- Helfen Sie Entwicklern, alles so effizient wie möglich zu erledigen.
Die Plattform integriert diese Prinzipien in die einzigartigen Verarbeitungsarchitekturen der Plattform, einschließlich:
- Abfragen
- Suchvorgänge
- Massenvorgänge
- Schemaänderung
- Mandantenisolation
- Der Papierkorb
Die meisten modernen Datenbanksysteme bestimmen optimale Abfrageausführungspläne mithilfe einer kostenbasierten Abfrageoptimierung, die relevante Statistiken zu Zieltabellen- und Indexdaten berücksichtigt. Herkömmliche kostenbasierte Optimierungsstatistiken sind jedoch für Einzelmandantenanwendungen konzipiert und berücksichtigen nicht die Datenzugriffseigenschaften eines bestimmten Benutzers, der eine Abfrage in einer mandantenfähigen Umgebung ausführt. Beispielsweise würde eine bestimmte Abfrage, die auf ein Objekt mit einer großen Datenmenge abzielt, höchstwahrscheinlich effizienter ausgeführt, indem andere Ausführungspläne für Benutzer mit hoher Sichtbarkeit (ein Manager, der alle Zeilen anzeigen kann) als für Benutzer mit geringer Sichtbarkeit (Vertriebsmitarbeiter, die nur Zeilen anzeigen können, die sich auf sich selbst beziehen) verwendet werden.
Um ausreichende Statistiken für die Bestimmung optimaler Abfrageausführungspläne in einem mandantenfähigen System bereitzustellen, verwaltet die Plattform einen vollständigen Satz an Optimierungsstatistiken (Mandanten-, Gruppen- und Benutzerebene) für die Objekte jeder Organisation. Statistiken spiegeln die Anzahl der Zeilen wider, auf die eine bestimmte Abfrage potenziell zugreifen kann, wobei die gesamte organisationsspezifische Objektstatistik (z. B. die Gesamtanzahl der Zeilen, deren Inhaber die Organisation insgesamt ist) sowie genauere Statistiken (z. B. die Anzahl der Zeilen, auf die eine bestimmte Berechtigungsgruppe oder ein Endbenutzer potenziell zugreifen kann) berücksichtigt werden.
Die Plattform verwaltet auch andere Arten von Statistiken, die sich bei bestimmten Abfragen als hilfreich erweisen. Beispielsweise führt die Plattform Statistiken für alle benutzerdefinierten Indizes, um die Gesamtanzahl der nicht nullwertigen und eindeutigen Werte im entsprechenden Feld anzuzeigen, und Histogramme für Auswahllistenfelder, die die Kardinalität jedes Listenwerts anzeigen.
Wenn vorhandene Statistiken nicht vorhanden sind oder als nicht hilfreich erachtet werden, verwendet die Optimierungsfunktion der Plattform einige verschiedene Strategien, um einigermaßen optimale Abfragen zu erstellen. Wenn eine Abfrage beispielsweise nach dem Feld "Name" eines Objekts filtert, kann die Optimierungsfunktion die Tabelle "MT_Fallback_Indexes" verwenden, um angeforderte Zeilen effizient zu finden. In anderen Szenarien generiert die Optimierung zur Laufzeit dynamisch fehlende Statistiken.
Die Optimierung der Plattform wird zusammen mit Optimierungsstatistiken verwendet und basiert auch auf internen sicherheitsbezogenen Tabellen (Gruppen, Mitglieder, GroupBlowout und CustomShare), in denen Informationen über die Sicherheitsdomänen der Benutzer einer Organisation gespeichert werden, einschließlich der Gruppenmitgliedschaften eines bestimmten Benutzers und benutzerdefinierter Zugriffsrechte für Objekte und Zeilen. Solche Informationen sind für die Bestimmung der Selektivität von Abfragefiltern auf Benutzerbasis von unschätzbarem Wert. Weitere Informationen zum eingebetteten Sicherheitsmodell der Plattform finden Sie im Trailhead Platform Developer Basics.
Das Flussdiagramm in der folgenden Abbildung veranschaulicht, was geschieht, wenn die Plattform eine Anforderung für Daten verarbeitet, die sich in einer der großen Heap-Tabellen wie MT_Data befinden. Die Anforderung kann aus einer beliebigen Anzahl von Quellen stammen, beispielsweise einem API-Aufruf oder einer gespeicherten Prozedur. Zunächst führt die Plattform "Vorababfragen" aus, die Statistiken zum Mandantenbewusstsein berücksichtigen. Anschließend erstellt der Service basierend auf den von den Vorababfragen zurückgegebenen Ergebnissen eine optimale zugrunde liegende Datenbankabfrage für die Ausführung in der spezifischen Einstellung.
