Hver dag driver hundredtusindvis af virksomheder og millioner af brugere deres forretning i clouden ved hjælp af applikationer drevet af Salesforce Platform. Hvorfor er platformen så vellykket? Hvorfor kan du Trust det til at understøtte din virksomhed? Hvilke unikke fordele giver platformen for forretninger som din?
Dette tekniske kort forklarer, hvordan Salesforce Platform leverer pålidelige, skalerbare og nemme at tilpasse slutbrugeroplevelser ved brug af dens unikke softwarearkitektur til cloud computing. Når du har læst dette kort, vil du bedre forstå den underliggende teknologi, der gør Salesforce Platform til et overbevisende valg for dine forretningsapplikationer.
Salesforce Platform er det fremtrædende eksempel på en vellykket cloud computing-platform og et relateret applikationsøkosystem. Siden årtusindskiftet har platformen været det aktiverende grundlag for:
- Mange populære forretningsapplikationer til almindelige anvendelsessituationer som salg og kundeservice
- Branchespecifikke applikationer til mere specialiserede anvendelsessituationer som finansiering og sundhedspleje
- Millioner af tilpassede applikationer og applikationsudvidelser til unikke anvendelsessituationer
Salesforce Platform er stort set så succesfuldt og populært, fordi dets unikke softwarearkitektur understøtter applikationer, der er nemme at opbygge, bruge, tilpasse og udvide med enestående ydeevne og pålidelighed. Kernen i platformens softwarearkitektur er dens multilejer, metadatastyrede design.
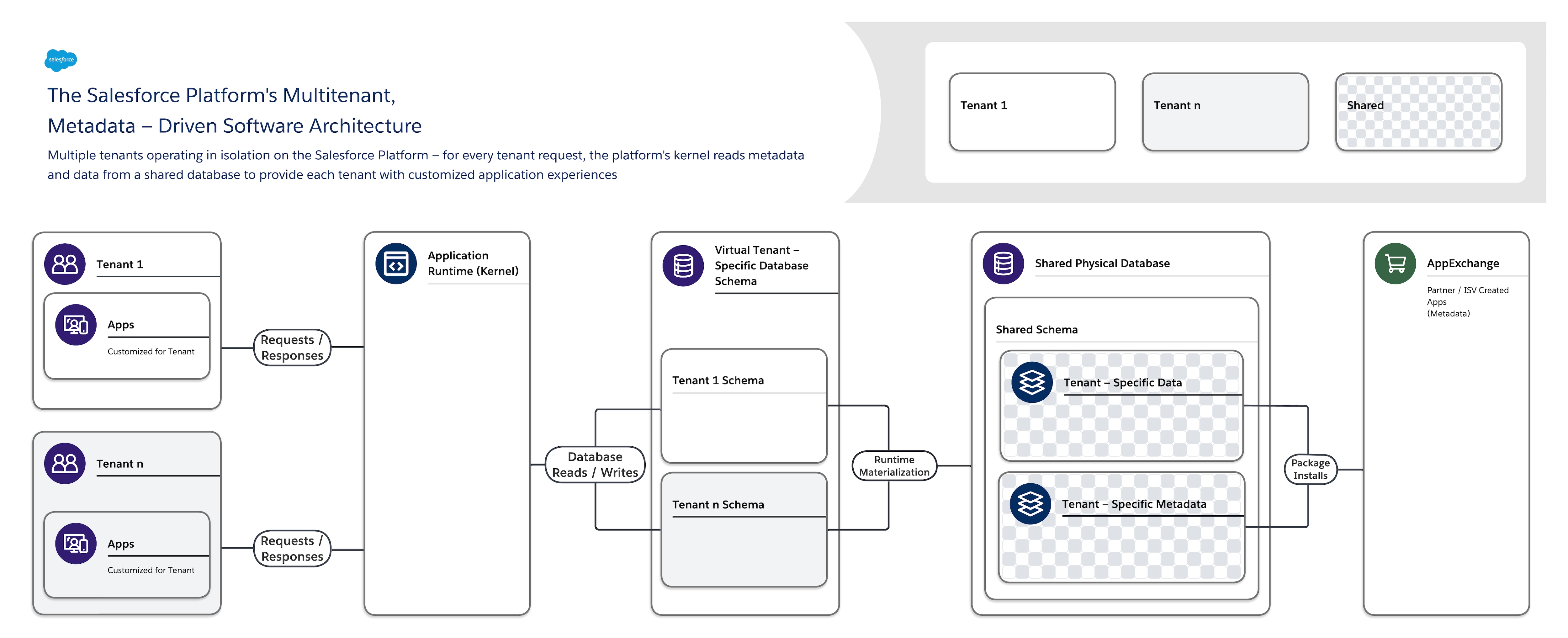
Salesforce Platforms softwarearkitektur er:
- Multitenant – Den isolerer og understøtter samtidig de forskellige krav hos mange lejer (organisationer, forretningsenheder osv.).
- Metadatastyret – Det gør det nemt og hurtigt for lejere at tilpasse deres apps og brugeroplevelser ved hjælp af metadata, data, der beskriver elementer som brugergrænsefladen (UI) og forretningslogik.
Når du opretter et nyt applikationsobjekt eller skriver noget kode ved brug af Salesforce Platform, opretter platformen ikke en faktisk tabel i en database eller kompilerer nogen kode. I stedet lagrer platformen ganske enkelt nogle metadata, som den derefter kan bruge på kørselstidspunktet til dynamisk at materialisere virtuelle applikationskomponenter. Platformen sikrer, at hver lejers metadata er private og nemme at opdatere uden nogen låsning eller nedetid, så hver lejer kan opbygge og tilpasse apps separat. Salesforce Platform bruger de samme metadata til at levere tilpassede API'er, RESTful og webtjenestegrænseflader (SOAP-baseret), som du kan bruge til at integrere dine applikationer med andre applikationer og automatiserede processer.
Færdige løsninger findes også i AppExchange, platformens omfattende appmarkedsplads. En AppExchange, der er bygget af et stort økosystem af betroede partnere og uafhængige softwareudbydere (ISV'er), er metadata fra en tredjepart, der beskriver gratis eller betalte applikationsudvidelser og hele applikationer, som du kan bruge til at opfylde specifikke forretningskrav.
For at understøtte denne højt tilpassede og udvidelige arkitektur bruger en enkelt forekomst af Salesforce Platform:
- En enkelt delt flertællingsdatabase med et enkelt skema, der lagrer lejerspecifikke metadata og data.
- En multitenantkernel (applikationskørsel), der læser metadata og data for dynamisk at levere lejerspecifikke applikationer, forretningslogik og API'er for hver lejers brugere på kørselstidspunktet.
Denne tydelige adskillelse af den Salesforce-administrerede kerne fra lejeradministrerede metadata gør det muligt for Salesforce, lejere og ISV'er uafhængigt at udvikle deres dele af systemet uden forstyrrelser.