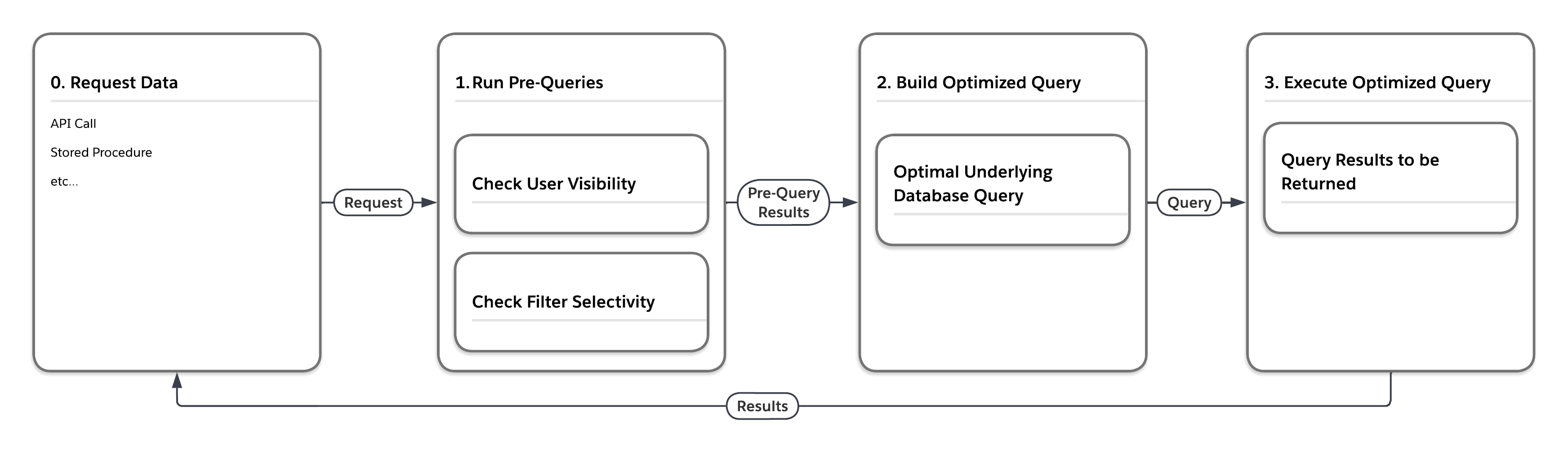
Wie die folgende Tabelle zeigt, kann die Plattform dieselbe Abfrage auf vier verschiedene Arten ausführen, je nachdem, welcher Benutzer die Abfrage sendet, und je nachdem, wie selektiv die Filterbedingungen der Abfrage sind.
| Messungen der Selektivität vor der Abfrage | Schreiben Sie eine Abfrage für den endgültigen Datenbankzugriff und erzwingen... | |
| Benutzer | Filter | |
| Niedrig | Niedrig | ... verschachtelte Schleifen verknüpfen, Laufwerk mit Ansicht der Zeilen, die der Benutzer sehen kann |
| Niedrig | Hoch | ... Verwendung des Filterindex |
| Hoch | Niedrig | ... geordnete Hash-Verknüpfung, Laufwerk mit MT_DATA |
| Hoch | Hoch | ... Verwendung des indexbezogenen Filters |
Benutzer erwarten, dass eine interaktive Suchfunktion den gesamten oder einen ausgewählten Umfang der Datenbank einer Anwendung scannt und Ergebnisse mit Antwortzeiten im Sekundenbereich zurückgibt. Um diese Funktion für Plattformanwendungen bereitzustellen, verwendet die Plattform eine von ihrem Transaktionsmodul getrennte Suchmaschine. Wenn Sie Datensätze aktualisieren, aktualisiert das Transaktionsmodul die zentrale Datenbank und leitet die zugehörigen Daten zur Indizierung an die Suchmaschine weiter. Wenn Sie nach Datensätzen suchen, verwendet die Suchmaschine ihre Indizes, um die Abfrage schnell zu verarbeiten, und gibt geordnete Ergebnisse mit Links zu verwandten Datenbankdatensätzen zurück.