For at bygge videre på denne oversigt giver de efterfølgende afsnit i denne artikel flere detaljer om platformens unikke funktioner, der stammer fra nøgleaspekter af dets design, herunder:
- Platformsdatalaget
- Platformsanvendelsesudvikling
- Intern platformsbehandling
- Platformsinfrastruktur
Sammen isolerer Salesforce Platforms applikationskørsel og det innovative datalag sikkert lejerspecifikke data, skematilpasninger og forretningslogik. På et højt niveau understøtter skemaet en række anvendelsessituationer:
- Når du opretter eller tilpasser en applikation, lagrer platformen relaterede metadata i delte databasetabeller, der vedligeholder metadata for alle lejere.
- Når du bruger en applikation til at læse eller skrive data, lagrer platformen dine data i delte databasetabeller, der vedligeholder data for alle lejere.
- I baggrunden bevarer platformen også interne metadata i en række tabeller, som kernen bruger til at optimere anmodningsforsinkelse på kørselstidspunktet.
Men hvordan kan en enkelt delt database og et skema bevare hver lejers data private? Hver lejer på platformen er kendt som en organisation, eller organisation for kort. Og hver organisationsspecifik registrering i delte databasetabeller har et OrgID. Når kernen får adgang til databasen, bruger den denne entydige identifikator til at sikre, at hver organisations aktiviteter er private.

Organisationsspecifikke objekter (think tables i traditionel relationel databasespråk), felter, gemte procedurer, databaseudløsere og mere er alle virtuelle konstruktioner beskrevet af metadata, som platformen gemmer i nogle få databasetabeller kendt som Universal Data Dictionary (UDD).
- MT_Objects er en databasetabel, der lagrer metadata om de objekter, som du definerer for en applikation, herunder en entydig identifikator for et objekt (ObjID), din organisation (OrgID) og det navn, du angiver for objektet (ObjName).
- Systemtabellen MT_Fields lagrer metadata om de felter (kolonner), som du erklærer for hvert objekt, herunder en entydig identifikator for et felt (FieldID), din organisation (OrgID), det objekt, der indeholder feltet (ObjID), navnet på feltet (FieldName), feltets datatype, en boolesk værdi, der angiver, om feltet kræver indeksering (IsIndexed), og placeringen af feltet i objektet i forhold til andre felter (FieldNum).
Da metadata er en nøgleingrediens, skal platformen optimere adgang til metadata. Ellers vil hyppig metadataadgang forhindre tjenesten i at skalere. Med denne potentielle flaskehals i tankerne bruger platformen massive og sofistikerede metadata-caches til at vedligeholde de senest anvendte metadata i hukommelsen, undgå ydeevneffektive disk-I/O- og kodeomsamling og forbedre applikationssvarstider.
Systemtabellen MT_Data lagrer de applikations tilgængelige data, der knyttes til alle organisationsspecifikke tabeller og deres felter som defineret af metadata i MT_Objects og MT_Fields. Hver række inkluderer identificeringsfelter, f.eks. et globalt entydigt id (GUID), den organisation, der ejer rækken (OrgID) og det omsluttende objekt-id (ObjID). Hver række i tabellen MT_Data har også et Navn-felt, der lagrer et "naturligt navn" for tilsvarende registreringer. En kontoregistrering kan f.eks. bruge "Kontonavn", en sagsregistrering kan bruge "Sagsnummer" osv.
Value0 ... ValueN flex-kolonner, også kendt som intervaller, lagrer applikationsdata, der knyttes til de tabeller og felter, der er angivet i henholdsvis MT_Objects og MT_Fields. Alle flex-kolonner bruger en strengdatatype med variabellængde, så de kan lagre enhver struktureret type applikationsdata (strenge, tal, datoer osv.). Som følgende figur illustrerer, kan ingen to felter af det samme objekt knyttes til det samme interval i MT_Data til lagring. Men et enkelt interval kan administrere oplysningerne for flere felter, når blot hvert felt stammer fra et andet objekt.
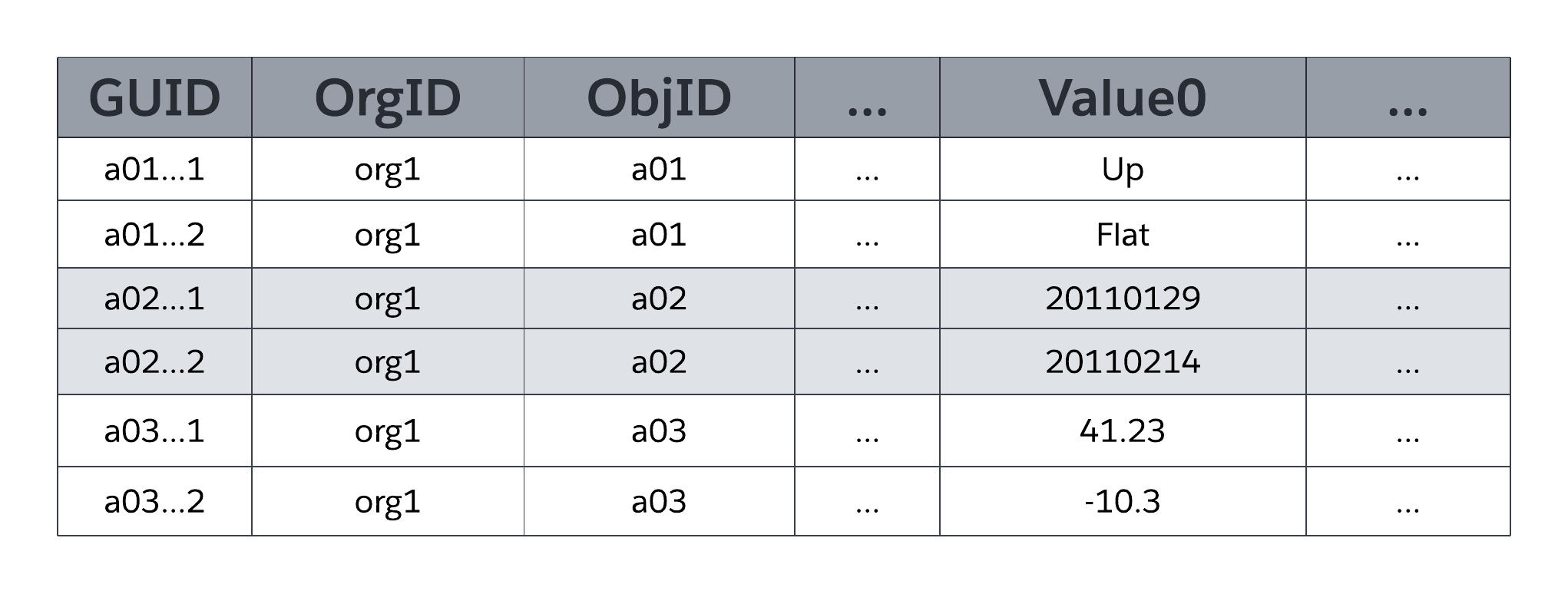
MT*-felter kan bruge en hvilken som helst af en række standardstrukturerede datatyper, f.eks. tekst, tal, dato og dato/tid, samt specialbrugte, _rich-structured datatyper* f.eks. plukliste (angivet felt), automatisk nummerering (automatiseret, systemgenereret sekvensnummer), formel (skrivebeskyttet afledt værdi), overordnet-detalje-relation (udenlandsk nøgle), afkrydsningsfelt (boolesk), mail, URL og andre. MT_Fields kan også være påkrævede (ikke nul) og have tilpassede valideringsregler (f.eks. skal et felt være større end et andet felt), som platformen håndhæver.
Når du erklærer eller redigerer et objekt, administrerer platformen en række metadata i MT_Objects, der definerer objektet. På samme måde administrerer platformen for hvert felt en række i MT_Fields, herunder metadata, der knytter feltet til en specifik flex-kolonne i MT_Data til lagring af tilsvarende feltdata. Da platformen administrerer objekt- og feltdefinitioner som metadata i stedet for faktiske databasestrukturer, kan systemet tolerere online vedligeholdelsesaktiviteter for flerlejerapplikationsskema uden at blokere den samtidige aktivitet for andre organisationer og brugere. Til sammenligning kræver onlinetabelomdefinition for traditionelle relationelle databasesystemer typisk midlertidige låse og ofte besværlige, komplicerede processer og planlagt applikationsnedetid.
Som den forenklede repræsentation af MT_Data i den forrige figur viser, er flex-kolonner af en universel datatype (variabellængdestreng), som gør det muligt for platformen at dele en enkelt flex-kolonne mellem flere felter, der bruger forskellige strukturerede datatyper (strenge, tal, datoer osv.).
Platformen lagrer alle flex-kolonnedata ved brug af et kanonisk format og bruger underliggende datasystemdatatypekonverteringsfunktioner (f.eks. TO_NUMBER, TO_DATE, TO_CHAR) efter behov, når applikationer læser data fra og skriver data til flex-kolonner.
MTData indeholder også kolonner, der ikke er vist i den foregående figur. Der er f.eks. fire kolonner til at administrere revisionsdata, herunder hvilken bruger, der oprettede en række, og hvornår denne række blev oprettet, og hvilken bruger, der sidst redigerede en række, og hvornår denne række sidst blev redigeret. MT_Data indeholder også en _IsDeleted-kolonne, som platformen bruger til at angive, hvornår en række er blevet slettet.
Platformen understøtter også erklæring af felter som tegn store objekter (CLOB'er) for at tillade lagring af lange tekstfelter på op til 32.000 tegn. For hver række i MTData, der har en CLOB, lagrer platformen CLOB'en ude af linje i en tabel kaldet _MT_Clob, som systemet kan forbinde med tilsvarende rækker i MT_Data efter behov.
Bemærk: Platformen lagrer også CLOB'er i et indekseret format uden for databasen til Hurtig tekst-søgninger. Se Søgninger for at få flere oplysninger om platformens tekstsøgemaskine.
Platformen indekserer automatisk forskellige typer felter for at levere skalerbar ydeevne.
Traditionelle databasesystemer er afhængige af oprindelige databaseindekser for hurtigt at finde specifikke rækker i en databasetabel, der har felter, der matcher en specifik betingelse. Det er dog ikke praktisk at oprette oprindelige databaseindekser for flexkolonnerne i MTData, da platformen bruger en enkelt flexkolonne til at lagre dataene fra mange felter med forskellige strukturerede datatyper. I stedet administrerer platformen et indeks af MT_Data ved synkront at kopiere feltdata, der er markeret til indeksering, til en relevant kolonne i en _MT_Indexes pivottabel.
MT_Indexes indeholder stærkt indtastede, indekserede kolonner, f.eks. StringValue, NumValue og DateValue, som platformen bruger til at finde feltdata af den tilsvarende datatype. F.eks. vil platformen kopiere en strengværdi i en MT_Data flex-kolonne til feltet StringValue i MT_Indexes, en datoværdi til feltet DateValue osv. De underliggende indekser for MT_Indexes er standarddatabaseindekser, der ikke er entydige. Når en intern systemforespørgsel inkluderer en søgeparameter, der refererer til et struktureret felt i et objekt, bruger platformens tilpassede forespørgselsoptimering MT_Indexes til at hjælpe med at optimere tilknyttede dataadgangshandlinger.
Bemærk: Platformen kan håndtere søgninger på tværs af flere sprog, fordi systemet bruger en sagsfoldingsalgoritme, der konverterer strengværdier til et universelt format, hvor der ikke skelnes mellem store og små bogstaver. Kolonnen StringValue i tabellen MT_Indexes lagrer strengværdier i dette format. På kørselstidspunktet opbygger forespørgselsoptimeringen automatisk dataadgangshandlinger, så den optimerede SQL-erklæring filtrerer på den tilsvarende sagsfoldede StringValue, som til gengæld svarer til den ordrette værdi, der leveres i søgeanmodningen.
Med platformen kan du angive, hvornår et felt i et objekt skal indeholde entydige værdier (der skelnes mellem store og små bogstaver). I betragtning af arrangementet af MT_Data og delt brug af værdikolonnerne for feltdata er det ikke praktisk at oprette entydige databaseindekser for objektet. (Denne situation svarer til den, der er diskuteret i det foregående afsnit for ikke-entydige indekser).
For at understøtte entydighed for tilpassede felter bruger platformen pivottabellen MT_Unique_Indexes. Denne tabel minder meget om tabellen MT_Indexes, bortset fra at de underliggende oprindelige databaseindekser i MT_Unique_Indexes gennemtvinger entydighed. Når en applikation forsøger at indsætte en dubletværdi i et felt, der kræver entydighed, eller en administrator forsøger at håndhæve entydighed på et eksisterende felt, der indeholder dubletværdier, returnerer platformen en relevant fejlmeddelelse til applikationen.
I sjældne tilfælde kan platformens eksterne søgemaskine (forklaret i Søgninger) blive overbelastet eller på anden måde utilgængelig og muligvis ikke kunne besvare en søgeanmodning rettidigt. I stedet for at returnere en skuffende fejl til slutbrugeren, vender platformen tilbage til en sekundær søgemekanisme for at levere rimelige søgeresultater.