Wenn Anwendungen Daten in Textfeldern aktualisieren (CLOBs, Name usw.), ist ein Pool von Hintergrundprozessen, die als Indizierungsserver bezeichnet werden, für die asynchrone Aktualisierung der entsprechenden Indizes verantwortlich, die die Suchmaschine außerhalb des zentralen Transaktionsmoduls verwaltet. Zum Optimieren des Indizierungsprozesses kopiert die Plattform geänderte Textdatenblöcke synchron in eine interne Tabelle, die beim Commit von Transaktionen indiziert werden soll, und bietet so eine relativ kleine Datenquelle, die die Datenmenge minimiert, die Indizierungsserver von der Festplatte lesen müssen. Die Suchmaschine führt automatisch separate Indizes für jede Organisation.
Je nach aktueller Auslastung und Auslastung der Indizierungsserver können Textindexaktualisierungen hinter den tatsächlichen Transaktionen zurückbleiben. Um unerwartete Suchergebnisse zu vermeiden, die aus veralteten Indizes stammen, führt die Plattform auch einen MRU-Cache mit kürzlich aktualisierten Zeilen, den das System beim Materialisieren von Volltextsuchergebnissen berücksichtigt. Die Plattform verwaltet MRU-Caches pro Benutzer und pro Organisation, um mögliche Suchumfänge effizient zu unterstützen.
Die Suchmaschine der Plattform optimiert die Rangfolge der Datensätze in den Suchergebnissen mithilfe mehrerer Methoden. Beispielsweise berücksichtigt das System die Sicherheitsdomäne des Benutzers, der eine Suche ausführt, und legt mehr Gewicht auf die Zeilen, auf die der aktuelle Benutzer zugreifen kann. Das System kann auch den Änderungsverlauf einer bestimmten Zeile berücksichtigen und aktiver aktualisierte Zeilen vor relativ statischen Zeilen einordnen. Der Benutzer kann die Suchergebnisse nach Bedarf gewichten, beispielsweise indem er die zuletzt geänderten Zeilen stärker in den Vordergrund stellt.
Transaktionsintensive Anwendungen generieren weniger Overhead und arbeiten viel besser, wenn sie sich wiederholende Vorgänge per Massenvorgang kombinieren und ausführen. Vergleichen Sie beispielsweise zwei Möglichkeiten, wie eine Anwendung viele neue Zeilen laden kann. Ein ineffizienter Ansatz besteht darin, eine Routine mit einer Schleife zu verwenden, die einzelne Zeilen einfügt und für jede Zeileneinfügung einen API-Aufruf nach dem anderen vornimmt. Ein wesentlich effizienterer Ansatz wäre das Erstellen eines Arrays von Zeilen und das Einfügen aller Zeilen durch die Routine mit einem einzigen API-Aufruf.
Die effiziente Massenverarbeitung mit der Plattform ist für Entwickler einfach, da sie in API-Aufrufe integriert ist. Intern verarbeitet die Plattform auch alle internen Schritte, die sich auf einen expliziten Massenvorgang beziehen.
Das Massenverarbeitungsmodul der Plattform berücksichtigt automatisch einzelne Fehler, die während eines Schritts auftreten. Wenn ein Massenvorgang im Teilspeichermodus gestartet wird, identifiziert das Modul einen bekannten Startstatus und versucht dann, jeden Schritt im Prozess auszuführen (Massenvalidierung von Felddaten, Massenauslöser, Massenspeicherdatensätze usw.). Wenn das Modul während eines Schritts Fehler feststellt, setzt das Modul die fehlerhaften Vorgänge und alle Nebenwirkungen zurück, entfernt die Zeilen, die für die Fehler verantwortlich sind, und fährt fort und versucht, die verbleibende Teilmenge der Zeilen per Massenvorgang zu verarbeiten. Dieser Prozess wird durch jede aufeinanderfolgende Phase wiederholt, bis das Modul eine Teilmenge von Zeilen ohne Fehler übernehmen kann. Die Anwendung kann ein Rückgabeobjekt untersuchen, um festzustellen, welche Zeilen fehlgeschlagen sind und welche Ausnahmen sie ausgelöst hat.
Hinweis: Für Massenvorgänge steht nach eigenem Ermessen ein Alles-oder-nichts-Modus zur Verfügung. Außerdem unterliegt die Ausführung von Auslösern während eines Massenvorgangs internen Reglern, die den Arbeitsaufwand einschränken.