En tilbagesøgning implementeres som en direkte databaseforespørgsel med søgebetingelser, der henviser til feltet Navn for målregistreringer. For at optimere globale objektsøgninger (søgninger, der strækker sig over tabeller) uden at skulle udføre potentielt dyre unionforespørgsler, vedligeholder platformen en MT_Fallback_Indexes-pivottabel, der registrerer navnet på alle registreringer. Opdateringer til MT_Fallback_Indexes sker synkront, når transaktioner redigerer registreringer, så tilbagerulningssøgninger altid har adgang til de mest aktuelle databaseoplysninger.
Tabellen MT_Name_Denorm er en lean-datatabel, der lagrer ObjID og Navn for hver registrering i MT_Data. Når en applikation har brug for at levere en liste over registreringer, der er involveret i en overordnet/underordnet relation, bruger platformen tabellen MT_Name_Denorm til at udføre en relativt enkel forespørgsel, der henter navnet på hver refereret registrering til visning i appen, f.eks. som en del af et hyperlink.
Platformen leverer relationsdatatyper, som en organisation kan bruge til at erklære relationer (referenceintegritet) mellem tabeller. Når du erklærer et objekts felt med en relationstype, tilknytter platformen feltet til et Værdi-felt i MT_Data og bruger derefter dette felt til at lagre ObjID for et relateret objekt.
For at optimere sammenføjningsoperationer vedligeholder platformen en MT_Relationships-pivottabel. Denne systemtabel har to underliggende database entydige sammensatte indekser, der tillader effektive objektgennemgange i begge retninger efter behov.
Med blot nogle få museklik giver platformen historiksporing for ethvert felt. Når en organisation aktiverer revision for et specifikt felt, registrerer systemet asynkront oplysninger om ændringer, der er foretaget i feltet (gamle og nye værdier, ændringsdato osv.) ved brug af en intern pivottabel som et revisionsspor.
Alle platformsdata, metadata og pivottabelstrukturer, herunder underliggende databaseindekser, partitioneres fysisk af OrgID ved brug af oprindelige databasepartitioneringsmekanismer. Datapartitionering er en gennemprøvet teknik, som databasesystemer leverer til fysisk at opdele store logiske datastrukturer i mindre, mere administrerbare stykker. Partitionering kan også hjælpe med at forbedre ydeevnen, skalerbarheden og tilgængeligheden af et stort databasesystem, f.eks. et miljø med flere lejere. Hver platformsforespørgsel målretter sig efter en specifik organisations oplysninger, så forespørgselsoptimering skal kun overveje at få adgang til datapartitioner, der indeholder en organisations data, snarere end en hel tabel eller et indeks. Denne almindelige optimering refereres nogle gange til som "partitionsopdeling".
Dette afsnit dækker, hvordan appudviklere kan oprette et skemas underliggende metadata og derefter opbygge apps, der administrerer data. Disse metadata og data lagres i det platformsdatalag, der er beskrevet i det foregående afsnit.
Udviklere kan deklarativt opbygge applikationskomponenter på serversiden ved brug af platformens browserbaserede udviklingsmiljø, almindeligt kaldet platformens opsætningsskærme. Opsætningens peg-og-klik-brugergrænseflade understøtter alle facetter af applikationsskemaprocessen, f.eks. oprettelse af en applikations datamodel (herunder objekter og deres felter samt relationer), sikkerheds- og delingsmodel (herunder brugere, profiler og rollehierarkier), brugergrænseflade (herunder skærmlayouts, dataindtastningsformularer og rapporter), deklarativ logik (arbejdsflows) og programmeringslogik (gemte procedurer og udløsere). Salesforce-forløb gør det f.eks. nemt at automatisere en lang række anvendelsessituationer. Opsætnings Flow Builder-brugergrænseflade, der vises nedenfor, giver dig mulighed for grafisk at designe og implementere arbejdsflows, der interagerer med brugere, eller starte automatisk baseret på en tidsplan eller når det udløses af en begivenhed.
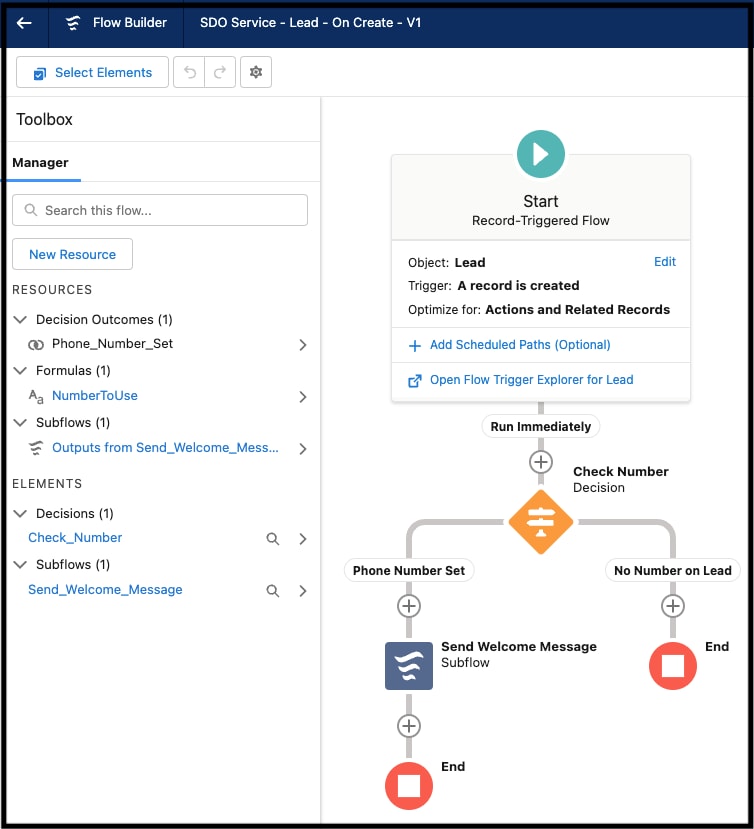
Opsætningsskærme gør det nemt for alle at udvikle og tilpasse applikationer uden (eller meget lidt) kode. F.eks.:
- Platformsindbyggede brugergrænseflader er nemme at opbygge uden nogen kode. I baggrunden understøtter en indbygget appbrugergrænseflade alle de sædvanlige dataadgangshandlinger, herunder forespørgsler, indsættelser, opdateringer og sletninger. Hver datamanipulationshandling, der udføres af oprindelige platformsapplikationer, kan redigere et objekt ad gangen og automatisk bekræfte hver ændring i en separat transaktion.
- Når du definerer et tekstfelt for et objekt, der indeholder følsomme data, kan du nemt konfigurere feltet, så platformen krypterer de tilsvarende data og eventuelt bruger en inputmaskering til at skjule skærmoplysninger fra forrygende øjne.
- En deklarativ valideringsregel er en enkel måde for en organisation at håndhæve en domæneintegritetsregel uden nogen programmering. Du kan f.eks. erklære en valideringsregel, der sikrer, at et LineItem-objekts Mængde-felt altid er større end nul.
- Et formelfelt er en deklarativ funktion i platformen, der gør det nemt at føje et beregnet felt til et objekt. Du kan f.eks. føje et felt til LineItem-objektet for at beregne en LineTotal-værdi.
- Et oprullet sammendragsfelt er et krydsobjektfelt, der gør det nemt at aggregere oplysninger om underordnede felter i et overordnet objekt. Du kan f.eks. oprette et OrderTotal-sammendragsfelt i SalesOrder-objektet baseret på feltet LineTotal i LineItem-objektet.
Bemærk: Intern implementerer platformen formel- og oprullede sammendragsfelter ved brug af oprindelige databasefunktioner og genberegner effektivt værdier synkront som en del af igangværende transaktioner.
Platformen leverer flere åbne, standardbaserede API'er, som udviklere kan bruge til at opbygge apps. Både RESTful- og webtjeneste-API'er (SOAP-baserede) giver adgang til platformens mange funktioner. Ved at bruge disse forskellige API'er kan en applikation:
- Manipuler metadata, der beskriver et applikationsskema
- Opret, læs, opdater og slet (CRUD) forretningsdata
- Masseindlæs eller forespørg på et stort antal registreringer asynkront
- Vis en næsten realtidsstream af data på en sikker og skalerbar måde
Apps kan bruge Salesforce Object Query Language (SOQL) til at konstruere enkle, men effektive databaseforespørgsler. I lighed med SELECT-kommandoen i SQL (Structured Query Language), gør SOQL det muligt for dig at angive kildeobjektet, en liste over felter, der skal hentes, og betingelser for valg af rækker i kildeobjektet. Følgende SOQL-forespørgsel returnerer f.eks. værdien af feltet Id og Navn for alle kontoregistreringer med et Navn, der er lig med strengen "Acme".
SELECT Id, Name FROM Account WHERE Name = 'Acme'
Platformen indeholder også et flersproget søgemaskine med fuld tekst, der automatisk indekserer alle tekstrelaterede felter. Apps kan gøre brug af denne forudintegrerede søgemaskine ved at bruge Salesforce Object Search Language (SOSL) til at udføre tekstsøgninger. I modsætning til SOQL, som kun kan forespørge på et objekt ad gangen, giver SOSL dig mulighed for at søge i tekst-, mail- og telefonfelter for flere objekter samtidigt. Følgende SOSL-erklæring søger f.eks. efter registreringer i objekterne Emne og Kontakt, der indeholder strengen "Joe Smith" i navnefeltet og returnerer feltet Navn og telefonnummer fra hver fundet registrering.
FIND {"Joe Smith"} IN Name Fields RETURNING lead(name, phone), contact(name, phone)
Apex, som på mange måder minder om Java, er et kraftfuldt udviklingssprog, som udviklere kan bruge til at centralisere procedurel logik i deres applikationsskema. Apex kan erklære programvariabler og konstanter, udføre traditionelle forløbskontrolerklæringer (hvis det er anderledes, løkker osv.), udføre datamanipuleringshandlinger (indsæt, opdater, upsert, slet) og udføre transaktionskontrolhandlinger (setSavepoint, tilbagerulning).
Du kan lagre Apex-programmer på platformen ved brug af to forskellige former: som en navngivet Apex-klasse med metoder (ligesom gemte procedurer i traditionel database-sprog), som applikationer udfører, når det er nødvendigt, eller som en databaseudløser, der udføres automatisk før eller efter en specifik databasemanipulationsbegivenhed. I begge formater kompilerer platformen Apex og lagrer den som metadata i UDD. Den første gang en organisation kører et Apex, indlæser platformens kørselsfortolker den kompilerede version af programmet i en MRU-cache (senest anvendt) for den pågældende organisation. Derefter, når enhver bruger fra den samme organisation har brug for at bruge den samme rutine, kan platformen gemme hukommelsen og undgå overhead af at genkompilere programmet igen ved at dele det program, der allerede er klar til kørsel i hukommelsen.
Med tilføjelsen af et enkelt nøgleord her og der kan udviklere bruge Apex til at understøtte mange unikke applikationskrav. Udviklere kan f.eks. vise en metode som et tilpasset RESTful- eller SOAP-baseret API-kald, gøre den asynkront planlægbar eller konfigurere den til at behandle en stor handling i batches.
Apex er meget mere end blot et andet processprog. Det er en integreret platformskomponent, der hjælper systemet med at levere pålidelig multilejer. F.eks. validerer platformen automatisk alle integrerede SOQL- og SOSL-erklæringer i en klasse for at forhindre kode, der ellers ville mislykkes på kørselstidspunktet. Platformen bevarer derefter tilsvarende objektafhængighedsoplysninger for gyldige klasser og bruger dem til at forhindre ændringer af metadata, der ellers ville afbryde afhængig kode.
Mange Apex og statiske systemmetoder giver enkle grænseflader til underliggende systemfunktioner. F.eks. har systemets statiske DML-metoder, f.eks. indsæt, opdater og slet, en enkel boolesk parameter, som udviklere kan bruge til at angive den ønskede indstilling for massebehandling (alle eller ingenting eller delvis lagring). Disse metoder returnerer også et resultatobjekt, som opkaldsrutinen kan læse for at bestemme, hvilke registreringer der mislykkedes, og hvorfor. Andre eksempler på direkte forbindelser mellem Apex og platformsfunktioner omfatter de indbyggede mailklasser og XmlStream-klasser.
I stor del klarer platformen sig godt og skalerer godt, fordi Salesforce har bygget den med to vigtige principper i tankerne:
- Angiv effektive, grundlæggende platformsfunktioner i høj skala.
- Hjælp udviklere med at gøre alt så effektivt som muligt.
Platformen indarbejder disse principper i platformens unikke behandlingsarkitekturer, herunder:
- Forespørgsler
- Søgninger
- Massehandlinger
- Skemaændring
- Multilejerisolering
- Papirkurven
De fleste moderne databasesystemer bestemmer de optimale forespørgselsudførelsesplaner ved at anvende en omkostningsbaseret forespørgselsoptimering, der tager relevante statistikker i betragtning om måltabel og indeksdata. Men konventionelle, omkostningsbaserede optimeringsstatistikker er designet til enkeltlejerapplikationer og tager ikke højde for dataadgangskarakteristika for enhver given bruger, der afvikler en forespørgsel i et miljø med flere lejere. En given forespørgsel, der målrettes mod et objekt med en stor mængde data, vil sandsynligvis blive afviklet mere effektivt ved brug af forskellige kørselsplaner for brugere med høj synlighed (en manager, der kan se alle rækker) kontra brugere med lav synlighed (salgspersoner, der kun kan se rækker, der er relateret til sig selv).