Bestimmte Arten von Änderungen an der Definition eines Objekts erfordern mehr als nur einfache UDD-Metadatenaktualisierungen. In solchen Fällen verwendet die Plattform effiziente Mechanismen, die dazu beitragen, die Gesamtleistungsauswirkungen auf den Cloud-Datenbankservice zu reduzieren.
Überlegen Sie beispielsweise, was im Hintergrund geschieht, wenn Sie den Datentyp einer Spalte von Auswahlliste zu Text ändern. Die Plattform weist zunächst ein neues Zeitfenster für die Daten der Spalte zu, kopiert die Auswahllistenbezeichnungen, die den aktuellen Werten zugeordnet sind, per Massenvorgang und aktualisiert dann die Metadaten der Spalte, sodass sie auf das neue Zeitfenster verweisen. Während all dies geschieht, ist der Zugriff auf Daten normal und Anwendungen funktionieren weiterhin ohne spürbare Auswirkungen.
Überlegen Sie sich als weiteres Beispiel, was geschieht, wenn Sie einem Objekt ein Rollup-Zusammenfassungsfeld hinzufügen. In diesem Fall berechnet die Plattform die anfänglichen Zusammenfassungen im Hintergrund mithilfe eines effizienten Massenvorgangs asynchron. Während der Hintergrundberechnung erhalten Benutzer, die das neue Feld anzeigen, einen Hinweis darauf, dass die Plattform den Wert des Felds derzeit berechnet.
Um eine böswillige oder unbeabsichtigte Monopolisierung freigegebener mandantenfähiger Systemressourcen zu verhindern, verfügt die Plattform über einen umfangreichen Satz an Reglern und Ressourcenobergrenzen, die der Ausführung von Plattformcode zugeordnet sind. Beispielsweise überwacht die Plattform die Ausführung eines Code-Skripts genau und begrenzt, wie viel CPU-Zeit sie verwenden kann, wie viel Speicher sie verbrauchen kann, wie viele Abfragen und DML-Anweisungen sie ausführen kann, wie viele mathematische Berechnungen sie ausführen kann, wie viele ausgehende Webservices sie aufrufen kann und vieles mehr. Einzelne Abfragen, deren Ausführung nach Ansicht der Optimierungsfunktion der Plattform zu teuer ist, lösen eine Laufzeitausnahme für den Aufrufer aus. Obwohl solche Obergrenzen etwas restriktiv klingen, sind sie notwendig, um die allgemeine Skalierbarkeit und Leistung des gemeinsam genutzten Datenbanksystems für alle betroffenen Anwendungen zu schützen. Langfristig tragen diese Maßnahmen dazu bei, bessere Codierungstechniken bei Entwicklern zu fördern und eine bessere Erfahrung für alle Benutzer zu schaffen, die die Plattform verwenden. Ein Entwickler, der beispielsweise zunächst versucht, eine Schleife zu codieren, die tausend Zeilen nacheinander ineffizient aktualisiert, erhält Laufzeitausnahmen aufgrund von Ressourcenobergrenzen und beginnt dann mit der Verwendung der effizienten API-Aufrufe für die Massenverarbeitung der Plattform.
Um potenzielle Systemprobleme durch schlecht geschriebene Anwendungen weiter zu vermeiden, ist die Bereitstellung einer neuen Produktionsanwendung ein streng verwalteter Prozess. Bevor eine Organisation eine neue Anwendung vom Entwicklungs- in den Produktionsstatus überführen kann, benötigt Salesforce Einheitentests, die die Funktionalität der Plattformcoderoutinen der Anwendung validieren. Gesendete Einheitentests müssen mindestens 75 Prozent des Quellcodes der Anwendung abdecken.
Salesforce führt gesendete Einheitentests in der Sandbox-Entwicklungsumgebung der Plattform aus, um festzustellen, ob der Anwendungscode die Leistung und Skalierbarkeit der Mandantenpopulation insgesamt beeinträchtigt. Die Ergebnisse eines einzelnen Einheitentests geben grundlegende Informationen an, beispielsweise die Gesamtanzahl der ausgeführten Zeilen, sowie spezifische Informationen über den Code, der durch den Test nicht ausgeführt wurde.
Sobald der Code einer Anwendung für die Produktion durch Salesforce zertifiziert ist, besteht der Bereitstellungsprozess für die Anwendung aus einer einzelnen Transaktion, die alle Metadaten der Anwendung in eine Produktionsplattforminstanz kopiert und die entsprechenden Einheitentests erneut ausführt. Wenn ein Teil des Prozesses fehlschlägt, wird die Transaktion von der Plattform einfach zurückgesetzt und es werden Ausnahmen zurückgegeben, um das Problem zu beheben.