For at levere tilstrækkelig statistik til at bestemme optimale forespørgselsudførelsesplaner i et multilejer-system, vedligeholder platformen et komplet sæt optimeringsstatistikker (lejer-, gruppe- og brugerniveau) for hver organisations objekter. Statistikker afspejler antallet af rækker, som en bestemt forespørgsel potentielt kan få adgang til, ved omhyggeligt at overveje generelle organisationsspecifikke objektstatistikker (f.eks. det samlede antal rækker, der ejes af organisationen som helhed), samt mere detaljerede statistikker (f.eks. antallet af rækker, som en bestemt rettighedsgruppe eller slutbruger potentielt kan få adgang til).
Platformen vedligeholder også andre typer statistikker, der viser sig at være nyttige med bestemte forespørgsler. F.eks. vedligeholder platformen statistikker for alle tilpassede indekser for at afsløre det samlede antal ikke-nul- og entydige værdier i det tilsvarende felt og histogrammer for pluklistefelter, der afslører kardinaliteten af hver listeværdi.
Når eksisterende statistikker ikke er på plads eller ikke betragtes som nyttige, har platformens optimering et par forskellige strategier, den bruger til at hjælpe med at opbygge rimeligt optimale forespørgsler. Når f.eks. en forespørgsel filtrerer på feltet Navn på et objekt, kan optimeringen bruge tabellen MT_Fallback_Indexes til effektivt at finde de ønskede rækker. I andre scenarier genererer optimeringen dynamisk manglende statistikker på kørselstidspunktet.
Bruges sammen med optimeringsstatistikker, er platformens optimering også baseret på interne sikkerhedsrelaterede tabeller (grupper, medlemmer, GroupBlowout og CustomShare), der bevarer oplysninger om sikkerhedsdomæner for en organisations brugere, herunder en angivet brugers gruppemedlemskaber og tilpassede adgangsrettigheder for objekter og rækker. Sådanne oplysninger er uvurderlige for at bestemme selektiviteten af forespørgselsfiltre på pr. bruger-basis. Se Platform Developer Basics Trailhead for at få flere oplysninger om platformens integrerede sikkerhedsmodel.
Forløbsdiagrammet i følgende figur illustrerer, hvad der sker, når platformen behandler en anmodning om data, der er i en af de store heap-tabeller, f.eks. MT_Data. Anmodningen kan stamme fra et hvilket som helst antal kilder, f.eks. et API-kald eller en lagret procedure. Først kører platformen "før-forespørgsler", der tager statistikker for multilejerbevidsthed med i betragtning. Baseret på de resultater, der returneres af forespørgslerne, opbygger tjenesten en optimal underliggende databaseforespørgsel til kørsel i den specifikke indstilling.
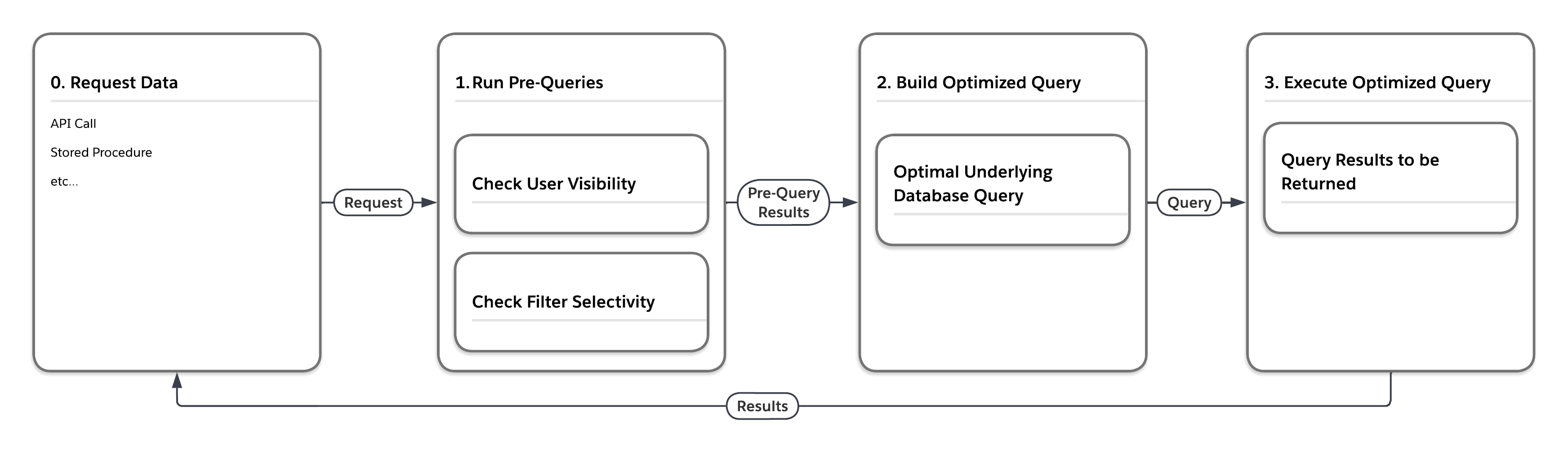
Som følgende tabel viser, kan platformen køre den samme forespørgsel på fire forskellige måder, afhængigt af den bruger, der indsender forespørgslen, og selektiviteten af forespørgslens filterbetingelser.
| Mål for præ-forespørgselsselektivitet | Skrive endelige databaseadgangsforespørgsel, tvinge... | |
| Bruger | Filtrer | |
| Lav | Lav | ... indlejrede løkker sammenføjes, køre ved brug af visning af rækker, som brugeren kan se |
| Lav | Høj | ... brug af indeks, der er relateret til filter |
| Høj | Lav | ... arrangeret hash-forbindelse, køre ved brug af MT_DATA |
| Høj | Høj | ... brug af indeksrelateret filter |
Brugere forventer, at en interaktiv søgefunktion scanner hele eller et valgt omfang af en applikations database og returnerer rangerede resultater med svartider på under sekunder. For at levere denne funktionalitet til platformsapplikationer bruger platformen en søgemaskine, der er adskilt fra dets transaktionsmotor. Når du opdaterer registreringer, opdaterer transaktionssystemet kernetabasen og videresender også relaterede data til søgemaskinen til indeksering. Når du søger efter registreringer, bruger søgemaskinen sine indekser til hurtigt at behandle forespørgslen og returnerer rangerede resultater med links til relaterede databaseregistreringer.
Når applikationer opdaterer data i tekstfelter (CLOB'er, Navn osv.), er en pulje af baggrundsprocesser ved navn indekseringsserver ansvarlige for asynkron opdatering af tilsvarende indekser, som søgemaskinen vedligeholder uden for kernetransaktionssystemet. For at optimere indekseringsprocessen kopierer platformen synkront ændrede segmenter af tekstdata til en intern "til at blive indekseret"-tabel, når transaktioner bekræftes, og leverer dermed en relativt lille datakilde, der minimerer mængden af data, som indekseringsserver skal læse fra disk. Søgemaskinen vedligeholder automatisk separate indekser for hver organisation.