Hinweis: Salesforce führt die Einheitentests für jede Anwendung mit jeder Entwicklungsversion der Plattform erneut aus, um proaktiv zu erfahren, ob neue Systemfunktionen und -verbesserungen vorhandene Anwendungen beeinträchtigen.
Nachdem eine Produktionsanwendung live geschaltet wurde, analysiert das integrierte Leistungsprofil der Plattform sie automatisch und gibt Administratoren zugehöriges Feedback. Leistungsanalyseberichte enthalten Informationen zu langsamen Abfragen, Datenmanipulationen und Unterprogrammen, die Sie überprüfen und zum Optimieren der Anwendungsfunktionen verwenden können. Das System protokolliert auch Informationen über Laufzeitausnahmen und gibt sie an Administratoren zurück, um ihnen beim Debuggen ihrer Anwendungen zu helfen.
Wenn eine Anwendung einen Datensatz aus einem Objekt löscht, markiert die Plattform die Zeile einfach zum Löschen, indem sie das Feld "IsDeleted" der Zeile in "MT* Data" (MT-Daten) ändert. Durch diese Aktion wird die Zeile im sogenannten Papierkorb* platziert. Auf der Plattform können Sie ausgewählte Zeilen bis zu 15 Tage lang aus dem Papierkorb wiederherstellen, bevor Sie sie endgültig aus MT_Data entfernen. Die Plattform begrenzt die Gesamtanzahl der Datensätze, die sie für eine Organisation führt, basierend auf den Speicherobergrenzen für diese Organisation.
Wenn ein Vorgang einen übergeordneten Datensatz löscht, der an einer Master-Detail-Beziehung beteiligt ist, löscht die Plattform automatisch alle zugehörigen untergeordneten Datensätze, vorausgesetzt, dies würde die bestehenden Regeln für die referenzielle Integrität nicht verletzen. Wenn Sie beispielsweise einen SalesOrder löschen, kaskadiert die Plattform die Löschung automatisch zu abhängigen LineItems. Wenn Sie anschließend einen übergeordneten Datensatz aus dem Papierkorb wiederherstellen, stellt das System automatisch auch alle untergeordneten Datensätze wieder her.
Wenn Sie dagegen einen referenzierten übergeordneten Datensatz löschen, der an einer Nachschlagebeziehung beteiligt ist, legt die Plattform alle abhängigen Schlüssel automatisch auf null fest. Wenn Sie den übergeordneten Datensatz anschließend wiederherstellen, stellt die Plattform automatisch die zuvor nullierten Nachschlagebeziehungen wieder her, mit Ausnahme der Beziehungen, die zwischen den Lösch- und Wiederherstellungsvorgängen neu zugewiesen wurden.
Im Papierkorb werden auch verworfene Felder und ihre Daten gespeichert, bis sie von einer Organisation endgültig gelöscht werden oder eine festgelegte Anzahl von Tagen verstrichen ist, je nachdem, was zuerst eintritt. Bis zu diesem Zeitpunkt stehen das gesamte Feld und alle seine Daten zur Wiederherstellung zur Verfügung.
Agilität ist der Schlüssel zum Erfolg von Unternehmen in unserer modernen Welt. Die zugrunde liegenden Schichten der Salesforce Platform helfen Ihren Geschäftsanwendungen, sich schnell an neue Herausforderungen anzupassen, sodass Sie sich weiterhin auf Ihr Unternehmen und nicht auf die Infrastruktur konzentrieren können.
Die Infrastruktur (z. B. grundlegende Services und Rechenressourcen) ist ausgeblendet und liegt der Technologie zugrunde, die die oberen Ebenen der Salesforce Platform unterstützt. Hyperforce ist die Salesforce Platform-Infrastruktur, die zu 100 % auf erneuerbaren Energien und Net-Zero basiert und wichtige Kundenherausforderungen wie Compliance, Trust und Skalierbarkeit löst.
Unternehmen, die an mehreren geografischen Standorten tätig sind, müssen neue, sich ändernde und variierende Vorschriften für die Datenverwaltung einhalten. Da Salesforce Hyperforce in einer wachsenden Anzahl von Ländern bereitstellt, die derzeit auf der Verfügbarkeit von AWS-Regionen basieren, können Plattformanwendungen und Benutzer ihre sensiblen Arbeitslasten auf eine Weise ausführen, die strenge Datenspeicher- oder Datenschutzstandards erfüllt. Mit der Salesforce-Betriebszone der Europäischen Union (EU) auf Hyperforce-Basis können Unternehmen in der EU ihre Daten ohne Weiteres in der EU aufbewahren.