Afhængig af den aktuelle indlæsning og anvendelse af indekseringsserver, kan tekstindeksopdateringer forsvinde efter faktiske transaktioner. For at undgå uventede søgeresultater, der stammer fra forældede indekser, vedligeholder platformen også en MRU-cache af senest opdaterede rækker, som systemet tager i betragtning, når der realiseres fuldtekstsøgeresultater. Platformen vedligeholder MRU-caches pr. bruger og pr. organisation for effektivt at understøtte mulige søgeomfang.
Platformens søgemaskine optimerer rangering af registreringer i søgeresultater ved brug af flere metoder. Systemet tager f.eks. sikkerhedsdomænet for den bruger, der foretager en søgning, med i betragtning og lægger mere vægt på de rækker, som den aktuelle bruger har adgang til. Systemet kan også overveje ændringshistorikken for en bestemt række og rangere mere aktivt opdaterede rækker frem for dem, der er relativt statiske. Brugeren kan vælge at vægte søgeresultater efter ønske, f.eks. ved at lægge mere vægt på senest redigerede rækker.
Transaktionsintensive applikationer genererer mindre overhead og klarer sig meget bedre, når de kombinerer og eksekverer gentagne handlinger i grupper. Du kan f.eks. sammenligne to måder, hvorpå en applikation kan indlæse mange nye rækker. En ineffektiv tilgang ville være at bruge en rutine med en løkke, der indsætter individuelle rækker og foretager et API-kald efter et andet for hver rækkeindsættelse. En meget mere effektiv tilgang ville være at oprette en opstilling af rækker og få rutinemæssigt indsat dem alle med et enkelt API-kald.
Effektiv massebehandling med platformen er enkel for udviklere, da den er indbygget i API-kald. Intern behandler platformen også alle interne trin, der er relateret til en eksplicit massehandling.
Platformens massebehandlingssystem tager automatisk højde for isolerede fejl, der opstår under ethvert trin undervejs. Når en massehandling starter i delvis lagringstilstand, identificerer systemet en kendt starttilstand og forsøger derefter at udføre hvert trin i processen (massevalider feltdata, massebrandpræuderende udløsere, masselagringsregistreringer osv.). Hvis systemet registrerer fejl under et trin, ruller systemet tilbage overtrædende handlinger og alle bivirkninger, fjerner de rækker, der er ansvarlige for fejlene og fortsætter med at forsøge at massebehandle det resterende undersæt af rækker. Denne proces gentages gennem hver efterfølgende fase, indtil systemet kan bekræfte et undersæt af rækker uden fejl. Applikationen kan undersøge et returobjekt for at identificere, hvilke rækker der mislykkedes, og hvilke undtagelser de rejste.
Bemærk: Efter eget skøn er der en alt-eller-ingen-tilstand tilgængelig for massehandlinger. Kørslen af udløsere under en massehandling er også underlagt interne styringer, der begrænser mængden af arbejde.
Visse typer ændringer af definitionen af et objekt kræver mere end enkle UDD-metadataopdateringer. I sådanne situationer bruger platformen effektive mekanismer, der hjælper med at reducere den generelle påvirkning af ydeevnen på clouddatabasetjenesten som helhed.
Overvej f.eks., hvad der sker i baggrunden, når du redigerer en kolonnes datatype fra plukliste til tekst. Platformen tildeler først et nyt interval for kolonnens data, massekopierer de pluklistebetegnelser, der er tilknyttet de aktuelle værdier, og opdaterer derefter kolonnens metadata, så den peger på det nye interval. Mens alt dette sker, er adgang til data normal, og applikationer fortsætter med at fungere uden nogen mærkbar påvirkning.
Som et andet eksempel kan du overveje, hvad der sker, når du føjer et oprullet sammendragsfelt til et objekt. I denne situation beregner platformen asynkront indledende sammendrag i baggrunden ved brug af en effektiv massehandling. Mens baggrundsberegningen sker, modtager brugere, der får vist det nye felt, en angivelse af, at platformen aktuelt beregner feltets værdi.
For at forhindre ondsindet eller utilsigtet monopolisering af delte systemressourcer med flere lejere, har platformen et omfattende sæt styringer og ressourcegrænser, der er knyttet til platformskodekørsel. F.eks. overvåger platformen nøje kørslen af et kodescript og begrænser, hvor meget CPU-tid den kan bruge, hvor meget hukommelse den kan bruge, hvor mange forespørgsler og DML-erklæringer den kan udføre, hvor mange matematiske beregninger den kan udføre, hvor mange udgående webtjenester den kan foretage og meget mere. Individuelle forespørgsler, som platformens optimering betragter som for dyre til at udføre, kaster en kørselsundtagelse til opkalderen. Selvom sådanne grænser kan lyde noget restriktive, er de nødvendige for at beskytte den generelle skalerbarhed og ydeevne for det delte databasesystem for alle involverede applikationer. På lang sigt hjælper disse mål med at fremme bedre kodningsteknikker blandt udviklere og skabe en bedre oplevelse for alle, der bruger platformen. En udvikler, der f.eks. til en start forsøger at kode en løkke, der ineffektivt opdaterer tusind rækker en række ad gangen, vil modtage kørselsundtagelser på grund af ressourcegrænser og derefter begynde at bruge platformens effektive massebehandling af API-kald.
Hvis du yderligere vil undgå potentielle systemproblemer, der introduceres af dårligt skrevne applikationer, er implementeringen af en ny produktionsapplikation en proces, der er strengt administreret. Før en organisation kan overføre en ny applikation fra udvikling til produktionsstatus, kræver Salesforce enhedstest, der validerer funktionaliteten af applikationens platformskoderutiner. Indsendte enhedstest skal ikke dække mindre end 75 procent af applikationens kildekode.
Salesforce kører indsendte enhedstest i platformens sandbox-udviklingsmiljø for at bestemme, om applikationskoden vil påvirke ydeevnen og skalerbarheden af den flerlejerpopulation generelt. Resultaterne af en individuel enhedstest angiver grundlæggende oplysninger, f.eks. det samlede antal eksekverede linjer samt specifikke oplysninger om den kode, der ikke blev eksekveret af testen.
Når en applikations kode er certificeret til produktion af Salesforce, består implementeringsprocessen for applikationen af en enkelt transaktion, der kopierer alle applikationens metadata til en produktionsplatformsforekomst og kører de tilsvarende enhedstest igen. Hvis en del af processen mislykkes, ruller platformen blot transaktionen tilbage og returnerer undtagelser for at hjælpe med at fejlfinde problemet.
Bemærk: Salesforce kører enhedstest for hver applikation med hver udviklingsversion af platformen for proaktivt at finde ud af, om nye systemfunktioner og forbedringer afbryder eksisterende applikationer.
Når en produktionsapplikation er live, analyserer platformens indbyggede ydeevneprofil den automatisk og giver tilknyttet feedback til administratorer. Ydeevneanalyserapporter inkluderer oplysninger om langsomme forespørgsler, datamanipulationer og underrutiner, som du kan gennemse og bruge til at justere applikationsfunktionalitet. Systemet logfører og returnerer også oplysninger om kørselsundtagelser til administratorer for at hjælpe dem med at fejlfinde deres applikationer.
Når en app sletter en registrering fra et objekt, markerer platformen ganske enkelt rækken til sletning ved at redigere rækkeens IsDeleted-felt i MTData. Denne handling placerer effektivt rækken i det, der kaldes _Recycle Bin. platformen giver dig mulighed for at gendanne valgte rækker fra papirkurven i op til 15 dage, før du permanent fjerner dem fra MT_Data. Platformen begrænser det samlede antal registreringer, den vedligeholder for en organisation, baseret på lagringsgrænserne for den pågældende organisation.
Når en handling sletter en overordnet registrering, der er involveret i en overordnet-detalje-relation, sletter platformen automatisk alle relaterede underordnede registreringer, forudsat at det ikke ville bryde nogen referenceintegritetsregler. Når du f.eks. sletter en SalesOrder, overlapper platformen automatisk sletningen til afhængige LineItems. Hvis du efterfølgende gendanner en overordnet registrering fra papirkurven, gendanner systemet også automatisk alle underordnede registreringer.
Når du derimod sletter en refereret overordnet registrering, der er involveret i en opslagsrelation, indstiller platformen automatisk alle afhængige nøgler til nul. Hvis du efterfølgende gendanner den overordnede registrering, gendanner platformen automatisk de tidligere nullede opslagsrelationer, bortset fra de relationer, der blev gentildelt mellem slette- og gendannelseshandlingerne.
Papirkurven lagrer også droppede felter og deres data, indtil en organisation permanent sletter dem, eller et angivet antal dage er gået, afhængigt af hvad der sker først. Indtil dette tidspunkt er hele feltet og alle dets data tilgængeligt for gendannelse.
Agilitet er nøglen for virksomheder til at lykkes i vores moderne verden. Salesforce Platforms underliggende lag hjælper dine forretningsapplikationer med hurtigt at tilpasse sig nye udfordringer, så du kan fortsætte med at fokusere på din forretning snarere end infrastruktur.
Infrastruktur (f.eks. grundlæggende tjenester og dataressourcer) er skjult, underliggende teknologi, der understøtter øverste lag i Salesforce Platform. Hyperforce er Salesforce Platforms infrastruktur, der er bygget på 100 % vedvarende energi og netto nul, og som løser vigtige kundeudfordringer, herunder compliance, Trust og skalerbarhed
Virksomheder, der opererer på flere geografiske placeringer, skal overholde nye, udviklende og varierende bestemmelser for dataadministration. Da Salesforce implementerer Hyperforce i et voksende antal lande, kan platformapplikationer og brugere køre deres følsomme arbejdsbelastninger på måder, der opfylder strenge standarder for datalagring eller databeskyttelse. Med f.eks. Salesforces EU-driftszone drevet af Hyperforce kan virksomheder i EU nemt opbevare deres data i EU.
Sikkerhed, pålidelighed og tilgængelighed er ikke-funktionelle krav, som enhver forretningsapplikation skal overveje for at kunne levere Trust til sine slutbrugere. Med Hyperforce gør Salesforce Platform det nemt for virksomheder at levere pålidelige forretningsapplikationer.
- Sikkerhed – Hyperforce har indbygget end-to-end-kryptering af kundedata, der er på pause og undervejs. Hyperforce Zero Trust håndhæver en streng identitetsbekræftelsesproces, der sikrer, at der ikke er nogen implicit adgang til ressourcer. Og Hyperforce anvender princippen om mindste rettigheder, der sikrer, at operationer godkendes i den rigtige mængde tid med den rigtige mængde adgang.
- Pålidelighed – Hver forekomst af Hyperforce bruger flere cloud-tilgængelighedszoner og moderniserede tilgange, der sætter fart på hændelsessvaret og leverer en meget tilgængelig og fleksibel platform.
- Tilgængelighed – Hyperforces moderne CI/CD-pipelines og blå/grønne applikationsversioner minimerer applikationens vedligeholdelsesperioder til blot ét minut om året.
Som grundlaget for apps som Sales Cloud og Service Cloud er Salesforce en gennemprøvet applikationsudviklingsplatform, hvor individuelle virksomheder og serviceudbydere har opbygget millioner af forretningsapplikationer til forskellige anvendelsessituationer, herunder supply chain management, fakturering, regnskab, handel, overensstemmelsessporing, HR-styring og skadesbehandling. Platformens entydige, metadatastyrede arkitektur med flere lejere er designet specifikt til clouden og understøtter pålideligt og sikkert missionskritiske applikationer på internetskala. Ved at bruge standardbaserede API'er og oprindelige udviklingsværktøjer kan platformudviklere nemt opbygge alle komponenter i en moderne web- eller mobilapplikation, herunder applikationens datamodel (herunder objekter og relationer), forretningslogik (herunder arbejdsflows og valideringer), integrationer med andre applikationer mm.
Siden dets oprettelse er platformen blevet optimeret af Salesforces teknikere til multilejering med funktioner, der gør det muligt for platformsapplikationer at skalere for at opfylde ændrede forretningskrav. Integrerede systemfunktioner – f.eks. masse-data-behandlings-API, Apex, en fuldtekstsøgemaskine og en unik forespørgselsoptimering – hjælper med at gøre afhængige applikationer meget effektive og skalerbare med lidt eller ingen indsats fra udviklere.
Salesforces administrerede tilgang til implementering af produktionsapplikationer sikrer fremragende ydeevne, skalerbarhed og pålidelighed for alle applikationer, der er afhængige af platformen. Salesforce overvåger og indsamler kontinuerligt driftsmæssige oplysninger fra platformsapplikationer for at hjælpe med at fremme trinvise forbedringer og nye systemfunktioner, der straks gavner eksisterende og nye applikationer.
Steve Bobrowski er en succesfuld iværksætter og teknologichef, der har arbejdet for mange førende virksomhedssoftwarefirmaer, herunder forskellige roller på tværs af Salesforce siden 2008. I dag arbejder Steve på Salesforces kontor for CTO for at hjælpe med firmaets teknologirkitekturstrategier.
Tom Leddy er arkitekt-evangelist i Salesforce. Han understøtter det globale Salesforce Architect Community ved at hjælpe med at oprette ressourcer, værktøjer og vejledning, der hjælper med at gøre det muligt for arkitekter at udføre deres bedste arbejde. Opret forbindelse til Tom på Twitter.