Sicherheit, Zuverlässigkeit und Verfügbarkeit sind nicht funktionale Anforderungen, die jede Geschäftsanwendung berücksichtigen muss, um das Versprechen von Trust gegenüber ihren Endbenutzern einzulösen. Mit Hyperforce können Unternehmen auf einfache Weise vertrauenswürdige Geschäftsanwendungen bereitstellen.
- Sicherheit: Hyperforce verfügt über eine native durchgängige Verschlüsselung von Kundendaten im Leerlauf und während der Übertragung. Die Zero Trust Architecture von Hyperforce erzwingt einen strengen Identitätsüberprüfungsprozess, der sicherstellt, dass kein impliziter Zugriff auf Ressourcen besteht. Und Hyperforce verwendet das Prinzip der geringsten Berechtigung, um sicherzustellen, dass Vorgänge genau für die richtige Zeit mit der richtigen Zugriffsmenge genehmigt werden.
- Zuverlässigkeit: Jede Hyperforce-Instanz verwendet mehrere Cloud-Verfügbarkeitszonen und modernisierte Ansätze, die die Reaktion auf Vorfälle beschleunigen, um eine hochverfügbare und widerstandsfähige Plattform bereitzustellen.
- Verfügbarkeit: Die modernen CI/CD-Pipelines und blau/grünen Anwendungsversionen von Hyperforce minimieren die Wartungszeiträume der Anwendung auf nur eine Minute pro Jahr.
Als Grundlage für Anwendungen wie Sales Cloud und Service Cloud ist Salesforce eine bewährte Anwendungsplattform, auf der einzelne Unternehmen und Serviceanbieter Millionen von Geschäftsanwendungen für unterschiedliche Anwendungsfälle erstellt haben, einschließlich Lieferkettenmanagement, Abrechnung, Buchhaltung, Handel, Compliance-Verfolgung, Personalverwaltung und Anspruchsverarbeitung. Die einzigartige mandantenfähige, metadatengestützte Architektur der Plattform wurde speziell für die Cloud entwickelt und unterstützt zuverlässig und sicher geschäftskritische Anwendungen im Internet. Mit standardbasierten APIs und nativen Entwicklungstools können Plattformentwickler ohne Weiteres alle Komponenten einer modernen Web- oder mobilen Anwendung erstellen, einschließlich des Datenmodells der Anwendung (einschließlich Objekten und Beziehungen), der Geschäftslogik (einschließlich Workflows und Validierungen), Integrationen in andere Anwendungen und mehr.
Seit ihrer Gründung wurde die Plattform von den Salesforce-Ingenieuren für die Mandantenschaft optimiert und bietet Funktionen, mit denen Plattformanwendungen an sich ändernde Geschäftsanforderungen angepasst werden können. Mithilfe von integrierten Systemfunktionen wie der API für die Massenverarbeitung von Daten, Apex, einer Volltextsuchmaschine und einer einzigartigen Abfrageoptimierung können abhängige Anwendungen mit geringem oder keinem Aufwand von Entwicklern hocheffizient und skalierbar gestaltet werden.
Der verwaltete Ansatz von Salesforce für die Bereitstellung von Produktionsanwendungen gewährleistet eine hervorragende Leistung, Skalierbarkeit und Zuverlässigkeit für alle Anwendungen, die auf der Plattform basieren. Salesforce überwacht und erfasst laufend Betriebsinformationen aus Plattformanwendungen, um schrittweise Verbesserungen und neue Systemfunktionen voranzutreiben, die sofort bestehenden und neuen Anwendungen zugute kommen.
Steve Bobrowski ist ein erfolgreicher Unternehmer und Technologieführer, der seit 2008 für viele führende Unternehmenssoftwareunternehmen gearbeitet hat, darunter verschiedene Rollen in Salesforce. Heute arbeitet Steve im Salesforce-Büro des CTO, um die Technologiearchitekturstrategien des Unternehmens zu unterstützen.
Tom Leddy ist Architect Evangelist bei Salesforce. Er unterstützt die globale Salesforce Architect Community, indem er beim Erstellen von Ressourcen, Tools und Anleitungen hilft, mit denen Architekten ihre beste Arbeit erledigen können. Verbinden Sie sich mit Tom auf Twitter.